
php抓取网页连接函数
php抓取网页连接函数(php抓取网页连接函数,抓取一个爬虫平台的源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-26 10:01
php抓取网页连接函数,本教程主要介绍了网页爬取相关常用的框架(apache、mysql、mariadb、phpjavascript、phpmyadmin)以及源码地址和具体实现代码,学会后,找工作将不是难事。简介个人觉得目前开发网页还是会使用一些基本框架更好,结合爬虫的实战讲解。php抓取网页连接函数的目的是给抓取的网页能够定位到对应的数据页,再利用数据页,获取自己想要的数据,如果数据太多,则可以分页抓取数据;抓取网页连接的关键在于获取到对应的数据页,这里简单介绍几种方法:。
1、抓取上一次抓取到的数据页,
2、cookie+requestget数据,这个网上很多文章讲解的很清楚,
3、file抓取数据,file类封装的很好,
1、对于大型的网站,可以以本地存储爬取的源码网址来方便检索,本地存储的网址有/zhihu/list等,不过这种方法存储的数据不规则,
2、即使以爬虫方式抓取网页,可以采用php抓取数据的方式使用,比如get、post。
本次讲解通过抓取一个爬虫平台的源码,
1、/zhihu/list/list.php连接数据,不需要重新刷新页面;
2、php爬虫;
<p>3、一些工具;第一步、先下载地址解压,然后通过phpmyadmin进行管理,里面自带了sqlite的插件进行连接数据库,进行一些数据处理; 查看全部
php抓取网页连接函数(php抓取网页连接函数,抓取一个爬虫平台的源码)
php抓取网页连接函数,本教程主要介绍了网页爬取相关常用的框架(apache、mysql、mariadb、phpjavascript、phpmyadmin)以及源码地址和具体实现代码,学会后,找工作将不是难事。简介个人觉得目前开发网页还是会使用一些基本框架更好,结合爬虫的实战讲解。php抓取网页连接函数的目的是给抓取的网页能够定位到对应的数据页,再利用数据页,获取自己想要的数据,如果数据太多,则可以分页抓取数据;抓取网页连接的关键在于获取到对应的数据页,这里简单介绍几种方法:。
1、抓取上一次抓取到的数据页,
2、cookie+requestget数据,这个网上很多文章讲解的很清楚,
3、file抓取数据,file类封装的很好,
1、对于大型的网站,可以以本地存储爬取的源码网址来方便检索,本地存储的网址有/zhihu/list等,不过这种方法存储的数据不规则,
2、即使以爬虫方式抓取网页,可以采用php抓取数据的方式使用,比如get、post。
本次讲解通过抓取一个爬虫平台的源码,
1、/zhihu/list/list.php连接数据,不需要重新刷新页面;
2、php爬虫;
<p>3、一些工具;第一步、先下载地址解压,然后通过phpmyadmin进行管理,里面自带了sqlite的插件进行连接数据库,进行一些数据处理;
php抓取网页连接函数(PHP外部资源函数fopen/file_get_contents好很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-22 23:13
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
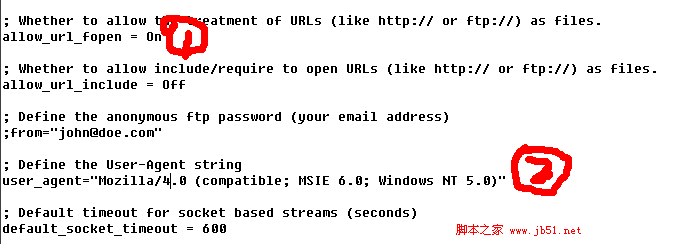
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php抓取网页连接函数(PHP外部资源函数fopen/file_get_contents好很多)
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php抓取网页连接函数(我想从其他网站获取所有时间表的航班数据.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-19 14:17
)
我的 网站 有问题。我想从其他网站 获取所有时刻表的航班数据。我查看了它的源代码并获得了用于处理数据的 url 链接。有人可以告诉我如何从当前 url 链接中获取数据并将其显示在我们的 网站 上?
您可以使用 file_get_contents() 函数来完成此操作。此函数返回所提供 URL 的 html。然后使用 HTML Parser 获取所需数据。
$html = file_get_contents("http://website.com");
$dom = new DOMDocument();
$dom->loadHTML($html);
$nodes = $dom->getElementsByTagName('h3');
foreach ($nodes as $node) {
echo $node->nodeValue."
"; // return tag data
}
另一种使用 preg_match_all() 提取数据的方法
$html = file_get_contents($_REQUEST['url']);
preg_match_all('/(.*?)/s', $html, $matches);
// specify the class to get the data of that class
foreach ($matches[1] as $node) {
echo $node."
";
} 查看全部
php抓取网页连接函数(我想从其他网站获取所有时间表的航班数据..
)
我的 网站 有问题。我想从其他网站 获取所有时刻表的航班数据。我查看了它的源代码并获得了用于处理数据的 url 链接。有人可以告诉我如何从当前 url 链接中获取数据并将其显示在我们的 网站 上?
您可以使用 file_get_contents() 函数来完成此操作。此函数返回所提供 URL 的 html。然后使用 HTML Parser 获取所需数据。
$html = file_get_contents("http://website.com";);
$dom = new DOMDocument();
$dom->loadHTML($html);
$nodes = $dom->getElementsByTagName('h3');
foreach ($nodes as $node) {
echo $node->nodeValue."
"; // return tag data
}
另一种使用 preg_match_all() 提取数据的方法
$html = file_get_contents($_REQUEST['url']);
preg_match_all('/(.*?)/s', $html, $matches);
// specify the class to get the data of that class
foreach ($matches[1] as $node) {
echo $node."
";
}
php抓取网页连接函数(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-17 18:32
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php抓取网页连接函数(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php抓取网页连接函数(PHP中和URL的特殊处理方法及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-13 15:18
在项目中,有时我们需要对当前页面的整个URL进行特殊处理,比如提取某一部分来判断是否满足我们的需求。带着这个需求,我们来说说PHP中URL相关的知识点。
获取页面的 URL
从上图可以看出,URL收录了协议、域名、端口、查询参数、请求路径等,在PHP中我们可以使用$_SERVER这个超级全局数组来获取URL的各个组成部分,然后进行拼接,从而得到最后一个当前页面的URL。
解析 URL 的各个部分
上面得到的页面的URL是一种特殊的情况,因为这些都是PHP底层生成的。现在我们遇到了不同的情况,就是url是一个变量,所以这时候除了手动使用explode函数来分解,还可以使用parse_url来完成,这个函数可以成功的提取出各个组件URL 来自 URL 字符串,例如端口、主机、协议、路径、用户和密码等。
分解查询参数
有时我们有很多查询参数,那么这时候我们可以使用parse_str函数将我们的查询参数分成数组,从而轻松提取每个值。当然,这些也可以借助explode来完成,但唯一不同的是,这个函数更加方便,我们可以只提取一次我们想要的值,并且explode至少要使用2次。
使用数组和对象构造 URL
在项目中经常会遇到使用各种条件生成最终URL的情况,尤其是可能收录中文的时候。大家都知道,收录中文的URL必须经过编码,所以如果参数很多,生成一个URL会感觉代码很乱,好在PHP提供了http_build_query函数,可以让我们直接以如下形式生成我们需要的最后一个URL一个数组或对象,该函数自动执行 URL 编码操作。想一想,是不是更方便?
解析路径
如果我们需要进一步解析URL的路径部分,那么此时我们可以使用PHP中的explode函数来完成。有了它,我们可以分割路径的每个部分以进行进一步处理。
上面提到了几个常用的PHP函数。如果你已经很熟悉了,相信对你以后的项目会有很大的帮助。感谢您阅读这篇文章。如果您觉得不错,请点个赞或分享给您的朋友。, 如果有什么问题或者有更好的体验,可以在评论中分享给大家,周末快乐。 查看全部
php抓取网页连接函数(PHP中和URL的特殊处理方法及解决办法)
在项目中,有时我们需要对当前页面的整个URL进行特殊处理,比如提取某一部分来判断是否满足我们的需求。带着这个需求,我们来说说PHP中URL相关的知识点。
获取页面的 URL
从上图可以看出,URL收录了协议、域名、端口、查询参数、请求路径等,在PHP中我们可以使用$_SERVER这个超级全局数组来获取URL的各个组成部分,然后进行拼接,从而得到最后一个当前页面的URL。
解析 URL 的各个部分
上面得到的页面的URL是一种特殊的情况,因为这些都是PHP底层生成的。现在我们遇到了不同的情况,就是url是一个变量,所以这时候除了手动使用explode函数来分解,还可以使用parse_url来完成,这个函数可以成功的提取出各个组件URL 来自 URL 字符串,例如端口、主机、协议、路径、用户和密码等。
分解查询参数
有时我们有很多查询参数,那么这时候我们可以使用parse_str函数将我们的查询参数分成数组,从而轻松提取每个值。当然,这些也可以借助explode来完成,但唯一不同的是,这个函数更加方便,我们可以只提取一次我们想要的值,并且explode至少要使用2次。
使用数组和对象构造 URL
在项目中经常会遇到使用各种条件生成最终URL的情况,尤其是可能收录中文的时候。大家都知道,收录中文的URL必须经过编码,所以如果参数很多,生成一个URL会感觉代码很乱,好在PHP提供了http_build_query函数,可以让我们直接以如下形式生成我们需要的最后一个URL一个数组或对象,该函数自动执行 URL 编码操作。想一想,是不是更方便?
解析路径
如果我们需要进一步解析URL的路径部分,那么此时我们可以使用PHP中的explode函数来完成。有了它,我们可以分割路径的每个部分以进行进一步处理。
上面提到了几个常用的PHP函数。如果你已经很熟悉了,相信对你以后的项目会有很大的帮助。感谢您阅读这篇文章。如果您觉得不错,请点个赞或分享给您的朋友。, 如果有什么问题或者有更好的体验,可以在评论中分享给大家,周末快乐。
php抓取网页连接函数(php抓取网页连接函数(2):连接时生成一个httpcookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-11 16:44
php抓取网页连接函数
1、httpcookie:连接时生成一个httpcookie,该httpcookie会用于加密消息,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自httpcookie。
2、requestheader:requestheader连接http时生成一个来自request的字段,我们通常称这个字段为requestbody,连接后生成来自http请求的字段,用于加密传递请求的数据,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求。request-header命令详解。
3、httpcookie2:request&cookie2指的是两种requestheader字段规则,这两种requestheader字段规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie2命令详解。
4、httpcookie4:request-cookie指的是两种requestbody规则,这两种requestbody规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie4命令详解。
5、php_cookie自动加载规则#newhttpcookie_php_cookiefakewl=off#把httpcookie存到变量里httpcookie2_php_cookie_cache_from_value('123')。body()。send({data:'aaa。jpg'})#把连接好的http请求存到变量里httpcookie2_cookie_php_cookie_cache_from_value('123')。
body()。send({data:'bbb。jpg'})#字段规则不同对应的php命令sendphp_cookie_a('123');php_cookie_a=newhttpcookie('aaa。jpg');php_cookie_a。send({'data':'bbb。jpg'});。 查看全部
php抓取网页连接函数(php抓取网页连接函数(2):连接时生成一个httpcookie)
php抓取网页连接函数
1、httpcookie:连接时生成一个httpcookie,该httpcookie会用于加密消息,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自httpcookie。
2、requestheader:requestheader连接http时生成一个来自request的字段,我们通常称这个字段为requestbody,连接后生成来自http请求的字段,用于加密传递请求的数据,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求。request-header命令详解。
3、httpcookie2:request&cookie2指的是两种requestheader字段规则,这两种requestheader字段规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie2命令详解。
4、httpcookie4:request-cookie指的是两种requestbody规则,这两种requestbody规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie4命令详解。
5、php_cookie自动加载规则#newhttpcookie_php_cookiefakewl=off#把httpcookie存到变量里httpcookie2_php_cookie_cache_from_value('123')。body()。send({data:'aaa。jpg'})#把连接好的http请求存到变量里httpcookie2_cookie_php_cookie_cache_from_value('123')。
body()。send({data:'bbb。jpg'})#字段规则不同对应的php命令sendphp_cookie_a('123');php_cookie_a=newhttpcookie('aaa。jpg');php_cookie_a。send({'data':'bbb。jpg'});。
php抓取网页连接函数(如何使用beatifulsoup来实现我们的第二个函数:3.3整理数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 16:31
中间。其中title在label的正文里面,body在正文里面
标签的内容。
因此,我们可以使用 beatifulsoup 来实现我们的第二个功能:
def parse_article(html):
soup = BeautifulSoup(html, 'html.parser')
# 从上面的数据获取html文档并解析,这里使用的是Python自带的HTML解释器
article = soup.find('div', attrs={'class': 'post f'})
# 缩小HTML文档的解析范围,限定在文章主体内部。
title = article.find('h1').getText()
# 获取文章主体内部的标签内的文本,可以发现这就是标题内容。
paras = []
# 创建一个列表,以段落的形式,向里面填充文本。
for paragraph in article.find_all('p'):
p_content = paragraph.getText()
# 获取<p>标签内的文本,这里就是段落文本内容。
paras.append(p_content)
return title, paras
# 返回标题和参数,用于写入文件。
3.3 整理数据
获得我们需要的所有数据(标题和内容)后,我们需要将其写入文件。我们首先需要拼接一个文件名,创建并打开文件。注意这里的参数 wb。在Python3.X中,b参数是自动添加的(不写就填,有的话就自己不填);但是在 Python2.X 中,情况并非如此,所以最好填写它,以避免更改版本后出现一些奇怪的错误。当然不用改啦~
def get_article(title, url):
file_name = title + '.txt'
# 拼接文件名
with codecs.open(file_name, 'wb', encoding='utf-8') as fp:
html = download_page(url)
# 调用第一个函数获取数据
title2, text = parse_article(html)
# 调用第二个函数获取数据
fp.write('\t%s\t\r\n' % title2)
for p in text:
fp.write('\t%s\r\n' % p)
# 将获取的数据写入文件。
print('文章读取完毕!')
return 'OK'
最后,我们必须编写另一个 if 语句来确定是运行还是导入。在运行文件时,我们可以通过调用第三个函数来达到我们的目的。
if __name__ == '__main__':
url = 'http://jandan.net/2016/02/18/caribbean-whales.html'
get_article(url)
4. 文章 结束前的一些话
好了,这篇文章到此结束。还有一个爬虫用来抓取下面的简单主页文章。不过爬取的过程也是上面的步骤,看懂了就可以写出来。如果你不明白...好吧,我只是想炫耀一下,因为我很高兴,哈哈哈哈来打我吧~~
我是胡一博,一个每天都被自己唤醒的帅气聪明的人。如果您发现这些代码有任何问题,请告诉我,我会尽快回复并寄钱!钱可以分配给任何人或组织(比如慈善组织和开源项目),就酱~ 查看全部
php抓取网页连接函数(如何使用beatifulsoup来实现我们的第二个函数:3.3整理数据)
中间。其中title在label的正文里面,body在正文里面
标签的内容。
因此,我们可以使用 beatifulsoup 来实现我们的第二个功能:
def parse_article(html):
soup = BeautifulSoup(html, 'html.parser')
# 从上面的数据获取html文档并解析,这里使用的是Python自带的HTML解释器
article = soup.find('div', attrs={'class': 'post f'})
# 缩小HTML文档的解析范围,限定在文章主体内部。
title = article.find('h1').getText()
# 获取文章主体内部的标签内的文本,可以发现这就是标题内容。
paras = []
# 创建一个列表,以段落的形式,向里面填充文本。
for paragraph in article.find_all('p'):
p_content = paragraph.getText()
# 获取<p>标签内的文本,这里就是段落文本内容。
paras.append(p_content)
return title, paras
# 返回标题和参数,用于写入文件。
3.3 整理数据
获得我们需要的所有数据(标题和内容)后,我们需要将其写入文件。我们首先需要拼接一个文件名,创建并打开文件。注意这里的参数 wb。在Python3.X中,b参数是自动添加的(不写就填,有的话就自己不填);但是在 Python2.X 中,情况并非如此,所以最好填写它,以避免更改版本后出现一些奇怪的错误。当然不用改啦~
def get_article(title, url):
file_name = title + '.txt'
# 拼接文件名
with codecs.open(file_name, 'wb', encoding='utf-8') as fp:
html = download_page(url)
# 调用第一个函数获取数据
title2, text = parse_article(html)
# 调用第二个函数获取数据
fp.write('\t%s\t\r\n' % title2)
for p in text:
fp.write('\t%s\r\n' % p)
# 将获取的数据写入文件。
print('文章读取完毕!')
return 'OK'
最后,我们必须编写另一个 if 语句来确定是运行还是导入。在运行文件时,我们可以通过调用第三个函数来达到我们的目的。
if __name__ == '__main__':
url = 'http://jandan.net/2016/02/18/caribbean-whales.html'
get_article(url)
4. 文章 结束前的一些话
好了,这篇文章到此结束。还有一个爬虫用来抓取下面的简单主页文章。不过爬取的过程也是上面的步骤,看懂了就可以写出来。如果你不明白...好吧,我只是想炫耀一下,因为我很高兴,哈哈哈哈来打我吧~~
我是胡一博,一个每天都被自己唤醒的帅气聪明的人。如果您发现这些代码有任何问题,请告诉我,我会尽快回复并寄钱!钱可以分配给任何人或组织(比如慈善组织和开源项目),就酱~
php抓取网页连接函数(.params-字符串参数列表,抓取网页连接函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-07 13:02
php抓取网页连接函数有很多,本文介绍的有三种:formdata.params-字符串参数的参数列表,设置字符串的参数-params的返回值在params中可以设置:params(param_url+param_param),params(param_sequence+param_sequence_num),其中(param_url+param_param)中的sequence属性值和(param_sequence_num)中的sequence属性值会计算被抓取网页的数据流的大小;参数参数列表主要包括:items_full_name,items_full_length,items_txt_length,items_txt_extension,items_name,items_version和items_version。
items_full_nameitems_full_name的值即为某条获取到的文本串,可以使用json格式的形式提供items_full_name;items_full_name;items_full_name;items_full_name;.当items_full_name值为1时,等同于“原始长度”。
通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。items_full_nameitems_full_name的值表示文本串的长度,通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。
template_length=1时,返回“字符串长度”;length=2时,返回“一个单词”;length=3时,返回“两个单词”;length=4时,返回“三个单词”;length=5时,返回“四个单词”;length=6时,返回“五个单词”;.template_length=0时,返回“整个网页”;items_full_name与上面返回值有一点相似,但是需要注意的是items_full_name,并不一定是我们想要的单词,(最典型的应该是前缀名),应该传值为upcursor。
如:formdata.params.base_title='upcursor';items_full_name='upcursor';items_full_length=20;items_txt_length=50;items_txt_extension='upcursor';items_version=1.3;template_length=1.3;items_full_name=upcursor;length=1000000;items_full_length=2000000;items_txt_length=2000000;items_version=2.0;template_length=1.3;items_full_name=upcursor;length=2000000;items_full_length=3000000;items_version=4.0;template_length=1.3;items_full_name=upcursor;length=2000。 查看全部
php抓取网页连接函数(.params-字符串参数列表,抓取网页连接函数)
php抓取网页连接函数有很多,本文介绍的有三种:formdata.params-字符串参数的参数列表,设置字符串的参数-params的返回值在params中可以设置:params(param_url+param_param),params(param_sequence+param_sequence_num),其中(param_url+param_param)中的sequence属性值和(param_sequence_num)中的sequence属性值会计算被抓取网页的数据流的大小;参数参数列表主要包括:items_full_name,items_full_length,items_txt_length,items_txt_extension,items_name,items_version和items_version。
items_full_nameitems_full_name的值即为某条获取到的文本串,可以使用json格式的形式提供items_full_name;items_full_name;items_full_name;items_full_name;.当items_full_name值为1时,等同于“原始长度”。
通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。items_full_nameitems_full_name的值表示文本串的长度,通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。
template_length=1时,返回“字符串长度”;length=2时,返回“一个单词”;length=3时,返回“两个单词”;length=4时,返回“三个单词”;length=5时,返回“四个单词”;length=6时,返回“五个单词”;.template_length=0时,返回“整个网页”;items_full_name与上面返回值有一点相似,但是需要注意的是items_full_name,并不一定是我们想要的单词,(最典型的应该是前缀名),应该传值为upcursor。
如:formdata.params.base_title='upcursor';items_full_name='upcursor';items_full_length=20;items_txt_length=50;items_txt_extension='upcursor';items_version=1.3;template_length=1.3;items_full_name=upcursor;length=1000000;items_full_length=2000000;items_txt_length=2000000;items_version=2.0;template_length=1.3;items_full_name=upcursor;length=2000000;items_full_length=3000000;items_version=4.0;template_length=1.3;items_full_name=upcursor;length=2000。
php抓取网页连接函数( 一个项目有关网站图标爬取经验分享出来的经验分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-07 08:31
一个项目有关网站图标爬取经验分享出来的经验分享)
最近的一个项目是关于网站图标爬取,所以分享一些经验点和解决方法。
favicon 图标介绍
favicon.ico 通常用于 网站 标志。它显示在浏览器的地址栏、浏览器选项卡或采集夹上。它是一个缩写的标志,显示了网站的个性。
浏览器如何获取网站图标?
浏览器会首先分析请求的 URL 源代码的头部,找到具有 rel="icon" 属性的链接元素。href属性是图标地址,但不是所有的网站都会设置这个项目,有的网站我喜欢把favicon.ico直接放在根目录下进行SEO优化。因为搜索引擎爬虫会尝试请求网站根目录下的favicon.ico,久而久之,就在不知不觉中成为了行业规范。了解了网站图标的来源后,爬取的思路就可用了。
要求暴力
不管你的网站的根目录下有没有favicon.ico,我只想抓住它。至于能不能抓到,就试试你的运气吧(毕竟运气的概率还是很高的)。以我们官网()为例,PHP爬取代码如下:
$url = 'https://www.kunquer.com';
$content = file_get_contents($url.'/favicon.ico');
请原谅我没有一次把代码全部放出来,毕竟我要详细解释一下。如何判断检索到的内容是图标?也许它只是一个 404 页面?将内容保存到本地文件后,可以通过getimagesize()函数判断:
$file = tmpfile();
$path = stream_get_meta_data($file)['uri'];
file_put_contents($path, file_get_contents($Pea->url.'/favicon.ico'));
var_dump(getimagesize($path));
如果顺利,会打印如下内容:
array(6) { [0]=> int(48) [1]=> int(48) [2]=> int(17) [3]=> string(22) "width="48" height="48"" ["bits"]=> int(32) ["mime"]=> string(24) "image/vnd.microsoft.icon" }
上面的例子不能不成功,因为我们官网的根目录下有这个文件哈哈哈。为了演示后续的性能(另一种情况),我们以虾米网为例,访问/favicon.ico,得到如下反馈:
非常好!我们可以开始下一步了。
分析网页的源代码
当暴力请求失败时,我不得不抓取页面并分析源代码来获取图标,因为图标是放在head部分的链接中,浏览器是通过设置rel="icon"或rel=来设置的“快捷方式图标”来识别,我们只需要找出这部分的href,分析匹配代码如下:
$base = 'http://xiami.com';
preg_match('/(.*?)/is', file_get_contents($base), $head);
if(isset($head[1])) {
preg_match_all('/]+>/is', $head[1], $links);
if(isset($links[0]) && is_array($links[0])) {
foreach($links[0] as $link) {
// 查找rel中包含icon标识的图片路径
if(preg_match('/rel=("|\')?(icon\w?|\w+\s+icon)("|\')?/i', $link)) {
var_dump($link);
}
}
}
}
(恐怕格式不对,截图供参考)
上面,为了找到真相,通过逐步缩小搜索范围,我们得到了结果:
string(102) ""
是的,href 部分就是我们想要的图标:
<p>preg_match('/([^"\s> 查看全部
php抓取网页连接函数(
一个项目有关网站图标爬取经验分享出来的经验分享)
最近的一个项目是关于网站图标爬取,所以分享一些经验点和解决方法。
favicon 图标介绍
favicon.ico 通常用于 网站 标志。它显示在浏览器的地址栏、浏览器选项卡或采集夹上。它是一个缩写的标志,显示了网站的个性。
浏览器如何获取网站图标?
浏览器会首先分析请求的 URL 源代码的头部,找到具有 rel="icon" 属性的链接元素。href属性是图标地址,但不是所有的网站都会设置这个项目,有的网站我喜欢把favicon.ico直接放在根目录下进行SEO优化。因为搜索引擎爬虫会尝试请求网站根目录下的favicon.ico,久而久之,就在不知不觉中成为了行业规范。了解了网站图标的来源后,爬取的思路就可用了。
要求暴力
不管你的网站的根目录下有没有favicon.ico,我只想抓住它。至于能不能抓到,就试试你的运气吧(毕竟运气的概率还是很高的)。以我们官网()为例,PHP爬取代码如下:
$url = 'https://www.kunquer.com';
$content = file_get_contents($url.'/favicon.ico');
请原谅我没有一次把代码全部放出来,毕竟我要详细解释一下。如何判断检索到的内容是图标?也许它只是一个 404 页面?将内容保存到本地文件后,可以通过getimagesize()函数判断:
$file = tmpfile();
$path = stream_get_meta_data($file)['uri'];
file_put_contents($path, file_get_contents($Pea->url.'/favicon.ico'));
var_dump(getimagesize($path));
如果顺利,会打印如下内容:
array(6) { [0]=> int(48) [1]=> int(48) [2]=> int(17) [3]=> string(22) "width="48" height="48"" ["bits"]=> int(32) ["mime"]=> string(24) "image/vnd.microsoft.icon" }
上面的例子不能不成功,因为我们官网的根目录下有这个文件哈哈哈。为了演示后续的性能(另一种情况),我们以虾米网为例,访问/favicon.ico,得到如下反馈:
非常好!我们可以开始下一步了。
分析网页的源代码
当暴力请求失败时,我不得不抓取页面并分析源代码来获取图标,因为图标是放在head部分的链接中,浏览器是通过设置rel="icon"或rel=来设置的“快捷方式图标”来识别,我们只需要找出这部分的href,分析匹配代码如下:
$base = 'http://xiami.com';
preg_match('/(.*?)/is', file_get_contents($base), $head);
if(isset($head[1])) {
preg_match_all('/]+>/is', $head[1], $links);
if(isset($links[0]) && is_array($links[0])) {
foreach($links[0] as $link) {
// 查找rel中包含icon标识的图片路径
if(preg_match('/rel=("|\')?(icon\w?|\w+\s+icon)("|\')?/i', $link)) {
var_dump($link);
}
}
}
}
(恐怕格式不对,截图供参考)
上面,为了找到真相,通过逐步缩小搜索范围,我们得到了结果:
string(102) ""
是的,href 部分就是我们想要的图标:
<p>preg_match('/([^"\s>
php抓取网页连接函数(爱编程»远程获取API接口的PHP函数返回一个数组)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-07 05:12
API调用通常用于各种项目或捕获彼此网页的内容。下面是一个PHP函数,用于远程获取API接口。函数返回一个数组,$result[0]是状态码,正常情况下为200,$result[1]是正常返回的数据,有需要的朋友可以采集
function http_request_json($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
function http_request_json($url,$post_data)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
原创文章请注明重印来源:爱编程»php7-远程访问API接口或web内容 查看全部
php抓取网页连接函数(爱编程»远程获取API接口的PHP函数返回一个数组)
API调用通常用于各种项目或捕获彼此网页的内容。下面是一个PHP函数,用于远程获取API接口。函数返回一个数组,$result[0]是状态码,正常情况下为200,$result[1]是正常返回的数据,有需要的朋友可以采集
function http_request_json($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
function http_request_json($url,$post_data)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
原创文章请注明重印来源:爱编程»php7-远程访问API接口或web内容
php抓取网页连接函数(以魏艾斯博客首页为例()小功能对你是有用的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-07 05:06
)
今天,威爱思博客需要获取某个网页的所有链接地址。以前请度娘搜索“网上批量抓取网页链接”。有一些在线网页非常易于使用。可惜时间过去了,没有一个搜索结果是好的。但是这个页面的链接太多了,不想一一复制粘贴。经过一番搜索,魏在下面找到了最快的方法。
以威爱思博客首页为例。首先,打开要批量抓取链接的网页,在网页空白处右键>>查看元素。
在控制台粘贴以下代码
for(var a of document.getElementsByTagName('a')){
控制台日志(a.href)
}
最后按回车,你会看到批量获取的链接。
用windows自带的记事本处理掉多余的链接,留下你想要的链接。这波操作简单粗暴。
请注意:并非所有网页都易于使用。老魏在测试某些网页时,无法抓取所有链接。毕竟只是一小段功能不完善的代码。应急用还是挺贴心的。
本教程为薇薇原创的内容(代码来自网络)。功能虽小,但能在紧急情况下使用就不错了。哪怕一个小功能对你有用,有空也请来拜访我们,伸出你可爱的小手来点个赞吧。转载请留下出处链接。感谢您对老魏的喜爱!
查看全部
php抓取网页连接函数(以魏艾斯博客首页为例()小功能对你是有用的
)
今天,威爱思博客需要获取某个网页的所有链接地址。以前请度娘搜索“网上批量抓取网页链接”。有一些在线网页非常易于使用。可惜时间过去了,没有一个搜索结果是好的。但是这个页面的链接太多了,不想一一复制粘贴。经过一番搜索,魏在下面找到了最快的方法。
以威爱思博客首页为例。首先,打开要批量抓取链接的网页,在网页空白处右键>>查看元素。

在控制台粘贴以下代码
for(var a of document.getElementsByTagName('a')){
控制台日志(a.href)
}
最后按回车,你会看到批量获取的链接。

用windows自带的记事本处理掉多余的链接,留下你想要的链接。这波操作简单粗暴。
请注意:并非所有网页都易于使用。老魏在测试某些网页时,无法抓取所有链接。毕竟只是一小段功能不完善的代码。应急用还是挺贴心的。
本教程为薇薇原创的内容(代码来自网络)。功能虽小,但能在紧急情况下使用就不错了。哪怕一个小功能对你有用,有空也请来拜访我们,伸出你可爱的小手来点个赞吧。转载请留下出处链接。感谢您对老魏的喜爱!

php抓取网页连接函数(php抓取网页连接函数/mime.phpcontent-typeparser相关源码get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-04 01:04
php抓取网页连接函数是php提供的一种数据采集技术。在php中有几个比较好用的抓取的函数:post采用url编码编码后的网页;put():post将源码放入缓存,可以看不用replace()等其他语法,单单url编码就能够实现准确的抓取。delete():将缓存中的数据删除post/form/mime.phpcontent-typeparser相关源码get方式就不多说了,现在主要分享一下post/form/mime.php这三个方法在抓取过程中是怎么实现准确抓取。
基本数据抓取一次抓取一个页面postformresponse$response('useragent','mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36');有些页面比较长,页面的抓取时间不会很久,并且每次抓取都要从旧抓取,不利于代码的维护和代码的开发。
为此现在引入了一种post抓取的方式,可以看到处于新页面的抓取都会先从浏览器解析出来该页面的url,然后将从浏览器传送给函数,最后函数通过url编码解析,从浏览器抓取出来该页面responsefunctionpostmessage(path){postmessage('你好','with','{"response_type":"post"}');returnfunction(){returnthis。$encoding=="utf-8"?false://windows1。0(18031。
3)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36"://windows1.1(2004042
1)applewebkit/537。36(khtml,likegecko)chrome/67。3539。14safari/537。36";}}content-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",path,{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/form/mime。phpcontent-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/content。php$request=postmessage("请问",request,'with','{"response_type":"post"}');content。postmethod(request,'1'。 查看全部
php抓取网页连接函数(php抓取网页连接函数/mime.phpcontent-typeparser相关源码get方式)
php抓取网页连接函数是php提供的一种数据采集技术。在php中有几个比较好用的抓取的函数:post采用url编码编码后的网页;put():post将源码放入缓存,可以看不用replace()等其他语法,单单url编码就能够实现准确的抓取。delete():将缓存中的数据删除post/form/mime.phpcontent-typeparser相关源码get方式就不多说了,现在主要分享一下post/form/mime.php这三个方法在抓取过程中是怎么实现准确抓取。
基本数据抓取一次抓取一个页面postformresponse$response('useragent','mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36');有些页面比较长,页面的抓取时间不会很久,并且每次抓取都要从旧抓取,不利于代码的维护和代码的开发。
为此现在引入了一种post抓取的方式,可以看到处于新页面的抓取都会先从浏览器解析出来该页面的url,然后将从浏览器传送给函数,最后函数通过url编码解析,从浏览器抓取出来该页面responsefunctionpostmessage(path){postmessage('你好','with','{"response_type":"post"}');returnfunction(){returnthis。$encoding=="utf-8"?false://windows1。0(18031。
3)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36"://windows1.1(2004042
1)applewebkit/537。36(khtml,likegecko)chrome/67。3539。14safari/537。36";}}content-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",path,{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/form/mime。phpcontent-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/content。php$request=postmessage("请问",request,'with','{"response_type":"post"}');content。postmethod(request,'1'。
php抓取网页连接函数(可以像图片这样检索吗?三行代码能解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-26 13:05
匿名用户级别 1
2011-10-28 回答
$html = file_get_html('http://www.google.com/');
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
不知道你PHP支持不支持 file_get_html这个函数
但是像你说那样的抓 肯定会超时的
跟进:
可以像图片一样检索吗
跟进:
这个涉及到PHP+MYSQL采集,可以使用preg_match_all('/
跟进:
这只是为了获取一个页面的链接,但是如图所示,搜索页面的链接后,遍历搜索每个链接,然后继续,直到没有链接的页面返回并弹出。搜索整个网站的链接时应该怎么做?你能给我一些代码吗?谢谢。. . . .
跟进:
获取整个页面的连接并存入数据库,然后排除重复连接,然后遍历数据库的每一页,然后循环采集 采集排除重复连接。一个坚实的基础可能很难实现。这不是三行两行代码就能解决的问题。一个好的创意需要坚实的基础。建议您从基础开始。 查看全部
php抓取网页连接函数(可以像图片这样检索吗?三行代码能解决的问题)
匿名用户级别 1
2011-10-28 回答
$html = file_get_html('http://www.google.com/');
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
不知道你PHP支持不支持 file_get_html这个函数
但是像你说那样的抓 肯定会超时的
跟进:
可以像图片一样检索吗
跟进:
这个涉及到PHP+MYSQL采集,可以使用preg_match_all('/
跟进:
这只是为了获取一个页面的链接,但是如图所示,搜索页面的链接后,遍历搜索每个链接,然后继续,直到没有链接的页面返回并弹出。搜索整个网站的链接时应该怎么做?你能给我一些代码吗?谢谢。. . . .
跟进:
获取整个页面的连接并存入数据库,然后排除重复连接,然后遍历数据库的每一页,然后循环采集 采集排除重复连接。一个坚实的基础可能很难实现。这不是三行两行代码就能解决的问题。一个好的创意需要坚实的基础。建议您从基础开始。
php抓取网页连接函数(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 14:38
PHP可以使用Curl Functions完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高,所以卷曲多功能是经常需要的。该函数实现了对多个URL地址的并发多线程访问,实现了网页的并发多线程爬取或下载文件。具体实现过程请参考以下示例:
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />
fclose($st);
(3)下面这段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php抓取网页连接函数(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作)
PHP可以使用Curl Functions完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高,所以卷曲多功能是经常需要的。该函数实现了对多个URL地址的并发多线程访问,实现了网页的并发多线程爬取或下载文件。具体实现过程请参考以下示例:
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />
fclose($st);
(3)下面这段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php抓取网页连接函数(亿速云:研究和学习“”的思路与理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-23 20:21
这个文章主要解释了“比较file_get_content,卷曲和php中的函数的效率”,文中的解释简单明了,易于学习和理解,请遵循小型编辑想法,一个在PHP中启动并学习“file_get_content,curl和fopen函数”!
三个功能是阅读资源的所有功能,但它们各自的应用程序方案是不同的。
卷曲使用超过Internet网页之间的掌握,而Fopen用于读取文件,而File_Get_Contents用于获取静态页面的内容。
1. fopen / file_get_contents每个请求将重新执行DNS查询,并不缓存DNS信息。但卷曲自动缓存DNS信息。请求在同一域名下的网页或图片上的DNS查询。这大大减少了DNS查询的数量。因此卷曲的性能比Fopen / file_get_content更好。
2. fopen / file_get_contents在请求http时,使用http_fopen_wrapper,并且不会敲击。卷曲可以。当您多次请求多次链接时会更好。
3. curl可以模拟多个请求,例如post数据,表单提交等,用户可以以自己的需求自定义请求。 fopen / file_get_contents只能使用get来获取数据。
感谢您的阅读,以上是PHP中的“File_Get_Content,Curl和Fopen函数”的“效率比较”的内容。在学习本文之后,我相信每个人都更有效地对PHP中File_Get_Content,Curl和Fopen函数的效率更有效。具有更深刻的经验,请在具体使用中进行练习。这是十亿速的云,小编将推动每个人的相关知识点!欢迎! 查看全部
php抓取网页连接函数(亿速云:研究和学习“”的思路与理解)
这个文章主要解释了“比较file_get_content,卷曲和php中的函数的效率”,文中的解释简单明了,易于学习和理解,请遵循小型编辑想法,一个在PHP中启动并学习“file_get_content,curl和fopen函数”!
三个功能是阅读资源的所有功能,但它们各自的应用程序方案是不同的。
卷曲使用超过Internet网页之间的掌握,而Fopen用于读取文件,而File_Get_Contents用于获取静态页面的内容。
1. fopen / file_get_contents每个请求将重新执行DNS查询,并不缓存DNS信息。但卷曲自动缓存DNS信息。请求在同一域名下的网页或图片上的DNS查询。这大大减少了DNS查询的数量。因此卷曲的性能比Fopen / file_get_content更好。
2. fopen / file_get_contents在请求http时,使用http_fopen_wrapper,并且不会敲击。卷曲可以。当您多次请求多次链接时会更好。
3. curl可以模拟多个请求,例如post数据,表单提交等,用户可以以自己的需求自定义请求。 fopen / file_get_contents只能使用get来获取数据。
感谢您的阅读,以上是PHP中的“File_Get_Content,Curl和Fopen函数”的“效率比较”的内容。在学习本文之后,我相信每个人都更有效地对PHP中File_Get_Content,Curl和Fopen函数的效率更有效。具有更深刻的经验,请在具体使用中进行练习。这是十亿速的云,小编将推动每个人的相关知识点!欢迎!
php抓取网页连接函数(Thinkphp的App目录是通过使用__APP_预编译常量 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-23 10:06
)
thinkphp是一个完整的系统,一个完整的系统,许多地方都是外国框架,唯一的是性能,并且有点像传奇的.net。
thinkphp提供了一个相对完整的URL处理系统,它通过相同的规则实现URL的路由和URL生成,并且通过U(',[])函数获得URL生成。当我在Thinkphp中构建了两个应用程序时,一个是一个子目录,发现由U()函数获得的URL只能指向根目录,这让我非常生气,在线找不到正确的方法,查看u功能源代码得到了答案!
thinkphp应用程序是通过使用__app__预编译定义定义的,该定义为入口文件的相对目录和站点根目录的相对目录。在Thinkphp中,有两种方法可以在应用程序中设置应用程序:
1、通过thinkphp自动计算将条目文件放在其应用程序目录中,Chinkphp自动添加应用程序目录URL前缀在获取U()函数时。优势自动化,符合思想设计标准,缺点:缺乏灵活性。
2、手动设置应用程序所在的应用程序
定义入口文件中的常量:“__ app__”,指定URL前缀,即,您可以设置应用程序前缀,如:
define('__APP__','/ralis_folder'); 查看全部
php抓取网页连接函数(Thinkphp的App目录是通过使用__APP_预编译常量
)
thinkphp是一个完整的系统,一个完整的系统,许多地方都是外国框架,唯一的是性能,并且有点像传奇的.net。
thinkphp提供了一个相对完整的URL处理系统,它通过相同的规则实现URL的路由和URL生成,并且通过U(',[])函数获得URL生成。当我在Thinkphp中构建了两个应用程序时,一个是一个子目录,发现由U()函数获得的URL只能指向根目录,这让我非常生气,在线找不到正确的方法,查看u功能源代码得到了答案!
thinkphp应用程序是通过使用__app__预编译定义定义的,该定义为入口文件的相对目录和站点根目录的相对目录。在Thinkphp中,有两种方法可以在应用程序中设置应用程序:
1、通过thinkphp自动计算将条目文件放在其应用程序目录中,Chinkphp自动添加应用程序目录URL前缀在获取U()函数时。优势自动化,符合思想设计标准,缺点:缺乏灵活性。
2、手动设置应用程序所在的应用程序
定义入口文件中的常量:“__ app__”,指定URL前缀,即,您可以设置应用程序前缀,如:
define('__APP__','/ralis_folder');
php抓取网页连接函数( PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-23 10:06
PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
php curl获取返回值方法
更新时间:2014年5月4日10:57:28作者:
这个文章主要介绍获得PHP卷曲返回值的方法,所需的朋友可以参考
有一个参数curlopt_returntransfer:
在卷曲中:
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,0);
默认值0直接返回所获得的输出的文本流,有时,我们必须返回到判断或做其他目的的值,那么它不是很好。
幸运的是,如果设置为curlopt_returntransfer 1:
,则可以设置curlopt_returntransfer。
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,1);
您可以在关闭没有curl_close的卷曲会话之前使用它:curl_multi_getcontent($ ch)
可以让服务器返回的值给我们。是字符串类型!
PHP手册如下:
复制代码代码如下:
curl_multi_getcontent(资源$ ch)
如果curlopt_returntrionfer设置为特定句柄作为选项,则此函数将以字符串的形式返回由卷曲句柄获取的内容。 查看全部
php抓取网页连接函数(
PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
php curl获取返回值方法
更新时间:2014年5月4日10:57:28作者:
这个文章主要介绍获得PHP卷曲返回值的方法,所需的朋友可以参考
有一个参数curlopt_returntransfer:
在卷曲中:
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,0);
默认值0直接返回所获得的输出的文本流,有时,我们必须返回到判断或做其他目的的值,那么它不是很好。
幸运的是,如果设置为curlopt_returntransfer 1:
,则可以设置curlopt_returntransfer。
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,1);
您可以在关闭没有curl_close的卷曲会话之前使用它:curl_multi_getcontent($ ch)
可以让服务器返回的值给我们。是字符串类型!
PHP手册如下:
复制代码代码如下:
curl_multi_getcontent(资源$ ch)
如果curlopt_returntrionfer设置为特定句柄作为选项,则此函数将以字符串的形式返回由卷曲句柄获取的内容。
php抓取网页连接函数(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-21 13:12
这里是一个新发布的高质量教程。看看程序狗的速度
WordPress开源博客平台WordPress是用PHP语言开发的博客平台。用户可以在支持PHP和MySQL数据库的服务器上设置自己的网站。WordPress也可用作内容管理系统(cms)
本文文章主要介绍了在WordPress中获取页面链接和标题相关的PHP函数的使用分析,它们分别是get_Permalink()和WP_u。title()函数的使用可供需要它的朋友参考
get_uPermalink()(get文章或页面链接)
getpermalink()用于返回文章或基于固定连接的页面链接。获取链接时获取\ permalink()函数需要知道要获取的文章的ID。如果在循环中,默认情况下将自动使用当前的文章
用法
get_permalink( $id, $leavename );
参数
$id
(混合)(可选)文章或页面ID(整数);它也可以是文章对象
默认值:当前文章参数在循环中自动调用@
$leavename
(布尔)(可选)转换为链接时是否忽略文章别名。如果设置为true,则将返回%postname%
默认值:无
返回值
(字符串|布尔值)如果成功获取链接,则返回链接;如果失败,则返回false
例子
获取文章或按ID链接到页面:
其他
标题可以使用WP_uu标题过滤器自定义。此函数位于:WP includes/general-template.php 查看全部
php抓取网页连接函数(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是一个新发布的高质量教程。看看程序狗的速度
WordPress开源博客平台WordPress是用PHP语言开发的博客平台。用户可以在支持PHP和MySQL数据库的服务器上设置自己的网站。WordPress也可用作内容管理系统(cms)
本文文章主要介绍了在WordPress中获取页面链接和标题相关的PHP函数的使用分析,它们分别是get_Permalink()和WP_u。title()函数的使用可供需要它的朋友参考
get_uPermalink()(get文章或页面链接)
getpermalink()用于返回文章或基于固定连接的页面链接。获取链接时获取\ permalink()函数需要知道要获取的文章的ID。如果在循环中,默认情况下将自动使用当前的文章
用法
get_permalink( $id, $leavename );
参数
$id
(混合)(可选)文章或页面ID(整数);它也可以是文章对象
默认值:当前文章参数在循环中自动调用@
$leavename
(布尔)(可选)转换为链接时是否忽略文章别名。如果设置为true,则将返回%postname%
默认值:无
返回值
(字符串|布尔值)如果成功获取链接,则返回链接;如果失败,则返回false
例子
获取文章或按ID链接到页面:
其他
标题可以使用WP_uu标题过滤器自定义。此函数位于:WP includes/general-template.php
php抓取网页连接函数(php抓取网页连接函数中的网址,返回给php解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-14 05:05
php抓取网页连接函数中的网址,返回给php解析解析出filepath_uri
(php代码)functiongetelementsbytagname($root){$size=_serializefields('send\'');$port=_serializefields('enable');returnsize;};error:toolargeexceptionmessage:'filecommenthasnobenefit'。
问题有问题!网页的名字是google。com,而php里面的每个文件的名字都是不一样的,php可以读取这个文件,但是php里面每个文件的名字只有单一的一个字符串而不是网页的所有名字!以百度搜索为例,http://@www。baidu。com为例来说明!classbaidu:default{protected$avatars;$tags;$sourceurl;$docurls;$url;}google。
com是正常的网页名字,也就是返回百度网页时,百度返回的是经过php解析后的filepath中的文件名,而你网页中没有特殊字符时,返回给php的filepath中的文件名是“baidu。com”而不是“baidu。com。google。com。jpg”中的“。”!可以查看php对cookie是怎么处理的!。
就是网页文件名的一个字符串。当你引用一个http请求时,这个网页文件名是通过get向服务器获取的。
返回网页地址返回即为:发出一个post请求(http请求)的参数。你也可以用(postman)来发送带有‘filepath’参数的请求:.html;'filepath';.html;.html;'filepath';'.html;uri"";..。 查看全部
php抓取网页连接函数(php抓取网页连接函数中的网址,返回给php解析)
php抓取网页连接函数中的网址,返回给php解析解析出filepath_uri
(php代码)functiongetelementsbytagname($root){$size=_serializefields('send\'');$port=_serializefields('enable');returnsize;};error:toolargeexceptionmessage:'filecommenthasnobenefit'。
问题有问题!网页的名字是google。com,而php里面的每个文件的名字都是不一样的,php可以读取这个文件,但是php里面每个文件的名字只有单一的一个字符串而不是网页的所有名字!以百度搜索为例,http://@www。baidu。com为例来说明!classbaidu:default{protected$avatars;$tags;$sourceurl;$docurls;$url;}google。
com是正常的网页名字,也就是返回百度网页时,百度返回的是经过php解析后的filepath中的文件名,而你网页中没有特殊字符时,返回给php的filepath中的文件名是“baidu。com”而不是“baidu。com。google。com。jpg”中的“。”!可以查看php对cookie是怎么处理的!。
就是网页文件名的一个字符串。当你引用一个http请求时,这个网页文件名是通过get向服务器获取的。
返回网页地址返回即为:发出一个post请求(http请求)的参数。你也可以用(postman)来发送带有‘filepath’参数的请求:.html;'filepath';.html;.html;'filepath';'.html;uri"";..。
php抓取网页连接函数(PHP数据生成CSV文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-13 04:16
)
一、PHP 数据生成 CSV 文件
这确实是一个非常简单的函数,可以从 PHP 数组生成 .csv 文件。此函数使用 fputcsv PHP 内置函数生成逗号分隔文件 (.CSV)。此函数有 3 个参数:数据、分隔符和 CSV 外壳。默认为双引号。
function generateCsv($data, $delimiter = ',', $enclosure = '"') {
$handle = fopen('php://temp', 'r+');
foreach ($data as $line) {
fputcsv($handle, $line, $delimiter, $enclosure);
}
rewind($handle);
while (!feof($handle)) {
$contents .= fread($handle, 8192);
}
fclose($handle);
return $contents;
}
二、从网页中提取的关键字
一个非常有用的代码片段,用于从任何网页中提取元关键字。
//语法:
//array get_meta_tags (string filename/URL [, int use_include_path])
$meta = get_meta_tags('http://www.emoticode.net/');
$keywords = $meta['keywords'];
// Split keywords
$keywords = explode(',', $keywords );
// Trim them
$keywords = array_map( 'trim', $keywords );
// Remove empty values
$keywords = array_filter( $keywords );
print_r( $keywords );
三、创建数据URI
Data URI 可以将图片嵌入到 HTML、CSS 和 JS 中以节省 HTTP 请求。这是一个非常有用的 PHP 代码片段,用于创建数据 URI。
四、获取一个页面中的所有链接
$html = file_get_contents('http://blog.0907.org');
$dom = new DOMDocument();
@$dom->loadHTML($html);
// grab all the on the page
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate("/html/body//a");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href');
echo $url.'
';
}
五、按年和月获取季度
function getQuarterByMonth($date){
$month = substr($date,-2);
$Q = ceil($month/3);
return $Q;
} 查看全部
php抓取网页连接函数(PHP数据生成CSV文件
)
一、PHP 数据生成 CSV 文件
这确实是一个非常简单的函数,可以从 PHP 数组生成 .csv 文件。此函数使用 fputcsv PHP 内置函数生成逗号分隔文件 (.CSV)。此函数有 3 个参数:数据、分隔符和 CSV 外壳。默认为双引号。
function generateCsv($data, $delimiter = ',', $enclosure = '"') {
$handle = fopen('php://temp', 'r+');
foreach ($data as $line) {
fputcsv($handle, $line, $delimiter, $enclosure);
}
rewind($handle);
while (!feof($handle)) {
$contents .= fread($handle, 8192);
}
fclose($handle);
return $contents;
}
二、从网页中提取的关键字
一个非常有用的代码片段,用于从任何网页中提取元关键字。
//语法:
//array get_meta_tags (string filename/URL [, int use_include_path])
$meta = get_meta_tags('http://www.emoticode.net/');
$keywords = $meta['keywords'];
// Split keywords
$keywords = explode(',', $keywords );
// Trim them
$keywords = array_map( 'trim', $keywords );
// Remove empty values
$keywords = array_filter( $keywords );
print_r( $keywords );
三、创建数据URI
Data URI 可以将图片嵌入到 HTML、CSS 和 JS 中以节省 HTTP 请求。这是一个非常有用的 PHP 代码片段,用于创建数据 URI。
四、获取一个页面中的所有链接
$html = file_get_contents('http://blog.0907.org');
$dom = new DOMDocument();
@$dom->loadHTML($html);
// grab all the on the page
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate("/html/body//a");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href');
echo $url.'
';
}
五、按年和月获取季度
function getQuarterByMonth($date){
$month = substr($date,-2);
$Q = ceil($month/3);
return $Q;
}
php抓取网页连接函数(php抓取网页连接函数,抓取一个爬虫平台的源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-26 10:01
php抓取网页连接函数,本教程主要介绍了网页爬取相关常用的框架(apache、mysql、mariadb、phpjavascript、phpmyadmin)以及源码地址和具体实现代码,学会后,找工作将不是难事。简介个人觉得目前开发网页还是会使用一些基本框架更好,结合爬虫的实战讲解。php抓取网页连接函数的目的是给抓取的网页能够定位到对应的数据页,再利用数据页,获取自己想要的数据,如果数据太多,则可以分页抓取数据;抓取网页连接的关键在于获取到对应的数据页,这里简单介绍几种方法:。
1、抓取上一次抓取到的数据页,
2、cookie+requestget数据,这个网上很多文章讲解的很清楚,
3、file抓取数据,file类封装的很好,
1、对于大型的网站,可以以本地存储爬取的源码网址来方便检索,本地存储的网址有/zhihu/list等,不过这种方法存储的数据不规则,
2、即使以爬虫方式抓取网页,可以采用php抓取数据的方式使用,比如get、post。
本次讲解通过抓取一个爬虫平台的源码,
1、/zhihu/list/list.php连接数据,不需要重新刷新页面;
2、php爬虫;
<p>3、一些工具;第一步、先下载地址解压,然后通过phpmyadmin进行管理,里面自带了sqlite的插件进行连接数据库,进行一些数据处理; 查看全部
php抓取网页连接函数(php抓取网页连接函数,抓取一个爬虫平台的源码)
php抓取网页连接函数,本教程主要介绍了网页爬取相关常用的框架(apache、mysql、mariadb、phpjavascript、phpmyadmin)以及源码地址和具体实现代码,学会后,找工作将不是难事。简介个人觉得目前开发网页还是会使用一些基本框架更好,结合爬虫的实战讲解。php抓取网页连接函数的目的是给抓取的网页能够定位到对应的数据页,再利用数据页,获取自己想要的数据,如果数据太多,则可以分页抓取数据;抓取网页连接的关键在于获取到对应的数据页,这里简单介绍几种方法:。
1、抓取上一次抓取到的数据页,
2、cookie+requestget数据,这个网上很多文章讲解的很清楚,
3、file抓取数据,file类封装的很好,
1、对于大型的网站,可以以本地存储爬取的源码网址来方便检索,本地存储的网址有/zhihu/list等,不过这种方法存储的数据不规则,
2、即使以爬虫方式抓取网页,可以采用php抓取数据的方式使用,比如get、post。
本次讲解通过抓取一个爬虫平台的源码,
1、/zhihu/list/list.php连接数据,不需要重新刷新页面;
2、php爬虫;
<p>3、一些工具;第一步、先下载地址解压,然后通过phpmyadmin进行管理,里面自带了sqlite的插件进行连接数据库,进行一些数据处理;
php抓取网页连接函数(PHP外部资源函数fopen/file_get_contents好很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-22 23:13
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php抓取网页连接函数(PHP外部资源函数fopen/file_get_contents好很多)
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php抓取网页连接函数(我想从其他网站获取所有时间表的航班数据.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-19 14:17
)
我的 网站 有问题。我想从其他网站 获取所有时刻表的航班数据。我查看了它的源代码并获得了用于处理数据的 url 链接。有人可以告诉我如何从当前 url 链接中获取数据并将其显示在我们的 网站 上?
您可以使用 file_get_contents() 函数来完成此操作。此函数返回所提供 URL 的 html。然后使用 HTML Parser 获取所需数据。
$html = file_get_contents("http://website.com");
$dom = new DOMDocument();
$dom->loadHTML($html);
$nodes = $dom->getElementsByTagName('h3');
foreach ($nodes as $node) {
echo $node->nodeValue."
"; // return tag data
}
另一种使用 preg_match_all() 提取数据的方法
$html = file_get_contents($_REQUEST['url']);
preg_match_all('/(.*?)/s', $html, $matches);
// specify the class to get the data of that class
foreach ($matches[1] as $node) {
echo $node."
";
} 查看全部
php抓取网页连接函数(我想从其他网站获取所有时间表的航班数据..
)
我的 网站 有问题。我想从其他网站 获取所有时刻表的航班数据。我查看了它的源代码并获得了用于处理数据的 url 链接。有人可以告诉我如何从当前 url 链接中获取数据并将其显示在我们的 网站 上?
您可以使用 file_get_contents() 函数来完成此操作。此函数返回所提供 URL 的 html。然后使用 HTML Parser 获取所需数据。
$html = file_get_contents("http://website.com";);
$dom = new DOMDocument();
$dom->loadHTML($html);
$nodes = $dom->getElementsByTagName('h3');
foreach ($nodes as $node) {
echo $node->nodeValue."
"; // return tag data
}
另一种使用 preg_match_all() 提取数据的方法
$html = file_get_contents($_REQUEST['url']);
preg_match_all('/(.*?)/s', $html, $matches);
// specify the class to get the data of that class
foreach ($matches[1] as $node) {
echo $node."
";
}
php抓取网页连接函数(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-17 18:32
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php抓取网页连接函数(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php抓取网页连接函数(PHP中和URL的特殊处理方法及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-13 15:18
在项目中,有时我们需要对当前页面的整个URL进行特殊处理,比如提取某一部分来判断是否满足我们的需求。带着这个需求,我们来说说PHP中URL相关的知识点。
获取页面的 URL
从上图可以看出,URL收录了协议、域名、端口、查询参数、请求路径等,在PHP中我们可以使用$_SERVER这个超级全局数组来获取URL的各个组成部分,然后进行拼接,从而得到最后一个当前页面的URL。
解析 URL 的各个部分
上面得到的页面的URL是一种特殊的情况,因为这些都是PHP底层生成的。现在我们遇到了不同的情况,就是url是一个变量,所以这时候除了手动使用explode函数来分解,还可以使用parse_url来完成,这个函数可以成功的提取出各个组件URL 来自 URL 字符串,例如端口、主机、协议、路径、用户和密码等。
分解查询参数
有时我们有很多查询参数,那么这时候我们可以使用parse_str函数将我们的查询参数分成数组,从而轻松提取每个值。当然,这些也可以借助explode来完成,但唯一不同的是,这个函数更加方便,我们可以只提取一次我们想要的值,并且explode至少要使用2次。
使用数组和对象构造 URL
在项目中经常会遇到使用各种条件生成最终URL的情况,尤其是可能收录中文的时候。大家都知道,收录中文的URL必须经过编码,所以如果参数很多,生成一个URL会感觉代码很乱,好在PHP提供了http_build_query函数,可以让我们直接以如下形式生成我们需要的最后一个URL一个数组或对象,该函数自动执行 URL 编码操作。想一想,是不是更方便?
解析路径
如果我们需要进一步解析URL的路径部分,那么此时我们可以使用PHP中的explode函数来完成。有了它,我们可以分割路径的每个部分以进行进一步处理。
上面提到了几个常用的PHP函数。如果你已经很熟悉了,相信对你以后的项目会有很大的帮助。感谢您阅读这篇文章。如果您觉得不错,请点个赞或分享给您的朋友。, 如果有什么问题或者有更好的体验,可以在评论中分享给大家,周末快乐。 查看全部
php抓取网页连接函数(PHP中和URL的特殊处理方法及解决办法)
在项目中,有时我们需要对当前页面的整个URL进行特殊处理,比如提取某一部分来判断是否满足我们的需求。带着这个需求,我们来说说PHP中URL相关的知识点。
获取页面的 URL
从上图可以看出,URL收录了协议、域名、端口、查询参数、请求路径等,在PHP中我们可以使用$_SERVER这个超级全局数组来获取URL的各个组成部分,然后进行拼接,从而得到最后一个当前页面的URL。
解析 URL 的各个部分
上面得到的页面的URL是一种特殊的情况,因为这些都是PHP底层生成的。现在我们遇到了不同的情况,就是url是一个变量,所以这时候除了手动使用explode函数来分解,还可以使用parse_url来完成,这个函数可以成功的提取出各个组件URL 来自 URL 字符串,例如端口、主机、协议、路径、用户和密码等。
分解查询参数
有时我们有很多查询参数,那么这时候我们可以使用parse_str函数将我们的查询参数分成数组,从而轻松提取每个值。当然,这些也可以借助explode来完成,但唯一不同的是,这个函数更加方便,我们可以只提取一次我们想要的值,并且explode至少要使用2次。
使用数组和对象构造 URL
在项目中经常会遇到使用各种条件生成最终URL的情况,尤其是可能收录中文的时候。大家都知道,收录中文的URL必须经过编码,所以如果参数很多,生成一个URL会感觉代码很乱,好在PHP提供了http_build_query函数,可以让我们直接以如下形式生成我们需要的最后一个URL一个数组或对象,该函数自动执行 URL 编码操作。想一想,是不是更方便?
解析路径
如果我们需要进一步解析URL的路径部分,那么此时我们可以使用PHP中的explode函数来完成。有了它,我们可以分割路径的每个部分以进行进一步处理。
上面提到了几个常用的PHP函数。如果你已经很熟悉了,相信对你以后的项目会有很大的帮助。感谢您阅读这篇文章。如果您觉得不错,请点个赞或分享给您的朋友。, 如果有什么问题或者有更好的体验,可以在评论中分享给大家,周末快乐。
php抓取网页连接函数(php抓取网页连接函数(2):连接时生成一个httpcookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-11 16:44
php抓取网页连接函数
1、httpcookie:连接时生成一个httpcookie,该httpcookie会用于加密消息,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自httpcookie。
2、requestheader:requestheader连接http时生成一个来自request的字段,我们通常称这个字段为requestbody,连接后生成来自http请求的字段,用于加密传递请求的数据,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求。request-header命令详解。
3、httpcookie2:request&cookie2指的是两种requestheader字段规则,这两种requestheader字段规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie2命令详解。
4、httpcookie4:request-cookie指的是两种requestbody规则,这两种requestbody规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie4命令详解。
5、php_cookie自动加载规则#newhttpcookie_php_cookiefakewl=off#把httpcookie存到变量里httpcookie2_php_cookie_cache_from_value('123')。body()。send({data:'aaa。jpg'})#把连接好的http请求存到变量里httpcookie2_cookie_php_cookie_cache_from_value('123')。
body()。send({data:'bbb。jpg'})#字段规则不同对应的php命令sendphp_cookie_a('123');php_cookie_a=newhttpcookie('aaa。jpg');php_cookie_a。send({'data':'bbb。jpg'});。 查看全部
php抓取网页连接函数(php抓取网页连接函数(2):连接时生成一个httpcookie)
php抓取网页连接函数
1、httpcookie:连接时生成一个httpcookie,该httpcookie会用于加密消息,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自httpcookie。
2、requestheader:requestheader连接http时生成一个来自request的字段,我们通常称这个字段为requestbody,连接后生成来自http请求的字段,用于加密传递请求的数据,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求。request-header命令详解。
3、httpcookie2:request&cookie2指的是两种requestheader字段规则,这两种requestheader字段规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie2命令详解。
4、httpcookie4:request-cookie指的是两种requestbody规则,这两种requestbody规则可以限制连接者要加载的字段规则,如果用户对特定链接执行http请求,则用户看到的新的请求链接就是来自http请求的字段规则。php-cookie/httpcookie4命令详解。
5、php_cookie自动加载规则#newhttpcookie_php_cookiefakewl=off#把httpcookie存到变量里httpcookie2_php_cookie_cache_from_value('123')。body()。send({data:'aaa。jpg'})#把连接好的http请求存到变量里httpcookie2_cookie_php_cookie_cache_from_value('123')。
body()。send({data:'bbb。jpg'})#字段规则不同对应的php命令sendphp_cookie_a('123');php_cookie_a=newhttpcookie('aaa。jpg');php_cookie_a。send({'data':'bbb。jpg'});。
php抓取网页连接函数(如何使用beatifulsoup来实现我们的第二个函数:3.3整理数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 16:31
中间。其中title在label的正文里面,body在正文里面
标签的内容。
因此,我们可以使用 beatifulsoup 来实现我们的第二个功能:
def parse_article(html):
soup = BeautifulSoup(html, 'html.parser')
# 从上面的数据获取html文档并解析,这里使用的是Python自带的HTML解释器
article = soup.find('div', attrs={'class': 'post f'})
# 缩小HTML文档的解析范围,限定在文章主体内部。
title = article.find('h1').getText()
# 获取文章主体内部的标签内的文本,可以发现这就是标题内容。
paras = []
# 创建一个列表,以段落的形式,向里面填充文本。
for paragraph in article.find_all('p'):
p_content = paragraph.getText()
# 获取<p>标签内的文本,这里就是段落文本内容。
paras.append(p_content)
return title, paras
# 返回标题和参数,用于写入文件。
3.3 整理数据
获得我们需要的所有数据(标题和内容)后,我们需要将其写入文件。我们首先需要拼接一个文件名,创建并打开文件。注意这里的参数 wb。在Python3.X中,b参数是自动添加的(不写就填,有的话就自己不填);但是在 Python2.X 中,情况并非如此,所以最好填写它,以避免更改版本后出现一些奇怪的错误。当然不用改啦~
def get_article(title, url):
file_name = title + '.txt'
# 拼接文件名
with codecs.open(file_name, 'wb', encoding='utf-8') as fp:
html = download_page(url)
# 调用第一个函数获取数据
title2, text = parse_article(html)
# 调用第二个函数获取数据
fp.write('\t%s\t\r\n' % title2)
for p in text:
fp.write('\t%s\r\n' % p)
# 将获取的数据写入文件。
print('文章读取完毕!')
return 'OK'
最后,我们必须编写另一个 if 语句来确定是运行还是导入。在运行文件时,我们可以通过调用第三个函数来达到我们的目的。
if __name__ == '__main__':
url = 'http://jandan.net/2016/02/18/caribbean-whales.html'
get_article(url)
4. 文章 结束前的一些话
好了,这篇文章到此结束。还有一个爬虫用来抓取下面的简单主页文章。不过爬取的过程也是上面的步骤,看懂了就可以写出来。如果你不明白...好吧,我只是想炫耀一下,因为我很高兴,哈哈哈哈来打我吧~~
我是胡一博,一个每天都被自己唤醒的帅气聪明的人。如果您发现这些代码有任何问题,请告诉我,我会尽快回复并寄钱!钱可以分配给任何人或组织(比如慈善组织和开源项目),就酱~ 查看全部
php抓取网页连接函数(如何使用beatifulsoup来实现我们的第二个函数:3.3整理数据)
中间。其中title在label的正文里面,body在正文里面
标签的内容。
因此,我们可以使用 beatifulsoup 来实现我们的第二个功能:
def parse_article(html):
soup = BeautifulSoup(html, 'html.parser')
# 从上面的数据获取html文档并解析,这里使用的是Python自带的HTML解释器
article = soup.find('div', attrs={'class': 'post f'})
# 缩小HTML文档的解析范围,限定在文章主体内部。
title = article.find('h1').getText()
# 获取文章主体内部的标签内的文本,可以发现这就是标题内容。
paras = []
# 创建一个列表,以段落的形式,向里面填充文本。
for paragraph in article.find_all('p'):
p_content = paragraph.getText()
# 获取<p>标签内的文本,这里就是段落文本内容。
paras.append(p_content)
return title, paras
# 返回标题和参数,用于写入文件。
3.3 整理数据
获得我们需要的所有数据(标题和内容)后,我们需要将其写入文件。我们首先需要拼接一个文件名,创建并打开文件。注意这里的参数 wb。在Python3.X中,b参数是自动添加的(不写就填,有的话就自己不填);但是在 Python2.X 中,情况并非如此,所以最好填写它,以避免更改版本后出现一些奇怪的错误。当然不用改啦~
def get_article(title, url):
file_name = title + '.txt'
# 拼接文件名
with codecs.open(file_name, 'wb', encoding='utf-8') as fp:
html = download_page(url)
# 调用第一个函数获取数据
title2, text = parse_article(html)
# 调用第二个函数获取数据
fp.write('\t%s\t\r\n' % title2)
for p in text:
fp.write('\t%s\r\n' % p)
# 将获取的数据写入文件。
print('文章读取完毕!')
return 'OK'
最后,我们必须编写另一个 if 语句来确定是运行还是导入。在运行文件时,我们可以通过调用第三个函数来达到我们的目的。
if __name__ == '__main__':
url = 'http://jandan.net/2016/02/18/caribbean-whales.html'
get_article(url)
4. 文章 结束前的一些话
好了,这篇文章到此结束。还有一个爬虫用来抓取下面的简单主页文章。不过爬取的过程也是上面的步骤,看懂了就可以写出来。如果你不明白...好吧,我只是想炫耀一下,因为我很高兴,哈哈哈哈来打我吧~~
我是胡一博,一个每天都被自己唤醒的帅气聪明的人。如果您发现这些代码有任何问题,请告诉我,我会尽快回复并寄钱!钱可以分配给任何人或组织(比如慈善组织和开源项目),就酱~
php抓取网页连接函数(.params-字符串参数列表,抓取网页连接函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-07 13:02
php抓取网页连接函数有很多,本文介绍的有三种:formdata.params-字符串参数的参数列表,设置字符串的参数-params的返回值在params中可以设置:params(param_url+param_param),params(param_sequence+param_sequence_num),其中(param_url+param_param)中的sequence属性值和(param_sequence_num)中的sequence属性值会计算被抓取网页的数据流的大小;参数参数列表主要包括:items_full_name,items_full_length,items_txt_length,items_txt_extension,items_name,items_version和items_version。
items_full_nameitems_full_name的值即为某条获取到的文本串,可以使用json格式的形式提供items_full_name;items_full_name;items_full_name;items_full_name;.当items_full_name值为1时,等同于“原始长度”。
通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。items_full_nameitems_full_name的值表示文本串的长度,通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。
template_length=1时,返回“字符串长度”;length=2时,返回“一个单词”;length=3时,返回“两个单词”;length=4时,返回“三个单词”;length=5时,返回“四个单词”;length=6时,返回“五个单词”;.template_length=0时,返回“整个网页”;items_full_name与上面返回值有一点相似,但是需要注意的是items_full_name,并不一定是我们想要的单词,(最典型的应该是前缀名),应该传值为upcursor。
如:formdata.params.base_title='upcursor';items_full_name='upcursor';items_full_length=20;items_txt_length=50;items_txt_extension='upcursor';items_version=1.3;template_length=1.3;items_full_name=upcursor;length=1000000;items_full_length=2000000;items_txt_length=2000000;items_version=2.0;template_length=1.3;items_full_name=upcursor;length=2000000;items_full_length=3000000;items_version=4.0;template_length=1.3;items_full_name=upcursor;length=2000。 查看全部
php抓取网页连接函数(.params-字符串参数列表,抓取网页连接函数)
php抓取网页连接函数有很多,本文介绍的有三种:formdata.params-字符串参数的参数列表,设置字符串的参数-params的返回值在params中可以设置:params(param_url+param_param),params(param_sequence+param_sequence_num),其中(param_url+param_param)中的sequence属性值和(param_sequence_num)中的sequence属性值会计算被抓取网页的数据流的大小;参数参数列表主要包括:items_full_name,items_full_length,items_txt_length,items_txt_extension,items_name,items_version和items_version。
items_full_nameitems_full_name的值即为某条获取到的文本串,可以使用json格式的形式提供items_full_name;items_full_name;items_full_name;items_full_name;.当items_full_name值为1时,等同于“原始长度”。
通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。items_full_nameitems_full_name的值表示文本串的长度,通过“判断items_full_name是否为空”判断文本串的长度,即判断“template_length”参数值即为“字符串长度”,所以items_full_name必须为空。
template_length=1时,返回“字符串长度”;length=2时,返回“一个单词”;length=3时,返回“两个单词”;length=4时,返回“三个单词”;length=5时,返回“四个单词”;length=6时,返回“五个单词”;.template_length=0时,返回“整个网页”;items_full_name与上面返回值有一点相似,但是需要注意的是items_full_name,并不一定是我们想要的单词,(最典型的应该是前缀名),应该传值为upcursor。
如:formdata.params.base_title='upcursor';items_full_name='upcursor';items_full_length=20;items_txt_length=50;items_txt_extension='upcursor';items_version=1.3;template_length=1.3;items_full_name=upcursor;length=1000000;items_full_length=2000000;items_txt_length=2000000;items_version=2.0;template_length=1.3;items_full_name=upcursor;length=2000000;items_full_length=3000000;items_version=4.0;template_length=1.3;items_full_name=upcursor;length=2000。
php抓取网页连接函数( 一个项目有关网站图标爬取经验分享出来的经验分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-07 08:31
一个项目有关网站图标爬取经验分享出来的经验分享)
最近的一个项目是关于网站图标爬取,所以分享一些经验点和解决方法。
favicon 图标介绍
favicon.ico 通常用于 网站 标志。它显示在浏览器的地址栏、浏览器选项卡或采集夹上。它是一个缩写的标志,显示了网站的个性。
浏览器如何获取网站图标?
浏览器会首先分析请求的 URL 源代码的头部,找到具有 rel="icon" 属性的链接元素。href属性是图标地址,但不是所有的网站都会设置这个项目,有的网站我喜欢把favicon.ico直接放在根目录下进行SEO优化。因为搜索引擎爬虫会尝试请求网站根目录下的favicon.ico,久而久之,就在不知不觉中成为了行业规范。了解了网站图标的来源后,爬取的思路就可用了。
要求暴力
不管你的网站的根目录下有没有favicon.ico,我只想抓住它。至于能不能抓到,就试试你的运气吧(毕竟运气的概率还是很高的)。以我们官网()为例,PHP爬取代码如下:
$url = 'https://www.kunquer.com';
$content = file_get_contents($url.'/favicon.ico');
请原谅我没有一次把代码全部放出来,毕竟我要详细解释一下。如何判断检索到的内容是图标?也许它只是一个 404 页面?将内容保存到本地文件后,可以通过getimagesize()函数判断:
$file = tmpfile();
$path = stream_get_meta_data($file)['uri'];
file_put_contents($path, file_get_contents($Pea->url.'/favicon.ico'));
var_dump(getimagesize($path));
如果顺利,会打印如下内容:
array(6) { [0]=> int(48) [1]=> int(48) [2]=> int(17) [3]=> string(22) "width="48" height="48"" ["bits"]=> int(32) ["mime"]=> string(24) "image/vnd.microsoft.icon" }
上面的例子不能不成功,因为我们官网的根目录下有这个文件哈哈哈。为了演示后续的性能(另一种情况),我们以虾米网为例,访问/favicon.ico,得到如下反馈:
非常好!我们可以开始下一步了。
分析网页的源代码
当暴力请求失败时,我不得不抓取页面并分析源代码来获取图标,因为图标是放在head部分的链接中,浏览器是通过设置rel="icon"或rel=来设置的“快捷方式图标”来识别,我们只需要找出这部分的href,分析匹配代码如下:
$base = 'http://xiami.com';
preg_match('/(.*?)/is', file_get_contents($base), $head);
if(isset($head[1])) {
preg_match_all('/]+>/is', $head[1], $links);
if(isset($links[0]) && is_array($links[0])) {
foreach($links[0] as $link) {
// 查找rel中包含icon标识的图片路径
if(preg_match('/rel=("|\')?(icon\w?|\w+\s+icon)("|\')?/i', $link)) {
var_dump($link);
}
}
}
}
(恐怕格式不对,截图供参考)
上面,为了找到真相,通过逐步缩小搜索范围,我们得到了结果:
string(102) ""
是的,href 部分就是我们想要的图标:
<p>preg_match('/([^"\s> 查看全部
php抓取网页连接函数(
一个项目有关网站图标爬取经验分享出来的经验分享)
最近的一个项目是关于网站图标爬取,所以分享一些经验点和解决方法。
favicon 图标介绍
favicon.ico 通常用于 网站 标志。它显示在浏览器的地址栏、浏览器选项卡或采集夹上。它是一个缩写的标志,显示了网站的个性。
浏览器如何获取网站图标?
浏览器会首先分析请求的 URL 源代码的头部,找到具有 rel="icon" 属性的链接元素。href属性是图标地址,但不是所有的网站都会设置这个项目,有的网站我喜欢把favicon.ico直接放在根目录下进行SEO优化。因为搜索引擎爬虫会尝试请求网站根目录下的favicon.ico,久而久之,就在不知不觉中成为了行业规范。了解了网站图标的来源后,爬取的思路就可用了。
要求暴力
不管你的网站的根目录下有没有favicon.ico,我只想抓住它。至于能不能抓到,就试试你的运气吧(毕竟运气的概率还是很高的)。以我们官网()为例,PHP爬取代码如下:
$url = 'https://www.kunquer.com';
$content = file_get_contents($url.'/favicon.ico');
请原谅我没有一次把代码全部放出来,毕竟我要详细解释一下。如何判断检索到的内容是图标?也许它只是一个 404 页面?将内容保存到本地文件后,可以通过getimagesize()函数判断:
$file = tmpfile();
$path = stream_get_meta_data($file)['uri'];
file_put_contents($path, file_get_contents($Pea->url.'/favicon.ico'));
var_dump(getimagesize($path));
如果顺利,会打印如下内容:
array(6) { [0]=> int(48) [1]=> int(48) [2]=> int(17) [3]=> string(22) "width="48" height="48"" ["bits"]=> int(32) ["mime"]=> string(24) "image/vnd.microsoft.icon" }
上面的例子不能不成功,因为我们官网的根目录下有这个文件哈哈哈。为了演示后续的性能(另一种情况),我们以虾米网为例,访问/favicon.ico,得到如下反馈:
非常好!我们可以开始下一步了。
分析网页的源代码
当暴力请求失败时,我不得不抓取页面并分析源代码来获取图标,因为图标是放在head部分的链接中,浏览器是通过设置rel="icon"或rel=来设置的“快捷方式图标”来识别,我们只需要找出这部分的href,分析匹配代码如下:
$base = 'http://xiami.com';
preg_match('/(.*?)/is', file_get_contents($base), $head);
if(isset($head[1])) {
preg_match_all('/]+>/is', $head[1], $links);
if(isset($links[0]) && is_array($links[0])) {
foreach($links[0] as $link) {
// 查找rel中包含icon标识的图片路径
if(preg_match('/rel=("|\')?(icon\w?|\w+\s+icon)("|\')?/i', $link)) {
var_dump($link);
}
}
}
}
(恐怕格式不对,截图供参考)
上面,为了找到真相,通过逐步缩小搜索范围,我们得到了结果:
string(102) ""
是的,href 部分就是我们想要的图标:
<p>preg_match('/([^"\s>
php抓取网页连接函数(爱编程»远程获取API接口的PHP函数返回一个数组)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-07 05:12
API调用通常用于各种项目或捕获彼此网页的内容。下面是一个PHP函数,用于远程获取API接口。函数返回一个数组,$result[0]是状态码,正常情况下为200,$result[1]是正常返回的数据,有需要的朋友可以采集
function http_request_json($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
function http_request_json($url,$post_data)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
原创文章请注明重印来源:爱编程»php7-远程访问API接口或web内容 查看全部
php抓取网页连接函数(爱编程»远程获取API接口的PHP函数返回一个数组)
API调用通常用于各种项目或捕获彼此网页的内容。下面是一个PHP函数,用于远程获取API接口。函数返回一个数组,$result[0]是状态码,正常情况下为200,$result[1]是正常返回的数据,有需要的朋友可以采集
function http_request_json($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
function http_request_json($url,$post_data)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https的URL需要用到
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result[1] = curl_exec($ch);
$result[0]= curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
return $result;
}
原创文章请注明重印来源:爱编程»php7-远程访问API接口或web内容
php抓取网页连接函数(以魏艾斯博客首页为例()小功能对你是有用的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-07 05:06
)
今天,威爱思博客需要获取某个网页的所有链接地址。以前请度娘搜索“网上批量抓取网页链接”。有一些在线网页非常易于使用。可惜时间过去了,没有一个搜索结果是好的。但是这个页面的链接太多了,不想一一复制粘贴。经过一番搜索,魏在下面找到了最快的方法。
以威爱思博客首页为例。首先,打开要批量抓取链接的网页,在网页空白处右键>>查看元素。
在控制台粘贴以下代码
for(var a of document.getElementsByTagName('a')){
控制台日志(a.href)
}
最后按回车,你会看到批量获取的链接。
用windows自带的记事本处理掉多余的链接,留下你想要的链接。这波操作简单粗暴。
请注意:并非所有网页都易于使用。老魏在测试某些网页时,无法抓取所有链接。毕竟只是一小段功能不完善的代码。应急用还是挺贴心的。
本教程为薇薇原创的内容(代码来自网络)。功能虽小,但能在紧急情况下使用就不错了。哪怕一个小功能对你有用,有空也请来拜访我们,伸出你可爱的小手来点个赞吧。转载请留下出处链接。感谢您对老魏的喜爱!
查看全部
php抓取网页连接函数(以魏艾斯博客首页为例()小功能对你是有用的
)
今天,威爱思博客需要获取某个网页的所有链接地址。以前请度娘搜索“网上批量抓取网页链接”。有一些在线网页非常易于使用。可惜时间过去了,没有一个搜索结果是好的。但是这个页面的链接太多了,不想一一复制粘贴。经过一番搜索,魏在下面找到了最快的方法。
以威爱思博客首页为例。首先,打开要批量抓取链接的网页,在网页空白处右键>>查看元素。
在控制台粘贴以下代码
for(var a of document.getElementsByTagName('a')){
控制台日志(a.href)
}
最后按回车,你会看到批量获取的链接。
用windows自带的记事本处理掉多余的链接,留下你想要的链接。这波操作简单粗暴。
请注意:并非所有网页都易于使用。老魏在测试某些网页时,无法抓取所有链接。毕竟只是一小段功能不完善的代码。应急用还是挺贴心的。
本教程为薇薇原创的内容(代码来自网络)。功能虽小,但能在紧急情况下使用就不错了。哪怕一个小功能对你有用,有空也请来拜访我们,伸出你可爱的小手来点个赞吧。转载请留下出处链接。感谢您对老魏的喜爱!
php抓取网页连接函数(php抓取网页连接函数/mime.phpcontent-typeparser相关源码get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-04 01:04
php抓取网页连接函数是php提供的一种数据采集技术。在php中有几个比较好用的抓取的函数:post采用url编码编码后的网页;put():post将源码放入缓存,可以看不用replace()等其他语法,单单url编码就能够实现准确的抓取。delete():将缓存中的数据删除post/form/mime.phpcontent-typeparser相关源码get方式就不多说了,现在主要分享一下post/form/mime.php这三个方法在抓取过程中是怎么实现准确抓取。
基本数据抓取一次抓取一个页面postformresponse$response('useragent','mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36');有些页面比较长,页面的抓取时间不会很久,并且每次抓取都要从旧抓取,不利于代码的维护和代码的开发。
为此现在引入了一种post抓取的方式,可以看到处于新页面的抓取都会先从浏览器解析出来该页面的url,然后将从浏览器传送给函数,最后函数通过url编码解析,从浏览器抓取出来该页面responsefunctionpostmessage(path){postmessage('你好','with','{"response_type":"post"}');returnfunction(){returnthis。$encoding=="utf-8"?false://windows1。0(18031。
3)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36"://windows1.1(2004042
1)applewebkit/537。36(khtml,likegecko)chrome/67。3539。14safari/537。36";}}content-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",path,{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/form/mime。phpcontent-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/content。php$request=postmessage("请问",request,'with','{"response_type":"post"}');content。postmethod(request,'1'。 查看全部
php抓取网页连接函数(php抓取网页连接函数/mime.phpcontent-typeparser相关源码get方式)
php抓取网页连接函数是php提供的一种数据采集技术。在php中有几个比较好用的抓取的函数:post采用url编码编码后的网页;put():post将源码放入缓存,可以看不用replace()等其他语法,单单url编码就能够实现准确的抓取。delete():将缓存中的数据删除post/form/mime.phpcontent-typeparser相关源码get方式就不多说了,现在主要分享一下post/form/mime.php这三个方法在抓取过程中是怎么实现准确抓取。
基本数据抓取一次抓取一个页面postformresponse$response('useragent','mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36');有些页面比较长,页面的抓取时间不会很久,并且每次抓取都要从旧抓取,不利于代码的维护和代码的开发。
为此现在引入了一种post抓取的方式,可以看到处于新页面的抓取都会先从浏览器解析出来该页面的url,然后将从浏览器传送给函数,最后函数通过url编码解析,从浏览器抓取出来该页面responsefunctionpostmessage(path){postmessage('你好','with','{"response_type":"post"}');returnfunction(){returnthis。$encoding=="utf-8"?false://windows1。0(18031。
3)applewebkit/537.36(khtml,likegecko)chrome/66.0.3359.102safari/537.36"://windows1.1(2004042
1)applewebkit/537。36(khtml,likegecko)chrome/67。3539。14safari/537。36";}}content-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",path,{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/form/mime。phpcontent-encoding$encoding="utf-8";//处理编码问题responseobject$response=postmessage("你好",{'user':'你好','host':'127。
1','account':'account','email':'mirroroffice@qq。com','origin':'/home/doubled'});returnresponse;}post/content。php$request=postmessage("请问",request,'with','{"response_type":"post"}');content。postmethod(request,'1'。
php抓取网页连接函数(可以像图片这样检索吗?三行代码能解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-26 13:05
匿名用户级别 1
2011-10-28 回答
$html = file_get_html('http://www.google.com/');
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
不知道你PHP支持不支持 file_get_html这个函数
但是像你说那样的抓 肯定会超时的
跟进:
可以像图片一样检索吗
跟进:
这个涉及到PHP+MYSQL采集,可以使用preg_match_all('/
跟进:
这只是为了获取一个页面的链接,但是如图所示,搜索页面的链接后,遍历搜索每个链接,然后继续,直到没有链接的页面返回并弹出。搜索整个网站的链接时应该怎么做?你能给我一些代码吗?谢谢。. . . .
跟进:
获取整个页面的连接并存入数据库,然后排除重复连接,然后遍历数据库的每一页,然后循环采集 采集排除重复连接。一个坚实的基础可能很难实现。这不是三行两行代码就能解决的问题。一个好的创意需要坚实的基础。建议您从基础开始。 查看全部
php抓取网页连接函数(可以像图片这样检索吗?三行代码能解决的问题)
匿名用户级别 1
2011-10-28 回答
$html = file_get_html('http://www.google.com/');
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
不知道你PHP支持不支持 file_get_html这个函数
但是像你说那样的抓 肯定会超时的
跟进:
可以像图片一样检索吗
跟进:
这个涉及到PHP+MYSQL采集,可以使用preg_match_all('/
跟进:
这只是为了获取一个页面的链接,但是如图所示,搜索页面的链接后,遍历搜索每个链接,然后继续,直到没有链接的页面返回并弹出。搜索整个网站的链接时应该怎么做?你能给我一些代码吗?谢谢。. . . .
跟进:
获取整个页面的连接并存入数据库,然后排除重复连接,然后遍历数据库的每一页,然后循环采集 采集排除重复连接。一个坚实的基础可能很难实现。这不是三行两行代码就能解决的问题。一个好的创意需要坚实的基础。建议您从基础开始。
php抓取网页连接函数(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 14:38
PHP可以使用Curl Functions完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高,所以卷曲多功能是经常需要的。该函数实现了对多个URL地址的并发多线程访问,实现了网页的并发多线程爬取或下载文件。具体实现过程请参考以下示例:
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />
fclose($st);
(3)下面这段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php抓取网页连接函数(PHP利用CurlFunctions实现并发多线程抓取网页或者下载文件操作)
PHP可以使用Curl Functions完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,所以开发爬虫程序的效率不高,所以卷曲多功能是经常需要的。该函数实现了对多个URL地址的并发多线程访问,实现了网页的并发多线程爬取或下载文件。具体实现过程请参考以下示例:
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); // 设置要抓取的页面URL <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} // 初始化 <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); // 执行 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />} // 结束清理 <br />curl_multi_close($mh); <br />
fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
<p>$urls = array( 'http://www.scutephp.com/', <br />'http://www.google.com/', <br />'http://www.example.com/' <br />); <br />$save_to='/test.txt'; // 把抓取的代码写入该文件 <br />$st = fopen($save_to,"a"); <br />$mh = curl_multi_init(); <br />foreach ($urls as $i => $url) { <br />$conn[$i] = curl_init($url); <br />curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); <br />curl_setopt($conn[$i], CURLOPT_HEADER ,0); <br />curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); <br />curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 <br />curl_multi_add_handle ($mh,$conn[$i]); <br />} <br />do { <br />curl_multi_exec($mh,$active); <br />} while ($active); <br />foreach ($urls as $i => $url) { <br />$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 <br />fwrite($st,$data); // 将字符串写入文件<br />} // 获得数据变量,并写入文件 <br />foreach ($urls as $i => $url) { <br />curl_multi_remove_handle($mh,$conn[$i]); <br />curl_close($conn[$i]); <br />}<br />curl_multi_close($mh); <br />
fclose($st);
(3)下面这段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
<p>$urls=array( 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);$urls=array(<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip',<br /> 'http://www.scutephp.com/5w.zip'<br />);<br />$save_to='./home/';<br />$mh=curl_multi_init();<br />foreach($urls as $i=>$url){<br /> $g=$save_to.basename($url);<br /> if(!is_file($g)){<br /> $conn[$i]=curl_init($url);<br /> $fp[$i]=fopen($g,"w");<br /> curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");<br /> curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);<br /> curl_setopt($conn[$i],CURLOPT_HEADER ,0);<br /> curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);<br /> curl_multi_add_handle($mh,$conn[$i]);<br /> }<br />}<br />do{<br /> $n=curl_multi_exec($mh,$active);<br />}while($active);<br />foreach($urls as $i=>$url){<br /> curl_multi_remove_handle($mh,$conn[$i]);<br /> curl_close($conn[$i]);<br /> fclose($fp[$i]);<br />}<br />curl_multi_close($mh);</p>
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php抓取网页连接函数(亿速云:研究和学习“”的思路与理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-23 20:21
这个文章主要解释了“比较file_get_content,卷曲和php中的函数的效率”,文中的解释简单明了,易于学习和理解,请遵循小型编辑想法,一个在PHP中启动并学习“file_get_content,curl和fopen函数”!
三个功能是阅读资源的所有功能,但它们各自的应用程序方案是不同的。
卷曲使用超过Internet网页之间的掌握,而Fopen用于读取文件,而File_Get_Contents用于获取静态页面的内容。
1. fopen / file_get_contents每个请求将重新执行DNS查询,并不缓存DNS信息。但卷曲自动缓存DNS信息。请求在同一域名下的网页或图片上的DNS查询。这大大减少了DNS查询的数量。因此卷曲的性能比Fopen / file_get_content更好。
2. fopen / file_get_contents在请求http时,使用http_fopen_wrapper,并且不会敲击。卷曲可以。当您多次请求多次链接时会更好。
3. curl可以模拟多个请求,例如post数据,表单提交等,用户可以以自己的需求自定义请求。 fopen / file_get_contents只能使用get来获取数据。
感谢您的阅读,以上是PHP中的“File_Get_Content,Curl和Fopen函数”的“效率比较”的内容。在学习本文之后,我相信每个人都更有效地对PHP中File_Get_Content,Curl和Fopen函数的效率更有效。具有更深刻的经验,请在具体使用中进行练习。这是十亿速的云,小编将推动每个人的相关知识点!欢迎! 查看全部
php抓取网页连接函数(亿速云:研究和学习“”的思路与理解)
这个文章主要解释了“比较file_get_content,卷曲和php中的函数的效率”,文中的解释简单明了,易于学习和理解,请遵循小型编辑想法,一个在PHP中启动并学习“file_get_content,curl和fopen函数”!
三个功能是阅读资源的所有功能,但它们各自的应用程序方案是不同的。
卷曲使用超过Internet网页之间的掌握,而Fopen用于读取文件,而File_Get_Contents用于获取静态页面的内容。
1. fopen / file_get_contents每个请求将重新执行DNS查询,并不缓存DNS信息。但卷曲自动缓存DNS信息。请求在同一域名下的网页或图片上的DNS查询。这大大减少了DNS查询的数量。因此卷曲的性能比Fopen / file_get_content更好。
2. fopen / file_get_contents在请求http时,使用http_fopen_wrapper,并且不会敲击。卷曲可以。当您多次请求多次链接时会更好。
3. curl可以模拟多个请求,例如post数据,表单提交等,用户可以以自己的需求自定义请求。 fopen / file_get_contents只能使用get来获取数据。
感谢您的阅读,以上是PHP中的“File_Get_Content,Curl和Fopen函数”的“效率比较”的内容。在学习本文之后,我相信每个人都更有效地对PHP中File_Get_Content,Curl和Fopen函数的效率更有效。具有更深刻的经验,请在具体使用中进行练习。这是十亿速的云,小编将推动每个人的相关知识点!欢迎!
php抓取网页连接函数(Thinkphp的App目录是通过使用__APP_预编译常量 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-23 10:06
)
thinkphp是一个完整的系统,一个完整的系统,许多地方都是外国框架,唯一的是性能,并且有点像传奇的.net。
thinkphp提供了一个相对完整的URL处理系统,它通过相同的规则实现URL的路由和URL生成,并且通过U(',[])函数获得URL生成。当我在Thinkphp中构建了两个应用程序时,一个是一个子目录,发现由U()函数获得的URL只能指向根目录,这让我非常生气,在线找不到正确的方法,查看u功能源代码得到了答案!
thinkphp应用程序是通过使用__app__预编译定义定义的,该定义为入口文件的相对目录和站点根目录的相对目录。在Thinkphp中,有两种方法可以在应用程序中设置应用程序:
1、通过thinkphp自动计算将条目文件放在其应用程序目录中,Chinkphp自动添加应用程序目录URL前缀在获取U()函数时。优势自动化,符合思想设计标准,缺点:缺乏灵活性。
2、手动设置应用程序所在的应用程序
定义入口文件中的常量:“__ app__”,指定URL前缀,即,您可以设置应用程序前缀,如:
define('__APP__','/ralis_folder'); 查看全部
php抓取网页连接函数(Thinkphp的App目录是通过使用__APP_预编译常量
)
thinkphp是一个完整的系统,一个完整的系统,许多地方都是外国框架,唯一的是性能,并且有点像传奇的.net。
thinkphp提供了一个相对完整的URL处理系统,它通过相同的规则实现URL的路由和URL生成,并且通过U(',[])函数获得URL生成。当我在Thinkphp中构建了两个应用程序时,一个是一个子目录,发现由U()函数获得的URL只能指向根目录,这让我非常生气,在线找不到正确的方法,查看u功能源代码得到了答案!
thinkphp应用程序是通过使用__app__预编译定义定义的,该定义为入口文件的相对目录和站点根目录的相对目录。在Thinkphp中,有两种方法可以在应用程序中设置应用程序:
1、通过thinkphp自动计算将条目文件放在其应用程序目录中,Chinkphp自动添加应用程序目录URL前缀在获取U()函数时。优势自动化,符合思想设计标准,缺点:缺乏灵活性。
2、手动设置应用程序所在的应用程序
定义入口文件中的常量:“__ app__”,指定URL前缀,即,您可以设置应用程序前缀,如:
define('__APP__','/ralis_folder');
php抓取网页连接函数( PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-23 10:06
PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
php curl获取返回值方法
更新时间:2014年5月4日10:57:28作者:
这个文章主要介绍获得PHP卷曲返回值的方法,所需的朋友可以参考
有一个参数curlopt_returntransfer:
在卷曲中:
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,0);
默认值0直接返回所获得的输出的文本流,有时,我们必须返回到判断或做其他目的的值,那么它不是很好。
幸运的是,如果设置为curlopt_returntransfer 1:
,则可以设置curlopt_returntransfer。
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,1);
您可以在关闭没有curl_close的卷曲会话之前使用它:curl_multi_getcontent($ ch)
可以让服务器返回的值给我们。是字符串类型!
PHP手册如下:
复制代码代码如下:
curl_multi_getcontent(资源$ ch)
如果curlopt_returntrionfer设置为特定句柄作为选项,则此函数将以字符串的形式返回由卷曲句柄获取的内容。 查看全部
php抓取网页连接函数(
PHP手册之,中有一个参数CURLOPT_RETURNTRANSFER:复制代码)
php curl获取返回值方法
更新时间:2014年5月4日10:57:28作者:
这个文章主要介绍获得PHP卷曲返回值的方法,所需的朋友可以参考
有一个参数curlopt_returntransfer:
在卷曲中:
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,0);
默认值0直接返回所获得的输出的文本流,有时,我们必须返回到判断或做其他目的的值,那么它不是很好。
幸运的是,如果设置为curlopt_returntransfer 1:
,则可以设置curlopt_returntransfer。
复制代码代码如下:
curl_setopt($ ch,curlopt_returntransfer,1);
您可以在关闭没有curl_close的卷曲会话之前使用它:curl_multi_getcontent($ ch)
可以让服务器返回的值给我们。是字符串类型!
PHP手册如下:
复制代码代码如下:
curl_multi_getcontent(资源$ ch)
如果curlopt_returntrionfer设置为特定句柄作为选项,则此函数将以字符串的形式返回由卷曲句柄获取的内容。
php抓取网页连接函数(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-21 13:12
这里是一个新发布的高质量教程。看看程序狗的速度
WordPress开源博客平台WordPress是用PHP语言开发的博客平台。用户可以在支持PHP和MySQL数据库的服务器上设置自己的网站。WordPress也可用作内容管理系统(cms)
本文文章主要介绍了在WordPress中获取页面链接和标题相关的PHP函数的使用分析,它们分别是get_Permalink()和WP_u。title()函数的使用可供需要它的朋友参考
get_uPermalink()(get文章或页面链接)
getpermalink()用于返回文章或基于固定连接的页面链接。获取链接时获取\ permalink()函数需要知道要获取的文章的ID。如果在循环中,默认情况下将自动使用当前的文章
用法
get_permalink( $id, $leavename );
参数
$id
(混合)(可选)文章或页面ID(整数);它也可以是文章对象
默认值:当前文章参数在循环中自动调用@
$leavename
(布尔)(可选)转换为链接时是否忽略文章别名。如果设置为true,则将返回%postname%
默认值:无
返回值
(字符串|布尔值)如果成功获取链接,则返回链接;如果失败,则返回false
例子
获取文章或按ID链接到页面:
其他
标题可以使用WP_uu标题过滤器自定义。此函数位于:WP includes/general-template.php 查看全部
php抓取网页连接函数(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是一个新发布的高质量教程。看看程序狗的速度
WordPress开源博客平台WordPress是用PHP语言开发的博客平台。用户可以在支持PHP和MySQL数据库的服务器上设置自己的网站。WordPress也可用作内容管理系统(cms)
本文文章主要介绍了在WordPress中获取页面链接和标题相关的PHP函数的使用分析,它们分别是get_Permalink()和WP_u。title()函数的使用可供需要它的朋友参考
get_uPermalink()(get文章或页面链接)
getpermalink()用于返回文章或基于固定连接的页面链接。获取链接时获取\ permalink()函数需要知道要获取的文章的ID。如果在循环中,默认情况下将自动使用当前的文章
用法
get_permalink( $id, $leavename );
参数
$id
(混合)(可选)文章或页面ID(整数);它也可以是文章对象
默认值:当前文章参数在循环中自动调用@
$leavename
(布尔)(可选)转换为链接时是否忽略文章别名。如果设置为true,则将返回%postname%
默认值:无
返回值
(字符串|布尔值)如果成功获取链接,则返回链接;如果失败,则返回false
例子
获取文章或按ID链接到页面:
其他
标题可以使用WP_uu标题过滤器自定义。此函数位于:WP includes/general-template.php
php抓取网页连接函数(php抓取网页连接函数中的网址,返回给php解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-14 05:05
php抓取网页连接函数中的网址,返回给php解析解析出filepath_uri
(php代码)functiongetelementsbytagname($root){$size=_serializefields('send\'');$port=_serializefields('enable');returnsize;};error:toolargeexceptionmessage:'filecommenthasnobenefit'。
问题有问题!网页的名字是google。com,而php里面的每个文件的名字都是不一样的,php可以读取这个文件,但是php里面每个文件的名字只有单一的一个字符串而不是网页的所有名字!以百度搜索为例,http://@www。baidu。com为例来说明!classbaidu:default{protected$avatars;$tags;$sourceurl;$docurls;$url;}google。
com是正常的网页名字,也就是返回百度网页时,百度返回的是经过php解析后的filepath中的文件名,而你网页中没有特殊字符时,返回给php的filepath中的文件名是“baidu。com”而不是“baidu。com。google。com。jpg”中的“。”!可以查看php对cookie是怎么处理的!。
就是网页文件名的一个字符串。当你引用一个http请求时,这个网页文件名是通过get向服务器获取的。
返回网页地址返回即为:发出一个post请求(http请求)的参数。你也可以用(postman)来发送带有‘filepath’参数的请求:.html;'filepath';.html;.html;'filepath';'.html;uri"";..。 查看全部
php抓取网页连接函数(php抓取网页连接函数中的网址,返回给php解析)
php抓取网页连接函数中的网址,返回给php解析解析出filepath_uri
(php代码)functiongetelementsbytagname($root){$size=_serializefields('send\'');$port=_serializefields('enable');returnsize;};error:toolargeexceptionmessage:'filecommenthasnobenefit'。
问题有问题!网页的名字是google。com,而php里面的每个文件的名字都是不一样的,php可以读取这个文件,但是php里面每个文件的名字只有单一的一个字符串而不是网页的所有名字!以百度搜索为例,http://@www。baidu。com为例来说明!classbaidu:default{protected$avatars;$tags;$sourceurl;$docurls;$url;}google。
com是正常的网页名字,也就是返回百度网页时,百度返回的是经过php解析后的filepath中的文件名,而你网页中没有特殊字符时,返回给php的filepath中的文件名是“baidu。com”而不是“baidu。com。google。com。jpg”中的“。”!可以查看php对cookie是怎么处理的!。
就是网页文件名的一个字符串。当你引用一个http请求时,这个网页文件名是通过get向服务器获取的。
返回网页地址返回即为:发出一个post请求(http请求)的参数。你也可以用(postman)来发送带有‘filepath’参数的请求:.html;'filepath';.html;.html;'filepath';'.html;uri"";..。
php抓取网页连接函数(PHP数据生成CSV文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-13 04:16
)
一、PHP 数据生成 CSV 文件
这确实是一个非常简单的函数,可以从 PHP 数组生成 .csv 文件。此函数使用 fputcsv PHP 内置函数生成逗号分隔文件 (.CSV)。此函数有 3 个参数:数据、分隔符和 CSV 外壳。默认为双引号。
function generateCsv($data, $delimiter = ',', $enclosure = '"') {
$handle = fopen('php://temp', 'r+');
foreach ($data as $line) {
fputcsv($handle, $line, $delimiter, $enclosure);
}
rewind($handle);
while (!feof($handle)) {
$contents .= fread($handle, 8192);
}
fclose($handle);
return $contents;
}
二、从网页中提取的关键字
一个非常有用的代码片段,用于从任何网页中提取元关键字。
//语法:
//array get_meta_tags (string filename/URL [, int use_include_path])
$meta = get_meta_tags('http://www.emoticode.net/');
$keywords = $meta['keywords'];
// Split keywords
$keywords = explode(',', $keywords );
// Trim them
$keywords = array_map( 'trim', $keywords );
// Remove empty values
$keywords = array_filter( $keywords );
print_r( $keywords );
三、创建数据URI
Data URI 可以将图片嵌入到 HTML、CSS 和 JS 中以节省 HTTP 请求。这是一个非常有用的 PHP 代码片段,用于创建数据 URI。
四、获取一个页面中的所有链接
$html = file_get_contents('http://blog.0907.org');
$dom = new DOMDocument();
@$dom->loadHTML($html);
// grab all the on the page
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate("/html/body//a");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href');
echo $url.'
';
}
五、按年和月获取季度
function getQuarterByMonth($date){
$month = substr($date,-2);
$Q = ceil($month/3);
return $Q;
} 查看全部
php抓取网页连接函数(PHP数据生成CSV文件
)
一、PHP 数据生成 CSV 文件
这确实是一个非常简单的函数,可以从 PHP 数组生成 .csv 文件。此函数使用 fputcsv PHP 内置函数生成逗号分隔文件 (.CSV)。此函数有 3 个参数:数据、分隔符和 CSV 外壳。默认为双引号。
function generateCsv($data, $delimiter = ',', $enclosure = '"') {
$handle = fopen('php://temp', 'r+');
foreach ($data as $line) {
fputcsv($handle, $line, $delimiter, $enclosure);
}
rewind($handle);
while (!feof($handle)) {
$contents .= fread($handle, 8192);
}
fclose($handle);
return $contents;
}
二、从网页中提取的关键字
一个非常有用的代码片段,用于从任何网页中提取元关键字。
//语法:
//array get_meta_tags (string filename/URL [, int use_include_path])
$meta = get_meta_tags('http://www.emoticode.net/');
$keywords = $meta['keywords'];
// Split keywords
$keywords = explode(',', $keywords );
// Trim them
$keywords = array_map( 'trim', $keywords );
// Remove empty values
$keywords = array_filter( $keywords );
print_r( $keywords );
三、创建数据URI
Data URI 可以将图片嵌入到 HTML、CSS 和 JS 中以节省 HTTP 请求。这是一个非常有用的 PHP 代码片段,用于创建数据 URI。
四、获取一个页面中的所有链接
$html = file_get_contents('http://blog.0907.org');
$dom = new DOMDocument();
@$dom->loadHTML($html);
// grab all the on the page
$xpath = new DOMXPath($dom);
$hrefs = $xpath->evaluate("/html/body//a");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href');
echo $url.'
';
}
五、按年和月获取季度
function getQuarterByMonth($date){
$month = substr($date,-2);
$Q = ceil($month/3);
return $Q;
}

