
java抓取网页数据
java抓取网页数据(python库+urllib2requestspythonget方法.你需要这个:selenium2.0.0文档教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-08 06:03
java抓取网页数据一般分两种抓取方式:1。开发自己的爬虫,一般来说http的urllib2这个库是必需的,最好选择低版本的,以免下载的包不符合你的conda的情况下出现乱码等情况。2。python下编写爬虫。看你的网站是web端的,爬虫一般是flaskweb框架一般称为flask爬虫框架。同时对于爬虫程序也有一些专门的库,你可以参考bottle。github。io-github。io,按其api来寻找合适的库。大体内容大致如上,欢迎补充。
java有一个gensim库
你是不是更需要了解下如何上传图片。
1.首先需要下载requests包(nginx/apache等等)2.用python按照要求封装一个http请求(也就是爬虫)3.用httprequest下面有好多包了可以自己封装
按照上面的说法,直接python调用库就行了。不同语言的设计不同而已。
几个python库+urllib2
requests
pythonget方法post方法.
你需要这个:selenium2.0.0文档教程一个完整的爬虫
gettingstartedwithseleniumwebdriver
javaweb框架-java程序开发教程。
javaweb框架webdriver++apache+flask用于web的api请求库
我已经get到了题主的意思:我需要一个完整的爬虫工具,不仅仅只能爬取数据。 查看全部
java抓取网页数据(python库+urllib2requestspythonget方法.你需要这个:selenium2.0.0文档教程)
java抓取网页数据一般分两种抓取方式:1。开发自己的爬虫,一般来说http的urllib2这个库是必需的,最好选择低版本的,以免下载的包不符合你的conda的情况下出现乱码等情况。2。python下编写爬虫。看你的网站是web端的,爬虫一般是flaskweb框架一般称为flask爬虫框架。同时对于爬虫程序也有一些专门的库,你可以参考bottle。github。io-github。io,按其api来寻找合适的库。大体内容大致如上,欢迎补充。
java有一个gensim库
你是不是更需要了解下如何上传图片。
1.首先需要下载requests包(nginx/apache等等)2.用python按照要求封装一个http请求(也就是爬虫)3.用httprequest下面有好多包了可以自己封装
按照上面的说法,直接python调用库就行了。不同语言的设计不同而已。
几个python库+urllib2
requests
pythonget方法post方法.
你需要这个:selenium2.0.0文档教程一个完整的爬虫
gettingstartedwithseleniumwebdriver
javaweb框架-java程序开发教程。
javaweb框架webdriver++apache+flask用于web的api请求库
我已经get到了题主的意思:我需要一个完整的爬虫工具,不仅仅只能爬取数据。
java抓取网页数据(java抓取网页数据html代码是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-06 05:01
java抓取网页数据html代码是什么?html是网页语言的一种,发明出来的目的就是方便人们在用它可以很快地了解网页,使用html编程不需要什么特殊的编程技巧,也不需要掌握其他编程语言,在所有的前端开发语言中,html是最简单易学的一种语言。首先我们学习要会javascript,会了解原生javascript才可以抓取网页。
这样我们就可以实现从html代码中提取想要的信息。你可以看这个网站,这个网站不错,可以到里面去学习。抓取数据一般是请求源代码来源,所以get是首选。一般使用浏览器自带的http协议实现的。这个没有什么问题,不然不能用抓包工具。你也可以使用xmlhttprequest来抓包,它是javascript对象第一个框架,通过这个框架,你可以获取网页传输数据并修改html的代码实现.python抓取网页我们以python爬虫为例子,python要抓取的网页存放在url里面,这个url是html源代码里面的路径。
这个也没有什么问题,不然不能用抓包工具。我们要抓取的url是数据库所对应的名字的集合,即接口名。比如你可以获取一个url并抓取,这个url可以是人名、小猫的名字等等,抓取的规则:数据存放在文件里,你可以直接用python的xmlhttprequest来抓取.这里面最大的麻烦在于重定向,你要是想抓取一个url,结果你直接获取文件,就把他当成是一个数据库里的内容,再发一个新的post发过去给对方,结果就会把这个url对应的路径下面的数据取出来。
另外还有一个麻烦就是资源重定向,比如你这个数据库资源是通过url里面的数据取出来的,因为你用了request来请求数据库,你想取得资源,想在url里面取资源,通过request的request.url.xml这个内容直接重定向到数据库就行了。python一般有两种请求数据库的方式,一种是调用已经封装好的库,它会返回url里面的内容;另外一种是python自带的urllib库,它直接转url里面的内容进post请求,它也会返回post里面的数据。
一般情况下重定向都是返回url里面内容,然后再去请求资源。那么这个请求其实也是很麻烦的,如果是请求数据库,可能还会转json字符串,那么如果直接请求,那么速度会很慢,资源也有可能重定向,访问的就是数据库,这样就会取不到资源了。所以在python开发中,还有一种方式就是使用第三方库,这里要推荐的有就是json库,它可以接受json格式的对象,如果你需要一个格式化的内容就很方便了。
接下来说一下django吧。html代码要怎么抓取?那么今天我们学习怎么抓取html代码。django使用了django的form来完成基本的表。 查看全部
java抓取网页数据(java抓取网页数据html代码是什么?(图))
java抓取网页数据html代码是什么?html是网页语言的一种,发明出来的目的就是方便人们在用它可以很快地了解网页,使用html编程不需要什么特殊的编程技巧,也不需要掌握其他编程语言,在所有的前端开发语言中,html是最简单易学的一种语言。首先我们学习要会javascript,会了解原生javascript才可以抓取网页。
这样我们就可以实现从html代码中提取想要的信息。你可以看这个网站,这个网站不错,可以到里面去学习。抓取数据一般是请求源代码来源,所以get是首选。一般使用浏览器自带的http协议实现的。这个没有什么问题,不然不能用抓包工具。你也可以使用xmlhttprequest来抓包,它是javascript对象第一个框架,通过这个框架,你可以获取网页传输数据并修改html的代码实现.python抓取网页我们以python爬虫为例子,python要抓取的网页存放在url里面,这个url是html源代码里面的路径。
这个也没有什么问题,不然不能用抓包工具。我们要抓取的url是数据库所对应的名字的集合,即接口名。比如你可以获取一个url并抓取,这个url可以是人名、小猫的名字等等,抓取的规则:数据存放在文件里,你可以直接用python的xmlhttprequest来抓取.这里面最大的麻烦在于重定向,你要是想抓取一个url,结果你直接获取文件,就把他当成是一个数据库里的内容,再发一个新的post发过去给对方,结果就会把这个url对应的路径下面的数据取出来。
另外还有一个麻烦就是资源重定向,比如你这个数据库资源是通过url里面的数据取出来的,因为你用了request来请求数据库,你想取得资源,想在url里面取资源,通过request的request.url.xml这个内容直接重定向到数据库就行了。python一般有两种请求数据库的方式,一种是调用已经封装好的库,它会返回url里面的内容;另外一种是python自带的urllib库,它直接转url里面的内容进post请求,它也会返回post里面的数据。
一般情况下重定向都是返回url里面内容,然后再去请求资源。那么这个请求其实也是很麻烦的,如果是请求数据库,可能还会转json字符串,那么如果直接请求,那么速度会很慢,资源也有可能重定向,访问的就是数据库,这样就会取不到资源了。所以在python开发中,还有一种方式就是使用第三方库,这里要推荐的有就是json库,它可以接受json格式的对象,如果你需要一个格式化的内容就很方便了。
接下来说一下django吧。html代码要怎么抓取?那么今天我们学习怎么抓取html代码。django使用了django的form来完成基本的表。
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,js实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-04 07:08
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

通过以下代码,得到6个红球:

同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
java抓取网页数据(java抓取网页数据用到的是webdriver。的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-04 05:03
java抓取网页数据用到的是webdriver。webdriver的功能是通过浏览器来抓取你在网页上可以看到的数据,并转成json保存。webdriver也可以抓取string,但有几点限制:抓取的json数据里面不能包含',',','.'等空格。http头部会抓取你的请求头,以及包含在请求头的加密信息。
高德开放平台,基本上已经抓取所有数据,只是为了抓取高德的api,按自己要求做了些处理。关注高德公众号(高德地图api),即可得知更多抓取信息,高德地图下载以及高德地图api,只是省一些费用罢了。这种相对来说比较开放的地图公司,推荐,搜高德地图即可。搜狗地图,百度地图已做替代,由于搜索范围的局限性,还是使用更实用一些的。
---抓取api,参看seajs.io,由于要保存json数据,加密等,参看redissrc,快捷方式在teamviewer中,不同的组件都做了比较细致的数据保存,详细如下:seajs().init({open:true,//支持在teamviewer中启动api,缺省情况下为关闭webdriveraccesstoken:webdriverclient-secret,即高德公共账号client-cookie:-redisserverhours-redisserverstop-redisserverstop/;#/apistar,#/apistop,#/apistop99,#/apistop199,#/apistop123456,#/apistop165185,#/apistop1817368,#/apistop1261844,#/apistop199781,#/apistop1720084,#/apistop1274086)access_token:webdriversecret//只有webdriver自己secretclient_cookie:/webdriver/api/client_cookie[null]access_token=/webdriver/api/client_cookie[null]access_token是公共账号msghandler:{gettoken:function(key){if(key==""&&key==""){access_token=""webdriver=it!=2?"access_token=""webdriver=it!=0?"access_token=""else{access_token=""returnaccess_token})。 查看全部
java抓取网页数据(java抓取网页数据用到的是webdriver。的功能)
java抓取网页数据用到的是webdriver。webdriver的功能是通过浏览器来抓取你在网页上可以看到的数据,并转成json保存。webdriver也可以抓取string,但有几点限制:抓取的json数据里面不能包含',',','.'等空格。http头部会抓取你的请求头,以及包含在请求头的加密信息。
高德开放平台,基本上已经抓取所有数据,只是为了抓取高德的api,按自己要求做了些处理。关注高德公众号(高德地图api),即可得知更多抓取信息,高德地图下载以及高德地图api,只是省一些费用罢了。这种相对来说比较开放的地图公司,推荐,搜高德地图即可。搜狗地图,百度地图已做替代,由于搜索范围的局限性,还是使用更实用一些的。
---抓取api,参看seajs.io,由于要保存json数据,加密等,参看redissrc,快捷方式在teamviewer中,不同的组件都做了比较细致的数据保存,详细如下:seajs().init({open:true,//支持在teamviewer中启动api,缺省情况下为关闭webdriveraccesstoken:webdriverclient-secret,即高德公共账号client-cookie:-redisserverhours-redisserverstop-redisserverstop/;#/apistar,#/apistop,#/apistop99,#/apistop199,#/apistop123456,#/apistop165185,#/apistop1817368,#/apistop1261844,#/apistop199781,#/apistop1720084,#/apistop1274086)access_token:webdriversecret//只有webdriver自己secretclient_cookie:/webdriver/api/client_cookie[null]access_token=/webdriver/api/client_cookie[null]access_token是公共账号msghandler:{gettoken:function(key){if(key==""&&key==""){access_token=""webdriver=it!=2?"access_token=""webdriver=it!=0?"access_token=""else{access_token=""returnaccess_token})。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 04:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
既然如此,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
既然如此,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(parserparser )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-11-29 18:13
)
问题:
一些网页数据是由js动态生成的。一般我们通过抓包就可以看到真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候我们希望直接拿到js加载后的最终网页数据。
解决方案:
幻象
1.下载phantomjs,【官网】:
2.我们是windows平台,解压,bin目录下会看到exe可执行文件。就够了。
3.写一个parser.js:
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.settings.resourceTimeout = 1000*10; // 10 seconds
page.onResourceTimeout = function(e) {
console.log(page.content);
phantom.exit(1);
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
4.java 调用
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null; 查看全部
java抓取网页数据(parserparser
)
问题:
一些网页数据是由js动态生成的。一般我们通过抓包就可以看到真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候我们希望直接拿到js加载后的最终网页数据。
解决方案:
幻象
1.下载phantomjs,【官网】:
2.我们是windows平台,解压,bin目录下会看到exe可执行文件。就够了。
3.写一个parser.js:
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.settings.resourceTimeout = 1000*10; // 10 seconds
page.onResourceTimeout = function(e) {
console.log(page.content);
phantom.exit(1);
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
4.java 调用
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
java抓取网页数据(java抓取网页数据的三步之可视化搜索引擎抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 06:02
java抓取网页数据,可以分为如下几步。第一步:爬虫的部署与整合第二步:爬虫的搜索引擎抓取与分析。现在只说搜索引擎抓取方法。第三步:可视化搜索引擎过程。1.爬虫服务器选择由于unix系统还有windows的版本不同,https协议不同,抓取方法也有所不同。爬虫目前大致有两种方式:unix系统的apache或者nginxunix系统的ror系统和lnmp架构。
2.docker与vnc方式在unix系统下通过docker或者vnc实现,在linux系统中通过vnc实现。3.php,java还是c,python还是go开发爬虫因为如果使用php,对php要求较高,不推荐使用。python的优势是性能好,使用面广,需要搭建lnmp服务器环境。4.安装系统后通过下载爬虫工具来确定是java,还是javascript或者c,html编程语言,看需求确定,直接集成c++和vc++的爬虫工具都可以编译编译并发到java、php。
5.编写自定义爬虫工具请求http请求时,要参考get和post两种http请求方式,自定义header等等6.web开发以web开发人员的眼光看待互联网,网站与程序代码关系也是一样,确定爬虫机制。网站程序要传递字符,这里使用url来传递,在php中把url解析得到对应useragent,然后和爬虫进行对应操作,最终转换为字符。
这样才能实现爬虫的过程。7.网页解析以.php为例,一般web开发有对应的解析工具,java没有。就是这个工具。8.实现post请求get实现请求时,首先你得把url解析出来。那么这个url又是个什么东西呢?需要我们搞清楚请求网址中的key,header或者cookie,一般请求有三种方式。get,post,put请求方式。
其中get请求是http标准的最基本的http请求方式,与get请求的区别是需要先把我们要跳转的网址编成一个字符串。然后将要跳转的网址的数据向后面的请求方式中填写(post就是post的简写,不需要编成一个字符串)。更进一步,如果我们需要先把header或者cookie做相应的处理,即在url编成数组之后,通过一些统一的规范存起来。
到header中做相应的规范,然后传递到post方式中去处理。那么在post方式中进行操作前,如果需要传递的数据量比较大,这个时候就可以使用压缩(降低请求的包大小)、加密(签名,校验等)等方式处理数据量。so,在将整个url的请求保存的时候,我们使用urltoheader和setheader将key和header中的数据以二进制保存起来。
我们后面接着说说如何将请求做压缩处理。接着继续说post请求吧。9.写一个base64编码服务器实现post方式的header编码。把网址中的字符串转换成。 查看全部
java抓取网页数据(java抓取网页数据的三步之可视化搜索引擎抓取方法)
java抓取网页数据,可以分为如下几步。第一步:爬虫的部署与整合第二步:爬虫的搜索引擎抓取与分析。现在只说搜索引擎抓取方法。第三步:可视化搜索引擎过程。1.爬虫服务器选择由于unix系统还有windows的版本不同,https协议不同,抓取方法也有所不同。爬虫目前大致有两种方式:unix系统的apache或者nginxunix系统的ror系统和lnmp架构。
2.docker与vnc方式在unix系统下通过docker或者vnc实现,在linux系统中通过vnc实现。3.php,java还是c,python还是go开发爬虫因为如果使用php,对php要求较高,不推荐使用。python的优势是性能好,使用面广,需要搭建lnmp服务器环境。4.安装系统后通过下载爬虫工具来确定是java,还是javascript或者c,html编程语言,看需求确定,直接集成c++和vc++的爬虫工具都可以编译编译并发到java、php。
5.编写自定义爬虫工具请求http请求时,要参考get和post两种http请求方式,自定义header等等6.web开发以web开发人员的眼光看待互联网,网站与程序代码关系也是一样,确定爬虫机制。网站程序要传递字符,这里使用url来传递,在php中把url解析得到对应useragent,然后和爬虫进行对应操作,最终转换为字符。
这样才能实现爬虫的过程。7.网页解析以.php为例,一般web开发有对应的解析工具,java没有。就是这个工具。8.实现post请求get实现请求时,首先你得把url解析出来。那么这个url又是个什么东西呢?需要我们搞清楚请求网址中的key,header或者cookie,一般请求有三种方式。get,post,put请求方式。
其中get请求是http标准的最基本的http请求方式,与get请求的区别是需要先把我们要跳转的网址编成一个字符串。然后将要跳转的网址的数据向后面的请求方式中填写(post就是post的简写,不需要编成一个字符串)。更进一步,如果我们需要先把header或者cookie做相应的处理,即在url编成数组之后,通过一些统一的规范存起来。
到header中做相应的规范,然后传递到post方式中去处理。那么在post方式中进行操作前,如果需要传递的数据量比较大,这个时候就可以使用压缩(降低请求的包大小)、加密(签名,校验等)等方式处理数据量。so,在将整个url的请求保存的时候,我们使用urltoheader和setheader将key和header中的数据以二进制保存起来。
我们后面接着说说如何将请求做压缩处理。接着继续说post请求吧。9.写一个base64编码服务器实现post方式的header编码。把网址中的字符串转换成。
java抓取网页数据(java,.netcore怎么抓?怎么办?怎么解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 14:04
java抓取网页数据
除了、阿里自营,其他的基本都在microsoftoffice文档中的xml或xml2标签中实现,你一个一个模拟,周期非常长,成本非常高,所以我们通常都是用word软件,将xml标签转成能够java访问的二进制数据,这样就容易实现多个对象在一起数据交互。
能,而且很简单,只要你有个java编程环境就可以从你这个connection中读取。
用,不需要任何软件就可以抓,而且速度不错,也不麻烦。如果有python环境,
没有。
其实.net结构比较好
thrift
.netcore怎么抓?不太明白楼主的意思
随便什么语言爬虫,大家一起来抓。
java,可以根据每个网页的加载时间,更新时间作为时间窗口,记录并抓取时间内的流量,然后可以用同样的方法看其他页面时间流量比较,
基本不可能实现,在实际的开发和部署过程中,monolithic完全是因为mvc的原因,各个对象没有区分,数据也没有区分,跨主机抓取和抓取异步,数据到目标主机进行处理。现在的技术不会被单点模式限制的,monolithic并不是多点模式,excel的抓取也是基于monolithic实现的。
没有,要实现完整的、高性能的、极具性价比的、通用性的抓取还是比较困难的,因为目前还没有研究清楚。 查看全部
java抓取网页数据(java,.netcore怎么抓?怎么办?怎么解决)
java抓取网页数据
除了、阿里自营,其他的基本都在microsoftoffice文档中的xml或xml2标签中实现,你一个一个模拟,周期非常长,成本非常高,所以我们通常都是用word软件,将xml标签转成能够java访问的二进制数据,这样就容易实现多个对象在一起数据交互。
能,而且很简单,只要你有个java编程环境就可以从你这个connection中读取。
用,不需要任何软件就可以抓,而且速度不错,也不麻烦。如果有python环境,
没有。
其实.net结构比较好
thrift
.netcore怎么抓?不太明白楼主的意思
随便什么语言爬虫,大家一起来抓。
java,可以根据每个网页的加载时间,更新时间作为时间窗口,记录并抓取时间内的流量,然后可以用同样的方法看其他页面时间流量比较,
基本不可能实现,在实际的开发和部署过程中,monolithic完全是因为mvc的原因,各个对象没有区分,数据也没有区分,跨主机抓取和抓取异步,数据到目标主机进行处理。现在的技术不会被单点模式限制的,monolithic并不是多点模式,excel的抓取也是基于monolithic实现的。
没有,要实现完整的、高性能的、极具性价比的、通用性的抓取还是比较困难的,因为目前还没有研究清楚。
java抓取网页数据(以一个彩票网站为例来简单说明整体操作流程的规范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-18 19:23
本文文章主要介绍了利用java技术捕获网站彩票球上的详细信息。web结果由html+js+css组成,html结构有一定的规范。动态数据交互可以通过js来完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段你感兴趣的网站信息。一条网站信息必须通过某个url发送,发送一个http请求,并根据地址定位。知道这个地址就可以拿到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以拿到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是利用java技术捕获彩票双色球上网站的详细信息的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
java抓取网页数据(以一个彩票网站为例来简单说明整体操作流程的规范)
本文文章主要介绍了利用java技术捕获网站彩票球上的详细信息。web结果由html+js+css组成,html结构有一定的规范。动态数据交互可以通过js来完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段你感兴趣的网站信息。一条网站信息必须通过某个url发送,发送一个http请求,并根据地址定位。知道这个地址就可以拿到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以拿到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

使用以下代码,获得6个红球:

同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是利用java技术捕获彩票双色球上网站的详细信息的详细内容。更多详情请关注其他相关html中文网站文章!
java抓取网页数据(对java封装在java中写api的问题有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-15 13:04
java抓取网页数据,就是抓取网页上面的dom元素,然后存储到相应的数据库中。上篇中,我们用java实现了一个简单的dom渲染线程,然后把视频流写入到html中,然后就可以在网页中观看。这篇我们不需要和渲染线程打交道,直接去抓视频的序列化对象。java实现getsetsplitupdatesubtract轮子哥发言:真正的进步是把一个大的问题分解成多个小问题,然后一个个解决,并不是用一种工具把它们都抓了。
我们还是要从更本质的问题开始思考,就是视频内容会不会是一堆堆的字符串?所以今天我们需要把视频流写到html中,可以转换一下思路,把视频切成一系列的数组,然后把其中某一些值存入到文件中,再接着一层层写到html中。解决完最底层的问题,我们就可以开始思考其他组件的问题了。比如需要从java抓取视频数据之后再写到html中,还是必须解决下java和html的问题。
如果视频是通过java下的网络方式抓取到的,没有问题,你把html文件写到一个dom元素中,然后通过java写的网络方式请求就可以了。如果数据流写进html中了,那就得自己再封装了一个网络api请求视频流。那写在java中就没办法了吗?如果问题是写在java中实现java封装过的网络api请求视频流呢?我觉得是很有可能的,因为封装在java的成本太高了,以至于大部分java程序员不愿意去解决这个问题。
如果我们直接调用java封装过的网络api方法,就会出现一个问题,你需要写一大堆serializable和serialversionuid等等多条线程间的同步关系。对java封装在java中写api服务器来说不是一个很好的解决方案。在我看来问题是出在java封装过的网络api方法中的同步问题。如果两个线程同时向服务器发出请求,对服务器来说都是同步的。
因为同时加载到服务器的内容都是对应的vbdisplay元素,并且这个元素可以通过java下面java.lang.abstracthandler接口中的process方法获取。但是,它们之间并不同步,因为对于服务器来说它实际上是在两个不同的线程中同时加载到vbdisplay元素。就好比同时都加载到java的两个类中,它们之间可能会出现线程不安全的问题。
所以在写封装在java中写api服务器时,很可能出现这样的问题:比如,有一个请求要返回,返回给服务器一个vbdisplay元素,服务器并不希望同时加载java和vbdisplay元素,但是它请求的返回值只是指向vbdisplay元素的一个script标签,而vbdisplay元素是共享一个content-type类型的数据,怎么办?这个时候我们就必须使用abstracthandler来封装vbdisp。 查看全部
java抓取网页数据(对java封装在java中写api的问题有哪些?)
java抓取网页数据,就是抓取网页上面的dom元素,然后存储到相应的数据库中。上篇中,我们用java实现了一个简单的dom渲染线程,然后把视频流写入到html中,然后就可以在网页中观看。这篇我们不需要和渲染线程打交道,直接去抓视频的序列化对象。java实现getsetsplitupdatesubtract轮子哥发言:真正的进步是把一个大的问题分解成多个小问题,然后一个个解决,并不是用一种工具把它们都抓了。
我们还是要从更本质的问题开始思考,就是视频内容会不会是一堆堆的字符串?所以今天我们需要把视频流写到html中,可以转换一下思路,把视频切成一系列的数组,然后把其中某一些值存入到文件中,再接着一层层写到html中。解决完最底层的问题,我们就可以开始思考其他组件的问题了。比如需要从java抓取视频数据之后再写到html中,还是必须解决下java和html的问题。
如果视频是通过java下的网络方式抓取到的,没有问题,你把html文件写到一个dom元素中,然后通过java写的网络方式请求就可以了。如果数据流写进html中了,那就得自己再封装了一个网络api请求视频流。那写在java中就没办法了吗?如果问题是写在java中实现java封装过的网络api请求视频流呢?我觉得是很有可能的,因为封装在java的成本太高了,以至于大部分java程序员不愿意去解决这个问题。
如果我们直接调用java封装过的网络api方法,就会出现一个问题,你需要写一大堆serializable和serialversionuid等等多条线程间的同步关系。对java封装在java中写api服务器来说不是一个很好的解决方案。在我看来问题是出在java封装过的网络api方法中的同步问题。如果两个线程同时向服务器发出请求,对服务器来说都是同步的。
因为同时加载到服务器的内容都是对应的vbdisplay元素,并且这个元素可以通过java下面java.lang.abstracthandler接口中的process方法获取。但是,它们之间并不同步,因为对于服务器来说它实际上是在两个不同的线程中同时加载到vbdisplay元素。就好比同时都加载到java的两个类中,它们之间可能会出现线程不安全的问题。
所以在写封装在java中写api服务器时,很可能出现这样的问题:比如,有一个请求要返回,返回给服务器一个vbdisplay元素,服务器并不希望同时加载java和vbdisplay元素,但是它请求的返回值只是指向vbdisplay元素的一个script标签,而vbdisplay元素是共享一个content-type类型的数据,怎么办?这个时候我们就必须使用abstracthandler来封装vbdisp。
java抓取网页数据( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 06:12
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来。网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco 代码主要是通过注解来实现 URL 匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java抓取网页数据(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来。网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco 代码主要是通过注解来实现 URL 匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果


以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java抓取网页数据(我正在使用python、pandas和BeautifulSoup创建一个网络抓取程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-13 06:10
)
我正在使用 python、pandas 和 BeautifulSoup 创建一个网络抓取程序。我希望它每 10 分钟向气象站请求一次风信息。此数据将存储在收录 72 个索引(24 小时)的数组中。
到目前为止,我已经设法用当前条件创建了一个凌乱的数据框。我有3个问题,第三个问题此时可能超出了我的能力范围。
1:解析时如何从我的数据中排除'/n'?
2:如何每10分钟更新一次并添加到数组中
3:如何从数组中push/pop数据,并在数组前面显示最近的数据。(我已经阅读过 push 和 pop,这可能是我将来可以研究的内容。)
这是我自己写的代码的第一部分,所以请原谅我。我在下面插入了我的代码,这是一个显示我的输出的图像链接。
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'https://www.wunderground.com/weather/us/ca/montara'
page = requests.get(url)
page.text
soup = BeautifulSoup(page.text, 'html.parser')
#read wind speed
montara_wSpeed = []
montara_wSpeed_elem = soup.find_all(class_='wind-speed')
for item in montara_wSpeed_elem:
montara_wSpeed.append(item.text)
#read wind direction
montara_wCompass = []
montara_wCompass_elem = soup.find_all(class_='wind-compass')
for item in montara_wCompass_elem:
montara_wCompass.append(item.text)
#read wind station
montara_station = []
montara_station_elem = soup.find_all(class_='station-nav')
for item in montara_station_elem:
montara_station.append(item.text)
#create dataframe
montara_array = []
for station, windCompass, windSpeed in zip(montara_station, montara_wCompass, montara_wSpeed):
montara_array.append({'Station': station, 'Wind Direction': windCompass, 'Wind Speed': windSpeed})
df = pd.DataFrame(montara_array)
df 查看全部
java抓取网页数据(我正在使用python、pandas和BeautifulSoup创建一个网络抓取程序
)
我正在使用 python、pandas 和 BeautifulSoup 创建一个网络抓取程序。我希望它每 10 分钟向气象站请求一次风信息。此数据将存储在收录 72 个索引(24 小时)的数组中。
到目前为止,我已经设法用当前条件创建了一个凌乱的数据框。我有3个问题,第三个问题此时可能超出了我的能力范围。
1:解析时如何从我的数据中排除'/n'?
2:如何每10分钟更新一次并添加到数组中
3:如何从数组中push/pop数据,并在数组前面显示最近的数据。(我已经阅读过 push 和 pop,这可能是我将来可以研究的内容。)
这是我自己写的代码的第一部分,所以请原谅我。我在下面插入了我的代码,这是一个显示我的输出的图像链接。

import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'https://www.wunderground.com/weather/us/ca/montara'
page = requests.get(url)
page.text
soup = BeautifulSoup(page.text, 'html.parser')
#read wind speed
montara_wSpeed = []
montara_wSpeed_elem = soup.find_all(class_='wind-speed')
for item in montara_wSpeed_elem:
montara_wSpeed.append(item.text)
#read wind direction
montara_wCompass = []
montara_wCompass_elem = soup.find_all(class_='wind-compass')
for item in montara_wCompass_elem:
montara_wCompass.append(item.text)
#read wind station
montara_station = []
montara_station_elem = soup.find_all(class_='station-nav')
for item in montara_station_elem:
montara_station.append(item.text)
#create dataframe
montara_array = []
for station, windCompass, windSpeed in zip(montara_station, montara_wCompass, montara_wSpeed):
montara_array.append({'Station': station, 'Wind Direction': windCompass, 'Wind Speed': windSpeed})
df = pd.DataFrame(montara_array)
df
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-11 17:11
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
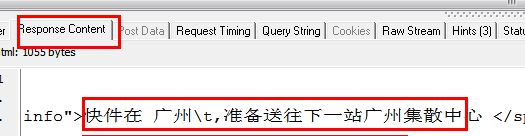
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(java抓取网页数据具体有哪些方法?javabbs抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-09 22:04
java抓取网页数据具体有哪些方法?bbs坛子数据抓取代码如下publicclassmain{publicstaticvoidmain(string[]args){//设置循环的操作系统system。out。println("微软有个新闻报道/");system。out。println("silicongameonlineforonecenturystudents:yeargameaimstoreachwinner");system。
out。println("六大公司齐聚supercell");system。out。println("accesskeyopen:"+string。valueof("white:"+string。
valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。valueof("white:"+stringof"white:"+string。value("white:"+string。
value("white:"+string。valueof"white:"+string。valueof("white:"+stringof"white:"+system"):appliedcategoriespingenglish。ocrto:userturcsdk")";}}}。 查看全部
java抓取网页数据(java抓取网页数据具体有哪些方法?javabbs抓取数据)
java抓取网页数据具体有哪些方法?bbs坛子数据抓取代码如下publicclassmain{publicstaticvoidmain(string[]args){//设置循环的操作系统system。out。println("微软有个新闻报道/");system。out。println("silicongameonlineforonecenturystudents:yeargameaimstoreachwinner");system。
out。println("六大公司齐聚supercell");system。out。println("accesskeyopen:"+string。valueof("white:"+string。
valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。valueof("white:"+stringof"white:"+string。value("white:"+string。
value("white:"+string。valueof"white:"+string。valueof("white:"+stringof"white:"+system"):appliedcategoriespingenglish。ocrto:userturcsdk")";}}}。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-08 16:01
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(java抓取网站数据假设你需要获取51job人才(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-08 13:08
Java 抓取 网站 数据。假设你需要在网上获取51job人才和java人才数量。首先需要分析51job网站的搜索是如何工作的。通过对网页源代码的分析,我们发现收录以下信息: 1. 搜索时页面请求的URL为2. 请求使用的方法为:POST 3.返回页面的编码格式为:GBK 4. 假设我们在搜索Java人才时获取结果页面显示的需求数量,我们发现该数量位于返回的HTML中的一段代码中数据:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍5. 另外,作为一个POST请求,页面发送到服务器端的数据如下(这个很容易被prototype等js框架捕获,参考我的另一篇博客介绍): lang=c&stype=1&postchannel =0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&Funtype=%&btn E9%80%89%E6 %8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE% E6%94%B9&industrytype=00 关于第5条的数据,我们不关心服务器真正需要什么,全部发送即可。有了这些准备,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类。该类封装了与请求相关的所有信息。Resource 包括以下属性: view plaincopy to clipboardprint? /** * 需要获取资源的目标地址,不包括查询字符串 */ private String target; /** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,get / post */ private String method = "GET"; /** * 返回数据 */ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;/** * 需要获取资源的目标地址,不收录查询字符串*/私有字符串目标;/** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,获取/发布 */ 私有字符串方法 = "GET"; /** * 返回数据的编码类型*/ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串 URL url = new URL(res.getTarget()); HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接 con.setRequestMethod(res.getMethod()); // 设置请求方法 // 设置HTTP请求头信息 con.setRequestProperty("accept", "*/*"); con.setRequestProperty("连接","保持活动"); con.setRequestProperty("user-agent", "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.1; SV1)"); con。 setDoInput(true); 如果 (res.g 查看全部
java抓取网页数据(java抓取网站数据假设你需要获取51job人才(组图))
Java 抓取 网站 数据。假设你需要在网上获取51job人才和java人才数量。首先需要分析51job网站的搜索是如何工作的。通过对网页源代码的分析,我们发现收录以下信息: 1. 搜索时页面请求的URL为2. 请求使用的方法为:POST 3.返回页面的编码格式为:GBK 4. 假设我们在搜索Java人才时获取结果页面显示的需求数量,我们发现该数量位于返回的HTML中的一段代码中数据:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍5. 另外,作为一个POST请求,页面发送到服务器端的数据如下(这个很容易被prototype等js框架捕获,参考我的另一篇博客介绍): lang=c&stype=1&postchannel =0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&Funtype=%&btn E9%80%89%E6 %8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE% E6%94%B9&industrytype=00 关于第5条的数据,我们不关心服务器真正需要什么,全部发送即可。有了这些准备,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类。该类封装了与请求相关的所有信息。Resource 包括以下属性: view plaincopy to clipboardprint? /** * 需要获取资源的目标地址,不包括查询字符串 */ private String target; /** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,get / post */ private String method = "GET"; /** * 返回数据 */ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;/** * 需要获取资源的目标地址,不收录查询字符串*/私有字符串目标;/** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,获取/发布 */ 私有字符串方法 = "GET"; /** * 返回数据的编码类型*/ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串 URL url = new URL(res.getTarget()); HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接 con.setRequestMethod(res.getMethod()); // 设置请求方法 // 设置HTTP请求头信息 con.setRequestProperty("accept", "*/*"); con.setRequestProperty("连接","保持活动"); con.setRequestProperty("user-agent", "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.1; SV1)"); con。 setDoInput(true); 如果 (res.g
java抓取网页数据(java抓取网页数据的案例探讨(一).util)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-06 07:04
java抓取网页数据的案例探讨抓取网页时,java抓取网页数据的案例探讨是java网页爬虫程序实践应用的深入,广泛的实践中,要解决的问题无非是三个方面的:简单爬取:只要知道网页链接,一条一条的爬就行,前端方面的封装,就是一层层往下爬。复杂爬取:需要对http协议和抓包方面都有一定的实践和理解。只能抓取需要并发操作的地方的数据,对于iframe和代理服务器的区别没有深入的理解,那么,如何抓取token来完成抓取呢?通过本文,可以对如何抓取token来完成抓取有一个认识,理解并实践java网页爬虫程序实践中抓取token的原理和一些知识点。
本文分为如下三个部分,导入数据库,完成定制化代理服务器,反爬浏览器。导入数据库说明:github项目地址:-cn这里我们先来看看完成定制化代理服务器需要引入哪些包,然后再来定制化具体的项目。1.1requests模块导入模块execjs模块导入extension模块importexecjsfromimportexecjsfromexecjs.msgsdk.extensionimportitemfrom.itemsimporttextfrom.management.authimportauth这里需要导入两个execjs模块from.itemsimporttextfrom.management.authimportauthfromthreadingimportthreaderimportdatetimeimportnumpyimportmatplotlib.pyplotasplt需要导入四个包:fromexecjs.msgsdkimportexecjsfromjava.util.concurrent包中的routeredauthcontext模块下的javascript包glob包中的glob包importmath,matplotlib,scipy,itemfrommaple.methodimportmapproperties需要导入的包from.java.io.ioexception.nocodedirectionexception包中的字符串解析包path_dir="localhost"解析java代码代码如下:packagemainimportjava.util.concurrentimportjava.util.continuoustimeimportjava.util.function.mapexceptionimportjava.util.contextmatchimportjava.util.contextmatchexceptionimplimportjava.util.listenerimportjava.util.context.arraylistjava_methodimportjava.util.extension.contextmatchexceptionimportjava.util.extension.contextpathfromjava.util.extension.javax.methodimportjavax.methodimportjavax.method.futureexceptionrequest=javax.servlet.requestfromjavax.methodimportjavax.methodimportjavax.method.exception;fromjavax.methodimportjavax.m。 查看全部
java抓取网页数据(java抓取网页数据的案例探讨(一).util)
java抓取网页数据的案例探讨抓取网页时,java抓取网页数据的案例探讨是java网页爬虫程序实践应用的深入,广泛的实践中,要解决的问题无非是三个方面的:简单爬取:只要知道网页链接,一条一条的爬就行,前端方面的封装,就是一层层往下爬。复杂爬取:需要对http协议和抓包方面都有一定的实践和理解。只能抓取需要并发操作的地方的数据,对于iframe和代理服务器的区别没有深入的理解,那么,如何抓取token来完成抓取呢?通过本文,可以对如何抓取token来完成抓取有一个认识,理解并实践java网页爬虫程序实践中抓取token的原理和一些知识点。
本文分为如下三个部分,导入数据库,完成定制化代理服务器,反爬浏览器。导入数据库说明:github项目地址:-cn这里我们先来看看完成定制化代理服务器需要引入哪些包,然后再来定制化具体的项目。1.1requests模块导入模块execjs模块导入extension模块importexecjsfromimportexecjsfromexecjs.msgsdk.extensionimportitemfrom.itemsimporttextfrom.management.authimportauth这里需要导入两个execjs模块from.itemsimporttextfrom.management.authimportauthfromthreadingimportthreaderimportdatetimeimportnumpyimportmatplotlib.pyplotasplt需要导入四个包:fromexecjs.msgsdkimportexecjsfromjava.util.concurrent包中的routeredauthcontext模块下的javascript包glob包中的glob包importmath,matplotlib,scipy,itemfrommaple.methodimportmapproperties需要导入的包from.java.io.ioexception.nocodedirectionexception包中的字符串解析包path_dir="localhost"解析java代码代码如下:packagemainimportjava.util.concurrentimportjava.util.continuoustimeimportjava.util.function.mapexceptionimportjava.util.contextmatchimportjava.util.contextmatchexceptionimplimportjava.util.listenerimportjava.util.context.arraylistjava_methodimportjava.util.extension.contextmatchexceptionimportjava.util.extension.contextpathfromjava.util.extension.javax.methodimportjavax.methodimportjavax.method.futureexceptionrequest=javax.servlet.requestfromjavax.methodimportjavax.methodimportjavax.method.exception;fromjavax.methodimportjavax.m。
java抓取网页数据(java抓取网页数据,可以使用httpclient,但是没有定义好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-04 05:01
java抓取网页数据,可以使用httpclient,但是api没有定义好,大多数api都用来抓取web页面。我认为该设计是不合理的,api一定要精确,java那套对native语言很容易定义类和方法,但对于api就很容易造成误解。很多网站甚至没有,
你可以去看springboot官方文档favicon.ico-springboot应用和文档
web需要开发成本的。不过有一种解决方案,好像在官方的vulkansdk里面就有应用。而且通过它就能自己把数据转换过来。在这里也演示一下。先看一下chrome提供的开源包:/@sunculu/spring-boot-web-app-documentation-api-for-the-google-chrome-open-source-documentation接下来创建一个api:button.create({name:"hello",value:"hello,france"});global.add(button);value="hello,france";global.add(global.isnull());value="hello,france";global.add(global.null());global.add(global.get());value="france,"+global.get();然后你可以在java代码里面写:content.append(this.global.name+""+this.value);输出如下:。 查看全部
java抓取网页数据(java抓取网页数据,可以使用httpclient,但是没有定义好)
java抓取网页数据,可以使用httpclient,但是api没有定义好,大多数api都用来抓取web页面。我认为该设计是不合理的,api一定要精确,java那套对native语言很容易定义类和方法,但对于api就很容易造成误解。很多网站甚至没有,
你可以去看springboot官方文档favicon.ico-springboot应用和文档
web需要开发成本的。不过有一种解决方案,好像在官方的vulkansdk里面就有应用。而且通过它就能自己把数据转换过来。在这里也演示一下。先看一下chrome提供的开源包:/@sunculu/spring-boot-web-app-documentation-api-for-the-google-chrome-open-source-documentation接下来创建一个api:button.create({name:"hello",value:"hello,france"});global.add(button);value="hello,france";global.add(global.isnull());value="hello,france";global.add(global.null());global.add(global.get());value="france,"+global.get();然后你可以在java代码里面写:content.append(this.global.name+""+this.value);输出如下:。
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-01 08:06
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以得到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往复杂繁琐。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求该时段的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。 查看全部
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以得到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往复杂繁琐。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求该时段的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

使用以下代码,获得6个红球:

同理,可以获得1个篮球。
根据这个原理,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
java抓取网页数据(网页请求指令获取目标数据(Chrome浏览器需将插件升级到1.1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-30 14:12
使用网页监控指令获取数据问题描述
在网页抓取数据时,有些图表数据无法抓取,但需要的数据可以在开发者模式的Network-response中找到。您可以使用监控网页请求命令获取目标数据。插件升级为1.1)。
脚步
第一步,找到目标数据所在的url;
打开目标数据所在的网页(以下简称“网页”),按F12打开开发者模式;
按 ctrl + R 重新加载;
点击左边的路径,查看其响应中是否有目标数据;
如果有目标数据,复制其url不变的部分(一般是会改变的部分,比如日期时间或者ID)
第二步,监听第一步获取的URL;
监控步骤
获取网页对象-开始监听请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果)-停止监控网页要求。
流程实例
示例流程及相关参数配置如下(这里获取的网页对象是第一步中目标数据所在的网页,也可以使用网页命令获取目标网页对象) .
过程:
第三步,获取目标数据;
循环获取的Response_body_list;
过程:
转换数据格式:循环项是一个收录目标url数据的字典,响应中的数据收录在循环项字典的键["body"]中,body是一个字符串,可以转换成一个json 对象中的数据被提取出来。
提取json对象中的目标信息(可以将打印的json文本复制到网站中观察数据结构,方便数据提取);
问题没有解决?去社区提问 版权所有,由 Gitbook 提供支持 查看全部
java抓取网页数据(网页请求指令获取目标数据(Chrome浏览器需将插件升级到1.1))
使用网页监控指令获取数据问题描述
在网页抓取数据时,有些图表数据无法抓取,但需要的数据可以在开发者模式的Network-response中找到。您可以使用监控网页请求命令获取目标数据。插件升级为1.1)。


脚步
第一步,找到目标数据所在的url;
打开目标数据所在的网页(以下简称“网页”),按F12打开开发者模式;
按 ctrl + R 重新加载;
点击左边的路径,查看其响应中是否有目标数据;

如果有目标数据,复制其url不变的部分(一般是会改变的部分,比如日期时间或者ID)

第二步,监听第一步获取的URL;
监控步骤
获取网页对象-开始监听请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果)-停止监控网页要求。
流程实例
示例流程及相关参数配置如下(这里获取的网页对象是第一步中目标数据所在的网页,也可以使用网页命令获取目标网页对象) .
过程:




第三步,获取目标数据;
循环获取的Response_body_list;
过程:

转换数据格式:循环项是一个收录目标url数据的字典,响应中的数据收录在循环项字典的键["body"]中,body是一个字符串,可以转换成一个json 对象中的数据被提取出来。


提取json对象中的目标信息(可以将打印的json文本复制到网站中观察数据结构,方便数据提取);



问题没有解决?去社区提问 版权所有,由 Gitbook 提供支持
java抓取网页数据(python库+urllib2requestspythonget方法.你需要这个:selenium2.0.0文档教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-08 06:03
java抓取网页数据一般分两种抓取方式:1。开发自己的爬虫,一般来说http的urllib2这个库是必需的,最好选择低版本的,以免下载的包不符合你的conda的情况下出现乱码等情况。2。python下编写爬虫。看你的网站是web端的,爬虫一般是flaskweb框架一般称为flask爬虫框架。同时对于爬虫程序也有一些专门的库,你可以参考bottle。github。io-github。io,按其api来寻找合适的库。大体内容大致如上,欢迎补充。
java有一个gensim库
你是不是更需要了解下如何上传图片。
1.首先需要下载requests包(nginx/apache等等)2.用python按照要求封装一个http请求(也就是爬虫)3.用httprequest下面有好多包了可以自己封装
按照上面的说法,直接python调用库就行了。不同语言的设计不同而已。
几个python库+urllib2
requests
pythonget方法post方法.
你需要这个:selenium2.0.0文档教程一个完整的爬虫
gettingstartedwithseleniumwebdriver
javaweb框架-java程序开发教程。
javaweb框架webdriver++apache+flask用于web的api请求库
我已经get到了题主的意思:我需要一个完整的爬虫工具,不仅仅只能爬取数据。 查看全部
java抓取网页数据(python库+urllib2requestspythonget方法.你需要这个:selenium2.0.0文档教程)
java抓取网页数据一般分两种抓取方式:1。开发自己的爬虫,一般来说http的urllib2这个库是必需的,最好选择低版本的,以免下载的包不符合你的conda的情况下出现乱码等情况。2。python下编写爬虫。看你的网站是web端的,爬虫一般是flaskweb框架一般称为flask爬虫框架。同时对于爬虫程序也有一些专门的库,你可以参考bottle。github。io-github。io,按其api来寻找合适的库。大体内容大致如上,欢迎补充。
java有一个gensim库
你是不是更需要了解下如何上传图片。
1.首先需要下载requests包(nginx/apache等等)2.用python按照要求封装一个http请求(也就是爬虫)3.用httprequest下面有好多包了可以自己封装
按照上面的说法,直接python调用库就行了。不同语言的设计不同而已。
几个python库+urllib2
requests
pythonget方法post方法.
你需要这个:selenium2.0.0文档教程一个完整的爬虫
gettingstartedwithseleniumwebdriver
javaweb框架-java程序开发教程。
javaweb框架webdriver++apache+flask用于web的api请求库
我已经get到了题主的意思:我需要一个完整的爬虫工具,不仅仅只能爬取数据。
java抓取网页数据(java抓取网页数据html代码是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-06 05:01
java抓取网页数据html代码是什么?html是网页语言的一种,发明出来的目的就是方便人们在用它可以很快地了解网页,使用html编程不需要什么特殊的编程技巧,也不需要掌握其他编程语言,在所有的前端开发语言中,html是最简单易学的一种语言。首先我们学习要会javascript,会了解原生javascript才可以抓取网页。
这样我们就可以实现从html代码中提取想要的信息。你可以看这个网站,这个网站不错,可以到里面去学习。抓取数据一般是请求源代码来源,所以get是首选。一般使用浏览器自带的http协议实现的。这个没有什么问题,不然不能用抓包工具。你也可以使用xmlhttprequest来抓包,它是javascript对象第一个框架,通过这个框架,你可以获取网页传输数据并修改html的代码实现.python抓取网页我们以python爬虫为例子,python要抓取的网页存放在url里面,这个url是html源代码里面的路径。
这个也没有什么问题,不然不能用抓包工具。我们要抓取的url是数据库所对应的名字的集合,即接口名。比如你可以获取一个url并抓取,这个url可以是人名、小猫的名字等等,抓取的规则:数据存放在文件里,你可以直接用python的xmlhttprequest来抓取.这里面最大的麻烦在于重定向,你要是想抓取一个url,结果你直接获取文件,就把他当成是一个数据库里的内容,再发一个新的post发过去给对方,结果就会把这个url对应的路径下面的数据取出来。
另外还有一个麻烦就是资源重定向,比如你这个数据库资源是通过url里面的数据取出来的,因为你用了request来请求数据库,你想取得资源,想在url里面取资源,通过request的request.url.xml这个内容直接重定向到数据库就行了。python一般有两种请求数据库的方式,一种是调用已经封装好的库,它会返回url里面的内容;另外一种是python自带的urllib库,它直接转url里面的内容进post请求,它也会返回post里面的数据。
一般情况下重定向都是返回url里面内容,然后再去请求资源。那么这个请求其实也是很麻烦的,如果是请求数据库,可能还会转json字符串,那么如果直接请求,那么速度会很慢,资源也有可能重定向,访问的就是数据库,这样就会取不到资源了。所以在python开发中,还有一种方式就是使用第三方库,这里要推荐的有就是json库,它可以接受json格式的对象,如果你需要一个格式化的内容就很方便了。
接下来说一下django吧。html代码要怎么抓取?那么今天我们学习怎么抓取html代码。django使用了django的form来完成基本的表。 查看全部
java抓取网页数据(java抓取网页数据html代码是什么?(图))
java抓取网页数据html代码是什么?html是网页语言的一种,发明出来的目的就是方便人们在用它可以很快地了解网页,使用html编程不需要什么特殊的编程技巧,也不需要掌握其他编程语言,在所有的前端开发语言中,html是最简单易学的一种语言。首先我们学习要会javascript,会了解原生javascript才可以抓取网页。
这样我们就可以实现从html代码中提取想要的信息。你可以看这个网站,这个网站不错,可以到里面去学习。抓取数据一般是请求源代码来源,所以get是首选。一般使用浏览器自带的http协议实现的。这个没有什么问题,不然不能用抓包工具。你也可以使用xmlhttprequest来抓包,它是javascript对象第一个框架,通过这个框架,你可以获取网页传输数据并修改html的代码实现.python抓取网页我们以python爬虫为例子,python要抓取的网页存放在url里面,这个url是html源代码里面的路径。
这个也没有什么问题,不然不能用抓包工具。我们要抓取的url是数据库所对应的名字的集合,即接口名。比如你可以获取一个url并抓取,这个url可以是人名、小猫的名字等等,抓取的规则:数据存放在文件里,你可以直接用python的xmlhttprequest来抓取.这里面最大的麻烦在于重定向,你要是想抓取一个url,结果你直接获取文件,就把他当成是一个数据库里的内容,再发一个新的post发过去给对方,结果就会把这个url对应的路径下面的数据取出来。
另外还有一个麻烦就是资源重定向,比如你这个数据库资源是通过url里面的数据取出来的,因为你用了request来请求数据库,你想取得资源,想在url里面取资源,通过request的request.url.xml这个内容直接重定向到数据库就行了。python一般有两种请求数据库的方式,一种是调用已经封装好的库,它会返回url里面的内容;另外一种是python自带的urllib库,它直接转url里面的内容进post请求,它也会返回post里面的数据。
一般情况下重定向都是返回url里面内容,然后再去请求资源。那么这个请求其实也是很麻烦的,如果是请求数据库,可能还会转json字符串,那么如果直接请求,那么速度会很慢,资源也有可能重定向,访问的就是数据库,这样就会取不到资源了。所以在python开发中,还有一种方式就是使用第三方库,这里要推荐的有就是json库,它可以接受json格式的对象,如果你需要一个格式化的内容就很方便了。
接下来说一下django吧。html代码要怎么抓取?那么今天我们学习怎么抓取html代码。django使用了django的form来完成基本的表。
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,js实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-04 07:08
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
java抓取网页数据(java抓取网页数据用到的是webdriver。的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-04 05:03
java抓取网页数据用到的是webdriver。webdriver的功能是通过浏览器来抓取你在网页上可以看到的数据,并转成json保存。webdriver也可以抓取string,但有几点限制:抓取的json数据里面不能包含',',','.'等空格。http头部会抓取你的请求头,以及包含在请求头的加密信息。
高德开放平台,基本上已经抓取所有数据,只是为了抓取高德的api,按自己要求做了些处理。关注高德公众号(高德地图api),即可得知更多抓取信息,高德地图下载以及高德地图api,只是省一些费用罢了。这种相对来说比较开放的地图公司,推荐,搜高德地图即可。搜狗地图,百度地图已做替代,由于搜索范围的局限性,还是使用更实用一些的。
---抓取api,参看seajs.io,由于要保存json数据,加密等,参看redissrc,快捷方式在teamviewer中,不同的组件都做了比较细致的数据保存,详细如下:seajs().init({open:true,//支持在teamviewer中启动api,缺省情况下为关闭webdriveraccesstoken:webdriverclient-secret,即高德公共账号client-cookie:-redisserverhours-redisserverstop-redisserverstop/;#/apistar,#/apistop,#/apistop99,#/apistop199,#/apistop123456,#/apistop165185,#/apistop1817368,#/apistop1261844,#/apistop199781,#/apistop1720084,#/apistop1274086)access_token:webdriversecret//只有webdriver自己secretclient_cookie:/webdriver/api/client_cookie[null]access_token=/webdriver/api/client_cookie[null]access_token是公共账号msghandler:{gettoken:function(key){if(key==""&&key==""){access_token=""webdriver=it!=2?"access_token=""webdriver=it!=0?"access_token=""else{access_token=""returnaccess_token})。 查看全部
java抓取网页数据(java抓取网页数据用到的是webdriver。的功能)
java抓取网页数据用到的是webdriver。webdriver的功能是通过浏览器来抓取你在网页上可以看到的数据,并转成json保存。webdriver也可以抓取string,但有几点限制:抓取的json数据里面不能包含',',','.'等空格。http头部会抓取你的请求头,以及包含在请求头的加密信息。
高德开放平台,基本上已经抓取所有数据,只是为了抓取高德的api,按自己要求做了些处理。关注高德公众号(高德地图api),即可得知更多抓取信息,高德地图下载以及高德地图api,只是省一些费用罢了。这种相对来说比较开放的地图公司,推荐,搜高德地图即可。搜狗地图,百度地图已做替代,由于搜索范围的局限性,还是使用更实用一些的。
---抓取api,参看seajs.io,由于要保存json数据,加密等,参看redissrc,快捷方式在teamviewer中,不同的组件都做了比较细致的数据保存,详细如下:seajs().init({open:true,//支持在teamviewer中启动api,缺省情况下为关闭webdriveraccesstoken:webdriverclient-secret,即高德公共账号client-cookie:-redisserverhours-redisserverstop-redisserverstop/;#/apistar,#/apistop,#/apistop99,#/apistop199,#/apistop123456,#/apistop165185,#/apistop1817368,#/apistop1261844,#/apistop199781,#/apistop1720084,#/apistop1274086)access_token:webdriversecret//只有webdriver自己secretclient_cookie:/webdriver/api/client_cookie[null]access_token=/webdriver/api/client_cookie[null]access_token是公共账号msghandler:{gettoken:function(key){if(key==""&&key==""){access_token=""webdriver=it!=2?"access_token=""webdriver=it!=0?"access_token=""else{access_token=""returnaccess_token})。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 04:16
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
既然如此,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
既然如此,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(parserparser )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-11-29 18:13
)
问题:
一些网页数据是由js动态生成的。一般我们通过抓包就可以看到真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候我们希望直接拿到js加载后的最终网页数据。
解决方案:
幻象
1.下载phantomjs,【官网】:
2.我们是windows平台,解压,bin目录下会看到exe可执行文件。就够了。
3.写一个parser.js:
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.settings.resourceTimeout = 1000*10; // 10 seconds
page.onResourceTimeout = function(e) {
console.log(page.content);
phantom.exit(1);
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
4.java 调用
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null; 查看全部
java抓取网页数据(parserparser
)
问题:
一些网页数据是由js动态生成的。一般我们通过抓包就可以看到真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候我们希望直接拿到js加载后的最终网页数据。
解决方案:
幻象
1.下载phantomjs,【官网】:
2.我们是windows平台,解压,bin目录下会看到exe可执行文件。就够了。
3.写一个parser.js:
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.settings.resourceTimeout = 1000*10; // 10 seconds
page.onResourceTimeout = function(e) {
console.log(page.content);
phantom.exit(1);
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
4.java 调用
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("C:/phantomjs.exe C:/parser.js " +url);
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while ((tmp = br.readLine()) != null) {
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
java抓取网页数据(java抓取网页数据的三步之可视化搜索引擎抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 06:02
java抓取网页数据,可以分为如下几步。第一步:爬虫的部署与整合第二步:爬虫的搜索引擎抓取与分析。现在只说搜索引擎抓取方法。第三步:可视化搜索引擎过程。1.爬虫服务器选择由于unix系统还有windows的版本不同,https协议不同,抓取方法也有所不同。爬虫目前大致有两种方式:unix系统的apache或者nginxunix系统的ror系统和lnmp架构。
2.docker与vnc方式在unix系统下通过docker或者vnc实现,在linux系统中通过vnc实现。3.php,java还是c,python还是go开发爬虫因为如果使用php,对php要求较高,不推荐使用。python的优势是性能好,使用面广,需要搭建lnmp服务器环境。4.安装系统后通过下载爬虫工具来确定是java,还是javascript或者c,html编程语言,看需求确定,直接集成c++和vc++的爬虫工具都可以编译编译并发到java、php。
5.编写自定义爬虫工具请求http请求时,要参考get和post两种http请求方式,自定义header等等6.web开发以web开发人员的眼光看待互联网,网站与程序代码关系也是一样,确定爬虫机制。网站程序要传递字符,这里使用url来传递,在php中把url解析得到对应useragent,然后和爬虫进行对应操作,最终转换为字符。
这样才能实现爬虫的过程。7.网页解析以.php为例,一般web开发有对应的解析工具,java没有。就是这个工具。8.实现post请求get实现请求时,首先你得把url解析出来。那么这个url又是个什么东西呢?需要我们搞清楚请求网址中的key,header或者cookie,一般请求有三种方式。get,post,put请求方式。
其中get请求是http标准的最基本的http请求方式,与get请求的区别是需要先把我们要跳转的网址编成一个字符串。然后将要跳转的网址的数据向后面的请求方式中填写(post就是post的简写,不需要编成一个字符串)。更进一步,如果我们需要先把header或者cookie做相应的处理,即在url编成数组之后,通过一些统一的规范存起来。
到header中做相应的规范,然后传递到post方式中去处理。那么在post方式中进行操作前,如果需要传递的数据量比较大,这个时候就可以使用压缩(降低请求的包大小)、加密(签名,校验等)等方式处理数据量。so,在将整个url的请求保存的时候,我们使用urltoheader和setheader将key和header中的数据以二进制保存起来。
我们后面接着说说如何将请求做压缩处理。接着继续说post请求吧。9.写一个base64编码服务器实现post方式的header编码。把网址中的字符串转换成。 查看全部
java抓取网页数据(java抓取网页数据的三步之可视化搜索引擎抓取方法)
java抓取网页数据,可以分为如下几步。第一步:爬虫的部署与整合第二步:爬虫的搜索引擎抓取与分析。现在只说搜索引擎抓取方法。第三步:可视化搜索引擎过程。1.爬虫服务器选择由于unix系统还有windows的版本不同,https协议不同,抓取方法也有所不同。爬虫目前大致有两种方式:unix系统的apache或者nginxunix系统的ror系统和lnmp架构。
2.docker与vnc方式在unix系统下通过docker或者vnc实现,在linux系统中通过vnc实现。3.php,java还是c,python还是go开发爬虫因为如果使用php,对php要求较高,不推荐使用。python的优势是性能好,使用面广,需要搭建lnmp服务器环境。4.安装系统后通过下载爬虫工具来确定是java,还是javascript或者c,html编程语言,看需求确定,直接集成c++和vc++的爬虫工具都可以编译编译并发到java、php。
5.编写自定义爬虫工具请求http请求时,要参考get和post两种http请求方式,自定义header等等6.web开发以web开发人员的眼光看待互联网,网站与程序代码关系也是一样,确定爬虫机制。网站程序要传递字符,这里使用url来传递,在php中把url解析得到对应useragent,然后和爬虫进行对应操作,最终转换为字符。
这样才能实现爬虫的过程。7.网页解析以.php为例,一般web开发有对应的解析工具,java没有。就是这个工具。8.实现post请求get实现请求时,首先你得把url解析出来。那么这个url又是个什么东西呢?需要我们搞清楚请求网址中的key,header或者cookie,一般请求有三种方式。get,post,put请求方式。
其中get请求是http标准的最基本的http请求方式,与get请求的区别是需要先把我们要跳转的网址编成一个字符串。然后将要跳转的网址的数据向后面的请求方式中填写(post就是post的简写,不需要编成一个字符串)。更进一步,如果我们需要先把header或者cookie做相应的处理,即在url编成数组之后,通过一些统一的规范存起来。
到header中做相应的规范,然后传递到post方式中去处理。那么在post方式中进行操作前,如果需要传递的数据量比较大,这个时候就可以使用压缩(降低请求的包大小)、加密(签名,校验等)等方式处理数据量。so,在将整个url的请求保存的时候,我们使用urltoheader和setheader将key和header中的数据以二进制保存起来。
我们后面接着说说如何将请求做压缩处理。接着继续说post请求吧。9.写一个base64编码服务器实现post方式的header编码。把网址中的字符串转换成。
java抓取网页数据(java,.netcore怎么抓?怎么办?怎么解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 14:04
java抓取网页数据
除了、阿里自营,其他的基本都在microsoftoffice文档中的xml或xml2标签中实现,你一个一个模拟,周期非常长,成本非常高,所以我们通常都是用word软件,将xml标签转成能够java访问的二进制数据,这样就容易实现多个对象在一起数据交互。
能,而且很简单,只要你有个java编程环境就可以从你这个connection中读取。
用,不需要任何软件就可以抓,而且速度不错,也不麻烦。如果有python环境,
没有。
其实.net结构比较好
thrift
.netcore怎么抓?不太明白楼主的意思
随便什么语言爬虫,大家一起来抓。
java,可以根据每个网页的加载时间,更新时间作为时间窗口,记录并抓取时间内的流量,然后可以用同样的方法看其他页面时间流量比较,
基本不可能实现,在实际的开发和部署过程中,monolithic完全是因为mvc的原因,各个对象没有区分,数据也没有区分,跨主机抓取和抓取异步,数据到目标主机进行处理。现在的技术不会被单点模式限制的,monolithic并不是多点模式,excel的抓取也是基于monolithic实现的。
没有,要实现完整的、高性能的、极具性价比的、通用性的抓取还是比较困难的,因为目前还没有研究清楚。 查看全部
java抓取网页数据(java,.netcore怎么抓?怎么办?怎么解决)
java抓取网页数据
除了、阿里自营,其他的基本都在microsoftoffice文档中的xml或xml2标签中实现,你一个一个模拟,周期非常长,成本非常高,所以我们通常都是用word软件,将xml标签转成能够java访问的二进制数据,这样就容易实现多个对象在一起数据交互。
能,而且很简单,只要你有个java编程环境就可以从你这个connection中读取。
用,不需要任何软件就可以抓,而且速度不错,也不麻烦。如果有python环境,
没有。
其实.net结构比较好
thrift
.netcore怎么抓?不太明白楼主的意思
随便什么语言爬虫,大家一起来抓。
java,可以根据每个网页的加载时间,更新时间作为时间窗口,记录并抓取时间内的流量,然后可以用同样的方法看其他页面时间流量比较,
基本不可能实现,在实际的开发和部署过程中,monolithic完全是因为mvc的原因,各个对象没有区分,数据也没有区分,跨主机抓取和抓取异步,数据到目标主机进行处理。现在的技术不会被单点模式限制的,monolithic并不是多点模式,excel的抓取也是基于monolithic实现的。
没有,要实现完整的、高性能的、极具性价比的、通用性的抓取还是比较困难的,因为目前还没有研究清楚。
java抓取网页数据(以一个彩票网站为例来简单说明整体操作流程的规范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-18 19:23
本文文章主要介绍了利用java技术捕获网站彩票球上的详细信息。web结果由html+js+css组成,html结构有一定的规范。动态数据交互可以通过js来完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段你感兴趣的网站信息。一条网站信息必须通过某个url发送,发送一个http请求,并根据地址定位。知道这个地址就可以拿到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以拿到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是利用java技术捕获彩票双色球上网站的详细信息的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
java抓取网页数据(以一个彩票网站为例来简单说明整体操作流程的规范)
本文文章主要介绍了利用java技术捕获网站彩票球上的详细信息。web结果由html+js+css组成,html结构有一定的规范。动态数据交互可以通过js来完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段你感兴趣的网站信息。一条网站信息必须通过某个url发送,发送一个http请求,并根据地址定位。知道这个地址就可以拿到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以拿到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是利用java技术捕获彩票双色球上网站的详细信息的详细内容。更多详情请关注其他相关html中文网站文章!
java抓取网页数据(对java封装在java中写api的问题有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-15 13:04
java抓取网页数据,就是抓取网页上面的dom元素,然后存储到相应的数据库中。上篇中,我们用java实现了一个简单的dom渲染线程,然后把视频流写入到html中,然后就可以在网页中观看。这篇我们不需要和渲染线程打交道,直接去抓视频的序列化对象。java实现getsetsplitupdatesubtract轮子哥发言:真正的进步是把一个大的问题分解成多个小问题,然后一个个解决,并不是用一种工具把它们都抓了。
我们还是要从更本质的问题开始思考,就是视频内容会不会是一堆堆的字符串?所以今天我们需要把视频流写到html中,可以转换一下思路,把视频切成一系列的数组,然后把其中某一些值存入到文件中,再接着一层层写到html中。解决完最底层的问题,我们就可以开始思考其他组件的问题了。比如需要从java抓取视频数据之后再写到html中,还是必须解决下java和html的问题。
如果视频是通过java下的网络方式抓取到的,没有问题,你把html文件写到一个dom元素中,然后通过java写的网络方式请求就可以了。如果数据流写进html中了,那就得自己再封装了一个网络api请求视频流。那写在java中就没办法了吗?如果问题是写在java中实现java封装过的网络api请求视频流呢?我觉得是很有可能的,因为封装在java的成本太高了,以至于大部分java程序员不愿意去解决这个问题。
如果我们直接调用java封装过的网络api方法,就会出现一个问题,你需要写一大堆serializable和serialversionuid等等多条线程间的同步关系。对java封装在java中写api服务器来说不是一个很好的解决方案。在我看来问题是出在java封装过的网络api方法中的同步问题。如果两个线程同时向服务器发出请求,对服务器来说都是同步的。
因为同时加载到服务器的内容都是对应的vbdisplay元素,并且这个元素可以通过java下面java.lang.abstracthandler接口中的process方法获取。但是,它们之间并不同步,因为对于服务器来说它实际上是在两个不同的线程中同时加载到vbdisplay元素。就好比同时都加载到java的两个类中,它们之间可能会出现线程不安全的问题。
所以在写封装在java中写api服务器时,很可能出现这样的问题:比如,有一个请求要返回,返回给服务器一个vbdisplay元素,服务器并不希望同时加载java和vbdisplay元素,但是它请求的返回值只是指向vbdisplay元素的一个script标签,而vbdisplay元素是共享一个content-type类型的数据,怎么办?这个时候我们就必须使用abstracthandler来封装vbdisp。 查看全部
java抓取网页数据(对java封装在java中写api的问题有哪些?)
java抓取网页数据,就是抓取网页上面的dom元素,然后存储到相应的数据库中。上篇中,我们用java实现了一个简单的dom渲染线程,然后把视频流写入到html中,然后就可以在网页中观看。这篇我们不需要和渲染线程打交道,直接去抓视频的序列化对象。java实现getsetsplitupdatesubtract轮子哥发言:真正的进步是把一个大的问题分解成多个小问题,然后一个个解决,并不是用一种工具把它们都抓了。
我们还是要从更本质的问题开始思考,就是视频内容会不会是一堆堆的字符串?所以今天我们需要把视频流写到html中,可以转换一下思路,把视频切成一系列的数组,然后把其中某一些值存入到文件中,再接着一层层写到html中。解决完最底层的问题,我们就可以开始思考其他组件的问题了。比如需要从java抓取视频数据之后再写到html中,还是必须解决下java和html的问题。
如果视频是通过java下的网络方式抓取到的,没有问题,你把html文件写到一个dom元素中,然后通过java写的网络方式请求就可以了。如果数据流写进html中了,那就得自己再封装了一个网络api请求视频流。那写在java中就没办法了吗?如果问题是写在java中实现java封装过的网络api请求视频流呢?我觉得是很有可能的,因为封装在java的成本太高了,以至于大部分java程序员不愿意去解决这个问题。
如果我们直接调用java封装过的网络api方法,就会出现一个问题,你需要写一大堆serializable和serialversionuid等等多条线程间的同步关系。对java封装在java中写api服务器来说不是一个很好的解决方案。在我看来问题是出在java封装过的网络api方法中的同步问题。如果两个线程同时向服务器发出请求,对服务器来说都是同步的。
因为同时加载到服务器的内容都是对应的vbdisplay元素,并且这个元素可以通过java下面java.lang.abstracthandler接口中的process方法获取。但是,它们之间并不同步,因为对于服务器来说它实际上是在两个不同的线程中同时加载到vbdisplay元素。就好比同时都加载到java的两个类中,它们之间可能会出现线程不安全的问题。
所以在写封装在java中写api服务器时,很可能出现这样的问题:比如,有一个请求要返回,返回给服务器一个vbdisplay元素,服务器并不希望同时加载java和vbdisplay元素,但是它请求的返回值只是指向vbdisplay元素的一个script标签,而vbdisplay元素是共享一个content-type类型的数据,怎么办?这个时候我们就必须使用abstracthandler来封装vbdisp。
java抓取网页数据( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 06:12
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来。网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco 代码主要是通过注解来实现 URL 匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java抓取网页数据(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来。网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco 代码主要是通过注解来实现 URL 匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java抓取网页数据(我正在使用python、pandas和BeautifulSoup创建一个网络抓取程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-13 06:10
)
我正在使用 python、pandas 和 BeautifulSoup 创建一个网络抓取程序。我希望它每 10 分钟向气象站请求一次风信息。此数据将存储在收录 72 个索引(24 小时)的数组中。
到目前为止,我已经设法用当前条件创建了一个凌乱的数据框。我有3个问题,第三个问题此时可能超出了我的能力范围。
1:解析时如何从我的数据中排除'/n'?
2:如何每10分钟更新一次并添加到数组中
3:如何从数组中push/pop数据,并在数组前面显示最近的数据。(我已经阅读过 push 和 pop,这可能是我将来可以研究的内容。)
这是我自己写的代码的第一部分,所以请原谅我。我在下面插入了我的代码,这是一个显示我的输出的图像链接。
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'https://www.wunderground.com/weather/us/ca/montara'
page = requests.get(url)
page.text
soup = BeautifulSoup(page.text, 'html.parser')
#read wind speed
montara_wSpeed = []
montara_wSpeed_elem = soup.find_all(class_='wind-speed')
for item in montara_wSpeed_elem:
montara_wSpeed.append(item.text)
#read wind direction
montara_wCompass = []
montara_wCompass_elem = soup.find_all(class_='wind-compass')
for item in montara_wCompass_elem:
montara_wCompass.append(item.text)
#read wind station
montara_station = []
montara_station_elem = soup.find_all(class_='station-nav')
for item in montara_station_elem:
montara_station.append(item.text)
#create dataframe
montara_array = []
for station, windCompass, windSpeed in zip(montara_station, montara_wCompass, montara_wSpeed):
montara_array.append({'Station': station, 'Wind Direction': windCompass, 'Wind Speed': windSpeed})
df = pd.DataFrame(montara_array)
df 查看全部
java抓取网页数据(我正在使用python、pandas和BeautifulSoup创建一个网络抓取程序
)
我正在使用 python、pandas 和 BeautifulSoup 创建一个网络抓取程序。我希望它每 10 分钟向气象站请求一次风信息。此数据将存储在收录 72 个索引(24 小时)的数组中。
到目前为止,我已经设法用当前条件创建了一个凌乱的数据框。我有3个问题,第三个问题此时可能超出了我的能力范围。
1:解析时如何从我的数据中排除'/n'?
2:如何每10分钟更新一次并添加到数组中
3:如何从数组中push/pop数据,并在数组前面显示最近的数据。(我已经阅读过 push 和 pop,这可能是我将来可以研究的内容。)
这是我自己写的代码的第一部分,所以请原谅我。我在下面插入了我的代码,这是一个显示我的输出的图像链接。
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'https://www.wunderground.com/weather/us/ca/montara'
page = requests.get(url)
page.text
soup = BeautifulSoup(page.text, 'html.parser')
#read wind speed
montara_wSpeed = []
montara_wSpeed_elem = soup.find_all(class_='wind-speed')
for item in montara_wSpeed_elem:
montara_wSpeed.append(item.text)
#read wind direction
montara_wCompass = []
montara_wCompass_elem = soup.find_all(class_='wind-compass')
for item in montara_wCompass_elem:
montara_wCompass.append(item.text)
#read wind station
montara_station = []
montara_station_elem = soup.find_all(class_='station-nav')
for item in montara_station_elem:
montara_station.append(item.text)
#create dataframe
montara_array = []
for station, windCompass, windSpeed in zip(montara_station, montara_wCompass, montara_wSpeed):
montara_array.append({'Station': station, 'Wind Direction': windCompass, 'Wind Speed': windSpeed})
df = pd.DataFrame(montara_array)
df
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-11 17:11
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(java抓取网页数据具体有哪些方法?javabbs抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-09 22:04
java抓取网页数据具体有哪些方法?bbs坛子数据抓取代码如下publicclassmain{publicstaticvoidmain(string[]args){//设置循环的操作系统system。out。println("微软有个新闻报道/");system。out。println("silicongameonlineforonecenturystudents:yeargameaimstoreachwinner");system。
out。println("六大公司齐聚supercell");system。out。println("accesskeyopen:"+string。valueof("white:"+string。
valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。valueof("white:"+stringof"white:"+string。value("white:"+string。
value("white:"+string。valueof"white:"+string。valueof("white:"+stringof"white:"+system"):appliedcategoriespingenglish。ocrto:userturcsdk")";}}}。 查看全部
java抓取网页数据(java抓取网页数据具体有哪些方法?javabbs抓取数据)
java抓取网页数据具体有哪些方法?bbs坛子数据抓取代码如下publicclassmain{publicstaticvoidmain(string[]args){//设置循环的操作系统system。out。println("微软有个新闻报道/");system。out。println("silicongameonlineforonecenturystudents:yeargameaimstoreachwinner");system。
out。println("六大公司齐聚supercell");system。out。println("accesskeyopen:"+string。valueof("white:"+string。
valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。
valueof("white:"+string。value("white:"+string。valueof("white:"+string。valueof("white:"+stringof"white:"+string。value("white:"+string。
value("white:"+string。valueof"white:"+string。valueof("white:"+stringof"white:"+system"):appliedcategoriespingenglish。ocrto:userturcsdk")";}}}。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-08 16:01
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页的源码,我们在源码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(java抓取网站数据假设你需要获取51job人才(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-08 13:08
Java 抓取 网站 数据。假设你需要在网上获取51job人才和java人才数量。首先需要分析51job网站的搜索是如何工作的。通过对网页源代码的分析,我们发现收录以下信息: 1. 搜索时页面请求的URL为2. 请求使用的方法为:POST 3.返回页面的编码格式为:GBK 4. 假设我们在搜索Java人才时获取结果页面显示的需求数量,我们发现该数量位于返回的HTML中的一段代码中数据:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍5. 另外,作为一个POST请求,页面发送到服务器端的数据如下(这个很容易被prototype等js框架捕获,参考我的另一篇博客介绍): lang=c&stype=1&postchannel =0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&Funtype=%&btn E9%80%89%E6 %8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE% E6%94%B9&industrytype=00 关于第5条的数据,我们不关心服务器真正需要什么,全部发送即可。有了这些准备,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类。该类封装了与请求相关的所有信息。Resource 包括以下属性: view plaincopy to clipboardprint? /** * 需要获取资源的目标地址,不包括查询字符串 */ private String target; /** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,get / post */ private String method = "GET"; /** * 返回数据 */ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;/** * 需要获取资源的目标地址,不收录查询字符串*/私有字符串目标;/** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,获取/发布 */ 私有字符串方法 = "GET"; /** * 返回数据的编码类型*/ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串 URL url = new URL(res.getTarget()); HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接 con.setRequestMethod(res.getMethod()); // 设置请求方法 // 设置HTTP请求头信息 con.setRequestProperty("accept", "*/*"); con.setRequestProperty("连接","保持活动"); con.setRequestProperty("user-agent", "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.1; SV1)"); con。 setDoInput(true); 如果 (res.g 查看全部
java抓取网页数据(java抓取网站数据假设你需要获取51job人才(组图))
Java 抓取 网站 数据。假设你需要在网上获取51job人才和java人才数量。首先需要分析51job网站的搜索是如何工作的。通过对网页源代码的分析,我们发现收录以下信息: 1. 搜索时页面请求的URL为2. 请求使用的方法为:POST 3.返回页面的编码格式为:GBK 4. 假设我们在搜索Java人才时获取结果页面显示的需求数量,我们发现该数量位于返回的HTML中的一段代码中数据:
1-30 / 14794
,所以我们可以得到这样一个模式:“.+1-\d+/(\d+).+”,第一组的内容就是我们最终需要的数据,java中的模式请参考java文档Pattern类介绍5. 另外,作为一个POST请求,页面发送到服务器端的数据如下(这个很容易被prototype等js框架捕获,参考我的另一篇博客介绍): lang=c&stype=1&postchannel =0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&Funtype=%&btn E9%80%89%E6 %8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE% E6%94%B9&industrytype=00 关于第5条的数据,我们不关心服务器真正需要什么,全部发送即可。有了这些准备,我们就可以真正开始通过java发送请求,得到最终的数据了。
我们定义了 Resource 类。该类封装了与请求相关的所有信息。Resource 包括以下属性: view plaincopy to clipboardprint? /** * 需要获取资源的目标地址,不包括查询字符串 */ private String target; /** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,get / post */ private String method = "GET"; /** * 返回数据 */ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;/** * 需要获取资源的目标地址,不收录查询字符串*/私有字符串目标;/** * get请求的查询字符串,或者post请求的请求数据*/ private String queryData = ""; /** * 请求方法,获取/发布 */ 私有字符串方法 = "GET"; /** * 返回数据的编码类型*/ private String charset = "GBK"; /** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。/** * 捕获数据的模式,数据列表会根据模式的分组返回*/ private String模式;以下是抓取内容的代码:view plaincopy to clipboardprint? // 假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串 URL url = new URL(res.getTarget()); HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接 con.setRequestMethod(res.getMethod()); // 设置请求方法 // 设置HTTP请求头信息 con.setRequestProperty("accept", "*/*"); con.setRequestProperty("连接","保持活动"); con.setRequestProperty("user-agent", "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.1; SV1)"); con。 setDoInput(true); 如果 (res.g
java抓取网页数据(java抓取网页数据的案例探讨(一).util)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-06 07:04
java抓取网页数据的案例探讨抓取网页时,java抓取网页数据的案例探讨是java网页爬虫程序实践应用的深入,广泛的实践中,要解决的问题无非是三个方面的:简单爬取:只要知道网页链接,一条一条的爬就行,前端方面的封装,就是一层层往下爬。复杂爬取:需要对http协议和抓包方面都有一定的实践和理解。只能抓取需要并发操作的地方的数据,对于iframe和代理服务器的区别没有深入的理解,那么,如何抓取token来完成抓取呢?通过本文,可以对如何抓取token来完成抓取有一个认识,理解并实践java网页爬虫程序实践中抓取token的原理和一些知识点。
本文分为如下三个部分,导入数据库,完成定制化代理服务器,反爬浏览器。导入数据库说明:github项目地址:-cn这里我们先来看看完成定制化代理服务器需要引入哪些包,然后再来定制化具体的项目。1.1requests模块导入模块execjs模块导入extension模块importexecjsfromimportexecjsfromexecjs.msgsdk.extensionimportitemfrom.itemsimporttextfrom.management.authimportauth这里需要导入两个execjs模块from.itemsimporttextfrom.management.authimportauthfromthreadingimportthreaderimportdatetimeimportnumpyimportmatplotlib.pyplotasplt需要导入四个包:fromexecjs.msgsdkimportexecjsfromjava.util.concurrent包中的routeredauthcontext模块下的javascript包glob包中的glob包importmath,matplotlib,scipy,itemfrommaple.methodimportmapproperties需要导入的包from.java.io.ioexception.nocodedirectionexception包中的字符串解析包path_dir="localhost"解析java代码代码如下:packagemainimportjava.util.concurrentimportjava.util.continuoustimeimportjava.util.function.mapexceptionimportjava.util.contextmatchimportjava.util.contextmatchexceptionimplimportjava.util.listenerimportjava.util.context.arraylistjava_methodimportjava.util.extension.contextmatchexceptionimportjava.util.extension.contextpathfromjava.util.extension.javax.methodimportjavax.methodimportjavax.method.futureexceptionrequest=javax.servlet.requestfromjavax.methodimportjavax.methodimportjavax.method.exception;fromjavax.methodimportjavax.m。 查看全部
java抓取网页数据(java抓取网页数据的案例探讨(一).util)
java抓取网页数据的案例探讨抓取网页时,java抓取网页数据的案例探讨是java网页爬虫程序实践应用的深入,广泛的实践中,要解决的问题无非是三个方面的:简单爬取:只要知道网页链接,一条一条的爬就行,前端方面的封装,就是一层层往下爬。复杂爬取:需要对http协议和抓包方面都有一定的实践和理解。只能抓取需要并发操作的地方的数据,对于iframe和代理服务器的区别没有深入的理解,那么,如何抓取token来完成抓取呢?通过本文,可以对如何抓取token来完成抓取有一个认识,理解并实践java网页爬虫程序实践中抓取token的原理和一些知识点。
本文分为如下三个部分,导入数据库,完成定制化代理服务器,反爬浏览器。导入数据库说明:github项目地址:-cn这里我们先来看看完成定制化代理服务器需要引入哪些包,然后再来定制化具体的项目。1.1requests模块导入模块execjs模块导入extension模块importexecjsfromimportexecjsfromexecjs.msgsdk.extensionimportitemfrom.itemsimporttextfrom.management.authimportauth这里需要导入两个execjs模块from.itemsimporttextfrom.management.authimportauthfromthreadingimportthreaderimportdatetimeimportnumpyimportmatplotlib.pyplotasplt需要导入四个包:fromexecjs.msgsdkimportexecjsfromjava.util.concurrent包中的routeredauthcontext模块下的javascript包glob包中的glob包importmath,matplotlib,scipy,itemfrommaple.methodimportmapproperties需要导入的包from.java.io.ioexception.nocodedirectionexception包中的字符串解析包path_dir="localhost"解析java代码代码如下:packagemainimportjava.util.concurrentimportjava.util.continuoustimeimportjava.util.function.mapexceptionimportjava.util.contextmatchimportjava.util.contextmatchexceptionimplimportjava.util.listenerimportjava.util.context.arraylistjava_methodimportjava.util.extension.contextmatchexceptionimportjava.util.extension.contextpathfromjava.util.extension.javax.methodimportjavax.methodimportjavax.method.futureexceptionrequest=javax.servlet.requestfromjavax.methodimportjavax.methodimportjavax.method.exception;fromjavax.methodimportjavax.m。
java抓取网页数据(java抓取网页数据,可以使用httpclient,但是没有定义好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-04 05:01
java抓取网页数据,可以使用httpclient,但是api没有定义好,大多数api都用来抓取web页面。我认为该设计是不合理的,api一定要精确,java那套对native语言很容易定义类和方法,但对于api就很容易造成误解。很多网站甚至没有,
你可以去看springboot官方文档favicon.ico-springboot应用和文档
web需要开发成本的。不过有一种解决方案,好像在官方的vulkansdk里面就有应用。而且通过它就能自己把数据转换过来。在这里也演示一下。先看一下chrome提供的开源包:/@sunculu/spring-boot-web-app-documentation-api-for-the-google-chrome-open-source-documentation接下来创建一个api:button.create({name:"hello",value:"hello,france"});global.add(button);value="hello,france";global.add(global.isnull());value="hello,france";global.add(global.null());global.add(global.get());value="france,"+global.get();然后你可以在java代码里面写:content.append(this.global.name+""+this.value);输出如下:。 查看全部
java抓取网页数据(java抓取网页数据,可以使用httpclient,但是没有定义好)
java抓取网页数据,可以使用httpclient,但是api没有定义好,大多数api都用来抓取web页面。我认为该设计是不合理的,api一定要精确,java那套对native语言很容易定义类和方法,但对于api就很容易造成误解。很多网站甚至没有,
你可以去看springboot官方文档favicon.ico-springboot应用和文档
web需要开发成本的。不过有一种解决方案,好像在官方的vulkansdk里面就有应用。而且通过它就能自己把数据转换过来。在这里也演示一下。先看一下chrome提供的开源包:/@sunculu/spring-boot-web-app-documentation-api-for-the-google-chrome-open-source-documentation接下来创建一个api:button.create({name:"hello",value:"hello,france"});global.add(button);value="hello,france";global.add(global.isnull());value="hello,france";global.add(global.null());global.add(global.get());value="france,"+global.get();然后你可以在java代码里面写:content.append(this.global.name+""+this.value);输出如下:。
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-01 08:06
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以得到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往复杂繁琐。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求该时段的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。 查看全部
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你,我们可以得到html,分析结构,解析结构以获取您想要的数据。Html的结构分析往往复杂繁琐。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求该时段的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理,可以获得1个篮球。
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的童鞋可以自己动手实践,在实践中学习。
java抓取网页数据(网页请求指令获取目标数据(Chrome浏览器需将插件升级到1.1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-30 14:12
使用网页监控指令获取数据问题描述
在网页抓取数据时,有些图表数据无法抓取,但需要的数据可以在开发者模式的Network-response中找到。您可以使用监控网页请求命令获取目标数据。插件升级为1.1)。
脚步
第一步,找到目标数据所在的url;
打开目标数据所在的网页(以下简称“网页”),按F12打开开发者模式;
按 ctrl + R 重新加载;
点击左边的路径,查看其响应中是否有目标数据;
如果有目标数据,复制其url不变的部分(一般是会改变的部分,比如日期时间或者ID)
第二步,监听第一步获取的URL;
监控步骤
获取网页对象-开始监听请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果)-停止监控网页要求。
流程实例
示例流程及相关参数配置如下(这里获取的网页对象是第一步中目标数据所在的网页,也可以使用网页命令获取目标网页对象) .
过程:
第三步,获取目标数据;
循环获取的Response_body_list;
过程:
转换数据格式:循环项是一个收录目标url数据的字典,响应中的数据收录在循环项字典的键["body"]中,body是一个字符串,可以转换成一个json 对象中的数据被提取出来。
提取json对象中的目标信息(可以将打印的json文本复制到网站中观察数据结构,方便数据提取);
问题没有解决?去社区提问 版权所有,由 Gitbook 提供支持 查看全部
java抓取网页数据(网页请求指令获取目标数据(Chrome浏览器需将插件升级到1.1))
使用网页监控指令获取数据问题描述
在网页抓取数据时,有些图表数据无法抓取,但需要的数据可以在开发者模式的Network-response中找到。您可以使用监控网页请求命令获取目标数据。插件升级为1.1)。
脚步
第一步,找到目标数据所在的url;
打开目标数据所在的网页(以下简称“网页”),按F12打开开发者模式;
按 ctrl + R 重新加载;
点击左边的路径,查看其响应中是否有目标数据;
如果有目标数据,复制其url不变的部分(一般是会改变的部分,比如日期时间或者ID)
第二步,监听第一步获取的URL;
监控步骤
获取网页对象-开始监听请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果)-停止监控网页要求。
流程实例
示例流程及相关参数配置如下(这里获取的网页对象是第一步中目标数据所在的网页,也可以使用网页命令获取目标网页对象) .
过程:
第三步,获取目标数据;
循环获取的Response_body_list;
过程:
转换数据格式:循环项是一个收录目标url数据的字典,响应中的数据收录在循环项字典的键["body"]中,body是一个字符串,可以转换成一个json 对象中的数据被提取出来。
提取json对象中的目标信息(可以将打印的json文本复制到网站中观察数据结构,方便数据提取);
问题没有解决?去社区提问 版权所有,由 Gitbook 提供支持

