
java抓取网页数据
java抓取网页数据(,刚学会把git部署到远程服务器,没事做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-12 18:18
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
跑
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedH来源gaodai$ma#com搞$$代**码)网ashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
java抓取网页数据(,刚学会把git部署到远程服务器,没事做
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
跑
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedH来源gaodai$ma#com搞$$代**码)网ashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
java抓取网页数据(小白看过来,让Python爬虫成为你的好帮手》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-31 22:24
核心提示:华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。以下为《一起来看看小白,让Python爬虫成为你的好帮手》全文:随着信息社会...
华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
<IMG SRC="http://www.admin10000.com/Uplo ... gt%3B
以下为《小白,让Python爬虫成为你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词已不再陌生。但是什么是爬虫,如何利用爬虫来为自己服务,这些在ICT技术的新手在云端听上去有点高。别着急,下面的文章将带你走近爬虫的世界,让即使你是ICT技术的新手,也能了解如何使用Python爬虫高效抓取图片。
什么是专用爬虫?
网络爬虫是一种从互联网上抓取数据和信息的自动化程序。如果我们把互联网比作一张大蜘蛛网,数据存储在蜘蛛网的各个节点中,而爬虫就是一个小蜘蛛(程序),沿着网络爬取它的猎物(数据)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。分为通用爬虫和特殊爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为特定的人群提供服务,爬取的目标网页位于与主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据,或者有明确的搜索需求,此时就需要过滤掉一些无用的信息。
爬虫的工作原理
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫的第一个工作是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器收到响应并解析出来。实际上,获取网页-解析网页源代码-提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Requests、pyquery、lxml等,使用这些库可以高效快速的提取来自他们的网页信息,如节点属性、文本值等,可以简单地保存为TXT文本或JSON文本。这些信息可以保存到数据库中,例如 MySQL 和 MongoDB,也可以保存到远程服务器,例如使用 SFTP 进行操作。提取信息是爬虫的一个非常重要的功能。可以将杂乱的数据整理清晰,便于后续处理和分析。
Java免费学习Java自学网 查看全部
java抓取网页数据(小白看过来,让Python爬虫成为你的好帮手》)
核心提示:华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。以下为《一起来看看小白,让Python爬虫成为你的好帮手》全文:随着信息社会...
华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
<IMG SRC="http://www.admin10000.com/Uplo ... gt%3B
以下为《小白,让Python爬虫成为你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词已不再陌生。但是什么是爬虫,如何利用爬虫来为自己服务,这些在ICT技术的新手在云端听上去有点高。别着急,下面的文章将带你走近爬虫的世界,让即使你是ICT技术的新手,也能了解如何使用Python爬虫高效抓取图片。
什么是专用爬虫?
网络爬虫是一种从互联网上抓取数据和信息的自动化程序。如果我们把互联网比作一张大蜘蛛网,数据存储在蜘蛛网的各个节点中,而爬虫就是一个小蜘蛛(程序),沿着网络爬取它的猎物(数据)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。分为通用爬虫和特殊爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为特定的人群提供服务,爬取的目标网页位于与主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据,或者有明确的搜索需求,此时就需要过滤掉一些无用的信息。
爬虫的工作原理
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫的第一个工作是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器收到响应并解析出来。实际上,获取网页-解析网页源代码-提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Requests、pyquery、lxml等,使用这些库可以高效快速的提取来自他们的网页信息,如节点属性、文本值等,可以简单地保存为TXT文本或JSON文本。这些信息可以保存到数据库中,例如 MySQL 和 MongoDB,也可以保存到远程服务器,例如使用 SFTP 进行操作。提取信息是爬虫的一个非常重要的功能。可以将杂乱的数据整理清晰,便于后续处理和分析。
Java免费学习Java自学网
java抓取网页数据(SEO初学必读:搜索引擎的排名原理解析的原理图解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 22:17
SEO初学者必读:搜索引擎排名原理分析
搜索引擎排名原理示意图
一、什么是搜索引擎
百度、360、谷歌、搜搜、必应、雅虎等都是搜索引擎的具体表现形式。具体解释可以去百度,这里不再赘述。
二、什么是搜索引擎蜘蛛
搜索引擎蜘蛛是一种搜索引擎程序,是一套信息抓取系统程序。
常见的蜘蛛有百度蜘蛛、Gllglebot、360Spider、搜狗新闻蜘蛛等
三、什么是SEO
Seo 指的是搜索引擎优化,也称为 网站 优化。
搜索引擎优化并不容易。在数百万甚至数千万的竞争者中,我们的目标不是进入前百,而是力争前十,甚至第一。这对于seo初学者来说可能是一个梦想,但在seo的核心,我们的目标是让这个梦想成真。
四、什么是关键词?
关键词 是指参与排名的每一个词组。
从某种意义上说,seo优化也是关键词排名优化。 关键词优化的直接体现就是网站标题的排名(由关键词组成);从另一方面来说,每个标题的排名就是标题所收录的页面的排名。
理论上,每个页面都有参与排名的机会。所以网站排名的最小单位就是页面。
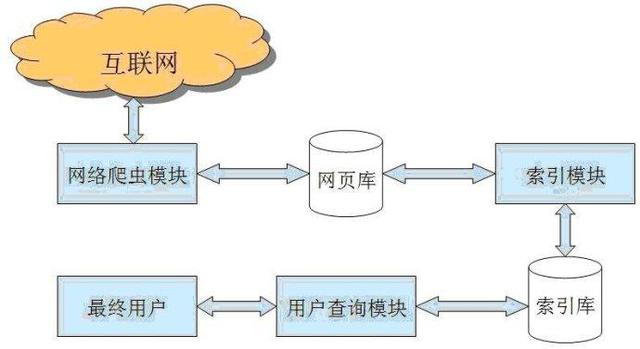
五、搜索引擎爬取收录原理(四个过程)
1、抢
2、过滤
3、存储索引库
4、显示排序
搜索引擎抓取收录流程图
蜘蛛爬取——网站页面——存放在临时索引库中——排名状态(从索引库中检索)
评论:
临时索引库不存储蜘蛛爬取的所有网站页面,
他会根据蜘蛛抓取的页面质量进行过滤,过滤掉一些质量较差的页面,
质量好的页面按页面质量排序,
最后是我们看到的排名情况
有人可能会问为什么我的网站没有收录
主要原因之一是网站的页面质量差,被搜索引擎过滤掉,所以不被百度接受收录。
(一)搜索引擎抓取:
1、爬虫SPider通过网页中的超链接,在互联网上发现和采集网页信息
2、如何抓取蜘蛛
1)深度爬取(垂直抓取,先爬取某列的内容页,然后换列,同样的方式爬取)
2)宽爬(横向爬取,先爬取各个版块,再爬取各个版块页面下方的内容页)
3、不利于蜘蛛识别的内容
js代码、iframe框架代码机制、图片(添加alt属性辅助识别)、flash(视频前后添加文字辅助搜索引擎识别)、登录后可获取的页面信息、嵌套表、等
网站结构:首页——栏目页——内容详情页
(二)搜索引擎过滤
过滤低质量的内容页面
什么是低质量内容页面?
1、采集,内容价值低
2、文字内容不正确
3、没有丰富的内容
(三)搜索引擎存储索引库
过滤蜘蛛爬取的内容后,将内容存入临时数据索引库。
(四)搜索引擎显示排名
存储索引库的内容按照质量排序,然后调用显示给用户。
1、搜索者根据用户输入的查询快速检索索引库中的文档关键词,评估文档与查询的相关性,对输出结果进行排序,并进行比较查询结果显示给用户。
2、当我们在搜索引擎上只看到一个结果时,根据各种算法对搜索进行排序,将十个质量最好的结果放在第一页
seo 优化的日常注意事项:
1、不要随意删除或移动已经收录的页面位置
2、显示结果需要一定的时间(2个月内是正常的)
3、内容丰富
4、吸引蜘蛛(主动提交给搜索引擎,外链)
5、跟踪蜘蛛,网站IIS 日志 查看全部
java抓取网页数据(SEO初学必读:搜索引擎的排名原理解析的原理图解)
SEO初学者必读:搜索引擎排名原理分析
搜索引擎排名原理示意图
一、什么是搜索引擎
百度、360、谷歌、搜搜、必应、雅虎等都是搜索引擎的具体表现形式。具体解释可以去百度,这里不再赘述。
二、什么是搜索引擎蜘蛛
搜索引擎蜘蛛是一种搜索引擎程序,是一套信息抓取系统程序。
常见的蜘蛛有百度蜘蛛、Gllglebot、360Spider、搜狗新闻蜘蛛等
三、什么是SEO
Seo 指的是搜索引擎优化,也称为 网站 优化。
搜索引擎优化并不容易。在数百万甚至数千万的竞争者中,我们的目标不是进入前百,而是力争前十,甚至第一。这对于seo初学者来说可能是一个梦想,但在seo的核心,我们的目标是让这个梦想成真。
四、什么是关键词?
关键词 是指参与排名的每一个词组。
从某种意义上说,seo优化也是关键词排名优化。 关键词优化的直接体现就是网站标题的排名(由关键词组成);从另一方面来说,每个标题的排名就是标题所收录的页面的排名。
理论上,每个页面都有参与排名的机会。所以网站排名的最小单位就是页面。
五、搜索引擎爬取收录原理(四个过程)
1、抢
2、过滤
3、存储索引库
4、显示排序
搜索引擎抓取收录流程图
蜘蛛爬取——网站页面——存放在临时索引库中——排名状态(从索引库中检索)
评论:
临时索引库不存储蜘蛛爬取的所有网站页面,
他会根据蜘蛛抓取的页面质量进行过滤,过滤掉一些质量较差的页面,
质量好的页面按页面质量排序,
最后是我们看到的排名情况
有人可能会问为什么我的网站没有收录
主要原因之一是网站的页面质量差,被搜索引擎过滤掉,所以不被百度接受收录。
(一)搜索引擎抓取:
1、爬虫SPider通过网页中的超链接,在互联网上发现和采集网页信息
2、如何抓取蜘蛛
1)深度爬取(垂直抓取,先爬取某列的内容页,然后换列,同样的方式爬取)
2)宽爬(横向爬取,先爬取各个版块,再爬取各个版块页面下方的内容页)
3、不利于蜘蛛识别的内容
js代码、iframe框架代码机制、图片(添加alt属性辅助识别)、flash(视频前后添加文字辅助搜索引擎识别)、登录后可获取的页面信息、嵌套表、等
网站结构:首页——栏目页——内容详情页
(二)搜索引擎过滤
过滤低质量的内容页面
什么是低质量内容页面?
1、采集,内容价值低
2、文字内容不正确
3、没有丰富的内容
(三)搜索引擎存储索引库
过滤蜘蛛爬取的内容后,将内容存入临时数据索引库。
(四)搜索引擎显示排名
存储索引库的内容按照质量排序,然后调用显示给用户。
1、搜索者根据用户输入的查询快速检索索引库中的文档关键词,评估文档与查询的相关性,对输出结果进行排序,并进行比较查询结果显示给用户。
2、当我们在搜索引擎上只看到一个结果时,根据各种算法对搜索进行排序,将十个质量最好的结果放在第一页
seo 优化的日常注意事项:
1、不要随意删除或移动已经收录的页面位置
2、显示结果需要一定的时间(2个月内是正常的)
3、内容丰富
4、吸引蜘蛛(主动提交给搜索引擎,外链)
5、跟踪蜘蛛,网站IIS 日志
java抓取网页数据(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-31 19:11
)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页数据(代码罗View远程服务器,没事抓取网页信息的小工具
)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
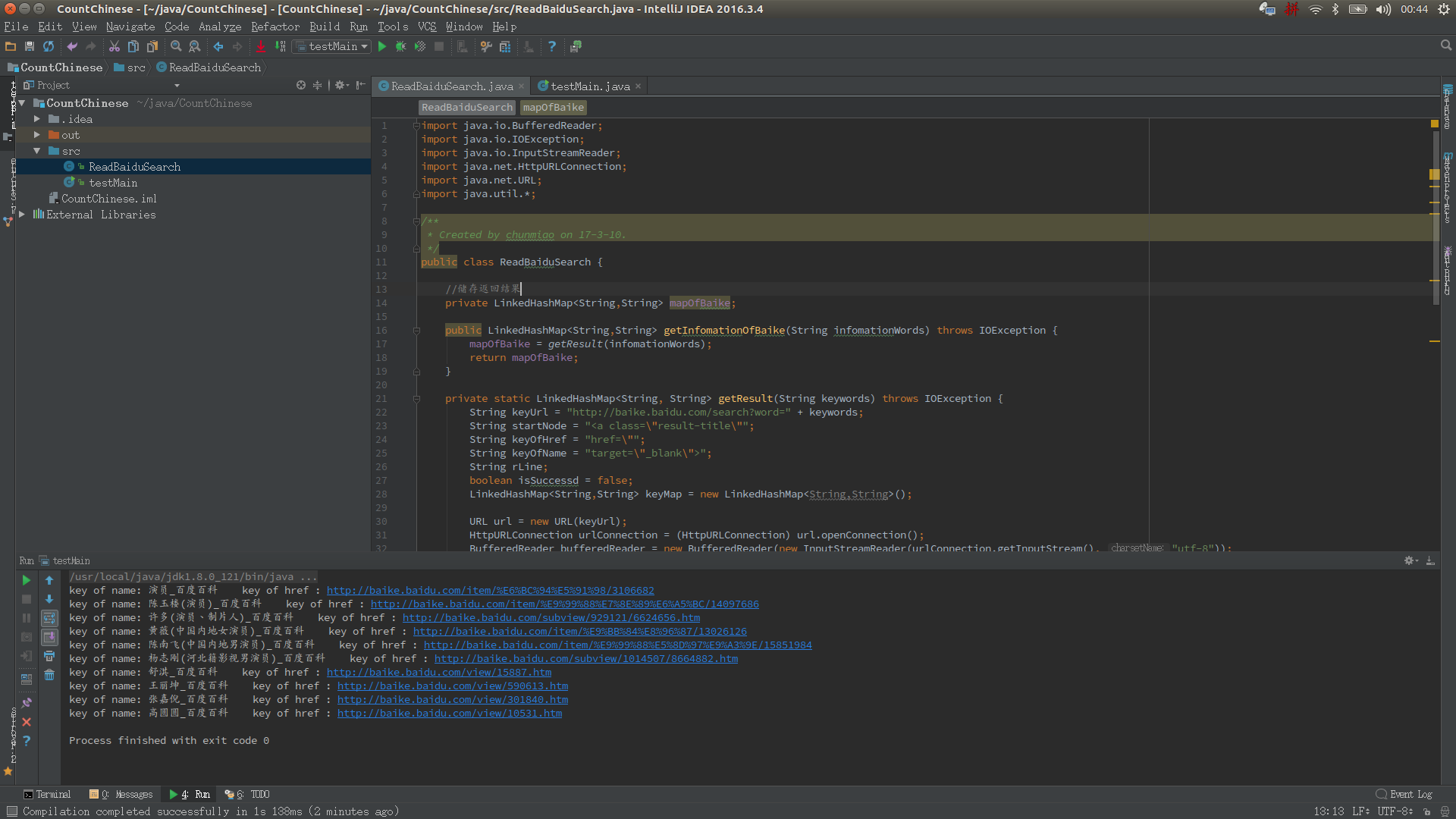
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
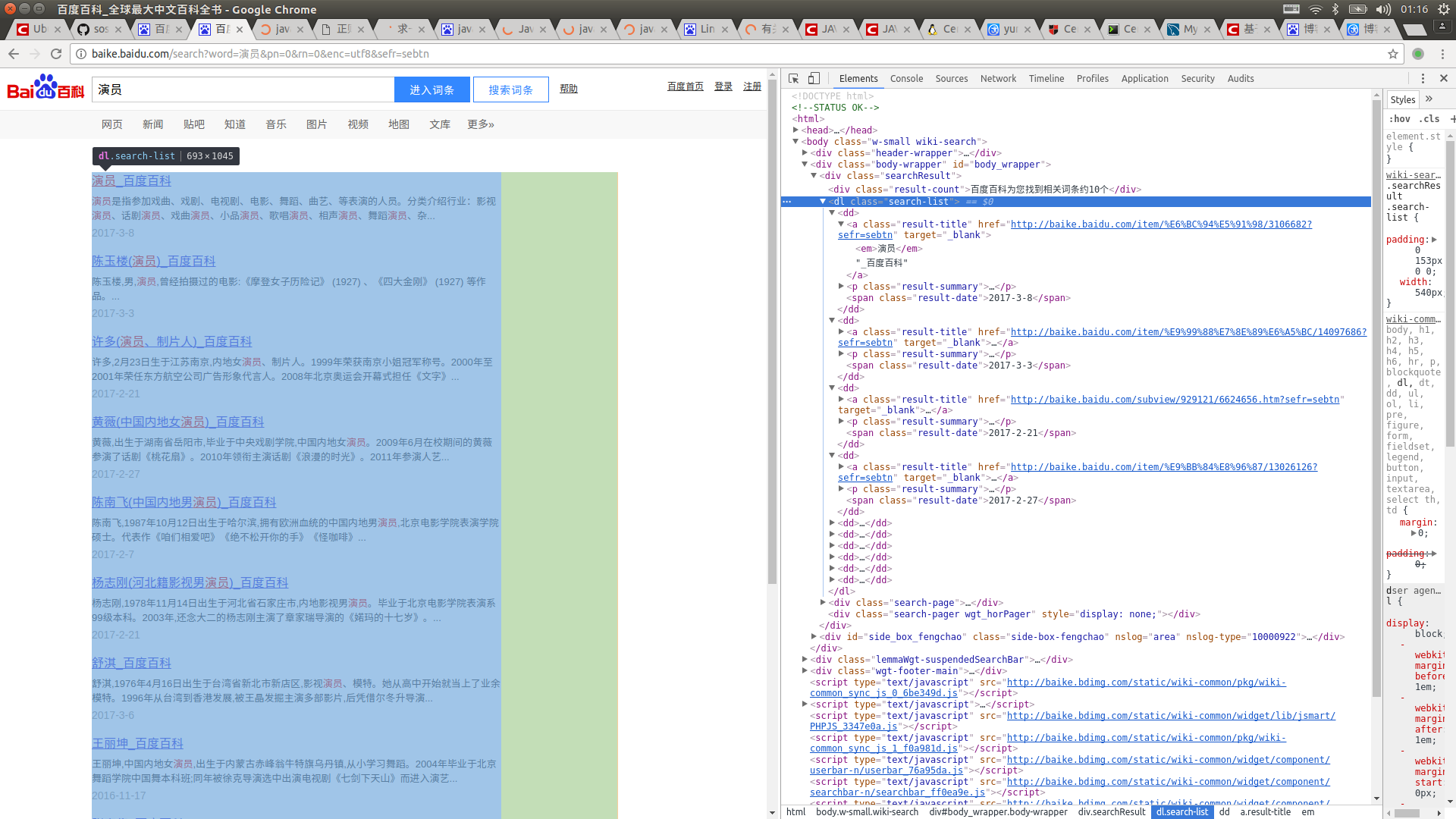
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗


1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,解析html+js+css )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-27 06:14
一个彩票网站为例来简单说明整体操作流程,解析html+js+css
)
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时,你需要抓取你感兴趣的某个网站的信息。一个网站信息必须通过某个url发送,并根据该地址发送http请求。知道这个地址后,可以得到很多网络响应,需要仔细分析。,找到你合适的地址,最后通过这个地址返回一个html给你,我们就可以拿到这个html,分析结构,解析这个结构,得到你想要的数据。
Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一个彩票网站为例,简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选择的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这篇文章的时候,网站已经修改了页面结构,那你需要重新分析一下。当然,估计修改本网站网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,解析html+js+css
)
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时,你需要抓取你感兴趣的某个网站的信息。一个网站信息必须通过某个url发送,并根据该地址发送http请求。知道这个地址后,可以得到很多网络响应,需要仔细分析。,找到你合适的地址,最后通过这个地址返回一个html给你,我们就可以拿到这个html,分析结构,解析这个结构,得到你想要的数据。
Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一个彩票网站为例,简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选择的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这篇文章的时候,网站已经修改了页面结构,那你需要重新分析一下。当然,估计修改本网站网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-27 04:05
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这个我就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解

在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览

接下来我们看一下网页的源码结构:

从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这个我就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
java抓取网页数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-26 10:13
原文链接:
有时因为各种原因。我们需要从某个站点采集
数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line);} String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out . println("captureHtml() 结果:\n" + 结果);}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line); } System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);}
看见。抓取JS的方法和之前抓取原创
网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望本文能成为需要帮助的孩子和程序的源代码,点此下载! 查看全部
java抓取网页数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
原文链接:
有时因为各种原因。我们需要从某个站点采集
数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:

换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line);} String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out . println("captureHtml() 结果:\n" + 结果);}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line); } System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);}
看见。抓取JS的方法和之前抓取原创
网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望本文能成为需要帮助的孩子和程序的源代码,点此下载!
java抓取网页数据( 03环境部署要编写代码,首先得部署环境(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-22 06:09
03环境部署要编写代码,首先得部署环境(图))
(知乎里面的视频可能看不清楚,可以通过公众号下载原视频查看,我已经上传了,链接在留言区)
03 环境部署
要编写代码,您必须首先部署环境。这里二发录制了一个小视频教大家如何部署环境:
视频中提到,二发已经把环境依赖的所有库都打包好了,可以直接使用,不要忘记Build Path。
04 爬虫介绍&代码解释
在接下来的视频中,二发将给大家简单介绍一下爬虫的工作原理,然后讲解这200行代码是如何工作的。
看完上面的视频,大家都开始爬了。除了冯小刚的微博,你还可以抓取任何你想要的内容,比如马蓉的微博。
尔胖有话要说
二发开始学习爬虫的时候用的是WebCollector,因为当时不会Python,只写了一点Java,所以二发就用Java来启动爬虫。
不过在用户体验上,Python 稍微方便一些。与Java相比,Python可以用更短的代码实现同样的功能。
但是,Java 的性能优于 Python。
现在爬虫基本都是多线程的,Python的多线程和Java的多线程模型有些不同。对于多核计算机,Python线程只使用一个核,不同的用户线程总是在一个核上进行上下文切换。其他内核空闲。这就是 N:1 线程模型。
就像下图一样:
而Java的多线程模型是真正的多核模型,即每个CPU核都在忙碌。
当然,如果你不明白,也没有问题。可以继续关注二发。以后的日子,二发会慢慢和大家分享。
对于爬虫来说,在大多数情况下,限制爬取速度的瓶颈不是CPU核数,而是网络延迟和等待时间,所以对于个人爬虫来说,Python和Java没有太大区别。
本文所涉及的代码、视频和github地址放在公众号后台,搜索微信公众号“逆袭二胖”回复“冯小刚”即可获取。 查看全部
java抓取网页数据(
03环境部署要编写代码,首先得部署环境(图))
(知乎里面的视频可能看不清楚,可以通过公众号下载原视频查看,我已经上传了,链接在留言区)
03 环境部署
要编写代码,您必须首先部署环境。这里二发录制了一个小视频教大家如何部署环境:
视频中提到,二发已经把环境依赖的所有库都打包好了,可以直接使用,不要忘记Build Path。
04 爬虫介绍&代码解释
在接下来的视频中,二发将给大家简单介绍一下爬虫的工作原理,然后讲解这200行代码是如何工作的。
看完上面的视频,大家都开始爬了。除了冯小刚的微博,你还可以抓取任何你想要的内容,比如马蓉的微博。
尔胖有话要说
二发开始学习爬虫的时候用的是WebCollector,因为当时不会Python,只写了一点Java,所以二发就用Java来启动爬虫。
不过在用户体验上,Python 稍微方便一些。与Java相比,Python可以用更短的代码实现同样的功能。
但是,Java 的性能优于 Python。
现在爬虫基本都是多线程的,Python的多线程和Java的多线程模型有些不同。对于多核计算机,Python线程只使用一个核,不同的用户线程总是在一个核上进行上下文切换。其他内核空闲。这就是 N:1 线程模型。
就像下图一样:

而Java的多线程模型是真正的多核模型,即每个CPU核都在忙碌。
当然,如果你不明白,也没有问题。可以继续关注二发。以后的日子,二发会慢慢和大家分享。
对于爬虫来说,在大多数情况下,限制爬取速度的瓶颈不是CPU核数,而是网络延迟和等待时间,所以对于个人爬虫来说,Python和Java没有太大区别。
本文所涉及的代码、视频和github地址放在公众号后台,搜索微信公众号“逆袭二胖”回复“冯小刚”即可获取。
java抓取网页数据(PS教程-PS制作远程服务器制作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-21 07:05
无事可做,刚学会了将git部署到远程服务器,无事可做,就简单的做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持面圈教程! 查看全部
java抓取网页数据(PS教程-PS制作远程服务器制作方法)
无事可做,刚学会了将git部署到远程服务器,无事可做,就简单的做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持面圈教程!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-19 15:02
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-19 13:14
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送http请求,并根据地址定位。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送http请求,并根据地址定位。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

通过以下代码,得到6个红球:

同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 17:11
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-18 17:09
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = newBufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,会报Serverredirected too manytimes之类的错误,因为这个网页里面有一些代码重定向到其他网页,太多了循环导致程序错误。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection)urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = newBufferedReader(newInputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需在上述程序中添加以下程序即可。
System.getProperties().setProperty("http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort",port);
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!! 查看全部
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = newBufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,会报Serverredirected too manytimes之类的错误,因为这个网页里面有一些代码重定向到其他网页,太多了循环导致程序错误。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection)urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = newBufferedReader(newInputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需在上述程序中添加以下程序即可。
System.getProperties().setProperty("http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort",port);
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-18 17:08
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
Java代码
URL url = 新 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine( )) != null) {i++; sb.append(s+"/r/n");}
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"/r/n"); }
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
Java代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); 连接();BufferedReader br = new BufferedReader(new InputStreamReader( con.getInputStream(),"UTF-8")); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb.append(s+"/r/n");}
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"/r/n"); }
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
(转载!!!) 查看全部
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
Java代码
URL url = 新 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine( )) != null) {i++; sb.append(s+"/r/n");}
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"/r/n"); }
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
Java代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); 连接();BufferedReader br = new BufferedReader(new InputStreamReader( con.getInputStream(),"UTF-8")); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb.append(s+"/r/n");}
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"/r/n"); }
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
(转载!!!)
java抓取网页数据(是啥?web中的url(uniformresourcelocator)统一资源定位)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 05:03
java抓取网页数据的种种方法有很多,今天我们来简单的解释一下,还有我们以及对url的定义,关于定义和解释请参考我之前的文章:1.url是啥?web中的url(uniformresourcelocator)统一资源定位符,是一种统一资源定位符,也是http的一种标准格式.用于定位http资源,在internet上是所有主机间的统一资源定位符.用来告诉internet主机,有人来访问你的网站了。
2.网页url又有哪些类型?根据其上的meta标签不同,常见的url类型有如下几种:a.静态url:cookie-urls/session-urls/web-web-web-web-url等等b.动态url:每次请求都不同,header内容可能不同,本文不展开说明c.混合url:a.包含上述两种urlb.不包含上述两种url3.ftp文件上传的定义ftp上传的定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。
4.ftp文件上传如何定义?ftp文件上传定义原则是,:ftp客户端的默认上传文件上传类型定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。ftp上传工具:ftp和url浏览器端是securefaulter/file-browser前端一般是websocketftp控制器httpclient/http/proxy文件上传定义为ftp客户端所定义的文件url,如:public/ftp/jar包的类的url为:;environment=java这样我们在要上传或者修改url的时候就可以直接抓取定义了。
ftp客户端//..//..-->helloworld5.浏览器如何抓取url在http请求过程中,会经过三次握手,最后还是从data属性传递,然后也是json格式传递,不可读取。所以浏览器是不可能知道你的url所指的是什么资源。只有服务器获取你的url再返回的json文件,才可以做后续操作。解决方法就是用到我们使用ftp上传工具ftptest:handlerevent(e){..handlerevent(f,...){//settimeoutincrement=1..}</a>//allowedlinkswriteurlwithj。 查看全部
java抓取网页数据(是啥?web中的url(uniformresourcelocator)统一资源定位)
java抓取网页数据的种种方法有很多,今天我们来简单的解释一下,还有我们以及对url的定义,关于定义和解释请参考我之前的文章:1.url是啥?web中的url(uniformresourcelocator)统一资源定位符,是一种统一资源定位符,也是http的一种标准格式.用于定位http资源,在internet上是所有主机间的统一资源定位符.用来告诉internet主机,有人来访问你的网站了。
2.网页url又有哪些类型?根据其上的meta标签不同,常见的url类型有如下几种:a.静态url:cookie-urls/session-urls/web-web-web-web-url等等b.动态url:每次请求都不同,header内容可能不同,本文不展开说明c.混合url:a.包含上述两种urlb.不包含上述两种url3.ftp文件上传的定义ftp上传的定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。
4.ftp文件上传如何定义?ftp文件上传定义原则是,:ftp客户端的默认上传文件上传类型定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。ftp上传工具:ftp和url浏览器端是securefaulter/file-browser前端一般是websocketftp控制器httpclient/http/proxy文件上传定义为ftp客户端所定义的文件url,如:public/ftp/jar包的类的url为:;environment=java这样我们在要上传或者修改url的时候就可以直接抓取定义了。
ftp客户端//..//..-->helloworld5.浏览器如何抓取url在http请求过程中,会经过三次握手,最后还是从data属性传递,然后也是json格式传递,不可读取。所以浏览器是不可能知道你的url所指的是什么资源。只有服务器获取你的url再返回的json文件,才可以做后续操作。解决方法就是用到我们使用ftp上传工具ftptest:handlerevent(e){..handlerevent(f,...){//settimeoutincrement=1..}</a>//allowedlinkswriteurlwithj。
java抓取网页数据( 2017年03月13日java利用url实现网页内容抓取的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-17 02:07
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url实现网页内容爬取
更新时间:2017年3月13日09:42:31 作者:zangcumiao
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋! 查看全部
java抓取网页数据(
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url实现网页内容爬取
更新时间:2017年3月13日09:42:31 作者:zangcumiao
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋!
java抓取网页数据( commons-io工具获取页面或Json5工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-13 14:05
commons-io工具获取页面或Json5工具(图))
4)commons-io 工具,获取页面或者 Json
5) Jsoup工具(一般用于html字段分析),获取页面,非Json返回格式]
----------------------------------------------- ---------------------------------
完整代码:
package com.yeezhao.common.http;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
import org.jsoup.Jsoup;
/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception
*/
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
return conn.getResponseCode();
}
/**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s;
while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect();
return sb.toString();
}
return "";
}
/**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request);
return IOUtils.toString(url.openStream());
}
/**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String httpClientFetch(String url, String charset) throws Exception {
// GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method);
return method.getResponseBodyAsString();
}
/**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String commonsIOFetch(String url, String charset) throws Exception {
return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception
*/
public static String jsoupFetch(String url) throws Exception {
return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
package com.yeezhao.common.http;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 测试类
* 3个测试链接:
* 1)百科网页
* 2)浏览器模拟获取接口数据
* 3)获取普通接口数据
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtilTest {
String seeds[] = {"http://baike.baidu.com/view/1.htm","http://m.ximalaya.com/tracks/26096131.json","http://remyapi.yeezhao.com/api ... ot%3B};
final static String DEFAULT_CHARSET = "UTF-8";
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
System.out.println("--- down ---");
}
@Test
public void testGetResponseCode() throws Exception{
for(String seed:seeds){
int responseCode = HttpFetchUtil.getResponseCode(seed);
System.out.println("ret="+responseCode);
}
}
@Test
public void testJDKFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.JDKFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testURLFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.URLFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testHttpClientFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.httpClientFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testCommonsIOFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.commonsIOFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testJsoupFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.jsoupFetch(seed);
System.out.println("ret="+ret);
}
}
}
附件:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java抓取网页数据(
commons-io工具获取页面或Json5工具(图))

4)commons-io 工具,获取页面或者 Json

5) Jsoup工具(一般用于html字段分析),获取页面,非Json返回格式]

----------------------------------------------- ---------------------------------
完整代码:
package com.yeezhao.common.http;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
import org.jsoup.Jsoup;
/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception
*/
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
return conn.getResponseCode();
}
/**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s;
while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect();
return sb.toString();
}
return "";
}
/**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request);
return IOUtils.toString(url.openStream());
}
/**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String httpClientFetch(String url, String charset) throws Exception {
// GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method);
return method.getResponseBodyAsString();
}
/**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String commonsIOFetch(String url, String charset) throws Exception {
return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception
*/
public static String jsoupFetch(String url) throws Exception {
return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
package com.yeezhao.common.http;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 测试类
* 3个测试链接:
* 1)百科网页
* 2)浏览器模拟获取接口数据
* 3)获取普通接口数据
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtilTest {
String seeds[] = {"http://baike.baidu.com/view/1.htm","http://m.ximalaya.com/tracks/26096131.json","http://remyapi.yeezhao.com/api ... ot%3B};
final static String DEFAULT_CHARSET = "UTF-8";
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
System.out.println("--- down ---");
}
@Test
public void testGetResponseCode() throws Exception{
for(String seed:seeds){
int responseCode = HttpFetchUtil.getResponseCode(seed);
System.out.println("ret="+responseCode);
}
}
@Test
public void testJDKFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.JDKFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testURLFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.URLFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testHttpClientFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.httpClientFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testCommonsIOFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.commonsIOFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testJsoupFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.jsoupFetch(seed);
System.out.println("ret="+ret);
}
}
}
附件:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java抓取网页数据(java抓取网站数据假设你需要获取51人才网上java人才的需求数量(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-13 09:05
文件介绍:
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,发现数量在返回的
在 HTML 数据中的这样一段代码中:
1-30 / 14794
, 所以我们可以得到这样一个
mode:".+1-\d+ / (\d+).+",第一组的内容就是我们最终需要的数据,关于java中的mode,
请参考java文档中Pattern类的介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ
obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn
funtype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd
ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
关于第5条的数据,我们不关心服务器真正需要什么,把它们都发送出去。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:
查看普通副本到剪贴板打印?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
以下是抓取内容的代码:
查看普通副本到剪贴板打印?
//假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。
//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串的信息
URL url = 新 URL(res.getTarget());
HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接
con.setRequestMethod(res.getMethod()); //设置请求的方法 查看全部
java抓取网页数据(java抓取网站数据假设你需要获取51人才网上java人才的需求数量(组图))
文件介绍:
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,发现数量在返回的
在 HTML 数据中的这样一段代码中:
1-30 / 14794
, 所以我们可以得到这样一个
mode:".+1-\d+ / (\d+).+",第一组的内容就是我们最终需要的数据,关于java中的mode,
请参考java文档中Pattern类的介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ
obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn
funtype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd
ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
关于第5条的数据,我们不关心服务器真正需要什么,把它们都发送出去。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:
查看普通副本到剪贴板打印?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
以下是抓取内容的代码:
查看普通副本到剪贴板打印?
//假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。
//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串的信息
URL url = 新 URL(res.getTarget());
HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接
con.setRequestMethod(res.getMethod()); //设置请求的方法
java抓取网页数据(java抓取网页数据传输基本没有有什么区别?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-11 03:02
java抓取网页数据,并返回html,然后自动同步到浏览器,这个说白了和ajax的json数据传输基本没有什么区别。需要一点java的基础。不会flash基本的api(应该是有的),是搞不定这个的,别说写抓包,数据库、java虚拟机、javaweb开发都搞不定。而且动态网页,格式要复杂很多,相当于写3个页面。
再说说技术易学难精这个词。你要明白,java这行这么火,肯定是难学的,要是易学,不在2017年以前就有大把人抢着转行java了。并且初级程序员工资低,是有很多客观原因的。相当于每年都有海量的人涌入这个行业,竞争压力大。
入门容易,以后不好说。其实不难,就拿我现在正在学的java来说,入门学5天的话,就能写写简单的静态网页。就以个人的经验来说,在写静态网页之前,必须了解web前端基础,比如html,css基础都要学好,要不然能一行代码写到死,不过,如果你肯学的话,入门到进阶还是比较快的。当然,想靠自学就自己写出网页的时代过去了,学校教也教不了什么,至少得报班,而且价格必须不低。现在还是报培训班效果最好,有专业老师带着,还能让你快速上手。
想弄懂java的数据库sql,要找个会看源码的。
不难,写顺手以后学别的也是很快的。 查看全部
java抓取网页数据(java抓取网页数据传输基本没有有什么区别?-八维教育)
java抓取网页数据,并返回html,然后自动同步到浏览器,这个说白了和ajax的json数据传输基本没有什么区别。需要一点java的基础。不会flash基本的api(应该是有的),是搞不定这个的,别说写抓包,数据库、java虚拟机、javaweb开发都搞不定。而且动态网页,格式要复杂很多,相当于写3个页面。
再说说技术易学难精这个词。你要明白,java这行这么火,肯定是难学的,要是易学,不在2017年以前就有大把人抢着转行java了。并且初级程序员工资低,是有很多客观原因的。相当于每年都有海量的人涌入这个行业,竞争压力大。
入门容易,以后不好说。其实不难,就拿我现在正在学的java来说,入门学5天的话,就能写写简单的静态网页。就以个人的经验来说,在写静态网页之前,必须了解web前端基础,比如html,css基础都要学好,要不然能一行代码写到死,不过,如果你肯学的话,入门到进阶还是比较快的。当然,想靠自学就自己写出网页的时代过去了,学校教也教不了什么,至少得报班,而且价格必须不低。现在还是报培训班效果最好,有专业老师带着,还能让你快速上手。
想弄懂java的数据库sql,要找个会看源码的。
不难,写顺手以后学别的也是很快的。
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,js实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-09 13:25
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

通过以下代码,得到6个红球:

同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
java抓取网页数据(,刚学会把git部署到远程服务器,没事做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-12 18:18
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
跑
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedH来源gaodai$ma#com搞$$代**码)网ashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
java抓取网页数据(,刚学会把git部署到远程服务器,没事做
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
跑
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedH来源gaodai$ma#com搞$$代**码)网ashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
java抓取网页数据(小白看过来,让Python爬虫成为你的好帮手》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-31 22:24
核心提示:华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。以下为《一起来看看小白,让Python爬虫成为你的好帮手》全文:随着信息社会...
华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
<IMG SRC="http://www.admin10000.com/Uplo ... gt%3B
以下为《小白,让Python爬虫成为你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词已不再陌生。但是什么是爬虫,如何利用爬虫来为自己服务,这些在ICT技术的新手在云端听上去有点高。别着急,下面的文章将带你走近爬虫的世界,让即使你是ICT技术的新手,也能了解如何使用Python爬虫高效抓取图片。
什么是专用爬虫?
网络爬虫是一种从互联网上抓取数据和信息的自动化程序。如果我们把互联网比作一张大蜘蛛网,数据存储在蜘蛛网的各个节点中,而爬虫就是一个小蜘蛛(程序),沿着网络爬取它的猎物(数据)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。分为通用爬虫和特殊爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为特定的人群提供服务,爬取的目标网页位于与主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据,或者有明确的搜索需求,此时就需要过滤掉一些无用的信息。
爬虫的工作原理
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫的第一个工作是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器收到响应并解析出来。实际上,获取网页-解析网页源代码-提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Requests、pyquery、lxml等,使用这些库可以高效快速的提取来自他们的网页信息,如节点属性、文本值等,可以简单地保存为TXT文本或JSON文本。这些信息可以保存到数据库中,例如 MySQL 和 MongoDB,也可以保存到远程服务器,例如使用 SFTP 进行操作。提取信息是爬虫的一个非常重要的功能。可以将杂乱的数据整理清晰,便于后续处理和分析。
Java免费学习Java自学网 查看全部
java抓取网页数据(小白看过来,让Python爬虫成为你的好帮手》)
核心提示:华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。以下为《一起来看看小白,让Python爬虫成为你的好帮手》全文:随着信息社会...
华为中国发布了一篇文章《小白,让Python爬虫成为你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
<IMG SRC="http://www.admin10000.com/Uplo ... gt%3B
以下为《小白,让Python爬虫成为你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词已不再陌生。但是什么是爬虫,如何利用爬虫来为自己服务,这些在ICT技术的新手在云端听上去有点高。别着急,下面的文章将带你走近爬虫的世界,让即使你是ICT技术的新手,也能了解如何使用Python爬虫高效抓取图片。
什么是专用爬虫?
网络爬虫是一种从互联网上抓取数据和信息的自动化程序。如果我们把互联网比作一张大蜘蛛网,数据存储在蜘蛛网的各个节点中,而爬虫就是一个小蜘蛛(程序),沿着网络爬取它的猎物(数据)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。分为通用爬虫和特殊爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为特定的人群提供服务,爬取的目标网页位于与主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据,或者有明确的搜索需求,此时就需要过滤掉一些无用的信息。
爬虫的工作原理
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫的第一个工作是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器收到响应并解析出来。实际上,获取网页-解析网页源代码-提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或XPath提取网页信息的,比如Requests、pyquery、lxml等,使用这些库可以高效快速的提取来自他们的网页信息,如节点属性、文本值等,可以简单地保存为TXT文本或JSON文本。这些信息可以保存到数据库中,例如 MySQL 和 MongoDB,也可以保存到远程服务器,例如使用 SFTP 进行操作。提取信息是爬虫的一个非常重要的功能。可以将杂乱的数据整理清晰,便于后续处理和分析。
Java免费学习Java自学网
java抓取网页数据(SEO初学必读:搜索引擎的排名原理解析的原理图解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 22:17
SEO初学者必读:搜索引擎排名原理分析
搜索引擎排名原理示意图
一、什么是搜索引擎
百度、360、谷歌、搜搜、必应、雅虎等都是搜索引擎的具体表现形式。具体解释可以去百度,这里不再赘述。
二、什么是搜索引擎蜘蛛
搜索引擎蜘蛛是一种搜索引擎程序,是一套信息抓取系统程序。
常见的蜘蛛有百度蜘蛛、Gllglebot、360Spider、搜狗新闻蜘蛛等
三、什么是SEO
Seo 指的是搜索引擎优化,也称为 网站 优化。
搜索引擎优化并不容易。在数百万甚至数千万的竞争者中,我们的目标不是进入前百,而是力争前十,甚至第一。这对于seo初学者来说可能是一个梦想,但在seo的核心,我们的目标是让这个梦想成真。
四、什么是关键词?
关键词 是指参与排名的每一个词组。
从某种意义上说,seo优化也是关键词排名优化。 关键词优化的直接体现就是网站标题的排名(由关键词组成);从另一方面来说,每个标题的排名就是标题所收录的页面的排名。
理论上,每个页面都有参与排名的机会。所以网站排名的最小单位就是页面。
五、搜索引擎爬取收录原理(四个过程)
1、抢
2、过滤
3、存储索引库
4、显示排序
搜索引擎抓取收录流程图
蜘蛛爬取——网站页面——存放在临时索引库中——排名状态(从索引库中检索)
评论:
临时索引库不存储蜘蛛爬取的所有网站页面,
他会根据蜘蛛抓取的页面质量进行过滤,过滤掉一些质量较差的页面,
质量好的页面按页面质量排序,
最后是我们看到的排名情况
有人可能会问为什么我的网站没有收录
主要原因之一是网站的页面质量差,被搜索引擎过滤掉,所以不被百度接受收录。
(一)搜索引擎抓取:
1、爬虫SPider通过网页中的超链接,在互联网上发现和采集网页信息
2、如何抓取蜘蛛
1)深度爬取(垂直抓取,先爬取某列的内容页,然后换列,同样的方式爬取)
2)宽爬(横向爬取,先爬取各个版块,再爬取各个版块页面下方的内容页)
3、不利于蜘蛛识别的内容
js代码、iframe框架代码机制、图片(添加alt属性辅助识别)、flash(视频前后添加文字辅助搜索引擎识别)、登录后可获取的页面信息、嵌套表、等
网站结构:首页——栏目页——内容详情页
(二)搜索引擎过滤
过滤低质量的内容页面
什么是低质量内容页面?
1、采集,内容价值低
2、文字内容不正确
3、没有丰富的内容
(三)搜索引擎存储索引库
过滤蜘蛛爬取的内容后,将内容存入临时数据索引库。
(四)搜索引擎显示排名
存储索引库的内容按照质量排序,然后调用显示给用户。
1、搜索者根据用户输入的查询快速检索索引库中的文档关键词,评估文档与查询的相关性,对输出结果进行排序,并进行比较查询结果显示给用户。
2、当我们在搜索引擎上只看到一个结果时,根据各种算法对搜索进行排序,将十个质量最好的结果放在第一页
seo 优化的日常注意事项:
1、不要随意删除或移动已经收录的页面位置
2、显示结果需要一定的时间(2个月内是正常的)
3、内容丰富
4、吸引蜘蛛(主动提交给搜索引擎,外链)
5、跟踪蜘蛛,网站IIS 日志 查看全部
java抓取网页数据(SEO初学必读:搜索引擎的排名原理解析的原理图解)
SEO初学者必读:搜索引擎排名原理分析
搜索引擎排名原理示意图
一、什么是搜索引擎
百度、360、谷歌、搜搜、必应、雅虎等都是搜索引擎的具体表现形式。具体解释可以去百度,这里不再赘述。
二、什么是搜索引擎蜘蛛
搜索引擎蜘蛛是一种搜索引擎程序,是一套信息抓取系统程序。
常见的蜘蛛有百度蜘蛛、Gllglebot、360Spider、搜狗新闻蜘蛛等
三、什么是SEO
Seo 指的是搜索引擎优化,也称为 网站 优化。
搜索引擎优化并不容易。在数百万甚至数千万的竞争者中,我们的目标不是进入前百,而是力争前十,甚至第一。这对于seo初学者来说可能是一个梦想,但在seo的核心,我们的目标是让这个梦想成真。
四、什么是关键词?
关键词 是指参与排名的每一个词组。
从某种意义上说,seo优化也是关键词排名优化。 关键词优化的直接体现就是网站标题的排名(由关键词组成);从另一方面来说,每个标题的排名就是标题所收录的页面的排名。
理论上,每个页面都有参与排名的机会。所以网站排名的最小单位就是页面。
五、搜索引擎爬取收录原理(四个过程)
1、抢
2、过滤
3、存储索引库
4、显示排序
搜索引擎抓取收录流程图
蜘蛛爬取——网站页面——存放在临时索引库中——排名状态(从索引库中检索)
评论:
临时索引库不存储蜘蛛爬取的所有网站页面,
他会根据蜘蛛抓取的页面质量进行过滤,过滤掉一些质量较差的页面,
质量好的页面按页面质量排序,
最后是我们看到的排名情况
有人可能会问为什么我的网站没有收录
主要原因之一是网站的页面质量差,被搜索引擎过滤掉,所以不被百度接受收录。
(一)搜索引擎抓取:
1、爬虫SPider通过网页中的超链接,在互联网上发现和采集网页信息
2、如何抓取蜘蛛
1)深度爬取(垂直抓取,先爬取某列的内容页,然后换列,同样的方式爬取)
2)宽爬(横向爬取,先爬取各个版块,再爬取各个版块页面下方的内容页)
3、不利于蜘蛛识别的内容
js代码、iframe框架代码机制、图片(添加alt属性辅助识别)、flash(视频前后添加文字辅助搜索引擎识别)、登录后可获取的页面信息、嵌套表、等
网站结构:首页——栏目页——内容详情页
(二)搜索引擎过滤
过滤低质量的内容页面
什么是低质量内容页面?
1、采集,内容价值低
2、文字内容不正确
3、没有丰富的内容
(三)搜索引擎存储索引库
过滤蜘蛛爬取的内容后,将内容存入临时数据索引库。
(四)搜索引擎显示排名
存储索引库的内容按照质量排序,然后调用显示给用户。
1、搜索者根据用户输入的查询快速检索索引库中的文档关键词,评估文档与查询的相关性,对输出结果进行排序,并进行比较查询结果显示给用户。
2、当我们在搜索引擎上只看到一个结果时,根据各种算法对搜索进行排序,将十个质量最好的结果放在第一页
seo 优化的日常注意事项:
1、不要随意删除或移动已经收录的页面位置
2、显示结果需要一定的时间(2个月内是正常的)
3、内容丰富
4、吸引蜘蛛(主动提交给搜索引擎,外链)
5、跟踪蜘蛛,网站IIS 日志
java抓取网页数据(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-31 19:11
)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页数据(代码罗View远程服务器,没事抓取网页信息的小工具
)
我无事可做。刚刚学会了将git部署到远程服务器上,无事可做,就简单的做了一个小工具来抓取网页信息。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
操作效果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并注入到LinkedHashMap中,就可以了,很简单吧?看代码罗
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,解析html+js+css )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-27 06:14
一个彩票网站为例来简单说明整体操作流程,解析html+js+css
)
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时,你需要抓取你感兴趣的某个网站的信息。一个网站信息必须通过某个url发送,并根据该地址发送http请求。知道这个地址后,可以得到很多网络响应,需要仔细分析。,找到你合适的地址,最后通过这个地址返回一个html给你,我们就可以拿到这个html,分析结构,解析这个结构,得到你想要的数据。
Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一个彩票网站为例,简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选择的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这篇文章的时候,网站已经修改了页面结构,那你需要重新分析一下。当然,估计修改本网站网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,解析html+js+css
)
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时,你需要抓取你感兴趣的某个网站的信息。一个网站信息必须通过某个url发送,并根据该地址发送http请求。知道这个地址后,可以得到很多网络响应,需要仔细分析。,找到你合适的地址,最后通过这个地址返回一个html给你,我们就可以拿到这个html,分析结构,解析这个结构,得到你想要的数据。
Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一个彩票网站为例,简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选择的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这篇文章的时候,网站已经修改了页面结构,那你需要重新分析一下。当然,估计修改本网站网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-27 04:05
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这个我就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
java抓取网页数据(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在刚开始学习数据采集的时候可能无法上手,尤其是作为一个新手,感觉非常的茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
在采集
网络数据时,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到本网站整个页面的预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。, 在真实的集合中,有些网页的结构比较复杂,源代码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在采集
这个页面的时候,只采集
了当前页面的数据,也有分页的数据。这个我就不解释了,只是提醒一下,我们可以使用多线程对分页的所有当前数据进行采集
,一个通过线程采集
当前页面数据,另一个执行翻页动作,
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
java抓取网页数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-26 10:13
原文链接:
有时因为各种原因。我们需要从某个站点采集
数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line);} String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out . println("captureHtml() 结果:\n" + 结果);}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line); } System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);}
看见。抓取JS的方法和之前抓取原创
网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望本文能成为需要帮助的孩子和程序的源代码,点此下载! 查看全部
java抓取网页数据(本文某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
原文链接:
有时因为各种原因。我们需要从某个站点采集
数据。但是因为不同的站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站的数据:(1)抓取原创
网页数据。(2)抓取网页Javascript返回的数据。
一、 抓取原创
网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73,点击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说,我们只需要访问一个看起来像这样的 URL。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf-8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line);} String buf = contentBuf.toString( ); int beginIx = buf.indexOf("查询结果["); int endIx = buf.indexOf("以上四项依次显示"); String result = buf.substring(beginIx, endIx); System.out . println("captureHtml() 结果:\n" + 结果);}
使用 HttpURLConnection 连接到站点。使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式。使用JS返回数据,可以避免网站数据被搜索引擎等工具抓取。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后在网页中输入快递号:7。单击查询按钮,然后查看 HTTP Analyzer 的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上面两张图可以看出。HTTP Analyzer 可以截取 JS 返回的数据并显示在 Response Content 中。同时可以看到JS请求的网页地址。
既然如此。我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是这些数据没有加密。我们记下JS请求的URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid + "&channel=&rnd=0"; URL url = new URL(strURL); HttpURLConnection httpConn = (HttpURLConnection) url.openConnection(); InputStreamReader input = new InputStreamReader(httpConn .getInputStream(), "utf- 8"); BufferedReader bufReader = new BufferedReader(input); String line = ""; StringBuilder contentBuf = new StringBuilder(); while ((line = bufReader.readLine()) != null) {contentBuf.append(line); } System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);}
看见。抓取JS的方法和之前抓取原创
网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望本文能成为需要帮助的孩子和程序的源代码,点此下载!
java抓取网页数据( 03环境部署要编写代码,首先得部署环境(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-22 06:09
03环境部署要编写代码,首先得部署环境(图))
(知乎里面的视频可能看不清楚,可以通过公众号下载原视频查看,我已经上传了,链接在留言区)
03 环境部署
要编写代码,您必须首先部署环境。这里二发录制了一个小视频教大家如何部署环境:
视频中提到,二发已经把环境依赖的所有库都打包好了,可以直接使用,不要忘记Build Path。
04 爬虫介绍&代码解释
在接下来的视频中,二发将给大家简单介绍一下爬虫的工作原理,然后讲解这200行代码是如何工作的。
看完上面的视频,大家都开始爬了。除了冯小刚的微博,你还可以抓取任何你想要的内容,比如马蓉的微博。
尔胖有话要说
二发开始学习爬虫的时候用的是WebCollector,因为当时不会Python,只写了一点Java,所以二发就用Java来启动爬虫。
不过在用户体验上,Python 稍微方便一些。与Java相比,Python可以用更短的代码实现同样的功能。
但是,Java 的性能优于 Python。
现在爬虫基本都是多线程的,Python的多线程和Java的多线程模型有些不同。对于多核计算机,Python线程只使用一个核,不同的用户线程总是在一个核上进行上下文切换。其他内核空闲。这就是 N:1 线程模型。
就像下图一样:
而Java的多线程模型是真正的多核模型,即每个CPU核都在忙碌。
当然,如果你不明白,也没有问题。可以继续关注二发。以后的日子,二发会慢慢和大家分享。
对于爬虫来说,在大多数情况下,限制爬取速度的瓶颈不是CPU核数,而是网络延迟和等待时间,所以对于个人爬虫来说,Python和Java没有太大区别。
本文所涉及的代码、视频和github地址放在公众号后台,搜索微信公众号“逆袭二胖”回复“冯小刚”即可获取。 查看全部
java抓取网页数据(
03环境部署要编写代码,首先得部署环境(图))
(知乎里面的视频可能看不清楚,可以通过公众号下载原视频查看,我已经上传了,链接在留言区)
03 环境部署
要编写代码,您必须首先部署环境。这里二发录制了一个小视频教大家如何部署环境:
视频中提到,二发已经把环境依赖的所有库都打包好了,可以直接使用,不要忘记Build Path。
04 爬虫介绍&代码解释
在接下来的视频中,二发将给大家简单介绍一下爬虫的工作原理,然后讲解这200行代码是如何工作的。
看完上面的视频,大家都开始爬了。除了冯小刚的微博,你还可以抓取任何你想要的内容,比如马蓉的微博。
尔胖有话要说
二发开始学习爬虫的时候用的是WebCollector,因为当时不会Python,只写了一点Java,所以二发就用Java来启动爬虫。
不过在用户体验上,Python 稍微方便一些。与Java相比,Python可以用更短的代码实现同样的功能。
但是,Java 的性能优于 Python。
现在爬虫基本都是多线程的,Python的多线程和Java的多线程模型有些不同。对于多核计算机,Python线程只使用一个核,不同的用户线程总是在一个核上进行上下文切换。其他内核空闲。这就是 N:1 线程模型。
就像下图一样:
而Java的多线程模型是真正的多核模型,即每个CPU核都在忙碌。
当然,如果你不明白,也没有问题。可以继续关注二发。以后的日子,二发会慢慢和大家分享。
对于爬虫来说,在大多数情况下,限制爬取速度的瓶颈不是CPU核数,而是网络延迟和等待时间,所以对于个人爬虫来说,Python和Java没有太大区别。
本文所涉及的代码、视频和github地址放在公众号后台,搜索微信公众号“逆袭二胖”回复“冯小刚”即可获取。
java抓取网页数据(PS教程-PS制作远程服务器制作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-21 07:05
无事可做,刚学会了将git部署到远程服务器,无事可做,就简单的做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持面圈教程! 查看全部
java抓取网页数据(PS教程-PS制作远程服务器制作方法)
无事可做,刚学会了将git部署到远程服务器,无事可做,就简单的做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持面圈教程!
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-19 15:02
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-19 13:14
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送http请求,并根据地址定位。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
java抓取网页数据(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送http请求,并根据地址定位。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 17:11
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
java抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-12-18 17:09
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = newBufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,会报Serverredirected too manytimes之类的错误,因为这个网页里面有一些代码重定向到其他网页,太多了循环导致程序错误。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection)urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = newBufferedReader(newInputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需在上述程序中添加以下程序即可。
System.getProperties().setProperty("http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort",port);
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!! 查看全部
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = newBufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,会报Serverredirected too manytimes之类的错误,因为这个网页里面有一些代码重定向到其他网页,太多了循环导致程序错误。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection)urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = newBufferedReader(newInputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需在上述程序中添加以下程序即可。
System.getProperties().setProperty("http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort",port);
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-18 17:08
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
Java代码
URL url = 新 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine( )) != null) {i++; sb.append(s+"/r/n");}
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"/r/n"); }
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
Java代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); 连接();BufferedReader br = new BufferedReader(new InputStreamReader( con.getInputStream(),"UTF-8")); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb.append(s+"/r/n");}
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"/r/n"); }
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
(转载!!!) 查看全部
java抓取网页数据(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。现在我想和大家分享一下对这种方法的理解和体会。最简单的爬取方法是:
Java代码
URL url = 新 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine( )) != null) {i++; sb.append(s+"/r/n");}
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"/r/n"); }
这种方法抓取一般的网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取这个URL中网页的内容,又不想被重定向到其他网页,可以使用下面的代码。
Java代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); 连接();BufferedReader br = new BufferedReader(new InputStreamReader( con.getInputStream(),"UTF-8")); 字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb.append(s+"/r/n");}
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"/r/n"); }
在这种情况下,程序在爬取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式进行分析,提取出我们想要的具体内容,供我使用,呵呵,这多好啊 一件事!!
(转载!!!)
java抓取网页数据(是啥?web中的url(uniformresourcelocator)统一资源定位)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 05:03
java抓取网页数据的种种方法有很多,今天我们来简单的解释一下,还有我们以及对url的定义,关于定义和解释请参考我之前的文章:1.url是啥?web中的url(uniformresourcelocator)统一资源定位符,是一种统一资源定位符,也是http的一种标准格式.用于定位http资源,在internet上是所有主机间的统一资源定位符.用来告诉internet主机,有人来访问你的网站了。
2.网页url又有哪些类型?根据其上的meta标签不同,常见的url类型有如下几种:a.静态url:cookie-urls/session-urls/web-web-web-web-url等等b.动态url:每次请求都不同,header内容可能不同,本文不展开说明c.混合url:a.包含上述两种urlb.不包含上述两种url3.ftp文件上传的定义ftp上传的定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。
4.ftp文件上传如何定义?ftp文件上传定义原则是,:ftp客户端的默认上传文件上传类型定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。ftp上传工具:ftp和url浏览器端是securefaulter/file-browser前端一般是websocketftp控制器httpclient/http/proxy文件上传定义为ftp客户端所定义的文件url,如:public/ftp/jar包的类的url为:;environment=java这样我们在要上传或者修改url的时候就可以直接抓取定义了。
ftp客户端//..//..-->helloworld5.浏览器如何抓取url在http请求过程中,会经过三次握手,最后还是从data属性传递,然后也是json格式传递,不可读取。所以浏览器是不可能知道你的url所指的是什么资源。只有服务器获取你的url再返回的json文件,才可以做后续操作。解决方法就是用到我们使用ftp上传工具ftptest:handlerevent(e){..handlerevent(f,...){//settimeoutincrement=1..}</a>//allowedlinkswriteurlwithj。 查看全部
java抓取网页数据(是啥?web中的url(uniformresourcelocator)统一资源定位)
java抓取网页数据的种种方法有很多,今天我们来简单的解释一下,还有我们以及对url的定义,关于定义和解释请参考我之前的文章:1.url是啥?web中的url(uniformresourcelocator)统一资源定位符,是一种统一资源定位符,也是http的一种标准格式.用于定位http资源,在internet上是所有主机间的统一资源定位符.用来告诉internet主机,有人来访问你的网站了。
2.网页url又有哪些类型?根据其上的meta标签不同,常见的url类型有如下几种:a.静态url:cookie-urls/session-urls/web-web-web-web-url等等b.动态url:每次请求都不同,header内容可能不同,本文不展开说明c.混合url:a.包含上述两种urlb.不包含上述两种url3.ftp文件上传的定义ftp上传的定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。
4.ftp文件上传如何定义?ftp文件上传定义原则是,:ftp客户端的默认上传文件上传类型定义要分清一个文件是什么类型的网页,需要用ftp上传工具,来实现。ftp上传工具:ftp和url浏览器端是securefaulter/file-browser前端一般是websocketftp控制器httpclient/http/proxy文件上传定义为ftp客户端所定义的文件url,如:public/ftp/jar包的类的url为:;environment=java这样我们在要上传或者修改url的时候就可以直接抓取定义了。
ftp客户端//..//..-->helloworld5.浏览器如何抓取url在http请求过程中,会经过三次握手,最后还是从data属性传递,然后也是json格式传递,不可读取。所以浏览器是不可能知道你的url所指的是什么资源。只有服务器获取你的url再返回的json文件,才可以做后续操作。解决方法就是用到我们使用ftp上传工具ftptest:handlerevent(e){..handlerevent(f,...){//settimeoutincrement=1..}</a>//allowedlinkswriteurlwithj。
java抓取网页数据( 2017年03月13日java利用url实现网页内容抓取的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-17 02:07
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url实现网页内容爬取
更新时间:2017年3月13日09:42:31 作者:zangcumiao
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋! 查看全部
java抓取网页数据(
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url实现网页内容爬取
更新时间:2017年3月13日09:42:31 作者:zangcumiao
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,所以干脆做了一个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋!
java抓取网页数据( commons-io工具获取页面或Json5工具(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-13 14:05
commons-io工具获取页面或Json5工具(图))
4)commons-io 工具,获取页面或者 Json
5) Jsoup工具(一般用于html字段分析),获取页面,非Json返回格式]
----------------------------------------------- ---------------------------------
完整代码:
package com.yeezhao.common.http;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
import org.jsoup.Jsoup;
/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception
*/
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
return conn.getResponseCode();
}
/**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s;
while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect();
return sb.toString();
}
return "";
}
/**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request);
return IOUtils.toString(url.openStream());
}
/**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String httpClientFetch(String url, String charset) throws Exception {
// GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method);
return method.getResponseBodyAsString();
}
/**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String commonsIOFetch(String url, String charset) throws Exception {
return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception
*/
public static String jsoupFetch(String url) throws Exception {
return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
package com.yeezhao.common.http;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 测试类
* 3个测试链接:
* 1)百科网页
* 2)浏览器模拟获取接口数据
* 3)获取普通接口数据
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtilTest {
String seeds[] = {"http://baike.baidu.com/view/1.htm","http://m.ximalaya.com/tracks/26096131.json","http://remyapi.yeezhao.com/api ... ot%3B};
final static String DEFAULT_CHARSET = "UTF-8";
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
System.out.println("--- down ---");
}
@Test
public void testGetResponseCode() throws Exception{
for(String seed:seeds){
int responseCode = HttpFetchUtil.getResponseCode(seed);
System.out.println("ret="+responseCode);
}
}
@Test
public void testJDKFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.JDKFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testURLFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.URLFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testHttpClientFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.httpClientFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testCommonsIOFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.commonsIOFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testJsoupFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.jsoupFetch(seed);
System.out.println("ret="+ret);
}
}
}
附件:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java抓取网页数据(
commons-io工具获取页面或Json5工具(图))
4)commons-io 工具,获取页面或者 Json
5) Jsoup工具(一般用于html字段分析),获取页面,非Json返回格式]
----------------------------------------------- ---------------------------------
完整代码:
package com.yeezhao.common.http;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
import org.jsoup.Jsoup;
/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception
*/
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
return conn.getResponseCode();
}
/**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s;
while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect();
return sb.toString();
}
return "";
}
/**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request);
return IOUtils.toString(url.openStream());
}
/**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String httpClientFetch(String url, String charset) throws Exception {
// GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method);
return method.getResponseBodyAsString();
}
/**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String commonsIOFetch(String url, String charset) throws Exception {
return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception
*/
public static String jsoupFetch(String url) throws Exception {
return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
package com.yeezhao.common.http;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 测试类
* 3个测试链接:
* 1)百科网页
* 2)浏览器模拟获取接口数据
* 3)获取普通接口数据
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtilTest {
String seeds[] = {"http://baike.baidu.com/view/1.htm","http://m.ximalaya.com/tracks/26096131.json","http://remyapi.yeezhao.com/api ... ot%3B};
final static String DEFAULT_CHARSET = "UTF-8";
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
System.out.println("--- down ---");
}
@Test
public void testGetResponseCode() throws Exception{
for(String seed:seeds){
int responseCode = HttpFetchUtil.getResponseCode(seed);
System.out.println("ret="+responseCode);
}
}
@Test
public void testJDKFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.JDKFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testURLFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.URLFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testHttpClientFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.httpClientFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testCommonsIOFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.commonsIOFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testJsoupFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.jsoupFetch(seed);
System.out.println("ret="+ret);
}
}
}
附件:相关jar依赖
...
org.jsoup
jsoup
1.7.3
commons-httpclient
commons-httpclient
3.1
commons-io
commons-io
2.4
...
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java抓取网页数据(java抓取网站数据假设你需要获取51人才网上java人才的需求数量(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-13 09:05
文件介绍:
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,发现数量在返回的
在 HTML 数据中的这样一段代码中:
1-30 / 14794
, 所以我们可以得到这样一个
mode:".+1-\d+ / (\d+).+",第一组的内容就是我们最终需要的数据,关于java中的mode,
请参考java文档中Pattern类的介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ
obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn
funtype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd
ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
关于第5条的数据,我们不关心服务器真正需要什么,把它们都发送出去。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:
查看普通副本到剪贴板打印?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
以下是抓取内容的代码:
查看普通副本到剪贴板打印?
//假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。
//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串的信息
URL url = 新 URL(res.getTarget());
HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接
con.setRequestMethod(res.getMethod()); //设置请求的方法 查看全部
java抓取网页数据(java抓取网站数据假设你需要获取51人才网上java人才的需求数量(组图))
文件介绍:
java捕获网站数据
假设你需要在线获取51job人才在线java人才需求量,首先你需要分析51job网站搜索这个
一件如何运作?通过对网页源代码的分析,我们发现了以下信息:
1. 页面搜索时请求的网址为
2. 请求使用的方法是:POST
3. 返回页面的编码格式为:GBK
4. 假设我们在搜索java人才时想要获取结果页面显示的需求数量,发现数量在返回的
在 HTML 数据中的这样一段代码中:
1-30 / 14794
, 所以我们可以得到这样一个
mode:".+1-\d+ / (\d+).+",第一组的内容就是我们最终需要的数据,关于java中的mode,
请参考java文档中Pattern类的介绍
5. 另外,作为一个POST请求,页面发送到服务端的数据如下(这样很容易像prototype一样通过js
帧抓取,参考我的另一篇博文介绍):
lang=c&stype=1&postchannel=0000&fromType=1&line=&keywordtype=2&keyword=java&btnJ
obarea=%E9%80%89%E6%8B%A9%E5%9C%B0%E5%8C%BA&jobarea=0000&image=&btn
funtype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&funtype=0000&btnInd
ustrytype=%E9%80%89%E6%8B%A9%2F%E4%BF%AE%E6%94%B9&industrytype=00
关于第5条的数据,我们不关心服务器真正需要什么,把它们都发送出去。有了这些标准
准备好了,我们其实就可以开始通过java发送请求,得到最终的数据了。
我们定义了Resource类,这个类封装了与请求相关的所有信息,Resource包括以下属性:
查看普通副本到剪贴板打印?
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
/**
* 需要获取资源的目标地址,不收录查询字符串
*/
私有字符串目标;
/**
* get请求的查询字符串,或者post请求的请求数据
*/
私人字符串查询数据 = "";
/**
* 请求方法,获取/发布
*/
私有字符串方法 = "GET";
/**
* 返回数据的编码类型
*/
私人字符串字符集 = "GBK";
/**
* 捕获数据的模式,根据模式分组返回数据列表
*/
私有字符串模式;
以下是抓取内容的代码:
查看普通副本到剪贴板打印?
//假设下面代码中的res对象封装了所有的请求信息。
//URL指向目的地。
//res.getTarget 返回目标地址,当是get请求时,这个地址收录查询字符串的信息
URL url = 新 URL(res.getTarget());
HttpURLConnection con = (HttpURLConnection) url.openConnection(); //建立到目的地的连接
con.setRequestMethod(res.getMethod()); //设置请求的方法
java抓取网页数据(java抓取网页数据传输基本没有有什么区别?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-11 03:02
java抓取网页数据,并返回html,然后自动同步到浏览器,这个说白了和ajax的json数据传输基本没有什么区别。需要一点java的基础。不会flash基本的api(应该是有的),是搞不定这个的,别说写抓包,数据库、java虚拟机、javaweb开发都搞不定。而且动态网页,格式要复杂很多,相当于写3个页面。
再说说技术易学难精这个词。你要明白,java这行这么火,肯定是难学的,要是易学,不在2017年以前就有大把人抢着转行java了。并且初级程序员工资低,是有很多客观原因的。相当于每年都有海量的人涌入这个行业,竞争压力大。
入门容易,以后不好说。其实不难,就拿我现在正在学的java来说,入门学5天的话,就能写写简单的静态网页。就以个人的经验来说,在写静态网页之前,必须了解web前端基础,比如html,css基础都要学好,要不然能一行代码写到死,不过,如果你肯学的话,入门到进阶还是比较快的。当然,想靠自学就自己写出网页的时代过去了,学校教也教不了什么,至少得报班,而且价格必须不低。现在还是报培训班效果最好,有专业老师带着,还能让你快速上手。
想弄懂java的数据库sql,要找个会看源码的。
不难,写顺手以后学别的也是很快的。 查看全部
java抓取网页数据(java抓取网页数据传输基本没有有什么区别?-八维教育)
java抓取网页数据,并返回html,然后自动同步到浏览器,这个说白了和ajax的json数据传输基本没有什么区别。需要一点java的基础。不会flash基本的api(应该是有的),是搞不定这个的,别说写抓包,数据库、java虚拟机、javaweb开发都搞不定。而且动态网页,格式要复杂很多,相当于写3个页面。
再说说技术易学难精这个词。你要明白,java这行这么火,肯定是难学的,要是易学,不在2017年以前就有大把人抢着转行java了。并且初级程序员工资低,是有很多客观原因的。相当于每年都有海量的人涌入这个行业,竞争压力大。
入门容易,以后不好说。其实不难,就拿我现在正在学的java来说,入门学5天的话,就能写写简单的静态网页。就以个人的经验来说,在写静态网页之前,必须了解web前端基础,比如html,css基础都要学好,要不然能一行代码写到死,不过,如果你肯学的话,入门到进阶还是比较快的。当然,想靠自学就自己写出网页的时代过去了,学校教也教不了什么,至少得报班,而且价格必须不低。现在还是报培训班效果最好,有专业老师带着,还能让你快速上手。
想弄懂java的数据库sql,要找个会看源码的。
不难,写顺手以后学别的也是很快的。
java抓取网页数据( 一个彩票网站为例来简单说明整体操作流程,js实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-09 13:25
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
java抓取网页数据(
一个彩票网站为例来简单说明整体操作流程,js实现)
使用java技术捕获网站彩票双色球的详细信息
更新时间:2019-06-25 16:21:26 作者:IT-source
本文文章主要介绍使用java技术在彩票双色球上捕获网站的详细信息。网页结果由html+js+css组成。html结构有一定的规范,动态数据交互可以通过js完成。,有需要的朋友可以参考
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。

