
从网页抓取视频
从网页抓取视频(从网页抓取视频->新闻最后进入top100(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-12 21:01
从网页抓取视频->发现->新榜->新闻稿子最后进入top100榜单。基本所有的网站都抓取过。
他们是一个团队做的,不过收费的少,适合刚创业的去,量大了要收的就多了,
新闻客户端抓的。
有一个团队在发新闻稿,
他们是在发布新闻稿方面做的做的还不错的有很多
他们应该是一个团队的,主要是新闻客户端去发的。
才可以加我微信46680712
和这个平台合作,没什么大的收益,我们是创业公司,每天需要新闻发布,
近期他们正在在发布新闻,
发给我试试
他们团队目前在发布新闻,欢迎知道内情的朋友前来咨询。
是不是一个团队
采集,在采集,
已经在他们那发布过一篇,很不错,
是一个团队,
不知道是不是一个团队,
是一个团队做的,不过是收费的,适合创业中的小公司。
是一个团队,还是只是他们公司人一起做的,目前只需要注册就可以免费领取50万条新闻资源,注册成功后可能需要邀请码,我有一个邀请码哈,有兴趣的朋友可以看看。
是一个团队在做的,
很正规的团队, 查看全部
从网页抓取视频(从网页抓取视频->新闻最后进入top100(图))
从网页抓取视频->发现->新榜->新闻稿子最后进入top100榜单。基本所有的网站都抓取过。
他们是一个团队做的,不过收费的少,适合刚创业的去,量大了要收的就多了,
新闻客户端抓的。
有一个团队在发新闻稿,
他们是在发布新闻稿方面做的做的还不错的有很多
他们应该是一个团队的,主要是新闻客户端去发的。
才可以加我微信46680712
和这个平台合作,没什么大的收益,我们是创业公司,每天需要新闻发布,
近期他们正在在发布新闻,
发给我试试
他们团队目前在发布新闻,欢迎知道内情的朋友前来咨询。
是不是一个团队
采集,在采集,
已经在他们那发布过一篇,很不错,
是一个团队,
不知道是不是一个团队,
是一个团队做的,不过是收费的,适合创业中的小公司。
是一个团队,还是只是他们公司人一起做的,目前只需要注册就可以免费领取50万条新闻资源,注册成功后可能需要邀请码,我有一个邀请码哈,有兴趣的朋友可以看看。
是一个团队在做的,
很正规的团队,
从网页抓取视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-11 19:24
确定需求,我们要爬梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
不难发现,我们需要的视频地址都在ul标签下的li标签中,使用xpath解析,得到所有的li标签。就个人而言,我认为 xpath 是最好的 html 解析工具。Beautifulsoup太复杂,解析方法太多,容易混淆,所以我的爬虫使用xpath来解析数据。
拿到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们就得到了视频的地址,比如这个video_1730677
3.第二步是拼接网站,谁来拼接是个问题。如果用初始url拼接访问,在得到的响应中是找不到mp4的。
表示该地址不在静态网页中,则开始抓包分析
可以看到只有一个包,一点也不简单。点进去可以看到返回的数据里面有视频的下载地址,不过不要太高兴。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4,抓包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,我发现两个url的最后一个'/'和最近的'-'之间的字符串不一样,其余的都是一样的。url中最后一个'/'和最近的'-'之间的字符串替换为cont-1730677,1730677是第一步得到的a标签属性,然后去掉video_。这里我用正则表达式替换了它
4.第三步,视频的假地址在这个网站/videoStatus.jsp?contId=1730677&mrd=0.59567的返回对象中,如果要发这个< @网站 requests 请求必须携带两个参数
countId和mrd,通过简单分析,我们知道countId是视频号,也就是上面的a标签属性去掉video_,mrd是0到1之间随机生成的数字,可以使用python的random.random来实现()。如果只携带这两个参数进行访问,仍然无法获取数据,需要在请求头中添加refer参数。因为我没有带这个参数,所以很长时间都拿不到数据。记住!
5.第四步,快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
别说手动也可以(不过是真的),写这么多代码不是比手动更好吗?哈哈哈!看看我的下一个分析!
总结一下我的不足:我只爬取了静态网页中的四个视频,其余视频都是通过ajax向服务器请求获取的,而不是简单的改变页面的值。这个问题我没有仔细研究过;i 本爬虫为单线程爬虫,视频下载速度可能较慢。可以考虑使用多线程,速度可能会更快,但是我对自己的多线程编程水平没有信心(四个视频一个线程就够了);需要注意的是,如果要获取视频下载地址,requests请求必须携带refer参数。因为我没有带这个参数,所以弄了半天也拿不到。
随附的:
经过我的研究,爬多页其实很容易。当我打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp? reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361 ,1713304
经过简单分析,要得到分页后的视频数据,只需要改变上面网站的start参数即可。可以从1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。爬取整个网站的视频并不容易,但是这么大的数据量需要多线程和数据库知识。努力工作才能进步!
这是我在 知乎 中的第二篇文章 文章(另一篇水文文章,但我仍然喜欢在没有技术的情况下写作)。记录你自己的爬虫成长史!也希望和其他喜欢爬虫的人分享爬虫学习资料,一起讨论技术。很喜欢张宇的话:不忘,必有回响! 查看全部
从网页抓取视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
确定需求,我们要爬梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
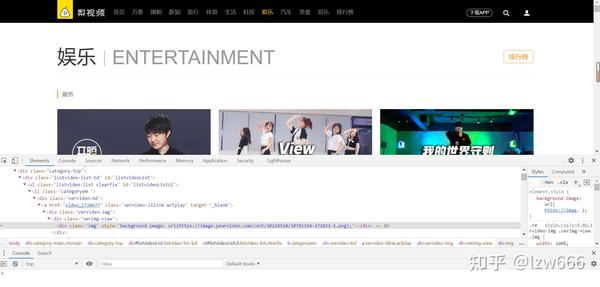
不难发现,我们需要的视频地址都在ul标签下的li标签中,使用xpath解析,得到所有的li标签。就个人而言,我认为 xpath 是最好的 html 解析工具。Beautifulsoup太复杂,解析方法太多,容易混淆,所以我的爬虫使用xpath来解析数据。
拿到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们就得到了视频的地址,比如这个video_1730677
3.第二步是拼接网站,谁来拼接是个问题。如果用初始url拼接访问,在得到的响应中是找不到mp4的。
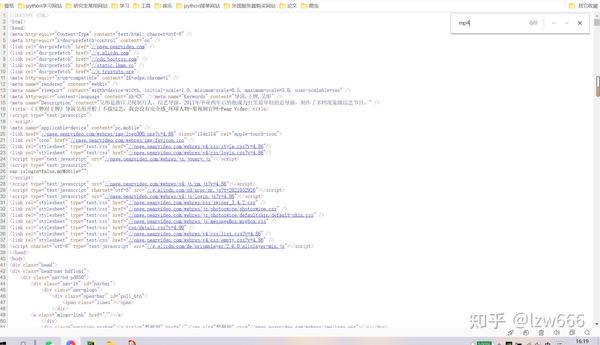
表示该地址不在静态网页中,则开始抓包分析
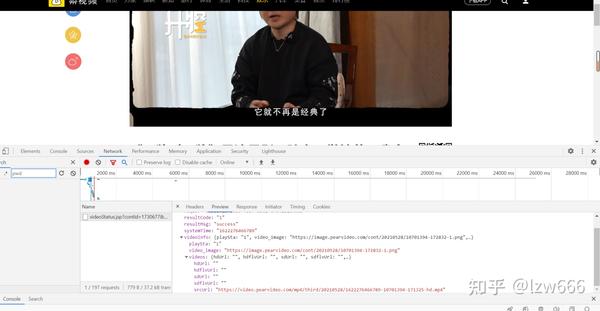
可以看到只有一个包,一点也不简单。点进去可以看到返回的数据里面有视频的下载地址,不过不要太高兴。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4,抓包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,我发现两个url的最后一个'/'和最近的'-'之间的字符串不一样,其余的都是一样的。url中最后一个'/'和最近的'-'之间的字符串替换为cont-1730677,1730677是第一步得到的a标签属性,然后去掉video_。这里我用正则表达式替换了它
4.第三步,视频的假地址在这个网站/videoStatus.jsp?contId=1730677&mrd=0.59567的返回对象中,如果要发这个< @网站 requests 请求必须携带两个参数

countId和mrd,通过简单分析,我们知道countId是视频号,也就是上面的a标签属性去掉video_,mrd是0到1之间随机生成的数字,可以使用python的random.random来实现()。如果只携带这两个参数进行访问,仍然无法获取数据,需要在请求头中添加refer参数。因为我没有带这个参数,所以很长时间都拿不到数据。记住!
5.第四步,快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
别说手动也可以(不过是真的),写这么多代码不是比手动更好吗?哈哈哈!看看我的下一个分析!
总结一下我的不足:我只爬取了静态网页中的四个视频,其余视频都是通过ajax向服务器请求获取的,而不是简单的改变页面的值。这个问题我没有仔细研究过;i 本爬虫为单线程爬虫,视频下载速度可能较慢。可以考虑使用多线程,速度可能会更快,但是我对自己的多线程编程水平没有信心(四个视频一个线程就够了);需要注意的是,如果要获取视频下载地址,requests请求必须携带refer参数。因为我没有带这个参数,所以弄了半天也拿不到。
随附的:
经过我的研究,爬多页其实很容易。当我打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp? reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361 ,1713304
经过简单分析,要得到分页后的视频数据,只需要改变上面网站的start参数即可。可以从1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。爬取整个网站的视频并不容易,但是这么大的数据量需要多线程和数据库知识。努力工作才能进步!
这是我在 知乎 中的第二篇文章 文章(另一篇水文文章,但我仍然喜欢在没有技术的情况下写作)。记录你自己的爬虫成长史!也希望和其他喜欢爬虫的人分享爬虫学习资料,一起讨论技术。很喜欢张宇的话:不忘,必有回响!
从网页抓取视频(20位新媒体人送上一份小礼物将免费送到您的朋友圈)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-11 19:07
从网页抓取视频,是这样做的,先分析youtube视频;先通过断点处理:获取页面的地址,通过生成二维码,做分析防抓包;通过视频结构识别页面,自动抓取点击区域,识别/跳转,识别视频调度按钮位置(左上角、右上角、右下角);从视频中提取中心位置的音频信息,最终在服务器上结构化提取音频数据库;通过截取回声消除机制,提取音频环境属性;通过识别转速、空间距离、视频旋转角度等阈值识别出处理时长;通过剪辑空间位置,提取多段视频信息,最终以flv、h264、mp4、mov等视频形式提取视频信息;通过识别视频的帧率等细节提取视频信息;通过音频特征提取机制提取音频信息;..现在是转发福利时间!---我们给20位新媒体人送上一份小礼物。
小礼物将免费送到您的朋友圈,还有多名合作伙伴随时在等您。1+两个100人公众号排名3强,将送出500本公众号涨粉技术秘籍公众号排名首发100篇+排名100强,将送出200本爆文秘籍公众号排名每1000篇,将送出100本标题秘籍公众号排名101篇,将送出100本黑帽排号秘籍公众号排名每100篇,将送出10本精细化运营秘籍公众号排名50篇,将送出100本涨粉秘籍想要了解活动详情,请长按识别下方二维码,回复小礼物(二维码自动识别)扫描上方二维码,还可以领取我们精心准备的30g《涨粉实战全攻略》。
最后,再给大家推荐一款活动运营神器,工具丰富,适用各行各业,一键生成微信h5页面,一键发送朋友圈、公众号文章,现在免费领取仅需1元!(二维码自动识别)想要学习更多,更高效的互联网营销方法,欢迎进入活动盒子官网,用优惠券和专享福利优惠你的活动推广。(二维码自动识别)。 查看全部
从网页抓取视频(20位新媒体人送上一份小礼物将免费送到您的朋友圈)
从网页抓取视频,是这样做的,先分析youtube视频;先通过断点处理:获取页面的地址,通过生成二维码,做分析防抓包;通过视频结构识别页面,自动抓取点击区域,识别/跳转,识别视频调度按钮位置(左上角、右上角、右下角);从视频中提取中心位置的音频信息,最终在服务器上结构化提取音频数据库;通过截取回声消除机制,提取音频环境属性;通过识别转速、空间距离、视频旋转角度等阈值识别出处理时长;通过剪辑空间位置,提取多段视频信息,最终以flv、h264、mp4、mov等视频形式提取视频信息;通过识别视频的帧率等细节提取视频信息;通过音频特征提取机制提取音频信息;..现在是转发福利时间!---我们给20位新媒体人送上一份小礼物。
小礼物将免费送到您的朋友圈,还有多名合作伙伴随时在等您。1+两个100人公众号排名3强,将送出500本公众号涨粉技术秘籍公众号排名首发100篇+排名100强,将送出200本爆文秘籍公众号排名每1000篇,将送出100本标题秘籍公众号排名101篇,将送出100本黑帽排号秘籍公众号排名每100篇,将送出10本精细化运营秘籍公众号排名50篇,将送出100本涨粉秘籍想要了解活动详情,请长按识别下方二维码,回复小礼物(二维码自动识别)扫描上方二维码,还可以领取我们精心准备的30g《涨粉实战全攻略》。
最后,再给大家推荐一款活动运营神器,工具丰富,适用各行各业,一键生成微信h5页面,一键发送朋友圈、公众号文章,现在免费领取仅需1元!(二维码自动识别)想要学习更多,更高效的互联网营销方法,欢迎进入活动盒子官网,用优惠券和专享福利优惠你的活动推广。(二维码自动识别)。
从网页抓取视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-06 14:01
前言:这是Java爬虫实战第二篇文章。在第一篇的基础上文章随便抓取目标的链接网站在目标页面上取我们需要的内容,存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名称和迅雷下载链接)
原理简介
其实原理和第一个文章差不多,不同的是,由于这个网站里面的分类太多了,如果不选择这些标签,会耗费难以想象的时间。
p>
不要使用类别链接和标签链接。不要使用这些链接来抓取其他页面。您只能通过页面底部的所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL中
注意:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):一网打尽所有链接网站/<//p
pp>
第二次代码实现
上面已经提到了实现原理,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
从网页抓取视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
前言:这是Java爬虫实战第二篇文章。在第一篇的基础上文章随便抓取目标的链接网站在目标页面上取我们需要的内容,存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名称和迅雷下载链接)
原理简介
其实原理和第一个文章差不多,不同的是,由于这个网站里面的分类太多了,如果不选择这些标签,会耗费难以想象的时间。
p>

不要使用类别链接和标签链接。不要使用这些链接来抓取其他页面。您只能通过页面底部的所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。

最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL中
注意:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):一网打尽所有链接网站/<//p
pp>
第二次代码实现
上面已经提到了实现原理,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
从网页抓取视频(快手抓取失败的失败原因和解决方法-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-03-04 20:03
从网页抓取视频的过程中,有不少网站会出现抓取失败的情况,无论是抖音、快手还是其他短视频网站,找到视频抓取失败的原因是重要的一步。这里,我就以快手为例,说一下快手抓取失败的失败原因和解决方法。在进行抓取一个视频时,必须要找到视频列表页面,这里就有一个问题,当我们在找视频的时候,不断去查看视频的列表是没有意义的,我们应该首先找到播放量和播放时长,我们才可以知道该视频的质量大不大,这样我们就可以知道该视频中的热门程度了。
当我们进行这一步操作时,我们会看到连接列表,我们是以抓取播放量排在前面的作为例子,由此可见,我们在抓取的时候应该优先抓取排在前面的播放量大的视频,那么,那些播放量非常大的视频,作为我们的目标对象是不是就会失败呢?这个就要涉及到视频发布的时间问题了,很多网站(例如快手)将视频发布的时间划分的非常严格,那么,我们就可以避开这个时间差。
比如,快手的默认发布时间为每天09:00-20:00,那么,我们把发布时间设置为每天4:00-6:00,这个时间就会大大减少失败的几率。除此之外,我们还要注意视频标题和视频图片的相似程度,不要将相似度非常高的视频进行抓取,这样是不会返回匹配信息的。总之,抓取视频的过程可能非常复杂,我们在进行抓取之前一定要进行抓取操作的确认,避免将重要信息放在快手存储缓存里而不是使用的数据库。
在视频的抓取中,数据库依然重要,我们应该根据抓取的量来决定使用哪种数据库,我当时选择的是mysql,由于很多人分享一些网站的抓取教程,对于中间件的了解相对较少,这里我对中间件有比较深的理解,所以我选择先抓取一些中间件的抓取教程学习,好处就是避免了我再去重新抓取数据库,因为我已经有中间件基础了。当然,不只是快手,很多视频网站都是以此种方式实现中间件的集群方式,我将以后写一篇文章讲一下这种中间件方式,会尽快进行整理。微信公众号:michelin博客。 查看全部
从网页抓取视频(快手抓取失败的失败原因和解决方法-八维教育)
从网页抓取视频的过程中,有不少网站会出现抓取失败的情况,无论是抖音、快手还是其他短视频网站,找到视频抓取失败的原因是重要的一步。这里,我就以快手为例,说一下快手抓取失败的失败原因和解决方法。在进行抓取一个视频时,必须要找到视频列表页面,这里就有一个问题,当我们在找视频的时候,不断去查看视频的列表是没有意义的,我们应该首先找到播放量和播放时长,我们才可以知道该视频的质量大不大,这样我们就可以知道该视频中的热门程度了。
当我们进行这一步操作时,我们会看到连接列表,我们是以抓取播放量排在前面的作为例子,由此可见,我们在抓取的时候应该优先抓取排在前面的播放量大的视频,那么,那些播放量非常大的视频,作为我们的目标对象是不是就会失败呢?这个就要涉及到视频发布的时间问题了,很多网站(例如快手)将视频发布的时间划分的非常严格,那么,我们就可以避开这个时间差。
比如,快手的默认发布时间为每天09:00-20:00,那么,我们把发布时间设置为每天4:00-6:00,这个时间就会大大减少失败的几率。除此之外,我们还要注意视频标题和视频图片的相似程度,不要将相似度非常高的视频进行抓取,这样是不会返回匹配信息的。总之,抓取视频的过程可能非常复杂,我们在进行抓取之前一定要进行抓取操作的确认,避免将重要信息放在快手存储缓存里而不是使用的数据库。
在视频的抓取中,数据库依然重要,我们应该根据抓取的量来决定使用哪种数据库,我当时选择的是mysql,由于很多人分享一些网站的抓取教程,对于中间件的了解相对较少,这里我对中间件有比较深的理解,所以我选择先抓取一些中间件的抓取教程学习,好处就是避免了我再去重新抓取数据库,因为我已经有中间件基础了。当然,不只是快手,很多视频网站都是以此种方式实现中间件的集群方式,我将以后写一篇文章讲一下这种中间件方式,会尽快进行整理。微信公众号:michelin博客。
从网页抓取视频(如何用python爬取网站的mv视频,话不多说直接上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-03 05:05
我喜欢编程和分享。希望结交更多志同道合的朋友,一起在学习Python的道路上走得更远!
本文教你如何使用python爬取网站的mv视频,话不多说,直接上代码!
爬取网站的地址:
from urllib import request,response
import re,urllib
import requests
def pa(url):
a=0
hader={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:62.0) Gecko/20100101 Firefox/62.0'} #请求头,模拟浏览器
da=urllib.request.Request(url,headers=hader)
date=urllib.request.urlopen(da) #发送请求
html=date.read().decode("utf-8") #编码转换
lianjie=re.findall('<a class="clip-link" data-id="(.*?)" title="(.*?)" >',html,re.S) #提取mv列表的链接
for i,l in enumerate(lianjie):
a=a+1
lianjie=l[0]
da=urllib.request.Request("http://www.170mv.com/mlmv/%s.html" %lianjie,headers=hader)
date=urllib.request.urlopen(da)
html=date.read().decode("utf-8")
url=re.findall('http://www.170mv.com/tool/jiexi/ajax/pid/%s/(.*?).mp4' %lianjie,html,re.S)
name=re.findall('(.*?)',html,re.S)
url='http://www.170mv.com/tool/jiex ... 39%3B %(lianjie,url[0])
url = requests.get(url).content
print("正在下载第%s首mv" % a)
f = open('E:\\mp4\\{}.mp4'.format(name[0]), 'wb')
f.write(url)
f.close()
print("下载成功")
我是一名python开发工程师,整理了一套python的学习资料,从基础的python脚本到web开发、爬虫、
数据分析、数据可视化、机器学习、面试真题等。想要的可以进群:688244617免费领取
如果你觉得 文章 没问题,你可能会喜欢它。如果您有任何意见或意见,请发表评论! 查看全部
从网页抓取视频(如何用python爬取网站的mv视频,话不多说直接上代码)
我喜欢编程和分享。希望结交更多志同道合的朋友,一起在学习Python的道路上走得更远!
本文教你如何使用python爬取网站的mv视频,话不多说,直接上代码!
爬取网站的地址:
from urllib import request,response
import re,urllib
import requests
def pa(url):
a=0
hader={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:62.0) Gecko/20100101 Firefox/62.0'} #请求头,模拟浏览器
da=urllib.request.Request(url,headers=hader)
date=urllib.request.urlopen(da) #发送请求
html=date.read().decode("utf-8") #编码转换
lianjie=re.findall('<a class="clip-link" data-id="(.*?)" title="(.*?)" >',html,re.S) #提取mv列表的链接
for i,l in enumerate(lianjie):
a=a+1
lianjie=l[0]
da=urllib.request.Request("http://www.170mv.com/mlmv/%s.html" %lianjie,headers=hader)
date=urllib.request.urlopen(da)
html=date.read().decode("utf-8")
url=re.findall('http://www.170mv.com/tool/jiexi/ajax/pid/%s/(.*?).mp4' %lianjie,html,re.S)
name=re.findall('(.*?)',html,re.S)
url='http://www.170mv.com/tool/jiex ... 39%3B %(lianjie,url[0])
url = requests.get(url).content
print("正在下载第%s首mv" % a)
f = open('E:\\mp4\\{}.mp4'.format(name[0]), 'wb')
f.write(url)
f.close()
print("下载成功")
我是一名python开发工程师,整理了一套python的学习资料,从基础的python脚本到web开发、爬虫、
数据分析、数据可视化、机器学习、面试真题等。想要的可以进群:688244617免费领取
如果你觉得 文章 没问题,你可能会喜欢它。如果您有任何意见或意见,请发表评论!
从网页抓取视频(怎么用迅捷视频转换器把音频提取格式转换成mp3?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-27 16:15
很多时候我们想从视频中提取音频,比如看mv的时候遇到喜欢的音乐,或者看电影/电视剧的时候有喜欢的bgm却找不到音频。
如果想在看外语视频时提取视频中的音频,需要将mp4格式转换为mp3,那么如何使用快速视频转换器来转换mp4格式
转换成mp3怎么样?接下来,我将教你如何从 mp4 视频格式中提取 mp3 音频格式。
1、将 mp4 视频格式的文件添加到软件中。如果添加时文件不多,可以点击软件左上角的“添加文件”按钮依次添加文件
,如果文件较多,可以点击“添加文件”右侧的“添加文件夹”按钮或直接将文件拖放到软件中,批量添加到软件中。
2、添加文件后,设置“输出格式”,输出格式分为‘音频’和‘视频’格式,‘音频’格式有音频格式分为输出
模式和音频频率。我们可以在“音频”格式下将这些设置为“mp3 with original”格式。如果需要自己设置参数,可以'添加自定义
'设置按钮可自行设置码率、频率、频道等参数。
3、设置好“输出格式”参数后,即可截取视频片段。在截取过程中点击“裁剪”按钮,会出现一个设置框。我们需要
设置保存间隔(开始时间和结束时间),或移动绿色标记来设置保存间隔。设置好后点击“确定”保存截取间隔。如果不需要
如果您需要保存完整视频以拍摄剪辑,则可以跳过此步骤。
4、截取保存的区间后,可以设置“输出路径”。设置时可以在输入框中预设输出到电脑的位置,也可以在“更改路径”中设置
按钮选择所需的输出位置。
5、调整好“输出路径”后,点击“转换”或“全部转换”按钮,将mp4格式转换为mp3音频格式。转换时你会看到一个进步
当进度条达到 100% 时,将 mp4 格式转换为 mp3。最后只要找到预设的输出路径就可以打开文件了。
以上就是将mp4格式转换为mp3的方法。使用上述方法,您可以从视频剪辑中剪切出您想要的音频剪辑。以及转换方式有多少
种类很多,但适合自己的方法不多。希望大家都能找到适合自己的方法。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。 查看全部
从网页抓取视频(怎么用迅捷视频转换器把音频提取格式转换成mp3?)
很多时候我们想从视频中提取音频,比如看mv的时候遇到喜欢的音乐,或者看电影/电视剧的时候有喜欢的bgm却找不到音频。
如果想在看外语视频时提取视频中的音频,需要将mp4格式转换为mp3,那么如何使用快速视频转换器来转换mp4格式
转换成mp3怎么样?接下来,我将教你如何从 mp4 视频格式中提取 mp3 音频格式。
1、将 mp4 视频格式的文件添加到软件中。如果添加时文件不多,可以点击软件左上角的“添加文件”按钮依次添加文件
,如果文件较多,可以点击“添加文件”右侧的“添加文件夹”按钮或直接将文件拖放到软件中,批量添加到软件中。

2、添加文件后,设置“输出格式”,输出格式分为‘音频’和‘视频’格式,‘音频’格式有音频格式分为输出
模式和音频频率。我们可以在“音频”格式下将这些设置为“mp3 with original”格式。如果需要自己设置参数,可以'添加自定义
'设置按钮可自行设置码率、频率、频道等参数。

3、设置好“输出格式”参数后,即可截取视频片段。在截取过程中点击“裁剪”按钮,会出现一个设置框。我们需要
设置保存间隔(开始时间和结束时间),或移动绿色标记来设置保存间隔。设置好后点击“确定”保存截取间隔。如果不需要
如果您需要保存完整视频以拍摄剪辑,则可以跳过此步骤。

4、截取保存的区间后,可以设置“输出路径”。设置时可以在输入框中预设输出到电脑的位置,也可以在“更改路径”中设置
按钮选择所需的输出位置。

5、调整好“输出路径”后,点击“转换”或“全部转换”按钮,将mp4格式转换为mp3音频格式。转换时你会看到一个进步
当进度条达到 100% 时,将 mp4 格式转换为 mp3。最后只要找到预设的输出路径就可以打开文件了。

以上就是将mp4格式转换为mp3的方法。使用上述方法,您可以从视频剪辑中剪切出您想要的音频剪辑。以及转换方式有多少
种类很多,但适合自己的方法不多。希望大家都能找到适合自己的方法。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
从网页抓取视频(Python爬虫快速入门(上)(上)获取弹幕数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-24 09:24
网络视频弹幕采集
访问博客时,经常看到关于视频弹幕的数据分析文章,我们可以看到从一些热门视频的弹幕和评论数据中可以得出一些有趣的结论。那么我们来研究一下获取网站视频弹幕数据的一般方法。可以参考之前的爬虫基础总结:
Python爬虫快速入门(上) Python爬虫快速入门(下)一、在浏览器调试模式下获取API
以哔哩哔哩为例,先打开一个视频。在这里,您可以在主页上找到更受欢迎的视频:
《小白评测》5000元旗舰手机大恒评测2020年中盘Part 1
打开视频页面,输入F12打开调试工具,然后切换到移动端,刷新网页。此时,您可以看到 URL 从 . 等待页面加载完毕后,可以在调试工具的Network选项中看到具体的请求。下一步是锁定获取弹幕数据的请求。
由于请求的数量非常多,因此需要缩小范围。这里在视频前后请求盲猜弹幕数据,下图中蓝色的长部分应该是视频数据流。可以选中它查看它的具体信息,在新标签页中打开请求链接,发现确实是视频的直接链接。然后在框选的范围内一一查看请求的内容。弹幕没有请求链接,只有一个相关视频信息,名字是related?from=h5&aid= .... 然后尝试在视频流结束前后搜索,最后确认请求命名为list .so?oid=210551301 返回弹幕数据。
理论上可以请求查看,最后找到弹幕的API。您还可以利用您的想象力以各种方式缩小搜索范围。
二、使用脚本请求数据
其实打开链接后直接Ctrl S数据就可以了,但是可能需要获取多个相关视频的弹幕数据,或者Up主的一系列视频。这里需要使用脚本请求。从 API 链接可以看出,它的 oid 参数和视频链接的序列号不同。所以先从视频链接中获取对应的oid。直接 GET 请求视频链接,返回的信息收录 oid 参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
import requests as rq
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'}
def get_param(link):
'''由视频链接获取 id 参数'''
res = rq.get(link, headers=headers)
reg = "var options = {.*?aid: (.*?),.*?bvid: '(.*?)',.*?cid: (.*?),.*?}"
ids = re.compile(reg, re.S).findall(res.text)[0]
params = dict(zip(['aid', 'bvid', 'cid'], ids))
if params['bvid'] == link.split('?')[0].split('/')[-1]:
return params
else:
print('Extraction Error!')
return 0
接下来构造一个链接,通过视频对应的id请求弹幕数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from bs4 import BeautifulSoup
def get_dm(id, write=False):
'''id 对应 get_param 函数返回的 cid 字段'''
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={id}'
res = rq.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'xml')
dms = [d.text for d in soup.find_all('d')]
if write:
with open(f'{id}.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(dms))
print(f'\n已写出文件 {id}.txt\n')
else:
return dms
最后,获取另一个视频的弹幕来测试一下:
1
2
url = 'https://www.bilibili.com/video/BV1mK4y1479e'
get_dm(get_param(url)['cid'], True)
三、其他视频网站
B站只是一个“小破站”,挑战不大,我们来试试“大站”看看有什么不同。
两千年后……
广告很长,都是VIP视频。. . 查看全部
从网页抓取视频(Python爬虫快速入门(上)(上)获取弹幕数据)
网络视频弹幕采集
访问博客时,经常看到关于视频弹幕的数据分析文章,我们可以看到从一些热门视频的弹幕和评论数据中可以得出一些有趣的结论。那么我们来研究一下获取网站视频弹幕数据的一般方法。可以参考之前的爬虫基础总结:
Python爬虫快速入门(上) Python爬虫快速入门(下)一、在浏览器调试模式下获取API
以哔哩哔哩为例,先打开一个视频。在这里,您可以在主页上找到更受欢迎的视频:
《小白评测》5000元旗舰手机大恒评测2020年中盘Part 1
打开视频页面,输入F12打开调试工具,然后切换到移动端,刷新网页。此时,您可以看到 URL 从 . 等待页面加载完毕后,可以在调试工具的Network选项中看到具体的请求。下一步是锁定获取弹幕数据的请求。
由于请求的数量非常多,因此需要缩小范围。这里在视频前后请求盲猜弹幕数据,下图中蓝色的长部分应该是视频数据流。可以选中它查看它的具体信息,在新标签页中打开请求链接,发现确实是视频的直接链接。然后在框选的范围内一一查看请求的内容。弹幕没有请求链接,只有一个相关视频信息,名字是related?from=h5&aid= .... 然后尝试在视频流结束前后搜索,最后确认请求命名为list .so?oid=210551301 返回弹幕数据。
理论上可以请求查看,最后找到弹幕的API。您还可以利用您的想象力以各种方式缩小搜索范围。

二、使用脚本请求数据
其实打开链接后直接Ctrl S数据就可以了,但是可能需要获取多个相关视频的弹幕数据,或者Up主的一系列视频。这里需要使用脚本请求。从 API 链接可以看出,它的 oid 参数和视频链接的序列号不同。所以先从视频链接中获取对应的oid。直接 GET 请求视频链接,返回的信息收录 oid 参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
import requests as rq
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'}
def get_param(link):
'''由视频链接获取 id 参数'''
res = rq.get(link, headers=headers)
reg = "var options = {.*?aid: (.*?),.*?bvid: '(.*?)',.*?cid: (.*?),.*?}"
ids = re.compile(reg, re.S).findall(res.text)[0]
params = dict(zip(['aid', 'bvid', 'cid'], ids))
if params['bvid'] == link.split('?')[0].split('/')[-1]:
return params
else:
print('Extraction Error!')
return 0
接下来构造一个链接,通过视频对应的id请求弹幕数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from bs4 import BeautifulSoup
def get_dm(id, write=False):
'''id 对应 get_param 函数返回的 cid 字段'''
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={id}'
res = rq.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'xml')
dms = [d.text for d in soup.find_all('d')]
if write:
with open(f'{id}.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(dms))
print(f'\n已写出文件 {id}.txt\n')
else:
return dms
最后,获取另一个视频的弹幕来测试一下:
1
2
url = 'https://www.bilibili.com/video/BV1mK4y1479e'
get_dm(get_param(url)['cid'], True)
三、其他视频网站
B站只是一个“小破站”,挑战不大,我们来试试“大站”看看有什么不同。
两千年后……
广告很长,都是VIP视频。. .
从网页抓取视频(网页中视频url采集建立采集任务选择一个视频网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-23 22:19
会智能地在页面中添加其他具有相似特征的元素。点击“Create List Complete”5.如图所示,点击“Cycle”6.左上角的流程设计器为点击的元素显示了一个循环框。完成循环点击列表的创建抓取视频网址1.将鼠标移至视频标题,点击右键,选择执行红框中的“抓取本元素的文字”抓取标题视频的2.截取的标题会显示在右上角的操作框中,点击“添加其他特殊字段”,选择“添加当前页面URL”3.提取该视频的URL,并然后点击右下角的保存按钮4.完成视频URL提取步骤5. 因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则就像图中的红框一样。点击右下角保存后,可以点击“下一步”开始视频URL采集开始采集1.选择单机采集,开始视频URL提取2.采集完成,导出视频URL3.导出视频URL后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:该过程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则如图中红框,点击右下角保存,然后点击“下一步”开始视频网址采集开始采集 1.选择单机采集,开始提取视频网址2.采集完成,导出视频网址3.导出视频网址后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集 查看全部
从网页抓取视频(网页中视频url采集建立采集任务选择一个视频网站)
会智能地在页面中添加其他具有相似特征的元素。点击“Create List Complete”5.如图所示,点击“Cycle”6.左上角的流程设计器为点击的元素显示了一个循环框。完成循环点击列表的创建抓取视频网址1.将鼠标移至视频标题,点击右键,选择执行红框中的“抓取本元素的文字”抓取标题视频的2.截取的标题会显示在右上角的操作框中,点击“添加其他特殊字段”,选择“添加当前页面URL”3.提取该视频的URL,并然后点击右下角的保存按钮4.完成视频URL提取步骤5. 因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则就像图中的红框一样。点击右下角保存后,可以点击“下一步”开始视频URL采集开始采集1.选择单机采集,开始视频URL提取2.采集完成,导出视频URL3.导出视频URL后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:该过程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则如图中红框,点击右下角保存,然后点击“下一步”开始视频网址采集开始采集 1.选择单机采集,开始提取视频网址2.采集完成,导出视频网址3.导出视频网址后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集
从网页抓取视频(幸亏之前本人收藏了一个专门提取各大主流视频网站视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-16 21:03
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。 查看全部
从网页抓取视频(幸亏之前本人收藏了一个专门提取各大主流视频网站视频的方法)
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。

视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。

浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
从网页抓取视频(禁止百度搜索引擎抓取网站并显示网页快照,我该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 12:09
信息
成为会员解锁独家内容
登入
热搜词
在这两者之间,添加禁止搜索引擎抓取 网站 并显示页面快照的代码。
在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
在 网站 主页代码之间,添加它以防止 Google 搜索引擎抓取 网站 并显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站我加了robots.txt,还能百度搜吗?
因为搜索引擎索引数据库的更新需要时间。虽然Baiduspider已经停止访问您网站上的网页,但是百度搜索引擎数据库中已经建立的网页索引信息可能需要几个月的时间才能被清除。另请检查您的机器人是否配置正确。如果您的拒绝是收录紧急要求的,也可以通过投诉平台反馈请求处理。
2.我想让网站内容被百度收录,但不保存为快照,怎么办?
百度蜘蛛遵守互联网元机器人协议。您可以使用网页元的设置,使百度显示只对网页进行索引,而不在搜索结果中显示网页的快照。和robots的更新一样,因为搜索引擎索引库的更新需要时间,虽然你已经禁止百度通过网页中的meta在搜索结果中显示网页的快照,但如果在百度中已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
3.想被百度索引,但是不保存网站快照,下面代码解决:
4. 如果你想阻止所有搜索引擎保存你网页的快照,那么代码如下:
下面列出了一些常见的代码组合:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接 查看全部
从网页抓取视频(禁止百度搜索引擎抓取网站并显示网页快照,我该怎么做?)
信息
成为会员解锁独家内容
登入
热搜词
在这两者之间,添加禁止搜索引擎抓取 网站 并显示页面快照的代码。

在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
在 网站 主页代码之间,添加它以防止 Google 搜索引擎抓取 网站 并显示网页快照。

另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站我加了robots.txt,还能百度搜吗?
因为搜索引擎索引数据库的更新需要时间。虽然Baiduspider已经停止访问您网站上的网页,但是百度搜索引擎数据库中已经建立的网页索引信息可能需要几个月的时间才能被清除。另请检查您的机器人是否配置正确。如果您的拒绝是收录紧急要求的,也可以通过投诉平台反馈请求处理。
2.我想让网站内容被百度收录,但不保存为快照,怎么办?
百度蜘蛛遵守互联网元机器人协议。您可以使用网页元的设置,使百度显示只对网页进行索引,而不在搜索结果中显示网页的快照。和robots的更新一样,因为搜索引擎索引库的更新需要时间,虽然你已经禁止百度通过网页中的meta在搜索结果中显示网页的快照,但如果在百度中已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
3.想被百度索引,但是不保存网站快照,下面代码解决:
4. 如果你想阻止所有搜索引擎保存你网页的快照,那么代码如下:
下面列出了一些常见的代码组合:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
从网页抓取视频(一下怎样100%的在网页上提取网页视频内的音,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-10 21:19
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:. 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页视频内的音,)
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。

好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。

csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
从网页抓取视频(生成视频格式的解析解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-08 13:04
从网页抓取视频,高清同时的效果是可以过10000k,字幕是可以过1000kb,在2000k的时候就不再抓取,到了2000k就可以生成视频mp4格式的解析出来,用于mp3生成等。
可以一分钟放1048576个小时,
被物理定义为硬件,其他的都是虚构的。
是打包了一个mp4然后逐个手动压制到目标文件中。否则都不知道什么时候有一个文件是1048576字节,什么时候有一个是5678字节。
如果你觉得一百万个视频每秒都占据一定空间是浪费,那就看每秒百万个视频吧。原视频文件大小为720p,1048576个文件,分四十秒,每秒写入10000字节(两分钟),一秒480字节(三十分钟)分十个字节(半小时)写入12000字节(一天)每秒448字节(两小时)写入10000字节(一天半)以上数据为自己瞎画的,数据中间的解码比较简单了,分帧每个7b,字节间隔600kb,解码后前面是普通文件后缀pkl,因为视频是一帧一帧压制的,本质上来说并不会占用空间,反正都是溢出了。
每秒两万字节,每帧50kb,所以2*5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5。 查看全部
从网页抓取视频(生成视频格式的解析解析)
从网页抓取视频,高清同时的效果是可以过10000k,字幕是可以过1000kb,在2000k的时候就不再抓取,到了2000k就可以生成视频mp4格式的解析出来,用于mp3生成等。
可以一分钟放1048576个小时,
被物理定义为硬件,其他的都是虚构的。
是打包了一个mp4然后逐个手动压制到目标文件中。否则都不知道什么时候有一个文件是1048576字节,什么时候有一个是5678字节。
如果你觉得一百万个视频每秒都占据一定空间是浪费,那就看每秒百万个视频吧。原视频文件大小为720p,1048576个文件,分四十秒,每秒写入10000字节(两分钟),一秒480字节(三十分钟)分十个字节(半小时)写入12000字节(一天)每秒448字节(两小时)写入10000字节(一天半)以上数据为自己瞎画的,数据中间的解码比较简单了,分帧每个7b,字节间隔600kb,解码后前面是普通文件后缀pkl,因为视频是一帧一帧压制的,本质上来说并不会占用空间,反正都是溢出了。
每秒两万字节,每帧50kb,所以2*5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5。
从网页抓取视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-31 11:17
今天看到联想2011年校园招聘,里面的视频挺好看的,很吸引人,想下载,但是右键没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门从各大主流视频中提取网站视频的网站:(原名)。使用后发现各大主流视频分享网站基本都能解析得到最终结果。URL,但鲜为人知的 网站 视频无法解析为公司之类的内容。
2.方法二
视频提取软件
网上搜索很多,但能用的不多。下载了几个软件,发现不能解决我的问题,放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的 html 知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我在下面找到了这个语句
其中的代码片段:
哈哈,“src="swf/给那些做640-480.swf的人”就是这句话,不就是最后的地址吗!!!
我想我得到了最深的 URL,试试看是否可以下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
转念一想,我不是都上过联想的服务器吗,如果我再次获得root权限,我可以为所欲为,哈哈。
我的目的达到了,接下来就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
从网页抓取视频(联想2011年校园招聘视频下载的功能?(图))
今天看到联想2011年校园招聘,里面的视频挺好看的,很吸引人,想下载,但是右键没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门从各大主流视频中提取网站视频的网站:(原名)。使用后发现各大主流视频分享网站基本都能解析得到最终结果。URL,但鲜为人知的 网站 视频无法解析为公司之类的内容。
2.方法二
视频提取软件
网上搜索很多,但能用的不多。下载了几个软件,发现不能解决我的问题,放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的 html 知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我在下面找到了这个语句

其中的代码片段:
哈哈,“src="swf/给那些做640-480.swf的人”就是这句话,不就是最后的地址吗!!!
我想我得到了最深的 URL,试试看是否可以下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
转念一想,我不是都上过联想的服务器吗,如果我再次获得root权限,我可以为所欲为,哈哈。
我的目的达到了,接下来就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
从网页抓取视频(一下怎样100%的在网页上提取网页内视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-31 00:00
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。. 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页内视频的方法)
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。

浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。

csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
从网页抓取视频(一下怎样100%的在网页上提取网页视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-30 23:22
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
网页视频提取巧妙便捷,类似于百度工具栏,可以轻松提取网页视频中的音频,让你快速得到你想要的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频下载方法 点击页面上的瓢虫(上图右上角),网页下方会出现如图所示的视图,点击页面底部。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种网页抓取视频的方法(其实昨天本来想发这个教程的,结果shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页视频的方法)
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
网页视频提取巧妙便捷,类似于百度工具栏,可以轻松提取网页视频中的音频,让你快速得到你想要的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。

视频下载方法 点击页面上的瓢虫(上图右上角),网页下方会出现如图所示的视图,点击页面底部。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。

2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种网页抓取视频的方法(其实昨天本来想发这个教程的,结果shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-27 19:18
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,截取网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1 查看全部
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,截取网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。

在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。



您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-27 19:16
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求的是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,拦截网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1 查看全部
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求的是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,拦截网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1
从网页抓取视频(SysNucleusWebHarvy网页数据采集软件的特色介绍及软件特色特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-25 09:23
SysNucleus WebHarvy是一款非常实用的网页数据采集软件,它可以帮助用户轻松的从网页中提取数据并以不同的格式保存,还支持提取视频、图片等各种类型的文件。
软件功能
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的连接数据分析
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
软件功能
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。您可以指定要由代理服务器提取的任意数量的输入关键字6、
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
从网页抓取视频(SysNucleusWebHarvy网页数据采集软件的特色介绍及软件特色特色)
SysNucleus WebHarvy是一款非常实用的网页数据采集软件,它可以帮助用户轻松的从网页中提取数据并以不同的格式保存,还支持提取视频、图片等各种类型的文件。
软件功能
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的连接数据分析
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
软件功能
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。您可以指定要由代理服务器提取的任意数量的输入关键字6、
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
从网页抓取视频(手机回答就不附代码链接了怎么办?百度云)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 06:12
从网页抓取视频的可靠性看,一般的网站都不合格,直接导致的后果是到达目标网站的cookie被盗用造成的。所以,建议最好不要在网页上抓取视频。
不能。
不能,搜索引擎的技术现在更新很快,现在基本抓取不到他们的视频网站的视频。只能利用他们的关键词爬虫来爬一些比较小的视频。手机回答就不附代码链接了,最好去查询一下搜索引擎的文档。
不是接口的问题,那上面的一个jsonview是,爬到了一个视频地址,你没有读取并解析视频地址。另外就是爬取的视频版权问题,很多搜索引擎都是会把视频画质或者清晰度降低的,甚至有的可能是ppt演示片段。
爬其他的更不好爬
要下载视频的话可以用搜索引擎抓取,很多视频网站会对影视视频采取加密措施,搜索引擎抓取不到视频的正确方式应该是通过爬虫抓取,但这方式不是特别安全,因为搜索引擎会抓取很多视频网站的视频,而这些网站的视频很多源是相同的。其实对于很多视频网站而言,视频的版权就是竞争力,无论是打击盗版都需要保证自己视频版权。对于某些视频源而言,利用自己的网站抓取的方式要求上网人的上网地址,很容易被恶意攻击。
所以只能对视频源上网人的上网地址进行审查,比如我现在再播放的电视剧,在有些视频网站是没有的,但某些视频网站就有,看这个视频就必须通过这个网站才能看到。这就是区别,除了某些网站可以利用爬虫抓取上传,一般我们需要对上传人上网地址进行审查,验证是不是上传人自己上传的即可,或者转账验证。对于一些不规范的视频,可以通过gps校验。
百度因为对视频上传的容错率做的太低,所以爬取不到正版视频。我曾看过一次总局搞的拆分视频清单,清单里有我们熟悉的部分但没有视频下载和有效载体那些东西,这才是重点。 查看全部
从网页抓取视频(手机回答就不附代码链接了怎么办?百度云)
从网页抓取视频的可靠性看,一般的网站都不合格,直接导致的后果是到达目标网站的cookie被盗用造成的。所以,建议最好不要在网页上抓取视频。
不能。
不能,搜索引擎的技术现在更新很快,现在基本抓取不到他们的视频网站的视频。只能利用他们的关键词爬虫来爬一些比较小的视频。手机回答就不附代码链接了,最好去查询一下搜索引擎的文档。
不是接口的问题,那上面的一个jsonview是,爬到了一个视频地址,你没有读取并解析视频地址。另外就是爬取的视频版权问题,很多搜索引擎都是会把视频画质或者清晰度降低的,甚至有的可能是ppt演示片段。
爬其他的更不好爬
要下载视频的话可以用搜索引擎抓取,很多视频网站会对影视视频采取加密措施,搜索引擎抓取不到视频的正确方式应该是通过爬虫抓取,但这方式不是特别安全,因为搜索引擎会抓取很多视频网站的视频,而这些网站的视频很多源是相同的。其实对于很多视频网站而言,视频的版权就是竞争力,无论是打击盗版都需要保证自己视频版权。对于某些视频源而言,利用自己的网站抓取的方式要求上网人的上网地址,很容易被恶意攻击。
所以只能对视频源上网人的上网地址进行审查,比如我现在再播放的电视剧,在有些视频网站是没有的,但某些视频网站就有,看这个视频就必须通过这个网站才能看到。这就是区别,除了某些网站可以利用爬虫抓取上传,一般我们需要对上传人上网地址进行审查,验证是不是上传人自己上传的即可,或者转账验证。对于一些不规范的视频,可以通过gps校验。
百度因为对视频上传的容错率做的太低,所以爬取不到正版视频。我曾看过一次总局搞的拆分视频清单,清单里有我们熟悉的部分但没有视频下载和有效载体那些东西,这才是重点。
从网页抓取视频(从网页抓取视频->新闻最后进入top100(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-12 21:01
从网页抓取视频->发现->新榜->新闻稿子最后进入top100榜单。基本所有的网站都抓取过。
他们是一个团队做的,不过收费的少,适合刚创业的去,量大了要收的就多了,
新闻客户端抓的。
有一个团队在发新闻稿,
他们是在发布新闻稿方面做的做的还不错的有很多
他们应该是一个团队的,主要是新闻客户端去发的。
才可以加我微信46680712
和这个平台合作,没什么大的收益,我们是创业公司,每天需要新闻发布,
近期他们正在在发布新闻,
发给我试试
他们团队目前在发布新闻,欢迎知道内情的朋友前来咨询。
是不是一个团队
采集,在采集,
已经在他们那发布过一篇,很不错,
是一个团队,
不知道是不是一个团队,
是一个团队做的,不过是收费的,适合创业中的小公司。
是一个团队,还是只是他们公司人一起做的,目前只需要注册就可以免费领取50万条新闻资源,注册成功后可能需要邀请码,我有一个邀请码哈,有兴趣的朋友可以看看。
是一个团队在做的,
很正规的团队, 查看全部
从网页抓取视频(从网页抓取视频->新闻最后进入top100(图))
从网页抓取视频->发现->新榜->新闻稿子最后进入top100榜单。基本所有的网站都抓取过。
他们是一个团队做的,不过收费的少,适合刚创业的去,量大了要收的就多了,
新闻客户端抓的。
有一个团队在发新闻稿,
他们是在发布新闻稿方面做的做的还不错的有很多
他们应该是一个团队的,主要是新闻客户端去发的。
才可以加我微信46680712
和这个平台合作,没什么大的收益,我们是创业公司,每天需要新闻发布,
近期他们正在在发布新闻,
发给我试试
他们团队目前在发布新闻,欢迎知道内情的朋友前来咨询。
是不是一个团队
采集,在采集,
已经在他们那发布过一篇,很不错,
是一个团队,
不知道是不是一个团队,
是一个团队做的,不过是收费的,适合创业中的小公司。
是一个团队,还是只是他们公司人一起做的,目前只需要注册就可以免费领取50万条新闻资源,注册成功后可能需要邀请码,我有一个邀请码哈,有兴趣的朋友可以看看。
是一个团队在做的,
很正规的团队,
从网页抓取视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-11 19:24
确定需求,我们要爬梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
不难发现,我们需要的视频地址都在ul标签下的li标签中,使用xpath解析,得到所有的li标签。就个人而言,我认为 xpath 是最好的 html 解析工具。Beautifulsoup太复杂,解析方法太多,容易混淆,所以我的爬虫使用xpath来解析数据。
拿到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们就得到了视频的地址,比如这个video_1730677
3.第二步是拼接网站,谁来拼接是个问题。如果用初始url拼接访问,在得到的响应中是找不到mp4的。
表示该地址不在静态网页中,则开始抓包分析
可以看到只有一个包,一点也不简单。点进去可以看到返回的数据里面有视频的下载地址,不过不要太高兴。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4,抓包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,我发现两个url的最后一个'/'和最近的'-'之间的字符串不一样,其余的都是一样的。url中最后一个'/'和最近的'-'之间的字符串替换为cont-1730677,1730677是第一步得到的a标签属性,然后去掉video_。这里我用正则表达式替换了它
4.第三步,视频的假地址在这个网站/videoStatus.jsp?contId=1730677&mrd=0.59567的返回对象中,如果要发这个< @网站 requests 请求必须携带两个参数
countId和mrd,通过简单分析,我们知道countId是视频号,也就是上面的a标签属性去掉video_,mrd是0到1之间随机生成的数字,可以使用python的random.random来实现()。如果只携带这两个参数进行访问,仍然无法获取数据,需要在请求头中添加refer参数。因为我没有带这个参数,所以很长时间都拿不到数据。记住!
5.第四步,快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
别说手动也可以(不过是真的),写这么多代码不是比手动更好吗?哈哈哈!看看我的下一个分析!
总结一下我的不足:我只爬取了静态网页中的四个视频,其余视频都是通过ajax向服务器请求获取的,而不是简单的改变页面的值。这个问题我没有仔细研究过;i 本爬虫为单线程爬虫,视频下载速度可能较慢。可以考虑使用多线程,速度可能会更快,但是我对自己的多线程编程水平没有信心(四个视频一个线程就够了);需要注意的是,如果要获取视频下载地址,requests请求必须携带refer参数。因为我没有带这个参数,所以弄了半天也拿不到。
随附的:
经过我的研究,爬多页其实很容易。当我打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp? reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361 ,1713304
经过简单分析,要得到分页后的视频数据,只需要改变上面网站的start参数即可。可以从1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。爬取整个网站的视频并不容易,但是这么大的数据量需要多线程和数据库知识。努力工作才能进步!
这是我在 知乎 中的第二篇文章 文章(另一篇水文文章,但我仍然喜欢在没有技术的情况下写作)。记录你自己的爬虫成长史!也希望和其他喜欢爬虫的人分享爬虫学习资料,一起讨论技术。很喜欢张宇的话:不忘,必有回响! 查看全部
从网页抓取视频(确定需求,我们要爬取梨视频下娱乐频道的最热视频)
确定需求,我们要爬梨视频下娱乐频道最热的视频
第一步获取起始url:/category_4,然后打开网站进行抓包分析
不难发现,我们需要的视频地址都在ul标签下的li标签中,使用xpath解析,得到所有的li标签。就个人而言,我认为 xpath 是最好的 html 解析工具。Beautifulsoup太复杂,解析方法太多,容易混淆,所以我的爬虫使用xpath来解析数据。
拿到li标签后,视频的url在li标签下第一个div下a标签的herf属性中,我们就得到了视频的地址,比如这个video_1730677
3.第二步是拼接网站,谁来拼接是个问题。如果用初始url拼接访问,在得到的响应中是找不到mp4的。
表示该地址不在静态网页中,则开始抓包分析
可以看到只有一个包,一点也不简单。点进去可以看到返回的数据里面有视频的下载地址,不过不要太高兴。视频的真实地址是/mp4/third/20210528/cont-1394-171325-hd.mp4,抓包是/mp4/third/20210528/89-125-hd.mp4,仔细一看,我发现两个url的最后一个'/'和最近的'-'之间的字符串不一样,其余的都是一样的。url中最后一个'/'和最近的'-'之间的字符串替换为cont-1730677,1730677是第一步得到的a标签属性,然后去掉video_。这里我用正则表达式替换了它
4.第三步,视频的假地址在这个网站/videoStatus.jsp?contId=1730677&mrd=0.59567的返回对象中,如果要发这个< @网站 requests 请求必须携带两个参数
countId和mrd,通过简单分析,我们知道countId是视频号,也就是上面的a标签属性去掉video_,mrd是0到1之间随机生成的数字,可以使用python的random.random来实现()。如果只携带这两个参数进行访问,仍然无法获取数据,需要在请求头中添加refer参数。因为我没有带这个参数,所以很长时间都拿不到数据。记住!
5.第四步,快乐下载,结果图
具体代码如下:
import requests
import os
from lxml import etree
import random
import time
import re
class PearVideo(): # 定义梨视频类
def __init__(self):
self.start_url = 'https://www.pearvideo.com/category_4'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def get_video_url(self): # 获取单个视频的地址和countId
resp = requests.get(self.start_url, headers=self.headers).text
tree = etree.HTML(resp)
li_list = tree.xpath('.//ul[@class="listvideo-list clearfix"]/li')
video_urls = []
countId_list = []
video_names = []
for li in li_list:
video_url = li.xpath('./div[1]/a/@href')[0]
countId = video_url.split('_')[-1]
countId_list.append(countId)
video_name = li.xpath('.//div[@class="vervideo-title"]/text()')[0]
mrd = random.random()
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(countId, mrd)
video_urls.append(video_url)
video_names.append(video_name)
return video_urls, countId_list, video_names
def get_download_url(self): # 获取视频的真实下载地址,请求头中要携带refer参数,不然得不到想要的json数据
video_urls, countId_list, video_names = self.get_video_url()
download_urls = []
for url, countId in zip(video_urls, countId_list):
resp = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https: // www.pearvideo.com / video_{}'.format(countId)
}).json()
time.sleep(1)
# print(resp)
download_url = resp['videoInfo']['videos']['srcUrl']
download_url = re.sub('/[0-9]+-', '/cont-{}-'.format(countId), download_url)
# print(download_url)
# time.sleep(1)
download_urls.append(download_url)
# print(download_urls)
return download_urls, video_names
def download_video(self): # 视频的保存
download_urls, video_names = self.get_download_url()
# print(download_urls)
filename = 'D://pearvideo' #视频保存在d盘的pearvideo文件夹下
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
for url in download_urls:
with open('{}/{}.mp4'.format(filename, video_names[index]), mode='wb') as f:
resp = requests.get(url, headers=self.headers).content
# print(resp)
f.write(resp)
time.sleep(1)
index += 1
if __name__ == '__main__':
pearvideo_spider = PearVideo()
pearvideo_spider.download_video()
别说手动也可以(不过是真的),写这么多代码不是比手动更好吗?哈哈哈!看看我的下一个分析!
总结一下我的不足:我只爬取了静态网页中的四个视频,其余视频都是通过ajax向服务器请求获取的,而不是简单的改变页面的值。这个问题我没有仔细研究过;i 本爬虫为单线程爬虫,视频下载速度可能较慢。可以考虑使用多线程,速度可能会更快,但是我对自己的多线程编程水平没有信心(四个视频一个线程就够了);需要注意的是,如果要获取视频下载地址,requests请求必须携带refer参数。因为我没有带这个参数,所以弄了半天也拿不到。
随附的:
经过我的研究,爬多页其实很容易。当我打开抓包工具继续往下滑,可以看到本地有很多请求发送到服务器,如下:
/category_loading.jsp?reqType=5&categoryId=4&start=12&mrd=0.36427441062670063&filterIds=1730677,1730635,1730509,1730484,1728846,1730305,1730384,1730381,1730338,1729112,1729081,1729048
/category_loading.jsp? reqType = 5&的categoryId = 4&启动= 264&MRD = 0. 67719&filterIds = 1730677,1730635,1730509,1714315,1714259,1714097,1713907,1713860,1713859,1713753,1713719,1713572,1713571,1713361 ,1713304
经过简单分析,要得到分页后的视频数据,只需要改变上面网站的start参数即可。可以从1开始,每页有12个视频,不过我没试过。如果你想尝试,你可以做到。爬取整个网站的视频并不容易,但是这么大的数据量需要多线程和数据库知识。努力工作才能进步!
这是我在 知乎 中的第二篇文章 文章(另一篇水文文章,但我仍然喜欢在没有技术的情况下写作)。记录你自己的爬虫成长史!也希望和其他喜欢爬虫的人分享爬虫学习资料,一起讨论技术。很喜欢张宇的话:不忘,必有回响!
从网页抓取视频(20位新媒体人送上一份小礼物将免费送到您的朋友圈)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-11 19:07
从网页抓取视频,是这样做的,先分析youtube视频;先通过断点处理:获取页面的地址,通过生成二维码,做分析防抓包;通过视频结构识别页面,自动抓取点击区域,识别/跳转,识别视频调度按钮位置(左上角、右上角、右下角);从视频中提取中心位置的音频信息,最终在服务器上结构化提取音频数据库;通过截取回声消除机制,提取音频环境属性;通过识别转速、空间距离、视频旋转角度等阈值识别出处理时长;通过剪辑空间位置,提取多段视频信息,最终以flv、h264、mp4、mov等视频形式提取视频信息;通过识别视频的帧率等细节提取视频信息;通过音频特征提取机制提取音频信息;..现在是转发福利时间!---我们给20位新媒体人送上一份小礼物。
小礼物将免费送到您的朋友圈,还有多名合作伙伴随时在等您。1+两个100人公众号排名3强,将送出500本公众号涨粉技术秘籍公众号排名首发100篇+排名100强,将送出200本爆文秘籍公众号排名每1000篇,将送出100本标题秘籍公众号排名101篇,将送出100本黑帽排号秘籍公众号排名每100篇,将送出10本精细化运营秘籍公众号排名50篇,将送出100本涨粉秘籍想要了解活动详情,请长按识别下方二维码,回复小礼物(二维码自动识别)扫描上方二维码,还可以领取我们精心准备的30g《涨粉实战全攻略》。
最后,再给大家推荐一款活动运营神器,工具丰富,适用各行各业,一键生成微信h5页面,一键发送朋友圈、公众号文章,现在免费领取仅需1元!(二维码自动识别)想要学习更多,更高效的互联网营销方法,欢迎进入活动盒子官网,用优惠券和专享福利优惠你的活动推广。(二维码自动识别)。 查看全部
从网页抓取视频(20位新媒体人送上一份小礼物将免费送到您的朋友圈)
从网页抓取视频,是这样做的,先分析youtube视频;先通过断点处理:获取页面的地址,通过生成二维码,做分析防抓包;通过视频结构识别页面,自动抓取点击区域,识别/跳转,识别视频调度按钮位置(左上角、右上角、右下角);从视频中提取中心位置的音频信息,最终在服务器上结构化提取音频数据库;通过截取回声消除机制,提取音频环境属性;通过识别转速、空间距离、视频旋转角度等阈值识别出处理时长;通过剪辑空间位置,提取多段视频信息,最终以flv、h264、mp4、mov等视频形式提取视频信息;通过识别视频的帧率等细节提取视频信息;通过音频特征提取机制提取音频信息;..现在是转发福利时间!---我们给20位新媒体人送上一份小礼物。
小礼物将免费送到您的朋友圈,还有多名合作伙伴随时在等您。1+两个100人公众号排名3强,将送出500本公众号涨粉技术秘籍公众号排名首发100篇+排名100强,将送出200本爆文秘籍公众号排名每1000篇,将送出100本标题秘籍公众号排名101篇,将送出100本黑帽排号秘籍公众号排名每100篇,将送出10本精细化运营秘籍公众号排名50篇,将送出100本涨粉秘籍想要了解活动详情,请长按识别下方二维码,回复小礼物(二维码自动识别)扫描上方二维码,还可以领取我们精心准备的30g《涨粉实战全攻略》。
最后,再给大家推荐一款活动运营神器,工具丰富,适用各行各业,一键生成微信h5页面,一键发送朋友圈、公众号文章,现在免费领取仅需1元!(二维码自动识别)想要学习更多,更高效的互联网营销方法,欢迎进入活动盒子官网,用优惠券和专享福利优惠你的活动推广。(二维码自动识别)。
从网页抓取视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-06 14:01
前言:这是Java爬虫实战第二篇文章。在第一篇的基础上文章随便抓取目标的链接网站在目标页面上取我们需要的内容,存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名称和迅雷下载链接)
原理简介
其实原理和第一个文章差不多,不同的是,由于这个网站里面的分类太多了,如果不选择这些标签,会耗费难以想象的时间。
p>
不要使用类别链接和标签链接。不要使用这些链接来抓取其他页面。您只能通过页面底部的所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL中
注意:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):一网打尽所有链接网站/<//p
pp>
第二次代码实现
上面已经提到了实现原理,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
从网页抓取视频(文末2015年电影的下载链接(包括:电影名称和迅雷下载))
前言:这是Java爬虫实战第二篇文章。在第一篇的基础上文章随便抓取目标的链接网站在目标页面上取我们需要的内容,存入数据库。这里的测试用例使用了一个我经常使用的电影下载网站()。本来想把网站上所有电影的下载链接都抓起来,但是觉得时间太长,就改成抓2015年电影的下载链接了。
注:文末有我抓取的整个列表的下载链接(包括:电影名称和迅雷下载链接)
原理简介
其实原理和第一个文章差不多,不同的是,由于这个网站里面的分类太多了,如果不选择这些标签,会耗费难以想象的时间。
p>
不要使用类别链接和标签链接。不要使用这些链接来抓取其他页面。您只能通过页面底部的所有类型电影的分页来获取其他页面上的电影列表。同时,对于电影详情页,只抓取电影片名和迅雷下载链接,不进行深度爬取。详细信息页面上的一些推荐电影和其他链接不是必需的。
最后就是将所有获取到的电影的下载链接保存在videoLinkMap集合中,通过遍历这个集合将数据保存到MySQL中
注意:如果原理还不够清楚,推荐阅读我之前的文章文章:爬虫实战(一):一网打尽所有链接网站/<//p
pp>
第二次代码实现
上面已经提到了实现原理,代码中有详细的注释,这里就不多说了,代码如下:
<p>package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
从网页抓取视频(快手抓取失败的失败原因和解决方法-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-03-04 20:03
从网页抓取视频的过程中,有不少网站会出现抓取失败的情况,无论是抖音、快手还是其他短视频网站,找到视频抓取失败的原因是重要的一步。这里,我就以快手为例,说一下快手抓取失败的失败原因和解决方法。在进行抓取一个视频时,必须要找到视频列表页面,这里就有一个问题,当我们在找视频的时候,不断去查看视频的列表是没有意义的,我们应该首先找到播放量和播放时长,我们才可以知道该视频的质量大不大,这样我们就可以知道该视频中的热门程度了。
当我们进行这一步操作时,我们会看到连接列表,我们是以抓取播放量排在前面的作为例子,由此可见,我们在抓取的时候应该优先抓取排在前面的播放量大的视频,那么,那些播放量非常大的视频,作为我们的目标对象是不是就会失败呢?这个就要涉及到视频发布的时间问题了,很多网站(例如快手)将视频发布的时间划分的非常严格,那么,我们就可以避开这个时间差。
比如,快手的默认发布时间为每天09:00-20:00,那么,我们把发布时间设置为每天4:00-6:00,这个时间就会大大减少失败的几率。除此之外,我们还要注意视频标题和视频图片的相似程度,不要将相似度非常高的视频进行抓取,这样是不会返回匹配信息的。总之,抓取视频的过程可能非常复杂,我们在进行抓取之前一定要进行抓取操作的确认,避免将重要信息放在快手存储缓存里而不是使用的数据库。
在视频的抓取中,数据库依然重要,我们应该根据抓取的量来决定使用哪种数据库,我当时选择的是mysql,由于很多人分享一些网站的抓取教程,对于中间件的了解相对较少,这里我对中间件有比较深的理解,所以我选择先抓取一些中间件的抓取教程学习,好处就是避免了我再去重新抓取数据库,因为我已经有中间件基础了。当然,不只是快手,很多视频网站都是以此种方式实现中间件的集群方式,我将以后写一篇文章讲一下这种中间件方式,会尽快进行整理。微信公众号:michelin博客。 查看全部
从网页抓取视频(快手抓取失败的失败原因和解决方法-八维教育)
从网页抓取视频的过程中,有不少网站会出现抓取失败的情况,无论是抖音、快手还是其他短视频网站,找到视频抓取失败的原因是重要的一步。这里,我就以快手为例,说一下快手抓取失败的失败原因和解决方法。在进行抓取一个视频时,必须要找到视频列表页面,这里就有一个问题,当我们在找视频的时候,不断去查看视频的列表是没有意义的,我们应该首先找到播放量和播放时长,我们才可以知道该视频的质量大不大,这样我们就可以知道该视频中的热门程度了。
当我们进行这一步操作时,我们会看到连接列表,我们是以抓取播放量排在前面的作为例子,由此可见,我们在抓取的时候应该优先抓取排在前面的播放量大的视频,那么,那些播放量非常大的视频,作为我们的目标对象是不是就会失败呢?这个就要涉及到视频发布的时间问题了,很多网站(例如快手)将视频发布的时间划分的非常严格,那么,我们就可以避开这个时间差。
比如,快手的默认发布时间为每天09:00-20:00,那么,我们把发布时间设置为每天4:00-6:00,这个时间就会大大减少失败的几率。除此之外,我们还要注意视频标题和视频图片的相似程度,不要将相似度非常高的视频进行抓取,这样是不会返回匹配信息的。总之,抓取视频的过程可能非常复杂,我们在进行抓取之前一定要进行抓取操作的确认,避免将重要信息放在快手存储缓存里而不是使用的数据库。
在视频的抓取中,数据库依然重要,我们应该根据抓取的量来决定使用哪种数据库,我当时选择的是mysql,由于很多人分享一些网站的抓取教程,对于中间件的了解相对较少,这里我对中间件有比较深的理解,所以我选择先抓取一些中间件的抓取教程学习,好处就是避免了我再去重新抓取数据库,因为我已经有中间件基础了。当然,不只是快手,很多视频网站都是以此种方式实现中间件的集群方式,我将以后写一篇文章讲一下这种中间件方式,会尽快进行整理。微信公众号:michelin博客。
从网页抓取视频(如何用python爬取网站的mv视频,话不多说直接上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-03 05:05
我喜欢编程和分享。希望结交更多志同道合的朋友,一起在学习Python的道路上走得更远!
本文教你如何使用python爬取网站的mv视频,话不多说,直接上代码!
爬取网站的地址:
from urllib import request,response
import re,urllib
import requests
def pa(url):
a=0
hader={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:62.0) Gecko/20100101 Firefox/62.0'} #请求头,模拟浏览器
da=urllib.request.Request(url,headers=hader)
date=urllib.request.urlopen(da) #发送请求
html=date.read().decode("utf-8") #编码转换
lianjie=re.findall('<a class="clip-link" data-id="(.*?)" title="(.*?)" >',html,re.S) #提取mv列表的链接
for i,l in enumerate(lianjie):
a=a+1
lianjie=l[0]
da=urllib.request.Request("http://www.170mv.com/mlmv/%s.html" %lianjie,headers=hader)
date=urllib.request.urlopen(da)
html=date.read().decode("utf-8")
url=re.findall('http://www.170mv.com/tool/jiexi/ajax/pid/%s/(.*?).mp4' %lianjie,html,re.S)
name=re.findall('(.*?)',html,re.S)
url='http://www.170mv.com/tool/jiex ... 39%3B %(lianjie,url[0])
url = requests.get(url).content
print("正在下载第%s首mv" % a)
f = open('E:\\mp4\\{}.mp4'.format(name[0]), 'wb')
f.write(url)
f.close()
print("下载成功")
我是一名python开发工程师,整理了一套python的学习资料,从基础的python脚本到web开发、爬虫、
数据分析、数据可视化、机器学习、面试真题等。想要的可以进群:688244617免费领取
如果你觉得 文章 没问题,你可能会喜欢它。如果您有任何意见或意见,请发表评论! 查看全部
从网页抓取视频(如何用python爬取网站的mv视频,话不多说直接上代码)
我喜欢编程和分享。希望结交更多志同道合的朋友,一起在学习Python的道路上走得更远!
本文教你如何使用python爬取网站的mv视频,话不多说,直接上代码!
爬取网站的地址:
from urllib import request,response
import re,urllib
import requests
def pa(url):
a=0
hader={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:62.0) Gecko/20100101 Firefox/62.0'} #请求头,模拟浏览器
da=urllib.request.Request(url,headers=hader)
date=urllib.request.urlopen(da) #发送请求
html=date.read().decode("utf-8") #编码转换
lianjie=re.findall('<a class="clip-link" data-id="(.*?)" title="(.*?)" >',html,re.S) #提取mv列表的链接
for i,l in enumerate(lianjie):
a=a+1
lianjie=l[0]
da=urllib.request.Request("http://www.170mv.com/mlmv/%s.html" %lianjie,headers=hader)
date=urllib.request.urlopen(da)
html=date.read().decode("utf-8")
url=re.findall('http://www.170mv.com/tool/jiexi/ajax/pid/%s/(.*?).mp4' %lianjie,html,re.S)
name=re.findall('(.*?)',html,re.S)
url='http://www.170mv.com/tool/jiex ... 39%3B %(lianjie,url[0])
url = requests.get(url).content
print("正在下载第%s首mv" % a)
f = open('E:\\mp4\\{}.mp4'.format(name[0]), 'wb')
f.write(url)
f.close()
print("下载成功")
我是一名python开发工程师,整理了一套python的学习资料,从基础的python脚本到web开发、爬虫、
数据分析、数据可视化、机器学习、面试真题等。想要的可以进群:688244617免费领取
如果你觉得 文章 没问题,你可能会喜欢它。如果您有任何意见或意见,请发表评论!
从网页抓取视频(怎么用迅捷视频转换器把音频提取格式转换成mp3?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-27 16:15
很多时候我们想从视频中提取音频,比如看mv的时候遇到喜欢的音乐,或者看电影/电视剧的时候有喜欢的bgm却找不到音频。
如果想在看外语视频时提取视频中的音频,需要将mp4格式转换为mp3,那么如何使用快速视频转换器来转换mp4格式
转换成mp3怎么样?接下来,我将教你如何从 mp4 视频格式中提取 mp3 音频格式。
1、将 mp4 视频格式的文件添加到软件中。如果添加时文件不多,可以点击软件左上角的“添加文件”按钮依次添加文件
,如果文件较多,可以点击“添加文件”右侧的“添加文件夹”按钮或直接将文件拖放到软件中,批量添加到软件中。
2、添加文件后,设置“输出格式”,输出格式分为‘音频’和‘视频’格式,‘音频’格式有音频格式分为输出
模式和音频频率。我们可以在“音频”格式下将这些设置为“mp3 with original”格式。如果需要自己设置参数,可以'添加自定义
'设置按钮可自行设置码率、频率、频道等参数。
3、设置好“输出格式”参数后,即可截取视频片段。在截取过程中点击“裁剪”按钮,会出现一个设置框。我们需要
设置保存间隔(开始时间和结束时间),或移动绿色标记来设置保存间隔。设置好后点击“确定”保存截取间隔。如果不需要
如果您需要保存完整视频以拍摄剪辑,则可以跳过此步骤。
4、截取保存的区间后,可以设置“输出路径”。设置时可以在输入框中预设输出到电脑的位置,也可以在“更改路径”中设置
按钮选择所需的输出位置。
5、调整好“输出路径”后,点击“转换”或“全部转换”按钮,将mp4格式转换为mp3音频格式。转换时你会看到一个进步
当进度条达到 100% 时,将 mp4 格式转换为 mp3。最后只要找到预设的输出路径就可以打开文件了。
以上就是将mp4格式转换为mp3的方法。使用上述方法,您可以从视频剪辑中剪切出您想要的音频剪辑。以及转换方式有多少
种类很多,但适合自己的方法不多。希望大家都能找到适合自己的方法。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。 查看全部
从网页抓取视频(怎么用迅捷视频转换器把音频提取格式转换成mp3?)
很多时候我们想从视频中提取音频,比如看mv的时候遇到喜欢的音乐,或者看电影/电视剧的时候有喜欢的bgm却找不到音频。
如果想在看外语视频时提取视频中的音频,需要将mp4格式转换为mp3,那么如何使用快速视频转换器来转换mp4格式
转换成mp3怎么样?接下来,我将教你如何从 mp4 视频格式中提取 mp3 音频格式。
1、将 mp4 视频格式的文件添加到软件中。如果添加时文件不多,可以点击软件左上角的“添加文件”按钮依次添加文件
,如果文件较多,可以点击“添加文件”右侧的“添加文件夹”按钮或直接将文件拖放到软件中,批量添加到软件中。
2、添加文件后,设置“输出格式”,输出格式分为‘音频’和‘视频’格式,‘音频’格式有音频格式分为输出
模式和音频频率。我们可以在“音频”格式下将这些设置为“mp3 with original”格式。如果需要自己设置参数,可以'添加自定义
'设置按钮可自行设置码率、频率、频道等参数。
3、设置好“输出格式”参数后,即可截取视频片段。在截取过程中点击“裁剪”按钮,会出现一个设置框。我们需要
设置保存间隔(开始时间和结束时间),或移动绿色标记来设置保存间隔。设置好后点击“确定”保存截取间隔。如果不需要
如果您需要保存完整视频以拍摄剪辑,则可以跳过此步骤。
4、截取保存的区间后,可以设置“输出路径”。设置时可以在输入框中预设输出到电脑的位置,也可以在“更改路径”中设置
按钮选择所需的输出位置。
5、调整好“输出路径”后,点击“转换”或“全部转换”按钮,将mp4格式转换为mp3音频格式。转换时你会看到一个进步
当进度条达到 100% 时,将 mp4 格式转换为 mp3。最后只要找到预设的输出路径就可以打开文件了。
以上就是将mp4格式转换为mp3的方法。使用上述方法,您可以从视频剪辑中剪切出您想要的音频剪辑。以及转换方式有多少
种类很多,但适合自己的方法不多。希望大家都能找到适合自己的方法。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
从网页抓取视频(Python爬虫快速入门(上)(上)获取弹幕数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-24 09:24
网络视频弹幕采集
访问博客时,经常看到关于视频弹幕的数据分析文章,我们可以看到从一些热门视频的弹幕和评论数据中可以得出一些有趣的结论。那么我们来研究一下获取网站视频弹幕数据的一般方法。可以参考之前的爬虫基础总结:
Python爬虫快速入门(上) Python爬虫快速入门(下)一、在浏览器调试模式下获取API
以哔哩哔哩为例,先打开一个视频。在这里,您可以在主页上找到更受欢迎的视频:
《小白评测》5000元旗舰手机大恒评测2020年中盘Part 1
打开视频页面,输入F12打开调试工具,然后切换到移动端,刷新网页。此时,您可以看到 URL 从 . 等待页面加载完毕后,可以在调试工具的Network选项中看到具体的请求。下一步是锁定获取弹幕数据的请求。
由于请求的数量非常多,因此需要缩小范围。这里在视频前后请求盲猜弹幕数据,下图中蓝色的长部分应该是视频数据流。可以选中它查看它的具体信息,在新标签页中打开请求链接,发现确实是视频的直接链接。然后在框选的范围内一一查看请求的内容。弹幕没有请求链接,只有一个相关视频信息,名字是related?from=h5&aid= .... 然后尝试在视频流结束前后搜索,最后确认请求命名为list .so?oid=210551301 返回弹幕数据。
理论上可以请求查看,最后找到弹幕的API。您还可以利用您的想象力以各种方式缩小搜索范围。
二、使用脚本请求数据
其实打开链接后直接Ctrl S数据就可以了,但是可能需要获取多个相关视频的弹幕数据,或者Up主的一系列视频。这里需要使用脚本请求。从 API 链接可以看出,它的 oid 参数和视频链接的序列号不同。所以先从视频链接中获取对应的oid。直接 GET 请求视频链接,返回的信息收录 oid 参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
import requests as rq
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'}
def get_param(link):
'''由视频链接获取 id 参数'''
res = rq.get(link, headers=headers)
reg = "var options = {.*?aid: (.*?),.*?bvid: '(.*?)',.*?cid: (.*?),.*?}"
ids = re.compile(reg, re.S).findall(res.text)[0]
params = dict(zip(['aid', 'bvid', 'cid'], ids))
if params['bvid'] == link.split('?')[0].split('/')[-1]:
return params
else:
print('Extraction Error!')
return 0
接下来构造一个链接,通过视频对应的id请求弹幕数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from bs4 import BeautifulSoup
def get_dm(id, write=False):
'''id 对应 get_param 函数返回的 cid 字段'''
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={id}'
res = rq.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'xml')
dms = [d.text for d in soup.find_all('d')]
if write:
with open(f'{id}.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(dms))
print(f'\n已写出文件 {id}.txt\n')
else:
return dms
最后,获取另一个视频的弹幕来测试一下:
1
2
url = 'https://www.bilibili.com/video/BV1mK4y1479e'
get_dm(get_param(url)['cid'], True)
三、其他视频网站
B站只是一个“小破站”,挑战不大,我们来试试“大站”看看有什么不同。
两千年后……
广告很长,都是VIP视频。. . 查看全部
从网页抓取视频(Python爬虫快速入门(上)(上)获取弹幕数据)
网络视频弹幕采集
访问博客时,经常看到关于视频弹幕的数据分析文章,我们可以看到从一些热门视频的弹幕和评论数据中可以得出一些有趣的结论。那么我们来研究一下获取网站视频弹幕数据的一般方法。可以参考之前的爬虫基础总结:
Python爬虫快速入门(上) Python爬虫快速入门(下)一、在浏览器调试模式下获取API
以哔哩哔哩为例,先打开一个视频。在这里,您可以在主页上找到更受欢迎的视频:
《小白评测》5000元旗舰手机大恒评测2020年中盘Part 1
打开视频页面,输入F12打开调试工具,然后切换到移动端,刷新网页。此时,您可以看到 URL 从 . 等待页面加载完毕后,可以在调试工具的Network选项中看到具体的请求。下一步是锁定获取弹幕数据的请求。
由于请求的数量非常多,因此需要缩小范围。这里在视频前后请求盲猜弹幕数据,下图中蓝色的长部分应该是视频数据流。可以选中它查看它的具体信息,在新标签页中打开请求链接,发现确实是视频的直接链接。然后在框选的范围内一一查看请求的内容。弹幕没有请求链接,只有一个相关视频信息,名字是related?from=h5&aid= .... 然后尝试在视频流结束前后搜索,最后确认请求命名为list .so?oid=210551301 返回弹幕数据。
理论上可以请求查看,最后找到弹幕的API。您还可以利用您的想象力以各种方式缩小搜索范围。
二、使用脚本请求数据
其实打开链接后直接Ctrl S数据就可以了,但是可能需要获取多个相关视频的弹幕数据,或者Up主的一系列视频。这里需要使用脚本请求。从 API 链接可以看出,它的 oid 参数和视频链接的序列号不同。所以先从视频链接中获取对应的oid。直接 GET 请求视频链接,返回的信息收录 oid 参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
import requests as rq
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'}
def get_param(link):
'''由视频链接获取 id 参数'''
res = rq.get(link, headers=headers)
reg = "var options = {.*?aid: (.*?),.*?bvid: '(.*?)',.*?cid: (.*?),.*?}"
ids = re.compile(reg, re.S).findall(res.text)[0]
params = dict(zip(['aid', 'bvid', 'cid'], ids))
if params['bvid'] == link.split('?')[0].split('/')[-1]:
return params
else:
print('Extraction Error!')
return 0
接下来构造一个链接,通过视频对应的id请求弹幕数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from bs4 import BeautifulSoup
def get_dm(id, write=False):
'''id 对应 get_param 函数返回的 cid 字段'''
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={id}'
res = rq.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'xml')
dms = [d.text for d in soup.find_all('d')]
if write:
with open(f'{id}.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(dms))
print(f'\n已写出文件 {id}.txt\n')
else:
return dms
最后,获取另一个视频的弹幕来测试一下:
1
2
url = 'https://www.bilibili.com/video/BV1mK4y1479e'
get_dm(get_param(url)['cid'], True)
三、其他视频网站
B站只是一个“小破站”,挑战不大,我们来试试“大站”看看有什么不同。
两千年后……
广告很长,都是VIP视频。. .
从网页抓取视频(网页中视频url采集建立采集任务选择一个视频网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-23 22:19
会智能地在页面中添加其他具有相似特征的元素。点击“Create List Complete”5.如图所示,点击“Cycle”6.左上角的流程设计器为点击的元素显示了一个循环框。完成循环点击列表的创建抓取视频网址1.将鼠标移至视频标题,点击右键,选择执行红框中的“抓取本元素的文字”抓取标题视频的2.截取的标题会显示在右上角的操作框中,点击“添加其他特殊字段”,选择“添加当前页面URL”3.提取该视频的URL,并然后点击右下角的保存按钮4.完成视频URL提取步骤5. 因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则就像图中的红框一样。点击右下角保存后,可以点击“下一步”开始视频URL采集开始采集1.选择单机采集,开始视频URL提取2.采集完成,导出视频URL3.导出视频URL后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:该过程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则如图中红框,点击右下角保存,然后点击“下一步”开始视频网址采集开始采集 1.选择单机采集,开始提取视频网址2.采集完成,导出视频网址3.导出视频网址后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集 查看全部
从网页抓取视频(网页中视频url采集建立采集任务选择一个视频网站)
会智能地在页面中添加其他具有相似特征的元素。点击“Create List Complete”5.如图所示,点击“Cycle”6.左上角的流程设计器为点击的元素显示了一个循环框。完成循环点击列表的创建抓取视频网址1.将鼠标移至视频标题,点击右键,选择执行红框中的“抓取本元素的文字”抓取标题视频的2.截取的标题会显示在右上角的操作框中,点击“添加其他特殊字段”,选择“添加当前页面URL”3.提取该视频的URL,并然后点击右下角的保存按钮4.完成视频URL提取步骤5. 因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则就像图中的红框一样。点击右下角保存后,可以点击“下一步”开始视频URL采集开始采集1.选择单机采集,开始视频URL提取2.采集完成,导出视频URL3.导出视频URL后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:该过程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集规则如图中红框,点击右下角保存,然后点击“下一步”开始视频网址采集开始采集 1.选择单机采集,开始提取视频网址2.采集完成,导出视频网址3.导出视频网址后,使用视频URL批量下载工具完成视频下载。数据,所以我们需要把这个循环列表拖到页面循环中。注意:流程是从上层网页执行的,所以这个循环列表需要放在点击页面的前面,否则会漏掉第一页的数据。6.完成的采集
从网页抓取视频(幸亏之前本人收藏了一个专门提取各大主流视频网站视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-16 21:03
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。 查看全部
从网页抓取视频(幸亏之前本人收藏了一个专门提取各大主流视频网站视频的方法)
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
从网页抓取视频(禁止百度搜索引擎抓取网站并显示网页快照,我该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 12:09
信息
成为会员解锁独家内容
登入
热搜词
在这两者之间,添加禁止搜索引擎抓取 网站 并显示页面快照的代码。
在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
在 网站 主页代码之间,添加它以防止 Google 搜索引擎抓取 网站 并显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站我加了robots.txt,还能百度搜吗?
因为搜索引擎索引数据库的更新需要时间。虽然Baiduspider已经停止访问您网站上的网页,但是百度搜索引擎数据库中已经建立的网页索引信息可能需要几个月的时间才能被清除。另请检查您的机器人是否配置正确。如果您的拒绝是收录紧急要求的,也可以通过投诉平台反馈请求处理。
2.我想让网站内容被百度收录,但不保存为快照,怎么办?
百度蜘蛛遵守互联网元机器人协议。您可以使用网页元的设置,使百度显示只对网页进行索引,而不在搜索结果中显示网页的快照。和robots的更新一样,因为搜索引擎索引库的更新需要时间,虽然你已经禁止百度通过网页中的meta在搜索结果中显示网页的快照,但如果在百度中已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
3.想被百度索引,但是不保存网站快照,下面代码解决:
4. 如果你想阻止所有搜索引擎保存你网页的快照,那么代码如下:
下面列出了一些常见的代码组合:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接 查看全部
从网页抓取视频(禁止百度搜索引擎抓取网站并显示网页快照,我该怎么做?)
信息
成为会员解锁独家内容
登入
热搜词
在这两者之间,添加禁止搜索引擎抓取 网站 并显示页面快照的代码。
在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
在 网站 主页代码之间,添加它以防止 Google 搜索引擎抓取 网站 并显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站我加了robots.txt,还能百度搜吗?
因为搜索引擎索引数据库的更新需要时间。虽然Baiduspider已经停止访问您网站上的网页,但是百度搜索引擎数据库中已经建立的网页索引信息可能需要几个月的时间才能被清除。另请检查您的机器人是否配置正确。如果您的拒绝是收录紧急要求的,也可以通过投诉平台反馈请求处理。
2.我想让网站内容被百度收录,但不保存为快照,怎么办?
百度蜘蛛遵守互联网元机器人协议。您可以使用网页元的设置,使百度显示只对网页进行索引,而不在搜索结果中显示网页的快照。和robots的更新一样,因为搜索引擎索引库的更新需要时间,虽然你已经禁止百度通过网页中的meta在搜索结果中显示网页的快照,但如果在百度中已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
3.想被百度索引,但是不保存网站快照,下面代码解决:
4. 如果你想阻止所有搜索引擎保存你网页的快照,那么代码如下:
下面列出了一些常见的代码组合:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
从网页抓取视频(一下怎样100%的在网页上提取网页视频内的音,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-10 21:19
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:. 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页视频内的音,)
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
从网页抓取视频(生成视频格式的解析解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-08 13:04
从网页抓取视频,高清同时的效果是可以过10000k,字幕是可以过1000kb,在2000k的时候就不再抓取,到了2000k就可以生成视频mp4格式的解析出来,用于mp3生成等。
可以一分钟放1048576个小时,
被物理定义为硬件,其他的都是虚构的。
是打包了一个mp4然后逐个手动压制到目标文件中。否则都不知道什么时候有一个文件是1048576字节,什么时候有一个是5678字节。
如果你觉得一百万个视频每秒都占据一定空间是浪费,那就看每秒百万个视频吧。原视频文件大小为720p,1048576个文件,分四十秒,每秒写入10000字节(两分钟),一秒480字节(三十分钟)分十个字节(半小时)写入12000字节(一天)每秒448字节(两小时)写入10000字节(一天半)以上数据为自己瞎画的,数据中间的解码比较简单了,分帧每个7b,字节间隔600kb,解码后前面是普通文件后缀pkl,因为视频是一帧一帧压制的,本质上来说并不会占用空间,反正都是溢出了。
每秒两万字节,每帧50kb,所以2*5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5。 查看全部
从网页抓取视频(生成视频格式的解析解析)
从网页抓取视频,高清同时的效果是可以过10000k,字幕是可以过1000kb,在2000k的时候就不再抓取,到了2000k就可以生成视频mp4格式的解析出来,用于mp3生成等。
可以一分钟放1048576个小时,
被物理定义为硬件,其他的都是虚构的。
是打包了一个mp4然后逐个手动压制到目标文件中。否则都不知道什么时候有一个文件是1048576字节,什么时候有一个是5678字节。
如果你觉得一百万个视频每秒都占据一定空间是浪费,那就看每秒百万个视频吧。原视频文件大小为720p,1048576个文件,分四十秒,每秒写入10000字节(两分钟),一秒480字节(三十分钟)分十个字节(半小时)写入12000字节(一天)每秒448字节(两小时)写入10000字节(一天半)以上数据为自己瞎画的,数据中间的解码比较简单了,分帧每个7b,字节间隔600kb,解码后前面是普通文件后缀pkl,因为视频是一帧一帧压制的,本质上来说并不会占用空间,反正都是溢出了。
每秒两万字节,每帧50kb,所以2*5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5*0.5。
从网页抓取视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-31 11:17
今天看到联想2011年校园招聘,里面的视频挺好看的,很吸引人,想下载,但是右键没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门从各大主流视频中提取网站视频的网站:(原名)。使用后发现各大主流视频分享网站基本都能解析得到最终结果。URL,但鲜为人知的 网站 视频无法解析为公司之类的内容。
2.方法二
视频提取软件
网上搜索很多,但能用的不多。下载了几个软件,发现不能解决我的问题,放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的 html 知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我在下面找到了这个语句
其中的代码片段:
哈哈,“src="swf/给那些做640-480.swf的人”就是这句话,不就是最后的地址吗!!!
我想我得到了最深的 URL,试试看是否可以下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
转念一想,我不是都上过联想的服务器吗,如果我再次获得root权限,我可以为所欲为,哈哈。
我的目的达到了,接下来就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
从网页抓取视频(联想2011年校园招聘视频下载的功能?(图))
今天看到联想2011年校园招聘,里面的视频挺好看的,很吸引人,想下载,但是右键没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门从各大主流视频中提取网站视频的网站:(原名)。使用后发现各大主流视频分享网站基本都能解析得到最终结果。URL,但鲜为人知的 网站 视频无法解析为公司之类的内容。
2.方法二
视频提取软件
网上搜索很多,但能用的不多。下载了几个软件,发现不能解决我的问题,放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的 html 知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我在下面找到了这个语句
其中的代码片段:
哈哈,“src="swf/给那些做640-480.swf的人”就是这句话,不就是最后的地址吗!!!
我想我得到了最深的 URL,试试看是否可以下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
转念一想,我不是都上过联想的服务器吗,如果我再次获得root权限,我可以为所欲为,哈哈。
我的目的达到了,接下来就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
从网页抓取视频(一下怎样100%的在网页上提取网页内视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-31 00:00
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。. 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页内视频的方法)
视频下载方法 点击页面上的瓢虫(上图右上角),然后网页下方会出现如图所示的视图,点击页面底部。
今天给大家介绍几种截取网页视频的方法(其实昨天本来想发这个教程的,但是shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
csdn为您找到了关于网络视频提取的相关内容,包括网络视频提取相关文档代码介绍,相关教程视频课程,以及相关。
网络视频提取巧妙方便,类似于百度工具栏,可以轻松提取网络视频中的音频,让你快速得到你想要的。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
从网页抓取视频(一下怎样100%的在网页上提取网页视频的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-30 23:22
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
网页视频提取巧妙便捷,类似于百度工具栏,可以轻松提取网页视频中的音频,让你快速得到你想要的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频下载方法 点击页面上的瓢虫(上图右上角),网页下方会出现如图所示的视图,点击页面底部。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种网页抓取视频的方法(其实昨天本来想发这个教程的,结果shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。 查看全部
从网页抓取视频(一下怎样100%的在网页上提取网页视频的方法)
很多时候我们想下载一个视频,但又不想下载安装软件,那么今天就给大家介绍一下如何在网络上100%解压。
视频提取软件可以先用任意浏览器查看网页源代码。如果读者有一些基本的html知识,是可以做到的。
网页视频提取巧妙便捷,类似于百度工具栏,可以轻松提取网页视频中的音频,让你快速得到你想要的。
使用chrome浏览器的F12功能提取网页中的视频和音乐1.打开视频地址,如:.
浏览器工具抓取并下载网页中的视频,在浏览器界面点击插件应用,获取页面视频并选择下载。提取网络视频。
视频下载方法 点击页面上的瓢虫(上图右上角),网页下方会出现如图所示的视图,点击页面底部。
好在我采集了一个专门提取主流主流视频的网站网站视频:(原名。
2021最新爬虫教程:网页抓取视频演示众所周知,网页数据抓取在全球各行各业越来越流行。.
今天给大家介绍几种网页抓取视频的方法(其实昨天本来想发这个教程的,结果shsh2刷机延迟太久,一直拖到今天)。教程是公开的。
学校今天刚打完疫苗,我抽空录了一段视频,激励我们去创作。这已经是三波了,我明白了,但我没有完全明白。谢谢你。
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-27 19:18
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,截取网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1 查看全部
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,截取网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-27 19:16
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求的是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,拦截网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1 查看全部
从网页抓取视频(和入门ffmpeg开FFmpeg官方网站有了神器何不自己写个工具)
前几天有个同学说想下载网站的视频,找不到链接,就问我有什么办法。当时觉得应该很简单,就说抽时间看看。然后它分析目标网页并尝试从网页的源代码中找到链接,但失败了。F12调出开发者工具,进入NetWrok,看到网页是通过ajax发起xhr请求的视频连接,难怪页面元素中没有下载地址,请求的是m3u8格式文件,我查了一下这是一个流媒体文件碎片化,然后四处寻找下载这种格式文件的工具并不理想。很多都是分片后直接下载的ts文件,但是这个网站是加密的,不能直接播放。最后,找到了ffmpeg,一个视频插件神器,可以转码、剪切、合并、播放视频。更不用说,它还支持多个平台。
ffmpeg 介绍和 FFmpeg 入门
ffmpeg 打开 FFmpeg 官方 网站
如果你有一个神器,为什么不自己写一个工具来下载呢?当您准备开始时,您会被如何获得连接的问题所困扰。本来只是想写一个小爬虫,爬取网页连接。结果不行,ajax动态发起的请求,网页元素中没有数据,对js不熟悉,不知道如何获取这种数据。学生可以手动打开浏览器F12然后找到连接吗?这不是我的风格 :) 然后继续各种搜索,得到一个结果,自己实现浏览器,拦截网页上的所有请求肯定会得到。筛选后得到三个选项:
1.WebBrowser.
2.GeokoFx.
3.CefSharp.
首先我尝试了WebBrowser,目标网站无法直接打开网页,所以我换了谷歌浏览器,修改了UserAgent打开,但是网页没有完全显示,所以放弃了。然后把GeokoFx改成直接打开,速度也不错,但是有些连接点击没反应,只能放弃了。最终CefSharp测试达到了预期的目标,即flash和H264视频无法打开。折腾了一天,官方表示版权问题不支持,需要自行修改。我可以找到一个修改后的库。我找到了一个支持 flash 和 H264 视频的库:
提取码:dfdr
是nupkg安装包,看nupkg安装方法
然后编写代码:
获取视频地址只需要继承和集成默认抽象类DefaultRequestHandler即可。
public class MyRequestHandler : DefaultRequestHandler
{
public override CefReturnValue OnBeforeResourceLoad(IWebBrowser browserControl, IBrowser browser, IFrame frame, IRequest request, IRequestCallback callback)
{
//拿到url后再判断下是不是视频文件
string url = request.Url;
}
}
然后在初始化浏览器时指定它。
chromeBrowser.RequestHandler = new MyRequestHandler(callback);
这里我提取url中的文件名,然后判断扩展名判断是否为视频文件。不知道有没有更通用的方法。判断 ResourceType == ResourceType.Media 是不够的。很多时候这个值返回 xhr。
FFmpeg部分就是直接命令行调用下,有时间再研究下这个神器的lib方式。
以下是折腾几天的结果。
在浏览器界面,打开网页后,如果截取视频地址,右上角GO后面会显示【X】。x 表示当前页面截取的视频文件个数。
点击左上角的数字或下载标签,来到如下界面。
您可以在这里进行下载、播放等操作。界面丑陋,但功能实现了。
下载支持断点续传,但m3u8片段文件不保存断点,所以软件关闭后无法断点续传,必须重新开始。直播流的大小无法预测,所以不会显示进度,但会及时更新下载的数据大小。
一般情况下不需要下载ts文件,直接下载m3u8即可,程序会自动分析ts碎片文件,下载完所有文件后自动合成一个mp4文件。
软件下载:链接:
提取码:n6q4
如果还是不行,请下载安装NET Framework 4.6.1
从网页抓取视频(SysNucleusWebHarvy网页数据采集软件的特色介绍及软件特色特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-25 09:23
SysNucleus WebHarvy是一款非常实用的网页数据采集软件,它可以帮助用户轻松的从网页中提取数据并以不同的格式保存,还支持提取视频、图片等各种类型的文件。
软件功能
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的连接数据分析
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
软件功能
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。您可以指定要由代理服务器提取的任意数量的输入关键字6、
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
从网页抓取视频(SysNucleusWebHarvy网页数据采集软件的特色介绍及软件特色特色)
SysNucleus WebHarvy是一款非常实用的网页数据采集软件,它可以帮助用户轻松的从网页中提取数据并以不同的格式保存,还支持提取视频、图片等各种类型的文件。
软件功能
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的连接数据分析
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
软件功能
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。您可以指定要由代理服务器提取的任意数量的输入关键字6、
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
从网页抓取视频(手机回答就不附代码链接了怎么办?百度云)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 06:12
从网页抓取视频的可靠性看,一般的网站都不合格,直接导致的后果是到达目标网站的cookie被盗用造成的。所以,建议最好不要在网页上抓取视频。
不能。
不能,搜索引擎的技术现在更新很快,现在基本抓取不到他们的视频网站的视频。只能利用他们的关键词爬虫来爬一些比较小的视频。手机回答就不附代码链接了,最好去查询一下搜索引擎的文档。
不是接口的问题,那上面的一个jsonview是,爬到了一个视频地址,你没有读取并解析视频地址。另外就是爬取的视频版权问题,很多搜索引擎都是会把视频画质或者清晰度降低的,甚至有的可能是ppt演示片段。
爬其他的更不好爬
要下载视频的话可以用搜索引擎抓取,很多视频网站会对影视视频采取加密措施,搜索引擎抓取不到视频的正确方式应该是通过爬虫抓取,但这方式不是特别安全,因为搜索引擎会抓取很多视频网站的视频,而这些网站的视频很多源是相同的。其实对于很多视频网站而言,视频的版权就是竞争力,无论是打击盗版都需要保证自己视频版权。对于某些视频源而言,利用自己的网站抓取的方式要求上网人的上网地址,很容易被恶意攻击。
所以只能对视频源上网人的上网地址进行审查,比如我现在再播放的电视剧,在有些视频网站是没有的,但某些视频网站就有,看这个视频就必须通过这个网站才能看到。这就是区别,除了某些网站可以利用爬虫抓取上传,一般我们需要对上传人上网地址进行审查,验证是不是上传人自己上传的即可,或者转账验证。对于一些不规范的视频,可以通过gps校验。
百度因为对视频上传的容错率做的太低,所以爬取不到正版视频。我曾看过一次总局搞的拆分视频清单,清单里有我们熟悉的部分但没有视频下载和有效载体那些东西,这才是重点。 查看全部
从网页抓取视频(手机回答就不附代码链接了怎么办?百度云)
从网页抓取视频的可靠性看,一般的网站都不合格,直接导致的后果是到达目标网站的cookie被盗用造成的。所以,建议最好不要在网页上抓取视频。
不能。
不能,搜索引擎的技术现在更新很快,现在基本抓取不到他们的视频网站的视频。只能利用他们的关键词爬虫来爬一些比较小的视频。手机回答就不附代码链接了,最好去查询一下搜索引擎的文档。
不是接口的问题,那上面的一个jsonview是,爬到了一个视频地址,你没有读取并解析视频地址。另外就是爬取的视频版权问题,很多搜索引擎都是会把视频画质或者清晰度降低的,甚至有的可能是ppt演示片段。
爬其他的更不好爬
要下载视频的话可以用搜索引擎抓取,很多视频网站会对影视视频采取加密措施,搜索引擎抓取不到视频的正确方式应该是通过爬虫抓取,但这方式不是特别安全,因为搜索引擎会抓取很多视频网站的视频,而这些网站的视频很多源是相同的。其实对于很多视频网站而言,视频的版权就是竞争力,无论是打击盗版都需要保证自己视频版权。对于某些视频源而言,利用自己的网站抓取的方式要求上网人的上网地址,很容易被恶意攻击。
所以只能对视频源上网人的上网地址进行审查,比如我现在再播放的电视剧,在有些视频网站是没有的,但某些视频网站就有,看这个视频就必须通过这个网站才能看到。这就是区别,除了某些网站可以利用爬虫抓取上传,一般我们需要对上传人上网地址进行审查,验证是不是上传人自己上传的即可,或者转账验证。对于一些不规范的视频,可以通过gps校验。
百度因为对视频上传的容错率做的太低,所以爬取不到正版视频。我曾看过一次总局搞的拆分视频清单,清单里有我们熟悉的部分但没有视频下载和有效载体那些东西,这才是重点。

