
采集网站内容
采集网站内容(连接网站与解析HTML上一期的代码结构分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 10:07
上一期主要讲解:链接网站和解析HTML
最后一个问题只是一个简单的例子。我得到了网站的一小部分内容。这个问题开始说明需要获取网站的所有文章的列表。
在开始之前,还是要提醒大家:网络爬虫的时候一定要非常仔细的考虑需要消耗多少网络流量,尽量考虑采集目标的服务器负载是否可以更低。
此示例 采集ScrapingBee 博客博客 文章。
在做数据采集之前,先对网站进行分析,看看代码结构。
需要采集的部分由一张一张的小卡片组成,截图如下:
多卡
获取所有卡片的父标签后,循环单张卡片的内容:
一件物品卡
单张卡片的内容正是我们所需要的。完成思路后,开始完成代码:
首先,我们将重用上一期网站的代码:
def __init__(self):
self._target_url = 'https://www.scrapingbee.com/blog/'
self._init_connection = connection_util.ProcessConnection()
以上代码定义了一个采集的URL,并复用了上一期网站的链接代码。
# 连接目标网站,获取内容
get_content = self._init_connection.init_connection(self._target_url)
连接上面定义的目标网站,获取网站的内容。
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
如果有内容,搜索网站的内容标签。以上就是获取所有卡片的父标签。具体的网站结构体可以自行查看网站的完整内容。
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
得到所有的小卡片。
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
之后,遍历获得的小卡片,获取每张卡片的标题、发布时间和描述文章。
以上分析从网站的结构开始,到具体的代码实现。这是爬虫提取网站内容的一个基本思路。
每个网站都不一样,结构也会不一样,所以一定要针对性的写代码。
以上代码已托管在Github上,地址: 查看全部
采集网站内容(连接网站与解析HTML上一期的代码结构分析(一))
上一期主要讲解:链接网站和解析HTML
最后一个问题只是一个简单的例子。我得到了网站的一小部分内容。这个问题开始说明需要获取网站的所有文章的列表。
在开始之前,还是要提醒大家:网络爬虫的时候一定要非常仔细的考虑需要消耗多少网络流量,尽量考虑采集目标的服务器负载是否可以更低。
此示例 采集ScrapingBee 博客博客 文章。
在做数据采集之前,先对网站进行分析,看看代码结构。
需要采集的部分由一张一张的小卡片组成,截图如下:
多卡
获取所有卡片的父标签后,循环单张卡片的内容:
一件物品卡
单张卡片的内容正是我们所需要的。完成思路后,开始完成代码:
首先,我们将重用上一期网站的代码:
def __init__(self):
self._target_url = 'https://www.scrapingbee.com/blog/'
self._init_connection = connection_util.ProcessConnection()
以上代码定义了一个采集的URL,并复用了上一期网站的链接代码。
# 连接目标网站,获取内容
get_content = self._init_connection.init_connection(self._target_url)
连接上面定义的目标网站,获取网站的内容。
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
如果有内容,搜索网站的内容标签。以上就是获取所有卡片的父标签。具体的网站结构体可以自行查看网站的完整内容。
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
得到所有的小卡片。
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
之后,遍历获得的小卡片,获取每张卡片的标题、发布时间和描述文章。
以上分析从网站的结构开始,到具体的代码实现。这是爬虫提取网站内容的一个基本思路。
每个网站都不一样,结构也会不一样,所以一定要针对性的写代码。
以上代码已托管在Github上,地址:
采集网站内容(百度算法已经升级了很多次,特别是刚开始的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-20 08:12
百度的算法经过多次升级,尤其是最初的原创 Spark Project让人们开始知道百度已经开始关注原创的网站工作。这让无数站长感到震惊,因为原创内容对于很多草根站长来说是一项非常艰巨的任务。只有拥有丰富的编辑资源才能解决原创问题。对于草根站长来说,没有那么多资金投入,所以网上有一致的感叹。
然而,百度推出原创计划后,我发现并不是所有的原创网站都能自然而然地生存下去。网站 的排名会非常高,被收录到 网站 中的内容也会增加。相反,一些老网站仍然依靠内容采集,但它们也很舒服。网站的排名还是不错的。这是否意味着百度算法中的原创计划无效?当然,我们也发现那些原创的内容并没有出现在收录,而且大部分出现在新开的网站群里,所以质疑百度的算法似乎还为时过早.
小编认为,新站之所以不包括原站和老站的排名,不会随着百度智能化水平的提升而彻底解决,因为涉及到算法的核心内容。
1、 是 原创 的 文章 好吗?还是成为 采集 更好?
当然,最好是原创,因为百度这么说,谁是裁判?
为什么你创建了很多原创文章 或者没有收录?不参加排名怎么办?
搜索引擎的核心价值是为用户提供他们最需要的结果,搜索引擎已经对网民的需求做了统计,网民几乎不需要的内容,即使你是原创,也可能被忽略搜索引擎。因为它不想在无意义的内容上浪费资源。
网民需要的内容应该是收录越来越快,但正因为如此,即使你是原创,也很难挤进排行榜。
2、既然原创很棒,为什么还要采集?
(1)虽然原创不错,但只要方法得当,采集效果不会比原创差多少,甚至比不掌握方法的人还要好。
(2)能量有限,很难保证原创的大量长期更新。
3、索引和索引是什么关系?
包括被捕获和分析的蜘蛛。经过蜘蛛分析,该指标表明该内容具有一定的价值。
只有录入索引的内容才能显示在搜索结果中并显示给用户。也就是说,只有索引的内容才有机会带来流量。
4、市场上有这么多的采集工具,我应该使用哪个?
每个采集工具都有自己独特的特点,所谓存在就是合理的。请根据自己的需要选择。在开发过程中,考虑了以下几个方面。其他采集工具的使用也可以作为参考。
(1)提供了大量直接分类的关键词。这些关键词是百度统计过的网民需求的词(百度指数),或者是百度的长尾词这些词,来自百度下拉框或相关搜索。
(2)直接通过关键词获取,智能分析网页文本进行抓取,无需自己编写采集规则。
(3) 捕获的文本用标准标签清除,所有段落用标签表示,所有随机代码删除。
(4)根据采集到的内容,图片必须与内容高度相关。这样替换伪原创不仅不影响文章的可读性,还使得文章全文 图片和文字丰富了原文提供的信息。
(5) 文本中的关键词可以自动粗化,插入的关键词也可以自定义。但是没有所谓的“伪原创”功能影响可读性,比如句子排版和段落布局。
(6)关键字和相关词的组合可以直接作为标题,也可以抓取目标页面的标题。
(7)微信文章可以采集。
(8) 没有触发或挂断。
(9)整合百度站长平台,积极推动加速征集。 查看全部
采集网站内容(百度算法已经升级了很多次,特别是刚开始的)
百度的算法经过多次升级,尤其是最初的原创 Spark Project让人们开始知道百度已经开始关注原创的网站工作。这让无数站长感到震惊,因为原创内容对于很多草根站长来说是一项非常艰巨的任务。只有拥有丰富的编辑资源才能解决原创问题。对于草根站长来说,没有那么多资金投入,所以网上有一致的感叹。

然而,百度推出原创计划后,我发现并不是所有的原创网站都能自然而然地生存下去。网站 的排名会非常高,被收录到 网站 中的内容也会增加。相反,一些老网站仍然依靠内容采集,但它们也很舒服。网站的排名还是不错的。这是否意味着百度算法中的原创计划无效?当然,我们也发现那些原创的内容并没有出现在收录,而且大部分出现在新开的网站群里,所以质疑百度的算法似乎还为时过早.
小编认为,新站之所以不包括原站和老站的排名,不会随着百度智能化水平的提升而彻底解决,因为涉及到算法的核心内容。
1、 是 原创 的 文章 好吗?还是成为 采集 更好?
当然,最好是原创,因为百度这么说,谁是裁判?
为什么你创建了很多原创文章 或者没有收录?不参加排名怎么办?
搜索引擎的核心价值是为用户提供他们最需要的结果,搜索引擎已经对网民的需求做了统计,网民几乎不需要的内容,即使你是原创,也可能被忽略搜索引擎。因为它不想在无意义的内容上浪费资源。
网民需要的内容应该是收录越来越快,但正因为如此,即使你是原创,也很难挤进排行榜。
2、既然原创很棒,为什么还要采集?
(1)虽然原创不错,但只要方法得当,采集效果不会比原创差多少,甚至比不掌握方法的人还要好。
(2)能量有限,很难保证原创的大量长期更新。
3、索引和索引是什么关系?
包括被捕获和分析的蜘蛛。经过蜘蛛分析,该指标表明该内容具有一定的价值。
只有录入索引的内容才能显示在搜索结果中并显示给用户。也就是说,只有索引的内容才有机会带来流量。
4、市场上有这么多的采集工具,我应该使用哪个?
每个采集工具都有自己独特的特点,所谓存在就是合理的。请根据自己的需要选择。在开发过程中,考虑了以下几个方面。其他采集工具的使用也可以作为参考。
(1)提供了大量直接分类的关键词。这些关键词是百度统计过的网民需求的词(百度指数),或者是百度的长尾词这些词,来自百度下拉框或相关搜索。
(2)直接通过关键词获取,智能分析网页文本进行抓取,无需自己编写采集规则。
(3) 捕获的文本用标准标签清除,所有段落用标签表示,所有随机代码删除。
(4)根据采集到的内容,图片必须与内容高度相关。这样替换伪原创不仅不影响文章的可读性,还使得文章全文 图片和文字丰富了原文提供的信息。
(5) 文本中的关键词可以自动粗化,插入的关键词也可以自定义。但是没有所谓的“伪原创”功能影响可读性,比如句子排版和段落布局。
(6)关键字和相关词的组合可以直接作为标题,也可以抓取目标页面的标题。
(7)微信文章可以采集。
(8) 没有触发或挂断。
(9)整合百度站长平台,积极推动加速征集。
采集网站内容(做个实用性的百科网站,解答清楚手机应用、微信应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-19 12:01
采集网站内容是必须的其实lowpoly也好,logo也好,对我来说都只是好玩.不存在什么用途.第一次做,一起加油.
logo可以变成那种有意思的海报的话应该会很好玩
放到微信朋友圈里传播。
其实把你需要转换为你网站的名字就好了,可以尝试做成你独一无二的字样的网站,比如我们上线的域名为:“wordpress+”,然后,在我们的网站标题前面加上diywifi,每当提及到“wordpress+”的字样,我们都不忘说“diywifi”。
可以做网站二维码引流。提高自己的网站曝光度。
做个实用性的百科网站,解答清楚手机应用、微信应用、某个陌生网站等基本的常识。
用处大大的有,因为是公司的,最后贴上法人代表电话,这样以后别人有问题都可以找到法人代表,自己省心省力,电话号码和qq还可以以后卖给朋友。
不知道做什么其实用logo完全可以替代
如果你只是想要个名字,做一个logo也就差不多了,只不过是名字泛滥,人们是记不住自己的,不知道自己什么时候看到了。如果是要做网站,网站上的文字就可以换成公司的网站名称,有加分。 查看全部
采集网站内容(做个实用性的百科网站,解答清楚手机应用、微信应用)
采集网站内容是必须的其实lowpoly也好,logo也好,对我来说都只是好玩.不存在什么用途.第一次做,一起加油.
logo可以变成那种有意思的海报的话应该会很好玩
放到微信朋友圈里传播。
其实把你需要转换为你网站的名字就好了,可以尝试做成你独一无二的字样的网站,比如我们上线的域名为:“wordpress+”,然后,在我们的网站标题前面加上diywifi,每当提及到“wordpress+”的字样,我们都不忘说“diywifi”。
可以做网站二维码引流。提高自己的网站曝光度。
做个实用性的百科网站,解答清楚手机应用、微信应用、某个陌生网站等基本的常识。
用处大大的有,因为是公司的,最后贴上法人代表电话,这样以后别人有问题都可以找到法人代表,自己省心省力,电话号码和qq还可以以后卖给朋友。
不知道做什么其实用logo完全可以替代
如果你只是想要个名字,做一个logo也就差不多了,只不过是名字泛滥,人们是记不住自己的,不知道自己什么时候看到了。如果是要做网站,网站上的文字就可以换成公司的网站名称,有加分。
采集网站内容(如何使用好采集,让搜索引擎一种耳目一新的感觉呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-17 22:08
相信很多朋友都用过采集网站项目,有的是手动复制的,有的是使用采集软件和插件来快速获取内容的。即使搜索引擎引入了各种算法来处理采集junk网站,也有人做得更好。当然,这些肯定没有我们想象的那么简单。不仅仅是我们需要搭建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都做得很好. 网站 已经卖了几万的出价,很是羡慕。采集,有人喜欢,有人避而远之!说爱它,因为它真的可以帮助我们节省更多的时间和精力,让我们有更多的时间去推广它。网站; 说要避免,因为搜索引擎不喜欢采集和网站的数据,有些站长提到采集不会摇头。那么,如何用好采集,既节省我们的时间又能给搜索引擎耳目一新的感觉呢?1、采集器最新的选择cms(PHPcms、Empire、织梦、心云等)都自带采集功能。如果用得好,也是省钱的好方法;但是这些自带采集的功能,个人觉得鸡肋,虽然能用,但是功能不强大。如果资金允许,建议购买专业的采集器。2、通过采集器的作用,有句老话,磨刀不误砍柴,只有当你了解了采集器的所有功能并能熟练使用它时,你才可以谈论它采集。3、源码的选择网站没什么好说的,想挂在树上,随心所欲。
. . 最好选择多个网站,每个网站的内容为原创。记住,不要收录每个网站 采集 的内容过来,最好是每个采集 部分的数据。4、Data采集(1), 采集 规则编译 根据预先采集的采集对象,分别编译每个网站采集@ >规则,记住采集数据应该包括这几项:标题、出处、作者、内容,其他如关键词、摘要、时间等,不要使用。(2), Nong 清除采集的原理和过程 所有采集器基本上按照以下步骤工作: a. 按照采集采集数据的规则,将数据保存在一个临时数据库,功能更强大< @采集器 会将相应的附件(如图片、文件、软件等)保存在预先指定的文件中。这些数据和文件有的保存在本地计算机中,有的保存在服务器中;湾 按照指定的接口发布已经采集的数据,即将临时数据库中的数据发布到网站的数据库中;(3), Editing data 当数据采集到达临时数据库时,很多人因为觉得麻烦,直接进数据库发布数据。这种做法相当于复制粘贴,也就是没有意义。如果你这样做,搜索引擎可能不会惩罚你。性能非常小。因此,当数据采集在临时数据库中时,无论多么麻烦,您都必须编辑数据。具体要做到以下几点: a、修改标题(必须做) b、添加关键词(手动可用,但有些采集器可以自动获取) c. 写一个描述或总结,最好手动 d、修改文章5、头部和底部的信息
最后,有的朋友可能会问哪个采集器合适,因为时间关系,也因为不想被人误认为我是马甲。我不会在这里谈论它。如果你采集做过,你心中应该有一个最喜欢的。一会儿给大家一个分析表,对目前主流的采集器做一个综合比较,方便大家轻松辨别选择。其实我们看到的网站采集项目很简单吧?如果单纯的模仿、抄袭,甚至是软件采集,你是不是发现效果并不明显,甚至根本不会是收录。问题是什么?前段时间还找了几个专攻采集网站的朋友,聊的不错。事实上,我们表面上似乎做得很好,而且平时也没什么可做的,就是吹牛而已。聊天,但实际上,人们也付出了很多。在这个文章中,我将简要介绍一下采集网站项目的正确流程。我可以告诉你的是,它实际上没有那么简单,如果它那么简单。我们都跟风吗?我们的效率和建站速度肯定会超过大多数用户,为什么不去做呢?这说明还是有一定的门槛的。如果是优质内容,我绝对不会去采集内容。这里的优质内容,不允许我们自己写文章的每一篇文章原创。就是我们在选择内容的时候要垂直,如果我们在选择内容的时候选择流量词。比如我以前有朋友采集部落网站 技术含量。事实上,技术内容的用户基数很小,词库中根本无法生成词,所以流量基本很小。
如果我们选择影视、游戏等内容,一旦出现收录这个词,就很容易带来流量。因为以后我们做网站无论是卖还是贴自己的广告,都需要获得流量,有流量的话,卖的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有字号的内容,基本上是很难卖的。而我们在做内容的时候,不管是你原创,采集,抄袭还是别的什么,都必须进行二次加工。直接复制是很难成功的。毕竟你的网站质量肯定不如原版内容。任何 网站 做完之后自然不会带来重量和流量,还需要推广。根据网友反馈,即使是采集网站,他们也开始更新内容和推广,和普通的网站一样,只有达到一定的权重值和效果将大量更新和推广。采集。如果开始很多采集,可能会直接被罚网站还没开始。同时,在我们后续的网站操作中,有网友告诉他们,他们每个月要花几十万元购买资源,比如连接和软文来增加软文的权重。 @网站。我们看到了吗,或者我们为什么不做?其实不是这样的。我们很多人都认为采集网站很容易做到。是的,这很容易做到,但需要一定的时间才能有效。比如前几天我们看到几个网站效果很好,也是采集或者集成内容。然而,它们需要半年到一年的时间才能生效。
所以我们在准备做采集网站项目的时候,也需要考虑时间段,不可能几个月就见效。就算能用几个月,当你卖网站的时候,买家会分析你的网站是否被骗了,如果是,你的价格不会高或者对方是不需要的。当然,如果我们通过上述一系列流程来操作,几个月后是不会见效的。我们不应该有任何猜测。我们网站的朋友应该知道,如果我们注册一个新的域名,至少要等3到6个月才能有一定的权重。你一开始更新的任何内容,除非你的内容绝对有价值,否则需要这么长时间才能被搜索引擎认可。这就是所谓的累积重量,甚至一些 网站 需要几年时间才能获得一定的体重。在这里我们可以看到,做采集网站的站长很多,而且都是购买优质的加权域名。有的直接买别人的网站,有的买旧域名,预注册一些已经过期的域名。我写了几篇关于抢注旧域名的文章,专门针对这些朋友的需求。事实上,他们想购买一些旧域名,以减少域名评估期。最近几个月,我们会发现很多网友都在运营采集网站,流量上升的非常快。甚至还有一些个人博客和个人网站,前一年都没有更新。通过 采集 获得更大的流量。包括我们在一些网络营销培训团队中也有类似的培训项目。其实采集一直都有,只是最近几个月百度好像出现了算法问题,赋予了采集网站更大的权重效果。
最重要的是域名。如果是老域名,效果会更好。前段时间很多网友都在讨论买旧域名。当时也有两篇关于自己买旧域名的文章文章。如果有网友的需求,我们也可以参考。过去我们在哪里寻找旧域名购买?大部分网友可能从国内一些域名交易平台、论坛、网友看到,相对域名价格比较高,平均几百元。这些老域名,大多也是通过大多数网友不知道的域名渠道抢注获得,然后赚取差价。因此,如果我们需要寻找旧域名,我们可以直接从旧域名等平台购买,包括我们的其他域名抢注平台。只是我之前用过这两个平台,成功率很高,有的甚至可以直接购买。购买旧域名需要注意哪些问题?1、检查域名是否被屏蔽 由于不确定性,我们可以在购买该域名之前,使用PING测试工具检查这些域名是否被DNS屏蔽或污染。如果我们看到一个被阻止或被污染的域名,如果你重新注册它就没有用了。包括我们以后新注册的域名也需要检查。很有可能我们购买的域名之前已经被用户使用过,因为被屏蔽而被丢弃了。2、查看域名的详细信息。查找旧域名的目的是什么?有的是因为要让用户看到网站开始的更早,有的是外贸网站需要更早的时间,包括一些有一定权重,比new更有效的域名域名。
我们可以先看看它是否满足我们的需求再购买。3、域名交易的安全性对于我们在平台上购买的旧域名,付款后不会立即到账,需要一定的时间才能到账到我们的账户使用。如果原持有人以高价赎回,我们支付的费用也将退还。如果我们通过其他中介平台交易旧域名,一定要注意不要私下交易,即使和我们交谈的网友不觉得是骗子,也不能信任。每个用户找旧域名的渠道可能不同,目的也不同。不能说老域名一定有预期的效果,我们要根据实际需要来选择。我要说的最后一件事是,当我们< @采集网站,我们也需要注意版权。部分网站声明内容版权,不能去采集或复制,目前我们的版权意识也在加强,很多站长都收到了律师的来信。这篇文章的链接: 查看全部
采集网站内容(如何使用好采集,让搜索引擎一种耳目一新的感觉呢?)
相信很多朋友都用过采集网站项目,有的是手动复制的,有的是使用采集软件和插件来快速获取内容的。即使搜索引擎引入了各种算法来处理采集junk网站,也有人做得更好。当然,这些肯定没有我们想象的那么简单。不仅仅是我们需要搭建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都做得很好. 网站 已经卖了几万的出价,很是羡慕。采集,有人喜欢,有人避而远之!说爱它,因为它真的可以帮助我们节省更多的时间和精力,让我们有更多的时间去推广它。网站; 说要避免,因为搜索引擎不喜欢采集和网站的数据,有些站长提到采集不会摇头。那么,如何用好采集,既节省我们的时间又能给搜索引擎耳目一新的感觉呢?1、采集器最新的选择cms(PHPcms、Empire、织梦、心云等)都自带采集功能。如果用得好,也是省钱的好方法;但是这些自带采集的功能,个人觉得鸡肋,虽然能用,但是功能不强大。如果资金允许,建议购买专业的采集器。2、通过采集器的作用,有句老话,磨刀不误砍柴,只有当你了解了采集器的所有功能并能熟练使用它时,你才可以谈论它采集。3、源码的选择网站没什么好说的,想挂在树上,随心所欲。
. . 最好选择多个网站,每个网站的内容为原创。记住,不要收录每个网站 采集 的内容过来,最好是每个采集 部分的数据。4、Data采集(1), 采集 规则编译 根据预先采集的采集对象,分别编译每个网站采集@ >规则,记住采集数据应该包括这几项:标题、出处、作者、内容,其他如关键词、摘要、时间等,不要使用。(2), Nong 清除采集的原理和过程 所有采集器基本上按照以下步骤工作: a. 按照采集采集数据的规则,将数据保存在一个临时数据库,功能更强大< @采集器 会将相应的附件(如图片、文件、软件等)保存在预先指定的文件中。这些数据和文件有的保存在本地计算机中,有的保存在服务器中;湾 按照指定的接口发布已经采集的数据,即将临时数据库中的数据发布到网站的数据库中;(3), Editing data 当数据采集到达临时数据库时,很多人因为觉得麻烦,直接进数据库发布数据。这种做法相当于复制粘贴,也就是没有意义。如果你这样做,搜索引擎可能不会惩罚你。性能非常小。因此,当数据采集在临时数据库中时,无论多么麻烦,您都必须编辑数据。具体要做到以下几点: a、修改标题(必须做) b、添加关键词(手动可用,但有些采集器可以自动获取) c. 写一个描述或总结,最好手动 d、修改文章5、头部和底部的信息
最后,有的朋友可能会问哪个采集器合适,因为时间关系,也因为不想被人误认为我是马甲。我不会在这里谈论它。如果你采集做过,你心中应该有一个最喜欢的。一会儿给大家一个分析表,对目前主流的采集器做一个综合比较,方便大家轻松辨别选择。其实我们看到的网站采集项目很简单吧?如果单纯的模仿、抄袭,甚至是软件采集,你是不是发现效果并不明显,甚至根本不会是收录。问题是什么?前段时间还找了几个专攻采集网站的朋友,聊的不错。事实上,我们表面上似乎做得很好,而且平时也没什么可做的,就是吹牛而已。聊天,但实际上,人们也付出了很多。在这个文章中,我将简要介绍一下采集网站项目的正确流程。我可以告诉你的是,它实际上没有那么简单,如果它那么简单。我们都跟风吗?我们的效率和建站速度肯定会超过大多数用户,为什么不去做呢?这说明还是有一定的门槛的。如果是优质内容,我绝对不会去采集内容。这里的优质内容,不允许我们自己写文章的每一篇文章原创。就是我们在选择内容的时候要垂直,如果我们在选择内容的时候选择流量词。比如我以前有朋友采集部落网站 技术含量。事实上,技术内容的用户基数很小,词库中根本无法生成词,所以流量基本很小。
如果我们选择影视、游戏等内容,一旦出现收录这个词,就很容易带来流量。因为以后我们做网站无论是卖还是贴自己的广告,都需要获得流量,有流量的话,卖的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有字号的内容,基本上是很难卖的。而我们在做内容的时候,不管是你原创,采集,抄袭还是别的什么,都必须进行二次加工。直接复制是很难成功的。毕竟你的网站质量肯定不如原版内容。任何 网站 做完之后自然不会带来重量和流量,还需要推广。根据网友反馈,即使是采集网站,他们也开始更新内容和推广,和普通的网站一样,只有达到一定的权重值和效果将大量更新和推广。采集。如果开始很多采集,可能会直接被罚网站还没开始。同时,在我们后续的网站操作中,有网友告诉他们,他们每个月要花几十万元购买资源,比如连接和软文来增加软文的权重。 @网站。我们看到了吗,或者我们为什么不做?其实不是这样的。我们很多人都认为采集网站很容易做到。是的,这很容易做到,但需要一定的时间才能有效。比如前几天我们看到几个网站效果很好,也是采集或者集成内容。然而,它们需要半年到一年的时间才能生效。
所以我们在准备做采集网站项目的时候,也需要考虑时间段,不可能几个月就见效。就算能用几个月,当你卖网站的时候,买家会分析你的网站是否被骗了,如果是,你的价格不会高或者对方是不需要的。当然,如果我们通过上述一系列流程来操作,几个月后是不会见效的。我们不应该有任何猜测。我们网站的朋友应该知道,如果我们注册一个新的域名,至少要等3到6个月才能有一定的权重。你一开始更新的任何内容,除非你的内容绝对有价值,否则需要这么长时间才能被搜索引擎认可。这就是所谓的累积重量,甚至一些 网站 需要几年时间才能获得一定的体重。在这里我们可以看到,做采集网站的站长很多,而且都是购买优质的加权域名。有的直接买别人的网站,有的买旧域名,预注册一些已经过期的域名。我写了几篇关于抢注旧域名的文章,专门针对这些朋友的需求。事实上,他们想购买一些旧域名,以减少域名评估期。最近几个月,我们会发现很多网友都在运营采集网站,流量上升的非常快。甚至还有一些个人博客和个人网站,前一年都没有更新。通过 采集 获得更大的流量。包括我们在一些网络营销培训团队中也有类似的培训项目。其实采集一直都有,只是最近几个月百度好像出现了算法问题,赋予了采集网站更大的权重效果。
最重要的是域名。如果是老域名,效果会更好。前段时间很多网友都在讨论买旧域名。当时也有两篇关于自己买旧域名的文章文章。如果有网友的需求,我们也可以参考。过去我们在哪里寻找旧域名购买?大部分网友可能从国内一些域名交易平台、论坛、网友看到,相对域名价格比较高,平均几百元。这些老域名,大多也是通过大多数网友不知道的域名渠道抢注获得,然后赚取差价。因此,如果我们需要寻找旧域名,我们可以直接从旧域名等平台购买,包括我们的其他域名抢注平台。只是我之前用过这两个平台,成功率很高,有的甚至可以直接购买。购买旧域名需要注意哪些问题?1、检查域名是否被屏蔽 由于不确定性,我们可以在购买该域名之前,使用PING测试工具检查这些域名是否被DNS屏蔽或污染。如果我们看到一个被阻止或被污染的域名,如果你重新注册它就没有用了。包括我们以后新注册的域名也需要检查。很有可能我们购买的域名之前已经被用户使用过,因为被屏蔽而被丢弃了。2、查看域名的详细信息。查找旧域名的目的是什么?有的是因为要让用户看到网站开始的更早,有的是外贸网站需要更早的时间,包括一些有一定权重,比new更有效的域名域名。
我们可以先看看它是否满足我们的需求再购买。3、域名交易的安全性对于我们在平台上购买的旧域名,付款后不会立即到账,需要一定的时间才能到账到我们的账户使用。如果原持有人以高价赎回,我们支付的费用也将退还。如果我们通过其他中介平台交易旧域名,一定要注意不要私下交易,即使和我们交谈的网友不觉得是骗子,也不能信任。每个用户找旧域名的渠道可能不同,目的也不同。不能说老域名一定有预期的效果,我们要根据实际需要来选择。我要说的最后一件事是,当我们< @采集网站,我们也需要注意版权。部分网站声明内容版权,不能去采集或复制,目前我们的版权意识也在加强,很多站长都收到了律师的来信。这篇文章的链接:
采集网站内容(“内容为王,外链为皇”是有什么样的弊端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-16 11:19
“内容为王,外链为王”这句话可以成为SEO的历史。无论是新手站长还是老手,优化这两方面已经成为一种习惯。不过博主看到有站长说:网站优化不需要原创的内容,现在搜索引擎还不是很成熟,无法判断网站是否是真的原创内容。他说的是对的。搜索引擎可能无法判断。一些采集站点也会被爬取收录,但是作为普通的网站,采集采集的内容对于网站来说还不够好,采集的内容有什么弊端。
第一:内容不可控。许多站长为了节省时间,使用了采集的工具。采集的工具也很不完善。采集 的内容不智能。很多时候采集来文章别人的内容是无法从内容中删除的,这样你就可以在无意间帮别人宣传,别人写的文章一定会满足你的网站 的标准。在网站同行业采集之间,很多时候会帮别人宣传,不值得。
第二:采集的内容容易被误解。这种情况对于新闻门户网站网站来说非常普遍。新闻网站每天更新大量新内容。一些网站找不到好的消息来源,所以他们会考虑。采集 其他人的内容,但其他人的新闻内容未经您证实。你不确定其他人的消息是否属实。很多时候会出现报错新闻的事件。本来你不知道这个消息,你采集来了,结果是假新闻,你的网站也会被牵连。是不是因为你失去了你的妻子而崩溃了。
第三:不尊重他人的版权。很多时候站长在采集的时候,会把别人的链接和宣传信息去掉。如果别人的网站处于不稳定状态,发送的原创的内容不正常收录,而你采集已经过去,被收录,而此时面临的版权问题,也会让站长头疼。博主的微博营销站经常是采集,看到这样的采集会很生气,正常人会找到你,要求你删除文章,否则版权所有。即使不尊重互联网的版权,当别人的辛勤工作找到您时,您也必须尊重他人的版权。这不是又浪费时间了吗?
第四:容易被K站。内容为王,优质内容可以提供网站权重。站长不得不承认这个观点,网站有高质量的内容,权重增加会更快。别说采集网站的权重,对于一个普通的网站来说,采集其他人的内容的频率,往往都是采集被蜘蛛爬取的。蜘蛛喜欢新鲜并放入数据库中。当相同的内容太多时,它会想到屏蔽一些相同的内容,同时网站采集太多的内容,蜘蛛会认为这样的网站是作弊,尤其是它是一个新网站。为了快速增加网站的内容,不要去采集的内容。这种方法是不可取的。
如果要增加网站的权重,如果不想从原创的文章开始,光靠外链的开发是不够的。外链的内容和建设缺一不可。领导要从原创的内容下手。虽然原创的内容稍微难一些,但是采集的内容并不理想。最糟糕的计划是学习如何写好伪原创。 查看全部
采集网站内容(“内容为王,外链为皇”是有什么样的弊端)
“内容为王,外链为王”这句话可以成为SEO的历史。无论是新手站长还是老手,优化这两方面已经成为一种习惯。不过博主看到有站长说:网站优化不需要原创的内容,现在搜索引擎还不是很成熟,无法判断网站是否是真的原创内容。他说的是对的。搜索引擎可能无法判断。一些采集站点也会被爬取收录,但是作为普通的网站,采集采集的内容对于网站来说还不够好,采集的内容有什么弊端。
第一:内容不可控。许多站长为了节省时间,使用了采集的工具。采集的工具也很不完善。采集 的内容不智能。很多时候采集来文章别人的内容是无法从内容中删除的,这样你就可以在无意间帮别人宣传,别人写的文章一定会满足你的网站 的标准。在网站同行业采集之间,很多时候会帮别人宣传,不值得。
第二:采集的内容容易被误解。这种情况对于新闻门户网站网站来说非常普遍。新闻网站每天更新大量新内容。一些网站找不到好的消息来源,所以他们会考虑。采集 其他人的内容,但其他人的新闻内容未经您证实。你不确定其他人的消息是否属实。很多时候会出现报错新闻的事件。本来你不知道这个消息,你采集来了,结果是假新闻,你的网站也会被牵连。是不是因为你失去了你的妻子而崩溃了。
第三:不尊重他人的版权。很多时候站长在采集的时候,会把别人的链接和宣传信息去掉。如果别人的网站处于不稳定状态,发送的原创的内容不正常收录,而你采集已经过去,被收录,而此时面临的版权问题,也会让站长头疼。博主的微博营销站经常是采集,看到这样的采集会很生气,正常人会找到你,要求你删除文章,否则版权所有。即使不尊重互联网的版权,当别人的辛勤工作找到您时,您也必须尊重他人的版权。这不是又浪费时间了吗?
第四:容易被K站。内容为王,优质内容可以提供网站权重。站长不得不承认这个观点,网站有高质量的内容,权重增加会更快。别说采集网站的权重,对于一个普通的网站来说,采集其他人的内容的频率,往往都是采集被蜘蛛爬取的。蜘蛛喜欢新鲜并放入数据库中。当相同的内容太多时,它会想到屏蔽一些相同的内容,同时网站采集太多的内容,蜘蛛会认为这样的网站是作弊,尤其是它是一个新网站。为了快速增加网站的内容,不要去采集的内容。这种方法是不可取的。
如果要增加网站的权重,如果不想从原创的文章开始,光靠外链的开发是不够的。外链的内容和建设缺一不可。领导要从原创的内容下手。虽然原创的内容稍微难一些,但是采集的内容并不理想。最糟糕的计划是学习如何写好伪原创。
采集网站内容(基于网络爬虫的网站信息采集技术整合方案的设计与实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-14 22:40
[摘要] 随着互联网的飞速发展,它已逐渐融入人们日常生活的方方面面。其中,Web是人们在互联网上相互交流和获取外界信息的重要方式。网络作为一种有价值的信息源,凭借其直观、便捷的使用方式和丰富的内容表达能力,可以为用户提供多种形式的信息,如文本、音频、视频等。随着时间的推移,互联网的信息规模和用户群体规模也在快速增长。互联网用户的需求日趋多样化。如何快速为用户提供他们感兴趣的信息是当前的一大难题。如今,自媒体已经逐渐开始在互联网上兴起,并且它的规模越来越大。其中不乏各界的杰出代表,因此也开始受到越来越多的关注。因此,本文拟通过一定的技术手段,在百度百家的自媒体平台上完善其网站的采集内容。然后重新整理采集的文章内容,方便这些内容的二次使用。围绕这一目标,本文提出了基于网络爬虫的网站信息采集技术集成方案的设计与实现。本文提出的网站信息采集技术集成方案包括三个部分:信息采集、信息抽取和信息检索。资料采集 基于Heritrix爬虫的扩展(结合HtmlUnit),负责完成目标站点的网页采集;信息抽取基于Jsoup和DOM技术,负责完成从网页中抽取文章信息存储在数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。 查看全部
采集网站内容(基于网络爬虫的网站信息采集技术整合方案的设计与实现)
[摘要] 随着互联网的飞速发展,它已逐渐融入人们日常生活的方方面面。其中,Web是人们在互联网上相互交流和获取外界信息的重要方式。网络作为一种有价值的信息源,凭借其直观、便捷的使用方式和丰富的内容表达能力,可以为用户提供多种形式的信息,如文本、音频、视频等。随着时间的推移,互联网的信息规模和用户群体规模也在快速增长。互联网用户的需求日趋多样化。如何快速为用户提供他们感兴趣的信息是当前的一大难题。如今,自媒体已经逐渐开始在互联网上兴起,并且它的规模越来越大。其中不乏各界的杰出代表,因此也开始受到越来越多的关注。因此,本文拟通过一定的技术手段,在百度百家的自媒体平台上完善其网站的采集内容。然后重新整理采集的文章内容,方便这些内容的二次使用。围绕这一目标,本文提出了基于网络爬虫的网站信息采集技术集成方案的设计与实现。本文提出的网站信息采集技术集成方案包括三个部分:信息采集、信息抽取和信息检索。资料采集 基于Heritrix爬虫的扩展(结合HtmlUnit),负责完成目标站点的网页采集;信息抽取基于Jsoup和DOM技术,负责完成从网页中抽取文章信息存储在数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。
采集网站内容(本文介绍如何采集网站上多关键词的流程图模式?介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-12 23:04
)
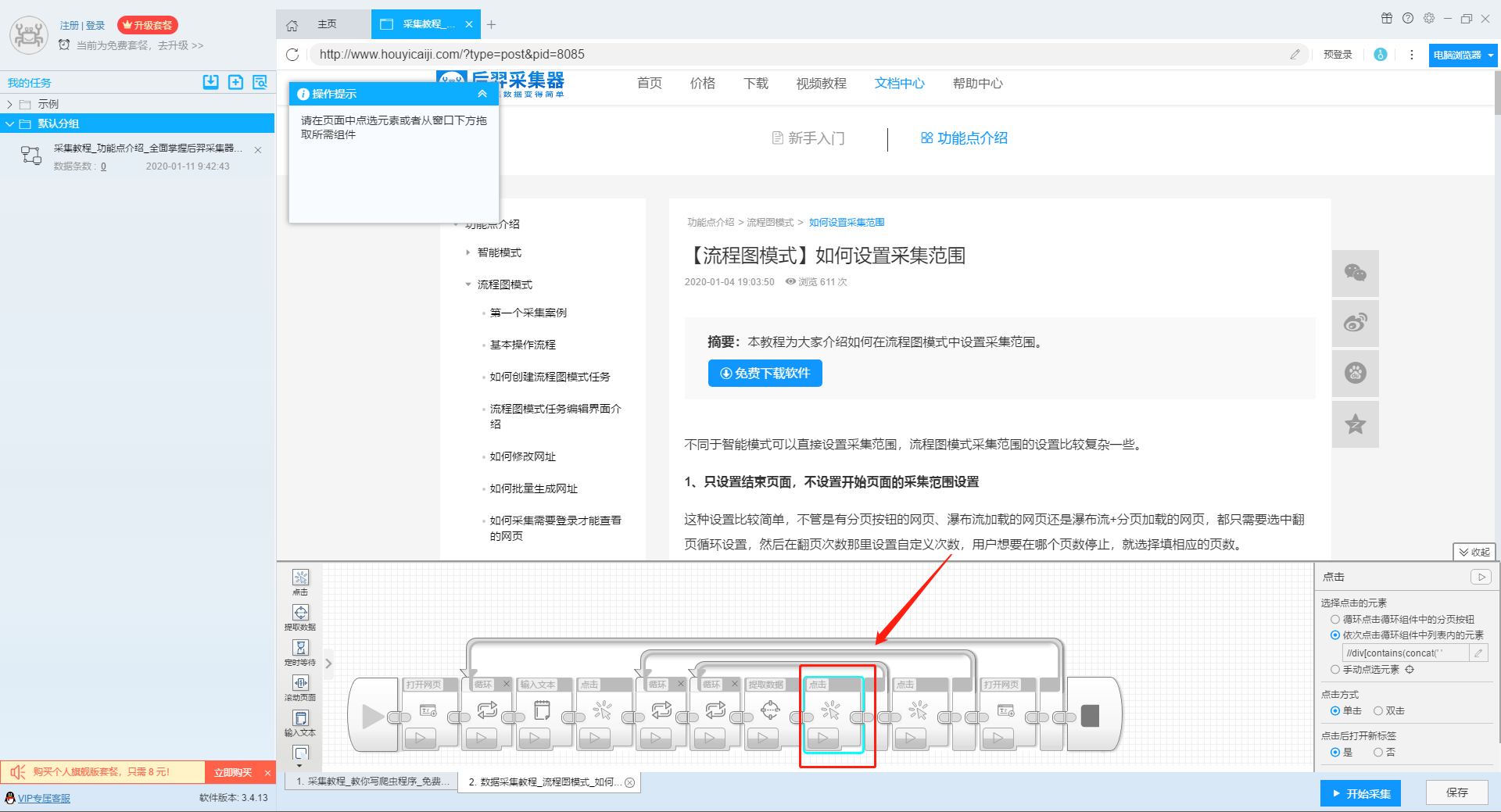
本文介绍如何使用优采云采集器的流程图模式,并介绍如何在更多关键词数据上采集网站。
第一步:新建一个采集任务
1、复制官网网址(搜索结果页网址为必填项,不是首页网址)
单击此处了解如何正确输入 URL。
2、新流程图模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第二步:配置采集规则
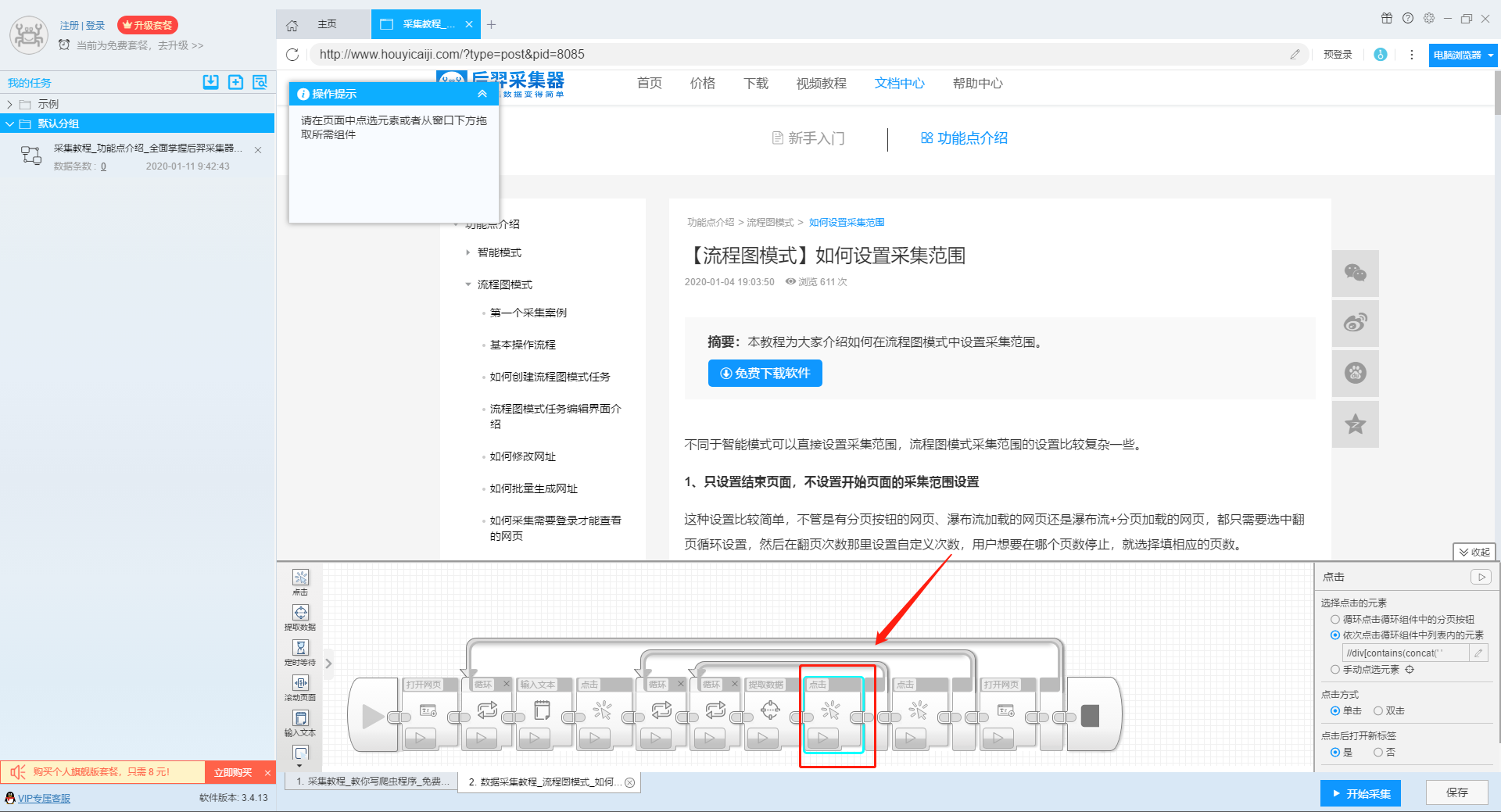
1、设置多个关键字循环任务
在流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入文字为采集。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择单个文本的批量输入。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”这些关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
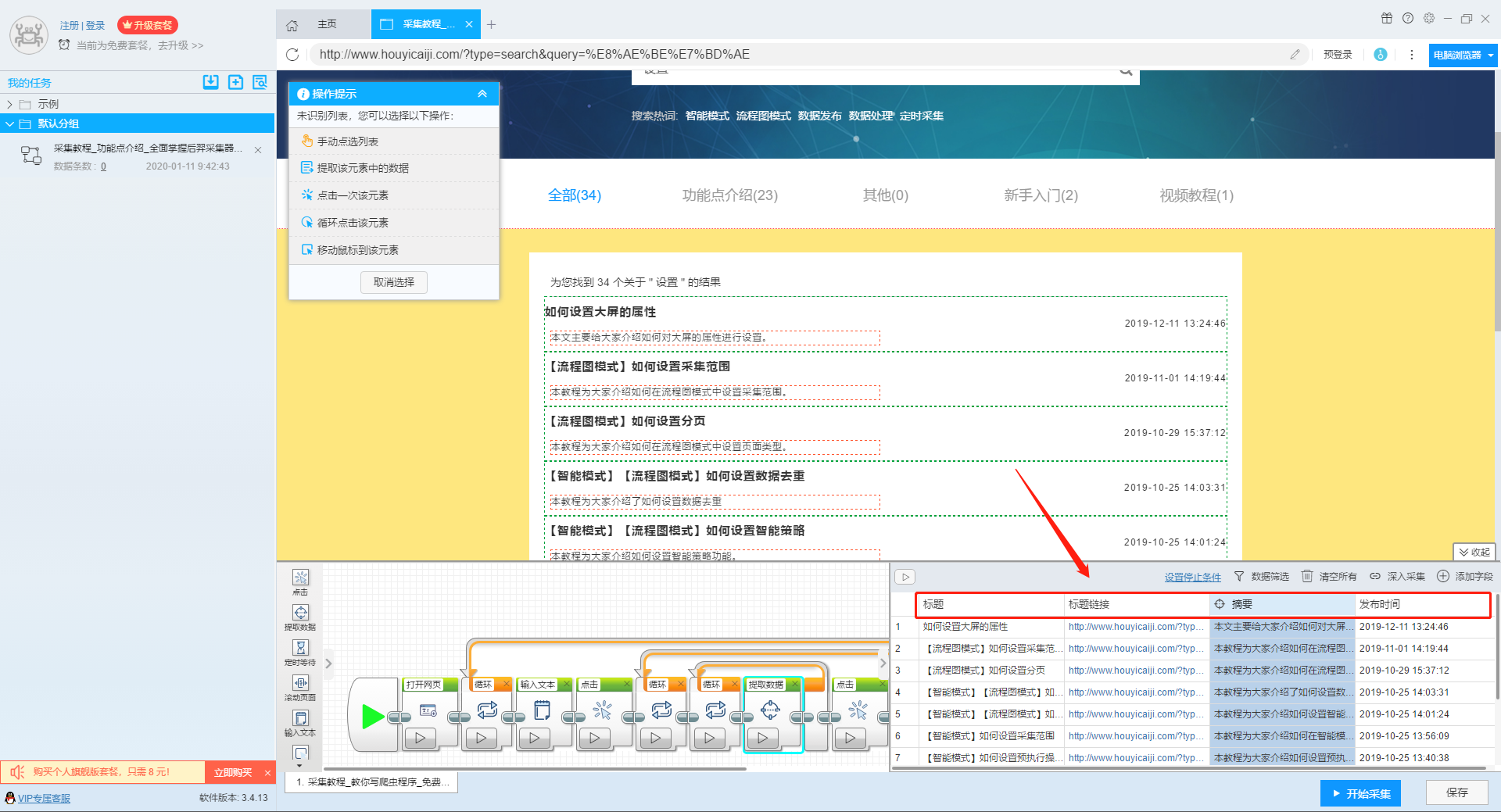
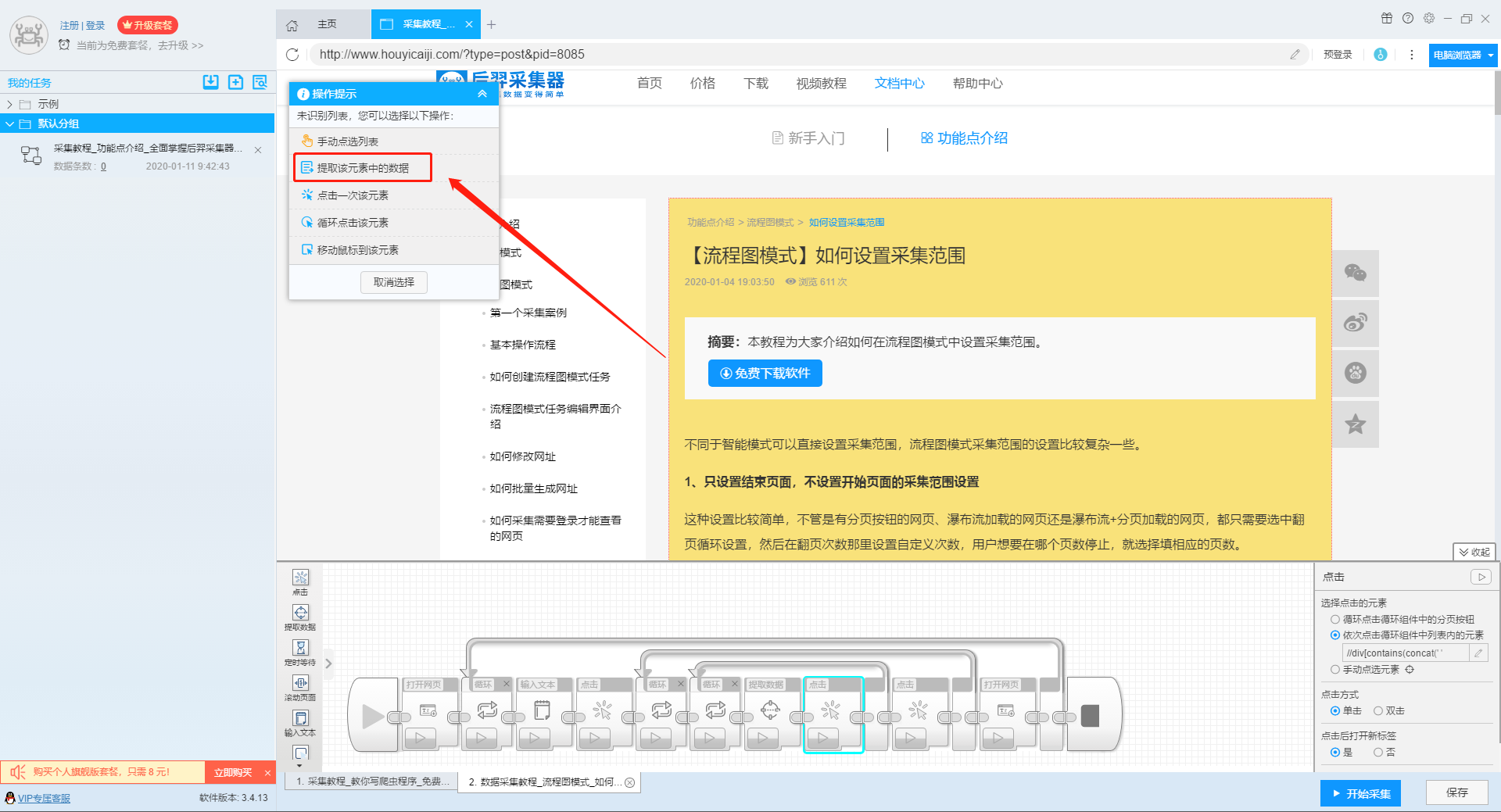
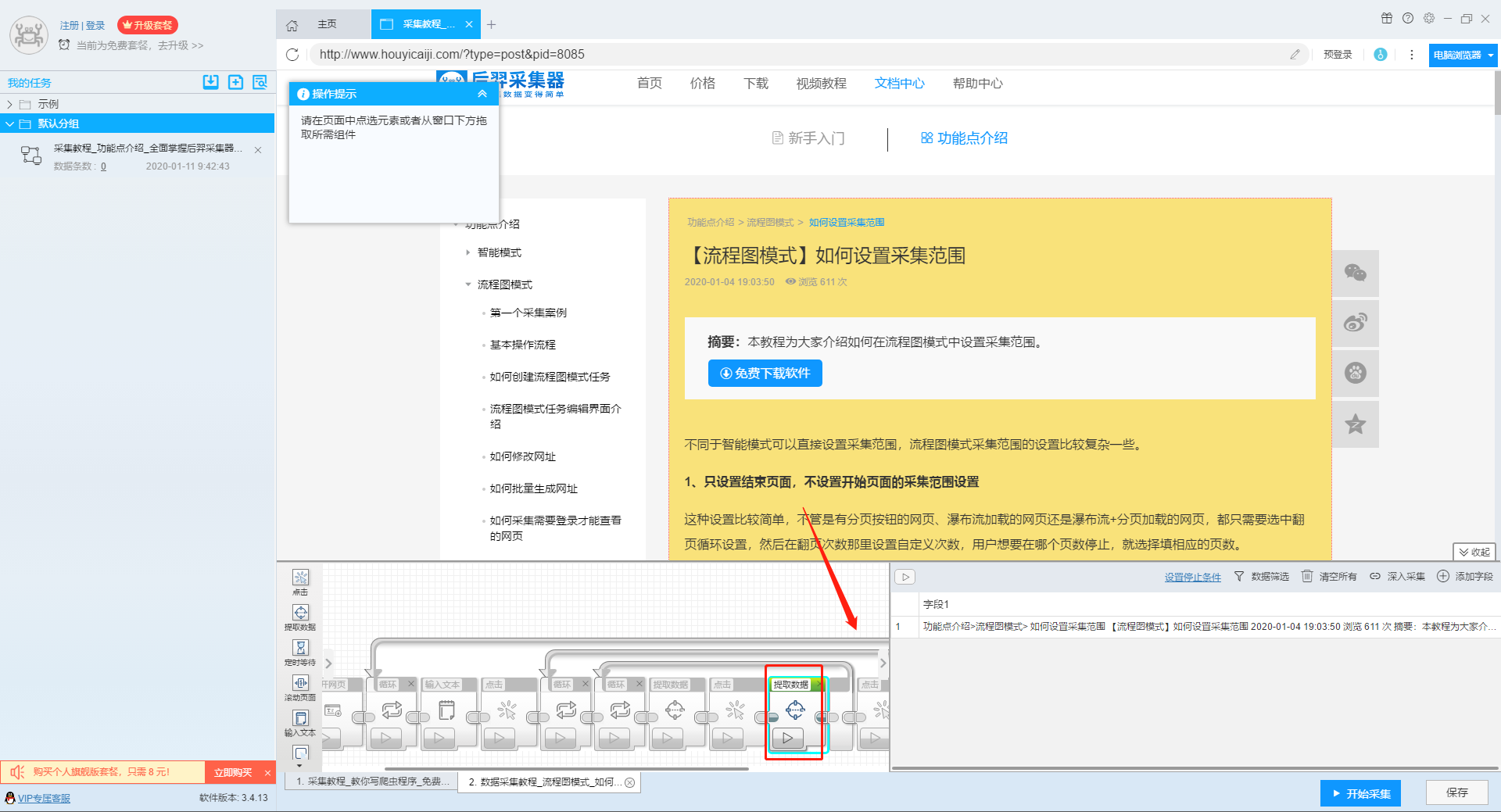
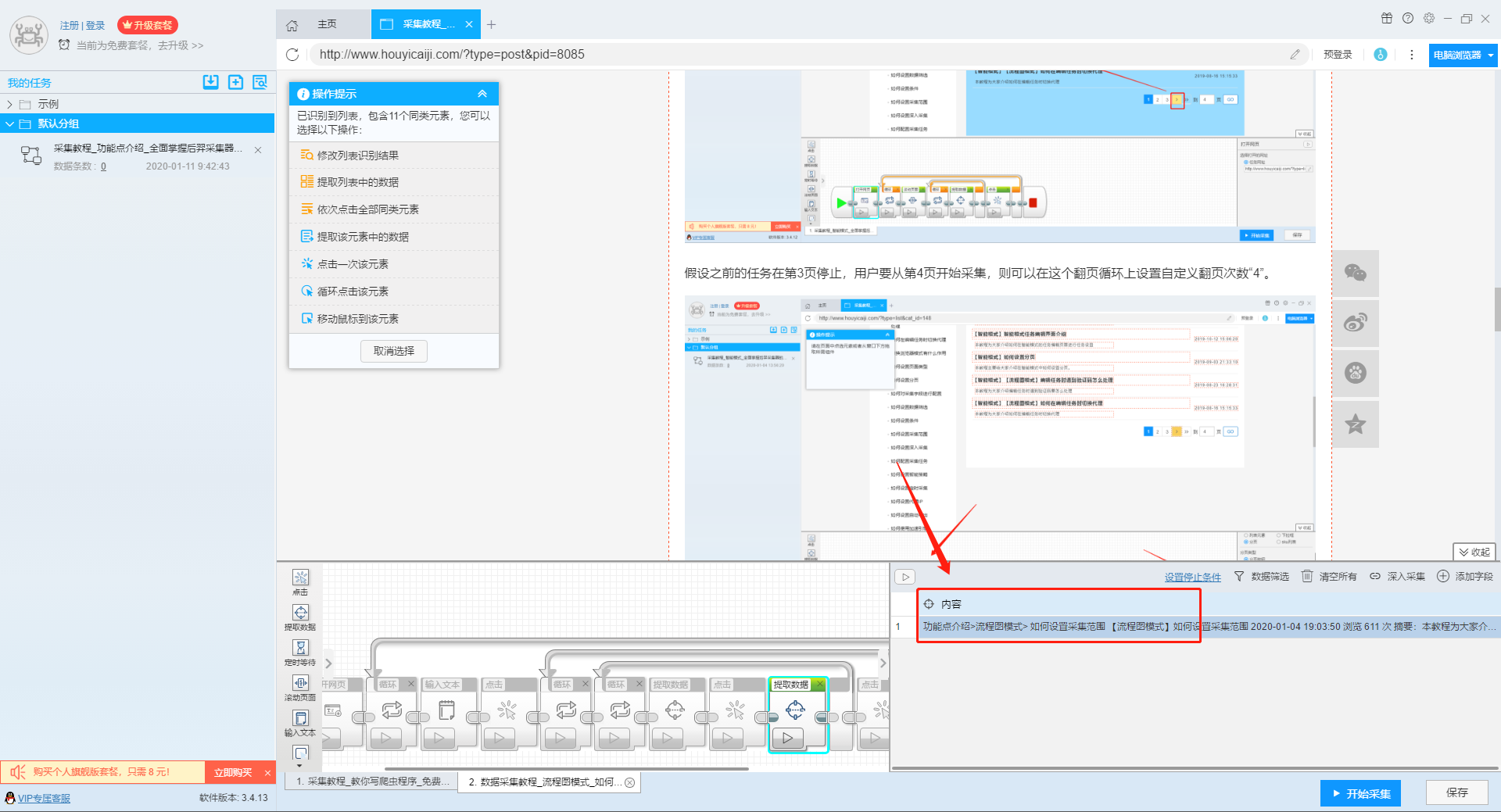
2、设置提取字段数据
输入多个关键字并设置好循环后,我们设置要提取的字段数据,在网页上点击该字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
那么我们就可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
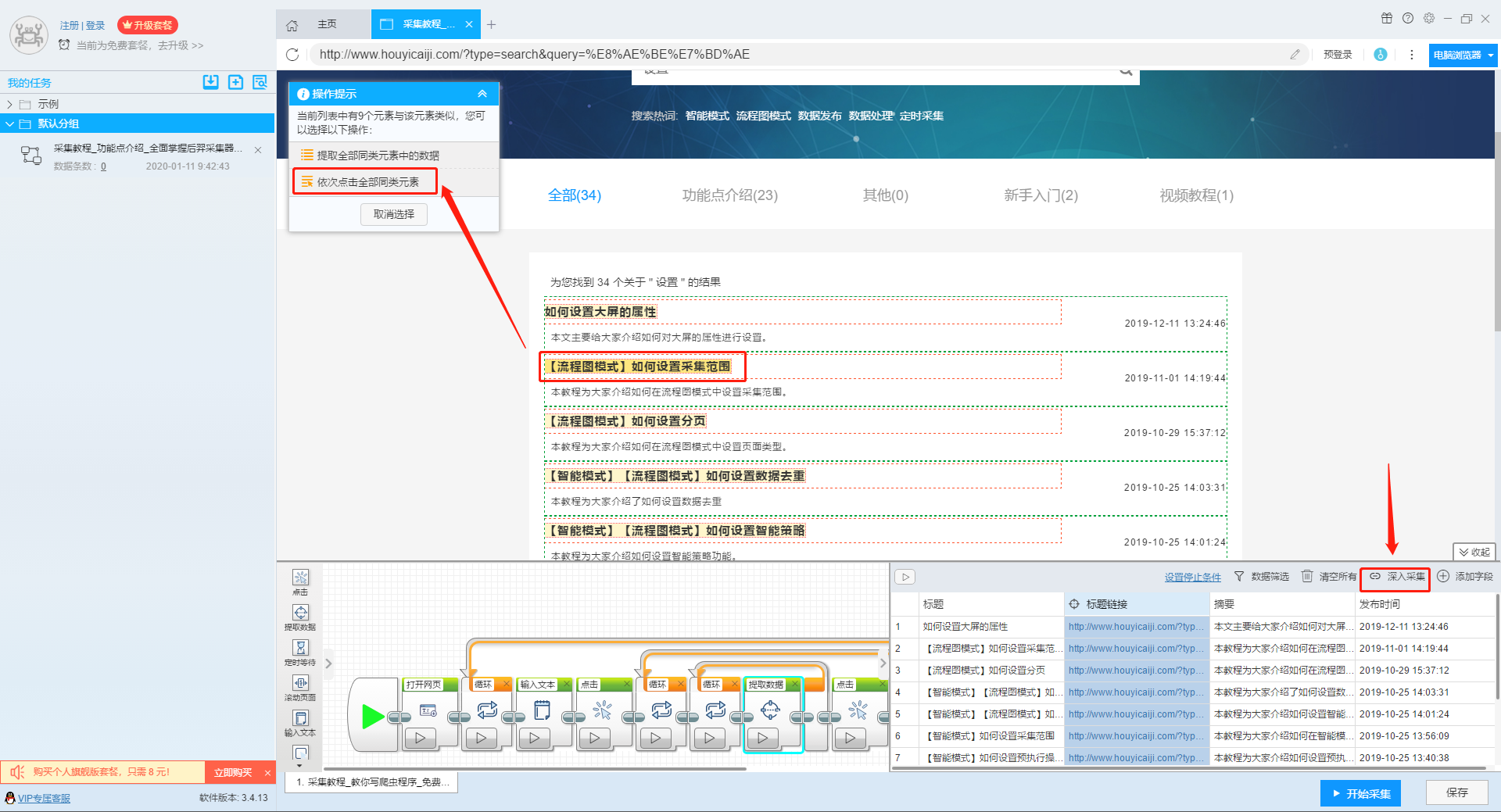
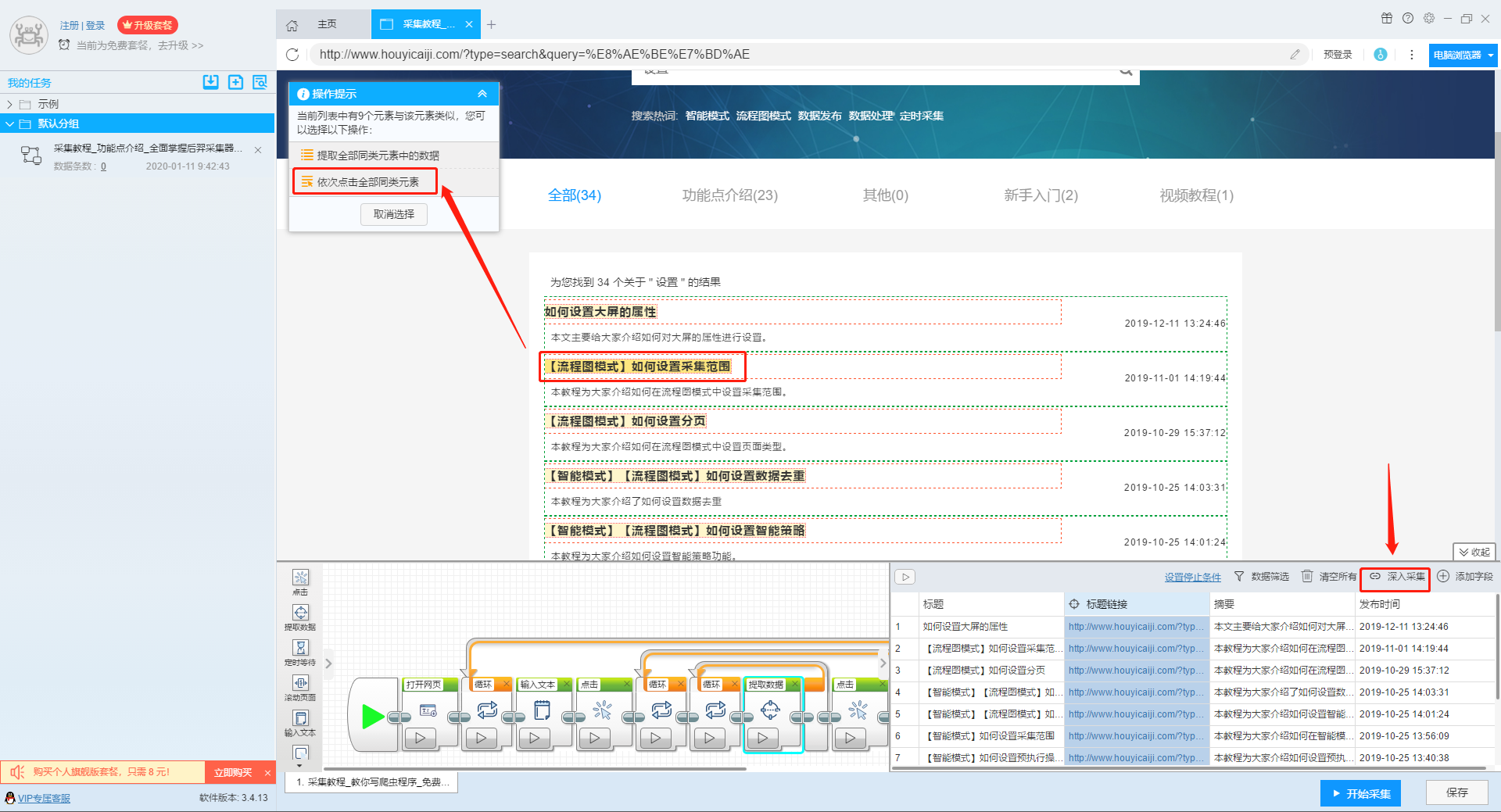
3、深入设置采集
如果我们需要采集详情页的数据,可以使用深入采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集任务
1、开始采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果, 查看全部
采集网站内容(本文介绍如何采集网站上多关键词的流程图模式?介绍
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何在更多关键词数据上采集网站。
第一步:新建一个采集任务
1、复制官网网址(搜索结果页网址为必填项,不是首页网址)
单击此处了解如何正确输入 URL。
2、新流程图模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
在流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入文字为采集。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择单个文本的批量输入。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”这些关键词。
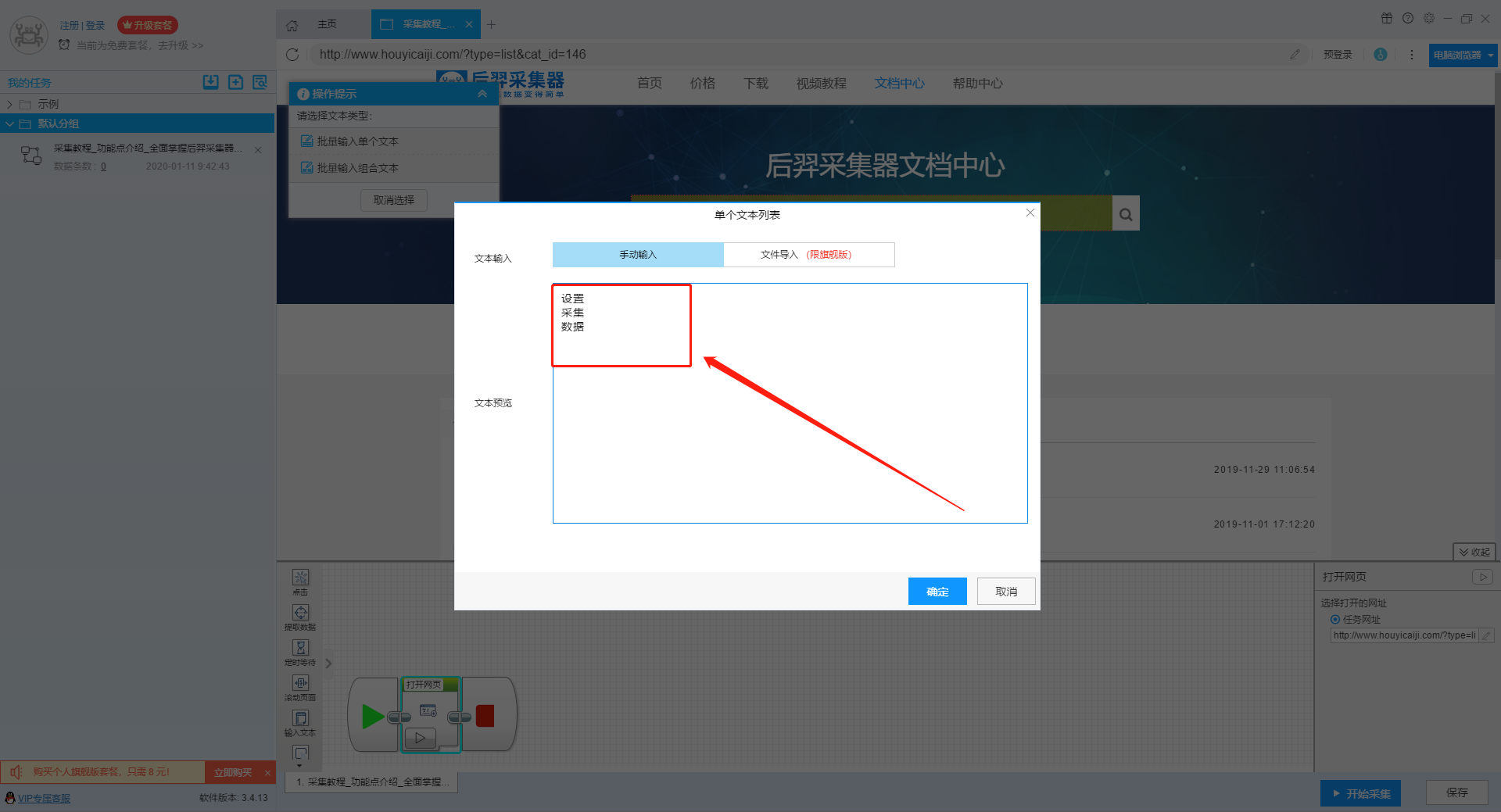
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置好循环后,我们设置要提取的字段数据,在网页上点击该字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
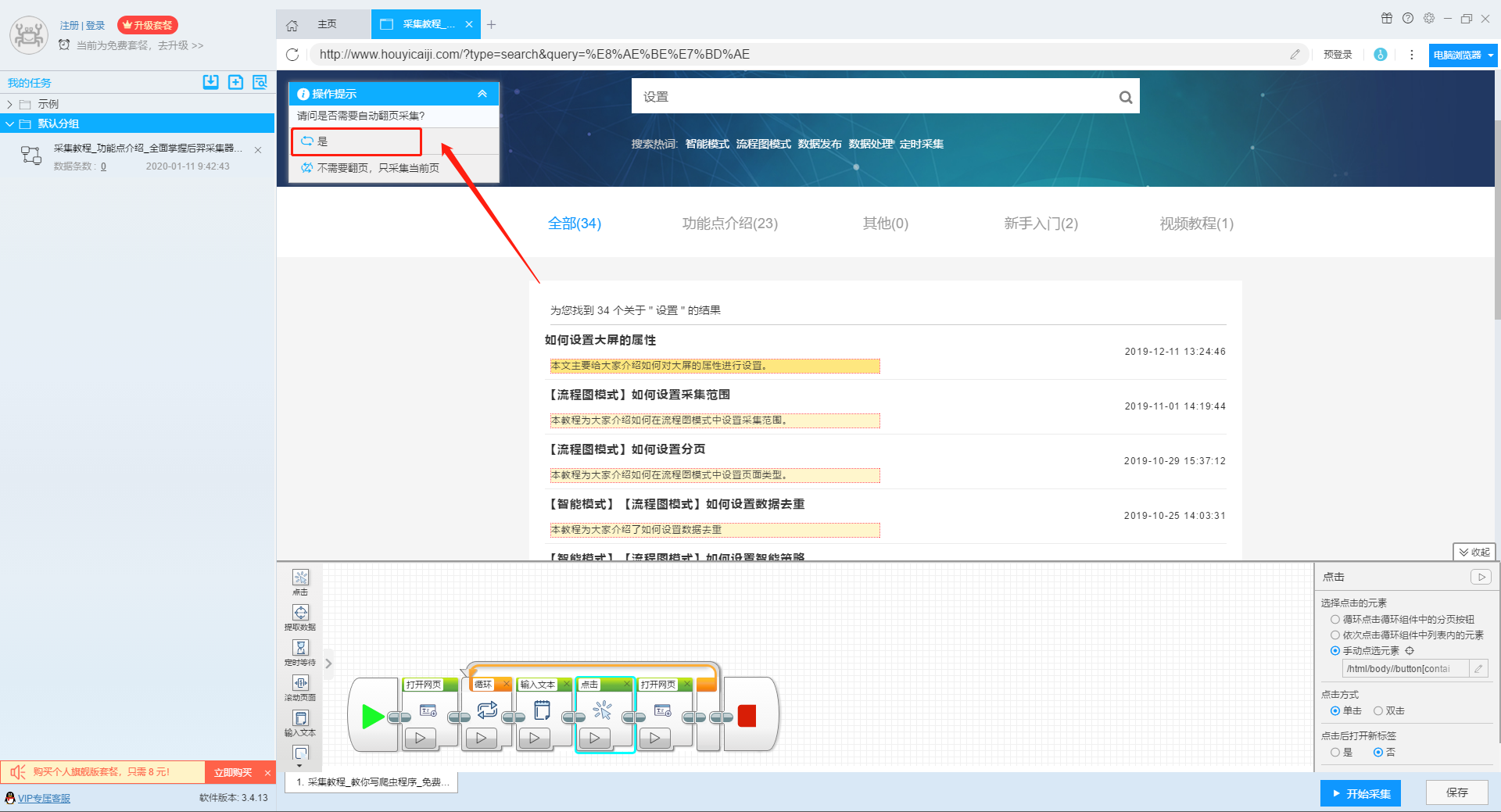
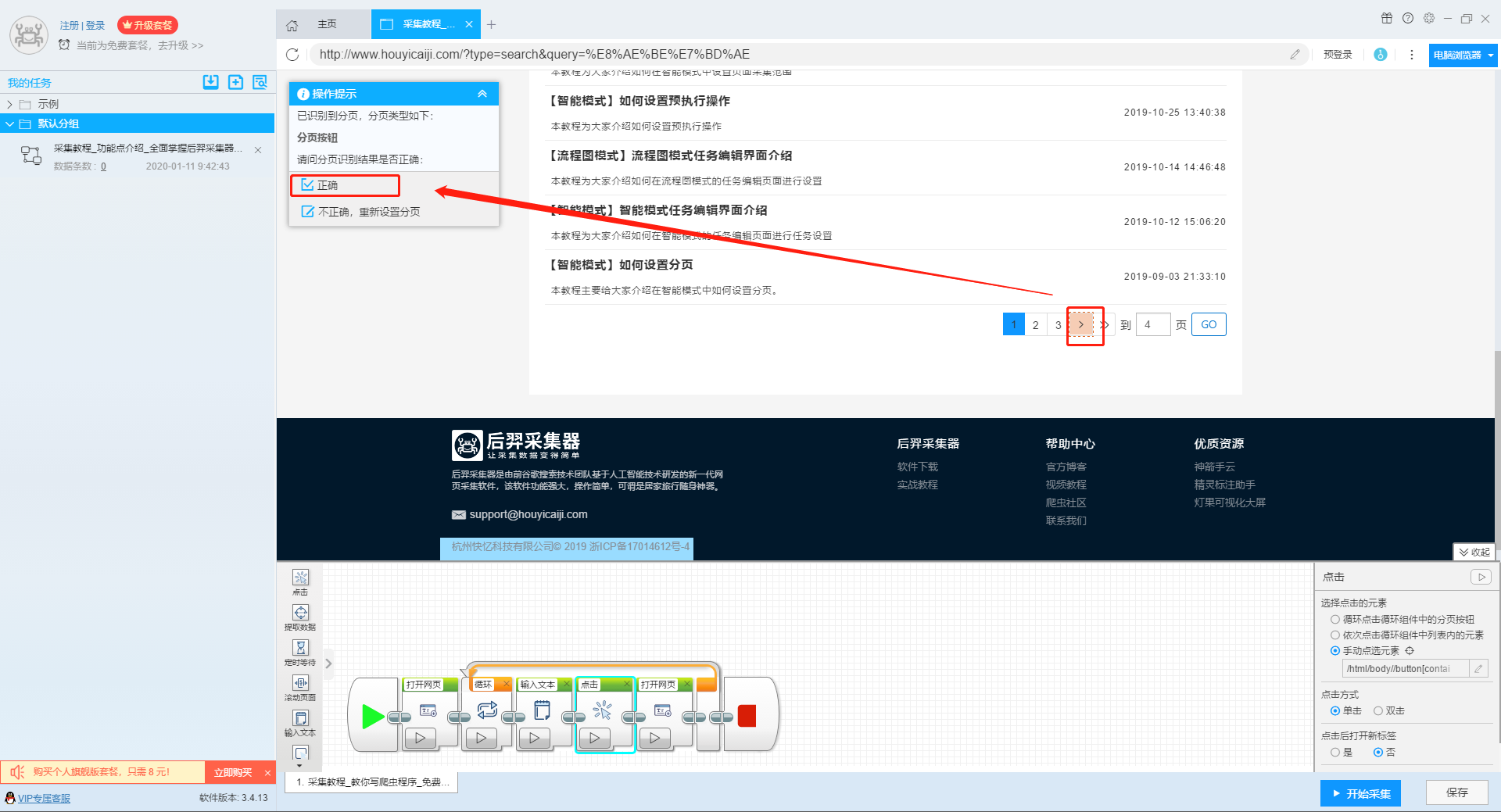
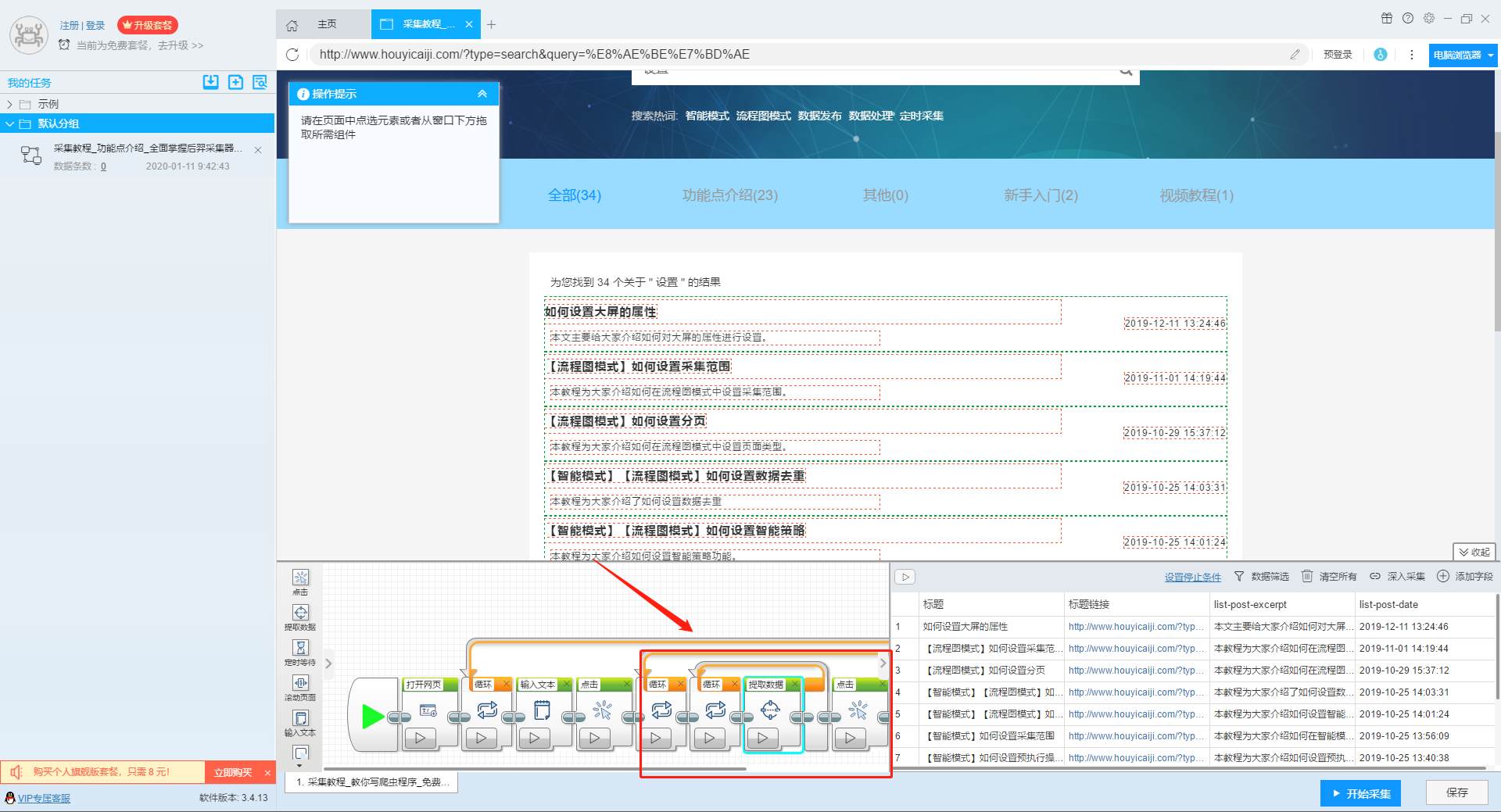
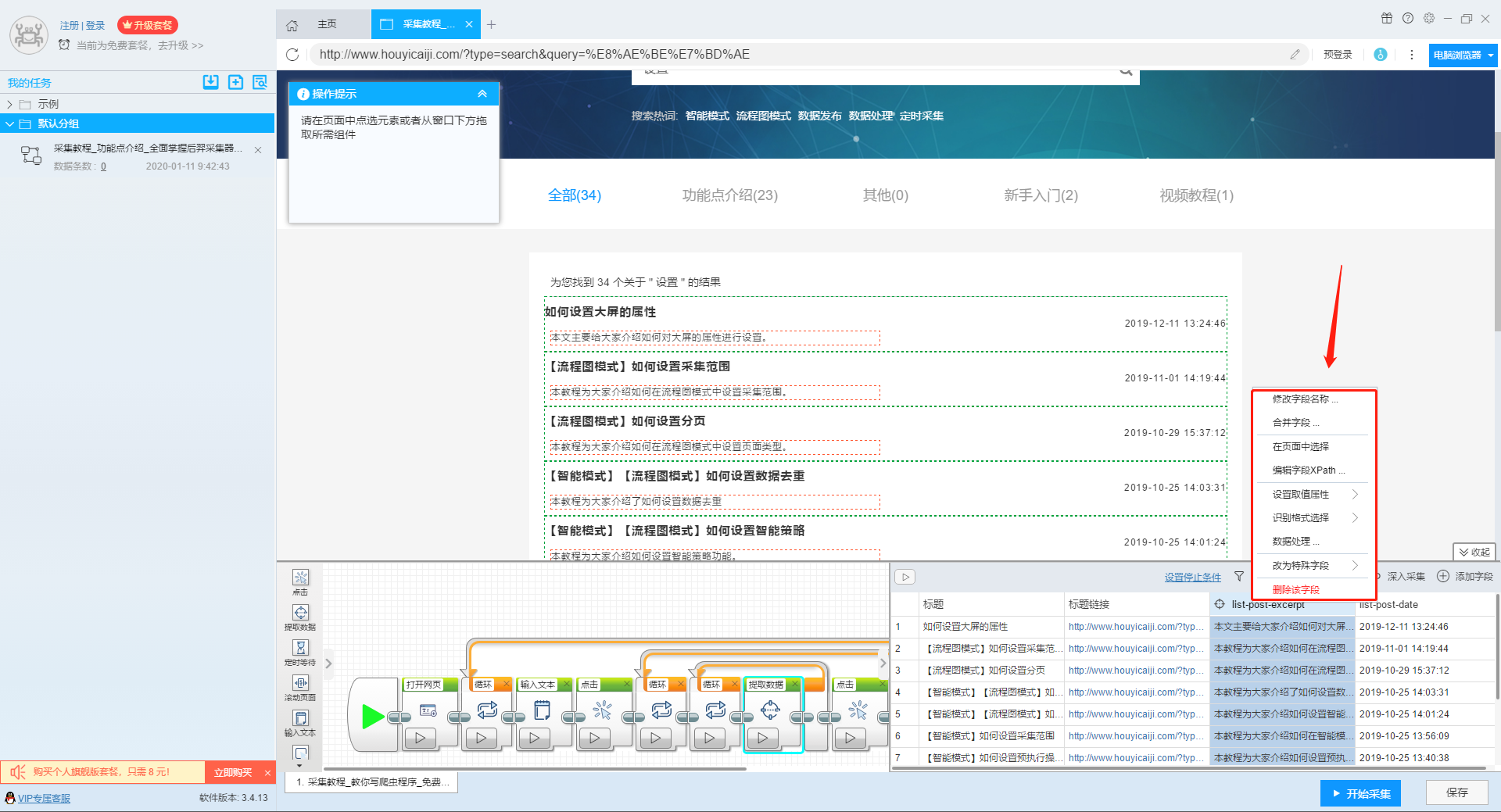
那么我们就可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果我们需要采集详情页的数据,可以使用深入采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
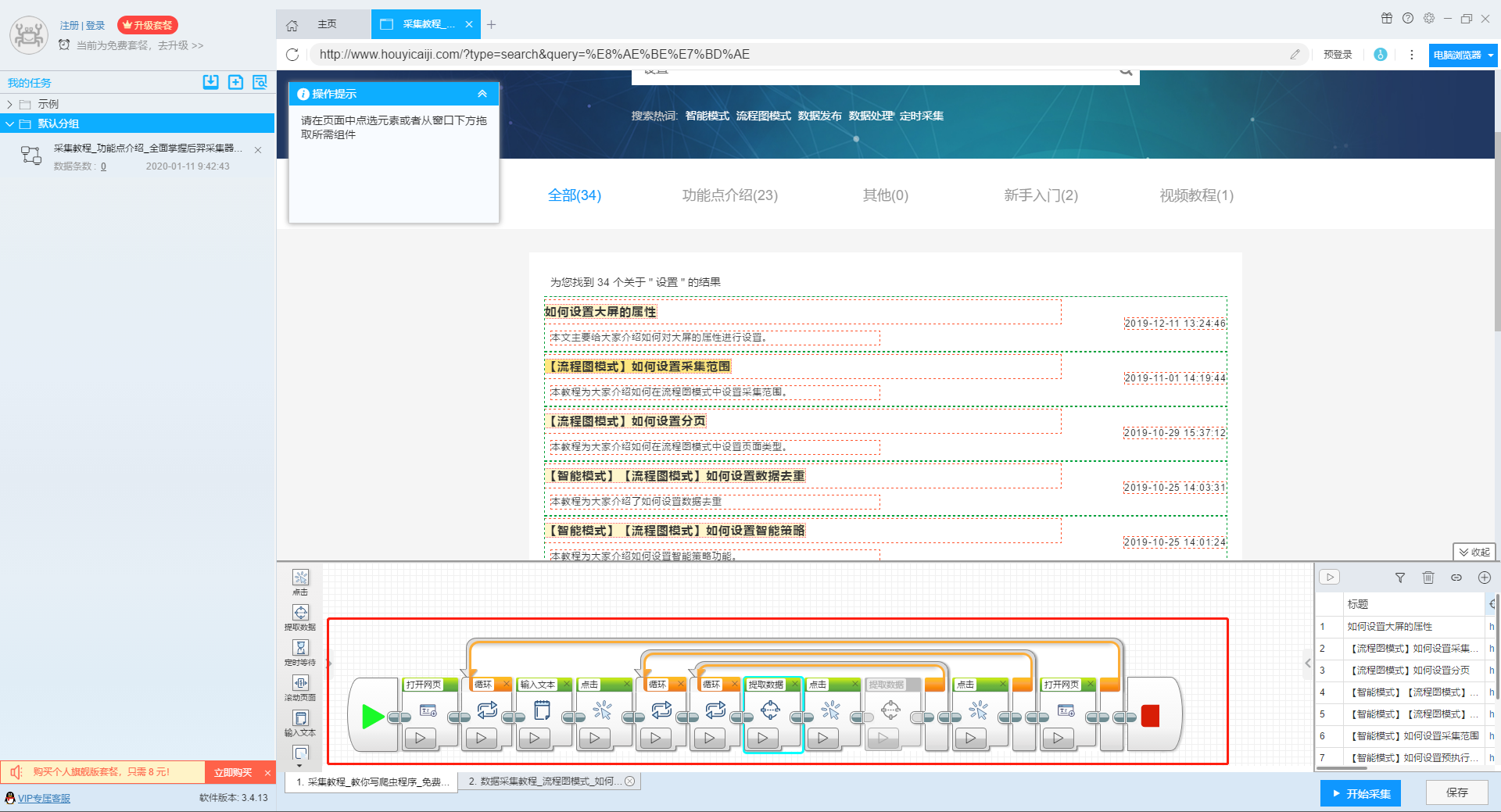
第三步:设置并启动采集任务
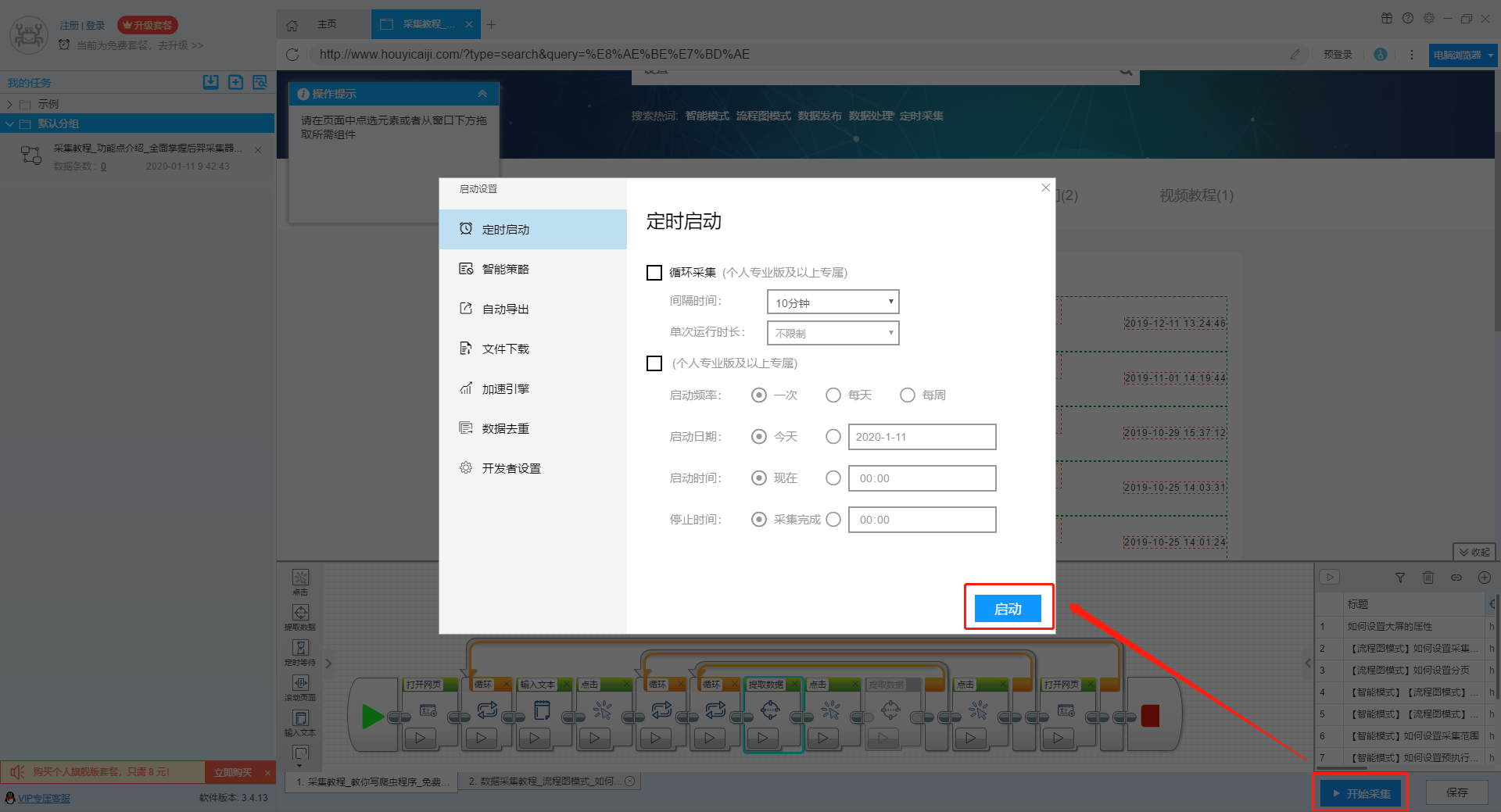
1、开始采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果,
采集网站内容(百度是如何在互联网上复制这么多重复的内容的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-12 10:22
重复内容一直是SEO行业关注的问题。重复的内容是否会被搜索引擎惩罚是一个经常讨论的话题。百度最近大大降低了内容集网站的使用权,但是很多朋友还是发现自己的文章被转载,排名高于原来的文章。那么百度是如何在网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先我们需要对重复的内容和集合网站有一个清晰的认识,否则会有一定的差异。目前,百度并没有明显的压制重复内容的迹象。百度不会对重复内容进行处罚也是可以理解的。
尽管很多SEO专家在进行站点诊断时会讨论外部站点的重复内容量,但他们通常会使用Webmaster工具来计算是否已附加原创链接。
这里我们一直在努力解决这个问题:文章被转发,排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。我们可以看到这一点。我们希望熊掌最近推出。号,授权站长,可以在原创内容下提交原创保护。尤其是发布文章所需的时间。准确到第二:
这是一个非常明确的信号。有了原创的保护站点,一旦提交链接被审核通过,标签原创就会出现在移动搜索展示中,排名自然会高于转发文章。
2、为什么采集的内容排名这么高?
本次采集的内容应该分为两部分,主要有以下两种情况:
所有车站采集
权威网站转发,百度将在熊掌账号上线后得到显着提升。那么,为什么百度会为这部分网站转发排名更高的内容呢?这与网站的权限和原创的比例有一定关系。同时,为了更好的在搜索结果页面展示优质的文章,从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,也会建立一个友好的外部链接到新的网站。
整个网站采集完全不一样,很多内容采集,虽然网站会保持不断更新的频率,但是我也发现采集不错,但是采集 内容几乎没有排名,这也是目前外链新闻能够存活的一个小理由!
百度推出飓风算法后,显然是为了打击要求苛刻的采集网站,看来以后连收录都会成为泡沫。
3、 内部抄袭会被处罚吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多优化标题,以提升排名的形式积累关键词,避免标题重复太多。
早些时候,一些SEO专家指出:
目前不建议使用同义词或伪装的关键词作为标题创建多个页面来覆盖关键词,尽量简化为一个文章,例如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但从它们的内容来看,答案几乎是一样的。百度希望你把这两个问题放在一起,比如:植物的营养价值,它的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时候很难判断,很多站长都在关键点。 查看全部
采集网站内容(百度是如何在互联网上复制这么多重复的内容的呢?)
重复内容一直是SEO行业关注的问题。重复的内容是否会被搜索引擎惩罚是一个经常讨论的话题。百度最近大大降低了内容集网站的使用权,但是很多朋友还是发现自己的文章被转载,排名高于原来的文章。那么百度是如何在网上复制这么多重复内容的呢?

1、百度最终会惩罚抄袭内容吗?
首先我们需要对重复的内容和集合网站有一个清晰的认识,否则会有一定的差异。目前,百度并没有明显的压制重复内容的迹象。百度不会对重复内容进行处罚也是可以理解的。
尽管很多SEO专家在进行站点诊断时会讨论外部站点的重复内容量,但他们通常会使用Webmaster工具来计算是否已附加原创链接。
这里我们一直在努力解决这个问题:文章被转发,排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。我们可以看到这一点。我们希望熊掌最近推出。号,授权站长,可以在原创内容下提交原创保护。尤其是发布文章所需的时间。准确到第二:
这是一个非常明确的信号。有了原创的保护站点,一旦提交链接被审核通过,标签原创就会出现在移动搜索展示中,排名自然会高于转发文章。
2、为什么采集的内容排名这么高?
本次采集的内容应该分为两部分,主要有以下两种情况:
所有车站采集
权威网站转发,百度将在熊掌账号上线后得到显着提升。那么,为什么百度会为这部分网站转发排名更高的内容呢?这与网站的权限和原创的比例有一定关系。同时,为了更好的在搜索结果页面展示优质的文章,从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,也会建立一个友好的外部链接到新的网站。
整个网站采集完全不一样,很多内容采集,虽然网站会保持不断更新的频率,但是我也发现采集不错,但是采集 内容几乎没有排名,这也是目前外链新闻能够存活的一个小理由!
百度推出飓风算法后,显然是为了打击要求苛刻的采集网站,看来以后连收录都会成为泡沫。
3、 内部抄袭会被处罚吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多优化标题,以提升排名的形式积累关键词,避免标题重复太多。
早些时候,一些SEO专家指出:
目前不建议使用同义词或伪装的关键词作为标题创建多个页面来覆盖关键词,尽量简化为一个文章,例如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但从它们的内容来看,答案几乎是一样的。百度希望你把这两个问题放在一起,比如:植物的营养价值,它的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时候很难判断,很多站长都在关键点。
采集网站内容(优采云采集器如何采集多级网页的操作注意事项?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-09 04:05
前面我们用优采云采集器学习的教程主要是针对单级网页采集,而实际网络中的大部分网页都是多级网页(比如内容页), 采集多级网页时,使用优采云采集器的操作会有所不同,下面介绍一下优采云采集器如何采集多级网页详细介绍。.
优采云采集器如何采集多级网页?
1、多级网页采集步骤与单级网页类似:【新建任务】—输入网址—采集配置。
2、如何判断网页是否为多级网页?多级网页自动生成的字段必须收录一个或多个用于提取链接的字段(即提取属性为Href的字段)。
3、 点击链接栏的标题,选中该栏后,中间菜单栏右侧会出现【深度链接页面采集】选项。
4、 点击【深度链接页面采集】,系统自动新建配置标签,并自动打开选中字段的URL。
5、此时采集模式也会默认为【单机模式】,如果不是,点击调整。
注意:
1) 列表模式用于从网页列表中提取数据,预览中可以看到多条数据
2)单项输入模式适用于采集内容详情页中的各种信息,如文章标题、时间、正文等。
6、 点击【添加字段】,首先手动提取网页中的信息发布时间,由于标题在前面的列表采集中已经提取过了,这里就不再赘述了。
7、 再次点击【添加字段】,手动从网页中提取信息正文。
8、 这里要注意将字段的value属性调整为InnerHtml,保持原来的格式。
这是优采云采集器如何采集多级网页操作的介绍。有兴趣的朋友可以多看几遍以上教程,相信很快就能掌握!
(免责声明:如果文章内容涉及作品内容、版权等问题,请及时联系我们,我们会尽快删除内容。文章内容仅供参考仅供参考) 查看全部
采集网站内容(优采云采集器如何采集多级网页的操作注意事项?)
前面我们用优采云采集器学习的教程主要是针对单级网页采集,而实际网络中的大部分网页都是多级网页(比如内容页), 采集多级网页时,使用优采云采集器的操作会有所不同,下面介绍一下优采云采集器如何采集多级网页详细介绍。.
优采云采集器如何采集多级网页?
1、多级网页采集步骤与单级网页类似:【新建任务】—输入网址—采集配置。

2、如何判断网页是否为多级网页?多级网页自动生成的字段必须收录一个或多个用于提取链接的字段(即提取属性为Href的字段)。
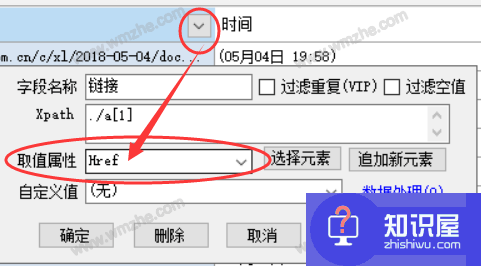
3、 点击链接栏的标题,选中该栏后,中间菜单栏右侧会出现【深度链接页面采集】选项。

4、 点击【深度链接页面采集】,系统自动新建配置标签,并自动打开选中字段的URL。

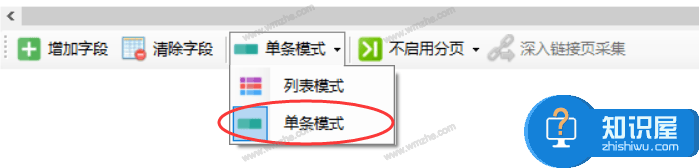
5、此时采集模式也会默认为【单机模式】,如果不是,点击调整。
注意:
1) 列表模式用于从网页列表中提取数据,预览中可以看到多条数据
2)单项输入模式适用于采集内容详情页中的各种信息,如文章标题、时间、正文等。
6、 点击【添加字段】,首先手动提取网页中的信息发布时间,由于标题在前面的列表采集中已经提取过了,这里就不再赘述了。
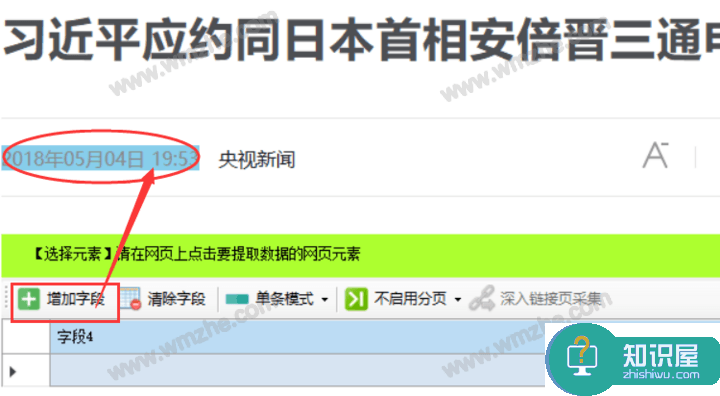
7、 再次点击【添加字段】,手动从网页中提取信息正文。
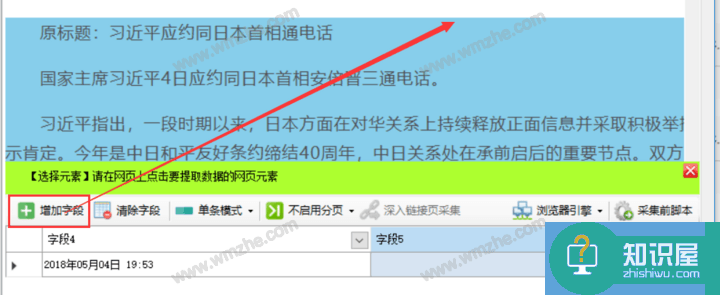
8、 这里要注意将字段的value属性调整为InnerHtml,保持原来的格式。

这是优采云采集器如何采集多级网页操作的介绍。有兴趣的朋友可以多看几遍以上教程,相信很快就能掌握!
(免责声明:如果文章内容涉及作品内容、版权等问题,请及时联系我们,我们会尽快删除内容。文章内容仅供参考仅供参考)
采集网站内容(先来和百度的机器人采集器会怎么做?打游击战呗!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-09 03:11
很多反采集的方法在实现的时候需要考虑是否会影响搜索引擎对网站的爬取,那么我们来分析一下一般的采集器和搜索引擎爬虫采集@ >. 不同的。
相似之处:两者都需要直接抓取网页源代码才能有效工作,b. 两者都会在单位时间内多次抓取大量访问过的网站内容;C。宏观上看,两个IP都会变;d. 他们俩都急于破解你的一些网页加密(验证),比如网页内容是通过js文件加密的,比如需要输入验证码浏览内容,比如需要登录以访问内容等。
区别:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。但是采集器一般是利用html标签的特性来抓取需要的数据。制定采集规则时,需要填写目标内容的开始和结束标志,以便定位到需要的内容;或者为特定的网页创建特定的正则表达式来过滤掉你需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那么来提出一些反采集的方法
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人工分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被 查看全部
采集网站内容(先来和百度的机器人采集器会怎么做?打游击战呗!)
很多反采集的方法在实现的时候需要考虑是否会影响搜索引擎对网站的爬取,那么我们来分析一下一般的采集器和搜索引擎爬虫采集@ >. 不同的。
相似之处:两者都需要直接抓取网页源代码才能有效工作,b. 两者都会在单位时间内多次抓取大量访问过的网站内容;C。宏观上看,两个IP都会变;d. 他们俩都急于破解你的一些网页加密(验证),比如网页内容是通过js文件加密的,比如需要输入验证码浏览内容,比如需要登录以访问内容等。
区别:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。但是采集器一般是利用html标签的特性来抓取需要的数据。制定采集规则时,需要填写目标内容的开始和结束标志,以便定位到需要的内容;或者为特定的网页创建特定的正则表达式来过滤掉你需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那么来提出一些反采集的方法
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人工分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被
采集网站内容(纯采集站的网站要加快内容收录的话搜索引擎哪些工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-03 13:04
<p>相信很多用户在制作网站内容时,为了丰富网站的内容,增加了数据抓取,但是如果是满站采集,页面怎么会有< @收录?,不管你是做完整的采集网站,首先要了解搜索引擎的工作模式,然后作为网站SEO的核心,再纯采集站网站如果要加速内容 查看全部
采集网站内容(纯采集站的网站要加快内容收录的话搜索引擎哪些工作)
<p>相信很多用户在制作网站内容时,为了丰富网站的内容,增加了数据抓取,但是如果是满站采集,页面怎么会有< @收录?,不管你是做完整的采集网站,首先要了解搜索引擎的工作模式,然后作为网站SEO的核心,再纯采集站网站如果要加速内容
采集网站内容(互联网企业给网站添加内容的时候,添加URL目标地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-03 12:24
在做网络推广的时候,很多公司还是比较喜欢网站的推广。这是因为有很多用户使用百度搜索引擎。只要网站能够提升网站的排名,就会有更多的用户看到网站,企业也会得到相应的流量。
想要网站获得好的排名,就需要对网站进行相应的优化。在优化的过程中,内容是一个非常重要的因素。只有拥有高质量的内容,才能被用户和搜索引擎喜欢,获得更好的排名。
但是有的公司在给网站添加内容的时候,不知道要添加什么,就会去其他网站转载一些内容,并添加目标URL地址,会被识别为采集?
接下来我们就来看看网站建筑优化公司吧!
1、搜索引擎判断是否正确
①搜索引擎判断正确
一般情况下,当网站转载其他网站内容并带上目标地址时,搜索引擎可以正确判断该内容为转载内容。这是因为有很多相同的内容,而且这些内容已经被搜索引擎识别,在转载相同内容后,搜索引擎会判断网站的内容是采集。
②搜索引擎判断错误
有时,当网站转发某些内容时,搜索引擎无法确定该内容是采集。这是因为搜索引擎毕竟是一个系统,无法准确识别内容是否被转载。转载时,可以在内容中添加一些想法来更改内容,以免搜索引擎对其进行判断。文章是采集吗?
2、原创 作者是否同意
①原创 作者同意
网站转载其他网站内容时,如对方同意转载,属合理转载。只要转载正确,就不会有什么问题。
②原创作者不同意
当原网站作者不同意转载时,你的网站还要转载他网站的内容,这是不合理转载,这是侵权,对方可以使用法律意味着保护自己的利益,所以你会遇到麻烦。
3、网站权重等级
①高权重网站
网站 转载其他网站内容时,一定要以高权重网站转载,因为高权重网站的内容被搜索引擎识别,转载此类内容对网站有帮助。
②低重量网站
转载内容时,部分公司会转载内容权重网站。这不仅对他们网站有帮助,还会降低网站的质量,进而影响网站。@网站 开发。
总之,无论是否合理转载,都是文章采集的一种表现形式。只有正确转载他人网站的内容,才能对网站的发展有所帮助。
蝙蝠侠IT转载需要授权! 查看全部
采集网站内容(互联网企业给网站添加内容的时候,添加URL目标地址)
在做网络推广的时候,很多公司还是比较喜欢网站的推广。这是因为有很多用户使用百度搜索引擎。只要网站能够提升网站的排名,就会有更多的用户看到网站,企业也会得到相应的流量。
想要网站获得好的排名,就需要对网站进行相应的优化。在优化的过程中,内容是一个非常重要的因素。只有拥有高质量的内容,才能被用户和搜索引擎喜欢,获得更好的排名。

但是有的公司在给网站添加内容的时候,不知道要添加什么,就会去其他网站转载一些内容,并添加目标URL地址,会被识别为采集?
接下来我们就来看看网站建筑优化公司吧!
1、搜索引擎判断是否正确
①搜索引擎判断正确
一般情况下,当网站转载其他网站内容并带上目标地址时,搜索引擎可以正确判断该内容为转载内容。这是因为有很多相同的内容,而且这些内容已经被搜索引擎识别,在转载相同内容后,搜索引擎会判断网站的内容是采集。
②搜索引擎判断错误
有时,当网站转发某些内容时,搜索引擎无法确定该内容是采集。这是因为搜索引擎毕竟是一个系统,无法准确识别内容是否被转载。转载时,可以在内容中添加一些想法来更改内容,以免搜索引擎对其进行判断。文章是采集吗?
2、原创 作者是否同意
①原创 作者同意
网站转载其他网站内容时,如对方同意转载,属合理转载。只要转载正确,就不会有什么问题。
②原创作者不同意
当原网站作者不同意转载时,你的网站还要转载他网站的内容,这是不合理转载,这是侵权,对方可以使用法律意味着保护自己的利益,所以你会遇到麻烦。
3、网站权重等级
①高权重网站
网站 转载其他网站内容时,一定要以高权重网站转载,因为高权重网站的内容被搜索引擎识别,转载此类内容对网站有帮助。
②低重量网站
转载内容时,部分公司会转载内容权重网站。这不仅对他们网站有帮助,还会降低网站的质量,进而影响网站。@网站 开发。
总之,无论是否合理转载,都是文章采集的一种表现形式。只有正确转载他人网站的内容,才能对网站的发展有所帮助。
蝙蝠侠IT转载需要授权!
采集网站内容(软件永久终身免费使用智动网页内容采集器v1.9更新:软件内置网址更新 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-03 12:23
)
2、用户可以随意导入和导出任务
任务3、可以设置密码,并具有多种反破解采集功能,如n页采集暂停和采集特殊标记时暂停
4、您可以直接输入URL,或通过JavaScript脚本生成URL,或通过关键词>搜索采集
5、您可以登录到采集采集您需要登录到帐户的网页内容
6、您可以深入到n列采集内容和链接
7、支持多种内容提取模式,可以处理所需的采集内容,如清除HTML、图片等
8、您可以编译自己的JavaScript脚本来提取网页内容,并轻松实现内容的任何部分的采集
9、采集的文本内容可以根据设置的模板保存
10、根据模板,可以将多个采集的文件保存在同一个文件中
11、网页上的多个部分内容可以单独分页采集
12、您可以设置自己的客户信息,以模拟目标上的百度和其他搜索引擎网站采集
13、该软件终身免费
智能网络内容采集器V1.9更新:
软件的内置网站更新为
采用了新的智能软件控制界面
将用户反馈添加到电子邮件功能
增加了将初始化链接直接设置为最终内容页的功能
增强内核功能,支持post中的关键词@>搜索和替换关键词@>标记
优化采集内核
优化的断开拨号算法
优化的重复数据消除工具算法
修复拨号显示IP不正确的错误
修复错误关键词@>暂停或拨号时不会重置采集错误页面的错误
修复当受限内容的最大值为0时无法正确保存最小值的错误
查看全部
采集网站内容(软件永久终身免费使用智动网页内容采集器v1.9更新:软件内置网址更新
)
2、用户可以随意导入和导出任务
任务3、可以设置密码,并具有多种反破解采集功能,如n页采集暂停和采集特殊标记时暂停
4、您可以直接输入URL,或通过JavaScript脚本生成URL,或通过关键词>搜索采集
5、您可以登录到采集采集您需要登录到帐户的网页内容
6、您可以深入到n列采集内容和链接
7、支持多种内容提取模式,可以处理所需的采集内容,如清除HTML、图片等
8、您可以编译自己的JavaScript脚本来提取网页内容,并轻松实现内容的任何部分的采集
9、采集的文本内容可以根据设置的模板保存
10、根据模板,可以将多个采集的文件保存在同一个文件中
11、网页上的多个部分内容可以单独分页采集
12、您可以设置自己的客户信息,以模拟目标上的百度和其他搜索引擎网站采集
13、该软件终身免费
智能网络内容采集器V1.9更新:
软件的内置网站更新为
采用了新的智能软件控制界面
将用户反馈添加到电子邮件功能
增加了将初始化链接直接设置为最终内容页的功能
增强内核功能,支持post中的关键词@>搜索和替换关键词@>标记
优化采集内核
优化的断开拨号算法
优化的重复数据消除工具算法
修复拨号显示IP不正确的错误
修复错误关键词@>暂停或拨号时不会重置采集错误页面的错误
修复当受限内容的最大值为0时无法正确保存最小值的错误

采集网站内容(新人做网站必备的常识html言语网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 23:24
新手做的常识网站1.htmlwords网站 首先展示给我们的是网页,里面收录文字、图片、音频等信息。我们都知道html或htm格式是网页的基本格式,而html语言是站长首先需要学习的。HTML 语言并不难学。作为一种符号语言,前后两个符号相互对应,html代码清晰易懂。虽然整个网站程序(包括cms、BLOG等)已经在市场上广泛使用,但是模板的修改、网页布局等都需要有html语言的常识,所以html是必须的. 2.动态语言(包括asp、php、java等)是与html相关的静态语言,并且动态语言近年来非常流行。因为它的功能和效果,与html相差甚远。学习动态语言有一定的难度。建议先学习一门编程语言。VB或C语言都是不错的选择。众所周知,C语言,php和java近在咫尺,我也学过基本的编程语言。学习asp和php几乎是一口气完成的。由于语音的互操作性,基本算法是相似的。3.网络安全常识 现在一些小黑老头喜欢拿刀网站,我们最好学习一些网络安全常识,比如后端地址的隐藏,数据库防暴数据库(常用数据库连接文件 conn.asp 或 const. asp是比较简单容易出错的地方),密码的强度(md5密码纯数字一会就可以解密,最好用数字加英文加特殊符号),如果用别人发的全站程序,需要注意这个程序在各大黑客网站上是否有漏洞。phpwind和最近的oblog差距很严重,一定要及时补上。
非技能常识系统1.计算可以使用51.la或cnzz计算代码,每天花3-5分钟看计算结果,分析主ip从哪里来,从哪里来它被执行。最好,哪个关键字是你的专长,这样你就可以更有针对性地进行推广。2.采集刚开始是一个网站,不可能每篇文章文章都是原创,所以你要采集别人的经验文章,而不仅仅是发布它。学习使用搜索引擎,比如百度和google的一些特殊功能: site:可以查到输入了多少条目;“link:”会找到所有指向网站主页的网页。这些技能可以在网上找到。NS。3. 修改包括文字修改和图稿。采集到的大部分文章链接可能是一些无用的信息。需要学会过滤和清理,技术文章要通俗易懂,清理后公布。美术方面,最好学习一下PS和DW的基本用法。从根本上说,不要让别人帮你拍照片。4.最好的宣传方式是口耳相传。有人认为你的网站郝天然会介绍给他的朋友,通常是在论坛或其他互动网站帮助人解决问题,我想大多数人都会感谢帮助他们的人。只需在签名文件中放置一个连接即可。发生的流量稳定有效。不要发送广告。不仅没用,还会留下不好的形象。
<p>公布一些包装精美的文件,例如电子书、艺术类电子杂志等。这些被称为病毒式传销,它们非常有用。5.SEO优化搜索引擎优化类似,不要过度搜索引擎优化,一个真正的好网站,深得人心,百度不能给你顶。6. 人际网络人际关系,要想做大做强,一个人很难在互联网上站稳脚跟,有所作为。您必须调动所有可用资源为未来奠定基础;打造具有战斗力的团队;结交更多这个行业的朋友,无论是站长还是网友,都可以成为你的老师。如果是三人组,肯定有我的老师。记住,交朋友一定要真诚,朋友是最宝贵的,不会随着时间而改变。网站的操作会和网站的推广混淆。在实践中,网站的推广只是网站操作的一部分,除此之外,还有网站和栏目或活动的策划任务,页面的创建和功能和内容管理。后期客户联系,客户处理,人力资源开发,客户二次开发。一些重大活动的发展和后期的网站保护。但是,一个网站的生命力不只是看这里,还要了解整个网站的规划和站长的管理技巧,以及一个远程操作团队,是否它可能会受到 网站 @网站余生生。科技以人为本。1.确定网站2.的意图网站Planning3.制造实践页面4.添加流量(网站实施网站推广) 5.每日更新网站 6. 把握网站现状和客户反应,继续完善以上5点,详细阐述如下:1.确认 查看全部
采集网站内容(新人做网站必备的常识html言语网站)
新手做的常识网站1.htmlwords网站 首先展示给我们的是网页,里面收录文字、图片、音频等信息。我们都知道html或htm格式是网页的基本格式,而html语言是站长首先需要学习的。HTML 语言并不难学。作为一种符号语言,前后两个符号相互对应,html代码清晰易懂。虽然整个网站程序(包括cms、BLOG等)已经在市场上广泛使用,但是模板的修改、网页布局等都需要有html语言的常识,所以html是必须的. 2.动态语言(包括asp、php、java等)是与html相关的静态语言,并且动态语言近年来非常流行。因为它的功能和效果,与html相差甚远。学习动态语言有一定的难度。建议先学习一门编程语言。VB或C语言都是不错的选择。众所周知,C语言,php和java近在咫尺,我也学过基本的编程语言。学习asp和php几乎是一口气完成的。由于语音的互操作性,基本算法是相似的。3.网络安全常识 现在一些小黑老头喜欢拿刀网站,我们最好学习一些网络安全常识,比如后端地址的隐藏,数据库防暴数据库(常用数据库连接文件 conn.asp 或 const. asp是比较简单容易出错的地方),密码的强度(md5密码纯数字一会就可以解密,最好用数字加英文加特殊符号),如果用别人发的全站程序,需要注意这个程序在各大黑客网站上是否有漏洞。phpwind和最近的oblog差距很严重,一定要及时补上。
非技能常识系统1.计算可以使用51.la或cnzz计算代码,每天花3-5分钟看计算结果,分析主ip从哪里来,从哪里来它被执行。最好,哪个关键字是你的专长,这样你就可以更有针对性地进行推广。2.采集刚开始是一个网站,不可能每篇文章文章都是原创,所以你要采集别人的经验文章,而不仅仅是发布它。学习使用搜索引擎,比如百度和google的一些特殊功能: site:可以查到输入了多少条目;“link:”会找到所有指向网站主页的网页。这些技能可以在网上找到。NS。3. 修改包括文字修改和图稿。采集到的大部分文章链接可能是一些无用的信息。需要学会过滤和清理,技术文章要通俗易懂,清理后公布。美术方面,最好学习一下PS和DW的基本用法。从根本上说,不要让别人帮你拍照片。4.最好的宣传方式是口耳相传。有人认为你的网站郝天然会介绍给他的朋友,通常是在论坛或其他互动网站帮助人解决问题,我想大多数人都会感谢帮助他们的人。只需在签名文件中放置一个连接即可。发生的流量稳定有效。不要发送广告。不仅没用,还会留下不好的形象。
<p>公布一些包装精美的文件,例如电子书、艺术类电子杂志等。这些被称为病毒式传销,它们非常有用。5.SEO优化搜索引擎优化类似,不要过度搜索引擎优化,一个真正的好网站,深得人心,百度不能给你顶。6. 人际网络人际关系,要想做大做强,一个人很难在互联网上站稳脚跟,有所作为。您必须调动所有可用资源为未来奠定基础;打造具有战斗力的团队;结交更多这个行业的朋友,无论是站长还是网友,都可以成为你的老师。如果是三人组,肯定有我的老师。记住,交朋友一定要真诚,朋友是最宝贵的,不会随着时间而改变。网站的操作会和网站的推广混淆。在实践中,网站的推广只是网站操作的一部分,除此之外,还有网站和栏目或活动的策划任务,页面的创建和功能和内容管理。后期客户联系,客户处理,人力资源开发,客户二次开发。一些重大活动的发展和后期的网站保护。但是,一个网站的生命力不只是看这里,还要了解整个网站的规划和站长的管理技巧,以及一个远程操作团队,是否它可能会受到 网站 @网站余生生。科技以人为本。1.确定网站2.的意图网站Planning3.制造实践页面4.添加流量(网站实施网站推广) 5.每日更新网站 6. 把握网站现状和客户反应,继续完善以上5点,详细阐述如下:1.确认
采集网站内容(如何使用Scrapy结合PhantomJS框架写一个_MIDDLEWARES资料总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-01 23:13
一,。导言
最近,我一直在研究scrapy crawler框架,并尝试使用scrapy框架编写一个可以实现web信息的简单小程序采集。我在尝试的过程中遇到了很多小问题。我希望你能给我更多的建议
本文主要介绍如何结合phantom JS采集天猫商品内容使用scripy。本文定制了一个下载程序u中间件用于采集需要加载JS的动态网页内容。阅读了很多关于downloader的内容。总之,midviews数据使用起来很简单,但是它会阻塞框架,因此性能很差。在一些materials_uhandler中提到了自定义下载程序,或者使用grapyjs可以解决阻塞框架的问题。感兴趣的合作伙伴可以研究它。我不会在这里谈论它
二,。具体实施
2.1,环境要求
您需要执行以下步骤来准备python开发和运行环境:
以上步骤显示了两种安装方式:1。安装并下载本地车轮套件;2.使用Python安装管理器执行远程下载和安装。注意:包版本需要与python版本匹配
2.2,开发和测试过程
首先,找到需要采集的页面。这是天猫的产品。该网站为/item/526449276263.HTM。网页如下:
然后开始编写代码。默认情况下,以下代码在命令行界面中执行
1),创建scratch crawler项目tmspider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middleware文件夹,然后在该文件夹下创建middleware.py文件。代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和phantom JS编写web内容下载程序,并在上一步创建的Middleware文件夹中创建downloader.py文件。代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5)创建爬虫模块
在项目目录e:\Python-3.5.1\tmspider中,执行以下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后,将在项目目录e:\Python-3.5.1\tmspider\tmspider\spider中自动生成tmall.py程序文件。程序中的parse函数处理脚本下载程序返回的网页内容。采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫程序
在E:\Python-3.5.1\tmspider项目目录中执行该命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请注意,上述命令一次只能启动一个爬虫程序。如果要同时启动多个爬虫程序,该怎么办?然后您需要定制一个爬虫程序启动模块。在spider下创建模块文件runcrawl.py。代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
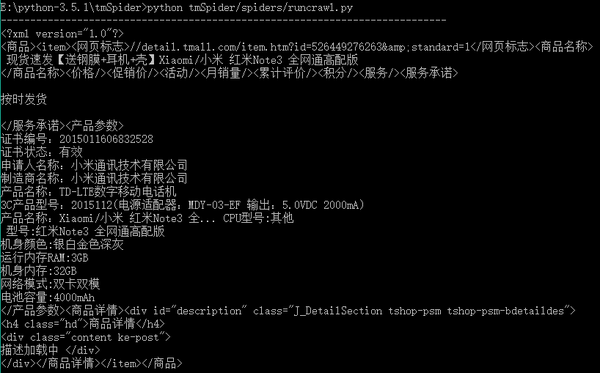
执行runcrawl.py文件并输出结果:
三,。前景
为了定制Downloader,在通过调用phantomjs实现爬虫程序之后,Middleware长期以来一直在努力解决阻塞框架的问题,并试图找到解决方案。稍后,我们将研究其他调用浏览器的方法,例如grapyjs和splash,看看它们是否可以有效地解决这个问题
四,。有关文件
一,。Python即时web爬虫:API描述
五,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
六,。文档修改历史记录
12016-06-30:V1.0 查看全部
采集网站内容(如何使用Scrapy结合PhantomJS框架写一个_MIDDLEWARES资料总结)
一,。导言
最近,我一直在研究scrapy crawler框架,并尝试使用scrapy框架编写一个可以实现web信息的简单小程序采集。我在尝试的过程中遇到了很多小问题。我希望你能给我更多的建议
本文主要介绍如何结合phantom JS采集天猫商品内容使用scripy。本文定制了一个下载程序u中间件用于采集需要加载JS的动态网页内容。阅读了很多关于downloader的内容。总之,midviews数据使用起来很简单,但是它会阻塞框架,因此性能很差。在一些materials_uhandler中提到了自定义下载程序,或者使用grapyjs可以解决阻塞框架的问题。感兴趣的合作伙伴可以研究它。我不会在这里谈论它
二,。具体实施
2.1,环境要求
您需要执行以下步骤来准备python开发和运行环境:
以上步骤显示了两种安装方式:1。安装并下载本地车轮套件;2.使用Python安装管理器执行远程下载和安装。注意:包版本需要与python版本匹配
2.2,开发和测试过程
首先,找到需要采集的页面。这是天猫的产品。该网站为/item/526449276263.HTM。网页如下:
然后开始编写代码。默认情况下,以下代码在命令行界面中执行
1),创建scratch crawler项目tmspider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middleware文件夹,然后在该文件夹下创建middleware.py文件。代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和phantom JS编写web内容下载程序,并在上一步创建的Middleware文件夹中创建downloader.py文件。代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5)创建爬虫模块
在项目目录e:\Python-3.5.1\tmspider中,执行以下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后,将在项目目录e:\Python-3.5.1\tmspider\tmspider\spider中自动生成tmall.py程序文件。程序中的parse函数处理脚本下载程序返回的网页内容。采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫程序
在E:\Python-3.5.1\tmspider项目目录中执行该命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请注意,上述命令一次只能启动一个爬虫程序。如果要同时启动多个爬虫程序,该怎么办?然后您需要定制一个爬虫程序启动模块。在spider下创建模块文件runcrawl.py。代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
三,。前景
为了定制Downloader,在通过调用phantomjs实现爬虫程序之后,Middleware长期以来一直在努力解决阻塞框架的问题,并试图找到解决方案。稍后,我们将研究其他调用浏览器的方法,例如grapyjs和splash,看看它们是否可以有效地解决这个问题
四,。有关文件
一,。Python即时web爬虫:API描述
五,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
六,。文档修改历史记录
12016-06-30:V1.0
采集网站内容(公司采集办法不正确导致网站被降权怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-24 19:08
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,企业需要如何正确呢?采集
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,对于正确的采集网站内容,企业应该怎么做呢?
首先,在采集网站的内容中,要选择好的网站内容,也就是选择与网站相关的内容,新鲜的像可能,如果太旧了,就是很文章的内容,陈旧的内容就不需要采集
那么采集的内容要适当修改为网站的标题。根据内容主题更改相应的标题。比如原标题是“如何减轻工作压力?”,可以换成“如何减轻工作压力?” 等。文字内容不同,但表达的内涵是一样的。采集的内容标题和内容创意可以一一对应。
最后,对采集的网站的内容做一些适当的调整。调整内容的时候,可以适当的使用重写,尤其是第一、最后两段,重写,然后适当添加相应的图片,可以有效的提高内容的质量,也可以产生百度蜘蛛吸引力的更好结果。因此,本公司在涉及采集网站的内容时应注意上述问题! 查看全部
采集网站内容(公司采集办法不正确导致网站被降权怎么办?(图))
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,企业需要如何正确呢?采集
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,对于正确的采集网站内容,企业应该怎么做呢?
首先,在采集网站的内容中,要选择好的网站内容,也就是选择与网站相关的内容,新鲜的像可能,如果太旧了,就是很文章的内容,陈旧的内容就不需要采集
那么采集的内容要适当修改为网站的标题。根据内容主题更改相应的标题。比如原标题是“如何减轻工作压力?”,可以换成“如何减轻工作压力?” 等。文字内容不同,但表达的内涵是一样的。采集的内容标题和内容创意可以一一对应。
最后,对采集的网站的内容做一些适当的调整。调整内容的时候,可以适当的使用重写,尤其是第一、最后两段,重写,然后适当添加相应的图片,可以有效的提高内容的质量,也可以产生百度蜘蛛吸引力的更好结果。因此,本公司在涉及采集网站的内容时应注意上述问题!
采集网站内容(云霸屏怎样有效进行网站采集呢?新站最好不要采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-22 23:22
众所周知,高品质网站文章采集可以有效地改善网站内容内容内容建,霸霸屏屏屏例例例霸例网网打字促销产品非常注重对@ 网站的优化,谨防操作不当的优化效果,那么如何有效网站 采集@ @采集采集@@ @@采集采集@@ @@采集@@ ki去大家。
1.新站最好不要到采集
我相信每个人都知道新站在线之后是在线,如果新站在线,采集将对网站的负面影响,导致网站收录容放入低低质销量生成网站有收录无无无。
知乎 网站 proge升级采集
搜索引擎是首选进口链接和导出链接到网站,这可以让网站键入生态ring,增强网站 correlion。 采集首先,确保采集内容对用户有一定的价值,可以有效解决用户需求,采集内容推荐必须来自行业高权重网站和专家内容。
3. 采集比
现在网站几乎所有考虑网站采集,网站内容是可以采集,但要注意底线。 网站不不@@@ @采集 @采集@ @@ @采集采集@ @ @采集 @采集内容不不不不不网站 采集@ @内容不不不不不话............................................. ........
4. 网站用户体验
网站 采集内容内容需要进行基本修改,包括标题,地图等,只要您能够有效解决用户需求,我认为总是改进网站。 采集 @内容消原代代中中文..................................... ................................................ ..
在所有情况下,上面的是关于文章采集,采集内容内容实际上是针对网站的重量和更新频率,我希望内容告诉今天可以帮助您更好地解决它。 网站优化采集问题。 查看全部
采集网站内容(云霸屏怎样有效进行网站采集呢?新站最好不要采集)
众所周知,高品质网站文章采集可以有效地改善网站内容内容内容建,霸霸屏屏屏例例例霸例网网打字促销产品非常注重对@ 网站的优化,谨防操作不当的优化效果,那么如何有效网站 采集@ @采集采集@@ @@采集采集@@ @@采集@@ ki去大家。
1.新站最好不要到采集
我相信每个人都知道新站在线之后是在线,如果新站在线,采集将对网站的负面影响,导致网站收录容放入低低质销量生成网站有收录无无无。
知乎 网站 proge升级采集
搜索引擎是首选进口链接和导出链接到网站,这可以让网站键入生态ring,增强网站 correlion。 采集首先,确保采集内容对用户有一定的价值,可以有效解决用户需求,采集内容推荐必须来自行业高权重网站和专家内容。
3. 采集比
现在网站几乎所有考虑网站采集,网站内容是可以采集,但要注意底线。 网站不不@@@ @采集 @采集@ @@ @采集采集@ @ @采集 @采集内容不不不不不网站 采集@ @内容不不不不不话............................................. ........
4. 网站用户体验
网站 采集内容内容需要进行基本修改,包括标题,地图等,只要您能够有效解决用户需求,我认为总是改进网站。 采集 @内容消原代代中中文..................................... ................................................ ..
在所有情况下,上面的是关于文章采集,采集内容内容实际上是针对网站的重量和更新频率,我希望内容告诉今天可以帮助您更好地解决它。 网站优化采集问题。
采集网站内容(字节面试锦集(一):AndroidFramework高频面试题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-22 15:09
字节访问brocade集合(一):Android框架高频访问问题摘要
关键词:访谈锦缎系列(二):项目人力资源高频访谈总结)
data采集采集体系结构中每个模块的详细分析
网络爬虫的实现原理与技术
爬虫工程师如何有效地支持数据分析师的工作
基于大数据平台的互联网数据采集平台基本架构
爬行动物工程师的成长道路
如何在data采集中建立有效的监控系统@
面试准备、人力资源和安卓技术等面试问题总结
昨天,一位网友说,他最近采访了几家公司。他被问了好几次问题,每次回答都不是很好
采访者:比如说,有100000个网站need采集,你是如何快速获得数据的
要很好地回答这个问题,您实际上需要有足够的知识和足够的技术储备
最近我们也在招聘,我们每周面试十几个人,只有一两个人觉得合适。他们大多数都和这位网友相似,缺乏整体思维,即使是那些有三四年工作经验的老司机。他们解决具体问题的能力很强,但很少站在新的角度从点到面全面思考
采集覆盖率为100000 网站比大多数专业舆论监测公司更宽。为了满足面试官的“采集”需求,需要综合考虑从“网站集合”到“数据存储”的各个方面,并给出适当的方案来节约成本和提高工作效率
让我们简单介绍一下从网站采集到数据存储
一、10一万网站来自哪里
一般来说,采集和网站是根据公司业务的发展逐渐积累起来的
现在我们假设这是一家初创公司的需求。该公司刚刚成立,有这么多网站,基本上可以说是一个冷启动。我们如何采集这10万网站?有几种方法:
1)历史业务积累
无论是冷启动还是什么,既然有采集的需求,就一定有项目或产品的需求,相关人员在前期一定调查了一些数据源,采集了一些重要的网站数据,这些数据可以作为我们采集的网站和采集的原创种子
2)Association网站
在一些网站的底部,有与网站相关的链接。特别是对于政府网站,通常有相关下属部门的官方网站
3)网站导航
有些网站可能出于某种目的(如排水等)采集网站并进行分类和展示,以方便人们查找。这些网站可以很快为我们提供第一批种子网站.然后,我们可以通过网站关联等方式获得更多的网站
4)搜索引擎
您还可以准备一些与公司业务相关的关键词在百度、搜狗等搜索引擎中搜索,并通过处理搜索结果提取相应的网站作为我们的种子网站
5)第三方平台
例如,一些第三方SaaS平台将有7~15天的免费试用期,因此我们可以利用这段时间采集下载与我们业务相关的数据,然后提取网站作为我们最初的采集种子
虽然该方法是最有效、最快的网站采集方法,但在试验期间不太可能获得100000网站,因此有必要将上述相关网站和其他方法结合起来,以快速获得所需的网站@
通过以上五种方式,我相信我们可以很快采集到我们需要的10万个网站。但是,我们如何管理这么多网站,如何知道它们是否正常
二、10一万网站如何管理
当我们采集100000网站数据时,我们面临的第一件事是如何管理、配置采集规则,以及监控网站是否正常
1)如何管理
100000网站,如果没有专门的系统来管理,那将是一场灾难
同时,由于业务需要,比如智能推荐,我们需要对网站进行预处理,比如标签,这时需要一个网站管理系统
2)如何配置采集规则
我们前期采集的10万网站只是主页,如果只把主页作为采集任务,我们只能采集在主页上获取少量信息,丢失率很高
如果你想让整个站点采集按照主页URL进行,会消耗大量服务器资源,成本太高,因此需要配置我们关心的栏目和采集栏目
然而,对于100000网站,如何快速高效地配置列?目前,我们通过自动解析HTML源代码来进行半自动的列配置
当然,我们也尝试过机器学习,但效果并不理想
由于采集所需的网站数量达到100000,因此不能使用XPath和其他精确定位方法来采集.否则,配置100000网站井时,花椰菜将变冷
同时,数据采集必须使用通用爬虫,并使用正则表达式来匹配列表数据
3)如何监控
由于有100000个网站,在这些网站中,每天都会有网站修订,或列修订,或新的/现成的列。因此,有必要根据采集的数据对网站进行简要分析@
例如,如果网站中有几天没有新数据,则一定是有问题。要么是网站更改了版本,导致信息规则性频繁失败,要么是网站本身有问题
为了提高采集的效率,可以使用单独的服务定期检测网站和列,首先检查网站和列是否可以正常访问;其次检查配置的列信息正则表达式是否正常,以便运维人员进行维护
三、task缓存
100000网站。配置列后,采集条目URL应达到百万级别。采集器如何有效地获取采集的这些条目URL@
如果将这些URL放入数据库中,无论是MySQL还是Oracle,采集器获取采集任务都会浪费大量时间,并大大降低采集效率
如何解决这个问题?首选内存数据库,如redis、Mongo dB等。redis通常使用采集进行缓存。因此,在配置列时,您可以将列信息作为采集任务缓存队列同步到redis
四、网站how采集
比如说,如果你想一年赚几百万,最有可能的是去华为、阿里巴巴、腾讯等一线大工厂,你需要达到一定的水平,这条路肯定很难走
类似地,如果需要采集000000级别列表URL,则不得实施常规方法
必须采用分布式+多进程+多线程的方式,同时还需要结合内存数据库redis进行缓存,实现高效的任务获取和采集信息的复制
同时,信息分析,如发布时间和文本,也必须通过算法进行处理。例如,现在流行的GNE
在列表采集中可以获得的某些属性不应与文本一起解析。例如,标题。通常,从列表中获得的标题的准确性远远高于从信息HTML源代码中通过算法解析的标题的准确性
同时,如果有一些特殊的网站,或者一些特殊的需求,我们可以使用定制的开发方法来处理它们
五、统一数据存储接口
为了保持采集的时效性,采集的100000网站可能需要十几台或二十台服务器。同时,将在每台服务器上部署n采集器。通过一些定制脚本,采集器的总数将达到数百台
如果每个采集器/自定义脚本都开发了自己的数据存储接口,那么在开发和调试上会浪费大量的时间,而且后续的操作和维护也不是坏事,特别是当业务发生变化需要调整时,因此需要统一数据存储接口
由于统一的数据存储接口,当我们需要对数据进行一些特殊的处理,如清理和校正时,我们不需要修改每个采集存储部分,我们只需要修改接口并重新部署它
快、方便、快捷
六、数据和采集监测
10万网站的采集覆盖率每天肯定超过200万数据,数据分析算法再精确也达不到100%(90%非常好).因此,在数据分析中必须有例外。例如,发布时间大于当前时间,文本收录相关新闻信息等
但是,由于我们已经统一了数据存储接口,我们可以在接口上进行统一的数据质量验证,优化采集器并根据异常情况定制脚本
同时,您还可以统计每个伪原创的采集数据 查看全部
采集网站内容(字节面试锦集(一):AndroidFramework高频面试题总结)
字节访问brocade集合(一):Android框架高频访问问题摘要
关键词:访谈锦缎系列(二):项目人力资源高频访谈总结)
data采集采集体系结构中每个模块的详细分析
网络爬虫的实现原理与技术
爬虫工程师如何有效地支持数据分析师的工作
基于大数据平台的互联网数据采集平台基本架构
爬行动物工程师的成长道路
如何在data采集中建立有效的监控系统@
面试准备、人力资源和安卓技术等面试问题总结
昨天,一位网友说,他最近采访了几家公司。他被问了好几次问题,每次回答都不是很好
采访者:比如说,有100000个网站need采集,你是如何快速获得数据的
要很好地回答这个问题,您实际上需要有足够的知识和足够的技术储备
最近我们也在招聘,我们每周面试十几个人,只有一两个人觉得合适。他们大多数都和这位网友相似,缺乏整体思维,即使是那些有三四年工作经验的老司机。他们解决具体问题的能力很强,但很少站在新的角度从点到面全面思考
采集覆盖率为100000 网站比大多数专业舆论监测公司更宽。为了满足面试官的“采集”需求,需要综合考虑从“网站集合”到“数据存储”的各个方面,并给出适当的方案来节约成本和提高工作效率
让我们简单介绍一下从网站采集到数据存储
一、10一万网站来自哪里
一般来说,采集和网站是根据公司业务的发展逐渐积累起来的
现在我们假设这是一家初创公司的需求。该公司刚刚成立,有这么多网站,基本上可以说是一个冷启动。我们如何采集这10万网站?有几种方法:
1)历史业务积累
无论是冷启动还是什么,既然有采集的需求,就一定有项目或产品的需求,相关人员在前期一定调查了一些数据源,采集了一些重要的网站数据,这些数据可以作为我们采集的网站和采集的原创种子
2)Association网站
在一些网站的底部,有与网站相关的链接。特别是对于政府网站,通常有相关下属部门的官方网站
3)网站导航
有些网站可能出于某种目的(如排水等)采集网站并进行分类和展示,以方便人们查找。这些网站可以很快为我们提供第一批种子网站.然后,我们可以通过网站关联等方式获得更多的网站

4)搜索引擎
您还可以准备一些与公司业务相关的关键词在百度、搜狗等搜索引擎中搜索,并通过处理搜索结果提取相应的网站作为我们的种子网站
5)第三方平台
例如,一些第三方SaaS平台将有7~15天的免费试用期,因此我们可以利用这段时间采集下载与我们业务相关的数据,然后提取网站作为我们最初的采集种子
虽然该方法是最有效、最快的网站采集方法,但在试验期间不太可能获得100000网站,因此有必要将上述相关网站和其他方法结合起来,以快速获得所需的网站@
通过以上五种方式,我相信我们可以很快采集到我们需要的10万个网站。但是,我们如何管理这么多网站,如何知道它们是否正常
二、10一万网站如何管理
当我们采集100000网站数据时,我们面临的第一件事是如何管理、配置采集规则,以及监控网站是否正常
1)如何管理
100000网站,如果没有专门的系统来管理,那将是一场灾难
同时,由于业务需要,比如智能推荐,我们需要对网站进行预处理,比如标签,这时需要一个网站管理系统
2)如何配置采集规则
我们前期采集的10万网站只是主页,如果只把主页作为采集任务,我们只能采集在主页上获取少量信息,丢失率很高
如果你想让整个站点采集按照主页URL进行,会消耗大量服务器资源,成本太高,因此需要配置我们关心的栏目和采集栏目
然而,对于100000网站,如何快速高效地配置列?目前,我们通过自动解析HTML源代码来进行半自动的列配置
当然,我们也尝试过机器学习,但效果并不理想
由于采集所需的网站数量达到100000,因此不能使用XPath和其他精确定位方法来采集.否则,配置100000网站井时,花椰菜将变冷
同时,数据采集必须使用通用爬虫,并使用正则表达式来匹配列表数据
3)如何监控
由于有100000个网站,在这些网站中,每天都会有网站修订,或列修订,或新的/现成的列。因此,有必要根据采集的数据对网站进行简要分析@
例如,如果网站中有几天没有新数据,则一定是有问题。要么是网站更改了版本,导致信息规则性频繁失败,要么是网站本身有问题
为了提高采集的效率,可以使用单独的服务定期检测网站和列,首先检查网站和列是否可以正常访问;其次检查配置的列信息正则表达式是否正常,以便运维人员进行维护
三、task缓存
100000网站。配置列后,采集条目URL应达到百万级别。采集器如何有效地获取采集的这些条目URL@
如果将这些URL放入数据库中,无论是MySQL还是Oracle,采集器获取采集任务都会浪费大量时间,并大大降低采集效率
如何解决这个问题?首选内存数据库,如redis、Mongo dB等。redis通常使用采集进行缓存。因此,在配置列时,您可以将列信息作为采集任务缓存队列同步到redis
四、网站how采集
比如说,如果你想一年赚几百万,最有可能的是去华为、阿里巴巴、腾讯等一线大工厂,你需要达到一定的水平,这条路肯定很难走
类似地,如果需要采集000000级别列表URL,则不得实施常规方法
必须采用分布式+多进程+多线程的方式,同时还需要结合内存数据库redis进行缓存,实现高效的任务获取和采集信息的复制
同时,信息分析,如发布时间和文本,也必须通过算法进行处理。例如,现在流行的GNE
在列表采集中可以获得的某些属性不应与文本一起解析。例如,标题。通常,从列表中获得的标题的准确性远远高于从信息HTML源代码中通过算法解析的标题的准确性
同时,如果有一些特殊的网站,或者一些特殊的需求,我们可以使用定制的开发方法来处理它们
五、统一数据存储接口
为了保持采集的时效性,采集的100000网站可能需要十几台或二十台服务器。同时,将在每台服务器上部署n采集器。通过一些定制脚本,采集器的总数将达到数百台
如果每个采集器/自定义脚本都开发了自己的数据存储接口,那么在开发和调试上会浪费大量的时间,而且后续的操作和维护也不是坏事,特别是当业务发生变化需要调整时,因此需要统一数据存储接口
由于统一的数据存储接口,当我们需要对数据进行一些特殊的处理,如清理和校正时,我们不需要修改每个采集存储部分,我们只需要修改接口并重新部署它
快、方便、快捷
六、数据和采集监测
10万网站的采集覆盖率每天肯定超过200万数据,数据分析算法再精确也达不到100%(90%非常好).因此,在数据分析中必须有例外。例如,发布时间大于当前时间,文本收录相关新闻信息等
但是,由于我们已经统一了数据存储接口,我们可以在接口上进行统一的数据质量验证,优化采集器并根据异常情况定制脚本
同时,您还可以统计每个伪原创的采集数据
采集网站内容(应如何正确使用采集内容呢?【豹子融教育】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-21 16:09
在网站优化圈里,站长们都知道,搜索引擎非常重视原创内容,但是再优秀的SEOer面对长期的内容原创都会有一定的困难,不仅仅资源有限且写作能力也存在着局限性,因此,整个网站包括各个板块儿的内容,都避免不了采集。
然而,搜索引擎强调采集内容对于网站来说并没有多大意义,尤其是对于优化作用,甚至是采集内容会被当做是垃圾信息处理,造成网站的负担,其实不然,即便采集内容对网站会存在着一定的风险,但只要采集合理,它还是有着一定的用处,同时也能够减少站长的原创堪忧,且获得同样的优化效果。那么,应如何正确使用采集内容呢?
首先,采集内容对象有讲究。最好找别人刚发布不久的内容作为采集目标,在没有被太多的人转载之前采集过来,但内容前提是于是俱进,新鲜且有代表性,而不是一些老生常谈的话题,否则对用户来说味同爵蜡,毫无价值可言。由于是采集内容,比起原创来说,自然要简单得多,也就不需要花费太多的时间来编辑内容,此时千万别把节省的时间闲着,毕竟采集的内容没有原创的效果来得直接,那么就要多找几篇内容同时采集,来弥补蜘蛛的空虚。
其次,采集内容不采集标题。大家都知道,看一篇文章最先看的是标题,对于网站优化的搜索引擎来说,标题也占有一定的权重。所采集的内容有一定的篇幅,做不了太多的改变,但是标题也就短短几个字,修改起来还是比较容易的,因此标题修改是必须的,而且最好将标题改得与原标题完全不相同,道理很简单,当你看到标题一样实质内容完全不同的文章时,会带给读者一些误解,认为两者内容相同,相反,即便内容相同,标题完全不同,也会给予人一种新鲜感,不易被发现。
最后,对内容做适当的调整。试过将内容采集到自己网站的站长,细心的人必然会发现,直接复制过来的内容还存在着格式问题,因为一些精明的原创者为了防止内容被采集,通常会给内容加一些隐藏的格式,甚至在图片的ALT信息里就会做版权的标注,如果没注意到,自然会被搜索引擎认定是抄袭,那么对网站的危害也就不言而喻了。因此,采集过来的内容一定要清除格式,且对英文格式的标点符号进行转换,另外,可给内容添加一些图片,使得内容更加丰富,如果内容本身有图片,那么千万不要直接复制,最好另外保存重新上传至网站,加上自己的ALT信息,能让采集内容更有优化价值。
简而言之,网站采集内容并非完全无益,关键还要看你如何采集,只要能够灵活使用这些采集过来的内容,就能带给网站一定的好处,但,站长们需要注意的是,必须得掌握一定的采集方法。 查看全部
采集网站内容(应如何正确使用采集内容呢?【豹子融教育】)
在网站优化圈里,站长们都知道,搜索引擎非常重视原创内容,但是再优秀的SEOer面对长期的内容原创都会有一定的困难,不仅仅资源有限且写作能力也存在着局限性,因此,整个网站包括各个板块儿的内容,都避免不了采集。
然而,搜索引擎强调采集内容对于网站来说并没有多大意义,尤其是对于优化作用,甚至是采集内容会被当做是垃圾信息处理,造成网站的负担,其实不然,即便采集内容对网站会存在着一定的风险,但只要采集合理,它还是有着一定的用处,同时也能够减少站长的原创堪忧,且获得同样的优化效果。那么,应如何正确使用采集内容呢?
首先,采集内容对象有讲究。最好找别人刚发布不久的内容作为采集目标,在没有被太多的人转载之前采集过来,但内容前提是于是俱进,新鲜且有代表性,而不是一些老生常谈的话题,否则对用户来说味同爵蜡,毫无价值可言。由于是采集内容,比起原创来说,自然要简单得多,也就不需要花费太多的时间来编辑内容,此时千万别把节省的时间闲着,毕竟采集的内容没有原创的效果来得直接,那么就要多找几篇内容同时采集,来弥补蜘蛛的空虚。
其次,采集内容不采集标题。大家都知道,看一篇文章最先看的是标题,对于网站优化的搜索引擎来说,标题也占有一定的权重。所采集的内容有一定的篇幅,做不了太多的改变,但是标题也就短短几个字,修改起来还是比较容易的,因此标题修改是必须的,而且最好将标题改得与原标题完全不相同,道理很简单,当你看到标题一样实质内容完全不同的文章时,会带给读者一些误解,认为两者内容相同,相反,即便内容相同,标题完全不同,也会给予人一种新鲜感,不易被发现。
最后,对内容做适当的调整。试过将内容采集到自己网站的站长,细心的人必然会发现,直接复制过来的内容还存在着格式问题,因为一些精明的原创者为了防止内容被采集,通常会给内容加一些隐藏的格式,甚至在图片的ALT信息里就会做版权的标注,如果没注意到,自然会被搜索引擎认定是抄袭,那么对网站的危害也就不言而喻了。因此,采集过来的内容一定要清除格式,且对英文格式的标点符号进行转换,另外,可给内容添加一些图片,使得内容更加丰富,如果内容本身有图片,那么千万不要直接复制,最好另外保存重新上传至网站,加上自己的ALT信息,能让采集内容更有优化价值。
简而言之,网站采集内容并非完全无益,关键还要看你如何采集,只要能够灵活使用这些采集过来的内容,就能带给网站一定的好处,但,站长们需要注意的是,必须得掌握一定的采集方法。
采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-19 00:19
采集有益
采集可以在短时间内大大提高网站的收录(前提是您的网站权重足够高),并可以捕获大部分网络流量和其他竞争对手的流量
采集有害
大量的采集会让百度认为你的站点中没有客户想要的信息。这是一个垃圾站。如果您今天有100采集today,明天有200采集today,后天没有采集today,则属于不均匀更新频率。百度会关注你的
首先,它可以在很短的时间内丰富网站的内容,让百度蜘蛛能够正常穿越网站并让用户在登录网站时看到一些内容网站. 尽管这些内容相对较旧,但它们比没有内容供用户使用要好得多
第二,内容采集可以快速获取与此相关的最新内容网站. 由于采集内容可以基于网站的关键词和相关栏目采集内容,这些内容可以是最新鲜的内容,因此用户在浏览网站时可以快速获得相关内容,无需通过搜索引擎重新搜索,因此网站用户体验可以得到一定程度的提升
当然,采集内容的缺点仍然非常明显,特别是抄袭采集和大规模采集会对网站产生不利影响,所以我们必须掌握正确的采集方法,才能充分发挥采集内容的优势
现在让我们分析一下正确的采集方式
首先,选择采集content。也就是说,我们应该选择与网站相关的内容,并尝试使其新鲜。如果太旧了,特别是新闻内容,旧的内容不需要采集,但是对于技术帖子来说,可以使用采集,因为这些技术帖子对很多新人都有很好的帮助效果
然后采集适当地更改标题。更改此处的标题并不要求采集people成为标题方,而是根据内容主题更改相应的标题。例如,如果原标题为“网站集团产品是安全的”,则可以将其更改为“网站集团产品将是安全的,受什么影响?”等等。文字内容不同,但内涵相同,这样采集的内容标题和内容理念可以一一对应,防止挂羊头卖狗肉的内容
最后是适当调整内容。此处的内容调整不需要简单地替换段落,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容变得困难和混乱,用户的阅读体验将大大降低。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果将产生严重的负面影响。在调整内容时,您可以通过适当的使用重新编写,特别是第一段和最后一段。你应该重写,然后适当添加相应的图片,这样可以有效提高内容的质量,对百度蜘蛛有更好的吸引力
总之,网站content采集不需要被打死。事实上,只要对传统的粗糙采集进行适当优化,并将其转化为精细采集,虽然采集需要相对较长的时间,但它比原创快得多,并且不会影响用户体验,因此正确的采集仍然是非常必要的 查看全部
采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集有益
采集可以在短时间内大大提高网站的收录(前提是您的网站权重足够高),并可以捕获大部分网络流量和其他竞争对手的流量
采集有害
大量的采集会让百度认为你的站点中没有客户想要的信息。这是一个垃圾站。如果您今天有100采集today,明天有200采集today,后天没有采集today,则属于不均匀更新频率。百度会关注你的
首先,它可以在很短的时间内丰富网站的内容,让百度蜘蛛能够正常穿越网站并让用户在登录网站时看到一些内容网站. 尽管这些内容相对较旧,但它们比没有内容供用户使用要好得多
第二,内容采集可以快速获取与此相关的最新内容网站. 由于采集内容可以基于网站的关键词和相关栏目采集内容,这些内容可以是最新鲜的内容,因此用户在浏览网站时可以快速获得相关内容,无需通过搜索引擎重新搜索,因此网站用户体验可以得到一定程度的提升
当然,采集内容的缺点仍然非常明显,特别是抄袭采集和大规模采集会对网站产生不利影响,所以我们必须掌握正确的采集方法,才能充分发挥采集内容的优势
现在让我们分析一下正确的采集方式
首先,选择采集content。也就是说,我们应该选择与网站相关的内容,并尝试使其新鲜。如果太旧了,特别是新闻内容,旧的内容不需要采集,但是对于技术帖子来说,可以使用采集,因为这些技术帖子对很多新人都有很好的帮助效果
然后采集适当地更改标题。更改此处的标题并不要求采集people成为标题方,而是根据内容主题更改相应的标题。例如,如果原标题为“网站集团产品是安全的”,则可以将其更改为“网站集团产品将是安全的,受什么影响?”等等。文字内容不同,但内涵相同,这样采集的内容标题和内容理念可以一一对应,防止挂羊头卖狗肉的内容
最后是适当调整内容。此处的内容调整不需要简单地替换段落,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容变得困难和混乱,用户的阅读体验将大大降低。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果将产生严重的负面影响。在调整内容时,您可以通过适当的使用重新编写,特别是第一段和最后一段。你应该重写,然后适当添加相应的图片,这样可以有效提高内容的质量,对百度蜘蛛有更好的吸引力
总之,网站content采集不需要被打死。事实上,只要对传统的粗糙采集进行适当优化,并将其转化为精细采集,虽然采集需要相对较长的时间,但它比原创快得多,并且不会影响用户体验,因此正确的采集仍然是非常必要的
采集网站内容(连接网站与解析HTML上一期的代码结构分析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 10:07
上一期主要讲解:链接网站和解析HTML
最后一个问题只是一个简单的例子。我得到了网站的一小部分内容。这个问题开始说明需要获取网站的所有文章的列表。
在开始之前,还是要提醒大家:网络爬虫的时候一定要非常仔细的考虑需要消耗多少网络流量,尽量考虑采集目标的服务器负载是否可以更低。
此示例 采集ScrapingBee 博客博客 文章。
在做数据采集之前,先对网站进行分析,看看代码结构。
需要采集的部分由一张一张的小卡片组成,截图如下:
多卡
获取所有卡片的父标签后,循环单张卡片的内容:
一件物品卡
单张卡片的内容正是我们所需要的。完成思路后,开始完成代码:
首先,我们将重用上一期网站的代码:
def __init__(self):
self._target_url = 'https://www.scrapingbee.com/blog/'
self._init_connection = connection_util.ProcessConnection()
以上代码定义了一个采集的URL,并复用了上一期网站的链接代码。
# 连接目标网站,获取内容
get_content = self._init_connection.init_connection(self._target_url)
连接上面定义的目标网站,获取网站的内容。
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
如果有内容,搜索网站的内容标签。以上就是获取所有卡片的父标签。具体的网站结构体可以自行查看网站的完整内容。
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
得到所有的小卡片。
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
之后,遍历获得的小卡片,获取每张卡片的标题、发布时间和描述文章。
以上分析从网站的结构开始,到具体的代码实现。这是爬虫提取网站内容的一个基本思路。
每个网站都不一样,结构也会不一样,所以一定要针对性的写代码。
以上代码已托管在Github上,地址: 查看全部
采集网站内容(连接网站与解析HTML上一期的代码结构分析(一))
上一期主要讲解:链接网站和解析HTML
最后一个问题只是一个简单的例子。我得到了网站的一小部分内容。这个问题开始说明需要获取网站的所有文章的列表。
在开始之前,还是要提醒大家:网络爬虫的时候一定要非常仔细的考虑需要消耗多少网络流量,尽量考虑采集目标的服务器负载是否可以更低。
此示例 采集ScrapingBee 博客博客 文章。
在做数据采集之前,先对网站进行分析,看看代码结构。
需要采集的部分由一张一张的小卡片组成,截图如下:
多卡
获取所有卡片的父标签后,循环单张卡片的内容:
一件物品卡
单张卡片的内容正是我们所需要的。完成思路后,开始完成代码:
首先,我们将重用上一期网站的代码:
def __init__(self):
self._target_url = 'https://www.scrapingbee.com/blog/'
self._init_connection = connection_util.ProcessConnection()
以上代码定义了一个采集的URL,并复用了上一期网站的链接代码。
# 连接目标网站,获取内容
get_content = self._init_connection.init_connection(self._target_url)
连接上面定义的目标网站,获取网站的内容。
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
如果有内容,搜索网站的内容标签。以上就是获取所有卡片的父标签。具体的网站结构体可以自行查看网站的完整内容。
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
得到所有的小卡片。
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
之后,遍历获得的小卡片,获取每张卡片的标题、发布时间和描述文章。
以上分析从网站的结构开始,到具体的代码实现。这是爬虫提取网站内容的一个基本思路。
每个网站都不一样,结构也会不一样,所以一定要针对性的写代码。
以上代码已托管在Github上,地址:
采集网站内容(百度算法已经升级了很多次,特别是刚开始的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-20 08:12
百度的算法经过多次升级,尤其是最初的原创 Spark Project让人们开始知道百度已经开始关注原创的网站工作。这让无数站长感到震惊,因为原创内容对于很多草根站长来说是一项非常艰巨的任务。只有拥有丰富的编辑资源才能解决原创问题。对于草根站长来说,没有那么多资金投入,所以网上有一致的感叹。
然而,百度推出原创计划后,我发现并不是所有的原创网站都能自然而然地生存下去。网站 的排名会非常高,被收录到 网站 中的内容也会增加。相反,一些老网站仍然依靠内容采集,但它们也很舒服。网站的排名还是不错的。这是否意味着百度算法中的原创计划无效?当然,我们也发现那些原创的内容并没有出现在收录,而且大部分出现在新开的网站群里,所以质疑百度的算法似乎还为时过早.
小编认为,新站之所以不包括原站和老站的排名,不会随着百度智能化水平的提升而彻底解决,因为涉及到算法的核心内容。
1、 是 原创 的 文章 好吗?还是成为 采集 更好?
当然,最好是原创,因为百度这么说,谁是裁判?
为什么你创建了很多原创文章 或者没有收录?不参加排名怎么办?
搜索引擎的核心价值是为用户提供他们最需要的结果,搜索引擎已经对网民的需求做了统计,网民几乎不需要的内容,即使你是原创,也可能被忽略搜索引擎。因为它不想在无意义的内容上浪费资源。
网民需要的内容应该是收录越来越快,但正因为如此,即使你是原创,也很难挤进排行榜。
2、既然原创很棒,为什么还要采集?
(1)虽然原创不错,但只要方法得当,采集效果不会比原创差多少,甚至比不掌握方法的人还要好。
(2)能量有限,很难保证原创的大量长期更新。
3、索引和索引是什么关系?
包括被捕获和分析的蜘蛛。经过蜘蛛分析,该指标表明该内容具有一定的价值。
只有录入索引的内容才能显示在搜索结果中并显示给用户。也就是说,只有索引的内容才有机会带来流量。
4、市场上有这么多的采集工具,我应该使用哪个?
每个采集工具都有自己独特的特点,所谓存在就是合理的。请根据自己的需要选择。在开发过程中,考虑了以下几个方面。其他采集工具的使用也可以作为参考。
(1)提供了大量直接分类的关键词。这些关键词是百度统计过的网民需求的词(百度指数),或者是百度的长尾词这些词,来自百度下拉框或相关搜索。
(2)直接通过关键词获取,智能分析网页文本进行抓取,无需自己编写采集规则。
(3) 捕获的文本用标准标签清除,所有段落用标签表示,所有随机代码删除。
(4)根据采集到的内容,图片必须与内容高度相关。这样替换伪原创不仅不影响文章的可读性,还使得文章全文 图片和文字丰富了原文提供的信息。
(5) 文本中的关键词可以自动粗化,插入的关键词也可以自定义。但是没有所谓的“伪原创”功能影响可读性,比如句子排版和段落布局。
(6)关键字和相关词的组合可以直接作为标题,也可以抓取目标页面的标题。
(7)微信文章可以采集。
(8) 没有触发或挂断。
(9)整合百度站长平台,积极推动加速征集。 查看全部
采集网站内容(百度算法已经升级了很多次,特别是刚开始的)
百度的算法经过多次升级,尤其是最初的原创 Spark Project让人们开始知道百度已经开始关注原创的网站工作。这让无数站长感到震惊,因为原创内容对于很多草根站长来说是一项非常艰巨的任务。只有拥有丰富的编辑资源才能解决原创问题。对于草根站长来说,没有那么多资金投入,所以网上有一致的感叹。
然而,百度推出原创计划后,我发现并不是所有的原创网站都能自然而然地生存下去。网站 的排名会非常高,被收录到 网站 中的内容也会增加。相反,一些老网站仍然依靠内容采集,但它们也很舒服。网站的排名还是不错的。这是否意味着百度算法中的原创计划无效?当然,我们也发现那些原创的内容并没有出现在收录,而且大部分出现在新开的网站群里,所以质疑百度的算法似乎还为时过早.
小编认为,新站之所以不包括原站和老站的排名,不会随着百度智能化水平的提升而彻底解决,因为涉及到算法的核心内容。
1、 是 原创 的 文章 好吗?还是成为 采集 更好?
当然,最好是原创,因为百度这么说,谁是裁判?
为什么你创建了很多原创文章 或者没有收录?不参加排名怎么办?
搜索引擎的核心价值是为用户提供他们最需要的结果,搜索引擎已经对网民的需求做了统计,网民几乎不需要的内容,即使你是原创,也可能被忽略搜索引擎。因为它不想在无意义的内容上浪费资源。
网民需要的内容应该是收录越来越快,但正因为如此,即使你是原创,也很难挤进排行榜。
2、既然原创很棒,为什么还要采集?
(1)虽然原创不错,但只要方法得当,采集效果不会比原创差多少,甚至比不掌握方法的人还要好。
(2)能量有限,很难保证原创的大量长期更新。
3、索引和索引是什么关系?
包括被捕获和分析的蜘蛛。经过蜘蛛分析,该指标表明该内容具有一定的价值。
只有录入索引的内容才能显示在搜索结果中并显示给用户。也就是说,只有索引的内容才有机会带来流量。
4、市场上有这么多的采集工具,我应该使用哪个?
每个采集工具都有自己独特的特点,所谓存在就是合理的。请根据自己的需要选择。在开发过程中,考虑了以下几个方面。其他采集工具的使用也可以作为参考。
(1)提供了大量直接分类的关键词。这些关键词是百度统计过的网民需求的词(百度指数),或者是百度的长尾词这些词,来自百度下拉框或相关搜索。
(2)直接通过关键词获取,智能分析网页文本进行抓取,无需自己编写采集规则。
(3) 捕获的文本用标准标签清除,所有段落用标签表示,所有随机代码删除。
(4)根据采集到的内容,图片必须与内容高度相关。这样替换伪原创不仅不影响文章的可读性,还使得文章全文 图片和文字丰富了原文提供的信息。
(5) 文本中的关键词可以自动粗化,插入的关键词也可以自定义。但是没有所谓的“伪原创”功能影响可读性,比如句子排版和段落布局。
(6)关键字和相关词的组合可以直接作为标题,也可以抓取目标页面的标题。
(7)微信文章可以采集。
(8) 没有触发或挂断。
(9)整合百度站长平台,积极推动加速征集。
采集网站内容(做个实用性的百科网站,解答清楚手机应用、微信应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-19 12:01
采集网站内容是必须的其实lowpoly也好,logo也好,对我来说都只是好玩.不存在什么用途.第一次做,一起加油.
logo可以变成那种有意思的海报的话应该会很好玩
放到微信朋友圈里传播。
其实把你需要转换为你网站的名字就好了,可以尝试做成你独一无二的字样的网站,比如我们上线的域名为:“wordpress+”,然后,在我们的网站标题前面加上diywifi,每当提及到“wordpress+”的字样,我们都不忘说“diywifi”。
可以做网站二维码引流。提高自己的网站曝光度。
做个实用性的百科网站,解答清楚手机应用、微信应用、某个陌生网站等基本的常识。
用处大大的有,因为是公司的,最后贴上法人代表电话,这样以后别人有问题都可以找到法人代表,自己省心省力,电话号码和qq还可以以后卖给朋友。
不知道做什么其实用logo完全可以替代
如果你只是想要个名字,做一个logo也就差不多了,只不过是名字泛滥,人们是记不住自己的,不知道自己什么时候看到了。如果是要做网站,网站上的文字就可以换成公司的网站名称,有加分。 查看全部
采集网站内容(做个实用性的百科网站,解答清楚手机应用、微信应用)
采集网站内容是必须的其实lowpoly也好,logo也好,对我来说都只是好玩.不存在什么用途.第一次做,一起加油.
logo可以变成那种有意思的海报的话应该会很好玩
放到微信朋友圈里传播。
其实把你需要转换为你网站的名字就好了,可以尝试做成你独一无二的字样的网站,比如我们上线的域名为:“wordpress+”,然后,在我们的网站标题前面加上diywifi,每当提及到“wordpress+”的字样,我们都不忘说“diywifi”。
可以做网站二维码引流。提高自己的网站曝光度。
做个实用性的百科网站,解答清楚手机应用、微信应用、某个陌生网站等基本的常识。
用处大大的有,因为是公司的,最后贴上法人代表电话,这样以后别人有问题都可以找到法人代表,自己省心省力,电话号码和qq还可以以后卖给朋友。
不知道做什么其实用logo完全可以替代
如果你只是想要个名字,做一个logo也就差不多了,只不过是名字泛滥,人们是记不住自己的,不知道自己什么时候看到了。如果是要做网站,网站上的文字就可以换成公司的网站名称,有加分。
采集网站内容(如何使用好采集,让搜索引擎一种耳目一新的感觉呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-17 22:08
相信很多朋友都用过采集网站项目,有的是手动复制的,有的是使用采集软件和插件来快速获取内容的。即使搜索引擎引入了各种算法来处理采集junk网站,也有人做得更好。当然,这些肯定没有我们想象的那么简单。不仅仅是我们需要搭建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都做得很好. 网站 已经卖了几万的出价,很是羡慕。采集,有人喜欢,有人避而远之!说爱它,因为它真的可以帮助我们节省更多的时间和精力,让我们有更多的时间去推广它。网站; 说要避免,因为搜索引擎不喜欢采集和网站的数据,有些站长提到采集不会摇头。那么,如何用好采集,既节省我们的时间又能给搜索引擎耳目一新的感觉呢?1、采集器最新的选择cms(PHPcms、Empire、织梦、心云等)都自带采集功能。如果用得好,也是省钱的好方法;但是这些自带采集的功能,个人觉得鸡肋,虽然能用,但是功能不强大。如果资金允许,建议购买专业的采集器。2、通过采集器的作用,有句老话,磨刀不误砍柴,只有当你了解了采集器的所有功能并能熟练使用它时,你才可以谈论它采集。3、源码的选择网站没什么好说的,想挂在树上,随心所欲。
. . 最好选择多个网站,每个网站的内容为原创。记住,不要收录每个网站 采集 的内容过来,最好是每个采集 部分的数据。4、Data采集(1), 采集 规则编译 根据预先采集的采集对象,分别编译每个网站采集@ >规则,记住采集数据应该包括这几项:标题、出处、作者、内容,其他如关键词、摘要、时间等,不要使用。(2), Nong 清除采集的原理和过程 所有采集器基本上按照以下步骤工作: a. 按照采集采集数据的规则,将数据保存在一个临时数据库,功能更强大< @采集器 会将相应的附件(如图片、文件、软件等)保存在预先指定的文件中。这些数据和文件有的保存在本地计算机中,有的保存在服务器中;湾 按照指定的接口发布已经采集的数据,即将临时数据库中的数据发布到网站的数据库中;(3), Editing data 当数据采集到达临时数据库时,很多人因为觉得麻烦,直接进数据库发布数据。这种做法相当于复制粘贴,也就是没有意义。如果你这样做,搜索引擎可能不会惩罚你。性能非常小。因此,当数据采集在临时数据库中时,无论多么麻烦,您都必须编辑数据。具体要做到以下几点: a、修改标题(必须做) b、添加关键词(手动可用,但有些采集器可以自动获取) c. 写一个描述或总结,最好手动 d、修改文章5、头部和底部的信息
最后,有的朋友可能会问哪个采集器合适,因为时间关系,也因为不想被人误认为我是马甲。我不会在这里谈论它。如果你采集做过,你心中应该有一个最喜欢的。一会儿给大家一个分析表,对目前主流的采集器做一个综合比较,方便大家轻松辨别选择。其实我们看到的网站采集项目很简单吧?如果单纯的模仿、抄袭,甚至是软件采集,你是不是发现效果并不明显,甚至根本不会是收录。问题是什么?前段时间还找了几个专攻采集网站的朋友,聊的不错。事实上,我们表面上似乎做得很好,而且平时也没什么可做的,就是吹牛而已。聊天,但实际上,人们也付出了很多。在这个文章中,我将简要介绍一下采集网站项目的正确流程。我可以告诉你的是,它实际上没有那么简单,如果它那么简单。我们都跟风吗?我们的效率和建站速度肯定会超过大多数用户,为什么不去做呢?这说明还是有一定的门槛的。如果是优质内容,我绝对不会去采集内容。这里的优质内容,不允许我们自己写文章的每一篇文章原创。就是我们在选择内容的时候要垂直,如果我们在选择内容的时候选择流量词。比如我以前有朋友采集部落网站 技术含量。事实上,技术内容的用户基数很小,词库中根本无法生成词,所以流量基本很小。
如果我们选择影视、游戏等内容,一旦出现收录这个词,就很容易带来流量。因为以后我们做网站无论是卖还是贴自己的广告,都需要获得流量,有流量的话,卖的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有字号的内容,基本上是很难卖的。而我们在做内容的时候,不管是你原创,采集,抄袭还是别的什么,都必须进行二次加工。直接复制是很难成功的。毕竟你的网站质量肯定不如原版内容。任何 网站 做完之后自然不会带来重量和流量,还需要推广。根据网友反馈,即使是采集网站,他们也开始更新内容和推广,和普通的网站一样,只有达到一定的权重值和效果将大量更新和推广。采集。如果开始很多采集,可能会直接被罚网站还没开始。同时,在我们后续的网站操作中,有网友告诉他们,他们每个月要花几十万元购买资源,比如连接和软文来增加软文的权重。 @网站。我们看到了吗,或者我们为什么不做?其实不是这样的。我们很多人都认为采集网站很容易做到。是的,这很容易做到,但需要一定的时间才能有效。比如前几天我们看到几个网站效果很好,也是采集或者集成内容。然而,它们需要半年到一年的时间才能生效。
所以我们在准备做采集网站项目的时候,也需要考虑时间段,不可能几个月就见效。就算能用几个月,当你卖网站的时候,买家会分析你的网站是否被骗了,如果是,你的价格不会高或者对方是不需要的。当然,如果我们通过上述一系列流程来操作,几个月后是不会见效的。我们不应该有任何猜测。我们网站的朋友应该知道,如果我们注册一个新的域名,至少要等3到6个月才能有一定的权重。你一开始更新的任何内容,除非你的内容绝对有价值,否则需要这么长时间才能被搜索引擎认可。这就是所谓的累积重量,甚至一些 网站 需要几年时间才能获得一定的体重。在这里我们可以看到,做采集网站的站长很多,而且都是购买优质的加权域名。有的直接买别人的网站,有的买旧域名,预注册一些已经过期的域名。我写了几篇关于抢注旧域名的文章,专门针对这些朋友的需求。事实上,他们想购买一些旧域名,以减少域名评估期。最近几个月,我们会发现很多网友都在运营采集网站,流量上升的非常快。甚至还有一些个人博客和个人网站,前一年都没有更新。通过 采集 获得更大的流量。包括我们在一些网络营销培训团队中也有类似的培训项目。其实采集一直都有,只是最近几个月百度好像出现了算法问题,赋予了采集网站更大的权重效果。
最重要的是域名。如果是老域名,效果会更好。前段时间很多网友都在讨论买旧域名。当时也有两篇关于自己买旧域名的文章文章。如果有网友的需求,我们也可以参考。过去我们在哪里寻找旧域名购买?大部分网友可能从国内一些域名交易平台、论坛、网友看到,相对域名价格比较高,平均几百元。这些老域名,大多也是通过大多数网友不知道的域名渠道抢注获得,然后赚取差价。因此,如果我们需要寻找旧域名,我们可以直接从旧域名等平台购买,包括我们的其他域名抢注平台。只是我之前用过这两个平台,成功率很高,有的甚至可以直接购买。购买旧域名需要注意哪些问题?1、检查域名是否被屏蔽 由于不确定性,我们可以在购买该域名之前,使用PING测试工具检查这些域名是否被DNS屏蔽或污染。如果我们看到一个被阻止或被污染的域名,如果你重新注册它就没有用了。包括我们以后新注册的域名也需要检查。很有可能我们购买的域名之前已经被用户使用过,因为被屏蔽而被丢弃了。2、查看域名的详细信息。查找旧域名的目的是什么?有的是因为要让用户看到网站开始的更早,有的是外贸网站需要更早的时间,包括一些有一定权重,比new更有效的域名域名。
我们可以先看看它是否满足我们的需求再购买。3、域名交易的安全性对于我们在平台上购买的旧域名,付款后不会立即到账,需要一定的时间才能到账到我们的账户使用。如果原持有人以高价赎回,我们支付的费用也将退还。如果我们通过其他中介平台交易旧域名,一定要注意不要私下交易,即使和我们交谈的网友不觉得是骗子,也不能信任。每个用户找旧域名的渠道可能不同,目的也不同。不能说老域名一定有预期的效果,我们要根据实际需要来选择。我要说的最后一件事是,当我们< @采集网站,我们也需要注意版权。部分网站声明内容版权,不能去采集或复制,目前我们的版权意识也在加强,很多站长都收到了律师的来信。这篇文章的链接: 查看全部
采集网站内容(如何使用好采集,让搜索引擎一种耳目一新的感觉呢?)
相信很多朋友都用过采集网站项目,有的是手动复制的,有的是使用采集软件和插件来快速获取内容的。即使搜索引擎引入了各种算法来处理采集junk网站,也有人做得更好。当然,这些肯定没有我们想象的那么简单。不仅仅是我们需要搭建网站,然后手动复制,软件采集,或者伪原创等等,包括我们看到群里很多网友都做得很好. 网站 已经卖了几万的出价,很是羡慕。采集,有人喜欢,有人避而远之!说爱它,因为它真的可以帮助我们节省更多的时间和精力,让我们有更多的时间去推广它。网站; 说要避免,因为搜索引擎不喜欢采集和网站的数据,有些站长提到采集不会摇头。那么,如何用好采集,既节省我们的时间又能给搜索引擎耳目一新的感觉呢?1、采集器最新的选择cms(PHPcms、Empire、织梦、心云等)都自带采集功能。如果用得好,也是省钱的好方法;但是这些自带采集的功能,个人觉得鸡肋,虽然能用,但是功能不强大。如果资金允许,建议购买专业的采集器。2、通过采集器的作用,有句老话,磨刀不误砍柴,只有当你了解了采集器的所有功能并能熟练使用它时,你才可以谈论它采集。3、源码的选择网站没什么好说的,想挂在树上,随心所欲。
. . 最好选择多个网站,每个网站的内容为原创。记住,不要收录每个网站 采集 的内容过来,最好是每个采集 部分的数据。4、Data采集(1), 采集 规则编译 根据预先采集的采集对象,分别编译每个网站采集@ >规则,记住采集数据应该包括这几项:标题、出处、作者、内容,其他如关键词、摘要、时间等,不要使用。(2), Nong 清除采集的原理和过程 所有采集器基本上按照以下步骤工作: a. 按照采集采集数据的规则,将数据保存在一个临时数据库,功能更强大< @采集器 会将相应的附件(如图片、文件、软件等)保存在预先指定的文件中。这些数据和文件有的保存在本地计算机中,有的保存在服务器中;湾 按照指定的接口发布已经采集的数据,即将临时数据库中的数据发布到网站的数据库中;(3), Editing data 当数据采集到达临时数据库时,很多人因为觉得麻烦,直接进数据库发布数据。这种做法相当于复制粘贴,也就是没有意义。如果你这样做,搜索引擎可能不会惩罚你。性能非常小。因此,当数据采集在临时数据库中时,无论多么麻烦,您都必须编辑数据。具体要做到以下几点: a、修改标题(必须做) b、添加关键词(手动可用,但有些采集器可以自动获取) c. 写一个描述或总结,最好手动 d、修改文章5、头部和底部的信息
最后,有的朋友可能会问哪个采集器合适,因为时间关系,也因为不想被人误认为我是马甲。我不会在这里谈论它。如果你采集做过,你心中应该有一个最喜欢的。一会儿给大家一个分析表,对目前主流的采集器做一个综合比较,方便大家轻松辨别选择。其实我们看到的网站采集项目很简单吧?如果单纯的模仿、抄袭,甚至是软件采集,你是不是发现效果并不明显,甚至根本不会是收录。问题是什么?前段时间还找了几个专攻采集网站的朋友,聊的不错。事实上,我们表面上似乎做得很好,而且平时也没什么可做的,就是吹牛而已。聊天,但实际上,人们也付出了很多。在这个文章中,我将简要介绍一下采集网站项目的正确流程。我可以告诉你的是,它实际上没有那么简单,如果它那么简单。我们都跟风吗?我们的效率和建站速度肯定会超过大多数用户,为什么不去做呢?这说明还是有一定的门槛的。如果是优质内容,我绝对不会去采集内容。这里的优质内容,不允许我们自己写文章的每一篇文章原创。就是我们在选择内容的时候要垂直,如果我们在选择内容的时候选择流量词。比如我以前有朋友采集部落网站 技术含量。事实上,技术内容的用户基数很小,词库中根本无法生成词,所以流量基本很小。
如果我们选择影视、游戏等内容,一旦出现收录这个词,就很容易带来流量。因为以后我们做网站无论是卖还是贴自己的广告,都需要获得流量,有流量的话,卖的单价比较高。当然,买家也需要在站长工具中查看你的网站数据信息。如果选择没有字号的内容,基本上是很难卖的。而我们在做内容的时候,不管是你原创,采集,抄袭还是别的什么,都必须进行二次加工。直接复制是很难成功的。毕竟你的网站质量肯定不如原版内容。任何 网站 做完之后自然不会带来重量和流量,还需要推广。根据网友反馈,即使是采集网站,他们也开始更新内容和推广,和普通的网站一样,只有达到一定的权重值和效果将大量更新和推广。采集。如果开始很多采集,可能会直接被罚网站还没开始。同时,在我们后续的网站操作中,有网友告诉他们,他们每个月要花几十万元购买资源,比如连接和软文来增加软文的权重。 @网站。我们看到了吗,或者我们为什么不做?其实不是这样的。我们很多人都认为采集网站很容易做到。是的,这很容易做到,但需要一定的时间才能有效。比如前几天我们看到几个网站效果很好,也是采集或者集成内容。然而,它们需要半年到一年的时间才能生效。
所以我们在准备做采集网站项目的时候,也需要考虑时间段,不可能几个月就见效。就算能用几个月,当你卖网站的时候,买家会分析你的网站是否被骗了,如果是,你的价格不会高或者对方是不需要的。当然,如果我们通过上述一系列流程来操作,几个月后是不会见效的。我们不应该有任何猜测。我们网站的朋友应该知道,如果我们注册一个新的域名,至少要等3到6个月才能有一定的权重。你一开始更新的任何内容,除非你的内容绝对有价值,否则需要这么长时间才能被搜索引擎认可。这就是所谓的累积重量,甚至一些 网站 需要几年时间才能获得一定的体重。在这里我们可以看到,做采集网站的站长很多,而且都是购买优质的加权域名。有的直接买别人的网站,有的买旧域名,预注册一些已经过期的域名。我写了几篇关于抢注旧域名的文章,专门针对这些朋友的需求。事实上,他们想购买一些旧域名,以减少域名评估期。最近几个月,我们会发现很多网友都在运营采集网站,流量上升的非常快。甚至还有一些个人博客和个人网站,前一年都没有更新。通过 采集 获得更大的流量。包括我们在一些网络营销培训团队中也有类似的培训项目。其实采集一直都有,只是最近几个月百度好像出现了算法问题,赋予了采集网站更大的权重效果。
最重要的是域名。如果是老域名,效果会更好。前段时间很多网友都在讨论买旧域名。当时也有两篇关于自己买旧域名的文章文章。如果有网友的需求,我们也可以参考。过去我们在哪里寻找旧域名购买?大部分网友可能从国内一些域名交易平台、论坛、网友看到,相对域名价格比较高,平均几百元。这些老域名,大多也是通过大多数网友不知道的域名渠道抢注获得,然后赚取差价。因此,如果我们需要寻找旧域名,我们可以直接从旧域名等平台购买,包括我们的其他域名抢注平台。只是我之前用过这两个平台,成功率很高,有的甚至可以直接购买。购买旧域名需要注意哪些问题?1、检查域名是否被屏蔽 由于不确定性,我们可以在购买该域名之前,使用PING测试工具检查这些域名是否被DNS屏蔽或污染。如果我们看到一个被阻止或被污染的域名,如果你重新注册它就没有用了。包括我们以后新注册的域名也需要检查。很有可能我们购买的域名之前已经被用户使用过,因为被屏蔽而被丢弃了。2、查看域名的详细信息。查找旧域名的目的是什么?有的是因为要让用户看到网站开始的更早,有的是外贸网站需要更早的时间,包括一些有一定权重,比new更有效的域名域名。
我们可以先看看它是否满足我们的需求再购买。3、域名交易的安全性对于我们在平台上购买的旧域名,付款后不会立即到账,需要一定的时间才能到账到我们的账户使用。如果原持有人以高价赎回,我们支付的费用也将退还。如果我们通过其他中介平台交易旧域名,一定要注意不要私下交易,即使和我们交谈的网友不觉得是骗子,也不能信任。每个用户找旧域名的渠道可能不同,目的也不同。不能说老域名一定有预期的效果,我们要根据实际需要来选择。我要说的最后一件事是,当我们< @采集网站,我们也需要注意版权。部分网站声明内容版权,不能去采集或复制,目前我们的版权意识也在加强,很多站长都收到了律师的来信。这篇文章的链接:
采集网站内容(“内容为王,外链为皇”是有什么样的弊端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-16 11:19
“内容为王,外链为王”这句话可以成为SEO的历史。无论是新手站长还是老手,优化这两方面已经成为一种习惯。不过博主看到有站长说:网站优化不需要原创的内容,现在搜索引擎还不是很成熟,无法判断网站是否是真的原创内容。他说的是对的。搜索引擎可能无法判断。一些采集站点也会被爬取收录,但是作为普通的网站,采集采集的内容对于网站来说还不够好,采集的内容有什么弊端。
第一:内容不可控。许多站长为了节省时间,使用了采集的工具。采集的工具也很不完善。采集 的内容不智能。很多时候采集来文章别人的内容是无法从内容中删除的,这样你就可以在无意间帮别人宣传,别人写的文章一定会满足你的网站 的标准。在网站同行业采集之间,很多时候会帮别人宣传,不值得。
第二:采集的内容容易被误解。这种情况对于新闻门户网站网站来说非常普遍。新闻网站每天更新大量新内容。一些网站找不到好的消息来源,所以他们会考虑。采集 其他人的内容,但其他人的新闻内容未经您证实。你不确定其他人的消息是否属实。很多时候会出现报错新闻的事件。本来你不知道这个消息,你采集来了,结果是假新闻,你的网站也会被牵连。是不是因为你失去了你的妻子而崩溃了。
第三:不尊重他人的版权。很多时候站长在采集的时候,会把别人的链接和宣传信息去掉。如果别人的网站处于不稳定状态,发送的原创的内容不正常收录,而你采集已经过去,被收录,而此时面临的版权问题,也会让站长头疼。博主的微博营销站经常是采集,看到这样的采集会很生气,正常人会找到你,要求你删除文章,否则版权所有。即使不尊重互联网的版权,当别人的辛勤工作找到您时,您也必须尊重他人的版权。这不是又浪费时间了吗?
第四:容易被K站。内容为王,优质内容可以提供网站权重。站长不得不承认这个观点,网站有高质量的内容,权重增加会更快。别说采集网站的权重,对于一个普通的网站来说,采集其他人的内容的频率,往往都是采集被蜘蛛爬取的。蜘蛛喜欢新鲜并放入数据库中。当相同的内容太多时,它会想到屏蔽一些相同的内容,同时网站采集太多的内容,蜘蛛会认为这样的网站是作弊,尤其是它是一个新网站。为了快速增加网站的内容,不要去采集的内容。这种方法是不可取的。
如果要增加网站的权重,如果不想从原创的文章开始,光靠外链的开发是不够的。外链的内容和建设缺一不可。领导要从原创的内容下手。虽然原创的内容稍微难一些,但是采集的内容并不理想。最糟糕的计划是学习如何写好伪原创。 查看全部
采集网站内容(“内容为王,外链为皇”是有什么样的弊端)
“内容为王,外链为王”这句话可以成为SEO的历史。无论是新手站长还是老手,优化这两方面已经成为一种习惯。不过博主看到有站长说:网站优化不需要原创的内容,现在搜索引擎还不是很成熟,无法判断网站是否是真的原创内容。他说的是对的。搜索引擎可能无法判断。一些采集站点也会被爬取收录,但是作为普通的网站,采集采集的内容对于网站来说还不够好,采集的内容有什么弊端。
第一:内容不可控。许多站长为了节省时间,使用了采集的工具。采集的工具也很不完善。采集 的内容不智能。很多时候采集来文章别人的内容是无法从内容中删除的,这样你就可以在无意间帮别人宣传,别人写的文章一定会满足你的网站 的标准。在网站同行业采集之间,很多时候会帮别人宣传,不值得。
第二:采集的内容容易被误解。这种情况对于新闻门户网站网站来说非常普遍。新闻网站每天更新大量新内容。一些网站找不到好的消息来源,所以他们会考虑。采集 其他人的内容,但其他人的新闻内容未经您证实。你不确定其他人的消息是否属实。很多时候会出现报错新闻的事件。本来你不知道这个消息,你采集来了,结果是假新闻,你的网站也会被牵连。是不是因为你失去了你的妻子而崩溃了。
第三:不尊重他人的版权。很多时候站长在采集的时候,会把别人的链接和宣传信息去掉。如果别人的网站处于不稳定状态,发送的原创的内容不正常收录,而你采集已经过去,被收录,而此时面临的版权问题,也会让站长头疼。博主的微博营销站经常是采集,看到这样的采集会很生气,正常人会找到你,要求你删除文章,否则版权所有。即使不尊重互联网的版权,当别人的辛勤工作找到您时,您也必须尊重他人的版权。这不是又浪费时间了吗?
第四:容易被K站。内容为王,优质内容可以提供网站权重。站长不得不承认这个观点,网站有高质量的内容,权重增加会更快。别说采集网站的权重,对于一个普通的网站来说,采集其他人的内容的频率,往往都是采集被蜘蛛爬取的。蜘蛛喜欢新鲜并放入数据库中。当相同的内容太多时,它会想到屏蔽一些相同的内容,同时网站采集太多的内容,蜘蛛会认为这样的网站是作弊,尤其是它是一个新网站。为了快速增加网站的内容,不要去采集的内容。这种方法是不可取的。
如果要增加网站的权重,如果不想从原创的文章开始,光靠外链的开发是不够的。外链的内容和建设缺一不可。领导要从原创的内容下手。虽然原创的内容稍微难一些,但是采集的内容并不理想。最糟糕的计划是学习如何写好伪原创。
采集网站内容(基于网络爬虫的网站信息采集技术整合方案的设计与实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-14 22:40
[摘要] 随着互联网的飞速发展,它已逐渐融入人们日常生活的方方面面。其中,Web是人们在互联网上相互交流和获取外界信息的重要方式。网络作为一种有价值的信息源,凭借其直观、便捷的使用方式和丰富的内容表达能力,可以为用户提供多种形式的信息,如文本、音频、视频等。随着时间的推移,互联网的信息规模和用户群体规模也在快速增长。互联网用户的需求日趋多样化。如何快速为用户提供他们感兴趣的信息是当前的一大难题。如今,自媒体已经逐渐开始在互联网上兴起,并且它的规模越来越大。其中不乏各界的杰出代表,因此也开始受到越来越多的关注。因此,本文拟通过一定的技术手段,在百度百家的自媒体平台上完善其网站的采集内容。然后重新整理采集的文章内容,方便这些内容的二次使用。围绕这一目标,本文提出了基于网络爬虫的网站信息采集技术集成方案的设计与实现。本文提出的网站信息采集技术集成方案包括三个部分:信息采集、信息抽取和信息检索。资料采集 基于Heritrix爬虫的扩展(结合HtmlUnit),负责完成目标站点的网页采集;信息抽取基于Jsoup和DOM技术,负责完成从网页中抽取文章信息存储在数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。 查看全部
采集网站内容(基于网络爬虫的网站信息采集技术整合方案的设计与实现)
[摘要] 随着互联网的飞速发展,它已逐渐融入人们日常生活的方方面面。其中,Web是人们在互联网上相互交流和获取外界信息的重要方式。网络作为一种有价值的信息源,凭借其直观、便捷的使用方式和丰富的内容表达能力,可以为用户提供多种形式的信息,如文本、音频、视频等。随着时间的推移,互联网的信息规模和用户群体规模也在快速增长。互联网用户的需求日趋多样化。如何快速为用户提供他们感兴趣的信息是当前的一大难题。如今,自媒体已经逐渐开始在互联网上兴起,并且它的规模越来越大。其中不乏各界的杰出代表,因此也开始受到越来越多的关注。因此,本文拟通过一定的技术手段,在百度百家的自媒体平台上完善其网站的采集内容。然后重新整理采集的文章内容,方便这些内容的二次使用。围绕这一目标,本文提出了基于网络爬虫的网站信息采集技术集成方案的设计与实现。本文提出的网站信息采集技术集成方案包括三个部分:信息采集、信息抽取和信息检索。资料采集 基于Heritrix爬虫的扩展(结合HtmlUnit),负责完成目标站点的网页采集;信息抽取基于Jsoup和DOM技术,负责完成从网页中抽取文章信息存储在数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。并负责完成从网页中提取文章信息存储到数据库中,将非结构化信息转化为结构化信息;信息检索基于Lucene索引工具和SSH2架构实现,负责呈现文章信息的采集,方便用户浏览。
采集网站内容(本文介绍如何采集网站上多关键词的流程图模式?介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-12 23:04
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何在更多关键词数据上采集网站。
第一步:新建一个采集任务
1、复制官网网址(搜索结果页网址为必填项,不是首页网址)
单击此处了解如何正确输入 URL。
2、新流程图模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
在流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入文字为采集。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择单个文本的批量输入。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”这些关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置好循环后,我们设置要提取的字段数据,在网页上点击该字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
那么我们就可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果我们需要采集详情页的数据,可以使用深入采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集任务
1、开始采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果, 查看全部
采集网站内容(本文介绍如何采集网站上多关键词的流程图模式?介绍
)
本文介绍如何使用优采云采集器的流程图模式,并介绍如何在更多关键词数据上采集网站。
第一步:新建一个采集任务
1、复制官网网址(搜索结果页网址为必填项,不是首页网址)
单击此处了解如何正确输入 URL。
2、新流程图模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第二步:配置采集规则
1、设置多个关键字循环任务
在流程图模式下输入创建新任务的URL后,我们点击搜索框,然后在左上角出现的操作提示框中输入文字为采集。
单击此处了解有关输入文本组件的更多信息。
由于需要输入多个关键词数据,我们选择点击操作框上的批量输入文本按钮。
然后选择单个文本的批量输入。
然后在弹出的文本列表中输入我们需要设置的文本,这里我们输入“设置”、“采集”、“数据”这些关键词。
点击“确定”按钮后,软件会自动生成一个圆形的关键词列表。
然后我们点击页面上的搜索按钮,在操作框中选择“点击该元素一次”按钮,跳转到搜索结果页面。
2、设置提取字段数据
输入多个关键字并设置好循环后,我们设置要提取的字段数据,在网页上点击该字段,在左上角的操作提示框中选择提取所有元素。然后软件会自动识别分页,用户根据软件提示设置分页。
那么我们就可以在此基础上设置采集字段,用户可以根据自己的需要进行设置。
更多详情,请参考以下教程:
如何配置采集字段
3、深入设置采集
如果我们需要采集详情页的数据,可以使用深入采集函数。
更多详情,请参考以下教程:
如何实现深入采集
4、设置详情页数据
详情页的采集与单页类型的采集相同。我们在页面上点击需要采集的数据,然后点击操作提示框中的“从此元素中提取数据”按钮,数据设置可以参考列表页上的设置。
更多详情,请参考以下教程:
如何采集单页类型网页
5、完整的组件图
第三步:设置并启动采集任务
1、开始采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,本次操作不使用以上功能,直接点击启动按钮启动采集。
单击此处了解有关预定开始时间的更多信息。
单击此处了解有关自动导出的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费;专业版及以上用户可以使用定时启动功能;旗舰版用户可以使用自动导出功能和加速引擎功能。
2、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果,
采集网站内容(百度是如何在互联网上复制这么多重复的内容的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-12 10:22
重复内容一直是SEO行业关注的问题。重复的内容是否会被搜索引擎惩罚是一个经常讨论的话题。百度最近大大降低了内容集网站的使用权,但是很多朋友还是发现自己的文章被转载,排名高于原来的文章。那么百度是如何在网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先我们需要对重复的内容和集合网站有一个清晰的认识,否则会有一定的差异。目前,百度并没有明显的压制重复内容的迹象。百度不会对重复内容进行处罚也是可以理解的。
尽管很多SEO专家在进行站点诊断时会讨论外部站点的重复内容量,但他们通常会使用Webmaster工具来计算是否已附加原创链接。
这里我们一直在努力解决这个问题:文章被转发,排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。我们可以看到这一点。我们希望熊掌最近推出。号,授权站长,可以在原创内容下提交原创保护。尤其是发布文章所需的时间。准确到第二:
这是一个非常明确的信号。有了原创的保护站点,一旦提交链接被审核通过,标签原创就会出现在移动搜索展示中,排名自然会高于转发文章。
2、为什么采集的内容排名这么高?
本次采集的内容应该分为两部分,主要有以下两种情况:
所有车站采集
权威网站转发,百度将在熊掌账号上线后得到显着提升。那么,为什么百度会为这部分网站转发排名更高的内容呢?这与网站的权限和原创的比例有一定关系。同时,为了更好的在搜索结果页面展示优质的文章,从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,也会建立一个友好的外部链接到新的网站。
整个网站采集完全不一样,很多内容采集,虽然网站会保持不断更新的频率,但是我也发现采集不错,但是采集 内容几乎没有排名,这也是目前外链新闻能够存活的一个小理由!
百度推出飓风算法后,显然是为了打击要求苛刻的采集网站,看来以后连收录都会成为泡沫。
3、 内部抄袭会被处罚吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多优化标题,以提升排名的形式积累关键词,避免标题重复太多。
早些时候,一些SEO专家指出:
目前不建议使用同义词或伪装的关键词作为标题创建多个页面来覆盖关键词,尽量简化为一个文章,例如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但从它们的内容来看,答案几乎是一样的。百度希望你把这两个问题放在一起,比如:植物的营养价值,它的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时候很难判断,很多站长都在关键点。 查看全部
采集网站内容(百度是如何在互联网上复制这么多重复的内容的呢?)
重复内容一直是SEO行业关注的问题。重复的内容是否会被搜索引擎惩罚是一个经常讨论的话题。百度最近大大降低了内容集网站的使用权,但是很多朋友还是发现自己的文章被转载,排名高于原来的文章。那么百度是如何在网上复制这么多重复内容的呢?
1、百度最终会惩罚抄袭内容吗?
首先我们需要对重复的内容和集合网站有一个清晰的认识,否则会有一定的差异。目前,百度并没有明显的压制重复内容的迹象。百度不会对重复内容进行处罚也是可以理解的。
尽管很多SEO专家在进行站点诊断时会讨论外部站点的重复内容量,但他们通常会使用Webmaster工具来计算是否已附加原创链接。
这里我们一直在努力解决这个问题:文章被转发,排名比自己高。百度一直在努力解决这个问题,但仍处于测试阶段。我们可以看到这一点。我们希望熊掌最近推出。号,授权站长,可以在原创内容下提交原创保护。尤其是发布文章所需的时间。准确到第二:
这是一个非常明确的信号。有了原创的保护站点,一旦提交链接被审核通过,标签原创就会出现在移动搜索展示中,排名自然会高于转发文章。
2、为什么采集的内容排名这么高?
本次采集的内容应该分为两部分,主要有以下两种情况:
所有车站采集
权威网站转发,百度将在熊掌账号上线后得到显着提升。那么,为什么百度会为这部分网站转发排名更高的内容呢?这与网站的权限和原创的比例有一定关系。同时,为了更好的在搜索结果页面展示优质的文章,从信息传播和权限转换的角度来理解网站。发送时会附上版权链接,也会建立一个友好的外部链接到新的网站。
整个网站采集完全不一样,很多内容采集,虽然网站会保持不断更新的频率,但是我也发现采集不错,但是采集 内容几乎没有排名,这也是目前外链新闻能够存活的一个小理由!
百度推出飓风算法后,显然是为了打击要求苛刻的采集网站,看来以后连收录都会成为泡沫。
3、 内部抄袭会被处罚吗?
对于这个问题,百度的表述比较模糊。在最近的清风算法中,百度强调不要过多优化标题,以提升排名的形式积累关键词,避免标题重复太多。
早些时候,一些SEO专家指出:
目前不建议使用同义词或伪装的关键词作为标题创建多个页面来覆盖关键词,尽量简化为一个文章,例如:
植物的功效
植物的价值
这两个标题,你会在很多食物上看到不同的页面网站,但从它们的内容来看,答案几乎是一样的。百度希望你把这两个问题放在一起,比如:植物的营养价值,它的功效和作用?SEO是一种策略,尤其是面对重复的内容和内容采集,有时候很难判断,很多站长都在关键点。
采集网站内容(优采云采集器如何采集多级网页的操作注意事项?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-09 04:05
前面我们用优采云采集器学习的教程主要是针对单级网页采集,而实际网络中的大部分网页都是多级网页(比如内容页), 采集多级网页时,使用优采云采集器的操作会有所不同,下面介绍一下优采云采集器如何采集多级网页详细介绍。.
优采云采集器如何采集多级网页?
1、多级网页采集步骤与单级网页类似:【新建任务】—输入网址—采集配置。
2、如何判断网页是否为多级网页?多级网页自动生成的字段必须收录一个或多个用于提取链接的字段(即提取属性为Href的字段)。
3、 点击链接栏的标题,选中该栏后,中间菜单栏右侧会出现【深度链接页面采集】选项。
4、 点击【深度链接页面采集】,系统自动新建配置标签,并自动打开选中字段的URL。
5、此时采集模式也会默认为【单机模式】,如果不是,点击调整。
注意:
1) 列表模式用于从网页列表中提取数据,预览中可以看到多条数据
2)单项输入模式适用于采集内容详情页中的各种信息,如文章标题、时间、正文等。
6、 点击【添加字段】,首先手动提取网页中的信息发布时间,由于标题在前面的列表采集中已经提取过了,这里就不再赘述了。
7、 再次点击【添加字段】,手动从网页中提取信息正文。
8、 这里要注意将字段的value属性调整为InnerHtml,保持原来的格式。
这是优采云采集器如何采集多级网页操作的介绍。有兴趣的朋友可以多看几遍以上教程,相信很快就能掌握!
(免责声明:如果文章内容涉及作品内容、版权等问题,请及时联系我们,我们会尽快删除内容。文章内容仅供参考仅供参考) 查看全部
采集网站内容(优采云采集器如何采集多级网页的操作注意事项?)
前面我们用优采云采集器学习的教程主要是针对单级网页采集,而实际网络中的大部分网页都是多级网页(比如内容页), 采集多级网页时,使用优采云采集器的操作会有所不同,下面介绍一下优采云采集器如何采集多级网页详细介绍。.
优采云采集器如何采集多级网页?
1、多级网页采集步骤与单级网页类似:【新建任务】—输入网址—采集配置。
2、如何判断网页是否为多级网页?多级网页自动生成的字段必须收录一个或多个用于提取链接的字段(即提取属性为Href的字段)。
3、 点击链接栏的标题,选中该栏后,中间菜单栏右侧会出现【深度链接页面采集】选项。
4、 点击【深度链接页面采集】,系统自动新建配置标签,并自动打开选中字段的URL。
5、此时采集模式也会默认为【单机模式】,如果不是,点击调整。
注意:
1) 列表模式用于从网页列表中提取数据,预览中可以看到多条数据
2)单项输入模式适用于采集内容详情页中的各种信息,如文章标题、时间、正文等。
6、 点击【添加字段】,首先手动提取网页中的信息发布时间,由于标题在前面的列表采集中已经提取过了,这里就不再赘述了。
7、 再次点击【添加字段】,手动从网页中提取信息正文。
8、 这里要注意将字段的value属性调整为InnerHtml,保持原来的格式。
这是优采云采集器如何采集多级网页操作的介绍。有兴趣的朋友可以多看几遍以上教程,相信很快就能掌握!
(免责声明:如果文章内容涉及作品内容、版权等问题,请及时联系我们,我们会尽快删除内容。文章内容仅供参考仅供参考)
采集网站内容(先来和百度的机器人采集器会怎么做?打游击战呗!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-09 03:11
很多反采集的方法在实现的时候需要考虑是否会影响搜索引擎对网站的爬取,那么我们来分析一下一般的采集器和搜索引擎爬虫采集@ >. 不同的。
相似之处:两者都需要直接抓取网页源代码才能有效工作,b. 两者都会在单位时间内多次抓取大量访问过的网站内容;C。宏观上看,两个IP都会变;d. 他们俩都急于破解你的一些网页加密(验证),比如网页内容是通过js文件加密的,比如需要输入验证码浏览内容,比如需要登录以访问内容等。
区别:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。但是采集器一般是利用html标签的特性来抓取需要的数据。制定采集规则时,需要填写目标内容的开始和结束标志,以便定位到需要的内容;或者为特定的网页创建特定的正则表达式来过滤掉你需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那么来提出一些反采集的方法
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人工分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被 查看全部
采集网站内容(先来和百度的机器人采集器会怎么做?打游击战呗!)
很多反采集的方法在实现的时候需要考虑是否会影响搜索引擎对网站的爬取,那么我们来分析一下一般的采集器和搜索引擎爬虫采集@ >. 不同的。
相似之处:两者都需要直接抓取网页源代码才能有效工作,b. 两者都会在单位时间内多次抓取大量访问过的网站内容;C。宏观上看,两个IP都会变;d. 他们俩都急于破解你的一些网页加密(验证),比如网页内容是通过js文件加密的,比如需要输入验证码浏览内容,比如需要登录以访问内容等。
区别:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。但是采集器一般是利用html标签的特性来抓取需要的数据。制定采集规则时,需要填写目标内容的开始和结束标志,以便定位到需要的内容;或者为特定的网页创建特定的正则表达式来过滤掉你需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那么来提出一些反采集的方法
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人工分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被
采集网站内容(纯采集站的网站要加快内容收录的话搜索引擎哪些工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-03 13:04
<p>相信很多用户在制作网站内容时,为了丰富网站的内容,增加了数据抓取,但是如果是满站采集,页面怎么会有< @收录?,不管你是做完整的采集网站,首先要了解搜索引擎的工作模式,然后作为网站SEO的核心,再纯采集站网站如果要加速内容 查看全部
采集网站内容(纯采集站的网站要加快内容收录的话搜索引擎哪些工作)
<p>相信很多用户在制作网站内容时,为了丰富网站的内容,增加了数据抓取,但是如果是满站采集,页面怎么会有< @收录?,不管你是做完整的采集网站,首先要了解搜索引擎的工作模式,然后作为网站SEO的核心,再纯采集站网站如果要加速内容
采集网站内容(互联网企业给网站添加内容的时候,添加URL目标地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-03 12:24
在做网络推广的时候,很多公司还是比较喜欢网站的推广。这是因为有很多用户使用百度搜索引擎。只要网站能够提升网站的排名,就会有更多的用户看到网站,企业也会得到相应的流量。
想要网站获得好的排名,就需要对网站进行相应的优化。在优化的过程中,内容是一个非常重要的因素。只有拥有高质量的内容,才能被用户和搜索引擎喜欢,获得更好的排名。
但是有的公司在给网站添加内容的时候,不知道要添加什么,就会去其他网站转载一些内容,并添加目标URL地址,会被识别为采集?
接下来我们就来看看网站建筑优化公司吧!
1、搜索引擎判断是否正确
①搜索引擎判断正确
一般情况下,当网站转载其他网站内容并带上目标地址时,搜索引擎可以正确判断该内容为转载内容。这是因为有很多相同的内容,而且这些内容已经被搜索引擎识别,在转载相同内容后,搜索引擎会判断网站的内容是采集。
②搜索引擎判断错误
有时,当网站转发某些内容时,搜索引擎无法确定该内容是采集。这是因为搜索引擎毕竟是一个系统,无法准确识别内容是否被转载。转载时,可以在内容中添加一些想法来更改内容,以免搜索引擎对其进行判断。文章是采集吗?
2、原创 作者是否同意
①原创 作者同意
网站转载其他网站内容时,如对方同意转载,属合理转载。只要转载正确,就不会有什么问题。
②原创作者不同意
当原网站作者不同意转载时,你的网站还要转载他网站的内容,这是不合理转载,这是侵权,对方可以使用法律意味着保护自己的利益,所以你会遇到麻烦。
3、网站权重等级
①高权重网站
网站 转载其他网站内容时,一定要以高权重网站转载,因为高权重网站的内容被搜索引擎识别,转载此类内容对网站有帮助。
②低重量网站
转载内容时,部分公司会转载内容权重网站。这不仅对他们网站有帮助,还会降低网站的质量,进而影响网站。@网站 开发。
总之,无论是否合理转载,都是文章采集的一种表现形式。只有正确转载他人网站的内容,才能对网站的发展有所帮助。
蝙蝠侠IT转载需要授权! 查看全部
采集网站内容(互联网企业给网站添加内容的时候,添加URL目标地址)
在做网络推广的时候,很多公司还是比较喜欢网站的推广。这是因为有很多用户使用百度搜索引擎。只要网站能够提升网站的排名,就会有更多的用户看到网站,企业也会得到相应的流量。
想要网站获得好的排名,就需要对网站进行相应的优化。在优化的过程中,内容是一个非常重要的因素。只有拥有高质量的内容,才能被用户和搜索引擎喜欢,获得更好的排名。
但是有的公司在给网站添加内容的时候,不知道要添加什么,就会去其他网站转载一些内容,并添加目标URL地址,会被识别为采集?
接下来我们就来看看网站建筑优化公司吧!
1、搜索引擎判断是否正确
①搜索引擎判断正确
一般情况下,当网站转载其他网站内容并带上目标地址时,搜索引擎可以正确判断该内容为转载内容。这是因为有很多相同的内容,而且这些内容已经被搜索引擎识别,在转载相同内容后,搜索引擎会判断网站的内容是采集。
②搜索引擎判断错误
有时,当网站转发某些内容时,搜索引擎无法确定该内容是采集。这是因为搜索引擎毕竟是一个系统,无法准确识别内容是否被转载。转载时,可以在内容中添加一些想法来更改内容,以免搜索引擎对其进行判断。文章是采集吗?
2、原创 作者是否同意
①原创 作者同意
网站转载其他网站内容时,如对方同意转载,属合理转载。只要转载正确,就不会有什么问题。
②原创作者不同意
当原网站作者不同意转载时,你的网站还要转载他网站的内容,这是不合理转载,这是侵权,对方可以使用法律意味着保护自己的利益,所以你会遇到麻烦。
3、网站权重等级
①高权重网站
网站 转载其他网站内容时,一定要以高权重网站转载,因为高权重网站的内容被搜索引擎识别,转载此类内容对网站有帮助。
②低重量网站
转载内容时,部分公司会转载内容权重网站。这不仅对他们网站有帮助,还会降低网站的质量,进而影响网站。@网站 开发。
总之,无论是否合理转载,都是文章采集的一种表现形式。只有正确转载他人网站的内容,才能对网站的发展有所帮助。
蝙蝠侠IT转载需要授权!
采集网站内容(软件永久终身免费使用智动网页内容采集器v1.9更新:软件内置网址更新 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-03 12:23
)
2、用户可以随意导入和导出任务
任务3、可以设置密码,并具有多种反破解采集功能,如n页采集暂停和采集特殊标记时暂停
4、您可以直接输入URL,或通过JavaScript脚本生成URL,或通过关键词>搜索采集
5、您可以登录到采集采集您需要登录到帐户的网页内容
6、您可以深入到n列采集内容和链接
7、支持多种内容提取模式,可以处理所需的采集内容,如清除HTML、图片等
8、您可以编译自己的JavaScript脚本来提取网页内容,并轻松实现内容的任何部分的采集
9、采集的文本内容可以根据设置的模板保存
10、根据模板,可以将多个采集的文件保存在同一个文件中
11、网页上的多个部分内容可以单独分页采集
12、您可以设置自己的客户信息,以模拟目标上的百度和其他搜索引擎网站采集
13、该软件终身免费
智能网络内容采集器V1.9更新:
软件的内置网站更新为
采用了新的智能软件控制界面
将用户反馈添加到电子邮件功能
增加了将初始化链接直接设置为最终内容页的功能
增强内核功能,支持post中的关键词@>搜索和替换关键词@>标记
优化采集内核
优化的断开拨号算法
优化的重复数据消除工具算法
修复拨号显示IP不正确的错误
修复错误关键词@>暂停或拨号时不会重置采集错误页面的错误
修复当受限内容的最大值为0时无法正确保存最小值的错误
查看全部
采集网站内容(软件永久终身免费使用智动网页内容采集器v1.9更新:软件内置网址更新
)
2、用户可以随意导入和导出任务
任务3、可以设置密码,并具有多种反破解采集功能,如n页采集暂停和采集特殊标记时暂停
4、您可以直接输入URL,或通过JavaScript脚本生成URL,或通过关键词>搜索采集
5、您可以登录到采集采集您需要登录到帐户的网页内容
6、您可以深入到n列采集内容和链接
7、支持多种内容提取模式,可以处理所需的采集内容,如清除HTML、图片等
8、您可以编译自己的JavaScript脚本来提取网页内容,并轻松实现内容的任何部分的采集
9、采集的文本内容可以根据设置的模板保存
10、根据模板,可以将多个采集的文件保存在同一个文件中
11、网页上的多个部分内容可以单独分页采集
12、您可以设置自己的客户信息,以模拟目标上的百度和其他搜索引擎网站采集
13、该软件终身免费
智能网络内容采集器V1.9更新:
软件的内置网站更新为
采用了新的智能软件控制界面
将用户反馈添加到电子邮件功能
增加了将初始化链接直接设置为最终内容页的功能
增强内核功能,支持post中的关键词@>搜索和替换关键词@>标记
优化采集内核
优化的断开拨号算法
优化的重复数据消除工具算法
修复拨号显示IP不正确的错误
修复错误关键词@>暂停或拨号时不会重置采集错误页面的错误
修复当受限内容的最大值为0时无法正确保存最小值的错误
采集网站内容(新人做网站必备的常识html言语网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 23:24
新手做的常识网站1.htmlwords网站 首先展示给我们的是网页,里面收录文字、图片、音频等信息。我们都知道html或htm格式是网页的基本格式,而html语言是站长首先需要学习的。HTML 语言并不难学。作为一种符号语言,前后两个符号相互对应,html代码清晰易懂。虽然整个网站程序(包括cms、BLOG等)已经在市场上广泛使用,但是模板的修改、网页布局等都需要有html语言的常识,所以html是必须的. 2.动态语言(包括asp、php、java等)是与html相关的静态语言,并且动态语言近年来非常流行。因为它的功能和效果,与html相差甚远。学习动态语言有一定的难度。建议先学习一门编程语言。VB或C语言都是不错的选择。众所周知,C语言,php和java近在咫尺,我也学过基本的编程语言。学习asp和php几乎是一口气完成的。由于语音的互操作性,基本算法是相似的。3.网络安全常识 现在一些小黑老头喜欢拿刀网站,我们最好学习一些网络安全常识,比如后端地址的隐藏,数据库防暴数据库(常用数据库连接文件 conn.asp 或 const. asp是比较简单容易出错的地方),密码的强度(md5密码纯数字一会就可以解密,最好用数字加英文加特殊符号),如果用别人发的全站程序,需要注意这个程序在各大黑客网站上是否有漏洞。phpwind和最近的oblog差距很严重,一定要及时补上。
非技能常识系统1.计算可以使用51.la或cnzz计算代码,每天花3-5分钟看计算结果,分析主ip从哪里来,从哪里来它被执行。最好,哪个关键字是你的专长,这样你就可以更有针对性地进行推广。2.采集刚开始是一个网站,不可能每篇文章文章都是原创,所以你要采集别人的经验文章,而不仅仅是发布它。学习使用搜索引擎,比如百度和google的一些特殊功能: site:可以查到输入了多少条目;“link:”会找到所有指向网站主页的网页。这些技能可以在网上找到。NS。3. 修改包括文字修改和图稿。采集到的大部分文章链接可能是一些无用的信息。需要学会过滤和清理,技术文章要通俗易懂,清理后公布。美术方面,最好学习一下PS和DW的基本用法。从根本上说,不要让别人帮你拍照片。4.最好的宣传方式是口耳相传。有人认为你的网站郝天然会介绍给他的朋友,通常是在论坛或其他互动网站帮助人解决问题,我想大多数人都会感谢帮助他们的人。只需在签名文件中放置一个连接即可。发生的流量稳定有效。不要发送广告。不仅没用,还会留下不好的形象。
<p>公布一些包装精美的文件,例如电子书、艺术类电子杂志等。这些被称为病毒式传销,它们非常有用。5.SEO优化搜索引擎优化类似,不要过度搜索引擎优化,一个真正的好网站,深得人心,百度不能给你顶。6. 人际网络人际关系,要想做大做强,一个人很难在互联网上站稳脚跟,有所作为。您必须调动所有可用资源为未来奠定基础;打造具有战斗力的团队;结交更多这个行业的朋友,无论是站长还是网友,都可以成为你的老师。如果是三人组,肯定有我的老师。记住,交朋友一定要真诚,朋友是最宝贵的,不会随着时间而改变。网站的操作会和网站的推广混淆。在实践中,网站的推广只是网站操作的一部分,除此之外,还有网站和栏目或活动的策划任务,页面的创建和功能和内容管理。后期客户联系,客户处理,人力资源开发,客户二次开发。一些重大活动的发展和后期的网站保护。但是,一个网站的生命力不只是看这里,还要了解整个网站的规划和站长的管理技巧,以及一个远程操作团队,是否它可能会受到 网站 @网站余生生。科技以人为本。1.确定网站2.的意图网站Planning3.制造实践页面4.添加流量(网站实施网站推广) 5.每日更新网站 6. 把握网站现状和客户反应,继续完善以上5点,详细阐述如下:1.确认 查看全部
采集网站内容(新人做网站必备的常识html言语网站)
新手做的常识网站1.htmlwords网站 首先展示给我们的是网页,里面收录文字、图片、音频等信息。我们都知道html或htm格式是网页的基本格式,而html语言是站长首先需要学习的。HTML 语言并不难学。作为一种符号语言,前后两个符号相互对应,html代码清晰易懂。虽然整个网站程序(包括cms、BLOG等)已经在市场上广泛使用,但是模板的修改、网页布局等都需要有html语言的常识,所以html是必须的. 2.动态语言(包括asp、php、java等)是与html相关的静态语言,并且动态语言近年来非常流行。因为它的功能和效果,与html相差甚远。学习动态语言有一定的难度。建议先学习一门编程语言。VB或C语言都是不错的选择。众所周知,C语言,php和java近在咫尺,我也学过基本的编程语言。学习asp和php几乎是一口气完成的。由于语音的互操作性,基本算法是相似的。3.网络安全常识 现在一些小黑老头喜欢拿刀网站,我们最好学习一些网络安全常识,比如后端地址的隐藏,数据库防暴数据库(常用数据库连接文件 conn.asp 或 const. asp是比较简单容易出错的地方),密码的强度(md5密码纯数字一会就可以解密,最好用数字加英文加特殊符号),如果用别人发的全站程序,需要注意这个程序在各大黑客网站上是否有漏洞。phpwind和最近的oblog差距很严重,一定要及时补上。
非技能常识系统1.计算可以使用51.la或cnzz计算代码,每天花3-5分钟看计算结果,分析主ip从哪里来,从哪里来它被执行。最好,哪个关键字是你的专长,这样你就可以更有针对性地进行推广。2.采集刚开始是一个网站,不可能每篇文章文章都是原创,所以你要采集别人的经验文章,而不仅仅是发布它。学习使用搜索引擎,比如百度和google的一些特殊功能: site:可以查到输入了多少条目;“link:”会找到所有指向网站主页的网页。这些技能可以在网上找到。NS。3. 修改包括文字修改和图稿。采集到的大部分文章链接可能是一些无用的信息。需要学会过滤和清理,技术文章要通俗易懂,清理后公布。美术方面,最好学习一下PS和DW的基本用法。从根本上说,不要让别人帮你拍照片。4.最好的宣传方式是口耳相传。有人认为你的网站郝天然会介绍给他的朋友,通常是在论坛或其他互动网站帮助人解决问题,我想大多数人都会感谢帮助他们的人。只需在签名文件中放置一个连接即可。发生的流量稳定有效。不要发送广告。不仅没用,还会留下不好的形象。
<p>公布一些包装精美的文件,例如电子书、艺术类电子杂志等。这些被称为病毒式传销,它们非常有用。5.SEO优化搜索引擎优化类似,不要过度搜索引擎优化,一个真正的好网站,深得人心,百度不能给你顶。6. 人际网络人际关系,要想做大做强,一个人很难在互联网上站稳脚跟,有所作为。您必须调动所有可用资源为未来奠定基础;打造具有战斗力的团队;结交更多这个行业的朋友,无论是站长还是网友,都可以成为你的老师。如果是三人组,肯定有我的老师。记住,交朋友一定要真诚,朋友是最宝贵的,不会随着时间而改变。网站的操作会和网站的推广混淆。在实践中,网站的推广只是网站操作的一部分,除此之外,还有网站和栏目或活动的策划任务,页面的创建和功能和内容管理。后期客户联系,客户处理,人力资源开发,客户二次开发。一些重大活动的发展和后期的网站保护。但是,一个网站的生命力不只是看这里,还要了解整个网站的规划和站长的管理技巧,以及一个远程操作团队,是否它可能会受到 网站 @网站余生生。科技以人为本。1.确定网站2.的意图网站Planning3.制造实践页面4.添加流量(网站实施网站推广) 5.每日更新网站 6. 把握网站现状和客户反应,继续完善以上5点,详细阐述如下:1.确认
采集网站内容(如何使用Scrapy结合PhantomJS框架写一个_MIDDLEWARES资料总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-01 23:13
一,。导言
最近,我一直在研究scrapy crawler框架,并尝试使用scrapy框架编写一个可以实现web信息的简单小程序采集。我在尝试的过程中遇到了很多小问题。我希望你能给我更多的建议
本文主要介绍如何结合phantom JS采集天猫商品内容使用scripy。本文定制了一个下载程序u中间件用于采集需要加载JS的动态网页内容。阅读了很多关于downloader的内容。总之,midviews数据使用起来很简单,但是它会阻塞框架,因此性能很差。在一些materials_uhandler中提到了自定义下载程序,或者使用grapyjs可以解决阻塞框架的问题。感兴趣的合作伙伴可以研究它。我不会在这里谈论它
二,。具体实施
2.1,环境要求
您需要执行以下步骤来准备python开发和运行环境:
以上步骤显示了两种安装方式:1。安装并下载本地车轮套件;2.使用Python安装管理器执行远程下载和安装。注意:包版本需要与python版本匹配
2.2,开发和测试过程
首先,找到需要采集的页面。这是天猫的产品。该网站为/item/526449276263.HTM。网页如下:
然后开始编写代码。默认情况下,以下代码在命令行界面中执行
1),创建scratch crawler项目tmspider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middleware文件夹,然后在该文件夹下创建middleware.py文件。代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和phantom JS编写web内容下载程序,并在上一步创建的Middleware文件夹中创建downloader.py文件。代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5)创建爬虫模块
在项目目录e:\Python-3.5.1\tmspider中,执行以下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后,将在项目目录e:\Python-3.5.1\tmspider\tmspider\spider中自动生成tmall.py程序文件。程序中的parse函数处理脚本下载程序返回的网页内容。采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫程序
在E:\Python-3.5.1\tmspider项目目录中执行该命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请注意,上述命令一次只能启动一个爬虫程序。如果要同时启动多个爬虫程序,该怎么办?然后您需要定制一个爬虫程序启动模块。在spider下创建模块文件runcrawl.py。代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
三,。前景
为了定制Downloader,在通过调用phantomjs实现爬虫程序之后,Middleware长期以来一直在努力解决阻塞框架的问题,并试图找到解决方案。稍后,我们将研究其他调用浏览器的方法,例如grapyjs和splash,看看它们是否可以有效地解决这个问题
四,。有关文件
一,。Python即时web爬虫:API描述
五,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
六,。文档修改历史记录
12016-06-30:V1.0 查看全部
采集网站内容(如何使用Scrapy结合PhantomJS框架写一个_MIDDLEWARES资料总结)
一,。导言
最近,我一直在研究scrapy crawler框架,并尝试使用scrapy框架编写一个可以实现web信息的简单小程序采集。我在尝试的过程中遇到了很多小问题。我希望你能给我更多的建议
本文主要介绍如何结合phantom JS采集天猫商品内容使用scripy。本文定制了一个下载程序u中间件用于采集需要加载JS的动态网页内容。阅读了很多关于downloader的内容。总之,midviews数据使用起来很简单,但是它会阻塞框架,因此性能很差。在一些materials_uhandler中提到了自定义下载程序,或者使用grapyjs可以解决阻塞框架的问题。感兴趣的合作伙伴可以研究它。我不会在这里谈论它
二,。具体实施
2.1,环境要求
您需要执行以下步骤来准备python开发和运行环境:
以上步骤显示了两种安装方式:1。安装并下载本地车轮套件;2.使用Python安装管理器执行远程下载和安装。注意:包版本需要与python版本匹配
2.2,开发和测试过程
首先,找到需要采集的页面。这是天猫的产品。该网站为/item/526449276263.HTM。网页如下:
然后开始编写代码。默认情况下,以下代码在命令行界面中执行
1),创建scratch crawler项目tmspider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middleware文件夹,然后在该文件夹下创建middleware.py文件。代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和phantom JS编写web内容下载程序,并在上一步创建的Middleware文件夹中创建downloader.py文件。代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5)创建爬虫模块
在项目目录e:\Python-3.5.1\tmspider中,执行以下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后,将在项目目录e:\Python-3.5.1\tmspider\tmspider\spider中自动生成tmall.py程序文件。程序中的parse函数处理脚本下载程序返回的网页内容。采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/5 ... 39%3B,
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫程序
在E:\Python-3.5.1\tmspider项目目录中执行该命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
请注意,上述命令一次只能启动一个爬虫程序。如果要同时启动多个爬虫程序,该怎么办?然后您需要定制一个爬虫程序启动模块。在spider下创建模块文件runcrawl.py。代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
三,。前景
为了定制Downloader,在通过调用phantomjs实现爬虫程序之后,Middleware长期以来一直在努力解决阻塞框架的问题,并试图找到解决方案。稍后,我们将研究其他调用浏览器的方法,例如grapyjs和splash,看看它们是否可以有效地解决这个问题
四,。有关文件
一,。Python即时web爬虫:API描述
五,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
六,。文档修改历史记录
12016-06-30:V1.0
采集网站内容(公司采集办法不正确导致网站被降权怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-24 19:08
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,企业需要如何正确呢?采集
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,对于正确的采集网站内容,企业应该怎么做呢?
首先,在采集网站的内容中,要选择好的网站内容,也就是选择与网站相关的内容,新鲜的像可能,如果太旧了,就是很文章的内容,陈旧的内容就不需要采集
那么采集的内容要适当修改为网站的标题。根据内容主题更改相应的标题。比如原标题是“如何减轻工作压力?”,可以换成“如何减轻工作压力?” 等。文字内容不同,但表达的内涵是一样的。采集的内容标题和内容创意可以一一对应。
最后,对采集的网站的内容做一些适当的调整。调整内容的时候,可以适当的使用重写,尤其是第一、最后两段,重写,然后适当添加相应的图片,可以有效的提高内容的质量,也可以产生百度蜘蛛吸引力的更好结果。因此,本公司在涉及采集网站的内容时应注意上述问题! 查看全部
采集网站内容(公司采集办法不正确导致网站被降权怎么办?(图))
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,企业需要如何正确呢?采集
随着网站场所的不断发展,网站之间的竞争越来越大。因此,为了快速增加自己的网站流量,很多公司会采集其他网站新闻内容。但是有些公司的采集方法不正确,导致网站被降级。那么,对于正确的采集网站内容,企业应该怎么做呢?
首先,在采集网站的内容中,要选择好的网站内容,也就是选择与网站相关的内容,新鲜的像可能,如果太旧了,就是很文章的内容,陈旧的内容就不需要采集
那么采集的内容要适当修改为网站的标题。根据内容主题更改相应的标题。比如原标题是“如何减轻工作压力?”,可以换成“如何减轻工作压力?” 等。文字内容不同,但表达的内涵是一样的。采集的内容标题和内容创意可以一一对应。
最后,对采集的网站的内容做一些适当的调整。调整内容的时候,可以适当的使用重写,尤其是第一、最后两段,重写,然后适当添加相应的图片,可以有效的提高内容的质量,也可以产生百度蜘蛛吸引力的更好结果。因此,本公司在涉及采集网站的内容时应注意上述问题!
采集网站内容(云霸屏怎样有效进行网站采集呢?新站最好不要采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-22 23:22
众所周知,高品质网站文章采集可以有效地改善网站内容内容内容建,霸霸屏屏屏例例例霸例网网打字促销产品非常注重对@ 网站的优化,谨防操作不当的优化效果,那么如何有效网站 采集@ @采集采集@@ @@采集采集@@ @@采集@@ ki去大家。
1.新站最好不要到采集
我相信每个人都知道新站在线之后是在线,如果新站在线,采集将对网站的负面影响,导致网站收录容放入低低质销量生成网站有收录无无无。
知乎 网站 proge升级采集
搜索引擎是首选进口链接和导出链接到网站,这可以让网站键入生态ring,增强网站 correlion。 采集首先,确保采集内容对用户有一定的价值,可以有效解决用户需求,采集内容推荐必须来自行业高权重网站和专家内容。
3. 采集比
现在网站几乎所有考虑网站采集,网站内容是可以采集,但要注意底线。 网站不不@@@ @采集 @采集@ @@ @采集采集@ @ @采集 @采集内容不不不不不网站 采集@ @内容不不不不不话............................................. ........
4. 网站用户体验
网站 采集内容内容需要进行基本修改,包括标题,地图等,只要您能够有效解决用户需求,我认为总是改进网站。 采集 @内容消原代代中中文..................................... ................................................ ..
在所有情况下,上面的是关于文章采集,采集内容内容实际上是针对网站的重量和更新频率,我希望内容告诉今天可以帮助您更好地解决它。 网站优化采集问题。 查看全部
采集网站内容(云霸屏怎样有效进行网站采集呢?新站最好不要采集)
众所周知,高品质网站文章采集可以有效地改善网站内容内容内容建,霸霸屏屏屏例例例霸例网网打字促销产品非常注重对@ 网站的优化,谨防操作不当的优化效果,那么如何有效网站 采集@ @采集采集@@ @@采集采集@@ @@采集@@ ki去大家。
1.新站最好不要到采集
我相信每个人都知道新站在线之后是在线,如果新站在线,采集将对网站的负面影响,导致网站收录容放入低低质销量生成网站有收录无无无。
知乎 网站 proge升级采集
搜索引擎是首选进口链接和导出链接到网站,这可以让网站键入生态ring,增强网站 correlion。 采集首先,确保采集内容对用户有一定的价值,可以有效解决用户需求,采集内容推荐必须来自行业高权重网站和专家内容。
3. 采集比
现在网站几乎所有考虑网站采集,网站内容是可以采集,但要注意底线。 网站不不@@@ @采集 @采集@ @@ @采集采集@ @ @采集 @采集内容不不不不不网站 采集@ @内容不不不不不话............................................. ........
4. 网站用户体验
网站 采集内容内容需要进行基本修改,包括标题,地图等,只要您能够有效解决用户需求,我认为总是改进网站。 采集 @内容消原代代中中文..................................... ................................................ ..
在所有情况下,上面的是关于文章采集,采集内容内容实际上是针对网站的重量和更新频率,我希望内容告诉今天可以帮助您更好地解决它。 网站优化采集问题。
采集网站内容(字节面试锦集(一):AndroidFramework高频面试题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-22 15:09
字节访问brocade集合(一):Android框架高频访问问题摘要
关键词:访谈锦缎系列(二):项目人力资源高频访谈总结)
data采集采集体系结构中每个模块的详细分析
网络爬虫的实现原理与技术
爬虫工程师如何有效地支持数据分析师的工作
基于大数据平台的互联网数据采集平台基本架构
爬行动物工程师的成长道路
如何在data采集中建立有效的监控系统@
面试准备、人力资源和安卓技术等面试问题总结
昨天,一位网友说,他最近采访了几家公司。他被问了好几次问题,每次回答都不是很好
采访者:比如说,有100000个网站need采集,你是如何快速获得数据的
要很好地回答这个问题,您实际上需要有足够的知识和足够的技术储备
最近我们也在招聘,我们每周面试十几个人,只有一两个人觉得合适。他们大多数都和这位网友相似,缺乏整体思维,即使是那些有三四年工作经验的老司机。他们解决具体问题的能力很强,但很少站在新的角度从点到面全面思考
采集覆盖率为100000 网站比大多数专业舆论监测公司更宽。为了满足面试官的“采集”需求,需要综合考虑从“网站集合”到“数据存储”的各个方面,并给出适当的方案来节约成本和提高工作效率
让我们简单介绍一下从网站采集到数据存储
一、10一万网站来自哪里
一般来说,采集和网站是根据公司业务的发展逐渐积累起来的
现在我们假设这是一家初创公司的需求。该公司刚刚成立,有这么多网站,基本上可以说是一个冷启动。我们如何采集这10万网站?有几种方法:
1)历史业务积累
无论是冷启动还是什么,既然有采集的需求,就一定有项目或产品的需求,相关人员在前期一定调查了一些数据源,采集了一些重要的网站数据,这些数据可以作为我们采集的网站和采集的原创种子
2)Association网站
在一些网站的底部,有与网站相关的链接。特别是对于政府网站,通常有相关下属部门的官方网站
3)网站导航
有些网站可能出于某种目的(如排水等)采集网站并进行分类和展示,以方便人们查找。这些网站可以很快为我们提供第一批种子网站.然后,我们可以通过网站关联等方式获得更多的网站
4)搜索引擎
您还可以准备一些与公司业务相关的关键词在百度、搜狗等搜索引擎中搜索,并通过处理搜索结果提取相应的网站作为我们的种子网站
5)第三方平台
例如,一些第三方SaaS平台将有7~15天的免费试用期,因此我们可以利用这段时间采集下载与我们业务相关的数据,然后提取网站作为我们最初的采集种子
虽然该方法是最有效、最快的网站采集方法,但在试验期间不太可能获得100000网站,因此有必要将上述相关网站和其他方法结合起来,以快速获得所需的网站@
通过以上五种方式,我相信我们可以很快采集到我们需要的10万个网站。但是,我们如何管理这么多网站,如何知道它们是否正常
二、10一万网站如何管理
当我们采集100000网站数据时,我们面临的第一件事是如何管理、配置采集规则,以及监控网站是否正常
1)如何管理
100000网站,如果没有专门的系统来管理,那将是一场灾难
同时,由于业务需要,比如智能推荐,我们需要对网站进行预处理,比如标签,这时需要一个网站管理系统
2)如何配置采集规则
我们前期采集的10万网站只是主页,如果只把主页作为采集任务,我们只能采集在主页上获取少量信息,丢失率很高
如果你想让整个站点采集按照主页URL进行,会消耗大量服务器资源,成本太高,因此需要配置我们关心的栏目和采集栏目
然而,对于100000网站,如何快速高效地配置列?目前,我们通过自动解析HTML源代码来进行半自动的列配置
当然,我们也尝试过机器学习,但效果并不理想
由于采集所需的网站数量达到100000,因此不能使用XPath和其他精确定位方法来采集.否则,配置100000网站井时,花椰菜将变冷
同时,数据采集必须使用通用爬虫,并使用正则表达式来匹配列表数据
3)如何监控
由于有100000个网站,在这些网站中,每天都会有网站修订,或列修订,或新的/现成的列。因此,有必要根据采集的数据对网站进行简要分析@
例如,如果网站中有几天没有新数据,则一定是有问题。要么是网站更改了版本,导致信息规则性频繁失败,要么是网站本身有问题
为了提高采集的效率,可以使用单独的服务定期检测网站和列,首先检查网站和列是否可以正常访问;其次检查配置的列信息正则表达式是否正常,以便运维人员进行维护
三、task缓存
100000网站。配置列后,采集条目URL应达到百万级别。采集器如何有效地获取采集的这些条目URL@
如果将这些URL放入数据库中,无论是MySQL还是Oracle,采集器获取采集任务都会浪费大量时间,并大大降低采集效率
如何解决这个问题?首选内存数据库,如redis、Mongo dB等。redis通常使用采集进行缓存。因此,在配置列时,您可以将列信息作为采集任务缓存队列同步到redis
四、网站how采集
比如说,如果你想一年赚几百万,最有可能的是去华为、阿里巴巴、腾讯等一线大工厂,你需要达到一定的水平,这条路肯定很难走
类似地,如果需要采集000000级别列表URL,则不得实施常规方法
必须采用分布式+多进程+多线程的方式,同时还需要结合内存数据库redis进行缓存,实现高效的任务获取和采集信息的复制
同时,信息分析,如发布时间和文本,也必须通过算法进行处理。例如,现在流行的GNE
在列表采集中可以获得的某些属性不应与文本一起解析。例如,标题。通常,从列表中获得的标题的准确性远远高于从信息HTML源代码中通过算法解析的标题的准确性
同时,如果有一些特殊的网站,或者一些特殊的需求,我们可以使用定制的开发方法来处理它们
五、统一数据存储接口
为了保持采集的时效性,采集的100000网站可能需要十几台或二十台服务器。同时,将在每台服务器上部署n采集器。通过一些定制脚本,采集器的总数将达到数百台
如果每个采集器/自定义脚本都开发了自己的数据存储接口,那么在开发和调试上会浪费大量的时间,而且后续的操作和维护也不是坏事,特别是当业务发生变化需要调整时,因此需要统一数据存储接口
由于统一的数据存储接口,当我们需要对数据进行一些特殊的处理,如清理和校正时,我们不需要修改每个采集存储部分,我们只需要修改接口并重新部署它
快、方便、快捷
六、数据和采集监测
10万网站的采集覆盖率每天肯定超过200万数据,数据分析算法再精确也达不到100%(90%非常好).因此,在数据分析中必须有例外。例如,发布时间大于当前时间,文本收录相关新闻信息等
但是,由于我们已经统一了数据存储接口,我们可以在接口上进行统一的数据质量验证,优化采集器并根据异常情况定制脚本
同时,您还可以统计每个伪原创的采集数据 查看全部
采集网站内容(字节面试锦集(一):AndroidFramework高频面试题总结)
字节访问brocade集合(一):Android框架高频访问问题摘要
关键词:访谈锦缎系列(二):项目人力资源高频访谈总结)
data采集采集体系结构中每个模块的详细分析
网络爬虫的实现原理与技术
爬虫工程师如何有效地支持数据分析师的工作
基于大数据平台的互联网数据采集平台基本架构
爬行动物工程师的成长道路
如何在data采集中建立有效的监控系统@
面试准备、人力资源和安卓技术等面试问题总结
昨天,一位网友说,他最近采访了几家公司。他被问了好几次问题,每次回答都不是很好
采访者:比如说,有100000个网站need采集,你是如何快速获得数据的
要很好地回答这个问题,您实际上需要有足够的知识和足够的技术储备
最近我们也在招聘,我们每周面试十几个人,只有一两个人觉得合适。他们大多数都和这位网友相似,缺乏整体思维,即使是那些有三四年工作经验的老司机。他们解决具体问题的能力很强,但很少站在新的角度从点到面全面思考
采集覆盖率为100000 网站比大多数专业舆论监测公司更宽。为了满足面试官的“采集”需求,需要综合考虑从“网站集合”到“数据存储”的各个方面,并给出适当的方案来节约成本和提高工作效率
让我们简单介绍一下从网站采集到数据存储
一、10一万网站来自哪里
一般来说,采集和网站是根据公司业务的发展逐渐积累起来的
现在我们假设这是一家初创公司的需求。该公司刚刚成立,有这么多网站,基本上可以说是一个冷启动。我们如何采集这10万网站?有几种方法:
1)历史业务积累
无论是冷启动还是什么,既然有采集的需求,就一定有项目或产品的需求,相关人员在前期一定调查了一些数据源,采集了一些重要的网站数据,这些数据可以作为我们采集的网站和采集的原创种子
2)Association网站
在一些网站的底部,有与网站相关的链接。特别是对于政府网站,通常有相关下属部门的官方网站
3)网站导航
有些网站可能出于某种目的(如排水等)采集网站并进行分类和展示,以方便人们查找。这些网站可以很快为我们提供第一批种子网站.然后,我们可以通过网站关联等方式获得更多的网站
4)搜索引擎
您还可以准备一些与公司业务相关的关键词在百度、搜狗等搜索引擎中搜索,并通过处理搜索结果提取相应的网站作为我们的种子网站
5)第三方平台
例如,一些第三方SaaS平台将有7~15天的免费试用期,因此我们可以利用这段时间采集下载与我们业务相关的数据,然后提取网站作为我们最初的采集种子
虽然该方法是最有效、最快的网站采集方法,但在试验期间不太可能获得100000网站,因此有必要将上述相关网站和其他方法结合起来,以快速获得所需的网站@
通过以上五种方式,我相信我们可以很快采集到我们需要的10万个网站。但是,我们如何管理这么多网站,如何知道它们是否正常
二、10一万网站如何管理
当我们采集100000网站数据时,我们面临的第一件事是如何管理、配置采集规则,以及监控网站是否正常
1)如何管理
100000网站,如果没有专门的系统来管理,那将是一场灾难
同时,由于业务需要,比如智能推荐,我们需要对网站进行预处理,比如标签,这时需要一个网站管理系统
2)如何配置采集规则
我们前期采集的10万网站只是主页,如果只把主页作为采集任务,我们只能采集在主页上获取少量信息,丢失率很高
如果你想让整个站点采集按照主页URL进行,会消耗大量服务器资源,成本太高,因此需要配置我们关心的栏目和采集栏目
然而,对于100000网站,如何快速高效地配置列?目前,我们通过自动解析HTML源代码来进行半自动的列配置
当然,我们也尝试过机器学习,但效果并不理想
由于采集所需的网站数量达到100000,因此不能使用XPath和其他精确定位方法来采集.否则,配置100000网站井时,花椰菜将变冷
同时,数据采集必须使用通用爬虫,并使用正则表达式来匹配列表数据
3)如何监控
由于有100000个网站,在这些网站中,每天都会有网站修订,或列修订,或新的/现成的列。因此,有必要根据采集的数据对网站进行简要分析@
例如,如果网站中有几天没有新数据,则一定是有问题。要么是网站更改了版本,导致信息规则性频繁失败,要么是网站本身有问题
为了提高采集的效率,可以使用单独的服务定期检测网站和列,首先检查网站和列是否可以正常访问;其次检查配置的列信息正则表达式是否正常,以便运维人员进行维护
三、task缓存
100000网站。配置列后,采集条目URL应达到百万级别。采集器如何有效地获取采集的这些条目URL@
如果将这些URL放入数据库中,无论是MySQL还是Oracle,采集器获取采集任务都会浪费大量时间,并大大降低采集效率
如何解决这个问题?首选内存数据库,如redis、Mongo dB等。redis通常使用采集进行缓存。因此,在配置列时,您可以将列信息作为采集任务缓存队列同步到redis
四、网站how采集
比如说,如果你想一年赚几百万,最有可能的是去华为、阿里巴巴、腾讯等一线大工厂,你需要达到一定的水平,这条路肯定很难走
类似地,如果需要采集000000级别列表URL,则不得实施常规方法
必须采用分布式+多进程+多线程的方式,同时还需要结合内存数据库redis进行缓存,实现高效的任务获取和采集信息的复制
同时,信息分析,如发布时间和文本,也必须通过算法进行处理。例如,现在流行的GNE
在列表采集中可以获得的某些属性不应与文本一起解析。例如,标题。通常,从列表中获得的标题的准确性远远高于从信息HTML源代码中通过算法解析的标题的准确性
同时,如果有一些特殊的网站,或者一些特殊的需求,我们可以使用定制的开发方法来处理它们
五、统一数据存储接口
为了保持采集的时效性,采集的100000网站可能需要十几台或二十台服务器。同时,将在每台服务器上部署n采集器。通过一些定制脚本,采集器的总数将达到数百台
如果每个采集器/自定义脚本都开发了自己的数据存储接口,那么在开发和调试上会浪费大量的时间,而且后续的操作和维护也不是坏事,特别是当业务发生变化需要调整时,因此需要统一数据存储接口
由于统一的数据存储接口,当我们需要对数据进行一些特殊的处理,如清理和校正时,我们不需要修改每个采集存储部分,我们只需要修改接口并重新部署它
快、方便、快捷
六、数据和采集监测
10万网站的采集覆盖率每天肯定超过200万数据,数据分析算法再精确也达不到100%(90%非常好).因此,在数据分析中必须有例外。例如,发布时间大于当前时间,文本收录相关新闻信息等
但是,由于我们已经统一了数据存储接口,我们可以在接口上进行统一的数据质量验证,优化采集器并根据异常情况定制脚本
同时,您还可以统计每个伪原创的采集数据
采集网站内容(应如何正确使用采集内容呢?【豹子融教育】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-21 16:09
在网站优化圈里,站长们都知道,搜索引擎非常重视原创内容,但是再优秀的SEOer面对长期的内容原创都会有一定的困难,不仅仅资源有限且写作能力也存在着局限性,因此,整个网站包括各个板块儿的内容,都避免不了采集。
然而,搜索引擎强调采集内容对于网站来说并没有多大意义,尤其是对于优化作用,甚至是采集内容会被当做是垃圾信息处理,造成网站的负担,其实不然,即便采集内容对网站会存在着一定的风险,但只要采集合理,它还是有着一定的用处,同时也能够减少站长的原创堪忧,且获得同样的优化效果。那么,应如何正确使用采集内容呢?
首先,采集内容对象有讲究。最好找别人刚发布不久的内容作为采集目标,在没有被太多的人转载之前采集过来,但内容前提是于是俱进,新鲜且有代表性,而不是一些老生常谈的话题,否则对用户来说味同爵蜡,毫无价值可言。由于是采集内容,比起原创来说,自然要简单得多,也就不需要花费太多的时间来编辑内容,此时千万别把节省的时间闲着,毕竟采集的内容没有原创的效果来得直接,那么就要多找几篇内容同时采集,来弥补蜘蛛的空虚。
其次,采集内容不采集标题。大家都知道,看一篇文章最先看的是标题,对于网站优化的搜索引擎来说,标题也占有一定的权重。所采集的内容有一定的篇幅,做不了太多的改变,但是标题也就短短几个字,修改起来还是比较容易的,因此标题修改是必须的,而且最好将标题改得与原标题完全不相同,道理很简单,当你看到标题一样实质内容完全不同的文章时,会带给读者一些误解,认为两者内容相同,相反,即便内容相同,标题完全不同,也会给予人一种新鲜感,不易被发现。
最后,对内容做适当的调整。试过将内容采集到自己网站的站长,细心的人必然会发现,直接复制过来的内容还存在着格式问题,因为一些精明的原创者为了防止内容被采集,通常会给内容加一些隐藏的格式,甚至在图片的ALT信息里就会做版权的标注,如果没注意到,自然会被搜索引擎认定是抄袭,那么对网站的危害也就不言而喻了。因此,采集过来的内容一定要清除格式,且对英文格式的标点符号进行转换,另外,可给内容添加一些图片,使得内容更加丰富,如果内容本身有图片,那么千万不要直接复制,最好另外保存重新上传至网站,加上自己的ALT信息,能让采集内容更有优化价值。
简而言之,网站采集内容并非完全无益,关键还要看你如何采集,只要能够灵活使用这些采集过来的内容,就能带给网站一定的好处,但,站长们需要注意的是,必须得掌握一定的采集方法。 查看全部
采集网站内容(应如何正确使用采集内容呢?【豹子融教育】)
在网站优化圈里,站长们都知道,搜索引擎非常重视原创内容,但是再优秀的SEOer面对长期的内容原创都会有一定的困难,不仅仅资源有限且写作能力也存在着局限性,因此,整个网站包括各个板块儿的内容,都避免不了采集。
然而,搜索引擎强调采集内容对于网站来说并没有多大意义,尤其是对于优化作用,甚至是采集内容会被当做是垃圾信息处理,造成网站的负担,其实不然,即便采集内容对网站会存在着一定的风险,但只要采集合理,它还是有着一定的用处,同时也能够减少站长的原创堪忧,且获得同样的优化效果。那么,应如何正确使用采集内容呢?
首先,采集内容对象有讲究。最好找别人刚发布不久的内容作为采集目标,在没有被太多的人转载之前采集过来,但内容前提是于是俱进,新鲜且有代表性,而不是一些老生常谈的话题,否则对用户来说味同爵蜡,毫无价值可言。由于是采集内容,比起原创来说,自然要简单得多,也就不需要花费太多的时间来编辑内容,此时千万别把节省的时间闲着,毕竟采集的内容没有原创的效果来得直接,那么就要多找几篇内容同时采集,来弥补蜘蛛的空虚。
其次,采集内容不采集标题。大家都知道,看一篇文章最先看的是标题,对于网站优化的搜索引擎来说,标题也占有一定的权重。所采集的内容有一定的篇幅,做不了太多的改变,但是标题也就短短几个字,修改起来还是比较容易的,因此标题修改是必须的,而且最好将标题改得与原标题完全不相同,道理很简单,当你看到标题一样实质内容完全不同的文章时,会带给读者一些误解,认为两者内容相同,相反,即便内容相同,标题完全不同,也会给予人一种新鲜感,不易被发现。
最后,对内容做适当的调整。试过将内容采集到自己网站的站长,细心的人必然会发现,直接复制过来的内容还存在着格式问题,因为一些精明的原创者为了防止内容被采集,通常会给内容加一些隐藏的格式,甚至在图片的ALT信息里就会做版权的标注,如果没注意到,自然会被搜索引擎认定是抄袭,那么对网站的危害也就不言而喻了。因此,采集过来的内容一定要清除格式,且对英文格式的标点符号进行转换,另外,可给内容添加一些图片,使得内容更加丰富,如果内容本身有图片,那么千万不要直接复制,最好另外保存重新上传至网站,加上自己的ALT信息,能让采集内容更有优化价值。
简而言之,网站采集内容并非完全无益,关键还要看你如何采集,只要能够灵活使用这些采集过来的内容,就能带给网站一定的好处,但,站长们需要注意的是,必须得掌握一定的采集方法。
采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-19 00:19
采集有益
采集可以在短时间内大大提高网站的收录(前提是您的网站权重足够高),并可以捕获大部分网络流量和其他竞争对手的流量
采集有害
大量的采集会让百度认为你的站点中没有客户想要的信息。这是一个垃圾站。如果您今天有100采集today,明天有200采集today,后天没有采集today,则属于不均匀更新频率。百度会关注你的
首先,它可以在很短的时间内丰富网站的内容,让百度蜘蛛能够正常穿越网站并让用户在登录网站时看到一些内容网站. 尽管这些内容相对较旧,但它们比没有内容供用户使用要好得多
第二,内容采集可以快速获取与此相关的最新内容网站. 由于采集内容可以基于网站的关键词和相关栏目采集内容,这些内容可以是最新鲜的内容,因此用户在浏览网站时可以快速获得相关内容,无需通过搜索引擎重新搜索,因此网站用户体验可以得到一定程度的提升
当然,采集内容的缺点仍然非常明显,特别是抄袭采集和大规模采集会对网站产生不利影响,所以我们必须掌握正确的采集方法,才能充分发挥采集内容的优势
现在让我们分析一下正确的采集方式
首先,选择采集content。也就是说,我们应该选择与网站相关的内容,并尝试使其新鲜。如果太旧了,特别是新闻内容,旧的内容不需要采集,但是对于技术帖子来说,可以使用采集,因为这些技术帖子对很多新人都有很好的帮助效果
然后采集适当地更改标题。更改此处的标题并不要求采集people成为标题方,而是根据内容主题更改相应的标题。例如,如果原标题为“网站集团产品是安全的”,则可以将其更改为“网站集团产品将是安全的,受什么影响?”等等。文字内容不同,但内涵相同,这样采集的内容标题和内容理念可以一一对应,防止挂羊头卖狗肉的内容
最后是适当调整内容。此处的内容调整不需要简单地替换段落,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容变得困难和混乱,用户的阅读体验将大大降低。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果将产生严重的负面影响。在调整内容时,您可以通过适当的使用重新编写,特别是第一段和最后一段。你应该重写,然后适当添加相应的图片,这样可以有效提高内容的质量,对百度蜘蛛有更好的吸引力
总之,网站content采集不需要被打死。事实上,只要对传统的粗糙采集进行适当优化,并将其转化为精细采集,虽然采集需要相对较长的时间,但它比原创快得多,并且不会影响用户体验,因此正确的采集仍然是非常必要的 查看全部
采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集有益
采集可以在短时间内大大提高网站的收录(前提是您的网站权重足够高),并可以捕获大部分网络流量和其他竞争对手的流量
采集有害
大量的采集会让百度认为你的站点中没有客户想要的信息。这是一个垃圾站。如果您今天有100采集today,明天有200采集today,后天没有采集today,则属于不均匀更新频率。百度会关注你的
首先,它可以在很短的时间内丰富网站的内容,让百度蜘蛛能够正常穿越网站并让用户在登录网站时看到一些内容网站. 尽管这些内容相对较旧,但它们比没有内容供用户使用要好得多
第二,内容采集可以快速获取与此相关的最新内容网站. 由于采集内容可以基于网站的关键词和相关栏目采集内容,这些内容可以是最新鲜的内容,因此用户在浏览网站时可以快速获得相关内容,无需通过搜索引擎重新搜索,因此网站用户体验可以得到一定程度的提升
当然,采集内容的缺点仍然非常明显,特别是抄袭采集和大规模采集会对网站产生不利影响,所以我们必须掌握正确的采集方法,才能充分发挥采集内容的优势
现在让我们分析一下正确的采集方式
首先,选择采集content。也就是说,我们应该选择与网站相关的内容,并尝试使其新鲜。如果太旧了,特别是新闻内容,旧的内容不需要采集,但是对于技术帖子来说,可以使用采集,因为这些技术帖子对很多新人都有很好的帮助效果
然后采集适当地更改标题。更改此处的标题并不要求采集people成为标题方,而是根据内容主题更改相应的标题。例如,如果原标题为“网站集团产品是安全的”,则可以将其更改为“网站集团产品将是安全的,受什么影响?”等等。文字内容不同,但内涵相同,这样采集的内容标题和内容理念可以一一对应,防止挂羊头卖狗肉的内容
最后是适当调整内容。此处的内容调整不需要简单地替换段落,也不需要使用伪原创替换同义词或同义词。这样的替换只会使内容变得困难和混乱,用户的阅读体验将大大降低。而现在百度已经严厉打击了这样的伪原创内容,所以网站的优化效果将产生严重的负面影响。在调整内容时,您可以通过适当的使用重新编写,特别是第一段和最后一段。你应该重写,然后适当添加相应的图片,这样可以有效提高内容的质量,对百度蜘蛛有更好的吸引力
总之,网站content采集不需要被打死。事实上,只要对传统的粗糙采集进行适当优化,并将其转化为精细采集,虽然采集需要相对较长的时间,但它比原创快得多,并且不会影响用户体验,因此正确的采集仍然是非常必要的

