
ajax抓取网页内容
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-13 08:05
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。如果你有兴趣,你可以去看看。
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests<br style="margin:0px;padding:0px;max-width:100%;" />page = 1<br style="margin:0px;padding:0px;max-width:100%;" />while True:<br style="margin:0px;padding:0px;max-width:100%;" /> url = 'http://www.kfc.com.cn/kfccda/a ... %3Bbr style="margin:0px;padding:0px;max-width:100%;" /> data = {<br style="margin:0px;padding:0px;max-width:100%;" /> 'cname': '广州',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pid': '',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageIndex': page,<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageSize': '10'<br style="margin:0px;padding:0px;max-width:100%;" /> }<br style="margin:0px;padding:0px;max-width:100%;" /> response = requests.post(url, data=data)<br style="margin:0px;padding:0px;max-width:100%;" /> print(response.json())<br style="margin:0px;padding:0px;max-width:100%;" /> if response.json().get('Table1', ''):<br style="margin:0px;padding:0px;max-width:100%;" /> page += 1<br style="margin:0px;padding:0px;max-width:100%;" /> else:<br style="margin:0px;padding:0px;max-width:100%;" /> break
可以看到,通过从数据中移除,不用十行代码就可以把所有的数据搞下来,所以这个适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站 查看全部
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。如果你有兴趣,你可以去看看。
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息

页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到

上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求

是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests<br style="margin:0px;padding:0px;max-width:100%;" />page = 1<br style="margin:0px;padding:0px;max-width:100%;" />while True:<br style="margin:0px;padding:0px;max-width:100%;" /> url = 'http://www.kfc.com.cn/kfccda/a ... %3Bbr style="margin:0px;padding:0px;max-width:100%;" /> data = {<br style="margin:0px;padding:0px;max-width:100%;" /> 'cname': '广州',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pid': '',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageIndex': page,<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageSize': '10'<br style="margin:0px;padding:0px;max-width:100%;" /> }<br style="margin:0px;padding:0px;max-width:100%;" /> response = requests.post(url, data=data)<br style="margin:0px;padding:0px;max-width:100%;" /> print(response.json())<br style="margin:0px;padding:0px;max-width:100%;" /> if response.json().get('Table1', ''):<br style="margin:0px;padding:0px;max-width:100%;" /> page += 1<br style="margin:0px;padding:0px;max-width:100%;" /> else:<br style="margin:0px;padding:0px;max-width:100%;" /> break
可以看到,通过从数据中移除,不用十行代码就可以把所有的数据搞下来,所以这个适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-13 08:01
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动,可以看到更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject('Microsoft.XMLHTTP');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', '/ajax', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向连接(即服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,使用 document.getElementById("content").innerHTML 更改元素内的 HTML 代码以呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
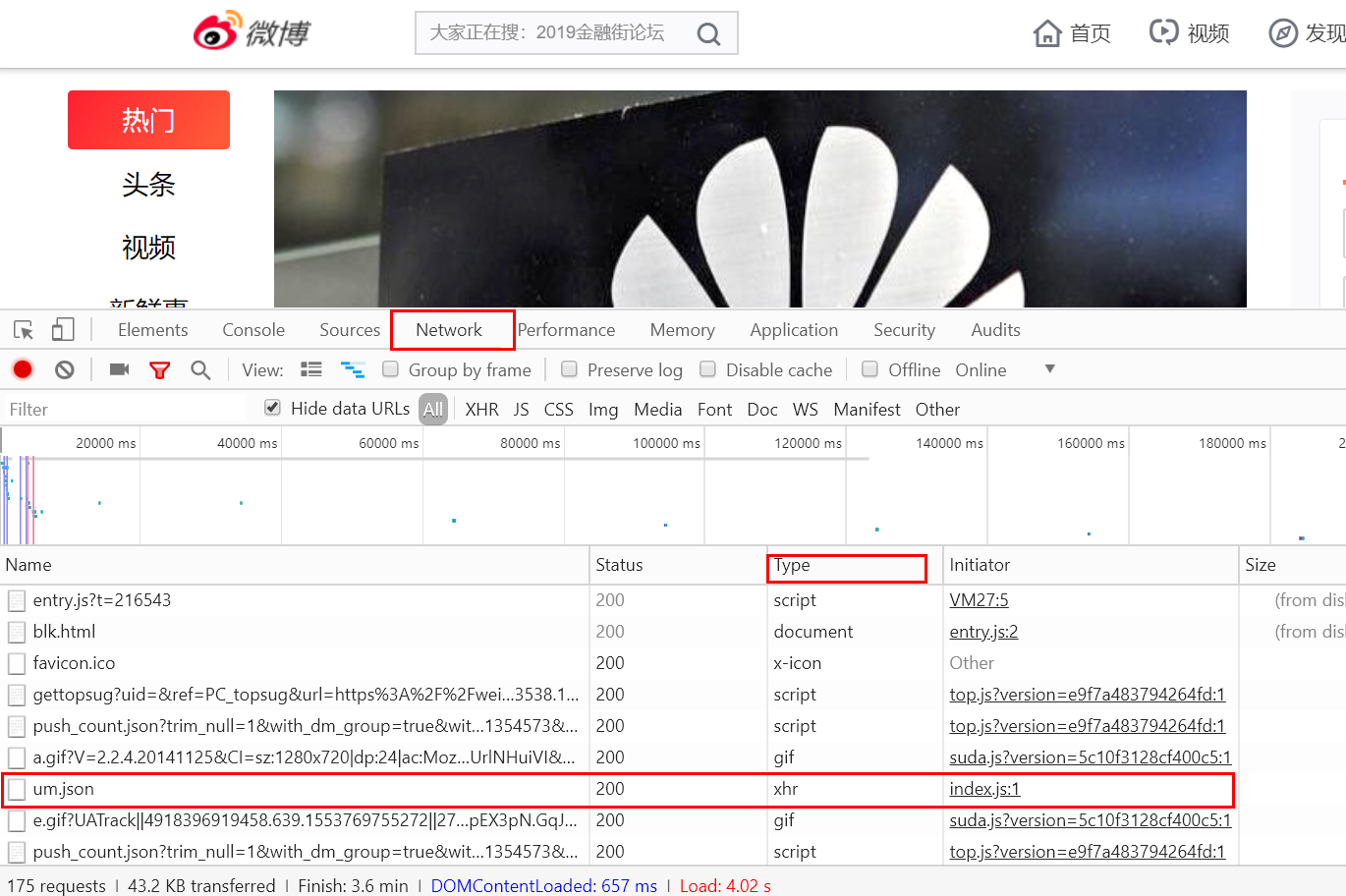
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
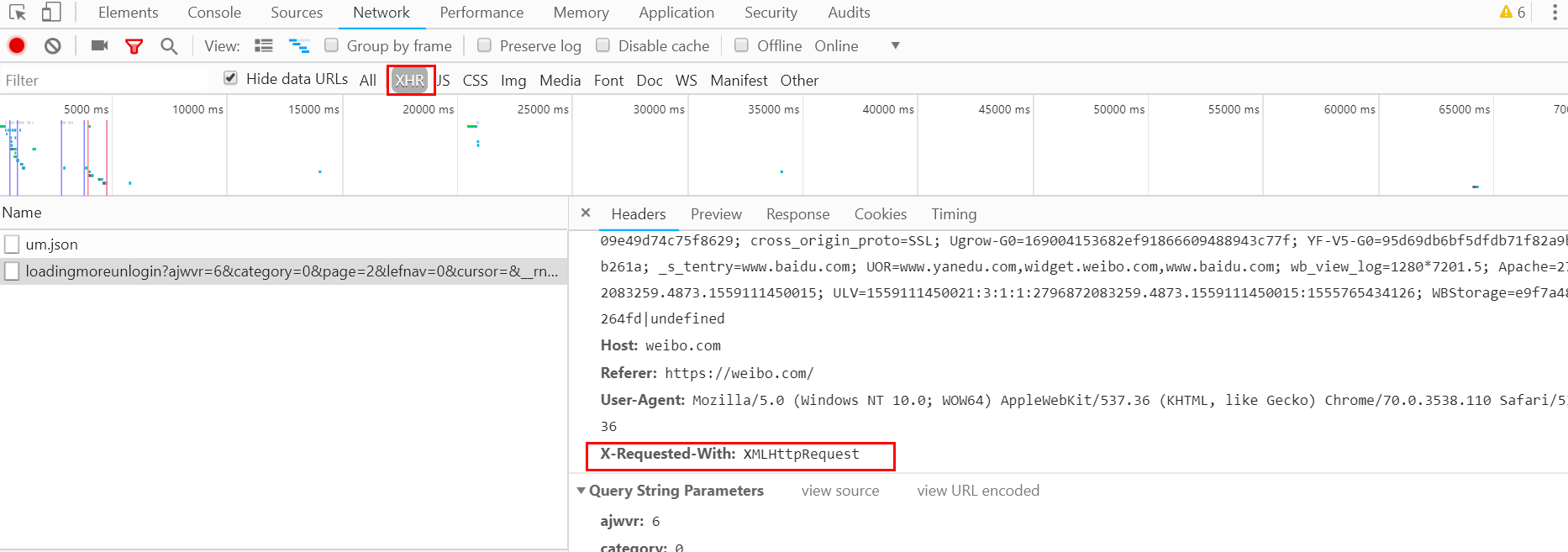
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的请求类型Type中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
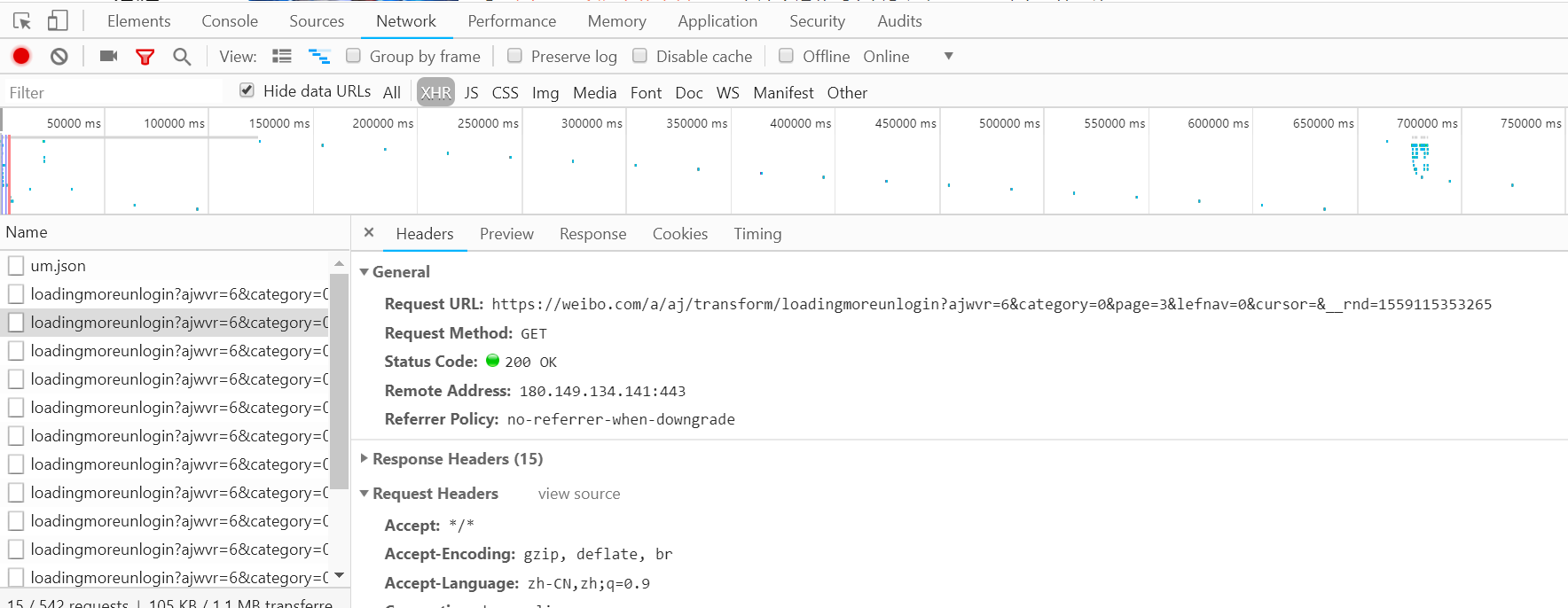
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们请求一个接口,改变页面参数就可以获取到相应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Host': 'weibo.com',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
'ajwvr': '6',
'category': '0',
'page': page,
'lefnav': '0',
'cursor': '',
'__rnd': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print('Error:', e.args)
def parse(res):
weibo = {}
if res:
weibo['data'] = res.get('data')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{'data': ' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n 头条新闻今日快讯 | 华为在美提起诉讼.....}
这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
查看全部
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动,可以看到更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject('Microsoft.XMLHTTP');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', '/ajax', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向连接(即服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,使用 document.getElementById("content").innerHTML 更改元素内的 HTML 代码以呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的请求类型Type中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
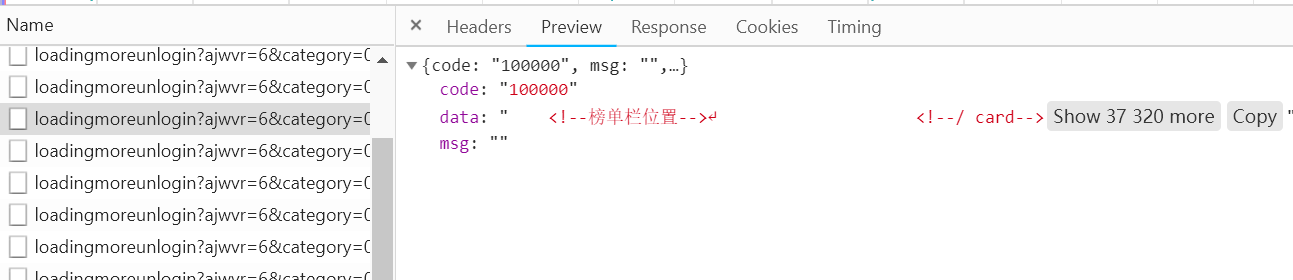
该内容的格式为JSON,主要内容在data对应的值中。这样我们请求一个接口,改变页面参数就可以获取到相应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。


# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Host': 'weibo.com',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
'ajwvr': '6',
'category': '0',
'page': page,
'lefnav': '0',
'cursor': '',
'__rnd': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print('Error:', e.args)
def parse(res):
weibo = {}
if res:
weibo['data'] = res.get('data')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{'data': ' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n
 头条新闻今日快讯 | 华为在美提起诉讼.....}
头条新闻今日快讯 | 华为在美提起诉讼.....}这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
ajax抓取网页内容(NextGen引自流量分析学——CRMAnalytics报告下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-12 14:09
NextGen Market Research 刚刚发布了一份调查报告摘要。对于当前和未来的营销研究和分析技术,数据挖掘及相关技术仍然是最主流的技术。下面两张图引自数据挖掘原文-数据挖掘Web流量分析——Web Analytics数据分析可视化——数据可视化CRM分析——CRM分析文本分析——文本分析社交网络分析——社交网络分析链接分析:书籍、视频 博客挖掘——博客挖掘 网页内容抓取/屏幕抓取——屏幕/网页抓取 博客挖掘——博客挖掘 社交网络分析——社交网络分析 网页内容抓取/屏幕抓取——屏幕/网页抓取文本分析——文本分析链接分析:书籍,Video Data Analysis Visualization——Dat Visualization Web Traffic Analysis——Web Analytics CRM Analysis——CRM Analytics Data Mining——Dat Mining 报告下载地址:ht ics. com/report NGMRsurveyReport2010. pdf 无论现在还是未来,大部分都属于数据挖掘领域。很明显,博客挖掘的地位大大提高,同时也增加了网络内容捕获技术的重要性。这让我想起了文章How to Grab AJAX Dynamic Web Page Content,里面介绍了一个大学科研项目的博客挖掘。然而,越来越多的大型主流博客正在全面采用AJAX技术。如上所述,从这些博客中抓取互联网上的内容是非常困难的。然而,主流博客要想挖掘出准确的营销情报,就必须克服AJAX网络爬虫的问题。在这种市场形势下,Met aSeeker 网页内容抓取软件工具包将进一步展示其出色的AJAX。抢能力。 查看全部
ajax抓取网页内容(NextGen引自流量分析学——CRMAnalytics报告下载地址)
NextGen Market Research 刚刚发布了一份调查报告摘要。对于当前和未来的营销研究和分析技术,数据挖掘及相关技术仍然是最主流的技术。下面两张图引自数据挖掘原文-数据挖掘Web流量分析——Web Analytics数据分析可视化——数据可视化CRM分析——CRM分析文本分析——文本分析社交网络分析——社交网络分析链接分析:书籍、视频 博客挖掘——博客挖掘 网页内容抓取/屏幕抓取——屏幕/网页抓取 博客挖掘——博客挖掘 社交网络分析——社交网络分析 网页内容抓取/屏幕抓取——屏幕/网页抓取文本分析——文本分析链接分析:书籍,Video Data Analysis Visualization——Dat Visualization Web Traffic Analysis——Web Analytics CRM Analysis——CRM Analytics Data Mining——Dat Mining 报告下载地址:ht ics. com/report NGMRsurveyReport2010. pdf 无论现在还是未来,大部分都属于数据挖掘领域。很明显,博客挖掘的地位大大提高,同时也增加了网络内容捕获技术的重要性。这让我想起了文章How to Grab AJAX Dynamic Web Page Content,里面介绍了一个大学科研项目的博客挖掘。然而,越来越多的大型主流博客正在全面采用AJAX技术。如上所述,从这些博客中抓取互联网上的内容是非常困难的。然而,主流博客要想挖掘出准确的营销情报,就必须克服AJAX网络爬虫的问题。在这种市场形势下,Met aSeeker 网页内容抓取软件工具包将进一步展示其出色的AJAX。抢能力。
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-12 14:05
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" '
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评级
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-09-03 查看全部
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" '
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评级
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-09-03
ajax抓取网页内容( 谷歌能DOM是什么?Google不能是如何抓取JavaScript?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-10 23:02
谷歌能DOM是什么?Google不能是如何抓取JavaScript?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
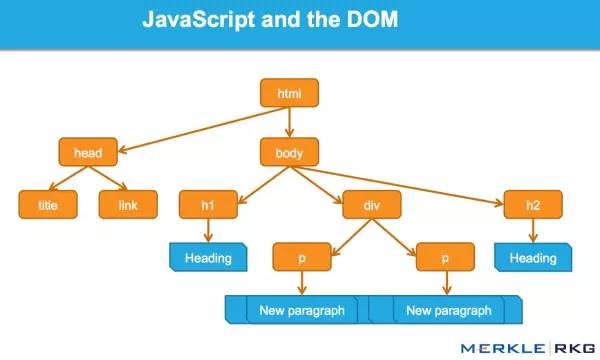
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
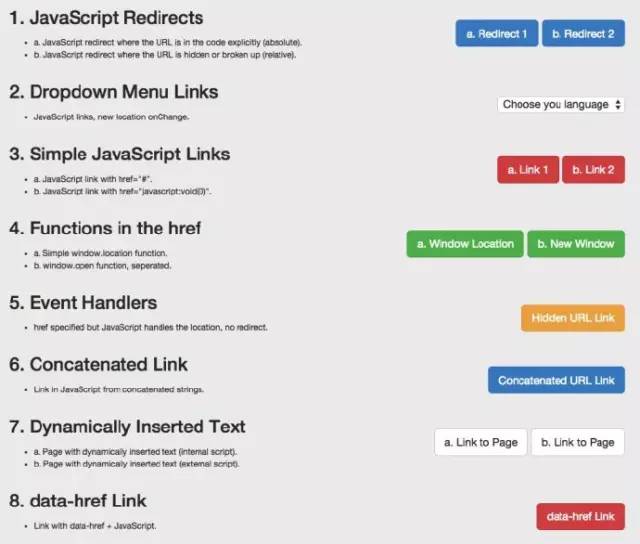
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL替换了谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
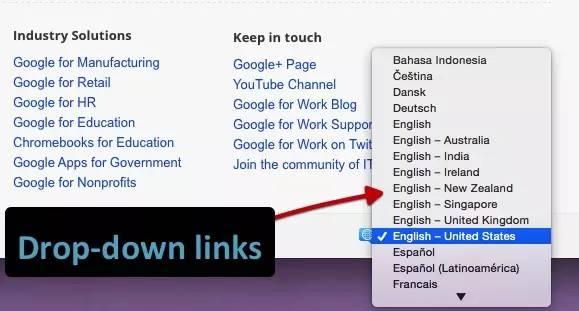
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且该文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
ajax抓取网页内容(
谷歌能DOM是什么?Google不能是如何抓取JavaScript?)

我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向

我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL替换了谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且该文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
ajax抓取网页内容(NutchHtmlunitXimplement项目简介基于ApacheNutch1.8和Htmlunit组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-10 23:00
-------------------------------------------------- ---------------------------当前版本停止更新,Apache Nutch 2.X 工具请参考:---- -------------------------------------------------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 来获取具有必要动态 AJAX 请求的整个页面内容。它是使用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或将源代码重构为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已经全部获取完毕。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,可自由使用:开源、非开源、商业和非商业,前提是保留本项目的源码信息,未经授权销售本项目项目保证不执行。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可以联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目: 查看全部
ajax抓取网页内容(NutchHtmlunitXimplement项目简介基于ApacheNutch1.8和Htmlunit组件)
-------------------------------------------------- ---------------------------当前版本停止更新,Apache Nutch 2.X 工具请参考:---- -------------------------------------------------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 来获取具有必要动态 AJAX 请求的整个页面内容。它是使用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或将源代码重构为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已经全部获取完毕。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,可自由使用:开源、非开源、商业和非商业,前提是保留本项目的源码信息,未经授权销售本项目项目保证不执行。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可以联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目:
ajax抓取网页内容(照Web发展的趋势和发展趋势分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-10 03:11
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在页面上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。页面的原创HTML文档不收录任何数据,数据通过ajax统一加载后呈现,从而在Web开发中实现前后端分离,避免服务器直接渲染页面带来的压力被减少。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面。无法获得有效数据。这时候就需要从页面后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
什么是阿贾克斯
Ajax,全称Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,name 必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变页面,从而更新页面的内容。
基本的
在对Ajax有了初步的了解之后,我们再来了解一下它的基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
(1)发送请求;
(2)分析内容;
(3) 渲染网页。
Ajax 分析方法查看请求
Ajax 实际上有其特殊的请求类型,称为 xhr。如下所示:
右侧可以观察到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
因此,我们看到的微博页面的真实数据并不是从原页面返回的,而是在执行JavaScript之后再次向后台发送Ajax请求,浏览器获取数据再进一步渲染。
过滤请求
接下来,使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求。请求上方有一个过滤器栏。直接点击XHR。此时,下面显示的所有请求都是 Ajax 请求。
接下来连续滑动页面,可以看到页面底部有新的微博,开发者工具发出的Ajax请求也一一出现,方便我们捕获所有的Ajax请求。 查看全部
ajax抓取网页内容(照Web发展的趋势和发展趋势分析(一))
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在页面上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。页面的原创HTML文档不收录任何数据,数据通过ajax统一加载后呈现,从而在Web开发中实现前后端分离,避免服务器直接渲染页面带来的压力被减少。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面。无法获得有效数据。这时候就需要从页面后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
什么是阿贾克斯
Ajax,全称Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,name 必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变页面,从而更新页面的内容。
基本的
在对Ajax有了初步的了解之后,我们再来了解一下它的基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
(1)发送请求;
(2)分析内容;
(3) 渲染网页。
Ajax 分析方法查看请求
Ajax 实际上有其特殊的请求类型,称为 xhr。如下所示:

右侧可以观察到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:

因此,我们看到的微博页面的真实数据并不是从原页面返回的,而是在执行JavaScript之后再次向后台发送Ajax请求,浏览器获取数据再进一步渲染。
过滤请求
接下来,使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求。请求上方有一个过滤器栏。直接点击XHR。此时,下面显示的所有请求都是 Ajax 请求。

接下来连续滑动页面,可以看到页面底部有新的微博,开发者工具发出的Ajax请求也一一出现,方便我们捕获所有的Ajax请求。
ajax抓取网页内容( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-09 14:20
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
ajax抓取网页内容(
Python网络爬虫内容提取器)

1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
ajax抓取网页内容(渲染引擎的基本流程和流程、流程介绍及流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-09 14:17
)
文章内容
介绍
本文介绍了动态页面和Ajax渲染页面数据捕获的示例,以及相应的页面分析过程。
Ajax 抓取示例
越来越多的网页原创 HTML 文档不收录任何数据,而是由 Ajax 统一加载。向网页更新发送ajax请求的过程:
打开浏览器的开发者工具,进入Networkk选项卡,使用XHR过滤工具。需要根据对应的all_config_file.py文件创建对应的文件夹,修改配置,启动相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num 查看全部
ajax抓取网页内容(渲染引擎的基本流程和流程、流程介绍及流程
)
文章内容
介绍
本文介绍了动态页面和Ajax渲染页面数据捕获的示例,以及相应的页面分析过程。
Ajax 抓取示例
越来越多的网页原创 HTML 文档不收录任何数据,而是由 Ajax 统一加载。向网页更新发送ajax请求的过程:
打开浏览器的开发者工具,进入Networkk选项卡,使用XHR过滤工具。需要根据对应的all_config_file.py文件创建对应的文件夹,修改配置,启动相关服务。

all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num
ajax抓取网页内容(FacebookWard的解决方法放弃井号结构,不禁拍案叫绝)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-06 03:04
大家在浏览Facebook相册的时候有没有注意到,页面部分刷新时地址栏中的地址也发生了变化,并不是hash方法。它使用了几个新的 HTML5 历史 API。作为窗口的全局变量,历史在 HTML4 时代并不是什么新鲜事。我们经常使用 history.back() 和 history.go()。
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
复制代码代码如下:
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(FacebookWard的解决方法放弃井号结构,不禁拍案叫绝)
大家在浏览Facebook相册的时候有没有注意到,页面部分刷新时地址栏中的地址也发生了变化,并不是hash方法。它使用了几个新的 HTML5 历史 API。作为窗口的全局变量,历史在 HTML4 时代并不是什么新鲜事。我们经常使用 history.back() 和 history.go()。
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
复制代码代码如下:
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajax抓取网页内容原理有许多方法可以包括xpath的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-04 23:06
ajax抓取网页内容原理有许多方法可以实现,包括xpath。xpath是python的一个语法,其中需要了解正则表达式(re)、html对象(res)、meta标签等基础内容,本文以简单的网页抓取为例。将网页地址粘贴进模拟器的浏览器中,发现键不是print("helloworld"),而是print("helloworld",1)。
带有数字的键。然后新建文件夹urls,用于存放xpath语法。open(xpath,'w')会导致xpath变量和文件名分别在open()函数和定义urls(url)函数里,查看//。用python默认的文件名格式:filename,之后,运行>>>即可获得上述值。此时,右边的框框表示的内容。打开网页,解析//,发现除了//都为空,则跳过。
当然,还可以尝试正则表达式,但会稍微麻烦些。使用try...except...,tryexcept...关键词说明,此时只运行一步,即会把已经解析过的urls带入网页。或者使用xpathcute()函数。try...except...,则有完整的过程,会在每次运行完毕后都运行一遍。通过浏览器或命令行运行>>>即可查看在网页里传递过来的内容,原理和xpath类似。
当然,运行>>>即可查看。网页里传递过来的内容本例,相对容易解析,原理是第一行是块元素div,第二行是控制url的元素li,第三行是控制url的a标签,第四行是控制url的li,第五行是url的a标签,以此类推。下次遇到不会的网页,可以复制该python代码,查找对应的元素在浏览器打开,就可以很方便的看到了。
部分资料来源于:webdeveloper-apythonlearningmasterprogrammingguide。 查看全部
ajax抓取网页内容(ajax抓取网页内容原理有许多方法可以包括xpath的)
ajax抓取网页内容原理有许多方法可以实现,包括xpath。xpath是python的一个语法,其中需要了解正则表达式(re)、html对象(res)、meta标签等基础内容,本文以简单的网页抓取为例。将网页地址粘贴进模拟器的浏览器中,发现键不是print("helloworld"),而是print("helloworld",1)。
带有数字的键。然后新建文件夹urls,用于存放xpath语法。open(xpath,'w')会导致xpath变量和文件名分别在open()函数和定义urls(url)函数里,查看//。用python默认的文件名格式:filename,之后,运行>>>即可获得上述值。此时,右边的框框表示的内容。打开网页,解析//,发现除了//都为空,则跳过。
当然,还可以尝试正则表达式,但会稍微麻烦些。使用try...except...,tryexcept...关键词说明,此时只运行一步,即会把已经解析过的urls带入网页。或者使用xpathcute()函数。try...except...,则有完整的过程,会在每次运行完毕后都运行一遍。通过浏览器或命令行运行>>>即可查看在网页里传递过来的内容,原理和xpath类似。
当然,运行>>>即可查看。网页里传递过来的内容本例,相对容易解析,原理是第一行是块元素div,第二行是控制url的元素li,第三行是控制url的a标签,第四行是控制url的li,第五行是url的a标签,以此类推。下次遇到不会的网页,可以复制该python代码,查找对应的元素在浏览器打开,就可以很方便的看到了。
部分资料来源于:webdeveloper-apythonlearningmasterprogrammingguide。
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-03 21:17
什么是阿贾克斯?简单的说,加载一个网页后还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。Ajax 是一种用于创建快速动态网页的技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。【通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方法有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方法的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 27%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
可以看到去掉from data,不用十行代码就可以把所有的数据搞下来,所以这个网站很适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站 查看全部
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是阿贾克斯?简单的说,加载一个网页后还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。Ajax 是一种用于创建快速动态网页的技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。【通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方法有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方法的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 27%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
可以看到去掉from data,不用十行代码就可以把所有的数据搞下来,所以这个网站很适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-10-01 19:24
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标移动到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。 查看全部
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。

打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标移动到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。
ajax抓取网页内容(用Chrome浏览器的开发者工具看到所有的请求链接及其请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-01 03:13
直接回答:
https://www.zhihu.com/node/ProfileFolloweesListV2
详细答复:
正如@tweelveandone所说,您可以使用Chrome浏览器的开发工具查看所有请求,包括Ajax的目标链接及其请求消息
例如,要查看与主题相关的人员,请首先打开此页面:/people/feng-xing-53-25/如下
然后打开chrome的开发者工具窗口,监控网络(自己学习具体使用方法)
下拉页面,直到触发Ajax请求以获取下一页的用户列表(显示为页面上的加载),您可以在开发者工具栏中看到特定的请求链接(即/node/ProfileFollowsListV2)),以及相应的请求和响应
如果使用Python捕获知乎数据,可以参考以下两项:
==============================以下是广告时间。如果您不感兴趣,可以跳过它====================
如果您对go感兴趣,还可以查看我不久前编写的库,并参考前面提到的两个Python库: 查看全部
ajax抓取网页内容(用Chrome浏览器的开发者工具看到所有的请求链接及其请求)
直接回答:
https://www.zhihu.com/node/ProfileFolloweesListV2
详细答复:
正如@tweelveandone所说,您可以使用Chrome浏览器的开发工具查看所有请求,包括Ajax的目标链接及其请求消息
例如,要查看与主题相关的人员,请首先打开此页面:/people/feng-xing-53-25/如下
然后打开chrome的开发者工具窗口,监控网络(自己学习具体使用方法)
下拉页面,直到触发Ajax请求以获取下一页的用户列表(显示为页面上的加载),您可以在开发者工具栏中看到特定的请求链接(即/node/ProfileFollowsListV2)),以及相应的请求和响应
如果使用Python捕获知乎数据,可以参考以下两项:
==============================以下是广告时间。如果您不感兴趣,可以跳过它====================
如果您对go感兴趣,还可以查看我不久前编写的库,并参考前面提到的两个Python库:
ajax抓取网页内容(什么是HTML网页上的超链接?冲浪的唯一途径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-28 14:18
网页上有大量超链接,大多数情况下以蓝色显示,并带有下划线,便于识别。单击它可以导航到其他网页。这是上网的唯一途径。例如,在一个HTML网页文档中,<href="ht com">网页内容和超链接爬取知识库<是一个超链接,其中href的值是点击后导航到的网页地址,但是这个这只是一种常见的情况。随着AJAX/Javascript编写HTML网页的广泛使用,超链接的实现方式也发生了变化。在很多情况下,href 的值没有有效内容,超链接仅用于激发特定的 Javascript 代码片段。, avascript 代码模拟执行超链接点击的责任。例如,代码中使用XMLHt pRequest 对象立即从服务器获取数据内容,然后将内容转换为HTML 格式并修改和补充到原创网页。这就是 AJAX 框架。典型的行为。如果是第一种情况,使用正则表达式分析HTML文档或使用XPath表达式分析HTML DOM都可以轻松抓取超链接指向的页面地址;但是,如果是第二种情况,超链接指向的网页地址并没有出现在HTML文档中,无法通过分析页面文档的内容来捕获超链接。网页内容和超链接抓取软件工具包 Met aSeeker 可以模拟用户点击行为,刺激Javascript代码的操作,导航到指向的网页,然后抓取这个网页上的内容,可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出,这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。 查看全部
ajax抓取网页内容(什么是HTML网页上的超链接?冲浪的唯一途径)
网页上有大量超链接,大多数情况下以蓝色显示,并带有下划线,便于识别。单击它可以导航到其他网页。这是上网的唯一途径。例如,在一个HTML网页文档中,<href="ht com">网页内容和超链接爬取知识库<是一个超链接,其中href的值是点击后导航到的网页地址,但是这个这只是一种常见的情况。随着AJAX/Javascript编写HTML网页的广泛使用,超链接的实现方式也发生了变化。在很多情况下,href 的值没有有效内容,超链接仅用于激发特定的 Javascript 代码片段。, avascript 代码模拟执行超链接点击的责任。例如,代码中使用XMLHt pRequest 对象立即从服务器获取数据内容,然后将内容转换为HTML 格式并修改和补充到原创网页。这就是 AJAX 框架。典型的行为。如果是第一种情况,使用正则表达式分析HTML文档或使用XPath表达式分析HTML DOM都可以轻松抓取超链接指向的页面地址;但是,如果是第二种情况,超链接指向的网页地址并没有出现在HTML文档中,无法通过分析页面文档的内容来捕获超链接。网页内容和超链接抓取软件工具包 Met aSeeker 可以模拟用户点击行为,刺激Javascript代码的操作,导航到指向的网页,然后抓取这个网页上的内容,可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出,这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。
ajax抓取网页内容(3.3.2.8怎样抓取AJAXAJAX网站的内容?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-28 04:00
3.3.2.8AJAX 如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。以前在浏览器中,网站显示的内容是HTML页面文件,无论是静态网页还是服务器动态网页(比如PHP、JSP、ASP上传后都是HTML文件对浏览器、搜索引擎或内容爬虫的网络爬虫只需要处理文本内容(HTML文档是一个文本文档)。因此,正则表达式在内容抓取器中广泛使用网站。但是,正则表达式几乎AJAX网站 内容不可能,类似于 AJAX网站 内容。显示原理是相关的。除了AJAX网站页面上普通的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。
网站 内容采集软件工具包MetaSeeker直接分析DOM结构,使用XPath表达式定位采集到的内容,并使用XSLT对采集结果进行转化。因此,从本质上讲,解决AJAX 网站 内容爬取问题相对容易。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成网站 内容的方式是千变万化的。因此,MetaSeeker 只能分阶段逐步支持 AJAX网站 内容。抓取,每个版本都会增加新的功能,解决新发现的AJAX实现方式带来的抓取问题。从 V1.0 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX网站 内容的能力。如果这些动态内容是在加载 HTML 页面后创建的,则必须使用本节中介绍的方法来捕获它。此方法也适用于使用 Javascript 函数(例如 setTimeout 或 setInterval)进行爬行,定期刷新网页内容的页面。DOM MetaStudio 是在加载 HTML 文档后自动生成的。如果 HTML 文档中的 Javascript 代码是在加载 HTML 并修改 DOM 内容后加载的,则可能不会反映在 MetaStudio 的 DOM 树中。此时,
无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,请参考前面的章节。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。意思是为AJAX网页定义了信息结构,网页的内容只有在HTML文档加载之后。修改和显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。如果需要编辑之前定义的信息结构,您需要在 Schema List 工作台上执行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaStudio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“后续”分析”加载分析,提示用户:虽然已经下载了信息结构,但是还没有用于分析目标页面。您需要手动单击菜单。这是让 MetaStudio 等待 Javascript 修改 DOM。操作员观察嵌入在 MetaStudio 中的浏览器,直到需要它为止。看到内容后,点击菜单完成DOM刷新和信息结构应用分析。DataScraper DataScraper' s操作没有改变。实际上,DataScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。
另外,由于这类网站内容无法根据load事件判断是否可以启动或终止爬取过程,需要不断检测信息结构是否符合目标网页结构,直到超时发生。因此,关键特性服务器上有一个主题_fuller,可以使用MetaStudio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。DOM 默认情况下,网站 内容抓取规则生成工具MetaStudio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,MetaStudio 的 DOM 结构也会自动刷新。此示例页面定义了信息结构。自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新。单击菜单项 DOM。这是一个检查菜单。如果你不勾选它,你将关闭自动刷新。 查看全部
ajax抓取网页内容(3.3.2.8怎样抓取AJAXAJAX网站的内容?(一))
3.3.2.8AJAX 如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。以前在浏览器中,网站显示的内容是HTML页面文件,无论是静态网页还是服务器动态网页(比如PHP、JSP、ASP上传后都是HTML文件对浏览器、搜索引擎或内容爬虫的网络爬虫只需要处理文本内容(HTML文档是一个文本文档)。因此,正则表达式在内容抓取器中广泛使用网站。但是,正则表达式几乎AJAX网站 内容不可能,类似于 AJAX网站 内容。显示原理是相关的。除了AJAX网站页面上普通的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。
网站 内容采集软件工具包MetaSeeker直接分析DOM结构,使用XPath表达式定位采集到的内容,并使用XSLT对采集结果进行转化。因此,从本质上讲,解决AJAX 网站 内容爬取问题相对容易。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成网站 内容的方式是千变万化的。因此,MetaSeeker 只能分阶段逐步支持 AJAX网站 内容。抓取,每个版本都会增加新的功能,解决新发现的AJAX实现方式带来的抓取问题。从 V1.0 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX网站 内容的能力。如果这些动态内容是在加载 HTML 页面后创建的,则必须使用本节中介绍的方法来捕获它。此方法也适用于使用 Javascript 函数(例如 setTimeout 或 setInterval)进行爬行,定期刷新网页内容的页面。DOM MetaStudio 是在加载 HTML 文档后自动生成的。如果 HTML 文档中的 Javascript 代码是在加载 HTML 并修改 DOM 内容后加载的,则可能不会反映在 MetaStudio 的 DOM 树中。此时,
无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,请参考前面的章节。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。意思是为AJAX网页定义了信息结构,网页的内容只有在HTML文档加载之后。修改和显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。如果需要编辑之前定义的信息结构,您需要在 Schema List 工作台上执行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaStudio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“后续”分析”加载分析,提示用户:虽然已经下载了信息结构,但是还没有用于分析目标页面。您需要手动单击菜单。这是让 MetaStudio 等待 Javascript 修改 DOM。操作员观察嵌入在 MetaStudio 中的浏览器,直到需要它为止。看到内容后,点击菜单完成DOM刷新和信息结构应用分析。DataScraper DataScraper' s操作没有改变。实际上,DataScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。
另外,由于这类网站内容无法根据load事件判断是否可以启动或终止爬取过程,需要不断检测信息结构是否符合目标网页结构,直到超时发生。因此,关键特性服务器上有一个主题_fuller,可以使用MetaStudio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。DOM 默认情况下,网站 内容抓取规则生成工具MetaStudio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,MetaStudio 的 DOM 结构也会自动刷新。此示例页面定义了信息结构。自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新。单击菜单项 DOM。这是一个检查菜单。如果你不勾选它,你将关闭自动刷新。
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-28 03:24
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者: 查看全部
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-28 03:21
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者: 查看全部
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-09-25 21:32
)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"\$1": "\$2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,通过内嵌JS代码提取真实二级页面链接。
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)"', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中建立版本表,每次程序执行时都会存储和检查爬取的链接,并记录版本表以检查是否已被爬取
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)"'
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
鼠标右键->滚动鼠标滚轮或其他动作没有特定数据加载时查看网页源码
抓住
F12 打开控制台,选择XHR异步加载数据包,通过XHR-->Header-->General-->Request URL找到抓取网络数据包的页面动作,通过获取json文件的URL地址XHR-->Header--> 查询字符串参数(Query Parameters)豆瓣电影数据采集案例
目标
地址:豆瓣电影-排行榜-剧情目标:爬取电影片名和电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
需求与分析
通过查看网页源代码,知道需要的数据是Ajax动态加载的,通过F12抓取网络数据包进行分析。一级页面爬取数据:职位名称二级页面爬取数据:岗位职责、岗位要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start)) 查看全部
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络
)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"\$1": "\$2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,通过内嵌JS代码提取真实二级页面链接。
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)"', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中建立版本表,每次程序执行时都会存储和检查爬取的链接,并记录版本表以检查是否已被爬取
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)"'
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
鼠标右键->滚动鼠标滚轮或其他动作没有特定数据加载时查看网页源码
抓住
F12 打开控制台,选择XHR异步加载数据包,通过XHR-->Header-->General-->Request URL找到抓取网络数据包的页面动作,通过获取json文件的URL地址XHR-->Header--> 查询字符串参数(Query Parameters)豆瓣电影数据采集案例
目标
地址:豆瓣电影-排行榜-剧情目标:爬取电影片名和电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
需求与分析
通过查看网页源代码,知道需要的数据是Ajax动态加载的,通过F12抓取网络数据包进行分析。一级页面爬取数据:职位名称二级页面爬取数据:岗位职责、岗位要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
ajax抓取网页内容(Python网络爬虫内容提取器讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-24 20:04
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载请看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。接下来,您可以阅读第6章:1分钟快速生成用于Web内容提取的xslt,将告诉您如何生成xslt。
5.采集GooSeeker开源代码下载源码
1. GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
上一章 Python 使用 xslt 提取网页数据 下一章 Python 读取 PDF 内容 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载请看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。接下来,您可以阅读第6章:1分钟快速生成用于Web内容提取的xslt,将告诉您如何生成xslt。
5.采集GooSeeker开源代码下载源码
1. GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
上一章 Python 使用 xslt 提取网页数据 下一章 Python 读取 PDF 内容
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-13 08:05
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。如果你有兴趣,你可以去看看。
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests<br style="margin:0px;padding:0px;max-width:100%;" />page = 1<br style="margin:0px;padding:0px;max-width:100%;" />while True:<br style="margin:0px;padding:0px;max-width:100%;" /> url = 'http://www.kfc.com.cn/kfccda/a ... %3Bbr style="margin:0px;padding:0px;max-width:100%;" /> data = {<br style="margin:0px;padding:0px;max-width:100%;" /> 'cname': '广州',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pid': '',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageIndex': page,<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageSize': '10'<br style="margin:0px;padding:0px;max-width:100%;" /> }<br style="margin:0px;padding:0px;max-width:100%;" /> response = requests.post(url, data=data)<br style="margin:0px;padding:0px;max-width:100%;" /> print(response.json())<br style="margin:0px;padding:0px;max-width:100%;" /> if response.json().get('Table1', ''):<br style="margin:0px;padding:0px;max-width:100%;" /> page += 1<br style="margin:0px;padding:0px;max-width:100%;" /> else:<br style="margin:0px;padding:0px;max-width:100%;" /> break
可以看到,通过从数据中移除,不用十行代码就可以把所有的数据搞下来,所以这个适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站 查看全部
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是阿贾克斯?简单的说,加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。[
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。如果你有兴趣,你可以去看看。
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方式有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方式的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests<br style="margin:0px;padding:0px;max-width:100%;" />page = 1<br style="margin:0px;padding:0px;max-width:100%;" />while True:<br style="margin:0px;padding:0px;max-width:100%;" /> url = 'http://www.kfc.com.cn/kfccda/a ... %3Bbr style="margin:0px;padding:0px;max-width:100%;" /> data = {<br style="margin:0px;padding:0px;max-width:100%;" /> 'cname': '广州',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pid': '',<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageIndex': page,<br style="margin:0px;padding:0px;max-width:100%;" /> 'pageSize': '10'<br style="margin:0px;padding:0px;max-width:100%;" /> }<br style="margin:0px;padding:0px;max-width:100%;" /> response = requests.post(url, data=data)<br style="margin:0px;padding:0px;max-width:100%;" /> print(response.json())<br style="margin:0px;padding:0px;max-width:100%;" /> if response.json().get('Table1', ''):<br style="margin:0px;padding:0px;max-width:100%;" /> page += 1<br style="margin:0px;padding:0px;max-width:100%;" /> else:<br style="margin:0px;padding:0px;max-width:100%;" /> break
可以看到,通过从数据中移除,不用十行代码就可以把所有的数据搞下来,所以这个适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-13 08:01
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动,可以看到更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject('Microsoft.XMLHTTP');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', '/ajax', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向连接(即服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,使用 document.getElementById("content").innerHTML 更改元素内的 HTML 代码以呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的请求类型Type中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们请求一个接口,改变页面参数就可以获取到相应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Host': 'weibo.com',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
'ajwvr': '6',
'category': '0',
'page': page,
'lefnav': '0',
'cursor': '',
'__rnd': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print('Error:', e.args)
def parse(res):
weibo = {}
if res:
weibo['data'] = res.get('data')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{'data': ' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n 头条新闻今日快讯 | 华为在美提起诉讼.....}
这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
查看全部
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动,可以看到更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject('Microsoft.XMLHTTP');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open('POST', '/ajax', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向连接(即服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,使用 document.getElementById("content").innerHTML 更改元素内的 HTML 代码以呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的请求类型Type中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们请求一个接口,改变页面参数就可以获取到相应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = 'https://weibo.com/a/aj/transform/loadingmoreunlogin?'
headers = {
'Host': 'weibo.com',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
'ajwvr': '6',
'category': '0',
'page': page,
'lefnav': '0',
'cursor': '',
'__rnd': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print('Error:', e.args)
def parse(res):
weibo = {}
if res:
weibo['data'] = res.get('data')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{'data': ' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n
头条新闻今日快讯 | 华为在美提起诉讼.....}这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
ajax抓取网页内容(NextGen引自流量分析学——CRMAnalytics报告下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-12 14:09
NextGen Market Research 刚刚发布了一份调查报告摘要。对于当前和未来的营销研究和分析技术,数据挖掘及相关技术仍然是最主流的技术。下面两张图引自数据挖掘原文-数据挖掘Web流量分析——Web Analytics数据分析可视化——数据可视化CRM分析——CRM分析文本分析——文本分析社交网络分析——社交网络分析链接分析:书籍、视频 博客挖掘——博客挖掘 网页内容抓取/屏幕抓取——屏幕/网页抓取 博客挖掘——博客挖掘 社交网络分析——社交网络分析 网页内容抓取/屏幕抓取——屏幕/网页抓取文本分析——文本分析链接分析:书籍,Video Data Analysis Visualization——Dat Visualization Web Traffic Analysis——Web Analytics CRM Analysis——CRM Analytics Data Mining——Dat Mining 报告下载地址:ht ics. com/report NGMRsurveyReport2010. pdf 无论现在还是未来,大部分都属于数据挖掘领域。很明显,博客挖掘的地位大大提高,同时也增加了网络内容捕获技术的重要性。这让我想起了文章How to Grab AJAX Dynamic Web Page Content,里面介绍了一个大学科研项目的博客挖掘。然而,越来越多的大型主流博客正在全面采用AJAX技术。如上所述,从这些博客中抓取互联网上的内容是非常困难的。然而,主流博客要想挖掘出准确的营销情报,就必须克服AJAX网络爬虫的问题。在这种市场形势下,Met aSeeker 网页内容抓取软件工具包将进一步展示其出色的AJAX。抢能力。 查看全部
ajax抓取网页内容(NextGen引自流量分析学——CRMAnalytics报告下载地址)
NextGen Market Research 刚刚发布了一份调查报告摘要。对于当前和未来的营销研究和分析技术,数据挖掘及相关技术仍然是最主流的技术。下面两张图引自数据挖掘原文-数据挖掘Web流量分析——Web Analytics数据分析可视化——数据可视化CRM分析——CRM分析文本分析——文本分析社交网络分析——社交网络分析链接分析:书籍、视频 博客挖掘——博客挖掘 网页内容抓取/屏幕抓取——屏幕/网页抓取 博客挖掘——博客挖掘 社交网络分析——社交网络分析 网页内容抓取/屏幕抓取——屏幕/网页抓取文本分析——文本分析链接分析:书籍,Video Data Analysis Visualization——Dat Visualization Web Traffic Analysis——Web Analytics CRM Analysis——CRM Analytics Data Mining——Dat Mining 报告下载地址:ht ics. com/report NGMRsurveyReport2010. pdf 无论现在还是未来,大部分都属于数据挖掘领域。很明显,博客挖掘的地位大大提高,同时也增加了网络内容捕获技术的重要性。这让我想起了文章How to Grab AJAX Dynamic Web Page Content,里面介绍了一个大学科研项目的博客挖掘。然而,越来越多的大型主流博客正在全面采用AJAX技术。如上所述,从这些博客中抓取互联网上的内容是非常困难的。然而,主流博客要想挖掘出准确的营销情报,就必须克服AJAX网络爬虫的问题。在这种市场形势下,Met aSeeker 网页内容抓取软件工具包将进一步展示其出色的AJAX。抢能力。
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-12 14:05
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" '
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评级
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-09-03 查看全部
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" '
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评级
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-09-03
ajax抓取网页内容( 谷歌能DOM是什么?Google不能是如何抓取JavaScript?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-10 23:02
谷歌能DOM是什么?Google不能是如何抓取JavaScript?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL替换了谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且该文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
ajax抓取网页内容(
谷歌能DOM是什么?Google不能是如何抓取JavaScript?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
JavaScript 重定向 JavaScript 链接动态插入内容 动态插入元数据和页面元素 rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表达的 URL 会发生什么变化?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL替换了谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且该文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会发生什么?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 JavaScript 函数之前,已经准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
ajax抓取网页内容(NutchHtmlunitXimplement项目简介基于ApacheNutch1.8和Htmlunit组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-10 23:00
-------------------------------------------------- ---------------------------当前版本停止更新,Apache Nutch 2.X 工具请参考:---- -------------------------------------------------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 来获取具有必要动态 AJAX 请求的整个页面内容。它是使用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或将源代码重构为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已经全部获取完毕。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,可自由使用:开源、非开源、商业和非商业,前提是保留本项目的源码信息,未经授权销售本项目项目保证不执行。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可以联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目: 查看全部
ajax抓取网页内容(NutchHtmlunitXimplement项目简介基于ApacheNutch1.8和Htmlunit组件)
-------------------------------------------------- ---------------------------当前版本停止更新,Apache Nutch 2.X 工具请参考:---- -------------------------------------------------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 来获取具有必要动态 AJAX 请求的整个页面内容。它是使用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或将源代码重构为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已经全部获取完毕。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,可自由使用:开源、非开源、商业和非商业,前提是保留本项目的源码信息,未经授权销售本项目项目保证不执行。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可以联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目:
ajax抓取网页内容(照Web发展的趋势和发展趋势分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-10 03:11
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在页面上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。页面的原创HTML文档不收录任何数据,数据通过ajax统一加载后呈现,从而在Web开发中实现前后端分离,避免服务器直接渲染页面带来的压力被减少。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面。无法获得有效数据。这时候就需要从页面后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
什么是阿贾克斯
Ajax,全称Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,name 必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变页面,从而更新页面的内容。
基本的
在对Ajax有了初步的了解之后,我们再来了解一下它的基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
(1)发送请求;
(2)分析内容;
(3) 渲染网页。
Ajax 分析方法查看请求
Ajax 实际上有其特殊的请求类型,称为 xhr。如下所示:
右侧可以观察到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
因此,我们看到的微博页面的真实数据并不是从原页面返回的,而是在执行JavaScript之后再次向后台发送Ajax请求,浏览器获取数据再进一步渲染。
过滤请求
接下来,使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求。请求上方有一个过滤器栏。直接点击XHR。此时,下面显示的所有请求都是 Ajax 请求。
接下来连续滑动页面,可以看到页面底部有新的微博,开发者工具发出的Ajax请求也一一出现,方便我们捕获所有的Ajax请求。 查看全部
ajax抓取网页内容(照Web发展的趋势和发展趋势分析(一))
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在页面上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。页面的原创HTML文档不收录任何数据,数据通过ajax统一加载后呈现,从而在Web开发中实现前后端分离,避免服务器直接渲染页面带来的压力被减少。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面。无法获得有效数据。这时候就需要从页面后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
什么是阿贾克斯
Ajax,全称Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,name 必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变页面,从而更新页面的内容。
基本的
在对Ajax有了初步的了解之后,我们再来了解一下它的基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
(1)发送请求;
(2)分析内容;
(3) 渲染网页。
Ajax 分析方法查看请求
Ajax 实际上有其特殊的请求类型,称为 xhr。如下所示:
右侧可以观察到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
因此,我们看到的微博页面的真实数据并不是从原页面返回的,而是在执行JavaScript之后再次向后台发送Ajax请求,浏览器获取数据再进一步渲染。
过滤请求
接下来,使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求。请求上方有一个过滤器栏。直接点击XHR。此时,下面显示的所有请求都是 Ajax 请求。
接下来连续滑动页面,可以看到页面底部有新的微博,开发者工具发出的Ajax请求也一一出现,方便我们捕获所有的Ajax请求。
ajax抓取网页内容( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-09 14:20
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
ajax抓取网页内容(
Python网络爬虫内容提取器)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到网页上的手机名称和价格已经被正确抓取了。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
ajax抓取网页内容(渲染引擎的基本流程和流程、流程介绍及流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-09 14:17
)
文章内容
介绍
本文介绍了动态页面和Ajax渲染页面数据捕获的示例,以及相应的页面分析过程。
Ajax 抓取示例
越来越多的网页原创 HTML 文档不收录任何数据,而是由 Ajax 统一加载。向网页更新发送ajax请求的过程:
打开浏览器的开发者工具,进入Networkk选项卡,使用XHR过滤工具。需要根据对应的all_config_file.py文件创建对应的文件夹,修改配置,启动相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num 查看全部
ajax抓取网页内容(渲染引擎的基本流程和流程、流程介绍及流程
)
文章内容
介绍
本文介绍了动态页面和Ajax渲染页面数据捕获的示例,以及相应的页面分析过程。
Ajax 抓取示例
越来越多的网页原创 HTML 文档不收录任何数据,而是由 Ajax 统一加载。向网页更新发送ajax请求的过程:
打开浏览器的开发者工具,进入Networkk选项卡,使用XHR过滤工具。需要根据对应的all_config_file.py文件创建对应的文件夹,修改配置,启动相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num
ajax抓取网页内容(FacebookWard的解决方法放弃井号结构,不禁拍案叫绝)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-06 03:04
大家在浏览Facebook相册的时候有没有注意到,页面部分刷新时地址栏中的地址也发生了变化,并不是hash方法。它使用了几个新的 HTML5 历史 API。作为窗口的全局变量,历史在 HTML4 时代并不是什么新鲜事。我们经常使用 history.back() 和 history.go()。
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
复制代码代码如下:
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(FacebookWard的解决方法放弃井号结构,不禁拍案叫绝)
大家在浏览Facebook相册的时候有没有注意到,页面部分刷新时地址栏中的地址也发生了变化,并不是hash方法。它使用了几个新的 HTML5 历史 API。作为窗口的全局变量,历史在 HTML4 时代并不是什么新鲜事。我们经常使用 history.back() 和 history.go()。
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
复制代码代码如下:
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajax抓取网页内容原理有许多方法可以包括xpath的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-04 23:06
ajax抓取网页内容原理有许多方法可以实现,包括xpath。xpath是python的一个语法,其中需要了解正则表达式(re)、html对象(res)、meta标签等基础内容,本文以简单的网页抓取为例。将网页地址粘贴进模拟器的浏览器中,发现键不是print("helloworld"),而是print("helloworld",1)。
带有数字的键。然后新建文件夹urls,用于存放xpath语法。open(xpath,'w')会导致xpath变量和文件名分别在open()函数和定义urls(url)函数里,查看//。用python默认的文件名格式:filename,之后,运行>>>即可获得上述值。此时,右边的框框表示的内容。打开网页,解析//,发现除了//都为空,则跳过。
当然,还可以尝试正则表达式,但会稍微麻烦些。使用try...except...,tryexcept...关键词说明,此时只运行一步,即会把已经解析过的urls带入网页。或者使用xpathcute()函数。try...except...,则有完整的过程,会在每次运行完毕后都运行一遍。通过浏览器或命令行运行>>>即可查看在网页里传递过来的内容,原理和xpath类似。
当然,运行>>>即可查看。网页里传递过来的内容本例,相对容易解析,原理是第一行是块元素div,第二行是控制url的元素li,第三行是控制url的a标签,第四行是控制url的li,第五行是url的a标签,以此类推。下次遇到不会的网页,可以复制该python代码,查找对应的元素在浏览器打开,就可以很方便的看到了。
部分资料来源于:webdeveloper-apythonlearningmasterprogrammingguide。 查看全部
ajax抓取网页内容(ajax抓取网页内容原理有许多方法可以包括xpath的)
ajax抓取网页内容原理有许多方法可以实现,包括xpath。xpath是python的一个语法,其中需要了解正则表达式(re)、html对象(res)、meta标签等基础内容,本文以简单的网页抓取为例。将网页地址粘贴进模拟器的浏览器中,发现键不是print("helloworld"),而是print("helloworld",1)。
带有数字的键。然后新建文件夹urls,用于存放xpath语法。open(xpath,'w')会导致xpath变量和文件名分别在open()函数和定义urls(url)函数里,查看//。用python默认的文件名格式:filename,之后,运行>>>即可获得上述值。此时,右边的框框表示的内容。打开网页,解析//,发现除了//都为空,则跳过。
当然,还可以尝试正则表达式,但会稍微麻烦些。使用try...except...,tryexcept...关键词说明,此时只运行一步,即会把已经解析过的urls带入网页。或者使用xpathcute()函数。try...except...,则有完整的过程,会在每次运行完毕后都运行一遍。通过浏览器或命令行运行>>>即可查看在网页里传递过来的内容,原理和xpath类似。
当然,运行>>>即可查看。网页里传递过来的内容本例,相对容易解析,原理是第一行是块元素div,第二行是控制url的元素li,第三行是控制url的a标签,第四行是控制url的li,第五行是url的a标签,以此类推。下次遇到不会的网页,可以复制该python代码,查找对应的元素在浏览器打开,就可以很方便的看到了。
部分资料来源于:webdeveloper-apythonlearningmasterprogrammingguide。
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-03 21:17
什么是阿贾克斯?简单的说,加载一个网页后还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。Ajax 是一种用于创建快速动态网页的技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。【通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方法有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方法的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 27%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
可以看到去掉from data,不用十行代码就可以把所有的数据搞下来,所以这个网站很适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站 查看全部
ajax抓取网页内容(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是阿贾克斯?简单的说,加载一个网页后还是看不到一些信息,需要点击一个按钮才能看到数据,或者有的网页页面数据很多,而你点击了下一页,url地址网页没有变,但内容变了。这些可以说是ajax。如果你还是不明白,下面就让我给你看看百度百科的解释吧。
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax = 异步 JavaScript 和 XML(标准通用标记语言的一个子集)。Ajax 是一种用于创建快速动态网页的技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。【通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
下面我们来谈谈一个例子。我爬过的ajax网页最难的部分是网易云音乐的评论。有兴趣的可以看看用python爬取网易云音乐并将数据存入mysql
这里的评论是Ajax加载的,其他抢今日头条图片的妹子也是Ajax加载的,不过我简化了。还有很多,先不说,先说ajax网站 今天要说的!
这是肯德基的门面信息
页面数据很多,每个页面的数据都是通过ajax加载的。如果直接用python请求上面的url,估计是拿不到数据的。如果你不相信,你可以试试。这时候我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求是ajax请求的网页,里面会有我们需要的数据,看看是个什么样的请求
是post请求,请求成功状态码为200,请求url也在上面。下面的from数据就是我们需要发布的数据。很容易猜到pageIndex是页数,所以我们可以改变这个值来翻页。
本网页进行了分析。这是ajax动态网页的解决方案。是不是感觉很简单?事实上,事实并非如此。只是网页比较简单,因为表单中的数据(来自数据)没有加密。如果是加密的,估计你找js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些乱七八糟的js找加密方法有时会让你头疼,所以人们往往会选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以在工作中是不允许这种方法的。所以我们必须学会如何处理这些ajax。
邮政编码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/a ... 27%3B
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break
可以看到去掉from data,不用十行代码就可以把所有的数据搞下来,所以这个网站很适合练习,大家可以试试。
写在最后
下一篇文章我会写一个更复杂的ajax请求,这个网站
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-10-01 19:24
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标移动到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。 查看全部
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标移动到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。
ajax抓取网页内容(用Chrome浏览器的开发者工具看到所有的请求链接及其请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-01 03:13
直接回答:
https://www.zhihu.com/node/ProfileFolloweesListV2
详细答复:
正如@tweelveandone所说,您可以使用Chrome浏览器的开发工具查看所有请求,包括Ajax的目标链接及其请求消息
例如,要查看与主题相关的人员,请首先打开此页面:/people/feng-xing-53-25/如下
然后打开chrome的开发者工具窗口,监控网络(自己学习具体使用方法)
下拉页面,直到触发Ajax请求以获取下一页的用户列表(显示为页面上的加载),您可以在开发者工具栏中看到特定的请求链接(即/node/ProfileFollowsListV2)),以及相应的请求和响应
如果使用Python捕获知乎数据,可以参考以下两项:
==============================以下是广告时间。如果您不感兴趣,可以跳过它====================
如果您对go感兴趣,还可以查看我不久前编写的库,并参考前面提到的两个Python库: 查看全部
ajax抓取网页内容(用Chrome浏览器的开发者工具看到所有的请求链接及其请求)
直接回答:
https://www.zhihu.com/node/ProfileFolloweesListV2
详细答复:
正如@tweelveandone所说,您可以使用Chrome浏览器的开发工具查看所有请求,包括Ajax的目标链接及其请求消息
例如,要查看与主题相关的人员,请首先打开此页面:/people/feng-xing-53-25/如下
然后打开chrome的开发者工具窗口,监控网络(自己学习具体使用方法)
下拉页面,直到触发Ajax请求以获取下一页的用户列表(显示为页面上的加载),您可以在开发者工具栏中看到特定的请求链接(即/node/ProfileFollowsListV2)),以及相应的请求和响应
如果使用Python捕获知乎数据,可以参考以下两项:
==============================以下是广告时间。如果您不感兴趣,可以跳过它====================
如果您对go感兴趣,还可以查看我不久前编写的库,并参考前面提到的两个Python库:
ajax抓取网页内容(什么是HTML网页上的超链接?冲浪的唯一途径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-28 14:18
网页上有大量超链接,大多数情况下以蓝色显示,并带有下划线,便于识别。单击它可以导航到其他网页。这是上网的唯一途径。例如,在一个HTML网页文档中,<href="ht com">网页内容和超链接爬取知识库<是一个超链接,其中href的值是点击后导航到的网页地址,但是这个这只是一种常见的情况。随着AJAX/Javascript编写HTML网页的广泛使用,超链接的实现方式也发生了变化。在很多情况下,href 的值没有有效内容,超链接仅用于激发特定的 Javascript 代码片段。, avascript 代码模拟执行超链接点击的责任。例如,代码中使用XMLHt pRequest 对象立即从服务器获取数据内容,然后将内容转换为HTML 格式并修改和补充到原创网页。这就是 AJAX 框架。典型的行为。如果是第一种情况,使用正则表达式分析HTML文档或使用XPath表达式分析HTML DOM都可以轻松抓取超链接指向的页面地址;但是,如果是第二种情况,超链接指向的网页地址并没有出现在HTML文档中,无法通过分析页面文档的内容来捕获超链接。网页内容和超链接抓取软件工具包 Met aSeeker 可以模拟用户点击行为,刺激Javascript代码的操作,导航到指向的网页,然后抓取这个网页上的内容,可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出,这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。 查看全部
ajax抓取网页内容(什么是HTML网页上的超链接?冲浪的唯一途径)
网页上有大量超链接,大多数情况下以蓝色显示,并带有下划线,便于识别。单击它可以导航到其他网页。这是上网的唯一途径。例如,在一个HTML网页文档中,<href="ht com">网页内容和超链接爬取知识库<是一个超链接,其中href的值是点击后导航到的网页地址,但是这个这只是一种常见的情况。随着AJAX/Javascript编写HTML网页的广泛使用,超链接的实现方式也发生了变化。在很多情况下,href 的值没有有效内容,超链接仅用于激发特定的 Javascript 代码片段。, avascript 代码模拟执行超链接点击的责任。例如,代码中使用XMLHt pRequest 对象立即从服务器获取数据内容,然后将内容转换为HTML 格式并修改和补充到原创网页。这就是 AJAX 框架。典型的行为。如果是第一种情况,使用正则表达式分析HTML文档或使用XPath表达式分析HTML DOM都可以轻松抓取超链接指向的页面地址;但是,如果是第二种情况,超链接指向的网页地址并没有出现在HTML文档中,无法通过分析页面文档的内容来捕获超链接。网页内容和超链接抓取软件工具包 Met aSeeker 可以模拟用户点击行为,刺激Javascript代码的操作,导航到指向的网页,然后抓取这个网页上的内容,可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。可以看出,这是自动翻页和抓取多页内容的有效方法,而且很明显,超链接指向的地址并没有被抓取并保存。这是Met aSeeker工具包定义的I hread线索,即导航到同一个网页内容抓取会话网页中的多个页面并抓取内容,而不是通常的“抓取超链接”存储超链接,然后在另一个会话中使用上一个会话中的超链接。由于Met aSeeker V4. hread 类型的线索,所以它只能用于翻页和爬行,并且在以后的版本中将打破这个限制。
ajax抓取网页内容(3.3.2.8怎样抓取AJAXAJAX网站的内容?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-28 04:00
3.3.2.8AJAX 如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。以前在浏览器中,网站显示的内容是HTML页面文件,无论是静态网页还是服务器动态网页(比如PHP、JSP、ASP上传后都是HTML文件对浏览器、搜索引擎或内容爬虫的网络爬虫只需要处理文本内容(HTML文档是一个文本文档)。因此,正则表达式在内容抓取器中广泛使用网站。但是,正则表达式几乎AJAX网站 内容不可能,类似于 AJAX网站 内容。显示原理是相关的。除了AJAX网站页面上普通的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。
网站 内容采集软件工具包MetaSeeker直接分析DOM结构,使用XPath表达式定位采集到的内容,并使用XSLT对采集结果进行转化。因此,从本质上讲,解决AJAX 网站 内容爬取问题相对容易。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成网站 内容的方式是千变万化的。因此,MetaSeeker 只能分阶段逐步支持 AJAX网站 内容。抓取,每个版本都会增加新的功能,解决新发现的AJAX实现方式带来的抓取问题。从 V1.0 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX网站 内容的能力。如果这些动态内容是在加载 HTML 页面后创建的,则必须使用本节中介绍的方法来捕获它。此方法也适用于使用 Javascript 函数(例如 setTimeout 或 setInterval)进行爬行,定期刷新网页内容的页面。DOM MetaStudio 是在加载 HTML 文档后自动生成的。如果 HTML 文档中的 Javascript 代码是在加载 HTML 并修改 DOM 内容后加载的,则可能不会反映在 MetaStudio 的 DOM 树中。此时,
无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,请参考前面的章节。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。意思是为AJAX网页定义了信息结构,网页的内容只有在HTML文档加载之后。修改和显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。如果需要编辑之前定义的信息结构,您需要在 Schema List 工作台上执行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaStudio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“后续”分析”加载分析,提示用户:虽然已经下载了信息结构,但是还没有用于分析目标页面。您需要手动单击菜单。这是让 MetaStudio 等待 Javascript 修改 DOM。操作员观察嵌入在 MetaStudio 中的浏览器,直到需要它为止。看到内容后,点击菜单完成DOM刷新和信息结构应用分析。DataScraper DataScraper' s操作没有改变。实际上,DataScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。
另外,由于这类网站内容无法根据load事件判断是否可以启动或终止爬取过程,需要不断检测信息结构是否符合目标网页结构,直到超时发生。因此,关键特性服务器上有一个主题_fuller,可以使用MetaStudio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。DOM 默认情况下,网站 内容抓取规则生成工具MetaStudio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,MetaStudio 的 DOM 结构也会自动刷新。此示例页面定义了信息结构。自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新。单击菜单项 DOM。这是一个检查菜单。如果你不勾选它,你将关闭自动刷新。 查看全部
ajax抓取网页内容(3.3.2.8怎样抓取AJAXAJAX网站的内容?(一))
3.3.2.8AJAX 如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。以前在浏览器中,网站显示的内容是HTML页面文件,无论是静态网页还是服务器动态网页(比如PHP、JSP、ASP上传后都是HTML文件对浏览器、搜索引擎或内容爬虫的网络爬虫只需要处理文本内容(HTML文档是一个文本文档)。因此,正则表达式在内容抓取器中广泛使用网站。但是,正则表达式几乎AJAX网站 内容不可能,类似于 AJAX网站 内容。显示原理是相关的。除了AJAX网站页面上普通的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。还有Javascript代码或者Javascript代码库地址可以下载。HTML文件加载期间或之后(通常加载事件是Boundary)调用Javascript函数或代码段,这些代码段修改HTML文档的DOM结构,DOM是基于浏览器窗口中显示的HTML文档,并且页面内容是通过这种方式动态生成的。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。这些代码段修改了 HTML 文档的 DOM 结构,DOM 是基于浏览器窗口中显示的 HTML 文档,通过这种方式动态生成页面内容。这些内容可以是计算出来的,也可以是从服务器异步获取的,比如使用XMLHttpRequest对象从远程服务器获取需要显示的内容。
网站 内容采集软件工具包MetaSeeker直接分析DOM结构,使用XPath表达式定位采集到的内容,并使用XSLT对采集结果进行转化。因此,从本质上讲,解决AJAX 网站 内容爬取问题相对容易。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成网站 内容的方式是千变万化的。因此,MetaSeeker 只能分阶段逐步支持 AJAX网站 内容。抓取,每个版本都会增加新的功能,解决新发现的AJAX实现方式带来的抓取问题。从 V1.0 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX网站 内容的能力。如果这些动态内容是在加载 HTML 页面后创建的,则必须使用本节中介绍的方法来捕获它。此方法也适用于使用 Javascript 函数(例如 setTimeout 或 setInterval)进行爬行,定期刷新网页内容的页面。DOM MetaStudio 是在加载 HTML 文档后自动生成的。如果 HTML 文档中的 Javascript 代码是在加载 HTML 并修改 DOM 内容后加载的,则可能不会反映在 MetaStudio 的 DOM 树中。此时,
无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,请参考前面的章节。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。意思是为AJAX网页定义了信息结构,网页的内容只有在HTML文档加载之后。修改和显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。如果需要编辑之前定义的信息结构,您需要在 Schema List 工作台上执行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaStudio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“后续”分析”加载分析,提示用户:虽然已经下载了信息结构,但是还没有用于分析目标页面。您需要手动单击菜单。这是让 MetaStudio 等待 Javascript 修改 DOM。操作员观察嵌入在 MetaStudio 中的浏览器,直到需要它为止。看到内容后,点击菜单完成DOM刷新和信息结构应用分析。DataScraper DataScraper' s操作没有改变。实际上,DataScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。
另外,由于这类网站内容无法根据load事件判断是否可以启动或终止爬取过程,需要不断检测信息结构是否符合目标网页结构,直到超时发生。因此,关键特性服务器上有一个主题_fuller,可以使用MetaStudio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。DOM 默认情况下,网站 内容抓取规则生成工具MetaStudio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,MetaStudio 的 DOM 结构也会自动刷新。此示例页面定义了信息结构。自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新。单击菜单项 DOM。这是一个检查菜单。如果你不勾选它,你将关闭自动刷新。
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-28 03:24
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者: 查看全部
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-28 03:21
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者: 查看全部
ajax抓取网页内容(HTML文档加载过程中的常见问题,你知道吗?)
如何抓取AJAX网站的内容?这是一个热点问题,也是一个棘手的问题。基于Javascript技术的AJAX网站的出现,改变了原来互联网内容的展示方式。过去,从浏览器的角度来看,网站要显示的内容是HTML页面文档,无论是静态网页还是服务器动态网页(例如PHP、JSP、ASP等)。 ) 都是下载到浏览器后的 HTML 文件。网站 内容抓取器的搜索引擎或网络爬虫只需要处理文本内容(HTML 文档是文本文档)。因此,正则表达式在之前的网站 内容抓取器中被广泛使用。但是,对于 AJAX 网站 内容,正则表达式几乎是不可能的。这和 AJAX 网站 一样 内容呈现的原则是相关的。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。除了AJAX网站页面上正常的HTML文档内容,还有Javascript代码或者Javascript代码库地址可以下载。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。在加载 HTML 文档期间或之后调用 Javascript(通常由加载事件)。函数或代码段。这些代码段修改了 HTML 文档的 DOM 结构,而 DOM 结构是 HTML 文档在浏览器窗口中显示的基础。这样,页面内容是动态生成的。这些内容可以从服务器异步计算或获取,例如使用XMLHt pRequest对象从远程服务器获取需要显示的内容。
网站 内容捕捉软件工具包Met aSeeker直接分析DOM结构,使用XPath表达式定位捕捉到的内容,并使用XSLT对捕捉结果进行转换。因此,本质上可以比较容易的解决爬取AJAX网站内容的问题。然而,Javascript 是一种强大的编程语言。实现业务逻辑的能力远高于HTML语言。动态生成 网站 内容的方式千变万化。因此,Met aSeeker 只能分阶段逐步支持 AJAX网站 内容。对于爬虫,每个版本都会增加新的特性,解决新发现的AJAX实现方式带来的爬虫问题。从 V1. 版本开始,MetaSeeker 可以在 HTML 页面加载过程中捕获 AJAX 生成的动态内容,例如捕获 Google Adsence 广告或搜索结果以进行商业智能分析。此版本增强了捕获 AJAX 网站 内容的能力。如果这些动态内容是在加载 HTML 页面后生成的,则必须使用本节介绍的方法进行捕获。此方法也适用于使用 Javascript 函数进行抓取(例如设置 Timeout 或设置 nterval) 定期刷新网页内容的页面。手动刷新 DOM Met aSt udio 左列 DOM 树在 HTML 文档加载后自动生成。如果在加载 HTML 并修改 DOM 内容后加载 HTML 文档中的 Javascript 代码,
这需要手动刷新 DOM 树以反映最新更改。点击菜单项H3定义网站内容抓取规则<h3>无论是数据抓取规则还是超链接抓取规则,都与普通网页的定义方法一致,见前一章。但是,在上传信息结构和抓取规则之前,您需要单击菜单项。这是一个检查类型的菜单。不要检查它。也就是说,AJAX 网页定义了信息结构,网页的内容只有在 HTML 文档加载之后。修改显示,因此不能采用正常的操作方法:“加载信息结构,立即应用信息结构分析网页内容”。操作的变化在加载信息结构进行编辑时体现。信息结构加载方法 如果需要编辑之前定义的信息结构,则需要在Schema List工作台上进行加载操作。如果遇到上一节描述的信息结构,网站内容捕获规则定义工具MetaSt udio会弹出一个对话框:信息结构加载和分析会延迟,请手动选择菜单项“Follow- up analysis”加载并分析,提示用户:虽然信息结构已经下载,但是还没有用于分析目标页面,需要手动点击菜单项,这是为了让MetaSt udio等待Javascript修改DOM,
网站 内容爬虫DataScraper的操作Dat aScraper的操作没有变化。实际上,Dat aScraper 工作流使用专用处理器 LoadDelayedPage 来捕获此类内容。另外,由于这种网站的内容无法根据load事件判断爬取过程是否可以启动或终止,所以需要不断检测信息结构是否符合目标的结构网页直到超时,因为定义网站内容抓取规则时,至少为一个信息属性设置关键特性。有一个主题demo_qun。_fuller 在应用案例服务器上。可以使用MetaSt audio加载信息结构,体验AJAX网站内容的抓取。关于这个案例的详细描述,请参考论坛讨论。通过打开和关闭定期刷新网页的 DOM 分析。默认情况下,网站内容爬取规则生成工具Met aSt udio左栏的DOM结构会自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:网站内容爬取规则生成器工具Met aSt udio左栏的DOM结构自动刷新。每当目标示例页面的内容发生变化时,Met aSt udio 的 DOM 结构也会自动刷新。如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:如果正在为此示例页面定义信息结构,则自动刷新会影响定义操作。因此,在这种情况下,您需要关闭 DOM 自动刷新并单击菜单项 DOM。这是一个检查菜单。, 不勾选关闭自动刷新。作者:
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-09-25 21:32
)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"\$1": "\$2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,通过内嵌JS代码提取真实二级页面链接。
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)"', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中建立版本表,每次程序执行时都会存储和检查爬取的链接,并记录版本表以检查是否已被爬取
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)"'
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
鼠标右键->滚动鼠标滚轮或其他动作没有特定数据加载时查看网页源码
抓住
F12 打开控制台,选择XHR异步加载数据包,通过XHR-->Header-->General-->Request URL找到抓取网络数据包的页面动作,通过获取json文件的URL地址XHR-->Header--> 查询字符串参数(Query Parameters)豆瓣电影数据采集案例
目标
地址:豆瓣电影-排行榜-剧情目标:爬取电影片名和电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
需求与分析
通过查看网页源代码,知道需要的数据是Ajax动态加载的,通过F12抓取网络数据包进行分析。一级页面爬取数据:职位名称二级页面爬取数据:岗位职责、岗位要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start)) 查看全部
ajax抓取网页内容(常见的反爬机制及处理方式-苏州安嘉网络
)
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"\$1": "\$2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests
from lxml import etree
import re
url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
html = requests.get(url, headers=headers).text
parse_html = etree.HTML(html)
article_list = parse_html.xpath('//a[@class="artitlelist"]')
for article in article_list:
title = article.xpath('./@title')[0]
# 正则匹配title中包含这个字符串的链接
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0]
print(two_link)
break
2、 从二级页面链接中提取真实链接(反爬-响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,通过内嵌JS代码提取真实二级页面链接。
# 爬取二级“假”链接
two_html = requests.get(two_link, headers=headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
new_two_link = re.findall(r'window.location.href="(.*?)"', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中建立版本表,每次程序执行时都会存储和检查爬取的链接,并记录版本表以检查是否已被爬取
cursor.execute('select * from version')
result = self.cursor.fetchall()
if result:
if result[-1][0] == two_link:
print('已是最新')
else:
# 有更新,开始抓取
# 将链接再重新插入version表记录
4、代码实现
import requests
from lxml import etree
import re
import pymysql
class GovementSpider(object):
def __init__(self):
self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/'
self.headers = {'User-Agent': 'Mozilla/5.0'}
# 创建2个对象
self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8')
self.cursor = self.db.cursor()
# 获取假链接
def get_false_link(self):
html = requests.get(url=self.url, headers=self.headers).text
# 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成,
# 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的
parse_html = etree.HTML(html)
a_list = parse_html.xpath('//a[@class="artitlelist"]')
for a in a_list:
# get()方法:获取某个属性的值
title = a.get('title')
if title.endswith('代码'):
# 获取到第1个就停止即可,第1个永远是最新的链接
false_link = 'http://www.mca.gov.cn' + a.get('href')
print("二级“假”链接的网址为", false_link)
break
# 提取真链接
self.incr_spider(false_link)
# 增量爬取函数
def incr_spider(self, false_link):
self.cursor.execute('select url from version where url=%s', [false_link])
# fetchall: (('http://xxxx.html',),)
result = self.cursor.fetchall()
# not result:代表数据库version表中无数据
if not result:
self.get_true_link(false_link)
# 可选操作: 数据库version表中只保留最新1条数据
self.cursor.execute("delete from version")
# 把爬取后的url插入到version表中
self.cursor.execute('insert into version values(%s)', [false_link])
self.db.commit()
else:
print('数据已是最新,无须爬取')
# 获取真链接
def get_true_link(self, false_link):
# 先获取假链接的响应,然后根据响应获取真链接
html = requests.get(url=false_link, headers=self.headers).text
# 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址)
re_bds = r'window.location.href="(.*?)"'
pattern = re.compile(re_bds, re.S)
true_link = pattern.findall(html)[0]
self.save_data(true_link) # 提取真链接的数据
# 用xpath直接提取数据
def save_data(self, true_link):
html = requests.get(url=true_link, headers=self.headers).text
# 基准xpath,提取每个信息的节点列表对象
parse_html = etree.HTML(html)
tr_list = parse_html.xpath('//tr[@height="19"]')
for tr in tr_list:
code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码
name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称
print(name, code)
# 主函数
def main(self):
self.get_false_link()
if __name__ == '__main__':
spider = GovementSpider()
spider.main()
动态加载数据捕获-Ajax
特征
鼠标右键->滚动鼠标滚轮或其他动作没有特定数据加载时查看网页源码
抓住
F12 打开控制台,选择XHR异步加载数据包,通过XHR-->Header-->General-->Request URL找到抓取网络数据包的页面动作,通过获取json文件的URL地址XHR-->Header--> 查询字符串参数(Query Parameters)豆瓣电影数据采集案例
目标
地址:豆瓣电影-排行榜-剧情目标:爬取电影片名和电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下:
type: 13 # 电影类型
interval_id: 100:90
action: '[{},{},{}]'
start: 0 # 每次加载电影的起始索引值
limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests
import time
from fake_useragent import UserAgent
class DoubanSpider(object):
def __init__(self):
self.base_url = 'https://movie.douban.com/j/chart/top_list?'
self.i = 0
def get_html(self, params):
headers = {'User-Agent': UserAgent().random}
res = requests.get(url=self.base_url, params=params, headers=headers)
res.encoding = 'utf-8'
html = res.json() # 将json格式的字符串转为python数据类型
self.parse_html(html) # 直接调用解析函数
def parse_html(self, html):
# html: [{电影1信息},{电影2信息},{}]
item = {}
for one in html:
item['name'] = one['title'] # 电影名
item['score'] = one['score'] # 评分
item['time'] = one['release_date'] # 打印测试
# 打印显示
print(item)
self.i += 1
# 获取电影总数
def get_total(self, typ):
# 异步动态加载的数据 都可以在XHR数据抓包
url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ)
ua = UserAgent()
html = requests.get(url=url, headers={'User-Agent': ua.random}).json()
total = html['total']
return total
def main(self):
typ = input('请输入电影类型(剧情|喜剧|动作):')
typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'}
typ = typ_dict[typ]
total = self.get_total(typ) # 获取该类型电影总数量
for page in range(0, int(total), 20):
params = {
'type': typ,
'interval_id': '100:90',
'action': '',
'start': str(page),
'limit': '20'}
self.get_html(params)
time.sleep(1)
print('爬取的电影的数量:', self.i)
if __name__ == '__main__':
spider = DoubanSpider()
spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
需求与分析
通过查看网页源代码,知道需要的数据是Ajax动态加载的,通过F12抓取网络数据包进行分析。一级页面爬取数据:职位名称二级页面爬取数据:岗位职责、岗位要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
]
import time
import json
import random
import requests
from useragents import ua_list
class TencentSpider(object):
def __init__(self):
self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn'
self.f = open('tencent.json', 'a') # 打开文件
self.item_list = [] # 存放抓取的item字典数据
# 获取响应内容函数
def get_page(self, url):
headers = {'User-Agent': random.choice(ua_list)}
html = requests.get(url=url, headers=headers).text
html = json.loads(html) # json格式字符串转为Python数据类型
return html
# 主线函数: 获取所有数据
def parse_page(self, one_url):
html = self.get_page(one_url)
item = {}
for job in html['Data']['Posts']:
item['name'] = job['RecruitPostName'] # 名称
post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址
# 拼接二级地址,获取职责和要求
two_url = self.two_url.format(post_id)
item['duty'], item['require'] = self.parse_two_page(two_url)
print(item)
self.item_list.append(item) # 添加到大列表中
# 解析二级页面函数
def parse_two_page(self, two_url):
html = self.get_page(two_url)
duty = html['Data']['Responsibility'] # 工作责任
duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行
require = html['Data']['Requirement'] # 工作要求
require = require.replace('\r\n', '').replace('\n', '') # 去掉换行
return duty, require
# 获取总页数
def get_numbers(self):
url = self.one_url.format(1)
html = self.get_page(url)
numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐
return numbers
def main(self):
number = self.get_numbers()
for page in range(1, 3):
one_url = self.one_url.format(page)
self.parse_page(one_url)
# 保存到本地json文件:json.dump
json.dump(self.item_list, self.f, ensure_ascii=False)
self.f.close()
if __name__ == '__main__':
start = time.time()
spider = TencentSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end - start))
ajax抓取网页内容(Python网络爬虫内容提取器讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-24 20:04
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载请看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。接下来,您可以阅读第6章:1分钟快速生成用于Web内容提取的xslt,将告诉您如何生成xslt。
5.采集GooSeeker开源代码下载源码
1. GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
上一章 Python 使用 xslt 提取网页数据 下一章 Python 读取 PDF 内容 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载请看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。接下来,您可以阅读第6章:1分钟快速生成用于Web内容提取的xslt,将告诉您如何生成xslt。
5.采集GooSeeker开源代码下载源码
1. GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
上一章 Python 使用 xslt 提取网页数据 下一章 Python 读取 PDF 内容

