
抓取网页数据工具
抓取网页数据工具(什么样的网页满足条件?_html()也是一个神器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-03 03:17
继续上面的,我们可以使用 Pandas 将 Excel 转换为 html 格式。文末说了对应的read_html()也是神器!
PS:大家也很乐于助人。我点了30个赞。小舞连忙安排。
最简单的爬虫:用 Pandas 爬取表格数据
有一件事要说,我们不得不承认,用 Pandas 爬取表格数据有一定的局限性。
只适合爬Table数据,那我们先看看什么样的网页满足条件?
什么样的网页结构?
用浏览器打开一个网页,用F12检查它的HTML结构,你会发现合格的网页结构有一个共同的特点。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas。
1
2
3
4 ...
5
6
7
8
9 ...
10
11 ...
12 ...
13 ...
14 ...
15 ...
16
17
18
19
这看起来不直观,打开了北京地区的空气质量网站。
F12,左侧是网页中的质量指标表,其网页结构完美符合表格数据网页结构。
非常适合和熊猫一起爬行。
pd.read_html()
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需要几行代码就可以抓取Table表数据,简直就是神器![1]
具体的 pd.read_html() 参数,可以查看其官方文档:
就拿刚才的网站开始吧!
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
3
4
这里只添加了几个参数,header是指定列标题所在的行。使用指南包,只需要两行代码。
1df.head()
2
3
1 
2
对比结果,可以看到成功获取到表格数据。
多种形式
最后一种情况,不知道有没有朋友注意到
1pd.read_html()[0]
2
3
对于pd.read_html(),获取网页结果后添加一个[0]。这是因为网页上可能有多个表格。在这种情况下,需要通过对列表的tables[x]进行切片来指定获取哪个表。
比如之前的网站,空气质量排名网页显然是由两个表格组成的。
这时候如果使用 pd.read_html() 来获取右边的表格,只需要稍作修改即可。
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
3
4
对比一下,可以看到网页右侧的表格是成功获取的。
以上就是使用 pd.read_html() 简单爬取静态网页。但我们之所以使用Python,其实是为了提高效率。但是,如果只有一个网页,用鼠标选择和复制不是更容易吗?所以Python操作的最大优势将体现在批处理操作上。
批量爬取
让我教你如何使用Pandas批量抓取网页表格数据????
以新浪金融机构持股汇总数据为例:
一共有47个页面,通过for循环构造了47个网页url,然后用pd.read_html()循环进行爬取。
1df = pd.DataFrame()
2for i in range(1, 48):
3 url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
4 df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
5
6
还是几行代码,很容易解决。
共获得47页1738条数据。
通过以上的小案例,相信大家可以轻松掌握Pandas的批量爬表数据????
参考
[1]
Python阅读财经:天秀!Pandas 可以用来写爬虫吗?
《人工智能数学》数学思维体操,学习人工智能的基石!通过205个典型例子+185个推导公式+37个经典习题+40个学习难度提示+19个项目,有效实践数学思想和解决方案。点击下图查看详情/购买!??? 查看全部
抓取网页数据工具(什么样的网页满足条件?_html()也是一个神器)
继续上面的,我们可以使用 Pandas 将 Excel 转换为 html 格式。文末说了对应的read_html()也是神器!
PS:大家也很乐于助人。我点了30个赞。小舞连忙安排。
最简单的爬虫:用 Pandas 爬取表格数据
有一件事要说,我们不得不承认,用 Pandas 爬取表格数据有一定的局限性。
只适合爬Table数据,那我们先看看什么样的网页满足条件?
什么样的网页结构?
用浏览器打开一个网页,用F12检查它的HTML结构,你会发现合格的网页结构有一个共同的特点。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas。
1
2
3
4 ...
5
6
7
8
9 ...
10
11 ...
12 ...
13 ...
14 ...
15 ...
16
17
18
19
这看起来不直观,打开了北京地区的空气质量网站。
F12,左侧是网页中的质量指标表,其网页结构完美符合表格数据网页结构。

非常适合和熊猫一起爬行。
pd.read_html()
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需要几行代码就可以抓取Table表数据,简直就是神器![1]
具体的 pd.read_html() 参数,可以查看其官方文档:
就拿刚才的网站开始吧!
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
3
4
这里只添加了几个参数,header是指定列标题所在的行。使用指南包,只需要两行代码。
1df.head()
2
3
1 
2
对比结果,可以看到成功获取到表格数据。

多种形式
最后一种情况,不知道有没有朋友注意到
1pd.read_html()[0]
2
3
对于pd.read_html(),获取网页结果后添加一个[0]。这是因为网页上可能有多个表格。在这种情况下,需要通过对列表的tables[x]进行切片来指定获取哪个表。
比如之前的网站,空气质量排名网页显然是由两个表格组成的。

这时候如果使用 pd.read_html() 来获取右边的表格,只需要稍作修改即可。
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
3
4
对比一下,可以看到网页右侧的表格是成功获取的。

以上就是使用 pd.read_html() 简单爬取静态网页。但我们之所以使用Python,其实是为了提高效率。但是,如果只有一个网页,用鼠标选择和复制不是更容易吗?所以Python操作的最大优势将体现在批处理操作上。
批量爬取
让我教你如何使用Pandas批量抓取网页表格数据????
以新浪金融机构持股汇总数据为例:

一共有47个页面,通过for循环构造了47个网页url,然后用pd.read_html()循环进行爬取。
1df = pd.DataFrame()
2for i in range(1, 48):
3 url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
4 df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
5
6
还是几行代码,很容易解决。

共获得47页1738条数据。

通过以上的小案例,相信大家可以轻松掌握Pandas的批量爬表数据????
参考
[1]
Python阅读财经:天秀!Pandas 可以用来写爬虫吗?

《人工智能数学》数学思维体操,学习人工智能的基石!通过205个典型例子+185个推导公式+37个经典习题+40个学习难度提示+19个项目,有效实践数学思想和解决方案。点击下图查看详情/购买!???
抓取网页数据工具(新站分析新站需针对的那些点,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-03 03:14
网站UEO优化的实现,那么新站的分析比较简单了解一些基本的操作,包括优化问题,然后作为一个新建的网站基于本质的推广方向进行合理的优化,包括:站内关键词、代码优化、外链、UEO、内链循环、内容数据等。在优化的基础上,再分析以上内容,分析新站需要定位的那些。观点!
现场关键词方向:
这是优化的基本知识。对于关键词关于网站整体排名趋势,以及后期维护定位,在选择关键词时,需要进行布局。一般来说,搜索引擎需要进行合理的关键词布局和扩展,从长尾词的定位到精准词,一般都集中在三大标签,对应的长尾词需要混在页面中;为了保证准确定位;一步一步优化关键词;
关键词的定位是从词义和词性上合理分布的。关键词 可以在页面中进行冗余扩展,但不宜重复使用 关键词。一般一页字数以1000-5000字为主,定位关键词不要超过5个;详情可与凯业SEO在线沟通;
新站代码优化:
这是一个共同点。代码是网站的源码,网站的源码有各种标签。优化代码,新站需要从简化代码入手。简化的代码是更大的代码。,并换成小代码,效果一样;如果要比较标签和其他标签,需要用文字描述,一般会涉及到新源代码中的图片路径;
新网站外部链接:
<p>这部分没有以前那么强大,但也是必要的优化之一。引导外部流量可以有效地为网站带来流量和权重;而优质的外链给网站新站的认可,搜索引擎从外链中找到你新站的链接,链接是网站和 查看全部
抓取网页数据工具(新站分析新站需针对的那些点,你知道吗?)
网站UEO优化的实现,那么新站的分析比较简单了解一些基本的操作,包括优化问题,然后作为一个新建的网站基于本质的推广方向进行合理的优化,包括:站内关键词、代码优化、外链、UEO、内链循环、内容数据等。在优化的基础上,再分析以上内容,分析新站需要定位的那些。观点!
现场关键词方向:
这是优化的基本知识。对于关键词关于网站整体排名趋势,以及后期维护定位,在选择关键词时,需要进行布局。一般来说,搜索引擎需要进行合理的关键词布局和扩展,从长尾词的定位到精准词,一般都集中在三大标签,对应的长尾词需要混在页面中;为了保证准确定位;一步一步优化关键词;
关键词的定位是从词义和词性上合理分布的。关键词 可以在页面中进行冗余扩展,但不宜重复使用 关键词。一般一页字数以1000-5000字为主,定位关键词不要超过5个;详情可与凯业SEO在线沟通;
新站代码优化:
这是一个共同点。代码是网站的源码,网站的源码有各种标签。优化代码,新站需要从简化代码入手。简化的代码是更大的代码。,并换成小代码,效果一样;如果要比较标签和其他标签,需要用文字描述,一般会涉及到新源代码中的图片路径;
新网站外部链接:
<p>这部分没有以前那么强大,但也是必要的优化之一。引导外部流量可以有效地为网站带来流量和权重;而优质的外链给网站新站的认可,搜索引擎从外链中找到你新站的链接,链接是网站和
抓取网页数据工具(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-26 15:07
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</ 查看全部
抓取网页数据工具(记录思路如下:记录SQL中的注释(使用--进行注释))
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</
抓取网页数据工具(WindowsLinux免费爬虫工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 19:20
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4.左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 克拉珀
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. PaseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮刀
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrpinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10. 德克西欧
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhse.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容 Gabber
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦分离器
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
Path 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Conntate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
抓取网页数据工具(WindowsLinux免费爬虫工具)
1. 八分法

Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack

作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4.左转

Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 克拉珀

Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器

OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. PaseHub

Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮刀

VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrpinghub

Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10. 德克西欧

作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhse.io

Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入io

用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r

Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容 Gabber

Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦分离器

Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath

Path 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it

Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy

WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵

Conntate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
抓取网页数据工具(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-02-11 19:18
最后介绍几个主要功能按钮: 1、上图中的两个按钮是用于切换谷歌地图/谷歌搜索引擎这两种抓取模式的。这个我就不用多说了,点一下就明白了。!
下图所示的工具之前已经给大家介绍过了。这是我制作的谷歌搜索提取工具2.0版本。
2.0版,主要是帮你在谷歌搜索引擎上直接提取网站和title信息,可以看我以前的文章《25h创建外贸网站@ > 挖矿工具,10s提取100个客户网站!”,看详细介绍!
今天主要给大家介绍一下我前两天刚刚修改的新版谷歌搜索提取工具3.0。与之前的版本相比,增加了googlemaps提取功能,可以帮助您直接提取googlemaps上的公司。资料显示,很多老外贸公司可能对谷歌地图并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有精准的买家,是外贸客户开发的常用渠道。
只要我们通过关键词搜索出公司信息页面,就可以直接点击开始爬取按钮,开发爬取信息。操作很简单,我们不用管他,它会自动翻页。直到搜索完成。
另外,相比3.0的版本2.0,谷歌搜索引擎抓取也进行了调整,不再像以前那样直接输入关键词进行抓取,而且之前也需要手动翻第二页。这次将整个真实网页直接转入工具,搜索翻页也是全自动的。完全模拟人工操作,减少弹出验证码的概率。即使弹出验证码,我们也可以手动填写!
最后,我来介绍一些主要的功能按钮:
1、
上图中的两个按钮用于切换谷歌地图/谷歌搜索引擎和两种抓取模式。这个不用我多说了,点一下就明白了!
2、
无翻转搜索是此更新的一个很好的功能。如果你电脑上的 fq 工具出现故障,你可以尝试检查一下,然后切换到更平滑的线。这样,你就可以使用这个工具来抓取谷歌了。获取信息(毕竟是给大家省钱的,肯定会比较慢!)
3、
红框选中的4个按钮当然不需要我过多解释,比如字面意思。全部导出是将搜索到的数据以excel格式导出到本地计算机。
4、
如果您上传此选项,我们一般默认不勾选。如果你不使用F墙工具,而是使用F墙路由访问外网,不妨勾选这个选项试试。(切记不要乱打勾,否则google页面加载不出来)
其他没什么好解释的,自己下载体验吧!该工具基于个人兴趣爱好,免费分享给大家。您不必担心是否充电。只要对大家有帮助,我一定会为大家优化更新更多功能!
下载链接:
部分电脑下载安装可能会弹出风险提示,点击“允许”放心使用,无需为任何年龄的你制造病毒!
还有,有bug或者好的建议可以在评论区写! 查看全部
抓取网页数据工具(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
最后介绍几个主要功能按钮: 1、上图中的两个按钮是用于切换谷歌地图/谷歌搜索引擎这两种抓取模式的。这个我就不用多说了,点一下就明白了。!
下图所示的工具之前已经给大家介绍过了。这是我制作的谷歌搜索提取工具2.0版本。

2.0版,主要是帮你在谷歌搜索引擎上直接提取网站和title信息,可以看我以前的文章《25h创建外贸网站@ > 挖矿工具,10s提取100个客户网站!”,看详细介绍!
今天主要给大家介绍一下我前两天刚刚修改的新版谷歌搜索提取工具3.0。与之前的版本相比,增加了googlemaps提取功能,可以帮助您直接提取googlemaps上的公司。资料显示,很多老外贸公司可能对谷歌地图并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有精准的买家,是外贸客户开发的常用渠道。

只要我们通过关键词搜索出公司信息页面,就可以直接点击开始爬取按钮,开发爬取信息。操作很简单,我们不用管他,它会自动翻页。直到搜索完成。
另外,相比3.0的版本2.0,谷歌搜索引擎抓取也进行了调整,不再像以前那样直接输入关键词进行抓取,而且之前也需要手动翻第二页。这次将整个真实网页直接转入工具,搜索翻页也是全自动的。完全模拟人工操作,减少弹出验证码的概率。即使弹出验证码,我们也可以手动填写!

最后,我来介绍一些主要的功能按钮:
1、

上图中的两个按钮用于切换谷歌地图/谷歌搜索引擎和两种抓取模式。这个不用我多说了,点一下就明白了!
2、

无翻转搜索是此更新的一个很好的功能。如果你电脑上的 fq 工具出现故障,你可以尝试检查一下,然后切换到更平滑的线。这样,你就可以使用这个工具来抓取谷歌了。获取信息(毕竟是给大家省钱的,肯定会比较慢!)
3、

红框选中的4个按钮当然不需要我过多解释,比如字面意思。全部导出是将搜索到的数据以excel格式导出到本地计算机。
4、

如果您上传此选项,我们一般默认不勾选。如果你不使用F墙工具,而是使用F墙路由访问外网,不妨勾选这个选项试试。(切记不要乱打勾,否则google页面加载不出来)
其他没什么好解释的,自己下载体验吧!该工具基于个人兴趣爱好,免费分享给大家。您不必担心是否充电。只要对大家有帮助,我一定会为大家优化更新更多功能!
下载链接:
部分电脑下载安装可能会弹出风险提示,点击“允许”放心使用,无需为任何年龄的你制造病毒!
还有,有bug或者好的建议可以在评论区写!
抓取网页数据工具(1.虎嗅资讯网数据--请求查阅该请求的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-11 01:28
1.虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据。不幸的是,虎秀信息网被我选中了。该网站是其信息渠道。此文章仅用于学习交流,不得用于其他用途。
一般操作,分析要爬取的页面
将页面拖到底部,会发现一个load more按钮,点击后,抓取请求,得到如下地址
2.虎嗅网文章数据----分析请求
查看请求的方法和地址,包括参数,如下图
获取以下信息
页面请求地址为: 请求方式:POST 请求参数比较重要的是一个叫page的参数
我们只需要根据以上内容编写pyspider代码部分即可。在on_start函数里面写一个循环事件,注意有一个数字2025,就是我刚才从请求中看到的总页数。当您阅读此 文章 时,这个数字应该更大。
1 @every(minutes=24 * 60)
2 def on_start(self):
3 for page in range(1,2025):
4 print("正在爬取第 {} 页".format(page))
5 self.crawl('https://www.huxiu.com/v2_actio ... 27%3B, method="POST",data={"page":page},callback=self.parse_page,validate_cert=False)
6
页面生成后,会调用parse_page函数解析爬取URL成功后crawl()方法返回的Response响应。
1 @config(age=10 * 24 * 60 * 60)
2 def parse_page(self, response):
3 content = response.json["data"]
4 doc = pq(content)
5 lis = doc('.mod-art').items()
6 data = [{
7 'title': item('.msubstr-row2').text(),
8 'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),
9 'name': item('.author-name').text(),
10 'write_time':item('.time').text(),
11 'comment':item('.icon-cmt+ em').text(),
12 'favorites':item('.icon-fvr+ em').text(),
13 'abstract':item('.mob-sub').text()
14 } for item in lis ]
15 return data
16
最后定义一个on_result()方法,专门用来获取return的结果数据。这个用来接收上面parse_page()返回的数据数据,其中的数据可以保存到MongoDB中。
1'''
2遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
3'''
4 # 页面每次返回的数据
5 def on_result(self,result):
6 if result:
7 self.save_to_mongo(result)
8
9
10 # 存储到mongo数据库
11 def save_to_mongo(self,result):
12 df = pd.DataFrame(result)
13 content = json.loads(df.T.to_json()).values()
14 if collection.insert_many(content):
15 print('存储数据成功')
16 # 暂停1s
17 time.sleep(1)
18
好的,保存代码,修改每秒运行次数和并发
点击run运行代码,但是运行之后会发现程序在抓取一个页面后就停止了。pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果 ID 号相同,则视为同一任务。再次爬行。
GET请求的分页URL一般不一样,所以ID号也会不一样,可以爬到多个页面。POST 请求的 URL 相同。第一个页面被爬取后,后面的页面将不会被爬取。
解决方法是重写ID号的生成方法,在on_start()方法前添加如下代码:
1 def get_taskid(self,task):
2 return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
3
基本操作后,文章被存储 查看全部
抓取网页数据工具(1.虎嗅资讯网数据--请求查阅该请求的方式)
1.虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据。不幸的是,虎秀信息网被我选中了。该网站是其信息渠道。此文章仅用于学习交流,不得用于其他用途。
一般操作,分析要爬取的页面
将页面拖到底部,会发现一个load more按钮,点击后,抓取请求,得到如下地址

2.虎嗅网文章数据----分析请求
查看请求的方法和地址,包括参数,如下图

获取以下信息
页面请求地址为: 请求方式:POST 请求参数比较重要的是一个叫page的参数
我们只需要根据以上内容编写pyspider代码部分即可。在on_start函数里面写一个循环事件,注意有一个数字2025,就是我刚才从请求中看到的总页数。当您阅读此 文章 时,这个数字应该更大。
1 @every(minutes=24 * 60)
2 def on_start(self):
3 for page in range(1,2025):
4 print("正在爬取第 {} 页".format(page))
5 self.crawl('https://www.huxiu.com/v2_actio ... 27%3B, method="POST",data={"page":page},callback=self.parse_page,validate_cert=False)
6
页面生成后,会调用parse_page函数解析爬取URL成功后crawl()方法返回的Response响应。
1 @config(age=10 * 24 * 60 * 60)
2 def parse_page(self, response):
3 content = response.json["data"]
4 doc = pq(content)
5 lis = doc('.mod-art').items()
6 data = [{
7 'title': item('.msubstr-row2').text(),
8 'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),
9 'name': item('.author-name').text(),
10 'write_time':item('.time').text(),
11 'comment':item('.icon-cmt+ em').text(),
12 'favorites':item('.icon-fvr+ em').text(),
13 'abstract':item('.mob-sub').text()
14 } for item in lis ]
15 return data
16
最后定义一个on_result()方法,专门用来获取return的结果数据。这个用来接收上面parse_page()返回的数据数据,其中的数据可以保存到MongoDB中。
1'''
2遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
3'''
4 # 页面每次返回的数据
5 def on_result(self,result):
6 if result:
7 self.save_to_mongo(result)
8
9
10 # 存储到mongo数据库
11 def save_to_mongo(self,result):
12 df = pd.DataFrame(result)
13 content = json.loads(df.T.to_json()).values()
14 if collection.insert_many(content):
15 print('存储数据成功')
16 # 暂停1s
17 time.sleep(1)
18
好的,保存代码,修改每秒运行次数和并发

点击run运行代码,但是运行之后会发现程序在抓取一个页面后就停止了。pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果 ID 号相同,则视为同一任务。再次爬行。
GET请求的分页URL一般不一样,所以ID号也会不一样,可以爬到多个页面。POST 请求的 URL 相同。第一个页面被爬取后,后面的页面将不会被爬取。
解决方法是重写ID号的生成方法,在on_start()方法前添加如下代码:
1 def get_taskid(self,task):
2 return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
3
基本操作后,文章被存储
抓取网页数据工具(注意事项Jailer运行的环境需要Javajre5的支持更新日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-09 06:14
Jailer数据抓包软件是一款功能强大的数据文件提取工具,用户可以使用该软件在线抓包数据,不破坏其他上万条数据,删除指定数据行,非常方便的抓包工具,欢迎有需要的用户下载它!
关于 Jailer 数据提取工具
Jailer 可以直接从关系数据库中导出连续的相关行数据,以便直接在您自己的开发/测试环境中使用。使用 Jailer,您可以在不损害其他数据完整性的情况下删除特定行的数据,从而提高数据库的效率。Jailer 是一个独立的平台,所以如果你没有运行数据库文件所需的相应应用程序也没关系,它可以直接生成 DbUnit 数据集、拓扑排序的 SQL-DML 和层次结构的 XML 文档,可以支持DB2、Firebird、Derby 和其他应用程序。
Jailer 数据采集软件的特点
1、开源,完全用 java 编写,独立于平台,与 DBMS 无关。
2、生成分层结构的 XML、拓扑排序的 sql-dml 和 DbUnit 数据集。
3、通过在不违反完整性的情况下删除和归档过时数据来提高数据库性能。
4、从您的生产数据库中导出一致和引用的完整行集,并将数据输入到您的开发和测试环境。
预防措施
Jailer运行的环境需要Java jre 5的支持
变更日志
1、改进的语法高亮
2、可以逐行编辑SQL语句执行结果的数据
3、在数据浏览器界面增加了编辑和执行任意SQL语句的能力
4、数据浏览器窗口中的集成数据库模式映射对话框 查看全部
抓取网页数据工具(注意事项Jailer运行的环境需要Javajre5的支持更新日志)
Jailer数据抓包软件是一款功能强大的数据文件提取工具,用户可以使用该软件在线抓包数据,不破坏其他上万条数据,删除指定数据行,非常方便的抓包工具,欢迎有需要的用户下载它!
关于 Jailer 数据提取工具
Jailer 可以直接从关系数据库中导出连续的相关行数据,以便直接在您自己的开发/测试环境中使用。使用 Jailer,您可以在不损害其他数据完整性的情况下删除特定行的数据,从而提高数据库的效率。Jailer 是一个独立的平台,所以如果你没有运行数据库文件所需的相应应用程序也没关系,它可以直接生成 DbUnit 数据集、拓扑排序的 SQL-DML 和层次结构的 XML 文档,可以支持DB2、Firebird、Derby 和其他应用程序。

Jailer 数据采集软件的特点
1、开源,完全用 java 编写,独立于平台,与 DBMS 无关。
2、生成分层结构的 XML、拓扑排序的 sql-dml 和 DbUnit 数据集。
3、通过在不违反完整性的情况下删除和归档过时数据来提高数据库性能。
4、从您的生产数据库中导出一致和引用的完整行集,并将数据输入到您的开发和测试环境。
预防措施
Jailer运行的环境需要Java jre 5的支持
变更日志
1、改进的语法高亮
2、可以逐行编辑SQL语句执行结果的数据
3、在数据浏览器界面增加了编辑和执行任意SQL语句的能力
4、数据浏览器窗口中的集成数据库模式映射对话框
抓取网页数据工具(极尽其所能将网页内容、HTTP报头、Cookie里的数据记录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-08 04:09
)
GoldDataSpider 是一个用于抓取网页和提取数据的工具。其核心代码与黄金数据采集融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。此外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
我们还提供规则可视化公式,请下载。也
入门
首先,我们需要给项目添加依赖,如下:
1、对于 maven 项目
com.100shouhou.golddata
golddata-spider
1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test
public void testGoldSpider(){
String ruleContent=
" { \n"+
" __node: li.sky.skyid \n"+
" date: \n"+
" { \n"+
" expr: h1 \n"+
" __label: 日期 \n"+
" } \n"+
" sn: \n"+
" { \n"+
" \n"+
" js: md5(baseUri+item.date+headers['Content-Type']);\n"+
" } \n"+
" weather: \n"+
" { \n"+
" expr: p.wea \n"+
" } \n"+
" temprature: \n"+
" { \n"+
" expr: p.tem>i \n"+
" } \n"+
" } \n";
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl("http://www.weather.com.cn/weat ... 6quot;)
.setRule(ruleContent)
.request();
List list=spider.extractList();
// List weathers=spider.extractList(Weather.class);
// Weather weathers=spider.extractFirst(Weather.class);
list.forEach( System.out::println);
}
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d}
{date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd}
{date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa}
{date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3}
{date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f}
{date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d}
{date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service
public class WeatherServiceImpl implements WeatherService{
public List listByCityId(Long cityId){
String url="http://www.weather.com.cn/weat ... ot%3B
String rule=""
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl(url)
.setRule(ruleContent)
.request();
return spider.extractList(Weather.class);
}
} 查看全部
抓取网页数据工具(极尽其所能将网页内容、HTTP报头、Cookie里的数据记录
)
GoldDataSpider 是一个用于抓取网页和提取数据的工具。其核心代码与黄金数据采集融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。此外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
我们还提供规则可视化公式,请下载。也
入门
首先,我们需要给项目添加依赖,如下:
1、对于 maven 项目
com.100shouhou.golddata
golddata-spider
1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test
public void testGoldSpider(){
String ruleContent=
" { \n"+
" __node: li.sky.skyid \n"+
" date: \n"+
" { \n"+
" expr: h1 \n"+
" __label: 日期 \n"+
" } \n"+
" sn: \n"+
" { \n"+
" \n"+
" js: md5(baseUri+item.date+headers['Content-Type']);\n"+
" } \n"+
" weather: \n"+
" { \n"+
" expr: p.wea \n"+
" } \n"+
" temprature: \n"+
" { \n"+
" expr: p.tem>i \n"+
" } \n"+
" } \n";
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl("http://www.weather.com.cn/weat ... 6quot;)
.setRule(ruleContent)
.request();
List list=spider.extractList();
// List weathers=spider.extractList(Weather.class);
// Weather weathers=spider.extractFirst(Weather.class);
list.forEach( System.out::println);
}
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d}
{date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd}
{date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa}
{date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3}
{date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f}
{date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d}
{date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service
public class WeatherServiceImpl implements WeatherService{
public List listByCityId(Long cityId){
String url="http://www.weather.com.cn/weat ... ot%3B
String rule=""
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl(url)
.setRule(ruleContent)
.request();
return spider.extractList(Weather.class);
}
}
抓取网页数据工具(网络爬虫工具越来越工具下载地址介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-07 23:07
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
刮刀
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
解析中心
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookie 等获取网页数据。其机器学习技术可以读取网页文档,对其进行分析并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
抓取中心
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
网管.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
进口.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
氦刮刀
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
刮.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
Web哈维
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心 查看全部
抓取网页数据工具(网络爬虫工具越来越工具下载地址介绍及应用)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
八分法

Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
HTTrack

作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
左转

Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
刮刀

Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
OutWit 集线器

OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
解析中心

Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookie 等获取网页数据。其机器学习技术可以读取网页文档,对其进行分析并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板

VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
抓取中心

Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
Dexi.io

作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
网管.io

Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
进口.io

用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿

80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
Spinn3r

Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
内容抓取器

Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
氦刮刀

Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
UiPath

UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
刮.it

Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
Web哈维

WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
内涵

Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心
抓取网页数据工具(爬取网页图片步骤及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-07 16:00
抓取网页数据工具:如果想要爬取网页中的图片,目录:图片class120.jpg大小:图片1.32mb,class204.jpg大小:图片1.22mb1.实现1.requests库requests库是一个python提供的异步请求库,官方教程:requestshelloworld爬取网页图片步骤如下:1.获取图片路径2.获取图片class3.解析图片所在class列表1.获取图片路径:2.获取图片class:我们先从class="h"中查看对应的图片类型为:class120.jpg我们先从对应的图片class中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:png,jpg)3.解析图片所在列表:我们先从对应的列表中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:image)好了,解析图片所在列表已经完成。
接下来我们操作下代码:接下来我们操作,获取图片class,关键语句如下:1.获取图片class我们首先来看看获取图片class方法:data=requests.get("")data=data.decode("utf-8")我们先看看怎么获取图片class,上面是从图片class中获取,代码如下:data=requests.get("")data=data.decode("utf-8")代码不是很多,你可以看出他返回的是一个png图片的数组。
我们再看一下怎么从图片列表中提取class:fromlxmlimportetreedata=etree.html(data)我们先查看下etree模块中etree的文档:[etree.html]importetreefrommultiprocessingimportpoolimportredefetree_from_lxml(en):asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="theimage"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="andtheimage"asserten=="ande-rate"asserten=="thejpg"asserten=="thee-rate"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)if__name__=="__main__":data=etree_from_lxml()print("success")这样我们成功提取class之后,再看下最终提取的结果:fromlxmlimportetreefrommultiprocessingimportpoolimportredefetree_from_lx。 查看全部
抓取网页数据工具(爬取网页图片步骤及应用)
抓取网页数据工具:如果想要爬取网页中的图片,目录:图片class120.jpg大小:图片1.32mb,class204.jpg大小:图片1.22mb1.实现1.requests库requests库是一个python提供的异步请求库,官方教程:requestshelloworld爬取网页图片步骤如下:1.获取图片路径2.获取图片class3.解析图片所在class列表1.获取图片路径:2.获取图片class:我们先从class="h"中查看对应的图片类型为:class120.jpg我们先从对应的图片class中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:png,jpg)3.解析图片所在列表:我们先从对应的列表中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:image)好了,解析图片所在列表已经完成。
接下来我们操作下代码:接下来我们操作,获取图片class,关键语句如下:1.获取图片class我们首先来看看获取图片class方法:data=requests.get("")data=data.decode("utf-8")我们先看看怎么获取图片class,上面是从图片class中获取,代码如下:data=requests.get("")data=data.decode("utf-8")代码不是很多,你可以看出他返回的是一个png图片的数组。
我们再看一下怎么从图片列表中提取class:fromlxmlimportetreedata=etree.html(data)我们先查看下etree模块中etree的文档:[etree.html]importetreefrommultiprocessingimportpoolimportredefetree_from_lxml(en):asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="theimage"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="andtheimage"asserten=="ande-rate"asserten=="thejpg"asserten=="thee-rate"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)if__name__=="__main__":data=etree_from_lxml()print("success")这样我们成功提取class之后,再看下最终提取的结果:fromlxmlimportetreefrommultiprocessingimportpoolimportredefetree_from_lx。
抓取网页数据工具(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-07 07:09
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越为人所知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个数据提取功能有限的 Chrome 扩展程序,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合那些有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
抓取网页数据工具(网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越为人所知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个数据提取功能有限的 Chrome 扩展程序,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合那些有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
抓取网页数据工具(金色数据采集器开源项目之金色采集器开源项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-06 18:01
介绍
Golden data采集器开源项目是一个网页爬取和数据提取的工具。其核心代码与黄金数据采集和数据融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。另外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
黄金数据平台
Golden Data是一个集采集和融合功能于一体的平台。它可以捕获数据和数据之间的关系并立即将其整合到关系应用数据库表中,并且重复采集融合不会产生重复数据。
完全免费的黄金数据社区版
金数据平台社区版是一款完全不限爬取(如不限爬虫数量、爬取速度/时间、爬取数据数量、导出数据量)的私有云软件。
我们提供Golden Data Platform的详细免费文档和培训视频,请点击这里查看和使用。
入门
首先,我们需要将依赖添加到项目中(因为我们已经将项目添加到了maven中央仓库),如下:
1、对于 maven 项目
com.100shouhou.golddata golddata-spider 1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test public void testGoldSpider(){ String ruleContent= " { \n"+ " __node: li.sky.skyid \n"+ " date: \n"+ " { \n"+ " expr: h1 \n"+ " __label: 日期 \n"+ " } \n"+ " sn: \n"+ " { \n"+ " \n"+ " js: md5(baseUri+item.date+headers['Content-Type']);\n"+ " } \n"+ " weather: \n"+ " { \n"+ " expr: p.wea \n"+ " } \n"+ " temprature: \n"+ " { \n"+ " expr: p.tem>i \n"+ " } \n"+ " } \n"; GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl("http://www.weather.com.cn/weat ... 6quot;) .setRule(ruleContent) .request(); List list=spider.extractList(); // List weathers=spider.extractList(Weather.class); // Weather weathers=spider.extractFirst(Weather.class); list.forEach( System.out::println); }
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d} {date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd} {date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa} {date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3} {date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f} {date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d} {date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service public class WeatherServiceImpl implements WeatherService{ public List listByCityId(Long cityId){ String url="http://www.weather.com.cn/weat ... ot%3B String rule="" GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl(url) .setRule(ruleContent) .request(); return spider.extractList(Weather.class); } }
此外,您可以免费使用可视化编辑器来编辑规则内容。可视化编辑器来自金数据平台,点击链接即可下载。可视化编辑器截图如下:
文档和培训视频
请点击这里查看规则和文件
可以查看oschina关于golden data相关的博文, 查看全部
抓取网页数据工具(金色数据采集器开源项目之金色采集器开源项目)
介绍
Golden data采集器开源项目是一个网页爬取和数据提取的工具。其核心代码与黄金数据采集和数据融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。另外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
黄金数据平台
Golden Data是一个集采集和融合功能于一体的平台。它可以捕获数据和数据之间的关系并立即将其整合到关系应用数据库表中,并且重复采集融合不会产生重复数据。
完全免费的黄金数据社区版
金数据平台社区版是一款完全不限爬取(如不限爬虫数量、爬取速度/时间、爬取数据数量、导出数据量)的私有云软件。
我们提供Golden Data Platform的详细免费文档和培训视频,请点击这里查看和使用。
入门
首先,我们需要将依赖添加到项目中(因为我们已经将项目添加到了maven中央仓库),如下:
1、对于 maven 项目
com.100shouhou.golddata golddata-spider 1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test public void testGoldSpider(){ String ruleContent= " { \n"+ " __node: li.sky.skyid \n"+ " date: \n"+ " { \n"+ " expr: h1 \n"+ " __label: 日期 \n"+ " } \n"+ " sn: \n"+ " { \n"+ " \n"+ " js: md5(baseUri+item.date+headers['Content-Type']);\n"+ " } \n"+ " weather: \n"+ " { \n"+ " expr: p.wea \n"+ " } \n"+ " temprature: \n"+ " { \n"+ " expr: p.tem>i \n"+ " } \n"+ " } \n"; GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl("http://www.weather.com.cn/weat ... 6quot;) .setRule(ruleContent) .request(); List list=spider.extractList(); // List weathers=spider.extractList(Weather.class); // Weather weathers=spider.extractFirst(Weather.class); list.forEach( System.out::println); }
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d} {date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd} {date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa} {date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3} {date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f} {date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d} {date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service public class WeatherServiceImpl implements WeatherService{ public List listByCityId(Long cityId){ String url="http://www.weather.com.cn/weat ... ot%3B String rule="" GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl(url) .setRule(ruleContent) .request(); return spider.extractList(Weather.class); } }
此外,您可以免费使用可视化编辑器来编辑规则内容。可视化编辑器来自金数据平台,点击链接即可下载。可视化编辑器截图如下:

文档和培训视频
请点击这里查看规则和文件
可以查看oschina关于golden data相关的博文,
抓取网页数据工具( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-06 17:24
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简易数据分析系列文章的第11期。
原文首发于博客园。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
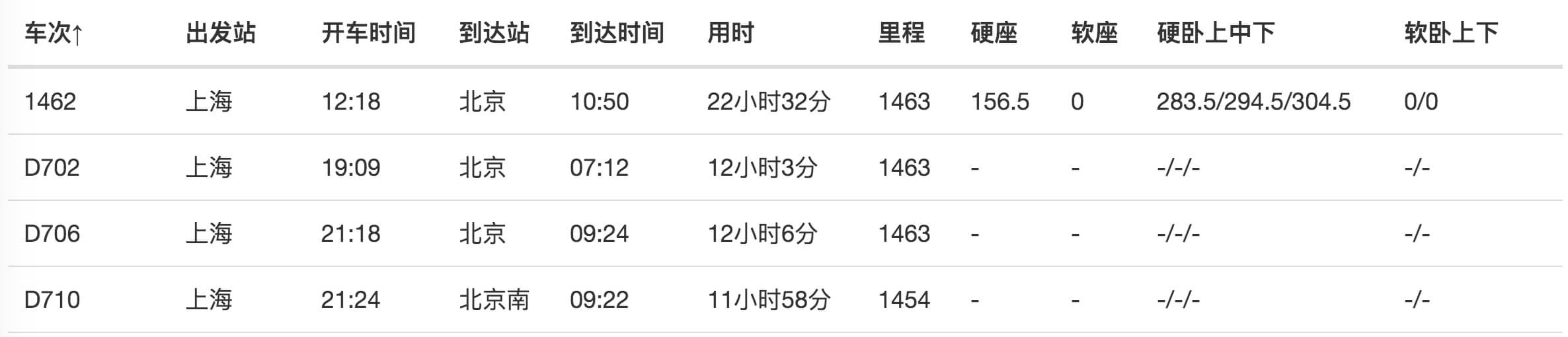
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程来爬取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
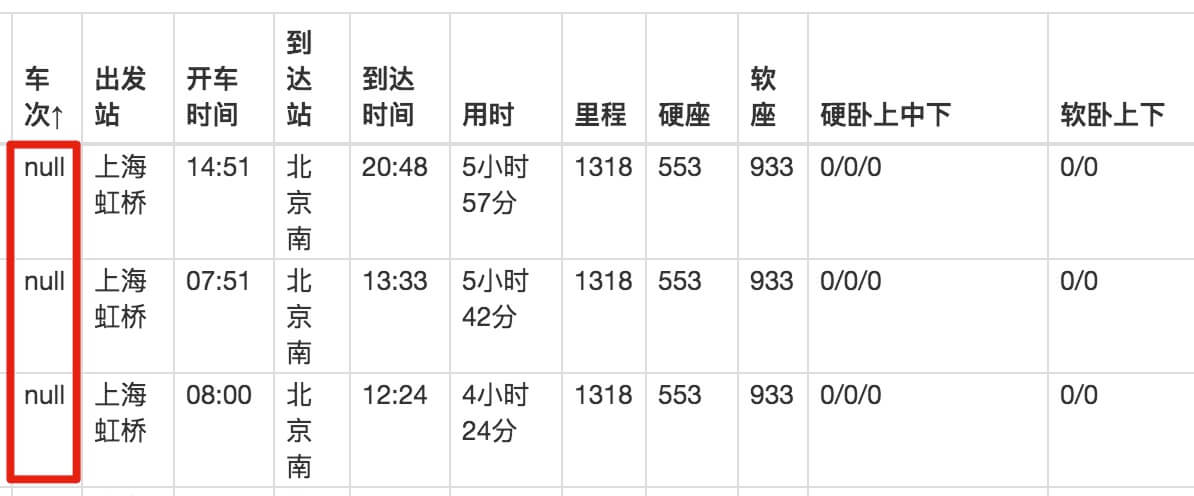
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是可以在互联网刚开发的时候提供开箱即用的表格;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成表格一样,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
抓取网页数据工具(
这是简易数据分析系列第11篇文章(图)Datapreview)

这是简易数据分析系列文章的第11期。
原文首发于博客园。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。

具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。

在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:

解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:

解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程来爬取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!

这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是可以在互联网刚开发的时候提供开箱即用的表格;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成表格一样,很容易自定义:

正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
抓取网页数据工具(ScreamingFrogSEOSpider14源程序破解安装教程,欢迎下载体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-02 00:12
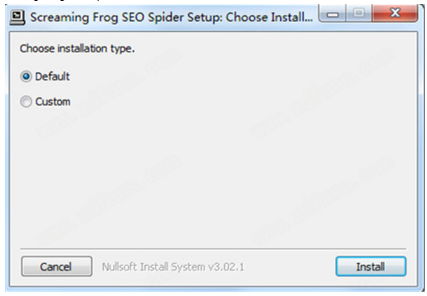
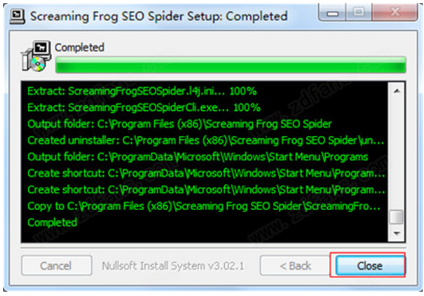
Screaming Frog SEO Spider是一款在现实生活中经常使用的电脑端网站资源检测爬虫软件。该软件可帮助用户即时抓取 网站 并查找断开的链接 (404) 和服务器错误。批量导出错误和要修复的源 URL,或直接发送给开发人员进行修复。简洁直观的界面让用户更容易找到自己想要的功能。它还可以帮助用户分析页面标题和元数据,并查看 Meta 机器人和说明。还有很多功能,需要的用户快来下载使用吧!
安装教程
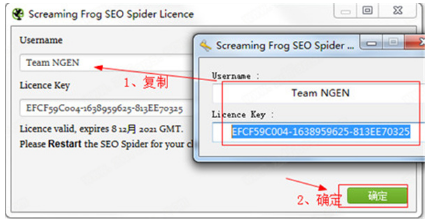
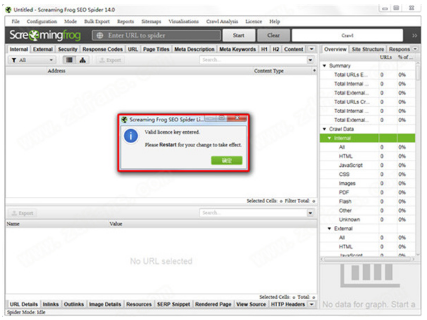
1、从本站下载解压后,可以得到Screaming Frog SEO Spider 14的源程序和破解文件;
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,点击Install安装,默认安装路径,安装类型;
3、耐心等待软件安装完成,点击关闭退出;
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框;
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定;
6、会弹出如下框,即安装激活成功,可以放心使用;
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并找到低内容页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
软件功能
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML 查看全部
抓取网页数据工具(ScreamingFrogSEOSpider14源程序破解安装教程,欢迎下载体验)
Screaming Frog SEO Spider是一款在现实生活中经常使用的电脑端网站资源检测爬虫软件。该软件可帮助用户即时抓取 网站 并查找断开的链接 (404) 和服务器错误。批量导出错误和要修复的源 URL,或直接发送给开发人员进行修复。简洁直观的界面让用户更容易找到自己想要的功能。它还可以帮助用户分析页面标题和元数据,并查看 Meta 机器人和说明。还有很多功能,需要的用户快来下载使用吧!
安装教程
1、从本站下载解压后,可以得到Screaming Frog SEO Spider 14的源程序和破解文件;

2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,点击Install安装,默认安装路径,安装类型;
3、耐心等待软件安装完成,点击关闭退出;
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框;

5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定;
6、会弹出如下框,即安装激活成功,可以放心使用;
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并找到低内容页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
软件功能
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-31 10:15
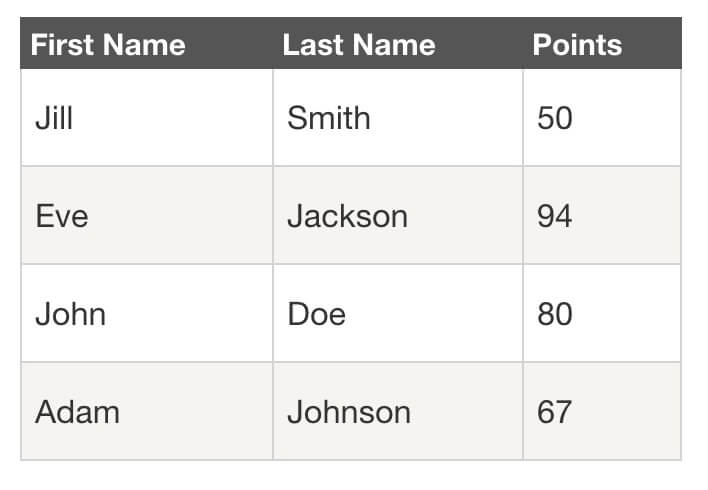
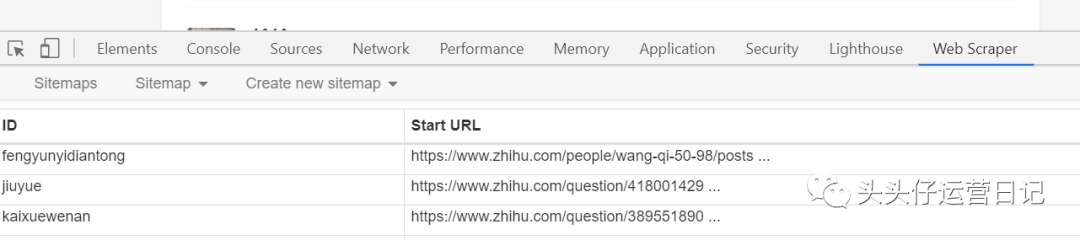
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。
从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个操作工具,我才知道爬取网络数据可以这么简单。
接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后一个一个操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那我就用今日头条来命名;站点地图 URL:将网页链接复制到星标 URL 列。比如图片中,我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别、年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别、年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
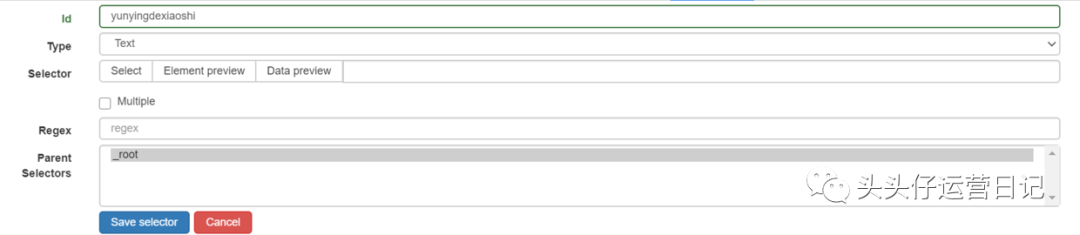
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles;select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,所以我们需要使用Element整体选择(如果网页需要滑动加载更多,然后选择Element Scroll Down);勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选它时,爬虫插件会帮助我们识别多个相同类型的文章文章;保留设置:其余未提及的部分保持默认设置。2. 单击选择以选择一个范围并按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。鼠标点击后变为红色选择该区域。多选:不要只选择一个,还可以选择以下几个。否则只有一行数据可以爬出来;完成选择:记得点击完成选择;保存:单击保存选择器。3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
创建一个新的选择器:点击添加新的选择器;输入id:id代表你在抓取哪个字段,所以可以取字段的英文,比如我要选择“作者”,就写“作者”;select Type:选择Text,因为要抓取的是文本;取消勾选Multiple:不要勾选Multiple前面的小框,因为我们这里抓取的是单个元素;保留设置:将其余未提及的部分保留为默认设置。4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,为Select;完成选择:记得点击完成选择;保存:单击保存选择器。5. 重复上述操作,直到选择好要爬的田地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。 查看全部
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。
从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个操作工具,我才知道爬取网络数据可以这么简单。
接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。

第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后一个一个操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。

第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:

Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那我就用今日头条来命名;站点地图 URL:将网页链接复制到星标 URL 列。比如图片中,我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别、年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别、年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:

输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles;select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,所以我们需要使用Element整体选择(如果网页需要滑动加载更多,然后选择Element Scroll Down);勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选它时,爬虫插件会帮助我们识别多个相同类型的文章文章;保留设置:其余未提及的部分保持默认设置。2. 单击选择以选择一个范围并按照以下步骤操作:

选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。鼠标点击后变为红色选择该区域。多选:不要只选择一个,还可以选择以下几个。否则只有一行数据可以爬出来;完成选择:记得点击完成选择;保存:单击保存选择器。3. 设置好一级Selector后,点击设置二级Selector,步骤如下:

创建一个新的选择器:点击添加新的选择器;输入id:id代表你在抓取哪个字段,所以可以取字段的英文,比如我要选择“作者”,就写“作者”;select Type:选择Text,因为要抓取的是文本;取消勾选Multiple:不要勾选Multiple前面的小框,因为我们这里抓取的是单个元素;保留设置:将其余未提及的部分保留为默认设置。4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,为Select;完成选择:记得点击完成选择;保存:单击保存选择器。5. 重复上述操作,直到选择好要爬的田地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。

如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。

导入 Excel 表格后,您可以过滤数据。

以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
抓取网页数据工具(Linux中curl的利用规则规则(图)详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-26 13:19
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:06年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息是通过ajax请求返回的(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
抓取网页数据工具(Linux中curl的利用规则规则(图)详解(组图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据

推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
卷曲

作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
curl的详细解释

作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件

作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲

作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲

作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
模拟请求工具 curl 的异常处理

作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法


作者:林冠红 683 浏览评论:06年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!

作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息是通过ajax请求返回的(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
抓取网页数据工具(亚马逊店铺商品数据批量工具,快来U大师下载使用它吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-24 22:20
亚马逊数据采集软件是在亚马逊(Amazon)平台上实时监控和采集竞争对手产品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。最常用的跨境电商平台数据采集软件,功能强大,使用起来非常方便实用。快来Master U下载使用吧!!!~~~
亚马逊店铺商品数据批量抓取工具,亚马逊商品数据抓取,亚马逊网站商品批量采集工具推荐
特征:
亚马逊店铺商品数据批量抓取工具用于实时监控和采集竞争对手在亚马逊平台上的商品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。它是目前使用最多的。跨境电商平台数据采集软件。
软件特点:
亚马逊店铺商品数据批量抓取工具其实有很多用途。一是监控竞争对手的出价和运费等,可以实时调整。您还可以采集您的网站中随处可见同行的产品数据,监控整个行业的趋势(如采集热门搜索词,采集产品Asin有好评的信息等),我们的采集系统可以有效绕过亚马逊的反采集Limited、Batch Unlimited采集、Any Field采集
使用说明:
优采云软件基于.net开发。如果软件下载后双击无法正常运行,可能是缺少netframworks 4.0环境。只要下载并安装了 netframworks 4.0,它就可以正常工作。运行,网络框架 4.0
预防措施:
程序运行时可能会被360等安全软件误报,软件本身无毒,无插件。运行前请添加信任或退出安全软件!
优采云平台集成了所有开发的软件包,可以自主选择需要的软件运行 查看全部
抓取网页数据工具(亚马逊店铺商品数据批量工具,快来U大师下载使用它吧)
亚马逊数据采集软件是在亚马逊(Amazon)平台上实时监控和采集竞争对手产品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。最常用的跨境电商平台数据采集软件,功能强大,使用起来非常方便实用。快来Master U下载使用吧!!!~~~
亚马逊店铺商品数据批量抓取工具,亚马逊商品数据抓取,亚马逊网站商品批量采集工具推荐
特征:
亚马逊店铺商品数据批量抓取工具用于实时监控和采集竞争对手在亚马逊平台上的商品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。它是目前使用最多的。跨境电商平台数据采集软件。
软件特点:
亚马逊店铺商品数据批量抓取工具其实有很多用途。一是监控竞争对手的出价和运费等,可以实时调整。您还可以采集您的网站中随处可见同行的产品数据,监控整个行业的趋势(如采集热门搜索词,采集产品Asin有好评的信息等),我们的采集系统可以有效绕过亚马逊的反采集Limited、Batch Unlimited采集、Any Field采集
使用说明:
优采云软件基于.net开发。如果软件下载后双击无法正常运行,可能是缺少netframworks 4.0环境。只要下载并安装了 netframworks 4.0,它就可以正常工作。运行,网络框架 4.0
预防措施:
程序运行时可能会被360等安全软件误报,软件本身无毒,无插件。运行前请添加信任或退出安全软件!
优采云平台集成了所有开发的软件包,可以自主选择需要的软件运行
抓取网页数据工具(原文链接提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-23 14:09
原创链接
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
图片1.png
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:对从内容页面提取的数据做进一步的处理,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果通过之前的规则无法准确提取内容或提取的内容为空,则选择此项,应用此项后,将再次使用正则匹配从原创页面中提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过起止字符串截取内容。适用于对提取内容的裁剪调整。
⑤纯正则替换:如果某些内容(如单个出现的文本)不能通过一般内容替换来操作,则需要通过强大的正则表达式进行复杂替换。
例如,“受欢迎的美式餐厅在这里”,我们将其替换为“美式餐厅”,正则表达式如下:
图片2.png
⑥数据转换:包括结果由简转繁、结果由繁转简、自动转拼音和时间校正转换,共四个处理。
⑦智能提取:包括第一张图片提取、时间智能提取、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动总结、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前后缀、随机插入、运行C#代码、批量替换内容、统计标签字符串A长度等一系列函数。
⑨完成单个URL:将当前内容完成为一个URL。
2、文件下载:可以自动检测和下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源码中的标准样式
标签的图片网址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:经过检查,源代码中的标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网络爬虫工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。 查看全部
抓取网页数据工具(原文链接提取的数据还不能直接拿来用?文件还没有被下载?)
原创链接
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
图片1.png
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:对从内容页面提取的数据做进一步的处理,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果通过之前的规则无法准确提取内容或提取的内容为空,则选择此项,应用此项后,将再次使用正则匹配从原创页面中提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过起止字符串截取内容。适用于对提取内容的裁剪调整。
⑤纯正则替换:如果某些内容(如单个出现的文本)不能通过一般内容替换来操作,则需要通过强大的正则表达式进行复杂替换。
例如,“受欢迎的美式餐厅在这里”,我们将其替换为“美式餐厅”,正则表达式如下:
图片2.png
⑥数据转换:包括结果由简转繁、结果由繁转简、自动转拼音和时间校正转换,共四个处理。
⑦智能提取:包括第一张图片提取、时间智能提取、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动总结、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前后缀、随机插入、运行C#代码、批量替换内容、统计标签字符串A长度等一系列函数。
⑨完成单个URL:将当前内容完成为一个URL。
2、文件下载:可以自动检测和下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源码中的标准样式
标签的图片网址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:经过检查,源代码中的标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网络爬虫工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。
抓取网页数据工具( 新媒体运营来说的爬虫工具——webscraper的特点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-23 14:08
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
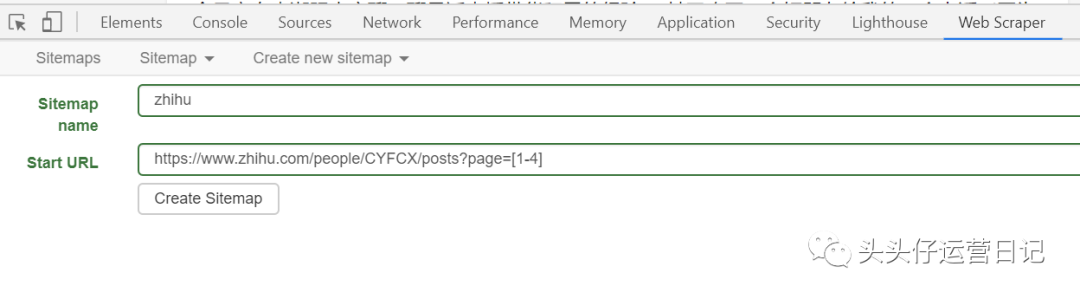
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
查看全部
抓取网页数据工具(
新媒体运营来说的爬虫工具——webscraper的特点
)

对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.

01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。

输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。

多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。

下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!


抓取网页数据工具(爬虫软件工程师教你怎么做SEO,没有什么比我们更了解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-23 10:09
)
爬虫软件工程师教你如何做SEO。没有什么比我们更了解搜索引擎了。我们都接触过数据聚合类型网站至少几千万的数据或者搜索引擎。URL就是人为设置一些URL供爬虫爬取。可以理解为爬取的入口URL,然后通过其内部链接传播爬取。
搜索引擎原则
在搜索引擎网站的后台,会有一个非常大的索引库,里面存储着大量的关键词,而每个关键词对应着很多的URL,这些URL被称为它是为“搜索引擎蜘蛛”或“网络爬虫”程序从浩瀚的互联网下载的点点滴滴采集而来。随着各种网站的出现,这些勤劳的“蜘蛛”每天都在网上爬行,从链接到链接,下载内容,分析提炼,找到关键词,如果“蜘蛛” " 认为 关键词 在数据库中不可用并且对用户有用,它将在后台存储在数据库中。相反,如果“蜘蛛”认为是垃圾邮件或重复信息,就会丢弃,继续爬取,查找最新和有用的信息并将其保存以供用户搜索。当用户搜索时,可以从索引库中检索到与该关键字相关的网站,并显示给访问者。一个关键词对应多个url,所以存在排序问题,对应的网站和关键词url会排在第一位。在“蜘蛛”爬取网页内容和提炼关键词的过程中,存在一个问题:“蜘蛛”能否理解。如果 网站 的内容是 Flash 和 JS 等,那么即使关键字合适,也是不可理解的。相应地,如果网站的内容能被搜索引擎识别,搜索引擎会增加网站的权重,增加网站的友好度,进而提高<
百度收录难的原因?大量网站被黑并在明天发布的原因。
通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后,放到检索区,形成稳定的排名。所以只要下载的东西可以通过说明找到,补充数据是不稳定的。是的,它可能会在各种计算过程中丢失。检索区的数据排名相对稳定。百度目前是缓存机制和补充数据的结合,正在向补充数据转变。
百度蜘蛛爬取策略
深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取一个页面时,百度先爬取更多的URL,深度优先爬取的目的是爬取到获得高质量的网页,这个策略是通过调度来计算和分配的。百度蜘蛛只负责爬取。权重优先是指对反向链接较多的页面优先抓取。这也是一种调度策略。40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
不要打破搜索引擎的最大禁忌
百度蜘蛛似乎更注重 网站 页面的层次结构。与谷歌相比,百度蜘蛛更注重网站内部页面结构的层次结构,有点像爬虫。越黑越深,越喜欢往里挖。我不信你做100页。很漂亮,只要链接没有层次结构,你充其量只能成为收录可怜的小东西。
搜索引擎告诉你怎么做SEO?
不管是什么类型的网站站长,他们的网站结构一定要简洁明了,这是站长需要知道的事情之一。一般设计时网站的页面层级不要超过三层。现在,很多存储架的网站层级都超过了三层。页面文件名可以使用字母或数字,但不要使用长的中转英文插件,对收录没有任何好处。并且在创建网站的过程中添加内容时,建议大家使用静态或者伪静态技术进行处理,有利于网站在搜索引擎中的友好性。
我刚刚用爬虫软件+技术处理创建了一个权重6 网站
采集伪原创:TensorFlow人工智能引擎/分词算法/DNN算法采用多线程分段精准处理,结合机器学习、人工智能、百度大脑的自然语言分词、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章
图片伪原创:背景融合算法,可以将1张图片伪原创转化为N张图片原创
模板伪原创:更改图片名,js名,css名,更改图片MD5、更改类样式名
网站发行商:Empire、易友、ZBLOG、织梦、WP、小旋风、站群、PB、Apple、搜外等。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!
查看全部
抓取网页数据工具(爬虫软件工程师教你怎么做SEO,没有什么比我们更了解
)
爬虫软件工程师教你如何做SEO。没有什么比我们更了解搜索引擎了。我们都接触过数据聚合类型网站至少几千万的数据或者搜索引擎。URL就是人为设置一些URL供爬虫爬取。可以理解为爬取的入口URL,然后通过其内部链接传播爬取。

搜索引擎原则
在搜索引擎网站的后台,会有一个非常大的索引库,里面存储着大量的关键词,而每个关键词对应着很多的URL,这些URL被称为它是为“搜索引擎蜘蛛”或“网络爬虫”程序从浩瀚的互联网下载的点点滴滴采集而来。随着各种网站的出现,这些勤劳的“蜘蛛”每天都在网上爬行,从链接到链接,下载内容,分析提炼,找到关键词,如果“蜘蛛” " 认为 关键词 在数据库中不可用并且对用户有用,它将在后台存储在数据库中。相反,如果“蜘蛛”认为是垃圾邮件或重复信息,就会丢弃,继续爬取,查找最新和有用的信息并将其保存以供用户搜索。当用户搜索时,可以从索引库中检索到与该关键字相关的网站,并显示给访问者。一个关键词对应多个url,所以存在排序问题,对应的网站和关键词url会排在第一位。在“蜘蛛”爬取网页内容和提炼关键词的过程中,存在一个问题:“蜘蛛”能否理解。如果 网站 的内容是 Flash 和 JS 等,那么即使关键字合适,也是不可理解的。相应地,如果网站的内容能被搜索引擎识别,搜索引擎会增加网站的权重,增加网站的友好度,进而提高<
百度收录难的原因?大量网站被黑并在明天发布的原因。
通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后,放到检索区,形成稳定的排名。所以只要下载的东西可以通过说明找到,补充数据是不稳定的。是的,它可能会在各种计算过程中丢失。检索区的数据排名相对稳定。百度目前是缓存机制和补充数据的结合,正在向补充数据转变。
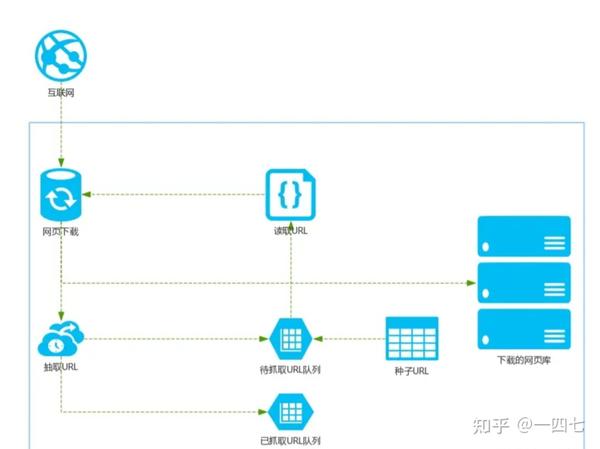
百度蜘蛛爬取策略
深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取一个页面时,百度先爬取更多的URL,深度优先爬取的目的是爬取到获得高质量的网页,这个策略是通过调度来计算和分配的。百度蜘蛛只负责爬取。权重优先是指对反向链接较多的页面优先抓取。这也是一种调度策略。40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
不要打破搜索引擎的最大禁忌
百度蜘蛛似乎更注重 网站 页面的层次结构。与谷歌相比,百度蜘蛛更注重网站内部页面结构的层次结构,有点像爬虫。越黑越深,越喜欢往里挖。我不信你做100页。很漂亮,只要链接没有层次结构,你充其量只能成为收录可怜的小东西。
搜索引擎告诉你怎么做SEO?
不管是什么类型的网站站长,他们的网站结构一定要简洁明了,这是站长需要知道的事情之一。一般设计时网站的页面层级不要超过三层。现在,很多存储架的网站层级都超过了三层。页面文件名可以使用字母或数字,但不要使用长的中转英文插件,对收录没有任何好处。并且在创建网站的过程中添加内容时,建议大家使用静态或者伪静态技术进行处理,有利于网站在搜索引擎中的友好性。
我刚刚用爬虫软件+技术处理创建了一个权重6 网站
采集伪原创:TensorFlow人工智能引擎/分词算法/DNN算法采用多线程分段精准处理,结合机器学习、人工智能、百度大脑的自然语言分词、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章
图片伪原创:背景融合算法,可以将1张图片伪原创转化为N张图片原创
模板伪原创:更改图片名,js名,css名,更改图片MD5、更改类样式名
网站发行商:Empire、易友、ZBLOG、织梦、WP、小旋风、站群、PB、Apple、搜外等。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!

抓取网页数据工具(什么样的网页满足条件?_html()也是一个神器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-03 03:17
继续上面的,我们可以使用 Pandas 将 Excel 转换为 html 格式。文末说了对应的read_html()也是神器!
PS:大家也很乐于助人。我点了30个赞。小舞连忙安排。
最简单的爬虫:用 Pandas 爬取表格数据
有一件事要说,我们不得不承认,用 Pandas 爬取表格数据有一定的局限性。
只适合爬Table数据,那我们先看看什么样的网页满足条件?
什么样的网页结构?
用浏览器打开一个网页,用F12检查它的HTML结构,你会发现合格的网页结构有一个共同的特点。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas。
1
2
3
4 ...
5
6
7
8
9 ...
10
11 ...
12 ...
13 ...
14 ...
15 ...
16
17
18
19
这看起来不直观,打开了北京地区的空气质量网站。
F12,左侧是网页中的质量指标表,其网页结构完美符合表格数据网页结构。
非常适合和熊猫一起爬行。
pd.read_html()
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需要几行代码就可以抓取Table表数据,简直就是神器![1]
具体的 pd.read_html() 参数,可以查看其官方文档:
就拿刚才的网站开始吧!
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
3
4
这里只添加了几个参数,header是指定列标题所在的行。使用指南包,只需要两行代码。
1df.head()
2
3
1 
2
对比结果,可以看到成功获取到表格数据。
多种形式
最后一种情况,不知道有没有朋友注意到
1pd.read_html()[0]
2
3
对于pd.read_html(),获取网页结果后添加一个[0]。这是因为网页上可能有多个表格。在这种情况下,需要通过对列表的tables[x]进行切片来指定获取哪个表。
比如之前的网站,空气质量排名网页显然是由两个表格组成的。
这时候如果使用 pd.read_html() 来获取右边的表格,只需要稍作修改即可。
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
3
4
对比一下,可以看到网页右侧的表格是成功获取的。
以上就是使用 pd.read_html() 简单爬取静态网页。但我们之所以使用Python,其实是为了提高效率。但是,如果只有一个网页,用鼠标选择和复制不是更容易吗?所以Python操作的最大优势将体现在批处理操作上。
批量爬取
让我教你如何使用Pandas批量抓取网页表格数据????
以新浪金融机构持股汇总数据为例:
一共有47个页面,通过for循环构造了47个网页url,然后用pd.read_html()循环进行爬取。
1df = pd.DataFrame()
2for i in range(1, 48):
3 url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
4 df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
5
6
还是几行代码,很容易解决。
共获得47页1738条数据。
通过以上的小案例,相信大家可以轻松掌握Pandas的批量爬表数据????
参考
[1]
Python阅读财经:天秀!Pandas 可以用来写爬虫吗?
《人工智能数学》数学思维体操,学习人工智能的基石!通过205个典型例子+185个推导公式+37个经典习题+40个学习难度提示+19个项目,有效实践数学思想和解决方案。点击下图查看详情/购买!??? 查看全部
抓取网页数据工具(什么样的网页满足条件?_html()也是一个神器)
继续上面的,我们可以使用 Pandas 将 Excel 转换为 html 格式。文末说了对应的read_html()也是神器!
PS:大家也很乐于助人。我点了30个赞。小舞连忙安排。
最简单的爬虫:用 Pandas 爬取表格数据
有一件事要说,我们不得不承认,用 Pandas 爬取表格数据有一定的局限性。
只适合爬Table数据,那我们先看看什么样的网页满足条件?
什么样的网页结构?
用浏览器打开一个网页,用F12检查它的HTML结构,你会发现合格的网页结构有一个共同的特点。
如果你发现 HTML 结构是下面的 Table 格式,你可以直接使用 Pandas。
1
2
3
4 ...
5
6
7
8
9 ...
10
11 ...
12 ...
13 ...
14 ...
15 ...
16
17
18
19
这看起来不直观,打开了北京地区的空气质量网站。
F12,左侧是网页中的质量指标表,其网页结构完美符合表格数据网页结构。
非常适合和熊猫一起爬行。
pd.read_html()
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需要几行代码就可以抓取Table表数据,简直就是神器![1]
具体的 pd.read_html() 参数,可以查看其官方文档:
就拿刚才的网站开始吧!
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/air/beijing/", encoding='utf-8',header=0)[0]
3
4
这里只添加了几个参数,header是指定列标题所在的行。使用指南包,只需要两行代码。
1df.head()
2
3
1 
2
对比结果,可以看到成功获取到表格数据。
多种形式
最后一种情况,不知道有没有朋友注意到
1pd.read_html()[0]
2
3
对于pd.read_html(),获取网页结果后添加一个[0]。这是因为网页上可能有多个表格。在这种情况下,需要通过对列表的tables[x]进行切片来指定获取哪个表。
比如之前的网站,空气质量排名网页显然是由两个表格组成的。
这时候如果使用 pd.read_html() 来获取右边的表格,只需要稍作修改即可。
1import pandas as pd
2df = pd.read_html("http://www.air-level.com/rank", encoding='utf-8',header=0)[1]
3
4
对比一下,可以看到网页右侧的表格是成功获取的。
以上就是使用 pd.read_html() 简单爬取静态网页。但我们之所以使用Python,其实是为了提高效率。但是,如果只有一个网页,用鼠标选择和复制不是更容易吗?所以Python操作的最大优势将体现在批处理操作上。
批量爬取
让我教你如何使用Pandas批量抓取网页表格数据????
以新浪金融机构持股汇总数据为例:
一共有47个页面,通过for循环构造了47个网页url,然后用pd.read_html()循环进行爬取。
1df = pd.DataFrame()
2for i in range(1, 48):
3 url = f'http://vip.stock.finance.sina. ... Fp%3D{i}'
4 df = pd.concat([df, pd.read_html(url)[0]]) # 爬取+合并DataFrame
5
6
还是几行代码,很容易解决。
共获得47页1738条数据。
通过以上的小案例,相信大家可以轻松掌握Pandas的批量爬表数据????
参考
[1]
Python阅读财经:天秀!Pandas 可以用来写爬虫吗?
《人工智能数学》数学思维体操,学习人工智能的基石!通过205个典型例子+185个推导公式+37个经典习题+40个学习难度提示+19个项目,有效实践数学思想和解决方案。点击下图查看详情/购买!???
抓取网页数据工具(新站分析新站需针对的那些点,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-03 03:14
网站UEO优化的实现,那么新站的分析比较简单了解一些基本的操作,包括优化问题,然后作为一个新建的网站基于本质的推广方向进行合理的优化,包括:站内关键词、代码优化、外链、UEO、内链循环、内容数据等。在优化的基础上,再分析以上内容,分析新站需要定位的那些。观点!
现场关键词方向:
这是优化的基本知识。对于关键词关于网站整体排名趋势,以及后期维护定位,在选择关键词时,需要进行布局。一般来说,搜索引擎需要进行合理的关键词布局和扩展,从长尾词的定位到精准词,一般都集中在三大标签,对应的长尾词需要混在页面中;为了保证准确定位;一步一步优化关键词;
关键词的定位是从词义和词性上合理分布的。关键词 可以在页面中进行冗余扩展,但不宜重复使用 关键词。一般一页字数以1000-5000字为主,定位关键词不要超过5个;详情可与凯业SEO在线沟通;
新站代码优化:
这是一个共同点。代码是网站的源码,网站的源码有各种标签。优化代码,新站需要从简化代码入手。简化的代码是更大的代码。,并换成小代码,效果一样;如果要比较标签和其他标签,需要用文字描述,一般会涉及到新源代码中的图片路径;
新网站外部链接:
<p>这部分没有以前那么强大,但也是必要的优化之一。引导外部流量可以有效地为网站带来流量和权重;而优质的外链给网站新站的认可,搜索引擎从外链中找到你新站的链接,链接是网站和 查看全部
抓取网页数据工具(新站分析新站需针对的那些点,你知道吗?)
网站UEO优化的实现,那么新站的分析比较简单了解一些基本的操作,包括优化问题,然后作为一个新建的网站基于本质的推广方向进行合理的优化,包括:站内关键词、代码优化、外链、UEO、内链循环、内容数据等。在优化的基础上,再分析以上内容,分析新站需要定位的那些。观点!
现场关键词方向:
这是优化的基本知识。对于关键词关于网站整体排名趋势,以及后期维护定位,在选择关键词时,需要进行布局。一般来说,搜索引擎需要进行合理的关键词布局和扩展,从长尾词的定位到精准词,一般都集中在三大标签,对应的长尾词需要混在页面中;为了保证准确定位;一步一步优化关键词;
关键词的定位是从词义和词性上合理分布的。关键词 可以在页面中进行冗余扩展,但不宜重复使用 关键词。一般一页字数以1000-5000字为主,定位关键词不要超过5个;详情可与凯业SEO在线沟通;
新站代码优化:
这是一个共同点。代码是网站的源码,网站的源码有各种标签。优化代码,新站需要从简化代码入手。简化的代码是更大的代码。,并换成小代码,效果一样;如果要比较标签和其他标签,需要用文字描述,一般会涉及到新源代码中的图片路径;
新网站外部链接:
<p>这部分没有以前那么强大,但也是必要的优化之一。引导外部流量可以有效地为网站带来流量和权重;而优质的外链给网站新站的认可,搜索引擎从外链中找到你新站的链接,链接是网站和
抓取网页数据工具(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-26 15:07
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</ 查看全部
抓取网页数据工具(记录思路如下:记录SQL中的注释(使用--进行注释))
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</
抓取网页数据工具(WindowsLinux免费爬虫工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-11 19:20
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4.左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 克拉珀
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. PaseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮刀
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrpinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10. 德克西欧
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhse.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容 Gabber
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦分离器
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
Path 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Conntate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
抓取网页数据工具(WindowsLinux免费爬虫工具)
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4.左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 克拉珀
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. PaseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮刀
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrpinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10. 德克西欧
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhse.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容 Gabber
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦分离器
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
Path 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Conntate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
抓取网页数据工具(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-02-11 19:18
最后介绍几个主要功能按钮: 1、上图中的两个按钮是用于切换谷歌地图/谷歌搜索引擎这两种抓取模式的。这个我就不用多说了,点一下就明白了。!
下图所示的工具之前已经给大家介绍过了。这是我制作的谷歌搜索提取工具2.0版本。
2.0版,主要是帮你在谷歌搜索引擎上直接提取网站和title信息,可以看我以前的文章《25h创建外贸网站@ > 挖矿工具,10s提取100个客户网站!”,看详细介绍!
今天主要给大家介绍一下我前两天刚刚修改的新版谷歌搜索提取工具3.0。与之前的版本相比,增加了googlemaps提取功能,可以帮助您直接提取googlemaps上的公司。资料显示,很多老外贸公司可能对谷歌地图并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有精准的买家,是外贸客户开发的常用渠道。
只要我们通过关键词搜索出公司信息页面,就可以直接点击开始爬取按钮,开发爬取信息。操作很简单,我们不用管他,它会自动翻页。直到搜索完成。
另外,相比3.0的版本2.0,谷歌搜索引擎抓取也进行了调整,不再像以前那样直接输入关键词进行抓取,而且之前也需要手动翻第二页。这次将整个真实网页直接转入工具,搜索翻页也是全自动的。完全模拟人工操作,减少弹出验证码的概率。即使弹出验证码,我们也可以手动填写!
最后,我来介绍一些主要的功能按钮:
1、
上图中的两个按钮用于切换谷歌地图/谷歌搜索引擎和两种抓取模式。这个不用我多说了,点一下就明白了!
2、
无翻转搜索是此更新的一个很好的功能。如果你电脑上的 fq 工具出现故障,你可以尝试检查一下,然后切换到更平滑的线。这样,你就可以使用这个工具来抓取谷歌了。获取信息(毕竟是给大家省钱的,肯定会比较慢!)
3、
红框选中的4个按钮当然不需要我过多解释,比如字面意思。全部导出是将搜索到的数据以excel格式导出到本地计算机。
4、
如果您上传此选项,我们一般默认不勾选。如果你不使用F墙工具,而是使用F墙路由访问外网,不妨勾选这个选项试试。(切记不要乱打勾,否则google页面加载不出来)
其他没什么好解释的,自己下载体验吧!该工具基于个人兴趣爱好,免费分享给大家。您不必担心是否充电。只要对大家有帮助,我一定会为大家优化更新更多功能!
下载链接:
部分电脑下载安装可能会弹出风险提示,点击“允许”放心使用,无需为任何年龄的你制造病毒!
还有,有bug或者好的建议可以在评论区写! 查看全部
抓取网页数据工具(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
最后介绍几个主要功能按钮: 1、上图中的两个按钮是用于切换谷歌地图/谷歌搜索引擎这两种抓取模式的。这个我就不用多说了,点一下就明白了。!
下图所示的工具之前已经给大家介绍过了。这是我制作的谷歌搜索提取工具2.0版本。
2.0版,主要是帮你在谷歌搜索引擎上直接提取网站和title信息,可以看我以前的文章《25h创建外贸网站@ > 挖矿工具,10s提取100个客户网站!”,看详细介绍!
今天主要给大家介绍一下我前两天刚刚修改的新版谷歌搜索提取工具3.0。与之前的版本相比,增加了googlemaps提取功能,可以帮助您直接提取googlemaps上的公司。资料显示,很多老外贸公司可能对谷歌地图并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有精准的买家,是外贸客户开发的常用渠道。
只要我们通过关键词搜索出公司信息页面,就可以直接点击开始爬取按钮,开发爬取信息。操作很简单,我们不用管他,它会自动翻页。直到搜索完成。
另外,相比3.0的版本2.0,谷歌搜索引擎抓取也进行了调整,不再像以前那样直接输入关键词进行抓取,而且之前也需要手动翻第二页。这次将整个真实网页直接转入工具,搜索翻页也是全自动的。完全模拟人工操作,减少弹出验证码的概率。即使弹出验证码,我们也可以手动填写!
最后,我来介绍一些主要的功能按钮:
1、
上图中的两个按钮用于切换谷歌地图/谷歌搜索引擎和两种抓取模式。这个不用我多说了,点一下就明白了!
2、
无翻转搜索是此更新的一个很好的功能。如果你电脑上的 fq 工具出现故障,你可以尝试检查一下,然后切换到更平滑的线。这样,你就可以使用这个工具来抓取谷歌了。获取信息(毕竟是给大家省钱的,肯定会比较慢!)
3、
红框选中的4个按钮当然不需要我过多解释,比如字面意思。全部导出是将搜索到的数据以excel格式导出到本地计算机。
4、
如果您上传此选项,我们一般默认不勾选。如果你不使用F墙工具,而是使用F墙路由访问外网,不妨勾选这个选项试试。(切记不要乱打勾,否则google页面加载不出来)
其他没什么好解释的,自己下载体验吧!该工具基于个人兴趣爱好,免费分享给大家。您不必担心是否充电。只要对大家有帮助,我一定会为大家优化更新更多功能!
下载链接:
部分电脑下载安装可能会弹出风险提示,点击“允许”放心使用,无需为任何年龄的你制造病毒!
还有,有bug或者好的建议可以在评论区写!
抓取网页数据工具(1.虎嗅资讯网数据--请求查阅该请求的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-11 01:28
1.虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据。不幸的是,虎秀信息网被我选中了。该网站是其信息渠道。此文章仅用于学习交流,不得用于其他用途。
一般操作,分析要爬取的页面
将页面拖到底部,会发现一个load more按钮,点击后,抓取请求,得到如下地址
2.虎嗅网文章数据----分析请求
查看请求的方法和地址,包括参数,如下图
获取以下信息
页面请求地址为: 请求方式:POST 请求参数比较重要的是一个叫page的参数
我们只需要根据以上内容编写pyspider代码部分即可。在on_start函数里面写一个循环事件,注意有一个数字2025,就是我刚才从请求中看到的总页数。当您阅读此 文章 时,这个数字应该更大。
1 @every(minutes=24 * 60)
2 def on_start(self):
3 for page in range(1,2025):
4 print("正在爬取第 {} 页".format(page))
5 self.crawl('https://www.huxiu.com/v2_actio ... 27%3B, method="POST",data={"page":page},callback=self.parse_page,validate_cert=False)
6
页面生成后,会调用parse_page函数解析爬取URL成功后crawl()方法返回的Response响应。
1 @config(age=10 * 24 * 60 * 60)
2 def parse_page(self, response):
3 content = response.json["data"]
4 doc = pq(content)
5 lis = doc('.mod-art').items()
6 data = [{
7 'title': item('.msubstr-row2').text(),
8 'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),
9 'name': item('.author-name').text(),
10 'write_time':item('.time').text(),
11 'comment':item('.icon-cmt+ em').text(),
12 'favorites':item('.icon-fvr+ em').text(),
13 'abstract':item('.mob-sub').text()
14 } for item in lis ]
15 return data
16
最后定义一个on_result()方法,专门用来获取return的结果数据。这个用来接收上面parse_page()返回的数据数据,其中的数据可以保存到MongoDB中。
1'''
2遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
3'''
4 # 页面每次返回的数据
5 def on_result(self,result):
6 if result:
7 self.save_to_mongo(result)
8
9
10 # 存储到mongo数据库
11 def save_to_mongo(self,result):
12 df = pd.DataFrame(result)
13 content = json.loads(df.T.to_json()).values()
14 if collection.insert_many(content):
15 print('存储数据成功')
16 # 暂停1s
17 time.sleep(1)
18
好的,保存代码,修改每秒运行次数和并发
点击run运行代码,但是运行之后会发现程序在抓取一个页面后就停止了。pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果 ID 号相同,则视为同一任务。再次爬行。
GET请求的分页URL一般不一样,所以ID号也会不一样,可以爬到多个页面。POST 请求的 URL 相同。第一个页面被爬取后,后面的页面将不会被爬取。
解决方法是重写ID号的生成方法,在on_start()方法前添加如下代码:
1 def get_taskid(self,task):
2 return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
3
基本操作后,文章被存储 查看全部
抓取网页数据工具(1.虎嗅资讯网数据--请求查阅该请求的方式)
1.虎嗅网文章数据----写在前面
今天继续使用pyspider爬取数据。不幸的是,虎秀信息网被我选中了。该网站是其信息渠道。此文章仅用于学习交流,不得用于其他用途。
一般操作,分析要爬取的页面
将页面拖到底部,会发现一个load more按钮,点击后,抓取请求,得到如下地址
2.虎嗅网文章数据----分析请求
查看请求的方法和地址,包括参数,如下图
获取以下信息
页面请求地址为: 请求方式:POST 请求参数比较重要的是一个叫page的参数
我们只需要根据以上内容编写pyspider代码部分即可。在on_start函数里面写一个循环事件,注意有一个数字2025,就是我刚才从请求中看到的总页数。当您阅读此 文章 时,这个数字应该更大。
1 @every(minutes=24 * 60)
2 def on_start(self):
3 for page in range(1,2025):
4 print("正在爬取第 {} 页".format(page))
5 self.crawl('https://www.huxiu.com/v2_actio ... 27%3B, method="POST",data={"page":page},callback=self.parse_page,validate_cert=False)
6
页面生成后,会调用parse_page函数解析爬取URL成功后crawl()方法返回的Response响应。
1 @config(age=10 * 24 * 60 * 60)
2 def parse_page(self, response):
3 content = response.json["data"]
4 doc = pq(content)
5 lis = doc('.mod-art').items()
6 data = [{
7 'title': item('.msubstr-row2').text(),
8 'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),
9 'name': item('.author-name').text(),
10 'write_time':item('.time').text(),
11 'comment':item('.icon-cmt+ em').text(),
12 'favorites':item('.icon-fvr+ em').text(),
13 'abstract':item('.mob-sub').text()
14 } for item in lis ]
15 return data
16
最后定义一个on_result()方法,专门用来获取return的结果数据。这个用来接收上面parse_page()返回的数据数据,其中的数据可以保存到MongoDB中。
1'''
2遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
3'''
4 # 页面每次返回的数据
5 def on_result(self,result):
6 if result:
7 self.save_to_mongo(result)
8
9
10 # 存储到mongo数据库
11 def save_to_mongo(self,result):
12 df = pd.DataFrame(result)
13 content = json.loads(df.T.to_json()).values()
14 if collection.insert_many(content):
15 print('存储数据成功')
16 # 暂停1s
17 time.sleep(1)
18
好的,保存代码,修改每秒运行次数和并发
点击run运行代码,但是运行之后会发现程序在抓取一个页面后就停止了。pyspider 使用 URL 的 MD5 值作为唯一 ID 号。如果 ID 号相同,则视为同一任务。再次爬行。
GET请求的分页URL一般不一样,所以ID号也会不一样,可以爬到多个页面。POST 请求的 URL 相同。第一个页面被爬取后,后面的页面将不会被爬取。
解决方法是重写ID号的生成方法,在on_start()方法前添加如下代码:
1 def get_taskid(self,task):
2 return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
3
基本操作后,文章被存储
抓取网页数据工具(注意事项Jailer运行的环境需要Javajre5的支持更新日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-09 06:14
Jailer数据抓包软件是一款功能强大的数据文件提取工具,用户可以使用该软件在线抓包数据,不破坏其他上万条数据,删除指定数据行,非常方便的抓包工具,欢迎有需要的用户下载它!
关于 Jailer 数据提取工具
Jailer 可以直接从关系数据库中导出连续的相关行数据,以便直接在您自己的开发/测试环境中使用。使用 Jailer,您可以在不损害其他数据完整性的情况下删除特定行的数据,从而提高数据库的效率。Jailer 是一个独立的平台,所以如果你没有运行数据库文件所需的相应应用程序也没关系,它可以直接生成 DbUnit 数据集、拓扑排序的 SQL-DML 和层次结构的 XML 文档,可以支持DB2、Firebird、Derby 和其他应用程序。
Jailer 数据采集软件的特点
1、开源,完全用 java 编写,独立于平台,与 DBMS 无关。
2、生成分层结构的 XML、拓扑排序的 sql-dml 和 DbUnit 数据集。
3、通过在不违反完整性的情况下删除和归档过时数据来提高数据库性能。
4、从您的生产数据库中导出一致和引用的完整行集,并将数据输入到您的开发和测试环境。
预防措施
Jailer运行的环境需要Java jre 5的支持
变更日志
1、改进的语法高亮
2、可以逐行编辑SQL语句执行结果的数据
3、在数据浏览器界面增加了编辑和执行任意SQL语句的能力
4、数据浏览器窗口中的集成数据库模式映射对话框 查看全部
抓取网页数据工具(注意事项Jailer运行的环境需要Javajre5的支持更新日志)
Jailer数据抓包软件是一款功能强大的数据文件提取工具,用户可以使用该软件在线抓包数据,不破坏其他上万条数据,删除指定数据行,非常方便的抓包工具,欢迎有需要的用户下载它!
关于 Jailer 数据提取工具
Jailer 可以直接从关系数据库中导出连续的相关行数据,以便直接在您自己的开发/测试环境中使用。使用 Jailer,您可以在不损害其他数据完整性的情况下删除特定行的数据,从而提高数据库的效率。Jailer 是一个独立的平台,所以如果你没有运行数据库文件所需的相应应用程序也没关系,它可以直接生成 DbUnit 数据集、拓扑排序的 SQL-DML 和层次结构的 XML 文档,可以支持DB2、Firebird、Derby 和其他应用程序。
Jailer 数据采集软件的特点
1、开源,完全用 java 编写,独立于平台,与 DBMS 无关。
2、生成分层结构的 XML、拓扑排序的 sql-dml 和 DbUnit 数据集。
3、通过在不违反完整性的情况下删除和归档过时数据来提高数据库性能。
4、从您的生产数据库中导出一致和引用的完整行集,并将数据输入到您的开发和测试环境。
预防措施
Jailer运行的环境需要Java jre 5的支持
变更日志
1、改进的语法高亮
2、可以逐行编辑SQL语句执行结果的数据
3、在数据浏览器界面增加了编辑和执行任意SQL语句的能力
4、数据浏览器窗口中的集成数据库模式映射对话框
抓取网页数据工具(极尽其所能将网页内容、HTTP报头、Cookie里的数据记录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-08 04:09
)
GoldDataSpider 是一个用于抓取网页和提取数据的工具。其核心代码与黄金数据采集融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。此外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
我们还提供规则可视化公式,请下载。也
入门
首先,我们需要给项目添加依赖,如下:
1、对于 maven 项目
com.100shouhou.golddata
golddata-spider
1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test
public void testGoldSpider(){
String ruleContent=
" { \n"+
" __node: li.sky.skyid \n"+
" date: \n"+
" { \n"+
" expr: h1 \n"+
" __label: 日期 \n"+
" } \n"+
" sn: \n"+
" { \n"+
" \n"+
" js: md5(baseUri+item.date+headers['Content-Type']);\n"+
" } \n"+
" weather: \n"+
" { \n"+
" expr: p.wea \n"+
" } \n"+
" temprature: \n"+
" { \n"+
" expr: p.tem>i \n"+
" } \n"+
" } \n";
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl("http://www.weather.com.cn/weat ... 6quot;)
.setRule(ruleContent)
.request();
List list=spider.extractList();
// List weathers=spider.extractList(Weather.class);
// Weather weathers=spider.extractFirst(Weather.class);
list.forEach( System.out::println);
}
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d}
{date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd}
{date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa}
{date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3}
{date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f}
{date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d}
{date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service
public class WeatherServiceImpl implements WeatherService{
public List listByCityId(Long cityId){
String url="http://www.weather.com.cn/weat ... ot%3B
String rule=""
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl(url)
.setRule(ruleContent)
.request();
return spider.extractList(Weather.class);
}
} 查看全部
抓取网页数据工具(极尽其所能将网页内容、HTTP报头、Cookie里的数据记录
)
GoldDataSpider 是一个用于抓取网页和提取数据的工具。其核心代码与黄金数据采集融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。此外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
我们还提供规则可视化公式,请下载。也
入门
首先,我们需要给项目添加依赖,如下:
1、对于 maven 项目
com.100shouhou.golddata
golddata-spider
1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test
public void testGoldSpider(){
String ruleContent=
" { \n"+
" __node: li.sky.skyid \n"+
" date: \n"+
" { \n"+
" expr: h1 \n"+
" __label: 日期 \n"+
" } \n"+
" sn: \n"+
" { \n"+
" \n"+
" js: md5(baseUri+item.date+headers['Content-Type']);\n"+
" } \n"+
" weather: \n"+
" { \n"+
" expr: p.wea \n"+
" } \n"+
" temprature: \n"+
" { \n"+
" expr: p.tem>i \n"+
" } \n"+
" } \n";
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl("http://www.weather.com.cn/weat ... 6quot;)
.setRule(ruleContent)
.request();
List list=spider.extractList();
// List weathers=spider.extractList(Weather.class);
// Weather weathers=spider.extractFirst(Weather.class);
list.forEach( System.out::println);
}
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d}
{date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd}
{date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa}
{date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3}
{date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f}
{date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d}
{date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service
public class WeatherServiceImpl implements WeatherService{
public List listByCityId(Long cityId){
String url="http://www.weather.com.cn/weat ... ot%3B
String rule=""
GoldSpider spider= com.xst.golddata.GoldSpider.newSpider()
.setUrl(url)
.setRule(ruleContent)
.request();
return spider.extractList(Weather.class);
}
}
抓取网页数据工具(网络爬虫工具越来越工具下载地址介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-07 23:07
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
刮刀
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
解析中心
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookie 等获取网页数据。其机器学习技术可以读取网页文档,对其进行分析并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
抓取中心
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
网管.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
进口.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
氦刮刀
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
刮.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
Web哈维
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心 查看全部
抓取网页数据工具(网络爬虫工具越来越工具下载地址介绍及应用)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
刮刀
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
解析中心
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookie 等获取网页数据。其机器学习技术可以读取网页文档,对其进行分析并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
抓取中心
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
网管.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
进口.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
氦刮刀
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
刮.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
Web哈维
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心
抓取网页数据工具(爬取网页图片步骤及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-07 16:00
抓取网页数据工具:如果想要爬取网页中的图片,目录:图片class120.jpg大小:图片1.32mb,class204.jpg大小:图片1.22mb1.实现1.requests库requests库是一个python提供的异步请求库,官方教程:requestshelloworld爬取网页图片步骤如下:1.获取图片路径2.获取图片class3.解析图片所在class列表1.获取图片路径:2.获取图片class:我们先从class="h"中查看对应的图片类型为:class120.jpg我们先从对应的图片class中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:png,jpg)3.解析图片所在列表:我们先从对应的列表中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:image)好了,解析图片所在列表已经完成。
接下来我们操作下代码:接下来我们操作,获取图片class,关键语句如下:1.获取图片class我们首先来看看获取图片class方法:data=requests.get("")data=data.decode("utf-8")我们先看看怎么获取图片class,上面是从图片class中获取,代码如下:data=requests.get("")data=data.decode("utf-8")代码不是很多,你可以看出他返回的是一个png图片的数组。
我们再看一下怎么从图片列表中提取class:fromlxmlimportetreedata=etree.html(data)我们先查看下etree模块中etree的文档:[etree.html]importetreefrommultiprocessingimportpoolimportredefetree_from_lxml(en):asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="theimage"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="andtheimage"asserten=="ande-rate"asserten=="thejpg"asserten=="thee-rate"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)if__name__=="__main__":data=etree_from_lxml()print("success")这样我们成功提取class之后,再看下最终提取的结果:fromlxmlimportetreefrommultiprocessingimportpoolimportredefetree_from_lx。 查看全部
抓取网页数据工具(爬取网页图片步骤及应用)
抓取网页数据工具:如果想要爬取网页中的图片,目录:图片class120.jpg大小:图片1.32mb,class204.jpg大小:图片1.22mb1.实现1.requests库requests库是一个python提供的异步请求库,官方教程:requestshelloworld爬取网页图片步骤如下:1.获取图片路径2.获取图片class3.解析图片所在class列表1.获取图片路径:2.获取图片class:我们先从class="h"中查看对应的图片类型为:class120.jpg我们先从对应的图片class中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:png,jpg)3.解析图片所在列表:我们先从对应的列表中获取:data=requests.get("")data=data.decode("utf-8")(对应图片类型为:image)好了,解析图片所在列表已经完成。
接下来我们操作下代码:接下来我们操作,获取图片class,关键语句如下:1.获取图片class我们首先来看看获取图片class方法:data=requests.get("")data=data.decode("utf-8")我们先看看怎么获取图片class,上面是从图片class中获取,代码如下:data=requests.get("")data=data.decode("utf-8")代码不是很多,你可以看出他返回的是一个png图片的数组。
我们再看一下怎么从图片列表中提取class:fromlxmlimportetreedata=etree.html(data)我们先查看下etree模块中etree的文档:[etree.html]importetreefrommultiprocessingimportpoolimportredefetree_from_lxml(en):asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="theimage"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)asserten=="e-rate"asserten=="thejpg"asserten=="thepng"asserten=="andtheimage"asserten=="ande-rate"asserten=="thejpg"asserten=="thee-rate"asserten=="thesimilarscreenshots."asserten=="anditdoes"..return"".join(en)if__name__=="__main__":data=etree_from_lxml()print("success")这样我们成功提取class之后,再看下最终提取的结果:fromlxmlimportetreefrommultiprocessingimportpoolimportredefetree_from_lx。
抓取网页数据工具(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-07 07:09
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越为人所知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个数据提取功能有限的 Chrome 扩展程序,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合那些有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
抓取网页数据工具(网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越为人所知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个数据提取功能有限的 Chrome 扩展程序,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。
总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合那些有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
抓取网页数据工具(金色数据采集器开源项目之金色采集器开源项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-02-06 18:01
介绍
Golden data采集器开源项目是一个网页爬取和数据提取的工具。其核心代码与黄金数据采集和数据融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。另外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
黄金数据平台
Golden Data是一个集采集和融合功能于一体的平台。它可以捕获数据和数据之间的关系并立即将其整合到关系应用数据库表中,并且重复采集融合不会产生重复数据。
完全免费的黄金数据社区版
金数据平台社区版是一款完全不限爬取(如不限爬虫数量、爬取速度/时间、爬取数据数量、导出数据量)的私有云软件。
我们提供Golden Data Platform的详细免费文档和培训视频,请点击这里查看和使用。
入门
首先,我们需要将依赖添加到项目中(因为我们已经将项目添加到了maven中央仓库),如下:
1、对于 maven 项目
com.100shouhou.golddata golddata-spider 1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test public void testGoldSpider(){ String ruleContent= " { \n"+ " __node: li.sky.skyid \n"+ " date: \n"+ " { \n"+ " expr: h1 \n"+ " __label: 日期 \n"+ " } \n"+ " sn: \n"+ " { \n"+ " \n"+ " js: md5(baseUri+item.date+headers['Content-Type']);\n"+ " } \n"+ " weather: \n"+ " { \n"+ " expr: p.wea \n"+ " } \n"+ " temprature: \n"+ " { \n"+ " expr: p.tem>i \n"+ " } \n"+ " } \n"; GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl("http://www.weather.com.cn/weat ... 6quot;) .setRule(ruleContent) .request(); List list=spider.extractList(); // List weathers=spider.extractList(Weather.class); // Weather weathers=spider.extractFirst(Weather.class); list.forEach( System.out::println); }
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d} {date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd} {date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa} {date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3} {date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f} {date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d} {date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service public class WeatherServiceImpl implements WeatherService{ public List listByCityId(Long cityId){ String url="http://www.weather.com.cn/weat ... ot%3B String rule="" GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl(url) .setRule(ruleContent) .request(); return spider.extractList(Weather.class); } }
此外,您可以免费使用可视化编辑器来编辑规则内容。可视化编辑器来自金数据平台,点击链接即可下载。可视化编辑器截图如下:
文档和培训视频
请点击这里查看规则和文件
可以查看oschina关于golden data相关的博文, 查看全部
抓取网页数据工具(金色数据采集器开源项目之金色采集器开源项目)
介绍
Golden data采集器开源项目是一个网页爬取和数据提取的工具。其核心代码与黄金数据采集和数据融合平台分离。
该项目提供从网页中抓取和提取数据的功能。它不仅可以提取网页内容,还可以从 URL、HTTP 标头和 cookie 中提取数据。
该项目定义了简洁、灵活和敏捷的结构或常规语法。尽最大努力从网页内容、HTTP 标头、cookie 中提取有意义和有价值的数据字段,甚至将其他网页和其他 网站 数据关联起来形成数据记录。另外,还可以嵌入http请求来补充数据字段,比如一些需要提供字典翻译的字段等等。
该项目还支持从各种类型的文档中提取数据,例如html/xml/json/javascript/text等。
黄金数据平台
Golden Data是一个集采集和融合功能于一体的平台。它可以捕获数据和数据之间的关系并立即将其整合到关系应用数据库表中,并且重复采集融合不会产生重复数据。
完全免费的黄金数据社区版
金数据平台社区版是一款完全不限爬取(如不限爬虫数量、爬取速度/时间、爬取数据数量、导出数据量)的私有云软件。
我们提供Golden Data Platform的详细免费文档和培训视频,请点击这里查看和使用。
入门
首先,我们需要将依赖添加到项目中(因为我们已经将项目添加到了maven中央仓库),如下:
1、对于 maven 项目
com.100shouhou.golddata golddata-spider 1.1.3
2、对于 gradle 项目
compile group: 'com.100shouhou.golddata', name: 'golddata-spider', version: '1.1.3'
然后就可以使用这个依赖提供的简洁明了的API,如下:
@Test public void testGoldSpider(){ String ruleContent= " { \n"+ " __node: li.sky.skyid \n"+ " date: \n"+ " { \n"+ " expr: h1 \n"+ " __label: 日期 \n"+ " } \n"+ " sn: \n"+ " { \n"+ " \n"+ " js: md5(baseUri+item.date+headers['Content-Type']);\n"+ " } \n"+ " weather: \n"+ " { \n"+ " expr: p.wea \n"+ " } \n"+ " temprature: \n"+ " { \n"+ " expr: p.tem>i \n"+ " } \n"+ " } \n"; GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl("http://www.weather.com.cn/weat ... 6quot;) .setRule(ruleContent) .request(); List list=spider.extractList(); // List weathers=spider.extractList(Weather.class); // Weather weathers=spider.extractFirst(Weather.class); list.forEach( System.out::println); }
运行上面的测试,你会看到类似下面的输出:
{date=19日(今天), weather=阴转小雨, temprature=10℃, sn=8bc265cb2bf23b6764b75144b255d81d} {date=20日(明天), weather=小雨转多云, temprature=11℃, sn=9efd7e7bbbfb9bb06e04c0c990568bfd} {date=21日(后天), weather=多云转中雨, temprature=11℃, sn=728539ac882721187741708860324afa} {date=22日(周六), weather=小雨, temprature=9℃, sn=a23fa2233e750a3bdd11b2e200ed06c3} {date=23日(周日), weather=小雨转多云, temprature=8℃, sn=b27e1b8a8e92a7bed384ceb3e4fdfb5f} {date=24日(周一), weather=多云转小雨, temprature=8℃, sn=c142b7fd12330ca031dd96b307c0d50d} {date=25日(周二), weather=小雨转中雨, temprature=6℃, sn=16f71d3c8f09394588532a3ed1a8bacf}
用作服务或 API
您可以在项目中将其用作调用服务和 API。例如如下:
@Service public class WeatherServiceImpl implements WeatherService{ public List listByCityId(Long cityId){ String url="http://www.weather.com.cn/weat ... ot%3B String rule="" GoldSpider spider= com.xst.golddata.GoldSpider.newSpider() .setUrl(url) .setRule(ruleContent) .request(); return spider.extractList(Weather.class); } }
此外,您可以免费使用可视化编辑器来编辑规则内容。可视化编辑器来自金数据平台,点击链接即可下载。可视化编辑器截图如下:
文档和培训视频
请点击这里查看规则和文件
可以查看oschina关于golden data相关的博文,
抓取网页数据工具( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-06 17:24
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简易数据分析系列文章的第11期。
原文首发于博客园。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程来爬取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是可以在互联网刚开发的时候提供开箱即用的表格;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成表格一样,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。 查看全部
抓取网页数据工具(
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简易数据分析系列文章的第11期。
原文首发于博客园。
今天我们将讨论如何在 Web 表单中捕获数据。首先我们来分析一下网页中的经典表格是如何组成的。
经典的表格都是关于这些知识点的,没了。让我们编写一个简单的表单 Web Scraper 爬虫。
1.创建站点地图
我们今天的练习 网站 是
%C9%CF%BA%A3&txt道达=%B1%B1%BE%A9
爬虫的内容是爬取上海到北京的所有火车时刻表。
我们首先创建一个收录整个表格的容器,并将Type选择为Table,表示我们要抓取表格。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。如果你看一下,你会发现这些数据实际上是表格数据类型的分类。在这种情况下,他列出了火车、出发站和行驶时间的类别。
在表格列类别中,默认勾选每行内容旁边的选择按钮,这意味着默认捕获这些列的内容。如果您不想爬取某种类型的内容,只需去掉相应的复选框即可。
当你点击保存选择器按钮的时候,你会发现Result键的一些选项报错,说invalid format format无效:
解决这个错误非常简单。一般来说,Result 键名的长度是不够的。您可以添加空格和标点符号。如果仍然出现错误,请尝试更改为英文名称:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程来爬取数据了。
2.我为什么不建议你使用 Web Scraper 的表格选择器?
如果按照刚才的教程,感觉会很流畅,但是看数据的时候,就傻眼了。
刚开始爬的时候,我们先用Data preview预览数据,发现数据很完美:
抓取数据后,在浏览器的预览面板中预览,会发现trains一栏的数据为null,表示没有抓取到相关内容:
我们下载捕获的CSV文件并在预览器中打开后,我们会发现出现了列车号的数据,但是出发站的数据又为空了!
这不是傻子!
我已经研究这个问题很长时间了。应该是Web Scraper对中文关键词索引的支持不是很友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表数据,可以使用前面的方案,先创建一个Element类型的容器,然后在容器中手动创建一个子选择器,这样就可以避免这个问题了。
以上只是一个原因,另一个原因是,在现代 网站 中,很少有人再使用 HTML 原创表格了。
HTML 为表格提供了基本的标签,例如 、 、 等,这些标签提供了默认样式。优点是可以在互联网刚开发的时候提供开箱即用的表格;缺点是样式过于简单,不易定制。后来很多网站用其他标签来模拟表格,就像PPT用各种大小的块组合成表格一样,很容易自定义:
正因如此,当你使用Table Selector匹配一个表格的时候,可能会匹配不上,因为从Web Scraper的角度来看,你看到的表格是高仿的,根本不是原装的,自然不是。认可。
3.总结
我们不建议直接使用 Web Scraper 的 Table Selector,因为它对中文支持不是很友好,也不太适合现代网页。如果有抢表的需求,可以使用之前创建父子选择器的方法来做。
抓取网页数据工具(ScreamingFrogSEOSpider14源程序破解安装教程,欢迎下载体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-02 00:12
Screaming Frog SEO Spider是一款在现实生活中经常使用的电脑端网站资源检测爬虫软件。该软件可帮助用户即时抓取 网站 并查找断开的链接 (404) 和服务器错误。批量导出错误和要修复的源 URL,或直接发送给开发人员进行修复。简洁直观的界面让用户更容易找到自己想要的功能。它还可以帮助用户分析页面标题和元数据,并查看 Meta 机器人和说明。还有很多功能,需要的用户快来下载使用吧!
安装教程
1、从本站下载解压后,可以得到Screaming Frog SEO Spider 14的源程序和破解文件;
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,点击Install安装,默认安装路径,安装类型;
3、耐心等待软件安装完成,点击关闭退出;
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框;
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定;
6、会弹出如下框,即安装激活成功,可以放心使用;
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并找到低内容页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
软件功能
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML 查看全部
抓取网页数据工具(ScreamingFrogSEOSpider14源程序破解安装教程,欢迎下载体验)
Screaming Frog SEO Spider是一款在现实生活中经常使用的电脑端网站资源检测爬虫软件。该软件可帮助用户即时抓取 网站 并查找断开的链接 (404) 和服务器错误。批量导出错误和要修复的源 URL,或直接发送给开发人员进行修复。简洁直观的界面让用户更容易找到自己想要的功能。它还可以帮助用户分析页面标题和元数据,并查看 Meta 机器人和说明。还有很多功能,需要的用户快来下载使用吧!
安装教程
1、从本站下载解压后,可以得到Screaming Frog SEO Spider 14的源程序和破解文件;
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,点击Install安装,默认安装路径,安装类型;
3、耐心等待软件安装完成,点击关闭退出;
4、运行程序进入操作界面,选择License按钮,点击Enter License弹出激活框;
5、然后打开Keygen-NGEN文件夹,运行Keygen.exe注册机,将注册机内容复制到激活框,点击确定;
6、会弹出如下框,即安装激活成功,可以放心使用;
7、以上为Screaming Frog SEO Spider 14破解安装教程,欢迎下载体验!
软件功能
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以进行修复,或发送给开发人员
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并找到低内容页面
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL
7、生成 XML 站点地图
通过 URL 快速创建具有高级配置的 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构
软件功能
1、查找损坏的链接、错误和重定向
2、分析页面标题和元数据
3、查看元机器人和说明
4、审核 hreflang 属性
5、发现重复页面
6、生成 XML 站点地图
7、网站可视化
8、爬取限制(无限制)
9、调度
10、爬取配置
11、保存抓取并重新上传
12、自定义源代码搜索
13、自定义提取
14、谷歌分析集成
15、搜索控制台集成
16、链接指标集成
17、渲染(JavaScript)
18、自定义robots.txt
19、AMP爬取和验证
20、结构化数据和验证
21、存储和查看原创和渲染的 HTML
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-31 10:15
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。
从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个操作工具,我才知道爬取网络数据可以这么简单。
接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后一个一个操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那我就用今日头条来命名;站点地图 URL:将网页链接复制到星标 URL 列。比如图片中,我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别、年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别、年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles;select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,所以我们需要使用Element整体选择(如果网页需要滑动加载更多,然后选择Element Scroll Down);勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选它时,爬虫插件会帮助我们识别多个相同类型的文章文章;保留设置:其余未提及的部分保持默认设置。2. 单击选择以选择一个范围并按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。鼠标点击后变为红色选择该区域。多选:不要只选择一个,还可以选择以下几个。否则只有一行数据可以爬出来;完成选择:记得点击完成选择;保存:单击保存选择器。3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
创建一个新的选择器:点击添加新的选择器;输入id:id代表你在抓取哪个字段,所以可以取字段的英文,比如我要选择“作者”,就写“作者”;select Type:选择Text,因为要抓取的是文本;取消勾选Multiple:不要勾选Multiple前面的小框,因为我们这里抓取的是单个元素;保留设置:将其余未提及的部分保留为默认设置。4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,为Select;完成选择:记得点击完成选择;保存:单击保存选择器。5. 重复上述操作,直到选择好要爬的田地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。 查看全部
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。
从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个操作工具,我才知道爬取网络数据可以这么简单。
接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后一个一个操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那我就用今日头条来命名;站点地图 URL:将网页链接复制到星标 URL 列。比如图片中,我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别、年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别、年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles;select Type:type代表你抓取的这部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,所以我们需要使用Element整体选择(如果网页需要滑动加载更多,然后选择Element Scroll Down);勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选它时,爬虫插件会帮助我们识别多个相同类型的文章文章;保留设置:其余未提及的部分保持默认设置。2. 单击选择以选择一个范围并按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。鼠标点击后变为红色选择该区域。多选:不要只选择一个,还可以选择以下几个。否则只有一行数据可以爬出来;完成选择:记得点击完成选择;保存:单击保存选择器。3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
创建一个新的选择器:点击添加新的选择器;输入id:id代表你在抓取哪个字段,所以可以取字段的英文,比如我要选择“作者”,就写“作者”;select Type:选择Text,因为要抓取的是文本;取消勾选Multiple:不要勾选Multiple前面的小框,因为我们这里抓取的是单个元素;保留设置:将其余未提及的部分保留为默认设置。4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,为Select;完成选择:记得点击完成选择;保存:单击保存选择器。5. 重复上述操作,直到选择好要爬的田地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
抓取网页数据工具(Linux中curl的利用规则规则(图)详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-26 13:19
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:06年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息是通过ajax请求返回的(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
抓取网页数据工具(Linux中curl的利用规则规则(图)详解(组图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:06年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息是通过ajax请求返回的(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
抓取网页数据工具(亚马逊店铺商品数据批量工具,快来U大师下载使用它吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-24 22:20
亚马逊数据采集软件是在亚马逊(Amazon)平台上实时监控和采集竞争对手产品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。最常用的跨境电商平台数据采集软件,功能强大,使用起来非常方便实用。快来Master U下载使用吧!!!~~~
亚马逊店铺商品数据批量抓取工具,亚马逊商品数据抓取,亚马逊网站商品批量采集工具推荐
特征:
亚马逊店铺商品数据批量抓取工具用于实时监控和采集竞争对手在亚马逊平台上的商品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。它是目前使用最多的。跨境电商平台数据采集软件。
软件特点:
亚马逊店铺商品数据批量抓取工具其实有很多用途。一是监控竞争对手的出价和运费等,可以实时调整。您还可以采集您的网站中随处可见同行的产品数据,监控整个行业的趋势(如采集热门搜索词,采集产品Asin有好评的信息等),我们的采集系统可以有效绕过亚马逊的反采集Limited、Batch Unlimited采集、Any Field采集
使用说明:
优采云软件基于.net开发。如果软件下载后双击无法正常运行,可能是缺少netframworks 4.0环境。只要下载并安装了 netframworks 4.0,它就可以正常工作。运行,网络框架 4.0
预防措施:
程序运行时可能会被360等安全软件误报,软件本身无毒,无插件。运行前请添加信任或退出安全软件!
优采云平台集成了所有开发的软件包,可以自主选择需要的软件运行 查看全部
抓取网页数据工具(亚马逊店铺商品数据批量工具,快来U大师下载使用它吧)
亚马逊数据采集软件是在亚马逊(Amazon)平台上实时监控和采集竞争对手产品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。最常用的跨境电商平台数据采集软件,功能强大,使用起来非常方便实用。快来Master U下载使用吧!!!~~~
亚马逊店铺商品数据批量抓取工具,亚马逊商品数据抓取,亚马逊网站商品批量采集工具推荐
特征:
亚马逊店铺商品数据批量抓取工具用于实时监控和采集竞争对手在亚马逊平台上的商品名称、价格、运费、ANSI、ANSI变体、店铺名称等数据。它是目前使用最多的。跨境电商平台数据采集软件。
软件特点:
亚马逊店铺商品数据批量抓取工具其实有很多用途。一是监控竞争对手的出价和运费等,可以实时调整。您还可以采集您的网站中随处可见同行的产品数据,监控整个行业的趋势(如采集热门搜索词,采集产品Asin有好评的信息等),我们的采集系统可以有效绕过亚马逊的反采集Limited、Batch Unlimited采集、Any Field采集
使用说明:
优采云软件基于.net开发。如果软件下载后双击无法正常运行,可能是缺少netframworks 4.0环境。只要下载并安装了 netframworks 4.0,它就可以正常工作。运行,网络框架 4.0
预防措施:
程序运行时可能会被360等安全软件误报,软件本身无毒,无插件。运行前请添加信任或退出安全软件!
优采云平台集成了所有开发的软件包,可以自主选择需要的软件运行
抓取网页数据工具(原文链接提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-23 14:09
原创链接
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
图片1.png
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:对从内容页面提取的数据做进一步的处理,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果通过之前的规则无法准确提取内容或提取的内容为空,则选择此项,应用此项后,将再次使用正则匹配从原创页面中提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过起止字符串截取内容。适用于对提取内容的裁剪调整。
⑤纯正则替换:如果某些内容(如单个出现的文本)不能通过一般内容替换来操作,则需要通过强大的正则表达式进行复杂替换。
例如,“受欢迎的美式餐厅在这里”,我们将其替换为“美式餐厅”,正则表达式如下:
图片2.png
⑥数据转换:包括结果由简转繁、结果由繁转简、自动转拼音和时间校正转换,共四个处理。
⑦智能提取:包括第一张图片提取、时间智能提取、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动总结、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前后缀、随机插入、运行C#代码、批量替换内容、统计标签字符串A长度等一系列函数。
⑨完成单个URL:将当前内容完成为一个URL。
2、文件下载:可以自动检测和下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源码中的标准样式
标签的图片网址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:经过检查,源代码中的标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网络爬虫工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。 查看全部
抓取网页数据工具(原文链接提取的数据还不能直接拿来用?文件还没有被下载?)
原创链接
提取出来的数据不能直接使用吗?文件还没下载?格式等不符合要求?别担心,网络抓取工具 优采云采集器 有自己的解决方案——数据处理。
图片1.png
网络爬虫的数据处理功能包括三个部分,即内容处理、文件下载和内容过滤。下面依次为大家介绍:
1、内容处理:对从内容页面提取的数据做进一步的处理,比如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序依次执行,即上一步的结果会作为下一步的参数。
让我们一一介绍:
①提取的内容为空:如果通过之前的规则无法准确提取内容或提取的内容为空,则选择此项,应用此项后,将再次使用正则匹配从原创页面中提取。
②内容替换/排除:将采集中的内容替换为字符串。如果需要排除,可以用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数等替换字符串(与工具栏中的同义词替换不同)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过起止字符串截取内容。适用于对提取内容的裁剪调整。
⑤纯正则替换:如果某些内容(如单个出现的文本)不能通过一般内容替换来操作,则需要通过强大的正则表达式进行复杂替换。
例如,“受欢迎的美式餐厅在这里”,我们将其替换为“美式餐厅”,正则表达式如下:
图片2.png
⑥数据转换:包括结果由简转繁、结果由繁转简、自动转拼音和时间校正转换,共四个处理。
⑦智能提取:包括第一张图片提取、时间智能提取、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动总结、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前后缀、随机插入、运行C#代码、批量替换内容、统计标签字符串A长度等一系列函数。
⑨完成单个URL:将当前内容完成为一个URL。
2、文件下载:可以自动检测和下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源码中的标准样式
标签的图片网址。
比如直接图片地址,或者不规则图片源代码,采集器会被视为文件下载。
①将相对地址补全为绝对地址:勾选后将标签采集的相对地址补全为绝对地址。
②下载图片:经过检查,源代码中的标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件的下载地址而不是真实的下载地址,点击后会有跳转。在这种情况下,勾选该选项会显示真实地址采集,但只获取下载地址,不下载。
④检测文件并下载:检查后可以从采集下载任意格式的文件附件。
3、内容过滤:通过设置内容过滤,可以删除部分不符合条件的记录或标记为不接受。内容过滤有以下几种处理方式:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件。
②采集结果不能为空:该功能可以防止某个字段出现空内容。
③采集结果不能重复:该功能可以防止字段内容重复。设置此项前,请确保没有采集数据,或者需要先清除采集数据。
④当内容长度小于(大于、等于、不等于)N时过滤:符号或字母或数字或汉字计为一个。
注意:如果满足以上四项中的一项或多项,可以在采集器的其他设置功能中直接删除这条记录,或者在采集下将该记录标记为不为采集 再次运行任务时。
在网络爬虫工具优采云采集器中配备了一系列数据处理的好处是,当我们只需要一个小操作时,就不需要编写插件,生成和编译,并且可以通过一键将数据处理成我们需要的方式。
抓取网页数据工具( 新媒体运营来说的爬虫工具——webscraper的特点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-23 14:08
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
查看全部
抓取网页数据工具(
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
抓取网页数据工具(爬虫软件工程师教你怎么做SEO,没有什么比我们更了解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-23 10:09
)
爬虫软件工程师教你如何做SEO。没有什么比我们更了解搜索引擎了。我们都接触过数据聚合类型网站至少几千万的数据或者搜索引擎。URL就是人为设置一些URL供爬虫爬取。可以理解为爬取的入口URL,然后通过其内部链接传播爬取。
搜索引擎原则
在搜索引擎网站的后台,会有一个非常大的索引库,里面存储着大量的关键词,而每个关键词对应着很多的URL,这些URL被称为它是为“搜索引擎蜘蛛”或“网络爬虫”程序从浩瀚的互联网下载的点点滴滴采集而来。随着各种网站的出现,这些勤劳的“蜘蛛”每天都在网上爬行,从链接到链接,下载内容,分析提炼,找到关键词,如果“蜘蛛” " 认为 关键词 在数据库中不可用并且对用户有用,它将在后台存储在数据库中。相反,如果“蜘蛛”认为是垃圾邮件或重复信息,就会丢弃,继续爬取,查找最新和有用的信息并将其保存以供用户搜索。当用户搜索时,可以从索引库中检索到与该关键字相关的网站,并显示给访问者。一个关键词对应多个url,所以存在排序问题,对应的网站和关键词url会排在第一位。在“蜘蛛”爬取网页内容和提炼关键词的过程中,存在一个问题:“蜘蛛”能否理解。如果 网站 的内容是 Flash 和 JS 等,那么即使关键字合适,也是不可理解的。相应地,如果网站的内容能被搜索引擎识别,搜索引擎会增加网站的权重,增加网站的友好度,进而提高<
百度收录难的原因?大量网站被黑并在明天发布的原因。
通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后,放到检索区,形成稳定的排名。所以只要下载的东西可以通过说明找到,补充数据是不稳定的。是的,它可能会在各种计算过程中丢失。检索区的数据排名相对稳定。百度目前是缓存机制和补充数据的结合,正在向补充数据转变。
百度蜘蛛爬取策略
深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取一个页面时,百度先爬取更多的URL,深度优先爬取的目的是爬取到获得高质量的网页,这个策略是通过调度来计算和分配的。百度蜘蛛只负责爬取。权重优先是指对反向链接较多的页面优先抓取。这也是一种调度策略。40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
不要打破搜索引擎的最大禁忌
百度蜘蛛似乎更注重 网站 页面的层次结构。与谷歌相比,百度蜘蛛更注重网站内部页面结构的层次结构,有点像爬虫。越黑越深,越喜欢往里挖。我不信你做100页。很漂亮,只要链接没有层次结构,你充其量只能成为收录可怜的小东西。
搜索引擎告诉你怎么做SEO?
不管是什么类型的网站站长,他们的网站结构一定要简洁明了,这是站长需要知道的事情之一。一般设计时网站的页面层级不要超过三层。现在,很多存储架的网站层级都超过了三层。页面文件名可以使用字母或数字,但不要使用长的中转英文插件,对收录没有任何好处。并且在创建网站的过程中添加内容时,建议大家使用静态或者伪静态技术进行处理,有利于网站在搜索引擎中的友好性。
我刚刚用爬虫软件+技术处理创建了一个权重6 网站
采集伪原创:TensorFlow人工智能引擎/分词算法/DNN算法采用多线程分段精准处理,结合机器学习、人工智能、百度大脑的自然语言分词、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章
图片伪原创:背景融合算法,可以将1张图片伪原创转化为N张图片原创
模板伪原创:更改图片名,js名,css名,更改图片MD5、更改类样式名
网站发行商:Empire、易友、ZBLOG、织梦、WP、小旋风、站群、PB、Apple、搜外等。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!
查看全部
抓取网页数据工具(爬虫软件工程师教你怎么做SEO,没有什么比我们更了解
)
爬虫软件工程师教你如何做SEO。没有什么比我们更了解搜索引擎了。我们都接触过数据聚合类型网站至少几千万的数据或者搜索引擎。URL就是人为设置一些URL供爬虫爬取。可以理解为爬取的入口URL,然后通过其内部链接传播爬取。
搜索引擎原则
在搜索引擎网站的后台,会有一个非常大的索引库,里面存储着大量的关键词,而每个关键词对应着很多的URL,这些URL被称为它是为“搜索引擎蜘蛛”或“网络爬虫”程序从浩瀚的互联网下载的点点滴滴采集而来。随着各种网站的出现,这些勤劳的“蜘蛛”每天都在网上爬行,从链接到链接,下载内容,分析提炼,找到关键词,如果“蜘蛛” " 认为 关键词 在数据库中不可用并且对用户有用,它将在后台存储在数据库中。相反,如果“蜘蛛”认为是垃圾邮件或重复信息,就会丢弃,继续爬取,查找最新和有用的信息并将其保存以供用户搜索。当用户搜索时,可以从索引库中检索到与该关键字相关的网站,并显示给访问者。一个关键词对应多个url,所以存在排序问题,对应的网站和关键词url会排在第一位。在“蜘蛛”爬取网页内容和提炼关键词的过程中,存在一个问题:“蜘蛛”能否理解。如果 网站 的内容是 Flash 和 JS 等,那么即使关键字合适,也是不可理解的。相应地,如果网站的内容能被搜索引擎识别,搜索引擎会增加网站的权重,增加网站的友好度,进而提高<
百度收录难的原因?大量网站被黑并在明天发布的原因。
通过百度蜘蛛下载的网页放在补充数据区,经过各种程序计算后,放到检索区,形成稳定的排名。所以只要下载的东西可以通过说明找到,补充数据是不稳定的。是的,它可能会在各种计算过程中丢失。检索区的数据排名相对稳定。百度目前是缓存机制和补充数据的结合,正在向补充数据转变。
百度蜘蛛爬取策略
深度优先和权重优先,当百度蜘蛛从起始站点(即种子站点指一些门户站点)爬取一个页面时,百度先爬取更多的URL,深度优先爬取的目的是爬取到获得高质量的网页,这个策略是通过调度来计算和分配的。百度蜘蛛只负责爬取。权重优先是指对反向链接较多的页面优先抓取。这也是一种调度策略。40%的网页抓取是正常范围,60%是好的,100%是不可能的。当然,越爬越好。
不要打破搜索引擎的最大禁忌
百度蜘蛛似乎更注重 网站 页面的层次结构。与谷歌相比,百度蜘蛛更注重网站内部页面结构的层次结构,有点像爬虫。越黑越深,越喜欢往里挖。我不信你做100页。很漂亮,只要链接没有层次结构,你充其量只能成为收录可怜的小东西。
搜索引擎告诉你怎么做SEO?
不管是什么类型的网站站长,他们的网站结构一定要简洁明了,这是站长需要知道的事情之一。一般设计时网站的页面层级不要超过三层。现在,很多存储架的网站层级都超过了三层。页面文件名可以使用字母或数字,但不要使用长的中转英文插件,对收录没有任何好处。并且在创建网站的过程中添加内容时,建议大家使用静态或者伪静态技术进行处理,有利于网站在搜索引擎中的友好性。
我刚刚用爬虫软件+技术处理创建了一个权重6 网站
采集伪原创:TensorFlow人工智能引擎/分词算法/DNN算法采用多线程分段精准处理,结合机器学习、人工智能、百度大脑的自然语言分词、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章
图片伪原创:背景融合算法,可以将1张图片伪原创转化为N张图片原创
模板伪原创:更改图片名,js名,css名,更改图片MD5、更改类样式名
网站发行商:Empire、易友、ZBLOG、织梦、WP、小旋风、站群、PB、Apple、搜外等。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!

