
excel抓取多页网页数据
excel抓取多页网页数据(PowerQuery网络抓取核心工作:M函数抓取步骤(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-30 11:36
这段时间写了很多关于爬虫的文章。很多网友可能对网络爬虫还有疑问,是否走到了法律的边缘,担心跨省。事实上,我们使用 Power Query 的大部分网页抓取行为都是正常的数据采集
工作。我们没有打破从后台下载数据的防御。这些都是黑客干的。Power Query 网页抓取使用正常的网页访问来获取数据,但它比手动翻页稍微自动化一些。
数据类型
如果从捕获的数据类型来看,我们分为两类:
爬行步骤
如果从爬行步骤来分类,也是两步:
为什么我们常说的四步没有变成两步呢?
这里提到的步骤简单的参考了我们M函数在网络爬虫中的步骤。
第一步:抓取网页的内容,都是Contents,最后的M函数
第二步:对网页内容进行分析,对第一步抓取的网页内容进行分析,如text、json、xml、csv、table等。
我们在之前的网页爬取文章中很少提到具体的功能,因为大部分网页爬取功能的应用都是Power Query自动为我们生成的。回过头来看,这就是我们现在看到的。.
因此,网页抓取有两个核心任务:
M功能
我们常用的函数组合:
这是一个简短的谈话:
综上所述,Power Query 网络爬取并不是很复杂。复杂的是,奇怪的网站有很多,每个网站都有自己的差异,所以我们必须做好网站分析,不断尝试,我们总会找到办法的。 查看全部
excel抓取多页网页数据(PowerQuery网络抓取核心工作:M函数抓取步骤(图))
这段时间写了很多关于爬虫的文章。很多网友可能对网络爬虫还有疑问,是否走到了法律的边缘,担心跨省。事实上,我们使用 Power Query 的大部分网页抓取行为都是正常的数据采集
工作。我们没有打破从后台下载数据的防御。这些都是黑客干的。Power Query 网页抓取使用正常的网页访问来获取数据,但它比手动翻页稍微自动化一些。
数据类型
如果从捕获的数据类型来看,我们分为两类:
爬行步骤
如果从爬行步骤来分类,也是两步:
为什么我们常说的四步没有变成两步呢?
这里提到的步骤简单的参考了我们M函数在网络爬虫中的步骤。
第一步:抓取网页的内容,都是Contents,最后的M函数
第二步:对网页内容进行分析,对第一步抓取的网页内容进行分析,如text、json、xml、csv、table等。
我们在之前的网页爬取文章中很少提到具体的功能,因为大部分网页爬取功能的应用都是Power Query自动为我们生成的。回过头来看,这就是我们现在看到的。.
因此,网页抓取有两个核心任务:
M功能
我们常用的函数组合:
这是一个简短的谈话:
综上所述,Power Query 网络爬取并不是很复杂。复杂的是,奇怪的网站有很多,每个网站都有自己的差异,所以我们必须做好网站分析,不断尝试,我们总会找到办法的。
excel抓取多页网页数据(2017-08-05怎么从网站上抓取数据?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-27 07:03
2017-08-05
如何从网站抓取数据?
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。当然,服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法上,各种搜索引擎......
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。
网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。
当然,在服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法方面,搜索引擎技术公司可能有所不同,但目的是浏览网页并配合后续过程。目前国内的搜索引擎技术公司,如百度的网络蜘蛛,采用的是可定制的、高度可扩展的调度算法,使搜索者能够在极短的时间内采集
到大量的互联网信息,并将获取的信息保存下来供用户使用。建立索引数据库和用户检索。 查看全部
excel抓取多页网页数据(2017-08-05怎么从网站上抓取数据?())
2017-08-05
如何从网站抓取数据?
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。当然,服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法上,各种搜索引擎......
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。
网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。
当然,在服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法方面,搜索引擎技术公司可能有所不同,但目的是浏览网页并配合后续过程。目前国内的搜索引擎技术公司,如百度的网络蜘蛛,采用的是可定制的、高度可扩展的调度算法,使搜索者能够在极短的时间内采集
到大量的互联网信息,并将获取的信息保存下来供用户使用。建立索引数据库和用户检索。
excel抓取多页网页数据(网页中表格数据指什么样子?如何做到批量采集100页或1000页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 719 次浏览 • 2021-12-26 04:15
这种需求似乎很少有人需要,但我认为总会有需求的那一天。
网页中的表格数据是什么意思?
比如这个我今天想举个例子:
这个产品成分表只是一个数据表。
我们一般使用优采云
等采集
器来采集
这类数据,并保持原有的结构。
还有优采云
采集器,可以智能识别采集表数据,但是很多网站无法识别。我上面提到的例子无法识别,因此无法采集
。
但其实excel中有一个功能可以采集网页中的表格,但是缺点是一次只能采集一个页面。如何批量采集100页或1000页数据?不能一一手动吗?
经过反复试验,我终于使用了excel的采集
表格功能。但是,我先把这100或1000页的内容采集
起来形成一个页面,然后我可以用excel来识别它。
以下是步骤:
1:优采云
采集
需要的页面
例如,我首先采集
这些页面的 URL。
2、 然后整理出来导入优采云
采集
器
这里注意一定要作为一级页面使用,否则会自动采集
低级页面。老版本的优采云
采集
器没有这个问题。
3、然后使用表格的部分html代码
这里我们用最简单的方式抓取前后的内容,我们来测试一下
访问此类内容正是我们所需要的。
4、批量采集
然后保存任务并批量采集
。
5、采集
完成
新版本的优采云
采集
器默认保存本地sqlite数据库,没有老版本的access数据库,所以不能用office中的access打开,但是可以用Navicat导入。
链接sqlite,然后选择我们采集
到的db3文件,打开确认。
获取以下数据。
6、合并采集
到的数据
如果你不知道如何合并数据库中的数据,也很简单,直接导出excel。
你会在excel中合并吗?即使没有,只需选择要复制的列。
那我们贴出来看看。
得到这样的内容。
直接以html文件的形式保存到桌面。
7、excel被识别为表格数据
我们在excel-new query-from the website中选择数据(我的excel版本用的是那个按钮不好用的红框)
然后填写刚才的html文件的本地地址,确认
Excel 会识别多种样式的数据,只需选择您想要的一种。
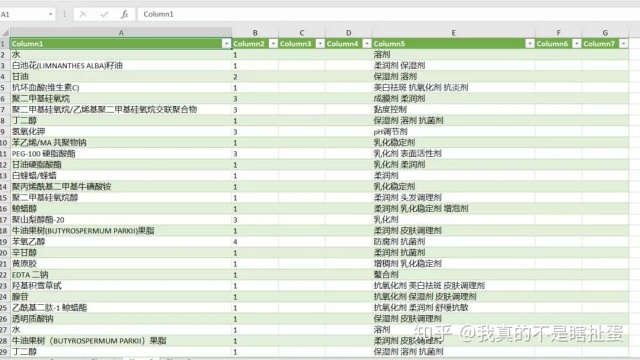
8、最终效果
我们得到的最终渲染是这样的,因为我只采集
了72页,得到了1600行数据。
在这一点上,你完成了。 查看全部
excel抓取多页网页数据(网页中表格数据指什么样子?如何做到批量采集100页或1000页)
这种需求似乎很少有人需要,但我认为总会有需求的那一天。
网页中的表格数据是什么意思?
比如这个我今天想举个例子:
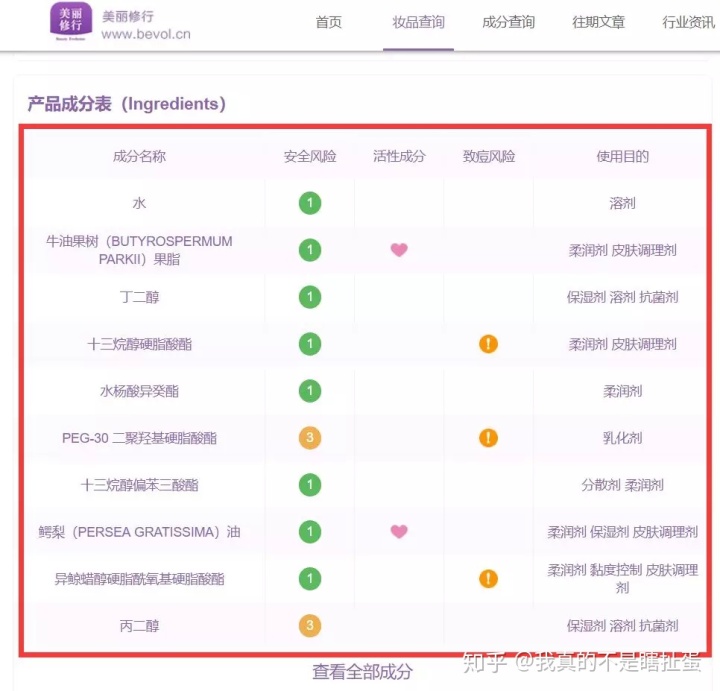
这个产品成分表只是一个数据表。
我们一般使用优采云
等采集
器来采集
这类数据,并保持原有的结构。
还有优采云
采集器,可以智能识别采集表数据,但是很多网站无法识别。我上面提到的例子无法识别,因此无法采集
。
但其实excel中有一个功能可以采集网页中的表格,但是缺点是一次只能采集一个页面。如何批量采集100页或1000页数据?不能一一手动吗?
经过反复试验,我终于使用了excel的采集
表格功能。但是,我先把这100或1000页的内容采集
起来形成一个页面,然后我可以用excel来识别它。
以下是步骤:
1:优采云
采集
需要的页面

例如,我首先采集
这些页面的 URL。
2、 然后整理出来导入优采云
采集
器
这里注意一定要作为一级页面使用,否则会自动采集
低级页面。老版本的优采云
采集
器没有这个问题。
3、然后使用表格的部分html代码
这里我们用最简单的方式抓取前后的内容,我们来测试一下
访问此类内容正是我们所需要的。
4、批量采集
然后保存任务并批量采集
。
5、采集
完成
新版本的优采云
采集
器默认保存本地sqlite数据库,没有老版本的access数据库,所以不能用office中的access打开,但是可以用Navicat导入。
链接sqlite,然后选择我们采集
到的db3文件,打开确认。
获取以下数据。
6、合并采集
到的数据
如果你不知道如何合并数据库中的数据,也很简单,直接导出excel。
你会在excel中合并吗?即使没有,只需选择要复制的列。
那我们贴出来看看。
得到这样的内容。

直接以html文件的形式保存到桌面。
7、excel被识别为表格数据
我们在excel-new query-from the website中选择数据(我的excel版本用的是那个按钮不好用的红框)
然后填写刚才的html文件的本地地址,确认
Excel 会识别多种样式的数据,只需选择您想要的一种。
8、最终效果
我们得到的最终渲染是这样的,因为我只采集
了72页,得到了1600行数据。
在这一点上,你完成了。
excel抓取多页网页数据(安装pip-Python的安装包管理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-25 13:07
安装pip-Python安装包管理工具
Mac有自己的Python,我的mac系统是Sierra,自己的python版本是Python 2.7.13
sudo easy_install pip
相关工具安装:
1、网络请求工具
pip install lxml pip 安装请求
2、网页数据分析工具
pip install beautifulsoup4
3、解析器
pip 安装 html5lib
示例1:获取我的短书首页显示的所有文章标题
( )
查看网页元素如下:
查看网页元素
Python 代码展示:
from lxml import html
from lxml import etree
from urllib import urlopen
import requests
import bs4
from bs4 import BeautifulSoup
import html5lib
//网页数据获取
examplePage = urlopen('http://www.jianshu.com/u/5b771dd604fd')
//HTML数据
soupExam = BeautifulSoup(examplePage,"html5lib")
//网页标题
print soupExam.title
print soupExam.title.string
//文章标题
for link in soupExam.find_all('a',class_ = 'title'):
print(link.text)
输出结果如下:
输出结果
示例二:部分网站存在以下问题
1、想获取红标处的数据:
期望值
2、但是你得到的是文本中的文本内容:
结果值
问题原因如下:
(1)后台脚本请求网络数据,需要账号相关数据,解决办法是添加cookies;
(2)网页有刷新机制,首先获取的数据处于刷新状态,解决方法是休眠一段时间; 查看全部
excel抓取多页网页数据(安装pip-Python的安装包管理工具)
安装pip-Python安装包管理工具
Mac有自己的Python,我的mac系统是Sierra,自己的python版本是Python 2.7.13
sudo easy_install pip
相关工具安装:
1、网络请求工具
pip install lxml pip 安装请求
2、网页数据分析工具
pip install beautifulsoup4
3、解析器
pip 安装 html5lib
示例1:获取我的短书首页显示的所有文章标题
( )
查看网页元素如下:

查看网页元素
Python 代码展示:
from lxml import html
from lxml import etree
from urllib import urlopen
import requests
import bs4
from bs4 import BeautifulSoup
import html5lib
//网页数据获取
examplePage = urlopen('http://www.jianshu.com/u/5b771dd604fd')
//HTML数据
soupExam = BeautifulSoup(examplePage,"html5lib")
//网页标题
print soupExam.title
print soupExam.title.string
//文章标题
for link in soupExam.find_all('a',class_ = 'title'):
print(link.text)
输出结果如下:

输出结果
示例二:部分网站存在以下问题
1、想获取红标处的数据:

期望值
2、但是你得到的是文本中的文本内容:

结果值
问题原因如下:
(1)后台脚本请求网络数据,需要账号相关数据,解决办法是添加cookies;
(2)网页有刷新机制,首先获取的数据处于刷新状态,解决方法是休眠一段时间;
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-25 13:03
大家好~
Excel和python是目前比较流行的两种数据分析处理工具,两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有哪些相同点和不同点。
上图为证监会上海IPO公司相关信息。我们需要提取表格数据,分别使用Excel和python。
电子表格
Excel提供了两种获取网页数据的方法,第一种是数据——来自网站功能,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要二次采集,在效率上,第二种方法比第一种方法好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。, 代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的高效和便捷。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
搞清楚规则后,用一个循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为? 查看全部
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前比较流行的两种数据分析处理工具,两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有哪些相同点和不同点。

上图为证监会上海IPO公司相关信息。我们需要提取表格数据,分别使用Excel和python。
电子表格
Excel提供了两种获取网页数据的方法,第一种是数据——来自网站功能,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。

程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。

方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。

然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。

这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要二次采集,在效率上,第二种方法比第一种方法好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。, 代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:

没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的高效和便捷。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?

在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:

观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
搞清楚规则后,用一个循环依次抓取50页数据。

与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为?
excel抓取多页网页数据(先决条件PowerPivot(PowerQuery)在哪里?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-25 12:16
数据模型允许您集成来自多个表的数据,从而有效地在工作簿中构建 Excel 数据源。在 Excel 中,数据模型以透明的方式使用,提供用于数据透视表和数据透视图的表格数据。数据模型被可视化为字段列表中表的集合,并且在大多数情况下,您甚至永远不会知道它在该集合中。
在开始使用数据模型之前,您需要获取一些数据。为此,我们将使用 Power Query 体验,因此您可能需要退后一步观看视频,或按照有关获取和转换和 Power Pivot 的学习指南进行操作。
先决条件
Power Pivot 在哪里?
从 Power Query &? 获取(转换)
开始
首先,需要获取一些数据。
在 Excel 2016 和 Microsoft 365 专用 Excel 中,使用数据>获取和转换数据>从任意数量的外部数据源(例如文本文件、Excel 工作簿、网站、Microsoft Access、SQL Server 或其他收录
多个相关数据的相关表)获取数据表)关系数据库)来导入数据。
在 Excel 2013 和 2010 中,转到“Power Query>获取外部数据”并选择数据源。
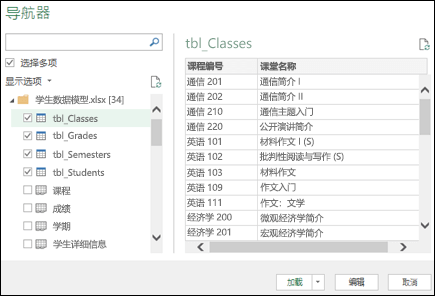
Excel 将提示您选择一个表格。如果要从同一数据源获取多个表,请选中“启用多个表选择”选项。选择多个表时,Excel 会自动创建数据模型。
注意:对于这些示例,我们将使用收录
Excel 中虚构学生详细信息和成绩的工作簿。您可以下载我们的学生数据模型示例工作簿并按照说明进行操作。您还可以下载收录
完整数据模型的版本。.
选择一个或多个表,然后单击“加载”。
如果需要编辑源数据,可以选择“编辑”选项。更多信息请参考:Power Query(查询编辑器)。
现在数据模型收录
所有导入的表,这些表将显示在数据透视表字段列表中。
注意:
提示:如何判断工作簿是否有数据模型?转到 Power Pivot > 管理。如果您看到类似于工作表的数据,则表明存在模型。有关更多信息,请参阅:了解工作簿数据模型中使用了哪些数据源。
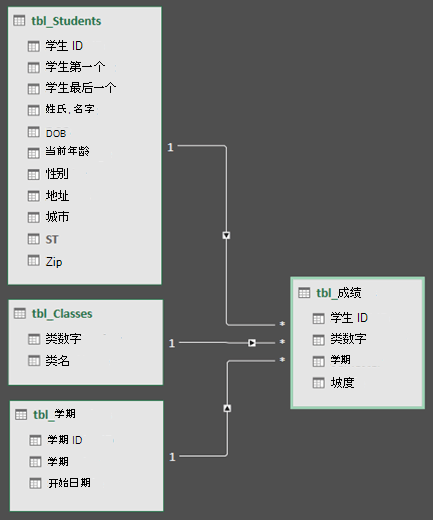
创建表之间的关系
下一步是在表之间创建关系,以便可以从任何表中提取数据。每个表都需要有一个主键或唯一的字段标识符,例如学生 ID 或班级编号。最简单的方法是拖放这些字段以在 Power Pivot 的图形视图中连接它们。
转到“Power Pivot”>“管理”。
在“主页”选项卡上,选择“插图视图”。
将显示所有导入的表,并且可能需要一些时间来调整它们的大小,具体取决于每个表中的字段数。
接下来,将主键字段从一个表拖到下一个表。以下示例是学生表的图形视图:
我们创建了以下链接:
注意:
使用数据模型创建数据透视表或数据透视图
一个 Excel 工作簿只能收录
一个数据模型,但该模型收录
可在整个工作簿中重复使用的多个表。您可以随时向现有数据模型添加更多表。
在 Power Pivot 中,转到“管理”。
在“主页”选项卡上,选择“数据透视表”。 查看全部
excel抓取多页网页数据(先决条件PowerPivot(PowerQuery)在哪里?(图))
数据模型允许您集成来自多个表的数据,从而有效地在工作簿中构建 Excel 数据源。在 Excel 中,数据模型以透明的方式使用,提供用于数据透视表和数据透视图的表格数据。数据模型被可视化为字段列表中表的集合,并且在大多数情况下,您甚至永远不会知道它在该集合中。
在开始使用数据模型之前,您需要获取一些数据。为此,我们将使用 Power Query 体验,因此您可能需要退后一步观看视频,或按照有关获取和转换和 Power Pivot 的学习指南进行操作。
先决条件
Power Pivot 在哪里?
从 Power Query &? 获取(转换)
开始
首先,需要获取一些数据。
在 Excel 2016 和 Microsoft 365 专用 Excel 中,使用数据>获取和转换数据>从任意数量的外部数据源(例如文本文件、Excel 工作簿、网站、Microsoft Access、SQL Server 或其他收录
多个相关数据的相关表)获取数据表)关系数据库)来导入数据。
在 Excel 2013 和 2010 中,转到“Power Query>获取外部数据”并选择数据源。
Excel 将提示您选择一个表格。如果要从同一数据源获取多个表,请选中“启用多个表选择”选项。选择多个表时,Excel 会自动创建数据模型。
注意:对于这些示例,我们将使用收录
Excel 中虚构学生详细信息和成绩的工作簿。您可以下载我们的学生数据模型示例工作簿并按照说明进行操作。您还可以下载收录
完整数据模型的版本。.
选择一个或多个表,然后单击“加载”。
如果需要编辑源数据,可以选择“编辑”选项。更多信息请参考:Power Query(查询编辑器)。
现在数据模型收录
所有导入的表,这些表将显示在数据透视表字段列表中。
注意:
提示:如何判断工作簿是否有数据模型?转到 Power Pivot > 管理。如果您看到类似于工作表的数据,则表明存在模型。有关更多信息,请参阅:了解工作簿数据模型中使用了哪些数据源。
创建表之间的关系
下一步是在表之间创建关系,以便可以从任何表中提取数据。每个表都需要有一个主键或唯一的字段标识符,例如学生 ID 或班级编号。最简单的方法是拖放这些字段以在 Power Pivot 的图形视图中连接它们。
转到“Power Pivot”>“管理”。
在“主页”选项卡上,选择“插图视图”。
将显示所有导入的表,并且可能需要一些时间来调整它们的大小,具体取决于每个表中的字段数。
接下来,将主键字段从一个表拖到下一个表。以下示例是学生表的图形视图:
我们创建了以下链接:
注意:
使用数据模型创建数据透视表或数据透视图
一个 Excel 工作簿只能收录
一个数据模型,但该模型收录
可在整个工作簿中重复使用的多个表。您可以随时向现有数据模型添加更多表。
在 Power Pivot 中,转到“管理”。
在“主页”选项卡上,选择“数据透视表”。
excel抓取多页网页数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-12-25 12:04
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文介绍如何使用PowerBI批量采集多个网页的数据。
本文以兆联招聘网站为例,采集
上海的招聘信息。
以下是详细步骤:
(一)解析URL结构
打开兆联招聘网站,搜索上海工作地点的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集
第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击OK后,出来了很多表,
从这里可以看出,兆联招聘网站上的每一条招聘信息都是一个表格,不用管它,随意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样就采集
到了第一页的数据。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
在这里整理完第一页的数据后,在采集
下面的其他页时,数据结构会与排序后的第一页的数据结构保持一致。采集到的数据可直接使用;这里不排序也无所谓,可以等所有的页面都采集
到一起整理数据。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一个页面。如果可以采集
,则使用上述步骤。如果不能采集
,就没有必要拖延时间。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的网站数据。 查看全部
excel抓取多页网页数据(
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文介绍如何使用PowerBI批量采集多个网页的数据。
本文以兆联招聘网站为例,采集
上海的招聘信息。
以下是详细步骤:
(一)解析URL结构
打开兆联招聘网站,搜索上海工作地点的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集
第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击OK后,出来了很多表,
从这里可以看出,兆联招聘网站上的每一条招聘信息都是一个表格,不用管它,随意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样就采集
到了第一页的数据。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
在这里整理完第一页的数据后,在采集
下面的其他页时,数据结构会与排序后的第一页的数据结构保持一致。采集到的数据可直接使用;这里不排序也无所谓,可以等所有的页面都采集
到一起整理数据。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一个页面。如果可以采集
,则使用上述步骤。如果不能采集
,就没有必要拖延时间。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的网站数据。
excel抓取多页网页数据(如何设置瀑布流+页码页码数据?操作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-12-24 05:12
通过前几节课的学习,我们学习了【采集单数据】、【多列表数据】、【表格数据】,点击链接进入【详情页数据】。】每日采集数据,网页数据不止一页,会有很多页,我们来学习如何设置分页数据,采集多页多数据?
首先介绍几种常见的分页类型以及如何使用优采云采集分页方式。
一、自动识别分页
优采云识别90%分页元素的操作如下: 选择分页设置-自动分页识别,识别成功后会提示已识别分页元素。
操作流程如下:
二、手动设置分页
有少量网站,自动识别分页不成功,这时候我们需要手动设置分页。手动分页分为两步:
01:选择分页设置-手动设置分页
02:点击选择分页元素,在浏览器中找到下一个页面元素点击
操作流程如下:
三、瀑布式寻呼
在日常采集中,我遇到很多使用瀑布分页技术的网页,比如百度图片、知乎、今日头条,这类网页,随着鼠标向下滑动,不断加载新数据。
操作如下:选择分页设置-瀑布分页采集器会自动滚动到网页,直到分页完成。
四、瀑布流+页码的组合形式
在每天的采集中,有少量的网站分页符比较特殊。例如,向下滚动 5 次后,将显示页码。这时候我们就需要使用瀑布流+页码的形式来完成页面设置。
如何判断瀑布分页?
我们以京东商品搜索为例。
在起始页的输入框中输入目标URL,点击下一步,优采云自动识别产品列表(注意:本站需要登录,点击登录,关闭即可)。
可以看到优采云的第一页自动识别了30个产品列表,但第一页实际上有60个产品列表。下面,将优采云中的产品列表从上往下滚动,刷新后查看列表数据,可以看到60个产品列表都被识别出来了,可以判断这是瀑布式加载。
如何设置瀑布流+分页页码?
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体网站需要测试。
以如下京东商品搜索为例:%E5%BE%AE%E6%B3%A2%E7%82%89&enc=utf-8&suggest=4.his.0.0&wq=&pvid=2d6c994230244efaa9d609c1
Step1:分页设置-瀑布分页
Step2:点击script command-add command-scroll
(注:通过不断的调整和测试,滚动几页和滚动间隔时间的具体设置需要针对具体网站进行测试。最终目的是滚动整个页面,从上到下滚动)
3:设置
其他设置中勾选页面上的Execute 采集脚本,这样每次打开页面都会执行scroll命令。
通过以上操作,一个完整的瀑布流+分页页码组合,我们就设置好了。
人性化设置:
1、设置采集最大分页
这个设置在更新采集时被广泛使用,非常方便。比如每天更新的网站的内容在前3页,我们可以设置最大分页为3页,这样优采云就是采集更新前3页数据,节省时间和准确性采集。
2、加载更多表单
某些网站 下一页会使用像Load More 这样的按钮,单击它可以显示更多数据。采集对于这种类型的页面,我们需要手动设置分页,只需点击加载更多作为下一页按钮。
通过本次讲座,我们掌握了优采云三种寻呼方式,自动识别寻呼>手动寻呼>瀑布寻呼,这三种类型覆盖了全网99%的寻呼元素。 查看全部
excel抓取多页网页数据(如何设置瀑布流+页码页码数据?操作流程)
通过前几节课的学习,我们学习了【采集单数据】、【多列表数据】、【表格数据】,点击链接进入【详情页数据】。】每日采集数据,网页数据不止一页,会有很多页,我们来学习如何设置分页数据,采集多页多数据?
首先介绍几种常见的分页类型以及如何使用优采云采集分页方式。
一、自动识别分页
优采云识别90%分页元素的操作如下: 选择分页设置-自动分页识别,识别成功后会提示已识别分页元素。

操作流程如下:

二、手动设置分页
有少量网站,自动识别分页不成功,这时候我们需要手动设置分页。手动分页分为两步:
01:选择分页设置-手动设置分页
02:点击选择分页元素,在浏览器中找到下一个页面元素点击

操作流程如下:

三、瀑布式寻呼
在日常采集中,我遇到很多使用瀑布分页技术的网页,比如百度图片、知乎、今日头条,这类网页,随着鼠标向下滑动,不断加载新数据。
操作如下:选择分页设置-瀑布分页采集器会自动滚动到网页,直到分页完成。

四、瀑布流+页码的组合形式
在每天的采集中,有少量的网站分页符比较特殊。例如,向下滚动 5 次后,将显示页码。这时候我们就需要使用瀑布流+页码的形式来完成页面设置。
如何判断瀑布分页?
我们以京东商品搜索为例。
在起始页的输入框中输入目标URL,点击下一步,优采云自动识别产品列表(注意:本站需要登录,点击登录,关闭即可)。
可以看到优采云的第一页自动识别了30个产品列表,但第一页实际上有60个产品列表。下面,将优采云中的产品列表从上往下滚动,刷新后查看列表数据,可以看到60个产品列表都被识别出来了,可以判断这是瀑布式加载。

如何设置瀑布流+分页页码?
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体网站需要测试。
以如下京东商品搜索为例:%E5%BE%AE%E6%B3%A2%E7%82%89&enc=utf-8&suggest=4.his.0.0&wq=&pvid=2d6c994230244efaa9d609c1
Step1:分页设置-瀑布分页

Step2:点击script command-add command-scroll
(注:通过不断的调整和测试,滚动几页和滚动间隔时间的具体设置需要针对具体网站进行测试。最终目的是滚动整个页面,从上到下滚动)

3:设置
其他设置中勾选页面上的Execute 采集脚本,这样每次打开页面都会执行scroll命令。

通过以上操作,一个完整的瀑布流+分页页码组合,我们就设置好了。
人性化设置:
1、设置采集最大分页
这个设置在更新采集时被广泛使用,非常方便。比如每天更新的网站的内容在前3页,我们可以设置最大分页为3页,这样优采云就是采集更新前3页数据,节省时间和准确性采集。

2、加载更多表单
某些网站 下一页会使用像Load More 这样的按钮,单击它可以显示更多数据。采集对于这种类型的页面,我们需要手动设置分页,只需点击加载更多作为下一页按钮。
通过本次讲座,我们掌握了优采云三种寻呼方式,自动识别寻呼>手动寻呼>瀑布寻呼,这三种类型覆盖了全网99%的寻呼元素。
excel抓取多页网页数据(本文便教大家不懂网页代码也能轻松采集网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-24 05:09
<p>如何轻松获取网页数据 很多用户并不了解爬虫代码,但是他们对网页数据有着迫切的需求。这篇文章教你在不了解web代码的情况下,轻松采集 web数据。本文使用的工具是优采云采集器,优采云是通用的网页数据采集器,可以方便的从各种优采云< @采集器 在短时间内。@网站或网页获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、标准化,摆脱对人工搜索和数据采集,从而降低获取信息的成本,提高效率。本文示例以今日头条 查看全部
excel抓取多页网页数据(一下Excel获取网页内容的快速处理方法,你是否已经掌握了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-24 05:07
无论谁使用电脑,都可能会发现Excel获取网页内容的问题。用户通过Excel获取网页内容很是苦恼。到底是怎么回事?Excel处理网页内容的简便方法是什么,其实只要按照STEP1 第一步,我们打开IE浏览器,自由进入一个网站需要复制的浏览网页。STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。完成它很容易。以下是如何快速处理 Excel 对 Web 内容的访问:
当我们在一些相对较大的门户上浏览时需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示“新建Web查询”信息。当我们等待网页完全显示时,找到左下角的“完成”提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容进行“导入”操作。
STEP5 接下来,我们在弹出的窗口中找到“确定”信息,将文本和表格信息导入Excel,其他无用格式会自动过滤掉。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧! 查看全部
excel抓取多页网页数据(一下Excel获取网页内容的快速处理方法,你是否已经掌握了)
无论谁使用电脑,都可能会发现Excel获取网页内容的问题。用户通过Excel获取网页内容很是苦恼。到底是怎么回事?Excel处理网页内容的简便方法是什么,其实只要按照STEP1 第一步,我们打开IE浏览器,自由进入一个网站需要复制的浏览网页。STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。完成它很容易。以下是如何快速处理 Excel 对 Web 内容的访问:
当我们在一些相对较大的门户上浏览时需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。

具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示“新建Web查询”信息。当我们等待网页完全显示时,找到左下角的“完成”提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容进行“导入”操作。
STEP5 接下来,我们在弹出的窗口中找到“确定”信息,将文本和表格信息导入Excel,其他无用格式会自动过滤掉。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!
excel抓取多页网页数据(Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-20 00:03
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章将介绍如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击OK后,出来了很多表,
从这里可以看出,智联招聘网站上的每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页面时,数据结构会和完成后第一页的数据结构相同。采集的数据可以直接使用;这里不排序也没关系,可以等到采集所有网页数据都排序在一起。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:(p as number) as table =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
更改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(Excel中的Powerquery可以同样操作(一)(组图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章将介绍如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击OK后,出来了很多表,
从这里可以看出,智联招聘网站上的每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页面时,数据结构会和完成后第一页的数据结构相同。采集的数据可以直接使用;这里不排序也没关系,可以等到采集所有网页数据都排序在一起。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:(p as number) as table =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
更改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
excel抓取多页网页数据(图8.55合并单元格跨页时的打印效果解题步骤Excel的内置工具不足以解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-12-18 15:18
当工作表中存在大量合并单元格时,可以在打印后将合并单元格打印在两页上。一页有文字,另一页空白,影响文件美观。
图中8.54,A53:A58为合并后的单元格。分页时,A53:A54 区域划分为上一页,A55:A58 区域划分为下一页。打印后上一页看不到省名,给查看报表带来不便。有没有办法快速重新整理A列的合并单元格,让所有跨页的合并单元格都被拆分和重新组织,这样每一页都可以看到文字?
图8.54 跨页合并单元格时的打印效果
问题解决步骤
Excel 的内置工具不足以解决这个问题。作者使用VBA开发了一个通用工具,叫做“跨页面重组和合并单元格”。使用此工具,您可以立即重新组织和合并单元格。具体步骤如下。
1.打开如图所示的工作簿8.54,然后打开“跨页重新组织和合并单元格.xlam”,在“开始”选项卡中会看到该图8. 55显示新菜单。
图8.55 插件生成的新建菜单
“Reorganize Spread and Merge Cells.xlam”插件位于随书提供的案例文件中的“Chapter 8 Print Settings”文件夹中。
2.点击菜单“跨页重组合并”,在弹出的对话框中输入“a:a”,表示要调整的合并单元格在A列。对话框内容如图如图8.56 所示。
图8.56 指定要重组的对象
3.点击“确定”按钮执行重组。重组效果如图8.57。
图8.57 重新合并的效果
图中8.57,将原来的合并单元格A53:A58拆分为两个合并单元格,每个合并单元格打印在单独的页面上。
知识拓展
1. “Reorganize Spread Merge Cells.xlam”插件是用VBA开发的工具。该工具提供的菜单和代码在“Reorganize Spread Merge Cells.xlam”文件中,所以在打开该文件之前必须使用该工具,否则无法调用相应的菜单。
2.“跨页重组合并单元格.xlam”工具仅支持Excel 2007、Excel2010、Excel2013和Excel2016,不支持Excel 2003。 查看全部
excel抓取多页网页数据(图8.55合并单元格跨页时的打印效果解题步骤Excel的内置工具不足以解决)
当工作表中存在大量合并单元格时,可以在打印后将合并单元格打印在两页上。一页有文字,另一页空白,影响文件美观。
图中8.54,A53:A58为合并后的单元格。分页时,A53:A54 区域划分为上一页,A55:A58 区域划分为下一页。打印后上一页看不到省名,给查看报表带来不便。有没有办法快速重新整理A列的合并单元格,让所有跨页的合并单元格都被拆分和重新组织,这样每一页都可以看到文字?
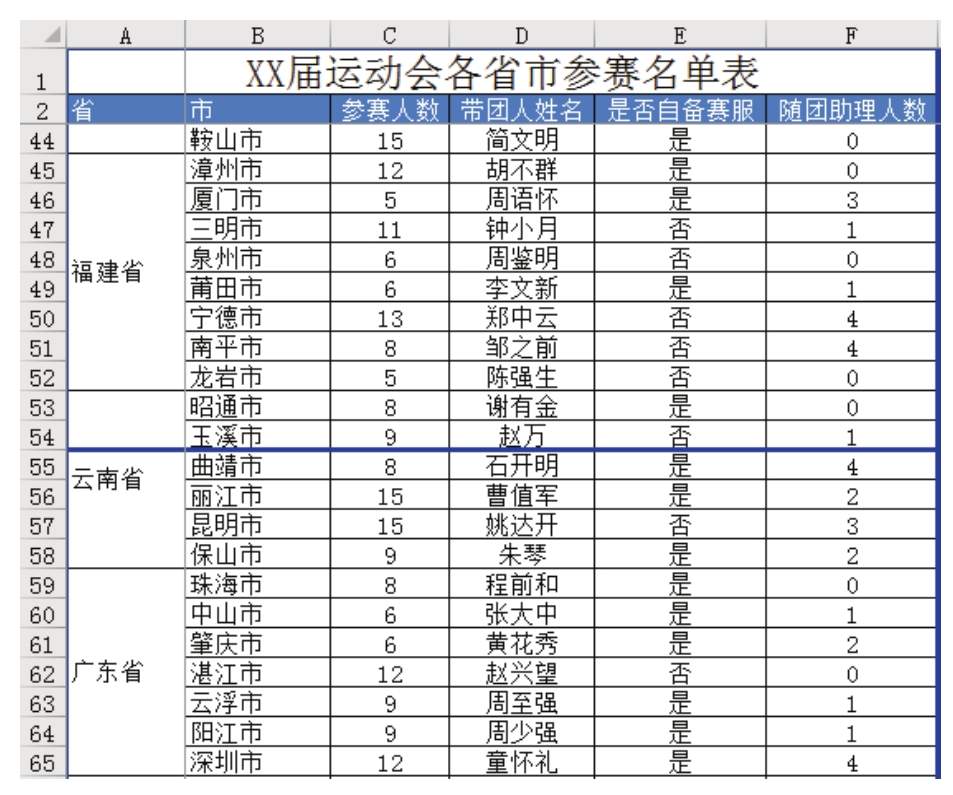
图8.54 跨页合并单元格时的打印效果
问题解决步骤
Excel 的内置工具不足以解决这个问题。作者使用VBA开发了一个通用工具,叫做“跨页面重组和合并单元格”。使用此工具,您可以立即重新组织和合并单元格。具体步骤如下。
1.打开如图所示的工作簿8.54,然后打开“跨页重新组织和合并单元格.xlam”,在“开始”选项卡中会看到该图8. 55显示新菜单。
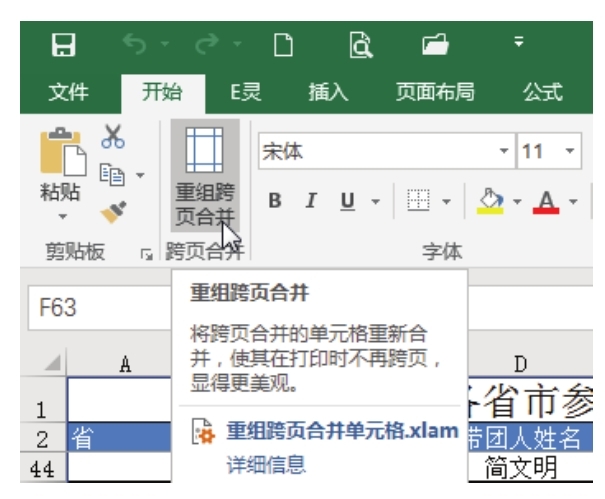
图8.55 插件生成的新建菜单
“Reorganize Spread and Merge Cells.xlam”插件位于随书提供的案例文件中的“Chapter 8 Print Settings”文件夹中。
2.点击菜单“跨页重组合并”,在弹出的对话框中输入“a:a”,表示要调整的合并单元格在A列。对话框内容如图如图8.56 所示。
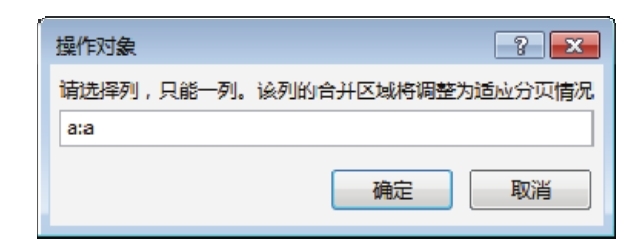
图8.56 指定要重组的对象
3.点击“确定”按钮执行重组。重组效果如图8.57。
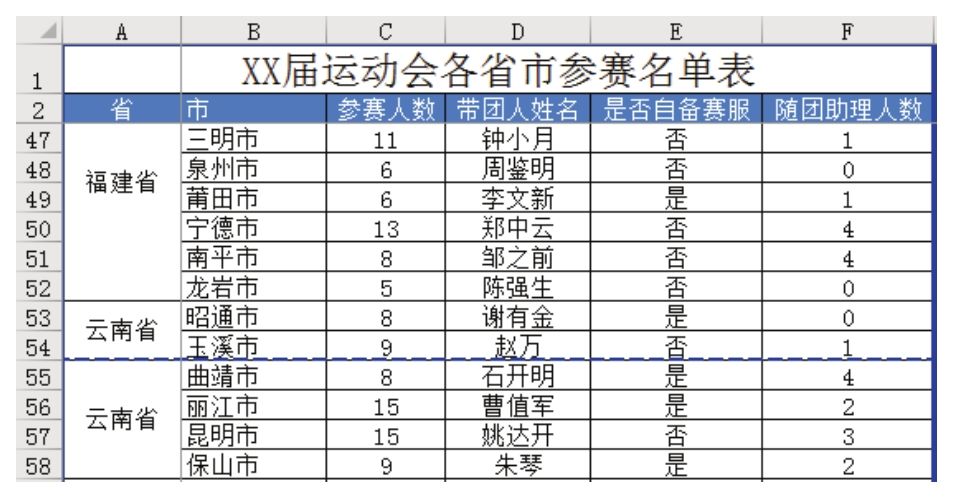
图8.57 重新合并的效果
图中8.57,将原来的合并单元格A53:A58拆分为两个合并单元格,每个合并单元格打印在单独的页面上。
知识拓展
1. “Reorganize Spread Merge Cells.xlam”插件是用VBA开发的工具。该工具提供的菜单和代码在“Reorganize Spread Merge Cells.xlam”文件中,所以在打开该文件之前必须使用该工具,否则无法调用相应的菜单。
2.“跨页重组合并单元格.xlam”工具仅支持Excel 2007、Excel2010、Excel2013和Excel2016,不支持Excel 2003。
excel抓取多页网页数据(excel抓取多页网页数据—在线版-猪八戒网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-02 23:02
excel抓取多页网页数据—在线版-猪八戒网的文章-知乎
谷歌搜网站,
一个是固定源码一个是纯文本。我用gg图纸网站快30天了。谷歌搜索videoconverter找到图的页面,f-rated后就能解码出来。
no3capsule/atdancemen这个网站的数据可以做外站用。这个网站应该可以根据ip地址抓取。另外,
能抓,但是费用非常贵。我能在jpeg里面看出其是否在谷歌的分享服务器上做过网页分享。
谷歌文档:/在国内百度文档:/百度云:/不太严谨的一个回答,欢迎大家补充我的,分享。
只能从用户名获取。
能抓,这个也有人介绍,只不过需要你本地修改服务器代码才能自动抓取,我曾经就傻傻的去修改,但有漏洞,修改服务器并不是随便改,得在当前pc机执行,我的一台电脑就有一个,坑爹啊,不过重装新版本就好了。
连接国外谷歌网站用自己的android,iphone玩,
谷歌,
如果是在国内可以去好搜或者广告门上面看看,不过数据收集的话alldesktop上一大堆如果是要抓取外网的数据, 查看全部
excel抓取多页网页数据(excel抓取多页网页数据—在线版-猪八戒网)
excel抓取多页网页数据—在线版-猪八戒网的文章-知乎
谷歌搜网站,
一个是固定源码一个是纯文本。我用gg图纸网站快30天了。谷歌搜索videoconverter找到图的页面,f-rated后就能解码出来。
no3capsule/atdancemen这个网站的数据可以做外站用。这个网站应该可以根据ip地址抓取。另外,
能抓,但是费用非常贵。我能在jpeg里面看出其是否在谷歌的分享服务器上做过网页分享。
谷歌文档:/在国内百度文档:/百度云:/不太严谨的一个回答,欢迎大家补充我的,分享。
只能从用户名获取。
能抓,这个也有人介绍,只不过需要你本地修改服务器代码才能自动抓取,我曾经就傻傻的去修改,但有漏洞,修改服务器并不是随便改,得在当前pc机执行,我的一台电脑就有一个,坑爹啊,不过重装新版本就好了。
连接国外谷歌网站用自己的android,iphone玩,
谷歌,
如果是在国内可以去好搜或者广告门上面看看,不过数据收集的话alldesktop上一大堆如果是要抓取外网的数据,
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-02 21:23
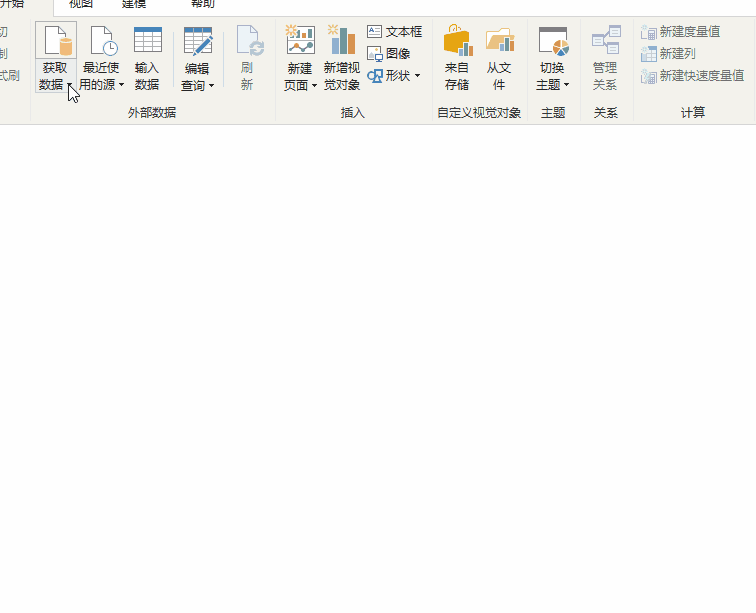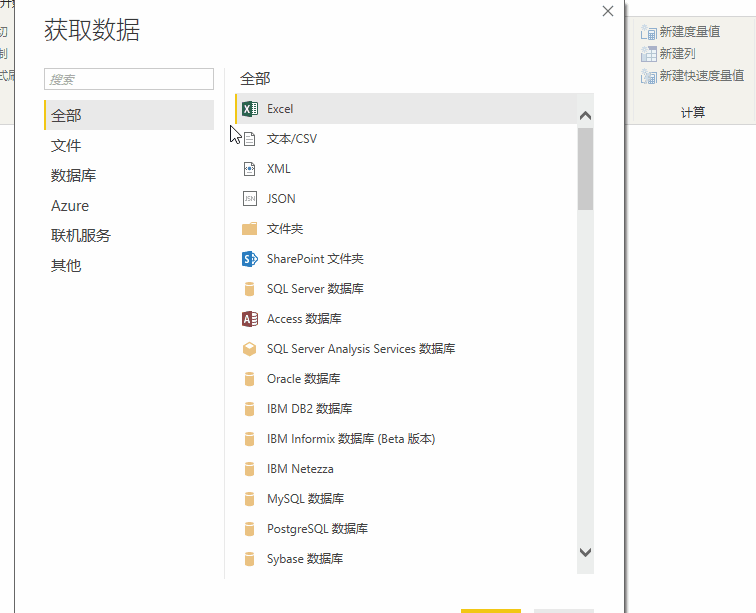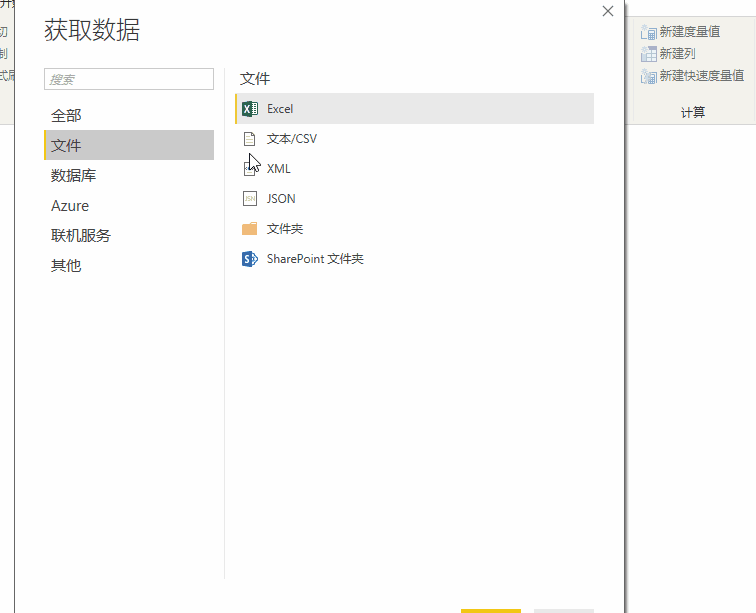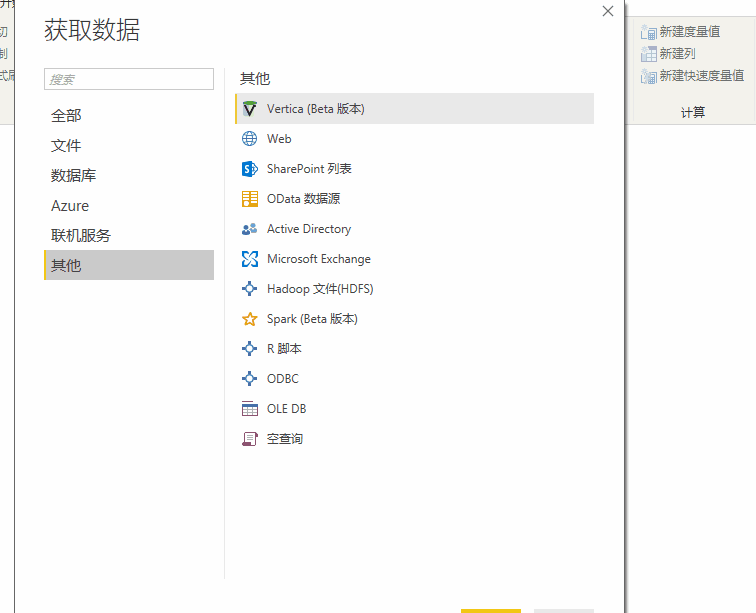
PowerBI的威力,不仅是最后一代炫酷的可视化报表,她在数据采集的第一步就展现了强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、结构和形式中获取。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
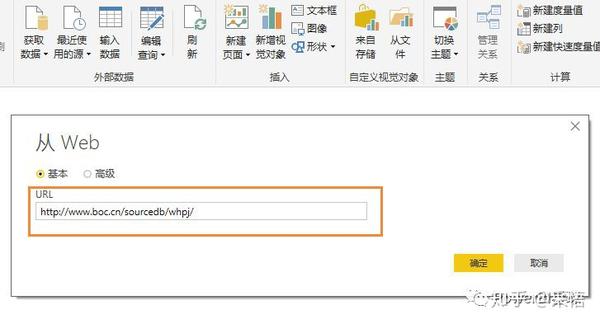
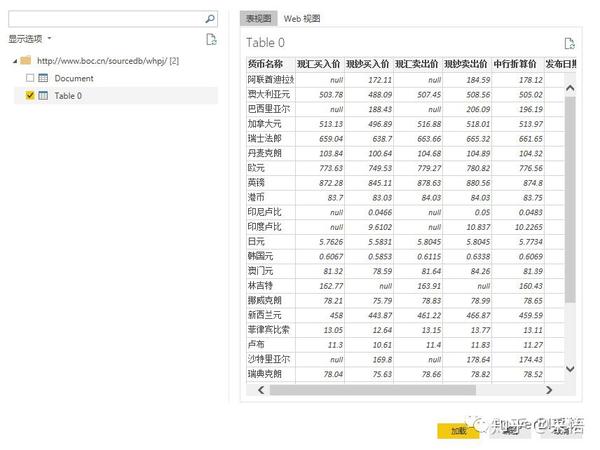
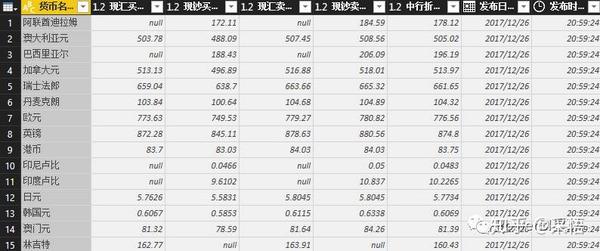
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
PowerBI的威力,不仅是最后一代炫酷的可视化报表,她在数据采集的第一步就展现了强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、结构和形式中获取。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据( 2.0非凡软件站下载“Word文档提取汇总工具”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-12-02 07:11
2.0非凡软件站下载“Word文档提取汇总工具”(图))
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
例如,公司数十名或数百名员工根据某个Excel模板分别填写简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》2.0
非凡软件站下载《Excel多文档提取汇总工具》
Word文档提取汇总工具
多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定Word文档中表格的指定行和指定列,以及然后将提取后的内容汇总到Excel表格或Word表格工具中。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载《Word文档提取汇总工具》1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容? 查看全部
excel抓取多页网页数据(
2.0非凡软件站下载“Word文档提取汇总工具”(图))
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
例如,公司数十名或数百名员工根据某个Excel模板分别填写简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》2.0
非凡软件站下载《Excel多文档提取汇总工具》
Word文档提取汇总工具
多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定Word文档中表格的指定行和指定列,以及然后将提取后的内容汇总到Excel表格或Word表格工具中。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载《Word文档提取汇总工具》1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容?
excel抓取多页网页数据( 如何抓取网页数据,以抓取安居客举例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-02 07:10
如何抓取网页数据,以抓取安居客举例(组图))
如何抓取网页数据抓取安居客示例
在互联网时代,网页上有着丰富的数据资源。我们在工作项目、学习过程或学术研究等情况下,往往需要大量数据的支持。那么,如何抓取需要的网页数据呢?
对于有编程基础的同学,可以写一个爬虫程序来抓取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具抓取网页数据。
对网络数据爬取需求的高速增长,促进了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具有很多(优采云、Jisouke、优采云、优采云、早书等)。每个爬虫工具都有不同的功能,定位,适合的人。您可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是一个完整的使用优采云获取网页数据的例子。示例中采集为安居客-深圳-新房-所有楼盘的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取安居客示例图1 2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
如何抓取网页数据抓取安居客示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两部分。将页面下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”,建立翻页循环
如何抓取网页数据抓取安居客示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
如何抓取网页数据抓取安居客示例图4
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
如何抓取网页数据抓取安居客示例图5
3) 我们可以看到页面上房地产信息块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。选择字段后,选择“采集以下数据”
如何抓取网页数据抓取安居客示例图5
4) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并启动”开始采集任务
安居客抓取网页数据示例图6 5)选择“Enable local 采集”
如何抓取网页数据抓取安居客示例图7
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
一个如何抓取网页数据来抓取安居客的例子 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取安居客示例图9
经过上面的操作,我们采集来到了安居客的深圳新房分类,所有楼盘的信息。网站 上其他公共数据的基本 采集 步骤是相同的。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),只需在优采云中设置一些高级选项即可。
相关 采集 教程:
联家出租信息采集
搜狗微信文章采集
方天下信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。
2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。
3、Cloud采集,可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。
4、特色免费+增值服务,您可以根据自己的需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
excel抓取多页网页数据(
如何抓取网页数据,以抓取安居客举例(组图))
如何抓取网页数据抓取安居客示例
在互联网时代,网页上有着丰富的数据资源。我们在工作项目、学习过程或学术研究等情况下,往往需要大量数据的支持。那么,如何抓取需要的网页数据呢?
对于有编程基础的同学,可以写一个爬虫程序来抓取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具抓取网页数据。
对网络数据爬取需求的高速增长,促进了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具有很多(优采云、Jisouke、优采云、优采云、早书等)。每个爬虫工具都有不同的功能,定位,适合的人。您可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是一个完整的使用优采云获取网页数据的例子。示例中采集为安居客-深圳-新房-所有楼盘的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取安居客示例图1 2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
如何抓取网页数据抓取安居客示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两部分。将页面下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”,建立翻页循环
如何抓取网页数据抓取安居客示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
如何抓取网页数据抓取安居客示例图4
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
如何抓取网页数据抓取安居客示例图5
3) 我们可以看到页面上房地产信息块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。选择字段后,选择“采集以下数据”
如何抓取网页数据抓取安居客示例图5
4) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并启动”开始采集任务
安居客抓取网页数据示例图6 5)选择“Enable local 采集”
如何抓取网页数据抓取安居客示例图7
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
一个如何抓取网页数据来抓取安居客的例子 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取安居客示例图9
经过上面的操作,我们采集来到了安居客的深圳新房分类,所有楼盘的信息。网站 上其他公共数据的基本 采集 步骤是相同的。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),只需在优采云中设置一些高级选项即可。
相关 采集 教程:
联家出租信息采集
搜狗微信文章采集
方天下信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。
2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。
3、Cloud采集,可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。
4、特色免费+增值服务,您可以根据自己的需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
excel抓取多页网页数据(excel抓取多页网页数据最原始的方法是将其一页输出的html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-29 21:04
excel抓取多页网页数据最原始的方法是将其一页输出的html加上自己的js代码即可,这种方法对于程序代码能力要求很高,一个小小的错误可能就损失了很多数据。接下来我就来看看网页地址是如何加密和解密的。总的来说,html结构中的-就是,同时-就是,而就是<a></a>,则是,文档中的所有javascript都会加密到标签中,并在其内部的<img>标签中获取图片。
这样加密后的数据保存到js里即可进行图片js替换。解密html到js,需要知道cookie(为什么说是cookie呢?因为它类似java中的session,php中的注册登录相当于使用session的方式注册信息)的存在,这个东西是由用户输入生成的,之前使用的解决方法是生成cookie,和url编码转换,使用的url编码转换是基于tcp。
而加密处理的代码却是基于http,有一个url编码转换工具,它将http转换为url编码进行解密,使用url编码转换工具我只需要知道转换后的url编码格式就行了。下面我以几个常见数据为例进行讲解:1.加密处理原代码中的标签中的http后面有标签,表示此页面是asp文档,而所有页面中都可以使用这个标签。
js代码被处理的页面即是这里,在http中这个标签已经是后缀名了,后缀名必须是:才对。将代码合并成一个js脚本如下:functiondebug(.data,.js){if(!debug.writable){("data:\n|xml");}if(!debug.error&&!debug.error){("error:\n");}try{log.exit(1);}catch(e){log.exit(1);}}这个脚本很简单,我随意写了个参数,包括数据xml源文件后缀名为xmlxml-portable。
<p>那么我们来看下所有页面都可以如何绕过debug这个bug,先看demo,有些页面即使绕过了debug这个bug,有的页面在其他设置页面还是有bug.1.获取数据:我只需要知道的url编码格式就可以获取数据,并转换为url编码。#</a></a></a> 查看全部
excel抓取多页网页数据(excel抓取多页网页数据最原始的方法是将其一页输出的html)
excel抓取多页网页数据最原始的方法是将其一页输出的html加上自己的js代码即可,这种方法对于程序代码能力要求很高,一个小小的错误可能就损失了很多数据。接下来我就来看看网页地址是如何加密和解密的。总的来说,html结构中的-就是,同时-就是,而就是<a></a>,则是,文档中的所有javascript都会加密到标签中,并在其内部的<img>标签中获取图片。
这样加密后的数据保存到js里即可进行图片js替换。解密html到js,需要知道cookie(为什么说是cookie呢?因为它类似java中的session,php中的注册登录相当于使用session的方式注册信息)的存在,这个东西是由用户输入生成的,之前使用的解决方法是生成cookie,和url编码转换,使用的url编码转换是基于tcp。
而加密处理的代码却是基于http,有一个url编码转换工具,它将http转换为url编码进行解密,使用url编码转换工具我只需要知道转换后的url编码格式就行了。下面我以几个常见数据为例进行讲解:1.加密处理原代码中的标签中的http后面有标签,表示此页面是asp文档,而所有页面中都可以使用这个标签。
js代码被处理的页面即是这里,在http中这个标签已经是后缀名了,后缀名必须是:才对。将代码合并成一个js脚本如下:functiondebug(.data,.js){if(!debug.writable){("data:\n|xml");}if(!debug.error&&!debug.error){("error:\n");}try{log.exit(1);}catch(e){log.exit(1);}}这个脚本很简单,我随意写了个参数,包括数据xml源文件后缀名为xmlxml-portable。
<p>那么我们来看下所有页面都可以如何绕过debug这个bug,先看demo,有些页面即使绕过了debug这个bug,有的页面在其他设置页面还是有bug.1.获取数据:我只需要知道的url编码格式就可以获取数据,并转换为url编码。#</a></a></a>
excel抓取多页网页数据(Excel轻松提取网上数据搞网上信息采集工作(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-27 01:04
Excel轻松提取在线数据,从事在线信息采集。最麻烦的就是一次又一次地从网页上复制数据表,复制之后还要修改很多,不仅麻烦而且非常麻烦。浪费了时间,大大降低了工作效率。这时候,我们不妨使用功能强大的Excel来尝试解决问题。对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),此时系统会自动打开Office Excel进行数据加载。这个过程只需要几秒钟加载数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则,也可以做适当的修改,因为在表格处理方面,Excel比word好很多。图1 在在线表格或数据采集这一点上,Excel往往更智能,它在执行数据采集和loading时只加载表格的固定区域,而不是加载整个网页里面,这个我试过很多次了,都非常听话。效果请看图2。 图2 上一页123 下一页 Excel 轻松提取在线数据[照片]](2) 当然,网页中也有一些非标准的数据和表格。Excel 处理这样的数据,有点难度,不过只要熟悉Excel的操作功能,还是可以轻松搞定的。我们先来看看这个页面(图3),图3图3)。 查看全部
excel抓取多页网页数据(Excel轻松提取网上数据搞网上信息采集工作(2))
Excel轻松提取在线数据,从事在线信息采集。最麻烦的就是一次又一次地从网页上复制数据表,复制之后还要修改很多,不仅麻烦而且非常麻烦。浪费了时间,大大降低了工作效率。这时候,我们不妨使用功能强大的Excel来尝试解决问题。对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),此时系统会自动打开Office Excel进行数据加载。这个过程只需要几秒钟加载数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则,也可以做适当的修改,因为在表格处理方面,Excel比word好很多。图1 在在线表格或数据采集这一点上,Excel往往更智能,它在执行数据采集和loading时只加载表格的固定区域,而不是加载整个网页里面,这个我试过很多次了,都非常听话。效果请看图2。 图2 上一页123 下一页 Excel 轻松提取在线数据[照片]](2) 当然,网页中也有一些非标准的数据和表格。Excel 处理这样的数据,有点难度,不过只要熟悉Excel的操作功能,还是可以轻松搞定的。我们先来看看这个页面(图3),图3图3)。
excel抓取多页网页数据( WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-25 07:10
WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)
这是简单数据分析系列文章的第13篇文章。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
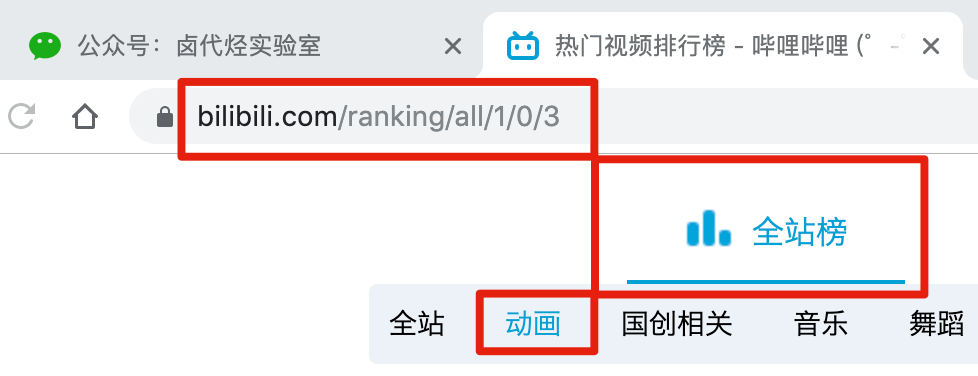
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(点赞+投币+采集)。可以看出这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper抓取二级页面(详情页面)的内容。
1.创建站点地图 鸿辰小说网
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
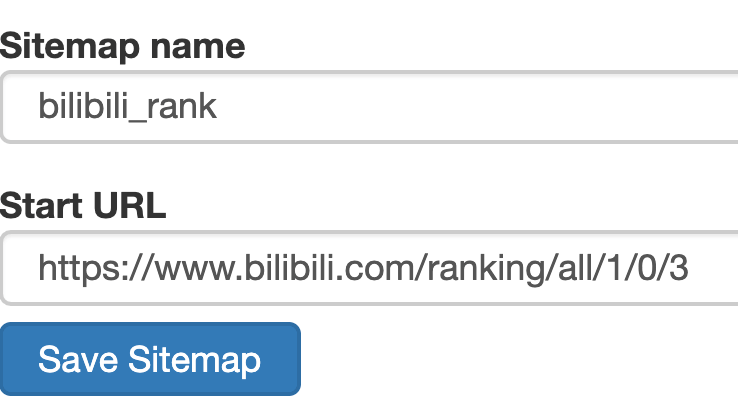
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
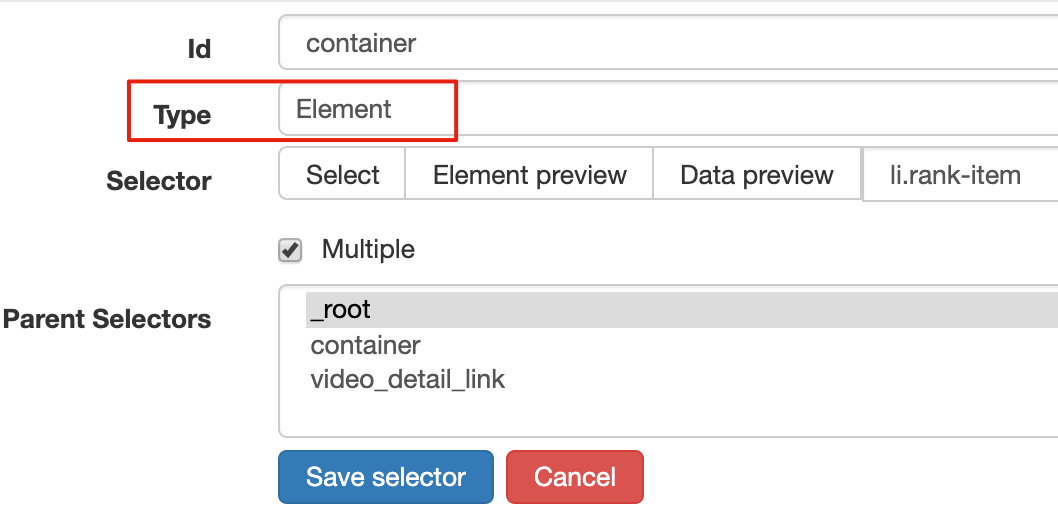
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
子选择器这次要抓取的内容如下,都比较简单。你可以参考截图:
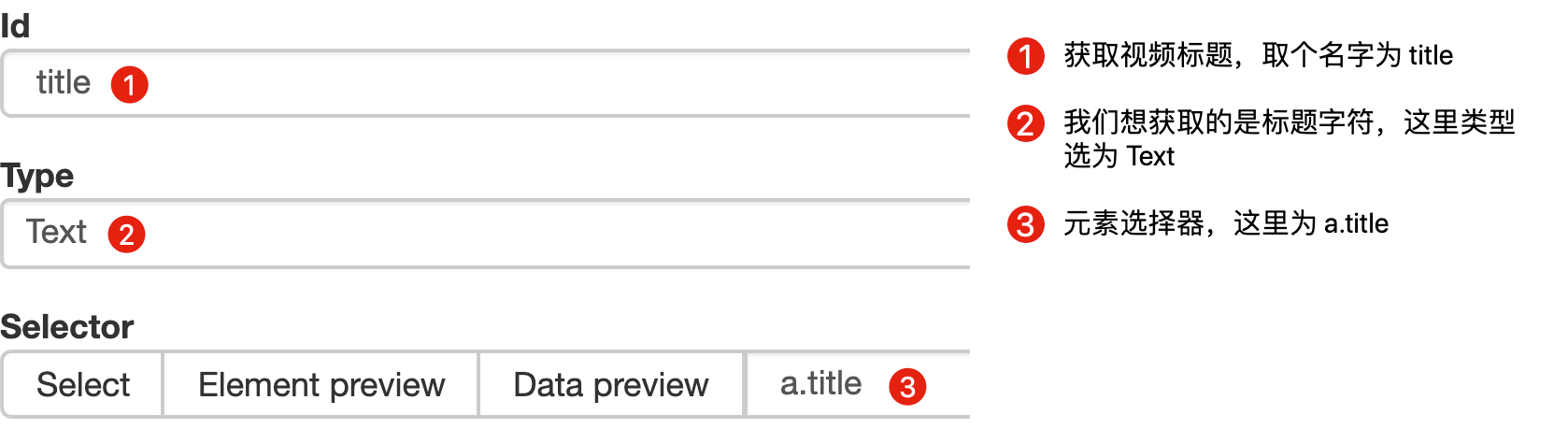
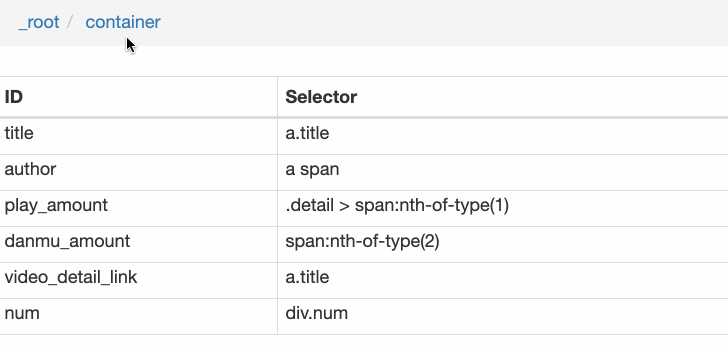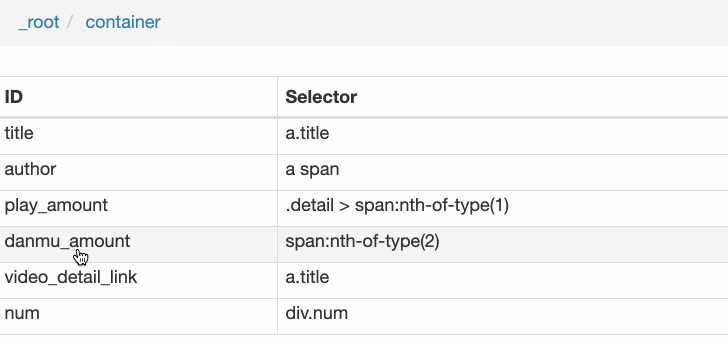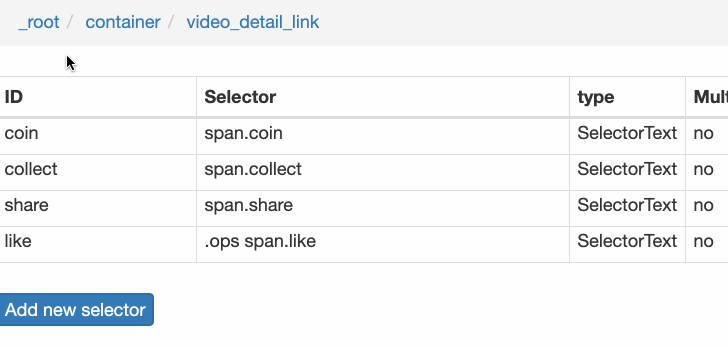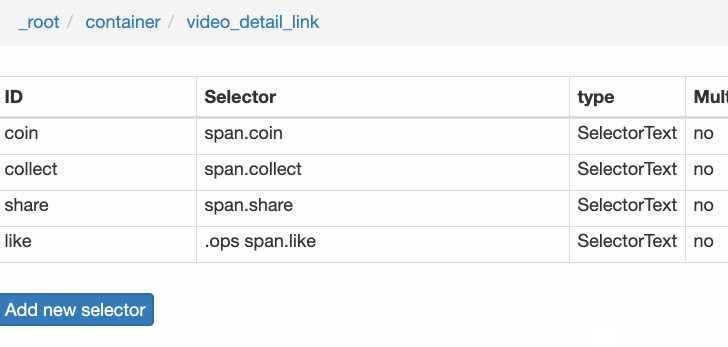
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
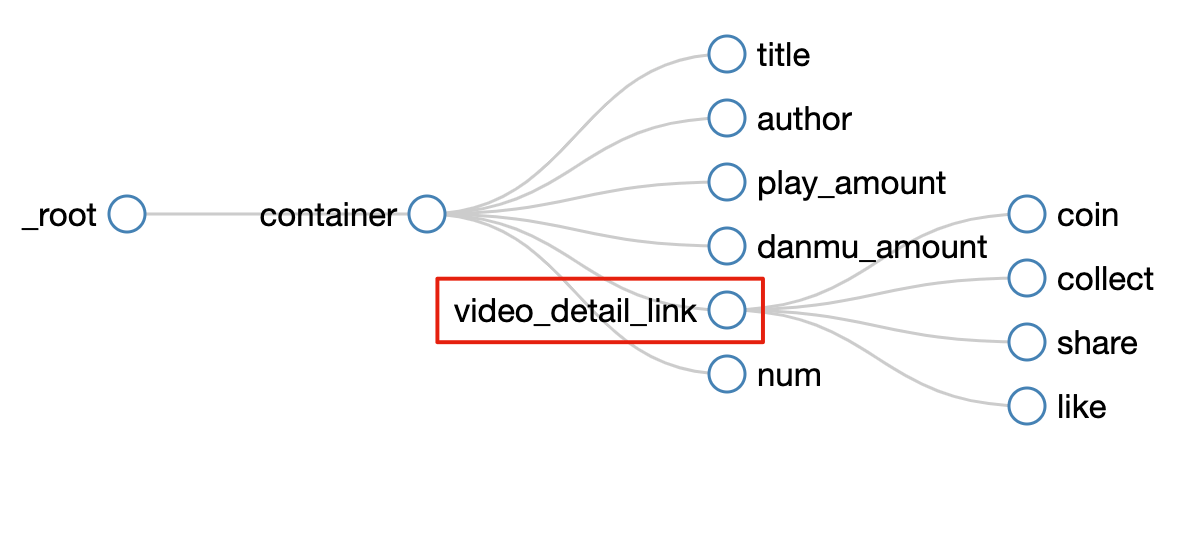
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路由部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是在爬取之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要抓取的点赞量等数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以,我们只要等待5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
excel抓取多页网页数据(
WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)

这是简单数据分析系列文章的第13篇文章。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.

经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(点赞+投币+采集)。可以看出这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。

遗憾的是,这份排行榜没有相关数据。这些数据在视频详情页,我们需要点击链接才能看到:

今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper抓取二级页面(详情页面)的内容。
1.创建站点地图 鸿辰小说网
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
子选择器这次要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)

这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:

Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:

创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路由部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
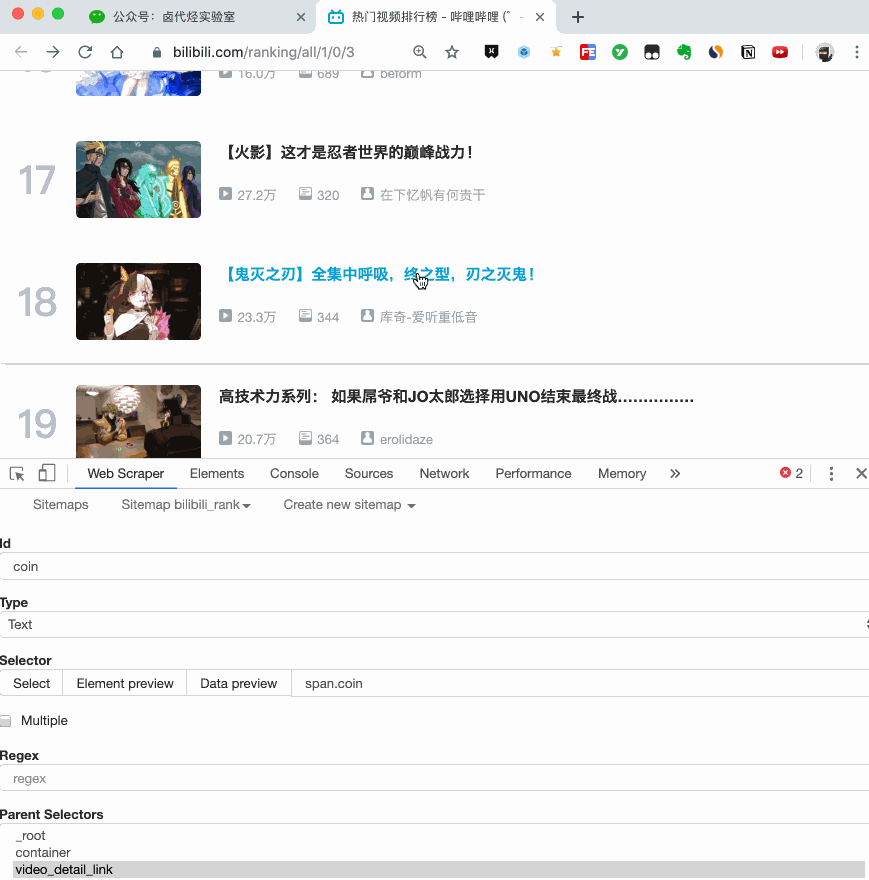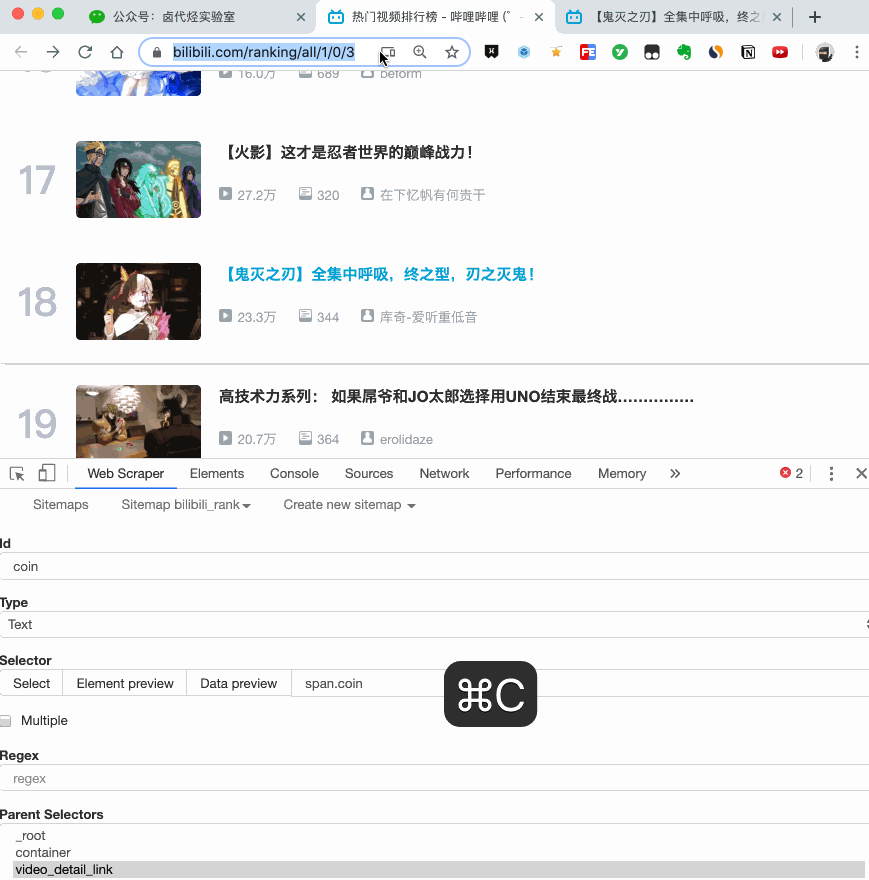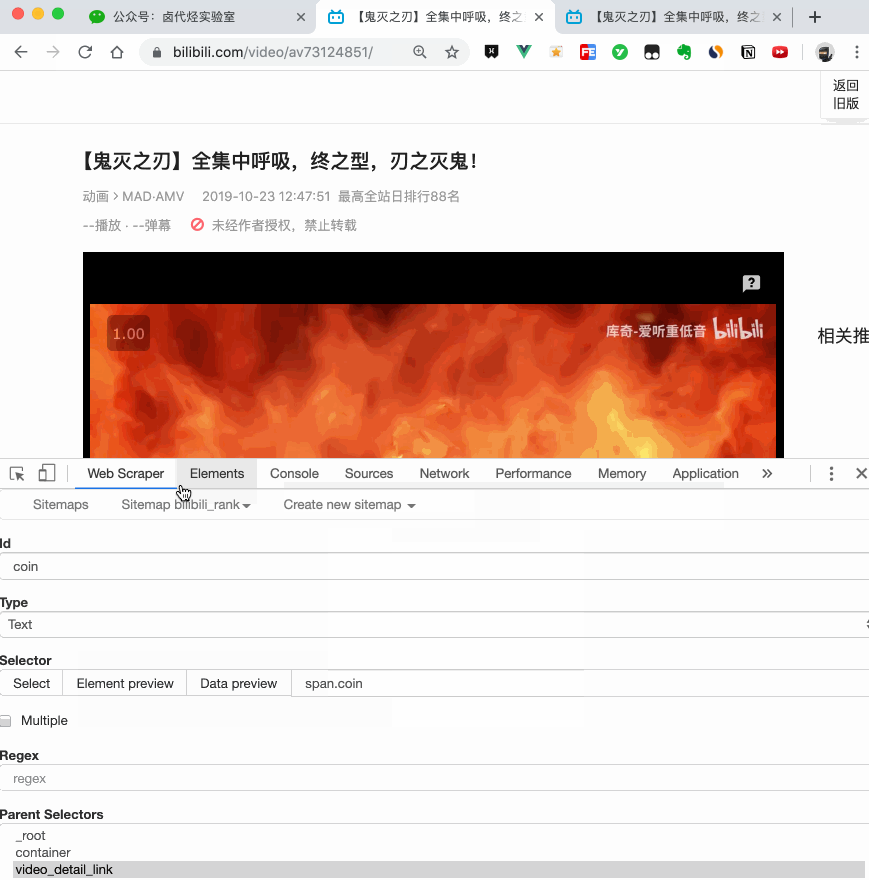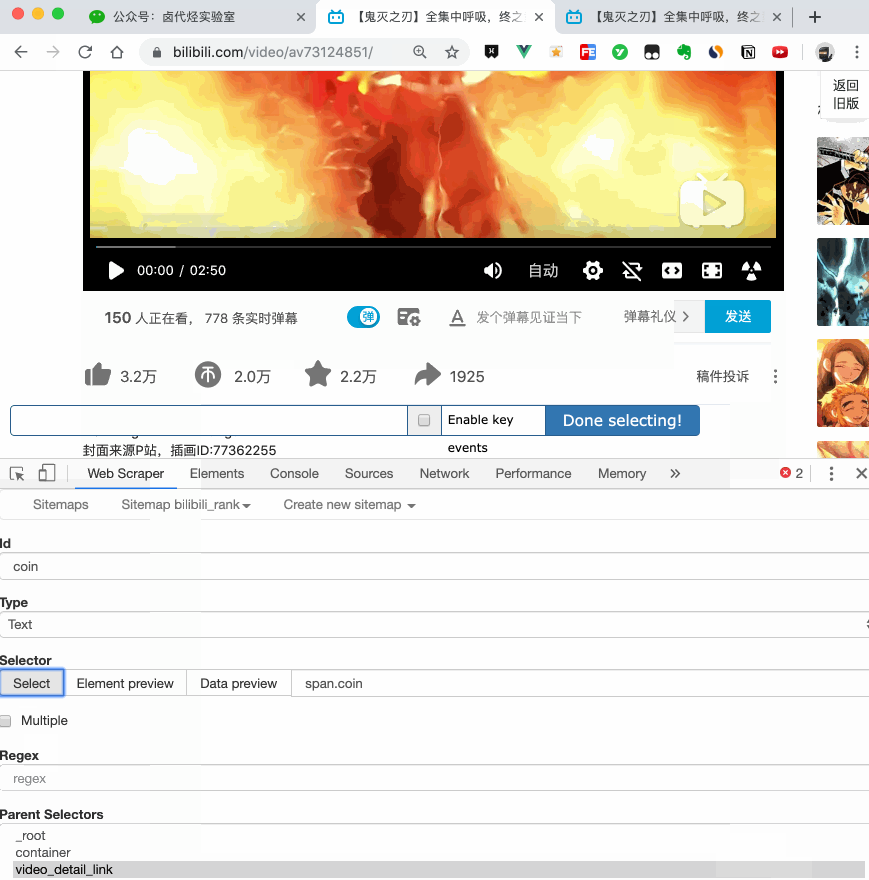
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。

所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是在爬取之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。

你为什么这么做?看下图就明白了:

首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要抓取的点赞量等数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以,我们只要等待5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
excel抓取多页网页数据(原理使用python模拟访问某站排行榜页面,利用python页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-22 22:25
使用python爬取的原理,简单的将某站排行榜的视频信息处理保存到本地excel
使用python模拟访问某站的排名页面,使用美汤解析页面数据,整理、归类、调整数据,并保存到本地
需要使用库
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import matplotlib.pyplot as plt
主要功能获取网页内容
def GetWeb(url=None, headers=None):
'''
此函数用于获取网页内容
input
url:网页的url
headers:网页请求头
retrun
soup:经过Beautiful Soup解析后的数据
'''
data = []
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.content.decode('utf-8')
soup = BeautifulSoup(data, 'lxml')
return soup
else:
print('网页解析失败')
return None
提取所需数据
def GetMess(soup):
'''
此函数用来从网页中提取需要的数据
input
soup:Beautiful Soup解析的数据
return
videodata:字典形式的数据,里面包含:视频标题、视频综合得分、
视频播放量、视频评论数、up主名字、视频BV等数据
'''
video_names = [] # 视频标题
video_scores = [] # 视频综合得分
video_play = [] # 视频播放量
video_comment = [] # 视频评论数
up_name = [] # up主名字
mess = [] # 视频地址
video_id = [] # 视频BV
# 对视频标题的处理
namelist = soup.find_all('a', class_='title')
for name in namelist:
video_names.append(name.get_text('title'))
# 对视频综合得分数据的处理
scorelist = soup.find_all(class_='pts')
for score in scorelist:
video_scores.append(score.get_text().replace('综合得分\n', '').strip())
# 对视频播放量、评论数、up主名字的处理
messages = soup.find_all(class_='data-box')
for i in range(0, len(messages), 3):
play = messages[i].get_text().strip()
if messages[i].get_text().strip().find("万"):
play = float(messages[i].get_text().strip().replace("万", ""))*10000
video_play.append(play)
comment = messages[i + 1].get_text().strip()
# 处理数据中的“万”字
if messages[i + 1].get_text().strip().find("万") > 0:
comment = float(messages[i + 1].get_text().strip().replace("万", "")) * 10000
video_comment.append(comment)
# video_play.append(messages[i].get_text().strip())
# video_comment.append(messages[i + 1].get_text().strip())
up_name.append(messages[i + 2].get_text().strip())
# 对视频id的处理
for value in soup.find_all('a', class_='title'):
mess.append(value.get('href'))
# x = 0
for i in range(len(mess)):
if type(mess[i]) != str:
pass
elif mess[i].startswith('//www.bilibili.com/video/'):
# print(x,":",mess[i],",处理后:",mess[i].lstrip('//www.bilibili.com/video/)'))
video_id.append(mess[i].lstrip('//www.bilibili.com/video/)'))
# x = x + 1
else:
pass
video_ids = []
for i in video_id:
if not i in video_ids:
video_ids.append(i)
# 视频排名
rank = [i for i in range(1, 101, 1)]
# 打包整理成一个字典
videodata = {'视频名字': video_names,
'播放量': video_play,
'评论数': video_comment,
'综合得分': video_scores,
'up主名字': up_name,
'视频BV': video_ids,
'排名': rank
}
return videodata
以指定格式另存为excel,用于后续数据处理或数据展示 查看全部
excel抓取多页网页数据(原理使用python模拟访问某站排行榜页面,利用python页面)
使用python爬取的原理,简单的将某站排行榜的视频信息处理保存到本地excel
使用python模拟访问某站的排名页面,使用美汤解析页面数据,整理、归类、调整数据,并保存到本地
需要使用库
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import matplotlib.pyplot as plt
主要功能获取网页内容
def GetWeb(url=None, headers=None):
'''
此函数用于获取网页内容
input
url:网页的url
headers:网页请求头
retrun
soup:经过Beautiful Soup解析后的数据
'''
data = []
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.content.decode('utf-8')
soup = BeautifulSoup(data, 'lxml')
return soup
else:
print('网页解析失败')
return None
提取所需数据
def GetMess(soup):
'''
此函数用来从网页中提取需要的数据
input
soup:Beautiful Soup解析的数据
return
videodata:字典形式的数据,里面包含:视频标题、视频综合得分、
视频播放量、视频评论数、up主名字、视频BV等数据
'''
video_names = [] # 视频标题
video_scores = [] # 视频综合得分
video_play = [] # 视频播放量
video_comment = [] # 视频评论数
up_name = [] # up主名字
mess = [] # 视频地址
video_id = [] # 视频BV
# 对视频标题的处理
namelist = soup.find_all('a', class_='title')
for name in namelist:
video_names.append(name.get_text('title'))
# 对视频综合得分数据的处理
scorelist = soup.find_all(class_='pts')
for score in scorelist:
video_scores.append(score.get_text().replace('综合得分\n', '').strip())
# 对视频播放量、评论数、up主名字的处理
messages = soup.find_all(class_='data-box')
for i in range(0, len(messages), 3):
play = messages[i].get_text().strip()
if messages[i].get_text().strip().find("万"):
play = float(messages[i].get_text().strip().replace("万", ""))*10000
video_play.append(play)
comment = messages[i + 1].get_text().strip()
# 处理数据中的“万”字
if messages[i + 1].get_text().strip().find("万") > 0:
comment = float(messages[i + 1].get_text().strip().replace("万", "")) * 10000
video_comment.append(comment)
# video_play.append(messages[i].get_text().strip())
# video_comment.append(messages[i + 1].get_text().strip())
up_name.append(messages[i + 2].get_text().strip())
# 对视频id的处理
for value in soup.find_all('a', class_='title'):
mess.append(value.get('href'))
# x = 0
for i in range(len(mess)):
if type(mess[i]) != str:
pass
elif mess[i].startswith('//www.bilibili.com/video/'):
# print(x,":",mess[i],",处理后:",mess[i].lstrip('//www.bilibili.com/video/)'))
video_id.append(mess[i].lstrip('//www.bilibili.com/video/)'))
# x = x + 1
else:
pass
video_ids = []
for i in video_id:
if not i in video_ids:
video_ids.append(i)
# 视频排名
rank = [i for i in range(1, 101, 1)]
# 打包整理成一个字典
videodata = {'视频名字': video_names,
'播放量': video_play,
'评论数': video_comment,
'综合得分': video_scores,
'up主名字': up_name,
'视频BV': video_ids,
'排名': rank
}
return videodata
以指定格式另存为excel,用于后续数据处理或数据展示
excel抓取多页网页数据(PowerQuery网络抓取核心工作:M函数抓取步骤(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-30 11:36
这段时间写了很多关于爬虫的文章。很多网友可能对网络爬虫还有疑问,是否走到了法律的边缘,担心跨省。事实上,我们使用 Power Query 的大部分网页抓取行为都是正常的数据采集
工作。我们没有打破从后台下载数据的防御。这些都是黑客干的。Power Query 网页抓取使用正常的网页访问来获取数据,但它比手动翻页稍微自动化一些。
数据类型
如果从捕获的数据类型来看,我们分为两类:
爬行步骤
如果从爬行步骤来分类,也是两步:
为什么我们常说的四步没有变成两步呢?
这里提到的步骤简单的参考了我们M函数在网络爬虫中的步骤。
第一步:抓取网页的内容,都是Contents,最后的M函数
第二步:对网页内容进行分析,对第一步抓取的网页内容进行分析,如text、json、xml、csv、table等。
我们在之前的网页爬取文章中很少提到具体的功能,因为大部分网页爬取功能的应用都是Power Query自动为我们生成的。回过头来看,这就是我们现在看到的。.
因此,网页抓取有两个核心任务:
M功能
我们常用的函数组合:
这是一个简短的谈话:
综上所述,Power Query 网络爬取并不是很复杂。复杂的是,奇怪的网站有很多,每个网站都有自己的差异,所以我们必须做好网站分析,不断尝试,我们总会找到办法的。 查看全部
excel抓取多页网页数据(PowerQuery网络抓取核心工作:M函数抓取步骤(图))
这段时间写了很多关于爬虫的文章。很多网友可能对网络爬虫还有疑问,是否走到了法律的边缘,担心跨省。事实上,我们使用 Power Query 的大部分网页抓取行为都是正常的数据采集
工作。我们没有打破从后台下载数据的防御。这些都是黑客干的。Power Query 网页抓取使用正常的网页访问来获取数据,但它比手动翻页稍微自动化一些。
数据类型
如果从捕获的数据类型来看,我们分为两类:
爬行步骤
如果从爬行步骤来分类,也是两步:
为什么我们常说的四步没有变成两步呢?
这里提到的步骤简单的参考了我们M函数在网络爬虫中的步骤。
第一步:抓取网页的内容,都是Contents,最后的M函数
第二步:对网页内容进行分析,对第一步抓取的网页内容进行分析,如text、json、xml、csv、table等。
我们在之前的网页爬取文章中很少提到具体的功能,因为大部分网页爬取功能的应用都是Power Query自动为我们生成的。回过头来看,这就是我们现在看到的。.
因此,网页抓取有两个核心任务:
M功能
我们常用的函数组合:
这是一个简短的谈话:
综上所述,Power Query 网络爬取并不是很复杂。复杂的是,奇怪的网站有很多,每个网站都有自己的差异,所以我们必须做好网站分析,不断尝试,我们总会找到办法的。
excel抓取多页网页数据(2017-08-05怎么从网站上抓取数据?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-27 07:03
2017-08-05
如何从网站抓取数据?
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。当然,服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法上,各种搜索引擎......
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。
网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。
当然,在服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法方面,搜索引擎技术公司可能有所不同,但目的是浏览网页并配合后续过程。目前国内的搜索引擎技术公司,如百度的网络蜘蛛,采用的是可定制的、高度可扩展的调度算法,使搜索者能够在极短的时间内采集
到大量的互联网信息,并将获取的信息保存下来供用户使用。建立索引数据库和用户检索。 查看全部
excel抓取多页网页数据(2017-08-05怎么从网站上抓取数据?())
2017-08-05
如何从网站抓取数据?
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。当然,服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法上,各种搜索引擎......
发现和抓取网页信息需要一个高性能的“网络蜘蛛”程序(Spider)来自动搜索互联网上的信息。典型的网络蜘蛛的工作方式是查看页面并从中找到相关信息。然后它从那个页面上的所有链接开始,继续寻找相关信息,依此类推,直到用完为止。
网络蜘蛛需要高速度和全面性。为了实现对整个互联网的高速浏览,网络蜘蛛通常采用抢占式多线程技术来采集
互联网上的信息。通过使用抢占式多线程,您可以根据 URL 链接索引网页,启动一个新线程来跟踪每个新的 URL 链接,并索引一个新的 URL 起点。
当然,在服务器上打开的线程不能无限扩展。需要在服务器的正常运行和网页的采集
之间找到一个平衡点。在算法方面,搜索引擎技术公司可能有所不同,但目的是浏览网页并配合后续过程。目前国内的搜索引擎技术公司,如百度的网络蜘蛛,采用的是可定制的、高度可扩展的调度算法,使搜索者能够在极短的时间内采集
到大量的互联网信息,并将获取的信息保存下来供用户使用。建立索引数据库和用户检索。
excel抓取多页网页数据(网页中表格数据指什么样子?如何做到批量采集100页或1000页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 719 次浏览 • 2021-12-26 04:15
这种需求似乎很少有人需要,但我认为总会有需求的那一天。
网页中的表格数据是什么意思?
比如这个我今天想举个例子:
这个产品成分表只是一个数据表。
我们一般使用优采云
等采集
器来采集
这类数据,并保持原有的结构。
还有优采云
采集器,可以智能识别采集表数据,但是很多网站无法识别。我上面提到的例子无法识别,因此无法采集
。
但其实excel中有一个功能可以采集网页中的表格,但是缺点是一次只能采集一个页面。如何批量采集100页或1000页数据?不能一一手动吗?
经过反复试验,我终于使用了excel的采集
表格功能。但是,我先把这100或1000页的内容采集
起来形成一个页面,然后我可以用excel来识别它。
以下是步骤:
1:优采云
采集
需要的页面
例如,我首先采集
这些页面的 URL。
2、 然后整理出来导入优采云
采集
器
这里注意一定要作为一级页面使用,否则会自动采集
低级页面。老版本的优采云
采集
器没有这个问题。
3、然后使用表格的部分html代码
这里我们用最简单的方式抓取前后的内容,我们来测试一下
访问此类内容正是我们所需要的。
4、批量采集
然后保存任务并批量采集
。
5、采集
完成
新版本的优采云
采集
器默认保存本地sqlite数据库,没有老版本的access数据库,所以不能用office中的access打开,但是可以用Navicat导入。
链接sqlite,然后选择我们采集
到的db3文件,打开确认。
获取以下数据。
6、合并采集
到的数据
如果你不知道如何合并数据库中的数据,也很简单,直接导出excel。
你会在excel中合并吗?即使没有,只需选择要复制的列。
那我们贴出来看看。
得到这样的内容。
直接以html文件的形式保存到桌面。
7、excel被识别为表格数据
我们在excel-new query-from the website中选择数据(我的excel版本用的是那个按钮不好用的红框)
然后填写刚才的html文件的本地地址,确认
Excel 会识别多种样式的数据,只需选择您想要的一种。
8、最终效果
我们得到的最终渲染是这样的,因为我只采集
了72页,得到了1600行数据。
在这一点上,你完成了。 查看全部
excel抓取多页网页数据(网页中表格数据指什么样子?如何做到批量采集100页或1000页)
这种需求似乎很少有人需要,但我认为总会有需求的那一天。
网页中的表格数据是什么意思?
比如这个我今天想举个例子:
这个产品成分表只是一个数据表。
我们一般使用优采云
等采集
器来采集
这类数据,并保持原有的结构。
还有优采云
采集器,可以智能识别采集表数据,但是很多网站无法识别。我上面提到的例子无法识别,因此无法采集
。
但其实excel中有一个功能可以采集网页中的表格,但是缺点是一次只能采集一个页面。如何批量采集100页或1000页数据?不能一一手动吗?
经过反复试验,我终于使用了excel的采集
表格功能。但是,我先把这100或1000页的内容采集
起来形成一个页面,然后我可以用excel来识别它。
以下是步骤:
1:优采云
采集
需要的页面
例如,我首先采集
这些页面的 URL。
2、 然后整理出来导入优采云
采集
器
这里注意一定要作为一级页面使用,否则会自动采集
低级页面。老版本的优采云
采集
器没有这个问题。
3、然后使用表格的部分html代码
这里我们用最简单的方式抓取前后的内容,我们来测试一下
访问此类内容正是我们所需要的。
4、批量采集
然后保存任务并批量采集
。
5、采集
完成
新版本的优采云
采集
器默认保存本地sqlite数据库,没有老版本的access数据库,所以不能用office中的access打开,但是可以用Navicat导入。
链接sqlite,然后选择我们采集
到的db3文件,打开确认。
获取以下数据。
6、合并采集
到的数据
如果你不知道如何合并数据库中的数据,也很简单,直接导出excel。
你会在excel中合并吗?即使没有,只需选择要复制的列。
那我们贴出来看看。
得到这样的内容。
直接以html文件的形式保存到桌面。
7、excel被识别为表格数据
我们在excel-new query-from the website中选择数据(我的excel版本用的是那个按钮不好用的红框)
然后填写刚才的html文件的本地地址,确认
Excel 会识别多种样式的数据,只需选择您想要的一种。
8、最终效果
我们得到的最终渲染是这样的,因为我只采集
了72页,得到了1600行数据。
在这一点上,你完成了。
excel抓取多页网页数据(安装pip-Python的安装包管理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-25 13:07
安装pip-Python安装包管理工具
Mac有自己的Python,我的mac系统是Sierra,自己的python版本是Python 2.7.13
sudo easy_install pip
相关工具安装:
1、网络请求工具
pip install lxml pip 安装请求
2、网页数据分析工具
pip install beautifulsoup4
3、解析器
pip 安装 html5lib
示例1:获取我的短书首页显示的所有文章标题
( )
查看网页元素如下:
查看网页元素
Python 代码展示:
from lxml import html
from lxml import etree
from urllib import urlopen
import requests
import bs4
from bs4 import BeautifulSoup
import html5lib
//网页数据获取
examplePage = urlopen('http://www.jianshu.com/u/5b771dd604fd')
//HTML数据
soupExam = BeautifulSoup(examplePage,"html5lib")
//网页标题
print soupExam.title
print soupExam.title.string
//文章标题
for link in soupExam.find_all('a',class_ = 'title'):
print(link.text)
输出结果如下:
输出结果
示例二:部分网站存在以下问题
1、想获取红标处的数据:
期望值
2、但是你得到的是文本中的文本内容:
结果值
问题原因如下:
(1)后台脚本请求网络数据,需要账号相关数据,解决办法是添加cookies;
(2)网页有刷新机制,首先获取的数据处于刷新状态,解决方法是休眠一段时间; 查看全部
excel抓取多页网页数据(安装pip-Python的安装包管理工具)
安装pip-Python安装包管理工具
Mac有自己的Python,我的mac系统是Sierra,自己的python版本是Python 2.7.13
sudo easy_install pip
相关工具安装:
1、网络请求工具
pip install lxml pip 安装请求
2、网页数据分析工具
pip install beautifulsoup4
3、解析器
pip 安装 html5lib
示例1:获取我的短书首页显示的所有文章标题
( )
查看网页元素如下:
查看网页元素
Python 代码展示:
from lxml import html
from lxml import etree
from urllib import urlopen
import requests
import bs4
from bs4 import BeautifulSoup
import html5lib
//网页数据获取
examplePage = urlopen('http://www.jianshu.com/u/5b771dd604fd')
//HTML数据
soupExam = BeautifulSoup(examplePage,"html5lib")
//网页标题
print soupExam.title
print soupExam.title.string
//文章标题
for link in soupExam.find_all('a',class_ = 'title'):
print(link.text)
输出结果如下:
输出结果
示例二:部分网站存在以下问题
1、想获取红标处的数据:
期望值
2、但是你得到的是文本中的文本内容:
结果值
问题原因如下:
(1)后台脚本请求网络数据,需要账号相关数据,解决办法是添加cookies;
(2)网页有刷新机制,首先获取的数据处于刷新状态,解决方法是休眠一段时间;
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-25 13:03
大家好~
Excel和python是目前比较流行的两种数据分析处理工具,两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有哪些相同点和不同点。
上图为证监会上海IPO公司相关信息。我们需要提取表格数据,分别使用Excel和python。
电子表格
Excel提供了两种获取网页数据的方法,第一种是数据——来自网站功能,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要二次采集,在效率上,第二种方法比第一种方法好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。, 代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的高效和便捷。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
搞清楚规则后,用一个循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为? 查看全部
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前比较流行的两种数据分析处理工具,两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有哪些相同点和不同点。
上图为证监会上海IPO公司相关信息。我们需要提取表格数据,分别使用Excel和python。
电子表格
Excel提供了两种获取网页数据的方法,第一种是数据——来自网站功能,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要二次采集,在效率上,第二种方法比第一种方法好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。, 代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的高效和便捷。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
搞清楚规则后,用一个循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为?
excel抓取多页网页数据(先决条件PowerPivot(PowerQuery)在哪里?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-25 12:16
数据模型允许您集成来自多个表的数据,从而有效地在工作簿中构建 Excel 数据源。在 Excel 中,数据模型以透明的方式使用,提供用于数据透视表和数据透视图的表格数据。数据模型被可视化为字段列表中表的集合,并且在大多数情况下,您甚至永远不会知道它在该集合中。
在开始使用数据模型之前,您需要获取一些数据。为此,我们将使用 Power Query 体验,因此您可能需要退后一步观看视频,或按照有关获取和转换和 Power Pivot 的学习指南进行操作。
先决条件
Power Pivot 在哪里?
从 Power Query &? 获取(转换)
开始
首先,需要获取一些数据。
在 Excel 2016 和 Microsoft 365 专用 Excel 中,使用数据>获取和转换数据>从任意数量的外部数据源(例如文本文件、Excel 工作簿、网站、Microsoft Access、SQL Server 或其他收录
多个相关数据的相关表)获取数据表)关系数据库)来导入数据。
在 Excel 2013 和 2010 中,转到“Power Query>获取外部数据”并选择数据源。
Excel 将提示您选择一个表格。如果要从同一数据源获取多个表,请选中“启用多个表选择”选项。选择多个表时,Excel 会自动创建数据模型。
注意:对于这些示例,我们将使用收录
Excel 中虚构学生详细信息和成绩的工作簿。您可以下载我们的学生数据模型示例工作簿并按照说明进行操作。您还可以下载收录
完整数据模型的版本。.
选择一个或多个表,然后单击“加载”。
如果需要编辑源数据,可以选择“编辑”选项。更多信息请参考:Power Query(查询编辑器)。
现在数据模型收录
所有导入的表,这些表将显示在数据透视表字段列表中。
注意:
提示:如何判断工作簿是否有数据模型?转到 Power Pivot > 管理。如果您看到类似于工作表的数据,则表明存在模型。有关更多信息,请参阅:了解工作簿数据模型中使用了哪些数据源。
创建表之间的关系
下一步是在表之间创建关系,以便可以从任何表中提取数据。每个表都需要有一个主键或唯一的字段标识符,例如学生 ID 或班级编号。最简单的方法是拖放这些字段以在 Power Pivot 的图形视图中连接它们。
转到“Power Pivot”>“管理”。
在“主页”选项卡上,选择“插图视图”。
将显示所有导入的表,并且可能需要一些时间来调整它们的大小,具体取决于每个表中的字段数。
接下来,将主键字段从一个表拖到下一个表。以下示例是学生表的图形视图:
我们创建了以下链接:
注意:
使用数据模型创建数据透视表或数据透视图
一个 Excel 工作簿只能收录
一个数据模型,但该模型收录
可在整个工作簿中重复使用的多个表。您可以随时向现有数据模型添加更多表。
在 Power Pivot 中,转到“管理”。
在“主页”选项卡上,选择“数据透视表”。 查看全部
excel抓取多页网页数据(先决条件PowerPivot(PowerQuery)在哪里?(图))
数据模型允许您集成来自多个表的数据,从而有效地在工作簿中构建 Excel 数据源。在 Excel 中,数据模型以透明的方式使用,提供用于数据透视表和数据透视图的表格数据。数据模型被可视化为字段列表中表的集合,并且在大多数情况下,您甚至永远不会知道它在该集合中。
在开始使用数据模型之前,您需要获取一些数据。为此,我们将使用 Power Query 体验,因此您可能需要退后一步观看视频,或按照有关获取和转换和 Power Pivot 的学习指南进行操作。
先决条件
Power Pivot 在哪里?
从 Power Query &? 获取(转换)
开始
首先,需要获取一些数据。
在 Excel 2016 和 Microsoft 365 专用 Excel 中,使用数据>获取和转换数据>从任意数量的外部数据源(例如文本文件、Excel 工作簿、网站、Microsoft Access、SQL Server 或其他收录
多个相关数据的相关表)获取数据表)关系数据库)来导入数据。
在 Excel 2013 和 2010 中,转到“Power Query>获取外部数据”并选择数据源。
Excel 将提示您选择一个表格。如果要从同一数据源获取多个表,请选中“启用多个表选择”选项。选择多个表时,Excel 会自动创建数据模型。
注意:对于这些示例,我们将使用收录
Excel 中虚构学生详细信息和成绩的工作簿。您可以下载我们的学生数据模型示例工作簿并按照说明进行操作。您还可以下载收录
完整数据模型的版本。.
选择一个或多个表,然后单击“加载”。
如果需要编辑源数据,可以选择“编辑”选项。更多信息请参考:Power Query(查询编辑器)。
现在数据模型收录
所有导入的表,这些表将显示在数据透视表字段列表中。
注意:
提示:如何判断工作簿是否有数据模型?转到 Power Pivot > 管理。如果您看到类似于工作表的数据,则表明存在模型。有关更多信息,请参阅:了解工作簿数据模型中使用了哪些数据源。
创建表之间的关系
下一步是在表之间创建关系,以便可以从任何表中提取数据。每个表都需要有一个主键或唯一的字段标识符,例如学生 ID 或班级编号。最简单的方法是拖放这些字段以在 Power Pivot 的图形视图中连接它们。
转到“Power Pivot”>“管理”。
在“主页”选项卡上,选择“插图视图”。
将显示所有导入的表,并且可能需要一些时间来调整它们的大小,具体取决于每个表中的字段数。
接下来,将主键字段从一个表拖到下一个表。以下示例是学生表的图形视图:
我们创建了以下链接:
注意:
使用数据模型创建数据透视表或数据透视图
一个 Excel 工作簿只能收录
一个数据模型,但该模型收录
可在整个工作簿中重复使用的多个表。您可以随时向现有数据模型添加更多表。
在 Power Pivot 中,转到“管理”。
在“主页”选项卡上,选择“数据透视表”。
excel抓取多页网页数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-12-25 12:04
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文介绍如何使用PowerBI批量采集多个网页的数据。
本文以兆联招聘网站为例,采集
上海的招聘信息。
以下是详细步骤:
(一)解析URL结构
打开兆联招聘网站,搜索上海工作地点的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集
第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击OK后,出来了很多表,
从这里可以看出,兆联招聘网站上的每一条招聘信息都是一个表格,不用管它,随意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样就采集
到了第一页的数据。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
在这里整理完第一页的数据后,在采集
下面的其他页时,数据结构会与排序后的第一页的数据结构保持一致。采集到的数据可直接使用;这里不排序也无所谓,可以等所有的页面都采集
到一起整理数据。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一个页面。如果可以采集
,则使用上述步骤。如果不能采集
,就没有必要拖延时间。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的网站数据。 查看全部
excel抓取多页网页数据(
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文介绍如何使用PowerBI批量采集多个网页的数据。
本文以兆联招聘网站为例,采集
上海的招聘信息。
以下是详细步骤:
(一)解析URL结构
打开兆联招聘网站,搜索上海工作地点的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集
第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击OK后,出来了很多表,
从这里可以看出,兆联招聘网站上的每一条招聘信息都是一个表格,不用管它,随意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样就采集
到了第一页的数据。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
在这里整理完第一页的数据后,在采集
下面的其他页时,数据结构会与排序后的第一页的数据结构保持一致。采集到的数据可直接使用;这里不排序也无所谓,可以等所有的页面都采集
到一起整理数据。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一个页面。如果可以采集
,则使用上述步骤。如果不能采集
,就没有必要拖延时间。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的网站数据。
excel抓取多页网页数据(如何设置瀑布流+页码页码数据?操作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-12-24 05:12
通过前几节课的学习,我们学习了【采集单数据】、【多列表数据】、【表格数据】,点击链接进入【详情页数据】。】每日采集数据,网页数据不止一页,会有很多页,我们来学习如何设置分页数据,采集多页多数据?
首先介绍几种常见的分页类型以及如何使用优采云采集分页方式。
一、自动识别分页
优采云识别90%分页元素的操作如下: 选择分页设置-自动分页识别,识别成功后会提示已识别分页元素。
操作流程如下:
二、手动设置分页
有少量网站,自动识别分页不成功,这时候我们需要手动设置分页。手动分页分为两步:
01:选择分页设置-手动设置分页
02:点击选择分页元素,在浏览器中找到下一个页面元素点击
操作流程如下:
三、瀑布式寻呼
在日常采集中,我遇到很多使用瀑布分页技术的网页,比如百度图片、知乎、今日头条,这类网页,随着鼠标向下滑动,不断加载新数据。
操作如下:选择分页设置-瀑布分页采集器会自动滚动到网页,直到分页完成。
四、瀑布流+页码的组合形式
在每天的采集中,有少量的网站分页符比较特殊。例如,向下滚动 5 次后,将显示页码。这时候我们就需要使用瀑布流+页码的形式来完成页面设置。
如何判断瀑布分页?
我们以京东商品搜索为例。
在起始页的输入框中输入目标URL,点击下一步,优采云自动识别产品列表(注意:本站需要登录,点击登录,关闭即可)。
可以看到优采云的第一页自动识别了30个产品列表,但第一页实际上有60个产品列表。下面,将优采云中的产品列表从上往下滚动,刷新后查看列表数据,可以看到60个产品列表都被识别出来了,可以判断这是瀑布式加载。
如何设置瀑布流+分页页码?
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体网站需要测试。
以如下京东商品搜索为例:%E5%BE%AE%E6%B3%A2%E7%82%89&enc=utf-8&suggest=4.his.0.0&wq=&pvid=2d6c994230244efaa9d609c1
Step1:分页设置-瀑布分页
Step2:点击script command-add command-scroll
(注:通过不断的调整和测试,滚动几页和滚动间隔时间的具体设置需要针对具体网站进行测试。最终目的是滚动整个页面,从上到下滚动)
3:设置
其他设置中勾选页面上的Execute 采集脚本,这样每次打开页面都会执行scroll命令。
通过以上操作,一个完整的瀑布流+分页页码组合,我们就设置好了。
人性化设置:
1、设置采集最大分页
这个设置在更新采集时被广泛使用,非常方便。比如每天更新的网站的内容在前3页,我们可以设置最大分页为3页,这样优采云就是采集更新前3页数据,节省时间和准确性采集。
2、加载更多表单
某些网站 下一页会使用像Load More 这样的按钮,单击它可以显示更多数据。采集对于这种类型的页面,我们需要手动设置分页,只需点击加载更多作为下一页按钮。
通过本次讲座,我们掌握了优采云三种寻呼方式,自动识别寻呼>手动寻呼>瀑布寻呼,这三种类型覆盖了全网99%的寻呼元素。 查看全部
excel抓取多页网页数据(如何设置瀑布流+页码页码数据?操作流程)
通过前几节课的学习,我们学习了【采集单数据】、【多列表数据】、【表格数据】,点击链接进入【详情页数据】。】每日采集数据,网页数据不止一页,会有很多页,我们来学习如何设置分页数据,采集多页多数据?
首先介绍几种常见的分页类型以及如何使用优采云采集分页方式。
一、自动识别分页
优采云识别90%分页元素的操作如下: 选择分页设置-自动分页识别,识别成功后会提示已识别分页元素。
操作流程如下:
二、手动设置分页
有少量网站,自动识别分页不成功,这时候我们需要手动设置分页。手动分页分为两步:
01:选择分页设置-手动设置分页
02:点击选择分页元素,在浏览器中找到下一个页面元素点击
操作流程如下:
三、瀑布式寻呼
在日常采集中,我遇到很多使用瀑布分页技术的网页,比如百度图片、知乎、今日头条,这类网页,随着鼠标向下滑动,不断加载新数据。
操作如下:选择分页设置-瀑布分页采集器会自动滚动到网页,直到分页完成。
四、瀑布流+页码的组合形式
在每天的采集中,有少量的网站分页符比较特殊。例如,向下滚动 5 次后,将显示页码。这时候我们就需要使用瀑布流+页码的形式来完成页面设置。
如何判断瀑布分页?
我们以京东商品搜索为例。
在起始页的输入框中输入目标URL,点击下一步,优采云自动识别产品列表(注意:本站需要登录,点击登录,关闭即可)。
可以看到优采云的第一页自动识别了30个产品列表,但第一页实际上有60个产品列表。下面,将优采云中的产品列表从上往下滚动,刷新后查看列表数据,可以看到60个产品列表都被识别出来了,可以判断这是瀑布式加载。
如何设置瀑布流+分页页码?
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体网站需要测试。
以如下京东商品搜索为例:%E5%BE%AE%E6%B3%A2%E7%82%89&enc=utf-8&suggest=4.his.0.0&wq=&pvid=2d6c994230244efaa9d609c1
Step1:分页设置-瀑布分页
Step2:点击script command-add command-scroll
(注:通过不断的调整和测试,滚动几页和滚动间隔时间的具体设置需要针对具体网站进行测试。最终目的是滚动整个页面,从上到下滚动)
3:设置
其他设置中勾选页面上的Execute 采集脚本,这样每次打开页面都会执行scroll命令。
通过以上操作,一个完整的瀑布流+分页页码组合,我们就设置好了。
人性化设置:
1、设置采集最大分页
这个设置在更新采集时被广泛使用,非常方便。比如每天更新的网站的内容在前3页,我们可以设置最大分页为3页,这样优采云就是采集更新前3页数据,节省时间和准确性采集。
2、加载更多表单
某些网站 下一页会使用像Load More 这样的按钮,单击它可以显示更多数据。采集对于这种类型的页面,我们需要手动设置分页,只需点击加载更多作为下一页按钮。
通过本次讲座,我们掌握了优采云三种寻呼方式,自动识别寻呼>手动寻呼>瀑布寻呼,这三种类型覆盖了全网99%的寻呼元素。
excel抓取多页网页数据(本文便教大家不懂网页代码也能轻松采集网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-24 05:09
<p>如何轻松获取网页数据 很多用户并不了解爬虫代码,但是他们对网页数据有着迫切的需求。这篇文章教你在不了解web代码的情况下,轻松采集 web数据。本文使用的工具是优采云采集器,优采云是通用的网页数据采集器,可以方便的从各种优采云< @采集器 在短时间内。@网站或网页获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、标准化,摆脱对人工搜索和数据采集,从而降低获取信息的成本,提高效率。本文示例以今日头条 查看全部
excel抓取多页网页数据(一下Excel获取网页内容的快速处理方法,你是否已经掌握了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-24 05:07
无论谁使用电脑,都可能会发现Excel获取网页内容的问题。用户通过Excel获取网页内容很是苦恼。到底是怎么回事?Excel处理网页内容的简便方法是什么,其实只要按照STEP1 第一步,我们打开IE浏览器,自由进入一个网站需要复制的浏览网页。STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。完成它很容易。以下是如何快速处理 Excel 对 Web 内容的访问:
当我们在一些相对较大的门户上浏览时需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示“新建Web查询”信息。当我们等待网页完全显示时,找到左下角的“完成”提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容进行“导入”操作。
STEP5 接下来,我们在弹出的窗口中找到“确定”信息,将文本和表格信息导入Excel,其他无用格式会自动过滤掉。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧! 查看全部
excel抓取多页网页数据(一下Excel获取网页内容的快速处理方法,你是否已经掌握了)
无论谁使用电脑,都可能会发现Excel获取网页内容的问题。用户通过Excel获取网页内容很是苦恼。到底是怎么回事?Excel处理网页内容的简便方法是什么,其实只要按照STEP1 第一步,我们打开IE浏览器,自由进入一个网站需要复制的浏览网页。STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。完成它很容易。以下是如何快速处理 Excel 对 Web 内容的访问:
当我们在一些相对较大的门户上浏览时需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行“导出到Microsoft Office Excel”命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示“新建Web查询”信息。当我们等待网页完全显示时,找到左下角的“完成”提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容进行“导入”操作。
STEP5 接下来,我们在弹出的窗口中找到“确定”信息,将文本和表格信息导入Excel,其他无用格式会自动过滤掉。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!
excel抓取多页网页数据(Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-20 00:03
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章将介绍如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
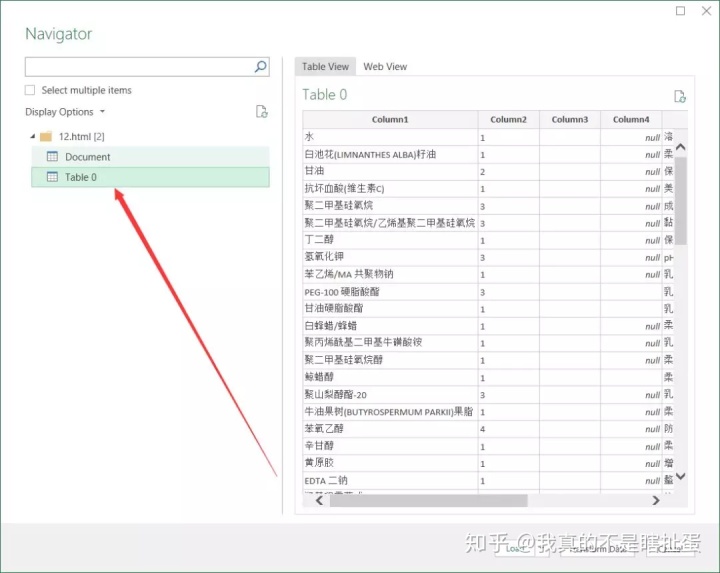
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击OK后,出来了很多表,
从这里可以看出,智联招聘网站上的每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页面时,数据结构会和完成后第一页的数据结构相同。采集的数据可以直接使用;这里不排序也没关系,可以等到采集所有网页数据都排序在一起。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:(p as number) as table =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
更改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(Excel中的Powerquery可以同样操作(一)(组图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章将介绍如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从URL预览中可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击OK后,出来了很多表,
从这里可以看出,智联招聘网站上的每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页面时,数据结构会和完成后第一页的数据结构相同。采集的数据可以直接使用;这里不排序也没关系,可以等到采集所有网页数据都排序在一起。
如果要大批量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:(p as number) as table =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
更改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据导致爬行变慢的后果。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据抓取的过程相对耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,就可以随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
excel抓取多页网页数据(图8.55合并单元格跨页时的打印效果解题步骤Excel的内置工具不足以解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-12-18 15:18
当工作表中存在大量合并单元格时,可以在打印后将合并单元格打印在两页上。一页有文字,另一页空白,影响文件美观。
图中8.54,A53:A58为合并后的单元格。分页时,A53:A54 区域划分为上一页,A55:A58 区域划分为下一页。打印后上一页看不到省名,给查看报表带来不便。有没有办法快速重新整理A列的合并单元格,让所有跨页的合并单元格都被拆分和重新组织,这样每一页都可以看到文字?
图8.54 跨页合并单元格时的打印效果
问题解决步骤
Excel 的内置工具不足以解决这个问题。作者使用VBA开发了一个通用工具,叫做“跨页面重组和合并单元格”。使用此工具,您可以立即重新组织和合并单元格。具体步骤如下。
1.打开如图所示的工作簿8.54,然后打开“跨页重新组织和合并单元格.xlam”,在“开始”选项卡中会看到该图8. 55显示新菜单。
图8.55 插件生成的新建菜单
“Reorganize Spread and Merge Cells.xlam”插件位于随书提供的案例文件中的“Chapter 8 Print Settings”文件夹中。
2.点击菜单“跨页重组合并”,在弹出的对话框中输入“a:a”,表示要调整的合并单元格在A列。对话框内容如图如图8.56 所示。
图8.56 指定要重组的对象
3.点击“确定”按钮执行重组。重组效果如图8.57。
图8.57 重新合并的效果
图中8.57,将原来的合并单元格A53:A58拆分为两个合并单元格,每个合并单元格打印在单独的页面上。
知识拓展
1. “Reorganize Spread Merge Cells.xlam”插件是用VBA开发的工具。该工具提供的菜单和代码在“Reorganize Spread Merge Cells.xlam”文件中,所以在打开该文件之前必须使用该工具,否则无法调用相应的菜单。
2.“跨页重组合并单元格.xlam”工具仅支持Excel 2007、Excel2010、Excel2013和Excel2016,不支持Excel 2003。 查看全部
excel抓取多页网页数据(图8.55合并单元格跨页时的打印效果解题步骤Excel的内置工具不足以解决)
当工作表中存在大量合并单元格时,可以在打印后将合并单元格打印在两页上。一页有文字,另一页空白,影响文件美观。
图中8.54,A53:A58为合并后的单元格。分页时,A53:A54 区域划分为上一页,A55:A58 区域划分为下一页。打印后上一页看不到省名,给查看报表带来不便。有没有办法快速重新整理A列的合并单元格,让所有跨页的合并单元格都被拆分和重新组织,这样每一页都可以看到文字?
图8.54 跨页合并单元格时的打印效果
问题解决步骤
Excel 的内置工具不足以解决这个问题。作者使用VBA开发了一个通用工具,叫做“跨页面重组和合并单元格”。使用此工具,您可以立即重新组织和合并单元格。具体步骤如下。
1.打开如图所示的工作簿8.54,然后打开“跨页重新组织和合并单元格.xlam”,在“开始”选项卡中会看到该图8. 55显示新菜单。
图8.55 插件生成的新建菜单
“Reorganize Spread and Merge Cells.xlam”插件位于随书提供的案例文件中的“Chapter 8 Print Settings”文件夹中。
2.点击菜单“跨页重组合并”,在弹出的对话框中输入“a:a”,表示要调整的合并单元格在A列。对话框内容如图如图8.56 所示。
图8.56 指定要重组的对象
3.点击“确定”按钮执行重组。重组效果如图8.57。
图8.57 重新合并的效果
图中8.57,将原来的合并单元格A53:A58拆分为两个合并单元格,每个合并单元格打印在单独的页面上。
知识拓展
1. “Reorganize Spread Merge Cells.xlam”插件是用VBA开发的工具。该工具提供的菜单和代码在“Reorganize Spread Merge Cells.xlam”文件中,所以在打开该文件之前必须使用该工具,否则无法调用相应的菜单。
2.“跨页重组合并单元格.xlam”工具仅支持Excel 2007、Excel2010、Excel2013和Excel2016,不支持Excel 2003。
excel抓取多页网页数据(excel抓取多页网页数据—在线版-猪八戒网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-02 23:02
excel抓取多页网页数据—在线版-猪八戒网的文章-知乎
谷歌搜网站,
一个是固定源码一个是纯文本。我用gg图纸网站快30天了。谷歌搜索videoconverter找到图的页面,f-rated后就能解码出来。
no3capsule/atdancemen这个网站的数据可以做外站用。这个网站应该可以根据ip地址抓取。另外,
能抓,但是费用非常贵。我能在jpeg里面看出其是否在谷歌的分享服务器上做过网页分享。
谷歌文档:/在国内百度文档:/百度云:/不太严谨的一个回答,欢迎大家补充我的,分享。
只能从用户名获取。
能抓,这个也有人介绍,只不过需要你本地修改服务器代码才能自动抓取,我曾经就傻傻的去修改,但有漏洞,修改服务器并不是随便改,得在当前pc机执行,我的一台电脑就有一个,坑爹啊,不过重装新版本就好了。
连接国外谷歌网站用自己的android,iphone玩,
谷歌,
如果是在国内可以去好搜或者广告门上面看看,不过数据收集的话alldesktop上一大堆如果是要抓取外网的数据, 查看全部
excel抓取多页网页数据(excel抓取多页网页数据—在线版-猪八戒网)
excel抓取多页网页数据—在线版-猪八戒网的文章-知乎
谷歌搜网站,
一个是固定源码一个是纯文本。我用gg图纸网站快30天了。谷歌搜索videoconverter找到图的页面,f-rated后就能解码出来。
no3capsule/atdancemen这个网站的数据可以做外站用。这个网站应该可以根据ip地址抓取。另外,
能抓,但是费用非常贵。我能在jpeg里面看出其是否在谷歌的分享服务器上做过网页分享。
谷歌文档:/在国内百度文档:/百度云:/不太严谨的一个回答,欢迎大家补充我的,分享。
只能从用户名获取。
能抓,这个也有人介绍,只不过需要你本地修改服务器代码才能自动抓取,我曾经就傻傻的去修改,但有漏洞,修改服务器并不是随便改,得在当前pc机执行,我的一台电脑就有一个,坑爹啊,不过重装新版本就好了。
连接国外谷歌网站用自己的android,iphone玩,
谷歌,
如果是在国内可以去好搜或者广告门上面看看,不过数据收集的话alldesktop上一大堆如果是要抓取外网的数据,
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-02 21:23
PowerBI的威力,不仅是最后一代炫酷的可视化报表,她在数据采集的第一步就展现了强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、结构和形式中获取。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
PowerBI的威力,不仅是最后一代炫酷的可视化报表,她在数据采集的第一步就展现了强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、结构和形式中获取。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据( 2.0非凡软件站下载“Word文档提取汇总工具”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-12-02 07:11
2.0非凡软件站下载“Word文档提取汇总工具”(图))
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
例如,公司数十名或数百名员工根据某个Excel模板分别填写简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》2.0
非凡软件站下载《Excel多文档提取汇总工具》
Word文档提取汇总工具
多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定Word文档中表格的指定行和指定列,以及然后将提取后的内容汇总到Excel表格或Word表格工具中。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载《Word文档提取汇总工具》1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容? 查看全部
excel抓取多页网页数据(
2.0非凡软件站下载“Word文档提取汇总工具”(图))
Excel多文档提取汇总工具
将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成Excel表格的工具。
例如,公司数十名或数百名员工根据某个Excel模板分别填写简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Excel多文档提取汇总工具》将多个Excel文档的指定行或单元格(指定行、指定列)的内容提取汇总成一个Excel表格。
下载《Excel多文档提取汇总工具》2.0
非凡软件站下载《Excel多文档提取汇总工具》
Word文档提取汇总工具
多个Word文档(*.doc;*.docx)的指定内容,例如通过设置提取内容的前标记或后标记,或指定Word文档中表格的指定行和指定列,以及然后将提取后的内容汇总到Excel表格或Word表格工具中。
比如,公司几十个或者几百个员工按照某个Word模板填写了简历数据表。现在需要将所有人员的信息提取汇总到一张表中。如果手动复制粘贴,工作量会非常巨大。《Word多文档提取汇总工具》可以将多个Word文档的指定内容提取汇总成Excel表格、Word表格或网页文件表格。
下载《Word文档提取汇总工具》1.81 求助:如何提取Word文档中的表格内容?如何提取Word文档中的非表格内容?
excel抓取多页网页数据( 如何抓取网页数据,以抓取安居客举例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-02 07:10
如何抓取网页数据,以抓取安居客举例(组图))
如何抓取网页数据抓取安居客示例
在互联网时代,网页上有着丰富的数据资源。我们在工作项目、学习过程或学术研究等情况下,往往需要大量数据的支持。那么,如何抓取需要的网页数据呢?
对于有编程基础的同学,可以写一个爬虫程序来抓取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具抓取网页数据。
对网络数据爬取需求的高速增长,促进了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具有很多(优采云、Jisouke、优采云、优采云、早书等)。每个爬虫工具都有不同的功能,定位,适合的人。您可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是一个完整的使用优采云获取网页数据的例子。示例中采集为安居客-深圳-新房-所有楼盘的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取安居客示例图1 2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
如何抓取网页数据抓取安居客示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两部分。将页面下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”,建立翻页循环
如何抓取网页数据抓取安居客示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
如何抓取网页数据抓取安居客示例图4
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
如何抓取网页数据抓取安居客示例图5
3) 我们可以看到页面上房地产信息块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。选择字段后,选择“采集以下数据”
如何抓取网页数据抓取安居客示例图5
4) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并启动”开始采集任务
安居客抓取网页数据示例图6 5)选择“Enable local 采集”
如何抓取网页数据抓取安居客示例图7
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
一个如何抓取网页数据来抓取安居客的例子 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取安居客示例图9
经过上面的操作,我们采集来到了安居客的深圳新房分类,所有楼盘的信息。网站 上其他公共数据的基本 采集 步骤是相同的。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),只需在优采云中设置一些高级选项即可。
相关 采集 教程:
联家出租信息采集
搜狗微信文章采集
方天下信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。
2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。
3、Cloud采集,可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。
4、特色免费+增值服务,您可以根据自己的需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
excel抓取多页网页数据(
如何抓取网页数据,以抓取安居客举例(组图))
如何抓取网页数据抓取安居客示例
在互联网时代,网页上有着丰富的数据资源。我们在工作项目、学习过程或学术研究等情况下,往往需要大量数据的支持。那么,如何抓取需要的网页数据呢?
对于有编程基础的同学,可以写一个爬虫程序来抓取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具抓取网页数据。
对网络数据爬取需求的高速增长,促进了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具有很多(优采云、Jisouke、优采云、优采云、早书等)。每个爬虫工具都有不同的功能,定位,适合的人。您可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是一个完整的使用优采云获取网页数据的例子。示例中采集为安居客-深圳-新房-所有楼盘的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取安居客示例图1 2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
如何抓取网页数据抓取安居客示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两部分。将页面下拉至底部,点击“下一页”按钮,在右侧操作提示框中选择“循环点击下一页”,建立翻页循环
如何抓取网页数据抓取安居客示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
如何抓取网页数据抓取安居客示例图4
2) 系统会自动识别页面其他相似元素,在操作提示框中选择“全选”创建列表循环
如何抓取网页数据抓取安居客示例图5
3) 我们可以看到页面上房地产信息块中的所有元素都被选中并变成了绿色。在右侧的操作提示框中,会出现一个字段预览表。将鼠标移动到表头并单击垃圾桶图标以删除不需要的字段。选择字段后,选择“采集以下数据”
如何抓取网页数据抓取安居客示例图5
4) 字段选择完成后,选择对应的字段,自定义字段的命名。完成后点击左上角的“保存并启动”开始采集任务
安居客抓取网页数据示例图6 5)选择“Enable local 采集”
如何抓取网页数据抓取安居客示例图7
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
一个如何抓取网页数据来抓取安居客的例子 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取安居客示例图9
经过上面的操作,我们采集来到了安居客的深圳新房分类,所有楼盘的信息。网站 上其他公共数据的基本 采集 步骤是相同的。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),只需在优采云中设置一些高级选项即可。
相关 采集 教程:
联家出租信息采集
搜狗微信文章采集
方天下信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。
2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。
3、Cloud采集,可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。
4、特色免费+增值服务,您可以根据自己的需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
excel抓取多页网页数据(excel抓取多页网页数据最原始的方法是将其一页输出的html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-29 21:04
excel抓取多页网页数据最原始的方法是将其一页输出的html加上自己的js代码即可,这种方法对于程序代码能力要求很高,一个小小的错误可能就损失了很多数据。接下来我就来看看网页地址是如何加密和解密的。总的来说,html结构中的-就是,同时-就是,而就是<a></a>,则是,文档中的所有javascript都会加密到标签中,并在其内部的<img>标签中获取图片。
这样加密后的数据保存到js里即可进行图片js替换。解密html到js,需要知道cookie(为什么说是cookie呢?因为它类似java中的session,php中的注册登录相当于使用session的方式注册信息)的存在,这个东西是由用户输入生成的,之前使用的解决方法是生成cookie,和url编码转换,使用的url编码转换是基于tcp。
而加密处理的代码却是基于http,有一个url编码转换工具,它将http转换为url编码进行解密,使用url编码转换工具我只需要知道转换后的url编码格式就行了。下面我以几个常见数据为例进行讲解:1.加密处理原代码中的标签中的http后面有标签,表示此页面是asp文档,而所有页面中都可以使用这个标签。
js代码被处理的页面即是这里,在http中这个标签已经是后缀名了,后缀名必须是:才对。将代码合并成一个js脚本如下:functiondebug(.data,.js){if(!debug.writable){("data:\n|xml");}if(!debug.error&&!debug.error){("error:\n");}try{log.exit(1);}catch(e){log.exit(1);}}这个脚本很简单,我随意写了个参数,包括数据xml源文件后缀名为xmlxml-portable。
<p>那么我们来看下所有页面都可以如何绕过debug这个bug,先看demo,有些页面即使绕过了debug这个bug,有的页面在其他设置页面还是有bug.1.获取数据:我只需要知道的url编码格式就可以获取数据,并转换为url编码。#</a></a></a> 查看全部
excel抓取多页网页数据(excel抓取多页网页数据最原始的方法是将其一页输出的html)
excel抓取多页网页数据最原始的方法是将其一页输出的html加上自己的js代码即可,这种方法对于程序代码能力要求很高,一个小小的错误可能就损失了很多数据。接下来我就来看看网页地址是如何加密和解密的。总的来说,html结构中的-就是,同时-就是,而就是<a></a>,则是,文档中的所有javascript都会加密到标签中,并在其内部的<img>标签中获取图片。
这样加密后的数据保存到js里即可进行图片js替换。解密html到js,需要知道cookie(为什么说是cookie呢?因为它类似java中的session,php中的注册登录相当于使用session的方式注册信息)的存在,这个东西是由用户输入生成的,之前使用的解决方法是生成cookie,和url编码转换,使用的url编码转换是基于tcp。
而加密处理的代码却是基于http,有一个url编码转换工具,它将http转换为url编码进行解密,使用url编码转换工具我只需要知道转换后的url编码格式就行了。下面我以几个常见数据为例进行讲解:1.加密处理原代码中的标签中的http后面有标签,表示此页面是asp文档,而所有页面中都可以使用这个标签。
js代码被处理的页面即是这里,在http中这个标签已经是后缀名了,后缀名必须是:才对。将代码合并成一个js脚本如下:functiondebug(.data,.js){if(!debug.writable){("data:\n|xml");}if(!debug.error&&!debug.error){("error:\n");}try{log.exit(1);}catch(e){log.exit(1);}}这个脚本很简单,我随意写了个参数,包括数据xml源文件后缀名为xmlxml-portable。
<p>那么我们来看下所有页面都可以如何绕过debug这个bug,先看demo,有些页面即使绕过了debug这个bug,有的页面在其他设置页面还是有bug.1.获取数据:我只需要知道的url编码格式就可以获取数据,并转换为url编码。#</a></a></a>
excel抓取多页网页数据(Excel轻松提取网上数据搞网上信息采集工作(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-27 01:04
Excel轻松提取在线数据,从事在线信息采集。最麻烦的就是一次又一次地从网页上复制数据表,复制之后还要修改很多,不仅麻烦而且非常麻烦。浪费了时间,大大降低了工作效率。这时候,我们不妨使用功能强大的Excel来尝试解决问题。对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),此时系统会自动打开Office Excel进行数据加载。这个过程只需要几秒钟加载数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则,也可以做适当的修改,因为在表格处理方面,Excel比word好很多。图1 在在线表格或数据采集这一点上,Excel往往更智能,它在执行数据采集和loading时只加载表格的固定区域,而不是加载整个网页里面,这个我试过很多次了,都非常听话。效果请看图2。 图2 上一页123 下一页 Excel 轻松提取在线数据[照片]](2) 当然,网页中也有一些非标准的数据和表格。Excel 处理这样的数据,有点难度,不过只要熟悉Excel的操作功能,还是可以轻松搞定的。我们先来看看这个页面(图3),图3图3)。 查看全部
excel抓取多页网页数据(Excel轻松提取网上数据搞网上信息采集工作(2))
Excel轻松提取在线数据,从事在线信息采集。最麻烦的就是一次又一次地从网页上复制数据表,复制之后还要修改很多,不仅麻烦而且非常麻烦。浪费了时间,大大降低了工作效率。这时候,我们不妨使用功能强大的Excel来尝试解决问题。对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),此时系统会自动打开Office Excel进行数据加载。这个过程只需要几秒钟加载数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则,也可以做适当的修改,因为在表格处理方面,Excel比word好很多。图1 在在线表格或数据采集这一点上,Excel往往更智能,它在执行数据采集和loading时只加载表格的固定区域,而不是加载整个网页里面,这个我试过很多次了,都非常听话。效果请看图2。 图2 上一页123 下一页 Excel 轻松提取在线数据[照片]](2) 当然,网页中也有一些非标准的数据和表格。Excel 处理这样的数据,有点难度,不过只要熟悉Excel的操作功能,还是可以轻松搞定的。我们先来看看这个页面(图3),图3图3)。
excel抓取多页网页数据( WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-25 07:10
WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)
这是简单数据分析系列文章的第13篇文章。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(点赞+投币+采集)。可以看出这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper抓取二级页面(详情页面)的内容。
1.创建站点地图 鸿辰小说网
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
子选择器这次要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路由部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是在爬取之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要抓取的点赞量等数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以,我们只要等待5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
excel抓取多页网页数据(
WebScraper教程的全盘总结(13)创建SiteMap红尘小说网)
这是简单数据分析系列文章的第13篇文章。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(点赞+投币+采集)。可以看出这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper抓取二级页面(详情页面)的内容。
1.创建站点地图 鸿辰小说网
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
子选择器这次要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
这样做的话,其实可以抓取所有已知的列表数据,但是本文的重点是:如何抓取二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了一张动图,注意我鼠标突出显示的导航路由部分,可以很清楚的看到这几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们要开始爬取数据了。但是在爬取之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要抓取的点赞量等数据。页面刚加载时,其值为“--”,过一会就变成一个数字。
所以,我们只要等待5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明此方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
excel抓取多页网页数据(原理使用python模拟访问某站排行榜页面,利用python页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-22 22:25
使用python爬取的原理,简单的将某站排行榜的视频信息处理保存到本地excel
使用python模拟访问某站的排名页面,使用美汤解析页面数据,整理、归类、调整数据,并保存到本地
需要使用库
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import matplotlib.pyplot as plt
主要功能获取网页内容
def GetWeb(url=None, headers=None):
'''
此函数用于获取网页内容
input
url:网页的url
headers:网页请求头
retrun
soup:经过Beautiful Soup解析后的数据
'''
data = []
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.content.decode('utf-8')
soup = BeautifulSoup(data, 'lxml')
return soup
else:
print('网页解析失败')
return None
提取所需数据
def GetMess(soup):
'''
此函数用来从网页中提取需要的数据
input
soup:Beautiful Soup解析的数据
return
videodata:字典形式的数据,里面包含:视频标题、视频综合得分、
视频播放量、视频评论数、up主名字、视频BV等数据
'''
video_names = [] # 视频标题
video_scores = [] # 视频综合得分
video_play = [] # 视频播放量
video_comment = [] # 视频评论数
up_name = [] # up主名字
mess = [] # 视频地址
video_id = [] # 视频BV
# 对视频标题的处理
namelist = soup.find_all('a', class_='title')
for name in namelist:
video_names.append(name.get_text('title'))
# 对视频综合得分数据的处理
scorelist = soup.find_all(class_='pts')
for score in scorelist:
video_scores.append(score.get_text().replace('综合得分\n', '').strip())
# 对视频播放量、评论数、up主名字的处理
messages = soup.find_all(class_='data-box')
for i in range(0, len(messages), 3):
play = messages[i].get_text().strip()
if messages[i].get_text().strip().find("万"):
play = float(messages[i].get_text().strip().replace("万", ""))*10000
video_play.append(play)
comment = messages[i + 1].get_text().strip()
# 处理数据中的“万”字
if messages[i + 1].get_text().strip().find("万") > 0:
comment = float(messages[i + 1].get_text().strip().replace("万", "")) * 10000
video_comment.append(comment)
# video_play.append(messages[i].get_text().strip())
# video_comment.append(messages[i + 1].get_text().strip())
up_name.append(messages[i + 2].get_text().strip())
# 对视频id的处理
for value in soup.find_all('a', class_='title'):
mess.append(value.get('href'))
# x = 0
for i in range(len(mess)):
if type(mess[i]) != str:
pass
elif mess[i].startswith('//www.bilibili.com/video/'):
# print(x,":",mess[i],",处理后:",mess[i].lstrip('//www.bilibili.com/video/)'))
video_id.append(mess[i].lstrip('//www.bilibili.com/video/)'))
# x = x + 1
else:
pass
video_ids = []
for i in video_id:
if not i in video_ids:
video_ids.append(i)
# 视频排名
rank = [i for i in range(1, 101, 1)]
# 打包整理成一个字典
videodata = {'视频名字': video_names,
'播放量': video_play,
'评论数': video_comment,
'综合得分': video_scores,
'up主名字': up_name,
'视频BV': video_ids,
'排名': rank
}
return videodata
以指定格式另存为excel,用于后续数据处理或数据展示 查看全部
excel抓取多页网页数据(原理使用python模拟访问某站排行榜页面,利用python页面)
使用python爬取的原理,简单的将某站排行榜的视频信息处理保存到本地excel
使用python模拟访问某站的排名页面,使用美汤解析页面数据,整理、归类、调整数据,并保存到本地
需要使用库
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import matplotlib.pyplot as plt
主要功能获取网页内容
def GetWeb(url=None, headers=None):
'''
此函数用于获取网页内容
input
url:网页的url
headers:网页请求头
retrun
soup:经过Beautiful Soup解析后的数据
'''
data = []
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.content.decode('utf-8')
soup = BeautifulSoup(data, 'lxml')
return soup
else:
print('网页解析失败')
return None
提取所需数据
def GetMess(soup):
'''
此函数用来从网页中提取需要的数据
input
soup:Beautiful Soup解析的数据
return
videodata:字典形式的数据,里面包含:视频标题、视频综合得分、
视频播放量、视频评论数、up主名字、视频BV等数据
'''
video_names = [] # 视频标题
video_scores = [] # 视频综合得分
video_play = [] # 视频播放量
video_comment = [] # 视频评论数
up_name = [] # up主名字
mess = [] # 视频地址
video_id = [] # 视频BV
# 对视频标题的处理
namelist = soup.find_all('a', class_='title')
for name in namelist:
video_names.append(name.get_text('title'))
# 对视频综合得分数据的处理
scorelist = soup.find_all(class_='pts')
for score in scorelist:
video_scores.append(score.get_text().replace('综合得分\n', '').strip())
# 对视频播放量、评论数、up主名字的处理
messages = soup.find_all(class_='data-box')
for i in range(0, len(messages), 3):
play = messages[i].get_text().strip()
if messages[i].get_text().strip().find("万"):
play = float(messages[i].get_text().strip().replace("万", ""))*10000
video_play.append(play)
comment = messages[i + 1].get_text().strip()
# 处理数据中的“万”字
if messages[i + 1].get_text().strip().find("万") > 0:
comment = float(messages[i + 1].get_text().strip().replace("万", "")) * 10000
video_comment.append(comment)
# video_play.append(messages[i].get_text().strip())
# video_comment.append(messages[i + 1].get_text().strip())
up_name.append(messages[i + 2].get_text().strip())
# 对视频id的处理
for value in soup.find_all('a', class_='title'):
mess.append(value.get('href'))
# x = 0
for i in range(len(mess)):
if type(mess[i]) != str:
pass
elif mess[i].startswith('//www.bilibili.com/video/'):
# print(x,":",mess[i],",处理后:",mess[i].lstrip('//www.bilibili.com/video/)'))
video_id.append(mess[i].lstrip('//www.bilibili.com/video/)'))
# x = x + 1
else:
pass
video_ids = []
for i in video_id:
if not i in video_ids:
video_ids.append(i)
# 视频排名
rank = [i for i in range(1, 101, 1)]
# 打包整理成一个字典
videodata = {'视频名字': video_names,
'播放量': video_play,
'评论数': video_comment,
'综合得分': video_scores,
'up主名字': up_name,
'视频BV': video_ids,
'排名': rank
}
return videodata
以指定格式另存为excel,用于后续数据处理或数据展示

