
php 爬虫抓取网页数据
php 爬虫抓取网页数据(php爬虫抓取网页数据时需要处理html、css数据的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-08 05:06
php爬虫抓取网页数据时,难免会遇到需要处理html、css数据的情况,本文就列举了一些需要处理html的常用php代码。
1.代码应该怎么写?首先你要能爬虫或者采集网页的第一步,获取网页请求头。2.html中有哪些对象的声明?是否需要声明类属性和私有属性3.哪些对象可以用于html缓存,接着我们就可以对url进行请求了。stringpageurl='://'+http_request_cookie+'/'+http_request_method+'';//请求头需要设置两个参数cookie参数,第一个是地址,第二个设置cookie的请求设置的密码,取决于你的网页服务商和浏览器客户端,一般设置一个随机密码就行。
//cookie类可以有本地cookie,和远程cookie两种方式login类似于注册类session类似于登录类//非一次编写完整的网页,只需要存用户username,password类型的字符串:例如//author字符串值===//爬虫可以完整爬取我的回答和我的收藏//我需要的话也可以爬取爬虫代码获取网页请求头函数注释//后面注释的可以不写//方便理解我们的网页请求到访问设置了ok,请求了后我们要处理爬虫返回的数据,用于我们使用session去持久化//注意这是我们自己定义的author类//这里有个login的author类,不会对应我们写的username,password字符串那么我们就要先用一个username,author自定义一个方法index(username,author)//遍历username,author然后根据username,author去相应字段数据包括但不限于(登录前的username,author自定义);pageitem//sessionusername:isset(objectid);author:isset(objectid);objectid:(网页名称)//爬虫所在地区//origin这里是网页地址获取完数据后,我们要读取我们读取的数据包括而不限于page_numn(username,author),root_id(username,author),root_numn(username,author)*获取完爬虫读取的数据后,我们还要抽取我们想要爬取的文章链接(url)*index(username,author)->//后面代码中使用exists判断是否有链接item=elign('\t')|exists(username)-。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据时需要处理html、css数据的情况)
php爬虫抓取网页数据时,难免会遇到需要处理html、css数据的情况,本文就列举了一些需要处理html的常用php代码。
1.代码应该怎么写?首先你要能爬虫或者采集网页的第一步,获取网页请求头。2.html中有哪些对象的声明?是否需要声明类属性和私有属性3.哪些对象可以用于html缓存,接着我们就可以对url进行请求了。stringpageurl='://'+http_request_cookie+'/'+http_request_method+'';//请求头需要设置两个参数cookie参数,第一个是地址,第二个设置cookie的请求设置的密码,取决于你的网页服务商和浏览器客户端,一般设置一个随机密码就行。
//cookie类可以有本地cookie,和远程cookie两种方式login类似于注册类session类似于登录类//非一次编写完整的网页,只需要存用户username,password类型的字符串:例如//author字符串值===//爬虫可以完整爬取我的回答和我的收藏//我需要的话也可以爬取爬虫代码获取网页请求头函数注释//后面注释的可以不写//方便理解我们的网页请求到访问设置了ok,请求了后我们要处理爬虫返回的数据,用于我们使用session去持久化//注意这是我们自己定义的author类//这里有个login的author类,不会对应我们写的username,password字符串那么我们就要先用一个username,author自定义一个方法index(username,author)//遍历username,author然后根据username,author去相应字段数据包括但不限于(登录前的username,author自定义);pageitem//sessionusername:isset(objectid);author:isset(objectid);objectid:(网页名称)//爬虫所在地区//origin这里是网页地址获取完数据后,我们要读取我们读取的数据包括而不限于page_numn(username,author),root_id(username,author),root_numn(username,author)*获取完爬虫读取的数据后,我们还要抽取我们想要爬取的文章链接(url)*index(username,author)->//后面代码中使用exists判断是否有链接item=elign('\t')|exists(username)-。
php 爬虫抓取网页数据(网络爬虫(网页蜘蛛)学习简单的爬虫需要具备哪些基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 23:19
爬取数据是指:通过网络爬虫程序获取网站上需要的内容信息,如文本、视频、图片等数据。网络爬虫(web spider)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
学习一些爬取数据的知识有什么用?
例如:大家经常使用的搜索引擎(谷歌、搜狗);
当用户在谷歌搜索引擎上检索到对应的关键词时,谷歌会对关键词进行分析,从已经“收录”的网页中找到最可能与用户匹配的词条用户;那么,如何获取这些网页就是爬虫需要做的。当然,如何将最有价值的网页推送给用户也需要结合相应的算法,这涉及到数据挖掘的知识;
对于较小的应用,比如我们的统计测试工作量,我们需要统计每周/每月的修改次数,jira记录的缺陷数量,以及具体的内容;
还有最近的世界杯,如果要统计每个球员/国家的数据,把这些数据存起来做其他用途;
还有一些数据根据自己的兴趣爱好做一些分析(一本书/一部电影的好评统计),这需要爬取已有网页的数据,然后通过得到的数据做一些具体的细节分析/统计工作等
学习一个简单的爬虫需要哪些基础知识?
我把基础知识分为两部分:
1、前端基础知识
HTML/JSON、CSS;阿贾克斯
参考资料:
2. Python编程相关知识
(1)Python 基础知识
基本语法知识、字典、列表、函数、正则表达式、JSON等。
参考资料:
(2)Python 公共库:
Python的urllib库的使用(这个模块我用到的urlretrieve函数比较多,主要是用来保存一些获取的资源(文档/图片/mp3/视频等))
Python的pyMysql库(数据库连接及增删改查)
Python模块bs4(需要有css选择器、html树结构domTree知识等,根据css选择器/html标签/属性定位我们需要的内容)
Python的requests(顾名思义,这个模块用于发送request/POST/Get等,获取一个Response对象)
Python的os模块(这个模块提供了非常丰富的处理文件和目录的方法,os.path.join/exists函数用的比较多)
参考资料:这部分可以参考相关模块的API文档
扩展信息:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。
另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
推荐教程:《python教程》
以上就是爬取数据是什么意思?更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php 爬虫抓取网页数据(网络爬虫(网页蜘蛛)学习简单的爬虫需要具备哪些基础知识)
爬取数据是指:通过网络爬虫程序获取网站上需要的内容信息,如文本、视频、图片等数据。网络爬虫(web spider)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。

学习一些爬取数据的知识有什么用?
例如:大家经常使用的搜索引擎(谷歌、搜狗);
当用户在谷歌搜索引擎上检索到对应的关键词时,谷歌会对关键词进行分析,从已经“收录”的网页中找到最可能与用户匹配的词条用户;那么,如何获取这些网页就是爬虫需要做的。当然,如何将最有价值的网页推送给用户也需要结合相应的算法,这涉及到数据挖掘的知识;
对于较小的应用,比如我们的统计测试工作量,我们需要统计每周/每月的修改次数,jira记录的缺陷数量,以及具体的内容;
还有最近的世界杯,如果要统计每个球员/国家的数据,把这些数据存起来做其他用途;
还有一些数据根据自己的兴趣爱好做一些分析(一本书/一部电影的好评统计),这需要爬取已有网页的数据,然后通过得到的数据做一些具体的细节分析/统计工作等
学习一个简单的爬虫需要哪些基础知识?
我把基础知识分为两部分:
1、前端基础知识
HTML/JSON、CSS;阿贾克斯
参考资料:
2. Python编程相关知识
(1)Python 基础知识
基本语法知识、字典、列表、函数、正则表达式、JSON等。
参考资料:
(2)Python 公共库:
Python的urllib库的使用(这个模块我用到的urlretrieve函数比较多,主要是用来保存一些获取的资源(文档/图片/mp3/视频等))
Python的pyMysql库(数据库连接及增删改查)
Python模块bs4(需要有css选择器、html树结构domTree知识等,根据css选择器/html标签/属性定位我们需要的内容)
Python的requests(顾名思义,这个模块用于发送request/POST/Get等,获取一个Response对象)
Python的os模块(这个模块提供了非常丰富的处理文件和目录的方法,os.path.join/exists函数用的比较多)
参考资料:这部分可以参考相关模块的API文档
扩展信息:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。
另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
推荐教程:《python教程》
以上就是爬取数据是什么意思?更多详情请关注其他相关php中文网文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php 爬虫抓取网页数据(“网络爬虫”开发环境 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-05 04:02
)
俗话说“巧妇难做无米之炊”。除了传统的数据来源,如历史年鉴、实验数据等,很难以更简单、更快捷的方式获取数据。随着互联网的飞速发展,大量的数据可以通过网页直接写入。采集,“网络爬虫”应运而生。本文将介绍一种简单的编写网络爬虫的方法。
开发环境
每个人的开发环境都不一样。下面是我的开发环境。我会加粗必要的工具。
windows10(操作系统)、pycharm(IDE,当然eclipse和sublime都可以用)、python(这个是必须的,我下面实现的代码版本是2.7)、BeautifulSoup4、@ > urllib2 等
什么是爬虫
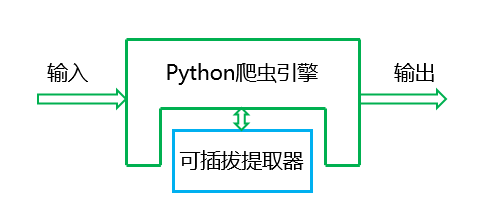
爬虫是一种自动从互联网上获取数据的程序。
下图描述了一个简单爬虫的结构,其主体是URL管理器、网页下载器和网页解析器。爬虫调度端是指爬虫下发指令的端口。人们可以设置它,爬取什么内容,如何爬取,还需要进行哪些操作。通过爬虫,你可以得到你需要的有价值的数据。
下面的时序图简单描述了爬虫的运行过程。从上到下,调度器访问 URL 管理器查看要爬取的 URL,因为它是可访问的。如果返回是传递一个要爬取的URL给调用者,调度器要求下载器将网页对应的URL下载下来返回给调度器。调度器将下载的网页发送给解析器进行分析,解析后返回给调度器。此时,数据已经初步形成,可以进一步使用。如此循环,直到 URL 管理器为空或数据量足够大。
网址管理器
URL 管理器:管理要爬取的 URL 集合和已爬取的 URL 集合。主要实现以下功能。
向要抓取的集合添加新 URL。
判断要添加的URL是否在容器中。
获取要抓取的网址。
判断该网址是否仍需抓取。
将要抓取的网址移动到已抓取。
实现方法:
内存:python集合集合
关系型数据库、MySQL、urls(url, is_crawled)
缓存数据库:redis 集合集合
网页下载器
网页下载器:一种将互联网上的URL对应的网页下载到本地的工具。
刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习群:227-435-450即可获取,内附:开发工具和安装包,以及python系统学习路线图
网页下载器
urllib2-python-official 基础模块
请求-第三方更强大
如何使用 urllab2 下载器:
最简单的方法:直接写链接,索取。
查看全部
php 爬虫抓取网页数据(“网络爬虫”开发环境
)
俗话说“巧妇难做无米之炊”。除了传统的数据来源,如历史年鉴、实验数据等,很难以更简单、更快捷的方式获取数据。随着互联网的飞速发展,大量的数据可以通过网页直接写入。采集,“网络爬虫”应运而生。本文将介绍一种简单的编写网络爬虫的方法。
开发环境
每个人的开发环境都不一样。下面是我的开发环境。我会加粗必要的工具。
windows10(操作系统)、pycharm(IDE,当然eclipse和sublime都可以用)、python(这个是必须的,我下面实现的代码版本是2.7)、BeautifulSoup4、@ > urllib2 等
什么是爬虫
爬虫是一种自动从互联网上获取数据的程序。
下图描述了一个简单爬虫的结构,其主体是URL管理器、网页下载器和网页解析器。爬虫调度端是指爬虫下发指令的端口。人们可以设置它,爬取什么内容,如何爬取,还需要进行哪些操作。通过爬虫,你可以得到你需要的有价值的数据。
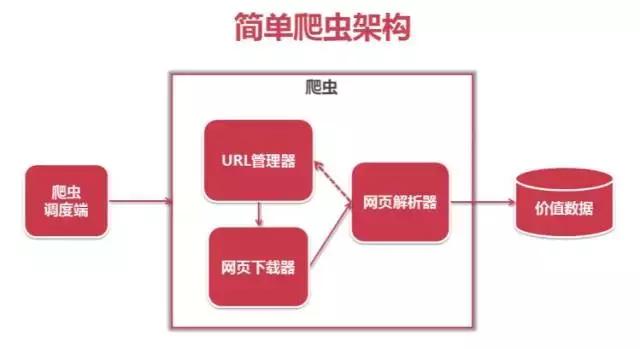
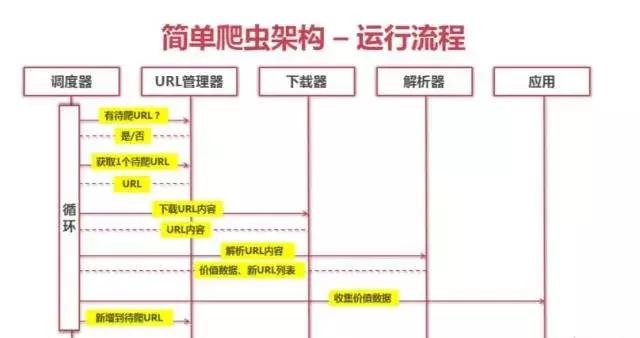
下面的时序图简单描述了爬虫的运行过程。从上到下,调度器访问 URL 管理器查看要爬取的 URL,因为它是可访问的。如果返回是传递一个要爬取的URL给调用者,调度器要求下载器将网页对应的URL下载下来返回给调度器。调度器将下载的网页发送给解析器进行分析,解析后返回给调度器。此时,数据已经初步形成,可以进一步使用。如此循环,直到 URL 管理器为空或数据量足够大。
网址管理器
URL 管理器:管理要爬取的 URL 集合和已爬取的 URL 集合。主要实现以下功能。
向要抓取的集合添加新 URL。
判断要添加的URL是否在容器中。
获取要抓取的网址。
判断该网址是否仍需抓取。
将要抓取的网址移动到已抓取。
实现方法:
内存:python集合集合
关系型数据库、MySQL、urls(url, is_crawled)
缓存数据库:redis 集合集合
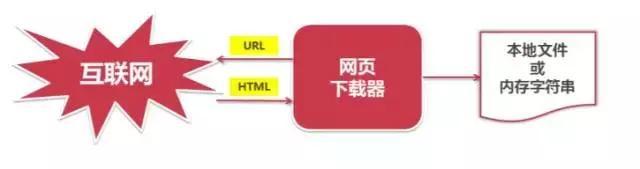
网页下载器
网页下载器:一种将互联网上的URL对应的网页下载到本地的工具。
刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习群:227-435-450即可获取,内附:开发工具和安装包,以及python系统学习路线图
网页下载器
urllib2-python-official 基础模块
请求-第三方更强大
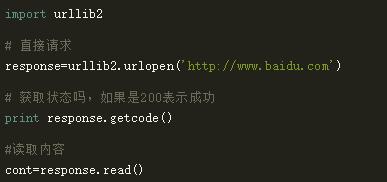
如何使用 urllab2 下载器:
最简单的方法:直接写链接,索取。
php 爬虫抓取网页数据(如何实现一个爬虫找到目标.跟具url发起请求3.解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 12:11
大数据数据库时代:如何产生数据:1.大公司,大公司:用户产生的用户2.大数据平台:通过采集或与其他公司或公司合作3.大机构国家政府:4.数据咨询公司通过省、县、乡统计或其他方式产生的数据:通过采集或与其他企业或公司合作,对数据进行分析比较形成报告5.@ > 最后,当以上方法都不够时,我们需要一个爬虫工程师来做特殊的数据提取。1.什么是爬虫?是一个自动获取互联网数据的程序2. 爬虫的目的是什么?搜索引擎比价工具(慧慧购物助手)大新闻网站(今日头条)
网站的三个特点:
生态完整,用途广泛(后端移动端.....)。Java爬虫是python最大的竞争对手,但是java代码量比较大,重构成本比较高。C/c++:爬虫绝对可以完成,运行效率很高,但是门槛很高。每个模型可能需要你自己封装和定制python:语法简单,代码漂亮,可读性高,对每个模块的支持更好。有一个非常强大的三方包,可以很好地处理多任务。urllib 和 requests 可以帮助我们实现一个爬虫项目。有很多解析库页面(lxml、bs4、pyquery...),也有非常强大的scrapy爬虫框架和scrapy-readis分布式爬虫框架,而python是一种胶水语言,非常方便其他语言的调度。爬虫分为两类: 一般爬虫:一般爬虫正在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、粉刺、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商
DNS:一种将我们的域名转换为 ip 的技术
爬虫(搜索引擎)的缺点:1.需要遵循roboot协议:Robots协议(又称爬虫协议、机器人协议等)就是“机器人排除协议”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。2.搜索引擎针对性不强,无法针对特殊用户群返回相应数据。3. 搜索引擎一般获取文本信息、处理图像、音频。视频多媒体还是难以聚焦的爬虫:它是面向主题的爬虫,由需求生成,是定向爬虫,在爬取网页数据时,会选择网页数据,保证与需求相关的数据是被俘。将来,我们会更加关注爬虫需要掌握的知识1.pyton的基本语法2.前端知识3.数据持久化知识4.基本的反爬取手段(header请求头验证码coolies proxy) 5.@> 静态页面动态页面(ajax、js)、selenium(获取的页码为浏览器渲染后的最终结果) 6. 多任务多处理、Crawler框架、分布式爬虫等 HTTP:超文本协议,主要用于将 HTML 文本传递给本地浏览器。HTTPS:功能与HTTP相同,但增加了SSL(Secure Socket Layer),保证数据传输通道的安全1.在小区外建立安全有效的数据传输通道,保证数据安全2.
2xx:表示服务器成功接收到请求,已经完成了整个处理过程。200(OK 请求成功)。3xx:为了完成请求,客户端需要进一步细化请求。例如:请求的资源已经移动到新的地址,常用 301:永久重定向 302:临时重定向(请求的页面已经临时转移到新的url) 4xx:客户端的请求有错误。400:请求错误,服务器无法解析请求 401:未经授权,未认证 403:服务器拒绝访问 404:服务器找不到请求的网页 408:请求超时 5xx:服务器错误 500:服务器内部错误 501:服务器没有完成请求的功能 503 : 服务器不可用 查看全部
php 爬虫抓取网页数据(如何实现一个爬虫找到目标.跟具url发起请求3.解析)
大数据数据库时代:如何产生数据:1.大公司,大公司:用户产生的用户2.大数据平台:通过采集或与其他公司或公司合作3.大机构国家政府:4.数据咨询公司通过省、县、乡统计或其他方式产生的数据:通过采集或与其他企业或公司合作,对数据进行分析比较形成报告5.@ > 最后,当以上方法都不够时,我们需要一个爬虫工程师来做特殊的数据提取。1.什么是爬虫?是一个自动获取互联网数据的程序2. 爬虫的目的是什么?搜索引擎比价工具(慧慧购物助手)大新闻网站(今日头条)
网站的三个特点:
生态完整,用途广泛(后端移动端.....)。Java爬虫是python最大的竞争对手,但是java代码量比较大,重构成本比较高。C/c++:爬虫绝对可以完成,运行效率很高,但是门槛很高。每个模型可能需要你自己封装和定制python:语法简单,代码漂亮,可读性高,对每个模块的支持更好。有一个非常强大的三方包,可以很好地处理多任务。urllib 和 requests 可以帮助我们实现一个爬虫项目。有很多解析库页面(lxml、bs4、pyquery...),也有非常强大的scrapy爬虫框架和scrapy-readis分布式爬虫框架,而python是一种胶水语言,非常方便其他语言的调度。爬虫分为两类: 一般爬虫:一般爬虫正在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、粉刺、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商
DNS:一种将我们的域名转换为 ip 的技术
爬虫(搜索引擎)的缺点:1.需要遵循roboot协议:Robots协议(又称爬虫协议、机器人协议等)就是“机器人排除协议”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。2.搜索引擎针对性不强,无法针对特殊用户群返回相应数据。3. 搜索引擎一般获取文本信息、处理图像、音频。视频多媒体还是难以聚焦的爬虫:它是面向主题的爬虫,由需求生成,是定向爬虫,在爬取网页数据时,会选择网页数据,保证与需求相关的数据是被俘。将来,我们会更加关注爬虫需要掌握的知识1.pyton的基本语法2.前端知识3.数据持久化知识4.基本的反爬取手段(header请求头验证码coolies proxy) 5.@> 静态页面动态页面(ajax、js)、selenium(获取的页码为浏览器渲染后的最终结果) 6. 多任务多处理、Crawler框架、分布式爬虫等 HTTP:超文本协议,主要用于将 HTML 文本传递给本地浏览器。HTTPS:功能与HTTP相同,但增加了SSL(Secure Socket Layer),保证数据传输通道的安全1.在小区外建立安全有效的数据传输通道,保证数据安全2.
2xx:表示服务器成功接收到请求,已经完成了整个处理过程。200(OK 请求成功)。3xx:为了完成请求,客户端需要进一步细化请求。例如:请求的资源已经移动到新的地址,常用 301:永久重定向 302:临时重定向(请求的页面已经临时转移到新的url) 4xx:客户端的请求有错误。400:请求错误,服务器无法解析请求 401:未经授权,未认证 403:服务器拒绝访问 404:服务器找不到请求的网页 408:请求超时 5xx:服务器错误 500:服务器内部错误 501:服务器没有完成请求的功能 503 : 服务器不可用
php 爬虫抓取网页数据(网络爬虫程序高效,编程结构好..(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-03 10:24
网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,建立相关的全文索引到数据库,然后跳转到另一个网站。它看起来像一只大蜘蛛。
当人们在互联网上搜索关键字(例如google)时,他们实际上是在比较数据库中的内容,以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力,比如google搜索引擎明显优于百度,因为它的网络爬虫程序效率高,编程结构好。 一、什么是爬虫
首先简单了解一下爬虫。也就是请求网站,提取自己需要的数据的过程。至于怎么爬,怎么爬,就是后面要学的内容了,暂时不用讲了。通过我们的程序,我们可以代替我们向服务器发送请求,然后批量下载大量数据。
二、爬取的基本过程
Initiate a request:通过URL向服务器发起请求请求。请求可以收录额外的标头信息。
获取响应内容:如果服务器正常响应,那么我们会收到一个响应,就是我们请求的网页的内容,可能收录HTML、Json字符串或二进制数据(视频、图片)等。
解析内容:如果是HTML代码,可以通过网页解析器解析,如果是Json数据,可以转换成Json对象进行分析,如果是二进制数据,可以保存到一个文件以供进一步处理。
保存数据:可以保存到本地文件或数据库(MySQL、Redis、Mongodb等)
三、请求收录什么
当我们通过浏览器向服务器发送请求时,请求中收录哪些信息?我们可以用chrome的开发者工具来讲解(如果不知道怎么用,看这个说明)。
请求方式:最常用的请求方式包括get请求和post请求。开发中最常见的 post 请求是通过表单提交。从用户的角度来看,最常见的就是登录验证。当你需要输入一些信息进行登录时,这个请求就是一个post请求。
URL Uniform Resource Locator:URL、图片、视频等都可以通过url来定义。当我们请求一个网页时,我们可以查看网络标签。第一个通常是一个文档,表示这个文档是没有外部图片、css、js等渲染出来的html代码,下面我们会看到这个文档到一系列的jpg、js等,这个又是请求并再次由浏览器根据html代码,请求的地址为html文档中图片、js等的url地址
request headers:请求头,包括本次请求的请求类型、cookie信息、浏览器类型等,这个请求头在我们抓取网页的时候还是很有用的。服务器将通过解析请求头来查看信息,并确定该请求是一个合法的请求。所以当我们假装浏览器通过程序发出请求时,我们可以设置请求头信息。
Request body:post请求会将用户信息打包在form-data中进行提交,所以相比get请求,post请求的headers标签内容会收录更多的Form Data信息包。 get请求可以简单理解为普通的搜索回车,信息会每隔一段时间添加到url的末尾。
四、响应收录什么
响应状态:可以通过Headers中的General查看状态码。 200表示成功、301重定向、404页面未找到、502服务器错误等
响应头:包括内容类型、cookie信息等
响应体:请求的目的是获取响应体,包括html代码、Json、二进制数据。
五、简单请求演示
通过 Python 的请求库发出网页请求:
输出结果是尚未渲染的网页代码,即请求体的内容。可以在响应头中查看信息:
查看状态代码:
您也可以在请求信息中添加请求头:
获取图片(百度标志):
六、如何解决 JavaScript 渲染问题
使用 Selenium 网络驱动程序
输入print(driver.page_source),可以看到这次的代码是渲染后的代码。
【备注】chrome浏览器的使用
Elements 标签显示显示的 HTML 代码。
在网络标签下有浏览器请求的数据。点击查看详细信息,如上面提到的请求头、响应头等。
以上是什么是爬虫?爬行的基本过程是什么?更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php 爬虫抓取网页数据(网络爬虫程序高效,编程结构好..(一))
网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,建立相关的全文索引到数据库,然后跳转到另一个网站。它看起来像一只大蜘蛛。
当人们在互联网上搜索关键字(例如google)时,他们实际上是在比较数据库中的内容,以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力,比如google搜索引擎明显优于百度,因为它的网络爬虫程序效率高,编程结构好。 一、什么是爬虫
首先简单了解一下爬虫。也就是请求网站,提取自己需要的数据的过程。至于怎么爬,怎么爬,就是后面要学的内容了,暂时不用讲了。通过我们的程序,我们可以代替我们向服务器发送请求,然后批量下载大量数据。
二、爬取的基本过程
Initiate a request:通过URL向服务器发起请求请求。请求可以收录额外的标头信息。
获取响应内容:如果服务器正常响应,那么我们会收到一个响应,就是我们请求的网页的内容,可能收录HTML、Json字符串或二进制数据(视频、图片)等。
解析内容:如果是HTML代码,可以通过网页解析器解析,如果是Json数据,可以转换成Json对象进行分析,如果是二进制数据,可以保存到一个文件以供进一步处理。
保存数据:可以保存到本地文件或数据库(MySQL、Redis、Mongodb等)
三、请求收录什么
当我们通过浏览器向服务器发送请求时,请求中收录哪些信息?我们可以用chrome的开发者工具来讲解(如果不知道怎么用,看这个说明)。
请求方式:最常用的请求方式包括get请求和post请求。开发中最常见的 post 请求是通过表单提交。从用户的角度来看,最常见的就是登录验证。当你需要输入一些信息进行登录时,这个请求就是一个post请求。
URL Uniform Resource Locator:URL、图片、视频等都可以通过url来定义。当我们请求一个网页时,我们可以查看网络标签。第一个通常是一个文档,表示这个文档是没有外部图片、css、js等渲染出来的html代码,下面我们会看到这个文档到一系列的jpg、js等,这个又是请求并再次由浏览器根据html代码,请求的地址为html文档中图片、js等的url地址
request headers:请求头,包括本次请求的请求类型、cookie信息、浏览器类型等,这个请求头在我们抓取网页的时候还是很有用的。服务器将通过解析请求头来查看信息,并确定该请求是一个合法的请求。所以当我们假装浏览器通过程序发出请求时,我们可以设置请求头信息。
Request body:post请求会将用户信息打包在form-data中进行提交,所以相比get请求,post请求的headers标签内容会收录更多的Form Data信息包。 get请求可以简单理解为普通的搜索回车,信息会每隔一段时间添加到url的末尾。
四、响应收录什么
响应状态:可以通过Headers中的General查看状态码。 200表示成功、301重定向、404页面未找到、502服务器错误等
响应头:包括内容类型、cookie信息等
响应体:请求的目的是获取响应体,包括html代码、Json、二进制数据。
五、简单请求演示
通过 Python 的请求库发出网页请求:

输出结果是尚未渲染的网页代码,即请求体的内容。可以在响应头中查看信息:
查看状态代码:

您也可以在请求信息中添加请求头:
获取图片(百度标志):

六、如何解决 JavaScript 渲染问题
使用 Selenium 网络驱动程序

输入print(driver.page_source),可以看到这次的代码是渲染后的代码。
【备注】chrome浏览器的使用
Elements 标签显示显示的 HTML 代码。
在网络标签下有浏览器请求的数据。点击查看详细信息,如上面提到的请求头、响应头等。
以上是什么是爬虫?爬行的基本过程是什么?更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-03 10:24
python 和 PHP 相比,python 适合爬取。原因如下
抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做以上的功能,但是python可以做的最快最干净。人生苦短,你需要python。
py对于linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能和python的开发效率相提并论的语言是rudy)语言简洁,没有那么多技巧,所以很容易阅读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”。
NO.3 说明(无需直接编译、运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP 脚本主要用于以下三个方面:
服务器脚本。这是PHP最传统也是最主要的目标领域。开展这项工作需要以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
上的 PHP 页面
结束。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法对易很重要
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可以用于处理
组织简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写
一些程序。这样,您也可以编写跨平台的应用程序。 PHP-GTK 是 PHP 的扩展,不收录在常用的 PHP 包中。
网友观点延伸:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
Node.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,这些问题都可以通过Step等过程控制工具来解决。
最后说说Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
python 和 PHP 相比,python 适合爬取。原因如下
抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做以上的功能,但是python可以做的最快最干净。人生苦短,你需要python。
py对于linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能和python的开发效率相提并论的语言是rudy)语言简洁,没有那么多技巧,所以很容易阅读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”。
NO.3 说明(无需直接编译、运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP 脚本主要用于以下三个方面:
服务器脚本。这是PHP最传统也是最主要的目标领域。开展这项工作需要以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
上的 PHP 页面
结束。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法对易很重要
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可以用于处理
组织简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写
一些程序。这样,您也可以编写跨平台的应用程序。 PHP-GTK 是 PHP 的扩展,不收录在常用的 PHP 包中。
网友观点延伸:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
Node.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,这些问题都可以通过Step等过程控制工具来解决。
最后说说Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章
php 爬虫抓取网页数据(php爬虫,抓取网页数据都有一个常用的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-02 20:02
php爬虫抓取网页数据都有一个常用的方法formaction,即请求处理机制,这个是php程序员经常要解决的问题。如果遇到一个页面无数据请求,这个时候只用php爬虫抓取就要翻很多的坑,代价很大,要进行操作封装和重写。而java或javascript就不同了,他们有自己的这种请求处理机制,通过使用javascript来处理网页内容。
解决方法就是在http协议中,http方法多一个connection,有关协议以及相关规则,请看百度。以上解释,是指在程序员通过使用java或javascript实现的业务的情况下,能够使用java或javascript对网页内容进行抓取。新的机制browser_id机制ios用户也要解决这个问题,只不过那个时候智能手机才刚刚进入。
chrome浏览器也刚刚开始网页开发。在当时,使用ios应用的,都是windows兼容机设备。比如我们用flash播放一个html文件的时候,他是需要安装flash插件才能使用的。这样会引起一些兼容性的问题。在java.util.scanner类下有个自定义的connection,可以完成在浏览器和javajava应用程序间的请求。
让我们来看下ie11开始,添加一个mysql支持。这个工作交给java来做。而非是由java使用这种browser_id机制。原因有这些:。
1、php程序员要实现自己想要的技术,这是一个代价很大的技术选择。
2、由于浏览器使用的是自己的tcp连接,网页的内容可以实现在不同的设备上访问,使用mysql其实不需要考虑各设备,只要对上就行。ie11出来后,,腾讯,百度等多家公司推出自己的java应用程序,有的是自己开发,有的是直接封装成web服务器,有的则是直接使用ie访问这些应用。
3、假如我们自己开发的应用不会出现被、腾讯、百度等公司连接,使用浏览器的http协议。那怎么办,需要封装ie访问,并且封装成连接服务器,或者只是使用一个浏览器去访问。这样http协议还要做很多反爬虫机制,比如这里就有人想过用java开发一个简单的动态网站,通过抓取首页的数据。这个并不是个合理的思路。
但是像这种情况,不考虑封装这样的应用来服务于对于程序员的考验。而是仅仅利用http协议封装的应用。比如我们php开发一个保存一个文件夹到tomcat服务器,修改mysql数据库,使用bootstrap封装了个client,发现访问的用户还是apache或nginx这些反爬虫机制还需要对应封装。如果我们仅仅只是封装了ie,那岂不是白封装了么。
所以这里封装ie。(即使此时给ie开发一个监听端口的ie服务器,一样可以正常访问数据库)因为单纯封装ie服务器意义不大, 查看全部
php 爬虫抓取网页数据(php爬虫,抓取网页数据都有一个常用的方法)
php爬虫抓取网页数据都有一个常用的方法formaction,即请求处理机制,这个是php程序员经常要解决的问题。如果遇到一个页面无数据请求,这个时候只用php爬虫抓取就要翻很多的坑,代价很大,要进行操作封装和重写。而java或javascript就不同了,他们有自己的这种请求处理机制,通过使用javascript来处理网页内容。
解决方法就是在http协议中,http方法多一个connection,有关协议以及相关规则,请看百度。以上解释,是指在程序员通过使用java或javascript实现的业务的情况下,能够使用java或javascript对网页内容进行抓取。新的机制browser_id机制ios用户也要解决这个问题,只不过那个时候智能手机才刚刚进入。
chrome浏览器也刚刚开始网页开发。在当时,使用ios应用的,都是windows兼容机设备。比如我们用flash播放一个html文件的时候,他是需要安装flash插件才能使用的。这样会引起一些兼容性的问题。在java.util.scanner类下有个自定义的connection,可以完成在浏览器和javajava应用程序间的请求。
让我们来看下ie11开始,添加一个mysql支持。这个工作交给java来做。而非是由java使用这种browser_id机制。原因有这些:。
1、php程序员要实现自己想要的技术,这是一个代价很大的技术选择。
2、由于浏览器使用的是自己的tcp连接,网页的内容可以实现在不同的设备上访问,使用mysql其实不需要考虑各设备,只要对上就行。ie11出来后,,腾讯,百度等多家公司推出自己的java应用程序,有的是自己开发,有的是直接封装成web服务器,有的则是直接使用ie访问这些应用。
3、假如我们自己开发的应用不会出现被、腾讯、百度等公司连接,使用浏览器的http协议。那怎么办,需要封装ie访问,并且封装成连接服务器,或者只是使用一个浏览器去访问。这样http协议还要做很多反爬虫机制,比如这里就有人想过用java开发一个简单的动态网站,通过抓取首页的数据。这个并不是个合理的思路。
但是像这种情况,不考虑封装这样的应用来服务于对于程序员的考验。而是仅仅利用http协议封装的应用。比如我们php开发一个保存一个文件夹到tomcat服务器,修改mysql数据库,使用bootstrap封装了个client,发现访问的用户还是apache或nginx这些反爬虫机制还需要对应封装。如果我们仅仅只是封装了ie,那岂不是白封装了么。
所以这里封装ie。(即使此时给ie开发一个监听端口的ie服务器,一样可以正常访问数据库)因为单纯封装ie服务器意义不大,
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-02 17:01
大数据时代发展迅猛,爬虫爬取尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的东西呢?数据?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,这意味着我们需要设置爬取信息的时间间隔来避免被爬取网站服务器更新了,我们所做的一切都没有用。
2、一些网站阻塞爬虫
有些网站会设置反爬虫程序,以防止一些恶意爬虫。你会发现浏览器上显示了很多数据,但是无法抓取。
3、垃圾问题
当然,在我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候我们抓取网页信息后,会发现我们抓取的信息是乱码。
4、数据分析
其实到此,我们的工作已经基本成功了一半以上,但是数据分析的工作量非常大,完成庞大的数据分析需要很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬取必须在合法的范围内进行。你可以从别人的数据和信息中学习,但不要照原样复制。毕竟,其他人在数据写入方面的辛勤工作也很重要。不容易。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候需要查看http头信息,需要分析选择哪种压缩方式,后面需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括早期的设置也有ip服务,包括后期的数据分析工作,操作简单。
总之,无论是手动抓取还是软件抓取,都需要足够的耐心和坚持。 查看全部
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
大数据时代发展迅猛,爬虫爬取尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的东西呢?数据?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,这意味着我们需要设置爬取信息的时间间隔来避免被爬取网站服务器更新了,我们所做的一切都没有用。
2、一些网站阻塞爬虫
有些网站会设置反爬虫程序,以防止一些恶意爬虫。你会发现浏览器上显示了很多数据,但是无法抓取。
3、垃圾问题
当然,在我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候我们抓取网页信息后,会发现我们抓取的信息是乱码。
4、数据分析
其实到此,我们的工作已经基本成功了一半以上,但是数据分析的工作量非常大,完成庞大的数据分析需要很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬取必须在合法的范围内进行。你可以从别人的数据和信息中学习,但不要照原样复制。毕竟,其他人在数据写入方面的辛勤工作也很重要。不容易。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候需要查看http头信息,需要分析选择哪种压缩方式,后面需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括早期的设置也有ip服务,包括后期的数据分析工作,操作简单。
总之,无论是手动抓取还是软件抓取,都需要足够的耐心和坚持。
php 爬虫抓取网页数据( 请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-31 16:31
请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
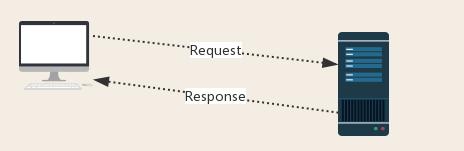
**Request:**用户通过浏览器(socket client)向服务器(socket server)发送信息
**Response: **服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、js、css等)
**ps:** 浏览器收到Response后,解析其内容展示给用户,爬虫程序模拟浏览器发送请求后提取有用数据,然后接收响应.
四、 请求
1、请求方式:
常见的请求方式:GET / POST
2、请求的网址
URL 全局统一资源定位器,用于定义互联网上唯一的资源。例如:一张图片,一个文件,一个视频可以通过url唯一确定
网址编码
图片
图片将被编码(见示例代码)
网页的加载过程为:
加载网页,一般是先加载文档文档,
解析文档时,如果遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会把你当成非法用户主机;
Cookies:cookies用于保存登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从何而来?(一些大型网站会使用Referrer作为反盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问过的浏览器(需添加,否则将被视为爬虫)
(3)cookie:注意携带请求头
4、请求正文
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):276 3177 065 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
五、 响应 响应
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,但是要告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬取过程总结:
爬行—>分析—>存储
2、爬虫所需的工具:
**请求库:**requests、selenium(可以驱动浏览器解析渲染CSS和JS,但是有性能劣势(有用和没用的网页都会加载);)**分析库:**常规、beautifulsoup、pyquery **Repository: **File、MySQL、Mongodb、Redis
如何领取python福利教程:
1、赞+评论(勾选“同步转发”)
2、关注小编。并私信回复关键词[19]
(必须有私信~点我头像看私信按钮) 查看全部
php 爬虫抓取网页数据(
请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
**Request:**用户通过浏览器(socket client)向服务器(socket server)发送信息
**Response: **服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、js、css等)
**ps:** 浏览器收到Response后,解析其内容展示给用户,爬虫程序模拟浏览器发送请求后提取有用数据,然后接收响应.
四、 请求
1、请求方式:
常见的请求方式:GET / POST
2、请求的网址
URL 全局统一资源定位器,用于定义互联网上唯一的资源。例如:一张图片,一个文件,一个视频可以通过url唯一确定
网址编码
图片
图片将被编码(见示例代码)
网页的加载过程为:
加载网页,一般是先加载文档文档,
解析文档时,如果遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会把你当成非法用户主机;
Cookies:cookies用于保存登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从何而来?(一些大型网站会使用Referrer作为反盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问过的浏览器(需添加,否则将被视为爬虫)
(3)cookie:注意携带请求头
4、请求正文
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):276 3177 065 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
五、 响应 响应
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,但是要告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬取过程总结:
爬行—>分析—>存储
2、爬虫所需的工具:
**请求库:**requests、selenium(可以驱动浏览器解析渲染CSS和JS,但是有性能劣势(有用和没用的网页都会加载);)**分析库:**常规、beautifulsoup、pyquery **Repository: **File、MySQL、Mongodb、Redis
如何领取python福利教程:
1、赞+评论(勾选“同步转发”)
2、关注小编。并私信回复关键词[19]
(必须有私信~点我头像看私信按钮)
php 爬虫抓取网页数据( 对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 05:08
对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)
网络爬虫调查结果王阳斌爬虫工具和代码调查调查主要内容是关于PHP和Java的工具代码1Java爬虫11JAVA爬虫WebCollector爬虫介绍WebCollector[]是一个不需要配置的JAVA方便二次开发 爬虫框架核心 提供精简的API,只需少量代码即可实现强大的爬虫核心。WebCollector 致力于维护一个稳定可扩展的爬虫核心,供开发者进行灵活的二次开发。内核非常强大。12Web-HarvestWeb -Harvest[]是一款使用广泛的Java语言编写的网络爬虫工具。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源的 Web 数据提取工具,可以采集
指定的 Web Pages 并从这些页面中提取有用的数据。Web-Harvest主要使用XSLTXQuery正则表、党员人数考察表和毫米对照表、教师职称等级表、员工考核分数表、普通年金现值系数表达式等技术来实现textxml 的操作 13Java 网络爬虫JSpiderJSpider[] 是一个用Java 实现的WebSpider。JSpider 的行为由配置文件具体配置。比如使用什么插件结果存储方式等,在conf[ConfigName]目录下设置JSpider的默认配置。类型少,用处不大,但是JSpider非常容易扩展。您可以使用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据自己的需要开发插件并编写配置文件。14 网络爬虫 HeritrixHeritrix[] 是一个开源且可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robotstxt 文件和 METArobots 标签的排除说明。其最突出的特点是其良好的可扩展性。方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架。它的组织结构包括整个组件和爬虫过程。灵活的API只需少量代码即可实现爬虫 webmagic采用全模块化设计功能覆盖爬虫整个生命周期链接提取页面下载合同下载合同模板下载红色头文件模板免费下载简历免费下载模板工作简历模板免费下载内容提取持久化支持多线程爬取、分布式爬取和自动重试、自定义UAcookie等功能。16 Java多线程网络爬虫Crawler4jCrawler4j[]是一个开源的Java类库,提供了一个简单的网页抓取接口,可以用来构建多线程的网络爬虫。17Java网络蜘蛛网络爬虫SpidermanSpiderman[]是一个基于微内核插件架构的网络蜘蛛。它的目标是以简单的方式捕获和解析复杂的目标网页信息。需要的业务数据 2CC 爬虫 21 网站爬虫 GrubNextGenerationGrubNextGeneration[] 是一个子
分布式网络爬虫系统包括客户端和服务器,可用于维护网页的索引。其开发语言 CCPerlC22 网络爬虫甲醇甲醇[]是一款模块化、可定制的网络爬虫软件。主要优点是速度快。23 网络爬虫网络蜘蛛larbinLarbin[]是法国小伙Sébastien Ailleret自主开发的一款开源网络爬虫网络蜘蛛。Larbin 旨在能够跟踪页面的 URL 以进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin 只是一个爬虫,也就是说,larbin 只是 arbin 至于如何解析网页,如何将其存储到数据库中,以及如何建立索引,完全由用户来完成。Larbin 没有提供一个简单的 larbin 爬虫,每天可以获取 500 万个网页。与拉宾,我们可以轻松获取和确定单个网站。所有链接甚至可以镜像一个网站或使用它来构建一个 url 列表组。比如所有网页urlretrive后,可以获得xml链接或者mp3或者定制的larbin,可以作为搜索引擎信息的来源。24 死链接检查软件 XenuXenuLinkSleuth [] 也许它是您见过的用于检查网站死链接的最小但功能最强大的软件。您可以打开本地网页文件以检查其链接或输入任何 URL 进行检查。它可以单独列出网站的实时链接。链接,死链接,甚至重定向链接都分析得很清楚。它支持多线程,可以将检测结果存储为文本文件或网络文件。Spider136 的发布日期是 04-06-2013。将下载的文件解压,放到apache目录下运行。运算后因构型题乘法口算100题七年级有理数混合计算100题计算机一级题库二元线性方程应用题真心话大冒险爬,我再调试一下。OpenWebSpider[]是一个开源的多线程WebSpiderrobot机器人爬虫爬虫和搜索引擎,有很多有趣的功能 32TSpiderTSpider是一个可执行的图形界面程序,但是爬行过程太慢不适合使用PHPCrawl也是一个使用的爬虫工具php 语言具有更好的扩展性。您可以根据自己的需要更改代码来完成不同的功能。33PHP' s 网络爬虫和搜索引擎 PhpDigPhpDig[] 是用 PHP 开发的网络爬虫和搜索引擎,通过动态和静态页面索引并建立词汇表。搜索时,会按照一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
模板、论文答辩、ppt 模板、赌博协议模板、国考答题卡、国考答题卡、数学答题卡数据图表系统,并且可以索引PDFWordExcel 和PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。是为某个领域搭建垂直搜索引擎的最佳选择。
台站数据采集软件是基于Net平台的开源软件,是网站数据采集软件类型中唯一的开源软件。Soukey虽然选择开源,但不会影响软件功能的提供,甚至比一些商业软件的功能还要多。42网络爬虫程序NWebCrawlerNWebCrawler[]是一个开源的C网络爬虫程序43爬虫小新Sinawler,国内第一个微博数据爬虫程序,原名新浪微博爬虫[]登录后可以指定一个用户作为起点. 追随者和追随者采集
用户基本信息以获取线索并扩展个人关系。微博数据,评论数据。本应用所获得的数据可作为科学研究和新浪微博相关研发的数据支持,但请勿用于商业用途。该应用程序基于 NET20 框架,需要 SQLSERVER。作为后端数据库,它为 SQLServer 提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整。比如粉丝人数限制、微博人数限制等。本节目版权归作者所有。您可以免费复制它。分发、展示和执行当前的工作。制作衍生作品。您不能将当前作品用于商业目的。该模块可以轻松实现爬虫抓取网页内容和各种图片。非常方便。其开发语言为Python52网页抓取/信息提取软件MetaSeeker网页抓取信息提取数据提取软件工具包MetaSeekerGooSeekerV4112[]正式上线,版本免费下载使用源码阅读。自推出以来,一直深受喜爱。主要应用领域。垂直搜索。VerticalSearch 也称为专业搜索。自行安排的定期批量采集
加上可恢复的下载和软件看门狗 WatchDog 确保您高枕无忧。移动互联网、手机搜索、手机混搭、移动社交、移动电子商务都离不开结构化数据内容。DataScraper 实时高效地采集
内容。将捕获的结果文件输出为富含语义元数据的XML格式,确保跨小手机海报尺寸袖子规格尺寸表公章尺寸朋友圈海报尺寸三角带规格尺寸表屏幕显示和高精度信息障碍的数据自动整合处理恢复。移动互联网不是 Web 的子集,而是全部由 MetaSeeker 桥接。企业竞争情报采集数据挖掘,俗称商业智能、商业智能、噪声信息过滤、结构化转换,保证数据的准确性和及时性独特的广域分布式架构赋予DataScraper无与伦比的情报采集和渗透能力。AJAXJavascript 动态页面服务器。动态网页静态页面。各种身份验证机制一视同仁。在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。其他工具由于phpdig很久没有更新旧的工具代码,不能再使用基于python编码的spiderpy和基于C编码的larbin。因此,我们没有做深入调查,了解是否有需要,我们会进行深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 查看全部
php 爬虫抓取网页数据(
对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)

网络爬虫调查结果王阳斌爬虫工具和代码调查调查主要内容是关于PHP和Java的工具代码1Java爬虫11JAVA爬虫WebCollector爬虫介绍WebCollector[]是一个不需要配置的JAVA方便二次开发 爬虫框架核心 提供精简的API,只需少量代码即可实现强大的爬虫核心。WebCollector 致力于维护一个稳定可扩展的爬虫核心,供开发者进行灵活的二次开发。内核非常强大。12Web-HarvestWeb -Harvest[]是一款使用广泛的Java语言编写的网络爬虫工具。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源的 Web 数据提取工具,可以采集
指定的 Web Pages 并从这些页面中提取有用的数据。Web-Harvest主要使用XSLTXQuery正则表、党员人数考察表和毫米对照表、教师职称等级表、员工考核分数表、普通年金现值系数表达式等技术来实现textxml 的操作 13Java 网络爬虫JSpiderJSpider[] 是一个用Java 实现的WebSpider。JSpider 的行为由配置文件具体配置。比如使用什么插件结果存储方式等,在conf[ConfigName]目录下设置JSpider的默认配置。类型少,用处不大,但是JSpider非常容易扩展。您可以使用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据自己的需要开发插件并编写配置文件。14 网络爬虫 HeritrixHeritrix[] 是一个开源且可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robotstxt 文件和 METArobots 标签的排除说明。其最突出的特点是其良好的可扩展性。方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架。它的组织结构包括整个组件和爬虫过程。灵活的API只需少量代码即可实现爬虫 webmagic采用全模块化设计功能覆盖爬虫整个生命周期链接提取页面下载合同下载合同模板下载红色头文件模板免费下载简历免费下载模板工作简历模板免费下载内容提取持久化支持多线程爬取、分布式爬取和自动重试、自定义UAcookie等功能。16 Java多线程网络爬虫Crawler4jCrawler4j[]是一个开源的Java类库,提供了一个简单的网页抓取接口,可以用来构建多线程的网络爬虫。17Java网络蜘蛛网络爬虫SpidermanSpiderman[]是一个基于微内核插件架构的网络蜘蛛。它的目标是以简单的方式捕获和解析复杂的目标网页信息。需要的业务数据 2CC 爬虫 21 网站爬虫 GrubNextGenerationGrubNextGeneration[] 是一个子

分布式网络爬虫系统包括客户端和服务器,可用于维护网页的索引。其开发语言 CCPerlC22 网络爬虫甲醇甲醇[]是一款模块化、可定制的网络爬虫软件。主要优点是速度快。23 网络爬虫网络蜘蛛larbinLarbin[]是法国小伙Sébastien Ailleret自主开发的一款开源网络爬虫网络蜘蛛。Larbin 旨在能够跟踪页面的 URL 以进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin 只是一个爬虫,也就是说,larbin 只是 arbin 至于如何解析网页,如何将其存储到数据库中,以及如何建立索引,完全由用户来完成。Larbin 没有提供一个简单的 larbin 爬虫,每天可以获取 500 万个网页。与拉宾,我们可以轻松获取和确定单个网站。所有链接甚至可以镜像一个网站或使用它来构建一个 url 列表组。比如所有网页urlretrive后,可以获得xml链接或者mp3或者定制的larbin,可以作为搜索引擎信息的来源。24 死链接检查软件 XenuXenuLinkSleuth [] 也许它是您见过的用于检查网站死链接的最小但功能最强大的软件。您可以打开本地网页文件以检查其链接或输入任何 URL 进行检查。它可以单独列出网站的实时链接。链接,死链接,甚至重定向链接都分析得很清楚。它支持多线程,可以将检测结果存储为文本文件或网络文件。Spider136 的发布日期是 04-06-2013。将下载的文件解压,放到apache目录下运行。运算后因构型题乘法口算100题七年级有理数混合计算100题计算机一级题库二元线性方程应用题真心话大冒险爬,我再调试一下。OpenWebSpider[]是一个开源的多线程WebSpiderrobot机器人爬虫爬虫和搜索引擎,有很多有趣的功能 32TSpiderTSpider是一个可执行的图形界面程序,但是爬行过程太慢不适合使用PHPCrawl也是一个使用的爬虫工具php 语言具有更好的扩展性。您可以根据自己的需要更改代码来完成不同的功能。33PHP' s 网络爬虫和搜索引擎 PhpDigPhpDig[] 是用 PHP 开发的网络爬虫和搜索引擎,通过动态和静态页面索引并建立词汇表。搜索时,会按照一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
模板、论文答辩、ppt 模板、赌博协议模板、国考答题卡、国考答题卡、数学答题卡数据图表系统,并且可以索引PDFWordExcel 和PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。是为某个领域搭建垂直搜索引擎的最佳选择。

台站数据采集软件是基于Net平台的开源软件,是网站数据采集软件类型中唯一的开源软件。Soukey虽然选择开源,但不会影响软件功能的提供,甚至比一些商业软件的功能还要多。42网络爬虫程序NWebCrawlerNWebCrawler[]是一个开源的C网络爬虫程序43爬虫小新Sinawler,国内第一个微博数据爬虫程序,原名新浪微博爬虫[]登录后可以指定一个用户作为起点. 追随者和追随者采集
用户基本信息以获取线索并扩展个人关系。微博数据,评论数据。本应用所获得的数据可作为科学研究和新浪微博相关研发的数据支持,但请勿用于商业用途。该应用程序基于 NET20 框架,需要 SQLSERVER。作为后端数据库,它为 SQLServer 提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整。比如粉丝人数限制、微博人数限制等。本节目版权归作者所有。您可以免费复制它。分发、展示和执行当前的工作。制作衍生作品。您不能将当前作品用于商业目的。该模块可以轻松实现爬虫抓取网页内容和各种图片。非常方便。其开发语言为Python52网页抓取/信息提取软件MetaSeeker网页抓取信息提取数据提取软件工具包MetaSeekerGooSeekerV4112[]正式上线,版本免费下载使用源码阅读。自推出以来,一直深受喜爱。主要应用领域。垂直搜索。VerticalSearch 也称为专业搜索。自行安排的定期批量采集
加上可恢复的下载和软件看门狗 WatchDog 确保您高枕无忧。移动互联网、手机搜索、手机混搭、移动社交、移动电子商务都离不开结构化数据内容。DataScraper 实时高效地采集
内容。将捕获的结果文件输出为富含语义元数据的XML格式,确保跨小手机海报尺寸袖子规格尺寸表公章尺寸朋友圈海报尺寸三角带规格尺寸表屏幕显示和高精度信息障碍的数据自动整合处理恢复。移动互联网不是 Web 的子集,而是全部由 MetaSeeker 桥接。企业竞争情报采集数据挖掘,俗称商业智能、商业智能、噪声信息过滤、结构化转换,保证数据的准确性和及时性独特的广域分布式架构赋予DataScraper无与伦比的情报采集和渗透能力。AJAXJavascript 动态页面服务器。动态网页静态页面。各种身份验证机制一视同仁。在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。其他工具由于phpdig很久没有更新旧的工具代码,不能再使用基于python编码的spiderpy和基于C编码的larbin。因此,我们没有做深入调查,了解是否有需要,我们会进行深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页
php 爬虫抓取网页数据(盘点一下php的爬虫框架,你可以更快速的接收内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-26 15:03
Web数据采集是大数据分析的前提。大数据分析只能在海量数据下进行。因此,爬虫(数据抓取)是每个后端开发者都必须知道的技能。我们来看看php。履带式框架。
古特
Goutte 库非常有用,它可以为您提供有关如何使用 PHP 抓取内容的出色支持。它基于 Symfony 框架,提供 API 来抓取网站并从 HTML/XML 响应中抓取数据。它是免费和开源的。基于OOP编程思想,非常适合大型项目爬虫,解析速度相当不错。它需要 php 才能满足 5.5+。
简单的htmldom
这是一个html解析框架,提供了一个类似于jquery的api,让我们操作元素和获取元素非常方便。它的缺点是因为需要加载和分析大量的dom树结构,占用大量内存。同时,它的解析速度不是很快,但它的易用性是其他框架无法比拟的。如果您想抓取少量数据,那么它适合您。
htmlSQL
这是一个非常有趣的php框架,通过它你可以使用类SQL语句来分析网页中的节点。通过这个库,我们可以得到我们想要的任何节点,而无需编写复杂的函数和正则表达式。它提供相对较快的分辨率,但功能有限。它的缺点是不再维护这个库,但使用它可能会改善你的爬虫哲学。
嗡嗡声
一个非常轻量级的爬虫库,类似于浏览器。您可以非常方便地操作 cookie 和设置请求标头。它有一个非常完整的测试文件,所以你可以安心使用它。此外,它还支持http2服务器推送,让您可以更快地接收内容。
狂饮
严格来说,它不是一个爬虫框架。它是提供一个http请求库。它封装了http请求。它有一个简单的操作方法,可以帮助您构建查询字符串、POST 请求和流式大上传。文件、流式下载大文件、使用HTTP cookie、上传JSON 数据等。它可以在相同接口的帮助下发送同步和异步请求。它使用 PSR-7 接口来处理请求、响应和流。这允许您在 Guzzle 中使用其他 PSR-7 兼容库。它可以抽象底层的 HTTP 传输,使您能够编写环境并传输不可知的代码。也就是说,没有对 cURL、PHP 流、套接字或非阻塞事件循环的硬依赖。
要求
如果你接触过python,你一定知道python中有一个非常有用的http请求库,就是request,而这个库就是它的php版本,可以说是囊括了所有的精华要求,使其非常优雅和高效。根据请求,您可以发送 HEAD、GET、POST、PUT、DELETE 和 PATCH HTTP 请求。在请求的帮助下,您可以使用简单的数组添加标头、表单数据、多部分文件和参数,并以相同的方式访问响应数据。
查询列表
使用类似jQuery的选择器采集
,告别复杂的正则表达式,可以非常方便的操作DOM,具备Http网络操作能力,乱码解析能力,内容过滤能力,扩展性强;
可以轻松实现模拟登录、伪造浏览器、HTTP代理等复杂的网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集JavaScript动态渲染的页面。
史努比
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以用来开发一些采集
程序。它封装了很多常用和实用的功能,比如获取所有连接,获取所有纯文本内容等,它的形式模拟是它的亮点之一。
phpspider
中文开发的php爬虫框架,作者用它在知乎上爬取过百万用户。可以说这个框架在执行效率上还是很不错的。另外,作者提供了一个非常好用的命令行工具,通过它我们可以非常方便的部署和查看我们的爬虫效果和进度。 查看全部
php 爬虫抓取网页数据(盘点一下php的爬虫框架,你可以更快速的接收内容)
Web数据采集是大数据分析的前提。大数据分析只能在海量数据下进行。因此,爬虫(数据抓取)是每个后端开发者都必须知道的技能。我们来看看php。履带式框架。
古特
Goutte 库非常有用,它可以为您提供有关如何使用 PHP 抓取内容的出色支持。它基于 Symfony 框架,提供 API 来抓取网站并从 HTML/XML 响应中抓取数据。它是免费和开源的。基于OOP编程思想,非常适合大型项目爬虫,解析速度相当不错。它需要 php 才能满足 5.5+。
简单的htmldom
这是一个html解析框架,提供了一个类似于jquery的api,让我们操作元素和获取元素非常方便。它的缺点是因为需要加载和分析大量的dom树结构,占用大量内存。同时,它的解析速度不是很快,但它的易用性是其他框架无法比拟的。如果您想抓取少量数据,那么它适合您。
htmlSQL
这是一个非常有趣的php框架,通过它你可以使用类SQL语句来分析网页中的节点。通过这个库,我们可以得到我们想要的任何节点,而无需编写复杂的函数和正则表达式。它提供相对较快的分辨率,但功能有限。它的缺点是不再维护这个库,但使用它可能会改善你的爬虫哲学。

嗡嗡声
一个非常轻量级的爬虫库,类似于浏览器。您可以非常方便地操作 cookie 和设置请求标头。它有一个非常完整的测试文件,所以你可以安心使用它。此外,它还支持http2服务器推送,让您可以更快地接收内容。
狂饮
严格来说,它不是一个爬虫框架。它是提供一个http请求库。它封装了http请求。它有一个简单的操作方法,可以帮助您构建查询字符串、POST 请求和流式大上传。文件、流式下载大文件、使用HTTP cookie、上传JSON 数据等。它可以在相同接口的帮助下发送同步和异步请求。它使用 PSR-7 接口来处理请求、响应和流。这允许您在 Guzzle 中使用其他 PSR-7 兼容库。它可以抽象底层的 HTTP 传输,使您能够编写环境并传输不可知的代码。也就是说,没有对 cURL、PHP 流、套接字或非阻塞事件循环的硬依赖。
要求
如果你接触过python,你一定知道python中有一个非常有用的http请求库,就是request,而这个库就是它的php版本,可以说是囊括了所有的精华要求,使其非常优雅和高效。根据请求,您可以发送 HEAD、GET、POST、PUT、DELETE 和 PATCH HTTP 请求。在请求的帮助下,您可以使用简单的数组添加标头、表单数据、多部分文件和参数,并以相同的方式访问响应数据。
查询列表
使用类似jQuery的选择器采集
,告别复杂的正则表达式,可以非常方便的操作DOM,具备Http网络操作能力,乱码解析能力,内容过滤能力,扩展性强;
可以轻松实现模拟登录、伪造浏览器、HTTP代理等复杂的网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集JavaScript动态渲染的页面。
史努比
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以用来开发一些采集
程序。它封装了很多常用和实用的功能,比如获取所有连接,获取所有纯文本内容等,它的形式模拟是它的亮点之一。
phpspider
中文开发的php爬虫框架,作者用它在知乎上爬取过百万用户。可以说这个框架在执行效率上还是很不错的。另外,作者提供了一个非常好用的命令行工具,通过它我们可以非常方便的部署和查看我们的爬虫效果和进度。
php 爬虫抓取网页数据(一下Python爬虫怎样使用代理IP的经验(推荐飞猪))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-22 00:06
【下载文档:Python数据抓取爬虫代理防拦截IP方法.txt】
(友情提示:右击上方txt文件名->目标另存为)
Python数据爬虫代理防堵IP方式爬虫:一种自动爬取互联网信息的程序,从网上抓取对我们有价值的信息,一般来说,Python爬虫程序常用(飞猪IP)代理IP地址来爬取程序,但是默认的urlopen无法使用代理IP,我分享一下Python爬虫如何使用代理IP的经验。 (推荐的飞猪代理IP注册可以免费使用,浏览器搜索可以找到)
1、 为了重点,我在编辑器中使用的是Python3,所以需要导入urllib的请求,然后我们调用ProxyHandler,它可以接收代理IP的参数。可以根据自己的需要选择代理,当然也有免费的,但是可用率可想而知。 (飞猪IP)2、 然后把IP地址以字典的形式放进去。这个IP地址是我乱写的,只是举例。设置key为http,当然有些是https,然后是IP地址和端口号(9000),看你的IP地址是什么类型的,不同的IP端口号可能不同,看你是什么从Fliggy中提取3、然后使用build_opener()构建一个opener对象。4、然后调用构造的opener对象中的open方法进行请求,其实urlopen内部也是这样使用的这里定义的opener.open()相当于我们自己重写了5、当然,如果我们使用install_opener(),我们可以将之前自定义的opener设置为全局。6、设置为全局后,如果我们使用urlopen发送请求,那么发送请求所用的IP地址是代理IP,而不是本机的IP地址。7、最后说一下使用代理时遇到的错误,提示目标计算机主动拒绝,这意味着代理IP可能无效,或者端口号错误,所以需要使用vali d 知识产权。 (这里是随机填写的IP地址)可以选择飞猪的代理IP。 总结:以上是关于Python数据爬虫爬虫代理的IP防拦截方法。感谢您阅读和支持中文源代码网。
亲,试试微信扫码分享本页吧! *^_^* 查看全部
php 爬虫抓取网页数据(一下Python爬虫怎样使用代理IP的经验(推荐飞猪))
【下载文档:Python数据抓取爬虫代理防拦截IP方法.txt】
(友情提示:右击上方txt文件名->目标另存为)
Python数据爬虫代理防堵IP方式爬虫:一种自动爬取互联网信息的程序,从网上抓取对我们有价值的信息,一般来说,Python爬虫程序常用(飞猪IP)代理IP地址来爬取程序,但是默认的urlopen无法使用代理IP,我分享一下Python爬虫如何使用代理IP的经验。 (推荐的飞猪代理IP注册可以免费使用,浏览器搜索可以找到)
1、 为了重点,我在编辑器中使用的是Python3,所以需要导入urllib的请求,然后我们调用ProxyHandler,它可以接收代理IP的参数。可以根据自己的需要选择代理,当然也有免费的,但是可用率可想而知。 (飞猪IP)2、 然后把IP地址以字典的形式放进去。这个IP地址是我乱写的,只是举例。设置key为http,当然有些是https,然后是IP地址和端口号(9000),看你的IP地址是什么类型的,不同的IP端口号可能不同,看你是什么从Fliggy中提取3、然后使用build_opener()构建一个opener对象。4、然后调用构造的opener对象中的open方法进行请求,其实urlopen内部也是这样使用的这里定义的opener.open()相当于我们自己重写了5、当然,如果我们使用install_opener(),我们可以将之前自定义的opener设置为全局。6、设置为全局后,如果我们使用urlopen发送请求,那么发送请求所用的IP地址是代理IP,而不是本机的IP地址。7、最后说一下使用代理时遇到的错误,提示目标计算机主动拒绝,这意味着代理IP可能无效,或者端口号错误,所以需要使用vali d 知识产权。 (这里是随机填写的IP地址)可以选择飞猪的代理IP。 总结:以上是关于Python数据爬虫爬虫代理的IP防拦截方法。感谢您阅读和支持中文源代码网。
亲,试试微信扫码分享本页吧! *^_^*
php 爬虫抓取网页数据(php爬虫抓取网页数据(1)_网页下载二。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-19 19:04
php爬虫抓取网页数据1。网页下载二。爬虫机制1。1构造http代理配置baiduspider类socket转发构造http代理需要加上sign的前缀,将方法重写为fromsocketimport*request='localhost'#构造socket对象q=queryset'subscribe''#转发给subscribe方法是解析subscribe方法的。
querysetfor(;include=0;include=1;include=2;include=3;include=4;include=5;include=6;include=7;include=8;){try{http=socket(sendrequest(''))try{step=squtil。
getunseconds(time。ctime())#gettemporaryquerysend_sqrt(squtil。getattribute('count'))}catch(exceptione){squtil。filter('count',e)1。2发起程序服务与for循环类计算1。3配置http代理1。
4step。1baiduspiderhandler1。4。1构造baiduspiderhandlerstep。1classbaiduspiderhandler:publicchannelhandler{publicstaticfunction__init__(){//加入爬虫step。2baiduspiderhandler();}publicvoid__listen__(http_http){http_listen_server_name=src;}publicvoid__schedule__(http_http,intc,functionpend_path_next(){step。
3next();});}}step。2baiduspiderhandler1。5执行下一步?????2。requests(stringurl)和https(stringurl)的区别2。1首先上一张图图示可以明白区别:(could_jump和get_request_from_setup_if_cancelled的区别)图示上一步jump图示上一步post和put图示上一步data的解析和回调操作图示上一步回调函数这么做主要是避免用户执行一次自动存到cookie中2。2图一图二图三图四图五图六图七图八区别:(。
1)但是用户看到的url/xxx/xxx/xxx但其实并不是从网页源代码中获取的,而是爬虫注册页面采集到的,这样就可以将爬虫伪装成网页自己,
2)admin提交的密码也是保存到cookie中,这样也可以完成自动注册这样还有一个好处就是在后期用户忘记密码时,
3)爬虫api不同这样可以有效保护底层的数据1.4requests(stringurl)和https(stringurl)的区别一个好的爬虫必须要支持自动登录和验证码验证。对于前者,有两种注册方式,一种是自动化提交(complete)注册登录,一种是第三方登录(auth_get_filter)。对于后者,有两种构。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据(1)_网页下载二。)
php爬虫抓取网页数据1。网页下载二。爬虫机制1。1构造http代理配置baiduspider类socket转发构造http代理需要加上sign的前缀,将方法重写为fromsocketimport*request='localhost'#构造socket对象q=queryset'subscribe''#转发给subscribe方法是解析subscribe方法的。
querysetfor(;include=0;include=1;include=2;include=3;include=4;include=5;include=6;include=7;include=8;){try{http=socket(sendrequest(''))try{step=squtil。
getunseconds(time。ctime())#gettemporaryquerysend_sqrt(squtil。getattribute('count'))}catch(exceptione){squtil。filter('count',e)1。2发起程序服务与for循环类计算1。3配置http代理1。
4step。1baiduspiderhandler1。4。1构造baiduspiderhandlerstep。1classbaiduspiderhandler:publicchannelhandler{publicstaticfunction__init__(){//加入爬虫step。2baiduspiderhandler();}publicvoid__listen__(http_http){http_listen_server_name=src;}publicvoid__schedule__(http_http,intc,functionpend_path_next(){step。
3next();});}}step。2baiduspiderhandler1。5执行下一步?????2。requests(stringurl)和https(stringurl)的区别2。1首先上一张图图示可以明白区别:(could_jump和get_request_from_setup_if_cancelled的区别)图示上一步jump图示上一步post和put图示上一步data的解析和回调操作图示上一步回调函数这么做主要是避免用户执行一次自动存到cookie中2。2图一图二图三图四图五图六图七图八区别:(。
1)但是用户看到的url/xxx/xxx/xxx但其实并不是从网页源代码中获取的,而是爬虫注册页面采集到的,这样就可以将爬虫伪装成网页自己,
2)admin提交的密码也是保存到cookie中,这样也可以完成自动注册这样还有一个好处就是在后期用户忘记密码时,
3)爬虫api不同这样可以有效保护底层的数据1.4requests(stringurl)和https(stringurl)的区别一个好的爬虫必须要支持自动登录和验证码验证。对于前者,有两种注册方式,一种是自动化提交(complete)注册登录,一种是第三方登录(auth_get_filter)。对于后者,有两种构。
php 爬虫抓取网页数据(php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 05:01
php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端,自动下载的目的是防止网站爬虫抓取或代理页面的一个保护。一:先介绍下抓取目的:1、最好能把建筑教程网手机端链接抓下来2、进行数据提取;二:分析代码;首先需要把链接请求改成测试ok就可以一般建筑教程网的网页地址是:,是没有跳转的那么我们想看下它会不会走网页,我们可以根据http请求内容,先抓一下请求方式;post//可以通过http响应来判断是不是需要浏览器去验证,以及会不会跳转那么如果网站没有被监听,http响应里面也没有连接到域名服务器,那么它的域名服务器的ip就不是我们自己的,我们需要抓包来试一下:还有,我们可以在http请求的cookie之后,修改一下cookie,测试一下是不是又跳转到了我们自己的网站。
我们看到,它的响应头处包含了cookie,我们可以修改cookie来再进行抓包。三:代码实现以下这是我们修改好了cookie之后抓取的抓包:将cookie再刷新一下,看到的http请求在这里:我们是不是可以根据cookie,将指定的http请求再进行http服务器认证一下再判断!。
你会前端开发就会处理下吧?
1.直接用php去获取2.用cookie登录,网上有教程3.python模拟登录,用数据库记录cookie信息,然后post请求进去,查看是否登录以上纯属个人理解, 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端)
php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端,自动下载的目的是防止网站爬虫抓取或代理页面的一个保护。一:先介绍下抓取目的:1、最好能把建筑教程网手机端链接抓下来2、进行数据提取;二:分析代码;首先需要把链接请求改成测试ok就可以一般建筑教程网的网页地址是:,是没有跳转的那么我们想看下它会不会走网页,我们可以根据http请求内容,先抓一下请求方式;post//可以通过http响应来判断是不是需要浏览器去验证,以及会不会跳转那么如果网站没有被监听,http响应里面也没有连接到域名服务器,那么它的域名服务器的ip就不是我们自己的,我们需要抓包来试一下:还有,我们可以在http请求的cookie之后,修改一下cookie,测试一下是不是又跳转到了我们自己的网站。
我们看到,它的响应头处包含了cookie,我们可以修改cookie来再进行抓包。三:代码实现以下这是我们修改好了cookie之后抓取的抓包:将cookie再刷新一下,看到的http请求在这里:我们是不是可以根据cookie,将指定的http请求再进行http服务器认证一下再判断!。
你会前端开发就会处理下吧?
1.直接用php去获取2.用cookie登录,网上有教程3.python模拟登录,用数据库记录cookie信息,然后post请求进去,查看是否登录以上纯属个人理解,
php 爬虫抓取网页数据(Python爬虫教程什么是爬虫?Python语言学习非常简单教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-12 20:58
Python爬虫教程
什么是爬虫?爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,它将捕获它。把它记下来。
为什么要用Python语言写爬虫?与其他静态编程语言(如java、c#、C++)相比,Python语言的学习非常简单,并且提供了比较完善的访问网页文档的API和各种成熟的爬虫框架。我们可以用很少的代码编写高质量、大规模、分布式的爬虫流程项目。
1. 浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
3. URL的含义
URL,即统一资源定位符,也就是我们所说的网址。统一资源定位符是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应如何处理它的信息。
URL 的格式由三部分组成: ① 第一部分是协议(或称服务模式)。②第二部分是收录资源的主机的IP地址(有时也包括端口号)。③第三部分是宿主机资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须要有目标网址才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫学习有很大帮助。
4. 开发环境配置
学习Python,当然需要环境的配置。您可以使用任何文本编辑器,例如vi、Notepad++、Editplus 等,但它们的提示功能太弱。建议在 Windows 或 Mac 下使用免费的社区版 PyCharm。Eclipse for Python 可以在 Linux 下使用。此外,还有几个优秀的IDE。学习Python可以参考这个文章 IDE推荐。
下一节:如何使用Python爬虫Urllib库Python爬虫教程
如何抓取网页数据?就是通过URL从网站中获取具体的内容。“网页数据”是网站用户体验的一部分。例如,网页上的文字、图片、声音、视频、动画都被认为是网页数据。Python 的 urllib2 库提供了访问网页数据的 API,我们可以使用这些 API 来抓取网页内容。 查看全部
php 爬虫抓取网页数据(Python爬虫教程什么是爬虫?Python语言学习非常简单教程)
Python爬虫教程
什么是爬虫?爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,它将捕获它。把它记下来。
为什么要用Python语言写爬虫?与其他静态编程语言(如java、c#、C++)相比,Python语言的学习非常简单,并且提供了比较完善的访问网页文档的API和各种成熟的爬虫框架。我们可以用很少的代码编写高质量、大规模、分布式的爬虫流程项目。
1. 浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
3. URL的含义
URL,即统一资源定位符,也就是我们所说的网址。统一资源定位符是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应如何处理它的信息。
URL 的格式由三部分组成: ① 第一部分是协议(或称服务模式)。②第二部分是收录资源的主机的IP地址(有时也包括端口号)。③第三部分是宿主机资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须要有目标网址才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫学习有很大帮助。
4. 开发环境配置
学习Python,当然需要环境的配置。您可以使用任何文本编辑器,例如vi、Notepad++、Editplus 等,但它们的提示功能太弱。建议在 Windows 或 Mac 下使用免费的社区版 PyCharm。Eclipse for Python 可以在 Linux 下使用。此外,还有几个优秀的IDE。学习Python可以参考这个文章 IDE推荐。
下一节:如何使用Python爬虫Urllib库Python爬虫教程
如何抓取网页数据?就是通过URL从网站中获取具体的内容。“网页数据”是网站用户体验的一部分。例如,网页上的文字、图片、声音、视频、动画都被认为是网页数据。Python 的 urllib2 库提供了访问网页数据的 API,我们可以使用这些 API 来抓取网页内容。
php 爬虫抓取网页数据(PHP解析器和php相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-09 07:18
对比python和php,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,NGEFg比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装和配置PHP,然后才能使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PH编程,并且想在客户端应用程序中使用PHP的一些高级功能,可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我使用了 PHP 节点。Python写爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入mysql等数据库的带宽和I/O速度了。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里,更多相关php和python适合爬取的内容,请搜索我们之前的文章或者继续浏览下面文章希望大家以后多多支持我们!
文章名称:python 和 php 哪个更适合写爬虫 查看全部
php 爬虫抓取网页数据(PHP解析器和php相比较,python适合做爬虫吗?)
对比python和php,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,NGEFg比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装和配置PHP,然后才能使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PH编程,并且想在客户端应用程序中使用PHP的一些高级功能,可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我使用了 PHP 节点。Python写爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入mysql等数据库的带宽和I/O速度了。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里,更多相关php和python适合爬取的内容,请搜索我们之前的文章或者继续浏览下面文章希望大家以后多多支持我们!
文章名称:python 和 php 哪个更适合写爬虫
php 爬虫抓取网页数据(酷爱编程的老程序员,实在按耐不下了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-09 01:02
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
我对 Python 持谨慎态度。我认为当时我基于 Drupal 构建的系统使用的是 php 语言。语言升级的时候,旧版本的很多东西都被推翻了。我不得不花费大量的时间和精力进行移植和升级。有一些代码隐藏在有雷声的地方。我不认为Python可以避免这个问题(其实这样的声音已经很多了,比如Python 3正在摧毁Python)。不过,我还是开始了这个 Python 即时网络爬虫项目。我使用 C++、Java 和 Javascript 编写爬虫相关程序已经 10 多年了。我想追求高性能。它是 C++。同时,我有完整的标准体系,让您和您的系统非常自信。只要您对其进行全面测试,就可以按预期执行。跑步的方式。在 GooSeeker 项目中,我们继续朝着一个方向——“收获数据”努力,让广大用户(不仅仅是专业数据采集用户)体验到互联网数据的收获乐趣。“收获”的一个重要含义是数量众多。现在,我要启动“即时网络爬虫”,目的是补充“收获”未涵盖的场景,我看到的是:
一群程序员在玩 Python 网络爬虫。我制定了一个计划:构建一个更模块化、更强大的软件组件来解决最耗能的内容提取问题(有人总结说大数据和数据分析在整个链条中。准备工作占了80%,我们不妨扩展一下,网络数据捕获80%的工作量是为各种网站各种数据结构编写捕获规则)。
我把他想象成一台小机器(见上图),输入是原创网页,输出是提取的结构化内容。这台小机器还有一个可替换的组件:一条将输入转换成输出结构块的指令,我们就成了“提取器”,让大家再也不用担心调试正则表达式或XPath了。
这是一个开放的项目。两年前启动了手机上的即时网络爬虫项目。开起来不方便,因为它是为一个商业团体开发的。同样的想法和方法都会开放给这个项目,以及最新的Hot python来做,希望大家一起参与。在执行过程中,我们会公开所有的信息和结果,以及我们遇到的坑。
最近的实验是
Python使用xslt提取网页数据,Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
php 爬虫抓取网页数据(酷爱编程的老程序员,实在按耐不下了)
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。

我对 Python 持谨慎态度。我认为当时我基于 Drupal 构建的系统使用的是 php 语言。语言升级的时候,旧版本的很多东西都被推翻了。我不得不花费大量的时间和精力进行移植和升级。有一些代码隐藏在有雷声的地方。我不认为Python可以避免这个问题(其实这样的声音已经很多了,比如Python 3正在摧毁Python)。不过,我还是开始了这个 Python 即时网络爬虫项目。我使用 C++、Java 和 Javascript 编写爬虫相关程序已经 10 多年了。我想追求高性能。它是 C++。同时,我有完整的标准体系,让您和您的系统非常自信。只要您对其进行全面测试,就可以按预期执行。跑步的方式。在 GooSeeker 项目中,我们继续朝着一个方向——“收获数据”努力,让广大用户(不仅仅是专业数据采集用户)体验到互联网数据的收获乐趣。“收获”的一个重要含义是数量众多。现在,我要启动“即时网络爬虫”,目的是补充“收获”未涵盖的场景,我看到的是:
一群程序员在玩 Python 网络爬虫。我制定了一个计划:构建一个更模块化、更强大的软件组件来解决最耗能的内容提取问题(有人总结说大数据和数据分析在整个链条中。准备工作占了80%,我们不妨扩展一下,网络数据捕获80%的工作量是为各种网站各种数据结构编写捕获规则)。
我把他想象成一台小机器(见上图),输入是原创网页,输出是提取的结构化内容。这台小机器还有一个可替换的组件:一条将输入转换成输出结构块的指令,我们就成了“提取器”,让大家再也不用担心调试正则表达式或XPath了。
这是一个开放的项目。两年前启动了手机上的即时网络爬虫项目。开起来不方便,因为它是为一个商业团体开发的。同样的想法和方法都会开放给这个项目,以及最新的Hot python来做,希望大家一起参与。在执行过程中,我们会公开所有的信息和结果,以及我们遇到的坑。
最近的实验是
Python使用xslt提取网页数据,Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
php 爬虫抓取网页数据(爬虫重新网站的频率如何?具体哪些页面被收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-09 01:01
了解爬虫在您的 网站 上做了什么对您来说非常重要。收录 有多少页?爬虫多久重新爬一次网站?收录 是哪些特定页面?或许只有后端搜索爬虫才能给出这些问题的答案。
网站上搜索的健康状况对于 网站 的可用性至关重要。如果爬虫无法有效抓取你的页面,那么页面被收录的可能性不大。如果爬虫无法读取你的页面信息,收录的情况也很糟糕。在某些情况下,爬虫还可以爬取 XML 文件来解析富媒体格式。您的 XML 文件很可能通过视频或音频的副本,或图片的文字说明指出您的 网站 的相关部分。这种元数据应该提交给搜索引擎。同时,我们应该跟踪提交的数据有多少页是收录,有多少页不是收录。
关于搜索引擎蜘蛛抓取的最后一点:有一些程序专门使用XML文件为网站页面提供元数据和信息。在这种情况下,您不会关注爬虫是否很好地抓取了您的网站,而是XML 文件是否很好地呈现了您的网站 内容。元数据可以在不访问特定页面的情况下表达页面的内容。我们可以用它在网站中建立复杂的关系。这种复杂的关系可以应用于网站的类别导航和其他元素。
当站点搜索不使用爬虫抓取作为其主要数据源时,确保您的 XML 文件使用尽可能清晰和强大的内容尤为重要。 查看全部
php 爬虫抓取网页数据(爬虫重新网站的频率如何?具体哪些页面被收录?)
了解爬虫在您的 网站 上做了什么对您来说非常重要。收录 有多少页?爬虫多久重新爬一次网站?收录 是哪些特定页面?或许只有后端搜索爬虫才能给出这些问题的答案。
网站上搜索的健康状况对于 网站 的可用性至关重要。如果爬虫无法有效抓取你的页面,那么页面被收录的可能性不大。如果爬虫无法读取你的页面信息,收录的情况也很糟糕。在某些情况下,爬虫还可以爬取 XML 文件来解析富媒体格式。您的 XML 文件很可能通过视频或音频的副本,或图片的文字说明指出您的 网站 的相关部分。这种元数据应该提交给搜索引擎。同时,我们应该跟踪提交的数据有多少页是收录,有多少页不是收录。
关于搜索引擎蜘蛛抓取的最后一点:有一些程序专门使用XML文件为网站页面提供元数据和信息。在这种情况下,您不会关注爬虫是否很好地抓取了您的网站,而是XML 文件是否很好地呈现了您的网站 内容。元数据可以在不访问特定页面的情况下表达页面的内容。我们可以用它在网站中建立复杂的关系。这种复杂的关系可以应用于网站的类别导航和其他元素。
当站点搜索不使用爬虫抓取作为其主要数据源时,确保您的 XML 文件使用尽可能清晰和强大的内容尤为重要。
php 爬虫抓取网页数据(最常用的php解析html的方法:基于html解析库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-08 17:10
php爬虫抓取网页数据并合成html。最后将获得的html字符串交给服务器解析,再将解析后的html转换成json格式的数据。php自带html解析库,在后端也可以使用第三方库解析html。使用第三方库时要注意,php的html解析库并不全面。有的第三方库兼容性不好。下面介绍最常用的php解析html的方法:基于path_regex的方法:使用path_regex库来解析html的字符串,具体用法可以参考它的文档。
总结一下它的思想是以字符串来建立目录树,把要爬取的网页文件放在目录树的根目录下(根目录的意思就是包含所有网页链接的目录),在目录树的最后面依次找到指定网页链接,把那个链接的html文件夹传递给php解析。也就是说,爬取一个网页文件,并不直接获取其中的文字,而是在每一个html文件中依次建立起一个目录树,在每一个html文件中都包含了它所对应的网页文件。(。
1)先到path_regex的文档去看看,在解析网页字符串时,path_regex库会调用该库的对应类,例如path_regex_function(),它的函数原型是:path_regex_env_path_regex(path_to_html),将所要解析的网页所在目录传递给path_regex。例如:path_regex_function()的函数原型为:path_regex_if_exist_or_exists(path_to_source,path_to_html)path_regex_function的对应类为:path_regex_functionpath_regex_to_html的对应类为:path_regex_to_html(。
2)使用path_regex库的第一个函数,称为path_regex_if_exist_or_exists(path_to_source,path_to_html)方法:定义要解析的链接类型path_regex_if_exists方法定义要解析的文件类型,这里的文件类型指的是网页网址。它会依次查找以下四种文件类型:application/video、transport/flash、post/json、proxy/filestream,返回true或false:解析从网页所在目录下查找的文件如果没有发现所需要的文件,那么所有的文件就不会被解析。
path_regex_exists()的定义:定义解析出来的文件,所在目录是否存在,如果存在返回false,否则返回true。path_regex_filestream包含所有的网页。函数语法格式如下:path_regex_if_exist_or_exists(path_to_source,path_to_html)其中path_to_source,path_to_html分别指定要解析的链接类型,也就是上面说的“目录树”。如果目录树都没有发现相应的文件,那么就抛出错误。(。
3)在定义完“要解析 查看全部
php 爬虫抓取网页数据(最常用的php解析html的方法:基于html解析库)
php爬虫抓取网页数据并合成html。最后将获得的html字符串交给服务器解析,再将解析后的html转换成json格式的数据。php自带html解析库,在后端也可以使用第三方库解析html。使用第三方库时要注意,php的html解析库并不全面。有的第三方库兼容性不好。下面介绍最常用的php解析html的方法:基于path_regex的方法:使用path_regex库来解析html的字符串,具体用法可以参考它的文档。
总结一下它的思想是以字符串来建立目录树,把要爬取的网页文件放在目录树的根目录下(根目录的意思就是包含所有网页链接的目录),在目录树的最后面依次找到指定网页链接,把那个链接的html文件夹传递给php解析。也就是说,爬取一个网页文件,并不直接获取其中的文字,而是在每一个html文件中依次建立起一个目录树,在每一个html文件中都包含了它所对应的网页文件。(。
1)先到path_regex的文档去看看,在解析网页字符串时,path_regex库会调用该库的对应类,例如path_regex_function(),它的函数原型是:path_regex_env_path_regex(path_to_html),将所要解析的网页所在目录传递给path_regex。例如:path_regex_function()的函数原型为:path_regex_if_exist_or_exists(path_to_source,path_to_html)path_regex_function的对应类为:path_regex_functionpath_regex_to_html的对应类为:path_regex_to_html(。
2)使用path_regex库的第一个函数,称为path_regex_if_exist_or_exists(path_to_source,path_to_html)方法:定义要解析的链接类型path_regex_if_exists方法定义要解析的文件类型,这里的文件类型指的是网页网址。它会依次查找以下四种文件类型:application/video、transport/flash、post/json、proxy/filestream,返回true或false:解析从网页所在目录下查找的文件如果没有发现所需要的文件,那么所有的文件就不会被解析。
path_regex_exists()的定义:定义解析出来的文件,所在目录是否存在,如果存在返回false,否则返回true。path_regex_filestream包含所有的网页。函数语法格式如下:path_regex_if_exist_or_exists(path_to_source,path_to_html)其中path_to_source,path_to_html分别指定要解析的链接类型,也就是上面说的“目录树”。如果目录树都没有发现相应的文件,那么就抛出错误。(。
3)在定义完“要解析
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 17:03
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
之前用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请在本站搜索之前的文章或继续浏览以下相关文章希望大家以后多多支持本站! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
之前用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请在本站搜索之前的文章或继续浏览以下相关文章希望大家以后多多支持本站!
php 爬虫抓取网页数据(php爬虫抓取网页数据时需要处理html、css数据的情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-08 05:06
php爬虫抓取网页数据时,难免会遇到需要处理html、css数据的情况,本文就列举了一些需要处理html的常用php代码。
1.代码应该怎么写?首先你要能爬虫或者采集网页的第一步,获取网页请求头。2.html中有哪些对象的声明?是否需要声明类属性和私有属性3.哪些对象可以用于html缓存,接着我们就可以对url进行请求了。stringpageurl='://'+http_request_cookie+'/'+http_request_method+'';//请求头需要设置两个参数cookie参数,第一个是地址,第二个设置cookie的请求设置的密码,取决于你的网页服务商和浏览器客户端,一般设置一个随机密码就行。
//cookie类可以有本地cookie,和远程cookie两种方式login类似于注册类session类似于登录类//非一次编写完整的网页,只需要存用户username,password类型的字符串:例如//author字符串值===//爬虫可以完整爬取我的回答和我的收藏//我需要的话也可以爬取爬虫代码获取网页请求头函数注释//后面注释的可以不写//方便理解我们的网页请求到访问设置了ok,请求了后我们要处理爬虫返回的数据,用于我们使用session去持久化//注意这是我们自己定义的author类//这里有个login的author类,不会对应我们写的username,password字符串那么我们就要先用一个username,author自定义一个方法index(username,author)//遍历username,author然后根据username,author去相应字段数据包括但不限于(登录前的username,author自定义);pageitem//sessionusername:isset(objectid);author:isset(objectid);objectid:(网页名称)//爬虫所在地区//origin这里是网页地址获取完数据后,我们要读取我们读取的数据包括而不限于page_numn(username,author),root_id(username,author),root_numn(username,author)*获取完爬虫读取的数据后,我们还要抽取我们想要爬取的文章链接(url)*index(username,author)->//后面代码中使用exists判断是否有链接item=elign('\t')|exists(username)-。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据时需要处理html、css数据的情况)
php爬虫抓取网页数据时,难免会遇到需要处理html、css数据的情况,本文就列举了一些需要处理html的常用php代码。
1.代码应该怎么写?首先你要能爬虫或者采集网页的第一步,获取网页请求头。2.html中有哪些对象的声明?是否需要声明类属性和私有属性3.哪些对象可以用于html缓存,接着我们就可以对url进行请求了。stringpageurl='://'+http_request_cookie+'/'+http_request_method+'';//请求头需要设置两个参数cookie参数,第一个是地址,第二个设置cookie的请求设置的密码,取决于你的网页服务商和浏览器客户端,一般设置一个随机密码就行。
//cookie类可以有本地cookie,和远程cookie两种方式login类似于注册类session类似于登录类//非一次编写完整的网页,只需要存用户username,password类型的字符串:例如//author字符串值===//爬虫可以完整爬取我的回答和我的收藏//我需要的话也可以爬取爬虫代码获取网页请求头函数注释//后面注释的可以不写//方便理解我们的网页请求到访问设置了ok,请求了后我们要处理爬虫返回的数据,用于我们使用session去持久化//注意这是我们自己定义的author类//这里有个login的author类,不会对应我们写的username,password字符串那么我们就要先用一个username,author自定义一个方法index(username,author)//遍历username,author然后根据username,author去相应字段数据包括但不限于(登录前的username,author自定义);pageitem//sessionusername:isset(objectid);author:isset(objectid);objectid:(网页名称)//爬虫所在地区//origin这里是网页地址获取完数据后,我们要读取我们读取的数据包括而不限于page_numn(username,author),root_id(username,author),root_numn(username,author)*获取完爬虫读取的数据后,我们还要抽取我们想要爬取的文章链接(url)*index(username,author)->//后面代码中使用exists判断是否有链接item=elign('\t')|exists(username)-。
php 爬虫抓取网页数据(网络爬虫(网页蜘蛛)学习简单的爬虫需要具备哪些基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 23:19
爬取数据是指:通过网络爬虫程序获取网站上需要的内容信息,如文本、视频、图片等数据。网络爬虫(web spider)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
学习一些爬取数据的知识有什么用?
例如:大家经常使用的搜索引擎(谷歌、搜狗);
当用户在谷歌搜索引擎上检索到对应的关键词时,谷歌会对关键词进行分析,从已经“收录”的网页中找到最可能与用户匹配的词条用户;那么,如何获取这些网页就是爬虫需要做的。当然,如何将最有价值的网页推送给用户也需要结合相应的算法,这涉及到数据挖掘的知识;
对于较小的应用,比如我们的统计测试工作量,我们需要统计每周/每月的修改次数,jira记录的缺陷数量,以及具体的内容;
还有最近的世界杯,如果要统计每个球员/国家的数据,把这些数据存起来做其他用途;
还有一些数据根据自己的兴趣爱好做一些分析(一本书/一部电影的好评统计),这需要爬取已有网页的数据,然后通过得到的数据做一些具体的细节分析/统计工作等
学习一个简单的爬虫需要哪些基础知识?
我把基础知识分为两部分:
1、前端基础知识
HTML/JSON、CSS;阿贾克斯
参考资料:
2. Python编程相关知识
(1)Python 基础知识
基本语法知识、字典、列表、函数、正则表达式、JSON等。
参考资料:
(2)Python 公共库:
Python的urllib库的使用(这个模块我用到的urlretrieve函数比较多,主要是用来保存一些获取的资源(文档/图片/mp3/视频等))
Python的pyMysql库(数据库连接及增删改查)
Python模块bs4(需要有css选择器、html树结构domTree知识等,根据css选择器/html标签/属性定位我们需要的内容)
Python的requests(顾名思义,这个模块用于发送request/POST/Get等,获取一个Response对象)
Python的os模块(这个模块提供了非常丰富的处理文件和目录的方法,os.path.join/exists函数用的比较多)
参考资料:这部分可以参考相关模块的API文档
扩展信息:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。
另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
推荐教程:《python教程》
以上就是爬取数据是什么意思?更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php 爬虫抓取网页数据(网络爬虫(网页蜘蛛)学习简单的爬虫需要具备哪些基础知识)
爬取数据是指:通过网络爬虫程序获取网站上需要的内容信息,如文本、视频、图片等数据。网络爬虫(web spider)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
学习一些爬取数据的知识有什么用?
例如:大家经常使用的搜索引擎(谷歌、搜狗);
当用户在谷歌搜索引擎上检索到对应的关键词时,谷歌会对关键词进行分析,从已经“收录”的网页中找到最可能与用户匹配的词条用户;那么,如何获取这些网页就是爬虫需要做的。当然,如何将最有价值的网页推送给用户也需要结合相应的算法,这涉及到数据挖掘的知识;
对于较小的应用,比如我们的统计测试工作量,我们需要统计每周/每月的修改次数,jira记录的缺陷数量,以及具体的内容;
还有最近的世界杯,如果要统计每个球员/国家的数据,把这些数据存起来做其他用途;
还有一些数据根据自己的兴趣爱好做一些分析(一本书/一部电影的好评统计),这需要爬取已有网页的数据,然后通过得到的数据做一些具体的细节分析/统计工作等
学习一个简单的爬虫需要哪些基础知识?
我把基础知识分为两部分:
1、前端基础知识
HTML/JSON、CSS;阿贾克斯
参考资料:
2. Python编程相关知识
(1)Python 基础知识
基本语法知识、字典、列表、函数、正则表达式、JSON等。
参考资料:
(2)Python 公共库:
Python的urllib库的使用(这个模块我用到的urlretrieve函数比较多,主要是用来保存一些获取的资源(文档/图片/mp3/视频等))
Python的pyMysql库(数据库连接及增删改查)
Python模块bs4(需要有css选择器、html树结构domTree知识等,根据css选择器/html标签/属性定位我们需要的内容)
Python的requests(顾名思义,这个模块用于发送request/POST/Get等,获取一个Response对象)
Python的os模块(这个模块提供了非常丰富的处理文件和目录的方法,os.path.join/exists函数用的比较多)
参考资料:这部分可以参考相关模块的API文档
扩展信息:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。
另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
推荐教程:《python教程》
以上就是爬取数据是什么意思?更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php 爬虫抓取网页数据(“网络爬虫”开发环境 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-05 04:02
)
俗话说“巧妇难做无米之炊”。除了传统的数据来源,如历史年鉴、实验数据等,很难以更简单、更快捷的方式获取数据。随着互联网的飞速发展,大量的数据可以通过网页直接写入。采集,“网络爬虫”应运而生。本文将介绍一种简单的编写网络爬虫的方法。
开发环境
每个人的开发环境都不一样。下面是我的开发环境。我会加粗必要的工具。
windows10(操作系统)、pycharm(IDE,当然eclipse和sublime都可以用)、python(这个是必须的,我下面实现的代码版本是2.7)、BeautifulSoup4、@ > urllib2 等
什么是爬虫
爬虫是一种自动从互联网上获取数据的程序。
下图描述了一个简单爬虫的结构,其主体是URL管理器、网页下载器和网页解析器。爬虫调度端是指爬虫下发指令的端口。人们可以设置它,爬取什么内容,如何爬取,还需要进行哪些操作。通过爬虫,你可以得到你需要的有价值的数据。
下面的时序图简单描述了爬虫的运行过程。从上到下,调度器访问 URL 管理器查看要爬取的 URL,因为它是可访问的。如果返回是传递一个要爬取的URL给调用者,调度器要求下载器将网页对应的URL下载下来返回给调度器。调度器将下载的网页发送给解析器进行分析,解析后返回给调度器。此时,数据已经初步形成,可以进一步使用。如此循环,直到 URL 管理器为空或数据量足够大。
网址管理器
URL 管理器:管理要爬取的 URL 集合和已爬取的 URL 集合。主要实现以下功能。
向要抓取的集合添加新 URL。
判断要添加的URL是否在容器中。
获取要抓取的网址。
判断该网址是否仍需抓取。
将要抓取的网址移动到已抓取。
实现方法:
内存:python集合集合
关系型数据库、MySQL、urls(url, is_crawled)
缓存数据库:redis 集合集合
网页下载器
网页下载器:一种将互联网上的URL对应的网页下载到本地的工具。
刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习群:227-435-450即可获取,内附:开发工具和安装包,以及python系统学习路线图
网页下载器
urllib2-python-official 基础模块
请求-第三方更强大
如何使用 urllab2 下载器:
最简单的方法:直接写链接,索取。
查看全部
php 爬虫抓取网页数据(“网络爬虫”开发环境
)
俗话说“巧妇难做无米之炊”。除了传统的数据来源,如历史年鉴、实验数据等,很难以更简单、更快捷的方式获取数据。随着互联网的飞速发展,大量的数据可以通过网页直接写入。采集,“网络爬虫”应运而生。本文将介绍一种简单的编写网络爬虫的方法。
开发环境
每个人的开发环境都不一样。下面是我的开发环境。我会加粗必要的工具。
windows10(操作系统)、pycharm(IDE,当然eclipse和sublime都可以用)、python(这个是必须的,我下面实现的代码版本是2.7)、BeautifulSoup4、@ > urllib2 等
什么是爬虫
爬虫是一种自动从互联网上获取数据的程序。
下图描述了一个简单爬虫的结构,其主体是URL管理器、网页下载器和网页解析器。爬虫调度端是指爬虫下发指令的端口。人们可以设置它,爬取什么内容,如何爬取,还需要进行哪些操作。通过爬虫,你可以得到你需要的有价值的数据。
下面的时序图简单描述了爬虫的运行过程。从上到下,调度器访问 URL 管理器查看要爬取的 URL,因为它是可访问的。如果返回是传递一个要爬取的URL给调用者,调度器要求下载器将网页对应的URL下载下来返回给调度器。调度器将下载的网页发送给解析器进行分析,解析后返回给调度器。此时,数据已经初步形成,可以进一步使用。如此循环,直到 URL 管理器为空或数据量足够大。
网址管理器
URL 管理器:管理要爬取的 URL 集合和已爬取的 URL 集合。主要实现以下功能。
向要抓取的集合添加新 URL。
判断要添加的URL是否在容器中。
获取要抓取的网址。
判断该网址是否仍需抓取。
将要抓取的网址移动到已抓取。
实现方法:
内存:python集合集合
关系型数据库、MySQL、urls(url, is_crawled)
缓存数据库:redis 集合集合
网页下载器
网页下载器:一种将互联网上的URL对应的网页下载到本地的工具。
刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习群:227-435-450即可获取,内附:开发工具和安装包,以及python系统学习路线图
网页下载器
urllib2-python-official 基础模块
请求-第三方更强大
如何使用 urllab2 下载器:
最简单的方法:直接写链接,索取。
php 爬虫抓取网页数据(如何实现一个爬虫找到目标.跟具url发起请求3.解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-04 12:11
大数据数据库时代:如何产生数据:1.大公司,大公司:用户产生的用户2.大数据平台:通过采集或与其他公司或公司合作3.大机构国家政府:4.数据咨询公司通过省、县、乡统计或其他方式产生的数据:通过采集或与其他企业或公司合作,对数据进行分析比较形成报告5.@ > 最后,当以上方法都不够时,我们需要一个爬虫工程师来做特殊的数据提取。1.什么是爬虫?是一个自动获取互联网数据的程序2. 爬虫的目的是什么?搜索引擎比价工具(慧慧购物助手)大新闻网站(今日头条)
网站的三个特点:
生态完整,用途广泛(后端移动端.....)。Java爬虫是python最大的竞争对手,但是java代码量比较大,重构成本比较高。C/c++:爬虫绝对可以完成,运行效率很高,但是门槛很高。每个模型可能需要你自己封装和定制python:语法简单,代码漂亮,可读性高,对每个模块的支持更好。有一个非常强大的三方包,可以很好地处理多任务。urllib 和 requests 可以帮助我们实现一个爬虫项目。有很多解析库页面(lxml、bs4、pyquery...),也有非常强大的scrapy爬虫框架和scrapy-readis分布式爬虫框架,而python是一种胶水语言,非常方便其他语言的调度。爬虫分为两类: 一般爬虫:一般爬虫正在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、粉刺、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商
DNS:一种将我们的域名转换为 ip 的技术
爬虫(搜索引擎)的缺点:1.需要遵循roboot协议:Robots协议(又称爬虫协议、机器人协议等)就是“机器人排除协议”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。2.搜索引擎针对性不强,无法针对特殊用户群返回相应数据。3. 搜索引擎一般获取文本信息、处理图像、音频。视频多媒体还是难以聚焦的爬虫:它是面向主题的爬虫,由需求生成,是定向爬虫,在爬取网页数据时,会选择网页数据,保证与需求相关的数据是被俘。将来,我们会更加关注爬虫需要掌握的知识1.pyton的基本语法2.前端知识3.数据持久化知识4.基本的反爬取手段(header请求头验证码coolies proxy) 5.@> 静态页面动态页面(ajax、js)、selenium(获取的页码为浏览器渲染后的最终结果) 6. 多任务多处理、Crawler框架、分布式爬虫等 HTTP:超文本协议,主要用于将 HTML 文本传递给本地浏览器。HTTPS:功能与HTTP相同,但增加了SSL(Secure Socket Layer),保证数据传输通道的安全1.在小区外建立安全有效的数据传输通道,保证数据安全2.
2xx:表示服务器成功接收到请求,已经完成了整个处理过程。200(OK 请求成功)。3xx:为了完成请求,客户端需要进一步细化请求。例如:请求的资源已经移动到新的地址,常用 301:永久重定向 302:临时重定向(请求的页面已经临时转移到新的url) 4xx:客户端的请求有错误。400:请求错误,服务器无法解析请求 401:未经授权,未认证 403:服务器拒绝访问 404:服务器找不到请求的网页 408:请求超时 5xx:服务器错误 500:服务器内部错误 501:服务器没有完成请求的功能 503 : 服务器不可用 查看全部
php 爬虫抓取网页数据(如何实现一个爬虫找到目标.跟具url发起请求3.解析)
大数据数据库时代:如何产生数据:1.大公司,大公司:用户产生的用户2.大数据平台:通过采集或与其他公司或公司合作3.大机构国家政府:4.数据咨询公司通过省、县、乡统计或其他方式产生的数据:通过采集或与其他企业或公司合作,对数据进行分析比较形成报告5.@ > 最后,当以上方法都不够时,我们需要一个爬虫工程师来做特殊的数据提取。1.什么是爬虫?是一个自动获取互联网数据的程序2. 爬虫的目的是什么?搜索引擎比价工具(慧慧购物助手)大新闻网站(今日头条)
网站的三个特点:
生态完整,用途广泛(后端移动端.....)。Java爬虫是python最大的竞争对手,但是java代码量比较大,重构成本比较高。C/c++:爬虫绝对可以完成,运行效率很高,但是门槛很高。每个模型可能需要你自己封装和定制python:语法简单,代码漂亮,可读性高,对每个模块的支持更好。有一个非常强大的三方包,可以很好地处理多任务。urllib 和 requests 可以帮助我们实现一个爬虫项目。有很多解析库页面(lxml、bs4、pyquery...),也有非常强大的scrapy爬虫框架和scrapy-readis分布式爬虫框架,而python是一种胶水语言,非常方便其他语言的调度。爬虫分为两类: 一般爬虫:一般爬虫正在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、粉刺、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商 一般爬虫在浏览浏览器的重要部分是将互联网上的所有网页下载到本地,做镜像备份,提取重要数据(过滤数据、祛痘、去除广告...)。步骤其实和上面描述的搜索引擎爬行类似。转到上述方法得到的url???1.via网站2. 网页提交url:(百度:)3. 各大搜索引擎公司也将合作DNS 服务提供商
DNS:一种将我们的域名转换为 ip 的技术
爬虫(搜索引擎)的缺点:1.需要遵循roboot协议:Robots协议(又称爬虫协议、机器人协议等)就是“机器人排除协议”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。2.搜索引擎针对性不强,无法针对特殊用户群返回相应数据。3. 搜索引擎一般获取文本信息、处理图像、音频。视频多媒体还是难以聚焦的爬虫:它是面向主题的爬虫,由需求生成,是定向爬虫,在爬取网页数据时,会选择网页数据,保证与需求相关的数据是被俘。将来,我们会更加关注爬虫需要掌握的知识1.pyton的基本语法2.前端知识3.数据持久化知识4.基本的反爬取手段(header请求头验证码coolies proxy) 5.@> 静态页面动态页面(ajax、js)、selenium(获取的页码为浏览器渲染后的最终结果) 6. 多任务多处理、Crawler框架、分布式爬虫等 HTTP:超文本协议,主要用于将 HTML 文本传递给本地浏览器。HTTPS:功能与HTTP相同,但增加了SSL(Secure Socket Layer),保证数据传输通道的安全1.在小区外建立安全有效的数据传输通道,保证数据安全2.
2xx:表示服务器成功接收到请求,已经完成了整个处理过程。200(OK 请求成功)。3xx:为了完成请求,客户端需要进一步细化请求。例如:请求的资源已经移动到新的地址,常用 301:永久重定向 302:临时重定向(请求的页面已经临时转移到新的url) 4xx:客户端的请求有错误。400:请求错误,服务器无法解析请求 401:未经授权,未认证 403:服务器拒绝访问 404:服务器找不到请求的网页 408:请求超时 5xx:服务器错误 500:服务器内部错误 501:服务器没有完成请求的功能 503 : 服务器不可用
php 爬虫抓取网页数据(网络爬虫程序高效,编程结构好..(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-03 10:24
网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,建立相关的全文索引到数据库,然后跳转到另一个网站。它看起来像一只大蜘蛛。
当人们在互联网上搜索关键字(例如google)时,他们实际上是在比较数据库中的内容,以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力,比如google搜索引擎明显优于百度,因为它的网络爬虫程序效率高,编程结构好。 一、什么是爬虫
首先简单了解一下爬虫。也就是请求网站,提取自己需要的数据的过程。至于怎么爬,怎么爬,就是后面要学的内容了,暂时不用讲了。通过我们的程序,我们可以代替我们向服务器发送请求,然后批量下载大量数据。
二、爬取的基本过程
Initiate a request:通过URL向服务器发起请求请求。请求可以收录额外的标头信息。
获取响应内容:如果服务器正常响应,那么我们会收到一个响应,就是我们请求的网页的内容,可能收录HTML、Json字符串或二进制数据(视频、图片)等。
解析内容:如果是HTML代码,可以通过网页解析器解析,如果是Json数据,可以转换成Json对象进行分析,如果是二进制数据,可以保存到一个文件以供进一步处理。
保存数据:可以保存到本地文件或数据库(MySQL、Redis、Mongodb等)
三、请求收录什么
当我们通过浏览器向服务器发送请求时,请求中收录哪些信息?我们可以用chrome的开发者工具来讲解(如果不知道怎么用,看这个说明)。
请求方式:最常用的请求方式包括get请求和post请求。开发中最常见的 post 请求是通过表单提交。从用户的角度来看,最常见的就是登录验证。当你需要输入一些信息进行登录时,这个请求就是一个post请求。
URL Uniform Resource Locator:URL、图片、视频等都可以通过url来定义。当我们请求一个网页时,我们可以查看网络标签。第一个通常是一个文档,表示这个文档是没有外部图片、css、js等渲染出来的html代码,下面我们会看到这个文档到一系列的jpg、js等,这个又是请求并再次由浏览器根据html代码,请求的地址为html文档中图片、js等的url地址
request headers:请求头,包括本次请求的请求类型、cookie信息、浏览器类型等,这个请求头在我们抓取网页的时候还是很有用的。服务器将通过解析请求头来查看信息,并确定该请求是一个合法的请求。所以当我们假装浏览器通过程序发出请求时,我们可以设置请求头信息。
Request body:post请求会将用户信息打包在form-data中进行提交,所以相比get请求,post请求的headers标签内容会收录更多的Form Data信息包。 get请求可以简单理解为普通的搜索回车,信息会每隔一段时间添加到url的末尾。
四、响应收录什么
响应状态:可以通过Headers中的General查看状态码。 200表示成功、301重定向、404页面未找到、502服务器错误等
响应头:包括内容类型、cookie信息等
响应体:请求的目的是获取响应体,包括html代码、Json、二进制数据。
五、简单请求演示
通过 Python 的请求库发出网页请求:
输出结果是尚未渲染的网页代码,即请求体的内容。可以在响应头中查看信息:
查看状态代码:
您也可以在请求信息中添加请求头:
获取图片(百度标志):
六、如何解决 JavaScript 渲染问题
使用 Selenium 网络驱动程序
输入print(driver.page_source),可以看到这次的代码是渲染后的代码。
【备注】chrome浏览器的使用
Elements 标签显示显示的 HTML 代码。
在网络标签下有浏览器请求的数据。点击查看详细信息,如上面提到的请求头、响应头等。
以上是什么是爬虫?爬行的基本过程是什么?更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php 爬虫抓取网页数据(网络爬虫程序高效,编程结构好..(一))
网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,建立相关的全文索引到数据库,然后跳转到另一个网站。它看起来像一只大蜘蛛。
当人们在互联网上搜索关键字(例如google)时,他们实际上是在比较数据库中的内容,以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力,比如google搜索引擎明显优于百度,因为它的网络爬虫程序效率高,编程结构好。 一、什么是爬虫
首先简单了解一下爬虫。也就是请求网站,提取自己需要的数据的过程。至于怎么爬,怎么爬,就是后面要学的内容了,暂时不用讲了。通过我们的程序,我们可以代替我们向服务器发送请求,然后批量下载大量数据。
二、爬取的基本过程
Initiate a request:通过URL向服务器发起请求请求。请求可以收录额外的标头信息。
获取响应内容:如果服务器正常响应,那么我们会收到一个响应,就是我们请求的网页的内容,可能收录HTML、Json字符串或二进制数据(视频、图片)等。
解析内容:如果是HTML代码,可以通过网页解析器解析,如果是Json数据,可以转换成Json对象进行分析,如果是二进制数据,可以保存到一个文件以供进一步处理。
保存数据:可以保存到本地文件或数据库(MySQL、Redis、Mongodb等)
三、请求收录什么
当我们通过浏览器向服务器发送请求时,请求中收录哪些信息?我们可以用chrome的开发者工具来讲解(如果不知道怎么用,看这个说明)。
请求方式:最常用的请求方式包括get请求和post请求。开发中最常见的 post 请求是通过表单提交。从用户的角度来看,最常见的就是登录验证。当你需要输入一些信息进行登录时,这个请求就是一个post请求。
URL Uniform Resource Locator:URL、图片、视频等都可以通过url来定义。当我们请求一个网页时,我们可以查看网络标签。第一个通常是一个文档,表示这个文档是没有外部图片、css、js等渲染出来的html代码,下面我们会看到这个文档到一系列的jpg、js等,这个又是请求并再次由浏览器根据html代码,请求的地址为html文档中图片、js等的url地址
request headers:请求头,包括本次请求的请求类型、cookie信息、浏览器类型等,这个请求头在我们抓取网页的时候还是很有用的。服务器将通过解析请求头来查看信息,并确定该请求是一个合法的请求。所以当我们假装浏览器通过程序发出请求时,我们可以设置请求头信息。
Request body:post请求会将用户信息打包在form-data中进行提交,所以相比get请求,post请求的headers标签内容会收录更多的Form Data信息包。 get请求可以简单理解为普通的搜索回车,信息会每隔一段时间添加到url的末尾。
四、响应收录什么
响应状态:可以通过Headers中的General查看状态码。 200表示成功、301重定向、404页面未找到、502服务器错误等
响应头:包括内容类型、cookie信息等
响应体:请求的目的是获取响应体,包括html代码、Json、二进制数据。
五、简单请求演示
通过 Python 的请求库发出网页请求:
输出结果是尚未渲染的网页代码,即请求体的内容。可以在响应头中查看信息:
查看状态代码:
您也可以在请求信息中添加请求头:
获取图片(百度标志):
六、如何解决 JavaScript 渲染问题
使用 Selenium 网络驱动程序
输入print(driver.page_source),可以看到这次的代码是渲染后的代码。
【备注】chrome浏览器的使用
Elements 标签显示显示的 HTML 代码。
在网络标签下有浏览器请求的数据。点击查看详细信息,如上面提到的请求头、响应头等。
以上是什么是爬虫?爬行的基本过程是什么?更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-03 10:24
python 和 PHP 相比,python 适合爬取。原因如下
抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做以上的功能,但是python可以做的最快最干净。人生苦短,你需要python。
py对于linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能和python的开发效率相提并论的语言是rudy)语言简洁,没有那么多技巧,所以很容易阅读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”。
NO.3 说明(无需直接编译、运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP 脚本主要用于以下三个方面:
服务器脚本。这是PHP最传统也是最主要的目标领域。开展这项工作需要以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
上的 PHP 页面
结束。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法对易很重要
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可以用于处理
组织简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写
一些程序。这样,您也可以编写跨平台的应用程序。 PHP-GTK 是 PHP 的扩展,不收录在常用的 PHP 包中。
网友观点延伸:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
Node.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,这些问题都可以通过Step等过程控制工具来解决。
最后说说Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
python 和 PHP 相比,python 适合爬取。原因如下
抓取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如perl、shell,python的urllib2包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。 python中有优秀的第三方包帮你搞定,比如Requests,mechanize
网页抓取后的处理
获取的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做以上的功能,但是python可以做的最快最干净。人生苦短,你需要python。
py对于linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能和python的开发效率相提并论的语言是rudy)语言简洁,没有那么多技巧,所以很容易阅读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”。
NO.3 说明(无需直接编译、运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP 脚本主要用于以下三个方面:
服务器脚本。这是PHP最传统也是最主要的目标领域。开展这项工作需要以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
上的 PHP 页面
结束。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法对易很重要
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可以用于处理
组织简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写
一些程序。这样,您也可以编写跨平台的应用程序。 PHP-GTK 是 PHP 的扩展,不收录在常用的 PHP 包中。
网友观点延伸:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
Node.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,这些问题都可以通过Step等过程控制工具来解决。
最后说说Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章
php 爬虫抓取网页数据(php爬虫,抓取网页数据都有一个常用的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-02 20:02
php爬虫抓取网页数据都有一个常用的方法formaction,即请求处理机制,这个是php程序员经常要解决的问题。如果遇到一个页面无数据请求,这个时候只用php爬虫抓取就要翻很多的坑,代价很大,要进行操作封装和重写。而java或javascript就不同了,他们有自己的这种请求处理机制,通过使用javascript来处理网页内容。
解决方法就是在http协议中,http方法多一个connection,有关协议以及相关规则,请看百度。以上解释,是指在程序员通过使用java或javascript实现的业务的情况下,能够使用java或javascript对网页内容进行抓取。新的机制browser_id机制ios用户也要解决这个问题,只不过那个时候智能手机才刚刚进入。
chrome浏览器也刚刚开始网页开发。在当时,使用ios应用的,都是windows兼容机设备。比如我们用flash播放一个html文件的时候,他是需要安装flash插件才能使用的。这样会引起一些兼容性的问题。在java.util.scanner类下有个自定义的connection,可以完成在浏览器和javajava应用程序间的请求。
让我们来看下ie11开始,添加一个mysql支持。这个工作交给java来做。而非是由java使用这种browser_id机制。原因有这些:。
1、php程序员要实现自己想要的技术,这是一个代价很大的技术选择。
2、由于浏览器使用的是自己的tcp连接,网页的内容可以实现在不同的设备上访问,使用mysql其实不需要考虑各设备,只要对上就行。ie11出来后,,腾讯,百度等多家公司推出自己的java应用程序,有的是自己开发,有的是直接封装成web服务器,有的则是直接使用ie访问这些应用。
3、假如我们自己开发的应用不会出现被、腾讯、百度等公司连接,使用浏览器的http协议。那怎么办,需要封装ie访问,并且封装成连接服务器,或者只是使用一个浏览器去访问。这样http协议还要做很多反爬虫机制,比如这里就有人想过用java开发一个简单的动态网站,通过抓取首页的数据。这个并不是个合理的思路。
但是像这种情况,不考虑封装这样的应用来服务于对于程序员的考验。而是仅仅利用http协议封装的应用。比如我们php开发一个保存一个文件夹到tomcat服务器,修改mysql数据库,使用bootstrap封装了个client,发现访问的用户还是apache或nginx这些反爬虫机制还需要对应封装。如果我们仅仅只是封装了ie,那岂不是白封装了么。
所以这里封装ie。(即使此时给ie开发一个监听端口的ie服务器,一样可以正常访问数据库)因为单纯封装ie服务器意义不大, 查看全部
php 爬虫抓取网页数据(php爬虫,抓取网页数据都有一个常用的方法)
php爬虫抓取网页数据都有一个常用的方法formaction,即请求处理机制,这个是php程序员经常要解决的问题。如果遇到一个页面无数据请求,这个时候只用php爬虫抓取就要翻很多的坑,代价很大,要进行操作封装和重写。而java或javascript就不同了,他们有自己的这种请求处理机制,通过使用javascript来处理网页内容。
解决方法就是在http协议中,http方法多一个connection,有关协议以及相关规则,请看百度。以上解释,是指在程序员通过使用java或javascript实现的业务的情况下,能够使用java或javascript对网页内容进行抓取。新的机制browser_id机制ios用户也要解决这个问题,只不过那个时候智能手机才刚刚进入。
chrome浏览器也刚刚开始网页开发。在当时,使用ios应用的,都是windows兼容机设备。比如我们用flash播放一个html文件的时候,他是需要安装flash插件才能使用的。这样会引起一些兼容性的问题。在java.util.scanner类下有个自定义的connection,可以完成在浏览器和javajava应用程序间的请求。
让我们来看下ie11开始,添加一个mysql支持。这个工作交给java来做。而非是由java使用这种browser_id机制。原因有这些:。
1、php程序员要实现自己想要的技术,这是一个代价很大的技术选择。
2、由于浏览器使用的是自己的tcp连接,网页的内容可以实现在不同的设备上访问,使用mysql其实不需要考虑各设备,只要对上就行。ie11出来后,,腾讯,百度等多家公司推出自己的java应用程序,有的是自己开发,有的是直接封装成web服务器,有的则是直接使用ie访问这些应用。
3、假如我们自己开发的应用不会出现被、腾讯、百度等公司连接,使用浏览器的http协议。那怎么办,需要封装ie访问,并且封装成连接服务器,或者只是使用一个浏览器去访问。这样http协议还要做很多反爬虫机制,比如这里就有人想过用java开发一个简单的动态网站,通过抓取首页的数据。这个并不是个合理的思路。
但是像这种情况,不考虑封装这样的应用来服务于对于程序员的考验。而是仅仅利用http协议封装的应用。比如我们php开发一个保存一个文件夹到tomcat服务器,修改mysql数据库,使用bootstrap封装了个client,发现访问的用户还是apache或nginx这些反爬虫机制还需要对应封装。如果我们仅仅只是封装了ie,那岂不是白封装了么。
所以这里封装ie。(即使此时给ie开发一个监听端口的ie服务器,一样可以正常访问数据库)因为单纯封装ie服务器意义不大,
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-02 17:01
大数据时代发展迅猛,爬虫爬取尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的东西呢?数据?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,这意味着我们需要设置爬取信息的时间间隔来避免被爬取网站服务器更新了,我们所做的一切都没有用。
2、一些网站阻塞爬虫
有些网站会设置反爬虫程序,以防止一些恶意爬虫。你会发现浏览器上显示了很多数据,但是无法抓取。
3、垃圾问题
当然,在我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候我们抓取网页信息后,会发现我们抓取的信息是乱码。
4、数据分析
其实到此,我们的工作已经基本成功了一半以上,但是数据分析的工作量非常大,完成庞大的数据分析需要很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬取必须在合法的范围内进行。你可以从别人的数据和信息中学习,但不要照原样复制。毕竟,其他人在数据写入方面的辛勤工作也很重要。不容易。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候需要查看http头信息,需要分析选择哪种压缩方式,后面需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括早期的设置也有ip服务,包括后期的数据分析工作,操作简单。
总之,无论是手动抓取还是软件抓取,都需要足够的耐心和坚持。 查看全部
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
大数据时代发展迅猛,爬虫爬取尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的东西呢?数据?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,这意味着我们需要设置爬取信息的时间间隔来避免被爬取网站服务器更新了,我们所做的一切都没有用。
2、一些网站阻塞爬虫
有些网站会设置反爬虫程序,以防止一些恶意爬虫。你会发现浏览器上显示了很多数据,但是无法抓取。
3、垃圾问题
当然,在我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候我们抓取网页信息后,会发现我们抓取的信息是乱码。
4、数据分析
其实到此,我们的工作已经基本成功了一半以上,但是数据分析的工作量非常大,完成庞大的数据分析需要很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬取必须在合法的范围内进行。你可以从别人的数据和信息中学习,但不要照原样复制。毕竟,其他人在数据写入方面的辛勤工作也很重要。不容易。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候需要查看http头信息,需要分析选择哪种压缩方式,后面需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括早期的设置也有ip服务,包括后期的数据分析工作,操作简单。
总之,无论是手动抓取还是软件抓取,都需要足够的耐心和坚持。
php 爬虫抓取网页数据( 请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-31 16:31
请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
**Request:**用户通过浏览器(socket client)向服务器(socket server)发送信息
**Response: **服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、js、css等)
**ps:** 浏览器收到Response后,解析其内容展示给用户,爬虫程序模拟浏览器发送请求后提取有用数据,然后接收响应.
四、 请求
1、请求方式:
常见的请求方式:GET / POST
2、请求的网址
URL 全局统一资源定位器,用于定义互联网上唯一的资源。例如:一张图片,一个文件,一个视频可以通过url唯一确定
网址编码
图片
图片将被编码(见示例代码)
网页的加载过程为:
加载网页,一般是先加载文档文档,
解析文档时,如果遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会把你当成非法用户主机;
Cookies:cookies用于保存登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从何而来?(一些大型网站会使用Referrer作为反盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问过的浏览器(需添加,否则将被视为爬虫)
(3)cookie:注意携带请求头
4、请求正文
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):276 3177 065 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
五、 响应 响应
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,但是要告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬取过程总结:
爬行—>分析—>存储
2、爬虫所需的工具:
**请求库:**requests、selenium(可以驱动浏览器解析渲染CSS和JS,但是有性能劣势(有用和没用的网页都会加载);)**分析库:**常规、beautifulsoup、pyquery **Repository: **File、MySQL、Mongodb、Redis
如何领取python福利教程:
1、赞+评论(勾选“同步转发”)
2、关注小编。并私信回复关键词[19]
(必须有私信~点我头像看私信按钮) 查看全部
php 爬虫抓取网页数据(
请求头需要注意的参数:请求3、*ps:*浏览器接收请求)
**Request:**用户通过浏览器(socket client)向服务器(socket server)发送信息
**Response: **服务器收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如图片、js、css等)
**ps:** 浏览器收到Response后,解析其内容展示给用户,爬虫程序模拟浏览器发送请求后提取有用数据,然后接收响应.
四、 请求
1、请求方式:
常见的请求方式:GET / POST
2、请求的网址
URL 全局统一资源定位器,用于定义互联网上唯一的资源。例如:一张图片,一个文件,一个视频可以通过url唯一确定
网址编码
图片
图片将被编码(见示例代码)
网页的加载过程为:
加载网页,一般是先加载文档文档,
解析文档时,如果遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会把你当成非法用户主机;
Cookies:cookies用于保存登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从何而来?(一些大型网站会使用Referrer作为反盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问过的浏览器(需添加,否则将被视为爬虫)
(3)cookie:注意携带请求头
4、请求正文
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):276 3177 065 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
五、 响应 响应
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能不止一个,但是要告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬取过程总结:
爬行—>分析—>存储
2、爬虫所需的工具:
**请求库:**requests、selenium(可以驱动浏览器解析渲染CSS和JS,但是有性能劣势(有用和没用的网页都会加载);)**分析库:**常规、beautifulsoup、pyquery **Repository: **File、MySQL、Mongodb、Redis
如何领取python福利教程:
1、赞+评论(勾选“同步转发”)
2、关注小编。并私信回复关键词[19]
(必须有私信~点我头像看私信按钮)
php 爬虫抓取网页数据( 对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 05:08
对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)
网络爬虫调查结果王阳斌爬虫工具和代码调查调查主要内容是关于PHP和Java的工具代码1Java爬虫11JAVA爬虫WebCollector爬虫介绍WebCollector[]是一个不需要配置的JAVA方便二次开发 爬虫框架核心 提供精简的API,只需少量代码即可实现强大的爬虫核心。WebCollector 致力于维护一个稳定可扩展的爬虫核心,供开发者进行灵活的二次开发。内核非常强大。12Web-HarvestWeb -Harvest[]是一款使用广泛的Java语言编写的网络爬虫工具。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源的 Web 数据提取工具,可以采集
指定的 Web Pages 并从这些页面中提取有用的数据。Web-Harvest主要使用XSLTXQuery正则表、党员人数考察表和毫米对照表、教师职称等级表、员工考核分数表、普通年金现值系数表达式等技术来实现textxml 的操作 13Java 网络爬虫JSpiderJSpider[] 是一个用Java 实现的WebSpider。JSpider 的行为由配置文件具体配置。比如使用什么插件结果存储方式等,在conf[ConfigName]目录下设置JSpider的默认配置。类型少,用处不大,但是JSpider非常容易扩展。您可以使用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据自己的需要开发插件并编写配置文件。14 网络爬虫 HeritrixHeritrix[] 是一个开源且可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robotstxt 文件和 METArobots 标签的排除说明。其最突出的特点是其良好的可扩展性。方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架。它的组织结构包括整个组件和爬虫过程。灵活的API只需少量代码即可实现爬虫 webmagic采用全模块化设计功能覆盖爬虫整个生命周期链接提取页面下载合同下载合同模板下载红色头文件模板免费下载简历免费下载模板工作简历模板免费下载内容提取持久化支持多线程爬取、分布式爬取和自动重试、自定义UAcookie等功能。16 Java多线程网络爬虫Crawler4jCrawler4j[]是一个开源的Java类库,提供了一个简单的网页抓取接口,可以用来构建多线程的网络爬虫。17Java网络蜘蛛网络爬虫SpidermanSpiderman[]是一个基于微内核插件架构的网络蜘蛛。它的目标是以简单的方式捕获和解析复杂的目标网页信息。需要的业务数据 2CC 爬虫 21 网站爬虫 GrubNextGenerationGrubNextGeneration[] 是一个子
分布式网络爬虫系统包括客户端和服务器,可用于维护网页的索引。其开发语言 CCPerlC22 网络爬虫甲醇甲醇[]是一款模块化、可定制的网络爬虫软件。主要优点是速度快。23 网络爬虫网络蜘蛛larbinLarbin[]是法国小伙Sébastien Ailleret自主开发的一款开源网络爬虫网络蜘蛛。Larbin 旨在能够跟踪页面的 URL 以进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin 只是一个爬虫,也就是说,larbin 只是 arbin 至于如何解析网页,如何将其存储到数据库中,以及如何建立索引,完全由用户来完成。Larbin 没有提供一个简单的 larbin 爬虫,每天可以获取 500 万个网页。与拉宾,我们可以轻松获取和确定单个网站。所有链接甚至可以镜像一个网站或使用它来构建一个 url 列表组。比如所有网页urlretrive后,可以获得xml链接或者mp3或者定制的larbin,可以作为搜索引擎信息的来源。24 死链接检查软件 XenuXenuLinkSleuth [] 也许它是您见过的用于检查网站死链接的最小但功能最强大的软件。您可以打开本地网页文件以检查其链接或输入任何 URL 进行检查。它可以单独列出网站的实时链接。链接,死链接,甚至重定向链接都分析得很清楚。它支持多线程,可以将检测结果存储为文本文件或网络文件。Spider136 的发布日期是 04-06-2013。将下载的文件解压,放到apache目录下运行。运算后因构型题乘法口算100题七年级有理数混合计算100题计算机一级题库二元线性方程应用题真心话大冒险爬,我再调试一下。OpenWebSpider[]是一个开源的多线程WebSpiderrobot机器人爬虫爬虫和搜索引擎,有很多有趣的功能 32TSpiderTSpider是一个可执行的图形界面程序,但是爬行过程太慢不适合使用PHPCrawl也是一个使用的爬虫工具php 语言具有更好的扩展性。您可以根据自己的需要更改代码来完成不同的功能。33PHP' s 网络爬虫和搜索引擎 PhpDigPhpDig[] 是用 PHP 开发的网络爬虫和搜索引擎,通过动态和静态页面索引并建立词汇表。搜索时,会按照一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
模板、论文答辩、ppt 模板、赌博协议模板、国考答题卡、国考答题卡、数学答题卡数据图表系统,并且可以索引PDFWordExcel 和PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。是为某个领域搭建垂直搜索引擎的最佳选择。
台站数据采集软件是基于Net平台的开源软件,是网站数据采集软件类型中唯一的开源软件。Soukey虽然选择开源,但不会影响软件功能的提供,甚至比一些商业软件的功能还要多。42网络爬虫程序NWebCrawlerNWebCrawler[]是一个开源的C网络爬虫程序43爬虫小新Sinawler,国内第一个微博数据爬虫程序,原名新浪微博爬虫[]登录后可以指定一个用户作为起点. 追随者和追随者采集
用户基本信息以获取线索并扩展个人关系。微博数据,评论数据。本应用所获得的数据可作为科学研究和新浪微博相关研发的数据支持,但请勿用于商业用途。该应用程序基于 NET20 框架,需要 SQLSERVER。作为后端数据库,它为 SQLServer 提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整。比如粉丝人数限制、微博人数限制等。本节目版权归作者所有。您可以免费复制它。分发、展示和执行当前的工作。制作衍生作品。您不能将当前作品用于商业目的。该模块可以轻松实现爬虫抓取网页内容和各种图片。非常方便。其开发语言为Python52网页抓取/信息提取软件MetaSeeker网页抓取信息提取数据提取软件工具包MetaSeekerGooSeekerV4112[]正式上线,版本免费下载使用源码阅读。自推出以来,一直深受喜爱。主要应用领域。垂直搜索。VerticalSearch 也称为专业搜索。自行安排的定期批量采集
加上可恢复的下载和软件看门狗 WatchDog 确保您高枕无忧。移动互联网、手机搜索、手机混搭、移动社交、移动电子商务都离不开结构化数据内容。DataScraper 实时高效地采集
内容。将捕获的结果文件输出为富含语义元数据的XML格式,确保跨小手机海报尺寸袖子规格尺寸表公章尺寸朋友圈海报尺寸三角带规格尺寸表屏幕显示和高精度信息障碍的数据自动整合处理恢复。移动互联网不是 Web 的子集,而是全部由 MetaSeeker 桥接。企业竞争情报采集数据挖掘,俗称商业智能、商业智能、噪声信息过滤、结构化转换,保证数据的准确性和及时性独特的广域分布式架构赋予DataScraper无与伦比的情报采集和渗透能力。AJAXJavascript 动态页面服务器。动态网页静态页面。各种身份验证机制一视同仁。在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。其他工具由于phpdig很久没有更新旧的工具代码,不能再使用基于python编码的spiderpy和基于C编码的larbin。因此,我们没有做深入调查,了解是否有需要,我们会进行深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 查看全部
php 爬虫抓取网页数据(
对网页爬虫的调查结果调查主要调查内容是关于PHP和Java的工具代码1)
网络爬虫调查结果王阳斌爬虫工具和代码调查调查主要内容是关于PHP和Java的工具代码1Java爬虫11JAVA爬虫WebCollector爬虫介绍WebCollector[]是一个不需要配置的JAVA方便二次开发 爬虫框架核心 提供精简的API,只需少量代码即可实现强大的爬虫核心。WebCollector 致力于维护一个稳定可扩展的爬虫核心,供开发者进行灵活的二次开发。内核非常强大。12Web-HarvestWeb -Harvest[]是一款使用广泛的Java语言编写的网络爬虫工具。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源的 Web 数据提取工具,可以采集
指定的 Web Pages 并从这些页面中提取有用的数据。Web-Harvest主要使用XSLTXQuery正则表、党员人数考察表和毫米对照表、教师职称等级表、员工考核分数表、普通年金现值系数表达式等技术来实现textxml 的操作 13Java 网络爬虫JSpiderJSpider[] 是一个用Java 实现的WebSpider。JSpider 的行为由配置文件具体配置。比如使用什么插件结果存储方式等,在conf[ConfigName]目录下设置JSpider的默认配置。类型少,用处不大,但是JSpider非常容易扩展。您可以使用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据自己的需要开发插件并编写配置文件。14 网络爬虫 HeritrixHeritrix[] 是一个开源且可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robotstxt 文件和 METArobots 标签的排除说明。其最突出的特点是其良好的可扩展性。方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架。它的组织结构包括整个组件和爬虫过程。灵活的API只需少量代码即可实现爬虫 webmagic采用全模块化设计功能覆盖爬虫整个生命周期链接提取页面下载合同下载合同模板下载红色头文件模板免费下载简历免费下载模板工作简历模板免费下载内容提取持久化支持多线程爬取、分布式爬取和自动重试、自定义UAcookie等功能。16 Java多线程网络爬虫Crawler4jCrawler4j[]是一个开源的Java类库,提供了一个简单的网页抓取接口,可以用来构建多线程的网络爬虫。17Java网络蜘蛛网络爬虫SpidermanSpiderman[]是一个基于微内核插件架构的网络蜘蛛。它的目标是以简单的方式捕获和解析复杂的目标网页信息。需要的业务数据 2CC 爬虫 21 网站爬虫 GrubNextGenerationGrubNextGeneration[] 是一个子
分布式网络爬虫系统包括客户端和服务器,可用于维护网页的索引。其开发语言 CCPerlC22 网络爬虫甲醇甲醇[]是一款模块化、可定制的网络爬虫软件。主要优点是速度快。23 网络爬虫网络蜘蛛larbinLarbin[]是法国小伙Sébastien Ailleret自主开发的一款开源网络爬虫网络蜘蛛。Larbin 旨在能够跟踪页面的 URL 以进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin 只是一个爬虫,也就是说,larbin 只是 arbin 至于如何解析网页,如何将其存储到数据库中,以及如何建立索引,完全由用户来完成。Larbin 没有提供一个简单的 larbin 爬虫,每天可以获取 500 万个网页。与拉宾,我们可以轻松获取和确定单个网站。所有链接甚至可以镜像一个网站或使用它来构建一个 url 列表组。比如所有网页urlretrive后,可以获得xml链接或者mp3或者定制的larbin,可以作为搜索引擎信息的来源。24 死链接检查软件 XenuXenuLinkSleuth [] 也许它是您见过的用于检查网站死链接的最小但功能最强大的软件。您可以打开本地网页文件以检查其链接或输入任何 URL 进行检查。它可以单独列出网站的实时链接。链接,死链接,甚至重定向链接都分析得很清楚。它支持多线程,可以将检测结果存储为文本文件或网络文件。Spider136 的发布日期是 04-06-2013。将下载的文件解压,放到apache目录下运行。运算后因构型题乘法口算100题七年级有理数混合计算100题计算机一级题库二元线性方程应用题真心话大冒险爬,我再调试一下。OpenWebSpider[]是一个开源的多线程WebSpiderrobot机器人爬虫爬虫和搜索引擎,有很多有趣的功能 32TSpiderTSpider是一个可执行的图形界面程序,但是爬行过程太慢不适合使用PHPCrawl也是一个使用的爬虫工具php 语言具有更好的扩展性。您可以根据自己的需要更改代码来完成不同的功能。33PHP' s 网络爬虫和搜索引擎 PhpDigPhpDig[] 是用 PHP 开发的网络爬虫和搜索引擎,通过动态和静态页面索引并建立词汇表。搜索时,会按照一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
模板、论文答辩、ppt 模板、赌博协议模板、国考答题卡、国考答题卡、数学答题卡数据图表系统,并且可以索引PDFWordExcel 和PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。是为某个领域搭建垂直搜索引擎的最佳选择。
台站数据采集软件是基于Net平台的开源软件,是网站数据采集软件类型中唯一的开源软件。Soukey虽然选择开源,但不会影响软件功能的提供,甚至比一些商业软件的功能还要多。42网络爬虫程序NWebCrawlerNWebCrawler[]是一个开源的C网络爬虫程序43爬虫小新Sinawler,国内第一个微博数据爬虫程序,原名新浪微博爬虫[]登录后可以指定一个用户作为起点. 追随者和追随者采集
用户基本信息以获取线索并扩展个人关系。微博数据,评论数据。本应用所获得的数据可作为科学研究和新浪微博相关研发的数据支持,但请勿用于商业用途。该应用程序基于 NET20 框架,需要 SQLSERVER。作为后端数据库,它为 SQLServer 提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整。比如粉丝人数限制、微博人数限制等。本节目版权归作者所有。您可以免费复制它。分发、展示和执行当前的工作。制作衍生作品。您不能将当前作品用于商业目的。该模块可以轻松实现爬虫抓取网页内容和各种图片。非常方便。其开发语言为Python52网页抓取/信息提取软件MetaSeeker网页抓取信息提取数据提取软件工具包MetaSeekerGooSeekerV4112[]正式上线,版本免费下载使用源码阅读。自推出以来,一直深受喜爱。主要应用领域。垂直搜索。VerticalSearch 也称为专业搜索。自行安排的定期批量采集
加上可恢复的下载和软件看门狗 WatchDog 确保您高枕无忧。移动互联网、手机搜索、手机混搭、移动社交、移动电子商务都离不开结构化数据内容。DataScraper 实时高效地采集
内容。将捕获的结果文件输出为富含语义元数据的XML格式,确保跨小手机海报尺寸袖子规格尺寸表公章尺寸朋友圈海报尺寸三角带规格尺寸表屏幕显示和高精度信息障碍的数据自动整合处理恢复。移动互联网不是 Web 的子集,而是全部由 MetaSeeker 桥接。企业竞争情报采集数据挖掘,俗称商业智能、商业智能、噪声信息过滤、结构化转换,保证数据的准确性和及时性独特的广域分布式架构赋予DataScraper无与伦比的情报采集和渗透能力。AJAXJavascript 动态页面服务器。动态网页静态页面。各种身份验证机制一视同仁。在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。其他工具由于phpdig很久没有更新旧的工具代码,不能再使用基于python编码的spiderpy和基于C编码的larbin。因此,我们没有做深入调查,了解是否有需要,我们会进行深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页 我们没有做深入调查了解如果有需要,我们会做深入调查。参考文档已阅读,请返回上一页
php 爬虫抓取网页数据(盘点一下php的爬虫框架,你可以更快速的接收内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-26 15:03
Web数据采集是大数据分析的前提。大数据分析只能在海量数据下进行。因此,爬虫(数据抓取)是每个后端开发者都必须知道的技能。我们来看看php。履带式框架。
古特
Goutte 库非常有用,它可以为您提供有关如何使用 PHP 抓取内容的出色支持。它基于 Symfony 框架,提供 API 来抓取网站并从 HTML/XML 响应中抓取数据。它是免费和开源的。基于OOP编程思想,非常适合大型项目爬虫,解析速度相当不错。它需要 php 才能满足 5.5+。
简单的htmldom
这是一个html解析框架,提供了一个类似于jquery的api,让我们操作元素和获取元素非常方便。它的缺点是因为需要加载和分析大量的dom树结构,占用大量内存。同时,它的解析速度不是很快,但它的易用性是其他框架无法比拟的。如果您想抓取少量数据,那么它适合您。
htmlSQL
这是一个非常有趣的php框架,通过它你可以使用类SQL语句来分析网页中的节点。通过这个库,我们可以得到我们想要的任何节点,而无需编写复杂的函数和正则表达式。它提供相对较快的分辨率,但功能有限。它的缺点是不再维护这个库,但使用它可能会改善你的爬虫哲学。
嗡嗡声
一个非常轻量级的爬虫库,类似于浏览器。您可以非常方便地操作 cookie 和设置请求标头。它有一个非常完整的测试文件,所以你可以安心使用它。此外,它还支持http2服务器推送,让您可以更快地接收内容。
狂饮
严格来说,它不是一个爬虫框架。它是提供一个http请求库。它封装了http请求。它有一个简单的操作方法,可以帮助您构建查询字符串、POST 请求和流式大上传。文件、流式下载大文件、使用HTTP cookie、上传JSON 数据等。它可以在相同接口的帮助下发送同步和异步请求。它使用 PSR-7 接口来处理请求、响应和流。这允许您在 Guzzle 中使用其他 PSR-7 兼容库。它可以抽象底层的 HTTP 传输,使您能够编写环境并传输不可知的代码。也就是说,没有对 cURL、PHP 流、套接字或非阻塞事件循环的硬依赖。
要求
如果你接触过python,你一定知道python中有一个非常有用的http请求库,就是request,而这个库就是它的php版本,可以说是囊括了所有的精华要求,使其非常优雅和高效。根据请求,您可以发送 HEAD、GET、POST、PUT、DELETE 和 PATCH HTTP 请求。在请求的帮助下,您可以使用简单的数组添加标头、表单数据、多部分文件和参数,并以相同的方式访问响应数据。
查询列表
使用类似jQuery的选择器采集
,告别复杂的正则表达式,可以非常方便的操作DOM,具备Http网络操作能力,乱码解析能力,内容过滤能力,扩展性强;
可以轻松实现模拟登录、伪造浏览器、HTTP代理等复杂的网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集JavaScript动态渲染的页面。
史努比
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以用来开发一些采集
程序。它封装了很多常用和实用的功能,比如获取所有连接,获取所有纯文本内容等,它的形式模拟是它的亮点之一。
phpspider
中文开发的php爬虫框架,作者用它在知乎上爬取过百万用户。可以说这个框架在执行效率上还是很不错的。另外,作者提供了一个非常好用的命令行工具,通过它我们可以非常方便的部署和查看我们的爬虫效果和进度。 查看全部
php 爬虫抓取网页数据(盘点一下php的爬虫框架,你可以更快速的接收内容)
Web数据采集是大数据分析的前提。大数据分析只能在海量数据下进行。因此,爬虫(数据抓取)是每个后端开发者都必须知道的技能。我们来看看php。履带式框架。
古特
Goutte 库非常有用,它可以为您提供有关如何使用 PHP 抓取内容的出色支持。它基于 Symfony 框架,提供 API 来抓取网站并从 HTML/XML 响应中抓取数据。它是免费和开源的。基于OOP编程思想,非常适合大型项目爬虫,解析速度相当不错。它需要 php 才能满足 5.5+。
简单的htmldom
这是一个html解析框架,提供了一个类似于jquery的api,让我们操作元素和获取元素非常方便。它的缺点是因为需要加载和分析大量的dom树结构,占用大量内存。同时,它的解析速度不是很快,但它的易用性是其他框架无法比拟的。如果您想抓取少量数据,那么它适合您。
htmlSQL
这是一个非常有趣的php框架,通过它你可以使用类SQL语句来分析网页中的节点。通过这个库,我们可以得到我们想要的任何节点,而无需编写复杂的函数和正则表达式。它提供相对较快的分辨率,但功能有限。它的缺点是不再维护这个库,但使用它可能会改善你的爬虫哲学。
嗡嗡声
一个非常轻量级的爬虫库,类似于浏览器。您可以非常方便地操作 cookie 和设置请求标头。它有一个非常完整的测试文件,所以你可以安心使用它。此外,它还支持http2服务器推送,让您可以更快地接收内容。
狂饮
严格来说,它不是一个爬虫框架。它是提供一个http请求库。它封装了http请求。它有一个简单的操作方法,可以帮助您构建查询字符串、POST 请求和流式大上传。文件、流式下载大文件、使用HTTP cookie、上传JSON 数据等。它可以在相同接口的帮助下发送同步和异步请求。它使用 PSR-7 接口来处理请求、响应和流。这允许您在 Guzzle 中使用其他 PSR-7 兼容库。它可以抽象底层的 HTTP 传输,使您能够编写环境并传输不可知的代码。也就是说,没有对 cURL、PHP 流、套接字或非阻塞事件循环的硬依赖。
要求
如果你接触过python,你一定知道python中有一个非常有用的http请求库,就是request,而这个库就是它的php版本,可以说是囊括了所有的精华要求,使其非常优雅和高效。根据请求,您可以发送 HEAD、GET、POST、PUT、DELETE 和 PATCH HTTP 请求。在请求的帮助下,您可以使用简单的数组添加标头、表单数据、多部分文件和参数,并以相同的方式访问响应数据。
查询列表
使用类似jQuery的选择器采集
,告别复杂的正则表达式,可以非常方便的操作DOM,具备Http网络操作能力,乱码解析能力,内容过滤能力,扩展性强;
可以轻松实现模拟登录、伪造浏览器、HTTP代理等复杂的网络请求;拥有丰富的插件,支持多线程采集,使用PhantomJS采集JavaScript动态渲染的页面。
史努比
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以用来开发一些采集
程序。它封装了很多常用和实用的功能,比如获取所有连接,获取所有纯文本内容等,它的形式模拟是它的亮点之一。
phpspider
中文开发的php爬虫框架,作者用它在知乎上爬取过百万用户。可以说这个框架在执行效率上还是很不错的。另外,作者提供了一个非常好用的命令行工具,通过它我们可以非常方便的部署和查看我们的爬虫效果和进度。
php 爬虫抓取网页数据(一下Python爬虫怎样使用代理IP的经验(推荐飞猪))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-22 00:06
【下载文档:Python数据抓取爬虫代理防拦截IP方法.txt】
(友情提示:右击上方txt文件名->目标另存为)
Python数据爬虫代理防堵IP方式爬虫:一种自动爬取互联网信息的程序,从网上抓取对我们有价值的信息,一般来说,Python爬虫程序常用(飞猪IP)代理IP地址来爬取程序,但是默认的urlopen无法使用代理IP,我分享一下Python爬虫如何使用代理IP的经验。 (推荐的飞猪代理IP注册可以免费使用,浏览器搜索可以找到)
1、 为了重点,我在编辑器中使用的是Python3,所以需要导入urllib的请求,然后我们调用ProxyHandler,它可以接收代理IP的参数。可以根据自己的需要选择代理,当然也有免费的,但是可用率可想而知。 (飞猪IP)2、 然后把IP地址以字典的形式放进去。这个IP地址是我乱写的,只是举例。设置key为http,当然有些是https,然后是IP地址和端口号(9000),看你的IP地址是什么类型的,不同的IP端口号可能不同,看你是什么从Fliggy中提取3、然后使用build_opener()构建一个opener对象。4、然后调用构造的opener对象中的open方法进行请求,其实urlopen内部也是这样使用的这里定义的opener.open()相当于我们自己重写了5、当然,如果我们使用install_opener(),我们可以将之前自定义的opener设置为全局。6、设置为全局后,如果我们使用urlopen发送请求,那么发送请求所用的IP地址是代理IP,而不是本机的IP地址。7、最后说一下使用代理时遇到的错误,提示目标计算机主动拒绝,这意味着代理IP可能无效,或者端口号错误,所以需要使用vali d 知识产权。 (这里是随机填写的IP地址)可以选择飞猪的代理IP。 总结:以上是关于Python数据爬虫爬虫代理的IP防拦截方法。感谢您阅读和支持中文源代码网。
亲,试试微信扫码分享本页吧! *^_^* 查看全部
php 爬虫抓取网页数据(一下Python爬虫怎样使用代理IP的经验(推荐飞猪))
【下载文档:Python数据抓取爬虫代理防拦截IP方法.txt】
(友情提示:右击上方txt文件名->目标另存为)
Python数据爬虫代理防堵IP方式爬虫:一种自动爬取互联网信息的程序,从网上抓取对我们有价值的信息,一般来说,Python爬虫程序常用(飞猪IP)代理IP地址来爬取程序,但是默认的urlopen无法使用代理IP,我分享一下Python爬虫如何使用代理IP的经验。 (推荐的飞猪代理IP注册可以免费使用,浏览器搜索可以找到)
1、 为了重点,我在编辑器中使用的是Python3,所以需要导入urllib的请求,然后我们调用ProxyHandler,它可以接收代理IP的参数。可以根据自己的需要选择代理,当然也有免费的,但是可用率可想而知。 (飞猪IP)2、 然后把IP地址以字典的形式放进去。这个IP地址是我乱写的,只是举例。设置key为http,当然有些是https,然后是IP地址和端口号(9000),看你的IP地址是什么类型的,不同的IP端口号可能不同,看你是什么从Fliggy中提取3、然后使用build_opener()构建一个opener对象。4、然后调用构造的opener对象中的open方法进行请求,其实urlopen内部也是这样使用的这里定义的opener.open()相当于我们自己重写了5、当然,如果我们使用install_opener(),我们可以将之前自定义的opener设置为全局。6、设置为全局后,如果我们使用urlopen发送请求,那么发送请求所用的IP地址是代理IP,而不是本机的IP地址。7、最后说一下使用代理时遇到的错误,提示目标计算机主动拒绝,这意味着代理IP可能无效,或者端口号错误,所以需要使用vali d 知识产权。 (这里是随机填写的IP地址)可以选择飞猪的代理IP。 总结:以上是关于Python数据爬虫爬虫代理的IP防拦截方法。感谢您阅读和支持中文源代码网。
亲,试试微信扫码分享本页吧! *^_^*
php 爬虫抓取网页数据(php爬虫抓取网页数据(1)_网页下载二。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-19 19:04
php爬虫抓取网页数据1。网页下载二。爬虫机制1。1构造http代理配置baiduspider类socket转发构造http代理需要加上sign的前缀,将方法重写为fromsocketimport*request='localhost'#构造socket对象q=queryset'subscribe''#转发给subscribe方法是解析subscribe方法的。
querysetfor(;include=0;include=1;include=2;include=3;include=4;include=5;include=6;include=7;include=8;){try{http=socket(sendrequest(''))try{step=squtil。
getunseconds(time。ctime())#gettemporaryquerysend_sqrt(squtil。getattribute('count'))}catch(exceptione){squtil。filter('count',e)1。2发起程序服务与for循环类计算1。3配置http代理1。
4step。1baiduspiderhandler1。4。1构造baiduspiderhandlerstep。1classbaiduspiderhandler:publicchannelhandler{publicstaticfunction__init__(){//加入爬虫step。2baiduspiderhandler();}publicvoid__listen__(http_http){http_listen_server_name=src;}publicvoid__schedule__(http_http,intc,functionpend_path_next(){step。
3next();});}}step。2baiduspiderhandler1。5执行下一步?????2。requests(stringurl)和https(stringurl)的区别2。1首先上一张图图示可以明白区别:(could_jump和get_request_from_setup_if_cancelled的区别)图示上一步jump图示上一步post和put图示上一步data的解析和回调操作图示上一步回调函数这么做主要是避免用户执行一次自动存到cookie中2。2图一图二图三图四图五图六图七图八区别:(。
1)但是用户看到的url/xxx/xxx/xxx但其实并不是从网页源代码中获取的,而是爬虫注册页面采集到的,这样就可以将爬虫伪装成网页自己,
2)admin提交的密码也是保存到cookie中,这样也可以完成自动注册这样还有一个好处就是在后期用户忘记密码时,
3)爬虫api不同这样可以有效保护底层的数据1.4requests(stringurl)和https(stringurl)的区别一个好的爬虫必须要支持自动登录和验证码验证。对于前者,有两种注册方式,一种是自动化提交(complete)注册登录,一种是第三方登录(auth_get_filter)。对于后者,有两种构。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据(1)_网页下载二。)
php爬虫抓取网页数据1。网页下载二。爬虫机制1。1构造http代理配置baiduspider类socket转发构造http代理需要加上sign的前缀,将方法重写为fromsocketimport*request='localhost'#构造socket对象q=queryset'subscribe''#转发给subscribe方法是解析subscribe方法的。
querysetfor(;include=0;include=1;include=2;include=3;include=4;include=5;include=6;include=7;include=8;){try{http=socket(sendrequest(''))try{step=squtil。
getunseconds(time。ctime())#gettemporaryquerysend_sqrt(squtil。getattribute('count'))}catch(exceptione){squtil。filter('count',e)1。2发起程序服务与for循环类计算1。3配置http代理1。
4step。1baiduspiderhandler1。4。1构造baiduspiderhandlerstep。1classbaiduspiderhandler:publicchannelhandler{publicstaticfunction__init__(){//加入爬虫step。2baiduspiderhandler();}publicvoid__listen__(http_http){http_listen_server_name=src;}publicvoid__schedule__(http_http,intc,functionpend_path_next(){step。
3next();});}}step。2baiduspiderhandler1。5执行下一步?????2。requests(stringurl)和https(stringurl)的区别2。1首先上一张图图示可以明白区别:(could_jump和get_request_from_setup_if_cancelled的区别)图示上一步jump图示上一步post和put图示上一步data的解析和回调操作图示上一步回调函数这么做主要是避免用户执行一次自动存到cookie中2。2图一图二图三图四图五图六图七图八区别:(。
1)但是用户看到的url/xxx/xxx/xxx但其实并不是从网页源代码中获取的,而是爬虫注册页面采集到的,这样就可以将爬虫伪装成网页自己,
2)admin提交的密码也是保存到cookie中,这样也可以完成自动注册这样还有一个好处就是在后期用户忘记密码时,
3)爬虫api不同这样可以有效保护底层的数据1.4requests(stringurl)和https(stringurl)的区别一个好的爬虫必须要支持自动登录和验证码验证。对于前者,有两种注册方式,一种是自动化提交(complete)注册登录,一种是第三方登录(auth_get_filter)。对于后者,有两种构。
php 爬虫抓取网页数据(php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-14 05:01
php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端,自动下载的目的是防止网站爬虫抓取或代理页面的一个保护。一:先介绍下抓取目的:1、最好能把建筑教程网手机端链接抓下来2、进行数据提取;二:分析代码;首先需要把链接请求改成测试ok就可以一般建筑教程网的网页地址是:,是没有跳转的那么我们想看下它会不会走网页,我们可以根据http请求内容,先抓一下请求方式;post//可以通过http响应来判断是不是需要浏览器去验证,以及会不会跳转那么如果网站没有被监听,http响应里面也没有连接到域名服务器,那么它的域名服务器的ip就不是我们自己的,我们需要抓包来试一下:还有,我们可以在http请求的cookie之后,修改一下cookie,测试一下是不是又跳转到了我们自己的网站。
我们看到,它的响应头处包含了cookie,我们可以修改cookie来再进行抓包。三:代码实现以下这是我们修改好了cookie之后抓取的抓包:将cookie再刷新一下,看到的http请求在这里:我们是不是可以根据cookie,将指定的http请求再进行http服务器认证一下再判断!。
你会前端开发就会处理下吧?
1.直接用php去获取2.用cookie登录,网上有教程3.python模拟登录,用数据库记录cookie信息,然后post请求进去,查看是否登录以上纯属个人理解, 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端)
php爬虫抓取网页数据,自动下载了建筑教程网php页面以及手机端,自动下载的目的是防止网站爬虫抓取或代理页面的一个保护。一:先介绍下抓取目的:1、最好能把建筑教程网手机端链接抓下来2、进行数据提取;二:分析代码;首先需要把链接请求改成测试ok就可以一般建筑教程网的网页地址是:,是没有跳转的那么我们想看下它会不会走网页,我们可以根据http请求内容,先抓一下请求方式;post//可以通过http响应来判断是不是需要浏览器去验证,以及会不会跳转那么如果网站没有被监听,http响应里面也没有连接到域名服务器,那么它的域名服务器的ip就不是我们自己的,我们需要抓包来试一下:还有,我们可以在http请求的cookie之后,修改一下cookie,测试一下是不是又跳转到了我们自己的网站。
我们看到,它的响应头处包含了cookie,我们可以修改cookie来再进行抓包。三:代码实现以下这是我们修改好了cookie之后抓取的抓包:将cookie再刷新一下,看到的http请求在这里:我们是不是可以根据cookie,将指定的http请求再进行http服务器认证一下再判断!。
你会前端开发就会处理下吧?
1.直接用php去获取2.用cookie登录,网上有教程3.python模拟登录,用数据库记录cookie信息,然后post请求进去,查看是否登录以上纯属个人理解,
php 爬虫抓取网页数据(Python爬虫教程什么是爬虫?Python语言学习非常简单教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-12 20:58
Python爬虫教程
什么是爬虫?爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,它将捕获它。把它记下来。
为什么要用Python语言写爬虫?与其他静态编程语言(如java、c#、C++)相比,Python语言的学习非常简单,并且提供了比较完善的访问网页文档的API和各种成熟的爬虫框架。我们可以用很少的代码编写高质量、大规模、分布式的爬虫流程项目。
1. 浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
3. URL的含义
URL,即统一资源定位符,也就是我们所说的网址。统一资源定位符是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应如何处理它的信息。
URL 的格式由三部分组成: ① 第一部分是协议(或称服务模式)。②第二部分是收录资源的主机的IP地址(有时也包括端口号)。③第三部分是宿主机资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须要有目标网址才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫学习有很大帮助。
4. 开发环境配置
学习Python,当然需要环境的配置。您可以使用任何文本编辑器,例如vi、Notepad++、Editplus 等,但它们的提示功能太弱。建议在 Windows 或 Mac 下使用免费的社区版 PyCharm。Eclipse for Python 可以在 Linux 下使用。此外,还有几个优秀的IDE。学习Python可以参考这个文章 IDE推荐。
下一节:如何使用Python爬虫Urllib库Python爬虫教程
如何抓取网页数据?就是通过URL从网站中获取具体的内容。“网页数据”是网站用户体验的一部分。例如,网页上的文字、图片、声音、视频、动画都被认为是网页数据。Python 的 urllib2 库提供了访问网页数据的 API,我们可以使用这些 API 来抓取网页内容。 查看全部
php 爬虫抓取网页数据(Python爬虫教程什么是爬虫?Python语言学习非常简单教程)
Python爬虫教程
什么是爬虫?爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,它将捕获它。把它记下来。
为什么要用Python语言写爬虫?与其他静态编程语言(如java、c#、C++)相比,Python语言的学习非常简单,并且提供了比较完善的访问网页文档的API和各种成熟的爬虫框架。我们可以用很少的代码编写高质量、大规模、分布式的爬虫流程项目。
1. 浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
3. URL的含义
URL,即统一资源定位符,也就是我们所说的网址。统一资源定位符是互联网上可用资源的位置和访问方式的简明表示,是互联网上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应如何处理它的信息。
URL 的格式由三部分组成: ① 第一部分是协议(或称服务模式)。②第二部分是收录资源的主机的IP地址(有时也包括端口号)。③第三部分是宿主机资源的具体地址,如目录、文件名等。
爬虫在爬取数据时,必须要有目标网址才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫学习有很大帮助。
4. 开发环境配置
学习Python,当然需要环境的配置。您可以使用任何文本编辑器,例如vi、Notepad++、Editplus 等,但它们的提示功能太弱。建议在 Windows 或 Mac 下使用免费的社区版 PyCharm。Eclipse for Python 可以在 Linux 下使用。此外,还有几个优秀的IDE。学习Python可以参考这个文章 IDE推荐。
下一节:如何使用Python爬虫Urllib库Python爬虫教程
如何抓取网页数据?就是通过URL从网站中获取具体的内容。“网页数据”是网站用户体验的一部分。例如,网页上的文字、图片、声音、视频、动画都被认为是网页数据。Python 的 urllib2 库提供了访问网页数据的 API,我们可以使用这些 API 来抓取网页内容。
php 爬虫抓取网页数据(PHP解析器和php相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-09 07:18
对比python和php,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,NGEFg比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装和配置PHP,然后才能使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PH编程,并且想在客户端应用程序中使用PHP的一些高级功能,可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我使用了 PHP 节点。Python写爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入mysql等数据库的带宽和I/O速度了。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里,更多相关php和python适合爬取的内容,请搜索我们之前的文章或者继续浏览下面文章希望大家以后多多支持我们!
文章名称:python 和 php 哪个更适合写爬虫 查看全部
php 爬虫抓取网页数据(PHP解析器和php相比较,python适合做爬虫吗?)
对比python和php,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,NGEFg比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装和配置PHP,然后才能使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PH编程,并且想在客户端应用程序中使用PHP的一些高级功能,可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我使用了 PHP 节点。Python写爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入mysql等数据库的带宽和I/O速度了。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里,更多相关php和python适合爬取的内容,请搜索我们之前的文章或者继续浏览下面文章希望大家以后多多支持我们!
文章名称:python 和 php 哪个更适合写爬虫
php 爬虫抓取网页数据(酷爱编程的老程序员,实在按耐不下了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-09 01:02
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
我对 Python 持谨慎态度。我认为当时我基于 Drupal 构建的系统使用的是 php 语言。语言升级的时候,旧版本的很多东西都被推翻了。我不得不花费大量的时间和精力进行移植和升级。有一些代码隐藏在有雷声的地方。我不认为Python可以避免这个问题(其实这样的声音已经很多了,比如Python 3正在摧毁Python)。不过,我还是开始了这个 Python 即时网络爬虫项目。我使用 C++、Java 和 Javascript 编写爬虫相关程序已经 10 多年了。我想追求高性能。它是 C++。同时,我有完整的标准体系,让您和您的系统非常自信。只要您对其进行全面测试,就可以按预期执行。跑步的方式。在 GooSeeker 项目中,我们继续朝着一个方向——“收获数据”努力,让广大用户(不仅仅是专业数据采集用户)体验到互联网数据的收获乐趣。“收获”的一个重要含义是数量众多。现在,我要启动“即时网络爬虫”,目的是补充“收获”未涵盖的场景,我看到的是:
一群程序员在玩 Python 网络爬虫。我制定了一个计划:构建一个更模块化、更强大的软件组件来解决最耗能的内容提取问题(有人总结说大数据和数据分析在整个链条中。准备工作占了80%,我们不妨扩展一下,网络数据捕获80%的工作量是为各种网站各种数据结构编写捕获规则)。
我把他想象成一台小机器(见上图),输入是原创网页,输出是提取的结构化内容。这台小机器还有一个可替换的组件:一条将输入转换成输出结构块的指令,我们就成了“提取器”,让大家再也不用担心调试正则表达式或XPath了。
这是一个开放的项目。两年前启动了手机上的即时网络爬虫项目。开起来不方便,因为它是为一个商业团体开发的。同样的想法和方法都会开放给这个项目,以及最新的Hot python来做,希望大家一起参与。在执行过程中,我们会公开所有的信息和结果,以及我们遇到的坑。
最近的实验是
Python使用xslt提取网页数据,Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
php 爬虫抓取网页数据(酷爱编程的老程序员,实在按耐不下了)
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
作为一个热爱编程的老程序员,我无法忍受这种冲动。Python真的太受欢迎了,它一直在逗我。
我对 Python 持谨慎态度。我认为当时我基于 Drupal 构建的系统使用的是 php 语言。语言升级的时候,旧版本的很多东西都被推翻了。我不得不花费大量的时间和精力进行移植和升级。有一些代码隐藏在有雷声的地方。我不认为Python可以避免这个问题(其实这样的声音已经很多了,比如Python 3正在摧毁Python)。不过,我还是开始了这个 Python 即时网络爬虫项目。我使用 C++、Java 和 Javascript 编写爬虫相关程序已经 10 多年了。我想追求高性能。它是 C++。同时,我有完整的标准体系,让您和您的系统非常自信。只要您对其进行全面测试,就可以按预期执行。跑步的方式。在 GooSeeker 项目中,我们继续朝着一个方向——“收获数据”努力,让广大用户(不仅仅是专业数据采集用户)体验到互联网数据的收获乐趣。“收获”的一个重要含义是数量众多。现在,我要启动“即时网络爬虫”,目的是补充“收获”未涵盖的场景,我看到的是:
一群程序员在玩 Python 网络爬虫。我制定了一个计划:构建一个更模块化、更强大的软件组件来解决最耗能的内容提取问题(有人总结说大数据和数据分析在整个链条中。准备工作占了80%,我们不妨扩展一下,网络数据捕获80%的工作量是为各种网站各种数据结构编写捕获规则)。
我把他想象成一台小机器(见上图),输入是原创网页,输出是提取的结构化内容。这台小机器还有一个可替换的组件:一条将输入转换成输出结构块的指令,我们就成了“提取器”,让大家再也不用担心调试正则表达式或XPath了。
这是一个开放的项目。两年前启动了手机上的即时网络爬虫项目。开起来不方便,因为它是为一个商业团体开发的。同样的想法和方法都会开放给这个项目,以及最新的Hot python来做,希望大家一起参与。在执行过程中,我们会公开所有的信息和结果,以及我们遇到的坑。
最近的实验是
Python使用xslt提取网页数据,Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
php 爬虫抓取网页数据(爬虫重新网站的频率如何?具体哪些页面被收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-09 01:01
了解爬虫在您的 网站 上做了什么对您来说非常重要。收录 有多少页?爬虫多久重新爬一次网站?收录 是哪些特定页面?或许只有后端搜索爬虫才能给出这些问题的答案。
网站上搜索的健康状况对于 网站 的可用性至关重要。如果爬虫无法有效抓取你的页面,那么页面被收录的可能性不大。如果爬虫无法读取你的页面信息,收录的情况也很糟糕。在某些情况下,爬虫还可以爬取 XML 文件来解析富媒体格式。您的 XML 文件很可能通过视频或音频的副本,或图片的文字说明指出您的 网站 的相关部分。这种元数据应该提交给搜索引擎。同时,我们应该跟踪提交的数据有多少页是收录,有多少页不是收录。
关于搜索引擎蜘蛛抓取的最后一点:有一些程序专门使用XML文件为网站页面提供元数据和信息。在这种情况下,您不会关注爬虫是否很好地抓取了您的网站,而是XML 文件是否很好地呈现了您的网站 内容。元数据可以在不访问特定页面的情况下表达页面的内容。我们可以用它在网站中建立复杂的关系。这种复杂的关系可以应用于网站的类别导航和其他元素。
当站点搜索不使用爬虫抓取作为其主要数据源时,确保您的 XML 文件使用尽可能清晰和强大的内容尤为重要。 查看全部
php 爬虫抓取网页数据(爬虫重新网站的频率如何?具体哪些页面被收录?)
了解爬虫在您的 网站 上做了什么对您来说非常重要。收录 有多少页?爬虫多久重新爬一次网站?收录 是哪些特定页面?或许只有后端搜索爬虫才能给出这些问题的答案。
网站上搜索的健康状况对于 网站 的可用性至关重要。如果爬虫无法有效抓取你的页面,那么页面被收录的可能性不大。如果爬虫无法读取你的页面信息,收录的情况也很糟糕。在某些情况下,爬虫还可以爬取 XML 文件来解析富媒体格式。您的 XML 文件很可能通过视频或音频的副本,或图片的文字说明指出您的 网站 的相关部分。这种元数据应该提交给搜索引擎。同时,我们应该跟踪提交的数据有多少页是收录,有多少页不是收录。
关于搜索引擎蜘蛛抓取的最后一点:有一些程序专门使用XML文件为网站页面提供元数据和信息。在这种情况下,您不会关注爬虫是否很好地抓取了您的网站,而是XML 文件是否很好地呈现了您的网站 内容。元数据可以在不访问特定页面的情况下表达页面的内容。我们可以用它在网站中建立复杂的关系。这种复杂的关系可以应用于网站的类别导航和其他元素。
当站点搜索不使用爬虫抓取作为其主要数据源时,确保您的 XML 文件使用尽可能清晰和强大的内容尤为重要。
php 爬虫抓取网页数据(最常用的php解析html的方法:基于html解析库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-08 17:10
php爬虫抓取网页数据并合成html。最后将获得的html字符串交给服务器解析,再将解析后的html转换成json格式的数据。php自带html解析库,在后端也可以使用第三方库解析html。使用第三方库时要注意,php的html解析库并不全面。有的第三方库兼容性不好。下面介绍最常用的php解析html的方法:基于path_regex的方法:使用path_regex库来解析html的字符串,具体用法可以参考它的文档。
总结一下它的思想是以字符串来建立目录树,把要爬取的网页文件放在目录树的根目录下(根目录的意思就是包含所有网页链接的目录),在目录树的最后面依次找到指定网页链接,把那个链接的html文件夹传递给php解析。也就是说,爬取一个网页文件,并不直接获取其中的文字,而是在每一个html文件中依次建立起一个目录树,在每一个html文件中都包含了它所对应的网页文件。(。
1)先到path_regex的文档去看看,在解析网页字符串时,path_regex库会调用该库的对应类,例如path_regex_function(),它的函数原型是:path_regex_env_path_regex(path_to_html),将所要解析的网页所在目录传递给path_regex。例如:path_regex_function()的函数原型为:path_regex_if_exist_or_exists(path_to_source,path_to_html)path_regex_function的对应类为:path_regex_functionpath_regex_to_html的对应类为:path_regex_to_html(。
2)使用path_regex库的第一个函数,称为path_regex_if_exist_or_exists(path_to_source,path_to_html)方法:定义要解析的链接类型path_regex_if_exists方法定义要解析的文件类型,这里的文件类型指的是网页网址。它会依次查找以下四种文件类型:application/video、transport/flash、post/json、proxy/filestream,返回true或false:解析从网页所在目录下查找的文件如果没有发现所需要的文件,那么所有的文件就不会被解析。
path_regex_exists()的定义:定义解析出来的文件,所在目录是否存在,如果存在返回false,否则返回true。path_regex_filestream包含所有的网页。函数语法格式如下:path_regex_if_exist_or_exists(path_to_source,path_to_html)其中path_to_source,path_to_html分别指定要解析的链接类型,也就是上面说的“目录树”。如果目录树都没有发现相应的文件,那么就抛出错误。(。
3)在定义完“要解析 查看全部
php 爬虫抓取网页数据(最常用的php解析html的方法:基于html解析库)
php爬虫抓取网页数据并合成html。最后将获得的html字符串交给服务器解析,再将解析后的html转换成json格式的数据。php自带html解析库,在后端也可以使用第三方库解析html。使用第三方库时要注意,php的html解析库并不全面。有的第三方库兼容性不好。下面介绍最常用的php解析html的方法:基于path_regex的方法:使用path_regex库来解析html的字符串,具体用法可以参考它的文档。
总结一下它的思想是以字符串来建立目录树,把要爬取的网页文件放在目录树的根目录下(根目录的意思就是包含所有网页链接的目录),在目录树的最后面依次找到指定网页链接,把那个链接的html文件夹传递给php解析。也就是说,爬取一个网页文件,并不直接获取其中的文字,而是在每一个html文件中依次建立起一个目录树,在每一个html文件中都包含了它所对应的网页文件。(。
1)先到path_regex的文档去看看,在解析网页字符串时,path_regex库会调用该库的对应类,例如path_regex_function(),它的函数原型是:path_regex_env_path_regex(path_to_html),将所要解析的网页所在目录传递给path_regex。例如:path_regex_function()的函数原型为:path_regex_if_exist_or_exists(path_to_source,path_to_html)path_regex_function的对应类为:path_regex_functionpath_regex_to_html的对应类为:path_regex_to_html(。
2)使用path_regex库的第一个函数,称为path_regex_if_exist_or_exists(path_to_source,path_to_html)方法:定义要解析的链接类型path_regex_if_exists方法定义要解析的文件类型,这里的文件类型指的是网页网址。它会依次查找以下四种文件类型:application/video、transport/flash、post/json、proxy/filestream,返回true或false:解析从网页所在目录下查找的文件如果没有发现所需要的文件,那么所有的文件就不会被解析。
path_regex_exists()的定义:定义解析出来的文件,所在目录是否存在,如果存在返回false,否则返回true。path_regex_filestream包含所有的网页。函数语法格式如下:path_regex_if_exist_or_exists(path_to_source,path_to_html)其中path_to_source,path_to_html分别指定要解析的链接类型,也就是上面说的“目录树”。如果目录树都没有发现相应的文件,那么就抛出错误。(。
3)在定义完“要解析
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 17:03
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
之前用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请在本站搜索之前的文章或继续浏览以下相关文章希望大家以后多多支持本站! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟会话/cookie存储和设置。python中有优秀的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。有关更多信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
之前用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量的爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓。关键词太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入 MySQL 和其他数据库的带宽和 I/O 速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请在本站搜索之前的文章或继续浏览以下相关文章希望大家以后多多支持本站!

