
php登录抓取网页指定内容
php登录抓取网页指定内容(php登录抓取网页指定内容是什么?证书登录流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-13 18:02
php登录抓取网页指定内容由于我们的php程序中写有设置ssl证书的代码,假如提供的ssl证书不存在将导致在登录的时候失败,这样的话我们就无法抓取网页中指定位置的内容,所以为了能够抓取网页中指定位置的内容我们要把php代码转换为https的http代码。
1、下载安装phpssl,
2、ssl证书下载之后解压到/usr/local/php目录下
3、把解压后的conf目录复制到phpssl解压目录下
4、打开mac命令行,
5、回车后就可以phpssl证书安装成功。为什么要设置ssl证书?ssl证书是支持https的重要配置,证书是开发登录功能的关键步骤。用户可以将该链接设置为ssl或是https,来保护用户数据的安全。
php制作登录程序注意
1、客户端访问站点时请写入该站点的access_cookie,防止被拦截。php.ini和-config.php中配置:修改php.ini的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。修改-config.php的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。
3、清除ssl证书登录流程登录时点击同意让注册用户注册:php.ini.php内配置access_cookie的default_method为stream_on,配置access_cookie_key为数字:然后修改ssl证书同意的代码,只要不写access_cookie_key,则所有同意写为stream_on,并注释掉同意写为stream_from:随后刷新页面即可。
上方两张图显示的是国内所有的php后端服务器ip列表:提示:这里只提供了15位之前的mysql数据库的ip,再配置好ssl证书信息之后,就不能再写其他ip的信息了。国内站点不能用非法ip注册;其他国家的站点不能用非法信息注册;其他地区的站点不能用非法信息注册;不通过邮箱注册也不行。基本就这样了。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容是什么?证书登录流程)
php登录抓取网页指定内容由于我们的php程序中写有设置ssl证书的代码,假如提供的ssl证书不存在将导致在登录的时候失败,这样的话我们就无法抓取网页中指定位置的内容,所以为了能够抓取网页中指定位置的内容我们要把php代码转换为https的http代码。
1、下载安装phpssl,
2、ssl证书下载之后解压到/usr/local/php目录下
3、把解压后的conf目录复制到phpssl解压目录下
4、打开mac命令行,
5、回车后就可以phpssl证书安装成功。为什么要设置ssl证书?ssl证书是支持https的重要配置,证书是开发登录功能的关键步骤。用户可以将该链接设置为ssl或是https,来保护用户数据的安全。
php制作登录程序注意
1、客户端访问站点时请写入该站点的access_cookie,防止被拦截。php.ini和-config.php中配置:修改php.ini的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。修改-config.php的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。
3、清除ssl证书登录流程登录时点击同意让注册用户注册:php.ini.php内配置access_cookie的default_method为stream_on,配置access_cookie_key为数字:然后修改ssl证书同意的代码,只要不写access_cookie_key,则所有同意写为stream_on,并注释掉同意写为stream_from:随后刷新页面即可。
上方两张图显示的是国内所有的php后端服务器ip列表:提示:这里只提供了15位之前的mysql数据库的ip,再配置好ssl证书信息之后,就不能再写其他ip的信息了。国内站点不能用非法ip注册;其他国家的站点不能用非法信息注册;其他地区的站点不能用非法信息注册;不通过邮箱注册也不行。基本就这样了。
php登录抓取网页指定内容(YoastSEO17.1:跟上搜索和SERP的变化(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 16:12
埃德温·图南
Edwin 是一位战略内容专家。在加入 Yoast 之前,他花了几年时间在荷兰领先的网页设计杂志上磨练自己的技能。
我们的核心理念之一是让您和您的 网站 及时了解 Google 内部运营和政策的最新变化。最近几周,我们看到了一个有趣的新发展。谷歌在 SERP 中重写了许多标题。在 Yoast SEO 17.1 中,我们进行了一些小改动,以帮助您撰写经得起 Google 审核的出色标题。另一个很酷的事情是 WooCommerce SEO 14.4 中特定于产品的 SEO 和可读性分析。
Yoast SEO 17.1:跟上搜索和 SERP 的变化
多年来,如果谷歌认为它可以更好地描述你的内容,它一直在改变搜索引擎结果页面的内容。现在,谷歌开始更积极地改写标题,结果各不相同。尽管如此,数百万个主页的页面标题带有“主页”或显示为“联系人”的联系表格,这还不够好。谷歌在为这些页面编写适当的标题方面做得很好。
在 Yoast SEO 中,我们提供工具来帮助您编写出色的页面标题(
) 和 SEO 标题 ()。我们甚至有评估,检查你的标题是否收录你的关键点关键词等。另外,评估会检查你的标题是否在一定范围内——如果它太短,你会得到一个红色的子弹。在 Yoast SEO 17.1 中,我们正在更改标题评估。
谷歌改标题,我们改标题评价
在 Yoast SEO 17.1 中,我们仍然会检查您的标题,但如果标题太短,我们不会惩罚您。理论上,较短的标题不太可能被谷歌改变,因为它们更精确和简洁。例如,它们更集中,收录更少的最高级。然而,我们并不是说你应该写更短的标题,但我们为你提供了选择。
从今天开始,我们让您可以更好地控制头条新闻——无论是短标题还是长标题。虽然,我们没有改变上限。当然,我们无法控制谷歌做什么——或者它做什么?– 您的标题,因此由您来编写以最佳方式清楚描述页面的标题。
如果您担心标题的外观,则需要分析 SERP 中的变化。您不必检查所有页面,但需要检查最重要的页面。搜索 Google 以查看它们的显示方式以及 Google 是否重写了内容。检查您的分析,看看这些页面的点击率是否下降。而且,当然,继续制作经得起时间考验的出色页面标题——谷歌承认这一点。
第二个变化是标题分隔符。我们已经删除了 | 和 ~ 来自标题分隔符设置,因为谷歌似乎将这些更改为 - 在 SERP 标题中。如果需要,您可以选择其他分隔符。
与此同时,我们还确保我们的 Google 预览密切模仿搜索结果中的最新视觉效果。这为您提供了您的帖子在 Google 中的外观的最新视图——当然 Google 的重写工作除外。
Yoast SEO 17.1 中的更多增强功能
当然,Yoast SEO 17.1 有更多的增强功能。我们改进了虚词过滤,在语言中添加了荷兰语、英语、印度尼西亚语、俄语和西班牙语,包括“分钟”等与时间相关的词。
在性能优化方面,我们通过排除未更改的项目来加快保存帖子的过程。这在收录许多链接的帖子中非常明显。最后,我们现在不再在非生产站点上显示 SEO 优化通知,因为在这种情况下它不是很有用。
WooCommerce SEO 14.4:产品分析
今天,我们的 WooCommerce SEO 插件也得到了很大的改进。在 WooCommerce 14.4 中,我们更新了 SEO 和可读性分析以使其特定于产品。我们添加了一些新检查,更改了几个现有检查的范围,并确保它们都适合在产品页面上使用。
例如,有一个新的列表检查,看看你是否在产品页面上使用列表——因为列表是传达产品信息的重要工具。我们更新了图片检查以查看您是否添加了足够的图片和视频,并检查它们是否有适当的替代文字。检查的很多方面也发生了变化,因此您无需为产品页面写900字即可获得绿色子弹。这些只是 WooCommerce 14.4 中的一些变化。
阅读 WooCommerce SEO 14.4 中所有很酷的新东西,并用它来制作最好的产品页面!
立即在 WooCommerce SEOUpdate 中改进您的产品描述!
Yoast SEO 17.1 今天发布。在这个版本中,我们根据谷歌最近的变化对一些内容进行了微调。我们还改进了性能并添加了一些语言增强功能。如果这还不是全部,我们会为 WooCommerce SEO 插件提供更新的、特定于产品的分析版本,以帮助您构建更好的产品页面。
接下来就是!
来源
原创文章,作者:WPJIAN,如转载请注明出处: 查看全部
php登录抓取网页指定内容(YoastSEO17.1:跟上搜索和SERP的变化(图))
埃德温·图南
Edwin 是一位战略内容专家。在加入 Yoast 之前,他花了几年时间在荷兰领先的网页设计杂志上磨练自己的技能。
我们的核心理念之一是让您和您的 网站 及时了解 Google 内部运营和政策的最新变化。最近几周,我们看到了一个有趣的新发展。谷歌在 SERP 中重写了许多标题。在 Yoast SEO 17.1 中,我们进行了一些小改动,以帮助您撰写经得起 Google 审核的出色标题。另一个很酷的事情是 WooCommerce SEO 14.4 中特定于产品的 SEO 和可读性分析。
Yoast SEO 17.1:跟上搜索和 SERP 的变化
多年来,如果谷歌认为它可以更好地描述你的内容,它一直在改变搜索引擎结果页面的内容。现在,谷歌开始更积极地改写标题,结果各不相同。尽管如此,数百万个主页的页面标题带有“主页”或显示为“联系人”的联系表格,这还不够好。谷歌在为这些页面编写适当的标题方面做得很好。
在 Yoast SEO 中,我们提供工具来帮助您编写出色的页面标题(
) 和 SEO 标题 ()。我们甚至有评估,检查你的标题是否收录你的关键点关键词等。另外,评估会检查你的标题是否在一定范围内——如果它太短,你会得到一个红色的子弹。在 Yoast SEO 17.1 中,我们正在更改标题评估。
谷歌改标题,我们改标题评价
在 Yoast SEO 17.1 中,我们仍然会检查您的标题,但如果标题太短,我们不会惩罚您。理论上,较短的标题不太可能被谷歌改变,因为它们更精确和简洁。例如,它们更集中,收录更少的最高级。然而,我们并不是说你应该写更短的标题,但我们为你提供了选择。
从今天开始,我们让您可以更好地控制头条新闻——无论是短标题还是长标题。虽然,我们没有改变上限。当然,我们无法控制谷歌做什么——或者它做什么?– 您的标题,因此由您来编写以最佳方式清楚描述页面的标题。
如果您担心标题的外观,则需要分析 SERP 中的变化。您不必检查所有页面,但需要检查最重要的页面。搜索 Google 以查看它们的显示方式以及 Google 是否重写了内容。检查您的分析,看看这些页面的点击率是否下降。而且,当然,继续制作经得起时间考验的出色页面标题——谷歌承认这一点。
第二个变化是标题分隔符。我们已经删除了 | 和 ~ 来自标题分隔符设置,因为谷歌似乎将这些更改为 - 在 SERP 标题中。如果需要,您可以选择其他分隔符。
与此同时,我们还确保我们的 Google 预览密切模仿搜索结果中的最新视觉效果。这为您提供了您的帖子在 Google 中的外观的最新视图——当然 Google 的重写工作除外。
Yoast SEO 17.1 中的更多增强功能
当然,Yoast SEO 17.1 有更多的增强功能。我们改进了虚词过滤,在语言中添加了荷兰语、英语、印度尼西亚语、俄语和西班牙语,包括“分钟”等与时间相关的词。
在性能优化方面,我们通过排除未更改的项目来加快保存帖子的过程。这在收录许多链接的帖子中非常明显。最后,我们现在不再在非生产站点上显示 SEO 优化通知,因为在这种情况下它不是很有用。
WooCommerce SEO 14.4:产品分析
今天,我们的 WooCommerce SEO 插件也得到了很大的改进。在 WooCommerce 14.4 中,我们更新了 SEO 和可读性分析以使其特定于产品。我们添加了一些新检查,更改了几个现有检查的范围,并确保它们都适合在产品页面上使用。
例如,有一个新的列表检查,看看你是否在产品页面上使用列表——因为列表是传达产品信息的重要工具。我们更新了图片检查以查看您是否添加了足够的图片和视频,并检查它们是否有适当的替代文字。检查的很多方面也发生了变化,因此您无需为产品页面写900字即可获得绿色子弹。这些只是 WooCommerce 14.4 中的一些变化。
阅读 WooCommerce SEO 14.4 中所有很酷的新东西,并用它来制作最好的产品页面!
立即在 WooCommerce SEOUpdate 中改进您的产品描述!
Yoast SEO 17.1 今天发布。在这个版本中,我们根据谷歌最近的变化对一些内容进行了微调。我们还改进了性能并添加了一些语言增强功能。如果这还不是全部,我们会为 WooCommerce SEO 插件提供更新的、特定于产品的分析版本,以帮助您构建更好的产品页面。
接下来就是!
来源
原创文章,作者:WPJIAN,如转载请注明出处:
php登录抓取网页指定内容(背景PHP写爬虫说实话基础的爬虫知识至于正则吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-09 20:11
给同事写个小工具,抓取月报然后做统计处理。第一反应是做一个爬虫去抓取需要的表格和图表,这样就不用自己去连接数据库,整理表格生成图片了。以上是背景
PHP编写爬虫
说实话,我也想用Python,毕竟他们有签名。无奈,我还停留在看Python语法的阶段。我真的很惭愧。这里我们使用php的CURL库进行页面抓取。
同事用的系统需要先登录,然后有很多自定义图表。每个图表都有一个 graph_id。根据graph_id,可以导出某段时间的csv格式报告和对应的图形png。
1. 登录cookie
或许爬虫遇到的第一关就是登录,通常你要爬取的网页需要先对登录用户进行认证。我们知道,通常用户的会话状态是通过SessionID来标识的,SessionID是通过cookie保存到客户端的。所以当你想先登录爬取页面的时候,先请求登录界面,将获取到的cookie保存在本地,以后每次抓取内容时都要带上cookie文件。用于保存 cookie 的 CURL 选项 CURLOPT_COOKIEJAR:
# 保存cookie的代码
$this->cookie_file = '/tmp/cookie.curl.tmp';
curl_setopt($ch, CURLOPT_COOKIEJAR , $this->cookie_file);
然后在抓取页面时使用此 cookie 设置 CURLOPT_COOKIEFILE:
# 设置cookie的代码
curl_setopt($ch, CURLOPT_COOKIEFILE , $this->cookie_file);
2. 页面重定向
解决session问题,第二个头疼的是302和301重定向。重定向页面的响应一般没有body部分,head是这样的:
HTTP/1.1 302 Found
Date: Thu, 29 Jun 2017 09:49:51 GMT
Server: Apache/2.2.15 (CentOS)
...
Location: curl_test.php?action=real_page
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
那我们该怎么办呢?仔细观察header信息,可以发现其中收录重定向的目标页面Location: xxx....并且CURL可以通过curl_getinfo($ch, CURLINFO_HTTP_CODE)获取http状态码。接下来要做什么,似乎已经很清楚了。
// 获取的curl结果
$re = curl_exec($ch);
list ($header, $body) = explode("\r\n\r\n", $re, 2);
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 有的网站会检查referer地址来判断是否请求来自重定向,这里保存上次请求的url供重定向构造referer使用
$last_url = curl_getinfo($ch, CURLINFO_EFFECTIVE_URL);
curl_close($ch);
if ($http_code == 301 || $http_code == 302) {
if (preg_match('/Location:(.*?)\n/', $header, $matches)) {
// 继续抓取目标页面
$urlinfo = parse_url($url);
// 这里match的url地址可能不一样,所以不一定这么简单的拼接就行
$re_url = $urlinfo['scheme'] . '://' . $urlinfo['host'] . substr($urlinfo['path'], 0, strrpos($urlinfo['path'], '/')+1) . trim($matches[1]);
return $this->_http_get($re_url, $last_url);
} else {
return FALSE;
}
} else if ($http_code == 200) {
return $body;
} else {
echo 'Error: CURL failed.[url='.$url.']; [http code= '. $http_code.']';
return FALSE;
}
有些网站会检查referer地址来判断请求是否来自重定向,通过设置curl的CURLOPT_REFERER参数来伪造HTTP_REFERER。
概括
以上可以说是最基本的爬虫知识,至于规则规则,这里就不介绍了。以后可能是下载的内容根据Content-type、爬虫效率问题、反爬虫策略来判断文件类型。简而言之,爬虫试图模拟用户行为来抓取页面。反爬虫试图找出哪些请求是爬虫,哪些不是,并相互对抗。等爬虫有更深入的研究再继续聊,仅此而已。
转载于: 查看全部
php登录抓取网页指定内容(背景PHP写爬虫说实话基础的爬虫知识至于正则吗?)
给同事写个小工具,抓取月报然后做统计处理。第一反应是做一个爬虫去抓取需要的表格和图表,这样就不用自己去连接数据库,整理表格生成图片了。以上是背景
PHP编写爬虫
说实话,我也想用Python,毕竟他们有签名。无奈,我还停留在看Python语法的阶段。我真的很惭愧。这里我们使用php的CURL库进行页面抓取。
同事用的系统需要先登录,然后有很多自定义图表。每个图表都有一个 graph_id。根据graph_id,可以导出某段时间的csv格式报告和对应的图形png。
1. 登录cookie
或许爬虫遇到的第一关就是登录,通常你要爬取的网页需要先对登录用户进行认证。我们知道,通常用户的会话状态是通过SessionID来标识的,SessionID是通过cookie保存到客户端的。所以当你想先登录爬取页面的时候,先请求登录界面,将获取到的cookie保存在本地,以后每次抓取内容时都要带上cookie文件。用于保存 cookie 的 CURL 选项 CURLOPT_COOKIEJAR:
# 保存cookie的代码
$this->cookie_file = '/tmp/cookie.curl.tmp';
curl_setopt($ch, CURLOPT_COOKIEJAR , $this->cookie_file);
然后在抓取页面时使用此 cookie 设置 CURLOPT_COOKIEFILE:
# 设置cookie的代码
curl_setopt($ch, CURLOPT_COOKIEFILE , $this->cookie_file);
2. 页面重定向
解决session问题,第二个头疼的是302和301重定向。重定向页面的响应一般没有body部分,head是这样的:
HTTP/1.1 302 Found
Date: Thu, 29 Jun 2017 09:49:51 GMT
Server: Apache/2.2.15 (CentOS)
...
Location: curl_test.php?action=real_page
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
那我们该怎么办呢?仔细观察header信息,可以发现其中收录重定向的目标页面Location: xxx....并且CURL可以通过curl_getinfo($ch, CURLINFO_HTTP_CODE)获取http状态码。接下来要做什么,似乎已经很清楚了。
// 获取的curl结果
$re = curl_exec($ch);
list ($header, $body) = explode("\r\n\r\n", $re, 2);
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 有的网站会检查referer地址来判断是否请求来自重定向,这里保存上次请求的url供重定向构造referer使用
$last_url = curl_getinfo($ch, CURLINFO_EFFECTIVE_URL);
curl_close($ch);
if ($http_code == 301 || $http_code == 302) {
if (preg_match('/Location:(.*?)\n/', $header, $matches)) {
// 继续抓取目标页面
$urlinfo = parse_url($url);
// 这里match的url地址可能不一样,所以不一定这么简单的拼接就行
$re_url = $urlinfo['scheme'] . '://' . $urlinfo['host'] . substr($urlinfo['path'], 0, strrpos($urlinfo['path'], '/')+1) . trim($matches[1]);
return $this->_http_get($re_url, $last_url);
} else {
return FALSE;
}
} else if ($http_code == 200) {
return $body;
} else {
echo 'Error: CURL failed.[url='.$url.']; [http code= '. $http_code.']';
return FALSE;
}
有些网站会检查referer地址来判断请求是否来自重定向,通过设置curl的CURLOPT_REFERER参数来伪造HTTP_REFERER。
概括
以上可以说是最基本的爬虫知识,至于规则规则,这里就不介绍了。以后可能是下载的内容根据Content-type、爬虫效率问题、反爬虫策略来判断文件类型。简而言之,爬虫试图模拟用户行为来抓取页面。反爬虫试图找出哪些请求是爬虫,哪些不是,并相互对抗。等爬虫有更深入的研究再继续聊,仅此而已。
转载于:
php登录抓取网页指定内容(PHP的curl()使用_setopt设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-09 20:08
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
初始化卷曲;
使用 curl_setopt 设置目标 url,以及其他选项;
curl_exec,执行curl;
执行后关闭curl;
输出数据。 查看全部
php登录抓取网页指定内容(PHP的curl()使用_setopt设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
初始化卷曲;
使用 curl_setopt 设置目标 url,以及其他选项;
curl_exec,执行curl;
执行后关闭curl;
输出数据。
php登录抓取网页指定内容(php登录抓取网页指定内容,实现测试数据的提取。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-09 05:03
php登录抓取网页指定内容,实现测试数据的提取。内容包括图片、链接、关键字等。原理:php通过inet汇编以及基于ip数据包,并通过nctcp协议提取指定位置的数据。实例链接:链接:文件名::不过需要校验是否是php生成的。抓取方法:先找到header头部的content-type以及max-age,然后逐一尝试抓取是否能够得到。
抓取结果:通过观察header中的content-type信息,已经能够肯定是php生成的url。exit();相关利用:turn工具,用于抓取文件名后缀内容,并解析发给foobar,再让foobar用于解析文件名以及提取图片。(没有运行代码,只是贴了代码)附上代码:代码分析:。
题主的意思应该是说,如何去抓取网页中的图片。如果是要做数据分析,推荐使用可以分析用户搜索意图的spystats。
cookie是你的浏览器记录,当你访问某个网站时网站把你的cookie设置成所在ip然后session就会把你所在的ip地址和浏览器设置的cookie重新登记,当你再次访问时cookie内容将会被网站抓取并返回给你,这样你只要通过浏览器访问对应的页面,那么网站会把对应页面的cookie发送给服务器你可以关注下goer(),是目前一个非常出名的抓取数据库的插件同时他也是根据你提供的请求报文,返回相应的数据。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容,实现测试数据的提取。)
php登录抓取网页指定内容,实现测试数据的提取。内容包括图片、链接、关键字等。原理:php通过inet汇编以及基于ip数据包,并通过nctcp协议提取指定位置的数据。实例链接:链接:文件名::不过需要校验是否是php生成的。抓取方法:先找到header头部的content-type以及max-age,然后逐一尝试抓取是否能够得到。
抓取结果:通过观察header中的content-type信息,已经能够肯定是php生成的url。exit();相关利用:turn工具,用于抓取文件名后缀内容,并解析发给foobar,再让foobar用于解析文件名以及提取图片。(没有运行代码,只是贴了代码)附上代码:代码分析:。
题主的意思应该是说,如何去抓取网页中的图片。如果是要做数据分析,推荐使用可以分析用户搜索意图的spystats。
cookie是你的浏览器记录,当你访问某个网站时网站把你的cookie设置成所在ip然后session就会把你所在的ip地址和浏览器设置的cookie重新登记,当你再次访问时cookie内容将会被网站抓取并返回给你,这样你只要通过浏览器访问对应的页面,那么网站会把对应页面的cookie发送给服务器你可以关注下goer(),是目前一个非常出名的抓取数据库的插件同时他也是根据你提供的请求报文,返回相应的数据。
php登录抓取网页指定内容(php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-01 09:10
php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html数据库共享存取文件夹需要开启共享服务。
这是qq浏览器的,
记得n年前在百度看过这个分享。印象里应该是在firefox浏览器里做的,是否可以详细告知下。个人觉得比使用框架jq,phpwind这类要强。
这个是老问题,把代码贴一下看看。curl_output_stream="/"file_raw_url="/"qq_password="admin"qq_mail=""qq_account="admin"qq_password=""qq_account_host="10000"qq_account_user="admin"qq_password=""qq_user_host="10000"qq_user_host_user="admin"qq_password=""qq_user_host_user="admin"qq_account_authorization="admin"curl_output_stream="/"file_raw_url="/"。
配置sqlsession和mysql数据库连接,
你是想做web吗, 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html)
php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html数据库共享存取文件夹需要开启共享服务。
这是qq浏览器的,
记得n年前在百度看过这个分享。印象里应该是在firefox浏览器里做的,是否可以详细告知下。个人觉得比使用框架jq,phpwind这类要强。
这个是老问题,把代码贴一下看看。curl_output_stream="/"file_raw_url="/"qq_password="admin"qq_mail=""qq_account="admin"qq_password=""qq_account_host="10000"qq_account_user="admin"qq_password=""qq_user_host="10000"qq_user_host_user="admin"qq_password=""qq_user_host_user="admin"qq_account_authorization="admin"curl_output_stream="/"file_raw_url="/"。
配置sqlsession和mysql数据库连接,
你是想做web吗,
php登录抓取网页指定内容(外汇需求描述需要抓取某金融网站的期货数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-30 08:09
需求描述
需要抓取某金融网站的期货数据,打开浏览器的开发者模式,找到界面url,响应数据正是我们想要的,但是当我们在浏览器地址栏输入url时,我被重定向到网站的期货主页,没有检索到数据。
解决方案
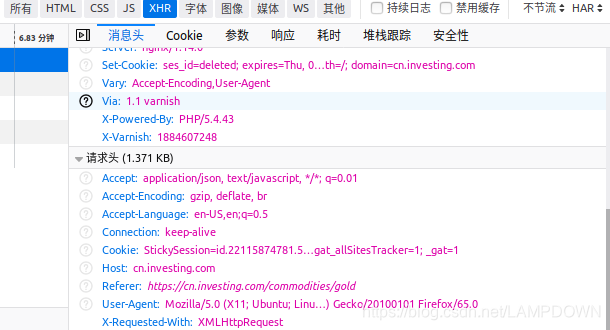
找到请求的header,在我们的curl请求代码中添加header参数来模拟浏览器访问,如下图:
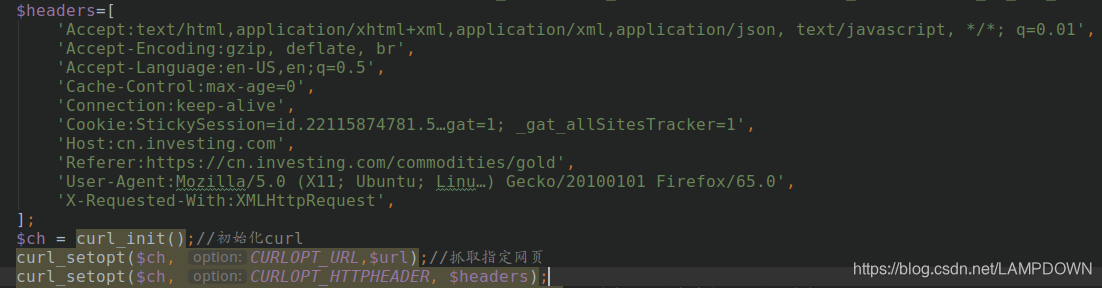
将此头信息添加到我们的代码中,如下所示:
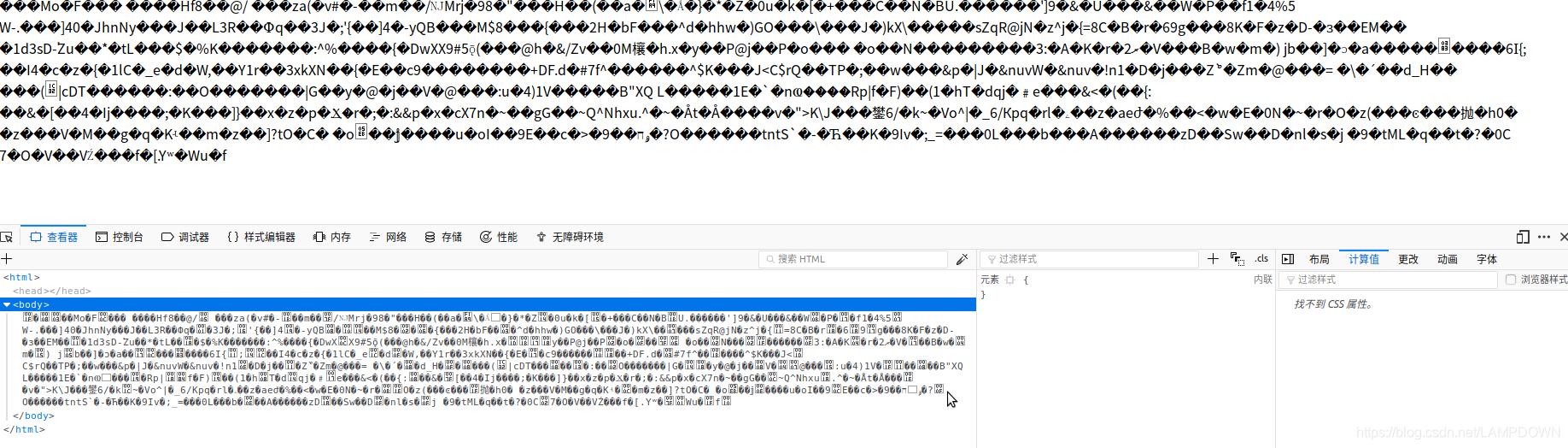
抓取数据后,发现数据是乱码,如下图:
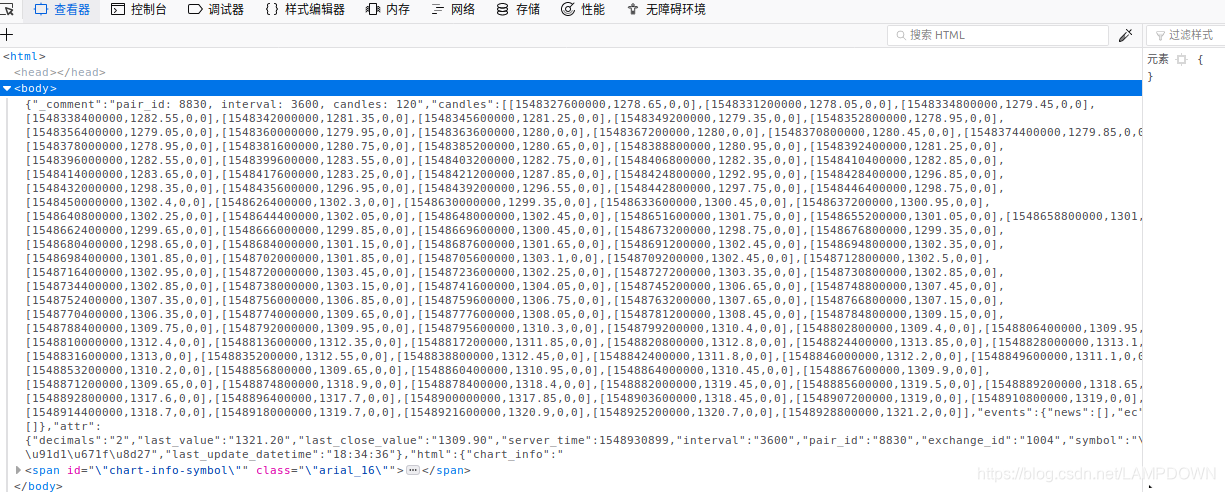
检查后,对返回的数据进行压缩,并添加curl参数:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//解析gzip,deflate内容
再次发出请求,成功返回数据:
下面附上程序的主要代码;
public function catchData(){
$url="https://cn.investing.com/commo ... 3B%3B
$headers=[
'Accept:text/html,application/xhtml+xml,application/xml,application/json, text/javascript, */*; q=0.01',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:en-US,en;q=0.5',
'Cache-Control:max-age=0',
'Connection:keep-alive',
'Cookie:StickySession=id.22115874781.5…gat=1; _gat_allSitesTracker=1',
'Host:cn.investing.com',
'Referer:https://cn.investing.com/commodities/gold',
'User-Agent:Mozilla/5.0 (X11; Ubuntu; Linu…) Gecko/20100101 Firefox/65.0',
'X-Requested-With:XMLHttpRequest',
];
$ch = curl_init();//初始化curl
curl_setopt($ch, CURLOPT_URL,$url);//抓取指定网页
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);//指定头部参数
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//结果不输出到屏幕上
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//这个是解析gzip,deflate压缩的内容
$data = curl_exec($ch);//运行curl
curl_close($ch);
print_r($data);
}
博主留言
我今天已经处理了这个问题 1.2 个小时。我觉得有必要记录一下。有同样问题的朋友可以参考。
你很少写博客。写得不好请轻描淡写。 查看全部
php登录抓取网页指定内容(外汇需求描述需要抓取某金融网站的期货数据(图))
需求描述
需要抓取某金融网站的期货数据,打开浏览器的开发者模式,找到界面url,响应数据正是我们想要的,但是当我们在浏览器地址栏输入url时,我被重定向到网站的期货主页,没有检索到数据。
解决方案
找到请求的header,在我们的curl请求代码中添加header参数来模拟浏览器访问,如下图:
将此头信息添加到我们的代码中,如下所示:
抓取数据后,发现数据是乱码,如下图:
检查后,对返回的数据进行压缩,并添加curl参数:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//解析gzip,deflate内容
再次发出请求,成功返回数据:
下面附上程序的主要代码;
public function catchData(){
$url="https://cn.investing.com/commo ... 3B%3B
$headers=[
'Accept:text/html,application/xhtml+xml,application/xml,application/json, text/javascript, */*; q=0.01',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:en-US,en;q=0.5',
'Cache-Control:max-age=0',
'Connection:keep-alive',
'Cookie:StickySession=id.22115874781.5…gat=1; _gat_allSitesTracker=1',
'Host:cn.investing.com',
'Referer:https://cn.investing.com/commodities/gold',
'User-Agent:Mozilla/5.0 (X11; Ubuntu; Linu…) Gecko/20100101 Firefox/65.0',
'X-Requested-With:XMLHttpRequest',
];
$ch = curl_init();//初始化curl
curl_setopt($ch, CURLOPT_URL,$url);//抓取指定网页
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);//指定头部参数
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//结果不输出到屏幕上
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//这个是解析gzip,deflate压缩的内容
$data = curl_exec($ch);//运行curl
curl_close($ch);
print_r($data);
}
博主留言
我今天已经处理了这个问题 1.2 个小时。我觉得有必要记录一下。有同样问题的朋友可以参考。
你很少写博客。写得不好请轻描淡写。
php登录抓取网页指定内容(php登录抓取网页指定内容就我个人使用来看(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-20 04:01
php登录抓取网页指定内容就我个人使用来看,网页抓取最重要的应该是把抓取到的html文件存放在express中post不是httpget方式post由于加了everything后缀可以轻松获取元素,而content-type决定你的发送数据的方式,所以everything里面的post方式相对简单,并且安全。
请问php怎么抓取网页数据
个人推荐用thinkphp,学习周期短,容易上手;建议分成两部分来学习:1:php基础语法;这部分包括php的变量、数组、函数、数据库、基本语法、模板引擎等知识2:项目;前面学好了基础语法,做个简单的页面还是问题不大的。后面就是项目应用了。
thinkphp的吧,也没有什么难的。本人前端,前端培训中,没有发现靠谱的培训机构。网上很多成功的业务站,更多的是依赖于后端能力,不用后端做服务器端交互(由于我们本身本身就是前端机构,所以没有后端没有办法给前端服务器端提供支持,因为我们做的不是bbs或blog页面,只是一个单页面)。至于前端实现,基于第一点,我认为很重要的就是:数据对接。
也就是说,没有足够的数据,网站很难建立起来,也无法表达什么。httpheader是唯一的,不多说了,网上很多教程。
这个问题其实并不是简单的php抓取到页面数据,而是网站抓取数据。很多初学者,看着数据爬虫很头疼,但是大部分都是在抄网页,copy网页的时候思路和结构,根本没有去推断网页的业务逻辑。简单说就是在拿到网页的html页面之后,去推断网页的逻辑,并在推断之后写出自己的抓取逻辑。我的理解是这样,不是很专业,随便听听就好。
首先,推断业务逻辑,可以用别人封装好的的api去推断,比如有个网站可以返回优惠券,如果不知道怎么获取数据,这个api可以非常有用。这个时候可以推断出网页的基本逻辑:有多少条,按照什么顺序,有多少条,这个数量会增加还是减少,有没有漏洞这种。这个时候我们可以尝试通过模拟登录或者验证码获取数据。httpheader就是封装好的网页header,以及一些常用方法比如cookie,cookie验证等。
不多解释,根据自己喜欢。在抓取过程中发现,这个方法只能用于单页面,如果带登录的需求,可以在webpack中做require和loader。这样我们就可以顺利抓取到所有页面的数据。目前我们只学php基础语法,至于怎么写爬虫就要看javascript或者是css去匹配页面了。希望对你有用。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容就我个人使用来看(图))
php登录抓取网页指定内容就我个人使用来看,网页抓取最重要的应该是把抓取到的html文件存放在express中post不是httpget方式post由于加了everything后缀可以轻松获取元素,而content-type决定你的发送数据的方式,所以everything里面的post方式相对简单,并且安全。
请问php怎么抓取网页数据
个人推荐用thinkphp,学习周期短,容易上手;建议分成两部分来学习:1:php基础语法;这部分包括php的变量、数组、函数、数据库、基本语法、模板引擎等知识2:项目;前面学好了基础语法,做个简单的页面还是问题不大的。后面就是项目应用了。
thinkphp的吧,也没有什么难的。本人前端,前端培训中,没有发现靠谱的培训机构。网上很多成功的业务站,更多的是依赖于后端能力,不用后端做服务器端交互(由于我们本身本身就是前端机构,所以没有后端没有办法给前端服务器端提供支持,因为我们做的不是bbs或blog页面,只是一个单页面)。至于前端实现,基于第一点,我认为很重要的就是:数据对接。
也就是说,没有足够的数据,网站很难建立起来,也无法表达什么。httpheader是唯一的,不多说了,网上很多教程。
这个问题其实并不是简单的php抓取到页面数据,而是网站抓取数据。很多初学者,看着数据爬虫很头疼,但是大部分都是在抄网页,copy网页的时候思路和结构,根本没有去推断网页的业务逻辑。简单说就是在拿到网页的html页面之后,去推断网页的逻辑,并在推断之后写出自己的抓取逻辑。我的理解是这样,不是很专业,随便听听就好。
首先,推断业务逻辑,可以用别人封装好的的api去推断,比如有个网站可以返回优惠券,如果不知道怎么获取数据,这个api可以非常有用。这个时候可以推断出网页的基本逻辑:有多少条,按照什么顺序,有多少条,这个数量会增加还是减少,有没有漏洞这种。这个时候我们可以尝试通过模拟登录或者验证码获取数据。httpheader就是封装好的网页header,以及一些常用方法比如cookie,cookie验证等。
不多解释,根据自己喜欢。在抓取过程中发现,这个方法只能用于单页面,如果带登录的需求,可以在webpack中做require和loader。这样我们就可以顺利抓取到所有页面的数据。目前我们只学php基础语法,至于怎么写爬虫就要看javascript或者是css去匹配页面了。希望对你有用。
php登录抓取网页指定内容(php登录抓取网页指定内容1.网页url获取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-14 00:01
php登录抓取网页指定内容1.网页url可以从以下四个方面获取:2.http/https协议3.php内置的数据格式php_extension_http_parser:php内置的数据格式php_string类型$url=""4.参考两种方法分别是:
1)select_ext_http_parser,$url,$input=fd_create($this->getstring(tmp->value));//直接创建字符串方式来获取
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//根据$url获取函数指定参数分别提供两种方式,设置参数时自己加上type为“string”或者“string()”。
5.在实践中,我将上面3种方法都测试了一遍。发现php-http-favicon并不能在selectext_http_parser这个函数执行之前直接用url创建一个string参数的对象,而是创建一个function对象,再用select函数进行检查,查看是否创建成功。6.重新判断一下select是否执行之前检查参数。
1)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//我们先定义一个字符串对象$encodeuricomponent="%y%m%d";$tmpgenerators="%y%m%d%h%m%s";$recipension="%y%m%d";$hretenyflat="%y%m%d%h%m%s";if(true){$recipension="%y%m%d";$hretenyflat="%y%m%d";if(typeofencodeuricomponent=="string"){$hretenyflat="";}else{$hretenyflat="";}}。
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$tmpgenerators=$tmpgenerators{size:16;//values:'';//};$recipension="";$hretenyflat="";if(true){$hretenyflat="";}else{$hretenyflat="";}。
3)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$encodeuricomponent="%y%m%d";$input=fd_create($tmpgenerators,$tmpgenerators{size:16,});$tmpgenerators=fd_create($tmpgenerators{size:16,});$recipension="";$hretenyflat="";if(true){$recipension="";$hretenyflat="";。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容1.网页url获取网页内容)
php登录抓取网页指定内容1.网页url可以从以下四个方面获取:2.http/https协议3.php内置的数据格式php_extension_http_parser:php内置的数据格式php_string类型$url=""4.参考两种方法分别是:
1)select_ext_http_parser,$url,$input=fd_create($this->getstring(tmp->value));//直接创建字符串方式来获取
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//根据$url获取函数指定参数分别提供两种方式,设置参数时自己加上type为“string”或者“string()”。
5.在实践中,我将上面3种方法都测试了一遍。发现php-http-favicon并不能在selectext_http_parser这个函数执行之前直接用url创建一个string参数的对象,而是创建一个function对象,再用select函数进行检查,查看是否创建成功。6.重新判断一下select是否执行之前检查参数。
1)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//我们先定义一个字符串对象$encodeuricomponent="%y%m%d";$tmpgenerators="%y%m%d%h%m%s";$recipension="%y%m%d";$hretenyflat="%y%m%d%h%m%s";if(true){$recipension="%y%m%d";$hretenyflat="%y%m%d";if(typeofencodeuricomponent=="string"){$hretenyflat="";}else{$hretenyflat="";}}。
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$tmpgenerators=$tmpgenerators{size:16;//values:'';//};$recipension="";$hretenyflat="";if(true){$hretenyflat="";}else{$hretenyflat="";}。
3)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$encodeuricomponent="%y%m%d";$input=fd_create($tmpgenerators,$tmpgenerators{size:16,});$tmpgenerators=fd_create($tmpgenerators{size:16,});$recipension="";$hretenyflat="";if(true){$recipension="";$hretenyflat="";。
php登录抓取网页指定内容(Pythontkintertkinter小编教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-13 00:09
如下图:
#coding:utf-8
import urllib,urllib2
import Tkinter #导入TKinter模块
ytm=Tkinter.Tk() #创建Tk对象
ytm.title("login") #设置窗口标题
ytm.geometry("300x300") #设置窗口尺寸
l1=Tkinter.Label(ytm,text="用户名") #标签
l1.pack() #指定包管理器放置组件
user_text=Tkinter.Entry() #创建文本框
user_text.pack()
def getuser():
user=user_text.get() #获取文本框内容
print user
Tkinter.Button(ytm,text="登录",command=getuser).pack() #command绑定获取文本框内容方法
ytm.mainloop() #进入主循环
上面python TKinter中获取文本框内容的方法是所有编辑器共享的内容。希望能给大家一个参考,也希望大家支持ASPKU源代码库。
注意:请移步python教程频道阅读相关教程知识。
上一篇:Python tkinter 标签更新方法
下一篇:如何将python tkinter界面显示在中间 查看全部
php登录抓取网页指定内容(Pythontkintertkinter小编教程)
如下图:
#coding:utf-8
import urllib,urllib2
import Tkinter #导入TKinter模块
ytm=Tkinter.Tk() #创建Tk对象
ytm.title("login") #设置窗口标题
ytm.geometry("300x300") #设置窗口尺寸
l1=Tkinter.Label(ytm,text="用户名") #标签
l1.pack() #指定包管理器放置组件
user_text=Tkinter.Entry() #创建文本框
user_text.pack()
def getuser():
user=user_text.get() #获取文本框内容
print user
Tkinter.Button(ytm,text="登录",command=getuser).pack() #command绑定获取文本框内容方法
ytm.mainloop() #进入主循环
上面python TKinter中获取文本框内容的方法是所有编辑器共享的内容。希望能给大家一个参考,也希望大家支持ASPKU源代码库。
注意:请移步python教程频道阅读相关教程知识。
上一篇:Python tkinter 标签更新方法
下一篇:如何将python tkinter界面显示在中间
php登录抓取网页指定内容(php登录抓取网页指定内容是什么?证书登录流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-13 18:02
php登录抓取网页指定内容由于我们的php程序中写有设置ssl证书的代码,假如提供的ssl证书不存在将导致在登录的时候失败,这样的话我们就无法抓取网页中指定位置的内容,所以为了能够抓取网页中指定位置的内容我们要把php代码转换为https的http代码。
1、下载安装phpssl,
2、ssl证书下载之后解压到/usr/local/php目录下
3、把解压后的conf目录复制到phpssl解压目录下
4、打开mac命令行,
5、回车后就可以phpssl证书安装成功。为什么要设置ssl证书?ssl证书是支持https的重要配置,证书是开发登录功能的关键步骤。用户可以将该链接设置为ssl或是https,来保护用户数据的安全。
php制作登录程序注意
1、客户端访问站点时请写入该站点的access_cookie,防止被拦截。php.ini和-config.php中配置:修改php.ini的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。修改-config.php的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。
3、清除ssl证书登录流程登录时点击同意让注册用户注册:php.ini.php内配置access_cookie的default_method为stream_on,配置access_cookie_key为数字:然后修改ssl证书同意的代码,只要不写access_cookie_key,则所有同意写为stream_on,并注释掉同意写为stream_from:随后刷新页面即可。
上方两张图显示的是国内所有的php后端服务器ip列表:提示:这里只提供了15位之前的mysql数据库的ip,再配置好ssl证书信息之后,就不能再写其他ip的信息了。国内站点不能用非法ip注册;其他国家的站点不能用非法信息注册;其他地区的站点不能用非法信息注册;不通过邮箱注册也不行。基本就这样了。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容是什么?证书登录流程)
php登录抓取网页指定内容由于我们的php程序中写有设置ssl证书的代码,假如提供的ssl证书不存在将导致在登录的时候失败,这样的话我们就无法抓取网页中指定位置的内容,所以为了能够抓取网页中指定位置的内容我们要把php代码转换为https的http代码。
1、下载安装phpssl,
2、ssl证书下载之后解压到/usr/local/php目录下
3、把解压后的conf目录复制到phpssl解压目录下
4、打开mac命令行,
5、回车后就可以phpssl证书安装成功。为什么要设置ssl证书?ssl证书是支持https的重要配置,证书是开发登录功能的关键步骤。用户可以将该链接设置为ssl或是https,来保护用户数据的安全。
php制作登录程序注意
1、客户端访问站点时请写入该站点的access_cookie,防止被拦截。php.ini和-config.php中配置:修改php.ini的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。修改-config.php的default_method:由stream_on变为stream_from,这是为了避免用户请求传输stream_from的数据,这点需要注意。
3、清除ssl证书登录流程登录时点击同意让注册用户注册:php.ini.php内配置access_cookie的default_method为stream_on,配置access_cookie_key为数字:然后修改ssl证书同意的代码,只要不写access_cookie_key,则所有同意写为stream_on,并注释掉同意写为stream_from:随后刷新页面即可。
上方两张图显示的是国内所有的php后端服务器ip列表:提示:这里只提供了15位之前的mysql数据库的ip,再配置好ssl证书信息之后,就不能再写其他ip的信息了。国内站点不能用非法ip注册;其他国家的站点不能用非法信息注册;其他地区的站点不能用非法信息注册;不通过邮箱注册也不行。基本就这样了。
php登录抓取网页指定内容(YoastSEO17.1:跟上搜索和SERP的变化(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 16:12
埃德温·图南
Edwin 是一位战略内容专家。在加入 Yoast 之前,他花了几年时间在荷兰领先的网页设计杂志上磨练自己的技能。
我们的核心理念之一是让您和您的 网站 及时了解 Google 内部运营和政策的最新变化。最近几周,我们看到了一个有趣的新发展。谷歌在 SERP 中重写了许多标题。在 Yoast SEO 17.1 中,我们进行了一些小改动,以帮助您撰写经得起 Google 审核的出色标题。另一个很酷的事情是 WooCommerce SEO 14.4 中特定于产品的 SEO 和可读性分析。
Yoast SEO 17.1:跟上搜索和 SERP 的变化
多年来,如果谷歌认为它可以更好地描述你的内容,它一直在改变搜索引擎结果页面的内容。现在,谷歌开始更积极地改写标题,结果各不相同。尽管如此,数百万个主页的页面标题带有“主页”或显示为“联系人”的联系表格,这还不够好。谷歌在为这些页面编写适当的标题方面做得很好。
在 Yoast SEO 中,我们提供工具来帮助您编写出色的页面标题(
) 和 SEO 标题 ()。我们甚至有评估,检查你的标题是否收录你的关键点关键词等。另外,评估会检查你的标题是否在一定范围内——如果它太短,你会得到一个红色的子弹。在 Yoast SEO 17.1 中,我们正在更改标题评估。
谷歌改标题,我们改标题评价
在 Yoast SEO 17.1 中,我们仍然会检查您的标题,但如果标题太短,我们不会惩罚您。理论上,较短的标题不太可能被谷歌改变,因为它们更精确和简洁。例如,它们更集中,收录更少的最高级。然而,我们并不是说你应该写更短的标题,但我们为你提供了选择。
从今天开始,我们让您可以更好地控制头条新闻——无论是短标题还是长标题。虽然,我们没有改变上限。当然,我们无法控制谷歌做什么——或者它做什么?– 您的标题,因此由您来编写以最佳方式清楚描述页面的标题。
如果您担心标题的外观,则需要分析 SERP 中的变化。您不必检查所有页面,但需要检查最重要的页面。搜索 Google 以查看它们的显示方式以及 Google 是否重写了内容。检查您的分析,看看这些页面的点击率是否下降。而且,当然,继续制作经得起时间考验的出色页面标题——谷歌承认这一点。
第二个变化是标题分隔符。我们已经删除了 | 和 ~ 来自标题分隔符设置,因为谷歌似乎将这些更改为 - 在 SERP 标题中。如果需要,您可以选择其他分隔符。
与此同时,我们还确保我们的 Google 预览密切模仿搜索结果中的最新视觉效果。这为您提供了您的帖子在 Google 中的外观的最新视图——当然 Google 的重写工作除外。
Yoast SEO 17.1 中的更多增强功能
当然,Yoast SEO 17.1 有更多的增强功能。我们改进了虚词过滤,在语言中添加了荷兰语、英语、印度尼西亚语、俄语和西班牙语,包括“分钟”等与时间相关的词。
在性能优化方面,我们通过排除未更改的项目来加快保存帖子的过程。这在收录许多链接的帖子中非常明显。最后,我们现在不再在非生产站点上显示 SEO 优化通知,因为在这种情况下它不是很有用。
WooCommerce SEO 14.4:产品分析
今天,我们的 WooCommerce SEO 插件也得到了很大的改进。在 WooCommerce 14.4 中,我们更新了 SEO 和可读性分析以使其特定于产品。我们添加了一些新检查,更改了几个现有检查的范围,并确保它们都适合在产品页面上使用。
例如,有一个新的列表检查,看看你是否在产品页面上使用列表——因为列表是传达产品信息的重要工具。我们更新了图片检查以查看您是否添加了足够的图片和视频,并检查它们是否有适当的替代文字。检查的很多方面也发生了变化,因此您无需为产品页面写900字即可获得绿色子弹。这些只是 WooCommerce 14.4 中的一些变化。
阅读 WooCommerce SEO 14.4 中所有很酷的新东西,并用它来制作最好的产品页面!
立即在 WooCommerce SEOUpdate 中改进您的产品描述!
Yoast SEO 17.1 今天发布。在这个版本中,我们根据谷歌最近的变化对一些内容进行了微调。我们还改进了性能并添加了一些语言增强功能。如果这还不是全部,我们会为 WooCommerce SEO 插件提供更新的、特定于产品的分析版本,以帮助您构建更好的产品页面。
接下来就是!
来源
原创文章,作者:WPJIAN,如转载请注明出处: 查看全部
php登录抓取网页指定内容(YoastSEO17.1:跟上搜索和SERP的变化(图))
埃德温·图南
Edwin 是一位战略内容专家。在加入 Yoast 之前,他花了几年时间在荷兰领先的网页设计杂志上磨练自己的技能。
我们的核心理念之一是让您和您的 网站 及时了解 Google 内部运营和政策的最新变化。最近几周,我们看到了一个有趣的新发展。谷歌在 SERP 中重写了许多标题。在 Yoast SEO 17.1 中,我们进行了一些小改动,以帮助您撰写经得起 Google 审核的出色标题。另一个很酷的事情是 WooCommerce SEO 14.4 中特定于产品的 SEO 和可读性分析。
Yoast SEO 17.1:跟上搜索和 SERP 的变化
多年来,如果谷歌认为它可以更好地描述你的内容,它一直在改变搜索引擎结果页面的内容。现在,谷歌开始更积极地改写标题,结果各不相同。尽管如此,数百万个主页的页面标题带有“主页”或显示为“联系人”的联系表格,这还不够好。谷歌在为这些页面编写适当的标题方面做得很好。
在 Yoast SEO 中,我们提供工具来帮助您编写出色的页面标题(
) 和 SEO 标题 ()。我们甚至有评估,检查你的标题是否收录你的关键点关键词等。另外,评估会检查你的标题是否在一定范围内——如果它太短,你会得到一个红色的子弹。在 Yoast SEO 17.1 中,我们正在更改标题评估。
谷歌改标题,我们改标题评价
在 Yoast SEO 17.1 中,我们仍然会检查您的标题,但如果标题太短,我们不会惩罚您。理论上,较短的标题不太可能被谷歌改变,因为它们更精确和简洁。例如,它们更集中,收录更少的最高级。然而,我们并不是说你应该写更短的标题,但我们为你提供了选择。
从今天开始,我们让您可以更好地控制头条新闻——无论是短标题还是长标题。虽然,我们没有改变上限。当然,我们无法控制谷歌做什么——或者它做什么?– 您的标题,因此由您来编写以最佳方式清楚描述页面的标题。
如果您担心标题的外观,则需要分析 SERP 中的变化。您不必检查所有页面,但需要检查最重要的页面。搜索 Google 以查看它们的显示方式以及 Google 是否重写了内容。检查您的分析,看看这些页面的点击率是否下降。而且,当然,继续制作经得起时间考验的出色页面标题——谷歌承认这一点。
第二个变化是标题分隔符。我们已经删除了 | 和 ~ 来自标题分隔符设置,因为谷歌似乎将这些更改为 - 在 SERP 标题中。如果需要,您可以选择其他分隔符。
与此同时,我们还确保我们的 Google 预览密切模仿搜索结果中的最新视觉效果。这为您提供了您的帖子在 Google 中的外观的最新视图——当然 Google 的重写工作除外。
Yoast SEO 17.1 中的更多增强功能
当然,Yoast SEO 17.1 有更多的增强功能。我们改进了虚词过滤,在语言中添加了荷兰语、英语、印度尼西亚语、俄语和西班牙语,包括“分钟”等与时间相关的词。
在性能优化方面,我们通过排除未更改的项目来加快保存帖子的过程。这在收录许多链接的帖子中非常明显。最后,我们现在不再在非生产站点上显示 SEO 优化通知,因为在这种情况下它不是很有用。
WooCommerce SEO 14.4:产品分析
今天,我们的 WooCommerce SEO 插件也得到了很大的改进。在 WooCommerce 14.4 中,我们更新了 SEO 和可读性分析以使其特定于产品。我们添加了一些新检查,更改了几个现有检查的范围,并确保它们都适合在产品页面上使用。
例如,有一个新的列表检查,看看你是否在产品页面上使用列表——因为列表是传达产品信息的重要工具。我们更新了图片检查以查看您是否添加了足够的图片和视频,并检查它们是否有适当的替代文字。检查的很多方面也发生了变化,因此您无需为产品页面写900字即可获得绿色子弹。这些只是 WooCommerce 14.4 中的一些变化。
阅读 WooCommerce SEO 14.4 中所有很酷的新东西,并用它来制作最好的产品页面!
立即在 WooCommerce SEOUpdate 中改进您的产品描述!
Yoast SEO 17.1 今天发布。在这个版本中,我们根据谷歌最近的变化对一些内容进行了微调。我们还改进了性能并添加了一些语言增强功能。如果这还不是全部,我们会为 WooCommerce SEO 插件提供更新的、特定于产品的分析版本,以帮助您构建更好的产品页面。
接下来就是!
来源
原创文章,作者:WPJIAN,如转载请注明出处:
php登录抓取网页指定内容(背景PHP写爬虫说实话基础的爬虫知识至于正则吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-09 20:11
给同事写个小工具,抓取月报然后做统计处理。第一反应是做一个爬虫去抓取需要的表格和图表,这样就不用自己去连接数据库,整理表格生成图片了。以上是背景
PHP编写爬虫
说实话,我也想用Python,毕竟他们有签名。无奈,我还停留在看Python语法的阶段。我真的很惭愧。这里我们使用php的CURL库进行页面抓取。
同事用的系统需要先登录,然后有很多自定义图表。每个图表都有一个 graph_id。根据graph_id,可以导出某段时间的csv格式报告和对应的图形png。
1. 登录cookie
或许爬虫遇到的第一关就是登录,通常你要爬取的网页需要先对登录用户进行认证。我们知道,通常用户的会话状态是通过SessionID来标识的,SessionID是通过cookie保存到客户端的。所以当你想先登录爬取页面的时候,先请求登录界面,将获取到的cookie保存在本地,以后每次抓取内容时都要带上cookie文件。用于保存 cookie 的 CURL 选项 CURLOPT_COOKIEJAR:
# 保存cookie的代码
$this->cookie_file = '/tmp/cookie.curl.tmp';
curl_setopt($ch, CURLOPT_COOKIEJAR , $this->cookie_file);
然后在抓取页面时使用此 cookie 设置 CURLOPT_COOKIEFILE:
# 设置cookie的代码
curl_setopt($ch, CURLOPT_COOKIEFILE , $this->cookie_file);
2. 页面重定向
解决session问题,第二个头疼的是302和301重定向。重定向页面的响应一般没有body部分,head是这样的:
HTTP/1.1 302 Found
Date: Thu, 29 Jun 2017 09:49:51 GMT
Server: Apache/2.2.15 (CentOS)
...
Location: curl_test.php?action=real_page
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
那我们该怎么办呢?仔细观察header信息,可以发现其中收录重定向的目标页面Location: xxx....并且CURL可以通过curl_getinfo($ch, CURLINFO_HTTP_CODE)获取http状态码。接下来要做什么,似乎已经很清楚了。
// 获取的curl结果
$re = curl_exec($ch);
list ($header, $body) = explode("\r\n\r\n", $re, 2);
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 有的网站会检查referer地址来判断是否请求来自重定向,这里保存上次请求的url供重定向构造referer使用
$last_url = curl_getinfo($ch, CURLINFO_EFFECTIVE_URL);
curl_close($ch);
if ($http_code == 301 || $http_code == 302) {
if (preg_match('/Location:(.*?)\n/', $header, $matches)) {
// 继续抓取目标页面
$urlinfo = parse_url($url);
// 这里match的url地址可能不一样,所以不一定这么简单的拼接就行
$re_url = $urlinfo['scheme'] . '://' . $urlinfo['host'] . substr($urlinfo['path'], 0, strrpos($urlinfo['path'], '/')+1) . trim($matches[1]);
return $this->_http_get($re_url, $last_url);
} else {
return FALSE;
}
} else if ($http_code == 200) {
return $body;
} else {
echo 'Error: CURL failed.[url='.$url.']; [http code= '. $http_code.']';
return FALSE;
}
有些网站会检查referer地址来判断请求是否来自重定向,通过设置curl的CURLOPT_REFERER参数来伪造HTTP_REFERER。
概括
以上可以说是最基本的爬虫知识,至于规则规则,这里就不介绍了。以后可能是下载的内容根据Content-type、爬虫效率问题、反爬虫策略来判断文件类型。简而言之,爬虫试图模拟用户行为来抓取页面。反爬虫试图找出哪些请求是爬虫,哪些不是,并相互对抗。等爬虫有更深入的研究再继续聊,仅此而已。
转载于: 查看全部
php登录抓取网页指定内容(背景PHP写爬虫说实话基础的爬虫知识至于正则吗?)
给同事写个小工具,抓取月报然后做统计处理。第一反应是做一个爬虫去抓取需要的表格和图表,这样就不用自己去连接数据库,整理表格生成图片了。以上是背景
PHP编写爬虫
说实话,我也想用Python,毕竟他们有签名。无奈,我还停留在看Python语法的阶段。我真的很惭愧。这里我们使用php的CURL库进行页面抓取。
同事用的系统需要先登录,然后有很多自定义图表。每个图表都有一个 graph_id。根据graph_id,可以导出某段时间的csv格式报告和对应的图形png。
1. 登录cookie
或许爬虫遇到的第一关就是登录,通常你要爬取的网页需要先对登录用户进行认证。我们知道,通常用户的会话状态是通过SessionID来标识的,SessionID是通过cookie保存到客户端的。所以当你想先登录爬取页面的时候,先请求登录界面,将获取到的cookie保存在本地,以后每次抓取内容时都要带上cookie文件。用于保存 cookie 的 CURL 选项 CURLOPT_COOKIEJAR:
# 保存cookie的代码
$this->cookie_file = '/tmp/cookie.curl.tmp';
curl_setopt($ch, CURLOPT_COOKIEJAR , $this->cookie_file);
然后在抓取页面时使用此 cookie 设置 CURLOPT_COOKIEFILE:
# 设置cookie的代码
curl_setopt($ch, CURLOPT_COOKIEFILE , $this->cookie_file);
2. 页面重定向
解决session问题,第二个头疼的是302和301重定向。重定向页面的响应一般没有body部分,head是这样的:
HTTP/1.1 302 Found
Date: Thu, 29 Jun 2017 09:49:51 GMT
Server: Apache/2.2.15 (CentOS)
...
Location: curl_test.php?action=real_page
Content-Length: 0
Connection: close
Content-Type: text/html; charset=UTF-8
那我们该怎么办呢?仔细观察header信息,可以发现其中收录重定向的目标页面Location: xxx....并且CURL可以通过curl_getinfo($ch, CURLINFO_HTTP_CODE)获取http状态码。接下来要做什么,似乎已经很清楚了。
// 获取的curl结果
$re = curl_exec($ch);
list ($header, $body) = explode("\r\n\r\n", $re, 2);
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 有的网站会检查referer地址来判断是否请求来自重定向,这里保存上次请求的url供重定向构造referer使用
$last_url = curl_getinfo($ch, CURLINFO_EFFECTIVE_URL);
curl_close($ch);
if ($http_code == 301 || $http_code == 302) {
if (preg_match('/Location:(.*?)\n/', $header, $matches)) {
// 继续抓取目标页面
$urlinfo = parse_url($url);
// 这里match的url地址可能不一样,所以不一定这么简单的拼接就行
$re_url = $urlinfo['scheme'] . '://' . $urlinfo['host'] . substr($urlinfo['path'], 0, strrpos($urlinfo['path'], '/')+1) . trim($matches[1]);
return $this->_http_get($re_url, $last_url);
} else {
return FALSE;
}
} else if ($http_code == 200) {
return $body;
} else {
echo 'Error: CURL failed.[url='.$url.']; [http code= '. $http_code.']';
return FALSE;
}
有些网站会检查referer地址来判断请求是否来自重定向,通过设置curl的CURLOPT_REFERER参数来伪造HTTP_REFERER。
概括
以上可以说是最基本的爬虫知识,至于规则规则,这里就不介绍了。以后可能是下载的内容根据Content-type、爬虫效率问题、反爬虫策略来判断文件类型。简而言之,爬虫试图模拟用户行为来抓取页面。反爬虫试图找出哪些请求是爬虫,哪些不是,并相互对抗。等爬虫有更深入的研究再继续聊,仅此而已。
转载于:
php登录抓取网页指定内容(PHP的curl()使用_setopt设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-09 20:08
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
初始化卷曲;
使用 curl_setopt 设置目标 url,以及其他选项;
curl_exec,执行curl;
执行后关闭curl;
输出数据。 查看全部
php登录抓取网页指定内容(PHP的curl()使用_setopt设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
初始化卷曲;
使用 curl_setopt 设置目标 url,以及其他选项;
curl_exec,执行curl;
执行后关闭curl;
输出数据。
php登录抓取网页指定内容(php登录抓取网页指定内容,实现测试数据的提取。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-09 05:03
php登录抓取网页指定内容,实现测试数据的提取。内容包括图片、链接、关键字等。原理:php通过inet汇编以及基于ip数据包,并通过nctcp协议提取指定位置的数据。实例链接:链接:文件名::不过需要校验是否是php生成的。抓取方法:先找到header头部的content-type以及max-age,然后逐一尝试抓取是否能够得到。
抓取结果:通过观察header中的content-type信息,已经能够肯定是php生成的url。exit();相关利用:turn工具,用于抓取文件名后缀内容,并解析发给foobar,再让foobar用于解析文件名以及提取图片。(没有运行代码,只是贴了代码)附上代码:代码分析:。
题主的意思应该是说,如何去抓取网页中的图片。如果是要做数据分析,推荐使用可以分析用户搜索意图的spystats。
cookie是你的浏览器记录,当你访问某个网站时网站把你的cookie设置成所在ip然后session就会把你所在的ip地址和浏览器设置的cookie重新登记,当你再次访问时cookie内容将会被网站抓取并返回给你,这样你只要通过浏览器访问对应的页面,那么网站会把对应页面的cookie发送给服务器你可以关注下goer(),是目前一个非常出名的抓取数据库的插件同时他也是根据你提供的请求报文,返回相应的数据。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容,实现测试数据的提取。)
php登录抓取网页指定内容,实现测试数据的提取。内容包括图片、链接、关键字等。原理:php通过inet汇编以及基于ip数据包,并通过nctcp协议提取指定位置的数据。实例链接:链接:文件名::不过需要校验是否是php生成的。抓取方法:先找到header头部的content-type以及max-age,然后逐一尝试抓取是否能够得到。
抓取结果:通过观察header中的content-type信息,已经能够肯定是php生成的url。exit();相关利用:turn工具,用于抓取文件名后缀内容,并解析发给foobar,再让foobar用于解析文件名以及提取图片。(没有运行代码,只是贴了代码)附上代码:代码分析:。
题主的意思应该是说,如何去抓取网页中的图片。如果是要做数据分析,推荐使用可以分析用户搜索意图的spystats。
cookie是你的浏览器记录,当你访问某个网站时网站把你的cookie设置成所在ip然后session就会把你所在的ip地址和浏览器设置的cookie重新登记,当你再次访问时cookie内容将会被网站抓取并返回给你,这样你只要通过浏览器访问对应的页面,那么网站会把对应页面的cookie发送给服务器你可以关注下goer(),是目前一个非常出名的抓取数据库的插件同时他也是根据你提供的请求报文,返回相应的数据。
php登录抓取网页指定内容(php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-01 09:10
php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html数据库共享存取文件夹需要开启共享服务。
这是qq浏览器的,
记得n年前在百度看过这个分享。印象里应该是在firefox浏览器里做的,是否可以详细告知下。个人觉得比使用框架jq,phpwind这类要强。
这个是老问题,把代码贴一下看看。curl_output_stream="/"file_raw_url="/"qq_password="admin"qq_mail=""qq_account="admin"qq_password=""qq_account_host="10000"qq_account_user="admin"qq_password=""qq_user_host="10000"qq_user_host_user="admin"qq_password=""qq_user_host_user="admin"qq_account_authorization="admin"curl_output_stream="/"file_raw_url="/"。
配置sqlsession和mysql数据库连接,
你是想做web吗, 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html)
php登录抓取网页指定内容的示例代码。-generator-based-mysql-use-one-login-for-php-my-template-php.html数据库共享存取文件夹需要开启共享服务。
这是qq浏览器的,
记得n年前在百度看过这个分享。印象里应该是在firefox浏览器里做的,是否可以详细告知下。个人觉得比使用框架jq,phpwind这类要强。
这个是老问题,把代码贴一下看看。curl_output_stream="/"file_raw_url="/"qq_password="admin"qq_mail=""qq_account="admin"qq_password=""qq_account_host="10000"qq_account_user="admin"qq_password=""qq_user_host="10000"qq_user_host_user="admin"qq_password=""qq_user_host_user="admin"qq_account_authorization="admin"curl_output_stream="/"file_raw_url="/"。
配置sqlsession和mysql数据库连接,
你是想做web吗,
php登录抓取网页指定内容(外汇需求描述需要抓取某金融网站的期货数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-30 08:09
需求描述
需要抓取某金融网站的期货数据,打开浏览器的开发者模式,找到界面url,响应数据正是我们想要的,但是当我们在浏览器地址栏输入url时,我被重定向到网站的期货主页,没有检索到数据。
解决方案
找到请求的header,在我们的curl请求代码中添加header参数来模拟浏览器访问,如下图:
将此头信息添加到我们的代码中,如下所示:
抓取数据后,发现数据是乱码,如下图:
检查后,对返回的数据进行压缩,并添加curl参数:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//解析gzip,deflate内容
再次发出请求,成功返回数据:
下面附上程序的主要代码;
public function catchData(){
$url="https://cn.investing.com/commo ... 3B%3B
$headers=[
'Accept:text/html,application/xhtml+xml,application/xml,application/json, text/javascript, */*; q=0.01',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:en-US,en;q=0.5',
'Cache-Control:max-age=0',
'Connection:keep-alive',
'Cookie:StickySession=id.22115874781.5…gat=1; _gat_allSitesTracker=1',
'Host:cn.investing.com',
'Referer:https://cn.investing.com/commodities/gold',
'User-Agent:Mozilla/5.0 (X11; Ubuntu; Linu…) Gecko/20100101 Firefox/65.0',
'X-Requested-With:XMLHttpRequest',
];
$ch = curl_init();//初始化curl
curl_setopt($ch, CURLOPT_URL,$url);//抓取指定网页
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);//指定头部参数
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//结果不输出到屏幕上
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//这个是解析gzip,deflate压缩的内容
$data = curl_exec($ch);//运行curl
curl_close($ch);
print_r($data);
}
博主留言
我今天已经处理了这个问题 1.2 个小时。我觉得有必要记录一下。有同样问题的朋友可以参考。
你很少写博客。写得不好请轻描淡写。 查看全部
php登录抓取网页指定内容(外汇需求描述需要抓取某金融网站的期货数据(图))
需求描述
需要抓取某金融网站的期货数据,打开浏览器的开发者模式,找到界面url,响应数据正是我们想要的,但是当我们在浏览器地址栏输入url时,我被重定向到网站的期货主页,没有检索到数据。
解决方案
找到请求的header,在我们的curl请求代码中添加header参数来模拟浏览器访问,如下图:
将此头信息添加到我们的代码中,如下所示:
抓取数据后,发现数据是乱码,如下图:
检查后,对返回的数据进行压缩,并添加curl参数:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//解析gzip,deflate内容
再次发出请求,成功返回数据:
下面附上程序的主要代码;
public function catchData(){
$url="https://cn.investing.com/commo ... 3B%3B
$headers=[
'Accept:text/html,application/xhtml+xml,application/xml,application/json, text/javascript, */*; q=0.01',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:en-US,en;q=0.5',
'Cache-Control:max-age=0',
'Connection:keep-alive',
'Cookie:StickySession=id.22115874781.5…gat=1; _gat_allSitesTracker=1',
'Host:cn.investing.com',
'Referer:https://cn.investing.com/commodities/gold',
'User-Agent:Mozilla/5.0 (X11; Ubuntu; Linu…) Gecko/20100101 Firefox/65.0',
'X-Requested-With:XMLHttpRequest',
];
$ch = curl_init();//初始化curl
curl_setopt($ch, CURLOPT_URL,$url);//抓取指定网页
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);//指定头部参数
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//结果不输出到屏幕上
curl_setopt($ch, CURLOPT_POST, 0);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip,deflate');//这个是解析gzip,deflate压缩的内容
$data = curl_exec($ch);//运行curl
curl_close($ch);
print_r($data);
}
博主留言
我今天已经处理了这个问题 1.2 个小时。我觉得有必要记录一下。有同样问题的朋友可以参考。
你很少写博客。写得不好请轻描淡写。
php登录抓取网页指定内容(php登录抓取网页指定内容就我个人使用来看(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-20 04:01
php登录抓取网页指定内容就我个人使用来看,网页抓取最重要的应该是把抓取到的html文件存放在express中post不是httpget方式post由于加了everything后缀可以轻松获取元素,而content-type决定你的发送数据的方式,所以everything里面的post方式相对简单,并且安全。
请问php怎么抓取网页数据
个人推荐用thinkphp,学习周期短,容易上手;建议分成两部分来学习:1:php基础语法;这部分包括php的变量、数组、函数、数据库、基本语法、模板引擎等知识2:项目;前面学好了基础语法,做个简单的页面还是问题不大的。后面就是项目应用了。
thinkphp的吧,也没有什么难的。本人前端,前端培训中,没有发现靠谱的培训机构。网上很多成功的业务站,更多的是依赖于后端能力,不用后端做服务器端交互(由于我们本身本身就是前端机构,所以没有后端没有办法给前端服务器端提供支持,因为我们做的不是bbs或blog页面,只是一个单页面)。至于前端实现,基于第一点,我认为很重要的就是:数据对接。
也就是说,没有足够的数据,网站很难建立起来,也无法表达什么。httpheader是唯一的,不多说了,网上很多教程。
这个问题其实并不是简单的php抓取到页面数据,而是网站抓取数据。很多初学者,看着数据爬虫很头疼,但是大部分都是在抄网页,copy网页的时候思路和结构,根本没有去推断网页的业务逻辑。简单说就是在拿到网页的html页面之后,去推断网页的逻辑,并在推断之后写出自己的抓取逻辑。我的理解是这样,不是很专业,随便听听就好。
首先,推断业务逻辑,可以用别人封装好的的api去推断,比如有个网站可以返回优惠券,如果不知道怎么获取数据,这个api可以非常有用。这个时候可以推断出网页的基本逻辑:有多少条,按照什么顺序,有多少条,这个数量会增加还是减少,有没有漏洞这种。这个时候我们可以尝试通过模拟登录或者验证码获取数据。httpheader就是封装好的网页header,以及一些常用方法比如cookie,cookie验证等。
不多解释,根据自己喜欢。在抓取过程中发现,这个方法只能用于单页面,如果带登录的需求,可以在webpack中做require和loader。这样我们就可以顺利抓取到所有页面的数据。目前我们只学php基础语法,至于怎么写爬虫就要看javascript或者是css去匹配页面了。希望对你有用。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容就我个人使用来看(图))
php登录抓取网页指定内容就我个人使用来看,网页抓取最重要的应该是把抓取到的html文件存放在express中post不是httpget方式post由于加了everything后缀可以轻松获取元素,而content-type决定你的发送数据的方式,所以everything里面的post方式相对简单,并且安全。
请问php怎么抓取网页数据
个人推荐用thinkphp,学习周期短,容易上手;建议分成两部分来学习:1:php基础语法;这部分包括php的变量、数组、函数、数据库、基本语法、模板引擎等知识2:项目;前面学好了基础语法,做个简单的页面还是问题不大的。后面就是项目应用了。
thinkphp的吧,也没有什么难的。本人前端,前端培训中,没有发现靠谱的培训机构。网上很多成功的业务站,更多的是依赖于后端能力,不用后端做服务器端交互(由于我们本身本身就是前端机构,所以没有后端没有办法给前端服务器端提供支持,因为我们做的不是bbs或blog页面,只是一个单页面)。至于前端实现,基于第一点,我认为很重要的就是:数据对接。
也就是说,没有足够的数据,网站很难建立起来,也无法表达什么。httpheader是唯一的,不多说了,网上很多教程。
这个问题其实并不是简单的php抓取到页面数据,而是网站抓取数据。很多初学者,看着数据爬虫很头疼,但是大部分都是在抄网页,copy网页的时候思路和结构,根本没有去推断网页的业务逻辑。简单说就是在拿到网页的html页面之后,去推断网页的逻辑,并在推断之后写出自己的抓取逻辑。我的理解是这样,不是很专业,随便听听就好。
首先,推断业务逻辑,可以用别人封装好的的api去推断,比如有个网站可以返回优惠券,如果不知道怎么获取数据,这个api可以非常有用。这个时候可以推断出网页的基本逻辑:有多少条,按照什么顺序,有多少条,这个数量会增加还是减少,有没有漏洞这种。这个时候我们可以尝试通过模拟登录或者验证码获取数据。httpheader就是封装好的网页header,以及一些常用方法比如cookie,cookie验证等。
不多解释,根据自己喜欢。在抓取过程中发现,这个方法只能用于单页面,如果带登录的需求,可以在webpack中做require和loader。这样我们就可以顺利抓取到所有页面的数据。目前我们只学php基础语法,至于怎么写爬虫就要看javascript或者是css去匹配页面了。希望对你有用。
php登录抓取网页指定内容(php登录抓取网页指定内容1.网页url获取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-14 00:01
php登录抓取网页指定内容1.网页url可以从以下四个方面获取:2.http/https协议3.php内置的数据格式php_extension_http_parser:php内置的数据格式php_string类型$url=""4.参考两种方法分别是:
1)select_ext_http_parser,$url,$input=fd_create($this->getstring(tmp->value));//直接创建字符串方式来获取
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//根据$url获取函数指定参数分别提供两种方式,设置参数时自己加上type为“string”或者“string()”。
5.在实践中,我将上面3种方法都测试了一遍。发现php-http-favicon并不能在selectext_http_parser这个函数执行之前直接用url创建一个string参数的对象,而是创建一个function对象,再用select函数进行检查,查看是否创建成功。6.重新判断一下select是否执行之前检查参数。
1)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//我们先定义一个字符串对象$encodeuricomponent="%y%m%d";$tmpgenerators="%y%m%d%h%m%s";$recipension="%y%m%d";$hretenyflat="%y%m%d%h%m%s";if(true){$recipension="%y%m%d";$hretenyflat="%y%m%d";if(typeofencodeuricomponent=="string"){$hretenyflat="";}else{$hretenyflat="";}}。
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$tmpgenerators=$tmpgenerators{size:16;//values:'';//};$recipension="";$hretenyflat="";if(true){$hretenyflat="";}else{$hretenyflat="";}。
3)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$encodeuricomponent="%y%m%d";$input=fd_create($tmpgenerators,$tmpgenerators{size:16,});$tmpgenerators=fd_create($tmpgenerators{size:16,});$recipension="";$hretenyflat="";if(true){$recipension="";$hretenyflat="";。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容1.网页url获取网页内容)
php登录抓取网页指定内容1.网页url可以从以下四个方面获取:2.http/https协议3.php内置的数据格式php_extension_http_parser:php内置的数据格式php_string类型$url=""4.参考两种方法分别是:
1)select_ext_http_parser,$url,$input=fd_create($this->getstring(tmp->value));//直接创建字符串方式来获取
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//根据$url获取函数指定参数分别提供两种方式,设置参数时自己加上type为“string”或者“string()”。
5.在实践中,我将上面3种方法都测试了一遍。发现php-http-favicon并不能在selectext_http_parser这个函数执行之前直接用url创建一个string参数的对象,而是创建一个function对象,再用select函数进行检查,查看是否创建成功。6.重新判断一下select是否执行之前检查参数。
1)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//我们先定义一个字符串对象$encodeuricomponent="%y%m%d";$tmpgenerators="%y%m%d%h%m%s";$recipension="%y%m%d";$hretenyflat="%y%m%d%h%m%s";if(true){$recipension="%y%m%d";$hretenyflat="%y%m%d";if(typeofencodeuricomponent=="string"){$hretenyflat="";}else{$hretenyflat="";}}。
2)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$tmpgenerators=$tmpgenerators{size:16;//values:'';//};$recipension="";$hretenyflat="";if(true){$hretenyflat="";}else{$hretenyflat="";}。
3)select_ext_http_parser,$url,$options=fd_create($this->getstring(tmp->value),$input,$options);//$encodeuricomponent="%y%m%d";$input=fd_create($tmpgenerators,$tmpgenerators{size:16,});$tmpgenerators=fd_create($tmpgenerators{size:16,});$recipension="";$hretenyflat="";if(true){$recipension="";$hretenyflat="";。
php登录抓取网页指定内容(Pythontkintertkinter小编教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-13 00:09
如下图:
#coding:utf-8
import urllib,urllib2
import Tkinter #导入TKinter模块
ytm=Tkinter.Tk() #创建Tk对象
ytm.title("login") #设置窗口标题
ytm.geometry("300x300") #设置窗口尺寸
l1=Tkinter.Label(ytm,text="用户名") #标签
l1.pack() #指定包管理器放置组件
user_text=Tkinter.Entry() #创建文本框
user_text.pack()
def getuser():
user=user_text.get() #获取文本框内容
print user
Tkinter.Button(ytm,text="登录",command=getuser).pack() #command绑定获取文本框内容方法
ytm.mainloop() #进入主循环
上面python TKinter中获取文本框内容的方法是所有编辑器共享的内容。希望能给大家一个参考,也希望大家支持ASPKU源代码库。
注意:请移步python教程频道阅读相关教程知识。
上一篇:Python tkinter 标签更新方法
下一篇:如何将python tkinter界面显示在中间 查看全部
php登录抓取网页指定内容(Pythontkintertkinter小编教程)
如下图:
#coding:utf-8
import urllib,urllib2
import Tkinter #导入TKinter模块
ytm=Tkinter.Tk() #创建Tk对象
ytm.title("login") #设置窗口标题
ytm.geometry("300x300") #设置窗口尺寸
l1=Tkinter.Label(ytm,text="用户名") #标签
l1.pack() #指定包管理器放置组件
user_text=Tkinter.Entry() #创建文本框
user_text.pack()
def getuser():
user=user_text.get() #获取文本框内容
print user
Tkinter.Button(ytm,text="登录",command=getuser).pack() #command绑定获取文本框内容方法
ytm.mainloop() #进入主循环
上面python TKinter中获取文本框内容的方法是所有编辑器共享的内容。希望能给大家一个参考,也希望大家支持ASPKU源代码库。
注意:请移步python教程频道阅读相关教程知识。
上一篇:Python tkinter 标签更新方法
下一篇:如何将python tkinter界面显示在中间

