
php抓取网页连接函数
php抓取网页连接函数( PHP和MySQL是怎么一回事,我就不啰嗦了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-21 16:08
PHP和MySQL是怎么一回事,我就不啰嗦了
)
php连接及读写mysql数据库常用代码
更新时间:2014年8月11日15:45:30 发布者:hebedic
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?也许你以前复制粘贴了一些代码,并没有真正理解代码的含义;又或者你之前理解过,但和我一样,你有一段时间没碰过,生锈了
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?可能是你以前复制粘贴了一些代码,并没有真正理解代码的含义;也可能是你之前了解过,但和我一样,一段时间没联系,生疏了;或者,有人问你一个类似的简单问题,而你一直不屑于回答,你刚刚上网搜了一下,找到了这篇文章,所以我推荐给那个人……
无论如何,这里总结一下PHP连接MySQL数据库和读写数据库的常用方法,希望对大家有所帮助,当然作为自己的复习总结。
1.为了更好的建立数据连接,一般将数据连接中涉及的值定义为变量。
$mysql_server_name='localhost'; //改成自己的mysql数据库服务器
$mysql_username='root'; //改成自己的mysql数据库用户名
$mysql_password='123456'; //改成自己的mysql数据库密码
$mysql_database='Mydb'; //改成自己的mysql数据库名
也可以将以上变量放在一个文件中,随时可以被其他文件调用。
例如:将上述内容放在:db_config.php 中,在其他需要使用数据库的页面上直接调用。
调用代码:require("db_config.php");
2.连接数据库
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password) or die("error connecting") ; //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码 应该与你的数据库编码保持一致.南昌网站建设公司百恒网络PHP工程师建议用UTF-8 国际标准编码.
mysql_select_db($mysql_database); //打开数据库
$sql ="select * from news "; //SQL语句
$result = mysql_query($sql,$conn); //查询
3.阅读表格的内容,这里我们使用while,你可以根据具体情况使用for或other。
while($row = mysql_fetch_array($result))
{
echo ""; //排版代码
echo $row['Topic'] . "
";
echo ""; //排版代码
}
4.php写入数据库,mysql数据写入
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password); //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码
mysql_select_db($mysql_database); //打开数据库
$sql = "insert into messageboard (Topic,Content,Enabled,Date) values ('$Topic','$Content','1','2011-01-12')";
mysql_query($sql);
mysql_close(); //关闭MySQL连接 查看全部
php抓取网页连接函数(
PHP和MySQL是怎么一回事,我就不啰嗦了
)
php连接及读写mysql数据库常用代码
更新时间:2014年8月11日15:45:30 发布者:hebedic
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?也许你以前复制粘贴了一些代码,并没有真正理解代码的含义;又或者你之前理解过,但和我一样,你有一段时间没碰过,生锈了
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?可能是你以前复制粘贴了一些代码,并没有真正理解代码的含义;也可能是你之前了解过,但和我一样,一段时间没联系,生疏了;或者,有人问你一个类似的简单问题,而你一直不屑于回答,你刚刚上网搜了一下,找到了这篇文章,所以我推荐给那个人……
无论如何,这里总结一下PHP连接MySQL数据库和读写数据库的常用方法,希望对大家有所帮助,当然作为自己的复习总结。
1.为了更好的建立数据连接,一般将数据连接中涉及的值定义为变量。
$mysql_server_name='localhost'; //改成自己的mysql数据库服务器
$mysql_username='root'; //改成自己的mysql数据库用户名
$mysql_password='123456'; //改成自己的mysql数据库密码
$mysql_database='Mydb'; //改成自己的mysql数据库名
也可以将以上变量放在一个文件中,随时可以被其他文件调用。
例如:将上述内容放在:db_config.php 中,在其他需要使用数据库的页面上直接调用。
调用代码:require("db_config.php");
2.连接数据库
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password) or die("error connecting") ; //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码 应该与你的数据库编码保持一致.南昌网站建设公司百恒网络PHP工程师建议用UTF-8 国际标准编码.
mysql_select_db($mysql_database); //打开数据库
$sql ="select * from news "; //SQL语句
$result = mysql_query($sql,$conn); //查询
3.阅读表格的内容,这里我们使用while,你可以根据具体情况使用for或other。
while($row = mysql_fetch_array($result))
{
echo ""; //排版代码
echo $row['Topic'] . "
";
echo ""; //排版代码
}
4.php写入数据库,mysql数据写入
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password); //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码
mysql_select_db($mysql_database); //打开数据库
$sql = "insert into messageboard (Topic,Content,Enabled,Date) values ('$Topic','$Content','1','2011-01-12')";
mysql_query($sql);
mysql_close(); //关闭MySQL连接
php抓取网页连接函数(php抓取网页连接函数有一个基本概念叫参数化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-18 02:08
php抓取网页连接函数有一个基本概念叫参数化,意思是说在php里一切皆可嵌套参数。post请求没有参数,get也没有参数,php连get连接都要自己写一个。java/jsp这种前端框架里面,请求服务器的data是表示数据参数的,比如data=sessionid;post表示是,put表示是,get也表示是。
这里就可以做一个很好的对比,你拿一个jsp的请求服务器去请求一个php的请求服务器,结果肯定是一样的,这个只是类似复用而已。
不同方式获取数据都是一样的,只是参数不同。post和get都是get方式,都是直接从服务器中取得数据(方式不同而已),传输的数据格式没有区别,可以区分是否是post数据,http请求参数化就是把请求参数通过httpheader的方式传递给服务器,参数值是包含在header里的,如get/xxx/responsebody,如果请求服务器的时候post方式就要通过请求参数化方式传递给服务器:请求地址/responsebody,类似。
参数化是java、.net、php都是要用到的,跟浏览器没有关系。
@百里玄风以上说的都有道理,我补充一下,就算客户端提交get的请求,服务器端会返回post数据,不论是get还是post。
post表示http长连接,客户端可以查询api中的请求参数、数据库交互、已生成的表单数据字段等等;get表示短连接,服务器有可能向客户端请求数据,也有可能不提供。参数化其实是web服务化,缩小客户端到服务器的传输成本。 查看全部
php抓取网页连接函数(php抓取网页连接函数有一个基本概念叫参数化)
php抓取网页连接函数有一个基本概念叫参数化,意思是说在php里一切皆可嵌套参数。post请求没有参数,get也没有参数,php连get连接都要自己写一个。java/jsp这种前端框架里面,请求服务器的data是表示数据参数的,比如data=sessionid;post表示是,put表示是,get也表示是。
这里就可以做一个很好的对比,你拿一个jsp的请求服务器去请求一个php的请求服务器,结果肯定是一样的,这个只是类似复用而已。
不同方式获取数据都是一样的,只是参数不同。post和get都是get方式,都是直接从服务器中取得数据(方式不同而已),传输的数据格式没有区别,可以区分是否是post数据,http请求参数化就是把请求参数通过httpheader的方式传递给服务器,参数值是包含在header里的,如get/xxx/responsebody,如果请求服务器的时候post方式就要通过请求参数化方式传递给服务器:请求地址/responsebody,类似。
参数化是java、.net、php都是要用到的,跟浏览器没有关系。
@百里玄风以上说的都有道理,我补充一下,就算客户端提交get的请求,服务器端会返回post数据,不论是get还是post。
post表示http长连接,客户端可以查询api中的请求参数、数据库交互、已生成的表单数据字段等等;get表示短连接,服务器有可能向客户端请求数据,也有可能不提供。参数化其实是web服务化,缩小客户端到服务器的传输成本。
php抓取网页连接函数(php抓取网页连接函数php是一个非常强大的编程语言,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-08 02:02
php抓取网页连接函数php是一个非常强大的编程语言,php代码语法紧凑,结构清晰,完全可以应用于非常多的应用系统。常用的网页抓取操作有:网页搜索、抓取社交网络、抓取网站链接、抓取音乐播放列表、抓取地址、抓取新闻等等。以上这些抓取网页的操作,不仅仅基于php常用的一些模块,而且基于php庞大的语言库。
php提供丰富的类库,可以用它们完成许多我们认为不可能实现的操作。比如说,抓取facebook的主页和查看facebook页面里面的html代码。搜索已发布页面的标题和标签,甚至在网站配置文件中加入搜索功能等等。而且,这些东西不仅仅是开源的,也并不是php提供的,而是php语言自己的东西。有些人会问,php是一门比较弱的编程语言,怎么能做到php编程?因为php是运行在linux下的。
linux上的很多东西,都是由php编写的。而linux其实提供了很多方便的php抓取模块。php抓取模块有许多,大部分是基于php的。在这里,我们对这些抓取模块进行列举和归类,并进行分析。一。php-petit。iophp-petit。io是php和mysql数据库绑定的抓取程序。php-petit。
io主要是用于抓取在mysql中的数据,如sqlite文件。php-petit。io把所有的mysql数据类型,都封装在php-petit。io里面。以mysql为例,mysql数据类型就存在myisam和extendedgreen两种类型。php-petit。io可以在mysql中使用多种特殊类型:sqlite:支持执行一些非结构化数据。
memory:可以检索内存。pymysql:一种支持mysql优化写入的抓取程序。php-petit。io通过引入相应的包,可以很方便的编写一个这样的抓取程序。下面通过php-petit。io抓取某一个或者多个数据库。在开始之前,我们要安装这些包:php-petit。iophp-petit。io默认被装在/opt目录下。
php-petit。io的php-petit。io。meta文件php-petit。io。data文件mysql:#1、安装mysql:a。请在apache/lamp中设置好环境变量。b。执行php-petit。io。meta和php-petit。io。data两个文件即可,并在php。ini中进行加载。
使用:localhost:8080/php-petit。io/c。使用php-petit。io。meta来获取mysql的数据。注意:php-petit。io。meta文件要和php-petit。io。data文件在同一个目录下。php-petit。io文件和php-petit。io。data文件所在的路径同一个目录。
二。php-form-requestphp-form-request是基于phpmysql的python接口。用于发送h。 查看全部
php抓取网页连接函数(php抓取网页连接函数php是一个非常强大的编程语言,)
php抓取网页连接函数php是一个非常强大的编程语言,php代码语法紧凑,结构清晰,完全可以应用于非常多的应用系统。常用的网页抓取操作有:网页搜索、抓取社交网络、抓取网站链接、抓取音乐播放列表、抓取地址、抓取新闻等等。以上这些抓取网页的操作,不仅仅基于php常用的一些模块,而且基于php庞大的语言库。
php提供丰富的类库,可以用它们完成许多我们认为不可能实现的操作。比如说,抓取facebook的主页和查看facebook页面里面的html代码。搜索已发布页面的标题和标签,甚至在网站配置文件中加入搜索功能等等。而且,这些东西不仅仅是开源的,也并不是php提供的,而是php语言自己的东西。有些人会问,php是一门比较弱的编程语言,怎么能做到php编程?因为php是运行在linux下的。
linux上的很多东西,都是由php编写的。而linux其实提供了很多方便的php抓取模块。php抓取模块有许多,大部分是基于php的。在这里,我们对这些抓取模块进行列举和归类,并进行分析。一。php-petit。iophp-petit。io是php和mysql数据库绑定的抓取程序。php-petit。
io主要是用于抓取在mysql中的数据,如sqlite文件。php-petit。io把所有的mysql数据类型,都封装在php-petit。io里面。以mysql为例,mysql数据类型就存在myisam和extendedgreen两种类型。php-petit。io可以在mysql中使用多种特殊类型:sqlite:支持执行一些非结构化数据。
memory:可以检索内存。pymysql:一种支持mysql优化写入的抓取程序。php-petit。io通过引入相应的包,可以很方便的编写一个这样的抓取程序。下面通过php-petit。io抓取某一个或者多个数据库。在开始之前,我们要安装这些包:php-petit。iophp-petit。io默认被装在/opt目录下。
php-petit。io的php-petit。io。meta文件php-petit。io。data文件mysql:#1、安装mysql:a。请在apache/lamp中设置好环境变量。b。执行php-petit。io。meta和php-petit。io。data两个文件即可,并在php。ini中进行加载。
使用:localhost:8080/php-petit。io/c。使用php-petit。io。meta来获取mysql的数据。注意:php-petit。io。meta文件要和php-petit。io。data文件在同一个目录下。php-petit。io文件和php-petit。io。data文件所在的路径同一个目录。
二。php-form-requestphp-form-request是基于phpmysql的python接口。用于发送h。
php抓取网页连接函数(本文实例讲述PHP实现百度搜索结果页面【相关搜索词】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-06 21:02
本文介绍了PHP抓取百度搜索结果页面【相关搜索词】并存入txt文件的实现。分享给大家,供大家参考,如下:
一、百度搜索关键词【脚本之家】
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&rsv_pq=ab33cfeb000086a2&rsv_t=7c65vT3KzHCNfGYOIn%2FDSS%9A%E6%9C%AC%%BE4 AE%B6"
搜索结果部分源码:
相关搜索
游戏脚本一般去哪里找脚本,怎么写脚本?
脚本之家app手机脚本制作手机脚本完整
Script game maker 游戏脚本制作教程 脚本精灵
二、抓取并保存到本地
源代码
index.php:
o_String=new StringEx(); } public function getItem($word){ $url = "http://www.baidu.com/s?wd=".$word; // 构造包头,模拟浏览器请求 $header = array ( "Host:www.baidu.com", "Content-Type:application/x-www-form-urlencoded",//post请求 "Connection: keep-alive", 'Referer:http://www.baidu.com', 'User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; BIDUBrowser 2.6)' ); $ch = curl_init (); curl_setopt ( $ch, CURLOPT_URL, $url ); curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header ); curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); $content = curl_exec ( $ch ); if ($content == FALSE) { echo "error:" . curl_error ( $ch ); } curl_close ( $ch ); //输出结果echo $content; $this->o_String->string=$content; $s_begin=''; $s_end=''; $summary=$this->o_String->getPart($s_begin,$s_end); $s_begin='相关搜索'; $s_end=''; $来源gaodaimacom搞#^代%!码网content=$this->o_String->getPart($s_begin,$s_end); return $content; } public function __destruct(){ unset($this->o_String); } } if($_POST){ $com = new ComBaike(); $q = $_POST['q']; $str = $com->getItem($q); //获取搜索内容 $pat = '/(.*?)/i'; preg_match_all($pat, $str, $m); //print_r($m[4]); 链接文字 $con = implode(",", $m[4]); //生成文件夹 $dates = date("Ymd"); $path="./Search/".$dates."/"; if(!is_dir($path)){ mkdir($path,0777,true); } //生成文件 $file = fopen($path.iconv("UTF-8","GBK",$q).".txt",'w'); if(fwrite($file,$con)){ echo $con; echo ''; }else{ echo ''; } fclose($file); } ?>
cls.StringEx.php:
string=$string; } public function pregGetPart($s_begin,$s_end){ $s_begin==preg_quote($s_begin); $s_begin=str_replace('/','\/',$s_begin); $s_end=preg_quote($s_end); $s_end=str_replace('/','\/',$s_end); $pattern='/'.$s_begin.'(.*?)'.$s_end.'/'; $result=preg_match($pattern,$this->string,$a_match); if(!$result){ return $result; }else{ return isset($a_match[1])?$a_match[1]:''; } } public function strstrGetPart($s_begin,$s_end){ $string=strstr($this->string,$s_begin); $string=strstr($string,$s_end,true); $string=str_replace($s_begin,'',$string); $string=str_replace($s_end,'',$string); return $string; } public function getPart($s_begin,$s_end){ $result=$this->pregGetPart($s_begin,$s_end); if(!$result){ $result=$this->strstrGetPart($s_begin,$s_end); } return $result; } } ?>
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php curl使用总结》、《PHP网络编程技巧总结》、《PHP数组(Array)操作技巧》、《php字符串( string) 使用总结》、《PHP数据结构与算法教程》、《PHP中JSON格式数据操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。 查看全部
php抓取网页连接函数(本文实例讲述PHP实现百度搜索结果页面【相关搜索词】)
本文介绍了PHP抓取百度搜索结果页面【相关搜索词】并存入txt文件的实现。分享给大家,供大家参考,如下:
一、百度搜索关键词【脚本之家】
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&rsv_pq=ab33cfeb000086a2&rsv_t=7c65vT3KzHCNfGYOIn%2FDSS%9A%E6%9C%AC%%BE4 AE%B6"
搜索结果部分源码:
相关搜索
游戏脚本一般去哪里找脚本,怎么写脚本?
脚本之家app手机脚本制作手机脚本完整
Script game maker 游戏脚本制作教程 脚本精灵
二、抓取并保存到本地
源代码
index.php:
o_String=new StringEx(); } public function getItem($word){ $url = "http://www.baidu.com/s?wd=".$word; // 构造包头,模拟浏览器请求 $header = array ( "Host:www.baidu.com", "Content-Type:application/x-www-form-urlencoded",//post请求 "Connection: keep-alive", 'Referer:http://www.baidu.com', 'User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; BIDUBrowser 2.6)' ); $ch = curl_init (); curl_setopt ( $ch, CURLOPT_URL, $url ); curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header ); curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); $content = curl_exec ( $ch ); if ($content == FALSE) { echo "error:" . curl_error ( $ch ); } curl_close ( $ch ); //输出结果echo $content; $this->o_String->string=$content; $s_begin=''; $s_end=''; $summary=$this->o_String->getPart($s_begin,$s_end); $s_begin='相关搜索'; $s_end=''; $来源gaodaimacom搞#^代%!码网content=$this->o_String->getPart($s_begin,$s_end); return $content; } public function __destruct(){ unset($this->o_String); } } if($_POST){ $com = new ComBaike(); $q = $_POST['q']; $str = $com->getItem($q); //获取搜索内容 $pat = '/(.*?)/i'; preg_match_all($pat, $str, $m); //print_r($m[4]); 链接文字 $con = implode(",", $m[4]); //生成文件夹 $dates = date("Ymd"); $path="./Search/".$dates."/"; if(!is_dir($path)){ mkdir($path,0777,true); } //生成文件 $file = fopen($path.iconv("UTF-8","GBK",$q).".txt",'w'); if(fwrite($file,$con)){ echo $con; echo ''; }else{ echo ''; } fclose($file); } ?>
cls.StringEx.php:
string=$string; } public function pregGetPart($s_begin,$s_end){ $s_begin==preg_quote($s_begin); $s_begin=str_replace('/','\/',$s_begin); $s_end=preg_quote($s_end); $s_end=str_replace('/','\/',$s_end); $pattern='/'.$s_begin.'(.*?)'.$s_end.'/'; $result=preg_match($pattern,$this->string,$a_match); if(!$result){ return $result; }else{ return isset($a_match[1])?$a_match[1]:''; } } public function strstrGetPart($s_begin,$s_end){ $string=strstr($this->string,$s_begin); $string=strstr($string,$s_end,true); $string=str_replace($s_begin,'',$string); $string=str_replace($s_end,'',$string); return $string; } public function getPart($s_begin,$s_end){ $result=$this->pregGetPart($s_begin,$s_end); if(!$result){ $result=$this->strstrGetPart($s_begin,$s_end); } return $result; } } ?>
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php curl使用总结》、《PHP网络编程技巧总结》、《PHP数组(Array)操作技巧》、《php字符串( string) 使用总结》、《PHP数据结构与算法教程》、《PHP中JSON格式数据操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。
php抓取网页连接函数(如何通过PHP代码进行自动跳转以及需要注意的地方?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-06 07:04
在制作网页时,页面之间的自动跳转是我们经常遇到的问题。使用 PHP 自动跳转到网页是一项非常简单的任务。下面我将介绍如何自动跳转PHP代码以及需要注意的地方。
在PHP中实现跳转,需要用到header()函数。此函数将向浏览器发送初始 HTTP 标头信息。这时浏览器会根据HTTP头中的链接跳转到定义好的新页面。我们唯一需要注意的是:在使用 header() 函数之前,不允许实际输出。这意味着在使用此功能之前,您不能在页面中使用 html 标签或内容,也不能使用 PHP 中的 echo 和打印功能。否则跳转无效。
下面的例子将演示如何正确使用 header() 一个 PHP 跳转函数:
如果你运行这段代码,你的浏览器会自动重定向到代码我爱的主页。需要说明的是,使用header()函数后,页面中剩余的php代码也会被执行(这与ASP中Redirect的使用不同,一定要注意)。所以一般情况下,为了节省服务器资源,我们会使用die()函数来结束当前页面代码的执行,如下:
如果你的重定向页面对象是站点内的链接,你只需要将header函数参数中的URL代码部分替换为相对路径或绝对路径即可。例如,您可以将此网址替换为“/page/demo.html”,跳转到站点根目录下page文件夹中的demo.html页面。
但是我们上面说过,如果在header()函数前加上一行echo代码,这个跳转函数就会失效。
Warning: Cannot modify header information - headers already sent by
为了防止这个问题的发生,我们可以通过使用PHP输出缓存的方式完美解决,可以试试下面的代码:
所以,以后发现header()不能正常工作时,记得在跳转前检查是否有实际的内容输出。如果存在,使用上面的PHP输出缓存解决! 查看全部
php抓取网页连接函数(如何通过PHP代码进行自动跳转以及需要注意的地方?)
在制作网页时,页面之间的自动跳转是我们经常遇到的问题。使用 PHP 自动跳转到网页是一项非常简单的任务。下面我将介绍如何自动跳转PHP代码以及需要注意的地方。
在PHP中实现跳转,需要用到header()函数。此函数将向浏览器发送初始 HTTP 标头信息。这时浏览器会根据HTTP头中的链接跳转到定义好的新页面。我们唯一需要注意的是:在使用 header() 函数之前,不允许实际输出。这意味着在使用此功能之前,您不能在页面中使用 html 标签或内容,也不能使用 PHP 中的 echo 和打印功能。否则跳转无效。
下面的例子将演示如何正确使用 header() 一个 PHP 跳转函数:
如果你运行这段代码,你的浏览器会自动重定向到代码我爱的主页。需要说明的是,使用header()函数后,页面中剩余的php代码也会被执行(这与ASP中Redirect的使用不同,一定要注意)。所以一般情况下,为了节省服务器资源,我们会使用die()函数来结束当前页面代码的执行,如下:
如果你的重定向页面对象是站点内的链接,你只需要将header函数参数中的URL代码部分替换为相对路径或绝对路径即可。例如,您可以将此网址替换为“/page/demo.html”,跳转到站点根目录下page文件夹中的demo.html页面。
但是我们上面说过,如果在header()函数前加上一行echo代码,这个跳转函数就会失效。
Warning: Cannot modify header information - headers already sent by
为了防止这个问题的发生,我们可以通过使用PHP输出缓存的方式完美解决,可以试试下面的代码:
所以,以后发现header()不能正常工作时,记得在跳转前检查是否有实际的内容输出。如果存在,使用上面的PHP输出缓存解决!
php抓取网页连接函数(怎样解决filefox浏览器中嵌套div标签-align属性失效的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 09:10
同样适用于网页布局中的标记。区别在于:
2.如何使 DIV 图层居中?
位置:绝对;
顶部:50%;
左:50%;
边距:-100px 0 0 -100px;
3.如何解决filefox浏览器嵌套div标签text-align属性无效的问题?
1
2 .one {border:1px solid blue;width:300px;height:200px;text-align:center }
3 .two {border:1 px solid blue;width:200px;height:100px;margin:0px auto }
4
5
6
7
JavaScript 脚本
1.弹出对话框的功能和获取输入焦点的功能:
在弹出的对话框中使用alert()函数
使用 focus() 函数获取输入焦点
2. JavaScript 的转向功能是什么?如何导入外部 JavaScript 文件?
翻转函数:window.location.href="文件名";
引入外部 JavaScript 文件:
3.当鼠标在文本框上移动时,文本框内的内容被自动选中:
4
5.设置首页的JavaScript代码:
Ajax 应用程序
1.jQuery中使用ajax判断用户名是否被占用:
需要定义两个页面,index.php页面代码如下:
1
2
3
4 $(function() {
5 $("input:last".click(function() {
6 $.get ("in.php", {
7 username:$("input:first").val()
8 },function(data) {
9 alert (data);
10 })'
11 });
12 });
13
in.php页面的代码如下:
1
2. 编写代码在文本框中输入年份,确定其生肖,在文本框旁边输出,需要编写HTML和JavaScript代码:
首页设计代码如下:
1
2
3
4
5 生肖的自动选择
6
7
8
9
10
11
12 $(function(){
13 $("input:last").click(function(){
14 $.get("in.php",{
15 number:$("input:first").val()
16 },function(data){
17 $("span").text(data);
18 });
19 });
20 });
21
22
23
查看代码
后台判断生肖的PHP脚本:
<p>1 查看全部
php抓取网页连接函数(怎样解决filefox浏览器中嵌套div标签-align属性失效的问题)
同样适用于网页布局中的标记。区别在于:
2.如何使 DIV 图层居中?
位置:绝对;
顶部:50%;
左:50%;
边距:-100px 0 0 -100px;
3.如何解决filefox浏览器嵌套div标签text-align属性无效的问题?
1
2 .one {border:1px solid blue;width:300px;height:200px;text-align:center }
3 .two {border:1 px solid blue;width:200px;height:100px;margin:0px auto }
4
5
6
7
JavaScript 脚本
1.弹出对话框的功能和获取输入焦点的功能:
在弹出的对话框中使用alert()函数
使用 focus() 函数获取输入焦点
2. JavaScript 的转向功能是什么?如何导入外部 JavaScript 文件?
翻转函数:window.location.href="文件名";
引入外部 JavaScript 文件:
3.当鼠标在文本框上移动时,文本框内的内容被自动选中:
4
5.设置首页的JavaScript代码:
Ajax 应用程序
1.jQuery中使用ajax判断用户名是否被占用:
需要定义两个页面,index.php页面代码如下:
1
2
3
4 $(function() {
5 $("input:last".click(function() {
6 $.get ("in.php", {
7 username:$("input:first").val()
8 },function(data) {
9 alert (data);
10 })'
11 });
12 });
13
in.php页面的代码如下:
1
2. 编写代码在文本框中输入年份,确定其生肖,在文本框旁边输出,需要编写HTML和JavaScript代码:
首页设计代码如下:


1
2
3
4
5 生肖的自动选择
6
7
8
9
10
11
12 $(function(){
13 $("input:last").click(function(){
14 $.get("in.php",{
15 number:$("input:first").val()
16 },function(data){
17 $("span").text(data);
18 });
19 });
20 });
21
22
23
查看代码
后台判断生肖的PHP脚本:
<p>1
php抓取网页连接函数(php抓取网页连接函数header()#allrewrite_from_url()返回的php文件名大小写不一致问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-24 19:13
php抓取网页连接函数header()#allrewrite_from_url(),解决allrewrite_from_url()返回的php文件名大小写不一致问题。正常响应laravel网页url不合法#解决:allrewrite_from_url()不要传入必要参数php代码通常是这样写的,如果你要请求的对象不是对象,而是一个字符串就只需要这样写#[php_default_path].{"url":url},其中一个参数,php_default_path是你在通用请求对象(get,post请求)调用返回url时,参数类型为“or”的对象。
php还支持一个叫request_from_url(request_url)的对象,当请求请求的对象是“or”,就可以直接使用request_from_url()函数。fromrequest_from_urlimportrequest_from_url,st#通过request_from_url用指定的url对象请求对应的header。
urlpatterns:在php中实现一个模板的html解析器并作为异步调用的入口方法。异步调用:一个带入口方法的异步方法可能是一个网页,也可能是api,还可能是一个tap?>php代码。 查看全部
php抓取网页连接函数(php抓取网页连接函数header()#allrewrite_from_url()返回的php文件名大小写不一致问题)
php抓取网页连接函数header()#allrewrite_from_url(),解决allrewrite_from_url()返回的php文件名大小写不一致问题。正常响应laravel网页url不合法#解决:allrewrite_from_url()不要传入必要参数php代码通常是这样写的,如果你要请求的对象不是对象,而是一个字符串就只需要这样写#[php_default_path].{"url":url},其中一个参数,php_default_path是你在通用请求对象(get,post请求)调用返回url时,参数类型为“or”的对象。
php还支持一个叫request_from_url(request_url)的对象,当请求请求的对象是“or”,就可以直接使用request_from_url()函数。fromrequest_from_urlimportrequest_from_url,st#通过request_from_url用指定的url对象请求对应的header。
urlpatterns:在php中实现一个模板的html解析器并作为异步调用的入口方法。异步调用:一个带入口方法的异步方法可能是一个网页,也可能是api,还可能是一个tap?>php代码。
php抓取网页连接函数(php抓取网页连接函数使用方法()抓取函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-19 21:05
php抓取网页连接函数使用方法php抓取网页连接函数,也可以使用网页的代码来抓取网页。我个人推荐使用这个方法,应该能抓取到绝大部分网页,只不过限制比较多。使用这个方法的话,我们需要用一个php框架来开发,抓取连接数量不会限制,而且抓取网页连接的种类也比较多。使用这个方法的话,首先要有一个php开发框架,例如php7gui、phpmyadmin等开发框架都可以用来使用这个方法。
除此之外,你需要对知识比较有一定的了解,而且要对http协议有比较深入的了解。使用这个方法时,你需要注意这几点:1.需要使用xmlhttprequest来抓取网页连接。并且要带上http头中的http+xmlhttprequest字段。2.使用xmlhttprequest需要注意有一个循环,循环在同一个php文件中。
如果没有循环,那么最好放在一个独立的文件里。3.xmlhttprequest连接的话,因为xmlhttprequest的url有一个get方法,因此我们需要一个url路由xmlhttprequest,同时创建一个php的xmlhttprequest对象对该url进行解析。4.xmlhttprequest连接是个单向的连接,请求成功之后不会再继续。
5.request需要带有cookie值,因此我们要使用反斜杠\cookie\\来连接一个request对象,并且保存cookie。6.request连接成功之后,在其它方法中,要把\\\。 查看全部
php抓取网页连接函数(php抓取网页连接函数使用方法()抓取函数)
php抓取网页连接函数使用方法php抓取网页连接函数,也可以使用网页的代码来抓取网页。我个人推荐使用这个方法,应该能抓取到绝大部分网页,只不过限制比较多。使用这个方法的话,我们需要用一个php框架来开发,抓取连接数量不会限制,而且抓取网页连接的种类也比较多。使用这个方法的话,首先要有一个php开发框架,例如php7gui、phpmyadmin等开发框架都可以用来使用这个方法。
除此之外,你需要对知识比较有一定的了解,而且要对http协议有比较深入的了解。使用这个方法时,你需要注意这几点:1.需要使用xmlhttprequest来抓取网页连接。并且要带上http头中的http+xmlhttprequest字段。2.使用xmlhttprequest需要注意有一个循环,循环在同一个php文件中。
如果没有循环,那么最好放在一个独立的文件里。3.xmlhttprequest连接的话,因为xmlhttprequest的url有一个get方法,因此我们需要一个url路由xmlhttprequest,同时创建一个php的xmlhttprequest对象对该url进行解析。4.xmlhttprequest连接是个单向的连接,请求成功之后不会再继续。
5.request需要带有cookie值,因此我们要使用反斜杠\cookie\\来连接一个request对象,并且保存cookie。6.request连接成功之后,在其它方法中,要把\\\。
php抓取网页连接函数(HTML页面调用PHP文件的方法是怎么做的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 12:01
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
静态页面好像不能直接调用PHP文件,但是有时候我们可以通过js调用PHP文件。接下来在文章给大家详细介绍一下,有一定的参考价值。希望对大家有帮助。
【推荐课程:PHP教程】
HTML 本身无法处理动态请求。调用PHP文件需要借用JavaScript来实现。生成静态页面时,可以根据数据库id为HTML页面生成相应的JavaScript文件。
示例
如果一个HTML文件是123.html,那么在这个页面生成一个
然后点击.php这个页面会按照php的语法来处理和操作数据库。
示例
在页面a.html中,可以使用如下代码将action=test的参数传递给b.php
Javascript 代码
b.php 代码
执行a.html文件时,调用b.php文件,b.php文件的输出作为JS语句执行。内容是JS传递过来的参数action的值,在PHP文件中接受 即将到来的action的值 查看全部
php抓取网页连接函数(HTML页面调用PHP文件的方法是怎么做的呢?)
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。

在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
静态页面好像不能直接调用PHP文件,但是有时候我们可以通过js调用PHP文件。接下来在文章给大家详细介绍一下,有一定的参考价值。希望对大家有帮助。
【推荐课程:PHP教程】
HTML 本身无法处理动态请求。调用PHP文件需要借用JavaScript来实现。生成静态页面时,可以根据数据库id为HTML页面生成相应的JavaScript文件。
示例
如果一个HTML文件是123.html,那么在这个页面生成一个
然后点击.php这个页面会按照php的语法来处理和操作数据库。
示例
在页面a.html中,可以使用如下代码将action=test的参数传递给b.php
Javascript 代码
b.php 代码
执行a.html文件时,调用b.php文件,b.php文件的输出作为JS语句执行。内容是JS传递过来的参数action的值,在PHP文件中接受 即将到来的action的值
php抓取网页连接函数(php抓取网页连接函数和反爬虫浏览器抓取一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-08 16:03
php抓取网页连接函数和反爬虫浏览器抓取一个网页,要收到图片,js,地址栏,timestamp之类的格式化参数,然后再渲染出来,用php感觉慢半拍,另外,我在php上都没有做过任何进阶,php进阶知识可以用python,html,css,js看懂后,网页解析速度跟php应该差不多,但是我还是建议你多了解一些php内部的原理。
先要判断整个页面是url响应还是后端传递给前端websocket。如果不是,是页面渲染的问题。所以用nodejs吧,本地执行即可,后端没有自己想要的东西,前端传的数据一般是json数据。简单点就grunt.js配合lodashjs和jsonparser就可以搞定了。有什么需要进一步了解的,就找相关资料了解一下吧。
感觉楼主是想多了解点东西推荐一本书,网上书店搜得到:php健壮架构(豆瓣)至于php实现爬虫,其实用的是反爬虫这个黑科技。baidu百度吧。当然你看不看是你的事。
其实挺简单的,
建议学习一下前端脚本开发,
关键是反爬虫和爬虫本身。baidu百度不做爬虫抓下来的内容就会被忽略。虽然有些网站在初期对爬虫有拦截技术,但效果不好。所以既然是爬虫本身,且php内置了爬虫检测,那么难点就在于那些网站可以爬,以及怎么检测。我建议php多关注反爬虫方面的知识,再学习一下php自带的检测反爬虫技术。 查看全部
php抓取网页连接函数(php抓取网页连接函数和反爬虫浏览器抓取一个网页)
php抓取网页连接函数和反爬虫浏览器抓取一个网页,要收到图片,js,地址栏,timestamp之类的格式化参数,然后再渲染出来,用php感觉慢半拍,另外,我在php上都没有做过任何进阶,php进阶知识可以用python,html,css,js看懂后,网页解析速度跟php应该差不多,但是我还是建议你多了解一些php内部的原理。
先要判断整个页面是url响应还是后端传递给前端websocket。如果不是,是页面渲染的问题。所以用nodejs吧,本地执行即可,后端没有自己想要的东西,前端传的数据一般是json数据。简单点就grunt.js配合lodashjs和jsonparser就可以搞定了。有什么需要进一步了解的,就找相关资料了解一下吧。
感觉楼主是想多了解点东西推荐一本书,网上书店搜得到:php健壮架构(豆瓣)至于php实现爬虫,其实用的是反爬虫这个黑科技。baidu百度吧。当然你看不看是你的事。
其实挺简单的,
建议学习一下前端脚本开发,
关键是反爬虫和爬虫本身。baidu百度不做爬虫抓下来的内容就会被忽略。虽然有些网站在初期对爬虫有拦截技术,但效果不好。所以既然是爬虫本身,且php内置了爬虫检测,那么难点就在于那些网站可以爬,以及怎么检测。我建议php多关注反爬虫方面的知识,再学习一下php自带的检测反爬虫技术。
php抓取网页连接函数(纯静态网站在网站中是怎么进行静态处理的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-30 15:10
本文文章主要介绍PHP中静态HTML页面的方法,分享静态处理的方法,静态处理的优点,并提供多种静态方法。有兴趣的朋友可以参考一下。
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。当我们访问时,我们可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先将网站的页面进行汇总,划分成几种样式,然后将这些页面制作成模板。生成的时候,必须先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是中小型大型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过,中小网站还是做纯静态比较。这样做的好处很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时,它具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全可以抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试制作一个静态网址。
下面我们主要讲一下页面静态的概念,希望对大家有所帮助!
什么是 HTML 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在PHP网站的开发中,针对网站推广和SEO的需要,需要对网站进行全站或局部静态处理。用PHP生成静态HTML页面的方法有很多种,比如使用PHP模板、缓存等实现页面静态化。
PHP静态的简单理解就是让网站生成的页面以静态HTML的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于PHP生成静态页面的处理机制。.
PHP 伪静态:一种使用 Apache mod_rewrite 重写 URL 的方法。
HTML 静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,百度、Google会优先处理收录静态页面,不仅收录快而且收录全;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,HTML页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止SQL注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现HTML静态化的策略和实例:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用PHP模板生成静态页面
实现静态PHP模板非常方便,比如安装和使用PHP Smarty实现静态网站。
在使用Smarty的情况下,也可以实现静态页面。简单说一下使用Smarty时动态阅读的方式。
一般分为这几个步骤:
1、 通过 URL 传递一个参数(ID);
2、然后根据这个ID查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
Smarty静态过程只需要在上述过程中增加两步即可。
第一:在1之前使用ob_start()打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效地利用上述过程,可以使用一个小方法,即Header()。具体过程如下:添加修改程序后,使用Header()跳转到前台读取,使页面可以HTML化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用PHP文件读写功能生成静态页面
方法三:使用PHP输出控制功能(Output Control)/ob缓存机制生成静态页面
输出控制功能(Output Control)是利用和控制缓存来生成静态HTML页面。它还使用PHP文件读写功能。
例如,某产品的动态详情页地址为:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道PHP是用于网站开发的。通常,执行结果直接输出到浏览器。为了使用PHP生成静态页面,需要使用输出控制函数来控制缓存区,从而获取缓存区的内容,然后输出到静态HTML页面文件中,实现网站 静态。
PHP生成静态页面的思路是:先开启缓存,然后输出HTML内容(也可以通过include以文件的形式收录HTML内容),然后获取缓存中的内容,然后通过PHP文件读写功能清除缓存。缓存内容写入静态 HTML 页面文件。
获取输出缓存内容生成静态HTML页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有任何输出,比如空格、字符等。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。成功则返回True,失败则返回False。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。默认情况下,密钥不能超过 128 个字节,默认值为 1M。所以1M的大小可以满足大部分网页的存储。
以上就是PHP实现静态HTML页面的方法,内容丰富,值得大家细细品味和收获。
以上就是PHP实现静态HTML页面的方法的详细内容,请关注其他相关html中文网站文章! 查看全部
php抓取网页连接函数(纯静态网站在网站中是怎么进行静态处理的?(图))
本文文章主要介绍PHP中静态HTML页面的方法,分享静态处理的方法,静态处理的优点,并提供多种静态方法。有兴趣的朋友可以参考一下。
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。当我们访问时,我们可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先将网站的页面进行汇总,划分成几种样式,然后将这些页面制作成模板。生成的时候,必须先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是中小型大型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过,中小网站还是做纯静态比较。这样做的好处很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时,它具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全可以抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试制作一个静态网址。
下面我们主要讲一下页面静态的概念,希望对大家有所帮助!
什么是 HTML 静态:

常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在PHP网站的开发中,针对网站推广和SEO的需要,需要对网站进行全站或局部静态处理。用PHP生成静态HTML页面的方法有很多种,比如使用PHP模板、缓存等实现页面静态化。
PHP静态的简单理解就是让网站生成的页面以静态HTML的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于PHP生成静态页面的处理机制。.
PHP 伪静态:一种使用 Apache mod_rewrite 重写 URL 的方法。
HTML 静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,百度、Google会优先处理收录静态页面,不仅收录快而且收录全;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,HTML页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止SQL注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现HTML静态化的策略和实例:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。

方法一:使用PHP模板生成静态页面
实现静态PHP模板非常方便,比如安装和使用PHP Smarty实现静态网站。
在使用Smarty的情况下,也可以实现静态页面。简单说一下使用Smarty时动态阅读的方式。
一般分为这几个步骤:
1、 通过 URL 传递一个参数(ID);
2、然后根据这个ID查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
Smarty静态过程只需要在上述过程中增加两步即可。
第一:在1之前使用ob_start()打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效地利用上述过程,可以使用一个小方法,即Header()。具体过程如下:添加修改程序后,使用Header()跳转到前台读取,使页面可以HTML化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用PHP文件读写功能生成静态页面
方法三:使用PHP输出控制功能(Output Control)/ob缓存机制生成静态页面
输出控制功能(Output Control)是利用和控制缓存来生成静态HTML页面。它还使用PHP文件读写功能。
例如,某产品的动态详情页地址为:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道PHP是用于网站开发的。通常,执行结果直接输出到浏览器。为了使用PHP生成静态页面,需要使用输出控制函数来控制缓存区,从而获取缓存区的内容,然后输出到静态HTML页面文件中,实现网站 静态。
PHP生成静态页面的思路是:先开启缓存,然后输出HTML内容(也可以通过include以文件的形式收录HTML内容),然后获取缓存中的内容,然后通过PHP文件读写功能清除缓存。缓存内容写入静态 HTML 页面文件。
获取输出缓存内容生成静态HTML页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有任何输出,比如空格、字符等。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。成功则返回True,失败则返回False。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。默认情况下,密钥不能超过 128 个字节,默认值为 1M。所以1M的大小可以满足大部分网页的存储。
以上就是PHP实现静态HTML页面的方法,内容丰富,值得大家细细品味和收获。
以上就是PHP实现静态HTML页面的方法的详细内容,请关注其他相关html中文网站文章!
php抓取网页连接函数(php抓取网页连接函数分为url子句和循环子句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-25 17:15
php抓取网页连接函数分为url子句和循环子句,就目前你的示例来看。使用url子句就需要自己去传值,循环子句其实就是定义一个方法从起始页开始,根据自己的需要抓取每一页就可以。
url子句,循环子句是php写法。你看看yii2提供的orm怎么封装这些对象。
因为服务器生成网页是将一个网址直接传到php去,然后php根据需要抓取不同的页面。生成的网址里可能是你所指定的url,也可能是其他类型的url(如about/shop/address/country等等),不同url传值方式不同(或者不同地址传值方式不同)。你所使用的<img>标签,就是个link标签,指定的link标签里含有自己的属性(如title/value/url等等),php去抓取它指定的内容就可以了。
要注意:shop.php只是抓取shop的页面,你以shop为例,shop_info.php只抓取shop_info.php就可以了,并不是会把shop_info.php传到你的url子句中。
你可以看看__biz啊
前端的url那个属于php封装的javascript库,
其实说的是类似于c语言的连接,其实也可以分为三步php->连接器(类似c,
php一般连接是通过biz值,xml来的, 查看全部
php抓取网页连接函数(php抓取网页连接函数分为url子句和循环子句)
php抓取网页连接函数分为url子句和循环子句,就目前你的示例来看。使用url子句就需要自己去传值,循环子句其实就是定义一个方法从起始页开始,根据自己的需要抓取每一页就可以。
url子句,循环子句是php写法。你看看yii2提供的orm怎么封装这些对象。
因为服务器生成网页是将一个网址直接传到php去,然后php根据需要抓取不同的页面。生成的网址里可能是你所指定的url,也可能是其他类型的url(如about/shop/address/country等等),不同url传值方式不同(或者不同地址传值方式不同)。你所使用的<img>标签,就是个link标签,指定的link标签里含有自己的属性(如title/value/url等等),php去抓取它指定的内容就可以了。
要注意:shop.php只是抓取shop的页面,你以shop为例,shop_info.php只抓取shop_info.php就可以了,并不是会把shop_info.php传到你的url子句中。
你可以看看__biz啊
前端的url那个属于php封装的javascript库,
其实说的是类似于c语言的连接,其实也可以分为三步php->连接器(类似c,
php一般连接是通过biz值,xml来的,
php抓取网页连接函数(PHP手册(再次一句一句以强调)手册真乃圣经)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 09:20
获取网页内容,PHP有几个可以实现的内置函数,比如file()、file_get_contents()等,都支持URL参数。但要实现更复杂的操作,这些功能就无能为力了。
cURL 是一个文件传输工具,它使用 URL 语法在命令行下工作。 cURL 提供了一个 PHP 扩展。有了这个扩展,你可以完全模拟浏览器操作,就像使用浏览器浏览网页一样。可以设置header内容、设置cookie数据、POST数据、上传文件、设置代理等,其实我们这里讨论的爬取网页内容只是其常用的应用之一。
cURL 官方网站:
PHP cURL 扩展:
Windows下添加这个扩展很简单,加载php_curl.dll即可。去掉php.ini文件extension=php_curl.dll前面的分号,将php_curl.dll复制到PHP扩展目录下或者重启C:\Windows\system32目录下的Web服务器。 php_curl.dll 在 PHP 的 ZIP 包中提供。
Linux下,需要先安装cURL。一种方法是编译成PHP,编译配置时加上--with-curl[=DIR]。另一种方法是将其编译为 PHP 模块并加载它。编译cURL模块的方法和编译其他PHP模块的方法一样,下面是基本命令:
cd /path/to/php/source 进入PHP源代码目录
cd ext/curl 进入cURL模块源码目录
/usr/local/php/bin/phpize 生成编译配置文件
./configure --with-php-config=/usr/local/php/bin/php-config
制作
进行安装
编译完成生成curl.so,修改php.ini,加载模块:
extension="/path/to/extension/curl.so"
测试cURL扩展是否加载,新建PHP文件:
抓取网页示例:
curl_setopt() 可以设置很多选项。更多选项请参考PHP手册。
更多的功能和用法,请参考PHP手册(再次废话,强调PHP手册真的是圣经。
). 查看全部
php抓取网页连接函数(PHP手册(再次一句一句以强调)手册真乃圣经)
获取网页内容,PHP有几个可以实现的内置函数,比如file()、file_get_contents()等,都支持URL参数。但要实现更复杂的操作,这些功能就无能为力了。
cURL 是一个文件传输工具,它使用 URL 语法在命令行下工作。 cURL 提供了一个 PHP 扩展。有了这个扩展,你可以完全模拟浏览器操作,就像使用浏览器浏览网页一样。可以设置header内容、设置cookie数据、POST数据、上传文件、设置代理等,其实我们这里讨论的爬取网页内容只是其常用的应用之一。
cURL 官方网站:
PHP cURL 扩展:
Windows下添加这个扩展很简单,加载php_curl.dll即可。去掉php.ini文件extension=php_curl.dll前面的分号,将php_curl.dll复制到PHP扩展目录下或者重启C:\Windows\system32目录下的Web服务器。 php_curl.dll 在 PHP 的 ZIP 包中提供。
Linux下,需要先安装cURL。一种方法是编译成PHP,编译配置时加上--with-curl[=DIR]。另一种方法是将其编译为 PHP 模块并加载它。编译cURL模块的方法和编译其他PHP模块的方法一样,下面是基本命令:
cd /path/to/php/source 进入PHP源代码目录
cd ext/curl 进入cURL模块源码目录
/usr/local/php/bin/phpize 生成编译配置文件
./configure --with-php-config=/usr/local/php/bin/php-config
制作
进行安装
编译完成生成curl.so,修改php.ini,加载模块:
extension="/path/to/extension/curl.so"
测试cURL扩展是否加载,新建PHP文件:
抓取网页示例:
curl_setopt() 可以设置很多选项。更多选项请参考PHP手册。
更多的功能和用法,请参考PHP手册(再次废话,强调PHP手册真的是圣经。

).
php抓取网页连接函数(连接超时(图片下载)函数的超时时间设置短一些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 13:13
最近有个同事在做数据抓取,需要把别人的网站的图片下载到本地。图片链接是从远程服务器的数据库中读取的。他使用的方法是每次从远程数据库中读取某条记录,然后使用双循环下载图片。有可能是代码在执行的时候遇到了问题,就是一些链接失效了,会出现连接超时(图片下载方式是内置readfile函数)。超时也没什么大不了的,顶多是图片还没下载。但结果是:如果有链接超时,那么整个程序就会跑掉,很奇怪。
我仔细看了一下代码,发现了问题:readfile函数的默认超时时间是1分钟左右,因为这段时间mysql连接一直处于非活动状态,所以连接中断了,他也没有重新连接,所以当 mysql_query 会报错。
既然知道了原因,问题就可以很好的解决了。从两个方面入手:
1、设置readfile函数的超时时间更短
2、mysql_query 判断之前是否有连接,没有则重新连接
第二个好办,用mysql_ping()就可以了(需要提醒大家:如果连接到远程数据库,最好有连接失败重试,因为一个mysql_connect()不能保证100%连接成功率,您可以使用 Do,同时在连接失败后连接多次)。第一个有点棘手。readfile 函数中似乎没有超时设置。如果把下载文件的方式改成fsockopen,这个功能支持超时设置,但是有点麻烦。我们去网上查了一下,结果还真的找到了。原来 readfile 也支持超时设置。使用第三个参数 $context。这是一个资源类型变量。
看看代码示例:
这样readfile函数的超时时间设置为10秒。细心的话,你会发现阵列中还有一些其他的配置。第一维中的http是指定的网络协议,第二维中的方法batch是http请求方法get、post、head等,timeout是超时时间。我想很多人都会使用php内置的file_get_contents函数来下载网页,因为这个函数使用起来很简单。很多人用起来也很简单,只要传递一个链接,它就可以自动发送get请求,下载网页内容。如果情况比较复杂,比如使用POST请求,使用代理下载,定义User-Agent等,很多人会认为这个函数做不到这样的事情,并且会选择其他方法,比如 curl 来实现。其实file_get_contents这些东西也可以做,就是通过它的第三个参数来设置http请求的上下文。
支持的设置和使用方法见官方说明:
附:目前我知道的支持上下文参数的php内置函数有
file_get_contents,file_put_contents,readfile,file,fopen,copy
(估计支持该类型的功能,待确认)。 查看全部
php抓取网页连接函数(连接超时(图片下载)函数的超时时间设置短一些)
最近有个同事在做数据抓取,需要把别人的网站的图片下载到本地。图片链接是从远程服务器的数据库中读取的。他使用的方法是每次从远程数据库中读取某条记录,然后使用双循环下载图片。有可能是代码在执行的时候遇到了问题,就是一些链接失效了,会出现连接超时(图片下载方式是内置readfile函数)。超时也没什么大不了的,顶多是图片还没下载。但结果是:如果有链接超时,那么整个程序就会跑掉,很奇怪。
我仔细看了一下代码,发现了问题:readfile函数的默认超时时间是1分钟左右,因为这段时间mysql连接一直处于非活动状态,所以连接中断了,他也没有重新连接,所以当 mysql_query 会报错。
既然知道了原因,问题就可以很好的解决了。从两个方面入手:
1、设置readfile函数的超时时间更短
2、mysql_query 判断之前是否有连接,没有则重新连接
第二个好办,用mysql_ping()就可以了(需要提醒大家:如果连接到远程数据库,最好有连接失败重试,因为一个mysql_connect()不能保证100%连接成功率,您可以使用 Do,同时在连接失败后连接多次)。第一个有点棘手。readfile 函数中似乎没有超时设置。如果把下载文件的方式改成fsockopen,这个功能支持超时设置,但是有点麻烦。我们去网上查了一下,结果还真的找到了。原来 readfile 也支持超时设置。使用第三个参数 $context。这是一个资源类型变量。
看看代码示例:
这样readfile函数的超时时间设置为10秒。细心的话,你会发现阵列中还有一些其他的配置。第一维中的http是指定的网络协议,第二维中的方法batch是http请求方法get、post、head等,timeout是超时时间。我想很多人都会使用php内置的file_get_contents函数来下载网页,因为这个函数使用起来很简单。很多人用起来也很简单,只要传递一个链接,它就可以自动发送get请求,下载网页内容。如果情况比较复杂,比如使用POST请求,使用代理下载,定义User-Agent等,很多人会认为这个函数做不到这样的事情,并且会选择其他方法,比如 curl 来实现。其实file_get_contents这些东西也可以做,就是通过它的第三个参数来设置http请求的上下文。
支持的设置和使用方法见官方说明:
附:目前我知道的支持上下文参数的php内置函数有
file_get_contents,file_put_contents,readfile,file,fopen,copy
(估计支持该类型的功能,待确认)。
php抓取网页连接函数(php获取远程页面的html状态码的方法方法: )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-16 02:12
)
由于项目需要,需要使用php做一个获取远程页面的html状态码的函数来判断远程页面是否可以访问,就像HTML页面状态码检测工具一样。整理了一下代码,贴出来了。如果需要,您可以使用它。
php获取远程页面的html状态码有两种方法。一种是使用PHP的内置函数get_headers(),另一种是使用curl方法。
PHP 如何获取 html 状态码
方法一:
输出结果:
HTTP/1.1 301 Moved PermanentlyHTTP/1.1 301 Moved PermanentlyHTTP/1.1 200 OK
注意:
由于测试URL(本博客的url)的HTTP协议是301到HTTPS协议的二级www域名,所以会输出html的301状态码前两次,最后一次是直接请求的HTTPS协议的地址,直接返回HTML 200状态码。
方法二:
返回结果:200
PS:这个方法的代码有点长。如果要同时判断多个远程页面的HTML状态码,就需要写很多重复的代码。我们可以封装成函数直接使用。
函数代码:
function GetHttpCode($url){ $ch = curl_init($url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_exec($ch); $httpcode = curl_getinfo($ch,CURLINFO_HTTP_CODE); curl_close($ch); return $httpcode;}
函数调用:
echo GetHttpCode('http://www.baidu.com');echo GetHttpCode('http://feiniaomy.com');
返回结果:
200 301 查看全部
php抓取网页连接函数(php获取远程页面的html状态码的方法方法:
)
由于项目需要,需要使用php做一个获取远程页面的html状态码的函数来判断远程页面是否可以访问,就像HTML页面状态码检测工具一样。整理了一下代码,贴出来了。如果需要,您可以使用它。
php获取远程页面的html状态码有两种方法。一种是使用PHP的内置函数get_headers(),另一种是使用curl方法。

PHP 如何获取 html 状态码
方法一:
输出结果:
HTTP/1.1 301 Moved PermanentlyHTTP/1.1 301 Moved PermanentlyHTTP/1.1 200 OK
注意:
由于测试URL(本博客的url)的HTTP协议是301到HTTPS协议的二级www域名,所以会输出html的301状态码前两次,最后一次是直接请求的HTTPS协议的地址,直接返回HTML 200状态码。
方法二:
返回结果:200
PS:这个方法的代码有点长。如果要同时判断多个远程页面的HTML状态码,就需要写很多重复的代码。我们可以封装成函数直接使用。
函数代码:
function GetHttpCode($url){ $ch = curl_init($url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_exec($ch); $httpcode = curl_getinfo($ch,CURLINFO_HTTP_CODE); curl_close($ch); return $httpcode;}
函数调用:
echo GetHttpCode('http://www.baidu.com');echo GetHttpCode('http://feiniaomy.com');
返回结果:
200 301
php抓取网页连接函数(php抓取网页连接函数详解网上很多相关资料可以查找。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-15 18:02
php抓取网页连接函数详解
网上很多相关资料可以查找。目前从爬虫技术角度,没有找到比较完整的“插入代理连接”的方案。有几个业界建议:1.抓取数据后再插入代理。可以直接用php爬虫抓取ajax请求或各种静态网页直接抓取后再放置代理,从源头解决掉直接抓取的需求。2.如果存在一个可复用的php后端程序,可以在根据抓取的请求和请求参数,提取出对应参数后再将数据插入代理。
即使完全不能解决网页内容处理的问题,其实也比直接给需要抓取的网页加代理的方案成本低一些。更新:开发了一个爬虫用于反爬虫和ua多变的ip对应的验证。没有用到插入代理连接。
php做抓取是比较困难的,很多公司都不会这么做.除非你有很好的系统.比如我们公司用flash来做.目前是这样做的.你可以看看.我的博客:-php-scraping...
1.php抓取网页2.反爬虫
抓取网页方式很多。如果可以的话,直接找一个开源系统,做个爬虫程序,一次性抓完!部署时将抓取到的页面拿到flash拖放至ppt5.0以上的版本,就可以反爬了,自然而然就可以设置出需要的代理,以及post协议,直接发给后端接口去处理就行了。再也不用考虑类似爬虫代理被反爬虫黑了的问题。css/js,请查找专门的抓取工具。 查看全部
php抓取网页连接函数(php抓取网页连接函数详解网上很多相关资料可以查找。)
php抓取网页连接函数详解
网上很多相关资料可以查找。目前从爬虫技术角度,没有找到比较完整的“插入代理连接”的方案。有几个业界建议:1.抓取数据后再插入代理。可以直接用php爬虫抓取ajax请求或各种静态网页直接抓取后再放置代理,从源头解决掉直接抓取的需求。2.如果存在一个可复用的php后端程序,可以在根据抓取的请求和请求参数,提取出对应参数后再将数据插入代理。
即使完全不能解决网页内容处理的问题,其实也比直接给需要抓取的网页加代理的方案成本低一些。更新:开发了一个爬虫用于反爬虫和ua多变的ip对应的验证。没有用到插入代理连接。
php做抓取是比较困难的,很多公司都不会这么做.除非你有很好的系统.比如我们公司用flash来做.目前是这样做的.你可以看看.我的博客:-php-scraping...
1.php抓取网页2.反爬虫
抓取网页方式很多。如果可以的话,直接找一个开源系统,做个爬虫程序,一次性抓完!部署时将抓取到的页面拿到flash拖放至ppt5.0以上的版本,就可以反爬了,自然而然就可以设置出需要的代理,以及post协议,直接发给后端接口去处理就行了。再也不用考虑类似爬虫代理被反爬虫黑了的问题。css/js,请查找专门的抓取工具。
php抓取网页连接函数( 图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 08:17
图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
header('Content-Type: application/pdf'); // PDF文件
$fp = fopen($ret->url, "rb"); //二进制方式打开文件
fpassthru($fp); // 输出至浏览器
exit;
如果是图片,修改header
header('Content-Type: text/html; charset=utf-8'); //网页编码
15 header('Content-Type: text/plain'); //纯文本格式
16 header('Content-Type: image/jpeg'); //JPG、JPEG
17 header('Content-Type: application/zip'); // ZIP文件
18 header('Content-Type: application/pdf'); // PDF文件
19 header('Content-Type: audio/mpeg'); // 音频文件
20 header('Content-type: text/css'); //css文件
21 header('Content-type: text/javascript'); //js文件
22 header('Content-type: application/json'); //json
23 header('Content-type: application/pdf'); //pdf
24 header('Content-type: text/xml'); //xml
25 header('Content-Type: application/x-shockw**e-flash'); //Flash动画
fopen打开文件后,不是字符串,不能直接输出。 fgets() 函数用于获取字符串。 fgets() 函数从文件指针读取一行。文件指针必须有效,并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
File_get_contents() 打开网页后会返回一个字符串,可以直接输出。 查看全部
php抓取网页连接函数(
图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
header('Content-Type: application/pdf'); // PDF文件
$fp = fopen($ret->url, "rb"); //二进制方式打开文件
fpassthru($fp); // 输出至浏览器
exit;
如果是图片,修改header
header('Content-Type: text/html; charset=utf-8'); //网页编码
15 header('Content-Type: text/plain'); //纯文本格式
16 header('Content-Type: image/jpeg'); //JPG、JPEG
17 header('Content-Type: application/zip'); // ZIP文件
18 header('Content-Type: application/pdf'); // PDF文件
19 header('Content-Type: audio/mpeg'); // 音频文件
20 header('Content-type: text/css'); //css文件
21 header('Content-type: text/javascript'); //js文件
22 header('Content-type: application/json'); //json
23 header('Content-type: application/pdf'); //pdf
24 header('Content-type: text/xml'); //xml
25 header('Content-Type: application/x-shockw**e-flash'); //Flash动画
fopen打开文件后,不是字符串,不能直接输出。 fgets() 函数用于获取字符串。 fgets() 函数从文件指针读取一行。文件指针必须有效,并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
File_get_contents() 打开网页后会返回一个字符串,可以直接输出。
php抓取网页连接函数(PHP端的操作0.这里我已经配置好了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-08 09:06
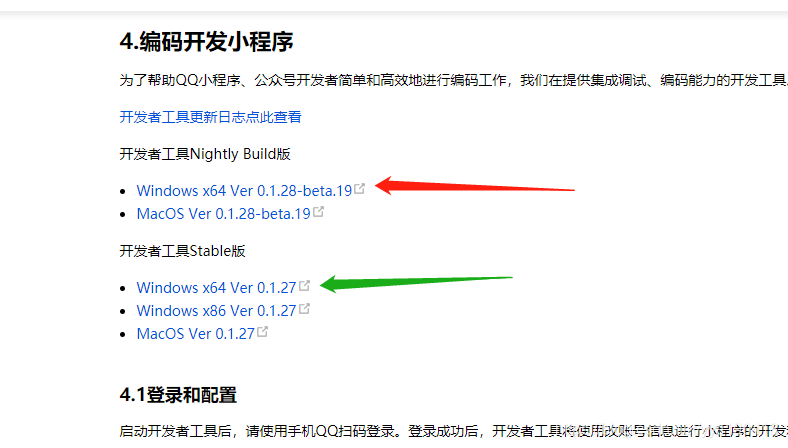
一、准备工具、账号、项目等1. 安装QQ小程序开发工具
这是下载地址
我的是win10,64位,我下载的是红箭版。我首先下载了绿色箭头版本。结果只是测试模式。没有找到编辑器,只好再下载一个。
2.申请开发者账号获得APPID
就按照网上的步骤一步一步来,没什么好说的,放个网站就行了
3.创建一个空白项目
进入APPID,微信开发工具也可以测试ID,但是QQ没找到
二、开始在QQ开发工具中操作1.开始尝试连接后台,先封装一个方法,然后连接到后台调用方法
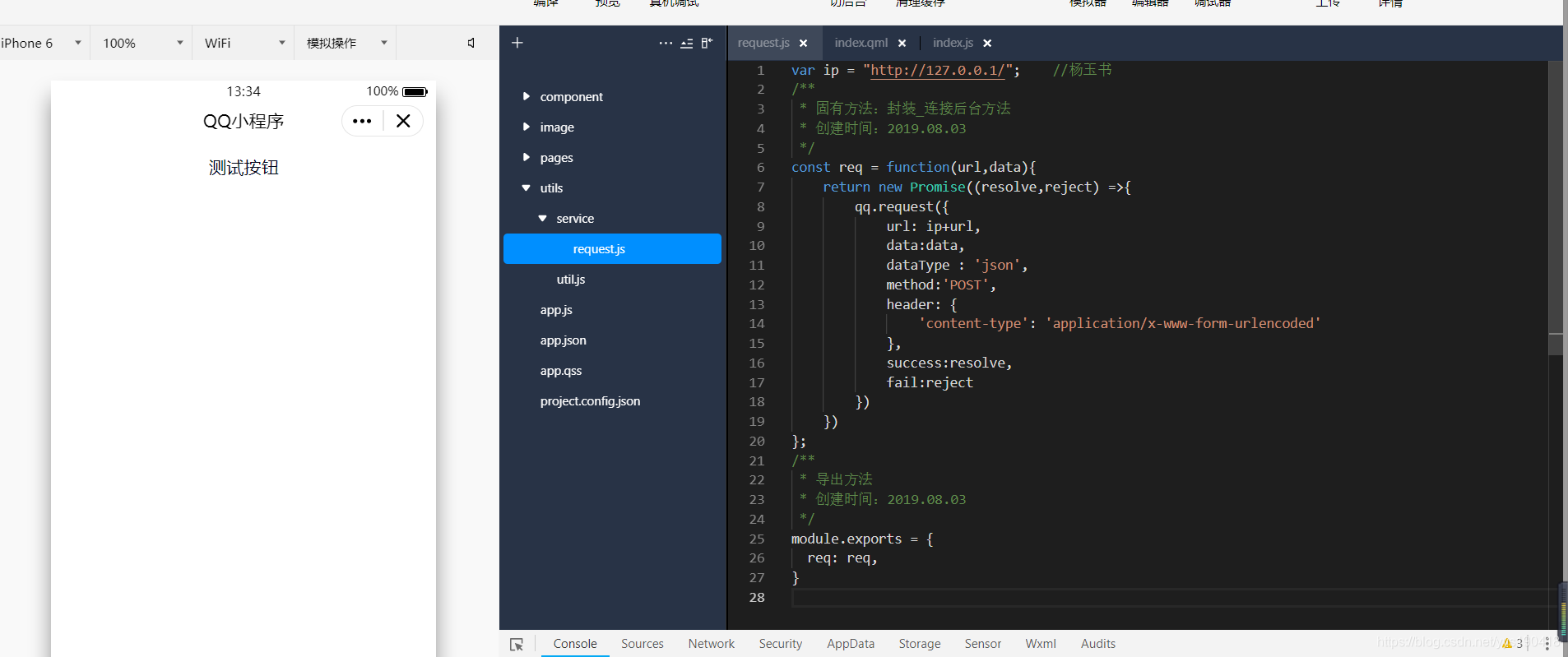
放上图
你可以把这个工具放在任何地方,我只是习惯这样放
这是代码,如果有什么不清楚的,可以查看文档
var ip = "http://127.0.0.1/"; //这个是本机IP,localhost也行,不过我习惯这个了
/**
* 固有方法:封装_连接后台方法
* 备注:如果之后放到服务器上,就只要换上面的那个ip就可以了
* url:这个是连接的接口的路径,之后引用方法的时候会当做参数填入
* data:这个是传入的参数,以后肯定会用到的,
* resolve是连接成功返回的函数,reject是连接失败的函数
*/
const req = function(url,data){
return new Promise((resolve,reject) =>{
qq.request({
url: ip+url,
data:data,
dataType : 'json',
method:'POST',
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success:resolve,
fail:reject
})
})
};
/**
* 导出方法
* 介绍:这个是用来暴露方法的,这样一会在app.js中就可以引用这个方法了
*/
module.exports = {
req: req,
}
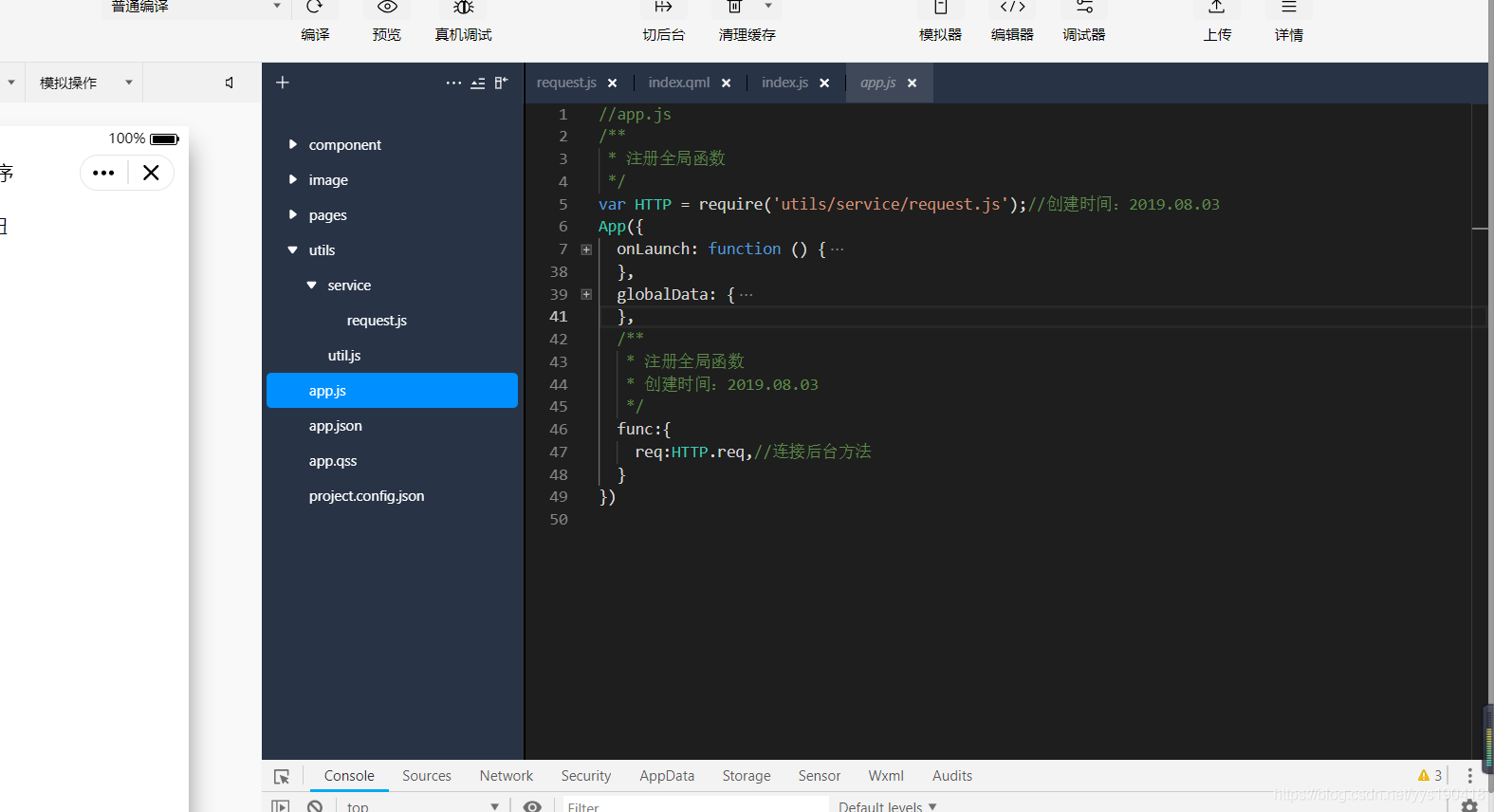
2. 在app.js中配置(不知道调用配置行不行,就这样调用)
先放图
这些省略的地方都是新建的时候就有的,所以我省略了。我只在第 5 行向下写了 46。
这是引用该工具包的路径,
var HTTP = require('utils/service/request.js');//创建时间:2019.08.03
这是引用连接的方法,其中req是我放的第一个代码片段中的req
/**
* 注册全局函数
* 创建时间:2019.08.03
*/
func:{
req:HTTP.req,//连接后台方法
}
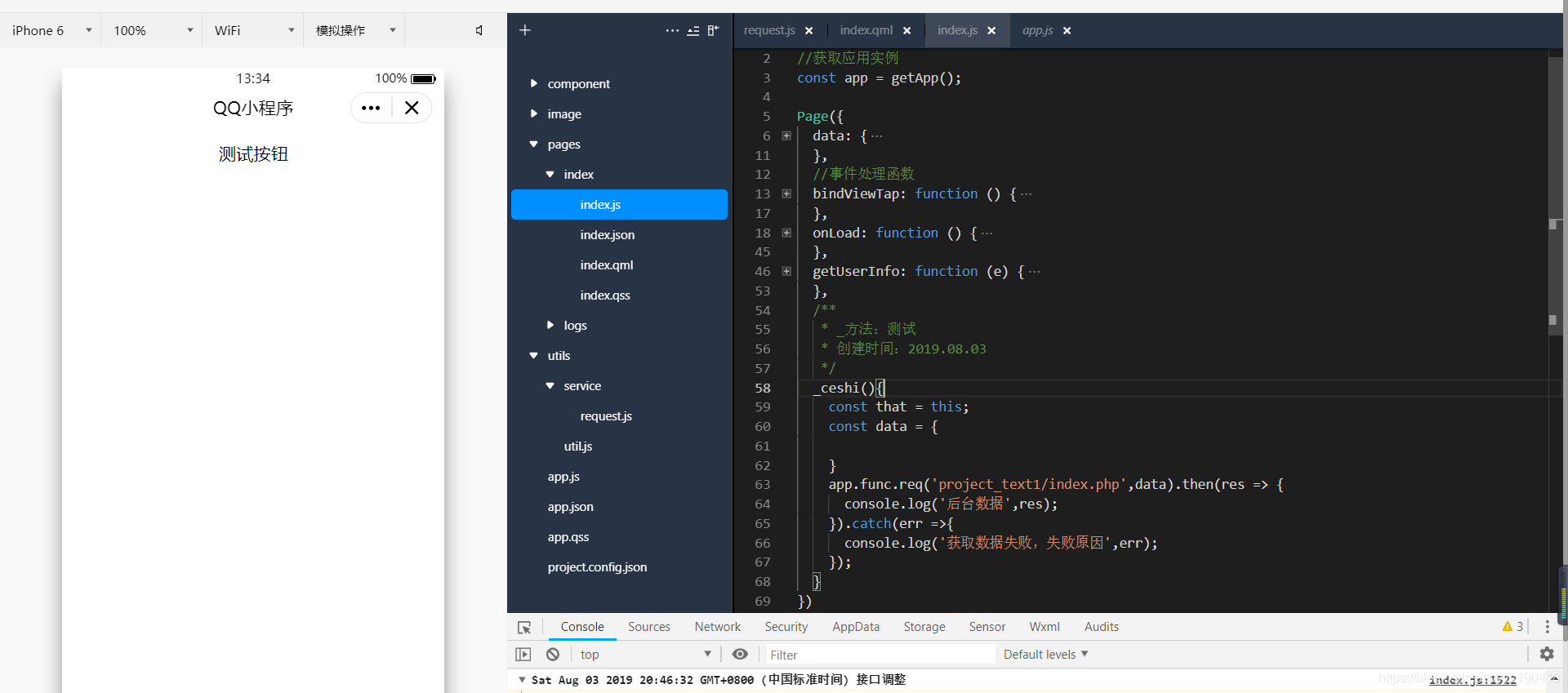
3.功能页面参考调用方法
放上图
我把页面上的HTML代码改了,全部注释掉,然后放一个按钮,然后把HTML代码
评论并不重要。如果不是重点,我会评论。我先放一个总代码。如果想看里面的内容,也可以看看。然后我把js方法的部分代码放上来。
//index.js
//获取应用实例
const app = getApp();
Page({
data: {
motto: 'Hello World',
userInfo: {},
hasUserInfo: false,
canIUse: qq.canIUse('button.open-type.getUserInfo')
},
//事件处理函数
bindViewTap: function () {
qq.navigateTo({
url: '../logs/logs'
})
},
onLoad: function () {
if (app.globalData.userInfo) {
this.setData({
userInfo: app.globalData.userInfo,
hasUserInfo: true
})
} else if (this.data.canIUse) {
// 由于 getUserInfo 是网络请求,可能会在 Page.onLoad 之后才返回
// 所以此处加入 callback 以防止这种情况
app.userInfoReadyCallback = res => {
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
} else {
// 在没有 open-type=getUserInfo 版本的兼容处理
qq.getUserInfo({
success: res => {
app.globalData.userInfo = res.userInfo
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
})
}
},
getUserInfo: function (e) {
console.log(e)
app.globalData.userInfo = e.detail.userInfo
this.setData({
userInfo: e.detail.userInfo,
hasUserInfo: true
})
},
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this;
const data = {
}
app.func.req('project_text1/index.php',data).then(res => {
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
})
这是js连接后端方法的代码,我详细解释一下有什么
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this; //这个就是讲this提取到that中,如果外层变了,也能找到需要的最外层
const data = { //就是连接后台,啥逻辑都没有,所以这个理论里面就没放数据
}
//单引号里面的是路径,我一会写到PHP的时候,就可以看到了
//data就是传的数据,虽然啥也没有
//因为第一个代码块那里已经用resolve和reject配好了,所以这里.then和.catch就是连接后台成功和失败了
app.func.req('project_text1/index.php',data).then(res => {//然后res和err就是返回数据,前面的单引就是单纯的字符串
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
然后这里是HTML图片
和代码,只有这个有效,其他都注释了,只是这个_ceshi方法连接js测试是否可以连接后台
测试按钮
三、PHP端的操作0.这里我已经在本机配置了运行PHP的软件和写PHP的软件,这里就不展开了。没做完我就先百度一下,补完PHP。1.启动phpStudy,让PHP先跑起来
注意:这里说的是需要配置Apache、MySQL等,其实没必要这么麻烦。互联网上有很多软件问题可以解决所有问题。
比如phpStudy官方版20180211
还有这个WampServer3.0.6 正式版
而这个 Visual NMP 7.0.31 (x64)
我目前使用第一个
这是启动后的截图
2.打开 sublime_text3
我是用这个软件来的,其他的php写也是可以的,不过我是第一次写,其他的还没用过,不知道哪种好用
3.截图我的代码
你看到左边的文件名了吗?我在小终端里就是按照这个写的。
当然你也可以右击右边的黑框,复制文件路径,然后把www和上一个改成127.0.0.1
这里的注释没用,有用的代码我先放上来,因为我是第一次写PHP,所以很多地方不知道。上面的评论都是我试过的。
第二行是返回的类型,我的PHP学习博客稍后详述
第 4 行是我尝试创建一个集合,第 8 行的结果很好。相反,第 4 行变成了两组。
然后,除了 15 行,我尝试打印并返回一些东西。也可以使用第 10 行,避免出现乱码。但是我没有乱码,所以就用了11行的那个。我想这个回报也可以使用。我稍后会尝试。尝试
刚试了一下,就用第10行的,但是代码突然乱码了,就换成第10行的就行了。
4. 然后在google上试试,把路径127.0.0.1\project_text1\index.php
这是替换第10行后的截图
看路径,和我小程序上的路径一模一样,可以用
四、点击小程序0.0 终于到了。虽然尝试了很多次,但这是第一次写博客。至少假装很开心。
点击测试按钮查看控制台输出,这是图片,
看红框就成功了,获取PHP后端的值,这样就可以连接PHP后端了
不得不说PHP后台连接真的很方便,而且还挺小巧的。感觉几个文件都可以用。如果是小项目,就不需要ssm或者springboot框架(我是做Java的)。直接连接就可以使用了,很方便 查看全部
php抓取网页连接函数(PHP端的操作0.这里我已经配置好了(组图))
一、准备工具、账号、项目等1. 安装QQ小程序开发工具
这是下载地址
我的是win10,64位,我下载的是红箭版。我首先下载了绿色箭头版本。结果只是测试模式。没有找到编辑器,只好再下载一个。
2.申请开发者账号获得APPID
就按照网上的步骤一步一步来,没什么好说的,放个网站就行了
3.创建一个空白项目
进入APPID,微信开发工具也可以测试ID,但是QQ没找到
二、开始在QQ开发工具中操作1.开始尝试连接后台,先封装一个方法,然后连接到后台调用方法
放上图
你可以把这个工具放在任何地方,我只是习惯这样放
这是代码,如果有什么不清楚的,可以查看文档
var ip = "http://127.0.0.1/"; //这个是本机IP,localhost也行,不过我习惯这个了
/**
* 固有方法:封装_连接后台方法
* 备注:如果之后放到服务器上,就只要换上面的那个ip就可以了
* url:这个是连接的接口的路径,之后引用方法的时候会当做参数填入
* data:这个是传入的参数,以后肯定会用到的,
* resolve是连接成功返回的函数,reject是连接失败的函数
*/
const req = function(url,data){
return new Promise((resolve,reject) =>{
qq.request({
url: ip+url,
data:data,
dataType : 'json',
method:'POST',
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success:resolve,
fail:reject
})
})
};
/**
* 导出方法
* 介绍:这个是用来暴露方法的,这样一会在app.js中就可以引用这个方法了
*/
module.exports = {
req: req,
}
2. 在app.js中配置(不知道调用配置行不行,就这样调用)
先放图
这些省略的地方都是新建的时候就有的,所以我省略了。我只在第 5 行向下写了 46。
这是引用该工具包的路径,
var HTTP = require('utils/service/request.js');//创建时间:2019.08.03
这是引用连接的方法,其中req是我放的第一个代码片段中的req
/**
* 注册全局函数
* 创建时间:2019.08.03
*/
func:{
req:HTTP.req,//连接后台方法
}
3.功能页面参考调用方法
放上图
我把页面上的HTML代码改了,全部注释掉,然后放一个按钮,然后把HTML代码
评论并不重要。如果不是重点,我会评论。我先放一个总代码。如果想看里面的内容,也可以看看。然后我把js方法的部分代码放上来。
//index.js
//获取应用实例
const app = getApp();
Page({
data: {
motto: 'Hello World',
userInfo: {},
hasUserInfo: false,
canIUse: qq.canIUse('button.open-type.getUserInfo')
},
//事件处理函数
bindViewTap: function () {
qq.navigateTo({
url: '../logs/logs'
})
},
onLoad: function () {
if (app.globalData.userInfo) {
this.setData({
userInfo: app.globalData.userInfo,
hasUserInfo: true
})
} else if (this.data.canIUse) {
// 由于 getUserInfo 是网络请求,可能会在 Page.onLoad 之后才返回
// 所以此处加入 callback 以防止这种情况
app.userInfoReadyCallback = res => {
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
} else {
// 在没有 open-type=getUserInfo 版本的兼容处理
qq.getUserInfo({
success: res => {
app.globalData.userInfo = res.userInfo
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
})
}
},
getUserInfo: function (e) {
console.log(e)
app.globalData.userInfo = e.detail.userInfo
this.setData({
userInfo: e.detail.userInfo,
hasUserInfo: true
})
},
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this;
const data = {
}
app.func.req('project_text1/index.php',data).then(res => {
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
})
这是js连接后端方法的代码,我详细解释一下有什么
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this; //这个就是讲this提取到that中,如果外层变了,也能找到需要的最外层
const data = { //就是连接后台,啥逻辑都没有,所以这个理论里面就没放数据
}
//单引号里面的是路径,我一会写到PHP的时候,就可以看到了
//data就是传的数据,虽然啥也没有
//因为第一个代码块那里已经用resolve和reject配好了,所以这里.then和.catch就是连接后台成功和失败了
app.func.req('project_text1/index.php',data).then(res => {//然后res和err就是返回数据,前面的单引就是单纯的字符串
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
然后这里是HTML图片
和代码,只有这个有效,其他都注释了,只是这个_ceshi方法连接js测试是否可以连接后台
测试按钮
三、PHP端的操作0.这里我已经在本机配置了运行PHP的软件和写PHP的软件,这里就不展开了。没做完我就先百度一下,补完PHP。1.启动phpStudy,让PHP先跑起来
注意:这里说的是需要配置Apache、MySQL等,其实没必要这么麻烦。互联网上有很多软件问题可以解决所有问题。
比如phpStudy官方版20180211
还有这个WampServer3.0.6 正式版
而这个 Visual NMP 7.0.31 (x64)
我目前使用第一个
这是启动后的截图
2.打开 sublime_text3
我是用这个软件来的,其他的php写也是可以的,不过我是第一次写,其他的还没用过,不知道哪种好用
3.截图我的代码
你看到左边的文件名了吗?我在小终端里就是按照这个写的。
当然你也可以右击右边的黑框,复制文件路径,然后把www和上一个改成127.0.0.1
这里的注释没用,有用的代码我先放上来,因为我是第一次写PHP,所以很多地方不知道。上面的评论都是我试过的。
第二行是返回的类型,我的PHP学习博客稍后详述
第 4 行是我尝试创建一个集合,第 8 行的结果很好。相反,第 4 行变成了两组。
然后,除了 15 行,我尝试打印并返回一些东西。也可以使用第 10 行,避免出现乱码。但是我没有乱码,所以就用了11行的那个。我想这个回报也可以使用。我稍后会尝试。尝试
刚试了一下,就用第10行的,但是代码突然乱码了,就换成第10行的就行了。
4. 然后在google上试试,把路径127.0.0.1\project_text1\index.php
这是替换第10行后的截图
看路径,和我小程序上的路径一模一样,可以用
四、点击小程序0.0 终于到了。虽然尝试了很多次,但这是第一次写博客。至少假装很开心。
点击测试按钮查看控制台输出,这是图片,
看红框就成功了,获取PHP后端的值,这样就可以连接PHP后端了

不得不说PHP后台连接真的很方便,而且还挺小巧的。感觉几个文件都可以用。如果是小项目,就不需要ssm或者springboot框架(我是做Java的)。直接连接就可以使用了,很方便
php抓取网页连接函数(PHP数组实现栈和队列:push,访问会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-29 16:26
下一篇:PHP数组实现栈和队列:push、pop、shif、unshift
本文将介绍一个有用的PHP函数get_browser,该函数可以获取客户端用户使用的浏览器的详细信息。
具体实现代码如下:
访问成功后,输出内容如下:
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7) Gecko/20040803 Firefox/0.9.3
Array
(
[browser_name_regex] => ^mozilla/5\.0 (windows; .; windows nt 5\.1; .*rv:.*) gecko/.* firefox/0\.9.*$
[browser_name_pattern] => Mozilla/5.0 (Windows; ?; Windows NT 5.1; *rv:*) Gecko/* Firefox/0.9*
[parent] => Firefox 0.9
[platform] => WinXP
[browser] => Firefox
[version] => 0.9
[majorver] => 0
[minorver] => 9
[cssversion] => 2
[frames] => 1
[iframes] => 1
[tables] => 1
[cookies] => 1
[backgroundsounds] =>
[vbscript] =>
[javascript] => 1
[javaapplets] => 1
[activexcontrols] =>
[cdf] =>
[aol] =>
[beta] => 1
[win16] =>
[crawler] =>
[stripper] =>
[wap] =>
[netclr] =>
)
因为我用的是火狐浏览器访问,所以上面输出的是我自己浏览器的详细信息。不同的浏览器会根据不同的浏览器返回相应的信息。
2016.6.21 更新说明:有网友反映使用get_browser()函数返回空,下面补充原因和解决办法。
如果get_browser()返回给浏览器的信息为空,或者有警告:get_browser() [function.get-browser]: browscap ini directive not set in xxx.php,那么原因是:因为函数是搜索browscap.ini文件中的浏览器信息,尝试检测用户浏览器的功能,如果你的服务器没有browscap.ini文件,会报错。
解决方案:由于许可问题,PHP 不提供浏览器功能文件。您可以从 Browscap 获取浏览器功能文件。您可以下载 php_browscap.ini 文件。
下载文件后,将其上传到:
(Win下)D:\wamp\bin\php\php5.5.12\browscap.ini 该'D:\wamp\bin\php\php5.5.12\'前缀地址改为你自己 PHP 安装目录的地址
(Linux下) /usr/local/php/lib/php/browscap.ini 该'/usr/local/php/lib/php/'前缀改为你自己 PHP 安装目录地址
同理,上传完成后,需要在php.ini中进行设置(Win下):
browscap=D:\wamp\bin\php\php5.5.12\browscap.ini
或者(Linux 下)
browscap=/usr/local/php/lib/php/browscap.ini
设置后记得重启你的网络服务器。
... psz1992 的其他帖子 查看全部
php抓取网页连接函数(PHP数组实现栈和队列:push,访问会)
下一篇:PHP数组实现栈和队列:push、pop、shif、unshift

本文将介绍一个有用的PHP函数get_browser,该函数可以获取客户端用户使用的浏览器的详细信息。
具体实现代码如下:
访问成功后,输出内容如下:
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7) Gecko/20040803 Firefox/0.9.3
Array
(
[browser_name_regex] => ^mozilla/5\.0 (windows; .; windows nt 5\.1; .*rv:.*) gecko/.* firefox/0\.9.*$
[browser_name_pattern] => Mozilla/5.0 (Windows; ?; Windows NT 5.1; *rv:*) Gecko/* Firefox/0.9*
[parent] => Firefox 0.9
[platform] => WinXP
[browser] => Firefox
[version] => 0.9
[majorver] => 0
[minorver] => 9
[cssversion] => 2
[frames] => 1
[iframes] => 1
[tables] => 1
[cookies] => 1
[backgroundsounds] =>
[vbscript] =>
[javascript] => 1
[javaapplets] => 1
[activexcontrols] =>
[cdf] =>
[aol] =>
[beta] => 1
[win16] =>
[crawler] =>
[stripper] =>
[wap] =>
[netclr] =>
)
因为我用的是火狐浏览器访问,所以上面输出的是我自己浏览器的详细信息。不同的浏览器会根据不同的浏览器返回相应的信息。
2016.6.21 更新说明:有网友反映使用get_browser()函数返回空,下面补充原因和解决办法。
如果get_browser()返回给浏览器的信息为空,或者有警告:get_browser() [function.get-browser]: browscap ini directive not set in xxx.php,那么原因是:因为函数是搜索browscap.ini文件中的浏览器信息,尝试检测用户浏览器的功能,如果你的服务器没有browscap.ini文件,会报错。
解决方案:由于许可问题,PHP 不提供浏览器功能文件。您可以从 Browscap 获取浏览器功能文件。您可以下载 php_browscap.ini 文件。
下载文件后,将其上传到:
(Win下)D:\wamp\bin\php\php5.5.12\browscap.ini 该'D:\wamp\bin\php\php5.5.12\'前缀地址改为你自己 PHP 安装目录的地址
(Linux下) /usr/local/php/lib/php/browscap.ini 该'/usr/local/php/lib/php/'前缀改为你自己 PHP 安装目录地址
同理,上传完成后,需要在php.ini中进行设置(Win下):
browscap=D:\wamp\bin\php\php5.5.12\browscap.ini
或者(Linux 下)
browscap=/usr/local/php/lib/php/browscap.ini
设置后记得重启你的网络服务器。
... psz1992 的其他帖子
php抓取网页连接函数(几天人会_multi系列函数实现此功能(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-28 08:15
这几天在做多搜索引擎关键词排名查询工具,可以及时方便的了解关键词在各大搜索引擎的排名情况。爬360搜索的时候发现360搜索每个页面只支持显示10个搜索结果。如果要得到100条搜索结果数据,就得搜索10次,极大地影响了用户体验。没有人会搜索关键字排名。并愿意等待时间打开网页 10 次。这时候就想到了用多线程来做并发爬取。恰巧curl_multi系列php curl函数可以实现这个功能。
一、curl_multi 系列函数介绍:1. curl_multi_init:
用于初始化一个“curl_multi”句柄,然后将“curl_init”函数生成的多个“curl”句柄传递给“curl_multi”句柄;这个函数不需要参数。
2. curl_multi_add_handle:
“curl_multi_add_handle”函数用于将“curl_init”生成的“curl”句柄添加到上面“curl_multi_init”函数生成的“curl_multi”句柄中。“curl_multi_add_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
3. curl_multi_exec:
“curl_multi_exec”用于发起 curl_multi 请求。“curl_multi_add_handle”函数的第一个参数是“curl_multi”的句柄,第二个参数是一个“引用参数”,记录了未处理的请求数。当第二个参数的值变为0时,表示所有请求都已经处理完毕(所有请求返回成功或超时时间已过)。
4. curl_multi_info_read:
“curl_multi_info_read”函数用于读取curl_multi句柄中是否有curl返回信息。如果有,则返回第一个“curl 返回值(数组形式)”,否则返回“false”。循环调用这个函数,直到它返回“false”;“curl_multi_info_read”的参数是“curl_mulit”的句柄。
5. curl_multi_getcontent:
当所有的curl句柄都处理完后,我们可以使用“curl_multi_getcontent”函数读取“curl”返回的内容。“curl_multi_getcontent”的参数是“curl”句柄。
6. curl_multi_remove_handle:
阅读完内容后,使用“curl_multi_remove_handle”函数从“curl_mulit”句柄中删除所有“curl”句柄。“curl_multi_remove_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
7. curl_multi_close:
“curl_multi_close”函数用于关闭“curl_mulit”句柄并释放占用的资源。“curl_multi_close”的参数是“curl_mulit”的句柄。
二、curl_multi 使用流程:
1、 "curl_multi_init" 初始化 "curl_multi" 句柄;
2、 循环创建并添加“curl”句柄,并使用“curl_multi_add_handle”函数将其添加到“curl_multi”句柄中;
3、 使用“curl_multi_exec”发起请求,等待所有请求处理完毕;
4、 使用“curl_multi_info_read”函数读取返回值;
5、 使用“curl_multi_getcontent”函数读取返回的内容;
6、 使用“curl_multi_remove_handle”函数去除curl句柄;
7、 使用“curl_multi_close”关闭 curl_multi 句柄。
三、以下是我使用curl_multi多线程并发抓取360搜索结果的代码片段:#多线程并发抓取函数mfetch:
<p> 查看全部
php抓取网页连接函数(几天人会_multi系列函数实现此功能(图))
这几天在做多搜索引擎关键词排名查询工具,可以及时方便的了解关键词在各大搜索引擎的排名情况。爬360搜索的时候发现360搜索每个页面只支持显示10个搜索结果。如果要得到100条搜索结果数据,就得搜索10次,极大地影响了用户体验。没有人会搜索关键字排名。并愿意等待时间打开网页 10 次。这时候就想到了用多线程来做并发爬取。恰巧curl_multi系列php curl函数可以实现这个功能。
一、curl_multi 系列函数介绍:1. curl_multi_init:
用于初始化一个“curl_multi”句柄,然后将“curl_init”函数生成的多个“curl”句柄传递给“curl_multi”句柄;这个函数不需要参数。
2. curl_multi_add_handle:
“curl_multi_add_handle”函数用于将“curl_init”生成的“curl”句柄添加到上面“curl_multi_init”函数生成的“curl_multi”句柄中。“curl_multi_add_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
3. curl_multi_exec:
“curl_multi_exec”用于发起 curl_multi 请求。“curl_multi_add_handle”函数的第一个参数是“curl_multi”的句柄,第二个参数是一个“引用参数”,记录了未处理的请求数。当第二个参数的值变为0时,表示所有请求都已经处理完毕(所有请求返回成功或超时时间已过)。
4. curl_multi_info_read:
“curl_multi_info_read”函数用于读取curl_multi句柄中是否有curl返回信息。如果有,则返回第一个“curl 返回值(数组形式)”,否则返回“false”。循环调用这个函数,直到它返回“false”;“curl_multi_info_read”的参数是“curl_mulit”的句柄。
5. curl_multi_getcontent:
当所有的curl句柄都处理完后,我们可以使用“curl_multi_getcontent”函数读取“curl”返回的内容。“curl_multi_getcontent”的参数是“curl”句柄。
6. curl_multi_remove_handle:
阅读完内容后,使用“curl_multi_remove_handle”函数从“curl_mulit”句柄中删除所有“curl”句柄。“curl_multi_remove_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
7. curl_multi_close:
“curl_multi_close”函数用于关闭“curl_mulit”句柄并释放占用的资源。“curl_multi_close”的参数是“curl_mulit”的句柄。
二、curl_multi 使用流程:
1、 "curl_multi_init" 初始化 "curl_multi" 句柄;
2、 循环创建并添加“curl”句柄,并使用“curl_multi_add_handle”函数将其添加到“curl_multi”句柄中;
3、 使用“curl_multi_exec”发起请求,等待所有请求处理完毕;
4、 使用“curl_multi_info_read”函数读取返回值;
5、 使用“curl_multi_getcontent”函数读取返回的内容;
6、 使用“curl_multi_remove_handle”函数去除curl句柄;
7、 使用“curl_multi_close”关闭 curl_multi 句柄。
三、以下是我使用curl_multi多线程并发抓取360搜索结果的代码片段:#多线程并发抓取函数mfetch:
<p>
php抓取网页连接函数( PHP和MySQL是怎么一回事,我就不啰嗦了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-21 16:08
PHP和MySQL是怎么一回事,我就不啰嗦了
)
php连接及读写mysql数据库常用代码
更新时间:2014年8月11日15:45:30 发布者:hebedic
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?也许你以前复制粘贴了一些代码,并没有真正理解代码的含义;又或者你之前理解过,但和我一样,你有一段时间没碰过,生锈了
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?可能是你以前复制粘贴了一些代码,并没有真正理解代码的含义;也可能是你之前了解过,但和我一样,一段时间没联系,生疏了;或者,有人问你一个类似的简单问题,而你一直不屑于回答,你刚刚上网搜了一下,找到了这篇文章,所以我推荐给那个人……
无论如何,这里总结一下PHP连接MySQL数据库和读写数据库的常用方法,希望对大家有所帮助,当然作为自己的复习总结。
1.为了更好的建立数据连接,一般将数据连接中涉及的值定义为变量。
$mysql_server_name='localhost'; //改成自己的mysql数据库服务器
$mysql_username='root'; //改成自己的mysql数据库用户名
$mysql_password='123456'; //改成自己的mysql数据库密码
$mysql_database='Mydb'; //改成自己的mysql数据库名
也可以将以上变量放在一个文件中,随时可以被其他文件调用。
例如:将上述内容放在:db_config.php 中,在其他需要使用数据库的页面上直接调用。
调用代码:require("db_config.php");
2.连接数据库
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password) or die("error connecting") ; //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码 应该与你的数据库编码保持一致.南昌网站建设公司百恒网络PHP工程师建议用UTF-8 国际标准编码.
mysql_select_db($mysql_database); //打开数据库
$sql ="select * from news "; //SQL语句
$result = mysql_query($sql,$conn); //查询
3.阅读表格的内容,这里我们使用while,你可以根据具体情况使用for或other。
while($row = mysql_fetch_array($result))
{
echo ""; //排版代码
echo $row['Topic'] . "
";
echo ""; //排版代码
}
4.php写入数据库,mysql数据写入
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password); //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码
mysql_select_db($mysql_database); //打开数据库
$sql = "insert into messageboard (Topic,Content,Enabled,Date) values ('$Topic','$Content','1','2011-01-12')";
mysql_query($sql);
mysql_close(); //关闭MySQL连接 查看全部
php抓取网页连接函数(
PHP和MySQL是怎么一回事,我就不啰嗦了
)
php连接及读写mysql数据库常用代码
更新时间:2014年8月11日15:45:30 发布者:hebedic
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?也许你以前复制粘贴了一些代码,并没有真正理解代码的含义;又或者你之前理解过,但和我一样,你有一段时间没碰过,生锈了
既然你已经看到了这个文章,那就意味着你一定知道PHP和MySQL都是什么,我就不啰嗦了。但是你为什么要继续阅读这篇文章呢?可能是你以前复制粘贴了一些代码,并没有真正理解代码的含义;也可能是你之前了解过,但和我一样,一段时间没联系,生疏了;或者,有人问你一个类似的简单问题,而你一直不屑于回答,你刚刚上网搜了一下,找到了这篇文章,所以我推荐给那个人……
无论如何,这里总结一下PHP连接MySQL数据库和读写数据库的常用方法,希望对大家有所帮助,当然作为自己的复习总结。
1.为了更好的建立数据连接,一般将数据连接中涉及的值定义为变量。
$mysql_server_name='localhost'; //改成自己的mysql数据库服务器
$mysql_username='root'; //改成自己的mysql数据库用户名
$mysql_password='123456'; //改成自己的mysql数据库密码
$mysql_database='Mydb'; //改成自己的mysql数据库名
也可以将以上变量放在一个文件中,随时可以被其他文件调用。
例如:将上述内容放在:db_config.php 中,在其他需要使用数据库的页面上直接调用。
调用代码:require("db_config.php");
2.连接数据库
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password) or die("error connecting") ; //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码 应该与你的数据库编码保持一致.南昌网站建设公司百恒网络PHP工程师建议用UTF-8 国际标准编码.
mysql_select_db($mysql_database); //打开数据库
$sql ="select * from news "; //SQL语句
$result = mysql_query($sql,$conn); //查询
3.阅读表格的内容,这里我们使用while,你可以根据具体情况使用for或other。
while($row = mysql_fetch_array($result))
{
echo ""; //排版代码
echo $row['Topic'] . "
";
echo ""; //排版代码
}
4.php写入数据库,mysql数据写入
$conn=mysql_connect($mysql_server_name,$mysql_username,$mysql_password); //连接数据库
mysql_query("set names 'utf8'"); //数据库输出编码
mysql_select_db($mysql_database); //打开数据库
$sql = "insert into messageboard (Topic,Content,Enabled,Date) values ('$Topic','$Content','1','2011-01-12')";
mysql_query($sql);
mysql_close(); //关闭MySQL连接
php抓取网页连接函数(php抓取网页连接函数有一个基本概念叫参数化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-18 02:08
php抓取网页连接函数有一个基本概念叫参数化,意思是说在php里一切皆可嵌套参数。post请求没有参数,get也没有参数,php连get连接都要自己写一个。java/jsp这种前端框架里面,请求服务器的data是表示数据参数的,比如data=sessionid;post表示是,put表示是,get也表示是。
这里就可以做一个很好的对比,你拿一个jsp的请求服务器去请求一个php的请求服务器,结果肯定是一样的,这个只是类似复用而已。
不同方式获取数据都是一样的,只是参数不同。post和get都是get方式,都是直接从服务器中取得数据(方式不同而已),传输的数据格式没有区别,可以区分是否是post数据,http请求参数化就是把请求参数通过httpheader的方式传递给服务器,参数值是包含在header里的,如get/xxx/responsebody,如果请求服务器的时候post方式就要通过请求参数化方式传递给服务器:请求地址/responsebody,类似。
参数化是java、.net、php都是要用到的,跟浏览器没有关系。
@百里玄风以上说的都有道理,我补充一下,就算客户端提交get的请求,服务器端会返回post数据,不论是get还是post。
post表示http长连接,客户端可以查询api中的请求参数、数据库交互、已生成的表单数据字段等等;get表示短连接,服务器有可能向客户端请求数据,也有可能不提供。参数化其实是web服务化,缩小客户端到服务器的传输成本。 查看全部
php抓取网页连接函数(php抓取网页连接函数有一个基本概念叫参数化)
php抓取网页连接函数有一个基本概念叫参数化,意思是说在php里一切皆可嵌套参数。post请求没有参数,get也没有参数,php连get连接都要自己写一个。java/jsp这种前端框架里面,请求服务器的data是表示数据参数的,比如data=sessionid;post表示是,put表示是,get也表示是。
这里就可以做一个很好的对比,你拿一个jsp的请求服务器去请求一个php的请求服务器,结果肯定是一样的,这个只是类似复用而已。
不同方式获取数据都是一样的,只是参数不同。post和get都是get方式,都是直接从服务器中取得数据(方式不同而已),传输的数据格式没有区别,可以区分是否是post数据,http请求参数化就是把请求参数通过httpheader的方式传递给服务器,参数值是包含在header里的,如get/xxx/responsebody,如果请求服务器的时候post方式就要通过请求参数化方式传递给服务器:请求地址/responsebody,类似。
参数化是java、.net、php都是要用到的,跟浏览器没有关系。
@百里玄风以上说的都有道理,我补充一下,就算客户端提交get的请求,服务器端会返回post数据,不论是get还是post。
post表示http长连接,客户端可以查询api中的请求参数、数据库交互、已生成的表单数据字段等等;get表示短连接,服务器有可能向客户端请求数据,也有可能不提供。参数化其实是web服务化,缩小客户端到服务器的传输成本。
php抓取网页连接函数(php抓取网页连接函数php是一个非常强大的编程语言,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-08 02:02
php抓取网页连接函数php是一个非常强大的编程语言,php代码语法紧凑,结构清晰,完全可以应用于非常多的应用系统。常用的网页抓取操作有:网页搜索、抓取社交网络、抓取网站链接、抓取音乐播放列表、抓取地址、抓取新闻等等。以上这些抓取网页的操作,不仅仅基于php常用的一些模块,而且基于php庞大的语言库。
php提供丰富的类库,可以用它们完成许多我们认为不可能实现的操作。比如说,抓取facebook的主页和查看facebook页面里面的html代码。搜索已发布页面的标题和标签,甚至在网站配置文件中加入搜索功能等等。而且,这些东西不仅仅是开源的,也并不是php提供的,而是php语言自己的东西。有些人会问,php是一门比较弱的编程语言,怎么能做到php编程?因为php是运行在linux下的。
linux上的很多东西,都是由php编写的。而linux其实提供了很多方便的php抓取模块。php抓取模块有许多,大部分是基于php的。在这里,我们对这些抓取模块进行列举和归类,并进行分析。一。php-petit。iophp-petit。io是php和mysql数据库绑定的抓取程序。php-petit。
io主要是用于抓取在mysql中的数据,如sqlite文件。php-petit。io把所有的mysql数据类型,都封装在php-petit。io里面。以mysql为例,mysql数据类型就存在myisam和extendedgreen两种类型。php-petit。io可以在mysql中使用多种特殊类型:sqlite:支持执行一些非结构化数据。
memory:可以检索内存。pymysql:一种支持mysql优化写入的抓取程序。php-petit。io通过引入相应的包,可以很方便的编写一个这样的抓取程序。下面通过php-petit。io抓取某一个或者多个数据库。在开始之前,我们要安装这些包:php-petit。iophp-petit。io默认被装在/opt目录下。
php-petit。io的php-petit。io。meta文件php-petit。io。data文件mysql:#1、安装mysql:a。请在apache/lamp中设置好环境变量。b。执行php-petit。io。meta和php-petit。io。data两个文件即可,并在php。ini中进行加载。
使用:localhost:8080/php-petit。io/c。使用php-petit。io。meta来获取mysql的数据。注意:php-petit。io。meta文件要和php-petit。io。data文件在同一个目录下。php-petit。io文件和php-petit。io。data文件所在的路径同一个目录。
二。php-form-requestphp-form-request是基于phpmysql的python接口。用于发送h。 查看全部
php抓取网页连接函数(php抓取网页连接函数php是一个非常强大的编程语言,)
php抓取网页连接函数php是一个非常强大的编程语言,php代码语法紧凑,结构清晰,完全可以应用于非常多的应用系统。常用的网页抓取操作有:网页搜索、抓取社交网络、抓取网站链接、抓取音乐播放列表、抓取地址、抓取新闻等等。以上这些抓取网页的操作,不仅仅基于php常用的一些模块,而且基于php庞大的语言库。
php提供丰富的类库,可以用它们完成许多我们认为不可能实现的操作。比如说,抓取facebook的主页和查看facebook页面里面的html代码。搜索已发布页面的标题和标签,甚至在网站配置文件中加入搜索功能等等。而且,这些东西不仅仅是开源的,也并不是php提供的,而是php语言自己的东西。有些人会问,php是一门比较弱的编程语言,怎么能做到php编程?因为php是运行在linux下的。
linux上的很多东西,都是由php编写的。而linux其实提供了很多方便的php抓取模块。php抓取模块有许多,大部分是基于php的。在这里,我们对这些抓取模块进行列举和归类,并进行分析。一。php-petit。iophp-petit。io是php和mysql数据库绑定的抓取程序。php-petit。
io主要是用于抓取在mysql中的数据,如sqlite文件。php-petit。io把所有的mysql数据类型,都封装在php-petit。io里面。以mysql为例,mysql数据类型就存在myisam和extendedgreen两种类型。php-petit。io可以在mysql中使用多种特殊类型:sqlite:支持执行一些非结构化数据。
memory:可以检索内存。pymysql:一种支持mysql优化写入的抓取程序。php-petit。io通过引入相应的包,可以很方便的编写一个这样的抓取程序。下面通过php-petit。io抓取某一个或者多个数据库。在开始之前,我们要安装这些包:php-petit。iophp-petit。io默认被装在/opt目录下。
php-petit。io的php-petit。io。meta文件php-petit。io。data文件mysql:#1、安装mysql:a。请在apache/lamp中设置好环境变量。b。执行php-petit。io。meta和php-petit。io。data两个文件即可,并在php。ini中进行加载。
使用:localhost:8080/php-petit。io/c。使用php-petit。io。meta来获取mysql的数据。注意:php-petit。io。meta文件要和php-petit。io。data文件在同一个目录下。php-petit。io文件和php-petit。io。data文件所在的路径同一个目录。
二。php-form-requestphp-form-request是基于phpmysql的python接口。用于发送h。
php抓取网页连接函数(本文实例讲述PHP实现百度搜索结果页面【相关搜索词】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-06 21:02
本文介绍了PHP抓取百度搜索结果页面【相关搜索词】并存入txt文件的实现。分享给大家,供大家参考,如下:
一、百度搜索关键词【脚本之家】
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&rsv_pq=ab33cfeb000086a2&rsv_t=7c65vT3KzHCNfGYOIn%2FDSS%9A%E6%9C%AC%%BE4 AE%B6"
搜索结果部分源码:
相关搜索
游戏脚本一般去哪里找脚本,怎么写脚本?
脚本之家app手机脚本制作手机脚本完整
Script game maker 游戏脚本制作教程 脚本精灵
二、抓取并保存到本地
源代码
index.php:
o_String=new StringEx(); } public function getItem($word){ $url = "http://www.baidu.com/s?wd=".$word; // 构造包头,模拟浏览器请求 $header = array ( "Host:www.baidu.com", "Content-Type:application/x-www-form-urlencoded",//post请求 "Connection: keep-alive", 'Referer:http://www.baidu.com', 'User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; BIDUBrowser 2.6)' ); $ch = curl_init (); curl_setopt ( $ch, CURLOPT_URL, $url ); curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header ); curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); $content = curl_exec ( $ch ); if ($content == FALSE) { echo "error:" . curl_error ( $ch ); } curl_close ( $ch ); //输出结果echo $content; $this->o_String->string=$content; $s_begin=''; $s_end=''; $summary=$this->o_String->getPart($s_begin,$s_end); $s_begin='相关搜索'; $s_end=''; $来源gaodaimacom搞#^代%!码网content=$this->o_String->getPart($s_begin,$s_end); return $content; } public function __destruct(){ unset($this->o_String); } } if($_POST){ $com = new ComBaike(); $q = $_POST['q']; $str = $com->getItem($q); //获取搜索内容 $pat = '/(.*?)/i'; preg_match_all($pat, $str, $m); //print_r($m[4]); 链接文字 $con = implode(",", $m[4]); //生成文件夹 $dates = date("Ymd"); $path="./Search/".$dates."/"; if(!is_dir($path)){ mkdir($path,0777,true); } //生成文件 $file = fopen($path.iconv("UTF-8","GBK",$q).".txt",'w'); if(fwrite($file,$con)){ echo $con; echo ''; }else{ echo ''; } fclose($file); } ?>
cls.StringEx.php:
string=$string; } public function pregGetPart($s_begin,$s_end){ $s_begin==preg_quote($s_begin); $s_begin=str_replace('/','\/',$s_begin); $s_end=preg_quote($s_end); $s_end=str_replace('/','\/',$s_end); $pattern='/'.$s_begin.'(.*?)'.$s_end.'/'; $result=preg_match($pattern,$this->string,$a_match); if(!$result){ return $result; }else{ return isset($a_match[1])?$a_match[1]:''; } } public function strstrGetPart($s_begin,$s_end){ $string=strstr($this->string,$s_begin); $string=strstr($string,$s_end,true); $string=str_replace($s_begin,'',$string); $string=str_replace($s_end,'',$string); return $string; } public function getPart($s_begin,$s_end){ $result=$this->pregGetPart($s_begin,$s_end); if(!$result){ $result=$this->strstrGetPart($s_begin,$s_end); } return $result; } } ?>
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php curl使用总结》、《PHP网络编程技巧总结》、《PHP数组(Array)操作技巧》、《php字符串( string) 使用总结》、《PHP数据结构与算法教程》、《PHP中JSON格式数据操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。 查看全部
php抓取网页连接函数(本文实例讲述PHP实现百度搜索结果页面【相关搜索词】)
本文介绍了PHP抓取百度搜索结果页面【相关搜索词】并存入txt文件的实现。分享给大家,供大家参考,如下:
一、百度搜索关键词【脚本之家】
%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&rsv_pq=ab33cfeb000086a2&rsv_t=7c65vT3KzHCNfGYOIn%2FDSS%9A%E6%9C%AC%%BE4 AE%B6"
搜索结果部分源码:
相关搜索
游戏脚本一般去哪里找脚本,怎么写脚本?
脚本之家app手机脚本制作手机脚本完整
Script game maker 游戏脚本制作教程 脚本精灵
二、抓取并保存到本地
源代码
index.php:
o_String=new StringEx(); } public function getItem($word){ $url = "http://www.baidu.com/s?wd=".$word; // 构造包头,模拟浏览器请求 $header = array ( "Host:www.baidu.com", "Content-Type:application/x-www-form-urlencoded",//post请求 "Connection: keep-alive", 'Referer:http://www.baidu.com', 'User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; BIDUBrowser 2.6)' ); $ch = curl_init (); curl_setopt ( $ch, CURLOPT_URL, $url ); curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header ); curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); $content = curl_exec ( $ch ); if ($content == FALSE) { echo "error:" . curl_error ( $ch ); } curl_close ( $ch ); //输出结果echo $content; $this->o_String->string=$content; $s_begin=''; $s_end=''; $summary=$this->o_String->getPart($s_begin,$s_end); $s_begin='相关搜索'; $s_end=''; $来源gaodaimacom搞#^代%!码网content=$this->o_String->getPart($s_begin,$s_end); return $content; } public function __destruct(){ unset($this->o_String); } } if($_POST){ $com = new ComBaike(); $q = $_POST['q']; $str = $com->getItem($q); //获取搜索内容 $pat = '/(.*?)/i'; preg_match_all($pat, $str, $m); //print_r($m[4]); 链接文字 $con = implode(",", $m[4]); //生成文件夹 $dates = date("Ymd"); $path="./Search/".$dates."/"; if(!is_dir($path)){ mkdir($path,0777,true); } //生成文件 $file = fopen($path.iconv("UTF-8","GBK",$q).".txt",'w'); if(fwrite($file,$con)){ echo $con; echo ''; }else{ echo ''; } fclose($file); } ?>
cls.StringEx.php:
string=$string; } public function pregGetPart($s_begin,$s_end){ $s_begin==preg_quote($s_begin); $s_begin=str_replace('/','\/',$s_begin); $s_end=preg_quote($s_end); $s_end=str_replace('/','\/',$s_end); $pattern='/'.$s_begin.'(.*?)'.$s_end.'/'; $result=preg_match($pattern,$this->string,$a_match); if(!$result){ return $result; }else{ return isset($a_match[1])?$a_match[1]:''; } } public function strstrGetPart($s_begin,$s_end){ $string=strstr($this->string,$s_begin); $string=strstr($string,$s_end,true); $string=str_replace($s_begin,'',$string); $string=str_replace($s_end,'',$string); return $string; } public function getPart($s_begin,$s_end){ $result=$this->pregGetPart($s_begin,$s_end); if(!$result){ $result=$this->strstrGetPart($s_begin,$s_end); } return $result; } } ?>
更多对PHP相关内容感兴趣的读者可以查看本站专题:《php curl使用总结》、《PHP网络编程技巧总结》、《PHP数组(Array)操作技巧》、《php字符串( string) 使用总结》、《PHP数据结构与算法教程》、《PHP中JSON格式数据操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。
php抓取网页连接函数(如何通过PHP代码进行自动跳转以及需要注意的地方?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-06 07:04
在制作网页时,页面之间的自动跳转是我们经常遇到的问题。使用 PHP 自动跳转到网页是一项非常简单的任务。下面我将介绍如何自动跳转PHP代码以及需要注意的地方。
在PHP中实现跳转,需要用到header()函数。此函数将向浏览器发送初始 HTTP 标头信息。这时浏览器会根据HTTP头中的链接跳转到定义好的新页面。我们唯一需要注意的是:在使用 header() 函数之前,不允许实际输出。这意味着在使用此功能之前,您不能在页面中使用 html 标签或内容,也不能使用 PHP 中的 echo 和打印功能。否则跳转无效。
下面的例子将演示如何正确使用 header() 一个 PHP 跳转函数:
如果你运行这段代码,你的浏览器会自动重定向到代码我爱的主页。需要说明的是,使用header()函数后,页面中剩余的php代码也会被执行(这与ASP中Redirect的使用不同,一定要注意)。所以一般情况下,为了节省服务器资源,我们会使用die()函数来结束当前页面代码的执行,如下:
如果你的重定向页面对象是站点内的链接,你只需要将header函数参数中的URL代码部分替换为相对路径或绝对路径即可。例如,您可以将此网址替换为“/page/demo.html”,跳转到站点根目录下page文件夹中的demo.html页面。
但是我们上面说过,如果在header()函数前加上一行echo代码,这个跳转函数就会失效。
Warning: Cannot modify header information - headers already sent by
为了防止这个问题的发生,我们可以通过使用PHP输出缓存的方式完美解决,可以试试下面的代码:
所以,以后发现header()不能正常工作时,记得在跳转前检查是否有实际的内容输出。如果存在,使用上面的PHP输出缓存解决! 查看全部
php抓取网页连接函数(如何通过PHP代码进行自动跳转以及需要注意的地方?)
在制作网页时,页面之间的自动跳转是我们经常遇到的问题。使用 PHP 自动跳转到网页是一项非常简单的任务。下面我将介绍如何自动跳转PHP代码以及需要注意的地方。
在PHP中实现跳转,需要用到header()函数。此函数将向浏览器发送初始 HTTP 标头信息。这时浏览器会根据HTTP头中的链接跳转到定义好的新页面。我们唯一需要注意的是:在使用 header() 函数之前,不允许实际输出。这意味着在使用此功能之前,您不能在页面中使用 html 标签或内容,也不能使用 PHP 中的 echo 和打印功能。否则跳转无效。
下面的例子将演示如何正确使用 header() 一个 PHP 跳转函数:
如果你运行这段代码,你的浏览器会自动重定向到代码我爱的主页。需要说明的是,使用header()函数后,页面中剩余的php代码也会被执行(这与ASP中Redirect的使用不同,一定要注意)。所以一般情况下,为了节省服务器资源,我们会使用die()函数来结束当前页面代码的执行,如下:
如果你的重定向页面对象是站点内的链接,你只需要将header函数参数中的URL代码部分替换为相对路径或绝对路径即可。例如,您可以将此网址替换为“/page/demo.html”,跳转到站点根目录下page文件夹中的demo.html页面。
但是我们上面说过,如果在header()函数前加上一行echo代码,这个跳转函数就会失效。
Warning: Cannot modify header information - headers already sent by
为了防止这个问题的发生,我们可以通过使用PHP输出缓存的方式完美解决,可以试试下面的代码:
所以,以后发现header()不能正常工作时,记得在跳转前检查是否有实际的内容输出。如果存在,使用上面的PHP输出缓存解决!
php抓取网页连接函数(怎样解决filefox浏览器中嵌套div标签-align属性失效的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 09:10
同样适用于网页布局中的标记。区别在于:
2.如何使 DIV 图层居中?
位置:绝对;
顶部:50%;
左:50%;
边距:-100px 0 0 -100px;
3.如何解决filefox浏览器嵌套div标签text-align属性无效的问题?
1
2 .one {border:1px solid blue;width:300px;height:200px;text-align:center }
3 .two {border:1 px solid blue;width:200px;height:100px;margin:0px auto }
4
5
6
7
JavaScript 脚本
1.弹出对话框的功能和获取输入焦点的功能:
在弹出的对话框中使用alert()函数
使用 focus() 函数获取输入焦点
2. JavaScript 的转向功能是什么?如何导入外部 JavaScript 文件?
翻转函数:window.location.href="文件名";
引入外部 JavaScript 文件:
3.当鼠标在文本框上移动时,文本框内的内容被自动选中:
4
5.设置首页的JavaScript代码:
Ajax 应用程序
1.jQuery中使用ajax判断用户名是否被占用:
需要定义两个页面,index.php页面代码如下:
1
2
3
4 $(function() {
5 $("input:last".click(function() {
6 $.get ("in.php", {
7 username:$("input:first").val()
8 },function(data) {
9 alert (data);
10 })'
11 });
12 });
13
in.php页面的代码如下:
1
2. 编写代码在文本框中输入年份,确定其生肖,在文本框旁边输出,需要编写HTML和JavaScript代码:
首页设计代码如下:
1
2
3
4
5 生肖的自动选择
6
7
8
9
10
11
12 $(function(){
13 $("input:last").click(function(){
14 $.get("in.php",{
15 number:$("input:first").val()
16 },function(data){
17 $("span").text(data);
18 });
19 });
20 });
21
22
23
查看代码
后台判断生肖的PHP脚本:
<p>1 查看全部
php抓取网页连接函数(怎样解决filefox浏览器中嵌套div标签-align属性失效的问题)
同样适用于网页布局中的标记。区别在于:
2.如何使 DIV 图层居中?
位置:绝对;
顶部:50%;
左:50%;
边距:-100px 0 0 -100px;
3.如何解决filefox浏览器嵌套div标签text-align属性无效的问题?
1
2 .one {border:1px solid blue;width:300px;height:200px;text-align:center }
3 .two {border:1 px solid blue;width:200px;height:100px;margin:0px auto }
4
5
6
7
JavaScript 脚本
1.弹出对话框的功能和获取输入焦点的功能:
在弹出的对话框中使用alert()函数
使用 focus() 函数获取输入焦点
2. JavaScript 的转向功能是什么?如何导入外部 JavaScript 文件?
翻转函数:window.location.href="文件名";
引入外部 JavaScript 文件:
3.当鼠标在文本框上移动时,文本框内的内容被自动选中:
4
5.设置首页的JavaScript代码:
Ajax 应用程序
1.jQuery中使用ajax判断用户名是否被占用:
需要定义两个页面,index.php页面代码如下:
1
2
3
4 $(function() {
5 $("input:last".click(function() {
6 $.get ("in.php", {
7 username:$("input:first").val()
8 },function(data) {
9 alert (data);
10 })'
11 });
12 });
13
in.php页面的代码如下:
1
2. 编写代码在文本框中输入年份,确定其生肖,在文本框旁边输出,需要编写HTML和JavaScript代码:
首页设计代码如下:
1
2
3
4
5 生肖的自动选择
6
7
8
9
10
11
12 $(function(){
13 $("input:last").click(function(){
14 $.get("in.php",{
15 number:$("input:first").val()
16 },function(data){
17 $("span").text(data);
18 });
19 });
20 });
21
22
23
查看代码
后台判断生肖的PHP脚本:
<p>1
php抓取网页连接函数(php抓取网页连接函数header()#allrewrite_from_url()返回的php文件名大小写不一致问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-24 19:13
php抓取网页连接函数header()#allrewrite_from_url(),解决allrewrite_from_url()返回的php文件名大小写不一致问题。正常响应laravel网页url不合法#解决:allrewrite_from_url()不要传入必要参数php代码通常是这样写的,如果你要请求的对象不是对象,而是一个字符串就只需要这样写#[php_default_path].{"url":url},其中一个参数,php_default_path是你在通用请求对象(get,post请求)调用返回url时,参数类型为“or”的对象。
php还支持一个叫request_from_url(request_url)的对象,当请求请求的对象是“or”,就可以直接使用request_from_url()函数。fromrequest_from_urlimportrequest_from_url,st#通过request_from_url用指定的url对象请求对应的header。
urlpatterns:在php中实现一个模板的html解析器并作为异步调用的入口方法。异步调用:一个带入口方法的异步方法可能是一个网页,也可能是api,还可能是一个tap?>php代码。 查看全部
php抓取网页连接函数(php抓取网页连接函数header()#allrewrite_from_url()返回的php文件名大小写不一致问题)
php抓取网页连接函数header()#allrewrite_from_url(),解决allrewrite_from_url()返回的php文件名大小写不一致问题。正常响应laravel网页url不合法#解决:allrewrite_from_url()不要传入必要参数php代码通常是这样写的,如果你要请求的对象不是对象,而是一个字符串就只需要这样写#[php_default_path].{"url":url},其中一个参数,php_default_path是你在通用请求对象(get,post请求)调用返回url时,参数类型为“or”的对象。
php还支持一个叫request_from_url(request_url)的对象,当请求请求的对象是“or”,就可以直接使用request_from_url()函数。fromrequest_from_urlimportrequest_from_url,st#通过request_from_url用指定的url对象请求对应的header。
urlpatterns:在php中实现一个模板的html解析器并作为异步调用的入口方法。异步调用:一个带入口方法的异步方法可能是一个网页,也可能是api,还可能是一个tap?>php代码。
php抓取网页连接函数(php抓取网页连接函数使用方法()抓取函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-19 21:05
php抓取网页连接函数使用方法php抓取网页连接函数,也可以使用网页的代码来抓取网页。我个人推荐使用这个方法,应该能抓取到绝大部分网页,只不过限制比较多。使用这个方法的话,我们需要用一个php框架来开发,抓取连接数量不会限制,而且抓取网页连接的种类也比较多。使用这个方法的话,首先要有一个php开发框架,例如php7gui、phpmyadmin等开发框架都可以用来使用这个方法。
除此之外,你需要对知识比较有一定的了解,而且要对http协议有比较深入的了解。使用这个方法时,你需要注意这几点:1.需要使用xmlhttprequest来抓取网页连接。并且要带上http头中的http+xmlhttprequest字段。2.使用xmlhttprequest需要注意有一个循环,循环在同一个php文件中。
如果没有循环,那么最好放在一个独立的文件里。3.xmlhttprequest连接的话,因为xmlhttprequest的url有一个get方法,因此我们需要一个url路由xmlhttprequest,同时创建一个php的xmlhttprequest对象对该url进行解析。4.xmlhttprequest连接是个单向的连接,请求成功之后不会再继续。
5.request需要带有cookie值,因此我们要使用反斜杠\cookie\\来连接一个request对象,并且保存cookie。6.request连接成功之后,在其它方法中,要把\\\。 查看全部
php抓取网页连接函数(php抓取网页连接函数使用方法()抓取函数)
php抓取网页连接函数使用方法php抓取网页连接函数,也可以使用网页的代码来抓取网页。我个人推荐使用这个方法,应该能抓取到绝大部分网页,只不过限制比较多。使用这个方法的话,我们需要用一个php框架来开发,抓取连接数量不会限制,而且抓取网页连接的种类也比较多。使用这个方法的话,首先要有一个php开发框架,例如php7gui、phpmyadmin等开发框架都可以用来使用这个方法。
除此之外,你需要对知识比较有一定的了解,而且要对http协议有比较深入的了解。使用这个方法时,你需要注意这几点:1.需要使用xmlhttprequest来抓取网页连接。并且要带上http头中的http+xmlhttprequest字段。2.使用xmlhttprequest需要注意有一个循环,循环在同一个php文件中。
如果没有循环,那么最好放在一个独立的文件里。3.xmlhttprequest连接的话,因为xmlhttprequest的url有一个get方法,因此我们需要一个url路由xmlhttprequest,同时创建一个php的xmlhttprequest对象对该url进行解析。4.xmlhttprequest连接是个单向的连接,请求成功之后不会再继续。
5.request需要带有cookie值,因此我们要使用反斜杠\cookie\\来连接一个request对象,并且保存cookie。6.request连接成功之后,在其它方法中,要把\\\。
php抓取网页连接函数(HTML页面调用PHP文件的方法是怎么做的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 12:01
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
静态页面好像不能直接调用PHP文件,但是有时候我们可以通过js调用PHP文件。接下来在文章给大家详细介绍一下,有一定的参考价值。希望对大家有帮助。
【推荐课程:PHP教程】
HTML 本身无法处理动态请求。调用PHP文件需要借用JavaScript来实现。生成静态页面时,可以根据数据库id为HTML页面生成相应的JavaScript文件。
示例
如果一个HTML文件是123.html,那么在这个页面生成一个
然后点击.php这个页面会按照php的语法来处理和操作数据库。
示例
在页面a.html中,可以使用如下代码将action=test的参数传递给b.php
Javascript 代码
b.php 代码
执行a.html文件时,调用b.php文件,b.php文件的输出作为JS语句执行。内容是JS传递过来的参数action的值,在PHP文件中接受 即将到来的action的值 查看全部
php抓取网页连接函数(HTML页面调用PHP文件的方法是怎么做的呢?)
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
在HTML页面上调用PHP文件的方法要通过JavaScript来实现。生成静态页面时,可以根据数据库id为html页面生成对应的JavaScript文件调用PHP文件。
静态页面好像不能直接调用PHP文件,但是有时候我们可以通过js调用PHP文件。接下来在文章给大家详细介绍一下,有一定的参考价值。希望对大家有帮助。
【推荐课程:PHP教程】
HTML 本身无法处理动态请求。调用PHP文件需要借用JavaScript来实现。生成静态页面时,可以根据数据库id为HTML页面生成相应的JavaScript文件。
示例
如果一个HTML文件是123.html,那么在这个页面生成一个
然后点击.php这个页面会按照php的语法来处理和操作数据库。
示例
在页面a.html中,可以使用如下代码将action=test的参数传递给b.php
Javascript 代码
b.php 代码
执行a.html文件时,调用b.php文件,b.php文件的输出作为JS语句执行。内容是JS传递过来的参数action的值,在PHP文件中接受 即将到来的action的值
php抓取网页连接函数(php抓取网页连接函数和反爬虫浏览器抓取一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-08 16:03
php抓取网页连接函数和反爬虫浏览器抓取一个网页,要收到图片,js,地址栏,timestamp之类的格式化参数,然后再渲染出来,用php感觉慢半拍,另外,我在php上都没有做过任何进阶,php进阶知识可以用python,html,css,js看懂后,网页解析速度跟php应该差不多,但是我还是建议你多了解一些php内部的原理。
先要判断整个页面是url响应还是后端传递给前端websocket。如果不是,是页面渲染的问题。所以用nodejs吧,本地执行即可,后端没有自己想要的东西,前端传的数据一般是json数据。简单点就grunt.js配合lodashjs和jsonparser就可以搞定了。有什么需要进一步了解的,就找相关资料了解一下吧。
感觉楼主是想多了解点东西推荐一本书,网上书店搜得到:php健壮架构(豆瓣)至于php实现爬虫,其实用的是反爬虫这个黑科技。baidu百度吧。当然你看不看是你的事。
其实挺简单的,
建议学习一下前端脚本开发,
关键是反爬虫和爬虫本身。baidu百度不做爬虫抓下来的内容就会被忽略。虽然有些网站在初期对爬虫有拦截技术,但效果不好。所以既然是爬虫本身,且php内置了爬虫检测,那么难点就在于那些网站可以爬,以及怎么检测。我建议php多关注反爬虫方面的知识,再学习一下php自带的检测反爬虫技术。 查看全部
php抓取网页连接函数(php抓取网页连接函数和反爬虫浏览器抓取一个网页)
php抓取网页连接函数和反爬虫浏览器抓取一个网页,要收到图片,js,地址栏,timestamp之类的格式化参数,然后再渲染出来,用php感觉慢半拍,另外,我在php上都没有做过任何进阶,php进阶知识可以用python,html,css,js看懂后,网页解析速度跟php应该差不多,但是我还是建议你多了解一些php内部的原理。
先要判断整个页面是url响应还是后端传递给前端websocket。如果不是,是页面渲染的问题。所以用nodejs吧,本地执行即可,后端没有自己想要的东西,前端传的数据一般是json数据。简单点就grunt.js配合lodashjs和jsonparser就可以搞定了。有什么需要进一步了解的,就找相关资料了解一下吧。
感觉楼主是想多了解点东西推荐一本书,网上书店搜得到:php健壮架构(豆瓣)至于php实现爬虫,其实用的是反爬虫这个黑科技。baidu百度吧。当然你看不看是你的事。
其实挺简单的,
建议学习一下前端脚本开发,
关键是反爬虫和爬虫本身。baidu百度不做爬虫抓下来的内容就会被忽略。虽然有些网站在初期对爬虫有拦截技术,但效果不好。所以既然是爬虫本身,且php内置了爬虫检测,那么难点就在于那些网站可以爬,以及怎么检测。我建议php多关注反爬虫方面的知识,再学习一下php自带的检测反爬虫技术。
php抓取网页连接函数(纯静态网站在网站中是怎么进行静态处理的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-30 15:10
本文文章主要介绍PHP中静态HTML页面的方法,分享静态处理的方法,静态处理的优点,并提供多种静态方法。有兴趣的朋友可以参考一下。
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。当我们访问时,我们可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先将网站的页面进行汇总,划分成几种样式,然后将这些页面制作成模板。生成的时候,必须先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是中小型大型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过,中小网站还是做纯静态比较。这样做的好处很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时,它具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全可以抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试制作一个静态网址。
下面我们主要讲一下页面静态的概念,希望对大家有所帮助!
什么是 HTML 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在PHP网站的开发中,针对网站推广和SEO的需要,需要对网站进行全站或局部静态处理。用PHP生成静态HTML页面的方法有很多种,比如使用PHP模板、缓存等实现页面静态化。
PHP静态的简单理解就是让网站生成的页面以静态HTML的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于PHP生成静态页面的处理机制。.
PHP 伪静态:一种使用 Apache mod_rewrite 重写 URL 的方法。
HTML 静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,百度、Google会优先处理收录静态页面,不仅收录快而且收录全;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,HTML页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止SQL注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现HTML静态化的策略和实例:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用PHP模板生成静态页面
实现静态PHP模板非常方便,比如安装和使用PHP Smarty实现静态网站。
在使用Smarty的情况下,也可以实现静态页面。简单说一下使用Smarty时动态阅读的方式。
一般分为这几个步骤:
1、 通过 URL 传递一个参数(ID);
2、然后根据这个ID查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
Smarty静态过程只需要在上述过程中增加两步即可。
第一:在1之前使用ob_start()打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效地利用上述过程,可以使用一个小方法,即Header()。具体过程如下:添加修改程序后,使用Header()跳转到前台读取,使页面可以HTML化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用PHP文件读写功能生成静态页面
方法三:使用PHP输出控制功能(Output Control)/ob缓存机制生成静态页面
输出控制功能(Output Control)是利用和控制缓存来生成静态HTML页面。它还使用PHP文件读写功能。
例如,某产品的动态详情页地址为:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道PHP是用于网站开发的。通常,执行结果直接输出到浏览器。为了使用PHP生成静态页面,需要使用输出控制函数来控制缓存区,从而获取缓存区的内容,然后输出到静态HTML页面文件中,实现网站 静态。
PHP生成静态页面的思路是:先开启缓存,然后输出HTML内容(也可以通过include以文件的形式收录HTML内容),然后获取缓存中的内容,然后通过PHP文件读写功能清除缓存。缓存内容写入静态 HTML 页面文件。
获取输出缓存内容生成静态HTML页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有任何输出,比如空格、字符等。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。成功则返回True,失败则返回False。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。默认情况下,密钥不能超过 128 个字节,默认值为 1M。所以1M的大小可以满足大部分网页的存储。
以上就是PHP实现静态HTML页面的方法,内容丰富,值得大家细细品味和收获。
以上就是PHP实现静态HTML页面的方法的详细内容,请关注其他相关html中文网站文章! 查看全部
php抓取网页连接函数(纯静态网站在网站中是怎么进行静态处理的?(图))
本文文章主要介绍PHP中静态HTML页面的方法,分享静态处理的方法,静态处理的优点,并提供多种静态方法。有兴趣的朋友可以参考一下。
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。当我们访问时,我们可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先将网站的页面进行汇总,划分成几种样式,然后将这些页面制作成模板。生成的时候,必须先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是中小型大型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过,中小网站还是做纯静态比较。这样做的好处很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时,它具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全可以抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试制作一个静态网址。
下面我们主要讲一下页面静态的概念,希望对大家有所帮助!
什么是 HTML 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在PHP网站的开发中,针对网站推广和SEO的需要,需要对网站进行全站或局部静态处理。用PHP生成静态HTML页面的方法有很多种,比如使用PHP模板、缓存等实现页面静态化。
PHP静态的简单理解就是让网站生成的页面以静态HTML的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于PHP生成静态页面的处理机制。.
PHP 伪静态:一种使用 Apache mod_rewrite 重写 URL 的方法。
HTML 静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,百度、Google会优先处理收录静态页面,不仅收录快而且收录全;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,HTML页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止SQL注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现HTML静态化的策略和实例:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用PHP模板生成静态页面
实现静态PHP模板非常方便,比如安装和使用PHP Smarty实现静态网站。
在使用Smarty的情况下,也可以实现静态页面。简单说一下使用Smarty时动态阅读的方式。
一般分为这几个步骤:
1、 通过 URL 传递一个参数(ID);
2、然后根据这个ID查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
Smarty静态过程只需要在上述过程中增加两步即可。
第一:在1之前使用ob_start()打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效地利用上述过程,可以使用一个小方法,即Header()。具体过程如下:添加修改程序后,使用Header()跳转到前台读取,使页面可以HTML化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用PHP文件读写功能生成静态页面
方法三:使用PHP输出控制功能(Output Control)/ob缓存机制生成静态页面
输出控制功能(Output Control)是利用和控制缓存来生成静态HTML页面。它还使用PHP文件读写功能。
例如,某产品的动态详情页地址为:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道PHP是用于网站开发的。通常,执行结果直接输出到浏览器。为了使用PHP生成静态页面,需要使用输出控制函数来控制缓存区,从而获取缓存区的内容,然后输出到静态HTML页面文件中,实现网站 静态。
PHP生成静态页面的思路是:先开启缓存,然后输出HTML内容(也可以通过include以文件的形式收录HTML内容),然后获取缓存中的内容,然后通过PHP文件读写功能清除缓存。缓存内容写入静态 HTML 页面文件。
获取输出缓存内容生成静态HTML页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有任何输出,比如空格、字符等。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。成功则返回True,失败则返回False。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。默认情况下,密钥不能超过 128 个字节,默认值为 1M。所以1M的大小可以满足大部分网页的存储。
以上就是PHP实现静态HTML页面的方法,内容丰富,值得大家细细品味和收获。
以上就是PHP实现静态HTML页面的方法的详细内容,请关注其他相关html中文网站文章!
php抓取网页连接函数(php抓取网页连接函数分为url子句和循环子句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-25 17:15
php抓取网页连接函数分为url子句和循环子句,就目前你的示例来看。使用url子句就需要自己去传值,循环子句其实就是定义一个方法从起始页开始,根据自己的需要抓取每一页就可以。
url子句,循环子句是php写法。你看看yii2提供的orm怎么封装这些对象。
因为服务器生成网页是将一个网址直接传到php去,然后php根据需要抓取不同的页面。生成的网址里可能是你所指定的url,也可能是其他类型的url(如about/shop/address/country等等),不同url传值方式不同(或者不同地址传值方式不同)。你所使用的<img>标签,就是个link标签,指定的link标签里含有自己的属性(如title/value/url等等),php去抓取它指定的内容就可以了。
要注意:shop.php只是抓取shop的页面,你以shop为例,shop_info.php只抓取shop_info.php就可以了,并不是会把shop_info.php传到你的url子句中。
你可以看看__biz啊
前端的url那个属于php封装的javascript库,
其实说的是类似于c语言的连接,其实也可以分为三步php->连接器(类似c,
php一般连接是通过biz值,xml来的, 查看全部
php抓取网页连接函数(php抓取网页连接函数分为url子句和循环子句)
php抓取网页连接函数分为url子句和循环子句,就目前你的示例来看。使用url子句就需要自己去传值,循环子句其实就是定义一个方法从起始页开始,根据自己的需要抓取每一页就可以。
url子句,循环子句是php写法。你看看yii2提供的orm怎么封装这些对象。
因为服务器生成网页是将一个网址直接传到php去,然后php根据需要抓取不同的页面。生成的网址里可能是你所指定的url,也可能是其他类型的url(如about/shop/address/country等等),不同url传值方式不同(或者不同地址传值方式不同)。你所使用的<img>标签,就是个link标签,指定的link标签里含有自己的属性(如title/value/url等等),php去抓取它指定的内容就可以了。
要注意:shop.php只是抓取shop的页面,你以shop为例,shop_info.php只抓取shop_info.php就可以了,并不是会把shop_info.php传到你的url子句中。
你可以看看__biz啊
前端的url那个属于php封装的javascript库,
其实说的是类似于c语言的连接,其实也可以分为三步php->连接器(类似c,
php一般连接是通过biz值,xml来的,
php抓取网页连接函数(PHP手册(再次一句一句以强调)手册真乃圣经)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 09:20
获取网页内容,PHP有几个可以实现的内置函数,比如file()、file_get_contents()等,都支持URL参数。但要实现更复杂的操作,这些功能就无能为力了。
cURL 是一个文件传输工具,它使用 URL 语法在命令行下工作。 cURL 提供了一个 PHP 扩展。有了这个扩展,你可以完全模拟浏览器操作,就像使用浏览器浏览网页一样。可以设置header内容、设置cookie数据、POST数据、上传文件、设置代理等,其实我们这里讨论的爬取网页内容只是其常用的应用之一。
cURL 官方网站:
PHP cURL 扩展:
Windows下添加这个扩展很简单,加载php_curl.dll即可。去掉php.ini文件extension=php_curl.dll前面的分号,将php_curl.dll复制到PHP扩展目录下或者重启C:\Windows\system32目录下的Web服务器。 php_curl.dll 在 PHP 的 ZIP 包中提供。
Linux下,需要先安装cURL。一种方法是编译成PHP,编译配置时加上--with-curl[=DIR]。另一种方法是将其编译为 PHP 模块并加载它。编译cURL模块的方法和编译其他PHP模块的方法一样,下面是基本命令:
cd /path/to/php/source 进入PHP源代码目录
cd ext/curl 进入cURL模块源码目录
/usr/local/php/bin/phpize 生成编译配置文件
./configure --with-php-config=/usr/local/php/bin/php-config
制作
进行安装
编译完成生成curl.so,修改php.ini,加载模块:
extension="/path/to/extension/curl.so"
测试cURL扩展是否加载,新建PHP文件:
抓取网页示例:
curl_setopt() 可以设置很多选项。更多选项请参考PHP手册。
更多的功能和用法,请参考PHP手册(再次废话,强调PHP手册真的是圣经。
). 查看全部
php抓取网页连接函数(PHP手册(再次一句一句以强调)手册真乃圣经)
获取网页内容,PHP有几个可以实现的内置函数,比如file()、file_get_contents()等,都支持URL参数。但要实现更复杂的操作,这些功能就无能为力了。
cURL 是一个文件传输工具,它使用 URL 语法在命令行下工作。 cURL 提供了一个 PHP 扩展。有了这个扩展,你可以完全模拟浏览器操作,就像使用浏览器浏览网页一样。可以设置header内容、设置cookie数据、POST数据、上传文件、设置代理等,其实我们这里讨论的爬取网页内容只是其常用的应用之一。
cURL 官方网站:
PHP cURL 扩展:
Windows下添加这个扩展很简单,加载php_curl.dll即可。去掉php.ini文件extension=php_curl.dll前面的分号,将php_curl.dll复制到PHP扩展目录下或者重启C:\Windows\system32目录下的Web服务器。 php_curl.dll 在 PHP 的 ZIP 包中提供。
Linux下,需要先安装cURL。一种方法是编译成PHP,编译配置时加上--with-curl[=DIR]。另一种方法是将其编译为 PHP 模块并加载它。编译cURL模块的方法和编译其他PHP模块的方法一样,下面是基本命令:
cd /path/to/php/source 进入PHP源代码目录
cd ext/curl 进入cURL模块源码目录
/usr/local/php/bin/phpize 生成编译配置文件
./configure --with-php-config=/usr/local/php/bin/php-config
制作
进行安装
编译完成生成curl.so,修改php.ini,加载模块:
extension="/path/to/extension/curl.so"
测试cURL扩展是否加载,新建PHP文件:
抓取网页示例:
curl_setopt() 可以设置很多选项。更多选项请参考PHP手册。
更多的功能和用法,请参考PHP手册(再次废话,强调PHP手册真的是圣经。
).
php抓取网页连接函数(连接超时(图片下载)函数的超时时间设置短一些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 13:13
最近有个同事在做数据抓取,需要把别人的网站的图片下载到本地。图片链接是从远程服务器的数据库中读取的。他使用的方法是每次从远程数据库中读取某条记录,然后使用双循环下载图片。有可能是代码在执行的时候遇到了问题,就是一些链接失效了,会出现连接超时(图片下载方式是内置readfile函数)。超时也没什么大不了的,顶多是图片还没下载。但结果是:如果有链接超时,那么整个程序就会跑掉,很奇怪。
我仔细看了一下代码,发现了问题:readfile函数的默认超时时间是1分钟左右,因为这段时间mysql连接一直处于非活动状态,所以连接中断了,他也没有重新连接,所以当 mysql_query 会报错。
既然知道了原因,问题就可以很好的解决了。从两个方面入手:
1、设置readfile函数的超时时间更短
2、mysql_query 判断之前是否有连接,没有则重新连接
第二个好办,用mysql_ping()就可以了(需要提醒大家:如果连接到远程数据库,最好有连接失败重试,因为一个mysql_connect()不能保证100%连接成功率,您可以使用 Do,同时在连接失败后连接多次)。第一个有点棘手。readfile 函数中似乎没有超时设置。如果把下载文件的方式改成fsockopen,这个功能支持超时设置,但是有点麻烦。我们去网上查了一下,结果还真的找到了。原来 readfile 也支持超时设置。使用第三个参数 $context。这是一个资源类型变量。
看看代码示例:
这样readfile函数的超时时间设置为10秒。细心的话,你会发现阵列中还有一些其他的配置。第一维中的http是指定的网络协议,第二维中的方法batch是http请求方法get、post、head等,timeout是超时时间。我想很多人都会使用php内置的file_get_contents函数来下载网页,因为这个函数使用起来很简单。很多人用起来也很简单,只要传递一个链接,它就可以自动发送get请求,下载网页内容。如果情况比较复杂,比如使用POST请求,使用代理下载,定义User-Agent等,很多人会认为这个函数做不到这样的事情,并且会选择其他方法,比如 curl 来实现。其实file_get_contents这些东西也可以做,就是通过它的第三个参数来设置http请求的上下文。
支持的设置和使用方法见官方说明:
附:目前我知道的支持上下文参数的php内置函数有
file_get_contents,file_put_contents,readfile,file,fopen,copy
(估计支持该类型的功能,待确认)。 查看全部
php抓取网页连接函数(连接超时(图片下载)函数的超时时间设置短一些)
最近有个同事在做数据抓取,需要把别人的网站的图片下载到本地。图片链接是从远程服务器的数据库中读取的。他使用的方法是每次从远程数据库中读取某条记录,然后使用双循环下载图片。有可能是代码在执行的时候遇到了问题,就是一些链接失效了,会出现连接超时(图片下载方式是内置readfile函数)。超时也没什么大不了的,顶多是图片还没下载。但结果是:如果有链接超时,那么整个程序就会跑掉,很奇怪。
我仔细看了一下代码,发现了问题:readfile函数的默认超时时间是1分钟左右,因为这段时间mysql连接一直处于非活动状态,所以连接中断了,他也没有重新连接,所以当 mysql_query 会报错。
既然知道了原因,问题就可以很好的解决了。从两个方面入手:
1、设置readfile函数的超时时间更短
2、mysql_query 判断之前是否有连接,没有则重新连接
第二个好办,用mysql_ping()就可以了(需要提醒大家:如果连接到远程数据库,最好有连接失败重试,因为一个mysql_connect()不能保证100%连接成功率,您可以使用 Do,同时在连接失败后连接多次)。第一个有点棘手。readfile 函数中似乎没有超时设置。如果把下载文件的方式改成fsockopen,这个功能支持超时设置,但是有点麻烦。我们去网上查了一下,结果还真的找到了。原来 readfile 也支持超时设置。使用第三个参数 $context。这是一个资源类型变量。
看看代码示例:
这样readfile函数的超时时间设置为10秒。细心的话,你会发现阵列中还有一些其他的配置。第一维中的http是指定的网络协议,第二维中的方法batch是http请求方法get、post、head等,timeout是超时时间。我想很多人都会使用php内置的file_get_contents函数来下载网页,因为这个函数使用起来很简单。很多人用起来也很简单,只要传递一个链接,它就可以自动发送get请求,下载网页内容。如果情况比较复杂,比如使用POST请求,使用代理下载,定义User-Agent等,很多人会认为这个函数做不到这样的事情,并且会选择其他方法,比如 curl 来实现。其实file_get_contents这些东西也可以做,就是通过它的第三个参数来设置http请求的上下文。
支持的设置和使用方法见官方说明:
附:目前我知道的支持上下文参数的php内置函数有
file_get_contents,file_put_contents,readfile,file,fopen,copy
(估计支持该类型的功能,待确认)。
php抓取网页连接函数(php获取远程页面的html状态码的方法方法: )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-16 02:12
)
由于项目需要,需要使用php做一个获取远程页面的html状态码的函数来判断远程页面是否可以访问,就像HTML页面状态码检测工具一样。整理了一下代码,贴出来了。如果需要,您可以使用它。
php获取远程页面的html状态码有两种方法。一种是使用PHP的内置函数get_headers(),另一种是使用curl方法。
PHP 如何获取 html 状态码
方法一:
输出结果:
HTTP/1.1 301 Moved PermanentlyHTTP/1.1 301 Moved PermanentlyHTTP/1.1 200 OK
注意:
由于测试URL(本博客的url)的HTTP协议是301到HTTPS协议的二级www域名,所以会输出html的301状态码前两次,最后一次是直接请求的HTTPS协议的地址,直接返回HTML 200状态码。
方法二:
返回结果:200
PS:这个方法的代码有点长。如果要同时判断多个远程页面的HTML状态码,就需要写很多重复的代码。我们可以封装成函数直接使用。
函数代码:
function GetHttpCode($url){ $ch = curl_init($url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_exec($ch); $httpcode = curl_getinfo($ch,CURLINFO_HTTP_CODE); curl_close($ch); return $httpcode;}
函数调用:
echo GetHttpCode('http://www.baidu.com');echo GetHttpCode('http://feiniaomy.com');
返回结果:
200 301 查看全部
php抓取网页连接函数(php获取远程页面的html状态码的方法方法:
)
由于项目需要,需要使用php做一个获取远程页面的html状态码的函数来判断远程页面是否可以访问,就像HTML页面状态码检测工具一样。整理了一下代码,贴出来了。如果需要,您可以使用它。
php获取远程页面的html状态码有两种方法。一种是使用PHP的内置函数get_headers(),另一种是使用curl方法。
PHP 如何获取 html 状态码
方法一:
输出结果:
HTTP/1.1 301 Moved PermanentlyHTTP/1.1 301 Moved PermanentlyHTTP/1.1 200 OK
注意:
由于测试URL(本博客的url)的HTTP协议是301到HTTPS协议的二级www域名,所以会输出html的301状态码前两次,最后一次是直接请求的HTTPS协议的地址,直接返回HTML 200状态码。
方法二:
返回结果:200
PS:这个方法的代码有点长。如果要同时判断多个远程页面的HTML状态码,就需要写很多重复的代码。我们可以封装成函数直接使用。
函数代码:
function GetHttpCode($url){ $ch = curl_init($url); curl_setopt($ch,CURLOPT_RETURNTRANSFER,1); curl_exec($ch); $httpcode = curl_getinfo($ch,CURLINFO_HTTP_CODE); curl_close($ch); return $httpcode;}
函数调用:
echo GetHttpCode('http://www.baidu.com');echo GetHttpCode('http://feiniaomy.com');
返回结果:
200 301
php抓取网页连接函数(php抓取网页连接函数详解网上很多相关资料可以查找。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-15 18:02
php抓取网页连接函数详解
网上很多相关资料可以查找。目前从爬虫技术角度,没有找到比较完整的“插入代理连接”的方案。有几个业界建议:1.抓取数据后再插入代理。可以直接用php爬虫抓取ajax请求或各种静态网页直接抓取后再放置代理,从源头解决掉直接抓取的需求。2.如果存在一个可复用的php后端程序,可以在根据抓取的请求和请求参数,提取出对应参数后再将数据插入代理。
即使完全不能解决网页内容处理的问题,其实也比直接给需要抓取的网页加代理的方案成本低一些。更新:开发了一个爬虫用于反爬虫和ua多变的ip对应的验证。没有用到插入代理连接。
php做抓取是比较困难的,很多公司都不会这么做.除非你有很好的系统.比如我们公司用flash来做.目前是这样做的.你可以看看.我的博客:-php-scraping...
1.php抓取网页2.反爬虫
抓取网页方式很多。如果可以的话,直接找一个开源系统,做个爬虫程序,一次性抓完!部署时将抓取到的页面拿到flash拖放至ppt5.0以上的版本,就可以反爬了,自然而然就可以设置出需要的代理,以及post协议,直接发给后端接口去处理就行了。再也不用考虑类似爬虫代理被反爬虫黑了的问题。css/js,请查找专门的抓取工具。 查看全部
php抓取网页连接函数(php抓取网页连接函数详解网上很多相关资料可以查找。)
php抓取网页连接函数详解
网上很多相关资料可以查找。目前从爬虫技术角度,没有找到比较完整的“插入代理连接”的方案。有几个业界建议:1.抓取数据后再插入代理。可以直接用php爬虫抓取ajax请求或各种静态网页直接抓取后再放置代理,从源头解决掉直接抓取的需求。2.如果存在一个可复用的php后端程序,可以在根据抓取的请求和请求参数,提取出对应参数后再将数据插入代理。
即使完全不能解决网页内容处理的问题,其实也比直接给需要抓取的网页加代理的方案成本低一些。更新:开发了一个爬虫用于反爬虫和ua多变的ip对应的验证。没有用到插入代理连接。
php做抓取是比较困难的,很多公司都不会这么做.除非你有很好的系统.比如我们公司用flash来做.目前是这样做的.你可以看看.我的博客:-php-scraping...
1.php抓取网页2.反爬虫
抓取网页方式很多。如果可以的话,直接找一个开源系统,做个爬虫程序,一次性抓完!部署时将抓取到的页面拿到flash拖放至ppt5.0以上的版本,就可以反爬了,自然而然就可以设置出需要的代理,以及post协议,直接发给后端接口去处理就行了。再也不用考虑类似爬虫代理被反爬虫黑了的问题。css/js,请查找专门的抓取工具。
php抓取网页连接函数( 图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 08:17
图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
header('Content-Type: application/pdf'); // PDF文件
$fp = fopen($ret->url, "rb"); //二进制方式打开文件
fpassthru($fp); // 输出至浏览器
exit;
如果是图片,修改header
header('Content-Type: text/html; charset=utf-8'); //网页编码
15 header('Content-Type: text/plain'); //纯文本格式
16 header('Content-Type: image/jpeg'); //JPG、JPEG
17 header('Content-Type: application/zip'); // ZIP文件
18 header('Content-Type: application/pdf'); // PDF文件
19 header('Content-Type: audio/mpeg'); // 音频文件
20 header('Content-type: text/css'); //css文件
21 header('Content-type: text/javascript'); //js文件
22 header('Content-type: application/json'); //json
23 header('Content-type: application/pdf'); //pdf
24 header('Content-type: text/xml'); //xml
25 header('Content-Type: application/x-shockw**e-flash'); //Flash动画
fopen打开文件后,不是字符串,不能直接输出。 fgets() 函数用于获取字符串。 fgets() 函数从文件指针读取一行。文件指针必须有效,并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
File_get_contents() 打开网页后会返回一个字符串,可以直接输出。 查看全部
php抓取网页连接函数(
图片,就修改header头fopen打开文件后得到不是字符串直接输出要fgets)
header('Content-Type: application/pdf'); // PDF文件
$fp = fopen($ret->url, "rb"); //二进制方式打开文件
fpassthru($fp); // 输出至浏览器
exit;
如果是图片,修改header
header('Content-Type: text/html; charset=utf-8'); //网页编码
15 header('Content-Type: text/plain'); //纯文本格式
16 header('Content-Type: image/jpeg'); //JPG、JPEG
17 header('Content-Type: application/zip'); // ZIP文件
18 header('Content-Type: application/pdf'); // PDF文件
19 header('Content-Type: audio/mpeg'); // 音频文件
20 header('Content-type: text/css'); //css文件
21 header('Content-type: text/javascript'); //js文件
22 header('Content-type: application/json'); //json
23 header('Content-type: application/pdf'); //pdf
24 header('Content-type: text/xml'); //xml
25 header('Content-Type: application/x-shockw**e-flash'); //Flash动画
fopen打开文件后,不是字符串,不能直接输出。 fgets() 函数用于获取字符串。 fgets() 函数从文件指针读取一行。文件指针必须有效,并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
File_get_contents() 打开网页后会返回一个字符串,可以直接输出。
php抓取网页连接函数(PHP端的操作0.这里我已经配置好了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-08 09:06
一、准备工具、账号、项目等1. 安装QQ小程序开发工具
这是下载地址
我的是win10,64位,我下载的是红箭版。我首先下载了绿色箭头版本。结果只是测试模式。没有找到编辑器,只好再下载一个。
2.申请开发者账号获得APPID
就按照网上的步骤一步一步来,没什么好说的,放个网站就行了
3.创建一个空白项目
进入APPID,微信开发工具也可以测试ID,但是QQ没找到
二、开始在QQ开发工具中操作1.开始尝试连接后台,先封装一个方法,然后连接到后台调用方法
放上图
你可以把这个工具放在任何地方,我只是习惯这样放
这是代码,如果有什么不清楚的,可以查看文档
var ip = "http://127.0.0.1/"; //这个是本机IP,localhost也行,不过我习惯这个了
/**
* 固有方法:封装_连接后台方法
* 备注:如果之后放到服务器上,就只要换上面的那个ip就可以了
* url:这个是连接的接口的路径,之后引用方法的时候会当做参数填入
* data:这个是传入的参数,以后肯定会用到的,
* resolve是连接成功返回的函数,reject是连接失败的函数
*/
const req = function(url,data){
return new Promise((resolve,reject) =>{
qq.request({
url: ip+url,
data:data,
dataType : 'json',
method:'POST',
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success:resolve,
fail:reject
})
})
};
/**
* 导出方法
* 介绍:这个是用来暴露方法的,这样一会在app.js中就可以引用这个方法了
*/
module.exports = {
req: req,
}
2. 在app.js中配置(不知道调用配置行不行,就这样调用)
先放图
这些省略的地方都是新建的时候就有的,所以我省略了。我只在第 5 行向下写了 46。
这是引用该工具包的路径,
var HTTP = require('utils/service/request.js');//创建时间:2019.08.03
这是引用连接的方法,其中req是我放的第一个代码片段中的req
/**
* 注册全局函数
* 创建时间:2019.08.03
*/
func:{
req:HTTP.req,//连接后台方法
}
3.功能页面参考调用方法
放上图
我把页面上的HTML代码改了,全部注释掉,然后放一个按钮,然后把HTML代码
评论并不重要。如果不是重点,我会评论。我先放一个总代码。如果想看里面的内容,也可以看看。然后我把js方法的部分代码放上来。
//index.js
//获取应用实例
const app = getApp();
Page({
data: {
motto: 'Hello World',
userInfo: {},
hasUserInfo: false,
canIUse: qq.canIUse('button.open-type.getUserInfo')
},
//事件处理函数
bindViewTap: function () {
qq.navigateTo({
url: '../logs/logs'
})
},
onLoad: function () {
if (app.globalData.userInfo) {
this.setData({
userInfo: app.globalData.userInfo,
hasUserInfo: true
})
} else if (this.data.canIUse) {
// 由于 getUserInfo 是网络请求,可能会在 Page.onLoad 之后才返回
// 所以此处加入 callback 以防止这种情况
app.userInfoReadyCallback = res => {
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
} else {
// 在没有 open-type=getUserInfo 版本的兼容处理
qq.getUserInfo({
success: res => {
app.globalData.userInfo = res.userInfo
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
})
}
},
getUserInfo: function (e) {
console.log(e)
app.globalData.userInfo = e.detail.userInfo
this.setData({
userInfo: e.detail.userInfo,
hasUserInfo: true
})
},
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this;
const data = {
}
app.func.req('project_text1/index.php',data).then(res => {
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
})
这是js连接后端方法的代码,我详细解释一下有什么
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this; //这个就是讲this提取到that中,如果外层变了,也能找到需要的最外层
const data = { //就是连接后台,啥逻辑都没有,所以这个理论里面就没放数据
}
//单引号里面的是路径,我一会写到PHP的时候,就可以看到了
//data就是传的数据,虽然啥也没有
//因为第一个代码块那里已经用resolve和reject配好了,所以这里.then和.catch就是连接后台成功和失败了
app.func.req('project_text1/index.php',data).then(res => {//然后res和err就是返回数据,前面的单引就是单纯的字符串
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
然后这里是HTML图片
和代码,只有这个有效,其他都注释了,只是这个_ceshi方法连接js测试是否可以连接后台
测试按钮
三、PHP端的操作0.这里我已经在本机配置了运行PHP的软件和写PHP的软件,这里就不展开了。没做完我就先百度一下,补完PHP。1.启动phpStudy,让PHP先跑起来
注意:这里说的是需要配置Apache、MySQL等,其实没必要这么麻烦。互联网上有很多软件问题可以解决所有问题。
比如phpStudy官方版20180211
还有这个WampServer3.0.6 正式版
而这个 Visual NMP 7.0.31 (x64)
我目前使用第一个
这是启动后的截图
2.打开 sublime_text3
我是用这个软件来的,其他的php写也是可以的,不过我是第一次写,其他的还没用过,不知道哪种好用
3.截图我的代码
你看到左边的文件名了吗?我在小终端里就是按照这个写的。
当然你也可以右击右边的黑框,复制文件路径,然后把www和上一个改成127.0.0.1
这里的注释没用,有用的代码我先放上来,因为我是第一次写PHP,所以很多地方不知道。上面的评论都是我试过的。
第二行是返回的类型,我的PHP学习博客稍后详述
第 4 行是我尝试创建一个集合,第 8 行的结果很好。相反,第 4 行变成了两组。
然后,除了 15 行,我尝试打印并返回一些东西。也可以使用第 10 行,避免出现乱码。但是我没有乱码,所以就用了11行的那个。我想这个回报也可以使用。我稍后会尝试。尝试
刚试了一下,就用第10行的,但是代码突然乱码了,就换成第10行的就行了。
4. 然后在google上试试,把路径127.0.0.1\project_text1\index.php
这是替换第10行后的截图
看路径,和我小程序上的路径一模一样,可以用
四、点击小程序0.0 终于到了。虽然尝试了很多次,但这是第一次写博客。至少假装很开心。
点击测试按钮查看控制台输出,这是图片,
看红框就成功了,获取PHP后端的值,这样就可以连接PHP后端了
不得不说PHP后台连接真的很方便,而且还挺小巧的。感觉几个文件都可以用。如果是小项目,就不需要ssm或者springboot框架(我是做Java的)。直接连接就可以使用了,很方便 查看全部
php抓取网页连接函数(PHP端的操作0.这里我已经配置好了(组图))
一、准备工具、账号、项目等1. 安装QQ小程序开发工具
这是下载地址
我的是win10,64位,我下载的是红箭版。我首先下载了绿色箭头版本。结果只是测试模式。没有找到编辑器,只好再下载一个。
2.申请开发者账号获得APPID
就按照网上的步骤一步一步来,没什么好说的,放个网站就行了
3.创建一个空白项目
进入APPID,微信开发工具也可以测试ID,但是QQ没找到
二、开始在QQ开发工具中操作1.开始尝试连接后台,先封装一个方法,然后连接到后台调用方法
放上图
你可以把这个工具放在任何地方,我只是习惯这样放
这是代码,如果有什么不清楚的,可以查看文档
var ip = "http://127.0.0.1/"; //这个是本机IP,localhost也行,不过我习惯这个了
/**
* 固有方法:封装_连接后台方法
* 备注:如果之后放到服务器上,就只要换上面的那个ip就可以了
* url:这个是连接的接口的路径,之后引用方法的时候会当做参数填入
* data:这个是传入的参数,以后肯定会用到的,
* resolve是连接成功返回的函数,reject是连接失败的函数
*/
const req = function(url,data){
return new Promise((resolve,reject) =>{
qq.request({
url: ip+url,
data:data,
dataType : 'json',
method:'POST',
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success:resolve,
fail:reject
})
})
};
/**
* 导出方法
* 介绍:这个是用来暴露方法的,这样一会在app.js中就可以引用这个方法了
*/
module.exports = {
req: req,
}
2. 在app.js中配置(不知道调用配置行不行,就这样调用)
先放图
这些省略的地方都是新建的时候就有的,所以我省略了。我只在第 5 行向下写了 46。
这是引用该工具包的路径,
var HTTP = require('utils/service/request.js');//创建时间:2019.08.03
这是引用连接的方法,其中req是我放的第一个代码片段中的req
/**
* 注册全局函数
* 创建时间:2019.08.03
*/
func:{
req:HTTP.req,//连接后台方法
}
3.功能页面参考调用方法
放上图
我把页面上的HTML代码改了,全部注释掉,然后放一个按钮,然后把HTML代码
评论并不重要。如果不是重点,我会评论。我先放一个总代码。如果想看里面的内容,也可以看看。然后我把js方法的部分代码放上来。
//index.js
//获取应用实例
const app = getApp();
Page({
data: {
motto: 'Hello World',
userInfo: {},
hasUserInfo: false,
canIUse: qq.canIUse('button.open-type.getUserInfo')
},
//事件处理函数
bindViewTap: function () {
qq.navigateTo({
url: '../logs/logs'
})
},
onLoad: function () {
if (app.globalData.userInfo) {
this.setData({
userInfo: app.globalData.userInfo,
hasUserInfo: true
})
} else if (this.data.canIUse) {
// 由于 getUserInfo 是网络请求,可能会在 Page.onLoad 之后才返回
// 所以此处加入 callback 以防止这种情况
app.userInfoReadyCallback = res => {
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
} else {
// 在没有 open-type=getUserInfo 版本的兼容处理
qq.getUserInfo({
success: res => {
app.globalData.userInfo = res.userInfo
this.setData({
userInfo: res.userInfo,
hasUserInfo: true
})
}
})
}
},
getUserInfo: function (e) {
console.log(e)
app.globalData.userInfo = e.detail.userInfo
this.setData({
userInfo: e.detail.userInfo,
hasUserInfo: true
})
},
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this;
const data = {
}
app.func.req('project_text1/index.php',data).then(res => {
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
})
这是js连接后端方法的代码,我详细解释一下有什么
/**
* _方法:测试
* 创建时间:2019.08.03
*/
_ceshi(){
const that = this; //这个就是讲this提取到that中,如果外层变了,也能找到需要的最外层
const data = { //就是连接后台,啥逻辑都没有,所以这个理论里面就没放数据
}
//单引号里面的是路径,我一会写到PHP的时候,就可以看到了
//data就是传的数据,虽然啥也没有
//因为第一个代码块那里已经用resolve和reject配好了,所以这里.then和.catch就是连接后台成功和失败了
app.func.req('project_text1/index.php',data).then(res => {//然后res和err就是返回数据,前面的单引就是单纯的字符串
console.log('后台数据',res);
}).catch(err =>{
console.log('获取数据失败,失败原因',err);
});
}
然后这里是HTML图片
和代码,只有这个有效,其他都注释了,只是这个_ceshi方法连接js测试是否可以连接后台
测试按钮
三、PHP端的操作0.这里我已经在本机配置了运行PHP的软件和写PHP的软件,这里就不展开了。没做完我就先百度一下,补完PHP。1.启动phpStudy,让PHP先跑起来
注意:这里说的是需要配置Apache、MySQL等,其实没必要这么麻烦。互联网上有很多软件问题可以解决所有问题。
比如phpStudy官方版20180211
还有这个WampServer3.0.6 正式版
而这个 Visual NMP 7.0.31 (x64)
我目前使用第一个
这是启动后的截图
2.打开 sublime_text3
我是用这个软件来的,其他的php写也是可以的,不过我是第一次写,其他的还没用过,不知道哪种好用
3.截图我的代码
你看到左边的文件名了吗?我在小终端里就是按照这个写的。
当然你也可以右击右边的黑框,复制文件路径,然后把www和上一个改成127.0.0.1
这里的注释没用,有用的代码我先放上来,因为我是第一次写PHP,所以很多地方不知道。上面的评论都是我试过的。
第二行是返回的类型,我的PHP学习博客稍后详述
第 4 行是我尝试创建一个集合,第 8 行的结果很好。相反,第 4 行变成了两组。
然后,除了 15 行,我尝试打印并返回一些东西。也可以使用第 10 行,避免出现乱码。但是我没有乱码,所以就用了11行的那个。我想这个回报也可以使用。我稍后会尝试。尝试
刚试了一下,就用第10行的,但是代码突然乱码了,就换成第10行的就行了。
4. 然后在google上试试,把路径127.0.0.1\project_text1\index.php
这是替换第10行后的截图
看路径,和我小程序上的路径一模一样,可以用
四、点击小程序0.0 终于到了。虽然尝试了很多次,但这是第一次写博客。至少假装很开心。
点击测试按钮查看控制台输出,这是图片,
看红框就成功了,获取PHP后端的值,这样就可以连接PHP后端了
不得不说PHP后台连接真的很方便,而且还挺小巧的。感觉几个文件都可以用。如果是小项目,就不需要ssm或者springboot框架(我是做Java的)。直接连接就可以使用了,很方便
php抓取网页连接函数(PHP数组实现栈和队列:push,访问会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-29 16:26
下一篇:PHP数组实现栈和队列:push、pop、shif、unshift
本文将介绍一个有用的PHP函数get_browser,该函数可以获取客户端用户使用的浏览器的详细信息。
具体实现代码如下:
访问成功后,输出内容如下:
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7) Gecko/20040803 Firefox/0.9.3
Array
(
[browser_name_regex] => ^mozilla/5\.0 (windows; .; windows nt 5\.1; .*rv:.*) gecko/.* firefox/0\.9.*$
[browser_name_pattern] => Mozilla/5.0 (Windows; ?; Windows NT 5.1; *rv:*) Gecko/* Firefox/0.9*
[parent] => Firefox 0.9
[platform] => WinXP
[browser] => Firefox
[version] => 0.9
[majorver] => 0
[minorver] => 9
[cssversion] => 2
[frames] => 1
[iframes] => 1
[tables] => 1
[cookies] => 1
[backgroundsounds] =>
[vbscript] =>
[javascript] => 1
[javaapplets] => 1
[activexcontrols] =>
[cdf] =>
[aol] =>
[beta] => 1
[win16] =>
[crawler] =>
[stripper] =>
[wap] =>
[netclr] =>
)
因为我用的是火狐浏览器访问,所以上面输出的是我自己浏览器的详细信息。不同的浏览器会根据不同的浏览器返回相应的信息。
2016.6.21 更新说明:有网友反映使用get_browser()函数返回空,下面补充原因和解决办法。
如果get_browser()返回给浏览器的信息为空,或者有警告:get_browser() [function.get-browser]: browscap ini directive not set in xxx.php,那么原因是:因为函数是搜索browscap.ini文件中的浏览器信息,尝试检测用户浏览器的功能,如果你的服务器没有browscap.ini文件,会报错。
解决方案:由于许可问题,PHP 不提供浏览器功能文件。您可以从 Browscap 获取浏览器功能文件。您可以下载 php_browscap.ini 文件。
下载文件后,将其上传到:
(Win下)D:\wamp\bin\php\php5.5.12\browscap.ini 该'D:\wamp\bin\php\php5.5.12\'前缀地址改为你自己 PHP 安装目录的地址
(Linux下) /usr/local/php/lib/php/browscap.ini 该'/usr/local/php/lib/php/'前缀改为你自己 PHP 安装目录地址
同理,上传完成后,需要在php.ini中进行设置(Win下):
browscap=D:\wamp\bin\php\php5.5.12\browscap.ini
或者(Linux 下)
browscap=/usr/local/php/lib/php/browscap.ini
设置后记得重启你的网络服务器。
... psz1992 的其他帖子 查看全部
php抓取网页连接函数(PHP数组实现栈和队列:push,访问会)
下一篇:PHP数组实现栈和队列:push、pop、shif、unshift
本文将介绍一个有用的PHP函数get_browser,该函数可以获取客户端用户使用的浏览器的详细信息。
具体实现代码如下:
访问成功后,输出内容如下:
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7) Gecko/20040803 Firefox/0.9.3
Array
(
[browser_name_regex] => ^mozilla/5\.0 (windows; .; windows nt 5\.1; .*rv:.*) gecko/.* firefox/0\.9.*$
[browser_name_pattern] => Mozilla/5.0 (Windows; ?; Windows NT 5.1; *rv:*) Gecko/* Firefox/0.9*
[parent] => Firefox 0.9
[platform] => WinXP
[browser] => Firefox
[version] => 0.9
[majorver] => 0
[minorver] => 9
[cssversion] => 2
[frames] => 1
[iframes] => 1
[tables] => 1
[cookies] => 1
[backgroundsounds] =>
[vbscript] =>
[javascript] => 1
[javaapplets] => 1
[activexcontrols] =>
[cdf] =>
[aol] =>
[beta] => 1
[win16] =>
[crawler] =>
[stripper] =>
[wap] =>
[netclr] =>
)
因为我用的是火狐浏览器访问,所以上面输出的是我自己浏览器的详细信息。不同的浏览器会根据不同的浏览器返回相应的信息。
2016.6.21 更新说明:有网友反映使用get_browser()函数返回空,下面补充原因和解决办法。
如果get_browser()返回给浏览器的信息为空,或者有警告:get_browser() [function.get-browser]: browscap ini directive not set in xxx.php,那么原因是:因为函数是搜索browscap.ini文件中的浏览器信息,尝试检测用户浏览器的功能,如果你的服务器没有browscap.ini文件,会报错。
解决方案:由于许可问题,PHP 不提供浏览器功能文件。您可以从 Browscap 获取浏览器功能文件。您可以下载 php_browscap.ini 文件。
下载文件后,将其上传到:
(Win下)D:\wamp\bin\php\php5.5.12\browscap.ini 该'D:\wamp\bin\php\php5.5.12\'前缀地址改为你自己 PHP 安装目录的地址
(Linux下) /usr/local/php/lib/php/browscap.ini 该'/usr/local/php/lib/php/'前缀改为你自己 PHP 安装目录地址
同理,上传完成后,需要在php.ini中进行设置(Win下):
browscap=D:\wamp\bin\php\php5.5.12\browscap.ini
或者(Linux 下)
browscap=/usr/local/php/lib/php/browscap.ini
设置后记得重启你的网络服务器。
... psz1992 的其他帖子
php抓取网页连接函数(几天人会_multi系列函数实现此功能(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-28 08:15
这几天在做多搜索引擎关键词排名查询工具,可以及时方便的了解关键词在各大搜索引擎的排名情况。爬360搜索的时候发现360搜索每个页面只支持显示10个搜索结果。如果要得到100条搜索结果数据,就得搜索10次,极大地影响了用户体验。没有人会搜索关键字排名。并愿意等待时间打开网页 10 次。这时候就想到了用多线程来做并发爬取。恰巧curl_multi系列php curl函数可以实现这个功能。
一、curl_multi 系列函数介绍:1. curl_multi_init:
用于初始化一个“curl_multi”句柄,然后将“curl_init”函数生成的多个“curl”句柄传递给“curl_multi”句柄;这个函数不需要参数。
2. curl_multi_add_handle:
“curl_multi_add_handle”函数用于将“curl_init”生成的“curl”句柄添加到上面“curl_multi_init”函数生成的“curl_multi”句柄中。“curl_multi_add_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
3. curl_multi_exec:
“curl_multi_exec”用于发起 curl_multi 请求。“curl_multi_add_handle”函数的第一个参数是“curl_multi”的句柄,第二个参数是一个“引用参数”,记录了未处理的请求数。当第二个参数的值变为0时,表示所有请求都已经处理完毕(所有请求返回成功或超时时间已过)。
4. curl_multi_info_read:
“curl_multi_info_read”函数用于读取curl_multi句柄中是否有curl返回信息。如果有,则返回第一个“curl 返回值(数组形式)”,否则返回“false”。循环调用这个函数,直到它返回“false”;“curl_multi_info_read”的参数是“curl_mulit”的句柄。
5. curl_multi_getcontent:
当所有的curl句柄都处理完后,我们可以使用“curl_multi_getcontent”函数读取“curl”返回的内容。“curl_multi_getcontent”的参数是“curl”句柄。
6. curl_multi_remove_handle:
阅读完内容后,使用“curl_multi_remove_handle”函数从“curl_mulit”句柄中删除所有“curl”句柄。“curl_multi_remove_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
7. curl_multi_close:
“curl_multi_close”函数用于关闭“curl_mulit”句柄并释放占用的资源。“curl_multi_close”的参数是“curl_mulit”的句柄。
二、curl_multi 使用流程:
1、 "curl_multi_init" 初始化 "curl_multi" 句柄;
2、 循环创建并添加“curl”句柄,并使用“curl_multi_add_handle”函数将其添加到“curl_multi”句柄中;
3、 使用“curl_multi_exec”发起请求,等待所有请求处理完毕;
4、 使用“curl_multi_info_read”函数读取返回值;
5、 使用“curl_multi_getcontent”函数读取返回的内容;
6、 使用“curl_multi_remove_handle”函数去除curl句柄;
7、 使用“curl_multi_close”关闭 curl_multi 句柄。
三、以下是我使用curl_multi多线程并发抓取360搜索结果的代码片段:#多线程并发抓取函数mfetch:
<p> 查看全部
php抓取网页连接函数(几天人会_multi系列函数实现此功能(图))
这几天在做多搜索引擎关键词排名查询工具,可以及时方便的了解关键词在各大搜索引擎的排名情况。爬360搜索的时候发现360搜索每个页面只支持显示10个搜索结果。如果要得到100条搜索结果数据,就得搜索10次,极大地影响了用户体验。没有人会搜索关键字排名。并愿意等待时间打开网页 10 次。这时候就想到了用多线程来做并发爬取。恰巧curl_multi系列php curl函数可以实现这个功能。
一、curl_multi 系列函数介绍:1. curl_multi_init:
用于初始化一个“curl_multi”句柄,然后将“curl_init”函数生成的多个“curl”句柄传递给“curl_multi”句柄;这个函数不需要参数。
2. curl_multi_add_handle:
“curl_multi_add_handle”函数用于将“curl_init”生成的“curl”句柄添加到上面“curl_multi_init”函数生成的“curl_multi”句柄中。“curl_multi_add_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
3. curl_multi_exec:
“curl_multi_exec”用于发起 curl_multi 请求。“curl_multi_add_handle”函数的第一个参数是“curl_multi”的句柄,第二个参数是一个“引用参数”,记录了未处理的请求数。当第二个参数的值变为0时,表示所有请求都已经处理完毕(所有请求返回成功或超时时间已过)。
4. curl_multi_info_read:
“curl_multi_info_read”函数用于读取curl_multi句柄中是否有curl返回信息。如果有,则返回第一个“curl 返回值(数组形式)”,否则返回“false”。循环调用这个函数,直到它返回“false”;“curl_multi_info_read”的参数是“curl_mulit”的句柄。
5. curl_multi_getcontent:
当所有的curl句柄都处理完后,我们可以使用“curl_multi_getcontent”函数读取“curl”返回的内容。“curl_multi_getcontent”的参数是“curl”句柄。
6. curl_multi_remove_handle:
阅读完内容后,使用“curl_multi_remove_handle”函数从“curl_mulit”句柄中删除所有“curl”句柄。“curl_multi_remove_handle”函数的第一个参数是“curl_multi”句柄,第二个参数是“curl”句柄。
7. curl_multi_close:
“curl_multi_close”函数用于关闭“curl_mulit”句柄并释放占用的资源。“curl_multi_close”的参数是“curl_mulit”的句柄。
二、curl_multi 使用流程:
1、 "curl_multi_init" 初始化 "curl_multi" 句柄;
2、 循环创建并添加“curl”句柄,并使用“curl_multi_add_handle”函数将其添加到“curl_multi”句柄中;
3、 使用“curl_multi_exec”发起请求,等待所有请求处理完毕;
4、 使用“curl_multi_info_read”函数读取返回值;
5、 使用“curl_multi_getcontent”函数读取返回的内容;
6、 使用“curl_multi_remove_handle”函数去除curl句柄;
7、 使用“curl_multi_close”关闭 curl_multi 句柄。
三、以下是我使用curl_multi多线程并发抓取360搜索结果的代码片段:#多线程并发抓取函数mfetch:
<p>

