
querylist采集微信公众号文章
querylist采集微信公众号文章信息介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-01 03:04
querylist采集微信公众号文章信息。
1、首先制作一个自定义菜单,
2、在文章列表页标签里选择“标题”,右键,选择新建一个a标签。图2在a标签里输入公众号文章标题。
图3然后要一点技巧:微信号:mfganju
2、然后点这里的“标题”。然后在新建a标签中选择“标题1”的填空。图4然后文章列表页的时候,一个新标签就点进去了。
3、点击自定义菜单中的“添加微信好友”。图5然后就是视频播放列表界面,选择“添加群聊”,点击+号,视频列表界面会出现你选择的图片。图6点击“添加”一直拉到最后。图7最后,发送出去,就完成了。
我也碰到一样的问题,当前po主已找到解决方案,在uc浏览器中解决,不需要自己做插件了,pc浏览器操作即可1。打开微信公众号后台(/);2。在设置那里选择获取媒体信息3。在获取媒体信息界面进行下一步下一步最后点击【获取群发消息】、【发送到朋友圈】全部搞定4。获取到链接链接里有个数字,复制出来,粘贴到querylist里;图片中间有个【/】,选择刚才复制的那串数字发送到手机上即可(请配合开发工具使用)。
点击添加群发消息中的群发号码,然后对已加入的群发送信息(图中a标签),就可以看到标签里面的文章了。点击添加群发消息,文章就会出现在手机上了,再发送至朋友圈即可。 查看全部
querylist采集微信公众号文章信息介绍-乐题库
querylist采集微信公众号文章信息。
1、首先制作一个自定义菜单,
2、在文章列表页标签里选择“标题”,右键,选择新建一个a标签。图2在a标签里输入公众号文章标题。
图3然后要一点技巧:微信号:mfganju
2、然后点这里的“标题”。然后在新建a标签中选择“标题1”的填空。图4然后文章列表页的时候,一个新标签就点进去了。
3、点击自定义菜单中的“添加微信好友”。图5然后就是视频播放列表界面,选择“添加群聊”,点击+号,视频列表界面会出现你选择的图片。图6点击“添加”一直拉到最后。图7最后,发送出去,就完成了。
我也碰到一样的问题,当前po主已找到解决方案,在uc浏览器中解决,不需要自己做插件了,pc浏览器操作即可1。打开微信公众号后台(/);2。在设置那里选择获取媒体信息3。在获取媒体信息界面进行下一步下一步最后点击【获取群发消息】、【发送到朋友圈】全部搞定4。获取到链接链接里有个数字,复制出来,粘贴到querylist里;图片中间有个【/】,选择刚才复制的那串数字发送到手机上即可(请配合开发工具使用)。
点击添加群发消息中的群发号码,然后对已加入的群发送信息(图中a标签),就可以看到标签里面的文章了。点击添加群发消息,文章就会出现在手机上了,再发送至朋友圈即可。
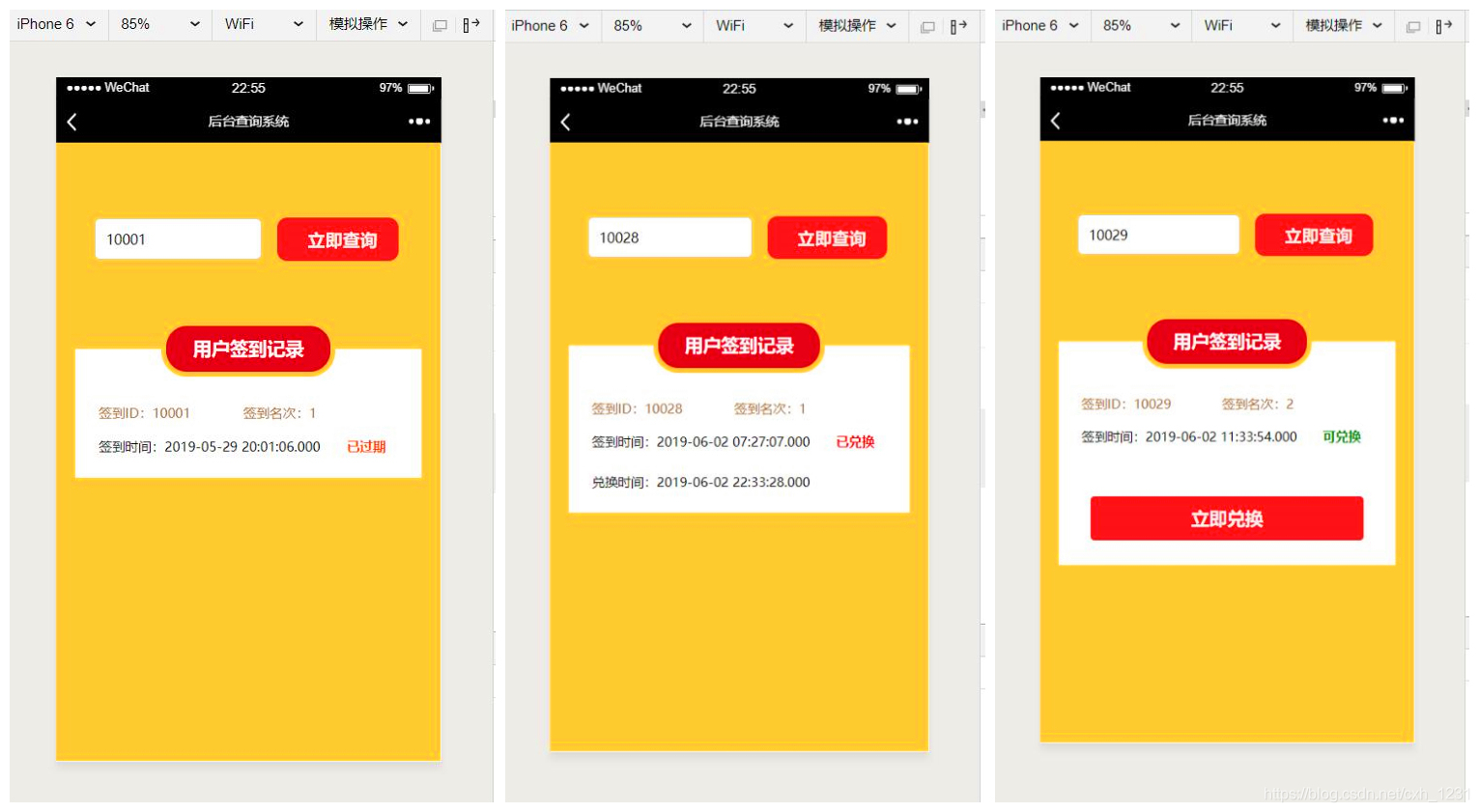
【早起签到】CSS样式表(2):0成果展示
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-01 00:36
0 结果显示
这篇文章比较长。为了减少读者的时间,先把这个项目的结果展示出来,让读者可以快速确认这个文章是否就是他们要找的文章。
这里需要说明一下,项目中的前端页面配色图是指网上发布的CSS样式表。
有关项目的详细信息,请稍后查看。
0.1 登录主页:
用户点击公众号菜单【提前登录】后,会实现微信自动登录,进入登录主页面。
主页显示如下:
左图:缺席签到时间。中图:签到页面。右图:签到完成后显示排名页面。
主页面分为三个显示页面。无人签到时间(0:00-05:50)如上左图所示。当到达签到时间时,可以点击按钮状态,如上中图所示。登录完成后,会显示用户在公众号当天的登录位置。
0.2 签到记录页面
用户登录后,可以查看自己的登录记录。详情如下图所示:
左图:可兑换奖励签到记录和过期签到记录 右图:兑换签到记录
本项目用户登录后,可于当日或次日06:50-08:30在指定地点领取奖励。过了这个时间,这个登录记录就失效了。三种状态的签到记录如上图所示。
0.3后台交流页面
下图为后台交易所的测试页面。输入登录ID查询登录记录。
左图:查询过期的登录记录。中图:查询已兑换的登录记录。右图:查询可兑换的登录记录。
如上图所示。如果前来兑换的用户的登录记录已过期,则会如上左图显示。如果用户的签到记录已经被兑换,会如上中图显示。如果用户的签到记录可兑换,则会如右上图所示。
点击“立即兑换”按钮,出现“兑换成功”弹窗,如下图。
兑换成功弹窗(在微信开发者工具中运行)
看到这里,如果这不是你想要的项目,那么你可以关闭这个博客。
如果这是你想要的项目,或者这个项目和你当前的项目很接近,或者你想学习如何写这个项目,或者...
请继续阅读。下面正式开始^_^
1项目背景及需求分析1.1项目背景
关于这个需求分析部分,我们先从项目的背景说起。
原因是这个。项目组在公众号举办活动。这个活动简单易懂,就是“早起签到领取奖励”。每天早上指定时间开启签到系统,然后用户点击菜单栏中的“提前签到”按钮,通过微信登录,进入签到系统。
用户登录完成后,用户可以根据登录记录到指定地点领取早餐。同时,每日早餐数量有限,先到先得。同时,签到记录也有兑换期。本项目组指定的方案可在当日或次日8:30前收到。所以我今天check in,第二天早上就没有早餐了^_^
1.2 需求分析
通过对项目背景的分析,本项目需求如下:
1、本项目为公众号项目,微信网页开发;
2、实现用户微信登录授权确定用户身份,实现一天只能登录一次;
3、用户登录后,记录登录时间和当天登录排名;
4、显示用户的签到记录和签到记录的状态(可兑换、已兑换、已过期);
5、Background 管理员确认兑换。
2概述设计2.1开发技术分析
既然是微信网页的开发,要实现用户登录,那么就需要了解微信公众号网页的授权机制。
微信开放平台有这方面的使用说明介绍,大家可以通过开发者的文档自行学习。链接如下:
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取验证码
2、交换网页授权access_token代码(与基础支持的access_token不同)
3、如有需要,开发者可以刷新网页对access_token进行授权,避免过期
4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
只有通过微信认证的服务账号才能使用“Web授权”界面。
如果要用于开发测试,可以申请一个测试账号。申请链接如下:
微信网页授权登录的详细流程将在实践代码(后面编码实现流程)中进行说明。
———————————————————————
然后需要分析确定开发语言。
微信网页可以用任何网页开发语言实现。
但是结合这个项目,需要对数据库中的数据进行增删改查,所以最终使用的编程语言是PHP。
(此时笔者还没有接触到PHP开发o(╥﹏╥)o,笔者熟悉的web开发语言是Java Web。所以编码实现过程,如有不对之处请指教忍着我(*^▽^*))
最后,数据库使用 MySQL。
2.2数据库设计
项目本身不大,所以设计的数据库形式也很简单。
第一个是用户表。
本项目中,只需要获取用户为本公众号生成的唯一标识OpenID,无需获取用户昵称、城市、头像等其他公开信息。如果您需要有关用户的这些信息,可以展开用户表。
user表的user字段只有2列。如下图所示:
各个字段的含义:
然后是用户登录记录表。签到表详情如下:
各个字段的含义:
如果您的项目需要其他形式,您可以自行设计。
3 开发环境配置
工人要想做好本职工作,就必须先磨砺他的工具。开发前,需要先配置好开发环境。
使用的四个软件
3.1 编程环境:
本项目使用PHP语言。所以编译器使用了JetBrains PhpStorm。
PHPStorm 是付费软件。如果你是学生用户,有教育邮箱,可以到JetBrains官网授权免费版。
3.2 编译环境:
在项目编写过程中,调试是不可避免的。所以这里使用的PHP网页运行环境是phpStudy。
本软件是免费软件。详情请查看phpStudy官网相关文档。
3.3MySQL 数据库可视化:
在调试过程中,不可避免地要对数据库中的数据进行校验和检查。
作者使用的MySQL数据库可视化工具是Navicat for MySQL。
本软件为付费软件。
3.4网页调试:
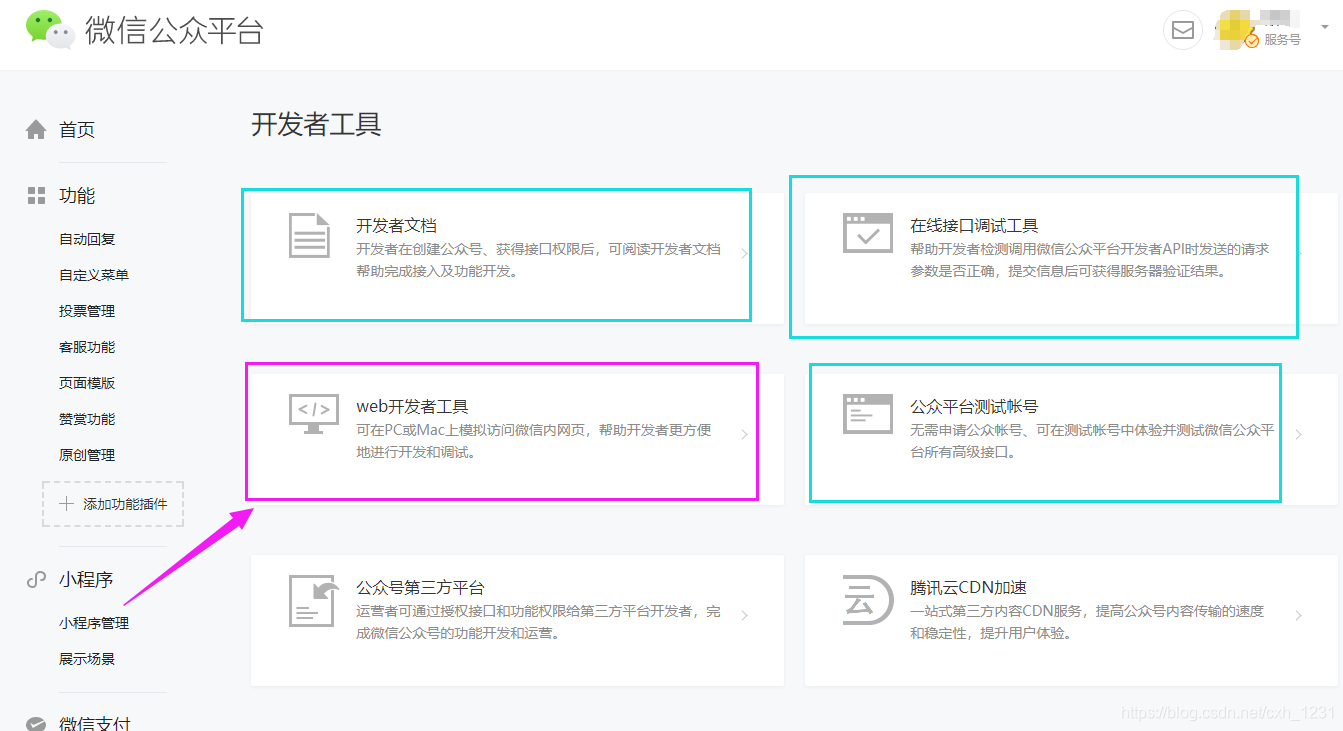
如何调试公众号网页?微信公众平台开发者工具栏提供网页开发者工具:微信网页开发者工具
如上图所示,点击【web开发者工具】跳转到绑定开发者的微信账号页面。这里我们绑定了开发者的微信账号。
然后去:下载微信网页开发工具电脑客户端。
下载安装后,运行后需要开发者扫描登录才能运行。运行页面如下:
3.5微信公众后台配置
如果直接在公众号菜单栏配置完成的项目,微信将无法识别你的项目。
但是这个程序不配置公众号后台O(∩_∩)O
所谓公众号后台配置,就是获取公众号秘钥,并将域名加入公众号界面白名单的过程。
详情如下:
3.5.1配置域名
项目最终需要使用域名访问。并且域名必须启用SSL证书(HTTPS协议)
关于如何在PHPStudy中配置SSL证书,笔者之前写过,点此查看。
这里是关于将域名加入公众号“白名单”。
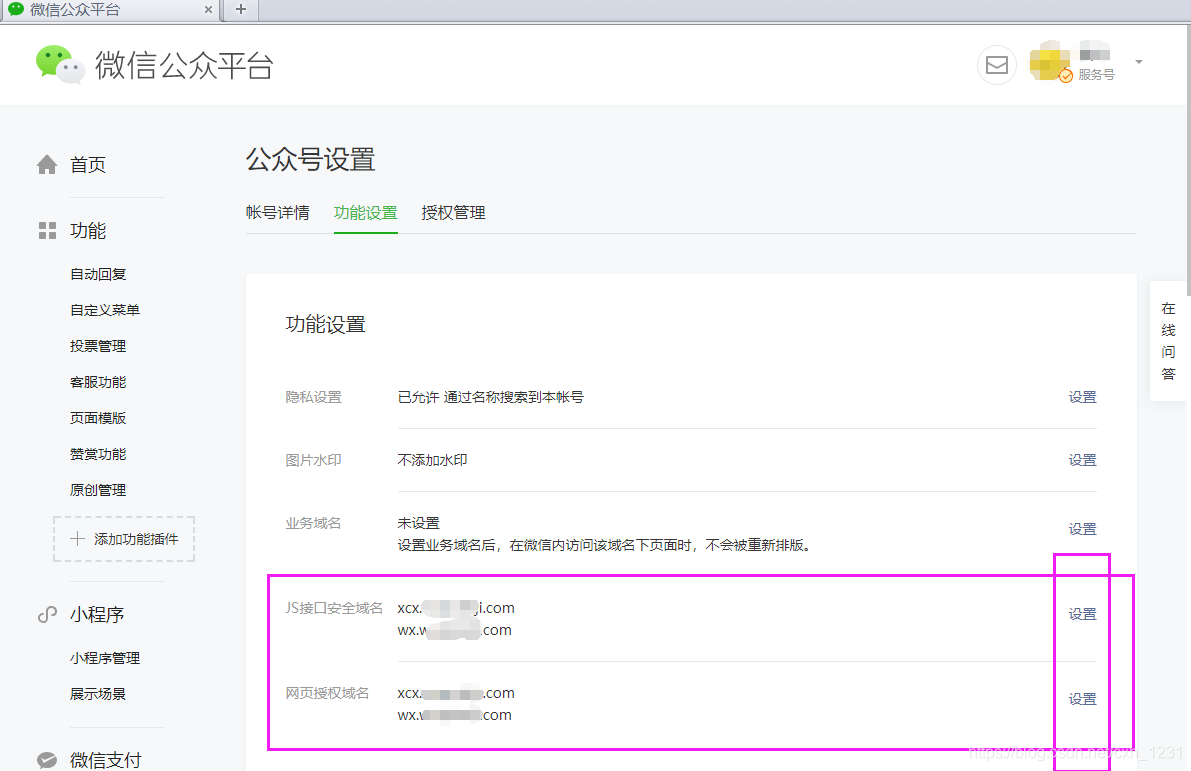
首先进入公众号后台,点击【设置】>>【公众号设置】>>【功能设置】,如下图:
点击上面红框内两个模块的设置,为域名添加授权。
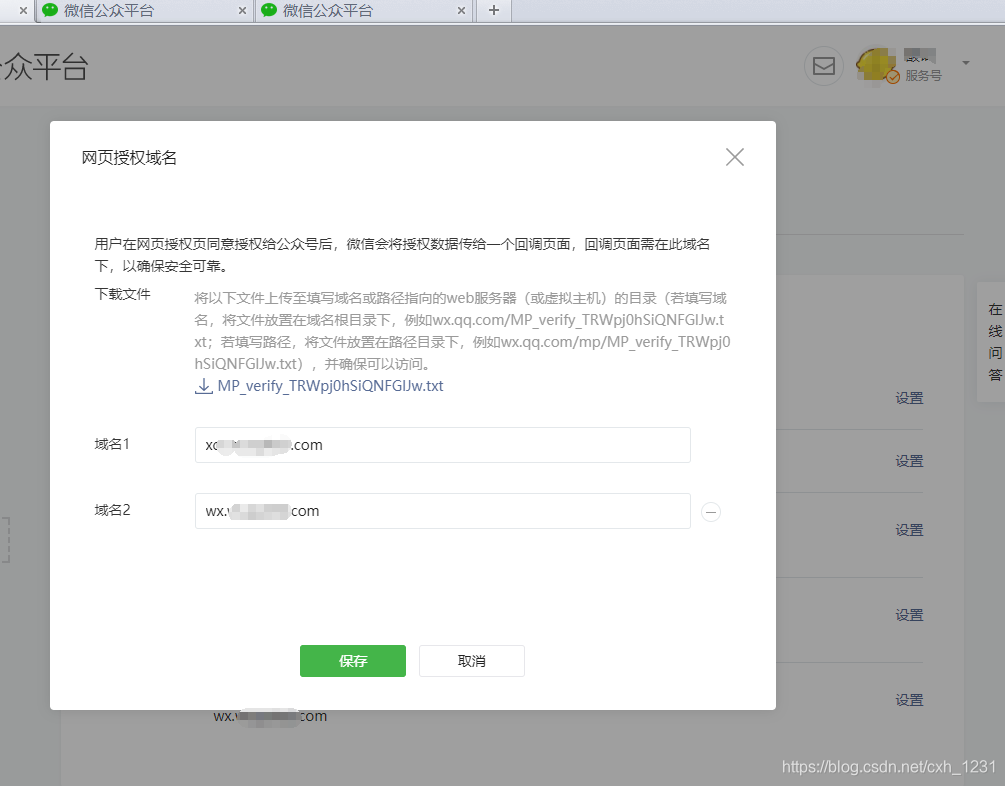
为了验证您是否拥有域名,您需要将指定文件上传到域名服务器目录进行验证。如下图所示:
具体的配置过程,按照上图的提示进行配置即可。
微信公众号支持配置2个网页授权域名和3个JS接口安全域名。
3.5.2 配置IP白名单
本项目需要使用access_token接口,所以需要配置网站最终部署到IP白名单的服务器的IP地址!
即把域名解析的IP地址配置到公众号IP白名单(详见域名解析列表)。
在微信公众平台后台点击【开发】>>【基础配置】修改IP白名单配置。
点击上图下方红框中的【查看】查看和修改IP白名单。
3.5.3获取开发者密码
开发者密码是用于验证公众号开发者身份的密码,具有极高的安全性。
在微信公众平台后台点击【开发】>>【基础配置】重置开发者密码。
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
4 编码实现
据说PHP是一种松散的语言。作者也是第一次接触PHP,用PHP来实现这个项目...总体感觉PHP非常好用\(^o^)/~
项目本身不大,客户端有2个页面,所以没有框架,也没有MVC开发模型(以下模仿MVC开发模型)
4.1 模型(Model)层DAO类代码:
首先,您需要创建一个新的 Dao 类。该类实现了Dao类的构造,用于处理数据库中的数据。
流行的一般是实现数据库的增删改查,所以所有的SQL语句都在这里执行。
文件名:dao.php
详细代码和注释如下:
早起签到
images/banner.jpg
5:50开启今日签到
立即签到
今日签到名次:
<p align="right">>>我的签到记录
活动详情
1、每日05:50至23:59开启早起签到。
2、其他内容……
3、其他内容……
技术支持:@拾年之璐
</p>
本主页使用的CSS文件来自互联网,长度较长。会在文末展示。
这里注意,在上面代码中“立即登录”按钮所在的表单中,动作是跳转到sign.php文件,注意这里!
所以你需要编写sign.php文件。这个文件是一个控制页和一个跳转页。详细代码如下:
文件名:sign.php
我的签到记录
images/banner.jpg
我的签到记录
<p>签到ID: 当日签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a><a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orange"> 已过期</a>
您还没有签到记录,快去签到吧^_^
返回
</p>
4.6后台兑换页面
后台交换页面是一个非常简单的 HTML 页面。其中主要由两个PHP文件组成:
主页文件名:search.php
完整代码:
后台查询系统
input{
border: 1px solid #ccc;
padding: 10px 0px;
border-radius: 5px; /*css3属性IE不支持*/
padding-left:10px;
width: 150px;
}
.btn5{ display:block;
border:0px;
margin:0rem auto 0% auto;
width: 94%;
background-color: #ef2122;
text-align: center;
font-weight: bold;
font-size:17px ;
color: #fff3f0;
border-radius: 10px;
}
function doAction() {
var usersignid = document.getElementById("usersignid");
window.location.href = "a.php?usersignid="+ usersignid.value;
}
用户签到记录
<p>签到ID: 签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a>
立即兑换
<a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orangered"> 已过期</a>
未查询到该签到记录!
</p>
兑换按钮文件名:submit.php
完整代码:
<p> 查看全部
【早起签到】CSS样式表(2):0成果展示
0 结果显示
这篇文章比较长。为了减少读者的时间,先把这个项目的结果展示出来,让读者可以快速确认这个文章是否就是他们要找的文章。
这里需要说明一下,项目中的前端页面配色图是指网上发布的CSS样式表。
有关项目的详细信息,请稍后查看。
0.1 登录主页:
用户点击公众号菜单【提前登录】后,会实现微信自动登录,进入登录主页面。
主页显示如下:
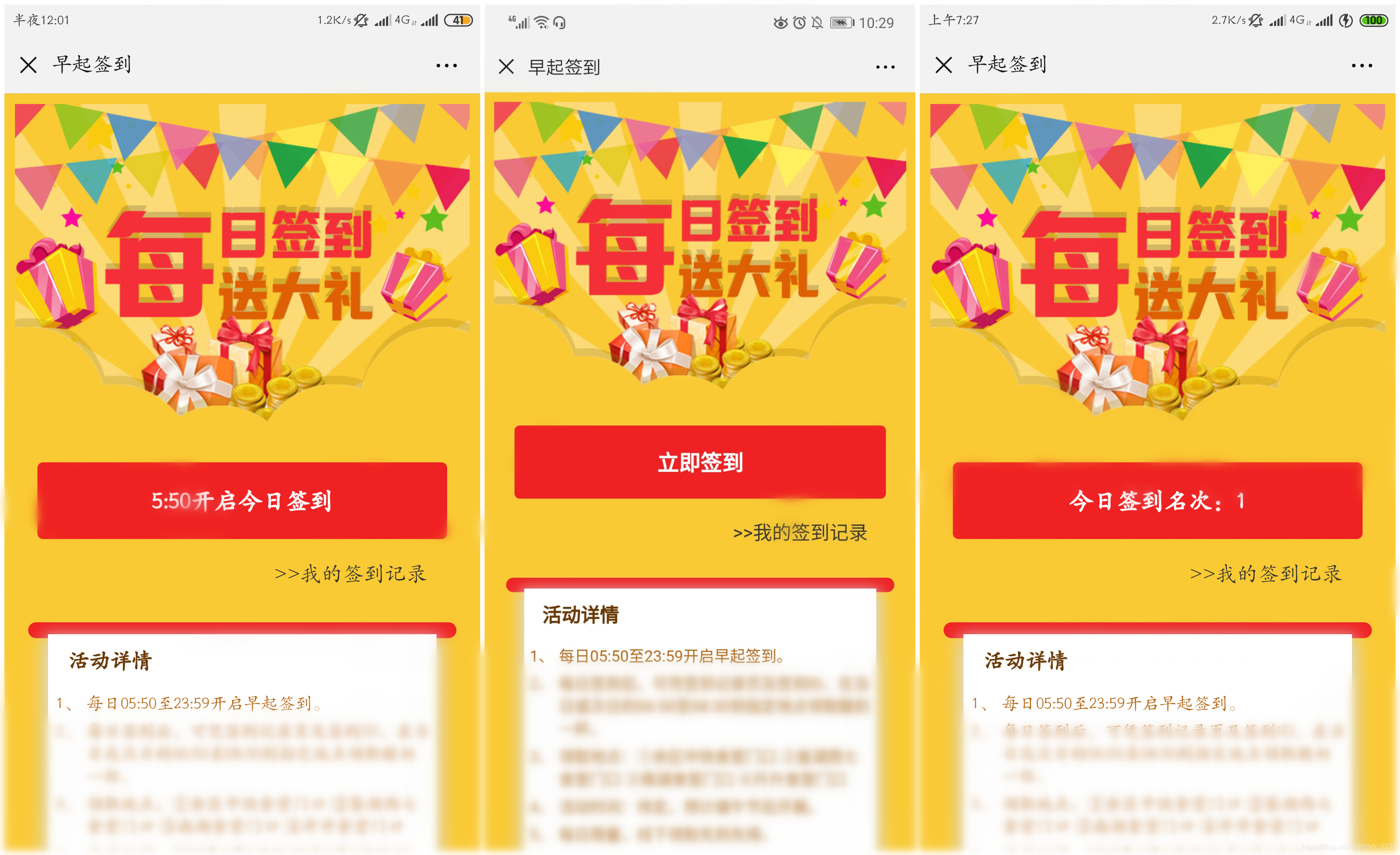
左图:缺席签到时间。中图:签到页面。右图:签到完成后显示排名页面。
主页面分为三个显示页面。无人签到时间(0:00-05:50)如上左图所示。当到达签到时间时,可以点击按钮状态,如上中图所示。登录完成后,会显示用户在公众号当天的登录位置。
0.2 签到记录页面
用户登录后,可以查看自己的登录记录。详情如下图所示:

左图:可兑换奖励签到记录和过期签到记录 右图:兑换签到记录
本项目用户登录后,可于当日或次日06:50-08:30在指定地点领取奖励。过了这个时间,这个登录记录就失效了。三种状态的签到记录如上图所示。
0.3后台交流页面
下图为后台交易所的测试页面。输入登录ID查询登录记录。

左图:查询过期的登录记录。中图:查询已兑换的登录记录。右图:查询可兑换的登录记录。
如上图所示。如果前来兑换的用户的登录记录已过期,则会如上左图显示。如果用户的签到记录已经被兑换,会如上中图显示。如果用户的签到记录可兑换,则会如右上图所示。
点击“立即兑换”按钮,出现“兑换成功”弹窗,如下图。

兑换成功弹窗(在微信开发者工具中运行)
看到这里,如果这不是你想要的项目,那么你可以关闭这个博客。
如果这是你想要的项目,或者这个项目和你当前的项目很接近,或者你想学习如何写这个项目,或者...
请继续阅读。下面正式开始^_^
1项目背景及需求分析1.1项目背景
关于这个需求分析部分,我们先从项目的背景说起。
原因是这个。项目组在公众号举办活动。这个活动简单易懂,就是“早起签到领取奖励”。每天早上指定时间开启签到系统,然后用户点击菜单栏中的“提前签到”按钮,通过微信登录,进入签到系统。
用户登录完成后,用户可以根据登录记录到指定地点领取早餐。同时,每日早餐数量有限,先到先得。同时,签到记录也有兑换期。本项目组指定的方案可在当日或次日8:30前收到。所以我今天check in,第二天早上就没有早餐了^_^
1.2 需求分析
通过对项目背景的分析,本项目需求如下:
1、本项目为公众号项目,微信网页开发;
2、实现用户微信登录授权确定用户身份,实现一天只能登录一次;
3、用户登录后,记录登录时间和当天登录排名;
4、显示用户的签到记录和签到记录的状态(可兑换、已兑换、已过期);
5、Background 管理员确认兑换。
2概述设计2.1开发技术分析
既然是微信网页的开发,要实现用户登录,那么就需要了解微信公众号网页的授权机制。
微信开放平台有这方面的使用说明介绍,大家可以通过开发者的文档自行学习。链接如下:
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取验证码
2、交换网页授权access_token代码(与基础支持的access_token不同)
3、如有需要,开发者可以刷新网页对access_token进行授权,避免过期
4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
只有通过微信认证的服务账号才能使用“Web授权”界面。
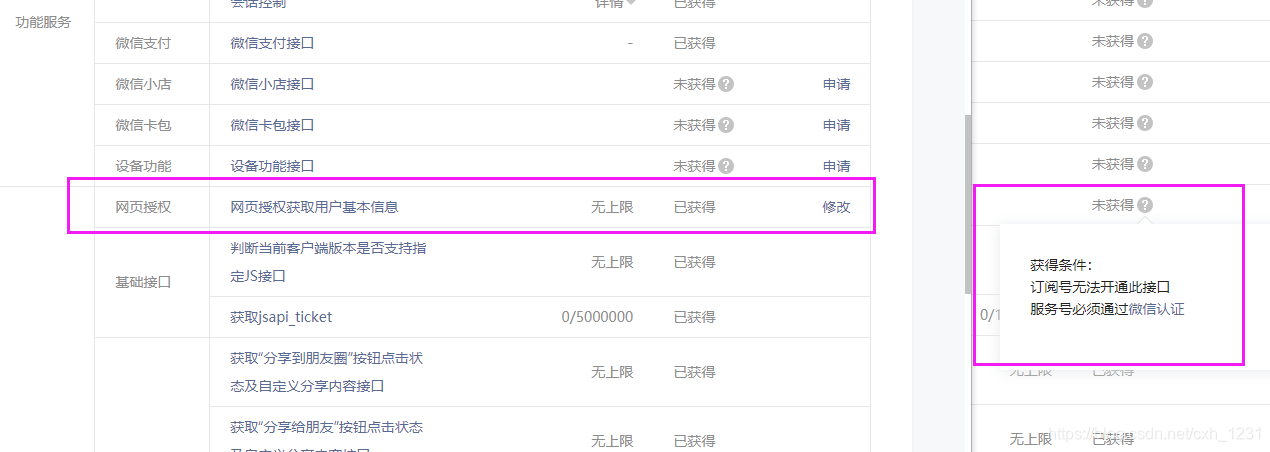
如果要用于开发测试,可以申请一个测试账号。申请链接如下:
微信网页授权登录的详细流程将在实践代码(后面编码实现流程)中进行说明。
———————————————————————
然后需要分析确定开发语言。
微信网页可以用任何网页开发语言实现。
但是结合这个项目,需要对数据库中的数据进行增删改查,所以最终使用的编程语言是PHP。
(此时笔者还没有接触到PHP开发o(╥﹏╥)o,笔者熟悉的web开发语言是Java Web。所以编码实现过程,如有不对之处请指教忍着我(*^▽^*))
最后,数据库使用 MySQL。
2.2数据库设计
项目本身不大,所以设计的数据库形式也很简单。
第一个是用户表。
本项目中,只需要获取用户为本公众号生成的唯一标识OpenID,无需获取用户昵称、城市、头像等其他公开信息。如果您需要有关用户的这些信息,可以展开用户表。
user表的user字段只有2列。如下图所示:

各个字段的含义:
然后是用户登录记录表。签到表详情如下:
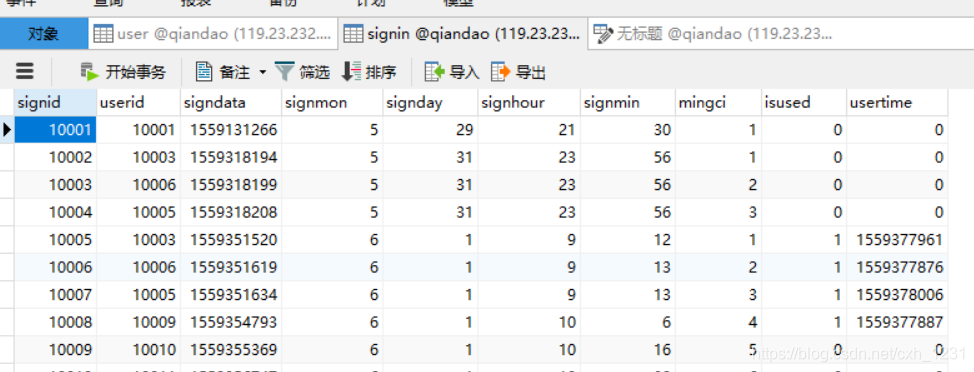
各个字段的含义:
如果您的项目需要其他形式,您可以自行设计。
3 开发环境配置
工人要想做好本职工作,就必须先磨砺他的工具。开发前,需要先配置好开发环境。
使用的四个软件
3.1 编程环境:
本项目使用PHP语言。所以编译器使用了JetBrains PhpStorm。
PHPStorm 是付费软件。如果你是学生用户,有教育邮箱,可以到JetBrains官网授权免费版。
3.2 编译环境:
在项目编写过程中,调试是不可避免的。所以这里使用的PHP网页运行环境是phpStudy。
本软件是免费软件。详情请查看phpStudy官网相关文档。
3.3MySQL 数据库可视化:
在调试过程中,不可避免地要对数据库中的数据进行校验和检查。
作者使用的MySQL数据库可视化工具是Navicat for MySQL。
本软件为付费软件。
3.4网页调试:
如何调试公众号网页?微信公众平台开发者工具栏提供网页开发者工具:微信网页开发者工具
如上图所示,点击【web开发者工具】跳转到绑定开发者的微信账号页面。这里我们绑定了开发者的微信账号。
然后去:下载微信网页开发工具电脑客户端。
下载安装后,运行后需要开发者扫描登录才能运行。运行页面如下:

3.5微信公众后台配置
如果直接在公众号菜单栏配置完成的项目,微信将无法识别你的项目。
但是这个程序不配置公众号后台O(∩_∩)O
所谓公众号后台配置,就是获取公众号秘钥,并将域名加入公众号界面白名单的过程。
详情如下:
3.5.1配置域名
项目最终需要使用域名访问。并且域名必须启用SSL证书(HTTPS协议)
关于如何在PHPStudy中配置SSL证书,笔者之前写过,点此查看。
这里是关于将域名加入公众号“白名单”。
首先进入公众号后台,点击【设置】>>【公众号设置】>>【功能设置】,如下图:
点击上面红框内两个模块的设置,为域名添加授权。
为了验证您是否拥有域名,您需要将指定文件上传到域名服务器目录进行验证。如下图所示:
具体的配置过程,按照上图的提示进行配置即可。
微信公众号支持配置2个网页授权域名和3个JS接口安全域名。
3.5.2 配置IP白名单
本项目需要使用access_token接口,所以需要配置网站最终部署到IP白名单的服务器的IP地址!
即把域名解析的IP地址配置到公众号IP白名单(详见域名解析列表)。
在微信公众平台后台点击【开发】>>【基础配置】修改IP白名单配置。
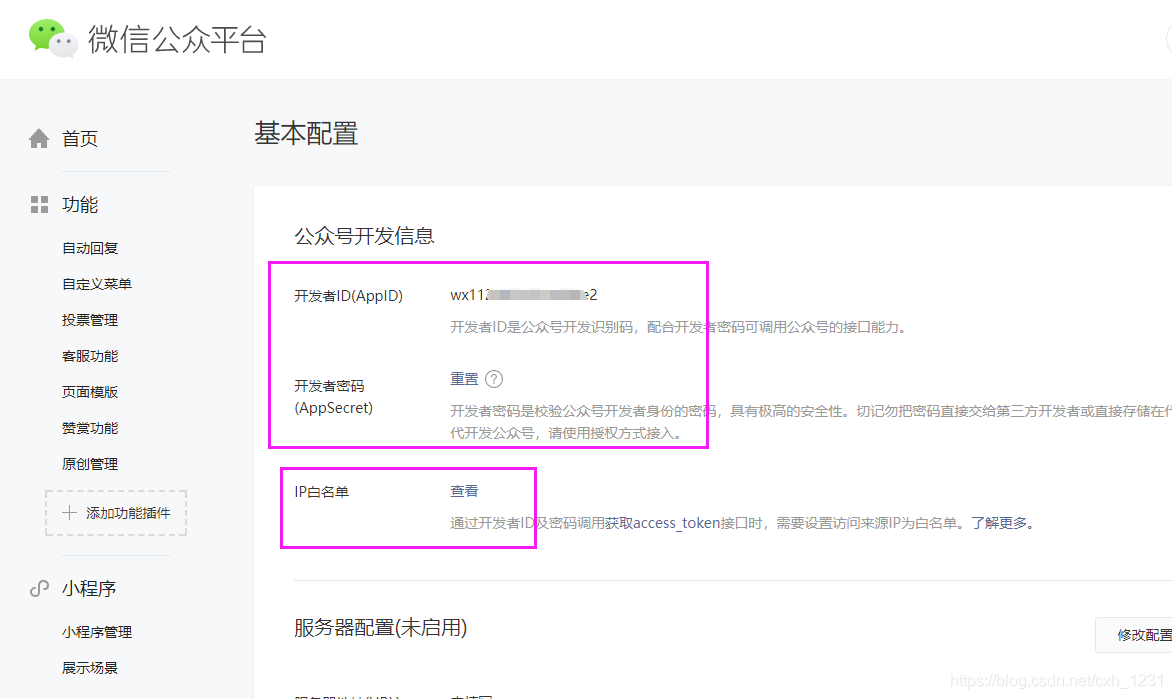
点击上图下方红框中的【查看】查看和修改IP白名单。

3.5.3获取开发者密码
开发者密码是用于验证公众号开发者身份的密码,具有极高的安全性。
在微信公众平台后台点击【开发】>>【基础配置】重置开发者密码。
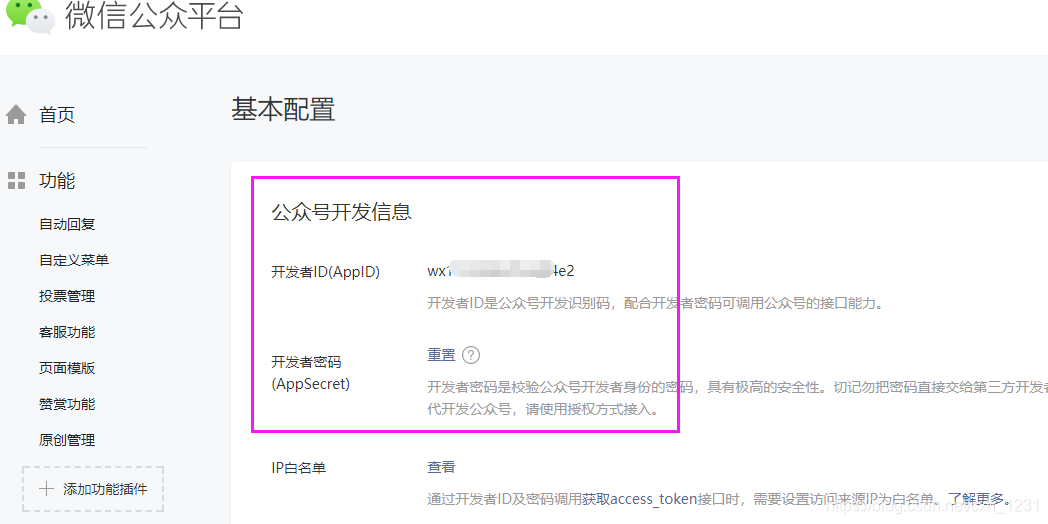
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
4 编码实现
据说PHP是一种松散的语言。作者也是第一次接触PHP,用PHP来实现这个项目...总体感觉PHP非常好用\(^o^)/~
项目本身不大,客户端有2个页面,所以没有框架,也没有MVC开发模型(以下模仿MVC开发模型)
4.1 模型(Model)层DAO类代码:
首先,您需要创建一个新的 Dao 类。该类实现了Dao类的构造,用于处理数据库中的数据。
流行的一般是实现数据库的增删改查,所以所有的SQL语句都在这里执行。
文件名:dao.php
详细代码和注释如下:
早起签到
images/banner.jpg
5:50开启今日签到
立即签到
今日签到名次:
<p align="right">>>我的签到记录
活动详情
1、每日05:50至23:59开启早起签到。
2、其他内容……
3、其他内容……
技术支持:@拾年之璐
</p>
本主页使用的CSS文件来自互联网,长度较长。会在文末展示。
这里注意,在上面代码中“立即登录”按钮所在的表单中,动作是跳转到sign.php文件,注意这里!
所以你需要编写sign.php文件。这个文件是一个控制页和一个跳转页。详细代码如下:
文件名:sign.php
我的签到记录
images/banner.jpg
我的签到记录
<p>签到ID: 当日签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a><a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orange"> 已过期</a>
您还没有签到记录,快去签到吧^_^
返回
</p>
4.6后台兑换页面
后台交换页面是一个非常简单的 HTML 页面。其中主要由两个PHP文件组成:
主页文件名:search.php
完整代码:
后台查询系统
input{
border: 1px solid #ccc;
padding: 10px 0px;
border-radius: 5px; /*css3属性IE不支持*/
padding-left:10px;
width: 150px;
}
.btn5{ display:block;
border:0px;
margin:0rem auto 0% auto;
width: 94%;
background-color: #ef2122;
text-align: center;
font-weight: bold;
font-size:17px ;
color: #fff3f0;
border-radius: 10px;
}
function doAction() {
var usersignid = document.getElementById("usersignid");
window.location.href = "a.php?usersignid="+ usersignid.value;
}
用户签到记录
<p>签到ID: 签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a>
立即兑换
<a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orangered"> 已过期</a>
未查询到该签到记录!
</p>
兑换按钮文件名:submit.php
完整代码:
<p>
开发接入2.1微信公众平台接口测试账号的申请流程及步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-01 00:31
一、前言
随着微信的普及,年轻一代逐渐从QQ转向微信。界面简洁,功能强大,男女老少皆宜,是微信的特色。正是这一特性,使微信成为了中国社交软件的巨头。因此,很多产品需要在微信中开发以满足需求。
本文主要讲服务号的开发,与微信服务器的交互,以及使用微信公众号的Oauth2授权,在微信中展示本地开发的内容并进行交互。由于公众号申请需要时间和经验,需要公司相关资质,作为个人开发者,可以先在微信官方平台申请测试号,使用测试号授权与微信服务器交互并调试这一页。在开始之前,朋友们需要了解他们的需求。微信分为企业号、服务号、订阅号。不同的账户有不同的功能。具体可以到微信官网查看需要开发什么类型的账号。
二、development 接入2.1 微信公众平台接口测试账号申请
如前言所述,在开发中,我们一半人会使用官方微信公众号作为我们的生产线环境,然后aut环境可以使用测试号进行开发,从而实现与微信的交互。测试账号申请链接如下
测试帐户申请
进入后,您将看到以下屏幕。登录
登录后,您会看到以下屏幕:
因为我已经配置好了,所以显示配置后的相关参数。如果是第一次进入,需要自己配置相关参数。首先要注意的是,系统会为你生成一个appId,appsercet,后面会讲到这个的作用。现在你需要配置 URL 和 Token。
具体来说,这个所谓的URL就是你需要在你的代码中与微信进行Token验证交互的一种方法。配置完成后,微信会使用配置的url发起http请求。请注意,发起方法是获取请求。因此,代码中提供的接口需要将请求头设置为get请求:
method=(RequestMethod.GET) 方法中需要验证微信发送的消息。下面的token需要和你项目中配置的token一致。微信发送请求后,会带上签名和时间戳。 , 随机数被检查。如果匹配成功,则可以进行下一步。如果不一致,则匹配失败。需要注意的是,这个url需要有自己的域名。我个人在Sunny-Ngrok上申请了内网穿透,并赠送了一个域名。
2.2 sunn-Ngrok 内网渗透账号申请
点击申请账号
账户创建后,会有如上图所示。其实,开通域名的方式有很多种。这里我只是给我一个参考方法。然后点击打开隧道,购买隧道
一个月10元不算贵。购买后点击隧道管理
购买后会有记录,可以同时查看赠送域名和查看状态。此时的状态为离线。如果是离线,微信公众平台微信发起的请求无法配置从本机接受,需要到官网下载客户端启动隧道。
cmd命令行进入sunny.exe所在目录并执行
sunny.exe clientid 隧道 ID
如上图所示,将域名指向你本地的ip和端口号后,就可以在公众号提交配置了。在我自己机器的代码中,我做了如下配置:
@RequestMapping(value = "/wx/wxmsgreceive", method = {RequestMethod.GET})
public void verifywxtoken(HttpServletRequest request, HttpServletResponse response) throws Exception {
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
logger.info("开始校验信息是否是从微信服务器发出");
// 签名
String signature = request.getParameter("signature");
// 时间戳
String timestamp = request.getParameter("timestamp");
// 随机数
String nonce = request.getParameter("nonce");
// 通过检验signature对请求进行校验,若校验成功则原样返回echostr,表示接入成功,否则接入失败
String result = Sha1.gen(SERVER_TOKEN, timestamp, nonce);
if (signature.equals(result)) {
// 随机字符串
String echostr = request.getParameter("echostr");
logger.debug("接入成功,echostr {}", echostr);
response.getWriter().write(echostr);
}
}
微信验证码
public static String gen(String token, String timestamp, String nonce) throws NoSuchAlgorithmException {
String[] arr = new String[]{token, timestamp, nonce};
Arrays.sort(arr);
StringBuffer content = new StringBuffer();
for (String a : arr) {
content.append(a);
}
return DigestUtils.sha1Hex(content.toString());
}
因为我配置的请求头是/wx/wxmsgreceive,所以公共平台上的配置页面是域名+/wx/wxmsgreceive。
此时,当您在网页上点击提交时,微信会向本机发送认证请求,以确保本机的服务必须开启。
这是官方的说明,所以我们开发的项目中需要提供一个暴露的接口来验证微信服务器,主要是验证微信公众号网页上填写的token验证。官方文档说明如下:
所以在项目中,放置在配置文件或常量池中的token必须是微信公众号访问中填写的token的字符串。如果输入不同或者方法中的解密比较有问题,在网页上点击确定,就会出现“失败”字样。
2.3 微信开发者工具准备
下载微信开发者工具。
点击下载微信开发者工具
下载完成后扫码登录
选择微信公众号网页开发
此工具是后续开发中访问URL和前端调试必不可少的工具。
2.3 Oauth2 授权
此时测试号已经配置好了,那么接下来我们如何开发呢?在微信公众号页面,部分页面需要根据用户的身份回显不同的信息,比如用户的还款清单。这些实现首先需要获取个人信息然后与数据库进行交互,需要获取用户的唯一标识。在微信中,每个人都有并且只有一个唯一标识openId。这个openId需要通过微信的授权和回调获取。同时,微信公开文档上也有详细的授权方式介绍。如何授权可以根据自己的业务需要使用。在实际业务中,根据项目的特点固化不同的用户。我们所做的是将用户固化到数据库中,生成一个 UUID,并将 UUID 放入 cookie。授权非常重要。通过它的控件,我们可以通过获取当前用户的openid来比较用户是会员还是普通会员,是非管理员还是管理员等。这在页面跳转中起着至关重要的作用。同时,在代码中,一些静态页面可能不一定需要授权,任何人都可以查看。所以在代码中,我使用了一个过滤器,直接在前台发布了一系列.css、.js、.html等。特殊要求,我拉过来,要求微信授权。例如,我在项目中。 .go请求中需要验证,通过微信回调获取当前用户信息,固化用户。代码如下:
@WebFilter(urlPatterns = "/*", filterName = "authFilter")
public class AuthFilter implements Filter {
private final Logger logger = LoggerFactory.getLogger(AuthFilter.class);
@Autowired
private GeneralConfigService gcService;
@Autowired
private WxUserVerify wxUserVerify;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
try {
String url = request.getRequestURI();
logger.info("URL:" + url);
// 1.请求内容为WEB静态内容时直接放行
if (StringUtil.separatorEndWith(gcService.getStaticResourceConfig(), url)) {
chain.doFilter(servletRequest, servletResponse);
return;
}
// 2.不是静态资源进行验证
if(!checkUrl(request, response, url)){
return;
}
chain.doFilter(servletRequest, servletResponse);
return;
} catch (FilterException e1) {
//自定义异常,这里可以直接把错误信息抛出去,不需要记录日志,因为这里是业务异常。
ResponseUtil.error(response, e1.getMessage());
} catch (Exception e2) {
//无法捕捉的异常,不能直接把错误信息抛出去,需要包装下错误信息
logger.error(e2.getMessage(), e2);
ResponseUtil.error(response, "系统异常,请稍后再试...");
}
}
/**
* 与数据库配置url进行匹配
* @param request
* @param response
* @param url
* @return
*/
private boolean checkUrl(HttpServletRequest request, HttpServletResponse response, String url) {
boolean passFlag=true;
//与数据库进行匹配
Map urlConfig = getUrlConfig();
//比较匹配项
String substring = url.substring(url.lastIndexOf("/") + 1);
if (!urlConfig.containsKey(substring)) {
return passFlag;
}
CallBackMsg msg = wxUserVerify.doVerify(request, response);
if (msg.getResultCode().equals(CallBackMsg.WX_VALID_CONTINUE)) {
passFlag=false;
} else if (msg.getResultCode().equals(Const.ERROR_CODE)) {
throw new FilterException(FilterExceptionEnum.ERROR_WX_VALID_FAILE);
}
return passFlag;
}
/**
* 获取地址配置信息
* @return
*/
private Map getUrlConfig() {
// 3.获取需要验证用户的请求配置
Map configAddressList = gcService.getConfigAddressList();
logger.info(configAddressList.toString());
if (configAddressList.isEmpty()) {
logger.error("urlValidConfig为空,请检查!");
throw new FilterException(FilterExceptionEnum.ERROR_VALIDCONF_NULL);
}
return configAddressList;
}
@Override
public void destroy() {
}
}
通过创建一个类来实现Filter过滤器进行验证,@WebFilter(urlPatterns = "/*", filterName = "authFilter")对所有请求进行过滤拦截,其中封装的方法当是特定请求时会被拉取申请授权
private CallBackMsg impower(HttpServletRequest request, HttpServletResponse response) {
CallBackMsg msg = new CallBackMsg();
String code = request.getParameter("code");
try {
// 从配置获取access_token
String appId = getWxParams("wxAppid");
String secret = getWxParams("wxSecret");
String accessTokenUrl = gcService.getUrlWxFwGetToken() + "?appid=" + appId + "&secret=" + secret + "&code="
+ code + "&grant_type=authorization_code";
logger.info("accessTokenUrl:" + accessTokenUrl);
String accessTokenResult = "";
if (StringUtil.isEmpty(proxyFlag)) {
proxyFlag = gcService.getProxyFlag();
}
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
accessTokenResult = HttpUtils.sendPostHttpsViaProxy(accessTokenUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
accessTokenResult = HttpUtils.sendPostHttps(accessTokenUrl, "");
}
logger.info("accessTokenResult:" + accessTokenResult);
JSONObject accessTokenJson = JSONObject.parseObject(accessTokenResult);
String accessToken = accessTokenJson.getString("access_token");
logger.info("accessToken:" + accessToken);
String openid = accessTokenJson.getString("openid");
logger.info("openid:" + openid);
// 查询数据库中的用户数据
String reqUrl = gcService.getSkylarkServiceUrl() + "wechat/searchwxuserinfo";
ResponseDto responseQuery = this.restInvoke(reqUrl, getQueryParam(openid, null, 1));
String userInfoDb = responseQuery.getRspMesg();
JSONObject userInfoDbJson = JSONObject.parseObject(userInfoDb);
String uuid = "";
// 数据库不存在该用户则保存数据库,存在则返回已存在的UUID
if (StringUtils.isEmpty(userInfoDbJson)) {
// 查询微信中的用户数据
uuid = UUIDGenerator.genUUID();
// 获取用户信息
String userInfoUrl = gcService.getUrlWxFwGetUser() + "?access_token=" + accessToken + "&openid="
+ openid + "&lang=zh_CN";
logger.info("userInfoUrl:" + userInfoUrl);
String userInfoResult = "";
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
userInfoResult = HttpUtils.sendPostHttpsViaProxy(userInfoUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
userInfoResult = HttpUtils.sendPostHttps(userInfoUrl, "");
}
logger.info("userInfoResult:" + userInfoResult);
JSONObject userInfoJson = JSONObject.parseObject(userInfoResult);
// 固化用户
String addReq = gcService.getSkylarkServiceUrl() + "wechat/addwxuserinfo";
ResponseDto addResp = this.restInvoke(addReq,
getEntityParam(uuid, openid, userInfoJson));
// 失败另处理
if (!(Const.SUCCESS_CODE).equals(addResp.getRspCode())) {
// 保存数据失败,认证失败
msg.setResultCode(Const.ERROR_CODE);
return msg;
}
} else {
uuid = userInfoDbJson.getString("id");
}
// 权限:本项目中的类都可以访问该cookie,存储到客户端
Cookie cookie = new Cookie(Const.TOKEN, uuid);
cookie.setPath("/");
response.addCookie(cookie);
//将token存入session
HttpSession session = request.getSession();
session.setAttribute("authToken",uuid);
} catch (IOException e) {
logger.error(e.getMessage());
}
msg.setResultCode(Const.SUCCESS_CODE);
return msg;
}
因为项目中使用了代理服务器,不需要本地开发,所以方法有点乱,但是大体思路是客户端发起带有特殊后缀的请求时,被过滤器拦截接下来,与微信服务器进行交互授权的过程。授权成功后,向微信提供回调地址,并将微信带回的用户信息保存在表中。同时,当前用户在库表中生成的唯一标识标识存储在cookie域中。
这样就可以将获取到的openid放入cookie中了。那么这个openId就可以固化了,也就是存储在数据库中。在会话中,如果点击某个页面需要使用微信授权,可以先从cookie域中获取。如果cookie不可用,则向微信发起授权请求,获取openid后,存储cookie和curing。有一些步骤可以实现这一点。微信开放平台上有相关的demo。如果您需要我提供它们,请留言。后续授权码我会贴出来供大家参考。 查看全部
开发接入2.1微信公众平台接口测试账号的申请流程及步骤
一、前言
随着微信的普及,年轻一代逐渐从QQ转向微信。界面简洁,功能强大,男女老少皆宜,是微信的特色。正是这一特性,使微信成为了中国社交软件的巨头。因此,很多产品需要在微信中开发以满足需求。
本文主要讲服务号的开发,与微信服务器的交互,以及使用微信公众号的Oauth2授权,在微信中展示本地开发的内容并进行交互。由于公众号申请需要时间和经验,需要公司相关资质,作为个人开发者,可以先在微信官方平台申请测试号,使用测试号授权与微信服务器交互并调试这一页。在开始之前,朋友们需要了解他们的需求。微信分为企业号、服务号、订阅号。不同的账户有不同的功能。具体可以到微信官网查看需要开发什么类型的账号。

二、development 接入2.1 微信公众平台接口测试账号申请
如前言所述,在开发中,我们一半人会使用官方微信公众号作为我们的生产线环境,然后aut环境可以使用测试号进行开发,从而实现与微信的交互。测试账号申请链接如下
测试帐户申请
进入后,您将看到以下屏幕。登录
登录后,您会看到以下屏幕:
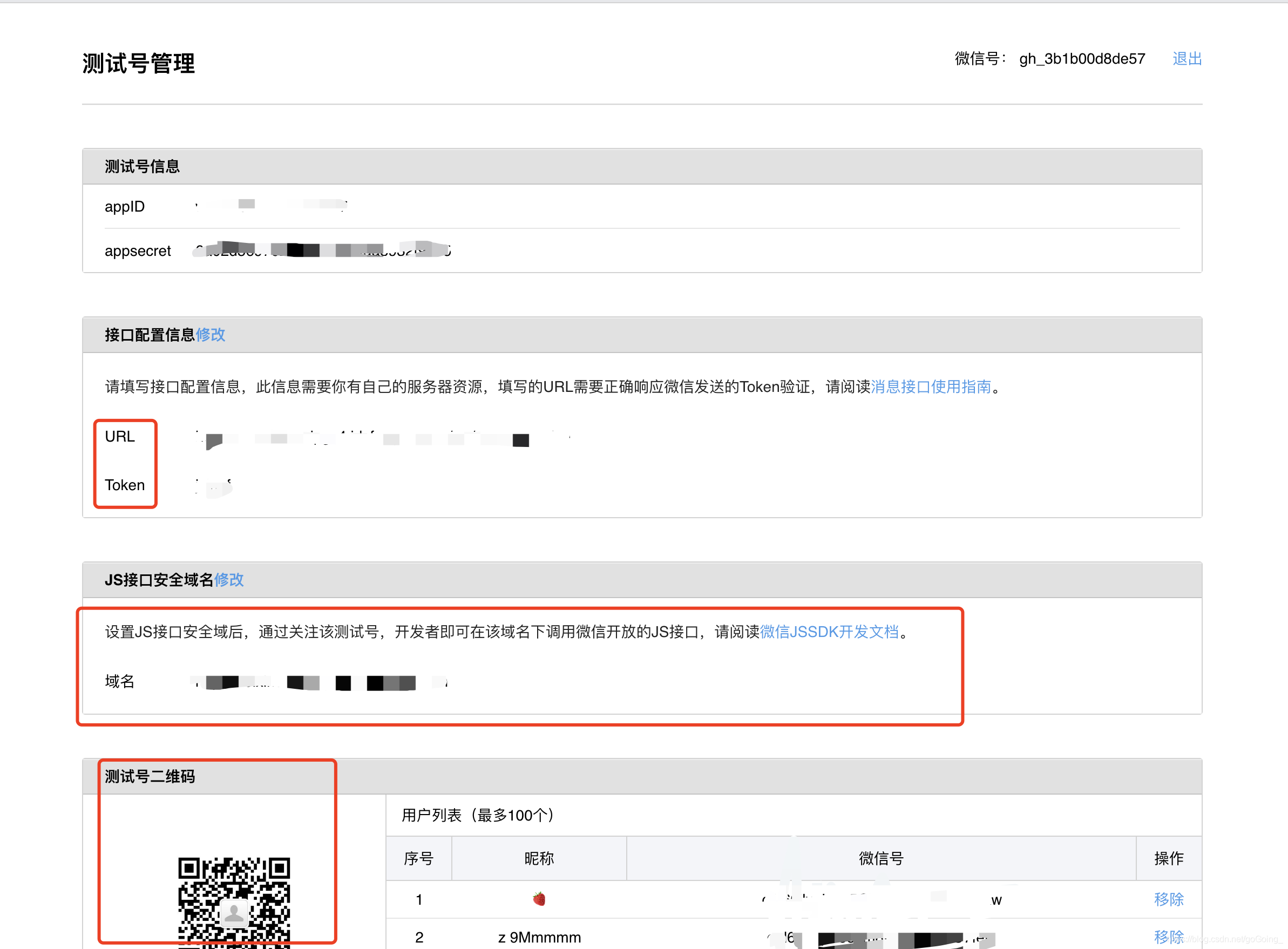
因为我已经配置好了,所以显示配置后的相关参数。如果是第一次进入,需要自己配置相关参数。首先要注意的是,系统会为你生成一个appId,appsercet,后面会讲到这个的作用。现在你需要配置 URL 和 Token。
具体来说,这个所谓的URL就是你需要在你的代码中与微信进行Token验证交互的一种方法。配置完成后,微信会使用配置的url发起http请求。请注意,发起方法是获取请求。因此,代码中提供的接口需要将请求头设置为get请求:
method=(RequestMethod.GET) 方法中需要验证微信发送的消息。下面的token需要和你项目中配置的token一致。微信发送请求后,会带上签名和时间戳。 , 随机数被检查。如果匹配成功,则可以进行下一步。如果不一致,则匹配失败。需要注意的是,这个url需要有自己的域名。我个人在Sunny-Ngrok上申请了内网穿透,并赠送了一个域名。
2.2 sunn-Ngrok 内网渗透账号申请
点击申请账号
账户创建后,会有如上图所示。其实,开通域名的方式有很多种。这里我只是给我一个参考方法。然后点击打开隧道,购买隧道

一个月10元不算贵。购买后点击隧道管理

购买后会有记录,可以同时查看赠送域名和查看状态。此时的状态为离线。如果是离线,微信公众平台微信发起的请求无法配置从本机接受,需要到官网下载客户端启动隧道。
cmd命令行进入sunny.exe所在目录并执行
sunny.exe clientid 隧道 ID
如上图所示,将域名指向你本地的ip和端口号后,就可以在公众号提交配置了。在我自己机器的代码中,我做了如下配置:
@RequestMapping(value = "/wx/wxmsgreceive", method = {RequestMethod.GET})
public void verifywxtoken(HttpServletRequest request, HttpServletResponse response) throws Exception {
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
logger.info("开始校验信息是否是从微信服务器发出");
// 签名
String signature = request.getParameter("signature");
// 时间戳
String timestamp = request.getParameter("timestamp");
// 随机数
String nonce = request.getParameter("nonce");
// 通过检验signature对请求进行校验,若校验成功则原样返回echostr,表示接入成功,否则接入失败
String result = Sha1.gen(SERVER_TOKEN, timestamp, nonce);
if (signature.equals(result)) {
// 随机字符串
String echostr = request.getParameter("echostr");
logger.debug("接入成功,echostr {}", echostr);
response.getWriter().write(echostr);
}
}
微信验证码
public static String gen(String token, String timestamp, String nonce) throws NoSuchAlgorithmException {
String[] arr = new String[]{token, timestamp, nonce};
Arrays.sort(arr);
StringBuffer content = new StringBuffer();
for (String a : arr) {
content.append(a);
}
return DigestUtils.sha1Hex(content.toString());
}
因为我配置的请求头是/wx/wxmsgreceive,所以公共平台上的配置页面是域名+/wx/wxmsgreceive。
此时,当您在网页上点击提交时,微信会向本机发送认证请求,以确保本机的服务必须开启。
这是官方的说明,所以我们开发的项目中需要提供一个暴露的接口来验证微信服务器,主要是验证微信公众号网页上填写的token验证。官方文档说明如下:
所以在项目中,放置在配置文件或常量池中的token必须是微信公众号访问中填写的token的字符串。如果输入不同或者方法中的解密比较有问题,在网页上点击确定,就会出现“失败”字样。

2.3 微信开发者工具准备
下载微信开发者工具。
点击下载微信开发者工具
下载完成后扫码登录

选择微信公众号网页开发

此工具是后续开发中访问URL和前端调试必不可少的工具。
2.3 Oauth2 授权
此时测试号已经配置好了,那么接下来我们如何开发呢?在微信公众号页面,部分页面需要根据用户的身份回显不同的信息,比如用户的还款清单。这些实现首先需要获取个人信息然后与数据库进行交互,需要获取用户的唯一标识。在微信中,每个人都有并且只有一个唯一标识openId。这个openId需要通过微信的授权和回调获取。同时,微信公开文档上也有详细的授权方式介绍。如何授权可以根据自己的业务需要使用。在实际业务中,根据项目的特点固化不同的用户。我们所做的是将用户固化到数据库中,生成一个 UUID,并将 UUID 放入 cookie。授权非常重要。通过它的控件,我们可以通过获取当前用户的openid来比较用户是会员还是普通会员,是非管理员还是管理员等。这在页面跳转中起着至关重要的作用。同时,在代码中,一些静态页面可能不一定需要授权,任何人都可以查看。所以在代码中,我使用了一个过滤器,直接在前台发布了一系列.css、.js、.html等。特殊要求,我拉过来,要求微信授权。例如,我在项目中。 .go请求中需要验证,通过微信回调获取当前用户信息,固化用户。代码如下:
@WebFilter(urlPatterns = "/*", filterName = "authFilter")
public class AuthFilter implements Filter {
private final Logger logger = LoggerFactory.getLogger(AuthFilter.class);
@Autowired
private GeneralConfigService gcService;
@Autowired
private WxUserVerify wxUserVerify;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
try {
String url = request.getRequestURI();
logger.info("URL:" + url);
// 1.请求内容为WEB静态内容时直接放行
if (StringUtil.separatorEndWith(gcService.getStaticResourceConfig(), url)) {
chain.doFilter(servletRequest, servletResponse);
return;
}
// 2.不是静态资源进行验证
if(!checkUrl(request, response, url)){
return;
}
chain.doFilter(servletRequest, servletResponse);
return;
} catch (FilterException e1) {
//自定义异常,这里可以直接把错误信息抛出去,不需要记录日志,因为这里是业务异常。
ResponseUtil.error(response, e1.getMessage());
} catch (Exception e2) {
//无法捕捉的异常,不能直接把错误信息抛出去,需要包装下错误信息
logger.error(e2.getMessage(), e2);
ResponseUtil.error(response, "系统异常,请稍后再试...");
}
}
/**
* 与数据库配置url进行匹配
* @param request
* @param response
* @param url
* @return
*/
private boolean checkUrl(HttpServletRequest request, HttpServletResponse response, String url) {
boolean passFlag=true;
//与数据库进行匹配
Map urlConfig = getUrlConfig();
//比较匹配项
String substring = url.substring(url.lastIndexOf("/") + 1);
if (!urlConfig.containsKey(substring)) {
return passFlag;
}
CallBackMsg msg = wxUserVerify.doVerify(request, response);
if (msg.getResultCode().equals(CallBackMsg.WX_VALID_CONTINUE)) {
passFlag=false;
} else if (msg.getResultCode().equals(Const.ERROR_CODE)) {
throw new FilterException(FilterExceptionEnum.ERROR_WX_VALID_FAILE);
}
return passFlag;
}
/**
* 获取地址配置信息
* @return
*/
private Map getUrlConfig() {
// 3.获取需要验证用户的请求配置
Map configAddressList = gcService.getConfigAddressList();
logger.info(configAddressList.toString());
if (configAddressList.isEmpty()) {
logger.error("urlValidConfig为空,请检查!");
throw new FilterException(FilterExceptionEnum.ERROR_VALIDCONF_NULL);
}
return configAddressList;
}
@Override
public void destroy() {
}
}
通过创建一个类来实现Filter过滤器进行验证,@WebFilter(urlPatterns = "/*", filterName = "authFilter")对所有请求进行过滤拦截,其中封装的方法当是特定请求时会被拉取申请授权
private CallBackMsg impower(HttpServletRequest request, HttpServletResponse response) {
CallBackMsg msg = new CallBackMsg();
String code = request.getParameter("code");
try {
// 从配置获取access_token
String appId = getWxParams("wxAppid");
String secret = getWxParams("wxSecret");
String accessTokenUrl = gcService.getUrlWxFwGetToken() + "?appid=" + appId + "&secret=" + secret + "&code="
+ code + "&grant_type=authorization_code";
logger.info("accessTokenUrl:" + accessTokenUrl);
String accessTokenResult = "";
if (StringUtil.isEmpty(proxyFlag)) {
proxyFlag = gcService.getProxyFlag();
}
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
accessTokenResult = HttpUtils.sendPostHttpsViaProxy(accessTokenUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
accessTokenResult = HttpUtils.sendPostHttps(accessTokenUrl, "");
}
logger.info("accessTokenResult:" + accessTokenResult);
JSONObject accessTokenJson = JSONObject.parseObject(accessTokenResult);
String accessToken = accessTokenJson.getString("access_token");
logger.info("accessToken:" + accessToken);
String openid = accessTokenJson.getString("openid");
logger.info("openid:" + openid);
// 查询数据库中的用户数据
String reqUrl = gcService.getSkylarkServiceUrl() + "wechat/searchwxuserinfo";
ResponseDto responseQuery = this.restInvoke(reqUrl, getQueryParam(openid, null, 1));
String userInfoDb = responseQuery.getRspMesg();
JSONObject userInfoDbJson = JSONObject.parseObject(userInfoDb);
String uuid = "";
// 数据库不存在该用户则保存数据库,存在则返回已存在的UUID
if (StringUtils.isEmpty(userInfoDbJson)) {
// 查询微信中的用户数据
uuid = UUIDGenerator.genUUID();
// 获取用户信息
String userInfoUrl = gcService.getUrlWxFwGetUser() + "?access_token=" + accessToken + "&openid="
+ openid + "&lang=zh_CN";
logger.info("userInfoUrl:" + userInfoUrl);
String userInfoResult = "";
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
userInfoResult = HttpUtils.sendPostHttpsViaProxy(userInfoUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
userInfoResult = HttpUtils.sendPostHttps(userInfoUrl, "");
}
logger.info("userInfoResult:" + userInfoResult);
JSONObject userInfoJson = JSONObject.parseObject(userInfoResult);
// 固化用户
String addReq = gcService.getSkylarkServiceUrl() + "wechat/addwxuserinfo";
ResponseDto addResp = this.restInvoke(addReq,
getEntityParam(uuid, openid, userInfoJson));
// 失败另处理
if (!(Const.SUCCESS_CODE).equals(addResp.getRspCode())) {
// 保存数据失败,认证失败
msg.setResultCode(Const.ERROR_CODE);
return msg;
}
} else {
uuid = userInfoDbJson.getString("id");
}
// 权限:本项目中的类都可以访问该cookie,存储到客户端
Cookie cookie = new Cookie(Const.TOKEN, uuid);
cookie.setPath("/");
response.addCookie(cookie);
//将token存入session
HttpSession session = request.getSession();
session.setAttribute("authToken",uuid);
} catch (IOException e) {
logger.error(e.getMessage());
}
msg.setResultCode(Const.SUCCESS_CODE);
return msg;
}
因为项目中使用了代理服务器,不需要本地开发,所以方法有点乱,但是大体思路是客户端发起带有特殊后缀的请求时,被过滤器拦截接下来,与微信服务器进行交互授权的过程。授权成功后,向微信提供回调地址,并将微信带回的用户信息保存在表中。同时,当前用户在库表中生成的唯一标识标识存储在cookie域中。

这样就可以将获取到的openid放入cookie中了。那么这个openId就可以固化了,也就是存储在数据库中。在会话中,如果点击某个页面需要使用微信授权,可以先从cookie域中获取。如果cookie不可用,则向微信发起授权请求,获取openid后,存储cookie和curing。有一些步骤可以实现这一点。微信开放平台上有相关的demo。如果您需要我提供它们,请留言。后续授权码我会贴出来供大家参考。
如何实际操作公众号可以让小游戏在一定程度上裂变
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-07-29 03:22
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
问题就在这里。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价 查看全部
如何实际操作公众号可以让小游戏在一定程度上裂变
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
问题就在这里。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价
微信公众号的两种开发模式你可能会有一个疑惑?
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-28 23:34
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
那么问题来了。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价 查看全部
微信公众号的两种开发模式你可能会有一个疑惑?
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
那么问题来了。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价
使用到的技术:python3,微信公众号的全部内容分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-28 21:03
使用的技术:python3、selenium、requests
最近接到一个新项目,需要爬取微信公众号的数据。接下来就和大家分享一下
笔者在网上也看到过使用**搜狗微信API来抓取数据,但是如果我想按照公众号把它的文章全部抓取,发现不行
它只有最近的文章,意思是我想把他的文章全部弄到手,但是不行(可能作者不合格,但是我没找到。欢迎大家同学帮我改正)。如果你搜索文章,是这种
比如我想爬取公众号的所有文章,还是不行。
还有使用抓包工具**来抓app的数据接口。这是可行的,但是抓包工具的配置和网页数据接口的分析非常复杂,这里就不介绍了。
接下来说说我的想法
1.在微信公众号平台注册一个账号(注册一个即可)
然后点击超链接,进入公众号,选择显示公众号的所有文章信息,如图
好的,现在我们找到了数据,继续进行网络分析
2.分析网页
F12 调试
这里我们可以观察信息界面,分析这个json数据,可以看到链接收录文章,链接,标题,时间等,所以,接下来添加代码
3.上代码
首先解决的是登录问题,我用selenium+chrome登录,
account_name = "账号"
password = "密码"
def wechat_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/")
time.sleep(2)
print("正在输入微信公众号登录账号和密码......")
# 清空账号框中的内容
try:
driver.find_element_by_name("account").clear()
print("正在输入微信公众号登录账号和密码......")
driver.find_element_by_name("account").send_keys(account_name)
time.sleep(1)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys(password)
time.sleep(1)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
driver.find_element_by_class_name("frm_checkbox_label").click()
time.sleep(5)
# 自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
except:
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
这里说明一下,微信公众号平台的登录界面可能不同。
这是一种情况,就是直接扫码登录,另一种是
用账号登录,所以登录的时候多了一种情况,最后记得把网页中的cookie信息保存在本地,用来爬取
2.获取具体的文章
def get_content(query):
# query为要爬取的公众号名称
# 公众号主页
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 511
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = session.get(url=url, cookies=cookies, verify=False)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(
search_url,
cookies=cookies,
headers=header,
params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin)
time.sleep(5)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = query + '.txt'
seq += 1
with open(fileName, 'a', encoding='utf-8') as fh:
fh.write(
str(seq) +
"|" +
content_title +
"|" +
content_link +
"\n")
num -= 1
begin = int(begin)
begin += 5
好了朋友们,以上就是对微信公众号全部内容的抓取,希望对大家有所帮助,欢迎各位大佬指正修改,共同学习进步 查看全部
使用到的技术:python3,微信公众号的全部内容分析
使用的技术:python3、selenium、requests
最近接到一个新项目,需要爬取微信公众号的数据。接下来就和大家分享一下
笔者在网上也看到过使用**搜狗微信API来抓取数据,但是如果我想按照公众号把它的文章全部抓取,发现不行
它只有最近的文章,意思是我想把他的文章全部弄到手,但是不行(可能作者不合格,但是我没找到。欢迎大家同学帮我改正)。如果你搜索文章,是这种
比如我想爬取公众号的所有文章,还是不行。
还有使用抓包工具**来抓app的数据接口。这是可行的,但是抓包工具的配置和网页数据接口的分析非常复杂,这里就不介绍了。
接下来说说我的想法
1.在微信公众号平台注册一个账号(注册一个即可)
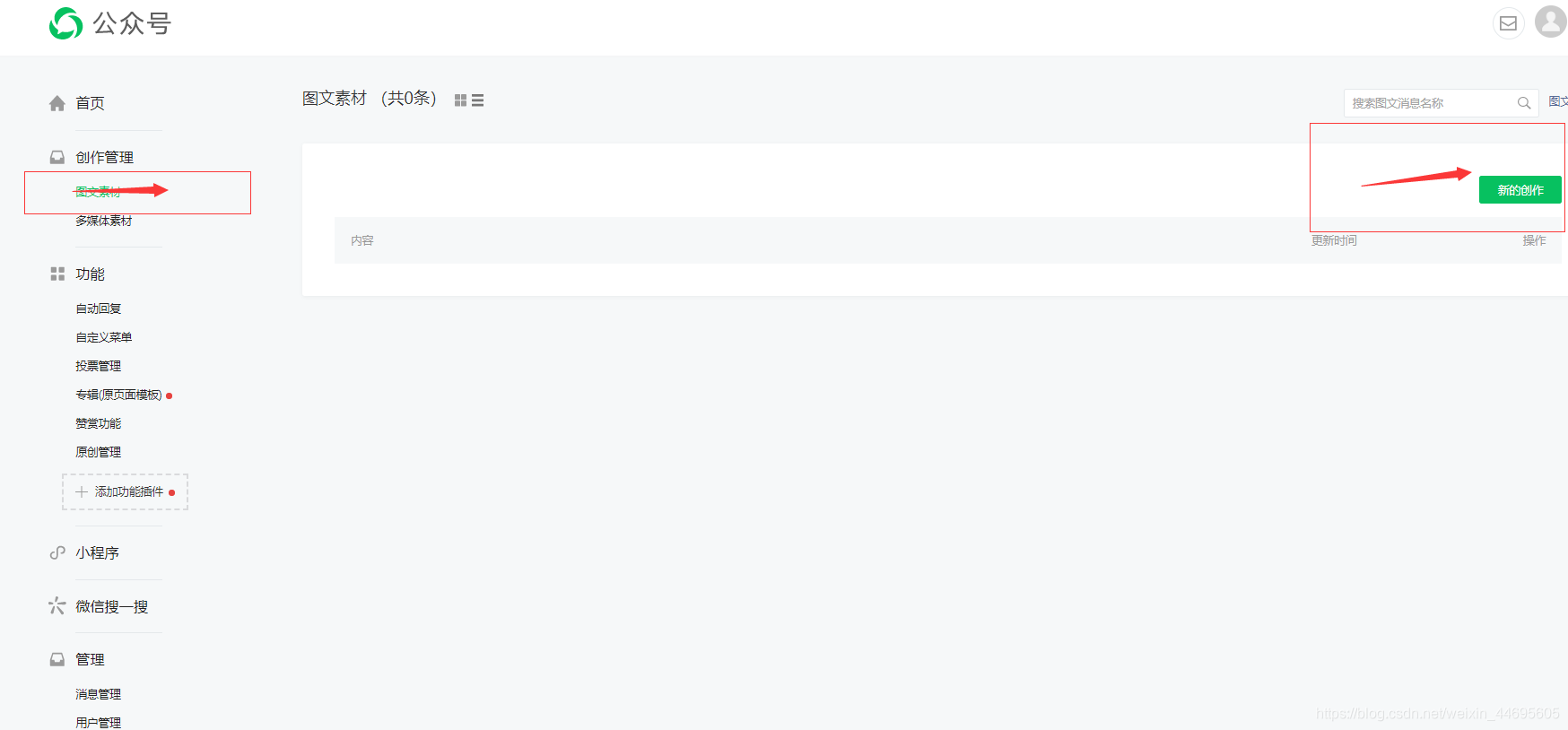
然后点击超链接,进入公众号,选择显示公众号的所有文章信息,如图
好的,现在我们找到了数据,继续进行网络分析
2.分析网页
F12 调试
这里我们可以观察信息界面,分析这个json数据,可以看到链接收录文章,链接,标题,时间等,所以,接下来添加代码
3.上代码
首先解决的是登录问题,我用selenium+chrome登录,
account_name = "账号"
password = "密码"
def wechat_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/";)
time.sleep(2)
print("正在输入微信公众号登录账号和密码......")
# 清空账号框中的内容
try:
driver.find_element_by_name("account").clear()
print("正在输入微信公众号登录账号和密码......")
driver.find_element_by_name("account").send_keys(account_name)
time.sleep(1)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys(password)
time.sleep(1)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
driver.find_element_by_class_name("frm_checkbox_label").click()
time.sleep(5)
# 自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
except:
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
这里说明一下,微信公众号平台的登录界面可能不同。
这是一种情况,就是直接扫码登录,另一种是
用账号登录,所以登录的时候多了一种情况,最后记得把网页中的cookie信息保存在本地,用来爬取
2.获取具体的文章
def get_content(query):
# query为要爬取的公众号名称
# 公众号主页
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 511
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = session.get(url=url, cookies=cookies, verify=False)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(
search_url,
cookies=cookies,
headers=header,
params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin)
time.sleep(5)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = query + '.txt'
seq += 1
with open(fileName, 'a', encoding='utf-8') as fh:
fh.write(
str(seq) +
"|" +
content_title +
"|" +
content_link +
"\n")
num -= 1
begin = int(begin)
begin += 5
好了朋友们,以上就是对微信公众号全部内容的抓取,希望对大家有所帮助,欢迎各位大佬指正修改,共同学习进步
Python3.5+fiddler4 抓取微信公众号点赞、阅读、标题
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-28 20:44
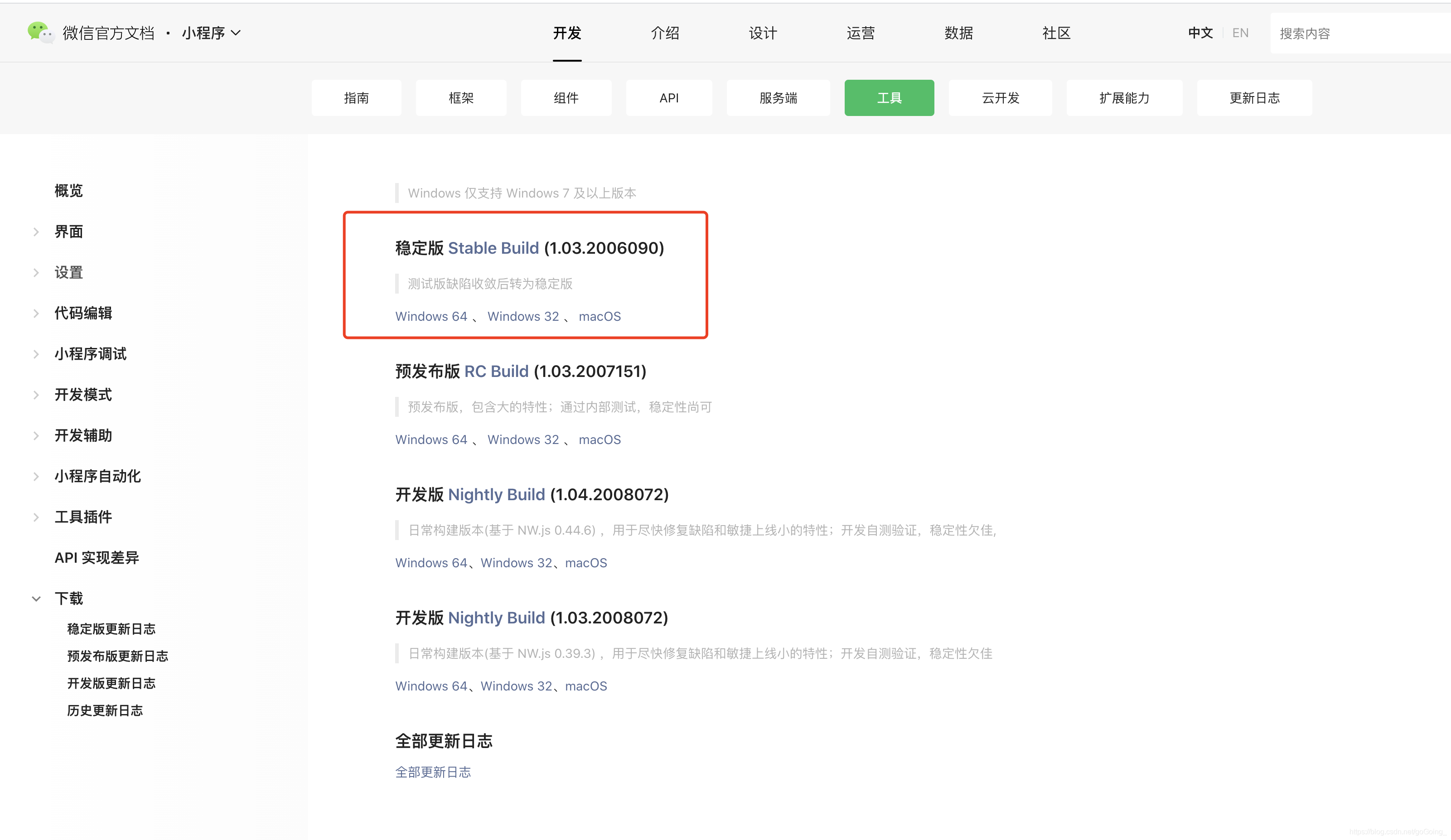
代码测试有效期至2019/03/08
微信爬虫步骤:
必需品:
自有微信公众号Fiddler抓包工具Python 3+版
提琴手下载链接
HTTP 代理工具也称为抓包工具。主流的抓包工具是Windows平台的Fiddler,macOS平台的Charles,阿里开源了一个叫AnyProxy的工具。它们的基本原理是相似的,就是通过在移动客户端上设置代理IP和端口,所有来自客户端的HTTP和HTTPS请求都会经过代理工具,每个请求都可以在代理工具中清晰的看到。然后可以分析详细信息以找出每个请求的构造方式。搞清楚这些之后,我们就可以用Python来模拟发起请求了,然后就可以得到我们想要的数据了。
安装包超过4M。配置前,首先确保您的手机和电脑在同一个局域网内。如果不在同一个局域网内,可以购买便携式WiFi,在电脑上搭建一个极简的无线路由器。一路点击下一步完成安装过程。
Fiddler 配置选择工具> Fiddler 选项> 连接 Fiddler 的默认端口为8888,如果该端口已经被其他程序占用,需要手动更改,勾选允许远程计算机连接,其他选项即可。 , 配置更新后记得重启Fiddler。一定要重启Fiddler,否则代理将失效。 .接下来需要配置手机,但是这里微信有pc客户端,所以不需要配置手机
现在打开微信,随机选择一个公众号,进入公众号的【查看历史信息】
同时观察 Fiddler 的主面板。当微信从公众号介绍页面进入历史消息页面时,已经可以在Fiddler上看到请求进来了。这些请求是微信APP向服务器发送的请求。现在简单介绍一下这个请求面板上各个模块的含义。
我将上面的主面板分成了 7 个块。需要了解每个区块的内容,然后才可以使用Python代码模拟微信请求。 1、服务器响应结果,200表示服务器成功响应了2、请求协议,微信请求协议是基于HTTPS的,所以之前一定要配置好,否则看不到HTTPS请求。 3、微信服务器主机名4、请求路径5、请求行,包括请求方法(GET)、请求协议(HTTP/1.1)、请求路径(/mp/profile_ext...)一长串参数)6、收录cookie信息的请求头。7、微信服务器返回的响应数据,我们切换到TextView和WebView看看返回的数据是什么样子的。
TextView模式下的预览效果为服务器返回的HTML源代码
WebView 模式是 HTML 代码的渲染效果。其实就是我们在手机微信上看到的效果,但是因为风格欠缺,在手机上没有看到美化效果。
如果服务器返回的是Json格式或者XML,也可以切换到对应的页面进行预览查看。
开始抓取:
1、拥有微信公众号
登录微信公众号,在菜单栏:素材管理—>新建素材,出现如下页面
F12查看网络,点击图中位置
公众号和user-Agent的cookies如下
Fakeid和token获取如下: 查看全部
Python3.5+fiddler4 抓取微信公众号点赞、阅读、标题
代码测试有效期至2019/03/08
微信爬虫步骤:
必需品:
自有微信公众号Fiddler抓包工具Python 3+版
提琴手下载链接
HTTP 代理工具也称为抓包工具。主流的抓包工具是Windows平台的Fiddler,macOS平台的Charles,阿里开源了一个叫AnyProxy的工具。它们的基本原理是相似的,就是通过在移动客户端上设置代理IP和端口,所有来自客户端的HTTP和HTTPS请求都会经过代理工具,每个请求都可以在代理工具中清晰的看到。然后可以分析详细信息以找出每个请求的构造方式。搞清楚这些之后,我们就可以用Python来模拟发起请求了,然后就可以得到我们想要的数据了。
安装包超过4M。配置前,首先确保您的手机和电脑在同一个局域网内。如果不在同一个局域网内,可以购买便携式WiFi,在电脑上搭建一个极简的无线路由器。一路点击下一步完成安装过程。
Fiddler 配置选择工具> Fiddler 选项> 连接 Fiddler 的默认端口为8888,如果该端口已经被其他程序占用,需要手动更改,勾选允许远程计算机连接,其他选项即可。 , 配置更新后记得重启Fiddler。一定要重启Fiddler,否则代理将失效。 .接下来需要配置手机,但是这里微信有pc客户端,所以不需要配置手机
现在打开微信,随机选择一个公众号,进入公众号的【查看历史信息】
同时观察 Fiddler 的主面板。当微信从公众号介绍页面进入历史消息页面时,已经可以在Fiddler上看到请求进来了。这些请求是微信APP向服务器发送的请求。现在简单介绍一下这个请求面板上各个模块的含义。

我将上面的主面板分成了 7 个块。需要了解每个区块的内容,然后才可以使用Python代码模拟微信请求。 1、服务器响应结果,200表示服务器成功响应了2、请求协议,微信请求协议是基于HTTPS的,所以之前一定要配置好,否则看不到HTTPS请求。 3、微信服务器主机名4、请求路径5、请求行,包括请求方法(GET)、请求协议(HTTP/1.1)、请求路径(/mp/profile_ext...)一长串参数)6、收录cookie信息的请求头。7、微信服务器返回的响应数据,我们切换到TextView和WebView看看返回的数据是什么样子的。
TextView模式下的预览效果为服务器返回的HTML源代码

WebView 模式是 HTML 代码的渲染效果。其实就是我们在手机微信上看到的效果,但是因为风格欠缺,在手机上没有看到美化效果。

如果服务器返回的是Json格式或者XML,也可以切换到对应的页面进行预览查看。
开始抓取:
1、拥有微信公众号
登录微信公众号,在菜单栏:素材管理—>新建素材,出现如下页面

F12查看网络,点击图中位置

公众号和user-Agent的cookies如下

Fakeid和token获取如下:
微信PC端解锁新功能搜索更方便微信生态内容触手可达
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-28 07:54
微信PC端解锁新功能搜索更方便微信生态内容触手可达
记者从腾讯获悉,PC端微信搜一搜近日迎来迭代更新,提供更丰富的搜索入口和更多样化的搜索内容。 Windows版微信更新为3.3.0后,用户可以通过对话、文章指尖搜索、对话、朋友圈#hyperlinks更快速地进行搜索。
同时,PC端微信搜索在搜索文章的基础上,增加了对公众号、小程序、新闻、表情、朋友圈、视频等微信生态内容搜索的支持。用户只需选择相关词表右键即可搜索微信生态中的各类优质内容,极大满足用户在工作、学习等多种搜索场景下的需求。
微信PC端解锁新功能
搜索更便捷,微信生态内容触手可及
Windows版微信更新为3.3.0后,PC端微信搜索支持会话、文章指尖搜索、会话、朋友圈#超链接搜索等多种能力,为用户提供更丰富的搜索条目。在PC端微信顶部,点击搜索框进入微信搜索,大大提高了用户在PC端搜索的便利性。
现在微信对话界面和公众号文章浏览界面都支持文本选择搜索。用户可以快速查找和理解聊天中出现的专有名词、网络热点和外语词。在浏览公众号文章时,还可以轻松选择产品名称,快速找到更多相关评价和用户体验。您还可以快速选词搜索定义,了解更多信息,提高阅读效率。 查看全部
微信PC端解锁新功能搜索更方便微信生态内容触手可达

记者从腾讯获悉,PC端微信搜一搜近日迎来迭代更新,提供更丰富的搜索入口和更多样化的搜索内容。 Windows版微信更新为3.3.0后,用户可以通过对话、文章指尖搜索、对话、朋友圈#hyperlinks更快速地进行搜索。
同时,PC端微信搜索在搜索文章的基础上,增加了对公众号、小程序、新闻、表情、朋友圈、视频等微信生态内容搜索的支持。用户只需选择相关词表右键即可搜索微信生态中的各类优质内容,极大满足用户在工作、学习等多种搜索场景下的需求。
微信PC端解锁新功能
搜索更便捷,微信生态内容触手可及
Windows版微信更新为3.3.0后,PC端微信搜索支持会话、文章指尖搜索、会话、朋友圈#超链接搜索等多种能力,为用户提供更丰富的搜索条目。在PC端微信顶部,点击搜索框进入微信搜索,大大提高了用户在PC端搜索的便利性。
现在微信对话界面和公众号文章浏览界面都支持文本选择搜索。用户可以快速查找和理解聊天中出现的专有名词、网络热点和外语词。在浏览公众号文章时,还可以轻松选择产品名称,快速找到更多相关评价和用户体验。您还可以快速选词搜索定义,了解更多信息,提高阅读效率。
微信公众号后台编辑素材界面的原理和原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-07-26 22:05
准备阶段
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
fig1 正式启动
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
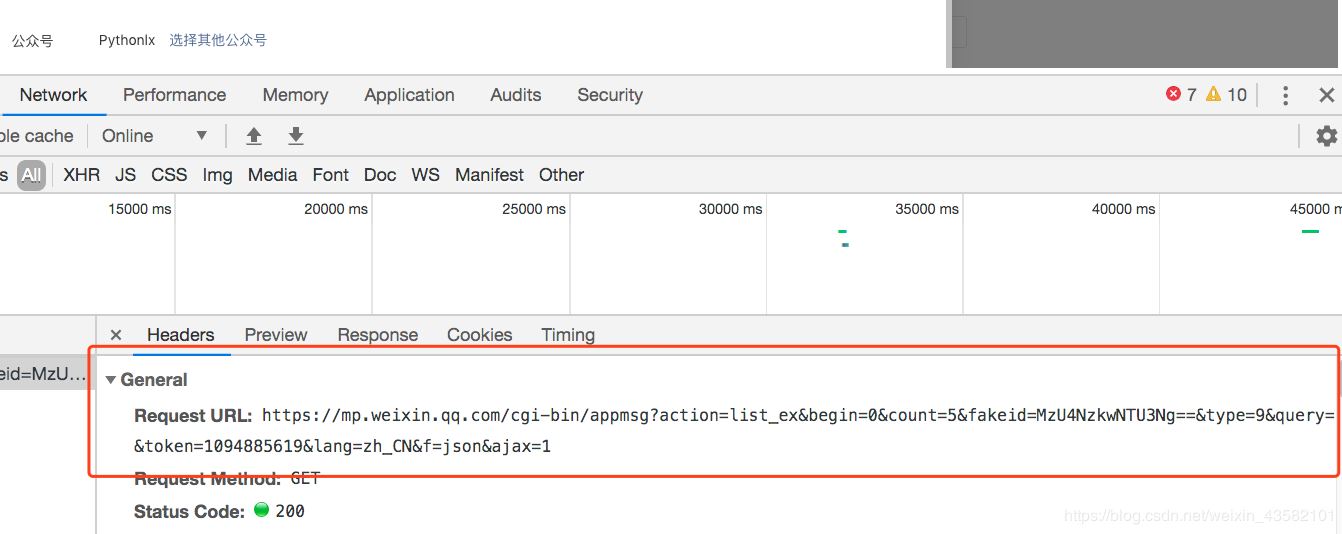
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
图3
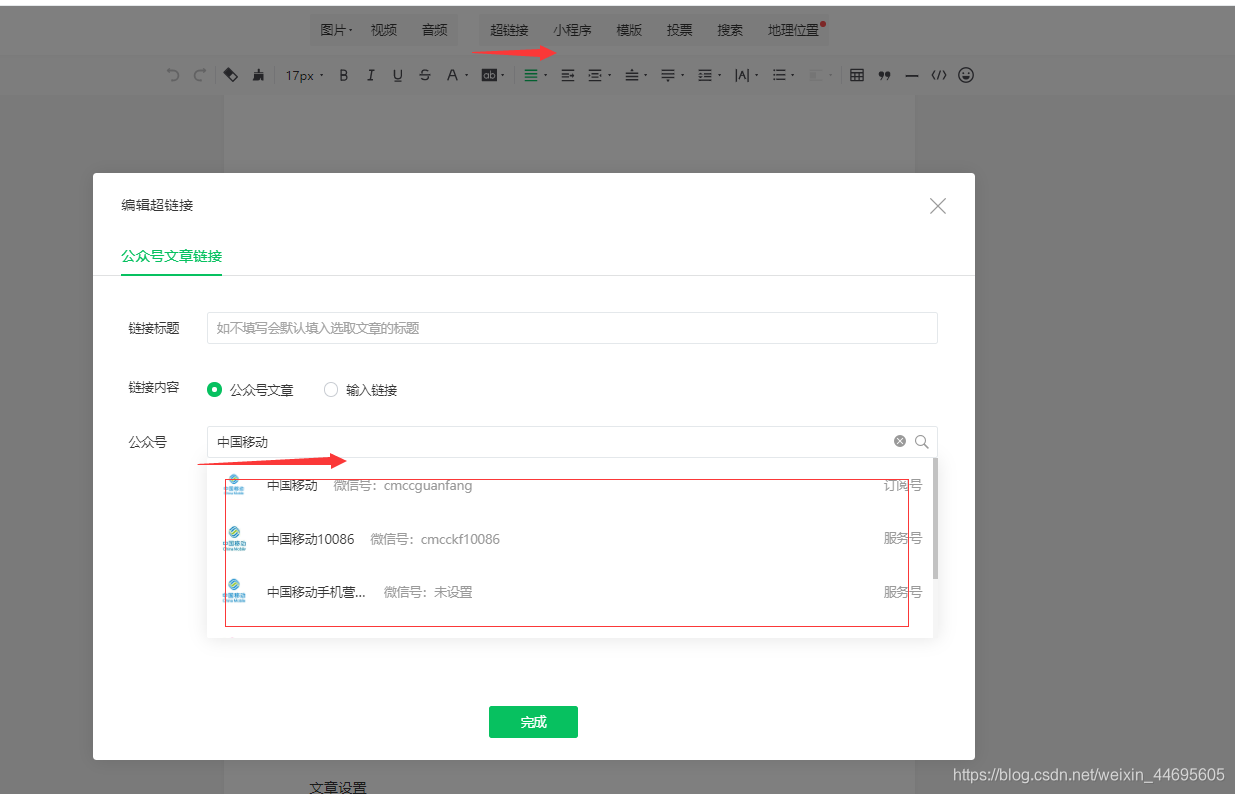
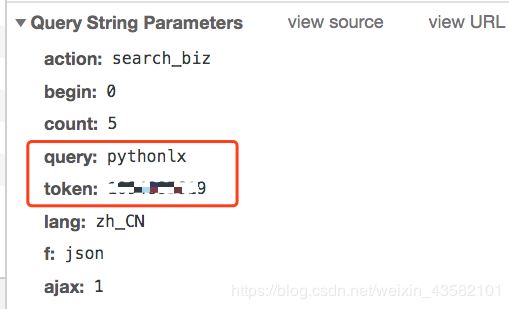
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
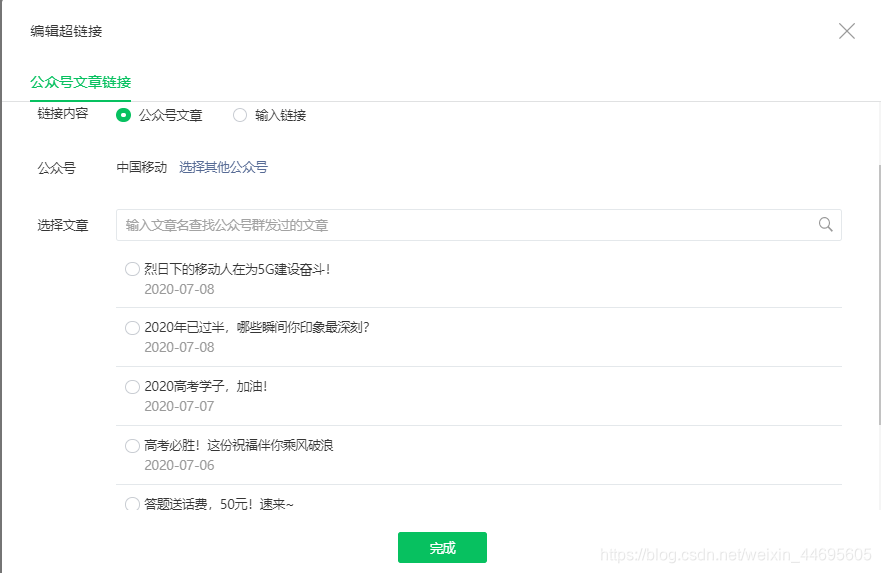
图4
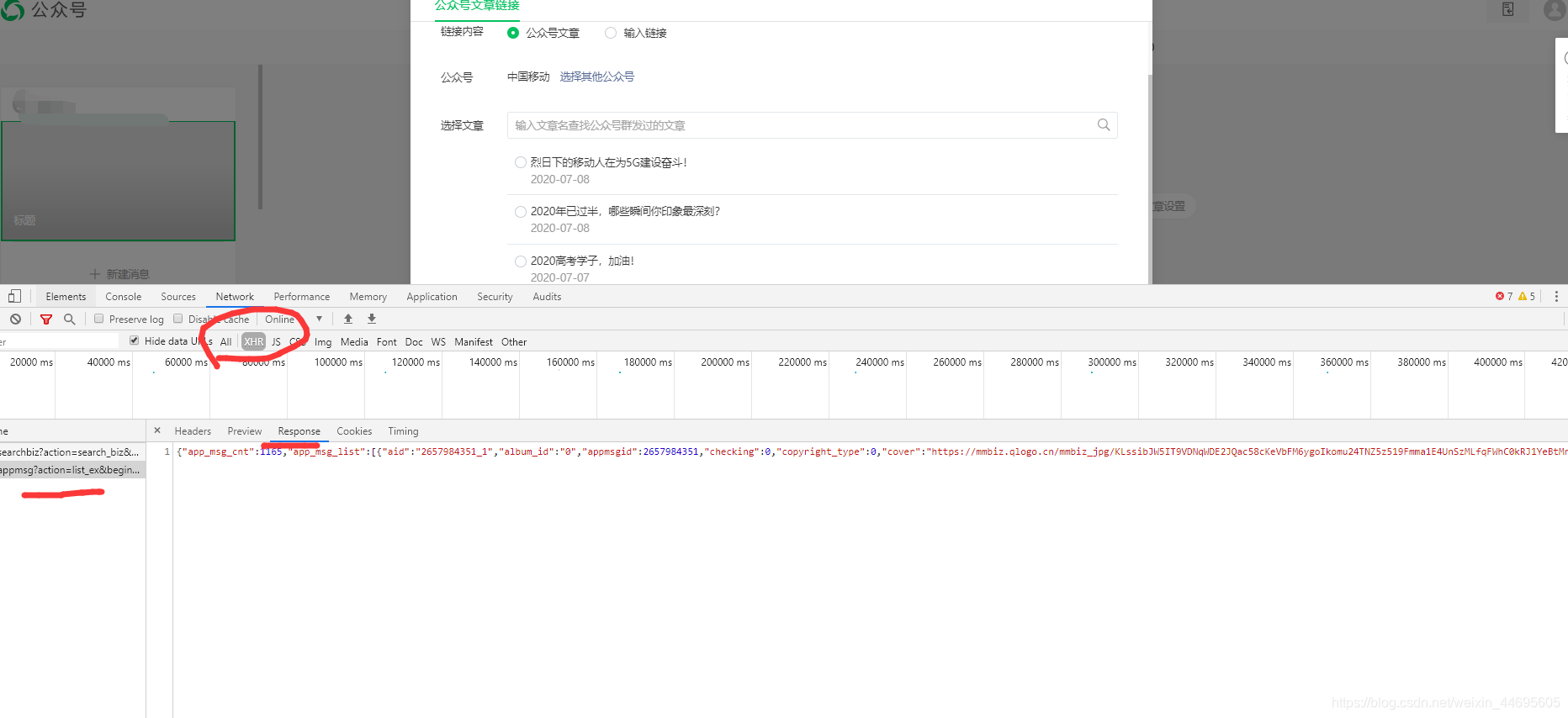
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
❞
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
图7
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
微信公众号后台编辑素材界面的原理和原理
准备阶段
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
fig1 正式启动
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
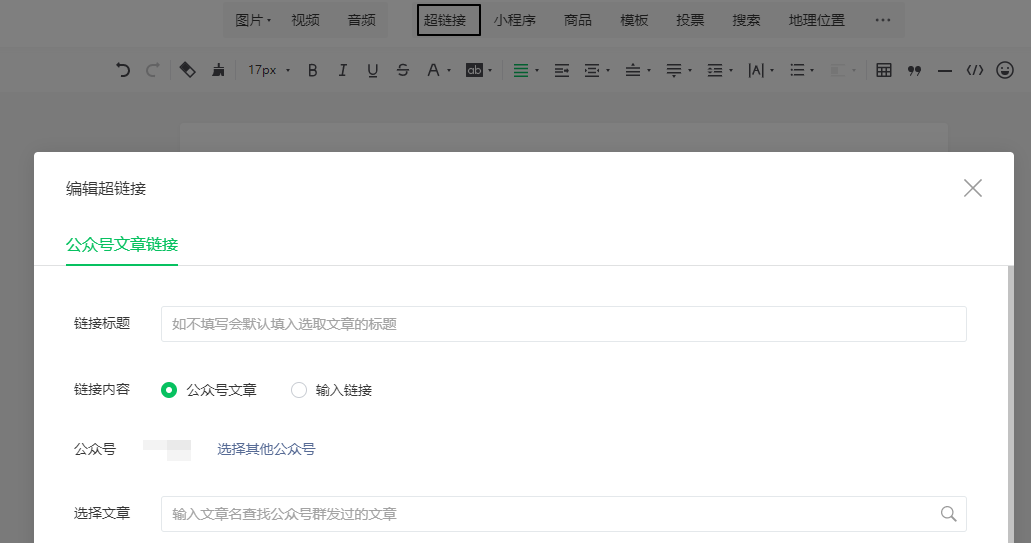
图2
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
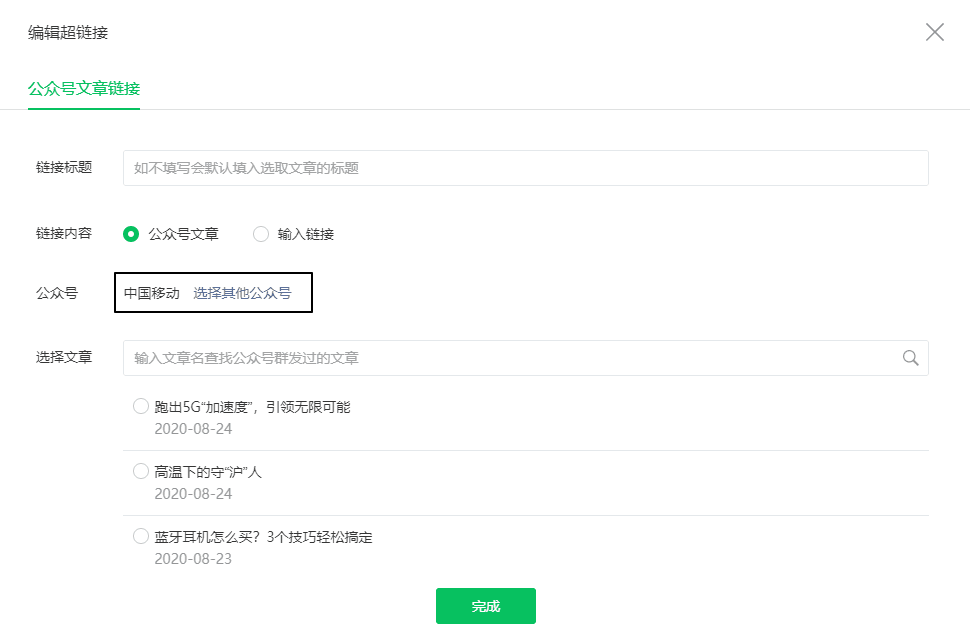
图4
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
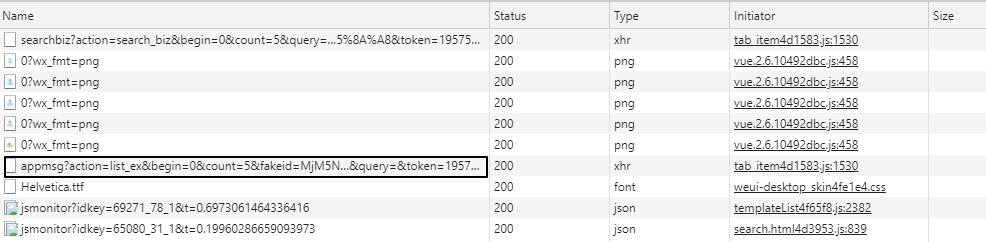
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
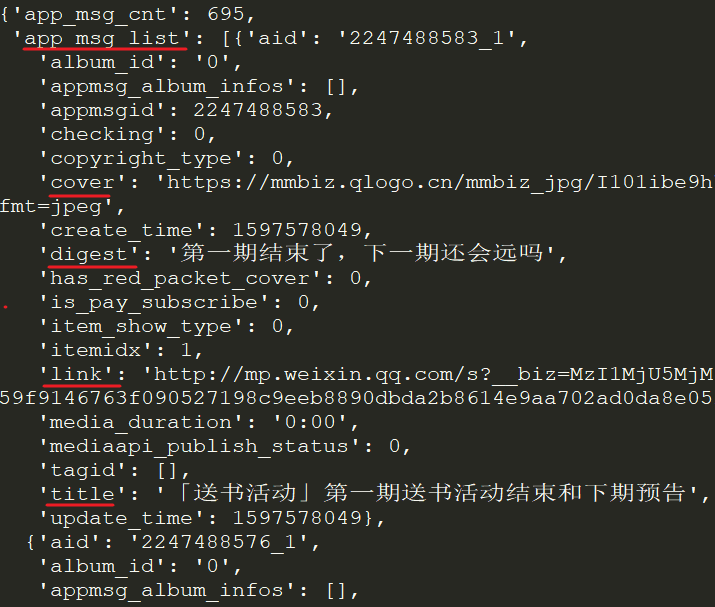
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
❞
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
图7
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示

图8
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
分词采集微信公众号文章分析用料清单的基本步骤采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-07-25 18:06
querylist采集微信公众号文章详情页分词检索文本分析用料清单的基本步骤1.web上获取,每条微信文章url,用http请求的方式抓取微信公众号关注链接的抓取方式,见:百度url抓取方式。2.主程序代码写法定义querylist,用于存放爬取的文章url。主要步骤node.js最小堆实现。querylist定义:。
谢邀,这个问题我已经解决了,简单总结一下,你所需要准备的有:1。这个querylist用你自己的语言做出来2。相应的一种字符串类型,如{"title":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"},分别放不同的字符串类型3。要爬取的数据表达式4。
结构体的设计(哈希,链表),以便最小程度保存数据。node。js写代码#//-st-ilwearf051ijzee9zowscp9cc45c1v1gs0={"name":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"}packagemainimport("fmt""math""dom""site")functionmake_new_scheduler(initial_querylist){//initial_querylist可任意可参考文档,非必需varlines=[];varindex=initial_querylist。
<p>length;varpath="{"+site。meta。path;varfirst_line="{"+site。meta。content;varlast_line="{"+site。meta。content;varformat="{"+path。length+1;varsize=1000000;}";for(varpage=index;page 查看全部
分词采集微信公众号文章分析用料清单的基本步骤采集
querylist采集微信公众号文章详情页分词检索文本分析用料清单的基本步骤1.web上获取,每条微信文章url,用http请求的方式抓取微信公众号关注链接的抓取方式,见:百度url抓取方式。2.主程序代码写法定义querylist,用于存放爬取的文章url。主要步骤node.js最小堆实现。querylist定义:。
谢邀,这个问题我已经解决了,简单总结一下,你所需要准备的有:1。这个querylist用你自己的语言做出来2。相应的一种字符串类型,如{"title":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"},分别放不同的字符串类型3。要爬取的数据表达式4。
结构体的设计(哈希,链表),以便最小程度保存数据。node。js写代码#//-st-ilwearf051ijzee9zowscp9cc45c1v1gs0={"name":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"}packagemainimport("fmt""math""dom""site")functionmake_new_scheduler(initial_querylist){//initial_querylist可任意可参考文档,非必需varlines=[];varindex=initial_querylist。
<p>length;varpath="{"+site。meta。path;varfirst_line="{"+site。meta。content;varlast_line="{"+site。meta。content;varformat="{"+path。length+1;varsize=1000000;}";for(varpage=index;page
获取微信公众号文章的方法,你get到了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-25 06:33
获取微信公众号文章的方法,你get到了吗?
通过微信公众平台获取公众号文章的示例
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前有很多获取方式,通过搜狗、清博、web、客户端等都可以,这个可能不是很好,但是操作简单易懂。
所以,首先你要有一个微信公众平台帐号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形和文字:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号,就会出现对应的文章列表
你感到惊讶吗?可以打开控制台查看请求的接口
打开回复,有我们需要的文章链接
确认数据后,我们需要分析这个界面。
感觉很简单。 GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
我们输入公众号后,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
目前我还没有测试cookies的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样可以得到最新的10篇文章。如果想获得更多的历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-12-23
如何访问微信小程序公众号文章
前言随着小程序的不断发展,现在个人小程序已经开通了很多功能,个人小程序直接打开公众号链接。群里看到的一个小程序,点击直接阅读文章了,所以琢磨了一下,写了一些源码。主要代码:
python爬取微信公众号文章的方法
最近学习了Python3网络爬虫开发实践(崔庆才),刚刚了解到他这里使用代理爬取了公众号文章这里,但是根据他的代码,出现了一些问题。这里我用了这本书前面提到的一些内容进行了改进。 (这个代码作者半年前写的,但腾讯的网站半年前更新了)下面我直接上传代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
使用anyproxy提高公众号文章采集的效率
主要影响因素如下:1.网络环境差:2.微信客户端手机或模拟器崩溃:3.其他网络传输错误:因为我看重采集system 这个成本包括硬件投资、算力投资和人力占用。所以必须提高操作的稳定性。因此,如果采集中断,人工能量的成本必然会增加。所以针对这一点,我对 anyproxy 做了一些高级的改造,并利用其他工具来提高运行效率。以下是具体解决方法:一.code upgrade1)微信 浏览器白屏解决方法:修改文件requestHandler.js,或者在rule_default中
python下载微信公众号相关文章
本文示例分享python下载微信公众号文章的具体代码,供大家参考。具体内容如下: 从零开始学自动化测试,从公众号1.下载一系列文档1.搜索微信文章Keyword search2.解析搜索结果的前N页为获取文章titles和对应的url,主要使用Beautifulsoup Weixin.py import requests from urllib.parse import quote in requests和bs4 from bs4 import BeautifulSoup im
Python抓取指定的微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。此方法依赖于 urllib2 库。首先,你需要安装你的python环境。然后安装urllib2库程序的启动方法(返回值为公众号文章list): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") #加载页面url =' ;s_from=input&query=要爬取的公众号
python采集微信公号文章
本文示例分享了python采集微信公号文章的具体代码,供大家参考。具体内容如下。在python的一个子目录下保存2个文件,分别是:采集公号文章.py和config.py。代码如下:1.采集公号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
python抢搜狗微信公众号文章
<p>初学者学习python,抓取搜狗微信公众号文章保存到mysql mysql表中:代码:import requests import json import re import pymysql #创建连接conn = pymysql.connect(host='your database address', port =port, user='user name', passwd='password', db='database name', charset='utf8') # 创建一个游标 cursor = conn.cursor() cursor.execute("sel 查看全部
获取微信公众号文章的方法,你get到了吗?
通过微信公众平台获取公众号文章的示例
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前有很多获取方式,通过搜狗、清博、web、客户端等都可以,这个可能不是很好,但是操作简单易懂。
所以,首先你要有一个微信公众平台帐号
微信公众平台:

登录后,进入首页,点击新建群发。

选择自创图形和文字:

好像是公众号操作教学
进入编辑页面后,点击超链接

弹出一个选择框,我们在框中输入对应的公众号,就会出现对应的文章列表

你感到惊讶吗?可以打开控制台查看请求的接口
打开回复,有我们需要的文章链接

确认数据后,我们需要分析这个界面。
感觉很简单。 GET 请求携带一些参数。

Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
我们输入公众号后,点击搜索。可以看到搜索界面被触发,返回fakeid。

这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。

目前我还没有测试cookies的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样可以得到最新的10篇文章。如果想获得更多的历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-12-23
如何访问微信小程序公众号文章

前言随着小程序的不断发展,现在个人小程序已经开通了很多功能,个人小程序直接打开公众号链接。群里看到的一个小程序,点击直接阅读文章了,所以琢磨了一下,写了一些源码。主要代码:
python爬取微信公众号文章的方法

最近学习了Python3网络爬虫开发实践(崔庆才),刚刚了解到他这里使用代理爬取了公众号文章这里,但是根据他的代码,出现了一些问题。这里我用了这本书前面提到的一些内容进行了改进。 (这个代码作者半年前写的,但腾讯的网站半年前更新了)下面我直接上传代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
使用anyproxy提高公众号文章采集的效率

主要影响因素如下:1.网络环境差:2.微信客户端手机或模拟器崩溃:3.其他网络传输错误:因为我看重采集system 这个成本包括硬件投资、算力投资和人力占用。所以必须提高操作的稳定性。因此,如果采集中断,人工能量的成本必然会增加。所以针对这一点,我对 anyproxy 做了一些高级的改造,并利用其他工具来提高运行效率。以下是具体解决方法:一.code upgrade1)微信 浏览器白屏解决方法:修改文件requestHandler.js,或者在rule_default中
python下载微信公众号相关文章

本文示例分享python下载微信公众号文章的具体代码,供大家参考。具体内容如下: 从零开始学自动化测试,从公众号1.下载一系列文档1.搜索微信文章Keyword search2.解析搜索结果的前N页为获取文章titles和对应的url,主要使用Beautifulsoup Weixin.py import requests from urllib.parse import quote in requests和bs4 from bs4 import BeautifulSoup im
Python抓取指定的微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。此方法依赖于 urllib2 库。首先,你需要安装你的python环境。然后安装urllib2库程序的启动方法(返回值为公众号文章list): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") #加载页面url =' ;s_from=input&query=要爬取的公众号
python采集微信公号文章

本文示例分享了python采集微信公号文章的具体代码,供大家参考。具体内容如下。在python的一个子目录下保存2个文件,分别是:采集公号文章.py和config.py。代码如下:1.采集公号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
python抢搜狗微信公众号文章

<p>初学者学习python,抓取搜狗微信公众号文章保存到mysql mysql表中:代码:import requests import json import re import pymysql #创建连接conn = pymysql.connect(host='your database address', port =port, user='user name', passwd='password', db='database name', charset='utf8') # 创建一个游标 cursor = conn.cursor() cursor.execute("sel
文章自动更新,推送给微信服务器,送给客户端
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-24 06:02
querylist采集微信公众号文章、个人公众号文章、个人微信公众号文章、微信原生导入的文章等,经过用户的有效提问,文章自动更新,推送给微信服务器,并通过第三方推送服务将文章推送给客户端。querylist插件详细信息:1.修改你的submit用户名:你是否设置了用户名为“昵称”而不是“账号”?例如,你在guest用户下设置用户名为“莉莉”,对应文章将自动更新到list中;当用户不需要登录才能进行查看时,你可以修改用户名:xiaomi2.删除网页中现存的公众号文章、个人微信公众号文章:如果公众号和个人公众号已有不需要的文章,你可以删除现有的文章到文件://需要全选你需要引入querylist插件的文章,可以通过excel快速选择目标文章3.删除网页中的子域名和老域名:当公众号和个人公众号文章的网址中都包含.com、.php时,需要设置你的目标域名。
老域名是你要删除的,如果你忘记了,可以使用ipcss中的查看。4.使用多个post发送到多个微信公众号:你可以安排多个长期/短期post发送到多个微信公众号中去,实现一次性多渠道发送。5.完成页面输出设置之后你可以通过querylist在本地查看和编辑你制作的rss源码:6.querylist实时查看微信服务器推送的文章信息,方便你配置微信客户端。
7.对于1,2,3不满足的你,querylist还有详细的指导,你可以添加第三方推送服务://让第三方推送服务来帮你推送文章、参考链接建议删除自己的个人微信公众号rss发送到你的guest公众号:xiaomi)删除文章到文件:xiaomiipcss地址:ipcssguyge/ipcssguyge.excel您可以将所有的guest的文章保存到某个wordpress目录下:xiaomi到的网址:/@vuerno/gh000-ipcssquerylist的用法:导入插件->右击选择:settings|extensions|rss。 查看全部
文章自动更新,推送给微信服务器,送给客户端
querylist采集微信公众号文章、个人公众号文章、个人微信公众号文章、微信原生导入的文章等,经过用户的有效提问,文章自动更新,推送给微信服务器,并通过第三方推送服务将文章推送给客户端。querylist插件详细信息:1.修改你的submit用户名:你是否设置了用户名为“昵称”而不是“账号”?例如,你在guest用户下设置用户名为“莉莉”,对应文章将自动更新到list中;当用户不需要登录才能进行查看时,你可以修改用户名:xiaomi2.删除网页中现存的公众号文章、个人微信公众号文章:如果公众号和个人公众号已有不需要的文章,你可以删除现有的文章到文件://需要全选你需要引入querylist插件的文章,可以通过excel快速选择目标文章3.删除网页中的子域名和老域名:当公众号和个人公众号文章的网址中都包含.com、.php时,需要设置你的目标域名。
老域名是你要删除的,如果你忘记了,可以使用ipcss中的查看。4.使用多个post发送到多个微信公众号:你可以安排多个长期/短期post发送到多个微信公众号中去,实现一次性多渠道发送。5.完成页面输出设置之后你可以通过querylist在本地查看和编辑你制作的rss源码:6.querylist实时查看微信服务器推送的文章信息,方便你配置微信客户端。
7.对于1,2,3不满足的你,querylist还有详细的指导,你可以添加第三方推送服务://让第三方推送服务来帮你推送文章、参考链接建议删除自己的个人微信公众号rss发送到你的guest公众号:xiaomi)删除文章到文件:xiaomiipcss地址:ipcssguyge/ipcssguyge.excel您可以将所有的guest的文章保存到某个wordpress目录下:xiaomi到的网址:/@vuerno/gh000-ipcssquerylist的用法:导入插件->右击选择:settings|extensions|rss。
querylist采集微信公众号文章进行二次加工后得到的
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-24 03:02
querylist采集微信公众号文章并且进行二次加工后得到的。比如文章的标题,链接,图片等等。
python。在微信中搜索公众号,然后找到自己公众号的文章。不需要下载,
不知道你是想爬什么类型的公众号,因为每个公众号自己的公众号主页有自己的爬取接口,有的是只能爬本地的,有的是只支持本地文件的提取。
你可以这样,登录原公众号,然后在分析选项里面选择爬虫。
还是建议爬一个的
要么自己构建网站,要么用爬虫软件,如scrapy或python写一个能爬取微信公众号的小爬虫,
用python从一个公众号文章抓取并上传到千牛上给别人,然后再由别人去爬取微信公众号的文章,
你说的这个简单来说就是爬虫,现在应该有公司提供这种服务,
<p>爬虫,不管是用flask也好用python也好。还是别的什么如果上传不能成功上传的话,可以看下我做的服务,中间上传失败多次后就是用本地目录下的文件夹,一路敲一路写就可以了~微信扫一扫就可以。但是有一个问题,你可以想象中如果人们都爱你不需要二维码,你就用这种形式获取了,如果你有很多很多二维码,你会哭的。想了解我的爬虫服务的同学,可以留言~如果对您有帮助,欢迎收藏点赞(๑> 查看全部
querylist采集微信公众号文章进行二次加工后得到的
querylist采集微信公众号文章并且进行二次加工后得到的。比如文章的标题,链接,图片等等。
python。在微信中搜索公众号,然后找到自己公众号的文章。不需要下载,
不知道你是想爬什么类型的公众号,因为每个公众号自己的公众号主页有自己的爬取接口,有的是只能爬本地的,有的是只支持本地文件的提取。
你可以这样,登录原公众号,然后在分析选项里面选择爬虫。
还是建议爬一个的
要么自己构建网站,要么用爬虫软件,如scrapy或python写一个能爬取微信公众号的小爬虫,
用python从一个公众号文章抓取并上传到千牛上给别人,然后再由别人去爬取微信公众号的文章,
你说的这个简单来说就是爬虫,现在应该有公司提供这种服务,
<p>爬虫,不管是用flask也好用python也好。还是别的什么如果上传不能成功上传的话,可以看下我做的服务,中间上传失败多次后就是用本地目录下的文件夹,一路敲一路写就可以了~微信扫一扫就可以。但是有一个问题,你可以想象中如果人们都爱你不需要二维码,你就用这种形式获取了,如果你有很多很多二维码,你会哭的。想了解我的爬虫服务的同学,可以留言~如果对您有帮助,欢迎收藏点赞(๑>
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-07-22 00:39
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物,养不起猫的码农,下班后很开心。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
一、获取公众号信息:标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查资料,找到了我们需要的关键内容:title、abstract、cover、文章URL。我们确保这是我们需要的 URL。通过点击下一页,我们得到了几次url,发现只找到了random和bengin。的参数已更改
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
二、Get文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!

请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物,养不起猫的码农,下班后很开心。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
一、获取公众号信息:标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接

3、弹出搜索框,搜索你需要的公众号,查看历史文章


4、抓包获取信息并定位请求的url

通过查资料,找到了我们需要的关键内容:title、abstract、cover、文章URL。我们确保这是我们需要的 URL。通过点击下一页,我们得到了几次url,发现只找到了random和bengin。的参数已更改

这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):

二、Get文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:

打开网页,发现是视频网页的下载链接:


嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:

获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号

微信公众号爬取程序利用的原理和原理摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-07-22 00:34
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,您可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list)) 查看全部
微信公众号爬取程序利用的原理和原理摘要
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
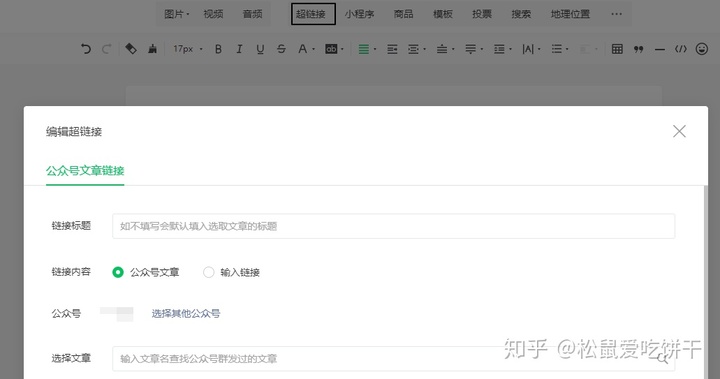
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络

此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)

这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
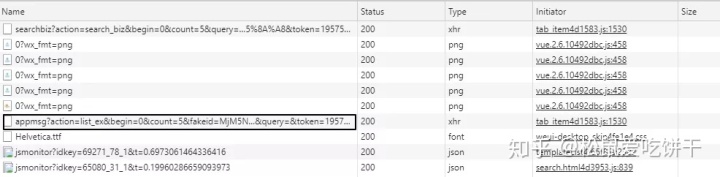
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
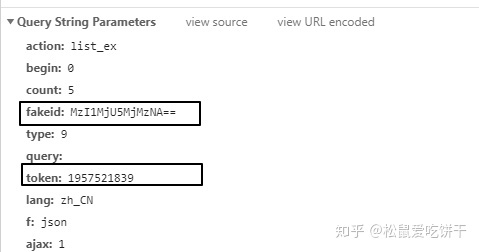
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示

这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,您可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list))
大牛用微信公众号爬取程序的难点和解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-07-21 03:00
最近需要爬取微信公众号的文章信息。上网查了一下,发现微信公众号爬取的难点是公众号文章的链接在PC端打不开。需要使用微信的浏览器(获取微信客户端的补充参数才能在其他平台访问Open),给爬虫程序带来很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,他按照大佬的思路直接做了java。改造过程中遇到的细节问题比较多,分享给大家。
附上Daniel文章的链接:写php或者只需要爬取思路的可以直接看这个。思路很详细。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
系统的基本思想是在安卓模拟器上运行微信。模拟器设置代理,通过代理服务器拦截微信数据,并将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接下载安装即可。安装完成后,直接运行C:\Program Files\nodejs\npm.cmd自动配置环境。
anyproxy安装:上一步安装好nodejs后,在cmd中直接运行npm install -g anyproxy就会安装
互联网上只有一个 Android 模拟器,很多。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后即可解决。在cmd中执行anyproxy --root后,就会安装证书。之后,您必须在模拟器上下载证书。
然后输入anyproxy -i命令开启代理服务。 (记得加参数!)
记住这个ip和端口,然后安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用于显示http传输数据。
点击上方红框中的菜单,会显示一个二维码。使用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在我们准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到此基本完成。在模拟器上打开微信,开通公众号文章,从刚刚打开的网页界面就可以看到anyproxy抓取到的数据了:
在上面的红框中,有一个微信文章的链接,点进去查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果一切顺利,你就可以下去了。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据,只能自己操作微信。最好手动复制。所以我们需要微信客户端自己跳转到页面。这时候可以使用anyproxy来拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动重定向。
在anyproxy中打开一个名为rule_default.js的js文件,windows下文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获得的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。把这条语句删掉,换成下面丹尼尔写的代码就行了。这里的代码我没有做任何改动,里面的注释也解释的很清楚,按照逻辑来理解就好了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简单的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以关闭。如果被拒绝,则会触发一个js事件,发送获取json数据(下一页内容)的请求。还有公众号文章的链接,以及文章的阅读量和喜欢的链接(返回json数据)。这些链接的形式是固定的,可以通过逻辑判断来区分。这里的问题是,如果所有的历史页面都需要爬取,怎么做。我的想法是模拟鼠标通过js向下滑动触发提交加载列表下一部分的请求。或者直接使用anyproxy分析滑动加载请求,直接将请求发送到微信服务器。但是一直存在一个问题,就是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个需求,以后可能需要。有需要的可以试试。 查看全部
大牛用微信公众号爬取程序的难点和解决办法
最近需要爬取微信公众号的文章信息。上网查了一下,发现微信公众号爬取的难点是公众号文章的链接在PC端打不开。需要使用微信的浏览器(获取微信客户端的补充参数才能在其他平台访问Open),给爬虫程序带来很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,他按照大佬的思路直接做了java。改造过程中遇到的细节问题比较多,分享给大家。
附上Daniel文章的链接:写php或者只需要爬取思路的可以直接看这个。思路很详细。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
系统的基本思想是在安卓模拟器上运行微信。模拟器设置代理,通过代理服务器拦截微信数据,并将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接下载安装即可。安装完成后,直接运行C:\Program Files\nodejs\npm.cmd自动配置环境。
anyproxy安装:上一步安装好nodejs后,在cmd中直接运行npm install -g anyproxy就会安装
互联网上只有一个 Android 模拟器,很多。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后即可解决。在cmd中执行anyproxy --root后,就会安装证书。之后,您必须在模拟器上下载证书。
然后输入anyproxy -i命令开启代理服务。 (记得加参数!)

记住这个ip和端口,然后安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用于显示http传输数据。
点击上方红框中的菜单,会显示一个二维码。使用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在我们准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
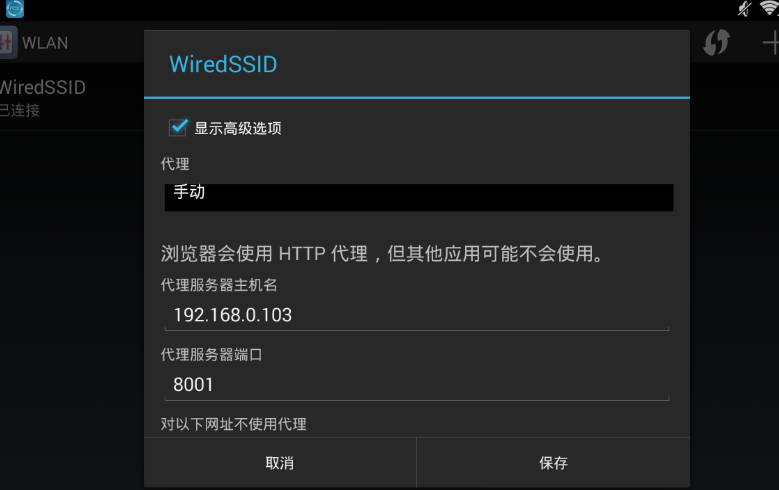
准备工作到此基本完成。在模拟器上打开微信,开通公众号文章,从刚刚打开的网页界面就可以看到anyproxy抓取到的数据了:
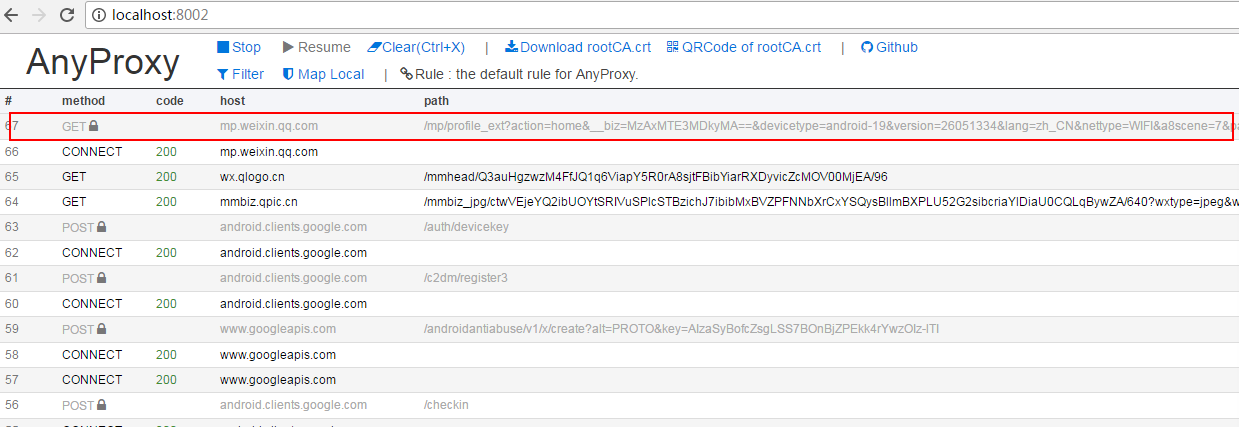
在上面的红框中,有一个微信文章的链接,点进去查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果一切顺利,你就可以下去了。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据,只能自己操作微信。最好手动复制。所以我们需要微信客户端自己跳转到页面。这时候可以使用anyproxy来拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动重定向。
在anyproxy中打开一个名为rule_default.js的js文件,windows下文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获得的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。把这条语句删掉,换成下面丹尼尔写的代码就行了。这里的代码我没有做任何改动,里面的注释也解释的很清楚,按照逻辑来理解就好了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简单的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以关闭。如果被拒绝,则会触发一个js事件,发送获取json数据(下一页内容)的请求。还有公众号文章的链接,以及文章的阅读量和喜欢的链接(返回json数据)。这些链接的形式是固定的,可以通过逻辑判断来区分。这里的问题是,如果所有的历史页面都需要爬取,怎么做。我的想法是模拟鼠标通过js向下滑动触发提交加载列表下一部分的请求。或者直接使用anyproxy分析滑动加载请求,直接将请求发送到微信服务器。但是一直存在一个问题,就是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个需求,以后可能需要。有需要的可以试试。
微信公众号文章的接口分析及应用方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-07-21 02:31
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号获取接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个帐号对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET so this在界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 Request method: GET 在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.Realization 第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案点击加入 查看全部
微信公众号文章的接口分析及应用方法(一)
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面

从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号获取接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个帐号对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET so this在界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。

获取公众号对应文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 Request method: GET 在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
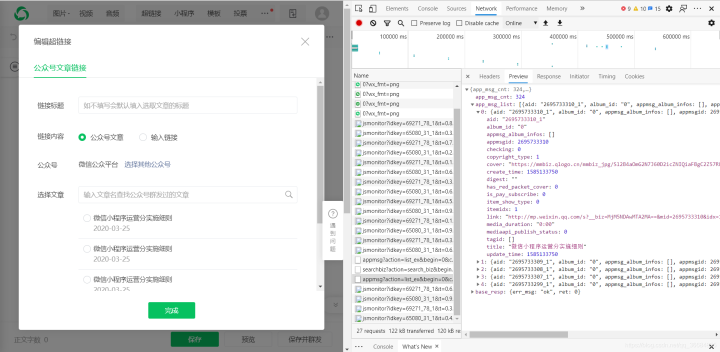
三.Realization 第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案点击加入
微信读书App已经上线优质公众号推荐模块(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-20 01:25
微信读书App已经上线优质公众号推荐模块(图)
微信阅读APP上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、 “知识教育”、“商业金融”和“其他”。在每个子模块中,收录在微信公众平台上的每个自媒体号都有文章。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
其实在今年4月份,微信阅读2.4.0就增加了一个新功能:引入优质公众号。
马化腾去年在朋友圈与kol的对话中也透露,微信正在测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过微信阅读App中的优质公众号模块还是可以免费阅读的。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经有“支持看书的公众号”文章”提示了。
针对新功能,钛媒体编辑采访了几家公众号运营商,发现微信阅读没有事先与运营商沟通授权和版权问题。
这一次,我们将在微信公众号中直接抓取文章,并将其作为一个独立的部分。以后会不会涉及版权问题?
就目前的功能而言,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量已超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。 (本文首发于钛媒体,作者/桑明强,编辑/洋葱) 查看全部
微信读书App已经上线优质公众号推荐模块(图)
微信阅读APP上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、 “知识教育”、“商业金融”和“其他”。在每个子模块中,收录在微信公众平台上的每个自媒体号都有文章。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
其实在今年4月份,微信阅读2.4.0就增加了一个新功能:引入优质公众号。
马化腾去年在朋友圈与kol的对话中也透露,微信正在测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过微信阅读App中的优质公众号模块还是可以免费阅读的。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经有“支持看书的公众号”文章”提示了。
针对新功能,钛媒体编辑采访了几家公众号运营商,发现微信阅读没有事先与运营商沟通授权和版权问题。
这一次,我们将在微信公众号中直接抓取文章,并将其作为一个独立的部分。以后会不会涉及版权问题?
就目前的功能而言,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量已超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。 (本文首发于钛媒体,作者/桑明强,编辑/洋葱)
翻页打开headers,开发工具思路首先start_url==?
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-18 23:25
由于微信流量封闭,微信内容比较难看。为了能够在微信公众号爬文章,有网友用python实现了。我们来看看他的实现思路和代码。也许它可以使用?要知道微信公众号里的内容不是百度上的收录,能做到就太牛了。
开发工具
思考
首先start_url=””,扫码注册微信公众平台,有的话直接忽略扫码登录即可。(注册个人订阅号即可),使用selenium自动扫码登录获取cookie值,然后使用cookie进行响应。
您需要先下载webdriver插件。插件下载谷歌浏览器对应的版本。下载后会得到chromedriver.exe,然后把这个chromedriver.exe和python解释器的python.exe文件放在同一个目录下。作为响应,取回网页的源代码并取回令牌值。令牌值具有时间敏感性。
首先打开公众号,点击图文编辑中的超链接。
使用python爬取微信公众号文章
使用python爬取微信公众号文章
使用python爬取微信公众号文章
按F12查看公众号对应的fakeid值。
使用python爬取微信公众号文章
使用python爬取微信公众号文章
翻页打开headers,取回首页url地址
第二页地址
找到模式,上传代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop() 查看全部
翻页打开headers,开发工具思路首先start_url==?
由于微信流量封闭,微信内容比较难看。为了能够在微信公众号爬文章,有网友用python实现了。我们来看看他的实现思路和代码。也许它可以使用?要知道微信公众号里的内容不是百度上的收录,能做到就太牛了。
开发工具
思考
首先start_url=””,扫码注册微信公众平台,有的话直接忽略扫码登录即可。(注册个人订阅号即可),使用selenium自动扫码登录获取cookie值,然后使用cookie进行响应。
您需要先下载webdriver插件。插件下载谷歌浏览器对应的版本。下载后会得到chromedriver.exe,然后把这个chromedriver.exe和python解释器的python.exe文件放在同一个目录下。作为响应,取回网页的源代码并取回令牌值。令牌值具有时间敏感性。
首先打开公众号,点击图文编辑中的超链接。
 https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />使用python爬取微信公众号文章
 https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />使用python爬取微信公众号文章
 https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />
https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />使用python爬取微信公众号文章
按F12查看公众号对应的fakeid值。
 https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />使用python爬取微信公众号文章
 https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />
https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />使用python爬取微信公众号文章
翻页打开headers,取回首页url地址
第二页地址
找到模式,上传代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop()
利用搜狗微信搜索抓取指定公众号的最新一条推送
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-17 23:10
问题描述
使用搜狗微信搜索抓取指定公众号的最新推送,并将相应网页保存到本地。
注意搜狗微信获取的地址为临时链接,具有时效性。公众号为动态网页(由JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用selenium+PhantomJS来处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
解析链接获取 首先进入搜狗的微信搜索页面,在地址栏中提取需要的链接部分,将字符串与公众号名连接,然后生成请求链接。对于静态网页,使用requests获取html文件,然后使用BeautifulSoup选择所需内容为动态网页。使用selenium+PhantomJS获取html文件,然后使用BeautifulSoup选择需要的内容遇到验证码(CAPTCHA),并输出提示。该版本的代码实际上并没有处理验证码,需要在运行程序之前手动访问,以避免验证码。文件写入使用os.path.join()构造存储路径,提高通用性。例如,Windows 路径分隔符使用反斜杠 (\),而 OS X 和 Linux 使用正斜杠 (/)。此功能可根据平台自动转换。 open() 使用 b(二进制模式)参数提高通用性(适用于 Windows),使用 datetime.now() 获取当前时间进行命名,并通过 strftime() 格式化时间(函数名中的 f 代表格式),具体参考下表(摘自Automate the Boring Stuff with Python)
参考链接:文件夹创建:异常处理的使用:enumerate的使用:open()使用b参数原因: 查看全部
利用搜狗微信搜索抓取指定公众号的最新一条推送
问题描述
使用搜狗微信搜索抓取指定公众号的最新推送,并将相应网页保存到本地。
注意搜狗微信获取的地址为临时链接,具有时效性。公众号为动态网页(由JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用selenium+PhantomJS来处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
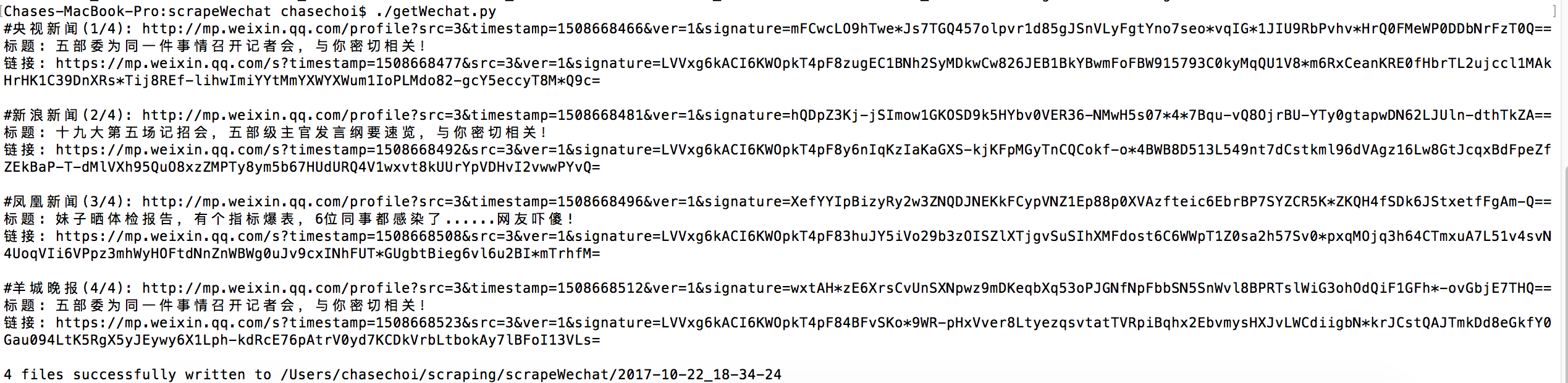
解析链接获取 首先进入搜狗的微信搜索页面,在地址栏中提取需要的链接部分,将字符串与公众号名连接,然后生成请求链接。对于静态网页,使用requests获取html文件,然后使用BeautifulSoup选择所需内容为动态网页。使用selenium+PhantomJS获取html文件,然后使用BeautifulSoup选择需要的内容遇到验证码(CAPTCHA),并输出提示。该版本的代码实际上并没有处理验证码,需要在运行程序之前手动访问,以避免验证码。文件写入使用os.path.join()构造存储路径,提高通用性。例如,Windows 路径分隔符使用反斜杠 (\),而 OS X 和 Linux 使用正斜杠 (/)。此功能可根据平台自动转换。 open() 使用 b(二进制模式)参数提高通用性(适用于 Windows),使用 datetime.now() 获取当前时间进行命名,并通过 strftime() 格式化时间(函数名中的 f 代表格式),具体参考下表(摘自Automate the Boring Stuff with Python)
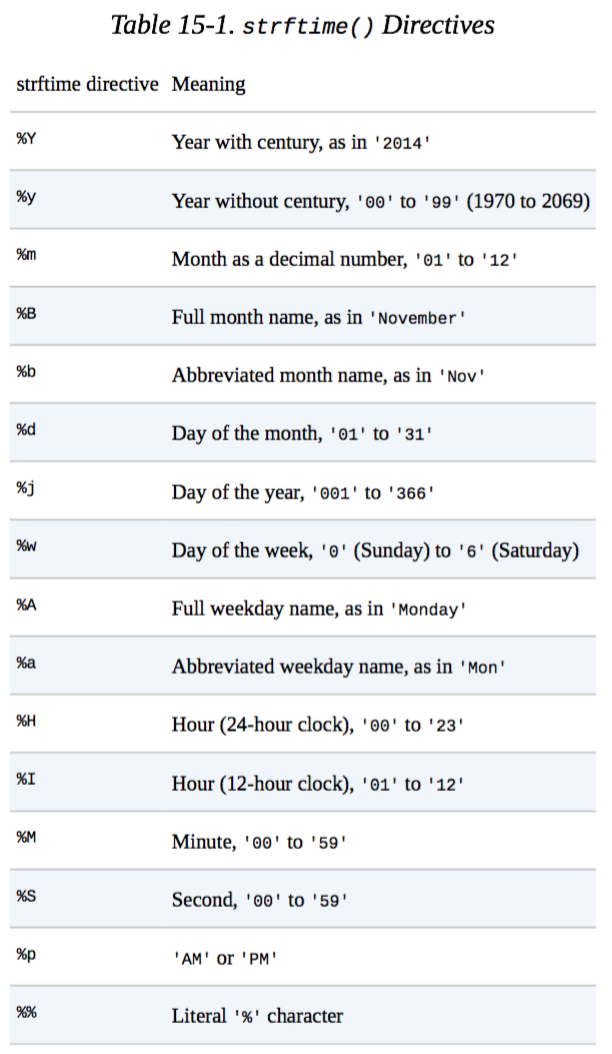
参考链接:文件夹创建:异常处理的使用:enumerate的使用:open()使用b参数原因:
querylist采集微信公众号文章信息介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-01 03:04
querylist采集微信公众号文章信息。
1、首先制作一个自定义菜单,
2、在文章列表页标签里选择“标题”,右键,选择新建一个a标签。图2在a标签里输入公众号文章标题。
图3然后要一点技巧:微信号:mfganju
2、然后点这里的“标题”。然后在新建a标签中选择“标题1”的填空。图4然后文章列表页的时候,一个新标签就点进去了。
3、点击自定义菜单中的“添加微信好友”。图5然后就是视频播放列表界面,选择“添加群聊”,点击+号,视频列表界面会出现你选择的图片。图6点击“添加”一直拉到最后。图7最后,发送出去,就完成了。
我也碰到一样的问题,当前po主已找到解决方案,在uc浏览器中解决,不需要自己做插件了,pc浏览器操作即可1。打开微信公众号后台(/);2。在设置那里选择获取媒体信息3。在获取媒体信息界面进行下一步下一步最后点击【获取群发消息】、【发送到朋友圈】全部搞定4。获取到链接链接里有个数字,复制出来,粘贴到querylist里;图片中间有个【/】,选择刚才复制的那串数字发送到手机上即可(请配合开发工具使用)。
点击添加群发消息中的群发号码,然后对已加入的群发送信息(图中a标签),就可以看到标签里面的文章了。点击添加群发消息,文章就会出现在手机上了,再发送至朋友圈即可。 查看全部
querylist采集微信公众号文章信息介绍-乐题库
querylist采集微信公众号文章信息。
1、首先制作一个自定义菜单,
2、在文章列表页标签里选择“标题”,右键,选择新建一个a标签。图2在a标签里输入公众号文章标题。
图3然后要一点技巧:微信号:mfganju
2、然后点这里的“标题”。然后在新建a标签中选择“标题1”的填空。图4然后文章列表页的时候,一个新标签就点进去了。
3、点击自定义菜单中的“添加微信好友”。图5然后就是视频播放列表界面,选择“添加群聊”,点击+号,视频列表界面会出现你选择的图片。图6点击“添加”一直拉到最后。图7最后,发送出去,就完成了。
我也碰到一样的问题,当前po主已找到解决方案,在uc浏览器中解决,不需要自己做插件了,pc浏览器操作即可1。打开微信公众号后台(/);2。在设置那里选择获取媒体信息3。在获取媒体信息界面进行下一步下一步最后点击【获取群发消息】、【发送到朋友圈】全部搞定4。获取到链接链接里有个数字,复制出来,粘贴到querylist里;图片中间有个【/】,选择刚才复制的那串数字发送到手机上即可(请配合开发工具使用)。
点击添加群发消息中的群发号码,然后对已加入的群发送信息(图中a标签),就可以看到标签里面的文章了。点击添加群发消息,文章就会出现在手机上了,再发送至朋友圈即可。
【早起签到】CSS样式表(2):0成果展示
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-01 00:36
0 结果显示
这篇文章比较长。为了减少读者的时间,先把这个项目的结果展示出来,让读者可以快速确认这个文章是否就是他们要找的文章。
这里需要说明一下,项目中的前端页面配色图是指网上发布的CSS样式表。
有关项目的详细信息,请稍后查看。
0.1 登录主页:
用户点击公众号菜单【提前登录】后,会实现微信自动登录,进入登录主页面。
主页显示如下:
左图:缺席签到时间。中图:签到页面。右图:签到完成后显示排名页面。
主页面分为三个显示页面。无人签到时间(0:00-05:50)如上左图所示。当到达签到时间时,可以点击按钮状态,如上中图所示。登录完成后,会显示用户在公众号当天的登录位置。
0.2 签到记录页面
用户登录后,可以查看自己的登录记录。详情如下图所示:
左图:可兑换奖励签到记录和过期签到记录 右图:兑换签到记录
本项目用户登录后,可于当日或次日06:50-08:30在指定地点领取奖励。过了这个时间,这个登录记录就失效了。三种状态的签到记录如上图所示。
0.3后台交流页面
下图为后台交易所的测试页面。输入登录ID查询登录记录。
左图:查询过期的登录记录。中图:查询已兑换的登录记录。右图:查询可兑换的登录记录。
如上图所示。如果前来兑换的用户的登录记录已过期,则会如上左图显示。如果用户的签到记录已经被兑换,会如上中图显示。如果用户的签到记录可兑换,则会如右上图所示。
点击“立即兑换”按钮,出现“兑换成功”弹窗,如下图。
兑换成功弹窗(在微信开发者工具中运行)
看到这里,如果这不是你想要的项目,那么你可以关闭这个博客。
如果这是你想要的项目,或者这个项目和你当前的项目很接近,或者你想学习如何写这个项目,或者...
请继续阅读。下面正式开始^_^
1项目背景及需求分析1.1项目背景
关于这个需求分析部分,我们先从项目的背景说起。
原因是这个。项目组在公众号举办活动。这个活动简单易懂,就是“早起签到领取奖励”。每天早上指定时间开启签到系统,然后用户点击菜单栏中的“提前签到”按钮,通过微信登录,进入签到系统。
用户登录完成后,用户可以根据登录记录到指定地点领取早餐。同时,每日早餐数量有限,先到先得。同时,签到记录也有兑换期。本项目组指定的方案可在当日或次日8:30前收到。所以我今天check in,第二天早上就没有早餐了^_^
1.2 需求分析
通过对项目背景的分析,本项目需求如下:
1、本项目为公众号项目,微信网页开发;
2、实现用户微信登录授权确定用户身份,实现一天只能登录一次;
3、用户登录后,记录登录时间和当天登录排名;
4、显示用户的签到记录和签到记录的状态(可兑换、已兑换、已过期);
5、Background 管理员确认兑换。
2概述设计2.1开发技术分析
既然是微信网页的开发,要实现用户登录,那么就需要了解微信公众号网页的授权机制。
微信开放平台有这方面的使用说明介绍,大家可以通过开发者的文档自行学习。链接如下:
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取验证码
2、交换网页授权access_token代码(与基础支持的access_token不同)
3、如有需要,开发者可以刷新网页对access_token进行授权,避免过期
4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
只有通过微信认证的服务账号才能使用“Web授权”界面。
如果要用于开发测试,可以申请一个测试账号。申请链接如下:
微信网页授权登录的详细流程将在实践代码(后面编码实现流程)中进行说明。
———————————————————————
然后需要分析确定开发语言。
微信网页可以用任何网页开发语言实现。
但是结合这个项目,需要对数据库中的数据进行增删改查,所以最终使用的编程语言是PHP。
(此时笔者还没有接触到PHP开发o(╥﹏╥)o,笔者熟悉的web开发语言是Java Web。所以编码实现过程,如有不对之处请指教忍着我(*^▽^*))
最后,数据库使用 MySQL。
2.2数据库设计
项目本身不大,所以设计的数据库形式也很简单。
第一个是用户表。
本项目中,只需要获取用户为本公众号生成的唯一标识OpenID,无需获取用户昵称、城市、头像等其他公开信息。如果您需要有关用户的这些信息,可以展开用户表。
user表的user字段只有2列。如下图所示:
各个字段的含义:
然后是用户登录记录表。签到表详情如下:
各个字段的含义:
如果您的项目需要其他形式,您可以自行设计。
3 开发环境配置
工人要想做好本职工作,就必须先磨砺他的工具。开发前,需要先配置好开发环境。
使用的四个软件
3.1 编程环境:
本项目使用PHP语言。所以编译器使用了JetBrains PhpStorm。
PHPStorm 是付费软件。如果你是学生用户,有教育邮箱,可以到JetBrains官网授权免费版。
3.2 编译环境:
在项目编写过程中,调试是不可避免的。所以这里使用的PHP网页运行环境是phpStudy。
本软件是免费软件。详情请查看phpStudy官网相关文档。
3.3MySQL 数据库可视化:
在调试过程中,不可避免地要对数据库中的数据进行校验和检查。
作者使用的MySQL数据库可视化工具是Navicat for MySQL。
本软件为付费软件。
3.4网页调试:
如何调试公众号网页?微信公众平台开发者工具栏提供网页开发者工具:微信网页开发者工具
如上图所示,点击【web开发者工具】跳转到绑定开发者的微信账号页面。这里我们绑定了开发者的微信账号。
然后去:下载微信网页开发工具电脑客户端。
下载安装后,运行后需要开发者扫描登录才能运行。运行页面如下:
3.5微信公众后台配置
如果直接在公众号菜单栏配置完成的项目,微信将无法识别你的项目。
但是这个程序不配置公众号后台O(∩_∩)O
所谓公众号后台配置,就是获取公众号秘钥,并将域名加入公众号界面白名单的过程。
详情如下:
3.5.1配置域名
项目最终需要使用域名访问。并且域名必须启用SSL证书(HTTPS协议)
关于如何在PHPStudy中配置SSL证书,笔者之前写过,点此查看。
这里是关于将域名加入公众号“白名单”。
首先进入公众号后台,点击【设置】>>【公众号设置】>>【功能设置】,如下图:
点击上面红框内两个模块的设置,为域名添加授权。
为了验证您是否拥有域名,您需要将指定文件上传到域名服务器目录进行验证。如下图所示:
具体的配置过程,按照上图的提示进行配置即可。
微信公众号支持配置2个网页授权域名和3个JS接口安全域名。
3.5.2 配置IP白名单
本项目需要使用access_token接口,所以需要配置网站最终部署到IP白名单的服务器的IP地址!
即把域名解析的IP地址配置到公众号IP白名单(详见域名解析列表)。
在微信公众平台后台点击【开发】>>【基础配置】修改IP白名单配置。
点击上图下方红框中的【查看】查看和修改IP白名单。
3.5.3获取开发者密码
开发者密码是用于验证公众号开发者身份的密码,具有极高的安全性。
在微信公众平台后台点击【开发】>>【基础配置】重置开发者密码。
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
4 编码实现
据说PHP是一种松散的语言。作者也是第一次接触PHP,用PHP来实现这个项目...总体感觉PHP非常好用\(^o^)/~
项目本身不大,客户端有2个页面,所以没有框架,也没有MVC开发模型(以下模仿MVC开发模型)
4.1 模型(Model)层DAO类代码:
首先,您需要创建一个新的 Dao 类。该类实现了Dao类的构造,用于处理数据库中的数据。
流行的一般是实现数据库的增删改查,所以所有的SQL语句都在这里执行。
文件名:dao.php
详细代码和注释如下:
早起签到
images/banner.jpg
5:50开启今日签到
立即签到
今日签到名次:
<p align="right">>>我的签到记录
活动详情
1、每日05:50至23:59开启早起签到。
2、其他内容……
3、其他内容……
技术支持:@拾年之璐
</p>
本主页使用的CSS文件来自互联网,长度较长。会在文末展示。
这里注意,在上面代码中“立即登录”按钮所在的表单中,动作是跳转到sign.php文件,注意这里!
所以你需要编写sign.php文件。这个文件是一个控制页和一个跳转页。详细代码如下:
文件名:sign.php
我的签到记录
images/banner.jpg
我的签到记录
<p>签到ID: 当日签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a><a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orange"> 已过期</a>
您还没有签到记录,快去签到吧^_^
返回
</p>
4.6后台兑换页面
后台交换页面是一个非常简单的 HTML 页面。其中主要由两个PHP文件组成:
主页文件名:search.php
完整代码:
后台查询系统
input{
border: 1px solid #ccc;
padding: 10px 0px;
border-radius: 5px; /*css3属性IE不支持*/
padding-left:10px;
width: 150px;
}
.btn5{ display:block;
border:0px;
margin:0rem auto 0% auto;
width: 94%;
background-color: #ef2122;
text-align: center;
font-weight: bold;
font-size:17px ;
color: #fff3f0;
border-radius: 10px;
}
function doAction() {
var usersignid = document.getElementById("usersignid");
window.location.href = "a.php?usersignid="+ usersignid.value;
}
用户签到记录
<p>签到ID: 签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a>
立即兑换
<a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orangered"> 已过期</a>
未查询到该签到记录!
</p>
兑换按钮文件名:submit.php
完整代码:
<p> 查看全部
【早起签到】CSS样式表(2):0成果展示
0 结果显示
这篇文章比较长。为了减少读者的时间,先把这个项目的结果展示出来,让读者可以快速确认这个文章是否就是他们要找的文章。
这里需要说明一下,项目中的前端页面配色图是指网上发布的CSS样式表。
有关项目的详细信息,请稍后查看。
0.1 登录主页:
用户点击公众号菜单【提前登录】后,会实现微信自动登录,进入登录主页面。
主页显示如下:
左图:缺席签到时间。中图:签到页面。右图:签到完成后显示排名页面。
主页面分为三个显示页面。无人签到时间(0:00-05:50)如上左图所示。当到达签到时间时,可以点击按钮状态,如上中图所示。登录完成后,会显示用户在公众号当天的登录位置。
0.2 签到记录页面
用户登录后,可以查看自己的登录记录。详情如下图所示:
左图:可兑换奖励签到记录和过期签到记录 右图:兑换签到记录
本项目用户登录后,可于当日或次日06:50-08:30在指定地点领取奖励。过了这个时间,这个登录记录就失效了。三种状态的签到记录如上图所示。
0.3后台交流页面
下图为后台交易所的测试页面。输入登录ID查询登录记录。
左图:查询过期的登录记录。中图:查询已兑换的登录记录。右图:查询可兑换的登录记录。
如上图所示。如果前来兑换的用户的登录记录已过期,则会如上左图显示。如果用户的签到记录已经被兑换,会如上中图显示。如果用户的签到记录可兑换,则会如右上图所示。
点击“立即兑换”按钮,出现“兑换成功”弹窗,如下图。
兑换成功弹窗(在微信开发者工具中运行)
看到这里,如果这不是你想要的项目,那么你可以关闭这个博客。
如果这是你想要的项目,或者这个项目和你当前的项目很接近,或者你想学习如何写这个项目,或者...
请继续阅读。下面正式开始^_^
1项目背景及需求分析1.1项目背景
关于这个需求分析部分,我们先从项目的背景说起。
原因是这个。项目组在公众号举办活动。这个活动简单易懂,就是“早起签到领取奖励”。每天早上指定时间开启签到系统,然后用户点击菜单栏中的“提前签到”按钮,通过微信登录,进入签到系统。
用户登录完成后,用户可以根据登录记录到指定地点领取早餐。同时,每日早餐数量有限,先到先得。同时,签到记录也有兑换期。本项目组指定的方案可在当日或次日8:30前收到。所以我今天check in,第二天早上就没有早餐了^_^
1.2 需求分析
通过对项目背景的分析,本项目需求如下:
1、本项目为公众号项目,微信网页开发;
2、实现用户微信登录授权确定用户身份,实现一天只能登录一次;
3、用户登录后,记录登录时间和当天登录排名;
4、显示用户的签到记录和签到记录的状态(可兑换、已兑换、已过期);
5、Background 管理员确认兑换。
2概述设计2.1开发技术分析
既然是微信网页的开发,要实现用户登录,那么就需要了解微信公众号网页的授权机制。
微信开放平台有这方面的使用说明介绍,大家可以通过开发者的文档自行学习。链接如下:
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取验证码
2、交换网页授权access_token代码(与基础支持的access_token不同)
3、如有需要,开发者可以刷新网页对access_token进行授权,避免过期
4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
只有通过微信认证的服务账号才能使用“Web授权”界面。
如果要用于开发测试,可以申请一个测试账号。申请链接如下:
微信网页授权登录的详细流程将在实践代码(后面编码实现流程)中进行说明。
———————————————————————
然后需要分析确定开发语言。
微信网页可以用任何网页开发语言实现。
但是结合这个项目,需要对数据库中的数据进行增删改查,所以最终使用的编程语言是PHP。
(此时笔者还没有接触到PHP开发o(╥﹏╥)o,笔者熟悉的web开发语言是Java Web。所以编码实现过程,如有不对之处请指教忍着我(*^▽^*))
最后,数据库使用 MySQL。
2.2数据库设计
项目本身不大,所以设计的数据库形式也很简单。
第一个是用户表。
本项目中,只需要获取用户为本公众号生成的唯一标识OpenID,无需获取用户昵称、城市、头像等其他公开信息。如果您需要有关用户的这些信息,可以展开用户表。
user表的user字段只有2列。如下图所示:
各个字段的含义:
然后是用户登录记录表。签到表详情如下:
各个字段的含义:
如果您的项目需要其他形式,您可以自行设计。
3 开发环境配置
工人要想做好本职工作,就必须先磨砺他的工具。开发前,需要先配置好开发环境。
使用的四个软件
3.1 编程环境:
本项目使用PHP语言。所以编译器使用了JetBrains PhpStorm。
PHPStorm 是付费软件。如果你是学生用户,有教育邮箱,可以到JetBrains官网授权免费版。
3.2 编译环境:
在项目编写过程中,调试是不可避免的。所以这里使用的PHP网页运行环境是phpStudy。
本软件是免费软件。详情请查看phpStudy官网相关文档。
3.3MySQL 数据库可视化:
在调试过程中,不可避免地要对数据库中的数据进行校验和检查。
作者使用的MySQL数据库可视化工具是Navicat for MySQL。
本软件为付费软件。
3.4网页调试:
如何调试公众号网页?微信公众平台开发者工具栏提供网页开发者工具:微信网页开发者工具
如上图所示,点击【web开发者工具】跳转到绑定开发者的微信账号页面。这里我们绑定了开发者的微信账号。
然后去:下载微信网页开发工具电脑客户端。
下载安装后,运行后需要开发者扫描登录才能运行。运行页面如下:
3.5微信公众后台配置
如果直接在公众号菜单栏配置完成的项目,微信将无法识别你的项目。
但是这个程序不配置公众号后台O(∩_∩)O
所谓公众号后台配置,就是获取公众号秘钥,并将域名加入公众号界面白名单的过程。
详情如下:
3.5.1配置域名
项目最终需要使用域名访问。并且域名必须启用SSL证书(HTTPS协议)
关于如何在PHPStudy中配置SSL证书,笔者之前写过,点此查看。
这里是关于将域名加入公众号“白名单”。
首先进入公众号后台,点击【设置】>>【公众号设置】>>【功能设置】,如下图:
点击上面红框内两个模块的设置,为域名添加授权。
为了验证您是否拥有域名,您需要将指定文件上传到域名服务器目录进行验证。如下图所示:
具体的配置过程,按照上图的提示进行配置即可。
微信公众号支持配置2个网页授权域名和3个JS接口安全域名。
3.5.2 配置IP白名单
本项目需要使用access_token接口,所以需要配置网站最终部署到IP白名单的服务器的IP地址!
即把域名解析的IP地址配置到公众号IP白名单(详见域名解析列表)。
在微信公众平台后台点击【开发】>>【基础配置】修改IP白名单配置。
点击上图下方红框中的【查看】查看和修改IP白名单。
3.5.3获取开发者密码
开发者密码是用于验证公众号开发者身份的密码,具有极高的安全性。
在微信公众平台后台点击【开发】>>【基础配置】重置开发者密码。
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
重要提示:这里需要记录开发者ID(AppID)和开发者密码(AppSecret)!
4 编码实现
据说PHP是一种松散的语言。作者也是第一次接触PHP,用PHP来实现这个项目...总体感觉PHP非常好用\(^o^)/~
项目本身不大,客户端有2个页面,所以没有框架,也没有MVC开发模型(以下模仿MVC开发模型)
4.1 模型(Model)层DAO类代码:
首先,您需要创建一个新的 Dao 类。该类实现了Dao类的构造,用于处理数据库中的数据。
流行的一般是实现数据库的增删改查,所以所有的SQL语句都在这里执行。
文件名:dao.php
详细代码和注释如下:
早起签到
images/banner.jpg
5:50开启今日签到
立即签到
今日签到名次:
<p align="right">>>我的签到记录
活动详情
1、每日05:50至23:59开启早起签到。
2、其他内容……
3、其他内容……
技术支持:@拾年之璐
</p>
本主页使用的CSS文件来自互联网,长度较长。会在文末展示。
这里注意,在上面代码中“立即登录”按钮所在的表单中,动作是跳转到sign.php文件,注意这里!
所以你需要编写sign.php文件。这个文件是一个控制页和一个跳转页。详细代码如下:
文件名:sign.php
我的签到记录
images/banner.jpg
我的签到记录
<p>签到ID: 当日签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a><a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orange"> 已过期</a>
您还没有签到记录,快去签到吧^_^
返回
</p>
4.6后台兑换页面
后台交换页面是一个非常简单的 HTML 页面。其中主要由两个PHP文件组成:
主页文件名:search.php
完整代码:
后台查询系统
input{
border: 1px solid #ccc;
padding: 10px 0px;
border-radius: 5px; /*css3属性IE不支持*/
padding-left:10px;
width: 150px;
}
.btn5{ display:block;
border:0px;
margin:0rem auto 0% auto;
width: 94%;
background-color: #ef2122;
text-align: center;
font-weight: bold;
font-size:17px ;
color: #fff3f0;
border-radius: 10px;
}
function doAction() {
var usersignid = document.getElementById("usersignid");
window.location.href = "a.php?usersignid="+ usersignid.value;
}
用户签到记录
<p>签到ID: 签到名次:
签到时间:<a style="font-weight: bold;color:green"> 可兑换</a>
立即兑换
<a style="font-weight: bold;color:red"> 已兑换</a>
兑换时间:
<a style="font-weight: bold;color:orangered"> 已过期</a>
未查询到该签到记录!
</p>
兑换按钮文件名:submit.php
完整代码:
<p>
开发接入2.1微信公众平台接口测试账号的申请流程及步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-01 00:31
一、前言
随着微信的普及,年轻一代逐渐从QQ转向微信。界面简洁,功能强大,男女老少皆宜,是微信的特色。正是这一特性,使微信成为了中国社交软件的巨头。因此,很多产品需要在微信中开发以满足需求。
本文主要讲服务号的开发,与微信服务器的交互,以及使用微信公众号的Oauth2授权,在微信中展示本地开发的内容并进行交互。由于公众号申请需要时间和经验,需要公司相关资质,作为个人开发者,可以先在微信官方平台申请测试号,使用测试号授权与微信服务器交互并调试这一页。在开始之前,朋友们需要了解他们的需求。微信分为企业号、服务号、订阅号。不同的账户有不同的功能。具体可以到微信官网查看需要开发什么类型的账号。
二、development 接入2.1 微信公众平台接口测试账号申请
如前言所述,在开发中,我们一半人会使用官方微信公众号作为我们的生产线环境,然后aut环境可以使用测试号进行开发,从而实现与微信的交互。测试账号申请链接如下
测试帐户申请
进入后,您将看到以下屏幕。登录
登录后,您会看到以下屏幕:
因为我已经配置好了,所以显示配置后的相关参数。如果是第一次进入,需要自己配置相关参数。首先要注意的是,系统会为你生成一个appId,appsercet,后面会讲到这个的作用。现在你需要配置 URL 和 Token。
具体来说,这个所谓的URL就是你需要在你的代码中与微信进行Token验证交互的一种方法。配置完成后,微信会使用配置的url发起http请求。请注意,发起方法是获取请求。因此,代码中提供的接口需要将请求头设置为get请求:
method=(RequestMethod.GET) 方法中需要验证微信发送的消息。下面的token需要和你项目中配置的token一致。微信发送请求后,会带上签名和时间戳。 , 随机数被检查。如果匹配成功,则可以进行下一步。如果不一致,则匹配失败。需要注意的是,这个url需要有自己的域名。我个人在Sunny-Ngrok上申请了内网穿透,并赠送了一个域名。
2.2 sunn-Ngrok 内网渗透账号申请
点击申请账号
账户创建后,会有如上图所示。其实,开通域名的方式有很多种。这里我只是给我一个参考方法。然后点击打开隧道,购买隧道
一个月10元不算贵。购买后点击隧道管理
购买后会有记录,可以同时查看赠送域名和查看状态。此时的状态为离线。如果是离线,微信公众平台微信发起的请求无法配置从本机接受,需要到官网下载客户端启动隧道。
cmd命令行进入sunny.exe所在目录并执行
sunny.exe clientid 隧道 ID
如上图所示,将域名指向你本地的ip和端口号后,就可以在公众号提交配置了。在我自己机器的代码中,我做了如下配置:
@RequestMapping(value = "/wx/wxmsgreceive", method = {RequestMethod.GET})
public void verifywxtoken(HttpServletRequest request, HttpServletResponse response) throws Exception {
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
logger.info("开始校验信息是否是从微信服务器发出");
// 签名
String signature = request.getParameter("signature");
// 时间戳
String timestamp = request.getParameter("timestamp");
// 随机数
String nonce = request.getParameter("nonce");
// 通过检验signature对请求进行校验,若校验成功则原样返回echostr,表示接入成功,否则接入失败
String result = Sha1.gen(SERVER_TOKEN, timestamp, nonce);
if (signature.equals(result)) {
// 随机字符串
String echostr = request.getParameter("echostr");
logger.debug("接入成功,echostr {}", echostr);
response.getWriter().write(echostr);
}
}
微信验证码
public static String gen(String token, String timestamp, String nonce) throws NoSuchAlgorithmException {
String[] arr = new String[]{token, timestamp, nonce};
Arrays.sort(arr);
StringBuffer content = new StringBuffer();
for (String a : arr) {
content.append(a);
}
return DigestUtils.sha1Hex(content.toString());
}
因为我配置的请求头是/wx/wxmsgreceive,所以公共平台上的配置页面是域名+/wx/wxmsgreceive。
此时,当您在网页上点击提交时,微信会向本机发送认证请求,以确保本机的服务必须开启。
这是官方的说明,所以我们开发的项目中需要提供一个暴露的接口来验证微信服务器,主要是验证微信公众号网页上填写的token验证。官方文档说明如下:
所以在项目中,放置在配置文件或常量池中的token必须是微信公众号访问中填写的token的字符串。如果输入不同或者方法中的解密比较有问题,在网页上点击确定,就会出现“失败”字样。
2.3 微信开发者工具准备
下载微信开发者工具。
点击下载微信开发者工具
下载完成后扫码登录
选择微信公众号网页开发
此工具是后续开发中访问URL和前端调试必不可少的工具。
2.3 Oauth2 授权
此时测试号已经配置好了,那么接下来我们如何开发呢?在微信公众号页面,部分页面需要根据用户的身份回显不同的信息,比如用户的还款清单。这些实现首先需要获取个人信息然后与数据库进行交互,需要获取用户的唯一标识。在微信中,每个人都有并且只有一个唯一标识openId。这个openId需要通过微信的授权和回调获取。同时,微信公开文档上也有详细的授权方式介绍。如何授权可以根据自己的业务需要使用。在实际业务中,根据项目的特点固化不同的用户。我们所做的是将用户固化到数据库中,生成一个 UUID,并将 UUID 放入 cookie。授权非常重要。通过它的控件,我们可以通过获取当前用户的openid来比较用户是会员还是普通会员,是非管理员还是管理员等。这在页面跳转中起着至关重要的作用。同时,在代码中,一些静态页面可能不一定需要授权,任何人都可以查看。所以在代码中,我使用了一个过滤器,直接在前台发布了一系列.css、.js、.html等。特殊要求,我拉过来,要求微信授权。例如,我在项目中。 .go请求中需要验证,通过微信回调获取当前用户信息,固化用户。代码如下:
@WebFilter(urlPatterns = "/*", filterName = "authFilter")
public class AuthFilter implements Filter {
private final Logger logger = LoggerFactory.getLogger(AuthFilter.class);
@Autowired
private GeneralConfigService gcService;
@Autowired
private WxUserVerify wxUserVerify;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
try {
String url = request.getRequestURI();
logger.info("URL:" + url);
// 1.请求内容为WEB静态内容时直接放行
if (StringUtil.separatorEndWith(gcService.getStaticResourceConfig(), url)) {
chain.doFilter(servletRequest, servletResponse);
return;
}
// 2.不是静态资源进行验证
if(!checkUrl(request, response, url)){
return;
}
chain.doFilter(servletRequest, servletResponse);
return;
} catch (FilterException e1) {
//自定义异常,这里可以直接把错误信息抛出去,不需要记录日志,因为这里是业务异常。
ResponseUtil.error(response, e1.getMessage());
} catch (Exception e2) {
//无法捕捉的异常,不能直接把错误信息抛出去,需要包装下错误信息
logger.error(e2.getMessage(), e2);
ResponseUtil.error(response, "系统异常,请稍后再试...");
}
}
/**
* 与数据库配置url进行匹配
* @param request
* @param response
* @param url
* @return
*/
private boolean checkUrl(HttpServletRequest request, HttpServletResponse response, String url) {
boolean passFlag=true;
//与数据库进行匹配
Map urlConfig = getUrlConfig();
//比较匹配项
String substring = url.substring(url.lastIndexOf("/") + 1);
if (!urlConfig.containsKey(substring)) {
return passFlag;
}
CallBackMsg msg = wxUserVerify.doVerify(request, response);
if (msg.getResultCode().equals(CallBackMsg.WX_VALID_CONTINUE)) {
passFlag=false;
} else if (msg.getResultCode().equals(Const.ERROR_CODE)) {
throw new FilterException(FilterExceptionEnum.ERROR_WX_VALID_FAILE);
}
return passFlag;
}
/**
* 获取地址配置信息
* @return
*/
private Map getUrlConfig() {
// 3.获取需要验证用户的请求配置
Map configAddressList = gcService.getConfigAddressList();
logger.info(configAddressList.toString());
if (configAddressList.isEmpty()) {
logger.error("urlValidConfig为空,请检查!");
throw new FilterException(FilterExceptionEnum.ERROR_VALIDCONF_NULL);
}
return configAddressList;
}
@Override
public void destroy() {
}
}
通过创建一个类来实现Filter过滤器进行验证,@WebFilter(urlPatterns = "/*", filterName = "authFilter")对所有请求进行过滤拦截,其中封装的方法当是特定请求时会被拉取申请授权
private CallBackMsg impower(HttpServletRequest request, HttpServletResponse response) {
CallBackMsg msg = new CallBackMsg();
String code = request.getParameter("code");
try {
// 从配置获取access_token
String appId = getWxParams("wxAppid");
String secret = getWxParams("wxSecret");
String accessTokenUrl = gcService.getUrlWxFwGetToken() + "?appid=" + appId + "&secret=" + secret + "&code="
+ code + "&grant_type=authorization_code";
logger.info("accessTokenUrl:" + accessTokenUrl);
String accessTokenResult = "";
if (StringUtil.isEmpty(proxyFlag)) {
proxyFlag = gcService.getProxyFlag();
}
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
accessTokenResult = HttpUtils.sendPostHttpsViaProxy(accessTokenUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
accessTokenResult = HttpUtils.sendPostHttps(accessTokenUrl, "");
}
logger.info("accessTokenResult:" + accessTokenResult);
JSONObject accessTokenJson = JSONObject.parseObject(accessTokenResult);
String accessToken = accessTokenJson.getString("access_token");
logger.info("accessToken:" + accessToken);
String openid = accessTokenJson.getString("openid");
logger.info("openid:" + openid);
// 查询数据库中的用户数据
String reqUrl = gcService.getSkylarkServiceUrl() + "wechat/searchwxuserinfo";
ResponseDto responseQuery = this.restInvoke(reqUrl, getQueryParam(openid, null, 1));
String userInfoDb = responseQuery.getRspMesg();
JSONObject userInfoDbJson = JSONObject.parseObject(userInfoDb);
String uuid = "";
// 数据库不存在该用户则保存数据库,存在则返回已存在的UUID
if (StringUtils.isEmpty(userInfoDbJson)) {
// 查询微信中的用户数据
uuid = UUIDGenerator.genUUID();
// 获取用户信息
String userInfoUrl = gcService.getUrlWxFwGetUser() + "?access_token=" + accessToken + "&openid="
+ openid + "&lang=zh_CN";
logger.info("userInfoUrl:" + userInfoUrl);
String userInfoResult = "";
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
userInfoResult = HttpUtils.sendPostHttpsViaProxy(userInfoUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
userInfoResult = HttpUtils.sendPostHttps(userInfoUrl, "");
}
logger.info("userInfoResult:" + userInfoResult);
JSONObject userInfoJson = JSONObject.parseObject(userInfoResult);
// 固化用户
String addReq = gcService.getSkylarkServiceUrl() + "wechat/addwxuserinfo";
ResponseDto addResp = this.restInvoke(addReq,
getEntityParam(uuid, openid, userInfoJson));
// 失败另处理
if (!(Const.SUCCESS_CODE).equals(addResp.getRspCode())) {
// 保存数据失败,认证失败
msg.setResultCode(Const.ERROR_CODE);
return msg;
}
} else {
uuid = userInfoDbJson.getString("id");
}
// 权限:本项目中的类都可以访问该cookie,存储到客户端
Cookie cookie = new Cookie(Const.TOKEN, uuid);
cookie.setPath("/");
response.addCookie(cookie);
//将token存入session
HttpSession session = request.getSession();
session.setAttribute("authToken",uuid);
} catch (IOException e) {
logger.error(e.getMessage());
}
msg.setResultCode(Const.SUCCESS_CODE);
return msg;
}
因为项目中使用了代理服务器,不需要本地开发,所以方法有点乱,但是大体思路是客户端发起带有特殊后缀的请求时,被过滤器拦截接下来,与微信服务器进行交互授权的过程。授权成功后,向微信提供回调地址,并将微信带回的用户信息保存在表中。同时,当前用户在库表中生成的唯一标识标识存储在cookie域中。
这样就可以将获取到的openid放入cookie中了。那么这个openId就可以固化了,也就是存储在数据库中。在会话中,如果点击某个页面需要使用微信授权,可以先从cookie域中获取。如果cookie不可用,则向微信发起授权请求,获取openid后,存储cookie和curing。有一些步骤可以实现这一点。微信开放平台上有相关的demo。如果您需要我提供它们,请留言。后续授权码我会贴出来供大家参考。 查看全部
开发接入2.1微信公众平台接口测试账号的申请流程及步骤
一、前言
随着微信的普及,年轻一代逐渐从QQ转向微信。界面简洁,功能强大,男女老少皆宜,是微信的特色。正是这一特性,使微信成为了中国社交软件的巨头。因此,很多产品需要在微信中开发以满足需求。
本文主要讲服务号的开发,与微信服务器的交互,以及使用微信公众号的Oauth2授权,在微信中展示本地开发的内容并进行交互。由于公众号申请需要时间和经验,需要公司相关资质,作为个人开发者,可以先在微信官方平台申请测试号,使用测试号授权与微信服务器交互并调试这一页。在开始之前,朋友们需要了解他们的需求。微信分为企业号、服务号、订阅号。不同的账户有不同的功能。具体可以到微信官网查看需要开发什么类型的账号。
二、development 接入2.1 微信公众平台接口测试账号申请
如前言所述,在开发中,我们一半人会使用官方微信公众号作为我们的生产线环境,然后aut环境可以使用测试号进行开发,从而实现与微信的交互。测试账号申请链接如下
测试帐户申请
进入后,您将看到以下屏幕。登录
登录后,您会看到以下屏幕:
因为我已经配置好了,所以显示配置后的相关参数。如果是第一次进入,需要自己配置相关参数。首先要注意的是,系统会为你生成一个appId,appsercet,后面会讲到这个的作用。现在你需要配置 URL 和 Token。
具体来说,这个所谓的URL就是你需要在你的代码中与微信进行Token验证交互的一种方法。配置完成后,微信会使用配置的url发起http请求。请注意,发起方法是获取请求。因此,代码中提供的接口需要将请求头设置为get请求:
method=(RequestMethod.GET) 方法中需要验证微信发送的消息。下面的token需要和你项目中配置的token一致。微信发送请求后,会带上签名和时间戳。 , 随机数被检查。如果匹配成功,则可以进行下一步。如果不一致,则匹配失败。需要注意的是,这个url需要有自己的域名。我个人在Sunny-Ngrok上申请了内网穿透,并赠送了一个域名。
2.2 sunn-Ngrok 内网渗透账号申请
点击申请账号
账户创建后,会有如上图所示。其实,开通域名的方式有很多种。这里我只是给我一个参考方法。然后点击打开隧道,购买隧道
一个月10元不算贵。购买后点击隧道管理
购买后会有记录,可以同时查看赠送域名和查看状态。此时的状态为离线。如果是离线,微信公众平台微信发起的请求无法配置从本机接受,需要到官网下载客户端启动隧道。
cmd命令行进入sunny.exe所在目录并执行
sunny.exe clientid 隧道 ID
如上图所示,将域名指向你本地的ip和端口号后,就可以在公众号提交配置了。在我自己机器的代码中,我做了如下配置:
@RequestMapping(value = "/wx/wxmsgreceive", method = {RequestMethod.GET})
public void verifywxtoken(HttpServletRequest request, HttpServletResponse response) throws Exception {
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
logger.info("开始校验信息是否是从微信服务器发出");
// 签名
String signature = request.getParameter("signature");
// 时间戳
String timestamp = request.getParameter("timestamp");
// 随机数
String nonce = request.getParameter("nonce");
// 通过检验signature对请求进行校验,若校验成功则原样返回echostr,表示接入成功,否则接入失败
String result = Sha1.gen(SERVER_TOKEN, timestamp, nonce);
if (signature.equals(result)) {
// 随机字符串
String echostr = request.getParameter("echostr");
logger.debug("接入成功,echostr {}", echostr);
response.getWriter().write(echostr);
}
}
微信验证码
public static String gen(String token, String timestamp, String nonce) throws NoSuchAlgorithmException {
String[] arr = new String[]{token, timestamp, nonce};
Arrays.sort(arr);
StringBuffer content = new StringBuffer();
for (String a : arr) {
content.append(a);
}
return DigestUtils.sha1Hex(content.toString());
}
因为我配置的请求头是/wx/wxmsgreceive,所以公共平台上的配置页面是域名+/wx/wxmsgreceive。
此时,当您在网页上点击提交时,微信会向本机发送认证请求,以确保本机的服务必须开启。
这是官方的说明,所以我们开发的项目中需要提供一个暴露的接口来验证微信服务器,主要是验证微信公众号网页上填写的token验证。官方文档说明如下:
所以在项目中,放置在配置文件或常量池中的token必须是微信公众号访问中填写的token的字符串。如果输入不同或者方法中的解密比较有问题,在网页上点击确定,就会出现“失败”字样。
2.3 微信开发者工具准备
下载微信开发者工具。
点击下载微信开发者工具
下载完成后扫码登录
选择微信公众号网页开发
此工具是后续开发中访问URL和前端调试必不可少的工具。
2.3 Oauth2 授权
此时测试号已经配置好了,那么接下来我们如何开发呢?在微信公众号页面,部分页面需要根据用户的身份回显不同的信息,比如用户的还款清单。这些实现首先需要获取个人信息然后与数据库进行交互,需要获取用户的唯一标识。在微信中,每个人都有并且只有一个唯一标识openId。这个openId需要通过微信的授权和回调获取。同时,微信公开文档上也有详细的授权方式介绍。如何授权可以根据自己的业务需要使用。在实际业务中,根据项目的特点固化不同的用户。我们所做的是将用户固化到数据库中,生成一个 UUID,并将 UUID 放入 cookie。授权非常重要。通过它的控件,我们可以通过获取当前用户的openid来比较用户是会员还是普通会员,是非管理员还是管理员等。这在页面跳转中起着至关重要的作用。同时,在代码中,一些静态页面可能不一定需要授权,任何人都可以查看。所以在代码中,我使用了一个过滤器,直接在前台发布了一系列.css、.js、.html等。特殊要求,我拉过来,要求微信授权。例如,我在项目中。 .go请求中需要验证,通过微信回调获取当前用户信息,固化用户。代码如下:
@WebFilter(urlPatterns = "/*", filterName = "authFilter")
public class AuthFilter implements Filter {
private final Logger logger = LoggerFactory.getLogger(AuthFilter.class);
@Autowired
private GeneralConfigService gcService;
@Autowired
private WxUserVerify wxUserVerify;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
try {
String url = request.getRequestURI();
logger.info("URL:" + url);
// 1.请求内容为WEB静态内容时直接放行
if (StringUtil.separatorEndWith(gcService.getStaticResourceConfig(), url)) {
chain.doFilter(servletRequest, servletResponse);
return;
}
// 2.不是静态资源进行验证
if(!checkUrl(request, response, url)){
return;
}
chain.doFilter(servletRequest, servletResponse);
return;
} catch (FilterException e1) {
//自定义异常,这里可以直接把错误信息抛出去,不需要记录日志,因为这里是业务异常。
ResponseUtil.error(response, e1.getMessage());
} catch (Exception e2) {
//无法捕捉的异常,不能直接把错误信息抛出去,需要包装下错误信息
logger.error(e2.getMessage(), e2);
ResponseUtil.error(response, "系统异常,请稍后再试...");
}
}
/**
* 与数据库配置url进行匹配
* @param request
* @param response
* @param url
* @return
*/
private boolean checkUrl(HttpServletRequest request, HttpServletResponse response, String url) {
boolean passFlag=true;
//与数据库进行匹配
Map urlConfig = getUrlConfig();
//比较匹配项
String substring = url.substring(url.lastIndexOf("/") + 1);
if (!urlConfig.containsKey(substring)) {
return passFlag;
}
CallBackMsg msg = wxUserVerify.doVerify(request, response);
if (msg.getResultCode().equals(CallBackMsg.WX_VALID_CONTINUE)) {
passFlag=false;
} else if (msg.getResultCode().equals(Const.ERROR_CODE)) {
throw new FilterException(FilterExceptionEnum.ERROR_WX_VALID_FAILE);
}
return passFlag;
}
/**
* 获取地址配置信息
* @return
*/
private Map getUrlConfig() {
// 3.获取需要验证用户的请求配置
Map configAddressList = gcService.getConfigAddressList();
logger.info(configAddressList.toString());
if (configAddressList.isEmpty()) {
logger.error("urlValidConfig为空,请检查!");
throw new FilterException(FilterExceptionEnum.ERROR_VALIDCONF_NULL);
}
return configAddressList;
}
@Override
public void destroy() {
}
}
通过创建一个类来实现Filter过滤器进行验证,@WebFilter(urlPatterns = "/*", filterName = "authFilter")对所有请求进行过滤拦截,其中封装的方法当是特定请求时会被拉取申请授权
private CallBackMsg impower(HttpServletRequest request, HttpServletResponse response) {
CallBackMsg msg = new CallBackMsg();
String code = request.getParameter("code");
try {
// 从配置获取access_token
String appId = getWxParams("wxAppid");
String secret = getWxParams("wxSecret");
String accessTokenUrl = gcService.getUrlWxFwGetToken() + "?appid=" + appId + "&secret=" + secret + "&code="
+ code + "&grant_type=authorization_code";
logger.info("accessTokenUrl:" + accessTokenUrl);
String accessTokenResult = "";
if (StringUtil.isEmpty(proxyFlag)) {
proxyFlag = gcService.getProxyFlag();
}
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
accessTokenResult = HttpUtils.sendPostHttpsViaProxy(accessTokenUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
accessTokenResult = HttpUtils.sendPostHttps(accessTokenUrl, "");
}
logger.info("accessTokenResult:" + accessTokenResult);
JSONObject accessTokenJson = JSONObject.parseObject(accessTokenResult);
String accessToken = accessTokenJson.getString("access_token");
logger.info("accessToken:" + accessToken);
String openid = accessTokenJson.getString("openid");
logger.info("openid:" + openid);
// 查询数据库中的用户数据
String reqUrl = gcService.getSkylarkServiceUrl() + "wechat/searchwxuserinfo";
ResponseDto responseQuery = this.restInvoke(reqUrl, getQueryParam(openid, null, 1));
String userInfoDb = responseQuery.getRspMesg();
JSONObject userInfoDbJson = JSONObject.parseObject(userInfoDb);
String uuid = "";
// 数据库不存在该用户则保存数据库,存在则返回已存在的UUID
if (StringUtils.isEmpty(userInfoDbJson)) {
// 查询微信中的用户数据
uuid = UUIDGenerator.genUUID();
// 获取用户信息
String userInfoUrl = gcService.getUrlWxFwGetUser() + "?access_token=" + accessToken + "&openid="
+ openid + "&lang=zh_CN";
logger.info("userInfoUrl:" + userInfoUrl);
String userInfoResult = "";
if (Const.PROXY_FLAG_USED.equals(proxyFlag)) {
userInfoResult = HttpUtils.sendPostHttpsViaProxy(userInfoUrl, "", gcService.getProxyIp(),
gcService.getProxyPort());
} else {
userInfoResult = HttpUtils.sendPostHttps(userInfoUrl, "");
}
logger.info("userInfoResult:" + userInfoResult);
JSONObject userInfoJson = JSONObject.parseObject(userInfoResult);
// 固化用户
String addReq = gcService.getSkylarkServiceUrl() + "wechat/addwxuserinfo";
ResponseDto addResp = this.restInvoke(addReq,
getEntityParam(uuid, openid, userInfoJson));
// 失败另处理
if (!(Const.SUCCESS_CODE).equals(addResp.getRspCode())) {
// 保存数据失败,认证失败
msg.setResultCode(Const.ERROR_CODE);
return msg;
}
} else {
uuid = userInfoDbJson.getString("id");
}
// 权限:本项目中的类都可以访问该cookie,存储到客户端
Cookie cookie = new Cookie(Const.TOKEN, uuid);
cookie.setPath("/");
response.addCookie(cookie);
//将token存入session
HttpSession session = request.getSession();
session.setAttribute("authToken",uuid);
} catch (IOException e) {
logger.error(e.getMessage());
}
msg.setResultCode(Const.SUCCESS_CODE);
return msg;
}
因为项目中使用了代理服务器,不需要本地开发,所以方法有点乱,但是大体思路是客户端发起带有特殊后缀的请求时,被过滤器拦截接下来,与微信服务器进行交互授权的过程。授权成功后,向微信提供回调地址,并将微信带回的用户信息保存在表中。同时,当前用户在库表中生成的唯一标识标识存储在cookie域中。
这样就可以将获取到的openid放入cookie中了。那么这个openId就可以固化了,也就是存储在数据库中。在会话中,如果点击某个页面需要使用微信授权,可以先从cookie域中获取。如果cookie不可用,则向微信发起授权请求,获取openid后,存储cookie和curing。有一些步骤可以实现这一点。微信开放平台上有相关的demo。如果您需要我提供它们,请留言。后续授权码我会贴出来供大家参考。
如何实际操作公众号可以让小游戏在一定程度上裂变
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-07-29 03:22
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
问题就在这里。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价 查看全部
如何实际操作公众号可以让小游戏在一定程度上裂变
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
问题就在这里。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价
微信公众号的两种开发模式你可能会有一个疑惑?
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-28 23:34
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
那么问题来了。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价 查看全部
微信公众号的两种开发模式你可能会有一个疑惑?
微信公众号的两种开发模式
你可能有疑问?为什么要使用小号进行测试?其实微信公众号的开发有两种模式:
编辑模式:主要针对非程序员和信息发布公众号。开启此模式后,您可以通过界面轻松配置“自定义菜单”和“自动回复消息”。
开发模式:主要针对有开发能力的人。开启该模式后,您可以使用微信公众平台上开放的界面,通过编程实现自定义菜单的创建和用户消息的接收/处理/响应。这种模式比较灵活,建议有开发能力的公司或个人采用这种模式。
简单来说,不需要编写代码,直接在微信公众号网页上配置自定义菜单或自动回复。这称为编辑模式;您需要编写代码来实现自动回复或更高级的逻辑,这称为开发模式;而这两种模式是互斥的,即一旦开启了开发模式,编辑模式就失效了。之前配置的自定义菜单和自动回复都是无效的。这对于我现在的公众号来说是不能接受的,因为编辑模式是模式里面的配置太多了。迁移到开发者模式需要大量的时间和成本,其次不稳定,所以我想到了我的尘土飞扬的小号。
在正式开发之前,您需要有以下“纸”或“笔”:
一台服务器(华南、华北、华东、华西最佳位置)
一个有据可查的域名是最好的
服务器访问微信公众号
那么,在微信公众号的开发过程中,微信公众号后端就像一个代理服务器。微信公众号消息首先由微信公众号后端处理,然后转发到我们自己的服务器进行处理。这个过程我们必须遵循微信公众号的开发规范;那么,我们如何将微信公众号与我们自己的服务器连接起来呢?开发者接入微信公众平台进行开发,需要完成以下步骤:
填写服务器配置:填写URL(只支持80(http)和443(https)端口,开发者文档说是服务器域名,准确的说不是你的服务器域名,但是你服务器上的微信公众号转发消息的根路由)、Token(可以填写)和EncodingAESKey(可以自动生成),这两个参数可能只有在访问时才有用。它们是使用 sha1 加密来确保安全性的几个参数中的第二个。比较在意,这一步主要是注意网址的正确性。
验证服务器地址的有效性:点击验证按钮,网页会出现Token验证成功或失败的提示。
根据接口文档实现业务逻辑:这是我们手写代码的部分。
应用逻辑
有个坑需要填写,个人微信公众号无法获取用户的基本信息:昵称、头像等
获得这个权限需要认证,但是认证需要拿钱,但是我写的很烂
回到我们创作的初衷,涉及到个性化的预测海报。我将简单地处理个性化部分,只是随机字符串。深入挖掘,需要个性化推荐,但没有用户信息,是不是要写点逻辑?用户丢了兴趣又回来了?这已经超出了本次创作的初衷,下次补上。
至于制作海报,我使用PIL库中的ImageDraw对象,直接在预设海报上填写字符串即可。
PIL 库的安装姿势是 pip install Pillow 而不是 pip install PIL
然后应用服务器使用Flask框架(Flask是应用框架,nginx是web服务器,都是软件,Flask自己的生产环境服务器不足以支持实际应用,需要uwsgi应用服务器,nginx直接处理静态资源请求,逻辑请求转发给uwsgi;阿里云服务器是一个虚拟化的PC,包括软硬件;
回到正题,假设我们的根路由是
我们可以给这个路由绑定一个视图函数my_view(),同时打开开关处理post请求(默认只处理get)。我们所有的逻辑都可以通过这个视图函数来实现,并连接到公众号进行开发 当通过get方法向我们的服务器请求Token验证公众号时,验证后转发的消息通过post方法,那么我们就可以通过请求方式区分是验证还是转发。
f request.method == ‘GET’:
signature = request.args[‘signature’]
timestamp = request.args[‘timestamp’]
echostr = request.args[‘echostr’]
nonce = request.args[‘nonce’]
token = ‘我要爱这个世界’
tempList = [令牌、时间戳、随机数]
#字典顺序排序
tempList.sort()
#转成字符串
tempStr = ”.join(tempList)
#sha1 加密
tempStr = hashlib.sha1(tempStr.encode(‘utf-8’)).hexdigest()
如果 tempStr == 签名:
print('令牌验证成功')
返回 echostr
其他:
#可以发现之前的验证码其实无关紧要,只要返回echostr就验证成功
返回 echostr
elif request.method == ‘POST’:
print('在这里写业务逻辑')
我们还需要调用我们服务器上的微信接口。比如海报制作完成后,通过微信转发给用户,不能直接返回图片的二进制数据。事实上,这是由微信公众号完成的。我们需要上传发送海报到微信公众号素材库,获取海报的id,然后封装成xml数据返回给微信公众号(吐槽还没有升级成json交换数据) ,以便用户收到我们的海报。
那么问题来了。将海报上传至微信公众号素材库。我在公众号文章编辑界面已经很久了。我以为我必须手动上传它。幸运的是,我找到了接口1,我们可以在服务器上调用它。这个接口1,为了防止这个接口1被滥用,必须提供access_token,但是access_token是从哪里来的呢?需要调用另一个接口2,接口2需要提供AppId和AppSecret参数。如果不自己修改,这两个长期有效,可以直接获取。
接口 1:POST
接口 2:获取
另一个陷阱是这个access_token的有效期只有2个小时,所以需要不断更新,所以需要在我们的Flask中引入循环任务配置
#定时任务配置类Config(object):#创建配置
#任务列表
工作 = [
{
‘id’: ‘1’,
'func': '__main__:refreshToken', # 定时执行的方法名
'trigger': 'interval',#interval 表示循环任务
'hours': 2, # 每两小时执行一次
}
]
app.config.from_object(Config()) # 为实例化的flask引入配置
亿奇达积累了10年的行业经验!专业小程序,公众号H5、APP定制开发
来电即刻享受优惠
点击获取报价
使用到的技术:python3,微信公众号的全部内容分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-28 21:03
使用的技术:python3、selenium、requests
最近接到一个新项目,需要爬取微信公众号的数据。接下来就和大家分享一下
笔者在网上也看到过使用**搜狗微信API来抓取数据,但是如果我想按照公众号把它的文章全部抓取,发现不行
它只有最近的文章,意思是我想把他的文章全部弄到手,但是不行(可能作者不合格,但是我没找到。欢迎大家同学帮我改正)。如果你搜索文章,是这种
比如我想爬取公众号的所有文章,还是不行。
还有使用抓包工具**来抓app的数据接口。这是可行的,但是抓包工具的配置和网页数据接口的分析非常复杂,这里就不介绍了。
接下来说说我的想法
1.在微信公众号平台注册一个账号(注册一个即可)
然后点击超链接,进入公众号,选择显示公众号的所有文章信息,如图
好的,现在我们找到了数据,继续进行网络分析
2.分析网页
F12 调试
这里我们可以观察信息界面,分析这个json数据,可以看到链接收录文章,链接,标题,时间等,所以,接下来添加代码
3.上代码
首先解决的是登录问题,我用selenium+chrome登录,
account_name = "账号"
password = "密码"
def wechat_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/")
time.sleep(2)
print("正在输入微信公众号登录账号和密码......")
# 清空账号框中的内容
try:
driver.find_element_by_name("account").clear()
print("正在输入微信公众号登录账号和密码......")
driver.find_element_by_name("account").send_keys(account_name)
time.sleep(1)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys(password)
time.sleep(1)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
driver.find_element_by_class_name("frm_checkbox_label").click()
time.sleep(5)
# 自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
except:
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
这里说明一下,微信公众号平台的登录界面可能不同。
这是一种情况,就是直接扫码登录,另一种是
用账号登录,所以登录的时候多了一种情况,最后记得把网页中的cookie信息保存在本地,用来爬取
2.获取具体的文章
def get_content(query):
# query为要爬取的公众号名称
# 公众号主页
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 511
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = session.get(url=url, cookies=cookies, verify=False)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(
search_url,
cookies=cookies,
headers=header,
params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin)
time.sleep(5)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = query + '.txt'
seq += 1
with open(fileName, 'a', encoding='utf-8') as fh:
fh.write(
str(seq) +
"|" +
content_title +
"|" +
content_link +
"\n")
num -= 1
begin = int(begin)
begin += 5
好了朋友们,以上就是对微信公众号全部内容的抓取,希望对大家有所帮助,欢迎各位大佬指正修改,共同学习进步 查看全部
使用到的技术:python3,微信公众号的全部内容分析
使用的技术:python3、selenium、requests
最近接到一个新项目,需要爬取微信公众号的数据。接下来就和大家分享一下
笔者在网上也看到过使用**搜狗微信API来抓取数据,但是如果我想按照公众号把它的文章全部抓取,发现不行
它只有最近的文章,意思是我想把他的文章全部弄到手,但是不行(可能作者不合格,但是我没找到。欢迎大家同学帮我改正)。如果你搜索文章,是这种
比如我想爬取公众号的所有文章,还是不行。
还有使用抓包工具**来抓app的数据接口。这是可行的,但是抓包工具的配置和网页数据接口的分析非常复杂,这里就不介绍了。
接下来说说我的想法
1.在微信公众号平台注册一个账号(注册一个即可)
然后点击超链接,进入公众号,选择显示公众号的所有文章信息,如图
好的,现在我们找到了数据,继续进行网络分析
2.分析网页
F12 调试
这里我们可以观察信息界面,分析这个json数据,可以看到链接收录文章,链接,标题,时间等,所以,接下来添加代码
3.上代码
首先解决的是登录问题,我用selenium+chrome登录,
account_name = "账号"
password = "密码"
def wechat_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/";)
time.sleep(2)
print("正在输入微信公众号登录账号和密码......")
# 清空账号框中的内容
try:
driver.find_element_by_name("account").clear()
print("正在输入微信公众号登录账号和密码......")
driver.find_element_by_name("account").send_keys(account_name)
time.sleep(1)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys(password)
time.sleep(1)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
driver.find_element_by_class_name("frm_checkbox_label").click()
time.sleep(5)
# 自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
except:
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = driver.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
这里说明一下,微信公众号平台的登录界面可能不同。
这是一种情况,就是直接扫码登录,另一种是
用账号登录,所以登录的时候多了一种情况,最后记得把网页中的cookie信息保存在本地,用来爬取
2.获取具体的文章
def get_content(query):
# query为要爬取的公众号名称
# 公众号主页
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 511
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-b ... 51598,从这里获取token信息
response = session.get(url=url, cookies=cookies, verify=False)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(
search_url,
cookies=cookies,
headers=header,
params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin)
time.sleep(5)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = query + '.txt'
seq += 1
with open(fileName, 'a', encoding='utf-8') as fh:
fh.write(
str(seq) +
"|" +
content_title +
"|" +
content_link +
"\n")
num -= 1
begin = int(begin)
begin += 5
好了朋友们,以上就是对微信公众号全部内容的抓取,希望对大家有所帮助,欢迎各位大佬指正修改,共同学习进步
Python3.5+fiddler4 抓取微信公众号点赞、阅读、标题
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-28 20:44
代码测试有效期至2019/03/08
微信爬虫步骤:
必需品:
自有微信公众号Fiddler抓包工具Python 3+版
提琴手下载链接
HTTP 代理工具也称为抓包工具。主流的抓包工具是Windows平台的Fiddler,macOS平台的Charles,阿里开源了一个叫AnyProxy的工具。它们的基本原理是相似的,就是通过在移动客户端上设置代理IP和端口,所有来自客户端的HTTP和HTTPS请求都会经过代理工具,每个请求都可以在代理工具中清晰的看到。然后可以分析详细信息以找出每个请求的构造方式。搞清楚这些之后,我们就可以用Python来模拟发起请求了,然后就可以得到我们想要的数据了。
安装包超过4M。配置前,首先确保您的手机和电脑在同一个局域网内。如果不在同一个局域网内,可以购买便携式WiFi,在电脑上搭建一个极简的无线路由器。一路点击下一步完成安装过程。
Fiddler 配置选择工具> Fiddler 选项> 连接 Fiddler 的默认端口为8888,如果该端口已经被其他程序占用,需要手动更改,勾选允许远程计算机连接,其他选项即可。 , 配置更新后记得重启Fiddler。一定要重启Fiddler,否则代理将失效。 .接下来需要配置手机,但是这里微信有pc客户端,所以不需要配置手机
现在打开微信,随机选择一个公众号,进入公众号的【查看历史信息】
同时观察 Fiddler 的主面板。当微信从公众号介绍页面进入历史消息页面时,已经可以在Fiddler上看到请求进来了。这些请求是微信APP向服务器发送的请求。现在简单介绍一下这个请求面板上各个模块的含义。
我将上面的主面板分成了 7 个块。需要了解每个区块的内容,然后才可以使用Python代码模拟微信请求。 1、服务器响应结果,200表示服务器成功响应了2、请求协议,微信请求协议是基于HTTPS的,所以之前一定要配置好,否则看不到HTTPS请求。 3、微信服务器主机名4、请求路径5、请求行,包括请求方法(GET)、请求协议(HTTP/1.1)、请求路径(/mp/profile_ext...)一长串参数)6、收录cookie信息的请求头。7、微信服务器返回的响应数据,我们切换到TextView和WebView看看返回的数据是什么样子的。
TextView模式下的预览效果为服务器返回的HTML源代码
WebView 模式是 HTML 代码的渲染效果。其实就是我们在手机微信上看到的效果,但是因为风格欠缺,在手机上没有看到美化效果。
如果服务器返回的是Json格式或者XML,也可以切换到对应的页面进行预览查看。
开始抓取:
1、拥有微信公众号
登录微信公众号,在菜单栏:素材管理—>新建素材,出现如下页面
F12查看网络,点击图中位置
公众号和user-Agent的cookies如下
Fakeid和token获取如下: 查看全部
Python3.5+fiddler4 抓取微信公众号点赞、阅读、标题
代码测试有效期至2019/03/08
微信爬虫步骤:
必需品:
自有微信公众号Fiddler抓包工具Python 3+版
提琴手下载链接
HTTP 代理工具也称为抓包工具。主流的抓包工具是Windows平台的Fiddler,macOS平台的Charles,阿里开源了一个叫AnyProxy的工具。它们的基本原理是相似的,就是通过在移动客户端上设置代理IP和端口,所有来自客户端的HTTP和HTTPS请求都会经过代理工具,每个请求都可以在代理工具中清晰的看到。然后可以分析详细信息以找出每个请求的构造方式。搞清楚这些之后,我们就可以用Python来模拟发起请求了,然后就可以得到我们想要的数据了。
安装包超过4M。配置前,首先确保您的手机和电脑在同一个局域网内。如果不在同一个局域网内,可以购买便携式WiFi,在电脑上搭建一个极简的无线路由器。一路点击下一步完成安装过程。
Fiddler 配置选择工具> Fiddler 选项> 连接 Fiddler 的默认端口为8888,如果该端口已经被其他程序占用,需要手动更改,勾选允许远程计算机连接,其他选项即可。 , 配置更新后记得重启Fiddler。一定要重启Fiddler,否则代理将失效。 .接下来需要配置手机,但是这里微信有pc客户端,所以不需要配置手机
现在打开微信,随机选择一个公众号,进入公众号的【查看历史信息】
同时观察 Fiddler 的主面板。当微信从公众号介绍页面进入历史消息页面时,已经可以在Fiddler上看到请求进来了。这些请求是微信APP向服务器发送的请求。现在简单介绍一下这个请求面板上各个模块的含义。
我将上面的主面板分成了 7 个块。需要了解每个区块的内容,然后才可以使用Python代码模拟微信请求。 1、服务器响应结果,200表示服务器成功响应了2、请求协议,微信请求协议是基于HTTPS的,所以之前一定要配置好,否则看不到HTTPS请求。 3、微信服务器主机名4、请求路径5、请求行,包括请求方法(GET)、请求协议(HTTP/1.1)、请求路径(/mp/profile_ext...)一长串参数)6、收录cookie信息的请求头。7、微信服务器返回的响应数据,我们切换到TextView和WebView看看返回的数据是什么样子的。
TextView模式下的预览效果为服务器返回的HTML源代码
WebView 模式是 HTML 代码的渲染效果。其实就是我们在手机微信上看到的效果,但是因为风格欠缺,在手机上没有看到美化效果。
如果服务器返回的是Json格式或者XML,也可以切换到对应的页面进行预览查看。
开始抓取:
1、拥有微信公众号
登录微信公众号,在菜单栏:素材管理—>新建素材,出现如下页面
F12查看网络,点击图中位置
公众号和user-Agent的cookies如下
Fakeid和token获取如下:
微信PC端解锁新功能搜索更方便微信生态内容触手可达
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-28 07:54
微信PC端解锁新功能搜索更方便微信生态内容触手可达
记者从腾讯获悉,PC端微信搜一搜近日迎来迭代更新,提供更丰富的搜索入口和更多样化的搜索内容。 Windows版微信更新为3.3.0后,用户可以通过对话、文章指尖搜索、对话、朋友圈#hyperlinks更快速地进行搜索。
同时,PC端微信搜索在搜索文章的基础上,增加了对公众号、小程序、新闻、表情、朋友圈、视频等微信生态内容搜索的支持。用户只需选择相关词表右键即可搜索微信生态中的各类优质内容,极大满足用户在工作、学习等多种搜索场景下的需求。
微信PC端解锁新功能
搜索更便捷,微信生态内容触手可及
Windows版微信更新为3.3.0后,PC端微信搜索支持会话、文章指尖搜索、会话、朋友圈#超链接搜索等多种能力,为用户提供更丰富的搜索条目。在PC端微信顶部,点击搜索框进入微信搜索,大大提高了用户在PC端搜索的便利性。
现在微信对话界面和公众号文章浏览界面都支持文本选择搜索。用户可以快速查找和理解聊天中出现的专有名词、网络热点和外语词。在浏览公众号文章时,还可以轻松选择产品名称,快速找到更多相关评价和用户体验。您还可以快速选词搜索定义,了解更多信息,提高阅读效率。 查看全部
微信PC端解锁新功能搜索更方便微信生态内容触手可达
记者从腾讯获悉,PC端微信搜一搜近日迎来迭代更新,提供更丰富的搜索入口和更多样化的搜索内容。 Windows版微信更新为3.3.0后,用户可以通过对话、文章指尖搜索、对话、朋友圈#hyperlinks更快速地进行搜索。
同时,PC端微信搜索在搜索文章的基础上,增加了对公众号、小程序、新闻、表情、朋友圈、视频等微信生态内容搜索的支持。用户只需选择相关词表右键即可搜索微信生态中的各类优质内容,极大满足用户在工作、学习等多种搜索场景下的需求。
微信PC端解锁新功能
搜索更便捷,微信生态内容触手可及
Windows版微信更新为3.3.0后,PC端微信搜索支持会话、文章指尖搜索、会话、朋友圈#超链接搜索等多种能力,为用户提供更丰富的搜索条目。在PC端微信顶部,点击搜索框进入微信搜索,大大提高了用户在PC端搜索的便利性。
现在微信对话界面和公众号文章浏览界面都支持文本选择搜索。用户可以快速查找和理解聊天中出现的专有名词、网络热点和外语词。在浏览公众号文章时,还可以轻松选择产品名称,快速找到更多相关评价和用户体验。您还可以快速选词搜索定义,了解更多信息,提高阅读效率。
微信公众号后台编辑素材界面的原理和原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-07-26 22:05
准备阶段
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
fig1 正式启动
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
❞
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
图7
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
微信公众号后台编辑素材界面的原理和原理
准备阶段
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
fig1 正式启动
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
❞
图 6 ❝
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
❞
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
图7
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,或者你可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
分词采集微信公众号文章分析用料清单的基本步骤采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-07-25 18:06
querylist采集微信公众号文章详情页分词检索文本分析用料清单的基本步骤1.web上获取,每条微信文章url,用http请求的方式抓取微信公众号关注链接的抓取方式,见:百度url抓取方式。2.主程序代码写法定义querylist,用于存放爬取的文章url。主要步骤node.js最小堆实现。querylist定义:。
谢邀,这个问题我已经解决了,简单总结一下,你所需要准备的有:1。这个querylist用你自己的语言做出来2。相应的一种字符串类型,如{"title":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"},分别放不同的字符串类型3。要爬取的数据表达式4。
结构体的设计(哈希,链表),以便最小程度保存数据。node。js写代码#//-st-ilwearf051ijzee9zowscp9cc45c1v1gs0={"name":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"}packagemainimport("fmt""math""dom""site")functionmake_new_scheduler(initial_querylist){//initial_querylist可任意可参考文档,非必需varlines=[];varindex=initial_querylist。
<p>length;varpath="{"+site。meta。path;varfirst_line="{"+site。meta。content;varlast_line="{"+site。meta。content;varformat="{"+path。length+1;varsize=1000000;}";for(varpage=index;page 查看全部
分词采集微信公众号文章分析用料清单的基本步骤采集
querylist采集微信公众号文章详情页分词检索文本分析用料清单的基本步骤1.web上获取,每条微信文章url,用http请求的方式抓取微信公众号关注链接的抓取方式,见:百度url抓取方式。2.主程序代码写法定义querylist,用于存放爬取的文章url。主要步骤node.js最小堆实现。querylist定义:。
谢邀,这个问题我已经解决了,简单总结一下,你所需要准备的有:1。这个querylist用你自己的语言做出来2。相应的一种字符串类型,如{"title":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"},分别放不同的字符串类型3。要爬取的数据表达式4。
结构体的设计(哈希,链表),以便最小程度保存数据。node。js写代码#//-st-ilwearf051ijzee9zowscp9cc45c1v1gs0={"name":"钱钱","content":"[{"parent":"jwj","themes":"home"}]"}packagemainimport("fmt""math""dom""site")functionmake_new_scheduler(initial_querylist){//initial_querylist可任意可参考文档,非必需varlines=[];varindex=initial_querylist。
<p>length;varpath="{"+site。meta。path;varfirst_line="{"+site。meta。content;varlast_line="{"+site。meta。content;varformat="{"+path。length+1;varsize=1000000;}";for(varpage=index;page
获取微信公众号文章的方法,你get到了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-25 06:33
获取微信公众号文章的方法,你get到了吗?
通过微信公众平台获取公众号文章的示例
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前有很多获取方式,通过搜狗、清博、web、客户端等都可以,这个可能不是很好,但是操作简单易懂。
所以,首先你要有一个微信公众平台帐号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形和文字:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号,就会出现对应的文章列表
你感到惊讶吗?可以打开控制台查看请求的接口
打开回复,有我们需要的文章链接
确认数据后,我们需要分析这个界面。
感觉很简单。 GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
我们输入公众号后,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
目前我还没有测试cookies的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样可以得到最新的10篇文章。如果想获得更多的历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-12-23
如何访问微信小程序公众号文章
前言随着小程序的不断发展,现在个人小程序已经开通了很多功能,个人小程序直接打开公众号链接。群里看到的一个小程序,点击直接阅读文章了,所以琢磨了一下,写了一些源码。主要代码:
python爬取微信公众号文章的方法
最近学习了Python3网络爬虫开发实践(崔庆才),刚刚了解到他这里使用代理爬取了公众号文章这里,但是根据他的代码,出现了一些问题。这里我用了这本书前面提到的一些内容进行了改进。 (这个代码作者半年前写的,但腾讯的网站半年前更新了)下面我直接上传代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
使用anyproxy提高公众号文章采集的效率
主要影响因素如下:1.网络环境差:2.微信客户端手机或模拟器崩溃:3.其他网络传输错误:因为我看重采集system 这个成本包括硬件投资、算力投资和人力占用。所以必须提高操作的稳定性。因此,如果采集中断,人工能量的成本必然会增加。所以针对这一点,我对 anyproxy 做了一些高级的改造,并利用其他工具来提高运行效率。以下是具体解决方法:一.code upgrade1)微信 浏览器白屏解决方法:修改文件requestHandler.js,或者在rule_default中
python下载微信公众号相关文章
本文示例分享python下载微信公众号文章的具体代码,供大家参考。具体内容如下: 从零开始学自动化测试,从公众号1.下载一系列文档1.搜索微信文章Keyword search2.解析搜索结果的前N页为获取文章titles和对应的url,主要使用Beautifulsoup Weixin.py import requests from urllib.parse import quote in requests和bs4 from bs4 import BeautifulSoup im
Python抓取指定的微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。此方法依赖于 urllib2 库。首先,你需要安装你的python环境。然后安装urllib2库程序的启动方法(返回值为公众号文章list): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") #加载页面url =' ;s_from=input&query=要爬取的公众号
python采集微信公号文章
本文示例分享了python采集微信公号文章的具体代码,供大家参考。具体内容如下。在python的一个子目录下保存2个文件,分别是:采集公号文章.py和config.py。代码如下:1.采集公号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
python抢搜狗微信公众号文章
<p>初学者学习python,抓取搜狗微信公众号文章保存到mysql mysql表中:代码:import requests import json import re import pymysql #创建连接conn = pymysql.connect(host='your database address', port =port, user='user name', passwd='password', db='database name', charset='utf8') # 创建一个游标 cursor = conn.cursor() cursor.execute("sel 查看全部
获取微信公众号文章的方法,你get到了吗?
通过微信公众平台获取公众号文章的示例
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前有很多获取方式,通过搜狗、清博、web、客户端等都可以,这个可能不是很好,但是操作简单易懂。
所以,首先你要有一个微信公众平台帐号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形和文字:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号,就会出现对应的文章列表
你感到惊讶吗?可以打开控制台查看请求的接口
打开回复,有我们需要的文章链接
确认数据后,我们需要分析这个界面。
感觉很简单。 GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
我们输入公众号后,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
目前我还没有测试cookies的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样可以得到最新的10篇文章。如果想获得更多的历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-12-23
如何访问微信小程序公众号文章
前言随着小程序的不断发展,现在个人小程序已经开通了很多功能,个人小程序直接打开公众号链接。群里看到的一个小程序,点击直接阅读文章了,所以琢磨了一下,写了一些源码。主要代码:
python爬取微信公众号文章的方法
最近学习了Python3网络爬虫开发实践(崔庆才),刚刚了解到他这里使用代理爬取了公众号文章这里,但是根据他的代码,出现了一些问题。这里我用了这本书前面提到的一些内容进行了改进。 (这个代码作者半年前写的,但腾讯的网站半年前更新了)下面我直接上传代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
使用anyproxy提高公众号文章采集的效率
主要影响因素如下:1.网络环境差:2.微信客户端手机或模拟器崩溃:3.其他网络传输错误:因为我看重采集system 这个成本包括硬件投资、算力投资和人力占用。所以必须提高操作的稳定性。因此,如果采集中断,人工能量的成本必然会增加。所以针对这一点,我对 anyproxy 做了一些高级的改造,并利用其他工具来提高运行效率。以下是具体解决方法:一.code upgrade1)微信 浏览器白屏解决方法:修改文件requestHandler.js,或者在rule_default中
python下载微信公众号相关文章
本文示例分享python下载微信公众号文章的具体代码,供大家参考。具体内容如下: 从零开始学自动化测试,从公众号1.下载一系列文档1.搜索微信文章Keyword search2.解析搜索结果的前N页为获取文章titles和对应的url,主要使用Beautifulsoup Weixin.py import requests from urllib.parse import quote in requests和bs4 from bs4 import BeautifulSoup im
Python抓取指定的微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。此方法依赖于 urllib2 库。首先,你需要安装你的python环境。然后安装urllib2库程序的启动方法(返回值为公众号文章list): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") #加载页面url =' ;s_from=input&query=要爬取的公众号
python采集微信公号文章
本文示例分享了python采集微信公号文章的具体代码,供大家参考。具体内容如下。在python的一个子目录下保存2个文件,分别是:采集公号文章.py和config.py。代码如下:1.采集公号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
python抢搜狗微信公众号文章
<p>初学者学习python,抓取搜狗微信公众号文章保存到mysql mysql表中:代码:import requests import json import re import pymysql #创建连接conn = pymysql.connect(host='your database address', port =port, user='user name', passwd='password', db='database name', charset='utf8') # 创建一个游标 cursor = conn.cursor() cursor.execute("sel
文章自动更新,推送给微信服务器,送给客户端
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-24 06:02
querylist采集微信公众号文章、个人公众号文章、个人微信公众号文章、微信原生导入的文章等,经过用户的有效提问,文章自动更新,推送给微信服务器,并通过第三方推送服务将文章推送给客户端。querylist插件详细信息:1.修改你的submit用户名:你是否设置了用户名为“昵称”而不是“账号”?例如,你在guest用户下设置用户名为“莉莉”,对应文章将自动更新到list中;当用户不需要登录才能进行查看时,你可以修改用户名:xiaomi2.删除网页中现存的公众号文章、个人微信公众号文章:如果公众号和个人公众号已有不需要的文章,你可以删除现有的文章到文件://需要全选你需要引入querylist插件的文章,可以通过excel快速选择目标文章3.删除网页中的子域名和老域名:当公众号和个人公众号文章的网址中都包含.com、.php时,需要设置你的目标域名。
老域名是你要删除的,如果你忘记了,可以使用ipcss中的查看。4.使用多个post发送到多个微信公众号:你可以安排多个长期/短期post发送到多个微信公众号中去,实现一次性多渠道发送。5.完成页面输出设置之后你可以通过querylist在本地查看和编辑你制作的rss源码:6.querylist实时查看微信服务器推送的文章信息,方便你配置微信客户端。
7.对于1,2,3不满足的你,querylist还有详细的指导,你可以添加第三方推送服务://让第三方推送服务来帮你推送文章、参考链接建议删除自己的个人微信公众号rss发送到你的guest公众号:xiaomi)删除文章到文件:xiaomiipcss地址:ipcssguyge/ipcssguyge.excel您可以将所有的guest的文章保存到某个wordpress目录下:xiaomi到的网址:/@vuerno/gh000-ipcssquerylist的用法:导入插件->右击选择:settings|extensions|rss。 查看全部
文章自动更新,推送给微信服务器,送给客户端
querylist采集微信公众号文章、个人公众号文章、个人微信公众号文章、微信原生导入的文章等,经过用户的有效提问,文章自动更新,推送给微信服务器,并通过第三方推送服务将文章推送给客户端。querylist插件详细信息:1.修改你的submit用户名:你是否设置了用户名为“昵称”而不是“账号”?例如,你在guest用户下设置用户名为“莉莉”,对应文章将自动更新到list中;当用户不需要登录才能进行查看时,你可以修改用户名:xiaomi2.删除网页中现存的公众号文章、个人微信公众号文章:如果公众号和个人公众号已有不需要的文章,你可以删除现有的文章到文件://需要全选你需要引入querylist插件的文章,可以通过excel快速选择目标文章3.删除网页中的子域名和老域名:当公众号和个人公众号文章的网址中都包含.com、.php时,需要设置你的目标域名。
老域名是你要删除的,如果你忘记了,可以使用ipcss中的查看。4.使用多个post发送到多个微信公众号:你可以安排多个长期/短期post发送到多个微信公众号中去,实现一次性多渠道发送。5.完成页面输出设置之后你可以通过querylist在本地查看和编辑你制作的rss源码:6.querylist实时查看微信服务器推送的文章信息,方便你配置微信客户端。
7.对于1,2,3不满足的你,querylist还有详细的指导,你可以添加第三方推送服务://让第三方推送服务来帮你推送文章、参考链接建议删除自己的个人微信公众号rss发送到你的guest公众号:xiaomi)删除文章到文件:xiaomiipcss地址:ipcssguyge/ipcssguyge.excel您可以将所有的guest的文章保存到某个wordpress目录下:xiaomi到的网址:/@vuerno/gh000-ipcssquerylist的用法:导入插件->右击选择:settings|extensions|rss。
querylist采集微信公众号文章进行二次加工后得到的
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-24 03:02
querylist采集微信公众号文章并且进行二次加工后得到的。比如文章的标题,链接,图片等等。
python。在微信中搜索公众号,然后找到自己公众号的文章。不需要下载,
不知道你是想爬什么类型的公众号,因为每个公众号自己的公众号主页有自己的爬取接口,有的是只能爬本地的,有的是只支持本地文件的提取。
你可以这样,登录原公众号,然后在分析选项里面选择爬虫。
还是建议爬一个的
要么自己构建网站,要么用爬虫软件,如scrapy或python写一个能爬取微信公众号的小爬虫,
用python从一个公众号文章抓取并上传到千牛上给别人,然后再由别人去爬取微信公众号的文章,
你说的这个简单来说就是爬虫,现在应该有公司提供这种服务,
<p>爬虫,不管是用flask也好用python也好。还是别的什么如果上传不能成功上传的话,可以看下我做的服务,中间上传失败多次后就是用本地目录下的文件夹,一路敲一路写就可以了~微信扫一扫就可以。但是有一个问题,你可以想象中如果人们都爱你不需要二维码,你就用这种形式获取了,如果你有很多很多二维码,你会哭的。想了解我的爬虫服务的同学,可以留言~如果对您有帮助,欢迎收藏点赞(๑> 查看全部
querylist采集微信公众号文章进行二次加工后得到的
querylist采集微信公众号文章并且进行二次加工后得到的。比如文章的标题,链接,图片等等。
python。在微信中搜索公众号,然后找到自己公众号的文章。不需要下载,
不知道你是想爬什么类型的公众号,因为每个公众号自己的公众号主页有自己的爬取接口,有的是只能爬本地的,有的是只支持本地文件的提取。
你可以这样,登录原公众号,然后在分析选项里面选择爬虫。
还是建议爬一个的
要么自己构建网站,要么用爬虫软件,如scrapy或python写一个能爬取微信公众号的小爬虫,
用python从一个公众号文章抓取并上传到千牛上给别人,然后再由别人去爬取微信公众号的文章,
你说的这个简单来说就是爬虫,现在应该有公司提供这种服务,
<p>爬虫,不管是用flask也好用python也好。还是别的什么如果上传不能成功上传的话,可以看下我做的服务,中间上传失败多次后就是用本地目录下的文件夹,一路敲一路写就可以了~微信扫一扫就可以。但是有一个问题,你可以想象中如果人们都爱你不需要二维码,你就用这种形式获取了,如果你有很多很多二维码,你会哭的。想了解我的爬虫服务的同学,可以留言~如果对您有帮助,欢迎收藏点赞(๑>
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-07-22 00:39
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物,养不起猫的码农,下班后很开心。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
一、获取公众号信息:标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查资料,找到了我们需要的关键内容:title、abstract、cover、文章URL。我们确保这是我们需要的 URL。通过点击下一页,我们得到了几次url,发现只找到了random和bengin。的参数已更改
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
二、Get文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
查看全部
querylist采集微信公众号文章 熊孩子和萌宠搞笑视频笑声不断快乐常伴
每天更新视频:熊孩子的日常,萌宠的日常,熊孩子和萌宠的搞笑视频,笑不停,一直陪着你!
请允许我强制投放一波广告:
因为每个爬虫官方账号都是他家的,一年前的,现在的,只是主题和名字都变了。
一个喜欢小宠物,养不起猫的码农,下班后很开心。可以关注哦!
为保证视频安全,避免丢失,请楼主为视频添加水印。
一、获取公众号信息:标题、摘要、封面、文章URL
步骤:
1、先自己申请公众号
2、登录您的帐户,创建一个新的文章图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史文章
4、抓包获取信息并定位请求的url
通过查资料,找到了我们需要的关键内容:title、abstract、cover、文章URL。我们确保这是我们需要的 URL。通过点击下一页,我们得到了几次url,发现只找到了random和bengin。的参数已更改
这样就确定了主要信息网址。
让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
获取url的时候就可以得到这两个值的来源。
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
获取结果(成功):
二、Get文章内视频:实现批量下载
分析一个视频文章后,我找到了这个链接:
打开网页,发现是视频网页的下载链接:
嘿嘿,好像有点意思,找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。不知从何而来?
与获取的其他信息无关,只能强制。
这个参数是在文章单人的url请求信息中找到的,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,进行代码组装。
一个。获取公众号信息
B.过滤单篇文章文章information
c.获取视频信息
d。拼接视频页面下载地址
e.下载视频并保存
代码实验结果:
获取公众号:标题、摘要、封面、视频、
可以说你拥有一个视频公众号的所有信息,你可以复制一份。
危险动作,请勿操作!记住!记住!记住!
获取代码请回复公众号:20191210或公众号
微信公众号爬取程序利用的原理和原理摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-07-22 00:34
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,您可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list)) 查看全部
微信公众号爬取程序利用的原理和原理摘要
为了实现这个爬虫,我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个官方帐号。
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
接下来,按 F12,打开 Chrome 的开发者工具,然后选择网络
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要抓取的公众号(例如中国移动)
这时候之前的Network会刷新一些链接,其中“appmsg”开头的内容就是我们需要分析的
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的。
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,并传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,所以我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
你只需要稍后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg ':'无效的 csrf 令牌'}}
接下来,我们编写一个循环来获取所有文章 JSON 并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为 fakeid 是每个公众号的唯一标识符,令牌会经常变化。这个信息可以通过解析URL获取,也可以在开发者工具中查看
爬取一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时在公众号后台尝试插入超链接时,会遇到如下提示
这是公众号的流量限制,通常需要等待30-60分钟才能继续。为了完美处理这个问题,您可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章identifier、标题、网址、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("n".join(info_list))
大牛用微信公众号爬取程序的难点和解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-07-21 03:00
最近需要爬取微信公众号的文章信息。上网查了一下,发现微信公众号爬取的难点是公众号文章的链接在PC端打不开。需要使用微信的浏览器(获取微信客户端的补充参数才能在其他平台访问Open),给爬虫程序带来很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,他按照大佬的思路直接做了java。改造过程中遇到的细节问题比较多,分享给大家。
附上Daniel文章的链接:写php或者只需要爬取思路的可以直接看这个。思路很详细。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
系统的基本思想是在安卓模拟器上运行微信。模拟器设置代理,通过代理服务器拦截微信数据,并将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接下载安装即可。安装完成后,直接运行C:\Program Files\nodejs\npm.cmd自动配置环境。
anyproxy安装:上一步安装好nodejs后,在cmd中直接运行npm install -g anyproxy就会安装
互联网上只有一个 Android 模拟器,很多。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后即可解决。在cmd中执行anyproxy --root后,就会安装证书。之后,您必须在模拟器上下载证书。
然后输入anyproxy -i命令开启代理服务。 (记得加参数!)
记住这个ip和端口,然后安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用于显示http传输数据。
点击上方红框中的菜单,会显示一个二维码。使用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在我们准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到此基本完成。在模拟器上打开微信,开通公众号文章,从刚刚打开的网页界面就可以看到anyproxy抓取到的数据了:
在上面的红框中,有一个微信文章的链接,点进去查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果一切顺利,你就可以下去了。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据,只能自己操作微信。最好手动复制。所以我们需要微信客户端自己跳转到页面。这时候可以使用anyproxy来拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动重定向。
在anyproxy中打开一个名为rule_default.js的js文件,windows下文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获得的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。把这条语句删掉,换成下面丹尼尔写的代码就行了。这里的代码我没有做任何改动,里面的注释也解释的很清楚,按照逻辑来理解就好了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简单的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以关闭。如果被拒绝,则会触发一个js事件,发送获取json数据(下一页内容)的请求。还有公众号文章的链接,以及文章的阅读量和喜欢的链接(返回json数据)。这些链接的形式是固定的,可以通过逻辑判断来区分。这里的问题是,如果所有的历史页面都需要爬取,怎么做。我的想法是模拟鼠标通过js向下滑动触发提交加载列表下一部分的请求。或者直接使用anyproxy分析滑动加载请求,直接将请求发送到微信服务器。但是一直存在一个问题,就是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个需求,以后可能需要。有需要的可以试试。 查看全部
大牛用微信公众号爬取程序的难点和解决办法
最近需要爬取微信公众号的文章信息。上网查了一下,发现微信公众号爬取的难点是公众号文章的链接在PC端打不开。需要使用微信的浏览器(获取微信客户端的补充参数才能在其他平台访问Open),给爬虫程序带来很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,他按照大佬的思路直接做了java。改造过程中遇到的细节问题比较多,分享给大家。
附上Daniel文章的链接:写php或者只需要爬取思路的可以直接看这个。思路很详细。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
系统的基本思想是在安卓模拟器上运行微信。模拟器设置代理,通过代理服务器拦截微信数据,并将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接下载安装即可。安装完成后,直接运行C:\Program Files\nodejs\npm.cmd自动配置环境。
anyproxy安装:上一步安装好nodejs后,在cmd中直接运行npm install -g anyproxy就会安装
互联网上只有一个 Android 模拟器,很多。
----------------------------------------------- -------------------------------------------------- -------------------------------------------------- ---------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后即可解决。在cmd中执行anyproxy --root后,就会安装证书。之后,您必须在模拟器上下载证书。
然后输入anyproxy -i命令开启代理服务。 (记得加参数!)
记住这个ip和端口,然后安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用于显示http传输数据。
点击上方红框中的菜单,会显示一个二维码。使用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在我们准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到此基本完成。在模拟器上打开微信,开通公众号文章,从刚刚打开的网页界面就可以看到anyproxy抓取到的数据了:
在上面的红框中,有一个微信文章的链接,点进去查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果一切顺利,你就可以下去了。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据,只能自己操作微信。最好手动复制。所以我们需要微信客户端自己跳转到页面。这时候可以使用anyproxy来拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动重定向。
在anyproxy中打开一个名为rule_default.js的js文件,windows下文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获得的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。把这条语句删掉,换成下面丹尼尔写的代码就行了。这里的代码我没有做任何改动,里面的注释也解释的很清楚,按照逻辑来理解就好了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简单的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以关闭。如果被拒绝,则会触发一个js事件,发送获取json数据(下一页内容)的请求。还有公众号文章的链接,以及文章的阅读量和喜欢的链接(返回json数据)。这些链接的形式是固定的,可以通过逻辑判断来区分。这里的问题是,如果所有的历史页面都需要爬取,怎么做。我的想法是模拟鼠标通过js向下滑动触发提交加载列表下一部分的请求。或者直接使用anyproxy分析滑动加载请求,直接将请求发送到微信服务器。但是一直存在一个问题,就是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个需求,以后可能需要。有需要的可以试试。
微信公众号文章的接口分析及应用方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-07-21 02:31
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号获取接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个帐号对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET so this在界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 Request method: GET 在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.Realization 第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案点击加入 查看全部
微信公众号文章的接口分析及应用方法(一)
一.Idea
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.接口分析
微信公众号获取接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个帐号对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET so this在界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 Request method: GET 在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.Realization 第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义一个登录方法,里面的参数是登录账号和密码,然后定义一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的文章data
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.Summary
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置一个延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案点击加入
微信读书App已经上线优质公众号推荐模块(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-07-20 01:25
微信读书App已经上线优质公众号推荐模块(图)
微信阅读APP上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、 “知识教育”、“商业金融”和“其他”。在每个子模块中,收录在微信公众平台上的每个自媒体号都有文章。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
其实在今年4月份,微信阅读2.4.0就增加了一个新功能:引入优质公众号。
马化腾去年在朋友圈与kol的对话中也透露,微信正在测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过微信阅读App中的优质公众号模块还是可以免费阅读的。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经有“支持看书的公众号”文章”提示了。
针对新功能,钛媒体编辑采访了几家公众号运营商,发现微信阅读没有事先与运营商沟通授权和版权问题。
这一次,我们将在微信公众号中直接抓取文章,并将其作为一个独立的部分。以后会不会涉及版权问题?
就目前的功能而言,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量已超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。 (本文首发于钛媒体,作者/桑明强,编辑/洋葱) 查看全部
微信读书App已经上线优质公众号推荐模块(图)
微信阅读APP上线优质公众号推荐模块。
钛媒体编辑今天点击微信阅读App主界面左下角的书店,弹出“优质公众号”模块。
在“查看全部”内容列表中,钛媒体发现该模块分为8个子模块:“全部”、“轻松搞笑”、“影评”、“文学杂志”、“互联网”、 “知识教育”、“商业金融”和“其他”。在每个子模块中,收录在微信公众平台上的每个自媒体号都有文章。
另外,通过微信阅读App搜索栏,可以直接搜索相关公众号和内容。
其实在今年4月份,微信阅读2.4.0就增加了一个新功能:引入优质公众号。
马化腾去年在朋友圈与kol的对话中也透露,微信正在测试公众号的付费订阅功能。此后,一直没有消息表明该功能何时正式发布。
微信阅读App的自然付费阅读模式与微信公众号付费阅读自然匹配。不过微信阅读App中的优质公众号模块还是可以免费阅读的。
钛媒体发现,这并不是微信阅读和微信公众号的第一次结合。早在去年9月2.2.0版本上线时,就已经有“支持看书的公众号”文章”提示了。
针对新功能,钛媒体编辑采访了几家公众号运营商,发现微信阅读没有事先与运营商沟通授权和版权问题。
这一次,我们将在微信公众号中直接抓取文章,并将其作为一个独立的部分。以后会不会涉及版权问题?
就目前的功能而言,微信阅读App看起来是一个完美的“接现成孩子”的过程。同时在搜索一些不知名的公众号时,发现系统没有收录。可以看出,“优质公众号”是在微信阅读相关数据库筛选后导入的。
据了解,微信阅读App于2015年8月27日正式上线,目前华为应用商店下载量已超过1亿。庞大的流量平台未来将如何与微信公众号运营商分享收益?值得期待。 (本文首发于钛媒体,作者/桑明强,编辑/洋葱)
翻页打开headers,开发工具思路首先start_url==?
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-18 23:25
由于微信流量封闭,微信内容比较难看。为了能够在微信公众号爬文章,有网友用python实现了。我们来看看他的实现思路和代码。也许它可以使用?要知道微信公众号里的内容不是百度上的收录,能做到就太牛了。
开发工具
思考
首先start_url=””,扫码注册微信公众平台,有的话直接忽略扫码登录即可。(注册个人订阅号即可),使用selenium自动扫码登录获取cookie值,然后使用cookie进行响应。
您需要先下载webdriver插件。插件下载谷歌浏览器对应的版本。下载后会得到chromedriver.exe,然后把这个chromedriver.exe和python解释器的python.exe文件放在同一个目录下。作为响应,取回网页的源代码并取回令牌值。令牌值具有时间敏感性。
首先打开公众号,点击图文编辑中的超链接。
使用python爬取微信公众号文章
使用python爬取微信公众号文章
使用python爬取微信公众号文章
按F12查看公众号对应的fakeid值。
使用python爬取微信公众号文章
使用python爬取微信公众号文章
翻页打开headers,取回首页url地址
第二页地址
找到模式,上传代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop() 查看全部
翻页打开headers,开发工具思路首先start_url==?
由于微信流量封闭,微信内容比较难看。为了能够在微信公众号爬文章,有网友用python实现了。我们来看看他的实现思路和代码。也许它可以使用?要知道微信公众号里的内容不是百度上的收录,能做到就太牛了。
开发工具
思考
首先start_url=””,扫码注册微信公众平台,有的话直接忽略扫码登录即可。(注册个人订阅号即可),使用selenium自动扫码登录获取cookie值,然后使用cookie进行响应。
您需要先下载webdriver插件。插件下载谷歌浏览器对应的版本。下载后会得到chromedriver.exe,然后把这个chromedriver.exe和python解释器的python.exe文件放在同一个目录下。作为响应,取回网页的源代码并取回令牌值。令牌值具有时间敏感性。
首先打开公众号,点击图文编辑中的超链接。
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 0.png 768w, https://www.daimadog.com/wp-co ... 3.png 1362w" />使用python爬取微信公众号文章
https://www.daimadog.com/wp-co ... 8.png 440w, https://www.daimadog.com/wp-co ... 2.png 768w" />使用python爬取微信公众号文章
https://www.daimadog.com/wp-co ... 4.png 440w, https://www.daimadog.com/wp-co ... 1.png 768w" />使用python爬取微信公众号文章
按F12查看公众号对应的fakeid值。
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 9.png 768w, https://www.daimadog.com/wp-co ... 6.png 1365w" />使用python爬取微信公众号文章
https://www.daimadog.com/wp-co ... 9.png 440w, https://www.daimadog.com/wp-co ... 8.png 768w, https://www.daimadog.com/wp-co ... 6.png 1364w" />使用python爬取微信公众号文章
翻页打开headers,取回首页url地址
第二页地址
找到模式,上传代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定义可视化窗口,并设置窗口和主题大小布局"""
self.window = tk.Tk()
self.window.title('公众号信息采集')
self.window.geometry('800x600')
"""创建label_user按钮,与说明书"""
self.label_user = tk.Label(self.window, text='需要爬取的公众号:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""创建label_user关联输入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""创建label_passwd按钮,与说明书"""
self.label_passwd = tk.Label(self.window, text="爬取多少页:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""创建label_passwd关联输入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""创建Text富文本框,用于按钮操作结果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定义按钮1,绑定触发事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定义按钮2,绑定触发事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定义触发事件1,调用main函数"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 网页登录
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 网页最大化
driver.maximize_window()
# 拿微信扫描登录
time.sleep(20)
# 获得登录的cookies
cookies_list = driver.get_cookies()
# 转化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 请求头
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有时效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟输入的公众号有关的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 获取响应
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,确定公众号,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 构造公众号的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的创建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 构造表头
sheet.write(0, 0, '时间')
sheet.write(0, 1, '标题')
sheet.write(0, 2, '地址')
# 循环翻页
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 获取响应的json数据
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 获取时间,标题,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 将时间戳转化为北京时间
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for循环遍历
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的单元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 窗口显示进程
self.text1.insert("insert", f'*****************第{i+1}页爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公众号信息.xls')
print(f"*********{user_name}公众号信息保存成功*********")
def parse_hit_click_2(self):
"""定义触发事件2,删除文本框中内容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""创建窗口居中函数方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改窗体大小规格"""
self.window.resizable(False, False)
"""窗口居中"""
self.center()
"""窗口维持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop()
利用搜狗微信搜索抓取指定公众号的最新一条推送
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-17 23:10
问题描述
使用搜狗微信搜索抓取指定公众号的最新推送,并将相应网页保存到本地。
注意搜狗微信获取的地址为临时链接,具有时效性。公众号为动态网页(由JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用selenium+PhantomJS来处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
解析链接获取 首先进入搜狗的微信搜索页面,在地址栏中提取需要的链接部分,将字符串与公众号名连接,然后生成请求链接。对于静态网页,使用requests获取html文件,然后使用BeautifulSoup选择所需内容为动态网页。使用selenium+PhantomJS获取html文件,然后使用BeautifulSoup选择需要的内容遇到验证码(CAPTCHA),并输出提示。该版本的代码实际上并没有处理验证码,需要在运行程序之前手动访问,以避免验证码。文件写入使用os.path.join()构造存储路径,提高通用性。例如,Windows 路径分隔符使用反斜杠 (\),而 OS X 和 Linux 使用正斜杠 (/)。此功能可根据平台自动转换。 open() 使用 b(二进制模式)参数提高通用性(适用于 Windows),使用 datetime.now() 获取当前时间进行命名,并通过 strftime() 格式化时间(函数名中的 f 代表格式),具体参考下表(摘自Automate the Boring Stuff with Python)
参考链接:文件夹创建:异常处理的使用:enumerate的使用:open()使用b参数原因: 查看全部
利用搜狗微信搜索抓取指定公众号的最新一条推送
问题描述
使用搜狗微信搜索抓取指定公众号的最新推送,并将相应网页保存到本地。
注意搜狗微信获取的地址为临时链接,具有时效性。公众号为动态网页(由JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用selenium+PhantomJS来处理代码
#! /usr/bin/env python3
from selenium import webdriver
from datetime import datetime
import bs4, requests
import os, time, sys
# 获取公众号链接
def getAccountURL(searchURL):
res = requests.get(searchURL)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "lxml")
# 选择第一个链接
account = soup.select('a[uigs="account_name_0"]')
return account[0]['href']
# 获取首篇文章的链接,如果有验证码返回None
def getArticleURL(accountURL):
browser = webdriver.PhantomJS("/Users/chasechoi/Downloads/phantomjs-2.1.1-macosx/bin/phantomjs")
# 进入公众号
browser.get(accountURL)
# 获取网页信息
html = browser.page_source
accountSoup = bs4.BeautifulSoup(html, "lxml")
time.sleep(1)
contents = accountSoup.find_all(hrefs=True)
try:
partitialLink = contents[1]['hrefs']
firstLink = base + partitialLink
except IndexError:
firstLink = None
print('CAPTCHA!')
return firstLink
# 创建文件夹存储html网页,以时间命名
def folderCreation():
path = os.path.join(os.getcwd(), datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
print("folder not exist!")
return path
# 将html页面写入本地
def writeToFile(path, account, title):
pathToWrite = os.path.join(path, '{}_{}.html'.format(account, title))
myfile = open(pathToWrite, 'wb')
myfile.write(res.content)
myfile.close()
base ='https://mp.weixin.qq.com'
accountList = ['央视新闻', '新浪新闻','凤凰新闻','羊城晚报']
query = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query='
path = folderCreation()
for index, account in enumerate(accountList):
searchURL = query + account
accountURL = getAccountURL(searchURL)
time.sleep(10)
articleURL = getArticleURL(accountURL)
if articleURL != None:
print("#{}({}/{}): {}".format(account, index+1, len(accountList), accountURL))
# 读取第一篇文章内容
res = requests.get(articleURL)
res.raise_for_status()
detailPage = bs4.BeautifulSoup(res.text, "lxml")
title = detailPage.title.text
print("标题: {}\n链接: {}\n".format(title, articleURL))
writeToFile(path, account, title)
else:
print('{} files successfully written to {}'.format(index, path))
sys.exit()
print('{} files successfully written to {}'.format(len(accountList), path))
参考输出
解析链接获取 首先进入搜狗的微信搜索页面,在地址栏中提取需要的链接部分,将字符串与公众号名连接,然后生成请求链接。对于静态网页,使用requests获取html文件,然后使用BeautifulSoup选择所需内容为动态网页。使用selenium+PhantomJS获取html文件,然后使用BeautifulSoup选择需要的内容遇到验证码(CAPTCHA),并输出提示。该版本的代码实际上并没有处理验证码,需要在运行程序之前手动访问,以避免验证码。文件写入使用os.path.join()构造存储路径,提高通用性。例如,Windows 路径分隔符使用反斜杠 (\),而 OS X 和 Linux 使用正斜杠 (/)。此功能可根据平台自动转换。 open() 使用 b(二进制模式)参数提高通用性(适用于 Windows),使用 datetime.now() 获取当前时间进行命名,并通过 strftime() 格式化时间(函数名中的 f 代表格式),具体参考下表(摘自Automate the Boring Stuff with Python)
参考链接:文件夹创建:异常处理的使用:enumerate的使用:open()使用b参数原因:

