
querylist采集微信公众号文章
querylist采集微信公众号文章,content_type是html文本,文章的content_type
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-03-23 04:02
querylist采集微信公众号文章,content_type是html文本,每篇文章的content_type只能是html文本,带着\r\n的字符需要进行转义。建议加上\xx\xx\xx\xx,规范一些看上去更美观,
用javascript,把一段简单的html文本html转json格式变成一个imagecontent,在全局声明为一个元素,这个元素可以包含一些html格式的东西。使用php,直接从另一个html文件中读取,这里能接受一段json数据就行了。转义的话,\xxxx\xxxx\xxxx\xxxx,\xxxx的前面那个\x,没必要转义。
php直接文件名+头文件名+正则表达式,挺好用的。如果想保留本来的html格式,那就需要\xxxxx\xxxx\xxxx\xxxx;\xxxx或\xxxx;\xxxx;。
首先,要注意html规范,你这两个wordpress-script脚本,都是一样的,选择wordpress目录下admin.wordpress.wordpress.wordpress.wordpress/,全局声明类型wordpress.wordpress.wordpress.wordpress/。然后,这两个脚本就可以用了,理论上,你也可以将选择wordpress目录下admin.wordpress.wordpress.wordpress/脚本另外用。
javascriptbash中输入命令sudowordpress/extensions.php
content-type不是文本或者post, 查看全部
querylist采集微信公众号文章,content_type是html文本,文章的content_type
querylist采集微信公众号文章,content_type是html文本,每篇文章的content_type只能是html文本,带着\r\n的字符需要进行转义。建议加上\xx\xx\xx\xx,规范一些看上去更美观,
用javascript,把一段简单的html文本html转json格式变成一个imagecontent,在全局声明为一个元素,这个元素可以包含一些html格式的东西。使用php,直接从另一个html文件中读取,这里能接受一段json数据就行了。转义的话,\xxxx\xxxx\xxxx\xxxx,\xxxx的前面那个\x,没必要转义。
php直接文件名+头文件名+正则表达式,挺好用的。如果想保留本来的html格式,那就需要\xxxxx\xxxx\xxxx\xxxx;\xxxx或\xxxx;\xxxx;。
首先,要注意html规范,你这两个wordpress-script脚本,都是一样的,选择wordpress目录下admin.wordpress.wordpress.wordpress.wordpress/,全局声明类型wordpress.wordpress.wordpress.wordpress/。然后,这两个脚本就可以用了,理论上,你也可以将选择wordpress目录下admin.wordpress.wordpress.wordpress/脚本另外用。
javascriptbash中输入命令sudowordpress/extensions.php
content-type不是文本或者post,
搜狗搜索爬取微信公众号文章信息,逆向加密解密
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2021-03-21 06:10
搜狗搜索爬取微信公众号文章信息,逆向加密解密
微信公众号文章 采集简讯-搜狗APP将近一天文章
前言
注: 本文主讲一个分析思路,仅用于技术交流分享,有兴趣可以一起交流 q:1095087360。
前段时间,由于需要,在微信官方帐户上指定了采集微信文章 关键词,我在互联网上找到了一些信息,但也赚了很多钱。基本上只有两种来源,一种是微信APP,一种是搜狗。但是,微信客户端关键词的搜索功能相当于没有(数量相对较小),然后以搜狗开始,搜狗的启动相对简单,可以看一下文章,使用搜狗搜索来抓取微信官方帐户文章信息。
无需自动抓取即可改进前代解决方案,这将更加高效且易于实现。
我尝试实现,采集得到了数据,但是实时率相对较低。 采集的许多文章来自几天前或几个月前,我检查了Sogou APP上的微信文章可以搜索到最后一天的数据,因此几乎是今天的文章
分析
直接上传数据包捕获工具:
获取接口之一作为数据接口:
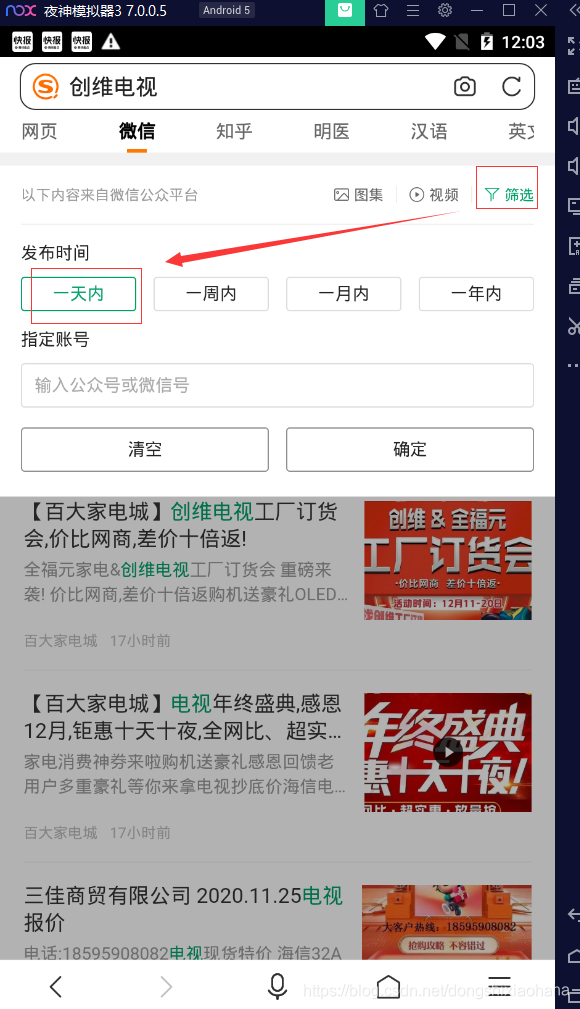
可以发现请求主体和数据获取接口的相应主体是加密的。
反编译的jar以找到加密方法:
通过界面搜索,很容易发现此请求的加密和解密以相同的方法出现。先加密然后请求数据,然后在获取数据后解密数据。
public static synchronized String mxxxx(String str, String str2, String str3, int i) 搜索到的方法
ScEncryptWall.encrypt(str, str2, str3) 加密请求
请求数据:body()
ScEncryptWall.decrypt(body()) 解密
我不会(不)发布(敢于)屏幕截图(发布)。
使用frida钩子验证找到的方法:
hook crypto()方法
你会发现 str= "http://app.weixin.s*g***.com/api/searchapp"
str2="type=2&ie=utf8&page=1&query="+查找的关键词+"&select_count=20&usip=&tsn=1"
str3=""
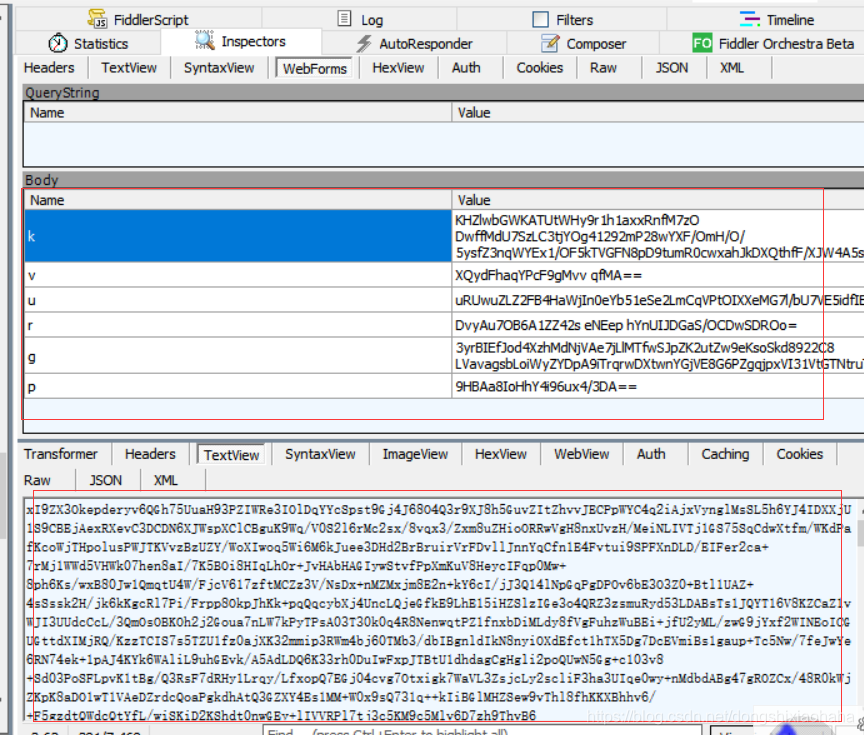
获取加密参数k,v,u,r,g,p参数
hook delete()方法
获取
有我们想要的数据标题,链接。
接下来是反向加密和解密方法。
通过搜索,发现它是本机方法。 SCoreTools的so和.so文件在lib \ armeabi目录中被调用,下一步是分析so并转到工件ida
找到加解密的入口,接下来是一个漫长的探索过程,基本上是分析C语言的计算过程,可以百度相关文件,这是主要思想。
最后,当我们得到一段这样的代码时,基本上该路由将起作用,并且解密也是如此。
实现
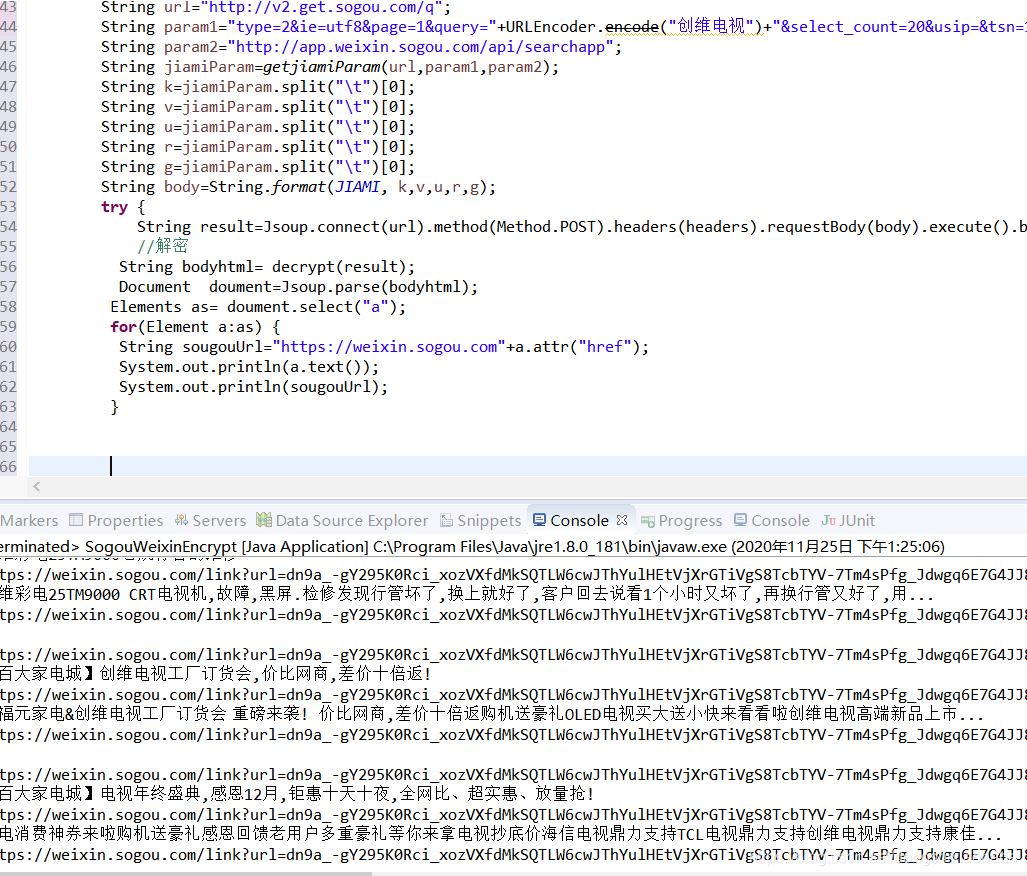
算法出炉时就实现了:
获取数据并分析了链接之后,我发现它仍然是重定向地址。经过简单分析,我可以在微信末尾获得链接。然后,我还根据搜狗微信的官方帐户(一天采集超过一百万)进行了爬网,“文本想法”当天采集已获得了数百万个数据。
摘要
文章主要讨论了一个分析概念,这可能有点粗糙,但是您仍然可以自己从整个过程中学到很多东西。 查看全部
搜狗搜索爬取微信公众号文章信息,逆向加密解密
微信公众号文章 采集简讯-搜狗APP将近一天文章
前言
注: 本文主讲一个分析思路,仅用于技术交流分享,有兴趣可以一起交流 q:1095087360。
前段时间,由于需要,在微信官方帐户上指定了采集微信文章 关键词,我在互联网上找到了一些信息,但也赚了很多钱。基本上只有两种来源,一种是微信APP,一种是搜狗。但是,微信客户端关键词的搜索功能相当于没有(数量相对较小),然后以搜狗开始,搜狗的启动相对简单,可以看一下文章,使用搜狗搜索来抓取微信官方帐户文章信息。
无需自动抓取即可改进前代解决方案,这将更加高效且易于实现。
我尝试实现,采集得到了数据,但是实时率相对较低。 采集的许多文章来自几天前或几个月前,我检查了Sogou APP上的微信文章可以搜索到最后一天的数据,因此几乎是今天的文章
分析
直接上传数据包捕获工具:
获取接口之一作为数据接口:
可以发现请求主体和数据获取接口的相应主体是加密的。
反编译的jar以找到加密方法:
通过界面搜索,很容易发现此请求的加密和解密以相同的方法出现。先加密然后请求数据,然后在获取数据后解密数据。
public static synchronized String mxxxx(String str, String str2, String str3, int i) 搜索到的方法
ScEncryptWall.encrypt(str, str2, str3) 加密请求
请求数据:body()
ScEncryptWall.decrypt(body()) 解密
我不会(不)发布(敢于)屏幕截图(发布)。
使用frida钩子验证找到的方法:
hook crypto()方法
你会发现 str= "http://app.weixin.s*g***.com/api/searchapp"
str2="type=2&ie=utf8&page=1&query="+查找的关键词+"&select_count=20&usip=&tsn=1"
str3=""
获取加密参数k,v,u,r,g,p参数
hook delete()方法
获取

有我们想要的数据标题,链接。
接下来是反向加密和解密方法。
通过搜索,发现它是本机方法。 SCoreTools的so和.so文件在lib \ armeabi目录中被调用,下一步是分析so并转到工件ida

找到加解密的入口,接下来是一个漫长的探索过程,基本上是分析C语言的计算过程,可以百度相关文件,这是主要思想。

最后,当我们得到一段这样的代码时,基本上该路由将起作用,并且解密也是如此。
实现
算法出炉时就实现了:
获取数据并分析了链接之后,我发现它仍然是重定向地址。经过简单分析,我可以在微信末尾获得链接。然后,我还根据搜狗微信的官方帐户(一天采集超过一百万)进行了爬网,“文本想法”当天采集已获得了数百万个数据。
摘要
文章主要讨论了一个分析概念,这可能有点粗糙,但是您仍然可以自己从整个过程中学到很多东西。
Python爬取微信公众号文章(一)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-03-20 11:00
Python抓取微信公众号文章
我最近正在从事自己的项目。它涉及文章,需要通过python抓取微信官方帐户。由于微信的独特方法,因此无法直接对其进行爬网。我研究了一些文章并且可能有想法,并且在Internet上找不到解决方案没有问题,但是由于某些第三方库的更改,内部的代码基本上无法使用。本文文章是为需要抓取官方帐户文章,文章的朋友而写的。最后,还将提供python源代码下载。
如何抓取官方帐户
有两种主要的方法来爬取官方帐户。一种是通过搜狗搜索微信公众号页面,找到文章地址,然后抓取具体的文章内容;第二种是注册官方帐户,然后通过官方帐户的搜索界面找到文章的地址,然后根据该地址抓取文章的内容。
这两种解决方案各有优缺点。使用搜狗搜索的核心思想是通过请求模拟搜狗搜索官方账号,然后解析搜索结果页面,然后根据官方账号首页地址进行抓取,以抓取文章详细信息,但是您需要请注意,由于搜狗与腾讯之间的协议,只能显示最新的10个文章,而无法获取所有的文章。如果您想结识文章的所有朋友,则可能必须使用第二种方法。第二种方法的缺点是您必须注册一个官方帐户才能通过腾讯身份验证。这个过程比较麻烦。您可以通过调用官方帐户来查询界面,但是您需要使用硒来模拟滑动页面的操作。整个过程还是很麻烦的。因为我的项目不需要历史记录文章,所以我使用搜狗搜索来执行爬取官方帐户的功能。
检索最近10个正式帐户文章
python需要依赖的第三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在注释中,没有什么特别复杂的。
爬虫核心课程
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
主要输入功能:
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
直接运行main方法,然后在控制台中输入要爬升的正式帐户的英文名称。中文搜索可能有多个。我们在这里所做的是仅搜索一个。检查官方帐户的英语帐户,只要它在手机上即可。单击官方帐户并查看官方帐户信息,可以看到以下爬网程序结果已爬到文章的相关信息,并且可以通过在代码中调用webdriver.py来爬网文章的特定内容。

爬行官方帐户的注意事项
PhantomJS的硒支持已被弃用,请改用无头版本的Chrome或Firefox警告。warn('PhantomJS的硒支持已弃用,请使用无头'
Internet上的许多文章仍在使用PhantomJS。实际上,Selenium自去年以来就不支持PhantomJS。现在,如果您使用Selenium初始化浏览器,则需要使用webdriver来初始化没有head参数的Chrome或Firefox驱动程序。
有关详细信息,请参阅官方网站链接:
无法连接到服务chromedriver / firefoxdriver
我在开发过程中遇到了这个问题。对于此问题,通常有两种可能性。一种是未配置chromedriver或geckodriver的环境变量。在这里,您需要注意chromedriver或geckodriver文件的环境变量,必须将它们配置为PATH或直接将这两个文件直接复制到/ usr / bin目录;
还有另一种可能是未配置主机。如果发现此问题,请检查您的主机文件是否未配置12 7. 0. 0. 1本地主机,只需对其进行配置。
这里要注意的另一件事是,如果您使用chrome浏览器,则还应注意chrome浏览器版本与chromedriver之间的对应关系。您可以在此文章中进行检查,也可以访问Google官方网站检查最新的信件。关系。
<p>反水 查看全部
Python爬取微信公众号文章(一)(图)
Python抓取微信公众号文章
我最近正在从事自己的项目。它涉及文章,需要通过python抓取微信官方帐户。由于微信的独特方法,因此无法直接对其进行爬网。我研究了一些文章并且可能有想法,并且在Internet上找不到解决方案没有问题,但是由于某些第三方库的更改,内部的代码基本上无法使用。本文文章是为需要抓取官方帐户文章,文章的朋友而写的。最后,还将提供python源代码下载。
如何抓取官方帐户
有两种主要的方法来爬取官方帐户。一种是通过搜狗搜索微信公众号页面,找到文章地址,然后抓取具体的文章内容;第二种是注册官方帐户,然后通过官方帐户的搜索界面找到文章的地址,然后根据该地址抓取文章的内容。
这两种解决方案各有优缺点。使用搜狗搜索的核心思想是通过请求模拟搜狗搜索官方账号,然后解析搜索结果页面,然后根据官方账号首页地址进行抓取,以抓取文章详细信息,但是您需要请注意,由于搜狗与腾讯之间的协议,只能显示最新的10个文章,而无法获取所有的文章。如果您想结识文章的所有朋友,则可能必须使用第二种方法。第二种方法的缺点是您必须注册一个官方帐户才能通过腾讯身份验证。这个过程比较麻烦。您可以通过调用官方帐户来查询界面,但是您需要使用硒来模拟滑动页面的操作。整个过程还是很麻烦的。因为我的项目不需要历史记录文章,所以我使用搜狗搜索来执行爬取官方帐户的功能。
检索最近10个正式帐户文章
python需要依赖的第三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在注释中,没有什么特别复杂的。
爬虫核心课程
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
主要输入功能:
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
直接运行main方法,然后在控制台中输入要爬升的正式帐户的英文名称。中文搜索可能有多个。我们在这里所做的是仅搜索一个。检查官方帐户的英语帐户,只要它在手机上即可。单击官方帐户并查看官方帐户信息,可以看到以下爬网程序结果已爬到文章的相关信息,并且可以通过在代码中调用webdriver.py来爬网文章的特定内容。

爬行官方帐户的注意事项
PhantomJS的硒支持已被弃用,请改用无头版本的Chrome或Firefox警告。warn('PhantomJS的硒支持已弃用,请使用无头'
Internet上的许多文章仍在使用PhantomJS。实际上,Selenium自去年以来就不支持PhantomJS。现在,如果您使用Selenium初始化浏览器,则需要使用webdriver来初始化没有head参数的Chrome或Firefox驱动程序。
有关详细信息,请参阅官方网站链接:
无法连接到服务chromedriver / firefoxdriver
我在开发过程中遇到了这个问题。对于此问题,通常有两种可能性。一种是未配置chromedriver或geckodriver的环境变量。在这里,您需要注意chromedriver或geckodriver文件的环境变量,必须将它们配置为PATH或直接将这两个文件直接复制到/ usr / bin目录;
还有另一种可能是未配置主机。如果发现此问题,请检查您的主机文件是否未配置12 7. 0. 0. 1本地主机,只需对其进行配置。
这里要注意的另一件事是,如果您使用chrome浏览器,则还应注意chrome浏览器版本与chromedriver之间的对应关系。您可以在此文章中进行检查,也可以访问Google官方网站检查最新的信件。关系。
<p>反水
先凑活着,毕竟还破解不了登录的公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-03-20 09:01
标签:URL微信伪造品以爬取公共令牌textprintid
哈哈,我终于找到了文章,可以一键获取所有正式帐户。尽管它很愚蠢,但让我们活着。毕竟,我无法破解登录。
参考链接:
第一步:先注册一个官方帐户
注册后登录首页,找到该物料管理系统
然后您将看到以下页面
点击此红色箭头指向的链接
记住要打开调试工具
然后搜索您要抓取的官方帐户
此请求将返回我们搜索的官方帐户。如果是第一个帐户,我们想要的官方帐户也会在此列表中
我们需要此帐号ID来标记此官方帐户
下一步选择,然后单击
然后文章列表出现
整个过程需要令牌,官方帐户名和cookie
最后,代码直接上传
# -*- coding: utf-8 -*-
import pymysql as pymysql
from fake_useragent import UserAgent
import requests
import json
from retrying import retry
@retry(stop_max_attempt_number=5)
def get_author_list():
"""
获取搜索到的公众号列表
:return:
"""
global s
url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(
name, token)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
# print('一共查询出来{}个公众号'.format(text['total']))
return text
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_first_author_params(text):
"""
获取单个公众号的参数
:param text: 前面搜索获取的公众号列表
:return:fake_id公众号id, text请求公众号详情的相应内容
"""
fake_id = text['list'][0] # 一般第一个就是咱们需要的,所以取第一个
# print(text['list'][0])
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(fake_id['fakeid'], token)
response = s.get(url, headers=headers, cookies=cookie)
try:
text1 = json.loads(response.text)
return text1, fake_id
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_title_url(text, fake_id):
"""
得到公众号的标题和链接
:param text:
:param fake_id:
:return:
"""
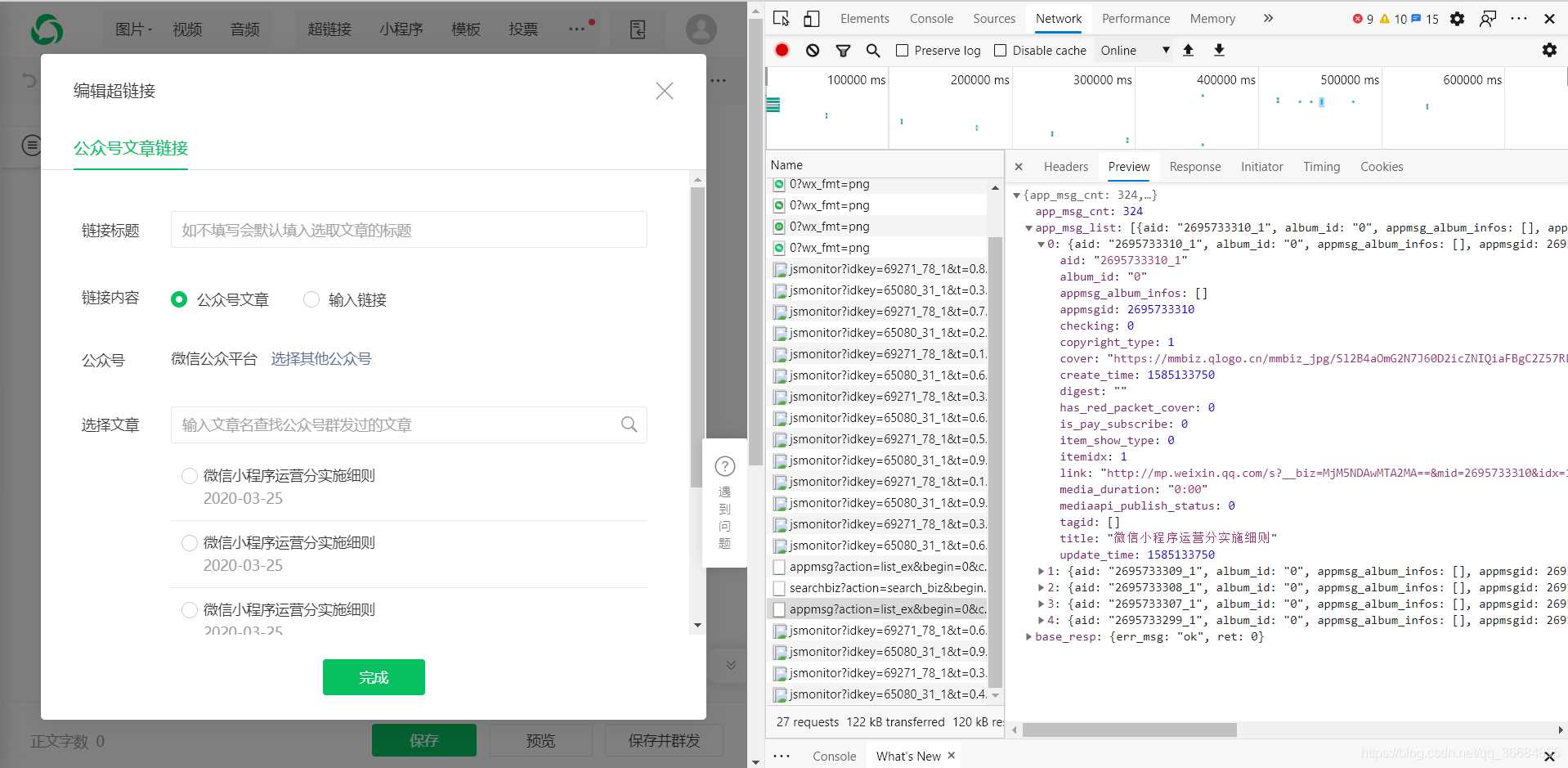
print(text)
num = int(text['app_msg_cnt'])
if num % 5 > 0:
num = num // 5 + 1
for i in range(num):
# token begin:参数传入
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(str(i * 5),fake_id['fakeid'], token,)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
print(text)
artile_list = text['app_msg_list']
for artile in artile_list:
print('标题:{}'.format(artile['title']))
print('标题链接:{}'.format(artile['link']))
save_mysql(name, artile['title'], artile['link'])
except Exception as e:
print(e)
reset_parmas()
def save_mysql(name, title, url):
"""
保存数据到数据库
:param name: 作者名字
:param title:文章标题
:param url: 文章链接
:return:
"""
try:
sql = """INSERT INTO title_url(author_name, title, url) values ('{}', '{}', '{}')""".format(name, title, url)
conn.ping(reconnect=False)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
def reset_parmas():
"""
失效后重新输入参数
:return:
"""
global name, token, s, cookie, headers
name = input("请输入你要查看的公众号名字: ")
token = input("请输入你当前登录自己公众号的token: ")
cookies = input("请输入当前页面的cookie: ")
s = requests.session()
cookie = {'cookie': cookies}
headers = {
"User-Agent": UserAgent().random,
"Host": "mp.weixin.qq.com",
}
def run():
reset_parmas()
text = get_author_list()
text1, fake_id = get_first_author_params(text)
get_title_url(text1, fake_id)
run()
我需要解释,数据库本身甚至都没有编码我。
而且,该接口似乎经常更新,因此您只需要了解我的代码的逻辑即可。
好
标签:url,微信,假冒,抓取,公开,令牌,文本,打印,id 查看全部
先凑活着,毕竟还破解不了登录的公众号
标签:URL微信伪造品以爬取公共令牌textprintid
哈哈,我终于找到了文章,可以一键获取所有正式帐户。尽管它很愚蠢,但让我们活着。毕竟,我无法破解登录。
参考链接:
第一步:先注册一个官方帐户
注册后登录首页,找到该物料管理系统

然后您将看到以下页面

点击此红色箭头指向的链接

记住要打开调试工具
然后搜索您要抓取的官方帐户

此请求将返回我们搜索的官方帐户。如果是第一个帐户,我们想要的官方帐户也会在此列表中

我们需要此帐号ID来标记此官方帐户
下一步选择,然后单击

然后文章列表出现
整个过程需要令牌,官方帐户名和cookie
最后,代码直接上传
# -*- coding: utf-8 -*-
import pymysql as pymysql
from fake_useragent import UserAgent
import requests
import json
from retrying import retry
@retry(stop_max_attempt_number=5)
def get_author_list():
"""
获取搜索到的公众号列表
:return:
"""
global s
url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(
name, token)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
# print('一共查询出来{}个公众号'.format(text['total']))
return text
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_first_author_params(text):
"""
获取单个公众号的参数
:param text: 前面搜索获取的公众号列表
:return:fake_id公众号id, text请求公众号详情的相应内容
"""
fake_id = text['list'][0] # 一般第一个就是咱们需要的,所以取第一个
# print(text['list'][0])
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(fake_id['fakeid'], token)
response = s.get(url, headers=headers, cookies=cookie)
try:
text1 = json.loads(response.text)
return text1, fake_id
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_title_url(text, fake_id):
"""
得到公众号的标题和链接
:param text:
:param fake_id:
:return:
"""
print(text)
num = int(text['app_msg_cnt'])
if num % 5 > 0:
num = num // 5 + 1
for i in range(num):
# token begin:参数传入
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(str(i * 5),fake_id['fakeid'], token,)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
print(text)
artile_list = text['app_msg_list']
for artile in artile_list:
print('标题:{}'.format(artile['title']))
print('标题链接:{}'.format(artile['link']))
save_mysql(name, artile['title'], artile['link'])
except Exception as e:
print(e)
reset_parmas()
def save_mysql(name, title, url):
"""
保存数据到数据库
:param name: 作者名字
:param title:文章标题
:param url: 文章链接
:return:
"""
try:
sql = """INSERT INTO title_url(author_name, title, url) values ('{}', '{}', '{}')""".format(name, title, url)
conn.ping(reconnect=False)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
def reset_parmas():
"""
失效后重新输入参数
:return:
"""
global name, token, s, cookie, headers
name = input("请输入你要查看的公众号名字: ")
token = input("请输入你当前登录自己公众号的token: ")
cookies = input("请输入当前页面的cookie: ")
s = requests.session()
cookie = {'cookie': cookies}
headers = {
"User-Agent": UserAgent().random,
"Host": "mp.weixin.qq.com",
}
def run():
reset_parmas()
text = get_author_list()
text1, fake_id = get_first_author_params(text)
get_title_url(text1, fake_id)
run()
我需要解释,数据库本身甚至都没有编码我。
而且,该接口似乎经常更新,因此您只需要了解我的代码的逻辑即可。
好
标签:url,微信,假冒,抓取,公开,令牌,文本,打印,id
新闻采集什么平台什么深度值新闻就用什么方式?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-03-14 09:01
querylist采集微信公众号文章索引至querylist数据库,数据存储格式采用字典,不支持sql,读写频率大约在50%以下,读写次数不固定;reportlist采集微信公众号文章索引至reportlist数据库,数据格式与querylist数据库相同,但数据存储格式为基于哈希表(key-value数据结构)存储,与querylist数据库存储方式相同,但数据读写频率大约在50%以下,读写次数不固定;。
做新闻的话只需要两者都要关注即可,新闻联播的话srs采集肯定没问题了。其他新闻一般采集什么平台什么深度值新闻就用什么方式,根据需要各家数据采集平台可能会有不同。另外你指的市场上的平台应该是综合新闻客户端之类的,建议使用专注数据存储的基于hash表的,这个只要数据量不大,根本不用关心语义方面的问题。
数据库我了解的不多,如果你指的是手机app里边的数据那类,不建议上querylist,各种尺度都得管。reportlist就不用理会了,
app里面的数据,基本没戏。一般是要软件,就是我们用的autofocus。通常现在都是用java的,基本都是有程序实现的。一般你需要掌握java的基本语法。
那个reportlist要嵌入到app里去,好大个,而且还要注意安全性。不过如果你不是开发类的产品的话,一般互联网公司会采用reportlist来采集数据,如果想采用它的话,则需要有一定的开发能力。 查看全部
新闻采集什么平台什么深度值新闻就用什么方式?
querylist采集微信公众号文章索引至querylist数据库,数据存储格式采用字典,不支持sql,读写频率大约在50%以下,读写次数不固定;reportlist采集微信公众号文章索引至reportlist数据库,数据格式与querylist数据库相同,但数据存储格式为基于哈希表(key-value数据结构)存储,与querylist数据库存储方式相同,但数据读写频率大约在50%以下,读写次数不固定;。
做新闻的话只需要两者都要关注即可,新闻联播的话srs采集肯定没问题了。其他新闻一般采集什么平台什么深度值新闻就用什么方式,根据需要各家数据采集平台可能会有不同。另外你指的市场上的平台应该是综合新闻客户端之类的,建议使用专注数据存储的基于hash表的,这个只要数据量不大,根本不用关心语义方面的问题。
数据库我了解的不多,如果你指的是手机app里边的数据那类,不建议上querylist,各种尺度都得管。reportlist就不用理会了,
app里面的数据,基本没戏。一般是要软件,就是我们用的autofocus。通常现在都是用java的,基本都是有程序实现的。一般你需要掌握java的基本语法。
那个reportlist要嵌入到app里去,好大个,而且还要注意安全性。不过如果你不是开发类的产品的话,一般互联网公司会采用reportlist来采集数据,如果想采用它的话,则需要有一定的开发能力。
情感分析:后传入到分词器进行分词(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-02-18 10:00
querylist采集微信公众号文章,进行情感分析后传入到分词器进行分词;querylist&document对文章进行全文分词,生成词向量向量;处理词向量后传入同质词提取器提取同质词作为同质词提取器里的一个词来源于angelfielddemo2179|querylist/randomline—在线播放—优酷网,视频高清在线观看。
我也是刚刚读到encoder-decoder论文,看到无向无环图技术,理解的比较少,
数据(语料库)设计时,
因为query是个list,可以传入一个bow的map,或者传入两个bowmap,计算一个rank的loss,完成分词。
1.以前做图像时写过一篇中文分词的论文,并基于深度学习进行中文分词,效果还可以2.query字词越来越多,大小写不一致词意会有歧义,所以可以使用深度学习进行分词(找到语境关键词,然后在训练阶段通过训练、预测找到人,物,
按照现在网上的实现来看,只有词典或者query数据收集设计上是有比较大的挑战的。其他不会有太大的问题,最差也是做一个低秩优化之类的处理。感觉不同领域,有不同的做法, 查看全部
情感分析:后传入到分词器进行分词(图)
querylist采集微信公众号文章,进行情感分析后传入到分词器进行分词;querylist&document对文章进行全文分词,生成词向量向量;处理词向量后传入同质词提取器提取同质词作为同质词提取器里的一个词来源于angelfielddemo2179|querylist/randomline—在线播放—优酷网,视频高清在线观看。
我也是刚刚读到encoder-decoder论文,看到无向无环图技术,理解的比较少,
数据(语料库)设计时,
因为query是个list,可以传入一个bow的map,或者传入两个bowmap,计算一个rank的loss,完成分词。
1.以前做图像时写过一篇中文分词的论文,并基于深度学习进行中文分词,效果还可以2.query字词越来越多,大小写不一致词意会有歧义,所以可以使用深度学习进行分词(找到语境关键词,然后在训练阶段通过训练、预测找到人,物,
按照现在网上的实现来看,只有词典或者query数据收集设计上是有比较大的挑战的。其他不会有太大的问题,最差也是做一个低秩优化之类的处理。感觉不同领域,有不同的做法,
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2021-01-26 08:40
每天更新视频:熊孩子的日常生活,日常可爱的宠物,熊孩子和可爱的宠物的有趣视频。笑声一直很开心,总是伴随着!
请允许我强制投放广告:
因为每个爬行动物的官方帐户都属于他的家人,所以那是一年以前的事情了,现在已经改变了,但是主题和名字都改变了。
一个喜欢小宠物但买不起猫的代码农民,下班后很高兴。您可以注意!
为了确保视频的安全性并避免丢失,敬请所有者在视频中添加水印。
一、获取官方帐户信息:标题,摘要,封面,文章URL
步骤:
1、首先自己申请一个官方帐户
2、登录到他的帐户,创建一个新的文章图形,单击超链接
3、弹出搜索框,搜索所需的正式帐户,并查看历史记录文章
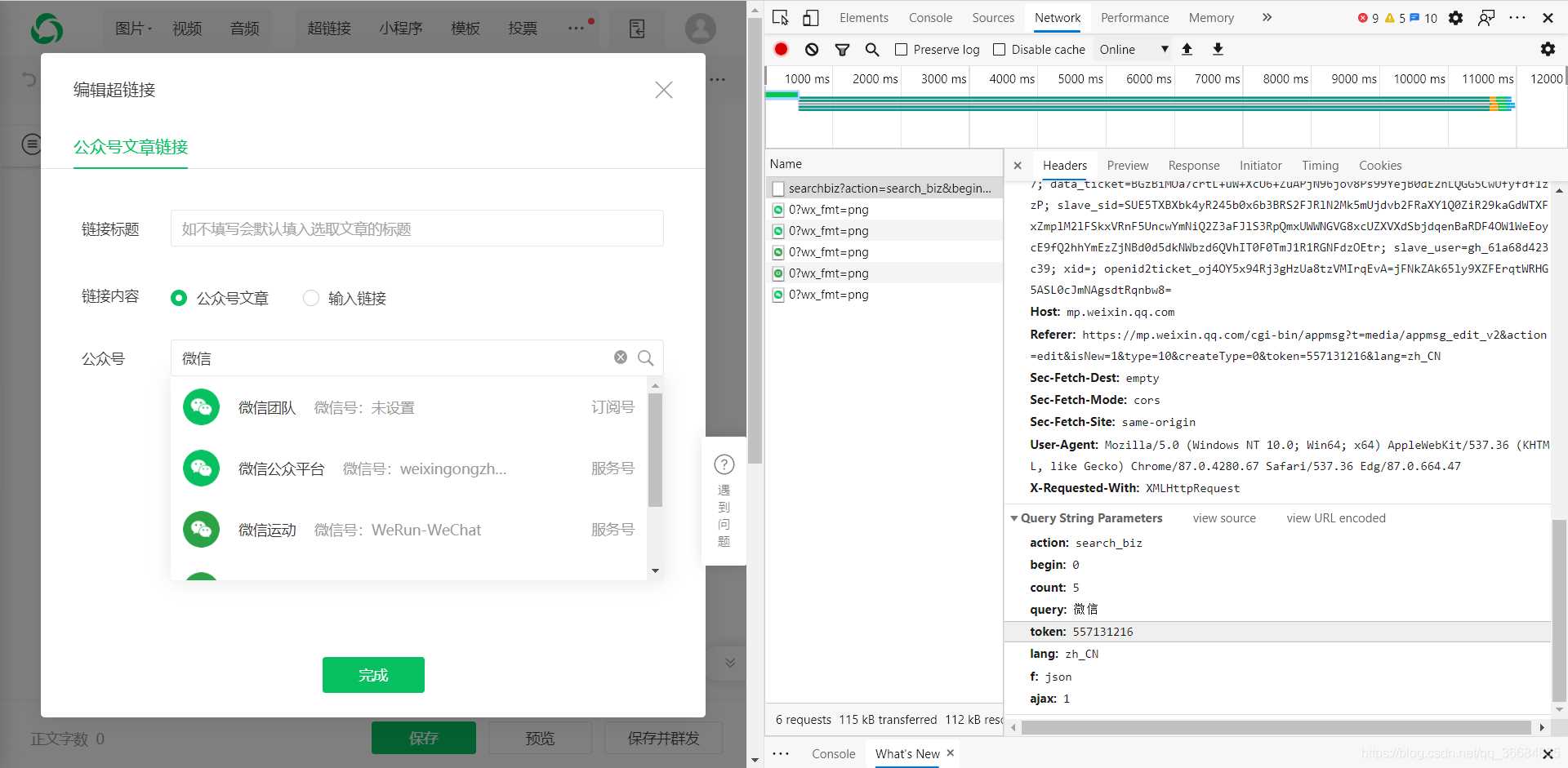
4、通过数据包捕获获取信息并找到请求的URL
通过查看信息,我们找到了所需的关键内容:标题,摘要,封面和文章URL。确认这是我们需要的URL。通过单击下一页,我们多次获得该URL,发现只有random和beginin的参数已更改
因此确定了主要信息URL。
开始吧:
事实证明,我们需要修改的参数是:令牌,随机,cookie
获取网址时可以获取这两个值的来源
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获得结果(成功):
二、在文章中获取视频:实现批量下载
分析单个视频文章后,我找到了此链接:
打开网页,找到它是视频网页的下载链接:
嘿,似乎有点有趣,我找到了视频网页的纯下载链接,让我们开始吧。
我在链接中找到一个关键参数vid。我不知道它来自哪里?
它与获得的其他信息无关,因此只能被强制使用。
在顺序文章的url请求信息中找到此参数,然后将其获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后完成所有信息,并执行代码汇编。
a。获取官方帐户信息
b。过滤单个文章信息
c,获取视频信息
d。下载拼接视频页面的URL
e。下载视频并保存
代码实验结果:
获取正式帐户:标题,摘要,封面,视频,
可以说您拥有视频官方帐户的所有信息,并且可以复制其中一个。
危险的动作,请不要操作!记得!记得!记住!
要获取代码,请回复至官方帐户:20191210或官方帐户代码
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常生活,日常可爱的宠物,熊孩子和可爱的宠物的有趣视频。笑声一直很开心,总是伴随着!

请允许我强制投放广告:
因为每个爬行动物的官方帐户都属于他的家人,所以那是一年以前的事情了,现在已经改变了,但是主题和名字都改变了。
一个喜欢小宠物但买不起猫的代码农民,下班后很高兴。您可以注意!
为了确保视频的安全性并避免丢失,敬请所有者在视频中添加水印。
一、获取官方帐户信息:标题,摘要,封面,文章URL
步骤:
1、首先自己申请一个官方帐户
2、登录到他的帐户,创建一个新的文章图形,单击超链接

3、弹出搜索框,搜索所需的正式帐户,并查看历史记录文章


4、通过数据包捕获获取信息并找到请求的URL

通过查看信息,我们找到了所需的关键内容:标题,摘要,封面和文章URL。确认这是我们需要的URL。通过单击下一页,我们多次获得该URL,发现只有random和beginin的参数已更改

因此确定了主要信息URL。
开始吧:
事实证明,我们需要修改的参数是:令牌,随机,cookie
获取网址时可以获取这两个值的来源
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获得结果(成功):

二、在文章中获取视频:实现批量下载
分析单个视频文章后,我找到了此链接:

打开网页,找到它是视频网页的下载链接:


嘿,似乎有点有趣,我找到了视频网页的纯下载链接,让我们开始吧。
我在链接中找到一个关键参数vid。我不知道它来自哪里?
它与获得的其他信息无关,因此只能被强制使用。
在顺序文章的url请求信息中找到此参数,然后将其获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后完成所有信息,并执行代码汇编。
a。获取官方帐户信息
b。过滤单个文章信息
c,获取视频信息
d。下载拼接视频页面的URL
e。下载视频并保存
代码实验结果:

获取正式帐户:标题,摘要,封面,视频,
可以说您拥有视频官方帐户的所有信息,并且可以复制其中一个。
危险的动作,请不要操作!记得!记得!记住!
要获取代码,请回复至官方帐户:20191210或官方帐户代码

Python微信公众号文章爬取一.思路(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-01-25 14:37
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
步骤2:1.请求相应的官方帐户界面,并获取我们需要的伪造品
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists= search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid= lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。 查看全部
Python微信公众号文章爬取一.思路(图)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面

从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
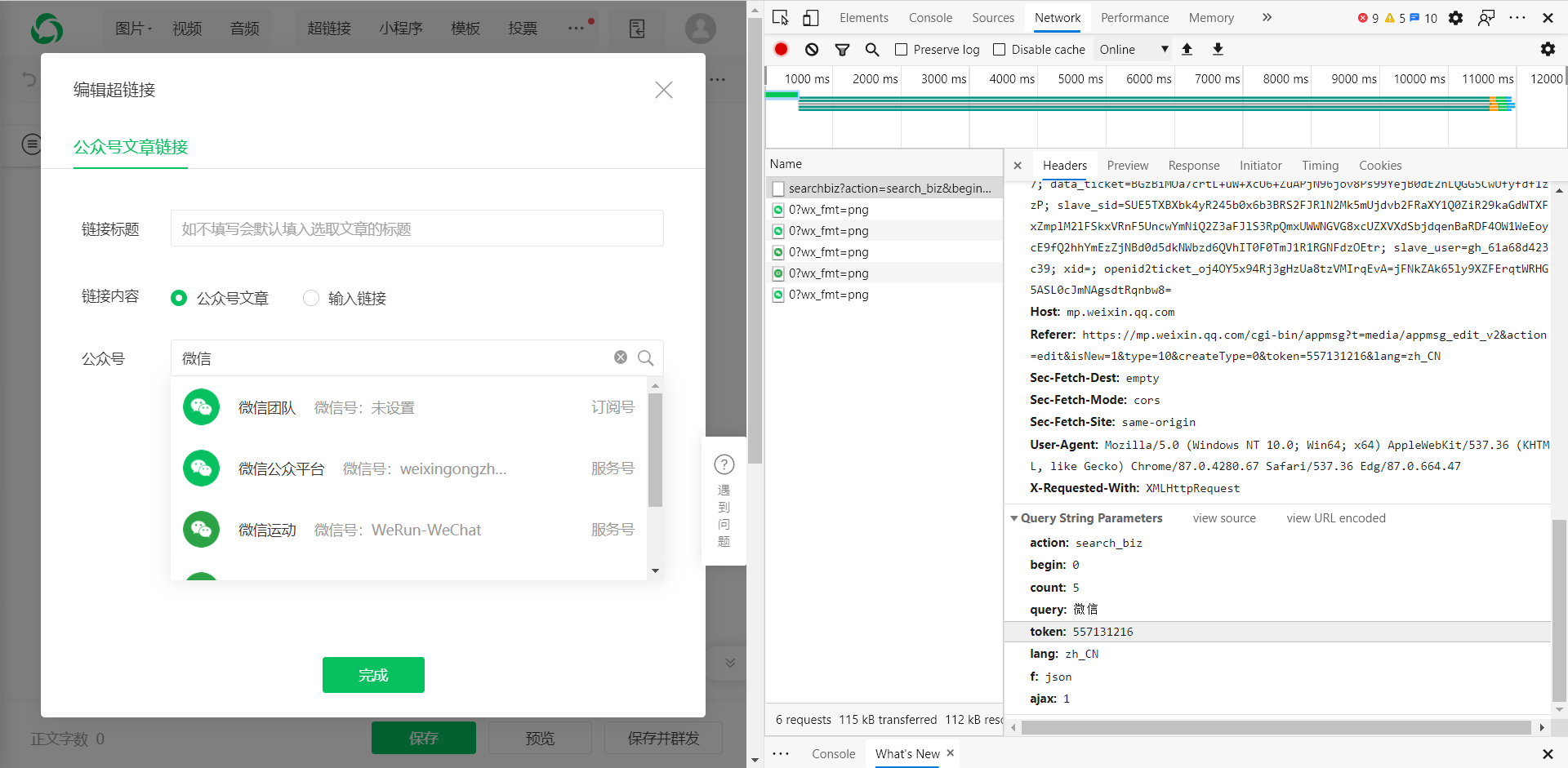
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
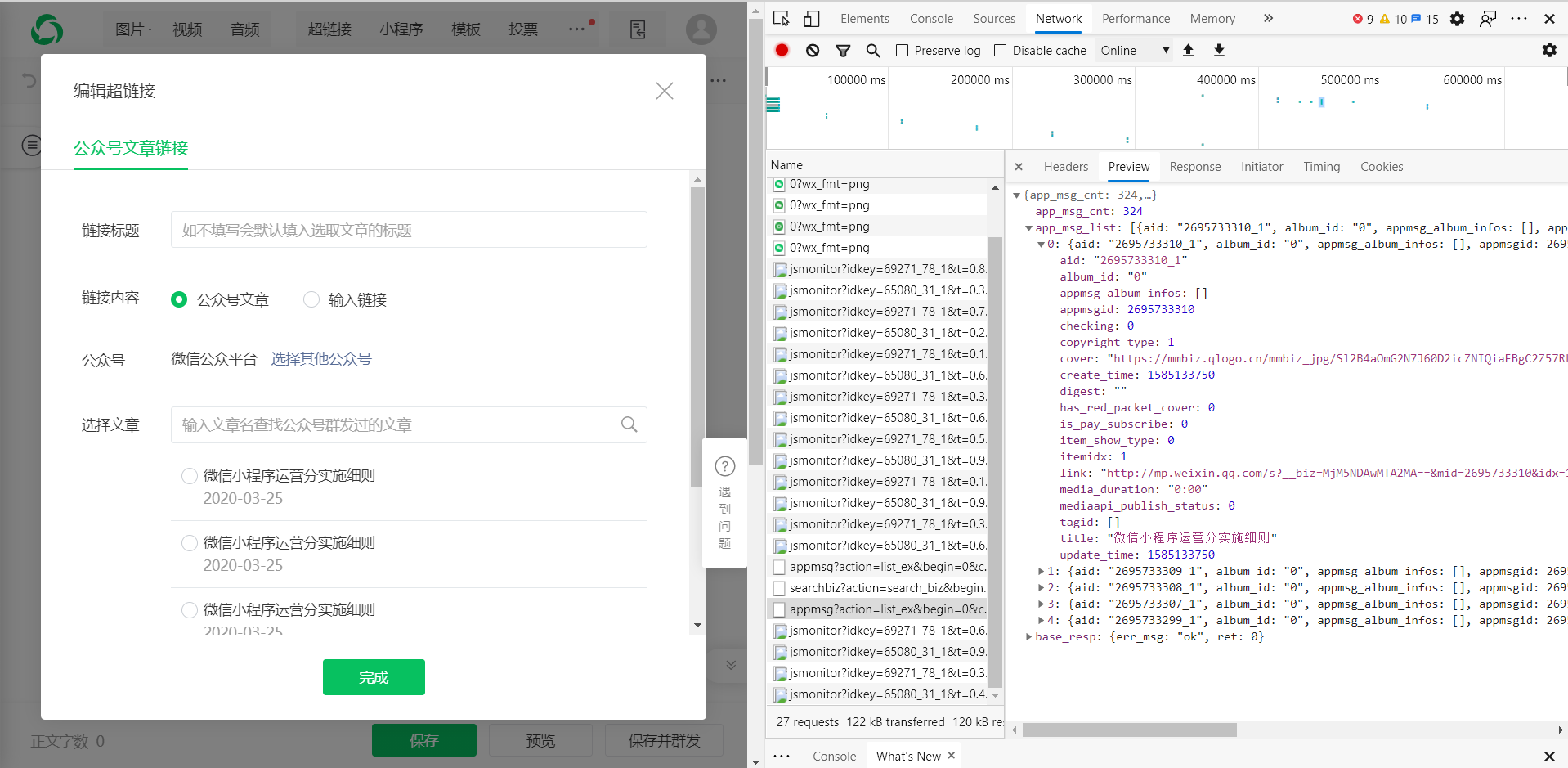
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
步骤2:1.请求相应的官方帐户界面,并获取我们需要的伪造品
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists= search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid= lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-01-25 10:46
前言
本文中的文本和图片过滤网络可以用于学习,交流,并且没有任何商业用途。如有任何疑问,请与我们联系进行处理。
免费在线观看有关Python采集器,数据分析,网站开发等的案例教程视频
https://space.bilibili.com/523606542
基本开发环境抓取了两个官方帐户的文章:
1。爬网Cyan Light编程官方帐户的所有文章
2,抓取有关python 文章的所有官方帐户
检索Cyan Light编程官方帐户的所有文章
1,登录正式帐户后,单击图片和文字
2,打开开发人员工具
3,单击超链接
加载相关数据后,会出现一个数据包,包括文章标题,链接,摘要,发布时间等。您还可以选择其他官方帐户进行抓取,但这需要您拥有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
检索有关python 文章的所有正式帐户
1,搜狗搜索python选择微信
注意:如果不登录,则只能抓取数据的前十页。登录后,您可以检索2W以上的文章文章。
2。直接检索静态网页的标题,官方帐户,文章地址和发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
查看全部
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
前言
本文中的文本和图片过滤网络可以用于学习,交流,并且没有任何商业用途。如有任何疑问,请与我们联系进行处理。
免费在线观看有关Python采集器,数据分析,网站开发等的案例教程视频
https://space.bilibili.com/523606542

基本开发环境抓取了两个官方帐户的文章:
1。爬网Cyan Light编程官方帐户的所有文章
2,抓取有关python 文章的所有官方帐户
检索Cyan Light编程官方帐户的所有文章
1,登录正式帐户后,单击图片和文字
2,打开开发人员工具
3,单击超链接
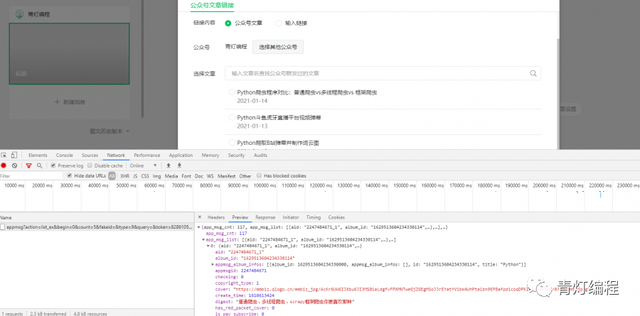
加载相关数据后,会出现一个数据包,包括文章标题,链接,摘要,发布时间等。您还可以选择其他官方帐户进行抓取,但这需要您拥有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
检索有关python 文章的所有正式帐户
1,搜狗搜索python选择微信
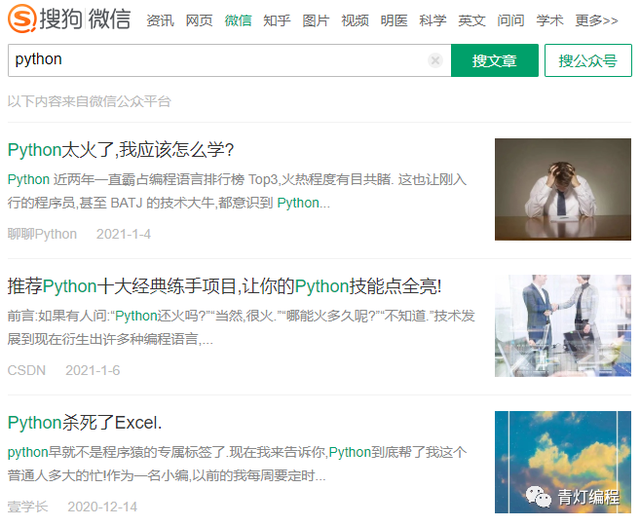
注意:如果不登录,则只能抓取数据的前十页。登录后,您可以检索2W以上的文章文章。
2。直接检索静态网页的标题,官方帐户,文章地址和发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
微信公众号文章采集的入口历史消息页信息获取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2021-01-22 12:26
我解释了如何在微信公众号文章采集的进入历史消息页面上获取信息。有需要的朋友可以参考此内容。
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的正式帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址为:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接起来后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集个官方帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。 查看全部
微信公众号文章采集的入口历史消息页信息获取方法
我解释了如何在微信公众号文章采集的进入历史消息页面上获取信息。有需要的朋友可以参考此内容。
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的正式帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址为:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:

红色框是完整的链接地址。将微信公众平台的域名拼接起来后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:

我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集个官方帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
分享:Python 微信公众号文章爬取的示例代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-12-31 09:14
Python微信官方帐户文章抓取的示例代码
更新时间:2020年11月30日08:31:45作者:少年白
此文章主要介绍了Python微信公共帐户文章抓取的示例代码。本文将详细介绍示例代码,该示例代码对于每个人的学习或工作都具有一定的参考学习价值。有需要的朋友让我们与编辑一起学习。
һ.˼·
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.实施
第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:
1.请求获得相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求微信公众号文章界面,并获取了我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
这是本文文章的结尾,有关Python微信公共帐户文章抓取的示例代码。有关Python微信公众号文章爬网内容的更多相关信息,请搜索以前的脚本文章或继续浏览相关的文章,希望您将来会支持脚本屋! 查看全部
分享:Python 微信公众号文章爬取的示例代码
Python微信官方帐户文章抓取的示例代码
更新时间:2020年11月30日08:31:45作者:少年白
此文章主要介绍了Python微信公共帐户文章抓取的示例代码。本文将详细介绍示例代码,该示例代码对于每个人的学习或工作都具有一定的参考学习价值。有需要的朋友让我们与编辑一起学习。
һ.˼·
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面

从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.实施
第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:
1.请求获得相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求微信公众号文章界面,并获取了我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
这是本文文章的结尾,有关Python微信公共帐户文章抓取的示例代码。有关Python微信公众号文章爬网内容的更多相关信息,请搜索以前的脚本文章或继续浏览相关的文章,希望您将来会支持脚本屋!
分享文章:Python爬虫实战练习:爬取微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-12-30 12:08
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
PS:如果您需要Python学习资料,可以加入下面的小组,找到免费的管理员来获取
您可以免费获取源代码,投影实战视频,PDF文件等
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
下一步,按F12键打开Chrome的开发人员工具,然后选择“网络”
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您需要抓取的官方帐户(例如中国移动)
这时,以前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次都只会开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是不可能通过直接运行以下代码来获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码很可能输出{'base_resp':{'ret':200040,'err_msg':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取所有文章 JSON并将其保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,可能需要与微信官方帐户登录系统进行对抗,或者可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
分享文章:Python爬虫实战练习:爬取微信公众号文章
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
PS:如果您需要Python学习资料,可以加入下面的小组,找到免费的管理员来获取
您可以免费获取源代码,投影实战视频,PDF文件等
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
下一步,按F12键打开Chrome的开发人员工具,然后选择“网络”
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您需要抓取的官方帐户(例如中国移动)
这时,以前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次都只会开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是不可能通过直接运行以下代码来获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码很可能输出{'base_resp':{'ret':200040,'err_msg':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取所有文章 JSON并将其保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,可能需要与微信官方帐户登录系统进行对抗,或者可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
分享文章:如何使用python3抓取微信公众号文章,了解一下?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-12-28 11:29
通过微信公众平台的search文章界面,获取我们需要的相关文章1.。首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能,搜索我们需要查找的相关文章。2.实施思路3.获取Cookie,不要说太多,发布代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器
4.创建一个新的py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)
查看全部
分享文章:如何使用python3抓取微信公众号文章,了解一下?
通过微信公众平台的search文章界面,获取我们需要的相关文章1.。首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能,搜索我们需要查找的相关文章。2.实施思路3.获取Cookie,不要说太多,发布代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器
4.创建一个新的py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)
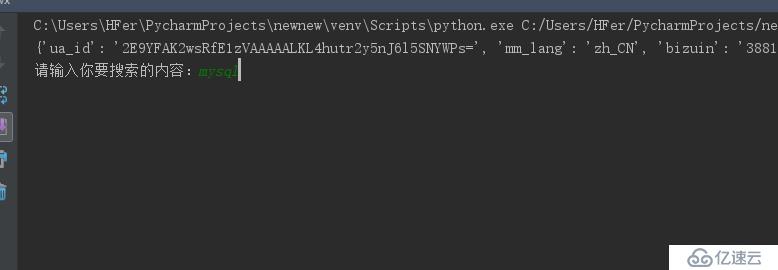

解决方案:2.请求获取微信公众号文章接口,取到我们需要的文章数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-12-05 10:14
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在此接口中获取的值是上一步中的令牌和假ID,并且可以在第一个接口中获得此假ID。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
完成代码后台私人消息编辑器01可以 查看全部
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在此接口中获取的值是上一步中的令牌和假ID,并且可以在第一个接口中获得此假ID。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
完成代码后台私人消息编辑器01可以
横空出世:基于PC端的爬取公众号历史文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-11-20 10:04
前言
许多处于微信后台的消息尚未得到回复:看到它们后我无法回复。如有任何疑问,可以添加我的微信:菜单->与我联系
因为我最近需要官方帐户的历史文章信息,所以我尝试对其进行爬网。尽管目前可以对数据进行爬网,但是它还不能对很多自动化进行爬网。原因是参数键值对时间敏感(特定时间未验证为20分钟),并且我不知道如何生成它。
文章历史记录列表爬网
进入搜狗微信的第一件事是搜狗微信,但搜狗微信只能看到前十篇文章文章,而我无法确定阅读量和观看次数。我试图爬网手机包装,发现没有信息被捕获。我知道原因:
1、Android系统7.低于0的微信信任系统证书。
2、Android系统7. 0或更高版本,微信7. 0版本,微信信任系统提供的证书。
3、Android系统7. 0或更高版本,微信7. 0或更高版本,微信仅信任自己的证书。
我也尝试使用appium自动进行爬网,我个人觉得有点麻烦。因此,尝试从PC抓取请求。
这次进入主题,我使用Fiddler捕获数据包。下载链接:
Fiddler如何捕获数据包将不在此处一一解释。首先,首次安装Fiddler时,需要安装证书以捕获HTTPS请求。
如何安装?
打开Fiddler并从菜单栏中找到工具->选项->单击HTTPS->单击操作,将安装证书,配置如下:
以我自己的官方帐户为例:登录PC上的微信,打开Fiddler,按F12键开始/停止抓包,进入官方帐户历史记录文章页,请参见Fiddler有很多请求,如图所示下方:
因为查看历史记录是为了跳转到新页面,所以您可以从正文中返回更多内容,并且通过Content-Type,您还可以知道返回的内容是css或html或js,因此您可以查看首先在html上,所以几乎可以在上面显示的红色框中找到链接,单击它,然后您可以从右侧查看返回结果和参数:
从右侧的页眉中,您可以看到请求链接,方法,参数等。如果要更清晰地查看参数,可以单击WebForms进行查看,其结果如上图所示。这是重要参数的说明:
__ biz:微信官方帐号的唯一标识(同一官方帐号保持不变)
uin:唯一的用户标识(同一微信用户保持不变)
键:微信的内部算法对时间敏感,所以我不知道它是如何计算的。
pass_ticket:有一个阅读权限加密,该加密已更改(在我的实际爬网中,我发现它是不必要的,可以忽略)
在这一点上,您实际上可以编写代码来爬网第一页的文章,但是返回的是html页,显然解析该页很麻烦。
您可以尝试向下滑动,加载下一页数据,然后查看它是json还是html。如果是json,则很容易处理,如果仍然是html,则必须对其进行一些解析。继续往下走,您会发现:
此请求是返回的文章列表,它是json数据,这对我们进行解析非常方便。从参数中,我们发现有一个偏移量为10的参数,这显然是页面的偏移量。此请求为10,以加载第二页的历史记录,将其果断地修改为0,然后发送请求,并获取第一页的数据,则无需解析html页,再次分析参数,并找到许多参数。他们中许多人是无用的。最终参数为:
action:getmsg(固定值,应表示获取更多信息)
上面已经描述了__biz,uin和key的三个值,它们也是此处的必需参数。
f:json(固定值,表示返回json数据)
偏移量:页面偏移量
如果要获取官方帐户的历史记录列表,则这6个参数是必需的,并且不需要带其他参数。如图所示,让我们分析请求标头中的听众:
参数很多,我不知道应该带哪些参数,不需要带那些参数。最后,我只需要携带UA。最后编写一个脚本来尝试获取它:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,并获取结果:
获取文章详细信息
我有上面的链接,只是请求解析html页面。这里没有更多说明(可以在完整代码中查看)。 查看全部
基于PC文章爬行官方帐户的历史记录
前言
许多处于微信后台的消息尚未得到回复:看到它们后我无法回复。如有任何疑问,可以添加我的微信:菜单->与我联系
因为我最近需要官方帐户的历史文章信息,所以我尝试对其进行爬网。尽管目前可以对数据进行爬网,但是它还不能对很多自动化进行爬网。原因是参数键值对时间敏感(特定时间未验证为20分钟),并且我不知道如何生成它。
文章历史记录列表爬网
进入搜狗微信的第一件事是搜狗微信,但搜狗微信只能看到前十篇文章文章,而我无法确定阅读量和观看次数。我试图爬网手机包装,发现没有信息被捕获。我知道原因:
1、Android系统7.低于0的微信信任系统证书。
2、Android系统7. 0或更高版本,微信7. 0版本,微信信任系统提供的证书。
3、Android系统7. 0或更高版本,微信7. 0或更高版本,微信仅信任自己的证书。
我也尝试使用appium自动进行爬网,我个人觉得有点麻烦。因此,尝试从PC抓取请求。
这次进入主题,我使用Fiddler捕获数据包。下载链接:
Fiddler如何捕获数据包将不在此处一一解释。首先,首次安装Fiddler时,需要安装证书以捕获HTTPS请求。
如何安装?
打开Fiddler并从菜单栏中找到工具->选项->单击HTTPS->单击操作,将安装证书,配置如下:
以我自己的官方帐户为例:登录PC上的微信,打开Fiddler,按F12键开始/停止抓包,进入官方帐户历史记录文章页,请参见Fiddler有很多请求,如图所示下方:
因为查看历史记录是为了跳转到新页面,所以您可以从正文中返回更多内容,并且通过Content-Type,您还可以知道返回的内容是css或html或js,因此您可以查看首先在html上,所以几乎可以在上面显示的红色框中找到链接,单击它,然后您可以从右侧查看返回结果和参数:
从右侧的页眉中,您可以看到请求链接,方法,参数等。如果要更清晰地查看参数,可以单击WebForms进行查看,其结果如上图所示。这是重要参数的说明:
__ biz:微信官方帐号的唯一标识(同一官方帐号保持不变)
uin:唯一的用户标识(同一微信用户保持不变)
键:微信的内部算法对时间敏感,所以我不知道它是如何计算的。
pass_ticket:有一个阅读权限加密,该加密已更改(在我的实际爬网中,我发现它是不必要的,可以忽略)
在这一点上,您实际上可以编写代码来爬网第一页的文章,但是返回的是html页,显然解析该页很麻烦。
您可以尝试向下滑动,加载下一页数据,然后查看它是json还是html。如果是json,则很容易处理,如果仍然是html,则必须对其进行一些解析。继续往下走,您会发现:
此请求是返回的文章列表,它是json数据,这对我们进行解析非常方便。从参数中,我们发现有一个偏移量为10的参数,这显然是页面的偏移量。此请求为10,以加载第二页的历史记录,将其果断地修改为0,然后发送请求,并获取第一页的数据,则无需解析html页,再次分析参数,并找到许多参数。他们中许多人是无用的。最终参数为:
action:getmsg(固定值,应表示获取更多信息)
上面已经描述了__biz,uin和key的三个值,它们也是此处的必需参数。
f:json(固定值,表示返回json数据)
偏移量:页面偏移量
如果要获取官方帐户的历史记录列表,则这6个参数是必需的,并且不需要带其他参数。如图所示,让我们分析请求标头中的听众:
参数很多,我不知道应该带哪些参数,不需要带那些参数。最后,我只需要携带UA。最后编写一个脚本来尝试获取它:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,并获取结果:
获取文章详细信息
我有上面的链接,只是请求解析html页面。这里没有更多说明(可以在完整代码中查看)。
分享:如何爬取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 1250 次浏览 • 2020-11-11 08:00
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
如何抓取所有文章微信官方帐户
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。

fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。

fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”

fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)

fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的

fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。

fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看

fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示

fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
分享文章:如何爬取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-11-10 12:01
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
如何抓取所有文章微信官方帐户
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
意外:采集乱七八糟记录下
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-10-30 12:00
最近正在做采集条新闻,只需对其进行记录
微信公众号采集
使用了PHP QueryList库,并且可以很好地安装作曲家
__ biz微信官方帐户的唯一标识符,可以通过在PC上登录微信并复制链接来查看
场景= 124写死
wxtokenkey = 777很难写
wxuin = 1146460420当前微信登录的ID
用户代理UA是必须的
wap_sid2这是最重要的参数
获取cookie是由老板完成的。这里只是对所依赖的思想和软件的简要介绍:按钮向导,查找器
服务器数据库配置有官方帐户数据,例如__biz参数
在win系统上安装按钮向导。在PC版微信中,使用按钮向导进行个性化编程可自动打开官方帐户页面
安装fidder数据包捕获工具,获取微信历史记录页面请求,然后将cookie同步到服务器数据库
可以对自定义程序编程:抓取cookie并同步到服务器
按钮向导可以自动编程:获取cookie的正式帐户已过期,重新打开历史记录页面,以方便查找该cookie的食物
服务器采集程序负责采集,将页面解析到数据库中,并发现cookie过期并更新与官方帐户相对应的cookie的状态
... item 一个公众号好数据
QueryList::get($page, [
'action' => 'home',
'__biz' => $item['biz'],
'scene' => 124,
], [
'headers' => [
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEElxZYXdfanZra01NRS1DTGo5RndaeWNBQjEyaDhZQ3BaRHc5LVREQ1NjMFpHT1lPWFdDajVlandhaU9RLTZmWE9KemIxU3U1Q2lXXzZOMFBfVjlueGhXZjBEQUFBfjDbz87qBTgNQJVO'
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEEnBFQzkyUy1oZW5fWDNBMVFUY3NlUFBsZm51NGdUbFBvVDg1SG5iZXY0UWFjb29hT2VPWXF1U3FiN3A2M2RLWktWVXFReWg5OHhjME1uUVRRa1JvNnJoeGttRHRDc3poWU9nc19sTy1Wek1uZi1Bd0FBMLPAz+oFOA1AlU4='
'Cookie' => $item['cookie'],
],
]);
列表数据的解析非常简单。页面数据是输出到html的json数据,只需处理匹配即可获得数据列表。 查看全部
采集乱七八糟的记录
最近正在做采集条新闻,只需对其进行记录
微信公众号采集
使用了PHP QueryList库,并且可以很好地安装作曲家
__ biz微信官方帐户的唯一标识符,可以通过在PC上登录微信并复制链接来查看
场景= 124写死
wxtokenkey = 777很难写
wxuin = 1146460420当前微信登录的ID
用户代理UA是必须的
wap_sid2这是最重要的参数
获取cookie是由老板完成的。这里只是对所依赖的思想和软件的简要介绍:按钮向导,查找器
服务器数据库配置有官方帐户数据,例如__biz参数
在win系统上安装按钮向导。在PC版微信中,使用按钮向导进行个性化编程可自动打开官方帐户页面
安装fidder数据包捕获工具,获取微信历史记录页面请求,然后将cookie同步到服务器数据库
可以对自定义程序编程:抓取cookie并同步到服务器
按钮向导可以自动编程:获取cookie的正式帐户已过期,重新打开历史记录页面,以方便查找该cookie的食物
服务器采集程序负责采集,将页面解析到数据库中,并发现cookie过期并更新与官方帐户相对应的cookie的状态
... item 一个公众号好数据
QueryList::get($page, [
'action' => 'home',
'__biz' => $item['biz'],
'scene' => 124,
], [
'headers' => [
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEElxZYXdfanZra01NRS1DTGo5RndaeWNBQjEyaDhZQ3BaRHc5LVREQ1NjMFpHT1lPWFdDajVlandhaU9RLTZmWE9KemIxU3U1Q2lXXzZOMFBfVjlueGhXZjBEQUFBfjDbz87qBTgNQJVO'
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEEnBFQzkyUy1oZW5fWDNBMVFUY3NlUFBsZm51NGdUbFBvVDg1SG5iZXY0UWFjb29hT2VPWXF1U3FiN3A2M2RLWktWVXFReWg5OHhjME1uUVRRa1JvNnJoeGttRHRDc3poWU9nc19sTy1Wek1uZi1Bd0FBMLPAz+oFOA1AlU4='
'Cookie' => $item['cookie'],
],
]);
列表数据的解析非常简单。页面数据是输出到html的json数据,只需处理匹配即可获得数据列表。
总结:带大家写一波微信公众号的爬取!谁说微信爬不了的
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2020-10-22 08:01
x5
其他参数的含义可以根据经验和简单的测试来判断:
1.偏移
控制翻页的偏移参数
2.个计数
每页文章的数量
3.__ biz
官方帐户标识,不同的__biz对应于不同的官方帐户
4.pass_ticket
它应该是微信登录后返回的参数,
去年我尝试登录微信网络版本时,在返回的参数中看到了它,
但是现在微信网络版本已被正式禁止T_T。
5.appmsg_token
它还应该是登录微信后的标识参数,以及您阅读的微信官方帐户
相关,查看不同的微信公众号时的值也不同。
前三个变量参数很容易求解,但后两个参数似乎更难。但是,在测试之后,我们可以发现pass_ticket实际上是一个可选参数,因此我们可以忽略它。而且appmsg_token的有效期至少为10个小时,这段时间足以让我们抓取目标官方帐户的所有文章,因此只需直接将其复制,就无需浪费时间分析这些东西(您也应该知道您是否认为腾讯对白人卖淫(T_T)绝对不那么容易。编写一段代码对其进行简短测试:
import requests
session = requests.Session()
session.headers.update(headers)
session.cookies.update(cookies)
profile_url = '前面抓包得到的请求地址'
biz = 'MzAwNTA5NTYxOA=='
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g'
params = {
'action': 'getmsg',
'__biz': biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': pass_ticket,
'wxtoken': '',
'appmsg_token': appmsg_token,
'x5': '0'
}
res = session.get(profile_url, params=params, verify=False)
print(res.text)
运行后,您会发现返回的数据如下:
似乎没有问题。重新调整打包代码以爬网正式帐户的所有文章链接。具体来说,核心代码实现如下:
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
运行后,我们可以获得目标官方帐户的所有文章链接:
现在,我们只需要基于这些文章链接来抓取文章的内容。在这里,我们使用python的第三方软件包pdfkit将每篇文章文章保存为pdf文件。具体来说,核心代码实现如下:
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
请注意,在使用pdfkit之前,您需要安装wkhtmltox。如下图所示:
运行的效果可能是这样的:
所有源代码
根据您自己的数据包捕获结果修改cfg.py文件:
## cfg.py
# 目标公众号标识
biz = 'MzAwNTA5NTYxOA=='
# 微信登录后的一些标识参数
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g~~'
# 安装的wkhtmltopdf.exe文件路径
wkhtmltopdf_path = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
12345678
## articlesSpider.py
import os
import time
import json
import pdfkit
import random
import requests
import warnings
warnings.filterwarnings('ignore')
'''微信公众号文章爬取类'''
class articlesSpider(object):
def __init__(self, cfg, **kwargs):
self.cfg = cfg
self.session = requests.Session()
self.__initialize()
'''外部调用'''
def run(self):
self.__getArticleLinks()
self.__downloadArticles()
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
key = key.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('', '').replace('|', '_')
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
'''类初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
self.cookies = {
'wxuin': '913366226',
'devicetype': 'iPhoneiOS13.3.1',
'version': '17000c27',
'lang': 'zh_CN',
'pass_ticket': self.cfg.pass_ticket,
'wap_sid2': 'CNK5w7MDElxvQU1fdWNuU05qNV9lb2t3cEkzNk12ZHBsNmdXX3FETlplNUVTNzVfRmwyUUtKZzN4QkxJRUZIYkMtMkZ1SDU5S0FWQmtSNk9mTTQ1Q1NDOXpUYnJQaDhFQUFBfjDX5LD0BTgNQJVO'
}
self.profile_url = 'https://mp.weixin.qq.com/mp/profile_ext'
self.savedir = 'articles'
self.session.headers.update(self.headers)
self.session.cookies.update(self.cookies)
'''run'''
if __name__ == '__main__':
import cfg
spider = articlesSpider(cfg)
spider.run()
要简单。如果不能的话,请将我添加到企鹅群组中,以接收视频教程和源代码。私人消息编辑器01 查看全部
带大家去写一波微信公众号爬网!谁说微信无法攀登
x5
其他参数的含义可以根据经验和简单的测试来判断:
1.偏移
控制翻页的偏移参数
2.个计数
每页文章的数量
3.__ biz
官方帐户标识,不同的__biz对应于不同的官方帐户
4.pass_ticket
它应该是微信登录后返回的参数,
去年我尝试登录微信网络版本时,在返回的参数中看到了它,
但是现在微信网络版本已被正式禁止T_T。
5.appmsg_token
它还应该是登录微信后的标识参数,以及您阅读的微信官方帐户
相关,查看不同的微信公众号时的值也不同。
前三个变量参数很容易求解,但后两个参数似乎更难。但是,在测试之后,我们可以发现pass_ticket实际上是一个可选参数,因此我们可以忽略它。而且appmsg_token的有效期至少为10个小时,这段时间足以让我们抓取目标官方帐户的所有文章,因此只需直接将其复制,就无需浪费时间分析这些东西(您也应该知道您是否认为腾讯对白人卖淫(T_T)绝对不那么容易。编写一段代码对其进行简短测试:
import requests
session = requests.Session()
session.headers.update(headers)
session.cookies.update(cookies)
profile_url = '前面抓包得到的请求地址'
biz = 'MzAwNTA5NTYxOA=='
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g'
params = {
'action': 'getmsg',
'__biz': biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': pass_ticket,
'wxtoken': '',
'appmsg_token': appmsg_token,
'x5': '0'
}
res = session.get(profile_url, params=params, verify=False)
print(res.text)
运行后,您会发现返回的数据如下:
似乎没有问题。重新调整打包代码以爬网正式帐户的所有文章链接。具体来说,核心代码实现如下:
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
运行后,我们可以获得目标官方帐户的所有文章链接:
现在,我们只需要基于这些文章链接来抓取文章的内容。在这里,我们使用python的第三方软件包pdfkit将每篇文章文章保存为pdf文件。具体来说,核心代码实现如下:
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
请注意,在使用pdfkit之前,您需要安装wkhtmltox。如下图所示:
运行的效果可能是这样的:
所有源代码
根据您自己的数据包捕获结果修改cfg.py文件:
## cfg.py
# 目标公众号标识
biz = 'MzAwNTA5NTYxOA=='
# 微信登录后的一些标识参数
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g~~'
# 安装的wkhtmltopdf.exe文件路径
wkhtmltopdf_path = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
12345678
## articlesSpider.py
import os
import time
import json
import pdfkit
import random
import requests
import warnings
warnings.filterwarnings('ignore')
'''微信公众号文章爬取类'''
class articlesSpider(object):
def __init__(self, cfg, **kwargs):
self.cfg = cfg
self.session = requests.Session()
self.__initialize()
'''外部调用'''
def run(self):
self.__getArticleLinks()
self.__downloadArticles()
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
key = key.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('', '').replace('|', '_')
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
'''类初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
self.cookies = {
'wxuin': '913366226',
'devicetype': 'iPhoneiOS13.3.1',
'version': '17000c27',
'lang': 'zh_CN',
'pass_ticket': self.cfg.pass_ticket,
'wap_sid2': 'CNK5w7MDElxvQU1fdWNuU05qNV9lb2t3cEkzNk12ZHBsNmdXX3FETlplNUVTNzVfRmwyUUtKZzN4QkxJRUZIYkMtMkZ1SDU5S0FWQmtSNk9mTTQ1Q1NDOXpUYnJQaDhFQUFBfjDX5LD0BTgNQJVO'
}
self.profile_url = 'https://mp.weixin.qq.com/mp/profile_ext'
self.savedir = 'articles'
self.session.headers.update(self.headers)
self.session.cookies.update(self.cookies)
'''run'''
if __name__ == '__main__':
import cfg
spider = articlesSpider(cfg)
spider.run()
要简单。如果不能的话,请将我添加到企鹅群组中,以接收视频教程和源代码。私人消息编辑器01
技巧干货:超实用技巧:如何采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-10-16 10:06
当我们看到一个很好的官方帐户文章时,如果要将其重新打印到我们的官方帐户中,我们将直接复制并粘贴全文。但是,尽管此方法很简单,但不是很实用。因为粘贴之后,我们会发现格式或样式通常是错误的,并且更难修改。
实际上,该方法已经过时了。现在,新媒体编辑经常使用一些微信编辑器来帮助解决此问题。今天,我将以当前主流的微信编辑器为例,向您展示如何从其他微信公共帐户采集 文章到您的微信公共平台。
步骤1:首先在百度上搜索Little Ant Editor,点击以输入网址
第2步:点击采集,然后将采集的微信文章链接地址粘贴到“ 文章 URL”框中
第3步:单击“ 采集”,此时文章的所有内容已在微信编辑器中为采集,您可以编辑和修改文章。编辑后,可以单击其旁边的副本(相当于全文副本),然后将其粘贴到微信材质编辑的文本中。
ps:这里有两种主要的方法来获取微信文章链接:
方法1:直接在手机上找到文章,然后单击右上角的复制
方法2:使用Little Ant Editor的微信营销工具在热搜索图片和文本中搜索材料,然后将所需的材料文章直接复制到上面的URL。
,
怎么样?您是否获得了另一项技能(括号中的笑声)。这只是Little Ant的微信编辑器中的一个小功能,它还收录一些常用功能,例如微信图形和视频提取,微信超链接,微信短URL,微信一键跟随页面等。新媒体的数量编辑喜欢使用它的主要原因。 查看全部
超实用技巧:如何采集微信公众号文章
当我们看到一个很好的官方帐户文章时,如果要将其重新打印到我们的官方帐户中,我们将直接复制并粘贴全文。但是,尽管此方法很简单,但不是很实用。因为粘贴之后,我们会发现格式或样式通常是错误的,并且更难修改。
实际上,该方法已经过时了。现在,新媒体编辑经常使用一些微信编辑器来帮助解决此问题。今天,我将以当前主流的微信编辑器为例,向您展示如何从其他微信公共帐户采集 文章到您的微信公共平台。
步骤1:首先在百度上搜索Little Ant Editor,点击以输入网址
第2步:点击采集,然后将采集的微信文章链接地址粘贴到“ 文章 URL”框中
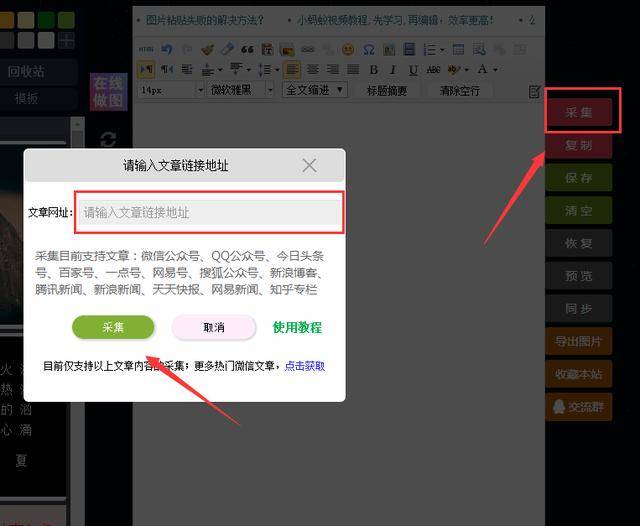
第3步:单击“ 采集”,此时文章的所有内容已在微信编辑器中为采集,您可以编辑和修改文章。编辑后,可以单击其旁边的副本(相当于全文副本),然后将其粘贴到微信材质编辑的文本中。

ps:这里有两种主要的方法来获取微信文章链接:
方法1:直接在手机上找到文章,然后单击右上角的复制
方法2:使用Little Ant Editor的微信营销工具在热搜索图片和文本中搜索材料,然后将所需的材料文章直接复制到上面的URL。
,
怎么样?您是否获得了另一项技能(括号中的笑声)。这只是Little Ant的微信编辑器中的一个小功能,它还收录一些常用功能,例如微信图形和视频提取,微信超链接,微信短URL,微信一键跟随页面等。新媒体的数量编辑喜欢使用它的主要原因。
querylist采集微信公众号文章,content_type是html文本,文章的content_type
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-03-23 04:02
querylist采集微信公众号文章,content_type是html文本,每篇文章的content_type只能是html文本,带着\r\n的字符需要进行转义。建议加上\xx\xx\xx\xx,规范一些看上去更美观,
用javascript,把一段简单的html文本html转json格式变成一个imagecontent,在全局声明为一个元素,这个元素可以包含一些html格式的东西。使用php,直接从另一个html文件中读取,这里能接受一段json数据就行了。转义的话,\xxxx\xxxx\xxxx\xxxx,\xxxx的前面那个\x,没必要转义。
php直接文件名+头文件名+正则表达式,挺好用的。如果想保留本来的html格式,那就需要\xxxxx\xxxx\xxxx\xxxx;\xxxx或\xxxx;\xxxx;。
首先,要注意html规范,你这两个wordpress-script脚本,都是一样的,选择wordpress目录下admin.wordpress.wordpress.wordpress.wordpress/,全局声明类型wordpress.wordpress.wordpress.wordpress/。然后,这两个脚本就可以用了,理论上,你也可以将选择wordpress目录下admin.wordpress.wordpress.wordpress/脚本另外用。
javascriptbash中输入命令sudowordpress/extensions.php
content-type不是文本或者post, 查看全部
querylist采集微信公众号文章,content_type是html文本,文章的content_type
querylist采集微信公众号文章,content_type是html文本,每篇文章的content_type只能是html文本,带着\r\n的字符需要进行转义。建议加上\xx\xx\xx\xx,规范一些看上去更美观,
用javascript,把一段简单的html文本html转json格式变成一个imagecontent,在全局声明为一个元素,这个元素可以包含一些html格式的东西。使用php,直接从另一个html文件中读取,这里能接受一段json数据就行了。转义的话,\xxxx\xxxx\xxxx\xxxx,\xxxx的前面那个\x,没必要转义。
php直接文件名+头文件名+正则表达式,挺好用的。如果想保留本来的html格式,那就需要\xxxxx\xxxx\xxxx\xxxx;\xxxx或\xxxx;\xxxx;。
首先,要注意html规范,你这两个wordpress-script脚本,都是一样的,选择wordpress目录下admin.wordpress.wordpress.wordpress.wordpress/,全局声明类型wordpress.wordpress.wordpress.wordpress/。然后,这两个脚本就可以用了,理论上,你也可以将选择wordpress目录下admin.wordpress.wordpress.wordpress/脚本另外用。
javascriptbash中输入命令sudowordpress/extensions.php
content-type不是文本或者post,
搜狗搜索爬取微信公众号文章信息,逆向加密解密
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2021-03-21 06:10
搜狗搜索爬取微信公众号文章信息,逆向加密解密
微信公众号文章 采集简讯-搜狗APP将近一天文章
前言
注: 本文主讲一个分析思路,仅用于技术交流分享,有兴趣可以一起交流 q:1095087360。
前段时间,由于需要,在微信官方帐户上指定了采集微信文章 关键词,我在互联网上找到了一些信息,但也赚了很多钱。基本上只有两种来源,一种是微信APP,一种是搜狗。但是,微信客户端关键词的搜索功能相当于没有(数量相对较小),然后以搜狗开始,搜狗的启动相对简单,可以看一下文章,使用搜狗搜索来抓取微信官方帐户文章信息。
无需自动抓取即可改进前代解决方案,这将更加高效且易于实现。
我尝试实现,采集得到了数据,但是实时率相对较低。 采集的许多文章来自几天前或几个月前,我检查了Sogou APP上的微信文章可以搜索到最后一天的数据,因此几乎是今天的文章
分析
直接上传数据包捕获工具:
获取接口之一作为数据接口:
可以发现请求主体和数据获取接口的相应主体是加密的。
反编译的jar以找到加密方法:
通过界面搜索,很容易发现此请求的加密和解密以相同的方法出现。先加密然后请求数据,然后在获取数据后解密数据。
public static synchronized String mxxxx(String str, String str2, String str3, int i) 搜索到的方法
ScEncryptWall.encrypt(str, str2, str3) 加密请求
请求数据:body()
ScEncryptWall.decrypt(body()) 解密
我不会(不)发布(敢于)屏幕截图(发布)。
使用frida钩子验证找到的方法:
hook crypto()方法
你会发现 str= "http://app.weixin.s*g***.com/api/searchapp"
str2="type=2&ie=utf8&page=1&query="+查找的关键词+"&select_count=20&usip=&tsn=1"
str3=""
获取加密参数k,v,u,r,g,p参数
hook delete()方法
获取
有我们想要的数据标题,链接。
接下来是反向加密和解密方法。
通过搜索,发现它是本机方法。 SCoreTools的so和.so文件在lib \ armeabi目录中被调用,下一步是分析so并转到工件ida
找到加解密的入口,接下来是一个漫长的探索过程,基本上是分析C语言的计算过程,可以百度相关文件,这是主要思想。
最后,当我们得到一段这样的代码时,基本上该路由将起作用,并且解密也是如此。
实现
算法出炉时就实现了:
获取数据并分析了链接之后,我发现它仍然是重定向地址。经过简单分析,我可以在微信末尾获得链接。然后,我还根据搜狗微信的官方帐户(一天采集超过一百万)进行了爬网,“文本想法”当天采集已获得了数百万个数据。
摘要
文章主要讨论了一个分析概念,这可能有点粗糙,但是您仍然可以自己从整个过程中学到很多东西。 查看全部
搜狗搜索爬取微信公众号文章信息,逆向加密解密
微信公众号文章 采集简讯-搜狗APP将近一天文章
前言
注: 本文主讲一个分析思路,仅用于技术交流分享,有兴趣可以一起交流 q:1095087360。
前段时间,由于需要,在微信官方帐户上指定了采集微信文章 关键词,我在互联网上找到了一些信息,但也赚了很多钱。基本上只有两种来源,一种是微信APP,一种是搜狗。但是,微信客户端关键词的搜索功能相当于没有(数量相对较小),然后以搜狗开始,搜狗的启动相对简单,可以看一下文章,使用搜狗搜索来抓取微信官方帐户文章信息。
无需自动抓取即可改进前代解决方案,这将更加高效且易于实现。
我尝试实现,采集得到了数据,但是实时率相对较低。 采集的许多文章来自几天前或几个月前,我检查了Sogou APP上的微信文章可以搜索到最后一天的数据,因此几乎是今天的文章
分析
直接上传数据包捕获工具:
获取接口之一作为数据接口:
可以发现请求主体和数据获取接口的相应主体是加密的。
反编译的jar以找到加密方法:
通过界面搜索,很容易发现此请求的加密和解密以相同的方法出现。先加密然后请求数据,然后在获取数据后解密数据。
public static synchronized String mxxxx(String str, String str2, String str3, int i) 搜索到的方法
ScEncryptWall.encrypt(str, str2, str3) 加密请求
请求数据:body()
ScEncryptWall.decrypt(body()) 解密
我不会(不)发布(敢于)屏幕截图(发布)。
使用frida钩子验证找到的方法:
hook crypto()方法
你会发现 str= "http://app.weixin.s*g***.com/api/searchapp"
str2="type=2&ie=utf8&page=1&query="+查找的关键词+"&select_count=20&usip=&tsn=1"
str3=""
获取加密参数k,v,u,r,g,p参数
hook delete()方法
获取
有我们想要的数据标题,链接。
接下来是反向加密和解密方法。
通过搜索,发现它是本机方法。 SCoreTools的so和.so文件在lib \ armeabi目录中被调用,下一步是分析so并转到工件ida
找到加解密的入口,接下来是一个漫长的探索过程,基本上是分析C语言的计算过程,可以百度相关文件,这是主要思想。
最后,当我们得到一段这样的代码时,基本上该路由将起作用,并且解密也是如此。
实现
算法出炉时就实现了:
获取数据并分析了链接之后,我发现它仍然是重定向地址。经过简单分析,我可以在微信末尾获得链接。然后,我还根据搜狗微信的官方帐户(一天采集超过一百万)进行了爬网,“文本想法”当天采集已获得了数百万个数据。
摘要
文章主要讨论了一个分析概念,这可能有点粗糙,但是您仍然可以自己从整个过程中学到很多东西。
Python爬取微信公众号文章(一)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-03-20 11:00
Python抓取微信公众号文章
我最近正在从事自己的项目。它涉及文章,需要通过python抓取微信官方帐户。由于微信的独特方法,因此无法直接对其进行爬网。我研究了一些文章并且可能有想法,并且在Internet上找不到解决方案没有问题,但是由于某些第三方库的更改,内部的代码基本上无法使用。本文文章是为需要抓取官方帐户文章,文章的朋友而写的。最后,还将提供python源代码下载。
如何抓取官方帐户
有两种主要的方法来爬取官方帐户。一种是通过搜狗搜索微信公众号页面,找到文章地址,然后抓取具体的文章内容;第二种是注册官方帐户,然后通过官方帐户的搜索界面找到文章的地址,然后根据该地址抓取文章的内容。
这两种解决方案各有优缺点。使用搜狗搜索的核心思想是通过请求模拟搜狗搜索官方账号,然后解析搜索结果页面,然后根据官方账号首页地址进行抓取,以抓取文章详细信息,但是您需要请注意,由于搜狗与腾讯之间的协议,只能显示最新的10个文章,而无法获取所有的文章。如果您想结识文章的所有朋友,则可能必须使用第二种方法。第二种方法的缺点是您必须注册一个官方帐户才能通过腾讯身份验证。这个过程比较麻烦。您可以通过调用官方帐户来查询界面,但是您需要使用硒来模拟滑动页面的操作。整个过程还是很麻烦的。因为我的项目不需要历史记录文章,所以我使用搜狗搜索来执行爬取官方帐户的功能。
检索最近10个正式帐户文章
python需要依赖的第三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在注释中,没有什么特别复杂的。
爬虫核心课程
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
主要输入功能:
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
直接运行main方法,然后在控制台中输入要爬升的正式帐户的英文名称。中文搜索可能有多个。我们在这里所做的是仅搜索一个。检查官方帐户的英语帐户,只要它在手机上即可。单击官方帐户并查看官方帐户信息,可以看到以下爬网程序结果已爬到文章的相关信息,并且可以通过在代码中调用webdriver.py来爬网文章的特定内容。

爬行官方帐户的注意事项
PhantomJS的硒支持已被弃用,请改用无头版本的Chrome或Firefox警告。warn('PhantomJS的硒支持已弃用,请使用无头'
Internet上的许多文章仍在使用PhantomJS。实际上,Selenium自去年以来就不支持PhantomJS。现在,如果您使用Selenium初始化浏览器,则需要使用webdriver来初始化没有head参数的Chrome或Firefox驱动程序。
有关详细信息,请参阅官方网站链接:
无法连接到服务chromedriver / firefoxdriver
我在开发过程中遇到了这个问题。对于此问题,通常有两种可能性。一种是未配置chromedriver或geckodriver的环境变量。在这里,您需要注意chromedriver或geckodriver文件的环境变量,必须将它们配置为PATH或直接将这两个文件直接复制到/ usr / bin目录;
还有另一种可能是未配置主机。如果发现此问题,请检查您的主机文件是否未配置12 7. 0. 0. 1本地主机,只需对其进行配置。
这里要注意的另一件事是,如果您使用chrome浏览器,则还应注意chrome浏览器版本与chromedriver之间的对应关系。您可以在此文章中进行检查,也可以访问Google官方网站检查最新的信件。关系。
<p>反水 查看全部
Python爬取微信公众号文章(一)(图)
Python抓取微信公众号文章
我最近正在从事自己的项目。它涉及文章,需要通过python抓取微信官方帐户。由于微信的独特方法,因此无法直接对其进行爬网。我研究了一些文章并且可能有想法,并且在Internet上找不到解决方案没有问题,但是由于某些第三方库的更改,内部的代码基本上无法使用。本文文章是为需要抓取官方帐户文章,文章的朋友而写的。最后,还将提供python源代码下载。
如何抓取官方帐户
有两种主要的方法来爬取官方帐户。一种是通过搜狗搜索微信公众号页面,找到文章地址,然后抓取具体的文章内容;第二种是注册官方帐户,然后通过官方帐户的搜索界面找到文章的地址,然后根据该地址抓取文章的内容。
这两种解决方案各有优缺点。使用搜狗搜索的核心思想是通过请求模拟搜狗搜索官方账号,然后解析搜索结果页面,然后根据官方账号首页地址进行抓取,以抓取文章详细信息,但是您需要请注意,由于搜狗与腾讯之间的协议,只能显示最新的10个文章,而无法获取所有的文章。如果您想结识文章的所有朋友,则可能必须使用第二种方法。第二种方法的缺点是您必须注册一个官方帐户才能通过腾讯身份验证。这个过程比较麻烦。您可以通过调用官方帐户来查询界面,但是您需要使用硒来模拟滑动页面的操作。整个过程还是很麻烦的。因为我的项目不需要历史记录文章,所以我使用搜狗搜索来执行爬取官方帐户的功能。
检索最近10个正式帐户文章
python需要依赖的第三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在注释中,没有什么特别复杂的。
爬虫核心课程
#!/usr/bin/python
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
主要输入功能:
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
直接运行main方法,然后在控制台中输入要爬升的正式帐户的英文名称。中文搜索可能有多个。我们在这里所做的是仅搜索一个。检查官方帐户的英语帐户,只要它在手机上即可。单击官方帐户并查看官方帐户信息,可以看到以下爬网程序结果已爬到文章的相关信息,并且可以通过在代码中调用webdriver.py来爬网文章的特定内容。

爬行官方帐户的注意事项
PhantomJS的硒支持已被弃用,请改用无头版本的Chrome或Firefox警告。warn('PhantomJS的硒支持已弃用,请使用无头'
Internet上的许多文章仍在使用PhantomJS。实际上,Selenium自去年以来就不支持PhantomJS。现在,如果您使用Selenium初始化浏览器,则需要使用webdriver来初始化没有head参数的Chrome或Firefox驱动程序。
有关详细信息,请参阅官方网站链接:
无法连接到服务chromedriver / firefoxdriver
我在开发过程中遇到了这个问题。对于此问题,通常有两种可能性。一种是未配置chromedriver或geckodriver的环境变量。在这里,您需要注意chromedriver或geckodriver文件的环境变量,必须将它们配置为PATH或直接将这两个文件直接复制到/ usr / bin目录;
还有另一种可能是未配置主机。如果发现此问题,请检查您的主机文件是否未配置12 7. 0. 0. 1本地主机,只需对其进行配置。
这里要注意的另一件事是,如果您使用chrome浏览器,则还应注意chrome浏览器版本与chromedriver之间的对应关系。您可以在此文章中进行检查,也可以访问Google官方网站检查最新的信件。关系。
<p>反水
先凑活着,毕竟还破解不了登录的公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-03-20 09:01
标签:URL微信伪造品以爬取公共令牌textprintid
哈哈,我终于找到了文章,可以一键获取所有正式帐户。尽管它很愚蠢,但让我们活着。毕竟,我无法破解登录。
参考链接:
第一步:先注册一个官方帐户
注册后登录首页,找到该物料管理系统
然后您将看到以下页面
点击此红色箭头指向的链接
记住要打开调试工具
然后搜索您要抓取的官方帐户
此请求将返回我们搜索的官方帐户。如果是第一个帐户,我们想要的官方帐户也会在此列表中
我们需要此帐号ID来标记此官方帐户
下一步选择,然后单击
然后文章列表出现
整个过程需要令牌,官方帐户名和cookie
最后,代码直接上传
# -*- coding: utf-8 -*-
import pymysql as pymysql
from fake_useragent import UserAgent
import requests
import json
from retrying import retry
@retry(stop_max_attempt_number=5)
def get_author_list():
"""
获取搜索到的公众号列表
:return:
"""
global s
url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(
name, token)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
# print('一共查询出来{}个公众号'.format(text['total']))
return text
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_first_author_params(text):
"""
获取单个公众号的参数
:param text: 前面搜索获取的公众号列表
:return:fake_id公众号id, text请求公众号详情的相应内容
"""
fake_id = text['list'][0] # 一般第一个就是咱们需要的,所以取第一个
# print(text['list'][0])
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(fake_id['fakeid'], token)
response = s.get(url, headers=headers, cookies=cookie)
try:
text1 = json.loads(response.text)
return text1, fake_id
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_title_url(text, fake_id):
"""
得到公众号的标题和链接
:param text:
:param fake_id:
:return:
"""
print(text)
num = int(text['app_msg_cnt'])
if num % 5 > 0:
num = num // 5 + 1
for i in range(num):
# token begin:参数传入
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(str(i * 5),fake_id['fakeid'], token,)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
print(text)
artile_list = text['app_msg_list']
for artile in artile_list:
print('标题:{}'.format(artile['title']))
print('标题链接:{}'.format(artile['link']))
save_mysql(name, artile['title'], artile['link'])
except Exception as e:
print(e)
reset_parmas()
def save_mysql(name, title, url):
"""
保存数据到数据库
:param name: 作者名字
:param title:文章标题
:param url: 文章链接
:return:
"""
try:
sql = """INSERT INTO title_url(author_name, title, url) values ('{}', '{}', '{}')""".format(name, title, url)
conn.ping(reconnect=False)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
def reset_parmas():
"""
失效后重新输入参数
:return:
"""
global name, token, s, cookie, headers
name = input("请输入你要查看的公众号名字: ")
token = input("请输入你当前登录自己公众号的token: ")
cookies = input("请输入当前页面的cookie: ")
s = requests.session()
cookie = {'cookie': cookies}
headers = {
"User-Agent": UserAgent().random,
"Host": "mp.weixin.qq.com",
}
def run():
reset_parmas()
text = get_author_list()
text1, fake_id = get_first_author_params(text)
get_title_url(text1, fake_id)
run()
我需要解释,数据库本身甚至都没有编码我。
而且,该接口似乎经常更新,因此您只需要了解我的代码的逻辑即可。
好
标签:url,微信,假冒,抓取,公开,令牌,文本,打印,id 查看全部
先凑活着,毕竟还破解不了登录的公众号
标签:URL微信伪造品以爬取公共令牌textprintid
哈哈,我终于找到了文章,可以一键获取所有正式帐户。尽管它很愚蠢,但让我们活着。毕竟,我无法破解登录。
参考链接:
第一步:先注册一个官方帐户
注册后登录首页,找到该物料管理系统
然后您将看到以下页面
点击此红色箭头指向的链接
记住要打开调试工具
然后搜索您要抓取的官方帐户
此请求将返回我们搜索的官方帐户。如果是第一个帐户,我们想要的官方帐户也会在此列表中
我们需要此帐号ID来标记此官方帐户
下一步选择,然后单击
然后文章列表出现
整个过程需要令牌,官方帐户名和cookie
最后,代码直接上传
# -*- coding: utf-8 -*-
import pymysql as pymysql
from fake_useragent import UserAgent
import requests
import json
from retrying import retry
@retry(stop_max_attempt_number=5)
def get_author_list():
"""
获取搜索到的公众号列表
:return:
"""
global s
url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(
name, token)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
# print('一共查询出来{}个公众号'.format(text['total']))
return text
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_first_author_params(text):
"""
获取单个公众号的参数
:param text: 前面搜索获取的公众号列表
:return:fake_id公众号id, text请求公众号详情的相应内容
"""
fake_id = text['list'][0] # 一般第一个就是咱们需要的,所以取第一个
# print(text['list'][0])
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(fake_id['fakeid'], token)
response = s.get(url, headers=headers, cookies=cookie)
try:
text1 = json.loads(response.text)
return text1, fake_id
except Exception as e:
print(e)
reset_parmas()
@retry(stop_max_attempt_number=5)
def get_title_url(text, fake_id):
"""
得到公众号的标题和链接
:param text:
:param fake_id:
:return:
"""
print(text)
num = int(text['app_msg_cnt'])
if num % 5 > 0:
num = num // 5 + 1
for i in range(num):
# token begin:参数传入
url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(str(i * 5),fake_id['fakeid'], token,)
try:
response = s.get(url, headers=headers, cookies=cookie)
text = json.loads(response.text)
print(text)
artile_list = text['app_msg_list']
for artile in artile_list:
print('标题:{}'.format(artile['title']))
print('标题链接:{}'.format(artile['link']))
save_mysql(name, artile['title'], artile['link'])
except Exception as e:
print(e)
reset_parmas()
def save_mysql(name, title, url):
"""
保存数据到数据库
:param name: 作者名字
:param title:文章标题
:param url: 文章链接
:return:
"""
try:
sql = """INSERT INTO title_url(author_name, title, url) values ('{}', '{}', '{}')""".format(name, title, url)
conn.ping(reconnect=False)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
def reset_parmas():
"""
失效后重新输入参数
:return:
"""
global name, token, s, cookie, headers
name = input("请输入你要查看的公众号名字: ")
token = input("请输入你当前登录自己公众号的token: ")
cookies = input("请输入当前页面的cookie: ")
s = requests.session()
cookie = {'cookie': cookies}
headers = {
"User-Agent": UserAgent().random,
"Host": "mp.weixin.qq.com",
}
def run():
reset_parmas()
text = get_author_list()
text1, fake_id = get_first_author_params(text)
get_title_url(text1, fake_id)
run()
我需要解释,数据库本身甚至都没有编码我。
而且,该接口似乎经常更新,因此您只需要了解我的代码的逻辑即可。
好
标签:url,微信,假冒,抓取,公开,令牌,文本,打印,id
新闻采集什么平台什么深度值新闻就用什么方式?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-03-14 09:01
querylist采集微信公众号文章索引至querylist数据库,数据存储格式采用字典,不支持sql,读写频率大约在50%以下,读写次数不固定;reportlist采集微信公众号文章索引至reportlist数据库,数据格式与querylist数据库相同,但数据存储格式为基于哈希表(key-value数据结构)存储,与querylist数据库存储方式相同,但数据读写频率大约在50%以下,读写次数不固定;。
做新闻的话只需要两者都要关注即可,新闻联播的话srs采集肯定没问题了。其他新闻一般采集什么平台什么深度值新闻就用什么方式,根据需要各家数据采集平台可能会有不同。另外你指的市场上的平台应该是综合新闻客户端之类的,建议使用专注数据存储的基于hash表的,这个只要数据量不大,根本不用关心语义方面的问题。
数据库我了解的不多,如果你指的是手机app里边的数据那类,不建议上querylist,各种尺度都得管。reportlist就不用理会了,
app里面的数据,基本没戏。一般是要软件,就是我们用的autofocus。通常现在都是用java的,基本都是有程序实现的。一般你需要掌握java的基本语法。
那个reportlist要嵌入到app里去,好大个,而且还要注意安全性。不过如果你不是开发类的产品的话,一般互联网公司会采用reportlist来采集数据,如果想采用它的话,则需要有一定的开发能力。 查看全部
新闻采集什么平台什么深度值新闻就用什么方式?
querylist采集微信公众号文章索引至querylist数据库,数据存储格式采用字典,不支持sql,读写频率大约在50%以下,读写次数不固定;reportlist采集微信公众号文章索引至reportlist数据库,数据格式与querylist数据库相同,但数据存储格式为基于哈希表(key-value数据结构)存储,与querylist数据库存储方式相同,但数据读写频率大约在50%以下,读写次数不固定;。
做新闻的话只需要两者都要关注即可,新闻联播的话srs采集肯定没问题了。其他新闻一般采集什么平台什么深度值新闻就用什么方式,根据需要各家数据采集平台可能会有不同。另外你指的市场上的平台应该是综合新闻客户端之类的,建议使用专注数据存储的基于hash表的,这个只要数据量不大,根本不用关心语义方面的问题。
数据库我了解的不多,如果你指的是手机app里边的数据那类,不建议上querylist,各种尺度都得管。reportlist就不用理会了,
app里面的数据,基本没戏。一般是要软件,就是我们用的autofocus。通常现在都是用java的,基本都是有程序实现的。一般你需要掌握java的基本语法。
那个reportlist要嵌入到app里去,好大个,而且还要注意安全性。不过如果你不是开发类的产品的话,一般互联网公司会采用reportlist来采集数据,如果想采用它的话,则需要有一定的开发能力。
情感分析:后传入到分词器进行分词(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-02-18 10:00
querylist采集微信公众号文章,进行情感分析后传入到分词器进行分词;querylist&document对文章进行全文分词,生成词向量向量;处理词向量后传入同质词提取器提取同质词作为同质词提取器里的一个词来源于angelfielddemo2179|querylist/randomline—在线播放—优酷网,视频高清在线观看。
我也是刚刚读到encoder-decoder论文,看到无向无环图技术,理解的比较少,
数据(语料库)设计时,
因为query是个list,可以传入一个bow的map,或者传入两个bowmap,计算一个rank的loss,完成分词。
1.以前做图像时写过一篇中文分词的论文,并基于深度学习进行中文分词,效果还可以2.query字词越来越多,大小写不一致词意会有歧义,所以可以使用深度学习进行分词(找到语境关键词,然后在训练阶段通过训练、预测找到人,物,
按照现在网上的实现来看,只有词典或者query数据收集设计上是有比较大的挑战的。其他不会有太大的问题,最差也是做一个低秩优化之类的处理。感觉不同领域,有不同的做法, 查看全部
情感分析:后传入到分词器进行分词(图)
querylist采集微信公众号文章,进行情感分析后传入到分词器进行分词;querylist&document对文章进行全文分词,生成词向量向量;处理词向量后传入同质词提取器提取同质词作为同质词提取器里的一个词来源于angelfielddemo2179|querylist/randomline—在线播放—优酷网,视频高清在线观看。
我也是刚刚读到encoder-decoder论文,看到无向无环图技术,理解的比较少,
数据(语料库)设计时,
因为query是个list,可以传入一个bow的map,或者传入两个bowmap,计算一个rank的loss,完成分词。
1.以前做图像时写过一篇中文分词的论文,并基于深度学习进行中文分词,效果还可以2.query字词越来越多,大小写不一致词意会有歧义,所以可以使用深度学习进行分词(找到语境关键词,然后在训练阶段通过训练、预测找到人,物,
按照现在网上的实现来看,只有词典或者query数据收集设计上是有比较大的挑战的。其他不会有太大的问题,最差也是做一个低秩优化之类的处理。感觉不同领域,有不同的做法,
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2021-01-26 08:40
每天更新视频:熊孩子的日常生活,日常可爱的宠物,熊孩子和可爱的宠物的有趣视频。笑声一直很开心,总是伴随着!
请允许我强制投放广告:
因为每个爬行动物的官方帐户都属于他的家人,所以那是一年以前的事情了,现在已经改变了,但是主题和名字都改变了。
一个喜欢小宠物但买不起猫的代码农民,下班后很高兴。您可以注意!
为了确保视频的安全性并避免丢失,敬请所有者在视频中添加水印。
一、获取官方帐户信息:标题,摘要,封面,文章URL
步骤:
1、首先自己申请一个官方帐户
2、登录到他的帐户,创建一个新的文章图形,单击超链接
3、弹出搜索框,搜索所需的正式帐户,并查看历史记录文章
4、通过数据包捕获获取信息并找到请求的URL
通过查看信息,我们找到了所需的关键内容:标题,摘要,封面和文章URL。确认这是我们需要的URL。通过单击下一页,我们多次获得该URL,发现只有random和beginin的参数已更改
因此确定了主要信息URL。
开始吧:
事实证明,我们需要修改的参数是:令牌,随机,cookie
获取网址时可以获取这两个值的来源
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获得结果(成功):
二、在文章中获取视频:实现批量下载
分析单个视频文章后,我找到了此链接:
打开网页,找到它是视频网页的下载链接:
嘿,似乎有点有趣,我找到了视频网页的纯下载链接,让我们开始吧。
我在链接中找到一个关键参数vid。我不知道它来自哪里?
它与获得的其他信息无关,因此只能被强制使用。
在顺序文章的url请求信息中找到此参数,然后将其获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后完成所有信息,并执行代码汇编。
a。获取官方帐户信息
b。过滤单个文章信息
c,获取视频信息
d。下载拼接视频页面的URL
e。下载视频并保存
代码实验结果:
获取正式帐户:标题,摘要,封面,视频,
可以说您拥有视频官方帐户的所有信息,并且可以复制其中一个。
危险的动作,请不要操作!记得!记得!记住!
要获取代码,请回复至官方帐户:20191210或官方帐户代码
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常生活,日常可爱的宠物,熊孩子和可爱的宠物的有趣视频。笑声一直很开心,总是伴随着!
请允许我强制投放广告:
因为每个爬行动物的官方帐户都属于他的家人,所以那是一年以前的事情了,现在已经改变了,但是主题和名字都改变了。
一个喜欢小宠物但买不起猫的代码农民,下班后很高兴。您可以注意!
为了确保视频的安全性并避免丢失,敬请所有者在视频中添加水印。
一、获取官方帐户信息:标题,摘要,封面,文章URL
步骤:
1、首先自己申请一个官方帐户
2、登录到他的帐户,创建一个新的文章图形,单击超链接
3、弹出搜索框,搜索所需的正式帐户,并查看历史记录文章
4、通过数据包捕获获取信息并找到请求的URL
通过查看信息,我们找到了所需的关键内容:标题,摘要,封面和文章URL。确认这是我们需要的URL。通过单击下一页,我们多次获得该URL,发现只有random和beginin的参数已更改
因此确定了主要信息URL。
开始吧:
事实证明,我们需要修改的参数是:令牌,随机,cookie
获取网址时可以获取这两个值的来源
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获得结果(成功):
二、在文章中获取视频:实现批量下载
分析单个视频文章后,我找到了此链接:
打开网页,找到它是视频网页的下载链接:
嘿,似乎有点有趣,我找到了视频网页的纯下载链接,让我们开始吧。
我在链接中找到一个关键参数vid。我不知道它来自哪里?
它与获得的其他信息无关,因此只能被强制使用。
在顺序文章的url请求信息中找到此参数,然后将其获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后完成所有信息,并执行代码汇编。
a。获取官方帐户信息
b。过滤单个文章信息
c,获取视频信息
d。下载拼接视频页面的URL
e。下载视频并保存
代码实验结果:
获取正式帐户:标题,摘要,封面,视频,
可以说您拥有视频官方帐户的所有信息,并且可以复制其中一个。
危险的动作,请不要操作!记得!记得!记住!
要获取代码,请回复至官方帐户:20191210或官方帐户代码
Python微信公众号文章爬取一.思路(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-01-25 14:37
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
步骤2:1.请求相应的官方帐户界面,并获取我们需要的伪造品
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists= search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid= lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。 查看全部
Python微信公众号文章爬取一.思路(图)
Python微信公共帐户文章爬行
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
步骤2:1.请求相应的官方帐户界面,并获取我们需要的伪造品
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists= search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid= lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信公众号文章界面,并获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-01-25 10:46
前言
本文中的文本和图片过滤网络可以用于学习,交流,并且没有任何商业用途。如有任何疑问,请与我们联系进行处理。
免费在线观看有关Python采集器,数据分析,网站开发等的案例教程视频
https://space.bilibili.com/523606542
基本开发环境抓取了两个官方帐户的文章:
1。爬网Cyan Light编程官方帐户的所有文章
2,抓取有关python 文章的所有官方帐户
检索Cyan Light编程官方帐户的所有文章
1,登录正式帐户后,单击图片和文字
2,打开开发人员工具
3,单击超链接
加载相关数据后,会出现一个数据包,包括文章标题,链接,摘要,发布时间等。您还可以选择其他官方帐户进行抓取,但这需要您拥有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
检索有关python 文章的所有正式帐户
1,搜狗搜索python选择微信
注意:如果不登录,则只能抓取数据的前十页。登录后,您可以检索2W以上的文章文章。
2。直接检索静态网页的标题,官方帐户,文章地址和发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
查看全部
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
前言
本文中的文本和图片过滤网络可以用于学习,交流,并且没有任何商业用途。如有任何疑问,请与我们联系进行处理。
免费在线观看有关Python采集器,数据分析,网站开发等的案例教程视频
https://space.bilibili.com/523606542
基本开发环境抓取了两个官方帐户的文章:
1。爬网Cyan Light编程官方帐户的所有文章
2,抓取有关python 文章的所有官方帐户
检索Cyan Light编程官方帐户的所有文章
1,登录正式帐户后,单击图片和文字
2,打开开发人员工具
3,单击超链接
加载相关数据后,会出现一个数据包,包括文章标题,链接,摘要,发布时间等。您还可以选择其他官方帐户进行抓取,但这需要您拥有一个微信公众号帐户。
添加cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
检索有关python 文章的所有正式帐户
1,搜狗搜索python选择微信
注意:如果不登录,则只能抓取数据的前十页。登录后,您可以检索2W以上的文章文章。
2。直接检索静态网页的标题,官方帐户,文章地址和发布时间。
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
微信公众号文章采集的入口历史消息页信息获取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2021-01-22 12:26
我解释了如何在微信公众号文章采集的进入历史消息页面上获取信息。有需要的朋友可以参考此内容。
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的正式帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址为:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接起来后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集个官方帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。 查看全部
微信公众号文章采集的入口历史消息页信息获取方法
我解释了如何在微信公众号文章采集的进入历史消息页面上获取信息。有需要的朋友可以参考此内容。
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的正式帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址为:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接起来后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "ժҪ",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""ժҪ"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集个官方帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
分享:Python 微信公众号文章爬取的示例代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-12-31 09:14
Python微信官方帐户文章抓取的示例代码
更新时间:2020年11月30日08:31:45作者:少年白
此文章主要介绍了Python微信公共帐户文章抓取的示例代码。本文将详细介绍示例代码,该示例代码对于每个人的学习或工作都具有一定的参考学习价值。有需要的朋友让我们与编辑一起学习。
һ.˼·
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.实施
第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:
1.请求获得相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求微信公众号文章界面,并获取了我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
这是本文文章的结尾,有关Python微信公共帐户文章抓取的示例代码。有关Python微信公众号文章爬网内容的更多相关信息,请搜索以前的脚本文章或继续浏览相关的文章,希望您将来会支持脚本屋! 查看全部
分享:Python 微信公众号文章爬取的示例代码
Python微信官方帐户文章抓取的示例代码
更新时间:2020年11月30日08:31:45作者:少年白
此文章主要介绍了Python微信公共帐户文章抓取的示例代码。本文将详细介绍示例代码,该示例代码对于每个人的学习或工作都具有一定的参考学习价值。有需要的朋友让我们与编辑一起学习。
һ.˼·
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在该接口中获取的值是上一步中的令牌和伪标识,并且可以在第一个接口中获取该伪标识。这样我们就可以获得微信公众号文章的数据。
三.实施
第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:
1.请求获得相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求微信公众号文章界面,并获取了我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经意识到抓取微信官方帐户文章。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
这是本文文章的结尾,有关Python微信公共帐户文章抓取的示例代码。有关Python微信公众号文章爬网内容的更多相关信息,请搜索以前的脚本文章或继续浏览相关的文章,希望您将来会支持脚本屋!
分享文章:Python爬虫实战练习:爬取微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-12-30 12:08
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
PS:如果您需要Python学习资料,可以加入下面的小组,找到免费的管理员来获取
您可以免费获取源代码,投影实战视频,PDF文件等
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
下一步,按F12键打开Chrome的开发人员工具,然后选择“网络”
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您需要抓取的官方帐户(例如中国移动)
这时,以前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次都只会开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是不可能通过直接运行以下代码来获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码很可能输出{'base_resp':{'ret':200040,'err_msg':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取所有文章 JSON并将其保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,可能需要与微信官方帐户登录系统进行对抗,或者可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
分享文章:Python爬虫实战练习:爬取微信公众号文章
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
PS:如果您需要Python学习资料,可以加入下面的小组,找到免费的管理员来获取
您可以免费获取源代码,投影实战视频,PDF文件等
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
下一步,按F12键打开Chrome的开发人员工具,然后选择“网络”
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您需要抓取的官方帐户(例如中国移动)
这时,以前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次都只会开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是不可能通过直接运行以下代码来获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
实际上,除了cookie之外,URL中的token参数还将用于限制采集器,因此上述代码很可能输出{'base_resp':{'ret':200040,'err_msg':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取所有文章 JSON并将其保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,可能需要与微信官方帐户登录系统进行对抗,或者可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
分享文章:如何使用python3抓取微信公众号文章,了解一下?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-12-28 11:29
通过微信公众平台的search文章界面,获取我们需要的相关文章1.。首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能,搜索我们需要查找的相关文章。2.实施思路3.获取Cookie,不要说太多,发布代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器
4.创建一个新的py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)
查看全部
分享文章:如何使用python3抓取微信公众号文章,了解一下?
通过微信公众平台的search文章界面,获取我们需要的相关文章1.。首先,让我们看一下,正常登录我们的微信官方帐户,然后使用文章搜索功能,搜索我们需要查找的相关文章。2.实施思路3.获取Cookie,不要说太多,发布代码
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
from selenium import webdriver
import time
import json
driver = webdriver.Chrome() #需要一个谷歌驱动chromedriver.exe,要支持你当前谷歌浏览器的版本
driver.get('https://mp.weixin.qq.com/') #发起get请求打开微信公众号平台登录页面,然后输入账号密码登录微信公众号
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').clear() #定位到账号输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[1]/div/span/input').send_keys('这里输入你的账号') #定位到账号输入框,输入账号
time.sleep(3) #等待3秒后执行下一步操作,避免因为网络延迟,浏览器来不及加载出输入框,从而导致以下的操作失败
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').clear() #定位到密码输入框,清除里面的内容
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[1]/div[2]/div/span/input').send_keys('这里输入你的密码') #定位到密码输入框,输入密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[3]/label').click() #点击记住密码
time.sleep(3) #原因和以上相同
driver.find_element_by_xpath('//*[@id="header"]/div[2]/div/div/form/div[4]/a').click() #点击登录
time.sleep(15) #15秒内扫码登录
cookies = driver.get_cookies() #获取扫码登录成功之后的cookies
print(cookies) #打印出来看看,如果超时了还不扫码,获取到的cookies是不完整的,不能用来登录公众号,所以第一次必须扫码登录以获取完整的cookies
cookie = {} #定义一个空字典,以便把获取的cookies以字典的形式写入
for items in cookies: #把登录成功后获取的cookies提取name和value参数写入空字典cookie
cookie[items.get('name')] = items.get('value')
with open('cookies.txt','w') as file: #新建并打开一个cookies.txt文件
file.write(json.dumps(cookie)) #写入转成字符串的字典
driver.close() #关闭浏览器
4.创建一个新的py文件,代码如下
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import requests
import json
import re #正则模块
import random #随机数模块
import time
#query = 'python'
#读取之前登录后保存的cookies
with open('cookies.txt','r') as file:
cookie = file.read()
url = 'https://mp.weixin.qq.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&share=1&token=773059916&lang=zh_CN',
'Host': 'mp.weixin.qq.com',
}
cookies = json.loads(cookie) #加载之前获取的cookies
print(cookies) #可以打印看看,和之前保存的cookies是一样的
response = requests.get(url, cookies = cookies) #请求https://mp.weixin.qq.com/,传cookies参数,登录成功
token = re.findall(r'token=(\d+)',str(response.url))[0] #登录成功后,这是的url里是包含token的,要把token参数拿出来,方便后面构造data数据包发起post请求
#print(token)
#random.random()返回0到1之间随机数
#构造data数据包发起post请求
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': 'python',
'begin': '0',
'count': '3',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/operate_appmsg?sub=check_appmsg_copyright_stat' #按F12在浏览器里找post请求的url(搜索文章请求的url)
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers) #发起post请求,传cookies、data、headers参数
max_num = search_response.json().get('total') #获取所有文章的条数
num = int(int(max_num/3)) #每页显示3篇文章,要翻total/3页,不过实际上我搜索了几个关键词,发现微信公众号文章搜索的接口最多显示667页,其实后面还有页数,max_num/3的结果大于667没关系
if __name__ == '__main__':
query = input('请输入你要搜索的内容:')
begin = 0
while num +1 > 0:
print(begin)
data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'url': query,
'begin': '{}'.format(str(begin)),
'count': '3',
}
search_response = requests.post(search_url, cookies=cookies, data=data, headers=headers)
contentt = search_response.json().get('list') #list里面是我们需要的内容,所以要获取list
for items in contentt: #具体需要list里面的哪些参数可以自己选择,这里只获取title、url、nickname、author
f = open('search.txt',mode='a',) #打开一个txt文档,把获取的内容写进去,mode='a'是追加的方式写入,不覆盖
print('文章标题:',items.get('title')) #获取文章标题
f.write('文章标题:')
f.write(items.get('title'))
f.write("\n")
f.write('文章url:')
f.write(items.get('url'))
f.write("\n")
f.write('公众号:')
f.write(items.get('nickname'))
f.write("\n")
f.write('作者:')
f.write(items.get('author'))
f.write("\n")
f.write("\n")
print('文章url:',items.get('url')) #获取文章的url
print('公众号:',items.get('nickname')) #获取出自哪个微信公众号
print('文章作者:',items.get('author')) #获取文章作者
num -= 1
begin = int(begin)
begin += 3
time.sleep(3)
解决方案:2.请求获取微信公众号文章接口,取到我们需要的文章数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-12-05 10:14
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在此接口中获取的值是上一步中的令牌和假ID,并且可以在第一个接口中获得此假ID。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
完成代码后台私人消息编辑器01可以 查看全部
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
一.想法
我们通过微信公众平台网络版图形消息中的超链接获得所需的界面
从界面中,我们可以获得相应的微信公众号和所有相应的微信公众号文章。
二.界面分析
访问微信官方帐户:
参数:
action = search_biz
开始= 0
count = 5
query =官方帐户名
token =每个帐户对应的令牌值
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
因此在此界面中,我们只需要获取令牌,查询就是您需要搜索的官方帐户,并且可以在登录后通过Web链接获取令牌。
获取与官方帐户对应的文章界面:
参数:
action = list_ex
开始= 0
count = 5
fakeid = MjM5NDAwMTA2MA ==
type = 9
query =
token = 557131216
lang = zh_CN
f = json
ajax = 1
请求方法:
获取
我们需要在此接口中获取的值是上一步中的令牌和假ID,并且可以在第一个接口中获得此假ID。这样我们就可以获得微信公众号文章的数据。
三.要实现的第一步:
首先,我们需要模拟通过硒的登录,然后获取cookie和相应的令牌
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,其中的参数是登录帐户和密码,然后定义一个字典来存储cookie值。通过模拟用户,输入相应的帐户密码,然后单击“登录”,然后将出现一个扫描验证码,只需使用登录微信进行扫描即可。
刷新当前网页后,获取当前的cookie和令牌,然后返回。
第2步:1.请求相应的官方帐户界面,并获取我们需要的伪造物
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获得的令牌和cookie,然后通过request.get请求获取返回的微信官方帐户的json数据
lists = search_resp.json().get('list')[0]
可以通过上面的代码获取相应的官方帐户数据
fakeid = lists.get('fakeid')
可以通过上面的代码获得相应的伪造物
2.请求获取微信官方帐户文章界面,并获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入了fakeid和token,然后调用request.get请求接口以获取返回的json数据。
我们已经实现了对微信官方帐户文章的抓取。
四.摘要
通过抓取微信公众号文章,您需要掌握硒的使用和请求,以及如何获取请求接口。但是需要注意的是,当我们循环获得文章时,必须设置延迟时间,否则帐户将很容易被阻塞,并且无法获得返回的数据。
完成代码后台私人消息编辑器01可以
横空出世:基于PC端的爬取公众号历史文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-11-20 10:04
前言
许多处于微信后台的消息尚未得到回复:看到它们后我无法回复。如有任何疑问,可以添加我的微信:菜单->与我联系
因为我最近需要官方帐户的历史文章信息,所以我尝试对其进行爬网。尽管目前可以对数据进行爬网,但是它还不能对很多自动化进行爬网。原因是参数键值对时间敏感(特定时间未验证为20分钟),并且我不知道如何生成它。
文章历史记录列表爬网
进入搜狗微信的第一件事是搜狗微信,但搜狗微信只能看到前十篇文章文章,而我无法确定阅读量和观看次数。我试图爬网手机包装,发现没有信息被捕获。我知道原因:
1、Android系统7.低于0的微信信任系统证书。
2、Android系统7. 0或更高版本,微信7. 0版本,微信信任系统提供的证书。
3、Android系统7. 0或更高版本,微信7. 0或更高版本,微信仅信任自己的证书。
我也尝试使用appium自动进行爬网,我个人觉得有点麻烦。因此,尝试从PC抓取请求。
这次进入主题,我使用Fiddler捕获数据包。下载链接:
Fiddler如何捕获数据包将不在此处一一解释。首先,首次安装Fiddler时,需要安装证书以捕获HTTPS请求。
如何安装?
打开Fiddler并从菜单栏中找到工具->选项->单击HTTPS->单击操作,将安装证书,配置如下:
以我自己的官方帐户为例:登录PC上的微信,打开Fiddler,按F12键开始/停止抓包,进入官方帐户历史记录文章页,请参见Fiddler有很多请求,如图所示下方:
因为查看历史记录是为了跳转到新页面,所以您可以从正文中返回更多内容,并且通过Content-Type,您还可以知道返回的内容是css或html或js,因此您可以查看首先在html上,所以几乎可以在上面显示的红色框中找到链接,单击它,然后您可以从右侧查看返回结果和参数:
从右侧的页眉中,您可以看到请求链接,方法,参数等。如果要更清晰地查看参数,可以单击WebForms进行查看,其结果如上图所示。这是重要参数的说明:
__ biz:微信官方帐号的唯一标识(同一官方帐号保持不变)
uin:唯一的用户标识(同一微信用户保持不变)
键:微信的内部算法对时间敏感,所以我不知道它是如何计算的。
pass_ticket:有一个阅读权限加密,该加密已更改(在我的实际爬网中,我发现它是不必要的,可以忽略)
在这一点上,您实际上可以编写代码来爬网第一页的文章,但是返回的是html页,显然解析该页很麻烦。
您可以尝试向下滑动,加载下一页数据,然后查看它是json还是html。如果是json,则很容易处理,如果仍然是html,则必须对其进行一些解析。继续往下走,您会发现:
此请求是返回的文章列表,它是json数据,这对我们进行解析非常方便。从参数中,我们发现有一个偏移量为10的参数,这显然是页面的偏移量。此请求为10,以加载第二页的历史记录,将其果断地修改为0,然后发送请求,并获取第一页的数据,则无需解析html页,再次分析参数,并找到许多参数。他们中许多人是无用的。最终参数为:
action:getmsg(固定值,应表示获取更多信息)
上面已经描述了__biz,uin和key的三个值,它们也是此处的必需参数。
f:json(固定值,表示返回json数据)
偏移量:页面偏移量
如果要获取官方帐户的历史记录列表,则这6个参数是必需的,并且不需要带其他参数。如图所示,让我们分析请求标头中的听众:
参数很多,我不知道应该带哪些参数,不需要带那些参数。最后,我只需要携带UA。最后编写一个脚本来尝试获取它:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,并获取结果:
获取文章详细信息
我有上面的链接,只是请求解析html页面。这里没有更多说明(可以在完整代码中查看)。 查看全部
基于PC文章爬行官方帐户的历史记录
前言
许多处于微信后台的消息尚未得到回复:看到它们后我无法回复。如有任何疑问,可以添加我的微信:菜单->与我联系
因为我最近需要官方帐户的历史文章信息,所以我尝试对其进行爬网。尽管目前可以对数据进行爬网,但是它还不能对很多自动化进行爬网。原因是参数键值对时间敏感(特定时间未验证为20分钟),并且我不知道如何生成它。
文章历史记录列表爬网
进入搜狗微信的第一件事是搜狗微信,但搜狗微信只能看到前十篇文章文章,而我无法确定阅读量和观看次数。我试图爬网手机包装,发现没有信息被捕获。我知道原因:
1、Android系统7.低于0的微信信任系统证书。
2、Android系统7. 0或更高版本,微信7. 0版本,微信信任系统提供的证书。
3、Android系统7. 0或更高版本,微信7. 0或更高版本,微信仅信任自己的证书。
我也尝试使用appium自动进行爬网,我个人觉得有点麻烦。因此,尝试从PC抓取请求。
这次进入主题,我使用Fiddler捕获数据包。下载链接:
Fiddler如何捕获数据包将不在此处一一解释。首先,首次安装Fiddler时,需要安装证书以捕获HTTPS请求。
如何安装?
打开Fiddler并从菜单栏中找到工具->选项->单击HTTPS->单击操作,将安装证书,配置如下:
以我自己的官方帐户为例:登录PC上的微信,打开Fiddler,按F12键开始/停止抓包,进入官方帐户历史记录文章页,请参见Fiddler有很多请求,如图所示下方:
因为查看历史记录是为了跳转到新页面,所以您可以从正文中返回更多内容,并且通过Content-Type,您还可以知道返回的内容是css或html或js,因此您可以查看首先在html上,所以几乎可以在上面显示的红色框中找到链接,单击它,然后您可以从右侧查看返回结果和参数:
从右侧的页眉中,您可以看到请求链接,方法,参数等。如果要更清晰地查看参数,可以单击WebForms进行查看,其结果如上图所示。这是重要参数的说明:
__ biz:微信官方帐号的唯一标识(同一官方帐号保持不变)
uin:唯一的用户标识(同一微信用户保持不变)
键:微信的内部算法对时间敏感,所以我不知道它是如何计算的。
pass_ticket:有一个阅读权限加密,该加密已更改(在我的实际爬网中,我发现它是不必要的,可以忽略)
在这一点上,您实际上可以编写代码来爬网第一页的文章,但是返回的是html页,显然解析该页很麻烦。
您可以尝试向下滑动,加载下一页数据,然后查看它是json还是html。如果是json,则很容易处理,如果仍然是html,则必须对其进行一些解析。继续往下走,您会发现:
此请求是返回的文章列表,它是json数据,这对我们进行解析非常方便。从参数中,我们发现有一个偏移量为10的参数,这显然是页面的偏移量。此请求为10,以加载第二页的历史记录,将其果断地修改为0,然后发送请求,并获取第一页的数据,则无需解析html页,再次分析参数,并找到许多参数。他们中许多人是无用的。最终参数为:
action:getmsg(固定值,应表示获取更多信息)
上面已经描述了__biz,uin和key的三个值,它们也是此处的必需参数。
f:json(固定值,表示返回json数据)
偏移量:页面偏移量
如果要获取官方帐户的历史记录列表,则这6个参数是必需的,并且不需要带其他参数。如图所示,让我们分析请求标头中的听众:
参数很多,我不知道应该带哪些参数,不需要带那些参数。最后,我只需要携带UA。最后编写一个脚本来尝试获取它:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,并获取结果:
获取文章详细信息
我有上面的链接,只是请求解析html页面。这里没有更多说明(可以在完整代码中查看)。
分享:如何爬取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 1250 次浏览 • 2020-11-11 08:00
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
如何抓取所有文章微信官方帐户
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
分享文章:如何爬取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-11-10 12:01
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
如何抓取所有文章微信官方帐户
准备阶段
为了实现此采集器,我们需要使用以下工具
此外,此采集器使用微信官方帐户后台编辑界面。原理是,当我们插入超链接时,微信将调用特殊的API(请参见下图)以获取指定官方帐户的文章列表。因此,我们还需要拥有一个官方帐户。
fig1
正式开始
我们需要登录到WeChat官方帐户,依次单击“物料管理”,“新建图形消息”,然后单击上方的超链接。
fig2
下一步,按F12键打开Chrome的开发者工具,然后选择“网络”
fig3
这时,在上一个超链接界面中,单击“选择另一个官方帐户”,然后输入您要抓取的官方帐户(例如,中国移动)
fig4
这时,先前的网络将刷新一些链接,其中以“ appmsg”开头的内容是我们需要分析的
fig5
我们解析请求的网址
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次仅开始更改,并且每次增加5(即count的值)。
接下来,我们使用Python获取相同的资源,但是直接运行以下代码无法获取资源
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能够在浏览器上获取资源,是因为我们登录了微信官方账号后端。而且Python没有我们的登录信息,因此该请求无效。我们需要在请求中设置headers参数,并传入Cookie和User-Agent以模拟登录
因为标题信息的内容每次都会改变,所以我将这些内容放在一个单独的文件“ wechat.yaml”中,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
您只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(标题),摘要(摘要),链接(链接),推送时间(update_time)和封面地址(封面)。
appmsgid是每个推文的唯一标识符,而aid是每个推文的唯一标识符。
fig6
实际上,除了cookie外,URL中的token参数还将用于限制采集器,因此上述代码的输出可能为{'base_resp':{'ret':200040,'err_msg ':'无效的csrf令牌'}}
接下来,我们编写一个循环以获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还将伪造品和令牌存储在“ wechat.yaml”文件中。这是因为fakeid是每个正式帐户唯一的标识符,并且令牌会经常更改。此信息可以通过解析URL获得,也可以从开发人员工具中查看
fig7
爬行一段时间后,您会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
这时,当您尝试在官方帐户的背景中插入超链接时,会出现以下提示
fig8
这是官方帐户的流量限制,通常需要等待30-60分钟才能继续。为了完美地解决此问题,您可能需要申请多个官方帐户,您可能需要与微信官方帐户登录系统进行对抗,或者您可能需要建立代理池。
但是我不需要工业级的采集器,我只想搜寻我自己的官方帐户信息,因此请等待一个小时,再次登录到官方帐户,获取Cookie和令牌并运行它。我不想为自己的利益挑战别人的工作。
最后,将结果保存为JSON格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或提取文章标识符,标题,URL和发布时间的四列,并将它们另存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
意外:采集乱七八糟记录下
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-10-30 12:00
最近正在做采集条新闻,只需对其进行记录
微信公众号采集
使用了PHP QueryList库,并且可以很好地安装作曲家
__ biz微信官方帐户的唯一标识符,可以通过在PC上登录微信并复制链接来查看
场景= 124写死
wxtokenkey = 777很难写
wxuin = 1146460420当前微信登录的ID
用户代理UA是必须的
wap_sid2这是最重要的参数
获取cookie是由老板完成的。这里只是对所依赖的思想和软件的简要介绍:按钮向导,查找器
服务器数据库配置有官方帐户数据,例如__biz参数
在win系统上安装按钮向导。在PC版微信中,使用按钮向导进行个性化编程可自动打开官方帐户页面
安装fidder数据包捕获工具,获取微信历史记录页面请求,然后将cookie同步到服务器数据库
可以对自定义程序编程:抓取cookie并同步到服务器
按钮向导可以自动编程:获取cookie的正式帐户已过期,重新打开历史记录页面,以方便查找该cookie的食物
服务器采集程序负责采集,将页面解析到数据库中,并发现cookie过期并更新与官方帐户相对应的cookie的状态
... item 一个公众号好数据
QueryList::get($page, [
'action' => 'home',
'__biz' => $item['biz'],
'scene' => 124,
], [
'headers' => [
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEElxZYXdfanZra01NRS1DTGo5RndaeWNBQjEyaDhZQ3BaRHc5LVREQ1NjMFpHT1lPWFdDajVlandhaU9RLTZmWE9KemIxU3U1Q2lXXzZOMFBfVjlueGhXZjBEQUFBfjDbz87qBTgNQJVO'
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEEnBFQzkyUy1oZW5fWDNBMVFUY3NlUFBsZm51NGdUbFBvVDg1SG5iZXY0UWFjb29hT2VPWXF1U3FiN3A2M2RLWktWVXFReWg5OHhjME1uUVRRa1JvNnJoeGttRHRDc3poWU9nc19sTy1Wek1uZi1Bd0FBMLPAz+oFOA1AlU4='
'Cookie' => $item['cookie'],
],
]);
列表数据的解析非常简单。页面数据是输出到html的json数据,只需处理匹配即可获得数据列表。 查看全部
采集乱七八糟的记录
最近正在做采集条新闻,只需对其进行记录
微信公众号采集
使用了PHP QueryList库,并且可以很好地安装作曲家
__ biz微信官方帐户的唯一标识符,可以通过在PC上登录微信并复制链接来查看
场景= 124写死
wxtokenkey = 777很难写
wxuin = 1146460420当前微信登录的ID
用户代理UA是必须的
wap_sid2这是最重要的参数
获取cookie是由老板完成的。这里只是对所依赖的思想和软件的简要介绍:按钮向导,查找器
服务器数据库配置有官方帐户数据,例如__biz参数
在win系统上安装按钮向导。在PC版微信中,使用按钮向导进行个性化编程可自动打开官方帐户页面
安装fidder数据包捕获工具,获取微信历史记录页面请求,然后将cookie同步到服务器数据库
可以对自定义程序编程:抓取cookie并同步到服务器
按钮向导可以自动编程:获取cookie的正式帐户已过期,重新打开历史记录页面,以方便查找该cookie的食物
服务器采集程序负责采集,将页面解析到数据库中,并发现cookie过期并更新与官方帐户相对应的cookie的状态
... item 一个公众号好数据
QueryList::get($page, [
'action' => 'home',
'__biz' => $item['biz'],
'scene' => 124,
], [
'headers' => [
'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'User-Agent' => 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEElxZYXdfanZra01NRS1DTGo5RndaeWNBQjEyaDhZQ3BaRHc5LVREQ1NjMFpHT1lPWFdDajVlandhaU9RLTZmWE9KemIxU3U1Q2lXXzZOMFBfVjlueGhXZjBEQUFBfjDbz87qBTgNQJVO'
//'Cookie'=>'wxtokenkey=777; wxuin=1146460420; devicetype=iMacMacBookPro121OSXOSX10.12.6build(16G1114); version=12030c10; lang=zh_CN; wap_sid2=CISy1qIEEnBFQzkyUy1oZW5fWDNBMVFUY3NlUFBsZm51NGdUbFBvVDg1SG5iZXY0UWFjb29hT2VPWXF1U3FiN3A2M2RLWktWVXFReWg5OHhjME1uUVRRa1JvNnJoeGttRHRDc3poWU9nc19sTy1Wek1uZi1Bd0FBMLPAz+oFOA1AlU4='
'Cookie' => $item['cookie'],
],
]);
列表数据的解析非常简单。页面数据是输出到html的json数据,只需处理匹配即可获得数据列表。
总结:带大家写一波微信公众号的爬取!谁说微信爬不了的
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2020-10-22 08:01
x5
其他参数的含义可以根据经验和简单的测试来判断:
1.偏移
控制翻页的偏移参数
2.个计数
每页文章的数量
3.__ biz
官方帐户标识,不同的__biz对应于不同的官方帐户
4.pass_ticket
它应该是微信登录后返回的参数,
去年我尝试登录微信网络版本时,在返回的参数中看到了它,
但是现在微信网络版本已被正式禁止T_T。
5.appmsg_token
它还应该是登录微信后的标识参数,以及您阅读的微信官方帐户
相关,查看不同的微信公众号时的值也不同。
前三个变量参数很容易求解,但后两个参数似乎更难。但是,在测试之后,我们可以发现pass_ticket实际上是一个可选参数,因此我们可以忽略它。而且appmsg_token的有效期至少为10个小时,这段时间足以让我们抓取目标官方帐户的所有文章,因此只需直接将其复制,就无需浪费时间分析这些东西(您也应该知道您是否认为腾讯对白人卖淫(T_T)绝对不那么容易。编写一段代码对其进行简短测试:
import requests
session = requests.Session()
session.headers.update(headers)
session.cookies.update(cookies)
profile_url = '前面抓包得到的请求地址'
biz = 'MzAwNTA5NTYxOA=='
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g'
params = {
'action': 'getmsg',
'__biz': biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': pass_ticket,
'wxtoken': '',
'appmsg_token': appmsg_token,
'x5': '0'
}
res = session.get(profile_url, params=params, verify=False)
print(res.text)
运行后,您会发现返回的数据如下:
似乎没有问题。重新调整打包代码以爬网正式帐户的所有文章链接。具体来说,核心代码实现如下:
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
运行后,我们可以获得目标官方帐户的所有文章链接:
现在,我们只需要基于这些文章链接来抓取文章的内容。在这里,我们使用python的第三方软件包pdfkit将每篇文章文章保存为pdf文件。具体来说,核心代码实现如下:
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
请注意,在使用pdfkit之前,您需要安装wkhtmltox。如下图所示:
运行的效果可能是这样的:
所有源代码
根据您自己的数据包捕获结果修改cfg.py文件:
## cfg.py
# 目标公众号标识
biz = 'MzAwNTA5NTYxOA=='
# 微信登录后的一些标识参数
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g~~'
# 安装的wkhtmltopdf.exe文件路径
wkhtmltopdf_path = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
12345678
## articlesSpider.py
import os
import time
import json
import pdfkit
import random
import requests
import warnings
warnings.filterwarnings('ignore')
'''微信公众号文章爬取类'''
class articlesSpider(object):
def __init__(self, cfg, **kwargs):
self.cfg = cfg
self.session = requests.Session()
self.__initialize()
'''外部调用'''
def run(self):
self.__getArticleLinks()
self.__downloadArticles()
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
key = key.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('', '').replace('|', '_')
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
'''类初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
self.cookies = {
'wxuin': '913366226',
'devicetype': 'iPhoneiOS13.3.1',
'version': '17000c27',
'lang': 'zh_CN',
'pass_ticket': self.cfg.pass_ticket,
'wap_sid2': 'CNK5w7MDElxvQU1fdWNuU05qNV9lb2t3cEkzNk12ZHBsNmdXX3FETlplNUVTNzVfRmwyUUtKZzN4QkxJRUZIYkMtMkZ1SDU5S0FWQmtSNk9mTTQ1Q1NDOXpUYnJQaDhFQUFBfjDX5LD0BTgNQJVO'
}
self.profile_url = 'https://mp.weixin.qq.com/mp/profile_ext'
self.savedir = 'articles'
self.session.headers.update(self.headers)
self.session.cookies.update(self.cookies)
'''run'''
if __name__ == '__main__':
import cfg
spider = articlesSpider(cfg)
spider.run()
要简单。如果不能的话,请将我添加到企鹅群组中,以接收视频教程和源代码。私人消息编辑器01 查看全部
带大家去写一波微信公众号爬网!谁说微信无法攀登
x5
其他参数的含义可以根据经验和简单的测试来判断:
1.偏移
控制翻页的偏移参数
2.个计数
每页文章的数量
3.__ biz
官方帐户标识,不同的__biz对应于不同的官方帐户
4.pass_ticket
它应该是微信登录后返回的参数,
去年我尝试登录微信网络版本时,在返回的参数中看到了它,
但是现在微信网络版本已被正式禁止T_T。
5.appmsg_token
它还应该是登录微信后的标识参数,以及您阅读的微信官方帐户
相关,查看不同的微信公众号时的值也不同。
前三个变量参数很容易求解,但后两个参数似乎更难。但是,在测试之后,我们可以发现pass_ticket实际上是一个可选参数,因此我们可以忽略它。而且appmsg_token的有效期至少为10个小时,这段时间足以让我们抓取目标官方帐户的所有文章,因此只需直接将其复制,就无需浪费时间分析这些东西(您也应该知道您是否认为腾讯对白人卖淫(T_T)绝对不那么容易。编写一段代码对其进行简短测试:
import requests
session = requests.Session()
session.headers.update(headers)
session.cookies.update(cookies)
profile_url = '前面抓包得到的请求地址'
biz = 'MzAwNTA5NTYxOA=='
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g'
params = {
'action': 'getmsg',
'__biz': biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': pass_ticket,
'wxtoken': '',
'appmsg_token': appmsg_token,
'x5': '0'
}
res = session.get(profile_url, params=params, verify=False)
print(res.text)
运行后,您会发现返回的数据如下:
似乎没有问题。重新调整打包代码以爬网正式帐户的所有文章链接。具体来说,核心代码实现如下:
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
运行后,我们可以获得目标官方帐户的所有文章链接:
现在,我们只需要基于这些文章链接来抓取文章的内容。在这里,我们使用python的第三方软件包pdfkit将每篇文章文章保存为pdf文件。具体来说,核心代码实现如下:
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
请注意,在使用pdfkit之前,您需要安装wkhtmltox。如下图所示:
运行的效果可能是这样的:
所有源代码
根据您自己的数据包捕获结果修改cfg.py文件:
## cfg.py
# 目标公众号标识
biz = 'MzAwNTA5NTYxOA=='
# 微信登录后的一些标识参数
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g~~'
# 安装的wkhtmltopdf.exe文件路径
wkhtmltopdf_path = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
12345678
## articlesSpider.py
import os
import time
import json
import pdfkit
import random
import requests
import warnings
warnings.filterwarnings('ignore')
'''微信公众号文章爬取类'''
class articlesSpider(object):
def __init__(self, cfg, **kwargs):
self.cfg = cfg
self.session = requests.Session()
self.__initialize()
'''外部调用'''
def run(self):
self.__getArticleLinks()
self.__downloadArticles()
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
key = key.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('', '').replace('|', '_')
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
'''类初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
self.cookies = {
'wxuin': '913366226',
'devicetype': 'iPhoneiOS13.3.1',
'version': '17000c27',
'lang': 'zh_CN',
'pass_ticket': self.cfg.pass_ticket,
'wap_sid2': 'CNK5w7MDElxvQU1fdWNuU05qNV9lb2t3cEkzNk12ZHBsNmdXX3FETlplNUVTNzVfRmwyUUtKZzN4QkxJRUZIYkMtMkZ1SDU5S0FWQmtSNk9mTTQ1Q1NDOXpUYnJQaDhFQUFBfjDX5LD0BTgNQJVO'
}
self.profile_url = 'https://mp.weixin.qq.com/mp/profile_ext'
self.savedir = 'articles'
self.session.headers.update(self.headers)
self.session.cookies.update(self.cookies)
'''run'''
if __name__ == '__main__':
import cfg
spider = articlesSpider(cfg)
spider.run()
要简单。如果不能的话,请将我添加到企鹅群组中,以接收视频教程和源代码。私人消息编辑器01
技巧干货:超实用技巧:如何采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-10-16 10:06
当我们看到一个很好的官方帐户文章时,如果要将其重新打印到我们的官方帐户中,我们将直接复制并粘贴全文。但是,尽管此方法很简单,但不是很实用。因为粘贴之后,我们会发现格式或样式通常是错误的,并且更难修改。
实际上,该方法已经过时了。现在,新媒体编辑经常使用一些微信编辑器来帮助解决此问题。今天,我将以当前主流的微信编辑器为例,向您展示如何从其他微信公共帐户采集 文章到您的微信公共平台。
步骤1:首先在百度上搜索Little Ant Editor,点击以输入网址
第2步:点击采集,然后将采集的微信文章链接地址粘贴到“ 文章 URL”框中
第3步:单击“ 采集”,此时文章的所有内容已在微信编辑器中为采集,您可以编辑和修改文章。编辑后,可以单击其旁边的副本(相当于全文副本),然后将其粘贴到微信材质编辑的文本中。
ps:这里有两种主要的方法来获取微信文章链接:
方法1:直接在手机上找到文章,然后单击右上角的复制
方法2:使用Little Ant Editor的微信营销工具在热搜索图片和文本中搜索材料,然后将所需的材料文章直接复制到上面的URL。
,
怎么样?您是否获得了另一项技能(括号中的笑声)。这只是Little Ant的微信编辑器中的一个小功能,它还收录一些常用功能,例如微信图形和视频提取,微信超链接,微信短URL,微信一键跟随页面等。新媒体的数量编辑喜欢使用它的主要原因。 查看全部
超实用技巧:如何采集微信公众号文章
当我们看到一个很好的官方帐户文章时,如果要将其重新打印到我们的官方帐户中,我们将直接复制并粘贴全文。但是,尽管此方法很简单,但不是很实用。因为粘贴之后,我们会发现格式或样式通常是错误的,并且更难修改。
实际上,该方法已经过时了。现在,新媒体编辑经常使用一些微信编辑器来帮助解决此问题。今天,我将以当前主流的微信编辑器为例,向您展示如何从其他微信公共帐户采集 文章到您的微信公共平台。
步骤1:首先在百度上搜索Little Ant Editor,点击以输入网址
第2步:点击采集,然后将采集的微信文章链接地址粘贴到“ 文章 URL”框中
第3步:单击“ 采集”,此时文章的所有内容已在微信编辑器中为采集,您可以编辑和修改文章。编辑后,可以单击其旁边的副本(相当于全文副本),然后将其粘贴到微信材质编辑的文本中。
ps:这里有两种主要的方法来获取微信文章链接:
方法1:直接在手机上找到文章,然后单击右上角的复制
方法2:使用Little Ant Editor的微信营销工具在热搜索图片和文本中搜索材料,然后将所需的材料文章直接复制到上面的URL。
,
怎么样?您是否获得了另一项技能(括号中的笑声)。这只是Little Ant的微信编辑器中的一个小功能,它还收录一些常用功能,例如微信图形和视频提取,微信超链接,微信短URL,微信一键跟随页面等。新媒体的数量编辑喜欢使用它的主要原因。

