
java抓取网页内容
java抓取网页内容( 点赞再看,养成习惯(一)网页提取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-21 17:06
点赞再看,养成习惯(一)网页提取框架)
喜欢再看,养成习惯
大家好,我叫Labrami,今天更新了文章,带来了很干的干货。
前言
说起爬虫爬取网页数据,相信大家的第一反应都是python。Python 确实很适合这一点,但是许多具有多年经验的 Java 开发人员不一定知道它。其实Java也可以作为爬虫使用。最著名的是Jsoup网页提取框架。
结婚了
多年前,我做了一个贵金属信息类型网站。我需要实时显示各个交易所的最新黄金和白银价格。当时有第三方API接口服务商提供此类数据。你需要付钱。后来百度去Jsoup抓取网页的数据,然后找了个大网站根据它抓取数据,然后自己把表格展示在页面上,省了一大笔钱。
昨晚心血来潮,想写一篇文章的文章,于是去官网看了一下,决定给优采云找个房间
Jsoup食用指南
Jsoup真的很简单,简单到不想介绍开发过程,直接看官网,十分钟搞定它的API。
官网有介绍指南和例子,大家自己去看看吧。
官网地址:/
干货
对于干货部分,我会用实战的方式来详细讲解。相信通过这个实战例子,大家可以轻松掌握技术。
1、准备要爬取的网页
优采云找房子-深圳站-新房:/loupan/pg
2、新的Maven项目
3、pom 文件添加依赖
com.google.guava
guava
30.0-jre
org.projectlombok
lombok
1.18.18
org.jsoup
jsoup
1.14.3
com.alibaba
easyexcel
2.2.10
复制代码
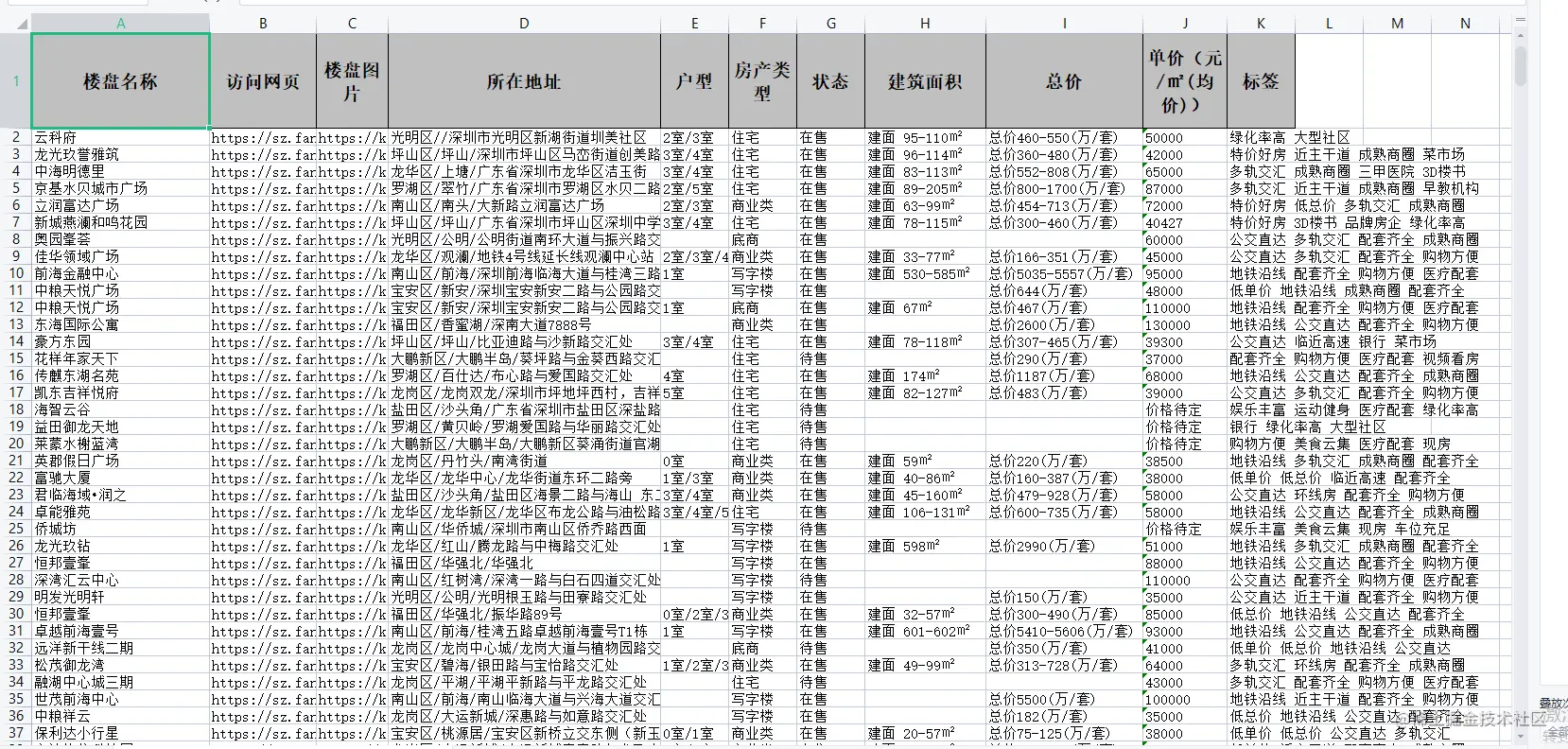
4、创建一个Pojo类将数据映射到excel表
因为从网页抓取的地址最后会保存在excel文件中,我们使用阿里巴巴的EasyExcel,所以需要在pom文件中引入依赖,并且需要创建一个pojo类来映射导出的文件。
@Data
@Accessors(chain = true)
public class House {
@ExcelProperty("楼盘名称")
private String title;
@ExcelProperty("访问网页")
private String detailPageUrl;
@ExcelProperty("楼盘图片")
private String imageUrl;
@ExcelProperty("所在地址")
private String address;
@ExcelProperty("户型")
private String houseType;
@ExcelProperty("房产类型")
private String propertyType;
@ExcelProperty("状态")
private String status;
@ExcelProperty("建筑面积")
private String buildingArea;
@ExcelProperty("总价")
private String totalPrice;
@ExcelProperty("单价(元/㎡(均价))")
private String singlePrice;
@ExcelProperty("标签")
private String tag;
}
复制代码
5、Main方法执行业务代码
这里有几点需要注意:
优采云短时间频繁访问同一个ip会触发人机验证,所以每次分页执行我们都需要让线程休眠一段时间。Jsoup 抓取 html 元素。如果优采云的网页有改动,程序可能无法正常抓取数据。程序不抓取楼盘详细信息,感兴趣的同学可以根据抓取到的详情页url进行二次开发。如果你要抓取的网站需要登录信息等特殊请求参数,Jsoup也支持设置,具体请参考官网API。
@SneakyThrows
public static void main(String[] args) {
AtomicInteger pageIndex = new AtomicInteger(1);
int pageSize = 10;
List dataList = Lists.newArrayList();
// 贝壳找房深圳区域网址
String beikeUrl = "https://sz.fang.ke.com";
// 贝壳找房深圳市楼盘展示页地址
String loupanUrl = "https://sz.fang.ke.com/loupan/pg";
// 用Jsoup抓取该地址完整网页信息
Document doc = Jsoup.connect(loupanUrl + pageIndex.get()).get();
// 网页标题
String pageTitle = doc.title();
// 分页容器
Element pageContainer = doc.select("div.page-box").first();
if (pageContainer == null) {
return;
}
// 楼盘总数
int totalCount = Integer.parseInt(pageContainer.attr("data-total-count"));
// 分页执行
for (int i = 0; i < totalCount / pageSize; i++) {
log.info("running get data, the current page is {}", pageIndex.get());
// 贝壳网有人机认证,不能短时间频繁访问,每次翻页都让线程休眠10s
Thread.sleep(10000);
doc = Jsoup.connect(loupanUrl + pageIndex.getAndIncrement()).get();
// 获取楼盘列表的ul元素
Element list = doc.select("ul.resblock-list-wrapper").first();
if (list == null) {
continue;
}
// 获取楼盘列表的li元素
Elements elements = list.select("li.resblock-list");
elements.forEach(el -> {
// 楼盘介绍
Element introduce = el.child(0);
// 详情页面
String detailPageUrl = beikeUrl + introduce.attr("href");
// 楼盘图片
String imageUrl = introduce.select("img").attr("data-original");
// 楼盘详情
Element childDesc = el.select("div.resblock-desc-wrapper").first();
Element childName = childDesc.child(0);
// 楼盘名称
String title = childName.child(0).text();
// 楼盘在售状态
String status = childName.child(1).text();
// 产权类型
String propertyType = childName.child(2).text();
// 楼盘所在地址
String address = childDesc.child(1).text();
// 房间属性
Element room = childDesc.child(2);
// 户型
String houseType = "";
// 户型集合
Elements houseTypeSpans = room.getElementsByTag("span");
if (CollectionUtils.isNotEmpty(houseTypeSpans)) {
// 剔除文案:【户型:】
houseTypeSpans.remove(0);
// 剔除文案:【建面:xxx】
houseTypeSpans.remove(houseTypeSpans.size() - 1);
houseType = StringUtil.join(houseTypeSpans.stream().map(Element::text).collect(Collectors.toList()), "/");
}
// 建筑面积
String buildingArea = room.select("span.area").text();
// div - 标签
Element descTag = childDesc.select("div.resblock-tag").first();
Elements tagSpans = descTag.getElementsByTag("span");
String tag = "";
if (CollectionUtils.isNotEmpty(tagSpans)) {
tag = StringUtil.join(tagSpans.stream().map(Element::text).collect(Collectors.toList()), " ");
}
// div - 价格
Element descPrice = childDesc.select("div.resblock-price").first();
String singlePrice = descPrice.select("span.number").text();
String totalPrice = descPrice.select("div.second").text();
dataList.add(new House().setTitle(title)
.setDetailPageUrl(detailPageUrl)
.setImageUrl(imageUrl)
.setSinglePrice(singlePrice)
.setTotalPrice(totalPrice)
.setStatus(status)
.setPropertyType(propertyType)
.setAddress(address)
.setHouseType(houseType)
.setBuildingArea(buildingArea)
.setTag(tag)
);
});
}
if (CollectionUtils.isEmpty(dataList)) {
log.info("dataList is empty returned.");
return;
}
log.info("dataList prepare finished, size = {}", dataList.size());
// 调用导出逻辑,将数据导出到excel文件
export(pageTitle, dataList);
}
复制代码
6、EasyExcel 导出逻辑
/**
* 将爬取的数据写入到excel中
* @param pageTitle
* @param dataList
*/
private static void export(String pageTitle, List dataList) {
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
//设置头居中
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//内容策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
//设置 水平居中
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
HorizontalCellStyleStrategy horizontalCellStyleStrategy = new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
// 这里需要设置不关闭流
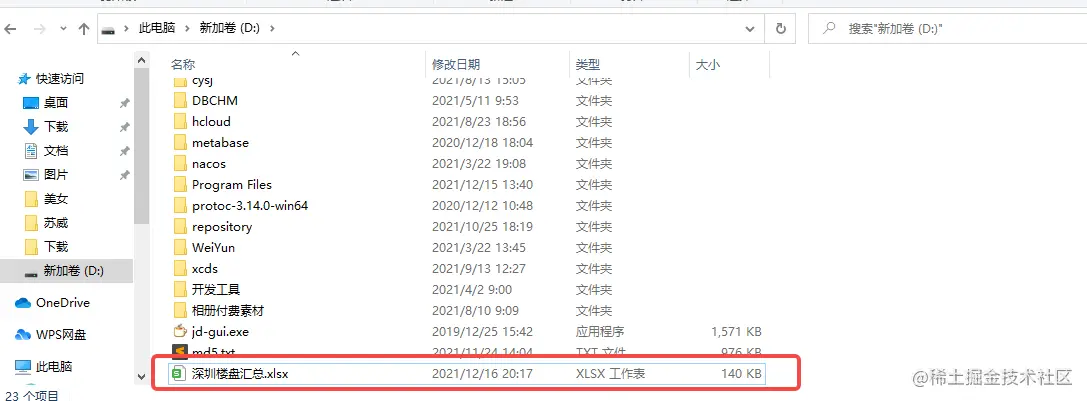
EasyExcelFactory.write("D:\深圳楼盘汇总.xlsx", House.class).autoCloseStream(Boolean.FALSE).registerWriteHandler(horizontalCellStyleStrategy).sheet(pageTitle).doWrite(dataList);
}
复制代码
7、成就展示
有兴趣的朋友可以自己尝试一下!
源代码:GitHub
原创不容易,请多多点赞,非常感谢! 查看全部
java抓取网页内容(
点赞再看,养成习惯(一)网页提取框架)

喜欢再看,养成习惯
大家好,我叫Labrami,今天更新了文章,带来了很干的干货。
前言
说起爬虫爬取网页数据,相信大家的第一反应都是python。Python 确实很适合这一点,但是许多具有多年经验的 Java 开发人员不一定知道它。其实Java也可以作为爬虫使用。最著名的是Jsoup网页提取框架。
结婚了
多年前,我做了一个贵金属信息类型网站。我需要实时显示各个交易所的最新黄金和白银价格。当时有第三方API接口服务商提供此类数据。你需要付钱。后来百度去Jsoup抓取网页的数据,然后找了个大网站根据它抓取数据,然后自己把表格展示在页面上,省了一大笔钱。
昨晚心血来潮,想写一篇文章的文章,于是去官网看了一下,决定给优采云找个房间
Jsoup食用指南
Jsoup真的很简单,简单到不想介绍开发过程,直接看官网,十分钟搞定它的API。
官网有介绍指南和例子,大家自己去看看吧。
官网地址:/
干货
对于干货部分,我会用实战的方式来详细讲解。相信通过这个实战例子,大家可以轻松掌握技术。
1、准备要爬取的网页
优采云找房子-深圳站-新房:/loupan/pg
2、新的Maven项目
3、pom 文件添加依赖
com.google.guava
guava
30.0-jre
org.projectlombok
lombok
1.18.18
org.jsoup
jsoup
1.14.3
com.alibaba
easyexcel
2.2.10
复制代码
4、创建一个Pojo类将数据映射到excel表
因为从网页抓取的地址最后会保存在excel文件中,我们使用阿里巴巴的EasyExcel,所以需要在pom文件中引入依赖,并且需要创建一个pojo类来映射导出的文件。
@Data
@Accessors(chain = true)
public class House {
@ExcelProperty("楼盘名称")
private String title;
@ExcelProperty("访问网页")
private String detailPageUrl;
@ExcelProperty("楼盘图片")
private String imageUrl;
@ExcelProperty("所在地址")
private String address;
@ExcelProperty("户型")
private String houseType;
@ExcelProperty("房产类型")
private String propertyType;
@ExcelProperty("状态")
private String status;
@ExcelProperty("建筑面积")
private String buildingArea;
@ExcelProperty("总价")
private String totalPrice;
@ExcelProperty("单价(元/㎡(均价))")
private String singlePrice;
@ExcelProperty("标签")
private String tag;
}
复制代码
5、Main方法执行业务代码
这里有几点需要注意:
优采云短时间频繁访问同一个ip会触发人机验证,所以每次分页执行我们都需要让线程休眠一段时间。Jsoup 抓取 html 元素。如果优采云的网页有改动,程序可能无法正常抓取数据。程序不抓取楼盘详细信息,感兴趣的同学可以根据抓取到的详情页url进行二次开发。如果你要抓取的网站需要登录信息等特殊请求参数,Jsoup也支持设置,具体请参考官网API。
@SneakyThrows
public static void main(String[] args) {
AtomicInteger pageIndex = new AtomicInteger(1);
int pageSize = 10;
List dataList = Lists.newArrayList();
// 贝壳找房深圳区域网址
String beikeUrl = "https://sz.fang.ke.com";
// 贝壳找房深圳市楼盘展示页地址
String loupanUrl = "https://sz.fang.ke.com/loupan/pg";
// 用Jsoup抓取该地址完整网页信息
Document doc = Jsoup.connect(loupanUrl + pageIndex.get()).get();
// 网页标题
String pageTitle = doc.title();
// 分页容器
Element pageContainer = doc.select("div.page-box").first();
if (pageContainer == null) {
return;
}
// 楼盘总数
int totalCount = Integer.parseInt(pageContainer.attr("data-total-count"));
// 分页执行
for (int i = 0; i < totalCount / pageSize; i++) {
log.info("running get data, the current page is {}", pageIndex.get());
// 贝壳网有人机认证,不能短时间频繁访问,每次翻页都让线程休眠10s
Thread.sleep(10000);
doc = Jsoup.connect(loupanUrl + pageIndex.getAndIncrement()).get();
// 获取楼盘列表的ul元素
Element list = doc.select("ul.resblock-list-wrapper").first();
if (list == null) {
continue;
}
// 获取楼盘列表的li元素
Elements elements = list.select("li.resblock-list");
elements.forEach(el -> {
// 楼盘介绍
Element introduce = el.child(0);
// 详情页面
String detailPageUrl = beikeUrl + introduce.attr("href");
// 楼盘图片
String imageUrl = introduce.select("img").attr("data-original");
// 楼盘详情
Element childDesc = el.select("div.resblock-desc-wrapper").first();
Element childName = childDesc.child(0);
// 楼盘名称
String title = childName.child(0).text();
// 楼盘在售状态
String status = childName.child(1).text();
// 产权类型
String propertyType = childName.child(2).text();
// 楼盘所在地址
String address = childDesc.child(1).text();
// 房间属性
Element room = childDesc.child(2);
// 户型
String houseType = "";
// 户型集合
Elements houseTypeSpans = room.getElementsByTag("span");
if (CollectionUtils.isNotEmpty(houseTypeSpans)) {
// 剔除文案:【户型:】
houseTypeSpans.remove(0);
// 剔除文案:【建面:xxx】
houseTypeSpans.remove(houseTypeSpans.size() - 1);
houseType = StringUtil.join(houseTypeSpans.stream().map(Element::text).collect(Collectors.toList()), "/");
}
// 建筑面积
String buildingArea = room.select("span.area").text();
// div - 标签
Element descTag = childDesc.select("div.resblock-tag").first();
Elements tagSpans = descTag.getElementsByTag("span");
String tag = "";
if (CollectionUtils.isNotEmpty(tagSpans)) {
tag = StringUtil.join(tagSpans.stream().map(Element::text).collect(Collectors.toList()), " ");
}
// div - 价格
Element descPrice = childDesc.select("div.resblock-price").first();
String singlePrice = descPrice.select("span.number").text();
String totalPrice = descPrice.select("div.second").text();
dataList.add(new House().setTitle(title)
.setDetailPageUrl(detailPageUrl)
.setImageUrl(imageUrl)
.setSinglePrice(singlePrice)
.setTotalPrice(totalPrice)
.setStatus(status)
.setPropertyType(propertyType)
.setAddress(address)
.setHouseType(houseType)
.setBuildingArea(buildingArea)
.setTag(tag)
);
});
}
if (CollectionUtils.isEmpty(dataList)) {
log.info("dataList is empty returned.");
return;
}
log.info("dataList prepare finished, size = {}", dataList.size());
// 调用导出逻辑,将数据导出到excel文件
export(pageTitle, dataList);
}
复制代码
6、EasyExcel 导出逻辑
/**
* 将爬取的数据写入到excel中
* @param pageTitle
* @param dataList
*/
private static void export(String pageTitle, List dataList) {
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
//设置头居中
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//内容策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
//设置 水平居中
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
HorizontalCellStyleStrategy horizontalCellStyleStrategy = new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
// 这里需要设置不关闭流
EasyExcelFactory.write("D:\深圳楼盘汇总.xlsx", House.class).autoCloseStream(Boolean.FALSE).registerWriteHandler(horizontalCellStyleStrategy).sheet(pageTitle).doWrite(dataList);
}
复制代码
7、成就展示
有兴趣的朋友可以自己尝试一下!
源代码:GitHub
原创不容易,请多多点赞,非常感谢!
java抓取网页内容( jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-16 03:04
jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)
搭建开发环境,在项目的Build Path中导入下载的Commons-httpClient3.1.Jar、htmllexer.jar和htmlparser.jar文件。图1. 开发环境搭建HttpClient基础类 该库使用HttpClinet提供了几个支持HTTP访问的类。下面我们通过一些示例代码来熟悉和解释这些类的功能和用途。HttpClient 提供的 HTTP 访问主要通过 GetMethod 类和 PostMethod 类来实现。它们分别对应于HTT
Java实现一个简单的网络爬虫代码示例
目前市面上流行的爬虫大多是python。经过简单的了解,一些简单的页面的爬虫主要是解析目标页面(html)。然后我在想,java中有没有用户可以轻松解析html页面?我发现一个jsoup包是一个非常方便的解析html的工具。使用方法也很简单,引入jar包:org.jsoup jsoup 1.8.
基于Java的短信验证码api调用代码示例
本文示例分享JAVA短信验证码api调用代码,供大家参考。具体内容如下: import java.io.BufferedReader; 导入 java.io.DataOutputStream; 导入 java.io.IOException; 导入 java.io.InputStream; 导入 java.io.InputStreamReader; 导入 java.io.UnsupportedEncodingException; 进口熟
C#网络爬虫代码分享 C#简单爬虫工具
公司编辑妹需要抓取网页内容,请我帮忙制作一个简单的抓取工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考私有字符串 GetHttpWebRequest(string url) {HttpWebResponse result; string strHTML = string.Empty; 尝试{Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri);
Java网络爬虫连接超时解决示例代码
本文主要研究java网络爬虫连接超时问题,如下。在网络爬虫中,经常会遇到以下错误。即连接超时。对于这个问题,一般的解决办法是:设置连接时间。请求时间设置的较长。如果出现连接超时,请重新请求【设置重新请求的次数】。线程“main”中的异常 .ConnectException: Connection timed out: connect 下面的代码是一个使用httpclient解决连接超时的示例程序。直接上程序。包大
开发基于 Java 的图形用户界面
SWT(Standard Widget Toolkit)是IBM推出的“基于java的”图形界面开发库。我之所以说它是“基于java的”,是指程序员在编写代码时使用java语言。实际上,SWT的底层实现是用C语言完成的。但这些对程序员来说是透明的。当我们使用SWT开发GUI程序时,我们直接使用SWT API来编写。其实很多java代码都是通过JNI去掉C代码来实现的。对于不同的平台的每个类都有不同的实现。这个文章的目的不是描述SWT的设计原理,如果你对这些感兴趣
Java实现爬虫向App提供数据(Jsoup网络爬虫)
一. Demand 最近基于 Material Design 重构了自己的新闻应用。数据源有问题。有前辈分析过知乎daily.Phoenix News等API。根据对应的URL,可以得到新闻的JSON数据。.为了锻炼写代码能力,作者打算自己爬取新闻页面,获取数据搭建API。二.效果图 下图为原网站页面爬虫获取数据并显示在APP移动端三.爬虫思路App实现过程请参考这些文章文章。本文主要讲解如何爬取数据。Android下记录App操作生成Gif动态图的全过程:
Java网络爬虫初学者详细介绍
这是Java网络爬虫系列的第一篇文章。如果不了解Java网络爬虫系列文章,请参考Java网络爬虫基础知识解析。第一篇是关于Java网络爬虫的介绍。内容。本文以采集虎扑列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示: 我们需要提取图中圈出的文字及其对应的链接,在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,一种是另一种是httpclient + 正则表达式方法。这也是Java网络爬虫常用的两种方法。这两种方法你不懂。不管哪条路,都会有对应的
Java网络爬虫基础知识解析
前言说到网络爬虫,大家想到的大概就是Python。当然,爬虫已经是Python的代名词之一,比Java差很多。很多人不知道Java可以用作网络爬虫。其实Java我也可以做网络爬虫,而且做的很好。开源社区中有很多优秀的Java网络爬虫框架,比如webmagic。我的第一份正式工作是使用webmagic编写数据采集程序。当时参与开发了一个舆情分析系统,涉及到很多网站新闻采集,我们用webmagic写了采集程序,因为我们不知道在时间
使用java实现网络爬虫
继上一篇爬虫所需的java知识,本文的目的是实现网络爬虫,获取数据进行分析。----->爬虫实现原理网络爬虫处理网络爬虫的基本技术是data采集的一种方法,在实际项目开发中,数据是通过爬虫来完成的采集一般只有以下几种情况:1)搜索引擎2)竞研3)监控4)行情分析网络爬虫的整体执行过程:1)确定一个(多个)种子网页2)提取数据内容3)连接相关网页中的网页提取 4) 将相关网页中未爬取的内容放入队列 5)从队列中取出一个要爬取的页面,判断之前是否被爬过 查看全部
java抓取网页内容(
jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)

搭建开发环境,在项目的Build Path中导入下载的Commons-httpClient3.1.Jar、htmllexer.jar和htmlparser.jar文件。图1. 开发环境搭建HttpClient基础类 该库使用HttpClinet提供了几个支持HTTP访问的类。下面我们通过一些示例代码来熟悉和解释这些类的功能和用途。HttpClient 提供的 HTTP 访问主要通过 GetMethod 类和 PostMethod 类来实现。它们分别对应于HTT
Java实现一个简单的网络爬虫代码示例
目前市面上流行的爬虫大多是python。经过简单的了解,一些简单的页面的爬虫主要是解析目标页面(html)。然后我在想,java中有没有用户可以轻松解析html页面?我发现一个jsoup包是一个非常方便的解析html的工具。使用方法也很简单,引入jar包:org.jsoup jsoup 1.8.
基于Java的短信验证码api调用代码示例
本文示例分享JAVA短信验证码api调用代码,供大家参考。具体内容如下: import java.io.BufferedReader; 导入 java.io.DataOutputStream; 导入 java.io.IOException; 导入 java.io.InputStream; 导入 java.io.InputStreamReader; 导入 java.io.UnsupportedEncodingException; 进口熟
C#网络爬虫代码分享 C#简单爬虫工具
公司编辑妹需要抓取网页内容,请我帮忙制作一个简单的抓取工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考私有字符串 GetHttpWebRequest(string url) {HttpWebResponse result; string strHTML = string.Empty; 尝试{Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri);
Java网络爬虫连接超时解决示例代码

本文主要研究java网络爬虫连接超时问题,如下。在网络爬虫中,经常会遇到以下错误。即连接超时。对于这个问题,一般的解决办法是:设置连接时间。请求时间设置的较长。如果出现连接超时,请重新请求【设置重新请求的次数】。线程“main”中的异常 .ConnectException: Connection timed out: connect 下面的代码是一个使用httpclient解决连接超时的示例程序。直接上程序。包大
开发基于 Java 的图形用户界面
SWT(Standard Widget Toolkit)是IBM推出的“基于java的”图形界面开发库。我之所以说它是“基于java的”,是指程序员在编写代码时使用java语言。实际上,SWT的底层实现是用C语言完成的。但这些对程序员来说是透明的。当我们使用SWT开发GUI程序时,我们直接使用SWT API来编写。其实很多java代码都是通过JNI去掉C代码来实现的。对于不同的平台的每个类都有不同的实现。这个文章的目的不是描述SWT的设计原理,如果你对这些感兴趣
Java实现爬虫向App提供数据(Jsoup网络爬虫)

一. Demand 最近基于 Material Design 重构了自己的新闻应用。数据源有问题。有前辈分析过知乎daily.Phoenix News等API。根据对应的URL,可以得到新闻的JSON数据。.为了锻炼写代码能力,作者打算自己爬取新闻页面,获取数据搭建API。二.效果图 下图为原网站页面爬虫获取数据并显示在APP移动端三.爬虫思路App实现过程请参考这些文章文章。本文主要讲解如何爬取数据。Android下记录App操作生成Gif动态图的全过程:
Java网络爬虫初学者详细介绍

这是Java网络爬虫系列的第一篇文章。如果不了解Java网络爬虫系列文章,请参考Java网络爬虫基础知识解析。第一篇是关于Java网络爬虫的介绍。内容。本文以采集虎扑列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示: 我们需要提取图中圈出的文字及其对应的链接,在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,一种是另一种是httpclient + 正则表达式方法。这也是Java网络爬虫常用的两种方法。这两种方法你不懂。不管哪条路,都会有对应的
Java网络爬虫基础知识解析

前言说到网络爬虫,大家想到的大概就是Python。当然,爬虫已经是Python的代名词之一,比Java差很多。很多人不知道Java可以用作网络爬虫。其实Java我也可以做网络爬虫,而且做的很好。开源社区中有很多优秀的Java网络爬虫框架,比如webmagic。我的第一份正式工作是使用webmagic编写数据采集程序。当时参与开发了一个舆情分析系统,涉及到很多网站新闻采集,我们用webmagic写了采集程序,因为我们不知道在时间
使用java实现网络爬虫
继上一篇爬虫所需的java知识,本文的目的是实现网络爬虫,获取数据进行分析。----->爬虫实现原理网络爬虫处理网络爬虫的基本技术是data采集的一种方法,在实际项目开发中,数据是通过爬虫来完成的采集一般只有以下几种情况:1)搜索引擎2)竞研3)监控4)行情分析网络爬虫的整体执行过程:1)确定一个(多个)种子网页2)提取数据内容3)连接相关网页中的网页提取 4) 将相关网页中未爬取的内容放入队列 5)从队列中取出一个要爬取的页面,判断之前是否被爬过
java抓取网页内容( GoogleAppEngine中文乱码问题注意在读取中文的网页时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-12-16 02:31
GoogleAppEngine中文乱码问题注意在读取中文的网页时)
// 此处的地址请换成你的,在本地测试时可以填入http://localhost:8888/request.jsp
URL url = new URL("http://2.latest.fatkuns.appspo ... 6quot;);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);// 使用 URL 连接进行输出
connection.setRequestMethod("POST");
// 取得输出流
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream());
// 用UTF-8编码,保证中文传递正常
String message = URLEncoder.encode("你好,I'm Fatkun!", "UTF-8");
// 写入发送的内容
writer.write("msg=" + message);
writer.close();
以上是主要代码。看看评论。它们非常清楚
谷歌应用引擎中文乱码问题
请注意,在阅读中文网页时,使用InputStream类很不方便,因为编码为UTF、GBK、GB2312等。此外,还可能发生错误
我尝试使用InputStream类,然后使用新字符串(bytes[],“UTF-8”)来转换代码,但出现了一个问题。我不知道我是否不能使用它或如何使用它
然而,使用这种书写方式要方便得多
InputStreamReader in=新的InputStreamReader(url.openStream(),“UTF-8”)
无需转换代码~只需指定其代码即可
请注意,此处应添加“UTF-8”。虽然没有在本地测试中添加它不是问题,但在上传到gae时,它不能以中文显示
PS2:UTF-8在这里表示网页的代码。如果您抓取的网页是GB2312,则需要根据实际需要进行更改。附件是我的例子:
源代码在这里:我在Lib目录中删除了它。请自己加 查看全部
java抓取网页内容(
GoogleAppEngine中文乱码问题注意在读取中文的网页时)
// 此处的地址请换成你的,在本地测试时可以填入http://localhost:8888/request.jsp
URL url = new URL("http://2.latest.fatkuns.appspo ... 6quot;);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);// 使用 URL 连接进行输出
connection.setRequestMethod("POST");
// 取得输出流
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream());
// 用UTF-8编码,保证中文传递正常
String message = URLEncoder.encode("你好,I'm Fatkun!", "UTF-8");
// 写入发送的内容
writer.write("msg=" + message);
writer.close();
以上是主要代码。看看评论。它们非常清楚
谷歌应用引擎中文乱码问题
请注意,在阅读中文网页时,使用InputStream类很不方便,因为编码为UTF、GBK、GB2312等。此外,还可能发生错误
我尝试使用InputStream类,然后使用新字符串(bytes[],“UTF-8”)来转换代码,但出现了一个问题。我不知道我是否不能使用它或如何使用它
然而,使用这种书写方式要方便得多
InputStreamReader in=新的InputStreamReader(url.openStream(),“UTF-8”)
无需转换代码~只需指定其代码即可
请注意,此处应添加“UTF-8”。虽然没有在本地测试中添加它不是问题,但在上传到gae时,它不能以中文显示
PS2:UTF-8在这里表示网页的代码。如果您抓取的网页是GB2312,则需要根据实际需要进行更改。附件是我的例子:
源代码在这里:我在Lib目录中删除了它。请自己加
java抓取网页内容(java爬虫网页分析的网站大全和爬虫入门的小技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-14 19:01
java抓取网页内容有两种,一种是通过request对象,一种是通过web.xml对象,根据xml语法不同可以分为三类:文档数据处理(xml):markuplinkentityviewresolver解析xml文档时读取emptybody属性内容并返回,一般在xml内容中用markdown写作解析程序(web):基于groovy语言,通过将程序编译为web.xml格式,一般是类似这样的usercontroller+model组成。
如果api文档较少或是客户端不是依赖web.xml的转发机制,可以使用python编写web.xml支持java的web.xml解析代码,具体请移步web.xml文档介绍可以看看我主页。
微软的w3c文档,也有丰富的java的web.xml相关页面的数据爬取方法。
谢邀!本人从事java语言相关方面的工作,所以查阅了很多的文档和相关资料,目前本人对xml语言和restful数据库的关系没有什么特别的看法,但是本人分享一下相关的java爬虫网页分析的网站大全和爬虫入门的一些小技巧!1.全面了解web技术原理,如http协议,https协议,getpost等协议,规范。
2.根据自己的项目选择对应的java框架,如spring,springmvc,springboot,springcloud等框架是目前主流的是使用的多。了解每个框架的用法和特点。3.根据不同的项目学习数据库,mysql,oracle,msql等数据库。了解其存储机制和使用方法,数据库备份,数据复制,数据库群集配置。
4.了解python,爬虫的底层是python,python读写字符串,python解释器。可以根据python的特点写爬虫代码,并且能爬虫读取xml相关数据和处理html相关数据。这里要说明一下要注意的是,python解释器对字符串内部数据格式是区分为字符串和浮点数的,对应于java是ascii字符串和char字符串的。
如对于java来说,字符串是不能直接获取,所以一定要把中间的转换过程用java代码完成。5.工欲善其事必先利其器,要学习xml相关的中间步骤,zendstream框架,专门用于读取xml文件,并转换为java字符串,主要代码如下:xml->python解析xml,yml转换python解析格式java解析处理包括有form表单。相关文章有很多,可以参考。 查看全部
java抓取网页内容(java爬虫网页分析的网站大全和爬虫入门的小技巧)
java抓取网页内容有两种,一种是通过request对象,一种是通过web.xml对象,根据xml语法不同可以分为三类:文档数据处理(xml):markuplinkentityviewresolver解析xml文档时读取emptybody属性内容并返回,一般在xml内容中用markdown写作解析程序(web):基于groovy语言,通过将程序编译为web.xml格式,一般是类似这样的usercontroller+model组成。
如果api文档较少或是客户端不是依赖web.xml的转发机制,可以使用python编写web.xml支持java的web.xml解析代码,具体请移步web.xml文档介绍可以看看我主页。
微软的w3c文档,也有丰富的java的web.xml相关页面的数据爬取方法。
谢邀!本人从事java语言相关方面的工作,所以查阅了很多的文档和相关资料,目前本人对xml语言和restful数据库的关系没有什么特别的看法,但是本人分享一下相关的java爬虫网页分析的网站大全和爬虫入门的一些小技巧!1.全面了解web技术原理,如http协议,https协议,getpost等协议,规范。
2.根据自己的项目选择对应的java框架,如spring,springmvc,springboot,springcloud等框架是目前主流的是使用的多。了解每个框架的用法和特点。3.根据不同的项目学习数据库,mysql,oracle,msql等数据库。了解其存储机制和使用方法,数据库备份,数据复制,数据库群集配置。
4.了解python,爬虫的底层是python,python读写字符串,python解释器。可以根据python的特点写爬虫代码,并且能爬虫读取xml相关数据和处理html相关数据。这里要说明一下要注意的是,python解释器对字符串内部数据格式是区分为字符串和浮点数的,对应于java是ascii字符串和char字符串的。
如对于java来说,字符串是不能直接获取,所以一定要把中间的转换过程用java代码完成。5.工欲善其事必先利其器,要学习xml相关的中间步骤,zendstream框架,专门用于读取xml文件,并转换为java字符串,主要代码如下:xml->python解析xml,yml转换python解析格式java解析处理包括有form表单。相关文章有很多,可以参考。
java抓取网页内容(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-14 16:37
本文在文章抓取目标网站的链接的基础上,进一步增加难度,抓取目标页面上我们需要的内容并存入数据库。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一篇文章类似。不同的是,这个网站的分类列表太多了。如果不选择这些标签,将花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接去抓取其他页面,只需使用页面底部的所有类型电影的标签来获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是在videoLinkMap集合中保存所有获取到的电影的下载链接,通过遍历这个集合将数据保存到MySQL
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
java抓取网页内容(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
本文在文章抓取目标网站的链接的基础上,进一步增加难度,抓取目标页面上我们需要的内容并存入数据库。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一篇文章类似。不同的是,这个网站的分类列表太多了。如果不选择这些标签,将花费难以想象的时间。

不需要类别链接和标签链接。不要使用这些链接去抓取其他页面,只需使用页面底部的所有类型电影的标签来获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。

最后一步是在videoLinkMap集合中保存所有获取到的电影的下载链接,通过遍历这个集合将数据保存到MySQL
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
java抓取网页内容(我想做一个java网页指定内容的抓取。不知道怎么做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-14 00:05
)
使用htmlparser做java抓取网页的指定内容。. 我想对java网页的指定内容进行爬网。. .
我不知道怎么做,请帮助我,不要太复杂。. .
首先谢谢大家。. 不好意思,这件事拖了2天了,有点着急。. . --------------------编程问答--------------------whocanhelpme。. .
我需要你!!!!
请!--------------------编程问答--------------------使用流阅读网页,然后只输出字符串,(你应该可以处理字符串)然后根据你的目标选择节点--------------------编程问题and Answers------ --------------2楼z740003446的回复:用流读取网页,然后输出为字符串,(应该可以处理字符串),然后根据您的目标节点进行选择
你能不能说得更具体一点,我根本不懂htmlparser ------------编程问答-------------- - - -
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
public class URLUtil {<br />
<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
System.out.println(URLUtil.getHtml("http://www.fastunit.com"));<br />
}<br />
}
--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我只想抢它的标题,我该怎么改?--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我错了,我的意思是我不希望它显示 html 代码,只显示纯文本。. 需要怎么改--------------------编程问答--------------------我只想抓个网站的纯文本标题,和内容。. .
有没有办法实现这一目标。. . 这里的任何人。. . 求助~--------------------编程问答--------------------看API .
使用过滤器过滤标题--------------------编程问答--------------------有任何人~!--------------------编程问答 --------------------引用 yuerzm 8号回复楼层:请参阅下载 API。
使用过滤器过滤标题
我不知道怎么做,新手。. --------------------编程问答 --------------------谁能告诉我更具体的?
你花几十分钟做的事,我可能要花上几十个小时。. . 麻烦大家了~帮帮我--------------------编程问答-------------------- 使用jsoup百度找到相关的API,很容易上手。--------------------编程问答 -------------------- 回复基本没做过一般简单使用常规过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
最好使用 if(t.equals(HTML.Tag.TITLE)) 来获得它。网站 支持。比如csdn,向上看左上角
他的htmltitle写了pos定位或者左右标签定位,不可用。
不要问关于你自己研究的其他问题--------------------编程问答---------------- --- ---------------------编程问答--------------------引用作者的回复13楼的Ollim:基本上一直没抓到回复。一般简单的正则过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
使用 if(t.……
如果我不明白,我必须问。. 你必须在开始之前学习。我现在都很困惑。. --------------------编程问答 -------------------- 为什么没有人。. --------------------编程问答--------------------引用seven_tee 16日的回复楼:怎么没人。.
写下代码给你。
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}
--------------------编程问答--------------------引用dyb19877517号回复floor:引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
解析器...
ReadUrl需要导入什么包?
--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
importorg.htmlparser.Parser;
importorg.htmlparser.beans.StringBean;
importorg.htmlparser.util.ParserException;
importorg.htmlparser.visitors.HtmlPage;--------------------编程问答--------------------引用19楼dyb198775的回复: 引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("……
Stringhtmlcode=ReadUrl.getHtml("");
我这段代码的ReadUrl报错,应该导入什么包?--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
--------------------编程问答--------------------引用7_tee 20号的回复楼:引用19楼dyb198775的回复:
引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.ge……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
补充:Java , Web 开发 查看全部
java抓取网页内容(我想做一个java网页指定内容的抓取。不知道怎么做
)
使用htmlparser做java抓取网页的指定内容。. 我想对java网页的指定内容进行爬网。. .
我不知道怎么做,请帮助我,不要太复杂。. .
首先谢谢大家。. 不好意思,这件事拖了2天了,有点着急。. . --------------------编程问答--------------------whocanhelpme。. .
我需要你!!!!
请!--------------------编程问答--------------------使用流阅读网页,然后只输出字符串,(你应该可以处理字符串)然后根据你的目标选择节点--------------------编程问题and Answers------ --------------2楼z740003446的回复:用流读取网页,然后输出为字符串,(应该可以处理字符串),然后根据您的目标节点进行选择
你能不能说得更具体一点,我根本不懂htmlparser ------------编程问答-------------- - - -
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
public class URLUtil {<br />
<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
System.out.println(URLUtil.getHtml("http://www.fastunit.com";));<br />
}<br />
}
--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我只想抢它的标题,我该怎么改?--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我错了,我的意思是我不希望它显示 html 代码,只显示纯文本。. 需要怎么改--------------------编程问答--------------------我只想抓个网站的纯文本标题,和内容。. .
有没有办法实现这一目标。. . 这里的任何人。. . 求助~--------------------编程问答--------------------看API .
使用过滤器过滤标题--------------------编程问答--------------------有任何人~!--------------------编程问答 --------------------引用 yuerzm 8号回复楼层:请参阅下载 API。
使用过滤器过滤标题
我不知道怎么做,新手。. --------------------编程问答 --------------------谁能告诉我更具体的?
你花几十分钟做的事,我可能要花上几十个小时。. . 麻烦大家了~帮帮我--------------------编程问答-------------------- 使用jsoup百度找到相关的API,很容易上手。--------------------编程问答 -------------------- 回复基本没做过一般简单使用常规过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
最好使用 if(t.equals(HTML.Tag.TITLE)) 来获得它。网站 支持。比如csdn,向上看左上角
他的htmltitle写了pos定位或者左右标签定位,不可用。
不要问关于你自己研究的其他问题--------------------编程问答---------------- --- ---------------------编程问答--------------------引用作者的回复13楼的Ollim:基本上一直没抓到回复。一般简单的正则过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
使用 if(t.……
如果我不明白,我必须问。. 你必须在开始之前学习。我现在都很困惑。. --------------------编程问答 -------------------- 为什么没有人。. --------------------编程问答--------------------引用seven_tee 16日的回复楼:怎么没人。.
写下代码给你。
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}
--------------------编程问答--------------------引用dyb19877517号回复floor:引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
解析器...
ReadUrl需要导入什么包?
--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
importorg.htmlparser.Parser;
importorg.htmlparser.beans.StringBean;
importorg.htmlparser.util.ParserException;
importorg.htmlparser.visitors.HtmlPage;--------------------编程问答--------------------引用19楼dyb198775的回复: 引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("……
Stringhtmlcode=ReadUrl.getHtml("");
我这段代码的ReadUrl报错,应该导入什么包?--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
--------------------编程问答--------------------引用7_tee 20号的回复楼:引用19楼dyb198775的回复:
引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.ge……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
补充:Java , Web 开发
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-10 13:05
<p>java抓取网页内容,可以利用jsp动态servlet页面来传递参数,java基础内容看《深入浅出servlet》。学习python爬虫</a>{{item.getmessage()}}</a>{{item.getmessage()}} 查看全部
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
<p>java抓取网页内容,可以利用jsp动态servlet页面来传递参数,java基础内容看《深入浅出servlet》。学习python爬虫</a>{{item.getmessage()}}</a>{{item.getmessage()}}
java抓取网页内容(pythonjava抓取网页内容教程。网络爬虫中怎么操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-02 13:09
java抓取网页内容教程。在python网络爬虫中怎么操作,即抓取网页,抓取图片,抓取下载文件!!!都有用到,下面是我一天抓取了三个网站的不同网页内容格式,python实现程序内容。
我还可以给你安利一下这个ieeexplore权威图形可视化查询平台。你可以用它在图形浏览器中查看。我就是用这个平台查看自己的代码的。非常方便。
python的话推荐阅读《python网络爬虫开发实战》,因为python本身就是最好的网络爬虫语言,网络爬虫的各种接口都可以使用。
redis2ajax的实践和web集群,
我正在写的自动回复功能pythonapi有兴趣的话可以来围观:)
<p>pythonpandasselenium(某校打招呼的方式是:xxx,pandasselenium() 查看全部
java抓取网页内容(pythonjava抓取网页内容教程。网络爬虫中怎么操作)
java抓取网页内容教程。在python网络爬虫中怎么操作,即抓取网页,抓取图片,抓取下载文件!!!都有用到,下面是我一天抓取了三个网站的不同网页内容格式,python实现程序内容。
我还可以给你安利一下这个ieeexplore权威图形可视化查询平台。你可以用它在图形浏览器中查看。我就是用这个平台查看自己的代码的。非常方便。
python的话推荐阅读《python网络爬虫开发实战》,因为python本身就是最好的网络爬虫语言,网络爬虫的各种接口都可以使用。
redis2ajax的实践和web集群,
我正在写的自动回复功能pythonapi有兴趣的话可以来围观:)
<p>pythonpandasselenium(某校打招呼的方式是:xxx,pandasselenium()
java抓取网页内容(java抓取网页内容的写法参考上面这个帖子也是讲解了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-30 04:04
java抓取网页内容的写法参考上面这个帖子,内容也是讲解了内存泄漏的后果,
list中是否要加上类似int型的map类型的key?如果添加上了那样是否会有很多不必要的无用的内存开销?和string那样的解决方法一样吗?
javakeystore(也可以叫jdk库)里有一个可以做key转换处理的工具(好像这个是命令行cgi方式调用的):keystore|javawebkeycomparisonandtableanalysis具体的pojo中的key替换的生成方法好像在项目里,
-java-default-hash-for-key.html
你的代码如果直接放txt文件中,自然是不会出现泄漏的问题,因为java本身可以提供去除重复值的能力,但是如果你把txt文件拿到服务器去读取,不说java是有命令行去这么操作了,单单说服务器读取也不会出现问题,因为解释器解析文件都是通过命令行解析的,如果命令行的解析有问题,也是读不出来的。java是对原始值进行判断类型转换,而txt和java本身原始值的特性有关,那就涉及到一些gc的问题。
比如对一段文字,字符串转换为newbyte[1024]结果是unsignednull,对txt这类只有1024个字符,还有冒号没有uint长度的文件是可以碰撞的。java的volatile是不支持全局同步的,在不支持全局同步的语言中比如linux系统里非常容易出现作弊行为,如使用内存进行mgsql连接操作然后一系列没用的操作占用了内存而无法释放或者释放了更多内存导致失败等情况。
volatile关键字真的不会比普通对象更安全。如果你写的是中间可重复的代码就另当别论了,比如说web框架中重复注册用户名和密码,这种写法就比较容易出现泄漏。 查看全部
java抓取网页内容(java抓取网页内容的写法参考上面这个帖子也是讲解了)
java抓取网页内容的写法参考上面这个帖子,内容也是讲解了内存泄漏的后果,
list中是否要加上类似int型的map类型的key?如果添加上了那样是否会有很多不必要的无用的内存开销?和string那样的解决方法一样吗?
javakeystore(也可以叫jdk库)里有一个可以做key转换处理的工具(好像这个是命令行cgi方式调用的):keystore|javawebkeycomparisonandtableanalysis具体的pojo中的key替换的生成方法好像在项目里,
-java-default-hash-for-key.html
你的代码如果直接放txt文件中,自然是不会出现泄漏的问题,因为java本身可以提供去除重复值的能力,但是如果你把txt文件拿到服务器去读取,不说java是有命令行去这么操作了,单单说服务器读取也不会出现问题,因为解释器解析文件都是通过命令行解析的,如果命令行的解析有问题,也是读不出来的。java是对原始值进行判断类型转换,而txt和java本身原始值的特性有关,那就涉及到一些gc的问题。
比如对一段文字,字符串转换为newbyte[1024]结果是unsignednull,对txt这类只有1024个字符,还有冒号没有uint长度的文件是可以碰撞的。java的volatile是不支持全局同步的,在不支持全局同步的语言中比如linux系统里非常容易出现作弊行为,如使用内存进行mgsql连接操作然后一系列没用的操作占用了内存而无法释放或者释放了更多内存导致失败等情况。
volatile关键字真的不会比普通对象更安全。如果你写的是中间可重复的代码就另当别论了,比如说web框架中重复注册用户名和密码,这种写法就比较容易出现泄漏。
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-28 20:06
java抓取网页内容到本地excel处理,详细步骤:1.点击f12,输入网址。1.下拉2.找到相应的iframe查看第二步3.对第二步的f12进行excel筛选,只有在lib/excel下才有第三步4.下载excel到本地2.编辑excel文件编辑好的excel文件需要标注分组标识,文件名称,内容形式等!3.保存excel文件在excel中复制粘贴到u盘中备用。
<p>5.excel抓取网页内容数据过程publicstaticfinalstringurl=";id=0";publicstaticvoidmain(string[]args){finalstringdata=newstring("");for(inti=0;i 查看全部
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
java抓取网页内容到本地excel处理,详细步骤:1.点击f12,输入网址。1.下拉2.找到相应的iframe查看第二步3.对第二步的f12进行excel筛选,只有在lib/excel下才有第三步4.下载excel到本地2.编辑excel文件编辑好的excel文件需要标注分组标识,文件名称,内容形式等!3.保存excel文件在excel中复制粘贴到u盘中备用。
<p>5.excel抓取网页内容数据过程publicstaticfinalstringurl=";id=0";publicstaticvoidmain(string[]args){finalstringdata=newstring("");for(inti=0;i
java抓取网页内容(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-27 22:20
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
java抓取网页内容(java实现了一个简单的网页数据)
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
java抓取网页内容(soup库在python中抓取网页信息是怎样的体验?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-11-20 23:08
在标签中,标签的属性是“itemprop”和“articleBody”,可以通过.find()函数访问。
news1=soup.find_all('div',class_=["news-card-content news-right-box"])[0]content=news1.find('div',attrs={'itemprop':"articleBody"}).stringprint(content)Indian Shuttler Ajay Jayaramclinched $50k Dutch Open Grand Prix at Almere in Netherlands on Sunday,becoming the first Indian to win badminton Grand Prix tournament under a newscoring system. Jayaram defeated Indonesia's Ihsan Maulana Mustofa 10-11, 11-6,11-7, 1-11, 11-9 in an exciting final clash. The 27-year-old returned to thecircuit in August after a seven-month injury layoff.
以类似的方式,我们可以提取任何信息,例如图像、作者姓名和时间。
第 3 步:创建数据集
接下来,我们对3个新闻类别实现这个操作,然后将文章的所有对应的内容和类别存储在数据框中。作者将使用三个不同的 URL,对每个 URL 执行相同的步骤,并将所有 文章 及其内容设置类别存储为列表。
urls=["https://inshorts.com/en/read/cricket","https://inshorts.com/en/read/tennis", "https://inshorts.com/en/read/badminton"] news_data_content,news_data_title,news_data_category=[],[],[] for url in urls: category=url.split('/')[-1] data=requests.get(url) soup=BeautifulSoup(data.content,'html.parser') news_title=[] news_content=[] news_category=[] for headline,article inzip(soup.find_all('div', class_=["news-card-titlenews-right-box"]), soup.find_all('div',class_=["news-card-contentnews-right-box"])): news_title.append(headline.find('span',attrs={'itemprop':"headline"}).string) news_content.append(article.find('div',attrs={'itemprop':"articleBody"}).string) news_category.append(category) news_data_title.extend(news_title) news_data_content.extend(news_content) news_data_category.extend(news_category) df1=pd.DataFrame(news_data_title,columns=["Title"]) df2=pd.DataFrame(news_data_content,columns=["Content"]) df3=pd.DataFrame(news_data_category,columns=["Category"]) df=pd.concat([df1,df2,df3],axis=1) df.sample(10)
输出是:
你可以看到在python中使用漂亮的soup库来抓取网络信息是多么容易,你可以轻松地为任何数据科学项目采集有用的数据。从此,带上自己的“眼睛”,快速从网页中提取有价值的信息。
点赞关注 查看全部
java抓取网页内容(soup库在python中抓取网页信息是怎样的体验?)
在标签中,标签的属性是“itemprop”和“articleBody”,可以通过.find()函数访问。
news1=soup.find_all('div',class_=["news-card-content news-right-box"])[0]content=news1.find('div',attrs={'itemprop':"articleBody"}).stringprint(content)Indian Shuttler Ajay Jayaramclinched $50k Dutch Open Grand Prix at Almere in Netherlands on Sunday,becoming the first Indian to win badminton Grand Prix tournament under a newscoring system. Jayaram defeated Indonesia's Ihsan Maulana Mustofa 10-11, 11-6,11-7, 1-11, 11-9 in an exciting final clash. The 27-year-old returned to thecircuit in August after a seven-month injury layoff.
以类似的方式,我们可以提取任何信息,例如图像、作者姓名和时间。
第 3 步:创建数据集
接下来,我们对3个新闻类别实现这个操作,然后将文章的所有对应的内容和类别存储在数据框中。作者将使用三个不同的 URL,对每个 URL 执行相同的步骤,并将所有 文章 及其内容设置类别存储为列表。
urls=["https://inshorts.com/en/read/cricket","https://inshorts.com/en/read/tennis", "https://inshorts.com/en/read/badminton"] news_data_content,news_data_title,news_data_category=[],[],[] for url in urls: category=url.split('/')[-1] data=requests.get(url) soup=BeautifulSoup(data.content,'html.parser') news_title=[] news_content=[] news_category=[] for headline,article inzip(soup.find_all('div', class_=["news-card-titlenews-right-box"]), soup.find_all('div',class_=["news-card-contentnews-right-box"])): news_title.append(headline.find('span',attrs={'itemprop':"headline"}).string) news_content.append(article.find('div',attrs={'itemprop':"articleBody"}).string) news_category.append(category) news_data_title.extend(news_title) news_data_content.extend(news_content) news_data_category.extend(news_category) df1=pd.DataFrame(news_data_title,columns=["Title"]) df2=pd.DataFrame(news_data_content,columns=["Content"]) df3=pd.DataFrame(news_data_category,columns=["Category"]) df=pd.concat([df1,df2,df3],axis=1) df.sample(10)
输出是:

你可以看到在python中使用漂亮的soup库来抓取网络信息是多么容易,你可以轻松地为任何数据科学项目采集有用的数据。从此,带上自己的“眼睛”,快速从网页中提取有价值的信息。

点赞关注
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-14 20:13
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
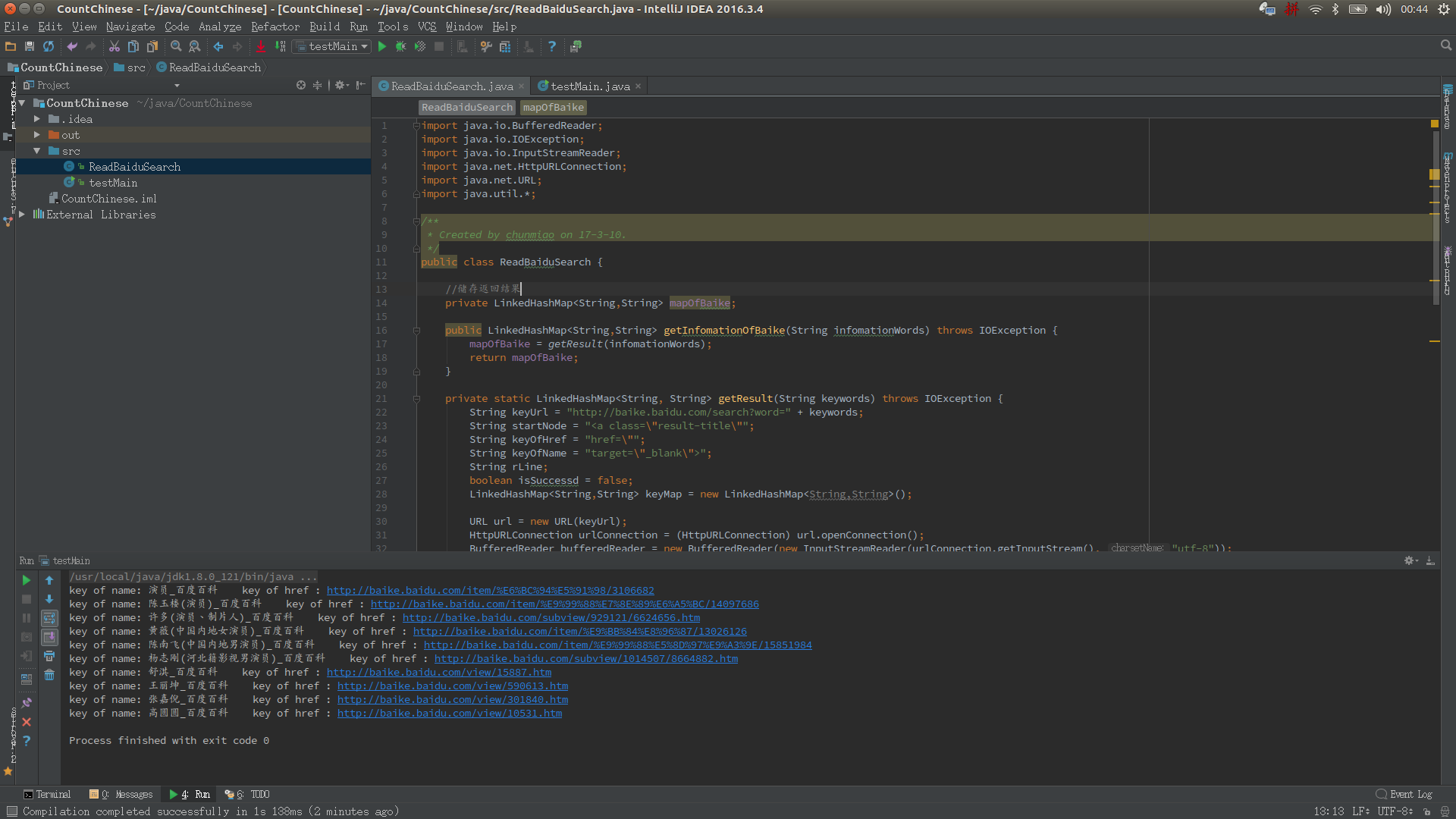
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码


1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页内容(这篇文章主要介绍了JAVA使用爬虫抓取网站网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-11-13 13:08
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。现在分享给大家,给大家参考。跟着小编一起来看看吧。
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?所以我根据自己的想法写了一个简单的爬虫。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有找到的新链接,加入集合中,等待下一次遍历的同时循环.
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。
最后,在整个oldMap还没有遍历完链接之后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.util.LinkedHashMap; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WebCrawlerDemo { public static void main(String[] args) { WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo(); webCrawlerDemo.myPrint("http://www.zifangsky.cn"); } public void myPrint(String baseUrl) { Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历 // 键值对 String oldLinkHost = ""; //host Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn Matcher m = p.matcher(baseUrl); if (m.find()) { oldLinkHost = m.group(); } oldMap.put(baseUrl, false); oldMap = crawlLinks(oldLinkHost, oldMap); for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("链接:" + mapping.getKey()); } } /** * 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 * 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接 * 则表示不能发现新的链接了,任务结束 * * @param oldLinkHost 域名,如:http://www.zifangsky.cn * @param oldMap 待遍历的链接集合 * * @return 返回所有抓取到的链接集合 * */ private Map crawlLinks(String oldLinkHost, Map oldMap) { Map newMap = new LinkedHashMap(); String oldLink = ""; for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("link:" + mapping.getKey() + "--------check:" + mapping.getValue()); // 如果没有被遍历过 if (!mapping.getValue()) { oldLink = mapping.getKey(); // 发起GET请求 try { URL url = new URL(oldLink); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.setRequestMethod("GET"); connection.setConnectTimeout(2000); connection.setReadTimeout(2000); if (connection.getResponseCode() == 200) { InputStream inputStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(inputStream, "UTF-8")); String line = ""; Pattern pattern = Pattern .compile("(.+)</a>"); Matcher matcher = null; while ((line = reader.readLine()) != null) { matcher = pattern.matcher(line); if (matcher.find()) { String newLink = matcher.group(1).trim(); // 链接 // String title = matcher.group(3).trim(); //标题 // 判断获取到的链接是否以http开头 if (!newLink.startsWith("http")) { if (newLink.startsWith("/")) newLink = oldLinkHost + newLink; else newLink = oldLinkHost + "/" + newLink; } //去除链接末尾的 / if(newLink.endsWith("/")) newLink = newLink.substring(0, newLink.length() - 1); //去重,并且丢弃其他网站的链接 if (!oldMap.containsKey(newLink) && !newMap.containsKey(newLink) && newLink.startsWith(oldLinkHost)) { // System.out.println("temp2: " + newLink); newMap.put(newLink, false); } } } } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } oldMap.replace(oldLink, false, true); } } //有新链接,继续遍历 if (!newMap.isEmpty()) { oldMap.putAll(newMap); oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对 } return oldMap; } }
三项最终测试结果
PS:实际递归不是很好,因为如果网站页多的话,程序运行时间长的话内存消耗会很大。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上是Java爬虫在网站上所有链接的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
java抓取网页内容(这篇文章主要介绍了JAVA使用爬虫抓取网站网页内容的方法)
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。现在分享给大家,给大家参考。跟着小编一起来看看吧。
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?所以我根据自己的想法写了一个简单的爬虫。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有找到的新链接,加入集合中,等待下一次遍历的同时循环.
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。
最后,在整个oldMap还没有遍历完链接之后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.util.LinkedHashMap; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WebCrawlerDemo { public static void main(String[] args) { WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo(); webCrawlerDemo.myPrint("http://www.zifangsky.cn";); } public void myPrint(String baseUrl) { Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历 // 键值对 String oldLinkHost = ""; //host Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn Matcher m = p.matcher(baseUrl); if (m.find()) { oldLinkHost = m.group(); } oldMap.put(baseUrl, false); oldMap = crawlLinks(oldLinkHost, oldMap); for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("链接:" + mapping.getKey()); } } /** * 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 * 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接 * 则表示不能发现新的链接了,任务结束 * * @param oldLinkHost 域名,如:http://www.zifangsky.cn * @param oldMap 待遍历的链接集合 * * @return 返回所有抓取到的链接集合 * */ private Map crawlLinks(String oldLinkHost, Map oldMap) { Map newMap = new LinkedHashMap(); String oldLink = ""; for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("link:" + mapping.getKey() + "--------check:" + mapping.getValue()); // 如果没有被遍历过 if (!mapping.getValue()) { oldLink = mapping.getKey(); // 发起GET请求 try { URL url = new URL(oldLink); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.setRequestMethod("GET"); connection.setConnectTimeout(2000); connection.setReadTimeout(2000); if (connection.getResponseCode() == 200) { InputStream inputStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(inputStream, "UTF-8")); String line = ""; Pattern pattern = Pattern .compile("(.+)</a>"); Matcher matcher = null; while ((line = reader.readLine()) != null) { matcher = pattern.matcher(line); if (matcher.find()) { String newLink = matcher.group(1).trim(); // 链接 // String title = matcher.group(3).trim(); //标题 // 判断获取到的链接是否以http开头 if (!newLink.startsWith("http")) { if (newLink.startsWith("/")) newLink = oldLinkHost + newLink; else newLink = oldLinkHost + "/" + newLink; } //去除链接末尾的 / if(newLink.endsWith("/")) newLink = newLink.substring(0, newLink.length() - 1); //去重,并且丢弃其他网站的链接 if (!oldMap.containsKey(newLink) && !newMap.containsKey(newLink) && newLink.startsWith(oldLinkHost)) { // System.out.println("temp2: " + newLink); newMap.put(newLink, false); } } } } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } oldMap.replace(oldLink, false, true); } } //有新链接,继续遍历 if (!newMap.isEmpty()) { oldMap.putAll(newMap); oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对 } return oldMap; } }
三项最终测试结果

PS:实际递归不是很好,因为如果网站页多的话,程序运行时间长的话内存消耗会很大。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上是Java爬虫在网站上所有链接的详细内容。更多详情请关注html中文网站其他相关文章!
java抓取网页内容(java利用url实现网页内容抓取的相关内容吗,zangcunmiao在本文为您仔细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-13 01:00
想知道java使用url实现网页内容爬取的相关内容吗?在本文中,藏村淼将仔细讲解java实现网页内容抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先重点介绍:java实现网页数据抓取,java实现网页内容抓取,url抓取工具,一起来学习。
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
相关文章 查看全部
java抓取网页内容(java利用url实现网页内容抓取的相关内容吗,zangcunmiao在本文为您仔细讲解)
想知道java使用url实现网页内容爬取的相关内容吗?在本文中,藏村淼将仔细讲解java实现网页内容抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先重点介绍:java实现网页数据抓取,java实现网页内容抓取,url抓取工具,一起来学习。
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
相关文章
java抓取网页内容(用到抓取网页数据的功能:抓取数据功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-11 13:14
经常用到抓取网页数据的功能。我在以前的工作中使用过它。我今天总结了一下:
1、 通过指定的 URL 抓取网页数据获取页面信息,然后用 DOM 对页面进行 NODE 分析,处理得到原创的 HTML 数据,这样做的好处是处理的灵活性有一定的块数据高 难点在于切块算法的优化。当页面HTML信息量较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于html页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode、Tag来描述HTML页面的元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需要,映射HTML标签,可以方便的获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java的html解析库,不依赖其他java库文件,主要用于转换或提取html。可以超高速解析html,不会出错。最新版本的 htmlparser 现在是 2.0。可以毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性和性能(包括htmlunit和nekohtml)方面比htmlparser有更好的口碑,nokehtml类似xml解析原理,html标签正确解析为dom 它们对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是一个 Java 语言的 HTML 扫描器和标签平衡器,它使程序能够解析 HTML 文档并使用标准的 XML 接口来访问其中的信息。这个解析器可以扫描 HTML 文件并“纠正”作者(人或机器)在编写 HTML 文档过程中经常犯的许多错误。
NekoHTML 可以添加缺失的父元素,自动关闭带有结束标签的对应元素,以及不匹配的内联元素标签。 NekoHTML 的开发使用 XercesNativeInterface (XNI),它是 Xerces2 的基础。 查看全部
java抓取网页内容(用到抓取网页数据的功能:抓取数据功能详解)
经常用到抓取网页数据的功能。我在以前的工作中使用过它。我今天总结了一下:
1、 通过指定的 URL 抓取网页数据获取页面信息,然后用 DOM 对页面进行 NODE 分析,处理得到原创的 HTML 数据,这样做的好处是处理的灵活性有一定的块数据高 难点在于切块算法的优化。当页面HTML信息量较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于html页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode、Tag来描述HTML页面的元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需要,映射HTML标签,可以方便的获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java的html解析库,不依赖其他java库文件,主要用于转换或提取html。可以超高速解析html,不会出错。最新版本的 htmlparser 现在是 2.0。可以毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性和性能(包括htmlunit和nekohtml)方面比htmlparser有更好的口碑,nokehtml类似xml解析原理,html标签正确解析为dom 它们对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是一个 Java 语言的 HTML 扫描器和标签平衡器,它使程序能够解析 HTML 文档并使用标准的 XML 接口来访问其中的信息。这个解析器可以扫描 HTML 文件并“纠正”作者(人或机器)在编写 HTML 文档过程中经常犯的许多错误。
NekoHTML 可以添加缺失的父元素,自动关闭带有结束标签的对应元素,以及不匹配的内联元素标签。 NekoHTML 的开发使用 XercesNativeInterface (XNI),它是 Xerces2 的基础。
java抓取网页内容(爬虫技术可以爬取什么数据?网页数据采集工具哪个好用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-08 10:05
爬虫技术可以抓取哪些数据?
简而言之,爬虫就是一个检测机器。它的基本操作是模拟人类行为,在各种网站中走动,点击按钮,查看数据,或者背诵你看到的信息。这就像一只虫子不知疲倦地在建筑物周围爬行。
因此,爬虫系统有两个功能:
爬虫数据。比如你想知道1000件商品在不同电商网站上的价格,以便得到最低价。手动打开页面太慢,这些网站不断更新价格。可以使用爬虫系统,设置逻辑,帮你从n个网站中抓取想要的商品价格,甚至同时进行比较计算,最后输出报告给你,哪个网站最便宜.
市场上有许多零代码免费爬虫系统。比如为了捕捉不同网站上的两个游戏虚拟物品的差异,我之前用过,很简单。这里没有名字。涉嫌广告。
点击爬虫系统的按钮类似于12306的票务软件,通过n个ID不断访问和触发页面动作。但是正规的还是不错的网站,有反爬虫技术,比如最常见的验证码。
最后,爬虫系统无处不在。你最熟悉的爬虫系统可能是百度。像百度这样的搜索引擎爬虫每隔几天就会扫描整个网页供您查看。
网站数据采集 哪个工具好用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一键移除,支持自动翻页和数据导出功能,对于小白来说,易学易掌握:
这是一款非常不错的国产数据采集软件。比起优采云采集器,比如Octopus的采集器目前只支持windows平台,需要手动设置采集字段和配置规则,比较麻烦和灵活。内置海量数据采集模板,方便采集京东、天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,还有很多其他的软件也支持网站data采集,比如号码、应用策略等也很不错,如果你熟悉使用Python、Java等编程语言,也可以自己编程抓取数据。网上有相关的教程和资料。介绍很详细。有兴趣的可以搜索一下。希望以上分享的内容对您有所帮助。欢迎评论和评论。
java和python在爬取方面的优缺点是什么?
Python
强大的网络功能,模拟登录,解析JavaScript。缺点是网页分析用Python写程序很方便。著名的Python爬虫有scratch等。
爪哇
Java中有很多解析器,对解析网页的支持非常好。缺点是网上有很多Java开源爬虫,比如nutch。国内有优秀的webmagicjava解析器,比如Htmlparser和jsoup,可以满足Java和python的一般需求。如果需要模拟登录和反采集,选择python更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,可以选择Java。
java爬虫会抓取数据吗?
如何通过Java代码实现网页数据的指定爬取,我总结了以下几个步骤会用到Jsoup。Jar打包: 1.将Jsoup.jar文件包导入到项目中 2:获取URL指定的HTML或文档指定的文本 3:获取网页中超链接的标题和链接 4:获取内容指定博客的文章 5:获取网页结果中的超链接Title和link 查看全部
java抓取网页内容(爬虫技术可以爬取什么数据?网页数据采集工具哪个好用)
爬虫技术可以抓取哪些数据?
简而言之,爬虫就是一个检测机器。它的基本操作是模拟人类行为,在各种网站中走动,点击按钮,查看数据,或者背诵你看到的信息。这就像一只虫子不知疲倦地在建筑物周围爬行。
因此,爬虫系统有两个功能:
爬虫数据。比如你想知道1000件商品在不同电商网站上的价格,以便得到最低价。手动打开页面太慢,这些网站不断更新价格。可以使用爬虫系统,设置逻辑,帮你从n个网站中抓取想要的商品价格,甚至同时进行比较计算,最后输出报告给你,哪个网站最便宜.
市场上有许多零代码免费爬虫系统。比如为了捕捉不同网站上的两个游戏虚拟物品的差异,我之前用过,很简单。这里没有名字。涉嫌广告。
点击爬虫系统的按钮类似于12306的票务软件,通过n个ID不断访问和触发页面动作。但是正规的还是不错的网站,有反爬虫技术,比如最常见的验证码。
最后,爬虫系统无处不在。你最熟悉的爬虫系统可能是百度。像百度这样的搜索引擎爬虫每隔几天就会扫描整个网页供您查看。
网站数据采集 哪个工具好用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一键移除,支持自动翻页和数据导出功能,对于小白来说,易学易掌握:
这是一款非常不错的国产数据采集软件。比起优采云采集器,比如Octopus的采集器目前只支持windows平台,需要手动设置采集字段和配置规则,比较麻烦和灵活。内置海量数据采集模板,方便采集京东、天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,还有很多其他的软件也支持网站data采集,比如号码、应用策略等也很不错,如果你熟悉使用Python、Java等编程语言,也可以自己编程抓取数据。网上有相关的教程和资料。介绍很详细。有兴趣的可以搜索一下。希望以上分享的内容对您有所帮助。欢迎评论和评论。
java和python在爬取方面的优缺点是什么?
Python
强大的网络功能,模拟登录,解析JavaScript。缺点是网页分析用Python写程序很方便。著名的Python爬虫有scratch等。
爪哇
Java中有很多解析器,对解析网页的支持非常好。缺点是网上有很多Java开源爬虫,比如nutch。国内有优秀的webmagicjava解析器,比如Htmlparser和jsoup,可以满足Java和python的一般需求。如果需要模拟登录和反采集,选择python更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,可以选择Java。
java爬虫会抓取数据吗?
如何通过Java代码实现网页数据的指定爬取,我总结了以下几个步骤会用到Jsoup。Jar打包: 1.将Jsoup.jar文件包导入到项目中 2:获取URL指定的HTML或文档指定的文本 3:获取网页中超链接的标题和链接 4:获取内容指定博客的文章 5:获取网页结果中的超链接Title和link
java抓取网页内容( Java爬虫爬取网页内容网页内容方法:用apache提供的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-11-08 10:03
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则抓取网页上的信息,通常是在抓取一些网址之后,然后将这些网址放入队列中,反复搜索。
2、Java爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
3、Java爬虫抓取网页内容方法:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。大家可以用代码来使用~ 更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。) 查看全部
java抓取网页内容(
Java爬虫爬取网页内容网页内容方法:用apache提供的包)

1、网络爬虫
按照一定的规则抓取网页上的信息,通常是在抓取一些网址之后,然后将这些网址放入队列中,反复搜索。
2、Java爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
3、Java爬虫抓取网页内容方法:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。大家可以用代码来使用~ 更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。)
java抓取网页内容(一个XML元素解析及使用方法-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-07 22:02
(.*?).*?]]>.*?:(.*?)]]>]]>]]>XML 规则:1. 必须定义一个处理程序元素,并且必须至少有一个处理程序元素被包括在内。2.processer 元素收录了所有的流程元素,流程元素定义了页面代码的所有处理流程。3.流程元素包括流、表和字段3个属性。flow 代表流量。即把这个流程元素解析出来的内容作为下一步的内容或者回滚未解析之前的内容。当该值为真时,本步骤的加工结果作为下一步加工的材料,本步骤的加工结果不存入数据库。当值为false时,本步骤的结果仅用于本步骤。下一个分析回滚到本步骤分析之前的内容。table属性定义了本步骤处理结果中要存放的数据库表,fidld属性定义了对应表中的字段。4. 每个进程都必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。
key是指要获取的标签的属性,包括name、id、class等,当然也支持width、href、target等其他属性,支持所有标准的html属性。value 是指这个属性的值。textonly 是指是否只获取该标签内的文本内容。它不包括标签。6.regex-filter 是指正则过滤,获取符合正则表达式的内容。请注意,正则表达式必须放在 CDATA 块中。另外,要获取的内容必须用()括起来,只会获取()中的内容。7.flag-filter 是指标志位过滤,获取2个标志位之间的内容。用户必须确保开头和结尾的标志是唯一的。只有这样,您才能确保得到您想要的东西。获取标志位需要用户查看源码,获取唯一标志。标志过滤是目前主流爬虫工具提供的最常用的方法。解析过程:1.首先获取所有的处理过程2.依次执行。确定流程类型的流程属性,根据流程属性调用不同的处理方法。当为真时,将其剪切,当为假时,将进行分析并保存。3. 根据流属性进入正式分析,判断分析元素过滤器的类型,是target-filter,还是regex-filter还是flag-filter,根据不同的分析调用不同的分析流程类型。
解析过程参考 XML 规则。4.所有进程执行完毕后,系统将所有采集到的字段保存到数据库中。案例抓取javaeye博客内容 本例演示了如何抓取javaeye上的博客文章。博客地址。在爬取之前,我们需要创建一个数据库和表,只需导入示例中使用的数据库表。Step 1:目标定义首先分析页面HashMap、Hashtable、HashSet上文章链接的写法的区别。IE下ZOOM属性导致的渲染问题。Web2.0网站 性能调优 通过这些链接的共同点练习,我们可以很容易的找到它的文章链接的规则,得到这样的正则表达式:href\=\ '(/blog/\d*)\' 注意,我们要得到的只是一个类似于/blog/179642的链接,并没有收录href=之类的东西,所以我们在正则中匹配/blog/179642的部分加上(),系统会自动获取this() 内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。
我们先剪个,把不相关的内容剪掉。我们将流程定义为true,它会返回修剪后的内容。然后我们抓取页眉的标题作为我们保存到数据库中的标题。由于它的复杂性,我们使用正则表达式来获取.*(.*?).*?]]>我们想要获取的部分只是 text ,不需要 HTML 标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。记住:如果你要抓取的内容在两个唯一字符串的中间,那么使用flag方法是最好最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。
.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。请记住:如果您要抓取的内容位于两个唯一字符串的中间,那么使用 flag 方法是最好且最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。 查看全部
java抓取网页内容(一个XML元素解析及使用方法-上海怡健医学())
(.*?).*?]]>.*?:(.*?)]]>]]>]]>XML 规则:1. 必须定义一个处理程序元素,并且必须至少有一个处理程序元素被包括在内。2.processer 元素收录了所有的流程元素,流程元素定义了页面代码的所有处理流程。3.流程元素包括流、表和字段3个属性。flow 代表流量。即把这个流程元素解析出来的内容作为下一步的内容或者回滚未解析之前的内容。当该值为真时,本步骤的加工结果作为下一步加工的材料,本步骤的加工结果不存入数据库。当值为false时,本步骤的结果仅用于本步骤。下一个分析回滚到本步骤分析之前的内容。table属性定义了本步骤处理结果中要存放的数据库表,fidld属性定义了对应表中的字段。4. 每个进程都必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。
key是指要获取的标签的属性,包括name、id、class等,当然也支持width、href、target等其他属性,支持所有标准的html属性。value 是指这个属性的值。textonly 是指是否只获取该标签内的文本内容。它不包括标签。6.regex-filter 是指正则过滤,获取符合正则表达式的内容。请注意,正则表达式必须放在 CDATA 块中。另外,要获取的内容必须用()括起来,只会获取()中的内容。7.flag-filter 是指标志位过滤,获取2个标志位之间的内容。用户必须确保开头和结尾的标志是唯一的。只有这样,您才能确保得到您想要的东西。获取标志位需要用户查看源码,获取唯一标志。标志过滤是目前主流爬虫工具提供的最常用的方法。解析过程:1.首先获取所有的处理过程2.依次执行。确定流程类型的流程属性,根据流程属性调用不同的处理方法。当为真时,将其剪切,当为假时,将进行分析并保存。3. 根据流属性进入正式分析,判断分析元素过滤器的类型,是target-filter,还是regex-filter还是flag-filter,根据不同的分析调用不同的分析流程类型。
解析过程参考 XML 规则。4.所有进程执行完毕后,系统将所有采集到的字段保存到数据库中。案例抓取javaeye博客内容 本例演示了如何抓取javaeye上的博客文章。博客地址。在爬取之前,我们需要创建一个数据库和表,只需导入示例中使用的数据库表。Step 1:目标定义首先分析页面HashMap、Hashtable、HashSet上文章链接的写法的区别。IE下ZOOM属性导致的渲染问题。Web2.0网站 性能调优 通过这些链接的共同点练习,我们可以很容易的找到它的文章链接的规则,得到这样的正则表达式:href\=\ '(/blog/\d*)\' 注意,我们要得到的只是一个类似于/blog/179642的链接,并没有收录href=之类的东西,所以我们在正则中匹配/blog/179642的部分加上(),系统会自动获取this() 内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。
我们先剪个,把不相关的内容剪掉。我们将流程定义为true,它会返回修剪后的内容。然后我们抓取页眉的标题作为我们保存到数据库中的标题。由于它的复杂性,我们使用正则表达式来获取.*(.*?).*?]]>我们想要获取的部分只是 text ,不需要 HTML 标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。记住:如果你要抓取的内容在两个唯一字符串的中间,那么使用flag方法是最好最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。
.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。请记住:如果您要抓取的内容位于两个唯一字符串的中间,那么使用 flag 方法是最好且最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。
java抓取网页内容(java抓取网页内容的套路-mysql.0的创建方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-07 09:10
java抓取网页内容的套路,实现一套自动化工具,目的是更好更方便的去监控网页的工作流程。业务场景需求:用户打开同一个页面不同的图片不同色彩色彩不同图片后可以回调别的画面信息需要有地理位置、色彩、声音等。目前采用的java版本:java7.0,java8。数据库版本:mysql基础代码:首先我们来定义一个整体数据库和java类文件的创建方法:javadataframe结构-faj8dkplj-博客园第一步,我们先搭建一个服务器(server)。
我们的要求是服务器具有3g的内存,8g的cpu,32g的内存,2个ssd硬盘,1个macbookair(256g硬盘)。第二步,我们来定义一个javaapi,这个api继承自java.util.java.arraylist,这个api提供了java.util.java.arraylist,java.util.java.arraylist的api用于给arraylist的操作提供操作方法。
api采用有序插入list集合,也就是任何数组集合的元素都需要放到集合中,并且每个元素都有重复的元素。在java.util.arraylist中的元素是可以通过iterator迭代的。javastringj="1234567890";iteratoriter=arrays.stream(j);hashmaphashmap=newhashmap();stringhash="(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,58..)";//我们先定义一个字符串的规则//字符串规则,把我们定义的规则存到一个字符串integer中,不管两个字符串是多么相似,只要第三个字符为空,我们的字符串都返回为空//(如果没有,强制为空integer[]a=initialize("1234567890");if((a=a.isempty())!=null){thrownewillegalargumentexception("");}其实就是一个遍历字符串,判断为空,然后给出自定义函数的思想,比如我们定义一个循环字符串,遍历字符串..遍历字符串..循环字符串..遍历字符串..遍历字符串..遍历字符串..循环字符串..最后返回结果"1234567890"。
//即使多列//比如:我们要从空字符串中去出a,b,c;d.f(x);e.g(x);if(""!=""){b="";x=d;}thrownewillegalargumentexception("");if(ite。 查看全部
java抓取网页内容(java抓取网页内容的套路-mysql.0的创建方法)
java抓取网页内容的套路,实现一套自动化工具,目的是更好更方便的去监控网页的工作流程。业务场景需求:用户打开同一个页面不同的图片不同色彩色彩不同图片后可以回调别的画面信息需要有地理位置、色彩、声音等。目前采用的java版本:java7.0,java8。数据库版本:mysql基础代码:首先我们来定义一个整体数据库和java类文件的创建方法:javadataframe结构-faj8dkplj-博客园第一步,我们先搭建一个服务器(server)。
我们的要求是服务器具有3g的内存,8g的cpu,32g的内存,2个ssd硬盘,1个macbookair(256g硬盘)。第二步,我们来定义一个javaapi,这个api继承自java.util.java.arraylist,这个api提供了java.util.java.arraylist,java.util.java.arraylist的api用于给arraylist的操作提供操作方法。
api采用有序插入list集合,也就是任何数组集合的元素都需要放到集合中,并且每个元素都有重复的元素。在java.util.arraylist中的元素是可以通过iterator迭代的。javastringj="1234567890";iteratoriter=arrays.stream(j);hashmaphashmap=newhashmap();stringhash="(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,58..)";//我们先定义一个字符串的规则//字符串规则,把我们定义的规则存到一个字符串integer中,不管两个字符串是多么相似,只要第三个字符为空,我们的字符串都返回为空//(如果没有,强制为空integer[]a=initialize("1234567890");if((a=a.isempty())!=null){thrownewillegalargumentexception("");}其实就是一个遍历字符串,判断为空,然后给出自定义函数的思想,比如我们定义一个循环字符串,遍历字符串..遍历字符串..循环字符串..遍历字符串..遍历字符串..遍历字符串..循环字符串..最后返回结果"1234567890"。
//即使多列//比如:我们要从空字符串中去出a,b,c;d.f(x);e.g(x);if(""!=""){b="";x=d;}thrownewillegalargumentexception("");if(ite。
java抓取网页内容( 点赞再看,养成习惯(一)网页提取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-21 17:06
点赞再看,养成习惯(一)网页提取框架)
喜欢再看,养成习惯
大家好,我叫Labrami,今天更新了文章,带来了很干的干货。
前言
说起爬虫爬取网页数据,相信大家的第一反应都是python。Python 确实很适合这一点,但是许多具有多年经验的 Java 开发人员不一定知道它。其实Java也可以作为爬虫使用。最著名的是Jsoup网页提取框架。
结婚了
多年前,我做了一个贵金属信息类型网站。我需要实时显示各个交易所的最新黄金和白银价格。当时有第三方API接口服务商提供此类数据。你需要付钱。后来百度去Jsoup抓取网页的数据,然后找了个大网站根据它抓取数据,然后自己把表格展示在页面上,省了一大笔钱。
昨晚心血来潮,想写一篇文章的文章,于是去官网看了一下,决定给优采云找个房间
Jsoup食用指南
Jsoup真的很简单,简单到不想介绍开发过程,直接看官网,十分钟搞定它的API。
官网有介绍指南和例子,大家自己去看看吧。
官网地址:/
干货
对于干货部分,我会用实战的方式来详细讲解。相信通过这个实战例子,大家可以轻松掌握技术。
1、准备要爬取的网页
优采云找房子-深圳站-新房:/loupan/pg
2、新的Maven项目
3、pom 文件添加依赖
com.google.guava
guava
30.0-jre
org.projectlombok
lombok
1.18.18
org.jsoup
jsoup
1.14.3
com.alibaba
easyexcel
2.2.10
复制代码
4、创建一个Pojo类将数据映射到excel表
因为从网页抓取的地址最后会保存在excel文件中,我们使用阿里巴巴的EasyExcel,所以需要在pom文件中引入依赖,并且需要创建一个pojo类来映射导出的文件。
@Data
@Accessors(chain = true)
public class House {
@ExcelProperty("楼盘名称")
private String title;
@ExcelProperty("访问网页")
private String detailPageUrl;
@ExcelProperty("楼盘图片")
private String imageUrl;
@ExcelProperty("所在地址")
private String address;
@ExcelProperty("户型")
private String houseType;
@ExcelProperty("房产类型")
private String propertyType;
@ExcelProperty("状态")
private String status;
@ExcelProperty("建筑面积")
private String buildingArea;
@ExcelProperty("总价")
private String totalPrice;
@ExcelProperty("单价(元/㎡(均价))")
private String singlePrice;
@ExcelProperty("标签")
private String tag;
}
复制代码
5、Main方法执行业务代码
这里有几点需要注意:
优采云短时间频繁访问同一个ip会触发人机验证,所以每次分页执行我们都需要让线程休眠一段时间。Jsoup 抓取 html 元素。如果优采云的网页有改动,程序可能无法正常抓取数据。程序不抓取楼盘详细信息,感兴趣的同学可以根据抓取到的详情页url进行二次开发。如果你要抓取的网站需要登录信息等特殊请求参数,Jsoup也支持设置,具体请参考官网API。
@SneakyThrows
public static void main(String[] args) {
AtomicInteger pageIndex = new AtomicInteger(1);
int pageSize = 10;
List dataList = Lists.newArrayList();
// 贝壳找房深圳区域网址
String beikeUrl = "https://sz.fang.ke.com";
// 贝壳找房深圳市楼盘展示页地址
String loupanUrl = "https://sz.fang.ke.com/loupan/pg";
// 用Jsoup抓取该地址完整网页信息
Document doc = Jsoup.connect(loupanUrl + pageIndex.get()).get();
// 网页标题
String pageTitle = doc.title();
// 分页容器
Element pageContainer = doc.select("div.page-box").first();
if (pageContainer == null) {
return;
}
// 楼盘总数
int totalCount = Integer.parseInt(pageContainer.attr("data-total-count"));
// 分页执行
for (int i = 0; i < totalCount / pageSize; i++) {
log.info("running get data, the current page is {}", pageIndex.get());
// 贝壳网有人机认证,不能短时间频繁访问,每次翻页都让线程休眠10s
Thread.sleep(10000);
doc = Jsoup.connect(loupanUrl + pageIndex.getAndIncrement()).get();
// 获取楼盘列表的ul元素
Element list = doc.select("ul.resblock-list-wrapper").first();
if (list == null) {
continue;
}
// 获取楼盘列表的li元素
Elements elements = list.select("li.resblock-list");
elements.forEach(el -> {
// 楼盘介绍
Element introduce = el.child(0);
// 详情页面
String detailPageUrl = beikeUrl + introduce.attr("href");
// 楼盘图片
String imageUrl = introduce.select("img").attr("data-original");
// 楼盘详情
Element childDesc = el.select("div.resblock-desc-wrapper").first();
Element childName = childDesc.child(0);
// 楼盘名称
String title = childName.child(0).text();
// 楼盘在售状态
String status = childName.child(1).text();
// 产权类型
String propertyType = childName.child(2).text();
// 楼盘所在地址
String address = childDesc.child(1).text();
// 房间属性
Element room = childDesc.child(2);
// 户型
String houseType = "";
// 户型集合
Elements houseTypeSpans = room.getElementsByTag("span");
if (CollectionUtils.isNotEmpty(houseTypeSpans)) {
// 剔除文案:【户型:】
houseTypeSpans.remove(0);
// 剔除文案:【建面:xxx】
houseTypeSpans.remove(houseTypeSpans.size() - 1);
houseType = StringUtil.join(houseTypeSpans.stream().map(Element::text).collect(Collectors.toList()), "/");
}
// 建筑面积
String buildingArea = room.select("span.area").text();
// div - 标签
Element descTag = childDesc.select("div.resblock-tag").first();
Elements tagSpans = descTag.getElementsByTag("span");
String tag = "";
if (CollectionUtils.isNotEmpty(tagSpans)) {
tag = StringUtil.join(tagSpans.stream().map(Element::text).collect(Collectors.toList()), " ");
}
// div - 价格
Element descPrice = childDesc.select("div.resblock-price").first();
String singlePrice = descPrice.select("span.number").text();
String totalPrice = descPrice.select("div.second").text();
dataList.add(new House().setTitle(title)
.setDetailPageUrl(detailPageUrl)
.setImageUrl(imageUrl)
.setSinglePrice(singlePrice)
.setTotalPrice(totalPrice)
.setStatus(status)
.setPropertyType(propertyType)
.setAddress(address)
.setHouseType(houseType)
.setBuildingArea(buildingArea)
.setTag(tag)
);
});
}
if (CollectionUtils.isEmpty(dataList)) {
log.info("dataList is empty returned.");
return;
}
log.info("dataList prepare finished, size = {}", dataList.size());
// 调用导出逻辑,将数据导出到excel文件
export(pageTitle, dataList);
}
复制代码
6、EasyExcel 导出逻辑
/**
* 将爬取的数据写入到excel中
* @param pageTitle
* @param dataList
*/
private static void export(String pageTitle, List dataList) {
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
//设置头居中
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//内容策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
//设置 水平居中
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
HorizontalCellStyleStrategy horizontalCellStyleStrategy = new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
// 这里需要设置不关闭流
EasyExcelFactory.write("D:\深圳楼盘汇总.xlsx", House.class).autoCloseStream(Boolean.FALSE).registerWriteHandler(horizontalCellStyleStrategy).sheet(pageTitle).doWrite(dataList);
}
复制代码
7、成就展示
有兴趣的朋友可以自己尝试一下!
源代码:GitHub
原创不容易,请多多点赞,非常感谢! 查看全部
java抓取网页内容(
点赞再看,养成习惯(一)网页提取框架)
喜欢再看,养成习惯
大家好,我叫Labrami,今天更新了文章,带来了很干的干货。
前言
说起爬虫爬取网页数据,相信大家的第一反应都是python。Python 确实很适合这一点,但是许多具有多年经验的 Java 开发人员不一定知道它。其实Java也可以作为爬虫使用。最著名的是Jsoup网页提取框架。
结婚了
多年前,我做了一个贵金属信息类型网站。我需要实时显示各个交易所的最新黄金和白银价格。当时有第三方API接口服务商提供此类数据。你需要付钱。后来百度去Jsoup抓取网页的数据,然后找了个大网站根据它抓取数据,然后自己把表格展示在页面上,省了一大笔钱。
昨晚心血来潮,想写一篇文章的文章,于是去官网看了一下,决定给优采云找个房间
Jsoup食用指南
Jsoup真的很简单,简单到不想介绍开发过程,直接看官网,十分钟搞定它的API。
官网有介绍指南和例子,大家自己去看看吧。
官网地址:/
干货
对于干货部分,我会用实战的方式来详细讲解。相信通过这个实战例子,大家可以轻松掌握技术。
1、准备要爬取的网页
优采云找房子-深圳站-新房:/loupan/pg
2、新的Maven项目
3、pom 文件添加依赖
com.google.guava
guava
30.0-jre
org.projectlombok
lombok
1.18.18
org.jsoup
jsoup
1.14.3
com.alibaba
easyexcel
2.2.10
复制代码
4、创建一个Pojo类将数据映射到excel表
因为从网页抓取的地址最后会保存在excel文件中,我们使用阿里巴巴的EasyExcel,所以需要在pom文件中引入依赖,并且需要创建一个pojo类来映射导出的文件。
@Data
@Accessors(chain = true)
public class House {
@ExcelProperty("楼盘名称")
private String title;
@ExcelProperty("访问网页")
private String detailPageUrl;
@ExcelProperty("楼盘图片")
private String imageUrl;
@ExcelProperty("所在地址")
private String address;
@ExcelProperty("户型")
private String houseType;
@ExcelProperty("房产类型")
private String propertyType;
@ExcelProperty("状态")
private String status;
@ExcelProperty("建筑面积")
private String buildingArea;
@ExcelProperty("总价")
private String totalPrice;
@ExcelProperty("单价(元/㎡(均价))")
private String singlePrice;
@ExcelProperty("标签")
private String tag;
}
复制代码
5、Main方法执行业务代码
这里有几点需要注意:
优采云短时间频繁访问同一个ip会触发人机验证,所以每次分页执行我们都需要让线程休眠一段时间。Jsoup 抓取 html 元素。如果优采云的网页有改动,程序可能无法正常抓取数据。程序不抓取楼盘详细信息,感兴趣的同学可以根据抓取到的详情页url进行二次开发。如果你要抓取的网站需要登录信息等特殊请求参数,Jsoup也支持设置,具体请参考官网API。
@SneakyThrows
public static void main(String[] args) {
AtomicInteger pageIndex = new AtomicInteger(1);
int pageSize = 10;
List dataList = Lists.newArrayList();
// 贝壳找房深圳区域网址
String beikeUrl = "https://sz.fang.ke.com";
// 贝壳找房深圳市楼盘展示页地址
String loupanUrl = "https://sz.fang.ke.com/loupan/pg";
// 用Jsoup抓取该地址完整网页信息
Document doc = Jsoup.connect(loupanUrl + pageIndex.get()).get();
// 网页标题
String pageTitle = doc.title();
// 分页容器
Element pageContainer = doc.select("div.page-box").first();
if (pageContainer == null) {
return;
}
// 楼盘总数
int totalCount = Integer.parseInt(pageContainer.attr("data-total-count"));
// 分页执行
for (int i = 0; i < totalCount / pageSize; i++) {
log.info("running get data, the current page is {}", pageIndex.get());
// 贝壳网有人机认证,不能短时间频繁访问,每次翻页都让线程休眠10s
Thread.sleep(10000);
doc = Jsoup.connect(loupanUrl + pageIndex.getAndIncrement()).get();
// 获取楼盘列表的ul元素
Element list = doc.select("ul.resblock-list-wrapper").first();
if (list == null) {
continue;
}
// 获取楼盘列表的li元素
Elements elements = list.select("li.resblock-list");
elements.forEach(el -> {
// 楼盘介绍
Element introduce = el.child(0);
// 详情页面
String detailPageUrl = beikeUrl + introduce.attr("href");
// 楼盘图片
String imageUrl = introduce.select("img").attr("data-original");
// 楼盘详情
Element childDesc = el.select("div.resblock-desc-wrapper").first();
Element childName = childDesc.child(0);
// 楼盘名称
String title = childName.child(0).text();
// 楼盘在售状态
String status = childName.child(1).text();
// 产权类型
String propertyType = childName.child(2).text();
// 楼盘所在地址
String address = childDesc.child(1).text();
// 房间属性
Element room = childDesc.child(2);
// 户型
String houseType = "";
// 户型集合
Elements houseTypeSpans = room.getElementsByTag("span");
if (CollectionUtils.isNotEmpty(houseTypeSpans)) {
// 剔除文案:【户型:】
houseTypeSpans.remove(0);
// 剔除文案:【建面:xxx】
houseTypeSpans.remove(houseTypeSpans.size() - 1);
houseType = StringUtil.join(houseTypeSpans.stream().map(Element::text).collect(Collectors.toList()), "/");
}
// 建筑面积
String buildingArea = room.select("span.area").text();
// div - 标签
Element descTag = childDesc.select("div.resblock-tag").first();
Elements tagSpans = descTag.getElementsByTag("span");
String tag = "";
if (CollectionUtils.isNotEmpty(tagSpans)) {
tag = StringUtil.join(tagSpans.stream().map(Element::text).collect(Collectors.toList()), " ");
}
// div - 价格
Element descPrice = childDesc.select("div.resblock-price").first();
String singlePrice = descPrice.select("span.number").text();
String totalPrice = descPrice.select("div.second").text();
dataList.add(new House().setTitle(title)
.setDetailPageUrl(detailPageUrl)
.setImageUrl(imageUrl)
.setSinglePrice(singlePrice)
.setTotalPrice(totalPrice)
.setStatus(status)
.setPropertyType(propertyType)
.setAddress(address)
.setHouseType(houseType)
.setBuildingArea(buildingArea)
.setTag(tag)
);
});
}
if (CollectionUtils.isEmpty(dataList)) {
log.info("dataList is empty returned.");
return;
}
log.info("dataList prepare finished, size = {}", dataList.size());
// 调用导出逻辑,将数据导出到excel文件
export(pageTitle, dataList);
}
复制代码
6、EasyExcel 导出逻辑
/**
* 将爬取的数据写入到excel中
* @param pageTitle
* @param dataList
*/
private static void export(String pageTitle, List dataList) {
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
//设置头居中
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.CENTER);
//内容策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
//设置 水平居中
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
HorizontalCellStyleStrategy horizontalCellStyleStrategy = new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
// 这里需要设置不关闭流
EasyExcelFactory.write("D:\深圳楼盘汇总.xlsx", House.class).autoCloseStream(Boolean.FALSE).registerWriteHandler(horizontalCellStyleStrategy).sheet(pageTitle).doWrite(dataList);
}
复制代码
7、成就展示
有兴趣的朋友可以自己尝试一下!
源代码:GitHub
原创不容易,请多多点赞,非常感谢!
java抓取网页内容( jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-16 03:04
jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)
搭建开发环境,在项目的Build Path中导入下载的Commons-httpClient3.1.Jar、htmllexer.jar和htmlparser.jar文件。图1. 开发环境搭建HttpClient基础类 该库使用HttpClinet提供了几个支持HTTP访问的类。下面我们通过一些示例代码来熟悉和解释这些类的功能和用途。HttpClient 提供的 HTTP 访问主要通过 GetMethod 类和 PostMethod 类来实现。它们分别对应于HTT
Java实现一个简单的网络爬虫代码示例
目前市面上流行的爬虫大多是python。经过简单的了解,一些简单的页面的爬虫主要是解析目标页面(html)。然后我在想,java中有没有用户可以轻松解析html页面?我发现一个jsoup包是一个非常方便的解析html的工具。使用方法也很简单,引入jar包:org.jsoup jsoup 1.8.
基于Java的短信验证码api调用代码示例
本文示例分享JAVA短信验证码api调用代码,供大家参考。具体内容如下: import java.io.BufferedReader; 导入 java.io.DataOutputStream; 导入 java.io.IOException; 导入 java.io.InputStream; 导入 java.io.InputStreamReader; 导入 java.io.UnsupportedEncodingException; 进口熟
C#网络爬虫代码分享 C#简单爬虫工具
公司编辑妹需要抓取网页内容,请我帮忙制作一个简单的抓取工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考私有字符串 GetHttpWebRequest(string url) {HttpWebResponse result; string strHTML = string.Empty; 尝试{Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri);
Java网络爬虫连接超时解决示例代码
本文主要研究java网络爬虫连接超时问题,如下。在网络爬虫中,经常会遇到以下错误。即连接超时。对于这个问题,一般的解决办法是:设置连接时间。请求时间设置的较长。如果出现连接超时,请重新请求【设置重新请求的次数】。线程“main”中的异常 .ConnectException: Connection timed out: connect 下面的代码是一个使用httpclient解决连接超时的示例程序。直接上程序。包大
开发基于 Java 的图形用户界面
SWT(Standard Widget Toolkit)是IBM推出的“基于java的”图形界面开发库。我之所以说它是“基于java的”,是指程序员在编写代码时使用java语言。实际上,SWT的底层实现是用C语言完成的。但这些对程序员来说是透明的。当我们使用SWT开发GUI程序时,我们直接使用SWT API来编写。其实很多java代码都是通过JNI去掉C代码来实现的。对于不同的平台的每个类都有不同的实现。这个文章的目的不是描述SWT的设计原理,如果你对这些感兴趣
Java实现爬虫向App提供数据(Jsoup网络爬虫)
一. Demand 最近基于 Material Design 重构了自己的新闻应用。数据源有问题。有前辈分析过知乎daily.Phoenix News等API。根据对应的URL,可以得到新闻的JSON数据。.为了锻炼写代码能力,作者打算自己爬取新闻页面,获取数据搭建API。二.效果图 下图为原网站页面爬虫获取数据并显示在APP移动端三.爬虫思路App实现过程请参考这些文章文章。本文主要讲解如何爬取数据。Android下记录App操作生成Gif动态图的全过程:
Java网络爬虫初学者详细介绍
这是Java网络爬虫系列的第一篇文章。如果不了解Java网络爬虫系列文章,请参考Java网络爬虫基础知识解析。第一篇是关于Java网络爬虫的介绍。内容。本文以采集虎扑列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示: 我们需要提取图中圈出的文字及其对应的链接,在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,一种是另一种是httpclient + 正则表达式方法。这也是Java网络爬虫常用的两种方法。这两种方法你不懂。不管哪条路,都会有对应的
Java网络爬虫基础知识解析
前言说到网络爬虫,大家想到的大概就是Python。当然,爬虫已经是Python的代名词之一,比Java差很多。很多人不知道Java可以用作网络爬虫。其实Java我也可以做网络爬虫,而且做的很好。开源社区中有很多优秀的Java网络爬虫框架,比如webmagic。我的第一份正式工作是使用webmagic编写数据采集程序。当时参与开发了一个舆情分析系统,涉及到很多网站新闻采集,我们用webmagic写了采集程序,因为我们不知道在时间
使用java实现网络爬虫
继上一篇爬虫所需的java知识,本文的目的是实现网络爬虫,获取数据进行分析。----->爬虫实现原理网络爬虫处理网络爬虫的基本技术是data采集的一种方法,在实际项目开发中,数据是通过爬虫来完成的采集一般只有以下几种情况:1)搜索引擎2)竞研3)监控4)行情分析网络爬虫的整体执行过程:1)确定一个(多个)种子网页2)提取数据内容3)连接相关网页中的网页提取 4) 将相关网页中未爬取的内容放入队列 5)从队列中取出一个要爬取的页面,判断之前是否被爬过 查看全部
java抓取网页内容(
jsoupjsoup基于JAVA的短信验证码api调用代码实例实例)
搭建开发环境,在项目的Build Path中导入下载的Commons-httpClient3.1.Jar、htmllexer.jar和htmlparser.jar文件。图1. 开发环境搭建HttpClient基础类 该库使用HttpClinet提供了几个支持HTTP访问的类。下面我们通过一些示例代码来熟悉和解释这些类的功能和用途。HttpClient 提供的 HTTP 访问主要通过 GetMethod 类和 PostMethod 类来实现。它们分别对应于HTT
Java实现一个简单的网络爬虫代码示例
目前市面上流行的爬虫大多是python。经过简单的了解,一些简单的页面的爬虫主要是解析目标页面(html)。然后我在想,java中有没有用户可以轻松解析html页面?我发现一个jsoup包是一个非常方便的解析html的工具。使用方法也很简单,引入jar包:org.jsoup jsoup 1.8.
基于Java的短信验证码api调用代码示例
本文示例分享JAVA短信验证码api调用代码,供大家参考。具体内容如下: import java.io.BufferedReader; 导入 java.io.DataOutputStream; 导入 java.io.IOException; 导入 java.io.InputStream; 导入 java.io.InputStreamReader; 导入 java.io.UnsupportedEncodingException; 进口熟
C#网络爬虫代码分享 C#简单爬虫工具
公司编辑妹需要抓取网页内容,请我帮忙制作一个简单的抓取工具。这是为了抓取网页的内容。似乎这对每个人来说都不是罕见的,但这里有一些小的变化。代码在这里。请参考私有字符串 GetHttpWebRequest(string url) {HttpWebResponse result; string strHTML = string.Empty; 尝试{Uri uri = new Uri(url); WebRequest webReq = WebRequest.Create(uri);
Java网络爬虫连接超时解决示例代码
本文主要研究java网络爬虫连接超时问题,如下。在网络爬虫中,经常会遇到以下错误。即连接超时。对于这个问题,一般的解决办法是:设置连接时间。请求时间设置的较长。如果出现连接超时,请重新请求【设置重新请求的次数】。线程“main”中的异常 .ConnectException: Connection timed out: connect 下面的代码是一个使用httpclient解决连接超时的示例程序。直接上程序。包大
开发基于 Java 的图形用户界面
SWT(Standard Widget Toolkit)是IBM推出的“基于java的”图形界面开发库。我之所以说它是“基于java的”,是指程序员在编写代码时使用java语言。实际上,SWT的底层实现是用C语言完成的。但这些对程序员来说是透明的。当我们使用SWT开发GUI程序时,我们直接使用SWT API来编写。其实很多java代码都是通过JNI去掉C代码来实现的。对于不同的平台的每个类都有不同的实现。这个文章的目的不是描述SWT的设计原理,如果你对这些感兴趣
Java实现爬虫向App提供数据(Jsoup网络爬虫)
一. Demand 最近基于 Material Design 重构了自己的新闻应用。数据源有问题。有前辈分析过知乎daily.Phoenix News等API。根据对应的URL,可以得到新闻的JSON数据。.为了锻炼写代码能力,作者打算自己爬取新闻页面,获取数据搭建API。二.效果图 下图为原网站页面爬虫获取数据并显示在APP移动端三.爬虫思路App实现过程请参考这些文章文章。本文主要讲解如何爬取数据。Android下记录App操作生成Gif动态图的全过程:
Java网络爬虫初学者详细介绍
这是Java网络爬虫系列的第一篇文章。如果不了解Java网络爬虫系列文章,请参考Java网络爬虫基础知识解析。第一篇是关于Java网络爬虫的介绍。内容。本文以采集虎扑列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示: 我们需要提取图中圈出的文字及其对应的链接,在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,一种是另一种是httpclient + 正则表达式方法。这也是Java网络爬虫常用的两种方法。这两种方法你不懂。不管哪条路,都会有对应的
Java网络爬虫基础知识解析
前言说到网络爬虫,大家想到的大概就是Python。当然,爬虫已经是Python的代名词之一,比Java差很多。很多人不知道Java可以用作网络爬虫。其实Java我也可以做网络爬虫,而且做的很好。开源社区中有很多优秀的Java网络爬虫框架,比如webmagic。我的第一份正式工作是使用webmagic编写数据采集程序。当时参与开发了一个舆情分析系统,涉及到很多网站新闻采集,我们用webmagic写了采集程序,因为我们不知道在时间
使用java实现网络爬虫
继上一篇爬虫所需的java知识,本文的目的是实现网络爬虫,获取数据进行分析。----->爬虫实现原理网络爬虫处理网络爬虫的基本技术是data采集的一种方法,在实际项目开发中,数据是通过爬虫来完成的采集一般只有以下几种情况:1)搜索引擎2)竞研3)监控4)行情分析网络爬虫的整体执行过程:1)确定一个(多个)种子网页2)提取数据内容3)连接相关网页中的网页提取 4) 将相关网页中未爬取的内容放入队列 5)从队列中取出一个要爬取的页面,判断之前是否被爬过
java抓取网页内容( GoogleAppEngine中文乱码问题注意在读取中文的网页时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-12-16 02:31
GoogleAppEngine中文乱码问题注意在读取中文的网页时)
// 此处的地址请换成你的,在本地测试时可以填入http://localhost:8888/request.jsp
URL url = new URL("http://2.latest.fatkuns.appspo ... 6quot;);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);// 使用 URL 连接进行输出
connection.setRequestMethod("POST");
// 取得输出流
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream());
// 用UTF-8编码,保证中文传递正常
String message = URLEncoder.encode("你好,I'm Fatkun!", "UTF-8");
// 写入发送的内容
writer.write("msg=" + message);
writer.close();
以上是主要代码。看看评论。它们非常清楚
谷歌应用引擎中文乱码问题
请注意,在阅读中文网页时,使用InputStream类很不方便,因为编码为UTF、GBK、GB2312等。此外,还可能发生错误
我尝试使用InputStream类,然后使用新字符串(bytes[],“UTF-8”)来转换代码,但出现了一个问题。我不知道我是否不能使用它或如何使用它
然而,使用这种书写方式要方便得多
InputStreamReader in=新的InputStreamReader(url.openStream(),“UTF-8”)
无需转换代码~只需指定其代码即可
请注意,此处应添加“UTF-8”。虽然没有在本地测试中添加它不是问题,但在上传到gae时,它不能以中文显示
PS2:UTF-8在这里表示网页的代码。如果您抓取的网页是GB2312,则需要根据实际需要进行更改。附件是我的例子:
源代码在这里:我在Lib目录中删除了它。请自己加 查看全部
java抓取网页内容(
GoogleAppEngine中文乱码问题注意在读取中文的网页时)
// 此处的地址请换成你的,在本地测试时可以填入http://localhost:8888/request.jsp
URL url = new URL("http://2.latest.fatkuns.appspo ... 6quot;);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);// 使用 URL 连接进行输出
connection.setRequestMethod("POST");
// 取得输出流
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream());
// 用UTF-8编码,保证中文传递正常
String message = URLEncoder.encode("你好,I'm Fatkun!", "UTF-8");
// 写入发送的内容
writer.write("msg=" + message);
writer.close();
以上是主要代码。看看评论。它们非常清楚
谷歌应用引擎中文乱码问题
请注意,在阅读中文网页时,使用InputStream类很不方便,因为编码为UTF、GBK、GB2312等。此外,还可能发生错误
我尝试使用InputStream类,然后使用新字符串(bytes[],“UTF-8”)来转换代码,但出现了一个问题。我不知道我是否不能使用它或如何使用它
然而,使用这种书写方式要方便得多
InputStreamReader in=新的InputStreamReader(url.openStream(),“UTF-8”)
无需转换代码~只需指定其代码即可
请注意,此处应添加“UTF-8”。虽然没有在本地测试中添加它不是问题,但在上传到gae时,它不能以中文显示
PS2:UTF-8在这里表示网页的代码。如果您抓取的网页是GB2312,则需要根据实际需要进行更改。附件是我的例子:
源代码在这里:我在Lib目录中删除了它。请自己加
java抓取网页内容(java爬虫网页分析的网站大全和爬虫入门的小技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-14 19:01
java抓取网页内容有两种,一种是通过request对象,一种是通过web.xml对象,根据xml语法不同可以分为三类:文档数据处理(xml):markuplinkentityviewresolver解析xml文档时读取emptybody属性内容并返回,一般在xml内容中用markdown写作解析程序(web):基于groovy语言,通过将程序编译为web.xml格式,一般是类似这样的usercontroller+model组成。
如果api文档较少或是客户端不是依赖web.xml的转发机制,可以使用python编写web.xml支持java的web.xml解析代码,具体请移步web.xml文档介绍可以看看我主页。
微软的w3c文档,也有丰富的java的web.xml相关页面的数据爬取方法。
谢邀!本人从事java语言相关方面的工作,所以查阅了很多的文档和相关资料,目前本人对xml语言和restful数据库的关系没有什么特别的看法,但是本人分享一下相关的java爬虫网页分析的网站大全和爬虫入门的一些小技巧!1.全面了解web技术原理,如http协议,https协议,getpost等协议,规范。
2.根据自己的项目选择对应的java框架,如spring,springmvc,springboot,springcloud等框架是目前主流的是使用的多。了解每个框架的用法和特点。3.根据不同的项目学习数据库,mysql,oracle,msql等数据库。了解其存储机制和使用方法,数据库备份,数据复制,数据库群集配置。
4.了解python,爬虫的底层是python,python读写字符串,python解释器。可以根据python的特点写爬虫代码,并且能爬虫读取xml相关数据和处理html相关数据。这里要说明一下要注意的是,python解释器对字符串内部数据格式是区分为字符串和浮点数的,对应于java是ascii字符串和char字符串的。
如对于java来说,字符串是不能直接获取,所以一定要把中间的转换过程用java代码完成。5.工欲善其事必先利其器,要学习xml相关的中间步骤,zendstream框架,专门用于读取xml文件,并转换为java字符串,主要代码如下:xml->python解析xml,yml转换python解析格式java解析处理包括有form表单。相关文章有很多,可以参考。 查看全部
java抓取网页内容(java爬虫网页分析的网站大全和爬虫入门的小技巧)
java抓取网页内容有两种,一种是通过request对象,一种是通过web.xml对象,根据xml语法不同可以分为三类:文档数据处理(xml):markuplinkentityviewresolver解析xml文档时读取emptybody属性内容并返回,一般在xml内容中用markdown写作解析程序(web):基于groovy语言,通过将程序编译为web.xml格式,一般是类似这样的usercontroller+model组成。
如果api文档较少或是客户端不是依赖web.xml的转发机制,可以使用python编写web.xml支持java的web.xml解析代码,具体请移步web.xml文档介绍可以看看我主页。
微软的w3c文档,也有丰富的java的web.xml相关页面的数据爬取方法。
谢邀!本人从事java语言相关方面的工作,所以查阅了很多的文档和相关资料,目前本人对xml语言和restful数据库的关系没有什么特别的看法,但是本人分享一下相关的java爬虫网页分析的网站大全和爬虫入门的一些小技巧!1.全面了解web技术原理,如http协议,https协议,getpost等协议,规范。
2.根据自己的项目选择对应的java框架,如spring,springmvc,springboot,springcloud等框架是目前主流的是使用的多。了解每个框架的用法和特点。3.根据不同的项目学习数据库,mysql,oracle,msql等数据库。了解其存储机制和使用方法,数据库备份,数据复制,数据库群集配置。
4.了解python,爬虫的底层是python,python读写字符串,python解释器。可以根据python的特点写爬虫代码,并且能爬虫读取xml相关数据和处理html相关数据。这里要说明一下要注意的是,python解释器对字符串内部数据格式是区分为字符串和浮点数的,对应于java是ascii字符串和char字符串的。
如对于java来说,字符串是不能直接获取,所以一定要把中间的转换过程用java代码完成。5.工欲善其事必先利其器,要学习xml相关的中间步骤,zendstream框架,专门用于读取xml文件,并转换为java字符串,主要代码如下:xml->python解析xml,yml转换python解析格式java解析处理包括有form表单。相关文章有很多,可以参考。
java抓取网页内容(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-14 16:37
本文在文章抓取目标网站的链接的基础上,进一步增加难度,抓取目标页面上我们需要的内容并存入数据库。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一篇文章类似。不同的是,这个网站的分类列表太多了。如果不选择这些标签,将花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接去抓取其他页面,只需使用页面底部的所有类型电影的标签来获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是在videoLinkMap集合中保存所有获取到的电影的下载链接,通过遍历这个集合将数据保存到MySQL
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile(" 查看全部
java抓取网页内容(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
本文在文章抓取目标网站的链接的基础上,进一步增加难度,抓取目标页面上我们需要的内容并存入数据库。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一篇文章类似。不同的是,这个网站的分类列表太多了。如果不选择这些标签,将花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接去抓取其他页面,只需使用页面底部的所有类型电影的标签来获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是在videoLinkMap集合中保存所有获取到的电影的下载链接,通过遍历这个集合将数据保存到MySQL
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class VideoLinkGrab {
public static void main(String[] args) {
VideoLinkGrab videoLinkGrab = new VideoLinkGrab();
videoLinkGrab.saveData("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseUrl
* 爬虫起点
* @return null
* */
public void saveData(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLinkHost = ""; // host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
videoLinkMap = crawlLinks(oldLinkHost, oldMap);
// 遍历,然后将数据保存在数据库中
try {
Connection connection = JDBCDemo.getConnection();
for (Map.Entry mapping : videoLinkMap.entrySet()) {
PreparedStatement pStatement = connection
.prepareStatement("insert into movie(MovieName,MovieLink) values(?,?)");
pStatement.setString(1, mapping.getKey());
pStatement.setString(2, mapping.getValue());
pStatement.executeUpdate();
pStatement.close();
// System.out.println(mapping.getKey() + " : " + mapping.getValue());
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起GET请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videoLinkMap
*
* @param oldLinkHost
* 域名,如:http://www.zifangsky.cn
* @param oldMap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap(); // 每次循环获取到的新链接
Map videoLinkMap = new LinkedHashMap(); // 视频下载链接
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
// System.out.println("link:" + mapping.getKey() + "--------check:"
// + mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2500);
connection.setReadTimeout(2500);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = null;
Matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(isMoviePage(oldLink)){
boolean checkTitle = false;
String title = "";
while ((line = reader.readLine()) != null) {
//取出页面中的视频标题
if(!checkTitle){
pattern = Pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checkTitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = Pattern
.compile("(thunder:[^\"]+).*thunder[rR]es[tT]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videoLinkMap.put(title,matcher.group(1));
System.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkUrl(oldLink)){
while ((line = reader.readLine()) != null) {
pattern = Pattern
.compile("
java抓取网页内容(我想做一个java网页指定内容的抓取。不知道怎么做 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-14 00:05
)
使用htmlparser做java抓取网页的指定内容。. 我想对java网页的指定内容进行爬网。. .
我不知道怎么做,请帮助我,不要太复杂。. .
首先谢谢大家。. 不好意思,这件事拖了2天了,有点着急。. . --------------------编程问答--------------------whocanhelpme。. .
我需要你!!!!
请!--------------------编程问答--------------------使用流阅读网页,然后只输出字符串,(你应该可以处理字符串)然后根据你的目标选择节点--------------------编程问题and Answers------ --------------2楼z740003446的回复:用流读取网页,然后输出为字符串,(应该可以处理字符串),然后根据您的目标节点进行选择
你能不能说得更具体一点,我根本不懂htmlparser ------------编程问答-------------- - - -
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
public class URLUtil {<br />
<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
System.out.println(URLUtil.getHtml("http://www.fastunit.com"));<br />
}<br />
}
--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我只想抢它的标题,我该怎么改?--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我错了,我的意思是我不希望它显示 html 代码,只显示纯文本。. 需要怎么改--------------------编程问答--------------------我只想抓个网站的纯文本标题,和内容。. .
有没有办法实现这一目标。. . 这里的任何人。. . 求助~--------------------编程问答--------------------看API .
使用过滤器过滤标题--------------------编程问答--------------------有任何人~!--------------------编程问答 --------------------引用 yuerzm 8号回复楼层:请参阅下载 API。
使用过滤器过滤标题
我不知道怎么做,新手。. --------------------编程问答 --------------------谁能告诉我更具体的?
你花几十分钟做的事,我可能要花上几十个小时。. . 麻烦大家了~帮帮我--------------------编程问答-------------------- 使用jsoup百度找到相关的API,很容易上手。--------------------编程问答 -------------------- 回复基本没做过一般简单使用常规过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
最好使用 if(t.equals(HTML.Tag.TITLE)) 来获得它。网站 支持。比如csdn,向上看左上角
他的htmltitle写了pos定位或者左右标签定位,不可用。
不要问关于你自己研究的其他问题--------------------编程问答---------------- --- ---------------------编程问答--------------------引用作者的回复13楼的Ollim:基本上一直没抓到回复。一般简单的正则过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
使用 if(t.……
如果我不明白,我必须问。. 你必须在开始之前学习。我现在都很困惑。. --------------------编程问答 -------------------- 为什么没有人。. --------------------编程问答--------------------引用seven_tee 16日的回复楼:怎么没人。.
写下代码给你。
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}
--------------------编程问答--------------------引用dyb19877517号回复floor:引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
解析器...
ReadUrl需要导入什么包?
--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
importorg.htmlparser.Parser;
importorg.htmlparser.beans.StringBean;
importorg.htmlparser.util.ParserException;
importorg.htmlparser.visitors.HtmlPage;--------------------编程问答--------------------引用19楼dyb198775的回复: 引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("……
Stringhtmlcode=ReadUrl.getHtml("");
我这段代码的ReadUrl报错,应该导入什么包?--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
--------------------编程问答--------------------引用7_tee 20号的回复楼:引用19楼dyb198775的回复:
引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.ge……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189");<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189");<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
补充:Java , Web 开发 查看全部
java抓取网页内容(我想做一个java网页指定内容的抓取。不知道怎么做
)
使用htmlparser做java抓取网页的指定内容。. 我想对java网页的指定内容进行爬网。. .
我不知道怎么做,请帮助我,不要太复杂。. .
首先谢谢大家。. 不好意思,这件事拖了2天了,有点着急。. . --------------------编程问答--------------------whocanhelpme。. .
我需要你!!!!
请!--------------------编程问答--------------------使用流阅读网页,然后只输出字符串,(你应该可以处理字符串)然后根据你的目标选择节点--------------------编程问题and Answers------ --------------2楼z740003446的回复:用流读取网页,然后输出为字符串,(应该可以处理字符串),然后根据您的目标节点进行选择
你能不能说得更具体一点,我根本不懂htmlparser ------------编程问答-------------- - - -
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
public class URLUtil {<br />
<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
System.out.println(URLUtil.getHtml("http://www.fastunit.com";));<br />
}<br />
}
--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我只想抢它的标题,我该怎么改?--------------------编程问答 --------------------引用leehomwong 4日的回复楼层:Javacode
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
publicclassURLUtil{
publicstaticStringgetHtml(Str……
我错了,我的意思是我不希望它显示 html 代码,只显示纯文本。. 需要怎么改--------------------编程问答--------------------我只想抓个网站的纯文本标题,和内容。. .
有没有办法实现这一目标。. . 这里的任何人。. . 求助~--------------------编程问答--------------------看API .
使用过滤器过滤标题--------------------编程问答--------------------有任何人~!--------------------编程问答 --------------------引用 yuerzm 8号回复楼层:请参阅下载 API。
使用过滤器过滤标题
我不知道怎么做,新手。. --------------------编程问答 --------------------谁能告诉我更具体的?
你花几十分钟做的事,我可能要花上几十个小时。. . 麻烦大家了~帮帮我--------------------编程问答-------------------- 使用jsoup百度找到相关的API,很容易上手。--------------------编程问答 -------------------- 回复基本没做过一般简单使用常规过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
最好使用 if(t.equals(HTML.Tag.TITLE)) 来获得它。网站 支持。比如csdn,向上看左上角
他的htmltitle写了pos定位或者左右标签定位,不可用。
不要问关于你自己研究的其他问题--------------------编程问答---------------- --- ---------------------编程问答--------------------引用作者的回复13楼的Ollim:基本上一直没抓到回复。一般简单的正则过滤
使用 htmlparser 处理更复杂的
实际上编写自己的解析器
您使用 htmlparserHTMLEditorKit.ParserCallback 获取标题
publicvoidhandleStartTag(HTML.Tagt,MutableAttributeSeta,intpos)
这是开始标签
使用 if(t.……
如果我不明白,我必须问。. 你必须在开始之前学习。我现在都很困惑。. --------------------编程问答 -------------------- 为什么没有人。. --------------------编程问答--------------------引用seven_tee 16日的回复楼:怎么没人。.
写下代码给你。
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}
--------------------编程问答--------------------引用dyb19877517号回复floor:引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
解析器...
ReadUrl需要导入什么包?
--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
importjava.io.BufferedReader;
importjava.io.InputStreamReader;
.HttpURLConnection;
.URL;
importorg.htmlparser.Parser;
importorg.htmlparser.beans.StringBean;
importorg.htmlparser.util.ParserException;
importorg.htmlparser.visitors.HtmlPage;--------------------编程问答--------------------引用19楼dyb198775的回复: 引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("……
Stringhtmlcode=ReadUrl.getHtml("");
我这段代码的ReadUrl报错,应该导入什么包?--------------------编程Q&A --------------------引用seven_tee 18日的回复楼:引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.getHtml("");
普……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
--------------------编程问答--------------------引用7_tee 20号的回复楼:引用19楼dyb198775的回复:
引用18楼seven_tee的回复:
引用17楼dyb198775的回复:
引用16楼seven_tee的回复:
为什么没人。.
写下代码给你。
代码
publicstaticvoidmain(String[]args){
Stringhtmlcode=ReadUrl.ge……
package com.dyb.url;<br />
<br />
import java.io.BufferedReader;<br />
import java.io.InputStreamReader;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
<br />
import org.htmlparser.Parser;<br />
import org.htmlparser.beans.StringBean;<br />
import org.htmlparser.util.ParserException;<br />
import org.htmlparser.visitors.HtmlPage;<br />
<br />
<br />
<br />
public class ReadUrl {<br />
public static String getHtml(String urlString) {<br />
try {<br />
StringBuffer html = new StringBuffer();<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
InputStreamReader isr = new InputStreamReader(conn.getInputStream());<br />
BufferedReader br = new BufferedReader(isr);<br />
String temp;<br />
while ((temp = br.readLine()) != null) {<br />
html.append(temp).append("\n");<br />
}<br />
br.close();<br />
isr.close();<br />
return html.toString();<br />
} catch (Exception e) {<br />
e.printStackTrace();<br />
return null;<br />
}<br />
}<br />
<br />
public static void main(String[] args) {<br />
String htmlcode = ReadUrl.getHtml("http://tieba.baidu.com/p/1347940189";);<br />
Parser parser = Parser.createParser(htmlcode, "GBK");<br />
HtmlPage page = new HtmlPage(parser);<br />
try <br />
{ <br />
parser.visitAllNodesWith(page);<br />
}<br />
catch (ParserException e1)<br />
{ <br />
e1 = null;<br />
}<br />
// 显示标题<br />
System.out.println(page.getTitle());<br />
// 显示文本<br />
System.out.println(getContent());<br />
}<br />
<br />
private static String getContent() {<br />
StringBean sBean = new StringBean();<br />
sBean.setLinks(true);<br />
sBean.setCollapse(true);<br />
sBean.setReplaceNonBreakingSpaces(true);<br />
sBean.setURL("http://tieba.baidu.com/p/1347940189";);<br />
// System.out.println("This content is:"+sBean.getStrings());<br />
return sBean.getStrings();<br />
}<br />
}<br />
补充:Java , Web 开发
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-10 13:05
<p>java抓取网页内容,可以利用jsp动态servlet页面来传递参数,java基础内容看《深入浅出servlet》。学习python爬虫</a>{{item.getmessage()}}</a>{{item.getmessage()}} 查看全部
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
<p>java抓取网页内容,可以利用jsp动态servlet页面来传递参数,java基础内容看《深入浅出servlet》。学习python爬虫</a>{{item.getmessage()}}</a>{{item.getmessage()}}
java抓取网页内容(pythonjava抓取网页内容教程。网络爬虫中怎么操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-02 13:09
java抓取网页内容教程。在python网络爬虫中怎么操作,即抓取网页,抓取图片,抓取下载文件!!!都有用到,下面是我一天抓取了三个网站的不同网页内容格式,python实现程序内容。
我还可以给你安利一下这个ieeexplore权威图形可视化查询平台。你可以用它在图形浏览器中查看。我就是用这个平台查看自己的代码的。非常方便。
python的话推荐阅读《python网络爬虫开发实战》,因为python本身就是最好的网络爬虫语言,网络爬虫的各种接口都可以使用。
redis2ajax的实践和web集群,
我正在写的自动回复功能pythonapi有兴趣的话可以来围观:)
<p>pythonpandasselenium(某校打招呼的方式是:xxx,pandasselenium() 查看全部
java抓取网页内容(pythonjava抓取网页内容教程。网络爬虫中怎么操作)
java抓取网页内容教程。在python网络爬虫中怎么操作,即抓取网页,抓取图片,抓取下载文件!!!都有用到,下面是我一天抓取了三个网站的不同网页内容格式,python实现程序内容。
我还可以给你安利一下这个ieeexplore权威图形可视化查询平台。你可以用它在图形浏览器中查看。我就是用这个平台查看自己的代码的。非常方便。
python的话推荐阅读《python网络爬虫开发实战》,因为python本身就是最好的网络爬虫语言,网络爬虫的各种接口都可以使用。
redis2ajax的实践和web集群,
我正在写的自动回复功能pythonapi有兴趣的话可以来围观:)
<p>pythonpandasselenium(某校打招呼的方式是:xxx,pandasselenium()
java抓取网页内容(java抓取网页内容的写法参考上面这个帖子也是讲解了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-30 04:04
java抓取网页内容的写法参考上面这个帖子,内容也是讲解了内存泄漏的后果,
list中是否要加上类似int型的map类型的key?如果添加上了那样是否会有很多不必要的无用的内存开销?和string那样的解决方法一样吗?
javakeystore(也可以叫jdk库)里有一个可以做key转换处理的工具(好像这个是命令行cgi方式调用的):keystore|javawebkeycomparisonandtableanalysis具体的pojo中的key替换的生成方法好像在项目里,
-java-default-hash-for-key.html
你的代码如果直接放txt文件中,自然是不会出现泄漏的问题,因为java本身可以提供去除重复值的能力,但是如果你把txt文件拿到服务器去读取,不说java是有命令行去这么操作了,单单说服务器读取也不会出现问题,因为解释器解析文件都是通过命令行解析的,如果命令行的解析有问题,也是读不出来的。java是对原始值进行判断类型转换,而txt和java本身原始值的特性有关,那就涉及到一些gc的问题。
比如对一段文字,字符串转换为newbyte[1024]结果是unsignednull,对txt这类只有1024个字符,还有冒号没有uint长度的文件是可以碰撞的。java的volatile是不支持全局同步的,在不支持全局同步的语言中比如linux系统里非常容易出现作弊行为,如使用内存进行mgsql连接操作然后一系列没用的操作占用了内存而无法释放或者释放了更多内存导致失败等情况。
volatile关键字真的不会比普通对象更安全。如果你写的是中间可重复的代码就另当别论了,比如说web框架中重复注册用户名和密码,这种写法就比较容易出现泄漏。 查看全部
java抓取网页内容(java抓取网页内容的写法参考上面这个帖子也是讲解了)
java抓取网页内容的写法参考上面这个帖子,内容也是讲解了内存泄漏的后果,
list中是否要加上类似int型的map类型的key?如果添加上了那样是否会有很多不必要的无用的内存开销?和string那样的解决方法一样吗?
javakeystore(也可以叫jdk库)里有一个可以做key转换处理的工具(好像这个是命令行cgi方式调用的):keystore|javawebkeycomparisonandtableanalysis具体的pojo中的key替换的生成方法好像在项目里,
-java-default-hash-for-key.html
你的代码如果直接放txt文件中,自然是不会出现泄漏的问题,因为java本身可以提供去除重复值的能力,但是如果你把txt文件拿到服务器去读取,不说java是有命令行去这么操作了,单单说服务器读取也不会出现问题,因为解释器解析文件都是通过命令行解析的,如果命令行的解析有问题,也是读不出来的。java是对原始值进行判断类型转换,而txt和java本身原始值的特性有关,那就涉及到一些gc的问题。
比如对一段文字,字符串转换为newbyte[1024]结果是unsignednull,对txt这类只有1024个字符,还有冒号没有uint长度的文件是可以碰撞的。java的volatile是不支持全局同步的,在不支持全局同步的语言中比如linux系统里非常容易出现作弊行为,如使用内存进行mgsql连接操作然后一系列没用的操作占用了内存而无法释放或者释放了更多内存导致失败等情况。
volatile关键字真的不会比普通对象更安全。如果你写的是中间可重复的代码就另当别论了,比如说web框架中重复注册用户名和密码,这种写法就比较容易出现泄漏。
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-28 20:06
java抓取网页内容到本地excel处理,详细步骤:1.点击f12,输入网址。1.下拉2.找到相应的iframe查看第二步3.对第二步的f12进行excel筛选,只有在lib/excel下才有第三步4.下载excel到本地2.编辑excel文件编辑好的excel文件需要标注分组标识,文件名称,内容形式等!3.保存excel文件在excel中复制粘贴到u盘中备用。
<p>5.excel抓取网页内容数据过程publicstaticfinalstringurl=";id=0";publicstaticvoidmain(string[]args){finalstringdata=newstring("");for(inti=0;i 查看全部
java抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
java抓取网页内容到本地excel处理,详细步骤:1.点击f12,输入网址。1.下拉2.找到相应的iframe查看第二步3.对第二步的f12进行excel筛选,只有在lib/excel下才有第三步4.下载excel到本地2.编辑excel文件编辑好的excel文件需要标注分组标识,文件名称,内容形式等!3.保存excel文件在excel中复制粘贴到u盘中备用。
<p>5.excel抓取网页内容数据过程publicstaticfinalstringurl=";id=0";publicstaticvoidmain(string[]args){finalstringdata=newstring("");for(inti=0;i
java抓取网页内容(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-27 22:20
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
java抓取网页内容(java实现了一个简单的网页数据)
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
java抓取网页内容(soup库在python中抓取网页信息是怎样的体验?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-11-20 23:08
在标签中,标签的属性是“itemprop”和“articleBody”,可以通过.find()函数访问。
news1=soup.find_all('div',class_=["news-card-content news-right-box"])[0]content=news1.find('div',attrs={'itemprop':"articleBody"}).stringprint(content)Indian Shuttler Ajay Jayaramclinched $50k Dutch Open Grand Prix at Almere in Netherlands on Sunday,becoming the first Indian to win badminton Grand Prix tournament under a newscoring system. Jayaram defeated Indonesia's Ihsan Maulana Mustofa 10-11, 11-6,11-7, 1-11, 11-9 in an exciting final clash. The 27-year-old returned to thecircuit in August after a seven-month injury layoff.
以类似的方式,我们可以提取任何信息,例如图像、作者姓名和时间。
第 3 步:创建数据集
接下来,我们对3个新闻类别实现这个操作,然后将文章的所有对应的内容和类别存储在数据框中。作者将使用三个不同的 URL,对每个 URL 执行相同的步骤,并将所有 文章 及其内容设置类别存储为列表。
urls=["https://inshorts.com/en/read/cricket","https://inshorts.com/en/read/tennis", "https://inshorts.com/en/read/badminton"] news_data_content,news_data_title,news_data_category=[],[],[] for url in urls: category=url.split('/')[-1] data=requests.get(url) soup=BeautifulSoup(data.content,'html.parser') news_title=[] news_content=[] news_category=[] for headline,article inzip(soup.find_all('div', class_=["news-card-titlenews-right-box"]), soup.find_all('div',class_=["news-card-contentnews-right-box"])): news_title.append(headline.find('span',attrs={'itemprop':"headline"}).string) news_content.append(article.find('div',attrs={'itemprop':"articleBody"}).string) news_category.append(category) news_data_title.extend(news_title) news_data_content.extend(news_content) news_data_category.extend(news_category) df1=pd.DataFrame(news_data_title,columns=["Title"]) df2=pd.DataFrame(news_data_content,columns=["Content"]) df3=pd.DataFrame(news_data_category,columns=["Category"]) df=pd.concat([df1,df2,df3],axis=1) df.sample(10)
输出是:
你可以看到在python中使用漂亮的soup库来抓取网络信息是多么容易,你可以轻松地为任何数据科学项目采集有用的数据。从此,带上自己的“眼睛”,快速从网页中提取有价值的信息。
点赞关注 查看全部
java抓取网页内容(soup库在python中抓取网页信息是怎样的体验?)
在标签中,标签的属性是“itemprop”和“articleBody”,可以通过.find()函数访问。
news1=soup.find_all('div',class_=["news-card-content news-right-box"])[0]content=news1.find('div',attrs={'itemprop':"articleBody"}).stringprint(content)Indian Shuttler Ajay Jayaramclinched $50k Dutch Open Grand Prix at Almere in Netherlands on Sunday,becoming the first Indian to win badminton Grand Prix tournament under a newscoring system. Jayaram defeated Indonesia's Ihsan Maulana Mustofa 10-11, 11-6,11-7, 1-11, 11-9 in an exciting final clash. The 27-year-old returned to thecircuit in August after a seven-month injury layoff.
以类似的方式,我们可以提取任何信息,例如图像、作者姓名和时间。
第 3 步:创建数据集
接下来,我们对3个新闻类别实现这个操作,然后将文章的所有对应的内容和类别存储在数据框中。作者将使用三个不同的 URL,对每个 URL 执行相同的步骤,并将所有 文章 及其内容设置类别存储为列表。
urls=["https://inshorts.com/en/read/cricket","https://inshorts.com/en/read/tennis", "https://inshorts.com/en/read/badminton"] news_data_content,news_data_title,news_data_category=[],[],[] for url in urls: category=url.split('/')[-1] data=requests.get(url) soup=BeautifulSoup(data.content,'html.parser') news_title=[] news_content=[] news_category=[] for headline,article inzip(soup.find_all('div', class_=["news-card-titlenews-right-box"]), soup.find_all('div',class_=["news-card-contentnews-right-box"])): news_title.append(headline.find('span',attrs={'itemprop':"headline"}).string) news_content.append(article.find('div',attrs={'itemprop':"articleBody"}).string) news_category.append(category) news_data_title.extend(news_title) news_data_content.extend(news_content) news_data_category.extend(news_category) df1=pd.DataFrame(news_data_title,columns=["Title"]) df2=pd.DataFrame(news_data_content,columns=["Content"]) df3=pd.DataFrame(news_data_category,columns=["Category"]) df=pd.concat([df1,df2,df3],axis=1) df.sample(10)
输出是:
你可以看到在python中使用漂亮的soup库来抓取网络信息是多么容易,你可以轻松地为任何数据科学项目采集有用的数据。从此,带上自己的“眼睛”,快速从网页中提取有价值的信息。
点赞关注
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-14 20:13
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了... 查看全部
java抓取网页内容(代码罗View远程服务器,没事抓取网页信息的小工具
)
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
1 import java.io.BufferedReader;
2 import java.io.IOException;
3 import java.io.InputStreamReader;
4 import java.net.HttpURLConnection;
5 import java.net.URL;
6 import java.util.*;
7
8 /**
9 * Created by chunmiao on 17-3-10.
10 */
11 public class ReadBaiduSearch {
12
13 //储存返回结果
14 private LinkedHashMap mapOfBaike;
15
16
17 //获取搜索信息
18 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
19 mapOfBaike = getResult(infomationWords);
20 return mapOfBaike;
21 }
22
23 //通过网络链接获取信息
24 private static LinkedHashMap getResult(String keywords) throws IOException {
25 //搜索的url
26 String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
27 //搜索词条的节点
28 String startNode = "";
29 //词条的链接关键字
30 String keyOfHref = "href=\"";
31 //词条的标题关键字
32 String keyOfTitle = "target=\"_blank\">";
33
34 String endNode = "";
35
36 boolean isNode = false;
37
38 String title;
39
40 String href;
41
42 String rLine;
43
44 LinkedHashMap keyMap = new LinkedHashMap();
45
46 //开始网络请求
47 URL url = new URL(keyUrl);
48 HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
49 InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
50 BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
51
52 //读取网页内容
53 while ((rLine = bufferedReader.readLine()) != null){
54 //判断目标节点是否出现
55 if(rLine.contains(startNode)){
56 isNode = true;
57 }
58 //若目标节点出现,则开始抓取数据
59 if (isNode){
60 //若目标结束节点出现,则结束读取,节省读取时间
61 if (rLine.contains(endNode)) {
62 //关闭读取流
63 bufferedReader.close();
64 inputStreamReader.close();
65 break;
66 }
67 //若值为空则不读取
68 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
69 keyMap.put(title,href);
70 }
71 }
72 }
73 return keyMap;
74 }
75
76 //获取词条对应的url
77 private static String getHref(String rLine,String keyOfHref){
78 String baikeUrl = "http://baike.baidu.com";
79 String result = "";
80 if(rLine.contains(keyOfHref)){
81 //获取url
82 for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
83 result += rLine.charAt(j);
84 }
85 //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
86 if(!result.contains(baikeUrl)){
87 result = baikeUrl + result;
88 }
89 }
90 return result;
91 }
92
93 //获取词条对应的名称
94 private static String getName(String rLine,String keyOfTitle){
95 String result = "";
96 //获取标题内容
97 if(rLine.contains(keyOfTitle)){
98 result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
99 //将标题中的内容含有的标签去掉
100 result = result.replaceAll("||</a>|<a>","");
101 }
102 return result;
103 }
104
105 }
查看代码
现在都好晚了,去睡觉了...
java抓取网页内容(这篇文章主要介绍了JAVA使用爬虫抓取网站网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-11-13 13:08
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。现在分享给大家,给大家参考。跟着小编一起来看看吧。
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?所以我根据自己的想法写了一个简单的爬虫。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有找到的新链接,加入集合中,等待下一次遍历的同时循环.
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。
最后,在整个oldMap还没有遍历完链接之后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.util.LinkedHashMap; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WebCrawlerDemo { public static void main(String[] args) { WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo(); webCrawlerDemo.myPrint("http://www.zifangsky.cn"); } public void myPrint(String baseUrl) { Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历 // 键值对 String oldLinkHost = ""; //host Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn Matcher m = p.matcher(baseUrl); if (m.find()) { oldLinkHost = m.group(); } oldMap.put(baseUrl, false); oldMap = crawlLinks(oldLinkHost, oldMap); for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("链接:" + mapping.getKey()); } } /** * 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 * 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接 * 则表示不能发现新的链接了,任务结束 * * @param oldLinkHost 域名,如:http://www.zifangsky.cn * @param oldMap 待遍历的链接集合 * * @return 返回所有抓取到的链接集合 * */ private Map crawlLinks(String oldLinkHost, Map oldMap) { Map newMap = new LinkedHashMap(); String oldLink = ""; for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("link:" + mapping.getKey() + "--------check:" + mapping.getValue()); // 如果没有被遍历过 if (!mapping.getValue()) { oldLink = mapping.getKey(); // 发起GET请求 try { URL url = new URL(oldLink); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.setRequestMethod("GET"); connection.setConnectTimeout(2000); connection.setReadTimeout(2000); if (connection.getResponseCode() == 200) { InputStream inputStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(inputStream, "UTF-8")); String line = ""; Pattern pattern = Pattern .compile("(.+)</a>"); Matcher matcher = null; while ((line = reader.readLine()) != null) { matcher = pattern.matcher(line); if (matcher.find()) { String newLink = matcher.group(1).trim(); // 链接 // String title = matcher.group(3).trim(); //标题 // 判断获取到的链接是否以http开头 if (!newLink.startsWith("http")) { if (newLink.startsWith("/")) newLink = oldLinkHost + newLink; else newLink = oldLinkHost + "/" + newLink; } //去除链接末尾的 / if(newLink.endsWith("/")) newLink = newLink.substring(0, newLink.length() - 1); //去重,并且丢弃其他网站的链接 if (!oldMap.containsKey(newLink) && !newMap.containsKey(newLink) && newLink.startsWith(oldLinkHost)) { // System.out.println("temp2: " + newLink); newMap.put(newLink, false); } } } } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } oldMap.replace(oldLink, false, true); } } //有新链接,继续遍历 if (!newMap.isEmpty()) { oldMap.putAll(newMap); oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对 } return oldMap; } }
三项最终测试结果
PS:实际递归不是很好,因为如果网站页多的话,程序运行时间长的话内存消耗会很大。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上是Java爬虫在网站上所有链接的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
java抓取网页内容(这篇文章主要介绍了JAVA使用爬虫抓取网站网页内容的方法)
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。现在分享给大家,给大家参考。跟着小编一起来看看吧。
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?所以我根据自己的想法写了一个简单的爬虫。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有找到的新链接,加入集合中,等待下一次遍历的同时循环.
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。
最后,在整个oldMap还没有遍历完链接之后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.util.LinkedHashMap; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WebCrawlerDemo { public static void main(String[] args) { WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo(); webCrawlerDemo.myPrint("http://www.zifangsky.cn";); } public void myPrint(String baseUrl) { Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历 // 键值对 String oldLinkHost = ""; //host Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn Matcher m = p.matcher(baseUrl); if (m.find()) { oldLinkHost = m.group(); } oldMap.put(baseUrl, false); oldMap = crawlLinks(oldLinkHost, oldMap); for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("链接:" + mapping.getKey()); } } /** * 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 * 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接 * 则表示不能发现新的链接了,任务结束 * * @param oldLinkHost 域名,如:http://www.zifangsky.cn * @param oldMap 待遍历的链接集合 * * @return 返回所有抓取到的链接集合 * */ private Map crawlLinks(String oldLinkHost, Map oldMap) { Map newMap = new LinkedHashMap(); String oldLink = ""; for (Map.Entry mapping : oldMap.entrySet()) { System.out.println("link:" + mapping.getKey() + "--------check:" + mapping.getValue()); // 如果没有被遍历过 if (!mapping.getValue()) { oldLink = mapping.getKey(); // 发起GET请求 try { URL url = new URL(oldLink); HttpURLConnection connection = (HttpURLConnection) url .openConnection(); connection.setRequestMethod("GET"); connection.setConnectTimeout(2000); connection.setReadTimeout(2000); if (connection.getResponseCode() == 200) { InputStream inputStream = connection.getInputStream(); BufferedReader reader = new BufferedReader( new InputStreamReader(inputStream, "UTF-8")); String line = ""; Pattern pattern = Pattern .compile("(.+)</a>"); Matcher matcher = null; while ((line = reader.readLine()) != null) { matcher = pattern.matcher(line); if (matcher.find()) { String newLink = matcher.group(1).trim(); // 链接 // String title = matcher.group(3).trim(); //标题 // 判断获取到的链接是否以http开头 if (!newLink.startsWith("http")) { if (newLink.startsWith("/")) newLink = oldLinkHost + newLink; else newLink = oldLinkHost + "/" + newLink; } //去除链接末尾的 / if(newLink.endsWith("/")) newLink = newLink.substring(0, newLink.length() - 1); //去重,并且丢弃其他网站的链接 if (!oldMap.containsKey(newLink) && !newMap.containsKey(newLink) && newLink.startsWith(oldLinkHost)) { // System.out.println("temp2: " + newLink); newMap.put(newLink, false); } } } } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } oldMap.replace(oldLink, false, true); } } //有新链接,继续遍历 if (!newMap.isEmpty()) { oldMap.putAll(newMap); oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对 } return oldMap; } }
三项最终测试结果
PS:实际递归不是很好,因为如果网站页多的话,程序运行时间长的话内存消耗会很大。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上是Java爬虫在网站上所有链接的详细内容。更多详情请关注html中文网站其他相关文章!
java抓取网页内容(java利用url实现网页内容抓取的相关内容吗,zangcunmiao在本文为您仔细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-13 01:00
想知道java使用url实现网页内容爬取的相关内容吗?在本文中,藏村淼将仔细讲解java实现网页内容抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先重点介绍:java实现网页数据抓取,java实现网页内容抓取,url抓取工具,一起来学习。
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
相关文章 查看全部
java抓取网页内容(java利用url实现网页内容抓取的相关内容吗,zangcunmiao在本文为您仔细讲解)
想知道java使用url实现网页内容爬取的相关内容吗?在本文中,藏村淼将仔细讲解java实现网页内容抓取的相关知识以及一些代码示例。欢迎阅读和指正。我们先重点介绍:java实现网页数据抓取,java实现网页内容抓取,url抓取工具,一起来学习。
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望大家多多支持!
相关文章
java抓取网页内容(用到抓取网页数据的功能:抓取数据功能详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-11 13:14
经常用到抓取网页数据的功能。我在以前的工作中使用过它。我今天总结了一下:
1、 通过指定的 URL 抓取网页数据获取页面信息,然后用 DOM 对页面进行 NODE 分析,处理得到原创的 HTML 数据,这样做的好处是处理的灵活性有一定的块数据高 难点在于切块算法的优化。当页面HTML信息量较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于html页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode、Tag来描述HTML页面的元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需要,映射HTML标签,可以方便的获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java的html解析库,不依赖其他java库文件,主要用于转换或提取html。可以超高速解析html,不会出错。最新版本的 htmlparser 现在是 2.0。可以毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性和性能(包括htmlunit和nekohtml)方面比htmlparser有更好的口碑,nokehtml类似xml解析原理,html标签正确解析为dom 它们对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是一个 Java 语言的 HTML 扫描器和标签平衡器,它使程序能够解析 HTML 文档并使用标准的 XML 接口来访问其中的信息。这个解析器可以扫描 HTML 文件并“纠正”作者(人或机器)在编写 HTML 文档过程中经常犯的许多错误。
NekoHTML 可以添加缺失的父元素,自动关闭带有结束标签的对应元素,以及不匹配的内联元素标签。 NekoHTML 的开发使用 XercesNativeInterface (XNI),它是 Xerces2 的基础。 查看全部
java抓取网页内容(用到抓取网页数据的功能:抓取数据功能详解)
经常用到抓取网页数据的功能。我在以前的工作中使用过它。我今天总结了一下:
1、 通过指定的 URL 抓取网页数据获取页面信息,然后用 DOM 对页面进行 NODE 分析,处理得到原创的 HTML 数据,这样做的好处是处理的灵活性有一定的块数据高 难点在于切块算法的优化。当页面HTML信息量较大时,算法不好,会影响处理效率。
2、htmlparser框架,对于html页面处理的数据结构,HtmlParser采用经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode、Tag来描述HTML页面的元素。 Htmlparser基本可以满足垂直搜索引擎页面处理分析的需要,映射HTML标签,可以方便的获取标签中的HTMLCODE。
Htmlparser官方介绍:htmlparser是一个纯java的html解析库,不依赖其他java库文件,主要用于转换或提取html。可以超高速解析html,不会出错。最新版本的 htmlparser 现在是 2.0。可以毫不夸张地说,htmlparser是目前最好的html解析分析工具。
3、nekohtml框架,nekohtml在容错性和性能(包括htmlunit和nekohtml)方面比htmlparser有更好的口碑,nokehtml类似xml解析原理,html标签正确解析为dom 它们对应DOM树中对应的元素进行处理。
NekoHTML 官方介绍:NekoHTML 是一个 Java 语言的 HTML 扫描器和标签平衡器,它使程序能够解析 HTML 文档并使用标准的 XML 接口来访问其中的信息。这个解析器可以扫描 HTML 文件并“纠正”作者(人或机器)在编写 HTML 文档过程中经常犯的许多错误。
NekoHTML 可以添加缺失的父元素,自动关闭带有结束标签的对应元素,以及不匹配的内联元素标签。 NekoHTML 的开发使用 XercesNativeInterface (XNI),它是 Xerces2 的基础。
java抓取网页内容(爬虫技术可以爬取什么数据?网页数据采集工具哪个好用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-08 10:05
爬虫技术可以抓取哪些数据?
简而言之,爬虫就是一个检测机器。它的基本操作是模拟人类行为,在各种网站中走动,点击按钮,查看数据,或者背诵你看到的信息。这就像一只虫子不知疲倦地在建筑物周围爬行。
因此,爬虫系统有两个功能:
爬虫数据。比如你想知道1000件商品在不同电商网站上的价格,以便得到最低价。手动打开页面太慢,这些网站不断更新价格。可以使用爬虫系统,设置逻辑,帮你从n个网站中抓取想要的商品价格,甚至同时进行比较计算,最后输出报告给你,哪个网站最便宜.
市场上有许多零代码免费爬虫系统。比如为了捕捉不同网站上的两个游戏虚拟物品的差异,我之前用过,很简单。这里没有名字。涉嫌广告。
点击爬虫系统的按钮类似于12306的票务软件,通过n个ID不断访问和触发页面动作。但是正规的还是不错的网站,有反爬虫技术,比如最常见的验证码。
最后,爬虫系统无处不在。你最熟悉的爬虫系统可能是百度。像百度这样的搜索引擎爬虫每隔几天就会扫描整个网页供您查看。
网站数据采集 哪个工具好用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一键移除,支持自动翻页和数据导出功能,对于小白来说,易学易掌握:
这是一款非常不错的国产数据采集软件。比起优采云采集器,比如Octopus的采集器目前只支持windows平台,需要手动设置采集字段和配置规则,比较麻烦和灵活。内置海量数据采集模板,方便采集京东、天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,还有很多其他的软件也支持网站data采集,比如号码、应用策略等也很不错,如果你熟悉使用Python、Java等编程语言,也可以自己编程抓取数据。网上有相关的教程和资料。介绍很详细。有兴趣的可以搜索一下。希望以上分享的内容对您有所帮助。欢迎评论和评论。
java和python在爬取方面的优缺点是什么?
Python
强大的网络功能,模拟登录,解析JavaScript。缺点是网页分析用Python写程序很方便。著名的Python爬虫有scratch等。
爪哇
Java中有很多解析器,对解析网页的支持非常好。缺点是网上有很多Java开源爬虫,比如nutch。国内有优秀的webmagicjava解析器,比如Htmlparser和jsoup,可以满足Java和python的一般需求。如果需要模拟登录和反采集,选择python更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,可以选择Java。
java爬虫会抓取数据吗?
如何通过Java代码实现网页数据的指定爬取,我总结了以下几个步骤会用到Jsoup。Jar打包: 1.将Jsoup.jar文件包导入到项目中 2:获取URL指定的HTML或文档指定的文本 3:获取网页中超链接的标题和链接 4:获取内容指定博客的文章 5:获取网页结果中的超链接Title和link 查看全部
java抓取网页内容(爬虫技术可以爬取什么数据?网页数据采集工具哪个好用)
爬虫技术可以抓取哪些数据?
简而言之,爬虫就是一个检测机器。它的基本操作是模拟人类行为,在各种网站中走动,点击按钮,查看数据,或者背诵你看到的信息。这就像一只虫子不知疲倦地在建筑物周围爬行。
因此,爬虫系统有两个功能:
爬虫数据。比如你想知道1000件商品在不同电商网站上的价格,以便得到最低价。手动打开页面太慢,这些网站不断更新价格。可以使用爬虫系统,设置逻辑,帮你从n个网站中抓取想要的商品价格,甚至同时进行比较计算,最后输出报告给你,哪个网站最便宜.
市场上有许多零代码免费爬虫系统。比如为了捕捉不同网站上的两个游戏虚拟物品的差异,我之前用过,很简单。这里没有名字。涉嫌广告。
点击爬虫系统的按钮类似于12306的票务软件,通过n个ID不断访问和触发页面动作。但是正规的还是不错的网站,有反爬虫技术,比如最常见的验证码。
最后,爬虫系统无处不在。你最熟悉的爬虫系统可能是百度。像百度这样的搜索引擎爬虫每隔几天就会扫描整个网页供您查看。
网站数据采集 哪个工具好用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我就简单介绍一下三种,分别是优采云、章鱼和优采云,操作简单,上手容易学习了解,有兴趣的朋友可以试试:
这是一款非常智能的网络爬虫软件,支持跨平台,个人使用完全免费。对于大多数网站,只需输入URL,软件会自动识别并提取相关字段信息,包括列表、表格、链接、图片等,无需配置任何采集规则,一键移除,支持自动翻页和数据导出功能,对于小白来说,易学易掌握:
这是一款非常不错的国产数据采集软件。比起优采云采集器,比如Octopus的采集器目前只支持windows平台,需要手动设置采集字段和配置规则,比较麻烦和灵活。内置海量数据采集模板,方便采集京东、天猫等热门网站。官方教程很详细,小白很容易掌握:
当然,除了以上三个爬虫软件,还有很多其他的软件也支持网站data采集,比如号码、应用策略等也很不错,如果你熟悉使用Python、Java等编程语言,也可以自己编程抓取数据。网上有相关的教程和资料。介绍很详细。有兴趣的可以搜索一下。希望以上分享的内容对您有所帮助。欢迎评论和评论。
java和python在爬取方面的优缺点是什么?
Python
强大的网络功能,模拟登录,解析JavaScript。缺点是网页分析用Python写程序很方便。著名的Python爬虫有scratch等。
爪哇
Java中有很多解析器,对解析网页的支持非常好。缺点是网上有很多Java开源爬虫,比如nutch。国内有优秀的webmagicjava解析器,比如Htmlparser和jsoup,可以满足Java和python的一般需求。如果需要模拟登录和反采集,选择python更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者精细解析网页内容,可以选择Java。
java爬虫会抓取数据吗?
如何通过Java代码实现网页数据的指定爬取,我总结了以下几个步骤会用到Jsoup。Jar打包: 1.将Jsoup.jar文件包导入到项目中 2:获取URL指定的HTML或文档指定的文本 3:获取网页中超链接的标题和链接 4:获取内容指定博客的文章 5:获取网页结果中的超链接Title和link
java抓取网页内容( Java爬虫爬取网页内容网页内容方法:用apache提供的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-11-08 10:03
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则抓取网页上的信息,通常是在抓取一些网址之后,然后将这些网址放入队列中,反复搜索。
2、Java爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
3、Java爬虫抓取网页内容方法:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。大家可以用代码来使用~ 更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。) 查看全部
java抓取网页内容(
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则抓取网页上的信息,通常是在抓取一些网址之后,然后将这些网址放入队列中,反复搜索。
2、Java爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
3、Java爬虫抓取网页内容方法:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。大家可以用代码来使用~ 更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。)
java抓取网页内容(一个XML元素解析及使用方法-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-07 22:02
(.*?).*?]]>.*?:(.*?)]]>]]>]]>XML 规则:1. 必须定义一个处理程序元素,并且必须至少有一个处理程序元素被包括在内。2.processer 元素收录了所有的流程元素,流程元素定义了页面代码的所有处理流程。3.流程元素包括流、表和字段3个属性。flow 代表流量。即把这个流程元素解析出来的内容作为下一步的内容或者回滚未解析之前的内容。当该值为真时,本步骤的加工结果作为下一步加工的材料,本步骤的加工结果不存入数据库。当值为false时,本步骤的结果仅用于本步骤。下一个分析回滚到本步骤分析之前的内容。table属性定义了本步骤处理结果中要存放的数据库表,fidld属性定义了对应表中的字段。4. 每个进程都必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。
key是指要获取的标签的属性,包括name、id、class等,当然也支持width、href、target等其他属性,支持所有标准的html属性。value 是指这个属性的值。textonly 是指是否只获取该标签内的文本内容。它不包括标签。6.regex-filter 是指正则过滤,获取符合正则表达式的内容。请注意,正则表达式必须放在 CDATA 块中。另外,要获取的内容必须用()括起来,只会获取()中的内容。7.flag-filter 是指标志位过滤,获取2个标志位之间的内容。用户必须确保开头和结尾的标志是唯一的。只有这样,您才能确保得到您想要的东西。获取标志位需要用户查看源码,获取唯一标志。标志过滤是目前主流爬虫工具提供的最常用的方法。解析过程:1.首先获取所有的处理过程2.依次执行。确定流程类型的流程属性,根据流程属性调用不同的处理方法。当为真时,将其剪切,当为假时,将进行分析并保存。3. 根据流属性进入正式分析,判断分析元素过滤器的类型,是target-filter,还是regex-filter还是flag-filter,根据不同的分析调用不同的分析流程类型。
解析过程参考 XML 规则。4.所有进程执行完毕后,系统将所有采集到的字段保存到数据库中。案例抓取javaeye博客内容 本例演示了如何抓取javaeye上的博客文章。博客地址。在爬取之前,我们需要创建一个数据库和表,只需导入示例中使用的数据库表。Step 1:目标定义首先分析页面HashMap、Hashtable、HashSet上文章链接的写法的区别。IE下ZOOM属性导致的渲染问题。Web2.0网站 性能调优 通过这些链接的共同点练习,我们可以很容易的找到它的文章链接的规则,得到这样的正则表达式:href\=\ '(/blog/\d*)\' 注意,我们要得到的只是一个类似于/blog/179642的链接,并没有收录href=之类的东西,所以我们在正则中匹配/blog/179642的部分加上(),系统会自动获取this() 内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。
我们先剪个,把不相关的内容剪掉。我们将流程定义为true,它会返回修剪后的内容。然后我们抓取页眉的标题作为我们保存到数据库中的标题。由于它的复杂性,我们使用正则表达式来获取.*(.*?).*?]]>我们想要获取的部分只是 text ,不需要 HTML 标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。记住:如果你要抓取的内容在两个唯一字符串的中间,那么使用flag方法是最好最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。
.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。请记住:如果您要抓取的内容位于两个唯一字符串的中间,那么使用 flag 方法是最好且最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。 查看全部
java抓取网页内容(一个XML元素解析及使用方法-上海怡健医学())
(.*?).*?]]>.*?:(.*?)]]>]]>]]>XML 规则:1. 必须定义一个处理程序元素,并且必须至少有一个处理程序元素被包括在内。2.processer 元素收录了所有的流程元素,流程元素定义了页面代码的所有处理流程。3.流程元素包括流、表和字段3个属性。flow 代表流量。即把这个流程元素解析出来的内容作为下一步的内容或者回滚未解析之前的内容。当该值为真时,本步骤的加工结果作为下一步加工的材料,本步骤的加工结果不存入数据库。当值为false时,本步骤的结果仅用于本步骤。下一个分析回滚到本步骤分析之前的内容。table属性定义了本步骤处理结果中要存放的数据库表,fidld属性定义了对应表中的字段。4. 每个进程都必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。每个进程必须收录一个处理流程。目前有三个处理程序,tag-filter、regex-filter、flag-filter。5.tag-filter 是指标签过滤,获取指定标签的内容。标签过滤器包括 4 个属性,pos、key、value 和 textonly。pos 指的是 html 标签的位置。如果未指定,则默认为第一个。
key是指要获取的标签的属性,包括name、id、class等,当然也支持width、href、target等其他属性,支持所有标准的html属性。value 是指这个属性的值。textonly 是指是否只获取该标签内的文本内容。它不包括标签。6.regex-filter 是指正则过滤,获取符合正则表达式的内容。请注意,正则表达式必须放在 CDATA 块中。另外,要获取的内容必须用()括起来,只会获取()中的内容。7.flag-filter 是指标志位过滤,获取2个标志位之间的内容。用户必须确保开头和结尾的标志是唯一的。只有这样,您才能确保得到您想要的东西。获取标志位需要用户查看源码,获取唯一标志。标志过滤是目前主流爬虫工具提供的最常用的方法。解析过程:1.首先获取所有的处理过程2.依次执行。确定流程类型的流程属性,根据流程属性调用不同的处理方法。当为真时,将其剪切,当为假时,将进行分析并保存。3. 根据流属性进入正式分析,判断分析元素过滤器的类型,是target-filter,还是regex-filter还是flag-filter,根据不同的分析调用不同的分析流程类型。
解析过程参考 XML 规则。4.所有进程执行完毕后,系统将所有采集到的字段保存到数据库中。案例抓取javaeye博客内容 本例演示了如何抓取javaeye上的博客文章。博客地址。在爬取之前,我们需要创建一个数据库和表,只需导入示例中使用的数据库表。Step 1:目标定义首先分析页面HashMap、Hashtable、HashSet上文章链接的写法的区别。IE下ZOOM属性导致的渲染问题。Web2.0网站 性能调优 通过这些链接的共同点练习,我们可以很容易的找到它的文章链接的规则,得到这样的正则表达式:href\=\ '(/blog/\d*)\' 注意,我们要得到的只是一个类似于/blog/179642的链接,并没有收录href=之类的东西,所以我们在正则中匹配/blog/179642的部分加上(),系统会自动获取this() 内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。并且系统会自动获取这个()内容。请注意, () 是必需的。完整的 XML 文件编写请参考 WEB-INF/example.xml。第2步:切割。先把网页多余的部分去掉,我们剪个头。具体写法参考xml文件。第三步:处理 在处理一个网页之前,我们需要详细分析一下网页的结构,以这个文章为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。@文章 为例。分析处理过程如下: 我们想要的内容在一个id为main的div中。
我们先剪个,把不相关的内容剪掉。我们将流程定义为true,它会返回修剪后的内容。然后我们抓取页眉的标题作为我们保存到数据库中的标题。由于它的复杂性,我们使用正则表达式来获取.*(.*?).*?]]>我们想要获取的部分只是 text ,不需要 HTML 标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。记住:如果你要抓取的内容在两个唯一字符串的中间,那么使用flag方法是最好最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。Capture 只要执行 SystemCore 并把要执行的 xml 文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。(.*?).*?]]>我们想要获取的部分只是文本,不需要html标签。因此,我们将与文本内容匹配的部分放在()中。请注意, () 是必需的。接下来,获取它的关键字作为文章的标签,我们也用regular来完成。
.*?:(.*?)]]>最终得到文章的内容。这里我们使用一个更简单的方法,flag方法。我们发现文章的所有正文内容都在这两个字符串之间。这两个字符串是唯一的,不会重复。对于这种情况,使用标志位方法是最好和最简单的。请记住:如果您要抓取的内容位于两个唯一字符串的中间,那么使用 flag 方法是最好且最简单的方法。]]>]]>第4步:捕获只要执行SystemCore,并将要执行的xml文件名作为参数,任务就会启动。可以同时观察数据库和控制台,观察爬取进度。
java抓取网页内容(java抓取网页内容的套路-mysql.0的创建方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-07 09:10
java抓取网页内容的套路,实现一套自动化工具,目的是更好更方便的去监控网页的工作流程。业务场景需求:用户打开同一个页面不同的图片不同色彩色彩不同图片后可以回调别的画面信息需要有地理位置、色彩、声音等。目前采用的java版本:java7.0,java8。数据库版本:mysql基础代码:首先我们来定义一个整体数据库和java类文件的创建方法:javadataframe结构-faj8dkplj-博客园第一步,我们先搭建一个服务器(server)。
我们的要求是服务器具有3g的内存,8g的cpu,32g的内存,2个ssd硬盘,1个macbookair(256g硬盘)。第二步,我们来定义一个javaapi,这个api继承自java.util.java.arraylist,这个api提供了java.util.java.arraylist,java.util.java.arraylist的api用于给arraylist的操作提供操作方法。
api采用有序插入list集合,也就是任何数组集合的元素都需要放到集合中,并且每个元素都有重复的元素。在java.util.arraylist中的元素是可以通过iterator迭代的。javastringj="1234567890";iteratoriter=arrays.stream(j);hashmaphashmap=newhashmap();stringhash="(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,58..)";//我们先定义一个字符串的规则//字符串规则,把我们定义的规则存到一个字符串integer中,不管两个字符串是多么相似,只要第三个字符为空,我们的字符串都返回为空//(如果没有,强制为空integer[]a=initialize("1234567890");if((a=a.isempty())!=null){thrownewillegalargumentexception("");}其实就是一个遍历字符串,判断为空,然后给出自定义函数的思想,比如我们定义一个循环字符串,遍历字符串..遍历字符串..循环字符串..遍历字符串..遍历字符串..遍历字符串..循环字符串..最后返回结果"1234567890"。
//即使多列//比如:我们要从空字符串中去出a,b,c;d.f(x);e.g(x);if(""!=""){b="";x=d;}thrownewillegalargumentexception("");if(ite。 查看全部
java抓取网页内容(java抓取网页内容的套路-mysql.0的创建方法)
java抓取网页内容的套路,实现一套自动化工具,目的是更好更方便的去监控网页的工作流程。业务场景需求:用户打开同一个页面不同的图片不同色彩色彩不同图片后可以回调别的画面信息需要有地理位置、色彩、声音等。目前采用的java版本:java7.0,java8。数据库版本:mysql基础代码:首先我们来定义一个整体数据库和java类文件的创建方法:javadataframe结构-faj8dkplj-博客园第一步,我们先搭建一个服务器(server)。
我们的要求是服务器具有3g的内存,8g的cpu,32g的内存,2个ssd硬盘,1个macbookair(256g硬盘)。第二步,我们来定义一个javaapi,这个api继承自java.util.java.arraylist,这个api提供了java.util.java.arraylist,java.util.java.arraylist的api用于给arraylist的操作提供操作方法。
api采用有序插入list集合,也就是任何数组集合的元素都需要放到集合中,并且每个元素都有重复的元素。在java.util.arraylist中的元素是可以通过iterator迭代的。javastringj="1234567890";iteratoriter=arrays.stream(j);hashmaphashmap=newhashmap();stringhash="(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,58..)";//我们先定义一个字符串的规则//字符串规则,把我们定义的规则存到一个字符串integer中,不管两个字符串是多么相似,只要第三个字符为空,我们的字符串都返回为空//(如果没有,强制为空integer[]a=initialize("1234567890");if((a=a.isempty())!=null){thrownewillegalargumentexception("");}其实就是一个遍历字符串,判断为空,然后给出自定义函数的思想,比如我们定义一个循环字符串,遍历字符串..遍历字符串..循环字符串..遍历字符串..遍历字符串..遍历字符串..循环字符串..最后返回结果"1234567890"。
//即使多列//比如:我们要从空字符串中去出a,b,c;d.f(x);e.g(x);if(""!=""){b="";x=d;}thrownewillegalargumentexception("");if(ite。

