
python抓取网页数据
python抓取网页数据((P.S.你也可以在我的博客阅读这篇文章))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-09 00:27
(PS你也可以在我的博客上阅读这个文章)
嗯,到上一篇博客,我们已经能够成功地从网站中抓取一些简单的数据并将其存储在一个文件中。但是在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我们应该怎么做?
-------------------------------------
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过按“command+option+u”(Windows和Linux上的快捷键是“ctrl+u”)来查看网页的源代码。果然,页面显示的招聘信息并没有出现在源代码中。
至此,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最后的手段。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那么我们该如何处理呢?经验是,在这种情况下,大部分浏览器会在请求解析完HTML后,根据js的“指令”再发送一次请求,得到页面显示的内容,再通过渲染后显示到界面上js。好消息是,这类请求的内容往往是json格式的,所以与其增加爬取的任务,不如省去解析HTML的工作量。
即,继续打开Chrome的开发者工具,当我们点击“下一步”时,浏览器发送如下请求:
注意请求“positionAjax.json”。它的类型是“xhr”,它的全名是“XMLHttpRequest”。XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,它现在的可能性最大,我们点击后仔细观察:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表示:
通过观察内容,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息是真的。那么,应该如何模拟请求呢?我们切换到Headers栏,注意三个地方:
上面的截图展示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是不断地根据页码向这个接口发送请求,解析json内容,存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
让我们重新审视返回的 json。格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个列表,里面的每一项都是一个招聘信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
json字符串映射到Python的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
概括
本篇博客介绍了在HTML源码中没有的时候抓取一些数据的方法,适用于一些情况。对于数据的存储,暂时还在使用文件。在下一篇文章中,我们将使用MongoDB来存储数据,因此在此之间,希望您可以先在本机上安装和配置MongoDB。 查看全部
python抓取网页数据((P.S.你也可以在我的博客阅读这篇文章))
(PS你也可以在我的博客上阅读这个文章)
嗯,到上一篇博客,我们已经能够成功地从网站中抓取一些简单的数据并将其存储在一个文件中。但是在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我们应该怎么做?
-------------------------------------
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过按“command+option+u”(Windows和Linux上的快捷键是“ctrl+u”)来查看网页的源代码。果然,页面显示的招聘信息并没有出现在源代码中。
至此,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最后的手段。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那么我们该如何处理呢?经验是,在这种情况下,大部分浏览器会在请求解析完HTML后,根据js的“指令”再发送一次请求,得到页面显示的内容,再通过渲染后显示到界面上js。好消息是,这类请求的内容往往是json格式的,所以与其增加爬取的任务,不如省去解析HTML的工作量。
即,继续打开Chrome的开发者工具,当我们点击“下一步”时,浏览器发送如下请求:
注意请求“positionAjax.json”。它的类型是“xhr”,它的全名是“XMLHttpRequest”。XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,它现在的可能性最大,我们点击后仔细观察:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表示:
通过观察内容,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息是真的。那么,应该如何模拟请求呢?我们切换到Headers栏,注意三个地方:
上面的截图展示了本次请求的请求方式、请求地址等信息。

上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是不断地根据页码向这个接口发送请求,解析json内容,存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
让我们重新审视返回的 json。格式化后的层次关系如下:

很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个列表,里面的每一项都是一个招聘信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
json字符串映射到Python的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
概括
本篇博客介绍了在HTML源码中没有的时候抓取一些数据的方法,适用于一些情况。对于数据的存储,暂时还在使用文件。在下一篇文章中,我们将使用MongoDB来存储数据,因此在此之间,希望您可以先在本机上安装和配置MongoDB。
python抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 09:07
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
查看全部
python抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:

提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
python抓取网页数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-08 08:15
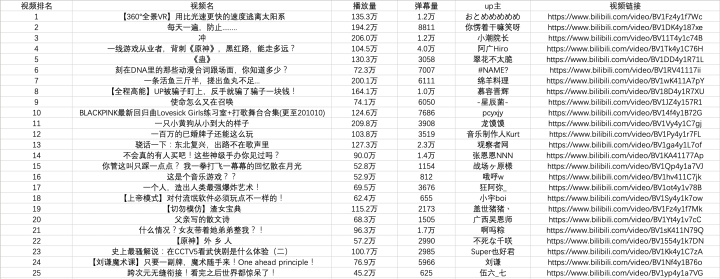
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不知道爬虫的具体工作流程,请仔细阅读本文
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
《爬虫四步》教你如何使用Python抓取和存储网页数据!可以看到返回的是一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
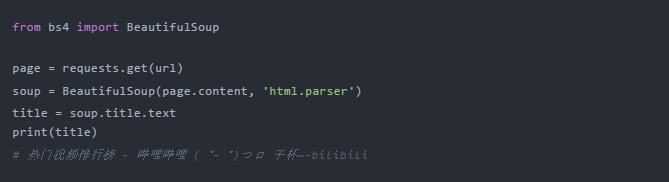
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后可以获取其中一个结构元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
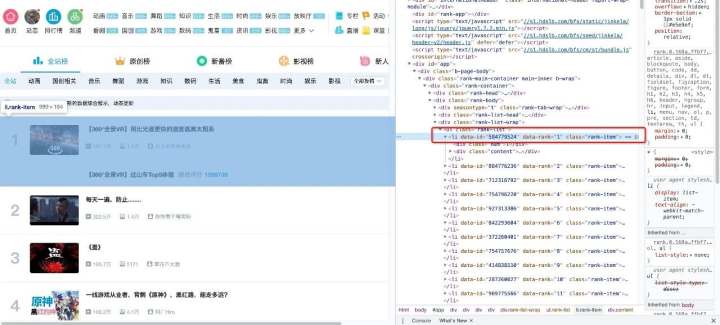
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
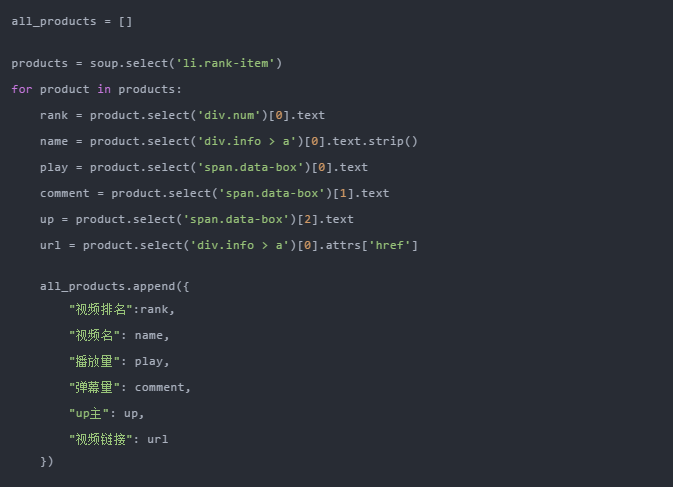
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
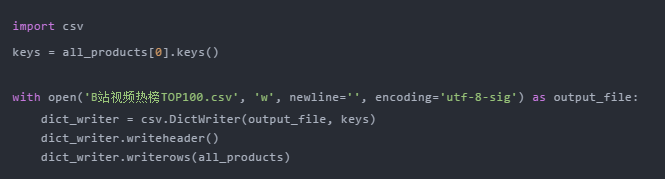
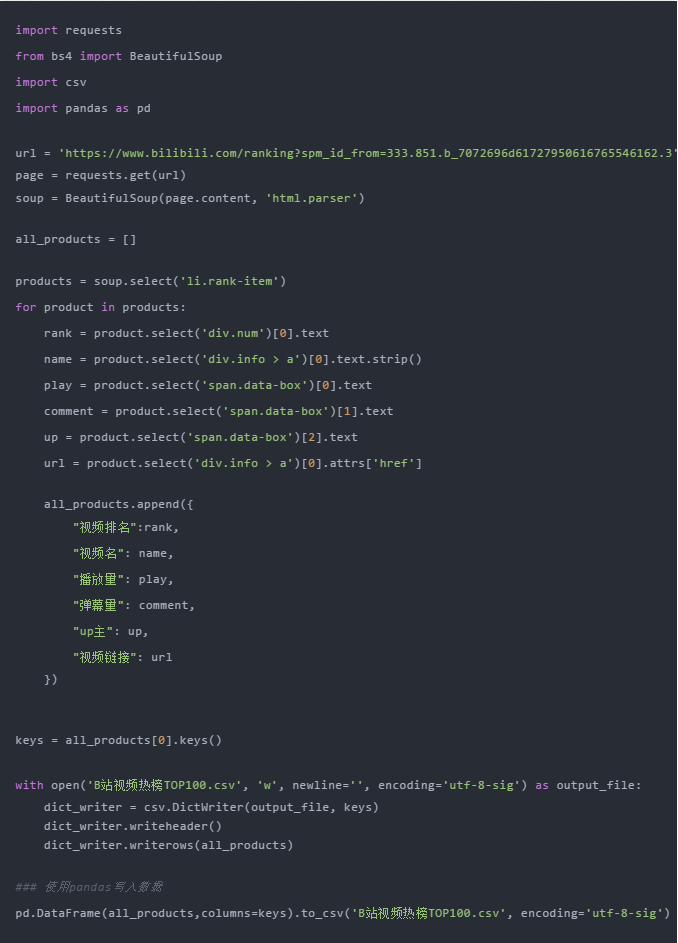
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
结尾 查看全部
python抓取网页数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不知道爬虫的具体工作流程,请仔细阅读本文
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容

《爬虫四步》教你如何使用Python抓取和存储网页数据!可以看到返回的是一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后可以获取其中一个结构元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码

概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
结尾
python抓取网页数据(Python网络爬虫内容提取器一文(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-06 05:26
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要提取Jisuke官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择xslt而不是离散xpath或者scratching正则表达式,请参考Python即时网络爬虫项目启动说明。我们希望通过这种架构,可以节省程序员的时间。半数以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源码下载地址请见文章末尾的GitHub源码。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p>from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count 查看全部
python抓取网页数据(Python网络爬虫内容提取器一文(一))
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要提取Jisuke官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式

2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择xslt而不是离散xpath或者scratching正则表达式,请参考Python即时网络爬虫项目启动说明。我们希望通过这种架构,可以节省程序员的时间。半数以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源码下载地址请见文章末尾的GitHub源码。
2.3、抢结果
捕获的结果如下:

2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p>from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count
python抓取网页数据(有人将robots.txt文件视为一组建议.py文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-06 05:20
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的《网络抓取的合法性和道德》和 Sellars 的二十年网络抓取和计算机欺诈和滥用法案。
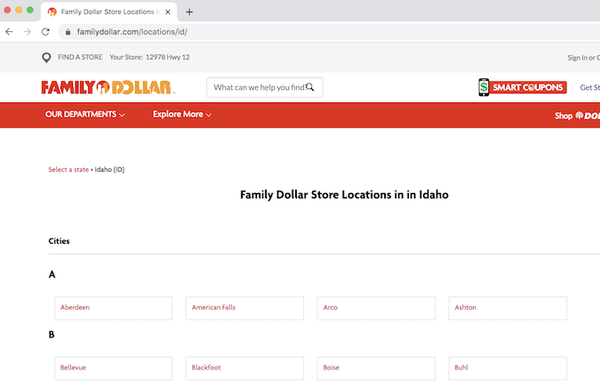
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细观察 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
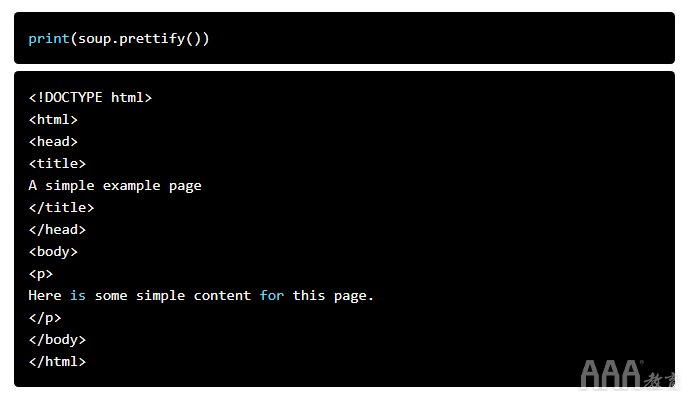
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常会返回一个精确的项目列表,因此第一步是使用方括号表示法为项目建立索引。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
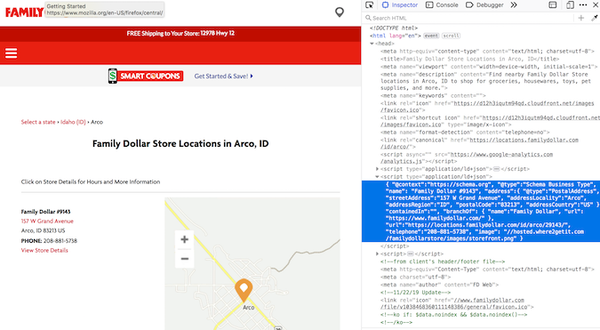
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
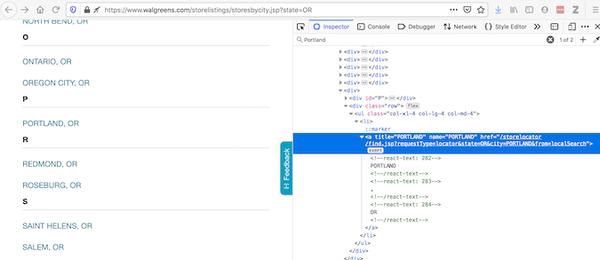
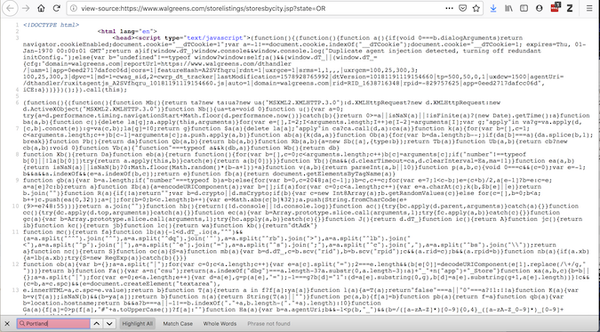
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。requests 不能这样做,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:/article/20/5/web-scraping-python
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出 查看全部
python抓取网页数据(有人将robots.txt文件视为一组建议.py文件)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的《网络抓取的合法性和道德》和 Sellars 的二十年网络抓取和计算机欺诈和滥用法案。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细观察 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。

家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常会返回一个精确的项目列表,因此第一步是使用方括号表示法为项目建立索引。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。requests 不能这样做,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
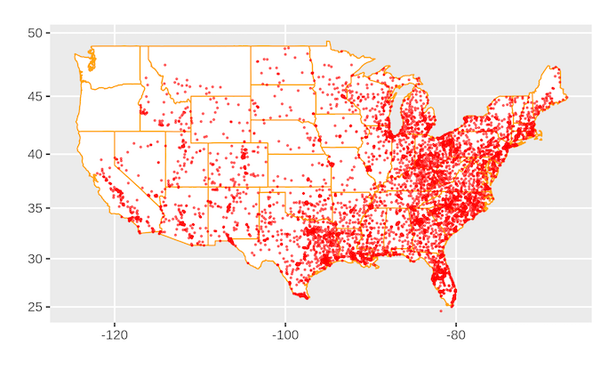
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/";)
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:/article/20/5/web-scraping-python
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出
python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-05 10:18
)
时间:2020-09-07 点击次数:作者:Sissi
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
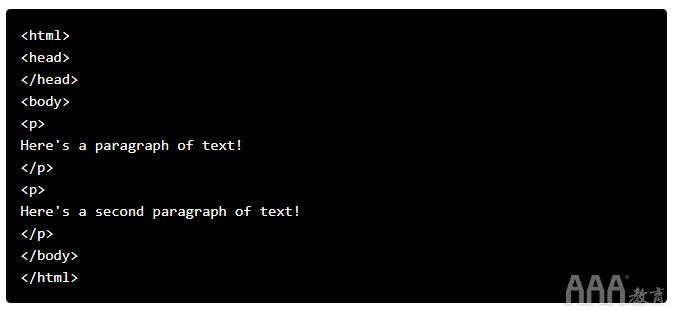
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
现在,我们将以 ap 标签的形式将我们的第一个内容添加到页面中。p 标签定义了一个段落,标签内的任何文本都显示为一个单独的段落:
外观如下:
标签的通用名称取决于它们相对于其他标签的位置:
1)child - 孩子是另一个标签中的标签。因此,p 上方的两个标签是 body 标签的子标签。
2)parent——父标签是另一个标签所在的标签。在顶部,html 标签是标签的父主体。
3)sibiling - 同级标签是嵌套在与另一个标签相同的父对象中的标签。例如,head 和 body 是兄弟,因为它们都在内部 html 中。两个 p 标签处于同一级别,因为它们都在内部主体中。
我们还可以向 HTML 标签添加属性来改变它们的行为:
外观如下:
在上面的例子中,我们添加了两个 a 标签。a 标签是一个链接,它告诉浏览器呈现到另一个网页的链接。href 标签的属性决定了链接的位置。
a 和 p 是非常常见的 html 标签。以下是一些其他内容:
1)div — 表示页面的分区或区域。
2)b-将其中的任何文本加粗。
3)i — 里面的任何文字都以斜体显示。
4)table — 创建一个表。
5)form-创建输入表单。
有关完整的标签列表,请参见此处。
在进行实际的网页抓取之前,让我们了解一下 class 和 id 属性。这些特殊属性为 HTML 元素提供名称,并使我们在爬行时更容易与它们交互。一个元素可以有多个类,一个类可以在元素之间共享。每个元素只能有一个ID,一个ID在页面上只能使用一次。Class 和 ID 是可选的,并非所有元素都有它们。
我们可以将类和 ID 添加到示例中:
外观如下:
请求库
我们要抓取网页的第一件事就是下载网页。我们可以使用 Python 来请求库下载页面。请求库将向 GET Web 服务器发送请求,该服务器将为我们下载给定网页的 HTML 内容。我们可以使用多种不同类型的请求,其中只有一种类型的 GET。如果您想了解更多信息,请查看我们的 API 教程。
我们试着下载一个简单的例子网站。我们需要先使用 request.get 方法下载它。
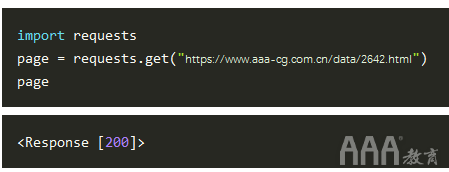
运行请求后,我们得到一个 Response 对象。该对象有一个status_code属性,表示页面是否下载成功:
status_codeof 200 表示页面已成功下载。我们不会在这里全面讨论状态代码,但以“a”开头的状态代码 2 通常表示成功,而以“a” 4 或“a”开头的代码 5 表示错误。
我们可以使用 content 属性来输出页面的 HTML 内容:
使用 BeautifulSoup 解析页面
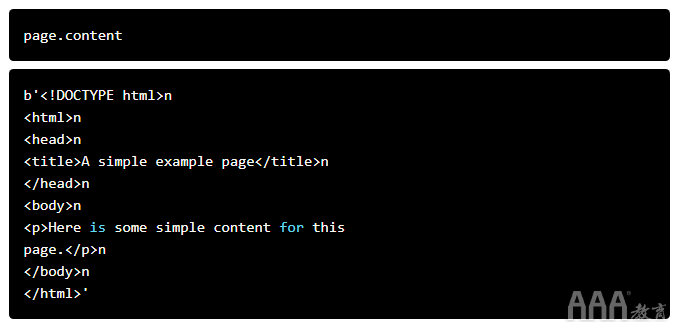
正如您在上面看到的,我们现在已经下载了一个 HTML 文档。
我们可以使用 BeautifulSoup 库来解析这个文档并从 p 标签中提取文本。我们必须首先导入库并创建 BeautifulSoup 类的实例来解析我们的文档:
现在,我们可以使用对象 prettify 上的方法在格式良好的页面中打印出 HTML 内容 BeautifulSoup:
由于所有标签都是嵌套的,我们可以一次在整个结构中移动一层。我们可以先使用 children 属性来选择页面顶部的所有汤元素。请注意,它的子节点返回一个列表生成器,因此我们需要 list 在其上调用此函数:
上面告诉我们页面顶部有两个标签——初始标签和标签。n 列表中还有一个换行符 ()。让我们看看列表中每个元素的类型是什么:
如您所见,所有项目都是 BeautifulSoup 对象。第一个是 Doctype 对象,它收录有关文档类型的信息。第二个是 NavigableString,它表示在 HTML 文档中找到的文本。最后一项是 Tag 对象,其中收录其他嵌套标签。Object 也是我们最常处理的最重要的对象类型 Tag。
Tag 对象允许我们浏览 HTML 文档并提取其他标签和文本。您可以在此处了解有关各种 BeautifulSoup 对象的更多信息。
现在,我们可以通过选择 html 列表中的第三项来选择标签及其子元素:
children 属性返回的列表中的每一项也是一个 BeautifulSoup 对象,所以我们也可以调用 children 上的 html 方法。
现在,我们可以在 html 标签中找到孩子:
正如你在上面看到的,有两个标签 head 和 body。我们要提取 p 标签内的文本,所以我们将深入研究文本:
现在,我们可以通过查找 body 标签的子标签来获取标签:
查看全部
python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取
)
时间:2020-09-07 点击次数:作者:Sissi
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:

我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:

在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:

我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:

正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
现在,我们将以 ap 标签的形式将我们的第一个内容添加到页面中。p 标签定义了一个段落,标签内的任何文本都显示为一个单独的段落:
外观如下:

标签的通用名称取决于它们相对于其他标签的位置:
1)child - 孩子是另一个标签中的标签。因此,p 上方的两个标签是 body 标签的子标签。
2)parent——父标签是另一个标签所在的标签。在顶部,html 标签是标签的父主体。
3)sibiling - 同级标签是嵌套在与另一个标签相同的父对象中的标签。例如,head 和 body 是兄弟,因为它们都在内部 html 中。两个 p 标签处于同一级别,因为它们都在内部主体中。
我们还可以向 HTML 标签添加属性来改变它们的行为:
外观如下:

在上面的例子中,我们添加了两个 a 标签。a 标签是一个链接,它告诉浏览器呈现到另一个网页的链接。href 标签的属性决定了链接的位置。
a 和 p 是非常常见的 html 标签。以下是一些其他内容:
1)div — 表示页面的分区或区域。
2)b-将其中的任何文本加粗。
3)i — 里面的任何文字都以斜体显示。
4)table — 创建一个表。
5)form-创建输入表单。
有关完整的标签列表,请参见此处。
在进行实际的网页抓取之前,让我们了解一下 class 和 id 属性。这些特殊属性为 HTML 元素提供名称,并使我们在爬行时更容易与它们交互。一个元素可以有多个类,一个类可以在元素之间共享。每个元素只能有一个ID,一个ID在页面上只能使用一次。Class 和 ID 是可选的,并非所有元素都有它们。
我们可以将类和 ID 添加到示例中:
外观如下:

请求库
我们要抓取网页的第一件事就是下载网页。我们可以使用 Python 来请求库下载页面。请求库将向 GET Web 服务器发送请求,该服务器将为我们下载给定网页的 HTML 内容。我们可以使用多种不同类型的请求,其中只有一种类型的 GET。如果您想了解更多信息,请查看我们的 API 教程。
我们试着下载一个简单的例子网站。我们需要先使用 request.get 方法下载它。
运行请求后,我们得到一个 Response 对象。该对象有一个status_code属性,表示页面是否下载成功:

status_codeof 200 表示页面已成功下载。我们不会在这里全面讨论状态代码,但以“a”开头的状态代码 2 通常表示成功,而以“a” 4 或“a”开头的代码 5 表示错误。
我们可以使用 content 属性来输出页面的 HTML 内容:
使用 BeautifulSoup 解析页面
正如您在上面看到的,我们现在已经下载了一个 HTML 文档。
我们可以使用 BeautifulSoup 库来解析这个文档并从 p 标签中提取文本。我们必须首先导入库并创建 BeautifulSoup 类的实例来解析我们的文档:

现在,我们可以使用对象 prettify 上的方法在格式良好的页面中打印出 HTML 内容 BeautifulSoup:
由于所有标签都是嵌套的,我们可以一次在整个结构中移动一层。我们可以先使用 children 属性来选择页面顶部的所有汤元素。请注意,它的子节点返回一个列表生成器,因此我们需要 list 在其上调用此函数:

上面告诉我们页面顶部有两个标签——初始标签和标签。n 列表中还有一个换行符 ()。让我们看看列表中每个元素的类型是什么:

如您所见,所有项目都是 BeautifulSoup 对象。第一个是 Doctype 对象,它收录有关文档类型的信息。第二个是 NavigableString,它表示在 HTML 文档中找到的文本。最后一项是 Tag 对象,其中收录其他嵌套标签。Object 也是我们最常处理的最重要的对象类型 Tag。
Tag 对象允许我们浏览 HTML 文档并提取其他标签和文本。您可以在此处了解有关各种 BeautifulSoup 对象的更多信息。
现在,我们可以通过选择 html 列表中的第三项来选择标签及其子元素:

children 属性返回的列表中的每一项也是一个 BeautifulSoup 对象,所以我们也可以调用 children 上的 html 方法。
现在,我们可以在 html 标签中找到孩子:

正如你在上面看到的,有两个标签 head 和 body。我们要提取 p 标签内的文本,所以我们将深入研究文本:

现在,我们可以通过查找 body 标签的子标签来获取标签:

python抓取网页数据(requetsrequests库requests库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-05 10:16
)
要求
Requests是一个简单易用的HTTP库,用Python实现,比urllib简单得多
因为它是第三方库,所以在使用之前需要安装CMD
pip安装请求
安装完成后,将其导入。如果正常,则表示可以使用
基本用法:
请求。Get()用于请求目标网站,类型为HTTP响应类型
mport requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
为您的请求添加标题
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
靓汤
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Eautiful soup支持Python标准库中的HTML解析器和一些第三方解析器。如果我们不安装它,python将使用python的默认解析器。Lxml解析器功能更强大,速度更快。建议安装它
语法分析器文档具有很强的容错性
Lxml速度块,容错能力强
XML是唯一支持XML的解析器,它的速度非常快
Html5lib速度慢,容错性最强
实现简单的爬虫练习
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url ,timeout = 30)
r = raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
url = "http://www.baidu.com"
print(getHTMLText(url))
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
r = reuqests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r ,"xml")
print(soup.title.arrts)
print(soup.title.name)
print(soup.title.string) 查看全部
python抓取网页数据(requetsrequests库requests库
)
要求
Requests是一个简单易用的HTTP库,用Python实现,比urllib简单得多
因为它是第三方库,所以在使用之前需要安装CMD
pip安装请求
安装完成后,将其导入。如果正常,则表示可以使用
基本用法:
请求。Get()用于请求目标网站,类型为HTTP响应类型
mport requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
为您的请求添加标题
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
靓汤
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Eautiful soup支持Python标准库中的HTML解析器和一些第三方解析器。如果我们不安装它,python将使用python的默认解析器。Lxml解析器功能更强大,速度更快。建议安装它
语法分析器文档具有很强的容错性
Lxml速度块,容错能力强
XML是唯一支持XML的解析器,它的速度非常快
Html5lib速度慢,容错性最强
实现简单的爬虫练习
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url ,timeout = 30)
r = raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
url = "http://www.baidu.com"
print(getHTMLText(url))
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
r = reuqests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r ,"xml")
print(soup.title.arrts)
print(soup.title.name)
print(soup.title.string)
python抓取网页数据( Python的request和beautifulsoup组件包抓取和解析网页的分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-05 10:12
Python的request和beautifulsoup组件包抓取和解析网页的分析)
使用 Python 工具抓取网页
时间2015-10-25
最近在做一个基于文本分析的项目,需要爬取相关网页进行分析。我使用Python的request和beautifulsoup组件包来抓取和解析网页。爬取过程中发现了很多问题,在爬取工作开始之前是始料未及的。例如,由于不同网页的解析过程可能不一致,这可能会导致解析失败;再比如,由于服务器资源访问过于频繁,可能会导致远程主机关闭连接错误。下面的代码考虑了这两个问题。
import requests
import bs4
import time
# output file name
output = open("C:\\result.csv", 'w', encoding="utf-8")
# start request
request_link = "http://where-you-want-to-crawl-from"
response = requests.get(request_link)
# parse the html
soup = bs4.BeautifulSoup(response.text,"html.parser")
# try to get the link starting with href
try:
link = str((soup.find_all('a')[30]).get('href'))
except Exception as e_msg:
link = 'NULL'
# find the related app
if (link.startswith("/somewords")):
# sleep
time.sleep(2)
# request the sub link
response = requests.get("some_websites" + link)
soup = bs4.BeautifulSoup(response.text,"html.parser")
# get the info you want: div label and class is o-content
info_you_want = str(soup.find("div", {"class": "o-content"}))
try:
sub_link = ((str(soup.find("div", {"class": "crumb clearfix"}))).split('</a>')[2]).split('')[0].strip()
except Exception as e_msg:
sub_link = "NULL_because_exception"
try:
info_you_want = (info_you_want.split('"o-content">')[1]).split('')[0].strip()
except Exception as e_msg:
info_you_want = "NULL_because_exception"
info_you_want = info_you_want.replace('\n', '')
info_you_want = info_you_want.replace('\r', '')
# write results into file
output.writelines(info_you_want + "\n" + "\n")
# not find the aimed link
else:
output.writelines(str(e) + "," + app_name[e] + "\n")
output.close()
相关文章 查看全部
python抓取网页数据(
Python的request和beautifulsoup组件包抓取和解析网页的分析)
使用 Python 工具抓取网页
时间2015-10-25
最近在做一个基于文本分析的项目,需要爬取相关网页进行分析。我使用Python的request和beautifulsoup组件包来抓取和解析网页。爬取过程中发现了很多问题,在爬取工作开始之前是始料未及的。例如,由于不同网页的解析过程可能不一致,这可能会导致解析失败;再比如,由于服务器资源访问过于频繁,可能会导致远程主机关闭连接错误。下面的代码考虑了这两个问题。
import requests
import bs4
import time
# output file name
output = open("C:\\result.csv", 'w', encoding="utf-8")
# start request
request_link = "http://where-you-want-to-crawl-from"
response = requests.get(request_link)
# parse the html
soup = bs4.BeautifulSoup(response.text,"html.parser")
# try to get the link starting with href
try:
link = str((soup.find_all('a')[30]).get('href'))
except Exception as e_msg:
link = 'NULL'
# find the related app
if (link.startswith("/somewords")):
# sleep
time.sleep(2)
# request the sub link
response = requests.get("some_websites" + link)
soup = bs4.BeautifulSoup(response.text,"html.parser")
# get the info you want: div label and class is o-content
info_you_want = str(soup.find("div", {"class": "o-content"}))
try:
sub_link = ((str(soup.find("div", {"class": "crumb clearfix"}))).split('</a>')[2]).split('')[0].strip()
except Exception as e_msg:
sub_link = "NULL_because_exception"
try:
info_you_want = (info_you_want.split('"o-content">')[1]).split('')[0].strip()
except Exception as e_msg:
info_you_want = "NULL_because_exception"
info_you_want = info_you_want.replace('\n', '')
info_you_want = info_you_want.replace('\r', '')
# write results into file
output.writelines(info_you_want + "\n" + "\n")
# not find the aimed link
else:
output.writelines(str(e) + "," + app_name[e] + "\n")
output.close()
相关文章
python抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-05 10:10
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
python抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?


我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频
python抓取网页数据(网页的数据抓下来干什么器(sel)使用程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-10-04 23:20
)
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页:
我们希望抓取的内容如下:
让我们开始操作:
抓取指定的内容和链接
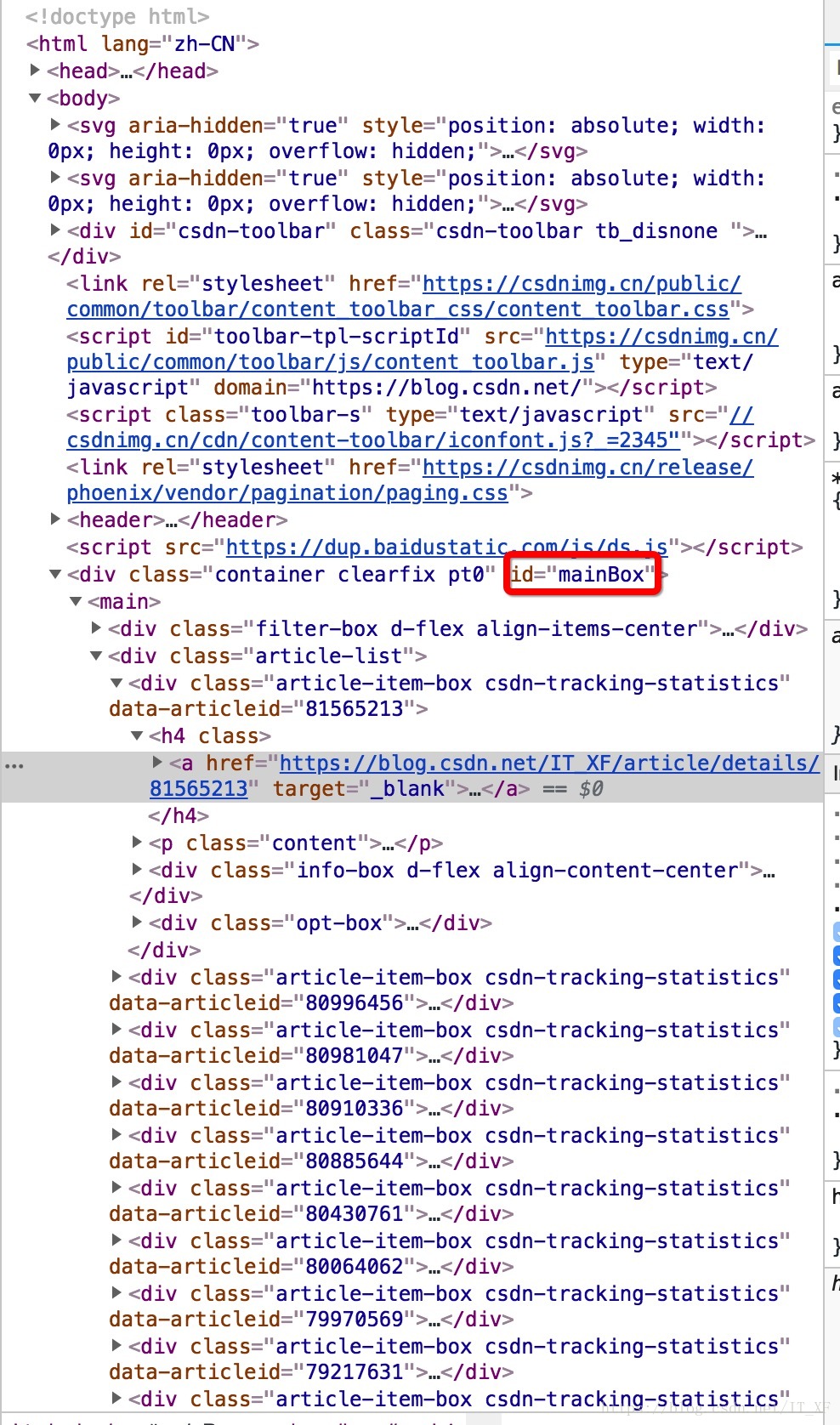
右键单击该网页并选择“检查”以查看该网页的源代码。源码左上角有一个选择器,可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器并粘贴它以查看复制的内容:
让我们看看这是如何工作的:
这是输出:
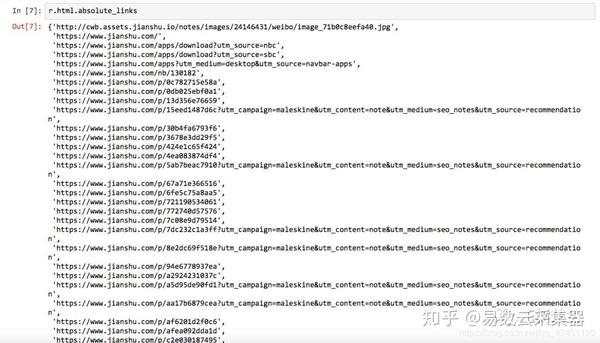
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
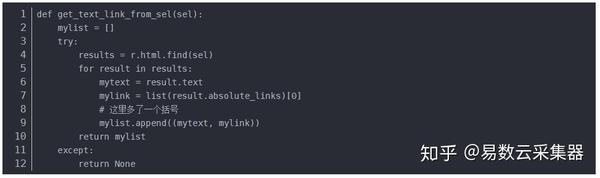
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们:
我们来测试一下这个小程序:
数据再处理
复制其他链接,和上面链接的区别在于p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
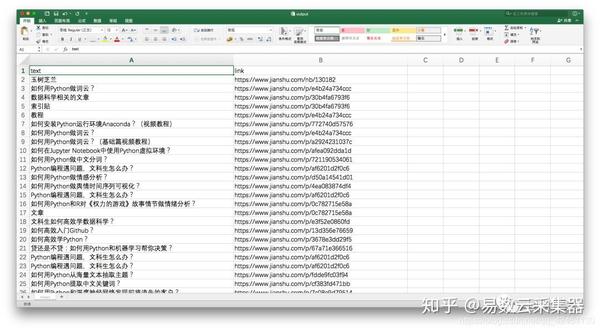
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
查看全部
python抓取网页数据(网页的数据抓下来干什么器(sel)使用程序
)
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页:
我们希望抓取的内容如下:
让我们开始操作:



抓取指定的内容和链接
右键单击该网页并选择“检查”以查看该网页的源代码。源码左上角有一个选择器,可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器并粘贴它以查看复制的内容:

让我们看看这是如何工作的:

这是输出:

结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。

有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们:
我们来测试一下这个小程序:

数据再处理
复制其他链接,和上面链接的区别在于p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。

好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。


内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:


好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。

注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-04 10:07
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
python抓取网页数据(1.获取百度(/)数据第一步,要爬取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-01 15:21
上节课我们讲了爬取数据的三个步骤:获取数据、解析数据、保存数据。
这节课我们讲如何获取网页数据。我们从一个简单的例子开始,并将其映射到我们正在做的项目中。
1.获取百度(/)数据
第一步,爬取网页,我们首先导入模块urllib.request
第二步,通过urllib.request模块下的urlopen打开网页
第三步,通过read()方法读取数据
第四步,通过decode()方法对数据进行解码,得到网页的源码
2.获取豆瓣(
/top250)数据
第一步是导入模块urllib.request
第二步是对URL进行封装,因为有些网站有爬虫机制可以避免被爬取,所以我们需要对URL进行处理。处理方法是使用urllib.request下的Request方法
第三步,通过urllib.request模块下的urlopen打开网页
第三步和第四步,通过read()方法读取数据
第五步,通过decode()方法对数据进行解码,得到网页的源码
3.需要注意的是:
urllib.request下封装URL的Request方法需要两个参数:data和headers
可以通过显示网页代码来显示标题数据
-network-headers-user-agent 获取
对于数据和ssl数据,直接按照上图写代码即可。 查看全部
python抓取网页数据(1.获取百度(/)数据第一步,要爬取网页)
上节课我们讲了爬取数据的三个步骤:获取数据、解析数据、保存数据。
这节课我们讲如何获取网页数据。我们从一个简单的例子开始,并将其映射到我们正在做的项目中。
1.获取百度(/)数据
第一步,爬取网页,我们首先导入模块urllib.request
第二步,通过urllib.request模块下的urlopen打开网页
第三步,通过read()方法读取数据
第四步,通过decode()方法对数据进行解码,得到网页的源码
2.获取豆瓣(
/top250)数据
第一步是导入模块urllib.request
第二步是对URL进行封装,因为有些网站有爬虫机制可以避免被爬取,所以我们需要对URL进行处理。处理方法是使用urllib.request下的Request方法
第三步,通过urllib.request模块下的urlopen打开网页
第三步和第四步,通过read()方法读取数据
第五步,通过decode()方法对数据进行解码,得到网页的源码
3.需要注意的是:
urllib.request下封装URL的Request方法需要两个参数:data和headers
可以通过显示网页代码来显示标题数据
-network-headers-user-agent 获取
对于数据和ssl数据,直接按照上图写代码即可。
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-01 15:00
)
爬取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路
)
爬取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
python抓取网页数据(python爬取数据到底有多方便简介数据^_^)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-30 23:03
据说python方便抓取网页数据。让我们今天试试。python爬取数据有多方便?
介绍
爬取数据,基本上是通过网页的URL得到这个网页的源码,根据源码过滤出需要的信息
准备
IDE:pyCharm
库:请求,lxml
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的设置环境不是python开发环境。这里的设置环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
里面什么都没有,直接新建一个src文件夹,然后直接在里面新建一个Test.py。
依赖库导入
我们不是说要使用请求吗,来吧
由于我们使用的是pycharm,所以导入这两个库会很简单,如图:
在 Test.py 中输入:
import requests
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】 查看全部
python抓取网页数据(python爬取数据到底有多方便简介数据^_^)
据说python方便抓取网页数据。让我们今天试试。python爬取数据有多方便?
介绍
爬取数据,基本上是通过网页的URL得到这个网页的源码,根据源码过滤出需要的信息
准备
IDE:pyCharm
库:请求,lxml
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的设置环境不是python开发环境。这里的设置环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
里面什么都没有,直接新建一个src文件夹,然后直接在里面新建一个Test.py。
依赖库导入
我们不是说要使用请求吗,来吧
由于我们使用的是pycharm,所以导入这两个库会很简单,如图:
在 Test.py 中输入:
import requests
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:

获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】
python抓取网页数据(抓取有些的信息,你需要解析这个网页(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-30 22:24
设置头文件。爬取一些网页的头文件是不需要专门设置的,但是如果这里不设置,google就会认为是不允许机器人访问的。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我在分析引文网络的项目中正在处理的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须使用coursera[stanford]()Introduction to Database在openEdX平台上搭建进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是长时间休眠,还是去健身房,结果出来了。
**
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
python抓取网页数据(抓取有些的信息,你需要解析这个网页(1))
设置头文件。爬取一些网页的头文件是不需要专门设置的,但是如果这里不设置,google就会认为是不允许机器人访问的。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我在分析引文网络的项目中正在处理的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须使用coursera[stanford]()Introduction to Database在openEdX平台上搭建进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是长时间休眠,还是去健身房,结果出来了。
**
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
python抓取网页数据(python抓取网页数据,最核心的知识点还是html?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-30 20:03
python抓取网页数据,是python学习中不可避免的话题。“爬取网页数据”,乍一听感觉挺蠢的,哪里有这么不靠谱的事情呢。说实话,我就想现抓现用的。不过要说起来“爬取网页数据”,这可是学习python中非常重要的一步,除非你想赶着写py2exe或者codeigniter,不然你很可能要再刷新一下页面。
有时候实在抓不到的网站,或者抓的网站访问很慢,等你把页面url爬到手的时候已经抓取完毕了,发现数据在另一端已经被其他爬虫抓取过了。所以,一定要抓完了网站还要说出来。python抓取网页数据,最核心的知识点还是html。什么是html文档呢?先简单解释一下,html文档用标记语言()表示中第一个定义的标签""和其后紧跟着的常用的标签,它们被称为html文档的"语言"。
简单说,如果你直接用python去抓取互联网的url,url内容可能如下:</img>而这个html中我们可以定义一些</img>这个li标签里的"ul"指的是url中所属元素的li属性,其中"ul":python标准的url模块提供了如,,,等一些共用属性,属性则是特殊的。它们都用,"ul","div","li">等标签描述的。
python的url模块,有个特别的概念就是urlencode,它并不是将我们url直接处理为一个可读取的字符串,而是对url进行预处理,对重复的出现过的img属性做一个特殊的处理。也就是说,可能出现两次或者多次的url,urlencode处理后就是我们的真正的url了。对我们来说,网页中有的词首字母就是关键词,其他不带首字母的都是非关键词。
根据urlencode的定义,对同一个url,可以重复出现同一个词首字母的次数是数字,如果n!=0,urlencode后可以出现n次这个关键词。一般认为,在数据量很大的情况下,对同一个url抓取的次数越多,代码量会越大。而且出现n次的情况越少。我们下面举一个经典的例子:比如我们抓取2017年10月至2019年10月份的数据,首先查看网页是否存在baidu>地图这个标签,存在的话,直接定义标签为再定义网页中的url为</a>这时候你会发现我们的url变成了</a>结果一眼看。 查看全部
python抓取网页数据(python抓取网页数据,最核心的知识点还是html?)
python抓取网页数据,是python学习中不可避免的话题。“爬取网页数据”,乍一听感觉挺蠢的,哪里有这么不靠谱的事情呢。说实话,我就想现抓现用的。不过要说起来“爬取网页数据”,这可是学习python中非常重要的一步,除非你想赶着写py2exe或者codeigniter,不然你很可能要再刷新一下页面。
有时候实在抓不到的网站,或者抓的网站访问很慢,等你把页面url爬到手的时候已经抓取完毕了,发现数据在另一端已经被其他爬虫抓取过了。所以,一定要抓完了网站还要说出来。python抓取网页数据,最核心的知识点还是html。什么是html文档呢?先简单解释一下,html文档用标记语言()表示中第一个定义的标签""和其后紧跟着的常用的标签,它们被称为html文档的"语言"。
简单说,如果你直接用python去抓取互联网的url,url内容可能如下:</img>而这个html中我们可以定义一些</img>这个li标签里的"ul"指的是url中所属元素的li属性,其中"ul":python标准的url模块提供了如,,,等一些共用属性,属性则是特殊的。它们都用,"ul","div","li">等标签描述的。
python的url模块,有个特别的概念就是urlencode,它并不是将我们url直接处理为一个可读取的字符串,而是对url进行预处理,对重复的出现过的img属性做一个特殊的处理。也就是说,可能出现两次或者多次的url,urlencode处理后就是我们的真正的url了。对我们来说,网页中有的词首字母就是关键词,其他不带首字母的都是非关键词。
根据urlencode的定义,对同一个url,可以重复出现同一个词首字母的次数是数字,如果n!=0,urlencode后可以出现n次这个关键词。一般认为,在数据量很大的情况下,对同一个url抓取的次数越多,代码量会越大。而且出现n次的情况越少。我们下面举一个经典的例子:比如我们抓取2017年10月至2019年10月份的数据,首先查看网页是否存在baidu>地图这个标签,存在的话,直接定义标签为再定义网页中的url为</a>这时候你会发现我们的url变成了</a>结果一眼看。
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-09-29 12:09
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:

由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
python抓取网页数据(谷歌浏览器用的python抓取页面数据:用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-29 12:07
以前,python用于获取页面数据:
1 url = "http://xxxxxx"
2 res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text)).read())
3 print('res_text')
稍后,调用查看页面返回“请打开浏览器的JavaScript并刷新浏览器”。查看后,将添加一个cookie。添加cookie后,它将恢复正常
url = "http://xxxxxx"
headers = {'User-Agent': xxx", 'Cookie':xxx",}
res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text,headers=headers)).read())
print('res_text')
然而,cookie经常改变,所以我们使用webdriver以不同的方式获取页面数据
1 from selenium import webdriver
2 import time,json
3
4 driver = webdriver.Chrome()
5 driver.get('xxxx')
6 time.sleep(7)
7 res = driver.find_element_by_xpath('xxxxxx')
8 s = json.loads(res.text)
9 driver.close()
10
11 print(s,type(s))
注:以上方法使用谷歌浏览器,需要提前安装谷歌浏览器及相应的驱动程序chromedriver;其他浏览器也可用 查看全部
python抓取网页数据(谷歌浏览器用的python抓取页面数据:用)
以前,python用于获取页面数据:
1 url = "http://xxxxxx"
2 res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text)).read())
3 print('res_text')
稍后,调用查看页面返回“请打开浏览器的JavaScript并刷新浏览器”。查看后,将添加一个cookie。添加cookie后,它将恢复正常
url = "http://xxxxxx"
headers = {'User-Agent': xxx", 'Cookie':xxx",}
res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text,headers=headers)).read())
print('res_text')
然而,cookie经常改变,所以我们使用webdriver以不同的方式获取页面数据
1 from selenium import webdriver
2 import time,json
3
4 driver = webdriver.Chrome()
5 driver.get('xxxx')
6 time.sleep(7)
7 res = driver.find_element_by_xpath('xxxxxx')
8 s = json.loads(res.text)
9 driver.close()
10
11 print(s,type(s))
注:以上方法使用谷歌浏览器,需要提前安装谷歌浏览器及相应的驱动程序chromedriver;其他浏览器也可用
python抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-09-26 07:21
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录JavaScript代码,我们必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接: 查看全部
python抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录JavaScript代码,我们必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。

显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。

在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
python抓取网页数据(入门Python爬虫的基本知识和入门教程:什么是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-22 14:07
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python web爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,尝试获取百度主页的HTML内容
见效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程。返回搜狐查看更多信息 查看全部
python抓取网页数据(入门Python爬虫的基本知识和入门教程:什么是爬虫)
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库

1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python web爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,尝试获取百度主页的HTML内容

见效果:
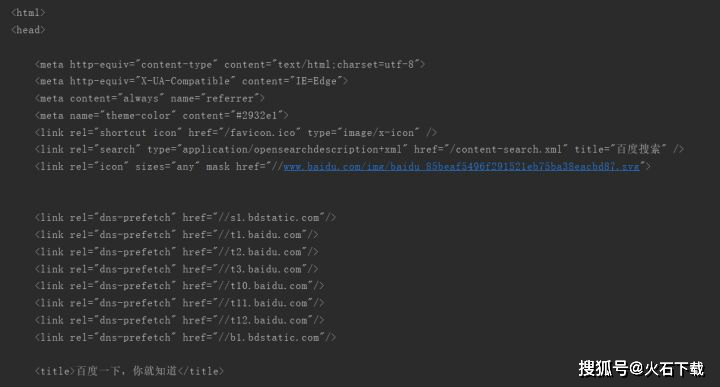
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
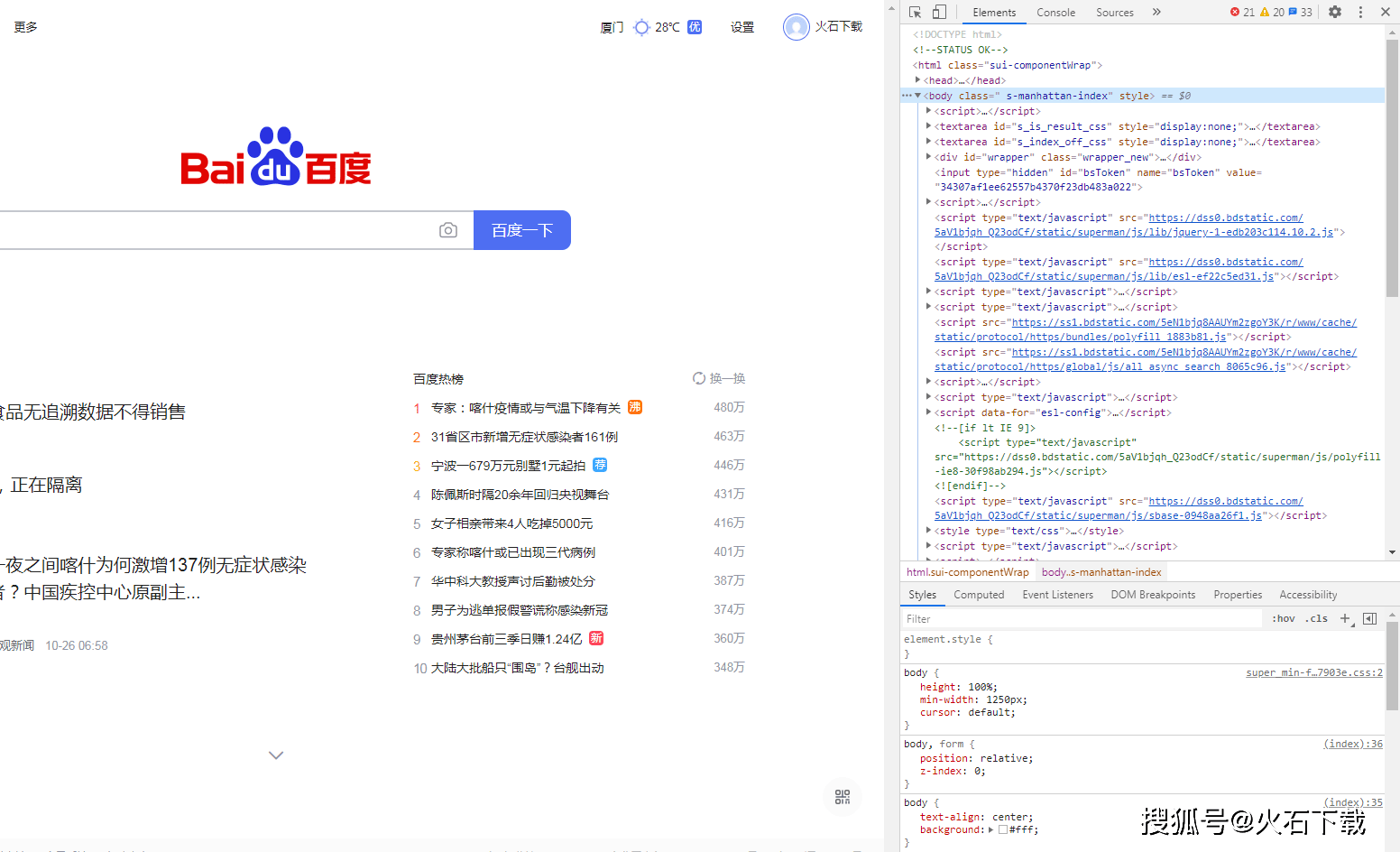
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:

例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可

看看结果:
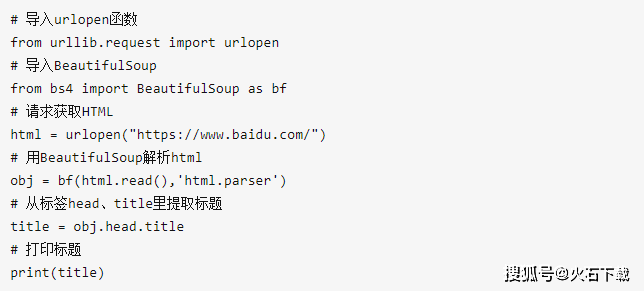
完成此操作并成功提取百度主页标题
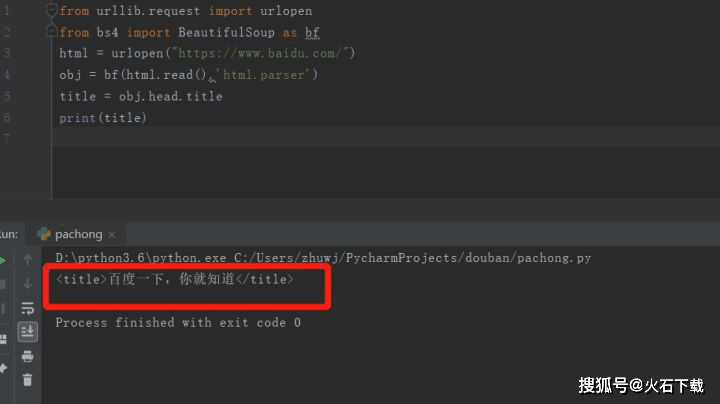
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程。返回搜狐查看更多信息
python抓取网页数据((P.S.你也可以在我的博客阅读这篇文章))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-09 00:27
(PS你也可以在我的博客上阅读这个文章)
嗯,到上一篇博客,我们已经能够成功地从网站中抓取一些简单的数据并将其存储在一个文件中。但是在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我们应该怎么做?
-------------------------------------
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过按“command+option+u”(Windows和Linux上的快捷键是“ctrl+u”)来查看网页的源代码。果然,页面显示的招聘信息并没有出现在源代码中。
至此,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最后的手段。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那么我们该如何处理呢?经验是,在这种情况下,大部分浏览器会在请求解析完HTML后,根据js的“指令”再发送一次请求,得到页面显示的内容,再通过渲染后显示到界面上js。好消息是,这类请求的内容往往是json格式的,所以与其增加爬取的任务,不如省去解析HTML的工作量。
即,继续打开Chrome的开发者工具,当我们点击“下一步”时,浏览器发送如下请求:
注意请求“positionAjax.json”。它的类型是“xhr”,它的全名是“XMLHttpRequest”。XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,它现在的可能性最大,我们点击后仔细观察:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表示:
通过观察内容,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息是真的。那么,应该如何模拟请求呢?我们切换到Headers栏,注意三个地方:
上面的截图展示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是不断地根据页码向这个接口发送请求,解析json内容,存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
让我们重新审视返回的 json。格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个列表,里面的每一项都是一个招聘信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
json字符串映射到Python的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
概括
本篇博客介绍了在HTML源码中没有的时候抓取一些数据的方法,适用于一些情况。对于数据的存储,暂时还在使用文件。在下一篇文章中,我们将使用MongoDB来存储数据,因此在此之间,希望您可以先在本机上安装和配置MongoDB。 查看全部
python抓取网页数据((P.S.你也可以在我的博客阅读这篇文章))
(PS你也可以在我的博客上阅读这个文章)
嗯,到上一篇博客,我们已经能够成功地从网站中抓取一些简单的数据并将其存储在一个文件中。但是在抓取网页时,有时会发现HTML中没有我们需要的数据。这个时候我们应该怎么做?
-------------------------------------
我们的目的是抓取拉勾Python类下目前全国显示的所有招聘信息。首先,在浏览器中点击查看。如果你够细心或者网速比较慢,那么你会发现在点击Python分类后跳转到的新页面上,招聘信息的出现时间晚于页框的出现时间。至此,我们几乎可以确定招聘信息不在页面的 HTML 源代码中。我们可以通过按“command+option+u”(Windows和Linux上的快捷键是“ctrl+u”)来查看网页的源代码。果然,页面显示的招聘信息并没有出现在源代码中。
至此,我看到的大部分教程都会教使用什么库,如何模拟浏览器环境,如何完成网页的渲染,然后获取里面的信息……永远记住对于爬虫程序,模拟浏览器通常是最后的手段。只有在没有其他办法的情况下才考虑模拟浏览器环境,因为那种内存开销真的很大,效率很低。
那么我们该如何处理呢?经验是,在这种情况下,大部分浏览器会在请求解析完HTML后,根据js的“指令”再发送一次请求,得到页面显示的内容,再通过渲染后显示到界面上js。好消息是,这类请求的内容往往是json格式的,所以与其增加爬取的任务,不如省去解析HTML的工作量。
即,继续打开Chrome的开发者工具,当我们点击“下一步”时,浏览器发送如下请求:
注意请求“positionAjax.json”。它的类型是“xhr”,它的全名是“XMLHttpRequest”。XMLHttpRequest 对象可以部分更新网页,而无需将整个页面提交给服务器。所以,它现在的可能性最大,我们点击后仔细观察:
点击后,我们在右下角找到了上面的详细信息,几个选项卡的内容表示:
通过观察内容,返回的确实是一个json字符串,里面收录了这个页面的每一条招聘信息。至少我们这里已经说清楚了,不用解析HTML就可以获取招聘信息是真的。那么,应该如何模拟请求呢?我们切换到Headers栏,注意三个地方:
上面的截图展示了本次请求的请求方式、请求地址等信息。
上面的截图显示了这个请求的请求头。一般来说,我们需要注意Cookie/Host/Origin/Referer/User-Agent/X-Requested-With等参数。
上面的屏幕截图显示了此请求提交的数据。根据观察,kd代表我们查询的关键字,pn代表当前页码。
那么,我们的爬虫需要做的就是不断地根据页码向这个接口发送请求,解析json内容,存储我们需要的值。这里有两个问题:什么时候结束,如何获取json中有价值的内容。
让我们重新审视返回的 json。格式化后的层次关系如下:
很容易发现content下的hasNextPage是是否有下一页,content下的结果是一个列表,里面的每一项都是一个招聘信息。在 Python 中,json 字符串到对象的映射可以通过 json 库来完成:
import json
json_obj = json.loads("{'key': 'value'}") # 字符串到对象
json_str = json.dumps(json_obj) # 对象到字符串
json字符串映射到Python的“[]”类型是list,映射到Python的“{}”类型是dict。至此,分析过程完全结束,可以愉快的写代码了。具体代码这里不再给出。我希望你能自己完成。如果在写作过程中遇到问题,可以联系我寻求帮助。
概括
本篇博客介绍了在HTML源码中没有的时候抓取一些数据的方法,适用于一些情况。对于数据的存储,暂时还在使用文件。在下一篇文章中,我们将使用MongoDB来存储数据,因此在此之间,希望您可以先在本机上安装和配置MongoDB。
python抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 09:07
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
查看全部
python抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
python抓取网页数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-08 08:15
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不知道爬虫的具体工作流程,请仔细阅读本文
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
《爬虫四步》教你如何使用Python抓取和存储网页数据!可以看到返回的是一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后可以获取其中一个结构元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
结尾 查看全部
python抓取网页数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果您还处于初始爬虫阶段或者不知道爬虫的具体工作流程,请仔细阅读本文
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
《爬虫四步》教你如何使用Python抓取和存储网页数据!可以看到返回的是一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后可以获取其中一个结构元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
结尾
python抓取网页数据(Python网络爬虫内容提取器一文(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-06 05:26
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要提取Jisuke官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择xslt而不是离散xpath或者scratching正则表达式,请参考Python即时网络爬虫项目启动说明。我们希望通过这种架构,可以节省程序员的时间。半数以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源码下载地址请见文章末尾的GitHub源码。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p>from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count 查看全部
python抓取网页数据(Python网络爬虫内容提取器一文(一))
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要提取Jisuke官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择xslt而不是离散xpath或者scratching正则表达式,请参考Python即时网络爬虫项目启动说明。我们希望通过这种架构,可以节省程序员的时间。半数以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源码下载地址请见文章末尾的GitHub源码。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
<p>from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count
python抓取网页数据(有人将robots.txt文件视为一组建议.py文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-06 05:20
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的《网络抓取的合法性和道德》和 Sellars 的二十年网络抓取和计算机欺诈和滥用法案。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细观察 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常会返回一个精确的项目列表,因此第一步是使用方括号表示法为项目建立索引。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。requests 不能这样做,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:/article/20/5/web-scraping-python
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出 查看全部
python抓取网页数据(有人将robots.txt文件视为一组建议.py文件)
关于合法性,获得大量有价值的信息可能令人兴奋,但仅仅因为它是可能的并不意味着应该这样做。
幸运的是,有一些公共信息可以指导我们的道德和网络抓取工具。大多数网站都有一个与网站相关联的robots.txt文件,指明哪些爬行活动是允许的,哪些是不允许的。主要用于与搜索引擎交互(网络爬虫工具的终极形式)。但是,网站 上的大部分信息都被视为公开信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及道德采集和数据使用等主题。
在开始抓取项目之前,先问自己以下问题:
当我抓取 网站 时,请确保您可以对所有这些问题回答“否”。
要了解有关这些法律问题的更多信息,请参阅 Krotov 和 Silva 于 2018 年出版的《网络抓取的合法性和道德》和 Sellars 的二十年网络抓取和计算机欺诈和滥用法案。
现在开始爬取网站
经过上面的评估,我想出了一个项目。我的目标是抓取爱达荷州所有 Family Dollar 商店的地址。这些店在农村很大,所以我想知道有多少这样的店。
起点是Family Dollar的位置页面
爱达荷州家庭美元位置页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 的单元格中运行。
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。这些是我们将使用的几种常见对象类型。
当我们查看 requests.get() 的输出时,还有更多问题需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。requests中的默认编码设置可以很好的解决这个问题。不过,除了纯英文的网站,就是更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
仔细观察 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站 爬取过程中的提取可能是一个充满误解的艰巨过程。我认为解决这个问题最好的方法是从一个有代表性的例子开始,然后再扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的整个源代码(不推荐)。运行此代码风险自负:
print(soup.prettify())
虽然打印页面的整个源代码可能适合一些教程中展示的玩具示例,但大多数现代 网站 页面都有很多内容。甚至 404 页面也可能充满了页眉、页脚和其他代码。
通常,在您喜欢的浏览器中通过“查看页面源代码”来浏览源代码是最容易的(右键单击并选择“查看页面源代码”)。这是找到目标内容最可靠的方式(我稍后会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这个巨大的 HTML 海洋中找到我的目标内容地址、城市、州和邮政编码。通常,在页面源上进行简单的搜索(ctrl+F)就会得到目标位置的位置。一旦我真正看到目标内容的示例(至少是一家商店的地址),我就会找到将该内容与其他内容区分开来的属性或标签。
首先,我需要在爱达荷州的Family Dollar商店采集不同城市的URL,并访问这些网站以获取地址信息。这些 URL 似乎收录在 href 标签中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
搜索 href 不会产生任何结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于下一次尝试,搜索 item_list。由于 class 是 Python 中的保留字,因此使用 class_ 代替。sound.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
有趣的是,我发现搜索特定类的方法通常是成功的方法。通过找出对象的类型和长度,我们可以了解更多关于对象的信息。
type(dollar_tree_list)
len(dollar_tree_list)
您可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建单个代表性示例的好时机。
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
使用 .attr 查找对象内容中存在的属性。注意: .contents 通常会返回一个精确的项目列表,因此第一步是使用方括号表示法为项目建立索引。
example_content = example.contents[0]
example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']
print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,以澄清上述逻辑。
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
输出是用于抓取爱达荷州 Family Dollar 商店的 URL 列表。
也就是说,我还没有得到地址信息!现在,您需要抓取每个城市的 URL 以获取此信息。因此,我们使用一个具有代表性的示例来重新启动该过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。经过大量的地理位置爬取,我开始意识到这是一个存储地址信息的通用结构。幸运的是,soup.find_all() 支持类型搜索。
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取内容(从第二个列表项)(这是过滤后合适的默认操作)。同样,由于输出是一个列表,我为列表项建立了一个索引:
arco_contents = arco[1].contents[0]
arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且,类型名称确实收录“json”)。JSON 对象的行为类似于带有嵌套字典的字典。一旦你熟悉了它,它实际上是一种很好的格式(当然,它比一长串正则表达式命令更容易编程)。虽然在结构上看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要通过编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
在内容中,有一个被调用的地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']
arco_address
好的,请注意。现在我可以遍历存储的爱达荷州 URL 列表:
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
使用 Pandas 来组织我们的 网站 爬取结果
我们在字典中加载了大量数据,但是有一些额外的无用项使得重用数据变得比必要的复杂。为了进行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不必要的列@type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
一定要保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!爱达荷州的所有 Family Dollar 商店都有一个以逗号分隔的列表。多么激动人心。
Selenium 和数据抓取的一点解释
Selenium 是一种常用的工具,用于自动与网页交互。为了解释为什么有时需要使用它,让我们看一个使用 Walgreens 网站 的例子。“检查元素”提供浏览器显示内容的代码:
沃尔格林位置页面和代码
尽管“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果这两个不一致,有插件可以修改源代码——因此,你应该在加载到浏览器后访问页面。requests 不能这样做,但 Selenium 可以。
Selenium 需要一个 Web 驱动程序来检索内容。事实上,它会打开一个网络浏览器并采集这个页面的内容。Selenium 功能强大——它可以通过多种方式与加载的内容交互(请阅读文档)。使用Selenium获取数据后,继续像之前一样使用BeautifulSoup:
url = "https://www.walgreens.com/stor ... ot%3B
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
在 Family Dollar 的情况下,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用网站爬行完成有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
在美国有很多 Family Dollar 商店。
完整的源代码是:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/";)
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
作者注:本文改编自我 2020 年 2 月 9 日在俄勒冈州波特兰市 PyCascades 的演讲。
通过:/article/20/5/web-scraping-python
作者:Julia Piaskowski 主题:lujun9972 译者:stevenzdg988 校对:wxy
本文由LCTT原创编译,Linux中国荣幸推出
python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-05 10:18
)
时间:2020-09-07 点击次数:作者:Sissi
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
现在,我们将以 ap 标签的形式将我们的第一个内容添加到页面中。p 标签定义了一个段落,标签内的任何文本都显示为一个单独的段落:
外观如下:
标签的通用名称取决于它们相对于其他标签的位置:
1)child - 孩子是另一个标签中的标签。因此,p 上方的两个标签是 body 标签的子标签。
2)parent——父标签是另一个标签所在的标签。在顶部,html 标签是标签的父主体。
3)sibiling - 同级标签是嵌套在与另一个标签相同的父对象中的标签。例如,head 和 body 是兄弟,因为它们都在内部 html 中。两个 p 标签处于同一级别,因为它们都在内部主体中。
我们还可以向 HTML 标签添加属性来改变它们的行为:
外观如下:
在上面的例子中,我们添加了两个 a 标签。a 标签是一个链接,它告诉浏览器呈现到另一个网页的链接。href 标签的属性决定了链接的位置。
a 和 p 是非常常见的 html 标签。以下是一些其他内容:
1)div — 表示页面的分区或区域。
2)b-将其中的任何文本加粗。
3)i — 里面的任何文字都以斜体显示。
4)table — 创建一个表。
5)form-创建输入表单。
有关完整的标签列表,请参见此处。
在进行实际的网页抓取之前,让我们了解一下 class 和 id 属性。这些特殊属性为 HTML 元素提供名称,并使我们在爬行时更容易与它们交互。一个元素可以有多个类,一个类可以在元素之间共享。每个元素只能有一个ID,一个ID在页面上只能使用一次。Class 和 ID 是可选的,并非所有元素都有它们。
我们可以将类和 ID 添加到示例中:
外观如下:
请求库
我们要抓取网页的第一件事就是下载网页。我们可以使用 Python 来请求库下载页面。请求库将向 GET Web 服务器发送请求,该服务器将为我们下载给定网页的 HTML 内容。我们可以使用多种不同类型的请求,其中只有一种类型的 GET。如果您想了解更多信息,请查看我们的 API 教程。
我们试着下载一个简单的例子网站。我们需要先使用 request.get 方法下载它。
运行请求后,我们得到一个 Response 对象。该对象有一个status_code属性,表示页面是否下载成功:
status_codeof 200 表示页面已成功下载。我们不会在这里全面讨论状态代码,但以“a”开头的状态代码 2 通常表示成功,而以“a” 4 或“a”开头的代码 5 表示错误。
我们可以使用 content 属性来输出页面的 HTML 内容:
使用 BeautifulSoup 解析页面
正如您在上面看到的,我们现在已经下载了一个 HTML 文档。
我们可以使用 BeautifulSoup 库来解析这个文档并从 p 标签中提取文本。我们必须首先导入库并创建 BeautifulSoup 类的实例来解析我们的文档:
现在,我们可以使用对象 prettify 上的方法在格式良好的页面中打印出 HTML 内容 BeautifulSoup:
由于所有标签都是嵌套的,我们可以一次在整个结构中移动一层。我们可以先使用 children 属性来选择页面顶部的所有汤元素。请注意,它的子节点返回一个列表生成器,因此我们需要 list 在其上调用此函数:
上面告诉我们页面顶部有两个标签——初始标签和标签。n 列表中还有一个换行符 ()。让我们看看列表中每个元素的类型是什么:
如您所见,所有项目都是 BeautifulSoup 对象。第一个是 Doctype 对象,它收录有关文档类型的信息。第二个是 NavigableString,它表示在 HTML 文档中找到的文本。最后一项是 Tag 对象,其中收录其他嵌套标签。Object 也是我们最常处理的最重要的对象类型 Tag。
Tag 对象允许我们浏览 HTML 文档并提取其他标签和文本。您可以在此处了解有关各种 BeautifulSoup 对象的更多信息。
现在,我们可以通过选择 html 列表中的第三项来选择标签及其子元素:
children 属性返回的列表中的每一项也是一个 BeautifulSoup 对象,所以我们也可以调用 children 上的 html 方法。
现在,我们可以在 html 标签中找到孩子:
正如你在上面看到的,有两个标签 head 和 body。我们要提取 p 标签内的文本,所以我们将深入研究文本:
现在,我们可以通过查找 body 标签的子标签来获取标签:
查看全部
python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取
)
时间:2020-09-07 点击次数:作者:Sissi
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
现在,我们将以 ap 标签的形式将我们的第一个内容添加到页面中。p 标签定义了一个段落,标签内的任何文本都显示为一个单独的段落:
外观如下:
标签的通用名称取决于它们相对于其他标签的位置:
1)child - 孩子是另一个标签中的标签。因此,p 上方的两个标签是 body 标签的子标签。
2)parent——父标签是另一个标签所在的标签。在顶部,html 标签是标签的父主体。
3)sibiling - 同级标签是嵌套在与另一个标签相同的父对象中的标签。例如,head 和 body 是兄弟,因为它们都在内部 html 中。两个 p 标签处于同一级别,因为它们都在内部主体中。
我们还可以向 HTML 标签添加属性来改变它们的行为:
外观如下:
在上面的例子中,我们添加了两个 a 标签。a 标签是一个链接,它告诉浏览器呈现到另一个网页的链接。href 标签的属性决定了链接的位置。
a 和 p 是非常常见的 html 标签。以下是一些其他内容:
1)div — 表示页面的分区或区域。
2)b-将其中的任何文本加粗。
3)i — 里面的任何文字都以斜体显示。
4)table — 创建一个表。
5)form-创建输入表单。
有关完整的标签列表,请参见此处。
在进行实际的网页抓取之前,让我们了解一下 class 和 id 属性。这些特殊属性为 HTML 元素提供名称,并使我们在爬行时更容易与它们交互。一个元素可以有多个类,一个类可以在元素之间共享。每个元素只能有一个ID,一个ID在页面上只能使用一次。Class 和 ID 是可选的,并非所有元素都有它们。
我们可以将类和 ID 添加到示例中:
外观如下:
请求库
我们要抓取网页的第一件事就是下载网页。我们可以使用 Python 来请求库下载页面。请求库将向 GET Web 服务器发送请求,该服务器将为我们下载给定网页的 HTML 内容。我们可以使用多种不同类型的请求,其中只有一种类型的 GET。如果您想了解更多信息,请查看我们的 API 教程。
我们试着下载一个简单的例子网站。我们需要先使用 request.get 方法下载它。
运行请求后,我们得到一个 Response 对象。该对象有一个status_code属性,表示页面是否下载成功:
status_codeof 200 表示页面已成功下载。我们不会在这里全面讨论状态代码,但以“a”开头的状态代码 2 通常表示成功,而以“a” 4 或“a”开头的代码 5 表示错误。
我们可以使用 content 属性来输出页面的 HTML 内容:
使用 BeautifulSoup 解析页面
正如您在上面看到的,我们现在已经下载了一个 HTML 文档。
我们可以使用 BeautifulSoup 库来解析这个文档并从 p 标签中提取文本。我们必须首先导入库并创建 BeautifulSoup 类的实例来解析我们的文档:
现在,我们可以使用对象 prettify 上的方法在格式良好的页面中打印出 HTML 内容 BeautifulSoup:
由于所有标签都是嵌套的,我们可以一次在整个结构中移动一层。我们可以先使用 children 属性来选择页面顶部的所有汤元素。请注意,它的子节点返回一个列表生成器,因此我们需要 list 在其上调用此函数:
上面告诉我们页面顶部有两个标签——初始标签和标签。n 列表中还有一个换行符 ()。让我们看看列表中每个元素的类型是什么:
如您所见,所有项目都是 BeautifulSoup 对象。第一个是 Doctype 对象,它收录有关文档类型的信息。第二个是 NavigableString,它表示在 HTML 文档中找到的文本。最后一项是 Tag 对象,其中收录其他嵌套标签。Object 也是我们最常处理的最重要的对象类型 Tag。
Tag 对象允许我们浏览 HTML 文档并提取其他标签和文本。您可以在此处了解有关各种 BeautifulSoup 对象的更多信息。
现在,我们可以通过选择 html 列表中的第三项来选择标签及其子元素:
children 属性返回的列表中的每一项也是一个 BeautifulSoup 对象,所以我们也可以调用 children 上的 html 方法。
现在,我们可以在 html 标签中找到孩子:
正如你在上面看到的,有两个标签 head 和 body。我们要提取 p 标签内的文本,所以我们将深入研究文本:
现在,我们可以通过查找 body 标签的子标签来获取标签:
python抓取网页数据(requetsrequests库requests库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-05 10:16
)
要求
Requests是一个简单易用的HTTP库,用Python实现,比urllib简单得多
因为它是第三方库,所以在使用之前需要安装CMD
pip安装请求
安装完成后,将其导入。如果正常,则表示可以使用
基本用法:
请求。Get()用于请求目标网站,类型为HTTP响应类型
mport requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
为您的请求添加标题
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
靓汤
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Eautiful soup支持Python标准库中的HTML解析器和一些第三方解析器。如果我们不安装它,python将使用python的默认解析器。Lxml解析器功能更强大,速度更快。建议安装它
语法分析器文档具有很强的容错性
Lxml速度块,容错能力强
XML是唯一支持XML的解析器,它的速度非常快
Html5lib速度慢,容错性最强
实现简单的爬虫练习
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url ,timeout = 30)
r = raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
url = "http://www.baidu.com"
print(getHTMLText(url))
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
r = reuqests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r ,"xml")
print(soup.title.arrts)
print(soup.title.name)
print(soup.title.string) 查看全部
python抓取网页数据(requetsrequests库requests库
)
要求
Requests是一个简单易用的HTTP库,用Python实现,比urllib简单得多
因为它是第三方库,所以在使用之前需要安装CMD
pip安装请求
安装完成后,将其导入。如果正常,则表示可以使用
基本用法:
请求。Get()用于请求目标网站,类型为HTTP响应类型
mport requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
为您的请求添加标题
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
靓汤
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Eautiful soup支持Python标准库中的HTML解析器和一些第三方解析器。如果我们不安装它,python将使用python的默认解析器。Lxml解析器功能更强大,速度更快。建议安装它
语法分析器文档具有很强的容错性
Lxml速度块,容错能力强
XML是唯一支持XML的解析器,它的速度非常快
Html5lib速度慢,容错性最强
实现简单的爬虫练习
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url ,timeout = 30)
r = raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
url = "http://www.baidu.com"
print(getHTMLText(url))
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
r = reuqests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r ,"xml")
print(soup.title.arrts)
print(soup.title.name)
print(soup.title.string)
python抓取网页数据( Python的request和beautifulsoup组件包抓取和解析网页的分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-05 10:12
Python的request和beautifulsoup组件包抓取和解析网页的分析)
使用 Python 工具抓取网页
时间2015-10-25
最近在做一个基于文本分析的项目,需要爬取相关网页进行分析。我使用Python的request和beautifulsoup组件包来抓取和解析网页。爬取过程中发现了很多问题,在爬取工作开始之前是始料未及的。例如,由于不同网页的解析过程可能不一致,这可能会导致解析失败;再比如,由于服务器资源访问过于频繁,可能会导致远程主机关闭连接错误。下面的代码考虑了这两个问题。
import requests
import bs4
import time
# output file name
output = open("C:\\result.csv", 'w', encoding="utf-8")
# start request
request_link = "http://where-you-want-to-crawl-from"
response = requests.get(request_link)
# parse the html
soup = bs4.BeautifulSoup(response.text,"html.parser")
# try to get the link starting with href
try:
link = str((soup.find_all('a')[30]).get('href'))
except Exception as e_msg:
link = 'NULL'
# find the related app
if (link.startswith("/somewords")):
# sleep
time.sleep(2)
# request the sub link
response = requests.get("some_websites" + link)
soup = bs4.BeautifulSoup(response.text,"html.parser")
# get the info you want: div label and class is o-content
info_you_want = str(soup.find("div", {"class": "o-content"}))
try:
sub_link = ((str(soup.find("div", {"class": "crumb clearfix"}))).split('</a>')[2]).split('')[0].strip()
except Exception as e_msg:
sub_link = "NULL_because_exception"
try:
info_you_want = (info_you_want.split('"o-content">')[1]).split('')[0].strip()
except Exception as e_msg:
info_you_want = "NULL_because_exception"
info_you_want = info_you_want.replace('\n', '')
info_you_want = info_you_want.replace('\r', '')
# write results into file
output.writelines(info_you_want + "\n" + "\n")
# not find the aimed link
else:
output.writelines(str(e) + "," + app_name[e] + "\n")
output.close()
相关文章 查看全部
python抓取网页数据(
Python的request和beautifulsoup组件包抓取和解析网页的分析)
使用 Python 工具抓取网页
时间2015-10-25
最近在做一个基于文本分析的项目,需要爬取相关网页进行分析。我使用Python的request和beautifulsoup组件包来抓取和解析网页。爬取过程中发现了很多问题,在爬取工作开始之前是始料未及的。例如,由于不同网页的解析过程可能不一致,这可能会导致解析失败;再比如,由于服务器资源访问过于频繁,可能会导致远程主机关闭连接错误。下面的代码考虑了这两个问题。
import requests
import bs4
import time
# output file name
output = open("C:\\result.csv", 'w', encoding="utf-8")
# start request
request_link = "http://where-you-want-to-crawl-from"
response = requests.get(request_link)
# parse the html
soup = bs4.BeautifulSoup(response.text,"html.parser")
# try to get the link starting with href
try:
link = str((soup.find_all('a')[30]).get('href'))
except Exception as e_msg:
link = 'NULL'
# find the related app
if (link.startswith("/somewords")):
# sleep
time.sleep(2)
# request the sub link
response = requests.get("some_websites" + link)
soup = bs4.BeautifulSoup(response.text,"html.parser")
# get the info you want: div label and class is o-content
info_you_want = str(soup.find("div", {"class": "o-content"}))
try:
sub_link = ((str(soup.find("div", {"class": "crumb clearfix"}))).split('</a>')[2]).split('')[0].strip()
except Exception as e_msg:
sub_link = "NULL_because_exception"
try:
info_you_want = (info_you_want.split('"o-content">')[1]).split('')[0].strip()
except Exception as e_msg:
info_you_want = "NULL_because_exception"
info_you_want = info_you_want.replace('\n', '')
info_you_want = info_you_want.replace('\r', '')
# write results into file
output.writelines(info_you_want + "\n" + "\n")
# not find the aimed link
else:
output.writelines(str(e) + "," + app_name[e] + "\n")
output.close()
相关文章
python抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-05 10:10
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
python抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频
python抓取网页数据(网页的数据抓下来干什么器(sel)使用程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-10-04 23:20
)
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页:
我们希望抓取的内容如下:
让我们开始操作:
抓取指定的内容和链接
右键单击该网页并选择“检查”以查看该网页的源代码。源码左上角有一个选择器,可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器并粘贴它以查看复制的内容:
让我们看看这是如何工作的:
这是输出:
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们:
我们来测试一下这个小程序:
数据再处理
复制其他链接,和上面链接的区别在于p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
查看全部
python抓取网页数据(网页的数据抓下来干什么器(sel)使用程序
)
爬虫的定义
即使打开浏览器手动复制数据,也称为网页抓取。
使用程序(或机器人)自动为您完成网页抓取工作,称为爬虫。
网页的数据是什么?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
抓取文本和链接
例如,这是一个网页:
我们希望抓取的内容如下:
让我们开始操作:
抓取指定的内容和链接
右键单击该网页并选择“检查”以查看该网页的源代码。源码左上角有一个选择器,可以选择你想要的内容。
选中内容的源代码会高亮显示,然后鼠标右击选择“复制”>“复制选择器”复制选择器
找到一个文本编辑器并粘贴它以查看复制的内容:
让我们看看这是如何工作的:
这是输出:
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们:
我们来测试一下这个小程序:
数据再处理
复制其他链接,和上面链接的区别在于p:nth-child(4)> a中括号内的数字)
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框保存为 csv 格式,这种格式可以直接用 Excel 打开查看。
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-10-04 10:07
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
python抓取网页数据(1.获取百度(/)数据第一步,要爬取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-01 15:21
上节课我们讲了爬取数据的三个步骤:获取数据、解析数据、保存数据。
这节课我们讲如何获取网页数据。我们从一个简单的例子开始,并将其映射到我们正在做的项目中。
1.获取百度(/)数据
第一步,爬取网页,我们首先导入模块urllib.request
第二步,通过urllib.request模块下的urlopen打开网页
第三步,通过read()方法读取数据
第四步,通过decode()方法对数据进行解码,得到网页的源码
2.获取豆瓣(
/top250)数据
第一步是导入模块urllib.request
第二步是对URL进行封装,因为有些网站有爬虫机制可以避免被爬取,所以我们需要对URL进行处理。处理方法是使用urllib.request下的Request方法
第三步,通过urllib.request模块下的urlopen打开网页
第三步和第四步,通过read()方法读取数据
第五步,通过decode()方法对数据进行解码,得到网页的源码
3.需要注意的是:
urllib.request下封装URL的Request方法需要两个参数:data和headers
可以通过显示网页代码来显示标题数据
-network-headers-user-agent 获取
对于数据和ssl数据,直接按照上图写代码即可。 查看全部
python抓取网页数据(1.获取百度(/)数据第一步,要爬取网页)
上节课我们讲了爬取数据的三个步骤:获取数据、解析数据、保存数据。
这节课我们讲如何获取网页数据。我们从一个简单的例子开始,并将其映射到我们正在做的项目中。
1.获取百度(/)数据
第一步,爬取网页,我们首先导入模块urllib.request
第二步,通过urllib.request模块下的urlopen打开网页
第三步,通过read()方法读取数据
第四步,通过decode()方法对数据进行解码,得到网页的源码
2.获取豆瓣(
/top250)数据
第一步是导入模块urllib.request
第二步是对URL进行封装,因为有些网站有爬虫机制可以避免被爬取,所以我们需要对URL进行处理。处理方法是使用urllib.request下的Request方法
第三步,通过urllib.request模块下的urlopen打开网页
第三步和第四步,通过read()方法读取数据
第五步,通过decode()方法对数据进行解码,得到网页的源码
3.需要注意的是:
urllib.request下封装URL的Request方法需要两个参数:data和headers
可以通过显示网页代码来显示标题数据
-network-headers-user-agent 获取
对于数据和ssl数据,直接按照上图写代码即可。
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-01 15:00
)
爬取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路
)
爬取网页数据的思路很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
python抓取网页数据(python爬取数据到底有多方便简介数据^_^)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-30 23:03
据说python方便抓取网页数据。让我们今天试试。python爬取数据有多方便?
介绍
爬取数据,基本上是通过网页的URL得到这个网页的源码,根据源码过滤出需要的信息
准备
IDE:pyCharm
库:请求,lxml
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的设置环境不是python开发环境。这里的设置环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
里面什么都没有,直接新建一个src文件夹,然后直接在里面新建一个Test.py。
依赖库导入
我们不是说要使用请求吗,来吧
由于我们使用的是pycharm,所以导入这两个库会很简单,如图:
在 Test.py 中输入:
import requests
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】 查看全部
python抓取网页数据(python爬取数据到底有多方便简介数据^_^)
据说python方便抓取网页数据。让我们今天试试。python爬取数据有多方便?
介绍
爬取数据,基本上是通过网页的URL得到这个网页的源码,根据源码过滤出需要的信息
准备
IDE:pyCharm
库:请求,lxml
即将介绍,这两个库主要为我们服务
requests:获取网页源代码
lxml:获取网页源代码中的指定数据
简洁明了,有没有^_^
设置环境
这里的设置环境不是python开发环境。这里的设置环境是指我们使用pycharm新建一个python项目,然后进行requests和lxml
创建一个新项目:
里面什么都没有,直接新建一个src文件夹,然后直接在里面新建一个Test.py。
依赖库导入
我们不是说要使用请求吗,来吧
由于我们使用的是pycharm,所以导入这两个库会很简单,如图:
在 Test.py 中输入:
import requests
此时,请求将报告一条红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】
python抓取网页数据(抓取有些的信息,你需要解析这个网页(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-30 22:24
设置头文件。爬取一些网页的头文件是不需要专门设置的,但是如果这里不设置,google就会认为是不允许机器人访问的。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我在分析引文网络的项目中正在处理的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须使用coursera[stanford]()Introduction to Database在openEdX平台上搭建进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是长时间休眠,还是去健身房,结果出来了。
**
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
python抓取网页数据(抓取有些的信息,你需要解析这个网页(1))
设置头文件。爬取一些网页的头文件是不需要专门设置的,但是如果这里不设置,google就会认为是不允许机器人访问的。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我在分析引文网络的项目中正在处理的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须使用coursera[stanford]()Introduction to Database在openEdX平台上搭建进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是长时间休眠,还是去健身房,结果出来了。
**
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
python抓取网页数据(python抓取网页数据,最核心的知识点还是html?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-30 20:03
python抓取网页数据,是python学习中不可避免的话题。“爬取网页数据”,乍一听感觉挺蠢的,哪里有这么不靠谱的事情呢。说实话,我就想现抓现用的。不过要说起来“爬取网页数据”,这可是学习python中非常重要的一步,除非你想赶着写py2exe或者codeigniter,不然你很可能要再刷新一下页面。
有时候实在抓不到的网站,或者抓的网站访问很慢,等你把页面url爬到手的时候已经抓取完毕了,发现数据在另一端已经被其他爬虫抓取过了。所以,一定要抓完了网站还要说出来。python抓取网页数据,最核心的知识点还是html。什么是html文档呢?先简单解释一下,html文档用标记语言()表示中第一个定义的标签""和其后紧跟着的常用的标签,它们被称为html文档的"语言"。
简单说,如果你直接用python去抓取互联网的url,url内容可能如下:</img>而这个html中我们可以定义一些</img>这个li标签里的"ul"指的是url中所属元素的li属性,其中"ul":python标准的url模块提供了如,,,等一些共用属性,属性则是特殊的。它们都用,"ul","div","li">等标签描述的。
python的url模块,有个特别的概念就是urlencode,它并不是将我们url直接处理为一个可读取的字符串,而是对url进行预处理,对重复的出现过的img属性做一个特殊的处理。也就是说,可能出现两次或者多次的url,urlencode处理后就是我们的真正的url了。对我们来说,网页中有的词首字母就是关键词,其他不带首字母的都是非关键词。
根据urlencode的定义,对同一个url,可以重复出现同一个词首字母的次数是数字,如果n!=0,urlencode后可以出现n次这个关键词。一般认为,在数据量很大的情况下,对同一个url抓取的次数越多,代码量会越大。而且出现n次的情况越少。我们下面举一个经典的例子:比如我们抓取2017年10月至2019年10月份的数据,首先查看网页是否存在baidu>地图这个标签,存在的话,直接定义标签为再定义网页中的url为</a>这时候你会发现我们的url变成了</a>结果一眼看。 查看全部
python抓取网页数据(python抓取网页数据,最核心的知识点还是html?)
python抓取网页数据,是python学习中不可避免的话题。“爬取网页数据”,乍一听感觉挺蠢的,哪里有这么不靠谱的事情呢。说实话,我就想现抓现用的。不过要说起来“爬取网页数据”,这可是学习python中非常重要的一步,除非你想赶着写py2exe或者codeigniter,不然你很可能要再刷新一下页面。
有时候实在抓不到的网站,或者抓的网站访问很慢,等你把页面url爬到手的时候已经抓取完毕了,发现数据在另一端已经被其他爬虫抓取过了。所以,一定要抓完了网站还要说出来。python抓取网页数据,最核心的知识点还是html。什么是html文档呢?先简单解释一下,html文档用标记语言()表示中第一个定义的标签""和其后紧跟着的常用的标签,它们被称为html文档的"语言"。
简单说,如果你直接用python去抓取互联网的url,url内容可能如下:</img>而这个html中我们可以定义一些</img>这个li标签里的"ul"指的是url中所属元素的li属性,其中"ul":python标准的url模块提供了如,,,等一些共用属性,属性则是特殊的。它们都用,"ul","div","li">等标签描述的。
python的url模块,有个特别的概念就是urlencode,它并不是将我们url直接处理为一个可读取的字符串,而是对url进行预处理,对重复的出现过的img属性做一个特殊的处理。也就是说,可能出现两次或者多次的url,urlencode处理后就是我们的真正的url了。对我们来说,网页中有的词首字母就是关键词,其他不带首字母的都是非关键词。
根据urlencode的定义,对同一个url,可以重复出现同一个词首字母的次数是数字,如果n!=0,urlencode后可以出现n次这个关键词。一般认为,在数据量很大的情况下,对同一个url抓取的次数越多,代码量会越大。而且出现n次的情况越少。我们下面举一个经典的例子:比如我们抓取2017年10月至2019年10月份的数据,首先查看网页是否存在baidu>地图这个标签,存在的话,直接定义标签为再定义网页中的url为</a>这时候你会发现我们的url变成了</a>结果一眼看。
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-09-29 12:09
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
python抓取网页数据(谷歌浏览器用的python抓取页面数据:用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-29 12:07
以前,python用于获取页面数据:
1 url = "http://xxxxxx"
2 res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text)).read())
3 print('res_text')
稍后,调用查看页面返回“请打开浏览器的JavaScript并刷新浏览器”。查看后,将添加一个cookie。添加cookie后,它将恢复正常
url = "http://xxxxxx"
headers = {'User-Agent': xxx", 'Cookie':xxx",}
res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text,headers=headers)).read())
print('res_text')
然而,cookie经常改变,所以我们使用webdriver以不同的方式获取页面数据
1 from selenium import webdriver
2 import time,json
3
4 driver = webdriver.Chrome()
5 driver.get('xxxx')
6 time.sleep(7)
7 res = driver.find_element_by_xpath('xxxxxx')
8 s = json.loads(res.text)
9 driver.close()
10
11 print(s,type(s))
注:以上方法使用谷歌浏览器,需要提前安装谷歌浏览器及相应的驱动程序chromedriver;其他浏览器也可用 查看全部
python抓取网页数据(谷歌浏览器用的python抓取页面数据:用)
以前,python用于获取页面数据:
1 url = "http://xxxxxx"
2 res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text)).read())
3 print('res_text')
稍后,调用查看页面返回“请打开浏览器的JavaScript并刷新浏览器”。查看后,将添加一个cookie。添加cookie后,它将恢复正常
url = "http://xxxxxx"
headers = {'User-Agent': xxx", 'Cookie':xxx",}
res_text = json.loads(urllib2.urlopen(urllib2.Request(server_url_text,headers=headers)).read())
print('res_text')
然而,cookie经常改变,所以我们使用webdriver以不同的方式获取页面数据
1 from selenium import webdriver
2 import time,json
3
4 driver = webdriver.Chrome()
5 driver.get('xxxx')
6 time.sleep(7)
7 res = driver.find_element_by_xpath('xxxxxx')
8 s = json.loads(res.text)
9 driver.close()
10
11 print(s,type(s))
注:以上方法使用谷歌浏览器,需要提前安装谷歌浏览器及相应的驱动程序chromedriver;其他浏览器也可用
python抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-09-26 07:21
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录JavaScript代码,我们必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接: 查看全部
python抓取网页数据(如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录JavaScript代码,我们必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想每周抓取Pycoders中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
python抓取网页数据(入门Python爬虫的基本知识和入门教程:什么是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-22 14:07
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python web爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,尝试获取百度主页的HTML内容
见效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程。返回搜狐查看更多信息 查看全部
python抓取网页数据(入门Python爬虫的基本知识和入门教程:什么是爬虫)
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python web爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,尝试获取百度主页的HTML内容
见效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程。返回搜狐查看更多信息

