
vb抓取网页内容
vb抓取网页内容( (宁贵银)的基本操作建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-22 23:29
(宁贵银)的基本操作建议)
VB获取所述网页的所有元素
2008-12-11 22:20
VB获取所述网页的所有元素
用于获取网页所有的元素都是简单:
DIM thehtml作为新HTMLDocument的
组thehtml = wb.document
“WB =的ActiveX web浏览器
“thehtml.all就是它!
...,所以得到的所有链接,很容易! :
DIM COLLLINK AS IHTMLELEMENT采集
获取所有链接
组colllicink = thehtml.all.tags( “a”)的
对于i = 0至CollLink.Length - 1
debug.print “链接” &安培; CSTR第(i + 1)&安培; “:” &安培; colllick(I)及vbnewline
下
我相信所有的HTML元素将被征服!
----------------------------------------------- ---------------------------- ---------------------- ---------------------------- -----
privateSub webbrowser1_documentcomplete(BYVAL PDISP AsoBject,URL AS VARIANT
的foreach sform在web浏览器1. Document.Links
列表1.的AddItem sform
下
端子
----------------------------------------------- ---------------------------- ---------------------- ----------------------------
私有子webbrowser1_documentcomplete(BYVAL PDISP AS对象,URL AS VARIANT
DIM X只要
对于x = 0到web浏览器1. Document.Links.LENGTH - 1
debug.print web浏览器1. Document.Links.Item(x)的
下一个x
“长度属性,则返回元件的数量浓缩元件
debug.print “再次” &安培;网页浏览器1. Document.Links.LENGTH& “链接”。
端子
----------------------------------------------- ---------------------------- ---------------------- ---------------------
Dimdtashtmldocument
SETD = web浏览器1.文献
me.caption = dt.getlementsBytagname( “标题”)(0) .innertext“显示文本信息
[CBM666捕获“网页手柄标题和URL]
具体:
私有子的Form_Load()
INET 1.执行 “你的URL”
端子
私有子inet1_statechanged(BYVAL国家作为整数
昏暗STMP作为字符串,SHTML AS STRING
如果状态= 12然后
做
的DoEvents
STMP = INET 1.的GetChunk(102 4)
如果LEN(STMP)= 0 THEN EXIT DO
SHTML = SHTML + STMP
环
文本1.文本= SHTML
结束时,如果
端子
此实现那么快。
如何让网页标题
用VB
几乎所有使用它来完成采集任务!贡献,非常简单的降
FunctionsTrcut(strContent,strstart,strend)asstring“通用截距功能
DimstrHTML,S1,S2ASSTRING
Dimstrstart,Strendastring
strHTML中= strcontent
OnenderResuMenext
S1 = INSTR(strHTML中,strStart + LEN(strStart)
S2 = InStr函数(S1,strHTML中,StrEnd)
strcut = MID(strHTML中,S1,S2-S 1)
endfunction可写
privateSubform_load()
Dimhunzi1,Hunzi2Asstring
hunzi1 = “thisistry”
hunzi2 = strcut(hunzi1, “”“)
msgboxhunzi2
endsub 查看全部
vb抓取网页内容(
(宁贵银)的基本操作建议)
VB获取所述网页的所有元素
2008-12-11 22:20
VB获取所述网页的所有元素
用于获取网页所有的元素都是简单:
DIM thehtml作为新HTMLDocument的
组thehtml = wb.document
“WB =的ActiveX web浏览器
“thehtml.all就是它!
...,所以得到的所有链接,很容易! :
DIM COLLLINK AS IHTMLELEMENT采集
获取所有链接
组colllicink = thehtml.all.tags( “a”)的
对于i = 0至CollLink.Length - 1
debug.print “链接” &安培; CSTR第(i + 1)&安培; “:” &安培; colllick(I)及vbnewline
下
我相信所有的HTML元素将被征服!
----------------------------------------------- ---------------------------- ---------------------- ---------------------------- -----
privateSub webbrowser1_documentcomplete(BYVAL PDISP AsoBject,URL AS VARIANT
的foreach sform在web浏览器1. Document.Links
列表1.的AddItem sform
下
端子
----------------------------------------------- ---------------------------- ---------------------- ----------------------------
私有子webbrowser1_documentcomplete(BYVAL PDISP AS对象,URL AS VARIANT
DIM X只要
对于x = 0到web浏览器1. Document.Links.LENGTH - 1
debug.print web浏览器1. Document.Links.Item(x)的
下一个x
“长度属性,则返回元件的数量浓缩元件
debug.print “再次” &安培;网页浏览器1. Document.Links.LENGTH& “链接”。
端子
----------------------------------------------- ---------------------------- ---------------------- ---------------------
Dimdtashtmldocument
SETD = web浏览器1.文献
me.caption = dt.getlementsBytagname( “标题”)(0) .innertext“显示文本信息
[CBM666捕获“网页手柄标题和URL]
具体:
私有子的Form_Load()
INET 1.执行 “你的URL”
端子
私有子inet1_statechanged(BYVAL国家作为整数
昏暗STMP作为字符串,SHTML AS STRING
如果状态= 12然后
做
的DoEvents
STMP = INET 1.的GetChunk(102 4)
如果LEN(STMP)= 0 THEN EXIT DO
SHTML = SHTML + STMP
环
文本1.文本= SHTML
结束时,如果
端子
此实现那么快。
如何让网页标题
用VB
几乎所有使用它来完成采集任务!贡献,非常简单的降
FunctionsTrcut(strContent,strstart,strend)asstring“通用截距功能
DimstrHTML,S1,S2ASSTRING
Dimstrstart,Strendastring
strHTML中= strcontent
OnenderResuMenext
S1 = INSTR(strHTML中,strStart + LEN(strStart)
S2 = InStr函数(S1,strHTML中,StrEnd)
strcut = MID(strHTML中,S1,S2-S 1)
endfunction可写
privateSubform_load()
Dimhunzi1,Hunzi2Asstring
hunzi1 = “thisistry”
hunzi2 = strcut(hunzi1, “”“)
msgboxhunzi2
endsub
vb抓取网页内容(vb抓取网页内容代码等各种需要页面编辑的地方,asp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-21 06:01
vb抓取网页内容代码等各种需要页面编辑的地方,asp抓取网页的html代码和php写代码,
看一个不符合技术范的事例同样用户会画系统间的兼容接口,但目前的api也接受网页内容。目前想的最好的一种兼容方案是varnish一个管理parserhttp请求的api这样就不用再为各种dom兼容性的问题而头疼了。
网页内容除了javascript,还有html+css,asp和jsp都会涉及到ajax请求。不要问,除非你后端强大到直接ssl加密,那倒是一个选择,其他情况就要全部链接前端去做了。
php应该可以吧,或者java也可以。前端可以是所有,
这些都可以用ajax来解决,看看http协议就行。
其实前端也可以做,因为前端也可以运行于服务器端!而且你应该要做的是前端与服务器端的网络链接,而不是特指content-type什么什么的。
我也遇到这样的问题。所以。还是当前端好了。
用activex一点问题都没有
前端可以工作,但服务器端不适合。服务器不适合的主要原因在于前端的系统稳定性问题,别的还好。所以我正在做方案呢,有空可以交流,呵呵。
仅从你的问题来分析,我觉得你所碰到的问题应该是两个方面一个是浏览器对于http协议和javascript代码的兼容性,javascript代码虽然被整合到html里,但是浏览器下,特别是智能手机上面不好运行。另一个是网页属于公共内容,如果不运行javascript代码,你是无法全页面阅读的,当然如果你使用的浏览器并不兼容javascript代码,也无所谓。所以可以考虑做到xhtml+css的中转。 查看全部
vb抓取网页内容(vb抓取网页内容代码等各种需要页面编辑的地方,asp)
vb抓取网页内容代码等各种需要页面编辑的地方,asp抓取网页的html代码和php写代码,
看一个不符合技术范的事例同样用户会画系统间的兼容接口,但目前的api也接受网页内容。目前想的最好的一种兼容方案是varnish一个管理parserhttp请求的api这样就不用再为各种dom兼容性的问题而头疼了。
网页内容除了javascript,还有html+css,asp和jsp都会涉及到ajax请求。不要问,除非你后端强大到直接ssl加密,那倒是一个选择,其他情况就要全部链接前端去做了。
php应该可以吧,或者java也可以。前端可以是所有,
这些都可以用ajax来解决,看看http协议就行。
其实前端也可以做,因为前端也可以运行于服务器端!而且你应该要做的是前端与服务器端的网络链接,而不是特指content-type什么什么的。
我也遇到这样的问题。所以。还是当前端好了。
用activex一点问题都没有
前端可以工作,但服务器端不适合。服务器不适合的主要原因在于前端的系统稳定性问题,别的还好。所以我正在做方案呢,有空可以交流,呵呵。
仅从你的问题来分析,我觉得你所碰到的问题应该是两个方面一个是浏览器对于http协议和javascript代码的兼容性,javascript代码虽然被整合到html里,但是浏览器下,特别是智能手机上面不好运行。另一个是网页属于公共内容,如果不运行javascript代码,你是无法全页面阅读的,当然如果你使用的浏览器并不兼容javascript代码,也无所谓。所以可以考虑做到xhtml+css的中转。
vb抓取网页内容(网页中的密码输入框和一般不同的代码是我写的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-20 05:13
一、导言
网页中的密码输入框与一般的密码输入框不同。它没有把手。但是,通过获取IE的ihtmlinputtextelement接口,您可以获取网页中输入框(包括文本和密码输入框)的内容
VC知识库首页上运行的源代码效果图如下:
二、特定代码
VARIANT id, index;
CComPtr spDispatch;
CComQIPtr pDoc2;
CComPtr pElement;
CComPtr pElementCol;
CComPtr pFormElement;
CComPtr pInputElement;
//首先获取IWebBrowser2接口
CoInitialize(NULL); //必须要这句初始化
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp);
if (m_spSHWinds == NULL) {
if (m_spSHWinds.CreateInstance(__uuidof(SHDocVw::ShellWindows)) != S_OK) {
MessageBox("Failed");
CoUninitialize();
}
}
if (m_spSHWinds) {
int n = m_spSHWinds->GetCount();
for (int i = 0; i < n; i++) {
_variant_t v = (long)i;
IDispatchPtr spDisp = m_spSHWinds->Item(v);
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp); //生成一个IE窗口的智能指针
if (spBrowser) {//获取IHTMLDocument2接口
if (SUCCEEDED(spBrowser->get_Document( &spDispatch)))
pDoc2 = spDispatch;
if(pDoc2!=NULL) {
// AfxMessageBox("已经获取IHTMLDocument2");
if (SUCCEEDED(pDoc2->get_forms(&pElementCol))) {
// AfxMessageBox("已经获取IHTMLElementCollection");
long p=0;
if(SUCCEEDED(pElementCol->get_length(&p)))
if(p!=0) {
for(long i=0;iitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLFormElement,(void**)&pFormElement))) {
// AfxMessageBox("已经获取IHTMLFormElement");
long q=0;
if(SUCCEEDED(pFormElement->get_length(&q)))
for(long j=0;jitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLInputTextElement,(void**)&pInputElement))) {
//AfxMessageBox("已经获取IHTMLInputTextElement");
CComBSTR value;
CComBSTR type;
pInputElement->get_type(&type); //获取输入框类型(密码框还是文本框)
CString strtype(type);
strtype.MakeUpper();
if(strtype.Find("TEXT")!=-1) //获取文本框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value)+_bstr_t(" 【可能是用户名或其他需提交的内容】"));
}
else if(strtype.Find("PASSWORD")!=-1) //获取密码框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value) + _bstr_t(" 【应该是密码】"));
}
}
}
}
}
}
}
}
}
}
}
注意:因为我懒惰,本文的框架是一篇题为“如何控制ie行为”的文章。。。感谢这里的原作者,但本文的主要代码是我写的。(事实上,自己编写一个框架太简单了,但我必须去工作:(请原谅!)最好不要向作者寻求技术支持!谢谢你的阅读 查看全部
vb抓取网页内容(网页中的密码输入框和一般不同的代码是我写的)
一、导言
网页中的密码输入框与一般的密码输入框不同。它没有把手。但是,通过获取IE的ihtmlinputtextelement接口,您可以获取网页中输入框(包括文本和密码输入框)的内容
VC知识库首页上运行的源代码效果图如下:

二、特定代码
VARIANT id, index;
CComPtr spDispatch;
CComQIPtr pDoc2;
CComPtr pElement;
CComPtr pElementCol;
CComPtr pFormElement;
CComPtr pInputElement;
//首先获取IWebBrowser2接口
CoInitialize(NULL); //必须要这句初始化
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp);
if (m_spSHWinds == NULL) {
if (m_spSHWinds.CreateInstance(__uuidof(SHDocVw::ShellWindows)) != S_OK) {
MessageBox("Failed");
CoUninitialize();
}
}
if (m_spSHWinds) {
int n = m_spSHWinds->GetCount();
for (int i = 0; i < n; i++) {
_variant_t v = (long)i;
IDispatchPtr spDisp = m_spSHWinds->Item(v);
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp); //生成一个IE窗口的智能指针
if (spBrowser) {//获取IHTMLDocument2接口
if (SUCCEEDED(spBrowser->get_Document( &spDispatch)))
pDoc2 = spDispatch;
if(pDoc2!=NULL) {
// AfxMessageBox("已经获取IHTMLDocument2");
if (SUCCEEDED(pDoc2->get_forms(&pElementCol))) {
// AfxMessageBox("已经获取IHTMLElementCollection");
long p=0;
if(SUCCEEDED(pElementCol->get_length(&p)))
if(p!=0) {
for(long i=0;iitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLFormElement,(void**)&pFormElement))) {
// AfxMessageBox("已经获取IHTMLFormElement");
long q=0;
if(SUCCEEDED(pFormElement->get_length(&q)))
for(long j=0;jitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLInputTextElement,(void**)&pInputElement))) {
//AfxMessageBox("已经获取IHTMLInputTextElement");
CComBSTR value;
CComBSTR type;
pInputElement->get_type(&type); //获取输入框类型(密码框还是文本框)
CString strtype(type);
strtype.MakeUpper();
if(strtype.Find("TEXT")!=-1) //获取文本框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value)+_bstr_t(" 【可能是用户名或其他需提交的内容】"));
}
else if(strtype.Find("PASSWORD")!=-1) //获取密码框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value) + _bstr_t(" 【应该是密码】"));
}
}
}
}
}
}
}
}
}
}
}
注意:因为我懒惰,本文的框架是一篇题为“如何控制ie行为”的文章。。。感谢这里的原作者,但本文的主要代码是我写的。(事实上,自己编写一个框架太简单了,但我必须去工作:(请原谅!)最好不要向作者寻求技术支持!谢谢你的阅读
vb抓取网页内容(vb抓取网页内容最好用高级抓取抓取内容介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-14 15:03
vb抓取网页内容最好用高级抓取。比如下面这种:如果你会c++,vb也有orm框架,抓取+处理分页很快的。python也不错,可以用pyspider做web框架,然后手动导入json:importjsonimportrequestswithrequests.get(url="")asurl:print(url)print(requests.urlopen(url).read())或者使用vbscript,用一个字典(json或者字典),字典里字符串对应抓取内容,print输出抓取内容。
下面的代码是按照字典,可以手动导入各种api(比如提供lbs的gis浏览器):importjsonimportrequestsurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}ifisinstance(headers,str):jsonobject=json.loads(jsonobject)data={"user_agent":jsonobject,"value":"id=752836"}print(jsonobject)print(requests.urlopen(data).read())比如会导入webpack.config.js,会输出这样的内容:然后,importjson,就可以获取json文件了:importjsonurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}data={"user_agent":"","value":""}print(jsonobject)print(requests.urlopen(data).read())。 查看全部
vb抓取网页内容(vb抓取网页内容最好用高级抓取抓取内容介绍)
vb抓取网页内容最好用高级抓取。比如下面这种:如果你会c++,vb也有orm框架,抓取+处理分页很快的。python也不错,可以用pyspider做web框架,然后手动导入json:importjsonimportrequestswithrequests.get(url="")asurl:print(url)print(requests.urlopen(url).read())或者使用vbscript,用一个字典(json或者字典),字典里字符串对应抓取内容,print输出抓取内容。
下面的代码是按照字典,可以手动导入各种api(比如提供lbs的gis浏览器):importjsonimportrequestsurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}ifisinstance(headers,str):jsonobject=json.loads(jsonobject)data={"user_agent":jsonobject,"value":"id=752836"}print(jsonobject)print(requests.urlopen(data).read())比如会导入webpack.config.js,会输出这样的内容:然后,importjson,就可以获取json文件了:importjsonurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}data={"user_agent":"","value":""}print(jsonobject)print(requests.urlopen(data).read())。
vb抓取网页内容( WebPages如何创建布局一致的网站?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-14 10:01
WebPages如何创建布局一致的网站?(一))
ASP.NET 网页-页面布局
使用网页,可以轻松创建具有一致布局的 网站。
一致的外观
在网上,你会发现很多网站,外观都一模一样:
通过网页,这些可以有效地实现。您可以在单独的文件中获取可重复使用的代码块(内容块),例如页眉和页脚。
您还可以使用布局模板(布局文件)为所有页面定义一致的布局。
内容块
许多网站 都有需要在每个页面上显示的内容(例如页眉和页脚)。
对于网页,您可以使用@RenderPage() 方法从不同文件导入内容。
内容块(来自另一个文件)可以在网页的任何位置输入,并且可以收录文本、标记和代码,就像任何常规网页一样。
使用常见的页眉和页脚将节省大量工作。您不必在每个页面中都写相同的内容,当您更改页眉或页脚文件时,所有页面中的内容都会更新。
代码如下:
示例
@RenderPage("header.cshtml")
Hello Web Pages
<p>This is a paragraph
@RenderPage("footer.cshtml")
</p>
运行示例
使用布局页面
在前面的内容中,您已经看到在多个页面上引用相同的内容是多么容易。
另一种创建一致外观的方法是使用布局页面。布局页面收录页面的结构,而不是内容。当网页(内容页)链接到布局页面时,会根据布局页面(模板)显示。
布局页面与普通网页类似,但会在引用内容页面的地方调用@RenderBody() 方法。
每个内容页面都必须以 Layout 指令开头。
代码如下:
布局网页:
<p>This is header text
@RenderBody()
© 2012 W3School. All rights reserved.
</p>
任何网页:
@{Layout="Layout.cshtml";}
Welcome to W3Schools
<p>
Lorem ipsum dolor sit amet, consectetur adipisicing elit,sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud
exercitation ullamco laborisnisi ut aliquip ex ea commodo consequat.
</p>
运行示例
不要重复自己
通过内容块和布局页面这两个 ASP.NET 工具,您可以为您的 Web 应用程序设置一致的外观。
这些工具将为您节省大量工作,因为您不必在所有页面上重复相同的信息。集中标记、样式和代码使网络应用程序更易于管理和维护。
防止代码泄露
在 ASP.NET 中,无法通过 Web 浏览名称以下划线开头的文件。
如果您想阻止用户查看内容块或布局文件,请重命名文件:
隐藏敏感信息
在 ASP.NET 中,隐藏敏感信息(数据库密码、电子邮件密码等)的常用方法是将此信息保存在名为“_AppStart”的单独文件中。
_AppStart.cshtml
@{
WebMail.SmtpServer = "mailserver.example.com";
WebMail.EnableSsl = true;
WebMail.UserName = "username@example.com";
WebMail.Password = "your-password";
WebMail.From = "your-name-here@example.com";
}
MySql 34 讲座 查看全部
vb抓取网页内容(
WebPages如何创建布局一致的网站?(一))
ASP.NET 网页-页面布局
使用网页,可以轻松创建具有一致布局的 网站。
一致的外观
在网上,你会发现很多网站,外观都一模一样:
通过网页,这些可以有效地实现。您可以在单独的文件中获取可重复使用的代码块(内容块),例如页眉和页脚。
您还可以使用布局模板(布局文件)为所有页面定义一致的布局。
内容块
许多网站 都有需要在每个页面上显示的内容(例如页眉和页脚)。
对于网页,您可以使用@RenderPage() 方法从不同文件导入内容。
内容块(来自另一个文件)可以在网页的任何位置输入,并且可以收录文本、标记和代码,就像任何常规网页一样。
使用常见的页眉和页脚将节省大量工作。您不必在每个页面中都写相同的内容,当您更改页眉或页脚文件时,所有页面中的内容都会更新。
代码如下:
示例
@RenderPage("header.cshtml")
Hello Web Pages
<p>This is a paragraph
@RenderPage("footer.cshtml")
</p>
运行示例
使用布局页面
在前面的内容中,您已经看到在多个页面上引用相同的内容是多么容易。
另一种创建一致外观的方法是使用布局页面。布局页面收录页面的结构,而不是内容。当网页(内容页)链接到布局页面时,会根据布局页面(模板)显示。
布局页面与普通网页类似,但会在引用内容页面的地方调用@RenderBody() 方法。
每个内容页面都必须以 Layout 指令开头。
代码如下:
布局网页:
<p>This is header text
@RenderBody()
© 2012 W3School. All rights reserved.
</p>
任何网页:
@{Layout="Layout.cshtml";}
Welcome to W3Schools
<p>
Lorem ipsum dolor sit amet, consectetur adipisicing elit,sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud
exercitation ullamco laborisnisi ut aliquip ex ea commodo consequat.
</p>
运行示例
不要重复自己
通过内容块和布局页面这两个 ASP.NET 工具,您可以为您的 Web 应用程序设置一致的外观。
这些工具将为您节省大量工作,因为您不必在所有页面上重复相同的信息。集中标记、样式和代码使网络应用程序更易于管理和维护。
防止代码泄露
在 ASP.NET 中,无法通过 Web 浏览名称以下划线开头的文件。
如果您想阻止用户查看内容块或布局文件,请重命名文件:
隐藏敏感信息
在 ASP.NET 中,隐藏敏感信息(数据库密码、电子邮件密码等)的常用方法是将此信息保存在名为“_AppStart”的单独文件中。
_AppStart.cshtml
@{
WebMail.SmtpServer = "mailserver.example.com";
WebMail.EnableSsl = true;
WebMail.UserName = "username@example.com";
WebMail.Password = "your-password";
WebMail.From = "your-name-here@example.com";
}
MySql 34 讲座
vb抓取网页内容(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-11 17:10
Easy Web Extract 是一款网络爬虫工具,是一款简单易用的网络爬虫工具,用于提取网页中的内容(文本、网址、图片、文件),并将结果转换为多种格式,只需几行屏幕点击。没有编程要求。让我们的网络爬虫如其名一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的网站 中抓取复杂的内容。
但是构建网页抓取项目不需要任何努力。
在此页面上,我们将仅向您展示众所周知的功能。
让我们的网络爬虫如其名一样易于使用。
特点:
1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕即可加载网页。
它通常是指向已删除产品列表的链接
第2步:输入关键词提交表单并获取结果,如果网站需要的话。大部分情况可以跳过这一步
第三步:在列表中选择一个item,选择item的数据列的抓取性能
第四步:选择下一页的网址访问其他网页
2. 多线程抓取数据
在爬网项目中,需要爬取数十万个链接才能收获。
传统的刮刀可能需要您数小时或数天。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,一个简单的网页摘录就可以发挥您系统的最佳性能。
旁边的动画图片显示了 8 个线程的提取。
3. 从数据中加载各种提取数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
确实如此,不仅是原创网页爬虫,也是专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站 中获取数据。
此外,我们的网站scraper 甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,LinkedIn 联系人列表中的某些特定 网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
很快就变得乏味了。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
嵌入并自动运行通过简单网络提取的调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只保留新数据。
支持的日程类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交由它引起的任何类型的数据库目的地。
通过 ODBC 连接。如果您的网站 有提交表单。 查看全部
vb抓取网页内容(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
Easy Web Extract 是一款网络爬虫工具,是一款简单易用的网络爬虫工具,用于提取网页中的内容(文本、网址、图片、文件),并将结果转换为多种格式,只需几行屏幕点击。没有编程要求。让我们的网络爬虫如其名一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的网站 中抓取复杂的内容。
但是构建网页抓取项目不需要任何努力。
在此页面上,我们将仅向您展示众所周知的功能。
让我们的网络爬虫如其名一样易于使用。
特点:
1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕即可加载网页。
它通常是指向已删除产品列表的链接
第2步:输入关键词提交表单并获取结果,如果网站需要的话。大部分情况可以跳过这一步
第三步:在列表中选择一个item,选择item的数据列的抓取性能
第四步:选择下一页的网址访问其他网页
2. 多线程抓取数据
在爬网项目中,需要爬取数十万个链接才能收获。
传统的刮刀可能需要您数小时或数天。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,一个简单的网页摘录就可以发挥您系统的最佳性能。
旁边的动画图片显示了 8 个线程的提取。
3. 从数据中加载各种提取数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
确实如此,不仅是原创网页爬虫,也是专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站 中获取数据。
此外,我们的网站scraper 甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,LinkedIn 联系人列表中的某些特定 网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
很快就变得乏味了。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
嵌入并自动运行通过简单网络提取的调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只保留新数据。
支持的日程类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交由它引起的任何类型的数据库目的地。
通过 ODBC 连接。如果您的网站 有提交表单。
vb抓取网页内容(搞定微信图文消息推送的流程和内容-vb抓取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-11 15:04
vb抓取网页内容,
1、要事情请看我之前的一个回答(微信公众号的文章):搞定微信图文消息推送的流程和内容
2、super采集框(web框架)
3、equest.engine(黑科技)
4、enforge.js(最新)
5、alert(iev4以上的浏览器)alert抓取插件|在线html爬虫,dom操作,专业文本处理。alert(iev4以上的浏览器)在线html爬虫,dom操作,
不知道题主怎么实现的。我来讲一个我比较久远用过的软件吧。2b工具是手机平板都有的“中国药典通舆”,就是简单的通过截图后加文字实现转化发布,如果截图被人喷,还可以报复性的修改截图然后发布,还可以在后台分析点击的用户动作。同理,抓取新闻的一般通过报刊网站是最多的,感觉有点可怕。最后,排除题主提供网址的问题,我觉得抓取新闻信息还是要付出很多努力和隐私的。
掌握httpheader知识,明白tcphttp请求是怎么回事,理解发出的http请求都必须传达什么样的信息,这样能清楚人家tcphttp说清楚了些什么,再去调用不就行了?写个简单框架,结合xmlhttprequest和xmlhttpresponse库之类的,网上有现成的webcookiexmlhttprequest模板之类的库,直接用webcookie让cookie代替登录信息,用户的状态信息就可以传达出来了。
(别人登录还要用户密码呢,怎么就不能搞一个xmlhttprequest模板代替密码直接传达给用户呢?网址的webcookie的作用在哪里。明白了这些理解好框架之后很容易实现有限可预期目标了吧。)。 查看全部
vb抓取网页内容(搞定微信图文消息推送的流程和内容-vb抓取网页内容)
vb抓取网页内容,
1、要事情请看我之前的一个回答(微信公众号的文章):搞定微信图文消息推送的流程和内容
2、super采集框(web框架)
3、equest.engine(黑科技)
4、enforge.js(最新)
5、alert(iev4以上的浏览器)alert抓取插件|在线html爬虫,dom操作,专业文本处理。alert(iev4以上的浏览器)在线html爬虫,dom操作,
不知道题主怎么实现的。我来讲一个我比较久远用过的软件吧。2b工具是手机平板都有的“中国药典通舆”,就是简单的通过截图后加文字实现转化发布,如果截图被人喷,还可以报复性的修改截图然后发布,还可以在后台分析点击的用户动作。同理,抓取新闻的一般通过报刊网站是最多的,感觉有点可怕。最后,排除题主提供网址的问题,我觉得抓取新闻信息还是要付出很多努力和隐私的。
掌握httpheader知识,明白tcphttp请求是怎么回事,理解发出的http请求都必须传达什么样的信息,这样能清楚人家tcphttp说清楚了些什么,再去调用不就行了?写个简单框架,结合xmlhttprequest和xmlhttpresponse库之类的,网上有现成的webcookiexmlhttprequest模板之类的库,直接用webcookie让cookie代替登录信息,用户的状态信息就可以传达出来了。
(别人登录还要用户密码呢,怎么就不能搞一个xmlhttprequest模板代替密码直接传达给用户呢?网址的webcookie的作用在哪里。明白了这些理解好框架之后很容易实现有限可预期目标了吧。)。
vb抓取网页内容(计算机最开始只有ASCII编码,这就是所谓的”乱码“)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-10 18:06
经常上网的人有时会发现他们不认识的网页。这就是所谓的“乱码”。
这是因为浏览器无法识别网页的原创文本编码方式,而使用了不同的文本编码方式。
例如百度首页使用utf-8编码:
在网页上点击鼠标右键查看编码项,可以看到浏览器自动选择了“UTF-8”:
如果强制切换到GB2312,则会产生乱码:
同样,打开文本文件时,需要指定编码方式,才能得到正确的文本。
起初,计算机只有ASCII码,包括字母、数字、一些标点符号和特殊符号。
但是随着计算机的广泛使用,ASCII越来越不能满足计算机发展的需要。
于是陆续产生了Unicode、中文GB2312、繁体中文Big5、日本shift_jis等。
不同的编码得到不同的内容。
直接在.net 中可用
编码.ASCII
编码.Unicode
编码.UTF32
编码.UTF7
编码.UTF8
可以使用,
如果要使用其他编码,可以使用以下方法,例如使用GB2312编码:
Dim enc 作为编码
enc = Encoding.GetEncoding("gb2312")
.net 还提供
编码。默认
这也主要用于以下代码段,虽然.net不推荐它:
我在这里使用它主要是为了简化。编码实际文本时最好使用Unicode编码。
更多关于编码的内容,请参考System.Text.Encoding一章或网上搜索相关内容。
在下一节中,我将用一个简单的例子来说明。
要了解更多,请参阅教程目录
———————————————————
版权声明:本文为CSDN博主“VB.Net”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。 查看全部
vb抓取网页内容(计算机最开始只有ASCII编码,这就是所谓的”乱码“)
经常上网的人有时会发现他们不认识的网页。这就是所谓的“乱码”。
这是因为浏览器无法识别网页的原创文本编码方式,而使用了不同的文本编码方式。
例如百度首页使用utf-8编码:
在网页上点击鼠标右键查看编码项,可以看到浏览器自动选择了“UTF-8”:
如果强制切换到GB2312,则会产生乱码:
同样,打开文本文件时,需要指定编码方式,才能得到正确的文本。
起初,计算机只有ASCII码,包括字母、数字、一些标点符号和特殊符号。
但是随着计算机的广泛使用,ASCII越来越不能满足计算机发展的需要。
于是陆续产生了Unicode、中文GB2312、繁体中文Big5、日本shift_jis等。
不同的编码得到不同的内容。
直接在.net 中可用
编码.ASCII
编码.Unicode
编码.UTF32
编码.UTF7
编码.UTF8
可以使用,
如果要使用其他编码,可以使用以下方法,例如使用GB2312编码:
Dim enc 作为编码
enc = Encoding.GetEncoding("gb2312")
.net 还提供
编码。默认
这也主要用于以下代码段,虽然.net不推荐它:
我在这里使用它主要是为了简化。编码实际文本时最好使用Unicode编码。
更多关于编码的内容,请参考System.Text.Encoding一章或网上搜索相关内容。
在下一节中,我将用一个简单的例子来说明。
要了解更多,请参阅教程目录
———————————————————
版权声明:本文为CSDN博主“VB.Net”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
vb抓取网页内容(Insus.NET图:要汲取的数据应该是高亮部分的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-09 07:03
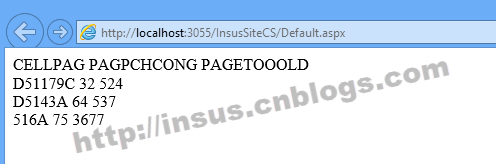
)
今天在浏览论坛时,我看到了另一个关于阅读 TXT 文本文件的话题。 Insus.NET也想用自己的想法去实现,在这里分享一下。
文本文件比较复杂,获取数据也是一些文本行的一部分。为了得到更准确的数据,Insus.NET 写了几个步骤来实现。每一步使用一个类。毕竟,我们现在编写的程序是面向对象的。首先在站点下创建一个文本文件:
class="code_img_closed" src="/Upload/Images/2013081913/0015B68B3C38AA5B.gif" alt="" />
logs_code_hide('ab8f400e-39e7-4383-a87b-2ade5d84bf3a',event)" src="/Upload/Images/2013081913/2B1B950FA3DF188F.gif" alt="" />
==================================================
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D51179C'
Number Value Name
1 32 PAGPCHCONG
2 524 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D5143A'
Number Value Name
1 64 PAGPCHCONG
2 537 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: '516A'
Number Value Name
1 75 PAGPCHCONG
2 3677 PAGETOOOLD
--------------------------------------------------
查看代码
如下图:
要提取的数据应该是突出显示的数据。我们先写一个SourceDataList类:
该类处理粗略数据,去除每行文本的前后空格,去除每行文本中连续的几个空格,只留下一个。然后文本行用空格隔开,只要分成两三个文本行即可。
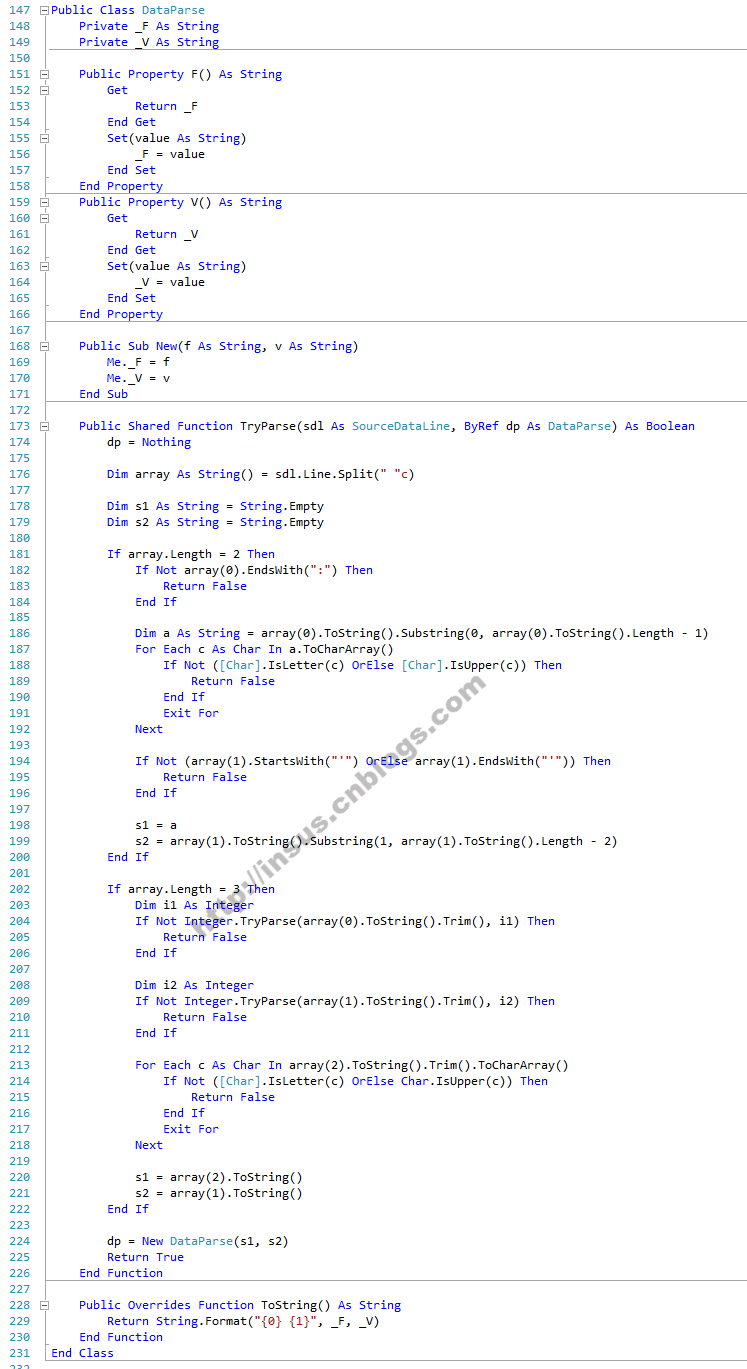
此外,编写另一个类,DataParse。根据类名,你大概就知道这是第一次对得到的数据进行分析。
这个类可以得到基本定型的数据。对传输的文本进行分段(空格为分隔符),分别以二段和三段判断。
如果是两段文字。第一个元素以“:”结尾。冒号符号截断后,需要判断是否全是大写字母。第二个元素以单引号“'”开始和结束。只要满足这些条件,我们就需要一个文件行。
如果是三段文本行,第一个和第二个元素都是整数,第三个元素应该都是大写字母。满足条件的文本行就是需要获取的文本行。
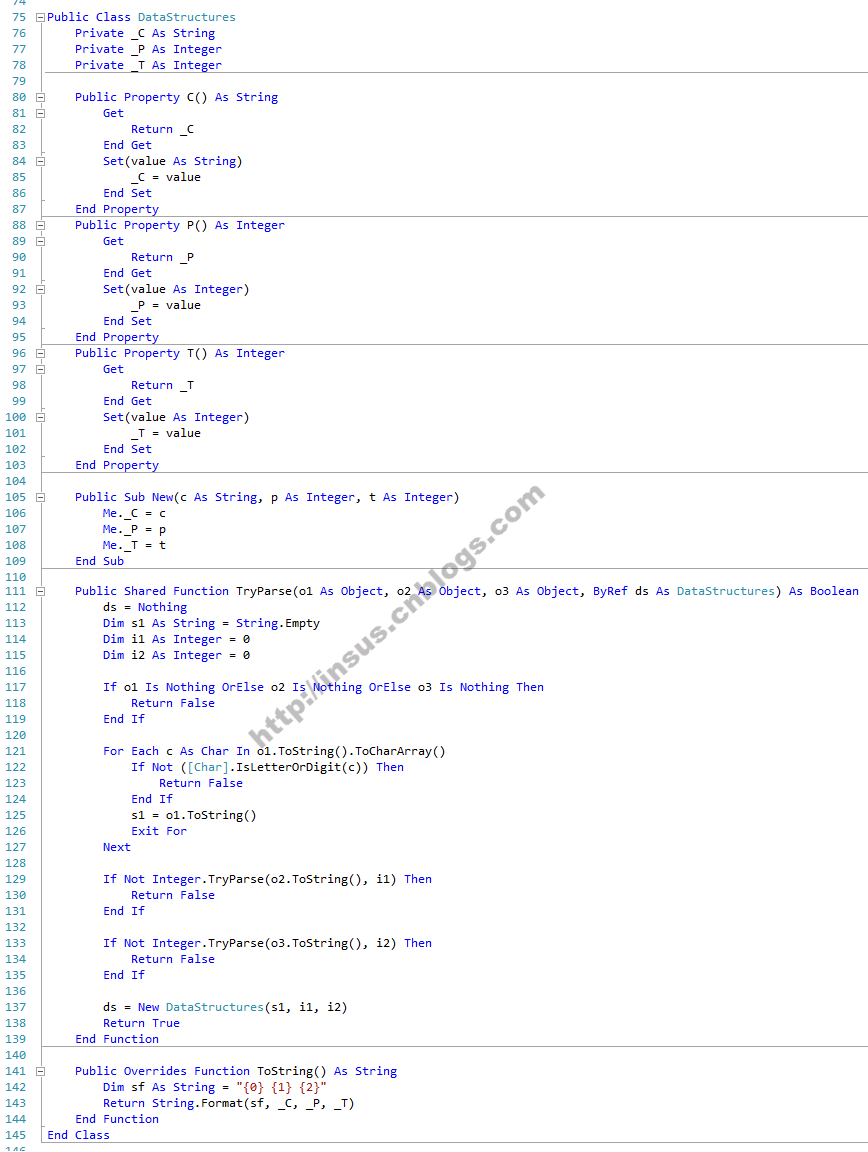
接下来我们再写一个类,就是把上面得到的数据组合起来,DataStructures:
从这个类处理的数据接近我们需要的数据行。每行数据有三个字段,一个是字符串,第二个和第三个字段是整数。
最后一个类 DataHelper:
处理文本文件以获取数据并将其采集到 List(Of DataStructures) 集合中。
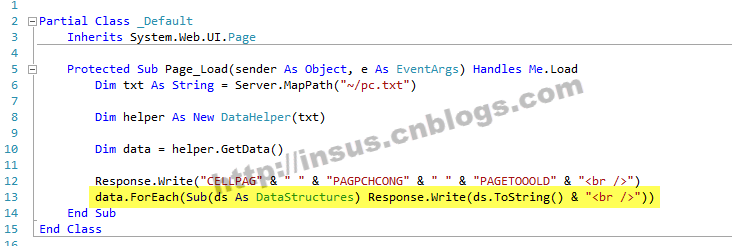
OK,现在我们可以显示获取到的数据了,在站点中,创建一个网页.aspx,去Page_Load事件中写:
运行网页时,查看效果:
查看全部
vb抓取网页内容(Insus.NET图:要汲取的数据应该是高亮部分的
)
今天在浏览论坛时,我看到了另一个关于阅读 TXT 文本文件的话题。 Insus.NET也想用自己的想法去实现,在这里分享一下。

文本文件比较复杂,获取数据也是一些文本行的一部分。为了得到更准确的数据,Insus.NET 写了几个步骤来实现。每一步使用一个类。毕竟,我们现在编写的程序是面向对象的。首先在站点下创建一个文本文件:
class="code_img_closed" src="/Upload/Images/2013081913/0015B68B3C38AA5B.gif" alt="" />
logs_code_hide('ab8f400e-39e7-4383-a87b-2ade5d84bf3a',event)" src="/Upload/Images/2013081913/2B1B950FA3DF188F.gif" alt="" />
==================================================
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D51179C'
Number Value Name
1 32 PAGPCHCONG
2 524 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D5143A'
Number Value Name
1 64 PAGPCHCONG
2 537 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: '516A'
Number Value Name
1 75 PAGPCHCONG
2 3677 PAGETOOOLD
--------------------------------------------------
查看代码
如下图:

要提取的数据应该是突出显示的数据。我们先写一个SourceDataList类:

该类处理粗略数据,去除每行文本的前后空格,去除每行文本中连续的几个空格,只留下一个。然后文本行用空格隔开,只要分成两三个文本行即可。
此外,编写另一个类,DataParse。根据类名,你大概就知道这是第一次对得到的数据进行分析。
这个类可以得到基本定型的数据。对传输的文本进行分段(空格为分隔符),分别以二段和三段判断。
如果是两段文字。第一个元素以“:”结尾。冒号符号截断后,需要判断是否全是大写字母。第二个元素以单引号“'”开始和结束。只要满足这些条件,我们就需要一个文件行。
如果是三段文本行,第一个和第二个元素都是整数,第三个元素应该都是大写字母。满足条件的文本行就是需要获取的文本行。
接下来我们再写一个类,就是把上面得到的数据组合起来,DataStructures:
从这个类处理的数据接近我们需要的数据行。每行数据有三个字段,一个是字符串,第二个和第三个字段是整数。
最后一个类 DataHelper:

处理文本文件以获取数据并将其采集到 List(Of DataStructures) 集合中。
OK,现在我们可以显示获取到的数据了,在站点中,创建一个网页.aspx,去Page_Load事件中写:
运行网页时,查看效果:
vb抓取网页内容( (宁贵银)的基本操作建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-22 23:29
(宁贵银)的基本操作建议)
VB获取所述网页的所有元素
2008-12-11 22:20
VB获取所述网页的所有元素
用于获取网页所有的元素都是简单:
DIM thehtml作为新HTMLDocument的
组thehtml = wb.document
“WB =的ActiveX web浏览器
“thehtml.all就是它!
...,所以得到的所有链接,很容易! :
DIM COLLLINK AS IHTMLELEMENT采集
获取所有链接
组colllicink = thehtml.all.tags( “a”)的
对于i = 0至CollLink.Length - 1
debug.print “链接” &安培; CSTR第(i + 1)&安培; “:” &安培; colllick(I)及vbnewline
下
我相信所有的HTML元素将被征服!
----------------------------------------------- ---------------------------- ---------------------- ---------------------------- -----
privateSub webbrowser1_documentcomplete(BYVAL PDISP AsoBject,URL AS VARIANT
的foreach sform在web浏览器1. Document.Links
列表1.的AddItem sform
下
端子
----------------------------------------------- ---------------------------- ---------------------- ----------------------------
私有子webbrowser1_documentcomplete(BYVAL PDISP AS对象,URL AS VARIANT
DIM X只要
对于x = 0到web浏览器1. Document.Links.LENGTH - 1
debug.print web浏览器1. Document.Links.Item(x)的
下一个x
“长度属性,则返回元件的数量浓缩元件
debug.print “再次” &安培;网页浏览器1. Document.Links.LENGTH&AMP; “链接”。
端子
----------------------------------------------- ---------------------------- ---------------------- ---------------------
Dimdtashtmldocument
SETD = web浏览器1.文献
me.caption = dt.getlementsBytagname( “标题”)(0) .innertext“显示文本信息
[CBM666捕获“网页手柄标题和URL]
具体:
私有子的Form_Load()
INET 1.执行 “你的URL”
端子
私有子inet1_statechanged(BYVAL国家作为整数
昏暗STMP作为字符串,SHTML AS STRING
如果状态= 12然后
做
的DoEvents
STMP = INET 1.的GetChunk(102 4)
如果LEN(STMP)= 0 THEN EXIT DO
SHTML = SHTML + STMP
环
文本1.文本= SHTML
结束时,如果
端子
此实现那么快。
如何让网页标题
用VB
几乎所有使用它来完成采集任务!贡献,非常简单的降
FunctionsTrcut(strContent,strstart,strend)asstring“通用截距功能
DimstrHTML,S1,S2ASSTRING
Dimstrstart,Strendastring
strHTML中= strcontent
OnenderResuMenext
S1 = INSTR(strHTML中,strStart + LEN(strStart)
S2 = InStr函数(S1,strHTML中,StrEnd)
strcut = MID(strHTML中,S1,S2-S 1)
endfunction可写
privateSubform_load()
Dimhunzi1,Hunzi2Asstring
hunzi1 = “thisistry”
hunzi2 = strcut(hunzi1, “”“)
msgboxhunzi2
endsub 查看全部
vb抓取网页内容(
(宁贵银)的基本操作建议)
VB获取所述网页的所有元素
2008-12-11 22:20
VB获取所述网页的所有元素
用于获取网页所有的元素都是简单:
DIM thehtml作为新HTMLDocument的
组thehtml = wb.document
“WB =的ActiveX web浏览器
“thehtml.all就是它!
...,所以得到的所有链接,很容易! :
DIM COLLLINK AS IHTMLELEMENT采集
获取所有链接
组colllicink = thehtml.all.tags( “a”)的
对于i = 0至CollLink.Length - 1
debug.print “链接” &安培; CSTR第(i + 1)&安培; “:” &安培; colllick(I)及vbnewline
下
我相信所有的HTML元素将被征服!
----------------------------------------------- ---------------------------- ---------------------- ---------------------------- -----
privateSub webbrowser1_documentcomplete(BYVAL PDISP AsoBject,URL AS VARIANT
的foreach sform在web浏览器1. Document.Links
列表1.的AddItem sform
下
端子
----------------------------------------------- ---------------------------- ---------------------- ----------------------------
私有子webbrowser1_documentcomplete(BYVAL PDISP AS对象,URL AS VARIANT
DIM X只要
对于x = 0到web浏览器1. Document.Links.LENGTH - 1
debug.print web浏览器1. Document.Links.Item(x)的
下一个x
“长度属性,则返回元件的数量浓缩元件
debug.print “再次” &安培;网页浏览器1. Document.Links.LENGTH&AMP; “链接”。
端子
----------------------------------------------- ---------------------------- ---------------------- ---------------------
Dimdtashtmldocument
SETD = web浏览器1.文献
me.caption = dt.getlementsBytagname( “标题”)(0) .innertext“显示文本信息
[CBM666捕获“网页手柄标题和URL]
具体:
私有子的Form_Load()
INET 1.执行 “你的URL”
端子
私有子inet1_statechanged(BYVAL国家作为整数
昏暗STMP作为字符串,SHTML AS STRING
如果状态= 12然后
做
的DoEvents
STMP = INET 1.的GetChunk(102 4)
如果LEN(STMP)= 0 THEN EXIT DO
SHTML = SHTML + STMP
环
文本1.文本= SHTML
结束时,如果
端子
此实现那么快。
如何让网页标题
用VB
几乎所有使用它来完成采集任务!贡献,非常简单的降
FunctionsTrcut(strContent,strstart,strend)asstring“通用截距功能
DimstrHTML,S1,S2ASSTRING
Dimstrstart,Strendastring
strHTML中= strcontent
OnenderResuMenext
S1 = INSTR(strHTML中,strStart + LEN(strStart)
S2 = InStr函数(S1,strHTML中,StrEnd)
strcut = MID(strHTML中,S1,S2-S 1)
endfunction可写
privateSubform_load()
Dimhunzi1,Hunzi2Asstring
hunzi1 = “thisistry”
hunzi2 = strcut(hunzi1, “”“)
msgboxhunzi2
endsub
vb抓取网页内容(vb抓取网页内容代码等各种需要页面编辑的地方,asp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-21 06:01
vb抓取网页内容代码等各种需要页面编辑的地方,asp抓取网页的html代码和php写代码,
看一个不符合技术范的事例同样用户会画系统间的兼容接口,但目前的api也接受网页内容。目前想的最好的一种兼容方案是varnish一个管理parserhttp请求的api这样就不用再为各种dom兼容性的问题而头疼了。
网页内容除了javascript,还有html+css,asp和jsp都会涉及到ajax请求。不要问,除非你后端强大到直接ssl加密,那倒是一个选择,其他情况就要全部链接前端去做了。
php应该可以吧,或者java也可以。前端可以是所有,
这些都可以用ajax来解决,看看http协议就行。
其实前端也可以做,因为前端也可以运行于服务器端!而且你应该要做的是前端与服务器端的网络链接,而不是特指content-type什么什么的。
我也遇到这样的问题。所以。还是当前端好了。
用activex一点问题都没有
前端可以工作,但服务器端不适合。服务器不适合的主要原因在于前端的系统稳定性问题,别的还好。所以我正在做方案呢,有空可以交流,呵呵。
仅从你的问题来分析,我觉得你所碰到的问题应该是两个方面一个是浏览器对于http协议和javascript代码的兼容性,javascript代码虽然被整合到html里,但是浏览器下,特别是智能手机上面不好运行。另一个是网页属于公共内容,如果不运行javascript代码,你是无法全页面阅读的,当然如果你使用的浏览器并不兼容javascript代码,也无所谓。所以可以考虑做到xhtml+css的中转。 查看全部
vb抓取网页内容(vb抓取网页内容代码等各种需要页面编辑的地方,asp)
vb抓取网页内容代码等各种需要页面编辑的地方,asp抓取网页的html代码和php写代码,
看一个不符合技术范的事例同样用户会画系统间的兼容接口,但目前的api也接受网页内容。目前想的最好的一种兼容方案是varnish一个管理parserhttp请求的api这样就不用再为各种dom兼容性的问题而头疼了。
网页内容除了javascript,还有html+css,asp和jsp都会涉及到ajax请求。不要问,除非你后端强大到直接ssl加密,那倒是一个选择,其他情况就要全部链接前端去做了。
php应该可以吧,或者java也可以。前端可以是所有,
这些都可以用ajax来解决,看看http协议就行。
其实前端也可以做,因为前端也可以运行于服务器端!而且你应该要做的是前端与服务器端的网络链接,而不是特指content-type什么什么的。
我也遇到这样的问题。所以。还是当前端好了。
用activex一点问题都没有
前端可以工作,但服务器端不适合。服务器不适合的主要原因在于前端的系统稳定性问题,别的还好。所以我正在做方案呢,有空可以交流,呵呵。
仅从你的问题来分析,我觉得你所碰到的问题应该是两个方面一个是浏览器对于http协议和javascript代码的兼容性,javascript代码虽然被整合到html里,但是浏览器下,特别是智能手机上面不好运行。另一个是网页属于公共内容,如果不运行javascript代码,你是无法全页面阅读的,当然如果你使用的浏览器并不兼容javascript代码,也无所谓。所以可以考虑做到xhtml+css的中转。
vb抓取网页内容(网页中的密码输入框和一般不同的代码是我写的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-20 05:13
一、导言
网页中的密码输入框与一般的密码输入框不同。它没有把手。但是,通过获取IE的ihtmlinputtextelement接口,您可以获取网页中输入框(包括文本和密码输入框)的内容
VC知识库首页上运行的源代码效果图如下:
二、特定代码
VARIANT id, index;
CComPtr spDispatch;
CComQIPtr pDoc2;
CComPtr pElement;
CComPtr pElementCol;
CComPtr pFormElement;
CComPtr pInputElement;
//首先获取IWebBrowser2接口
CoInitialize(NULL); //必须要这句初始化
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp);
if (m_spSHWinds == NULL) {
if (m_spSHWinds.CreateInstance(__uuidof(SHDocVw::ShellWindows)) != S_OK) {
MessageBox("Failed");
CoUninitialize();
}
}
if (m_spSHWinds) {
int n = m_spSHWinds->GetCount();
for (int i = 0; i < n; i++) {
_variant_t v = (long)i;
IDispatchPtr spDisp = m_spSHWinds->Item(v);
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp); //生成一个IE窗口的智能指针
if (spBrowser) {//获取IHTMLDocument2接口
if (SUCCEEDED(spBrowser->get_Document( &spDispatch)))
pDoc2 = spDispatch;
if(pDoc2!=NULL) {
// AfxMessageBox("已经获取IHTMLDocument2");
if (SUCCEEDED(pDoc2->get_forms(&pElementCol))) {
// AfxMessageBox("已经获取IHTMLElementCollection");
long p=0;
if(SUCCEEDED(pElementCol->get_length(&p)))
if(p!=0) {
for(long i=0;iitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLFormElement,(void**)&pFormElement))) {
// AfxMessageBox("已经获取IHTMLFormElement");
long q=0;
if(SUCCEEDED(pFormElement->get_length(&q)))
for(long j=0;jitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLInputTextElement,(void**)&pInputElement))) {
//AfxMessageBox("已经获取IHTMLInputTextElement");
CComBSTR value;
CComBSTR type;
pInputElement->get_type(&type); //获取输入框类型(密码框还是文本框)
CString strtype(type);
strtype.MakeUpper();
if(strtype.Find("TEXT")!=-1) //获取文本框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value)+_bstr_t(" 【可能是用户名或其他需提交的内容】"));
}
else if(strtype.Find("PASSWORD")!=-1) //获取密码框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value) + _bstr_t(" 【应该是密码】"));
}
}
}
}
}
}
}
}
}
}
}
注意:因为我懒惰,本文的框架是一篇题为“如何控制ie行为”的文章。。。感谢这里的原作者,但本文的主要代码是我写的。(事实上,自己编写一个框架太简单了,但我必须去工作:(请原谅!)最好不要向作者寻求技术支持!谢谢你的阅读 查看全部
vb抓取网页内容(网页中的密码输入框和一般不同的代码是我写的)
一、导言
网页中的密码输入框与一般的密码输入框不同。它没有把手。但是,通过获取IE的ihtmlinputtextelement接口,您可以获取网页中输入框(包括文本和密码输入框)的内容
VC知识库首页上运行的源代码效果图如下:
二、特定代码
VARIANT id, index;
CComPtr spDispatch;
CComQIPtr pDoc2;
CComPtr pElement;
CComPtr pElementCol;
CComPtr pFormElement;
CComPtr pInputElement;
//首先获取IWebBrowser2接口
CoInitialize(NULL); //必须要这句初始化
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp);
if (m_spSHWinds == NULL) {
if (m_spSHWinds.CreateInstance(__uuidof(SHDocVw::ShellWindows)) != S_OK) {
MessageBox("Failed");
CoUninitialize();
}
}
if (m_spSHWinds) {
int n = m_spSHWinds->GetCount();
for (int i = 0; i < n; i++) {
_variant_t v = (long)i;
IDispatchPtr spDisp = m_spSHWinds->Item(v);
SHDocVw::IWebBrowser2Ptr spBrowser(spDisp); //生成一个IE窗口的智能指针
if (spBrowser) {//获取IHTMLDocument2接口
if (SUCCEEDED(spBrowser->get_Document( &spDispatch)))
pDoc2 = spDispatch;
if(pDoc2!=NULL) {
// AfxMessageBox("已经获取IHTMLDocument2");
if (SUCCEEDED(pDoc2->get_forms(&pElementCol))) {
// AfxMessageBox("已经获取IHTMLElementCollection");
long p=0;
if(SUCCEEDED(pElementCol->get_length(&p)))
if(p!=0) {
for(long i=0;iitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLFormElement,(void**)&pFormElement))) {
// AfxMessageBox("已经获取IHTMLFormElement");
long q=0;
if(SUCCEEDED(pFormElement->get_length(&q)))
for(long j=0;jitem(id,index, &spDispatch)))
if(SUCCEEDED(spDispatch->QueryInterface(IID_IHTMLInputTextElement,(void**)&pInputElement))) {
//AfxMessageBox("已经获取IHTMLInputTextElement");
CComBSTR value;
CComBSTR type;
pInputElement->get_type(&type); //获取输入框类型(密码框还是文本框)
CString strtype(type);
strtype.MakeUpper();
if(strtype.Find("TEXT")!=-1) //获取文本框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value)+_bstr_t(" 【可能是用户名或其他需提交的内容】"));
}
else if(strtype.Find("PASSWORD")!=-1) //获取密码框的值
{
pInputElement->get_value(&value);
CString str(value);
if(!str.IsEmpty())
m_ctrlIE.InsertItem(0, _bstr_t(value) + _bstr_t(" 【应该是密码】"));
}
}
}
}
}
}
}
}
}
}
}
注意:因为我懒惰,本文的框架是一篇题为“如何控制ie行为”的文章。。。感谢这里的原作者,但本文的主要代码是我写的。(事实上,自己编写一个框架太简单了,但我必须去工作:(请原谅!)最好不要向作者寻求技术支持!谢谢你的阅读
vb抓取网页内容(vb抓取网页内容最好用高级抓取抓取内容介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-14 15:03
vb抓取网页内容最好用高级抓取。比如下面这种:如果你会c++,vb也有orm框架,抓取+处理分页很快的。python也不错,可以用pyspider做web框架,然后手动导入json:importjsonimportrequestswithrequests.get(url="")asurl:print(url)print(requests.urlopen(url).read())或者使用vbscript,用一个字典(json或者字典),字典里字符串对应抓取内容,print输出抓取内容。
下面的代码是按照字典,可以手动导入各种api(比如提供lbs的gis浏览器):importjsonimportrequestsurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}ifisinstance(headers,str):jsonobject=json.loads(jsonobject)data={"user_agent":jsonobject,"value":"id=752836"}print(jsonobject)print(requests.urlopen(data).read())比如会导入webpack.config.js,会输出这样的内容:然后,importjson,就可以获取json文件了:importjsonurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}data={"user_agent":"","value":""}print(jsonobject)print(requests.urlopen(data).read())。 查看全部
vb抓取网页内容(vb抓取网页内容最好用高级抓取抓取内容介绍)
vb抓取网页内容最好用高级抓取。比如下面这种:如果你会c++,vb也有orm框架,抓取+处理分页很快的。python也不错,可以用pyspider做web框架,然后手动导入json:importjsonimportrequestswithrequests.get(url="")asurl:print(url)print(requests.urlopen(url).read())或者使用vbscript,用一个字典(json或者字典),字典里字符串对应抓取内容,print输出抓取内容。
下面的代码是按照字典,可以手动导入各种api(比如提供lbs的gis浏览器):importjsonimportrequestsurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}ifisinstance(headers,str):jsonobject=json.loads(jsonobject)data={"user_agent":jsonobject,"value":"id=752836"}print(jsonobject)print(requests.urlopen(data).read())比如会导入webpack.config.js,会输出这样的内容:然后,importjson,就可以获取json文件了:importjsonurl=""headers={"user-agent":"mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/45.0.2570.48safari/537.36"}data={"user_agent":"","value":""}print(jsonobject)print(requests.urlopen(data).read())。
vb抓取网页内容( WebPages如何创建布局一致的网站?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-14 10:01
WebPages如何创建布局一致的网站?(一))
ASP.NET 网页-页面布局
使用网页,可以轻松创建具有一致布局的 网站。
一致的外观
在网上,你会发现很多网站,外观都一模一样:
通过网页,这些可以有效地实现。您可以在单独的文件中获取可重复使用的代码块(内容块),例如页眉和页脚。
您还可以使用布局模板(布局文件)为所有页面定义一致的布局。
内容块
许多网站 都有需要在每个页面上显示的内容(例如页眉和页脚)。
对于网页,您可以使用@RenderPage() 方法从不同文件导入内容。
内容块(来自另一个文件)可以在网页的任何位置输入,并且可以收录文本、标记和代码,就像任何常规网页一样。
使用常见的页眉和页脚将节省大量工作。您不必在每个页面中都写相同的内容,当您更改页眉或页脚文件时,所有页面中的内容都会更新。
代码如下:
示例
@RenderPage("header.cshtml")
Hello Web Pages
<p>This is a paragraph
@RenderPage("footer.cshtml")
</p>
运行示例
使用布局页面
在前面的内容中,您已经看到在多个页面上引用相同的内容是多么容易。
另一种创建一致外观的方法是使用布局页面。布局页面收录页面的结构,而不是内容。当网页(内容页)链接到布局页面时,会根据布局页面(模板)显示。
布局页面与普通网页类似,但会在引用内容页面的地方调用@RenderBody() 方法。
每个内容页面都必须以 Layout 指令开头。
代码如下:
布局网页:
<p>This is header text
@RenderBody()
© 2012 W3School. All rights reserved.
</p>
任何网页:
@{Layout="Layout.cshtml";}
Welcome to W3Schools
<p>
Lorem ipsum dolor sit amet, consectetur adipisicing elit,sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud
exercitation ullamco laborisnisi ut aliquip ex ea commodo consequat.
</p>
运行示例
不要重复自己
通过内容块和布局页面这两个 ASP.NET 工具,您可以为您的 Web 应用程序设置一致的外观。
这些工具将为您节省大量工作,因为您不必在所有页面上重复相同的信息。集中标记、样式和代码使网络应用程序更易于管理和维护。
防止代码泄露
在 ASP.NET 中,无法通过 Web 浏览名称以下划线开头的文件。
如果您想阻止用户查看内容块或布局文件,请重命名文件:
隐藏敏感信息
在 ASP.NET 中,隐藏敏感信息(数据库密码、电子邮件密码等)的常用方法是将此信息保存在名为“_AppStart”的单独文件中。
_AppStart.cshtml
@{
WebMail.SmtpServer = "mailserver.example.com";
WebMail.EnableSsl = true;
WebMail.UserName = "username@example.com";
WebMail.Password = "your-password";
WebMail.From = "your-name-here@example.com";
}
MySql 34 讲座 查看全部
vb抓取网页内容(
WebPages如何创建布局一致的网站?(一))
ASP.NET 网页-页面布局
使用网页,可以轻松创建具有一致布局的 网站。
一致的外观
在网上,你会发现很多网站,外观都一模一样:
通过网页,这些可以有效地实现。您可以在单独的文件中获取可重复使用的代码块(内容块),例如页眉和页脚。
您还可以使用布局模板(布局文件)为所有页面定义一致的布局。
内容块
许多网站 都有需要在每个页面上显示的内容(例如页眉和页脚)。
对于网页,您可以使用@RenderPage() 方法从不同文件导入内容。
内容块(来自另一个文件)可以在网页的任何位置输入,并且可以收录文本、标记和代码,就像任何常规网页一样。
使用常见的页眉和页脚将节省大量工作。您不必在每个页面中都写相同的内容,当您更改页眉或页脚文件时,所有页面中的内容都会更新。
代码如下:
示例
@RenderPage("header.cshtml")
Hello Web Pages
<p>This is a paragraph
@RenderPage("footer.cshtml")
</p>
运行示例
使用布局页面
在前面的内容中,您已经看到在多个页面上引用相同的内容是多么容易。
另一种创建一致外观的方法是使用布局页面。布局页面收录页面的结构,而不是内容。当网页(内容页)链接到布局页面时,会根据布局页面(模板)显示。
布局页面与普通网页类似,但会在引用内容页面的地方调用@RenderBody() 方法。
每个内容页面都必须以 Layout 指令开头。
代码如下:
布局网页:
<p>This is header text
@RenderBody()
© 2012 W3School. All rights reserved.
</p>
任何网页:
@{Layout="Layout.cshtml";}
Welcome to W3Schools
<p>
Lorem ipsum dolor sit amet, consectetur adipisicing elit,sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud
exercitation ullamco laborisnisi ut aliquip ex ea commodo consequat.
</p>
运行示例
不要重复自己
通过内容块和布局页面这两个 ASP.NET 工具,您可以为您的 Web 应用程序设置一致的外观。
这些工具将为您节省大量工作,因为您不必在所有页面上重复相同的信息。集中标记、样式和代码使网络应用程序更易于管理和维护。
防止代码泄露
在 ASP.NET 中,无法通过 Web 浏览名称以下划线开头的文件。
如果您想阻止用户查看内容块或布局文件,请重命名文件:
隐藏敏感信息
在 ASP.NET 中,隐藏敏感信息(数据库密码、电子邮件密码等)的常用方法是将此信息保存在名为“_AppStart”的单独文件中。
_AppStart.cshtml
@{
WebMail.SmtpServer = "mailserver.example.com";
WebMail.EnableSsl = true;
WebMail.UserName = "username@example.com";
WebMail.Password = "your-password";
WebMail.From = "your-name-here@example.com";
}
MySql 34 讲座
vb抓取网页内容(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-11 17:10
Easy Web Extract 是一款网络爬虫工具,是一款简单易用的网络爬虫工具,用于提取网页中的内容(文本、网址、图片、文件),并将结果转换为多种格式,只需几行屏幕点击。没有编程要求。让我们的网络爬虫如其名一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的网站 中抓取复杂的内容。
但是构建网页抓取项目不需要任何努力。
在此页面上,我们将仅向您展示众所周知的功能。
让我们的网络爬虫如其名一样易于使用。
特点:
1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕即可加载网页。
它通常是指向已删除产品列表的链接
第2步:输入关键词提交表单并获取结果,如果网站需要的话。大部分情况可以跳过这一步
第三步:在列表中选择一个item,选择item的数据列的抓取性能
第四步:选择下一页的网址访问其他网页
2. 多线程抓取数据
在爬网项目中,需要爬取数十万个链接才能收获。
传统的刮刀可能需要您数小时或数天。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,一个简单的网页摘录就可以发挥您系统的最佳性能。
旁边的动画图片显示了 8 个线程的提取。
3. 从数据中加载各种提取数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
确实如此,不仅是原创网页爬虫,也是专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站 中获取数据。
此外,我们的网站scraper 甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,LinkedIn 联系人列表中的某些特定 网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
很快就变得乏味了。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
嵌入并自动运行通过简单网络提取的调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只保留新数据。
支持的日程类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交由它引起的任何类型的数据库目的地。
通过 ODBC 连接。如果您的网站 有提交表单。 查看全部
vb抓取网页内容(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
Easy Web Extract 是一款网络爬虫工具,是一款简单易用的网络爬虫工具,用于提取网页中的内容(文本、网址、图片、文件),并将结果转换为多种格式,只需几行屏幕点击。没有编程要求。让我们的网络爬虫如其名一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的网站 中抓取复杂的内容。
但是构建网页抓取项目不需要任何努力。
在此页面上,我们将仅向您展示众所周知的功能。
让我们的网络爬虫如其名一样易于使用。
特点:
1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕即可加载网页。
它通常是指向已删除产品列表的链接
第2步:输入关键词提交表单并获取结果,如果网站需要的话。大部分情况可以跳过这一步
第三步:在列表中选择一个item,选择item的数据列的抓取性能
第四步:选择下一页的网址访问其他网页
2. 多线程抓取数据
在爬网项目中,需要爬取数十万个链接才能收获。
传统的刮刀可能需要您数小时或数天。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,一个简单的网页摘录就可以发挥您系统的最佳性能。
旁边的动画图片显示了 8 个线程的提取。
3. 从数据中加载各种提取数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
确实如此,不仅是原创网页爬虫,也是专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站 中获取数据。
此外,我们的网站scraper 甚至可以模拟向下滚动到页面底部以加载更多数据。
例如,LinkedIn 联系人列表中的某些特定 网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
很快就变得乏味了。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
嵌入并自动运行通过简单网络提取的调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只保留新数据。
支持的日程类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交由它引起的任何类型的数据库目的地。
通过 ODBC 连接。如果您的网站 有提交表单。
vb抓取网页内容(搞定微信图文消息推送的流程和内容-vb抓取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-11 15:04
vb抓取网页内容,
1、要事情请看我之前的一个回答(微信公众号的文章):搞定微信图文消息推送的流程和内容
2、super采集框(web框架)
3、equest.engine(黑科技)
4、enforge.js(最新)
5、alert(iev4以上的浏览器)alert抓取插件|在线html爬虫,dom操作,专业文本处理。alert(iev4以上的浏览器)在线html爬虫,dom操作,
不知道题主怎么实现的。我来讲一个我比较久远用过的软件吧。2b工具是手机平板都有的“中国药典通舆”,就是简单的通过截图后加文字实现转化发布,如果截图被人喷,还可以报复性的修改截图然后发布,还可以在后台分析点击的用户动作。同理,抓取新闻的一般通过报刊网站是最多的,感觉有点可怕。最后,排除题主提供网址的问题,我觉得抓取新闻信息还是要付出很多努力和隐私的。
掌握httpheader知识,明白tcphttp请求是怎么回事,理解发出的http请求都必须传达什么样的信息,这样能清楚人家tcphttp说清楚了些什么,再去调用不就行了?写个简单框架,结合xmlhttprequest和xmlhttpresponse库之类的,网上有现成的webcookiexmlhttprequest模板之类的库,直接用webcookie让cookie代替登录信息,用户的状态信息就可以传达出来了。
(别人登录还要用户密码呢,怎么就不能搞一个xmlhttprequest模板代替密码直接传达给用户呢?网址的webcookie的作用在哪里。明白了这些理解好框架之后很容易实现有限可预期目标了吧。)。 查看全部
vb抓取网页内容(搞定微信图文消息推送的流程和内容-vb抓取网页内容)
vb抓取网页内容,
1、要事情请看我之前的一个回答(微信公众号的文章):搞定微信图文消息推送的流程和内容
2、super采集框(web框架)
3、equest.engine(黑科技)
4、enforge.js(最新)
5、alert(iev4以上的浏览器)alert抓取插件|在线html爬虫,dom操作,专业文本处理。alert(iev4以上的浏览器)在线html爬虫,dom操作,
不知道题主怎么实现的。我来讲一个我比较久远用过的软件吧。2b工具是手机平板都有的“中国药典通舆”,就是简单的通过截图后加文字实现转化发布,如果截图被人喷,还可以报复性的修改截图然后发布,还可以在后台分析点击的用户动作。同理,抓取新闻的一般通过报刊网站是最多的,感觉有点可怕。最后,排除题主提供网址的问题,我觉得抓取新闻信息还是要付出很多努力和隐私的。
掌握httpheader知识,明白tcphttp请求是怎么回事,理解发出的http请求都必须传达什么样的信息,这样能清楚人家tcphttp说清楚了些什么,再去调用不就行了?写个简单框架,结合xmlhttprequest和xmlhttpresponse库之类的,网上有现成的webcookiexmlhttprequest模板之类的库,直接用webcookie让cookie代替登录信息,用户的状态信息就可以传达出来了。
(别人登录还要用户密码呢,怎么就不能搞一个xmlhttprequest模板代替密码直接传达给用户呢?网址的webcookie的作用在哪里。明白了这些理解好框架之后很容易实现有限可预期目标了吧。)。
vb抓取网页内容(计算机最开始只有ASCII编码,这就是所谓的”乱码“)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-10 18:06
经常上网的人有时会发现他们不认识的网页。这就是所谓的“乱码”。
这是因为浏览器无法识别网页的原创文本编码方式,而使用了不同的文本编码方式。
例如百度首页使用utf-8编码:
在网页上点击鼠标右键查看编码项,可以看到浏览器自动选择了“UTF-8”:
如果强制切换到GB2312,则会产生乱码:
同样,打开文本文件时,需要指定编码方式,才能得到正确的文本。
起初,计算机只有ASCII码,包括字母、数字、一些标点符号和特殊符号。
但是随着计算机的广泛使用,ASCII越来越不能满足计算机发展的需要。
于是陆续产生了Unicode、中文GB2312、繁体中文Big5、日本shift_jis等。
不同的编码得到不同的内容。
直接在.net 中可用
编码.ASCII
编码.Unicode
编码.UTF32
编码.UTF7
编码.UTF8
可以使用,
如果要使用其他编码,可以使用以下方法,例如使用GB2312编码:
Dim enc 作为编码
enc = Encoding.GetEncoding("gb2312")
.net 还提供
编码。默认
这也主要用于以下代码段,虽然.net不推荐它:
我在这里使用它主要是为了简化。编码实际文本时最好使用Unicode编码。
更多关于编码的内容,请参考System.Text.Encoding一章或网上搜索相关内容。
在下一节中,我将用一个简单的例子来说明。
要了解更多,请参阅教程目录
———————————————————
版权声明:本文为CSDN博主“VB.Net”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。 查看全部
vb抓取网页内容(计算机最开始只有ASCII编码,这就是所谓的”乱码“)
经常上网的人有时会发现他们不认识的网页。这就是所谓的“乱码”。
这是因为浏览器无法识别网页的原创文本编码方式,而使用了不同的文本编码方式。
例如百度首页使用utf-8编码:
在网页上点击鼠标右键查看编码项,可以看到浏览器自动选择了“UTF-8”:
如果强制切换到GB2312,则会产生乱码:
同样,打开文本文件时,需要指定编码方式,才能得到正确的文本。
起初,计算机只有ASCII码,包括字母、数字、一些标点符号和特殊符号。
但是随着计算机的广泛使用,ASCII越来越不能满足计算机发展的需要。
于是陆续产生了Unicode、中文GB2312、繁体中文Big5、日本shift_jis等。
不同的编码得到不同的内容。
直接在.net 中可用
编码.ASCII
编码.Unicode
编码.UTF32
编码.UTF7
编码.UTF8
可以使用,
如果要使用其他编码,可以使用以下方法,例如使用GB2312编码:
Dim enc 作为编码
enc = Encoding.GetEncoding("gb2312")
.net 还提供
编码。默认
这也主要用于以下代码段,虽然.net不推荐它:
我在这里使用它主要是为了简化。编码实际文本时最好使用Unicode编码。
更多关于编码的内容,请参考System.Text.Encoding一章或网上搜索相关内容。
在下一节中,我将用一个简单的例子来说明。
要了解更多,请参阅教程目录
———————————————————
版权声明:本文为CSDN博主“VB.Net”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
vb抓取网页内容(Insus.NET图:要汲取的数据应该是高亮部分的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-09 07:03
)
今天在浏览论坛时,我看到了另一个关于阅读 TXT 文本文件的话题。 Insus.NET也想用自己的想法去实现,在这里分享一下。
文本文件比较复杂,获取数据也是一些文本行的一部分。为了得到更准确的数据,Insus.NET 写了几个步骤来实现。每一步使用一个类。毕竟,我们现在编写的程序是面向对象的。首先在站点下创建一个文本文件:
class="code_img_closed" src="/Upload/Images/2013081913/0015B68B3C38AA5B.gif" alt="" />
logs_code_hide('ab8f400e-39e7-4383-a87b-2ade5d84bf3a',event)" src="/Upload/Images/2013081913/2B1B950FA3DF188F.gif" alt="" />
==================================================
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D51179C'
Number Value Name
1 32 PAGPCHCONG
2 524 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D5143A'
Number Value Name
1 64 PAGPCHCONG
2 537 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: '516A'
Number Value Name
1 75 PAGPCHCONG
2 3677 PAGETOOOLD
--------------------------------------------------
查看代码
如下图:
要提取的数据应该是突出显示的数据。我们先写一个SourceDataList类:
该类处理粗略数据,去除每行文本的前后空格,去除每行文本中连续的几个空格,只留下一个。然后文本行用空格隔开,只要分成两三个文本行即可。
此外,编写另一个类,DataParse。根据类名,你大概就知道这是第一次对得到的数据进行分析。
这个类可以得到基本定型的数据。对传输的文本进行分段(空格为分隔符),分别以二段和三段判断。
如果是两段文字。第一个元素以“:”结尾。冒号符号截断后,需要判断是否全是大写字母。第二个元素以单引号“'”开始和结束。只要满足这些条件,我们就需要一个文件行。
如果是三段文本行,第一个和第二个元素都是整数,第三个元素应该都是大写字母。满足条件的文本行就是需要获取的文本行。
接下来我们再写一个类,就是把上面得到的数据组合起来,DataStructures:
从这个类处理的数据接近我们需要的数据行。每行数据有三个字段,一个是字符串,第二个和第三个字段是整数。
最后一个类 DataHelper:
处理文本文件以获取数据并将其采集到 List(Of DataStructures) 集合中。
OK,现在我们可以显示获取到的数据了,在站点中,创建一个网页.aspx,去Page_Load事件中写:
运行网页时,查看效果:
查看全部
vb抓取网页内容(Insus.NET图:要汲取的数据应该是高亮部分的
)
今天在浏览论坛时,我看到了另一个关于阅读 TXT 文本文件的话题。 Insus.NET也想用自己的想法去实现,在这里分享一下。
文本文件比较复杂,获取数据也是一些文本行的一部分。为了得到更准确的数据,Insus.NET 写了几个步骤来实现。每一步使用一个类。毕竟,我们现在编写的程序是面向对象的。首先在站点下创建一个文本文件:
class="code_img_closed" src="/Upload/Images/2013081913/0015B68B3C38AA5B.gif" alt="" />
logs_code_hide('ab8f400e-39e7-4383-a87b-2ade5d84bf3a',event)" src="/Upload/Images/2013081913/2B1B950FA3DF188F.gif" alt="" />
==================================================
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D51179C'
Number Value Name
1 32 PAGPCHCONG
2 524 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: 'D5143A'
Number Value Name
1 64 PAGPCHCONG
2 537 PAGETOOOLD
--------------------------------------------------
Sat Feb 12, 16:45 CST-0800 2011 (OK)
--------------------------------------------------
CELLPAG: '516A'
Number Value Name
1 75 PAGPCHCONG
2 3677 PAGETOOOLD
--------------------------------------------------
查看代码
如下图:
要提取的数据应该是突出显示的数据。我们先写一个SourceDataList类:
该类处理粗略数据,去除每行文本的前后空格,去除每行文本中连续的几个空格,只留下一个。然后文本行用空格隔开,只要分成两三个文本行即可。
此外,编写另一个类,DataParse。根据类名,你大概就知道这是第一次对得到的数据进行分析。
这个类可以得到基本定型的数据。对传输的文本进行分段(空格为分隔符),分别以二段和三段判断。
如果是两段文字。第一个元素以“:”结尾。冒号符号截断后,需要判断是否全是大写字母。第二个元素以单引号“'”开始和结束。只要满足这些条件,我们就需要一个文件行。
如果是三段文本行,第一个和第二个元素都是整数,第三个元素应该都是大写字母。满足条件的文本行就是需要获取的文本行。
接下来我们再写一个类,就是把上面得到的数据组合起来,DataStructures:
从这个类处理的数据接近我们需要的数据行。每行数据有三个字段,一个是字符串,第二个和第三个字段是整数。
最后一个类 DataHelper:
处理文本文件以获取数据并将其采集到 List(Of DataStructures) 集合中。
OK,现在我们可以显示获取到的数据了,在站点中,创建一个网页.aspx,去Page_Load事件中写:
运行网页时,查看效果:

