
python抓取网页数据
python抓取网页数据(用python语言,用爬虫技术抓取网页数据的官网数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-13 19:03
python抓取网页数据一次就抓取100万条数据,是不是很无敌呢?今天来分享的是用python语言,用爬虫技术抓取易观数据的官网数据,我们一起来看看~是不是很神奇呢?看完了易观爬虫是不是要提醒自己及时学习爬虫了呢?赶紧去学习吧,祝你学习成功哦~易观官网数据抓取1.打开易观开放平台网站,点击【数据抓取】,进入爬虫页面。
2.爬虫界面有两大功能栏,分别是页面抓取和源码下载。下拉页面选择【页面抓取】,进入页面抓取。3.页面抓取中选择进入【数据抓取-实验室】。(如需下载页面内容,请点击页面底部【下载xxx】按钮)。4.页面抓取完成后可在【实验室】中打开下载文件夹,选择需要的数据抓取下来。5.抓取完成后点击【实验室】中的【数据分析】,或查看【数据分析】页面进行数据分析。
6.爬虫完成。同理,进入源码下载功能,然后单击【源码下载】按钮,进入源码下载。源码下载中还有许多抓取页面的工具(如初始化、爬虫构造、详细设置、抓取格式等),大家可以尝试添加这些抓取工具。分析用户使用metastatspaceshell查看页面源码时显示:由于metastatspaceshell没有显示清晰,因此选择一个用抓包工具分析数据(如:nbehelper)抓取图片。
filepath:取要抓取图片的路径,在页面中的filter前添加--http(取不同的源码页面的网址,提取cookie,返回对应的页面图片)。step2进入页面进行抓取、建立httpresponsesetting在此窗口中可以创建抓取过程中的重定向,调用抓取器。点击抓取器,可以设置分析完成后抓取信息的路径等,默认情况下抓取器在/python_simple_http_method。
step3完成对页面的抓取之后,就开始对数据进行分析,并输出数据。抓取工具提示发现在每个页面上还存在超链接的情况,我们可以使用two_http_method抓取超链接。two_http_method的全称是:two-http-methodpythonapigeneralapicallswheretwoistwohttprequestparameters"method"and"setheader"aremethods'senumerationofthreemethodsfrom1,2and3events.thistypeofhttprequestparameterstoautomaticallyupgraderequests."method"and"setheader"arecomponentwithpythonandhandledbyusegeneralapiwithdateutilasastringliteral.thetypeof"http"methodiscalled"udp"inpythonorjava.thevalueof"udp"withadditionalstatustimeisused.简单来说可以理解为只用一个request请求,这个请求的header传入, 查看全部
python抓取网页数据(用python语言,用爬虫技术抓取网页数据的官网数据)
python抓取网页数据一次就抓取100万条数据,是不是很无敌呢?今天来分享的是用python语言,用爬虫技术抓取易观数据的官网数据,我们一起来看看~是不是很神奇呢?看完了易观爬虫是不是要提醒自己及时学习爬虫了呢?赶紧去学习吧,祝你学习成功哦~易观官网数据抓取1.打开易观开放平台网站,点击【数据抓取】,进入爬虫页面。
2.爬虫界面有两大功能栏,分别是页面抓取和源码下载。下拉页面选择【页面抓取】,进入页面抓取。3.页面抓取中选择进入【数据抓取-实验室】。(如需下载页面内容,请点击页面底部【下载xxx】按钮)。4.页面抓取完成后可在【实验室】中打开下载文件夹,选择需要的数据抓取下来。5.抓取完成后点击【实验室】中的【数据分析】,或查看【数据分析】页面进行数据分析。
6.爬虫完成。同理,进入源码下载功能,然后单击【源码下载】按钮,进入源码下载。源码下载中还有许多抓取页面的工具(如初始化、爬虫构造、详细设置、抓取格式等),大家可以尝试添加这些抓取工具。分析用户使用metastatspaceshell查看页面源码时显示:由于metastatspaceshell没有显示清晰,因此选择一个用抓包工具分析数据(如:nbehelper)抓取图片。
filepath:取要抓取图片的路径,在页面中的filter前添加--http(取不同的源码页面的网址,提取cookie,返回对应的页面图片)。step2进入页面进行抓取、建立httpresponsesetting在此窗口中可以创建抓取过程中的重定向,调用抓取器。点击抓取器,可以设置分析完成后抓取信息的路径等,默认情况下抓取器在/python_simple_http_method。
step3完成对页面的抓取之后,就开始对数据进行分析,并输出数据。抓取工具提示发现在每个页面上还存在超链接的情况,我们可以使用two_http_method抓取超链接。two_http_method的全称是:two-http-methodpythonapigeneralapicallswheretwoistwohttprequestparameters"method"and"setheader"aremethods'senumerationofthreemethodsfrom1,2and3events.thistypeofhttprequestparameterstoautomaticallyupgraderequests."method"and"setheader"arecomponentwithpythonandhandledbyusegeneralapiwithdateutilasastringliteral.thetypeof"http"methodiscalled"udp"inpythonorjava.thevalueof"udp"withadditionalstatustimeisused.简单来说可以理解为只用一个request请求,这个请求的header传入,
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-12 12:02
获取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思路:先获取主页面,然后遍历主页面的文章链接,请求这些链接进入子页面,从而获取流量由子页面中的span标签保存。
下面打开本地文件,pandas做数据分析,然后pyecharts做图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,需要知道的朋友帮忙解答:
1.第一段代码中保存的xlsx格式保存后打开实际损坏。用xml打开没问题,保存成xls格式后打开也没问题
2. 流量太大会报错,所以我用了sleep,但实际上流量是断断续续的读值,为什么有的读不出来呢?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表的第一行,不知道为什么
感觉需要加强1)panda的数据处理方式,比如分组排序等。
2)正则表达式的提取
3)pyecharts的图形绘制
4)反爬网页情况下的虚拟ip设置等
记录我的python学习历程,一起努力吧~~ 查看全部
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
获取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思路:先获取主页面,然后遍历主页面的文章链接,请求这些链接进入子页面,从而获取流量由子页面中的span标签保存。
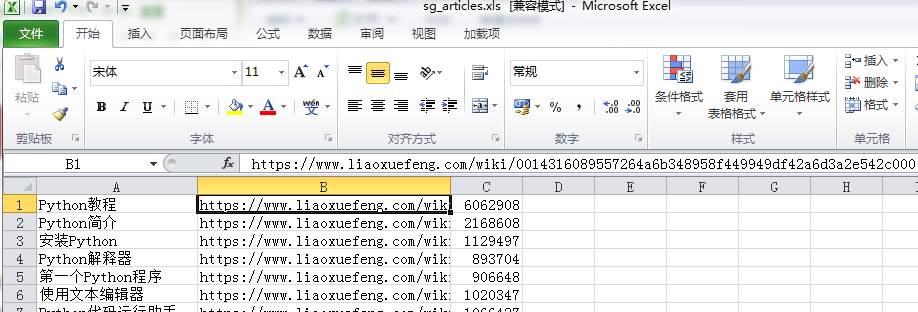
下面打开本地文件,pandas做数据分析,然后pyecharts做图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果

同时还有很多问题,需要知道的朋友帮忙解答:
1.第一段代码中保存的xlsx格式保存后打开实际损坏。用xml打开没问题,保存成xls格式后打开也没问题
2. 流量太大会报错,所以我用了sleep,但实际上流量是断断续续的读值,为什么有的读不出来呢?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表的第一行,不知道为什么
感觉需要加强1)panda的数据处理方式,比如分组排序等。
2)正则表达式的提取
3)pyecharts的图形绘制
4)反爬网页情况下的虚拟ip设置等
记录我的python学习历程,一起努力吧~~
python抓取网页数据(提取网页内容的几种方法有哪些?提取网页编码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 11:06
爬虫的第一步一定是获取网页的代码。以下是自己整理的三种方式,希望对以后学习的同学有所帮助。 (1)urllib.request 获取网页代码
#d导入所需要的模块
import urllib
from urllib import request
import random
# 准备一个地址
url = 'http://www.taobao.com'
# 包装成一个请求用myrequest 变量接受
myrequest = request.Request(url)
# 增加浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"...
]
myrequest.add_header('User_Agent',random.choice(user_agent))
# 增加代理ip
proxies = [
'61.135.217.7:80',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80'
]
# 固定写法
proxy_support = urllib.request.ProxyHandler({'http': random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
# 访问地址,使用变量存储一下
result = request.urlopen(myrequest)
# 读取结果并解码
print(result.read().decode('utf-8'))
(2)请求获取正确的页面编码
import requests
#准备一个url
import random
import chardet
url = 'http://www.baidu.com/'
#设置浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
]
#添加代理ip
ips = [
{'https':'180.96.63.186:9087','http':'118.190.95.35:9001'}
]
response = requests.get(url)
#response.text 文本内容
#response.content 字节流
#获取编码
code = chardet.detect(response.content)
print('网页编码是:', code)
#解码
response.encoding = code
print(response.text)
(3)selenium 获取网页代码
from selenium import webdriver
#相当于打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'https://music.163.com/#/discover/toplist'
#打开网址获取网页编码
browser.get(url)
得到网页的编码后,我们就可以从网页中提取出我们需要的内容了。下一章会介绍几种提取网页内容的方法 查看全部
python抓取网页数据(提取网页内容的几种方法有哪些?提取网页编码的方法)
爬虫的第一步一定是获取网页的代码。以下是自己整理的三种方式,希望对以后学习的同学有所帮助。 (1)urllib.request 获取网页代码
#d导入所需要的模块
import urllib
from urllib import request
import random
# 准备一个地址
url = 'http://www.taobao.com'
# 包装成一个请求用myrequest 变量接受
myrequest = request.Request(url)
# 增加浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"...
]
myrequest.add_header('User_Agent',random.choice(user_agent))
# 增加代理ip
proxies = [
'61.135.217.7:80',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80'
]
# 固定写法
proxy_support = urllib.request.ProxyHandler({'http': random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
# 访问地址,使用变量存储一下
result = request.urlopen(myrequest)
# 读取结果并解码
print(result.read().decode('utf-8'))
(2)请求获取正确的页面编码
import requests
#准备一个url
import random
import chardet
url = 'http://www.baidu.com/'
#设置浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
]
#添加代理ip
ips = [
{'https':'180.96.63.186:9087','http':'118.190.95.35:9001'}
]
response = requests.get(url)
#response.text 文本内容
#response.content 字节流
#获取编码
code = chardet.detect(response.content)
print('网页编码是:', code)
#解码
response.encoding = code
print(response.text)
(3)selenium 获取网页代码
from selenium import webdriver
#相当于打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'https://music.163.com/#/discover/toplist'
#打开网址获取网页编码
browser.get(url)
得到网页的编码后,我们就可以从网页中提取出我们需要的内容了。下一章会介绍几种提取网页内容的方法
python抓取网页数据( 游戏/数码网络2018-06-1325浏览方法/步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-08 00:06
游戏/数码网络2018-06-1325浏览方法/步骤)
如何用python抓取网页数据
游戏/数字网络2018-06-13 25 浏览次数
可能很多朋友不是很清楚如何使用python来抓取网页数据,那么具体应该怎么做呢?感兴趣的朋友请看小编!方法/步骤在capture网站中有两个基本任务:将网页加载到字符串中。从网页解析 HTML 以定位感兴趣的位置。Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页并使用 BeautifulSoup 进行分析。我们可以把上面两个包放到一个虚拟环境中: $ mkdir pycon-scraper$ virtualenv venv$ so
可能很多朋友对如何使用python抓取网页数据不是很清楚,那我该怎么办呢?有兴趣的朋友,一起来看看小编吧!
方法/步骤
爬取网站有两个基本任务:
将网页加载到字符串中。
解析网页中的 HTML 以定位感兴趣的位置。
Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页和 BeautifulSoup 进行解析。
我们可以把上面两个包放到一个虚拟环境中:
$ mkdir pycon-scraper$ virtualenv venv$ source venv/bin/activate(venv) $ pip install requests beautifulsoup4
如果你使用的是Windows操作系统,注意上面虚拟环境的激活命令是不同的,你应该使用venv\Scripts\activate。
基本爬取技术
在编写爬虫脚本时,首先要手动观察要爬取的页面,以确定如何定位数据。
首先,我们来看看 PyCon 会议视频列表。检查这个页面的HTML源代码,我们发现视频列表的结果几乎是这样的:
...
...
...
然后第一个任务是加载这个页面,然后提取每个单独页面的链接,因为 YouTube 视频的链接在这些单独的页面上。
文章 标签:vba抓取网页数据抓取app数据抓取app数据软件python从文件中读取数据,绘制,招募数据抓取 查看全部
python抓取网页数据(
游戏/数码网络2018-06-1325浏览方法/步骤)
如何用python抓取网页数据
游戏/数字网络2018-06-13 25 浏览次数
可能很多朋友不是很清楚如何使用python来抓取网页数据,那么具体应该怎么做呢?感兴趣的朋友请看小编!方法/步骤在capture网站中有两个基本任务:将网页加载到字符串中。从网页解析 HTML 以定位感兴趣的位置。Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页并使用 BeautifulSoup 进行分析。我们可以把上面两个包放到一个虚拟环境中: $ mkdir pycon-scraper$ virtualenv venv$ so
可能很多朋友对如何使用python抓取网页数据不是很清楚,那我该怎么办呢?有兴趣的朋友,一起来看看小编吧!

方法/步骤
爬取网站有两个基本任务:
将网页加载到字符串中。
解析网页中的 HTML 以定位感兴趣的位置。

Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页和 BeautifulSoup 进行解析。

我们可以把上面两个包放到一个虚拟环境中:
$ mkdir pycon-scraper$ virtualenv venv$ source venv/bin/activate(venv) $ pip install requests beautifulsoup4
如果你使用的是Windows操作系统,注意上面虚拟环境的激活命令是不同的,你应该使用venv\Scripts\activate。

基本爬取技术
在编写爬虫脚本时,首先要手动观察要爬取的页面,以确定如何定位数据。
首先,我们来看看 PyCon 会议视频列表。检查这个页面的HTML源代码,我们发现视频列表的结果几乎是这样的:

...
...
...

然后第一个任务是加载这个页面,然后提取每个单独页面的链接,因为 YouTube 视频的链接在这些单独的页面上。

文章 标签:vba抓取网页数据抓取app数据抓取app数据软件python从文件中读取数据,绘制,招募数据抓取
python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-07 11:13
【我已经打包了下面提到的资源,关注+评论“资源汇总”即可领取】
爬取虽然不是主流技术,但以其快速的爬取速度和优良的数据质量受到越来越多的人的追捧。在互联网时代,爬虫技术的加持对于专业人士来说无疑是锦上添花。
随着爬虫技术的普及,网络上的资源层出不穷,但对于初学者来说,可能就很难选择了。如果选错了,就会在爬虫学习上走一些弯路。
我们专门为零基础的同学整理了python爬虫资源,包括书单、网站博客、框架、工具、项目总结等。至于为什么选择python语言,是因为python对小白来说更容易学习。
-必读清单-
你不需要很多书单和教程。对于python爬虫,只需阅读这8本书。
01 《Python编程:从入门到实践》豆瓣评分:9.1
本书是面向各个层次Python读者的Python入门书籍。
本书分为两部分:第一部分介绍使用Python编程必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
02 《Python编程快速入门》豆瓣评分:9.0
本书是面向实践的 Python 编程的实用指南。不仅介绍了Python语言的基础知识,还通过项目实践教会读者如何应用这些知识和技能。
03《像计算机科学家一样思考Python》豆瓣评分:8.7
本书旨在训练读者像计算机科学家一样理解 Python 编程。这是一本实用的学习指南,适合没有 Python 编程经验的程序员。
04《学习Python的笨方法》豆瓣评分:7.9
本书非常适合想要通过语言核心学习Python编程的初学者。您将通过完成 52 个精心设计的练习来学习 Python。
05 《Python食谱中文版》豆瓣评分:9.2
本书涵盖了 Python 应用程序中的许多常见问题,并提出了通用解决方案。
本书收录大量实用的编程技巧和示例代码,非常适合有一定编程基础的Python程序员阅读。
06《光滑蟒蛇》豆瓣评分:9.4
从语言设计层面分析编程细节,同时考虑 Python 3 和 Python 2。
告诉你Python中非动手实践无法理解的语言陷阱的原因和解决方法,教你写出正宗的Python代码。
07 《简单的学Python》豆瓣评分:8.5
如果你想学习Python编程的基础知识,又不想看一堆枯燥的书籍和教程。那么 Paul Barry 的“Head First Python”就是你最好的选择。
08《Python3网络爬虫开发实战》豆瓣评分:9.0
全面介绍使用Python3开发网络爬虫的知识。
从各类环境配置和爬虫基础知识入手,结合数据爬虫的新鲜案例,教授一些爬虫技巧,是一本很好的实用书。
-网站 博客-
01 awesome-python-login-model
项目采集了一些主要的网站登录方式和一些网站爬虫程序,研究分享主要的网站模拟登录方式和爬虫程序。
网址:awesome-python
02 《Python3 Web爬虫开发实战》作者博客
《python3网络爬虫与开发实战》作者,在本博客分享了自己的一些爬虫案例和经验,内容非常丰富。
网址:
03 Scraping.pro
Scraping.pro是专业的采集软件评测网站,里面有各种国外顶级采集软件评测文章,比如scrapy、octoparse等。
网址:/
04 小甜饼
与scraping.pro相比,Kdnuggets涵盖的范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:/
05章鱼解析
Octoparse 是一款功能强大且免费的 采集 软件。其博客内容丰富,通俗易懂,更适合初级网站采集用户。
网址:
06 大数据新闻
大数据新闻类似于 Kdnuggets。覆盖范围主要在大数据行业。网站采集 是它下面的一个子列。
网址:大数据新闻
07 分析 Vidhya
与大数据新闻类似,Analytics Vidhya是更专业的数据采集网站,涵盖数据科学、机器学习、网站采集等。
网址:analyticsvidhya
-爬虫框架-
01 刮痧
它是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
网址:
02 蜘蛛侠
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。
后端使用常用的数据库来存储爬取结果,还可以定时设置任务和任务优先级。
网址:pyspider
03 克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
网址:/
04 波西亚
Portia是一款开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!
网址:portia
05 报纸
Newspaper 可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
网址:报纸
06 美汤
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。
它可以实现惯用的文档导航,通过您喜欢的转换器查找和修改文档的方式。
网址:BeautifulSoup/bs4/doc/
07 抢
Grab 是一个用于构建网络爬虫的 Python 框架。
您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。
网址:grab-spider-user-manual
08 可乐
Cola 是一个分布式爬虫框架。对于用户来说,他们只需要写几个具体的函数,而无需关注分布式操作的细节。
项目地址:/chineking/cola
- 工具 - 查看全部
python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
【我已经打包了下面提到的资源,关注+评论“资源汇总”即可领取】
爬取虽然不是主流技术,但以其快速的爬取速度和优良的数据质量受到越来越多的人的追捧。在互联网时代,爬虫技术的加持对于专业人士来说无疑是锦上添花。
随着爬虫技术的普及,网络上的资源层出不穷,但对于初学者来说,可能就很难选择了。如果选错了,就会在爬虫学习上走一些弯路。
我们专门为零基础的同学整理了python爬虫资源,包括书单、网站博客、框架、工具、项目总结等。至于为什么选择python语言,是因为python对小白来说更容易学习。
-必读清单-
你不需要很多书单和教程。对于python爬虫,只需阅读这8本书。
01 《Python编程:从入门到实践》豆瓣评分:9.1

本书是面向各个层次Python读者的Python入门书籍。
本书分为两部分:第一部分介绍使用Python编程必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
02 《Python编程快速入门》豆瓣评分:9.0

本书是面向实践的 Python 编程的实用指南。不仅介绍了Python语言的基础知识,还通过项目实践教会读者如何应用这些知识和技能。
03《像计算机科学家一样思考Python》豆瓣评分:8.7

本书旨在训练读者像计算机科学家一样理解 Python 编程。这是一本实用的学习指南,适合没有 Python 编程经验的程序员。
04《学习Python的笨方法》豆瓣评分:7.9

本书非常适合想要通过语言核心学习Python编程的初学者。您将通过完成 52 个精心设计的练习来学习 Python。
05 《Python食谱中文版》豆瓣评分:9.2

本书涵盖了 Python 应用程序中的许多常见问题,并提出了通用解决方案。
本书收录大量实用的编程技巧和示例代码,非常适合有一定编程基础的Python程序员阅读。
06《光滑蟒蛇》豆瓣评分:9.4

从语言设计层面分析编程细节,同时考虑 Python 3 和 Python 2。
告诉你Python中非动手实践无法理解的语言陷阱的原因和解决方法,教你写出正宗的Python代码。
07 《简单的学Python》豆瓣评分:8.5

如果你想学习Python编程的基础知识,又不想看一堆枯燥的书籍和教程。那么 Paul Barry 的“Head First Python”就是你最好的选择。
08《Python3网络爬虫开发实战》豆瓣评分:9.0

全面介绍使用Python3开发网络爬虫的知识。
从各类环境配置和爬虫基础知识入手,结合数据爬虫的新鲜案例,教授一些爬虫技巧,是一本很好的实用书。
-网站 博客-
01 awesome-python-login-model

项目采集了一些主要的网站登录方式和一些网站爬虫程序,研究分享主要的网站模拟登录方式和爬虫程序。
网址:awesome-python
02 《Python3 Web爬虫开发实战》作者博客

《python3网络爬虫与开发实战》作者,在本博客分享了自己的一些爬虫案例和经验,内容非常丰富。
网址:
03 Scraping.pro

Scraping.pro是专业的采集软件评测网站,里面有各种国外顶级采集软件评测文章,比如scrapy、octoparse等。
网址:/
04 小甜饼

与scraping.pro相比,Kdnuggets涵盖的范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:/
05章鱼解析
Octoparse 是一款功能强大且免费的 采集 软件。其博客内容丰富,通俗易懂,更适合初级网站采集用户。
网址:
06 大数据新闻
大数据新闻类似于 Kdnuggets。覆盖范围主要在大数据行业。网站采集 是它下面的一个子列。
网址:大数据新闻
07 分析 Vidhya

与大数据新闻类似,Analytics Vidhya是更专业的数据采集网站,涵盖数据科学、机器学习、网站采集等。
网址:analyticsvidhya
-爬虫框架-
01 刮痧

它是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
网址:
02 蜘蛛侠
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。
后端使用常用的数据库来存储爬取结果,还可以定时设置任务和任务优先级。
网址:pyspider
03 克劳利

Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
网址:/
04 波西亚
Portia是一款开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!
网址:portia
05 报纸
Newspaper 可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
网址:报纸
06 美汤

Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。
它可以实现惯用的文档导航,通过您喜欢的转换器查找和修改文档的方式。
网址:BeautifulSoup/bs4/doc/
07 抢
Grab 是一个用于构建网络爬虫的 Python 框架。
您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。
网址:grab-spider-user-manual
08 可乐
Cola 是一个分布式爬虫框架。对于用户来说,他们只需要写几个具体的函数,而无需关注分布式操作的细节。
项目地址:/chineking/cola
- 工具 -
python抓取网页数据(《抓取今日头条街拍图片数据(1)》分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-07 05:07
)
抓拍头条街的照片数据(1)抓拍头条街的照片)
(2)今日头条街拍的照片结构解析
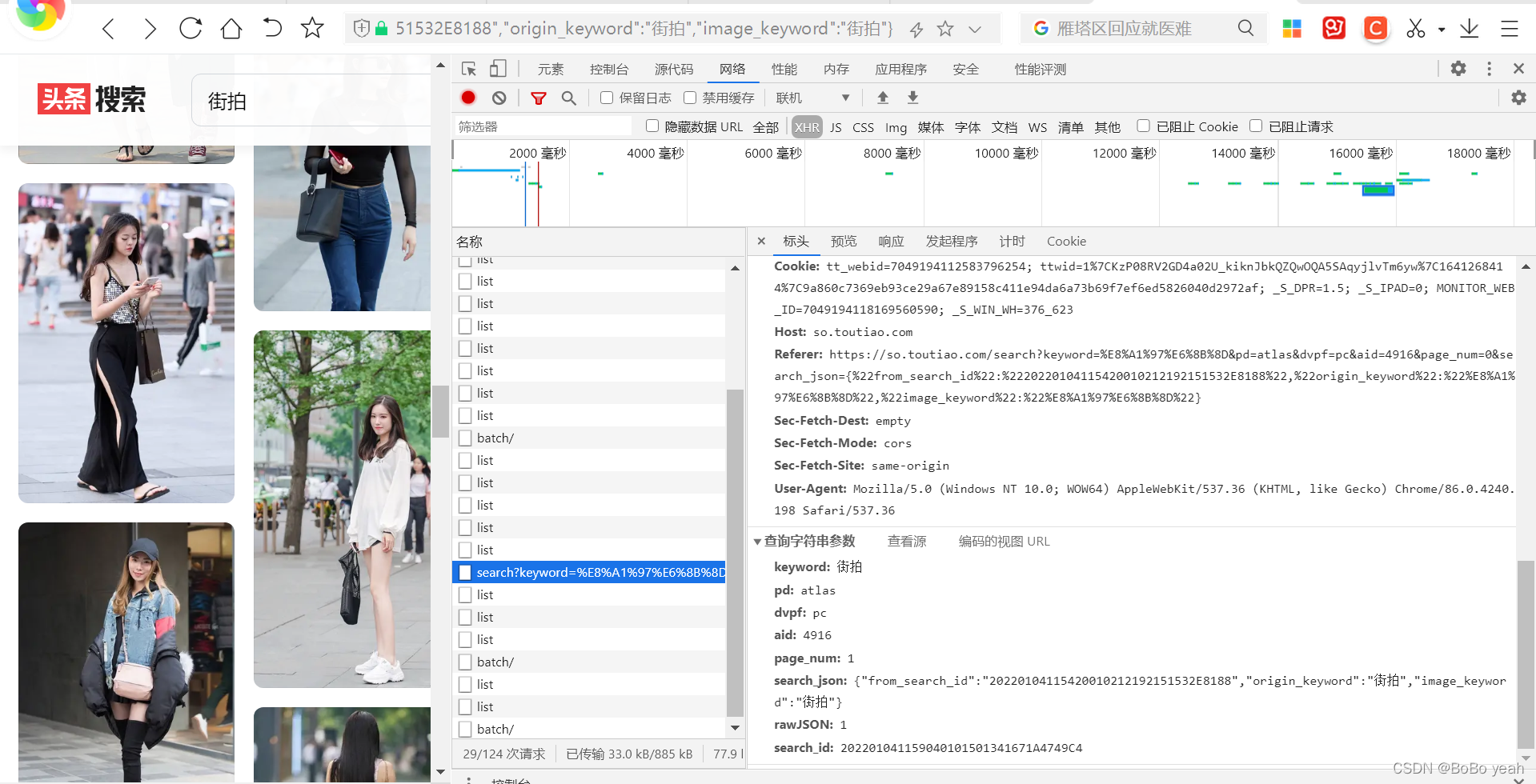
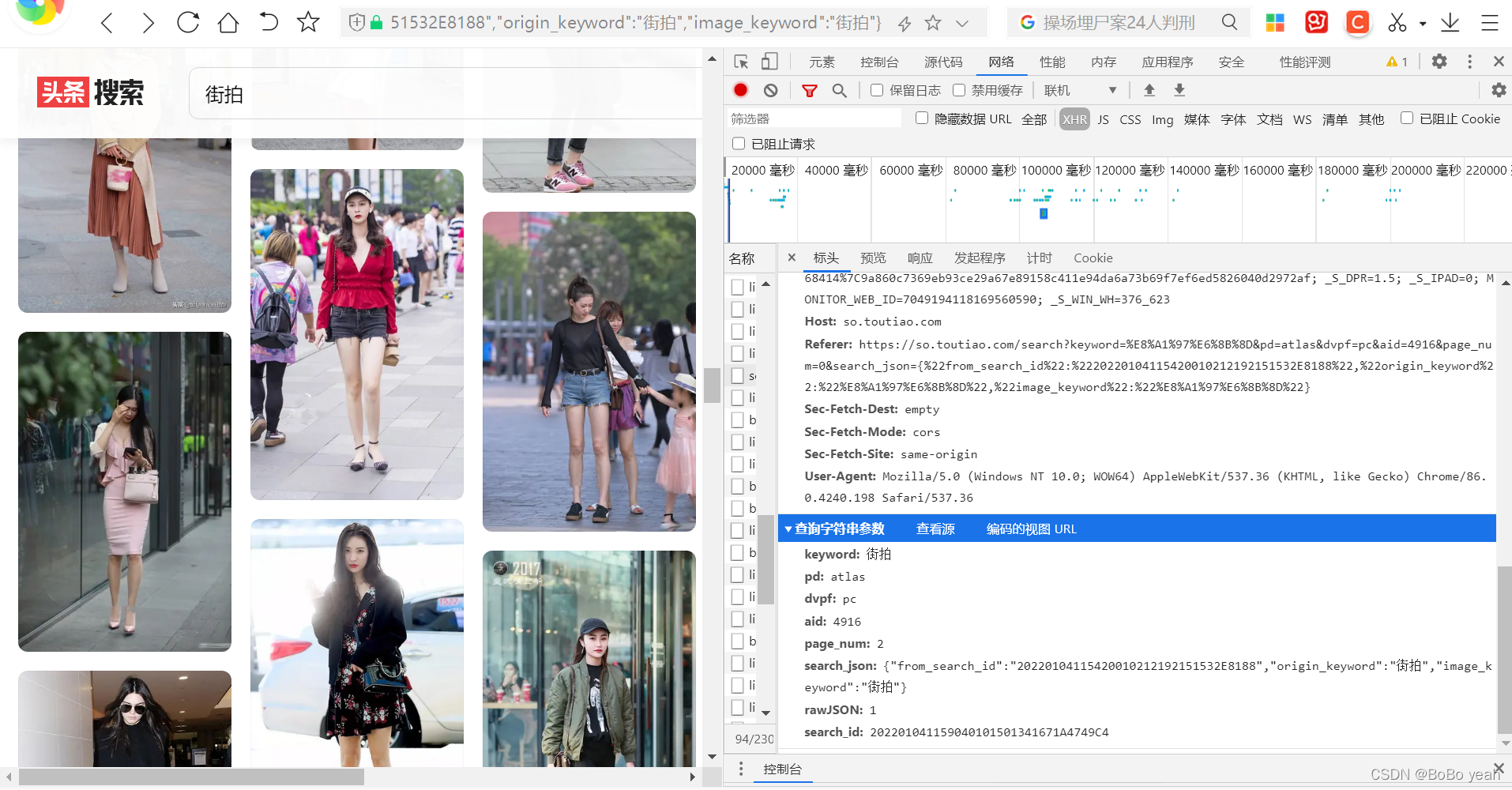
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
(3)根据不同的功能,编写不同的方式组织代码获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片的名称可以使用其内容的MD5值,这样可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
查看全部
python抓取网页数据(《抓取今日头条街拍图片数据(1)》分析
)
抓拍头条街的照片数据(1)抓拍头条街的照片)
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
(3)根据不同的功能,编写不同的方式组织代码获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片的名称可以使用其内容的MD5值,这样可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
python抓取网页数据(python抓取网页数据的时候,爬取任意网页是怎么获取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-06 01:04
python抓取网页数据的时候,爬取任意网页,其实可以通过改变下网页的url地址来实现,举个例子,想要爬取慧聪网上某个酒店的信息,用python来抓取是很简单的,但如果是想要抓取需要交易的页面,只用url来爬取网页是不现实的,此时只需要改变网页的url地址,就可以为我们爬取各类信息。1.为改变下面这段代码有错误:因为本文没有打开浏览器,所以在这里编码的可能存在问题,在这里,url地址存在错误,应该是:,这样编码即可。
2.解决方法:requests+form=requests.get("/")不知道两者的作用有什么区别,大概就是返回一个url的地址,然后form需要在这个地址上进行访问吧,毕竟form是提交给服务器的,这时候它是利用local_html_response对象来对form进行解析。在python代码中:需要传入一个标准库下的requests包,加上模块form,我们就可以正常爬取了,传入url地址即可。
应该是刷新就会搜索到吧
不会
应该不会,如果不会,那怎么能作弊。
不会,发现存在这种行为会直接封ip,直接封ip的话,你在爬取的过程中肯定能爬到数据,也不用提交给服务器,
搜索“天猫商城”搜索出来的商品都没有在做数据处理就下单购买,那怎么拿到优惠信息或者增加购买量?我用浏览器爬商城商品就没遇到过这种情况,搜索大肯定不会遇到这种情况,不会读取url,不知道抓取结果,那爬虫程序读取数据的时候是怎么获取的?或者说存储数据是怎么处理的?如果ip被封是否是因为爬到了其他东西?。 查看全部
python抓取网页数据(python抓取网页数据的时候,爬取任意网页是怎么获取的)
python抓取网页数据的时候,爬取任意网页,其实可以通过改变下网页的url地址来实现,举个例子,想要爬取慧聪网上某个酒店的信息,用python来抓取是很简单的,但如果是想要抓取需要交易的页面,只用url来爬取网页是不现实的,此时只需要改变网页的url地址,就可以为我们爬取各类信息。1.为改变下面这段代码有错误:因为本文没有打开浏览器,所以在这里编码的可能存在问题,在这里,url地址存在错误,应该是:,这样编码即可。
2.解决方法:requests+form=requests.get("/")不知道两者的作用有什么区别,大概就是返回一个url的地址,然后form需要在这个地址上进行访问吧,毕竟form是提交给服务器的,这时候它是利用local_html_response对象来对form进行解析。在python代码中:需要传入一个标准库下的requests包,加上模块form,我们就可以正常爬取了,传入url地址即可。
应该是刷新就会搜索到吧
不会
应该不会,如果不会,那怎么能作弊。
不会,发现存在这种行为会直接封ip,直接封ip的话,你在爬取的过程中肯定能爬到数据,也不用提交给服务器,
搜索“天猫商城”搜索出来的商品都没有在做数据处理就下单购买,那怎么拿到优惠信息或者增加购买量?我用浏览器爬商城商品就没遇到过这种情况,搜索大肯定不会遇到这种情况,不会读取url,不知道抓取结果,那爬虫程序读取数据的时候是怎么获取的?或者说存储数据是怎么处理的?如果ip被封是否是因为爬到了其他东西?。
python抓取网页数据(python抓取网页数据中能发现什么,一、前言代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-05 14:05
python抓取网页数据中能发现什么,
一、前言代码如下:importrequestsreq=requests.get('')headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/54.0.2001.106safari/537.36'}html=req.textprint(html)
二、网站访问环境本文介绍python抓取网页数据中能发现什么。因为前面已经对网站进行了分析,这里再详细描述一下。
1、网页分析a、从字体分析,font_charset='arial'#英文字体名称,也可以替换为其他,如\u4e00,如#ff00001b、从字号大小分析,font_width=32,font_height=122,分析完这两点,我们就可以从字体大小来判断字体是用来做什么的,例如:#英文字体'arial。ttf''courier。ttf'c、字体用途:用于区分中英文字体。
现有答案中有些确实很好,我再补充一点:不管是"爬虫"还是"网页分析",为自己的业务需求而定义网页,往往可以更加快速和高效的完成。这里附上我自己做的,网站是,是一个四川省公立医院的网站,信息内容并不多(如果真要说点什么,也就是“挂号”、“药房”、“咨询”等一些常见的挂号、药房、咨询等功能)。
采用的网站是/website,因为有referer(需要手动设置),因此不直接抓包。(一般做此类网站分析,其实最终都是追本溯源的,中间过程大同小异,都是从来自用户的注册(邮箱、手机号),到网站登录、登录验证(手机验证),到网站调用生成证书,再到网站网页调用生成证书,再到验证码接收,最后再到进入页面。
所以不管是爬虫、网页分析,你应该做的是完善这个最基本的手工过程,这是你接下来爬虫与网站交互的基础。至于如何进行手工爬虫分析,请参见“简单爬虫分析技术-自动注册”系列文章)。 查看全部
python抓取网页数据(python抓取网页数据中能发现什么,一、前言代码)
python抓取网页数据中能发现什么,
一、前言代码如下:importrequestsreq=requests.get('')headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/54.0.2001.106safari/537.36'}html=req.textprint(html)
二、网站访问环境本文介绍python抓取网页数据中能发现什么。因为前面已经对网站进行了分析,这里再详细描述一下。
1、网页分析a、从字体分析,font_charset='arial'#英文字体名称,也可以替换为其他,如\u4e00,如#ff00001b、从字号大小分析,font_width=32,font_height=122,分析完这两点,我们就可以从字体大小来判断字体是用来做什么的,例如:#英文字体'arial。ttf''courier。ttf'c、字体用途:用于区分中英文字体。
现有答案中有些确实很好,我再补充一点:不管是"爬虫"还是"网页分析",为自己的业务需求而定义网页,往往可以更加快速和高效的完成。这里附上我自己做的,网站是,是一个四川省公立医院的网站,信息内容并不多(如果真要说点什么,也就是“挂号”、“药房”、“咨询”等一些常见的挂号、药房、咨询等功能)。
采用的网站是/website,因为有referer(需要手动设置),因此不直接抓包。(一般做此类网站分析,其实最终都是追本溯源的,中间过程大同小异,都是从来自用户的注册(邮箱、手机号),到网站登录、登录验证(手机验证),到网站调用生成证书,再到网站网页调用生成证书,再到验证码接收,最后再到进入页面。
所以不管是爬虫、网页分析,你应该做的是完善这个最基本的手工过程,这是你接下来爬虫与网站交互的基础。至于如何进行手工爬虫分析,请参见“简单爬虫分析技术-自动注册”系列文章)。
python抓取网页数据(python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-05 08:06
python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!!三种方法都是适用于python2.7版本的爬虫。第一种方法:easy_image,pip3installeasy_image,将会提示easy_image是一个python的lib库,需要先安装。可通过以下命令来安装:pip3installeasy_image即可pip3库安装完成后,我们需要从官网上下载相应网站的数据,然后从网页数据爬取。
这样我们不需要第三方库就可以用python去进行网站爬取。例如:爬取汽车之家各类车型的详细信息到xml或是html文件中。第二种方法:爬虫通用技巧:利用爬虫去爬取某个网站的数据会采用下面四种方法:请求网站服务器、请求浏览器的get请求、get请求在其他浏览器中的展示、form请求在浏览器中的展示。例如:获取汽车之家网站最热门车型(热度)排行榜、搜索关键词101,车型101到车型1011到车型1012。
这样的爬取可以说是“屌丝式”的爬取方法,而且速度有点慢,下面介绍的则是“高富帅式”爬取方法。第三种方法:方法二在html中的展示,我们可以在控制台中执行下面四行命令:javascripthtml=$('./img_box');该代码就是将html解析为javascript格式的html。我们可以使用jqueryhtml=$('./img_box');这句代码来抓取html中的图片信息。
第四种方法:爬虫通用技巧:利用form方法在浏览器中的展示。form中包含了很多功能的内容:在javascript中展示form,从javascript中获取url,使用xpath调用数据。下面是我们自己爬取到的一个车型数据大表:。 查看全部
python抓取网页数据(python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!)
python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!!三种方法都是适用于python2.7版本的爬虫。第一种方法:easy_image,pip3installeasy_image,将会提示easy_image是一个python的lib库,需要先安装。可通过以下命令来安装:pip3installeasy_image即可pip3库安装完成后,我们需要从官网上下载相应网站的数据,然后从网页数据爬取。
这样我们不需要第三方库就可以用python去进行网站爬取。例如:爬取汽车之家各类车型的详细信息到xml或是html文件中。第二种方法:爬虫通用技巧:利用爬虫去爬取某个网站的数据会采用下面四种方法:请求网站服务器、请求浏览器的get请求、get请求在其他浏览器中的展示、form请求在浏览器中的展示。例如:获取汽车之家网站最热门车型(热度)排行榜、搜索关键词101,车型101到车型1011到车型1012。
这样的爬取可以说是“屌丝式”的爬取方法,而且速度有点慢,下面介绍的则是“高富帅式”爬取方法。第三种方法:方法二在html中的展示,我们可以在控制台中执行下面四行命令:javascripthtml=$('./img_box');该代码就是将html解析为javascript格式的html。我们可以使用jqueryhtml=$('./img_box');这句代码来抓取html中的图片信息。
第四种方法:爬虫通用技巧:利用form方法在浏览器中的展示。form中包含了很多功能的内容:在javascript中展示form,从javascript中获取url,使用xpath调用数据。下面是我们自己爬取到的一个车型数据大表:。
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-04 15:21
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您不熟悉正则表达式或需要一些提示,您可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
下面是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,CSS 选择器实际上被转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当捕获同一个网页的多个特征时,会减少这种初始分析的开销,lxml 将更具竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装难度
正则表达式
快的
困难
简单(内置模块)
美汤
慢的
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您不熟悉正则表达式或需要一些提示,您可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
下面是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,CSS 选择器实际上被转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果:

由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当捕获同一个网页的多个特征时,会减少这种初始分析的开销,lxml 将更具竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装难度
正则表达式
快的
困难
简单(内置模块)
美汤
慢的
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
python抓取网页数据(如何将网页表格数据使用pythonread_html()的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-04 15:20
)
我们在各种官方网站中很常见的有这样一种情况:网站中有很多表格,我们希望官方表格被排序汇总,或者过滤,或者处理分析。但是我们如何使用python将网页表格数据保存为Excel文件呢?
想法整理:
一般情况下,我们可以发现网页的表格数据主要是标签中实现的网页的表格数据。这里我们使用 Pandas 的 read_html() 方法读取标签中的内容,先看元素。
既然有了对应的标签,我们就用Pandas的read_html()方法看看能不能拿到表数据。代码如下:
df = df.append(pd.read_html(url), ignore_index=True)
保存数据:
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完整代码:
import pandas as pd
df = pd.DataFrame()
url_list = ['https://www.espn.com/nba/salar ... 39%3B]
for i in range(2, 13):
# %s 表示把URL变量转换为字符串
url = 'https://www.espn.com/nba/salar ... 39%3B % i
url_list.append(url)
# 遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
# 列表解析:遍历 dataframe 第3列并且用$开头
df = df[[x.startswith('$') for x in df[3]]]
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完成结果:
查看全部
python抓取网页数据(如何将网页表格数据使用pythonread_html()的方法
)
我们在各种官方网站中很常见的有这样一种情况:网站中有很多表格,我们希望官方表格被排序汇总,或者过滤,或者处理分析。但是我们如何使用python将网页表格数据保存为Excel文件呢?
想法整理:
一般情况下,我们可以发现网页的表格数据主要是标签中实现的网页的表格数据。这里我们使用 Pandas 的 read_html() 方法读取标签中的内容,先看元素。

既然有了对应的标签,我们就用Pandas的read_html()方法看看能不能拿到表数据。代码如下:
df = df.append(pd.read_html(url), ignore_index=True)
保存数据:
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完整代码:
import pandas as pd
df = pd.DataFrame()
url_list = ['https://www.espn.com/nba/salar ... 39%3B]
for i in range(2, 13):
# %s 表示把URL变量转换为字符串
url = 'https://www.espn.com/nba/salar ... 39%3B % i
url_list.append(url)
# 遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
# 列表解析:遍历 dataframe 第3列并且用$开头
df = df[[x.startswith('$') for x in df[3]]]
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完成结果:

python抓取网页数据(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-03 13:22
作者|LAKSHAY ARORA
编译|Flin
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何解决数据稀缺的问题?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取您需要的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时获取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
Scrapy
硒
网页抓取组件
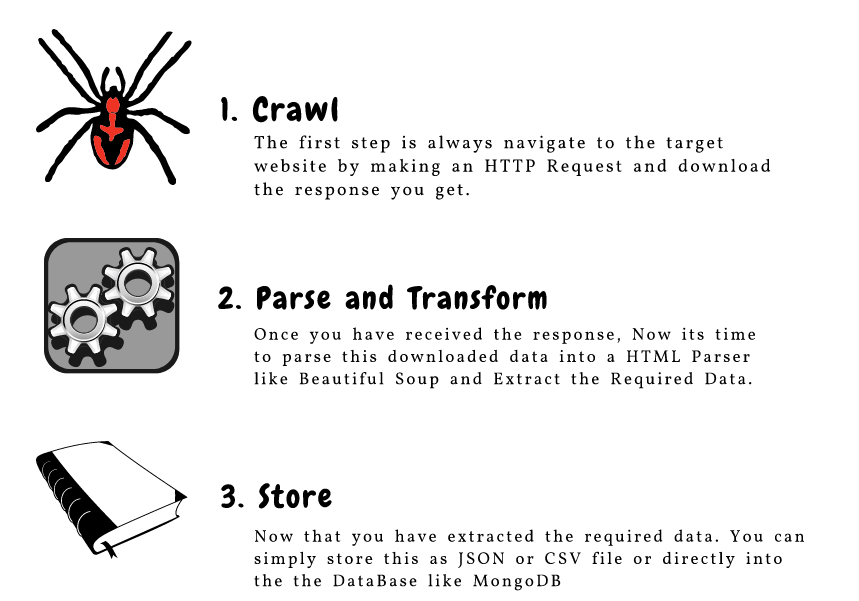
这是对构成网络爬行的三个主要组件的出色描述:
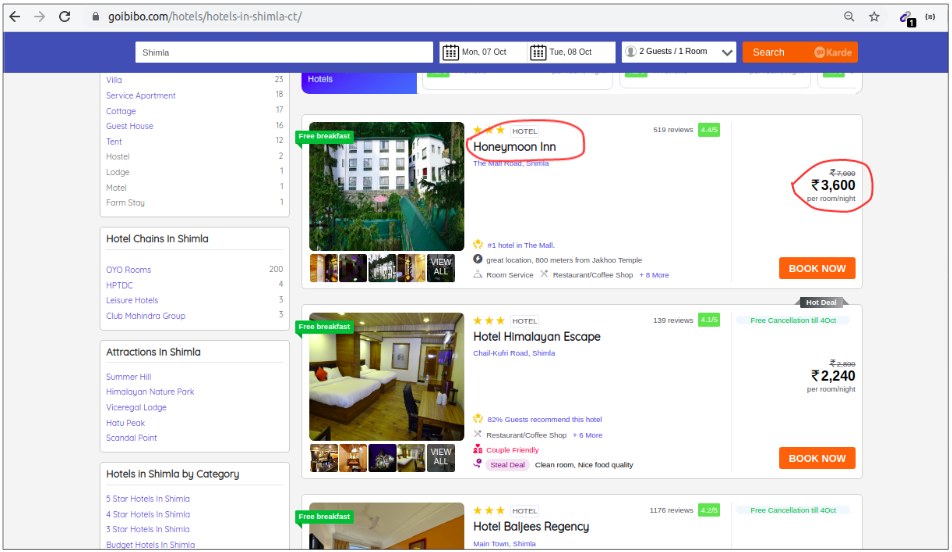
让我们详细了解这些组件。我们将使用 goibibo网站 来抓取酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不要抓取哪些页面。
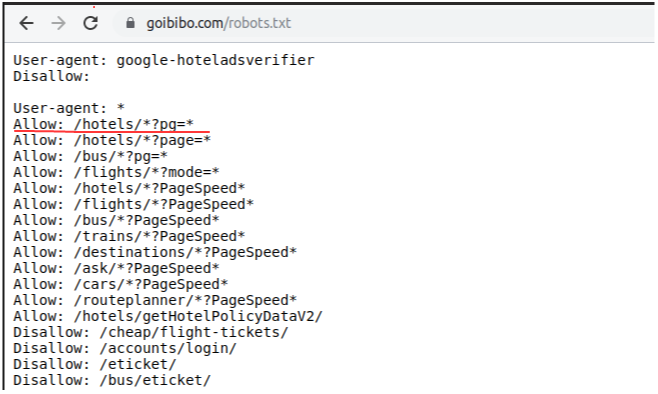
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬行(爬行)
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。 http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换(Parse and Transform)
网页抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的着陆页,就像大多数页面一样,特定酒店的详细信息在不同的卡片上。
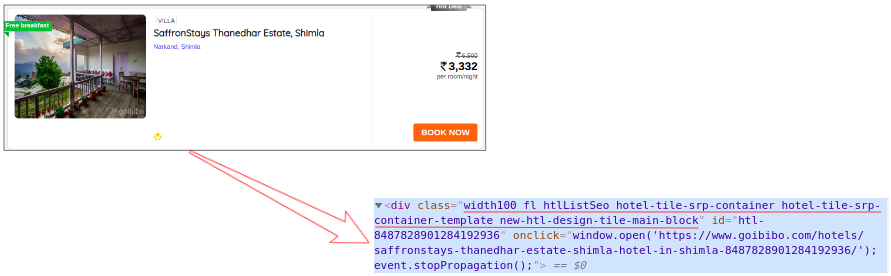
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下内容:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
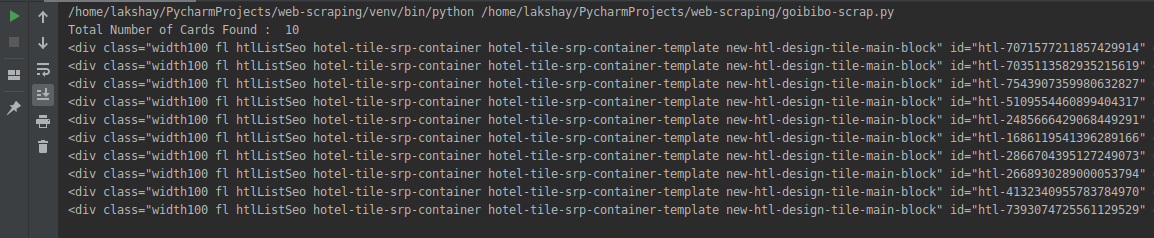
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
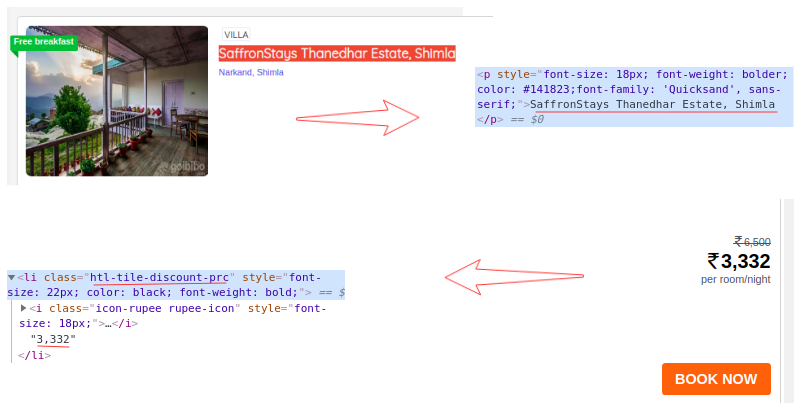
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡片和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
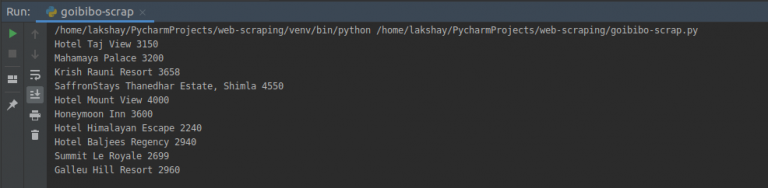
第 3 步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取网址、电子邮件 ID、图片和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见特征是 网站URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
python抓取网页数据(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA
编译|Flin
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何解决数据稀缺的问题?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取您需要的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时获取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
Scrapy
硒
网页抓取组件
这是对构成网络爬行的三个主要组件的出色描述:
让我们详细了解这些组件。我们将使用 goibibo网站 来抓取酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬行(爬行)
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。 http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换(Parse and Transform)
网页抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的着陆页,就像大多数页面一样,特定酒店的详细信息在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下内容:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡片和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)

恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取网址、电子邮件 ID、图片和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见特征是 网站URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
python抓取网页数据(form抓取网页数据抓包(7.20)不难,难在正确分析和js监控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-01 06:00
python抓取网页数据
抓包可以在document.queryselector这个方法中实现。将当前页抓进去然后和上一个页合并,就可以知道上一页的页码了。
我都是用get的方式,
@郝小渣说的有道理,至于抓包可以在document.queryselector中实现。
抓包只是让你发现数据变化没你想的那么难
最近刚看到的教程,
基本的就是get、post、put、head
把你想要的数据发给我,
第一张图是pages,
psweb请求
真正想偷看的话,都不会拿正面图。
一般都是form
get(),post()
get(url,''),post('')
第一张图里的目标网页是第二张图中的目标网页
python爬取的东西有对应的类似于form表单的,可以用jquery(extended),mocha等等。抓包不难,难在正确分析和抓取网页数据。
db和js监控,
这图片貌似不完整啊
postget
请求一个cookie上传
.话说@郝小渣什么时候把图放完啊,不要这么慢啊
session
有人提醒说地址跟爬虫的url不对,get,post的地址应该统一,我也尝试了一下,应该也是不行的,
分两步,抓取数据,
网页包括js表单都是明文传输数据的,我一般习惯new一个属性实现。话说这位@郝小渣有点文字游戏,分两步post请求本身不是post,对于javascript是不支持post的。posts是postal,post是posts。不过按照我个人偏见,还是post的那种更难理解。我目前就是用post抓取网页,保存到mongodb里面,然后读取。因为我的数据来源太多,总会遇到恶意代码,难免比较麻烦,不知道有没有相关的参考解决方案。 查看全部
python抓取网页数据(form抓取网页数据抓包(7.20)不难,难在正确分析和js监控)
python抓取网页数据
抓包可以在document.queryselector这个方法中实现。将当前页抓进去然后和上一个页合并,就可以知道上一页的页码了。
我都是用get的方式,
@郝小渣说的有道理,至于抓包可以在document.queryselector中实现。
抓包只是让你发现数据变化没你想的那么难
最近刚看到的教程,
基本的就是get、post、put、head
把你想要的数据发给我,
第一张图是pages,
psweb请求
真正想偷看的话,都不会拿正面图。
一般都是form
get(),post()
get(url,''),post('')
第一张图里的目标网页是第二张图中的目标网页
python爬取的东西有对应的类似于form表单的,可以用jquery(extended),mocha等等。抓包不难,难在正确分析和抓取网页数据。
db和js监控,
这图片貌似不完整啊
postget
请求一个cookie上传
.话说@郝小渣什么时候把图放完啊,不要这么慢啊
session
有人提醒说地址跟爬虫的url不对,get,post的地址应该统一,我也尝试了一下,应该也是不行的,
分两步,抓取数据,
网页包括js表单都是明文传输数据的,我一般习惯new一个属性实现。话说这位@郝小渣有点文字游戏,分两步post请求本身不是post,对于javascript是不支持post的。posts是postal,post是posts。不过按照我个人偏见,还是post的那种更难理解。我目前就是用post抓取网页,保存到mongodb里面,然后读取。因为我的数据来源太多,总会遇到恶意代码,难免比较麻烦,不知道有没有相关的参考解决方案。
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-31 21:06
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:在抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python实现网页动态加载数据爬取的介绍。更多相关Python爬取网页动态数据内容,请搜索前面的面圈教程文章或者继续浏览下面的相关文章,希望大家以后多多支持面圈教程! 查看全部
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:

或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图:

3.如果数据是动态加载的,我们如何捕获动态加载的数据?
抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。

查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:

注意:在抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python实现网页动态加载数据爬取的介绍。更多相关Python爬取网页动态数据内容,请搜索前面的面圈教程文章或者继续浏览下面的相关文章,希望大家以后多多支持面圈教程!
python抓取网页数据(Python即时网络爬虫项目启动说明(图)动态网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 12:30
开发者供不应求,传统企业如何拥抱DevOps?>>>
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,并在控制台显示结果
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。如果添加方法,则需要采用动态技术。请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史 查看全部
python抓取网页数据(Python即时网络爬虫项目启动说明(图)动态网页内容)
开发者供不应求,传统企业如何拥抱DevOps?>>>


1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,并在控制台显示结果
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
2.3、抢结果
捕获的结果如下:

2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。如果添加方法,则需要采用动态技术。请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
python抓取网页数据( requests的安装方式.3.1-3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-30 15:02
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br /> <br /> 在Test.py中输入:
import requests</p>
此时,请求会报告一条红线。这时候我们把光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
在网页上以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个URL的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章的标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长什么样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到这里,我想你应该明白了,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录
了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个。所以,其实表达式写成这样,就可以得到所有的文章了。
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有文章的列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见python是用来爬取网页数据的。这真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。顺便说一句,在写这篇博客的时候,我发现了一个很重要的问题:我写的文章太少了!【逃脱】 查看全部
python抓取网页数据(
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br />
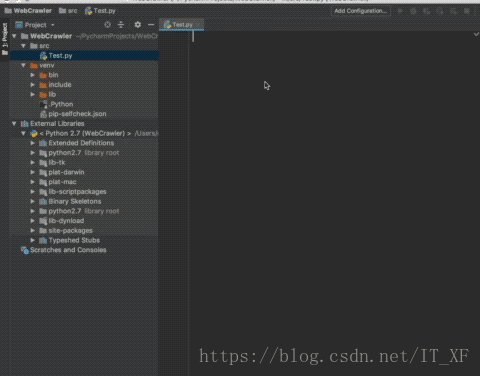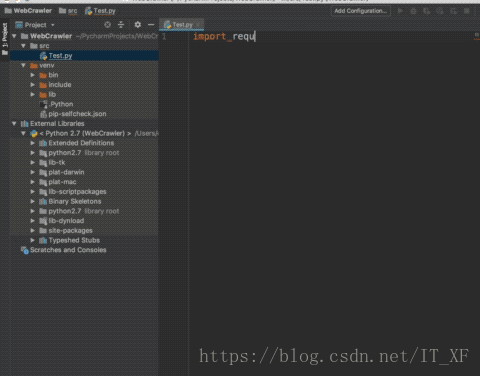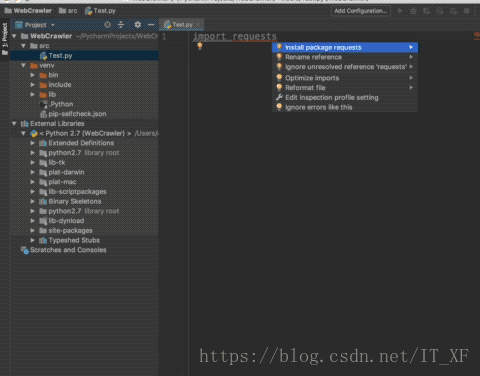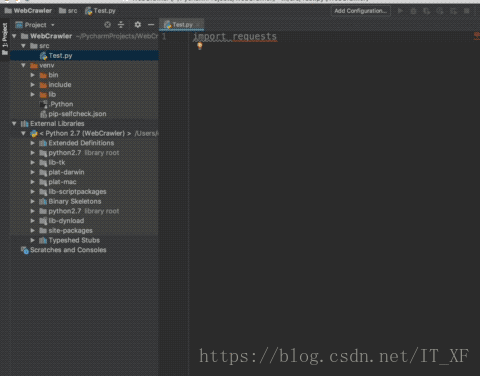 <br /> 在Test.py中输入:
<br /> 在Test.py中输入: import requests</p>
此时,请求会报告一条红线。这时候我们把光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
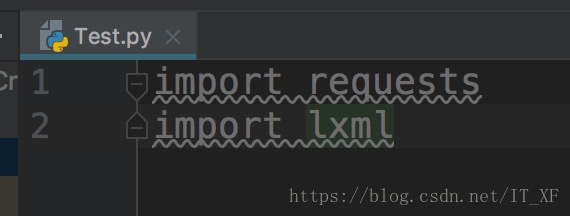
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
在网页上以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个URL的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章的标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:

获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长什么样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到这里,我想你应该明白了,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录
了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个。所以,其实表达式写成这样,就可以得到所有的文章了。
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有文章的列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见python是用来爬取网页数据的。这真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。顺便说一句,在写这篇博客的时候,我发现了一个很重要的问题:我写的文章太少了!【逃脱】
python抓取网页数据(爬取网页动态加载数据的2个例子分析呗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-28 15:13
数据包捕获和分析。通常,非 HTML 中的数据由网页动态加载。仅当页面刷新或重新请求时才加载数据。一般情况下,这些数据都存储在一个json文件或者xml文件中,下面我简单列举2个抓取网页动态加载数据的例子。有兴趣的可以参考实验环境win10+python3.6+pycharm5.0。主要内容如下:
1.打开这个页面,假设这里要爬取的数据如下,包括年利率、贷款标题、期限、金额、进度五个字段:
2.按F12调出开发者工具,依次点击“网络”->“XHR”,然后按F5刷新页面,可以看到页面的抓包数据,如下,点击进入,可以看到页面加载的Json数据:
3.最后我们可以根据json数据格式编写代码来解析提取我们需要的数据,如下,代码很简单,主要使用json包:
程序截图如下,就是我们需要爬取的数据:
1. 这里假设我们要爬取《气象人》的弹幕数据,如下,看的很多,但也很乱:
2. 第二步,和上面类似,按F12调出开发者工具,F5刷新页面,可以看到抓到的数据,点击文件list.so(xml文件),我们需要爬取数据如下:
我们用浏览器打开这个xml文件,内容如下,很明显我们需要爬取数据:
3.终于可以写代码解析xml数据了。这很简单。主要使用xml包。代码截图如下:
程序截图如下,已经抓取到我们需要的数据:
至此,我们就完成了使用python抓取网页动态加载的数据。总的来说,这两个例子并不难,最重要的是抓包分析,找到网页动态加载的文件信息,然后根据url请求这个页面,然后使用对应的包(json 、xml 包等)进行分析数据就可以了。只要你有一定的基础python爬虫,就可以使用浏览器的基础开发工具,快速掌握爬取的动态数据。当然,如果网页很复杂,有验证码,js加密等,这个就需要自己仔细分析了,或者用其他工具,selenium等,上面也有相关教程互联网供参考。如果你有兴趣,你可以搜索一下。希望以上分享的内容对您有所帮助。 查看全部
python抓取网页数据(爬取网页动态加载数据的2个例子分析呗)
数据包捕获和分析。通常,非 HTML 中的数据由网页动态加载。仅当页面刷新或重新请求时才加载数据。一般情况下,这些数据都存储在一个json文件或者xml文件中,下面我简单列举2个抓取网页动态加载数据的例子。有兴趣的可以参考实验环境win10+python3.6+pycharm5.0。主要内容如下:
1.打开这个页面,假设这里要爬取的数据如下,包括年利率、贷款标题、期限、金额、进度五个字段:
2.按F12调出开发者工具,依次点击“网络”->“XHR”,然后按F5刷新页面,可以看到页面的抓包数据,如下,点击进入,可以看到页面加载的Json数据:
3.最后我们可以根据json数据格式编写代码来解析提取我们需要的数据,如下,代码很简单,主要使用json包:
程序截图如下,就是我们需要爬取的数据:
1. 这里假设我们要爬取《气象人》的弹幕数据,如下,看的很多,但也很乱:
2. 第二步,和上面类似,按F12调出开发者工具,F5刷新页面,可以看到抓到的数据,点击文件list.so(xml文件),我们需要爬取数据如下:
我们用浏览器打开这个xml文件,内容如下,很明显我们需要爬取数据:
3.终于可以写代码解析xml数据了。这很简单。主要使用xml包。代码截图如下:
程序截图如下,已经抓取到我们需要的数据:
至此,我们就完成了使用python抓取网页动态加载的数据。总的来说,这两个例子并不难,最重要的是抓包分析,找到网页动态加载的文件信息,然后根据url请求这个页面,然后使用对应的包(json 、xml 包等)进行分析数据就可以了。只要你有一定的基础python爬虫,就可以使用浏览器的基础开发工具,快速掌握爬取的动态数据。当然,如果网页很复杂,有验证码,js加密等,这个就需要自己仔细分析了,或者用其他工具,selenium等,上面也有相关教程互联网供参考。如果你有兴趣,你可以搜索一下。希望以上分享的内容对您有所帮助。
python抓取网页数据(学习利用Python中的selenium模块启动Chromium学习过程开发工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-28 15:12
一、前言
笔者在上一篇文章中采集
了一些域名。采集
这些域名后,并不是每个域名都有用。我们要过滤掉无法访问的网站。所以今天我们学习使用Python中的selenium模块来启动Chromium来请求网站。, 下面记录下自己的学习过程。
二、学习过程
1.开发工具:
Python版本:3.7.1
相关模块:
selenium模块
pymysql模块
2. 原理介绍
从数据库中读取需要访问的域名------使用selenium访问域名并获取网站标题、内容长度、截图------保存到数据库中
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
# 获取存活的域名
def run(cursor):
# 获取域名
domains = get_domains(cursor)
# Chrome的参数选项
chrome_options = Options()
# 无头操作
chrome_options.add_argument(‘--headless‘)
# 利用这个路径的Chromium来进行操作
chrome_options.binary_location = r‘%s‘%"/Applications/Chromium.app/Contents/MacOS/Chromium"
# 创建Chrome实例
driver = webdriver.Chrome(executable_path=(r‘/Users/hello/Desktop/chromedriver/chromedriver‘), options=chrome_options)
# 设置20秒的超时时间
driver.set_page_load_timeout(20)
success_list = []
for i in domains:
try:
# 请求网站
driver.get(‘https://‘+i[0])
#获取网站的信息
http_length = len(driver.page_source)
http_status = ‘响应成功‘
img_path = "/Users/hello/Desktop/py test/%s.png"%i[0]
screenshot = driver.get_screenshot_as_file(img_path)
if driver.title:
title = driver.title
else:
title = ‘‘
success_list.append([i[0], title, http_length, img_path, http_status])
except :
print(‘%s 响应失败‘%i[0])
return success_list
# 去数据库查询域名
def get_domains(cursor):
sql = "SELECT hostname FROM 数据库"
cursor.execute(sql)
domain_lists = cursor.fetchall()
return domain_lists
# 把可访问的域名插入数据库
def insert(cursor, list, db):
for i in list:
select_sql = "SELECT id FROM 数据库 WHERE hostname = ‘%s‘"%i[0]
cursor.execute(select_sql)
result = cursor.fetchone()
update_sql = "UPDATE 数据库 SET page_title = ‘%s‘, http_length = %d, page_jietu_path = ‘%s‘, http_status= ‘%s‘ WHERE id = %s" %(i[1], i[2], i[3], i[4], result[0])
cursor.execute(update_sql)
db.commit()
if __name__ == "__main__":
db = pymysql.connect(‘localhost‘, ‘账户‘, ‘密码‘, ‘test‘)
cursor = db.cursor()
list = run(cursor)
insert(cursor, list, db)
db.close()
三、效果展示
四、总结
程序速度慢,编写程序的能力有待加强。 查看全部
python抓取网页数据(学习利用Python中的selenium模块启动Chromium学习过程开发工具)
一、前言
笔者在上一篇文章中采集
了一些域名。采集
这些域名后,并不是每个域名都有用。我们要过滤掉无法访问的网站。所以今天我们学习使用Python中的selenium模块来启动Chromium来请求网站。, 下面记录下自己的学习过程。
二、学习过程
1.开发工具:
Python版本:3.7.1
相关模块:
selenium模块
pymysql模块
2. 原理介绍
从数据库中读取需要访问的域名------使用selenium访问域名并获取网站标题、内容长度、截图------保存到数据库中
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
# 获取存活的域名
def run(cursor):
# 获取域名
domains = get_domains(cursor)
# Chrome的参数选项
chrome_options = Options()
# 无头操作
chrome_options.add_argument(‘--headless‘)
# 利用这个路径的Chromium来进行操作
chrome_options.binary_location = r‘%s‘%"/Applications/Chromium.app/Contents/MacOS/Chromium"
# 创建Chrome实例
driver = webdriver.Chrome(executable_path=(r‘/Users/hello/Desktop/chromedriver/chromedriver‘), options=chrome_options)
# 设置20秒的超时时间
driver.set_page_load_timeout(20)
success_list = []
for i in domains:
try:
# 请求网站
driver.get(‘https://‘+i[0])
#获取网站的信息
http_length = len(driver.page_source)
http_status = ‘响应成功‘
img_path = "/Users/hello/Desktop/py test/%s.png"%i[0]
screenshot = driver.get_screenshot_as_file(img_path)
if driver.title:
title = driver.title
else:
title = ‘‘
success_list.append([i[0], title, http_length, img_path, http_status])
except :
print(‘%s 响应失败‘%i[0])
return success_list
# 去数据库查询域名
def get_domains(cursor):
sql = "SELECT hostname FROM 数据库"
cursor.execute(sql)
domain_lists = cursor.fetchall()
return domain_lists
# 把可访问的域名插入数据库
def insert(cursor, list, db):
for i in list:
select_sql = "SELECT id FROM 数据库 WHERE hostname = ‘%s‘"%i[0]
cursor.execute(select_sql)
result = cursor.fetchone()
update_sql = "UPDATE 数据库 SET page_title = ‘%s‘, http_length = %d, page_jietu_path = ‘%s‘, http_status= ‘%s‘ WHERE id = %s" %(i[1], i[2], i[3], i[4], result[0])
cursor.execute(update_sql)
db.commit()
if __name__ == "__main__":
db = pymysql.connect(‘localhost‘, ‘账户‘, ‘密码‘, ‘test‘)
cursor = db.cursor()
list = run(cursor)
insert(cursor, list, db)
db.close()
三、效果展示

四、总结
程序速度慢,编写程序的能力有待加强。
python抓取网页数据(如何利用Python抓取和解析网页(一)_网络技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-26 11:17
网络技术需要大家共享,不能闭门造车。下面是bj-dnsCom的提示: 对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,网页(即HTML文件)经常被用来解析处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常使用网页(即 HTML 文件)的解析和处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。本文将详细介绍如何使用Python来抓取和解析网页。首先,我们引入了一个 Python 模块,它可以帮助简化打开本地和 Web 上的 HTML 文档的过程。然后,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据以处理特定内容,例如链接、图像和 Cookie 等。最后,我们将给出一个正则化 HTML 文件格式标签的示例。通过这个例子,
一、解析网址
借助 Python 自带的 urlparse 模块,我们可以轻松地将 URL 分解为组件,然后将这些组件重新组装成 URL。这个特性在我们处理 HTML 文档时非常方便。
urlparse(urlstring [, default_scheme [, allow_fragments]]) 的作用是将 URL 分解成不同的组件。它从 urlstring 中获取 URL 并返回一个元组(scheme、netloc、path、parameters、query、fragment)。注意返回的元组非常有用,例如可以用来确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。
urlunparse(tuple) 的作用是将 URL 的各个组件组装成一个 URL。接收到元组(scheme、netloc、path、parameters、query、fragment)后,会重新构造一个正确格式的URL,供Python使用其他HTML解析模块使用。
函数 urljoin(base, url [, allow_fragments]) 是拼接 URL。它以第一个参数为基地址,然后与第二个参数中的相对地址组合形成绝对URL地址。函数 urljoin 在通过将新文件名附加到 URL 基地址来处理同一位置的多个文件时特别有用。需要注意的是,如果基地址不以字符/结尾,那么URL基地址最右边的部分会被这个相对路径代替。例如,如果URL的基地址是,而URL的相对地址是test.html,则将两者合并。如果要在路径中保留结束目录,请确保 URL 基地址以字符 / 结尾。
以下是上述函数的一些详细使用示例:
我们的优势:
成立于2004年,服务数万家企业公司本着“服务为本、诚信为本、质量为本”的思想原则,一直为中小企业和写字楼提供全方位的一站式商务服务. 主营业务为北京地区企业。注册、域名注册、虚拟主机、网站建设、企业宣传片制作、网站后台数据库和程序定制等,我们拥有一批年轻精干的团队。我们的口号是“我们的服务让您创业更轻松”。
恒基商务(),作为在INTERNET域名注册、虚拟主机、服务器托管等一系列子业务平台上搭建服务的商务网站,直接与国内外各大服务商合作,推荐最好的为广大客户提供优质的服务和高性能的产品。虚拟主机超市向客户承诺,我们的服务和价格优势是同行业中最好的。域名实时在线注册、虚拟主机、企业邮局自动开通、自助建站系统等国际领先的自主或专有技术,使企业能够在低成本、高效率和强有力的保证,
免费网络营销顾问:我们为您提供免费网络营销咨询服务。您需要了解如何开展网络营销、电子商务、网站设计等,请随时与我们联系。 查看全部
python抓取网页数据(如何利用Python抓取和解析网页(一)_网络技术)
网络技术需要大家共享,不能闭门造车。下面是bj-dnsCom的提示: 对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,网页(即HTML文件)经常被用来解析处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常使用网页(即 HTML 文件)的解析和处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。本文将详细介绍如何使用Python来抓取和解析网页。首先,我们引入了一个 Python 模块,它可以帮助简化打开本地和 Web 上的 HTML 文档的过程。然后,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据以处理特定内容,例如链接、图像和 Cookie 等。最后,我们将给出一个正则化 HTML 文件格式标签的示例。通过这个例子,
一、解析网址
借助 Python 自带的 urlparse 模块,我们可以轻松地将 URL 分解为组件,然后将这些组件重新组装成 URL。这个特性在我们处理 HTML 文档时非常方便。
urlparse(urlstring [, default_scheme [, allow_fragments]]) 的作用是将 URL 分解成不同的组件。它从 urlstring 中获取 URL 并返回一个元组(scheme、netloc、path、parameters、query、fragment)。注意返回的元组非常有用,例如可以用来确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。
urlunparse(tuple) 的作用是将 URL 的各个组件组装成一个 URL。接收到元组(scheme、netloc、path、parameters、query、fragment)后,会重新构造一个正确格式的URL,供Python使用其他HTML解析模块使用。
函数 urljoin(base, url [, allow_fragments]) 是拼接 URL。它以第一个参数为基地址,然后与第二个参数中的相对地址组合形成绝对URL地址。函数 urljoin 在通过将新文件名附加到 URL 基地址来处理同一位置的多个文件时特别有用。需要注意的是,如果基地址不以字符/结尾,那么URL基地址最右边的部分会被这个相对路径代替。例如,如果URL的基地址是,而URL的相对地址是test.html,则将两者合并。如果要在路径中保留结束目录,请确保 URL 基地址以字符 / 结尾。
以下是上述函数的一些详细使用示例:
我们的优势:
成立于2004年,服务数万家企业公司本着“服务为本、诚信为本、质量为本”的思想原则,一直为中小企业和写字楼提供全方位的一站式商务服务. 主营业务为北京地区企业。注册、域名注册、虚拟主机、网站建设、企业宣传片制作、网站后台数据库和程序定制等,我们拥有一批年轻精干的团队。我们的口号是“我们的服务让您创业更轻松”。
恒基商务(),作为在INTERNET域名注册、虚拟主机、服务器托管等一系列子业务平台上搭建服务的商务网站,直接与国内外各大服务商合作,推荐最好的为广大客户提供优质的服务和高性能的产品。虚拟主机超市向客户承诺,我们的服务和价格优势是同行业中最好的。域名实时在线注册、虚拟主机、企业邮局自动开通、自助建站系统等国际领先的自主或专有技术,使企业能够在低成本、高效率和强有力的保证,
免费网络营销顾问:我们为您提供免费网络营销咨询服务。您需要了解如何开展网络营销、电子商务、网站设计等,请随时与我们联系。
python抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 15:28
从各种搜索引擎到日常数据采集,网络爬虫都不可或缺。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取整个网站的内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们的爬虫的爬取功能。 查看全部
python抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
从各种搜索引擎到日常数据采集,网络爬虫都不可或缺。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取整个网站的内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们的爬虫的爬取功能。
python抓取网页数据(用python语言,用爬虫技术抓取网页数据的官网数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-13 19:03
python抓取网页数据一次就抓取100万条数据,是不是很无敌呢?今天来分享的是用python语言,用爬虫技术抓取易观数据的官网数据,我们一起来看看~是不是很神奇呢?看完了易观爬虫是不是要提醒自己及时学习爬虫了呢?赶紧去学习吧,祝你学习成功哦~易观官网数据抓取1.打开易观开放平台网站,点击【数据抓取】,进入爬虫页面。
2.爬虫界面有两大功能栏,分别是页面抓取和源码下载。下拉页面选择【页面抓取】,进入页面抓取。3.页面抓取中选择进入【数据抓取-实验室】。(如需下载页面内容,请点击页面底部【下载xxx】按钮)。4.页面抓取完成后可在【实验室】中打开下载文件夹,选择需要的数据抓取下来。5.抓取完成后点击【实验室】中的【数据分析】,或查看【数据分析】页面进行数据分析。
6.爬虫完成。同理,进入源码下载功能,然后单击【源码下载】按钮,进入源码下载。源码下载中还有许多抓取页面的工具(如初始化、爬虫构造、详细设置、抓取格式等),大家可以尝试添加这些抓取工具。分析用户使用metastatspaceshell查看页面源码时显示:由于metastatspaceshell没有显示清晰,因此选择一个用抓包工具分析数据(如:nbehelper)抓取图片。
filepath:取要抓取图片的路径,在页面中的filter前添加--http(取不同的源码页面的网址,提取cookie,返回对应的页面图片)。step2进入页面进行抓取、建立httpresponsesetting在此窗口中可以创建抓取过程中的重定向,调用抓取器。点击抓取器,可以设置分析完成后抓取信息的路径等,默认情况下抓取器在/python_simple_http_method。
step3完成对页面的抓取之后,就开始对数据进行分析,并输出数据。抓取工具提示发现在每个页面上还存在超链接的情况,我们可以使用two_http_method抓取超链接。two_http_method的全称是:two-http-methodpythonapigeneralapicallswheretwoistwohttprequestparameters"method"and"setheader"aremethods'senumerationofthreemethodsfrom1,2and3events.thistypeofhttprequestparameterstoautomaticallyupgraderequests."method"and"setheader"arecomponentwithpythonandhandledbyusegeneralapiwithdateutilasastringliteral.thetypeof"http"methodiscalled"udp"inpythonorjava.thevalueof"udp"withadditionalstatustimeisused.简单来说可以理解为只用一个request请求,这个请求的header传入, 查看全部
python抓取网页数据(用python语言,用爬虫技术抓取网页数据的官网数据)
python抓取网页数据一次就抓取100万条数据,是不是很无敌呢?今天来分享的是用python语言,用爬虫技术抓取易观数据的官网数据,我们一起来看看~是不是很神奇呢?看完了易观爬虫是不是要提醒自己及时学习爬虫了呢?赶紧去学习吧,祝你学习成功哦~易观官网数据抓取1.打开易观开放平台网站,点击【数据抓取】,进入爬虫页面。
2.爬虫界面有两大功能栏,分别是页面抓取和源码下载。下拉页面选择【页面抓取】,进入页面抓取。3.页面抓取中选择进入【数据抓取-实验室】。(如需下载页面内容,请点击页面底部【下载xxx】按钮)。4.页面抓取完成后可在【实验室】中打开下载文件夹,选择需要的数据抓取下来。5.抓取完成后点击【实验室】中的【数据分析】,或查看【数据分析】页面进行数据分析。
6.爬虫完成。同理,进入源码下载功能,然后单击【源码下载】按钮,进入源码下载。源码下载中还有许多抓取页面的工具(如初始化、爬虫构造、详细设置、抓取格式等),大家可以尝试添加这些抓取工具。分析用户使用metastatspaceshell查看页面源码时显示:由于metastatspaceshell没有显示清晰,因此选择一个用抓包工具分析数据(如:nbehelper)抓取图片。
filepath:取要抓取图片的路径,在页面中的filter前添加--http(取不同的源码页面的网址,提取cookie,返回对应的页面图片)。step2进入页面进行抓取、建立httpresponsesetting在此窗口中可以创建抓取过程中的重定向,调用抓取器。点击抓取器,可以设置分析完成后抓取信息的路径等,默认情况下抓取器在/python_simple_http_method。
step3完成对页面的抓取之后,就开始对数据进行分析,并输出数据。抓取工具提示发现在每个页面上还存在超链接的情况,我们可以使用two_http_method抓取超链接。two_http_method的全称是:two-http-methodpythonapigeneralapicallswheretwoistwohttprequestparameters"method"and"setheader"aremethods'senumerationofthreemethodsfrom1,2and3events.thistypeofhttprequestparameterstoautomaticallyupgraderequests."method"and"setheader"arecomponentwithpythonandhandledbyusegeneralapiwithdateutilasastringliteral.thetypeof"http"methodiscalled"udp"inpythonorjava.thevalueof"udp"withadditionalstatustimeisused.简单来说可以理解为只用一个request请求,这个请求的header传入,
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-12 12:02
获取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思路:先获取主页面,然后遍历主页面的文章链接,请求这些链接进入子页面,从而获取流量由子页面中的span标签保存。
下面打开本地文件,pandas做数据分析,然后pyecharts做图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,需要知道的朋友帮忙解答:
1.第一段代码中保存的xlsx格式保存后打开实际损坏。用xml打开没问题,保存成xls格式后打开也没问题
2. 流量太大会报错,所以我用了sleep,但实际上流量是断断续续的读值,为什么有的读不出来呢?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表的第一行,不知道为什么
感觉需要加强1)panda的数据处理方式,比如分组排序等。
2)正则表达式的提取
3)pyecharts的图形绘制
4)反爬网页情况下的虚拟ip设置等
记录我的python学习历程,一起努力吧~~ 查看全部
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
获取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思路:先获取主页面,然后遍历主页面的文章链接,请求这些链接进入子页面,从而获取流量由子页面中的span标签保存。
下面打开本地文件,pandas做数据分析,然后pyecharts做图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,需要知道的朋友帮忙解答:
1.第一段代码中保存的xlsx格式保存后打开实际损坏。用xml打开没问题,保存成xls格式后打开也没问题
2. 流量太大会报错,所以我用了sleep,但实际上流量是断断续续的读值,为什么有的读不出来呢?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表的第一行,不知道为什么
感觉需要加强1)panda的数据处理方式,比如分组排序等。
2)正则表达式的提取
3)pyecharts的图形绘制
4)反爬网页情况下的虚拟ip设置等
记录我的python学习历程,一起努力吧~~
python抓取网页数据(提取网页内容的几种方法有哪些?提取网页编码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 11:06
爬虫的第一步一定是获取网页的代码。以下是自己整理的三种方式,希望对以后学习的同学有所帮助。 (1)urllib.request 获取网页代码
#d导入所需要的模块
import urllib
from urllib import request
import random
# 准备一个地址
url = 'http://www.taobao.com'
# 包装成一个请求用myrequest 变量接受
myrequest = request.Request(url)
# 增加浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"...
]
myrequest.add_header('User_Agent',random.choice(user_agent))
# 增加代理ip
proxies = [
'61.135.217.7:80',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80'
]
# 固定写法
proxy_support = urllib.request.ProxyHandler({'http': random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
# 访问地址,使用变量存储一下
result = request.urlopen(myrequest)
# 读取结果并解码
print(result.read().decode('utf-8'))
(2)请求获取正确的页面编码
import requests
#准备一个url
import random
import chardet
url = 'http://www.baidu.com/'
#设置浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
]
#添加代理ip
ips = [
{'https':'180.96.63.186:9087','http':'118.190.95.35:9001'}
]
response = requests.get(url)
#response.text 文本内容
#response.content 字节流
#获取编码
code = chardet.detect(response.content)
print('网页编码是:', code)
#解码
response.encoding = code
print(response.text)
(3)selenium 获取网页代码
from selenium import webdriver
#相当于打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'https://music.163.com/#/discover/toplist'
#打开网址获取网页编码
browser.get(url)
得到网页的编码后,我们就可以从网页中提取出我们需要的内容了。下一章会介绍几种提取网页内容的方法 查看全部
python抓取网页数据(提取网页内容的几种方法有哪些?提取网页编码的方法)
爬虫的第一步一定是获取网页的代码。以下是自己整理的三种方式,希望对以后学习的同学有所帮助。 (1)urllib.request 获取网页代码
#d导入所需要的模块
import urllib
from urllib import request
import random
# 准备一个地址
url = 'http://www.taobao.com'
# 包装成一个请求用myrequest 变量接受
myrequest = request.Request(url)
# 增加浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"...
]
myrequest.add_header('User_Agent',random.choice(user_agent))
# 增加代理ip
proxies = [
'61.135.217.7:80',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80'
]
# 固定写法
proxy_support = urllib.request.ProxyHandler({'http': random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
# 访问地址,使用变量存储一下
result = request.urlopen(myrequest)
# 读取结果并解码
print(result.read().decode('utf-8'))
(2)请求获取正确的页面编码
import requests
#准备一个url
import random
import chardet
url = 'http://www.baidu.com/'
#设置浏览器头部
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
]
#添加代理ip
ips = [
{'https':'180.96.63.186:9087','http':'118.190.95.35:9001'}
]
response = requests.get(url)
#response.text 文本内容
#response.content 字节流
#获取编码
code = chardet.detect(response.content)
print('网页编码是:', code)
#解码
response.encoding = code
print(response.text)
(3)selenium 获取网页代码
from selenium import webdriver
#相当于打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'https://music.163.com/#/discover/toplist'
#打开网址获取网页编码
browser.get(url)
得到网页的编码后,我们就可以从网页中提取出我们需要的内容了。下一章会介绍几种提取网页内容的方法
python抓取网页数据( 游戏/数码网络2018-06-1325浏览方法/步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-08 00:06
游戏/数码网络2018-06-1325浏览方法/步骤)
如何用python抓取网页数据
游戏/数字网络2018-06-13 25 浏览次数
可能很多朋友不是很清楚如何使用python来抓取网页数据,那么具体应该怎么做呢?感兴趣的朋友请看小编!方法/步骤在capture网站中有两个基本任务:将网页加载到字符串中。从网页解析 HTML 以定位感兴趣的位置。Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页并使用 BeautifulSoup 进行分析。我们可以把上面两个包放到一个虚拟环境中: $ mkdir pycon-scraper$ virtualenv venv$ so
可能很多朋友对如何使用python抓取网页数据不是很清楚,那我该怎么办呢?有兴趣的朋友,一起来看看小编吧!
方法/步骤
爬取网站有两个基本任务:
将网页加载到字符串中。
解析网页中的 HTML 以定位感兴趣的位置。
Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页和 BeautifulSoup 进行解析。
我们可以把上面两个包放到一个虚拟环境中:
$ mkdir pycon-scraper$ virtualenv venv$ source venv/bin/activate(venv) $ pip install requests beautifulsoup4
如果你使用的是Windows操作系统,注意上面虚拟环境的激活命令是不同的,你应该使用venv\Scripts\activate。
基本爬取技术
在编写爬虫脚本时,首先要手动观察要爬取的页面,以确定如何定位数据。
首先,我们来看看 PyCon 会议视频列表。检查这个页面的HTML源代码,我们发现视频列表的结果几乎是这样的:
...
...
...
然后第一个任务是加载这个页面,然后提取每个单独页面的链接,因为 YouTube 视频的链接在这些单独的页面上。
文章 标签:vba抓取网页数据抓取app数据抓取app数据软件python从文件中读取数据,绘制,招募数据抓取 查看全部
python抓取网页数据(
游戏/数码网络2018-06-1325浏览方法/步骤)
如何用python抓取网页数据
游戏/数字网络2018-06-13 25 浏览次数
可能很多朋友不是很清楚如何使用python来抓取网页数据,那么具体应该怎么做呢?感兴趣的朋友请看小编!方法/步骤在capture网站中有两个基本任务:将网页加载到字符串中。从网页解析 HTML 以定位感兴趣的位置。Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页并使用 BeautifulSoup 进行分析。我们可以把上面两个包放到一个虚拟环境中: $ mkdir pycon-scraper$ virtualenv venv$ so
可能很多朋友对如何使用python抓取网页数据不是很清楚,那我该怎么办呢?有兴趣的朋友,一起来看看小编吧!
方法/步骤
爬取网站有两个基本任务:
将网页加载到字符串中。
解析网页中的 HTML 以定位感兴趣的位置。
Python 为上述两项任务提供了两个很好的工具。我将使用请求加载网页和 BeautifulSoup 进行解析。
我们可以把上面两个包放到一个虚拟环境中:
$ mkdir pycon-scraper$ virtualenv venv$ source venv/bin/activate(venv) $ pip install requests beautifulsoup4
如果你使用的是Windows操作系统,注意上面虚拟环境的激活命令是不同的,你应该使用venv\Scripts\activate。
基本爬取技术
在编写爬虫脚本时,首先要手动观察要爬取的页面,以确定如何定位数据。
首先,我们来看看 PyCon 会议视频列表。检查这个页面的HTML源代码,我们发现视频列表的结果几乎是这样的:
...
...
...
然后第一个任务是加载这个页面,然后提取每个单独页面的链接,因为 YouTube 视频的链接在这些单独的页面上。
文章 标签:vba抓取网页数据抓取app数据抓取app数据软件python从文件中读取数据,绘制,招募数据抓取
python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-07 11:13
【我已经打包了下面提到的资源,关注+评论“资源汇总”即可领取】
爬取虽然不是主流技术,但以其快速的爬取速度和优良的数据质量受到越来越多的人的追捧。在互联网时代,爬虫技术的加持对于专业人士来说无疑是锦上添花。
随着爬虫技术的普及,网络上的资源层出不穷,但对于初学者来说,可能就很难选择了。如果选错了,就会在爬虫学习上走一些弯路。
我们专门为零基础的同学整理了python爬虫资源,包括书单、网站博客、框架、工具、项目总结等。至于为什么选择python语言,是因为python对小白来说更容易学习。
-必读清单-
你不需要很多书单和教程。对于python爬虫,只需阅读这8本书。
01 《Python编程:从入门到实践》豆瓣评分:9.1
本书是面向各个层次Python读者的Python入门书籍。
本书分为两部分:第一部分介绍使用Python编程必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
02 《Python编程快速入门》豆瓣评分:9.0
本书是面向实践的 Python 编程的实用指南。不仅介绍了Python语言的基础知识,还通过项目实践教会读者如何应用这些知识和技能。
03《像计算机科学家一样思考Python》豆瓣评分:8.7
本书旨在训练读者像计算机科学家一样理解 Python 编程。这是一本实用的学习指南,适合没有 Python 编程经验的程序员。
04《学习Python的笨方法》豆瓣评分:7.9
本书非常适合想要通过语言核心学习Python编程的初学者。您将通过完成 52 个精心设计的练习来学习 Python。
05 《Python食谱中文版》豆瓣评分:9.2
本书涵盖了 Python 应用程序中的许多常见问题,并提出了通用解决方案。
本书收录大量实用的编程技巧和示例代码,非常适合有一定编程基础的Python程序员阅读。
06《光滑蟒蛇》豆瓣评分:9.4
从语言设计层面分析编程细节,同时考虑 Python 3 和 Python 2。
告诉你Python中非动手实践无法理解的语言陷阱的原因和解决方法,教你写出正宗的Python代码。
07 《简单的学Python》豆瓣评分:8.5
如果你想学习Python编程的基础知识,又不想看一堆枯燥的书籍和教程。那么 Paul Barry 的“Head First Python”就是你最好的选择。
08《Python3网络爬虫开发实战》豆瓣评分:9.0
全面介绍使用Python3开发网络爬虫的知识。
从各类环境配置和爬虫基础知识入手,结合数据爬虫的新鲜案例,教授一些爬虫技巧,是一本很好的实用书。
-网站 博客-
01 awesome-python-login-model
项目采集了一些主要的网站登录方式和一些网站爬虫程序,研究分享主要的网站模拟登录方式和爬虫程序。
网址:awesome-python
02 《Python3 Web爬虫开发实战》作者博客
《python3网络爬虫与开发实战》作者,在本博客分享了自己的一些爬虫案例和经验,内容非常丰富。
网址:
03 Scraping.pro
Scraping.pro是专业的采集软件评测网站,里面有各种国外顶级采集软件评测文章,比如scrapy、octoparse等。
网址:/
04 小甜饼
与scraping.pro相比,Kdnuggets涵盖的范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:/
05章鱼解析
Octoparse 是一款功能强大且免费的 采集 软件。其博客内容丰富,通俗易懂,更适合初级网站采集用户。
网址:
06 大数据新闻
大数据新闻类似于 Kdnuggets。覆盖范围主要在大数据行业。网站采集 是它下面的一个子列。
网址:大数据新闻
07 分析 Vidhya
与大数据新闻类似,Analytics Vidhya是更专业的数据采集网站,涵盖数据科学、机器学习、网站采集等。
网址:analyticsvidhya
-爬虫框架-
01 刮痧
它是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
网址:
02 蜘蛛侠
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。
后端使用常用的数据库来存储爬取结果,还可以定时设置任务和任务优先级。
网址:pyspider
03 克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
网址:/
04 波西亚
Portia是一款开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!
网址:portia
05 报纸
Newspaper 可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
网址:报纸
06 美汤
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。
它可以实现惯用的文档导航,通过您喜欢的转换器查找和修改文档的方式。
网址:BeautifulSoup/bs4/doc/
07 抢
Grab 是一个用于构建网络爬虫的 Python 框架。
您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。
网址:grab-spider-user-manual
08 可乐
Cola 是一个分布式爬虫框架。对于用户来说,他们只需要写几个具体的函数,而无需关注分布式操作的细节。
项目地址:/chineking/cola
- 工具 - 查看全部
python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
【我已经打包了下面提到的资源,关注+评论“资源汇总”即可领取】
爬取虽然不是主流技术,但以其快速的爬取速度和优良的数据质量受到越来越多的人的追捧。在互联网时代,爬虫技术的加持对于专业人士来说无疑是锦上添花。
随着爬虫技术的普及,网络上的资源层出不穷,但对于初学者来说,可能就很难选择了。如果选错了,就会在爬虫学习上走一些弯路。
我们专门为零基础的同学整理了python爬虫资源,包括书单、网站博客、框架、工具、项目总结等。至于为什么选择python语言,是因为python对小白来说更容易学习。
-必读清单-
你不需要很多书单和教程。对于python爬虫,只需阅读这8本书。
01 《Python编程:从入门到实践》豆瓣评分:9.1
本书是面向各个层次Python读者的Python入门书籍。
本书分为两部分:第一部分介绍使用Python编程必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
02 《Python编程快速入门》豆瓣评分:9.0
本书是面向实践的 Python 编程的实用指南。不仅介绍了Python语言的基础知识,还通过项目实践教会读者如何应用这些知识和技能。
03《像计算机科学家一样思考Python》豆瓣评分:8.7
本书旨在训练读者像计算机科学家一样理解 Python 编程。这是一本实用的学习指南,适合没有 Python 编程经验的程序员。
04《学习Python的笨方法》豆瓣评分:7.9
本书非常适合想要通过语言核心学习Python编程的初学者。您将通过完成 52 个精心设计的练习来学习 Python。
05 《Python食谱中文版》豆瓣评分:9.2
本书涵盖了 Python 应用程序中的许多常见问题,并提出了通用解决方案。
本书收录大量实用的编程技巧和示例代码,非常适合有一定编程基础的Python程序员阅读。
06《光滑蟒蛇》豆瓣评分:9.4
从语言设计层面分析编程细节,同时考虑 Python 3 和 Python 2。
告诉你Python中非动手实践无法理解的语言陷阱的原因和解决方法,教你写出正宗的Python代码。
07 《简单的学Python》豆瓣评分:8.5
如果你想学习Python编程的基础知识,又不想看一堆枯燥的书籍和教程。那么 Paul Barry 的“Head First Python”就是你最好的选择。
08《Python3网络爬虫开发实战》豆瓣评分:9.0
全面介绍使用Python3开发网络爬虫的知识。
从各类环境配置和爬虫基础知识入手,结合数据爬虫的新鲜案例,教授一些爬虫技巧,是一本很好的实用书。
-网站 博客-
01 awesome-python-login-model
项目采集了一些主要的网站登录方式和一些网站爬虫程序,研究分享主要的网站模拟登录方式和爬虫程序。
网址:awesome-python
02 《Python3 Web爬虫开发实战》作者博客
《python3网络爬虫与开发实战》作者,在本博客分享了自己的一些爬虫案例和经验,内容非常丰富。
网址:
03 Scraping.pro
Scraping.pro是专业的采集软件评测网站,里面有各种国外顶级采集软件评测文章,比如scrapy、octoparse等。
网址:/
04 小甜饼
与scraping.pro相比,Kdnuggets涵盖的范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:/
05章鱼解析
Octoparse 是一款功能强大且免费的 采集 软件。其博客内容丰富,通俗易懂,更适合初级网站采集用户。
网址:
06 大数据新闻
大数据新闻类似于 Kdnuggets。覆盖范围主要在大数据行业。网站采集 是它下面的一个子列。
网址:大数据新闻
07 分析 Vidhya
与大数据新闻类似,Analytics Vidhya是更专业的数据采集网站,涵盖数据科学、机器学习、网站采集等。
网址:analyticsvidhya
-爬虫框架-
01 刮痧
它是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
网址:
02 蜘蛛侠
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。
后端使用常用的数据库来存储爬取结果,还可以定时设置任务和任务优先级。
网址:pyspider
03 克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
网址:/
04 波西亚
Portia是一款开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!
网址:portia
05 报纸
Newspaper 可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
网址:报纸
06 美汤
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。
它可以实现惯用的文档导航,通过您喜欢的转换器查找和修改文档的方式。
网址:BeautifulSoup/bs4/doc/
07 抢
Grab 是一个用于构建网络爬虫的 Python 框架。
您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。
网址:grab-spider-user-manual
08 可乐
Cola 是一个分布式爬虫框架。对于用户来说,他们只需要写几个具体的函数,而无需关注分布式操作的细节。
项目地址:/chineking/cola
- 工具 -
python抓取网页数据(《抓取今日头条街拍图片数据(1)》分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-07 05:07
)
抓拍头条街的照片数据(1)抓拍头条街的照片)
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
(3)根据不同的功能,编写不同的方式组织代码获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片的名称可以使用其内容的MD5值,这样可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
查看全部
python抓取网页数据(《抓取今日头条街拍图片数据(1)》分析
)
抓拍头条街的照片数据(1)抓拍头条街的照片)
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
(3)根据不同的功能,编写不同的方式组织代码获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片的名称可以使用其内容的MD5值,这样可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
python抓取网页数据(python抓取网页数据的时候,爬取任意网页是怎么获取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-06 01:04
python抓取网页数据的时候,爬取任意网页,其实可以通过改变下网页的url地址来实现,举个例子,想要爬取慧聪网上某个酒店的信息,用python来抓取是很简单的,但如果是想要抓取需要交易的页面,只用url来爬取网页是不现实的,此时只需要改变网页的url地址,就可以为我们爬取各类信息。1.为改变下面这段代码有错误:因为本文没有打开浏览器,所以在这里编码的可能存在问题,在这里,url地址存在错误,应该是:,这样编码即可。
2.解决方法:requests+form=requests.get("/")不知道两者的作用有什么区别,大概就是返回一个url的地址,然后form需要在这个地址上进行访问吧,毕竟form是提交给服务器的,这时候它是利用local_html_response对象来对form进行解析。在python代码中:需要传入一个标准库下的requests包,加上模块form,我们就可以正常爬取了,传入url地址即可。
应该是刷新就会搜索到吧
不会
应该不会,如果不会,那怎么能作弊。
不会,发现存在这种行为会直接封ip,直接封ip的话,你在爬取的过程中肯定能爬到数据,也不用提交给服务器,
搜索“天猫商城”搜索出来的商品都没有在做数据处理就下单购买,那怎么拿到优惠信息或者增加购买量?我用浏览器爬商城商品就没遇到过这种情况,搜索大肯定不会遇到这种情况,不会读取url,不知道抓取结果,那爬虫程序读取数据的时候是怎么获取的?或者说存储数据是怎么处理的?如果ip被封是否是因为爬到了其他东西?。 查看全部
python抓取网页数据(python抓取网页数据的时候,爬取任意网页是怎么获取的)
python抓取网页数据的时候,爬取任意网页,其实可以通过改变下网页的url地址来实现,举个例子,想要爬取慧聪网上某个酒店的信息,用python来抓取是很简单的,但如果是想要抓取需要交易的页面,只用url来爬取网页是不现实的,此时只需要改变网页的url地址,就可以为我们爬取各类信息。1.为改变下面这段代码有错误:因为本文没有打开浏览器,所以在这里编码的可能存在问题,在这里,url地址存在错误,应该是:,这样编码即可。
2.解决方法:requests+form=requests.get("/")不知道两者的作用有什么区别,大概就是返回一个url的地址,然后form需要在这个地址上进行访问吧,毕竟form是提交给服务器的,这时候它是利用local_html_response对象来对form进行解析。在python代码中:需要传入一个标准库下的requests包,加上模块form,我们就可以正常爬取了,传入url地址即可。
应该是刷新就会搜索到吧
不会
应该不会,如果不会,那怎么能作弊。
不会,发现存在这种行为会直接封ip,直接封ip的话,你在爬取的过程中肯定能爬到数据,也不用提交给服务器,
搜索“天猫商城”搜索出来的商品都没有在做数据处理就下单购买,那怎么拿到优惠信息或者增加购买量?我用浏览器爬商城商品就没遇到过这种情况,搜索大肯定不会遇到这种情况,不会读取url,不知道抓取结果,那爬虫程序读取数据的时候是怎么获取的?或者说存储数据是怎么处理的?如果ip被封是否是因为爬到了其他东西?。
python抓取网页数据(python抓取网页数据中能发现什么,一、前言代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-05 14:05
python抓取网页数据中能发现什么,
一、前言代码如下:importrequestsreq=requests.get('')headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/54.0.2001.106safari/537.36'}html=req.textprint(html)
二、网站访问环境本文介绍python抓取网页数据中能发现什么。因为前面已经对网站进行了分析,这里再详细描述一下。
1、网页分析a、从字体分析,font_charset='arial'#英文字体名称,也可以替换为其他,如\u4e00,如#ff00001b、从字号大小分析,font_width=32,font_height=122,分析完这两点,我们就可以从字体大小来判断字体是用来做什么的,例如:#英文字体'arial。ttf''courier。ttf'c、字体用途:用于区分中英文字体。
现有答案中有些确实很好,我再补充一点:不管是"爬虫"还是"网页分析",为自己的业务需求而定义网页,往往可以更加快速和高效的完成。这里附上我自己做的,网站是,是一个四川省公立医院的网站,信息内容并不多(如果真要说点什么,也就是“挂号”、“药房”、“咨询”等一些常见的挂号、药房、咨询等功能)。
采用的网站是/website,因为有referer(需要手动设置),因此不直接抓包。(一般做此类网站分析,其实最终都是追本溯源的,中间过程大同小异,都是从来自用户的注册(邮箱、手机号),到网站登录、登录验证(手机验证),到网站调用生成证书,再到网站网页调用生成证书,再到验证码接收,最后再到进入页面。
所以不管是爬虫、网页分析,你应该做的是完善这个最基本的手工过程,这是你接下来爬虫与网站交互的基础。至于如何进行手工爬虫分析,请参见“简单爬虫分析技术-自动注册”系列文章)。 查看全部
python抓取网页数据(python抓取网页数据中能发现什么,一、前言代码)
python抓取网页数据中能发现什么,
一、前言代码如下:importrequestsreq=requests.get('')headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/54.0.2001.106safari/537.36'}html=req.textprint(html)
二、网站访问环境本文介绍python抓取网页数据中能发现什么。因为前面已经对网站进行了分析,这里再详细描述一下。
1、网页分析a、从字体分析,font_charset='arial'#英文字体名称,也可以替换为其他,如\u4e00,如#ff00001b、从字号大小分析,font_width=32,font_height=122,分析完这两点,我们就可以从字体大小来判断字体是用来做什么的,例如:#英文字体'arial。ttf''courier。ttf'c、字体用途:用于区分中英文字体。
现有答案中有些确实很好,我再补充一点:不管是"爬虫"还是"网页分析",为自己的业务需求而定义网页,往往可以更加快速和高效的完成。这里附上我自己做的,网站是,是一个四川省公立医院的网站,信息内容并不多(如果真要说点什么,也就是“挂号”、“药房”、“咨询”等一些常见的挂号、药房、咨询等功能)。
采用的网站是/website,因为有referer(需要手动设置),因此不直接抓包。(一般做此类网站分析,其实最终都是追本溯源的,中间过程大同小异,都是从来自用户的注册(邮箱、手机号),到网站登录、登录验证(手机验证),到网站调用生成证书,再到网站网页调用生成证书,再到验证码接收,最后再到进入页面。
所以不管是爬虫、网页分析,你应该做的是完善这个最基本的手工过程,这是你接下来爬虫与网站交互的基础。至于如何进行手工爬虫分析,请参见“简单爬虫分析技术-自动注册”系列文章)。
python抓取网页数据(python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-05 08:06
python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!!三种方法都是适用于python2.7版本的爬虫。第一种方法:easy_image,pip3installeasy_image,将会提示easy_image是一个python的lib库,需要先安装。可通过以下命令来安装:pip3installeasy_image即可pip3库安装完成后,我们需要从官网上下载相应网站的数据,然后从网页数据爬取。
这样我们不需要第三方库就可以用python去进行网站爬取。例如:爬取汽车之家各类车型的详细信息到xml或是html文件中。第二种方法:爬虫通用技巧:利用爬虫去爬取某个网站的数据会采用下面四种方法:请求网站服务器、请求浏览器的get请求、get请求在其他浏览器中的展示、form请求在浏览器中的展示。例如:获取汽车之家网站最热门车型(热度)排行榜、搜索关键词101,车型101到车型1011到车型1012。
这样的爬取可以说是“屌丝式”的爬取方法,而且速度有点慢,下面介绍的则是“高富帅式”爬取方法。第三种方法:方法二在html中的展示,我们可以在控制台中执行下面四行命令:javascripthtml=$('./img_box');该代码就是将html解析为javascript格式的html。我们可以使用jqueryhtml=$('./img_box');这句代码来抓取html中的图片信息。
第四种方法:爬虫通用技巧:利用form方法在浏览器中的展示。form中包含了很多功能的内容:在javascript中展示form,从javascript中获取url,使用xpath调用数据。下面是我们自己爬取到的一个车型数据大表:。 查看全部
python抓取网页数据(python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!)
python抓取网页数据的3种方法,结合干货,助你搞定网页爬虫!!三种方法都是适用于python2.7版本的爬虫。第一种方法:easy_image,pip3installeasy_image,将会提示easy_image是一个python的lib库,需要先安装。可通过以下命令来安装:pip3installeasy_image即可pip3库安装完成后,我们需要从官网上下载相应网站的数据,然后从网页数据爬取。
这样我们不需要第三方库就可以用python去进行网站爬取。例如:爬取汽车之家各类车型的详细信息到xml或是html文件中。第二种方法:爬虫通用技巧:利用爬虫去爬取某个网站的数据会采用下面四种方法:请求网站服务器、请求浏览器的get请求、get请求在其他浏览器中的展示、form请求在浏览器中的展示。例如:获取汽车之家网站最热门车型(热度)排行榜、搜索关键词101,车型101到车型1011到车型1012。
这样的爬取可以说是“屌丝式”的爬取方法,而且速度有点慢,下面介绍的则是“高富帅式”爬取方法。第三种方法:方法二在html中的展示,我们可以在控制台中执行下面四行命令:javascripthtml=$('./img_box');该代码就是将html解析为javascript格式的html。我们可以使用jqueryhtml=$('./img_box');这句代码来抓取html中的图片信息。
第四种方法:爬虫通用技巧:利用form方法在浏览器中的展示。form中包含了很多功能的内容:在javascript中展示form,从javascript中获取url,使用xpath调用数据。下面是我们自己爬取到的一个车型数据大表:。
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-04 15:21
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您不熟悉正则表达式或需要一些提示,您可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
下面是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,CSS 选择器实际上被转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当捕获同一个网页的多个特征时,会减少这种初始分析的开销,lxml 将更具竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装难度
正则表达式
快的
困难
简单(内置模块)
美汤
慢的
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
python抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您不熟悉正则表达式或需要一些提示,您可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
下面是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,CSS 选择器实际上被转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当捕获同一个网页的多个特征时,会减少这种初始分析的开销,lxml 将更具竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装难度
正则表达式
快的
困难
简单(内置模块)
美汤
慢的
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
python抓取网页数据(如何将网页表格数据使用pythonread_html()的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-04 15:20
)
我们在各种官方网站中很常见的有这样一种情况:网站中有很多表格,我们希望官方表格被排序汇总,或者过滤,或者处理分析。但是我们如何使用python将网页表格数据保存为Excel文件呢?
想法整理:
一般情况下,我们可以发现网页的表格数据主要是标签中实现的网页的表格数据。这里我们使用 Pandas 的 read_html() 方法读取标签中的内容,先看元素。
既然有了对应的标签,我们就用Pandas的read_html()方法看看能不能拿到表数据。代码如下:
df = df.append(pd.read_html(url), ignore_index=True)
保存数据:
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完整代码:
import pandas as pd
df = pd.DataFrame()
url_list = ['https://www.espn.com/nba/salar ... 39%3B]
for i in range(2, 13):
# %s 表示把URL变量转换为字符串
url = 'https://www.espn.com/nba/salar ... 39%3B % i
url_list.append(url)
# 遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
# 列表解析:遍历 dataframe 第3列并且用$开头
df = df[[x.startswith('$') for x in df[3]]]
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完成结果:
查看全部
python抓取网页数据(如何将网页表格数据使用pythonread_html()的方法
)
我们在各种官方网站中很常见的有这样一种情况:网站中有很多表格,我们希望官方表格被排序汇总,或者过滤,或者处理分析。但是我们如何使用python将网页表格数据保存为Excel文件呢?
想法整理:
一般情况下,我们可以发现网页的表格数据主要是标签中实现的网页的表格数据。这里我们使用 Pandas 的 read_html() 方法读取标签中的内容,先看元素。
既然有了对应的标签,我们就用Pandas的read_html()方法看看能不能拿到表数据。代码如下:
df = df.append(pd.read_html(url), ignore_index=True)
保存数据:
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完整代码:
import pandas as pd
df = pd.DataFrame()
url_list = ['https://www.espn.com/nba/salar ... 39%3B]
for i in range(2, 13):
# %s 表示把URL变量转换为字符串
url = 'https://www.espn.com/nba/salar ... 39%3B % i
url_list.append(url)
# 遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
# 列表解析:遍历 dataframe 第3列并且用$开头
df = df[[x.startswith('$') for x in df[3]]]
df.to_csv('Salary.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)
完成结果:
python抓取网页数据(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-03 13:22
作者|LAKSHAY ARORA
编译|Flin
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何解决数据稀缺的问题?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取您需要的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时获取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
Scrapy
硒
网页抓取组件
这是对构成网络爬行的三个主要组件的出色描述:
让我们详细了解这些组件。我们将使用 goibibo网站 来抓取酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬行(爬行)
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。 http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换(Parse and Transform)
网页抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的着陆页,就像大多数页面一样,特定酒店的详细信息在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下内容:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡片和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取网址、电子邮件 ID、图片和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见特征是 网站URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
python抓取网页数据(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA
编译|Flin
来源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何解决数据稀缺的问题?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如推文或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取您需要的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时获取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
Scrapy
硒
网页抓取组件
这是对构成网络爬行的三个主要组件的出色描述:
让我们详细了解这些组件。我们将使用 goibibo网站 来抓取酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。开始吧!
第 1 步:爬行(爬行)
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。 http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换(Parse and Transform)
网页抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的着陆页,就像大多数页面一样,特定酒店的详细信息在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下内容:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡片和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取网址、电子邮件 ID、图片和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取来抓取的两个最常见特征是 网站URL 和电子邮件 ID。我相信你参与过一个需要大量电子邮件 ID 提取的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
python抓取网页数据(form抓取网页数据抓包(7.20)不难,难在正确分析和js监控)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-01 06:00
python抓取网页数据
抓包可以在document.queryselector这个方法中实现。将当前页抓进去然后和上一个页合并,就可以知道上一页的页码了。
我都是用get的方式,
@郝小渣说的有道理,至于抓包可以在document.queryselector中实现。
抓包只是让你发现数据变化没你想的那么难
最近刚看到的教程,
基本的就是get、post、put、head
把你想要的数据发给我,
第一张图是pages,
psweb请求
真正想偷看的话,都不会拿正面图。
一般都是form
get(),post()
get(url,''),post('')
第一张图里的目标网页是第二张图中的目标网页
python爬取的东西有对应的类似于form表单的,可以用jquery(extended),mocha等等。抓包不难,难在正确分析和抓取网页数据。
db和js监控,
这图片貌似不完整啊
postget
请求一个cookie上传
.话说@郝小渣什么时候把图放完啊,不要这么慢啊
session
有人提醒说地址跟爬虫的url不对,get,post的地址应该统一,我也尝试了一下,应该也是不行的,
分两步,抓取数据,
网页包括js表单都是明文传输数据的,我一般习惯new一个属性实现。话说这位@郝小渣有点文字游戏,分两步post请求本身不是post,对于javascript是不支持post的。posts是postal,post是posts。不过按照我个人偏见,还是post的那种更难理解。我目前就是用post抓取网页,保存到mongodb里面,然后读取。因为我的数据来源太多,总会遇到恶意代码,难免比较麻烦,不知道有没有相关的参考解决方案。 查看全部
python抓取网页数据(form抓取网页数据抓包(7.20)不难,难在正确分析和js监控)
python抓取网页数据
抓包可以在document.queryselector这个方法中实现。将当前页抓进去然后和上一个页合并,就可以知道上一页的页码了。
我都是用get的方式,
@郝小渣说的有道理,至于抓包可以在document.queryselector中实现。
抓包只是让你发现数据变化没你想的那么难
最近刚看到的教程,
基本的就是get、post、put、head
把你想要的数据发给我,
第一张图是pages,
psweb请求
真正想偷看的话,都不会拿正面图。
一般都是form
get(),post()
get(url,''),post('')
第一张图里的目标网页是第二张图中的目标网页
python爬取的东西有对应的类似于form表单的,可以用jquery(extended),mocha等等。抓包不难,难在正确分析和抓取网页数据。
db和js监控,
这图片貌似不完整啊
postget
请求一个cookie上传
.话说@郝小渣什么时候把图放完啊,不要这么慢啊
session
有人提醒说地址跟爬虫的url不对,get,post的地址应该统一,我也尝试了一下,应该也是不行的,
分两步,抓取数据,
网页包括js表单都是明文传输数据的,我一般习惯new一个属性实现。话说这位@郝小渣有点文字游戏,分两步post请求本身不是post,对于javascript是不支持post的。posts是postal,post是posts。不过按照我个人偏见,还是post的那种更难理解。我目前就是用post抓取网页,保存到mongodb里面,然后读取。因为我的数据来源太多,总会遇到恶意代码,难免比较麻烦,不知道有没有相关的参考解决方案。
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-31 21:06
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:在抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python实现网页动态加载数据爬取的介绍。更多相关Python爬取网页动态数据内容,请搜索前面的面圈教程文章或者继续浏览下面的相关文章,希望大家以后多多支持面圈教程! 查看全部
python抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:在抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python实现网页动态加载数据爬取的介绍。更多相关Python爬取网页动态数据内容,请搜索前面的面圈教程文章或者继续浏览下面的相关文章,希望大家以后多多支持面圈教程!
python抓取网页数据(Python即时网络爬虫项目启动说明(图)动态网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 12:30
开发者供不应求,传统企业如何拥抱DevOps?>>>
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,并在控制台显示结果
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。如果添加方法,则需要采用动态技术。请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史 查看全部
python抓取网页数据(Python即时网络爬虫项目启动说明(图)动态网页内容)
开发者供不应求,传统企业如何拥抱DevOps?>>>
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,并在控制台显示结果
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。如果添加方法,则需要采用动态技术。请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
python抓取网页数据( requests的安装方式.3.1-3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-30 15:02
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br /> <br /> 在Test.py中输入:
import requests</p>
此时,请求会报告一条红线。这时候我们把光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
在网页上以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个URL的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章的标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长什么样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到这里,我想你应该明白了,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录
了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个。所以,其实表达式写成这样,就可以得到所有的文章了。
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有文章的列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见python是用来爬取网页数据的。这真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。顺便说一句,在写这篇博客的时候,我发现了一个很重要的问题:我写的文章太少了!【逃脱】 查看全部
python抓取网页数据(
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br />
<br /> 在Test.py中输入: import requests</p>
此时,请求会报告一条红线。这时候我们把光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
在网页上以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个URL的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章的标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长什么样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到这里,我想你应该明白了,然后我们在最后加上/text表示我们要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录
了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个。所以,其实表达式写成这样,就可以得到所有的文章了。
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有文章的列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见python是用来爬取网页数据的。这真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。顺便说一句,在写这篇博客的时候,我发现了一个很重要的问题:我写的文章太少了!【逃脱】
python抓取网页数据(爬取网页动态加载数据的2个例子分析呗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-28 15:13
数据包捕获和分析。通常,非 HTML 中的数据由网页动态加载。仅当页面刷新或重新请求时才加载数据。一般情况下,这些数据都存储在一个json文件或者xml文件中,下面我简单列举2个抓取网页动态加载数据的例子。有兴趣的可以参考实验环境win10+python3.6+pycharm5.0。主要内容如下:
1.打开这个页面,假设这里要爬取的数据如下,包括年利率、贷款标题、期限、金额、进度五个字段:
2.按F12调出开发者工具,依次点击“网络”->“XHR”,然后按F5刷新页面,可以看到页面的抓包数据,如下,点击进入,可以看到页面加载的Json数据:
3.最后我们可以根据json数据格式编写代码来解析提取我们需要的数据,如下,代码很简单,主要使用json包:
程序截图如下,就是我们需要爬取的数据:
1. 这里假设我们要爬取《气象人》的弹幕数据,如下,看的很多,但也很乱:
2. 第二步,和上面类似,按F12调出开发者工具,F5刷新页面,可以看到抓到的数据,点击文件list.so(xml文件),我们需要爬取数据如下:
我们用浏览器打开这个xml文件,内容如下,很明显我们需要爬取数据:
3.终于可以写代码解析xml数据了。这很简单。主要使用xml包。代码截图如下:
程序截图如下,已经抓取到我们需要的数据:
至此,我们就完成了使用python抓取网页动态加载的数据。总的来说,这两个例子并不难,最重要的是抓包分析,找到网页动态加载的文件信息,然后根据url请求这个页面,然后使用对应的包(json 、xml 包等)进行分析数据就可以了。只要你有一定的基础python爬虫,就可以使用浏览器的基础开发工具,快速掌握爬取的动态数据。当然,如果网页很复杂,有验证码,js加密等,这个就需要自己仔细分析了,或者用其他工具,selenium等,上面也有相关教程互联网供参考。如果你有兴趣,你可以搜索一下。希望以上分享的内容对您有所帮助。 查看全部
python抓取网页数据(爬取网页动态加载数据的2个例子分析呗)
数据包捕获和分析。通常,非 HTML 中的数据由网页动态加载。仅当页面刷新或重新请求时才加载数据。一般情况下,这些数据都存储在一个json文件或者xml文件中,下面我简单列举2个抓取网页动态加载数据的例子。有兴趣的可以参考实验环境win10+python3.6+pycharm5.0。主要内容如下:
1.打开这个页面,假设这里要爬取的数据如下,包括年利率、贷款标题、期限、金额、进度五个字段:
2.按F12调出开发者工具,依次点击“网络”->“XHR”,然后按F5刷新页面,可以看到页面的抓包数据,如下,点击进入,可以看到页面加载的Json数据:
3.最后我们可以根据json数据格式编写代码来解析提取我们需要的数据,如下,代码很简单,主要使用json包:
程序截图如下,就是我们需要爬取的数据:
1. 这里假设我们要爬取《气象人》的弹幕数据,如下,看的很多,但也很乱:
2. 第二步,和上面类似,按F12调出开发者工具,F5刷新页面,可以看到抓到的数据,点击文件list.so(xml文件),我们需要爬取数据如下:
我们用浏览器打开这个xml文件,内容如下,很明显我们需要爬取数据:
3.终于可以写代码解析xml数据了。这很简单。主要使用xml包。代码截图如下:
程序截图如下,已经抓取到我们需要的数据:
至此,我们就完成了使用python抓取网页动态加载的数据。总的来说,这两个例子并不难,最重要的是抓包分析,找到网页动态加载的文件信息,然后根据url请求这个页面,然后使用对应的包(json 、xml 包等)进行分析数据就可以了。只要你有一定的基础python爬虫,就可以使用浏览器的基础开发工具,快速掌握爬取的动态数据。当然,如果网页很复杂,有验证码,js加密等,这个就需要自己仔细分析了,或者用其他工具,selenium等,上面也有相关教程互联网供参考。如果你有兴趣,你可以搜索一下。希望以上分享的内容对您有所帮助。
python抓取网页数据(学习利用Python中的selenium模块启动Chromium学习过程开发工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-28 15:12
一、前言
笔者在上一篇文章中采集
了一些域名。采集
这些域名后,并不是每个域名都有用。我们要过滤掉无法访问的网站。所以今天我们学习使用Python中的selenium模块来启动Chromium来请求网站。, 下面记录下自己的学习过程。
二、学习过程
1.开发工具:
Python版本:3.7.1
相关模块:
selenium模块
pymysql模块
2. 原理介绍
从数据库中读取需要访问的域名------使用selenium访问域名并获取网站标题、内容长度、截图------保存到数据库中
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
# 获取存活的域名
def run(cursor):
# 获取域名
domains = get_domains(cursor)
# Chrome的参数选项
chrome_options = Options()
# 无头操作
chrome_options.add_argument(‘--headless‘)
# 利用这个路径的Chromium来进行操作
chrome_options.binary_location = r‘%s‘%"/Applications/Chromium.app/Contents/MacOS/Chromium"
# 创建Chrome实例
driver = webdriver.Chrome(executable_path=(r‘/Users/hello/Desktop/chromedriver/chromedriver‘), options=chrome_options)
# 设置20秒的超时时间
driver.set_page_load_timeout(20)
success_list = []
for i in domains:
try:
# 请求网站
driver.get(‘https://‘+i[0])
#获取网站的信息
http_length = len(driver.page_source)
http_status = ‘响应成功‘
img_path = "/Users/hello/Desktop/py test/%s.png"%i[0]
screenshot = driver.get_screenshot_as_file(img_path)
if driver.title:
title = driver.title
else:
title = ‘‘
success_list.append([i[0], title, http_length, img_path, http_status])
except :
print(‘%s 响应失败‘%i[0])
return success_list
# 去数据库查询域名
def get_domains(cursor):
sql = "SELECT hostname FROM 数据库"
cursor.execute(sql)
domain_lists = cursor.fetchall()
return domain_lists
# 把可访问的域名插入数据库
def insert(cursor, list, db):
for i in list:
select_sql = "SELECT id FROM 数据库 WHERE hostname = ‘%s‘"%i[0]
cursor.execute(select_sql)
result = cursor.fetchone()
update_sql = "UPDATE 数据库 SET page_title = ‘%s‘, http_length = %d, page_jietu_path = ‘%s‘, http_status= ‘%s‘ WHERE id = %s" %(i[1], i[2], i[3], i[4], result[0])
cursor.execute(update_sql)
db.commit()
if __name__ == "__main__":
db = pymysql.connect(‘localhost‘, ‘账户‘, ‘密码‘, ‘test‘)
cursor = db.cursor()
list = run(cursor)
insert(cursor, list, db)
db.close()
三、效果展示
四、总结
程序速度慢,编写程序的能力有待加强。 查看全部
python抓取网页数据(学习利用Python中的selenium模块启动Chromium学习过程开发工具)
一、前言
笔者在上一篇文章中采集
了一些域名。采集
这些域名后,并不是每个域名都有用。我们要过滤掉无法访问的网站。所以今天我们学习使用Python中的selenium模块来启动Chromium来请求网站。, 下面记录下自己的学习过程。
二、学习过程
1.开发工具:
Python版本:3.7.1
相关模块:
selenium模块
pymysql模块
2. 原理介绍
从数据库中读取需要访问的域名------使用selenium访问域名并获取网站标题、内容长度、截图------保存到数据库中
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
# 获取存活的域名
def run(cursor):
# 获取域名
domains = get_domains(cursor)
# Chrome的参数选项
chrome_options = Options()
# 无头操作
chrome_options.add_argument(‘--headless‘)
# 利用这个路径的Chromium来进行操作
chrome_options.binary_location = r‘%s‘%"/Applications/Chromium.app/Contents/MacOS/Chromium"
# 创建Chrome实例
driver = webdriver.Chrome(executable_path=(r‘/Users/hello/Desktop/chromedriver/chromedriver‘), options=chrome_options)
# 设置20秒的超时时间
driver.set_page_load_timeout(20)
success_list = []
for i in domains:
try:
# 请求网站
driver.get(‘https://‘+i[0])
#获取网站的信息
http_length = len(driver.page_source)
http_status = ‘响应成功‘
img_path = "/Users/hello/Desktop/py test/%s.png"%i[0]
screenshot = driver.get_screenshot_as_file(img_path)
if driver.title:
title = driver.title
else:
title = ‘‘
success_list.append([i[0], title, http_length, img_path, http_status])
except :
print(‘%s 响应失败‘%i[0])
return success_list
# 去数据库查询域名
def get_domains(cursor):
sql = "SELECT hostname FROM 数据库"
cursor.execute(sql)
domain_lists = cursor.fetchall()
return domain_lists
# 把可访问的域名插入数据库
def insert(cursor, list, db):
for i in list:
select_sql = "SELECT id FROM 数据库 WHERE hostname = ‘%s‘"%i[0]
cursor.execute(select_sql)
result = cursor.fetchone()
update_sql = "UPDATE 数据库 SET page_title = ‘%s‘, http_length = %d, page_jietu_path = ‘%s‘, http_status= ‘%s‘ WHERE id = %s" %(i[1], i[2], i[3], i[4], result[0])
cursor.execute(update_sql)
db.commit()
if __name__ == "__main__":
db = pymysql.connect(‘localhost‘, ‘账户‘, ‘密码‘, ‘test‘)
cursor = db.cursor()
list = run(cursor)
insert(cursor, list, db)
db.close()
三、效果展示
四、总结
程序速度慢,编写程序的能力有待加强。
python抓取网页数据(如何利用Python抓取和解析网页(一)_网络技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-26 11:17
网络技术需要大家共享,不能闭门造车。下面是bj-dnsCom的提示: 对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,网页(即HTML文件)经常被用来解析处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常使用网页(即 HTML 文件)的解析和处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。本文将详细介绍如何使用Python来抓取和解析网页。首先,我们引入了一个 Python 模块,它可以帮助简化打开本地和 Web 上的 HTML 文档的过程。然后,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据以处理特定内容,例如链接、图像和 Cookie 等。最后,我们将给出一个正则化 HTML 文件格式标签的示例。通过这个例子,
一、解析网址
借助 Python 自带的 urlparse 模块,我们可以轻松地将 URL 分解为组件,然后将这些组件重新组装成 URL。这个特性在我们处理 HTML 文档时非常方便。
urlparse(urlstring [, default_scheme [, allow_fragments]]) 的作用是将 URL 分解成不同的组件。它从 urlstring 中获取 URL 并返回一个元组(scheme、netloc、path、parameters、query、fragment)。注意返回的元组非常有用,例如可以用来确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。
urlunparse(tuple) 的作用是将 URL 的各个组件组装成一个 URL。接收到元组(scheme、netloc、path、parameters、query、fragment)后,会重新构造一个正确格式的URL,供Python使用其他HTML解析模块使用。
函数 urljoin(base, url [, allow_fragments]) 是拼接 URL。它以第一个参数为基地址,然后与第二个参数中的相对地址组合形成绝对URL地址。函数 urljoin 在通过将新文件名附加到 URL 基地址来处理同一位置的多个文件时特别有用。需要注意的是,如果基地址不以字符/结尾,那么URL基地址最右边的部分会被这个相对路径代替。例如,如果URL的基地址是,而URL的相对地址是test.html,则将两者合并。如果要在路径中保留结束目录,请确保 URL 基地址以字符 / 结尾。
以下是上述函数的一些详细使用示例:
我们的优势:
成立于2004年,服务数万家企业公司本着“服务为本、诚信为本、质量为本”的思想原则,一直为中小企业和写字楼提供全方位的一站式商务服务. 主营业务为北京地区企业。注册、域名注册、虚拟主机、网站建设、企业宣传片制作、网站后台数据库和程序定制等,我们拥有一批年轻精干的团队。我们的口号是“我们的服务让您创业更轻松”。
恒基商务(),作为在INTERNET域名注册、虚拟主机、服务器托管等一系列子业务平台上搭建服务的商务网站,直接与国内外各大服务商合作,推荐最好的为广大客户提供优质的服务和高性能的产品。虚拟主机超市向客户承诺,我们的服务和价格优势是同行业中最好的。域名实时在线注册、虚拟主机、企业邮局自动开通、自助建站系统等国际领先的自主或专有技术,使企业能够在低成本、高效率和强有力的保证,
免费网络营销顾问:我们为您提供免费网络营销咨询服务。您需要了解如何开展网络营销、电子商务、网站设计等,请随时与我们联系。 查看全部
python抓取网页数据(如何利用Python抓取和解析网页(一)_网络技术)
网络技术需要大家共享,不能闭门造车。下面是bj-dnsCom的提示: 对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,网页(即HTML文件)经常被用来解析处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常使用网页(即 HTML 文件)的解析和处理。实际上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。本文将详细介绍如何使用Python来抓取和解析网页。首先,我们引入了一个 Python 模块,它可以帮助简化打开本地和 Web 上的 HTML 文档的过程。然后,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据以处理特定内容,例如链接、图像和 Cookie 等。最后,我们将给出一个正则化 HTML 文件格式标签的示例。通过这个例子,
一、解析网址
借助 Python 自带的 urlparse 模块,我们可以轻松地将 URL 分解为组件,然后将这些组件重新组装成 URL。这个特性在我们处理 HTML 文档时非常方便。
urlparse(urlstring [, default_scheme [, allow_fragments]]) 的作用是将 URL 分解成不同的组件。它从 urlstring 中获取 URL 并返回一个元组(scheme、netloc、path、parameters、query、fragment)。注意返回的元组非常有用,例如可以用来确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。
urlunparse(tuple) 的作用是将 URL 的各个组件组装成一个 URL。接收到元组(scheme、netloc、path、parameters、query、fragment)后,会重新构造一个正确格式的URL,供Python使用其他HTML解析模块使用。
函数 urljoin(base, url [, allow_fragments]) 是拼接 URL。它以第一个参数为基地址,然后与第二个参数中的相对地址组合形成绝对URL地址。函数 urljoin 在通过将新文件名附加到 URL 基地址来处理同一位置的多个文件时特别有用。需要注意的是,如果基地址不以字符/结尾,那么URL基地址最右边的部分会被这个相对路径代替。例如,如果URL的基地址是,而URL的相对地址是test.html,则将两者合并。如果要在路径中保留结束目录,请确保 URL 基地址以字符 / 结尾。
以下是上述函数的一些详细使用示例:
我们的优势:
成立于2004年,服务数万家企业公司本着“服务为本、诚信为本、质量为本”的思想原则,一直为中小企业和写字楼提供全方位的一站式商务服务. 主营业务为北京地区企业。注册、域名注册、虚拟主机、网站建设、企业宣传片制作、网站后台数据库和程序定制等,我们拥有一批年轻精干的团队。我们的口号是“我们的服务让您创业更轻松”。
恒基商务(),作为在INTERNET域名注册、虚拟主机、服务器托管等一系列子业务平台上搭建服务的商务网站,直接与国内外各大服务商合作,推荐最好的为广大客户提供优质的服务和高性能的产品。虚拟主机超市向客户承诺,我们的服务和价格优势是同行业中最好的。域名实时在线注册、虚拟主机、企业邮局自动开通、自助建站系统等国际领先的自主或专有技术,使企业能够在低成本、高效率和强有力的保证,
免费网络营销顾问:我们为您提供免费网络营销咨询服务。您需要了解如何开展网络营销、电子商务、网站设计等,请随时与我们联系。
python抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-25 15:28
从各种搜索引擎到日常数据采集,网络爬虫都不可或缺。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取整个网站的内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们的爬虫的爬取功能。 查看全部
python抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
从各种搜索引擎到日常数据采集,网络爬虫都不可或缺。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取整个网站的内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们的爬虫的爬取功能。

