
java抓取网页内容
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-03 03:03
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:

第二步:查看web源代码。我们可以看到源代码中有一段:

从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:

换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:

第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:


从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页内容(Java目录:先爬取网页源码,先定义一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 16:04
Java目录:
最近在学习数据可视化。我想分析一下近年来各个城市的温度和空气质量的变化。我需要一些数据,所以我从互联网上抓取了一些有用的数据进行分析。
思路:先爬取网页源码,然后用正则表达式从源码中获取需要的数据。
可以通过以下方式获取网页源代码并在控制台输出。
String urlStr = ""; // 网址
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
//读到的内容不为空
while (bufRead.readLine() != null) {
System.out.println(bufRead.readLine());
}
bufRead.close();
} catch (IOException e) {
e.printStackTrace();
}
在这里测试一下
String urlStr = "http://datacenter.mep.gov.cn/r ... 3B%3B
控制台输出如下结果。
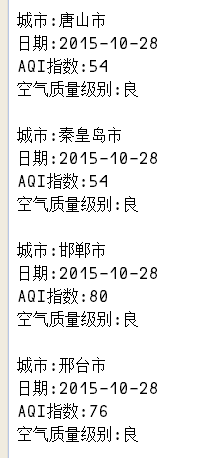
拿到网页的源码后,我们就可以使用正则表达式来获取我们需要的数据了。
我们先来分析一下源码。
我想要的数据 采集 是
以北京为例分析,我们得到如下正则表达式
// 城市正则
private String regularCity = ">[\u4e00-\u9fa5]{2,}市";
// 日期正则
private String regularDate = ">(([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))";
// AQI指数正则
private String regularAQI = ">[0-9]{2,}";
// 空气质量级别正则
private String regularQuality = ">[\u4e00-\u9fa5]";
我们首先定义一个方法,使用我们定义的正则表达式和网页的源代码来过滤数据。
/*
* 从网页源代码中过滤数据
* @param regular 正则
*
* @param code 源代码
*/
public String DataAcqu(String regular, String code) {
// 编译正则表达式
Pattern p = Pattern.compile(regular, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(code);
if (m.find()) {
// 返回采集到的数据
return m.group();
} else {
return "";
}
}
然后我们就可以得到我们需要的数据
public DataCode() {
// 用户输入网页地址
Scanner scan = new Scanner(System.in);
// 存储用户输入的网页地址
String urlStr = scan.nextLine();
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),
"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
String readStr = "";
// 创建一个DataAcqu类的对象(前面自己定义的用于采集数据的类)
DataAcqu dataAcq = new DataAcqu();
int i = 0; // 记录采集到的数据数量
// 如果读到的数据不为空
while ((readStr = bufRead .readLine()) != null) {
// 采集城市数据
String cityStr = dataAcq.DataAcqu(regularCity, readStr);
// 如果采集到符合条件的数据,打印出来
if (!cityStr.equals("")) {
// 将采集到的数据前后多余部分去掉(前面正则表达式为了准确取到相应的值,加入了">"和"")
cityStr = cityStr.substring(1, cityStr.indexOf(""));
System.out.println("城市:" + cityStr);
}
// 采集日期数据
String dateStr = dataAcq.DataAcqu(regularDate, readStr);
// 如果采集到符合条件的数据,打印出来
if (!dateStr.equals("")) {
dateStr = dateStr.substring(1, dateStr.indexOf(""));
System.out.println("日期:" + dateStr);
}
// 采集AQI指数数据
String AQIStr = dataAcq.DataAcqu(regularAQI, readStr);
// 如果采集到符合条件的数据,打印出来
if (!AQIStr.equals("")) {
AQIStr = AQIStr.substring(1, AQIStr.indexOf(""));
System.out.println("AQI指数:" + AQIStr);
}
// 采集空气质量级别数据
String qualityStr = dataAcq.DataAcqu(regularQuality, readStr);
// 如果采集到符合条件的数据,打印出来
if (!qualityStr.equals("")) {
qualityStr = qualityStr.substring(1,
qualityStr.indexOf(""));
System.out.println("空气质量级别:" + qualityStr);
System.out.println();
i++;
}
}
br.close(); // 读取完成后关闭读取器
System.out.println("采集完成,共采集到数据:" + i);
} catch (IOException e) {
e.printStackTrace();
}
}
运行后控制台输出如下信息
如果要将输出结果输出到输出文件,只需在代码中添加类似如下的代码即可
// 将数据输出到文件
PrintStream ps = new PrintStream("E:\\Java\\DataAcquisition\\data");
//将输出位置切换到文件
System.setOut(ps);
这样,我们就爬取到了我们需要的数据。 查看全部
java抓取网页内容(Java目录:先爬取网页源码,先定义一个方法)
Java目录:
最近在学习数据可视化。我想分析一下近年来各个城市的温度和空气质量的变化。我需要一些数据,所以我从互联网上抓取了一些有用的数据进行分析。
思路:先爬取网页源码,然后用正则表达式从源码中获取需要的数据。
可以通过以下方式获取网页源代码并在控制台输出。
String urlStr = ""; // 网址
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
//读到的内容不为空
while (bufRead.readLine() != null) {
System.out.println(bufRead.readLine());
}
bufRead.close();
} catch (IOException e) {
e.printStackTrace();
}
在这里测试一下
String urlStr = "http://datacenter.mep.gov.cn/r ... 3B%3B
控制台输出如下结果。

拿到网页的源码后,我们就可以使用正则表达式来获取我们需要的数据了。
我们先来分析一下源码。


我想要的数据 采集 是
以北京为例分析,我们得到如下正则表达式
// 城市正则
private String regularCity = ">[\u4e00-\u9fa5]{2,}市";
// 日期正则
private String regularDate = ">(([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))";
// AQI指数正则
private String regularAQI = ">[0-9]{2,}";
// 空气质量级别正则
private String regularQuality = ">[\u4e00-\u9fa5]";
我们首先定义一个方法,使用我们定义的正则表达式和网页的源代码来过滤数据。
/*
* 从网页源代码中过滤数据
* @param regular 正则
*
* @param code 源代码
*/
public String DataAcqu(String regular, String code) {
// 编译正则表达式
Pattern p = Pattern.compile(regular, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(code);
if (m.find()) {
// 返回采集到的数据
return m.group();
} else {
return "";
}
}
然后我们就可以得到我们需要的数据
public DataCode() {
// 用户输入网页地址
Scanner scan = new Scanner(System.in);
// 存储用户输入的网页地址
String urlStr = scan.nextLine();
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),
"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
String readStr = "";
// 创建一个DataAcqu类的对象(前面自己定义的用于采集数据的类)
DataAcqu dataAcq = new DataAcqu();
int i = 0; // 记录采集到的数据数量
// 如果读到的数据不为空
while ((readStr = bufRead .readLine()) != null) {
// 采集城市数据
String cityStr = dataAcq.DataAcqu(regularCity, readStr);
// 如果采集到符合条件的数据,打印出来
if (!cityStr.equals("")) {
// 将采集到的数据前后多余部分去掉(前面正则表达式为了准确取到相应的值,加入了">"和"")
cityStr = cityStr.substring(1, cityStr.indexOf(""));
System.out.println("城市:" + cityStr);
}
// 采集日期数据
String dateStr = dataAcq.DataAcqu(regularDate, readStr);
// 如果采集到符合条件的数据,打印出来
if (!dateStr.equals("")) {
dateStr = dateStr.substring(1, dateStr.indexOf(""));
System.out.println("日期:" + dateStr);
}
// 采集AQI指数数据
String AQIStr = dataAcq.DataAcqu(regularAQI, readStr);
// 如果采集到符合条件的数据,打印出来
if (!AQIStr.equals("")) {
AQIStr = AQIStr.substring(1, AQIStr.indexOf(""));
System.out.println("AQI指数:" + AQIStr);
}
// 采集空气质量级别数据
String qualityStr = dataAcq.DataAcqu(regularQuality, readStr);
// 如果采集到符合条件的数据,打印出来
if (!qualityStr.equals("")) {
qualityStr = qualityStr.substring(1,
qualityStr.indexOf(""));
System.out.println("空气质量级别:" + qualityStr);
System.out.println();
i++;
}
}
br.close(); // 读取完成后关闭读取器
System.out.println("采集完成,共采集到数据:" + i);
} catch (IOException e) {
e.printStackTrace();
}
}
运行后控制台输出如下信息
如果要将输出结果输出到输出文件,只需在代码中添加类似如下的代码即可
// 将数据输出到文件
PrintStream ps = new PrintStream("E:\\Java\\DataAcquisition\\data");
//将输出位置切换到文件
System.setOut(ps);

这样,我们就爬取到了我们需要的数据。
java抓取网页内容(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-30 13:00
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
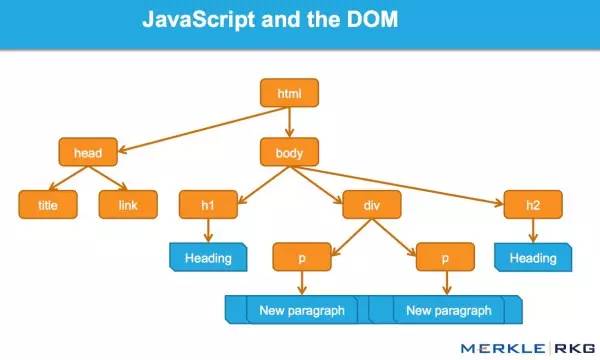
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下一次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
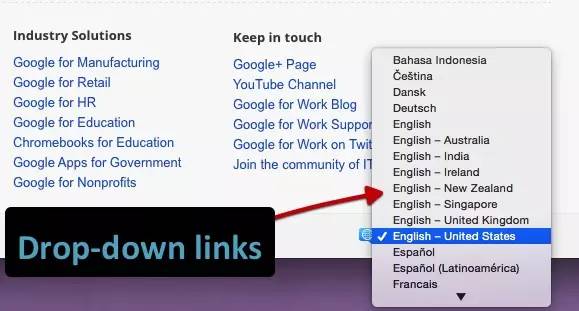
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
java抓取网页内容(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。

长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下一次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
java抓取网页内容(一个彩票网站为例来简单说明整体操作流程,分为以下几大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-30 12:20
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。当你知道这个地址时,你就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到这个html,分析结构,解析结构得到你想要的数据。Html的结构分析往往比较复杂繁琐,我们可以使用java支持包:jsoup,可以完成发送请求、解析html、获取你感兴趣的数据等功能
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块
2:分析页面,找到它的入口地址
我发现右边有一个下拉选择框。这是双色球的历史开奖号码。改变这个值,浏览器会再次请求这个时期的彩票信息。确保地址是:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理可以得到1个篮球
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java简单抓取网页数据的个人分享。有兴趣的童鞋可以自行实践,从实践中学习道理。 查看全部
java抓取网页内容(一个彩票网站为例来简单说明整体操作流程,分为以下几大)
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。当你知道这个地址时,你就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到这个html,分析结构,解析结构得到你想要的数据。Html的结构分析往往比较复杂繁琐,我们可以使用java支持包:jsoup,可以完成发送请求、解析html、获取你感兴趣的数据等功能
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块

2:分析页面,找到它的入口地址
我发现右边有一个下拉选择框。这是双色球的历史开奖号码。改变这个值,浏览器会再次请求这个时期的彩票信息。确保地址是:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

使用以下代码,获得6个红球:

同理可以得到1个篮球
根据这个原理,你可以得到你想要的数据:以下是我得到的数据

以上是java简单抓取网页数据的个人分享。有兴趣的童鞋可以自行实践,从实践中学习道理。
java抓取网页内容(百度首页做了个小测试,小伙伴们可算松了口气)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-29 08:16
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?) 查看全部
java抓取网页内容(百度首页做了个小测试,小伙伴们可算松了口气)
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!

好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:

啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?)
java抓取网页内容( 一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-29 08:12
一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫(一) 网络爬虫基本原理
强烈推荐IDEA2020.2破解激活,IntelliJ IDEA注册码,2020.2 IDEA激活码
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的IP,下载该URL对应的网页并存入下载的网页库中. 另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每次抓取一个页面都重新计算PageRank值,折中方案是:每抓取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2.《搜索引擎技术基础》刘义群等清华大学出版社
猜你喜欢:网络爬虫(二)Web Crawler基本原理Web Crawler(四) Java实现简单的Web Crawler Web Crawler(三) Java实现简单的Web Crawler) 查看全部
java抓取网页内容(
一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫(一) 网络爬虫基本原理
强烈推荐IDEA2020.2破解激活,IntelliJ IDEA注册码,2020.2 IDEA激活码
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:

网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的IP,下载该URL对应的网页并存入下载的网页库中. 另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每次抓取一个页面都重新计算PageRank值,折中方案是:每抓取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2.《搜索引擎技术基础》刘义群等清华大学出版社
猜你喜欢:网络爬虫(二)Web Crawler基本原理Web Crawler(四) Java实现简单的Web Crawler Web Crawler(三) Java实现简单的Web Crawler)
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-23 05:26
通过Java的API,您可以顺利地抓取网络上的大部分指定的Web内容,并分享此方法以了解和体验您。最简单的爬行方式是:
java代码
urlurl = newul(myurl); bufferedReaderbr = newbuferedreader(newinputstreamReader(url.openstream())); strings =“”; stringbuffersb = newstringbuffer(“”);而((s = br.readline())= null){i ++; sb.append(s +“\ r \ n”);}
此方法崩溃常规页面应该没有问题,但是当某些网页中有一些嵌套重定向连接时,它将报告服务器等错误重定向太多次,因为还有另一个网页。有些代码正在转到其他网页,并且循环是由程序引起的。如果您只想抓住此URL中的内容,您不希望允许它具有其他网页跳转,您可以使用以下代码。
java代码
urlurlmy = newul(myurl); httpurlconnectioncon =(httpurlconnection)urlmy.openconnection(); con.setfollowredirects(真实); con.setInstancefollowredireds(false); con.connect(); bufferedReaderbr = newbufferedreader(newinputstreamreader(con.getinputstream(),“utf-8”)); strings =“”; stringbuffersb = newstringsbuffer(“”);虽然((s = br.readline())!= null){sb.append(s +“\ r \ n”);}
这种单词,程序不会髋关节其他页面才能抓取其他内容,这是我们的目的。
如果我们在内部网络中,还需要给它一个代理,Java为具有特殊系统属性的代理服务器提供支持,只要添加到以下程序“。
java代码
system.getproperties()。 setProperty(“http.proxyhost”,proxyname; system.getproperties()。setProperty(“http.proxyport”,端口);
如果这是,您可以实现您想要抓取自己内部网络的内容。
上面的程序在SB字符串中盖章,我们可以通过正则表达分析,提取您想要的特定内容,对我来说,呵呵,这是一件美妙的事情! ! 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过Java的API,您可以顺利地抓取网络上的大部分指定的Web内容,并分享此方法以了解和体验您。最简单的爬行方式是:
java代码
urlurl = newul(myurl); bufferedReaderbr = newbuferedreader(newinputstreamReader(url.openstream())); strings =“”; stringbuffersb = newstringbuffer(“”);而((s = br.readline())= null){i ++; sb.append(s +“\ r \ n”);}
此方法崩溃常规页面应该没有问题,但是当某些网页中有一些嵌套重定向连接时,它将报告服务器等错误重定向太多次,因为还有另一个网页。有些代码正在转到其他网页,并且循环是由程序引起的。如果您只想抓住此URL中的内容,您不希望允许它具有其他网页跳转,您可以使用以下代码。
java代码
urlurlmy = newul(myurl); httpurlconnectioncon =(httpurlconnection)urlmy.openconnection(); con.setfollowredirects(真实); con.setInstancefollowredireds(false); con.connect(); bufferedReaderbr = newbufferedreader(newinputstreamreader(con.getinputstream(),“utf-8”)); strings =“”; stringbuffersb = newstringsbuffer(“”);虽然((s = br.readline())!= null){sb.append(s +“\ r \ n”);}
这种单词,程序不会髋关节其他页面才能抓取其他内容,这是我们的目的。
如果我们在内部网络中,还需要给它一个代理,Java为具有特殊系统属性的代理服务器提供支持,只要添加到以下程序“。
java代码
system.getproperties()。 setProperty(“http.proxyhost”,proxyname; system.getproperties()。setProperty(“http.proxyport”,端口);
如果这是,您可以实现您想要抓取自己内部网络的内容。
上面的程序在SB字符串中盖章,我们可以通过正则表达分析,提取您想要的特定内容,对我来说,呵呵,这是一件美妙的事情! !
java抓取网页内容(WebScraperTutorials安装路径介绍,以作记录供你我他参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-21 16:15
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------
对于第一个示例,请根据官网上的教学视频再次操作
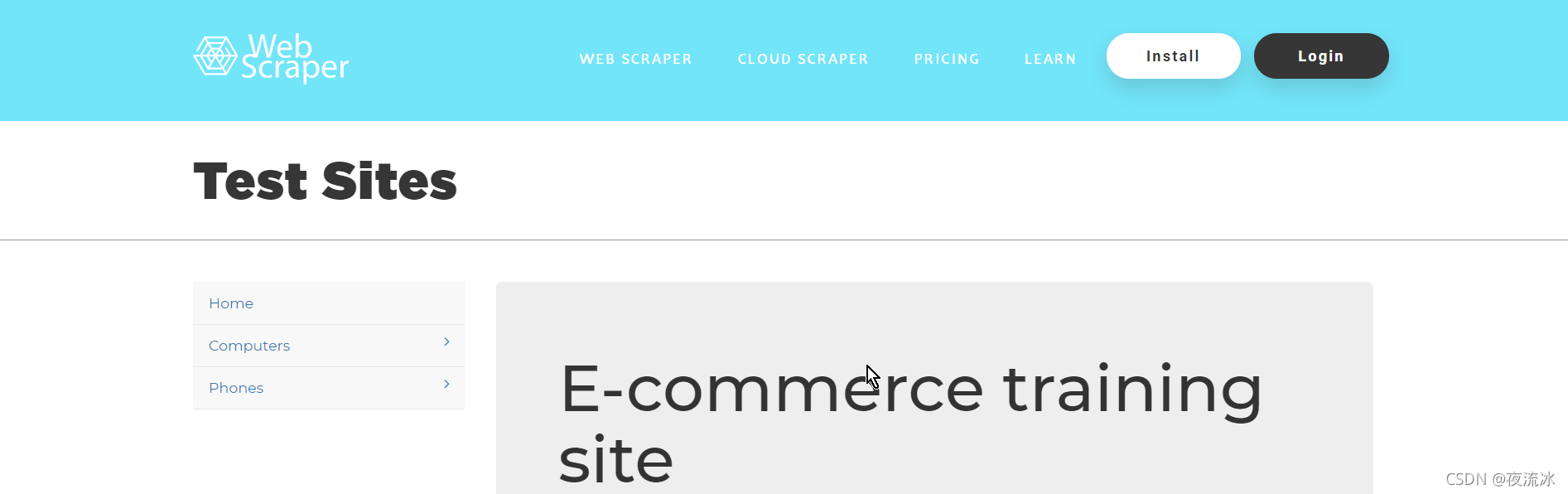
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
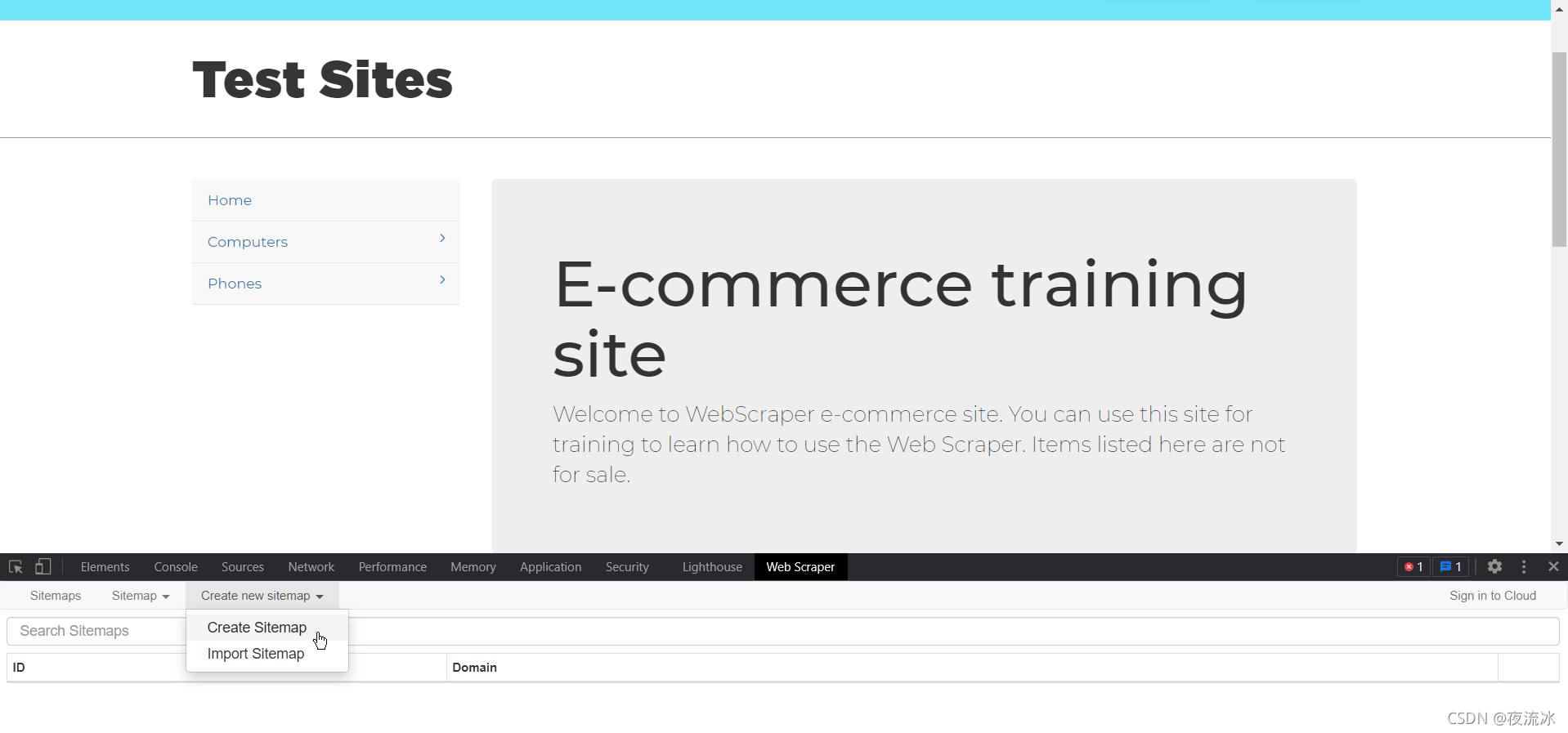
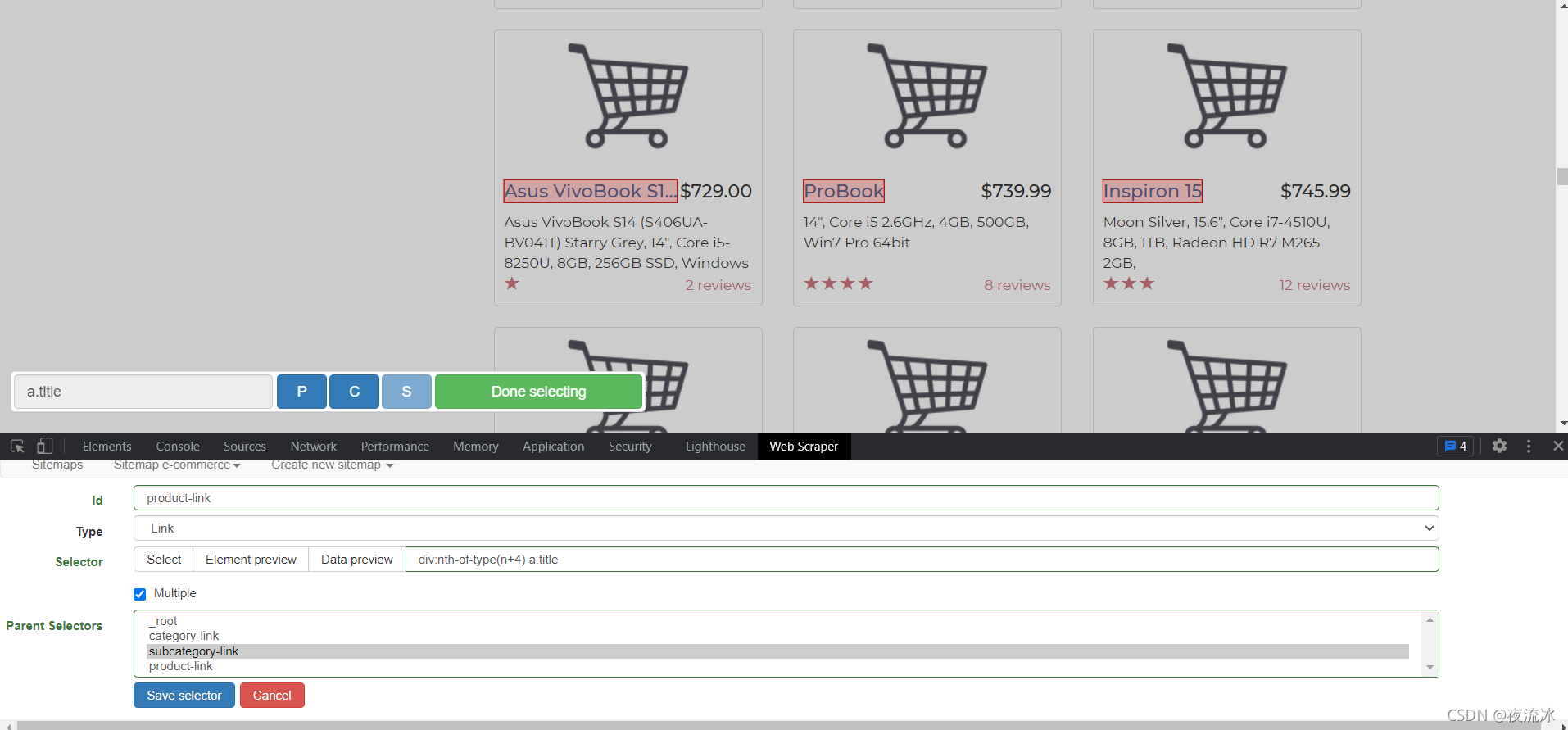
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
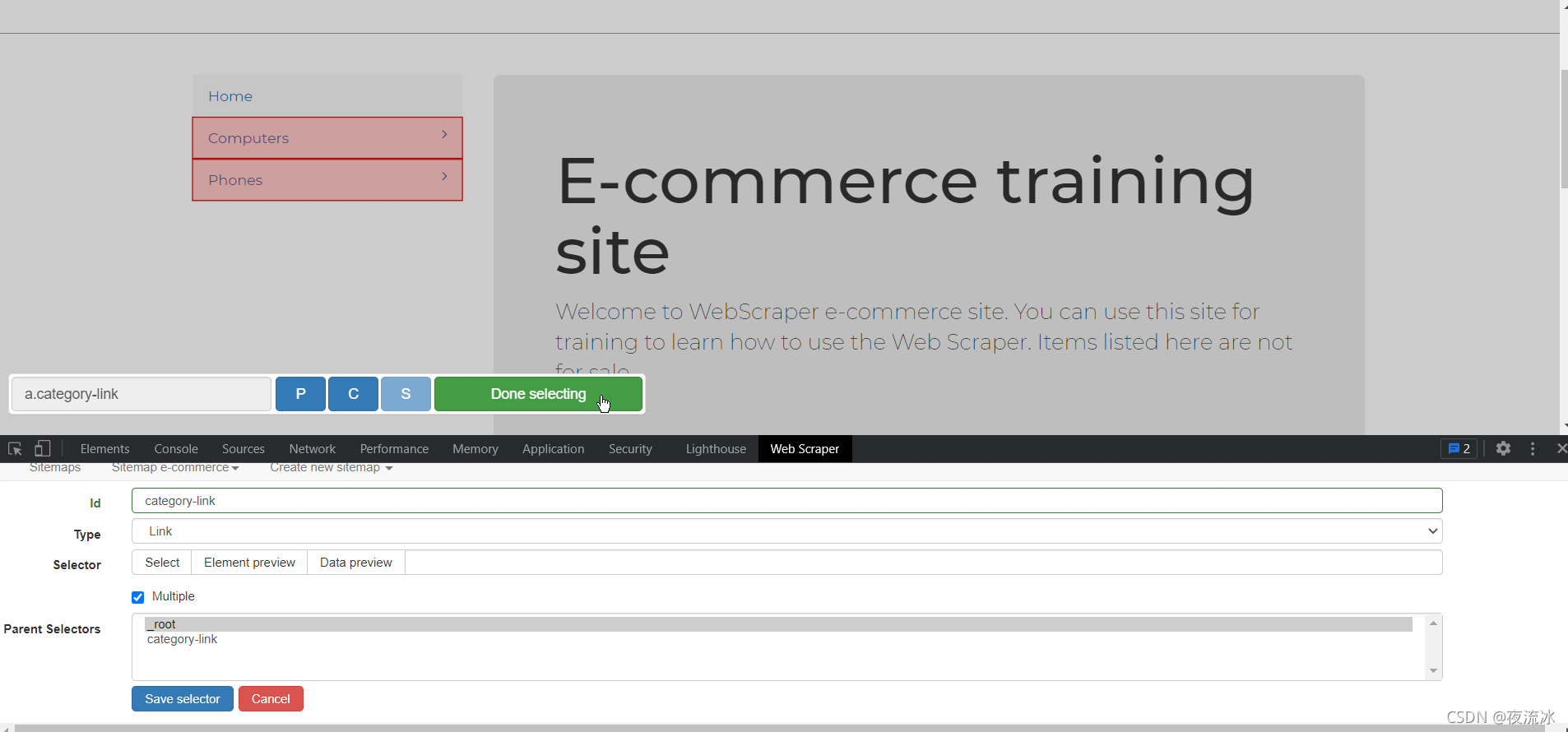
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
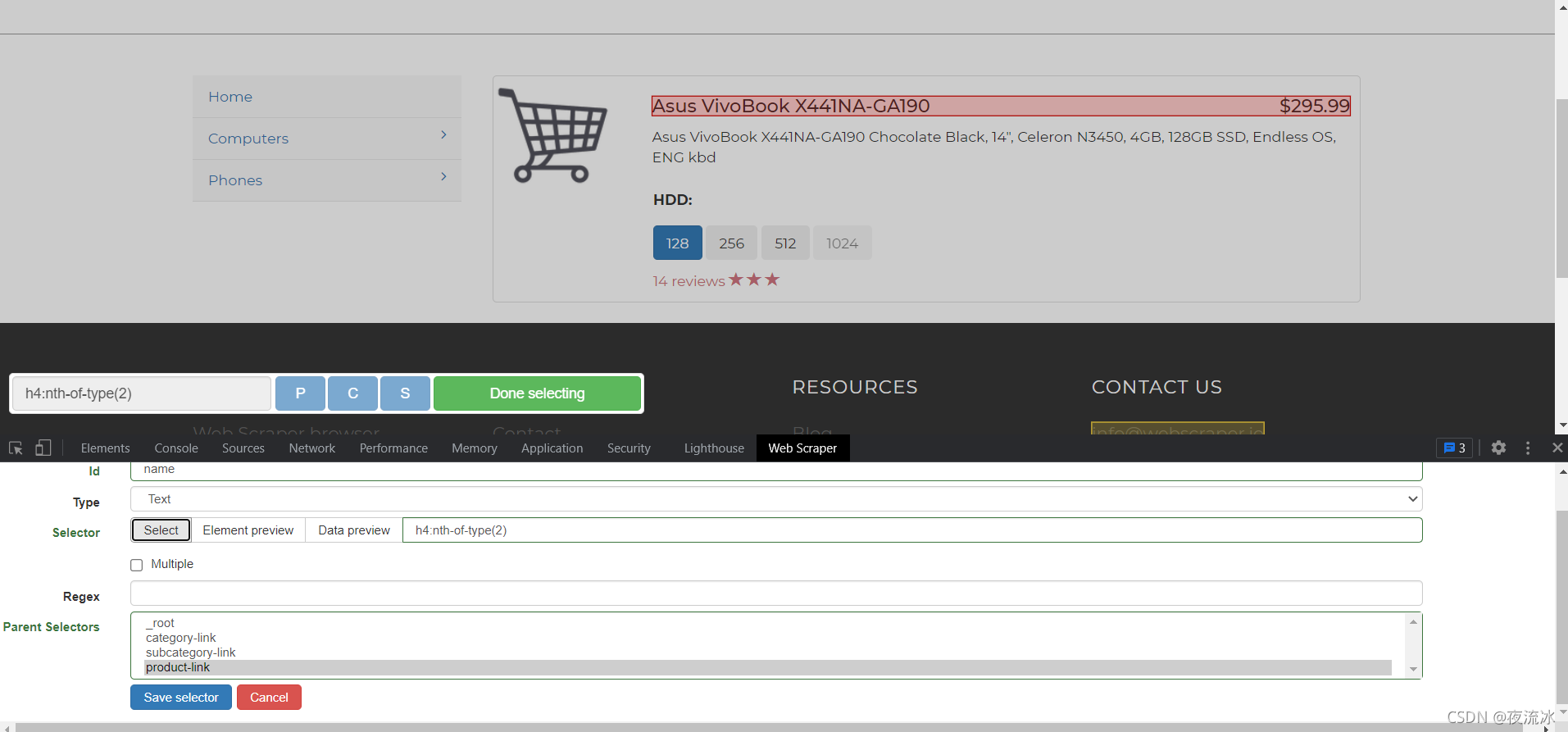
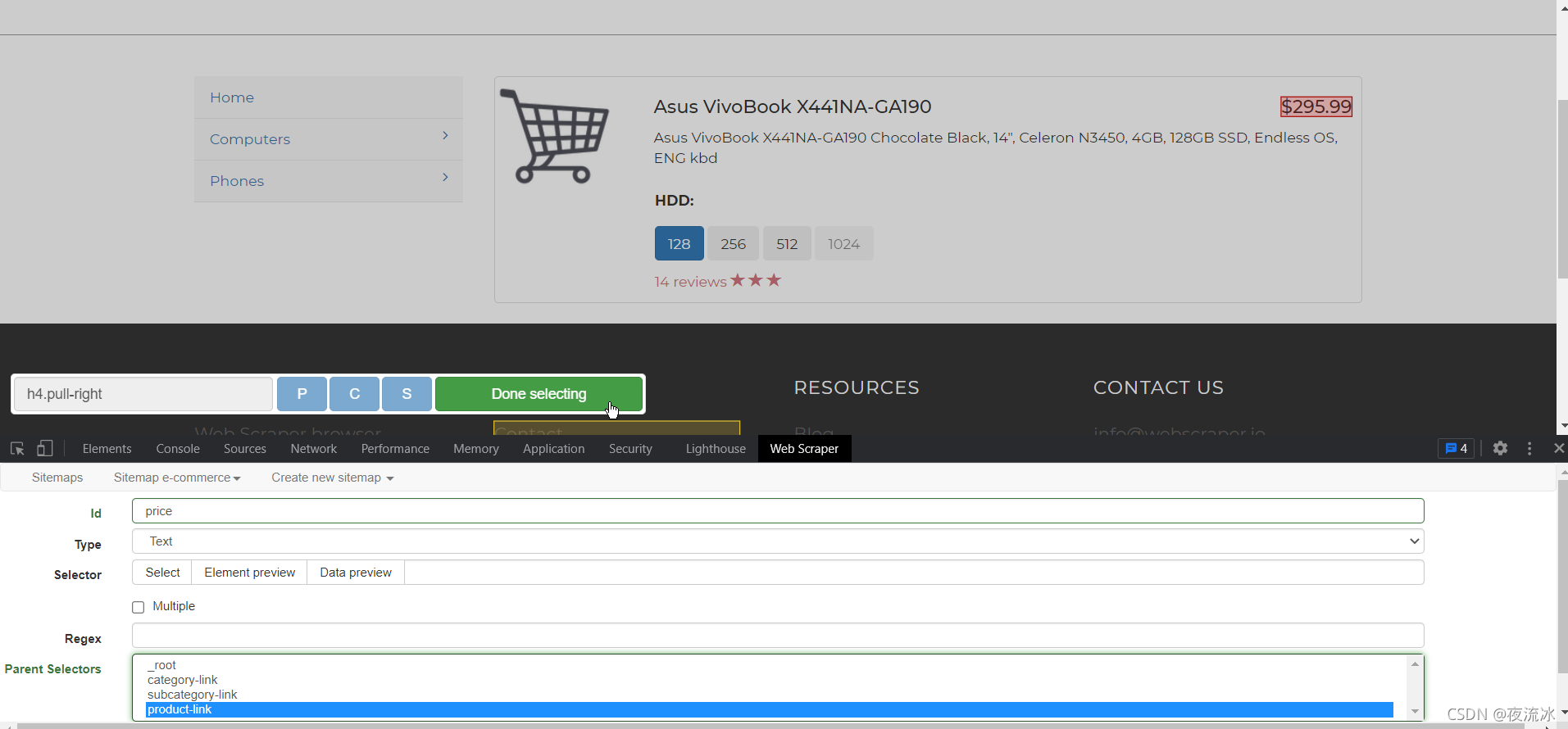
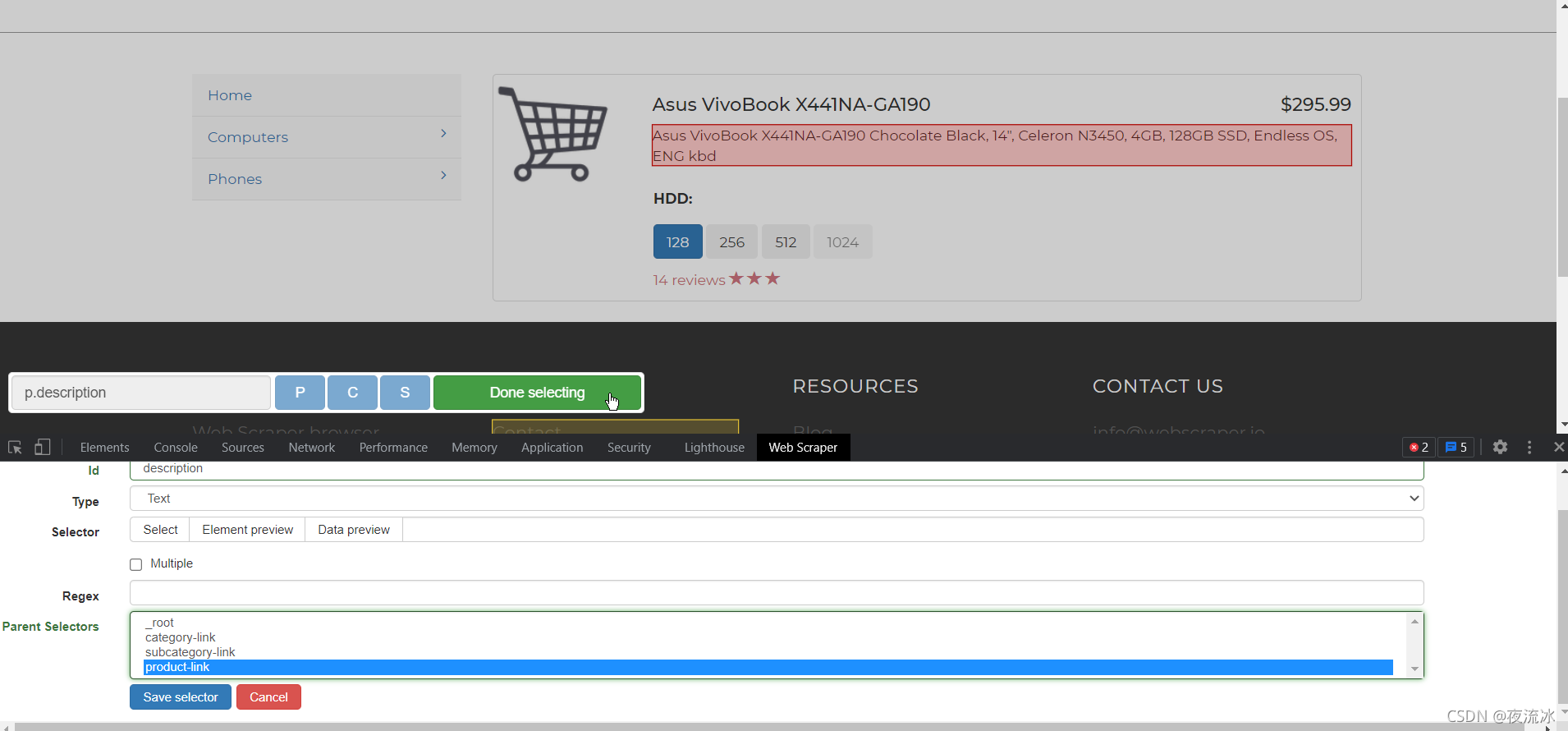
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
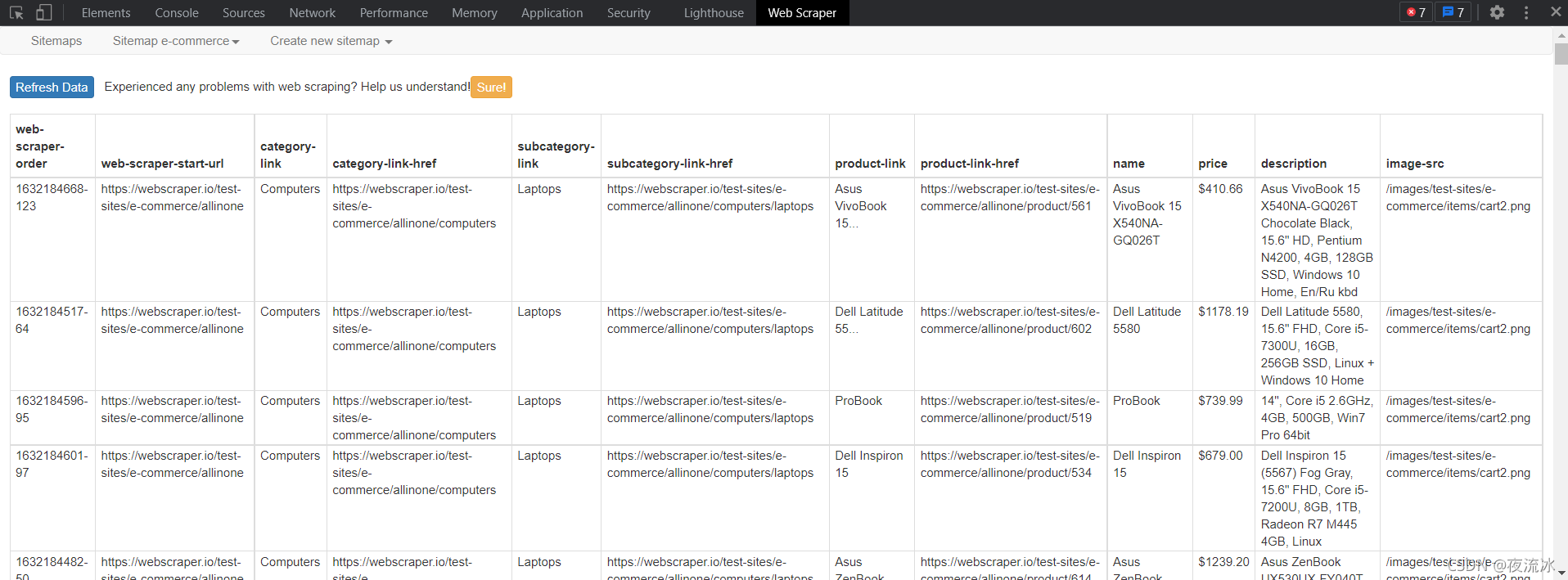
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
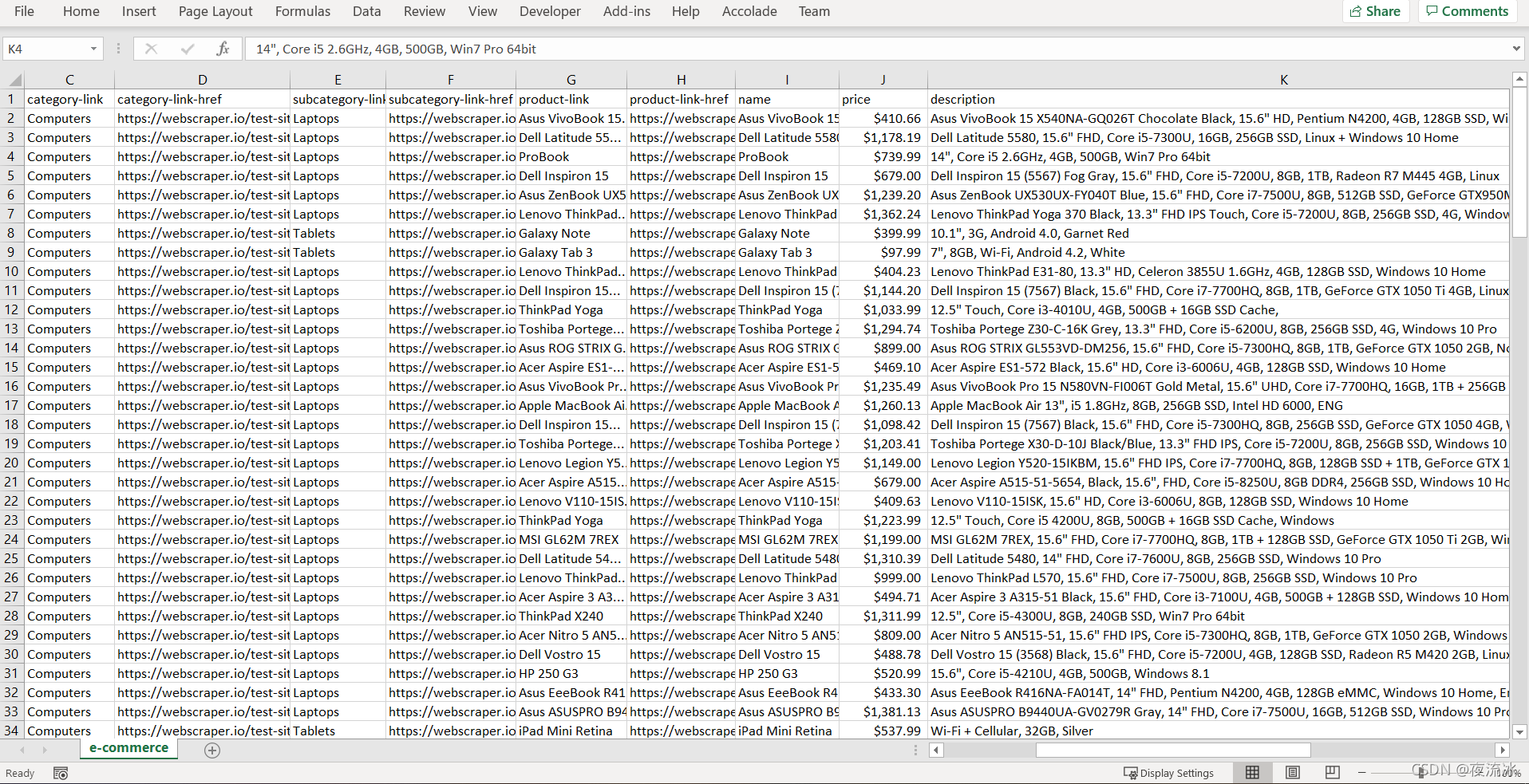
选择导出到CSV文件
打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击“浏览”返回数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取 查看全部
java抓取网页内容(WebScraperTutorials安装路径介绍,以作记录供你我他参考)
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务

此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器

对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常

您还可以使用选择器图查看我们创建的选择器的结构


单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据

休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件

打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击“浏览”返回数据显示

您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-17 18:01
通过JavaAPI,您可以成功捕获网络上大多数指定的网页内容。现在我与大家分享我对这种方法的理解和经验。最简单的方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBuffereReader(newInputStreamReader(url.openStream());字符串=”;StringBuffersb=newStringBuffer(“”);while((s=br.readLine())!=null){i++;sb.append(s+“\r\n”);}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
此方法在捕获常规网页时应该没有问题,但当某些网页中存在嵌套重定向连接时,它将报告错误,例如服务器重定向次数过多。这是因为此网页中的某些代码会转到其他网页,过多的循环会导致程序错误。如果您只想获取此URL中的网页内容,而不想将其跳转到其他网页,则可以使用以下代码
urlmy=newURL(myurl);HttpURLConnection=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollow(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(),“UTF-8”);字符串=”;StringBuffersb=newStringBuffer(“”);而((s=br.readLine())!=null){sb.append(s+“\r\n”);}
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
这样,当爬行时,程序就不会跳转到其他页面去抓取其他内容,这就达到了我们的目标
如果我们在内部网中,我们需要向其添加代理。Java为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可
Java代码
System.getProperties().setProperty(“http.proxyHost”,proxyName);System.getProperties().setProperty(“http.proxyPort”,port)
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
通过这种方式,您可以进入内部网,从Internet上获取所需内容
上述程序捕获的所有内容都存储在sb字符串中,因此我们可以通过正则表达式对其进行分析,并提取我们想要使用的特定内容 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JavaAPI,您可以成功捕获网络上大多数指定的网页内容。现在我与大家分享我对这种方法的理解和经验。最简单的方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBuffereReader(newInputStreamReader(url.openStream());字符串=”;StringBuffersb=newStringBuffer(“”);while((s=br.readLine())!=null){i++;sb.append(s+“\r\n”);}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
此方法在捕获常规网页时应该没有问题,但当某些网页中存在嵌套重定向连接时,它将报告错误,例如服务器重定向次数过多。这是因为此网页中的某些代码会转到其他网页,过多的循环会导致程序错误。如果您只想获取此URL中的网页内容,而不想将其跳转到其他网页,则可以使用以下代码
urlmy=newURL(myurl);HttpURLConnection=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollow(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(),“UTF-8”);字符串=”;StringBuffersb=newStringBuffer(“”);而((s=br.readLine())!=null){sb.append(s+“\r\n”);}
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
这样,当爬行时,程序就不会跳转到其他页面去抓取其他内容,这就达到了我们的目标
如果我们在内部网中,我们需要向其添加代理。Java为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可
Java代码

System.getProperties().setProperty(“http.proxyHost”,proxyName);System.getProperties().setProperty(“http.proxyPort”,port)
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
通过这种方式,您可以进入内部网,从Internet上获取所需内容
上述程序捕获的所有内容都存储在sb字符串中,因此我们可以通过正则表达式对其进行分析,并提取我们想要使用的特定内容
java抓取网页内容(读取本地和通过url抓取网页内容的html页面内容的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-17 16:27
)
今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办
我瞬间
了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
java抓取网页内容(读取本地和通过url抓取网页内容的html页面内容的方法
)
今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办

我瞬间

了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
java抓取网页内容(使用java语言抓取网页中的邮箱地址实现思路:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-16 21:13
在现实生活中,我们经常在浏览网页时看到我们需要的信息,但由于信息太大,无法一一保存
接下来,让我们以获取电子邮件地址为例,使用Java语言在网页中获取电子邮件地址
实现思路如下:
1、使用a。URL对象绑定网络上网页的地址
2、通过的openconnection()方法获取urlconnection对象。URL对象
3、通过urlconnection object的getinputstream()方法获取网络文件的InputStream对象InputStream
4、loop读取流中的每一行数据,将每一行字符与pattern对象编译的正则表达式匹配,并获取电子邮件地址
接下来,不用多说,直接转到代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test {
public static void main(String[] args) throws Exception {
//设定目标网址
URL url = new URL("目标网址");
// 打开连接
URLConnection conn = url.openConnection();
// 设置连接网络超时时间
conn.setConnectTimeout(1000 * 10);
// 读取指定网络地址中的文件
BufferedReader bufr = new BufferedReader(new InputStreamReader(conn.getInputStream()));
//在内存中构建一个空的字符串来准备获取读到的邮箱
String line = null;
// 设置匹配email的正则表达式;
String reg = "[a-zA-Z0-9_-]+@\\w+\\.[a-z]+(\\.[a-z]+)?";
Pattern p = Pattern.compile(reg);
//循环输出读到的邮箱地址
while((line = bufr.readLine()) != null) {
Matcher m = p.matcher(line);
while(m.find()) {
System.out.println(m.group());
}
}
}
}
我的水平有限,无法详细解释上述代码。请原谅我 查看全部
java抓取网页内容(使用java语言抓取网页中的邮箱地址实现思路:)
在现实生活中,我们经常在浏览网页时看到我们需要的信息,但由于信息太大,无法一一保存
接下来,让我们以获取电子邮件地址为例,使用Java语言在网页中获取电子邮件地址
实现思路如下:
1、使用a。URL对象绑定网络上网页的地址
2、通过的openconnection()方法获取urlconnection对象。URL对象
3、通过urlconnection object的getinputstream()方法获取网络文件的InputStream对象InputStream
4、loop读取流中的每一行数据,将每一行字符与pattern对象编译的正则表达式匹配,并获取电子邮件地址
接下来,不用多说,直接转到代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test {
public static void main(String[] args) throws Exception {
//设定目标网址
URL url = new URL("目标网址");
// 打开连接
URLConnection conn = url.openConnection();
// 设置连接网络超时时间
conn.setConnectTimeout(1000 * 10);
// 读取指定网络地址中的文件
BufferedReader bufr = new BufferedReader(new InputStreamReader(conn.getInputStream()));
//在内存中构建一个空的字符串来准备获取读到的邮箱
String line = null;
// 设置匹配email的正则表达式;
String reg = "[a-zA-Z0-9_-]+@\\w+\\.[a-z]+(\\.[a-z]+)?";
Pattern p = Pattern.compile(reg);
//循环输出读到的邮箱地址
while((line = bufr.readLine()) != null) {
Matcher m = p.matcher(line);
while(m.find()) {
System.out.println(m.group());
}
}
}
}
我的水平有限,无法详细解释上述代码。请原谅我
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-03 03:03
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
java抓取网页内容(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=”“+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuilderContentBuff=newStringBuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“依次显示上述四项”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果():“n”+结果”);}
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.out.println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
java抓取网页内容(Java目录:先爬取网页源码,先定义一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 16:04
Java目录:
最近在学习数据可视化。我想分析一下近年来各个城市的温度和空气质量的变化。我需要一些数据,所以我从互联网上抓取了一些有用的数据进行分析。
思路:先爬取网页源码,然后用正则表达式从源码中获取需要的数据。
可以通过以下方式获取网页源代码并在控制台输出。
String urlStr = ""; // 网址
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
//读到的内容不为空
while (bufRead.readLine() != null) {
System.out.println(bufRead.readLine());
}
bufRead.close();
} catch (IOException e) {
e.printStackTrace();
}
在这里测试一下
String urlStr = "http://datacenter.mep.gov.cn/r ... 3B%3B
控制台输出如下结果。
拿到网页的源码后,我们就可以使用正则表达式来获取我们需要的数据了。
我们先来分析一下源码。
我想要的数据 采集 是
以北京为例分析,我们得到如下正则表达式
// 城市正则
private String regularCity = ">[\u4e00-\u9fa5]{2,}市";
// 日期正则
private String regularDate = ">(([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))";
// AQI指数正则
private String regularAQI = ">[0-9]{2,}";
// 空气质量级别正则
private String regularQuality = ">[\u4e00-\u9fa5]";
我们首先定义一个方法,使用我们定义的正则表达式和网页的源代码来过滤数据。
/*
* 从网页源代码中过滤数据
* @param regular 正则
*
* @param code 源代码
*/
public String DataAcqu(String regular, String code) {
// 编译正则表达式
Pattern p = Pattern.compile(regular, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(code);
if (m.find()) {
// 返回采集到的数据
return m.group();
} else {
return "";
}
}
然后我们就可以得到我们需要的数据
public DataCode() {
// 用户输入网页地址
Scanner scan = new Scanner(System.in);
// 存储用户输入的网页地址
String urlStr = scan.nextLine();
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),
"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
String readStr = "";
// 创建一个DataAcqu类的对象(前面自己定义的用于采集数据的类)
DataAcqu dataAcq = new DataAcqu();
int i = 0; // 记录采集到的数据数量
// 如果读到的数据不为空
while ((readStr = bufRead .readLine()) != null) {
// 采集城市数据
String cityStr = dataAcq.DataAcqu(regularCity, readStr);
// 如果采集到符合条件的数据,打印出来
if (!cityStr.equals("")) {
// 将采集到的数据前后多余部分去掉(前面正则表达式为了准确取到相应的值,加入了">"和"")
cityStr = cityStr.substring(1, cityStr.indexOf(""));
System.out.println("城市:" + cityStr);
}
// 采集日期数据
String dateStr = dataAcq.DataAcqu(regularDate, readStr);
// 如果采集到符合条件的数据,打印出来
if (!dateStr.equals("")) {
dateStr = dateStr.substring(1, dateStr.indexOf(""));
System.out.println("日期:" + dateStr);
}
// 采集AQI指数数据
String AQIStr = dataAcq.DataAcqu(regularAQI, readStr);
// 如果采集到符合条件的数据,打印出来
if (!AQIStr.equals("")) {
AQIStr = AQIStr.substring(1, AQIStr.indexOf(""));
System.out.println("AQI指数:" + AQIStr);
}
// 采集空气质量级别数据
String qualityStr = dataAcq.DataAcqu(regularQuality, readStr);
// 如果采集到符合条件的数据,打印出来
if (!qualityStr.equals("")) {
qualityStr = qualityStr.substring(1,
qualityStr.indexOf(""));
System.out.println("空气质量级别:" + qualityStr);
System.out.println();
i++;
}
}
br.close(); // 读取完成后关闭读取器
System.out.println("采集完成,共采集到数据:" + i);
} catch (IOException e) {
e.printStackTrace();
}
}
运行后控制台输出如下信息
如果要将输出结果输出到输出文件,只需在代码中添加类似如下的代码即可
// 将数据输出到文件
PrintStream ps = new PrintStream("E:\\Java\\DataAcquisition\\data");
//将输出位置切换到文件
System.setOut(ps);
这样,我们就爬取到了我们需要的数据。 查看全部
java抓取网页内容(Java目录:先爬取网页源码,先定义一个方法)
Java目录:
最近在学习数据可视化。我想分析一下近年来各个城市的温度和空气质量的变化。我需要一些数据,所以我从互联网上抓取了一些有用的数据进行分析。
思路:先爬取网页源码,然后用正则表达式从源码中获取需要的数据。
可以通过以下方式获取网页源代码并在控制台输出。
String urlStr = ""; // 网址
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
//读到的内容不为空
while (bufRead.readLine() != null) {
System.out.println(bufRead.readLine());
}
bufRead.close();
} catch (IOException e) {
e.printStackTrace();
}
在这里测试一下
String urlStr = "http://datacenter.mep.gov.cn/r ... 3B%3B
控制台输出如下结果。
拿到网页的源码后,我们就可以使用正则表达式来获取我们需要的数据了。
我们先来分析一下源码。
我想要的数据 采集 是
以北京为例分析,我们得到如下正则表达式
// 城市正则
private String regularCity = ">[\u4e00-\u9fa5]{2,}市";
// 日期正则
private String regularDate = ">(([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))";
// AQI指数正则
private String regularAQI = ">[0-9]{2,}";
// 空气质量级别正则
private String regularQuality = ">[\u4e00-\u9fa5]";
我们首先定义一个方法,使用我们定义的正则表达式和网页的源代码来过滤数据。
/*
* 从网页源代码中过滤数据
* @param regular 正则
*
* @param code 源代码
*/
public String DataAcqu(String regular, String code) {
// 编译正则表达式
Pattern p = Pattern.compile(regular, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(code);
if (m.find()) {
// 返回采集到的数据
return m.group();
} else {
return "";
}
}
然后我们就可以得到我们需要的数据
public DataCode() {
// 用户输入网页地址
Scanner scan = new Scanner(System.in);
// 存储用户输入的网页地址
String urlStr = scan.nextLine();
try {
//创建一个url对象来指向要采集信息的网址
URL url = new URL(urlStr);
//将读取到的字节转化为字符
InputStreamReader inStrRead = new InputStreamReader(url.openStream(),
"utf-8");
//读取InputStreamReader转化成的字符
BufferedReader bufRead = new BufferedReader(inStrRead);
String readStr = "";
// 创建一个DataAcqu类的对象(前面自己定义的用于采集数据的类)
DataAcqu dataAcq = new DataAcqu();
int i = 0; // 记录采集到的数据数量
// 如果读到的数据不为空
while ((readStr = bufRead .readLine()) != null) {
// 采集城市数据
String cityStr = dataAcq.DataAcqu(regularCity, readStr);
// 如果采集到符合条件的数据,打印出来
if (!cityStr.equals("")) {
// 将采集到的数据前后多余部分去掉(前面正则表达式为了准确取到相应的值,加入了">"和"")
cityStr = cityStr.substring(1, cityStr.indexOf(""));
System.out.println("城市:" + cityStr);
}
// 采集日期数据
String dateStr = dataAcq.DataAcqu(regularDate, readStr);
// 如果采集到符合条件的数据,打印出来
if (!dateStr.equals("")) {
dateStr = dateStr.substring(1, dateStr.indexOf(""));
System.out.println("日期:" + dateStr);
}
// 采集AQI指数数据
String AQIStr = dataAcq.DataAcqu(regularAQI, readStr);
// 如果采集到符合条件的数据,打印出来
if (!AQIStr.equals("")) {
AQIStr = AQIStr.substring(1, AQIStr.indexOf(""));
System.out.println("AQI指数:" + AQIStr);
}
// 采集空气质量级别数据
String qualityStr = dataAcq.DataAcqu(regularQuality, readStr);
// 如果采集到符合条件的数据,打印出来
if (!qualityStr.equals("")) {
qualityStr = qualityStr.substring(1,
qualityStr.indexOf(""));
System.out.println("空气质量级别:" + qualityStr);
System.out.println();
i++;
}
}
br.close(); // 读取完成后关闭读取器
System.out.println("采集完成,共采集到数据:" + i);
} catch (IOException e) {
e.printStackTrace();
}
}
运行后控制台输出如下信息
如果要将输出结果输出到输出文件,只需在代码中添加类似如下的代码即可
// 将数据输出到文件
PrintStream ps = new PrintStream("E:\\Java\\DataAcquisition\\data");
//将输出位置切换到文件
System.setOut(ps);
这样,我们就爬取到了我们需要的数据。
java抓取网页内容(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-30 13:00
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下一次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
java抓取网页内容(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认 Google 可以以多种方式执行和 收录 Java。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 Java 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下一次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
java抓取网页内容(一个彩票网站为例来简单说明整体操作流程,分为以下几大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-30 12:20
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。当你知道这个地址时,你就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到这个html,分析结构,解析结构得到你想要的数据。Html的结构分析往往比较复杂繁琐,我们可以使用java支持包:jsoup,可以完成发送请求、解析html、获取你感兴趣的数据等功能
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块
2:分析页面,找到它的入口地址
我发现右边有一个下拉选择框。这是双色球的历史开奖号码。改变这个值,浏览器会再次请求这个时期的彩票信息。确保地址是:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理可以得到1个篮球
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java简单抓取网页数据的个人分享。有兴趣的童鞋可以自行实践,从实践中学习道理。 查看全部
java抓取网页内容(一个彩票网站为例来简单说明整体操作流程,分为以下几大)
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。当你知道这个地址时,你就可以得到很多网络响应需要仔细分析才能找到适合你的地址,最后通过这个地址返回一个html给你。我们可以拿到这个html,分析结构,解析结构得到你想要的数据。Html的结构分析往往比较复杂繁琐,我们可以使用java支持包:jsoup,可以完成发送请求、解析html、获取你感兴趣的数据等功能
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块
2:分析页面,找到它的入口地址
我发现右边有一个下拉选择框。这是双色球的历史开奖号码。改变这个值,浏览器会再次请求这个时期的彩票信息。确保地址是:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容比较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
使用以下代码,获得6个红球:
同理可以得到1个篮球
根据这个原理,你可以得到你想要的数据:以下是我得到的数据
以上是java简单抓取网页数据的个人分享。有兴趣的童鞋可以自行实践,从实践中学习道理。
java抓取网页内容(百度首页做了个小测试,小伙伴们可算松了口气)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-29 08:16
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?) 查看全部
java抓取网页内容(百度首页做了个小测试,小伙伴们可算松了口气)
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?)
java抓取网页内容( 一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-29 08:12
一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫(一) 网络爬虫基本原理
强烈推荐IDEA2020.2破解激活,IntelliJ IDEA注册码,2020.2 IDEA激活码
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的IP,下载该URL对应的网页并存入下载的网页库中. 另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每次抓取一个页面都重新计算PageRank值,折中方案是:每抓取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2.《搜索引擎技术基础》刘义群等清华大学出版社
猜你喜欢:网络爬虫(二)Web Crawler基本原理Web Crawler(四) Java实现简单的Web Crawler Web Crawler(三) Java实现简单的Web Crawler) 查看全部
java抓取网页内容(
一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫(一) 网络爬虫基本原理
强烈推荐IDEA2020.2破解激活,IntelliJ IDEA注册码,2020.2 IDEA激活码
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,得到主机的IP,下载该URL对应的网页并存入下载的网页库中. 另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待爬取的URL队列中,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的一些内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 可识网页:未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或待抓取的URL对应的页面得到的URL,被认为是一个已知网页。
5. 还有一些网页是爬虫无法直接爬取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每一个链接跟随一个链接,处理完这一行后转移到下一个起始页,继续跟随该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每次抓取一个页面都重新计算PageRank值,折中方案是:每抓取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2.《搜索引擎技术基础》刘义群等清华大学出版社
猜你喜欢:网络爬虫(二)Web Crawler基本原理Web Crawler(四) Java实现简单的Web Crawler Web Crawler(三) Java实现简单的Web Crawler)
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-23 05:26
通过Java的API,您可以顺利地抓取网络上的大部分指定的Web内容,并分享此方法以了解和体验您。最简单的爬行方式是:
java代码
urlurl = newul(myurl); bufferedReaderbr = newbuferedreader(newinputstreamReader(url.openstream())); strings =“”; stringbuffersb = newstringbuffer(“”);而((s = br.readline())= null){i ++; sb.append(s +“\ r \ n”);}
此方法崩溃常规页面应该没有问题,但是当某些网页中有一些嵌套重定向连接时,它将报告服务器等错误重定向太多次,因为还有另一个网页。有些代码正在转到其他网页,并且循环是由程序引起的。如果您只想抓住此URL中的内容,您不希望允许它具有其他网页跳转,您可以使用以下代码。
java代码
urlurlmy = newul(myurl); httpurlconnectioncon =(httpurlconnection)urlmy.openconnection(); con.setfollowredirects(真实); con.setInstancefollowredireds(false); con.connect(); bufferedReaderbr = newbufferedreader(newinputstreamreader(con.getinputstream(),“utf-8”)); strings =“”; stringbuffersb = newstringsbuffer(“”);虽然((s = br.readline())!= null){sb.append(s +“\ r \ n”);}
这种单词,程序不会髋关节其他页面才能抓取其他内容,这是我们的目的。
如果我们在内部网络中,还需要给它一个代理,Java为具有特殊系统属性的代理服务器提供支持,只要添加到以下程序“。
java代码
system.getproperties()。 setProperty(“http.proxyhost”,proxyname; system.getproperties()。setProperty(“http.proxyport”,端口);
如果这是,您可以实现您想要抓取自己内部网络的内容。
上面的程序在SB字符串中盖章,我们可以通过正则表达分析,提取您想要的特定内容,对我来说,呵呵,这是一件美妙的事情! ! 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过Java的API,您可以顺利地抓取网络上的大部分指定的Web内容,并分享此方法以了解和体验您。最简单的爬行方式是:
java代码
urlurl = newul(myurl); bufferedReaderbr = newbuferedreader(newinputstreamReader(url.openstream())); strings =“”; stringbuffersb = newstringbuffer(“”);而((s = br.readline())= null){i ++; sb.append(s +“\ r \ n”);}
此方法崩溃常规页面应该没有问题,但是当某些网页中有一些嵌套重定向连接时,它将报告服务器等错误重定向太多次,因为还有另一个网页。有些代码正在转到其他网页,并且循环是由程序引起的。如果您只想抓住此URL中的内容,您不希望允许它具有其他网页跳转,您可以使用以下代码。
java代码
urlurlmy = newul(myurl); httpurlconnectioncon =(httpurlconnection)urlmy.openconnection(); con.setfollowredirects(真实); con.setInstancefollowredireds(false); con.connect(); bufferedReaderbr = newbufferedreader(newinputstreamreader(con.getinputstream(),“utf-8”)); strings =“”; stringbuffersb = newstringsbuffer(“”);虽然((s = br.readline())!= null){sb.append(s +“\ r \ n”);}
这种单词,程序不会髋关节其他页面才能抓取其他内容,这是我们的目的。
如果我们在内部网络中,还需要给它一个代理,Java为具有特殊系统属性的代理服务器提供支持,只要添加到以下程序“。
java代码
system.getproperties()。 setProperty(“http.proxyhost”,proxyname; system.getproperties()。setProperty(“http.proxyport”,端口);
如果这是,您可以实现您想要抓取自己内部网络的内容。
上面的程序在SB字符串中盖章,我们可以通过正则表达分析,提取您想要的特定内容,对我来说,呵呵,这是一件美妙的事情! !
java抓取网页内容(WebScraperTutorials安装路径介绍,以作记录供你我他参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-21 16:15
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件
打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击“浏览”返回数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取 查看全部
java抓取网页内容(WebScraperTutorials安装路径介绍,以作记录供你我他参考)
官方网站WebScraper号称是头号网页捕获/提取插件,可安装在chrome和Firefox上
安装路径:
Web Scraper–获取Firefox的此扩展(美国版)
您也可以使用浏览器打开官方网站,然后单击“安装”自动选择“安装”
您还可以在浏览器右上角找到扩展图标,单击“打开”,下拉菜单,然后找到“管理扩展”,即输入chrome://extensions
单击左上角的“打开”,然后在左下角进入web应用商店,打开一个新页面,在其中搜索web scraper,然后安装它
有关说明,您最好看一下视频:
网络刮刀教程
这只是一个YouTube链接,可能有点困难。你可以在互联网上自由搜索,还有教学网站
此插件的正常版本是免费的,增强版是收费的。如果你有钱和需要,如果你不花它,你就会浪费它
此插件易于使用,因为它集成到浏览器中。非常适合新手和普通非专业技术人员使用。如果您需要更强大和定制的网页数据捕获,您可能需要更专业的工具或您自己的编程
下面是我使用此插件的介绍,供您参考
--------------------------------------------------------------------
第一步是安装,如上所述
步骤2:以chrome为例,在浏览器地址栏中输入:chrome://extensions/
检查是否已成功安装并启用web刮板
步骤3:F12或Ctrl+Shift+I,打开开发工具:
启用时,选择底部显示模式:
然后找到最后一个websharper选项卡并单击enter
好了,准备工作已经完成了
----------------------------------------------------------
对于第一个示例,请根据官网上的教学视频再次操作
打开官方测试网站:
Web测试站点
官方测试网站是一种电子商务网站. 让我们先简单浏览一下。它分为两个层次。第一级是主要类别:电脑和手机;第一个层次是子分类。“计算机和移动电话”下的分类收录特定的产品项,单击“产品项”即为特定的产品信息
我们的目标是通过浏览两级目录结构来提取所有产品信息
首先设置登录页面、门户URL和登录页面。从这个页面,网络刮板将浏览整个网站。我们需要创建多个选择器以形成树结构,类似于网站构造时的结构
这些选择器定义网站如何浏览以及如何提取数据
如下图所示,要创建站点地图,请输入地址作为上面的浏览器显示地址:Web scraper test sites
完整的数据提取基于站点地图。配置站点地图后,可以保存设置并在下次继续使用。我们需要重新提取并直接执行它
创建网站时,它被命名为电子商务
此时,它后面有一个数据预览按钮。点击后,发现当前没有数据,需要添加一个选择器
对于初始页面中的分层列,为了访问,我们需要以链接的形式创建选择器。单击添加新选择器
然后单击选择以链接的形式选择网页元素
选择器名为category linkm,类型为link。单击选择并选择两个链接。检查多个。父选择器是登录页面
单击“选择”以选择网页上的元素,然后单击“完成选择”
要验证选择结果,请单击“图元预览”检查选择是否正确,然后单击“数据预览”检查其工作是否正常
然后保存选择器
接下来,我们为下一级链接创建一个选择器
单击网页上的“计算机”继续以链接的形式创建选择器
单击保存。然后创建产品页面的链接选择器。首先单击笔记本电脑进入产品列表页面
单击产品链接进入产品页面,创建文本类型选择器,并提取所需数据
创建选择器后,让我们来看一看。根据层次关系点击选择器,随时点击选择器后面的数据预览,查看数据是否正常
您还可以使用选择器图查看我们创建的选择器的结构
单击scratch开始捕获数据,您将看到一个新的网页打开。浏览页面并根据我们设置的登录URL和选择器提取数据
休息一下,等待数据提取
完成后,弹出页面将关闭并提示
然后单击“刷新”以显示提取的数据
选择导出到CSV文件
打开CSV文件,数据如下:
好的,CSV文件已经在手了,已经结束了
单击“浏览”返回数据显示
您还可以导出导出站点地图,保存站点地图JSON内容,并在下次创建站点地图时直接导入,这样更方便快捷
如果有多个站点地图,则可以在操作之前选择或切换站点地图以进行数据提取
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-17 18:01
通过JavaAPI,您可以成功捕获网络上大多数指定的网页内容。现在我与大家分享我对这种方法的理解和经验。最简单的方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBuffereReader(newInputStreamReader(url.openStream());字符串=”;StringBuffersb=newStringBuffer(“”);while((s=br.readLine())!=null){i++;sb.append(s+“\r\n”);}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
此方法在捕获常规网页时应该没有问题,但当某些网页中存在嵌套重定向连接时,它将报告错误,例如服务器重定向次数过多。这是因为此网页中的某些代码会转到其他网页,过多的循环会导致程序错误。如果您只想获取此URL中的网页内容,而不想将其跳转到其他网页,则可以使用以下代码
urlmy=newURL(myurl);HttpURLConnection=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollow(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(),“UTF-8”);字符串=”;StringBuffersb=newStringBuffer(“”);而((s=br.readLine())!=null){sb.append(s+“\r\n”);}
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
这样,当爬行时,程序就不会跳转到其他页面去抓取其他内容,这就达到了我们的目标
如果我们在内部网中,我们需要向其添加代理。Java为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可
Java代码
System.getProperties().setProperty(“http.proxyHost”,proxyName);System.getProperties().setProperty(“http.proxyPort”,port)
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
通过这种方式,您可以进入内部网,从Internet上获取所需内容
上述程序捕获的所有内容都存储在sb字符串中,因此我们可以通过正则表达式对其进行分析,并提取我们想要使用的特定内容 查看全部
java抓取网页内容(JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JavaAPI,您可以成功捕获网络上大多数指定的网页内容。现在我与大家分享我对这种方法的理解和经验。最简单的方法是:
URLurl=newURL(myurl);BufferedReaderbr=newBuffereReader(newInputStreamReader(url.openStream());字符串=”;StringBuffersb=newStringBuffer(“”);while((s=br.readLine())!=null){i++;sb.append(s+“\r\n”);}
URL url = new URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
i++;
sb.append(s+"\r\n");
}
此方法在捕获常规网页时应该没有问题,但当某些网页中存在嵌套重定向连接时,它将报告错误,例如服务器重定向次数过多。这是因为此网页中的某些代码会转到其他网页,过多的循环会导致程序错误。如果您只想获取此URL中的网页内容,而不想将其跳转到其他网页,则可以使用以下代码
urlmy=newURL(myurl);HttpURLConnection=(HttpURLConnection)urlmy.openConnection();con.setFollowRedirects(true);con.setInstanceFollow(false);con.connect();BufferedReaderbr=newBufferedReader(newInputStreamReader(con.getInputStream(),“UTF-8”);字符串=”;StringBuffersb=newStringBuffer(“”);而((s=br.readLine())!=null){sb.append(s+“\r\n”);}
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
这样,当爬行时,程序就不会跳转到其他页面去抓取其他内容,这就达到了我们的目标
如果我们在内部网中,我们需要向其添加代理。Java为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可
Java代码
System.getProperties().setProperty(“http.proxyHost”,proxyName);System.getProperties().setProperty(“http.proxyPort”,port)
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty( "http.proxyPort", port );
通过这种方式,您可以进入内部网,从Internet上获取所需内容
上述程序捕获的所有内容都存储在sb字符串中,因此我们可以通过正则表达式对其进行分析,并提取我们想要使用的特定内容
java抓取网页内容(读取本地和通过url抓取网页内容的html页面内容的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-17 16:27
)
今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办
我瞬间
了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
java抓取网页内容(读取本地和通过url抓取网页内容的html页面内容的方法
)
今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办
我瞬间
了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
java抓取网页内容(使用java语言抓取网页中的邮箱地址实现思路:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-16 21:13
在现实生活中,我们经常在浏览网页时看到我们需要的信息,但由于信息太大,无法一一保存
接下来,让我们以获取电子邮件地址为例,使用Java语言在网页中获取电子邮件地址
实现思路如下:
1、使用a。URL对象绑定网络上网页的地址
2、通过的openconnection()方法获取urlconnection对象。URL对象
3、通过urlconnection object的getinputstream()方法获取网络文件的InputStream对象InputStream
4、loop读取流中的每一行数据,将每一行字符与pattern对象编译的正则表达式匹配,并获取电子邮件地址
接下来,不用多说,直接转到代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test {
public static void main(String[] args) throws Exception {
//设定目标网址
URL url = new URL("目标网址");
// 打开连接
URLConnection conn = url.openConnection();
// 设置连接网络超时时间
conn.setConnectTimeout(1000 * 10);
// 读取指定网络地址中的文件
BufferedReader bufr = new BufferedReader(new InputStreamReader(conn.getInputStream()));
//在内存中构建一个空的字符串来准备获取读到的邮箱
String line = null;
// 设置匹配email的正则表达式;
String reg = "[a-zA-Z0-9_-]+@\\w+\\.[a-z]+(\\.[a-z]+)?";
Pattern p = Pattern.compile(reg);
//循环输出读到的邮箱地址
while((line = bufr.readLine()) != null) {
Matcher m = p.matcher(line);
while(m.find()) {
System.out.println(m.group());
}
}
}
}
我的水平有限,无法详细解释上述代码。请原谅我 查看全部
java抓取网页内容(使用java语言抓取网页中的邮箱地址实现思路:)
在现实生活中,我们经常在浏览网页时看到我们需要的信息,但由于信息太大,无法一一保存
接下来,让我们以获取电子邮件地址为例,使用Java语言在网页中获取电子邮件地址
实现思路如下:
1、使用a。URL对象绑定网络上网页的地址
2、通过的openconnection()方法获取urlconnection对象。URL对象
3、通过urlconnection object的getinputstream()方法获取网络文件的InputStream对象InputStream
4、loop读取流中的每一行数据,将每一行字符与pattern对象编译的正则表达式匹配,并获取电子邮件地址
接下来,不用多说,直接转到代码:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test {
public static void main(String[] args) throws Exception {
//设定目标网址
URL url = new URL("目标网址");
// 打开连接
URLConnection conn = url.openConnection();
// 设置连接网络超时时间
conn.setConnectTimeout(1000 * 10);
// 读取指定网络地址中的文件
BufferedReader bufr = new BufferedReader(new InputStreamReader(conn.getInputStream()));
//在内存中构建一个空的字符串来准备获取读到的邮箱
String line = null;
// 设置匹配email的正则表达式;
String reg = "[a-zA-Z0-9_-]+@\\w+\\.[a-z]+(\\.[a-z]+)?";
Pattern p = Pattern.compile(reg);
//循环输出读到的邮箱地址
while((line = bufr.readLine()) != null) {
Matcher m = p.matcher(line);
while(m.find()) {
System.out.println(m.group());
}
}
}
}
我的水平有限,无法详细解释上述代码。请原谅我

