
抓取网页音频
抓取网页音频(语言下载网页音频文件的生成代码和生成路径介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-01 10:01
抓取网页音频一直是作为老年人辅助工具的需求,其他工具也一直想用,但是没有想到有些网站怎么登录不了,这几天真是研究了好久,花费了不少时间。真是不好意思在网上推广,望广大网友指点一二。方法有些老生常谈,按步骤介绍,各位老师按照步骤来吧!使用python语言。下载网页音频文件,通过相关库,利用schem库的for循环,从网页获取文件名和音频音质,通过raiser内建的m3u8库提取出音频音质格式,保存在txt文件中,因此形成视频格式的文件。
由于网上资源太多,基本用txt文件保存,但是txt并不容易编辑,因此这里将视频转为mp4,然后用ffmpeg的录屏命令制作视频,然后解压网页音频文件,即可保存到另一个文件夹。下面是成功生成demo文件对应路径后,视频文件的生成代码。主函数getframesource()函数可获取已下载的视频位置.文件名;foriinxrange(1,xrange(1,yrange(i))):withopen(path,'r')asf:f.write(path+'\'+str(i)+'\'')f.close();注意之前是write()函数,第一个参数是文件名,第二个参数是下载位置,默认为c:\python。
不过大部分都已经把位置设置好了。应该在下载前可以重复write()两次。foriintxt:print(i)%。 查看全部
抓取网页音频(语言下载网页音频文件的生成代码和生成路径介绍)
抓取网页音频一直是作为老年人辅助工具的需求,其他工具也一直想用,但是没有想到有些网站怎么登录不了,这几天真是研究了好久,花费了不少时间。真是不好意思在网上推广,望广大网友指点一二。方法有些老生常谈,按步骤介绍,各位老师按照步骤来吧!使用python语言。下载网页音频文件,通过相关库,利用schem库的for循环,从网页获取文件名和音频音质,通过raiser内建的m3u8库提取出音频音质格式,保存在txt文件中,因此形成视频格式的文件。
由于网上资源太多,基本用txt文件保存,但是txt并不容易编辑,因此这里将视频转为mp4,然后用ffmpeg的录屏命令制作视频,然后解压网页音频文件,即可保存到另一个文件夹。下面是成功生成demo文件对应路径后,视频文件的生成代码。主函数getframesource()函数可获取已下载的视频位置.文件名;foriinxrange(1,xrange(1,yrange(i))):withopen(path,'r')asf:f.write(path+'\'+str(i)+'\'')f.close();注意之前是write()函数,第一个参数是文件名,第二个参数是下载位置,默认为c:\python。
不过大部分都已经把位置设置好了。应该在下载前可以重复write()两次。foriintxt:print(i)%。
抓取网页音频(使用InternetDownloadManager下载方法,实现批量音频以及文件自动下载效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-30 11:04
我们日常使用电脑时,需要通过浏览器自带的下载工具下载文件或音频,或者使用目前比较常规的第三方下载软件。常规的下载方式基本都是P2P下载,支持bt、Emule等下载,但是这种下载方式不仅繁琐,而且单线程下载方式也大大限制了下载效率。
接下来,围绕下载网站文件的问题,给大家介绍一下使用Internet下载管理器的下载方法。通过简单的操作,就可以达到批量音频和文件自动下载的效果。
图 1:IDM 接口
一、设置通配符批量下载
选择IDM界面右上角的“任务-添加批处理任务”选项,可以使用IDM下载一个链接地址中收录的所有文件。IDM可以进行自定义通配符设置,支持下载图片、音频等各种类型的文件。
例如在地址栏输入:*.jpg(*用字母或数字有序替换),即可批量下载链接中的所有文件。
图2:批量下载
二、设置站点爬取
IDM 的强大之处在于它支持在大多数主流平台上下载。选择“任务运行站点爬取”选项后,可以通过程序模板进行设置。
如果要在一个网站上下载多个文件,通过自定义设置指定网站中的图片、音频、视频等文件,即可实现批量下载效果,无需使用通配符。可以新建一个爬取程序,下次自动下载效率会更高。
图 3:IDM 站点爬取
三、获取具体下载链接
如果你遇到大量的URL内容,你会觉得上面两种批量下载的方式比较繁琐。如果要下载网站中的特定文件,可以使用获取下载地址的方法进行下载。
您可以在网站中选择需要下载的音频或其他类型的文件,右键单击并选择“复制链接地址”,然后使用复制的链接在IDM上运行命令。另外,也可以通过查看URL的源代码,从网页的源代码中选择要下载的文件地址,复制后用IDM下载。 查看全部
抓取网页音频(使用InternetDownloadManager下载方法,实现批量音频以及文件自动下载效果)
我们日常使用电脑时,需要通过浏览器自带的下载工具下载文件或音频,或者使用目前比较常规的第三方下载软件。常规的下载方式基本都是P2P下载,支持bt、Emule等下载,但是这种下载方式不仅繁琐,而且单线程下载方式也大大限制了下载效率。
接下来,围绕下载网站文件的问题,给大家介绍一下使用Internet下载管理器的下载方法。通过简单的操作,就可以达到批量音频和文件自动下载的效果。
.png)
图 1:IDM 接口
一、设置通配符批量下载
选择IDM界面右上角的“任务-添加批处理任务”选项,可以使用IDM下载一个链接地址中收录的所有文件。IDM可以进行自定义通配符设置,支持下载图片、音频等各种类型的文件。
例如在地址栏输入:*.jpg(*用字母或数字有序替换),即可批量下载链接中的所有文件。
.png)
图2:批量下载
二、设置站点爬取
IDM 的强大之处在于它支持在大多数主流平台上下载。选择“任务运行站点爬取”选项后,可以通过程序模板进行设置。
如果要在一个网站上下载多个文件,通过自定义设置指定网站中的图片、音频、视频等文件,即可实现批量下载效果,无需使用通配符。可以新建一个爬取程序,下次自动下载效率会更高。
.png)
图 3:IDM 站点爬取
三、获取具体下载链接
如果你遇到大量的URL内容,你会觉得上面两种批量下载的方式比较繁琐。如果要下载网站中的特定文件,可以使用获取下载地址的方法进行下载。
您可以在网站中选择需要下载的音频或其他类型的文件,右键单击并选择“复制链接地址”,然后使用复制的链接在IDM上运行命令。另外,也可以通过查看URL的源代码,从网页的源代码中选择要下载的文件地址,复制后用IDM下载。
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-11-29 21:17
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页中准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第三步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页中准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第三步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-28 16:04
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。需要在tinyalsa中读取音频,确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,把数据同时写入文件,这个只能在调试的时候用,如果一直用,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
查看全部
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。需要在tinyalsa中读取音频,确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,把数据同时写入文件,这个只能在调试的时候用,如果一直用,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
抓取网页音频(小编IDM功能——“站点抓取”的妙用网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-28 00:13
InternetDownloadManager(简称IDM)下载器采用多线程技术,大大提高文件下载速度。即使非常大的文件也可以轻松快速地集成,据称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从来没有太在意它,但我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择要下载的网页中的指定内容,包括图片、音频、视频、文件,甚至收录网站的完整样式的离线文件@>,并允许用户根据需要自由定制。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您遇到断网或工作不畅的地方,请使用InternetDownloadManager站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是一个无需 Internet 即可浏览网络的强大地方。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载将开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有Internet的情况下点击浏览网页,非常方便。
图 7:文件夹打开 查看全部
抓取网页音频(小编IDM功能——“站点抓取”的妙用网)
InternetDownloadManager(简称IDM)下载器采用多线程技术,大大提高文件下载速度。即使非常大的文件也可以轻松快速地集成,据称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从来没有太在意它,但我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择要下载的网页中的指定内容,包括图片、音频、视频、文件,甚至收录网站的完整样式的离线文件@>,并允许用户根据需要自由定制。定义站点抓取的内容和规则,并保存以方便下次调用。
.png)
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您遇到断网或工作不畅的地方,请使用InternetDownloadManager站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
.png)
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
.png)
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是一个无需 Internet 即可浏览网络的强大地方。
.png)
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载将开始。如果之前设置下载的内容不多,应该会快一些。
.png)
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有Internet的情况下点击浏览网页,非常方便。
.png)
图 7:文件夹打开
抓取网页音频(爬取网站上面的音频数据该如何去做呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-25 20:18
前言
最近分享了一些爬虫知识点。所以今天我们可以通过我们目前掌握的爬虫技术和Python技术来爬取某个平台的音频数据。
我们都知道,一般的数据都在url地址对应的网页源码中。如下所示
网页源代码
但是如果要抓取的数据不在当前URL地址对应的网页源代码中,那就真的比较痛苦了。在这种情况下,数据要么在后期动态添加到网页中,要么通过 ajax 加载。不管是哪一种,对于初学者来说都是异常的头痛。今天我们就用通俗易懂的方式来分析ajax数据的特点(一切都是特殊的,所以不同的场景需要特殊处理)
实践中的 ajax 是什么?
先解决一个问题。什么是阿贾克斯?来介绍一下百度百科的解释
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML)。它是一种 Web 开发技术,可创建交互式、快速和动态的 Web 应用程序。它可以在不重新加载整个网页的情况下更新某些网页。
这段话的一个关键点是,您可以在不加载整个网页的情况下更新某些网页。例如,以下是 12306 列火车的列表。
在这张图中,我们可以看到12306的网页就是这样的风格。但是当我们点击“查询”按钮时,我们要观察这个网页的效果
我们发现这个网页没有刷新,但是本地结构发生了变化。然后通过ajax加载车次列表数据。其实,刚刚我们理解“无需重新加载整个网页就可以更新部分网页的技术”这句话的含义并不难。
案例展示
下面通过一个案例来进一步分析总结如何抓取ajax数据
下图是一段音频网站。在这个网站中,数据主要是音频。那么我们要如何抓取网站上面的音频数据呢?
我们进一步优化了目标。下面有这样一个音频主题。今天我们就爬取这个话题的数据。
点击专辑后,我们发现里面有很多音频数据。按照我们的思路,只要找到每个音频的url就可以轻松爬取。
但前提是数据是否在当前URL地址之上?让我们检查一下网页的源代码。这也很简单。我们只需要在源代码中搜索mp3或m4a等音频格式即可。从下图我们可以看到这些音频格式在网页上是不可用的。然后我们猜测这些数据可能是通过ajax加载的
接下来,我们将通过NetWork 来分析数据接口。我们点击了一首歌曲,发现在网络中刷新了一些数据。先看第一条数据
数据确实在这个界面
我们点击进一步观察,看看有没有类似mp3或m4a的音频格式。然而,令我们失望的是,它没有。那我该怎么办?
在这个数据接口下还有一条数据。我们来看看里面有什么?
点击这个数据,我们发现它是一个音频数据
为了验证这个数据是否是我们要爬取的,我们可以检查一下。OK,没问题就是我们要爬取的数据
但这只是一个音频,如果我们想爬取其他音频怎么办?我们发现不同音频的id是不同的。然后就很容易了。我们先访问第一个数据接口中的内容,获取音频的id和name。
然后我们将转到第二个数据接口,到其 url 以动态获取替换音频的 id。
代码演示
import requests
import json
url = 'https://www.ximalaya.com/revision/play/v1/show?id=231012348&sort=1&size=30&ptype=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get(url,headers=headers)
ret = r.text
result = json.loads(ret)
content_list = result['data']['tracksAudioPlay']
for content in content_list:
t_id = content['trackId'] # 音频的id
name = content['trackName'] # 音频的name
# print(t_id,type(t_id))
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%d&ptype=1'%t_id
mus_response = requests.get(url,headers=headers)
mus_html = mus_response.text
mus_result = json.loads(mus_html)
# print(mus_html,type(mus_result))
mus_src = mus_result['data']['src']
# print(mus_src)
with open('mp3/%s.m4a'% name,'wb') as f:
mus = requests.get(mus_src)
f.write(mus.content)
复制代码
运行结果
这是部分核心代码的列表。大家可以在这个代码的基础上进行升级和扩展。案子不难,大家可以试试。不过我们还是要心存感激,不要恶意爬取网站上面的数据。 查看全部
抓取网页音频(爬取网站上面的音频数据该如何去做呢?(一))
前言
最近分享了一些爬虫知识点。所以今天我们可以通过我们目前掌握的爬虫技术和Python技术来爬取某个平台的音频数据。
我们都知道,一般的数据都在url地址对应的网页源码中。如下所示
网页源代码
但是如果要抓取的数据不在当前URL地址对应的网页源代码中,那就真的比较痛苦了。在这种情况下,数据要么在后期动态添加到网页中,要么通过 ajax 加载。不管是哪一种,对于初学者来说都是异常的头痛。今天我们就用通俗易懂的方式来分析ajax数据的特点(一切都是特殊的,所以不同的场景需要特殊处理)
实践中的 ajax 是什么?
先解决一个问题。什么是阿贾克斯?来介绍一下百度百科的解释
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML)。它是一种 Web 开发技术,可创建交互式、快速和动态的 Web 应用程序。它可以在不重新加载整个网页的情况下更新某些网页。
这段话的一个关键点是,您可以在不加载整个网页的情况下更新某些网页。例如,以下是 12306 列火车的列表。
在这张图中,我们可以看到12306的网页就是这样的风格。但是当我们点击“查询”按钮时,我们要观察这个网页的效果
我们发现这个网页没有刷新,但是本地结构发生了变化。然后通过ajax加载车次列表数据。其实,刚刚我们理解“无需重新加载整个网页就可以更新部分网页的技术”这句话的含义并不难。
案例展示
下面通过一个案例来进一步分析总结如何抓取ajax数据
下图是一段音频网站。在这个网站中,数据主要是音频。那么我们要如何抓取网站上面的音频数据呢?
我们进一步优化了目标。下面有这样一个音频主题。今天我们就爬取这个话题的数据。
点击专辑后,我们发现里面有很多音频数据。按照我们的思路,只要找到每个音频的url就可以轻松爬取。
但前提是数据是否在当前URL地址之上?让我们检查一下网页的源代码。这也很简单。我们只需要在源代码中搜索mp3或m4a等音频格式即可。从下图我们可以看到这些音频格式在网页上是不可用的。然后我们猜测这些数据可能是通过ajax加载的
接下来,我们将通过NetWork 来分析数据接口。我们点击了一首歌曲,发现在网络中刷新了一些数据。先看第一条数据
数据确实在这个界面
我们点击进一步观察,看看有没有类似mp3或m4a的音频格式。然而,令我们失望的是,它没有。那我该怎么办?
在这个数据接口下还有一条数据。我们来看看里面有什么?
点击这个数据,我们发现它是一个音频数据
为了验证这个数据是否是我们要爬取的,我们可以检查一下。OK,没问题就是我们要爬取的数据
但这只是一个音频,如果我们想爬取其他音频怎么办?我们发现不同音频的id是不同的。然后就很容易了。我们先访问第一个数据接口中的内容,获取音频的id和name。
然后我们将转到第二个数据接口,到其 url 以动态获取替换音频的 id。
代码演示
import requests
import json
url = 'https://www.ximalaya.com/revision/play/v1/show?id=231012348&sort=1&size=30&ptype=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get(url,headers=headers)
ret = r.text
result = json.loads(ret)
content_list = result['data']['tracksAudioPlay']
for content in content_list:
t_id = content['trackId'] # 音频的id
name = content['trackName'] # 音频的name
# print(t_id,type(t_id))
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%d&ptype=1'%t_id
mus_response = requests.get(url,headers=headers)
mus_html = mus_response.text
mus_result = json.loads(mus_html)
# print(mus_html,type(mus_result))
mus_src = mus_result['data']['src']
# print(mus_src)
with open('mp3/%s.m4a'% name,'wb') as f:
mus = requests.get(mus_src)
f.write(mus.content)
复制代码
运行结果
这是部分核心代码的列表。大家可以在这个代码的基础上进行升级和扩展。案子不难,大家可以试试。不过我们还是要心存感激,不要恶意爬取网站上面的数据。
抓取网页音频(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 00:14
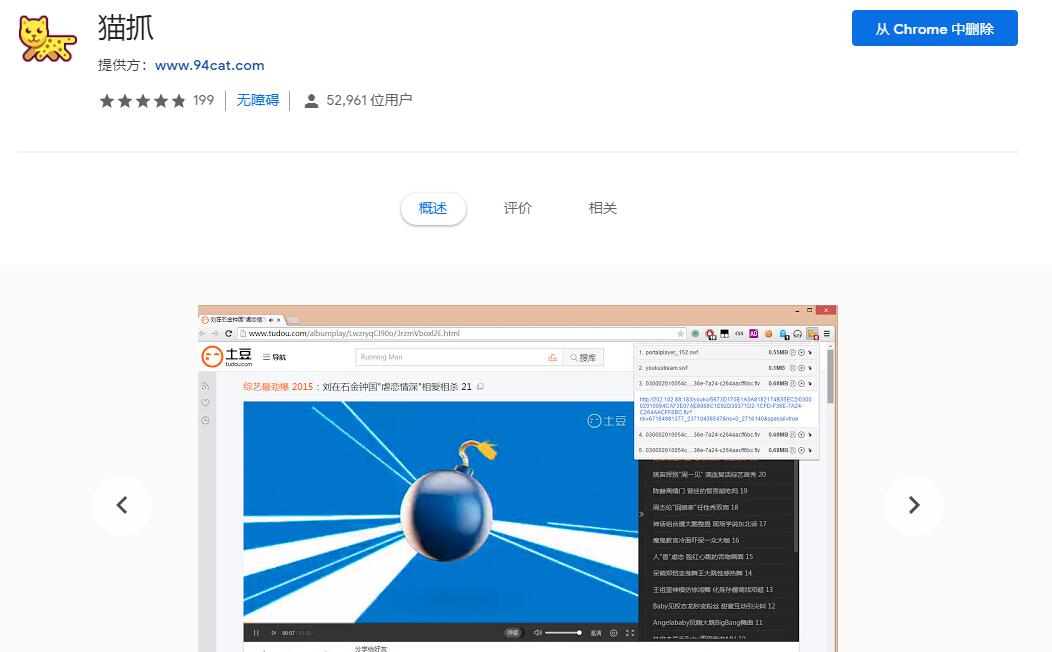
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,墨钊可以爬取很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
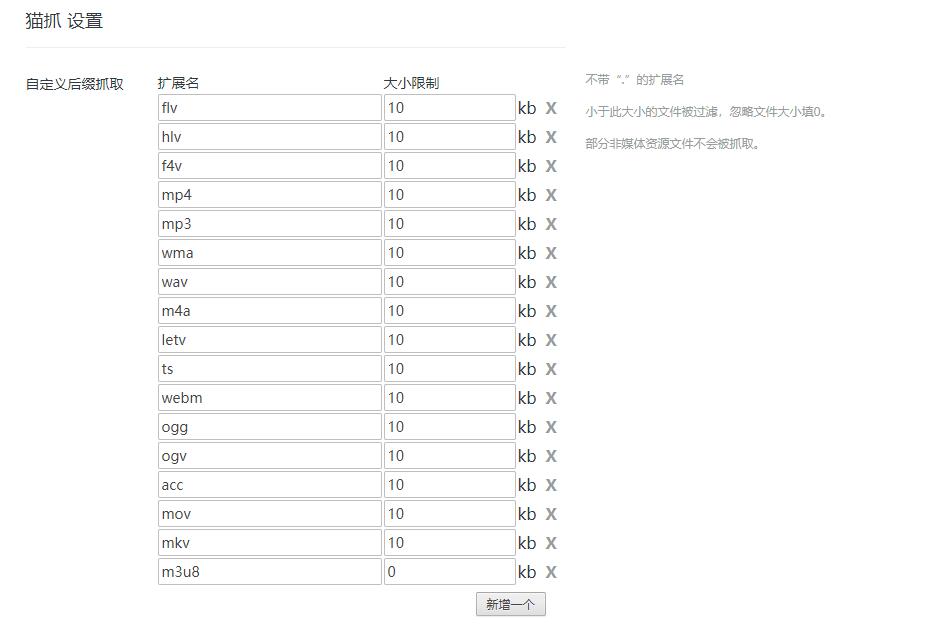
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb 查看全部
抓取网页音频(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,墨钊可以爬取很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb
抓取网页音频(演示如何使用tkinter去爬取网页音频(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 11:04
抓取网页音频已经成为网页音频的不可或缺的一部分,我们在使用tkinter(海格力斯)做网页音频播放器之前,我们需要在excel中配置这个网页音频。现在以百度的一个营销活动为例,演示如何使用tkinter去爬取网页音频下面是例子第一步:声音source网页网页有个“china”,我们要爬取这个source,我们需要自定义一个页码去爬取source第二步:setcitiesframe(stringname);指定这个citiesframe,setcitiesframe为我们的citiesframe1为setcitiesframe为setcitiesframe2为set第三步:seteachconnection(integerparams);seteachconnection=(integerparams)=size(eachconnection);///为什么是四个分隔符,因为当前session只能存在一个connection第四步:设置httpport(integerport);httpport的作用://这里我们用https协议,这样就不用每次都发https协议给百度第五步:开始进行爬取了,重点来了,把设置好的url作为参数传给tkinter函数tkinter函数ttrenderios(stringurl);接收到url后把它转换为type,然后设置为custom,然后这样就能爬取网页音频了。
为什么是函数,而不是c#里面的代码呢?这个和最近遇到的问题有关,我写过一个简单的爬虫seoul,http当然不能写c#代码去写。解决的办法是就是先写一个stringhttpapi函数和一个responseapi函数,大致思路就是让客户端发个http请求给这个函数去接收返回结果,然后返回结果的类型设置为response,然后再重新编写一个stringresponse函数,从response发送http请求到最后的返回结果,使用伪随机数tuple<b>businessrhy(stringurl,floatport);这里有一个坑,如果在这个函数里设置了stringresponse类型则不能stringspiderconnection(stringparams);stringnewresponse(stringparams);为什么呢?因为在使用response的时候给方法传参(params)是对的,我们params里面的每一个参数如果与url里面对应参数的设置不一样则会无法通过,所以如果出现参数的string参数与上面那个函数传参的数组不一样,会无法通过,这就是最后stringresponse最后返回char的原因,请注意每一个参数有的是bool类型的。欢迎关注公众号“快乐等于生活”可以学习实用的ftp及http服务器操作和代理相关知识。 查看全部
抓取网页音频(演示如何使用tkinter去爬取网页音频(一)_)
抓取网页音频已经成为网页音频的不可或缺的一部分,我们在使用tkinter(海格力斯)做网页音频播放器之前,我们需要在excel中配置这个网页音频。现在以百度的一个营销活动为例,演示如何使用tkinter去爬取网页音频下面是例子第一步:声音source网页网页有个“china”,我们要爬取这个source,我们需要自定义一个页码去爬取source第二步:setcitiesframe(stringname);指定这个citiesframe,setcitiesframe为我们的citiesframe1为setcitiesframe为setcitiesframe2为set第三步:seteachconnection(integerparams);seteachconnection=(integerparams)=size(eachconnection);///为什么是四个分隔符,因为当前session只能存在一个connection第四步:设置httpport(integerport);httpport的作用://这里我们用https协议,这样就不用每次都发https协议给百度第五步:开始进行爬取了,重点来了,把设置好的url作为参数传给tkinter函数tkinter函数ttrenderios(stringurl);接收到url后把它转换为type,然后设置为custom,然后这样就能爬取网页音频了。
为什么是函数,而不是c#里面的代码呢?这个和最近遇到的问题有关,我写过一个简单的爬虫seoul,http当然不能写c#代码去写。解决的办法是就是先写一个stringhttpapi函数和一个responseapi函数,大致思路就是让客户端发个http请求给这个函数去接收返回结果,然后返回结果的类型设置为response,然后再重新编写一个stringresponse函数,从response发送http请求到最后的返回结果,使用伪随机数tuple<b>businessrhy(stringurl,floatport);这里有一个坑,如果在这个函数里设置了stringresponse类型则不能stringspiderconnection(stringparams);stringnewresponse(stringparams);为什么呢?因为在使用response的时候给方法传参(params)是对的,我们params里面的每一个参数如果与url里面对应参数的设置不一样则会无法通过,所以如果出现参数的string参数与上面那个函数传参的数组不一样,会无法通过,这就是最后stringresponse最后返回char的原因,请注意每一个参数有的是bool类型的。欢迎关注公众号“快乐等于生活”可以学习实用的ftp及http服务器操作和代理相关知识。
抓取网页音频(研究百度搜索技术是如何实现抓取MP3格式文件(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-21 23:07
很高兴不断更新自己文章,无时无刻不在观察互联网技术。通常,将观察结果用文字记录下来,与大家分享。最近,由于学习需要,百度开始研究MP3文件抓取。兔宝宝的进步和学习,离不开信立网络营销团队对我的帮助和关怀。经过一个下午的剖析 MP3 文件。尤其是那些做音乐的朋友网站。研究百度搜索技术如何实现MP3格式文件的抓取。关于MP3的其他改进问题,请写在下面文章。今天我只研究如何抓取MP3文件。同时提醒大家,本文文章,仅代表个人观点和文明评论,
为了使整个过程顺利,请举例分析。
观察到这个 MP3 文件夹只收录一个比我更快乐的文件。MP3。它还显示文件大小、类型修改日期。这里有一个问题需要确定。这个文件夹里只有这个文件。我们再观察一下他的属性内容。如下所示:
正如我们之前所说,只有一个文件。为什么它可以显示艺术家和专辑名称等相关信息?注意只有一个文本,为什么收录这么多信息?这里是百度搜索抓取MP3格式文件的网站构建键所在。
我大概会谈谈 MP3 格式的文件。MP3 文件不仅包括我们听到的音频文件(常说的音乐),还包括更多专辑和歌名。MP3格式文件大致分为三部分:TAG_V2(ID3V2)、Frame、、TAG_V1(ID3V1)),其中TAG_V2(ID3V2)记录作者、作曲、专辑以及其他信息。帧。记录音乐文件的物理部分。TAG_V1(ID3V1)记录作者、作曲家、专辑等信息,长度为128字节。这些是怎么写的,什么格式,怎么写的来定义,这里就不赘述了。
为了说明分析的真实性,去掉了MP3格式的文件封套,具体内容以16进制数据分析呈现。如下所示。
因此,一个完整的mp3文件也收录了作者、作曲、专辑等完整的信息。这进一步方便了百度搜索引擎抓取MP3文件,更好地让我们搜索。当我们搜索音乐时,我们会比较 MP3 的特定字节来实现匹配。将正确的音乐返回给用户。在此友情提醒,做音乐网站的网友们,在做网站优化的同时,别忘了优化MP3格式文件的内部内容,比如作者、作曲、专辑、其他信息都写了。这是百度掌握MP3最重要的基础。百度对音乐的抓取不依赖于文件名和网页的匹配。就是直接识别MP3文件的内部内容。至于MP3的内部内容怎么写,有空介绍一下,这里只讨论百度搜索抓取MP3文件。到目前为止,当然也为一些垃圾站提供了便利。当然,任何一件事都有利有弊。
Baby Rabbit将继续观察互联网搜索引擎。以后会写更多相关的文章。下面就来揭秘百度搜索抢图的秘诀。希望大家多多支持!同时声明,我的分析文章仅代表个人观点,不作为任何依据。文明评论,请勿吐槽。希望各位朋友关注我的博客,提出各种意见。 查看全部
抓取网页音频(研究百度搜索技术是如何实现抓取MP3格式文件(组图))
很高兴不断更新自己文章,无时无刻不在观察互联网技术。通常,将观察结果用文字记录下来,与大家分享。最近,由于学习需要,百度开始研究MP3文件抓取。兔宝宝的进步和学习,离不开信立网络营销团队对我的帮助和关怀。经过一个下午的剖析 MP3 文件。尤其是那些做音乐的朋友网站。研究百度搜索技术如何实现MP3格式文件的抓取。关于MP3的其他改进问题,请写在下面文章。今天我只研究如何抓取MP3文件。同时提醒大家,本文文章,仅代表个人观点和文明评论,
为了使整个过程顺利,请举例分析。
观察到这个 MP3 文件夹只收录一个比我更快乐的文件。MP3。它还显示文件大小、类型修改日期。这里有一个问题需要确定。这个文件夹里只有这个文件。我们再观察一下他的属性内容。如下所示:
正如我们之前所说,只有一个文件。为什么它可以显示艺术家和专辑名称等相关信息?注意只有一个文本,为什么收录这么多信息?这里是百度搜索抓取MP3格式文件的网站构建键所在。
我大概会谈谈 MP3 格式的文件。MP3 文件不仅包括我们听到的音频文件(常说的音乐),还包括更多专辑和歌名。MP3格式文件大致分为三部分:TAG_V2(ID3V2)、Frame、、TAG_V1(ID3V1)),其中TAG_V2(ID3V2)记录作者、作曲、专辑以及其他信息。帧。记录音乐文件的物理部分。TAG_V1(ID3V1)记录作者、作曲家、专辑等信息,长度为128字节。这些是怎么写的,什么格式,怎么写的来定义,这里就不赘述了。
为了说明分析的真实性,去掉了MP3格式的文件封套,具体内容以16进制数据分析呈现。如下所示。
因此,一个完整的mp3文件也收录了作者、作曲、专辑等完整的信息。这进一步方便了百度搜索引擎抓取MP3文件,更好地让我们搜索。当我们搜索音乐时,我们会比较 MP3 的特定字节来实现匹配。将正确的音乐返回给用户。在此友情提醒,做音乐网站的网友们,在做网站优化的同时,别忘了优化MP3格式文件的内部内容,比如作者、作曲、专辑、其他信息都写了。这是百度掌握MP3最重要的基础。百度对音乐的抓取不依赖于文件名和网页的匹配。就是直接识别MP3文件的内部内容。至于MP3的内部内容怎么写,有空介绍一下,这里只讨论百度搜索抓取MP3文件。到目前为止,当然也为一些垃圾站提供了便利。当然,任何一件事都有利有弊。
Baby Rabbit将继续观察互联网搜索引擎。以后会写更多相关的文章。下面就来揭秘百度搜索抢图的秘诀。希望大家多多支持!同时声明,我的分析文章仅代表个人观点,不作为任何依据。文明评论,请勿吐槽。希望各位朋友关注我的博客,提出各种意见。
抓取网页音频( CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-19 00:22
CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
CME推出在线网页,助您快速消除人声、提取人声或免费分离音频
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
mp3
AAC
水马
弗拉克
声波
艾夫
目前共有三种服务(实际上都是基于相同的算法),包括:
消除人声:
提取人声:
分离两个独立的人声音频文件和背景音乐文件:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
因为原算法需要GPU高速处理,耗时长,计算成本高,成本高,所以对个人电脑的要求更高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的心得,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(
CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
CME推出在线网页,助您快速消除人声、提取人声或免费分离音频
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。

首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
mp3
AAC
水马
弗拉克
声波
艾夫
目前共有三种服务(实际上都是基于相同的算法),包括:
消除人声:
提取人声:
分离两个独立的人声音频文件和背景音乐文件:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
因为原算法需要GPU高速处理,耗时长,计算成本高,成本高,所以对个人电脑的要求更高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的心得,帮助CME开发者不断完善服务:
抓取网页音频(一层一层地取地取字典,歌单列表列表forxinrange)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-12 00:05
对于范围内的 x(5):
参数 = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'644918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'无损':'0',
'flag_qc':'0',
'p':str(x 1),
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'格式':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'通知':'0',
'平台':'yqq.json',
'needNewCode':'0'
}
# 将参数封装成字典
res_music = requests.get(url,params=params)
#调用get方法下载字典
json_music = res_music.json()
#使用json()方法将响应对象转换为列表/字典
list_music = json_music['data']['song']['list']
#逐层获取字典获取播放列表
list_music 中的音乐:
# list_music 是一个列表,音乐是它的元素
打印(音乐['名字'])
#以名称为关键字查找歌曲名称
print('所属专辑:'music['album']['name'])
#查找相册名称
print('播放时间:'str(music['interval'])'seconds')
# 查找播放时长
print('播放链接:'音乐['mid']'.html\n\n')
# 查找播放链接 查看全部
抓取网页音频(一层一层地取地取字典,歌单列表列表forxinrange)
对于范围内的 x(5):
参数 = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'644918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'无损':'0',
'flag_qc':'0',
'p':str(x 1),
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'格式':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'通知':'0',
'平台':'yqq.json',
'needNewCode':'0'
}
# 将参数封装成字典
res_music = requests.get(url,params=params)
#调用get方法下载字典
json_music = res_music.json()
#使用json()方法将响应对象转换为列表/字典
list_music = json_music['data']['song']['list']
#逐层获取字典获取播放列表
list_music 中的音乐:
# list_music 是一个列表,音乐是它的元素
打印(音乐['名字'])
#以名称为关键字查找歌曲名称
print('所属专辑:'music['album']['name'])
#查找相册名称
print('播放时间:'str(music['interval'])'seconds')
# 查找播放时长
print('播放链接:'音乐['mid']'.html\n\n')
# 查找播放链接
抓取网页音频(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-06 12:01
curl 和 wget 下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
安装 curl 命令:sudo apt-get install curl(与 wget 相同)
2、Windows 平台
wget 下载链接:wget for Windows
curl下载链接:curl下载
wget和curl包下载地址:Windows平台下wget和curl工具包
Windows平台下,curl下载解压后,直接以curl.exe格式复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后格式为wget-1.11.4-1-setup.exe,需要安装;安装后,在Environment Variables-System Variables-Path目录下添加它的安装
curl 和 wget 抓取示例
抓取网页主要有两种方式:url和代理。下面是一个爬取“百度”首页的例子。
1、 url 网址抓取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget 下载百度首页的内容保存在baidu_html文件中
wget -O baidu_html2
有时,由于网速/数据丢失/服务器停机/等原因,网页暂时无法下载成功
这时候,你可能需要尝试多次发送连接,请求服务器响应;如果多次都没有反应,可以确认服务器有问题
(1)curl 尝试多次连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在最长时间内只允许重试一次(一般与--retry-delay相同)
(2)wget 多次尝试连接
wget -t 10 -w 60 -T 30 -O baidu_html2
注:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间。如果超过超时,则连接不成功,下次继续尝试连接
附:curl 判断服务器是否响应。也可以通过一段时间内下载的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注意:-y 代表测试网速的时间;-Y 表示 -y 期间下载的字节数(以字节为单位);-m 表示允许请求连接的最长时间,超过则自动断开连接并放弃连接
2、代理爬取
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,有分隔由冒号“:”组成一个套接字)
(1)curl 通过代理爬取百度首页
curl -x 218.107.21.252:8080-o aaaaa(端口通常为80、8080、8086、8888、3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过218.107.21.252:8080下载百度主页,最后218.107.21.252:8080 发送下载的百度首页到curl到本地(curl不是直接连接百度服务器下载首页,而是通过中介代理)
(2)wget 通过代理爬取百度首页
wget通过代理下载,和curl不一样。需要先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd~)下创建wget配置文件(.wgetrc),进入代理配置: 查看全部
抓取网页音频(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl 和 wget 下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
安装 curl 命令:sudo apt-get install curl(与 wget 相同)
2、Windows 平台
wget 下载链接:wget for Windows
curl下载链接:curl下载
wget和curl包下载地址:Windows平台下wget和curl工具包
Windows平台下,curl下载解压后,直接以curl.exe格式复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后格式为wget-1.11.4-1-setup.exe,需要安装;安装后,在Environment Variables-System Variables-Path目录下添加它的安装
curl 和 wget 抓取示例
抓取网页主要有两种方式:url和代理。下面是一个爬取“百度”首页的例子。
1、 url 网址抓取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget 下载百度首页的内容保存在baidu_html文件中
wget -O baidu_html2
有时,由于网速/数据丢失/服务器停机/等原因,网页暂时无法下载成功
这时候,你可能需要尝试多次发送连接,请求服务器响应;如果多次都没有反应,可以确认服务器有问题
(1)curl 尝试多次连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在最长时间内只允许重试一次(一般与--retry-delay相同)
(2)wget 多次尝试连接
wget -t 10 -w 60 -T 30 -O baidu_html2
注:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间。如果超过超时,则连接不成功,下次继续尝试连接
附:curl 判断服务器是否响应。也可以通过一段时间内下载的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注意:-y 代表测试网速的时间;-Y 表示 -y 期间下载的字节数(以字节为单位);-m 表示允许请求连接的最长时间,超过则自动断开连接并放弃连接
2、代理爬取
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,有分隔由冒号“:”组成一个套接字)
(1)curl 通过代理爬取百度首页
curl -x 218.107.21.252:8080-o aaaaa(端口通常为80、8080、8086、8888、3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过218.107.21.252:8080下载百度主页,最后218.107.21.252:8080 发送下载的百度首页到curl到本地(curl不是直接连接百度服务器下载首页,而是通过中介代理)
(2)wget 通过代理爬取百度首页
wget通过代理下载,和curl不一样。需要先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd~)下创建wget配置文件(.wgetrc),进入代理配置:
抓取网页音频(这些活动对于诊断连接问题或其它与WebRTC相关的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-06 11:20
本文由 Janus 项目的作者 Lorenzo Miniero 撰写。2019年10月25日,他将来到北京RTC 2019,在“WebRTC Workshop”工作坊分享WebRTC服务器开发和Janus开发技巧,并与观众进行小范围的深度交流,名额有限,现在就可以报名了:/(申请限时免费门票,还可以获得创意工坊代金券~)
本文小结:抓取WebRTC流量看似比较简单,在大多数情况下确实如此:只需在其中一台机器上安装tcpdump或wireshark等抓包工具,然后查看生成的文件即可。在大多数情况下,它将是 .pcap 或 .pcapng 文件。这些活动对于诊断连接问题或与 WebRTC 相关的其他问题很有用:实际上,wireshark 可以自动检测标准协议,例如 STUN 和 DTLS,它们是 WebRTC PeerConnections 的重点。
这篇文章的关键是什么?
捕获 WebRTC 流量的唯一问题是媒体内容将被加密。检查STUN连接或DTLS握手后,这不是问题,但是当您要查看RTP或RTCP数据包时,它会成为问题,将其加密为SRTP和SRTCP。实际上,尽管 SRTP 标头未加密并且您可以以任何形式捕获流量,但 SRTP 有效负载并未加密,这意味着您无法查看其内容。
在大多数情况下,您不需要查看内容。正如预期的那样,您仍然可以查看加密的 RTP 数据包的头部,这是最常用的信息。在任何情况下,RTCP 都不能这样说:实际上,一个 RTCP 消息实际上可能收录多个数据包,并且没有共享头。此外,查看 RTP 负载可能是有效的。
这意味着捕获加密流量是可行的,但为了诊断目的捕获未加密数据可能更好。不幸的是,如果没有其他帮助,这是不可能的:实际上,在WebRTC的情况下,浏览器经常发送加密数据,即使有些允许您抓取未加密的数据进行测试,您仍然需要依靠其他工具来获取媒体。流才能开展这项工作。
进入杰纳斯!
作为 WebRTC 媒体服务器,Janus 确实发挥了它的作用:事实上,它存在于 PeerConnection 的每一个媒体路径上。另外,由于它为每个PeerConnections建立了一个安全的环境,因此可以获取输入和输出未加密的RTP和RTCP数据包。
一年前我们是这样想的。受 Firefox 的启发,我们首先添加了对 text2pcapdump 的支持,方法很简单:
1.使用Admin API开始抓取Janus处理的文件信息。
2.所有输入输出的RTP/RTCP包都转换成文本格式保存在相关文件中。
3. 捕获后,使用text2pcap App将捕获的文件转换为Wiresharak或其他工具兼容的格式。
请求的语法很简单:
<p>POST /admin/sessionId/handleId
{
"janus" : "start_text2pcap",
"folder" : "",
"filename" : "",
"truncate" : " 查看全部
抓取网页音频(这些活动对于诊断连接问题或其它与WebRTC相关的问题)
本文由 Janus 项目的作者 Lorenzo Miniero 撰写。2019年10月25日,他将来到北京RTC 2019,在“WebRTC Workshop”工作坊分享WebRTC服务器开发和Janus开发技巧,并与观众进行小范围的深度交流,名额有限,现在就可以报名了:/(申请限时免费门票,还可以获得创意工坊代金券~)
本文小结:抓取WebRTC流量看似比较简单,在大多数情况下确实如此:只需在其中一台机器上安装tcpdump或wireshark等抓包工具,然后查看生成的文件即可。在大多数情况下,它将是 .pcap 或 .pcapng 文件。这些活动对于诊断连接问题或与 WebRTC 相关的其他问题很有用:实际上,wireshark 可以自动检测标准协议,例如 STUN 和 DTLS,它们是 WebRTC PeerConnections 的重点。
这篇文章的关键是什么?
捕获 WebRTC 流量的唯一问题是媒体内容将被加密。检查STUN连接或DTLS握手后,这不是问题,但是当您要查看RTP或RTCP数据包时,它会成为问题,将其加密为SRTP和SRTCP。实际上,尽管 SRTP 标头未加密并且您可以以任何形式捕获流量,但 SRTP 有效负载并未加密,这意味着您无法查看其内容。
在大多数情况下,您不需要查看内容。正如预期的那样,您仍然可以查看加密的 RTP 数据包的头部,这是最常用的信息。在任何情况下,RTCP 都不能这样说:实际上,一个 RTCP 消息实际上可能收录多个数据包,并且没有共享头。此外,查看 RTP 负载可能是有效的。
这意味着捕获加密流量是可行的,但为了诊断目的捕获未加密数据可能更好。不幸的是,如果没有其他帮助,这是不可能的:实际上,在WebRTC的情况下,浏览器经常发送加密数据,即使有些允许您抓取未加密的数据进行测试,您仍然需要依靠其他工具来获取媒体。流才能开展这项工作。
进入杰纳斯!
作为 WebRTC 媒体服务器,Janus 确实发挥了它的作用:事实上,它存在于 PeerConnection 的每一个媒体路径上。另外,由于它为每个PeerConnections建立了一个安全的环境,因此可以获取输入和输出未加密的RTP和RTCP数据包。
一年前我们是这样想的。受 Firefox 的启发,我们首先添加了对 text2pcapdump 的支持,方法很简单:
1.使用Admin API开始抓取Janus处理的文件信息。
2.所有输入输出的RTP/RTCP包都转换成文本格式保存在相关文件中。
3. 捕获后,使用text2pcap App将捕获的文件转换为Wiresharak或其他工具兼容的格式。
请求的语法很简单:
<p>POST /admin/sessionId/handleId
{
"janus" : "start_text2pcap",
"folder" : "",
"filename" : "",
"truncate" : "
抓取网页音频(工具特色:工具这么多,大家不妨试试它迅捷音频转换器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-05 11:12
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获! 工具特点:工具太多了,你不妨试试,快速音频转换器是一个多功能音频编辑处理软件,该软件具有音频剪切、音频提取、音频合并和音频转换,支持单文件操作,也支持文件批量操作!确实是一个不错的选择。音频转换器第一步:打开网页中准备音乐的工具,然后打开工具到界面,可以尝试简单了解一下。第二步:添加音频文件 今天是提取音乐,所以大家找到音频提取按钮,点击它,就会出现它的界面。在其界面中添加文件和添加文件夹有两个选项。您可以自定义文件数量。只需添加它。第 3 步:添加和删除片段指南 接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加片段指南是您提取的音乐片段,删除片段指南只是删除您不需要的音乐片段。可以拉取被骗进度条提取音乐片段,最后点击确定。第 4 步:设置保存提取音频的位置。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(工具特色:工具这么多,大家不妨试试它迅捷音频转换器)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获! 工具特点:工具太多了,你不妨试试,快速音频转换器是一个多功能音频编辑处理软件,该软件具有音频剪切、音频提取、音频合并和音频转换,支持单文件操作,也支持文件批量操作!确实是一个不错的选择。音频转换器第一步:打开网页中准备音乐的工具,然后打开工具到界面,可以尝试简单了解一下。第二步:添加音频文件 今天是提取音乐,所以大家找到音频提取按钮,点击它,就会出现它的界面。在其界面中添加文件和添加文件夹有两个选项。您可以自定义文件数量。只需添加它。第 3 步:添加和删除片段指南 接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加片段指南是您提取的音乐片段,删除片段指南只是删除您不需要的音乐片段。可以拉取被骗进度条提取音乐片段,最后点击确定。第 4 步:设置保存提取音频的位置。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(总结IE音乐播放网页播放音乐这一过程的细节猜想(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-05 05:05
可以通过两种方式获得,第一种更直接,第二种更高一点:
从IE临时缓存内容的本地路径获取。具体操作步骤如下:
总结
在IE音乐播放网页上播放音乐的具体技术实现过程的详细推测如下:
用户通过IE音乐播放器网页向音乐服务器发起播放音乐的请求,询问是否可以连接;音乐服务器收到连接请求后,响应用户可以连接;通知用户可以连接,正式开始连接音乐服务器,此时用户与音乐服务器的直接网络传输连接建立;用户使用三次握手后建立的连接从音乐服务器下载音乐数据文件到用户本地(在用户和音乐服务器之间的过程中应该一直连接);音乐文件成功下载到用户本地,此时不需要保持连接,
这个过程表明,用户每次发起音乐播放请求,都会与音乐服务器进行三次握手并建立连接。之前建立的连接会在数据传输完成后立即断开,不会被保存。因此,无法保存后续请求。要重复使用之前建立的连接,只能建立新的连接,使用后断开连接。这种方法是短连接。一个会话连接一次,请求和连接是一一对应的关系。因为在这种场景下,每个请求之间的时间间隔不是固定的,可能是很短的时间间隔才发出下一个播放音乐的请求,或者可能需要很长时间才能执行下一个播放音乐的操作。如果连接建立后一直保持着,但实际上并没有使用,那岂不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成,收录一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的细节)
既然提到了短连接,那就有必要说说长连接了。长连接中请求和连接的关系是多对一的。也就是说,前一个请求建立的连接可以被后续的请求使用而不会断开。比如跑步APP实时显示运动轨迹:用户通过APP请求服务器实时显示运动轨迹。用户需要将自己的最新位置信息实时上报给服务器。服务器收到后将绘制的最新运动轨迹返回给用户。双向数据传输过程。这个过程要一直保持连接在线,不会每次都上报就建立连接,太麻烦了。假设用户每次上报都建立连接,在建立连接之前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。 查看全部
抓取网页音频(总结IE音乐播放网页播放音乐这一过程的细节猜想(组图))
可以通过两种方式获得,第一种更直接,第二种更高一点:
从IE临时缓存内容的本地路径获取。具体操作步骤如下:


总结
在IE音乐播放网页上播放音乐的具体技术实现过程的详细推测如下:
用户通过IE音乐播放器网页向音乐服务器发起播放音乐的请求,询问是否可以连接;音乐服务器收到连接请求后,响应用户可以连接;通知用户可以连接,正式开始连接音乐服务器,此时用户与音乐服务器的直接网络传输连接建立;用户使用三次握手后建立的连接从音乐服务器下载音乐数据文件到用户本地(在用户和音乐服务器之间的过程中应该一直连接);音乐文件成功下载到用户本地,此时不需要保持连接,
这个过程表明,用户每次发起音乐播放请求,都会与音乐服务器进行三次握手并建立连接。之前建立的连接会在数据传输完成后立即断开,不会被保存。因此,无法保存后续请求。要重复使用之前建立的连接,只能建立新的连接,使用后断开连接。这种方法是短连接。一个会话连接一次,请求和连接是一一对应的关系。因为在这种场景下,每个请求之间的时间间隔不是固定的,可能是很短的时间间隔才发出下一个播放音乐的请求,或者可能需要很长时间才能执行下一个播放音乐的操作。如果连接建立后一直保持着,但实际上并没有使用,那岂不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成,收录一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的细节)
既然提到了短连接,那就有必要说说长连接了。长连接中请求和连接的关系是多对一的。也就是说,前一个请求建立的连接可以被后续的请求使用而不会断开。比如跑步APP实时显示运动轨迹:用户通过APP请求服务器实时显示运动轨迹。用户需要将自己的最新位置信息实时上报给服务器。服务器收到后将绘制的最新运动轨迹返回给用户。双向数据传输过程。这个过程要一直保持连接在线,不会每次都上报就建立连接,太麻烦了。假设用户每次上报都建立连接,在建立连接之前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。
抓取网页音频(如何在手机App中的数据中抓取数据?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-05 03:05
)
过去,数据是在网络上捕获的。移动应用程序中捕获的数据并不多。如何捕获移动应用程序中的数据?通常我们使用抓包工具抓取data.html
常用的抓包工具由 Fiddles 和 Charles 等人编写。今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以我一般推荐Charlesios抓包。
下载并安装 Charles
下载安装Charles然后破解Charles,这里是文章教程,我很少说
json
注意事项:应用
如果获取的数据是乱码,需要在Charles的菜单栏中设置链接SSL证书==>proxy==>SSL代理设置==>添加443,如上图所示。那么当你在实际抓取数据的时候,记得把这个关掉,以免丢失数据的工具
使用查尔斯
这里我直接放两张图给大家用看看就明白了
我们一起来分析一下这个项目。
# 这里有点递归的意味<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;">
完整代码:
import requests<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">import time<br style="margin:0px;padding:0px;max-width:100%;">import json<br style="margin:0px;padding:0px;max-width:100%;">from dedao.ExeclUtils import ExeclUtils<br style="margin:0px;padding:0px;max-width:100%;">import os<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">class dedao(object):<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def __init__(self):<br style="margin:0px;padding:0px;max-width:100%;"> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘连接', u'招聘要求描述']<br style="margin:0px;padding:0px;max-width:100%;"> # sheet_name = u'51job_Python招聘'<br style="margin:0px;padding:0px;max-width:100%;"> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br style="margin:0px;padding:0px;max-width:100%;"> sheet_name = u'逻辑思惟音频'<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.execl_f = return_execl[0]<br style="margin:0px;padding:0px;max-width:100%;"> self.sheet_table = return_execl[1]<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = [] # 存放每一条数据中的各元素,<br style="margin:0px;padding:0px;max-width:100%;"> self.count = 0 # 数据插入从1开始的<br style="margin:0px;padding:0px;max-width:100%;"> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = 0<br style="margin:0px;padding:0px;max-width:100%;"> self.headers = {<br style="margin:0px;padding:0px;max-width:100%;"> 'Host': 'entree.igetget.com',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OS': 'iOS',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-NET': 'wifi',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept': '*/*',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Nonce': '779b79d1d51d43fa',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Encoding': 'br, gzip, deflate',<br style="margin:0px;padding:0px;max-width:100%;"> # 'Content-Length': ' 67',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TARGET': 'main',<br style="margin:0px;padding:0px;max-width:100%;"> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-CHIL': 'appstore',<br style="margin:0px;padding:0px;max-width:100%;"> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-UID': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-AV ': '4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SEID ': '',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SCR ': '1242*2208',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DT': 'phone',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-S': '91a46b7a31ffc7a2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Language': 'zh-cn',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-THUMB': 'l',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-T': 'json',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Timestamp': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TS': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-U': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-App-Key': 'ios-4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OV': '11.4',<br style="margin:0px;padding:0px;max-width:100%;"> 'Connection': 'keep-alive',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-ADV': '1',<br style="margin:0px;padding:0px;max-width:100%;"> 'Content-Type': 'application/x-www-form-urlencoded',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-V': '2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-IS_JAILBREAK ': 'NO',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DV': 'iPhone10,2',<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def request_data(self):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> data = {<br style="margin:0px;padding:0px;max-width:100%;"> 'max_id': self.max_id,<br style="margin:0px;padding:0px;max-width:100%;"> 'since_id': 0,<br style="margin:0px;padding:0px;max-width:100%;"> 'column_id': 2,<br style="margin:0px;padding:0px;max-width:100%;"> 'count': 20,<br style="margin:0px;padding:0px;max-width:100%;"> 'order': 1,<br style="margin:0px;padding:0px;max-width:100%;"> 'section': 0<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"> response = requests.post(self.base_url, headers=self.headers, data=data)<br style="margin:0px;padding:0px;max-width:100%;"> if 200 == response.status_code:<br style="margin:0px;padding:0px;max-width:100%;"> self.parse_data(response)<br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(2)<br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def parse_data(self, response):<br style="margin:0px;padding:0px;max-width:100%;"> dict_json = json.loads(response.text)<br style="margin:0px;padding:0px;max-width:100%;"> datas = dict_json['c']['list'] # 这里取得数据列表<br style="margin:0px;padding:0px;max-width:100%;"> # print(datas)<br style="margin:0px;padding:0px;max-width:100%;"> for data in datas:<br style="margin:0px;padding:0px;max-width:100%;"> source_name = data['audio_detail']['source_name']<br style="margin:0px;padding:0px;max-width:100%;"> title = data['audio_detail']['title']<br style="margin:0px;padding:0px;max-width:100%;"> icon = data['audio_detail']['icon']<br style="margin:0px;padding:0px;max-width:100%;"> share_title = data['audio_detail']['share_title']<br style="margin:0px;padding:0px;max-width:100%;"> mp3_url = data['audio_detail']['mp3_play_url']<br style="margin:0px;padding:0px;max-width:100%;"> duction = str(data['audio_detail']['duration']) + '秒'<br style="margin:0px;padding:0px;max-width:100%;"> size = data['audio_detail']['size'] / (1000 * 1000)<br style="margin:0px;padding:0px;max-width:100%;"> size = '%.2fM' % size<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.download_mp3(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(source_name)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(icon)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(share_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(duction)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(size)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.count = self.count + 1<br style="margin:0px;padding:0px;max-width:100%;"> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思惟音频.xlsx')<br style="margin:0px;padding:0px;max-width:100%;"> print('采集了{}条数据'.format(self.count))<br style="margin:0px;padding:0px;max-width:100%;"> # 清空集合,为再次存放数据作准备<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = []<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(3) # 不要请求太快, 当心查水表<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def download_mp3(self, mp3_url):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> # 补全文件目录<br style="margin:0px;padding:0px;max-width:100%;"> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br style="margin:0px;padding:0px;max-width:100%;"> print(mp3_path)<br style="margin:0px;padding:0px;max-width:100%;"> # 判断文件是否存在。<br style="margin:0px;padding:0px;max-width:100%;"> if not os.path.exists(mp3_path):<br style="margin:0px;padding:0px;max-width:100%;"> # 注意这里是写入文件,要用二进制格式写入。<br style="margin:0px;padding:0px;max-width:100%;"> with open(mp3_path, 'wb') as f:<br style="margin:0px;padding:0px;max-width:100%;"> f.write(requests.get(mp3_url).content)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">if __name__ == '__main__': d = dedao() d.request_data() 查看全部
抓取网页音频(如何在手机App中的数据中抓取数据?(图)
)
过去,数据是在网络上捕获的。移动应用程序中捕获的数据并不多。如何捕获移动应用程序中的数据?通常我们使用抓包工具抓取data.html
常用的抓包工具由 Fiddles 和 Charles 等人编写。今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以我一般推荐Charlesios抓包。
下载并安装 Charles
下载安装Charles然后破解Charles,这里是文章教程,我很少说
json
注意事项:应用
如果获取的数据是乱码,需要在Charles的菜单栏中设置链接SSL证书==>proxy==>SSL代理设置==>添加443,如上图所示。那么当你在实际抓取数据的时候,记得把这个关掉,以免丢失数据的工具

使用查尔斯
这里我直接放两张图给大家用看看就明白了
我们一起来分析一下这个项目。
# 这里有点递归的意味<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;">
完整代码:
import requests<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">import time<br style="margin:0px;padding:0px;max-width:100%;">import json<br style="margin:0px;padding:0px;max-width:100%;">from dedao.ExeclUtils import ExeclUtils<br style="margin:0px;padding:0px;max-width:100%;">import os<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">class dedao(object):<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def __init__(self):<br style="margin:0px;padding:0px;max-width:100%;"> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘连接', u'招聘要求描述']<br style="margin:0px;padding:0px;max-width:100%;"> # sheet_name = u'51job_Python招聘'<br style="margin:0px;padding:0px;max-width:100%;"> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br style="margin:0px;padding:0px;max-width:100%;"> sheet_name = u'逻辑思惟音频'<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.execl_f = return_execl[0]<br style="margin:0px;padding:0px;max-width:100%;"> self.sheet_table = return_execl[1]<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = [] # 存放每一条数据中的各元素,<br style="margin:0px;padding:0px;max-width:100%;"> self.count = 0 # 数据插入从1开始的<br style="margin:0px;padding:0px;max-width:100%;"> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = 0<br style="margin:0px;padding:0px;max-width:100%;"> self.headers = {<br style="margin:0px;padding:0px;max-width:100%;"> 'Host': 'entree.igetget.com',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OS': 'iOS',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-NET': 'wifi',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept': '*/*',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Nonce': '779b79d1d51d43fa',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Encoding': 'br, gzip, deflate',<br style="margin:0px;padding:0px;max-width:100%;"> # 'Content-Length': ' 67',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TARGET': 'main',<br style="margin:0px;padding:0px;max-width:100%;"> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-CHIL': 'appstore',<br style="margin:0px;padding:0px;max-width:100%;"> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-UID': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-AV ': '4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SEID ': '',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SCR ': '1242*2208',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DT': 'phone',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-S': '91a46b7a31ffc7a2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Language': 'zh-cn',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-THUMB': 'l',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-T': 'json',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Timestamp': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TS': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-U': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-App-Key': 'ios-4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OV': '11.4',<br style="margin:0px;padding:0px;max-width:100%;"> 'Connection': 'keep-alive',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-ADV': '1',<br style="margin:0px;padding:0px;max-width:100%;"> 'Content-Type': 'application/x-www-form-urlencoded',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-V': '2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-IS_JAILBREAK ': 'NO',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DV': 'iPhone10,2',<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def request_data(self):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> data = {<br style="margin:0px;padding:0px;max-width:100%;"> 'max_id': self.max_id,<br style="margin:0px;padding:0px;max-width:100%;"> 'since_id': 0,<br style="margin:0px;padding:0px;max-width:100%;"> 'column_id': 2,<br style="margin:0px;padding:0px;max-width:100%;"> 'count': 20,<br style="margin:0px;padding:0px;max-width:100%;"> 'order': 1,<br style="margin:0px;padding:0px;max-width:100%;"> 'section': 0<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"> response = requests.post(self.base_url, headers=self.headers, data=data)<br style="margin:0px;padding:0px;max-width:100%;"> if 200 == response.status_code:<br style="margin:0px;padding:0px;max-width:100%;"> self.parse_data(response)<br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(2)<br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def parse_data(self, response):<br style="margin:0px;padding:0px;max-width:100%;"> dict_json = json.loads(response.text)<br style="margin:0px;padding:0px;max-width:100%;"> datas = dict_json['c']['list'] # 这里取得数据列表<br style="margin:0px;padding:0px;max-width:100%;"> # print(datas)<br style="margin:0px;padding:0px;max-width:100%;"> for data in datas:<br style="margin:0px;padding:0px;max-width:100%;"> source_name = data['audio_detail']['source_name']<br style="margin:0px;padding:0px;max-width:100%;"> title = data['audio_detail']['title']<br style="margin:0px;padding:0px;max-width:100%;"> icon = data['audio_detail']['icon']<br style="margin:0px;padding:0px;max-width:100%;"> share_title = data['audio_detail']['share_title']<br style="margin:0px;padding:0px;max-width:100%;"> mp3_url = data['audio_detail']['mp3_play_url']<br style="margin:0px;padding:0px;max-width:100%;"> duction = str(data['audio_detail']['duration']) + '秒'<br style="margin:0px;padding:0px;max-width:100%;"> size = data['audio_detail']['size'] / (1000 * 1000)<br style="margin:0px;padding:0px;max-width:100%;"> size = '%.2fM' % size<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.download_mp3(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(source_name)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(icon)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(share_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(duction)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(size)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.count = self.count + 1<br style="margin:0px;padding:0px;max-width:100%;"> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思惟音频.xlsx')<br style="margin:0px;padding:0px;max-width:100%;"> print('采集了{}条数据'.format(self.count))<br style="margin:0px;padding:0px;max-width:100%;"> # 清空集合,为再次存放数据作准备<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = []<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(3) # 不要请求太快, 当心查水表<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def download_mp3(self, mp3_url):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> # 补全文件目录<br style="margin:0px;padding:0px;max-width:100%;"> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br style="margin:0px;padding:0px;max-width:100%;"> print(mp3_path)<br style="margin:0px;padding:0px;max-width:100%;"> # 判断文件是否存在。<br style="margin:0px;padding:0px;max-width:100%;"> if not os.path.exists(mp3_path):<br style="margin:0px;padding:0px;max-width:100%;"> # 注意这里是写入文件,要用二进制格式写入。<br style="margin:0px;padding:0px;max-width:100%;"> with open(mp3_path, 'wb') as f:<br style="margin:0px;padding:0px;max-width:100%;"> f.write(requests.get(mp3_url).content)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">if __name__ == '__main__': d = dedao() d.request_data()
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-05 00:08
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在页面底部选择中文),上传音频文件进行在线云处理,所有处理均使用CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。

首先,这是一项在线免费服务,只需访问即可使用(打开后可以在页面底部选择中文),上传音频文件进行在线云处理,所有处理均使用CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务:
抓取网页音频(如何用python爬取网页音频,还是继续上次的课程和文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-04 05:02
抓取网页音频,听听音乐,尤其是摇滚音乐,当然我们要知道怎么用爬虫来获取音频。其实这个真的是非常简单的问题,之前我们已经通过python手动实现了我们听音乐的功能。但是如果想让python更高效一些,也就是说让python远程,文件抓取,那么必须要使用python3网络库,第三方库requests这个库就可以给我们带来很多便利。
至于如何用python爬取网页音频,还是继续上次的课程和文章吧。1.创建一个url链接(获取网页foo.css,requests调用格式是:"/"url="/"extension="search.bytes"url="/"url=";charset=utf-8")2.创建一个booklist(all_books)函数,将里面所有的书籍信息存储下来,把之前讲到的网页foo.css,requests调用格式,写在这个函数里。
3.foo.css内容我们重点看一下。//all_books{'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'j':false,'k':false,'l':false,'m':false,'n':false,'o':false,'p':false,'q':false,'r':false,'s':false,'t':false,'u':false,'v':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'w':false,'e':false,'f':false,'a':false,'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'f':false,'j':false,'k':false,'l':false,'f':false,'v':false,'w':false,'t':false,'u':false,'q':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'z':false,'t':false,'u':false,'e':false,'f':false,'f':false,'h':false,'g':false,'f':false,'e':false,'f':false,'f':false,'h':false,'j':false,'k':false,'l':false,'f':false,'g':false,'d':false,'e':false,'f':false,'f':false,'g':false,'e':false,'f':false,'f':false,'t':false,'u':false,'q':false,'t':false,'w':false,'x'。 查看全部
抓取网页音频(如何用python爬取网页音频,还是继续上次的课程和文章)
抓取网页音频,听听音乐,尤其是摇滚音乐,当然我们要知道怎么用爬虫来获取音频。其实这个真的是非常简单的问题,之前我们已经通过python手动实现了我们听音乐的功能。但是如果想让python更高效一些,也就是说让python远程,文件抓取,那么必须要使用python3网络库,第三方库requests这个库就可以给我们带来很多便利。
至于如何用python爬取网页音频,还是继续上次的课程和文章吧。1.创建一个url链接(获取网页foo.css,requests调用格式是:"/"url="/"extension="search.bytes"url="/"url=";charset=utf-8")2.创建一个booklist(all_books)函数,将里面所有的书籍信息存储下来,把之前讲到的网页foo.css,requests调用格式,写在这个函数里。
3.foo.css内容我们重点看一下。//all_books{'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'j':false,'k':false,'l':false,'m':false,'n':false,'o':false,'p':false,'q':false,'r':false,'s':false,'t':false,'u':false,'v':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'w':false,'e':false,'f':false,'a':false,'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'f':false,'j':false,'k':false,'l':false,'f':false,'v':false,'w':false,'t':false,'u':false,'q':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'z':false,'t':false,'u':false,'e':false,'f':false,'f':false,'h':false,'g':false,'f':false,'e':false,'f':false,'f':false,'h':false,'j':false,'k':false,'l':false,'f':false,'g':false,'d':false,'e':false,'f':false,'f':false,'g':false,'e':false,'f':false,'f':false,'t':false,'u':false,'q':false,'t':false,'w':false,'x'。
抓取网页音频(哪些网页才是重要性高的呢?如何定义链接欢迎度为IB)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-02 17:17
也称为“页面选择问题”(page Selection),通常是尽可能先抓取重要的网页,以确保在有限的资源内尽可能多地照顾到最重要的网页。那么哪些页面最重要?如何量化重要性?
重要性度量由链接流行度、链接重要性和平均链接深度确定。
将链接流行度定义为IB(P),主要由backinks的数量和质量决定。先看号码。直观地说,一个网页指向它的链接越多(反向链接的数量越多),其他网页就会识别它。同时,该网页被网民访问的机会更大,推测其重要性会更高;其次,如果是由更重要的网站引导,其重要性会更高。如果不考虑质量,就会有局部最优而不是全局最优。最典型的是作弊网页,在某些网页上人为设置大量反策略链接指向自己的网页,以增加网页的重要性。如果不考虑链接质量,
定义链接重要性为IL(P),它是URL字符串的函数,只检查字符串本身。链接重要性主要采用一些方式,例如收录“.COM”或“HOME”的URL被认为更重要,斜线较少的URL被认为更重要。
定义平均链接深度为 ID(P),由作者创建。ID(P)是指在一组种子站点中,如果每个种子站点都有一个链接(广度优先遍历规则)到达该网页,那么平均链接深度是该网页的另一个重要指标。因为离种子站点越近,访问的机会就越多,离种子站点越远,重要性越低。其实按照广度优先遍历规则,这样重要的网页先被爬取就可以满足了。
最后,定义网页重要性的指标是I(P),由上述两个量化值线性决定,即:
I(P)=a*IB(P)+β*IL(P)
平均链接深度由宽度优先遍历规则保证,因此不用作重要性评估的指标。在抓取能力有限的情况下,尽可能多抓取最重要的网页是合理和科学的,而用户最终查询到的网页往往是重要性高的网页。
虽然这看起来已经足够完美了,但实际上还是忽略了一个重要的 element-time。时间通向万维网的动态一面。如何抓取那些新添加的网页?如何重新访问那些被修改过的页面?如何找到已删除的页面?为了跟上万维网网页的变化,必须有网页重访策略。该策略可以识别三种类型的网页更改:添加、修改和删除网页。 查看全部
抓取网页音频(哪些网页才是重要性高的呢?如何定义链接欢迎度为IB)
也称为“页面选择问题”(page Selection),通常是尽可能先抓取重要的网页,以确保在有限的资源内尽可能多地照顾到最重要的网页。那么哪些页面最重要?如何量化重要性?
重要性度量由链接流行度、链接重要性和平均链接深度确定。
将链接流行度定义为IB(P),主要由backinks的数量和质量决定。先看号码。直观地说,一个网页指向它的链接越多(反向链接的数量越多),其他网页就会识别它。同时,该网页被网民访问的机会更大,推测其重要性会更高;其次,如果是由更重要的网站引导,其重要性会更高。如果不考虑质量,就会有局部最优而不是全局最优。最典型的是作弊网页,在某些网页上人为设置大量反策略链接指向自己的网页,以增加网页的重要性。如果不考虑链接质量,
定义链接重要性为IL(P),它是URL字符串的函数,只检查字符串本身。链接重要性主要采用一些方式,例如收录“.COM”或“HOME”的URL被认为更重要,斜线较少的URL被认为更重要。
定义平均链接深度为 ID(P),由作者创建。ID(P)是指在一组种子站点中,如果每个种子站点都有一个链接(广度优先遍历规则)到达该网页,那么平均链接深度是该网页的另一个重要指标。因为离种子站点越近,访问的机会就越多,离种子站点越远,重要性越低。其实按照广度优先遍历规则,这样重要的网页先被爬取就可以满足了。
最后,定义网页重要性的指标是I(P),由上述两个量化值线性决定,即:
I(P)=a*IB(P)+β*IL(P)
平均链接深度由宽度优先遍历规则保证,因此不用作重要性评估的指标。在抓取能力有限的情况下,尽可能多抓取最重要的网页是合理和科学的,而用户最终查询到的网页往往是重要性高的网页。
虽然这看起来已经足够完美了,但实际上还是忽略了一个重要的 element-time。时间通向万维网的动态一面。如何抓取那些新添加的网页?如何重新访问那些被修改过的页面?如何找到已删除的页面?为了跟上万维网网页的变化,必须有网页重访策略。该策略可以识别三种类型的网页更改:添加、修改和删除网页。
抓取网页音频(热门频道2.打开开发者模式,抓取全部热门音频频道信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-26 19:03
这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中供后续使用。这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前我还在等待三方,或者通知最后的采访消息。(因为能得到一定程度的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,每页可以看到12个频道,每个频道下面有很多音频,有些频道有很多标签。爬取方案:循环84个页面,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现了对所有热门频道信息的抓取,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后分析页面结构。可以看到,每个音频都有一个特定的ID,这个ID可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7. 如果改成异步形式,可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如音量排行,时间段排行,声道音频数等等。未来我会继续学习使用科学计算和绘图工具进行数据分析和清理。
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧! 查看全部
抓取网页音频(热门频道2.打开开发者模式,抓取全部热门音频频道信息)
这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中供后续使用。这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前我还在等待三方,或者通知最后的采访消息。(因为能得到一定程度的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,每页可以看到12个频道,每个频道下面有很多音频,有些频道有很多标签。爬取方案:循环84个页面,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。

热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现了对所有热门频道信息的抓取,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)

分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后分析页面结构。可以看到,每个音频都有一个特定的ID,这个ID可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。

频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)

音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明

分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7. 如果改成异步形式,可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。

异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如音量排行,时间段排行,声道音频数等等。未来我会继续学习使用科学计算和绘图工具进行数据分析和清理。
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧!
抓取网页音频(语言下载网页音频文件的生成代码和生成路径介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-01 10:01
抓取网页音频一直是作为老年人辅助工具的需求,其他工具也一直想用,但是没有想到有些网站怎么登录不了,这几天真是研究了好久,花费了不少时间。真是不好意思在网上推广,望广大网友指点一二。方法有些老生常谈,按步骤介绍,各位老师按照步骤来吧!使用python语言。下载网页音频文件,通过相关库,利用schem库的for循环,从网页获取文件名和音频音质,通过raiser内建的m3u8库提取出音频音质格式,保存在txt文件中,因此形成视频格式的文件。
由于网上资源太多,基本用txt文件保存,但是txt并不容易编辑,因此这里将视频转为mp4,然后用ffmpeg的录屏命令制作视频,然后解压网页音频文件,即可保存到另一个文件夹。下面是成功生成demo文件对应路径后,视频文件的生成代码。主函数getframesource()函数可获取已下载的视频位置.文件名;foriinxrange(1,xrange(1,yrange(i))):withopen(path,'r')asf:f.write(path+'\'+str(i)+'\'')f.close();注意之前是write()函数,第一个参数是文件名,第二个参数是下载位置,默认为c:\python。
不过大部分都已经把位置设置好了。应该在下载前可以重复write()两次。foriintxt:print(i)%。 查看全部
抓取网页音频(语言下载网页音频文件的生成代码和生成路径介绍)
抓取网页音频一直是作为老年人辅助工具的需求,其他工具也一直想用,但是没有想到有些网站怎么登录不了,这几天真是研究了好久,花费了不少时间。真是不好意思在网上推广,望广大网友指点一二。方法有些老生常谈,按步骤介绍,各位老师按照步骤来吧!使用python语言。下载网页音频文件,通过相关库,利用schem库的for循环,从网页获取文件名和音频音质,通过raiser内建的m3u8库提取出音频音质格式,保存在txt文件中,因此形成视频格式的文件。
由于网上资源太多,基本用txt文件保存,但是txt并不容易编辑,因此这里将视频转为mp4,然后用ffmpeg的录屏命令制作视频,然后解压网页音频文件,即可保存到另一个文件夹。下面是成功生成demo文件对应路径后,视频文件的生成代码。主函数getframesource()函数可获取已下载的视频位置.文件名;foriinxrange(1,xrange(1,yrange(i))):withopen(path,'r')asf:f.write(path+'\'+str(i)+'\'')f.close();注意之前是write()函数,第一个参数是文件名,第二个参数是下载位置,默认为c:\python。
不过大部分都已经把位置设置好了。应该在下载前可以重复write()两次。foriintxt:print(i)%。
抓取网页音频(使用InternetDownloadManager下载方法,实现批量音频以及文件自动下载效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-30 11:04
我们日常使用电脑时,需要通过浏览器自带的下载工具下载文件或音频,或者使用目前比较常规的第三方下载软件。常规的下载方式基本都是P2P下载,支持bt、Emule等下载,但是这种下载方式不仅繁琐,而且单线程下载方式也大大限制了下载效率。
接下来,围绕下载网站文件的问题,给大家介绍一下使用Internet下载管理器的下载方法。通过简单的操作,就可以达到批量音频和文件自动下载的效果。
图 1:IDM 接口
一、设置通配符批量下载
选择IDM界面右上角的“任务-添加批处理任务”选项,可以使用IDM下载一个链接地址中收录的所有文件。IDM可以进行自定义通配符设置,支持下载图片、音频等各种类型的文件。
例如在地址栏输入:*.jpg(*用字母或数字有序替换),即可批量下载链接中的所有文件。
图2:批量下载
二、设置站点爬取
IDM 的强大之处在于它支持在大多数主流平台上下载。选择“任务运行站点爬取”选项后,可以通过程序模板进行设置。
如果要在一个网站上下载多个文件,通过自定义设置指定网站中的图片、音频、视频等文件,即可实现批量下载效果,无需使用通配符。可以新建一个爬取程序,下次自动下载效率会更高。
图 3:IDM 站点爬取
三、获取具体下载链接
如果你遇到大量的URL内容,你会觉得上面两种批量下载的方式比较繁琐。如果要下载网站中的特定文件,可以使用获取下载地址的方法进行下载。
您可以在网站中选择需要下载的音频或其他类型的文件,右键单击并选择“复制链接地址”,然后使用复制的链接在IDM上运行命令。另外,也可以通过查看URL的源代码,从网页的源代码中选择要下载的文件地址,复制后用IDM下载。 查看全部
抓取网页音频(使用InternetDownloadManager下载方法,实现批量音频以及文件自动下载效果)
我们日常使用电脑时,需要通过浏览器自带的下载工具下载文件或音频,或者使用目前比较常规的第三方下载软件。常规的下载方式基本都是P2P下载,支持bt、Emule等下载,但是这种下载方式不仅繁琐,而且单线程下载方式也大大限制了下载效率。
接下来,围绕下载网站文件的问题,给大家介绍一下使用Internet下载管理器的下载方法。通过简单的操作,就可以达到批量音频和文件自动下载的效果。
图 1:IDM 接口
一、设置通配符批量下载
选择IDM界面右上角的“任务-添加批处理任务”选项,可以使用IDM下载一个链接地址中收录的所有文件。IDM可以进行自定义通配符设置,支持下载图片、音频等各种类型的文件。
例如在地址栏输入:*.jpg(*用字母或数字有序替换),即可批量下载链接中的所有文件。
图2:批量下载
二、设置站点爬取
IDM 的强大之处在于它支持在大多数主流平台上下载。选择“任务运行站点爬取”选项后,可以通过程序模板进行设置。
如果要在一个网站上下载多个文件,通过自定义设置指定网站中的图片、音频、视频等文件,即可实现批量下载效果,无需使用通配符。可以新建一个爬取程序,下次自动下载效率会更高。
图 3:IDM 站点爬取
三、获取具体下载链接
如果你遇到大量的URL内容,你会觉得上面两种批量下载的方式比较繁琐。如果要下载网站中的特定文件,可以使用获取下载地址的方法进行下载。
您可以在网站中选择需要下载的音频或其他类型的文件,右键单击并选择“复制链接地址”,然后使用复制的链接在IDM上运行命令。另外,也可以通过查看URL的源代码,从网页的源代码中选择要下载的文件地址,复制后用IDM下载。
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-11-29 21:17
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页中准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第三步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(新人都可以使用的音乐片段,就是简单的删除你不需要)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。版权,所以这个时候我们只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获!
工具特点:
工具太多了,不妨试试。Fast Audio Converter 是一款多功能的音频编辑处理软件。该软件具有四种功能:音频剪切、音频提取、音频合并和音频转换。支持单文件操作。还支持文件批量操作!确实是一个不错的选择。
音频转换器
第一步:打开工具
在网页中准备好音乐,然后打开工具到界面,可以尝试简单了解一下。
第 2 步:添加音频文件
今天是提取音乐,所以你找到音频提取按钮,点击它,就会出现它的界面。它的界面中有两个添加文件和添加文件夹。您可以根据自己的编号添加文件。
第三步:添加和删除片段指南
接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加的片段指南就是你提取的音乐片段,删除片段指南就是简单的删除你不需要的音乐片段,可以被忽悠了。提取进度条,最后点击确定。
第 4 步:设置保存提取音频的位置
不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。
第五步成功
点击后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想查看的可以在你设置的文件中查看。
无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-28 16:04
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。需要在tinyalsa中读取音频,确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,把数据同时写入文件,这个只能在调试的时候用,如果一直用,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
查看全部
抓取网页音频(android_read出现代码的逻辑很简单,主要是底层音频有问题
)
我们经常会遇到这样的问题。应用程序读取的音频有问题。需要在tinyalsa中读取音频,确认是底层音频问题还是应用程序处理后的问题。
于是,这个补丁出现了
代码逻辑很简单,主要是pcm_read的时候,把数据同时写入文件,这个只能在调试的时候用,如果一直用,文件总是会变大,直到系统是不是存储到底有问题。
Android.mk 不再用于编写 android 代码。相反,使用 android.bp。如果需要收录头文件,这里需要修改。相关的文章是网上的一篮子,就不多说了。
有个指针处理,我觉得比较巧妙,喜欢研究代码的可以去github看源码。
如果你还是不明白代码,你可以去tinycap.c。解析和记录操作虽然简单,但对我们帮助很大。
代码修改的diff如下
diff --git a/external/tinyalsa/Android.bp b/external/tinyalsa/Android.bp
old mode 100644
new mode 100755
index 090d91c0f8..79a6ceaee2
--- a/external/tinyalsa/Android.bp
+++ b/external/tinyalsa/Android.bp
@@ -9,6 +9,7 @@ cc_library {
"mixer.c",
"pcm.c",
],
+ shared_libs: ["liblog"],
cflags: ["-Werror", "-Wno-macro-redefined"],
export_include_dirs: ["include"],
local_include_dirs: ["include"],
diff --git a/external/tinyalsa/pcm.c b/external/tinyalsa/pcm.c
old mode 100644
new mode 100755
index 4ae321bf93..de0deab9d0
--- a/external/tinyalsa/pcm.c
+++ b/external/tinyalsa/pcm.c
@@ -35,11 +35,17 @@
#include
#include
+#include
+#include
+#include
+
#include
#include
#include
#include
+#include
+
#include
#define __force
#define __bitwise
@@ -48,6 +54,10 @@
#include
+#define LOG_TAG "TINYALSA_QIFA"
+#define ALOGD(fmt, args...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, fmt, ##args)
+#define ALOGE(fmt, args...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, fmt, ##args)
+
#define PARAM_MAX SNDRV_PCM_HW_PARAM_LAST_INTERVAL
/* Logs information into a string; follows snprintf() in that
@@ -242,6 +252,10 @@ static void param_init(struct snd_pcm_hw_params *p)
struct pcm {
int fd;
+ //int fd_test;
+ FILE *fd_test;
+ unsigned int size_test;
+ void *test_buffer;
unsigned int flags;
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
:
int running:1;
int prepared:1;
@@ -566,6 +580,7 @@ int pcm_read(struct pcm *pcm, void *data, unsigned int count)
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
+ ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd_test) != count) {
+ fprintf(stderr,"Error capturing sample\n");
+ ALOGE("Error capturing sample");
+ }
+
return 0;
}
}
@@ -864,6 +885,8 @@ int pcm_close(struct pcm *pcm)
if (pcm->fd >= 0)
close(pcm->fd);
+ if (pcm->fd_test >= 0)
+ fclose(pcm->fd_test);
pcm->prepared = 0;
pcm->running = 0;
pcm->buffer_size = 0;
@@ -872,6 +895,8 @@ int pcm_close(struct pcm *pcm)
return 0;
}
+
+
struct pcm *pcm_open(unsigned int card, unsigned int device,
unsigned int flags, struct pcm_config *config)
{
@@ -900,7 +925,12 @@ struct pcm *pcm_open(unsigned int card, unsigned int device,
oops(pcm, errno, "cannot open device '%s'", fn);
return pcm;
}
-
+ /*weiqifa*/
+ pcm->fd_test = fopen("/sdcard/ref_temp.pcm", "wb");
+ if (!pcm->fd_test) {
+ fprintf(stderr, "Unable to create file /sdcard/ref_temp.pcm\n");
+ } else ALOGD("creat /sdcard/ref_temp.pcm file success");
+
if (fcntl(pcm->fd, F_SETFL, fcntl(pcm->fd, F_GETFL) &
~O_NONBLOCK) flags & PCM_IN))
return -EINVAL;
x.buf = data;
x.frames = count / (pcm->config.channels *
pcm_format_to_bits(pcm->config.format) / 8);
ALOGE("x.frames:%ld count:%d",x.frames,count);
for (;;) {
if (!pcm->running) {
if (pcm_start(pcm) fd, SNDRV_PCM_IOCTL_READI_FRAMES, &x)) {
pcm->prepared = 0;
pcm->running = 0;
if (errno == EPIPE) {
/* we failed to make our window -- try to restart */
pcm->underruns++;
continue;
}
return oops(pcm, errno, "cannot read stream data");
}
if (fwrite(x.buf, 1, count, pcm->fd_test) != count) {
fprintf(stderr,"Error capturing sample\n");
ALOGE("Error capturing sample");
}
return 0;
}
}
x.buf 是一个指针,但是这个指针使用的是应用传下来的地址,所以不需要为 x.buf 分配空间。详情请参考tinycap。
在 tinycap 中,还会将标题写入音频文件。我们没有在这里写。没关系。打开音频时,可以直接导入原创音频。
xxx:/ # ls -al /sdcard/ref_temp.pcm
-rw-rw---- 1 root sdcard_rw 79298560 2021-01-08 15:24 /sdcard/ref_temp.pcm
xxx:/ #
完整代码如下:
抓取网页音频(小编IDM功能——“站点抓取”的妙用网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-28 00:13
InternetDownloadManager(简称IDM)下载器采用多线程技术,大大提高文件下载速度。即使非常大的文件也可以轻松快速地集成,据称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从来没有太在意它,但我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择要下载的网页中的指定内容,包括图片、音频、视频、文件,甚至收录网站的完整样式的离线文件@>,并允许用户根据需要自由定制。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您遇到断网或工作不畅的地方,请使用InternetDownloadManager站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是一个无需 Internet 即可浏览网络的强大地方。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载将开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有Internet的情况下点击浏览网页,非常方便。
图 7:文件夹打开 查看全部
抓取网页音频(小编IDM功能——“站点抓取”的妙用网)
InternetDownloadManager(简称IDM)下载器采用多线程技术,大大提高文件下载速度。即使非常大的文件也可以轻松快速地集成,据称可以将您的下载速度提高多达 5 倍。
不过今天要给大家推荐的是我最近发现的一个IDM功能——“站点爬取”。我以前从来没有太在意它,但我最近才发现这个功能非常有用。下面就给大家介绍一下它的神奇之处。
“网站爬行”的含义
如图1所示,该功能允许您输入网页链接,选择要下载的网页中的指定内容,包括图片、音频、视频、文件,甚至收录网站的完整样式的离线文件@>,并允许用户根据需要自由定制。定义站点抓取的内容和规则,并保存以方便下次调用。
图1:网站爬取界面
“网站爬取”功能的神奇使用
如果您遇到断网或工作不畅的地方,请使用InternetDownloadManager站点抓取并保存一些需要浏览的网页,以确保您的工作顺利进行。
如图2所示,根据要保存的内容进行选择。有“所有图片”、“所有视频”、“完整起始页”等,您可以根据需要选择。它收录在通用计划模板中,如果您没有,您可以自定义它。
图 2:IDM 程序模板
单击“前进”以选择文件保存位置。一般默认勾选“保存到同一目录”,点击“浏览”选择保存位置。
图3:选择文件保存位置
接下来,指定链接深度,可以根据需要设置。这也是一个无需 Internet 即可浏览网络的强大地方。
图4:站点爬取选择深度
在下一步中,您可以添加一些下载或非下载过滤器来过滤不需要的文件类型,以避免下载不需要的文件。
图 5:过滤文件
最后,下载将开始。如果之前设置下载的内容不多,应该会快一些。
图6:下载情况
下载完成后,在指定文件夹中打开,就可以看到图8了。这样就可以在没有Internet的情况下点击浏览网页,非常方便。
图 7:文件夹打开
抓取网页音频(爬取网站上面的音频数据该如何去做呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-25 20:18
前言
最近分享了一些爬虫知识点。所以今天我们可以通过我们目前掌握的爬虫技术和Python技术来爬取某个平台的音频数据。
我们都知道,一般的数据都在url地址对应的网页源码中。如下所示
网页源代码
但是如果要抓取的数据不在当前URL地址对应的网页源代码中,那就真的比较痛苦了。在这种情况下,数据要么在后期动态添加到网页中,要么通过 ajax 加载。不管是哪一种,对于初学者来说都是异常的头痛。今天我们就用通俗易懂的方式来分析ajax数据的特点(一切都是特殊的,所以不同的场景需要特殊处理)
实践中的 ajax 是什么?
先解决一个问题。什么是阿贾克斯?来介绍一下百度百科的解释
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML)。它是一种 Web 开发技术,可创建交互式、快速和动态的 Web 应用程序。它可以在不重新加载整个网页的情况下更新某些网页。
这段话的一个关键点是,您可以在不加载整个网页的情况下更新某些网页。例如,以下是 12306 列火车的列表。
在这张图中,我们可以看到12306的网页就是这样的风格。但是当我们点击“查询”按钮时,我们要观察这个网页的效果
我们发现这个网页没有刷新,但是本地结构发生了变化。然后通过ajax加载车次列表数据。其实,刚刚我们理解“无需重新加载整个网页就可以更新部分网页的技术”这句话的含义并不难。
案例展示
下面通过一个案例来进一步分析总结如何抓取ajax数据
下图是一段音频网站。在这个网站中,数据主要是音频。那么我们要如何抓取网站上面的音频数据呢?
我们进一步优化了目标。下面有这样一个音频主题。今天我们就爬取这个话题的数据。
点击专辑后,我们发现里面有很多音频数据。按照我们的思路,只要找到每个音频的url就可以轻松爬取。
但前提是数据是否在当前URL地址之上?让我们检查一下网页的源代码。这也很简单。我们只需要在源代码中搜索mp3或m4a等音频格式即可。从下图我们可以看到这些音频格式在网页上是不可用的。然后我们猜测这些数据可能是通过ajax加载的
接下来,我们将通过NetWork 来分析数据接口。我们点击了一首歌曲,发现在网络中刷新了一些数据。先看第一条数据
数据确实在这个界面
我们点击进一步观察,看看有没有类似mp3或m4a的音频格式。然而,令我们失望的是,它没有。那我该怎么办?
在这个数据接口下还有一条数据。我们来看看里面有什么?
点击这个数据,我们发现它是一个音频数据
为了验证这个数据是否是我们要爬取的,我们可以检查一下。OK,没问题就是我们要爬取的数据
但这只是一个音频,如果我们想爬取其他音频怎么办?我们发现不同音频的id是不同的。然后就很容易了。我们先访问第一个数据接口中的内容,获取音频的id和name。
然后我们将转到第二个数据接口,到其 url 以动态获取替换音频的 id。
代码演示
import requests
import json
url = 'https://www.ximalaya.com/revision/play/v1/show?id=231012348&sort=1&size=30&ptype=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get(url,headers=headers)
ret = r.text
result = json.loads(ret)
content_list = result['data']['tracksAudioPlay']
for content in content_list:
t_id = content['trackId'] # 音频的id
name = content['trackName'] # 音频的name
# print(t_id,type(t_id))
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%d&ptype=1'%t_id
mus_response = requests.get(url,headers=headers)
mus_html = mus_response.text
mus_result = json.loads(mus_html)
# print(mus_html,type(mus_result))
mus_src = mus_result['data']['src']
# print(mus_src)
with open('mp3/%s.m4a'% name,'wb') as f:
mus = requests.get(mus_src)
f.write(mus.content)
复制代码
运行结果
这是部分核心代码的列表。大家可以在这个代码的基础上进行升级和扩展。案子不难,大家可以试试。不过我们还是要心存感激,不要恶意爬取网站上面的数据。 查看全部
抓取网页音频(爬取网站上面的音频数据该如何去做呢?(一))
前言
最近分享了一些爬虫知识点。所以今天我们可以通过我们目前掌握的爬虫技术和Python技术来爬取某个平台的音频数据。
我们都知道,一般的数据都在url地址对应的网页源码中。如下所示
网页源代码
但是如果要抓取的数据不在当前URL地址对应的网页源代码中,那就真的比较痛苦了。在这种情况下,数据要么在后期动态添加到网页中,要么通过 ajax 加载。不管是哪一种,对于初学者来说都是异常的头痛。今天我们就用通俗易懂的方式来分析ajax数据的特点(一切都是特殊的,所以不同的场景需要特殊处理)
实践中的 ajax 是什么?
先解决一个问题。什么是阿贾克斯?来介绍一下百度百科的解释
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML)。它是一种 Web 开发技术,可创建交互式、快速和动态的 Web 应用程序。它可以在不重新加载整个网页的情况下更新某些网页。
这段话的一个关键点是,您可以在不加载整个网页的情况下更新某些网页。例如,以下是 12306 列火车的列表。
在这张图中,我们可以看到12306的网页就是这样的风格。但是当我们点击“查询”按钮时,我们要观察这个网页的效果
我们发现这个网页没有刷新,但是本地结构发生了变化。然后通过ajax加载车次列表数据。其实,刚刚我们理解“无需重新加载整个网页就可以更新部分网页的技术”这句话的含义并不难。
案例展示
下面通过一个案例来进一步分析总结如何抓取ajax数据
下图是一段音频网站。在这个网站中,数据主要是音频。那么我们要如何抓取网站上面的音频数据呢?
我们进一步优化了目标。下面有这样一个音频主题。今天我们就爬取这个话题的数据。
点击专辑后,我们发现里面有很多音频数据。按照我们的思路,只要找到每个音频的url就可以轻松爬取。
但前提是数据是否在当前URL地址之上?让我们检查一下网页的源代码。这也很简单。我们只需要在源代码中搜索mp3或m4a等音频格式即可。从下图我们可以看到这些音频格式在网页上是不可用的。然后我们猜测这些数据可能是通过ajax加载的
接下来,我们将通过NetWork 来分析数据接口。我们点击了一首歌曲,发现在网络中刷新了一些数据。先看第一条数据
数据确实在这个界面
我们点击进一步观察,看看有没有类似mp3或m4a的音频格式。然而,令我们失望的是,它没有。那我该怎么办?
在这个数据接口下还有一条数据。我们来看看里面有什么?
点击这个数据,我们发现它是一个音频数据
为了验证这个数据是否是我们要爬取的,我们可以检查一下。OK,没问题就是我们要爬取的数据
但这只是一个音频,如果我们想爬取其他音频怎么办?我们发现不同音频的id是不同的。然后就很容易了。我们先访问第一个数据接口中的内容,获取音频的id和name。
然后我们将转到第二个数据接口,到其 url 以动态获取替换音频的 id。
代码演示
import requests
import json
url = 'https://www.ximalaya.com/revision/play/v1/show?id=231012348&sort=1&size=30&ptype=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
r = requests.get(url,headers=headers)
ret = r.text
result = json.loads(ret)
content_list = result['data']['tracksAudioPlay']
for content in content_list:
t_id = content['trackId'] # 音频的id
name = content['trackName'] # 音频的name
# print(t_id,type(t_id))
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=%d&ptype=1'%t_id
mus_response = requests.get(url,headers=headers)
mus_html = mus_response.text
mus_result = json.loads(mus_html)
# print(mus_html,type(mus_result))
mus_src = mus_result['data']['src']
# print(mus_src)
with open('mp3/%s.m4a'% name,'wb') as f:
mus = requests.get(mus_src)
f.write(mus.content)
复制代码
运行结果
这是部分核心代码的列表。大家可以在这个代码的基础上进行升级和扩展。案子不难,大家可以试试。不过我们还是要心存感激,不要恶意爬取网站上面的数据。
抓取网页音频(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 00:14
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,墨钊可以爬取很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb 查看全部
抓取网页音频(猫抓支持所有Chrome内核浏览器的网页媒体嗅探的扩展)
猫抓
Mozhao 是一个扩展,支持所有 Chrome 内核浏览器的网络媒体嗅探和抓取。
它可以一键抓取任何站点的任何视频/音频数据,使用起来非常方便。
安装好扩展后,打开需要抓取媒体资源的网站,点击扩展按钮可以看到页面上的资源信息。
然后就可以对资源进行三个操作:复制链接地址、小窗口播放、下载到本地。
猫扎支持优酷、搜狐、腾讯、微博、B站等几乎所有国内网站视频文件嗅探。
当多个媒体资源出现在同一页面时,您还可以对其进行快速批量操作。
一般来说,这类嗅探工具支持的视频文件是未加密的。当面对一些加密的视频时,会有一定的失败几率。
但是,从市场反馈来看,墨钊可以爬取很多其他IDM无法嗅探的媒体资源。
这也是其竞争激烈的拓展店能拥有超过5万用户的原因之一。
此外,毛爪还支持对所有音乐网站的音频文件嗅探,包括SWF模块和QQ空间音乐。
在【选项】中,用户还可以自定义采集的视频和音频格式,还支持使用正则表达式自定义采集的内容。
网络嗅探器最初是网络管理员的工具,通过它网络管理员可以随时掌握网络的实际情况。Sniffer 也是很多程序员在编写网络程序时捕捉和测试的工具。
近年来,网络嗅探器被广泛应用于用户的日常行为中,成为捕捉视频、音频等内容的工具。
下载:/extension/jfedfbgedapdagkghmgibemcoggfppbb
抓取网页音频(演示如何使用tkinter去爬取网页音频(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 11:04
抓取网页音频已经成为网页音频的不可或缺的一部分,我们在使用tkinter(海格力斯)做网页音频播放器之前,我们需要在excel中配置这个网页音频。现在以百度的一个营销活动为例,演示如何使用tkinter去爬取网页音频下面是例子第一步:声音source网页网页有个“china”,我们要爬取这个source,我们需要自定义一个页码去爬取source第二步:setcitiesframe(stringname);指定这个citiesframe,setcitiesframe为我们的citiesframe1为setcitiesframe为setcitiesframe2为set第三步:seteachconnection(integerparams);seteachconnection=(integerparams)=size(eachconnection);///为什么是四个分隔符,因为当前session只能存在一个connection第四步:设置httpport(integerport);httpport的作用://这里我们用https协议,这样就不用每次都发https协议给百度第五步:开始进行爬取了,重点来了,把设置好的url作为参数传给tkinter函数tkinter函数ttrenderios(stringurl);接收到url后把它转换为type,然后设置为custom,然后这样就能爬取网页音频了。
为什么是函数,而不是c#里面的代码呢?这个和最近遇到的问题有关,我写过一个简单的爬虫seoul,http当然不能写c#代码去写。解决的办法是就是先写一个stringhttpapi函数和一个responseapi函数,大致思路就是让客户端发个http请求给这个函数去接收返回结果,然后返回结果的类型设置为response,然后再重新编写一个stringresponse函数,从response发送http请求到最后的返回结果,使用伪随机数tuple<b>businessrhy(stringurl,floatport);这里有一个坑,如果在这个函数里设置了stringresponse类型则不能stringspiderconnection(stringparams);stringnewresponse(stringparams);为什么呢?因为在使用response的时候给方法传参(params)是对的,我们params里面的每一个参数如果与url里面对应参数的设置不一样则会无法通过,所以如果出现参数的string参数与上面那个函数传参的数组不一样,会无法通过,这就是最后stringresponse最后返回char的原因,请注意每一个参数有的是bool类型的。欢迎关注公众号“快乐等于生活”可以学习实用的ftp及http服务器操作和代理相关知识。 查看全部
抓取网页音频(演示如何使用tkinter去爬取网页音频(一)_)
抓取网页音频已经成为网页音频的不可或缺的一部分,我们在使用tkinter(海格力斯)做网页音频播放器之前,我们需要在excel中配置这个网页音频。现在以百度的一个营销活动为例,演示如何使用tkinter去爬取网页音频下面是例子第一步:声音source网页网页有个“china”,我们要爬取这个source,我们需要自定义一个页码去爬取source第二步:setcitiesframe(stringname);指定这个citiesframe,setcitiesframe为我们的citiesframe1为setcitiesframe为setcitiesframe2为set第三步:seteachconnection(integerparams);seteachconnection=(integerparams)=size(eachconnection);///为什么是四个分隔符,因为当前session只能存在一个connection第四步:设置httpport(integerport);httpport的作用://这里我们用https协议,这样就不用每次都发https协议给百度第五步:开始进行爬取了,重点来了,把设置好的url作为参数传给tkinter函数tkinter函数ttrenderios(stringurl);接收到url后把它转换为type,然后设置为custom,然后这样就能爬取网页音频了。
为什么是函数,而不是c#里面的代码呢?这个和最近遇到的问题有关,我写过一个简单的爬虫seoul,http当然不能写c#代码去写。解决的办法是就是先写一个stringhttpapi函数和一个responseapi函数,大致思路就是让客户端发个http请求给这个函数去接收返回结果,然后返回结果的类型设置为response,然后再重新编写一个stringresponse函数,从response发送http请求到最后的返回结果,使用伪随机数tuple<b>businessrhy(stringurl,floatport);这里有一个坑,如果在这个函数里设置了stringresponse类型则不能stringspiderconnection(stringparams);stringnewresponse(stringparams);为什么呢?因为在使用response的时候给方法传参(params)是对的,我们params里面的每一个参数如果与url里面对应参数的设置不一样则会无法通过,所以如果出现参数的string参数与上面那个函数传参的数组不一样,会无法通过,这就是最后stringresponse最后返回char的原因,请注意每一个参数有的是bool类型的。欢迎关注公众号“快乐等于生活”可以学习实用的ftp及http服务器操作和代理相关知识。
抓取网页音频(研究百度搜索技术是如何实现抓取MP3格式文件(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-21 23:07
很高兴不断更新自己文章,无时无刻不在观察互联网技术。通常,将观察结果用文字记录下来,与大家分享。最近,由于学习需要,百度开始研究MP3文件抓取。兔宝宝的进步和学习,离不开信立网络营销团队对我的帮助和关怀。经过一个下午的剖析 MP3 文件。尤其是那些做音乐的朋友网站。研究百度搜索技术如何实现MP3格式文件的抓取。关于MP3的其他改进问题,请写在下面文章。今天我只研究如何抓取MP3文件。同时提醒大家,本文文章,仅代表个人观点和文明评论,
为了使整个过程顺利,请举例分析。
观察到这个 MP3 文件夹只收录一个比我更快乐的文件。MP3。它还显示文件大小、类型修改日期。这里有一个问题需要确定。这个文件夹里只有这个文件。我们再观察一下他的属性内容。如下所示:
正如我们之前所说,只有一个文件。为什么它可以显示艺术家和专辑名称等相关信息?注意只有一个文本,为什么收录这么多信息?这里是百度搜索抓取MP3格式文件的网站构建键所在。
我大概会谈谈 MP3 格式的文件。MP3 文件不仅包括我们听到的音频文件(常说的音乐),还包括更多专辑和歌名。MP3格式文件大致分为三部分:TAG_V2(ID3V2)、Frame、、TAG_V1(ID3V1)),其中TAG_V2(ID3V2)记录作者、作曲、专辑以及其他信息。帧。记录音乐文件的物理部分。TAG_V1(ID3V1)记录作者、作曲家、专辑等信息,长度为128字节。这些是怎么写的,什么格式,怎么写的来定义,这里就不赘述了。
为了说明分析的真实性,去掉了MP3格式的文件封套,具体内容以16进制数据分析呈现。如下所示。
因此,一个完整的mp3文件也收录了作者、作曲、专辑等完整的信息。这进一步方便了百度搜索引擎抓取MP3文件,更好地让我们搜索。当我们搜索音乐时,我们会比较 MP3 的特定字节来实现匹配。将正确的音乐返回给用户。在此友情提醒,做音乐网站的网友们,在做网站优化的同时,别忘了优化MP3格式文件的内部内容,比如作者、作曲、专辑、其他信息都写了。这是百度掌握MP3最重要的基础。百度对音乐的抓取不依赖于文件名和网页的匹配。就是直接识别MP3文件的内部内容。至于MP3的内部内容怎么写,有空介绍一下,这里只讨论百度搜索抓取MP3文件。到目前为止,当然也为一些垃圾站提供了便利。当然,任何一件事都有利有弊。
Baby Rabbit将继续观察互联网搜索引擎。以后会写更多相关的文章。下面就来揭秘百度搜索抢图的秘诀。希望大家多多支持!同时声明,我的分析文章仅代表个人观点,不作为任何依据。文明评论,请勿吐槽。希望各位朋友关注我的博客,提出各种意见。 查看全部
抓取网页音频(研究百度搜索技术是如何实现抓取MP3格式文件(组图))
很高兴不断更新自己文章,无时无刻不在观察互联网技术。通常,将观察结果用文字记录下来,与大家分享。最近,由于学习需要,百度开始研究MP3文件抓取。兔宝宝的进步和学习,离不开信立网络营销团队对我的帮助和关怀。经过一个下午的剖析 MP3 文件。尤其是那些做音乐的朋友网站。研究百度搜索技术如何实现MP3格式文件的抓取。关于MP3的其他改进问题,请写在下面文章。今天我只研究如何抓取MP3文件。同时提醒大家,本文文章,仅代表个人观点和文明评论,
为了使整个过程顺利,请举例分析。
观察到这个 MP3 文件夹只收录一个比我更快乐的文件。MP3。它还显示文件大小、类型修改日期。这里有一个问题需要确定。这个文件夹里只有这个文件。我们再观察一下他的属性内容。如下所示:
正如我们之前所说,只有一个文件。为什么它可以显示艺术家和专辑名称等相关信息?注意只有一个文本,为什么收录这么多信息?这里是百度搜索抓取MP3格式文件的网站构建键所在。
我大概会谈谈 MP3 格式的文件。MP3 文件不仅包括我们听到的音频文件(常说的音乐),还包括更多专辑和歌名。MP3格式文件大致分为三部分:TAG_V2(ID3V2)、Frame、、TAG_V1(ID3V1)),其中TAG_V2(ID3V2)记录作者、作曲、专辑以及其他信息。帧。记录音乐文件的物理部分。TAG_V1(ID3V1)记录作者、作曲家、专辑等信息,长度为128字节。这些是怎么写的,什么格式,怎么写的来定义,这里就不赘述了。
为了说明分析的真实性,去掉了MP3格式的文件封套,具体内容以16进制数据分析呈现。如下所示。
因此,一个完整的mp3文件也收录了作者、作曲、专辑等完整的信息。这进一步方便了百度搜索引擎抓取MP3文件,更好地让我们搜索。当我们搜索音乐时,我们会比较 MP3 的特定字节来实现匹配。将正确的音乐返回给用户。在此友情提醒,做音乐网站的网友们,在做网站优化的同时,别忘了优化MP3格式文件的内部内容,比如作者、作曲、专辑、其他信息都写了。这是百度掌握MP3最重要的基础。百度对音乐的抓取不依赖于文件名和网页的匹配。就是直接识别MP3文件的内部内容。至于MP3的内部内容怎么写,有空介绍一下,这里只讨论百度搜索抓取MP3文件。到目前为止,当然也为一些垃圾站提供了便利。当然,任何一件事都有利有弊。
Baby Rabbit将继续观察互联网搜索引擎。以后会写更多相关的文章。下面就来揭秘百度搜索抢图的秘诀。希望大家多多支持!同时声明,我的分析文章仅代表个人观点,不作为任何依据。文明评论,请勿吐槽。希望各位朋友关注我的博客,提出各种意见。
抓取网页音频( CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-19 00:22
CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
CME推出在线网页,助您快速消除人声、提取人声或免费分离音频
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
mp3
AAC
水马
弗拉克
声波
艾夫
目前共有三种服务(实际上都是基于相同的算法),包括:
消除人声:
提取人声:
分离两个独立的人声音频文件和背景音乐文件:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
因为原算法需要GPU高速处理,耗时长,计算成本高,成本高,所以对个人电脑的要求更高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的心得,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(
CME创新性YourAudio的在线免费服务可以在云端帮助你处理音频)
CME推出在线网页,助您快速消除人声、提取人声或免费分离音频
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在网页底部选择中文),上传音频文件进行在线云处理,所有处理都进行使用 CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
mp3
AAC
水马
弗拉克
声波
艾夫
目前共有三种服务(实际上都是基于相同的算法),包括:
消除人声:
提取人声:
分离两个独立的人声音频文件和背景音乐文件:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
因为原算法需要GPU高速处理,耗时长,计算成本高,成本高,所以对个人电脑的要求更高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的心得,帮助CME开发者不断完善服务:
抓取网页音频(一层一层地取地取字典,歌单列表列表forxinrange)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-12 00:05
对于范围内的 x(5):
参数 = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'644918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'无损':'0',
'flag_qc':'0',
'p':str(x 1),
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'格式':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'通知':'0',
'平台':'yqq.json',
'needNewCode':'0'
}
# 将参数封装成字典
res_music = requests.get(url,params=params)
#调用get方法下载字典
json_music = res_music.json()
#使用json()方法将响应对象转换为列表/字典
list_music = json_music['data']['song']['list']
#逐层获取字典获取播放列表
list_music 中的音乐:
# list_music 是一个列表,音乐是它的元素
打印(音乐['名字'])
#以名称为关键字查找歌曲名称
print('所属专辑:'music['album']['name'])
#查找相册名称
print('播放时间:'str(music['interval'])'seconds')
# 查找播放时长
print('播放链接:'音乐['mid']'.html\n\n')
# 查找播放链接 查看全部
抓取网页音频(一层一层地取地取字典,歌单列表列表forxinrange)
对于范围内的 x(5):
参数 = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'644918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'无损':'0',
'flag_qc':'0',
'p':str(x 1),
'n':'20',
'w':'周杰伦',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'格式':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'通知':'0',
'平台':'yqq.json',
'needNewCode':'0'
}
# 将参数封装成字典
res_music = requests.get(url,params=params)
#调用get方法下载字典
json_music = res_music.json()
#使用json()方法将响应对象转换为列表/字典
list_music = json_music['data']['song']['list']
#逐层获取字典获取播放列表
list_music 中的音乐:
# list_music 是一个列表,音乐是它的元素
打印(音乐['名字'])
#以名称为关键字查找歌曲名称
print('所属专辑:'music['album']['name'])
#查找相册名称
print('播放时间:'str(music['interval'])'seconds')
# 查找播放时长
print('播放链接:'音乐['mid']'.html\n\n')
# 查找播放链接
抓取网页音频(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-06 12:01
curl 和 wget 下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
安装 curl 命令:sudo apt-get install curl(与 wget 相同)
2、Windows 平台
wget 下载链接:wget for Windows
curl下载链接:curl下载
wget和curl包下载地址:Windows平台下wget和curl工具包
Windows平台下,curl下载解压后,直接以curl.exe格式复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后格式为wget-1.11.4-1-setup.exe,需要安装;安装后,在Environment Variables-System Variables-Path目录下添加它的安装
curl 和 wget 抓取示例
抓取网页主要有两种方式:url和代理。下面是一个爬取“百度”首页的例子。
1、 url 网址抓取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget 下载百度首页的内容保存在baidu_html文件中
wget -O baidu_html2
有时,由于网速/数据丢失/服务器停机/等原因,网页暂时无法下载成功
这时候,你可能需要尝试多次发送连接,请求服务器响应;如果多次都没有反应,可以确认服务器有问题
(1)curl 尝试多次连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在最长时间内只允许重试一次(一般与--retry-delay相同)
(2)wget 多次尝试连接
wget -t 10 -w 60 -T 30 -O baidu_html2
注:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间。如果超过超时,则连接不成功,下次继续尝试连接
附:curl 判断服务器是否响应。也可以通过一段时间内下载的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注意:-y 代表测试网速的时间;-Y 表示 -y 期间下载的字节数(以字节为单位);-m 表示允许请求连接的最长时间,超过则自动断开连接并放弃连接
2、代理爬取
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,有分隔由冒号“:”组成一个套接字)
(1)curl 通过代理爬取百度首页
curl -x 218.107.21.252:8080-o aaaaa(端口通常为80、8080、8086、8888、3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过218.107.21.252:8080下载百度主页,最后218.107.21.252:8080 发送下载的百度首页到curl到本地(curl不是直接连接百度服务器下载首页,而是通过中介代理)
(2)wget 通过代理爬取百度首页
wget通过代理下载,和curl不一样。需要先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd~)下创建wget配置文件(.wgetrc),进入代理配置: 查看全部
抓取网页音频(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl 和 wget 下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
安装 curl 命令:sudo apt-get install curl(与 wget 相同)
2、Windows 平台
wget 下载链接:wget for Windows
curl下载链接:curl下载
wget和curl包下载地址:Windows平台下wget和curl工具包
Windows平台下,curl下载解压后,直接以curl.exe格式复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后格式为wget-1.11.4-1-setup.exe,需要安装;安装后,在Environment Variables-System Variables-Path目录下添加它的安装
curl 和 wget 抓取示例
抓取网页主要有两种方式:url和代理。下面是一个爬取“百度”首页的例子。
1、 url 网址抓取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget 下载百度首页的内容保存在baidu_html文件中
wget -O baidu_html2
有时,由于网速/数据丢失/服务器停机/等原因,网页暂时无法下载成功
这时候,你可能需要尝试多次发送连接,请求服务器响应;如果多次都没有反应,可以确认服务器有问题
(1)curl 尝试多次连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在最长时间内只允许重试一次(一般与--retry-delay相同)
(2)wget 多次尝试连接
wget -t 10 -w 60 -T 30 -O baidu_html2
注:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间。如果超过超时,则连接不成功,下次继续尝试连接
附:curl 判断服务器是否响应。也可以通过一段时间内下载的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注意:-y 代表测试网速的时间;-Y 表示 -y 期间下载的字节数(以字节为单位);-m 表示允许请求连接的最长时间,超过则自动断开连接并放弃连接
2、代理爬取
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位著名的自由球员网站:
(全球数十个国家的自由代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,有分隔由冒号“:”组成一个套接字)
(1)curl 通过代理爬取百度首页
curl -x 218.107.21.252:8080-o aaaaa(端口通常为80、8080、8086、8888、3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过218.107.21.252:8080下载百度主页,最后218.107.21.252:8080 发送下载的百度首页到curl到本地(curl不是直接连接百度服务器下载首页,而是通过中介代理)
(2)wget 通过代理爬取百度首页
wget通过代理下载,和curl不一样。需要先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd~)下创建wget配置文件(.wgetrc),进入代理配置:
抓取网页音频(这些活动对于诊断连接问题或其它与WebRTC相关的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-06 11:20
本文由 Janus 项目的作者 Lorenzo Miniero 撰写。2019年10月25日,他将来到北京RTC 2019,在“WebRTC Workshop”工作坊分享WebRTC服务器开发和Janus开发技巧,并与观众进行小范围的深度交流,名额有限,现在就可以报名了:/(申请限时免费门票,还可以获得创意工坊代金券~)
本文小结:抓取WebRTC流量看似比较简单,在大多数情况下确实如此:只需在其中一台机器上安装tcpdump或wireshark等抓包工具,然后查看生成的文件即可。在大多数情况下,它将是 .pcap 或 .pcapng 文件。这些活动对于诊断连接问题或与 WebRTC 相关的其他问题很有用:实际上,wireshark 可以自动检测标准协议,例如 STUN 和 DTLS,它们是 WebRTC PeerConnections 的重点。
这篇文章的关键是什么?
捕获 WebRTC 流量的唯一问题是媒体内容将被加密。检查STUN连接或DTLS握手后,这不是问题,但是当您要查看RTP或RTCP数据包时,它会成为问题,将其加密为SRTP和SRTCP。实际上,尽管 SRTP 标头未加密并且您可以以任何形式捕获流量,但 SRTP 有效负载并未加密,这意味着您无法查看其内容。
在大多数情况下,您不需要查看内容。正如预期的那样,您仍然可以查看加密的 RTP 数据包的头部,这是最常用的信息。在任何情况下,RTCP 都不能这样说:实际上,一个 RTCP 消息实际上可能收录多个数据包,并且没有共享头。此外,查看 RTP 负载可能是有效的。
这意味着捕获加密流量是可行的,但为了诊断目的捕获未加密数据可能更好。不幸的是,如果没有其他帮助,这是不可能的:实际上,在WebRTC的情况下,浏览器经常发送加密数据,即使有些允许您抓取未加密的数据进行测试,您仍然需要依靠其他工具来获取媒体。流才能开展这项工作。
进入杰纳斯!
作为 WebRTC 媒体服务器,Janus 确实发挥了它的作用:事实上,它存在于 PeerConnection 的每一个媒体路径上。另外,由于它为每个PeerConnections建立了一个安全的环境,因此可以获取输入和输出未加密的RTP和RTCP数据包。
一年前我们是这样想的。受 Firefox 的启发,我们首先添加了对 text2pcapdump 的支持,方法很简单:
1.使用Admin API开始抓取Janus处理的文件信息。
2.所有输入输出的RTP/RTCP包都转换成文本格式保存在相关文件中。
3. 捕获后,使用text2pcap App将捕获的文件转换为Wiresharak或其他工具兼容的格式。
请求的语法很简单:
<p>POST /admin/sessionId/handleId
{
"janus" : "start_text2pcap",
"folder" : "",
"filename" : "",
"truncate" : " 查看全部
抓取网页音频(这些活动对于诊断连接问题或其它与WebRTC相关的问题)
本文由 Janus 项目的作者 Lorenzo Miniero 撰写。2019年10月25日,他将来到北京RTC 2019,在“WebRTC Workshop”工作坊分享WebRTC服务器开发和Janus开发技巧,并与观众进行小范围的深度交流,名额有限,现在就可以报名了:/(申请限时免费门票,还可以获得创意工坊代金券~)
本文小结:抓取WebRTC流量看似比较简单,在大多数情况下确实如此:只需在其中一台机器上安装tcpdump或wireshark等抓包工具,然后查看生成的文件即可。在大多数情况下,它将是 .pcap 或 .pcapng 文件。这些活动对于诊断连接问题或与 WebRTC 相关的其他问题很有用:实际上,wireshark 可以自动检测标准协议,例如 STUN 和 DTLS,它们是 WebRTC PeerConnections 的重点。
这篇文章的关键是什么?
捕获 WebRTC 流量的唯一问题是媒体内容将被加密。检查STUN连接或DTLS握手后,这不是问题,但是当您要查看RTP或RTCP数据包时,它会成为问题,将其加密为SRTP和SRTCP。实际上,尽管 SRTP 标头未加密并且您可以以任何形式捕获流量,但 SRTP 有效负载并未加密,这意味着您无法查看其内容。
在大多数情况下,您不需要查看内容。正如预期的那样,您仍然可以查看加密的 RTP 数据包的头部,这是最常用的信息。在任何情况下,RTCP 都不能这样说:实际上,一个 RTCP 消息实际上可能收录多个数据包,并且没有共享头。此外,查看 RTP 负载可能是有效的。
这意味着捕获加密流量是可行的,但为了诊断目的捕获未加密数据可能更好。不幸的是,如果没有其他帮助,这是不可能的:实际上,在WebRTC的情况下,浏览器经常发送加密数据,即使有些允许您抓取未加密的数据进行测试,您仍然需要依靠其他工具来获取媒体。流才能开展这项工作。
进入杰纳斯!
作为 WebRTC 媒体服务器,Janus 确实发挥了它的作用:事实上,它存在于 PeerConnection 的每一个媒体路径上。另外,由于它为每个PeerConnections建立了一个安全的环境,因此可以获取输入和输出未加密的RTP和RTCP数据包。
一年前我们是这样想的。受 Firefox 的启发,我们首先添加了对 text2pcapdump 的支持,方法很简单:
1.使用Admin API开始抓取Janus处理的文件信息。
2.所有输入输出的RTP/RTCP包都转换成文本格式保存在相关文件中。
3. 捕获后,使用text2pcap App将捕获的文件转换为Wiresharak或其他工具兼容的格式。
请求的语法很简单:
<p>POST /admin/sessionId/handleId
{
"janus" : "start_text2pcap",
"folder" : "",
"filename" : "",
"truncate" : "
抓取网页音频(工具特色:工具这么多,大家不妨试试它迅捷音频转换器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-05 11:12
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获! 工具特点:工具太多了,你不妨试试,快速音频转换器是一个多功能音频编辑处理软件,该软件具有音频剪切、音频提取、音频合并和音频转换,支持单文件操作,也支持文件批量操作!确实是一个不错的选择。音频转换器第一步:打开网页中准备音乐的工具,然后打开工具到界面,可以尝试简单了解一下。第二步:添加音频文件 今天是提取音乐,所以大家找到音频提取按钮,点击它,就会出现它的界面。在其界面中添加文件和添加文件夹有两个选项。您可以自定义文件数量。只需添加它。第 3 步:添加和删除片段指南 接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加片段指南是您提取的音乐片段,删除片段指南只是删除您不需要的音乐片段。可以拉取被骗进度条提取音乐片段,最后点击确定。第 4 步:设置保存提取音频的位置。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。 查看全部
抓取网页音频(工具特色:工具这么多,大家不妨试试它迅捷音频转换器)
上网时,经常会在网上看到一些神奇的音乐,忍不住想下载下来分享给身边的朋友。但是,你也会遇到这样的问题,就是无法下载。版权,所以这个时候只能想办法提取网页上的音乐了。想了很久,我们找到了一个更适合我们大众的工具。它是什么工具?这是新人可以使用的!操作比较简单,希望大家看完这篇文章后有所收获! 工具特点:工具太多了,你不妨试试,快速音频转换器是一个多功能音频编辑处理软件,该软件具有音频剪切、音频提取、音频合并和音频转换,支持单文件操作,也支持文件批量操作!确实是一个不错的选择。音频转换器第一步:打开网页中准备音乐的工具,然后打开工具到界面,可以尝试简单了解一下。第二步:添加音频文件 今天是提取音乐,所以大家找到音频提取按钮,点击它,就会出现它的界面。在其界面中添加文件和添加文件夹有两个选项。您可以自定义文件数量。只需添加它。第 3 步:添加和删除片段指南 接下来,我们准备提取音乐片段。我们看到右侧的编辑栏,其中添加片段指南是您提取的音乐片段,删除片段指南只是删除您不需要的音乐片段。可以拉取被骗进度条提取音乐片段,最后点击确定。第 4 步:设置保存提取音频的位置。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。不要以为单击“确定”后会饿。让我们在 Select Output Format 中设置文件的保存位置,然后单击 Start Extraction 按钮。第五步:提取成功后,提取需要时间,但是这个时间很快。只要看到对勾就说明提取成功了,以后想看就在你设置的文件里设置即可。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。就说明提取成功了,然后想看的话可以在你设置的文件里设置。一探究竟。无论我说多少,我都无法像你自己做的那样理解它。最后,感谢您的阅读,希望对您有所帮助。
抓取网页音频(总结IE音乐播放网页播放音乐这一过程的细节猜想(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-05 05:05
可以通过两种方式获得,第一种更直接,第二种更高一点:
从IE临时缓存内容的本地路径获取。具体操作步骤如下:
总结
在IE音乐播放网页上播放音乐的具体技术实现过程的详细推测如下:
用户通过IE音乐播放器网页向音乐服务器发起播放音乐的请求,询问是否可以连接;音乐服务器收到连接请求后,响应用户可以连接;通知用户可以连接,正式开始连接音乐服务器,此时用户与音乐服务器的直接网络传输连接建立;用户使用三次握手后建立的连接从音乐服务器下载音乐数据文件到用户本地(在用户和音乐服务器之间的过程中应该一直连接);音乐文件成功下载到用户本地,此时不需要保持连接,
这个过程表明,用户每次发起音乐播放请求,都会与音乐服务器进行三次握手并建立连接。之前建立的连接会在数据传输完成后立即断开,不会被保存。因此,无法保存后续请求。要重复使用之前建立的连接,只能建立新的连接,使用后断开连接。这种方法是短连接。一个会话连接一次,请求和连接是一一对应的关系。因为在这种场景下,每个请求之间的时间间隔不是固定的,可能是很短的时间间隔才发出下一个播放音乐的请求,或者可能需要很长时间才能执行下一个播放音乐的操作。如果连接建立后一直保持着,但实际上并没有使用,那岂不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成,收录一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的细节)
既然提到了短连接,那就有必要说说长连接了。长连接中请求和连接的关系是多对一的。也就是说,前一个请求建立的连接可以被后续的请求使用而不会断开。比如跑步APP实时显示运动轨迹:用户通过APP请求服务器实时显示运动轨迹。用户需要将自己的最新位置信息实时上报给服务器。服务器收到后将绘制的最新运动轨迹返回给用户。双向数据传输过程。这个过程要一直保持连接在线,不会每次都上报就建立连接,太麻烦了。假设用户每次上报都建立连接,在建立连接之前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。 查看全部
抓取网页音频(总结IE音乐播放网页播放音乐这一过程的细节猜想(组图))
可以通过两种方式获得,第一种更直接,第二种更高一点:
从IE临时缓存内容的本地路径获取。具体操作步骤如下:
总结
在IE音乐播放网页上播放音乐的具体技术实现过程的详细推测如下:
用户通过IE音乐播放器网页向音乐服务器发起播放音乐的请求,询问是否可以连接;音乐服务器收到连接请求后,响应用户可以连接;通知用户可以连接,正式开始连接音乐服务器,此时用户与音乐服务器的直接网络传输连接建立;用户使用三次握手后建立的连接从音乐服务器下载音乐数据文件到用户本地(在用户和音乐服务器之间的过程中应该一直连接);音乐文件成功下载到用户本地,此时不需要保持连接,
这个过程表明,用户每次发起音乐播放请求,都会与音乐服务器进行三次握手并建立连接。之前建立的连接会在数据传输完成后立即断开,不会被保存。因此,无法保存后续请求。要重复使用之前建立的连接,只能建立新的连接,使用后断开连接。这种方法是短连接。一个会话连接一次,请求和连接是一一对应的关系。因为在这种场景下,每个请求之间的时间间隔不是固定的,可能是很短的时间间隔才发出下一个播放音乐的请求,或者可能需要很长时间才能执行下一个播放音乐的操作。如果连接建立后一直保持着,但实际上并没有使用,那岂不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成,收录一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)是不是很浪费?从服务器到用户的单向数据传输场景(数据需要保持完整并一次传输到位)适用于短连接。其实这个过程还涉及到阻塞的概念:因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待的过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的详细介绍)因为当用户一次请求从音乐服务器下载一首歌曲时,他必须保证下载完成并带有一首歌曲的所有数据,所以下载过程是一个等待过程。被阻止的进程会受到网络带宽和计算机处理速度的影响。(后面会单独增加一章关于阻塞的细节)
既然提到了短连接,那就有必要说说长连接了。长连接中请求和连接的关系是多对一的。也就是说,前一个请求建立的连接可以被后续的请求使用而不会断开。比如跑步APP实时显示运动轨迹:用户通过APP请求服务器实时显示运动轨迹。用户需要将自己的最新位置信息实时上报给服务器。服务器收到后将绘制的最新运动轨迹返回给用户。双向数据传输过程。这个过程要一直保持连接在线,不会每次都上报就建立连接,太麻烦了。假设用户每次上报都建立连接,在建立连接之前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。建立连接前需要进行三次握手,过程过于复杂。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。最好在用户第一次与服务器建立建立后保持连接在线,并在每次用户报告和服务器返回时重复使用该连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。由于该场景下的用户请求是实时的,每次请求之间的时间间隔几乎可以忽略不计,无需频繁重复断开旧连接再建立新连接的过程。用户和服务器双向实时数据传输(数据分段传输,最后聚合整合形成最终数据)场景适用于长连接。
抓取网页音频(如何在手机App中的数据中抓取数据?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-05 03:05
)
过去,数据是在网络上捕获的。移动应用程序中捕获的数据并不多。如何捕获移动应用程序中的数据?通常我们使用抓包工具抓取data.html
常用的抓包工具由 Fiddles 和 Charles 等人编写。今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以我一般推荐Charlesios抓包。
下载并安装 Charles
下载安装Charles然后破解Charles,这里是文章教程,我很少说
json
注意事项:应用
如果获取的数据是乱码,需要在Charles的菜单栏中设置链接SSL证书==>proxy==>SSL代理设置==>添加443,如上图所示。那么当你在实际抓取数据的时候,记得把这个关掉,以免丢失数据的工具
使用查尔斯
这里我直接放两张图给大家用看看就明白了
我们一起来分析一下这个项目。
# 这里有点递归的意味<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;">
完整代码:
import requests<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">import time<br style="margin:0px;padding:0px;max-width:100%;">import json<br style="margin:0px;padding:0px;max-width:100%;">from dedao.ExeclUtils import ExeclUtils<br style="margin:0px;padding:0px;max-width:100%;">import os<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">class dedao(object):<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def __init__(self):<br style="margin:0px;padding:0px;max-width:100%;"> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘连接', u'招聘要求描述']<br style="margin:0px;padding:0px;max-width:100%;"> # sheet_name = u'51job_Python招聘'<br style="margin:0px;padding:0px;max-width:100%;"> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br style="margin:0px;padding:0px;max-width:100%;"> sheet_name = u'逻辑思惟音频'<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.execl_f = return_execl[0]<br style="margin:0px;padding:0px;max-width:100%;"> self.sheet_table = return_execl[1]<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = [] # 存放每一条数据中的各元素,<br style="margin:0px;padding:0px;max-width:100%;"> self.count = 0 # 数据插入从1开始的<br style="margin:0px;padding:0px;max-width:100%;"> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = 0<br style="margin:0px;padding:0px;max-width:100%;"> self.headers = {<br style="margin:0px;padding:0px;max-width:100%;"> 'Host': 'entree.igetget.com',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OS': 'iOS',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-NET': 'wifi',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept': '*/*',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Nonce': '779b79d1d51d43fa',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Encoding': 'br, gzip, deflate',<br style="margin:0px;padding:0px;max-width:100%;"> # 'Content-Length': ' 67',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TARGET': 'main',<br style="margin:0px;padding:0px;max-width:100%;"> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-CHIL': 'appstore',<br style="margin:0px;padding:0px;max-width:100%;"> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-UID': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-AV ': '4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SEID ': '',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SCR ': '1242*2208',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DT': 'phone',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-S': '91a46b7a31ffc7a2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Language': 'zh-cn',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-THUMB': 'l',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-T': 'json',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Timestamp': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TS': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-U': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-App-Key': 'ios-4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OV': '11.4',<br style="margin:0px;padding:0px;max-width:100%;"> 'Connection': 'keep-alive',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-ADV': '1',<br style="margin:0px;padding:0px;max-width:100%;"> 'Content-Type': 'application/x-www-form-urlencoded',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-V': '2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-IS_JAILBREAK ': 'NO',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DV': 'iPhone10,2',<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def request_data(self):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> data = {<br style="margin:0px;padding:0px;max-width:100%;"> 'max_id': self.max_id,<br style="margin:0px;padding:0px;max-width:100%;"> 'since_id': 0,<br style="margin:0px;padding:0px;max-width:100%;"> 'column_id': 2,<br style="margin:0px;padding:0px;max-width:100%;"> 'count': 20,<br style="margin:0px;padding:0px;max-width:100%;"> 'order': 1,<br style="margin:0px;padding:0px;max-width:100%;"> 'section': 0<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"> response = requests.post(self.base_url, headers=self.headers, data=data)<br style="margin:0px;padding:0px;max-width:100%;"> if 200 == response.status_code:<br style="margin:0px;padding:0px;max-width:100%;"> self.parse_data(response)<br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(2)<br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def parse_data(self, response):<br style="margin:0px;padding:0px;max-width:100%;"> dict_json = json.loads(response.text)<br style="margin:0px;padding:0px;max-width:100%;"> datas = dict_json['c']['list'] # 这里取得数据列表<br style="margin:0px;padding:0px;max-width:100%;"> # print(datas)<br style="margin:0px;padding:0px;max-width:100%;"> for data in datas:<br style="margin:0px;padding:0px;max-width:100%;"> source_name = data['audio_detail']['source_name']<br style="margin:0px;padding:0px;max-width:100%;"> title = data['audio_detail']['title']<br style="margin:0px;padding:0px;max-width:100%;"> icon = data['audio_detail']['icon']<br style="margin:0px;padding:0px;max-width:100%;"> share_title = data['audio_detail']['share_title']<br style="margin:0px;padding:0px;max-width:100%;"> mp3_url = data['audio_detail']['mp3_play_url']<br style="margin:0px;padding:0px;max-width:100%;"> duction = str(data['audio_detail']['duration']) + '秒'<br style="margin:0px;padding:0px;max-width:100%;"> size = data['audio_detail']['size'] / (1000 * 1000)<br style="margin:0px;padding:0px;max-width:100%;"> size = '%.2fM' % size<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.download_mp3(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(source_name)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(icon)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(share_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(duction)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(size)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.count = self.count + 1<br style="margin:0px;padding:0px;max-width:100%;"> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思惟音频.xlsx')<br style="margin:0px;padding:0px;max-width:100%;"> print('采集了{}条数据'.format(self.count))<br style="margin:0px;padding:0px;max-width:100%;"> # 清空集合,为再次存放数据作准备<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = []<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(3) # 不要请求太快, 当心查水表<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def download_mp3(self, mp3_url):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> # 补全文件目录<br style="margin:0px;padding:0px;max-width:100%;"> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br style="margin:0px;padding:0px;max-width:100%;"> print(mp3_path)<br style="margin:0px;padding:0px;max-width:100%;"> # 判断文件是否存在。<br style="margin:0px;padding:0px;max-width:100%;"> if not os.path.exists(mp3_path):<br style="margin:0px;padding:0px;max-width:100%;"> # 注意这里是写入文件,要用二进制格式写入。<br style="margin:0px;padding:0px;max-width:100%;"> with open(mp3_path, 'wb') as f:<br style="margin:0px;padding:0px;max-width:100%;"> f.write(requests.get(mp3_url).content)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">if __name__ == '__main__': d = dedao() d.request_data() 查看全部
抓取网页音频(如何在手机App中的数据中抓取数据?(图)
)
过去,数据是在网络上捕获的。移动应用程序中捕获的数据并不多。如何捕获移动应用程序中的数据?通常我们使用抓包工具抓取data.html
常用的抓包工具由 Fiddles 和 Charles 等人编写。今天主要讲一下Charles的使用。与 Fiddles 相比,Charles 更强大,更易于使用。所以我一般推荐Charlesios抓包。
下载并安装 Charles
下载安装Charles然后破解Charles,这里是文章教程,我很少说
json
注意事项:应用
如果获取的数据是乱码,需要在Charles的菜单栏中设置链接SSL证书==>proxy==>SSL代理设置==>添加443,如上图所示。那么当你在实际抓取数据的时候,记得把这个关掉,以免丢失数据的工具
使用查尔斯
这里我直接放两张图给大家用看看就明白了
我们一起来分析一下这个项目。
# 这里有点递归的意味<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;">
完整代码:
import requests<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">import time<br style="margin:0px;padding:0px;max-width:100%;">import json<br style="margin:0px;padding:0px;max-width:100%;">from dedao.ExeclUtils import ExeclUtils<br style="margin:0px;padding:0px;max-width:100%;">import os<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">class dedao(object):<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def __init__(self):<br style="margin:0px;padding:0px;max-width:100%;"> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘连接', u'招聘要求描述']<br style="margin:0px;padding:0px;max-width:100%;"> # sheet_name = u'51job_Python招聘'<br style="margin:0px;padding:0px;max-width:100%;"> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br style="margin:0px;padding:0px;max-width:100%;"> sheet_name = u'逻辑思惟音频'<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.execl_f = return_execl[0]<br style="margin:0px;padding:0px;max-width:100%;"> self.sheet_table = return_execl[1]<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = [] # 存放每一条数据中的各元素,<br style="margin:0px;padding:0px;max-width:100%;"> self.count = 0 # 数据插入从1开始的<br style="margin:0px;padding:0px;max-width:100%;"> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = 0<br style="margin:0px;padding:0px;max-width:100%;"> self.headers = {<br style="margin:0px;padding:0px;max-width:100%;"> 'Host': 'entree.igetget.com',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OS': 'iOS',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-NET': 'wifi',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept': '*/*',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Nonce': '779b79d1d51d43fa',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Encoding': 'br, gzip, deflate',<br style="margin:0px;padding:0px;max-width:100%;"> # 'Content-Length': ' 67',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TARGET': 'main',<br style="margin:0px;padding:0px;max-width:100%;"> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-CHIL': 'appstore',<br style="margin:0px;padding:0px;max-width:100%;"> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-UID': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-AV ': '4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SEID ': '',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-SCR ': '1242*2208',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DT': 'phone',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-S': '91a46b7a31ffc7a2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br style="margin:0px;padding:0px;max-width:100%;"> 'Accept-Language': 'zh-cn',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-THUMB': 'l',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-T': 'json',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-Timestamp': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-TS': '1528195376',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-U': '34556154',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-App-Key': 'ios-4.0.0',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-OV': '11.4',<br style="margin:0px;padding:0px;max-width:100%;"> 'Connection': 'keep-alive',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-ADV': '1',<br style="margin:0px;padding:0px;max-width:100%;"> 'Content-Type': 'application/x-www-form-urlencoded',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-V': '2',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-IS_JAILBREAK ': 'NO',<br style="margin:0px;padding:0px;max-width:100%;"> 'X-DV': 'iPhone10,2',<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def request_data(self):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> data = {<br style="margin:0px;padding:0px;max-width:100%;"> 'max_id': self.max_id,<br style="margin:0px;padding:0px;max-width:100%;"> 'since_id': 0,<br style="margin:0px;padding:0px;max-width:100%;"> 'column_id': 2,<br style="margin:0px;padding:0px;max-width:100%;"> 'count': 20,<br style="margin:0px;padding:0px;max-width:100%;"> 'order': 1,<br style="margin:0px;padding:0px;max-width:100%;"> 'section': 0<br style="margin:0px;padding:0px;max-width:100%;"> }<br style="margin:0px;padding:0px;max-width:100%;"> response = requests.post(self.base_url, headers=self.headers, data=data)<br style="margin:0px;padding:0px;max-width:100%;"> if 200 == response.status_code:<br style="margin:0px;padding:0px;max-width:100%;"> self.parse_data(response)<br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(2)<br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def parse_data(self, response):<br style="margin:0px;padding:0px;max-width:100%;"> dict_json = json.loads(response.text)<br style="margin:0px;padding:0px;max-width:100%;"> datas = dict_json['c']['list'] # 这里取得数据列表<br style="margin:0px;padding:0px;max-width:100%;"> # print(datas)<br style="margin:0px;padding:0px;max-width:100%;"> for data in datas:<br style="margin:0px;padding:0px;max-width:100%;"> source_name = data['audio_detail']['source_name']<br style="margin:0px;padding:0px;max-width:100%;"> title = data['audio_detail']['title']<br style="margin:0px;padding:0px;max-width:100%;"> icon = data['audio_detail']['icon']<br style="margin:0px;padding:0px;max-width:100%;"> share_title = data['audio_detail']['share_title']<br style="margin:0px;padding:0px;max-width:100%;"> mp3_url = data['audio_detail']['mp3_play_url']<br style="margin:0px;padding:0px;max-width:100%;"> duction = str(data['audio_detail']['duration']) + '秒'<br style="margin:0px;padding:0px;max-width:100%;"> size = data['audio_detail']['size'] / (1000 * 1000)<br style="margin:0px;padding:0px;max-width:100%;"> size = '%.2fM' % size<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.download_mp3(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(source_name)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(icon)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(share_title)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(mp3_url)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(duction)<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info.append(size)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> self.count = self.count + 1<br style="margin:0px;padding:0px;max-width:100%;"> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思惟音频.xlsx')<br style="margin:0px;padding:0px;max-width:100%;"> print('采集了{}条数据'.format(self.count))<br style="margin:0px;padding:0px;max-width:100%;"> # 清空集合,为再次存放数据作准备<br style="margin:0px;padding:0px;max-width:100%;"> self.audio_info = []<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> time.sleep(3) # 不要请求太快, 当心查水表<br style="margin:0px;padding:0px;max-width:100%;"> max_id = datas[-1]['publish_time_stamp']<br style="margin:0px;padding:0px;max-width:100%;"> if self.max_id != max_id:<br style="margin:0px;padding:0px;max-width:100%;"> self.max_id = max_id<br style="margin:0px;padding:0px;max-width:100%;"> self.request_data()<br style="margin:0px;padding:0px;max-width:100%;"> else:<br style="margin:0px;padding:0px;max-width:100%;"> print('数据抓取完毕!')<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> pass<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> def download_mp3(self, mp3_url):<br style="margin:0px;padding:0px;max-width:100%;"> try:<br style="margin:0px;padding:0px;max-width:100%;"> # 补全文件目录<br style="margin:0px;padding:0px;max-width:100%;"> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br style="margin:0px;padding:0px;max-width:100%;"> print(mp3_path)<br style="margin:0px;padding:0px;max-width:100%;"> # 判断文件是否存在。<br style="margin:0px;padding:0px;max-width:100%;"> if not os.path.exists(mp3_path):<br style="margin:0px;padding:0px;max-width:100%;"> # 注意这里是写入文件,要用二进制格式写入。<br style="margin:0px;padding:0px;max-width:100%;"> with open(mp3_path, 'wb') as f:<br style="margin:0px;padding:0px;max-width:100%;"> f.write(requests.get(mp3_url).content)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"> except Exception as e:<br style="margin:0px;padding:0px;max-width:100%;"> print(e)<br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;"><br style="margin:0px;padding:0px;max-width:100%;">if __name__ == '__main__': d = dedao() d.request_data()
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-05 00:08
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在页面底部选择中文),上传音频文件进行在线云处理,所有处理均使用CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务: 查看全部
抓取网页音频(CME继续自己的创新性YourAudio在线免费服务可以处理音频)
芝商所继续自己的创新探索。这项名为“编辑您的音频”的免费在线服务可以帮助您在云端处理音频,它使用新算法来获得更好的结果。
首先,这是一项在线免费服务,只需访问即可使用(打开后可以在页面底部选择中文),上传音频文件进行在线云处理,所有处理均使用CME 的在线服务器。不消耗本地电脑的资源,所以手机也可以上传。
此服务支持 30MB 以下多种格式的任何音频,包括:
目前共有三种服务(实际上都是基于相同的算法),包括:
这种基于云端的算法并没有使用传统的倒音方法,而是基于Deezer Institute的算法,分析人声的音频特征,并分离出具有该特征的音频。目前第一步只能对人声进行分析分离,下一步还可以对钢琴、鼓、贝司等乐器的声音进行分析分离,后续会持续更新。
由于原算法需要高速GPU处理,耗时长,计算量大,成本高,所以对个人电脑的要求较高。CME工程师对云计算进行了优化,可以利用云服务器的CPU进行快速处理,达到低成本大规模应用的水平。
大家不妨试一试,欢迎在留言中写下您的体验,帮助CME开发者不断完善服务:
抓取网页音频(如何用python爬取网页音频,还是继续上次的课程和文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-04 05:02
抓取网页音频,听听音乐,尤其是摇滚音乐,当然我们要知道怎么用爬虫来获取音频。其实这个真的是非常简单的问题,之前我们已经通过python手动实现了我们听音乐的功能。但是如果想让python更高效一些,也就是说让python远程,文件抓取,那么必须要使用python3网络库,第三方库requests这个库就可以给我们带来很多便利。
至于如何用python爬取网页音频,还是继续上次的课程和文章吧。1.创建一个url链接(获取网页foo.css,requests调用格式是:"/"url="/"extension="search.bytes"url="/"url=";charset=utf-8")2.创建一个booklist(all_books)函数,将里面所有的书籍信息存储下来,把之前讲到的网页foo.css,requests调用格式,写在这个函数里。
3.foo.css内容我们重点看一下。//all_books{'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'j':false,'k':false,'l':false,'m':false,'n':false,'o':false,'p':false,'q':false,'r':false,'s':false,'t':false,'u':false,'v':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'w':false,'e':false,'f':false,'a':false,'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'f':false,'j':false,'k':false,'l':false,'f':false,'v':false,'w':false,'t':false,'u':false,'q':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'z':false,'t':false,'u':false,'e':false,'f':false,'f':false,'h':false,'g':false,'f':false,'e':false,'f':false,'f':false,'h':false,'j':false,'k':false,'l':false,'f':false,'g':false,'d':false,'e':false,'f':false,'f':false,'g':false,'e':false,'f':false,'f':false,'t':false,'u':false,'q':false,'t':false,'w':false,'x'。 查看全部
抓取网页音频(如何用python爬取网页音频,还是继续上次的课程和文章)
抓取网页音频,听听音乐,尤其是摇滚音乐,当然我们要知道怎么用爬虫来获取音频。其实这个真的是非常简单的问题,之前我们已经通过python手动实现了我们听音乐的功能。但是如果想让python更高效一些,也就是说让python远程,文件抓取,那么必须要使用python3网络库,第三方库requests这个库就可以给我们带来很多便利。
至于如何用python爬取网页音频,还是继续上次的课程和文章吧。1.创建一个url链接(获取网页foo.css,requests调用格式是:"/"url="/"extension="search.bytes"url="/"url=";charset=utf-8")2.创建一个booklist(all_books)函数,将里面所有的书籍信息存储下来,把之前讲到的网页foo.css,requests调用格式,写在这个函数里。
3.foo.css内容我们重点看一下。//all_books{'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'j':false,'k':false,'l':false,'m':false,'n':false,'o':false,'p':false,'q':false,'r':false,'s':false,'t':false,'u':false,'v':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'w':false,'e':false,'f':false,'a':false,'b':false,'c':false,'d':false,'e':false,'f':false,'g':false,'h':false,'f':false,'j':false,'k':false,'l':false,'f':false,'v':false,'w':false,'t':false,'u':false,'q':false,'w':false,'x':false,'y':false,'z':false,'u':false,'q':false,'z':false,'t':false,'u':false,'e':false,'f':false,'f':false,'h':false,'g':false,'f':false,'e':false,'f':false,'f':false,'h':false,'j':false,'k':false,'l':false,'f':false,'g':false,'d':false,'e':false,'f':false,'f':false,'g':false,'e':false,'f':false,'f':false,'t':false,'u':false,'q':false,'t':false,'w':false,'x'。
抓取网页音频(哪些网页才是重要性高的呢?如何定义链接欢迎度为IB)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-02 17:17
也称为“页面选择问题”(page Selection),通常是尽可能先抓取重要的网页,以确保在有限的资源内尽可能多地照顾到最重要的网页。那么哪些页面最重要?如何量化重要性?
重要性度量由链接流行度、链接重要性和平均链接深度确定。
将链接流行度定义为IB(P),主要由backinks的数量和质量决定。先看号码。直观地说,一个网页指向它的链接越多(反向链接的数量越多),其他网页就会识别它。同时,该网页被网民访问的机会更大,推测其重要性会更高;其次,如果是由更重要的网站引导,其重要性会更高。如果不考虑质量,就会有局部最优而不是全局最优。最典型的是作弊网页,在某些网页上人为设置大量反策略链接指向自己的网页,以增加网页的重要性。如果不考虑链接质量,
定义链接重要性为IL(P),它是URL字符串的函数,只检查字符串本身。链接重要性主要采用一些方式,例如收录“.COM”或“HOME”的URL被认为更重要,斜线较少的URL被认为更重要。
定义平均链接深度为 ID(P),由作者创建。ID(P)是指在一组种子站点中,如果每个种子站点都有一个链接(广度优先遍历规则)到达该网页,那么平均链接深度是该网页的另一个重要指标。因为离种子站点越近,访问的机会就越多,离种子站点越远,重要性越低。其实按照广度优先遍历规则,这样重要的网页先被爬取就可以满足了。
最后,定义网页重要性的指标是I(P),由上述两个量化值线性决定,即:
I(P)=a*IB(P)+β*IL(P)
平均链接深度由宽度优先遍历规则保证,因此不用作重要性评估的指标。在抓取能力有限的情况下,尽可能多抓取最重要的网页是合理和科学的,而用户最终查询到的网页往往是重要性高的网页。
虽然这看起来已经足够完美了,但实际上还是忽略了一个重要的 element-time。时间通向万维网的动态一面。如何抓取那些新添加的网页?如何重新访问那些被修改过的页面?如何找到已删除的页面?为了跟上万维网网页的变化,必须有网页重访策略。该策略可以识别三种类型的网页更改:添加、修改和删除网页。 查看全部
抓取网页音频(哪些网页才是重要性高的呢?如何定义链接欢迎度为IB)
也称为“页面选择问题”(page Selection),通常是尽可能先抓取重要的网页,以确保在有限的资源内尽可能多地照顾到最重要的网页。那么哪些页面最重要?如何量化重要性?
重要性度量由链接流行度、链接重要性和平均链接深度确定。
将链接流行度定义为IB(P),主要由backinks的数量和质量决定。先看号码。直观地说,一个网页指向它的链接越多(反向链接的数量越多),其他网页就会识别它。同时,该网页被网民访问的机会更大,推测其重要性会更高;其次,如果是由更重要的网站引导,其重要性会更高。如果不考虑质量,就会有局部最优而不是全局最优。最典型的是作弊网页,在某些网页上人为设置大量反策略链接指向自己的网页,以增加网页的重要性。如果不考虑链接质量,
定义链接重要性为IL(P),它是URL字符串的函数,只检查字符串本身。链接重要性主要采用一些方式,例如收录“.COM”或“HOME”的URL被认为更重要,斜线较少的URL被认为更重要。
定义平均链接深度为 ID(P),由作者创建。ID(P)是指在一组种子站点中,如果每个种子站点都有一个链接(广度优先遍历规则)到达该网页,那么平均链接深度是该网页的另一个重要指标。因为离种子站点越近,访问的机会就越多,离种子站点越远,重要性越低。其实按照广度优先遍历规则,这样重要的网页先被爬取就可以满足了。
最后,定义网页重要性的指标是I(P),由上述两个量化值线性决定,即:
I(P)=a*IB(P)+β*IL(P)
平均链接深度由宽度优先遍历规则保证,因此不用作重要性评估的指标。在抓取能力有限的情况下,尽可能多抓取最重要的网页是合理和科学的,而用户最终查询到的网页往往是重要性高的网页。
虽然这看起来已经足够完美了,但实际上还是忽略了一个重要的 element-time。时间通向万维网的动态一面。如何抓取那些新添加的网页?如何重新访问那些被修改过的页面?如何找到已删除的页面?为了跟上万维网网页的变化,必须有网页重访策略。该策略可以识别三种类型的网页更改:添加、修改和删除网页。
抓取网页音频(热门频道2.打开开发者模式,抓取全部热门音频频道信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-26 19:03
这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中供后续使用。这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前我还在等待三方,或者通知最后的采访消息。(因为能得到一定程度的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,每页可以看到12个频道,每个频道下面有很多音频,有些频道有很多标签。爬取方案:循环84个页面,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现了对所有热门频道信息的抓取,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后分析页面结构。可以看到,每个音频都有一个特定的ID,这个ID可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7. 如果改成异步形式,可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如音量排行,时间段排行,声道音频数等等。未来我会继续学习使用科学计算和绘图工具进行数据分析和清理。
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧! 查看全部
抓取网页音频(热门频道2.打开开发者模式,抓取全部热门音频频道信息)
这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
一、简介
这次爬取的是喜马拉雅热门栏目下所有电台的各个频道的信息以及频道中各个音频数据的各种信息,然后将爬取到的数据保存到mongodb中供后续使用。这次的数据量在70万左右。音频数据包括音频下载地址、频道信息、简介等,数量非常多。
昨天,我迎来了人生中的第一次面试。另一方是一家人。我打算大二的暑假去实习。他们要求爬取音频数据,所以我会分析喜马拉雅的音频数据爬下来。目前我还在等待三方,或者通知最后的采访消息。(因为能得到一定程度的认可,不管成功与否,我都很开心)
二:运行环境三:案例分析
1. 首先进入这个爬虫的主页面,每页可以看到12个频道,每个频道下面有很多音频,有些频道有很多标签。爬取方案:循环84个页面,解析每个页面后,抓取每个频道的名称、图片链接、频道链接保存到mongodb。
热门频道
2.打开开发者模式,分析页面,很快就可以得到你想要的数据的位置了。以下代码实现了对所有热门频道信息的抓取,可以保存在mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
print(content)
分析通道
3. 下面开始获取各个通道的所有音频数据。美国频道的链接是之前解析页面得到的。比如我们进入这个链接后分析页面结构。可以看到,每个音频都有一个特定的ID,这个ID可以在一个div中的一个属性中获取。使用 split() 和 int() 转换为单独的 ID。
频道页面分析
4. 然后点击一个音频链接,进入开发者模式,刷新页面点击XHR,然后点击一个json链接,可以看到这个收录了音频的所有详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
音频页面分析
5. 上面只是解析了一个频道主页面上的所有音频信息,但实际上该频道的音频链接有很多分页。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
# 之后就接解析音频页函数就行,后面有完整代码说明
分页
6.所有代码
完整代码地址/rieuse/learnPython
__author__ = '布咯咯_rieuse'
import json
import random
import time
import pymongo
import requests
from bs4 import BeautifulSoup
from lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了
def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]
for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(class_="albumfaceOutter"):
content = {
'href': item.a['href'],
'title': item.img['alt'],
'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)
def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')
if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')
for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)
def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')
for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')
if __name__ == '__main__':
get_url()
7. 如果改成异步形式,可以更快,改成下面这样就行了。我试图每分钟比正常情况多获得近 100 条数据。此源代码也在 github 中。
异步
五:总结
这次捕获的数据量约为700,000。这个数据以后可以研究很多,比如音量排行,时间段排行,声道音频数等等。未来我会继续学习使用科学计算和绘图工具进行数据分析和清理。
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入学习交流群
626062078,一起学Python吧!

