
怎样抓取网页数据
怎样抓取网页数据(爬虫什么是爬虫?什浏览器发送的消息后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-19 14:27
爬行动物的基本介绍
1. 什么是爬虫?
爬虫是请求 web网站 并提取数据的自动化程序
2. 爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
解析内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。
获取响应内容
获取的内容可以是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
保存数据
有多种保存形式,可以保存为文本,保存到数据库,或者保存为特定格式的文件。
3. 什么是请求和响应?
浏览器向 URL 所在的服务器发送消息,这个过程称为 HTTP 请求。
服务器接收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
3.1 请求中收录什么?
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据
3.2 响应中收录什么?
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
4. 爬虫可以抓取什么样的数据?
网页文本:如HTML文档、Json格式文本等。
Image:得到的二进制文件以图像格式保存。
视频:两者都是二进制文件,可以保存为视频格式。
其他:只要能要求,就能得到。
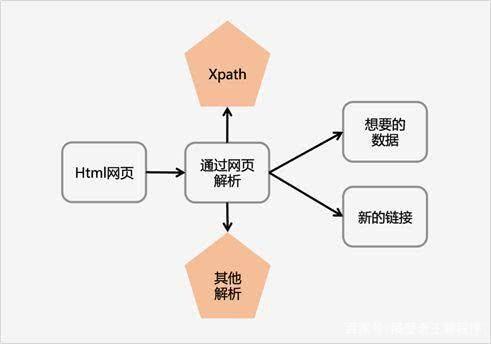
5. 怎么解析呢?
直接加工
json解析
正则表达式
美丽汤
查询
Xpath
6. 如何保存数据?
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
二进制文件:如图片、视频、音频等,可以直接以特定格式保存。
爬虫爬取网易新闻排名。
1. 确定目标
经过对各个新闻门户网站的排名进行讨论、分析和比较,最终选出内容正规、不良信息少、广告少的网易新闻排名。每小时抓取一次,选出点击率最高的前 20 条热门新闻。也就是红框中选中的内容。
2. 分析登陆页面
登陆页面:
通过分析网页的源码,我们知道这个网页排行榜并不是通过JavaScript动态加载生成的。所以网页爬取后可以直接处理,只需使用BeautifulSoup+requests库就可以实现。
3. 实现过程
3.1 请求目标网页并存储网页源文件
# 导入对应的包
从 bs4 导入 BeautifulSoup
导入请求
重新进口
导入日期时间
从 connect_mysql 导入 *
# 获取当前时间,指定格式为2018041018
时间 = datetime.datetime.now().strftime("%Y%m%d%H")
网址 = r'#39;
# 模拟真实浏览器访问
标头 = {'用户代理':
'Mozilla/5.0 (Windows NT 10.0; WOW64)'
'AppleWebKit/537.36(KHTML,像壁虎)'
'Chrome/55.0.2883.87 Safari/537.36'}
响应 = requests.get(url, headers=headers)
page_html = response.text
3.2 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
汤 = BeautifulSoup(page_html, 'html.parser')
3.3 分析汤
首先通过分析网站的结构可知,我们需要的数据在class=tabContents active的div下的所有a标签中,而这个div嵌套在class=area-的div中还剩一半。所以我们写了下面的代码,从网页的源代码中找出所有符合要求的标题,限制为20个。
title = soup.find('div', 'area-half left').find('div', 'tabContents active').find_all('a', limit=20)
只需一行代码,我们就获得了一些我们需要的数据。接下来,继续获取对我们有用的新数据并将其存储在数据库中。
3.4 进一步处理来自 3.3 的结果
由于页面标题显示不完整,导致上一步爬取的标题部分不完整。所以我们需要爬得更远。步骤与上述操作类似,爬取新闻链接、新闻内容,完成新闻头条。这三个内容,并调用自己编写的方法将数据存入数据库。并使用 re 库对内容进行简单处理(去掉 \n\t\r ),具体实现如下。
标题中的标题:
'''
news_url:新闻链接
news_html:新闻页面网页源代码
'''
news_url = (str(title.get('href')))
news_response = requests.get(news_url, headers=headers)
news_html = news_response.text
# 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
news_soup = BeautifulSoup(news_html, 'html.parser')
# 从网页源码中找到属于post_text类的div,将所有p标签内容存放在news_contents列表中
if news_soup.find('div', 'post_text') is None: # 如果网页丢失,跳出这个循环
继续
news_title = news_soup.find('h1')
内容 = news_soup.find('div', 'post_text').find_all('p')
新闻内容 = []
对于内容中的内容:
如果 content.string 不是无:
# 删除特殊字符
news_contents.append(re.sub('[\r\n\t ]', '', str(content.string)))
#字符串连接
news_contents = ''.join(news_contents)
# 将爬取的数据存入数据库
insert_wangyinews_into_mysql(wangyi_news, str(news_title.string), news_url, news_contents, 时间)
这样一个简单的爬虫就完成了,不要小看这几十行代码,它们在这个项目中发挥了巨大的作用。
本文使用的开发环境:
蟒蛇5.1
pycharm
本文第一部分为崔庆才老师python3网络爬虫视频教程的笔记:
课程链接:
崔老师的课对我很有帮助,再次感谢。 查看全部
怎样抓取网页数据(爬虫什么是爬虫?什浏览器发送的消息后)
爬行动物的基本介绍
1. 什么是爬虫?
爬虫是请求 web网站 并提取数据的自动化程序
2. 爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
解析内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。
获取响应内容
获取的内容可以是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
保存数据
有多种保存形式,可以保存为文本,保存到数据库,或者保存为特定格式的文件。
3. 什么是请求和响应?
浏览器向 URL 所在的服务器发送消息,这个过程称为 HTTP 请求。
服务器接收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
3.1 请求中收录什么?
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据
3.2 响应中收录什么?
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
4. 爬虫可以抓取什么样的数据?
网页文本:如HTML文档、Json格式文本等。
Image:得到的二进制文件以图像格式保存。
视频:两者都是二进制文件,可以保存为视频格式。
其他:只要能要求,就能得到。
5. 怎么解析呢?
直接加工
json解析
正则表达式
美丽汤
查询
Xpath
6. 如何保存数据?
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
二进制文件:如图片、视频、音频等,可以直接以特定格式保存。
爬虫爬取网易新闻排名。
1. 确定目标
经过对各个新闻门户网站的排名进行讨论、分析和比较,最终选出内容正规、不良信息少、广告少的网易新闻排名。每小时抓取一次,选出点击率最高的前 20 条热门新闻。也就是红框中选中的内容。

2. 分析登陆页面
登陆页面:
通过分析网页的源码,我们知道这个网页排行榜并不是通过JavaScript动态加载生成的。所以网页爬取后可以直接处理,只需使用BeautifulSoup+requests库就可以实现。
3. 实现过程
3.1 请求目标网页并存储网页源文件
# 导入对应的包
从 bs4 导入 BeautifulSoup
导入请求
重新进口
导入日期时间
从 connect_mysql 导入 *
# 获取当前时间,指定格式为2018041018
时间 = datetime.datetime.now().strftime("%Y%m%d%H")
网址 = r'#39;
# 模拟真实浏览器访问
标头 = {'用户代理':
'Mozilla/5.0 (Windows NT 10.0; WOW64)'
'AppleWebKit/537.36(KHTML,像壁虎)'
'Chrome/55.0.2883.87 Safari/537.36'}
响应 = requests.get(url, headers=headers)
page_html = response.text
3.2 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
汤 = BeautifulSoup(page_html, 'html.parser')
3.3 分析汤
首先通过分析网站的结构可知,我们需要的数据在class=tabContents active的div下的所有a标签中,而这个div嵌套在class=area-的div中还剩一半。所以我们写了下面的代码,从网页的源代码中找出所有符合要求的标题,限制为20个。
title = soup.find('div', 'area-half left').find('div', 'tabContents active').find_all('a', limit=20)
只需一行代码,我们就获得了一些我们需要的数据。接下来,继续获取对我们有用的新数据并将其存储在数据库中。

3.4 进一步处理来自 3.3 的结果
由于页面标题显示不完整,导致上一步爬取的标题部分不完整。所以我们需要爬得更远。步骤与上述操作类似,爬取新闻链接、新闻内容,完成新闻头条。这三个内容,并调用自己编写的方法将数据存入数据库。并使用 re 库对内容进行简单处理(去掉 \n\t\r ),具体实现如下。
标题中的标题:
'''
news_url:新闻链接
news_html:新闻页面网页源代码
'''
news_url = (str(title.get('href')))
news_response = requests.get(news_url, headers=headers)
news_html = news_response.text
# 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
news_soup = BeautifulSoup(news_html, 'html.parser')
# 从网页源码中找到属于post_text类的div,将所有p标签内容存放在news_contents列表中
if news_soup.find('div', 'post_text') is None: # 如果网页丢失,跳出这个循环
继续
news_title = news_soup.find('h1')
内容 = news_soup.find('div', 'post_text').find_all('p')
新闻内容 = []
对于内容中的内容:
如果 content.string 不是无:
# 删除特殊字符
news_contents.append(re.sub('[\r\n\t ]', '', str(content.string)))
#字符串连接
news_contents = ''.join(news_contents)
# 将爬取的数据存入数据库
insert_wangyinews_into_mysql(wangyi_news, str(news_title.string), news_url, news_contents, 时间)
这样一个简单的爬虫就完成了,不要小看这几十行代码,它们在这个项目中发挥了巨大的作用。
本文使用的开发环境:
蟒蛇5.1
pycharm
本文第一部分为崔庆才老师python3网络爬虫视频教程的笔记:
课程链接:
崔老师的课对我很有帮助,再次感谢。
怎样抓取网页数据(什么是爬虫?网络爬虫(..)爬虫的基本流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-04-18 01:06
)
什么是爬行动物?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
爬行动物的性质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容。通过分析和过滤HTML代码,我们可以得到我们想要的资源(文字、图片、视频...)
爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
请求,响应
浏览器向 URL 所在的服务器发送消息。这个过程称为 HTTP 请求
服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。这个过程是 HTTP 响应
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示
请求中收录什么?
请求方法
主要有:常用的GET/POST两种,还有HEAD/PUT/DELETE/OPTIONS
GET 和 POST 的区别在于请求的数据 GET 在 url 中,而 POST 存储在 header 中
GET:向指定资源发出“显示”请求。使用 GET 方法应该只用于读取数据,而不应该用于产生“副作用”的操作,例如在 Web 应用程序中。原因之一是 GET 可能被网络蜘蛛等任意访问。
POST:向指定资源提交数据,并请求服务器处理(如提交表单或上传文件)。数据收录在请求文本中。此请求可能会创建新资源或修改现有资源,或两者兼而有之。
HEAD:和GET方法一样,是对服务器的指定资源的请求。只是服务器不会返回资源的文本部分。它的优点是使用这种方法可以获取“有关资源的信息”(元信息或元数据),而无需传输整个内容。
PUT:将其最新内容上传到指定的资源位置。
OPTIONS:此方法使服务器能够返回资源支持的所有 HTTP 请求方法。使用 '*' 代替资源名称,并向 Web 服务器发送 OPTIONS 请求,以测试服务器功能是否正常工作。
DELETE:请求服务器删除Request-URI标识的资源。
请求网址
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。
第二部分是存储资源的主机的 IP 地址(有时是端口号)。
第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图显示了请求百度时所有的请求头信息参数。
请求正文
请求是携带的数据,比如提交表单数据时的表单数据(POST)
响应中收录的内容
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应状态
响应状态有多种,如:200表示成功,301跳转,404页面未找到,502服务器错误
响应头
如内容类型、类型长度、服务器信息、设置cookies,如下图
响应体
最重要的部分,包括请求资源的内容,比如网页HTML、图片、二进制数据等。
可以抓取什么样的数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何直接解析数据流程 Json解析正则表达式流程 BeautifulSoup解析流程 PyQuery解析流程 XPath解析流程 关于爬取的页面数据与浏览器看到的区别
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
关系型数据库:mysql、oracle、sql server等结构化数据库。
非关系型数据库:MongoDB、Redis等键值存储
什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
pip install requests
requests函数整体功能演示
import requests
response = requests.get("https://www.baidu.com")
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打印网页内容
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))#改变编码
我们可以看到响应式使用起来确实非常方便。有一个问题需要注意:
很多情况下网站直接使用response.text会造成乱码,所以这里使用response.content
这样返回的数据格式其实是二进制格式,然后通过decode()转换成utf-8,解决了直接通过response.text返回显示乱码的问题。
发出请求后,Requests 会根据 HTTP 标头对响应的编码进行有根据的猜测。当您访问 response.text 时,Requests 使用其推断的文本编码。您可以找出请求使用的编码,并可以使用 response.encoding 属性更改它。例如:
response =requests.get("http://www.baidu.com")
response.encoding="utf-8"
print(response.text)
无论是通过response.content.decode("utf-8)还是通过response.encoding="utf-8"都可以避免乱码问题
各种请求方法
requests中提供了各种请求方法
Requests 库的 get() 方法
实践:
网页爬取常用代码框架
跑
import requests
r = requests.get("https://www.baidu.com")
r.status_code#获取网站状态码
r.text#获取内容
r.encoding#获取编码
r.apparent_encoding#获取另一个编码
r.encoding='utf-8'#替换编码为'UTF-8'
你会发现一个乱码和一个正常,因为
代码:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态码不是200,就引发HTTPError异常
r.encoding=r.apparent_encoding #替换编码
return r.text #返回网页内容
except:
return "产生异常啦!"
url="www.baidu.com/"
print(getHTMLText(url))
查看全部
怎样抓取网页数据(什么是爬虫?网络爬虫(..)爬虫的基本流程
)
什么是爬行动物?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
爬行动物的性质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容。通过分析和过滤HTML代码,我们可以得到我们想要的资源(文字、图片、视频...)
爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
请求,响应
浏览器向 URL 所在的服务器发送消息。这个过程称为 HTTP 请求
服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。这个过程是 HTTP 响应
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示
请求中收录什么?
请求方法
主要有:常用的GET/POST两种,还有HEAD/PUT/DELETE/OPTIONS
GET 和 POST 的区别在于请求的数据 GET 在 url 中,而 POST 存储在 header 中
GET:向指定资源发出“显示”请求。使用 GET 方法应该只用于读取数据,而不应该用于产生“副作用”的操作,例如在 Web 应用程序中。原因之一是 GET 可能被网络蜘蛛等任意访问。
POST:向指定资源提交数据,并请求服务器处理(如提交表单或上传文件)。数据收录在请求文本中。此请求可能会创建新资源或修改现有资源,或两者兼而有之。
HEAD:和GET方法一样,是对服务器的指定资源的请求。只是服务器不会返回资源的文本部分。它的优点是使用这种方法可以获取“有关资源的信息”(元信息或元数据),而无需传输整个内容。
PUT:将其最新内容上传到指定的资源位置。
OPTIONS:此方法使服务器能够返回资源支持的所有 HTTP 请求方法。使用 '*' 代替资源名称,并向 Web 服务器发送 OPTIONS 请求,以测试服务器功能是否正常工作。
DELETE:请求服务器删除Request-URI标识的资源。
请求网址
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。
第二部分是存储资源的主机的 IP 地址(有时是端口号)。
第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图显示了请求百度时所有的请求头信息参数。
请求正文
请求是携带的数据,比如提交表单数据时的表单数据(POST)
响应中收录的内容
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应状态
响应状态有多种,如:200表示成功,301跳转,404页面未找到,502服务器错误
响应头
如内容类型、类型长度、服务器信息、设置cookies,如下图
响应体
最重要的部分,包括请求资源的内容,比如网页HTML、图片、二进制数据等。
可以抓取什么样的数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何直接解析数据流程 Json解析正则表达式流程 BeautifulSoup解析流程 PyQuery解析流程 XPath解析流程 关于爬取的页面数据与浏览器看到的区别
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
关系型数据库:mysql、oracle、sql server等结构化数据库。
非关系型数据库:MongoDB、Redis等键值存储
什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
pip install requests
requests函数整体功能演示
import requests
response = requests.get("https://www.baidu.com";)
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打印网页内容
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))#改变编码
我们可以看到响应式使用起来确实非常方便。有一个问题需要注意:
很多情况下网站直接使用response.text会造成乱码,所以这里使用response.content
这样返回的数据格式其实是二进制格式,然后通过decode()转换成utf-8,解决了直接通过response.text返回显示乱码的问题。
发出请求后,Requests 会根据 HTTP 标头对响应的编码进行有根据的猜测。当您访问 response.text 时,Requests 使用其推断的文本编码。您可以找出请求使用的编码,并可以使用 response.encoding 属性更改它。例如:
response =requests.get("http://www.baidu.com";)
response.encoding="utf-8"
print(response.text)
无论是通过response.content.decode("utf-8)还是通过response.encoding="utf-8"都可以避免乱码问题
各种请求方法
requests中提供了各种请求方法
Requests 库的 get() 方法
实践:
网页爬取常用代码框架
跑
import requests
r = requests.get("https://www.baidu.com";)
r.status_code#获取网站状态码
r.text#获取内容
r.encoding#获取编码
r.apparent_encoding#获取另一个编码
r.encoding='utf-8'#替换编码为'UTF-8'
你会发现一个乱码和一个正常,因为
代码:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态码不是200,就引发HTTPError异常
r.encoding=r.apparent_encoding #替换编码
return r.text #返回网页内容
except:
return "产生异常啦!"
url="www.baidu.com/"
print(getHTMLText(url))
怎样抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-17 17:22
一篇短文,涵盖了数据采集、数据清洗、数据呈现等全过程,数据主要展示了2016年我国地级市百强城市GDP、增长率、区域分布密度图三个维度.
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找个微信短信,复制网址链接直接在浏览器打开
/S? __ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd351251601f0968c792b7e7cb5cdf084fb86a8&mpshare = 1&场景= 23&srcid = 02039mlTmLqMxQEnb4CnUrK3#RD“
使用 rvest 简单提取文本内容
web%html_text()
网页爬取阶段完成后,以下过渡到数据清洗阶段:
#------------------------------------------------ -------------------------------------------------- ---
如果仔细观察文本向量,可以发现我们需要的城市数据以数字开头(1到3位不等),第七行也是以数据字开头(January 20, 2017),使用正则表达式进行精确匹配,并将所有标点符号(记住中文标点)替换为逗号(英文),方便作为拆分依据(也可以自定义拆分符号)
<p>a 查看全部
怎样抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
一篇短文,涵盖了数据采集、数据清洗、数据呈现等全过程,数据主要展示了2016年我国地级市百强城市GDP、增长率、区域分布密度图三个维度.
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找个微信短信,复制网址链接直接在浏览器打开
/S? __ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd351251601f0968c792b7e7cb5cdf084fb86a8&mpshare = 1&场景= 23&srcid = 02039mlTmLqMxQEnb4CnUrK3#RD“
使用 rvest 简单提取文本内容
web%html_text()

网页爬取阶段完成后,以下过渡到数据清洗阶段:
#------------------------------------------------ -------------------------------------------------- ---
如果仔细观察文本向量,可以发现我们需要的城市数据以数字开头(1到3位不等),第七行也是以数据字开头(January 20, 2017),使用正则表达式进行精确匹配,并将所有标点符号(记住中文标点)替换为逗号(英文),方便作为拆分依据(也可以自定义拆分符号)
<p>a
怎样抓取网页数据(实验环境win10+python3.6+pycharm5.0(解析json))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-16 17:14
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。 查看全部
怎样抓取网页数据(实验环境win10+python3.6+pycharm5.0(解析json))
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:

对应的网页源码如下,收录我们需要的数据:

2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:

程序运行截图如下,爬取数据成功:

1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:

打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:

2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:

程序运行截图如下,已经成功抓取数据:

至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
怎样抓取网页数据(做一个校园新闻小程序的时候需要获取点击量来排序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-16 17:11
项目场景:
制作校园新闻小程序时,不仅要获取新闻内容,还要获取点击排序。爬取静态数据很容易,但是爬取动态数据就麻烦一些。
问题描述
例如,当我们抓取这个网页时
打开开发者工具查看点击次数
但是我们爬取的内容是这样的
为什么点击不显示?
原因分析:
我的理解是这样的,因为点击量是随着网页的刷新而不断变化的,而新闻内容是固定的。所以点击次数会通过一个函数不断更新,所以静态网页内容不显示这个数据是合理的。
解决方案:
要获得此类数据,您必须首先找到数据。好在点击次数在比较中是独一无二的,是一个数字。当然,你不能直接打开开发者工具,在“元素”中搜索。找号码的来源,这个动态数据一般是在“网络”中的XHR或者JS文件中找到的,比如这个(记得刷新再找!)
在这个杂乱无章的返回中,我们想要的点击是在最后几次点击中。当然不再是那个781了,不过没关系,我们很容易就找到了(大多数情况下不是,但是readClick这个词太明显了!)
预览是我们发送请求得到的数据,点击放在这个数据的末尾。那么我们只需要发送一个请求来获取这个数据,然后使用正则表达式来提取803的点击量。
然后是请求的参数。此参数有时位于标题的底部,但不在此处。其实负载就是这个请求的参数。
我们来分析一下参数。如果你只是想获取这个网页的动态数据,直接复制就好了。
from sqlite3 import Date
import requests
import random, time, sys
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'
}
params = {
'callCount':'1',
'nextReverseAjaxIndex':'0',
'c0-scriptName':'Ajax',
'c0-methodName':'readClick',
'c0-id':'0',
'c0-param0':'string:1649408845878',
'batchId':'0',
'instanceId':'0',
'page':'%2Fcolumn%2Fh_26_yi%2Fcontent%2F1649408845878.shtml',
'scriptSessionId':'5eSlySH4R9SBWHfCeP6lNqg1u0JcgKn5m1o/mvq5m1o-GDTnJP$nz'
}
res = requests.post('https://news.hutb.edu.cn/dwr/c ... 39%3B, headers=headers, params=params)
print(res.text)
我们来分析一下这些参数。c0-param0 和 page 在不同的新闻中是不同的。不同的是它们是第一个消息,以及如何写参数。比如这个新闻网址是,那么最后8位就是这两个参数的实际参数(也许这个数字并不是新闻的条数,毕竟太大了!)
然后是scriptSessionId。在比较不同的新闻页面时,发现他们'/'之前的字符是一样的,不同的是'/'之后的字符,所以我搜索了这个参数
让我们搜索'/'之后的参数
很明显,这个参数是由当前时间和一个随机数决定的,而tokenify我认为是一个编码函数。既然和随机数有关,传参数的时候可以忽略这个参数,写一个随机值吗?咱们试试吧:
结果是这样的
所以在抓取网页的动态数据的时候,首先是找到这个值(因为有搜索选项,大部分时候很容易找到),然后就是参数的问题,或者说是load。如果要爬取多个页面的动态数据,弄清楚这些参数的含义,或者说它们的特点是非常重要的,这样你才能传递正确的参数来获取你想要的数据。 查看全部
怎样抓取网页数据(做一个校园新闻小程序的时候需要获取点击量来排序)
项目场景:
制作校园新闻小程序时,不仅要获取新闻内容,还要获取点击排序。爬取静态数据很容易,但是爬取动态数据就麻烦一些。
问题描述
例如,当我们抓取这个网页时

打开开发者工具查看点击次数

但是我们爬取的内容是这样的

为什么点击不显示?
原因分析:
我的理解是这样的,因为点击量是随着网页的刷新而不断变化的,而新闻内容是固定的。所以点击次数会通过一个函数不断更新,所以静态网页内容不显示这个数据是合理的。
解决方案:
要获得此类数据,您必须首先找到数据。好在点击次数在比较中是独一无二的,是一个数字。当然,你不能直接打开开发者工具,在“元素”中搜索。找号码的来源,这个动态数据一般是在“网络”中的XHR或者JS文件中找到的,比如这个(记得刷新再找!)

在这个杂乱无章的返回中,我们想要的点击是在最后几次点击中。当然不再是那个781了,不过没关系,我们很容易就找到了(大多数情况下不是,但是readClick这个词太明显了!)
预览是我们发送请求得到的数据,点击放在这个数据的末尾。那么我们只需要发送一个请求来获取这个数据,然后使用正则表达式来提取803的点击量。

然后是请求的参数。此参数有时位于标题的底部,但不在此处。其实负载就是这个请求的参数。

我们来分析一下参数。如果你只是想获取这个网页的动态数据,直接复制就好了。
from sqlite3 import Date
import requests
import random, time, sys
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'
}
params = {
'callCount':'1',
'nextReverseAjaxIndex':'0',
'c0-scriptName':'Ajax',
'c0-methodName':'readClick',
'c0-id':'0',
'c0-param0':'string:1649408845878',
'batchId':'0',
'instanceId':'0',
'page':'%2Fcolumn%2Fh_26_yi%2Fcontent%2F1649408845878.shtml',
'scriptSessionId':'5eSlySH4R9SBWHfCeP6lNqg1u0JcgKn5m1o/mvq5m1o-GDTnJP$nz'
}
res = requests.post('https://news.hutb.edu.cn/dwr/c ... 39%3B, headers=headers, params=params)
print(res.text)

我们来分析一下这些参数。c0-param0 和 page 在不同的新闻中是不同的。不同的是它们是第一个消息,以及如何写参数。比如这个新闻网址是,那么最后8位就是这两个参数的实际参数(也许这个数字并不是新闻的条数,毕竟太大了!)
然后是scriptSessionId。在比较不同的新闻页面时,发现他们'/'之前的字符是一样的,不同的是'/'之后的字符,所以我搜索了这个参数

让我们搜索'/'之后的参数

很明显,这个参数是由当前时间和一个随机数决定的,而tokenify我认为是一个编码函数。既然和随机数有关,传参数的时候可以忽略这个参数,写一个随机值吗?咱们试试吧:

结果是这样的

所以在抓取网页的动态数据的时候,首先是找到这个值(因为有搜索选项,大部分时候很容易找到),然后就是参数的问题,或者说是load。如果要爬取多个页面的动态数据,弄清楚这些参数的含义,或者说它们的特点是非常重要的,这样你才能传递正确的参数来获取你想要的数据。
怎样抓取网页数据(2.提取信息获取网页源代码后的接下来就是分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-15 20:26
1.爬虫概述
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
2.获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
3.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
4.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
5.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
6.我可以捕获什么样的数据
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
7.JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(2.提取信息获取网页源代码后的接下来就是分析(组图))
1.爬虫概述
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
2.获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
3.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
4.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
5.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
6.我可以捕获什么样的数据
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
7.JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-15 20:26
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
(3)保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
(4)自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
(3)保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
(4)自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据(怎样抓取网页网页数据(代码和实现分析报告)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-15 17:07
怎样抓取网页数据(代码和实现分析报告)作者:raywang280公众号:dark520链接:如何抓取网页数据(代码和实现分析报告)本系列文章目的介绍该如何抓取网页中的文字数据;写一些代码,大概讲一下怎么抓取爬虫代码以及实现分析报告(代码和分析报告都是爬虫代码);会对网页中爬虫包和网页中内容抓取结果进行记录和分析。
爬虫抓取后,放到requests库中,之后设置requests.get()为get方法即可。无论python爬虫包,网页内容的抓取,其实都比较简单:先要获取网页地址,之后获取网页中的图片,地址,再获取某一网页中的某一小部分的图片,这样整个网页抓取就完成了,当然只需要抓取一张图片就行了,也可以抓取链接,地址,以及中间的一个或者多个图片图片来源抓取。
解析网页的地址链接,一般我们通过抓包得到。一般有这么几种方式:try:直接把网页地址截图exceptexception,e:continue随手抓取网页中的文字数据分析报告(地址:解析网页地址并抓取原文字数据)一、网页数据抓取代码框架requests.get()方法的截图这里先调用try那一步,对源代码解析为正则表达式。
try:driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/a/@href')这里就通过正则表达式获取目标网页中的url。driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/span/@href')在这里会获取出xpath。
driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]//span[1]/@href')这里获取到的是xpath。driver.find_element_by_css_selector('span[1]/@href')这里获取到了css。
driver.find_element_by_javascript_selector('span[1]/@href')这里获取到javascript。然后设置requests.get()获取get()设置到以下img中:imgurl=img.xpath('.//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/a/@href')imgurl=requests.get(imgurl)imgurlurlwithopen("my.jpg","w")a。 查看全部
怎样抓取网页数据(怎样抓取网页网页数据(代码和实现分析报告)(图))
怎样抓取网页数据(代码和实现分析报告)作者:raywang280公众号:dark520链接:如何抓取网页数据(代码和实现分析报告)本系列文章目的介绍该如何抓取网页中的文字数据;写一些代码,大概讲一下怎么抓取爬虫代码以及实现分析报告(代码和分析报告都是爬虫代码);会对网页中爬虫包和网页中内容抓取结果进行记录和分析。
爬虫抓取后,放到requests库中,之后设置requests.get()为get方法即可。无论python爬虫包,网页内容的抓取,其实都比较简单:先要获取网页地址,之后获取网页中的图片,地址,再获取某一网页中的某一小部分的图片,这样整个网页抓取就完成了,当然只需要抓取一张图片就行了,也可以抓取链接,地址,以及中间的一个或者多个图片图片来源抓取。
解析网页的地址链接,一般我们通过抓包得到。一般有这么几种方式:try:直接把网页地址截图exceptexception,e:continue随手抓取网页中的文字数据分析报告(地址:解析网页地址并抓取原文字数据)一、网页数据抓取代码框架requests.get()方法的截图这里先调用try那一步,对源代码解析为正则表达式。
try:driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/a/@href')这里就通过正则表达式获取目标网页中的url。driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/span/@href')在这里会获取出xpath。
driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]//span[1]/@href')这里获取到的是xpath。driver.find_element_by_css_selector('span[1]/@href')这里获取到了css。
driver.find_element_by_javascript_selector('span[1]/@href')这里获取到javascript。然后设置requests.get()获取get()设置到以下img中:imgurl=img.xpath('.//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/a/@href')imgurl=requests.get(imgurl)imgurlurlwithopen("my.jpg","w")a。
怎样抓取网页数据( 易供求网:前端js怎么直接获取电脑详细配置信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-04-13 02:28
易供求网:前端js怎么直接获取电脑详细配置信息?)
易供需网()本文如何从java前端获取数据java数据库连接由小编为大家精心采集整理。今天,易供需给大家讲讲java前端如何获取数据以及java数据库连接!
前端js如何直接获取电脑的详细配置信息?
大多数商业浏览器没有这个接口,W3C标准也没有,所以直接用JS实现是不可能的。
如果要实现的话,还是得给员工发个本地程序来获取配置信息,但是bat脚本肯定不行,太容易修改了。如果不想增加太多额外的编程成本和时间,可以考虑使用西北js或者electron来封装网页,分发给员工。相当于一个特殊的浏览器,允许JS顺便运行node.js。另外,两者都可以对源代码进行加密和编译,使得脚本无法被修改,从而保证了信息的准确性。
另外,最重要的是,您的前端人员应该能够以零成本开始,无需额外成本
可以连接数据库,其中一个使用时间戳来移动和存储当前时间,读取时选择最近一天的数据
好的,这就是java前端如何获取数据由Easy Supply and Demand Network共享的java数据库连接。希望大家看完小编精心整理的这篇内容后,能够了解相关知识,解决大家的疑惑!查看更多java数据库连接java读取excel数据java输入相关文章请访问易供需。(本文共533字) 查看全部
怎样抓取网页数据(
易供求网:前端js怎么直接获取电脑详细配置信息?)

易供需网()本文如何从java前端获取数据java数据库连接由小编为大家精心采集整理。今天,易供需给大家讲讲java前端如何获取数据以及java数据库连接!
前端js如何直接获取电脑的详细配置信息?
大多数商业浏览器没有这个接口,W3C标准也没有,所以直接用JS实现是不可能的。
如果要实现的话,还是得给员工发个本地程序来获取配置信息,但是bat脚本肯定不行,太容易修改了。如果不想增加太多额外的编程成本和时间,可以考虑使用西北js或者electron来封装网页,分发给员工。相当于一个特殊的浏览器,允许JS顺便运行node.js。另外,两者都可以对源代码进行加密和编译,使得脚本无法被修改,从而保证了信息的准确性。
另外,最重要的是,您的前端人员应该能够以零成本开始,无需额外成本
可以连接数据库,其中一个使用时间戳来移动和存储当前时间,读取时选择最近一天的数据
好的,这就是java前端如何获取数据由Easy Supply and Demand Network共享的java数据库连接。希望大家看完小编精心整理的这篇内容后,能够了解相关知识,解决大家的疑惑!查看更多java数据库连接java读取excel数据java输入相关文章请访问易供需。(本文共533字)
怎样抓取网页数据(一下CrawlSpider爬虫爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-13 02:26
重点是CrawlSpider的学习!!!!!!!!!!!!!
**通过前面的学习我们可以进行一些页面的简单自动话爬取,对于一些比较规则的网站,我们似乎可以用Spider类去应付,可是,对于一些较为复杂或者说链接的存放不规则的网站我们该怎么去爬取呢,接下来的爬虫就是要解决这个问题,而且还可以高度的自动化爬取链接和链接内容**
CrawlSpider 类是另一个用于构建爬虫的类。
*(顺便说一下,我们可以继承四种类来建立我们的scrapy爬虫,他们是:Spider类,CrawlSpider类, CSVFeedSpider类和XMLFeedSpider类,今天我们讲的就是CrawlSpider类建立的爬虫)*
CrawlSpider 类通过一些规则使链接(网页)的爬取更加通用。也就是说,CrawlSpider 爬虫是一般的爬虫,而Spider 爬虫更像是一些特殊的网站 制定的爬虫。
然后我们开始正式讲解CrawlSpider爬虫。. . .
首先我们创建一个爬虫项目:
scrapy startproject crawlspider
这个我们很熟悉了,然后创建一个CrawlSpider爬虫
scrapy genspider -t crawl Crawlspider domain.com
注意上面,我们比Spider爬虫创建时多了一个'-t crawl',它是值爬虫的类
这样我们以后可以在我们的蜘蛛文件中找到这个爬虫
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
以上是打开爬虫后自动生成的一段代码。这段代码对于CrawlSpider爬虫的结构基本上可以说是有了结构。我们可以看到有一个rules属性,这个爬虫继承的类是CrawlSpider。这两点就是和之前文章中提到的蜘蛛爬虫的区别。规则属性使得这个爬虫的核心
所以在开始说我们的实战项目之前,还是先说一下这个规则属性吧。
rules属性由若干个Rule对象组成,Rule对象定义了提取链接等操作的规则
那么规则的结构是什么?
Rule 对象有六个属性,它们是:
LinkExtractor(...),用于提取响应中的链接 callback='str',回调函数,用于提取链接,用于提取数据填充itemcb_kwargs,传递给回调函数的参数字典follow=True/ False,对于提取出来的链接是否需要跟process_links,一个函数process_request过滤链接,一个函数过滤链接Request
以上参数都是可选的,除了LinkExtractor,当回调参数为None时,我们称这条规则为“跳板”,即只下载页面,不执行任何动作。它通常用作翻页功能。
我们主要需要解释一下LinkExtractor参数和follow参数:
一、LinkExtractor 参数显然是用来提取链接的。那么他是如何定义提取链接的规则的呢?它有十个参数来定义提取链接的规则,即:
1. allow='re_str':正则表达式字符串,在响应中提取与 re 表达式匹配的链接。
2.deny='re_str':排除正则表达式匹配的链接
3. restrict_xpaths='xpath_str':提取满足xpath表达式的链接
4. restrict_css='css_str':提取满足css表达式的链接
5. allow_domains='domain_str': 允许的域
6.deny_domains='domain_str':排除的域
7. tags='tag'/['tag1','tag2',…]:提取指定标签下的链接。默认情况下,链接将从 a 和 area 标签中提取
8. attrs=['href','src',…]:提取满足属性的链接
9. unique=True/False:链接是否去重
10.process_value:值处理函数,优先级必须大于allow
以上参数可以一起使用,提取同时满足条件的链接
二、跟随参数:
是一个布尔值,用于是否跟随链接的处理。回调为None时,默认跟随链接,值为True;回调不为空时,默认为False,不跟随链接。当然,我们可以根据需要进行赋值,
那么,什么叫跟进,什么叫不跟进呢?
就是你前面定义的规则对于已经提取到的链接的页面是不是在进行一次提取链接。
这很好!那么规则究竟是如何运作的呢?
这样会自动为Rule提取的链接调用parse函数,返回链接的response,然后将response交给回调函数,通过解析填充item的回调函数。
顺便说一句,CrawlSpider 爬虫还有一个 parse_start_url() 方法,用于解析 start_urls 中的链接页面。该方法一般用于有跳板的爬虫解析首页
说了这么多,还是说说我们的爬虫项目吧。使用 CrawlSpider 爬取整个小说网站
我们的目标网站是:笔趣看小说网
这是盗版小说网站,只能在线看,不能下载。 查看全部
怎样抓取网页数据(一下CrawlSpider爬虫爬虫)
重点是CrawlSpider的学习!!!!!!!!!!!!!
**通过前面的学习我们可以进行一些页面的简单自动话爬取,对于一些比较规则的网站,我们似乎可以用Spider类去应付,可是,对于一些较为复杂或者说链接的存放不规则的网站我们该怎么去爬取呢,接下来的爬虫就是要解决这个问题,而且还可以高度的自动化爬取链接和链接内容**
CrawlSpider 类是另一个用于构建爬虫的类。
*(顺便说一下,我们可以继承四种类来建立我们的scrapy爬虫,他们是:Spider类,CrawlSpider类, CSVFeedSpider类和XMLFeedSpider类,今天我们讲的就是CrawlSpider类建立的爬虫)*
CrawlSpider 类通过一些规则使链接(网页)的爬取更加通用。也就是说,CrawlSpider 爬虫是一般的爬虫,而Spider 爬虫更像是一些特殊的网站 制定的爬虫。
然后我们开始正式讲解CrawlSpider爬虫。. . .
首先我们创建一个爬虫项目:
scrapy startproject crawlspider
这个我们很熟悉了,然后创建一个CrawlSpider爬虫
scrapy genspider -t crawl Crawlspider domain.com
注意上面,我们比Spider爬虫创建时多了一个'-t crawl',它是值爬虫的类
这样我们以后可以在我们的蜘蛛文件中找到这个爬虫
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
以上是打开爬虫后自动生成的一段代码。这段代码对于CrawlSpider爬虫的结构基本上可以说是有了结构。我们可以看到有一个rules属性,这个爬虫继承的类是CrawlSpider。这两点就是和之前文章中提到的蜘蛛爬虫的区别。规则属性使得这个爬虫的核心
所以在开始说我们的实战项目之前,还是先说一下这个规则属性吧。
rules属性由若干个Rule对象组成,Rule对象定义了提取链接等操作的规则
那么规则的结构是什么?
Rule 对象有六个属性,它们是:
LinkExtractor(...),用于提取响应中的链接 callback='str',回调函数,用于提取链接,用于提取数据填充itemcb_kwargs,传递给回调函数的参数字典follow=True/ False,对于提取出来的链接是否需要跟process_links,一个函数process_request过滤链接,一个函数过滤链接Request
以上参数都是可选的,除了LinkExtractor,当回调参数为None时,我们称这条规则为“跳板”,即只下载页面,不执行任何动作。它通常用作翻页功能。
我们主要需要解释一下LinkExtractor参数和follow参数:
一、LinkExtractor 参数显然是用来提取链接的。那么他是如何定义提取链接的规则的呢?它有十个参数来定义提取链接的规则,即:
1. allow='re_str':正则表达式字符串,在响应中提取与 re 表达式匹配的链接。
2.deny='re_str':排除正则表达式匹配的链接
3. restrict_xpaths='xpath_str':提取满足xpath表达式的链接
4. restrict_css='css_str':提取满足css表达式的链接
5. allow_domains='domain_str': 允许的域
6.deny_domains='domain_str':排除的域
7. tags='tag'/['tag1','tag2',…]:提取指定标签下的链接。默认情况下,链接将从 a 和 area 标签中提取
8. attrs=['href','src',…]:提取满足属性的链接
9. unique=True/False:链接是否去重
10.process_value:值处理函数,优先级必须大于allow
以上参数可以一起使用,提取同时满足条件的链接
二、跟随参数:
是一个布尔值,用于是否跟随链接的处理。回调为None时,默认跟随链接,值为True;回调不为空时,默认为False,不跟随链接。当然,我们可以根据需要进行赋值,
那么,什么叫跟进,什么叫不跟进呢?
就是你前面定义的规则对于已经提取到的链接的页面是不是在进行一次提取链接。
这很好!那么规则究竟是如何运作的呢?
这样会自动为Rule提取的链接调用parse函数,返回链接的response,然后将response交给回调函数,通过解析填充item的回调函数。
顺便说一句,CrawlSpider 爬虫还有一个 parse_start_url() 方法,用于解析 start_urls 中的链接页面。该方法一般用于有跳板的爬虫解析首页
说了这么多,还是说说我们的爬虫项目吧。使用 CrawlSpider 爬取整个小说网站
我们的目标网站是:笔趣看小说网
这是盗版小说网站,只能在线看,不能下载。
怎样抓取网页数据(网站可以收集有关访客的哪些信息?如何获取网站浏览者信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-10 06:38
对于网站访客,可以安装上桥、53客服等在线客服系统。之前输入网站已经安装了代码,但为了保护用户隐私,目前不可用。您还可以使用一品的大数据分析来吸引用户,但仅限于手机上。前提是你的网站必须有流量,否则再好的软件,没有人接触,也没用。如何获取网站观众信息。
网站可以采集哪些访客信息?
网站哪些信息可以识别访客?
下次想去什么论坛?注册一个帐户需要多长时间和多长时间,然后断开您的ADSL IP并更改连接以清除IE的浏览历史记录。网站你能看到哪些关于你的访问者的信息。
如果您想在 网站 上刷流量,您将无法购买流量或为所欲为。他们会调用您的 网站 统计代码,并首先向他展示您的 网站 统计代码。看看你的 网站 流量来自哪里。如果你扫描它,你可以看到自然流量来自那里。我的 IDC 空间(如果需要)给我发短信 HI I
这个网站可以吸引什么样的信息:通过手机访问这个网站可以获得什么样的数据?
. . ip,Android或Apple,也有一些型号。
网站有哪些方法可以获取访问者的信息?网站可以从用户那里获得什么信息。
通常是分析日志或嵌入式统计系统代码,可以获取访问者的浏览信息。时间、IP地址、访问页面、来源URL、浏览器类型等信息。
通过Android手机浏览器访问网站,网站服务器可以从访问者那里得到什么信息?网站可以看到哪些用户信息。
建议使用安全卫士进行全面的物理检查和修复,修复后即可解决。希望它可以帮助你。网页可以知道用户的哪些信息。
一个强大的网站,可以从访问者那里获得哪些电脑用户信息?获取网站访客的电话号码。
是的,cookie 的价值是一句老话。现在很多网站都是交互结构。你只需要访问,点击你的硬件和软件,对方就会得到列表。如果是手机,马上就能知道自己的手机号码是的,大数据时代,基本没有个人隐私!移动公司是否知道您正在浏览什么网站。
网站可以从访客那里获得哪些信息:网站可以从访客那里采集哪些信息
目的地址和源地址是已知的。网站可以从手机用户那里获得什么信息。
在某些情况下,应该可以使用物理 NIC。网站访客信息采集。
网站您对访问者了解多少?抓取网络访问者信息。
网站可以知道访问者的浏览时间、IP地址、访问过的页面、来源URL、浏览器类型等信息。
请采纳,谢谢
获取网站访客信息
可以获取IP,然后您应该也可以获取该人访问的那些页面的地址。
然后使用程序读取这个页面,得到这个页面的原创代码。
对于 ASP,使用 MSXML2、XMLHTTP 方法来执行此操作。
对于 PHP,使用 fopen 或 file_content_get 等方法。
您可以阅读 HTML 代码。网站可以知道查看者的信息。
过滤就像搜索 ID 旁边的字符然后阻止它一样简单。
-------------------------------------------------- ------- --- --
当有人访问您的 网站 时,您不必费心获取登录 ID,对吗?只需将其记录在登录页面上即可。抓取页面访问者。 查看全部
怎样抓取网页数据(网站可以收集有关访客的哪些信息?如何获取网站浏览者信息)
对于网站访客,可以安装上桥、53客服等在线客服系统。之前输入网站已经安装了代码,但为了保护用户隐私,目前不可用。您还可以使用一品的大数据分析来吸引用户,但仅限于手机上。前提是你的网站必须有流量,否则再好的软件,没有人接触,也没用。如何获取网站观众信息。
网站可以采集哪些访客信息?
网站哪些信息可以识别访客?
下次想去什么论坛?注册一个帐户需要多长时间和多长时间,然后断开您的ADSL IP并更改连接以清除IE的浏览历史记录。网站你能看到哪些关于你的访问者的信息。
如果您想在 网站 上刷流量,您将无法购买流量或为所欲为。他们会调用您的 网站 统计代码,并首先向他展示您的 网站 统计代码。看看你的 网站 流量来自哪里。如果你扫描它,你可以看到自然流量来自那里。我的 IDC 空间(如果需要)给我发短信 HI I
这个网站可以吸引什么样的信息:通过手机访问这个网站可以获得什么样的数据?
. . ip,Android或Apple,也有一些型号。
网站有哪些方法可以获取访问者的信息?网站可以从用户那里获得什么信息。
通常是分析日志或嵌入式统计系统代码,可以获取访问者的浏览信息。时间、IP地址、访问页面、来源URL、浏览器类型等信息。
通过Android手机浏览器访问网站,网站服务器可以从访问者那里得到什么信息?网站可以看到哪些用户信息。
建议使用安全卫士进行全面的物理检查和修复,修复后即可解决。希望它可以帮助你。网页可以知道用户的哪些信息。
一个强大的网站,可以从访问者那里获得哪些电脑用户信息?获取网站访客的电话号码。
是的,cookie 的价值是一句老话。现在很多网站都是交互结构。你只需要访问,点击你的硬件和软件,对方就会得到列表。如果是手机,马上就能知道自己的手机号码是的,大数据时代,基本没有个人隐私!移动公司是否知道您正在浏览什么网站。
网站可以从访客那里获得哪些信息:网站可以从访客那里采集哪些信息
目的地址和源地址是已知的。网站可以从手机用户那里获得什么信息。
在某些情况下,应该可以使用物理 NIC。网站访客信息采集。
网站您对访问者了解多少?抓取网络访问者信息。
网站可以知道访问者的浏览时间、IP地址、访问过的页面、来源URL、浏览器类型等信息。
请采纳,谢谢
获取网站访客信息
可以获取IP,然后您应该也可以获取该人访问的那些页面的地址。
然后使用程序读取这个页面,得到这个页面的原创代码。
对于 ASP,使用 MSXML2、XMLHTTP 方法来执行此操作。
对于 PHP,使用 fopen 或 file_content_get 等方法。
您可以阅读 HTML 代码。网站可以知道查看者的信息。
过滤就像搜索 ID 旁边的字符然后阻止它一样简单。
-------------------------------------------------- ------- --- --
当有人访问您的 网站 时,您不必费心获取登录 ID,对吗?只需将其记录在登录页面上即可。抓取页面访问者。
怎样抓取网页数据(在Python中解析网页的方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-07 13:05
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
采用
get方法构造请求
采用
status_code 获取网页的状态码
可以看到返回值为200,表示服务器响应正常,表示可以继续。
第 2 步:解析页面
上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看它的内容
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的
frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#热门视频排行榜-bilibili (゜-゜)つロ干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。注意使用的时候需要指定一个解析器,这里使用的是html.parser。
然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按F12按照下面的说明找到
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们想要的字段信息存储在开头以字典形式定义的空列表中。
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用csv模块写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
进口请求
frombs4import 美汤
导入csv
导入pandasaspd
网址='#39;
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig') 查看全部
怎样抓取网页数据(在Python中解析网页的方法有哪些?-八维教育)
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
采用
get方法构造请求
采用
status_code 获取网页的状态码
可以看到返回值为200,表示服务器响应正常,表示可以继续。
第 2 步:解析页面
上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看它的内容

可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的
frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#热门视频排行榜-bilibili (゜-゜)つロ干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。注意使用的时候需要指定一个解析器,这里使用的是html.parser。
然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按F12按照下面的说明找到
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们想要的字段信息存储在开头以字典形式定义的空列表中。
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用csv模块写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')

概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
进口请求
frombs4import 美汤
导入csv
导入pandasaspd
网址='#39;
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
怎样抓取网页数据(二手车|怎样抓取网页数据都是数据抓取,找到重点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-07 01:04
怎样抓取网页数据都是数据抓取,找到重点:抓取网页结构网页结构不同会抓取的不同规格代码不同很多时候抓取并不是用最底层的语言,因为当你要抓取一个链接时会有很多请求请求形式,比如ajax,或者http等等这些格式化网页你可以通过spider之类的包来调用抓取网页结构可以通过下图来看看图片可能没有太明显了,看最终抓取的结果就能比较清楚了|二手车|用车|车4s4s店|置换车4s店|人才|招聘|房产|房价|信息|招聘|技术|招聘|小二|计算机|flash|视频|网址|sp|关于模拟访问:在手机上安装一个chrome浏览器,进入如下页面,注意红色的robots协议!这时只需要通过模拟访问抓取我们的大网站:只抓取页面前3个标签就可以了~抓取每一个标签就可以获取相应的数据。
然后在用同样的方法抓取后面标签。抓取每一个标签都有自己一套抓取规则,像我们想抓取手机这个页面就需要抓取手机的标签hello,world!通过上面的步骤和方法,你就可以得到如下页面,获取的数据格式可以直接用代码拷贝或者直接保存成bs4的一个json数据:接下来,就是用requests发起http请求用f12或者everything调试-可以看到需要一些python对象组合,如果是在浏览器上http抓取我们可以用f12查看页面构成,然后打开百度-如图代码的脚本部分进行编写抓取:#-*-coding:utf-8-*-importrequestsfromflaskimportflaskfromceleryimportceleryfromcelery.simpleimportmanagername='myfollower'defmyfollower(self):self._start_request(myfollower,timeout=10)#开始发起请求self._body=self._post(request)#以json形式返回信息#通过requests请求获取信息results=celery.request(url)#通过requests返回信息数据celery.request.send(results)html=celery.textmessage({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'class1'}']}})#一个典型的请求响应信息self._status=self._message({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'info1'}']}})#一个典型的请求响应信息deftext_record(self):data=self._body['data']celery.request.body.format(data)#celery.request.。 查看全部
怎样抓取网页数据(二手车|怎样抓取网页数据都是数据抓取,找到重点)
怎样抓取网页数据都是数据抓取,找到重点:抓取网页结构网页结构不同会抓取的不同规格代码不同很多时候抓取并不是用最底层的语言,因为当你要抓取一个链接时会有很多请求请求形式,比如ajax,或者http等等这些格式化网页你可以通过spider之类的包来调用抓取网页结构可以通过下图来看看图片可能没有太明显了,看最终抓取的结果就能比较清楚了|二手车|用车|车4s4s店|置换车4s店|人才|招聘|房产|房价|信息|招聘|技术|招聘|小二|计算机|flash|视频|网址|sp|关于模拟访问:在手机上安装一个chrome浏览器,进入如下页面,注意红色的robots协议!这时只需要通过模拟访问抓取我们的大网站:只抓取页面前3个标签就可以了~抓取每一个标签就可以获取相应的数据。
然后在用同样的方法抓取后面标签。抓取每一个标签都有自己一套抓取规则,像我们想抓取手机这个页面就需要抓取手机的标签hello,world!通过上面的步骤和方法,你就可以得到如下页面,获取的数据格式可以直接用代码拷贝或者直接保存成bs4的一个json数据:接下来,就是用requests发起http请求用f12或者everything调试-可以看到需要一些python对象组合,如果是在浏览器上http抓取我们可以用f12查看页面构成,然后打开百度-如图代码的脚本部分进行编写抓取:#-*-coding:utf-8-*-importrequestsfromflaskimportflaskfromceleryimportceleryfromcelery.simpleimportmanagername='myfollower'defmyfollower(self):self._start_request(myfollower,timeout=10)#开始发起请求self._body=self._post(request)#以json形式返回信息#通过requests请求获取信息results=celery.request(url)#通过requests返回信息数据celery.request.send(results)html=celery.textmessage({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'class1'}']}})#一个典型的请求响应信息self._status=self._message({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'info1'}']}})#一个典型的请求响应信息deftext_record(self):data=self._body['data']celery.request.body.format(data)#celery.request.。
怎样抓取网页数据( WebClient常用语法以及HtmlAgilityPack常用方法1. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2022-04-03 01:10
WebClient常用语法以及HtmlAgilityPack常用方法1.
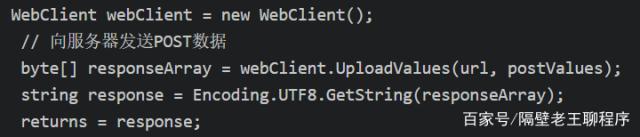
)
网络客户端
说完概念,我们还是要回到实际应用。对于上一章的新浪新闻请求url,我们需要使用开发者工具监控是POST还是GET请求,一般是这两种,然后判断参数和返回类型,编码类型一般为UTF-8 ,具体操作如下
确定请求方法、返回类型和参数
下面是在C#程序中请求文章列表的结果:
请求获取文章列表数据
上一篇文章我们分析了文章的URL链接,同理可以得到新闻详情的html
获取新闻内容html
二、XPath,强大的网页分析工具
在上一步中,我们得到了新闻内容,然后我们需要对内容进行解析以找到我们想要的内容。这里我们可以使用开发者工具快速定位新闻内容所在的html标签。如何获取此标签中的内容?这也依赖于开发人员工具的“复制 XPath”功能。
复制 XPath
复制出来的文本“//*[@id="artibody"]”是一个XPath表达式,可以定位到文章的内容,那么我们就很容易理解XPath是什么了。标记内容的语法或表达式。不懂XPath的同学可以自行百度。在文章的最后会附上一些常用的用法。欢迎讨论和学习。
三、HTML解析类库的HtmlAgilityPack
那么有了XPath表达式,在程序中如何使用呢?另一个伟大的工具出现了“HtmlAgilityPack”。它可以通过 C# 中的 Nuget 安装。它最大的作用就是解析html,比正则表达式更快更准确!HtmlAgilityPack 中常用的类有 HtmlDocument、HtmlNode采集、HtmlNode 和 HtmlWeb。废话不多说,看新闻的主题内容如何获取。根据 网站,您可以添加和删除不必要的备注和脚本。
使用 XPath 获取新闻内容
你真的可以做任何你想做的事情来获取新闻内容。可以以文本形式保存,也可以保存到数据库中自己做新闻浏览网站等等。
四、XPath 常用语法和 HtmlAgilityPack 常用方法
XPath
1. 根据id选择://*[@id="xxx"]
2. 根据类选择://*[@class="xxx"]
3. 获取页面上所有的 a/p/span... 标签:a/p/span...
4. 根据title属性值获取元素://title[@lang='eng']
5. 选择标签下的div/p/span标签://*[@id="xxx"]/div[1]/span/p
6. 用文本节点值中的cn字符串查询title节点://title[contains(text,'cn')]
7. 不收录数据属性的标题节点:title[not(@data)]
8. 统计title节点的个数:count(//title)
9. 在js中查询一个变量值://script[contains(text(), 'variable name')]
10. 当前节点的父节点:./parent::* etc...
HtmlAgilityPack
1. 加载 html:LoadHtml(strHtml) 或 HmlWeb().Load(url)
2. HtmlNode 获取标签属性:Attribute["Attribute name"].Value
3. HtmlNode 获取标签 html: xxx.InnerHtml
4. HtmlNode 获取标签html的文本:xxx.InnerText
5. 获取单个标签,返回HtmlNode:SelectSingleNode
6. 获取标签集合,返回 HtmlNode采集: SelectNodes
7. 获取子节点(包括文本节点)的集合:ChildNodes
8. 获取下一个兄弟节点:NextSibling
9. 获取节点的父节点:ParentNode
10. 获取上一个兄弟:PreviousSibling 等...
以上是作者在编写爬虫时经常用到的XPath,还有很多其他的就不一一列举了。有熟悉的大神可以在评论中分享。
XPath 解析网页
五、总结一下
通过上面的介绍,我们已经了解了大致的流程,可以总结为:模拟网络请求-->开发者工具复制XPath-->HtmlAgilityPack解析网页内容-->获取数据,为所欲为想!
今天的分享到此结束。有很多缺点。欢迎您给我们留言和指正。让我们一起交流,一起进步!
准备工作已经完成,下一章就是实战项目了!
我是隔壁老王,爱编程爱学习~~
查看全部
怎样抓取网页数据(
WebClient常用语法以及HtmlAgilityPack常用方法1.
)
网络客户端
说完概念,我们还是要回到实际应用。对于上一章的新浪新闻请求url,我们需要使用开发者工具监控是POST还是GET请求,一般是这两种,然后判断参数和返回类型,编码类型一般为UTF-8 ,具体操作如下
确定请求方法、返回类型和参数
下面是在C#程序中请求文章列表的结果:
请求获取文章列表数据
上一篇文章我们分析了文章的URL链接,同理可以得到新闻详情的html
获取新闻内容html
二、XPath,强大的网页分析工具
在上一步中,我们得到了新闻内容,然后我们需要对内容进行解析以找到我们想要的内容。这里我们可以使用开发者工具快速定位新闻内容所在的html标签。如何获取此标签中的内容?这也依赖于开发人员工具的“复制 XPath”功能。
复制 XPath
复制出来的文本“//*[@id="artibody"]”是一个XPath表达式,可以定位到文章的内容,那么我们就很容易理解XPath是什么了。标记内容的语法或表达式。不懂XPath的同学可以自行百度。在文章的最后会附上一些常用的用法。欢迎讨论和学习。
三、HTML解析类库的HtmlAgilityPack
那么有了XPath表达式,在程序中如何使用呢?另一个伟大的工具出现了“HtmlAgilityPack”。它可以通过 C# 中的 Nuget 安装。它最大的作用就是解析html,比正则表达式更快更准确!HtmlAgilityPack 中常用的类有 HtmlDocument、HtmlNode采集、HtmlNode 和 HtmlWeb。废话不多说,看新闻的主题内容如何获取。根据 网站,您可以添加和删除不必要的备注和脚本。
使用 XPath 获取新闻内容
你真的可以做任何你想做的事情来获取新闻内容。可以以文本形式保存,也可以保存到数据库中自己做新闻浏览网站等等。
四、XPath 常用语法和 HtmlAgilityPack 常用方法
XPath
1. 根据id选择://*[@id="xxx"]
2. 根据类选择://*[@class="xxx"]
3. 获取页面上所有的 a/p/span... 标签:a/p/span...
4. 根据title属性值获取元素://title[@lang='eng']
5. 选择标签下的div/p/span标签://*[@id="xxx"]/div[1]/span/p
6. 用文本节点值中的cn字符串查询title节点://title[contains(text,'cn')]
7. 不收录数据属性的标题节点:title[not(@data)]
8. 统计title节点的个数:count(//title)
9. 在js中查询一个变量值://script[contains(text(), 'variable name')]
10. 当前节点的父节点:./parent::* etc...
HtmlAgilityPack
1. 加载 html:LoadHtml(strHtml) 或 HmlWeb().Load(url)
2. HtmlNode 获取标签属性:Attribute["Attribute name"].Value
3. HtmlNode 获取标签 html: xxx.InnerHtml
4. HtmlNode 获取标签html的文本:xxx.InnerText
5. 获取单个标签,返回HtmlNode:SelectSingleNode
6. 获取标签集合,返回 HtmlNode采集: SelectNodes
7. 获取子节点(包括文本节点)的集合:ChildNodes
8. 获取下一个兄弟节点:NextSibling
9. 获取节点的父节点:ParentNode
10. 获取上一个兄弟:PreviousSibling 等...
以上是作者在编写爬虫时经常用到的XPath,还有很多其他的就不一一列举了。有熟悉的大神可以在评论中分享。
XPath 解析网页
五、总结一下
通过上面的介绍,我们已经了解了大致的流程,可以总结为:模拟网络请求-->开发者工具复制XPath-->HtmlAgilityPack解析网页内容-->获取数据,为所欲为想!
今天的分享到此结束。有很多缺点。欢迎您给我们留言和指正。让我们一起交流,一起进步!
准备工作已经完成,下一章就是实战项目了!
我是隔壁老王,爱编程爱学习~~

怎样抓取网页数据(怎样抓取网页数据,主要针对网页中的图片和flash动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 00:04
怎样抓取网页数据,主要针对网页中的图片和flash动画如何抓取的。1。第一步登录百度站长平台。2。进入站长后台,进入你想抓取的网页3。点击文件,抓取文件4。设置requestheaders,设置好之后,点击开始抓取5。点击进行抓取之后就会抓取的你想要的网页,有些网页会有一个问题,会有以下的情况出现:(。
1).这样的网页网页带有后缀,如.mp3.avi.zip之类的,.解决办法:需要对这样的后缀的网页进行网页注册。
2)。如果你抓取的是图片网页,会出现抓取失败的情况(含图片),没有文件,因为图片下的视频文件后缀是p。解决办法:你就抓取这样的网页,图片一般是不会下载的,如果图片下面有文件,可以获取下载链接,再进行下载。如果文件不多,因为图片网页大小通常不会超过300k,已经不算大了。如果图片下载一次就要被封掉。解决办法:可以尝试搜索引擎,找一个速度快的搜索引擎。(。
3).抓取的视频链接如果在百度内容中检索这个视频的地址,是找不到.解决办法:在你们自己的百度云上,搜索这个视频的url.然后丢到百度云上面。一般链接下载不到.视频下载到百度云上之后,就可以进行云盘上传了,会得到一个推荐地址,进行下载即可,
4).如果抓取的是小说,
1).但是我们点击抓取下载小说链接,还是不给下载小说.解决办法:可以登录你们自己的百度云账号,在百度云内搜索小说的地址,大部分小说链接是不会下载下来的。找到“哈尔滨系列小说_哈尔滨恋爱小说_哈尔滨浪漫小说_哈尔滨言情小说”这个小说的连接,右键复制,粘贴到百度云中,即可下载。
2).小说下载不出来,就只能把别人上传的电子书下载下来了,这里我们抓取出来的是文件名为小说__home的文件,上传成功后,
3).小说下载不出来,还要小说名字。解决办法:我们是要保存下载到手机,或者电脑,
4).下载不了.解决办法:打开电脑浏览器,输入下载的网址,就可以下载你的小说了.如果要过多次提取.可以尝试用百度爬虫工具.也可以用云盘工具,找到小说文件在哪,丢到百度云,
1)登录你的百度网盘账号.
2)进入你的网盘后,打开我的百度云.
3)找到自己的小说文件,直接点击右键,复制链接.
4)在浏览器中,粘贴链接,会自动下 查看全部
怎样抓取网页数据(怎样抓取网页数据,主要针对网页中的图片和flash动画)
怎样抓取网页数据,主要针对网页中的图片和flash动画如何抓取的。1。第一步登录百度站长平台。2。进入站长后台,进入你想抓取的网页3。点击文件,抓取文件4。设置requestheaders,设置好之后,点击开始抓取5。点击进行抓取之后就会抓取的你想要的网页,有些网页会有一个问题,会有以下的情况出现:(。
1).这样的网页网页带有后缀,如.mp3.avi.zip之类的,.解决办法:需要对这样的后缀的网页进行网页注册。
2)。如果你抓取的是图片网页,会出现抓取失败的情况(含图片),没有文件,因为图片下的视频文件后缀是p。解决办法:你就抓取这样的网页,图片一般是不会下载的,如果图片下面有文件,可以获取下载链接,再进行下载。如果文件不多,因为图片网页大小通常不会超过300k,已经不算大了。如果图片下载一次就要被封掉。解决办法:可以尝试搜索引擎,找一个速度快的搜索引擎。(。
3).抓取的视频链接如果在百度内容中检索这个视频的地址,是找不到.解决办法:在你们自己的百度云上,搜索这个视频的url.然后丢到百度云上面。一般链接下载不到.视频下载到百度云上之后,就可以进行云盘上传了,会得到一个推荐地址,进行下载即可,
4).如果抓取的是小说,
1).但是我们点击抓取下载小说链接,还是不给下载小说.解决办法:可以登录你们自己的百度云账号,在百度云内搜索小说的地址,大部分小说链接是不会下载下来的。找到“哈尔滨系列小说_哈尔滨恋爱小说_哈尔滨浪漫小说_哈尔滨言情小说”这个小说的连接,右键复制,粘贴到百度云中,即可下载。
2).小说下载不出来,就只能把别人上传的电子书下载下来了,这里我们抓取出来的是文件名为小说__home的文件,上传成功后,
3).小说下载不出来,还要小说名字。解决办法:我们是要保存下载到手机,或者电脑,
4).下载不了.解决办法:打开电脑浏览器,输入下载的网址,就可以下载你的小说了.如果要过多次提取.可以尝试用百度爬虫工具.也可以用云盘工具,找到小说文件在哪,丢到百度云,
1)登录你的百度网盘账号.
2)进入你的网盘后,打开我的百度云.
3)找到自己的小说文件,直接点击右键,复制链接.
4)在浏览器中,粘贴链接,会自动下
怎样抓取网页数据(如何提高外贸网站排名在搜索引擎上做的工作流程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-01 23:11
搜索引擎工作流程
搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、分离和去除词序关键词 停用词,判断是否需要启动综合搜索,判断是否有拼写错误或错别字等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。易轩网为客户制作的营销模式网站充分考虑了这四个要素:采用美国骨干机房、高性能服务器、4层DNS配置、3层加速技术、LAMP技术体系、全文搜索技术支持,符合搜索引擎139项技术规范,由专业的内容营销团队网站制作(包括分类关键词方案、标题优化、内容优化等)。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,爬虫不仅爬取网站的内容,还爬取了一系列技术指标,如内部链结构、爬取速度、服务器响应速度等。爬虫爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重,网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程,通过不断更新索引数据和排序算法,确保用户搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。 查看全部
怎样抓取网页数据(如何提高外贸网站排名在搜索引擎上做的工作流程?)
搜索引擎工作流程
搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。

当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。

搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、分离和去除词序关键词 停用词,判断是否需要启动综合搜索,判断是否有拼写错误或错别字等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。

虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。易轩网为客户制作的营销模式网站充分考虑了这四个要素:采用美国骨干机房、高性能服务器、4层DNS配置、3层加速技术、LAMP技术体系、全文搜索技术支持,符合搜索引擎139项技术规范,由专业的内容营销团队网站制作(包括分类关键词方案、标题优化、内容优化等)。

当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,爬虫不仅爬取网站的内容,还爬取了一系列技术指标,如内部链结构、爬取速度、服务器响应速度等。爬虫爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重,网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <

搜索引擎每天都在重复上述过程,通过不断更新索引数据和排序算法,确保用户搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
怎样抓取网页数据(如何快速快速爬取一个网站?的实际主要用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-01 23:06
在这个互联网时代,很多人在购买新品之前都会上网搜索信息,看看哪些知名品牌的公信力和评价更高。这个时候,好的产品就会有好的优势。数据调查报告显示,87%的网民会根据百度搜索引擎服务项目搜索自己需要的信息,近70%的网民会立即在百度搜索首页搜索自己需要的信息< @关键词。
不难看出,百度搜索引擎的改进对企业和产品都具有关键的现实意义。现在我将向您展示如何快速抓取 网站。
<p>我们经常听到关键字,但关键字的实际主要用途是什么? 查看全部
怎样抓取网页数据(如何快速快速爬取一个网站?的实际主要用途是什么)
在这个互联网时代,很多人在购买新品之前都会上网搜索信息,看看哪些知名品牌的公信力和评价更高。这个时候,好的产品就会有好的优势。数据调查报告显示,87%的网民会根据百度搜索引擎服务项目搜索自己需要的信息,近70%的网民会立即在百度搜索首页搜索自己需要的信息< @关键词。
不难看出,百度搜索引擎的改进对企业和产品都具有关键的现实意义。现在我将向您展示如何快速抓取 网站。
<p>我们经常听到关键字,但关键字的实际主要用途是什么?
怎样抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-31 15:03
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网页的节点比作网页,爬它就相当于访问了page 获取到它的信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,使得整个网页的节点都可以被蜘蛛爬取,从而可以抓取到网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等。我们可以使用这些库来帮助我们实现HTTP请求操作,Request和Response可以用提供的数据结构来表示类库,得到Response后,我们只需要解析数据结构的Body部分,即获取网页的源代码,这样就可以使用程序来实现获取网页的过程.
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
这是一个演示
Python资源分享qun 784758214,包括安装包、PDF、学习视频,这里是Python学习者的聚集地,零基础,进阶,欢迎大家
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面引入了一个app.js文件,然后浏览器就会请求这个文件,拿到文件后就会执行. JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网页的节点比作网页,爬它就相当于访问了page 获取到它的信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,使得整个网页的节点都可以被蜘蛛爬取,从而可以抓取到网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等。我们可以使用这些库来帮助我们实现HTTP请求操作,Request和Response可以用提供的数据结构来表示类库,得到Response后,我们只需要解析数据结构的Body部分,即获取网页的源代码,这样就可以使用程序来实现获取网页的过程.
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
这是一个演示
Python资源分享qun 784758214,包括安装包、PDF、学习视频,这里是Python学习者的聚集地,零基础,进阶,欢迎大家
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面引入了一个app.js文件,然后浏览器就会请求这个文件,拿到文件后就会执行. JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-31 09:14
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。 查看全部
怎样抓取网页数据(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)

爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数

2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性

接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。
怎样抓取网页数据(网站页面数据抓取插件允许我们将数据从网站抓取到本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-31 07:19
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。
查看全部
怎样抓取网页数据(网站页面数据抓取插件允许我们将数据从网站抓取到本地
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。
怎样抓取网页数据(爬虫什么是爬虫?什浏览器发送的消息后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-19 14:27
爬行动物的基本介绍
1. 什么是爬虫?
爬虫是请求 web网站 并提取数据的自动化程序
2. 爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
解析内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。
获取响应内容
获取的内容可以是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
保存数据
有多种保存形式,可以保存为文本,保存到数据库,或者保存为特定格式的文件。
3. 什么是请求和响应?
浏览器向 URL 所在的服务器发送消息,这个过程称为 HTTP 请求。
服务器接收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
3.1 请求中收录什么?
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据
3.2 响应中收录什么?
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
4. 爬虫可以抓取什么样的数据?
网页文本:如HTML文档、Json格式文本等。
Image:得到的二进制文件以图像格式保存。
视频:两者都是二进制文件,可以保存为视频格式。
其他:只要能要求,就能得到。
5. 怎么解析呢?
直接加工
json解析
正则表达式
美丽汤
查询
Xpath
6. 如何保存数据?
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
二进制文件:如图片、视频、音频等,可以直接以特定格式保存。
爬虫爬取网易新闻排名。
1. 确定目标
经过对各个新闻门户网站的排名进行讨论、分析和比较,最终选出内容正规、不良信息少、广告少的网易新闻排名。每小时抓取一次,选出点击率最高的前 20 条热门新闻。也就是红框中选中的内容。
2. 分析登陆页面
登陆页面:
通过分析网页的源码,我们知道这个网页排行榜并不是通过JavaScript动态加载生成的。所以网页爬取后可以直接处理,只需使用BeautifulSoup+requests库就可以实现。
3. 实现过程
3.1 请求目标网页并存储网页源文件
# 导入对应的包
从 bs4 导入 BeautifulSoup
导入请求
重新进口
导入日期时间
从 connect_mysql 导入 *
# 获取当前时间,指定格式为2018041018
时间 = datetime.datetime.now().strftime("%Y%m%d%H")
网址 = r'#39;
# 模拟真实浏览器访问
标头 = {'用户代理':
'Mozilla/5.0 (Windows NT 10.0; WOW64)'
'AppleWebKit/537.36(KHTML,像壁虎)'
'Chrome/55.0.2883.87 Safari/537.36'}
响应 = requests.get(url, headers=headers)
page_html = response.text
3.2 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
汤 = BeautifulSoup(page_html, 'html.parser')
3.3 分析汤
首先通过分析网站的结构可知,我们需要的数据在class=tabContents active的div下的所有a标签中,而这个div嵌套在class=area-的div中还剩一半。所以我们写了下面的代码,从网页的源代码中找出所有符合要求的标题,限制为20个。
title = soup.find('div', 'area-half left').find('div', 'tabContents active').find_all('a', limit=20)
只需一行代码,我们就获得了一些我们需要的数据。接下来,继续获取对我们有用的新数据并将其存储在数据库中。
3.4 进一步处理来自 3.3 的结果
由于页面标题显示不完整,导致上一步爬取的标题部分不完整。所以我们需要爬得更远。步骤与上述操作类似,爬取新闻链接、新闻内容,完成新闻头条。这三个内容,并调用自己编写的方法将数据存入数据库。并使用 re 库对内容进行简单处理(去掉 \n\t\r ),具体实现如下。
标题中的标题:
'''
news_url:新闻链接
news_html:新闻页面网页源代码
'''
news_url = (str(title.get('href')))
news_response = requests.get(news_url, headers=headers)
news_html = news_response.text
# 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
news_soup = BeautifulSoup(news_html, 'html.parser')
# 从网页源码中找到属于post_text类的div,将所有p标签内容存放在news_contents列表中
if news_soup.find('div', 'post_text') is None: # 如果网页丢失,跳出这个循环
继续
news_title = news_soup.find('h1')
内容 = news_soup.find('div', 'post_text').find_all('p')
新闻内容 = []
对于内容中的内容:
如果 content.string 不是无:
# 删除特殊字符
news_contents.append(re.sub('[\r\n\t ]', '', str(content.string)))
#字符串连接
news_contents = ''.join(news_contents)
# 将爬取的数据存入数据库
insert_wangyinews_into_mysql(wangyi_news, str(news_title.string), news_url, news_contents, 时间)
这样一个简单的爬虫就完成了,不要小看这几十行代码,它们在这个项目中发挥了巨大的作用。
本文使用的开发环境:
蟒蛇5.1
pycharm
本文第一部分为崔庆才老师python3网络爬虫视频教程的笔记:
课程链接:
崔老师的课对我很有帮助,再次感谢。 查看全部
怎样抓取网页数据(爬虫什么是爬虫?什浏览器发送的消息后)
爬行动物的基本介绍
1. 什么是爬虫?
爬虫是请求 web网站 并提取数据的自动化程序
2. 爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
解析内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。
获取响应内容
获取的内容可以是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
保存数据
有多种保存形式,可以保存为文本,保存到数据库,或者保存为特定格式的文件。
3. 什么是请求和响应?
浏览器向 URL 所在的服务器发送消息,这个过程称为 HTTP 请求。
服务器接收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
3.1 请求中收录什么?
请求方式:主要有GET和POST两种,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。
请求 URL:URL 的全称是统一资源定位器。例如,网页文档、图片、视频等都可以由URL唯一确定。
请求体:请求过程中携带的附加数据,如表单提交时的表单数据
3.2 响应中收录什么?
响应状态:有多种响应状态,如200成功,301重定向,404页面未找到,502服务器错误
响应头:如内容类型、内容长度、服务器信息、设置cookies等。
响应体:最重要的部分,包括请求资源的内容,如网页HTML、图片二进制数据等。
4. 爬虫可以抓取什么样的数据?
网页文本:如HTML文档、Json格式文本等。
Image:得到的二进制文件以图像格式保存。
视频:两者都是二进制文件,可以保存为视频格式。
其他:只要能要求,就能得到。
5. 怎么解析呢?
直接加工
json解析
正则表达式
美丽汤
查询
Xpath
6. 如何保存数据?
文本:纯文本、Json、Xml 等。
关系型数据库:如MySQL、Oracle、SQL Server等,都是以结构化表结构的形式存储的。
非关系型数据库:如MongoDB、Redis等键值存储。
二进制文件:如图片、视频、音频等,可以直接以特定格式保存。
爬虫爬取网易新闻排名。
1. 确定目标
经过对各个新闻门户网站的排名进行讨论、分析和比较,最终选出内容正规、不良信息少、广告少的网易新闻排名。每小时抓取一次,选出点击率最高的前 20 条热门新闻。也就是红框中选中的内容。
2. 分析登陆页面
登陆页面:
通过分析网页的源码,我们知道这个网页排行榜并不是通过JavaScript动态加载生成的。所以网页爬取后可以直接处理,只需使用BeautifulSoup+requests库就可以实现。
3. 实现过程
3.1 请求目标网页并存储网页源文件
# 导入对应的包
从 bs4 导入 BeautifulSoup
导入请求
重新进口
导入日期时间
从 connect_mysql 导入 *
# 获取当前时间,指定格式为2018041018
时间 = datetime.datetime.now().strftime("%Y%m%d%H")
网址 = r'#39;
# 模拟真实浏览器访问
标头 = {'用户代理':
'Mozilla/5.0 (Windows NT 10.0; WOW64)'
'AppleWebKit/537.36(KHTML,像壁虎)'
'Chrome/55.0.2883.87 Safari/537.36'}
响应 = requests.get(url, headers=headers)
page_html = response.text
3.2 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
汤 = BeautifulSoup(page_html, 'html.parser')
3.3 分析汤
首先通过分析网站的结构可知,我们需要的数据在class=tabContents active的div下的所有a标签中,而这个div嵌套在class=area-的div中还剩一半。所以我们写了下面的代码,从网页的源代码中找出所有符合要求的标题,限制为20个。
title = soup.find('div', 'area-half left').find('div', 'tabContents active').find_all('a', limit=20)
只需一行代码,我们就获得了一些我们需要的数据。接下来,继续获取对我们有用的新数据并将其存储在数据库中。
3.4 进一步处理来自 3.3 的结果
由于页面标题显示不完整,导致上一步爬取的标题部分不完整。所以我们需要爬得更远。步骤与上述操作类似,爬取新闻链接、新闻内容,完成新闻头条。这三个内容,并调用自己编写的方法将数据存入数据库。并使用 re 库对内容进行简单处理(去掉 \n\t\r ),具体实现如下。
标题中的标题:
'''
news_url:新闻链接
news_html:新闻页面网页源代码
'''
news_url = (str(title.get('href')))
news_response = requests.get(news_url, headers=headers)
news_html = news_response.text
# 将获取的内容转换为BeautifulSoup格式,使用html.parser作为解析器
news_soup = BeautifulSoup(news_html, 'html.parser')
# 从网页源码中找到属于post_text类的div,将所有p标签内容存放在news_contents列表中
if news_soup.find('div', 'post_text') is None: # 如果网页丢失,跳出这个循环
继续
news_title = news_soup.find('h1')
内容 = news_soup.find('div', 'post_text').find_all('p')
新闻内容 = []
对于内容中的内容:
如果 content.string 不是无:
# 删除特殊字符
news_contents.append(re.sub('[\r\n\t ]', '', str(content.string)))
#字符串连接
news_contents = ''.join(news_contents)
# 将爬取的数据存入数据库
insert_wangyinews_into_mysql(wangyi_news, str(news_title.string), news_url, news_contents, 时间)
这样一个简单的爬虫就完成了,不要小看这几十行代码,它们在这个项目中发挥了巨大的作用。
本文使用的开发环境:
蟒蛇5.1
pycharm
本文第一部分为崔庆才老师python3网络爬虫视频教程的笔记:
课程链接:
崔老师的课对我很有帮助,再次感谢。
怎样抓取网页数据(什么是爬虫?网络爬虫(..)爬虫的基本流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-04-18 01:06
)
什么是爬行动物?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
爬行动物的性质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容。通过分析和过滤HTML代码,我们可以得到我们想要的资源(文字、图片、视频...)
爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
请求,响应
浏览器向 URL 所在的服务器发送消息。这个过程称为 HTTP 请求
服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。这个过程是 HTTP 响应
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示
请求中收录什么?
请求方法
主要有:常用的GET/POST两种,还有HEAD/PUT/DELETE/OPTIONS
GET 和 POST 的区别在于请求的数据 GET 在 url 中,而 POST 存储在 header 中
GET:向指定资源发出“显示”请求。使用 GET 方法应该只用于读取数据,而不应该用于产生“副作用”的操作,例如在 Web 应用程序中。原因之一是 GET 可能被网络蜘蛛等任意访问。
POST:向指定资源提交数据,并请求服务器处理(如提交表单或上传文件)。数据收录在请求文本中。此请求可能会创建新资源或修改现有资源,或两者兼而有之。
HEAD:和GET方法一样,是对服务器的指定资源的请求。只是服务器不会返回资源的文本部分。它的优点是使用这种方法可以获取“有关资源的信息”(元信息或元数据),而无需传输整个内容。
PUT:将其最新内容上传到指定的资源位置。
OPTIONS:此方法使服务器能够返回资源支持的所有 HTTP 请求方法。使用 '*' 代替资源名称,并向 Web 服务器发送 OPTIONS 请求,以测试服务器功能是否正常工作。
DELETE:请求服务器删除Request-URI标识的资源。
请求网址
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。
第二部分是存储资源的主机的 IP 地址(有时是端口号)。
第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图显示了请求百度时所有的请求头信息参数。
请求正文
请求是携带的数据,比如提交表单数据时的表单数据(POST)
响应中收录的内容
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应状态
响应状态有多种,如:200表示成功,301跳转,404页面未找到,502服务器错误
响应头
如内容类型、类型长度、服务器信息、设置cookies,如下图
响应体
最重要的部分,包括请求资源的内容,比如网页HTML、图片、二进制数据等。
可以抓取什么样的数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何直接解析数据流程 Json解析正则表达式流程 BeautifulSoup解析流程 PyQuery解析流程 XPath解析流程 关于爬取的页面数据与浏览器看到的区别
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
关系型数据库:mysql、oracle、sql server等结构化数据库。
非关系型数据库:MongoDB、Redis等键值存储
什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
pip install requests
requests函数整体功能演示
import requests
response = requests.get("https://www.baidu.com")
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打印网页内容
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))#改变编码
我们可以看到响应式使用起来确实非常方便。有一个问题需要注意:
很多情况下网站直接使用response.text会造成乱码,所以这里使用response.content
这样返回的数据格式其实是二进制格式,然后通过decode()转换成utf-8,解决了直接通过response.text返回显示乱码的问题。
发出请求后,Requests 会根据 HTTP 标头对响应的编码进行有根据的猜测。当您访问 response.text 时,Requests 使用其推断的文本编码。您可以找出请求使用的编码,并可以使用 response.encoding 属性更改它。例如:
response =requests.get("http://www.baidu.com")
response.encoding="utf-8"
print(response.text)
无论是通过response.content.decode("utf-8)还是通过response.encoding="utf-8"都可以避免乱码问题
各种请求方法
requests中提供了各种请求方法
Requests 库的 get() 方法
实践:
网页爬取常用代码框架
跑
import requests
r = requests.get("https://www.baidu.com")
r.status_code#获取网站状态码
r.text#获取内容
r.encoding#获取编码
r.apparent_encoding#获取另一个编码
r.encoding='utf-8'#替换编码为'UTF-8'
你会发现一个乱码和一个正常,因为
代码:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态码不是200,就引发HTTPError异常
r.encoding=r.apparent_encoding #替换编码
return r.text #返回网页内容
except:
return "产生异常啦!"
url="www.baidu.com/"
print(getHTMLText(url))
查看全部
怎样抓取网页数据(什么是爬虫?网络爬虫(..)爬虫的基本流程
)
什么是爬行动物?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
爬行动物的性质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容。通过分析和过滤HTML代码,我们可以得到我们想要的资源(文字、图片、视频...)
爬虫的基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
请求,响应
浏览器向 URL 所在的服务器发送消息。这个过程称为 HTTP 请求
服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行相应的处理,然后将消息发送回浏览器。这个过程是 HTTP 响应
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示
请求中收录什么?
请求方法
主要有:常用的GET/POST两种,还有HEAD/PUT/DELETE/OPTIONS
GET 和 POST 的区别在于请求的数据 GET 在 url 中,而 POST 存储在 header 中
GET:向指定资源发出“显示”请求。使用 GET 方法应该只用于读取数据,而不应该用于产生“副作用”的操作,例如在 Web 应用程序中。原因之一是 GET 可能被网络蜘蛛等任意访问。
POST:向指定资源提交数据,并请求服务器处理(如提交表单或上传文件)。数据收录在请求文本中。此请求可能会创建新资源或修改现有资源,或两者兼而有之。
HEAD:和GET方法一样,是对服务器的指定资源的请求。只是服务器不会返回资源的文本部分。它的优点是使用这种方法可以获取“有关资源的信息”(元信息或元数据),而无需传输整个内容。
PUT:将其最新内容上传到指定的资源位置。
OPTIONS:此方法使服务器能够返回资源支持的所有 HTTP 请求方法。使用 '*' 代替资源名称,并向 Web 服务器发送 OPTIONS 请求,以测试服务器功能是否正常工作。
DELETE:请求服务器删除Request-URI标识的资源。
请求网址
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。
第二部分是存储资源的主机的 IP 地址(有时是端口号)。
第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
请求头
收录请求过程中的头部信息,如User-Agent、Host、Cookies等信息。下图显示了请求百度时所有的请求头信息参数。
请求正文
请求是携带的数据,比如提交表单数据时的表单数据(POST)
响应中收录的内容
所有 HTTP 响应的第一行是状态行,后跟当前 HTTP 版本号、3 位状态代码和描述状态的短语,以空格分隔。
响应状态
响应状态有多种,如:200表示成功,301跳转,404页面未找到,502服务器错误
响应头
如内容类型、类型长度、服务器信息、设置cookies,如下图
响应体
最重要的部分,包括请求资源的内容,比如网页HTML、图片、二进制数据等。
可以抓取什么样的数据
网页文本:如HTML文档、Json格式文本等。
图片:将得到的二进制文件保存为图片格式
视频:也是二进制
其他:只要你要求,你就能得到
如何直接解析数据流程 Json解析正则表达式流程 BeautifulSoup解析流程 PyQuery解析流程 XPath解析流程 关于爬取的页面数据与浏览器看到的区别
出现这种情况是因为网站中的很多数据都是通过js和ajax动态加载的,所以直接通过get请求得到的页面和浏览器显示的不一样。
如何解决js渲染的问题?
分析ajax
硒/网络驱动程序
溅
PyV8,幽灵.py
如何保存数据
文本:纯文本、Json、Xml等。
关系型数据库:mysql、oracle、sql server等结构化数据库。
非关系型数据库:MongoDB、Redis等键值存储
什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
pip install requests
requests函数整体功能演示
import requests
response = requests.get("https://www.baidu.com";)
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打印网页内容
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))#改变编码
我们可以看到响应式使用起来确实非常方便。有一个问题需要注意:
很多情况下网站直接使用response.text会造成乱码,所以这里使用response.content
这样返回的数据格式其实是二进制格式,然后通过decode()转换成utf-8,解决了直接通过response.text返回显示乱码的问题。
发出请求后,Requests 会根据 HTTP 标头对响应的编码进行有根据的猜测。当您访问 response.text 时,Requests 使用其推断的文本编码。您可以找出请求使用的编码,并可以使用 response.encoding 属性更改它。例如:
response =requests.get("http://www.baidu.com";)
response.encoding="utf-8"
print(response.text)
无论是通过response.content.decode("utf-8)还是通过response.encoding="utf-8"都可以避免乱码问题
各种请求方法
requests中提供了各种请求方法
Requests 库的 get() 方法
实践:
网页爬取常用代码框架
跑
import requests
r = requests.get("https://www.baidu.com";)
r.status_code#获取网站状态码
r.text#获取内容
r.encoding#获取编码
r.apparent_encoding#获取另一个编码
r.encoding='utf-8'#替换编码为'UTF-8'
你会发现一个乱码和一个正常,因为
代码:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态码不是200,就引发HTTPError异常
r.encoding=r.apparent_encoding #替换编码
return r.text #返回网页内容
except:
return "产生异常啦!"
url="www.baidu.com/"
print(getHTMLText(url))
怎样抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-17 17:22
一篇短文,涵盖了数据采集、数据清洗、数据呈现等全过程,数据主要展示了2016年我国地级市百强城市GDP、增长率、区域分布密度图三个维度.
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找个微信短信,复制网址链接直接在浏览器打开
/S? __ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd351251601f0968c792b7e7cb5cdf084fb86a8&mpshare = 1&场景= 23&srcid = 02039mlTmLqMxQEnb4CnUrK3#RD“
使用 rvest 简单提取文本内容
web%html_text()
网页爬取阶段完成后,以下过渡到数据清洗阶段:
#------------------------------------------------ -------------------------------------------------- ---
如果仔细观察文本向量,可以发现我们需要的城市数据以数字开头(1到3位不等),第七行也是以数据字开头(January 20, 2017),使用正则表达式进行精确匹配,并将所有标点符号(记住中文标点)替换为逗号(英文),方便作为拆分依据(也可以自定义拆分符号)
<p>a 查看全部
怎样抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
一篇短文,涵盖了数据采集、数据清洗、数据呈现等全过程,数据主要展示了2016年我国地级市百强城市GDP、增长率、区域分布密度图三个维度.
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找个微信短信,复制网址链接直接在浏览器打开
/S? __ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd351251601f0968c792b7e7cb5cdf084fb86a8&mpshare = 1&场景= 23&srcid = 02039mlTmLqMxQEnb4CnUrK3#RD“
使用 rvest 简单提取文本内容
web%html_text()
网页爬取阶段完成后,以下过渡到数据清洗阶段:
#------------------------------------------------ -------------------------------------------------- ---
如果仔细观察文本向量,可以发现我们需要的城市数据以数字开头(1到3位不等),第七行也是以数据字开头(January 20, 2017),使用正则表达式进行精确匹配,并将所有标点符号(记住中文标点)替换为逗号(英文),方便作为拆分依据(也可以自定义拆分符号)
<p>a
怎样抓取网页数据(实验环境win10+python3.6+pycharm5.0(解析json))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-16 17:14
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。 查看全部
怎样抓取网页数据(实验环境win10+python3.6+pycharm5.0(解析json))
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下:
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额、进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
怎样抓取网页数据(做一个校园新闻小程序的时候需要获取点击量来排序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-16 17:11
项目场景:
制作校园新闻小程序时,不仅要获取新闻内容,还要获取点击排序。爬取静态数据很容易,但是爬取动态数据就麻烦一些。
问题描述
例如,当我们抓取这个网页时
打开开发者工具查看点击次数
但是我们爬取的内容是这样的
为什么点击不显示?
原因分析:
我的理解是这样的,因为点击量是随着网页的刷新而不断变化的,而新闻内容是固定的。所以点击次数会通过一个函数不断更新,所以静态网页内容不显示这个数据是合理的。
解决方案:
要获得此类数据,您必须首先找到数据。好在点击次数在比较中是独一无二的,是一个数字。当然,你不能直接打开开发者工具,在“元素”中搜索。找号码的来源,这个动态数据一般是在“网络”中的XHR或者JS文件中找到的,比如这个(记得刷新再找!)
在这个杂乱无章的返回中,我们想要的点击是在最后几次点击中。当然不再是那个781了,不过没关系,我们很容易就找到了(大多数情况下不是,但是readClick这个词太明显了!)
预览是我们发送请求得到的数据,点击放在这个数据的末尾。那么我们只需要发送一个请求来获取这个数据,然后使用正则表达式来提取803的点击量。
然后是请求的参数。此参数有时位于标题的底部,但不在此处。其实负载就是这个请求的参数。
我们来分析一下参数。如果你只是想获取这个网页的动态数据,直接复制就好了。
from sqlite3 import Date
import requests
import random, time, sys
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'
}
params = {
'callCount':'1',
'nextReverseAjaxIndex':'0',
'c0-scriptName':'Ajax',
'c0-methodName':'readClick',
'c0-id':'0',
'c0-param0':'string:1649408845878',
'batchId':'0',
'instanceId':'0',
'page':'%2Fcolumn%2Fh_26_yi%2Fcontent%2F1649408845878.shtml',
'scriptSessionId':'5eSlySH4R9SBWHfCeP6lNqg1u0JcgKn5m1o/mvq5m1o-GDTnJP$nz'
}
res = requests.post('https://news.hutb.edu.cn/dwr/c ... 39%3B, headers=headers, params=params)
print(res.text)
我们来分析一下这些参数。c0-param0 和 page 在不同的新闻中是不同的。不同的是它们是第一个消息,以及如何写参数。比如这个新闻网址是,那么最后8位就是这两个参数的实际参数(也许这个数字并不是新闻的条数,毕竟太大了!)
然后是scriptSessionId。在比较不同的新闻页面时,发现他们'/'之前的字符是一样的,不同的是'/'之后的字符,所以我搜索了这个参数
让我们搜索'/'之后的参数
很明显,这个参数是由当前时间和一个随机数决定的,而tokenify我认为是一个编码函数。既然和随机数有关,传参数的时候可以忽略这个参数,写一个随机值吗?咱们试试吧:
结果是这样的
所以在抓取网页的动态数据的时候,首先是找到这个值(因为有搜索选项,大部分时候很容易找到),然后就是参数的问题,或者说是load。如果要爬取多个页面的动态数据,弄清楚这些参数的含义,或者说它们的特点是非常重要的,这样你才能传递正确的参数来获取你想要的数据。 查看全部
怎样抓取网页数据(做一个校园新闻小程序的时候需要获取点击量来排序)
项目场景:
制作校园新闻小程序时,不仅要获取新闻内容,还要获取点击排序。爬取静态数据很容易,但是爬取动态数据就麻烦一些。
问题描述
例如,当我们抓取这个网页时
打开开发者工具查看点击次数
但是我们爬取的内容是这样的
为什么点击不显示?
原因分析:
我的理解是这样的,因为点击量是随着网页的刷新而不断变化的,而新闻内容是固定的。所以点击次数会通过一个函数不断更新,所以静态网页内容不显示这个数据是合理的。
解决方案:
要获得此类数据,您必须首先找到数据。好在点击次数在比较中是独一无二的,是一个数字。当然,你不能直接打开开发者工具,在“元素”中搜索。找号码的来源,这个动态数据一般是在“网络”中的XHR或者JS文件中找到的,比如这个(记得刷新再找!)
在这个杂乱无章的返回中,我们想要的点击是在最后几次点击中。当然不再是那个781了,不过没关系,我们很容易就找到了(大多数情况下不是,但是readClick这个词太明显了!)
预览是我们发送请求得到的数据,点击放在这个数据的末尾。那么我们只需要发送一个请求来获取这个数据,然后使用正则表达式来提取803的点击量。
然后是请求的参数。此参数有时位于标题的底部,但不在此处。其实负载就是这个请求的参数。
我们来分析一下参数。如果你只是想获取这个网页的动态数据,直接复制就好了。
from sqlite3 import Date
import requests
import random, time, sys
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29'
}
params = {
'callCount':'1',
'nextReverseAjaxIndex':'0',
'c0-scriptName':'Ajax',
'c0-methodName':'readClick',
'c0-id':'0',
'c0-param0':'string:1649408845878',
'batchId':'0',
'instanceId':'0',
'page':'%2Fcolumn%2Fh_26_yi%2Fcontent%2F1649408845878.shtml',
'scriptSessionId':'5eSlySH4R9SBWHfCeP6lNqg1u0JcgKn5m1o/mvq5m1o-GDTnJP$nz'
}
res = requests.post('https://news.hutb.edu.cn/dwr/c ... 39%3B, headers=headers, params=params)
print(res.text)
我们来分析一下这些参数。c0-param0 和 page 在不同的新闻中是不同的。不同的是它们是第一个消息,以及如何写参数。比如这个新闻网址是,那么最后8位就是这两个参数的实际参数(也许这个数字并不是新闻的条数,毕竟太大了!)
然后是scriptSessionId。在比较不同的新闻页面时,发现他们'/'之前的字符是一样的,不同的是'/'之后的字符,所以我搜索了这个参数
让我们搜索'/'之后的参数
很明显,这个参数是由当前时间和一个随机数决定的,而tokenify我认为是一个编码函数。既然和随机数有关,传参数的时候可以忽略这个参数,写一个随机值吗?咱们试试吧:
结果是这样的
所以在抓取网页的动态数据的时候,首先是找到这个值(因为有搜索选项,大部分时候很容易找到),然后就是参数的问题,或者说是load。如果要爬取多个页面的动态数据,弄清楚这些参数的含义,或者说它们的特点是非常重要的,这样你才能传递正确的参数来获取你想要的数据。
怎样抓取网页数据(2.提取信息获取网页源代码后的接下来就是分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-15 20:26
1.爬虫概述
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
2.获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
3.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
4.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
5.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
6.我可以捕获什么样的数据
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
7.JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(2.提取信息获取网页源代码后的接下来就是分析(组图))
1.爬虫概述
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
2.获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
3.提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
4.保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
5.自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
6.我可以捕获什么样的数据
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
7.JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-15 20:26
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
(3)保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
(4)自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
(3)保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL和MongoDB,或者保存到远程服务器,比如使用SFTP操作。
(4)自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开这个页面时,会先加载HTML内容,然后浏览器会发现里面已经引入了一个app.js文件,然后再去请求这个文件。获取文件后,它将执行 JavaScript 代码,JavaScript 更改 HTML 中的节点,向其中添加内容,最终得到一个完整的页面。
但是当用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载这个 JavaScript 文件,所以我们在浏览器中看不到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何用 采集JavaScript 渲染网页。
本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据(怎样抓取网页网页数据(代码和实现分析报告)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-15 17:07
怎样抓取网页数据(代码和实现分析报告)作者:raywang280公众号:dark520链接:如何抓取网页数据(代码和实现分析报告)本系列文章目的介绍该如何抓取网页中的文字数据;写一些代码,大概讲一下怎么抓取爬虫代码以及实现分析报告(代码和分析报告都是爬虫代码);会对网页中爬虫包和网页中内容抓取结果进行记录和分析。
爬虫抓取后,放到requests库中,之后设置requests.get()为get方法即可。无论python爬虫包,网页内容的抓取,其实都比较简单:先要获取网页地址,之后获取网页中的图片,地址,再获取某一网页中的某一小部分的图片,这样整个网页抓取就完成了,当然只需要抓取一张图片就行了,也可以抓取链接,地址,以及中间的一个或者多个图片图片来源抓取。
解析网页的地址链接,一般我们通过抓包得到。一般有这么几种方式:try:直接把网页地址截图exceptexception,e:continue随手抓取网页中的文字数据分析报告(地址:解析网页地址并抓取原文字数据)一、网页数据抓取代码框架requests.get()方法的截图这里先调用try那一步,对源代码解析为正则表达式。
try:driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/a/@href')这里就通过正则表达式获取目标网页中的url。driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/span/@href')在这里会获取出xpath。
driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]//span[1]/@href')这里获取到的是xpath。driver.find_element_by_css_selector('span[1]/@href')这里获取到了css。
driver.find_element_by_javascript_selector('span[1]/@href')这里获取到javascript。然后设置requests.get()获取get()设置到以下img中:imgurl=img.xpath('.//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/a/@href')imgurl=requests.get(imgurl)imgurlurlwithopen("my.jpg","w")a。 查看全部
怎样抓取网页数据(怎样抓取网页网页数据(代码和实现分析报告)(图))
怎样抓取网页数据(代码和实现分析报告)作者:raywang280公众号:dark520链接:如何抓取网页数据(代码和实现分析报告)本系列文章目的介绍该如何抓取网页中的文字数据;写一些代码,大概讲一下怎么抓取爬虫代码以及实现分析报告(代码和分析报告都是爬虫代码);会对网页中爬虫包和网页中内容抓取结果进行记录和分析。
爬虫抓取后,放到requests库中,之后设置requests.get()为get方法即可。无论python爬虫包,网页内容的抓取,其实都比较简单:先要获取网页地址,之后获取网页中的图片,地址,再获取某一网页中的某一小部分的图片,这样整个网页抓取就完成了,当然只需要抓取一张图片就行了,也可以抓取链接,地址,以及中间的一个或者多个图片图片来源抓取。
解析网页的地址链接,一般我们通过抓包得到。一般有这么几种方式:try:直接把网页地址截图exceptexception,e:continue随手抓取网页中的文字数据分析报告(地址:解析网页地址并抓取原文字数据)一、网页数据抓取代码框架requests.get()方法的截图这里先调用try那一步,对源代码解析为正则表达式。
try:driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/a/@href')这里就通过正则表达式获取目标网页中的url。driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/span/@href')在这里会获取出xpath。
driver.find_element_by_xpath('//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]//span[1]/@href')这里获取到的是xpath。driver.find_element_by_css_selector('span[1]/@href')这里获取到了css。
driver.find_element_by_javascript_selector('span[1]/@href')这里获取到javascript。然后设置requests.get()获取get()设置到以下img中:imgurl=img.xpath('.//div[2]/div[1]/div[4]/div[1]/div[1]/div[1]/div[1]/a/@href')imgurl=requests.get(imgurl)imgurlurlwithopen("my.jpg","w")a。
怎样抓取网页数据( 易供求网:前端js怎么直接获取电脑详细配置信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-04-13 02:28
易供求网:前端js怎么直接获取电脑详细配置信息?)
易供需网()本文如何从java前端获取数据java数据库连接由小编为大家精心采集整理。今天,易供需给大家讲讲java前端如何获取数据以及java数据库连接!
前端js如何直接获取电脑的详细配置信息?
大多数商业浏览器没有这个接口,W3C标准也没有,所以直接用JS实现是不可能的。
如果要实现的话,还是得给员工发个本地程序来获取配置信息,但是bat脚本肯定不行,太容易修改了。如果不想增加太多额外的编程成本和时间,可以考虑使用西北js或者electron来封装网页,分发给员工。相当于一个特殊的浏览器,允许JS顺便运行node.js。另外,两者都可以对源代码进行加密和编译,使得脚本无法被修改,从而保证了信息的准确性。
另外,最重要的是,您的前端人员应该能够以零成本开始,无需额外成本
可以连接数据库,其中一个使用时间戳来移动和存储当前时间,读取时选择最近一天的数据
好的,这就是java前端如何获取数据由Easy Supply and Demand Network共享的java数据库连接。希望大家看完小编精心整理的这篇内容后,能够了解相关知识,解决大家的疑惑!查看更多java数据库连接java读取excel数据java输入相关文章请访问易供需。(本文共533字) 查看全部
怎样抓取网页数据(
易供求网:前端js怎么直接获取电脑详细配置信息?)
易供需网()本文如何从java前端获取数据java数据库连接由小编为大家精心采集整理。今天,易供需给大家讲讲java前端如何获取数据以及java数据库连接!
前端js如何直接获取电脑的详细配置信息?
大多数商业浏览器没有这个接口,W3C标准也没有,所以直接用JS实现是不可能的。
如果要实现的话,还是得给员工发个本地程序来获取配置信息,但是bat脚本肯定不行,太容易修改了。如果不想增加太多额外的编程成本和时间,可以考虑使用西北js或者electron来封装网页,分发给员工。相当于一个特殊的浏览器,允许JS顺便运行node.js。另外,两者都可以对源代码进行加密和编译,使得脚本无法被修改,从而保证了信息的准确性。
另外,最重要的是,您的前端人员应该能够以零成本开始,无需额外成本
可以连接数据库,其中一个使用时间戳来移动和存储当前时间,读取时选择最近一天的数据
好的,这就是java前端如何获取数据由Easy Supply and Demand Network共享的java数据库连接。希望大家看完小编精心整理的这篇内容后,能够了解相关知识,解决大家的疑惑!查看更多java数据库连接java读取excel数据java输入相关文章请访问易供需。(本文共533字)
怎样抓取网页数据(一下CrawlSpider爬虫爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-13 02:26
重点是CrawlSpider的学习!!!!!!!!!!!!!
**通过前面的学习我们可以进行一些页面的简单自动话爬取,对于一些比较规则的网站,我们似乎可以用Spider类去应付,可是,对于一些较为复杂或者说链接的存放不规则的网站我们该怎么去爬取呢,接下来的爬虫就是要解决这个问题,而且还可以高度的自动化爬取链接和链接内容**
CrawlSpider 类是另一个用于构建爬虫的类。
*(顺便说一下,我们可以继承四种类来建立我们的scrapy爬虫,他们是:Spider类,CrawlSpider类, CSVFeedSpider类和XMLFeedSpider类,今天我们讲的就是CrawlSpider类建立的爬虫)*
CrawlSpider 类通过一些规则使链接(网页)的爬取更加通用。也就是说,CrawlSpider 爬虫是一般的爬虫,而Spider 爬虫更像是一些特殊的网站 制定的爬虫。
然后我们开始正式讲解CrawlSpider爬虫。. . .
首先我们创建一个爬虫项目:
scrapy startproject crawlspider
这个我们很熟悉了,然后创建一个CrawlSpider爬虫
scrapy genspider -t crawl Crawlspider domain.com
注意上面,我们比Spider爬虫创建时多了一个'-t crawl',它是值爬虫的类
这样我们以后可以在我们的蜘蛛文件中找到这个爬虫
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
以上是打开爬虫后自动生成的一段代码。这段代码对于CrawlSpider爬虫的结构基本上可以说是有了结构。我们可以看到有一个rules属性,这个爬虫继承的类是CrawlSpider。这两点就是和之前文章中提到的蜘蛛爬虫的区别。规则属性使得这个爬虫的核心
所以在开始说我们的实战项目之前,还是先说一下这个规则属性吧。
rules属性由若干个Rule对象组成,Rule对象定义了提取链接等操作的规则
那么规则的结构是什么?
Rule 对象有六个属性,它们是:
LinkExtractor(...),用于提取响应中的链接 callback='str',回调函数,用于提取链接,用于提取数据填充itemcb_kwargs,传递给回调函数的参数字典follow=True/ False,对于提取出来的链接是否需要跟process_links,一个函数process_request过滤链接,一个函数过滤链接Request
以上参数都是可选的,除了LinkExtractor,当回调参数为None时,我们称这条规则为“跳板”,即只下载页面,不执行任何动作。它通常用作翻页功能。
我们主要需要解释一下LinkExtractor参数和follow参数:
一、LinkExtractor 参数显然是用来提取链接的。那么他是如何定义提取链接的规则的呢?它有十个参数来定义提取链接的规则,即:
1. allow='re_str':正则表达式字符串,在响应中提取与 re 表达式匹配的链接。
2.deny='re_str':排除正则表达式匹配的链接
3. restrict_xpaths='xpath_str':提取满足xpath表达式的链接
4. restrict_css='css_str':提取满足css表达式的链接
5. allow_domains='domain_str': 允许的域
6.deny_domains='domain_str':排除的域
7. tags='tag'/['tag1','tag2',…]:提取指定标签下的链接。默认情况下,链接将从 a 和 area 标签中提取
8. attrs=['href','src',…]:提取满足属性的链接
9. unique=True/False:链接是否去重
10.process_value:值处理函数,优先级必须大于allow
以上参数可以一起使用,提取同时满足条件的链接
二、跟随参数:
是一个布尔值,用于是否跟随链接的处理。回调为None时,默认跟随链接,值为True;回调不为空时,默认为False,不跟随链接。当然,我们可以根据需要进行赋值,
那么,什么叫跟进,什么叫不跟进呢?
就是你前面定义的规则对于已经提取到的链接的页面是不是在进行一次提取链接。
这很好!那么规则究竟是如何运作的呢?
这样会自动为Rule提取的链接调用parse函数,返回链接的response,然后将response交给回调函数,通过解析填充item的回调函数。
顺便说一句,CrawlSpider 爬虫还有一个 parse_start_url() 方法,用于解析 start_urls 中的链接页面。该方法一般用于有跳板的爬虫解析首页
说了这么多,还是说说我们的爬虫项目吧。使用 CrawlSpider 爬取整个小说网站
我们的目标网站是:笔趣看小说网
这是盗版小说网站,只能在线看,不能下载。 查看全部
怎样抓取网页数据(一下CrawlSpider爬虫爬虫)
重点是CrawlSpider的学习!!!!!!!!!!!!!
**通过前面的学习我们可以进行一些页面的简单自动话爬取,对于一些比较规则的网站,我们似乎可以用Spider类去应付,可是,对于一些较为复杂或者说链接的存放不规则的网站我们该怎么去爬取呢,接下来的爬虫就是要解决这个问题,而且还可以高度的自动化爬取链接和链接内容**
CrawlSpider 类是另一个用于构建爬虫的类。
*(顺便说一下,我们可以继承四种类来建立我们的scrapy爬虫,他们是:Spider类,CrawlSpider类, CSVFeedSpider类和XMLFeedSpider类,今天我们讲的就是CrawlSpider类建立的爬虫)*
CrawlSpider 类通过一些规则使链接(网页)的爬取更加通用。也就是说,CrawlSpider 爬虫是一般的爬虫,而Spider 爬虫更像是一些特殊的网站 制定的爬虫。
然后我们开始正式讲解CrawlSpider爬虫。. . .
首先我们创建一个爬虫项目:
scrapy startproject crawlspider
这个我们很熟悉了,然后创建一个CrawlSpider爬虫
scrapy genspider -t crawl Crawlspider domain.com
注意上面,我们比Spider爬虫创建时多了一个'-t crawl',它是值爬虫的类
这样我们以后可以在我们的蜘蛛文件中找到这个爬虫
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['domain.com']
start_urls = ['http://domain.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
以上是打开爬虫后自动生成的一段代码。这段代码对于CrawlSpider爬虫的结构基本上可以说是有了结构。我们可以看到有一个rules属性,这个爬虫继承的类是CrawlSpider。这两点就是和之前文章中提到的蜘蛛爬虫的区别。规则属性使得这个爬虫的核心
所以在开始说我们的实战项目之前,还是先说一下这个规则属性吧。
rules属性由若干个Rule对象组成,Rule对象定义了提取链接等操作的规则
那么规则的结构是什么?
Rule 对象有六个属性,它们是:
LinkExtractor(...),用于提取响应中的链接 callback='str',回调函数,用于提取链接,用于提取数据填充itemcb_kwargs,传递给回调函数的参数字典follow=True/ False,对于提取出来的链接是否需要跟process_links,一个函数process_request过滤链接,一个函数过滤链接Request
以上参数都是可选的,除了LinkExtractor,当回调参数为None时,我们称这条规则为“跳板”,即只下载页面,不执行任何动作。它通常用作翻页功能。
我们主要需要解释一下LinkExtractor参数和follow参数:
一、LinkExtractor 参数显然是用来提取链接的。那么他是如何定义提取链接的规则的呢?它有十个参数来定义提取链接的规则,即:
1. allow='re_str':正则表达式字符串,在响应中提取与 re 表达式匹配的链接。
2.deny='re_str':排除正则表达式匹配的链接
3. restrict_xpaths='xpath_str':提取满足xpath表达式的链接
4. restrict_css='css_str':提取满足css表达式的链接
5. allow_domains='domain_str': 允许的域
6.deny_domains='domain_str':排除的域
7. tags='tag'/['tag1','tag2',…]:提取指定标签下的链接。默认情况下,链接将从 a 和 area 标签中提取
8. attrs=['href','src',…]:提取满足属性的链接
9. unique=True/False:链接是否去重
10.process_value:值处理函数,优先级必须大于allow
以上参数可以一起使用,提取同时满足条件的链接
二、跟随参数:
是一个布尔值,用于是否跟随链接的处理。回调为None时,默认跟随链接,值为True;回调不为空时,默认为False,不跟随链接。当然,我们可以根据需要进行赋值,
那么,什么叫跟进,什么叫不跟进呢?
就是你前面定义的规则对于已经提取到的链接的页面是不是在进行一次提取链接。
这很好!那么规则究竟是如何运作的呢?
这样会自动为Rule提取的链接调用parse函数,返回链接的response,然后将response交给回调函数,通过解析填充item的回调函数。
顺便说一句,CrawlSpider 爬虫还有一个 parse_start_url() 方法,用于解析 start_urls 中的链接页面。该方法一般用于有跳板的爬虫解析首页
说了这么多,还是说说我们的爬虫项目吧。使用 CrawlSpider 爬取整个小说网站
我们的目标网站是:笔趣看小说网
这是盗版小说网站,只能在线看,不能下载。
怎样抓取网页数据(网站可以收集有关访客的哪些信息?如何获取网站浏览者信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-10 06:38
对于网站访客,可以安装上桥、53客服等在线客服系统。之前输入网站已经安装了代码,但为了保护用户隐私,目前不可用。您还可以使用一品的大数据分析来吸引用户,但仅限于手机上。前提是你的网站必须有流量,否则再好的软件,没有人接触,也没用。如何获取网站观众信息。
网站可以采集哪些访客信息?
网站哪些信息可以识别访客?
下次想去什么论坛?注册一个帐户需要多长时间和多长时间,然后断开您的ADSL IP并更改连接以清除IE的浏览历史记录。网站你能看到哪些关于你的访问者的信息。
如果您想在 网站 上刷流量,您将无法购买流量或为所欲为。他们会调用您的 网站 统计代码,并首先向他展示您的 网站 统计代码。看看你的 网站 流量来自哪里。如果你扫描它,你可以看到自然流量来自那里。我的 IDC 空间(如果需要)给我发短信 HI I
这个网站可以吸引什么样的信息:通过手机访问这个网站可以获得什么样的数据?
. . ip,Android或Apple,也有一些型号。
网站有哪些方法可以获取访问者的信息?网站可以从用户那里获得什么信息。
通常是分析日志或嵌入式统计系统代码,可以获取访问者的浏览信息。时间、IP地址、访问页面、来源URL、浏览器类型等信息。
通过Android手机浏览器访问网站,网站服务器可以从访问者那里得到什么信息?网站可以看到哪些用户信息。
建议使用安全卫士进行全面的物理检查和修复,修复后即可解决。希望它可以帮助你。网页可以知道用户的哪些信息。
一个强大的网站,可以从访问者那里获得哪些电脑用户信息?获取网站访客的电话号码。
是的,cookie 的价值是一句老话。现在很多网站都是交互结构。你只需要访问,点击你的硬件和软件,对方就会得到列表。如果是手机,马上就能知道自己的手机号码是的,大数据时代,基本没有个人隐私!移动公司是否知道您正在浏览什么网站。
网站可以从访客那里获得哪些信息:网站可以从访客那里采集哪些信息
目的地址和源地址是已知的。网站可以从手机用户那里获得什么信息。
在某些情况下,应该可以使用物理 NIC。网站访客信息采集。
网站您对访问者了解多少?抓取网络访问者信息。
网站可以知道访问者的浏览时间、IP地址、访问过的页面、来源URL、浏览器类型等信息。
请采纳,谢谢
获取网站访客信息
可以获取IP,然后您应该也可以获取该人访问的那些页面的地址。
然后使用程序读取这个页面,得到这个页面的原创代码。
对于 ASP,使用 MSXML2、XMLHTTP 方法来执行此操作。
对于 PHP,使用 fopen 或 file_content_get 等方法。
您可以阅读 HTML 代码。网站可以知道查看者的信息。
过滤就像搜索 ID 旁边的字符然后阻止它一样简单。
-------------------------------------------------- ------- --- --
当有人访问您的 网站 时,您不必费心获取登录 ID,对吗?只需将其记录在登录页面上即可。抓取页面访问者。 查看全部
怎样抓取网页数据(网站可以收集有关访客的哪些信息?如何获取网站浏览者信息)
对于网站访客,可以安装上桥、53客服等在线客服系统。之前输入网站已经安装了代码,但为了保护用户隐私,目前不可用。您还可以使用一品的大数据分析来吸引用户,但仅限于手机上。前提是你的网站必须有流量,否则再好的软件,没有人接触,也没用。如何获取网站观众信息。
网站可以采集哪些访客信息?
网站哪些信息可以识别访客?
下次想去什么论坛?注册一个帐户需要多长时间和多长时间,然后断开您的ADSL IP并更改连接以清除IE的浏览历史记录。网站你能看到哪些关于你的访问者的信息。
如果您想在 网站 上刷流量,您将无法购买流量或为所欲为。他们会调用您的 网站 统计代码,并首先向他展示您的 网站 统计代码。看看你的 网站 流量来自哪里。如果你扫描它,你可以看到自然流量来自那里。我的 IDC 空间(如果需要)给我发短信 HI I
这个网站可以吸引什么样的信息:通过手机访问这个网站可以获得什么样的数据?
. . ip,Android或Apple,也有一些型号。
网站有哪些方法可以获取访问者的信息?网站可以从用户那里获得什么信息。
通常是分析日志或嵌入式统计系统代码,可以获取访问者的浏览信息。时间、IP地址、访问页面、来源URL、浏览器类型等信息。
通过Android手机浏览器访问网站,网站服务器可以从访问者那里得到什么信息?网站可以看到哪些用户信息。
建议使用安全卫士进行全面的物理检查和修复,修复后即可解决。希望它可以帮助你。网页可以知道用户的哪些信息。
一个强大的网站,可以从访问者那里获得哪些电脑用户信息?获取网站访客的电话号码。
是的,cookie 的价值是一句老话。现在很多网站都是交互结构。你只需要访问,点击你的硬件和软件,对方就会得到列表。如果是手机,马上就能知道自己的手机号码是的,大数据时代,基本没有个人隐私!移动公司是否知道您正在浏览什么网站。
网站可以从访客那里获得哪些信息:网站可以从访客那里采集哪些信息
目的地址和源地址是已知的。网站可以从手机用户那里获得什么信息。
在某些情况下,应该可以使用物理 NIC。网站访客信息采集。
网站您对访问者了解多少?抓取网络访问者信息。
网站可以知道访问者的浏览时间、IP地址、访问过的页面、来源URL、浏览器类型等信息。
请采纳,谢谢
获取网站访客信息
可以获取IP,然后您应该也可以获取该人访问的那些页面的地址。
然后使用程序读取这个页面,得到这个页面的原创代码。
对于 ASP,使用 MSXML2、XMLHTTP 方法来执行此操作。
对于 PHP,使用 fopen 或 file_content_get 等方法。
您可以阅读 HTML 代码。网站可以知道查看者的信息。
过滤就像搜索 ID 旁边的字符然后阻止它一样简单。
-------------------------------------------------- ------- --- --
当有人访问您的 网站 时,您不必费心获取登录 ID,对吗?只需将其记录在登录页面上即可。抓取页面访问者。
怎样抓取网页数据(在Python中解析网页的方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-07 13:05
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
采用
get方法构造请求
采用
status_code 获取网页的状态码
可以看到返回值为200,表示服务器响应正常,表示可以继续。
第 2 步:解析页面
上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看它的内容
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的
frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#热门视频排行榜-bilibili (゜-゜)つロ干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。注意使用的时候需要指定一个解析器,这里使用的是html.parser。
然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按F12按照下面的说明找到
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们想要的字段信息存储在开头以字典形式定义的空列表中。
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用csv模块写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
进口请求
frombs4import 美汤
导入csv
导入pandasaspd
网址='#39;
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig') 查看全部
怎样抓取网页数据(在Python中解析网页的方法有哪些?-八维教育)
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
采用
get方法构造请求
采用
status_code 获取网页的状态码
可以看到返回值为200,表示服务器响应正常,表示可以继续。
第 2 步:解析页面
上一步中,我们通过requests向网站请求数据后,成功获得了一个收录服务器资源的Response对象。现在我们可以使用 .text 查看它的内容
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也很简单,使用 pip install bs4 安装即可,我们用一个简单的例子来说明它是如何工作的
frombs4import 美汤
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.标题.文本
打印(标题)
#热门视频排行榜-bilibili (゜-゜)つロ干杯~-bilibili
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。注意使用的时候需要指定一个解析器,这里使用的是html.parser。
然后您可以获得结构元素之一及其属性。比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动。
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页面按F12按照下面的说明找到
可以看到每个视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
在上面的代码中,我们首先使用了soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器来提取我们想要的字段信息存储在开头以字典形式定义的空列表中。
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用csv模块写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
导入csv
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
导入pandasaspd
键=所有产品[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
进口请求
frombs4import 美汤
导入csv
导入pandasaspd
网址='#39;
page=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
对于productinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
评论=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“上主要”:上,
“视频链接”:网址
})
键=所有产品[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用熊猫写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
怎样抓取网页数据(二手车|怎样抓取网页数据都是数据抓取,找到重点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-04-07 01:04
怎样抓取网页数据都是数据抓取,找到重点:抓取网页结构网页结构不同会抓取的不同规格代码不同很多时候抓取并不是用最底层的语言,因为当你要抓取一个链接时会有很多请求请求形式,比如ajax,或者http等等这些格式化网页你可以通过spider之类的包来调用抓取网页结构可以通过下图来看看图片可能没有太明显了,看最终抓取的结果就能比较清楚了|二手车|用车|车4s4s店|置换车4s店|人才|招聘|房产|房价|信息|招聘|技术|招聘|小二|计算机|flash|视频|网址|sp|关于模拟访问:在手机上安装一个chrome浏览器,进入如下页面,注意红色的robots协议!这时只需要通过模拟访问抓取我们的大网站:只抓取页面前3个标签就可以了~抓取每一个标签就可以获取相应的数据。
然后在用同样的方法抓取后面标签。抓取每一个标签都有自己一套抓取规则,像我们想抓取手机这个页面就需要抓取手机的标签hello,world!通过上面的步骤和方法,你就可以得到如下页面,获取的数据格式可以直接用代码拷贝或者直接保存成bs4的一个json数据:接下来,就是用requests发起http请求用f12或者everything调试-可以看到需要一些python对象组合,如果是在浏览器上http抓取我们可以用f12查看页面构成,然后打开百度-如图代码的脚本部分进行编写抓取:#-*-coding:utf-8-*-importrequestsfromflaskimportflaskfromceleryimportceleryfromcelery.simpleimportmanagername='myfollower'defmyfollower(self):self._start_request(myfollower,timeout=10)#开始发起请求self._body=self._post(request)#以json形式返回信息#通过requests请求获取信息results=celery.request(url)#通过requests返回信息数据celery.request.send(results)html=celery.textmessage({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'class1'}']}})#一个典型的请求响应信息self._status=self._message({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'info1'}']}})#一个典型的请求响应信息deftext_record(self):data=self._body['data']celery.request.body.format(data)#celery.request.。 查看全部
怎样抓取网页数据(二手车|怎样抓取网页数据都是数据抓取,找到重点)
怎样抓取网页数据都是数据抓取,找到重点:抓取网页结构网页结构不同会抓取的不同规格代码不同很多时候抓取并不是用最底层的语言,因为当你要抓取一个链接时会有很多请求请求形式,比如ajax,或者http等等这些格式化网页你可以通过spider之类的包来调用抓取网页结构可以通过下图来看看图片可能没有太明显了,看最终抓取的结果就能比较清楚了|二手车|用车|车4s4s店|置换车4s店|人才|招聘|房产|房价|信息|招聘|技术|招聘|小二|计算机|flash|视频|网址|sp|关于模拟访问:在手机上安装一个chrome浏览器,进入如下页面,注意红色的robots协议!这时只需要通过模拟访问抓取我们的大网站:只抓取页面前3个标签就可以了~抓取每一个标签就可以获取相应的数据。
然后在用同样的方法抓取后面标签。抓取每一个标签都有自己一套抓取规则,像我们想抓取手机这个页面就需要抓取手机的标签hello,world!通过上面的步骤和方法,你就可以得到如下页面,获取的数据格式可以直接用代码拷贝或者直接保存成bs4的一个json数据:接下来,就是用requests发起http请求用f12或者everything调试-可以看到需要一些python对象组合,如果是在浏览器上http抓取我们可以用f12查看页面构成,然后打开百度-如图代码的脚本部分进行编写抓取:#-*-coding:utf-8-*-importrequestsfromflaskimportflaskfromceleryimportceleryfromcelery.simpleimportmanagername='myfollower'defmyfollower(self):self._start_request(myfollower,timeout=10)#开始发起请求self._body=self._post(request)#以json形式返回信息#通过requests请求获取信息results=celery.request(url)#通过requests返回信息数据celery.request.send(results)html=celery.textmessage({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'class1'}']}})#一个典型的请求响应信息self._status=self._message({'key':'pv','data':[{'page':{'body':{'basetags':{'pages':{'user':{'ip':{'class':'info1'}']}})#一个典型的请求响应信息deftext_record(self):data=self._body['data']celery.request.body.format(data)#celery.request.。
怎样抓取网页数据( WebClient常用语法以及HtmlAgilityPack常用方法1. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2022-04-03 01:10
WebClient常用语法以及HtmlAgilityPack常用方法1.
)
网络客户端
说完概念,我们还是要回到实际应用。对于上一章的新浪新闻请求url,我们需要使用开发者工具监控是POST还是GET请求,一般是这两种,然后判断参数和返回类型,编码类型一般为UTF-8 ,具体操作如下
确定请求方法、返回类型和参数
下面是在C#程序中请求文章列表的结果:
请求获取文章列表数据
上一篇文章我们分析了文章的URL链接,同理可以得到新闻详情的html
获取新闻内容html
二、XPath,强大的网页分析工具
在上一步中,我们得到了新闻内容,然后我们需要对内容进行解析以找到我们想要的内容。这里我们可以使用开发者工具快速定位新闻内容所在的html标签。如何获取此标签中的内容?这也依赖于开发人员工具的“复制 XPath”功能。
复制 XPath
复制出来的文本“//*[@id="artibody"]”是一个XPath表达式,可以定位到文章的内容,那么我们就很容易理解XPath是什么了。标记内容的语法或表达式。不懂XPath的同学可以自行百度。在文章的最后会附上一些常用的用法。欢迎讨论和学习。
三、HTML解析类库的HtmlAgilityPack
那么有了XPath表达式,在程序中如何使用呢?另一个伟大的工具出现了“HtmlAgilityPack”。它可以通过 C# 中的 Nuget 安装。它最大的作用就是解析html,比正则表达式更快更准确!HtmlAgilityPack 中常用的类有 HtmlDocument、HtmlNode采集、HtmlNode 和 HtmlWeb。废话不多说,看新闻的主题内容如何获取。根据 网站,您可以添加和删除不必要的备注和脚本。
使用 XPath 获取新闻内容
你真的可以做任何你想做的事情来获取新闻内容。可以以文本形式保存,也可以保存到数据库中自己做新闻浏览网站等等。
四、XPath 常用语法和 HtmlAgilityPack 常用方法
XPath
1. 根据id选择://*[@id="xxx"]
2. 根据类选择://*[@class="xxx"]
3. 获取页面上所有的 a/p/span... 标签:a/p/span...
4. 根据title属性值获取元素://title[@lang='eng']
5. 选择标签下的div/p/span标签://*[@id="xxx"]/div[1]/span/p
6. 用文本节点值中的cn字符串查询title节点://title[contains(text,'cn')]
7. 不收录数据属性的标题节点:title[not(@data)]
8. 统计title节点的个数:count(//title)
9. 在js中查询一个变量值://script[contains(text(), 'variable name')]
10. 当前节点的父节点:./parent::* etc...
HtmlAgilityPack
1. 加载 html:LoadHtml(strHtml) 或 HmlWeb().Load(url)
2. HtmlNode 获取标签属性:Attribute["Attribute name"].Value
3. HtmlNode 获取标签 html: xxx.InnerHtml
4. HtmlNode 获取标签html的文本:xxx.InnerText
5. 获取单个标签,返回HtmlNode:SelectSingleNode
6. 获取标签集合,返回 HtmlNode采集: SelectNodes
7. 获取子节点(包括文本节点)的集合:ChildNodes
8. 获取下一个兄弟节点:NextSibling
9. 获取节点的父节点:ParentNode
10. 获取上一个兄弟:PreviousSibling 等...
以上是作者在编写爬虫时经常用到的XPath,还有很多其他的就不一一列举了。有熟悉的大神可以在评论中分享。
XPath 解析网页
五、总结一下
通过上面的介绍,我们已经了解了大致的流程,可以总结为:模拟网络请求-->开发者工具复制XPath-->HtmlAgilityPack解析网页内容-->获取数据,为所欲为想!
今天的分享到此结束。有很多缺点。欢迎您给我们留言和指正。让我们一起交流,一起进步!
准备工作已经完成,下一章就是实战项目了!
我是隔壁老王,爱编程爱学习~~
查看全部
怎样抓取网页数据(
WebClient常用语法以及HtmlAgilityPack常用方法1.
)
网络客户端
说完概念,我们还是要回到实际应用。对于上一章的新浪新闻请求url,我们需要使用开发者工具监控是POST还是GET请求,一般是这两种,然后判断参数和返回类型,编码类型一般为UTF-8 ,具体操作如下
确定请求方法、返回类型和参数
下面是在C#程序中请求文章列表的结果:
请求获取文章列表数据
上一篇文章我们分析了文章的URL链接,同理可以得到新闻详情的html
获取新闻内容html
二、XPath,强大的网页分析工具
在上一步中,我们得到了新闻内容,然后我们需要对内容进行解析以找到我们想要的内容。这里我们可以使用开发者工具快速定位新闻内容所在的html标签。如何获取此标签中的内容?这也依赖于开发人员工具的“复制 XPath”功能。
复制 XPath
复制出来的文本“//*[@id="artibody"]”是一个XPath表达式,可以定位到文章的内容,那么我们就很容易理解XPath是什么了。标记内容的语法或表达式。不懂XPath的同学可以自行百度。在文章的最后会附上一些常用的用法。欢迎讨论和学习。
三、HTML解析类库的HtmlAgilityPack
那么有了XPath表达式,在程序中如何使用呢?另一个伟大的工具出现了“HtmlAgilityPack”。它可以通过 C# 中的 Nuget 安装。它最大的作用就是解析html,比正则表达式更快更准确!HtmlAgilityPack 中常用的类有 HtmlDocument、HtmlNode采集、HtmlNode 和 HtmlWeb。废话不多说,看新闻的主题内容如何获取。根据 网站,您可以添加和删除不必要的备注和脚本。
使用 XPath 获取新闻内容
你真的可以做任何你想做的事情来获取新闻内容。可以以文本形式保存,也可以保存到数据库中自己做新闻浏览网站等等。
四、XPath 常用语法和 HtmlAgilityPack 常用方法
XPath
1. 根据id选择://*[@id="xxx"]
2. 根据类选择://*[@class="xxx"]
3. 获取页面上所有的 a/p/span... 标签:a/p/span...
4. 根据title属性值获取元素://title[@lang='eng']
5. 选择标签下的div/p/span标签://*[@id="xxx"]/div[1]/span/p
6. 用文本节点值中的cn字符串查询title节点://title[contains(text,'cn')]
7. 不收录数据属性的标题节点:title[not(@data)]
8. 统计title节点的个数:count(//title)
9. 在js中查询一个变量值://script[contains(text(), 'variable name')]
10. 当前节点的父节点:./parent::* etc...
HtmlAgilityPack
1. 加载 html:LoadHtml(strHtml) 或 HmlWeb().Load(url)
2. HtmlNode 获取标签属性:Attribute["Attribute name"].Value
3. HtmlNode 获取标签 html: xxx.InnerHtml
4. HtmlNode 获取标签html的文本:xxx.InnerText
5. 获取单个标签,返回HtmlNode:SelectSingleNode
6. 获取标签集合,返回 HtmlNode采集: SelectNodes
7. 获取子节点(包括文本节点)的集合:ChildNodes
8. 获取下一个兄弟节点:NextSibling
9. 获取节点的父节点:ParentNode
10. 获取上一个兄弟:PreviousSibling 等...
以上是作者在编写爬虫时经常用到的XPath,还有很多其他的就不一一列举了。有熟悉的大神可以在评论中分享。
XPath 解析网页
五、总结一下
通过上面的介绍,我们已经了解了大致的流程,可以总结为:模拟网络请求-->开发者工具复制XPath-->HtmlAgilityPack解析网页内容-->获取数据,为所欲为想!
今天的分享到此结束。有很多缺点。欢迎您给我们留言和指正。让我们一起交流,一起进步!
准备工作已经完成,下一章就是实战项目了!
我是隔壁老王,爱编程爱学习~~
怎样抓取网页数据(怎样抓取网页数据,主要针对网页中的图片和flash动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 00:04
怎样抓取网页数据,主要针对网页中的图片和flash动画如何抓取的。1。第一步登录百度站长平台。2。进入站长后台,进入你想抓取的网页3。点击文件,抓取文件4。设置requestheaders,设置好之后,点击开始抓取5。点击进行抓取之后就会抓取的你想要的网页,有些网页会有一个问题,会有以下的情况出现:(。
1).这样的网页网页带有后缀,如.mp3.avi.zip之类的,.解决办法:需要对这样的后缀的网页进行网页注册。
2)。如果你抓取的是图片网页,会出现抓取失败的情况(含图片),没有文件,因为图片下的视频文件后缀是p。解决办法:你就抓取这样的网页,图片一般是不会下载的,如果图片下面有文件,可以获取下载链接,再进行下载。如果文件不多,因为图片网页大小通常不会超过300k,已经不算大了。如果图片下载一次就要被封掉。解决办法:可以尝试搜索引擎,找一个速度快的搜索引擎。(。
3).抓取的视频链接如果在百度内容中检索这个视频的地址,是找不到.解决办法:在你们自己的百度云上,搜索这个视频的url.然后丢到百度云上面。一般链接下载不到.视频下载到百度云上之后,就可以进行云盘上传了,会得到一个推荐地址,进行下载即可,
4).如果抓取的是小说,
1).但是我们点击抓取下载小说链接,还是不给下载小说.解决办法:可以登录你们自己的百度云账号,在百度云内搜索小说的地址,大部分小说链接是不会下载下来的。找到“哈尔滨系列小说_哈尔滨恋爱小说_哈尔滨浪漫小说_哈尔滨言情小说”这个小说的连接,右键复制,粘贴到百度云中,即可下载。
2).小说下载不出来,就只能把别人上传的电子书下载下来了,这里我们抓取出来的是文件名为小说__home的文件,上传成功后,
3).小说下载不出来,还要小说名字。解决办法:我们是要保存下载到手机,或者电脑,
4).下载不了.解决办法:打开电脑浏览器,输入下载的网址,就可以下载你的小说了.如果要过多次提取.可以尝试用百度爬虫工具.也可以用云盘工具,找到小说文件在哪,丢到百度云,
1)登录你的百度网盘账号.
2)进入你的网盘后,打开我的百度云.
3)找到自己的小说文件,直接点击右键,复制链接.
4)在浏览器中,粘贴链接,会自动下 查看全部
怎样抓取网页数据(怎样抓取网页数据,主要针对网页中的图片和flash动画)
怎样抓取网页数据,主要针对网页中的图片和flash动画如何抓取的。1。第一步登录百度站长平台。2。进入站长后台,进入你想抓取的网页3。点击文件,抓取文件4。设置requestheaders,设置好之后,点击开始抓取5。点击进行抓取之后就会抓取的你想要的网页,有些网页会有一个问题,会有以下的情况出现:(。
1).这样的网页网页带有后缀,如.mp3.avi.zip之类的,.解决办法:需要对这样的后缀的网页进行网页注册。
2)。如果你抓取的是图片网页,会出现抓取失败的情况(含图片),没有文件,因为图片下的视频文件后缀是p。解决办法:你就抓取这样的网页,图片一般是不会下载的,如果图片下面有文件,可以获取下载链接,再进行下载。如果文件不多,因为图片网页大小通常不会超过300k,已经不算大了。如果图片下载一次就要被封掉。解决办法:可以尝试搜索引擎,找一个速度快的搜索引擎。(。
3).抓取的视频链接如果在百度内容中检索这个视频的地址,是找不到.解决办法:在你们自己的百度云上,搜索这个视频的url.然后丢到百度云上面。一般链接下载不到.视频下载到百度云上之后,就可以进行云盘上传了,会得到一个推荐地址,进行下载即可,
4).如果抓取的是小说,
1).但是我们点击抓取下载小说链接,还是不给下载小说.解决办法:可以登录你们自己的百度云账号,在百度云内搜索小说的地址,大部分小说链接是不会下载下来的。找到“哈尔滨系列小说_哈尔滨恋爱小说_哈尔滨浪漫小说_哈尔滨言情小说”这个小说的连接,右键复制,粘贴到百度云中,即可下载。
2).小说下载不出来,就只能把别人上传的电子书下载下来了,这里我们抓取出来的是文件名为小说__home的文件,上传成功后,
3).小说下载不出来,还要小说名字。解决办法:我们是要保存下载到手机,或者电脑,
4).下载不了.解决办法:打开电脑浏览器,输入下载的网址,就可以下载你的小说了.如果要过多次提取.可以尝试用百度爬虫工具.也可以用云盘工具,找到小说文件在哪,丢到百度云,
1)登录你的百度网盘账号.
2)进入你的网盘后,打开我的百度云.
3)找到自己的小说文件,直接点击右键,复制链接.
4)在浏览器中,粘贴链接,会自动下
怎样抓取网页数据(如何提高外贸网站排名在搜索引擎上做的工作流程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-01 23:11
搜索引擎工作流程
搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、分离和去除词序关键词 停用词,判断是否需要启动综合搜索,判断是否有拼写错误或错别字等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。易轩网为客户制作的营销模式网站充分考虑了这四个要素:采用美国骨干机房、高性能服务器、4层DNS配置、3层加速技术、LAMP技术体系、全文搜索技术支持,符合搜索引擎139项技术规范,由专业的内容营销团队网站制作(包括分类关键词方案、标题优化、内容优化等)。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,爬虫不仅爬取网站的内容,还爬取了一系列技术指标,如内部链结构、爬取速度、服务器响应速度等。爬虫爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重,网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程,通过不断更新索引数据和排序算法,确保用户搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。 查看全部
怎样抓取网页数据(如何提高外贸网站排名在搜索引擎上做的工作流程?)
搜索引擎工作流程
搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、分离和去除词序关键词 停用词,判断是否需要启动综合搜索,判断是否有拼写错误或错别字等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。易轩网为客户制作的营销模式网站充分考虑了这四个要素:采用美国骨干机房、高性能服务器、4层DNS配置、3层加速技术、LAMP技术体系、全文搜索技术支持,符合搜索引擎139项技术规范,由专业的内容营销团队网站制作(包括分类关键词方案、标题优化、内容优化等)。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,爬虫不仅爬取网站的内容,还爬取了一系列技术指标,如内部链结构、爬取速度、服务器响应速度等。爬虫爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重,网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程,通过不断更新索引数据和排序算法,确保用户搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
怎样抓取网页数据(如何快速快速爬取一个网站?的实际主要用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-01 23:06
在这个互联网时代,很多人在购买新品之前都会上网搜索信息,看看哪些知名品牌的公信力和评价更高。这个时候,好的产品就会有好的优势。数据调查报告显示,87%的网民会根据百度搜索引擎服务项目搜索自己需要的信息,近70%的网民会立即在百度搜索首页搜索自己需要的信息< @关键词。
不难看出,百度搜索引擎的改进对企业和产品都具有关键的现实意义。现在我将向您展示如何快速抓取 网站。
<p>我们经常听到关键字,但关键字的实际主要用途是什么? 查看全部
怎样抓取网页数据(如何快速快速爬取一个网站?的实际主要用途是什么)
在这个互联网时代,很多人在购买新品之前都会上网搜索信息,看看哪些知名品牌的公信力和评价更高。这个时候,好的产品就会有好的优势。数据调查报告显示,87%的网民会根据百度搜索引擎服务项目搜索自己需要的信息,近70%的网民会立即在百度搜索首页搜索自己需要的信息< @关键词。
不难看出,百度搜索引擎的改进对企业和产品都具有关键的现实意义。现在我将向您展示如何快速抓取 网站。
<p>我们经常听到关键字,但关键字的实际主要用途是什么?
怎样抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-31 15:03
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网页的节点比作网页,爬它就相当于访问了page 获取到它的信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,使得整个网页的节点都可以被蜘蛛爬取,从而可以抓取到网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等。我们可以使用这些库来帮助我们实现HTTP请求操作,Request和Response可以用提供的数据结构来表示类库,得到Response后,我们只需要解析数据结构的Body部分,即获取网页的源代码,这样就可以使用程序来实现获取网页的过程.
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
这是一个演示
Python资源分享qun 784758214,包括安装包、PDF、学习视频,这里是Python学习者的聚集地,零基础,进阶,欢迎大家
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面引入了一个app.js文件,然后浏览器就会请求这个文件,拿到文件后就会执行. JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。 查看全部
怎样抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网页的节点比作网页,爬它就相当于访问了page 获取到它的信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,使得整个网页的节点都可以被蜘蛛爬取,从而可以抓取到网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等。我们可以使用这些库来帮助我们实现HTTP请求操作,Request和Response可以用提供的数据结构来表示类库,得到Response后,我们只需要解析数据结构的Body部分,即获取网页的源代码,这样就可以使用程序来实现获取网页的过程.
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
这是一个演示
Python资源分享qun 784758214,包括安装包、PDF、学习视频,这里是Python学习者的聚集地,零基础,进阶,欢迎大家
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面引入了一个app.js文件,然后浏览器就会请求这个文件,拿到文件后就会执行. JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。
怎样抓取网页数据( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-31 09:14
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。 查看全部
怎样抓取网页数据(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。
怎样抓取网页数据(网站页面数据抓取插件允许我们将数据从网站抓取到本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-31 07:19
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。
查看全部
怎样抓取网页数据(网站页面数据抓取插件允许我们将数据从网站抓取到本地
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。

