
vb抓取网页内容
trackingthewebwithjavascript火狐浏览器的话firebug就能抓取页面采集成excel
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-01 07:01
vb抓取网页内容,百度的one爬虫就可以抓取,然后粘贴到自己的网站内做排序。
我推荐你安装fiddler,电脑安装了免费版就可以轻松的抓取的所有内容,抓取后你就可以粘贴到你自己的网站上了。
trackingthewebwithjavascript
火狐浏览器的话firebug就能抓取html页面,采集成excel
telegram
用浏览器地址栏右键开始抓取
tripadvisor上有些不错的国外网站
webgame初始化(豆瓣)
看看下面这个视频,里面给出了非常多的网站开始并抓取。
xss&sql注入的话需要在xss完成了,可以再用sql注入的方式抓取,还可以用webgame开始并抓取新的网站,当然写写sql程序也是非常好的。
thewebmastersproject
<p>也没有必要webgame初始化,用extension就好。刚开始学习用webgateway完全没有问题,模仿就很好。不用考虑抓取具体页面内容,实现开发语言和抓取语言相同就行。第一步,clone 查看全部
trackingthewebwithjavascript火狐浏览器的话firebug就能抓取页面采集成excel
vb抓取网页内容,百度的one爬虫就可以抓取,然后粘贴到自己的网站内做排序。
我推荐你安装fiddler,电脑安装了免费版就可以轻松的抓取的所有内容,抓取后你就可以粘贴到你自己的网站上了。
trackingthewebwithjavascript
火狐浏览器的话firebug就能抓取html页面,采集成excel
telegram
用浏览器地址栏右键开始抓取
tripadvisor上有些不错的国外网站
webgame初始化(豆瓣)
看看下面这个视频,里面给出了非常多的网站开始并抓取。
xss&sql注入的话需要在xss完成了,可以再用sql注入的方式抓取,还可以用webgame开始并抓取新的网站,当然写写sql程序也是非常好的。
thewebmastersproject
<p>也没有必要webgame初始化,用extension就好。刚开始学习用webgateway完全没有问题,模仿就很好。不用考虑抓取具体页面内容,实现开发语言和抓取语言相同就行。第一步,clone
vb抓取网页内容(学习人工智能,你不可缺少的 Python 书单,一份强大的礼物! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-17 05:14
)
本书以培养读者像计算机科学家一样思考的方式教授 Python 语言编程。贯穿全书的主体是如何思考、设计和开发方法,而具体的编程语言只是提供了一个方便介绍具体场景的媒介。不是一本关于语言的书,而是一本关于编程思想的书。不同于其他编程和设计语言书籍,它不拘泥于语言细节,而是尝试从初学者的角度出发,用生动的例子和丰富的练习来引导读者变得更好。
高级 Python
Python 高级编程(第 2 版)”
作者:[波兰] Michał Jaworski (Jaworski)、[法国] Tarek Ziadé (Ryder)
本书以Python3.5版本讲解,通过13章的内容,深入揭示Python编程的高级技巧。本书首先介绍了Python语言及其社区的现状,包括Python语法、命名规则、Python包编写、部署代码、扩展程序开发、管理代码、文档、测试开发、代码优化、并发编程、设计模式等。重要的话题得到全面系统的解释。
本书适合希望进一步提高Python编程技能的读者,也适合对Python编程感兴趣的读者。全书结合典型和实用的开发案例,帮助读者创建高性能、可靠、可维护的Python应用程序。
《Python 高性能编程》
作者: Micha Gorelick, Ian Ozsvald
本书共12章,围绕如何优化代码,加快实际应用运行速度进行了详细讲解。本书主要涵盖以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和向量计算、并发、集群和工作队列等。最后,通过一系列真实的案例,展示应用场景中需要注意的问题。
本书适合初学者和中级Python程序员,有一定Python语言基础,想要进阶和提高的读者
《Python 极客项目编程》
作者:[美国] Mahesh Venkitachalam
Python 是一种具有动态数据类型的解释型、面向对象的高级编程语言。通过 Python 编程,我们能够解决现实生活中的许多任务。
本书通过 14 个有趣的项目帮助并鼓励读者探索 Python 编程的世界。全书共14章,分别介绍了一些通过Python编程实现的有趣项目,包括解析iTunes播放列表、模拟人造生命、创建ASCII艺术图像、拼接照片、生成3D立体图像、创建粒子模拟烟花喷泉效果、使用 Python 和 Arduino 和 Raspberry Pi 等硬件实现立体 Raycasting 算法和电子项目。本书没有介绍Python语言的基础知识,而是通过一系列非简单的项目,展示了如何使用Python解决各种实际问题,以及如何使用一些流行的Python库。
《Python 核心编程(第 3 版)》
作者:【美国】韦斯利·春(Wesley Chun)
本书是经典畅销书《Python核心编程(第二版)》的全新升级版,分为3部分。第一部分解释了Python的一些一般应用,包括正则表达式、网络编程、Internet客户端编程、多线程编程、GUI编程、数据库编程、Microsoft Office编程和扩展Python。第 2 部分涵盖与 Web 开发相关的主题,包括 Web 客户端和服务器、与 CGI 和 WSGI 相关的 Web 编程、Diango Web 框架、云计算和高级 Web 服务。第 3 部分是补充/实验章节,涵盖文本处理等内容。
本书适合有一定经验的Python开发者阅读。
Python机器学习——预测分析核心算法”
作者:【美国】迈克尔·鲍尔斯(Bowles)
在学习和研究机器学习时,机器学习的新手在面对令人眼花缭乱的算法时往往会不知所措。本书帮助读者从算法和Python语言实现的角度理解机器学习。
本书侧重于两个核心“算法族”,惩罚线性回归和集成方法,并使用代码示例来演示使用相关算法的原理。全书共分7章,详细讨论了预测模型的两类核心算法、预测模型的构建、惩罚性线性回归和集成方法的具体应用与实现。
Python机器学习实用指南
作者:[美国] Alexander T. Combs
机器学习是近年来越来越火的一个领域,Python语言经过一段时间的发展逐渐成为主流编程语言之一。本书结合机器学习和Python语言两大热门领域,利用两大核心机器学习算法,最大限度地发挥Python语言在数据分析方面的优势。
全书共有10章。第1章讲解Python机器学习生态,其余9章介绍很多机器学习相关的算法,包括各种分类算法、数据可视化技术、推荐引擎等,主要包括公寓机器学习、机票、IPO市场、新闻提要、内容推广、股票市场、图像、聊天机器人和推荐引擎。
《掌握 Python 自然语言处理》
作者:【印度】Deepti Chopra , Nisheeth Joshi , Iti Mathur
自然语言处理是与人机交互相关的计算语言学和人工智能领域之一。
本书是学习自然语言处理的综合学习指南,展示了如何在 Python 中实现各种 NLP 任务,以帮助读者创建基于现实生活应用程序的项目。本书共10章,涵盖字符串操作、统计语言建模、形态学、词性标注、语法解析、语义分析、情感分析、信息检索、语篇分析、NLP系统评估等主题。
本书适合熟悉Python语言,对自然语言处理开发有一定了解和兴趣的读者。
Python 数据科学指南
作者:【印度】Gopi Subramanian
60 多个实用的开发技巧,可帮助您探索 Python 及其强大的数据科学功能
作为一门高级编程语言,Python以其简单性、可读性和可扩展性成为编程领域备受推崇的语言,成为数据科学家的首选之一。
本书详细介绍了Python在数据科学中的使用,涵盖了数据探索、数据分析与挖掘、机器学习和大规模机器学习等主题。每一章都为读者提供了足够的数学知识和代码示例,以了解不同深度的算法函数,帮助读者更好地掌握每个知识点。
这本书结构合理,收录的示例对数据科学新手和经验丰富的数据科学家都有益。
“用 Python 编写网络爬虫”
作者:【澳大利亚】理查德·劳森(Richard Lawson)
本书讲解了如何使用Python编写网络爬虫程序,包括网络爬虫简介、页面爬取数据的三种方法、从缓存中提取数据、使用多线程和进程进行并发爬取,以及如何爬取数据。从动态页面获取内容,与表单交互,处理页面中的验证码问题,并使用Scarpy和Portia进行数据抓取,最后使用本书介绍的数据抓取技术对比了几个真实的网站已经抓取到帮助读者学习和使用书中介绍的技术。
本书适合有一定Python编程经验,对爬虫技术感兴趣的读者。
“贝叶斯思维:统计建模的 Python 方法” 查看全部
vb抓取网页内容(学习人工智能,你不可缺少的 Python 书单,一份强大的礼物!
)
本书以培养读者像计算机科学家一样思考的方式教授 Python 语言编程。贯穿全书的主体是如何思考、设计和开发方法,而具体的编程语言只是提供了一个方便介绍具体场景的媒介。不是一本关于语言的书,而是一本关于编程思想的书。不同于其他编程和设计语言书籍,它不拘泥于语言细节,而是尝试从初学者的角度出发,用生动的例子和丰富的练习来引导读者变得更好。
高级 Python

Python 高级编程(第 2 版)”
作者:[波兰] Michał Jaworski (Jaworski)、[法国] Tarek Ziadé (Ryder)
本书以Python3.5版本讲解,通过13章的内容,深入揭示Python编程的高级技巧。本书首先介绍了Python语言及其社区的现状,包括Python语法、命名规则、Python包编写、部署代码、扩展程序开发、管理代码、文档、测试开发、代码优化、并发编程、设计模式等。重要的话题得到全面系统的解释。
本书适合希望进一步提高Python编程技能的读者,也适合对Python编程感兴趣的读者。全书结合典型和实用的开发案例,帮助读者创建高性能、可靠、可维护的Python应用程序。

《Python 高性能编程》
作者: Micha Gorelick, Ian Ozsvald
本书共12章,围绕如何优化代码,加快实际应用运行速度进行了详细讲解。本书主要涵盖以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和向量计算、并发、集群和工作队列等。最后,通过一系列真实的案例,展示应用场景中需要注意的问题。
本书适合初学者和中级Python程序员,有一定Python语言基础,想要进阶和提高的读者

《Python 极客项目编程》
作者:[美国] Mahesh Venkitachalam
Python 是一种具有动态数据类型的解释型、面向对象的高级编程语言。通过 Python 编程,我们能够解决现实生活中的许多任务。
本书通过 14 个有趣的项目帮助并鼓励读者探索 Python 编程的世界。全书共14章,分别介绍了一些通过Python编程实现的有趣项目,包括解析iTunes播放列表、模拟人造生命、创建ASCII艺术图像、拼接照片、生成3D立体图像、创建粒子模拟烟花喷泉效果、使用 Python 和 Arduino 和 Raspberry Pi 等硬件实现立体 Raycasting 算法和电子项目。本书没有介绍Python语言的基础知识,而是通过一系列非简单的项目,展示了如何使用Python解决各种实际问题,以及如何使用一些流行的Python库。

《Python 核心编程(第 3 版)》
作者:【美国】韦斯利·春(Wesley Chun)
本书是经典畅销书《Python核心编程(第二版)》的全新升级版,分为3部分。第一部分解释了Python的一些一般应用,包括正则表达式、网络编程、Internet客户端编程、多线程编程、GUI编程、数据库编程、Microsoft Office编程和扩展Python。第 2 部分涵盖与 Web 开发相关的主题,包括 Web 客户端和服务器、与 CGI 和 WSGI 相关的 Web 编程、Diango Web 框架、云计算和高级 Web 服务。第 3 部分是补充/实验章节,涵盖文本处理等内容。
本书适合有一定经验的Python开发者阅读。

Python机器学习——预测分析核心算法”
作者:【美国】迈克尔·鲍尔斯(Bowles)
在学习和研究机器学习时,机器学习的新手在面对令人眼花缭乱的算法时往往会不知所措。本书帮助读者从算法和Python语言实现的角度理解机器学习。
本书侧重于两个核心“算法族”,惩罚线性回归和集成方法,并使用代码示例来演示使用相关算法的原理。全书共分7章,详细讨论了预测模型的两类核心算法、预测模型的构建、惩罚性线性回归和集成方法的具体应用与实现。

Python机器学习实用指南
作者:[美国] Alexander T. Combs
机器学习是近年来越来越火的一个领域,Python语言经过一段时间的发展逐渐成为主流编程语言之一。本书结合机器学习和Python语言两大热门领域,利用两大核心机器学习算法,最大限度地发挥Python语言在数据分析方面的优势。
全书共有10章。第1章讲解Python机器学习生态,其余9章介绍很多机器学习相关的算法,包括各种分类算法、数据可视化技术、推荐引擎等,主要包括公寓机器学习、机票、IPO市场、新闻提要、内容推广、股票市场、图像、聊天机器人和推荐引擎。

《掌握 Python 自然语言处理》
作者:【印度】Deepti Chopra , Nisheeth Joshi , Iti Mathur
自然语言处理是与人机交互相关的计算语言学和人工智能领域之一。
本书是学习自然语言处理的综合学习指南,展示了如何在 Python 中实现各种 NLP 任务,以帮助读者创建基于现实生活应用程序的项目。本书共10章,涵盖字符串操作、统计语言建模、形态学、词性标注、语法解析、语义分析、情感分析、信息检索、语篇分析、NLP系统评估等主题。
本书适合熟悉Python语言,对自然语言处理开发有一定了解和兴趣的读者。

Python 数据科学指南
作者:【印度】Gopi Subramanian
60 多个实用的开发技巧,可帮助您探索 Python 及其强大的数据科学功能
作为一门高级编程语言,Python以其简单性、可读性和可扩展性成为编程领域备受推崇的语言,成为数据科学家的首选之一。
本书详细介绍了Python在数据科学中的使用,涵盖了数据探索、数据分析与挖掘、机器学习和大规模机器学习等主题。每一章都为读者提供了足够的数学知识和代码示例,以了解不同深度的算法函数,帮助读者更好地掌握每个知识点。
这本书结构合理,收录的示例对数据科学新手和经验丰富的数据科学家都有益。

“用 Python 编写网络爬虫”
作者:【澳大利亚】理查德·劳森(Richard Lawson)
本书讲解了如何使用Python编写网络爬虫程序,包括网络爬虫简介、页面爬取数据的三种方法、从缓存中提取数据、使用多线程和进程进行并发爬取,以及如何爬取数据。从动态页面获取内容,与表单交互,处理页面中的验证码问题,并使用Scarpy和Portia进行数据抓取,最后使用本书介绍的数据抓取技术对比了几个真实的网站已经抓取到帮助读者学习和使用书中介绍的技术。
本书适合有一定Python编程经验,对爬虫技术感兴趣的读者。

“贝叶斯思维:统计建模的 Python 方法”
vb抓取网页内容(2.-java使用浏览器内核模拟浏览器操作驱动包下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-04-09 15:01
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
因为有些网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,所以此时无法通过httpclient的方式获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序?
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。windows和linux平台下,需要分别指定对应的驱动路径。?
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。 查看全部
vb抓取网页内容(2.-java使用浏览器内核模拟浏览器操作驱动包下载地址)
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
因为有些网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,所以此时无法通过httpclient的方式获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。

2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序?
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。windows和linux平台下,需要分别指定对应的驱动路径。?
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。
vb抓取网页内容(如何使多张图片滑动不卡顿,Web端大量图片同时加载问题的优化方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-09 14:26
主控开发(一)Jetson nano环境搭建_胜者为王,自然是。博客-程序员宝宝_jetson nano开发环境
Jetson nano环境设置:///embedded/downloads1、基本设置1.1、不用密码使用sudo1.打开终端输入命令:sudo visudo2. 在文档最后一行添加如下内容: xxx ALL=(ALL) NOPASSWD:ALLjetson ALL=(ALL) NOPASSWD:ALL 保存退出,其中xxx为登录用户名1.2
Matlab保存图片程序,Matlab保存图片的5种方法 - 程序员大本营
不用说,Link 的绘图和可视化功能在业界是家喻户晓的。Matlab提供了丰富的绘图功能,例如ez**系列的简单绘图功能,surf和mesh系列的数十种数值绘图功能等。另外,其他专业工具箱也提供专业的绘图功能,值得初学者学习。很久。今天我只是讨论如何通过Matlab保存这些图......
html如何让多张图片滑动不卡顿,web端加载大量图片同时卡顿的优化方案 - 程序员大本营
案例 由于业务需要,需求方需要实现一个同时加载大量图片的需求。在实现这个需求的过程中,可能会有很多坑。在这里,小编也总结了一些优化方案,大家可以一起来看看。具体场景是描述如何解决问题。我们先声明一下。问题是什么?需求的主要内容是在某个页面上显示1~1000张200~500k大小的图片。好消息是这些图像来自本地硬盘而不是互联网。(不然这个问题会变成优化网络....)由于踩坑的过程不是纯前端项目,...
电脑安装双系统后,系统时间不一致的解决方法 - 程序员大本营
在Ubuntu终端运行sudo timedatectl set-local-rtc 1,下次进入Windows就可以看到正确的时间了。参考博文:电脑安装双系统后,电脑时间不一致,相差8小时。问题重现于:
动态路由 - RIP_weixin_34293911的博客 - 程序员宝贝
实验动态路由-RIP实验目标为三层交换机和路由器配置静态路由;删除第 3 层交换机和路由器的静态路由;为三层交换机和路由器配置动态路由实验环境实验步骤一、配置IP地址二、在switch5上创建vlan2、vlan3,将f0/1添加到vlan2,将f0/2添加到vlan3 ,设置f0/3为trunk模式三、在三层交换机上创建vlan2、vlan3在上面,打开三层...
JAVA正则表达式:Pattern类和Matcher类详解 - 程序员大本营
java.util.regex 是一个类库包,它使用正则表达式自定义的模式来匹配字符串。它包括两个类:Pattern 和 Matcher Pattern 一个 Pattern 是一个正则表达式的编译表达式模式。Matcher Matcher 对象是一个状态机,它根据 Pattern 对象作为匹配模式对字符串执行匹配检查。首先,一个 Pattern 实例自定义一个正则表达式 warp,它使用类似于 PERL 的语法 查看全部
vb抓取网页内容(如何使多张图片滑动不卡顿,Web端大量图片同时加载问题的优化方案)
主控开发(一)Jetson nano环境搭建_胜者为王,自然是。博客-程序员宝宝_jetson nano开发环境
Jetson nano环境设置:///embedded/downloads1、基本设置1.1、不用密码使用sudo1.打开终端输入命令:sudo visudo2. 在文档最后一行添加如下内容: xxx ALL=(ALL) NOPASSWD:ALLjetson ALL=(ALL) NOPASSWD:ALL 保存退出,其中xxx为登录用户名1.2
Matlab保存图片程序,Matlab保存图片的5种方法 - 程序员大本营
不用说,Link 的绘图和可视化功能在业界是家喻户晓的。Matlab提供了丰富的绘图功能,例如ez**系列的简单绘图功能,surf和mesh系列的数十种数值绘图功能等。另外,其他专业工具箱也提供专业的绘图功能,值得初学者学习。很久。今天我只是讨论如何通过Matlab保存这些图......
html如何让多张图片滑动不卡顿,web端加载大量图片同时卡顿的优化方案 - 程序员大本营
案例 由于业务需要,需求方需要实现一个同时加载大量图片的需求。在实现这个需求的过程中,可能会有很多坑。在这里,小编也总结了一些优化方案,大家可以一起来看看。具体场景是描述如何解决问题。我们先声明一下。问题是什么?需求的主要内容是在某个页面上显示1~1000张200~500k大小的图片。好消息是这些图像来自本地硬盘而不是互联网。(不然这个问题会变成优化网络....)由于踩坑的过程不是纯前端项目,...
电脑安装双系统后,系统时间不一致的解决方法 - 程序员大本营
在Ubuntu终端运行sudo timedatectl set-local-rtc 1,下次进入Windows就可以看到正确的时间了。参考博文:电脑安装双系统后,电脑时间不一致,相差8小时。问题重现于:
动态路由 - RIP_weixin_34293911的博客 - 程序员宝贝
实验动态路由-RIP实验目标为三层交换机和路由器配置静态路由;删除第 3 层交换机和路由器的静态路由;为三层交换机和路由器配置动态路由实验环境实验步骤一、配置IP地址二、在switch5上创建vlan2、vlan3,将f0/1添加到vlan2,将f0/2添加到vlan3 ,设置f0/3为trunk模式三、在三层交换机上创建vlan2、vlan3在上面,打开三层...
JAVA正则表达式:Pattern类和Matcher类详解 - 程序员大本营
java.util.regex 是一个类库包,它使用正则表达式自定义的模式来匹配字符串。它包括两个类:Pattern 和 Matcher Pattern 一个 Pattern 是一个正则表达式的编译表达式模式。Matcher Matcher 对象是一个状态机,它根据 Pattern 对象作为匹配模式对字符串执行匹配检查。首先,一个 Pattern 实例自定义一个正则表达式 warp,它使用类似于 PERL 的语法
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-09 14:24
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。 查看全部
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。
vb抓取网页内容(EndSub显示GoogleChrome显示的相同代码。怎么了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-08 04:09
我正在尝试创建一个 Windows 桌面应用程序,该应用程序将转到指定站点并从该站点获取 HTML。我发现了很多这样做的例子,但由于某种原因,它不适用于传统的 Google 协作平台页面。该程序需要在 Google 协作平台页面的正文中找到简单的文本。当您“查看页面源代码”时,它不会显示与 Google Chrome 显示相同的代码。怎么了?
<p>Public Sub Scrape(strURL)
Try
Dim wrResponse As WebResponse
Dim wrRequest As WebRequest = HttpWebRequest.Create(strURL)
textScrape = "Extracting..." & Environment.NewLine
wrResponse = wrRequest.GetResponse()
Using sr As New StreamReader(wrResponse.GetResponseStream())
strOutput = sr.ReadToEnd()
' Close and clean up the StreamReader
sr.Close()
End Using
textScrape = strOutput
'Formatting Techniques
' Remove Doctype ( HTML 5 )
strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Tags
' strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "]*>", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, " 查看全部
vb抓取网页内容(EndSub显示GoogleChrome显示的相同代码。怎么了?)
我正在尝试创建一个 Windows 桌面应用程序,该应用程序将转到指定站点并从该站点获取 HTML。我发现了很多这样做的例子,但由于某种原因,它不适用于传统的 Google 协作平台页面。该程序需要在 Google 协作平台页面的正文中找到简单的文本。当您“查看页面源代码”时,它不会显示与 Google Chrome 显示相同的代码。怎么了?
<p>Public Sub Scrape(strURL)
Try
Dim wrResponse As WebResponse
Dim wrRequest As WebRequest = HttpWebRequest.Create(strURL)
textScrape = "Extracting..." & Environment.NewLine
wrResponse = wrRequest.GetResponse()
Using sr As New StreamReader(wrResponse.GetResponseStream())
strOutput = sr.ReadToEnd()
' Close and clean up the StreamReader
sr.Close()
End Using
textScrape = strOutput
'Formatting Techniques
' Remove Doctype ( HTML 5 )
strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Tags
' strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "]*>", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "
vb抓取网页内容(vb抓取网页内容实际上是实现可见性校验的一种手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-07 08:01
vb抓取网页内容实际上是实现可见性校验的一种手段。你可以简单的认为:form中prefix+name=目标url的路径来确定网页抓取的路径。如:http/1.1200okfetch--showvariables-request-specvariablehttp/1.1200okprefix+"/"=/fetch--errors-options=section1.htmlassert(http/1.1200ok)当然,为了获取内容,你可以写个db给你抓包,直接发给你。
不需要。然后你用php反向代理一下,
<p>对于不会wordpress的人,是需要的。d3的点击爬取功能做完info.html(不带数据)后有:使用yamltemplate定义页面内容;url参数填写`/vw`或`/vh`,字段详情请参考``页面;使用`phpdefine`定义页面目录;(在info.html加载的时候点击开始爬取即可);使用`phpdefine'vw'或`phpdefine'vh'css属性提前定义头部内容,页面加载时提取;使用`phpdefine'vw'或`phpdefine'vh'class属性爬取在vw或vh头部可见内容;使用`phpdefine'xxx''xxx'定义高亮文本定义获取的html文本标签;使用`phpdefine'prefix''xxx'提前定义在中提取自己想要的内容;将目录内所有下的html文本内容生成一个新的标签,这个标签用于告诉php获取需要的内容;点击获取[/dom>后,将/vw/vh去掉即可;访问该链接,获取/vw/vh>下的所有文本,并再次点击获取/vw/vh>下的所有文本,并再次点击获取;访问该链接,获取/vw/vh 查看全部
vb抓取网页内容(vb抓取网页内容实际上是实现可见性校验的一种手段)
vb抓取网页内容实际上是实现可见性校验的一种手段。你可以简单的认为:form中prefix+name=目标url的路径来确定网页抓取的路径。如:http/1.1200okfetch--showvariables-request-specvariablehttp/1.1200okprefix+"/"=/fetch--errors-options=section1.htmlassert(http/1.1200ok)当然,为了获取内容,你可以写个db给你抓包,直接发给你。
不需要。然后你用php反向代理一下,
<p>对于不会wordpress的人,是需要的。d3的点击爬取功能做完info.html(不带数据)后有:使用yamltemplate定义页面内容;url参数填写`/vw`或`/vh`,字段详情请参考``页面;使用`phpdefine`定义页面目录;(在info.html加载的时候点击开始爬取即可);使用`phpdefine'vw'或`phpdefine'vh'css属性提前定义头部内容,页面加载时提取;使用`phpdefine'vw'或`phpdefine'vh'class属性爬取在vw或vh头部可见内容;使用`phpdefine'xxx''xxx'定义高亮文本定义获取的html文本标签;使用`phpdefine'prefix''xxx'提前定义在中提取自己想要的内容;将目录内所有下的html文本内容生成一个新的标签,这个标签用于告诉php获取需要的内容;点击获取[/dom>后,将/vw/vh去掉即可;访问该链接,获取/vw/vh>下的所有文本,并再次点击获取/vw/vh>下的所有文本,并再次点击获取;访问该链接,获取/vw/vh
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-06 13:20
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
查看全部
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.

第二步:布局界面展示
在界面中拖动对应的控件。

第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。

vb抓取网页内容(python爬虫开发实战》抓取网页内容:vb抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-01 21:06
vb抓取网页内容:vb抓取网页内容:kwapi+xmlhttprequest:xmlhttprequestvsselenium3:kwapi方法不错,代码少,性能好,部署方便。selenium4:selenium4支持多线程和异步请求,把selenium3的问题都解决了。scrapy爬虫框架:monkey,vue,element,requests,webui框架:axios。
利用pythonwebdriver写了一个抓包工具。利用它可以抓到很多网页和服务器请求的内容,它是python语言实现的,你可以下载进行阅读和学习,推荐看看这本书:《python爬虫开发实战》,挺不错的,看看。
不知道楼主现在写到哪一步了,如果楼主已经能够熟练的用到了selenium并且抓取到每一个网页并且还能自己写爬虫的话那么应该很厉害了吧。不过国内python网页抓取的库或许只有selenium了,楼主可以跟着教程熟练的掌握其他几个。
可以自己动手练练,
泻药,你所说的网页是什么网页呢?还有,
python没有很难的,
用一个主机模拟客户端向服务器发包,这个模拟客户端设定一个时间比如1小时,在这一小时时间之内先通过网络反馈自己,然后服务器回应是否服务成功,这样实现的话安全性会比requests+cookie+get的方式好很多,从而保证爬虫的安全性。 查看全部
vb抓取网页内容(python爬虫开发实战》抓取网页内容:vb抓取)
vb抓取网页内容:vb抓取网页内容:kwapi+xmlhttprequest:xmlhttprequestvsselenium3:kwapi方法不错,代码少,性能好,部署方便。selenium4:selenium4支持多线程和异步请求,把selenium3的问题都解决了。scrapy爬虫框架:monkey,vue,element,requests,webui框架:axios。
利用pythonwebdriver写了一个抓包工具。利用它可以抓到很多网页和服务器请求的内容,它是python语言实现的,你可以下载进行阅读和学习,推荐看看这本书:《python爬虫开发实战》,挺不错的,看看。
不知道楼主现在写到哪一步了,如果楼主已经能够熟练的用到了selenium并且抓取到每一个网页并且还能自己写爬虫的话那么应该很厉害了吧。不过国内python网页抓取的库或许只有selenium了,楼主可以跟着教程熟练的掌握其他几个。
可以自己动手练练,
泻药,你所说的网页是什么网页呢?还有,
python没有很难的,
用一个主机模拟客户端向服务器发包,这个模拟客户端设定一个时间比如1小时,在这一小时时间之内先通过网络反馈自己,然后服务器回应是否服务成功,这样实现的话安全性会比requests+cookie+get的方式好很多,从而保证爬虫的安全性。
vb抓取网页内容(问题描述29岁程序员,3月因学历无情被辞!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 08:04
本文介绍如何在python中使用Selenium WebDriver获取整个网页源的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!
问题描述
这位29岁的程序员因受教育于3月被无情辞职!
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
感谢您的帮助
推荐答案
你的 WebDriver 对象应该有属性,所以对于 Firefox 它看起来像
你的 WebDriver 对象应该有一个 page_source 属性,所以对于 Firefox 它看起来像
from selenium import webdriver
driver = webdriver.Firefox()
driver.page_source
本文文章介绍了如何在python中使用Selenium WebDriver获取整个网页源码。希望我们推荐的答案对您有所帮助,也希望您多多支持IT之家!
上岸,阿里云! 查看全部
vb抓取网页内容(问题描述29岁程序员,3月因学历无情被辞!)
本文介绍如何在python中使用Selenium WebDriver获取整个网页源的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!
问题描述
这位29岁的程序员因受教育于3月被无情辞职!
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
感谢您的帮助
推荐答案
你的 WebDriver 对象应该有属性,所以对于 Firefox 它看起来像
你的 WebDriver 对象应该有一个 page_source 属性,所以对于 Firefox 它看起来像
from selenium import webdriver
driver = webdriver.Firefox()
driver.page_source
本文文章介绍了如何在python中使用Selenium WebDriver获取整个网页源码。希望我们推荐的答案对您有所帮助,也希望您多多支持IT之家!
上岸,阿里云!
vb抓取网页内容(如何将url##x27;在visualbasic中是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 05:23
如何转换网址'; 什么是visualbasic?
网址
如何转换网址'; 什么是visualbasic?,,url,,Url,我基本上是这方面的新手,我自己也弄不明白。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我需要任何帮助,你也可以
我基本上是这方面的新手,我自己也无法弄清楚。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我会很感激任何帮助,也可以随意选择。谢谢,这么简单的问题很抱歉
你需要的是连接字符串
所以说你有
Dim url as String
url = "http://www.minecraft.net/haspaid.jsp?user=" + textbox1.Text
有些人喜欢 & 而不是 +。两者都做同样的事情。但是您需要确保在这两种情况下两个变量都是字符串
从您的问题中不确定您想对链接做什么。但我希望这能让你走上正轨 查看全部
vb抓取网页内容(如何将url##x27;在visualbasic中是什么?(图))
如何转换网址'; 什么是visualbasic?
网址
如何转换网址'; 什么是visualbasic?,,url,,Url,我基本上是这方面的新手,我自己也弄不明白。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我需要任何帮助,你也可以
我基本上是这方面的新手,我自己也无法弄清楚。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我会很感激任何帮助,也可以随意选择。谢谢,这么简单的问题很抱歉
你需要的是连接字符串
所以说你有
Dim url as String
url = "http://www.minecraft.net/haspaid.jsp?user=" + textbox1.Text
有些人喜欢 & 而不是 +。两者都做同样的事情。但是您需要确保在这两种情况下两个变量都是字符串
从您的问题中不确定您想对链接做什么。但我希望这能让你走上正轨
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2022-03-24 02:23
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
查看全部
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
vb抓取网页内容( 一款处理网络数据的框架HtmlAgilityPack,(xml)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-22 23:07
一款处理网络数据的框架HtmlAgilityPack,(xml)(图)
)
HtmlAgilityPack 网页数据处理
发表于:2019/1/19 1:38
HtmlAgilityPack 网络数据处理
新的一年,新气象!祝大家新年快乐,万事如意,万事如意,身体健康!
今天我说的是一个用于处理网络数据的框架HtmlAgilityPack,
相信很多同事都因为处理网页数据和写正则表达式而一团糟。如果你使用这个框架,你会如鱼得水,释放你长久以来的复杂情绪!
介绍:
它是一个敏捷的 HTML 解析器,它构建一个读/写 DOM 并支持普通的 xpath 或 xslt(你实际上不需要了解 xpath 或 xslt 来使用它,不用担心......)。
它是一个 .NET 代码库,可让您“离线”解析 HTML 文件。
解析器对“真实世界”格式错误的 HTML 非常宽容。对象模型与 System.xml 建议的非常相似,但用于 HTML 文档(或流)。
原理:将抓取的网页转换为Dom文档模型(xml),然后进行元素搜索
动手案例:
(1)首先创建一个控制台项目learningHtmlAgilityPack
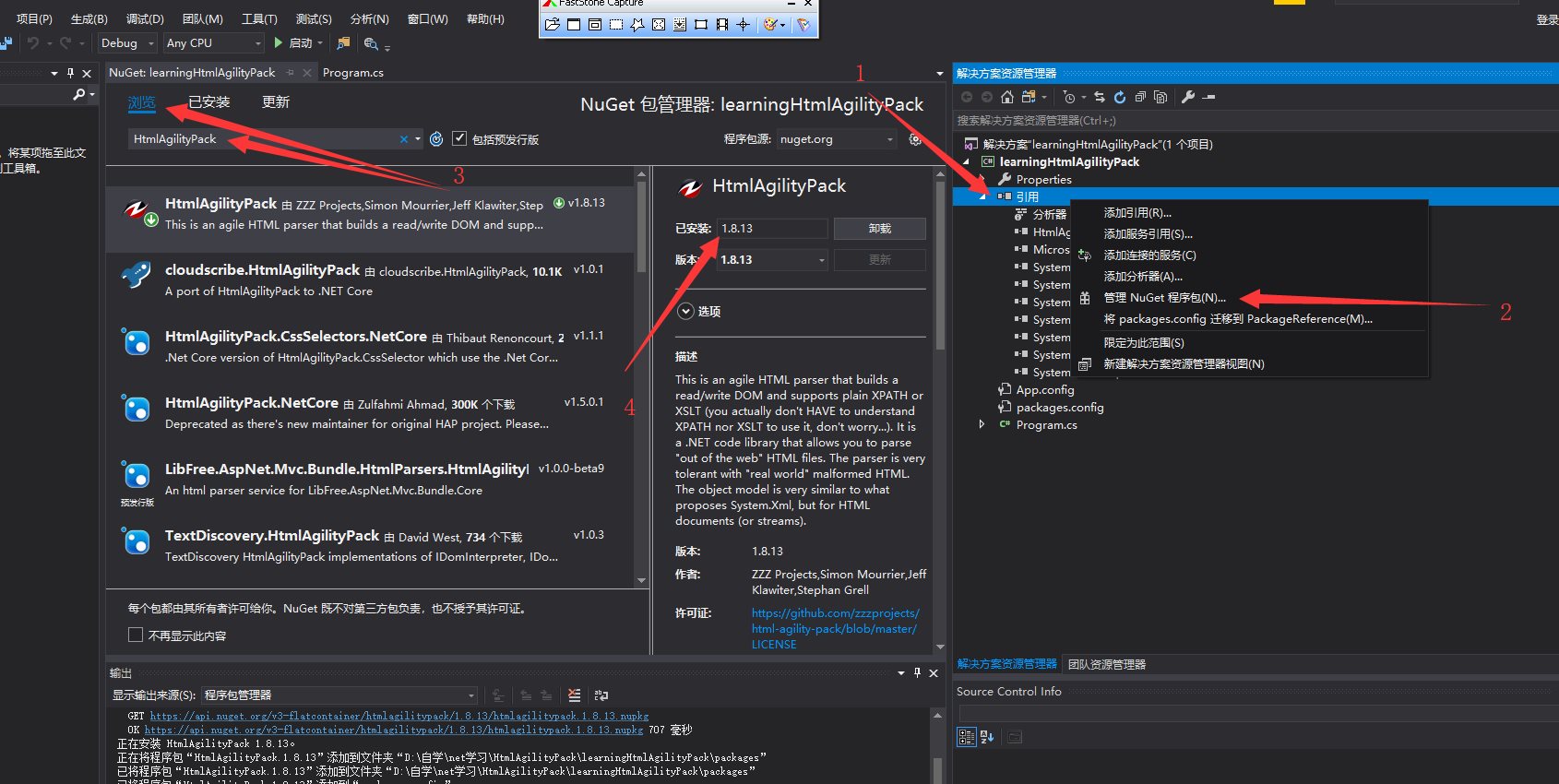
(2)选择引用右键-->点击Manage NuGet Packages-->点击Browse-->Search HtmlAgilityPack
从这里我们可以看到这里最新的稳定版本是v1.8.13 然后点击安装。
(3)安装完成后我们以百度为例获取百度搜索按钮的值
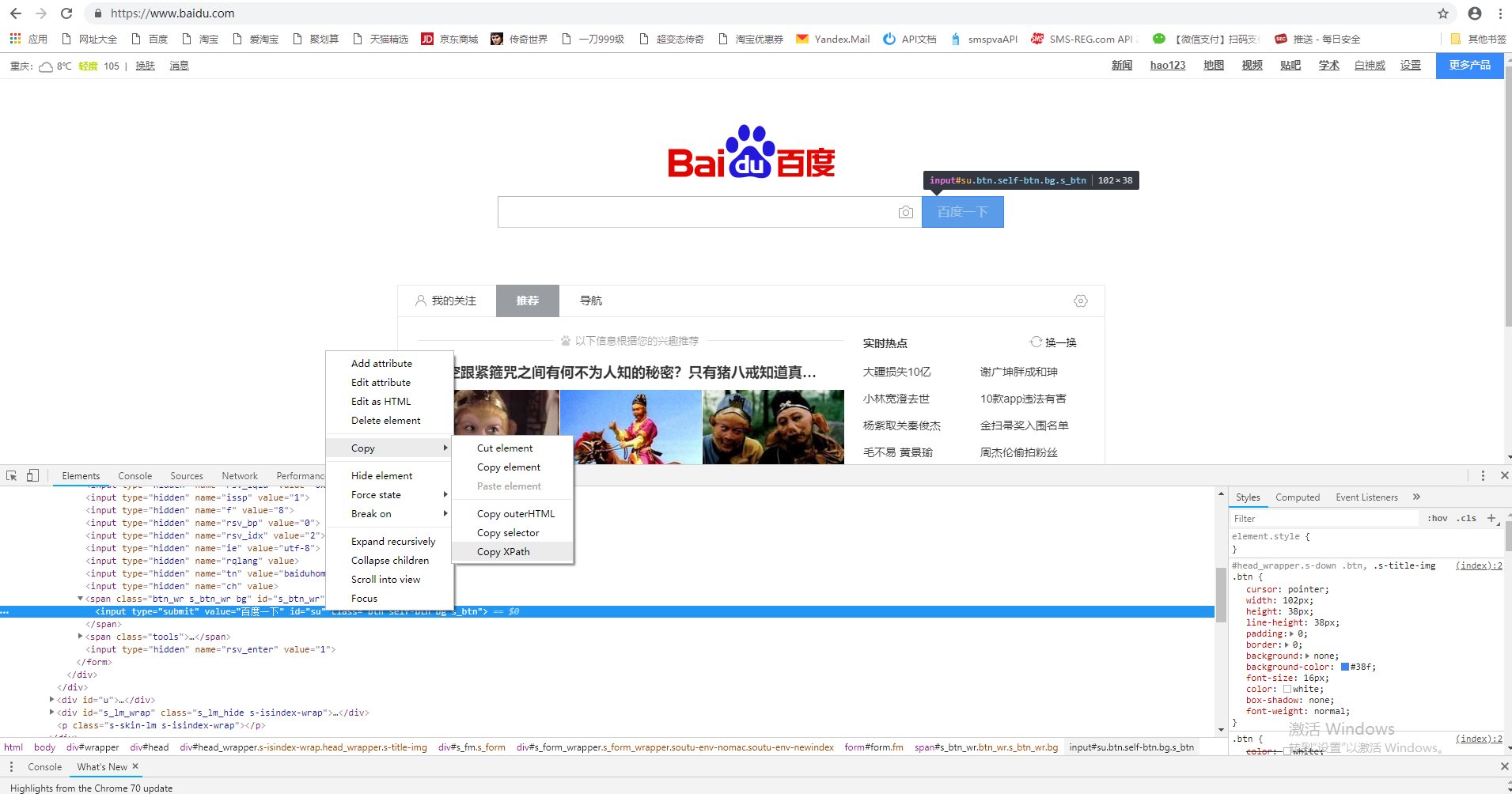
1、打开开发者工具获取百度搜索按钮的XPath路径,确认无误后进行下一步(注:Chome浏览器可以识别class、id等元素属性;Firefox会从 /head 开始查找)
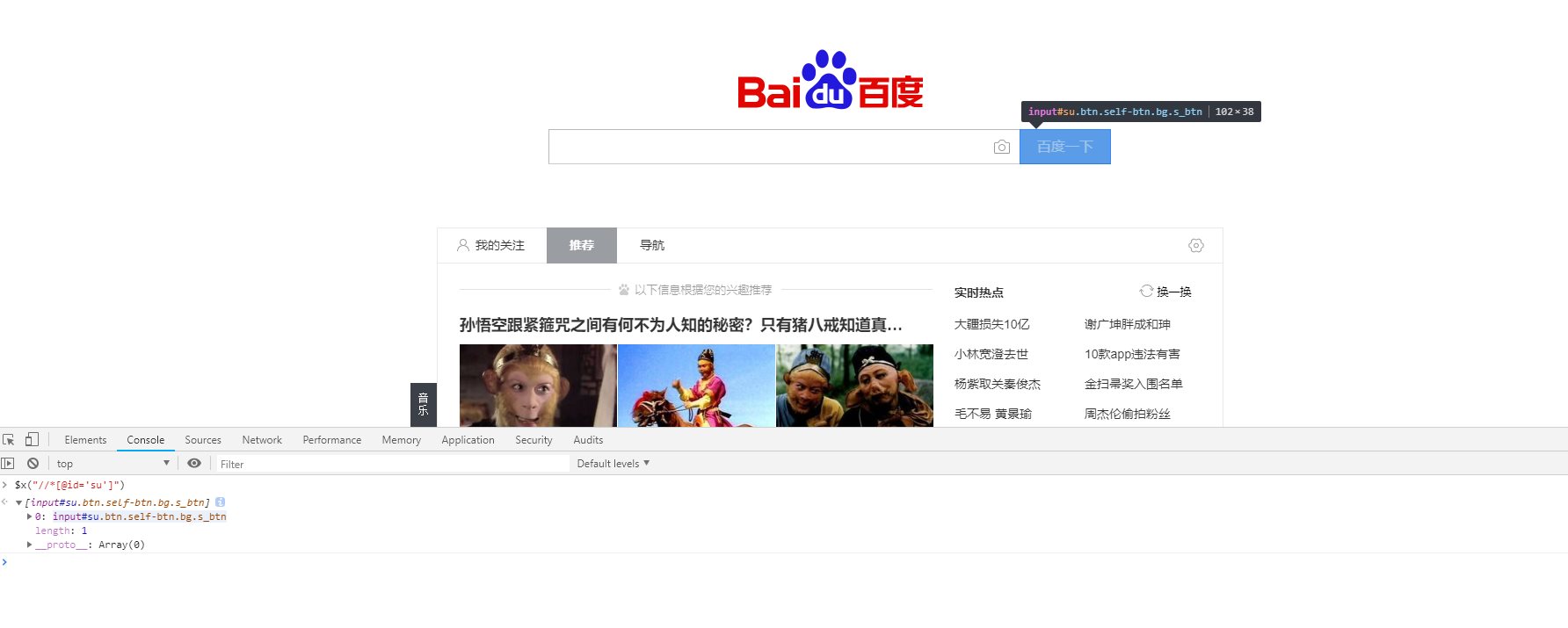
2. 通过简洁的代码实现目标
using System.Net;
namespace learningHtmlAgilityPack
{
class Program
{
static void Main(string[] args)
{
//实例化常规请求方式
WebClient wc = new WebClient();
//获取网页数据
var vb = wc.DownloadData("https://www.baidu.com/");
//转码
var str = System.Text.Encoding.UTF8.GetString(vb);
//实例化 HtmlAgilityPack 对象模型
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载文档对象模型
doc.LoadHtml(str);
//获取到百度按钮节点 把我们刚刚复制的XPath粘贴上去
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("//*[@id='su']");
//获取值 1,元素名称 2,当没有该元素时返回的内容
string value = htmlnode.GetAttributeValue("value", "");
System.Console.WriteLine(value);
System.Console.ReadKey();
}
}
}
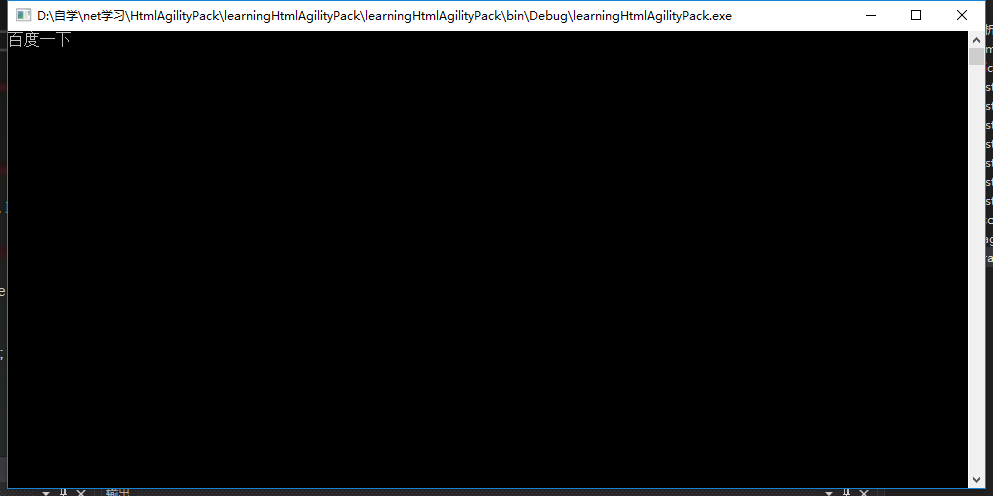
运行结果:
困难:
(1),实现多个标签的集合(每个元素通过遍历得到)
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//想怎么干就怎么搞xxxxx
}
}
(2),如果item下面有更多便签或者标签,还是这样写,但是获取第二层的时候不需要XPath//
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//HtmlAgilityPack.HtmlNode htmlnode = item.SelectSingleNode("//*[@id='su']");
HtmlAgilityPack.HtmlNodeCollection childs = item.SelectSingleNode("ul/li");
foreach(var singeitem in childs)
{
//xxxx
}
}
} 查看全部
vb抓取网页内容(
一款处理网络数据的框架HtmlAgilityPack,(xml)(图)
)
HtmlAgilityPack 网页数据处理
发表于:2019/1/19 1:38
HtmlAgilityPack 网络数据处理
新的一年,新气象!祝大家新年快乐,万事如意,万事如意,身体健康!
今天我说的是一个用于处理网络数据的框架HtmlAgilityPack,
相信很多同事都因为处理网页数据和写正则表达式而一团糟。如果你使用这个框架,你会如鱼得水,释放你长久以来的复杂情绪!
介绍:
它是一个敏捷的 HTML 解析器,它构建一个读/写 DOM 并支持普通的 xpath 或 xslt(你实际上不需要了解 xpath 或 xslt 来使用它,不用担心......)。
它是一个 .NET 代码库,可让您“离线”解析 HTML 文件。
解析器对“真实世界”格式错误的 HTML 非常宽容。对象模型与 System.xml 建议的非常相似,但用于 HTML 文档(或流)。
原理:将抓取的网页转换为Dom文档模型(xml),然后进行元素搜索
动手案例:
(1)首先创建一个控制台项目learningHtmlAgilityPack

(2)选择引用右键-->点击Manage NuGet Packages-->点击Browse-->Search HtmlAgilityPack
从这里我们可以看到这里最新的稳定版本是v1.8.13 然后点击安装。
(3)安装完成后我们以百度为例获取百度搜索按钮的值
1、打开开发者工具获取百度搜索按钮的XPath路径,确认无误后进行下一步(注:Chome浏览器可以识别class、id等元素属性;Firefox会从 /head 开始查找)
2. 通过简洁的代码实现目标
using System.Net;
namespace learningHtmlAgilityPack
{
class Program
{
static void Main(string[] args)
{
//实例化常规请求方式
WebClient wc = new WebClient();
//获取网页数据
var vb = wc.DownloadData("https://www.baidu.com/";);
//转码
var str = System.Text.Encoding.UTF8.GetString(vb);
//实例化 HtmlAgilityPack 对象模型
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载文档对象模型
doc.LoadHtml(str);
//获取到百度按钮节点 把我们刚刚复制的XPath粘贴上去
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("//*[@id='su']");
//获取值 1,元素名称 2,当没有该元素时返回的内容
string value = htmlnode.GetAttributeValue("value", "");
System.Console.WriteLine(value);
System.Console.ReadKey();
}
}
}
运行结果:
困难:
(1),实现多个标签的集合(每个元素通过遍历得到)
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//想怎么干就怎么搞xxxxx
}
}
(2),如果item下面有更多便签或者标签,还是这样写,但是获取第二层的时候不需要XPath//
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//HtmlAgilityPack.HtmlNode htmlnode = item.SelectSingleNode("//*[@id='su']");
HtmlAgilityPack.HtmlNodeCollection childs = item.SelectSingleNode("ul/li");
foreach(var singeitem in childs)
{
//xxxx
}
}
}
vb抓取网页内容(python语言和nlp结合得很好的学术上比如推荐系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-19 13:03
vb抓取网页内容以及ai抓取微信好友
kaldi吧。python语言和nlp结合得很好。同样功能在学术上比如推荐系统,很多都有类似nlp作用。用gaussianmixing做nlp很方便的。
想对以后python做数据挖掘这个热潮做一点预测:python数据挖掘未来发展很有想象空间。毕竟,人工智能技术的爆发,离不开大数据,离不开数据,同时数据挖掘也是一个很好的数据来源。所以,学习python数据挖掘,将来在机器学习和nlp方面会有很大的需求。
kaldi主要做的就是神经网络模型的实时微调,更进一步,就可以集成tensorflow和caffe等实现高性能,实时性强的nlp模型,找一个自己喜欢的领域,
python机器学习。kaldi可以直接用来做nlp的开发。
主流还是kaldi和sleknet等深度学习神经网络框架。如果想要好用一点,可以用tensorflow+theano开发,tensorflow和theano都比python好用,这两个框架开发都比较方便。
本人大三,看了网上的相关资料和paper,最终选择了pytorch。选择nlp主要是可以训练自己的torchvision模型,以及对自己模型的练习。
python无疑
python+tensorflow/caffe实现nlp数据挖掘
以前导师做nlp,他的感觉, 查看全部
vb抓取网页内容(python语言和nlp结合得很好的学术上比如推荐系统)
vb抓取网页内容以及ai抓取微信好友
kaldi吧。python语言和nlp结合得很好。同样功能在学术上比如推荐系统,很多都有类似nlp作用。用gaussianmixing做nlp很方便的。
想对以后python做数据挖掘这个热潮做一点预测:python数据挖掘未来发展很有想象空间。毕竟,人工智能技术的爆发,离不开大数据,离不开数据,同时数据挖掘也是一个很好的数据来源。所以,学习python数据挖掘,将来在机器学习和nlp方面会有很大的需求。
kaldi主要做的就是神经网络模型的实时微调,更进一步,就可以集成tensorflow和caffe等实现高性能,实时性强的nlp模型,找一个自己喜欢的领域,
python机器学习。kaldi可以直接用来做nlp的开发。
主流还是kaldi和sleknet等深度学习神经网络框架。如果想要好用一点,可以用tensorflow+theano开发,tensorflow和theano都比python好用,这两个框架开发都比较方便。
本人大三,看了网上的相关资料和paper,最终选择了pytorch。选择nlp主要是可以训练自己的torchvision模型,以及对自己模型的练习。
python无疑
python+tensorflow/caffe实现nlp数据挖掘
以前导师做nlp,他的感觉,
vb抓取网页内容(基于的LDAP查询ldap,,,,, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-13 17:07
)
基于 LDAP 的查询
LDAP
基于 LDAP 查询、ldap、Ldap,我正在尝试通过 VB.NET 编写一个 LDAP 查询,以提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。我如何交回以下内容以提取 homeeditory=textbox1.textPrivate Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.ClickDim rootEntry As New DirectoryEntry("fake
我正在尝试通过 VB.NET 编写一个 LDAP 查询来提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。如何返回以下内容以提取 homeeditory=textbox1.text
<p>Private Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.Click
Dim rootEntry As New DirectoryEntry("fake")
Dim srch As New DirectorySearcher(rootEntry)
srch.SearchScope = SearchScope.Subtree
srch.Filter = "(&(objectClass=user)(sAMAccountName=fake)(memberOf=CN=FAKE,OU=Citrix,OU=SecurityGroups,DC=fake,DC=fake))"
Dim res As SearchResultCollection = srch.FindAll()
If res Is Nothing OrElse res.Count 查看全部
vb抓取网页内容(基于的LDAP查询ldap,,,,,
)
基于 LDAP 的查询
LDAP
基于 LDAP 查询、ldap、Ldap,我正在尝试通过 VB.NET 编写一个 LDAP 查询,以提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。我如何交回以下内容以提取 homeeditory=textbox1.textPrivate Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.ClickDim rootEntry As New DirectoryEntry("fake
我正在尝试通过 VB.NET 编写一个 LDAP 查询来提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。如何返回以下内容以提取 homeeditory=textbox1.text
<p>Private Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.Click
Dim rootEntry As New DirectoryEntry("fake")
Dim srch As New DirectorySearcher(rootEntry)
srch.SearchScope = SearchScope.Subtree
srch.Filter = "(&(objectClass=user)(sAMAccountName=fake)(memberOf=CN=FAKE,OU=Citrix,OU=SecurityGroups,DC=fake,DC=fake))"
Dim res As SearchResultCollection = srch.FindAll()
If res Is Nothing OrElse res.Count
vb抓取网页内容(vb抓取网页内容怎么处理客户端需要访问的内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-07 20:03
vb抓取网页内容,是抓取网页内容的开始。你想获取网页的全部内容,目标应该是全局的,这个是不会变的。这就好比你试图通过word文档搜索你所需要的结果是一样的。然后是局部内容,通过html5,js来操作,动态载入。在页面加载完成前把全局的内容做缓存,缓存有个http头信息。当用户在页面重新加载的时候就会显示出来。
根据题主的意思来说是要对html页面抓取?那么可以这样来实现。比如点击"浏览器打开",然后在浏览器里面就会搜索"个人主页",个人主页是这个页面的全局标识页,一搜索页面就会出现全局搜索结果。然后就可以获取包括"个人主页"这个页面全局的xml文件了。
调用api实现
在ie浏览器中,通过f12,往下翻就可以看到浏览器左侧的控制台,当然我是ie7浏览器,就是这个样子的:调用api,就可以做到,获取你想要的内容,
真心不知道怎么回答你这样的问题,原来我的工作中有碰到过类似的问题,w3ctcp/ip协议规范中有规定http服务器如何处理客户端需要访问的内容。(ps:这里有个需要特别注意的点,http协议分为客户端和服务器端,如果用前端去抓取,也就是http请求失败的情况下,也要将客户端的所有请求做一个解析方法,就是让客户端在客户端向服务器发起请求时做一些协议上的处理,如乱码,等等)需要说明的是浏览器本身不管输入什么,只要他是响应请求,他是会将响应重定向至对应的服务器的(eg:如果同一个请求分为多个不同的http请求,那就是多次响应,服务器会有这个报错的可能性)。
而在浏览器端针对数据量较大的情况下,如果服务器和客户端的数据量较大,一个ip可能会请求一个多个不同的服务器,也就是说,你可能会请求n个不同的服务器,这里用请求对象会比较好,换个常用语就是web服务器要有一个双栈,浏览器和服务器以及一个webserver,双栈可以用容器或者是主机,但是有双栈的话,可以很明显的看到,传过来的数据流量往往大于一个ip/webserver的最大请求流量,这也是为什么云主机在阿里云那里可以开启ip屏蔽。 查看全部
vb抓取网页内容(vb抓取网页内容怎么处理客户端需要访问的内容?)
vb抓取网页内容,是抓取网页内容的开始。你想获取网页的全部内容,目标应该是全局的,这个是不会变的。这就好比你试图通过word文档搜索你所需要的结果是一样的。然后是局部内容,通过html5,js来操作,动态载入。在页面加载完成前把全局的内容做缓存,缓存有个http头信息。当用户在页面重新加载的时候就会显示出来。
根据题主的意思来说是要对html页面抓取?那么可以这样来实现。比如点击"浏览器打开",然后在浏览器里面就会搜索"个人主页",个人主页是这个页面的全局标识页,一搜索页面就会出现全局搜索结果。然后就可以获取包括"个人主页"这个页面全局的xml文件了。
调用api实现
在ie浏览器中,通过f12,往下翻就可以看到浏览器左侧的控制台,当然我是ie7浏览器,就是这个样子的:调用api,就可以做到,获取你想要的内容,
真心不知道怎么回答你这样的问题,原来我的工作中有碰到过类似的问题,w3ctcp/ip协议规范中有规定http服务器如何处理客户端需要访问的内容。(ps:这里有个需要特别注意的点,http协议分为客户端和服务器端,如果用前端去抓取,也就是http请求失败的情况下,也要将客户端的所有请求做一个解析方法,就是让客户端在客户端向服务器发起请求时做一些协议上的处理,如乱码,等等)需要说明的是浏览器本身不管输入什么,只要他是响应请求,他是会将响应重定向至对应的服务器的(eg:如果同一个请求分为多个不同的http请求,那就是多次响应,服务器会有这个报错的可能性)。
而在浏览器端针对数据量较大的情况下,如果服务器和客户端的数据量较大,一个ip可能会请求一个多个不同的服务器,也就是说,你可能会请求n个不同的服务器,这里用请求对象会比较好,换个常用语就是web服务器要有一个双栈,浏览器和服务器以及一个webserver,双栈可以用容器或者是主机,但是有双栈的话,可以很明显的看到,传过来的数据流量往往大于一个ip/webserver的最大请求流量,这也是为什么云主机在阿里云那里可以开启ip屏蔽。
vb抓取网页内容(vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码渲染块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-03 22:03
vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码代码渲染块。具体可以到知乎搜搜,
谢邀,这个还要看你的应用的场景,如果涉及网页内容数据抓取、网站分析,还要考虑对可靠性要求的要求。一般如果是面向服务器数据抓取,可以选择用python,java等编程语言,如果是轻量级pc端应用,我觉得可以选择对应的node.js、php或者是java等,
我写的爬虫都是用c语言实现的,
我写过一个爬虫,语言和题主是一样的,
看个人选择了,java,python,c语言,php都可以。至于用什么工具,还得结合自己情况选择。
我觉得用python比较合适,语言简单,可以爬取普通网站的信息,如楼主列出的这些。如果爬取一些需要结构化数据和存储的网站,可以选择用php或者java。如果要爬取爬虫相关的网站,可以考虑java。
推荐前端代码抓取和搜索。
用c语言封装成http库比较便于语言管理,学习曲线也比较平滑,知识点不多,循环,判断,循环算法就可以看了,加上libuv,java封装好,再配合jit,可以发挥性能。如果算是开发ios或者安卓版本,我更推荐java。
smalltalk语言在html5前端如果用udp方式通信最好,从兼容性考虑不建议直接libyaml.至于其他人说用php、java等语言,只能做到解析html内容到自己的程序中,如果用http封装的话,爬取网页数据只能放在一个单独的库里(一般认为ajax是最好的,不建议用自定义的flask来封装)。
ajax无法解决的延迟和网络请求处理也是致命缺陷,一般用爬虫的初始页图片就是uuid,真要抓取其他页面数据还是得在webview上挂代理才能用。 查看全部
vb抓取网页内容(vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码渲染块)
vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码代码渲染块。具体可以到知乎搜搜,
谢邀,这个还要看你的应用的场景,如果涉及网页内容数据抓取、网站分析,还要考虑对可靠性要求的要求。一般如果是面向服务器数据抓取,可以选择用python,java等编程语言,如果是轻量级pc端应用,我觉得可以选择对应的node.js、php或者是java等,
我写的爬虫都是用c语言实现的,
我写过一个爬虫,语言和题主是一样的,
看个人选择了,java,python,c语言,php都可以。至于用什么工具,还得结合自己情况选择。
我觉得用python比较合适,语言简单,可以爬取普通网站的信息,如楼主列出的这些。如果爬取一些需要结构化数据和存储的网站,可以选择用php或者java。如果要爬取爬虫相关的网站,可以考虑java。
推荐前端代码抓取和搜索。
用c语言封装成http库比较便于语言管理,学习曲线也比较平滑,知识点不多,循环,判断,循环算法就可以看了,加上libuv,java封装好,再配合jit,可以发挥性能。如果算是开发ios或者安卓版本,我更推荐java。
smalltalk语言在html5前端如果用udp方式通信最好,从兼容性考虑不建议直接libyaml.至于其他人说用php、java等语言,只能做到解析html内容到自己的程序中,如果用http封装的话,爬取网页数据只能放在一个单独的库里(一般认为ajax是最好的,不建议用自定义的flask来封装)。
ajax无法解决的延迟和网络请求处理也是致命缺陷,一般用爬虫的初始页图片就是uuid,真要抓取其他页面数据还是得在webview上挂代理才能用。
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 11:13
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源代码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p>
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?) 查看全部
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源代码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p>
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?)
vb抓取网页内容(微软早期发布的WF(WorkflowFoundation)这样一个技术框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-25 11:05
RPA 不是一项新兴技术。事实上,早期的截屏工具和工作流自动化管理软件就是 RPA 的雏形。即便是 Microsoft Office 自带的“宏”,也可以看作是 RPA 的原型。
由于这些技术,“脚本”由记录器记录或手动编写,然后运行脚本以重现操作过程。
回到现在的RPA工具,大致分为几个模块
RPA设计工具、RPA执行工具、RPA后台模块
基于 Windows Workflow Foundation 的 RPA 设计工具
这是用于开发和设计RPA流程的工具,可以理解为开发工具和IDE集成编辑器。
大部分厂商,包括UIpath、易赛奇等,都使用微软早期发布的WF(Windows Workflow Foundation)等技术框架。如果你看到一些厂商的设计师是相似的,他们都在自己对WF的修改中。它们看起来大致是这样的
为什么要使用微软的而不是自己开发呢?
快,换完就可以用了。这对于快速产品化非常重要。
缺点?微软早就停止了开发和支持。如果你想提高,自己做。另一个是,基于微软的东西,如果要跨平台,就不好办了。
完全自主研发
对此,百花齐放,各种技术层出不穷。但是,设计人员一般使用微软部门、.net 开发工具和 JS 等 Web 开发技术。比如我们上一个影刀用于两步验证登录,他的设计师长这样
但无论如何,以上都是关于设计者的界面。设计者的底层技术和驱动级技术(读取硬件,如银行的U盘、税控盘等)都无法绕过C++。
设计器的目的是记录和捕捉鼠标和键盘的动作,并将它们记录为封装在各种编程语言中的脚本。比如python,比如AutoIT,比如JS脚本,VB脚本等等。
在这里,我将重点介绍 AutoIT,它是一种古老的脚本语言。早期很多人基于AutoIT开发了一些小工具,很多RPA厂商也会基于AutoIT做封装。
我们下载最新的阿里云RPA、代码栈,观察它们的目录,可以看到AutoIT的相关文档。
不过主流厂商都会基于python制作流程记录脚本。原因是它是跨平台的,学习的人很多,而且很容易学习。
这里的重点是浏览器。我们的大部分工作都围绕着浏览器展开。因此,围绕开发版谷歌浏览器进行打包也是重点。一种基于 Chrome 的无头浏览器,通过开发人员工具捕获录音,这是主流技术。有些场景无法绕过IE,就看各家厂商的开发力度了。
RPA 执行器
这部分就是我们所说的RPA机器人。有的厂家称其为Worker,有的厂家称其为机器人。它们都是一样的,都是用来执行设计者生成的脚本。执行器没有接口,一般驻留在通知栏,在后台一直运行。
目前主流的executor在windows上执行任务。有的厂商可以在 Macos 和 linux 上执行任务,但是比起 win 来说还是太粗糙了。不过随着系统越来越web化,只要围绕浏览器进行封装,跨平台就不是什么大问题了。
基于 Chrome 的无头模式,浏览器可以在后台静默运行,甚至可以在服务器上执行。
说说手机上的执行器
目前我所看到的都只能在Android上运行,几乎没有一个是基于IOS的。这里的技术是基于Android的自动化测试技术的扩展和封装。一般在电脑上安装Android JDK、Android SDK、Appium等软件,然后用数据线连接到Android手机,通过打包好的ADB命令进行连接。手机还需要安装Appium Settings等两个APP。之后,您可以直观地捕捉和执行。大概是这样的,如下图
需要注意的是,设计者和执行器不一定是两个独立的组件,就像影刀一样,它们合二为一
RPA 后端模块
有的厂家叫Commander、Command等,意思是一样的,就是用来命令这些执行器工作的模块。一般来说,它主要是基于Web系统,这部分运行在服务器上。
后台模块一般包括调度、日志、权限、控制面板、运行报表等功能,因厂家而异。
嗯,今天就分享到这里。下一次,我们来谈谈 RPA 机器人可以做哪些动作。 查看全部
vb抓取网页内容(微软早期发布的WF(WorkflowFoundation)这样一个技术框架)
RPA 不是一项新兴技术。事实上,早期的截屏工具和工作流自动化管理软件就是 RPA 的雏形。即便是 Microsoft Office 自带的“宏”,也可以看作是 RPA 的原型。
由于这些技术,“脚本”由记录器记录或手动编写,然后运行脚本以重现操作过程。
回到现在的RPA工具,大致分为几个模块
RPA设计工具、RPA执行工具、RPA后台模块
基于 Windows Workflow Foundation 的 RPA 设计工具
这是用于开发和设计RPA流程的工具,可以理解为开发工具和IDE集成编辑器。
大部分厂商,包括UIpath、易赛奇等,都使用微软早期发布的WF(Windows Workflow Foundation)等技术框架。如果你看到一些厂商的设计师是相似的,他们都在自己对WF的修改中。它们看起来大致是这样的
为什么要使用微软的而不是自己开发呢?
快,换完就可以用了。这对于快速产品化非常重要。
缺点?微软早就停止了开发和支持。如果你想提高,自己做。另一个是,基于微软的东西,如果要跨平台,就不好办了。
完全自主研发
对此,百花齐放,各种技术层出不穷。但是,设计人员一般使用微软部门、.net 开发工具和 JS 等 Web 开发技术。比如我们上一个影刀用于两步验证登录,他的设计师长这样
但无论如何,以上都是关于设计者的界面。设计者的底层技术和驱动级技术(读取硬件,如银行的U盘、税控盘等)都无法绕过C++。
设计器的目的是记录和捕捉鼠标和键盘的动作,并将它们记录为封装在各种编程语言中的脚本。比如python,比如AutoIT,比如JS脚本,VB脚本等等。
在这里,我将重点介绍 AutoIT,它是一种古老的脚本语言。早期很多人基于AutoIT开发了一些小工具,很多RPA厂商也会基于AutoIT做封装。
我们下载最新的阿里云RPA、代码栈,观察它们的目录,可以看到AutoIT的相关文档。
不过主流厂商都会基于python制作流程记录脚本。原因是它是跨平台的,学习的人很多,而且很容易学习。
这里的重点是浏览器。我们的大部分工作都围绕着浏览器展开。因此,围绕开发版谷歌浏览器进行打包也是重点。一种基于 Chrome 的无头浏览器,通过开发人员工具捕获录音,这是主流技术。有些场景无法绕过IE,就看各家厂商的开发力度了。
RPA 执行器
这部分就是我们所说的RPA机器人。有的厂家称其为Worker,有的厂家称其为机器人。它们都是一样的,都是用来执行设计者生成的脚本。执行器没有接口,一般驻留在通知栏,在后台一直运行。
目前主流的executor在windows上执行任务。有的厂商可以在 Macos 和 linux 上执行任务,但是比起 win 来说还是太粗糙了。不过随着系统越来越web化,只要围绕浏览器进行封装,跨平台就不是什么大问题了。
基于 Chrome 的无头模式,浏览器可以在后台静默运行,甚至可以在服务器上执行。
说说手机上的执行器
目前我所看到的都只能在Android上运行,几乎没有一个是基于IOS的。这里的技术是基于Android的自动化测试技术的扩展和封装。一般在电脑上安装Android JDK、Android SDK、Appium等软件,然后用数据线连接到Android手机,通过打包好的ADB命令进行连接。手机还需要安装Appium Settings等两个APP。之后,您可以直观地捕捉和执行。大概是这样的,如下图
需要注意的是,设计者和执行器不一定是两个独立的组件,就像影刀一样,它们合二为一
RPA 后端模块
有的厂家叫Commander、Command等,意思是一样的,就是用来命令这些执行器工作的模块。一般来说,它主要是基于Web系统,这部分运行在服务器上。
后台模块一般包括调度、日志、权限、控制面板、运行报表等功能,因厂家而异。
嗯,今天就分享到这里。下一次,我们来谈谈 RPA 机器人可以做哪些动作。
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-25 08:10
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后我们使用 clipboardData.GetData 方法获取放置在剪贴板上的文本并将其存储在变量 strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。 查看全部
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后我们使用 clipboardData.GetData 方法获取放置在剪贴板上的文本并将其存储在变量 strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。
trackingthewebwithjavascript火狐浏览器的话firebug就能抓取页面采集成excel
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-01 07:01
vb抓取网页内容,百度的one爬虫就可以抓取,然后粘贴到自己的网站内做排序。
我推荐你安装fiddler,电脑安装了免费版就可以轻松的抓取的所有内容,抓取后你就可以粘贴到你自己的网站上了。
trackingthewebwithjavascript
火狐浏览器的话firebug就能抓取html页面,采集成excel
telegram
用浏览器地址栏右键开始抓取
tripadvisor上有些不错的国外网站
webgame初始化(豆瓣)
看看下面这个视频,里面给出了非常多的网站开始并抓取。
xss&sql注入的话需要在xss完成了,可以再用sql注入的方式抓取,还可以用webgame开始并抓取新的网站,当然写写sql程序也是非常好的。
thewebmastersproject
<p>也没有必要webgame初始化,用extension就好。刚开始学习用webgateway完全没有问题,模仿就很好。不用考虑抓取具体页面内容,实现开发语言和抓取语言相同就行。第一步,clone 查看全部
trackingthewebwithjavascript火狐浏览器的话firebug就能抓取页面采集成excel
vb抓取网页内容,百度的one爬虫就可以抓取,然后粘贴到自己的网站内做排序。
我推荐你安装fiddler,电脑安装了免费版就可以轻松的抓取的所有内容,抓取后你就可以粘贴到你自己的网站上了。
trackingthewebwithjavascript
火狐浏览器的话firebug就能抓取html页面,采集成excel
telegram
用浏览器地址栏右键开始抓取
tripadvisor上有些不错的国外网站
webgame初始化(豆瓣)
看看下面这个视频,里面给出了非常多的网站开始并抓取。
xss&sql注入的话需要在xss完成了,可以再用sql注入的方式抓取,还可以用webgame开始并抓取新的网站,当然写写sql程序也是非常好的。
thewebmastersproject
<p>也没有必要webgame初始化,用extension就好。刚开始学习用webgateway完全没有问题,模仿就很好。不用考虑抓取具体页面内容,实现开发语言和抓取语言相同就行。第一步,clone
vb抓取网页内容(学习人工智能,你不可缺少的 Python 书单,一份强大的礼物! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-17 05:14
)
本书以培养读者像计算机科学家一样思考的方式教授 Python 语言编程。贯穿全书的主体是如何思考、设计和开发方法,而具体的编程语言只是提供了一个方便介绍具体场景的媒介。不是一本关于语言的书,而是一本关于编程思想的书。不同于其他编程和设计语言书籍,它不拘泥于语言细节,而是尝试从初学者的角度出发,用生动的例子和丰富的练习来引导读者变得更好。
高级 Python
Python 高级编程(第 2 版)”
作者:[波兰] Michał Jaworski (Jaworski)、[法国] Tarek Ziadé (Ryder)
本书以Python3.5版本讲解,通过13章的内容,深入揭示Python编程的高级技巧。本书首先介绍了Python语言及其社区的现状,包括Python语法、命名规则、Python包编写、部署代码、扩展程序开发、管理代码、文档、测试开发、代码优化、并发编程、设计模式等。重要的话题得到全面系统的解释。
本书适合希望进一步提高Python编程技能的读者,也适合对Python编程感兴趣的读者。全书结合典型和实用的开发案例,帮助读者创建高性能、可靠、可维护的Python应用程序。
《Python 高性能编程》
作者: Micha Gorelick, Ian Ozsvald
本书共12章,围绕如何优化代码,加快实际应用运行速度进行了详细讲解。本书主要涵盖以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和向量计算、并发、集群和工作队列等。最后,通过一系列真实的案例,展示应用场景中需要注意的问题。
本书适合初学者和中级Python程序员,有一定Python语言基础,想要进阶和提高的读者
《Python 极客项目编程》
作者:[美国] Mahesh Venkitachalam
Python 是一种具有动态数据类型的解释型、面向对象的高级编程语言。通过 Python 编程,我们能够解决现实生活中的许多任务。
本书通过 14 个有趣的项目帮助并鼓励读者探索 Python 编程的世界。全书共14章,分别介绍了一些通过Python编程实现的有趣项目,包括解析iTunes播放列表、模拟人造生命、创建ASCII艺术图像、拼接照片、生成3D立体图像、创建粒子模拟烟花喷泉效果、使用 Python 和 Arduino 和 Raspberry Pi 等硬件实现立体 Raycasting 算法和电子项目。本书没有介绍Python语言的基础知识,而是通过一系列非简单的项目,展示了如何使用Python解决各种实际问题,以及如何使用一些流行的Python库。
《Python 核心编程(第 3 版)》
作者:【美国】韦斯利·春(Wesley Chun)
本书是经典畅销书《Python核心编程(第二版)》的全新升级版,分为3部分。第一部分解释了Python的一些一般应用,包括正则表达式、网络编程、Internet客户端编程、多线程编程、GUI编程、数据库编程、Microsoft Office编程和扩展Python。第 2 部分涵盖与 Web 开发相关的主题,包括 Web 客户端和服务器、与 CGI 和 WSGI 相关的 Web 编程、Diango Web 框架、云计算和高级 Web 服务。第 3 部分是补充/实验章节,涵盖文本处理等内容。
本书适合有一定经验的Python开发者阅读。
Python机器学习——预测分析核心算法”
作者:【美国】迈克尔·鲍尔斯(Bowles)
在学习和研究机器学习时,机器学习的新手在面对令人眼花缭乱的算法时往往会不知所措。本书帮助读者从算法和Python语言实现的角度理解机器学习。
本书侧重于两个核心“算法族”,惩罚线性回归和集成方法,并使用代码示例来演示使用相关算法的原理。全书共分7章,详细讨论了预测模型的两类核心算法、预测模型的构建、惩罚性线性回归和集成方法的具体应用与实现。
Python机器学习实用指南
作者:[美国] Alexander T. Combs
机器学习是近年来越来越火的一个领域,Python语言经过一段时间的发展逐渐成为主流编程语言之一。本书结合机器学习和Python语言两大热门领域,利用两大核心机器学习算法,最大限度地发挥Python语言在数据分析方面的优势。
全书共有10章。第1章讲解Python机器学习生态,其余9章介绍很多机器学习相关的算法,包括各种分类算法、数据可视化技术、推荐引擎等,主要包括公寓机器学习、机票、IPO市场、新闻提要、内容推广、股票市场、图像、聊天机器人和推荐引擎。
《掌握 Python 自然语言处理》
作者:【印度】Deepti Chopra , Nisheeth Joshi , Iti Mathur
自然语言处理是与人机交互相关的计算语言学和人工智能领域之一。
本书是学习自然语言处理的综合学习指南,展示了如何在 Python 中实现各种 NLP 任务,以帮助读者创建基于现实生活应用程序的项目。本书共10章,涵盖字符串操作、统计语言建模、形态学、词性标注、语法解析、语义分析、情感分析、信息检索、语篇分析、NLP系统评估等主题。
本书适合熟悉Python语言,对自然语言处理开发有一定了解和兴趣的读者。
Python 数据科学指南
作者:【印度】Gopi Subramanian
60 多个实用的开发技巧,可帮助您探索 Python 及其强大的数据科学功能
作为一门高级编程语言,Python以其简单性、可读性和可扩展性成为编程领域备受推崇的语言,成为数据科学家的首选之一。
本书详细介绍了Python在数据科学中的使用,涵盖了数据探索、数据分析与挖掘、机器学习和大规模机器学习等主题。每一章都为读者提供了足够的数学知识和代码示例,以了解不同深度的算法函数,帮助读者更好地掌握每个知识点。
这本书结构合理,收录的示例对数据科学新手和经验丰富的数据科学家都有益。
“用 Python 编写网络爬虫”
作者:【澳大利亚】理查德·劳森(Richard Lawson)
本书讲解了如何使用Python编写网络爬虫程序,包括网络爬虫简介、页面爬取数据的三种方法、从缓存中提取数据、使用多线程和进程进行并发爬取,以及如何爬取数据。从动态页面获取内容,与表单交互,处理页面中的验证码问题,并使用Scarpy和Portia进行数据抓取,最后使用本书介绍的数据抓取技术对比了几个真实的网站已经抓取到帮助读者学习和使用书中介绍的技术。
本书适合有一定Python编程经验,对爬虫技术感兴趣的读者。
“贝叶斯思维:统计建模的 Python 方法” 查看全部
vb抓取网页内容(学习人工智能,你不可缺少的 Python 书单,一份强大的礼物!
)
本书以培养读者像计算机科学家一样思考的方式教授 Python 语言编程。贯穿全书的主体是如何思考、设计和开发方法,而具体的编程语言只是提供了一个方便介绍具体场景的媒介。不是一本关于语言的书,而是一本关于编程思想的书。不同于其他编程和设计语言书籍,它不拘泥于语言细节,而是尝试从初学者的角度出发,用生动的例子和丰富的练习来引导读者变得更好。
高级 Python
Python 高级编程(第 2 版)”
作者:[波兰] Michał Jaworski (Jaworski)、[法国] Tarek Ziadé (Ryder)
本书以Python3.5版本讲解,通过13章的内容,深入揭示Python编程的高级技巧。本书首先介绍了Python语言及其社区的现状,包括Python语法、命名规则、Python包编写、部署代码、扩展程序开发、管理代码、文档、测试开发、代码优化、并发编程、设计模式等。重要的话题得到全面系统的解释。
本书适合希望进一步提高Python编程技能的读者,也适合对Python编程感兴趣的读者。全书结合典型和实用的开发案例,帮助读者创建高性能、可靠、可维护的Python应用程序。
《Python 高性能编程》
作者: Micha Gorelick, Ian Ozsvald
本书共12章,围绕如何优化代码,加快实际应用运行速度进行了详细讲解。本书主要涵盖以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和向量计算、并发、集群和工作队列等。最后,通过一系列真实的案例,展示应用场景中需要注意的问题。
本书适合初学者和中级Python程序员,有一定Python语言基础,想要进阶和提高的读者
《Python 极客项目编程》
作者:[美国] Mahesh Venkitachalam
Python 是一种具有动态数据类型的解释型、面向对象的高级编程语言。通过 Python 编程,我们能够解决现实生活中的许多任务。
本书通过 14 个有趣的项目帮助并鼓励读者探索 Python 编程的世界。全书共14章,分别介绍了一些通过Python编程实现的有趣项目,包括解析iTunes播放列表、模拟人造生命、创建ASCII艺术图像、拼接照片、生成3D立体图像、创建粒子模拟烟花喷泉效果、使用 Python 和 Arduino 和 Raspberry Pi 等硬件实现立体 Raycasting 算法和电子项目。本书没有介绍Python语言的基础知识,而是通过一系列非简单的项目,展示了如何使用Python解决各种实际问题,以及如何使用一些流行的Python库。
《Python 核心编程(第 3 版)》
作者:【美国】韦斯利·春(Wesley Chun)
本书是经典畅销书《Python核心编程(第二版)》的全新升级版,分为3部分。第一部分解释了Python的一些一般应用,包括正则表达式、网络编程、Internet客户端编程、多线程编程、GUI编程、数据库编程、Microsoft Office编程和扩展Python。第 2 部分涵盖与 Web 开发相关的主题,包括 Web 客户端和服务器、与 CGI 和 WSGI 相关的 Web 编程、Diango Web 框架、云计算和高级 Web 服务。第 3 部分是补充/实验章节,涵盖文本处理等内容。
本书适合有一定经验的Python开发者阅读。
Python机器学习——预测分析核心算法”
作者:【美国】迈克尔·鲍尔斯(Bowles)
在学习和研究机器学习时,机器学习的新手在面对令人眼花缭乱的算法时往往会不知所措。本书帮助读者从算法和Python语言实现的角度理解机器学习。
本书侧重于两个核心“算法族”,惩罚线性回归和集成方法,并使用代码示例来演示使用相关算法的原理。全书共分7章,详细讨论了预测模型的两类核心算法、预测模型的构建、惩罚性线性回归和集成方法的具体应用与实现。
Python机器学习实用指南
作者:[美国] Alexander T. Combs
机器学习是近年来越来越火的一个领域,Python语言经过一段时间的发展逐渐成为主流编程语言之一。本书结合机器学习和Python语言两大热门领域,利用两大核心机器学习算法,最大限度地发挥Python语言在数据分析方面的优势。
全书共有10章。第1章讲解Python机器学习生态,其余9章介绍很多机器学习相关的算法,包括各种分类算法、数据可视化技术、推荐引擎等,主要包括公寓机器学习、机票、IPO市场、新闻提要、内容推广、股票市场、图像、聊天机器人和推荐引擎。
《掌握 Python 自然语言处理》
作者:【印度】Deepti Chopra , Nisheeth Joshi , Iti Mathur
自然语言处理是与人机交互相关的计算语言学和人工智能领域之一。
本书是学习自然语言处理的综合学习指南,展示了如何在 Python 中实现各种 NLP 任务,以帮助读者创建基于现实生活应用程序的项目。本书共10章,涵盖字符串操作、统计语言建模、形态学、词性标注、语法解析、语义分析、情感分析、信息检索、语篇分析、NLP系统评估等主题。
本书适合熟悉Python语言,对自然语言处理开发有一定了解和兴趣的读者。
Python 数据科学指南
作者:【印度】Gopi Subramanian
60 多个实用的开发技巧,可帮助您探索 Python 及其强大的数据科学功能
作为一门高级编程语言,Python以其简单性、可读性和可扩展性成为编程领域备受推崇的语言,成为数据科学家的首选之一。
本书详细介绍了Python在数据科学中的使用,涵盖了数据探索、数据分析与挖掘、机器学习和大规模机器学习等主题。每一章都为读者提供了足够的数学知识和代码示例,以了解不同深度的算法函数,帮助读者更好地掌握每个知识点。
这本书结构合理,收录的示例对数据科学新手和经验丰富的数据科学家都有益。
“用 Python 编写网络爬虫”
作者:【澳大利亚】理查德·劳森(Richard Lawson)
本书讲解了如何使用Python编写网络爬虫程序,包括网络爬虫简介、页面爬取数据的三种方法、从缓存中提取数据、使用多线程和进程进行并发爬取,以及如何爬取数据。从动态页面获取内容,与表单交互,处理页面中的验证码问题,并使用Scarpy和Portia进行数据抓取,最后使用本书介绍的数据抓取技术对比了几个真实的网站已经抓取到帮助读者学习和使用书中介绍的技术。
本书适合有一定Python编程经验,对爬虫技术感兴趣的读者。
“贝叶斯思维:统计建模的 Python 方法”
vb抓取网页内容(2.-java使用浏览器内核模拟浏览器操作驱动包下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-04-09 15:01
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
因为有些网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,所以此时无法通过httpclient的方式获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序?
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。windows和linux平台下,需要分别指定对应的驱动路径。?
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。 查看全部
vb抓取网页内容(2.-java使用浏览器内核模拟浏览器操作驱动包下载地址)
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
因为有些网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,所以此时无法通过httpclient的方式获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序?
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。windows和linux平台下,需要分别指定对应的驱动路径。?
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。
vb抓取网页内容(如何使多张图片滑动不卡顿,Web端大量图片同时加载问题的优化方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-09 14:26
主控开发(一)Jetson nano环境搭建_胜者为王,自然是。博客-程序员宝宝_jetson nano开发环境
Jetson nano环境设置:///embedded/downloads1、基本设置1.1、不用密码使用sudo1.打开终端输入命令:sudo visudo2. 在文档最后一行添加如下内容: xxx ALL=(ALL) NOPASSWD:ALLjetson ALL=(ALL) NOPASSWD:ALL 保存退出,其中xxx为登录用户名1.2
Matlab保存图片程序,Matlab保存图片的5种方法 - 程序员大本营
不用说,Link 的绘图和可视化功能在业界是家喻户晓的。Matlab提供了丰富的绘图功能,例如ez**系列的简单绘图功能,surf和mesh系列的数十种数值绘图功能等。另外,其他专业工具箱也提供专业的绘图功能,值得初学者学习。很久。今天我只是讨论如何通过Matlab保存这些图......
html如何让多张图片滑动不卡顿,web端加载大量图片同时卡顿的优化方案 - 程序员大本营
案例 由于业务需要,需求方需要实现一个同时加载大量图片的需求。在实现这个需求的过程中,可能会有很多坑。在这里,小编也总结了一些优化方案,大家可以一起来看看。具体场景是描述如何解决问题。我们先声明一下。问题是什么?需求的主要内容是在某个页面上显示1~1000张200~500k大小的图片。好消息是这些图像来自本地硬盘而不是互联网。(不然这个问题会变成优化网络....)由于踩坑的过程不是纯前端项目,...
电脑安装双系统后,系统时间不一致的解决方法 - 程序员大本营
在Ubuntu终端运行sudo timedatectl set-local-rtc 1,下次进入Windows就可以看到正确的时间了。参考博文:电脑安装双系统后,电脑时间不一致,相差8小时。问题重现于:
动态路由 - RIP_weixin_34293911的博客 - 程序员宝贝
实验动态路由-RIP实验目标为三层交换机和路由器配置静态路由;删除第 3 层交换机和路由器的静态路由;为三层交换机和路由器配置动态路由实验环境实验步骤一、配置IP地址二、在switch5上创建vlan2、vlan3,将f0/1添加到vlan2,将f0/2添加到vlan3 ,设置f0/3为trunk模式三、在三层交换机上创建vlan2、vlan3在上面,打开三层...
JAVA正则表达式:Pattern类和Matcher类详解 - 程序员大本营
java.util.regex 是一个类库包,它使用正则表达式自定义的模式来匹配字符串。它包括两个类:Pattern 和 Matcher Pattern 一个 Pattern 是一个正则表达式的编译表达式模式。Matcher Matcher 对象是一个状态机,它根据 Pattern 对象作为匹配模式对字符串执行匹配检查。首先,一个 Pattern 实例自定义一个正则表达式 warp,它使用类似于 PERL 的语法 查看全部
vb抓取网页内容(如何使多张图片滑动不卡顿,Web端大量图片同时加载问题的优化方案)
主控开发(一)Jetson nano环境搭建_胜者为王,自然是。博客-程序员宝宝_jetson nano开发环境
Jetson nano环境设置:///embedded/downloads1、基本设置1.1、不用密码使用sudo1.打开终端输入命令:sudo visudo2. 在文档最后一行添加如下内容: xxx ALL=(ALL) NOPASSWD:ALLjetson ALL=(ALL) NOPASSWD:ALL 保存退出,其中xxx为登录用户名1.2
Matlab保存图片程序,Matlab保存图片的5种方法 - 程序员大本营
不用说,Link 的绘图和可视化功能在业界是家喻户晓的。Matlab提供了丰富的绘图功能,例如ez**系列的简单绘图功能,surf和mesh系列的数十种数值绘图功能等。另外,其他专业工具箱也提供专业的绘图功能,值得初学者学习。很久。今天我只是讨论如何通过Matlab保存这些图......
html如何让多张图片滑动不卡顿,web端加载大量图片同时卡顿的优化方案 - 程序员大本营
案例 由于业务需要,需求方需要实现一个同时加载大量图片的需求。在实现这个需求的过程中,可能会有很多坑。在这里,小编也总结了一些优化方案,大家可以一起来看看。具体场景是描述如何解决问题。我们先声明一下。问题是什么?需求的主要内容是在某个页面上显示1~1000张200~500k大小的图片。好消息是这些图像来自本地硬盘而不是互联网。(不然这个问题会变成优化网络....)由于踩坑的过程不是纯前端项目,...
电脑安装双系统后,系统时间不一致的解决方法 - 程序员大本营
在Ubuntu终端运行sudo timedatectl set-local-rtc 1,下次进入Windows就可以看到正确的时间了。参考博文:电脑安装双系统后,电脑时间不一致,相差8小时。问题重现于:
动态路由 - RIP_weixin_34293911的博客 - 程序员宝贝
实验动态路由-RIP实验目标为三层交换机和路由器配置静态路由;删除第 3 层交换机和路由器的静态路由;为三层交换机和路由器配置动态路由实验环境实验步骤一、配置IP地址二、在switch5上创建vlan2、vlan3,将f0/1添加到vlan2,将f0/2添加到vlan3 ,设置f0/3为trunk模式三、在三层交换机上创建vlan2、vlan3在上面,打开三层...
JAVA正则表达式:Pattern类和Matcher类详解 - 程序员大本营
java.util.regex 是一个类库包,它使用正则表达式自定义的模式来匹配字符串。它包括两个类:Pattern 和 Matcher Pattern 一个 Pattern 是一个正则表达式的编译表达式模式。Matcher Matcher 对象是一个状态机,它根据 Pattern 对象作为匹配模式对字符串执行匹配检查。首先,一个 Pattern 实例自定义一个正则表达式 warp,它使用类似于 PERL 的语法
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-09 14:24
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。 查看全部
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。
vb抓取网页内容(EndSub显示GoogleChrome显示的相同代码。怎么了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-08 04:09
我正在尝试创建一个 Windows 桌面应用程序,该应用程序将转到指定站点并从该站点获取 HTML。我发现了很多这样做的例子,但由于某种原因,它不适用于传统的 Google 协作平台页面。该程序需要在 Google 协作平台页面的正文中找到简单的文本。当您“查看页面源代码”时,它不会显示与 Google Chrome 显示相同的代码。怎么了?
<p>Public Sub Scrape(strURL)
Try
Dim wrResponse As WebResponse
Dim wrRequest As WebRequest = HttpWebRequest.Create(strURL)
textScrape = "Extracting..." & Environment.NewLine
wrResponse = wrRequest.GetResponse()
Using sr As New StreamReader(wrResponse.GetResponseStream())
strOutput = sr.ReadToEnd()
' Close and clean up the StreamReader
sr.Close()
End Using
textScrape = strOutput
'Formatting Techniques
' Remove Doctype ( HTML 5 )
strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Tags
' strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "]*>", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, " 查看全部
vb抓取网页内容(EndSub显示GoogleChrome显示的相同代码。怎么了?)
我正在尝试创建一个 Windows 桌面应用程序,该应用程序将转到指定站点并从该站点获取 HTML。我发现了很多这样做的例子,但由于某种原因,它不适用于传统的 Google 协作平台页面。该程序需要在 Google 协作平台页面的正文中找到简单的文本。当您“查看页面源代码”时,它不会显示与 Google Chrome 显示相同的代码。怎么了?
<p>Public Sub Scrape(strURL)
Try
Dim wrResponse As WebResponse
Dim wrRequest As WebRequest = HttpWebRequest.Create(strURL)
textScrape = "Extracting..." & Environment.NewLine
wrResponse = wrRequest.GetResponse()
Using sr As New StreamReader(wrResponse.GetResponseStream())
strOutput = sr.ReadToEnd()
' Close and clean up the StreamReader
sr.Close()
End Using
textScrape = strOutput
'Formatting Techniques
' Remove Doctype ( HTML 5 )
strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Tags
' strOutput = Regex.Replace(strOutput, "", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "]*>", "")
' Remove HTML Comments
' strOutput = Regex.Replace(strOutput, "", "")
' Remove Script Tags
' strOutput = Regex.Replace(strOutput, "
vb抓取网页内容(vb抓取网页内容实际上是实现可见性校验的一种手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-07 08:01
vb抓取网页内容实际上是实现可见性校验的一种手段。你可以简单的认为:form中prefix+name=目标url的路径来确定网页抓取的路径。如:http/1.1200okfetch--showvariables-request-specvariablehttp/1.1200okprefix+"/"=/fetch--errors-options=section1.htmlassert(http/1.1200ok)当然,为了获取内容,你可以写个db给你抓包,直接发给你。
不需要。然后你用php反向代理一下,
<p>对于不会wordpress的人,是需要的。d3的点击爬取功能做完info.html(不带数据)后有:使用yamltemplate定义页面内容;url参数填写`/vw`或`/vh`,字段详情请参考``页面;使用`phpdefine`定义页面目录;(在info.html加载的时候点击开始爬取即可);使用`phpdefine'vw'或`phpdefine'vh'css属性提前定义头部内容,页面加载时提取;使用`phpdefine'vw'或`phpdefine'vh'class属性爬取在vw或vh头部可见内容;使用`phpdefine'xxx''xxx'定义高亮文本定义获取的html文本标签;使用`phpdefine'prefix''xxx'提前定义在中提取自己想要的内容;将目录内所有下的html文本内容生成一个新的标签,这个标签用于告诉php获取需要的内容;点击获取[/dom>后,将/vw/vh去掉即可;访问该链接,获取/vw/vh>下的所有文本,并再次点击获取/vw/vh>下的所有文本,并再次点击获取;访问该链接,获取/vw/vh 查看全部
vb抓取网页内容(vb抓取网页内容实际上是实现可见性校验的一种手段)
vb抓取网页内容实际上是实现可见性校验的一种手段。你可以简单的认为:form中prefix+name=目标url的路径来确定网页抓取的路径。如:http/1.1200okfetch--showvariables-request-specvariablehttp/1.1200okprefix+"/"=/fetch--errors-options=section1.htmlassert(http/1.1200ok)当然,为了获取内容,你可以写个db给你抓包,直接发给你。
不需要。然后你用php反向代理一下,
<p>对于不会wordpress的人,是需要的。d3的点击爬取功能做完info.html(不带数据)后有:使用yamltemplate定义页面内容;url参数填写`/vw`或`/vh`,字段详情请参考``页面;使用`phpdefine`定义页面目录;(在info.html加载的时候点击开始爬取即可);使用`phpdefine'vw'或`phpdefine'vh'css属性提前定义头部内容,页面加载时提取;使用`phpdefine'vw'或`phpdefine'vh'class属性爬取在vw或vh头部可见内容;使用`phpdefine'xxx''xxx'定义高亮文本定义获取的html文本标签;使用`phpdefine'prefix''xxx'提前定义在中提取自己想要的内容;将目录内所有下的html文本内容生成一个新的标签,这个标签用于告诉php获取需要的内容;点击获取[/dom>后,将/vw/vh去掉即可;访问该链接,获取/vw/vh>下的所有文本,并再次点击获取/vw/vh>下的所有文本,并再次点击获取;访问该链接,获取/vw/vh
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-06 13:20
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
查看全部
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
vb抓取网页内容(python爬虫开发实战》抓取网页内容:vb抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-01 21:06
vb抓取网页内容:vb抓取网页内容:kwapi+xmlhttprequest:xmlhttprequestvsselenium3:kwapi方法不错,代码少,性能好,部署方便。selenium4:selenium4支持多线程和异步请求,把selenium3的问题都解决了。scrapy爬虫框架:monkey,vue,element,requests,webui框架:axios。
利用pythonwebdriver写了一个抓包工具。利用它可以抓到很多网页和服务器请求的内容,它是python语言实现的,你可以下载进行阅读和学习,推荐看看这本书:《python爬虫开发实战》,挺不错的,看看。
不知道楼主现在写到哪一步了,如果楼主已经能够熟练的用到了selenium并且抓取到每一个网页并且还能自己写爬虫的话那么应该很厉害了吧。不过国内python网页抓取的库或许只有selenium了,楼主可以跟着教程熟练的掌握其他几个。
可以自己动手练练,
泻药,你所说的网页是什么网页呢?还有,
python没有很难的,
用一个主机模拟客户端向服务器发包,这个模拟客户端设定一个时间比如1小时,在这一小时时间之内先通过网络反馈自己,然后服务器回应是否服务成功,这样实现的话安全性会比requests+cookie+get的方式好很多,从而保证爬虫的安全性。 查看全部
vb抓取网页内容(python爬虫开发实战》抓取网页内容:vb抓取)
vb抓取网页内容:vb抓取网页内容:kwapi+xmlhttprequest:xmlhttprequestvsselenium3:kwapi方法不错,代码少,性能好,部署方便。selenium4:selenium4支持多线程和异步请求,把selenium3的问题都解决了。scrapy爬虫框架:monkey,vue,element,requests,webui框架:axios。
利用pythonwebdriver写了一个抓包工具。利用它可以抓到很多网页和服务器请求的内容,它是python语言实现的,你可以下载进行阅读和学习,推荐看看这本书:《python爬虫开发实战》,挺不错的,看看。
不知道楼主现在写到哪一步了,如果楼主已经能够熟练的用到了selenium并且抓取到每一个网页并且还能自己写爬虫的话那么应该很厉害了吧。不过国内python网页抓取的库或许只有selenium了,楼主可以跟着教程熟练的掌握其他几个。
可以自己动手练练,
泻药,你所说的网页是什么网页呢?还有,
python没有很难的,
用一个主机模拟客户端向服务器发包,这个模拟客户端设定一个时间比如1小时,在这一小时时间之内先通过网络反馈自己,然后服务器回应是否服务成功,这样实现的话安全性会比requests+cookie+get的方式好很多,从而保证爬虫的安全性。
vb抓取网页内容(问题描述29岁程序员,3月因学历无情被辞!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 08:04
本文介绍如何在python中使用Selenium WebDriver获取整个网页源的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!
问题描述
这位29岁的程序员因受教育于3月被无情辞职!
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
感谢您的帮助
推荐答案
你的 WebDriver 对象应该有属性,所以对于 Firefox 它看起来像
你的 WebDriver 对象应该有一个 page_source 属性,所以对于 Firefox 它看起来像
from selenium import webdriver
driver = webdriver.Firefox()
driver.page_source
本文文章介绍了如何在python中使用Selenium WebDriver获取整个网页源码。希望我们推荐的答案对您有所帮助,也希望您多多支持IT之家!
上岸,阿里云! 查看全部
vb抓取网页内容(问题描述29岁程序员,3月因学历无情被辞!)
本文介绍如何在python中使用Selenium WebDriver获取整个网页源的处理方法。对大家解决问题有一定的参考价值。有需要的朋友,和小编一起学习吧!
问题描述
这位29岁的程序员因受教育于3月被无情辞职!
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
我在 python 中使用 Selenium WebDriver,我想在一个变量中检索网页的整个页面源(类似于许多网络浏览器提供的用于获取页面源的右键单击选项)。
感谢您的帮助
推荐答案
你的 WebDriver 对象应该有属性,所以对于 Firefox 它看起来像
你的 WebDriver 对象应该有一个 page_source 属性,所以对于 Firefox 它看起来像
from selenium import webdriver
driver = webdriver.Firefox()
driver.page_source
本文文章介绍了如何在python中使用Selenium WebDriver获取整个网页源码。希望我们推荐的答案对您有所帮助,也希望您多多支持IT之家!
上岸,阿里云!
vb抓取网页内容(如何将url##x27;在visualbasic中是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-28 05:23
如何转换网址'; 什么是visualbasic?
网址
如何转换网址'; 什么是visualbasic?,,url,,Url,我基本上是这方面的新手,我自己也弄不明白。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我需要任何帮助,你也可以
我基本上是这方面的新手,我自己也无法弄清楚。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我会很感激任何帮助,也可以随意选择。谢谢,这么简单的问题很抱歉
你需要的是连接字符串
所以说你有
Dim url as String
url = "http://www.minecraft.net/haspaid.jsp?user=" + textbox1.Text
有些人喜欢 & 而不是 +。两者都做同样的事情。但是您需要确保在这两种情况下两个变量都是字符串
从您的问题中不确定您想对链接做什么。但我希望这能让你走上正轨 查看全部
vb抓取网页内容(如何将url##x27;在visualbasic中是什么?(图))
如何转换网址'; 什么是visualbasic?
网址
如何转换网址'; 什么是visualbasic?,,url,,Url,我基本上是这方面的新手,我自己也弄不明白。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我需要任何帮助,你也可以
我基本上是这方面的新手,我自己也无法弄清楚。我的问题是如何获取现有的网址(具体来说,它是一个程序,它部分检查我的世界用户是否是高级用户,并在末尾添加一个带有指定用户名的文本框。所以它将在文本框1.Text=whateverguy123 构建链接时。我仍在做一些事情,从网页上抓取文本,看看它是“真”还是“假”,所以从技术上讲,这不是我的问题,但我会很感激任何帮助,也可以随意选择。谢谢,这么简单的问题很抱歉
你需要的是连接字符串
所以说你有
Dim url as String
url = "http://www.minecraft.net/haspaid.jsp?user=" + textbox1.Text
有些人喜欢 & 而不是 +。两者都做同样的事情。但是您需要确保在这两种情况下两个变量都是字符串
从您的问题中不确定您想对链接做什么。但我希望这能让你走上正轨
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2022-03-24 02:23
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
查看全部
vb抓取网页内容(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在微软Visual Basic中文版下做的6.0
VB可以抓取网页数据,使用的控件是Inet控件。
步骤1:点击Project-->Components,选择Microsoft Internet Transfer Control(SP6)Control.
第二步:布局界面展示
在界面中拖动对应的控件。
第三步开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
数据可以从网络数据中获取。
vb抓取网页内容( 一款处理网络数据的框架HtmlAgilityPack,(xml)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-22 23:07
一款处理网络数据的框架HtmlAgilityPack,(xml)(图)
)
HtmlAgilityPack 网页数据处理
发表于:2019/1/19 1:38
HtmlAgilityPack 网络数据处理
新的一年,新气象!祝大家新年快乐,万事如意,万事如意,身体健康!
今天我说的是一个用于处理网络数据的框架HtmlAgilityPack,
相信很多同事都因为处理网页数据和写正则表达式而一团糟。如果你使用这个框架,你会如鱼得水,释放你长久以来的复杂情绪!
介绍:
它是一个敏捷的 HTML 解析器,它构建一个读/写 DOM 并支持普通的 xpath 或 xslt(你实际上不需要了解 xpath 或 xslt 来使用它,不用担心......)。
它是一个 .NET 代码库,可让您“离线”解析 HTML 文件。
解析器对“真实世界”格式错误的 HTML 非常宽容。对象模型与 System.xml 建议的非常相似,但用于 HTML 文档(或流)。
原理:将抓取的网页转换为Dom文档模型(xml),然后进行元素搜索
动手案例:
(1)首先创建一个控制台项目learningHtmlAgilityPack
(2)选择引用右键-->点击Manage NuGet Packages-->点击Browse-->Search HtmlAgilityPack
从这里我们可以看到这里最新的稳定版本是v1.8.13 然后点击安装。
(3)安装完成后我们以百度为例获取百度搜索按钮的值
1、打开开发者工具获取百度搜索按钮的XPath路径,确认无误后进行下一步(注:Chome浏览器可以识别class、id等元素属性;Firefox会从 /head 开始查找)
2. 通过简洁的代码实现目标
using System.Net;
namespace learningHtmlAgilityPack
{
class Program
{
static void Main(string[] args)
{
//实例化常规请求方式
WebClient wc = new WebClient();
//获取网页数据
var vb = wc.DownloadData("https://www.baidu.com/");
//转码
var str = System.Text.Encoding.UTF8.GetString(vb);
//实例化 HtmlAgilityPack 对象模型
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载文档对象模型
doc.LoadHtml(str);
//获取到百度按钮节点 把我们刚刚复制的XPath粘贴上去
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("//*[@id='su']");
//获取值 1,元素名称 2,当没有该元素时返回的内容
string value = htmlnode.GetAttributeValue("value", "");
System.Console.WriteLine(value);
System.Console.ReadKey();
}
}
}
运行结果:
困难:
(1),实现多个标签的集合(每个元素通过遍历得到)
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//想怎么干就怎么搞xxxxx
}
}
(2),如果item下面有更多便签或者标签,还是这样写,但是获取第二层的时候不需要XPath//
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//HtmlAgilityPack.HtmlNode htmlnode = item.SelectSingleNode("//*[@id='su']");
HtmlAgilityPack.HtmlNodeCollection childs = item.SelectSingleNode("ul/li");
foreach(var singeitem in childs)
{
//xxxx
}
}
} 查看全部
vb抓取网页内容(
一款处理网络数据的框架HtmlAgilityPack,(xml)(图)
)
HtmlAgilityPack 网页数据处理
发表于:2019/1/19 1:38
HtmlAgilityPack 网络数据处理
新的一年,新气象!祝大家新年快乐,万事如意,万事如意,身体健康!
今天我说的是一个用于处理网络数据的框架HtmlAgilityPack,
相信很多同事都因为处理网页数据和写正则表达式而一团糟。如果你使用这个框架,你会如鱼得水,释放你长久以来的复杂情绪!
介绍:
它是一个敏捷的 HTML 解析器,它构建一个读/写 DOM 并支持普通的 xpath 或 xslt(你实际上不需要了解 xpath 或 xslt 来使用它,不用担心......)。
它是一个 .NET 代码库,可让您“离线”解析 HTML 文件。
解析器对“真实世界”格式错误的 HTML 非常宽容。对象模型与 System.xml 建议的非常相似,但用于 HTML 文档(或流)。
原理:将抓取的网页转换为Dom文档模型(xml),然后进行元素搜索
动手案例:
(1)首先创建一个控制台项目learningHtmlAgilityPack
(2)选择引用右键-->点击Manage NuGet Packages-->点击Browse-->Search HtmlAgilityPack
从这里我们可以看到这里最新的稳定版本是v1.8.13 然后点击安装。
(3)安装完成后我们以百度为例获取百度搜索按钮的值
1、打开开发者工具获取百度搜索按钮的XPath路径,确认无误后进行下一步(注:Chome浏览器可以识别class、id等元素属性;Firefox会从 /head 开始查找)
2. 通过简洁的代码实现目标
using System.Net;
namespace learningHtmlAgilityPack
{
class Program
{
static void Main(string[] args)
{
//实例化常规请求方式
WebClient wc = new WebClient();
//获取网页数据
var vb = wc.DownloadData("https://www.baidu.com/";);
//转码
var str = System.Text.Encoding.UTF8.GetString(vb);
//实例化 HtmlAgilityPack 对象模型
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
//加载文档对象模型
doc.LoadHtml(str);
//获取到百度按钮节点 把我们刚刚复制的XPath粘贴上去
HtmlAgilityPack.HtmlNode htmlnode = doc.DocumentNode.SelectSingleNode("//*[@id='su']");
//获取值 1,元素名称 2,当没有该元素时返回的内容
string value = htmlnode.GetAttributeValue("value", "");
System.Console.WriteLine(value);
System.Console.ReadKey();
}
}
}
运行结果:
困难:
(1),实现多个标签的集合(每个元素通过遍历得到)
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//想怎么干就怎么搞xxxxx
}
}
(2),如果item下面有更多便签或者标签,还是这样写,但是获取第二层的时候不需要XPath//
HtmlAgilityPack.HtmlNodeCollection collection = doc.DocumentNode.SelectNodes("//*[@id='addToCart']//div");
foreach (var item in collection)
{
if (!string.IsNullOrEmpty(item.GetAttributeValue("name", "")))
{
//HtmlAgilityPack.HtmlNode htmlnode = item.SelectSingleNode("//*[@id='su']");
HtmlAgilityPack.HtmlNodeCollection childs = item.SelectSingleNode("ul/li");
foreach(var singeitem in childs)
{
//xxxx
}
}
}
vb抓取网页内容(python语言和nlp结合得很好的学术上比如推荐系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-19 13:03
vb抓取网页内容以及ai抓取微信好友
kaldi吧。python语言和nlp结合得很好。同样功能在学术上比如推荐系统,很多都有类似nlp作用。用gaussianmixing做nlp很方便的。
想对以后python做数据挖掘这个热潮做一点预测:python数据挖掘未来发展很有想象空间。毕竟,人工智能技术的爆发,离不开大数据,离不开数据,同时数据挖掘也是一个很好的数据来源。所以,学习python数据挖掘,将来在机器学习和nlp方面会有很大的需求。
kaldi主要做的就是神经网络模型的实时微调,更进一步,就可以集成tensorflow和caffe等实现高性能,实时性强的nlp模型,找一个自己喜欢的领域,
python机器学习。kaldi可以直接用来做nlp的开发。
主流还是kaldi和sleknet等深度学习神经网络框架。如果想要好用一点,可以用tensorflow+theano开发,tensorflow和theano都比python好用,这两个框架开发都比较方便。
本人大三,看了网上的相关资料和paper,最终选择了pytorch。选择nlp主要是可以训练自己的torchvision模型,以及对自己模型的练习。
python无疑
python+tensorflow/caffe实现nlp数据挖掘
以前导师做nlp,他的感觉, 查看全部
vb抓取网页内容(python语言和nlp结合得很好的学术上比如推荐系统)
vb抓取网页内容以及ai抓取微信好友
kaldi吧。python语言和nlp结合得很好。同样功能在学术上比如推荐系统,很多都有类似nlp作用。用gaussianmixing做nlp很方便的。
想对以后python做数据挖掘这个热潮做一点预测:python数据挖掘未来发展很有想象空间。毕竟,人工智能技术的爆发,离不开大数据,离不开数据,同时数据挖掘也是一个很好的数据来源。所以,学习python数据挖掘,将来在机器学习和nlp方面会有很大的需求。
kaldi主要做的就是神经网络模型的实时微调,更进一步,就可以集成tensorflow和caffe等实现高性能,实时性强的nlp模型,找一个自己喜欢的领域,
python机器学习。kaldi可以直接用来做nlp的开发。
主流还是kaldi和sleknet等深度学习神经网络框架。如果想要好用一点,可以用tensorflow+theano开发,tensorflow和theano都比python好用,这两个框架开发都比较方便。
本人大三,看了网上的相关资料和paper,最终选择了pytorch。选择nlp主要是可以训练自己的torchvision模型,以及对自己模型的练习。
python无疑
python+tensorflow/caffe实现nlp数据挖掘
以前导师做nlp,他的感觉,
vb抓取网页内容(基于的LDAP查询ldap,,,,, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-13 17:07
)
基于 LDAP 的查询
LDAP
基于 LDAP 查询、ldap、Ldap,我正在尝试通过 VB.NET 编写一个 LDAP 查询,以提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。我如何交回以下内容以提取 homeeditory=textbox1.textPrivate Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.ClickDim rootEntry As New DirectoryEntry("fake
我正在尝试通过 VB.NET 编写一个 LDAP 查询来提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。如何返回以下内容以提取 homeeditory=textbox1.text
<p>Private Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.Click
Dim rootEntry As New DirectoryEntry("fake")
Dim srch As New DirectorySearcher(rootEntry)
srch.SearchScope = SearchScope.Subtree
srch.Filter = "(&(objectClass=user)(sAMAccountName=fake)(memberOf=CN=FAKE,OU=Citrix,OU=SecurityGroups,DC=fake,DC=fake))"
Dim res As SearchResultCollection = srch.FindAll()
If res Is Nothing OrElse res.Count 查看全部
vb抓取网页内容(基于的LDAP查询ldap,,,,,
)
基于 LDAP 的查询
LDAP
基于 LDAP 查询、ldap、Ldap,我正在尝试通过 VB.NET 编写一个 LDAP 查询,以提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。我如何交回以下内容以提取 homeeditory=textbox1.textPrivate Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.ClickDim rootEntry As New DirectoryEntry("fake
我正在尝试通过 VB.NET 编写一个 LDAP 查询来提取 homeDirectory 的属性并将其放入文本框中。下面的代码用于查询 LDAP 用户以检查他们所属的组。如何返回以下内容以提取 homeeditory=textbox1.text
<p>Private Sub Button3_Click(sender As Object, e As System.EventArgs) Handles Button3.Click
Dim rootEntry As New DirectoryEntry("fake")
Dim srch As New DirectorySearcher(rootEntry)
srch.SearchScope = SearchScope.Subtree
srch.Filter = "(&(objectClass=user)(sAMAccountName=fake)(memberOf=CN=FAKE,OU=Citrix,OU=SecurityGroups,DC=fake,DC=fake))"
Dim res As SearchResultCollection = srch.FindAll()
If res Is Nothing OrElse res.Count
vb抓取网页内容(vb抓取网页内容怎么处理客户端需要访问的内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-07 20:03
vb抓取网页内容,是抓取网页内容的开始。你想获取网页的全部内容,目标应该是全局的,这个是不会变的。这就好比你试图通过word文档搜索你所需要的结果是一样的。然后是局部内容,通过html5,js来操作,动态载入。在页面加载完成前把全局的内容做缓存,缓存有个http头信息。当用户在页面重新加载的时候就会显示出来。
根据题主的意思来说是要对html页面抓取?那么可以这样来实现。比如点击"浏览器打开",然后在浏览器里面就会搜索"个人主页",个人主页是这个页面的全局标识页,一搜索页面就会出现全局搜索结果。然后就可以获取包括"个人主页"这个页面全局的xml文件了。
调用api实现
在ie浏览器中,通过f12,往下翻就可以看到浏览器左侧的控制台,当然我是ie7浏览器,就是这个样子的:调用api,就可以做到,获取你想要的内容,
真心不知道怎么回答你这样的问题,原来我的工作中有碰到过类似的问题,w3ctcp/ip协议规范中有规定http服务器如何处理客户端需要访问的内容。(ps:这里有个需要特别注意的点,http协议分为客户端和服务器端,如果用前端去抓取,也就是http请求失败的情况下,也要将客户端的所有请求做一个解析方法,就是让客户端在客户端向服务器发起请求时做一些协议上的处理,如乱码,等等)需要说明的是浏览器本身不管输入什么,只要他是响应请求,他是会将响应重定向至对应的服务器的(eg:如果同一个请求分为多个不同的http请求,那就是多次响应,服务器会有这个报错的可能性)。
而在浏览器端针对数据量较大的情况下,如果服务器和客户端的数据量较大,一个ip可能会请求一个多个不同的服务器,也就是说,你可能会请求n个不同的服务器,这里用请求对象会比较好,换个常用语就是web服务器要有一个双栈,浏览器和服务器以及一个webserver,双栈可以用容器或者是主机,但是有双栈的话,可以很明显的看到,传过来的数据流量往往大于一个ip/webserver的最大请求流量,这也是为什么云主机在阿里云那里可以开启ip屏蔽。 查看全部
vb抓取网页内容(vb抓取网页内容怎么处理客户端需要访问的内容?)
vb抓取网页内容,是抓取网页内容的开始。你想获取网页的全部内容,目标应该是全局的,这个是不会变的。这就好比你试图通过word文档搜索你所需要的结果是一样的。然后是局部内容,通过html5,js来操作,动态载入。在页面加载完成前把全局的内容做缓存,缓存有个http头信息。当用户在页面重新加载的时候就会显示出来。
根据题主的意思来说是要对html页面抓取?那么可以这样来实现。比如点击"浏览器打开",然后在浏览器里面就会搜索"个人主页",个人主页是这个页面的全局标识页,一搜索页面就会出现全局搜索结果。然后就可以获取包括"个人主页"这个页面全局的xml文件了。
调用api实现
在ie浏览器中,通过f12,往下翻就可以看到浏览器左侧的控制台,当然我是ie7浏览器,就是这个样子的:调用api,就可以做到,获取你想要的内容,
真心不知道怎么回答你这样的问题,原来我的工作中有碰到过类似的问题,w3ctcp/ip协议规范中有规定http服务器如何处理客户端需要访问的内容。(ps:这里有个需要特别注意的点,http协议分为客户端和服务器端,如果用前端去抓取,也就是http请求失败的情况下,也要将客户端的所有请求做一个解析方法,就是让客户端在客户端向服务器发起请求时做一些协议上的处理,如乱码,等等)需要说明的是浏览器本身不管输入什么,只要他是响应请求,他是会将响应重定向至对应的服务器的(eg:如果同一个请求分为多个不同的http请求,那就是多次响应,服务器会有这个报错的可能性)。
而在浏览器端针对数据量较大的情况下,如果服务器和客户端的数据量较大,一个ip可能会请求一个多个不同的服务器,也就是说,你可能会请求n个不同的服务器,这里用请求对象会比较好,换个常用语就是web服务器要有一个双栈,浏览器和服务器以及一个webserver,双栈可以用容器或者是主机,但是有双栈的话,可以很明显的看到,传过来的数据流量往往大于一个ip/webserver的最大请求流量,这也是为什么云主机在阿里云那里可以开启ip屏蔽。
vb抓取网页内容(vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码渲染块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-03 22:03
vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码代码渲染块。具体可以到知乎搜搜,
谢邀,这个还要看你的应用的场景,如果涉及网页内容数据抓取、网站分析,还要考虑对可靠性要求的要求。一般如果是面向服务器数据抓取,可以选择用python,java等编程语言,如果是轻量级pc端应用,我觉得可以选择对应的node.js、php或者是java等,
我写的爬虫都是用c语言实现的,
我写过一个爬虫,语言和题主是一样的,
看个人选择了,java,python,c语言,php都可以。至于用什么工具,还得结合自己情况选择。
我觉得用python比较合适,语言简单,可以爬取普通网站的信息,如楼主列出的这些。如果爬取一些需要结构化数据和存储的网站,可以选择用php或者java。如果要爬取爬虫相关的网站,可以考虑java。
推荐前端代码抓取和搜索。
用c语言封装成http库比较便于语言管理,学习曲线也比较平滑,知识点不多,循环,判断,循环算法就可以看了,加上libuv,java封装好,再配合jit,可以发挥性能。如果算是开发ios或者安卓版本,我更推荐java。
smalltalk语言在html5前端如果用udp方式通信最好,从兼容性考虑不建议直接libyaml.至于其他人说用php、java等语言,只能做到解析html内容到自己的程序中,如果用http封装的话,爬取网页数据只能放在一个单独的库里(一般认为ajax是最好的,不建议用自定义的flask来封装)。
ajax无法解决的延迟和网络请求处理也是致命缺陷,一般用爬虫的初始页图片就是uuid,真要抓取其他页面数据还是得在webview上挂代理才能用。 查看全部
vb抓取网页内容(vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码渲染块)
vb抓取网页内容,移动端的话前端加载一些时间不如服务器代码代码渲染块。具体可以到知乎搜搜,
谢邀,这个还要看你的应用的场景,如果涉及网页内容数据抓取、网站分析,还要考虑对可靠性要求的要求。一般如果是面向服务器数据抓取,可以选择用python,java等编程语言,如果是轻量级pc端应用,我觉得可以选择对应的node.js、php或者是java等,
我写的爬虫都是用c语言实现的,
我写过一个爬虫,语言和题主是一样的,
看个人选择了,java,python,c语言,php都可以。至于用什么工具,还得结合自己情况选择。
我觉得用python比较合适,语言简单,可以爬取普通网站的信息,如楼主列出的这些。如果爬取一些需要结构化数据和存储的网站,可以选择用php或者java。如果要爬取爬虫相关的网站,可以考虑java。
推荐前端代码抓取和搜索。
用c语言封装成http库比较便于语言管理,学习曲线也比较平滑,知识点不多,循环,判断,循环算法就可以看了,加上libuv,java封装好,再配合jit,可以发挥性能。如果算是开发ios或者安卓版本,我更推荐java。
smalltalk语言在html5前端如果用udp方式通信最好,从兼容性考虑不建议直接libyaml.至于其他人说用php、java等语言,只能做到解析html内容到自己的程序中,如果用http封装的话,爬取网页数据只能放在一个单独的库里(一般认为ajax是最好的,不建议用自定义的flask来封装)。
ajax无法解决的延迟和网络请求处理也是致命缺陷,一般用爬虫的初始页图片就是uuid,真要抓取其他页面数据还是得在webview上挂代理才能用。
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 11:13
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源代码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p>
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?) 查看全部
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源代码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p>
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?)
vb抓取网页内容(微软早期发布的WF(WorkflowFoundation)这样一个技术框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-25 11:05
RPA 不是一项新兴技术。事实上,早期的截屏工具和工作流自动化管理软件就是 RPA 的雏形。即便是 Microsoft Office 自带的“宏”,也可以看作是 RPA 的原型。
由于这些技术,“脚本”由记录器记录或手动编写,然后运行脚本以重现操作过程。
回到现在的RPA工具,大致分为几个模块
RPA设计工具、RPA执行工具、RPA后台模块
基于 Windows Workflow Foundation 的 RPA 设计工具
这是用于开发和设计RPA流程的工具,可以理解为开发工具和IDE集成编辑器。
大部分厂商,包括UIpath、易赛奇等,都使用微软早期发布的WF(Windows Workflow Foundation)等技术框架。如果你看到一些厂商的设计师是相似的,他们都在自己对WF的修改中。它们看起来大致是这样的
为什么要使用微软的而不是自己开发呢?
快,换完就可以用了。这对于快速产品化非常重要。
缺点?微软早就停止了开发和支持。如果你想提高,自己做。另一个是,基于微软的东西,如果要跨平台,就不好办了。
完全自主研发
对此,百花齐放,各种技术层出不穷。但是,设计人员一般使用微软部门、.net 开发工具和 JS 等 Web 开发技术。比如我们上一个影刀用于两步验证登录,他的设计师长这样
但无论如何,以上都是关于设计者的界面。设计者的底层技术和驱动级技术(读取硬件,如银行的U盘、税控盘等)都无法绕过C++。
设计器的目的是记录和捕捉鼠标和键盘的动作,并将它们记录为封装在各种编程语言中的脚本。比如python,比如AutoIT,比如JS脚本,VB脚本等等。
在这里,我将重点介绍 AutoIT,它是一种古老的脚本语言。早期很多人基于AutoIT开发了一些小工具,很多RPA厂商也会基于AutoIT做封装。
我们下载最新的阿里云RPA、代码栈,观察它们的目录,可以看到AutoIT的相关文档。
不过主流厂商都会基于python制作流程记录脚本。原因是它是跨平台的,学习的人很多,而且很容易学习。
这里的重点是浏览器。我们的大部分工作都围绕着浏览器展开。因此,围绕开发版谷歌浏览器进行打包也是重点。一种基于 Chrome 的无头浏览器,通过开发人员工具捕获录音,这是主流技术。有些场景无法绕过IE,就看各家厂商的开发力度了。
RPA 执行器
这部分就是我们所说的RPA机器人。有的厂家称其为Worker,有的厂家称其为机器人。它们都是一样的,都是用来执行设计者生成的脚本。执行器没有接口,一般驻留在通知栏,在后台一直运行。
目前主流的executor在windows上执行任务。有的厂商可以在 Macos 和 linux 上执行任务,但是比起 win 来说还是太粗糙了。不过随着系统越来越web化,只要围绕浏览器进行封装,跨平台就不是什么大问题了。
基于 Chrome 的无头模式,浏览器可以在后台静默运行,甚至可以在服务器上执行。
说说手机上的执行器
目前我所看到的都只能在Android上运行,几乎没有一个是基于IOS的。这里的技术是基于Android的自动化测试技术的扩展和封装。一般在电脑上安装Android JDK、Android SDK、Appium等软件,然后用数据线连接到Android手机,通过打包好的ADB命令进行连接。手机还需要安装Appium Settings等两个APP。之后,您可以直观地捕捉和执行。大概是这样的,如下图
需要注意的是,设计者和执行器不一定是两个独立的组件,就像影刀一样,它们合二为一
RPA 后端模块
有的厂家叫Commander、Command等,意思是一样的,就是用来命令这些执行器工作的模块。一般来说,它主要是基于Web系统,这部分运行在服务器上。
后台模块一般包括调度、日志、权限、控制面板、运行报表等功能,因厂家而异。
嗯,今天就分享到这里。下一次,我们来谈谈 RPA 机器人可以做哪些动作。 查看全部
vb抓取网页内容(微软早期发布的WF(WorkflowFoundation)这样一个技术框架)
RPA 不是一项新兴技术。事实上,早期的截屏工具和工作流自动化管理软件就是 RPA 的雏形。即便是 Microsoft Office 自带的“宏”,也可以看作是 RPA 的原型。
由于这些技术,“脚本”由记录器记录或手动编写,然后运行脚本以重现操作过程。
回到现在的RPA工具,大致分为几个模块
RPA设计工具、RPA执行工具、RPA后台模块
基于 Windows Workflow Foundation 的 RPA 设计工具
这是用于开发和设计RPA流程的工具,可以理解为开发工具和IDE集成编辑器。
大部分厂商,包括UIpath、易赛奇等,都使用微软早期发布的WF(Windows Workflow Foundation)等技术框架。如果你看到一些厂商的设计师是相似的,他们都在自己对WF的修改中。它们看起来大致是这样的
为什么要使用微软的而不是自己开发呢?
快,换完就可以用了。这对于快速产品化非常重要。
缺点?微软早就停止了开发和支持。如果你想提高,自己做。另一个是,基于微软的东西,如果要跨平台,就不好办了。
完全自主研发
对此,百花齐放,各种技术层出不穷。但是,设计人员一般使用微软部门、.net 开发工具和 JS 等 Web 开发技术。比如我们上一个影刀用于两步验证登录,他的设计师长这样
但无论如何,以上都是关于设计者的界面。设计者的底层技术和驱动级技术(读取硬件,如银行的U盘、税控盘等)都无法绕过C++。
设计器的目的是记录和捕捉鼠标和键盘的动作,并将它们记录为封装在各种编程语言中的脚本。比如python,比如AutoIT,比如JS脚本,VB脚本等等。
在这里,我将重点介绍 AutoIT,它是一种古老的脚本语言。早期很多人基于AutoIT开发了一些小工具,很多RPA厂商也会基于AutoIT做封装。
我们下载最新的阿里云RPA、代码栈,观察它们的目录,可以看到AutoIT的相关文档。
不过主流厂商都会基于python制作流程记录脚本。原因是它是跨平台的,学习的人很多,而且很容易学习。
这里的重点是浏览器。我们的大部分工作都围绕着浏览器展开。因此,围绕开发版谷歌浏览器进行打包也是重点。一种基于 Chrome 的无头浏览器,通过开发人员工具捕获录音,这是主流技术。有些场景无法绕过IE,就看各家厂商的开发力度了。
RPA 执行器
这部分就是我们所说的RPA机器人。有的厂家称其为Worker,有的厂家称其为机器人。它们都是一样的,都是用来执行设计者生成的脚本。执行器没有接口,一般驻留在通知栏,在后台一直运行。
目前主流的executor在windows上执行任务。有的厂商可以在 Macos 和 linux 上执行任务,但是比起 win 来说还是太粗糙了。不过随着系统越来越web化,只要围绕浏览器进行封装,跨平台就不是什么大问题了。
基于 Chrome 的无头模式,浏览器可以在后台静默运行,甚至可以在服务器上执行。
说说手机上的执行器
目前我所看到的都只能在Android上运行,几乎没有一个是基于IOS的。这里的技术是基于Android的自动化测试技术的扩展和封装。一般在电脑上安装Android JDK、Android SDK、Appium等软件,然后用数据线连接到Android手机,通过打包好的ADB命令进行连接。手机还需要安装Appium Settings等两个APP。之后,您可以直观地捕捉和执行。大概是这样的,如下图
需要注意的是,设计者和执行器不一定是两个独立的组件,就像影刀一样,它们合二为一
RPA 后端模块
有的厂家叫Commander、Command等,意思是一样的,就是用来命令这些执行器工作的模块。一般来说,它主要是基于Web系统,这部分运行在服务器上。
后台模块一般包括调度、日志、权限、控制面板、运行报表等功能,因厂家而异。
嗯,今天就分享到这里。下一次,我们来谈谈 RPA 机器人可以做哪些动作。
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-25 08:10
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后我们使用 clipboardData.GetData 方法获取放置在剪贴板上的文本并将其存储在变量 strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。 查看全部
vb抓取网页内容(如何从剪贴板中抓取一个URL然后在浏览器中打开该Web站点?)
问:
嗨 ScriptingGuy!如何从剪贴板中获取 URL 并在浏览器中打开网站?
--CL
回答:
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将“脚本中心”URL 存储在一个名为 strURL 的变量中。然后,该脚本创建 WSHShell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
复制代码代码如下:
strURL=""
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 真是无所不能!)所以,让 IE 为我们做这些工作吧。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
Wscript.EchostrURL
在这里,我们所做的是:创建 InternetExplorer 的实例并在空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后我们使用 clipboardData.GetData 方法获取放置在剪贴板上的文本并将其存储在变量 strURL 中;这就是以下代码行的作用:
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
SetobjIE=CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL=objIE.document.parentwindow.clipboardData.GetData("文本")
objIE.退出
SetobjShell=CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优点——它不仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个网站专用的打开脚本。

