
js 抓取网页内容
js 抓取网页内容( 没错就是下方那些卡哇伊的蛋糕,哇哇哇~!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-10-08 03:11
没错就是下方那些卡哇伊的蛋糕,哇哇哇~!!
)
<p>Node.js的学习中,可用于抓取其他网站的模块是【cheerio】,这个模块并不是node的内置模块,所以首先我们需要先安装一下:
安装对应模块
安装命令:
npm install cheerio</p>
明确获取对象
cheerio 安装完成后,我们就可以开始抓取数据了。说清楚需要抓取的内容是甜点网站,需要抓取的代码如下:
如图,需要抓拍的内容就是图中标注的img图片,没错,就是下面的卡哇伊蛋糕,哇哇~好想吃,名字也好! ! !
开始抓取
好的,我们已经明确了要爬取的内容,现在开始爬取。在此之前,我们需要知道 Cheerio 收录了 jQuery 核心的一个子集,这意味着在操作 Cheerio 时,使用 JQ 相关语法就可以了,是不是很酷,哈哈哈,开始编码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
得到的图片链接,打印如下图片:
为了验证信息的准确性,也为了让博文页面不那么好吃,请点击我抓取的第一个链接的可爱甜点图片并附上:
查看全部
js 抓取网页内容(
没错就是下方那些卡哇伊的蛋糕,哇哇哇~!!
)
<p>Node.js的学习中,可用于抓取其他网站的模块是【cheerio】,这个模块并不是node的内置模块,所以首先我们需要先安装一下:
安装对应模块
安装命令:
npm install cheerio</p>
明确获取对象
cheerio 安装完成后,我们就可以开始抓取数据了。说清楚需要抓取的内容是甜点网站,需要抓取的代码如下:
如图,需要抓拍的内容就是图中标注的img图片,没错,就是下面的卡哇伊蛋糕,哇哇~好想吃,名字也好! ! !

开始抓取
好的,我们已经明确了要爬取的内容,现在开始爬取。在此之前,我们需要知道 Cheerio 收录了 jQuery 核心的一个子集,这意味着在操作 Cheerio 时,使用 JQ 相关语法就可以了,是不是很酷,哈哈哈,开始编码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
得到的图片链接,打印如下图片:

为了验证信息的准确性,也为了让博文页面不那么好吃,请点击我抓取的第一个链接的可爱甜点图片并附上:
js 抓取网页内容(国内docker仓库镜像对比安装运行Splash.jsJS渲染解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-08 03:09
)
随着越来越多的网站开始使用JS在客户端浏览器中动态渲染网站,我们需要的很多数据无法从原来的html中获取,加上Scrapy没有提供JS渲染分析功能。我们通常使用两种方法来抓取这种类型的网站数据:
通过分析网站,找到对应的数据接口,并模拟该接口获取我们需要的数据(见Scrapy捕捉Ajax动态页面),但是一旦网站接口被隐藏得很深,或者接口的加密太复杂了。这种方法可能行不通。在JS内核的帮助下,将获取到的收录JS脚本的页面交给JS内核进行渲染,最后将渲染出来的html返回给Scrapy进行分析,比较常见的就是WebKit和Scrapy-Splash
本文文章的目的是介绍如何使用Scrapy-Splash配合Scrapy抓取动态页面。
准备工作
Docker安装,具体安装步骤参考Docker官网
为什么要安装 Docker?
因为Scrapy-Splash使用Splash HTTP API,所以需要提供一个Splash实例,而且Docker镜像中有现成的Splash实例,使用起来非常方便。
Docker 镜像源变更,参考国内docker仓库镜像对比
安装并运行 Splash
docker pull scrapinghub/splash #从docker镜像中拉取splash实例
docker run -p 8050:8050 scrapinghub/splash #启动splash实例
Scrapy 配置
在Scrapy项目的setting.py中添加如下内容:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
实际代码分析
我们以腾讯证券的页面为例。腾讯证券新闻列表由js动态渲染
我们直接打开这个链接,然后打开开发者工具,找到新闻列表:
当我们查看第一个来自网络的请求的响应时,发现返回的html中的列表页面是空的
实际数据隐藏在JS中,加载完成后由JS操作DOM插入。
这里,由于实际数据是塞进一段js变量中的,不是通过ajax调用接口获取的,所以为了避免自己手动拦截js变量,我们将页面交给Scrapy-Splash用于渲染
import scrapy
from FinancialInfoSpider.items import ArticleItem
from scrapy_splash import SplashRequest
from w3lib.html import remove_tags
import re
from bs4 import BeautifulSoup
class TencentStockSpider(scrapy.Spider):
name = "TencentStock"
def start_requests(self):
urls = [
'http://stock.qq.com/l/stock/ywq/list20150423143546.htm',
]
for url in urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self,response):
sel = scrapy.Selector(response)
links = sel.xpath("//div[@class='qq_main']//ul[@class='listInfo']//li//div[@class='info']//h3//a/@href").extract()
requests = []
for link in links:
request = scrapy.Request(link, callback =self.parse_article)
requests.append(request)
return requests
def parse_article(self,response):
sel = scrapy.Selector(response)
article = ArticleItem()
article['title'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/h1/text()').extract()[0]
article['source'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[2]').xpath('string(.)').extract()[0]
article['pub_time'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[3]/text()').extract()[0]
html_content = sel.xpath('//*[@id="Cnt-Main-Article-QQ"]').extract()[0]
article['content'] = self.remove_html_tags(html_content)
return article
def remove_html_tags(self,html):
soup = BeautifulSoup(html)
[s.extract() for s in soup('script')]
[s.extract() for s in soup('style')]
content = ''
for substring in soup.stripped_strings:
content = content + substring
return content
主要代码就一句话,将获取到的页面发送到本地Splash实例进行渲染解析,最后将结果返回给parse函数进行解析
SplashRequest(url, self.parse, args={'wait': 0.5})
里面使用了 BeautifulSoup 库,用于去除 html 中的 script 和 style 标签。具体用法可以参考这两篇文章文章:
Python第二个爬虫工具Beautiful Soup的使用
使用 BeautifulSoup 删除 html 中的脚本和注释
输出结果:
查看全部
js 抓取网页内容(国内docker仓库镜像对比安装运行Splash.jsJS渲染解析
)
随着越来越多的网站开始使用JS在客户端浏览器中动态渲染网站,我们需要的很多数据无法从原来的html中获取,加上Scrapy没有提供JS渲染分析功能。我们通常使用两种方法来抓取这种类型的网站数据:
通过分析网站,找到对应的数据接口,并模拟该接口获取我们需要的数据(见Scrapy捕捉Ajax动态页面),但是一旦网站接口被隐藏得很深,或者接口的加密太复杂了。这种方法可能行不通。在JS内核的帮助下,将获取到的收录JS脚本的页面交给JS内核进行渲染,最后将渲染出来的html返回给Scrapy进行分析,比较常见的就是WebKit和Scrapy-Splash
本文文章的目的是介绍如何使用Scrapy-Splash配合Scrapy抓取动态页面。
准备工作
Docker安装,具体安装步骤参考Docker官网
为什么要安装 Docker?
因为Scrapy-Splash使用Splash HTTP API,所以需要提供一个Splash实例,而且Docker镜像中有现成的Splash实例,使用起来非常方便。
Docker 镜像源变更,参考国内docker仓库镜像对比
安装并运行 Splash
docker pull scrapinghub/splash #从docker镜像中拉取splash实例
docker run -p 8050:8050 scrapinghub/splash #启动splash实例
Scrapy 配置
在Scrapy项目的setting.py中添加如下内容:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
实际代码分析
我们以腾讯证券的页面为例。腾讯证券新闻列表由js动态渲染
我们直接打开这个链接,然后打开开发者工具,找到新闻列表:

当我们查看第一个来自网络的请求的响应时,发现返回的html中的列表页面是空的
实际数据隐藏在JS中,加载完成后由JS操作DOM插入。
这里,由于实际数据是塞进一段js变量中的,不是通过ajax调用接口获取的,所以为了避免自己手动拦截js变量,我们将页面交给Scrapy-Splash用于渲染
import scrapy
from FinancialInfoSpider.items import ArticleItem
from scrapy_splash import SplashRequest
from w3lib.html import remove_tags
import re
from bs4 import BeautifulSoup
class TencentStockSpider(scrapy.Spider):
name = "TencentStock"
def start_requests(self):
urls = [
'http://stock.qq.com/l/stock/ywq/list20150423143546.htm',
]
for url in urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self,response):
sel = scrapy.Selector(response)
links = sel.xpath("//div[@class='qq_main']//ul[@class='listInfo']//li//div[@class='info']//h3//a/@href").extract()
requests = []
for link in links:
request = scrapy.Request(link, callback =self.parse_article)
requests.append(request)
return requests
def parse_article(self,response):
sel = scrapy.Selector(response)
article = ArticleItem()
article['title'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/h1/text()').extract()[0]
article['source'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[2]').xpath('string(.)').extract()[0]
article['pub_time'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[3]/text()').extract()[0]
html_content = sel.xpath('//*[@id="Cnt-Main-Article-QQ"]').extract()[0]
article['content'] = self.remove_html_tags(html_content)
return article
def remove_html_tags(self,html):
soup = BeautifulSoup(html)
[s.extract() for s in soup('script')]
[s.extract() for s in soup('style')]
content = ''
for substring in soup.stripped_strings:
content = content + substring
return content
主要代码就一句话,将获取到的页面发送到本地Splash实例进行渲染解析,最后将结果返回给parse函数进行解析
SplashRequest(url, self.parse, args={'wait': 0.5})
里面使用了 BeautifulSoup 库,用于去除 html 中的 script 和 style 标签。具体用法可以参考这两篇文章文章:
Python第二个爬虫工具Beautiful Soup的使用
使用 BeautifulSoup 删除 html 中的脚本和注释
输出结果:
js 抓取网页内容( 这是17K的一个小说章节,内容是通过JS加载的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-06 12:02
这是17K的一个小说章节,内容是通过JS加载的
)
http://www.17k.com/chapter/76839/8810097.html
这是17世纪小说的一章。内容是通过JS加载的。当我们使用httpclient获取它时,我们无法获取章节的具体内容,因为我们得到的是原创页面
使用htmlunit模拟浏览器以获取执行的HTML页面,然后您可以获取所需的特定内容^_^
public class HtmlUnitTest {
public static void main(String[] args) throws Exception {
// 新建一个WebClient对象,此对象相当于浏览器
final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
// 构造一个URL
URL url = new URL("http://www.17k.com/chapter/76839/8810097.html");
// 通过getPage()方法,返回相应的页面
HtmlPage page = (HtmlPage) webClient.getPage(url);
System.out.println(page.getHtmlElementById("chapterContent").asText());
}
} 查看全部
js 抓取网页内容(
这是17K的一个小说章节,内容是通过JS加载的
)
http://www.17k.com/chapter/76839/8810097.html
这是17世纪小说的一章。内容是通过JS加载的。当我们使用httpclient获取它时,我们无法获取章节的具体内容,因为我们得到的是原创页面
使用htmlunit模拟浏览器以获取执行的HTML页面,然后您可以获取所需的特定内容^_^
public class HtmlUnitTest {
public static void main(String[] args) throws Exception {
// 新建一个WebClient对象,此对象相当于浏览器
final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
// 构造一个URL
URL url = new URL("http://www.17k.com/chapter/76839/8810097.html";);
// 通过getPage()方法,返回相应的页面
HtmlPage page = (HtmlPage) webClient.getPage(url);
System.out.println(page.getHtmlElementById("chapterContent").asText());
}
}
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-06 11:28
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
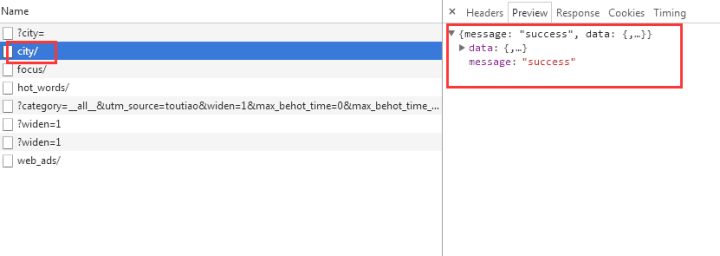
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
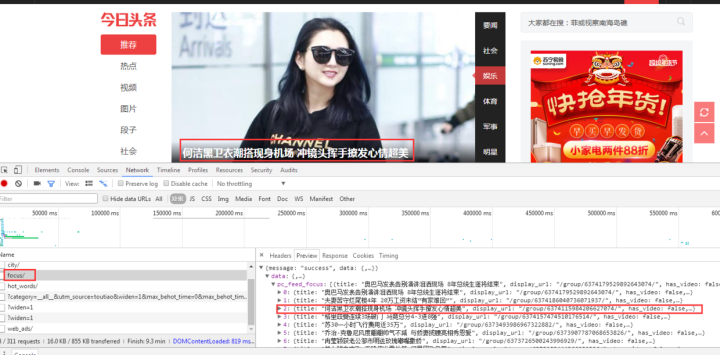
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
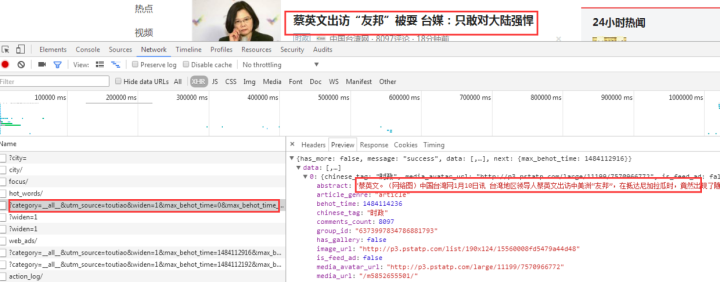
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
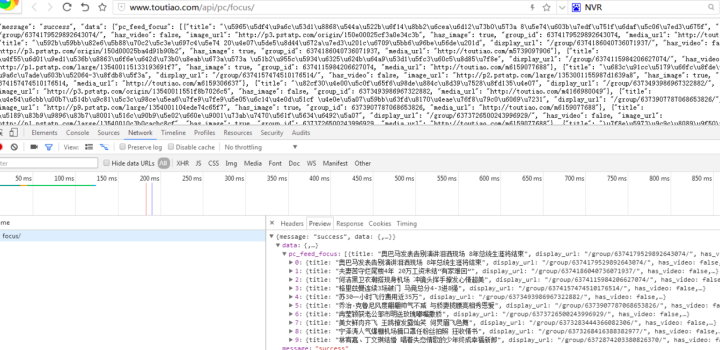
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:

查看源码,却是如下图:

网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具

网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:

让我们再次点击它:

原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:

图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这个应该是热搜关键词

这是照片新闻下的新闻。
我们打开一个接口链接看看:

返回一串乱码,但是从响应中查看的是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:

像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(方法如下最后得到的源码:其它的代码和点击打开链接这篇文章相比几乎没变)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-05 09:10
上次不是写了一个博客访问的自动爬取(点击打开链接),但是昨晚再跑的时候,发现不能用了。.
运行了几次,发现使用URLConnection得到的网页源码和浏览器直接看到的不一样。URLConnection 使用 IO 流读取的源代码
只有积分没有访问
并使用浏览器直接访问查看源码
有参观。
这也导致我的程序无法使用,需要更新。
想想看。原因可能是后台的主机把流量放在js里面进行动态展示,而我用来访问URLConnection的静态接口没有收到。
于是百度从过去开始百度来百度。.
发现一个帖子三年没发了
java爬虫项目中js执行后如何获取完整的网页源码?
多方回复,发现有htmlunit,于是自己测试了下
发现确实有效。js执行后获取源码。
别废话了。
方法如下
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// TODO Auto-generated method stub
WebClient wc=new WebClient(BrowserVersion.FIREFOX_24);
wc.setJavaScriptTimeout(5000);
wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
wc.getOptions().setCssEnabled(false);//禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
wc.getOptions().setTimeout(100000);//设置连接超时时间
wc.getOptions().setDoNotTrackEnabled(false);
HtmlPage page=wc.getPage("http://blog.csdn.net/su2014510 ... 6quot;);
String res=page.asText();
//处理源码
deal(res);
}
最终的源代码如下:
其他代码和这个文章相比几乎没有变化,点击打开链接。不明白的可以看这里,不再赘述。
执行后成功写入txt文件
使用htmlunit时会弹出很多异常警告
添加这些代码,它就会消失~
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit")
.setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient")
.setLevel(Level.OFF);
由于我们这里引入了htmlunit jar包,如果使用上次的脚本批处理是不行的~
而且要导入的jar包不是一个或多个,需要批量处理。
首先,我们需要使用 -cp 命令导入我们需要的所有 jar 包。
但是htmlunit的jar包太多了,于是想到了一个办法,用for循环遍历htmlunit文件夹中的jar文件,处理成字符串,然后使用-cp命令。整个代码如下
echo off
setlocal enabledelayedexpansion
::定义一个字符串
set str=
::遍历htmlunit文件夹
for /f "delims=" %%a in ('dir /b "E:\lib\htmlunit-2.14-bin\lib\*.jar"') do (
set "str=!str!E:\lib\htmlunit-2.14-bin\lib\%%a;"
)
echo on
e:
javac -cp .;%str% AutoMarkBlogView.java
java -cp .;%str% AutoMarkBlogView
pause
操作结果如下:
htmlunit jar包下载 查看全部
js 抓取网页内容(方法如下最后得到的源码:其它的代码和点击打开链接这篇文章相比几乎没变)
上次不是写了一个博客访问的自动爬取(点击打开链接),但是昨晚再跑的时候,发现不能用了。.
运行了几次,发现使用URLConnection得到的网页源码和浏览器直接看到的不一样。URLConnection 使用 IO 流读取的源代码
只有积分没有访问

并使用浏览器直接访问查看源码

有参观。
这也导致我的程序无法使用,需要更新。
想想看。原因可能是后台的主机把流量放在js里面进行动态展示,而我用来访问URLConnection的静态接口没有收到。
于是百度从过去开始百度来百度。.
发现一个帖子三年没发了
java爬虫项目中js执行后如何获取完整的网页源码?
多方回复,发现有htmlunit,于是自己测试了下
发现确实有效。js执行后获取源码。
别废话了。
方法如下
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// TODO Auto-generated method stub
WebClient wc=new WebClient(BrowserVersion.FIREFOX_24);
wc.setJavaScriptTimeout(5000);
wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
wc.getOptions().setCssEnabled(false);//禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
wc.getOptions().setTimeout(100000);//设置连接超时时间
wc.getOptions().setDoNotTrackEnabled(false);
HtmlPage page=wc.getPage("http://blog.csdn.net/su2014510 ... 6quot;);
String res=page.asText();
//处理源码
deal(res);
}
最终的源代码如下:

其他代码和这个文章相比几乎没有变化,点击打开链接。不明白的可以看这里,不再赘述。
执行后成功写入txt文件

使用htmlunit时会弹出很多异常警告
添加这些代码,它就会消失~
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit")
.setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient")
.setLevel(Level.OFF);
由于我们这里引入了htmlunit jar包,如果使用上次的脚本批处理是不行的~
而且要导入的jar包不是一个或多个,需要批量处理。
首先,我们需要使用 -cp 命令导入我们需要的所有 jar 包。
但是htmlunit的jar包太多了,于是想到了一个办法,用for循环遍历htmlunit文件夹中的jar文件,处理成字符串,然后使用-cp命令。整个代码如下
echo off
setlocal enabledelayedexpansion
::定义一个字符串
set str=
::遍历htmlunit文件夹
for /f "delims=" %%a in ('dir /b "E:\lib\htmlunit-2.14-bin\lib\*.jar"') do (
set "str=!str!E:\lib\htmlunit-2.14-bin\lib\%%a;"
)
echo on
e:
javac -cp .;%str% AutoMarkBlogView.java
java -cp .;%str% AutoMarkBlogView
pause
操作结果如下:
htmlunit jar包下载
js 抓取网页内容(html和js抓取网页内容的安全性?如何确定,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-04 16:05
js抓取网页内容,在没有明确限制时是可以自由抓取的,那么,只有抓取html和sql时才是不安全的,在有限的情况下,如何提高js抓取网页内容的安全性?所以,抓取html和js抓取网页内容时,需要做到页面结构的安全和确定。如何确定,
1、制定无效请求代码,如网站的url结构等,
2、请求代码经过审查元素后发现post参数等字段对应的值属于安全值,
3、不显示html,直接提交ajax请求,
4、js动态处理,发现post数据可以只列举,但是实际数据格式不清晰,此时可使用判断responseheader内容,如果ok的话再让js逻辑处理数据,效果不错,如果判断失败,则会有无效请求代码,调整后可以抓取成功。
前端的http请求大部分都是可以被js代码操作的。functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}抓取百度首页,最简单的是web浏览器=》network=》就可以抓取抓取地址tagpleaseenterthedivpage1.0一般的只能抓取到首页。 查看全部
js 抓取网页内容(html和js抓取网页内容的安全性?如何确定,)
js抓取网页内容,在没有明确限制时是可以自由抓取的,那么,只有抓取html和sql时才是不安全的,在有限的情况下,如何提高js抓取网页内容的安全性?所以,抓取html和js抓取网页内容时,需要做到页面结构的安全和确定。如何确定,
1、制定无效请求代码,如网站的url结构等,
2、请求代码经过审查元素后发现post参数等字段对应的值属于安全值,
3、不显示html,直接提交ajax请求,
4、js动态处理,发现post数据可以只列举,但是实际数据格式不清晰,此时可使用判断responseheader内容,如果ok的话再让js逻辑处理数据,效果不错,如果判断失败,则会有无效请求代码,调整后可以抓取成功。
前端的http请求大部分都是可以被js代码操作的。functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}抓取百度首页,最简单的是web浏览器=》network=》就可以抓取抓取地址tagpleaseenterthedivpage1.0一般的只能抓取到首页。
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-03 03:14
)
在上一篇文章()中,我们采用了模拟打开浏览器的方法,模拟点击网页中的Load More来动态加载网页,获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻孩子的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
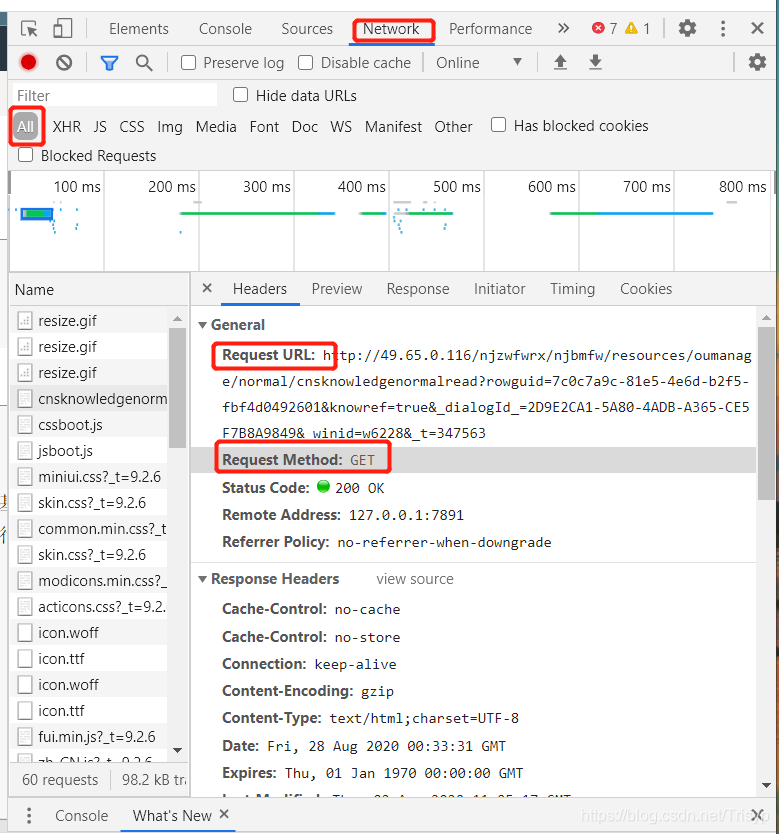
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
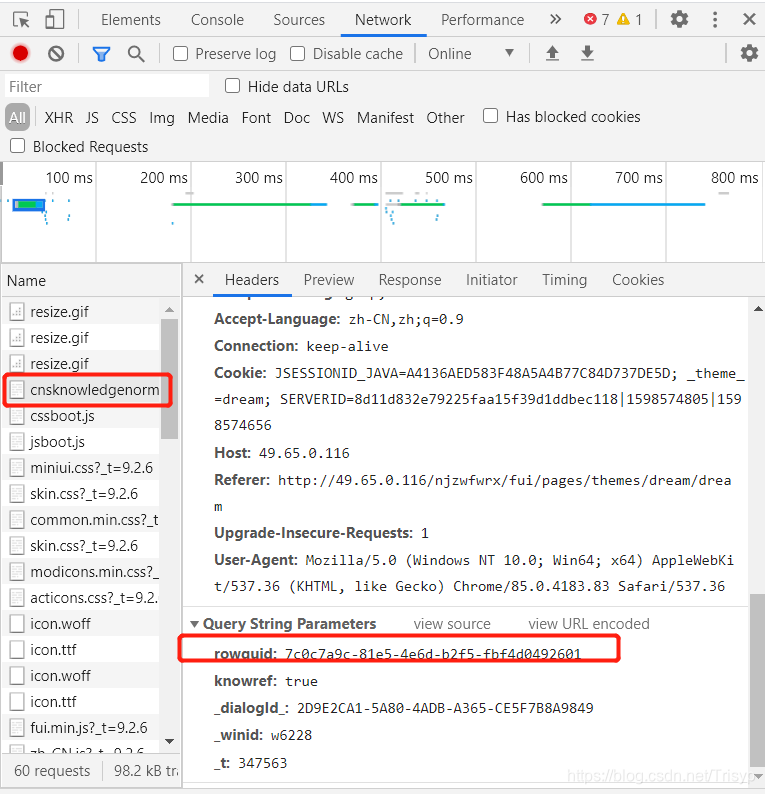
排除图片、gif、css等。如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标头
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
查看全部
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章()中,我们采用了模拟打开浏览器的方法,模拟点击网页中的Load More来动态加载网页,获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻孩子的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标头
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
js 抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-03 03:13
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理收录JavaScript执行结果的网页时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上问过这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中…… 查看全部
js 抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理收录JavaScript执行结果的网页时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上问过这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:


查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中……
js 抓取网页内容(pyopenssl.whl安装的时候需要用pipinstall?.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-03 03:10
)
最近在学习scrapy爬取动态js加载页面,写这个做个记录。
scrapy需要的环境是python2.7+lxml+pyopenssl+twisted+pywin32等,网上有教程可以参考等,注意安装pyopenssl.whl时需要使用pip install。 ..whl 另外,如果使用mysql,需要安装mysqldb模块。
最佳安装教程:
补充:scrapy1.1中支持Python3。官方文档说在linux环境下只支持python3,但是windows下也可以试试。供参考,中间需要手动下载lxml,使用pip install。..whl 执行安装,手动安装pypiwin32,然后导入twisted.txt的两个文件。
入门教程看官方文档,英文原版和中文版#topics-selectors-htmlcode。
Xpath是scrapy内置的一个比较简单的dom解析方法,但是作为一个习惯了php的simple_html_dom解析的人,还是很偏向xpath的。Xpath 过于严格,无法通过跳跃进行查询。必须逐层解析。,虽然xpath很麻烦,但是比较容易出错。Response.xpath().extract() 和 response.xpath().re() 以列表的形式执行。这点需要注意,在存储数据库时需要注意。此外,它的执行将由 Unicode 编码。在 re() 中执行常规匹配时,似乎需要 re(u'')。似乎是这样。这还没有完全理解。我在互联网上看到过。将研究 re(r'') 的措辞。. .
还有一种解析的方法,也是scrapy内置的css选择器。具体选拔文件可在w3cschool查阅。这里有一个选择方法,比如: li:nth-of-type(2) 是选择的第二个li节点
在使用scrapy的过程中,重点学习了如何抓取动态js加载的页面。现在很多网站在源代码中没有太多信息。主要信息只有从js文件加载后才能在review元素中找到。
所以现在我们需要一些东西来模拟浏览器,phantomjs是一个强大的模拟浏览器的工具,phantomjs是一个很小的浏览器内核,调用它可以非常方便快捷地进行分析。
cmd = 'phantomjs constructDom.js "%s"' % response.url
print "cmd:",cmd
stdout,stderr = subprocess.Popen(cmd,shell= True,stdout = subprocess.PIPE,stderr = subprocess.PIPE).communicate()
sel = Selector(text=stdout)
constructDom.js是一个解析网页的js,这是在网上的一段代码,拿来使用了
var page = require('webpage').create(),
system = require('system'),
address;
if(system.args.length === 1){
phantom.exit(1);
}else{
address = system.args[1];
page.open(address, function (status){
if(status !== 'success'){
phantom.exit();
}else{
var sc = page.evaluate(function(){
return document.body.innerHTML;
});
window.setTimeout(function (){
console.log(sc);
phantom.exit();
},1000);
}
});
}
上面四句展示了一个调用过程,这里只是调用了它的接口,我对phantomjs还没有太了解。
有时候需要让页面停留一段时间以等待加载,这时候得需要js代码sleep一段时间,但是js又没有sleep这个方法,而setTimeOut相当于另起了一个线程,并不能实现所需的sleep功能,下面一段代码可以间接的实现sleep的功能,相当于sleep了1秒钟。
<p>var t = Date.now();
function sleep(d){
while(Date.now - t 查看全部
js 抓取网页内容(pyopenssl.whl安装的时候需要用pipinstall?..
)
最近在学习scrapy爬取动态js加载页面,写这个做个记录。
scrapy需要的环境是python2.7+lxml+pyopenssl+twisted+pywin32等,网上有教程可以参考等,注意安装pyopenssl.whl时需要使用pip install。 ..whl 另外,如果使用mysql,需要安装mysqldb模块。
最佳安装教程:
补充:scrapy1.1中支持Python3。官方文档说在linux环境下只支持python3,但是windows下也可以试试。供参考,中间需要手动下载lxml,使用pip install。..whl 执行安装,手动安装pypiwin32,然后导入twisted.txt的两个文件。
入门教程看官方文档,英文原版和中文版#topics-selectors-htmlcode。
Xpath是scrapy内置的一个比较简单的dom解析方法,但是作为一个习惯了php的simple_html_dom解析的人,还是很偏向xpath的。Xpath 过于严格,无法通过跳跃进行查询。必须逐层解析。,虽然xpath很麻烦,但是比较容易出错。Response.xpath().extract() 和 response.xpath().re() 以列表的形式执行。这点需要注意,在存储数据库时需要注意。此外,它的执行将由 Unicode 编码。在 re() 中执行常规匹配时,似乎需要 re(u'')。似乎是这样。这还没有完全理解。我在互联网上看到过。将研究 re(r'') 的措辞。. .
还有一种解析的方法,也是scrapy内置的css选择器。具体选拔文件可在w3cschool查阅。这里有一个选择方法,比如: li:nth-of-type(2) 是选择的第二个li节点
在使用scrapy的过程中,重点学习了如何抓取动态js加载的页面。现在很多网站在源代码中没有太多信息。主要信息只有从js文件加载后才能在review元素中找到。
所以现在我们需要一些东西来模拟浏览器,phantomjs是一个强大的模拟浏览器的工具,phantomjs是一个很小的浏览器内核,调用它可以非常方便快捷地进行分析。
cmd = 'phantomjs constructDom.js "%s"' % response.url
print "cmd:",cmd
stdout,stderr = subprocess.Popen(cmd,shell= True,stdout = subprocess.PIPE,stderr = subprocess.PIPE).communicate()
sel = Selector(text=stdout)
constructDom.js是一个解析网页的js,这是在网上的一段代码,拿来使用了
var page = require('webpage').create(),
system = require('system'),
address;
if(system.args.length === 1){
phantom.exit(1);
}else{
address = system.args[1];
page.open(address, function (status){
if(status !== 'success'){
phantom.exit();
}else{
var sc = page.evaluate(function(){
return document.body.innerHTML;
});
window.setTimeout(function (){
console.log(sc);
phantom.exit();
},1000);
}
});
}
上面四句展示了一个调用过程,这里只是调用了它的接口,我对phantomjs还没有太了解。
有时候需要让页面停留一段时间以等待加载,这时候得需要js代码sleep一段时间,但是js又没有sleep这个方法,而setTimeOut相当于另起了一个线程,并不能实现所需的sleep功能,下面一段代码可以间接的实现sleep的功能,相当于sleep了1秒钟。
<p>var t = Date.now();
function sleep(d){
while(Date.now - t
js 抓取网页内容(1.安装phantomjs网上有很多。执行官网上的示例代码3.执行状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-03 03:05
1.安装phantomjs
网上有很多
2.在官方网站上执行示例代码
// Read the Phantom webpage '#intro' element text using jQuery and "includeJs"
"use strict";
var page = require('webpage').create();
page.onConsoleMessage = function(msg) {
console.log(msg);
};
page.open("http://phantomjs.org/", function(status) {
if (status === "success") {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
console.log("$(\".explanation\").text() -> " + $(".explanation").text());
});
phantom.exit(0);
});
} else {
phantom.exit(1);
}
});
3.执行状态一直卡在那里,不报告错误,不允许退出
要查看程序的内部执行状态,请添加操作日志
page.onResourceRequested = function (req) {
console.log('requested: ' + JSON.stringify(req, undefined, 4));
};
page.onResourceReceived = function (res) {
console.log('received: ' + JSON.stringify(res, undefined, 4));
};
4.发现该程序被困在JS请求中
http://ajax.googleapis.com/aja ... in.js
5.只需在您自己的服务器上使用Python的simplehttpserver构建一个HTTP服务器。首先通过FQ下载JS并将其放到web上
6.修改代码并将includejs指向您自己的HTTP服务器
备注:
在调试期间,phantomjs中发现的另一个问题是page.open是异步执行的,如下代码所示:
var webPage = require('webpage');
var page = webPage.create();
page.open('http://www.baidu.com/', function(status) {
console.log('Status: ' + status);
// Do other things here...
});
phantom.exit(1)
完成执行后,打印返回值echo$?,将得到1
你把
phantom.exit(1)
注释之后,您将获得状态值 查看全部
js 抓取网页内容(1.安装phantomjs网上有很多。执行官网上的示例代码3.执行状态)
1.安装phantomjs
网上有很多
2.在官方网站上执行示例代码
// Read the Phantom webpage '#intro' element text using jQuery and "includeJs"
"use strict";
var page = require('webpage').create();
page.onConsoleMessage = function(msg) {
console.log(msg);
};
page.open("http://phantomjs.org/", function(status) {
if (status === "success") {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
console.log("$(\".explanation\").text() -> " + $(".explanation").text());
});
phantom.exit(0);
});
} else {
phantom.exit(1);
}
});
3.执行状态一直卡在那里,不报告错误,不允许退出
要查看程序的内部执行状态,请添加操作日志
page.onResourceRequested = function (req) {
console.log('requested: ' + JSON.stringify(req, undefined, 4));
};
page.onResourceReceived = function (res) {
console.log('received: ' + JSON.stringify(res, undefined, 4));
};
4.发现该程序被困在JS请求中
http://ajax.googleapis.com/aja ... in.js
5.只需在您自己的服务器上使用Python的simplehttpserver构建一个HTTP服务器。首先通过FQ下载JS并将其放到web上
6.修改代码并将includejs指向您自己的HTTP服务器
备注:
在调试期间,phantomjs中发现的另一个问题是page.open是异步执行的,如下代码所示:
var webPage = require('webpage');
var page = webPage.create();
page.open('http://www.baidu.com/', function(status) {
console.log('Status: ' + status);
// Do other things here...
});
phantom.exit(1)
完成执行后,打印返回值echo$?,将得到1
你把
phantom.exit(1)
注释之后,您将获得状态值
js 抓取网页内容(不同如何调整网站已经运营js导航栏搜索引擎有效的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-30 17:03
不同的网站虽然各有千秋,但大部分都离不开网站的一些基本元素,比如网站导航。几乎每一个网站都有一个布局,无论是对用户还是搜索引擎都有很好的引导作用,但有些网站网站建的比较早或者模板已经过时了。导航是使用 JS 调用完成的。我们都知道js搜索引擎几乎不会爬,所以一个网站导航栏搜索引擎都认不出来,而且网站的关键词排名也很难做好. 那么,页面中的导航被JS调用了,如何调整页面SEO呢?
基于网站策划的经验,我们认为:
1.如何调整
网站 运行了一段时间,发现导航栏被js调用了。一般我们在做seo外包的时候都会遇到这样的问题。我们可以:
①更换
如果网站很久没有上线,页面不是太多,我们可以通过修改网站导航栏来解决这个问题。如果修改麻烦,也可以直接替换网页模板。改成非js,flash网站。
②导航
如果网站已经成为收录并且有一定的排名,我们不能轻易破坏现有的关键词排名,我们可以考虑在网站中加入子导航,这样seo 策略,曾经作为双导航出现,非常有效,但是现在优化算法迭代,这个方法早就失效了,但是在js导航中却是有效的网站,因为js导航本身并没有被抓取搜索引擎。而你设置的子导航会代替导航的作用,一般可以放在网站的底部。
③面包屑导航
增加一些导航次数并不代表就可以解决网站的排名问题。尤其是如果只是添加第二个导航,搜索引擎还是需要一定的时间来识别。这时候如果网站没有面包屑导航,时间会进一步延长,所以我们需要建立面包屑导航来促进搜索引擎识别页面,同时可以引导用户浏览 网站。
我们知道js调用对网站的影响,但同时我们也发现大部分网站没有使用js调用,优化可能不是很好,因素很多影响到这里,既然我们讨论了js导航优化,我们就延伸一下如何优化网站导航的话题:
2.如果导航优化
导航一般出现在网站的顶部。当然,第二个顶部会出现一些网站。顶部是横幅广告,或者出现在侧面。其实无论出现在哪里,都需要注意以下问题:
①seo标题
一般情况下,导航都有seo标题功能,即可以单独填写导航显示文字,搜索引擎抓取seo标题内容,可以解决用户浏览时需要简单导航、搜索的问题引擎需要更多信息来捕获。如果网站没有这个功能,可以考虑更换模板,因为seo标题很灵活,很容易做seo。
②位置调整
导航位置一般都有固定的样式,比如公司的网站:首页、关于我们、联系我们、新闻、百科等。这种布局利用了用户浏览,但我们认为网站的排名@> 更重要的是,一些没有排名值的页面可以后期排版,顺序可以改为:首页、百科、新闻、关于我们、联系我们。
③导航显示效果
导航显示效果主要是提高用户的点击率。我们可以通过设置醒目的颜色和字体来做到这一点,但要注意它,但它太特殊了,主要是方便用户。
总结:页面中的导航是由JS调用的。如何调整页面SEO问题,我们将在这里讨论,以上内容仅供参考。
蝙蝠侠IT转载需要授权! 查看全部
js 抓取网页内容(不同如何调整网站已经运营js导航栏搜索引擎有效的方法)
不同的网站虽然各有千秋,但大部分都离不开网站的一些基本元素,比如网站导航。几乎每一个网站都有一个布局,无论是对用户还是搜索引擎都有很好的引导作用,但有些网站网站建的比较早或者模板已经过时了。导航是使用 JS 调用完成的。我们都知道js搜索引擎几乎不会爬,所以一个网站导航栏搜索引擎都认不出来,而且网站的关键词排名也很难做好. 那么,页面中的导航被JS调用了,如何调整页面SEO呢?

基于网站策划的经验,我们认为:
1.如何调整
网站 运行了一段时间,发现导航栏被js调用了。一般我们在做seo外包的时候都会遇到这样的问题。我们可以:
①更换
如果网站很久没有上线,页面不是太多,我们可以通过修改网站导航栏来解决这个问题。如果修改麻烦,也可以直接替换网页模板。改成非js,flash网站。
②导航
如果网站已经成为收录并且有一定的排名,我们不能轻易破坏现有的关键词排名,我们可以考虑在网站中加入子导航,这样seo 策略,曾经作为双导航出现,非常有效,但是现在优化算法迭代,这个方法早就失效了,但是在js导航中却是有效的网站,因为js导航本身并没有被抓取搜索引擎。而你设置的子导航会代替导航的作用,一般可以放在网站的底部。
③面包屑导航
增加一些导航次数并不代表就可以解决网站的排名问题。尤其是如果只是添加第二个导航,搜索引擎还是需要一定的时间来识别。这时候如果网站没有面包屑导航,时间会进一步延长,所以我们需要建立面包屑导航来促进搜索引擎识别页面,同时可以引导用户浏览 网站。
我们知道js调用对网站的影响,但同时我们也发现大部分网站没有使用js调用,优化可能不是很好,因素很多影响到这里,既然我们讨论了js导航优化,我们就延伸一下如何优化网站导航的话题:
2.如果导航优化
导航一般出现在网站的顶部。当然,第二个顶部会出现一些网站。顶部是横幅广告,或者出现在侧面。其实无论出现在哪里,都需要注意以下问题:
①seo标题
一般情况下,导航都有seo标题功能,即可以单独填写导航显示文字,搜索引擎抓取seo标题内容,可以解决用户浏览时需要简单导航、搜索的问题引擎需要更多信息来捕获。如果网站没有这个功能,可以考虑更换模板,因为seo标题很灵活,很容易做seo。
②位置调整
导航位置一般都有固定的样式,比如公司的网站:首页、关于我们、联系我们、新闻、百科等。这种布局利用了用户浏览,但我们认为网站的排名@> 更重要的是,一些没有排名值的页面可以后期排版,顺序可以改为:首页、百科、新闻、关于我们、联系我们。
③导航显示效果
导航显示效果主要是提高用户的点击率。我们可以通过设置醒目的颜色和字体来做到这一点,但要注意它,但它太特殊了,主要是方便用户。
总结:页面中的导航是由JS调用的。如何调整页面SEO问题,我们将在这里讨论,以上内容仅供参考。
蝙蝠侠IT转载需要授权!
js 抓取网页内容(使用DOM格式有一个问题,如何抓取网页数据的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-27 18:16
昨天,我们使用webdriver抓取了一个电子商务的商品数据信息网站。Webdriver实际上使用DOM格式获取web数据。但是,使用DOM格式有一个问题。研究过前端的学生知道,如果他们使用DOM格式获取数据,他们必须等待DOM树形成,也就是说,DOM格式只有在完全完成后才能使用。但是,对于某些特殊情况,您不需要所有DOM,您可能只需要DOM的一部分。在这种情况下,webdriver会显得有点低效
今天,我们使用另一种方式获取网页中的内容,HTMLPasser。HTMLPasser使用Sax作为数据流来获取网页中的内容、解析句子和处理句子。在形成DOM树结构后,不再对其进行处理。Sax的全称是“XML的简单API”。事实上,它用于处理XML格式的数据。然而,HTML和XML在格式上有很多相似之处,所以它也可以用来处理HTML语言。当然,HTML和XML之间有很多不同之处。例如,XML要求每个标记必须严格关闭,但HTML没有这样的要求。Html仍然是随意的。它通常看起来与
对于此类标签,我们可以单独处理
首先是准备
pip install HTMLParser
第二种方法更简单。在目录C:\users\Wilson\appdata\local\programs\Python\Python 36\lib\site packages中找到htmlparser.py文件,然后将其中的所有Markupbase替换为Markupbase,这样就不会再出现上述问题
嗯,准备工作已经做好了。在加载Python代码之前,我需要创建一个简单的hello.html文件,并使用Python获取该文件中的所有DOM。这是hello.html
Hello html
wilson is so good
一个非常简单的HTML文件主要取决于HTMLPasser如何获取它
HTMLdemo.close()
上面的代码实际上继承了基类Htmlparser,重写了几个基本函数,并添加了打印函数以进行调试。手术结果如下
结果是识别并打印DOM树中的所有标记。这样,我们可以根据不同的标签和内容捕获所需的数据 查看全部
js 抓取网页内容(使用DOM格式有一个问题,如何抓取网页数据的?)
昨天,我们使用webdriver抓取了一个电子商务的商品数据信息网站。Webdriver实际上使用DOM格式获取web数据。但是,使用DOM格式有一个问题。研究过前端的学生知道,如果他们使用DOM格式获取数据,他们必须等待DOM树形成,也就是说,DOM格式只有在完全完成后才能使用。但是,对于某些特殊情况,您不需要所有DOM,您可能只需要DOM的一部分。在这种情况下,webdriver会显得有点低效
今天,我们使用另一种方式获取网页中的内容,HTMLPasser。HTMLPasser使用Sax作为数据流来获取网页中的内容、解析句子和处理句子。在形成DOM树结构后,不再对其进行处理。Sax的全称是“XML的简单API”。事实上,它用于处理XML格式的数据。然而,HTML和XML在格式上有很多相似之处,所以它也可以用来处理HTML语言。当然,HTML和XML之间有很多不同之处。例如,XML要求每个标记必须严格关闭,但HTML没有这样的要求。Html仍然是随意的。它通常看起来与
对于此类标签,我们可以单独处理
首先是准备
pip install HTMLParser
第二种方法更简单。在目录C:\users\Wilson\appdata\local\programs\Python\Python 36\lib\site packages中找到htmlparser.py文件,然后将其中的所有Markupbase替换为Markupbase,这样就不会再出现上述问题
嗯,准备工作已经做好了。在加载Python代码之前,我需要创建一个简单的hello.html文件,并使用Python获取该文件中的所有DOM。这是hello.html
Hello html
wilson is so good
一个非常简单的HTML文件主要取决于HTMLPasser如何获取它
HTMLdemo.close()
上面的代码实际上继承了基类Htmlparser,重写了几个基本函数,并添加了打印函数以进行调试。手术结果如下

结果是识别并打印DOM树中的所有标记。这样,我们可以根据不同的标签和内容捕获所需的数据
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-27 18:09
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的

网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:

在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:

结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:

返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(一天就能上线一个微信小程序,你准备好了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 18:07
最近在研究微信小程序的云开发功能。云开发最大的好处就是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,而且对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每条记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
js 抓取网页内容(一天就能上线一个微信小程序,你准备好了吗?)
最近在研究微信小程序的云开发功能。云开发最大的好处就是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,而且对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。

预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每条记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 15:16
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。

长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js 抓取网页内容(js抓取网页内容包括两个小部分:post和get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-27 05:01
js抓取网页内容包括两个小部分:post和get,两者的区别和联系是在于:当网页经过http请求(request)时,服务器要提供一些response数据供浏览器解析,这些数据如果是post方式传输就称之为post请求,反之就称之为get请求。两种方式的区别是:get方式请求的数据请求返回内容带有x-premium,post请求无该要求。
当然,这两种方式也有些其他的不同,比如:请求的url不一样,post请求要求对方知道自己的url;get方式请求的url没有x-premium。node的axios官方文档就列出了一个很全面的、按照你的场景进行了分类:按行为分类,post请求和get请求。按响应时间,post请求和get请求。按属性:属性或值组成的表单的提交方式。
对axios没有什么特别的,因为node最后会调用axiosapi函数来处理axios的相关事情,于是你可以这样理解:post请求是把数据发送到客户端(你),但是get请求的返回一定要带上url。于是就有了如下相应:post请求axios官方给的文档axiospostapi(axiosphone)get请求又叫做浏览器与服务器的"动态交互",对于这个是没有特别要求的,也就是要求响应一定要带url。
不同api对响应的格式做了不同规定。比如/data,这个值的对应值可以是字符串,可以是对象,也可以是数组,但只能是'{'=>{}'之类的形式。然后可以看node官方文档node_modules/axios.js官方还专门给出了一个帮助文档/.db/get.js,这个文件是用来给node.js构建远程db方案的(也是自己的项目用的),可以在里面看到node.js的axios接口。
(可以多看几遍文档)官方这些文档可以看一下。ps:由于node.js内置npm,所以很多重要的api是以npm命名的,比如axiosaxios-getaxios-read之类的。node.js用一句话总结一下就是:node.js的api讲究简洁且易用,而javascript则是面向对象的。或者可以这么理解:对node.js来说,有些原来有很好的接口后来成了不知道是鸡肋还是怎么用的接口,对javascript来说,则是更有意思的接口。
(当然,也不排除javascript更有前途的情况,这个暂时不在讨论范围内)所以javascript的api都不好,node.js的api好。当然对于不同情况下,就要用不同的api,那样更便于调试,而不用一脸懵逼似的去区分他们的不同。在post和get方式中,你还需要了解这些:线程同步和死锁问题。比如node.js中实现多线程的方法有很多种,例如request_thread,prev_thread等等,但是必须要确保这些线程是可以一起工作的。这个时候。 查看全部
js 抓取网页内容(js抓取网页内容包括两个小部分:post和get)
js抓取网页内容包括两个小部分:post和get,两者的区别和联系是在于:当网页经过http请求(request)时,服务器要提供一些response数据供浏览器解析,这些数据如果是post方式传输就称之为post请求,反之就称之为get请求。两种方式的区别是:get方式请求的数据请求返回内容带有x-premium,post请求无该要求。
当然,这两种方式也有些其他的不同,比如:请求的url不一样,post请求要求对方知道自己的url;get方式请求的url没有x-premium。node的axios官方文档就列出了一个很全面的、按照你的场景进行了分类:按行为分类,post请求和get请求。按响应时间,post请求和get请求。按属性:属性或值组成的表单的提交方式。
对axios没有什么特别的,因为node最后会调用axiosapi函数来处理axios的相关事情,于是你可以这样理解:post请求是把数据发送到客户端(你),但是get请求的返回一定要带上url。于是就有了如下相应:post请求axios官方给的文档axiospostapi(axiosphone)get请求又叫做浏览器与服务器的"动态交互",对于这个是没有特别要求的,也就是要求响应一定要带url。
不同api对响应的格式做了不同规定。比如/data,这个值的对应值可以是字符串,可以是对象,也可以是数组,但只能是'{'=>{}'之类的形式。然后可以看node官方文档node_modules/axios.js官方还专门给出了一个帮助文档/.db/get.js,这个文件是用来给node.js构建远程db方案的(也是自己的项目用的),可以在里面看到node.js的axios接口。
(可以多看几遍文档)官方这些文档可以看一下。ps:由于node.js内置npm,所以很多重要的api是以npm命名的,比如axiosaxios-getaxios-read之类的。node.js用一句话总结一下就是:node.js的api讲究简洁且易用,而javascript则是面向对象的。或者可以这么理解:对node.js来说,有些原来有很好的接口后来成了不知道是鸡肋还是怎么用的接口,对javascript来说,则是更有意思的接口。
(当然,也不排除javascript更有前途的情况,这个暂时不在讨论范围内)所以javascript的api都不好,node.js的api好。当然对于不同情况下,就要用不同的api,那样更便于调试,而不用一脸懵逼似的去区分他们的不同。在post和get方式中,你还需要了解这些:线程同步和死锁问题。比如node.js中实现多线程的方法有很多种,例如request_thread,prev_thread等等,但是必须要确保这些线程是可以一起工作的。这个时候。
js 抓取网页内容(一个好的网站就像一个明星如果没有粉丝的追捧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-27 01:06
今天给大家分享一个话题,也是最近比较有影响力和很火的话题,如何分析百度如何抓取网站内容。一个好的网站就像一个没有粉丝的名人,他的人气排名肯定不会上升。下面我以问答的形式与大家交流:
一、Q:百度本身也有CDN加速(Baidu Cloud Acceleration),会不会影响抓拍的排名?
答:在使用 CDN 加速此问题时,我们对所有站点一视同仁。但是我建议你使用技术能力强的CDN服务商来保证网站的稳定性和速度。百度会更喜欢它。
二、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
三、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
四、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
五、Q:现在我的网站被很多蜘蛛爬了,我想只让百度蜘蛛爬。百度蜘蛛的IP是什么?我可以设置白名单吗?
答:百度蜘蛛IP是不断变化的。网上确实有一些白名单。暂时有一些比较,但不保证以后不会改变。所以建议通过ua来判断网站。
六、Q:如果我写robots,只想禁止动态链接,会不会影响动态参数前面的正常链接的抓取?
答:不,你的原创页面还在,所以你一定会抓住它。
七、Q:比如我们有一个域名,我们想禁止所有带有?数字。我们不想禁止主页。我们如何得到它?
回答:?前面有一个*,后面有一个*。
八、问:我想知道,如果我现在有收录50,000,要多久才能重新找回我原来的收录50,000?
A:很难说不同的网站。一是你的网站做得好,人气很高。更新很快,质量也很快;如果您的网站不为人知且贡献很小,则可能会非常慢。
九、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
十、Q:现在很多网站都有自己的站点搜索,会生成站点搜索结果页面。如果百度不喜欢搜索结果页,我们会以此来影响我们吗?就是不喜欢,不然我们会受到惩罚吗网站?
答案:蜘蛛会抓住它。抓到之后,重要的是提取里面的链接。如果只有一两页这样的质量差的页面,也不是什么大问题。如果整体质量很差,你可能会受到惩罚。 查看全部
js 抓取网页内容(一个好的网站就像一个明星如果没有粉丝的追捧)
今天给大家分享一个话题,也是最近比较有影响力和很火的话题,如何分析百度如何抓取网站内容。一个好的网站就像一个没有粉丝的名人,他的人气排名肯定不会上升。下面我以问答的形式与大家交流:
一、Q:百度本身也有CDN加速(Baidu Cloud Acceleration),会不会影响抓拍的排名?
答:在使用 CDN 加速此问题时,我们对所有站点一视同仁。但是我建议你使用技术能力强的CDN服务商来保证网站的稳定性和速度。百度会更喜欢它。
二、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
三、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
四、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
五、Q:现在我的网站被很多蜘蛛爬了,我想只让百度蜘蛛爬。百度蜘蛛的IP是什么?我可以设置白名单吗?
答:百度蜘蛛IP是不断变化的。网上确实有一些白名单。暂时有一些比较,但不保证以后不会改变。所以建议通过ua来判断网站。
六、Q:如果我写robots,只想禁止动态链接,会不会影响动态参数前面的正常链接的抓取?
答:不,你的原创页面还在,所以你一定会抓住它。
七、Q:比如我们有一个域名,我们想禁止所有带有?数字。我们不想禁止主页。我们如何得到它?
回答:?前面有一个*,后面有一个*。
八、问:我想知道,如果我现在有收录50,000,要多久才能重新找回我原来的收录50,000?
A:很难说不同的网站。一是你的网站做得好,人气很高。更新很快,质量也很快;如果您的网站不为人知且贡献很小,则可能会非常慢。
九、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
十、Q:现在很多网站都有自己的站点搜索,会生成站点搜索结果页面。如果百度不喜欢搜索结果页,我们会以此来影响我们吗?就是不喜欢,不然我们会受到惩罚吗网站?
答案:蜘蛛会抓住它。抓到之后,重要的是提取里面的链接。如果只有一两页这样的质量差的页面,也不是什么大问题。如果整体质量很差,你可能会受到惩罚。
js 抓取网页内容(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 01:03
本文基于《AJAX动态网页信息抽取原理》
另外,前一篇文章总结了两种在AJAX网页上抓取文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
网页文字是在加载HTML文档(document)后的某个时间用Javascript代码获取并显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不代表所有的内容都已经加载完毕,需要特殊的判别机制。
以上两种情况其实并没有考虑到AJAX的一个重要特性:异步加载。也就是说,HTML 页面的文本内容不是与 HTML 文档同步加载的,而是在某些情况下(例如,
例如,用户点击超链接)从服务器异步获取并显示。此时无法使用load事件触发网页文本爬取。DataScraper 从版本 V4.2.0B57 开始
它已得到增强,能够抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果是定期自动抓取网页文字
, 通过设置调度指令文件
的
waitOnload 参数可以达到这个目的。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都是waitOnload=true,即等待
load事件,在提取异步加载的内容时很可能发生:Timeout to load the page
错误。从 V4.2.0B57 版本开始,增加了 DataScraper 菜单:配置
-> 等待加载
, 这是一个复选框菜单,去掉钩子,不再等待加载事件。
比如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于获取搜狐名人博客
和
相关评论,评论内容是AJAX动态生成的,当名人博客很火的时候,会有很多评论,这些评论被分成多个页面,当用户点击“下一页”超链接时,新的没有加载
而是从网站异步获取下一页的评论内容,动态修改当前网页的DOM结构来显示。因此,没有页面加载就没有加载事件。翻页检索这些评论
理论上需要设置waitOnload=false,否则会遇到Timeout加载页面错误。
注意
: 异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载。
然而,计算机程序无法理解语义。DataScraper 尝试使用智能方法进行判断,但仍有误判的可能,主要发生在目标网站的服务质量非常不稳定时
这时候异步加载内容和刷新显示的过程是间歇性的,而不是连续均匀的。这时候DataScraper就会做出误判。 查看全部
js 抓取网页内容(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
本文基于《AJAX动态网页信息抽取原理》
另外,前一篇文章总结了两种在AJAX网页上抓取文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
网页文字是在加载HTML文档(document)后的某个时间用Javascript代码获取并显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不代表所有的内容都已经加载完毕,需要特殊的判别机制。
以上两种情况其实并没有考虑到AJAX的一个重要特性:异步加载。也就是说,HTML 页面的文本内容不是与 HTML 文档同步加载的,而是在某些情况下(例如,
例如,用户点击超链接)从服务器异步获取并显示。此时无法使用load事件触发网页文本爬取。DataScraper 从版本 V4.2.0B57 开始
它已得到增强,能够抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果是定期自动抓取网页文字
, 通过设置调度指令文件
的
waitOnload 参数可以达到这个目的。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都是waitOnload=true,即等待
load事件,在提取异步加载的内容时很可能发生:Timeout to load the page
错误。从 V4.2.0B57 版本开始,增加了 DataScraper 菜单:配置
-> 等待加载
, 这是一个复选框菜单,去掉钩子,不再等待加载事件。
比如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于获取搜狐名人博客
和
相关评论,评论内容是AJAX动态生成的,当名人博客很火的时候,会有很多评论,这些评论被分成多个页面,当用户点击“下一页”超链接时,新的没有加载
而是从网站异步获取下一页的评论内容,动态修改当前网页的DOM结构来显示。因此,没有页面加载就没有加载事件。翻页检索这些评论
理论上需要设置waitOnload=false,否则会遇到Timeout加载页面错误。
注意
: 异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载。
然而,计算机程序无法理解语义。DataScraper 尝试使用智能方法进行判断,但仍有误判的可能,主要发生在目标网站的服务质量非常不稳定时
这时候异步加载内容和刷新显示的过程是间歇性的,而不是连续均匀的。这时候DataScraper就会做出误判。
js 抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-09-25 09:07
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
js 抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-25 09:03
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:

查看源码,却是如下图:

网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具

网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:

让我们再次点击它:

原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:

图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这个应该是热搜关键词

这是照片新闻下的新闻。
我们打开一个接口链接看看:

返回一串乱码,但是从响应中查看的是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:

像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容( 没错就是下方那些卡哇伊的蛋糕,哇哇哇~!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-10-08 03:11
没错就是下方那些卡哇伊的蛋糕,哇哇哇~!!
)
<p>Node.js的学习中,可用于抓取其他网站的模块是【cheerio】,这个模块并不是node的内置模块,所以首先我们需要先安装一下:
安装对应模块
安装命令:
npm install cheerio</p>
明确获取对象
cheerio 安装完成后,我们就可以开始抓取数据了。说清楚需要抓取的内容是甜点网站,需要抓取的代码如下:
如图,需要抓拍的内容就是图中标注的img图片,没错,就是下面的卡哇伊蛋糕,哇哇~好想吃,名字也好! ! !
开始抓取
好的,我们已经明确了要爬取的内容,现在开始爬取。在此之前,我们需要知道 Cheerio 收录了 jQuery 核心的一个子集,这意味着在操作 Cheerio 时,使用 JQ 相关语法就可以了,是不是很酷,哈哈哈,开始编码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
得到的图片链接,打印如下图片:
为了验证信息的准确性,也为了让博文页面不那么好吃,请点击我抓取的第一个链接的可爱甜点图片并附上:
查看全部
js 抓取网页内容(
没错就是下方那些卡哇伊的蛋糕,哇哇哇~!!
)
<p>Node.js的学习中,可用于抓取其他网站的模块是【cheerio】,这个模块并不是node的内置模块,所以首先我们需要先安装一下:
安装对应模块
安装命令:
npm install cheerio</p>
明确获取对象
cheerio 安装完成后,我们就可以开始抓取数据了。说清楚需要抓取的内容是甜点网站,需要抓取的代码如下:
如图,需要抓拍的内容就是图中标注的img图片,没错,就是下面的卡哇伊蛋糕,哇哇~好想吃,名字也好! ! !
开始抓取
好的,我们已经明确了要爬取的内容,现在开始爬取。在此之前,我们需要知道 Cheerio 收录了 jQuery 核心的一个子集,这意味着在操作 Cheerio 时,使用 JQ 相关语法就可以了,是不是很酷,哈哈哈,开始编码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
得到的图片链接,打印如下图片:
为了验证信息的准确性,也为了让博文页面不那么好吃,请点击我抓取的第一个链接的可爱甜点图片并附上:
js 抓取网页内容(国内docker仓库镜像对比安装运行Splash.jsJS渲染解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-08 03:09
)
随着越来越多的网站开始使用JS在客户端浏览器中动态渲染网站,我们需要的很多数据无法从原来的html中获取,加上Scrapy没有提供JS渲染分析功能。我们通常使用两种方法来抓取这种类型的网站数据:
通过分析网站,找到对应的数据接口,并模拟该接口获取我们需要的数据(见Scrapy捕捉Ajax动态页面),但是一旦网站接口被隐藏得很深,或者接口的加密太复杂了。这种方法可能行不通。在JS内核的帮助下,将获取到的收录JS脚本的页面交给JS内核进行渲染,最后将渲染出来的html返回给Scrapy进行分析,比较常见的就是WebKit和Scrapy-Splash
本文文章的目的是介绍如何使用Scrapy-Splash配合Scrapy抓取动态页面。
准备工作
Docker安装,具体安装步骤参考Docker官网
为什么要安装 Docker?
因为Scrapy-Splash使用Splash HTTP API,所以需要提供一个Splash实例,而且Docker镜像中有现成的Splash实例,使用起来非常方便。
Docker 镜像源变更,参考国内docker仓库镜像对比
安装并运行 Splash
docker pull scrapinghub/splash #从docker镜像中拉取splash实例
docker run -p 8050:8050 scrapinghub/splash #启动splash实例
Scrapy 配置
在Scrapy项目的setting.py中添加如下内容:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
实际代码分析
我们以腾讯证券的页面为例。腾讯证券新闻列表由js动态渲染
我们直接打开这个链接,然后打开开发者工具,找到新闻列表:
当我们查看第一个来自网络的请求的响应时,发现返回的html中的列表页面是空的
实际数据隐藏在JS中,加载完成后由JS操作DOM插入。
这里,由于实际数据是塞进一段js变量中的,不是通过ajax调用接口获取的,所以为了避免自己手动拦截js变量,我们将页面交给Scrapy-Splash用于渲染
import scrapy
from FinancialInfoSpider.items import ArticleItem
from scrapy_splash import SplashRequest
from w3lib.html import remove_tags
import re
from bs4 import BeautifulSoup
class TencentStockSpider(scrapy.Spider):
name = "TencentStock"
def start_requests(self):
urls = [
'http://stock.qq.com/l/stock/ywq/list20150423143546.htm',
]
for url in urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self,response):
sel = scrapy.Selector(response)
links = sel.xpath("//div[@class='qq_main']//ul[@class='listInfo']//li//div[@class='info']//h3//a/@href").extract()
requests = []
for link in links:
request = scrapy.Request(link, callback =self.parse_article)
requests.append(request)
return requests
def parse_article(self,response):
sel = scrapy.Selector(response)
article = ArticleItem()
article['title'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/h1/text()').extract()[0]
article['source'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[2]').xpath('string(.)').extract()[0]
article['pub_time'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[3]/text()').extract()[0]
html_content = sel.xpath('//*[@id="Cnt-Main-Article-QQ"]').extract()[0]
article['content'] = self.remove_html_tags(html_content)
return article
def remove_html_tags(self,html):
soup = BeautifulSoup(html)
[s.extract() for s in soup('script')]
[s.extract() for s in soup('style')]
content = ''
for substring in soup.stripped_strings:
content = content + substring
return content
主要代码就一句话,将获取到的页面发送到本地Splash实例进行渲染解析,最后将结果返回给parse函数进行解析
SplashRequest(url, self.parse, args={'wait': 0.5})
里面使用了 BeautifulSoup 库,用于去除 html 中的 script 和 style 标签。具体用法可以参考这两篇文章文章:
Python第二个爬虫工具Beautiful Soup的使用
使用 BeautifulSoup 删除 html 中的脚本和注释
输出结果:
查看全部
js 抓取网页内容(国内docker仓库镜像对比安装运行Splash.jsJS渲染解析
)
随着越来越多的网站开始使用JS在客户端浏览器中动态渲染网站,我们需要的很多数据无法从原来的html中获取,加上Scrapy没有提供JS渲染分析功能。我们通常使用两种方法来抓取这种类型的网站数据:
通过分析网站,找到对应的数据接口,并模拟该接口获取我们需要的数据(见Scrapy捕捉Ajax动态页面),但是一旦网站接口被隐藏得很深,或者接口的加密太复杂了。这种方法可能行不通。在JS内核的帮助下,将获取到的收录JS脚本的页面交给JS内核进行渲染,最后将渲染出来的html返回给Scrapy进行分析,比较常见的就是WebKit和Scrapy-Splash
本文文章的目的是介绍如何使用Scrapy-Splash配合Scrapy抓取动态页面。
准备工作
Docker安装,具体安装步骤参考Docker官网
为什么要安装 Docker?
因为Scrapy-Splash使用Splash HTTP API,所以需要提供一个Splash实例,而且Docker镜像中有现成的Splash实例,使用起来非常方便。
Docker 镜像源变更,参考国内docker仓库镜像对比
安装并运行 Splash
docker pull scrapinghub/splash #从docker镜像中拉取splash实例
docker run -p 8050:8050 scrapinghub/splash #启动splash实例
Scrapy 配置
在Scrapy项目的setting.py中添加如下内容:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
实际代码分析
我们以腾讯证券的页面为例。腾讯证券新闻列表由js动态渲染
我们直接打开这个链接,然后打开开发者工具,找到新闻列表:
当我们查看第一个来自网络的请求的响应时,发现返回的html中的列表页面是空的
实际数据隐藏在JS中,加载完成后由JS操作DOM插入。
这里,由于实际数据是塞进一段js变量中的,不是通过ajax调用接口获取的,所以为了避免自己手动拦截js变量,我们将页面交给Scrapy-Splash用于渲染
import scrapy
from FinancialInfoSpider.items import ArticleItem
from scrapy_splash import SplashRequest
from w3lib.html import remove_tags
import re
from bs4 import BeautifulSoup
class TencentStockSpider(scrapy.Spider):
name = "TencentStock"
def start_requests(self):
urls = [
'http://stock.qq.com/l/stock/ywq/list20150423143546.htm',
]
for url in urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self,response):
sel = scrapy.Selector(response)
links = sel.xpath("//div[@class='qq_main']//ul[@class='listInfo']//li//div[@class='info']//h3//a/@href").extract()
requests = []
for link in links:
request = scrapy.Request(link, callback =self.parse_article)
requests.append(request)
return requests
def parse_article(self,response):
sel = scrapy.Selector(response)
article = ArticleItem()
article['title'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/h1/text()').extract()[0]
article['source'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[2]').xpath('string(.)').extract()[0]
article['pub_time'] = sel.xpath('//*[@id="Main-Article-QQ"]/div/div[1]/div[1]/div[1]/div/div[1]/span[3]/text()').extract()[0]
html_content = sel.xpath('//*[@id="Cnt-Main-Article-QQ"]').extract()[0]
article['content'] = self.remove_html_tags(html_content)
return article
def remove_html_tags(self,html):
soup = BeautifulSoup(html)
[s.extract() for s in soup('script')]
[s.extract() for s in soup('style')]
content = ''
for substring in soup.stripped_strings:
content = content + substring
return content
主要代码就一句话,将获取到的页面发送到本地Splash实例进行渲染解析,最后将结果返回给parse函数进行解析
SplashRequest(url, self.parse, args={'wait': 0.5})
里面使用了 BeautifulSoup 库,用于去除 html 中的 script 和 style 标签。具体用法可以参考这两篇文章文章:
Python第二个爬虫工具Beautiful Soup的使用
使用 BeautifulSoup 删除 html 中的脚本和注释
输出结果:
js 抓取网页内容( 这是17K的一个小说章节,内容是通过JS加载的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-06 12:02
这是17K的一个小说章节,内容是通过JS加载的
)
http://www.17k.com/chapter/76839/8810097.html
这是17世纪小说的一章。内容是通过JS加载的。当我们使用httpclient获取它时,我们无法获取章节的具体内容,因为我们得到的是原创页面
使用htmlunit模拟浏览器以获取执行的HTML页面,然后您可以获取所需的特定内容^_^
public class HtmlUnitTest {
public static void main(String[] args) throws Exception {
// 新建一个WebClient对象,此对象相当于浏览器
final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
// 构造一个URL
URL url = new URL("http://www.17k.com/chapter/76839/8810097.html");
// 通过getPage()方法,返回相应的页面
HtmlPage page = (HtmlPage) webClient.getPage(url);
System.out.println(page.getHtmlElementById("chapterContent").asText());
}
} 查看全部
js 抓取网页内容(
这是17K的一个小说章节,内容是通过JS加载的
)
http://www.17k.com/chapter/76839/8810097.html
这是17世纪小说的一章。内容是通过JS加载的。当我们使用httpclient获取它时,我们无法获取章节的具体内容,因为我们得到的是原创页面
使用htmlunit模拟浏览器以获取执行的HTML页面,然后您可以获取所需的特定内容^_^
public class HtmlUnitTest {
public static void main(String[] args) throws Exception {
// 新建一个WebClient对象,此对象相当于浏览器
final WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
// 构造一个URL
URL url = new URL("http://www.17k.com/chapter/76839/8810097.html";);
// 通过getPage()方法,返回相应的页面
HtmlPage page = (HtmlPage) webClient.getPage(url);
System.out.println(page.getHtmlElementById("chapterContent").asText());
}
}
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-06 11:28
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(方法如下最后得到的源码:其它的代码和点击打开链接这篇文章相比几乎没变)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-05 09:10
上次不是写了一个博客访问的自动爬取(点击打开链接),但是昨晚再跑的时候,发现不能用了。.
运行了几次,发现使用URLConnection得到的网页源码和浏览器直接看到的不一样。URLConnection 使用 IO 流读取的源代码
只有积分没有访问
并使用浏览器直接访问查看源码
有参观。
这也导致我的程序无法使用,需要更新。
想想看。原因可能是后台的主机把流量放在js里面进行动态展示,而我用来访问URLConnection的静态接口没有收到。
于是百度从过去开始百度来百度。.
发现一个帖子三年没发了
java爬虫项目中js执行后如何获取完整的网页源码?
多方回复,发现有htmlunit,于是自己测试了下
发现确实有效。js执行后获取源码。
别废话了。
方法如下
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// TODO Auto-generated method stub
WebClient wc=new WebClient(BrowserVersion.FIREFOX_24);
wc.setJavaScriptTimeout(5000);
wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
wc.getOptions().setCssEnabled(false);//禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
wc.getOptions().setTimeout(100000);//设置连接超时时间
wc.getOptions().setDoNotTrackEnabled(false);
HtmlPage page=wc.getPage("http://blog.csdn.net/su2014510 ... 6quot;);
String res=page.asText();
//处理源码
deal(res);
}
最终的源代码如下:
其他代码和这个文章相比几乎没有变化,点击打开链接。不明白的可以看这里,不再赘述。
执行后成功写入txt文件
使用htmlunit时会弹出很多异常警告
添加这些代码,它就会消失~
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit")
.setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient")
.setLevel(Level.OFF);
由于我们这里引入了htmlunit jar包,如果使用上次的脚本批处理是不行的~
而且要导入的jar包不是一个或多个,需要批量处理。
首先,我们需要使用 -cp 命令导入我们需要的所有 jar 包。
但是htmlunit的jar包太多了,于是想到了一个办法,用for循环遍历htmlunit文件夹中的jar文件,处理成字符串,然后使用-cp命令。整个代码如下
echo off
setlocal enabledelayedexpansion
::定义一个字符串
set str=
::遍历htmlunit文件夹
for /f "delims=" %%a in ('dir /b "E:\lib\htmlunit-2.14-bin\lib\*.jar"') do (
set "str=!str!E:\lib\htmlunit-2.14-bin\lib\%%a;"
)
echo on
e:
javac -cp .;%str% AutoMarkBlogView.java
java -cp .;%str% AutoMarkBlogView
pause
操作结果如下:
htmlunit jar包下载 查看全部
js 抓取网页内容(方法如下最后得到的源码:其它的代码和点击打开链接这篇文章相比几乎没变)
上次不是写了一个博客访问的自动爬取(点击打开链接),但是昨晚再跑的时候,发现不能用了。.
运行了几次,发现使用URLConnection得到的网页源码和浏览器直接看到的不一样。URLConnection 使用 IO 流读取的源代码
只有积分没有访问
并使用浏览器直接访问查看源码
有参观。
这也导致我的程序无法使用,需要更新。
想想看。原因可能是后台的主机把流量放在js里面进行动态展示,而我用来访问URLConnection的静态接口没有收到。
于是百度从过去开始百度来百度。.
发现一个帖子三年没发了
java爬虫项目中js执行后如何获取完整的网页源码?
多方回复,发现有htmlunit,于是自己测试了下
发现确实有效。js执行后获取源码。
别废话了。
方法如下
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// TODO Auto-generated method stub
WebClient wc=new WebClient(BrowserVersion.FIREFOX_24);
wc.setJavaScriptTimeout(5000);
wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
wc.getOptions().setCssEnabled(false);//禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
wc.getOptions().setTimeout(100000);//设置连接超时时间
wc.getOptions().setDoNotTrackEnabled(false);
HtmlPage page=wc.getPage("http://blog.csdn.net/su2014510 ... 6quot;);
String res=page.asText();
//处理源码
deal(res);
}
最终的源代码如下:
其他代码和这个文章相比几乎没有变化,点击打开链接。不明白的可以看这里,不再赘述。
执行后成功写入txt文件
使用htmlunit时会弹出很多异常警告
添加这些代码,它就会消失~
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit")
.setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient")
.setLevel(Level.OFF);
由于我们这里引入了htmlunit jar包,如果使用上次的脚本批处理是不行的~
而且要导入的jar包不是一个或多个,需要批量处理。
首先,我们需要使用 -cp 命令导入我们需要的所有 jar 包。
但是htmlunit的jar包太多了,于是想到了一个办法,用for循环遍历htmlunit文件夹中的jar文件,处理成字符串,然后使用-cp命令。整个代码如下
echo off
setlocal enabledelayedexpansion
::定义一个字符串
set str=
::遍历htmlunit文件夹
for /f "delims=" %%a in ('dir /b "E:\lib\htmlunit-2.14-bin\lib\*.jar"') do (
set "str=!str!E:\lib\htmlunit-2.14-bin\lib\%%a;"
)
echo on
e:
javac -cp .;%str% AutoMarkBlogView.java
java -cp .;%str% AutoMarkBlogView
pause
操作结果如下:
htmlunit jar包下载
js 抓取网页内容(html和js抓取网页内容的安全性?如何确定,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-04 16:05
js抓取网页内容,在没有明确限制时是可以自由抓取的,那么,只有抓取html和sql时才是不安全的,在有限的情况下,如何提高js抓取网页内容的安全性?所以,抓取html和js抓取网页内容时,需要做到页面结构的安全和确定。如何确定,
1、制定无效请求代码,如网站的url结构等,
2、请求代码经过审查元素后发现post参数等字段对应的值属于安全值,
3、不显示html,直接提交ajax请求,
4、js动态处理,发现post数据可以只列举,但是实际数据格式不清晰,此时可使用判断responseheader内容,如果ok的话再让js逻辑处理数据,效果不错,如果判断失败,则会有无效请求代码,调整后可以抓取成功。
前端的http请求大部分都是可以被js代码操作的。functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}抓取百度首页,最简单的是web浏览器=》network=》就可以抓取抓取地址tagpleaseenterthedivpage1.0一般的只能抓取到首页。 查看全部
js 抓取网页内容(html和js抓取网页内容的安全性?如何确定,)
js抓取网页内容,在没有明确限制时是可以自由抓取的,那么,只有抓取html和sql时才是不安全的,在有限的情况下,如何提高js抓取网页内容的安全性?所以,抓取html和js抓取网页内容时,需要做到页面结构的安全和确定。如何确定,
1、制定无效请求代码,如网站的url结构等,
2、请求代码经过审查元素后发现post参数等字段对应的值属于安全值,
3、不显示html,直接提交ajax请求,
4、js动态处理,发现post数据可以只列举,但是实际数据格式不清晰,此时可使用判断responseheader内容,如果ok的话再让js逻辑处理数据,效果不错,如果判断失败,则会有无效请求代码,调整后可以抓取成功。
前端的http请求大部分都是可以被js代码操作的。functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}functiongethtml(url){varresult=someurl=document.getelementbyid(url)varresult=next(url)returnresult}抓取百度首页,最简单的是web浏览器=》network=》就可以抓取抓取地址tagpleaseenterthedivpage1.0一般的只能抓取到首页。
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-03 03:14
)
在上一篇文章()中,我们采用了模拟打开浏览器的方法,模拟点击网页中的Load More来动态加载网页,获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻孩子的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标头
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
查看全部
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章()中,我们采用了模拟打开浏览器的方法,模拟点击网页中的Load More来动态加载网页,获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻孩子的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标头
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
js 抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-03 03:13
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理收录JavaScript执行结果的网页时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上问过这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中…… 查看全部
js 抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理收录JavaScript执行结果的网页时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上问过这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中……
js 抓取网页内容(pyopenssl.whl安装的时候需要用pipinstall?.. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-03 03:10
)
最近在学习scrapy爬取动态js加载页面,写这个做个记录。
scrapy需要的环境是python2.7+lxml+pyopenssl+twisted+pywin32等,网上有教程可以参考等,注意安装pyopenssl.whl时需要使用pip install。 ..whl 另外,如果使用mysql,需要安装mysqldb模块。
最佳安装教程:
补充:scrapy1.1中支持Python3。官方文档说在linux环境下只支持python3,但是windows下也可以试试。供参考,中间需要手动下载lxml,使用pip install。..whl 执行安装,手动安装pypiwin32,然后导入twisted.txt的两个文件。
入门教程看官方文档,英文原版和中文版#topics-selectors-htmlcode。
Xpath是scrapy内置的一个比较简单的dom解析方法,但是作为一个习惯了php的simple_html_dom解析的人,还是很偏向xpath的。Xpath 过于严格,无法通过跳跃进行查询。必须逐层解析。,虽然xpath很麻烦,但是比较容易出错。Response.xpath().extract() 和 response.xpath().re() 以列表的形式执行。这点需要注意,在存储数据库时需要注意。此外,它的执行将由 Unicode 编码。在 re() 中执行常规匹配时,似乎需要 re(u'')。似乎是这样。这还没有完全理解。我在互联网上看到过。将研究 re(r'') 的措辞。. .
还有一种解析的方法,也是scrapy内置的css选择器。具体选拔文件可在w3cschool查阅。这里有一个选择方法,比如: li:nth-of-type(2) 是选择的第二个li节点
在使用scrapy的过程中,重点学习了如何抓取动态js加载的页面。现在很多网站在源代码中没有太多信息。主要信息只有从js文件加载后才能在review元素中找到。
所以现在我们需要一些东西来模拟浏览器,phantomjs是一个强大的模拟浏览器的工具,phantomjs是一个很小的浏览器内核,调用它可以非常方便快捷地进行分析。
cmd = 'phantomjs constructDom.js "%s"' % response.url
print "cmd:",cmd
stdout,stderr = subprocess.Popen(cmd,shell= True,stdout = subprocess.PIPE,stderr = subprocess.PIPE).communicate()
sel = Selector(text=stdout)
constructDom.js是一个解析网页的js,这是在网上的一段代码,拿来使用了
var page = require('webpage').create(),
system = require('system'),
address;
if(system.args.length === 1){
phantom.exit(1);
}else{
address = system.args[1];
page.open(address, function (status){
if(status !== 'success'){
phantom.exit();
}else{
var sc = page.evaluate(function(){
return document.body.innerHTML;
});
window.setTimeout(function (){
console.log(sc);
phantom.exit();
},1000);
}
});
}
上面四句展示了一个调用过程,这里只是调用了它的接口,我对phantomjs还没有太了解。
有时候需要让页面停留一段时间以等待加载,这时候得需要js代码sleep一段时间,但是js又没有sleep这个方法,而setTimeOut相当于另起了一个线程,并不能实现所需的sleep功能,下面一段代码可以间接的实现sleep的功能,相当于sleep了1秒钟。
<p>var t = Date.now();
function sleep(d){
while(Date.now - t 查看全部
js 抓取网页内容(pyopenssl.whl安装的时候需要用pipinstall?..
)
最近在学习scrapy爬取动态js加载页面,写这个做个记录。
scrapy需要的环境是python2.7+lxml+pyopenssl+twisted+pywin32等,网上有教程可以参考等,注意安装pyopenssl.whl时需要使用pip install。 ..whl 另外,如果使用mysql,需要安装mysqldb模块。
最佳安装教程:
补充:scrapy1.1中支持Python3。官方文档说在linux环境下只支持python3,但是windows下也可以试试。供参考,中间需要手动下载lxml,使用pip install。..whl 执行安装,手动安装pypiwin32,然后导入twisted.txt的两个文件。
入门教程看官方文档,英文原版和中文版#topics-selectors-htmlcode。
Xpath是scrapy内置的一个比较简单的dom解析方法,但是作为一个习惯了php的simple_html_dom解析的人,还是很偏向xpath的。Xpath 过于严格,无法通过跳跃进行查询。必须逐层解析。,虽然xpath很麻烦,但是比较容易出错。Response.xpath().extract() 和 response.xpath().re() 以列表的形式执行。这点需要注意,在存储数据库时需要注意。此外,它的执行将由 Unicode 编码。在 re() 中执行常规匹配时,似乎需要 re(u'')。似乎是这样。这还没有完全理解。我在互联网上看到过。将研究 re(r'') 的措辞。. .
还有一种解析的方法,也是scrapy内置的css选择器。具体选拔文件可在w3cschool查阅。这里有一个选择方法,比如: li:nth-of-type(2) 是选择的第二个li节点
在使用scrapy的过程中,重点学习了如何抓取动态js加载的页面。现在很多网站在源代码中没有太多信息。主要信息只有从js文件加载后才能在review元素中找到。
所以现在我们需要一些东西来模拟浏览器,phantomjs是一个强大的模拟浏览器的工具,phantomjs是一个很小的浏览器内核,调用它可以非常方便快捷地进行分析。
cmd = 'phantomjs constructDom.js "%s"' % response.url
print "cmd:",cmd
stdout,stderr = subprocess.Popen(cmd,shell= True,stdout = subprocess.PIPE,stderr = subprocess.PIPE).communicate()
sel = Selector(text=stdout)
constructDom.js是一个解析网页的js,这是在网上的一段代码,拿来使用了
var page = require('webpage').create(),
system = require('system'),
address;
if(system.args.length === 1){
phantom.exit(1);
}else{
address = system.args[1];
page.open(address, function (status){
if(status !== 'success'){
phantom.exit();
}else{
var sc = page.evaluate(function(){
return document.body.innerHTML;
});
window.setTimeout(function (){
console.log(sc);
phantom.exit();
},1000);
}
});
}
上面四句展示了一个调用过程,这里只是调用了它的接口,我对phantomjs还没有太了解。
有时候需要让页面停留一段时间以等待加载,这时候得需要js代码sleep一段时间,但是js又没有sleep这个方法,而setTimeOut相当于另起了一个线程,并不能实现所需的sleep功能,下面一段代码可以间接的实现sleep的功能,相当于sleep了1秒钟。
<p>var t = Date.now();
function sleep(d){
while(Date.now - t
js 抓取网页内容(1.安装phantomjs网上有很多。执行官网上的示例代码3.执行状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-03 03:05
1.安装phantomjs
网上有很多
2.在官方网站上执行示例代码
// Read the Phantom webpage '#intro' element text using jQuery and "includeJs"
"use strict";
var page = require('webpage').create();
page.onConsoleMessage = function(msg) {
console.log(msg);
};
page.open("http://phantomjs.org/", function(status) {
if (status === "success") {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
console.log("$(\".explanation\").text() -> " + $(".explanation").text());
});
phantom.exit(0);
});
} else {
phantom.exit(1);
}
});
3.执行状态一直卡在那里,不报告错误,不允许退出
要查看程序的内部执行状态,请添加操作日志
page.onResourceRequested = function (req) {
console.log('requested: ' + JSON.stringify(req, undefined, 4));
};
page.onResourceReceived = function (res) {
console.log('received: ' + JSON.stringify(res, undefined, 4));
};
4.发现该程序被困在JS请求中
http://ajax.googleapis.com/aja ... in.js
5.只需在您自己的服务器上使用Python的simplehttpserver构建一个HTTP服务器。首先通过FQ下载JS并将其放到web上
6.修改代码并将includejs指向您自己的HTTP服务器
备注:
在调试期间,phantomjs中发现的另一个问题是page.open是异步执行的,如下代码所示:
var webPage = require('webpage');
var page = webPage.create();
page.open('http://www.baidu.com/', function(status) {
console.log('Status: ' + status);
// Do other things here...
});
phantom.exit(1)
完成执行后,打印返回值echo$?,将得到1
你把
phantom.exit(1)
注释之后,您将获得状态值 查看全部
js 抓取网页内容(1.安装phantomjs网上有很多。执行官网上的示例代码3.执行状态)
1.安装phantomjs
网上有很多
2.在官方网站上执行示例代码
// Read the Phantom webpage '#intro' element text using jQuery and "includeJs"
"use strict";
var page = require('webpage').create();
page.onConsoleMessage = function(msg) {
console.log(msg);
};
page.open("http://phantomjs.org/", function(status) {
if (status === "success") {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
console.log("$(\".explanation\").text() -> " + $(".explanation").text());
});
phantom.exit(0);
});
} else {
phantom.exit(1);
}
});
3.执行状态一直卡在那里,不报告错误,不允许退出
要查看程序的内部执行状态,请添加操作日志
page.onResourceRequested = function (req) {
console.log('requested: ' + JSON.stringify(req, undefined, 4));
};
page.onResourceReceived = function (res) {
console.log('received: ' + JSON.stringify(res, undefined, 4));
};
4.发现该程序被困在JS请求中
http://ajax.googleapis.com/aja ... in.js
5.只需在您自己的服务器上使用Python的simplehttpserver构建一个HTTP服务器。首先通过FQ下载JS并将其放到web上
6.修改代码并将includejs指向您自己的HTTP服务器
备注:
在调试期间,phantomjs中发现的另一个问题是page.open是异步执行的,如下代码所示:
var webPage = require('webpage');
var page = webPage.create();
page.open('http://www.baidu.com/', function(status) {
console.log('Status: ' + status);
// Do other things here...
});
phantom.exit(1)
完成执行后,打印返回值echo$?,将得到1
你把
phantom.exit(1)
注释之后,您将获得状态值
js 抓取网页内容(不同如何调整网站已经运营js导航栏搜索引擎有效的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-30 17:03
不同的网站虽然各有千秋,但大部分都离不开网站的一些基本元素,比如网站导航。几乎每一个网站都有一个布局,无论是对用户还是搜索引擎都有很好的引导作用,但有些网站网站建的比较早或者模板已经过时了。导航是使用 JS 调用完成的。我们都知道js搜索引擎几乎不会爬,所以一个网站导航栏搜索引擎都认不出来,而且网站的关键词排名也很难做好. 那么,页面中的导航被JS调用了,如何调整页面SEO呢?
基于网站策划的经验,我们认为:
1.如何调整
网站 运行了一段时间,发现导航栏被js调用了。一般我们在做seo外包的时候都会遇到这样的问题。我们可以:
①更换
如果网站很久没有上线,页面不是太多,我们可以通过修改网站导航栏来解决这个问题。如果修改麻烦,也可以直接替换网页模板。改成非js,flash网站。
②导航
如果网站已经成为收录并且有一定的排名,我们不能轻易破坏现有的关键词排名,我们可以考虑在网站中加入子导航,这样seo 策略,曾经作为双导航出现,非常有效,但是现在优化算法迭代,这个方法早就失效了,但是在js导航中却是有效的网站,因为js导航本身并没有被抓取搜索引擎。而你设置的子导航会代替导航的作用,一般可以放在网站的底部。
③面包屑导航
增加一些导航次数并不代表就可以解决网站的排名问题。尤其是如果只是添加第二个导航,搜索引擎还是需要一定的时间来识别。这时候如果网站没有面包屑导航,时间会进一步延长,所以我们需要建立面包屑导航来促进搜索引擎识别页面,同时可以引导用户浏览 网站。
我们知道js调用对网站的影响,但同时我们也发现大部分网站没有使用js调用,优化可能不是很好,因素很多影响到这里,既然我们讨论了js导航优化,我们就延伸一下如何优化网站导航的话题:
2.如果导航优化
导航一般出现在网站的顶部。当然,第二个顶部会出现一些网站。顶部是横幅广告,或者出现在侧面。其实无论出现在哪里,都需要注意以下问题:
①seo标题
一般情况下,导航都有seo标题功能,即可以单独填写导航显示文字,搜索引擎抓取seo标题内容,可以解决用户浏览时需要简单导航、搜索的问题引擎需要更多信息来捕获。如果网站没有这个功能,可以考虑更换模板,因为seo标题很灵活,很容易做seo。
②位置调整
导航位置一般都有固定的样式,比如公司的网站:首页、关于我们、联系我们、新闻、百科等。这种布局利用了用户浏览,但我们认为网站的排名@> 更重要的是,一些没有排名值的页面可以后期排版,顺序可以改为:首页、百科、新闻、关于我们、联系我们。
③导航显示效果
导航显示效果主要是提高用户的点击率。我们可以通过设置醒目的颜色和字体来做到这一点,但要注意它,但它太特殊了,主要是方便用户。
总结:页面中的导航是由JS调用的。如何调整页面SEO问题,我们将在这里讨论,以上内容仅供参考。
蝙蝠侠IT转载需要授权! 查看全部
js 抓取网页内容(不同如何调整网站已经运营js导航栏搜索引擎有效的方法)
不同的网站虽然各有千秋,但大部分都离不开网站的一些基本元素,比如网站导航。几乎每一个网站都有一个布局,无论是对用户还是搜索引擎都有很好的引导作用,但有些网站网站建的比较早或者模板已经过时了。导航是使用 JS 调用完成的。我们都知道js搜索引擎几乎不会爬,所以一个网站导航栏搜索引擎都认不出来,而且网站的关键词排名也很难做好. 那么,页面中的导航被JS调用了,如何调整页面SEO呢?
基于网站策划的经验,我们认为:
1.如何调整
网站 运行了一段时间,发现导航栏被js调用了。一般我们在做seo外包的时候都会遇到这样的问题。我们可以:
①更换
如果网站很久没有上线,页面不是太多,我们可以通过修改网站导航栏来解决这个问题。如果修改麻烦,也可以直接替换网页模板。改成非js,flash网站。
②导航
如果网站已经成为收录并且有一定的排名,我们不能轻易破坏现有的关键词排名,我们可以考虑在网站中加入子导航,这样seo 策略,曾经作为双导航出现,非常有效,但是现在优化算法迭代,这个方法早就失效了,但是在js导航中却是有效的网站,因为js导航本身并没有被抓取搜索引擎。而你设置的子导航会代替导航的作用,一般可以放在网站的底部。
③面包屑导航
增加一些导航次数并不代表就可以解决网站的排名问题。尤其是如果只是添加第二个导航,搜索引擎还是需要一定的时间来识别。这时候如果网站没有面包屑导航,时间会进一步延长,所以我们需要建立面包屑导航来促进搜索引擎识别页面,同时可以引导用户浏览 网站。
我们知道js调用对网站的影响,但同时我们也发现大部分网站没有使用js调用,优化可能不是很好,因素很多影响到这里,既然我们讨论了js导航优化,我们就延伸一下如何优化网站导航的话题:
2.如果导航优化
导航一般出现在网站的顶部。当然,第二个顶部会出现一些网站。顶部是横幅广告,或者出现在侧面。其实无论出现在哪里,都需要注意以下问题:
①seo标题
一般情况下,导航都有seo标题功能,即可以单独填写导航显示文字,搜索引擎抓取seo标题内容,可以解决用户浏览时需要简单导航、搜索的问题引擎需要更多信息来捕获。如果网站没有这个功能,可以考虑更换模板,因为seo标题很灵活,很容易做seo。
②位置调整
导航位置一般都有固定的样式,比如公司的网站:首页、关于我们、联系我们、新闻、百科等。这种布局利用了用户浏览,但我们认为网站的排名@> 更重要的是,一些没有排名值的页面可以后期排版,顺序可以改为:首页、百科、新闻、关于我们、联系我们。
③导航显示效果
导航显示效果主要是提高用户的点击率。我们可以通过设置醒目的颜色和字体来做到这一点,但要注意它,但它太特殊了,主要是方便用户。
总结:页面中的导航是由JS调用的。如何调整页面SEO问题,我们将在这里讨论,以上内容仅供参考。
蝙蝠侠IT转载需要授权!
js 抓取网页内容(使用DOM格式有一个问题,如何抓取网页数据的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-27 18:16
昨天,我们使用webdriver抓取了一个电子商务的商品数据信息网站。Webdriver实际上使用DOM格式获取web数据。但是,使用DOM格式有一个问题。研究过前端的学生知道,如果他们使用DOM格式获取数据,他们必须等待DOM树形成,也就是说,DOM格式只有在完全完成后才能使用。但是,对于某些特殊情况,您不需要所有DOM,您可能只需要DOM的一部分。在这种情况下,webdriver会显得有点低效
今天,我们使用另一种方式获取网页中的内容,HTMLPasser。HTMLPasser使用Sax作为数据流来获取网页中的内容、解析句子和处理句子。在形成DOM树结构后,不再对其进行处理。Sax的全称是“XML的简单API”。事实上,它用于处理XML格式的数据。然而,HTML和XML在格式上有很多相似之处,所以它也可以用来处理HTML语言。当然,HTML和XML之间有很多不同之处。例如,XML要求每个标记必须严格关闭,但HTML没有这样的要求。Html仍然是随意的。它通常看起来与
对于此类标签,我们可以单独处理
首先是准备
pip install HTMLParser
第二种方法更简单。在目录C:\users\Wilson\appdata\local\programs\Python\Python 36\lib\site packages中找到htmlparser.py文件,然后将其中的所有Markupbase替换为Markupbase,这样就不会再出现上述问题
嗯,准备工作已经做好了。在加载Python代码之前,我需要创建一个简单的hello.html文件,并使用Python获取该文件中的所有DOM。这是hello.html
Hello html
wilson is so good
一个非常简单的HTML文件主要取决于HTMLPasser如何获取它
HTMLdemo.close()
上面的代码实际上继承了基类Htmlparser,重写了几个基本函数,并添加了打印函数以进行调试。手术结果如下
结果是识别并打印DOM树中的所有标记。这样,我们可以根据不同的标签和内容捕获所需的数据 查看全部
js 抓取网页内容(使用DOM格式有一个问题,如何抓取网页数据的?)
昨天,我们使用webdriver抓取了一个电子商务的商品数据信息网站。Webdriver实际上使用DOM格式获取web数据。但是,使用DOM格式有一个问题。研究过前端的学生知道,如果他们使用DOM格式获取数据,他们必须等待DOM树形成,也就是说,DOM格式只有在完全完成后才能使用。但是,对于某些特殊情况,您不需要所有DOM,您可能只需要DOM的一部分。在这种情况下,webdriver会显得有点低效
今天,我们使用另一种方式获取网页中的内容,HTMLPasser。HTMLPasser使用Sax作为数据流来获取网页中的内容、解析句子和处理句子。在形成DOM树结构后,不再对其进行处理。Sax的全称是“XML的简单API”。事实上,它用于处理XML格式的数据。然而,HTML和XML在格式上有很多相似之处,所以它也可以用来处理HTML语言。当然,HTML和XML之间有很多不同之处。例如,XML要求每个标记必须严格关闭,但HTML没有这样的要求。Html仍然是随意的。它通常看起来与
对于此类标签,我们可以单独处理
首先是准备
pip install HTMLParser
第二种方法更简单。在目录C:\users\Wilson\appdata\local\programs\Python\Python 36\lib\site packages中找到htmlparser.py文件,然后将其中的所有Markupbase替换为Markupbase,这样就不会再出现上述问题
嗯,准备工作已经做好了。在加载Python代码之前,我需要创建一个简单的hello.html文件,并使用Python获取该文件中的所有DOM。这是hello.html
Hello html
wilson is so good
一个非常简单的HTML文件主要取决于HTMLPasser如何获取它
HTMLdemo.close()
上面的代码实际上继承了基类Htmlparser,重写了几个基本函数,并添加了打印函数以进行调试。手术结果如下
结果是识别并打印DOM树中的所有标记。这样,我们可以根据不同的标签和内容捕获所需的数据
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-27 18:09
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(一天就能上线一个微信小程序,你准备好了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 18:07
最近在研究微信小程序的云开发功能。云开发最大的好处就是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,而且对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每条记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
js 抓取网页内容(一天就能上线一个微信小程序,你准备好了吗?)
最近在研究微信小程序的云开发功能。云开发最大的好处就是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,而且对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = $($(#q + i).find(.answer)[0]).text();
obj.B = $($(#q + i).find(.answer)[1]).text();
obj.C = $($(#q + i).find(.answer)[2]).text();
obj.D = $($(#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
$($(#q + i).find(.answer)[0]).attr(value) == 1
: $($(#q + i).find(.answer)[1]).attr(value) == 1
: $($(#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前也提示过格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每条记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 15:16
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js 抓取网页内容(js抓取网页内容包括两个小部分:post和get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-27 05:01
js抓取网页内容包括两个小部分:post和get,两者的区别和联系是在于:当网页经过http请求(request)时,服务器要提供一些response数据供浏览器解析,这些数据如果是post方式传输就称之为post请求,反之就称之为get请求。两种方式的区别是:get方式请求的数据请求返回内容带有x-premium,post请求无该要求。
当然,这两种方式也有些其他的不同,比如:请求的url不一样,post请求要求对方知道自己的url;get方式请求的url没有x-premium。node的axios官方文档就列出了一个很全面的、按照你的场景进行了分类:按行为分类,post请求和get请求。按响应时间,post请求和get请求。按属性:属性或值组成的表单的提交方式。
对axios没有什么特别的,因为node最后会调用axiosapi函数来处理axios的相关事情,于是你可以这样理解:post请求是把数据发送到客户端(你),但是get请求的返回一定要带上url。于是就有了如下相应:post请求axios官方给的文档axiospostapi(axiosphone)get请求又叫做浏览器与服务器的"动态交互",对于这个是没有特别要求的,也就是要求响应一定要带url。
不同api对响应的格式做了不同规定。比如/data,这个值的对应值可以是字符串,可以是对象,也可以是数组,但只能是'{'=>{}'之类的形式。然后可以看node官方文档node_modules/axios.js官方还专门给出了一个帮助文档/.db/get.js,这个文件是用来给node.js构建远程db方案的(也是自己的项目用的),可以在里面看到node.js的axios接口。
(可以多看几遍文档)官方这些文档可以看一下。ps:由于node.js内置npm,所以很多重要的api是以npm命名的,比如axiosaxios-getaxios-read之类的。node.js用一句话总结一下就是:node.js的api讲究简洁且易用,而javascript则是面向对象的。或者可以这么理解:对node.js来说,有些原来有很好的接口后来成了不知道是鸡肋还是怎么用的接口,对javascript来说,则是更有意思的接口。
(当然,也不排除javascript更有前途的情况,这个暂时不在讨论范围内)所以javascript的api都不好,node.js的api好。当然对于不同情况下,就要用不同的api,那样更便于调试,而不用一脸懵逼似的去区分他们的不同。在post和get方式中,你还需要了解这些:线程同步和死锁问题。比如node.js中实现多线程的方法有很多种,例如request_thread,prev_thread等等,但是必须要确保这些线程是可以一起工作的。这个时候。 查看全部
js 抓取网页内容(js抓取网页内容包括两个小部分:post和get)
js抓取网页内容包括两个小部分:post和get,两者的区别和联系是在于:当网页经过http请求(request)时,服务器要提供一些response数据供浏览器解析,这些数据如果是post方式传输就称之为post请求,反之就称之为get请求。两种方式的区别是:get方式请求的数据请求返回内容带有x-premium,post请求无该要求。
当然,这两种方式也有些其他的不同,比如:请求的url不一样,post请求要求对方知道自己的url;get方式请求的url没有x-premium。node的axios官方文档就列出了一个很全面的、按照你的场景进行了分类:按行为分类,post请求和get请求。按响应时间,post请求和get请求。按属性:属性或值组成的表单的提交方式。
对axios没有什么特别的,因为node最后会调用axiosapi函数来处理axios的相关事情,于是你可以这样理解:post请求是把数据发送到客户端(你),但是get请求的返回一定要带上url。于是就有了如下相应:post请求axios官方给的文档axiospostapi(axiosphone)get请求又叫做浏览器与服务器的"动态交互",对于这个是没有特别要求的,也就是要求响应一定要带url。
不同api对响应的格式做了不同规定。比如/data,这个值的对应值可以是字符串,可以是对象,也可以是数组,但只能是'{'=>{}'之类的形式。然后可以看node官方文档node_modules/axios.js官方还专门给出了一个帮助文档/.db/get.js,这个文件是用来给node.js构建远程db方案的(也是自己的项目用的),可以在里面看到node.js的axios接口。
(可以多看几遍文档)官方这些文档可以看一下。ps:由于node.js内置npm,所以很多重要的api是以npm命名的,比如axiosaxios-getaxios-read之类的。node.js用一句话总结一下就是:node.js的api讲究简洁且易用,而javascript则是面向对象的。或者可以这么理解:对node.js来说,有些原来有很好的接口后来成了不知道是鸡肋还是怎么用的接口,对javascript来说,则是更有意思的接口。
(当然,也不排除javascript更有前途的情况,这个暂时不在讨论范围内)所以javascript的api都不好,node.js的api好。当然对于不同情况下,就要用不同的api,那样更便于调试,而不用一脸懵逼似的去区分他们的不同。在post和get方式中,你还需要了解这些:线程同步和死锁问题。比如node.js中实现多线程的方法有很多种,例如request_thread,prev_thread等等,但是必须要确保这些线程是可以一起工作的。这个时候。
js 抓取网页内容(一个好的网站就像一个明星如果没有粉丝的追捧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-27 01:06
今天给大家分享一个话题,也是最近比较有影响力和很火的话题,如何分析百度如何抓取网站内容。一个好的网站就像一个没有粉丝的名人,他的人气排名肯定不会上升。下面我以问答的形式与大家交流:
一、Q:百度本身也有CDN加速(Baidu Cloud Acceleration),会不会影响抓拍的排名?
答:在使用 CDN 加速此问题时,我们对所有站点一视同仁。但是我建议你使用技术能力强的CDN服务商来保证网站的稳定性和速度。百度会更喜欢它。
二、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
三、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
四、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
五、Q:现在我的网站被很多蜘蛛爬了,我想只让百度蜘蛛爬。百度蜘蛛的IP是什么?我可以设置白名单吗?
答:百度蜘蛛IP是不断变化的。网上确实有一些白名单。暂时有一些比较,但不保证以后不会改变。所以建议通过ua来判断网站。
六、Q:如果我写robots,只想禁止动态链接,会不会影响动态参数前面的正常链接的抓取?
答:不,你的原创页面还在,所以你一定会抓住它。
七、Q:比如我们有一个域名,我们想禁止所有带有?数字。我们不想禁止主页。我们如何得到它?
回答:?前面有一个*,后面有一个*。
八、问:我想知道,如果我现在有收录50,000,要多久才能重新找回我原来的收录50,000?
A:很难说不同的网站。一是你的网站做得好,人气很高。更新很快,质量也很快;如果您的网站不为人知且贡献很小,则可能会非常慢。
九、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
十、Q:现在很多网站都有自己的站点搜索,会生成站点搜索结果页面。如果百度不喜欢搜索结果页,我们会以此来影响我们吗?就是不喜欢,不然我们会受到惩罚吗网站?
答案:蜘蛛会抓住它。抓到之后,重要的是提取里面的链接。如果只有一两页这样的质量差的页面,也不是什么大问题。如果整体质量很差,你可能会受到惩罚。 查看全部
js 抓取网页内容(一个好的网站就像一个明星如果没有粉丝的追捧)
今天给大家分享一个话题,也是最近比较有影响力和很火的话题,如何分析百度如何抓取网站内容。一个好的网站就像一个没有粉丝的名人,他的人气排名肯定不会上升。下面我以问答的形式与大家交流:
一、Q:百度本身也有CDN加速(Baidu Cloud Acceleration),会不会影响抓拍的排名?
答:在使用 CDN 加速此问题时,我们对所有站点一视同仁。但是我建议你使用技术能力强的CDN服务商来保证网站的稳定性和速度。百度会更喜欢它。
二、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
三、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
四、问:如何为具有相同内容的多个域建立数据库?
答:如果多个域在同一个主域下有相同的内容,则不可能为所有域都建一个库,而且正在建的库可能不是您想要的,所以尽量不要有相同的内容。
五、Q:现在我的网站被很多蜘蛛爬了,我想只让百度蜘蛛爬。百度蜘蛛的IP是什么?我可以设置白名单吗?
答:百度蜘蛛IP是不断变化的。网上确实有一些白名单。暂时有一些比较,但不保证以后不会改变。所以建议通过ua来判断网站。
六、Q:如果我写robots,只想禁止动态链接,会不会影响动态参数前面的正常链接的抓取?
答:不,你的原创页面还在,所以你一定会抓住它。
七、Q:比如我们有一个域名,我们想禁止所有带有?数字。我们不想禁止主页。我们如何得到它?
回答:?前面有一个*,后面有一个*。
八、问:我想知道,如果我现在有收录50,000,要多久才能重新找回我原来的收录50,000?
A:很难说不同的网站。一是你的网站做得好,人气很高。更新很快,质量也很快;如果您的网站不为人知且贡献很小,则可能会非常慢。
九、Q:如果页面上的网址太多,蜘蛛会选择性抓取吗?
答:不会,他会一一给你建议,但是会过滤掉JS、CSS等链接。但请注意,所有这些都是在获取后进行筛选,而不是所有的都会构建。
十、Q:现在很多网站都有自己的站点搜索,会生成站点搜索结果页面。如果百度不喜欢搜索结果页,我们会以此来影响我们吗?就是不喜欢,不然我们会受到惩罚吗网站?
答案:蜘蛛会抓住它。抓到之后,重要的是提取里面的链接。如果只有一两页这样的质量差的页面,也不是什么大问题。如果整体质量很差,你可能会受到惩罚。
js 抓取网页内容(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-27 01:03
本文基于《AJAX动态网页信息抽取原理》
另外,前一篇文章总结了两种在AJAX网页上抓取文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
网页文字是在加载HTML文档(document)后的某个时间用Javascript代码获取并显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不代表所有的内容都已经加载完毕,需要特殊的判别机制。
以上两种情况其实并没有考虑到AJAX的一个重要特性:异步加载。也就是说,HTML 页面的文本内容不是与 HTML 文档同步加载的,而是在某些情况下(例如,
例如,用户点击超链接)从服务器异步获取并显示。此时无法使用load事件触发网页文本爬取。DataScraper 从版本 V4.2.0B57 开始
它已得到增强,能够抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果是定期自动抓取网页文字
, 通过设置调度指令文件
的
waitOnload 参数可以达到这个目的。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都是waitOnload=true,即等待
load事件,在提取异步加载的内容时很可能发生:Timeout to load the page
错误。从 V4.2.0B57 版本开始,增加了 DataScraper 菜单:配置
-> 等待加载
, 这是一个复选框菜单,去掉钩子,不再等待加载事件。
比如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于获取搜狐名人博客
和
相关评论,评论内容是AJAX动态生成的,当名人博客很火的时候,会有很多评论,这些评论被分成多个页面,当用户点击“下一页”超链接时,新的没有加载
而是从网站异步获取下一页的评论内容,动态修改当前网页的DOM结构来显示。因此,没有页面加载就没有加载事件。翻页检索这些评论
理论上需要设置waitOnload=false,否则会遇到Timeout加载页面错误。
注意
: 异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载。
然而,计算机程序无法理解语义。DataScraper 尝试使用智能方法进行判断,但仍有误判的可能,主要发生在目标网站的服务质量非常不稳定时
这时候异步加载内容和刷新显示的过程是间歇性的,而不是连续均匀的。这时候DataScraper就会做出误判。 查看全部
js 抓取网页内容(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
本文基于《AJAX动态网页信息抽取原理》
另外,前一篇文章总结了两种在AJAX网页上抓取文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
网页文字是在加载HTML文档(document)后的某个时间用Javascript代码获取并显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不代表所有的内容都已经加载完毕,需要特殊的判别机制。
以上两种情况其实并没有考虑到AJAX的一个重要特性:异步加载。也就是说,HTML 页面的文本内容不是与 HTML 文档同步加载的,而是在某些情况下(例如,
例如,用户点击超链接)从服务器异步获取并显示。此时无法使用load事件触发网页文本爬取。DataScraper 从版本 V4.2.0B57 开始
它已得到增强,能够抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果是定期自动抓取网页文字
, 通过设置调度指令文件
的
waitOnload 参数可以达到这个目的。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都是waitOnload=true,即等待
load事件,在提取异步加载的内容时很可能发生:Timeout to load the page
错误。从 V4.2.0B57 版本开始,增加了 DataScraper 菜单:配置
-> 等待加载
, 这是一个复选框菜单,去掉钩子,不再等待加载事件。
比如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于获取搜狐名人博客
和
相关评论,评论内容是AJAX动态生成的,当名人博客很火的时候,会有很多评论,这些评论被分成多个页面,当用户点击“下一页”超链接时,新的没有加载
而是从网站异步获取下一页的评论内容,动态修改当前网页的DOM结构来显示。因此,没有页面加载就没有加载事件。翻页检索这些评论
理论上需要设置waitOnload=false,否则会遇到Timeout加载页面错误。
注意
: 异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载。
然而,计算机程序无法理解语义。DataScraper 尝试使用智能方法进行判断,但仍有误判的可能,主要发生在目标网站的服务质量非常不稳定时
这时候异步加载内容和刷新显示的过程是间歇性的,而不是连续均匀的。这时候DataScraper就会做出误判。
js 抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-09-25 09:07
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
js 抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-25 09:03
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤一下,看看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
这是照片新闻下的新闻。
我们打开一个接口链接看看:
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求和解析数据接口数据
先上传完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# coding:utf-8
import requests
import json
第二部分:向数据接口发出http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text

