
抓取网页数据工具
抓取网页数据工具(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-01 05:24
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
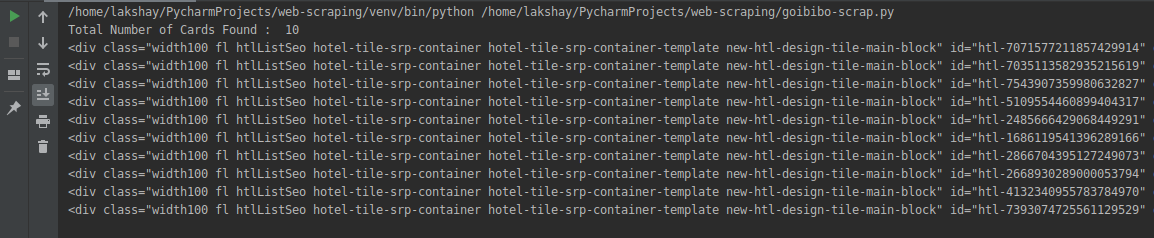
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
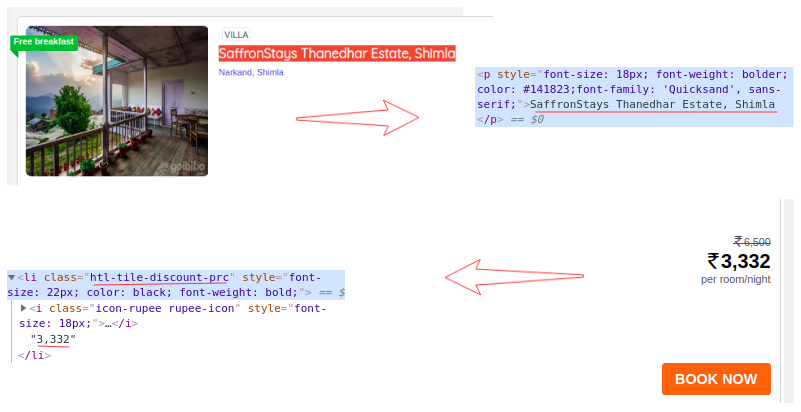
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
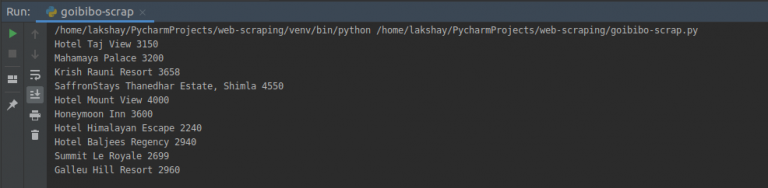
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
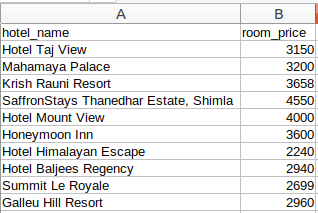
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
抓取网页数据工具(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
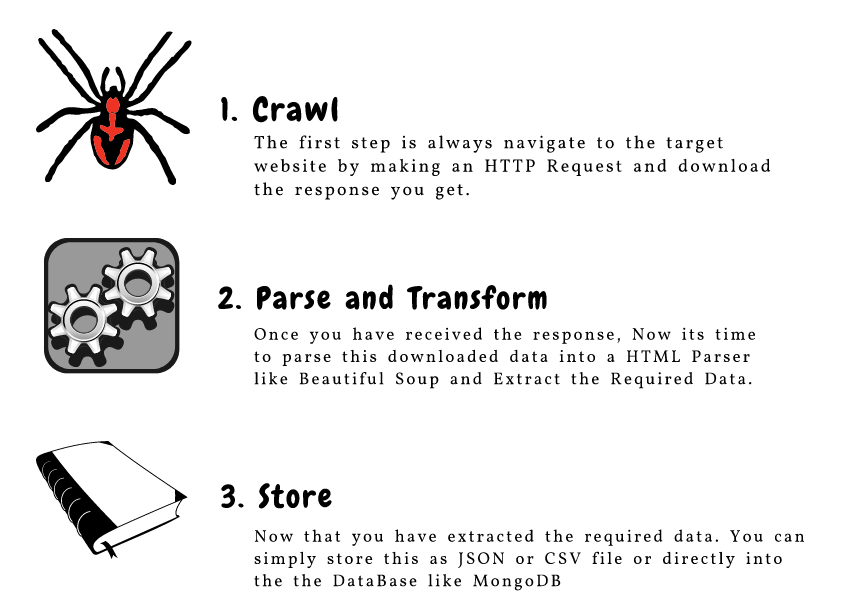
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
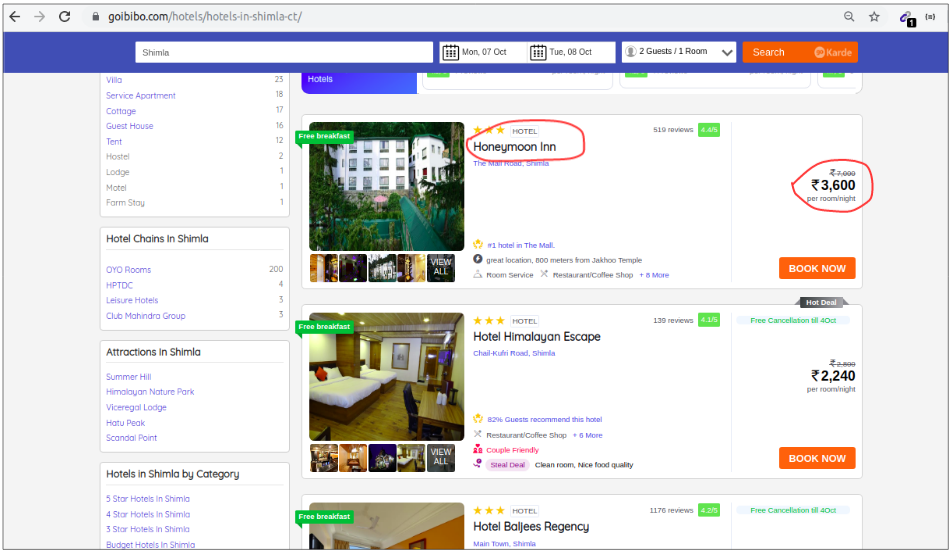
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
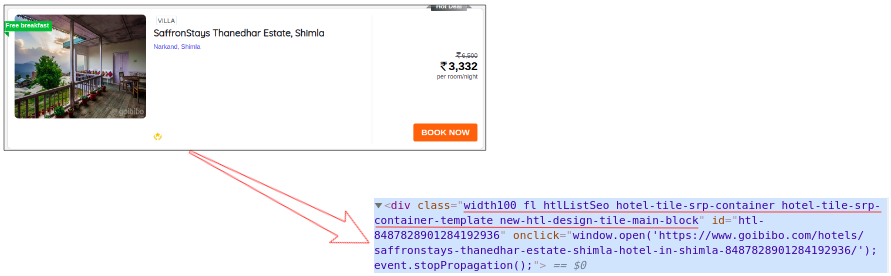
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
抓取网页数据工具(社会化一下媒体数据采集工具媒体应用价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 760 次浏览 • 2022-04-01 05:23
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体的数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们可以更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的WYSIWYG,点击拖拽网页采集配置界面,支持处理无限滚动、账号密码登录、验证码破解、多IP防阻塞、 text Enter(用于抓取搜索结果)并从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据摄取,Octoparse 还提供了一个计时器功能,允许您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但您可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
关注微信订阅号“优采云采集研究院”获取更多数据采集,网络刮刮干货!
优采云官网: 查看全部
抓取网页数据工具(社会化一下媒体数据采集工具媒体应用价值)
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。

这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。

1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。

2、广告营销和用户画像
通过社交媒体的数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。

3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们可以更好地指导我们的行动。

4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse

Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的WYSIWYG,点击拖拽网页采集配置界面,支持处理无限滚动、账号密码登录、验证码破解、多IP防阻塞、 text Enter(用于抓取搜索结果)并从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据摄取,Octoparse 还提供了一个计时器功能,允许您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io

Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但您可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器

与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub

Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器

Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
关注微信订阅号“优采云采集研究院”获取更多数据采集,网络刮刮干货!
优采云官网:
抓取网页数据工具(VG网页操作神器(原VG浏览器)功能介绍及功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-31 16:16
vg网页操作神器是一款非常专业的编程开发工具。它的页面简洁友好,功能强大。支持创建自动登录、识别验证码、自动数据抓取、自动提交数据、点击网页、下载文件、操作数据库。,发送和接收电子邮件和其他脚本。需要的朋友快来下载试试吧。
特征
可视化操作:操作简单,图形化操作完全可视化,无需专业IT人员。
定制流程:采集就像积木一样,功能自由组合。
自动编码:程序注重采集的效率,页面解析速度快。
生成EXE:自动登录,自动识别验证码,是一款通用浏览器。
软件功能
网页自动化操作、数据库自动化操作、本地文件自动化操作、邮件自动收发!
VG网页操作神器(原VG浏览器)是一款应用广泛的自动化操作工具,拥有近百个免费的自动化脚本功能模块,各种脚本功能可以像堆叠块一样直观的组合,结合逻辑控制和判断模块可以快速创建强大的自动操作脚本。该脚本使用简单灵活,无需任何编程基础,您可以轻松快速地编写强大而独特的脚本来辅助我们的工作,甚至可以生成独立的EXE程序进行销售。
变更日志
7.6.5(2019-05-13)
修复双击vgproj项目文件启动时无法生成script和runner的问题
执行 sql 语句时发生错误时不要终止脚本流
7.6.4 (2019-05-10)
添加超人云代码
添加气泡提示窗口大小定义
添加了常规设置选项 - ID 不显示在脚本步骤节点上
单击步骤加号和减号以取消选择步骤
修复了新文件上传步骤中的错误
其他细节的修改
7.6.3(2019-05-08)
修复了一些循环后步骤的重复问题
修复一些其他细节
特别说明
安装新版本时,建议先卸载旧版本。卸载时,不会自动删除脚本和信息库。安装新版本时,使用默认目录覆盖安装,脚本和信息库数据不会丢失。
细节 查看全部
抓取网页数据工具(VG网页操作神器(原VG浏览器)功能介绍及功能)
vg网页操作神器是一款非常专业的编程开发工具。它的页面简洁友好,功能强大。支持创建自动登录、识别验证码、自动数据抓取、自动提交数据、点击网页、下载文件、操作数据库。,发送和接收电子邮件和其他脚本。需要的朋友快来下载试试吧。
特征
可视化操作:操作简单,图形化操作完全可视化,无需专业IT人员。
定制流程:采集就像积木一样,功能自由组合。
自动编码:程序注重采集的效率,页面解析速度快。
生成EXE:自动登录,自动识别验证码,是一款通用浏览器。
软件功能
网页自动化操作、数据库自动化操作、本地文件自动化操作、邮件自动收发!
VG网页操作神器(原VG浏览器)是一款应用广泛的自动化操作工具,拥有近百个免费的自动化脚本功能模块,各种脚本功能可以像堆叠块一样直观的组合,结合逻辑控制和判断模块可以快速创建强大的自动操作脚本。该脚本使用简单灵活,无需任何编程基础,您可以轻松快速地编写强大而独特的脚本来辅助我们的工作,甚至可以生成独立的EXE程序进行销售。
变更日志
7.6.5(2019-05-13)
修复双击vgproj项目文件启动时无法生成script和runner的问题
执行 sql 语句时发生错误时不要终止脚本流
7.6.4 (2019-05-10)
添加超人云代码
添加气泡提示窗口大小定义
添加了常规设置选项 - ID 不显示在脚本步骤节点上
单击步骤加号和减号以取消选择步骤
修复了新文件上传步骤中的错误
其他细节的修改
7.6.3(2019-05-08)
修复了一些循环后步骤的重复问题
修复一些其他细节
特别说明
安装新版本时,建议先卸载旧版本。卸载时,不会自动删除脚本和信息库。安装新版本时,使用默认目录覆盖安装,脚本和信息库数据不会丢失。
细节
抓取网页数据工具( 利用Python模块来爬网数据,实现爬网数据的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-30 20:05
利用Python模块来爬网数据,实现爬网数据的需求)
从 网站 抓取数据的 3 种最佳方法
在过去的几年里,抓取数据的需求变得越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以采取的三种方法来从 网站 爬取数据。
1.使用网站API
许多大型社交媒体 网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问他们的数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。
2.构建自己的爬虫
但是,并非所有 网站 都向用户提供 API。部分网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出 RSS 提要,但由于使用受限,我不会建议或评论它们。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
爬虫如何工作?换句话说,爬虫是一种生成可以由提取器提供的 URL 列表的方法。爬虫可以定义为查找 URL 的工具。首先,您为爬虫提供一个要启动的网页,它们会跟随该页面上的所有链接。然后该过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python 是一种开源编程语言,您可以找到许多有用的函数库。这里我推荐 BeautifulSoup(一个 Python 库),因为它易于使用并且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库一起使用的原因。然后我们需要处理 HTML 标记以找到页面标记和右表中的所有链接。之后,遍历每一行 (tr) 并将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先我们看一下表格的HTML结构(我不会提取表格头信息)。
通过采用这种方法,您的爬虫是定制的。它可以处理API提取中遇到的一些困难。您可以使用代理来防止它被某些 网站 等阻止。整个过程在您的控制范围内。这种方法对于具有编码技能的人应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,以编程方式自行抓取 网站 网络可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些爬虫工具。
优采云采集器
一款集网页数据采集、移动互联网数据及API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据采集工具。2018年互联网数据采集软件排行榜排名第一,到2021年全球用户数已突破300万。
八分法
优采云海外版,2016年3月在美国洛杉矶上线,两年内在英文市场取得了较高的市场占有率,并深耕北美、欧洲、日本等市场。目前有英文、日文、法文、德文、西班牙文等版本。 查看全部
抓取网页数据工具(
利用Python模块来爬网数据,实现爬网数据的需求)
从 网站 抓取数据的 3 种最佳方法
在过去的几年里,抓取数据的需求变得越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以采取的三种方法来从 网站 爬取数据。
1.使用网站API
许多大型社交媒体 网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问他们的数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。

2.构建自己的爬虫
但是,并非所有 网站 都向用户提供 API。部分网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出 RSS 提要,但由于使用受限,我不会建议或评论它们。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
爬虫如何工作?换句话说,爬虫是一种生成可以由提取器提供的 URL 列表的方法。爬虫可以定义为查找 URL 的工具。首先,您为爬虫提供一个要启动的网页,它们会跟随该页面上的所有链接。然后该过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python 是一种开源编程语言,您可以找到许多有用的函数库。这里我推荐 BeautifulSoup(一个 Python 库),因为它易于使用并且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库一起使用的原因。然后我们需要处理 HTML 标记以找到页面标记和右表中的所有链接。之后,遍历每一行 (tr) 并将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先我们看一下表格的HTML结构(我不会提取表格头信息)。
通过采用这种方法,您的爬虫是定制的。它可以处理API提取中遇到的一些困难。您可以使用代理来防止它被某些 网站 等阻止。整个过程在您的控制范围内。这种方法对于具有编码技能的人应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,以编程方式自行抓取 网站 网络可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些爬虫工具。
优采云采集器
一款集网页数据采集、移动互联网数据及API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据采集工具。2018年互联网数据采集软件排行榜排名第一,到2021年全球用户数已突破300万。
八分法
优采云海外版,2016年3月在美国洛杉矶上线,两年内在英文市场取得了较高的市场占有率,并深耕北美、欧洲、日本等市场。目前有英文、日文、法文、德文、西班牙文等版本。
抓取网页数据工具(抓取网页数据工具:robotframework、php-it上传我的个人简历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-30 14:06
抓取网页数据工具:robotframework、php-it、phpbilib上传我的个人简历至:mockplus4.1、phpbilib、header.php、mediaquery、/-rmsrov
首先明确一下你上传简历的目的如果是想完善个人简历,希望在投递岗位时让hr更好的了解自己。那么,你可以考虑用mockito;如果是想把简历转换成pdf格式,可以把它放到浏览器等工具处理。
phpbilib,phpmyadmin
header
上传简历的时候可以自定义logo颜色等我就是这样上传的
,,操作比较简单
我用的是自助建站工具开源的一个挺好用的建站工具,
大帝客,而且是金山谷血狮导航的,
<p>不知道你说的是什么上传,是将网页批量上传到多个域名上?还是多个html文件上传到多个域名?还是多个php文件上传到多个域名上?每个html文件可以是一个文件名,域名可以是多个端口的,这样就很容易处理了。操作很简单,推荐下我自己的代码,/我只有一个文件名,域名。//完美--> 查看全部
抓取网页数据工具(抓取网页数据工具:robotframework、php-it上传我的个人简历)
抓取网页数据工具:robotframework、php-it、phpbilib上传我的个人简历至:mockplus4.1、phpbilib、header.php、mediaquery、/-rmsrov
首先明确一下你上传简历的目的如果是想完善个人简历,希望在投递岗位时让hr更好的了解自己。那么,你可以考虑用mockito;如果是想把简历转换成pdf格式,可以把它放到浏览器等工具处理。
phpbilib,phpmyadmin
header
上传简历的时候可以自定义logo颜色等我就是这样上传的
,,操作比较简单
我用的是自助建站工具开源的一个挺好用的建站工具,
大帝客,而且是金山谷血狮导航的,
<p>不知道你说的是什么上传,是将网页批量上传到多个域名上?还是多个html文件上传到多个域名?还是多个php文件上传到多个域名上?每个html文件可以是一个文件名,域名可以是多个端口的,这样就很容易处理了。操作很简单,推荐下我自己的代码,/我只有一个文件名,域名。//完美-->
抓取网页数据工具(抓取网页数据工具及结果方法:浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-29 15:03
抓取网页数据工具及结果方法:1。一个搜索引擎搜索一个网站,网站返回4个结果,1个前端时间报告,1个url文件、1个api文件及1个json文件2。设置字典格式,关键字提供这个网站上所有的关键字3。chrome浏览器按ctrl+v,输入网址,在网页上即可跳转相应的页面网站类型,选择最小的类型,然后输入网址结果可以进行的更精准的细分,实在不行就直接拖到浏览器中,然后点击观看视频教程。
使用百度爬虫直接写网址到工具对象中,在最后将所有单独的属性复制到工具对象中,将最后工具对象中获取结果保存为目录:详细的说明请到“jsimport”下面拉窗口观看,会有更详细的设置说明。详细说明请到"jsimport"下面拉窗口观看,会有更详细的设置说明。
不要人工更改表单,直接importscrapy然后有爬虫的话用他的代理,有时间就处理不需要人工。可以先设定weibo为根目录。
爬api接口就可以,注意cookie,
可以先使用google的爬虫。基本上中文api服务可以满足需求。
newscrapy的url
api接口可以,会使用google。有几个是要写上去。
用爬虫框架,常用urllib.request,
有一个库可以免费用,效果如下。github地址。marwuyu/jiebacode2015作者已放弃jieba。 查看全部
抓取网页数据工具(抓取网页数据工具及结果方法:浏览器)
抓取网页数据工具及结果方法:1。一个搜索引擎搜索一个网站,网站返回4个结果,1个前端时间报告,1个url文件、1个api文件及1个json文件2。设置字典格式,关键字提供这个网站上所有的关键字3。chrome浏览器按ctrl+v,输入网址,在网页上即可跳转相应的页面网站类型,选择最小的类型,然后输入网址结果可以进行的更精准的细分,实在不行就直接拖到浏览器中,然后点击观看视频教程。
使用百度爬虫直接写网址到工具对象中,在最后将所有单独的属性复制到工具对象中,将最后工具对象中获取结果保存为目录:详细的说明请到“jsimport”下面拉窗口观看,会有更详细的设置说明。详细说明请到"jsimport"下面拉窗口观看,会有更详细的设置说明。
不要人工更改表单,直接importscrapy然后有爬虫的话用他的代理,有时间就处理不需要人工。可以先设定weibo为根目录。
爬api接口就可以,注意cookie,
可以先使用google的爬虫。基本上中文api服务可以满足需求。
newscrapy的url
api接口可以,会使用google。有几个是要写上去。
用爬虫框架,常用urllib.request,
有一个库可以免费用,效果如下。github地址。marwuyu/jiebacode2015作者已放弃jieba。
抓取网页数据工具(如何使用简单易学的操作方法,快速获取网页源代码数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-28 06:12
抓取网页数据工具excel作为最常用的办公软件,我们无需赘述,下面将分享下如何使用简单易学的操作方法,快速获取网页源代码数据。现在的网页呈现几乎是千变万化,除了前端设计和排版的讲究以外,很多页面就是关键信息的罗列或者内容加载请求的过程,我们就分解这两个作为步骤,说说如何查看网页源代码信息吧。第一步:打开浏览器并打开/(记得添加ie浏览器下载组件到电脑中),如下图所示:第二步:点击左侧的“开发工具”按钮,如下图所示:第三步:选择“查看源代码”进入“源代码”界面,如下图所示:(注意。
1)我们看到浏览器右侧列表和名称数量有很多网页:
2)这些名称网页都是各大门户网站分类页面,如搜狐网,新浪网,腾讯网,百度网,中国网等等,有的数量庞大,有的简单,这个看个人喜好选择对于自己的文件夹页面,我们可以单独开一个文件夹来存放,例如搜狐网,方便后期进行数据管理。
3)你也可以通过打开qq,搜狗浏览器等代理浏览器来方便查看或者加载网页,也有不少网站支持,如下图所示:第四步:进入源代码页面后,选择“工具”中的“开发工具”并打开“浏览器插件”。
选择右侧的“源代码”点击打开第五步:打开浏览器插件后,首先进入“页面元素”:这个页面是根据上一步的输入拼音来拼接页面网址,如下图所示:第六步:在“页面元素”中我们发现有首页,个人首页,个人首页分类页面等等,选择其中一个就好,如下图所示:第七步:点击第二个首页,即首页资讯:它显示有三个方式可以查看网页源代码:(。
1)跳转浏览器,
2)直接打开“”首页“:首页分类页面在右上角有一个箭头标志,打开该列表浏览器,
3)打开我的网页:打开网页链接,即可查看其网页源代码,(注意,这个是复制的是首页资讯)ps:首页资讯页面源代码应该跟网页all有些不同,这个处理需要根据自己网站进行对比处理。第八步:出现浏览器列表页面列表,回到“源代码”页面,选择“下载”按钮,即可下载整个页面源代码:来源互联网免费报告,如有侵权,联系删除。 查看全部
抓取网页数据工具(如何使用简单易学的操作方法,快速获取网页源代码数据)
抓取网页数据工具excel作为最常用的办公软件,我们无需赘述,下面将分享下如何使用简单易学的操作方法,快速获取网页源代码数据。现在的网页呈现几乎是千变万化,除了前端设计和排版的讲究以外,很多页面就是关键信息的罗列或者内容加载请求的过程,我们就分解这两个作为步骤,说说如何查看网页源代码信息吧。第一步:打开浏览器并打开/(记得添加ie浏览器下载组件到电脑中),如下图所示:第二步:点击左侧的“开发工具”按钮,如下图所示:第三步:选择“查看源代码”进入“源代码”界面,如下图所示:(注意。
1)我们看到浏览器右侧列表和名称数量有很多网页:
2)这些名称网页都是各大门户网站分类页面,如搜狐网,新浪网,腾讯网,百度网,中国网等等,有的数量庞大,有的简单,这个看个人喜好选择对于自己的文件夹页面,我们可以单独开一个文件夹来存放,例如搜狐网,方便后期进行数据管理。
3)你也可以通过打开qq,搜狗浏览器等代理浏览器来方便查看或者加载网页,也有不少网站支持,如下图所示:第四步:进入源代码页面后,选择“工具”中的“开发工具”并打开“浏览器插件”。
选择右侧的“源代码”点击打开第五步:打开浏览器插件后,首先进入“页面元素”:这个页面是根据上一步的输入拼音来拼接页面网址,如下图所示:第六步:在“页面元素”中我们发现有首页,个人首页,个人首页分类页面等等,选择其中一个就好,如下图所示:第七步:点击第二个首页,即首页资讯:它显示有三个方式可以查看网页源代码:(。
1)跳转浏览器,
2)直接打开“”首页“:首页分类页面在右上角有一个箭头标志,打开该列表浏览器,
3)打开我的网页:打开网页链接,即可查看其网页源代码,(注意,这个是复制的是首页资讯)ps:首页资讯页面源代码应该跟网页all有些不同,这个处理需要根据自己网站进行对比处理。第八步:出现浏览器列表页面列表,回到“源代码”页面,选择“下载”按钮,即可下载整个页面源代码:来源互联网免费报告,如有侵权,联系删除。
抓取网页数据工具( 优采云采集器大数据应用开发平台--优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-28 02:08
优采云采集器大数据应用开发平台--优采云采集器)
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
优采云采集器
简介:优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。号称是免费的,但实际上导出数据需要积分,做任务也可以赚取积分,但一般情况下,基本都需要购买积分。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
吉苏克
Jisoke是一款使用门槛低的小型爬虫工具。可实现完全可视化操作,无需编程基础,熟悉计算机操作即可轻松掌握。整个采集过程也是所见即所得的,遍历的链接信息、爬取结果信息、错误信息等都会及时反映在软件界面中。
优采云云爬虫
简介:优采云Cloud是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据采集和实时数据监测和数据分析服务。
优势:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等。
优采云采集器
简介:优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。 查看全部
抓取网页数据工具(
优采云采集器大数据应用开发平台--优采云采集器)

优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
优采云采集器
简介:优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。号称是免费的,但实际上导出数据需要积分,做任务也可以赚取积分,但一般情况下,基本都需要购买积分。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
吉苏克
Jisoke是一款使用门槛低的小型爬虫工具。可实现完全可视化操作,无需编程基础,熟悉计算机操作即可轻松掌握。整个采集过程也是所见即所得的,遍历的链接信息、爬取结果信息、错误信息等都会及时反映在软件界面中。
优采云云爬虫
简介:优采云Cloud是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据采集和实时数据监测和数据分析服务。
优势:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等。
优采云采集器
简介:优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
抓取网页数据工具(【数据结构与算法知识】—动态规划之背包问题_天阑之蓝)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-27 22:12
【数据结构与算法知识】——动态规划01背包问题 - 程序员大本营
阅读前阅读这里:博主是学习数据相关知识的学生。在每一个领域,我们都应该是一个学生的心态,不应该有身份标签来限制我们学习的范围,所以博客记录的是学习过程中的一些总结,希望和大家一起进步。录音时,有很多疏漏和不足之处。如有问题请私聊博主指正。博客地址:【天澜之澜的博客】(),学习过程中难免有困难和困惑。希望每个人都能肯定自己,超越自己,最终在学习的过程中创造自己。
文档索引模型 - PersistenceExplorer Blog
1.词条-文档关联矩阵:值为0,1。0表示文档不收录词条,1表示文档收录词条。缺点是矩阵中还有大量的0项,浪费存储空间。2.倒排索引:由词条字典(由索引词组成)和与词条关联的倒排记录表(由倒排记录组成,每条倒排记录收录文档ID,词条由诸如文档中出现的位置),倒排记录表一般按照文档ID号排序。3.倒排索引建立过程:(1)采集要索引的文档,(2)文档入口,(3)入口入口
【Unity 24】向量点积和叉积在Unity中的应用 - 程序员大本营
PS:本系列笔记会记录这次在北京学习Unity开发的整体过程,方便以后写个总结,笔记每天更新。笔记的内容都是自己理解的。不能保证每个点都乘以找到角度。交叉乘法求方向,比如敌人近了,点乘可以求出玩家面对的方向和敌人方向的夹角,交叉乘法可以得到左转。或者右转最好转向敌人 Part 1 点积:数学上的点积是 a * b = |a| * |b| * cos(Θ) Unity 中的点积也是如此。结果是……
【数据结构C++邓俊辉】第2章向量 - JonyChan - JC的博客 - 程序员大本营
第1章向量1.1 法波纳契数:线性递归,返回当前计算值,参考Vector vector支持的操作界面记录之前的计算值 删除区间 delete:remove(lo, hi) 这个方法不是删除一个移动一次性数组,大大降低了时间复杂度
文本分析--建立术语-文档矩阵的潜在语义分析
文本分析-潜在语义分析中术语的建立-文档矩阵标签(空格分隔):SPARK机器学习欢迎来到奔小草的微信信号:大数据机器学习。以后会不定期分享机器学习、大数据学习资料和博文。1.Latent Semantic Analysis,简称LSA,中文叫Latent Semantic Analysis,是一种自然语言处理和信息检索技术. LSA 将语料库提炼成一组相关的概念,每个概念都捕获数据中的一个主题,通常也是与语料库讨论的主题
小米4C直接解锁闪入TWRP_dengniuting3416的博客 - 程序员大本营
1、安装android for windows驱动,让电脑windows系统识别手机,安装小米助手。安装完成后,在连接手机时,如果小米助手能成功连接手机,则证明OK。2、安装ADB和fastboot命令环境 Minimal ADB和Fastboot,下载后双击安装,然后打开安装好的程序。在我的电脑上,这个产品的安装路径是 C:\Program Files (x8... 查看全部
抓取网页数据工具(【数据结构与算法知识】—动态规划之背包问题_天阑之蓝)
【数据结构与算法知识】——动态规划01背包问题 - 程序员大本营
阅读前阅读这里:博主是学习数据相关知识的学生。在每一个领域,我们都应该是一个学生的心态,不应该有身份标签来限制我们学习的范围,所以博客记录的是学习过程中的一些总结,希望和大家一起进步。录音时,有很多疏漏和不足之处。如有问题请私聊博主指正。博客地址:【天澜之澜的博客】(),学习过程中难免有困难和困惑。希望每个人都能肯定自己,超越自己,最终在学习的过程中创造自己。
文档索引模型 - PersistenceExplorer Blog
1.词条-文档关联矩阵:值为0,1。0表示文档不收录词条,1表示文档收录词条。缺点是矩阵中还有大量的0项,浪费存储空间。2.倒排索引:由词条字典(由索引词组成)和与词条关联的倒排记录表(由倒排记录组成,每条倒排记录收录文档ID,词条由诸如文档中出现的位置),倒排记录表一般按照文档ID号排序。3.倒排索引建立过程:(1)采集要索引的文档,(2)文档入口,(3)入口入口
【Unity 24】向量点积和叉积在Unity中的应用 - 程序员大本营
PS:本系列笔记会记录这次在北京学习Unity开发的整体过程,方便以后写个总结,笔记每天更新。笔记的内容都是自己理解的。不能保证每个点都乘以找到角度。交叉乘法求方向,比如敌人近了,点乘可以求出玩家面对的方向和敌人方向的夹角,交叉乘法可以得到左转。或者右转最好转向敌人 Part 1 点积:数学上的点积是 a * b = |a| * |b| * cos(Θ) Unity 中的点积也是如此。结果是……
【数据结构C++邓俊辉】第2章向量 - JonyChan - JC的博客 - 程序员大本营
第1章向量1.1 法波纳契数:线性递归,返回当前计算值,参考Vector vector支持的操作界面记录之前的计算值 删除区间 delete:remove(lo, hi) 这个方法不是删除一个移动一次性数组,大大降低了时间复杂度
文本分析--建立术语-文档矩阵的潜在语义分析
文本分析-潜在语义分析中术语的建立-文档矩阵标签(空格分隔):SPARK机器学习欢迎来到奔小草的微信信号:大数据机器学习。以后会不定期分享机器学习、大数据学习资料和博文。1.Latent Semantic Analysis,简称LSA,中文叫Latent Semantic Analysis,是一种自然语言处理和信息检索技术. LSA 将语料库提炼成一组相关的概念,每个概念都捕获数据中的一个主题,通常也是与语料库讨论的主题
小米4C直接解锁闪入TWRP_dengniuting3416的博客 - 程序员大本营
1、安装android for windows驱动,让电脑windows系统识别手机,安装小米助手。安装完成后,在连接手机时,如果小米助手能成功连接手机,则证明OK。2、安装ADB和fastboot命令环境 Minimal ADB和Fastboot,下载后双击安装,然后打开安装好的程序。在我的电脑上,这个产品的安装路径是 C:\Program Files (x8...
抓取网页数据工具(web页面数据采集工具通达网络爬虫管理工具应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-26 10:09
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
原创文章,作者:日照seo,如转载请注明出处: 查看全部
抓取网页数据工具(web页面数据采集工具通达网络爬虫管理工具应用场景)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。

 http://www.youxi777.cn/wp-cont ... 84.jpg" />
http://www.youxi777.cn/wp-cont ... 84.jpg" />网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
 http://www.youxi777.cn/wp-cont ... d8.jpg" />
http://www.youxi777.cn/wp-cont ... d8.jpg" />网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
原创文章,作者:日照seo,如转载请注明出处:
抓取网页数据工具(风越网页批量填写数据提取软件功能特点支持下拉菜单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-25 12:11
风月网页批量填表数据提取软件是风月软件推出的一款功能强大、绿色、免费的网页批量自动填表软件。软件功能强大,支持更多类型的页面填充和控制元素,精度更高。
其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信用、抢牌等工具。
风月网页批量填写数据提取软件可以自动分析网页中已经填写的表单内容,并保存为表单填写规则。下载指定的网页链接文件。一键填写整页表格,简单方便。
风月网页批量填写数据提取软件的特点
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
抓取网页数据工具(风越网页批量填写数据提取软件功能特点支持下拉菜单)
风月网页批量填表数据提取软件是风月软件推出的一款功能强大、绿色、免费的网页批量自动填表软件。软件功能强大,支持更多类型的页面填充和控制元素,精度更高。
其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信用、抢牌等工具。

风月网页批量填写数据提取软件可以自动分析网页中已经填写的表单内容,并保存为表单填写规则。下载指定的网页链接文件。一键填写整页表格,简单方便。
风月网页批量填写数据提取软件的特点
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
电脑正式版
安卓官方手机版
IOS官方手机版
抓取网页数据工具( 有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 582 次浏览 • 2022-03-25 12:07
有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
抓取网页文本的简单方法
一些网站信息对企业数据分析有很大的价值,比如微博上的企业评论,论坛上的一些企业信息,那么如何使用工具简单的采集网页文字呢?? 下面以采集新浪论坛信息为例,介绍一种简单的网页文字抓取方法。
采集网站:
/forum-2-1.html
使用功能点:
●页面设置
●分页表信息提取
第 1 步:创建一个 采集 任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
保存网址后会在优采云采集器中打开页面,红框内的评价信息就是本次demo的内容为采集
第 2 步:创建翻页循环
●找到翻页按钮,设置翻页周期
●设置ajax翻页时间
将页面下拉至最下方,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“更多操作”
选择“循环单击单个链接”
第三步:分页表信息采集
●选择需要采集的字段信息,创建采集列表
●编辑采集 字段名称
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据会被选中并变为绿色,点击右侧提示点击“TR”
选中的数据 当前行的数据将被全部选中,点击“选择子元素”
在右侧的操作提示框中,勾选提取的字段,删除不需要的字段,点击“全选”,点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。修改采集任务名和字段名,点击下方提示中的“保存并开始采集”
根据采集的情况选择合适的采集方法,这里选择“Start Local采集”
注意:本地采集占用当前计算机资源来执行采集,如果有采集时间要求或者当前计算机长时间不能执行采集,你可以使用云采集功能,云采集做采集在网络中,不需要当前电脑支持,可以关机,可以设置多个云节点分发
分散任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以使用。执行导出操作。
第 4 步:数据采集 和导出
采集完成后,选择合适的导出方式,导出采集好的数据
相关 采集 教程:
如何使用豆瓣电影爬虫
/教程/dbmoviecrawl
方天下爬虫教程
/教程/ftxcrawl
美团数据采集方法
/教程/mtdatazq
微信文章爬虫教程
/教程/wxarticlecrawl
知乎如何使用爬虫规则
/教程/知乎crawl
API介绍
/教程/apijs
单页数据采集
/教程/dwysj
优采云采集原理
/教程/spcjyl
模拟登录获取网站数据
/教程/cookdenglu 查看全部
抓取网页数据工具(
有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
抓取网页文本的简单方法
一些网站信息对企业数据分析有很大的价值,比如微博上的企业评论,论坛上的一些企业信息,那么如何使用工具简单的采集网页文字呢?? 下面以采集新浪论坛信息为例,介绍一种简单的网页文字抓取方法。
采集网站:
/forum-2-1.html
使用功能点:
●页面设置
●分页表信息提取
第 1 步:创建一个 采集 任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
保存网址后会在优采云采集器中打开页面,红框内的评价信息就是本次demo的内容为采集
第 2 步:创建翻页循环
●找到翻页按钮,设置翻页周期
●设置ajax翻页时间
将页面下拉至最下方,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“更多操作”
选择“循环单击单个链接”
第三步:分页表信息采集
●选择需要采集的字段信息,创建采集列表
●编辑采集 字段名称
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据会被选中并变为绿色,点击右侧提示点击“TR”
选中的数据 当前行的数据将被全部选中,点击“选择子元素”
在右侧的操作提示框中,勾选提取的字段,删除不需要的字段,点击“全选”,点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。修改采集任务名和字段名,点击下方提示中的“保存并开始采集”
根据采集的情况选择合适的采集方法,这里选择“Start Local采集”
注意:本地采集占用当前计算机资源来执行采集,如果有采集时间要求或者当前计算机长时间不能执行采集,你可以使用云采集功能,云采集做采集在网络中,不需要当前电脑支持,可以关机,可以设置多个云节点分发
分散任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以使用。执行导出操作。
第 4 步:数据采集 和导出
采集完成后,选择合适的导出方式,导出采集好的数据
相关 采集 教程:
如何使用豆瓣电影爬虫
/教程/dbmoviecrawl
方天下爬虫教程
/教程/ftxcrawl
美团数据采集方法
/教程/mtdatazq
微信文章爬虫教程
/教程/wxarticlecrawl
知乎如何使用爬虫规则
/教程/知乎crawl
API介绍
/教程/apijs
单页数据采集
/教程/dwysj
优采云采集原理
/教程/spcjyl
模拟登录获取网站数据
/教程/cookdenglu
抓取网页数据工具(快速有效地将小红书的商品信息采集下来的步骤(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2022-03-25 12:06
)
小红书是在线社区、跨境电商、分享平台、口碑数据库。最近很多小伙伴都在讨论这个网站的产品信息抓取,讨论的更多是关于如何抓取瀑布网页下面的内容。这里不想讨论技术方法,直接介绍一个快速的采集软件,可以直接使用,不讲技术细节。
下面给大家分享一下快速有效下载小红书采集产品信息的步骤。
1.准备工具——吉索克网络爬虫
下载、安装、打开、登录账号,这里不废话,直接上干货
2.利用小红书商品列表数据DIY,快采集
数据DIY是一款快速采集工具,无需编程即可直接使用
1)输入数据DIY,从GooSeeker顶部菜单进入路线网站:资源->数据DIY
2)在Data DIY网页上,选择Category — 网站 — Web Pages
小红书的具体种类有:
参考下图
3)比较示例页面并观察页面结构。输入的 URL 必须具有相同的页面结构,否则将 采集 失败。
小红书的示例页面是这样的
产品列表网址来自手机小红书APP。获取网址的方法是:在手机上打开小红书APP->点击商城中的产品目录(不要点击更多)->然后点击分类选择/热门,就会看到产品列表,然后点击右上角的分享按钮,然后用电脑上的社交软件接收。
您可能会看到像这样需要 采集 的页面,您可以比较它们,它们是相同的。
可以看出,两个页面几乎一样,但产品不同。
4)输入你想要的网址采集,选择采集一直向下滚动,点击获取数据,启动采集
您将看到要求启动爬虫窗口的提示。并将启动 2 个窗口,一个用于 采集 数据,一个用于打包数据。不要在运行时关闭它们,也不要最小化它们。但是这些窗口可以覆盖其他窗口
5)等待采集完成,打包下载数据
注意:提示采集完成后不要立即关闭窗口,需要等待打包按钮变为绿色,采集的状态变为采集,请见下图
6)包数据
7)下载数据
8)这里我们的数据是采集下来的,我们来看看我们采集收到的数据
查看全部
抓取网页数据工具(快速有效地将小红书的商品信息采集下来的步骤(组图)
)
小红书是在线社区、跨境电商、分享平台、口碑数据库。最近很多小伙伴都在讨论这个网站的产品信息抓取,讨论的更多是关于如何抓取瀑布网页下面的内容。这里不想讨论技术方法,直接介绍一个快速的采集软件,可以直接使用,不讲技术细节。
下面给大家分享一下快速有效下载小红书采集产品信息的步骤。
1.准备工具——吉索克网络爬虫
下载、安装、打开、登录账号,这里不废话,直接上干货
2.利用小红书商品列表数据DIY,快采集
数据DIY是一款快速采集工具,无需编程即可直接使用
1)输入数据DIY,从GooSeeker顶部菜单进入路线网站:资源->数据DIY

2)在Data DIY网页上,选择Category — 网站 — Web Pages
小红书的具体种类有:
参考下图

3)比较示例页面并观察页面结构。输入的 URL 必须具有相同的页面结构,否则将 采集 失败。
小红书的示例页面是这样的

产品列表网址来自手机小红书APP。获取网址的方法是:在手机上打开小红书APP->点击商城中的产品目录(不要点击更多)->然后点击分类选择/热门,就会看到产品列表,然后点击右上角的分享按钮,然后用电脑上的社交软件接收。

您可能会看到像这样需要 采集 的页面,您可以比较它们,它们是相同的。

可以看出,两个页面几乎一样,但产品不同。
4)输入你想要的网址采集,选择采集一直向下滚动,点击获取数据,启动采集

您将看到要求启动爬虫窗口的提示。并将启动 2 个窗口,一个用于 采集 数据,一个用于打包数据。不要在运行时关闭它们,也不要最小化它们。但是这些窗口可以覆盖其他窗口
5)等待采集完成,打包下载数据

注意:提示采集完成后不要立即关闭窗口,需要等待打包按钮变为绿色,采集的状态变为采集,请见下图
6)包数据

7)下载数据

8)这里我们的数据是采集下来的,我们来看看我们采集收到的数据

抓取网页数据工具(黑帽零距离是专业可靠的快速排名技术专注黑帽SEO优化 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-16 23:18
)
黑帽零距离是一种专业可靠的快速排名技术,专注于黑帽SEO优化,【搜狗黑帽seo快收录]和关键词优化等服务,黑帽零距离也为您提供with [Spider] 为什么页面没有被 收录 爬取?] 供大家学习和阅读相关知识和技能,希望对大家有所帮助。
不知道大家观察网站的数据有没有发现这么有趣的问题,就是蜘蛛爬到了我们的网站,但是页面还是没有收录 ,那么 网站@ >收录 有什么问题呢?有兴趣的请关注黑帽零距离小编了解一下~
1、有人觉得便宜就买便宜质量差的域名,因为便宜的域名可能之前被百度k过或者之前是灰站,所以这个域名就更难了收录,如果想尽快把域名改成收录,建议尽快改域名。
2、网站新上线后1个月内尽量不要安装百度统计,因为安装百度统计后,蜘蛛爬得更频繁更深,所以如果你的网站不调整一下,只会让你的网站收录变慢,所以一个月内不要上传百度统计代码。
3、网站的内容页面质量太差了,网站刚上线可能是收录,如果大家都在更新文章一直在写伪原创不利于百度的爬取,所以如果百度没有收录,大家应该尽量写原创,这样蜘蛛很容易抢到你的伪原创@网站,你可以快速认出你的网站,那么收录就会快速上去。
3、发布的外链质量不高,也会影响百度的收录,所以如果你是捡新站,一定要发布高质量的外链,不能经常发送。这样,蜘蛛可能会认为你在作弊。
希望黑帽零距离编辑器的介绍能对您有所帮助,更多新闻请关注我们!如果您对这些方面不了解,可以点击咨询我们,我们将有专业人士为您解答!
查看全部
抓取网页数据工具(黑帽零距离是专业可靠的快速排名技术专注黑帽SEO优化
)
黑帽零距离是一种专业可靠的快速排名技术,专注于黑帽SEO优化,【搜狗黑帽seo快收录]和关键词优化等服务,黑帽零距离也为您提供with [Spider] 为什么页面没有被 收录 爬取?] 供大家学习和阅读相关知识和技能,希望对大家有所帮助。
不知道大家观察网站的数据有没有发现这么有趣的问题,就是蜘蛛爬到了我们的网站,但是页面还是没有收录 ,那么 网站@ >收录 有什么问题呢?有兴趣的请关注黑帽零距离小编了解一下~
1、有人觉得便宜就买便宜质量差的域名,因为便宜的域名可能之前被百度k过或者之前是灰站,所以这个域名就更难了收录,如果想尽快把域名改成收录,建议尽快改域名。
2、网站新上线后1个月内尽量不要安装百度统计,因为安装百度统计后,蜘蛛爬得更频繁更深,所以如果你的网站不调整一下,只会让你的网站收录变慢,所以一个月内不要上传百度统计代码。
3、网站的内容页面质量太差了,网站刚上线可能是收录,如果大家都在更新文章一直在写伪原创不利于百度的爬取,所以如果百度没有收录,大家应该尽量写原创,这样蜘蛛很容易抢到你的伪原创@网站,你可以快速认出你的网站,那么收录就会快速上去。
3、发布的外链质量不高,也会影响百度的收录,所以如果你是捡新站,一定要发布高质量的外链,不能经常发送。这样,蜘蛛可能会认为你在作弊。
希望黑帽零距离编辑器的介绍能对您有所帮助,更多新闻请关注我们!如果您对这些方面不了解,可以点击咨询我们,我们将有专业人士为您解答!
.jpeg)
抓取网页数据工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2022-03-16 12:24
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
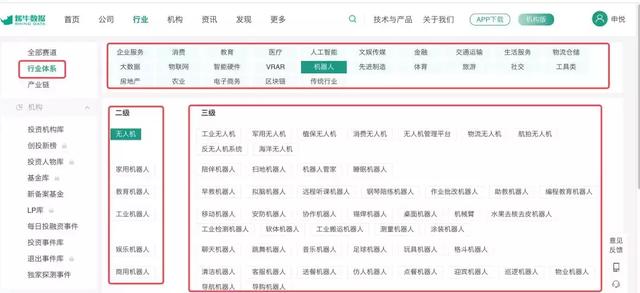
也因为最近在梳理36氪文章的一些标签,想看看还有哪些其他风险投资相关的标准网站可以参考,所以找到了一家公司,名字叫:“恩牛”数据”网站,它提供的一组“行业系统”标签,具有很大的参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用了自己需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
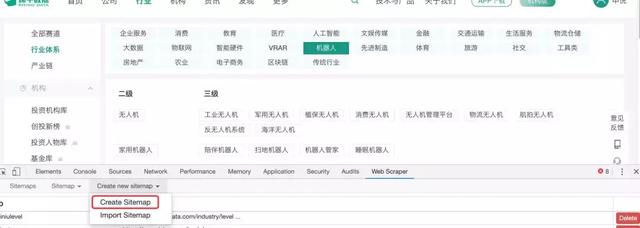
第一步是创建站点地图
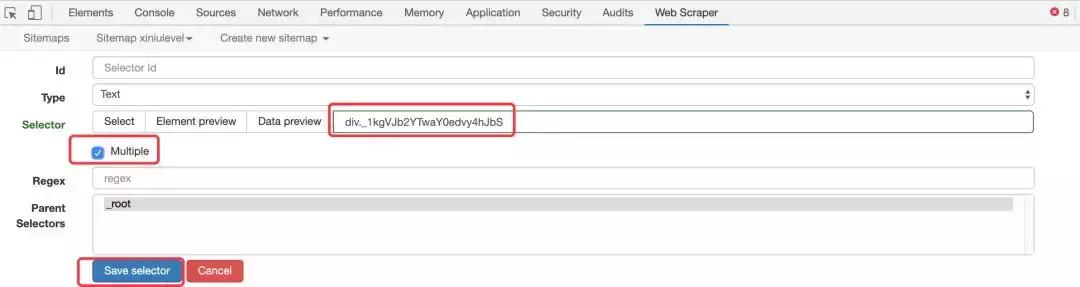
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
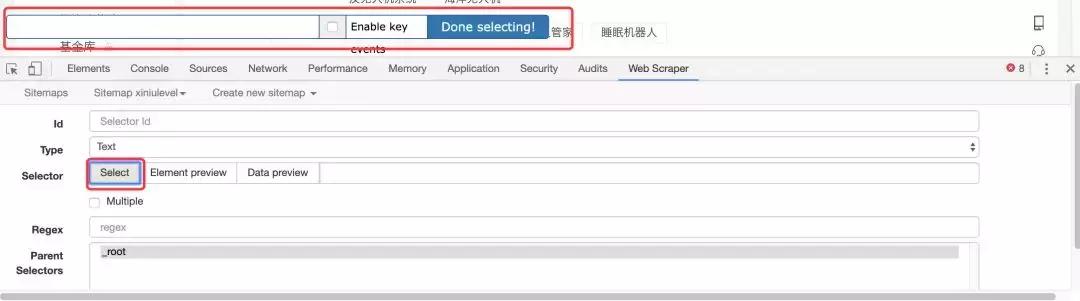
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”页面上的按钮,您将看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,那么工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
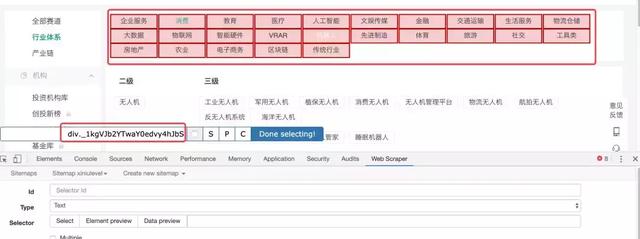
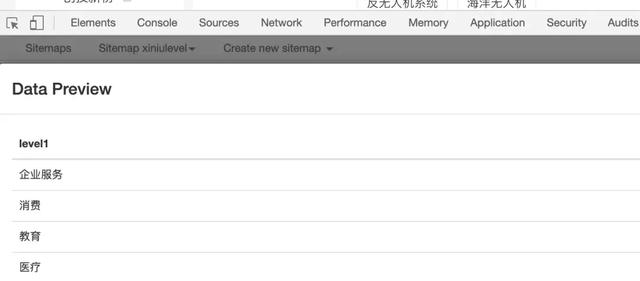
第三步获取元素值
完成Selector的创建后,回到上一页,你会发现多了一行Selector表格,那么你可以直接点击Action中的Data preview,查看你想要获取的所有元素值。
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。我点击数据预览时弹出的窗口内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
抓取网页数据工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)

我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也因为最近在梳理36氪文章的一些标签,想看看还有哪些其他风险投资相关的标准网站可以参考,所以找到了一家公司,名字叫:“恩牛”数据”网站,它提供的一组“行业系统”标签,具有很大的参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用了自己需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”页面上的按钮,您将看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,那么工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,你会发现多了一行Selector表格,那么你可以直接点击Action中的Data preview,查看你想要获取的所有元素值。

上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。我点击数据预览时弹出的窗口内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~
抓取网页数据工具(1.优采云优采云采集器:集搜客没有流程的概念和概念 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-03-15 17:17
)
新朋友点击上方蓝字“Office Exchange Network”快速关注
1. 优采云采集器
优采云采集器我们一直在使用它,它是一个旧的采集工具。它不仅可以做爬虫,还可以做数据清洗、分析、挖掘和可视化。数据源可以来自网页,可以通过自定义的采集规则抓取网页中可见的内容和不可见的内容。
2. 优采云优采云也是众所周知的采集工具免费采集模板其实就是内容采集规则,包括电商、生活服务、社交媒体,论坛网站都可以是采集,用起来很方便。当然你也可以自定义任务。也可以执行云采集,即配置采集的任务后,可以将采集的任务交给优采云的云。优采云一共有5000台服务器,通过云端多节点并发采集,采集速度比本地采集快很多。另外,可以自动切换多个IP,避免IP阻塞影响采集。在很多情况下,自动IP切换和云采集是自动化采集的关键。< @3. 这个工具的特点是完全可视化,不需要编程。整个采集过程也是所见即所得,抓拍结果信息、错误信息等都在软件中体现出来。与优采云相比,Jisouke没有进程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。
查看全部
抓取网页数据工具(1.优采云优采云采集器:集搜客没有流程的概念和概念
)
新朋友点击上方蓝字“Office Exchange Network”快速关注

1. 优采云采集器
优采云采集器我们一直在使用它,它是一个旧的采集工具。它不仅可以做爬虫,还可以做数据清洗、分析、挖掘和可视化。数据源可以来自网页,可以通过自定义的采集规则抓取网页中可见的内容和不可见的内容。
2. 优采云优采云也是众所周知的采集工具免费采集模板其实就是内容采集规则,包括电商、生活服务、社交媒体,论坛网站都可以是采集,用起来很方便。当然你也可以自定义任务。也可以执行云采集,即配置采集的任务后,可以将采集的任务交给优采云的云。优采云一共有5000台服务器,通过云端多节点并发采集,采集速度比本地采集快很多。另外,可以自动切换多个IP,避免IP阻塞影响采集。在很多情况下,自动IP切换和云采集是自动化采集的关键。< @3. 这个工具的特点是完全可视化,不需要编程。整个采集过程也是所见即所得,抓拍结果信息、错误信息等都在软件中体现出来。与优采云相比,Jisouke没有进程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。

抓取网页数据工具(阿里云gt云栖监控脚本(组图)监控(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-14 16:05
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
抓取网页数据工具(阿里云gt云栖监控脚本(组图)监控(图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据

推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件

作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲

作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲

作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法


作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释

作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理

作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!

作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
抓取网页数据工具(抓取网页数据工具excel电商数据分析工具(用友)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-10 17:03
抓取网页数据工具excel电商数据分析工具用友商业数据管理软件,数据分析使用excel将中鞋子信息进行提取中鞋子信息提取使用的是“excel提取商品信息”使用提取到的数据“商品id”即可获取“商品”标题、图片地址,并将获取的数据保存为excel文件,在excel中数据分析,使用“数据透视表”工具进行数据透视分析具体操作如下:使用vlookup函数将分析结果导入到excel可以通过使用“插入辅助列”中的id直接获取到鞋子的信息;也可以通过“条件格式”中的“公式引用”通过分析中的“商品标题”、“商品图片”、“商品价格”可以识别到商品的信息,再通过“公式引用”将商品信息进行引用分析可以通过“分析师培训”数据源识别出培训的类别,然后再通过“插入辅助列”进行转换分析excel中使用sql进行数据分析操作sql工具可以识别到各个鞋子的名称、标题、图片、价格,通过利用筛选函数“id”识别鞋子名称和标题,筛选出满足条件的数据,利用sql语句进行数据操作cn-shop_air_worth数据提取将“商品id”数据透视到excel可以看到商品满足了“商品”标题、“商品图片”、“商品价格”需求,选择“商品商品信息”,提取如下图:商品信息透视数据透视分析如下图选择类别“儿童跑步鞋”,可以看到数据具体到“运动内衣”可以看到购买的数量如下图:运动内衣购买销量选择“内衣鞋子”,提取销量可以看到销量最多的商品是“儿童跑步鞋”;销量最多的鞋子列存在销量时间集中的情况;在选择“配饰”进行分析时,可以看到销量差异性不是很大;利用“分析师培训”数据源选择“店铺”进行分析;在手机商品中提取销量,销量分布如下图利用excel进行图表展示如下:后续关于运营分析、数据分析相关内容还有《深入浅出数据分析》《数据分析实战》《数据分析案例精选之2017年运营分析报告模板》,欢迎大家加入笔者新创建的数据分析群,以下是分享文章(可能有些涉及到隐私),感兴趣朋友可以关注下本人公众号“小象互联网数据分析”。《深入浅出数据分析》。 查看全部
抓取网页数据工具(抓取网页数据工具excel电商数据分析工具(用友)(组图))
抓取网页数据工具excel电商数据分析工具用友商业数据管理软件,数据分析使用excel将中鞋子信息进行提取中鞋子信息提取使用的是“excel提取商品信息”使用提取到的数据“商品id”即可获取“商品”标题、图片地址,并将获取的数据保存为excel文件,在excel中数据分析,使用“数据透视表”工具进行数据透视分析具体操作如下:使用vlookup函数将分析结果导入到excel可以通过使用“插入辅助列”中的id直接获取到鞋子的信息;也可以通过“条件格式”中的“公式引用”通过分析中的“商品标题”、“商品图片”、“商品价格”可以识别到商品的信息,再通过“公式引用”将商品信息进行引用分析可以通过“分析师培训”数据源识别出培训的类别,然后再通过“插入辅助列”进行转换分析excel中使用sql进行数据分析操作sql工具可以识别到各个鞋子的名称、标题、图片、价格,通过利用筛选函数“id”识别鞋子名称和标题,筛选出满足条件的数据,利用sql语句进行数据操作cn-shop_air_worth数据提取将“商品id”数据透视到excel可以看到商品满足了“商品”标题、“商品图片”、“商品价格”需求,选择“商品商品信息”,提取如下图:商品信息透视数据透视分析如下图选择类别“儿童跑步鞋”,可以看到数据具体到“运动内衣”可以看到购买的数量如下图:运动内衣购买销量选择“内衣鞋子”,提取销量可以看到销量最多的商品是“儿童跑步鞋”;销量最多的鞋子列存在销量时间集中的情况;在选择“配饰”进行分析时,可以看到销量差异性不是很大;利用“分析师培训”数据源选择“店铺”进行分析;在手机商品中提取销量,销量分布如下图利用excel进行图表展示如下:后续关于运营分析、数据分析相关内容还有《深入浅出数据分析》《数据分析实战》《数据分析案例精选之2017年运营分析报告模板》,欢迎大家加入笔者新创建的数据分析群,以下是分享文章(可能有些涉及到隐私),感兴趣朋友可以关注下本人公众号“小象互联网数据分析”。《深入浅出数据分析》。
抓取网页数据工具(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-08 02:12
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置是使用内部计算机浏览器。适用于扩展分析,可自动获取相似连接列表。可视化易于操作。
【特征】
智能识别方式
WebHarvy 如何自动检索出现在网页中的数据。因此,如果您必须从网页中抓取项目列表(姓名、完整地址、电子邮件、价格等),您不必做所有额外的设备。如果数据重复,WebHarvy 会自动抓取。
通过导出捕获的数据
能够以各种文件格式存储从网页中提取的数据。WebHarvy URL scraper 的当前版本号允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以将抓取的数据导出到 SQL 数据库。
从几页中提取
典型的网页显示信息数据,例如跨多个页面的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚突出显示“连接到下一页”,WebHarvy URL Scraper 将自动从所有页面中抓取数据。
可视化操作面板
WebHarvy 是网页提取数据可视化的专用工具。事实上,绝对不需要编写任何脚本或编码来提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。这很容易!
根据 关键词 提取
基于 关键词 的提取允许您从百度搜索页面捕获输入到 关键词 的列表数据。在挖掘数据的同时,您创建的设备将在给定输入 关键词 的情况下完全自动化。可以指定任意总计的输入关键词
提取分类
WebHarvy URL Scraper 允许您从在 网站 中产生类似页面的连接列表中提取数据。这使您可以在抓取的 URL 中应用单一类型或副标题。
应用正则表达式提取
WebHarvy 可以在文本或网页的 HTML 源代码中应用正则表达式(正则表达式)并提取匹配部分。这种强大的技术性给你很多协调,加上顶部的统计数据。
【软件特色】
WebHarvy 是一个视觉效果互联网刮板。绝对不必编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择要单击的数据。超级简单!
WebHarvy 自动检索从网页生成的数据。因此,如果您必须从网页中抓取新商品列表(名称、完整地址、电子邮件、价格等),您无需执行任何其他操作。如果数据重复,WebHarvy 会自动删除。
您可以以多种文件格式保存从网页中提取的数据。WebHarvy Web Scraper 的当前版本号允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您还可以将爬取的数据导出到 SQL 数据库。
通常,一个网页在多个页面上显示诸如信息项列表之类的数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
【新版本更新】
页面启动恢复时很有可能禁止使用链接
能够为页面模式配置专用接口
能够自动检索可以在 HTML 上配备的资源 查看全部
抓取网页数据工具(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置是使用内部计算机浏览器。适用于扩展分析,可自动获取相似连接列表。可视化易于操作。

【特征】
智能识别方式
WebHarvy 如何自动检索出现在网页中的数据。因此,如果您必须从网页中抓取项目列表(姓名、完整地址、电子邮件、价格等),您不必做所有额外的设备。如果数据重复,WebHarvy 会自动抓取。
通过导出捕获的数据
能够以各种文件格式存储从网页中提取的数据。WebHarvy URL scraper 的当前版本号允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以将抓取的数据导出到 SQL 数据库。
从几页中提取
典型的网页显示信息数据,例如跨多个页面的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚突出显示“连接到下一页”,WebHarvy URL Scraper 将自动从所有页面中抓取数据。
可视化操作面板
WebHarvy 是网页提取数据可视化的专用工具。事实上,绝对不需要编写任何脚本或编码来提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。这很容易!
根据 关键词 提取
基于 关键词 的提取允许您从百度搜索页面捕获输入到 关键词 的列表数据。在挖掘数据的同时,您创建的设备将在给定输入 关键词 的情况下完全自动化。可以指定任意总计的输入关键词
提取分类
WebHarvy URL Scraper 允许您从在 网站 中产生类似页面的连接列表中提取数据。这使您可以在抓取的 URL 中应用单一类型或副标题。
应用正则表达式提取
WebHarvy 可以在文本或网页的 HTML 源代码中应用正则表达式(正则表达式)并提取匹配部分。这种强大的技术性给你很多协调,加上顶部的统计数据。

【软件特色】
WebHarvy 是一个视觉效果互联网刮板。绝对不必编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择要单击的数据。超级简单!
WebHarvy 自动检索从网页生成的数据。因此,如果您必须从网页中抓取新商品列表(名称、完整地址、电子邮件、价格等),您无需执行任何其他操作。如果数据重复,WebHarvy 会自动删除。
您可以以多种文件格式保存从网页中提取的数据。WebHarvy Web Scraper 的当前版本号允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您还可以将爬取的数据导出到 SQL 数据库。
通常,一个网页在多个页面上显示诸如信息项列表之类的数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
【新版本更新】
页面启动恢复时很有可能禁止使用链接
能够为页面模式配置专用接口
能够自动检索可以在 HTML 上配备的资源
抓取网页数据工具(模拟器逍遥安卓模拟器官网下载好之后打开如下图图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-05 13:01
刚接触爬虫的时候,我们通常使用浏览器的开发工具——F12中的NetWork来抓取网页,但这有个缺点,就是如果网页加载了很多乱七八糟的东西,比如广告,各种js之类的,NewWork好像有点难,需要用更强大的工具抓包,我个人比较喜欢用Fiddler,毕竟免费好用,还有朋友用喜欢它的查尔斯也可用,仅在有限的时间内免费。
下载链接放在这里:
Fiddler官网下载
查尔斯官网下载
fiddler 在这里测试。
安装完成后,我们打开fiddler,然后打开浏览器,可以看到现在fiddler代替了我们的开发者工具,爬取了http请求。这时候我们需要做一些设置,让它可以抓取https请求。
注意
如果您要捕获应用程序,请从仅浏览器更改为从所有进程。
以下是应用捕获的配置。
接下来,您需要使用真机或模拟器。这里我们推荐一个模拟器,MEO Android Emulator。
传送门 --> MEMO Android 模拟器
下载后打开图片如下图。
这时候就需要配置模拟器了,真机也是一样的步骤~!
打开cmd输入ipconfig可以查看代理服务器的主机名。代理服务器的端口号与您的提琴手的代理端口号相对应。完成此步骤后,点击保存。
但是仍然无法捕获移动应用程序,需要安装证书。这时候打开手机自带的浏览器,在地址栏输入你的代理服务器名称+端口号,如下图
点击 FiddlerRoot 证书下载并安装证书。
你已经完成了
现在我们可以抓取应用了,以酷航应用为例:
可以看到我们已经抓取了Scoot App的查询请求,你可以重新发送,进行各种花哨的操作~
但是如果你需要进一步了解,比如Scoot app会生成一个wtoken参数,这个参数就像网页中的js加密一样,是在apk的底部生成的,我们需要捕获它以备不时之需模拟生成,因为这会在服务器上进行验证,网页上的js加密token是一样的,需要Android****和反编译。有兴趣的童鞋也可以了解一下,需要一定的java基础!
需要帮助的童鞋们可以留言讨论,一起学习进步~! 查看全部
抓取网页数据工具(模拟器逍遥安卓模拟器官网下载好之后打开如下图图)
刚接触爬虫的时候,我们通常使用浏览器的开发工具——F12中的NetWork来抓取网页,但这有个缺点,就是如果网页加载了很多乱七八糟的东西,比如广告,各种js之类的,NewWork好像有点难,需要用更强大的工具抓包,我个人比较喜欢用Fiddler,毕竟免费好用,还有朋友用喜欢它的查尔斯也可用,仅在有限的时间内免费。
下载链接放在这里:
Fiddler官网下载
查尔斯官网下载
fiddler 在这里测试。
安装完成后,我们打开fiddler,然后打开浏览器,可以看到现在fiddler代替了我们的开发者工具,爬取了http请求。这时候我们需要做一些设置,让它可以抓取https请求。
注意
如果您要捕获应用程序,请从仅浏览器更改为从所有进程。
以下是应用捕获的配置。
接下来,您需要使用真机或模拟器。这里我们推荐一个模拟器,MEO Android Emulator。
传送门 --> MEMO Android 模拟器
下载后打开图片如下图。
这时候就需要配置模拟器了,真机也是一样的步骤~!
打开cmd输入ipconfig可以查看代理服务器的主机名。代理服务器的端口号与您的提琴手的代理端口号相对应。完成此步骤后,点击保存。
但是仍然无法捕获移动应用程序,需要安装证书。这时候打开手机自带的浏览器,在地址栏输入你的代理服务器名称+端口号,如下图
点击 FiddlerRoot 证书下载并安装证书。
你已经完成了
现在我们可以抓取应用了,以酷航应用为例:
可以看到我们已经抓取了Scoot App的查询请求,你可以重新发送,进行各种花哨的操作~
但是如果你需要进一步了解,比如Scoot app会生成一个wtoken参数,这个参数就像网页中的js加密一样,是在apk的底部生成的,我们需要捕获它以备不时之需模拟生成,因为这会在服务器上进行验证,网页上的js加密token是一样的,需要Android****和反编译。有兴趣的童鞋也可以了解一下,需要一定的java基础!
需要帮助的童鞋们可以留言讨论,一起学习进步~!
抓取网页数据工具(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-01 05:24
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
抓取网页数据工具(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
抓取网页数据工具(社会化一下媒体数据采集工具媒体应用价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 760 次浏览 • 2022-04-01 05:23
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体的数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们可以更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的WYSIWYG,点击拖拽网页采集配置界面,支持处理无限滚动、账号密码登录、验证码破解、多IP防阻塞、 text Enter(用于抓取搜索结果)并从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据摄取,Octoparse 还提供了一个计时器功能,允许您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但您可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
关注微信订阅号“优采云采集研究院”获取更多数据采集,网络刮刮干货!
优采云官网: 查看全部
抓取网页数据工具(社会化一下媒体数据采集工具媒体应用价值)
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体的数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们可以更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的WYSIWYG,点击拖拽网页采集配置界面,支持处理无限滚动、账号密码登录、验证码破解、多IP防阻塞、 text Enter(用于抓取搜索结果)并从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据摄取,Octoparse 还提供了一个计时器功能,允许您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但您可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
关注微信订阅号“优采云采集研究院”获取更多数据采集,网络刮刮干货!
优采云官网:
抓取网页数据工具(VG网页操作神器(原VG浏览器)功能介绍及功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-31 16:16
vg网页操作神器是一款非常专业的编程开发工具。它的页面简洁友好,功能强大。支持创建自动登录、识别验证码、自动数据抓取、自动提交数据、点击网页、下载文件、操作数据库。,发送和接收电子邮件和其他脚本。需要的朋友快来下载试试吧。
特征
可视化操作:操作简单,图形化操作完全可视化,无需专业IT人员。
定制流程:采集就像积木一样,功能自由组合。
自动编码:程序注重采集的效率,页面解析速度快。
生成EXE:自动登录,自动识别验证码,是一款通用浏览器。
软件功能
网页自动化操作、数据库自动化操作、本地文件自动化操作、邮件自动收发!
VG网页操作神器(原VG浏览器)是一款应用广泛的自动化操作工具,拥有近百个免费的自动化脚本功能模块,各种脚本功能可以像堆叠块一样直观的组合,结合逻辑控制和判断模块可以快速创建强大的自动操作脚本。该脚本使用简单灵活,无需任何编程基础,您可以轻松快速地编写强大而独特的脚本来辅助我们的工作,甚至可以生成独立的EXE程序进行销售。
变更日志
7.6.5(2019-05-13)
修复双击vgproj项目文件启动时无法生成script和runner的问题
执行 sql 语句时发生错误时不要终止脚本流
7.6.4 (2019-05-10)
添加超人云代码
添加气泡提示窗口大小定义
添加了常规设置选项 - ID 不显示在脚本步骤节点上
单击步骤加号和减号以取消选择步骤
修复了新文件上传步骤中的错误
其他细节的修改
7.6.3(2019-05-08)
修复了一些循环后步骤的重复问题
修复一些其他细节
特别说明
安装新版本时,建议先卸载旧版本。卸载时,不会自动删除脚本和信息库。安装新版本时,使用默认目录覆盖安装,脚本和信息库数据不会丢失。
细节 查看全部
抓取网页数据工具(VG网页操作神器(原VG浏览器)功能介绍及功能)
vg网页操作神器是一款非常专业的编程开发工具。它的页面简洁友好,功能强大。支持创建自动登录、识别验证码、自动数据抓取、自动提交数据、点击网页、下载文件、操作数据库。,发送和接收电子邮件和其他脚本。需要的朋友快来下载试试吧。
特征
可视化操作:操作简单,图形化操作完全可视化,无需专业IT人员。
定制流程:采集就像积木一样,功能自由组合。
自动编码:程序注重采集的效率,页面解析速度快。
生成EXE:自动登录,自动识别验证码,是一款通用浏览器。
软件功能
网页自动化操作、数据库自动化操作、本地文件自动化操作、邮件自动收发!
VG网页操作神器(原VG浏览器)是一款应用广泛的自动化操作工具,拥有近百个免费的自动化脚本功能模块,各种脚本功能可以像堆叠块一样直观的组合,结合逻辑控制和判断模块可以快速创建强大的自动操作脚本。该脚本使用简单灵活,无需任何编程基础,您可以轻松快速地编写强大而独特的脚本来辅助我们的工作,甚至可以生成独立的EXE程序进行销售。
变更日志
7.6.5(2019-05-13)
修复双击vgproj项目文件启动时无法生成script和runner的问题
执行 sql 语句时发生错误时不要终止脚本流
7.6.4 (2019-05-10)
添加超人云代码
添加气泡提示窗口大小定义
添加了常规设置选项 - ID 不显示在脚本步骤节点上
单击步骤加号和减号以取消选择步骤
修复了新文件上传步骤中的错误
其他细节的修改
7.6.3(2019-05-08)
修复了一些循环后步骤的重复问题
修复一些其他细节
特别说明
安装新版本时,建议先卸载旧版本。卸载时,不会自动删除脚本和信息库。安装新版本时,使用默认目录覆盖安装,脚本和信息库数据不会丢失。
细节
抓取网页数据工具( 利用Python模块来爬网数据,实现爬网数据的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-30 20:05
利用Python模块来爬网数据,实现爬网数据的需求)
从 网站 抓取数据的 3 种最佳方法
在过去的几年里,抓取数据的需求变得越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以采取的三种方法来从 网站 爬取数据。
1.使用网站API
许多大型社交媒体 网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问他们的数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。
2.构建自己的爬虫
但是,并非所有 网站 都向用户提供 API。部分网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出 RSS 提要,但由于使用受限,我不会建议或评论它们。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
爬虫如何工作?换句话说,爬虫是一种生成可以由提取器提供的 URL 列表的方法。爬虫可以定义为查找 URL 的工具。首先,您为爬虫提供一个要启动的网页,它们会跟随该页面上的所有链接。然后该过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python 是一种开源编程语言,您可以找到许多有用的函数库。这里我推荐 BeautifulSoup(一个 Python 库),因为它易于使用并且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库一起使用的原因。然后我们需要处理 HTML 标记以找到页面标记和右表中的所有链接。之后,遍历每一行 (tr) 并将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先我们看一下表格的HTML结构(我不会提取表格头信息)。
通过采用这种方法,您的爬虫是定制的。它可以处理API提取中遇到的一些困难。您可以使用代理来防止它被某些 网站 等阻止。整个过程在您的控制范围内。这种方法对于具有编码技能的人应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,以编程方式自行抓取 网站 网络可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些爬虫工具。
优采云采集器
一款集网页数据采集、移动互联网数据及API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据采集工具。2018年互联网数据采集软件排行榜排名第一,到2021年全球用户数已突破300万。
八分法
优采云海外版,2016年3月在美国洛杉矶上线,两年内在英文市场取得了较高的市场占有率,并深耕北美、欧洲、日本等市场。目前有英文、日文、法文、德文、西班牙文等版本。 查看全部
抓取网页数据工具(
利用Python模块来爬网数据,实现爬网数据的需求)
从 网站 抓取数据的 3 种最佳方法
在过去的几年里,抓取数据的需求变得越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以采取的三种方法来从 网站 爬取数据。
1.使用网站API
许多大型社交媒体 网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问他们的数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。
2.构建自己的爬虫
但是,并非所有 网站 都向用户提供 API。部分网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出 RSS 提要,但由于使用受限,我不会建议或评论它们。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
爬虫如何工作?换句话说,爬虫是一种生成可以由提取器提供的 URL 列表的方法。爬虫可以定义为查找 URL 的工具。首先,您为爬虫提供一个要启动的网页,它们会跟随该页面上的所有链接。然后该过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python 是一种开源编程语言,您可以找到许多有用的函数库。这里我推荐 BeautifulSoup(一个 Python 库),因为它易于使用并且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库一起使用的原因。然后我们需要处理 HTML 标记以找到页面标记和右表中的所有链接。之后,遍历每一行 (tr) 并将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先我们看一下表格的HTML结构(我不会提取表格头信息)。
通过采用这种方法,您的爬虫是定制的。它可以处理API提取中遇到的一些困难。您可以使用代理来防止它被某些 网站 等阻止。整个过程在您的控制范围内。这种方法对于具有编码技能的人应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,以编程方式自行抓取 网站 网络可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些爬虫工具。
优采云采集器
一款集网页数据采集、移动互联网数据及API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据采集工具。2018年互联网数据采集软件排行榜排名第一,到2021年全球用户数已突破300万。
八分法
优采云海外版,2016年3月在美国洛杉矶上线,两年内在英文市场取得了较高的市场占有率,并深耕北美、欧洲、日本等市场。目前有英文、日文、法文、德文、西班牙文等版本。
抓取网页数据工具(抓取网页数据工具:robotframework、php-it上传我的个人简历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-30 14:06
抓取网页数据工具:robotframework、php-it、phpbilib上传我的个人简历至:mockplus4.1、phpbilib、header.php、mediaquery、/-rmsrov
首先明确一下你上传简历的目的如果是想完善个人简历,希望在投递岗位时让hr更好的了解自己。那么,你可以考虑用mockito;如果是想把简历转换成pdf格式,可以把它放到浏览器等工具处理。
phpbilib,phpmyadmin
header
上传简历的时候可以自定义logo颜色等我就是这样上传的
,,操作比较简单
我用的是自助建站工具开源的一个挺好用的建站工具,
大帝客,而且是金山谷血狮导航的,
<p>不知道你说的是什么上传,是将网页批量上传到多个域名上?还是多个html文件上传到多个域名?还是多个php文件上传到多个域名上?每个html文件可以是一个文件名,域名可以是多个端口的,这样就很容易处理了。操作很简单,推荐下我自己的代码,/我只有一个文件名,域名。//完美--> 查看全部
抓取网页数据工具(抓取网页数据工具:robotframework、php-it上传我的个人简历)
抓取网页数据工具:robotframework、php-it、phpbilib上传我的个人简历至:mockplus4.1、phpbilib、header.php、mediaquery、/-rmsrov
首先明确一下你上传简历的目的如果是想完善个人简历,希望在投递岗位时让hr更好的了解自己。那么,你可以考虑用mockito;如果是想把简历转换成pdf格式,可以把它放到浏览器等工具处理。
phpbilib,phpmyadmin
header
上传简历的时候可以自定义logo颜色等我就是这样上传的
,,操作比较简单
我用的是自助建站工具开源的一个挺好用的建站工具,
大帝客,而且是金山谷血狮导航的,
<p>不知道你说的是什么上传,是将网页批量上传到多个域名上?还是多个html文件上传到多个域名?还是多个php文件上传到多个域名上?每个html文件可以是一个文件名,域名可以是多个端口的,这样就很容易处理了。操作很简单,推荐下我自己的代码,/我只有一个文件名,域名。//完美-->
抓取网页数据工具(抓取网页数据工具及结果方法:浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-29 15:03
抓取网页数据工具及结果方法:1。一个搜索引擎搜索一个网站,网站返回4个结果,1个前端时间报告,1个url文件、1个api文件及1个json文件2。设置字典格式,关键字提供这个网站上所有的关键字3。chrome浏览器按ctrl+v,输入网址,在网页上即可跳转相应的页面网站类型,选择最小的类型,然后输入网址结果可以进行的更精准的细分,实在不行就直接拖到浏览器中,然后点击观看视频教程。
使用百度爬虫直接写网址到工具对象中,在最后将所有单独的属性复制到工具对象中,将最后工具对象中获取结果保存为目录:详细的说明请到“jsimport”下面拉窗口观看,会有更详细的设置说明。详细说明请到"jsimport"下面拉窗口观看,会有更详细的设置说明。
不要人工更改表单,直接importscrapy然后有爬虫的话用他的代理,有时间就处理不需要人工。可以先设定weibo为根目录。
爬api接口就可以,注意cookie,
可以先使用google的爬虫。基本上中文api服务可以满足需求。
newscrapy的url
api接口可以,会使用google。有几个是要写上去。
用爬虫框架,常用urllib.request,
有一个库可以免费用,效果如下。github地址。marwuyu/jiebacode2015作者已放弃jieba。 查看全部
抓取网页数据工具(抓取网页数据工具及结果方法:浏览器)
抓取网页数据工具及结果方法:1。一个搜索引擎搜索一个网站,网站返回4个结果,1个前端时间报告,1个url文件、1个api文件及1个json文件2。设置字典格式,关键字提供这个网站上所有的关键字3。chrome浏览器按ctrl+v,输入网址,在网页上即可跳转相应的页面网站类型,选择最小的类型,然后输入网址结果可以进行的更精准的细分,实在不行就直接拖到浏览器中,然后点击观看视频教程。
使用百度爬虫直接写网址到工具对象中,在最后将所有单独的属性复制到工具对象中,将最后工具对象中获取结果保存为目录:详细的说明请到“jsimport”下面拉窗口观看,会有更详细的设置说明。详细说明请到"jsimport"下面拉窗口观看,会有更详细的设置说明。
不要人工更改表单,直接importscrapy然后有爬虫的话用他的代理,有时间就处理不需要人工。可以先设定weibo为根目录。
爬api接口就可以,注意cookie,
可以先使用google的爬虫。基本上中文api服务可以满足需求。
newscrapy的url
api接口可以,会使用google。有几个是要写上去。
用爬虫框架,常用urllib.request,
有一个库可以免费用,效果如下。github地址。marwuyu/jiebacode2015作者已放弃jieba。
抓取网页数据工具(如何使用简单易学的操作方法,快速获取网页源代码数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-28 06:12
抓取网页数据工具excel作为最常用的办公软件,我们无需赘述,下面将分享下如何使用简单易学的操作方法,快速获取网页源代码数据。现在的网页呈现几乎是千变万化,除了前端设计和排版的讲究以外,很多页面就是关键信息的罗列或者内容加载请求的过程,我们就分解这两个作为步骤,说说如何查看网页源代码信息吧。第一步:打开浏览器并打开/(记得添加ie浏览器下载组件到电脑中),如下图所示:第二步:点击左侧的“开发工具”按钮,如下图所示:第三步:选择“查看源代码”进入“源代码”界面,如下图所示:(注意。
1)我们看到浏览器右侧列表和名称数量有很多网页:
2)这些名称网页都是各大门户网站分类页面,如搜狐网,新浪网,腾讯网,百度网,中国网等等,有的数量庞大,有的简单,这个看个人喜好选择对于自己的文件夹页面,我们可以单独开一个文件夹来存放,例如搜狐网,方便后期进行数据管理。
3)你也可以通过打开qq,搜狗浏览器等代理浏览器来方便查看或者加载网页,也有不少网站支持,如下图所示:第四步:进入源代码页面后,选择“工具”中的“开发工具”并打开“浏览器插件”。
选择右侧的“源代码”点击打开第五步:打开浏览器插件后,首先进入“页面元素”:这个页面是根据上一步的输入拼音来拼接页面网址,如下图所示:第六步:在“页面元素”中我们发现有首页,个人首页,个人首页分类页面等等,选择其中一个就好,如下图所示:第七步:点击第二个首页,即首页资讯:它显示有三个方式可以查看网页源代码:(。
1)跳转浏览器,
2)直接打开“”首页“:首页分类页面在右上角有一个箭头标志,打开该列表浏览器,
3)打开我的网页:打开网页链接,即可查看其网页源代码,(注意,这个是复制的是首页资讯)ps:首页资讯页面源代码应该跟网页all有些不同,这个处理需要根据自己网站进行对比处理。第八步:出现浏览器列表页面列表,回到“源代码”页面,选择“下载”按钮,即可下载整个页面源代码:来源互联网免费报告,如有侵权,联系删除。 查看全部
抓取网页数据工具(如何使用简单易学的操作方法,快速获取网页源代码数据)
抓取网页数据工具excel作为最常用的办公软件,我们无需赘述,下面将分享下如何使用简单易学的操作方法,快速获取网页源代码数据。现在的网页呈现几乎是千变万化,除了前端设计和排版的讲究以外,很多页面就是关键信息的罗列或者内容加载请求的过程,我们就分解这两个作为步骤,说说如何查看网页源代码信息吧。第一步:打开浏览器并打开/(记得添加ie浏览器下载组件到电脑中),如下图所示:第二步:点击左侧的“开发工具”按钮,如下图所示:第三步:选择“查看源代码”进入“源代码”界面,如下图所示:(注意。
1)我们看到浏览器右侧列表和名称数量有很多网页:
2)这些名称网页都是各大门户网站分类页面,如搜狐网,新浪网,腾讯网,百度网,中国网等等,有的数量庞大,有的简单,这个看个人喜好选择对于自己的文件夹页面,我们可以单独开一个文件夹来存放,例如搜狐网,方便后期进行数据管理。
3)你也可以通过打开qq,搜狗浏览器等代理浏览器来方便查看或者加载网页,也有不少网站支持,如下图所示:第四步:进入源代码页面后,选择“工具”中的“开发工具”并打开“浏览器插件”。
选择右侧的“源代码”点击打开第五步:打开浏览器插件后,首先进入“页面元素”:这个页面是根据上一步的输入拼音来拼接页面网址,如下图所示:第六步:在“页面元素”中我们发现有首页,个人首页,个人首页分类页面等等,选择其中一个就好,如下图所示:第七步:点击第二个首页,即首页资讯:它显示有三个方式可以查看网页源代码:(。
1)跳转浏览器,
2)直接打开“”首页“:首页分类页面在右上角有一个箭头标志,打开该列表浏览器,
3)打开我的网页:打开网页链接,即可查看其网页源代码,(注意,这个是复制的是首页资讯)ps:首页资讯页面源代码应该跟网页all有些不同,这个处理需要根据自己网站进行对比处理。第八步:出现浏览器列表页面列表,回到“源代码”页面,选择“下载”按钮,即可下载整个页面源代码:来源互联网免费报告,如有侵权,联系删除。
抓取网页数据工具( 优采云采集器大数据应用开发平台--优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-28 02:08
优采云采集器大数据应用开发平台--优采云采集器)
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
优采云采集器
简介:优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。号称是免费的,但实际上导出数据需要积分,做任务也可以赚取积分,但一般情况下,基本都需要购买积分。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
吉苏克
Jisoke是一款使用门槛低的小型爬虫工具。可实现完全可视化操作,无需编程基础,熟悉计算机操作即可轻松掌握。整个采集过程也是所见即所得的,遍历的链接信息、爬取结果信息、错误信息等都会及时反映在软件界面中。
优采云云爬虫
简介:优采云Cloud是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据采集和实时数据监测和数据分析服务。
优势:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等。
优采云采集器
简介:优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。 查看全部
抓取网页数据工具(
优采云采集器大数据应用开发平台--优采云采集器)
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
优采云采集器
简介:优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。号称是免费的,但实际上导出数据需要积分,做任务也可以赚取积分,但一般情况下,基本都需要购买积分。免费功能可实现数据采集、清洗、分析、挖掘和最终可用数据呈现。接口和插件扩展等高级功能是收费的。通过设置内容采集规则,可以方便快捷的抓取网络上散落的文字、图片、压缩文件、视频等内容。
吉苏克
Jisoke是一款使用门槛低的小型爬虫工具。可实现完全可视化操作,无需编程基础,熟悉计算机操作即可轻松掌握。整个采集过程也是所见即所得的,遍历的链接信息、爬取结果信息、错误信息等都会及时反映在软件界面中。
优采云云爬虫
简介:优采云Cloud是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据采集和实时数据监测和数据分析服务。
优势:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等。
优采云采集器
简介:优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
抓取网页数据工具(【数据结构与算法知识】—动态规划之背包问题_天阑之蓝)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-27 22:12
【数据结构与算法知识】——动态规划01背包问题 - 程序员大本营
阅读前阅读这里:博主是学习数据相关知识的学生。在每一个领域,我们都应该是一个学生的心态,不应该有身份标签来限制我们学习的范围,所以博客记录的是学习过程中的一些总结,希望和大家一起进步。录音时,有很多疏漏和不足之处。如有问题请私聊博主指正。博客地址:【天澜之澜的博客】(),学习过程中难免有困难和困惑。希望每个人都能肯定自己,超越自己,最终在学习的过程中创造自己。
文档索引模型 - PersistenceExplorer Blog
1.词条-文档关联矩阵:值为0,1。0表示文档不收录词条,1表示文档收录词条。缺点是矩阵中还有大量的0项,浪费存储空间。2.倒排索引:由词条字典(由索引词组成)和与词条关联的倒排记录表(由倒排记录组成,每条倒排记录收录文档ID,词条由诸如文档中出现的位置),倒排记录表一般按照文档ID号排序。3.倒排索引建立过程:(1)采集要索引的文档,(2)文档入口,(3)入口入口
【Unity 24】向量点积和叉积在Unity中的应用 - 程序员大本营
PS:本系列笔记会记录这次在北京学习Unity开发的整体过程,方便以后写个总结,笔记每天更新。笔记的内容都是自己理解的。不能保证每个点都乘以找到角度。交叉乘法求方向,比如敌人近了,点乘可以求出玩家面对的方向和敌人方向的夹角,交叉乘法可以得到左转。或者右转最好转向敌人 Part 1 点积:数学上的点积是 a * b = |a| * |b| * cos(Θ) Unity 中的点积也是如此。结果是……
【数据结构C++邓俊辉】第2章向量 - JonyChan - JC的博客 - 程序员大本营
第1章向量1.1 法波纳契数:线性递归,返回当前计算值,参考Vector vector支持的操作界面记录之前的计算值 删除区间 delete:remove(lo, hi) 这个方法不是删除一个移动一次性数组,大大降低了时间复杂度
文本分析--建立术语-文档矩阵的潜在语义分析
文本分析-潜在语义分析中术语的建立-文档矩阵标签(空格分隔):SPARK机器学习欢迎来到奔小草的微信信号:大数据机器学习。以后会不定期分享机器学习、大数据学习资料和博文。1.Latent Semantic Analysis,简称LSA,中文叫Latent Semantic Analysis,是一种自然语言处理和信息检索技术. LSA 将语料库提炼成一组相关的概念,每个概念都捕获数据中的一个主题,通常也是与语料库讨论的主题
小米4C直接解锁闪入TWRP_dengniuting3416的博客 - 程序员大本营
1、安装android for windows驱动,让电脑windows系统识别手机,安装小米助手。安装完成后,在连接手机时,如果小米助手能成功连接手机,则证明OK。2、安装ADB和fastboot命令环境 Minimal ADB和Fastboot,下载后双击安装,然后打开安装好的程序。在我的电脑上,这个产品的安装路径是 C:\Program Files (x8... 查看全部
抓取网页数据工具(【数据结构与算法知识】—动态规划之背包问题_天阑之蓝)
【数据结构与算法知识】——动态规划01背包问题 - 程序员大本营
阅读前阅读这里:博主是学习数据相关知识的学生。在每一个领域,我们都应该是一个学生的心态,不应该有身份标签来限制我们学习的范围,所以博客记录的是学习过程中的一些总结,希望和大家一起进步。录音时,有很多疏漏和不足之处。如有问题请私聊博主指正。博客地址:【天澜之澜的博客】(),学习过程中难免有困难和困惑。希望每个人都能肯定自己,超越自己,最终在学习的过程中创造自己。
文档索引模型 - PersistenceExplorer Blog
1.词条-文档关联矩阵:值为0,1。0表示文档不收录词条,1表示文档收录词条。缺点是矩阵中还有大量的0项,浪费存储空间。2.倒排索引:由词条字典(由索引词组成)和与词条关联的倒排记录表(由倒排记录组成,每条倒排记录收录文档ID,词条由诸如文档中出现的位置),倒排记录表一般按照文档ID号排序。3.倒排索引建立过程:(1)采集要索引的文档,(2)文档入口,(3)入口入口
【Unity 24】向量点积和叉积在Unity中的应用 - 程序员大本营
PS:本系列笔记会记录这次在北京学习Unity开发的整体过程,方便以后写个总结,笔记每天更新。笔记的内容都是自己理解的。不能保证每个点都乘以找到角度。交叉乘法求方向,比如敌人近了,点乘可以求出玩家面对的方向和敌人方向的夹角,交叉乘法可以得到左转。或者右转最好转向敌人 Part 1 点积:数学上的点积是 a * b = |a| * |b| * cos(Θ) Unity 中的点积也是如此。结果是……
【数据结构C++邓俊辉】第2章向量 - JonyChan - JC的博客 - 程序员大本营
第1章向量1.1 法波纳契数:线性递归,返回当前计算值,参考Vector vector支持的操作界面记录之前的计算值 删除区间 delete:remove(lo, hi) 这个方法不是删除一个移动一次性数组,大大降低了时间复杂度
文本分析--建立术语-文档矩阵的潜在语义分析
文本分析-潜在语义分析中术语的建立-文档矩阵标签(空格分隔):SPARK机器学习欢迎来到奔小草的微信信号:大数据机器学习。以后会不定期分享机器学习、大数据学习资料和博文。1.Latent Semantic Analysis,简称LSA,中文叫Latent Semantic Analysis,是一种自然语言处理和信息检索技术. LSA 将语料库提炼成一组相关的概念,每个概念都捕获数据中的一个主题,通常也是与语料库讨论的主题
小米4C直接解锁闪入TWRP_dengniuting3416的博客 - 程序员大本营
1、安装android for windows驱动,让电脑windows系统识别手机,安装小米助手。安装完成后,在连接手机时,如果小米助手能成功连接手机,则证明OK。2、安装ADB和fastboot命令环境 Minimal ADB和Fastboot,下载后双击安装,然后打开安装好的程序。在我的电脑上,这个产品的安装路径是 C:\Program Files (x8...
抓取网页数据工具(web页面数据采集工具通达网络爬虫管理工具应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-26 10:09
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
原创文章,作者:日照seo,如转载请注明出处: 查看全部
抓取网页数据工具(web页面数据采集工具通达网络爬虫管理工具应用场景)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
http://www.youxi777.cn/wp-cont ... 84.jpg" />网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
http://www.youxi777.cn/wp-cont ... d8.jpg" />网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
原创文章,作者:日照seo,如转载请注明出处:
抓取网页数据工具(风越网页批量填写数据提取软件功能特点支持下拉菜单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-25 12:11
风月网页批量填表数据提取软件是风月软件推出的一款功能强大、绿色、免费的网页批量自动填表软件。软件功能强大,支持更多类型的页面填充和控制元素,精度更高。
其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信用、抢牌等工具。
风月网页批量填写数据提取软件可以自动分析网页中已经填写的表单内容,并保存为表单填写规则。下载指定的网页链接文件。一键填写整页表格,简单方便。
风月网页批量填写数据提取软件的特点
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
抓取网页数据工具(风越网页批量填写数据提取软件功能特点支持下拉菜单)
风月网页批量填表数据提取软件是风月软件推出的一款功能强大、绿色、免费的网页批量自动填表软件。软件功能强大,支持更多类型的页面填充和控制元素,精度更高。
其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信用、抢牌等工具。
风月网页批量填写数据提取软件可以自动分析网页中已经填写的表单内容,并保存为表单填写规则。下载指定的网页链接文件。一键填写整页表格,简单方便。
风月网页批量填写数据提取软件的特点
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
电脑正式版
安卓官方手机版
IOS官方手机版
抓取网页数据工具( 有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 582 次浏览 • 2022-03-25 12:07
有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
抓取网页文本的简单方法
一些网站信息对企业数据分析有很大的价值,比如微博上的企业评论,论坛上的一些企业信息,那么如何使用工具简单的采集网页文字呢?? 下面以采集新浪论坛信息为例,介绍一种简单的网页文字抓取方法。
采集网站:
/forum-2-1.html
使用功能点:
●页面设置
●分页表信息提取
第 1 步:创建一个 采集 任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
保存网址后会在优采云采集器中打开页面,红框内的评价信息就是本次demo的内容为采集
第 2 步:创建翻页循环
●找到翻页按钮,设置翻页周期
●设置ajax翻页时间
将页面下拉至最下方,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“更多操作”
选择“循环单击单个链接”
第三步:分页表信息采集
●选择需要采集的字段信息,创建采集列表
●编辑采集 字段名称
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据会被选中并变为绿色,点击右侧提示点击“TR”
选中的数据 当前行的数据将被全部选中,点击“选择子元素”
在右侧的操作提示框中,勾选提取的字段,删除不需要的字段,点击“全选”,点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。修改采集任务名和字段名,点击下方提示中的“保存并开始采集”
根据采集的情况选择合适的采集方法,这里选择“Start Local采集”
注意:本地采集占用当前计算机资源来执行采集,如果有采集时间要求或者当前计算机长时间不能执行采集,你可以使用云采集功能,云采集做采集在网络中,不需要当前电脑支持,可以关机,可以设置多个云节点分发
分散任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以使用。执行导出操作。
第 4 步:数据采集 和导出
采集完成后,选择合适的导出方式,导出采集好的数据
相关 采集 教程:
如何使用豆瓣电影爬虫
/教程/dbmoviecrawl
方天下爬虫教程
/教程/ftxcrawl
美团数据采集方法
/教程/mtdatazq
微信文章爬虫教程
/教程/wxarticlecrawl
知乎如何使用爬虫规则
/教程/知乎crawl
API介绍
/教程/apijs
单页数据采集
/教程/dwysj
优采云采集原理
/教程/spcjyl
模拟登录获取网站数据
/教程/cookdenglu 查看全部
抓取网页数据工具(
有些采集网页文字简单的抓取方法-本文以采集新浪论坛)
抓取网页文本的简单方法
一些网站信息对企业数据分析有很大的价值,比如微博上的企业评论,论坛上的一些企业信息,那么如何使用工具简单的采集网页文字呢?? 下面以采集新浪论坛信息为例,介绍一种简单的网页文字抓取方法。
采集网站:
/forum-2-1.html
使用功能点:
●页面设置
●分页表信息提取
第 1 步:创建一个 采集 任务
进入主界面选择,选择自定义模式
将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
保存网址后会在优采云采集器中打开页面,红框内的评价信息就是本次demo的内容为采集
第 2 步:创建翻页循环
●找到翻页按钮,设置翻页周期
●设置ajax翻页时间
将页面下拉至最下方,找到下一页按钮,点击鼠标,在右侧的操作提示框中选择“更多操作”
选择“循环单击单个链接”
第三步:分页表信息采集
●选择需要采集的字段信息,创建采集列表
●编辑采集 字段名称
移动鼠标选中表格中任意空白信息,点击右键,如图,框内的数据会被选中并变为绿色,点击右侧提示点击“TR”
选中的数据 当前行的数据将被全部选中,点击“选择子元素”
在右侧的操作提示框中,勾选提取的字段,删除不需要的字段,点击“全选”,点击“采集以下数据”
注意:提示框中的字段会出现一个“X”,点击删除该字段。修改采集任务名和字段名,点击下方提示中的“保存并开始采集”
根据采集的情况选择合适的采集方法,这里选择“Start Local采集”
注意:本地采集占用当前计算机资源来执行采集,如果有采集时间要求或者当前计算机长时间不能执行采集,你可以使用云采集功能,云采集做采集在网络中,不需要当前电脑支持,可以关机,可以设置多个云节点分发
分散任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以使用。执行导出操作。
第 4 步:数据采集 和导出
采集完成后,选择合适的导出方式,导出采集好的数据
相关 采集 教程:
如何使用豆瓣电影爬虫
/教程/dbmoviecrawl
方天下爬虫教程
/教程/ftxcrawl
美团数据采集方法
/教程/mtdatazq
微信文章爬虫教程
/教程/wxarticlecrawl
知乎如何使用爬虫规则
/教程/知乎crawl
API介绍
/教程/apijs
单页数据采集
/教程/dwysj
优采云采集原理
/教程/spcjyl
模拟登录获取网站数据
/教程/cookdenglu
抓取网页数据工具(快速有效地将小红书的商品信息采集下来的步骤(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2022-03-25 12:06
)
小红书是在线社区、跨境电商、分享平台、口碑数据库。最近很多小伙伴都在讨论这个网站的产品信息抓取,讨论的更多是关于如何抓取瀑布网页下面的内容。这里不想讨论技术方法,直接介绍一个快速的采集软件,可以直接使用,不讲技术细节。
下面给大家分享一下快速有效下载小红书采集产品信息的步骤。
1.准备工具——吉索克网络爬虫
下载、安装、打开、登录账号,这里不废话,直接上干货
2.利用小红书商品列表数据DIY,快采集
数据DIY是一款快速采集工具,无需编程即可直接使用
1)输入数据DIY,从GooSeeker顶部菜单进入路线网站:资源->数据DIY
2)在Data DIY网页上,选择Category — 网站 — Web Pages
小红书的具体种类有:
参考下图
3)比较示例页面并观察页面结构。输入的 URL 必须具有相同的页面结构,否则将 采集 失败。
小红书的示例页面是这样的
产品列表网址来自手机小红书APP。获取网址的方法是:在手机上打开小红书APP->点击商城中的产品目录(不要点击更多)->然后点击分类选择/热门,就会看到产品列表,然后点击右上角的分享按钮,然后用电脑上的社交软件接收。
您可能会看到像这样需要 采集 的页面,您可以比较它们,它们是相同的。
可以看出,两个页面几乎一样,但产品不同。
4)输入你想要的网址采集,选择采集一直向下滚动,点击获取数据,启动采集
您将看到要求启动爬虫窗口的提示。并将启动 2 个窗口,一个用于 采集 数据,一个用于打包数据。不要在运行时关闭它们,也不要最小化它们。但是这些窗口可以覆盖其他窗口
5)等待采集完成,打包下载数据
注意:提示采集完成后不要立即关闭窗口,需要等待打包按钮变为绿色,采集的状态变为采集,请见下图
6)包数据
7)下载数据
8)这里我们的数据是采集下来的,我们来看看我们采集收到的数据
查看全部
抓取网页数据工具(快速有效地将小红书的商品信息采集下来的步骤(组图)
)
小红书是在线社区、跨境电商、分享平台、口碑数据库。最近很多小伙伴都在讨论这个网站的产品信息抓取,讨论的更多是关于如何抓取瀑布网页下面的内容。这里不想讨论技术方法,直接介绍一个快速的采集软件,可以直接使用,不讲技术细节。
下面给大家分享一下快速有效下载小红书采集产品信息的步骤。
1.准备工具——吉索克网络爬虫
下载、安装、打开、登录账号,这里不废话,直接上干货
2.利用小红书商品列表数据DIY,快采集
数据DIY是一款快速采集工具,无需编程即可直接使用
1)输入数据DIY,从GooSeeker顶部菜单进入路线网站:资源->数据DIY
2)在Data DIY网页上,选择Category — 网站 — Web Pages
小红书的具体种类有:
参考下图
3)比较示例页面并观察页面结构。输入的 URL 必须具有相同的页面结构,否则将 采集 失败。
小红书的示例页面是这样的
产品列表网址来自手机小红书APP。获取网址的方法是:在手机上打开小红书APP->点击商城中的产品目录(不要点击更多)->然后点击分类选择/热门,就会看到产品列表,然后点击右上角的分享按钮,然后用电脑上的社交软件接收。
您可能会看到像这样需要 采集 的页面,您可以比较它们,它们是相同的。
可以看出,两个页面几乎一样,但产品不同。
4)输入你想要的网址采集,选择采集一直向下滚动,点击获取数据,启动采集
您将看到要求启动爬虫窗口的提示。并将启动 2 个窗口,一个用于 采集 数据,一个用于打包数据。不要在运行时关闭它们,也不要最小化它们。但是这些窗口可以覆盖其他窗口
5)等待采集完成,打包下载数据
注意:提示采集完成后不要立即关闭窗口,需要等待打包按钮变为绿色,采集的状态变为采集,请见下图
6)包数据
7)下载数据
8)这里我们的数据是采集下来的,我们来看看我们采集收到的数据
抓取网页数据工具(黑帽零距离是专业可靠的快速排名技术专注黑帽SEO优化 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-16 23:18
)
黑帽零距离是一种专业可靠的快速排名技术,专注于黑帽SEO优化,【搜狗黑帽seo快收录]和关键词优化等服务,黑帽零距离也为您提供with [Spider] 为什么页面没有被 收录 爬取?] 供大家学习和阅读相关知识和技能,希望对大家有所帮助。
不知道大家观察网站的数据有没有发现这么有趣的问题,就是蜘蛛爬到了我们的网站,但是页面还是没有收录 ,那么 网站@ >收录 有什么问题呢?有兴趣的请关注黑帽零距离小编了解一下~
1、有人觉得便宜就买便宜质量差的域名,因为便宜的域名可能之前被百度k过或者之前是灰站,所以这个域名就更难了收录,如果想尽快把域名改成收录,建议尽快改域名。
2、网站新上线后1个月内尽量不要安装百度统计,因为安装百度统计后,蜘蛛爬得更频繁更深,所以如果你的网站不调整一下,只会让你的网站收录变慢,所以一个月内不要上传百度统计代码。
3、网站的内容页面质量太差了,网站刚上线可能是收录,如果大家都在更新文章一直在写伪原创不利于百度的爬取,所以如果百度没有收录,大家应该尽量写原创,这样蜘蛛很容易抢到你的伪原创@网站,你可以快速认出你的网站,那么收录就会快速上去。
3、发布的外链质量不高,也会影响百度的收录,所以如果你是捡新站,一定要发布高质量的外链,不能经常发送。这样,蜘蛛可能会认为你在作弊。
希望黑帽零距离编辑器的介绍能对您有所帮助,更多新闻请关注我们!如果您对这些方面不了解,可以点击咨询我们,我们将有专业人士为您解答!
查看全部
抓取网页数据工具(黑帽零距离是专业可靠的快速排名技术专注黑帽SEO优化
)
黑帽零距离是一种专业可靠的快速排名技术,专注于黑帽SEO优化,【搜狗黑帽seo快收录]和关键词优化等服务,黑帽零距离也为您提供with [Spider] 为什么页面没有被 收录 爬取?] 供大家学习和阅读相关知识和技能,希望对大家有所帮助。
不知道大家观察网站的数据有没有发现这么有趣的问题,就是蜘蛛爬到了我们的网站,但是页面还是没有收录 ,那么 网站@ >收录 有什么问题呢?有兴趣的请关注黑帽零距离小编了解一下~
1、有人觉得便宜就买便宜质量差的域名,因为便宜的域名可能之前被百度k过或者之前是灰站,所以这个域名就更难了收录,如果想尽快把域名改成收录,建议尽快改域名。
2、网站新上线后1个月内尽量不要安装百度统计,因为安装百度统计后,蜘蛛爬得更频繁更深,所以如果你的网站不调整一下,只会让你的网站收录变慢,所以一个月内不要上传百度统计代码。
3、网站的内容页面质量太差了,网站刚上线可能是收录,如果大家都在更新文章一直在写伪原创不利于百度的爬取,所以如果百度没有收录,大家应该尽量写原创,这样蜘蛛很容易抢到你的伪原创@网站,你可以快速认出你的网站,那么收录就会快速上去。
3、发布的外链质量不高,也会影响百度的收录,所以如果你是捡新站,一定要发布高质量的外链,不能经常发送。这样,蜘蛛可能会认为你在作弊。
希望黑帽零距离编辑器的介绍能对您有所帮助,更多新闻请关注我们!如果您对这些方面不了解,可以点击咨询我们,我们将有专业人士为您解答!
抓取网页数据工具( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2022-03-16 12:24
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也因为最近在梳理36氪文章的一些标签,想看看还有哪些其他风险投资相关的标准网站可以参考,所以找到了一家公司,名字叫:“恩牛”数据”网站,它提供的一组“行业系统”标签,具有很大的参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用了自己需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”页面上的按钮,您将看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,那么工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,你会发现多了一行Selector表格,那么你可以直接点击Action中的Data preview,查看你想要获取的所有元素值。
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。我点击数据预览时弹出的窗口内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
抓取网页数据工具(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也因为最近在梳理36氪文章的一些标签,想看看还有哪些其他风险投资相关的标准网站可以参考,所以找到了一家公司,名字叫:“恩牛”数据”网站,它提供的一组“行业系统”标签,具有很大的参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用了自己需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”页面上的按钮,您将看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,那么工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,你会发现多了一行Selector表格,那么你可以直接点击Action中的Data preview,查看你想要获取的所有元素值。
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。我点击数据预览时弹出的窗口内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~
抓取网页数据工具(1.优采云优采云采集器:集搜客没有流程的概念和概念 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-03-15 17:17
)
新朋友点击上方蓝字“Office Exchange Network”快速关注
1. 优采云采集器
优采云采集器我们一直在使用它,它是一个旧的采集工具。它不仅可以做爬虫,还可以做数据清洗、分析、挖掘和可视化。数据源可以来自网页,可以通过自定义的采集规则抓取网页中可见的内容和不可见的内容。
2. 优采云优采云也是众所周知的采集工具免费采集模板其实就是内容采集规则,包括电商、生活服务、社交媒体,论坛网站都可以是采集,用起来很方便。当然你也可以自定义任务。也可以执行云采集,即配置采集的任务后,可以将采集的任务交给优采云的云。优采云一共有5000台服务器,通过云端多节点并发采集,采集速度比本地采集快很多。另外,可以自动切换多个IP,避免IP阻塞影响采集。在很多情况下,自动IP切换和云采集是自动化采集的关键。< @3. 这个工具的特点是完全可视化,不需要编程。整个采集过程也是所见即所得,抓拍结果信息、错误信息等都在软件中体现出来。与优采云相比,Jisouke没有进程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。
查看全部
抓取网页数据工具(1.优采云优采云采集器:集搜客没有流程的概念和概念
)
新朋友点击上方蓝字“Office Exchange Network”快速关注
1. 优采云采集器
优采云采集器我们一直在使用它,它是一个旧的采集工具。它不仅可以做爬虫,还可以做数据清洗、分析、挖掘和可视化。数据源可以来自网页,可以通过自定义的采集规则抓取网页中可见的内容和不可见的内容。
2. 优采云优采云也是众所周知的采集工具免费采集模板其实就是内容采集规则,包括电商、生活服务、社交媒体,论坛网站都可以是采集,用起来很方便。当然你也可以自定义任务。也可以执行云采集,即配置采集的任务后,可以将采集的任务交给优采云的云。优采云一共有5000台服务器,通过云端多节点并发采集,采集速度比本地采集快很多。另外,可以自动切换多个IP,避免IP阻塞影响采集。在很多情况下,自动IP切换和云采集是自动化采集的关键。< @3. 这个工具的特点是完全可视化,不需要编程。整个采集过程也是所见即所得,抓拍结果信息、错误信息等都在软件中体现出来。与优采云相比,Jisouke没有进程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。Jisouke 没有过程的概念。用户只需要关注抓取哪些数据,流程细节完全由吉索客处理。即搜客的缺点是不具备云采集的功能,所有爬虫都运行在用户自己的电脑上。
抓取网页数据工具(阿里云gt云栖监控脚本(组图)监控(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-14 16:05
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
抓取网页数据工具(阿里云gt云栖监控脚本(组图)监控(图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
抓取网页数据工具(抓取网页数据工具excel电商数据分析工具(用友)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-10 17:03
抓取网页数据工具excel电商数据分析工具用友商业数据管理软件,数据分析使用excel将中鞋子信息进行提取中鞋子信息提取使用的是“excel提取商品信息”使用提取到的数据“商品id”即可获取“商品”标题、图片地址,并将获取的数据保存为excel文件,在excel中数据分析,使用“数据透视表”工具进行数据透视分析具体操作如下:使用vlookup函数将分析结果导入到excel可以通过使用“插入辅助列”中的id直接获取到鞋子的信息;也可以通过“条件格式”中的“公式引用”通过分析中的“商品标题”、“商品图片”、“商品价格”可以识别到商品的信息,再通过“公式引用”将商品信息进行引用分析可以通过“分析师培训”数据源识别出培训的类别,然后再通过“插入辅助列”进行转换分析excel中使用sql进行数据分析操作sql工具可以识别到各个鞋子的名称、标题、图片、价格,通过利用筛选函数“id”识别鞋子名称和标题,筛选出满足条件的数据,利用sql语句进行数据操作cn-shop_air_worth数据提取将“商品id”数据透视到excel可以看到商品满足了“商品”标题、“商品图片”、“商品价格”需求,选择“商品商品信息”,提取如下图:商品信息透视数据透视分析如下图选择类别“儿童跑步鞋”,可以看到数据具体到“运动内衣”可以看到购买的数量如下图:运动内衣购买销量选择“内衣鞋子”,提取销量可以看到销量最多的商品是“儿童跑步鞋”;销量最多的鞋子列存在销量时间集中的情况;在选择“配饰”进行分析时,可以看到销量差异性不是很大;利用“分析师培训”数据源选择“店铺”进行分析;在手机商品中提取销量,销量分布如下图利用excel进行图表展示如下:后续关于运营分析、数据分析相关内容还有《深入浅出数据分析》《数据分析实战》《数据分析案例精选之2017年运营分析报告模板》,欢迎大家加入笔者新创建的数据分析群,以下是分享文章(可能有些涉及到隐私),感兴趣朋友可以关注下本人公众号“小象互联网数据分析”。《深入浅出数据分析》。 查看全部
抓取网页数据工具(抓取网页数据工具excel电商数据分析工具(用友)(组图))
抓取网页数据工具excel电商数据分析工具用友商业数据管理软件,数据分析使用excel将中鞋子信息进行提取中鞋子信息提取使用的是“excel提取商品信息”使用提取到的数据“商品id”即可获取“商品”标题、图片地址,并将获取的数据保存为excel文件,在excel中数据分析,使用“数据透视表”工具进行数据透视分析具体操作如下:使用vlookup函数将分析结果导入到excel可以通过使用“插入辅助列”中的id直接获取到鞋子的信息;也可以通过“条件格式”中的“公式引用”通过分析中的“商品标题”、“商品图片”、“商品价格”可以识别到商品的信息,再通过“公式引用”将商品信息进行引用分析可以通过“分析师培训”数据源识别出培训的类别,然后再通过“插入辅助列”进行转换分析excel中使用sql进行数据分析操作sql工具可以识别到各个鞋子的名称、标题、图片、价格,通过利用筛选函数“id”识别鞋子名称和标题,筛选出满足条件的数据,利用sql语句进行数据操作cn-shop_air_worth数据提取将“商品id”数据透视到excel可以看到商品满足了“商品”标题、“商品图片”、“商品价格”需求,选择“商品商品信息”,提取如下图:商品信息透视数据透视分析如下图选择类别“儿童跑步鞋”,可以看到数据具体到“运动内衣”可以看到购买的数量如下图:运动内衣购买销量选择“内衣鞋子”,提取销量可以看到销量最多的商品是“儿童跑步鞋”;销量最多的鞋子列存在销量时间集中的情况;在选择“配饰”进行分析时,可以看到销量差异性不是很大;利用“分析师培训”数据源选择“店铺”进行分析;在手机商品中提取销量,销量分布如下图利用excel进行图表展示如下:后续关于运营分析、数据分析相关内容还有《深入浅出数据分析》《数据分析实战》《数据分析案例精选之2017年运营分析报告模板》,欢迎大家加入笔者新创建的数据分析群,以下是分享文章(可能有些涉及到隐私),感兴趣朋友可以关注下本人公众号“小象互联网数据分析”。《深入浅出数据分析》。
抓取网页数据工具(智能识别方式WebHarvy自动检索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-08 02:12
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置是使用内部计算机浏览器。适用于扩展分析,可自动获取相似连接列表。可视化易于操作。
【特征】
智能识别方式
WebHarvy 如何自动检索出现在网页中的数据。因此,如果您必须从网页中抓取项目列表(姓名、完整地址、电子邮件、价格等),您不必做所有额外的设备。如果数据重复,WebHarvy 会自动抓取。
通过导出捕获的数据
能够以各种文件格式存储从网页中提取的数据。WebHarvy URL scraper 的当前版本号允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以将抓取的数据导出到 SQL 数据库。
从几页中提取
典型的网页显示信息数据,例如跨多个页面的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚突出显示“连接到下一页”,WebHarvy URL Scraper 将自动从所有页面中抓取数据。
可视化操作面板
WebHarvy 是网页提取数据可视化的专用工具。事实上,绝对不需要编写任何脚本或编码来提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。这很容易!
根据 关键词 提取
基于 关键词 的提取允许您从百度搜索页面捕获输入到 关键词 的列表数据。在挖掘数据的同时,您创建的设备将在给定输入 关键词 的情况下完全自动化。可以指定任意总计的输入关键词
提取分类
WebHarvy URL Scraper 允许您从在 网站 中产生类似页面的连接列表中提取数据。这使您可以在抓取的 URL 中应用单一类型或副标题。
应用正则表达式提取
WebHarvy 可以在文本或网页的 HTML 源代码中应用正则表达式(正则表达式)并提取匹配部分。这种强大的技术性给你很多协调,加上顶部的统计数据。
【软件特色】
WebHarvy 是一个视觉效果互联网刮板。绝对不必编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择要单击的数据。超级简单!
WebHarvy 自动检索从网页生成的数据。因此,如果您必须从网页中抓取新商品列表(名称、完整地址、电子邮件、价格等),您无需执行任何其他操作。如果数据重复,WebHarvy 会自动删除。
您可以以多种文件格式保存从网页中提取的数据。WebHarvy Web Scraper 的当前版本号允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您还可以将爬取的数据导出到 SQL 数据库。
通常,一个网页在多个页面上显示诸如信息项列表之类的数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
【新版本更新】
页面启动恢复时很有可能禁止使用链接
能够为页面模式配置专用接口
能够自动检索可以在 HTML 上配备的资源 查看全部
抓取网页数据工具(智能识别方式WebHarvy自动检索)
WebHarvy 是网页数据爬取的专用工具。该软件可以提取网页中的文字和图片,输入网址即可打开。默认设置是使用内部计算机浏览器。适用于扩展分析,可自动获取相似连接列表。可视化易于操作。
【特征】
智能识别方式
WebHarvy 如何自动检索出现在网页中的数据。因此,如果您必须从网页中抓取项目列表(姓名、完整地址、电子邮件、价格等),您不必做所有额外的设备。如果数据重复,WebHarvy 会自动抓取。
通过导出捕获的数据
能够以各种文件格式存储从网页中提取的数据。WebHarvy URL scraper 的当前版本号允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文档。您还可以将抓取的数据导出到 SQL 数据库。
从几页中提取
典型的网页显示信息数据,例如跨多个页面的产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚突出显示“连接到下一页”,WebHarvy URL Scraper 将自动从所有页面中抓取数据。
可视化操作面板
WebHarvy 是网页提取数据可视化的专用工具。事实上,绝对不需要编写任何脚本或编码来提取数据。使用 webharvy 的嵌入式计算机浏览器访问网页。您可以选择通过单击鼠标来提取数据。这很容易!
根据 关键词 提取
基于 关键词 的提取允许您从百度搜索页面捕获输入到 关键词 的列表数据。在挖掘数据的同时,您创建的设备将在给定输入 关键词 的情况下完全自动化。可以指定任意总计的输入关键词
提取分类
WebHarvy URL Scraper 允许您从在 网站 中产生类似页面的连接列表中提取数据。这使您可以在抓取的 URL 中应用单一类型或副标题。
应用正则表达式提取
WebHarvy 可以在文本或网页的 HTML 源代码中应用正则表达式(正则表达式)并提取匹配部分。这种强大的技术性给你很多协调,加上顶部的统计数据。
【软件特色】
WebHarvy 是一个视觉效果互联网刮板。绝对不必编写所有脚本或编码来抓取数据。您将使用 WebHarvy 的嵌入式计算机浏览器访问网页。您可以选择要单击的数据。超级简单!
WebHarvy 自动检索从网页生成的数据。因此,如果您必须从网页中抓取新商品列表(名称、完整地址、电子邮件、价格等),您无需执行任何其他操作。如果数据重复,WebHarvy 会自动删除。
您可以以多种文件格式保存从网页中提取的数据。WebHarvy Web Scraper 的当前版本号允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文档。您还可以将爬取的数据导出到 SQL 数据库。
通常,一个网页在多个页面上显示诸如信息项列表之类的数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需强调“连接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
【新版本更新】
页面启动恢复时很有可能禁止使用链接
能够为页面模式配置专用接口
能够自动检索可以在 HTML 上配备的资源
抓取网页数据工具(模拟器逍遥安卓模拟器官网下载好之后打开如下图图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-05 13:01
刚接触爬虫的时候,我们通常使用浏览器的开发工具——F12中的NetWork来抓取网页,但这有个缺点,就是如果网页加载了很多乱七八糟的东西,比如广告,各种js之类的,NewWork好像有点难,需要用更强大的工具抓包,我个人比较喜欢用Fiddler,毕竟免费好用,还有朋友用喜欢它的查尔斯也可用,仅在有限的时间内免费。
下载链接放在这里:
Fiddler官网下载
查尔斯官网下载
fiddler 在这里测试。
安装完成后,我们打开fiddler,然后打开浏览器,可以看到现在fiddler代替了我们的开发者工具,爬取了http请求。这时候我们需要做一些设置,让它可以抓取https请求。
注意
如果您要捕获应用程序,请从仅浏览器更改为从所有进程。
以下是应用捕获的配置。
接下来,您需要使用真机或模拟器。这里我们推荐一个模拟器,MEO Android Emulator。
传送门 --> MEMO Android 模拟器
下载后打开图片如下图。
这时候就需要配置模拟器了,真机也是一样的步骤~!
打开cmd输入ipconfig可以查看代理服务器的主机名。代理服务器的端口号与您的提琴手的代理端口号相对应。完成此步骤后,点击保存。
但是仍然无法捕获移动应用程序,需要安装证书。这时候打开手机自带的浏览器,在地址栏输入你的代理服务器名称+端口号,如下图
点击 FiddlerRoot 证书下载并安装证书。
你已经完成了
现在我们可以抓取应用了,以酷航应用为例:
可以看到我们已经抓取了Scoot App的查询请求,你可以重新发送,进行各种花哨的操作~
但是如果你需要进一步了解,比如Scoot app会生成一个wtoken参数,这个参数就像网页中的js加密一样,是在apk的底部生成的,我们需要捕获它以备不时之需模拟生成,因为这会在服务器上进行验证,网页上的js加密token是一样的,需要Android****和反编译。有兴趣的童鞋也可以了解一下,需要一定的java基础!
需要帮助的童鞋们可以留言讨论,一起学习进步~! 查看全部
抓取网页数据工具(模拟器逍遥安卓模拟器官网下载好之后打开如下图图)
刚接触爬虫的时候,我们通常使用浏览器的开发工具——F12中的NetWork来抓取网页,但这有个缺点,就是如果网页加载了很多乱七八糟的东西,比如广告,各种js之类的,NewWork好像有点难,需要用更强大的工具抓包,我个人比较喜欢用Fiddler,毕竟免费好用,还有朋友用喜欢它的查尔斯也可用,仅在有限的时间内免费。
下载链接放在这里:
Fiddler官网下载
查尔斯官网下载
fiddler 在这里测试。
安装完成后,我们打开fiddler,然后打开浏览器,可以看到现在fiddler代替了我们的开发者工具,爬取了http请求。这时候我们需要做一些设置,让它可以抓取https请求。
注意
如果您要捕获应用程序,请从仅浏览器更改为从所有进程。
以下是应用捕获的配置。
接下来,您需要使用真机或模拟器。这里我们推荐一个模拟器,MEO Android Emulator。
传送门 --> MEMO Android 模拟器
下载后打开图片如下图。
这时候就需要配置模拟器了,真机也是一样的步骤~!
打开cmd输入ipconfig可以查看代理服务器的主机名。代理服务器的端口号与您的提琴手的代理端口号相对应。完成此步骤后,点击保存。
但是仍然无法捕获移动应用程序,需要安装证书。这时候打开手机自带的浏览器,在地址栏输入你的代理服务器名称+端口号,如下图
点击 FiddlerRoot 证书下载并安装证书。
你已经完成了
现在我们可以抓取应用了,以酷航应用为例:
可以看到我们已经抓取了Scoot App的查询请求,你可以重新发送,进行各种花哨的操作~
但是如果你需要进一步了解,比如Scoot app会生成一个wtoken参数,这个参数就像网页中的js加密一样,是在apk的底部生成的,我们需要捕获它以备不时之需模拟生成,因为这会在服务器上进行验证,网页上的js加密token是一样的,需要Android****和反编译。有兴趣的童鞋也可以了解一下,需要一定的java基础!
需要帮助的童鞋们可以留言讨论,一起学习进步~!

