
采集
采集 列表页和详情页的使用方法有哪些?怎么用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-03-21 20:13
一个小概念:
大多数网站以列表页面和详细信息页面的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以将其视为列表页面。单击标题链接后,进入详细信息页面。
使用data 采集工具的一般目的是在详细信息页面中获取大量特定的内容数据,并将这些数据用于各种分析,发布自己的网站等。
列表页面:指的是列或目录页面,通常收录多个标题链接。例如:网站第一页或列页面是列表页面。主要功能:您可以通过列表页面获得到多个详细信息页面的链接。
详细信息页面:收录特定内容的页面,例如网页文章,其中收录:标题,作者,出版日期,正文内容,标签等。
要开始,请登录“ 优采云控制面板”:
详细的使用步骤:
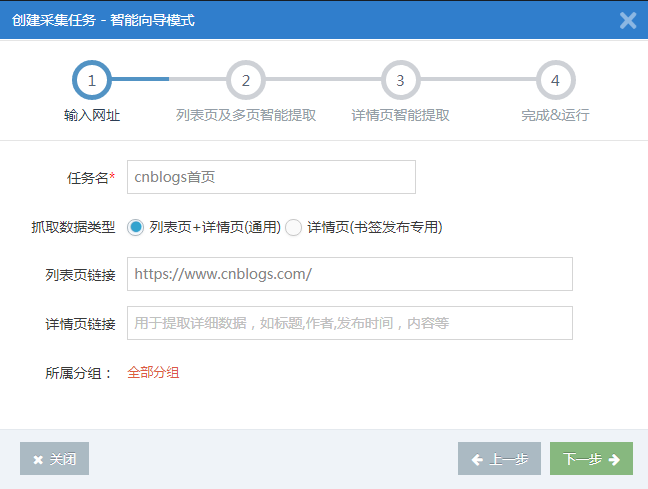
第一步:创建采集任务
单击左侧菜单按钮“创建采集任务”,输入采集任务名称和想要的采集“列表页面”的URL,例如:,可以保留详细信息页面链接空白,系统将自动识别它。
如下所示:
输入后,单击“下一步”。
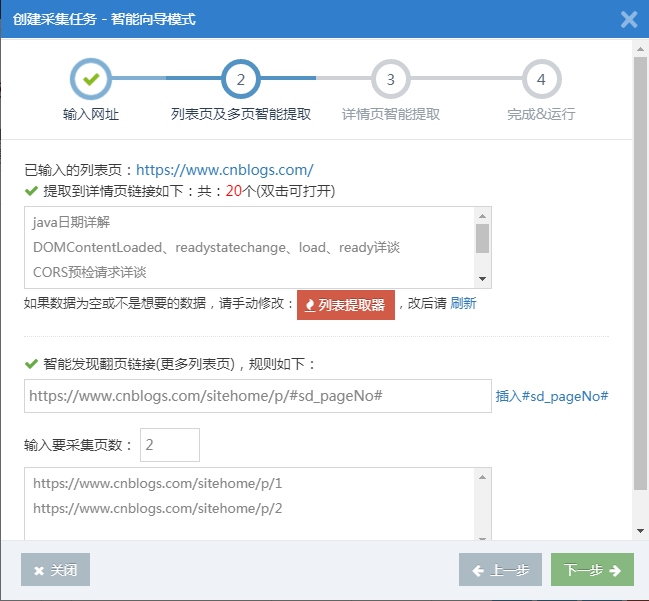
第2步:改善列表页面的智能提取结果(可选)
系统将首先使用智能算法来获取需要采集的详细信息页面链接(多个)。用户可以双击打开支票。如果您不需要数据,则可以单击“列表提取器”以手动指定它,仅在可视化中使用鼠标单击界面。
智能采集的结果如下:
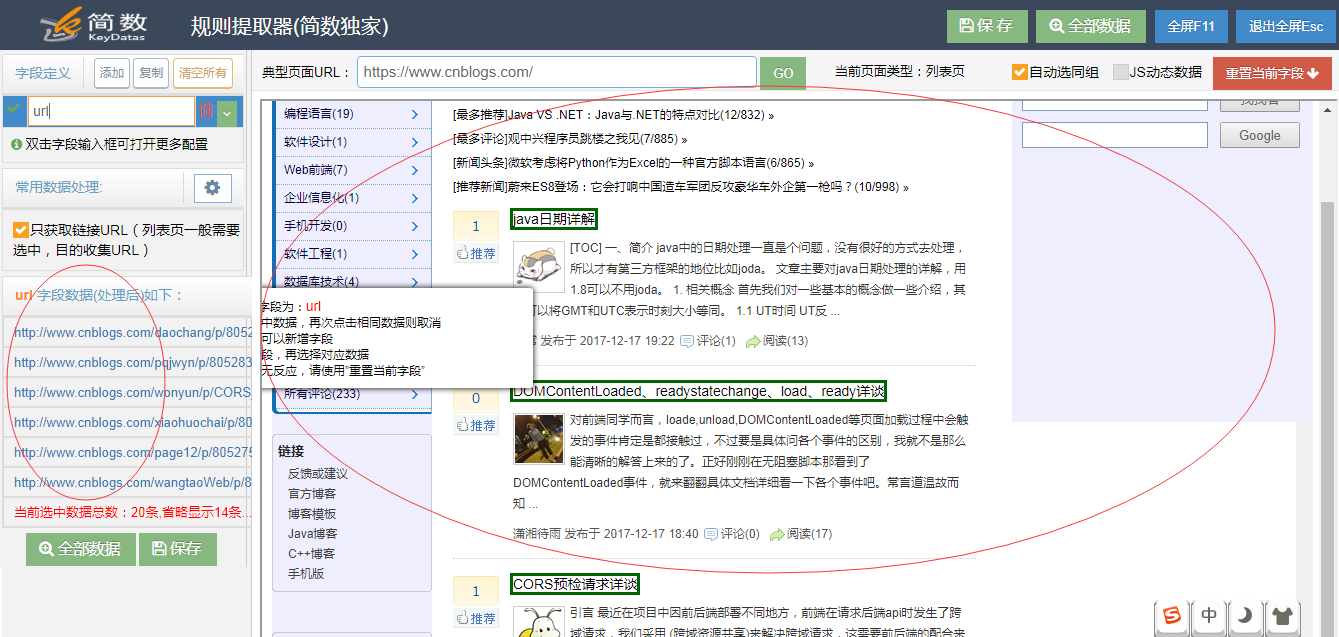
打开列表提取器后的下图:
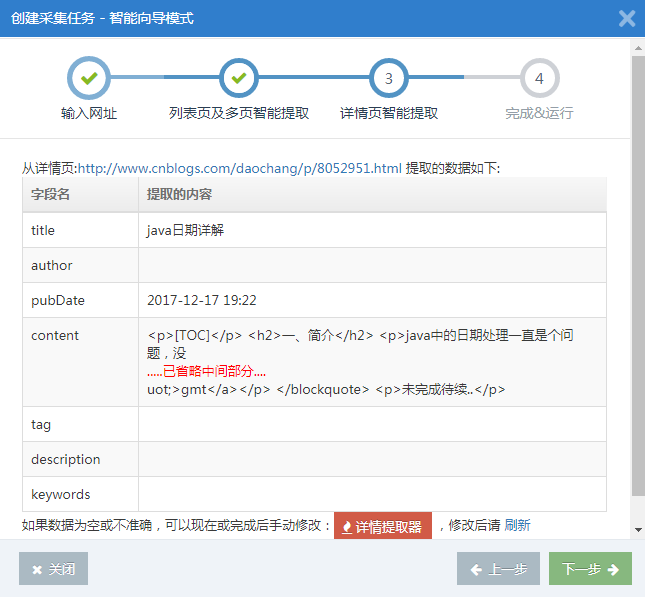
第3步:改善明细页的智能提取结果(可选)
在上一步中获得多个详细信息页面链接后,继续进行下一步。系统将使用详细页面链接之一来智能地提取详细页面数据(例如:标题,作者,发布日期,内容,标签等)
详细信息页面的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开“详细信息提取器”进行修改。
如下所示:
您可以修改,添加或删除左侧的字段。
您还可以为每个字段(双击字段)执行详细的设置或数据处理:替换,提取,过滤,设置默认值等,
如下所示:
第4步:启动并运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“结果数据和发布”中,您可以在此处修改数据或直接导出excel或发布您的网站(WordPress,织梦 DEDE, HTTP接口等)。
完成,数据采集就这么简单! ! ! 查看全部
采集 列表页和详情页的使用方法有哪些?怎么用?
一个小概念:
大多数网站以列表页面和详细信息页面的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以将其视为列表页面。单击标题链接后,进入详细信息页面。
使用data 采集工具的一般目的是在详细信息页面中获取大量特定的内容数据,并将这些数据用于各种分析,发布自己的网站等。
列表页面:指的是列或目录页面,通常收录多个标题链接。例如:网站第一页或列页面是列表页面。主要功能:您可以通过列表页面获得到多个详细信息页面的链接。
详细信息页面:收录特定内容的页面,例如网页文章,其中收录:标题,作者,出版日期,正文内容,标签等。
要开始,请登录“ 优采云控制面板”:
详细的使用步骤:
第一步:创建采集任务
单击左侧菜单按钮“创建采集任务”,输入采集任务名称和想要的采集“列表页面”的URL,例如:,可以保留详细信息页面链接空白,系统将自动识别它。
如下所示:
输入后,单击“下一步”。
第2步:改善列表页面的智能提取结果(可选)
系统将首先使用智能算法来获取需要采集的详细信息页面链接(多个)。用户可以双击打开支票。如果您不需要数据,则可以单击“列表提取器”以手动指定它,仅在可视化中使用鼠标单击界面。
智能采集的结果如下:
打开列表提取器后的下图:
第3步:改善明细页的智能提取结果(可选)
在上一步中获得多个详细信息页面链接后,继续进行下一步。系统将使用详细页面链接之一来智能地提取详细页面数据(例如:标题,作者,发布日期,内容,标签等)
详细信息页面的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开“详细信息提取器”进行修改。
如下所示:
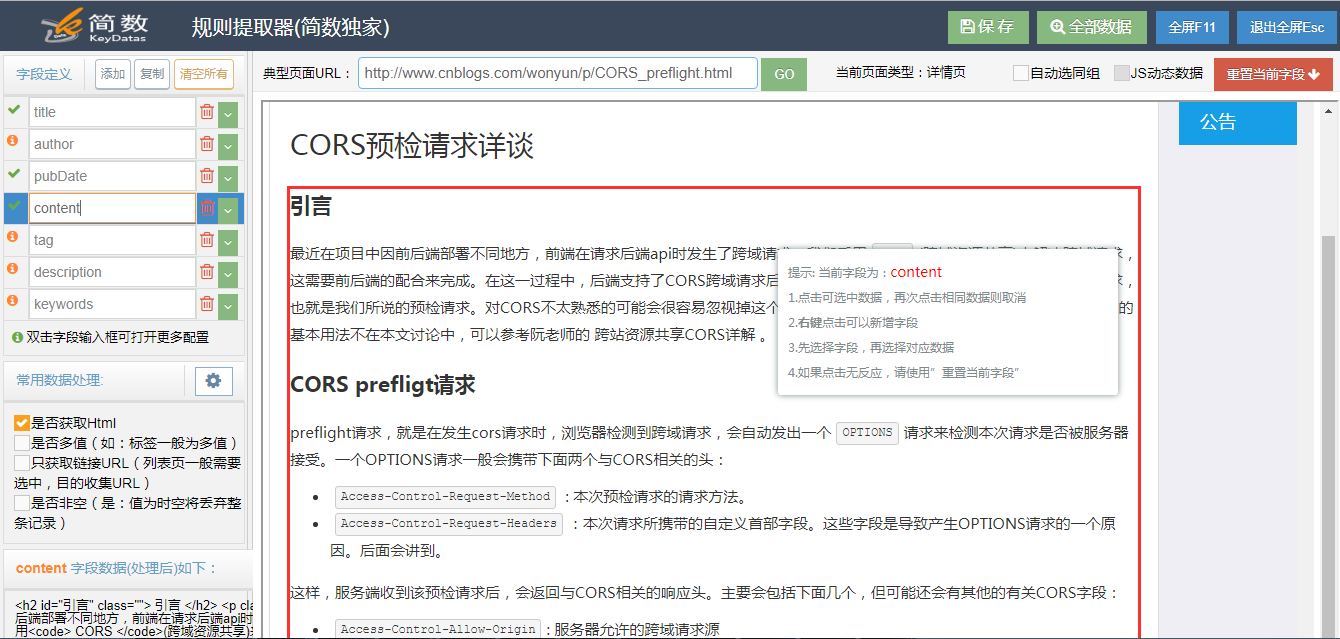
您可以修改,添加或删除左侧的字段。
您还可以为每个字段(双击字段)执行详细的设置或数据处理:替换,提取,过滤,设置默认值等,
如下所示:
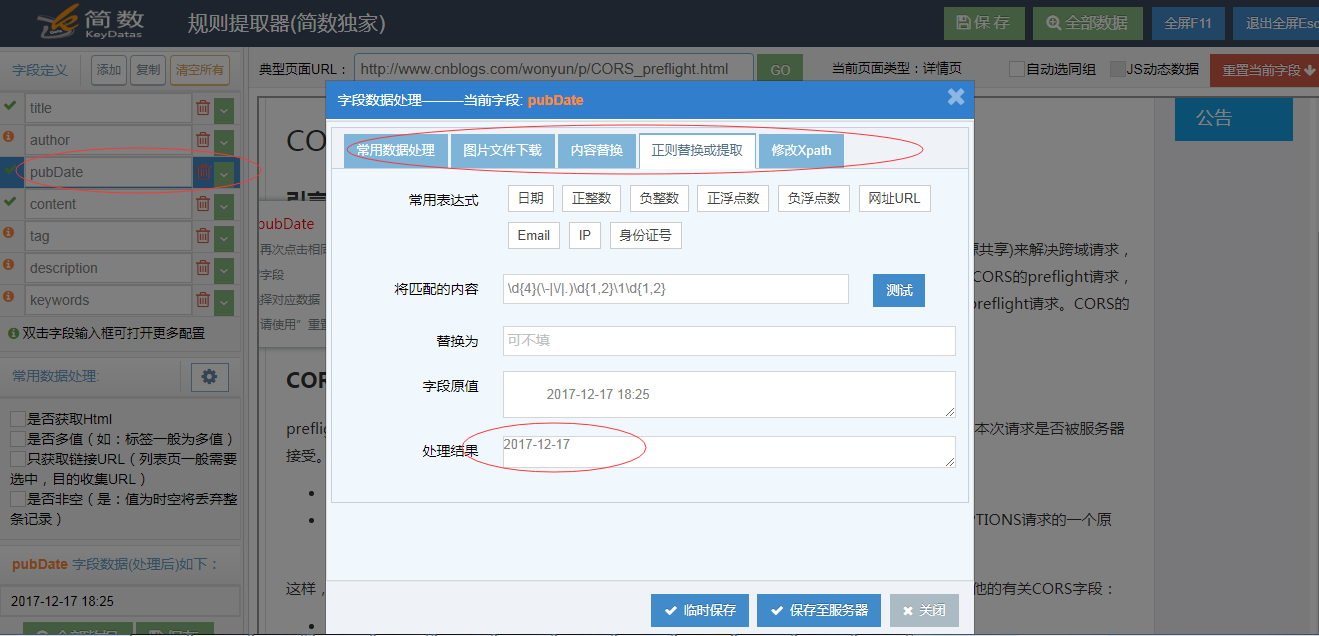
第4步:启动并运行
完成后,即可启动运行,进行数据采集了:
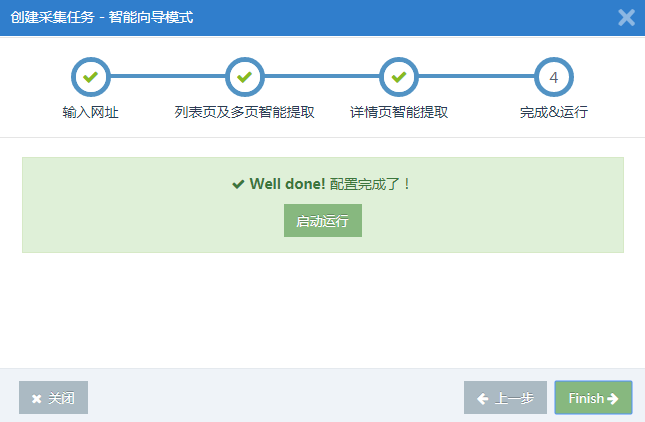
采集之后的数据结果,在采集任务的“结果数据和发布”中,您可以在此处修改数据或直接导出excel或发布您的网站(WordPress,织梦 DEDE, HTTP接口等)。
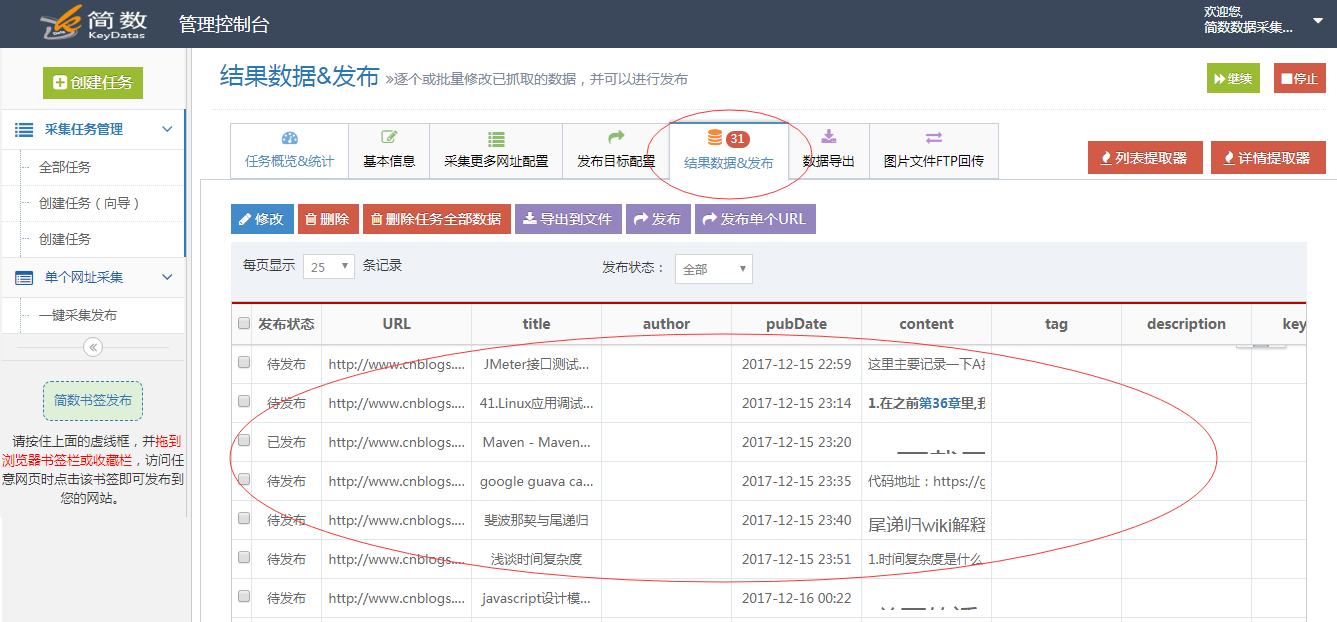
完成,数据采集就这么简单! ! !
全面了解:需求剖析:需求的获取、采集与抒发
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-29 04:21
需求剖析是产品总监的核心竞争力,本文以需求的来源、采集与描述三个方面为入口,结合案例,介绍了相对应的方式和使用工具。
一. 从那里获取需求?
需求的获取方法有很多,比如产品大牛的天马行空,用户粉丝的意见反馈,产品前期的用户督查等等,本文选定了几个常用的获取需求的方法来和读者分享一下。
1. 来源
1.1用户督查
(1)定量督查-问卷
(2)定性督查-采访
1.2 用户反馈
常见的用户反馈来自于互联网社交平台(微博、贴吧、知乎、微信、QQ、app store以及产品自带的客服投诉和建议模块。一般通过以下几条判定条件筛选出有用的反馈并加以解决相应问题:
(1)用户类型—什么用户提出的?(潜水用户/话题制造者/专业人士/死忠粉/VIP会员等)
一般专业人士提出的反馈结合了丰富的专业知识,比较有深度;死忠粉有常年使用产品的经验,对产品理解较深;VIP会员是产品的核心用户,及时解决她们的问题非常有必要。这些用户反馈的价值性相应低于通常或短期用户。
(2)使用场景—在哪些场景下提出的反馈?(地铁/公司/学校/车上/上班时/吃饭时/睡觉前等)
根据用户使用场景的频度和次数判定,一般使用频度高的场景下提出的反馈可能是大部分用户都碰到的,所以解决这种问题的优先级相应较高。
(3)反馈次数—是否有同类型、重复的反馈?(单个用户多次反馈相同问题/多个用户反馈相同问题)
如果同一个用户多次反馈相同问题,说明此问题早已轻度影响了该用户的用户体验,而且始终没有得到解决;反馈中一个问题被不同用户反复提起,说明大部分用户深受困惑,这两种情况下的反馈应优先被解决。
① 老板
在产品研制早期,经常会遇见会上老总一句话直接给需求,这些需求常常来自于老总丰富的工作经验以及敏锐的市场触觉,不能说老总提出的一定对,但是一定是有根据的。作为产品人员应当先消化和理解老总的看法,如果还是认为有问题,拿出相应的数据根据来劝说老总。
② 数据剖析
一般来说,产品人员可以通过一些数据网站(极光数据、百度指数、艾瑞咨询)获取市场趋势和用户喜好,进而获取用户需求;此外,运营及数据剖析专员
会按照市场做的相关数据统计(访问数、停留时间、跳出率等)提出部份需求。
2. 需求采集步骤
不同的阶段需求采集可使用的技巧也不一样,苏杰在《人人都是产品经理》一书提及,合理搭配定性和定量技巧,一般可依照产品时间轴分为四部份:
3. 需求的构成
需求不是单独存在的个体,而是与场景、用户、目标同时出现的。当描述一个需求时,需要交待时间、地点、人物、描述、需求(欲望)和技巧。举个简单的事例:
在一个阳光明媚的清晨(时间),我在去地铁站的路上(地点),但是距离有点远,走路要十五分钟(描述),于是我形成了一个赶快抵达地铁站的看法(欲望),决定扫描二维码,骑小黄车去地铁站(方法)。
这样描述上去需求会变得具体易懂,也有利于产品人员以后的需求抒发和管理。
二. 如何完整抒发需求?
在需求被采集之后,需要将各类需求具象化并装入需求池中,这里提供两种方式来抒发需求,一个是单项需求卡片描述单个需求,另一个是需求清单(feature list)来管理多个需求。
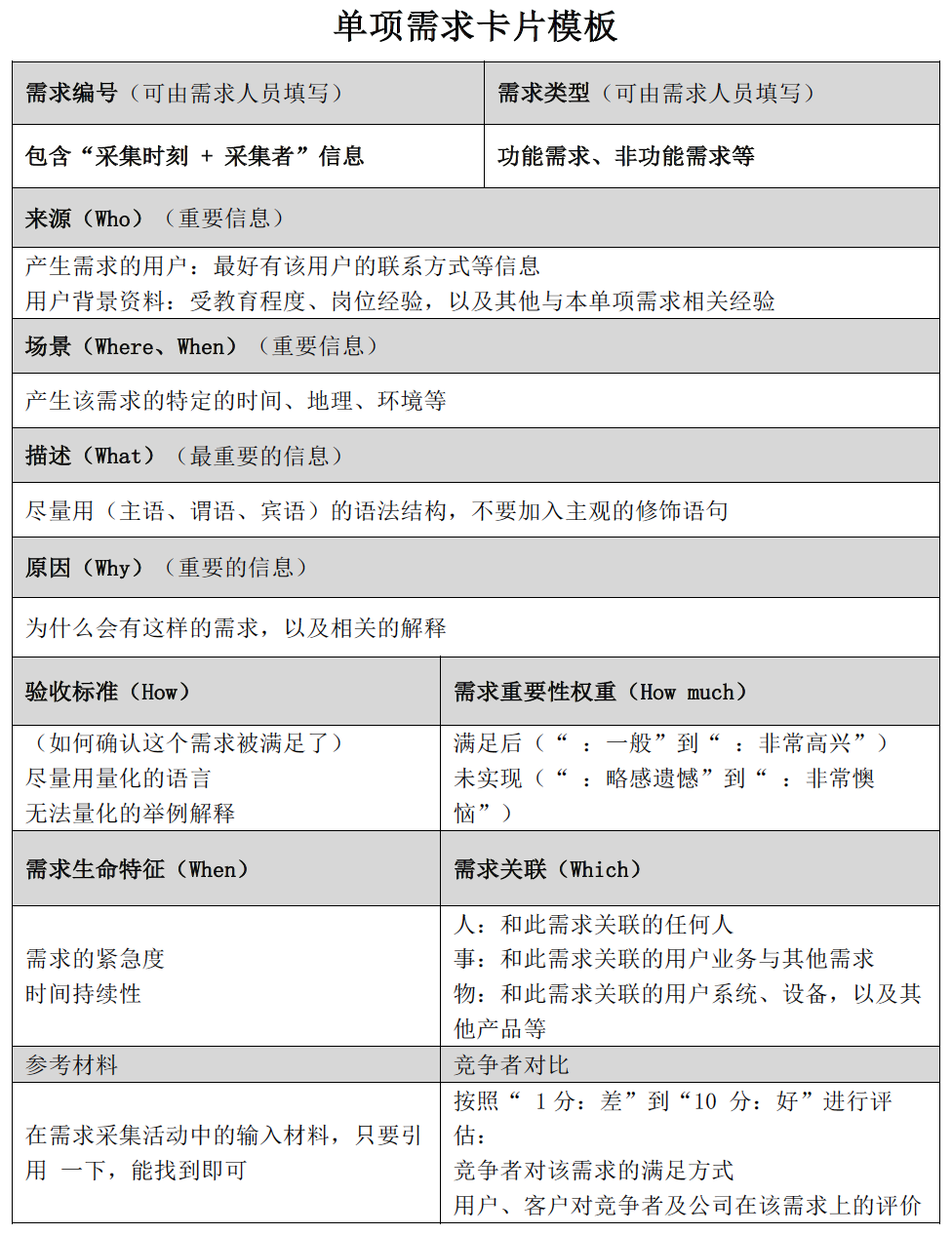
1. 单项需求卡片
此卡片的核心在于使开发人员了解每位需求的描述信息(who/where/what/when/why)以及重要紧急程度,为未经加工过的用户需求,多为需求属性陈述。下图为模版并详尽解释了各个栏目要填写的内容:
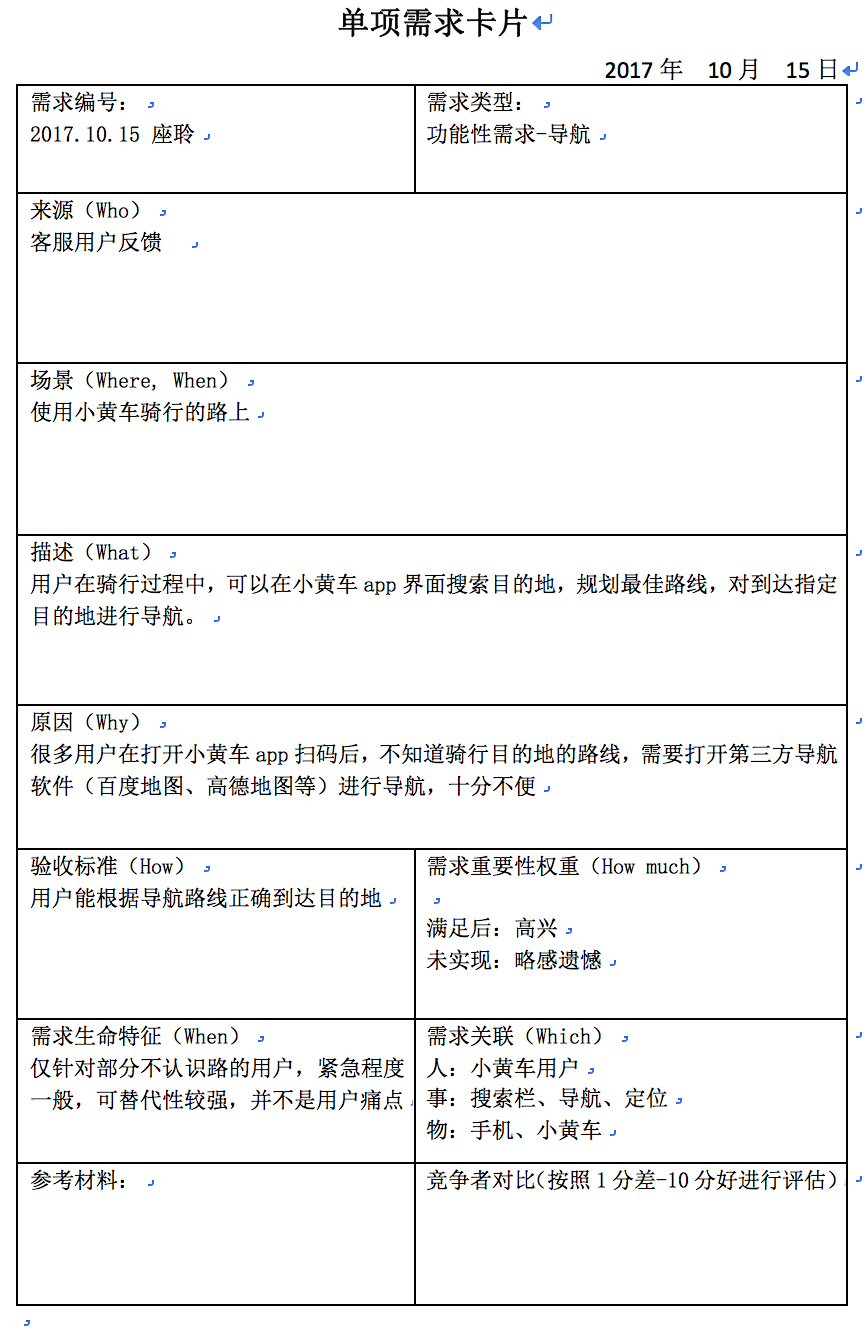
以小黄车为例,近来见到网上讨论是否要在小黄车APP降低导航功能(事实上笔者觉得此需求为伪需求),那么它的单项需求卡片卡片填写应当如下:
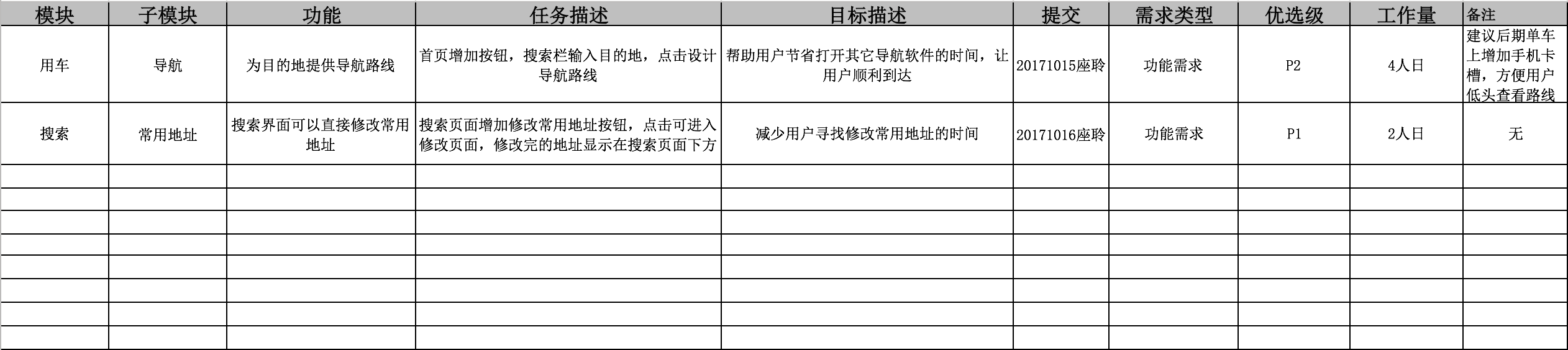
2. 需求清单
此清单将多个需求整合在一起,每一条对应每一个单项需求卡片的内容,跟单项需求卡片相比,需求清单一般是剖析之后的产品需求,偏向于研制时间成本和实现性价比。
案例如下:
单项需求卡片和需求清单不仅仅侧重于抒发需求,也涉及到部份需求管理内容。而且,面对随时都有可能蹦下来的需求,如何评估需求性价比并选择性列入需求池也是产品总监须要考虑的,希望在下一部分需求管理中和你们有更深入的交流讨论。
作者:座聆,产品汪一只,坐标北京 查看全部
需求剖析:需求的获取、采集与抒发

需求剖析是产品总监的核心竞争力,本文以需求的来源、采集与描述三个方面为入口,结合案例,介绍了相对应的方式和使用工具。
一. 从那里获取需求?
需求的获取方法有很多,比如产品大牛的天马行空,用户粉丝的意见反馈,产品前期的用户督查等等,本文选定了几个常用的获取需求的方法来和读者分享一下。
1. 来源
1.1用户督查
(1)定量督查-问卷
(2)定性督查-采访
1.2 用户反馈
常见的用户反馈来自于互联网社交平台(微博、贴吧、知乎、微信、QQ、app store以及产品自带的客服投诉和建议模块。一般通过以下几条判定条件筛选出有用的反馈并加以解决相应问题:
(1)用户类型—什么用户提出的?(潜水用户/话题制造者/专业人士/死忠粉/VIP会员等)
一般专业人士提出的反馈结合了丰富的专业知识,比较有深度;死忠粉有常年使用产品的经验,对产品理解较深;VIP会员是产品的核心用户,及时解决她们的问题非常有必要。这些用户反馈的价值性相应低于通常或短期用户。
(2)使用场景—在哪些场景下提出的反馈?(地铁/公司/学校/车上/上班时/吃饭时/睡觉前等)
根据用户使用场景的频度和次数判定,一般使用频度高的场景下提出的反馈可能是大部分用户都碰到的,所以解决这种问题的优先级相应较高。
(3)反馈次数—是否有同类型、重复的反馈?(单个用户多次反馈相同问题/多个用户反馈相同问题)
如果同一个用户多次反馈相同问题,说明此问题早已轻度影响了该用户的用户体验,而且始终没有得到解决;反馈中一个问题被不同用户反复提起,说明大部分用户深受困惑,这两种情况下的反馈应优先被解决。
① 老板
在产品研制早期,经常会遇见会上老总一句话直接给需求,这些需求常常来自于老总丰富的工作经验以及敏锐的市场触觉,不能说老总提出的一定对,但是一定是有根据的。作为产品人员应当先消化和理解老总的看法,如果还是认为有问题,拿出相应的数据根据来劝说老总。
② 数据剖析
一般来说,产品人员可以通过一些数据网站(极光数据、百度指数、艾瑞咨询)获取市场趋势和用户喜好,进而获取用户需求;此外,运营及数据剖析专员
会按照市场做的相关数据统计(访问数、停留时间、跳出率等)提出部份需求。
2. 需求采集步骤
不同的阶段需求采集可使用的技巧也不一样,苏杰在《人人都是产品经理》一书提及,合理搭配定性和定量技巧,一般可依照产品时间轴分为四部份:

3. 需求的构成
需求不是单独存在的个体,而是与场景、用户、目标同时出现的。当描述一个需求时,需要交待时间、地点、人物、描述、需求(欲望)和技巧。举个简单的事例:
在一个阳光明媚的清晨(时间),我在去地铁站的路上(地点),但是距离有点远,走路要十五分钟(描述),于是我形成了一个赶快抵达地铁站的看法(欲望),决定扫描二维码,骑小黄车去地铁站(方法)。
这样描述上去需求会变得具体易懂,也有利于产品人员以后的需求抒发和管理。
二. 如何完整抒发需求?
在需求被采集之后,需要将各类需求具象化并装入需求池中,这里提供两种方式来抒发需求,一个是单项需求卡片描述单个需求,另一个是需求清单(feature list)来管理多个需求。
1. 单项需求卡片
此卡片的核心在于使开发人员了解每位需求的描述信息(who/where/what/when/why)以及重要紧急程度,为未经加工过的用户需求,多为需求属性陈述。下图为模版并详尽解释了各个栏目要填写的内容:
以小黄车为例,近来见到网上讨论是否要在小黄车APP降低导航功能(事实上笔者觉得此需求为伪需求),那么它的单项需求卡片卡片填写应当如下:
2. 需求清单
此清单将多个需求整合在一起,每一条对应每一个单项需求卡片的内容,跟单项需求卡片相比,需求清单一般是剖析之后的产品需求,偏向于研制时间成本和实现性价比。

案例如下:
单项需求卡片和需求清单不仅仅侧重于抒发需求,也涉及到部份需求管理内容。而且,面对随时都有可能蹦下来的需求,如何评估需求性价比并选择性列入需求池也是产品总监须要考虑的,希望在下一部分需求管理中和你们有更深入的交流讨论。
作者:座聆,产品汪一只,坐标北京
信息采集员
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-27 13:26
定义信息采集员主要为公司提供各个渠道的时效信息。有些要求信息采集员每日登入网站,录入,修改和更新当天报价.互联网+呼叫中心+(地面服务能力)的组合模式。有些会就是打电话与各个部门或其他单位联系,询问她们是否须要我们的服务和产品,进行信息记录,同时将信息反馈到总公司。由技术部的人员进行剖析并与顾客进行初步接触,然后再由其负责协助技术部的人员做方案。互联网路上的信息非常庞大繁琐,为满足用户快速、准确、全面获取信息的需求,需要将大量的采集信息根据不同的标准来进行分类和打包处理。网络信息采集是将非结构化的信息从大量的网页中抽取下来保存到结构化的数据库中的过程。 信息采集系统以网路信息挖掘引擎为基础建立而成,它可以在最短的时间内,帮您把最新的信息从不同的Internet站点上采集下来,并在进行分类和统一格式后,第一时间之内把信息及时发布到自己的站点起来。从而增强信息及时性和节约或减轻工作量。信息采集员工作职责信息采集员是网站工作组成成员,要求要有较强的责任心和责任感,较好的观察能力和写作能力,来完成本职工作。工作职责:1. 负责本部门的信息采集和编撰工作,形成电子文档。2. 将信息文档交由本部门主管领导初审,经审合格后上传到指定信箱或发布到网上。
3. 原则上部门信息员只负责自己部门的信息发布,避免重复发布。4. 发表的信息要自行备案,由各部门的信息员统一管理,以备后用。5. 有网页栏目管理的部门,要注意保护好管理员账号及密码,防止别人窃取。如发生账号及密码泄漏,可以向网络中心申请修改。信息采集原则信息采集有以下5个方面的原则,这些原则是保证信息采集质量最基本的要求。(1)可靠性原则信息采集可靠性原则是指采集的信息必须是真实对象或环境所形成的,必须保证信息来源是可靠的,必须保证采集的信息能反映真实的状况,可靠性原则是信息采集的基础。(2)完整性原则信息采集完整性是指采集的信息在内容上必须完整无缺,信息采集必须根据一定的标准要求,采集反映事物概貌的信息,完整性原则是信息借助的基础。(3)实时性原则信息采集的实时性是指能及时获取所需的信息,一般有三层涵义:一是指信息自发生到被采集的时间间隔,间隔越短就越及时,最快的是信息采集与信息发生同步;二是指在企业或组织执行某一任务急需某一信息时才能很快采集到该信息,谓之及时;三是指采集某一任务所需的全部信息所花去的时间,花的时间越少谓之越快。实时性原则保证信息采集的时效。(4)准确性原则准确性原则是指采集到的信息与应用目标和工作需求的关联程度比较高,采集到信息的抒发是无误的,是属于采集目的范畴之内的,相对于企业或组织自身来说具有适用性,是有价值的。关联程度越高,适应性越强,就越确切。准确性原则保证信息采集的价值。(5)易用性原则:易用性原则是指采集到的信息根据一定的表示方式,便于使用。查看全文 查看全部
信息采集员
定义信息采集员主要为公司提供各个渠道的时效信息。有些要求信息采集员每日登入网站,录入,修改和更新当天报价.互联网+呼叫中心+(地面服务能力)的组合模式。有些会就是打电话与各个部门或其他单位联系,询问她们是否须要我们的服务和产品,进行信息记录,同时将信息反馈到总公司。由技术部的人员进行剖析并与顾客进行初步接触,然后再由其负责协助技术部的人员做方案。互联网路上的信息非常庞大繁琐,为满足用户快速、准确、全面获取信息的需求,需要将大量的采集信息根据不同的标准来进行分类和打包处理。网络信息采集是将非结构化的信息从大量的网页中抽取下来保存到结构化的数据库中的过程。 信息采集系统以网路信息挖掘引擎为基础建立而成,它可以在最短的时间内,帮您把最新的信息从不同的Internet站点上采集下来,并在进行分类和统一格式后,第一时间之内把信息及时发布到自己的站点起来。从而增强信息及时性和节约或减轻工作量。信息采集员工作职责信息采集员是网站工作组成成员,要求要有较强的责任心和责任感,较好的观察能力和写作能力,来完成本职工作。工作职责:1. 负责本部门的信息采集和编撰工作,形成电子文档。2. 将信息文档交由本部门主管领导初审,经审合格后上传到指定信箱或发布到网上。
3. 原则上部门信息员只负责自己部门的信息发布,避免重复发布。4. 发表的信息要自行备案,由各部门的信息员统一管理,以备后用。5. 有网页栏目管理的部门,要注意保护好管理员账号及密码,防止别人窃取。如发生账号及密码泄漏,可以向网络中心申请修改。信息采集原则信息采集有以下5个方面的原则,这些原则是保证信息采集质量最基本的要求。(1)可靠性原则信息采集可靠性原则是指采集的信息必须是真实对象或环境所形成的,必须保证信息来源是可靠的,必须保证采集的信息能反映真实的状况,可靠性原则是信息采集的基础。(2)完整性原则信息采集完整性是指采集的信息在内容上必须完整无缺,信息采集必须根据一定的标准要求,采集反映事物概貌的信息,完整性原则是信息借助的基础。(3)实时性原则信息采集的实时性是指能及时获取所需的信息,一般有三层涵义:一是指信息自发生到被采集的时间间隔,间隔越短就越及时,最快的是信息采集与信息发生同步;二是指在企业或组织执行某一任务急需某一信息时才能很快采集到该信息,谓之及时;三是指采集某一任务所需的全部信息所花去的时间,花的时间越少谓之越快。实时性原则保证信息采集的时效。(4)准确性原则准确性原则是指采集到的信息与应用目标和工作需求的关联程度比较高,采集到信息的抒发是无误的,是属于采集目的范畴之内的,相对于企业或组织自身来说具有适用性,是有价值的。关联程度越高,适应性越强,就越确切。准确性原则保证信息采集的价值。(5)易用性原则:易用性原则是指采集到的信息根据一定的表示方式,便于使用。查看全文
数据采集的几种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-25 18:30
业务系统
数据采集的几种形式方法一:读备份库
为了不影响业务系统的正常运行,可以采用读备份库的数据,这样就能及时获取数据进行一些剖析工作,但是有些从业务也会读取备份数据库,还须要考虑一致性和可用性问题。
数据库备份
方式一: 埋点(pingback)
可以在后端APP上记录用户点击,滑动速率,停留时间,进入的时间段,最后看的新闻等等信息,这些可以通过网路传输将埋点信息记录出来,用于数据剖析。但是这些方法有可能会对业务系统代码具有一定的侵入性,同时工作量也比较大,存在一定的安全隐患。
埋点
后端采集数据的service
/**
* 埋点接收数据
* @param pingBack
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody PingBack pingBack) {
Boolean result = patientService.savePingBack(pingBack);
return new ApiResponse().success(result);
}
已有的业务系统可以给数据采集系统发送数据
/**
* pingback方式插入
* @param patient
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody Patient patient) {
try{
Boolean result = patientService.savePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("insert error");
}finally {
pingBackService.jsonRequest(url+"insert", patient);
}
return null;
}
方式三: 发送消息的方法
上述埋点的形式在业务系统忙碌的情况下,会对数据采集系统形成大量的恳求,如果数据处理不及时会把数据采集服务击败,同时为了前馈,这里可以引入消息中间件,如果对时效性要求较高,可以采用推模式对数据采集系统进行推送,如果时效性不是很高,可以采用定时任务拉取数据,再进行剖析。
同时可以多个系统订阅消息中间件中不同Topic的数据,可以对数据进行重用,后端多个数据剖析系统之间互不影响,减轻了从业务系统采集多份数据的压力。
引入消息中间件
数据采集Service
/**
* 消息中间件的方式更新
* @param patient
* @return
*/
@RequestMapping(path = "/update", method = RequestMethod.POST)
@ResponseBody
public ApiResponse update(@RequestBody Patient patient) {
try{
Boolean result = patientService.updatePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("update error");
}finally {
sendMessageService.send(patient);
}
return null;
}
中间件发送数据实现(以kafka为例)
@Service
@Slf4j
public class SendMessageService {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("topic")
private String topic;
private ObjectMapper om = new ObjectMapper();
public boolean send(Object object){
String objectJson = "";
try {
objectJson = new ObjectMapper().writeValueAsString(object);
} catch (Exception e) {
log.error("can't trans the {} object to json string!", object);
return false;
}
try{
String result = kafkaTemplate.send("mysql-kafka-patient", objectJson).get().toString();
if(result!=null){
return true;
}
}catch (Exception e){
return false;
}
return false;
}
}
中间件拉取数据:
@KafkaListener(id = "forward", topics = "mysql-kafka-patient")
public String forward(String data) {
log.info("mysql-kafka-patient "+data);
JSONObject jsonObject1 = JSONObject.parseObject(data);
Message message = (Message) JSONObject.toJavaObject(jsonObject1,Message.class);
messageService.updateMessage(message);
return data;
}
方式四:读取MySQL中的binlog
MySQL会把数据的变更(插入和更新)保存在binlog中,需要在my.ini中配置开启,因此采用kafka订阅binlog,会将DB中须要的数组抓取下来,保存在备份库中,进行数据剖析,工作量较小,安全稳定。
name=mysql-b-source-pingBack
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/test?user=root&password=root
# timestamp+incrementing 时间戳自增混合模式
mode=timestamp+incrementing
# 自增字段 id
timestamp.column.name=commenttime
incrementing.column.name=id
# 白名单表 pingBack
table.whitelist=pingBack
# topic前缀 mysql-kafka-
topic.prefix=mysql-kafka-
具体使用可以参考:官方文档
分析对比数据采集方式优点缺点
埋点(pingback)
很细致的将后端用户操作记录出来,能够感知到DB储存之外的用户信息,时效性高
工作量大,可能对业务代码有侵入性;当业务量大的时侯,数据抓取服务也须要承载一定的压力,对数据不便捷统计和聚合
主库写备库读
及时感知备库中的信息 ,数据一致性强
可能存在大量不需要进行剖析的数组,对业务性能有影响
埋点+消息中间件
有效的解决业务量大时对数据存取性能的要求,根据数据抓取服务的需求可以拉也可以推,解耦业务代码
可能会遗失数据,降低了时效性 查看全部
数据采集的几种方式

业务系统
数据采集的几种形式方法一:读备份库
为了不影响业务系统的正常运行,可以采用读备份库的数据,这样就能及时获取数据进行一些剖析工作,但是有些从业务也会读取备份数据库,还须要考虑一致性和可用性问题。

数据库备份
方式一: 埋点(pingback)
可以在后端APP上记录用户点击,滑动速率,停留时间,进入的时间段,最后看的新闻等等信息,这些可以通过网路传输将埋点信息记录出来,用于数据剖析。但是这些方法有可能会对业务系统代码具有一定的侵入性,同时工作量也比较大,存在一定的安全隐患。

埋点
后端采集数据的service
/**
* 埋点接收数据
* @param pingBack
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody PingBack pingBack) {
Boolean result = patientService.savePingBack(pingBack);
return new ApiResponse().success(result);
}
已有的业务系统可以给数据采集系统发送数据
/**
* pingback方式插入
* @param patient
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody Patient patient) {
try{
Boolean result = patientService.savePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("insert error");
}finally {
pingBackService.jsonRequest(url+"insert", patient);
}
return null;
}
方式三: 发送消息的方法
上述埋点的形式在业务系统忙碌的情况下,会对数据采集系统形成大量的恳求,如果数据处理不及时会把数据采集服务击败,同时为了前馈,这里可以引入消息中间件,如果对时效性要求较高,可以采用推模式对数据采集系统进行推送,如果时效性不是很高,可以采用定时任务拉取数据,再进行剖析。
同时可以多个系统订阅消息中间件中不同Topic的数据,可以对数据进行重用,后端多个数据剖析系统之间互不影响,减轻了从业务系统采集多份数据的压力。

引入消息中间件
数据采集Service
/**
* 消息中间件的方式更新
* @param patient
* @return
*/
@RequestMapping(path = "/update", method = RequestMethod.POST)
@ResponseBody
public ApiResponse update(@RequestBody Patient patient) {
try{
Boolean result = patientService.updatePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("update error");
}finally {
sendMessageService.send(patient);
}
return null;
}
中间件发送数据实现(以kafka为例)
@Service
@Slf4j
public class SendMessageService {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("topic")
private String topic;
private ObjectMapper om = new ObjectMapper();
public boolean send(Object object){
String objectJson = "";
try {
objectJson = new ObjectMapper().writeValueAsString(object);
} catch (Exception e) {
log.error("can't trans the {} object to json string!", object);
return false;
}
try{
String result = kafkaTemplate.send("mysql-kafka-patient", objectJson).get().toString();
if(result!=null){
return true;
}
}catch (Exception e){
return false;
}
return false;
}
}
中间件拉取数据:
@KafkaListener(id = "forward", topics = "mysql-kafka-patient")
public String forward(String data) {
log.info("mysql-kafka-patient "+data);
JSONObject jsonObject1 = JSONObject.parseObject(data);
Message message = (Message) JSONObject.toJavaObject(jsonObject1,Message.class);
messageService.updateMessage(message);
return data;
}
方式四:读取MySQL中的binlog
MySQL会把数据的变更(插入和更新)保存在binlog中,需要在my.ini中配置开启,因此采用kafka订阅binlog,会将DB中须要的数组抓取下来,保存在备份库中,进行数据剖析,工作量较小,安全稳定。
name=mysql-b-source-pingBack
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/test?user=root&password=root
# timestamp+incrementing 时间戳自增混合模式
mode=timestamp+incrementing
# 自增字段 id
timestamp.column.name=commenttime
incrementing.column.name=id
# 白名单表 pingBack
table.whitelist=pingBack
# topic前缀 mysql-kafka-
topic.prefix=mysql-kafka-
具体使用可以参考:官方文档
分析对比数据采集方式优点缺点
埋点(pingback)
很细致的将后端用户操作记录出来,能够感知到DB储存之外的用户信息,时效性高
工作量大,可能对业务代码有侵入性;当业务量大的时侯,数据抓取服务也须要承载一定的压力,对数据不便捷统计和聚合
主库写备库读
及时感知备库中的信息 ,数据一致性强
可能存在大量不需要进行剖析的数组,对业务性能有影响
埋点+消息中间件
有效的解决业务量大时对数据存取性能的要求,根据数据抓取服务的需求可以拉也可以推,解耦业务代码
可能会遗失数据,降低了时效性
哪个是最好的图片捕获工具?热门图片采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-08 01:39
1. 图片搜索器(图片批量下载工具)
图片搜索器(图片批量下载工具)-智能挖掘,自动爬网搜索,在网站上下载图片,将项目保存到本地,然后通过“文件-”“打开项目”菜单加载并执行项目注意: 保存时,项目文件的后缀必须为“ pics”!
功能:
1. 下载整个网站的图片,速度如此之快以至于无法超越
2. 给它提供一些初始URL,它可以智能地挖掘,自动爬网和在网站上搜索图片
3. 它可以根据网页内容的标题将搜索到的图片保存到单独的文件夹中
4,名人美女,动漫图片,美丽的风景图片,全部.
门户: 图片搜索器(图像批量下载工具)
2.500px蜘蛛(批量图像下载)
500px Spide,它可以帮助您从500px网站下载自己喜欢的照片. 您可以一次选择要下载的照片,然后500px Spider会将所有这些照片下载到硬盘上. 500px Spider是一种易于使用且功能强大的工具,可为您节省无法保存照片的麻烦.
500px蜘蛛的主要特征:
管理下载的照片集管理每个作者的下载的照片集. 您可以浏览,更新,查找和删除这些照片集.
单独下载照片如果网络状况不好,下载的照片将显示为不完整,则可以使用此功能单独下载照片.
更新作者的最新上传. 下载作者的图片后,一段时间后,作者会上传新的图片. 目前,您可以使用更新功能仅下载用户最近上传的图片. 查看全部
图像采集工具使用特殊的图像识别技术批量获取图像地址,然后在本地下载图像以完成采集任务. 现在,Internet上有许多采集工具. 编辑者组织了几种实用的图像采集工具,与您分享小伙伴们的生活.
1. 图片搜索器(图片批量下载工具)

图片搜索器(图片批量下载工具)-智能挖掘,自动爬网搜索,在网站上下载图片,将项目保存到本地,然后通过“文件-”“打开项目”菜单加载并执行项目注意: 保存时,项目文件的后缀必须为“ pics”!
功能:
1. 下载整个网站的图片,速度如此之快以至于无法超越
2. 给它提供一些初始URL,它可以智能地挖掘,自动爬网和在网站上搜索图片
3. 它可以根据网页内容的标题将搜索到的图片保存到单独的文件夹中
4,名人美女,动漫图片,美丽的风景图片,全部.
门户: 图片搜索器(图像批量下载工具)
2.500px蜘蛛(批量图像下载)

500px Spide,它可以帮助您从500px网站下载自己喜欢的照片. 您可以一次选择要下载的照片,然后500px Spider会将所有这些照片下载到硬盘上. 500px Spider是一种易于使用且功能强大的工具,可为您节省无法保存照片的麻烦.
500px蜘蛛的主要特征:
管理下载的照片集管理每个作者的下载的照片集. 您可以浏览,更新,查找和删除这些照片集.
单独下载照片如果网络状况不好,下载的照片将显示为不完整,则可以使用此功能单独下载照片.
更新作者的最新上传. 下载作者的图片后,一段时间后,作者会上传新的图片. 目前,您可以使用更新功能仅下载用户最近上传的图片.
熊猫智能采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-08-07 05:14
在浏览器中可以看到的所有内容都属于优采云采集器软件的采集范围. 也就是说,只要在浏览器中可以看到您需要的内容,就可以在99.9%的情况下与Panda一起批量采集.
采集的数据可以发布在我自己的网站上吗?
是的. 优采云采集器的默认数据存储方法是将其存储在数据库中. 您可以使用网站后端的手动发布页面同时设置“模拟发布”,Panda将模拟手动发布操作的过程,并将采集的数据发布到指定的网站. 熊猫还具有独特的“多级模拟发布”功能,可以一次模拟所有内容,例如注册,发布和回复.
采集的数据可以存储在我现有的数据库表中吗?
是的. 在Panda中,默认采集的数据将自动存储在项目专用文件夹中的data.mdb文件中. 您可以在设置链接中指定数据库链接参数,并指定用于存储数据的表和字段. 这样,采集的结果数据将自动存储在数据库中,而无需手动编辑SQL仓库命令. 该软件将自动完成仓库事务,自动判断仓库字段的SQL语法,并自动判断重复的数据.
我不信任您,我需要查看采集结果并首先发布吗?
在购买之前,用户可以向熊猫官方客户服务中心申请提供试用版采集和试用版发行. 原则上,您只需要提供100元的押金即可申请. 如果不确定或结果不符合要求,可以退还押金. 在正式购买时,可以将已支付的押金折算为最终购买价格. 查看全部
您可以使用Cloud Collector软件做什么?
在浏览器中可以看到的所有内容都属于优采云采集器软件的采集范围. 也就是说,只要在浏览器中可以看到您需要的内容,就可以在99.9%的情况下与Panda一起批量采集.
采集的数据可以发布在我自己的网站上吗?
是的. 优采云采集器的默认数据存储方法是将其存储在数据库中. 您可以使用网站后端的手动发布页面同时设置“模拟发布”,Panda将模拟手动发布操作的过程,并将采集的数据发布到指定的网站. 熊猫还具有独特的“多级模拟发布”功能,可以一次模拟所有内容,例如注册,发布和回复.
采集的数据可以存储在我现有的数据库表中吗?
是的. 在Panda中,默认采集的数据将自动存储在项目专用文件夹中的data.mdb文件中. 您可以在设置链接中指定数据库链接参数,并指定用于存储数据的表和字段. 这样,采集的结果数据将自动存储在数据库中,而无需手动编辑SQL仓库命令. 该软件将自动完成仓库事务,自动判断仓库字段的SQL语法,并自动判断重复的数据.
我不信任您,我需要查看采集结果并首先发布吗?
在购买之前,用户可以向熊猫官方客户服务中心申请提供试用版采集和试用版发行. 原则上,您只需要提供100元的押金即可申请. 如果不确定或结果不符合要求,可以退还押金. 在正式购买时,可以将已支付的押金折算为最终购买价格.
探索代码Web大数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2020-08-06 04:05
Danma Technology的基于云计算研发的Web大数据采集系统-利用众多的云计算服务器协同工作,它可以快速采集大量数据并避免计算机硬件资源的瓶颈. 数据采集的要求越来越高,逐步解决了传统邮政采集无法解决的技术难题. 以探针Kapow / Dyson采集器为代表的新一代智能采集器可以模拟人类的思维和人类的操作,从而完全解决了诸如ajax之类的技术问题.
网页通常是为人们浏览而设计的,因此在Web大数据采集系统中模拟人类的智能采集器的工作非常顺畅. 无论背景技术是什么,当数据始终显示在人们面前时,智能采集器就可以开始提取. 最后,将计算机的功能发挥到极致,以便计算机可以代替人们来完成Web数据采集工作. 借助大数据云采集技术,计算机的计算能力也达到了极致. 目前,这种采集技术已经得到越来越广泛的应用. 只要各行各业从互联网获取一些数据或信息,就可以使用这种技术.
搜索代码Web大数据采集系统分为8个子系统,分别是大数据集群系统,数据采集系统,采集的数据源调查,数据爬网程序系统,数据清理系统,数据合并系统,任务调度系统,搜索引擎系统.
大数据集群系统
此系统可以存储TB级采集的数据,以实现数据持久性. 数据存储采用MongoDB集群解决方案,该集群具有两个主要特征:
数据采集系统
该系统配置有Kapow,PhantomJS和Mechanize采集环境,并在由Rancher安排的Docker容器中运行.
采集的数据源调查
在“数据搜寻器系统”启动之前,该系统是必不可少的链接. 经过调查,发现需要采集页面,要过滤的关键字,要提取的内容等.
数据搜寻器系统
爬虫程序都是独立的个体,与所需的数据采集系统服务器结合,由Rancher安排,该爬虫程序在DigitalOcean中自动启动,并根据输入参数捕获指定的数据,然后将其发送回我们的大型数据集群系统.
数据清理系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示,显示由搜寻器程序捕获的数据,并方便我们进行清理. 数据清理系统主要由两部分组成:
数据整合系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示和合并数据. 清除数据后,数据合并系统将自动匹配大数据集群中的数据,并通过熟人评分将可能的熟人数据关联起来. 匹配结果通过Web前端显示,并且数据可以手动或自动合并.
任务计划系统
该系统通过Ruby on Rails + Vue技术框架,Sidekiq队列调度和Redis调度数据持久性来实现Web前端任务调度系统. 通过任务计划系统,您可以动态打开和关闭,并定期启动搜寻器程序.
搜索引擎系统
该系统通过ElasticSearch集群实现搜索引擎服务. 搜索引擎是PC端检索系统从大数据集群快速检索数据的必要工具. 通过ElasticSearch集群,运行三个以上的Master角色以确保集群系统的稳定性,并运行两个以上的Client角色以确保查询的容错能力,两个或多个Data角色可确保查询和编写的及时性. 通过负载平衡连接客户端角色,以分散数据查询压力. 查看全部
探索代码Web大数据采集系统
Danma Technology的基于云计算研发的Web大数据采集系统-利用众多的云计算服务器协同工作,它可以快速采集大量数据并避免计算机硬件资源的瓶颈. 数据采集的要求越来越高,逐步解决了传统邮政采集无法解决的技术难题. 以探针Kapow / Dyson采集器为代表的新一代智能采集器可以模拟人类的思维和人类的操作,从而完全解决了诸如ajax之类的技术问题.
网页通常是为人们浏览而设计的,因此在Web大数据采集系统中模拟人类的智能采集器的工作非常顺畅. 无论背景技术是什么,当数据始终显示在人们面前时,智能采集器就可以开始提取. 最后,将计算机的功能发挥到极致,以便计算机可以代替人们来完成Web数据采集工作. 借助大数据云采集技术,计算机的计算能力也达到了极致. 目前,这种采集技术已经得到越来越广泛的应用. 只要各行各业从互联网获取一些数据或信息,就可以使用这种技术.
搜索代码Web大数据采集系统分为8个子系统,分别是大数据集群系统,数据采集系统,采集的数据源调查,数据爬网程序系统,数据清理系统,数据合并系统,任务调度系统,搜索引擎系统.

大数据集群系统
此系统可以存储TB级采集的数据,以实现数据持久性. 数据存储采用MongoDB集群解决方案,该集群具有两个主要特征:
数据采集系统
该系统配置有Kapow,PhantomJS和Mechanize采集环境,并在由Rancher安排的Docker容器中运行.
采集的数据源调查
在“数据搜寻器系统”启动之前,该系统是必不可少的链接. 经过调查,发现需要采集页面,要过滤的关键字,要提取的内容等.
数据搜寻器系统
爬虫程序都是独立的个体,与所需的数据采集系统服务器结合,由Rancher安排,该爬虫程序在DigitalOcean中自动启动,并根据输入参数捕获指定的数据,然后将其发送回我们的大型数据集群系统.
数据清理系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示,显示由搜寻器程序捕获的数据,并方便我们进行清理. 数据清理系统主要由两部分组成:
数据整合系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示和合并数据. 清除数据后,数据合并系统将自动匹配大数据集群中的数据,并通过熟人评分将可能的熟人数据关联起来. 匹配结果通过Web前端显示,并且数据可以手动或自动合并.
任务计划系统
该系统通过Ruby on Rails + Vue技术框架,Sidekiq队列调度和Redis调度数据持久性来实现Web前端任务调度系统. 通过任务计划系统,您可以动态打开和关闭,并定期启动搜寻器程序.
搜索引擎系统
该系统通过ElasticSearch集群实现搜索引擎服务. 搜索引擎是PC端检索系统从大数据集群快速检索数据的必要工具. 通过ElasticSearch集群,运行三个以上的Master角色以确保集群系统的稳定性,并运行两个以上的Client角色以确保查询的容错能力,两个或多个Data角色可确保查询和编写的及时性. 通过负载平衡连接客户端角色,以分散数据查询压力.
芭奇:不用编撰采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-03 21:03
一、首先打开这个功能。在网站右健可以看见这个功能:如下图。
二、打开后的功能如下,可以在左边填写指定采集的列表地址:
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上自动采集编写,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、htm,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下自动采集编写,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。 查看全部
一直以来,大家都在用各类类型采集器或网站程序自带的采集功能,它们有一个共同的特征,就是要写采集规则才可以采集到文章,这个技术性的问题,对菜鸟站升可不是一件容易的事,对老站长,它也是一个吃力的工作。那么,如果做站群的话,每个站都要定义一个采集规则的话,那就真是苦不堪言。有人说,站长是一个网络搬运工。这话说得也是有道理的。互联网上的文章,很多都是你搬我的,我搬你的,为了生活,不得不怎么做下去。现在芭奇站群软件新出一个新的新型采集功能,能大大减少站长的“搬运工”的时间,也不用再写可恶的采集规则了,这个功能就是互联网首创的功能---指定网址采集。下面我教你们怎么使用这个功能:
一、首先打开这个功能。在网站右健可以看见这个功能:如下图。
二、打开后的功能如下,可以在左边填写指定采集的列表地址:
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上自动采集编写,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、htm,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下自动采集编写,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
无人值守免费手动采集器绿色版 3.4.7
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-08-03 21:00
3.支持随机选用发布帐号
4.支持任意发布项语言翻译
5.支持编码转换、支持UBB代码
6.文件上传可选择好手动构建年月日子目录
7.模拟发布支持对难以安装插口的网站进行发布操作
8.方案可定时工作
9.防止网路运营商绑架HTTP功能
10.可自动进行单项采集发布
11.详尽的工作流程监视、信息反馈,让您迅速了解工作状态
软件特征1、设定好方案,即可24小时手动工作自动采集,不再须要人工干涉
2、与网站分离,通过独立制做的插口,可以支持任何网站或数据库
3、灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
4、小巧、低耗和良好的稳定性特别适宜运行于服务器
5、所有规则都可以导出导入,灵活的资源重用
6、采用FTP上传文件,稳定、安全
7、下载上传支持断点续传
8、高速伪原创
使用教程1、程序免安装,解压安装包双击“优采云采集器3.exe”即可启动程序
2、进入程序,点击“制定方案”自动采集,进入相应的方案设定
3、点击“您的方案”,在采集规则一栏中点击“搜索文件”图标
4、进行采集规则的配置
5、在中间规则一栏中点击“搜索文件”图标
6、进行中间规则的配置
7、在发布规则一栏中点击“搜索文件”图标
8、配置发布规则,将信息添加到您的网站
9、完成添加,点击“开始”即可开始手动采集
更新日志无人值守免费手动采集器 v3.1.7更新内容
1、修正:上一版中数据项不容许为空失效的问题。
2、新增:数据项如今可以设置前置数据整理组,在完成数据项的包括翻译在内的各项操作后进行第二次加工
3、新增:翻译降低‘待翻译数据项’栏,可以指定须要翻译的数据项名称
4、修正:多列表测试时结果显示不完整的问题
5、新增:方案设置中的采集间隔如今可以设置随机时间
6、新增:采集规则如今可以独立设置UserAgent,并且可以设置多个UA随机调用 查看全部
2.与采集数据分离的发布参数项,可自由对应采集数据或预设数值,极大提高发布规则的重用性
3.支持随机选用发布帐号
4.支持任意发布项语言翻译
5.支持编码转换、支持UBB代码
6.文件上传可选择好手动构建年月日子目录
7.模拟发布支持对难以安装插口的网站进行发布操作
8.方案可定时工作
9.防止网路运营商绑架HTTP功能
10.可自动进行单项采集发布
11.详尽的工作流程监视、信息反馈,让您迅速了解工作状态
软件特征1、设定好方案,即可24小时手动工作自动采集,不再须要人工干涉
2、与网站分离,通过独立制做的插口,可以支持任何网站或数据库
3、灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
4、小巧、低耗和良好的稳定性特别适宜运行于服务器
5、所有规则都可以导出导入,灵活的资源重用
6、采用FTP上传文件,稳定、安全
7、下载上传支持断点续传
8、高速伪原创
使用教程1、程序免安装,解压安装包双击“优采云采集器3.exe”即可启动程序
2、进入程序,点击“制定方案”自动采集,进入相应的方案设定

3、点击“您的方案”,在采集规则一栏中点击“搜索文件”图标

4、进行采集规则的配置

5、在中间规则一栏中点击“搜索文件”图标

6、进行中间规则的配置

7、在发布规则一栏中点击“搜索文件”图标

8、配置发布规则,将信息添加到您的网站

9、完成添加,点击“开始”即可开始手动采集

更新日志无人值守免费手动采集器 v3.1.7更新内容
1、修正:上一版中数据项不容许为空失效的问题。
2、新增:数据项如今可以设置前置数据整理组,在完成数据项的包括翻译在内的各项操作后进行第二次加工
3、新增:翻译降低‘待翻译数据项’栏,可以指定须要翻译的数据项名称
4、修正:多列表测试时结果显示不完整的问题
5、新增:方案设置中的采集间隔如今可以设置随机时间
6、新增:采集规则如今可以独立设置UserAgent,并且可以设置多个UA随机调用
分享一个利器,快速采集文章全靠它!
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2020-08-03 21:00
疫情期间智能采集组合文章,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一智能采集组合文章,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
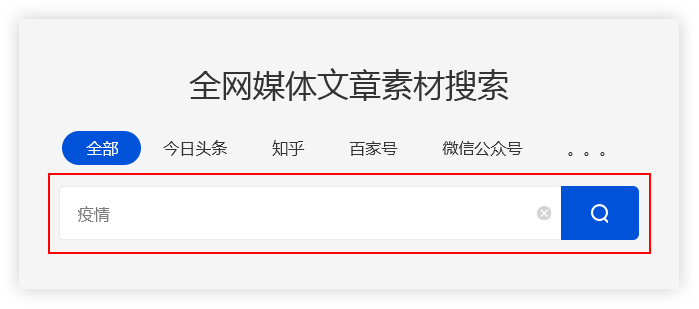
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需收集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
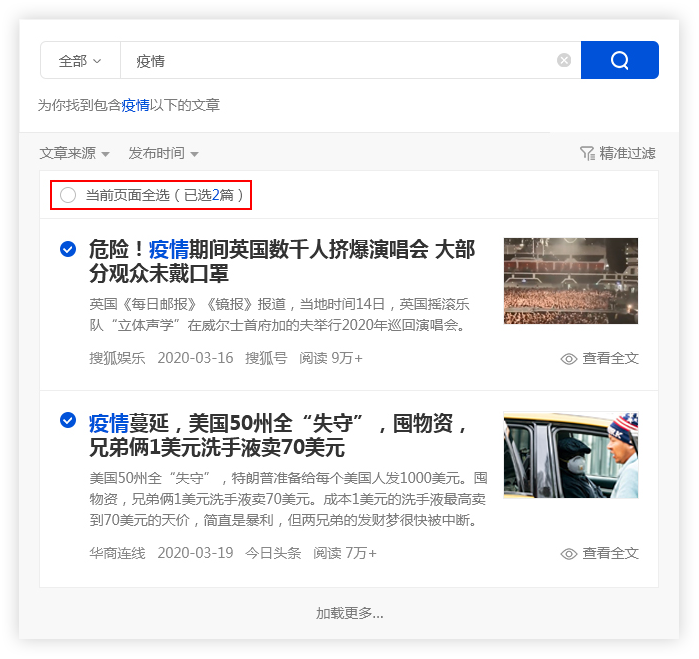
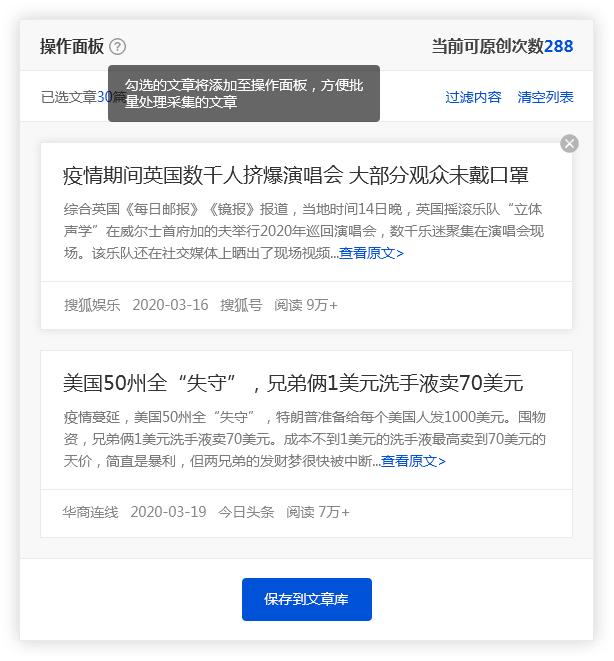
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
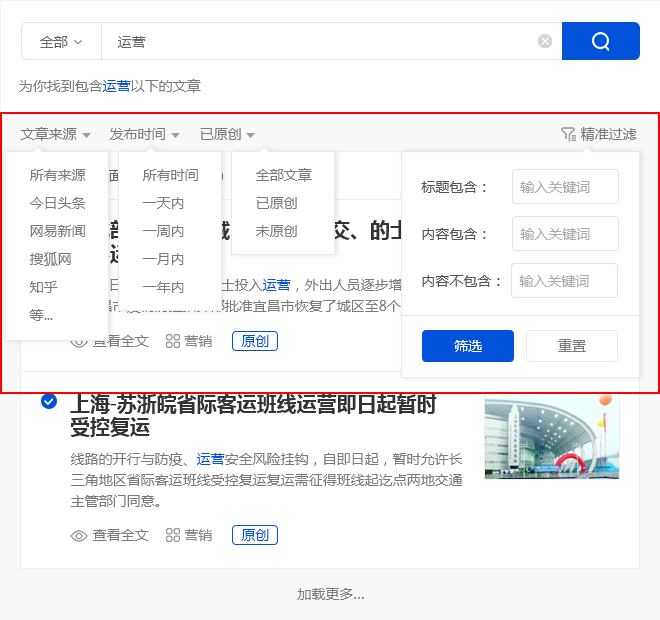
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤 查看全部
编辑

疫情期间智能采集组合文章,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一智能采集组合文章,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需收集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。

(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤
【站群使用神器】众大云采集Discuz版可快速手动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-03 19:01
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂站群自动采集器,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多站群自动采集器,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下: 查看全部
【站群使用神器】众大云采集Discuz版可快速手动采集数据
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂站群自动采集器,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多站群自动采集器,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下:
众大云采集插件 免费版v9.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-03 18:01
软件介绍
众大云采集插件具有易学,易懂,易用,成熟稳定等特点,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面!
软件功能
01.可以批量注册马甲用户云采集免费,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02.可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03.可以定时采集和手动发布,实现无人值守。
04.采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05.支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06.采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07.图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08.图片会加上您峰会或则门户设置的水印。
09.已经采集过的内容不会重复二次采集,内容不会重复冗余。
10.采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11.浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12.可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13.采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14.可以一键获取当日的实时热点内容,然后一键发布。
15.不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16.插件外置正文提取算法云采集免费,在前台发表内容的时侯,输入网址即可以采集到内容。 查看全部
众大云采集插件是一款非常好用的采集工具,能为用户去采集论坛中的贴子内容,还能批量注册、评论等等功能,采集功能实现手动采集,经过系统筛选,将重复的内容移除,提高采集的疗效。
软件介绍
众大云采集插件具有易学,易懂,易用,成熟稳定等特点,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面!

软件功能
01.可以批量注册马甲用户云采集免费,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02.可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03.可以定时采集和手动发布,实现无人值守。
04.采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05.支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06.采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07.图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08.图片会加上您峰会或则门户设置的水印。
09.已经采集过的内容不会重复二次采集,内容不会重复冗余。
10.采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11.浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12.可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13.采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14.可以一键获取当日的实时热点内容,然后一键发布。
15.不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16.插件外置正文提取算法云采集免费,在前台发表内容的时侯,输入网址即可以采集到内容。
众大云采集Discuz版下载地址 已被下载次
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-03 18:00
【温馨提示】
01、安装本插件以后云采集,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳云采集,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下: 查看全部
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后云采集,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳云采集,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下:
一米智能文章采集系统 v1.0 免费版文章采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-03 16:03
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。

一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。
如何配置手动采集、自动更新网站数据
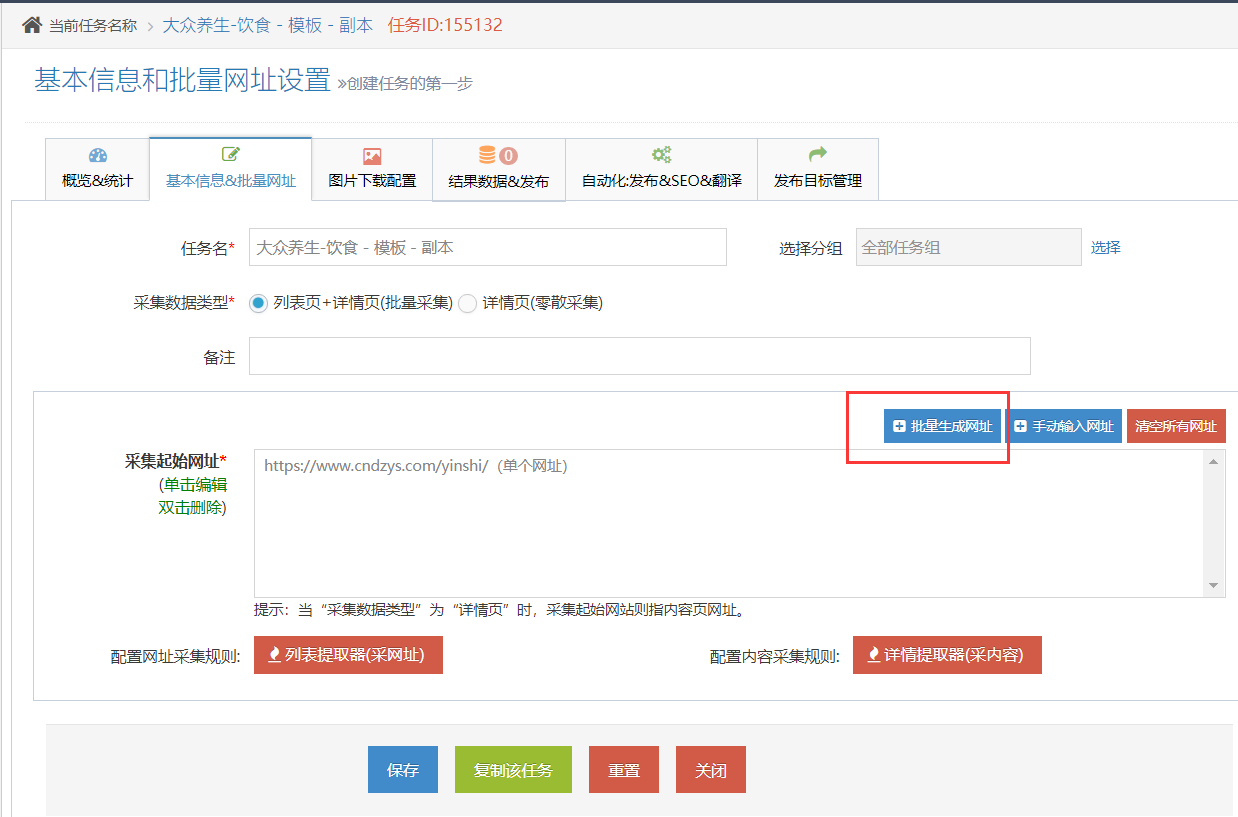
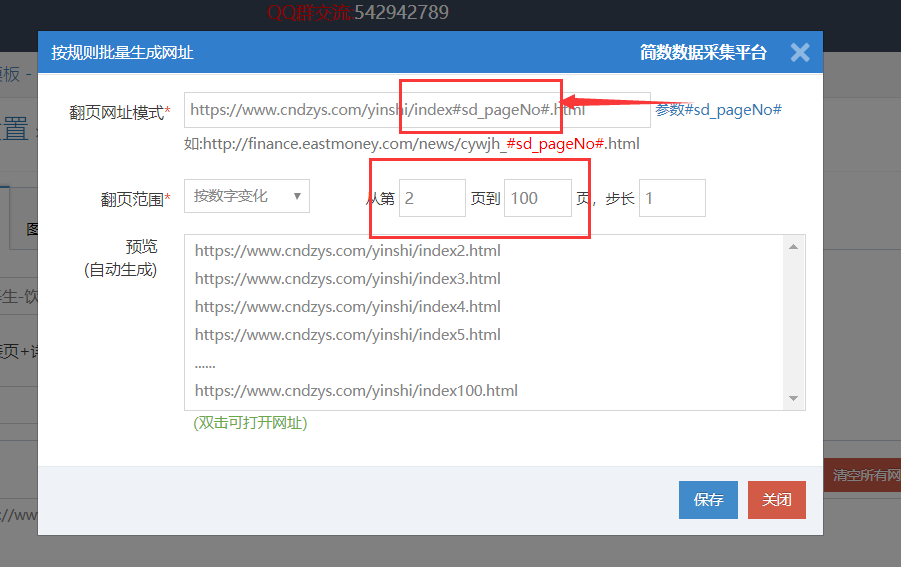
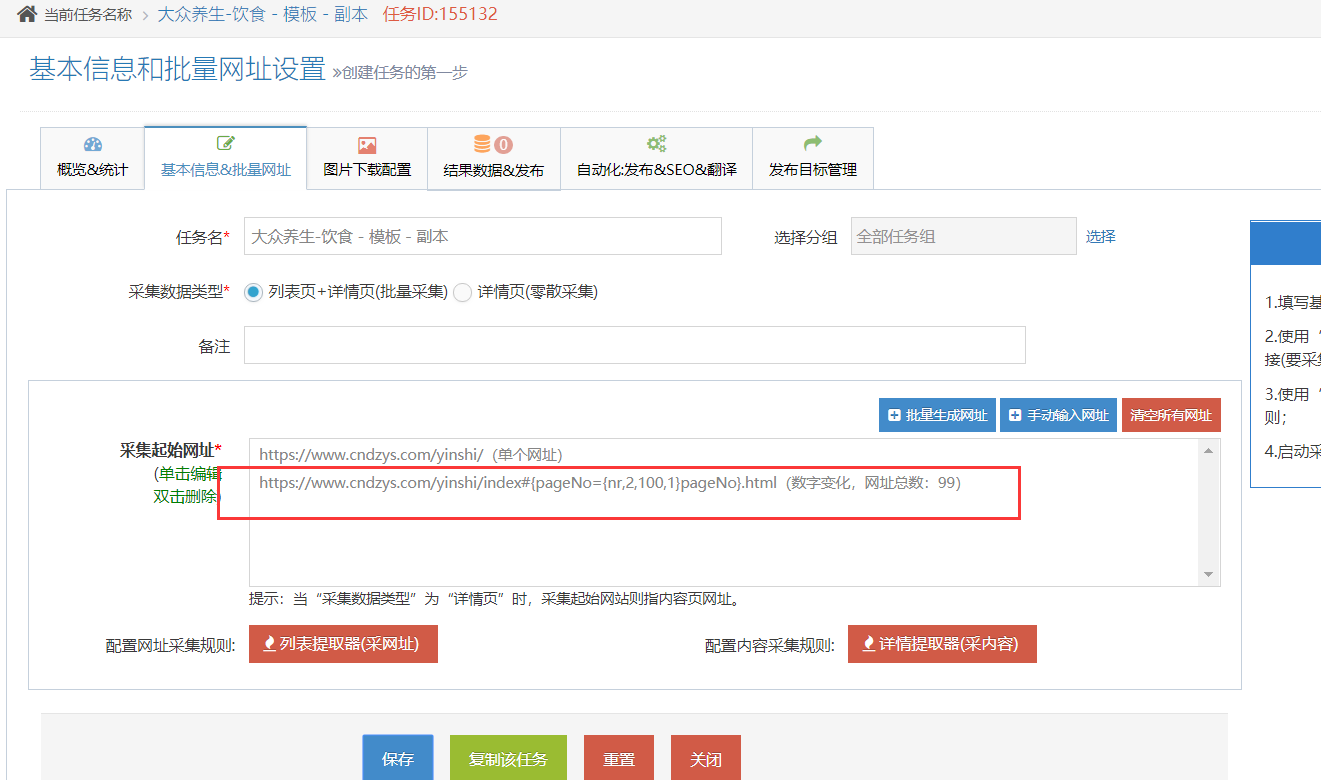
采集交流 • 优采云 发表了文章 • 0 个评论 • 639 次浏览 • 2020-08-03 16:01
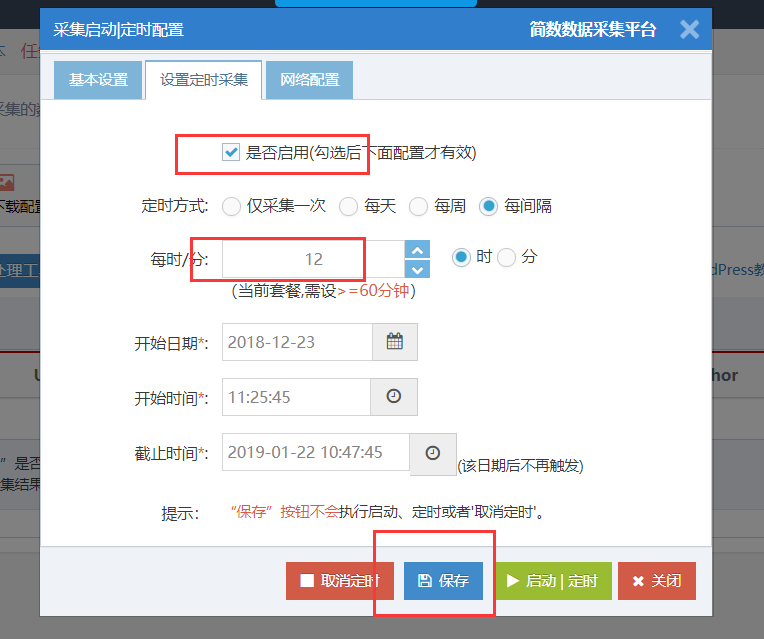
定时采集功能详情:定时采集配置;
自动发布功能详情:采集后手动发布配置;
基本流程: 1. 采集已有的全部数据
先设置采集已有的全部列表页中的数据;(下面以 “大众养身-饮食” 模板为例,假设共100页)
2. 采集更新数据
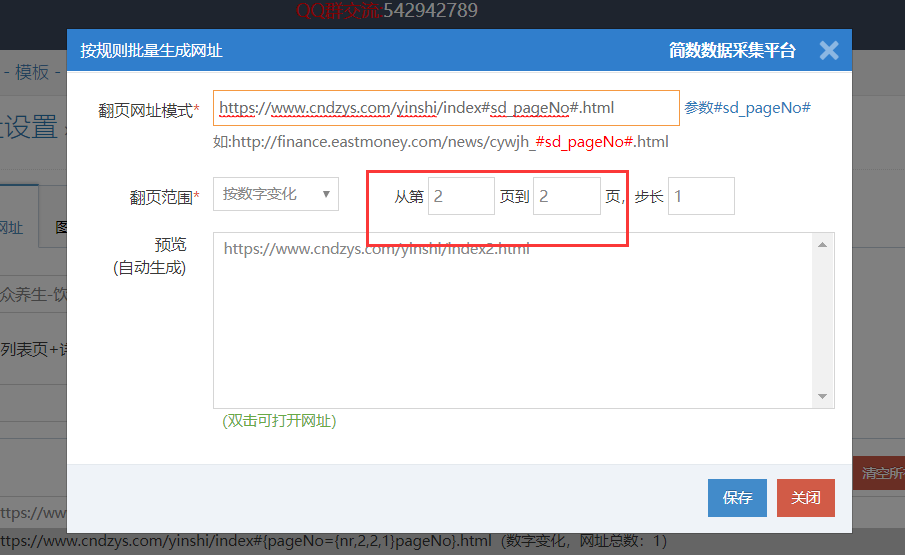
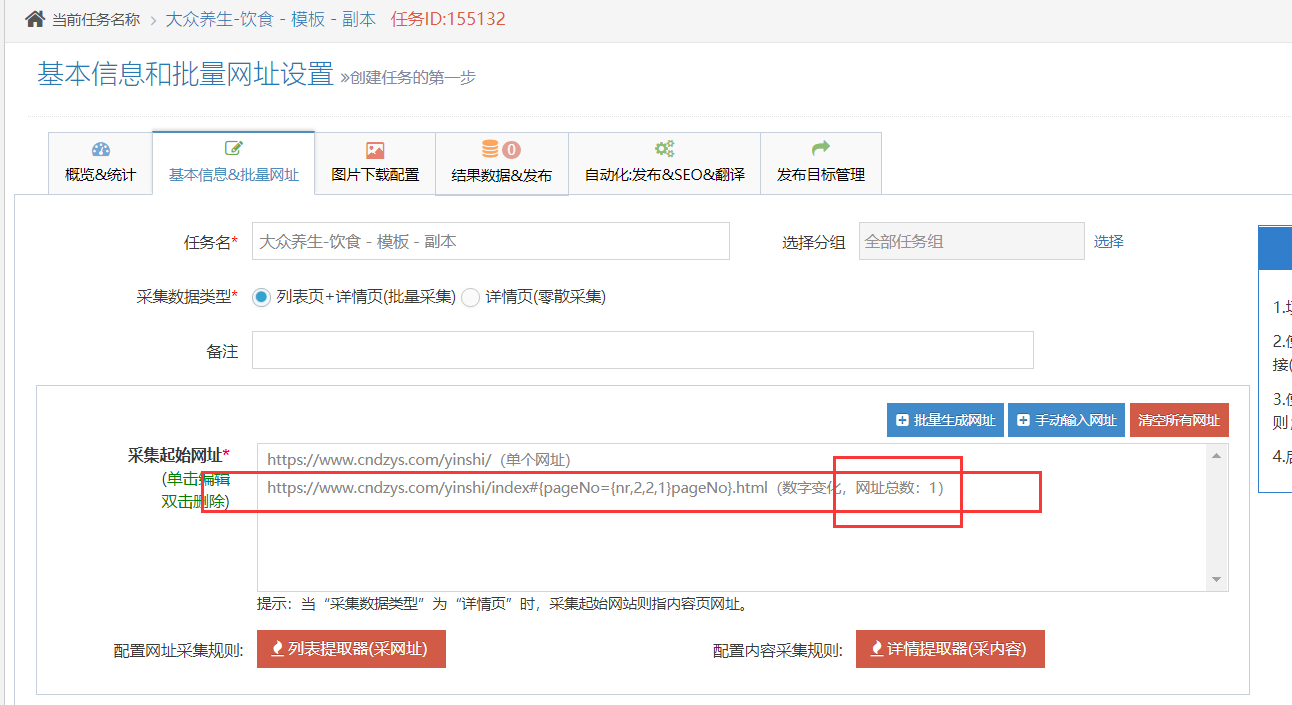
待已有的全部数据采集完成后,现只需定时采集更新的内容,用户通常会在 “启动 | 定时采集“ 处设置重复数据跳过来实现。
上述操作可行,但有个方法可急剧增强同步更新采集效率:
判断是否重复数据,系统是遍历配置采集的列表页中的文章与已采集入库的文章中有无相同标题,如果数据量多会影响采集速度。
用户可通过观察采集源网站的内容更新频度和数目网站自动采集系统,估算新内容会显示在列表页的前几页,并在 “采集起始网址” 处设置只采集前几页的内容,减少系统遍历列表页页数来提升采集效率。
如下例网站新内容12小时更新一次,且通常显示在列表页的前两页,则可配置只采集前两页列表的文章。
(如果没有这一步网站自动采集系统,按原先的设置,系统要遍历100页列表页判定是否有重复数据,现只需遍历2页列表页)
查看全部
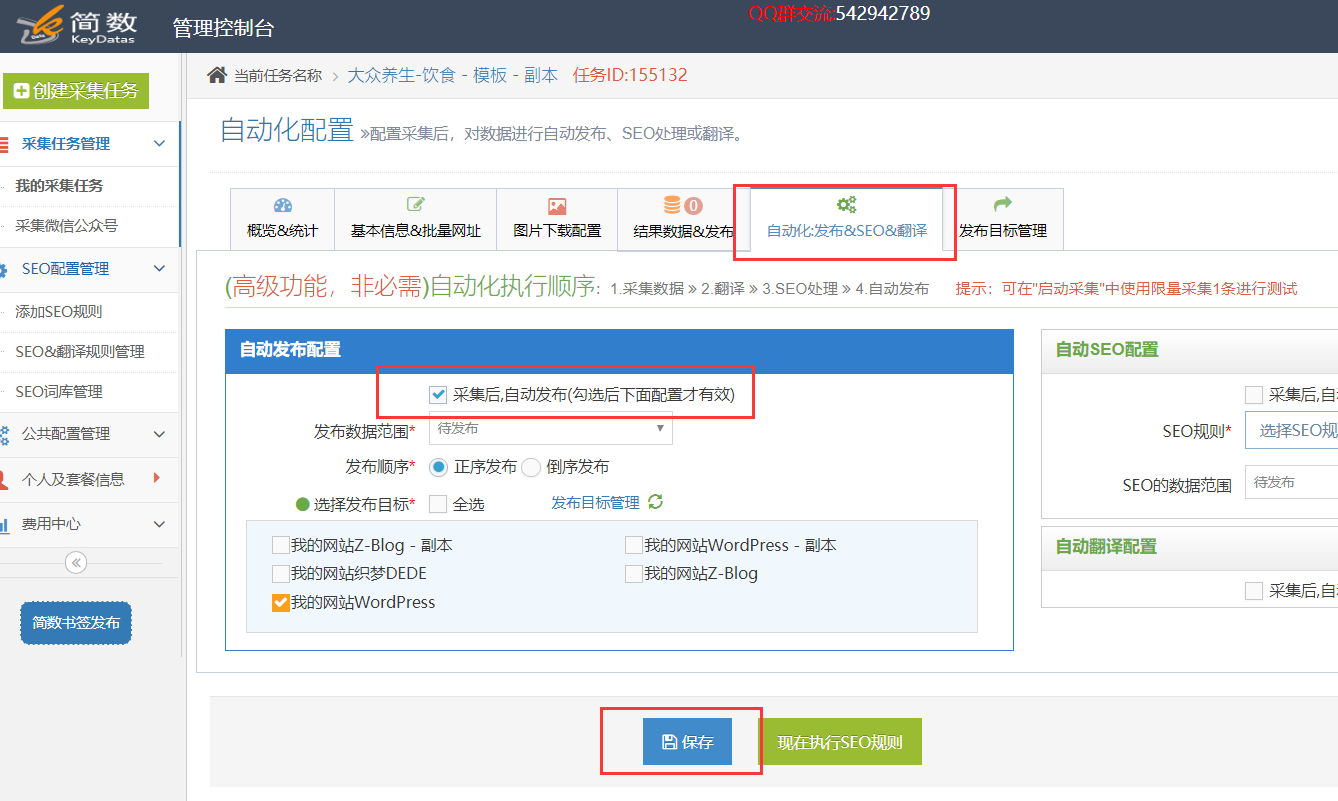
优采云采集平台通过设置 “定时采集” + “重复数据跳过” + “自动发布” 功能可实现同步更新数据,即定时检查采集源网站是否有内容更新,采集并发布新内容。
定时采集功能详情:定时采集配置;
自动发布功能详情:采集后手动发布配置;
基本流程: 1. 采集已有的全部数据
先设置采集已有的全部列表页中的数据;(下面以 “大众养身-饮食” 模板为例,假设共100页)
2. 采集更新数据
待已有的全部数据采集完成后,现只需定时采集更新的内容,用户通常会在 “启动 | 定时采集“ 处设置重复数据跳过来实现。
上述操作可行,但有个方法可急剧增强同步更新采集效率:
判断是否重复数据,系统是遍历配置采集的列表页中的文章与已采集入库的文章中有无相同标题,如果数据量多会影响采集速度。
用户可通过观察采集源网站的内容更新频度和数目网站自动采集系统,估算新内容会显示在列表页的前几页,并在 “采集起始网址” 处设置只采集前几页的内容,减少系统遍历列表页页数来提升采集效率。
如下例网站新内容12小时更新一次,且通常显示在列表页的前两页,则可配置只采集前两页列表的文章。
(如果没有这一步网站自动采集系统,按原先的设置,系统要遍历100页列表页判定是否有重复数据,现只需遍历2页列表页)
【伪原创】自动采集文章内容兼发布文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 534 次浏览 • 2020-08-03 16:00
LmCjl程序转优化猿程序猿是无所不能的,上到写代码,下到各种各样的事情,包括我自己组装单车和上下婴儿床,小到学钢琴,大到变革优化猿,我都O得K的。
自动采集文章内容兼发布内容
经历了几个月的敲敲打打,自动采集文章内容兼手动发布文章内容早已推下来了,简单容易的操作面板,可实现5~10分钟菜鸟熟练上手,同时便捷了做优化的大大们管理站群和发布文章的痛处,目前支持采集各大网站网站文章自动采集,识别率达到百分之99,同时支持各大个人网站的手动发布文章,教程早已发布在网站里面了。点击步入工具即可查看教程。
采集文章内容可辨识我想要的内容吗?
没问题的,只须要把你所需的文章内容网站文章自动采集,输入你想要的关键词,会手动筛选和匹配你想要的。
例如:
1.我想要带有SEO这个词的文章,其他的我都不要,只须要在采集管理的上面,输入包含关键词,即可。
最多可以管理多少个网站?
我可以说,多多益善吗?LmCjl目前管理的网站是658个,但是我还可以继续降低起来。
网站地址:
工具地址:
做简单好用的在线工具,无需下载,只须要记住:lmcjl
爱看书也爱远行
心情在路上
FIND YOURSELF
读好多的随记也写下好多的文字/浅浅淡淡
似乎能够感受到那是的安稳自由悠闲和
一种特殊的安静的力量
如果能够出发去遇到更多的未知的人和事
那我一定不辜负世界的温柔 查看全部
LmCjl程序转优化猿程序猿是无所不能的,上到写代码,下到各种各样的事情,包括我自己组装单车和上下婴儿床,小到学钢琴,大到变革优化猿,我都O得K的。
自动采集文章内容兼发布内容
经历了几个月的敲敲打打,自动采集文章内容兼手动发布文章内容早已推下来了,简单容易的操作面板,可实现5~10分钟菜鸟熟练上手,同时便捷了做优化的大大们管理站群和发布文章的痛处,目前支持采集各大网站网站文章自动采集,识别率达到百分之99,同时支持各大个人网站的手动发布文章,教程早已发布在网站里面了。点击步入工具即可查看教程。
采集文章内容可辨识我想要的内容吗?
没问题的,只须要把你所需的文章内容网站文章自动采集,输入你想要的关键词,会手动筛选和匹配你想要的。
例如:
1.我想要带有SEO这个词的文章,其他的我都不要,只须要在采集管理的上面,输入包含关键词,即可。
最多可以管理多少个网站?
我可以说,多多益善吗?LmCjl目前管理的网站是658个,但是我还可以继续降低起来。
网站地址:
工具地址:
做简单好用的在线工具,无需下载,只须要记住:lmcjl
爱看书也爱远行
心情在路上
FIND YOURSELF
读好多的随记也写下好多的文字/浅浅淡淡
似乎能够感受到那是的安稳自由悠闲和
一种特殊的安静的力量
如果能够出发去遇到更多的未知的人和事
那我一定不辜负世界的温柔
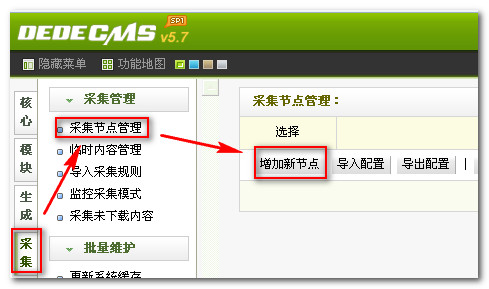
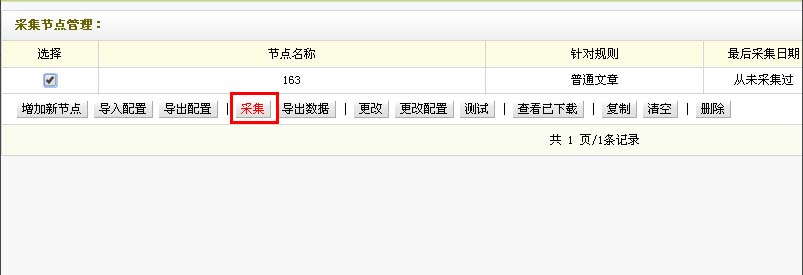
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-03 15:02
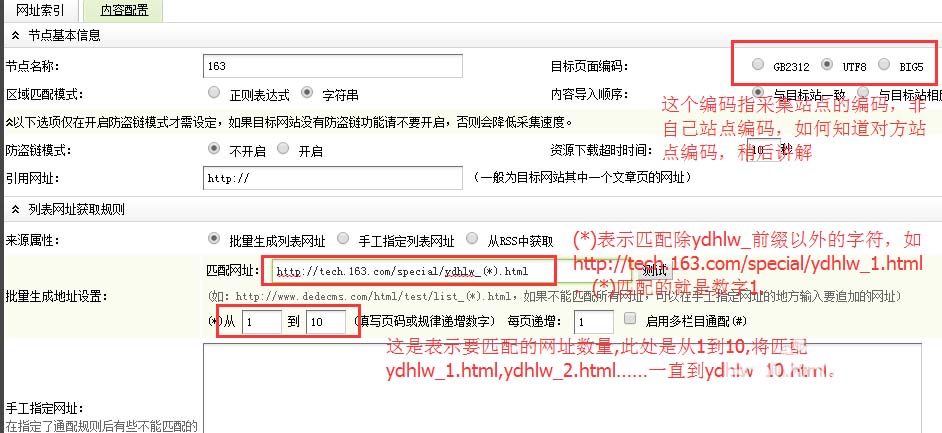
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
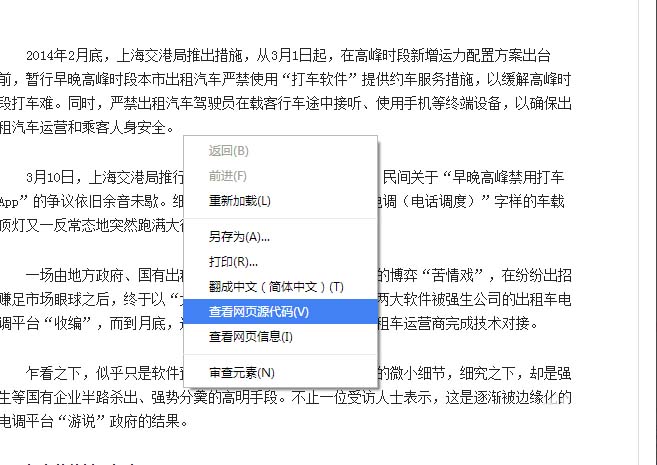
查看采集站点的编码和网站源码
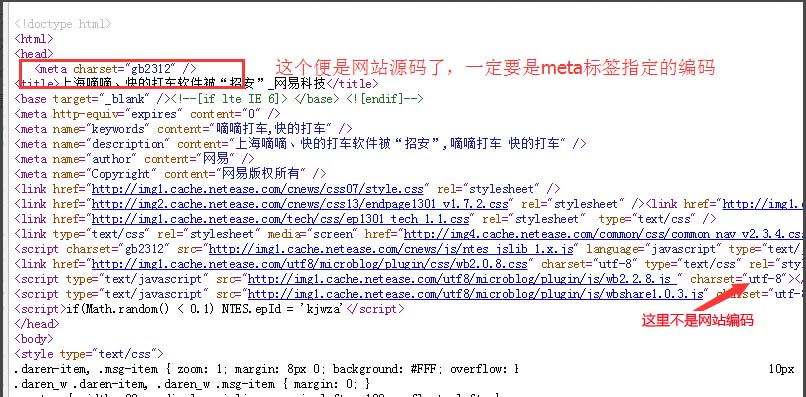
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
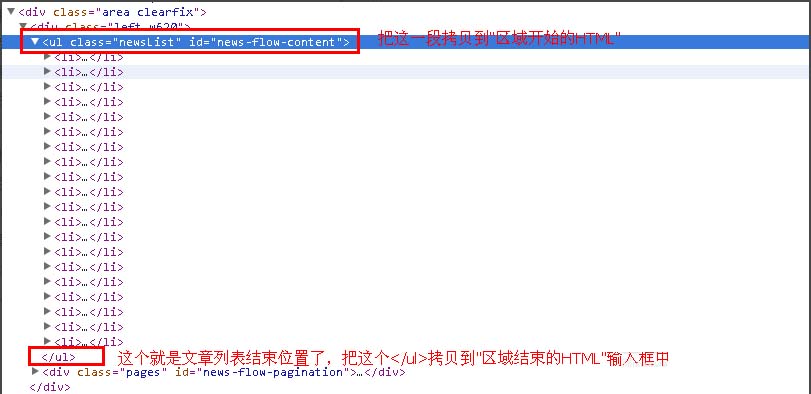
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
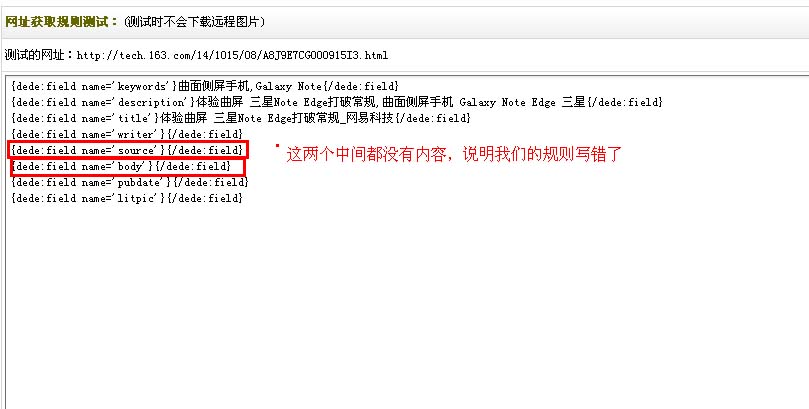
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
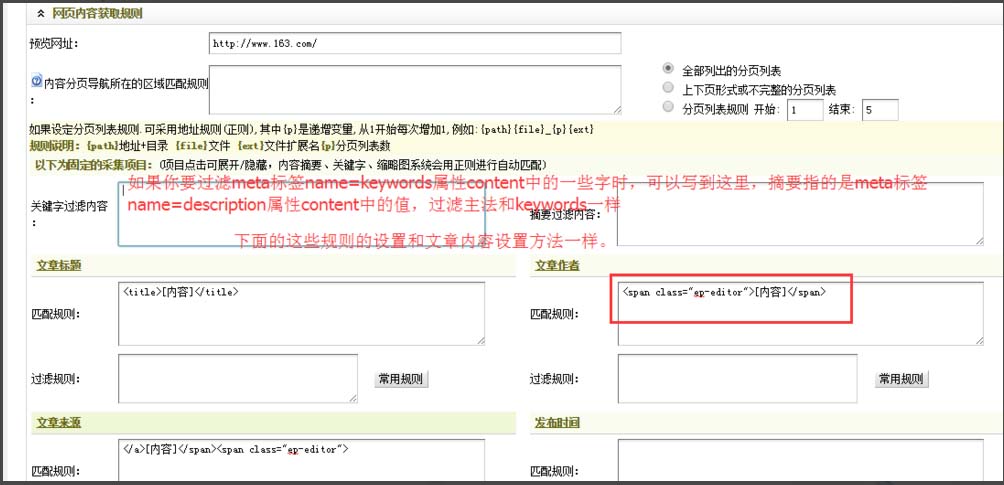
第五步:内容数组获取规则
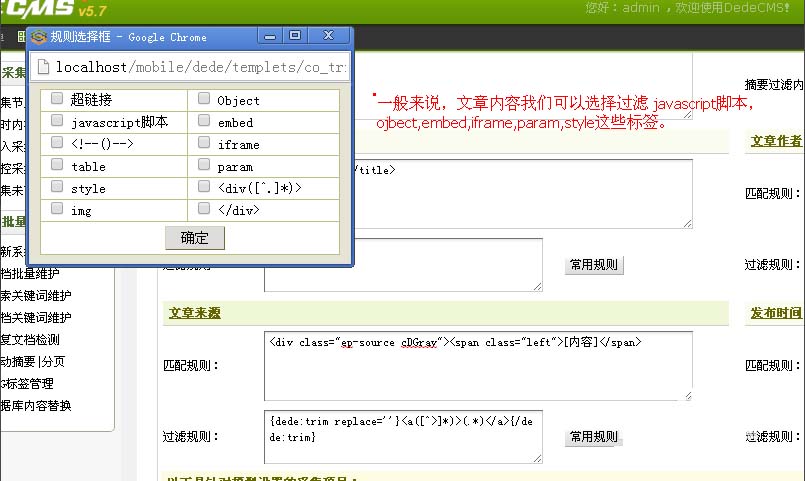
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
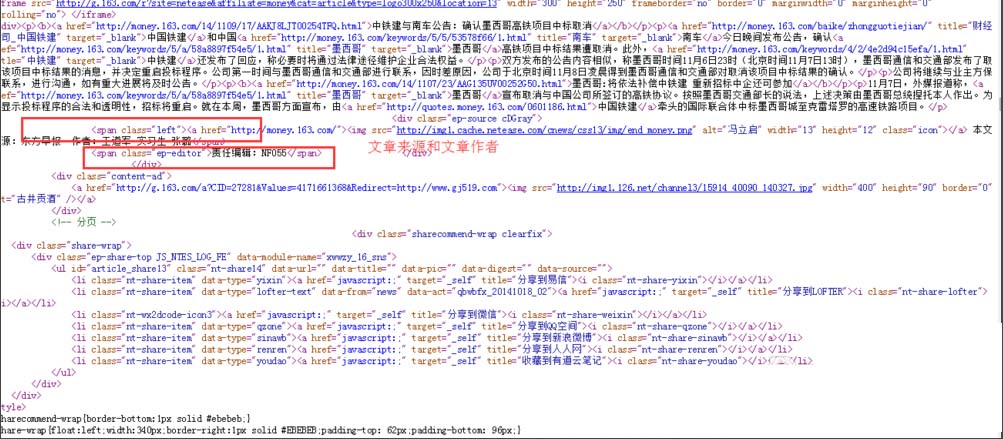
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
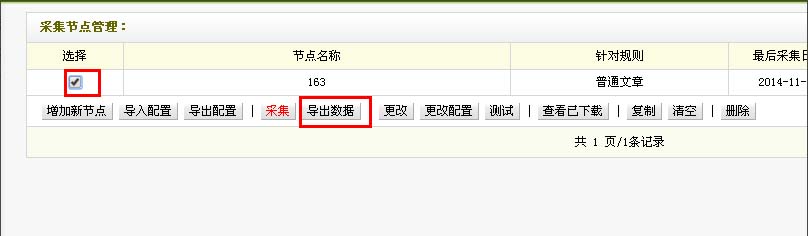
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
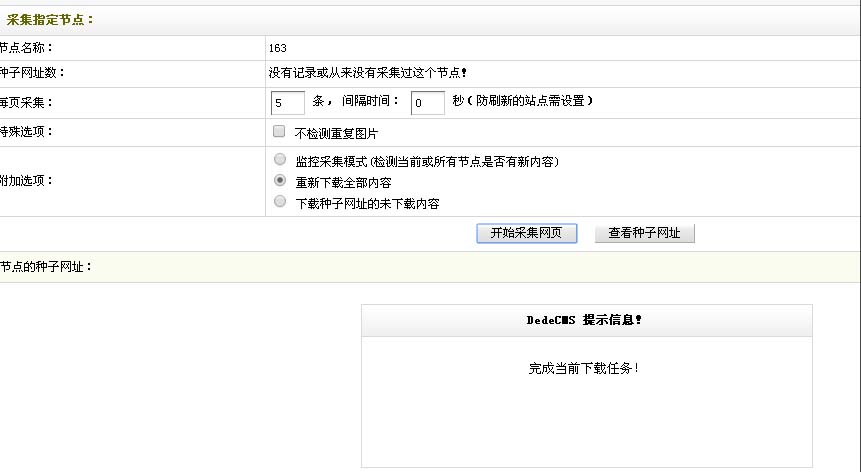
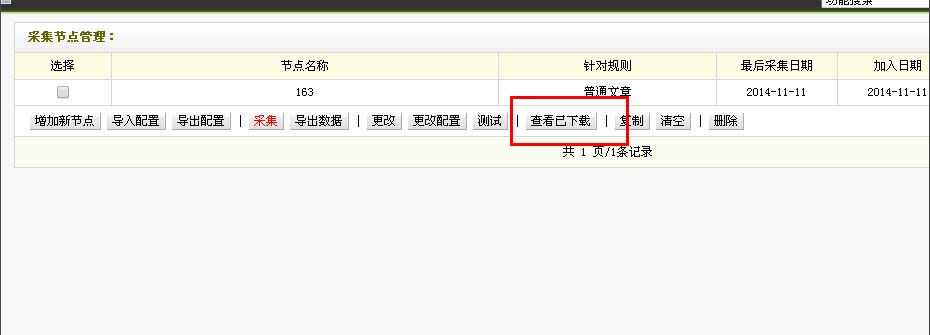
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
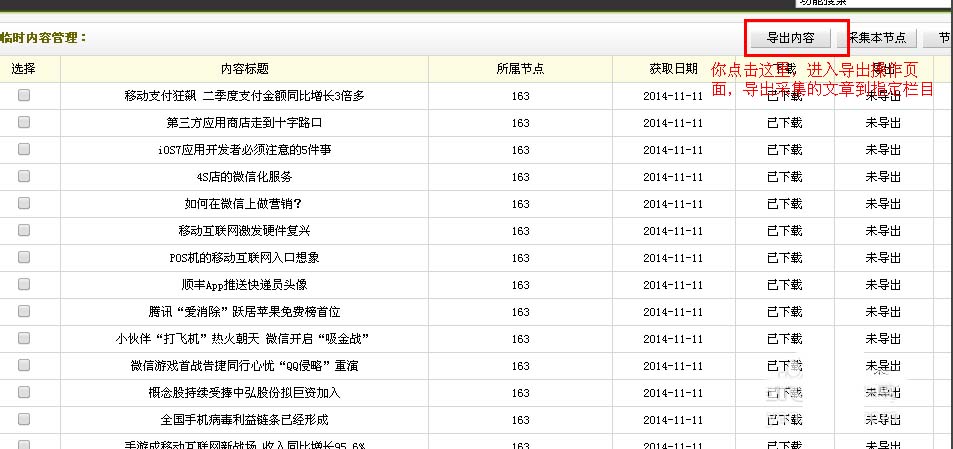
导出内容
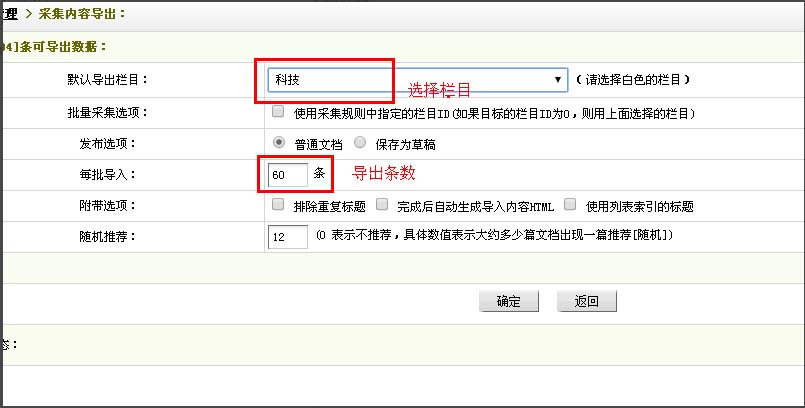
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"

第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。

第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存

采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果
一套内容采集系统 解放编辑人员
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-08-03 13:02
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用内容采集系统,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log内容采集系统,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新) 查看全部
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。

NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:


使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:


真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用内容采集系统,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:

HostRunnerService 的配置也很简单:

在RunTime.txt 中设定每晚定时采集几次:

当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log内容采集系统,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新)
明日以后无限资源辅助 自动采集挂机升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 1217 次浏览 • 2020-08-03 10:52
—————明日以后安卓版【点击下载】,赠送金币50000+典藏版ump9图纸。
明日以后无限资源辅助
资源是有其中最重要的道具,不管是木材资源、铁矿资源、麻资源,玩家是须要去采集、去挖掘的才有机率可以获得。游戏中的资源,这个是不能订购的,直接采集就可以获得,而且数目十分多,副材料是可以破防下来的,需求量十分高,需要用一些太基础的材料,然后合成中级资源。
资源辅助:点击下载
开启步骤
1、玩家可以先下载这个辅助,辅助还是比较好用的,可以设置一些手动挂机、自动采集。无限资源就是有采集和升级的功能挂机 采集,需要对应的资源,你直接勾选就可以了。
2、打开辅助,进行后台运行,运行以后在游戏中就可以显示下来挂机 采集,在右侧有一个透明显示。
3、点击左上角这儿,然后把软件设置下来,直接设置对应的采集方式对的,刷熟练度形式,点上去就可以了,他会手动的去升级去采集。
目前使用辅助还是有机率被封号的,玩家可以用大号测试一下,或者是就只玩大号,大号就不玩。
————点击下载明天过后【电脑版】,PC流畅运行,完美适配,下载送礼包。
以上有关于明天过后手动采集挂机升级相关内容了,如果想要了解更多资讯,直接在百度中搜索(明日以后琵琶网+你想查找的内容),还可以【点击这儿】关注礼包的动态。
《明日以后》【安卓下载】领取礼包(新币*20000+肾上腺剂*10)【点我进群】群号:945254345 查看全部
明日以后中的无限资源,资源是最重要的,玩家须要采集资源或则是订购资源,有的就是手动采集的,无限资源如何开?下面我带你们了解下。
—————明日以后安卓版【点击下载】,赠送金币50000+典藏版ump9图纸。
明日以后无限资源辅助
资源是有其中最重要的道具,不管是木材资源、铁矿资源、麻资源,玩家是须要去采集、去挖掘的才有机率可以获得。游戏中的资源,这个是不能订购的,直接采集就可以获得,而且数目十分多,副材料是可以破防下来的,需求量十分高,需要用一些太基础的材料,然后合成中级资源。
资源辅助:点击下载
开启步骤
1、玩家可以先下载这个辅助,辅助还是比较好用的,可以设置一些手动挂机、自动采集。无限资源就是有采集和升级的功能挂机 采集,需要对应的资源,你直接勾选就可以了。
2、打开辅助,进行后台运行,运行以后在游戏中就可以显示下来挂机 采集,在右侧有一个透明显示。
3、点击左上角这儿,然后把软件设置下来,直接设置对应的采集方式对的,刷熟练度形式,点上去就可以了,他会手动的去升级去采集。
目前使用辅助还是有机率被封号的,玩家可以用大号测试一下,或者是就只玩大号,大号就不玩。
————点击下载明天过后【电脑版】,PC流畅运行,完美适配,下载送礼包。
以上有关于明天过后手动采集挂机升级相关内容了,如果想要了解更多资讯,直接在百度中搜索(明日以后琵琶网+你想查找的内容),还可以【点击这儿】关注礼包的动态。
《明日以后》【安卓下载】领取礼包(新币*20000+肾上腺剂*10)【点我进群】群号:945254345
教你怎样将采集来的文章伪装成原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 497 次浏览 • 2020-08-03 09:07
然而,站长的精力虽然有限,不可能每晚只去撰写网站的内容而不做别的事情。况且有些站长手里的站点还不止一个。因此伪原创的高价值文章的撰写就变得十分有必要了。那么怎么能够写好呢?
1.采集与网站主题相关的内容
就像男人不可以穿长裤一样,网站的内容也要符合网站的主题才行,否则采集文章内容,用户对你建设网站的意图倍感蒙蔽,不知道你这个网站究竟是干哪些的。具体来说就是资讯站就要去采集那些热门的新闻资讯,而不是发一些校园故事;如果是网路营销网站采集文章内容,就要去采集那些与网路营销相关的内容。
采集对的文章是撰写高质量伪原创文章的步,毕竟资料首先得是正确的嘛。另外,采集的内容也要保证有一定的质量。一篇垃圾文章,你想把它改写成优质文章需要花费的精力也不少,有时候还不如自己写来得快。
2.用心更改文章
其一,改写文章的标题和首尾段。想要撰写伪原创文章,就算首尾段不改,标题也一定要改。但若果想得到更好的原创度的话,首尾段也要自己来写,保证首尾段以及标题的真正原创。并且,撰写的过程中要注意带入自己网站的关键词,删除与对方相关的一些信息。
其二,具体改写的时侯,可以通过修改成语的次序或则变化句式来进行原创的创作。简单的举个反例:今天小明事假回去了。就可以更改成“你晓得明天小明为何没来吗?因为他事假回去了。”
其三,大家还可以多采集几篇文章,然后感悟这几篇文章的意思,将它们融合在一起。相信这样的文章写下来原创度也是能得到保证的。 查看全部
在google代理商看来,网站的内容对网站而言就相当于是一个人的灵魂。试想一个人没有灵魂的话岂不就是行尸走肉?!那么没有优质内容的网站也就相当于是一个空架子,是没有用户想去访问和浏览的。
然而,站长的精力虽然有限,不可能每晚只去撰写网站的内容而不做别的事情。况且有些站长手里的站点还不止一个。因此伪原创的高价值文章的撰写就变得十分有必要了。那么怎么能够写好呢?
1.采集与网站主题相关的内容
就像男人不可以穿长裤一样,网站的内容也要符合网站的主题才行,否则采集文章内容,用户对你建设网站的意图倍感蒙蔽,不知道你这个网站究竟是干哪些的。具体来说就是资讯站就要去采集那些热门的新闻资讯,而不是发一些校园故事;如果是网路营销网站采集文章内容,就要去采集那些与网路营销相关的内容。
采集对的文章是撰写高质量伪原创文章的步,毕竟资料首先得是正确的嘛。另外,采集的内容也要保证有一定的质量。一篇垃圾文章,你想把它改写成优质文章需要花费的精力也不少,有时候还不如自己写来得快。
2.用心更改文章
其一,改写文章的标题和首尾段。想要撰写伪原创文章,就算首尾段不改,标题也一定要改。但若果想得到更好的原创度的话,首尾段也要自己来写,保证首尾段以及标题的真正原创。并且,撰写的过程中要注意带入自己网站的关键词,删除与对方相关的一些信息。
其二,具体改写的时侯,可以通过修改成语的次序或则变化句式来进行原创的创作。简单的举个反例:今天小明事假回去了。就可以更改成“你晓得明天小明为何没来吗?因为他事假回去了。”
其三,大家还可以多采集几篇文章,然后感悟这几篇文章的意思,将它们融合在一起。相信这样的文章写下来原创度也是能得到保证的。
采集 列表页和详情页的使用方法有哪些?怎么用?
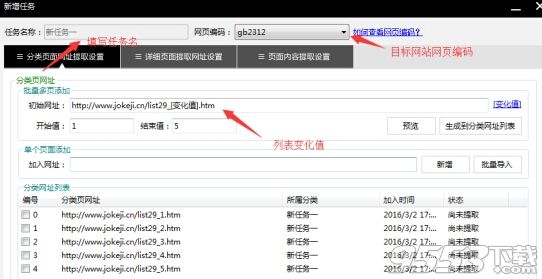
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-03-21 20:13
一个小概念:
大多数网站以列表页面和详细信息页面的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以将其视为列表页面。单击标题链接后,进入详细信息页面。
使用data 采集工具的一般目的是在详细信息页面中获取大量特定的内容数据,并将这些数据用于各种分析,发布自己的网站等。
列表页面:指的是列或目录页面,通常收录多个标题链接。例如:网站第一页或列页面是列表页面。主要功能:您可以通过列表页面获得到多个详细信息页面的链接。
详细信息页面:收录特定内容的页面,例如网页文章,其中收录:标题,作者,出版日期,正文内容,标签等。
要开始,请登录“ 优采云控制面板”:
详细的使用步骤:
第一步:创建采集任务
单击左侧菜单按钮“创建采集任务”,输入采集任务名称和想要的采集“列表页面”的URL,例如:,可以保留详细信息页面链接空白,系统将自动识别它。
如下所示:
输入后,单击“下一步”。
第2步:改善列表页面的智能提取结果(可选)
系统将首先使用智能算法来获取需要采集的详细信息页面链接(多个)。用户可以双击打开支票。如果您不需要数据,则可以单击“列表提取器”以手动指定它,仅在可视化中使用鼠标单击界面。
智能采集的结果如下:
打开列表提取器后的下图:
第3步:改善明细页的智能提取结果(可选)
在上一步中获得多个详细信息页面链接后,继续进行下一步。系统将使用详细页面链接之一来智能地提取详细页面数据(例如:标题,作者,发布日期,内容,标签等)
详细信息页面的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开“详细信息提取器”进行修改。
如下所示:
您可以修改,添加或删除左侧的字段。
您还可以为每个字段(双击字段)执行详细的设置或数据处理:替换,提取,过滤,设置默认值等,
如下所示:
第4步:启动并运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“结果数据和发布”中,您可以在此处修改数据或直接导出excel或发布您的网站(WordPress,织梦 DEDE, HTTP接口等)。
完成,数据采集就这么简单! ! ! 查看全部
采集 列表页和详情页的使用方法有哪些?怎么用?
一个小概念:
大多数网站以列表页面和详细信息页面的层次结构进行组织。例如,当我们进入新浪新闻频道时,有很多标题链接,可以将其视为列表页面。单击标题链接后,进入详细信息页面。
使用data 采集工具的一般目的是在详细信息页面中获取大量特定的内容数据,并将这些数据用于各种分析,发布自己的网站等。
列表页面:指的是列或目录页面,通常收录多个标题链接。例如:网站第一页或列页面是列表页面。主要功能:您可以通过列表页面获得到多个详细信息页面的链接。
详细信息页面:收录特定内容的页面,例如网页文章,其中收录:标题,作者,出版日期,正文内容,标签等。
要开始,请登录“ 优采云控制面板”:
详细的使用步骤:
第一步:创建采集任务
单击左侧菜单按钮“创建采集任务”,输入采集任务名称和想要的采集“列表页面”的URL,例如:,可以保留详细信息页面链接空白,系统将自动识别它。
如下所示:
输入后,单击“下一步”。
第2步:改善列表页面的智能提取结果(可选)
系统将首先使用智能算法来获取需要采集的详细信息页面链接(多个)。用户可以双击打开支票。如果您不需要数据,则可以单击“列表提取器”以手动指定它,仅在可视化中使用鼠标单击界面。
智能采集的结果如下:
打开列表提取器后的下图:
第3步:改善明细页的智能提取结果(可选)
在上一步中获得多个详细信息页面链接后,继续进行下一步。系统将使用详细页面链接之一来智能地提取详细页面数据(例如:标题,作者,发布日期,内容,标签等)
详细信息页面的智能提取结果如下:
如果智能提取的内容不是您想要的,则可以打开“详细信息提取器”进行修改。
如下所示:
您可以修改,添加或删除左侧的字段。
您还可以为每个字段(双击字段)执行详细的设置或数据处理:替换,提取,过滤,设置默认值等,
如下所示:
第4步:启动并运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“结果数据和发布”中,您可以在此处修改数据或直接导出excel或发布您的网站(WordPress,织梦 DEDE, HTTP接口等)。
完成,数据采集就这么简单! ! !
全面了解:需求剖析:需求的获取、采集与抒发
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-29 04:21
需求剖析是产品总监的核心竞争力,本文以需求的来源、采集与描述三个方面为入口,结合案例,介绍了相对应的方式和使用工具。
一. 从那里获取需求?
需求的获取方法有很多,比如产品大牛的天马行空,用户粉丝的意见反馈,产品前期的用户督查等等,本文选定了几个常用的获取需求的方法来和读者分享一下。
1. 来源
1.1用户督查
(1)定量督查-问卷
(2)定性督查-采访
1.2 用户反馈
常见的用户反馈来自于互联网社交平台(微博、贴吧、知乎、微信、QQ、app store以及产品自带的客服投诉和建议模块。一般通过以下几条判定条件筛选出有用的反馈并加以解决相应问题:
(1)用户类型—什么用户提出的?(潜水用户/话题制造者/专业人士/死忠粉/VIP会员等)
一般专业人士提出的反馈结合了丰富的专业知识,比较有深度;死忠粉有常年使用产品的经验,对产品理解较深;VIP会员是产品的核心用户,及时解决她们的问题非常有必要。这些用户反馈的价值性相应低于通常或短期用户。
(2)使用场景—在哪些场景下提出的反馈?(地铁/公司/学校/车上/上班时/吃饭时/睡觉前等)
根据用户使用场景的频度和次数判定,一般使用频度高的场景下提出的反馈可能是大部分用户都碰到的,所以解决这种问题的优先级相应较高。
(3)反馈次数—是否有同类型、重复的反馈?(单个用户多次反馈相同问题/多个用户反馈相同问题)
如果同一个用户多次反馈相同问题,说明此问题早已轻度影响了该用户的用户体验,而且始终没有得到解决;反馈中一个问题被不同用户反复提起,说明大部分用户深受困惑,这两种情况下的反馈应优先被解决。
① 老板
在产品研制早期,经常会遇见会上老总一句话直接给需求,这些需求常常来自于老总丰富的工作经验以及敏锐的市场触觉,不能说老总提出的一定对,但是一定是有根据的。作为产品人员应当先消化和理解老总的看法,如果还是认为有问题,拿出相应的数据根据来劝说老总。
② 数据剖析
一般来说,产品人员可以通过一些数据网站(极光数据、百度指数、艾瑞咨询)获取市场趋势和用户喜好,进而获取用户需求;此外,运营及数据剖析专员
会按照市场做的相关数据统计(访问数、停留时间、跳出率等)提出部份需求。
2. 需求采集步骤
不同的阶段需求采集可使用的技巧也不一样,苏杰在《人人都是产品经理》一书提及,合理搭配定性和定量技巧,一般可依照产品时间轴分为四部份:
3. 需求的构成
需求不是单独存在的个体,而是与场景、用户、目标同时出现的。当描述一个需求时,需要交待时间、地点、人物、描述、需求(欲望)和技巧。举个简单的事例:
在一个阳光明媚的清晨(时间),我在去地铁站的路上(地点),但是距离有点远,走路要十五分钟(描述),于是我形成了一个赶快抵达地铁站的看法(欲望),决定扫描二维码,骑小黄车去地铁站(方法)。
这样描述上去需求会变得具体易懂,也有利于产品人员以后的需求抒发和管理。
二. 如何完整抒发需求?
在需求被采集之后,需要将各类需求具象化并装入需求池中,这里提供两种方式来抒发需求,一个是单项需求卡片描述单个需求,另一个是需求清单(feature list)来管理多个需求。
1. 单项需求卡片
此卡片的核心在于使开发人员了解每位需求的描述信息(who/where/what/when/why)以及重要紧急程度,为未经加工过的用户需求,多为需求属性陈述。下图为模版并详尽解释了各个栏目要填写的内容:
以小黄车为例,近来见到网上讨论是否要在小黄车APP降低导航功能(事实上笔者觉得此需求为伪需求),那么它的单项需求卡片卡片填写应当如下:
2. 需求清单
此清单将多个需求整合在一起,每一条对应每一个单项需求卡片的内容,跟单项需求卡片相比,需求清单一般是剖析之后的产品需求,偏向于研制时间成本和实现性价比。
案例如下:
单项需求卡片和需求清单不仅仅侧重于抒发需求,也涉及到部份需求管理内容。而且,面对随时都有可能蹦下来的需求,如何评估需求性价比并选择性列入需求池也是产品总监须要考虑的,希望在下一部分需求管理中和你们有更深入的交流讨论。
作者:座聆,产品汪一只,坐标北京 查看全部
需求剖析:需求的获取、采集与抒发
需求剖析是产品总监的核心竞争力,本文以需求的来源、采集与描述三个方面为入口,结合案例,介绍了相对应的方式和使用工具。
一. 从那里获取需求?
需求的获取方法有很多,比如产品大牛的天马行空,用户粉丝的意见反馈,产品前期的用户督查等等,本文选定了几个常用的获取需求的方法来和读者分享一下。
1. 来源
1.1用户督查
(1)定量督查-问卷
(2)定性督查-采访
1.2 用户反馈
常见的用户反馈来自于互联网社交平台(微博、贴吧、知乎、微信、QQ、app store以及产品自带的客服投诉和建议模块。一般通过以下几条判定条件筛选出有用的反馈并加以解决相应问题:
(1)用户类型—什么用户提出的?(潜水用户/话题制造者/专业人士/死忠粉/VIP会员等)
一般专业人士提出的反馈结合了丰富的专业知识,比较有深度;死忠粉有常年使用产品的经验,对产品理解较深;VIP会员是产品的核心用户,及时解决她们的问题非常有必要。这些用户反馈的价值性相应低于通常或短期用户。
(2)使用场景—在哪些场景下提出的反馈?(地铁/公司/学校/车上/上班时/吃饭时/睡觉前等)
根据用户使用场景的频度和次数判定,一般使用频度高的场景下提出的反馈可能是大部分用户都碰到的,所以解决这种问题的优先级相应较高。
(3)反馈次数—是否有同类型、重复的反馈?(单个用户多次反馈相同问题/多个用户反馈相同问题)
如果同一个用户多次反馈相同问题,说明此问题早已轻度影响了该用户的用户体验,而且始终没有得到解决;反馈中一个问题被不同用户反复提起,说明大部分用户深受困惑,这两种情况下的反馈应优先被解决。
① 老板
在产品研制早期,经常会遇见会上老总一句话直接给需求,这些需求常常来自于老总丰富的工作经验以及敏锐的市场触觉,不能说老总提出的一定对,但是一定是有根据的。作为产品人员应当先消化和理解老总的看法,如果还是认为有问题,拿出相应的数据根据来劝说老总。
② 数据剖析
一般来说,产品人员可以通过一些数据网站(极光数据、百度指数、艾瑞咨询)获取市场趋势和用户喜好,进而获取用户需求;此外,运营及数据剖析专员
会按照市场做的相关数据统计(访问数、停留时间、跳出率等)提出部份需求。
2. 需求采集步骤
不同的阶段需求采集可使用的技巧也不一样,苏杰在《人人都是产品经理》一书提及,合理搭配定性和定量技巧,一般可依照产品时间轴分为四部份:
3. 需求的构成
需求不是单独存在的个体,而是与场景、用户、目标同时出现的。当描述一个需求时,需要交待时间、地点、人物、描述、需求(欲望)和技巧。举个简单的事例:
在一个阳光明媚的清晨(时间),我在去地铁站的路上(地点),但是距离有点远,走路要十五分钟(描述),于是我形成了一个赶快抵达地铁站的看法(欲望),决定扫描二维码,骑小黄车去地铁站(方法)。
这样描述上去需求会变得具体易懂,也有利于产品人员以后的需求抒发和管理。
二. 如何完整抒发需求?
在需求被采集之后,需要将各类需求具象化并装入需求池中,这里提供两种方式来抒发需求,一个是单项需求卡片描述单个需求,另一个是需求清单(feature list)来管理多个需求。
1. 单项需求卡片
此卡片的核心在于使开发人员了解每位需求的描述信息(who/where/what/when/why)以及重要紧急程度,为未经加工过的用户需求,多为需求属性陈述。下图为模版并详尽解释了各个栏目要填写的内容:
以小黄车为例,近来见到网上讨论是否要在小黄车APP降低导航功能(事实上笔者觉得此需求为伪需求),那么它的单项需求卡片卡片填写应当如下:
2. 需求清单
此清单将多个需求整合在一起,每一条对应每一个单项需求卡片的内容,跟单项需求卡片相比,需求清单一般是剖析之后的产品需求,偏向于研制时间成本和实现性价比。
案例如下:
单项需求卡片和需求清单不仅仅侧重于抒发需求,也涉及到部份需求管理内容。而且,面对随时都有可能蹦下来的需求,如何评估需求性价比并选择性列入需求池也是产品总监须要考虑的,希望在下一部分需求管理中和你们有更深入的交流讨论。
作者:座聆,产品汪一只,坐标北京
信息采集员
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-27 13:26
定义信息采集员主要为公司提供各个渠道的时效信息。有些要求信息采集员每日登入网站,录入,修改和更新当天报价.互联网+呼叫中心+(地面服务能力)的组合模式。有些会就是打电话与各个部门或其他单位联系,询问她们是否须要我们的服务和产品,进行信息记录,同时将信息反馈到总公司。由技术部的人员进行剖析并与顾客进行初步接触,然后再由其负责协助技术部的人员做方案。互联网路上的信息非常庞大繁琐,为满足用户快速、准确、全面获取信息的需求,需要将大量的采集信息根据不同的标准来进行分类和打包处理。网络信息采集是将非结构化的信息从大量的网页中抽取下来保存到结构化的数据库中的过程。 信息采集系统以网路信息挖掘引擎为基础建立而成,它可以在最短的时间内,帮您把最新的信息从不同的Internet站点上采集下来,并在进行分类和统一格式后,第一时间之内把信息及时发布到自己的站点起来。从而增强信息及时性和节约或减轻工作量。信息采集员工作职责信息采集员是网站工作组成成员,要求要有较强的责任心和责任感,较好的观察能力和写作能力,来完成本职工作。工作职责:1. 负责本部门的信息采集和编撰工作,形成电子文档。2. 将信息文档交由本部门主管领导初审,经审合格后上传到指定信箱或发布到网上。
3. 原则上部门信息员只负责自己部门的信息发布,避免重复发布。4. 发表的信息要自行备案,由各部门的信息员统一管理,以备后用。5. 有网页栏目管理的部门,要注意保护好管理员账号及密码,防止别人窃取。如发生账号及密码泄漏,可以向网络中心申请修改。信息采集原则信息采集有以下5个方面的原则,这些原则是保证信息采集质量最基本的要求。(1)可靠性原则信息采集可靠性原则是指采集的信息必须是真实对象或环境所形成的,必须保证信息来源是可靠的,必须保证采集的信息能反映真实的状况,可靠性原则是信息采集的基础。(2)完整性原则信息采集完整性是指采集的信息在内容上必须完整无缺,信息采集必须根据一定的标准要求,采集反映事物概貌的信息,完整性原则是信息借助的基础。(3)实时性原则信息采集的实时性是指能及时获取所需的信息,一般有三层涵义:一是指信息自发生到被采集的时间间隔,间隔越短就越及时,最快的是信息采集与信息发生同步;二是指在企业或组织执行某一任务急需某一信息时才能很快采集到该信息,谓之及时;三是指采集某一任务所需的全部信息所花去的时间,花的时间越少谓之越快。实时性原则保证信息采集的时效。(4)准确性原则准确性原则是指采集到的信息与应用目标和工作需求的关联程度比较高,采集到信息的抒发是无误的,是属于采集目的范畴之内的,相对于企业或组织自身来说具有适用性,是有价值的。关联程度越高,适应性越强,就越确切。准确性原则保证信息采集的价值。(5)易用性原则:易用性原则是指采集到的信息根据一定的表示方式,便于使用。查看全文 查看全部
信息采集员
定义信息采集员主要为公司提供各个渠道的时效信息。有些要求信息采集员每日登入网站,录入,修改和更新当天报价.互联网+呼叫中心+(地面服务能力)的组合模式。有些会就是打电话与各个部门或其他单位联系,询问她们是否须要我们的服务和产品,进行信息记录,同时将信息反馈到总公司。由技术部的人员进行剖析并与顾客进行初步接触,然后再由其负责协助技术部的人员做方案。互联网路上的信息非常庞大繁琐,为满足用户快速、准确、全面获取信息的需求,需要将大量的采集信息根据不同的标准来进行分类和打包处理。网络信息采集是将非结构化的信息从大量的网页中抽取下来保存到结构化的数据库中的过程。 信息采集系统以网路信息挖掘引擎为基础建立而成,它可以在最短的时间内,帮您把最新的信息从不同的Internet站点上采集下来,并在进行分类和统一格式后,第一时间之内把信息及时发布到自己的站点起来。从而增强信息及时性和节约或减轻工作量。信息采集员工作职责信息采集员是网站工作组成成员,要求要有较强的责任心和责任感,较好的观察能力和写作能力,来完成本职工作。工作职责:1. 负责本部门的信息采集和编撰工作,形成电子文档。2. 将信息文档交由本部门主管领导初审,经审合格后上传到指定信箱或发布到网上。
3. 原则上部门信息员只负责自己部门的信息发布,避免重复发布。4. 发表的信息要自行备案,由各部门的信息员统一管理,以备后用。5. 有网页栏目管理的部门,要注意保护好管理员账号及密码,防止别人窃取。如发生账号及密码泄漏,可以向网络中心申请修改。信息采集原则信息采集有以下5个方面的原则,这些原则是保证信息采集质量最基本的要求。(1)可靠性原则信息采集可靠性原则是指采集的信息必须是真实对象或环境所形成的,必须保证信息来源是可靠的,必须保证采集的信息能反映真实的状况,可靠性原则是信息采集的基础。(2)完整性原则信息采集完整性是指采集的信息在内容上必须完整无缺,信息采集必须根据一定的标准要求,采集反映事物概貌的信息,完整性原则是信息借助的基础。(3)实时性原则信息采集的实时性是指能及时获取所需的信息,一般有三层涵义:一是指信息自发生到被采集的时间间隔,间隔越短就越及时,最快的是信息采集与信息发生同步;二是指在企业或组织执行某一任务急需某一信息时才能很快采集到该信息,谓之及时;三是指采集某一任务所需的全部信息所花去的时间,花的时间越少谓之越快。实时性原则保证信息采集的时效。(4)准确性原则准确性原则是指采集到的信息与应用目标和工作需求的关联程度比较高,采集到信息的抒发是无误的,是属于采集目的范畴之内的,相对于企业或组织自身来说具有适用性,是有价值的。关联程度越高,适应性越强,就越确切。准确性原则保证信息采集的价值。(5)易用性原则:易用性原则是指采集到的信息根据一定的表示方式,便于使用。查看全文
数据采集的几种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-25 18:30
业务系统
数据采集的几种形式方法一:读备份库
为了不影响业务系统的正常运行,可以采用读备份库的数据,这样就能及时获取数据进行一些剖析工作,但是有些从业务也会读取备份数据库,还须要考虑一致性和可用性问题。
数据库备份
方式一: 埋点(pingback)
可以在后端APP上记录用户点击,滑动速率,停留时间,进入的时间段,最后看的新闻等等信息,这些可以通过网路传输将埋点信息记录出来,用于数据剖析。但是这些方法有可能会对业务系统代码具有一定的侵入性,同时工作量也比较大,存在一定的安全隐患。
埋点
后端采集数据的service
/**
* 埋点接收数据
* @param pingBack
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody PingBack pingBack) {
Boolean result = patientService.savePingBack(pingBack);
return new ApiResponse().success(result);
}
已有的业务系统可以给数据采集系统发送数据
/**
* pingback方式插入
* @param patient
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody Patient patient) {
try{
Boolean result = patientService.savePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("insert error");
}finally {
pingBackService.jsonRequest(url+"insert", patient);
}
return null;
}
方式三: 发送消息的方法
上述埋点的形式在业务系统忙碌的情况下,会对数据采集系统形成大量的恳求,如果数据处理不及时会把数据采集服务击败,同时为了前馈,这里可以引入消息中间件,如果对时效性要求较高,可以采用推模式对数据采集系统进行推送,如果时效性不是很高,可以采用定时任务拉取数据,再进行剖析。
同时可以多个系统订阅消息中间件中不同Topic的数据,可以对数据进行重用,后端多个数据剖析系统之间互不影响,减轻了从业务系统采集多份数据的压力。
引入消息中间件
数据采集Service
/**
* 消息中间件的方式更新
* @param patient
* @return
*/
@RequestMapping(path = "/update", method = RequestMethod.POST)
@ResponseBody
public ApiResponse update(@RequestBody Patient patient) {
try{
Boolean result = patientService.updatePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("update error");
}finally {
sendMessageService.send(patient);
}
return null;
}
中间件发送数据实现(以kafka为例)
@Service
@Slf4j
public class SendMessageService {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("topic")
private String topic;
private ObjectMapper om = new ObjectMapper();
public boolean send(Object object){
String objectJson = "";
try {
objectJson = new ObjectMapper().writeValueAsString(object);
} catch (Exception e) {
log.error("can't trans the {} object to json string!", object);
return false;
}
try{
String result = kafkaTemplate.send("mysql-kafka-patient", objectJson).get().toString();
if(result!=null){
return true;
}
}catch (Exception e){
return false;
}
return false;
}
}
中间件拉取数据:
@KafkaListener(id = "forward", topics = "mysql-kafka-patient")
public String forward(String data) {
log.info("mysql-kafka-patient "+data);
JSONObject jsonObject1 = JSONObject.parseObject(data);
Message message = (Message) JSONObject.toJavaObject(jsonObject1,Message.class);
messageService.updateMessage(message);
return data;
}
方式四:读取MySQL中的binlog
MySQL会把数据的变更(插入和更新)保存在binlog中,需要在my.ini中配置开启,因此采用kafka订阅binlog,会将DB中须要的数组抓取下来,保存在备份库中,进行数据剖析,工作量较小,安全稳定。
name=mysql-b-source-pingBack
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/test?user=root&password=root
# timestamp+incrementing 时间戳自增混合模式
mode=timestamp+incrementing
# 自增字段 id
timestamp.column.name=commenttime
incrementing.column.name=id
# 白名单表 pingBack
table.whitelist=pingBack
# topic前缀 mysql-kafka-
topic.prefix=mysql-kafka-
具体使用可以参考:官方文档
分析对比数据采集方式优点缺点
埋点(pingback)
很细致的将后端用户操作记录出来,能够感知到DB储存之外的用户信息,时效性高
工作量大,可能对业务代码有侵入性;当业务量大的时侯,数据抓取服务也须要承载一定的压力,对数据不便捷统计和聚合
主库写备库读
及时感知备库中的信息 ,数据一致性强
可能存在大量不需要进行剖析的数组,对业务性能有影响
埋点+消息中间件
有效的解决业务量大时对数据存取性能的要求,根据数据抓取服务的需求可以拉也可以推,解耦业务代码
可能会遗失数据,降低了时效性 查看全部
数据采集的几种方式
业务系统
数据采集的几种形式方法一:读备份库
为了不影响业务系统的正常运行,可以采用读备份库的数据,这样就能及时获取数据进行一些剖析工作,但是有些从业务也会读取备份数据库,还须要考虑一致性和可用性问题。
数据库备份
方式一: 埋点(pingback)
可以在后端APP上记录用户点击,滑动速率,停留时间,进入的时间段,最后看的新闻等等信息,这些可以通过网路传输将埋点信息记录出来,用于数据剖析。但是这些方法有可能会对业务系统代码具有一定的侵入性,同时工作量也比较大,存在一定的安全隐患。
埋点
后端采集数据的service
/**
* 埋点接收数据
* @param pingBack
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody PingBack pingBack) {
Boolean result = patientService.savePingBack(pingBack);
return new ApiResponse().success(result);
}
已有的业务系统可以给数据采集系统发送数据
/**
* pingback方式插入
* @param patient
* @return
*/
@RequestMapping(path = "/insert", method = RequestMethod.POST)
@ResponseBody
public ApiResponse insert(@RequestBody Patient patient) {
try{
Boolean result = patientService.savePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("insert error");
}finally {
pingBackService.jsonRequest(url+"insert", patient);
}
return null;
}
方式三: 发送消息的方法
上述埋点的形式在业务系统忙碌的情况下,会对数据采集系统形成大量的恳求,如果数据处理不及时会把数据采集服务击败,同时为了前馈,这里可以引入消息中间件,如果对时效性要求较高,可以采用推模式对数据采集系统进行推送,如果时效性不是很高,可以采用定时任务拉取数据,再进行剖析。
同时可以多个系统订阅消息中间件中不同Topic的数据,可以对数据进行重用,后端多个数据剖析系统之间互不影响,减轻了从业务系统采集多份数据的压力。
引入消息中间件
数据采集Service
/**
* 消息中间件的方式更新
* @param patient
* @return
*/
@RequestMapping(path = "/update", method = RequestMethod.POST)
@ResponseBody
public ApiResponse update(@RequestBody Patient patient) {
try{
Boolean result = patientService.updatePatient(patient);
return new ApiResponse().success(result);
}catch (InternalError error){
log.error("update error");
}finally {
sendMessageService.send(patient);
}
return null;
}
中间件发送数据实现(以kafka为例)
@Service
@Slf4j
public class SendMessageService {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("topic")
private String topic;
private ObjectMapper om = new ObjectMapper();
public boolean send(Object object){
String objectJson = "";
try {
objectJson = new ObjectMapper().writeValueAsString(object);
} catch (Exception e) {
log.error("can't trans the {} object to json string!", object);
return false;
}
try{
String result = kafkaTemplate.send("mysql-kafka-patient", objectJson).get().toString();
if(result!=null){
return true;
}
}catch (Exception e){
return false;
}
return false;
}
}
中间件拉取数据:
@KafkaListener(id = "forward", topics = "mysql-kafka-patient")
public String forward(String data) {
log.info("mysql-kafka-patient "+data);
JSONObject jsonObject1 = JSONObject.parseObject(data);
Message message = (Message) JSONObject.toJavaObject(jsonObject1,Message.class);
messageService.updateMessage(message);
return data;
}
方式四:读取MySQL中的binlog
MySQL会把数据的变更(插入和更新)保存在binlog中,需要在my.ini中配置开启,因此采用kafka订阅binlog,会将DB中须要的数组抓取下来,保存在备份库中,进行数据剖析,工作量较小,安全稳定。
name=mysql-b-source-pingBack
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/test?user=root&password=root
# timestamp+incrementing 时间戳自增混合模式
mode=timestamp+incrementing
# 自增字段 id
timestamp.column.name=commenttime
incrementing.column.name=id
# 白名单表 pingBack
table.whitelist=pingBack
# topic前缀 mysql-kafka-
topic.prefix=mysql-kafka-
具体使用可以参考:官方文档
分析对比数据采集方式优点缺点
埋点(pingback)
很细致的将后端用户操作记录出来,能够感知到DB储存之外的用户信息,时效性高
工作量大,可能对业务代码有侵入性;当业务量大的时侯,数据抓取服务也须要承载一定的压力,对数据不便捷统计和聚合
主库写备库读
及时感知备库中的信息 ,数据一致性强
可能存在大量不需要进行剖析的数组,对业务性能有影响
埋点+消息中间件
有效的解决业务量大时对数据存取性能的要求,根据数据抓取服务的需求可以拉也可以推,解耦业务代码
可能会遗失数据,降低了时效性
哪个是最好的图片捕获工具?热门图片采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-08 01:39
1. 图片搜索器(图片批量下载工具)
图片搜索器(图片批量下载工具)-智能挖掘,自动爬网搜索,在网站上下载图片,将项目保存到本地,然后通过“文件-”“打开项目”菜单加载并执行项目注意: 保存时,项目文件的后缀必须为“ pics”!
功能:
1. 下载整个网站的图片,速度如此之快以至于无法超越
2. 给它提供一些初始URL,它可以智能地挖掘,自动爬网和在网站上搜索图片
3. 它可以根据网页内容的标题将搜索到的图片保存到单独的文件夹中
4,名人美女,动漫图片,美丽的风景图片,全部.
门户: 图片搜索器(图像批量下载工具)
2.500px蜘蛛(批量图像下载)
500px Spide,它可以帮助您从500px网站下载自己喜欢的照片. 您可以一次选择要下载的照片,然后500px Spider会将所有这些照片下载到硬盘上. 500px Spider是一种易于使用且功能强大的工具,可为您节省无法保存照片的麻烦.
500px蜘蛛的主要特征:
管理下载的照片集管理每个作者的下载的照片集. 您可以浏览,更新,查找和删除这些照片集.
单独下载照片如果网络状况不好,下载的照片将显示为不完整,则可以使用此功能单独下载照片.
更新作者的最新上传. 下载作者的图片后,一段时间后,作者会上传新的图片. 目前,您可以使用更新功能仅下载用户最近上传的图片. 查看全部
图像采集工具使用特殊的图像识别技术批量获取图像地址,然后在本地下载图像以完成采集任务. 现在,Internet上有许多采集工具. 编辑者组织了几种实用的图像采集工具,与您分享小伙伴们的生活.
1. 图片搜索器(图片批量下载工具)
图片搜索器(图片批量下载工具)-智能挖掘,自动爬网搜索,在网站上下载图片,将项目保存到本地,然后通过“文件-”“打开项目”菜单加载并执行项目注意: 保存时,项目文件的后缀必须为“ pics”!
功能:
1. 下载整个网站的图片,速度如此之快以至于无法超越
2. 给它提供一些初始URL,它可以智能地挖掘,自动爬网和在网站上搜索图片
3. 它可以根据网页内容的标题将搜索到的图片保存到单独的文件夹中
4,名人美女,动漫图片,美丽的风景图片,全部.
门户: 图片搜索器(图像批量下载工具)
2.500px蜘蛛(批量图像下载)
500px Spide,它可以帮助您从500px网站下载自己喜欢的照片. 您可以一次选择要下载的照片,然后500px Spider会将所有这些照片下载到硬盘上. 500px Spider是一种易于使用且功能强大的工具,可为您节省无法保存照片的麻烦.
500px蜘蛛的主要特征:
管理下载的照片集管理每个作者的下载的照片集. 您可以浏览,更新,查找和删除这些照片集.
单独下载照片如果网络状况不好,下载的照片将显示为不完整,则可以使用此功能单独下载照片.
更新作者的最新上传. 下载作者的图片后,一段时间后,作者会上传新的图片. 目前,您可以使用更新功能仅下载用户最近上传的图片.
熊猫智能采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-08-07 05:14
在浏览器中可以看到的所有内容都属于优采云采集器软件的采集范围. 也就是说,只要在浏览器中可以看到您需要的内容,就可以在99.9%的情况下与Panda一起批量采集.
采集的数据可以发布在我自己的网站上吗?
是的. 优采云采集器的默认数据存储方法是将其存储在数据库中. 您可以使用网站后端的手动发布页面同时设置“模拟发布”,Panda将模拟手动发布操作的过程,并将采集的数据发布到指定的网站. 熊猫还具有独特的“多级模拟发布”功能,可以一次模拟所有内容,例如注册,发布和回复.
采集的数据可以存储在我现有的数据库表中吗?
是的. 在Panda中,默认采集的数据将自动存储在项目专用文件夹中的data.mdb文件中. 您可以在设置链接中指定数据库链接参数,并指定用于存储数据的表和字段. 这样,采集的结果数据将自动存储在数据库中,而无需手动编辑SQL仓库命令. 该软件将自动完成仓库事务,自动判断仓库字段的SQL语法,并自动判断重复的数据.
我不信任您,我需要查看采集结果并首先发布吗?
在购买之前,用户可以向熊猫官方客户服务中心申请提供试用版采集和试用版发行. 原则上,您只需要提供100元的押金即可申请. 如果不确定或结果不符合要求,可以退还押金. 在正式购买时,可以将已支付的押金折算为最终购买价格. 查看全部
您可以使用Cloud Collector软件做什么?
在浏览器中可以看到的所有内容都属于优采云采集器软件的采集范围. 也就是说,只要在浏览器中可以看到您需要的内容,就可以在99.9%的情况下与Panda一起批量采集.
采集的数据可以发布在我自己的网站上吗?
是的. 优采云采集器的默认数据存储方法是将其存储在数据库中. 您可以使用网站后端的手动发布页面同时设置“模拟发布”,Panda将模拟手动发布操作的过程,并将采集的数据发布到指定的网站. 熊猫还具有独特的“多级模拟发布”功能,可以一次模拟所有内容,例如注册,发布和回复.
采集的数据可以存储在我现有的数据库表中吗?
是的. 在Panda中,默认采集的数据将自动存储在项目专用文件夹中的data.mdb文件中. 您可以在设置链接中指定数据库链接参数,并指定用于存储数据的表和字段. 这样,采集的结果数据将自动存储在数据库中,而无需手动编辑SQL仓库命令. 该软件将自动完成仓库事务,自动判断仓库字段的SQL语法,并自动判断重复的数据.
我不信任您,我需要查看采集结果并首先发布吗?
在购买之前,用户可以向熊猫官方客户服务中心申请提供试用版采集和试用版发行. 原则上,您只需要提供100元的押金即可申请. 如果不确定或结果不符合要求,可以退还押金. 在正式购买时,可以将已支付的押金折算为最终购买价格.
探索代码Web大数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2020-08-06 04:05
Danma Technology的基于云计算研发的Web大数据采集系统-利用众多的云计算服务器协同工作,它可以快速采集大量数据并避免计算机硬件资源的瓶颈. 数据采集的要求越来越高,逐步解决了传统邮政采集无法解决的技术难题. 以探针Kapow / Dyson采集器为代表的新一代智能采集器可以模拟人类的思维和人类的操作,从而完全解决了诸如ajax之类的技术问题.
网页通常是为人们浏览而设计的,因此在Web大数据采集系统中模拟人类的智能采集器的工作非常顺畅. 无论背景技术是什么,当数据始终显示在人们面前时,智能采集器就可以开始提取. 最后,将计算机的功能发挥到极致,以便计算机可以代替人们来完成Web数据采集工作. 借助大数据云采集技术,计算机的计算能力也达到了极致. 目前,这种采集技术已经得到越来越广泛的应用. 只要各行各业从互联网获取一些数据或信息,就可以使用这种技术.
搜索代码Web大数据采集系统分为8个子系统,分别是大数据集群系统,数据采集系统,采集的数据源调查,数据爬网程序系统,数据清理系统,数据合并系统,任务调度系统,搜索引擎系统.
大数据集群系统
此系统可以存储TB级采集的数据,以实现数据持久性. 数据存储采用MongoDB集群解决方案,该集群具有两个主要特征:
数据采集系统
该系统配置有Kapow,PhantomJS和Mechanize采集环境,并在由Rancher安排的Docker容器中运行.
采集的数据源调查
在“数据搜寻器系统”启动之前,该系统是必不可少的链接. 经过调查,发现需要采集页面,要过滤的关键字,要提取的内容等.
数据搜寻器系统
爬虫程序都是独立的个体,与所需的数据采集系统服务器结合,由Rancher安排,该爬虫程序在DigitalOcean中自动启动,并根据输入参数捕获指定的数据,然后将其发送回我们的大型数据集群系统.
数据清理系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示,显示由搜寻器程序捕获的数据,并方便我们进行清理. 数据清理系统主要由两部分组成:
数据整合系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示和合并数据. 清除数据后,数据合并系统将自动匹配大数据集群中的数据,并通过熟人评分将可能的熟人数据关联起来. 匹配结果通过Web前端显示,并且数据可以手动或自动合并.
任务计划系统
该系统通过Ruby on Rails + Vue技术框架,Sidekiq队列调度和Redis调度数据持久性来实现Web前端任务调度系统. 通过任务计划系统,您可以动态打开和关闭,并定期启动搜寻器程序.
搜索引擎系统
该系统通过ElasticSearch集群实现搜索引擎服务. 搜索引擎是PC端检索系统从大数据集群快速检索数据的必要工具. 通过ElasticSearch集群,运行三个以上的Master角色以确保集群系统的稳定性,并运行两个以上的Client角色以确保查询的容错能力,两个或多个Data角色可确保查询和编写的及时性. 通过负载平衡连接客户端角色,以分散数据查询压力. 查看全部
探索代码Web大数据采集系统
Danma Technology的基于云计算研发的Web大数据采集系统-利用众多的云计算服务器协同工作,它可以快速采集大量数据并避免计算机硬件资源的瓶颈. 数据采集的要求越来越高,逐步解决了传统邮政采集无法解决的技术难题. 以探针Kapow / Dyson采集器为代表的新一代智能采集器可以模拟人类的思维和人类的操作,从而完全解决了诸如ajax之类的技术问题.
网页通常是为人们浏览而设计的,因此在Web大数据采集系统中模拟人类的智能采集器的工作非常顺畅. 无论背景技术是什么,当数据始终显示在人们面前时,智能采集器就可以开始提取. 最后,将计算机的功能发挥到极致,以便计算机可以代替人们来完成Web数据采集工作. 借助大数据云采集技术,计算机的计算能力也达到了极致. 目前,这种采集技术已经得到越来越广泛的应用. 只要各行各业从互联网获取一些数据或信息,就可以使用这种技术.
搜索代码Web大数据采集系统分为8个子系统,分别是大数据集群系统,数据采集系统,采集的数据源调查,数据爬网程序系统,数据清理系统,数据合并系统,任务调度系统,搜索引擎系统.
大数据集群系统
此系统可以存储TB级采集的数据,以实现数据持久性. 数据存储采用MongoDB集群解决方案,该集群具有两个主要特征:
数据采集系统
该系统配置有Kapow,PhantomJS和Mechanize采集环境,并在由Rancher安排的Docker容器中运行.
采集的数据源调查
在“数据搜寻器系统”启动之前,该系统是必不可少的链接. 经过调查,发现需要采集页面,要过滤的关键字,要提取的内容等.
数据搜寻器系统
爬虫程序都是独立的个体,与所需的数据采集系统服务器结合,由Rancher安排,该爬虫程序在DigitalOcean中自动启动,并根据输入参数捕获指定的数据,然后将其发送回我们的大型数据集群系统.
数据清理系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示,显示由搜寻器程序捕获的数据,并方便我们进行清理. 数据清理系统主要由两部分组成:
数据整合系统
该系统使用Ruby on Rails + Vue技术框架来实现Web前端显示和合并数据. 清除数据后,数据合并系统将自动匹配大数据集群中的数据,并通过熟人评分将可能的熟人数据关联起来. 匹配结果通过Web前端显示,并且数据可以手动或自动合并.
任务计划系统
该系统通过Ruby on Rails + Vue技术框架,Sidekiq队列调度和Redis调度数据持久性来实现Web前端任务调度系统. 通过任务计划系统,您可以动态打开和关闭,并定期启动搜寻器程序.
搜索引擎系统
该系统通过ElasticSearch集群实现搜索引擎服务. 搜索引擎是PC端检索系统从大数据集群快速检索数据的必要工具. 通过ElasticSearch集群,运行三个以上的Master角色以确保集群系统的稳定性,并运行两个以上的Client角色以确保查询的容错能力,两个或多个Data角色可确保查询和编写的及时性. 通过负载平衡连接客户端角色,以分散数据查询压力.
芭奇:不用编撰采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-03 21:03
一、首先打开这个功能。在网站右健可以看见这个功能:如下图。
二、打开后的功能如下,可以在左边填写指定采集的列表地址:
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上自动采集编写,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、htm,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下自动采集编写,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。 查看全部
一直以来,大家都在用各类类型采集器或网站程序自带的采集功能,它们有一个共同的特征,就是要写采集规则才可以采集到文章,这个技术性的问题,对菜鸟站升可不是一件容易的事,对老站长,它也是一个吃力的工作。那么,如果做站群的话,每个站都要定义一个采集规则的话,那就真是苦不堪言。有人说,站长是一个网络搬运工。这话说得也是有道理的。互联网上的文章,很多都是你搬我的,我搬你的,为了生活,不得不怎么做下去。现在芭奇站群软件新出一个新的新型采集功能,能大大减少站长的“搬运工”的时间,也不用再写可恶的采集规则了,这个功能就是互联网首创的功能---指定网址采集。下面我教你们怎么使用这个功能:
一、首先打开这个功能。在网站右健可以看见这个功能:如下图。
二、打开后的功能如下,可以在左边填写指定采集的列表地址:
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上自动采集编写,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、htm,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下自动采集编写,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
无人值守免费手动采集器绿色版 3.4.7
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-08-03 21:00
3.支持随机选用发布帐号
4.支持任意发布项语言翻译
5.支持编码转换、支持UBB代码
6.文件上传可选择好手动构建年月日子目录
7.模拟发布支持对难以安装插口的网站进行发布操作
8.方案可定时工作
9.防止网路运营商绑架HTTP功能
10.可自动进行单项采集发布
11.详尽的工作流程监视、信息反馈,让您迅速了解工作状态
软件特征1、设定好方案,即可24小时手动工作自动采集,不再须要人工干涉
2、与网站分离,通过独立制做的插口,可以支持任何网站或数据库
3、灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
4、小巧、低耗和良好的稳定性特别适宜运行于服务器
5、所有规则都可以导出导入,灵活的资源重用
6、采用FTP上传文件,稳定、安全
7、下载上传支持断点续传
8、高速伪原创
使用教程1、程序免安装,解压安装包双击“优采云采集器3.exe”即可启动程序
2、进入程序,点击“制定方案”自动采集,进入相应的方案设定
3、点击“您的方案”,在采集规则一栏中点击“搜索文件”图标
4、进行采集规则的配置
5、在中间规则一栏中点击“搜索文件”图标
6、进行中间规则的配置
7、在发布规则一栏中点击“搜索文件”图标
8、配置发布规则,将信息添加到您的网站
9、完成添加,点击“开始”即可开始手动采集
更新日志无人值守免费手动采集器 v3.1.7更新内容
1、修正:上一版中数据项不容许为空失效的问题。
2、新增:数据项如今可以设置前置数据整理组,在完成数据项的包括翻译在内的各项操作后进行第二次加工
3、新增:翻译降低‘待翻译数据项’栏,可以指定须要翻译的数据项名称
4、修正:多列表测试时结果显示不完整的问题
5、新增:方案设置中的采集间隔如今可以设置随机时间
6、新增:采集规则如今可以独立设置UserAgent,并且可以设置多个UA随机调用 查看全部
2.与采集数据分离的发布参数项,可自由对应采集数据或预设数值,极大提高发布规则的重用性
3.支持随机选用发布帐号
4.支持任意发布项语言翻译
5.支持编码转换、支持UBB代码
6.文件上传可选择好手动构建年月日子目录
7.模拟发布支持对难以安装插口的网站进行发布操作
8.方案可定时工作
9.防止网路运营商绑架HTTP功能
10.可自动进行单项采集发布
11.详尽的工作流程监视、信息反馈,让您迅速了解工作状态
软件特征1、设定好方案,即可24小时手动工作自动采集,不再须要人工干涉
2、与网站分离,通过独立制做的插口,可以支持任何网站或数据库
3、灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
4、小巧、低耗和良好的稳定性特别适宜运行于服务器
5、所有规则都可以导出导入,灵活的资源重用
6、采用FTP上传文件,稳定、安全
7、下载上传支持断点续传
8、高速伪原创
使用教程1、程序免安装,解压安装包双击“优采云采集器3.exe”即可启动程序
2、进入程序,点击“制定方案”自动采集,进入相应的方案设定
3、点击“您的方案”,在采集规则一栏中点击“搜索文件”图标
4、进行采集规则的配置
5、在中间规则一栏中点击“搜索文件”图标
6、进行中间规则的配置
7、在发布规则一栏中点击“搜索文件”图标
8、配置发布规则,将信息添加到您的网站
9、完成添加,点击“开始”即可开始手动采集
更新日志无人值守免费手动采集器 v3.1.7更新内容
1、修正:上一版中数据项不容许为空失效的问题。
2、新增:数据项如今可以设置前置数据整理组,在完成数据项的包括翻译在内的各项操作后进行第二次加工
3、新增:翻译降低‘待翻译数据项’栏,可以指定须要翻译的数据项名称
4、修正:多列表测试时结果显示不完整的问题
5、新增:方案设置中的采集间隔如今可以设置随机时间
6、新增:采集规则如今可以独立设置UserAgent,并且可以设置多个UA随机调用
分享一个利器,快速采集文章全靠它!
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2020-08-03 21:00
疫情期间智能采集组合文章,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一智能采集组合文章,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需收集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤 查看全部
编辑
疫情期间智能采集组合文章,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一智能采集组合文章,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需收集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤
【站群使用神器】众大云采集Discuz版可快速手动采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-03 19:01
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂站群自动采集器,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多站群自动采集器,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下: 查看全部
【站群使用神器】众大云采集Discuz版可快速手动采集数据
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂站群自动采集器,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多站群自动采集器,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下:
众大云采集插件 免费版v9.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-03 18:01
软件介绍
众大云采集插件具有易学,易懂,易用,成熟稳定等特点,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面!
软件功能
01.可以批量注册马甲用户云采集免费,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02.可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03.可以定时采集和手动发布,实现无人值守。
04.采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05.支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06.采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07.图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08.图片会加上您峰会或则门户设置的水印。
09.已经采集过的内容不会重复二次采集,内容不会重复冗余。
10.采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11.浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12.可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13.采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14.可以一键获取当日的实时热点内容,然后一键发布。
15.不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16.插件外置正文提取算法云采集免费,在前台发表内容的时侯,输入网址即可以采集到内容。 查看全部
众大云采集插件是一款非常好用的采集工具,能为用户去采集论坛中的贴子内容,还能批量注册、评论等等功能,采集功能实现手动采集,经过系统筛选,将重复的内容移除,提高采集的疗效。
软件介绍
众大云采集插件具有易学,易懂,易用,成熟稳定等特点,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面!
软件功能
01.可以批量注册马甲用户云采集免费,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02.可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03.可以定时采集和手动发布,实现无人值守。
04.采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05.支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06.采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07.图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08.图片会加上您峰会或则门户设置的水印。
09.已经采集过的内容不会重复二次采集,内容不会重复冗余。
10.采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11.浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12.可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13.采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14.可以一键获取当日的实时热点内容,然后一键发布。
15.不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16.插件外置正文提取算法云采集免费,在前台发表内容的时侯,输入网址即可以采集到内容。
众大云采集Discuz版下载地址 已被下载次
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-03 18:00
【温馨提示】
01、安装本插件以后云采集,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳云采集,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下: 查看全部
众大云采集Discuz版是一个专门为discuz进行开发的批量采集软件。安装此插件后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
【温馨提示】
01、安装本插件以后云采集,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的峰会版块或则门户栏目、群组发布。
02、可以把已然成功发布的内容推送到百度数据收录插口进行SEO优化,采集和收录共赢。
03、插件可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
04、插件从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,插件功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个站长必备的插件!
【本插件功能特性】
01、可以批量注册马甲用户,发帖人和评论用马甲,看上去跟真实注册用户发布的一模一样。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的峰会和门户上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定普通注册用户在前台也能使用此采集器,让普通注册会员帮您采集内容。
06、采集过来的内容图片可以正常显示而且保存为贴子图片附件或则门户文章的附件,图片永远不会遗失。
07、图片附件支持远程FTP保存,让您实现图片分离到另外一台服务器。
08、图片会加上您峰会或则门户设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的贴子或则门户文章、群组跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的贴子或则门户文章的查看数跟真实的一样。
12、可以指定贴子发布者(楼主)、门户文章作者、群组发帖者。
13、采集的内容可以发布到峰会的任何一个版块和门户的任何一个栏目、群组的任何一个圈子。
14、已经发布的内容可以推送到百度数据收录插口进行SEO优化,加快网站的百度索引量和收录量。
15、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
16、插件外置正文提取算法,支持采集任何网站任何栏目的内容。
17、可以一键获取当前的实时热点内容,然后一键发布。
【此插件给您带来的价值】
1、让您的峰会注册会员好多,人气太旺,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员帮忙解决,大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳云采集,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
v9.6.8更新升级如下:
一米智能文章采集系统 v1.0 免费版文章采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-03 16:03
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。
如何配置手动采集、自动更新网站数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 639 次浏览 • 2020-08-03 16:01
定时采集功能详情:定时采集配置;
自动发布功能详情:采集后手动发布配置;
基本流程: 1. 采集已有的全部数据
先设置采集已有的全部列表页中的数据;(下面以 “大众养身-饮食” 模板为例,假设共100页)
2. 采集更新数据
待已有的全部数据采集完成后,现只需定时采集更新的内容,用户通常会在 “启动 | 定时采集“ 处设置重复数据跳过来实现。
上述操作可行,但有个方法可急剧增强同步更新采集效率:
判断是否重复数据,系统是遍历配置采集的列表页中的文章与已采集入库的文章中有无相同标题,如果数据量多会影响采集速度。
用户可通过观察采集源网站的内容更新频度和数目网站自动采集系统,估算新内容会显示在列表页的前几页,并在 “采集起始网址” 处设置只采集前几页的内容,减少系统遍历列表页页数来提升采集效率。
如下例网站新内容12小时更新一次,且通常显示在列表页的前两页,则可配置只采集前两页列表的文章。
(如果没有这一步网站自动采集系统,按原先的设置,系统要遍历100页列表页判定是否有重复数据,现只需遍历2页列表页)
查看全部
优采云采集平台通过设置 “定时采集” + “重复数据跳过” + “自动发布” 功能可实现同步更新数据,即定时检查采集源网站是否有内容更新,采集并发布新内容。
定时采集功能详情:定时采集配置;
自动发布功能详情:采集后手动发布配置;
基本流程: 1. 采集已有的全部数据
先设置采集已有的全部列表页中的数据;(下面以 “大众养身-饮食” 模板为例,假设共100页)
2. 采集更新数据
待已有的全部数据采集完成后,现只需定时采集更新的内容,用户通常会在 “启动 | 定时采集“ 处设置重复数据跳过来实现。
上述操作可行,但有个方法可急剧增强同步更新采集效率:
判断是否重复数据,系统是遍历配置采集的列表页中的文章与已采集入库的文章中有无相同标题,如果数据量多会影响采集速度。
用户可通过观察采集源网站的内容更新频度和数目网站自动采集系统,估算新内容会显示在列表页的前几页,并在 “采集起始网址” 处设置只采集前几页的内容,减少系统遍历列表页页数来提升采集效率。
如下例网站新内容12小时更新一次,且通常显示在列表页的前两页,则可配置只采集前两页列表的文章。
(如果没有这一步网站自动采集系统,按原先的设置,系统要遍历100页列表页判定是否有重复数据,现只需遍历2页列表页)
【伪原创】自动采集文章内容兼发布文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 534 次浏览 • 2020-08-03 16:00
LmCjl程序转优化猿程序猿是无所不能的,上到写代码,下到各种各样的事情,包括我自己组装单车和上下婴儿床,小到学钢琴,大到变革优化猿,我都O得K的。
自动采集文章内容兼发布内容
经历了几个月的敲敲打打,自动采集文章内容兼手动发布文章内容早已推下来了,简单容易的操作面板,可实现5~10分钟菜鸟熟练上手,同时便捷了做优化的大大们管理站群和发布文章的痛处,目前支持采集各大网站网站文章自动采集,识别率达到百分之99,同时支持各大个人网站的手动发布文章,教程早已发布在网站里面了。点击步入工具即可查看教程。
采集文章内容可辨识我想要的内容吗?
没问题的,只须要把你所需的文章内容网站文章自动采集,输入你想要的关键词,会手动筛选和匹配你想要的。
例如:
1.我想要带有SEO这个词的文章,其他的我都不要,只须要在采集管理的上面,输入包含关键词,即可。
最多可以管理多少个网站?
我可以说,多多益善吗?LmCjl目前管理的网站是658个,但是我还可以继续降低起来。
网站地址:
工具地址:
做简单好用的在线工具,无需下载,只须要记住:lmcjl
爱看书也爱远行
心情在路上
FIND YOURSELF
读好多的随记也写下好多的文字/浅浅淡淡
似乎能够感受到那是的安稳自由悠闲和
一种特殊的安静的力量
如果能够出发去遇到更多的未知的人和事
那我一定不辜负世界的温柔 查看全部
LmCjl程序转优化猿程序猿是无所不能的,上到写代码,下到各种各样的事情,包括我自己组装单车和上下婴儿床,小到学钢琴,大到变革优化猿,我都O得K的。
自动采集文章内容兼发布内容
经历了几个月的敲敲打打,自动采集文章内容兼手动发布文章内容早已推下来了,简单容易的操作面板,可实现5~10分钟菜鸟熟练上手,同时便捷了做优化的大大们管理站群和发布文章的痛处,目前支持采集各大网站网站文章自动采集,识别率达到百分之99,同时支持各大个人网站的手动发布文章,教程早已发布在网站里面了。点击步入工具即可查看教程。
采集文章内容可辨识我想要的内容吗?
没问题的,只须要把你所需的文章内容网站文章自动采集,输入你想要的关键词,会手动筛选和匹配你想要的。
例如:
1.我想要带有SEO这个词的文章,其他的我都不要,只须要在采集管理的上面,输入包含关键词,即可。
最多可以管理多少个网站?
我可以说,多多益善吗?LmCjl目前管理的网站是658个,但是我还可以继续降低起来。
网站地址:
工具地址:
做简单好用的在线工具,无需下载,只须要记住:lmcjl
爱看书也爱远行
心情在路上
FIND YOURSELF
读好多的随记也写下好多的文字/浅浅淡淡
似乎能够感受到那是的安稳自由悠闲和
一种特殊的安静的力量
如果能够出发去遇到更多的未知的人和事
那我一定不辜负世界的温柔
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-03 15:02
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果
一套内容采集系统 解放编辑人员
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-08-03 13:02
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用内容采集系统,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log内容采集系统,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新) 查看全部
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用内容采集系统,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log内容采集系统,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新)
明日以后无限资源辅助 自动采集挂机升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 1217 次浏览 • 2020-08-03 10:52
—————明日以后安卓版【点击下载】,赠送金币50000+典藏版ump9图纸。
明日以后无限资源辅助
资源是有其中最重要的道具,不管是木材资源、铁矿资源、麻资源,玩家是须要去采集、去挖掘的才有机率可以获得。游戏中的资源,这个是不能订购的,直接采集就可以获得,而且数目十分多,副材料是可以破防下来的,需求量十分高,需要用一些太基础的材料,然后合成中级资源。
资源辅助:点击下载
开启步骤
1、玩家可以先下载这个辅助,辅助还是比较好用的,可以设置一些手动挂机、自动采集。无限资源就是有采集和升级的功能挂机 采集,需要对应的资源,你直接勾选就可以了。
2、打开辅助,进行后台运行,运行以后在游戏中就可以显示下来挂机 采集,在右侧有一个透明显示。
3、点击左上角这儿,然后把软件设置下来,直接设置对应的采集方式对的,刷熟练度形式,点上去就可以了,他会手动的去升级去采集。
目前使用辅助还是有机率被封号的,玩家可以用大号测试一下,或者是就只玩大号,大号就不玩。
————点击下载明天过后【电脑版】,PC流畅运行,完美适配,下载送礼包。
以上有关于明天过后手动采集挂机升级相关内容了,如果想要了解更多资讯,直接在百度中搜索(明日以后琵琶网+你想查找的内容),还可以【点击这儿】关注礼包的动态。
《明日以后》【安卓下载】领取礼包(新币*20000+肾上腺剂*10)【点我进群】群号:945254345 查看全部
明日以后中的无限资源,资源是最重要的,玩家须要采集资源或则是订购资源,有的就是手动采集的,无限资源如何开?下面我带你们了解下。
—————明日以后安卓版【点击下载】,赠送金币50000+典藏版ump9图纸。
明日以后无限资源辅助
资源是有其中最重要的道具,不管是木材资源、铁矿资源、麻资源,玩家是须要去采集、去挖掘的才有机率可以获得。游戏中的资源,这个是不能订购的,直接采集就可以获得,而且数目十分多,副材料是可以破防下来的,需求量十分高,需要用一些太基础的材料,然后合成中级资源。
资源辅助:点击下载
开启步骤
1、玩家可以先下载这个辅助,辅助还是比较好用的,可以设置一些手动挂机、自动采集。无限资源就是有采集和升级的功能挂机 采集,需要对应的资源,你直接勾选就可以了。
2、打开辅助,进行后台运行,运行以后在游戏中就可以显示下来挂机 采集,在右侧有一个透明显示。
3、点击左上角这儿,然后把软件设置下来,直接设置对应的采集方式对的,刷熟练度形式,点上去就可以了,他会手动的去升级去采集。
目前使用辅助还是有机率被封号的,玩家可以用大号测试一下,或者是就只玩大号,大号就不玩。
————点击下载明天过后【电脑版】,PC流畅运行,完美适配,下载送礼包。
以上有关于明天过后手动采集挂机升级相关内容了,如果想要了解更多资讯,直接在百度中搜索(明日以后琵琶网+你想查找的内容),还可以【点击这儿】关注礼包的动态。
《明日以后》【安卓下载】领取礼包(新币*20000+肾上腺剂*10)【点我进群】群号:945254345
教你怎样将采集来的文章伪装成原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 497 次浏览 • 2020-08-03 09:07
然而,站长的精力虽然有限,不可能每晚只去撰写网站的内容而不做别的事情。况且有些站长手里的站点还不止一个。因此伪原创的高价值文章的撰写就变得十分有必要了。那么怎么能够写好呢?
1.采集与网站主题相关的内容
就像男人不可以穿长裤一样,网站的内容也要符合网站的主题才行,否则采集文章内容,用户对你建设网站的意图倍感蒙蔽,不知道你这个网站究竟是干哪些的。具体来说就是资讯站就要去采集那些热门的新闻资讯,而不是发一些校园故事;如果是网路营销网站采集文章内容,就要去采集那些与网路营销相关的内容。
采集对的文章是撰写高质量伪原创文章的步,毕竟资料首先得是正确的嘛。另外,采集的内容也要保证有一定的质量。一篇垃圾文章,你想把它改写成优质文章需要花费的精力也不少,有时候还不如自己写来得快。
2.用心更改文章
其一,改写文章的标题和首尾段。想要撰写伪原创文章,就算首尾段不改,标题也一定要改。但若果想得到更好的原创度的话,首尾段也要自己来写,保证首尾段以及标题的真正原创。并且,撰写的过程中要注意带入自己网站的关键词,删除与对方相关的一些信息。
其二,具体改写的时侯,可以通过修改成语的次序或则变化句式来进行原创的创作。简单的举个反例:今天小明事假回去了。就可以更改成“你晓得明天小明为何没来吗?因为他事假回去了。”
其三,大家还可以多采集几篇文章,然后感悟这几篇文章的意思,将它们融合在一起。相信这样的文章写下来原创度也是能得到保证的。 查看全部
在google代理商看来,网站的内容对网站而言就相当于是一个人的灵魂。试想一个人没有灵魂的话岂不就是行尸走肉?!那么没有优质内容的网站也就相当于是一个空架子,是没有用户想去访问和浏览的。
然而,站长的精力虽然有限,不可能每晚只去撰写网站的内容而不做别的事情。况且有些站长手里的站点还不止一个。因此伪原创的高价值文章的撰写就变得十分有必要了。那么怎么能够写好呢?
1.采集与网站主题相关的内容
就像男人不可以穿长裤一样,网站的内容也要符合网站的主题才行,否则采集文章内容,用户对你建设网站的意图倍感蒙蔽,不知道你这个网站究竟是干哪些的。具体来说就是资讯站就要去采集那些热门的新闻资讯,而不是发一些校园故事;如果是网路营销网站采集文章内容,就要去采集那些与网路营销相关的内容。
采集对的文章是撰写高质量伪原创文章的步,毕竟资料首先得是正确的嘛。另外,采集的内容也要保证有一定的质量。一篇垃圾文章,你想把它改写成优质文章需要花费的精力也不少,有时候还不如自己写来得快。
2.用心更改文章
其一,改写文章的标题和首尾段。想要撰写伪原创文章,就算首尾段不改,标题也一定要改。但若果想得到更好的原创度的话,首尾段也要自己来写,保证首尾段以及标题的真正原创。并且,撰写的过程中要注意带入自己网站的关键词,删除与对方相关的一些信息。
其二,具体改写的时侯,可以通过修改成语的次序或则变化句式来进行原创的创作。简单的举个反例:今天小明事假回去了。就可以更改成“你晓得明天小明为何没来吗?因为他事假回去了。”
其三,大家还可以多采集几篇文章,然后感悟这几篇文章的意思,将它们融合在一起。相信这样的文章写下来原创度也是能得到保证的。

