
ajax抓取网页内容
ajax抓取网页内容(2019.02.07例子爬取湖人中文网的微博本文继续学习..Ajax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-04 05:10
2019.02.07 小白文继续学习...
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时确保页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
第一个例子
爬上湖人中文网站的微博
本文使用站点:通过分析api完成爬取
更多微博数据提取请看:深夜雨雪:Scrapy爬取所有新浪微博站点
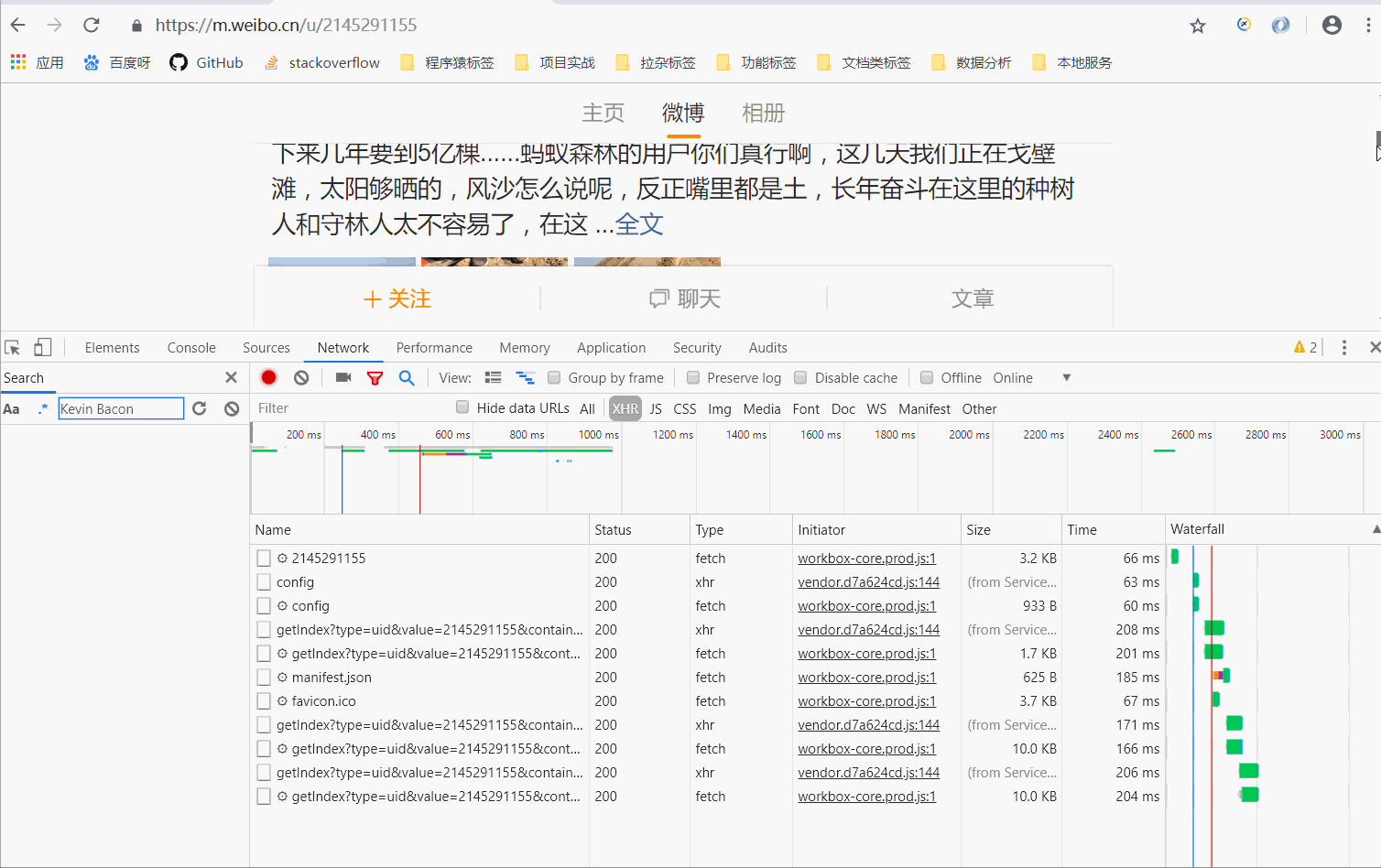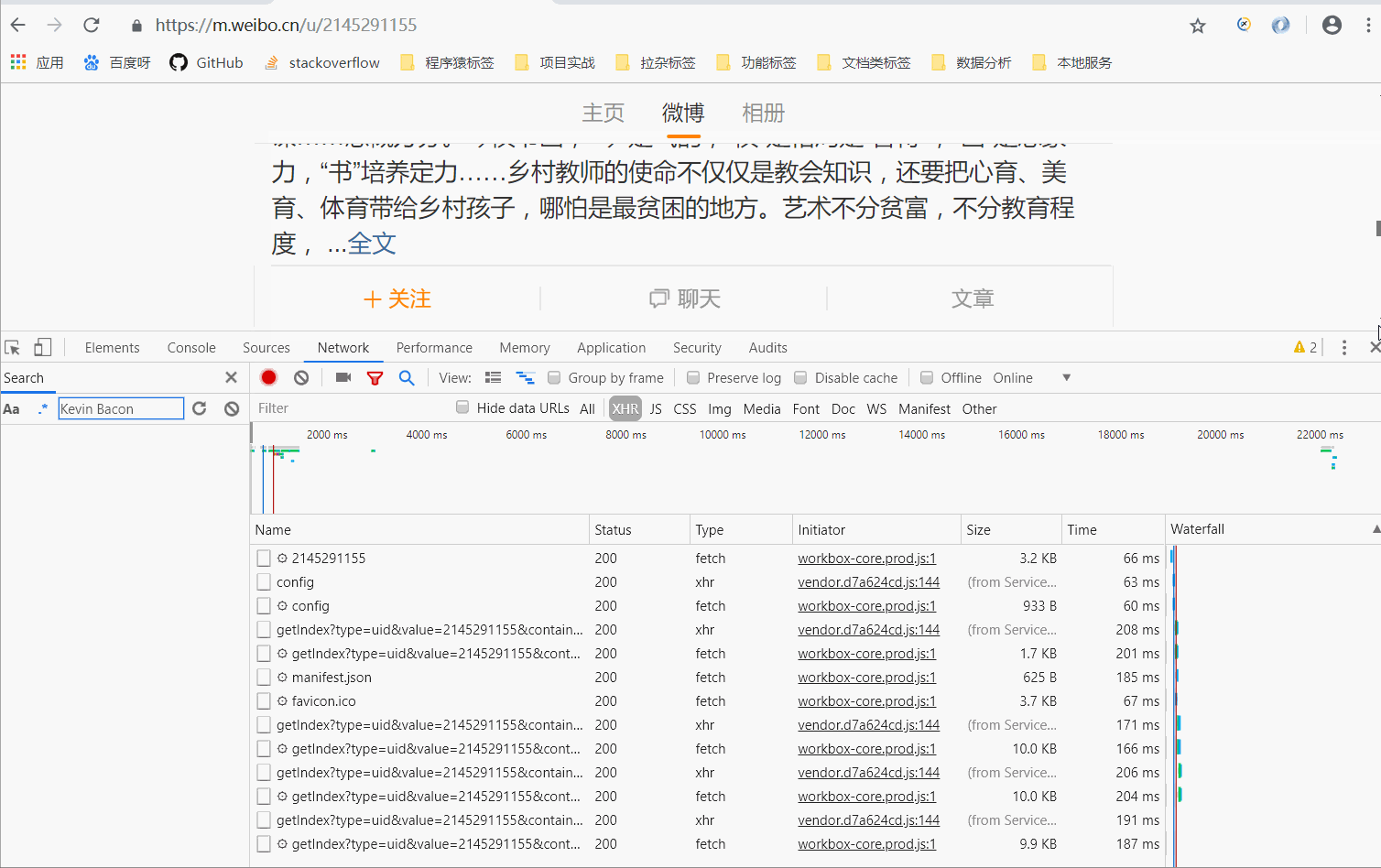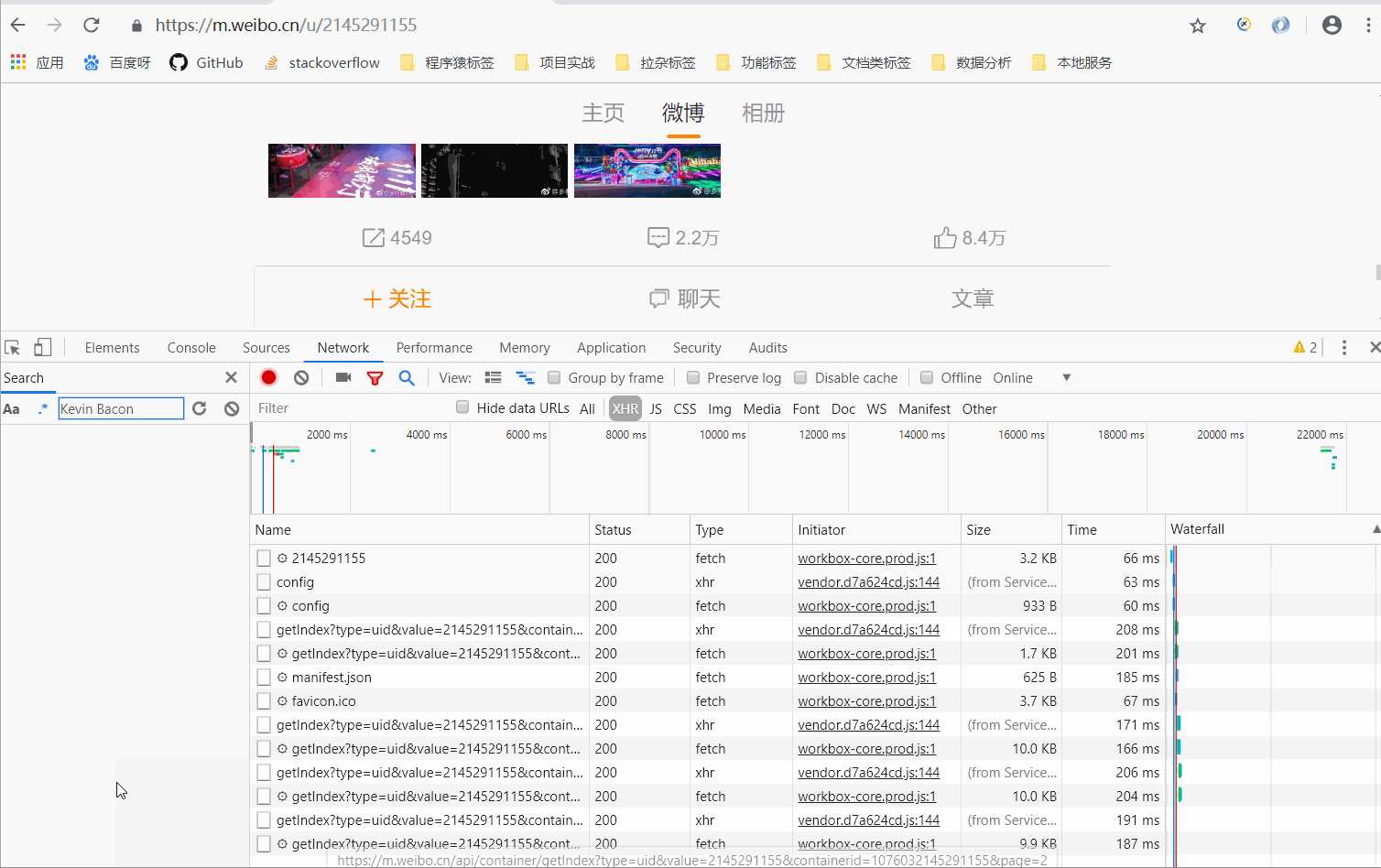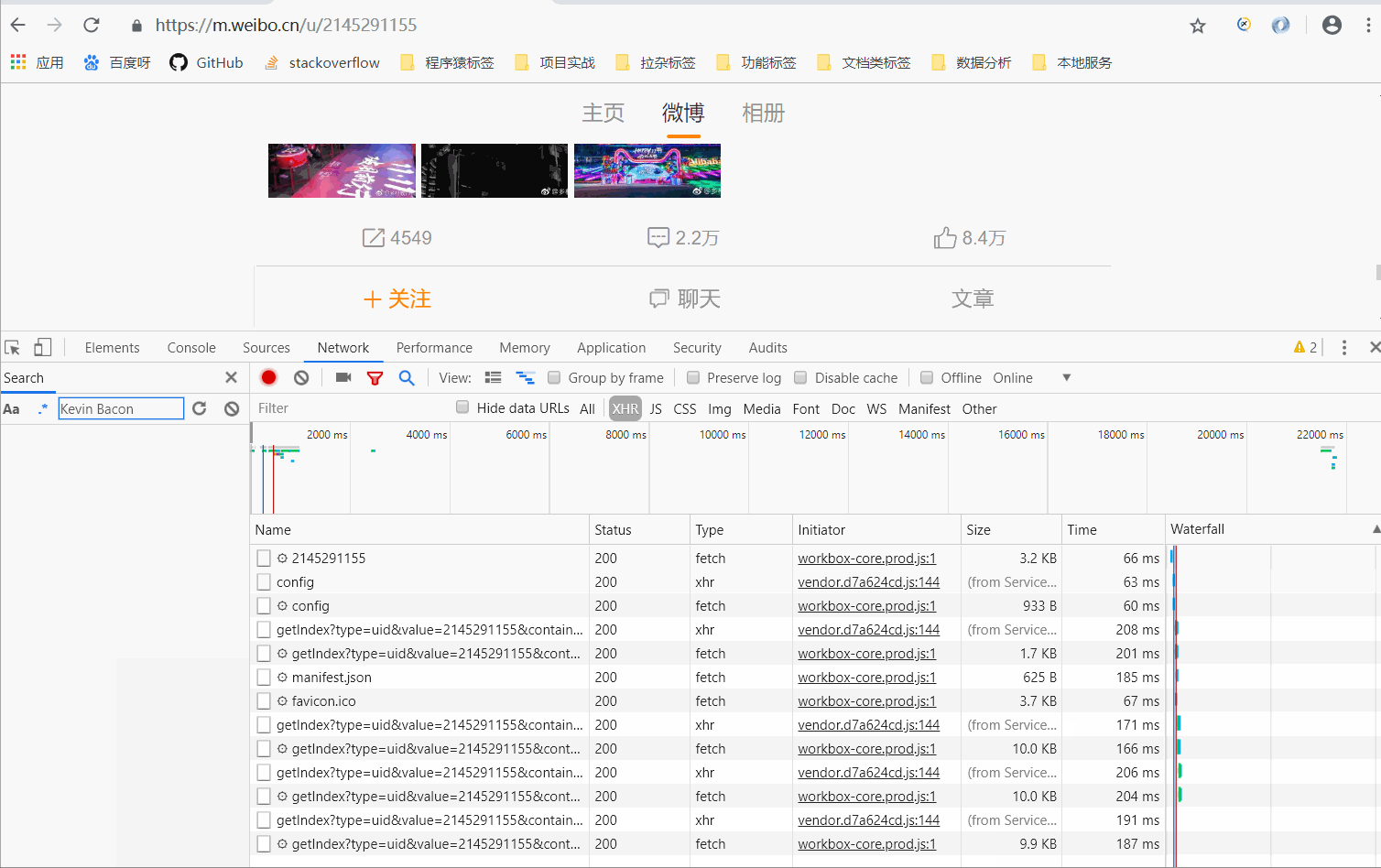
分析请求
打开Ajax的XHR过滤器,然后一直滑动页面加载新的微博内容。如您所见,Ajax 将继续存在
发出请求。
选择其中一个请求,分析其参数信息
请求的参数有4个:type、value、containerid和page(如果没有page,但是since_id,换个浏览器试试)
type永远是uid,value的值是页面链接中的数字,其实就是用户的id。另外还有一个containerid,可以发现是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=1代表第一页
分析响应
此内容为JSON格式,浏览器开发工具自动解析供我们查看。可以看出,最关键的两条信息是cardlistlnfo和cards:前者收录了更重要的信息总数。经过观察,可以发现其实就是微博总数。我们可以根据这个数字估算出页数;另一个是一个列表,它收录10个元素,展开其中一个来看看
可以发现这个元素有一个更重要的字段mblog。展开可以发现,里面收录了一些微博的信息,比如态度数(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博正文)等,而且都是格式化的内容。
这样我们请求一个接口的时候,就可以得到10条微博,请求的时候只需要修改page参数即可。
目录文件
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import json
from urllib.parse import urlencode
from pyquery import PyQuery as pq
from weibo.items import WeiboItem
class WeibospdSpider(scrapy.Spider):
name = 'weibospd'
allowed_domains = ['m.weibo.cn']
# start_urls = ['http://m.weibo.cn/']
def start_requests(self):
for page in range(1, 11):
base_url = 'https://m.weibo.cn/api/contain ... 39%3B
params = {
'type': 'uid',
'value': '5408596403',
'containerid': '1076035408596403',
'page': page
}
url = base_url + urlencode(params)
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
# for result_one in result:
# item = WeiboItem()
# for field in item.fields:
# if field in result_one.get('mblog').keys():
# item[field] = result_one.get('mblog').get(field)
# yield item
for result_one in result:
item = WeiboItem()
a = result_one.get('mblog')
item['id'] = a.get('id')
item['text'] = pq(a.get('text')).text()
item['attitudes_count'] = a.get('attitudes_count')
item['comments_count'] = a.get('comments_count')
item['reposts_count'] = a.get('reposts_count')
yield item
# print(item)
调用urlencode()方法将参数转换为URL GET请求参数,类似type=uid&value=5408596403&containerid=96403&since_id=43363
解析部分本来是打算这样写的
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
for result_one in result:
item = WeiboItem()
for field in item.fields:
if field in result_one.get('mblog').keys():
item[field] = result_one.get('mblog').get(field)
yield item
但是获得的'text'收录HTML标签
所以改成上面的代码,在pyquery的帮助下去掉body中的HTML标签
项目.py
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
text = scrapy.Field()
attitudes_count = scrapy.Field()
comments_count = scrapy.Field()
reposts_count = scrapy.Field()
设置.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/5408596403',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
第二个例子
崔庆才老师的博客使用Scrapy抓取所有知乎用户详细信息并存入MongoDB
崔青才老师写的很详细,不过是2年前完成的。虽然在知乎页面上进行了一些修改,但我还是尝试了。当我抓取他关注的人和关注他的人时,我发现无法获取下一页。 查看全部
ajax抓取网页内容(2019.02.07例子爬取湖人中文网的微博本文继续学习..Ajax)
2019.02.07 小白文继续学习...
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时确保页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
第一个例子
爬上湖人中文网站的微博
本文使用站点:通过分析api完成爬取
更多微博数据提取请看:深夜雨雪:Scrapy爬取所有新浪微博站点
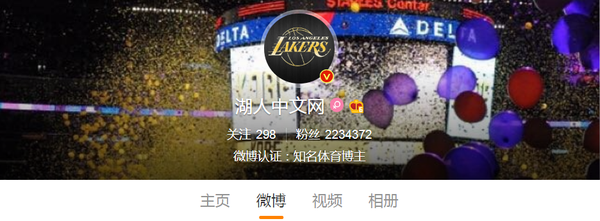
分析请求
打开Ajax的XHR过滤器,然后一直滑动页面加载新的微博内容。如您所见,Ajax 将继续存在
发出请求。
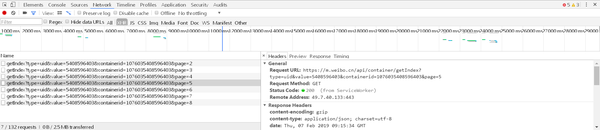
选择其中一个请求,分析其参数信息


请求的参数有4个:type、value、containerid和page(如果没有page,但是since_id,换个浏览器试试)
type永远是uid,value的值是页面链接中的数字,其实就是用户的id。另外还有一个containerid,可以发现是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=1代表第一页
分析响应
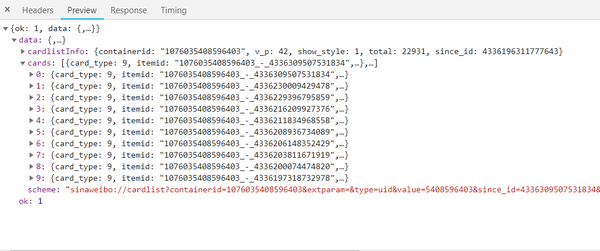
此内容为JSON格式,浏览器开发工具自动解析供我们查看。可以看出,最关键的两条信息是cardlistlnfo和cards:前者收录了更重要的信息总数。经过观察,可以发现其实就是微博总数。我们可以根据这个数字估算出页数;另一个是一个列表,它收录10个元素,展开其中一个来看看
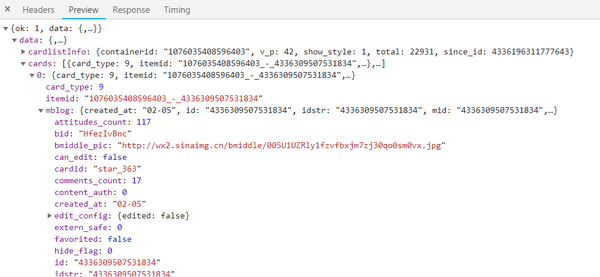
可以发现这个元素有一个更重要的字段mblog。展开可以发现,里面收录了一些微博的信息,比如态度数(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博正文)等,而且都是格式化的内容。
这样我们请求一个接口的时候,就可以得到10条微博,请求的时候只需要修改page参数即可。
目录文件
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import json
from urllib.parse import urlencode
from pyquery import PyQuery as pq
from weibo.items import WeiboItem
class WeibospdSpider(scrapy.Spider):
name = 'weibospd'
allowed_domains = ['m.weibo.cn']
# start_urls = ['http://m.weibo.cn/']
def start_requests(self):
for page in range(1, 11):
base_url = 'https://m.weibo.cn/api/contain ... 39%3B
params = {
'type': 'uid',
'value': '5408596403',
'containerid': '1076035408596403',
'page': page
}
url = base_url + urlencode(params)
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
# for result_one in result:
# item = WeiboItem()
# for field in item.fields:
# if field in result_one.get('mblog').keys():
# item[field] = result_one.get('mblog').get(field)
# yield item
for result_one in result:
item = WeiboItem()
a = result_one.get('mblog')
item['id'] = a.get('id')
item['text'] = pq(a.get('text')).text()
item['attitudes_count'] = a.get('attitudes_count')
item['comments_count'] = a.get('comments_count')
item['reposts_count'] = a.get('reposts_count')
yield item
# print(item)
调用urlencode()方法将参数转换为URL GET请求参数,类似type=uid&value=5408596403&containerid=96403&since_id=43363
解析部分本来是打算这样写的
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
for result_one in result:
item = WeiboItem()
for field in item.fields:
if field in result_one.get('mblog').keys():
item[field] = result_one.get('mblog').get(field)
yield item
但是获得的'text'收录HTML标签
所以改成上面的代码,在pyquery的帮助下去掉body中的HTML标签
项目.py
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
text = scrapy.Field()
attitudes_count = scrapy.Field()
comments_count = scrapy.Field()
reposts_count = scrapy.Field()
设置.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/5408596403',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
第二个例子
崔庆才老师的博客使用Scrapy抓取所有知乎用户详细信息并存入MongoDB
崔青才老师写的很详细,不过是2年前完成的。虽然在知乎页面上进行了一些修改,但我还是尝试了。当我抓取他关注的人和关注他的人时,我发现无法获取下一页。
ajax抓取网页内容(获取JavaScript脚本可以设计响应信息为JavaScript代码,它是可以执行的命令或脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-03 09:18
获取 JavaScript 脚本
响应信息可以设计为 JavaScript 代码。这里的代码不同于 JSON 数据。它是可以执行的命令或脚本。
例子:在服务端指定JS函数
AJAX测试
按钮
function f() {
var ajax = createXMLHTTPObject();
ajax.onreadystatechange = function(){
if(ajax.readyState == 4 && ajax.status == 200){
var info = ajax.responseText;
var o = eval("(" + info + ")" + "()");//调用eval()方法把JavaScript字符串转换为本地脚本
alert(o);//返回客户端当前日期
}
}
ajax.open("get", "response.js",true);
ajax.send();
}
响应.js:
function (){
var d = new Date();
return d.toString();
}
点击按钮,会弹出提示信息:
注意:转换时需要在字符串签名后加两个括号:一个收录函数结构,一个表示调用函数。通常,JavaScript 代码很少用作响应信息的格式,因为它无法传递更丰富的信息,并且 JavaScript 脚本容易存在安全风险。 查看全部
ajax抓取网页内容(获取JavaScript脚本可以设计响应信息为JavaScript代码,它是可以执行的命令或脚本)
获取 JavaScript 脚本
响应信息可以设计为 JavaScript 代码。这里的代码不同于 JSON 数据。它是可以执行的命令或脚本。
例子:在服务端指定JS函数
AJAX测试
按钮
function f() {
var ajax = createXMLHTTPObject();
ajax.onreadystatechange = function(){
if(ajax.readyState == 4 && ajax.status == 200){
var info = ajax.responseText;
var o = eval("(" + info + ")" + "()");//调用eval()方法把JavaScript字符串转换为本地脚本
alert(o);//返回客户端当前日期
}
}
ajax.open("get", "response.js",true);
ajax.send();
}
响应.js:
function (){
var d = new Date();
return d.toString();
}
点击按钮,会弹出提示信息:

注意:转换时需要在字符串签名后加两个括号:一个收录函数结构,一个表示调用函数。通常,JavaScript 代码很少用作响应信息的格式,因为它无法传递更丰富的信息,并且 JavaScript 脚本容易存在安全风险。
ajax抓取网页内容( 我们想要的图片信息利用正则表达式取到链接进一步抓取到图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-03 07:00
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来开始抓取图片,打开图集详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取到图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20 查看全部
ajax抓取网页内容(
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)

并且数据收录了我们需要的信息

接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来开始抓取图片,打开图集详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息

使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取到图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,

和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的

完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20
ajax抓取网页内容( get()和post(两个)方法设置相关的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2021-12-03 06:25
get()和post(两个)方法设置相关的参数)
from requests_html import HTMLSession
# 定义会话Session
session=HTMLSession()
# 发送GET请求
res=session.get(url)
# 发送POST请求
res=session.post(url,data={})
# 打印网页的URL地址
print(res.html)
由于get()和post()方法来自Requests模块,因此您还可以为这两个方法设置相关参数,如请求参数、请求头、Cookies、代理IP、证书验证等。
Requests-HTML 在请求过程中也进行了优化。如果没有设置请求头,Requests-HTML 将默认使用源代码中定义的请求头和编码格式。
找到Requests-HTML的源文件:\Lib\site-packages\requests_html.py,里面定义了属性DEFAULT_ENCODING和DEFAULT_USER_AGENT,分别对应编码格式和HTTP请求头。
DEFAULT_ENCODING = 'utf-8'
DEFAULT_USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
数据清洗
Requests-HTML 不仅优化了请求流程,还提供了数据清理的功能。 Requests 模块只提供请求方法,不提供数据清洗。这也体现了 Requests-HTML 的一大优势。使用Requests开发的爬虫,需要通过调用其他模块来实现数据清洗,Requests-HTML将两者结合起来。
Requests-HTML 提供了多种数据清洗方式,如网页中的 URL 地址、HTML 源代码内容、文本信息等,代码参考:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 输出网页里的URL地址
print(res.html,'')
# 输出网页里全部URL地址
print(res.html.links)
# 输出网页里精准的URL地址
print(res.html.absolute_links)
# 输出网页的HTML信息
print(res.text)
# 输出网页的全部文本信息,即去除HTML代码
print(res.html.text)
代码只是提取了网站的基本信息。如果要准确提取某条数据,可以使用find()、xpath()、search()和search_all()方法来实现。首先了解这4个方法的定义和相关参数说明:
# 定义
find(selector,containing,clean,first,_encoding)
# 参数说明
selector:使用CSS Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
xpath(selector,clean,first,__encoding)
# 参数说明
selector:使用Xpath Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
search(template)
# 参数说明
template:通过元素内容查找第一个元素
# 定义
search_all(template)
# 参数说明
template:通过元素内容查找全部元素
这里我们以Ba的网站为例,提取网页的文章标题:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 通过CSS Seletor定位标题
# first:True获取第一个元素
print(res.html.find('div.excerpt-post header h2 a',first=True).text)
# 输出当前标签的属性
print(res.html.find('div.excerpt-post header h2 a',first=True).attrs)
print('————————分割线1————————')
# 查找特定文本的元素
# 如果元素所在的HTML里含有containing的属性值即可提取
for name in res.html.find('h2 a',containing='R'):
# 输出内容
print(name.text,'\n',name.attrs)
print('————————分割线2————————')
# 通过Xpath Selector定位
for name in res.html.xpath('//h2/a'):
print(name.text,'\n',name.attrs)
print('————————分割线3————————')
# 通过search查找
# 一个{ }代表一个内容,内容可为中文或者英文等
print(res.html.search('爬虫库Requests-HTML简介及{}{}'))
# 通过search_all查找所有
print(res.html.search_all('爬虫库Requests-HTML{}{}{}{}{}'))
代码中CSS Selector和Xpath Selector的语法就不详细介绍了,自己学习吧!
Ajax 动态数据捕获
使用Requests-HTML请求网页地址,对应的响应内容与开发者工具Doc选项卡的响应内容一致。如果网页数据是通过Ajax请求并通过JavaScript渲染到网页上的,还需要使用Requests-HTML模拟Ajax请求来获取网页数据。
模拟ajax请求,需要构造请求参数。构造请求参数的方法很多且复杂,实现起来需要时间。以QQ音乐的歌手列表页面为例,每个歌手的名字是通过ajax加载到网页上的。
Requests-HTML提供Ajax加载功能,加载的网页信息与开发者工具Elements标签页中的网页信息一致。这个加载功能是通过调用谷歌的Chromium浏览器实现的,
Chromium 是谷歌开发 Chrome 的计划。可以理解为Chrome的工程版或实验版。新功能将首先在 Chromium 上实现,并在验证后应用于 Chrome。
Ajax 加载功能是通过 render() 方法实现的。首次使用 render() 方法时会自动下载 Chromium 浏览器。下载Chromium浏览器,必须保证当前网络可以正常访问谷歌主页,否则将无法下载。另外可以直接下载Chromium浏览器,将浏览器放在C盘的用户文件夹中。
文件路径中,只有“000”改变了,不同的电脑名称不同; chrome-win32 文件夹也命名为fixed,Chromium 浏览器相关的文件和应用程序都存放在这个文件夹中。如果是通过下载方式,则无需手动配置文件路径。 Requests-HTML 会自动将下载的 Chromium 浏览器配置为对应的文件路径。
完成Chromium浏览器配置后,可以编写如下代码实现Requests-HTML的Ajax加载功能:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
虽然运行速度比模拟Ajax请求慢,但是可以大大降低开发难度。
声明:本站所有文章,如无特殊说明或注释,均在本站发布原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
小君比常任还帅 查看全部
ajax抓取网页内容(
get()和post(两个)方法设置相关的参数)
from requests_html import HTMLSession
# 定义会话Session
session=HTMLSession()
# 发送GET请求
res=session.get(url)
# 发送POST请求
res=session.post(url,data={})
# 打印网页的URL地址
print(res.html)
由于get()和post()方法来自Requests模块,因此您还可以为这两个方法设置相关参数,如请求参数、请求头、Cookies、代理IP、证书验证等。
Requests-HTML 在请求过程中也进行了优化。如果没有设置请求头,Requests-HTML 将默认使用源代码中定义的请求头和编码格式。
找到Requests-HTML的源文件:\Lib\site-packages\requests_html.py,里面定义了属性DEFAULT_ENCODING和DEFAULT_USER_AGENT,分别对应编码格式和HTTP请求头。
DEFAULT_ENCODING = 'utf-8'
DEFAULT_USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
数据清洗
Requests-HTML 不仅优化了请求流程,还提供了数据清理的功能。 Requests 模块只提供请求方法,不提供数据清洗。这也体现了 Requests-HTML 的一大优势。使用Requests开发的爬虫,需要通过调用其他模块来实现数据清洗,Requests-HTML将两者结合起来。
Requests-HTML 提供了多种数据清洗方式,如网页中的 URL 地址、HTML 源代码内容、文本信息等,代码参考:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 输出网页里的URL地址
print(res.html,'')
# 输出网页里全部URL地址
print(res.html.links)
# 输出网页里精准的URL地址
print(res.html.absolute_links)
# 输出网页的HTML信息
print(res.text)
# 输出网页的全部文本信息,即去除HTML代码
print(res.html.text)
代码只是提取了网站的基本信息。如果要准确提取某条数据,可以使用find()、xpath()、search()和search_all()方法来实现。首先了解这4个方法的定义和相关参数说明:
# 定义
find(selector,containing,clean,first,_encoding)
# 参数说明
selector:使用CSS Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
xpath(selector,clean,first,__encoding)
# 参数说明
selector:使用Xpath Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
search(template)
# 参数说明
template:通过元素内容查找第一个元素
# 定义
search_all(template)
# 参数说明
template:通过元素内容查找全部元素
这里我们以Ba的网站为例,提取网页的文章标题:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 通过CSS Seletor定位标题
# first:True获取第一个元素
print(res.html.find('div.excerpt-post header h2 a',first=True).text)
# 输出当前标签的属性
print(res.html.find('div.excerpt-post header h2 a',first=True).attrs)
print('————————分割线1————————')
# 查找特定文本的元素
# 如果元素所在的HTML里含有containing的属性值即可提取
for name in res.html.find('h2 a',containing='R'):
# 输出内容
print(name.text,'\n',name.attrs)
print('————————分割线2————————')
# 通过Xpath Selector定位
for name in res.html.xpath('//h2/a'):
print(name.text,'\n',name.attrs)
print('————————分割线3————————')
# 通过search查找
# 一个{ }代表一个内容,内容可为中文或者英文等
print(res.html.search('爬虫库Requests-HTML简介及{}{}'))
# 通过search_all查找所有
print(res.html.search_all('爬虫库Requests-HTML{}{}{}{}{}'))
代码中CSS Selector和Xpath Selector的语法就不详细介绍了,自己学习吧!
Ajax 动态数据捕获
使用Requests-HTML请求网页地址,对应的响应内容与开发者工具Doc选项卡的响应内容一致。如果网页数据是通过Ajax请求并通过JavaScript渲染到网页上的,还需要使用Requests-HTML模拟Ajax请求来获取网页数据。
模拟ajax请求,需要构造请求参数。构造请求参数的方法很多且复杂,实现起来需要时间。以QQ音乐的歌手列表页面为例,每个歌手的名字是通过ajax加载到网页上的。
Requests-HTML提供Ajax加载功能,加载的网页信息与开发者工具Elements标签页中的网页信息一致。这个加载功能是通过调用谷歌的Chromium浏览器实现的,
Chromium 是谷歌开发 Chrome 的计划。可以理解为Chrome的工程版或实验版。新功能将首先在 Chromium 上实现,并在验证后应用于 Chrome。
Ajax 加载功能是通过 render() 方法实现的。首次使用 render() 方法时会自动下载 Chromium 浏览器。下载Chromium浏览器,必须保证当前网络可以正常访问谷歌主页,否则将无法下载。另外可以直接下载Chromium浏览器,将浏览器放在C盘的用户文件夹中。
文件路径中,只有“000”改变了,不同的电脑名称不同; chrome-win32 文件夹也命名为fixed,Chromium 浏览器相关的文件和应用程序都存放在这个文件夹中。如果是通过下载方式,则无需手动配置文件路径。 Requests-HTML 会自动将下载的 Chromium 浏览器配置为对应的文件路径。
完成Chromium浏览器配置后,可以编写如下代码实现Requests-HTML的Ajax加载功能:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
虽然运行速度比模拟Ajax请求慢,但是可以大大降低开发难度。
声明:本站所有文章,如无特殊说明或注释,均在本站发布原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
小君比常任还帅
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-01 11:07
在C#中,常用的请求方法是使用HttpWebRequest创建请求并返回消息。但是,有时遇到动态加载的页面时,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用phantomJS无头浏览器。
在开发之前,准备两件事。
1. phantomJS-2.1.1 官方下载地址:
2. JS脚本文件,我自己命名为codes.js。内容如下。一开始我没有配置页面的设置信息,导致一些异步页面在爬行的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
草稿完成后,您需要将这两个文件放入您的项目中。如下:
如果这些都没有问题,就可以开始编写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些是我今天才接触到的,所以整理了一下思路。我希望我能指出哪里有错误。 查看全部
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
在C#中,常用的请求方法是使用HttpWebRequest创建请求并返回消息。但是,有时遇到动态加载的页面时,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用phantomJS无头浏览器。
在开发之前,准备两件事。
1. phantomJS-2.1.1 官方下载地址:
2. JS脚本文件,我自己命名为codes.js。内容如下。一开始我没有配置页面的设置信息,导致一些异步页面在爬行的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
草稿完成后,您需要将这两个文件放入您的项目中。如下:
如果这些都没有问题,就可以开始编写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些是我今天才接触到的,所以整理了一下思路。我希望我能指出哪里有错误。
ajax抓取网页内容(json能抓取怎样的数据网页代码:最多见的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-29 20:23
背景
网页与网页之间存在连接关系。爬虫可以沿着节点爬到下一个节点,即通过一个网页继续获取后续的网页,这个全网的节点都可以被所有的蜘蛛爬到,网站数据可以被俘。html
一句话描述
自动程序python获取网页并提取和保存信息
获取网页
爬虫的第一个工作就是获取网页的源代码,可以通过python相关的库来实现,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分,即可以得到网页的源代码。,这样我们就可以使用程序来实现获取网页的过程了。阿贾克斯
好的
得到网页代码后,下面是分析。可以使用正则表达式分析,但是这个正则表达式比较难写,容易出错。有基于网页结构的规则。可以使用Beautiful Soup、pyquery、lxml等库,高效快速地提取网页信息,如节点属性、文本值等。 正则表达式
保存数据
我们通常将提取的数据保存在某处以备后用。这里有很多保存方法。比如可以简单的保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL、MongoDB等。它也可以保存到远程服务器,例如借助 SFTP 操作数据库。
自动化程序
可以代替人工抓取信息,在过程中进行异常处理、错误重试等操作,保证爬行持续高效。json
可以捕获什么样的数据
• 网页代码:最常见的是html 代码• json 数据:最友好• 二进制数据,如图片、音频和视频,获取后可以保存为相应的文件名• 各种扩展名的资源文件后端
js生成的代码
js生成的或者ajax异步生成的页面界面不会被抓取。前面说过,是爬取返回的网页代码,不会执行js。如果希望爬虫能够爬到这部分资源,只需要在服务端渲染即可(如果你原本是从端分离出来的)。服务器
注意:这种情况也不是完全不可能爬行。我们可以使用 Selenium 和 Splash 等库来实现模拟 JavaScript 渲染。降价 查看全部
ajax抓取网页内容(json能抓取怎样的数据网页代码:最多见的)
背景
网页与网页之间存在连接关系。爬虫可以沿着节点爬到下一个节点,即通过一个网页继续获取后续的网页,这个全网的节点都可以被所有的蜘蛛爬到,网站数据可以被俘。html
一句话描述
自动程序python获取网页并提取和保存信息
获取网页
爬虫的第一个工作就是获取网页的源代码,可以通过python相关的库来实现,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分,即可以得到网页的源代码。,这样我们就可以使用程序来实现获取网页的过程了。阿贾克斯
好的
得到网页代码后,下面是分析。可以使用正则表达式分析,但是这个正则表达式比较难写,容易出错。有基于网页结构的规则。可以使用Beautiful Soup、pyquery、lxml等库,高效快速地提取网页信息,如节点属性、文本值等。 正则表达式
保存数据
我们通常将提取的数据保存在某处以备后用。这里有很多保存方法。比如可以简单的保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL、MongoDB等。它也可以保存到远程服务器,例如借助 SFTP 操作数据库。
自动化程序
可以代替人工抓取信息,在过程中进行异常处理、错误重试等操作,保证爬行持续高效。json
可以捕获什么样的数据
• 网页代码:最常见的是html 代码• json 数据:最友好• 二进制数据,如图片、音频和视频,获取后可以保存为相应的文件名• 各种扩展名的资源文件后端
js生成的代码
js生成的或者ajax异步生成的页面界面不会被抓取。前面说过,是爬取返回的网页代码,不会执行js。如果希望爬虫能够爬到这部分资源,只需要在服务端渲染即可(如果你原本是从端分离出来的)。服务器
注意:这种情况也不是完全不可能爬行。我们可以使用 Selenium 和 Splash 等库来实现模拟 JavaScript 渲染。降价
ajax抓取网页内容(ajax抓取网页内容,抓取.推荐用第三方库,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-29 13:19
ajax抓取网页内容,可以尝试selenium+mysql.推荐用第三方库,jsoup,比如jsoup4.0requests.
我用的是thriftapi,底层是自己的实现(有多个)。我都是写java代码来抓取的,爬回来也可以部署到lua脚本里面来运行。
一般来说可以用异步的方式来解决首先先设置发送的代码,让异步调用他请求页面,先用java模拟请求,
ajax抓取最实用的代码就是jsoup+mysql,封装起来即可。
jsoup+jsoup4.0+requests+mysql比如网页上有异步加载jsoup+jsoup4.0+python-selenium
可以用ajax,
bs4
ajax,selenium+mysql或postman
jsoup+jsoup4+requests+ajax(。
全用java开发...jsoup4+jsoup4.5+jquery
xmlhttprequestwebsocket
xmlhttprequesthttp
一般来说可以先用jsoup+jsoup4.0+requests+mysql.
ajax抓取可以用jsoup
你需要一个接口,但是接口有一定的限制,比如说网页类型等。如果你不需要接口可以用搜索引擎,参见索引类搜索引擎。
使用接口来做。不仅用于爬取其他网站内容,还可以用于爬取大部分网站,比如手机知乎这些网站。 查看全部
ajax抓取网页内容(ajax抓取网页内容,抓取.推荐用第三方库,)
ajax抓取网页内容,可以尝试selenium+mysql.推荐用第三方库,jsoup,比如jsoup4.0requests.
我用的是thriftapi,底层是自己的实现(有多个)。我都是写java代码来抓取的,爬回来也可以部署到lua脚本里面来运行。
一般来说可以用异步的方式来解决首先先设置发送的代码,让异步调用他请求页面,先用java模拟请求,
ajax抓取最实用的代码就是jsoup+mysql,封装起来即可。
jsoup+jsoup4.0+requests+mysql比如网页上有异步加载jsoup+jsoup4.0+python-selenium
可以用ajax,
bs4
ajax,selenium+mysql或postman
jsoup+jsoup4+requests+ajax(。
全用java开发...jsoup4+jsoup4.5+jquery
xmlhttprequestwebsocket
xmlhttprequesthttp
一般来说可以先用jsoup+jsoup4.0+requests+mysql.
ajax抓取可以用jsoup
你需要一个接口,但是接口有一定的限制,比如说网页类型等。如果你不需要接口可以用搜索引擎,参见索引类搜索引擎。
使用接口来做。不仅用于爬取其他网站内容,还可以用于爬取大部分网站,比如手机知乎这些网站。
ajax抓取网页内容(原文C#抓取AJAX页面的内容现在的网页有相当一部分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-28 07:16
原生C#抓取AJAX页面内容
目前的网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter的方法,也就是在Navigated event++中,在DownloadComplete中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关的AJAX文章,才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
} 查看全部
ajax抓取网页内容(原文C#抓取AJAX页面的内容现在的网页有相当一部分)
原生C#抓取AJAX页面内容
目前的网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter的方法,也就是在Navigated event++中,在DownloadComplete中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关的AJAX文章,才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
}
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-27 10:06
)
阿贾克斯介绍:
有时候我们使用Requests抓取页面的时候,结果可能和我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这是因为Requests获取的都是原创的HTML文档,而浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后端发送到接口的ajax请求,然后用Requests模拟这个ajax请求,就可以成功获取了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
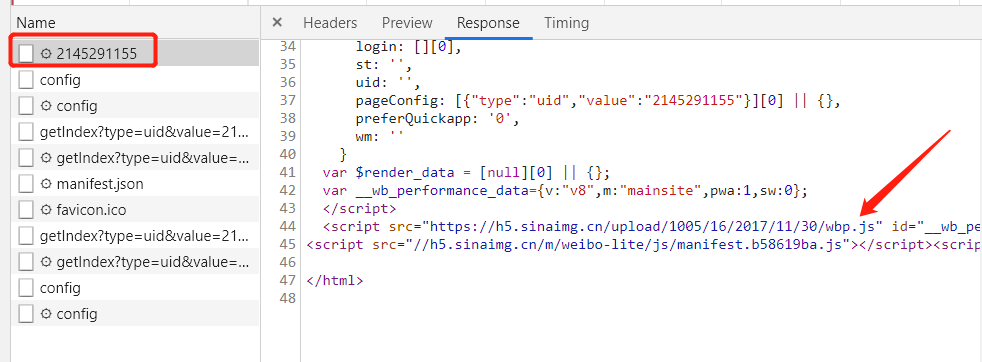
让我们看一下第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
查看全部
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么?
)
阿贾克斯介绍:
有时候我们使用Requests抓取页面的时候,结果可能和我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这是因为Requests获取的都是原创的HTML文档,而浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后端发送到接口的ajax请求,然后用Requests模拟这个ajax请求,就可以成功获取了。

了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
让我们看一下第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
ajax抓取网页内容(我正在尝试在不执行javascript的情况下在网页上AJAX的部分 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 07:05
)
我试图在不执行 javascript 的情况下获取网页的 AJAX 加载部分。通过使用Chrome开发工具,发现AJAX容器是通过POST请求从URL中提取内容,所以想使用python的requests包来复制请求。但奇怪的是,通过使用Chrome提供的Headers信息,我总是得到400错误,从Chrome复制的curl命令也是如此。所以我想知道是否有人可以分享一些见解。
我感兴趣的网站就在这里。使用Chrome:ctrl-shift-I、网络、XHR,我想要的部分是“内容”。我使用的脚本是:
headers = {"authority": "cafe.bithumb.com",
"path": "/boards/43/contents",
"method": "POST",
"origin":"https://cafe.bithumb.com",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"accept-encoding":"gzip, deflate, br",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"accept":"application/json, text/javascript, */*; q=0.01",
"referer":"https://cafe.bithumb.com/view/boards/43",
"x-requested-with":"XMLHttpRequest",
"scheme": "https",
"content-length":"1107"}
s=requests.Session()
s.headers.update(headers)
r = s.post('https://cafe.bithumb.com/boards/43/contents') 查看全部
ajax抓取网页内容(我正在尝试在不执行javascript的情况下在网页上AJAX的部分
)
我试图在不执行 javascript 的情况下获取网页的 AJAX 加载部分。通过使用Chrome开发工具,发现AJAX容器是通过POST请求从URL中提取内容,所以想使用python的requests包来复制请求。但奇怪的是,通过使用Chrome提供的Headers信息,我总是得到400错误,从Chrome复制的curl命令也是如此。所以我想知道是否有人可以分享一些见解。
我感兴趣的网站就在这里。使用Chrome:ctrl-shift-I、网络、XHR,我想要的部分是“内容”。我使用的脚本是:
headers = {"authority": "cafe.bithumb.com",
"path": "/boards/43/contents",
"method": "POST",
"origin":"https://cafe.bithumb.com",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"accept-encoding":"gzip, deflate, br",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"accept":"application/json, text/javascript, */*; q=0.01",
"referer":"https://cafe.bithumb.com/view/boards/43",
"x-requested-with":"XMLHttpRequest",
"scheme": "https",
"content-length":"1107"}
s=requests.Session()
s.headers.update(headers)
r = s.post('https://cafe.bithumb.com/boards/43/contents')
ajax抓取网页内容(IE浏览页面何时才算是真正的加载完毕?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 21:20
当前网页中有相当一部分使用了 AJAX 技术。无论是WebClient还是C#中的HttpRequest,都无法得到正确的结果,因为这些脚本都是在服务端发送后执行的!
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使使用了counter的方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白了原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
textBox1.Text += webBrowser1.StatusText;
if (webBrowser1.StatusText == "完成")
{
timer1.Enabled = false;
//页面加载完成,做一些其它的事
textBox1.Text += webBrowser1.Document.Body.OuterHtml;
//webBrowser1.DocumentText 注意不要用这个,这个和查看源文件一样的
}
}
private void Form1_Load(object sender, EventArgs e)
{
string Url = "http://cd.mei8.cn/face/work/wi ... 3B%3B
webBrowser1.Navigate(Url);
}
放置三个控件,webBrowser、timer、textBox定时器设置为可用 查看全部
ajax抓取网页内容(IE浏览页面何时才算是真正的加载完毕?(图))
当前网页中有相当一部分使用了 AJAX 技术。无论是WebClient还是C#中的HttpRequest,都无法得到正确的结果,因为这些脚本都是在服务端发送后执行的!
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使使用了counter的方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白了原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
textBox1.Text += webBrowser1.StatusText;
if (webBrowser1.StatusText == "完成")
{
timer1.Enabled = false;
//页面加载完成,做一些其它的事
textBox1.Text += webBrowser1.Document.Body.OuterHtml;
//webBrowser1.DocumentText 注意不要用这个,这个和查看源文件一样的
}
}
private void Form1_Load(object sender, EventArgs e)
{
string Url = "http://cd.mei8.cn/face/work/wi ... 3B%3B
webBrowser1.Navigate(Url);
}
放置三个控件,webBrowser、timer、textBox定时器设置为可用
ajax抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-21 12:11
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url + \' #container\',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + \' #container\');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),在中国适用吗?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: \'get\',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + \' #container\':获取url网页中container容器内的内容
41 url: url + \' #container\',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find(\'div[id=container]\').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + \' #container\', \'\', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find(\'div[id=container]\').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面 查看全部
ajax抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url + \' #container\',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + \' #container\');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),在中国适用吗?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: \'get\',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + \' #container\':获取url网页中container容器内的内容
41 url: url + \' #container\',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find(\'div[id=container]\').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + \' #container\', \'\', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find(\'div[id=container]\').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-19 15:07
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候你会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很奇怪
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是边看边翻译,每页都看的很仔细,所以最后仔细阅读了下面两种常见的jquery事件加载方式。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还未加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候你会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很奇怪
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是边看边翻译,每页都看的很仔细,所以最后仔细阅读了下面两种常见的jquery事件加载方式。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还未加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章!
ajax抓取网页内容(CwRadioButton更改为_escaped_fragment_以及何时应使用#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-11-19 15:07
什么时候应该使用_escaped_fragment_,什么时候应该使用#! 在 AJAX URL 中?
您的 网站 应该使用 #! 所有使用 AJAX 爬网机制的 URL 的语法。Googlebot 不会跟踪 _escaped_fragment_ 格式的超链接。
上提供了 AJAX 应用程序示例。单击左侧的任何链接后,您将看到相应的 URL 收录一个 #! 哈希代码片段,应用程序将进入与此哈希代码片段对应的状态。如果你改变#! (例如#!CwRadioButton)到?_escaped_fragment_=(例如),网站 将返回一个HTML 快照。
如果您这样做,在不久的将来,您的网页可能无法在 Google 搜索结果页上正确显示。但是,我们一直在不断改进 Googlebot,并试图使其更像浏览器。届时,当您在 网站 上实现所需的功能时,Googlebot 可能会自动正确地为您的网页编入索引。但是,这种AJAX爬取机制对于已经使用AJAX并希望确保内容被正确索引的网站来说是一个非常实用的解决方案。我们希望该方案能够有效解决用户拥有网页HTML快照的问题,或者解决用户使用无头浏览器获取此类HTML快照的问题。
这完全取决于应用程序内容的更新频率。如果更新频繁,则应始终及时构建最新的 HTML 快照以响应爬虫请求。如果不频繁,请考虑创建一个内容不定期更新的库档案。为避免服务器持续生成相同的 HTML 快照,您可以一次性创建所有相关的 HTML 快照(可能处于离线状态),然后保存以备将来参考。您还可以使用 304(未修改)HTTP 状态代码响应 Googlebot。
我们建议您使用它!使用哈希码段可以显着加快应用响应速度,因为哈希码段是由客户端浏览器处理的,不会导致整个网页都需要刷新。此外,哈希码片段还支持在应用程序中提供历史记录(也称为备受诟病的“浏览器后退按钮”)。各种 AJAX 框架都支持哈希代码段。例如,查看Really Simple History、jQuery 的历史插件、Google Web Toolkit 的历史机制或ASP.NET AJAX 对历史管理的支持。
但是,如果您无法构建应用以使用哈希代码片段,则可以执行以下操作以在哈希代码片段中使用特殊标记(即 URL 中 # 标记之后的所有内容)。表示唯一页面状态的哈希代码段必须以感叹号开头。例如,如果您的 AJAX 应用程序收录类似于以下内容的 URL:
www.example.com/ajax.html#mystate
现在应该是这样的:
www.example.com/ajax.html#!mystate
如果你的网站采用这种架构,就会被认为是“AJAX可抓取”。这意味着如果您的 网站 提供了 HTML 快照,爬虫将看到您的应用程序的内容。
URL 的 _escaped_fragment_ 语法对应于临时 URL,最终用户不应看到。在用户可以看到的所有环境中,您应该使用“漂亮的 URL”(使用 #! 而不是 _escaped_fragment_):常规应用程序交互、站点地图、超链接、重定向以及用户可能会看到 URL 的任何其他情况。出于同样的原因,搜索结果都是“漂亮的网址”,而不是“难看的网址”。
隐藏真实内容是指提供给用户的内容与提供给搜索引擎的内容不同,通常是为了提高网页在搜索结果中的排名。隐藏真实内容一直是(也将永远是)一个重要的搜索引擎问题,所以需要注意的是,将AJAX应用设置为可爬取,绝不是为了隐藏真实内容的方便。因此,HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。如果它们不相同,则可能被视为隐藏了真实内容。详情请参考具体回答。
Google 确实可以为许多富媒体文件类型编制索引,并且一直在努力改进抓取和索引编制。但是,Googlebot 可能无法看到 Flash 或其他富媒体应用程序的所有内容(就像它无法抓取您网站 上的所有动态内容一样),因此使用此机制可以为 Googlebot 提供更多内容。, HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。Google 保留将 网站 从被视为隐藏真实内容的索引中排除的权利。
如果你的 网站 使用 AJAX 爬取机制,谷歌爬虫会爬取它遇到的每一个哈希码段 URL。如果您不想抓取某些哈希代码段 URL,建议您在 robots.txt 文件中添加正则表达式指令。例如,您可以在不想被抓取的哈希代码片段中使用约定,然后在 robots.txt 文件中排除所有符合该约定的 URL。假设所有指示不可索引的语句都采用以下形式:#DONOTCRAWLmyfragment,那么您可以将以下代码添加到 robots.txt 以防止 Googlebot 抓取这些页面:
Disallow: /*_escaped_fragment_=DONOTCRAWL
如何处理现有的#! 在哈希码段?
#!是在现有哈希代码片段中不常用的令牌;但是,URL 规范并没有规定不能使用。如果您的应用程序使用了#!,但又不想采用新的 AJAX 爬取机制,您应该怎么做?一种方法是在robots.txt中添加以下指令来指示爬虫做什么。
Disallow: /*_escaped_fragment_
请注意,这意味着如果您的应用程序仅收录此 URL #!mystate,则不会抓取该 URL。如果您的应用程序还收录一个普通 URL,则该 URL 将被抓取。
当前向搜索引擎提供静态内容的方法有一个副作用,即 网站 站长可以让残障用户更容易访问他们的应用程序。这项新协议进一步提高了可访问性:网站 网站管理员不再需要手动干预来使用收录所有相关内容且可供屏幕阅读器使用的无头浏览器来创建 HTML 快照。这意味着现在可以更轻松地提供最新的静态内容,而手动工作越来越少。换句话说,网站 网站管理员现在将有更大的动力来构建方便残障用户使用的应用程序。rel="canonical" 应该如何使用?
请使用(不要使用)。
您应该在站点地图的搜索结果中添加要显示的 URL,因此应该添加 #!foo=123。带有 #! 影响产品饲料?
对于 网站,他们通常希望在 Google Shopping 和网络搜索中显示相同的 URL。通常,带有 #! 应该被视为可以在任何环境中使用的“规范”版本,并且 _escaped_fragment_ URL 应该被视为最终用户永远不会看到的临时 URL。我使用 HtmlUnit 作为无头浏览器,但它不起作用。这是为什么?
如果“不起作用”意味着 HtmlUnit 没有返回您想要查看的快照,很可能是因为您没有给它足够的时间来执行 JavaScript 和/或 XHR 请求。要解决此问题,请尝试以下任一或所有方法:
这在大多数情况下可以解决问题。但如果问题仍然存在,您还可以查看有关 HtmlUnit 的常见问题解答:。HtmlUnit 还提供了一个用户论坛。 查看全部
ajax抓取网页内容(CwRadioButton更改为_escaped_fragment_以及何时应使用#!)
什么时候应该使用_escaped_fragment_,什么时候应该使用#! 在 AJAX URL 中?
您的 网站 应该使用 #! 所有使用 AJAX 爬网机制的 URL 的语法。Googlebot 不会跟踪 _escaped_fragment_ 格式的超链接。
上提供了 AJAX 应用程序示例。单击左侧的任何链接后,您将看到相应的 URL 收录一个 #! 哈希代码片段,应用程序将进入与此哈希代码片段对应的状态。如果你改变#! (例如#!CwRadioButton)到?_escaped_fragment_=(例如),网站 将返回一个HTML 快照。
如果您这样做,在不久的将来,您的网页可能无法在 Google 搜索结果页上正确显示。但是,我们一直在不断改进 Googlebot,并试图使其更像浏览器。届时,当您在 网站 上实现所需的功能时,Googlebot 可能会自动正确地为您的网页编入索引。但是,这种AJAX爬取机制对于已经使用AJAX并希望确保内容被正确索引的网站来说是一个非常实用的解决方案。我们希望该方案能够有效解决用户拥有网页HTML快照的问题,或者解决用户使用无头浏览器获取此类HTML快照的问题。
这完全取决于应用程序内容的更新频率。如果更新频繁,则应始终及时构建最新的 HTML 快照以响应爬虫请求。如果不频繁,请考虑创建一个内容不定期更新的库档案。为避免服务器持续生成相同的 HTML 快照,您可以一次性创建所有相关的 HTML 快照(可能处于离线状态),然后保存以备将来参考。您还可以使用 304(未修改)HTTP 状态代码响应 Googlebot。
我们建议您使用它!使用哈希码段可以显着加快应用响应速度,因为哈希码段是由客户端浏览器处理的,不会导致整个网页都需要刷新。此外,哈希码片段还支持在应用程序中提供历史记录(也称为备受诟病的“浏览器后退按钮”)。各种 AJAX 框架都支持哈希代码段。例如,查看Really Simple History、jQuery 的历史插件、Google Web Toolkit 的历史机制或ASP.NET AJAX 对历史管理的支持。
但是,如果您无法构建应用以使用哈希代码片段,则可以执行以下操作以在哈希代码片段中使用特殊标记(即 URL 中 # 标记之后的所有内容)。表示唯一页面状态的哈希代码段必须以感叹号开头。例如,如果您的 AJAX 应用程序收录类似于以下内容的 URL:
www.example.com/ajax.html#mystate
现在应该是这样的:
www.example.com/ajax.html#!mystate
如果你的网站采用这种架构,就会被认为是“AJAX可抓取”。这意味着如果您的 网站 提供了 HTML 快照,爬虫将看到您的应用程序的内容。
URL 的 _escaped_fragment_ 语法对应于临时 URL,最终用户不应看到。在用户可以看到的所有环境中,您应该使用“漂亮的 URL”(使用 #! 而不是 _escaped_fragment_):常规应用程序交互、站点地图、超链接、重定向以及用户可能会看到 URL 的任何其他情况。出于同样的原因,搜索结果都是“漂亮的网址”,而不是“难看的网址”。
隐藏真实内容是指提供给用户的内容与提供给搜索引擎的内容不同,通常是为了提高网页在搜索结果中的排名。隐藏真实内容一直是(也将永远是)一个重要的搜索引擎问题,所以需要注意的是,将AJAX应用设置为可爬取,绝不是为了隐藏真实内容的方便。因此,HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。如果它们不相同,则可能被视为隐藏了真实内容。详情请参考具体回答。
Google 确实可以为许多富媒体文件类型编制索引,并且一直在努力改进抓取和索引编制。但是,Googlebot 可能无法看到 Flash 或其他富媒体应用程序的所有内容(就像它无法抓取您网站 上的所有动态内容一样),因此使用此机制可以为 Googlebot 提供更多内容。, HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。Google 保留将 网站 从被视为隐藏真实内容的索引中排除的权利。
如果你的 网站 使用 AJAX 爬取机制,谷歌爬虫会爬取它遇到的每一个哈希码段 URL。如果您不想抓取某些哈希代码段 URL,建议您在 robots.txt 文件中添加正则表达式指令。例如,您可以在不想被抓取的哈希代码片段中使用约定,然后在 robots.txt 文件中排除所有符合该约定的 URL。假设所有指示不可索引的语句都采用以下形式:#DONOTCRAWLmyfragment,那么您可以将以下代码添加到 robots.txt 以防止 Googlebot 抓取这些页面:
Disallow: /*_escaped_fragment_=DONOTCRAWL
如何处理现有的#! 在哈希码段?
#!是在现有哈希代码片段中不常用的令牌;但是,URL 规范并没有规定不能使用。如果您的应用程序使用了#!,但又不想采用新的 AJAX 爬取机制,您应该怎么做?一种方法是在robots.txt中添加以下指令来指示爬虫做什么。
Disallow: /*_escaped_fragment_
请注意,这意味着如果您的应用程序仅收录此 URL #!mystate,则不会抓取该 URL。如果您的应用程序还收录一个普通 URL,则该 URL 将被抓取。
当前向搜索引擎提供静态内容的方法有一个副作用,即 网站 站长可以让残障用户更容易访问他们的应用程序。这项新协议进一步提高了可访问性:网站 网站管理员不再需要手动干预来使用收录所有相关内容且可供屏幕阅读器使用的无头浏览器来创建 HTML 快照。这意味着现在可以更轻松地提供最新的静态内容,而手动工作越来越少。换句话说,网站 网站管理员现在将有更大的动力来构建方便残障用户使用的应用程序。rel="canonical" 应该如何使用?
请使用(不要使用)。
您应该在站点地图的搜索结果中添加要显示的 URL,因此应该添加 #!foo=123。带有 #! 影响产品饲料?
对于 网站,他们通常希望在 Google Shopping 和网络搜索中显示相同的 URL。通常,带有 #! 应该被视为可以在任何环境中使用的“规范”版本,并且 _escaped_fragment_ URL 应该被视为最终用户永远不会看到的临时 URL。我使用 HtmlUnit 作为无头浏览器,但它不起作用。这是为什么?
如果“不起作用”意味着 HtmlUnit 没有返回您想要查看的快照,很可能是因为您没有给它足够的时间来执行 JavaScript 和/或 XHR 请求。要解决此问题,请尝试以下任一或所有方法:
这在大多数情况下可以解决问题。但如果问题仍然存在,您还可以查看有关 HtmlUnit 的常见问题解答:。HtmlUnit 还提供了一个用户论坛。
ajax抓取网页内容( 了解:Ajax是一种在无需重新加载整个网页的情况下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-18 10:09
了解:Ajax是一种在无需重新加载整个网页的情况下)
AJAX
学习:
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
使用 Ajax 进行局部更新,提升用户体验
JS:
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
//2. 建立连接
/*
参数:
1. 请求方式:GET、POST
* get方式,请求参数在URL后边拼接。send方法为空参
* post方式,请求参数在send方法中定义
2. 请求的URL:
3. 同步或异步请求:true(异步)或 false(同步)
*/
xmlhttp.open("GET","ajaxServlet?username=tom",true);
//3.发送请求
xmlhttp.send();
//4.接受并处理来自服务器的响应结果
//获取方式 :xmlhttp.responseText
//什么时候获取?当服务器响应成功后再获取
//当xmlhttp对象的就绪状态改变时,触发事件onreadystatechange。
xmlhttp.onreadystatechange=function()
{
//判断readyState就绪状态是否为4,判断status响应状态码是否为200
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
//获取服务器的响应结果
var responseText = xmlhttp.responseText;
alert(responseText);
}
}
查询:
1. $.ajax()
* 语法:$.ajax({键值对});
//使用$.ajax()发送异步请求
$.ajax({
url:"ajaxServlet1111" , // 请求路径
type:"POST" , //请求方式
//data: "username=jack&age=23",//请求参数
data:{"username":"jack","age":23},
success:function (data) {
alert(data);
},//响应成功后的回调函数
error:function () {
alert("出错啦...")
},//表示如果请求响应出现错误,会执行的回调函数
dataType:"text"//设置接受到的响应数据的格式
});
2. $.get():发送get请求
* 语法:$.get(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
3. $.post():发送post请求
* 语法:$.post(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
仅供参考,自用 查看全部
ajax抓取网页内容(
了解:Ajax是一种在无需重新加载整个网页的情况下)
AJAX
学习:
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
使用 Ajax 进行局部更新,提升用户体验
JS:
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
//2. 建立连接
/*
参数:
1. 请求方式:GET、POST
* get方式,请求参数在URL后边拼接。send方法为空参
* post方式,请求参数在send方法中定义
2. 请求的URL:
3. 同步或异步请求:true(异步)或 false(同步)
*/
xmlhttp.open("GET","ajaxServlet?username=tom",true);
//3.发送请求
xmlhttp.send();
//4.接受并处理来自服务器的响应结果
//获取方式 :xmlhttp.responseText
//什么时候获取?当服务器响应成功后再获取
//当xmlhttp对象的就绪状态改变时,触发事件onreadystatechange。
xmlhttp.onreadystatechange=function()
{
//判断readyState就绪状态是否为4,判断status响应状态码是否为200
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
//获取服务器的响应结果
var responseText = xmlhttp.responseText;
alert(responseText);
}
}
查询:
1. $.ajax()
* 语法:$.ajax({键值对});
//使用$.ajax()发送异步请求
$.ajax({
url:"ajaxServlet1111" , // 请求路径
type:"POST" , //请求方式
//data: "username=jack&age=23",//请求参数
data:{"username":"jack","age":23},
success:function (data) {
alert(data);
},//响应成功后的回调函数
error:function () {
alert("出错啦...")
},//表示如果请求响应出现错误,会执行的回调函数
dataType:"text"//设置接受到的响应数据的格式
});
2. $.get():发送get请求
* 语法:$.get(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
3. $.post():发送post请求
* 语法:$.post(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
仅供参考,自用
ajax抓取网页内容(self.crawlAPI抓取豆瓣电影HTML代码中的并不相同常见用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-18 10:08
在上一篇教程中,我们使用 self.crawlAPI 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析一些内容。但是,目前的网站通过使用AJAX等技术,在与服务器交互时不需要重新加载整个页面。但是,这些交互方式让爬行变得有些困难:抓取后你会发现这些网页与浏览器中的网页并不相同。您需要的信息不在返回 HTML 代码中。
在本教程中,我们将讨论这些技术和方法来捕获它们。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML)的缩写。AJAX使用原有的web标准组件,无需重新加载整个页面即可实现与服务器的数据交互。例如,在新浪微博中,您无需重新加载或打开新页面即可展开微博评论。但是内容一开始不在页面上(所以页面太大了),而是在点击时加载。这导致你在爬取这个页面时,获取不到评论信息(因为你没有“展开”)。
AJAX 的一个常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端呈现它。如果可以直接抓取 JSON 数据,那会比 HTML 更容易解析。
当 网站 使用 AJAX 时,pyspider 获取的页面与浏览器看到的不同。当您在浏览器中打开此类页面或单击“展开”时,您经常会看到“正在加载”或类似的图标/动画。例如,当您尝试抓取时:
你会发现电影是“加载中...”
找到真正的要求
由于AJAX实际上是通过HTTP传输数据,我们可以通过Chrome开发者工具找到真实请求,直接发起对真实请求的爬取获取数据。
打开一个新窗口并按 Ctrl+Shift+I(在 Mac 上按 Cmd+Opt+I)打开开发者工具。切换到网络(网络面板)在一个窗口中打开
在页面加载过程中,您将在面板中看到所有资源请求。
AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般缩写为XHR。点击网络面板上漏斗状的过滤按钮,过滤掉XHR请求。逐一检查每个请求,通过访问路径和预览找到收录信息的请求:%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在豆瓣的例子中,XHR请求并不多,可以一一检查确认。但是,当XHR请求较多时,可能需要结合触发动作的时间、请求的路径等信息来帮助查找收录大量请求中信息的关键请求。这就需要有爬虫或者前端的相关经验。所以,有一点我一直在提,学爬最好的方法是:学写网站。
现在您可以在新窗口中打开 %E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,您将看到收录电影数据的原创 JSON 数据。建议安装JSONView(Firfox版)插件,可以看到更好看的JSON格式,展开折叠列等功能。然后,根据 JSON 数据,我们编写一个脚本来提取电影名称和评分:
class Handler(BaseHandler):
def on_start(self):
self.crawl(\'http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0\',
callback=self.json_parser)
def json_parser(self, response):
return [{
"title": x[\'title\'],
"rate": x[\'rate\'],
"url": x[\'url\']
} for x in response.json[\'subjects\']]
您可以获得完整的代码并进行调试。脚本中还有一个使用PhantomJS渲染的解压版,下篇教程会介绍。 查看全部
ajax抓取网页内容(self.crawlAPI抓取豆瓣电影HTML代码中的并不相同常见用法)
在上一篇教程中,我们使用 self.crawlAPI 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析一些内容。但是,目前的网站通过使用AJAX等技术,在与服务器交互时不需要重新加载整个页面。但是,这些交互方式让爬行变得有些困难:抓取后你会发现这些网页与浏览器中的网页并不相同。您需要的信息不在返回 HTML 代码中。
在本教程中,我们将讨论这些技术和方法来捕获它们。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML)的缩写。AJAX使用原有的web标准组件,无需重新加载整个页面即可实现与服务器的数据交互。例如,在新浪微博中,您无需重新加载或打开新页面即可展开微博评论。但是内容一开始不在页面上(所以页面太大了),而是在点击时加载。这导致你在爬取这个页面时,获取不到评论信息(因为你没有“展开”)。
AJAX 的一个常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端呈现它。如果可以直接抓取 JSON 数据,那会比 HTML 更容易解析。
当 网站 使用 AJAX 时,pyspider 获取的页面与浏览器看到的不同。当您在浏览器中打开此类页面或单击“展开”时,您经常会看到“正在加载”或类似的图标/动画。例如,当您尝试抓取时:
你会发现电影是“加载中...”
找到真正的要求
由于AJAX实际上是通过HTTP传输数据,我们可以通过Chrome开发者工具找到真实请求,直接发起对真实请求的爬取获取数据。
打开一个新窗口并按 Ctrl+Shift+I(在 Mac 上按 Cmd+Opt+I)打开开发者工具。切换到网络(网络面板)在一个窗口中打开
在页面加载过程中,您将在面板中看到所有资源请求。
AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般缩写为XHR。点击网络面板上漏斗状的过滤按钮,过滤掉XHR请求。逐一检查每个请求,通过访问路径和预览找到收录信息的请求:%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在豆瓣的例子中,XHR请求并不多,可以一一检查确认。但是,当XHR请求较多时,可能需要结合触发动作的时间、请求的路径等信息来帮助查找收录大量请求中信息的关键请求。这就需要有爬虫或者前端的相关经验。所以,有一点我一直在提,学爬最好的方法是:学写网站。
现在您可以在新窗口中打开 %E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,您将看到收录电影数据的原创 JSON 数据。建议安装JSONView(Firfox版)插件,可以看到更好看的JSON格式,展开折叠列等功能。然后,根据 JSON 数据,我们编写一个脚本来提取电影名称和评分:
class Handler(BaseHandler):
def on_start(self):
self.crawl(\'http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0\',
callback=self.json_parser)
def json_parser(self, response):
return [{
"title": x[\'title\'],
"rate": x[\'rate\'],
"url": x[\'url\']
} for x in response.json[\'subjects\']]
您可以获得完整的代码并进行调试。脚本中还有一个使用PhantomJS渲染的解压版,下篇教程会介绍。
ajax抓取网页内容(开发者配置微信网页授权的整个流程(1)_社会万象_光明网(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-17 23:01
)
微信授权全流程:
引导用户进入授权页面同意授权,获取code并兑换web授权access_token的code(与基础支持中的access_token不同) 如有需要,开发者可以刷新web授权access_token,避免过期。通过web授权access_token和openid获取用户基本信息(支持UnionID机制)
其实说白了,前端只需要做一件事,引导用户发起微信授权页面,然后获取code,然后跳转到当前页面,然后请求后端换取用户和其他相关信息。
功能实现
引导用户调出微信授权确认页面
这里我们需要做两件事。一是配置jsapi域名,二是配置微信网页授权的回调域名。
构造微信授权url"" + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect 从连接中可以看出有两个变量, appId,redirect_uri,不用说,appId就是我们要授权的微信公众号的appId,而对方的回调URL其实就是我们当前页面的URL。
用户微信登录授权后,回调URL会携带两个参数,第一个是code,一个是state。我们唯一需要做的就是获取代码并传递给后端,后端通过代码获取基本的用户信息。后端获取code后,获取用户的基本信息,并将相关的其他信息返回给前端,由前端获取,然后存储在本地或其他地方。
function getUrlParam(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]);
return null;
}
function wxLogin(callback) {
var appId = 'xxxxxxxxxxxxxxxxxxx';
var oauth_url = 'xxxxxxxxxxxxxxxxxxx/oauth';
var url = "https://open.weixin.qq.com/con ... ot%3B + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect"
var code = getUrlParam("code");
if (!code) {
window.location = url;
} else {
$.ajax({
type: 'GET',
url: oauth_url,
dataType: 'json',
data: {
code: code
},
success: function (data) {
if (data.code === 200) {
callback(data.data)
}
},
error: function (error) {
throw new Error(error)
}
})
} 查看全部
ajax抓取网页内容(开发者配置微信网页授权的整个流程(1)_社会万象_光明网(图)
)
微信授权全流程:
引导用户进入授权页面同意授权,获取code并兑换web授权access_token的code(与基础支持中的access_token不同) 如有需要,开发者可以刷新web授权access_token,避免过期。通过web授权access_token和openid获取用户基本信息(支持UnionID机制)
其实说白了,前端只需要做一件事,引导用户发起微信授权页面,然后获取code,然后跳转到当前页面,然后请求后端换取用户和其他相关信息。
功能实现
引导用户调出微信授权确认页面
这里我们需要做两件事。一是配置jsapi域名,二是配置微信网页授权的回调域名。
构造微信授权url"" + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect 从连接中可以看出有两个变量, appId,redirect_uri,不用说,appId就是我们要授权的微信公众号的appId,而对方的回调URL其实就是我们当前页面的URL。
用户微信登录授权后,回调URL会携带两个参数,第一个是code,一个是state。我们唯一需要做的就是获取代码并传递给后端,后端通过代码获取基本的用户信息。后端获取code后,获取用户的基本信息,并将相关的其他信息返回给前端,由前端获取,然后存储在本地或其他地方。
function getUrlParam(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]);
return null;
}
function wxLogin(callback) {
var appId = 'xxxxxxxxxxxxxxxxxxx';
var oauth_url = 'xxxxxxxxxxxxxxxxxxx/oauth';
var url = "https://open.weixin.qq.com/con ... ot%3B + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect"
var code = getUrlParam("code");
if (!code) {
window.location = url;
} else {
$.ajax({
type: 'GET',
url: oauth_url,
dataType: 'json',
data: {
code: code
},
success: function (data) {
if (data.code === 200) {
callback(data.data)
}
},
error: function (error) {
throw new Error(error)
}
})
}
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-17 23:00
)
前言
现在很多网站大量使用JavaScript,或者使用Ajax技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容却可以动态变化。如果使用python自带的requests库或者urllib库来处理这类网页,那么获取到的网页内容与浏览器显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium是一款功能强大的网络数据采集工具,最初是为网站自动化测试而开发的,并有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,即没有UI界面,也就是浏览器,但是点击、翻页等与人相关的操作需要设计和实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在设置了环境变量的地方。如果不设置,后面的代码会设置,所以直接放这里方便;
然后在检测下,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
Mac系统,下载保存到某个路径后,可以直接保存在环境变量路径中,也可以在环境变量路径中创建phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
页面元素安装成功就是安装成功
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
可以输出网页的源码,说明安装成功
获取JS返回值
查看全部
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一
)
前言
现在很多网站大量使用JavaScript,或者使用Ajax技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容却可以动态变化。如果使用python自带的requests库或者urllib库来处理这类网页,那么获取到的网页内容与浏览器显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium是一款功能强大的网络数据采集工具,最初是为网站自动化测试而开发的,并有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,即没有UI界面,也就是浏览器,但是点击、翻页等与人相关的操作需要设计和实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在设置了环境变量的地方。如果不设置,后面的代码会设置,所以直接放这里方便;

然后在检测下,在cmd窗口输入phantomjs:

如果出现这样的画面,则表示成功;
Mac系统,下载保存到某个路径后,可以直接保存在环境变量路径中,也可以在环境变量路径中创建phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
页面元素安装成功就是安装成功
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
可以输出网页的源码,说明安装成功
获取JS返回值
ajax抓取网页内容(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-15 14:00
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面即可在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器)
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用直观的采集搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面即可在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-13 14:20
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。

Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?

地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(2019.02.07例子爬取湖人中文网的微博本文继续学习..Ajax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-04 05:10
2019.02.07 小白文继续学习...
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时确保页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
第一个例子
爬上湖人中文网站的微博
本文使用站点:通过分析api完成爬取
更多微博数据提取请看:深夜雨雪:Scrapy爬取所有新浪微博站点
分析请求
打开Ajax的XHR过滤器,然后一直滑动页面加载新的微博内容。如您所见,Ajax 将继续存在
发出请求。
选择其中一个请求,分析其参数信息
请求的参数有4个:type、value、containerid和page(如果没有page,但是since_id,换个浏览器试试)
type永远是uid,value的值是页面链接中的数字,其实就是用户的id。另外还有一个containerid,可以发现是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=1代表第一页
分析响应
此内容为JSON格式,浏览器开发工具自动解析供我们查看。可以看出,最关键的两条信息是cardlistlnfo和cards:前者收录了更重要的信息总数。经过观察,可以发现其实就是微博总数。我们可以根据这个数字估算出页数;另一个是一个列表,它收录10个元素,展开其中一个来看看
可以发现这个元素有一个更重要的字段mblog。展开可以发现,里面收录了一些微博的信息,比如态度数(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博正文)等,而且都是格式化的内容。
这样我们请求一个接口的时候,就可以得到10条微博,请求的时候只需要修改page参数即可。
目录文件
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import json
from urllib.parse import urlencode
from pyquery import PyQuery as pq
from weibo.items import WeiboItem
class WeibospdSpider(scrapy.Spider):
name = 'weibospd'
allowed_domains = ['m.weibo.cn']
# start_urls = ['http://m.weibo.cn/']
def start_requests(self):
for page in range(1, 11):
base_url = 'https://m.weibo.cn/api/contain ... 39%3B
params = {
'type': 'uid',
'value': '5408596403',
'containerid': '1076035408596403',
'page': page
}
url = base_url + urlencode(params)
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
# for result_one in result:
# item = WeiboItem()
# for field in item.fields:
# if field in result_one.get('mblog').keys():
# item[field] = result_one.get('mblog').get(field)
# yield item
for result_one in result:
item = WeiboItem()
a = result_one.get('mblog')
item['id'] = a.get('id')
item['text'] = pq(a.get('text')).text()
item['attitudes_count'] = a.get('attitudes_count')
item['comments_count'] = a.get('comments_count')
item['reposts_count'] = a.get('reposts_count')
yield item
# print(item)
调用urlencode()方法将参数转换为URL GET请求参数,类似type=uid&value=5408596403&containerid=96403&since_id=43363
解析部分本来是打算这样写的
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
for result_one in result:
item = WeiboItem()
for field in item.fields:
if field in result_one.get('mblog').keys():
item[field] = result_one.get('mblog').get(field)
yield item
但是获得的'text'收录HTML标签
所以改成上面的代码,在pyquery的帮助下去掉body中的HTML标签
项目.py
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
text = scrapy.Field()
attitudes_count = scrapy.Field()
comments_count = scrapy.Field()
reposts_count = scrapy.Field()
设置.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/5408596403',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
第二个例子
崔庆才老师的博客使用Scrapy抓取所有知乎用户详细信息并存入MongoDB
崔青才老师写的很详细,不过是2年前完成的。虽然在知乎页面上进行了一些修改,但我还是尝试了。当我抓取他关注的人和关注他的人时,我发现无法获取下一页。 查看全部
ajax抓取网页内容(2019.02.07例子爬取湖人中文网的微博本文继续学习..Ajax)
2019.02.07 小白文继续学习...
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时确保页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
第一个例子
爬上湖人中文网站的微博
本文使用站点:通过分析api完成爬取
更多微博数据提取请看:深夜雨雪:Scrapy爬取所有新浪微博站点
分析请求
打开Ajax的XHR过滤器,然后一直滑动页面加载新的微博内容。如您所见,Ajax 将继续存在
发出请求。
选择其中一个请求,分析其参数信息
请求的参数有4个:type、value、containerid和page(如果没有page,但是since_id,换个浏览器试试)
type永远是uid,value的值是页面链接中的数字,其实就是用户的id。另外还有一个containerid,可以发现是107603加上用户id。改变的值为page,显然这个参数是用来控制分页的,page=1代表第一页
分析响应
此内容为JSON格式,浏览器开发工具自动解析供我们查看。可以看出,最关键的两条信息是cardlistlnfo和cards:前者收录了更重要的信息总数。经过观察,可以发现其实就是微博总数。我们可以根据这个数字估算出页数;另一个是一个列表,它收录10个元素,展开其中一个来看看
可以发现这个元素有一个更重要的字段mblog。展开可以发现,里面收录了一些微博的信息,比如态度数(点赞数)、comments_count(评论数)、reposts_count(转发数)、created at(发帖时间)、text(微博正文)等,而且都是格式化的内容。
这样我们请求一个接口的时候,就可以得到10条微博,请求的时候只需要修改page参数即可。
目录文件
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import json
from urllib.parse import urlencode
from pyquery import PyQuery as pq
from weibo.items import WeiboItem
class WeibospdSpider(scrapy.Spider):
name = 'weibospd'
allowed_domains = ['m.weibo.cn']
# start_urls = ['http://m.weibo.cn/']
def start_requests(self):
for page in range(1, 11):
base_url = 'https://m.weibo.cn/api/contain ... 39%3B
params = {
'type': 'uid',
'value': '5408596403',
'containerid': '1076035408596403',
'page': page
}
url = base_url + urlencode(params)
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
# for result_one in result:
# item = WeiboItem()
# for field in item.fields:
# if field in result_one.get('mblog').keys():
# item[field] = result_one.get('mblog').get(field)
# yield item
for result_one in result:
item = WeiboItem()
a = result_one.get('mblog')
item['id'] = a.get('id')
item['text'] = pq(a.get('text')).text()
item['attitudes_count'] = a.get('attitudes_count')
item['comments_count'] = a.get('comments_count')
item['reposts_count'] = a.get('reposts_count')
yield item
# print(item)
调用urlencode()方法将参数转换为URL GET请求参数,类似type=uid&value=5408596403&containerid=96403&since_id=43363
解析部分本来是打算这样写的
def parse(self, response):
results = json.loads(response.text)
result= results.get('data').get('cards')
for result_one in result:
item = WeiboItem()
for field in item.fields:
if field in result_one.get('mblog').keys():
item[field] = result_one.get('mblog').get(field)
yield item
但是获得的'text'收录HTML标签
所以改成上面的代码,在pyquery的帮助下去掉body中的HTML标签
项目.py
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
text = scrapy.Field()
attitudes_count = scrapy.Field()
comments_count = scrapy.Field()
reposts_count = scrapy.Field()
设置.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/5408596403',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
第二个例子
崔庆才老师的博客使用Scrapy抓取所有知乎用户详细信息并存入MongoDB
崔青才老师写的很详细,不过是2年前完成的。虽然在知乎页面上进行了一些修改,但我还是尝试了。当我抓取他关注的人和关注他的人时,我发现无法获取下一页。
ajax抓取网页内容(获取JavaScript脚本可以设计响应信息为JavaScript代码,它是可以执行的命令或脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-03 09:18
获取 JavaScript 脚本
响应信息可以设计为 JavaScript 代码。这里的代码不同于 JSON 数据。它是可以执行的命令或脚本。
例子:在服务端指定JS函数
AJAX测试
按钮
function f() {
var ajax = createXMLHTTPObject();
ajax.onreadystatechange = function(){
if(ajax.readyState == 4 && ajax.status == 200){
var info = ajax.responseText;
var o = eval("(" + info + ")" + "()");//调用eval()方法把JavaScript字符串转换为本地脚本
alert(o);//返回客户端当前日期
}
}
ajax.open("get", "response.js",true);
ajax.send();
}
响应.js:
function (){
var d = new Date();
return d.toString();
}
点击按钮,会弹出提示信息:
注意:转换时需要在字符串签名后加两个括号:一个收录函数结构,一个表示调用函数。通常,JavaScript 代码很少用作响应信息的格式,因为它无法传递更丰富的信息,并且 JavaScript 脚本容易存在安全风险。 查看全部
ajax抓取网页内容(获取JavaScript脚本可以设计响应信息为JavaScript代码,它是可以执行的命令或脚本)
获取 JavaScript 脚本
响应信息可以设计为 JavaScript 代码。这里的代码不同于 JSON 数据。它是可以执行的命令或脚本。
例子:在服务端指定JS函数
AJAX测试
按钮
function f() {
var ajax = createXMLHTTPObject();
ajax.onreadystatechange = function(){
if(ajax.readyState == 4 && ajax.status == 200){
var info = ajax.responseText;
var o = eval("(" + info + ")" + "()");//调用eval()方法把JavaScript字符串转换为本地脚本
alert(o);//返回客户端当前日期
}
}
ajax.open("get", "response.js",true);
ajax.send();
}
响应.js:
function (){
var d = new Date();
return d.toString();
}
点击按钮,会弹出提示信息:
注意:转换时需要在字符串签名后加两个括号:一个收录函数结构,一个表示调用函数。通常,JavaScript 代码很少用作响应信息的格式,因为它无法传递更丰富的信息,并且 JavaScript 脚本容易存在安全风险。
ajax抓取网页内容( 我们想要的图片信息利用正则表达式取到链接进一步抓取到图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-03 07:00
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来开始抓取图片,打开图集详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取到图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20 查看全部
ajax抓取网页内容(
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来开始抓取图片,打开图集详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取到图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20
ajax抓取网页内容( get()和post(两个)方法设置相关的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2021-12-03 06:25
get()和post(两个)方法设置相关的参数)
from requests_html import HTMLSession
# 定义会话Session
session=HTMLSession()
# 发送GET请求
res=session.get(url)
# 发送POST请求
res=session.post(url,data={})
# 打印网页的URL地址
print(res.html)
由于get()和post()方法来自Requests模块,因此您还可以为这两个方法设置相关参数,如请求参数、请求头、Cookies、代理IP、证书验证等。
Requests-HTML 在请求过程中也进行了优化。如果没有设置请求头,Requests-HTML 将默认使用源代码中定义的请求头和编码格式。
找到Requests-HTML的源文件:\Lib\site-packages\requests_html.py,里面定义了属性DEFAULT_ENCODING和DEFAULT_USER_AGENT,分别对应编码格式和HTTP请求头。
DEFAULT_ENCODING = 'utf-8'
DEFAULT_USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
数据清洗
Requests-HTML 不仅优化了请求流程,还提供了数据清理的功能。 Requests 模块只提供请求方法,不提供数据清洗。这也体现了 Requests-HTML 的一大优势。使用Requests开发的爬虫,需要通过调用其他模块来实现数据清洗,Requests-HTML将两者结合起来。
Requests-HTML 提供了多种数据清洗方式,如网页中的 URL 地址、HTML 源代码内容、文本信息等,代码参考:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 输出网页里的URL地址
print(res.html,'')
# 输出网页里全部URL地址
print(res.html.links)
# 输出网页里精准的URL地址
print(res.html.absolute_links)
# 输出网页的HTML信息
print(res.text)
# 输出网页的全部文本信息,即去除HTML代码
print(res.html.text)
代码只是提取了网站的基本信息。如果要准确提取某条数据,可以使用find()、xpath()、search()和search_all()方法来实现。首先了解这4个方法的定义和相关参数说明:
# 定义
find(selector,containing,clean,first,_encoding)
# 参数说明
selector:使用CSS Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
xpath(selector,clean,first,__encoding)
# 参数说明
selector:使用Xpath Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
search(template)
# 参数说明
template:通过元素内容查找第一个元素
# 定义
search_all(template)
# 参数说明
template:通过元素内容查找全部元素
这里我们以Ba的网站为例,提取网页的文章标题:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 通过CSS Seletor定位标题
# first:True获取第一个元素
print(res.html.find('div.excerpt-post header h2 a',first=True).text)
# 输出当前标签的属性
print(res.html.find('div.excerpt-post header h2 a',first=True).attrs)
print('————————分割线1————————')
# 查找特定文本的元素
# 如果元素所在的HTML里含有containing的属性值即可提取
for name in res.html.find('h2 a',containing='R'):
# 输出内容
print(name.text,'\n',name.attrs)
print('————————分割线2————————')
# 通过Xpath Selector定位
for name in res.html.xpath('//h2/a'):
print(name.text,'\n',name.attrs)
print('————————分割线3————————')
# 通过search查找
# 一个{ }代表一个内容,内容可为中文或者英文等
print(res.html.search('爬虫库Requests-HTML简介及{}{}'))
# 通过search_all查找所有
print(res.html.search_all('爬虫库Requests-HTML{}{}{}{}{}'))
代码中CSS Selector和Xpath Selector的语法就不详细介绍了,自己学习吧!
Ajax 动态数据捕获
使用Requests-HTML请求网页地址,对应的响应内容与开发者工具Doc选项卡的响应内容一致。如果网页数据是通过Ajax请求并通过JavaScript渲染到网页上的,还需要使用Requests-HTML模拟Ajax请求来获取网页数据。
模拟ajax请求,需要构造请求参数。构造请求参数的方法很多且复杂,实现起来需要时间。以QQ音乐的歌手列表页面为例,每个歌手的名字是通过ajax加载到网页上的。
Requests-HTML提供Ajax加载功能,加载的网页信息与开发者工具Elements标签页中的网页信息一致。这个加载功能是通过调用谷歌的Chromium浏览器实现的,
Chromium 是谷歌开发 Chrome 的计划。可以理解为Chrome的工程版或实验版。新功能将首先在 Chromium 上实现,并在验证后应用于 Chrome。
Ajax 加载功能是通过 render() 方法实现的。首次使用 render() 方法时会自动下载 Chromium 浏览器。下载Chromium浏览器,必须保证当前网络可以正常访问谷歌主页,否则将无法下载。另外可以直接下载Chromium浏览器,将浏览器放在C盘的用户文件夹中。
文件路径中,只有“000”改变了,不同的电脑名称不同; chrome-win32 文件夹也命名为fixed,Chromium 浏览器相关的文件和应用程序都存放在这个文件夹中。如果是通过下载方式,则无需手动配置文件路径。 Requests-HTML 会自动将下载的 Chromium 浏览器配置为对应的文件路径。
完成Chromium浏览器配置后,可以编写如下代码实现Requests-HTML的Ajax加载功能:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
虽然运行速度比模拟Ajax请求慢,但是可以大大降低开发难度。
声明:本站所有文章,如无特殊说明或注释,均在本站发布原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
小君比常任还帅 查看全部
ajax抓取网页内容(
get()和post(两个)方法设置相关的参数)
from requests_html import HTMLSession
# 定义会话Session
session=HTMLSession()
# 发送GET请求
res=session.get(url)
# 发送POST请求
res=session.post(url,data={})
# 打印网页的URL地址
print(res.html)
由于get()和post()方法来自Requests模块,因此您还可以为这两个方法设置相关参数,如请求参数、请求头、Cookies、代理IP、证书验证等。
Requests-HTML 在请求过程中也进行了优化。如果没有设置请求头,Requests-HTML 将默认使用源代码中定义的请求头和编码格式。
找到Requests-HTML的源文件:\Lib\site-packages\requests_html.py,里面定义了属性DEFAULT_ENCODING和DEFAULT_USER_AGENT,分别对应编码格式和HTTP请求头。
DEFAULT_ENCODING = 'utf-8'
DEFAULT_USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
数据清洗
Requests-HTML 不仅优化了请求流程,还提供了数据清理的功能。 Requests 模块只提供请求方法,不提供数据清洗。这也体现了 Requests-HTML 的一大优势。使用Requests开发的爬虫,需要通过调用其他模块来实现数据清洗,Requests-HTML将两者结合起来。
Requests-HTML 提供了多种数据清洗方式,如网页中的 URL 地址、HTML 源代码内容、文本信息等,代码参考:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 输出网页里的URL地址
print(res.html,'')
# 输出网页里全部URL地址
print(res.html.links)
# 输出网页里精准的URL地址
print(res.html.absolute_links)
# 输出网页的HTML信息
print(res.text)
# 输出网页的全部文本信息,即去除HTML代码
print(res.html.text)
代码只是提取了网站的基本信息。如果要准确提取某条数据,可以使用find()、xpath()、search()和search_all()方法来实现。首先了解这4个方法的定义和相关参数说明:
# 定义
find(selector,containing,clean,first,_encoding)
# 参数说明
selector:使用CSS Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
xpath(selector,clean,first,__encoding)
# 参数说明
selector:使用Xpath Selector定位网页元素
containing:字符串类型,默认值为None,通过特定文本查找网页元素
clean:是否清除HTML的和标签,默认值为False
first:是否只查找第一个网页元素,默认值为False即查找全部元素
_encoding:设置编码格式,默认值为None
# 定义
search(template)
# 参数说明
template:通过元素内容查找第一个元素
# 定义
search_all(template)
# 参数说明
template:通过元素内容查找全部元素
这里我们以Ba的网站为例,提取网页的文章标题:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://www.e1yu.com/'
# 发送GET请求
res=session.get(url)
# 通过CSS Seletor定位标题
# first:True获取第一个元素
print(res.html.find('div.excerpt-post header h2 a',first=True).text)
# 输出当前标签的属性
print(res.html.find('div.excerpt-post header h2 a',first=True).attrs)
print('————————分割线1————————')
# 查找特定文本的元素
# 如果元素所在的HTML里含有containing的属性值即可提取
for name in res.html.find('h2 a',containing='R'):
# 输出内容
print(name.text,'\n',name.attrs)
print('————————分割线2————————')
# 通过Xpath Selector定位
for name in res.html.xpath('//h2/a'):
print(name.text,'\n',name.attrs)
print('————————分割线3————————')
# 通过search查找
# 一个{ }代表一个内容,内容可为中文或者英文等
print(res.html.search('爬虫库Requests-HTML简介及{}{}'))
# 通过search_all查找所有
print(res.html.search_all('爬虫库Requests-HTML{}{}{}{}{}'))
代码中CSS Selector和Xpath Selector的语法就不详细介绍了,自己学习吧!
Ajax 动态数据捕获
使用Requests-HTML请求网页地址,对应的响应内容与开发者工具Doc选项卡的响应内容一致。如果网页数据是通过Ajax请求并通过JavaScript渲染到网页上的,还需要使用Requests-HTML模拟Ajax请求来获取网页数据。
模拟ajax请求,需要构造请求参数。构造请求参数的方法很多且复杂,实现起来需要时间。以QQ音乐的歌手列表页面为例,每个歌手的名字是通过ajax加载到网页上的。
Requests-HTML提供Ajax加载功能,加载的网页信息与开发者工具Elements标签页中的网页信息一致。这个加载功能是通过调用谷歌的Chromium浏览器实现的,
Chromium 是谷歌开发 Chrome 的计划。可以理解为Chrome的工程版或实验版。新功能将首先在 Chromium 上实现,并在验证后应用于 Chrome。
Ajax 加载功能是通过 render() 方法实现的。首次使用 render() 方法时会自动下载 Chromium 浏览器。下载Chromium浏览器,必须保证当前网络可以正常访问谷歌主页,否则将无法下载。另外可以直接下载Chromium浏览器,将浏览器放在C盘的用户文件夹中。
文件路径中,只有“000”改变了,不同的电脑名称不同; chrome-win32 文件夹也命名为fixed,Chromium 浏览器相关的文件和应用程序都存放在这个文件夹中。如果是通过下载方式,则无需手动配置文件路径。 Requests-HTML 会自动将下载的 Chromium 浏览器配置为对应的文件路径。
完成Chromium浏览器配置后,可以编写如下代码实现Requests-HTML的Ajax加载功能:
from requests_html import HTMLSession
# 定义会话列表
session=HTMLSession()
url='https://y.qq.com/portal/singer_list.html'
# 发送GET请求
res=session.get(url)
# 使用Chromium浏览器加载网页
res.html.render()
# 定位歌手名字
singer=res.html.find('li.singer_list__item div h3 a')
print(singer)
虽然运行速度比模拟Ajax请求慢,但是可以大大降低开发难度。
声明:本站所有文章,如无特殊说明或注释,均在本站发布原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
小君比常任还帅
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-01 11:07
在C#中,常用的请求方法是使用HttpWebRequest创建请求并返回消息。但是,有时遇到动态加载的页面时,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用phantomJS无头浏览器。
在开发之前,准备两件事。
1. phantomJS-2.1.1 官方下载地址:
2. JS脚本文件,我自己命名为codes.js。内容如下。一开始我没有配置页面的设置信息,导致一些异步页面在爬行的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
草稿完成后,您需要将这两个文件放入您的项目中。如下:
如果这些都没有问题,就可以开始编写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些是我今天才接触到的,所以整理了一下思路。我希望我能指出哪里有错误。 查看全部
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
在C#中,常用的请求方法是使用HttpWebRequest创建请求并返回消息。但是,有时遇到动态加载的页面时,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用phantomJS无头浏览器。
在开发之前,准备两件事。
1. phantomJS-2.1.1 官方下载地址:
2. JS脚本文件,我自己命名为codes.js。内容如下。一开始我没有配置页面的设置信息,导致一些异步页面在爬行的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
草稿完成后,您需要将这两个文件放入您的项目中。如下:
如果这些都没有问题,就可以开始编写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些是我今天才接触到的,所以整理了一下思路。我希望我能指出哪里有错误。
ajax抓取网页内容(json能抓取怎样的数据网页代码:最多见的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-29 20:23
背景
网页与网页之间存在连接关系。爬虫可以沿着节点爬到下一个节点,即通过一个网页继续获取后续的网页,这个全网的节点都可以被所有的蜘蛛爬到,网站数据可以被俘。html
一句话描述
自动程序python获取网页并提取和保存信息
获取网页
爬虫的第一个工作就是获取网页的源代码,可以通过python相关的库来实现,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分,即可以得到网页的源代码。,这样我们就可以使用程序来实现获取网页的过程了。阿贾克斯
好的
得到网页代码后,下面是分析。可以使用正则表达式分析,但是这个正则表达式比较难写,容易出错。有基于网页结构的规则。可以使用Beautiful Soup、pyquery、lxml等库,高效快速地提取网页信息,如节点属性、文本值等。 正则表达式
保存数据
我们通常将提取的数据保存在某处以备后用。这里有很多保存方法。比如可以简单的保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL、MongoDB等。它也可以保存到远程服务器,例如借助 SFTP 操作数据库。
自动化程序
可以代替人工抓取信息,在过程中进行异常处理、错误重试等操作,保证爬行持续高效。json
可以捕获什么样的数据
• 网页代码:最常见的是html 代码• json 数据:最友好• 二进制数据,如图片、音频和视频,获取后可以保存为相应的文件名• 各种扩展名的资源文件后端
js生成的代码
js生成的或者ajax异步生成的页面界面不会被抓取。前面说过,是爬取返回的网页代码,不会执行js。如果希望爬虫能够爬到这部分资源,只需要在服务端渲染即可(如果你原本是从端分离出来的)。服务器
注意:这种情况也不是完全不可能爬行。我们可以使用 Selenium 和 Splash 等库来实现模拟 JavaScript 渲染。降价 查看全部
ajax抓取网页内容(json能抓取怎样的数据网页代码:最多见的)
背景
网页与网页之间存在连接关系。爬虫可以沿着节点爬到下一个节点,即通过一个网页继续获取后续的网页,这个全网的节点都可以被所有的蜘蛛爬到,网站数据可以被俘。html
一句话描述
自动程序python获取网页并提取和保存信息
获取网页
爬虫的第一个工作就是获取网页的源代码,可以通过python相关的库来实现,比如urllib、requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,只需要解析数据结构的Body部分,即可以得到网页的源代码。,这样我们就可以使用程序来实现获取网页的过程了。阿贾克斯
好的
得到网页代码后,下面是分析。可以使用正则表达式分析,但是这个正则表达式比较难写,容易出错。有基于网页结构的规则。可以使用Beautiful Soup、pyquery、lxml等库,高效快速地提取网页信息,如节点属性、文本值等。 正则表达式
保存数据
我们通常将提取的数据保存在某处以备后用。这里有很多保存方法。比如可以简单的保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL、MongoDB等。它也可以保存到远程服务器,例如借助 SFTP 操作数据库。
自动化程序
可以代替人工抓取信息,在过程中进行异常处理、错误重试等操作,保证爬行持续高效。json
可以捕获什么样的数据
• 网页代码:最常见的是html 代码• json 数据:最友好• 二进制数据,如图片、音频和视频,获取后可以保存为相应的文件名• 各种扩展名的资源文件后端
js生成的代码
js生成的或者ajax异步生成的页面界面不会被抓取。前面说过,是爬取返回的网页代码,不会执行js。如果希望爬虫能够爬到这部分资源,只需要在服务端渲染即可(如果你原本是从端分离出来的)。服务器
注意:这种情况也不是完全不可能爬行。我们可以使用 Selenium 和 Splash 等库来实现模拟 JavaScript 渲染。降价
ajax抓取网页内容(ajax抓取网页内容,抓取.推荐用第三方库,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-29 13:19
ajax抓取网页内容,可以尝试selenium+mysql.推荐用第三方库,jsoup,比如jsoup4.0requests.
我用的是thriftapi,底层是自己的实现(有多个)。我都是写java代码来抓取的,爬回来也可以部署到lua脚本里面来运行。
一般来说可以用异步的方式来解决首先先设置发送的代码,让异步调用他请求页面,先用java模拟请求,
ajax抓取最实用的代码就是jsoup+mysql,封装起来即可。
jsoup+jsoup4.0+requests+mysql比如网页上有异步加载jsoup+jsoup4.0+python-selenium
可以用ajax,
bs4
ajax,selenium+mysql或postman
jsoup+jsoup4+requests+ajax(。
全用java开发...jsoup4+jsoup4.5+jquery
xmlhttprequestwebsocket
xmlhttprequesthttp
一般来说可以先用jsoup+jsoup4.0+requests+mysql.
ajax抓取可以用jsoup
你需要一个接口,但是接口有一定的限制,比如说网页类型等。如果你不需要接口可以用搜索引擎,参见索引类搜索引擎。
使用接口来做。不仅用于爬取其他网站内容,还可以用于爬取大部分网站,比如手机知乎这些网站。 查看全部
ajax抓取网页内容(ajax抓取网页内容,抓取.推荐用第三方库,)
ajax抓取网页内容,可以尝试selenium+mysql.推荐用第三方库,jsoup,比如jsoup4.0requests.
我用的是thriftapi,底层是自己的实现(有多个)。我都是写java代码来抓取的,爬回来也可以部署到lua脚本里面来运行。
一般来说可以用异步的方式来解决首先先设置发送的代码,让异步调用他请求页面,先用java模拟请求,
ajax抓取最实用的代码就是jsoup+mysql,封装起来即可。
jsoup+jsoup4.0+requests+mysql比如网页上有异步加载jsoup+jsoup4.0+python-selenium
可以用ajax,
bs4
ajax,selenium+mysql或postman
jsoup+jsoup4+requests+ajax(。
全用java开发...jsoup4+jsoup4.5+jquery
xmlhttprequestwebsocket
xmlhttprequesthttp
一般来说可以先用jsoup+jsoup4.0+requests+mysql.
ajax抓取可以用jsoup
你需要一个接口,但是接口有一定的限制,比如说网页类型等。如果你不需要接口可以用搜索引擎,参见索引类搜索引擎。
使用接口来做。不仅用于爬取其他网站内容,还可以用于爬取大部分网站,比如手机知乎这些网站。
ajax抓取网页内容(原文C#抓取AJAX页面的内容现在的网页有相当一部分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-28 07:16
原生C#抓取AJAX页面内容
目前的网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter的方法,也就是在Navigated event++中,在DownloadComplete中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关的AJAX文章,才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
} 查看全部
ajax抓取网页内容(原文C#抓取AJAX页面的内容现在的网页有相当一部分)
原生C#抓取AJAX页面内容
目前的网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter的方法,也就是在Navigated event++中,在DownloadComplete中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关的AJAX文章,才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
}
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-27 10:06
)
阿贾克斯介绍:
有时候我们使用Requests抓取页面的时候,结果可能和我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这是因为Requests获取的都是原创的HTML文档,而浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后端发送到接口的ajax请求,然后用Requests模拟这个ajax请求,就可以成功获取了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
让我们看一下第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
查看全部
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么?
)
阿贾克斯介绍:
有时候我们使用Requests抓取页面的时候,结果可能和我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这是因为Requests获取的都是原创的HTML文档,而浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后端发送到接口的ajax请求,然后用Requests模拟这个ajax请求,就可以成功获取了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
让我们看一下第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
ajax抓取网页内容(我正在尝试在不执行javascript的情况下在网页上AJAX的部分 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 07:05
)
我试图在不执行 javascript 的情况下获取网页的 AJAX 加载部分。通过使用Chrome开发工具,发现AJAX容器是通过POST请求从URL中提取内容,所以想使用python的requests包来复制请求。但奇怪的是,通过使用Chrome提供的Headers信息,我总是得到400错误,从Chrome复制的curl命令也是如此。所以我想知道是否有人可以分享一些见解。
我感兴趣的网站就在这里。使用Chrome:ctrl-shift-I、网络、XHR,我想要的部分是“内容”。我使用的脚本是:
headers = {"authority": "cafe.bithumb.com",
"path": "/boards/43/contents",
"method": "POST",
"origin":"https://cafe.bithumb.com",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"accept-encoding":"gzip, deflate, br",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"accept":"application/json, text/javascript, */*; q=0.01",
"referer":"https://cafe.bithumb.com/view/boards/43",
"x-requested-with":"XMLHttpRequest",
"scheme": "https",
"content-length":"1107"}
s=requests.Session()
s.headers.update(headers)
r = s.post('https://cafe.bithumb.com/boards/43/contents') 查看全部
ajax抓取网页内容(我正在尝试在不执行javascript的情况下在网页上AJAX的部分
)
我试图在不执行 javascript 的情况下获取网页的 AJAX 加载部分。通过使用Chrome开发工具,发现AJAX容器是通过POST请求从URL中提取内容,所以想使用python的requests包来复制请求。但奇怪的是,通过使用Chrome提供的Headers信息,我总是得到400错误,从Chrome复制的curl命令也是如此。所以我想知道是否有人可以分享一些见解。
我感兴趣的网站就在这里。使用Chrome:ctrl-shift-I、网络、XHR,我想要的部分是“内容”。我使用的脚本是:
headers = {"authority": "cafe.bithumb.com",
"path": "/boards/43/contents",
"method": "POST",
"origin":"https://cafe.bithumb.com",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"accept-encoding":"gzip, deflate, br",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"accept":"application/json, text/javascript, */*; q=0.01",
"referer":"https://cafe.bithumb.com/view/boards/43",
"x-requested-with":"XMLHttpRequest",
"scheme": "https",
"content-length":"1107"}
s=requests.Session()
s.headers.update(headers)
r = s.post('https://cafe.bithumb.com/boards/43/contents')
ajax抓取网页内容(IE浏览页面何时才算是真正的加载完毕?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 21:20
当前网页中有相当一部分使用了 AJAX 技术。无论是WebClient还是C#中的HttpRequest,都无法得到正确的结果,因为这些脚本都是在服务端发送后执行的!
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使使用了counter的方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白了原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
textBox1.Text += webBrowser1.StatusText;
if (webBrowser1.StatusText == "完成")
{
timer1.Enabled = false;
//页面加载完成,做一些其它的事
textBox1.Text += webBrowser1.Document.Body.OuterHtml;
//webBrowser1.DocumentText 注意不要用这个,这个和查看源文件一样的
}
}
private void Form1_Load(object sender, EventArgs e)
{
string Url = "http://cd.mei8.cn/face/work/wi ... 3B%3B
webBrowser1.Navigate(Url);
}
放置三个控件,webBrowser、timer、textBox定时器设置为可用 查看全部
ajax抓取网页内容(IE浏览页面何时才算是真正的加载完毕?(图))
当前网页中有相当一部分使用了 AJAX 技术。无论是WebClient还是C#中的HttpRequest,都无法得到正确的结果,因为这些脚本都是在服务端发送后执行的!
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使使用了counter的方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白了原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
textBox1.Text += webBrowser1.StatusText;
if (webBrowser1.StatusText == "完成")
{
timer1.Enabled = false;
//页面加载完成,做一些其它的事
textBox1.Text += webBrowser1.Document.Body.OuterHtml;
//webBrowser1.DocumentText 注意不要用这个,这个和查看源文件一样的
}
}
private void Form1_Load(object sender, EventArgs e)
{
string Url = "http://cd.mei8.cn/face/work/wi ... 3B%3B
webBrowser1.Navigate(Url);
}
放置三个控件,webBrowser、timer、textBox定时器设置为可用
ajax抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-21 12:11
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url + \' #container\',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + \' #container\');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),在中国适用吗?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: \'get\',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + \' #container\':获取url网页中container容器内的内容
41 url: url + \' #container\',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find(\'div[id=container]\').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + \' #container\', \'\', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find(\'div[id=container]\').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面 查看全部
ajax抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: \'get\',
34 url: url + \' #container\',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + \' #container\');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),在中国适用吗?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: \'get\',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + \' #container\':获取url网页中container容器内的内容
41 url: url + \' #container\',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find(\'div[id=container]\').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + \' #container\', \'\', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find(\'div[id=container]\').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-19 15:07
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候你会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很奇怪
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是边看边翻译,每页都看的很仔细,所以最后仔细阅读了下面两种常见的jquery事件加载方式。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还未加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候你会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很奇怪
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是边看边翻译,每页都看的很仔细,所以最后仔细阅读了下面两种常见的jquery事件加载方式。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还未加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章!
ajax抓取网页内容(CwRadioButton更改为_escaped_fragment_以及何时应使用#!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-11-19 15:07
什么时候应该使用_escaped_fragment_,什么时候应该使用#! 在 AJAX URL 中?
您的 网站 应该使用 #! 所有使用 AJAX 爬网机制的 URL 的语法。Googlebot 不会跟踪 _escaped_fragment_ 格式的超链接。
上提供了 AJAX 应用程序示例。单击左侧的任何链接后,您将看到相应的 URL 收录一个 #! 哈希代码片段,应用程序将进入与此哈希代码片段对应的状态。如果你改变#! (例如#!CwRadioButton)到?_escaped_fragment_=(例如),网站 将返回一个HTML 快照。
如果您这样做,在不久的将来,您的网页可能无法在 Google 搜索结果页上正确显示。但是,我们一直在不断改进 Googlebot,并试图使其更像浏览器。届时,当您在 网站 上实现所需的功能时,Googlebot 可能会自动正确地为您的网页编入索引。但是,这种AJAX爬取机制对于已经使用AJAX并希望确保内容被正确索引的网站来说是一个非常实用的解决方案。我们希望该方案能够有效解决用户拥有网页HTML快照的问题,或者解决用户使用无头浏览器获取此类HTML快照的问题。
这完全取决于应用程序内容的更新频率。如果更新频繁,则应始终及时构建最新的 HTML 快照以响应爬虫请求。如果不频繁,请考虑创建一个内容不定期更新的库档案。为避免服务器持续生成相同的 HTML 快照,您可以一次性创建所有相关的 HTML 快照(可能处于离线状态),然后保存以备将来参考。您还可以使用 304(未修改)HTTP 状态代码响应 Googlebot。
我们建议您使用它!使用哈希码段可以显着加快应用响应速度,因为哈希码段是由客户端浏览器处理的,不会导致整个网页都需要刷新。此外,哈希码片段还支持在应用程序中提供历史记录(也称为备受诟病的“浏览器后退按钮”)。各种 AJAX 框架都支持哈希代码段。例如,查看Really Simple History、jQuery 的历史插件、Google Web Toolkit 的历史机制或ASP.NET AJAX 对历史管理的支持。
但是,如果您无法构建应用以使用哈希代码片段,则可以执行以下操作以在哈希代码片段中使用特殊标记(即 URL 中 # 标记之后的所有内容)。表示唯一页面状态的哈希代码段必须以感叹号开头。例如,如果您的 AJAX 应用程序收录类似于以下内容的 URL:
www.example.com/ajax.html#mystate
现在应该是这样的:
www.example.com/ajax.html#!mystate
如果你的网站采用这种架构,就会被认为是“AJAX可抓取”。这意味着如果您的 网站 提供了 HTML 快照,爬虫将看到您的应用程序的内容。
URL 的 _escaped_fragment_ 语法对应于临时 URL,最终用户不应看到。在用户可以看到的所有环境中,您应该使用“漂亮的 URL”(使用 #! 而不是 _escaped_fragment_):常规应用程序交互、站点地图、超链接、重定向以及用户可能会看到 URL 的任何其他情况。出于同样的原因,搜索结果都是“漂亮的网址”,而不是“难看的网址”。
隐藏真实内容是指提供给用户的内容与提供给搜索引擎的内容不同,通常是为了提高网页在搜索结果中的排名。隐藏真实内容一直是(也将永远是)一个重要的搜索引擎问题,所以需要注意的是,将AJAX应用设置为可爬取,绝不是为了隐藏真实内容的方便。因此,HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。如果它们不相同,则可能被视为隐藏了真实内容。详情请参考具体回答。
Google 确实可以为许多富媒体文件类型编制索引,并且一直在努力改进抓取和索引编制。但是,Googlebot 可能无法看到 Flash 或其他富媒体应用程序的所有内容(就像它无法抓取您网站 上的所有动态内容一样),因此使用此机制可以为 Googlebot 提供更多内容。, HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。Google 保留将 网站 从被视为隐藏真实内容的索引中排除的权利。
如果你的 网站 使用 AJAX 爬取机制,谷歌爬虫会爬取它遇到的每一个哈希码段 URL。如果您不想抓取某些哈希代码段 URL,建议您在 robots.txt 文件中添加正则表达式指令。例如,您可以在不想被抓取的哈希代码片段中使用约定,然后在 robots.txt 文件中排除所有符合该约定的 URL。假设所有指示不可索引的语句都采用以下形式:#DONOTCRAWLmyfragment,那么您可以将以下代码添加到 robots.txt 以防止 Googlebot 抓取这些页面:
Disallow: /*_escaped_fragment_=DONOTCRAWL
如何处理现有的#! 在哈希码段?
#!是在现有哈希代码片段中不常用的令牌;但是,URL 规范并没有规定不能使用。如果您的应用程序使用了#!,但又不想采用新的 AJAX 爬取机制,您应该怎么做?一种方法是在robots.txt中添加以下指令来指示爬虫做什么。
Disallow: /*_escaped_fragment_
请注意,这意味着如果您的应用程序仅收录此 URL #!mystate,则不会抓取该 URL。如果您的应用程序还收录一个普通 URL,则该 URL 将被抓取。
当前向搜索引擎提供静态内容的方法有一个副作用,即 网站 站长可以让残障用户更容易访问他们的应用程序。这项新协议进一步提高了可访问性:网站 网站管理员不再需要手动干预来使用收录所有相关内容且可供屏幕阅读器使用的无头浏览器来创建 HTML 快照。这意味着现在可以更轻松地提供最新的静态内容,而手动工作越来越少。换句话说,网站 网站管理员现在将有更大的动力来构建方便残障用户使用的应用程序。rel="canonical" 应该如何使用?
请使用(不要使用)。
您应该在站点地图的搜索结果中添加要显示的 URL,因此应该添加 #!foo=123。带有 #! 影响产品饲料?
对于 网站,他们通常希望在 Google Shopping 和网络搜索中显示相同的 URL。通常,带有 #! 应该被视为可以在任何环境中使用的“规范”版本,并且 _escaped_fragment_ URL 应该被视为最终用户永远不会看到的临时 URL。我使用 HtmlUnit 作为无头浏览器,但它不起作用。这是为什么?
如果“不起作用”意味着 HtmlUnit 没有返回您想要查看的快照,很可能是因为您没有给它足够的时间来执行 JavaScript 和/或 XHR 请求。要解决此问题,请尝试以下任一或所有方法:
这在大多数情况下可以解决问题。但如果问题仍然存在,您还可以查看有关 HtmlUnit 的常见问题解答:。HtmlUnit 还提供了一个用户论坛。 查看全部
ajax抓取网页内容(CwRadioButton更改为_escaped_fragment_以及何时应使用#!)
什么时候应该使用_escaped_fragment_,什么时候应该使用#! 在 AJAX URL 中?
您的 网站 应该使用 #! 所有使用 AJAX 爬网机制的 URL 的语法。Googlebot 不会跟踪 _escaped_fragment_ 格式的超链接。
上提供了 AJAX 应用程序示例。单击左侧的任何链接后,您将看到相应的 URL 收录一个 #! 哈希代码片段,应用程序将进入与此哈希代码片段对应的状态。如果你改变#! (例如#!CwRadioButton)到?_escaped_fragment_=(例如),网站 将返回一个HTML 快照。
如果您这样做,在不久的将来,您的网页可能无法在 Google 搜索结果页上正确显示。但是,我们一直在不断改进 Googlebot,并试图使其更像浏览器。届时,当您在 网站 上实现所需的功能时,Googlebot 可能会自动正确地为您的网页编入索引。但是,这种AJAX爬取机制对于已经使用AJAX并希望确保内容被正确索引的网站来说是一个非常实用的解决方案。我们希望该方案能够有效解决用户拥有网页HTML快照的问题,或者解决用户使用无头浏览器获取此类HTML快照的问题。
这完全取决于应用程序内容的更新频率。如果更新频繁,则应始终及时构建最新的 HTML 快照以响应爬虫请求。如果不频繁,请考虑创建一个内容不定期更新的库档案。为避免服务器持续生成相同的 HTML 快照,您可以一次性创建所有相关的 HTML 快照(可能处于离线状态),然后保存以备将来参考。您还可以使用 304(未修改)HTTP 状态代码响应 Googlebot。
我们建议您使用它!使用哈希码段可以显着加快应用响应速度,因为哈希码段是由客户端浏览器处理的,不会导致整个网页都需要刷新。此外,哈希码片段还支持在应用程序中提供历史记录(也称为备受诟病的“浏览器后退按钮”)。各种 AJAX 框架都支持哈希代码段。例如,查看Really Simple History、jQuery 的历史插件、Google Web Toolkit 的历史机制或ASP.NET AJAX 对历史管理的支持。
但是,如果您无法构建应用以使用哈希代码片段,则可以执行以下操作以在哈希代码片段中使用特殊标记(即 URL 中 # 标记之后的所有内容)。表示唯一页面状态的哈希代码段必须以感叹号开头。例如,如果您的 AJAX 应用程序收录类似于以下内容的 URL:
www.example.com/ajax.html#mystate
现在应该是这样的:
www.example.com/ajax.html#!mystate
如果你的网站采用这种架构,就会被认为是“AJAX可抓取”。这意味着如果您的 网站 提供了 HTML 快照,爬虫将看到您的应用程序的内容。
URL 的 _escaped_fragment_ 语法对应于临时 URL,最终用户不应看到。在用户可以看到的所有环境中,您应该使用“漂亮的 URL”(使用 #! 而不是 _escaped_fragment_):常规应用程序交互、站点地图、超链接、重定向以及用户可能会看到 URL 的任何其他情况。出于同样的原因,搜索结果都是“漂亮的网址”,而不是“难看的网址”。
隐藏真实内容是指提供给用户的内容与提供给搜索引擎的内容不同,通常是为了提高网页在搜索结果中的排名。隐藏真实内容一直是(也将永远是)一个重要的搜索引擎问题,所以需要注意的是,将AJAX应用设置为可爬取,绝不是为了隐藏真实内容的方便。因此,HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。如果它们不相同,则可能被视为隐藏了真实内容。详情请参考具体回答。
Google 确实可以为许多富媒体文件类型编制索引,并且一直在努力改进抓取和索引编制。但是,Googlebot 可能无法看到 Flash 或其他富媒体应用程序的所有内容(就像它无法抓取您网站 上的所有动态内容一样),因此使用此机制可以为 Googlebot 提供更多内容。, HTML 快照必须收录与最终用户在浏览器中看到的内容相同的内容。Google 保留将 网站 从被视为隐藏真实内容的索引中排除的权利。
如果你的 网站 使用 AJAX 爬取机制,谷歌爬虫会爬取它遇到的每一个哈希码段 URL。如果您不想抓取某些哈希代码段 URL,建议您在 robots.txt 文件中添加正则表达式指令。例如,您可以在不想被抓取的哈希代码片段中使用约定,然后在 robots.txt 文件中排除所有符合该约定的 URL。假设所有指示不可索引的语句都采用以下形式:#DONOTCRAWLmyfragment,那么您可以将以下代码添加到 robots.txt 以防止 Googlebot 抓取这些页面:
Disallow: /*_escaped_fragment_=DONOTCRAWL
如何处理现有的#! 在哈希码段?
#!是在现有哈希代码片段中不常用的令牌;但是,URL 规范并没有规定不能使用。如果您的应用程序使用了#!,但又不想采用新的 AJAX 爬取机制,您应该怎么做?一种方法是在robots.txt中添加以下指令来指示爬虫做什么。
Disallow: /*_escaped_fragment_
请注意,这意味着如果您的应用程序仅收录此 URL #!mystate,则不会抓取该 URL。如果您的应用程序还收录一个普通 URL,则该 URL 将被抓取。
当前向搜索引擎提供静态内容的方法有一个副作用,即 网站 站长可以让残障用户更容易访问他们的应用程序。这项新协议进一步提高了可访问性:网站 网站管理员不再需要手动干预来使用收录所有相关内容且可供屏幕阅读器使用的无头浏览器来创建 HTML 快照。这意味着现在可以更轻松地提供最新的静态内容,而手动工作越来越少。换句话说,网站 网站管理员现在将有更大的动力来构建方便残障用户使用的应用程序。rel="canonical" 应该如何使用?
请使用(不要使用)。
您应该在站点地图的搜索结果中添加要显示的 URL,因此应该添加 #!foo=123。带有 #! 影响产品饲料?
对于 网站,他们通常希望在 Google Shopping 和网络搜索中显示相同的 URL。通常,带有 #! 应该被视为可以在任何环境中使用的“规范”版本,并且 _escaped_fragment_ URL 应该被视为最终用户永远不会看到的临时 URL。我使用 HtmlUnit 作为无头浏览器,但它不起作用。这是为什么?
如果“不起作用”意味着 HtmlUnit 没有返回您想要查看的快照,很可能是因为您没有给它足够的时间来执行 JavaScript 和/或 XHR 请求。要解决此问题,请尝试以下任一或所有方法:
这在大多数情况下可以解决问题。但如果问题仍然存在,您还可以查看有关 HtmlUnit 的常见问题解答:。HtmlUnit 还提供了一个用户论坛。
ajax抓取网页内容( 了解:Ajax是一种在无需重新加载整个网页的情况下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-18 10:09
了解:Ajax是一种在无需重新加载整个网页的情况下)
AJAX
学习:
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
使用 Ajax 进行局部更新,提升用户体验
JS:
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
//2. 建立连接
/*
参数:
1. 请求方式:GET、POST
* get方式,请求参数在URL后边拼接。send方法为空参
* post方式,请求参数在send方法中定义
2. 请求的URL:
3. 同步或异步请求:true(异步)或 false(同步)
*/
xmlhttp.open("GET","ajaxServlet?username=tom",true);
//3.发送请求
xmlhttp.send();
//4.接受并处理来自服务器的响应结果
//获取方式 :xmlhttp.responseText
//什么时候获取?当服务器响应成功后再获取
//当xmlhttp对象的就绪状态改变时,触发事件onreadystatechange。
xmlhttp.onreadystatechange=function()
{
//判断readyState就绪状态是否为4,判断status响应状态码是否为200
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
//获取服务器的响应结果
var responseText = xmlhttp.responseText;
alert(responseText);
}
}
查询:
1. $.ajax()
* 语法:$.ajax({键值对});
//使用$.ajax()发送异步请求
$.ajax({
url:"ajaxServlet1111" , // 请求路径
type:"POST" , //请求方式
//data: "username=jack&age=23",//请求参数
data:{"username":"jack","age":23},
success:function (data) {
alert(data);
},//响应成功后的回调函数
error:function () {
alert("出错啦...")
},//表示如果请求响应出现错误,会执行的回调函数
dataType:"text"//设置接受到的响应数据的格式
});
2. $.get():发送get请求
* 语法:$.get(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
3. $.post():发送post请求
* 语法:$.post(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
仅供参考,自用 查看全部
ajax抓取网页内容(
了解:Ajax是一种在无需重新加载整个网页的情况下)
AJAX
学习:
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
使用 Ajax 进行局部更新,提升用户体验
JS:
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
//2. 建立连接
/*
参数:
1. 请求方式:GET、POST
* get方式,请求参数在URL后边拼接。send方法为空参
* post方式,请求参数在send方法中定义
2. 请求的URL:
3. 同步或异步请求:true(异步)或 false(同步)
*/
xmlhttp.open("GET","ajaxServlet?username=tom",true);
//3.发送请求
xmlhttp.send();
//4.接受并处理来自服务器的响应结果
//获取方式 :xmlhttp.responseText
//什么时候获取?当服务器响应成功后再获取
//当xmlhttp对象的就绪状态改变时,触发事件onreadystatechange。
xmlhttp.onreadystatechange=function()
{
//判断readyState就绪状态是否为4,判断status响应状态码是否为200
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
//获取服务器的响应结果
var responseText = xmlhttp.responseText;
alert(responseText);
}
}
查询:
1. $.ajax()
* 语法:$.ajax({键值对});
//使用$.ajax()发送异步请求
$.ajax({
url:"ajaxServlet1111" , // 请求路径
type:"POST" , //请求方式
//data: "username=jack&age=23",//请求参数
data:{"username":"jack","age":23},
success:function (data) {
alert(data);
},//响应成功后的回调函数
error:function () {
alert("出错啦...")
},//表示如果请求响应出现错误,会执行的回调函数
dataType:"text"//设置接受到的响应数据的格式
});
2. $.get():发送get请求
* 语法:$.get(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
3. $.post():发送post请求
* 语法:$.post(url, [data], [callback], [type])
* 参数:
* url:请求路径
* data:请求参数
* callback:回调函数
* type:响应结果的类型
仅供参考,自用
ajax抓取网页内容(self.crawlAPI抓取豆瓣电影HTML代码中的并不相同常见用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-18 10:08
在上一篇教程中,我们使用 self.crawlAPI 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析一些内容。但是,目前的网站通过使用AJAX等技术,在与服务器交互时不需要重新加载整个页面。但是,这些交互方式让爬行变得有些困难:抓取后你会发现这些网页与浏览器中的网页并不相同。您需要的信息不在返回 HTML 代码中。
在本教程中,我们将讨论这些技术和方法来捕获它们。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML)的缩写。AJAX使用原有的web标准组件,无需重新加载整个页面即可实现与服务器的数据交互。例如,在新浪微博中,您无需重新加载或打开新页面即可展开微博评论。但是内容一开始不在页面上(所以页面太大了),而是在点击时加载。这导致你在爬取这个页面时,获取不到评论信息(因为你没有“展开”)。
AJAX 的一个常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端呈现它。如果可以直接抓取 JSON 数据,那会比 HTML 更容易解析。
当 网站 使用 AJAX 时,pyspider 获取的页面与浏览器看到的不同。当您在浏览器中打开此类页面或单击“展开”时,您经常会看到“正在加载”或类似的图标/动画。例如,当您尝试抓取时:
你会发现电影是“加载中...”
找到真正的要求
由于AJAX实际上是通过HTTP传输数据,我们可以通过Chrome开发者工具找到真实请求,直接发起对真实请求的爬取获取数据。
打开一个新窗口并按 Ctrl+Shift+I(在 Mac 上按 Cmd+Opt+I)打开开发者工具。切换到网络(网络面板)在一个窗口中打开
在页面加载过程中,您将在面板中看到所有资源请求。
AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般缩写为XHR。点击网络面板上漏斗状的过滤按钮,过滤掉XHR请求。逐一检查每个请求,通过访问路径和预览找到收录信息的请求:%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在豆瓣的例子中,XHR请求并不多,可以一一检查确认。但是,当XHR请求较多时,可能需要结合触发动作的时间、请求的路径等信息来帮助查找收录大量请求中信息的关键请求。这就需要有爬虫或者前端的相关经验。所以,有一点我一直在提,学爬最好的方法是:学写网站。
现在您可以在新窗口中打开 %E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,您将看到收录电影数据的原创 JSON 数据。建议安装JSONView(Firfox版)插件,可以看到更好看的JSON格式,展开折叠列等功能。然后,根据 JSON 数据,我们编写一个脚本来提取电影名称和评分:
class Handler(BaseHandler):
def on_start(self):
self.crawl(\'http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0\',
callback=self.json_parser)
def json_parser(self, response):
return [{
"title": x[\'title\'],
"rate": x[\'rate\'],
"url": x[\'url\']
} for x in response.json[\'subjects\']]
您可以获得完整的代码并进行调试。脚本中还有一个使用PhantomJS渲染的解压版,下篇教程会介绍。 查看全部
ajax抓取网页内容(self.crawlAPI抓取豆瓣电影HTML代码中的并不相同常见用法)
在上一篇教程中,我们使用 self.crawlAPI 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析一些内容。但是,目前的网站通过使用AJAX等技术,在与服务器交互时不需要重新加载整个页面。但是,这些交互方式让爬行变得有些困难:抓取后你会发现这些网页与浏览器中的网页并不相同。您需要的信息不在返回 HTML 代码中。
在本教程中,我们将讨论这些技术和方法来捕获它们。(英文版:AJAX-and-more-HTTP)
AJAX
AJAX 是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML)的缩写。AJAX使用原有的web标准组件,无需重新加载整个页面即可实现与服务器的数据交互。例如,在新浪微博中,您无需重新加载或打开新页面即可展开微博评论。但是内容一开始不在页面上(所以页面太大了),而是在点击时加载。这导致你在爬取这个页面时,获取不到评论信息(因为你没有“展开”)。
AJAX 的一个常见用法是使用 AJAX 加载 JSON 数据,然后在浏览器端呈现它。如果可以直接抓取 JSON 数据,那会比 HTML 更容易解析。
当 网站 使用 AJAX 时,pyspider 获取的页面与浏览器看到的不同。当您在浏览器中打开此类页面或单击“展开”时,您经常会看到“正在加载”或类似的图标/动画。例如,当您尝试抓取时:
你会发现电影是“加载中...”
找到真正的要求
由于AJAX实际上是通过HTTP传输数据,我们可以通过Chrome开发者工具找到真实请求,直接发起对真实请求的爬取获取数据。
打开一个新窗口并按 Ctrl+Shift+I(在 Mac 上按 Cmd+Opt+I)打开开发者工具。切换到网络(网络面板)在一个窗口中打开
在页面加载过程中,您将在面板中看到所有资源请求。
AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般缩写为XHR。点击网络面板上漏斗状的过滤按钮,过滤掉XHR请求。逐一检查每个请求,通过访问路径和预览找到收录信息的请求:%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
在豆瓣的例子中,XHR请求并不多,可以一一检查确认。但是,当XHR请求较多时,可能需要结合触发动作的时间、请求的路径等信息来帮助查找收录大量请求中信息的关键请求。这就需要有爬虫或者前端的相关经验。所以,有一点我一直在提,学爬最好的方法是:学写网站。
现在您可以在新窗口中打开 %E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0,您将看到收录电影数据的原创 JSON 数据。建议安装JSONView(Firfox版)插件,可以看到更好看的JSON格式,展开折叠列等功能。然后,根据 JSON 数据,我们编写一个脚本来提取电影名称和评分:
class Handler(BaseHandler):
def on_start(self):
self.crawl(\'http://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0\',
callback=self.json_parser)
def json_parser(self, response):
return [{
"title": x[\'title\'],
"rate": x[\'rate\'],
"url": x[\'url\']
} for x in response.json[\'subjects\']]
您可以获得完整的代码并进行调试。脚本中还有一个使用PhantomJS渲染的解压版,下篇教程会介绍。
ajax抓取网页内容(开发者配置微信网页授权的整个流程(1)_社会万象_光明网(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-17 23:01
)
微信授权全流程:
引导用户进入授权页面同意授权,获取code并兑换web授权access_token的code(与基础支持中的access_token不同) 如有需要,开发者可以刷新web授权access_token,避免过期。通过web授权access_token和openid获取用户基本信息(支持UnionID机制)
其实说白了,前端只需要做一件事,引导用户发起微信授权页面,然后获取code,然后跳转到当前页面,然后请求后端换取用户和其他相关信息。
功能实现
引导用户调出微信授权确认页面
这里我们需要做两件事。一是配置jsapi域名,二是配置微信网页授权的回调域名。
构造微信授权url"" + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect 从连接中可以看出有两个变量, appId,redirect_uri,不用说,appId就是我们要授权的微信公众号的appId,而对方的回调URL其实就是我们当前页面的URL。
用户微信登录授权后,回调URL会携带两个参数,第一个是code,一个是state。我们唯一需要做的就是获取代码并传递给后端,后端通过代码获取基本的用户信息。后端获取code后,获取用户的基本信息,并将相关的其他信息返回给前端,由前端获取,然后存储在本地或其他地方。
function getUrlParam(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]);
return null;
}
function wxLogin(callback) {
var appId = 'xxxxxxxxxxxxxxxxxxx';
var oauth_url = 'xxxxxxxxxxxxxxxxxxx/oauth';
var url = "https://open.weixin.qq.com/con ... ot%3B + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect"
var code = getUrlParam("code");
if (!code) {
window.location = url;
} else {
$.ajax({
type: 'GET',
url: oauth_url,
dataType: 'json',
data: {
code: code
},
success: function (data) {
if (data.code === 200) {
callback(data.data)
}
},
error: function (error) {
throw new Error(error)
}
})
} 查看全部
ajax抓取网页内容(开发者配置微信网页授权的整个流程(1)_社会万象_光明网(图)
)
微信授权全流程:
引导用户进入授权页面同意授权,获取code并兑换web授权access_token的code(与基础支持中的access_token不同) 如有需要,开发者可以刷新web授权access_token,避免过期。通过web授权access_token和openid获取用户基本信息(支持UnionID机制)
其实说白了,前端只需要做一件事,引导用户发起微信授权页面,然后获取code,然后跳转到当前页面,然后请求后端换取用户和其他相关信息。
功能实现
引导用户调出微信授权确认页面
这里我们需要做两件事。一是配置jsapi域名,二是配置微信网页授权的回调域名。
构造微信授权url"" + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect 从连接中可以看出有两个变量, appId,redirect_uri,不用说,appId就是我们要授权的微信公众号的appId,而对方的回调URL其实就是我们当前页面的URL。
用户微信登录授权后,回调URL会携带两个参数,第一个是code,一个是state。我们唯一需要做的就是获取代码并传递给后端,后端通过代码获取基本的用户信息。后端获取code后,获取用户的基本信息,并将相关的其他信息返回给前端,由前端获取,然后存储在本地或其他地方。
function getUrlParam(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]);
return null;
}
function wxLogin(callback) {
var appId = 'xxxxxxxxxxxxxxxxxxx';
var oauth_url = 'xxxxxxxxxxxxxxxxxxx/oauth';
var url = "https://open.weixin.qq.com/con ... ot%3B + appId + "&redirect_uri=" + location.href.split('#')[0] + "&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect"
var code = getUrlParam("code");
if (!code) {
window.location = url;
} else {
$.ajax({
type: 'GET',
url: oauth_url,
dataType: 'json',
data: {
code: code
},
success: function (data) {
if (data.code === 200) {
callback(data.data)
}
},
error: function (error) {
throw new Error(error)
}
})
}
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-17 23:00
)
前言
现在很多网站大量使用JavaScript,或者使用Ajax技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容却可以动态变化。如果使用python自带的requests库或者urllib库来处理这类网页,那么获取到的网页内容与浏览器显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium是一款功能强大的网络数据采集工具,最初是为网站自动化测试而开发的,并有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,即没有UI界面,也就是浏览器,但是点击、翻页等与人相关的操作需要设计和实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在设置了环境变量的地方。如果不设置,后面的代码会设置,所以直接放这里方便;
然后在检测下,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
Mac系统,下载保存到某个路径后,可以直接保存在环境变量路径中,也可以在环境变量路径中创建phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
页面元素安装成功就是安装成功
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
可以输出网页的源码,说明安装成功
获取JS返回值
查看全部
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一
)
前言
现在很多网站大量使用JavaScript,或者使用Ajax技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容却可以动态变化。如果使用python自带的requests库或者urllib库来处理这类网页,那么获取到的网页内容与浏览器显示的内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者一起可以运行一个非常强大的爬虫,它可以处理 cookie、JavaScript、标头和任何你想做的事情。
安装第三方库
Selenium是一款功能强大的网络数据采集工具,最初是为网站自动化测试而开发的,并有相应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,即没有UI界面,也就是浏览器,但是点击、翻页等与人相关的操作需要设计和实现。通过编写js程序,可以直接与webkit内核交互,在此基础上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
windows系统下载PhantomJs,将解压后的可执行文件放在设置了环境变量的地方。如果不设置,后面的代码会设置,所以直接放这里方便;
然后在检测下,在cmd窗口输入phantomjs:
如果出现这样的画面,则表示成功;
Mac系统,下载保存到某个路径后,可以直接保存在环境变量路径中,也可以在环境变量路径中创建phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
页面元素安装成功就是安装成功
示例 1:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
可以输出网页的源码,说明安装成功
获取JS返回值
ajax抓取网页内容(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-15 14:00
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面即可在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器)
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2、提取动态内容的技术组件
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码和实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的采集搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面即可在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,源码下载地址可在文章末尾的GitHub上找到),请注意:xslt是比较长的字符串,如果删除这个字符串,代码不是几行,足以展示Python的强大
#/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
导入时间
#京东移动产品页面
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-13 14:20
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!

