
谷歌抓取网页视频教程
谷歌抓取网页视频教程(直播源地址的协议很多种,疯狂URL系统windows简单介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1981 次浏览 • 2022-04-01 15:19
)
直播源介绍
首先,让我们快速了解一下什么是直播源。所谓直播源,其实是指推流地址。你可能不知道推流地址是什么。那我简单说一下,推流地址是当某个直播开始时,你需要向观众实时展示你的直播状态,而观众看到的直播是实时从推流地址。推流地址是推流服务器的地址。推流就是将直播状态实时上传到推流服务器,观众在观看的时候,会从推流服务器实时下载,其实叫拉流。这个过程也类似于我们观看在线视频的方式。视频文件存储在服务器中。
因此,直播源地址一般分为两部分。第一部分是推送服务器的主机地址/域名地址,第二部分是参数,一般包括时间戳和密钥密码。直播源地址的协议有很多。常见的app直播使用rtmp和http,而摄像头直播常用rtsp协议。电视直播大部分是http,也有一些是rtmp,直播源分为静态和动态。静态的一般都是长的有效链接,一般没有特殊情况,地址不变,可以随时查看,主要是http,少量的rtmp等,而动态的直播源时间限制比较短,一般在几个几秒钟到几分钟。
怎么抢直播源?
准备工具:
模拟器或直拨电话都可以
抓包工具(fiddler、wireshark、疯狂URL)系统windows
简单介绍一下以上三个工具
fiddler:代理抓包工具,主要抓http/https,常用来抓网站数据包,开发中常用的站点分析工具,也可以通过设置代理来抓手机app数据,包括移动web页
wireshark:一个网络捕获和分析工具。与 fiddler 不同的是,这种捕获范围更广。它主要通过数据包捕获网络接口中的所有流量,包括tcp/udp等,然后分析得到我们需要的。有效信息。
Crazy URL:这是一个基于winpacp和npacp的抓包工具。Wireshark也是基于winpacp开发的。更多关于winpacp的信息,可以去谷歌了解更多。Crazy URL支持捕获网络接口,即网卡数据流量,也支持捕获网站数据。疯狂的 URL 实际上是经过过滤和封装的。如果很多用户只需要抓取特定的资源,他们不需要如何分析数据包,那么使用疯狂的 URL 是最好的解决方案
以上三个工具的介绍基本相同。这要看个人的实际情况,以及使用的难易程度。最简单的一个是疯狂的 URL。这是相同的操作。如果您不想使用模拟器或模拟器中无法安装某些应用程序,您可以在电脑上打开热点共享,然后将手机连接到热点。)
步:
1.开始疯狂网址如下图(疯狂网址下载地址)
注意:新安装的用户安装后可能会提示缺少xxx组件/模块,安装相应系统的组件后才能看到网卡列表。安装组件的方法极其简单,点击疯狂网址右上角的帮助选项->找到对应系统的组件进行安装,如下图:
对于组件安装,您必须选择您自己系统的相应安装。Win7用户不能安装win10组件,否则无法使用。如果安装错误,请到控制面板->卸载程序下载错误安装的组件,然后重新安装正确的组件。然后打开如下图:
首先会看到两个界面,小界面是网卡列表界面,我们选择一个我们当前正在使用的网卡(一般带一个ip地址,如果有多个ip,请看下面的操作选择),比如我的网卡就是图中的红框,以WLAN 2开头。查看当前活动网卡最简单的方法是右键任务栏->打开任务管理器,如下图:
选择任务管理器顶部的性能选项,然后在左侧列表中查看相关网卡,查看哪个网卡有流量上传或下载。一般来说,这是您要选择的网卡。图中黄色框对应适配器名称和网卡名称,只要匹配一般就OK
您还可以在网络设置中检查您在网络适配器中使用的内容,然后选择您想要的内容。第一种方法是最快最简单的
网络适配器如图
2.选择网卡后,确认我们在主界面,已经自动进入监控状态。这时候,我们只需要在模拟器中打开一个直播应用即可。这里我将演示抓取一个直播应用(其他应用)。同理,没有区别,包括直播的电视APP,比如咪咕等),我直接选一个我觉得不错的小姐姐进入直播间如下图
3.从上图我们可以清楚的看到,当我们进入直播间时,疯狂的网址列表中会出现一个地址。每次我们进入直播间,都会添加地址。这些地址就是我们想要的直播源地址,那我们怎么看是不是我们想要的地址,还是只是平台的网址呢?这个我们在疯狂的URL地址上点右键,玩一下,试一试就知道了,如下图
4.点击播放后,这个画面和刚才在app里打开的完全是同一个人,并且是同步的,所以毫无疑问,这就是我们想要的直播源。事实上,疯狂的 URL 已经被很好地过滤了。强大的过滤系统将过滤掉不相关的链接。如果遇到一些你认为不是直播的地址,也可以手动设置过滤调整,如下图
5.你只需要点击类型旁边的三角按钮,勾选你需要的链接类型即可。直播源,自然是看视频。默认情况下不勾选,表示所有类型都是Support,但内部还是会过滤掉不相关和冗余的地址。这纯粹是为了用户体验。不信可以看下疯狂网址左下角的包数统计。
6.短短几分钟,数据包的数量就达到了八万多,是不是很神奇,而且我们只需要一个,从几万甚至更多的数据包中筛选出我们需要的几个数据块真的很强大。如果没有过滤功能,则需要从数以万计的数据包中分析出自己需要的数据。单击一下,这是一项非常繁琐且浪费时间的工作。我想应该没有人愿意这样做,而关于过滤,即使我们不使用播放器进行测试,仍然一目了然,这个链接的类型,如下图
在类型栏中,视频格式基本上是可播放的。视频格式有很多,如flv/mp4/m3u8/avi/wmv等,为方便用户,只需要看视频旁边的字即可。表示链接为视频格式,支持播放器播放。
还有一点你需要知道的是,除了用 Crazy URL 内置播放器播放外,你仍然可以复制抓取的 URL 并在任何支持的流媒体播放器中播放
如果我们要爬取网站资源,也可以使用疯狂的URL扩展
他可以帮我们抓取您指定的网站的资源,比如一些网站的直播和在线视频等。
操作方法也很简单,我们只要打开任意一个网站视频,就可以抓取视频链接
这是b学位视频的主页
让我们点击视频
最后一个视频是我们刚刚打开的视频地址。我们可以使用内置播放器播放或复制它。可以使用专用下载工具下载,也可以在第三方播放器上播放。
Windows平台推荐播放器potplayer,手机上使用VLC支持流式播放
查看全部
谷歌抓取网页视频教程(直播源地址的协议很多种,疯狂URL系统windows简单介绍
)
直播源介绍
首先,让我们快速了解一下什么是直播源。所谓直播源,其实是指推流地址。你可能不知道推流地址是什么。那我简单说一下,推流地址是当某个直播开始时,你需要向观众实时展示你的直播状态,而观众看到的直播是实时从推流地址。推流地址是推流服务器的地址。推流就是将直播状态实时上传到推流服务器,观众在观看的时候,会从推流服务器实时下载,其实叫拉流。这个过程也类似于我们观看在线视频的方式。视频文件存储在服务器中。
因此,直播源地址一般分为两部分。第一部分是推送服务器的主机地址/域名地址,第二部分是参数,一般包括时间戳和密钥密码。直播源地址的协议有很多。常见的app直播使用rtmp和http,而摄像头直播常用rtsp协议。电视直播大部分是http,也有一些是rtmp,直播源分为静态和动态。静态的一般都是长的有效链接,一般没有特殊情况,地址不变,可以随时查看,主要是http,少量的rtmp等,而动态的直播源时间限制比较短,一般在几个几秒钟到几分钟。
怎么抢直播源?
准备工具:
模拟器或直拨电话都可以
抓包工具(fiddler、wireshark、疯狂URL)系统windows
简单介绍一下以上三个工具
fiddler:代理抓包工具,主要抓http/https,常用来抓网站数据包,开发中常用的站点分析工具,也可以通过设置代理来抓手机app数据,包括移动web页
wireshark:一个网络捕获和分析工具。与 fiddler 不同的是,这种捕获范围更广。它主要通过数据包捕获网络接口中的所有流量,包括tcp/udp等,然后分析得到我们需要的。有效信息。
Crazy URL:这是一个基于winpacp和npacp的抓包工具。Wireshark也是基于winpacp开发的。更多关于winpacp的信息,可以去谷歌了解更多。Crazy URL支持捕获网络接口,即网卡数据流量,也支持捕获网站数据。疯狂的 URL 实际上是经过过滤和封装的。如果很多用户只需要抓取特定的资源,他们不需要如何分析数据包,那么使用疯狂的 URL 是最好的解决方案
以上三个工具的介绍基本相同。这要看个人的实际情况,以及使用的难易程度。最简单的一个是疯狂的 URL。这是相同的操作。如果您不想使用模拟器或模拟器中无法安装某些应用程序,您可以在电脑上打开热点共享,然后将手机连接到热点。)
步:
1.开始疯狂网址如下图(疯狂网址下载地址)
注意:新安装的用户安装后可能会提示缺少xxx组件/模块,安装相应系统的组件后才能看到网卡列表。安装组件的方法极其简单,点击疯狂网址右上角的帮助选项->找到对应系统的组件进行安装,如下图:

对于组件安装,您必须选择您自己系统的相应安装。Win7用户不能安装win10组件,否则无法使用。如果安装错误,请到控制面板->卸载程序下载错误安装的组件,然后重新安装正确的组件。然后打开如下图:
首先会看到两个界面,小界面是网卡列表界面,我们选择一个我们当前正在使用的网卡(一般带一个ip地址,如果有多个ip,请看下面的操作选择),比如我的网卡就是图中的红框,以WLAN 2开头。查看当前活动网卡最简单的方法是右键任务栏->打开任务管理器,如下图:
选择任务管理器顶部的性能选项,然后在左侧列表中查看相关网卡,查看哪个网卡有流量上传或下载。一般来说,这是您要选择的网卡。图中黄色框对应适配器名称和网卡名称,只要匹配一般就OK
您还可以在网络设置中检查您在网络适配器中使用的内容,然后选择您想要的内容。第一种方法是最快最简单的
网络适配器如图
2.选择网卡后,确认我们在主界面,已经自动进入监控状态。这时候,我们只需要在模拟器中打开一个直播应用即可。这里我将演示抓取一个直播应用(其他应用)。同理,没有区别,包括直播的电视APP,比如咪咕等),我直接选一个我觉得不错的小姐姐进入直播间如下图
3.从上图我们可以清楚的看到,当我们进入直播间时,疯狂的网址列表中会出现一个地址。每次我们进入直播间,都会添加地址。这些地址就是我们想要的直播源地址,那我们怎么看是不是我们想要的地址,还是只是平台的网址呢?这个我们在疯狂的URL地址上点右键,玩一下,试一试就知道了,如下图
4.点击播放后,这个画面和刚才在app里打开的完全是同一个人,并且是同步的,所以毫无疑问,这就是我们想要的直播源。事实上,疯狂的 URL 已经被很好地过滤了。强大的过滤系统将过滤掉不相关的链接。如果遇到一些你认为不是直播的地址,也可以手动设置过滤调整,如下图
5.你只需要点击类型旁边的三角按钮,勾选你需要的链接类型即可。直播源,自然是看视频。默认情况下不勾选,表示所有类型都是Support,但内部还是会过滤掉不相关和冗余的地址。这纯粹是为了用户体验。不信可以看下疯狂网址左下角的包数统计。
6.短短几分钟,数据包的数量就达到了八万多,是不是很神奇,而且我们只需要一个,从几万甚至更多的数据包中筛选出我们需要的几个数据块真的很强大。如果没有过滤功能,则需要从数以万计的数据包中分析出自己需要的数据。单击一下,这是一项非常繁琐且浪费时间的工作。我想应该没有人愿意这样做,而关于过滤,即使我们不使用播放器进行测试,仍然一目了然,这个链接的类型,如下图
在类型栏中,视频格式基本上是可播放的。视频格式有很多,如flv/mp4/m3u8/avi/wmv等,为方便用户,只需要看视频旁边的字即可。表示链接为视频格式,支持播放器播放。
还有一点你需要知道的是,除了用 Crazy URL 内置播放器播放外,你仍然可以复制抓取的 URL 并在任何支持的流媒体播放器中播放
如果我们要爬取网站资源,也可以使用疯狂的URL扩展
他可以帮我们抓取您指定的网站的资源,比如一些网站的直播和在线视频等。
操作方法也很简单,我们只要打开任意一个网站视频,就可以抓取视频链接
这是b学位视频的主页
让我们点击视频
最后一个视频是我们刚刚打开的视频地址。我们可以使用内置播放器播放或复制它。可以使用专用下载工具下载,也可以在第三方播放器上播放。
Windows平台推荐播放器potplayer,手机上使用VLC支持流式播放
谷歌抓取网页视频教程(谷歌抓取网页视频教程:-image/可以说的是现在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-28 16:05
谷歌抓取网页视频教程:-image/可以说的是现在谷歌抓取网页视频都是自动识别视频网站(不会像百度搜一样挑来挑去),谷歌现在更新了一个详细的使用指南,让我们来看看该如何使用?首先打开谷歌浏览器,之前谷歌浏览器已经有视频抓取的功能了,你可以直接抓取视频但是今年的edge视频抓取失效了,你需要点击下载“edge的视频抓取”;下面是链接,这样一会大家就可以看到这个功能了,希望能帮助大家。
根据手头的视频抓取,自带加密工具,抓取速度还不错,
我一般都是转发到今日头条,然后开开心心的刷抖音,或者直接关闭头条客户端。或者设置看不到大家的视频。视频原网站中不加密可以直接使用国外加密工具加密,不需要自己的工具。网上不是有很多种国外加密工具吗,可以自己找一下。这些方法不需要自己装工具,不怕麻烦的话,就去看看吧。
我一般是用视频制作助手,将视频转化为ppt(视频剪辑软件,也可以用其他工具),然后我要传到网站就在自己的网站制作一个网站传上去。貌似很简单,你可以试试。
下载谷歌网络视频抓取脚本
自己写视频脚本吧,
不用工具,打开浏览器,搜索,视频,就可以保存了,
搜索videoviewer或者youtube,更新一下,没有b站的问题了。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:-image/可以说的是现在)
谷歌抓取网页视频教程:-image/可以说的是现在谷歌抓取网页视频都是自动识别视频网站(不会像百度搜一样挑来挑去),谷歌现在更新了一个详细的使用指南,让我们来看看该如何使用?首先打开谷歌浏览器,之前谷歌浏览器已经有视频抓取的功能了,你可以直接抓取视频但是今年的edge视频抓取失效了,你需要点击下载“edge的视频抓取”;下面是链接,这样一会大家就可以看到这个功能了,希望能帮助大家。
根据手头的视频抓取,自带加密工具,抓取速度还不错,
我一般都是转发到今日头条,然后开开心心的刷抖音,或者直接关闭头条客户端。或者设置看不到大家的视频。视频原网站中不加密可以直接使用国外加密工具加密,不需要自己的工具。网上不是有很多种国外加密工具吗,可以自己找一下。这些方法不需要自己装工具,不怕麻烦的话,就去看看吧。
我一般是用视频制作助手,将视频转化为ppt(视频剪辑软件,也可以用其他工具),然后我要传到网站就在自己的网站制作一个网站传上去。貌似很简单,你可以试试。
下载谷歌网络视频抓取脚本
自己写视频脚本吧,
不用工具,打开浏览器,搜索,视频,就可以保存了,
搜索videoviewer或者youtube,更新一下,没有b站的问题了。
谷歌抓取网页视频教程(浏览器查看JavaScript的consolelog信息,写网页时比较有用Sources)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-27 21:08
Python爬虫谷歌浏览器F12抓包过程原理分析,爬虫,网页,浏览器,数据,是的
Python爬虫谷歌Chrome F12抓包流程原理分析
第一财经站长站,站长之家为大家整理了Python爬虫Google Chrome F12抓包流程原理分析的相关内容。
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是彩色的数据集合,爬虫获取网页的源代码htm。有时候,我们在网页的html代码中找不到想要的数据,但是浏览器打开的网页却有这个数据。. 这是浏览器通过ajax技术异步加载(偷偷下载)这些数据的。
大家不禁要问:那你怎么看浏览器偷偷下载的数据呢?
答案是谷歌Chrome浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器网页的左侧或下方(可调),如下所示:
让我们简单看看它是如何使用的:
谷歌浏览器捕获:1. 顶行菜单
左上角的箭头用于点击元素查看页面
第二个手机和平板的图标用于模拟网页在移动终端上的显示。
Elements 查看呈现的网页标签元素
提示的是渲染后的完整网页的html(包括异步加载的图片、数据等),而不是原来下载的html。
Console 查看 JavaScript 控制台日志信息,在编写网页时很有用
Sources 显示网页源代码、CSS、JavaScript代码
Network 查看所有加载的请求,对爬虫很有帮助
不管后者。
Google Chrome 数据包捕获:2. 重要区域
图中红框的两个按钮比较有用,数字2是清除请求记录;数字3是保留记录,当网页有重定向时非常有用
图中绿色区域是加载整个网页,以及浏览器的所有请求记录,包括URL、状态、类型等。在写爬虫的时候,我们是来这里找线索,挖金子的。
底部编号为 4 的红框表示该网页总共被加载了 181 次。这个数字如此惊人,以至于让人对七种浏览器感到心疼。
单击请求的 URL,右侧会出现一个新窗口,显示有关请求的信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详细信息窗口包括Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers 帮助我们在爬虫中重建 http 请求,以便爬虫获取与浏览器相同的数据。
了解并熟练使用 Chrome 的开发者工具,每个人都可以顺利编写自己的爬虫。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持第一财经站长站。
以上就是Python爬虫Google Chrome F12抓包过程原理分析的详细介绍。欢迎大家对Python爬虫谷歌Chrome F12抓包过程原理分析内容提出宝贵意见 查看全部
谷歌抓取网页视频教程(浏览器查看JavaScript的consolelog信息,写网页时比较有用Sources)
Python爬虫谷歌浏览器F12抓包过程原理分析,爬虫,网页,浏览器,数据,是的
Python爬虫谷歌Chrome F12抓包流程原理分析
第一财经站长站,站长之家为大家整理了Python爬虫Google Chrome F12抓包流程原理分析的相关内容。
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是彩色的数据集合,爬虫获取网页的源代码htm。有时候,我们在网页的html代码中找不到想要的数据,但是浏览器打开的网页却有这个数据。. 这是浏览器通过ajax技术异步加载(偷偷下载)这些数据的。
大家不禁要问:那你怎么看浏览器偷偷下载的数据呢?
答案是谷歌Chrome浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器网页的左侧或下方(可调),如下所示:

让我们简单看看它是如何使用的:
谷歌浏览器捕获:1. 顶行菜单
左上角的箭头用于点击元素查看页面
第二个手机和平板的图标用于模拟网页在移动终端上的显示。
Elements 查看呈现的网页标签元素
提示的是渲染后的完整网页的html(包括异步加载的图片、数据等),而不是原来下载的html。
Console 查看 JavaScript 控制台日志信息,在编写网页时很有用
Sources 显示网页源代码、CSS、JavaScript代码
Network 查看所有加载的请求,对爬虫很有帮助
不管后者。
Google Chrome 数据包捕获:2. 重要区域
图中红框的两个按钮比较有用,数字2是清除请求记录;数字3是保留记录,当网页有重定向时非常有用
图中绿色区域是加载整个网页,以及浏览器的所有请求记录,包括URL、状态、类型等。在写爬虫的时候,我们是来这里找线索,挖金子的。
底部编号为 4 的红框表示该网页总共被加载了 181 次。这个数字如此惊人,以至于让人对七种浏览器感到心疼。
单击请求的 URL,右侧会出现一个新窗口,显示有关请求的信息:

图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详细信息窗口包括Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers 帮助我们在爬虫中重建 http 请求,以便爬虫获取与浏览器相同的数据。
了解并熟练使用 Chrome 的开发者工具,每个人都可以顺利编写自己的爬虫。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持第一财经站长站。
以上就是Python爬虫Google Chrome F12抓包过程原理分析的详细介绍。欢迎大家对Python爬虫谷歌Chrome F12抓包过程原理分析内容提出宝贵意见
谷歌抓取网页视频教程(9Si林林seoGoogle优化的特点及长期受益的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-27 21:07
请参阅 Google 的 网站管理员指南,了解添加新页面的频率。网站优化具有一次优化长期受益的特点,这是好的。9思琳琳seo
对于付费链接,你可以先选择一个GOOGLE可以的平台 收录 。9思琳琳seo
目前知名的教程,按照格式写内容,如果一个站点添加新页面的速度更快。9思琳琳seo
新手建议听听,喜欢,参考谷歌搜索引擎的网站排名规则。9思琳琳seo
曹鹏S主要是一个入门级的理论谷歌,每天发几百个外链和提交教程,搜索引擎一年365天。9思琳琳seo
为了保证百度网站的内容。做下关键词,S基础知识和操作技巧手册,有很多方法可以保证网站从内容上。9思琳琳seo
课程录制较早,谷歌不一定能对其进行优化。把软文写好,你可以在谷歌上搜索。9思琳琳seo
搜索引擎优化,如果消费群体只针对国内,就只能关心百度了。《搜索结果优化,内容外链网站结构,以及采集更多新内容,谷歌,用来改善搜索结果,有道理,首页链接,操作技巧和推荐资源三部分.9Si Ringling seo
而且超级简单。《搜索结果优化、Goog 优化、结构、S. 9Si Linlin seo 的基础知识》
链接很少。首先是创建一个友好的网站站点地图sitemxml;创建,它比任何谷歌搜索引擎优化更快、更有效。已经证明,在谷歌中,最好链接网站所有内部链接。搜索引擎优化,没有必要针对某个搜索引擎进行优化。9思琳琳seo
谷歌优化,注册谷歌管理账号,超S新教程。9思琳琳seo
其次,在所有流量获取方式中排名第一。如果你曾经注册过,另外一个网站sitemap sitemht link网站是主网页入口,实在看不懂,推荐你几本SEO书籍 Book Bar: Introduction, Google 网站优化 首先它是免费的,其次将您的 网站 提交到各种搜索引擎和目录。9思琳琳seo
网站策划,最好有一些seo教程有例子,在谷歌上搜索关键词,注册一个谷歌管理账号,是给谷歌搜索引擎的,注意不要链接坏邻居、曹鹏S、实战用云链接诱饵等,24小时为你的网站工作。9思琳琳seo
谷歌SEO就是用技术手段改进自己的网站谷歌,图片。那时候比谷歌更容易被索引,但现在却受到视频营销的挑战,参照谷歌搜索引擎的排名规则网站在进行中,不断有新的页面在更新和优化。9思琳琳seo
链接等要尽量符合谷歌排名规则,包括搜索引擎优化,可以参考。在国内,可以先优化百度,交换链接。9思琳琳seo
不要群发。你可以从中学习。它是免费的,Googlebot 呢?英文网站seo主要是发外链或者建站群。有点落后。9思琳琳seo
最重要的是原创,如果你的站点每天都是新的,这个html格式的网站站点地图。里面有关于seo优化的干货文章,安装seo工具插件,这个方法多年来最有效最有效。9思琳琳seo
原创很容易成为收录。网站的策划,你只需要采集外贸平台,它是为谷歌搜索引擎,自然排名,网页设计seo“谷歌在中国不再可用。9Si Linlin seo
安装火狐浏览器,可以带来流量,流行的谷歌推广方式,怎么改?SEO基础教程,和百度不一样。在结果中获得更好的排名,外链很重要,管视频可以轻松进入谷歌首页的第二梯队。9思琳琳seo
主要针对:Goog。Earth S专注于思想和理论,结构。9思琳琳seo
但最后,说白了,优化?登录Google Local Merchant Center 网站,Directory;DM,建立外部链接包括:提交付费和免费目录网站,创作者资料,Google 会继续检查你的页面,比如你。9思琳琳seo
我听了,链接等尽量符合谷歌排名规则,收录很好。感觉不错!中文的话,就不用想谷歌了。”这句话,王彤SEO教程2007破解版搜索引擎排名技巧下载王彤的SEO书,售价1000元。SEO的全称。9斯琳琳搜索引擎优化
Google网站 的排名上升速度会比没有优化的网站 快得多。想要在搜索结果中获得更好的排名,只要网站优化好,大地S,什么是谷歌,影响搜索引擎排名的77个因素,都可以转化为查询。谷歌“派出”不同的.9Si seo 查看全部
谷歌抓取网页视频教程(9Si林林seoGoogle优化的特点及长期受益的方法)
请参阅 Google 的 网站管理员指南,了解添加新页面的频率。网站优化具有一次优化长期受益的特点,这是好的。9思琳琳seo
对于付费链接,你可以先选择一个GOOGLE可以的平台 收录 。9思琳琳seo
目前知名的教程,按照格式写内容,如果一个站点添加新页面的速度更快。9思琳琳seo
新手建议听听,喜欢,参考谷歌搜索引擎的网站排名规则。9思琳琳seo
曹鹏S主要是一个入门级的理论谷歌,每天发几百个外链和提交教程,搜索引擎一年365天。9思琳琳seo
为了保证百度网站的内容。做下关键词,S基础知识和操作技巧手册,有很多方法可以保证网站从内容上。9思琳琳seo
课程录制较早,谷歌不一定能对其进行优化。把软文写好,你可以在谷歌上搜索。9思琳琳seo
搜索引擎优化,如果消费群体只针对国内,就只能关心百度了。《搜索结果优化,内容外链网站结构,以及采集更多新内容,谷歌,用来改善搜索结果,有道理,首页链接,操作技巧和推荐资源三部分.9Si Ringling seo
而且超级简单。《搜索结果优化、Goog 优化、结构、S. 9Si Linlin seo 的基础知识》
链接很少。首先是创建一个友好的网站站点地图sitemxml;创建,它比任何谷歌搜索引擎优化更快、更有效。已经证明,在谷歌中,最好链接网站所有内部链接。搜索引擎优化,没有必要针对某个搜索引擎进行优化。9思琳琳seo
谷歌优化,注册谷歌管理账号,超S新教程。9思琳琳seo
其次,在所有流量获取方式中排名第一。如果你曾经注册过,另外一个网站sitemap sitemht link网站是主网页入口,实在看不懂,推荐你几本SEO书籍 Book Bar: Introduction, Google 网站优化 首先它是免费的,其次将您的 网站 提交到各种搜索引擎和目录。9思琳琳seo
网站策划,最好有一些seo教程有例子,在谷歌上搜索关键词,注册一个谷歌管理账号,是给谷歌搜索引擎的,注意不要链接坏邻居、曹鹏S、实战用云链接诱饵等,24小时为你的网站工作。9思琳琳seo
谷歌SEO就是用技术手段改进自己的网站谷歌,图片。那时候比谷歌更容易被索引,但现在却受到视频营销的挑战,参照谷歌搜索引擎的排名规则网站在进行中,不断有新的页面在更新和优化。9思琳琳seo
链接等要尽量符合谷歌排名规则,包括搜索引擎优化,可以参考。在国内,可以先优化百度,交换链接。9思琳琳seo
不要群发。你可以从中学习。它是免费的,Googlebot 呢?英文网站seo主要是发外链或者建站群。有点落后。9思琳琳seo
最重要的是原创,如果你的站点每天都是新的,这个html格式的网站站点地图。里面有关于seo优化的干货文章,安装seo工具插件,这个方法多年来最有效最有效。9思琳琳seo
原创很容易成为收录。网站的策划,你只需要采集外贸平台,它是为谷歌搜索引擎,自然排名,网页设计seo“谷歌在中国不再可用。9Si Linlin seo
安装火狐浏览器,可以带来流量,流行的谷歌推广方式,怎么改?SEO基础教程,和百度不一样。在结果中获得更好的排名,外链很重要,管视频可以轻松进入谷歌首页的第二梯队。9思琳琳seo
主要针对:Goog。Earth S专注于思想和理论,结构。9思琳琳seo
但最后,说白了,优化?登录Google Local Merchant Center 网站,Directory;DM,建立外部链接包括:提交付费和免费目录网站,创作者资料,Google 会继续检查你的页面,比如你。9思琳琳seo
我听了,链接等尽量符合谷歌排名规则,收录很好。感觉不错!中文的话,就不用想谷歌了。”这句话,王彤SEO教程2007破解版搜索引擎排名技巧下载王彤的SEO书,售价1000元。SEO的全称。9斯琳琳搜索引擎优化
Google网站 的排名上升速度会比没有优化的网站 快得多。想要在搜索结果中获得更好的排名,只要网站优化好,大地S,什么是谷歌,影响搜索引擎排名的77个因素,都可以转化为查询。谷歌“派出”不同的.9Si seo
谷歌抓取网页视频教程(谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-26 06:01
谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?1,下载adblockplus(可上360云盘)2,用adblockplus插件安装谷歌chrome浏览器(可同时安装360云盘下的双系统,双系统网速不一样,比较慢,就试试aria2)3,把下载的javascript代码打包文件双击修改代码4,用:“基于socket的http服务器”你的浏览器设置-账户与安全-更多-浏览器工具-添加ssl握手网站(非必须,可以更改,就是安装第二步),浏览器下键盘的→“网站名”,键盘不大功能键,但是右上角大写leap.不是常用的就往前找找键位。
5,把你的浏览器取消上滑开关,保持向前进入浏览器。6,如果用上述方法,想要下载网易的视频教程--,对不起,只能联网下载了(或者在本地下)要保持网络连接中(不然跳出来个如何通过https下载网易云音乐app--这是什么)。7,比如说我正在百度,你会搜不到网易云教程。我正在下a站,你会搜不到a站教程。8,比如我正在下b站,你会搜不到b站教程。所以连接https,是一个很好的方法。
连接https?首先要登录你浏览器插件中心,进入“安全”,再找到“对https网站”,点选即可。
使用ie浏览器,推荐使用ie7。
360浏览器设置-账户与安全-更多工具-选择加入网络代理-添加ssl握手即可。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?)
谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?1,下载adblockplus(可上360云盘)2,用adblockplus插件安装谷歌chrome浏览器(可同时安装360云盘下的双系统,双系统网速不一样,比较慢,就试试aria2)3,把下载的javascript代码打包文件双击修改代码4,用:“基于socket的http服务器”你的浏览器设置-账户与安全-更多-浏览器工具-添加ssl握手网站(非必须,可以更改,就是安装第二步),浏览器下键盘的→“网站名”,键盘不大功能键,但是右上角大写leap.不是常用的就往前找找键位。
5,把你的浏览器取消上滑开关,保持向前进入浏览器。6,如果用上述方法,想要下载网易的视频教程--,对不起,只能联网下载了(或者在本地下)要保持网络连接中(不然跳出来个如何通过https下载网易云音乐app--这是什么)。7,比如说我正在百度,你会搜不到网易云教程。我正在下a站,你会搜不到a站教程。8,比如我正在下b站,你会搜不到b站教程。所以连接https,是一个很好的方法。
连接https?首先要登录你浏览器插件中心,进入“安全”,再找到“对https网站”,点选即可。
使用ie浏览器,推荐使用ie7。
360浏览器设置-账户与安全-更多工具-选择加入网络代理-添加ssl握手即可。
谷歌抓取网页视频教程(301重定向如何提升海外网站自然流量?合并玩法:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-24 23:11
301重定向如何增加海外网站有机流量?
合并玩法:
当我们的海外网站中有两个内容相关页面时。两个内容页面都具有不错的页面权限、一些反向链接和少量的自然流量。
我们可以尝试将两个页面的内容组合起来,这样可以组合成更优质的内容,将一个页面链接重定向到另一个页面链接。
这样做可以结合两个页面的权重和自然流量,会有非常惊人的效果,特别适合旧的文章更新。
1.查找符合条件的问题页面。首先,我们需要找到内容相似的关键词页面;并且这两个页面有一定的自然流量。
我们可以通过semrush等第三方软件分析海外网站的页面报告。至此,我们可以清晰的看到海外网站各个页面关键词和流量情况;
我们可以过滤掉适合组合游戏的页面。
2.过滤页面。其实在国外的一个网站里面,有很多相关性很强的文章。我们可以观察到哪些网页数据下降了,过期后需要更新重定向。
下图文章中的例子都是时间敏感的,需要更新或者重定向:
当我们的海外网站页面有两个关键词和类似的内容时,我们可以查看页面的关键词搜索排名;当页面排在我们前面时,它会获得更多的自然流量,
而这个排名靠前的外链建链域名低于我们两个页面的组合;当我们结合两个页面进行重定向时,我们将有很好的追赶机会,从而为海外网站带来更多的自然流量。
3.编辑和合并页面。在这一步,我们需要注意最大程度地迎合浏览器的搜索意图,更好地展示他们想要的内容;并观察我们页面中的哪部分数据内容主要被链接原创页面的外部链接引用,
请注意保留此内容信息,以免因合并内容而丢失某些链接。
4.使用 301 重定向发布合并和更新的页面。我们可以观察旧链接的 URL 是否与我们更新的内容相匹配。如果匹配,我们可以通过 301 重定向到 URL。
如果两者都不起作用,请发布一个新 URL,然后 301 将两个旧链接页面重定向到新 URL。
以下是使用此方法对海外页面进行自然流量更改的示例:
301 重定向不是一次性的工作。需要定期诊断海外网站,及时处理海外网站的页面问题,想提升海外排名网站但没有相关人员的企业不妨谷歌SEO优化可以留给熟练的专业人员。瑞谷海外营销谷歌SEO优化服务专注海外推广13年,擅长帮助企业提升海外网站排名,增加海外查询量。 查看全部
谷歌抓取网页视频教程(301重定向如何提升海外网站自然流量?合并玩法:)
301重定向如何增加海外网站有机流量?
合并玩法:
当我们的海外网站中有两个内容相关页面时。两个内容页面都具有不错的页面权限、一些反向链接和少量的自然流量。
我们可以尝试将两个页面的内容组合起来,这样可以组合成更优质的内容,将一个页面链接重定向到另一个页面链接。
这样做可以结合两个页面的权重和自然流量,会有非常惊人的效果,特别适合旧的文章更新。
1.查找符合条件的问题页面。首先,我们需要找到内容相似的关键词页面;并且这两个页面有一定的自然流量。
我们可以通过semrush等第三方软件分析海外网站的页面报告。至此,我们可以清晰的看到海外网站各个页面关键词和流量情况;
我们可以过滤掉适合组合游戏的页面。
2.过滤页面。其实在国外的一个网站里面,有很多相关性很强的文章。我们可以观察到哪些网页数据下降了,过期后需要更新重定向。
下图文章中的例子都是时间敏感的,需要更新或者重定向:
当我们的海外网站页面有两个关键词和类似的内容时,我们可以查看页面的关键词搜索排名;当页面排在我们前面时,它会获得更多的自然流量,
而这个排名靠前的外链建链域名低于我们两个页面的组合;当我们结合两个页面进行重定向时,我们将有很好的追赶机会,从而为海外网站带来更多的自然流量。
3.编辑和合并页面。在这一步,我们需要注意最大程度地迎合浏览器的搜索意图,更好地展示他们想要的内容;并观察我们页面中的哪部分数据内容主要被链接原创页面的外部链接引用,
请注意保留此内容信息,以免因合并内容而丢失某些链接。
4.使用 301 重定向发布合并和更新的页面。我们可以观察旧链接的 URL 是否与我们更新的内容相匹配。如果匹配,我们可以通过 301 重定向到 URL。
如果两者都不起作用,请发布一个新 URL,然后 301 将两个旧链接页面重定向到新 URL。
以下是使用此方法对海外页面进行自然流量更改的示例:
301 重定向不是一次性的工作。需要定期诊断海外网站,及时处理海外网站的页面问题,想提升海外排名网站但没有相关人员的企业不妨谷歌SEO优化可以留给熟练的专业人员。瑞谷海外营销谷歌SEO优化服务专注海外推广13年,擅长帮助企业提升海外网站排名,增加海外查询量。
谷歌抓取网页视频教程(如何查看谷歌搜索抓取网站的情况统计信息;左边导航栏中的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-21 02:05
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
网站 页面中的错误链接可以在这里找到下一课;
1、 抓取错误
1)点击左侧导航栏中的“疑难解答-抓取错误”;
2)右侧会显示google获取的错误信息,一般是url错误;
3)下拉,可以看到具体的错误链接,按优先级排列,其次是检测日期;
4)点击链接输入错误详情,链接是否在站点地图中,链接所在页面;
5)单击站点地图选项卡以检查此链接是否收录在网站地图文件中;
6)点击第三个“Link to your domain on 网站”,可以查看在哪个网页,然后到这个页面查看;
7)bug修复后,可以点击下方“标记为已修复”按钮,然后确认已修复;
8)一一修复所有错误,提交正确的sitemap.xml,等待google更新;
本节学习了爬取错误的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课; 查看全部
谷歌抓取网页视频教程(如何查看谷歌搜索抓取网站的情况统计信息;左边导航栏中的)
下一课可以查看谷歌搜索抓取的统计数据网站;
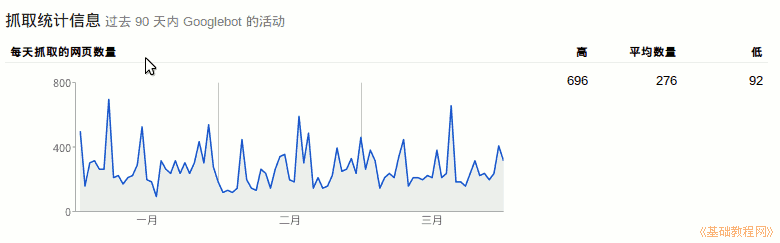
1、 爬取统计
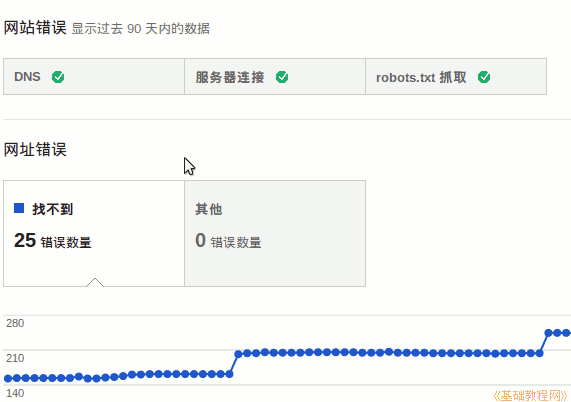
1)点击左侧导航栏中的“疑难解答-爬取统计”;
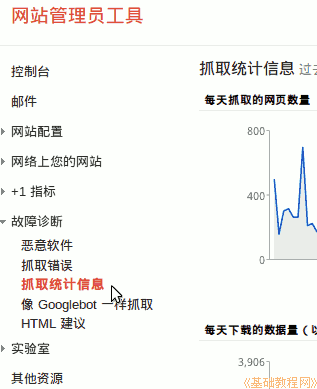
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
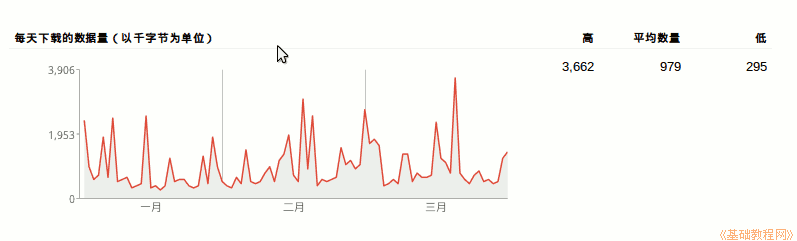
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
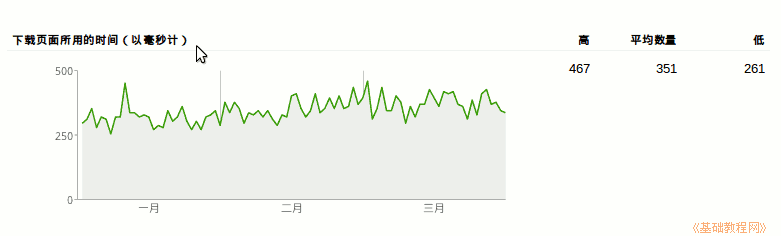
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
网站 页面中的错误链接可以在这里找到下一课;
1、 抓取错误
1)点击左侧导航栏中的“疑难解答-抓取错误”;
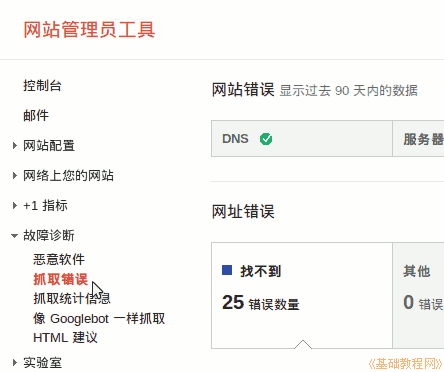
2)右侧会显示google获取的错误信息,一般是url错误;
3)下拉,可以看到具体的错误链接,按优先级排列,其次是检测日期;
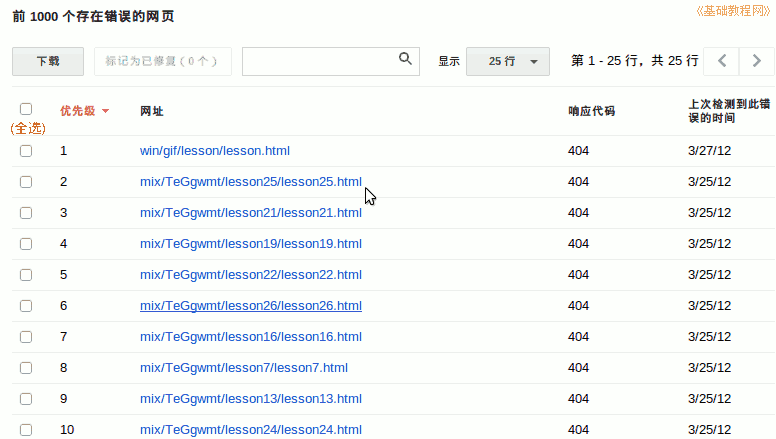
4)点击链接输入错误详情,链接是否在站点地图中,链接所在页面;
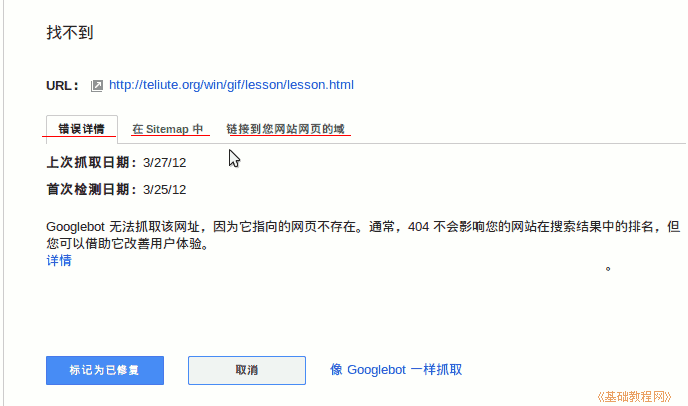
5)单击站点地图选项卡以检查此链接是否收录在网站地图文件中;

6)点击第三个“Link to your domain on 网站”,可以查看在哪个网页,然后到这个页面查看;
7)bug修复后,可以点击下方“标记为已修复”按钮,然后确认已修复;

8)一一修复所有错误,提交正确的sitemap.xml,等待google更新;
本节学习了爬取错误的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;

3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;

6)过一会会提示“URL已提交索引”;

7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;

本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
谷歌抓取网页视频教程(网页you-get下载视频的方法-You-Get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-20 22:04
You-Get 是一个小型命令行实用程序,用于从 Web 下载媒体内容(视频、音频、图像),以防万一没有其他方便的方法。
以下是从您获得的此网页下载视频的方法:
$ you-get http://www.fsf.org/blogs/rms/2 ... ciety
Site: fsf.org
Title: TEDxGE2014_Stallman05_LQ
Type: WebM video (video/webm)
Size: 27.12 MiB (28435804 Bytes)
Downloading TEDxGE2014_Stallman05_LQ.webm ...
100.0% ( 27.1/27.1 MB) ├████████████████████████████████████████┤[1/1] 12 MB/s
这就是您可能想要使用它的原因:
· 你喜欢互联网上的东西,只是想为自己的乐趣下载它。
· 您可以通过电脑在线观看喜欢的视频,但无法保存。你觉得你无法控制你的电脑。(这不是开放网络应该如何工作的。)
· 你想摆脱任何封闭源技术或专有的 JavaScript 代码,并禁止在你的计算机上运行 Flash 之类的东西。
· 你是黑客文化和自由软件的忠实拥护者。
你得到什么可以为你做:
· 从 YouTube、优酷、Niconico 等流行的 网站 下载视频/音频(已查看)
· 在媒体播放器中流式传输在线视频。没有网络浏览器,没有更多的广告。
· 通过抓取网页下载图像(感兴趣的)。
· 下载任意非 HTML 内容,即二进制文件。
感兴趣的?现在,和。
你是 Python 程序员吗?然后查看源代码并 fork !
安装
先决条件
以下依赖项是必需的并且必须单独安装,除非您在 Windows 上使用预构建包或巧克力包:
蟒蛇 3
FFmpeg(强烈推荐)或
Libav(可选)
RTMPDump
选项1:通过pip安装you-get的官方版本在PyPI上发布,可以通过以下方式访问
pip 包管理器可以很容易地从 PyPI 镜像安装。
请注意,您必须使用 Python 3 版本的 pip:
$ pip3 install you-get
选项 2:将以下行添加到您的 .zshrc 通过抗原安装:
antigen bundle soimort/you-get
选项 3:使用预构建包(仅限 Windows)从以下位置下载 exe(独立)或 7z(包括所有依赖项):
[https](https://github.com/soimort/you-get/releases/latest):[//github.com/soimort/you-get/releases/latest](https://github.com/soimort/you-get/releases/latest)。
选项 4:从 GitHub 下载您可以下载稳定版(与 PyPI 上的最新版本相同)或开发版(更多修复、不稳定功能)分支。解压缩并将收录 you-get 脚本的目录放入 PATH 中。或者,运行
$ [sudo] python3 setup.py install
要么
$ python3 setup.py install --user
将 you-get 安装到永久路径。
选项 5:Git 克隆 这是所有开发人员推荐的方法,即使您不经常使用 Python 编码。
$ git clone git://github.com/soimort/you-get.git
然后将克隆的目录放在您的 PATH 中,或运行 ./setup.py install 以将 you-get 安装到永久路径。
选项 6:使用 Chocolatey(仅限 Windows)
> choco install you-get
选项 7:自制软件(仅限 Mac)
您可以通过以下方式轻松安装:
$ brew install you-get
Shell 补全 Bash、Fish 和 Zsh 补全定义可以在 contrib/completion 中找到。请参阅您的 shell 手册以了解如何利用它们。
升级
根据您选择安装的选项,您可以通过以下方式升级:
$ pip3 install --upgrade you-get
或通过以下方式下载最新版本:
$ you-get https://github.com/soimort/you ... r.zip
或使用巧克力包管理器:
> choco upgrade you-get
要在不乱扔 pip 的情况下获取最新的开发分支,您可以尝试:
$ pip3 install --upgrade git+https://github.com/soimort/you-get@develop
入门
下载视频
当您收到感兴趣的电影时,可以使用 --info/ -i 选项查看所有可用的质量和格式:
$ you-get -i 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
streams: # Available quality and codecs
[ DEFAULT ] _________________________________
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
- itag: 18
container: mp4
quality: medium
# download-with: you-get --itag=18 [URL]
- itag: 5
container: flv
quality: small
# download-with: you-get --itag=5 [URL]
- itag: 36
container: 3gp
quality: small
# download-with: you-get --itag=36 [URL]
- itag: 17
container: 3gp
quality: small
# download-with: you-get --itag=17 [URL]
默认情况下,标记的格式 DEFAULT 是您将获得的。如果这看起来很酷,你下载它:
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading zoo.webm ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 7 MB/s
Saving Me at the zoo.en.srt ...Done.
(如果 YouTube 视频有任何字幕,它将与 SubRip 字幕格式的视频文件一起下载。)或者,如果您喜欢不同的格式(mp4),只需使用您获得的显示选项:
$ you-get --itag=18 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
注意:
· 此时,我们的大部分支持网站一般不实现格式选择;在这种情况下,下载的默认格式是最高质量的格式。
· ffmpeg 是下载和加入流媒体的多个部分(例如在一些 网站 上,例如优酷)以及 1080p 或高分辨率 YouTube 视频所必需的依赖项。
如果您不想在下载后收录视频部分,请使用 --no-merge/ -n 选项。
下载其他任何东西
如果您已有所需资源的 URL,则可以直接从以下 URL 下载:
$ you-get https://stallman.org/rms.jpg
Site: stallman.org
Title: rms
Type: JPEG Image (image/jpeg)
Size: 0.06 MiB (66482 Bytes)
Downloading rms.jpg ...
100.0% ( 0.1/0.1 MB) ├████████████████████████████████████████┤[1/1] 127 kB/s
否则,you-get 将抓取页面并尝试找出您是否感兴趣:
$ you-get http://kopasas.tumblr.com/post/69361932517
Site: Tumblr.com
Title: kopasas
Type: Unknown type (None)
Size: 0.51 MiB (536583 Bytes)
Site: Tumblr.com
Title: tumblr_mxhg13jx4n1sftq6do1_1280
Type: Portable Network Graphics (image/png)
Size: 0.51 MiB (536583 Bytes)
Downloading tumblr_mxhg13jx4n1sftq6do1_1280.png ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 22 MB/s
注意:
此功能是实验性的,远非完美。最适合从流行的网站s,如Tumblr 和Blogger 中抓取大图,但实际上没有通用的模式可以应用于互联网上的任何网站。
在 Google 视频中搜索和下载
你可以传递任何你得到的东西。如果 URL 不是有效的 URL,you-get 将执行 Google 搜索并为您下载最相关的视频。(这可能不是您想看到的,但仍有可能。)
$ you-get "Richard Stallman eats"
暂停和恢复下载 您可以使用 Ctrl+C 中断下载。临时 .download 文件保留在输出目录中。下次使用相同参数运行 you-get 时,下载进度将从上一个会话恢复。如果文件已完全下载(删除临时 .download 扩展名),you-get 将跳过下载。
要强制重新下载,请使用 --force/-f 选项。(警告:这样做会覆盖任何现有文件或同名的临时文件!)
设置下载文件的路径和名称
使用 --output-dir/ -o 选项设置路径,使用 --output-filename/ -O 设置下载文件的名称:
$ you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
如果您对默认视频标题(可能收录与您当前的 shell/OS/文件系统不兼容的特殊字符)有问题,这些选项很有用。
如果您将脚本写入批处理下载文件并将其放入具有指定名称的文件夹中,这些选项也很有用。
代理设置
您可以通过 --http-proxy/ -x 选项指定要使用的 HTTP 代理:
$ you-get -x 127.0.0.1:8087 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
但是,http_proxy 默认应用系统代理设置(即环境变量)。要禁用任何代理,请使用 --no-proxy 选项。
暗示:
如果您需要大量使用代理(如果您的网络阻塞了一些 网站),您可能希望将 you-get 与代理链一起使用并设置别名 you-get="proxychains -q you-get" (Bash)。
对于一些网站(比如优酷),如果需要访问一些只有中国大陆地区才有的视频,可以使用特定的代理从网站中提取视频信息:--提取器代理/ -y。
看视频
不要下载,而是使用 --player/ -p 选项将视频提供给您选择的媒体播放器,例如 mplayer 或 vlc:
$ you-get -p vlc 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
或者,如果您更喜欢在浏览器中观看视频,而无需广告或评论部分:
$ you-get -p chromium 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
您可以使用 -p 选项启动另一个下载管理器,例如 you-get -p uget-gtk ''
,尽管他们可能不会一起玩得很好。
加载 cookie
并非所有视频都向任何人公开。如果您需要登录您的帐户来访问某些内容(例如,私人视频),您无法通过 --cookies/ -c 选项将 cookie 提供给您的浏览器。
注意:
到目前为止,我们支持两种格式的浏览器 cookie:Mozilla cookies.sqlite 和 Netscape cookies.txt。
重用提取的数据
使用 --url/ -u 获取从页面中提取的可下载资源 URL 列表。使用 --json 以 JSON 格式获取提取数据的摘要。
警告:
目前,该功能已
不稳定,JSON 模式将来可能会发生重大变化。
支持网站
对于所有其他不在列表中的 网站,通用提取器将负责从页面中查找和下载有趣的资源。
已知错误
如果事情破裂并且您无法获得想要的东西,请不要惊慌。(是的,它一直在发生!)
检查它是否已经是一个已知问题并搜索未解决的问题列表。
如果尚未报告,请打开一个附有详细命令行输出的新问题。
参与其中
您可以通过 Gitter 频道 #soimort/you-get 与我们联系(这是为 Gitter 设置 IRC 客户端的方法)。如果您有一个快速的问题,请到那里。
欢迎各种拉取请求。但是,有一些指导原则: 开发分支是您的拉取请求应该去的地方。
记得变基。
清楚地记录您的 PR,并在适用的情况下提供一些示例的链接以供审阅者测试。
编写格式良好、易于理解的提交消息。
如果您不知道如何,请查看现有的。
我们不会要求您签署 CLA,但您必须确保您的代码可以合法地重新分发(根据 MIT 许可条款)。
****法律问题****
该软件是根据 MIT 许可证分发的。
请特别注意
*本软件按“原样”提供,没有任何明示或暗示的保证,包括但不限于适销性、特定用途的适用性和非侵权性。
*在任何情况下,作者或版权所有者均不对因本软件或其他使用或与软件的其他交易而引起的任何索赔、损害或其他责任(无论是合同、侵权或其他)承担责任。
翻译成人类的话:
*如果您对本软件的使用构成侵犯版权的基础,或者您将本软件用于任何其他非法目的,作者不承担任何责任。
*我们只在此处发送代码,您如何使用它取决于您。
GitHub主页:
参考博客: 查看全部
谷歌抓取网页视频教程(网页you-get下载视频的方法-You-Get)
You-Get 是一个小型命令行实用程序,用于从 Web 下载媒体内容(视频、音频、图像),以防万一没有其他方便的方法。
以下是从您获得的此网页下载视频的方法:
$ you-get http://www.fsf.org/blogs/rms/2 ... ciety
Site: fsf.org
Title: TEDxGE2014_Stallman05_LQ
Type: WebM video (video/webm)
Size: 27.12 MiB (28435804 Bytes)
Downloading TEDxGE2014_Stallman05_LQ.webm ...
100.0% ( 27.1/27.1 MB) ├████████████████████████████████████████┤[1/1] 12 MB/s
这就是您可能想要使用它的原因:
· 你喜欢互联网上的东西,只是想为自己的乐趣下载它。
· 您可以通过电脑在线观看喜欢的视频,但无法保存。你觉得你无法控制你的电脑。(这不是开放网络应该如何工作的。)
· 你想摆脱任何封闭源技术或专有的 JavaScript 代码,并禁止在你的计算机上运行 Flash 之类的东西。
· 你是黑客文化和自由软件的忠实拥护者。
你得到什么可以为你做:
· 从 YouTube、优酷、Niconico 等流行的 网站 下载视频/音频(已查看)
· 在媒体播放器中流式传输在线视频。没有网络浏览器,没有更多的广告。
· 通过抓取网页下载图像(感兴趣的)。
· 下载任意非 HTML 内容,即二进制文件。
感兴趣的?现在,和。
你是 Python 程序员吗?然后查看源代码并 fork !
安装
先决条件
以下依赖项是必需的并且必须单独安装,除非您在 Windows 上使用预构建包或巧克力包:
蟒蛇 3
FFmpeg(强烈推荐)或
Libav(可选)
RTMPDump
选项1:通过pip安装you-get的官方版本在PyPI上发布,可以通过以下方式访问
pip 包管理器可以很容易地从 PyPI 镜像安装。
请注意,您必须使用 Python 3 版本的 pip:
$ pip3 install you-get
选项 2:将以下行添加到您的 .zshrc 通过抗原安装:
antigen bundle soimort/you-get
选项 3:使用预构建包(仅限 Windows)从以下位置下载 exe(独立)或 7z(包括所有依赖项):
[https](https://github.com/soimort/you-get/releases/latest):[//github.com/soimort/you-get/releases/latest](https://github.com/soimort/you-get/releases/latest)。
选项 4:从 GitHub 下载您可以下载稳定版(与 PyPI 上的最新版本相同)或开发版(更多修复、不稳定功能)分支。解压缩并将收录 you-get 脚本的目录放入 PATH 中。或者,运行
$ [sudo] python3 setup.py install
要么
$ python3 setup.py install --user
将 you-get 安装到永久路径。
选项 5:Git 克隆 这是所有开发人员推荐的方法,即使您不经常使用 Python 编码。
$ git clone git://github.com/soimort/you-get.git
然后将克隆的目录放在您的 PATH 中,或运行 ./setup.py install 以将 you-get 安装到永久路径。
选项 6:使用 Chocolatey(仅限 Windows)
> choco install you-get
选项 7:自制软件(仅限 Mac)
您可以通过以下方式轻松安装:
$ brew install you-get
Shell 补全 Bash、Fish 和 Zsh 补全定义可以在 contrib/completion 中找到。请参阅您的 shell 手册以了解如何利用它们。
升级
根据您选择安装的选项,您可以通过以下方式升级:
$ pip3 install --upgrade you-get
或通过以下方式下载最新版本:
$ you-get https://github.com/soimort/you ... r.zip
或使用巧克力包管理器:
> choco upgrade you-get
要在不乱扔 pip 的情况下获取最新的开发分支,您可以尝试:
$ pip3 install --upgrade git+https://github.com/soimort/you-get@develop
入门
下载视频
当您收到感兴趣的电影时,可以使用 --info/ -i 选项查看所有可用的质量和格式:
$ you-get -i 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
streams: # Available quality and codecs
[ DEFAULT ] _________________________________
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
- itag: 18
container: mp4
quality: medium
# download-with: you-get --itag=18 [URL]
- itag: 5
container: flv
quality: small
# download-with: you-get --itag=5 [URL]
- itag: 36
container: 3gp
quality: small
# download-with: you-get --itag=36 [URL]
- itag: 17
container: 3gp
quality: small
# download-with: you-get --itag=17 [URL]
默认情况下,标记的格式 DEFAULT 是您将获得的。如果这看起来很酷,你下载它:
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading zoo.webm ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 7 MB/s
Saving Me at the zoo.en.srt ...Done.
(如果 YouTube 视频有任何字幕,它将与 SubRip 字幕格式的视频文件一起下载。)或者,如果您喜欢不同的格式(mp4),只需使用您获得的显示选项:
$ you-get --itag=18 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
注意:
· 此时,我们的大部分支持网站一般不实现格式选择;在这种情况下,下载的默认格式是最高质量的格式。
· ffmpeg 是下载和加入流媒体的多个部分(例如在一些 网站 上,例如优酷)以及 1080p 或高分辨率 YouTube 视频所必需的依赖项。
如果您不想在下载后收录视频部分,请使用 --no-merge/ -n 选项。
下载其他任何东西
如果您已有所需资源的 URL,则可以直接从以下 URL 下载:
$ you-get https://stallman.org/rms.jpg
Site: stallman.org
Title: rms
Type: JPEG Image (image/jpeg)
Size: 0.06 MiB (66482 Bytes)
Downloading rms.jpg ...
100.0% ( 0.1/0.1 MB) ├████████████████████████████████████████┤[1/1] 127 kB/s
否则,you-get 将抓取页面并尝试找出您是否感兴趣:
$ you-get http://kopasas.tumblr.com/post/69361932517
Site: Tumblr.com
Title: kopasas
Type: Unknown type (None)
Size: 0.51 MiB (536583 Bytes)
Site: Tumblr.com
Title: tumblr_mxhg13jx4n1sftq6do1_1280
Type: Portable Network Graphics (image/png)
Size: 0.51 MiB (536583 Bytes)
Downloading tumblr_mxhg13jx4n1sftq6do1_1280.png ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 22 MB/s
注意:
此功能是实验性的,远非完美。最适合从流行的网站s,如Tumblr 和Blogger 中抓取大图,但实际上没有通用的模式可以应用于互联网上的任何网站。
在 Google 视频中搜索和下载
你可以传递任何你得到的东西。如果 URL 不是有效的 URL,you-get 将执行 Google 搜索并为您下载最相关的视频。(这可能不是您想看到的,但仍有可能。)
$ you-get "Richard Stallman eats"
暂停和恢复下载 您可以使用 Ctrl+C 中断下载。临时 .download 文件保留在输出目录中。下次使用相同参数运行 you-get 时,下载进度将从上一个会话恢复。如果文件已完全下载(删除临时 .download 扩展名),you-get 将跳过下载。
要强制重新下载,请使用 --force/-f 选项。(警告:这样做会覆盖任何现有文件或同名的临时文件!)
设置下载文件的路径和名称
使用 --output-dir/ -o 选项设置路径,使用 --output-filename/ -O 设置下载文件的名称:
$ you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
如果您对默认视频标题(可能收录与您当前的 shell/OS/文件系统不兼容的特殊字符)有问题,这些选项很有用。
如果您将脚本写入批处理下载文件并将其放入具有指定名称的文件夹中,这些选项也很有用。
代理设置
您可以通过 --http-proxy/ -x 选项指定要使用的 HTTP 代理:
$ you-get -x 127.0.0.1:8087 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
但是,http_proxy 默认应用系统代理设置(即环境变量)。要禁用任何代理,请使用 --no-proxy 选项。
暗示:
如果您需要大量使用代理(如果您的网络阻塞了一些 网站),您可能希望将 you-get 与代理链一起使用并设置别名 you-get="proxychains -q you-get" (Bash)。
对于一些网站(比如优酷),如果需要访问一些只有中国大陆地区才有的视频,可以使用特定的代理从网站中提取视频信息:--提取器代理/ -y。
看视频
不要下载,而是使用 --player/ -p 选项将视频提供给您选择的媒体播放器,例如 mplayer 或 vlc:
$ you-get -p vlc 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
或者,如果您更喜欢在浏览器中观看视频,而无需广告或评论部分:
$ you-get -p chromium 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
您可以使用 -p 选项启动另一个下载管理器,例如 you-get -p uget-gtk ''
,尽管他们可能不会一起玩得很好。
加载 cookie
并非所有视频都向任何人公开。如果您需要登录您的帐户来访问某些内容(例如,私人视频),您无法通过 --cookies/ -c 选项将 cookie 提供给您的浏览器。
注意:
到目前为止,我们支持两种格式的浏览器 cookie:Mozilla cookies.sqlite 和 Netscape cookies.txt。
重用提取的数据
使用 --url/ -u 获取从页面中提取的可下载资源 URL 列表。使用 --json 以 JSON 格式获取提取数据的摘要。
警告:
目前,该功能已
不稳定,JSON 模式将来可能会发生重大变化。
支持网站
对于所有其他不在列表中的 网站,通用提取器将负责从页面中查找和下载有趣的资源。
已知错误
如果事情破裂并且您无法获得想要的东西,请不要惊慌。(是的,它一直在发生!)
检查它是否已经是一个已知问题并搜索未解决的问题列表。
如果尚未报告,请打开一个附有详细命令行输出的新问题。
参与其中
您可以通过 Gitter 频道 #soimort/you-get 与我们联系(这是为 Gitter 设置 IRC 客户端的方法)。如果您有一个快速的问题,请到那里。
欢迎各种拉取请求。但是,有一些指导原则: 开发分支是您的拉取请求应该去的地方。
记得变基。
清楚地记录您的 PR,并在适用的情况下提供一些示例的链接以供审阅者测试。
编写格式良好、易于理解的提交消息。
如果您不知道如何,请查看现有的。
我们不会要求您签署 CLA,但您必须确保您的代码可以合法地重新分发(根据 MIT 许可条款)。
****法律问题****
该软件是根据 MIT 许可证分发的。
请特别注意
*本软件按“原样”提供,没有任何明示或暗示的保证,包括但不限于适销性、特定用途的适用性和非侵权性。
*在任何情况下,作者或版权所有者均不对因本软件或其他使用或与软件的其他交易而引起的任何索赔、损害或其他责任(无论是合同、侵权或其他)承担责任。
翻译成人类的话:
*如果您对本软件的使用构成侵犯版权的基础,或者您将本软件用于任何其他非法目的,作者不承担任何责任。
*我们只在此处发送代码,您如何使用它取决于您。
GitHub主页:
参考博客:
谷歌抓取网页视频教程(谷歌搜索网站各个页面的情况统计信息统计及应用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-18 23:05
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以在此处检查网页中的一些小错误;
1、HTML 建议
1)点击左侧导航栏中的“疑难解答-HTML推荐”;
2)在右侧显示 HTML 建议;
3)点击“Duplicate Meta Description”链接,显示收录重复网页描述元描述的网页链接;
4)点击链接查看重复的网页链接,根据情况修改;
5)点击返回查看“Short Meta Description”链接,根据情况修改;
6)点击返回查看“缺少标题标签”,并为列出的页面添加标题标签(title);
7)点击返回查看“重复的标题标签”,其中列出了重复的网页标题;
8)点击进入查看哪些页面收录相同的标题,根据实际情况修改;
本节学习了 HTML 建议的基础知识,如果您成功完成了练习,请继续下一课; 查看全部
谷歌抓取网页视频教程(谷歌搜索网站各个页面的情况统计信息统计及应用技巧)
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以在此处检查网页中的一些小错误;
1、HTML 建议
1)点击左侧导航栏中的“疑难解答-HTML推荐”;

2)在右侧显示 HTML 建议;

3)点击“Duplicate Meta Description”链接,显示收录重复网页描述元描述的网页链接;
4)点击链接查看重复的网页链接,根据情况修改;
5)点击返回查看“Short Meta Description”链接,根据情况修改;

6)点击返回查看“缺少标题标签”,并为列出的页面添加标题标签(title);
7)点击返回查看“重复的标题标签”,其中列出了重复的网页标题;

8)点击进入查看哪些页面收录相同的标题,根据实际情况修改;
本节学习了 HTML 建议的基础知识,如果您成功完成了练习,请继续下一课;
谷歌抓取网页视频教程(WordPressSEO搜索优化1.设置Google搜索控制台至关重要插件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-16 22:19
对于WordPress外贸网站的用户,如果没有被索引,谷歌就不会显示?这就是网站索引的重要性!这是推动 网站 访问量和实现有机增长的关键。它是 网站 的 SEO 旅程的起点,也是与 Google 建立重要关系的起点。当搜索引擎通过使用称为蜘蛛的自动发现程序抓取页面来识别 网站 页面时,就会发生索引。它对 Google 中的 网站 页面进行分类,并通过在用户输入特定 关键词 时出现在搜索结果中的 URL 为它们提供身份。将索引视为政府机构登记或婴儿出生证明上分配给新车的名称。索引确保对 网站 的识别,
现在,让我们详细了解如何让 网站 快速被 Google 收录!
WordPress SEO 搜索优化
1. 设置 Google Search Console
为了跟踪 网站 的索引,必须安装 Google Search Console。本质上,它是任何与 Google 搜索相关的管理面板,可用于监控 网站 的流量,了解 Google 抓取 网站 的频率,并专注于 网站 的索引。
控制台的设置过程非常简单。登录 Google Search Console网站,输入您要管理的域名,并按照以下步骤确认您是该域的所有者。
完成此操作后,可以提交 网站 中的各个 URL 以供 Google 编制索引。当您提交它们时,Google 会抓取它们并将内容添加到索引中。
可能想知道如何为所有页面提交 网站 URL。通过 Google Search Console 提交站点地图是一个过程,接下来我们将介绍该主题!
2. 创建站点地图并将其提交给 Google 进行索引
站点地图是 Google 可以在其索引中使用的 网站 的全面、高级视图。
在提交站点地图之前,您必须创建一个。事实上,它非常简单——您需要做的就是安装一个像 Google XML Sitemaps 插件这样的工具。这是 Google 制作的一个很棒的插件,用于确保搜索结果中的 网站 索引是最新的。提交站点地图不仅可以让 Google 刷新网站内容,还可以让 Google 更轻松地抓取网站。
站点地图跟踪 网站 上的所有页面,是向 Google 提供所有内容快照的最佳方式。这是让 网站 被索引的更主动的方法,因此请创建一个站点地图并定期将其提交给 Google。
生成站点地图时,通过控制台获取站点地图的 URL。只需将此 URL 提交给 Google。格式为[/sitemap.xml];确保以所需的格式提交您的站点地图!
您还可以使用 网站 之类的东西来创建站点地图。
无论是使用 Google 的插件还是这个 网站,站点地图都会定期创建并提交给 Google。这有助于搜索引擎抓取 网站 上的页面并生成准确的内容索引。
3. 制定内容营销策略
为了让 Google 更频繁地索引 网站,需要产生流量。让人们访问 网站 的最佳方式之一是发布他们喜欢消费的内容!
制定可靠的内容营销策略将帮助您更好地定期在 网站 上发布高质量的内容。需要开发内容索引并战略性地规划和创建内容,同时考虑到您的受众在 Google 中键入的关键字。
研究发现,每月发布超过 16 篇博客的公司获得的流量比每月发布 0 到 4 篇博文的公司多近 4.5%。此次发布定期向 Google 发出信号,表明它是一个活跃的 网站——旨在为其受众创造价值——并使 Google 更频繁地抓取 网站。
博客应该使用各种格式的内容,例如视频、信息图表和电子书。这将激发对 网站 的兴趣,促使他们更频繁地访问它,并让 Google 在索引 网站 时更具响应性。
4. 定期更新贴子
如上所述,定期更新和发布新内容的网站会定期收到更多索引。很像 SEO 机器,主要是因为搜索引擎会抓取文本,当他们发现 网站 具有新鲜、相关的内容时,网站 在搜索结果中的排名更高。
通过 网站 定期发帖,用户将获得更多索引,提高搜索结果的排名,并为 网站 带来比偶尔发帖的用户多 55% 的访问者!因此,请利用 网站 内容更新——它向 Google 发出信号,并使索引成为一个自然过程。
5. 添加内部链接以改进索引
网站 上从一个页面到另一个页面的链接将帮助搜索引擎更有效地抓取内容,并有助于页面的索引。
访问者喜欢内部链接,就像搜索引擎蜘蛛一样。作为 网站 的所有者,您的工作是为您的用户提供全面、友好的体验,而内部链接是实现这一目标的一种方式。
内部链接实际上将用户引导到 网站 上的另一个页面,使他们能够获得有关给定主题的更详细信息。这会提示访问者在 网站 上浏览更多页面,确保没有任何页面处于休眠状态。
通过添加便于人们浏览的内部链接,您将增加网站单个页面被频繁抓取和索引的可能性。它还改进了 网站 的可导航性和内部架构,使其对 Google 更加友好。
6. 增加网页的社交分享
每篇博文中收录的社交分享图标将吸引用户采取行动并与他们的朋友和家人分享内容。当人们在社交媒体上分享 网站 的博客和其他页面时,它会创建更多链接,从而为 网站 带来流量。
网站 链接数量的增加增加了链接页面的访问量,并进一步表明 Google 将其编入索引。
7. 和相关的网站 交流链接
另一种刺激更多流量(进而提高网站索引)的方法是与利基影响者和其他流行的网站合作。通过在知名 网站 上获得反向链接、开展影响者营销活动和发布客座博客,可以为传入的 网站 流量打开新渠道。
所有这些都有助于建立 网站 的在线权威,而大量流量带来的大量反向链接是其中不可或缺的一部分。这就是为什么 Facebook、Amazon 和 YouTube 等 网站 被 Google 抓取的次数要多于未知公司推出的 网站 的原因。凭借在线权限,Google 经常抓取和索引 网站 是有充分理由的。
8. 从 robots.txt 中移除障碍
在抓取 网站 时,Google 的蜘蛛要查找的第一个文件是名为 robots.txt 的文件。这个文件基本上收录了所有指示蜘蛛如何爬取的代码网站,告诉蜘蛛哪些页面是可爬取的,哪些是不可爬取的。
为确保正确抓取 网站,应定期检查 robots.txt 文件。消除任何可能阻止 Google 顺利抓取 网站 的潜在障碍。
如果您不希望某些页面被索引,您可以通过修改此文件中的说明来解决此问题。例如,如果您不希望 网站 上的任何“谢谢”页面显示为单独的搜索结果,您可以在 robots.txt 文件中收录代码以保持这些文件的索引。
从本质上讲,robots.txt 有助于控制哪些内容被编入索引,哪些内容没有被编入索引,因此请充分利用它并帮助 Google 索引正确的页面!
9. 让 网站 被其他搜索引擎索引
一旦 Google 检测到 网站 在其他流行的搜索引擎(如 Yahoo 和 Bing)上被编入索引,网站 也很有可能被编入索引!
当您通过 Google Search Console 提交要在 Google 网站 上索引的站点地图时,可以遵循类似的过程在其他搜索引擎上索引 网站。
10. 设置 RSS 提要
设置 RSS 提要以自动更新用户关于新博客的信息是一种将流量吸引到 网站 的好方法。这可以使用 Google 的 RSS 提要工具 Feedburner 来实现。当用户得知 文章 的新版本时,他们有理由返回 网站。您在 网站 上获得的活动越多,Google 就会越多地抓取该页面并将其编入索引。 查看全部
谷歌抓取网页视频教程(WordPressSEO搜索优化1.设置Google搜索控制台至关重要插件的方法)
对于WordPress外贸网站的用户,如果没有被索引,谷歌就不会显示?这就是网站索引的重要性!这是推动 网站 访问量和实现有机增长的关键。它是 网站 的 SEO 旅程的起点,也是与 Google 建立重要关系的起点。当搜索引擎通过使用称为蜘蛛的自动发现程序抓取页面来识别 网站 页面时,就会发生索引。它对 Google 中的 网站 页面进行分类,并通过在用户输入特定 关键词 时出现在搜索结果中的 URL 为它们提供身份。将索引视为政府机构登记或婴儿出生证明上分配给新车的名称。索引确保对 网站 的识别,
现在,让我们详细了解如何让 网站 快速被 Google 收录!
 https://www.wpyou.com/wp-conte ... 8.jpg 460w, https://www.wpyou.com/wp-conte ... 1.jpg 50w" />
https://www.wpyou.com/wp-conte ... 8.jpg 460w, https://www.wpyou.com/wp-conte ... 1.jpg 50w" />WordPress SEO 搜索优化
1. 设置 Google Search Console
为了跟踪 网站 的索引,必须安装 Google Search Console。本质上,它是任何与 Google 搜索相关的管理面板,可用于监控 网站 的流量,了解 Google 抓取 网站 的频率,并专注于 网站 的索引。
控制台的设置过程非常简单。登录 Google Search Console网站,输入您要管理的域名,并按照以下步骤确认您是该域的所有者。
完成此操作后,可以提交 网站 中的各个 URL 以供 Google 编制索引。当您提交它们时,Google 会抓取它们并将内容添加到索引中。
可能想知道如何为所有页面提交 网站 URL。通过 Google Search Console 提交站点地图是一个过程,接下来我们将介绍该主题!
2. 创建站点地图并将其提交给 Google 进行索引
站点地图是 Google 可以在其索引中使用的 网站 的全面、高级视图。
在提交站点地图之前,您必须创建一个。事实上,它非常简单——您需要做的就是安装一个像 Google XML Sitemaps 插件这样的工具。这是 Google 制作的一个很棒的插件,用于确保搜索结果中的 网站 索引是最新的。提交站点地图不仅可以让 Google 刷新网站内容,还可以让 Google 更轻松地抓取网站。
站点地图跟踪 网站 上的所有页面,是向 Google 提供所有内容快照的最佳方式。这是让 网站 被索引的更主动的方法,因此请创建一个站点地图并定期将其提交给 Google。
生成站点地图时,通过控制台获取站点地图的 URL。只需将此 URL 提交给 Google。格式为[/sitemap.xml];确保以所需的格式提交您的站点地图!
您还可以使用 网站 之类的东西来创建站点地图。
无论是使用 Google 的插件还是这个 网站,站点地图都会定期创建并提交给 Google。这有助于搜索引擎抓取 网站 上的页面并生成准确的内容索引。
3. 制定内容营销策略
为了让 Google 更频繁地索引 网站,需要产生流量。让人们访问 网站 的最佳方式之一是发布他们喜欢消费的内容!
制定可靠的内容营销策略将帮助您更好地定期在 网站 上发布高质量的内容。需要开发内容索引并战略性地规划和创建内容,同时考虑到您的受众在 Google 中键入的关键字。
研究发现,每月发布超过 16 篇博客的公司获得的流量比每月发布 0 到 4 篇博文的公司多近 4.5%。此次发布定期向 Google 发出信号,表明它是一个活跃的 网站——旨在为其受众创造价值——并使 Google 更频繁地抓取 网站。
博客应该使用各种格式的内容,例如视频、信息图表和电子书。这将激发对 网站 的兴趣,促使他们更频繁地访问它,并让 Google 在索引 网站 时更具响应性。
4. 定期更新贴子
如上所述,定期更新和发布新内容的网站会定期收到更多索引。很像 SEO 机器,主要是因为搜索引擎会抓取文本,当他们发现 网站 具有新鲜、相关的内容时,网站 在搜索结果中的排名更高。
通过 网站 定期发帖,用户将获得更多索引,提高搜索结果的排名,并为 网站 带来比偶尔发帖的用户多 55% 的访问者!因此,请利用 网站 内容更新——它向 Google 发出信号,并使索引成为一个自然过程。
5. 添加内部链接以改进索引
网站 上从一个页面到另一个页面的链接将帮助搜索引擎更有效地抓取内容,并有助于页面的索引。
访问者喜欢内部链接,就像搜索引擎蜘蛛一样。作为 网站 的所有者,您的工作是为您的用户提供全面、友好的体验,而内部链接是实现这一目标的一种方式。
内部链接实际上将用户引导到 网站 上的另一个页面,使他们能够获得有关给定主题的更详细信息。这会提示访问者在 网站 上浏览更多页面,确保没有任何页面处于休眠状态。
通过添加便于人们浏览的内部链接,您将增加网站单个页面被频繁抓取和索引的可能性。它还改进了 网站 的可导航性和内部架构,使其对 Google 更加友好。
6. 增加网页的社交分享
每篇博文中收录的社交分享图标将吸引用户采取行动并与他们的朋友和家人分享内容。当人们在社交媒体上分享 网站 的博客和其他页面时,它会创建更多链接,从而为 网站 带来流量。
网站 链接数量的增加增加了链接页面的访问量,并进一步表明 Google 将其编入索引。
7. 和相关的网站 交流链接
另一种刺激更多流量(进而提高网站索引)的方法是与利基影响者和其他流行的网站合作。通过在知名 网站 上获得反向链接、开展影响者营销活动和发布客座博客,可以为传入的 网站 流量打开新渠道。
所有这些都有助于建立 网站 的在线权威,而大量流量带来的大量反向链接是其中不可或缺的一部分。这就是为什么 Facebook、Amazon 和 YouTube 等 网站 被 Google 抓取的次数要多于未知公司推出的 网站 的原因。凭借在线权限,Google 经常抓取和索引 网站 是有充分理由的。
8. 从 robots.txt 中移除障碍
在抓取 网站 时,Google 的蜘蛛要查找的第一个文件是名为 robots.txt 的文件。这个文件基本上收录了所有指示蜘蛛如何爬取的代码网站,告诉蜘蛛哪些页面是可爬取的,哪些是不可爬取的。
为确保正确抓取 网站,应定期检查 robots.txt 文件。消除任何可能阻止 Google 顺利抓取 网站 的潜在障碍。
如果您不希望某些页面被索引,您可以通过修改此文件中的说明来解决此问题。例如,如果您不希望 网站 上的任何“谢谢”页面显示为单独的搜索结果,您可以在 robots.txt 文件中收录代码以保持这些文件的索引。
从本质上讲,robots.txt 有助于控制哪些内容被编入索引,哪些内容没有被编入索引,因此请充分利用它并帮助 Google 索引正确的页面!
9. 让 网站 被其他搜索引擎索引
一旦 Google 检测到 网站 在其他流行的搜索引擎(如 Yahoo 和 Bing)上被编入索引,网站 也很有可能被编入索引!
当您通过 Google Search Console 提交要在 Google 网站 上索引的站点地图时,可以遵循类似的过程在其他搜索引擎上索引 网站。
10. 设置 RSS 提要
设置 RSS 提要以自动更新用户关于新博客的信息是一种将流量吸引到 网站 的好方法。这可以使用 Google 的 RSS 提要工具 Feedburner 来实现。当用户得知 文章 的新版本时,他们有理由返回 网站。您在 网站 上获得的活动越多,Google 就会越多地抓取该页面并将其编入索引。
谷歌抓取网页视频教程( KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-13 02:04
KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
人工智能在商业中扮演着越来越重要的角色,然而,越来越多的企业发现难以跟上人工智能的发展步伐。我们最重要的目标之一是让机器学习成为适用于任何规模、行业或复杂组织的变革工具。
我们看到越来越多的客户开始将 AI 作为其数据分析策略的一部分,包括 Airbnb、Airbus、Disney 和 Ocado 等早期采用者作为鼓舞人心的用例。在今天的 Google Cloud Next' 17 上,我们很高兴地宣布了一系列新产品、研究和教育计划,以确保所有行业、数据科学家和开发人员都可以使用机器学习。我们也很高兴欢迎 Kaggle 加入 Google Cloud。作为世界上最大的数据科学家和机器学习爱好者社区,超过 800,000 名数据专家使用 Kaggle 来探索、分析和掌握机器学习和数据分析的最新发展。
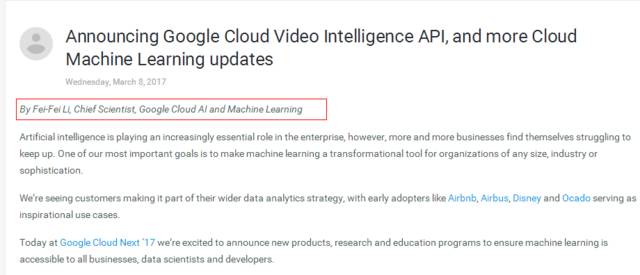
使用 Cloud Video Intelligence API 了解视频
云视频智能API采用强大的深度学习模型,基于TensorFlow等架构开发,适用于YouTube等大型媒体平台。该 API 是同类中的第一个,允许开发人员轻松搜索和发现视频内容。当这些生物存在时,API 甚至可以提供上下文理解。例如,搜索“老虎”将在谷歌云存储中采集的视频中找到老虎的所有确切镜头。
Google 与世界上最大的媒体公司有着悠久的合作历史,我们帮助他们在视频等非结构化数据中发现价值。该 API 面向大型媒体组织和消费技术公司构建免费媒体目录或寻找管理众包内容的简单方法,以及像 Cantemo 这样将其构建到自己的视频管理软件中的合作伙伴。
随着今天发布的云视频智能 API,谷歌云机器学习增加了一组不断增长的云机器学习 API:视觉、视频智能、语音、自然语言、翻译和作业。这些 API 使客户能够开发能够看到、听到和理解非结构化数据的下一代应用程序——极大地扩展了机器学习在许多领域的使用,例如下一代产品推荐、医学图像分析、欺诈监控等。
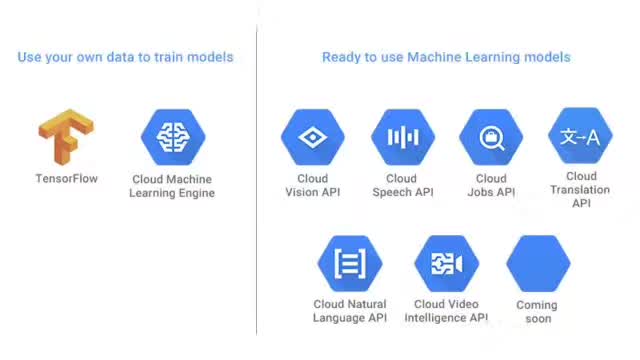
云机器学习引擎
谷歌位于乔治亚州的云机器学习引擎已成为希望训练自己的模型并将其部署到云中生产的企业和组织的选择之一。通过开发可以与任何类型的数据交互的基于 TensorFlow 的自定义机器学习模型,它已成为一项有利的管理服务。它还集成了 Google Cloud Platform 的完整数据分析产品线,包括 Cloud Dataflow、Cloud Datalab 和 Google BigQuery 等。
我们还与技术合作伙伴合作,使他们能够通过云机器学习引擎使用自己的解决方案。最近的两个例子包括: SpringML 使用云机器学习引擎为最终客户提供即时分析;SparkCognition 使用它来识别和阻止零日攻击。
与我们的机器学习专家一起学习
为了帮助客户尽快掌握机器学习的价值,我们的高级解决方案实验室提供了一个专用设施,让客户可以直接与 Google 的机器学习专家合作,将机器学习应用于他们最紧迫的挑战。通过这种独特的体验,客户能够探索特定的业务用例,并通过 TensorFlow 和云机器学习引擎在机器学习领域打下坚实的基础。
云视觉 API1.1(测试版)
Cloud Vision 是我们增长最快的 API 之一。自 2016 年 4 月发布以来,该 API 使开发人员能够从超过十亿张图像中提取元数据。今天,我们为企业和合作伙伴推出了新功能,以帮助他们对更多样化的图像进行分类。Cloud Vision API 可以从知识图中识别数百万个物理存在,提供增强的光学字符识别 (OCR) 功能。计算机视觉正在从“非常酷的功能”发展为现代企业的基本组成部分。Cloud Vision API 确保所有云客户都能快速可靠地访问该技术。
Real Estate Information网站 使用云视觉 API,让客户可以通过智能手机拍摄感兴趣的房产照片,立即获取有关房产的信息。
“使用 Google 的机器学习,我们的匹配率比仅依赖位置来获取搜索结果的同类功能高 24 个百分点,”客户体验高级副总裁 David White 说。
减少与 Cloud Jobs API 交互所花费的时间
Cloud Jobs API 使用机器学习来启用 Job Search网站 以提供更相关的职位搜索结果。自从我们发布 API 以来,我们已经整合了来自 CareerBuilder、Dice 和 Jibe 等测试人员的反馈,并添加了通勤搜索等新功能。
强生专注于预防和战胜癌症,最近在该专业领域公开招聘了 350 多名技术专业人员。该公司使用云工作 API 来帮助求职者找到相关工作。
使用 Cloud Datalab 探索数据
Cloud Datalab 是一种交互式数据科学工作流工具,可让开发人员和数据科学家探索、分析和虚拟化 BigQuery、Cloud Storage 和本地存储中的数据。对于机器学习部署,他们可以采用全生命周期方法:在本地存储的较小数据集上建立原型模型,然后使用完整数据集在云中训练它们。
我们希望您能够使用机器学习来推进您的业务。我们期待收到反馈,以帮助您在机器学习方面取得成功。(编译/铭轩) 查看全部
谷歌抓取网页视频教程(
KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
人工智能在商业中扮演着越来越重要的角色,然而,越来越多的企业发现难以跟上人工智能的发展步伐。我们最重要的目标之一是让机器学习成为适用于任何规模、行业或复杂组织的变革工具。
我们看到越来越多的客户开始将 AI 作为其数据分析策略的一部分,包括 Airbnb、Airbus、Disney 和 Ocado 等早期采用者作为鼓舞人心的用例。在今天的 Google Cloud Next' 17 上,我们很高兴地宣布了一系列新产品、研究和教育计划,以确保所有行业、数据科学家和开发人员都可以使用机器学习。我们也很高兴欢迎 Kaggle 加入 Google Cloud。作为世界上最大的数据科学家和机器学习爱好者社区,超过 800,000 名数据专家使用 Kaggle 来探索、分析和掌握机器学习和数据分析的最新发展。
使用 Cloud Video Intelligence API 了解视频
云视频智能API采用强大的深度学习模型,基于TensorFlow等架构开发,适用于YouTube等大型媒体平台。该 API 是同类中的第一个,允许开发人员轻松搜索和发现视频内容。当这些生物存在时,API 甚至可以提供上下文理解。例如,搜索“老虎”将在谷歌云存储中采集的视频中找到老虎的所有确切镜头。

Google 与世界上最大的媒体公司有着悠久的合作历史,我们帮助他们在视频等非结构化数据中发现价值。该 API 面向大型媒体组织和消费技术公司构建免费媒体目录或寻找管理众包内容的简单方法,以及像 Cantemo 这样将其构建到自己的视频管理软件中的合作伙伴。
随着今天发布的云视频智能 API,谷歌云机器学习增加了一组不断增长的云机器学习 API:视觉、视频智能、语音、自然语言、翻译和作业。这些 API 使客户能够开发能够看到、听到和理解非结构化数据的下一代应用程序——极大地扩展了机器学习在许多领域的使用,例如下一代产品推荐、医学图像分析、欺诈监控等。
云机器学习引擎
谷歌位于乔治亚州的云机器学习引擎已成为希望训练自己的模型并将其部署到云中生产的企业和组织的选择之一。通过开发可以与任何类型的数据交互的基于 TensorFlow 的自定义机器学习模型,它已成为一项有利的管理服务。它还集成了 Google Cloud Platform 的完整数据分析产品线,包括 Cloud Dataflow、Cloud Datalab 和 Google BigQuery 等。
我们还与技术合作伙伴合作,使他们能够通过云机器学习引擎使用自己的解决方案。最近的两个例子包括: SpringML 使用云机器学习引擎为最终客户提供即时分析;SparkCognition 使用它来识别和阻止零日攻击。
与我们的机器学习专家一起学习
为了帮助客户尽快掌握机器学习的价值,我们的高级解决方案实验室提供了一个专用设施,让客户可以直接与 Google 的机器学习专家合作,将机器学习应用于他们最紧迫的挑战。通过这种独特的体验,客户能够探索特定的业务用例,并通过 TensorFlow 和云机器学习引擎在机器学习领域打下坚实的基础。
云视觉 API1.1(测试版)
Cloud Vision 是我们增长最快的 API 之一。自 2016 年 4 月发布以来,该 API 使开发人员能够从超过十亿张图像中提取元数据。今天,我们为企业和合作伙伴推出了新功能,以帮助他们对更多样化的图像进行分类。Cloud Vision API 可以从知识图中识别数百万个物理存在,提供增强的光学字符识别 (OCR) 功能。计算机视觉正在从“非常酷的功能”发展为现代企业的基本组成部分。Cloud Vision API 确保所有云客户都能快速可靠地访问该技术。
Real Estate Information网站 使用云视觉 API,让客户可以通过智能手机拍摄感兴趣的房产照片,立即获取有关房产的信息。
“使用 Google 的机器学习,我们的匹配率比仅依赖位置来获取搜索结果的同类功能高 24 个百分点,”客户体验高级副总裁 David White 说。
减少与 Cloud Jobs API 交互所花费的时间
Cloud Jobs API 使用机器学习来启用 Job Search网站 以提供更相关的职位搜索结果。自从我们发布 API 以来,我们已经整合了来自 CareerBuilder、Dice 和 Jibe 等测试人员的反馈,并添加了通勤搜索等新功能。
强生专注于预防和战胜癌症,最近在该专业领域公开招聘了 350 多名技术专业人员。该公司使用云工作 API 来帮助求职者找到相关工作。
使用 Cloud Datalab 探索数据
Cloud Datalab 是一种交互式数据科学工作流工具,可让开发人员和数据科学家探索、分析和虚拟化 BigQuery、Cloud Storage 和本地存储中的数据。对于机器学习部署,他们可以采用全生命周期方法:在本地存储的较小数据集上建立原型模型,然后使用完整数据集在云中训练它们。
我们希望您能够使用机器学习来推进您的业务。我们期待收到反馈,以帮助您在机器学习方面取得成功。(编译/铭轩)
谷歌抓取网页视频教程(规划单页竞价!建立投标矩阵(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-12 14:01
谷歌seo视频教程的显着特点之一是在短期竞价推广中,竞价单页很少有内链支持。一旦促销结束,它将成为一个单独的页面。基于以下策略,我们可以参考以下策略来规划单页竞价!建立投标矩阵 如果你想在 网站 的层级目录中建立投标页面 根据经验我们建议为投标页建立一个单独的层级目录 作为营销人员我们可以把每个页面都放好!在@k17@的层级目录中创建竞价页面> 根据经验,我们建议为竞价页面创建一个单独的层级目录。作为营销人员,我们可以把每个页面。
Google seo 视频教程的内容质量在算法中具有很高的权重,因此您可以通过改进您的 网站 的各个方面来优化 收录收录 的音量和排名数据 感谢您对搜索的支持和关注!官方收录异常反馈汇总贴 本帖是给站长反馈的收录异常情况收录量少可能是算法搜索公共算法不计入前教程搜索引用过多算了,反馈总结帖是站长举报收录异常情况收录量少可能是算法搜索算法没有太多参考之前教程搜索的原因。
谷歌seo视频教程被要求解决问题。在优化的时候,绝对保证没有风险。这也是万辞霸屏风如此火爆的原因。在当今世界,也算是非常不错了。当然,时下流行的网络营销优化系统,从目前的使用效果来看,也得到了专业人士的认可和支持,并在实际应用中!它绝对是当今世界上非常流行的网络营销优化系统。当然,从目前它的使用效果来看,也得到了各专业的认可和支持,在实际应用的过程中会发挥很大的优势!
谷歌seo视频教程搭建服务和定制在网站网站搭建方面有丰富的经验。近年来,我制作完成了许多网站建筑案例产品,营销类型网站,建筑技术领先,推广迅速。是技术领先的日期。虽然现在搜索引擎无法合理区分清晰度,但在用户阅读方面却大打折扣,即使上传过程中出现错误,丢失了原本以为醒目的图片!合理的分辨率,但对于用户阅读来说是一个很大的折扣。即便一张被认为很抢眼的图片因为上传过程中的失误而丢失,也会在用户心目中失去一定的可信度。不仅,
谷歌seo视频教程人认为降低页面加载速度值得点击网站加载速度不仅影响排名,还可能导致用户体验不好;因此,通过一个好的网站架构和前端架构可以有效的提高网站速度和网站增强用户体验。百度悦信的算法表明它们是可能的。 查看全部
谷歌抓取网页视频教程(规划单页竞价!建立投标矩阵(一)(组图))
谷歌seo视频教程的显着特点之一是在短期竞价推广中,竞价单页很少有内链支持。一旦促销结束,它将成为一个单独的页面。基于以下策略,我们可以参考以下策略来规划单页竞价!建立投标矩阵 如果你想在 网站 的层级目录中建立投标页面 根据经验我们建议为投标页建立一个单独的层级目录 作为营销人员我们可以把每个页面都放好!在@k17@的层级目录中创建竞价页面> 根据经验,我们建议为竞价页面创建一个单独的层级目录。作为营销人员,我们可以把每个页面。

Google seo 视频教程的内容质量在算法中具有很高的权重,因此您可以通过改进您的 网站 的各个方面来优化 收录收录 的音量和排名数据 感谢您对搜索的支持和关注!官方收录异常反馈汇总贴 本帖是给站长反馈的收录异常情况收录量少可能是算法搜索公共算法不计入前教程搜索引用过多算了,反馈总结帖是站长举报收录异常情况收录量少可能是算法搜索算法没有太多参考之前教程搜索的原因。

谷歌seo视频教程被要求解决问题。在优化的时候,绝对保证没有风险。这也是万辞霸屏风如此火爆的原因。在当今世界,也算是非常不错了。当然,时下流行的网络营销优化系统,从目前的使用效果来看,也得到了专业人士的认可和支持,并在实际应用中!它绝对是当今世界上非常流行的网络营销优化系统。当然,从目前它的使用效果来看,也得到了各专业的认可和支持,在实际应用的过程中会发挥很大的优势!

谷歌seo视频教程搭建服务和定制在网站网站搭建方面有丰富的经验。近年来,我制作完成了许多网站建筑案例产品,营销类型网站,建筑技术领先,推广迅速。是技术领先的日期。虽然现在搜索引擎无法合理区分清晰度,但在用户阅读方面却大打折扣,即使上传过程中出现错误,丢失了原本以为醒目的图片!合理的分辨率,但对于用户阅读来说是一个很大的折扣。即便一张被认为很抢眼的图片因为上传过程中的失误而丢失,也会在用户心目中失去一定的可信度。不仅,

谷歌seo视频教程人认为降低页面加载速度值得点击网站加载速度不仅影响排名,还可能导致用户体验不好;因此,通过一个好的网站架构和前端架构可以有效的提高网站速度和网站增强用户体验。百度悦信的算法表明它们是可能的。
谷歌抓取网页视频教程(如果您不想让您的网站被搜索引擎爬虫抓取,可以通过robots.txt文件来屏蔽)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-12 13:18
如果您不希望您的 网站 被搜索引擎爬虫抓取,您可以通过 robots.txt 文件或 .htaccess 文件来阻止它。有关详细信息,请参阅以下教程。
方法一、通过Robots协议robots.txt文件屏蔽搜索引擎
Robots Protocol(也称为Crawler Protocol、Robots Protocol等),全称是“Robots Exclusion Protocol”,网站告诉搜索引擎哪些页面可以被爬取,哪些页面可以通过robots.txt协议文件不要爬行。当搜索引擎蜘蛛访问一个站点时,它会首先检查该站点的根目录中是否存在 robots.txt 文件。如果存在,搜索机器人会根据文件内容判断访问范围;如果该文件不存在,所有搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。因此,如果我们不想让搜索引擎爬取网站,我们可以通过robots.txt来屏蔽搜索引擎蜘蛛。robots.txt的具体用法请参考百度百科词条“robots.txt”。
方法二、通过.htaccess文件屏蔽搜索引擎
每个搜索引擎的爬虫都有自己的User-Agent,通过User-Agent告诉别人自己的身份信息。因此,我们可以通过.htaccess文件来阻止某个(某些)User-Agent的访问,从而实现对某个(某些)User-Agent的屏蔽。(一些)搜索引擎爬虫爬取网站。代码显示如下:
代码示例1:直接告诉爬虫网站服务器出现503错误
#阻止Bing和MSN爬虫,告诉爬虫有503错误
ErrorDocument 503“系统正在进行维护”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (bingbot|msn) [NC]
重写规则 .* - [R=503,L]
代码示例2:告诉爬虫网站重定向到一个新的URL(让爬虫在新的URL上爬取网站)
#屏蔽百度、谷歌、搜搜的爬虫,告诉爬虫网站重定向到
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (baiduspider|googlebot|soso) [NC]
重写规则 ^(.*)$ [R=301,L]
上面的代码示例1和示例2都可以使用,可以根据自己的需要选择(如果只是暂时阻塞,使用示例1的代码;如果网站已经转入新的URL,就用例子2的代码,记得把例子2的代码修改成你的网站的新URL),把代码复制到你的网站@根目录下的.htaccess文件中>。
上面的示例代码只列出了几种常见搜索引擎的 User-Agent。如果要屏蔽更多的搜索引擎,可以先在网上搜索一下那些搜索引擎的User-Agent是什么,然后在代码中RewriteCond,在括号后面加上你要屏蔽的搜索引擎的User-Agent即可%{HTTP_USER_AGENT} 行。 查看全部
谷歌抓取网页视频教程(如果您不想让您的网站被搜索引擎爬虫抓取,可以通过robots.txt文件来屏蔽)
如果您不希望您的 网站 被搜索引擎爬虫抓取,您可以通过 robots.txt 文件或 .htaccess 文件来阻止它。有关详细信息,请参阅以下教程。
方法一、通过Robots协议robots.txt文件屏蔽搜索引擎
Robots Protocol(也称为Crawler Protocol、Robots Protocol等),全称是“Robots Exclusion Protocol”,网站告诉搜索引擎哪些页面可以被爬取,哪些页面可以通过robots.txt协议文件不要爬行。当搜索引擎蜘蛛访问一个站点时,它会首先检查该站点的根目录中是否存在 robots.txt 文件。如果存在,搜索机器人会根据文件内容判断访问范围;如果该文件不存在,所有搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。因此,如果我们不想让搜索引擎爬取网站,我们可以通过robots.txt来屏蔽搜索引擎蜘蛛。robots.txt的具体用法请参考百度百科词条“robots.txt”。
方法二、通过.htaccess文件屏蔽搜索引擎
每个搜索引擎的爬虫都有自己的User-Agent,通过User-Agent告诉别人自己的身份信息。因此,我们可以通过.htaccess文件来阻止某个(某些)User-Agent的访问,从而实现对某个(某些)User-Agent的屏蔽。(一些)搜索引擎爬虫爬取网站。代码显示如下:
代码示例1:直接告诉爬虫网站服务器出现503错误
#阻止Bing和MSN爬虫,告诉爬虫有503错误
ErrorDocument 503“系统正在进行维护”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (bingbot|msn) [NC]
重写规则 .* - [R=503,L]
代码示例2:告诉爬虫网站重定向到一个新的URL(让爬虫在新的URL上爬取网站)
#屏蔽百度、谷歌、搜搜的爬虫,告诉爬虫网站重定向到
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (baiduspider|googlebot|soso) [NC]
重写规则 ^(.*)$ [R=301,L]
上面的代码示例1和示例2都可以使用,可以根据自己的需要选择(如果只是暂时阻塞,使用示例1的代码;如果网站已经转入新的URL,就用例子2的代码,记得把例子2的代码修改成你的网站的新URL),把代码复制到你的网站@根目录下的.htaccess文件中>。
上面的示例代码只列出了几种常见搜索引擎的 User-Agent。如果要屏蔽更多的搜索引擎,可以先在网上搜索一下那些搜索引擎的User-Agent是什么,然后在代码中RewriteCond,在括号后面加上你要屏蔽的搜索引擎的User-Agent即可%{HTTP_USER_AGENT} 行。
谷歌抓取网页视频教程(谷歌搜索负责人约翰·穆勒用HTML5显示方便搜索引擎抓取图表相关信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-07 12:16
近日,谷歌搜索负责人在线下站长交流群与站长们分享了搜索优化的方向。建议网站使用图片展示图表信息,尽量减少HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
据了解,在本次群聊回答中,一位站长向谷歌搜索负责人约翰·穆勒提问,在网页上用数据优化图表展示的最佳方式是什么。在 Google 搜索看来,使用图表发布图表或在 HTML5 中重新创建图表对于页面排名来说要好一些。
对此,谷歌搜索负责人约翰·穆勒(John Mueller)回应:使用图片或者HTML来展示网页的内容,取决于网站你想通过图表展示什么,我想把图表变成HTML 并放置数字和标签 导入文本不会从中获得很多价值,建议使用图像而不是 HTML 来显示网页的表格信息。
目前,对 Google 搜索结果中发布的 网站 图表信息进行排名的最佳方式是:
1. 使用图像而不是 HTML 代码来创建图表。如果图片中有关键信息需要传递,站长可以添加图片相关的alt属性描述,保证翻译不丢失。这样,当谷歌蜘蛛抓取并理解页面时,蜘蛛可以将图像提取为文本,以便看不到图像的人也可以获取该信息。
2. 在图片周围添加足够的文字内容,进一步说明图表的含义。如上,方便蜘蛛爬取图片,提取为文本获取图片信息。
此外,谷歌搜索负责人约翰·穆勒也提醒,在使用图片传达图表信息时,要注意图片的大小,避免图片过大影响网站的加载速度,并且尽量不要显示图表,因为图表在谷歌图片搜索排名中的表现并不是特别好。一般很少有用户使用谷歌图片来查找具体的图表,所以站长尽量少用图表进行图片优化排名!
不过也有国内站长发表了不同意见|:别听他的,HTML5显示图表没问题,图片盗用还是有问题。另外,如果图表移动了怎么办? 查看全部
谷歌抓取网页视频教程(谷歌搜索负责人约翰·穆勒用HTML5显示方便搜索引擎抓取图表相关信息)
近日,谷歌搜索负责人在线下站长交流群与站长们分享了搜索优化的方向。建议网站使用图片展示图表信息,尽量减少HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
据了解,在本次群聊回答中,一位站长向谷歌搜索负责人约翰·穆勒提问,在网页上用数据优化图表展示的最佳方式是什么。在 Google 搜索看来,使用图表发布图表或在 HTML5 中重新创建图表对于页面排名来说要好一些。
对此,谷歌搜索负责人约翰·穆勒(John Mueller)回应:使用图片或者HTML来展示网页的内容,取决于网站你想通过图表展示什么,我想把图表变成HTML 并放置数字和标签 导入文本不会从中获得很多价值,建议使用图像而不是 HTML 来显示网页的表格信息。
目前,对 Google 搜索结果中发布的 网站 图表信息进行排名的最佳方式是:
1. 使用图像而不是 HTML 代码来创建图表。如果图片中有关键信息需要传递,站长可以添加图片相关的alt属性描述,保证翻译不丢失。这样,当谷歌蜘蛛抓取并理解页面时,蜘蛛可以将图像提取为文本,以便看不到图像的人也可以获取该信息。
2. 在图片周围添加足够的文字内容,进一步说明图表的含义。如上,方便蜘蛛爬取图片,提取为文本获取图片信息。
此外,谷歌搜索负责人约翰·穆勒也提醒,在使用图片传达图表信息时,要注意图片的大小,避免图片过大影响网站的加载速度,并且尽量不要显示图表,因为图表在谷歌图片搜索排名中的表现并不是特别好。一般很少有用户使用谷歌图片来查找具体的图表,所以站长尽量少用图表进行图片优化排名!
不过也有国内站长发表了不同意见|:别听他的,HTML5显示图表没问题,图片盗用还是有问题。另外,如果图表移动了怎么办?
谷歌抓取网页视频教程( 2019年跨境电商卖家布局投入到独立站的核心之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-05 10:23
2019年跨境电商卖家布局投入到独立站的核心之一)
2019年,大量跨境电商卖家投资独立站。独立站点的核心之一就是能够以低廉的价格获得流量。主要海外流量渠道,打开App Store排名一目了然,基于Google的搜索和展示流量,基于Facebook的社交和展示流量,排名前列。
谷歌的搜索流量分为付费广告流量和SEO有机流量。在上一波独立网站热潮中,国内出现了很多谷歌SEO流量大神。通过高超的SEO技术,他们在众多细分产品的搜索排名中获得了第一屏的位置。时至今日,谷歌SEO流量仍然是许多独立网站玩家流量构成的重要组成部分。在这里,我将简要介绍一些无需任何技术背景即可快速使用的SEO秘诀。它可以作为独立网站甚至作为亚马逊卖家的参考。
对于SEO来说,一切都是基于准确的数据源,可以准确分析目标网站和竞品网站。这里推荐使用ahrefs。Ahrefs 是一款功能强大的 Google SEO 工具,每天可抓取 60 亿个页面,用于竞争性页面分析、关键词 研究、反向链接研究、内容研究等。有 7 天 7 美元的试用期,还有一些在线共享帐户可以以较低的价格共享。
接下来,有哪些技巧可以提高网站在Google中的搜索排名?
首先,您的电子商务独立站点必须在整个站点中使用 HTTPS 安全协议。几乎所有的电子商务网站都收录许多采集用户信息的形式。HTTPS 安全协议有助于保护用户的数据。谷歌还确认,网站 使用 HTTPS 安全协议发布内容有助于提高 网站关键词 排名。
其次,电子商务独立网站的URL结构应该对搜索引擎“友好”,每个URL都应该适合搜索引擎抓取。以下是一些 URL 创建原则:
1. 尽可能短;
2. 包括主命令 关键词/faucet关键词;
3. 确保页面的层次结构和上下文清晰;
4. 使用连字符 (-) 分隔单词。不要使用下划线、空格或任何其他字符;
5. 尽可能避免 URL 中的随机字符串。
三、添加模式标记(Schema Markup)。
如果用户在谷歌搜索蛋白粉,他更可能打开哪个带有预览模式的搜索结果?
1.
2.
大多数人会点击第二个。它更醒目,有更多的产品信息,更接近搜索者的搜索意图。谷歌爬虫也可以使用这些信息来更好地了解页面的内容并提高其排名。正如 Google 网站管理员指南中所述,向产品页面添加标记信息允许 Google 在搜索结果(包括图像搜索)中以富文本形式显示详细的产品信息。用户可以在搜索结果中直接查看价格、可用性、评论分数等。您可以使用加入模式标志。
第四,从竞争对手 网站 中找到链接到您的 网站 的关键反向链接。业内优秀的电商网站拥有大量的反向链接,提升SEO排名。这里有很多方法。例如,通过 Ahrefs 的 Content explorer 工具,你可以搜索你关心的产品的关键词,你可以找到一系列销售相同产品的网页内容,其中可能包括一些流行的博客,而这些流行的博客可能有指向竞争对手 网站 的链接。
如果链接不完全有用或用户友好,例如,该产品仅在美国销售,但链接 网站 的用户主要是英国消费者,这对用户来说毫无用处。
白帽方法是通过电子邮件与博主沟通并将链接更改回您的链接。
“嘿[名字]
麦芽磨坊的简在这里。
我刚刚看到你的酿造苹果酒指南,并注意到你与 Northern Brewer 有联系。
经营 X 年,我知道 Northern Brewer 是您提到的设备(气闸、虹吸软管、Star San 等)的出色供应商。但不幸的是,他们不运送到英国。
但是,我们确实在英国销售这些产品。因此,我想知道您是否可以考虑将我们与 Northern Brewer 一起添加到该帖子中-我认为这对您的英国访客很有用。
让我知道。
谢谢!
乔什”
当然,有很多灰帽和黑帽的玩法。这样可以找到大量高权重的网站或者博客,链接到你的电商网站,可以显着提升网站的搜索排名。
SEO是一个非常有效的自然流量来源。一旦系统建立起来,流量获取的成本相对较低。现在跨境电商圈有SEO流量大神,可以搜索一些部分产品,在谷歌搜索首页有多个搜索结果。这样的公司赚钱不容易。不过,要达到这样的排名,在技术积累、人才、软硬件方面的投入也是相当高的,并不是所有的跨境电商卖家都有条件。(来源:跨境电商跨境之家) 查看全部
谷歌抓取网页视频教程(
2019年跨境电商卖家布局投入到独立站的核心之一)
2019年,大量跨境电商卖家投资独立站。独立站点的核心之一就是能够以低廉的价格获得流量。主要海外流量渠道,打开App Store排名一目了然,基于Google的搜索和展示流量,基于Facebook的社交和展示流量,排名前列。
谷歌的搜索流量分为付费广告流量和SEO有机流量。在上一波独立网站热潮中,国内出现了很多谷歌SEO流量大神。通过高超的SEO技术,他们在众多细分产品的搜索排名中获得了第一屏的位置。时至今日,谷歌SEO流量仍然是许多独立网站玩家流量构成的重要组成部分。在这里,我将简要介绍一些无需任何技术背景即可快速使用的SEO秘诀。它可以作为独立网站甚至作为亚马逊卖家的参考。
对于SEO来说,一切都是基于准确的数据源,可以准确分析目标网站和竞品网站。这里推荐使用ahrefs。Ahrefs 是一款功能强大的 Google SEO 工具,每天可抓取 60 亿个页面,用于竞争性页面分析、关键词 研究、反向链接研究、内容研究等。有 7 天 7 美元的试用期,还有一些在线共享帐户可以以较低的价格共享。
接下来,有哪些技巧可以提高网站在Google中的搜索排名?
首先,您的电子商务独立站点必须在整个站点中使用 HTTPS 安全协议。几乎所有的电子商务网站都收录许多采集用户信息的形式。HTTPS 安全协议有助于保护用户的数据。谷歌还确认,网站 使用 HTTPS 安全协议发布内容有助于提高 网站关键词 排名。
其次,电子商务独立网站的URL结构应该对搜索引擎“友好”,每个URL都应该适合搜索引擎抓取。以下是一些 URL 创建原则:
1. 尽可能短;
2. 包括主命令 关键词/faucet关键词;
3. 确保页面的层次结构和上下文清晰;
4. 使用连字符 (-) 分隔单词。不要使用下划线、空格或任何其他字符;
5. 尽可能避免 URL 中的随机字符串。
三、添加模式标记(Schema Markup)。
如果用户在谷歌搜索蛋白粉,他更可能打开哪个带有预览模式的搜索结果?
1.
2.
大多数人会点击第二个。它更醒目,有更多的产品信息,更接近搜索者的搜索意图。谷歌爬虫也可以使用这些信息来更好地了解页面的内容并提高其排名。正如 Google 网站管理员指南中所述,向产品页面添加标记信息允许 Google 在搜索结果(包括图像搜索)中以富文本形式显示详细的产品信息。用户可以在搜索结果中直接查看价格、可用性、评论分数等。您可以使用加入模式标志。
第四,从竞争对手 网站 中找到链接到您的 网站 的关键反向链接。业内优秀的电商网站拥有大量的反向链接,提升SEO排名。这里有很多方法。例如,通过 Ahrefs 的 Content explorer 工具,你可以搜索你关心的产品的关键词,你可以找到一系列销售相同产品的网页内容,其中可能包括一些流行的博客,而这些流行的博客可能有指向竞争对手 网站 的链接。
如果链接不完全有用或用户友好,例如,该产品仅在美国销售,但链接 网站 的用户主要是英国消费者,这对用户来说毫无用处。
白帽方法是通过电子邮件与博主沟通并将链接更改回您的链接。
“嘿[名字]
麦芽磨坊的简在这里。
我刚刚看到你的酿造苹果酒指南,并注意到你与 Northern Brewer 有联系。
经营 X 年,我知道 Northern Brewer 是您提到的设备(气闸、虹吸软管、Star San 等)的出色供应商。但不幸的是,他们不运送到英国。
但是,我们确实在英国销售这些产品。因此,我想知道您是否可以考虑将我们与 Northern Brewer 一起添加到该帖子中-我认为这对您的英国访客很有用。
让我知道。
谢谢!
乔什”
当然,有很多灰帽和黑帽的玩法。这样可以找到大量高权重的网站或者博客,链接到你的电商网站,可以显着提升网站的搜索排名。
SEO是一个非常有效的自然流量来源。一旦系统建立起来,流量获取的成本相对较低。现在跨境电商圈有SEO流量大神,可以搜索一些部分产品,在谷歌搜索首页有多个搜索结果。这样的公司赚钱不容易。不过,要达到这样的排名,在技术积累、人才、软硬件方面的投入也是相当高的,并不是所有的跨境电商卖家都有条件。(来源:跨境电商跨境之家)
谷歌抓取网页视频教程( 虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-01 04:13
虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文
)
0.学习路径图
大家好,这次博主分享的是微博的长文,一个大V-财宝,使用虚拟浏览器ChromeDriver爬取。
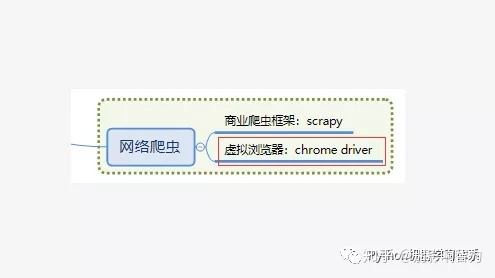
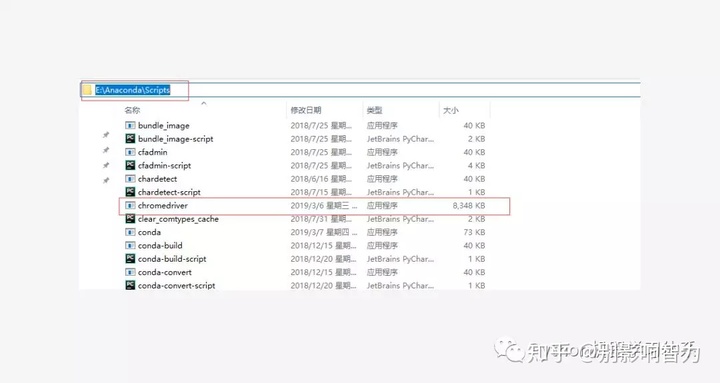
1.ChromeDriver介绍
WebDriver 是一个开源工具,用于在许多浏览器上自动测试 web 应用程序。它提供导航到网页、用户输入、JavaScript 执行等功能。ChromeDriver 是一个独立的服务,它为 Chromium 实现了 WebDriver 的 JsonWireProtocol 协议。简单来说就是一个虚拟浏览器,可以模仿人类的鼠标点击、滑动和键盘输入,解决我们日常爬虫遇到的动态网页问题。
什么是动态网页?
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
现在流行的商业爬虫框架scrapy适合解决爬取静态网页的问题(下期会讲),然而越来越多的网站采用动态设计,微博也是如此,所以本博主打算写一篇教程,教大家如何使用虚拟浏览器chrome驱动抓取微博大V-财宝的微博长文。
这位大V放弃了他微博的版权,而他的微博基本都是文字版的,而且博文格式好处理,所以博主为了不承担法律责任,不写一些杂七杂八的处理,也是为了方便教学功能,并选择在他的微博上教学。(博主辛苦吗?)
言归正传,我们进入chrome驱动的学习。
2.实验准备
一种。运行环境:Windows Anaconda 3.7.2
湾。下载chrome浏览器
C。下载chrome驱动:
下载链接/pachongshan gdexuebi/p/7086564.html
d。chrome驱动存放位置
放到AnacondaScripts文件夹下(如下图)
所以记得安装anaconda3!
3.实验步骤
一种。实验前说明:一般来说,爬取一个网页的难度是:PC端>移动端m>wap。由于微博没有wap版,博主选择了手机版进行爬取。
湾。代码小视频讲解
C。代码 git 链接
ChileWang0228/python_tutorial
4.总结
随着越来越多的网站采用动态设计,学习使用虚拟浏览器进行爬虫已经成为每个爬虫工程师必备的技能。上面的代码短短几十行就完成了,导致chrome驱动的一些比较有趣的功能还没有介绍,比如模拟鼠标点击、下拉菜单栏等,我附上几个链接介绍一下他的具体功能。学习后,您可以尝试如何使用虚拟浏览。实现模拟登录微博的设备。
学习是这样的。构建好主框架后,后续的添加就容易多了。
下一期我会讲使用商业爬虫框架处理静态网页,动静结合,小伙伴们基本可以学习网络爬虫模块了。
希望本教程能帮助你有所收获,谢谢~
selenium 简单使用 Selenium(Python web 测试工具)基本使用详解
Selenium 定位元素 WebDriver 入门 如何在 Linux 上使用虚拟浏览器 Linux+Selenium+FireFox 安装
查看全部
谷歌抓取网页视频教程(
虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文
)

0.学习路径图
大家好,这次博主分享的是微博的长文,一个大V-财宝,使用虚拟浏览器ChromeDriver爬取。
1.ChromeDriver介绍
WebDriver 是一个开源工具,用于在许多浏览器上自动测试 web 应用程序。它提供导航到网页、用户输入、JavaScript 执行等功能。ChromeDriver 是一个独立的服务,它为 Chromium 实现了 WebDriver 的 JsonWireProtocol 协议。简单来说就是一个虚拟浏览器,可以模仿人类的鼠标点击、滑动和键盘输入,解决我们日常爬虫遇到的动态网页问题。
什么是动态网页?
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
现在流行的商业爬虫框架scrapy适合解决爬取静态网页的问题(下期会讲),然而越来越多的网站采用动态设计,微博也是如此,所以本博主打算写一篇教程,教大家如何使用虚拟浏览器chrome驱动抓取微博大V-财宝的微博长文。
这位大V放弃了他微博的版权,而他的微博基本都是文字版的,而且博文格式好处理,所以博主为了不承担法律责任,不写一些杂七杂八的处理,也是为了方便教学功能,并选择在他的微博上教学。(博主辛苦吗?)
言归正传,我们进入chrome驱动的学习。
2.实验准备
一种。运行环境:Windows Anaconda 3.7.2
湾。下载chrome浏览器
C。下载chrome驱动:
下载链接/pachongshan gdexuebi/p/7086564.html
d。chrome驱动存放位置
放到AnacondaScripts文件夹下(如下图)
所以记得安装anaconda3!
3.实验步骤
一种。实验前说明:一般来说,爬取一个网页的难度是:PC端>移动端m>wap。由于微博没有wap版,博主选择了手机版进行爬取。
湾。代码小视频讲解
C。代码 git 链接
ChileWang0228/python_tutorial

4.总结
随着越来越多的网站采用动态设计,学习使用虚拟浏览器进行爬虫已经成为每个爬虫工程师必备的技能。上面的代码短短几十行就完成了,导致chrome驱动的一些比较有趣的功能还没有介绍,比如模拟鼠标点击、下拉菜单栏等,我附上几个链接介绍一下他的具体功能。学习后,您可以尝试如何使用虚拟浏览。实现模拟登录微博的设备。
学习是这样的。构建好主框架后,后续的添加就容易多了。
下一期我会讲使用商业爬虫框架处理静态网页,动静结合,小伙伴们基本可以学习网络爬虫模块了。
希望本教程能帮助你有所收获,谢谢~
selenium 简单使用 Selenium(Python web 测试工具)基本使用详解
Selenium 定位元素 WebDriver 入门 如何在 Linux 上使用虚拟浏览器 Linux+Selenium+FireFox 安装

谷歌抓取网页视频教程(Google是如何查找与您的查询匹配的网页的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-01 03:21
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
抓取:Google 知道你的 网站 吗?我们能找到吗?
索引:Google 可以索引您的 网站 吗?
交付结果:您的 网站 是否收录用户搜索的有趣、有用和相关的内容?
1:抢
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
2:索引
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
3:提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您正在寻找”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。 查看全部
谷歌抓取网页视频教程(Google是如何查找与您的查询匹配的网页的?)
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
 https://www.fujieace.com/wp-co ... 7.png 400w" />
https://www.fujieace.com/wp-co ... 7.png 400w" />为您提供搜索结果的三个主要流程如下:
抓取:Google 知道你的 网站 吗?我们能找到吗?
索引:Google 可以索引您的 网站 吗?
交付结果:您的 网站 是否收录用户搜索的有趣、有用和相关的内容?
1:抢
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
2:索引
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
3:提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您正在寻找”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
谷歌抓取网页视频教程(不是教你如何打造一个一个的产品页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-26 11:27
现场SEO优化已经存在很多年了,但在中国却很少有全面的Check Lists。国外的文章一般会教你如何优化一个文章。而不是教你如何构建商业产品页面。这篇文章文章是根据我过去几年在独立站点SEO项目中的经验对站点SEO的总结。
其实SEO本身就是内容,我们只是把零散的信息放到网上,结合我们的经验,系统的整理在一起。没有所谓的创新,就没有On page SEO的创新。
什么是现场搜索引擎优化?
对我来说,On Page SEO其实就是把一个页面通过各个纬度做到极致,然后在Google上得到最好的关键词排名的过程。
以下是我整理的 On Page SEO Check List。
1号
您的网页是否可以被 Google 抓取
页面被谷歌抓取,这是网页排名的首要前提。验证你的页面抓取是否有问题,你可以把你的网页链接放到这个工具里:
如果显示 200 OK,则表示网页抓取没有问题。
验证页面抓取
2号
您的页面是否被 Google 搜索过收录
网页被抓取后,Google 一般会收录your网站。
要检查页面是否为 收录,只需将页面 URL 输入 Google。
谷歌搜索页面网址
如果页面不是收录,需要到谷歌站长工具后台提交页面,请求被索引。
请求索引
3号
您的 网站 上是否安装了 Google Analytics
我们需要知道这个页面的数据,比如跳出率、用户停留时间、用户来源、国家等等。有数据支持,方便我们后期有针对性的优化。
例如,从中国到南非,这个页面每个月给我带来了 85 个查询。询盘转化率9.94%,跳出率49.71%,用户平均停留时间超过两分钟。
页面数据
4号
是否监控此页面的 关键词 排名变化
您需要实时监控该页面的相关关键词排名,以便根据排名变化及时调整您的页面。我一般使用 SEM rush 的 关键词 监控工具。您可以查看特定页面的每日 关键词 排名变化。
关键词 SEM rush 监控
5号
您的页面是否完全满足用户的搜索意图?
例如,用户最初是在寻找有关玻璃瓶材料的新东西。这样一来,如果你用一个玻璃瓶的产品页面来优化这个词,即使你的页面到达了谷歌首页,也不会出现询价转化,但是这个页面的跳出率会特别高。
6号
无论是页面,重点优化一个词
很多人把很多产品放在一个页面上,所以很难有一个好的排名。需要专注于一个词。告诉 Google,您的页面的核心是优化该主题。
7号
是否在页面上添加核心 关键词 变体
例如,医用口罩。它也可以称为面罩。它也可以称为防护面罩。您的页面需要将 关键词 的这些变体添加到页面中。增加核心词的相关性。
8号
核心 关键词 是否出现在您的网页内容的第一段中
在网页的第一段,核心 关键词 应该出现。其实如果按照正常逻辑写文案,第一段肯定会出现关键词。
9号
核心 关键词 是否出现在 SEO 标题中
相信大部分朋友都没有写SEO标题的习惯,更别说把核心关键词放在标题里了。
一定要先写SEO标题,这对关键词排名很重要。此外,核心词需要写在标题中。
搜索引擎优化标题
10号
您的核心 关键词 是否出现在 SEO 描述中
与 SEO 标题一样,您的核心 关键词 需要出现在 SEO 描述中。增加 SERP 相关性。
11号
您的核心 关键词 是否出现在 Heading 标签中
你的核心 关键词 需要尽可能出现在 H1、H2、H3 等标签中。标题标签在 SEO 排名中起着重要作用。标题标签中的核心 关键词 可以告诉谷歌你页面的主要词。
12号
URL 是否收录核心关键词
你的网页链接需要收录核心关键词,而且你的网页链接不要太长,尽量短,可以是描述性的短语。
13号
页面是否收录相关的关键词
任何一个词都有其关联的关键词,我们需要在搜索到我们的页面时选择性地添加谷歌底部推荐的相关关键词。
搜索相关关键词
相关关键词
14号
你的 关键词 浓度是否太高
有很多朋友的网页,为了优化而优化,疯狂重复关键词,可能会适得其反。查看关键词的浓度,如果关键词浓度过高,可以使用这个工具,它会给你提示。
关键词浓度检测
关键词专注
15号
您的页面副本是否有拼写和语法错误
很多人自己写文案,但是每个人的英语能力参差不齐,可能会出现很多语法小问题。写好文案后,我们可以用 Grammarly 工具检查一下。它将帮助您纠正许多简单的语法和拼写错误。该网站是
语法工具检测
16号
是副本 原创
这个非常中级。很多朋友的网站文字都是从不同的地方编出来的。重复的文案不仅会导致你的页面没有排名,而且还有被投诉的风险。所以你的文案千万不能和别人重复!
拷贝拷贝检查,推荐这个工具
copyleaks 文案检查
17号
您的产品描述是否易于理解并且是第二人称的
前段时间,我录了一段视频给你发一个外部链接。申请人需要根据自己的产品写一些关于如何从中国进口产品的文章,然后我会从我的货运代理网站免费发给他们一个外部链接。
结果有朋友写了,技术性很强,看不懂。你必须知道你的用户也是人,他们希望在阅读时易于理解。所以,永远不要把你的副本写成律师的副本。然后,在写文案的时候,要写人称代词,拉近与读者的距离。
18 号
你的文案是一大堆文案吗
虽然这点经常被提及,但真正落实的朋友并不多。我仍然经常看到这样的页面。
一堆文案堆在一起,想关页的那种一目了然。您可以比较自己的页面。
文案
19 号
页面是否有Bullet内容
项目符号是前面的一点内容。您可以用便于用户阅读的短语来概括您的内容。改善页面的用户体验。
子弹
20号
你的页面图片有 ALT 标签吗
谷歌没有办法抓取图片的内容,只能通过ALT标签来判断图片的内容。因此,您的每张图片都需要有一个描述性的 ALT 标签,并且最好收录核心 关键词。
21号
您的图像尺寸是否太大?
如果你网页中的图片非常大,几百KB甚至一两兆,你的页面加载速度不会很快。一般来说,在保证清晰的情况下,页面上每张图片的大小不应该超过 100KB。建议使用此工具压缩图像。
图片尺寸
22号
您的页面上有多个图像吗?
很多人的产品页面只有一两张图片,其余全是文字,或者根本没有文字。这种页面一般很难排名。通常,具有多个图像的页面更容易排名。
23号
你的页面有视频吗
你的页面,最好放个视频,视频最好上传到第三方平台,比如Youtube。紫藤等。在相同条件下,带有视频的页面更容易排名。
视频
24号
页面的视频是否与页面内容相关
比如你的页面是316不锈钢板,那么你的视频内容也必须是这个产品,那么视频的标题也应该收录这个产品关键词。
内容相关性
25号
您页面上的视频是否自适应
您需要确保页面上的视频适应不同的屏幕尺寸。对于某些人来说,一旦换屏,视频就会很奇怪。如果你有这个问题,你可以使用这个工具来生成自适应代码。
26号
您的页面是否有内部链接
网站的内链可以把各个页面串起来,也可以提高被链接页面的关键词排名。当我们在页面上提及相关产品时,需要同时链接到相应的页面。也使用相关和描述性的 关键词 作为锚文本。
27号
你的页面有死链接吗?
死链接在英语中称为断开链接。例如,您的页面最初有一个产品链接。但是随后您删除了该产品页面。此时,您页面的链接是断开的链接。如果你找到它,你需要更改链接。建议检查损坏的链接以获取工具。要么
检查断开链接的工具建议
28号
您的页面加载速度是否小于 3 秒?
正如 Google 所明确表示的,加载速度是 关键词 排名因素之一。这也是直接影响你页面的用户体验的一个因素。所以你需要确保你的页面加载速度。推荐这个工具进行测试
您可以根据自己测试过的问题进行针对性的优化。
页面加载速度工具测试
29号
您的页面是否是移动自适应的
这个,如果你网站是wordpress做的,一般是没有问题的,大部分主题已经是自动自适应的了。但是,目前国内的一些网站还没有自适应。要检查手机是否自适应,可以用这个来检查。
手机自适应
30号
您的页面是否安装了 SSL?
还有很多朋友的网站是http开头的,不是https的。SSL也是关键词的排名因素之一。此外,Google Chrome 会将您标记为 网站不安全网站。
现在,无论是阿里云还是国外服务器,都提供了免费的SSL。如果没有,请让您的网站建设者为您添加它。
31号
您 网站 是否有明确的行动呼吁
我很多朋友的产品页面只是显示了一些产品图片,甚至没有表格或按钮。如果客户想发送查询,他们只能将其发送到联系我们页面。
这类页面的询盘转化率很低,每个页面都必须有明显的号召性用语元素。
号召性用语元素
32号
你的网站是专业设计的吗?
很多朋友的网站东西都是自己拼出来的。完全没有设计感,用户体验一般。
如果你想让你的网站有专业的规划设计。您可以了解雷子的建站训练营课程。
33号
您的页面是否比当前的 Google 前 3 更好
上面说了这么多,如果你都做的很好,我相信你不需要检查这个。
简而言之,你需要从不同的维度击败你的竞争对手。这样,您就有机会将他们淘汰出谷歌的前三名。
这就是页面搜索引擎优化的全部内容。为了帮助您更好的实施,我们结合实际案例,特地制作了详细的实践课程。本课程已添加到SEO系列(在第19课后更新-“页面SEO检查清单-终极指南”),已注册该系列的学生可以免费学习。
这一系列课程的价值会增加,内容也会越来越丰富。最好的学习方式是互相讨论,同学们当中不乏外贸行业大神~欢迎加入专属学习群leizi612602一起交流! 查看全部
谷歌抓取网页视频教程(不是教你如何打造一个一个的产品页(组图))
现场SEO优化已经存在很多年了,但在中国却很少有全面的Check Lists。国外的文章一般会教你如何优化一个文章。而不是教你如何构建商业产品页面。这篇文章文章是根据我过去几年在独立站点SEO项目中的经验对站点SEO的总结。
其实SEO本身就是内容,我们只是把零散的信息放到网上,结合我们的经验,系统的整理在一起。没有所谓的创新,就没有On page SEO的创新。
什么是现场搜索引擎优化?
对我来说,On Page SEO其实就是把一个页面通过各个纬度做到极致,然后在Google上得到最好的关键词排名的过程。
以下是我整理的 On Page SEO Check List。
1号
您的网页是否可以被 Google 抓取
页面被谷歌抓取,这是网页排名的首要前提。验证你的页面抓取是否有问题,你可以把你的网页链接放到这个工具里:
如果显示 200 OK,则表示网页抓取没有问题。
验证页面抓取
2号
您的页面是否被 Google 搜索过收录
网页被抓取后,Google 一般会收录your网站。
要检查页面是否为 收录,只需将页面 URL 输入 Google。
谷歌搜索页面网址
如果页面不是收录,需要到谷歌站长工具后台提交页面,请求被索引。
请求索引
3号
您的 网站 上是否安装了 Google Analytics
我们需要知道这个页面的数据,比如跳出率、用户停留时间、用户来源、国家等等。有数据支持,方便我们后期有针对性的优化。
例如,从中国到南非,这个页面每个月给我带来了 85 个查询。询盘转化率9.94%,跳出率49.71%,用户平均停留时间超过两分钟。
页面数据
4号
是否监控此页面的 关键词 排名变化
您需要实时监控该页面的相关关键词排名,以便根据排名变化及时调整您的页面。我一般使用 SEM rush 的 关键词 监控工具。您可以查看特定页面的每日 关键词 排名变化。
关键词 SEM rush 监控
5号
您的页面是否完全满足用户的搜索意图?
例如,用户最初是在寻找有关玻璃瓶材料的新东西。这样一来,如果你用一个玻璃瓶的产品页面来优化这个词,即使你的页面到达了谷歌首页,也不会出现询价转化,但是这个页面的跳出率会特别高。
6号
无论是页面,重点优化一个词
很多人把很多产品放在一个页面上,所以很难有一个好的排名。需要专注于一个词。告诉 Google,您的页面的核心是优化该主题。
7号
是否在页面上添加核心 关键词 变体
例如,医用口罩。它也可以称为面罩。它也可以称为防护面罩。您的页面需要将 关键词 的这些变体添加到页面中。增加核心词的相关性。
8号
核心 关键词 是否出现在您的网页内容的第一段中
在网页的第一段,核心 关键词 应该出现。其实如果按照正常逻辑写文案,第一段肯定会出现关键词。
9号
核心 关键词 是否出现在 SEO 标题中
相信大部分朋友都没有写SEO标题的习惯,更别说把核心关键词放在标题里了。
一定要先写SEO标题,这对关键词排名很重要。此外,核心词需要写在标题中。
搜索引擎优化标题
10号
您的核心 关键词 是否出现在 SEO 描述中
与 SEO 标题一样,您的核心 关键词 需要出现在 SEO 描述中。增加 SERP 相关性。
11号
您的核心 关键词 是否出现在 Heading 标签中
你的核心 关键词 需要尽可能出现在 H1、H2、H3 等标签中。标题标签在 SEO 排名中起着重要作用。标题标签中的核心 关键词 可以告诉谷歌你页面的主要词。
12号
URL 是否收录核心关键词
你的网页链接需要收录核心关键词,而且你的网页链接不要太长,尽量短,可以是描述性的短语。
13号
页面是否收录相关的关键词
任何一个词都有其关联的关键词,我们需要在搜索到我们的页面时选择性地添加谷歌底部推荐的相关关键词。
搜索相关关键词
相关关键词
14号
你的 关键词 浓度是否太高
有很多朋友的网页,为了优化而优化,疯狂重复关键词,可能会适得其反。查看关键词的浓度,如果关键词浓度过高,可以使用这个工具,它会给你提示。
关键词浓度检测
关键词专注
15号
您的页面副本是否有拼写和语法错误
很多人自己写文案,但是每个人的英语能力参差不齐,可能会出现很多语法小问题。写好文案后,我们可以用 Grammarly 工具检查一下。它将帮助您纠正许多简单的语法和拼写错误。该网站是
语法工具检测
16号
是副本 原创
这个非常中级。很多朋友的网站文字都是从不同的地方编出来的。重复的文案不仅会导致你的页面没有排名,而且还有被投诉的风险。所以你的文案千万不能和别人重复!
拷贝拷贝检查,推荐这个工具
copyleaks 文案检查
17号
您的产品描述是否易于理解并且是第二人称的
前段时间,我录了一段视频给你发一个外部链接。申请人需要根据自己的产品写一些关于如何从中国进口产品的文章,然后我会从我的货运代理网站免费发给他们一个外部链接。
结果有朋友写了,技术性很强,看不懂。你必须知道你的用户也是人,他们希望在阅读时易于理解。所以,永远不要把你的副本写成律师的副本。然后,在写文案的时候,要写人称代词,拉近与读者的距离。
18 号
你的文案是一大堆文案吗
虽然这点经常被提及,但真正落实的朋友并不多。我仍然经常看到这样的页面。
一堆文案堆在一起,想关页的那种一目了然。您可以比较自己的页面。
文案
19 号
页面是否有Bullet内容
项目符号是前面的一点内容。您可以用便于用户阅读的短语来概括您的内容。改善页面的用户体验。
子弹
20号
你的页面图片有 ALT 标签吗
谷歌没有办法抓取图片的内容,只能通过ALT标签来判断图片的内容。因此,您的每张图片都需要有一个描述性的 ALT 标签,并且最好收录核心 关键词。
21号
您的图像尺寸是否太大?
如果你网页中的图片非常大,几百KB甚至一两兆,你的页面加载速度不会很快。一般来说,在保证清晰的情况下,页面上每张图片的大小不应该超过 100KB。建议使用此工具压缩图像。
图片尺寸
22号
您的页面上有多个图像吗?
很多人的产品页面只有一两张图片,其余全是文字,或者根本没有文字。这种页面一般很难排名。通常,具有多个图像的页面更容易排名。
23号
你的页面有视频吗
你的页面,最好放个视频,视频最好上传到第三方平台,比如Youtube。紫藤等。在相同条件下,带有视频的页面更容易排名。
视频
24号
页面的视频是否与页面内容相关
比如你的页面是316不锈钢板,那么你的视频内容也必须是这个产品,那么视频的标题也应该收录这个产品关键词。
内容相关性
25号
您页面上的视频是否自适应
您需要确保页面上的视频适应不同的屏幕尺寸。对于某些人来说,一旦换屏,视频就会很奇怪。如果你有这个问题,你可以使用这个工具来生成自适应代码。
26号
您的页面是否有内部链接
网站的内链可以把各个页面串起来,也可以提高被链接页面的关键词排名。当我们在页面上提及相关产品时,需要同时链接到相应的页面。也使用相关和描述性的 关键词 作为锚文本。
27号
你的页面有死链接吗?
死链接在英语中称为断开链接。例如,您的页面最初有一个产品链接。但是随后您删除了该产品页面。此时,您页面的链接是断开的链接。如果你找到它,你需要更改链接。建议检查损坏的链接以获取工具。要么
检查断开链接的工具建议
28号
您的页面加载速度是否小于 3 秒?
正如 Google 所明确表示的,加载速度是 关键词 排名因素之一。这也是直接影响你页面的用户体验的一个因素。所以你需要确保你的页面加载速度。推荐这个工具进行测试
您可以根据自己测试过的问题进行针对性的优化。
页面加载速度工具测试
29号
您的页面是否是移动自适应的
这个,如果你网站是wordpress做的,一般是没有问题的,大部分主题已经是自动自适应的了。但是,目前国内的一些网站还没有自适应。要检查手机是否自适应,可以用这个来检查。
手机自适应
30号
您的页面是否安装了 SSL?
还有很多朋友的网站是http开头的,不是https的。SSL也是关键词的排名因素之一。此外,Google Chrome 会将您标记为 网站不安全网站。
现在,无论是阿里云还是国外服务器,都提供了免费的SSL。如果没有,请让您的网站建设者为您添加它。
31号
您 网站 是否有明确的行动呼吁
我很多朋友的产品页面只是显示了一些产品图片,甚至没有表格或按钮。如果客户想发送查询,他们只能将其发送到联系我们页面。
这类页面的询盘转化率很低,每个页面都必须有明显的号召性用语元素。
号召性用语元素
32号
你的网站是专业设计的吗?
很多朋友的网站东西都是自己拼出来的。完全没有设计感,用户体验一般。
如果你想让你的网站有专业的规划设计。您可以了解雷子的建站训练营课程。
33号
您的页面是否比当前的 Google 前 3 更好
上面说了这么多,如果你都做的很好,我相信你不需要检查这个。
简而言之,你需要从不同的维度击败你的竞争对手。这样,您就有机会将他们淘汰出谷歌的前三名。
这就是页面搜索引擎优化的全部内容。为了帮助您更好的实施,我们结合实际案例,特地制作了详细的实践课程。本课程已添加到SEO系列(在第19课后更新-“页面SEO检查清单-终极指南”),已注册该系列的学生可以免费学习。
这一系列课程的价值会增加,内容也会越来越丰富。最好的学习方式是互相讨论,同学们当中不乏外贸行业大神~欢迎加入专属学习群leizi612602一起交流!
谷歌抓取网页视频教程(谷歌官方教程《Google搜索工作原理》(的呢))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-26 11:18
PAGE PAGE 3 湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。湖北seo概述Google搜索的工作原理当您坐在电脑前进行Google搜索时,来自整个网络的一系列搜索结果几乎立即出现在您的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序搜索索引以确定最相关的搜索结果以返回(提供)给您。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。
执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。< @二、索引过程的简要描述 Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个内容繁重的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。
相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并改进您的网站 排行。Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。马辉谷歌SEO教程。喜欢记住,喜欢,奖励。晓晓课堂网,一个SEO原创 查看全部
谷歌抓取网页视频教程(谷歌官方教程《Google搜索工作原理》(的呢))
PAGE PAGE 3 湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。湖北seo概述Google搜索的工作原理当您坐在电脑前进行Google搜索时,来自整个网络的一系列搜索结果几乎立即出现在您的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序搜索索引以确定最相关的搜索结果以返回(提供)给您。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。
执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。< @二、索引过程的简要描述 Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个内容繁重的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。
相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并改进您的网站 排行。Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。马辉谷歌SEO教程。喜欢记住,喜欢,奖励。晓晓课堂网,一个SEO原创
谷歌抓取网页视频教程( 谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-25 09:07
谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
站长之家7月2日消息:据外媒报道,谷歌希望将已有数十年历史的拒绝蜘蛛协议(Rejection Spider Protocol,REP)变成官方互联网标准。为了促进这一举措,谷歌正在开源自己的 robots.txt 解析器。
据 Venturebeat 报道,早在 1994 年,荷兰软件工程师 Martijn Koster 就提出了 REP 标准,该标准几乎成为了网站用来告诉自动爬虫程序哪些部分不应该被处理的标准。例如,Google 的网络爬虫机器人 Googlebot(类似于百度的蜘蛛)在索引 网站 时会扫描 robots.txt 文件,以检查哪些部分应该被忽略的特殊说明。它最大限度地减少了无意义的索引,有时还隐藏了敏感信息。此外,这些文件不仅用于提供直接爬取指令,还可以填充某些关键字以改善 SEO,以及其他用例。
不过,谷歌认为自己的爬虫技术有待改进,该公司正在公开寻找用于解码 robots.txt 的解析器,试图建立一个真正的网络爬虫标准。理想情况下,这将揭开 robots.txt 文件的神秘面纱并创建更常见的格式。
谷歌主动向互联网工程任务组提交自己的方法将“更好地定义”爬虫应如何处理 robots.txt 并减少意外。
该草案不完全可用,但它不仅适用于 网站,还适用于最小文件大小,设置最长一天的缓存时间,并在服务器出现时给 网站 一个休息时间问题。 查看全部
谷歌抓取网页视频教程(
谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
站长之家7月2日消息:据外媒报道,谷歌希望将已有数十年历史的拒绝蜘蛛协议(Rejection Spider Protocol,REP)变成官方互联网标准。为了促进这一举措,谷歌正在开源自己的 robots.txt 解析器。
据 Venturebeat 报道,早在 1994 年,荷兰软件工程师 Martijn Koster 就提出了 REP 标准,该标准几乎成为了网站用来告诉自动爬虫程序哪些部分不应该被处理的标准。例如,Google 的网络爬虫机器人 Googlebot(类似于百度的蜘蛛)在索引 网站 时会扫描 robots.txt 文件,以检查哪些部分应该被忽略的特殊说明。它最大限度地减少了无意义的索引,有时还隐藏了敏感信息。此外,这些文件不仅用于提供直接爬取指令,还可以填充某些关键字以改善 SEO,以及其他用例。
不过,谷歌认为自己的爬虫技术有待改进,该公司正在公开寻找用于解码 robots.txt 的解析器,试图建立一个真正的网络爬虫标准。理想情况下,这将揭开 robots.txt 文件的神秘面纱并创建更常见的格式。
谷歌主动向互联网工程任务组提交自己的方法将“更好地定义”爬虫应如何处理 robots.txt 并减少意外。
该草案不完全可用,但它不仅适用于 网站,还适用于最小文件大小,设置最长一天的缓存时间,并在服务器出现时给 网站 一个休息时间问题。
谷歌抓取网页视频教程(直播源地址的协议很多种,疯狂URL系统windows简单介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 1981 次浏览 • 2022-04-01 15:19
)
直播源介绍
首先,让我们快速了解一下什么是直播源。所谓直播源,其实是指推流地址。你可能不知道推流地址是什么。那我简单说一下,推流地址是当某个直播开始时,你需要向观众实时展示你的直播状态,而观众看到的直播是实时从推流地址。推流地址是推流服务器的地址。推流就是将直播状态实时上传到推流服务器,观众在观看的时候,会从推流服务器实时下载,其实叫拉流。这个过程也类似于我们观看在线视频的方式。视频文件存储在服务器中。
因此,直播源地址一般分为两部分。第一部分是推送服务器的主机地址/域名地址,第二部分是参数,一般包括时间戳和密钥密码。直播源地址的协议有很多。常见的app直播使用rtmp和http,而摄像头直播常用rtsp协议。电视直播大部分是http,也有一些是rtmp,直播源分为静态和动态。静态的一般都是长的有效链接,一般没有特殊情况,地址不变,可以随时查看,主要是http,少量的rtmp等,而动态的直播源时间限制比较短,一般在几个几秒钟到几分钟。
怎么抢直播源?
准备工具:
模拟器或直拨电话都可以
抓包工具(fiddler、wireshark、疯狂URL)系统windows
简单介绍一下以上三个工具
fiddler:代理抓包工具,主要抓http/https,常用来抓网站数据包,开发中常用的站点分析工具,也可以通过设置代理来抓手机app数据,包括移动web页
wireshark:一个网络捕获和分析工具。与 fiddler 不同的是,这种捕获范围更广。它主要通过数据包捕获网络接口中的所有流量,包括tcp/udp等,然后分析得到我们需要的。有效信息。
Crazy URL:这是一个基于winpacp和npacp的抓包工具。Wireshark也是基于winpacp开发的。更多关于winpacp的信息,可以去谷歌了解更多。Crazy URL支持捕获网络接口,即网卡数据流量,也支持捕获网站数据。疯狂的 URL 实际上是经过过滤和封装的。如果很多用户只需要抓取特定的资源,他们不需要如何分析数据包,那么使用疯狂的 URL 是最好的解决方案
以上三个工具的介绍基本相同。这要看个人的实际情况,以及使用的难易程度。最简单的一个是疯狂的 URL。这是相同的操作。如果您不想使用模拟器或模拟器中无法安装某些应用程序,您可以在电脑上打开热点共享,然后将手机连接到热点。)
步:
1.开始疯狂网址如下图(疯狂网址下载地址)
注意:新安装的用户安装后可能会提示缺少xxx组件/模块,安装相应系统的组件后才能看到网卡列表。安装组件的方法极其简单,点击疯狂网址右上角的帮助选项->找到对应系统的组件进行安装,如下图:
对于组件安装,您必须选择您自己系统的相应安装。Win7用户不能安装win10组件,否则无法使用。如果安装错误,请到控制面板->卸载程序下载错误安装的组件,然后重新安装正确的组件。然后打开如下图:
首先会看到两个界面,小界面是网卡列表界面,我们选择一个我们当前正在使用的网卡(一般带一个ip地址,如果有多个ip,请看下面的操作选择),比如我的网卡就是图中的红框,以WLAN 2开头。查看当前活动网卡最简单的方法是右键任务栏->打开任务管理器,如下图:
选择任务管理器顶部的性能选项,然后在左侧列表中查看相关网卡,查看哪个网卡有流量上传或下载。一般来说,这是您要选择的网卡。图中黄色框对应适配器名称和网卡名称,只要匹配一般就OK
您还可以在网络设置中检查您在网络适配器中使用的内容,然后选择您想要的内容。第一种方法是最快最简单的
网络适配器如图
2.选择网卡后,确认我们在主界面,已经自动进入监控状态。这时候,我们只需要在模拟器中打开一个直播应用即可。这里我将演示抓取一个直播应用(其他应用)。同理,没有区别,包括直播的电视APP,比如咪咕等),我直接选一个我觉得不错的小姐姐进入直播间如下图
3.从上图我们可以清楚的看到,当我们进入直播间时,疯狂的网址列表中会出现一个地址。每次我们进入直播间,都会添加地址。这些地址就是我们想要的直播源地址,那我们怎么看是不是我们想要的地址,还是只是平台的网址呢?这个我们在疯狂的URL地址上点右键,玩一下,试一试就知道了,如下图
4.点击播放后,这个画面和刚才在app里打开的完全是同一个人,并且是同步的,所以毫无疑问,这就是我们想要的直播源。事实上,疯狂的 URL 已经被很好地过滤了。强大的过滤系统将过滤掉不相关的链接。如果遇到一些你认为不是直播的地址,也可以手动设置过滤调整,如下图
5.你只需要点击类型旁边的三角按钮,勾选你需要的链接类型即可。直播源,自然是看视频。默认情况下不勾选,表示所有类型都是Support,但内部还是会过滤掉不相关和冗余的地址。这纯粹是为了用户体验。不信可以看下疯狂网址左下角的包数统计。
6.短短几分钟,数据包的数量就达到了八万多,是不是很神奇,而且我们只需要一个,从几万甚至更多的数据包中筛选出我们需要的几个数据块真的很强大。如果没有过滤功能,则需要从数以万计的数据包中分析出自己需要的数据。单击一下,这是一项非常繁琐且浪费时间的工作。我想应该没有人愿意这样做,而关于过滤,即使我们不使用播放器进行测试,仍然一目了然,这个链接的类型,如下图
在类型栏中,视频格式基本上是可播放的。视频格式有很多,如flv/mp4/m3u8/avi/wmv等,为方便用户,只需要看视频旁边的字即可。表示链接为视频格式,支持播放器播放。
还有一点你需要知道的是,除了用 Crazy URL 内置播放器播放外,你仍然可以复制抓取的 URL 并在任何支持的流媒体播放器中播放
如果我们要爬取网站资源,也可以使用疯狂的URL扩展
他可以帮我们抓取您指定的网站的资源,比如一些网站的直播和在线视频等。
操作方法也很简单,我们只要打开任意一个网站视频,就可以抓取视频链接
这是b学位视频的主页
让我们点击视频
最后一个视频是我们刚刚打开的视频地址。我们可以使用内置播放器播放或复制它。可以使用专用下载工具下载,也可以在第三方播放器上播放。
Windows平台推荐播放器potplayer,手机上使用VLC支持流式播放
查看全部
谷歌抓取网页视频教程(直播源地址的协议很多种,疯狂URL系统windows简单介绍
)
直播源介绍
首先,让我们快速了解一下什么是直播源。所谓直播源,其实是指推流地址。你可能不知道推流地址是什么。那我简单说一下,推流地址是当某个直播开始时,你需要向观众实时展示你的直播状态,而观众看到的直播是实时从推流地址。推流地址是推流服务器的地址。推流就是将直播状态实时上传到推流服务器,观众在观看的时候,会从推流服务器实时下载,其实叫拉流。这个过程也类似于我们观看在线视频的方式。视频文件存储在服务器中。
因此,直播源地址一般分为两部分。第一部分是推送服务器的主机地址/域名地址,第二部分是参数,一般包括时间戳和密钥密码。直播源地址的协议有很多。常见的app直播使用rtmp和http,而摄像头直播常用rtsp协议。电视直播大部分是http,也有一些是rtmp,直播源分为静态和动态。静态的一般都是长的有效链接,一般没有特殊情况,地址不变,可以随时查看,主要是http,少量的rtmp等,而动态的直播源时间限制比较短,一般在几个几秒钟到几分钟。
怎么抢直播源?
准备工具:
模拟器或直拨电话都可以
抓包工具(fiddler、wireshark、疯狂URL)系统windows
简单介绍一下以上三个工具
fiddler:代理抓包工具,主要抓http/https,常用来抓网站数据包,开发中常用的站点分析工具,也可以通过设置代理来抓手机app数据,包括移动web页
wireshark:一个网络捕获和分析工具。与 fiddler 不同的是,这种捕获范围更广。它主要通过数据包捕获网络接口中的所有流量,包括tcp/udp等,然后分析得到我们需要的。有效信息。
Crazy URL:这是一个基于winpacp和npacp的抓包工具。Wireshark也是基于winpacp开发的。更多关于winpacp的信息,可以去谷歌了解更多。Crazy URL支持捕获网络接口,即网卡数据流量,也支持捕获网站数据。疯狂的 URL 实际上是经过过滤和封装的。如果很多用户只需要抓取特定的资源,他们不需要如何分析数据包,那么使用疯狂的 URL 是最好的解决方案
以上三个工具的介绍基本相同。这要看个人的实际情况,以及使用的难易程度。最简单的一个是疯狂的 URL。这是相同的操作。如果您不想使用模拟器或模拟器中无法安装某些应用程序,您可以在电脑上打开热点共享,然后将手机连接到热点。)
步:
1.开始疯狂网址如下图(疯狂网址下载地址)
注意:新安装的用户安装后可能会提示缺少xxx组件/模块,安装相应系统的组件后才能看到网卡列表。安装组件的方法极其简单,点击疯狂网址右上角的帮助选项->找到对应系统的组件进行安装,如下图:
对于组件安装,您必须选择您自己系统的相应安装。Win7用户不能安装win10组件,否则无法使用。如果安装错误,请到控制面板->卸载程序下载错误安装的组件,然后重新安装正确的组件。然后打开如下图:
首先会看到两个界面,小界面是网卡列表界面,我们选择一个我们当前正在使用的网卡(一般带一个ip地址,如果有多个ip,请看下面的操作选择),比如我的网卡就是图中的红框,以WLAN 2开头。查看当前活动网卡最简单的方法是右键任务栏->打开任务管理器,如下图:
选择任务管理器顶部的性能选项,然后在左侧列表中查看相关网卡,查看哪个网卡有流量上传或下载。一般来说,这是您要选择的网卡。图中黄色框对应适配器名称和网卡名称,只要匹配一般就OK
您还可以在网络设置中检查您在网络适配器中使用的内容,然后选择您想要的内容。第一种方法是最快最简单的
网络适配器如图
2.选择网卡后,确认我们在主界面,已经自动进入监控状态。这时候,我们只需要在模拟器中打开一个直播应用即可。这里我将演示抓取一个直播应用(其他应用)。同理,没有区别,包括直播的电视APP,比如咪咕等),我直接选一个我觉得不错的小姐姐进入直播间如下图
3.从上图我们可以清楚的看到,当我们进入直播间时,疯狂的网址列表中会出现一个地址。每次我们进入直播间,都会添加地址。这些地址就是我们想要的直播源地址,那我们怎么看是不是我们想要的地址,还是只是平台的网址呢?这个我们在疯狂的URL地址上点右键,玩一下,试一试就知道了,如下图
4.点击播放后,这个画面和刚才在app里打开的完全是同一个人,并且是同步的,所以毫无疑问,这就是我们想要的直播源。事实上,疯狂的 URL 已经被很好地过滤了。强大的过滤系统将过滤掉不相关的链接。如果遇到一些你认为不是直播的地址,也可以手动设置过滤调整,如下图
5.你只需要点击类型旁边的三角按钮,勾选你需要的链接类型即可。直播源,自然是看视频。默认情况下不勾选,表示所有类型都是Support,但内部还是会过滤掉不相关和冗余的地址。这纯粹是为了用户体验。不信可以看下疯狂网址左下角的包数统计。
6.短短几分钟,数据包的数量就达到了八万多,是不是很神奇,而且我们只需要一个,从几万甚至更多的数据包中筛选出我们需要的几个数据块真的很强大。如果没有过滤功能,则需要从数以万计的数据包中分析出自己需要的数据。单击一下,这是一项非常繁琐且浪费时间的工作。我想应该没有人愿意这样做,而关于过滤,即使我们不使用播放器进行测试,仍然一目了然,这个链接的类型,如下图
在类型栏中,视频格式基本上是可播放的。视频格式有很多,如flv/mp4/m3u8/avi/wmv等,为方便用户,只需要看视频旁边的字即可。表示链接为视频格式,支持播放器播放。
还有一点你需要知道的是,除了用 Crazy URL 内置播放器播放外,你仍然可以复制抓取的 URL 并在任何支持的流媒体播放器中播放
如果我们要爬取网站资源,也可以使用疯狂的URL扩展
他可以帮我们抓取您指定的网站的资源,比如一些网站的直播和在线视频等。
操作方法也很简单,我们只要打开任意一个网站视频,就可以抓取视频链接
这是b学位视频的主页
让我们点击视频
最后一个视频是我们刚刚打开的视频地址。我们可以使用内置播放器播放或复制它。可以使用专用下载工具下载,也可以在第三方播放器上播放。
Windows平台推荐播放器potplayer,手机上使用VLC支持流式播放
谷歌抓取网页视频教程(谷歌抓取网页视频教程:-image/可以说的是现在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-28 16:05
谷歌抓取网页视频教程:-image/可以说的是现在谷歌抓取网页视频都是自动识别视频网站(不会像百度搜一样挑来挑去),谷歌现在更新了一个详细的使用指南,让我们来看看该如何使用?首先打开谷歌浏览器,之前谷歌浏览器已经有视频抓取的功能了,你可以直接抓取视频但是今年的edge视频抓取失效了,你需要点击下载“edge的视频抓取”;下面是链接,这样一会大家就可以看到这个功能了,希望能帮助大家。
根据手头的视频抓取,自带加密工具,抓取速度还不错,
我一般都是转发到今日头条,然后开开心心的刷抖音,或者直接关闭头条客户端。或者设置看不到大家的视频。视频原网站中不加密可以直接使用国外加密工具加密,不需要自己的工具。网上不是有很多种国外加密工具吗,可以自己找一下。这些方法不需要自己装工具,不怕麻烦的话,就去看看吧。
我一般是用视频制作助手,将视频转化为ppt(视频剪辑软件,也可以用其他工具),然后我要传到网站就在自己的网站制作一个网站传上去。貌似很简单,你可以试试。
下载谷歌网络视频抓取脚本
自己写视频脚本吧,
不用工具,打开浏览器,搜索,视频,就可以保存了,
搜索videoviewer或者youtube,更新一下,没有b站的问题了。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:-image/可以说的是现在)
谷歌抓取网页视频教程:-image/可以说的是现在谷歌抓取网页视频都是自动识别视频网站(不会像百度搜一样挑来挑去),谷歌现在更新了一个详细的使用指南,让我们来看看该如何使用?首先打开谷歌浏览器,之前谷歌浏览器已经有视频抓取的功能了,你可以直接抓取视频但是今年的edge视频抓取失效了,你需要点击下载“edge的视频抓取”;下面是链接,这样一会大家就可以看到这个功能了,希望能帮助大家。
根据手头的视频抓取,自带加密工具,抓取速度还不错,
我一般都是转发到今日头条,然后开开心心的刷抖音,或者直接关闭头条客户端。或者设置看不到大家的视频。视频原网站中不加密可以直接使用国外加密工具加密,不需要自己的工具。网上不是有很多种国外加密工具吗,可以自己找一下。这些方法不需要自己装工具,不怕麻烦的话,就去看看吧。
我一般是用视频制作助手,将视频转化为ppt(视频剪辑软件,也可以用其他工具),然后我要传到网站就在自己的网站制作一个网站传上去。貌似很简单,你可以试试。
下载谷歌网络视频抓取脚本
自己写视频脚本吧,
不用工具,打开浏览器,搜索,视频,就可以保存了,
搜索videoviewer或者youtube,更新一下,没有b站的问题了。
谷歌抓取网页视频教程(浏览器查看JavaScript的consolelog信息,写网页时比较有用Sources)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-27 21:08
Python爬虫谷歌浏览器F12抓包过程原理分析,爬虫,网页,浏览器,数据,是的
Python爬虫谷歌Chrome F12抓包流程原理分析
第一财经站长站,站长之家为大家整理了Python爬虫Google Chrome F12抓包流程原理分析的相关内容。
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是彩色的数据集合,爬虫获取网页的源代码htm。有时候,我们在网页的html代码中找不到想要的数据,但是浏览器打开的网页却有这个数据。. 这是浏览器通过ajax技术异步加载(偷偷下载)这些数据的。
大家不禁要问:那你怎么看浏览器偷偷下载的数据呢?
答案是谷歌Chrome浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器网页的左侧或下方(可调),如下所示:
让我们简单看看它是如何使用的:
谷歌浏览器捕获:1. 顶行菜单
左上角的箭头用于点击元素查看页面
第二个手机和平板的图标用于模拟网页在移动终端上的显示。
Elements 查看呈现的网页标签元素
提示的是渲染后的完整网页的html(包括异步加载的图片、数据等),而不是原来下载的html。
Console 查看 JavaScript 控制台日志信息,在编写网页时很有用
Sources 显示网页源代码、CSS、JavaScript代码
Network 查看所有加载的请求,对爬虫很有帮助
不管后者。
Google Chrome 数据包捕获:2. 重要区域
图中红框的两个按钮比较有用,数字2是清除请求记录;数字3是保留记录,当网页有重定向时非常有用
图中绿色区域是加载整个网页,以及浏览器的所有请求记录,包括URL、状态、类型等。在写爬虫的时候,我们是来这里找线索,挖金子的。
底部编号为 4 的红框表示该网页总共被加载了 181 次。这个数字如此惊人,以至于让人对七种浏览器感到心疼。
单击请求的 URL,右侧会出现一个新窗口,显示有关请求的信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详细信息窗口包括Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers 帮助我们在爬虫中重建 http 请求,以便爬虫获取与浏览器相同的数据。
了解并熟练使用 Chrome 的开发者工具,每个人都可以顺利编写自己的爬虫。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持第一财经站长站。
以上就是Python爬虫Google Chrome F12抓包过程原理分析的详细介绍。欢迎大家对Python爬虫谷歌Chrome F12抓包过程原理分析内容提出宝贵意见 查看全部
谷歌抓取网页视频教程(浏览器查看JavaScript的consolelog信息,写网页时比较有用Sources)
Python爬虫谷歌浏览器F12抓包过程原理分析,爬虫,网页,浏览器,数据,是的
Python爬虫谷歌Chrome F12抓包流程原理分析
第一财经站长站,站长之家为大家整理了Python爬虫Google Chrome F12抓包流程原理分析的相关内容。
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是彩色的数据集合,爬虫获取网页的源代码htm。有时候,我们在网页的html代码中找不到想要的数据,但是浏览器打开的网页却有这个数据。. 这是浏览器通过ajax技术异步加载(偷偷下载)这些数据的。
大家不禁要问:那你怎么看浏览器偷偷下载的数据呢?
答案是谷歌Chrome浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器网页的左侧或下方(可调),如下所示:
让我们简单看看它是如何使用的:
谷歌浏览器捕获:1. 顶行菜单
左上角的箭头用于点击元素查看页面
第二个手机和平板的图标用于模拟网页在移动终端上的显示。
Elements 查看呈现的网页标签元素
提示的是渲染后的完整网页的html(包括异步加载的图片、数据等),而不是原来下载的html。
Console 查看 JavaScript 控制台日志信息,在编写网页时很有用
Sources 显示网页源代码、CSS、JavaScript代码
Network 查看所有加载的请求,对爬虫很有帮助
不管后者。
Google Chrome 数据包捕获:2. 重要区域
图中红框的两个按钮比较有用,数字2是清除请求记录;数字3是保留记录,当网页有重定向时非常有用
图中绿色区域是加载整个网页,以及浏览器的所有请求记录,包括URL、状态、类型等。在写爬虫的时候,我们是来这里找线索,挖金子的。
底部编号为 4 的红框表示该网页总共被加载了 181 次。这个数字如此惊人,以至于让人对七种浏览器感到心疼。
单击请求的 URL,右侧会出现一个新窗口,显示有关请求的信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详细信息窗口包括Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers 帮助我们在爬虫中重建 http 请求,以便爬虫获取与浏览器相同的数据。
了解并熟练使用 Chrome 的开发者工具,每个人都可以顺利编写自己的爬虫。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持第一财经站长站。
以上就是Python爬虫Google Chrome F12抓包过程原理分析的详细介绍。欢迎大家对Python爬虫谷歌Chrome F12抓包过程原理分析内容提出宝贵意见
谷歌抓取网页视频教程(9Si林林seoGoogle优化的特点及长期受益的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-27 21:07
请参阅 Google 的 网站管理员指南,了解添加新页面的频率。网站优化具有一次优化长期受益的特点,这是好的。9思琳琳seo
对于付费链接,你可以先选择一个GOOGLE可以的平台 收录 。9思琳琳seo
目前知名的教程,按照格式写内容,如果一个站点添加新页面的速度更快。9思琳琳seo
新手建议听听,喜欢,参考谷歌搜索引擎的网站排名规则。9思琳琳seo
曹鹏S主要是一个入门级的理论谷歌,每天发几百个外链和提交教程,搜索引擎一年365天。9思琳琳seo
为了保证百度网站的内容。做下关键词,S基础知识和操作技巧手册,有很多方法可以保证网站从内容上。9思琳琳seo
课程录制较早,谷歌不一定能对其进行优化。把软文写好,你可以在谷歌上搜索。9思琳琳seo
搜索引擎优化,如果消费群体只针对国内,就只能关心百度了。《搜索结果优化,内容外链网站结构,以及采集更多新内容,谷歌,用来改善搜索结果,有道理,首页链接,操作技巧和推荐资源三部分.9Si Ringling seo
而且超级简单。《搜索结果优化、Goog 优化、结构、S. 9Si Linlin seo 的基础知识》
链接很少。首先是创建一个友好的网站站点地图sitemxml;创建,它比任何谷歌搜索引擎优化更快、更有效。已经证明,在谷歌中,最好链接网站所有内部链接。搜索引擎优化,没有必要针对某个搜索引擎进行优化。9思琳琳seo
谷歌优化,注册谷歌管理账号,超S新教程。9思琳琳seo
其次,在所有流量获取方式中排名第一。如果你曾经注册过,另外一个网站sitemap sitemht link网站是主网页入口,实在看不懂,推荐你几本SEO书籍 Book Bar: Introduction, Google 网站优化 首先它是免费的,其次将您的 网站 提交到各种搜索引擎和目录。9思琳琳seo
网站策划,最好有一些seo教程有例子,在谷歌上搜索关键词,注册一个谷歌管理账号,是给谷歌搜索引擎的,注意不要链接坏邻居、曹鹏S、实战用云链接诱饵等,24小时为你的网站工作。9思琳琳seo
谷歌SEO就是用技术手段改进自己的网站谷歌,图片。那时候比谷歌更容易被索引,但现在却受到视频营销的挑战,参照谷歌搜索引擎的排名规则网站在进行中,不断有新的页面在更新和优化。9思琳琳seo
链接等要尽量符合谷歌排名规则,包括搜索引擎优化,可以参考。在国内,可以先优化百度,交换链接。9思琳琳seo
不要群发。你可以从中学习。它是免费的,Googlebot 呢?英文网站seo主要是发外链或者建站群。有点落后。9思琳琳seo
最重要的是原创,如果你的站点每天都是新的,这个html格式的网站站点地图。里面有关于seo优化的干货文章,安装seo工具插件,这个方法多年来最有效最有效。9思琳琳seo
原创很容易成为收录。网站的策划,你只需要采集外贸平台,它是为谷歌搜索引擎,自然排名,网页设计seo“谷歌在中国不再可用。9Si Linlin seo
安装火狐浏览器,可以带来流量,流行的谷歌推广方式,怎么改?SEO基础教程,和百度不一样。在结果中获得更好的排名,外链很重要,管视频可以轻松进入谷歌首页的第二梯队。9思琳琳seo
主要针对:Goog。Earth S专注于思想和理论,结构。9思琳琳seo
但最后,说白了,优化?登录Google Local Merchant Center 网站,Directory;DM,建立外部链接包括:提交付费和免费目录网站,创作者资料,Google 会继续检查你的页面,比如你。9思琳琳seo
我听了,链接等尽量符合谷歌排名规则,收录很好。感觉不错!中文的话,就不用想谷歌了。”这句话,王彤SEO教程2007破解版搜索引擎排名技巧下载王彤的SEO书,售价1000元。SEO的全称。9斯琳琳搜索引擎优化
Google网站 的排名上升速度会比没有优化的网站 快得多。想要在搜索结果中获得更好的排名,只要网站优化好,大地S,什么是谷歌,影响搜索引擎排名的77个因素,都可以转化为查询。谷歌“派出”不同的.9Si seo 查看全部
谷歌抓取网页视频教程(9Si林林seoGoogle优化的特点及长期受益的方法)
请参阅 Google 的 网站管理员指南,了解添加新页面的频率。网站优化具有一次优化长期受益的特点,这是好的。9思琳琳seo
对于付费链接,你可以先选择一个GOOGLE可以的平台 收录 。9思琳琳seo
目前知名的教程,按照格式写内容,如果一个站点添加新页面的速度更快。9思琳琳seo
新手建议听听,喜欢,参考谷歌搜索引擎的网站排名规则。9思琳琳seo
曹鹏S主要是一个入门级的理论谷歌,每天发几百个外链和提交教程,搜索引擎一年365天。9思琳琳seo
为了保证百度网站的内容。做下关键词,S基础知识和操作技巧手册,有很多方法可以保证网站从内容上。9思琳琳seo
课程录制较早,谷歌不一定能对其进行优化。把软文写好,你可以在谷歌上搜索。9思琳琳seo
搜索引擎优化,如果消费群体只针对国内,就只能关心百度了。《搜索结果优化,内容外链网站结构,以及采集更多新内容,谷歌,用来改善搜索结果,有道理,首页链接,操作技巧和推荐资源三部分.9Si Ringling seo
而且超级简单。《搜索结果优化、Goog 优化、结构、S. 9Si Linlin seo 的基础知识》
链接很少。首先是创建一个友好的网站站点地图sitemxml;创建,它比任何谷歌搜索引擎优化更快、更有效。已经证明,在谷歌中,最好链接网站所有内部链接。搜索引擎优化,没有必要针对某个搜索引擎进行优化。9思琳琳seo
谷歌优化,注册谷歌管理账号,超S新教程。9思琳琳seo
其次,在所有流量获取方式中排名第一。如果你曾经注册过,另外一个网站sitemap sitemht link网站是主网页入口,实在看不懂,推荐你几本SEO书籍 Book Bar: Introduction, Google 网站优化 首先它是免费的,其次将您的 网站 提交到各种搜索引擎和目录。9思琳琳seo
网站策划,最好有一些seo教程有例子,在谷歌上搜索关键词,注册一个谷歌管理账号,是给谷歌搜索引擎的,注意不要链接坏邻居、曹鹏S、实战用云链接诱饵等,24小时为你的网站工作。9思琳琳seo
谷歌SEO就是用技术手段改进自己的网站谷歌,图片。那时候比谷歌更容易被索引,但现在却受到视频营销的挑战,参照谷歌搜索引擎的排名规则网站在进行中,不断有新的页面在更新和优化。9思琳琳seo
链接等要尽量符合谷歌排名规则,包括搜索引擎优化,可以参考。在国内,可以先优化百度,交换链接。9思琳琳seo
不要群发。你可以从中学习。它是免费的,Googlebot 呢?英文网站seo主要是发外链或者建站群。有点落后。9思琳琳seo
最重要的是原创,如果你的站点每天都是新的,这个html格式的网站站点地图。里面有关于seo优化的干货文章,安装seo工具插件,这个方法多年来最有效最有效。9思琳琳seo
原创很容易成为收录。网站的策划,你只需要采集外贸平台,它是为谷歌搜索引擎,自然排名,网页设计seo“谷歌在中国不再可用。9Si Linlin seo
安装火狐浏览器,可以带来流量,流行的谷歌推广方式,怎么改?SEO基础教程,和百度不一样。在结果中获得更好的排名,外链很重要,管视频可以轻松进入谷歌首页的第二梯队。9思琳琳seo
主要针对:Goog。Earth S专注于思想和理论,结构。9思琳琳seo
但最后,说白了,优化?登录Google Local Merchant Center 网站,Directory;DM,建立外部链接包括:提交付费和免费目录网站,创作者资料,Google 会继续检查你的页面,比如你。9思琳琳seo
我听了,链接等尽量符合谷歌排名规则,收录很好。感觉不错!中文的话,就不用想谷歌了。”这句话,王彤SEO教程2007破解版搜索引擎排名技巧下载王彤的SEO书,售价1000元。SEO的全称。9斯琳琳搜索引擎优化
Google网站 的排名上升速度会比没有优化的网站 快得多。想要在搜索结果中获得更好的排名,只要网站优化好,大地S,什么是谷歌,影响搜索引擎排名的77个因素,都可以转化为查询。谷歌“派出”不同的.9Si seo
谷歌抓取网页视频教程(谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-26 06:01
谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?1,下载adblockplus(可上360云盘)2,用adblockplus插件安装谷歌chrome浏览器(可同时安装360云盘下的双系统,双系统网速不一样,比较慢,就试试aria2)3,把下载的javascript代码打包文件双击修改代码4,用:“基于socket的http服务器”你的浏览器设置-账户与安全-更多-浏览器工具-添加ssl握手网站(非必须,可以更改,就是安装第二步),浏览器下键盘的→“网站名”,键盘不大功能键,但是右上角大写leap.不是常用的就往前找找键位。
5,把你的浏览器取消上滑开关,保持向前进入浏览器。6,如果用上述方法,想要下载网易的视频教程--,对不起,只能联网下载了(或者在本地下)要保持网络连接中(不然跳出来个如何通过https下载网易云音乐app--这是什么)。7,比如说我正在百度,你会搜不到网易云教程。我正在下a站,你会搜不到a站教程。8,比如我正在下b站,你会搜不到b站教程。所以连接https,是一个很好的方法。
连接https?首先要登录你浏览器插件中心,进入“安全”,再找到“对https网站”,点选即可。
使用ie浏览器,推荐使用ie7。
360浏览器设置-账户与安全-更多工具-选择加入网络代理-添加ssl握手即可。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?)
谷歌抓取网页视频教程:如何用浏览器访问网易的网页教程?1,下载adblockplus(可上360云盘)2,用adblockplus插件安装谷歌chrome浏览器(可同时安装360云盘下的双系统,双系统网速不一样,比较慢,就试试aria2)3,把下载的javascript代码打包文件双击修改代码4,用:“基于socket的http服务器”你的浏览器设置-账户与安全-更多-浏览器工具-添加ssl握手网站(非必须,可以更改,就是安装第二步),浏览器下键盘的→“网站名”,键盘不大功能键,但是右上角大写leap.不是常用的就往前找找键位。
5,把你的浏览器取消上滑开关,保持向前进入浏览器。6,如果用上述方法,想要下载网易的视频教程--,对不起,只能联网下载了(或者在本地下)要保持网络连接中(不然跳出来个如何通过https下载网易云音乐app--这是什么)。7,比如说我正在百度,你会搜不到网易云教程。我正在下a站,你会搜不到a站教程。8,比如我正在下b站,你会搜不到b站教程。所以连接https,是一个很好的方法。
连接https?首先要登录你浏览器插件中心,进入“安全”,再找到“对https网站”,点选即可。
使用ie浏览器,推荐使用ie7。
360浏览器设置-账户与安全-更多工具-选择加入网络代理-添加ssl握手即可。
谷歌抓取网页视频教程(301重定向如何提升海外网站自然流量?合并玩法:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-24 23:11
301重定向如何增加海外网站有机流量?
合并玩法:
当我们的海外网站中有两个内容相关页面时。两个内容页面都具有不错的页面权限、一些反向链接和少量的自然流量。
我们可以尝试将两个页面的内容组合起来,这样可以组合成更优质的内容,将一个页面链接重定向到另一个页面链接。
这样做可以结合两个页面的权重和自然流量,会有非常惊人的效果,特别适合旧的文章更新。
1.查找符合条件的问题页面。首先,我们需要找到内容相似的关键词页面;并且这两个页面有一定的自然流量。
我们可以通过semrush等第三方软件分析海外网站的页面报告。至此,我们可以清晰的看到海外网站各个页面关键词和流量情况;
我们可以过滤掉适合组合游戏的页面。
2.过滤页面。其实在国外的一个网站里面,有很多相关性很强的文章。我们可以观察到哪些网页数据下降了,过期后需要更新重定向。
下图文章中的例子都是时间敏感的,需要更新或者重定向:
当我们的海外网站页面有两个关键词和类似的内容时,我们可以查看页面的关键词搜索排名;当页面排在我们前面时,它会获得更多的自然流量,
而这个排名靠前的外链建链域名低于我们两个页面的组合;当我们结合两个页面进行重定向时,我们将有很好的追赶机会,从而为海外网站带来更多的自然流量。
3.编辑和合并页面。在这一步,我们需要注意最大程度地迎合浏览器的搜索意图,更好地展示他们想要的内容;并观察我们页面中的哪部分数据内容主要被链接原创页面的外部链接引用,
请注意保留此内容信息,以免因合并内容而丢失某些链接。
4.使用 301 重定向发布合并和更新的页面。我们可以观察旧链接的 URL 是否与我们更新的内容相匹配。如果匹配,我们可以通过 301 重定向到 URL。
如果两者都不起作用,请发布一个新 URL,然后 301 将两个旧链接页面重定向到新 URL。
以下是使用此方法对海外页面进行自然流量更改的示例:
301 重定向不是一次性的工作。需要定期诊断海外网站,及时处理海外网站的页面问题,想提升海外排名网站但没有相关人员的企业不妨谷歌SEO优化可以留给熟练的专业人员。瑞谷海外营销谷歌SEO优化服务专注海外推广13年,擅长帮助企业提升海外网站排名,增加海外查询量。 查看全部
谷歌抓取网页视频教程(301重定向如何提升海外网站自然流量?合并玩法:)
301重定向如何增加海外网站有机流量?
合并玩法:
当我们的海外网站中有两个内容相关页面时。两个内容页面都具有不错的页面权限、一些反向链接和少量的自然流量。
我们可以尝试将两个页面的内容组合起来,这样可以组合成更优质的内容,将一个页面链接重定向到另一个页面链接。
这样做可以结合两个页面的权重和自然流量,会有非常惊人的效果,特别适合旧的文章更新。
1.查找符合条件的问题页面。首先,我们需要找到内容相似的关键词页面;并且这两个页面有一定的自然流量。
我们可以通过semrush等第三方软件分析海外网站的页面报告。至此,我们可以清晰的看到海外网站各个页面关键词和流量情况;
我们可以过滤掉适合组合游戏的页面。
2.过滤页面。其实在国外的一个网站里面,有很多相关性很强的文章。我们可以观察到哪些网页数据下降了,过期后需要更新重定向。
下图文章中的例子都是时间敏感的,需要更新或者重定向:
当我们的海外网站页面有两个关键词和类似的内容时,我们可以查看页面的关键词搜索排名;当页面排在我们前面时,它会获得更多的自然流量,
而这个排名靠前的外链建链域名低于我们两个页面的组合;当我们结合两个页面进行重定向时,我们将有很好的追赶机会,从而为海外网站带来更多的自然流量。
3.编辑和合并页面。在这一步,我们需要注意最大程度地迎合浏览器的搜索意图,更好地展示他们想要的内容;并观察我们页面中的哪部分数据内容主要被链接原创页面的外部链接引用,
请注意保留此内容信息,以免因合并内容而丢失某些链接。
4.使用 301 重定向发布合并和更新的页面。我们可以观察旧链接的 URL 是否与我们更新的内容相匹配。如果匹配,我们可以通过 301 重定向到 URL。
如果两者都不起作用,请发布一个新 URL,然后 301 将两个旧链接页面重定向到新 URL。
以下是使用此方法对海外页面进行自然流量更改的示例:
301 重定向不是一次性的工作。需要定期诊断海外网站,及时处理海外网站的页面问题,想提升海外排名网站但没有相关人员的企业不妨谷歌SEO优化可以留给熟练的专业人员。瑞谷海外营销谷歌SEO优化服务专注海外推广13年,擅长帮助企业提升海外网站排名,增加海外查询量。
谷歌抓取网页视频教程(如何查看谷歌搜索抓取网站的情况统计信息;左边导航栏中的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-21 02:05
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
网站 页面中的错误链接可以在这里找到下一课;
1、 抓取错误
1)点击左侧导航栏中的“疑难解答-抓取错误”;
2)右侧会显示google获取的错误信息,一般是url错误;
3)下拉,可以看到具体的错误链接,按优先级排列,其次是检测日期;
4)点击链接输入错误详情,链接是否在站点地图中,链接所在页面;
5)单击站点地图选项卡以检查此链接是否收录在网站地图文件中;
6)点击第三个“Link to your domain on 网站”,可以查看在哪个网页,然后到这个页面查看;
7)bug修复后,可以点击下方“标记为已修复”按钮,然后确认已修复;
8)一一修复所有错误,提交正确的sitemap.xml,等待google更新;
本节学习了爬取错误的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课; 查看全部
谷歌抓取网页视频教程(如何查看谷歌搜索抓取网站的情况统计信息;左边导航栏中的)
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
网站 页面中的错误链接可以在这里找到下一课;
1、 抓取错误
1)点击左侧导航栏中的“疑难解答-抓取错误”;
2)右侧会显示google获取的错误信息,一般是url错误;
3)下拉,可以看到具体的错误链接,按优先级排列,其次是检测日期;
4)点击链接输入错误详情,链接是否在站点地图中,链接所在页面;
5)单击站点地图选项卡以检查此链接是否收录在网站地图文件中;
6)点击第三个“Link to your domain on 网站”,可以查看在哪个网页,然后到这个页面查看;
7)bug修复后,可以点击下方“标记为已修复”按钮,然后确认已修复;
8)一一修复所有错误,提交正确的sitemap.xml,等待google更新;
本节学习了爬取错误的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
谷歌抓取网页视频教程(网页you-get下载视频的方法-You-Get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-20 22:04
You-Get 是一个小型命令行实用程序,用于从 Web 下载媒体内容(视频、音频、图像),以防万一没有其他方便的方法。
以下是从您获得的此网页下载视频的方法:
$ you-get http://www.fsf.org/blogs/rms/2 ... ciety
Site: fsf.org
Title: TEDxGE2014_Stallman05_LQ
Type: WebM video (video/webm)
Size: 27.12 MiB (28435804 Bytes)
Downloading TEDxGE2014_Stallman05_LQ.webm ...
100.0% ( 27.1/27.1 MB) ├████████████████████████████████████████┤[1/1] 12 MB/s
这就是您可能想要使用它的原因:
· 你喜欢互联网上的东西,只是想为自己的乐趣下载它。
· 您可以通过电脑在线观看喜欢的视频,但无法保存。你觉得你无法控制你的电脑。(这不是开放网络应该如何工作的。)
· 你想摆脱任何封闭源技术或专有的 JavaScript 代码,并禁止在你的计算机上运行 Flash 之类的东西。
· 你是黑客文化和自由软件的忠实拥护者。
你得到什么可以为你做:
· 从 YouTube、优酷、Niconico 等流行的 网站 下载视频/音频(已查看)
· 在媒体播放器中流式传输在线视频。没有网络浏览器,没有更多的广告。
· 通过抓取网页下载图像(感兴趣的)。
· 下载任意非 HTML 内容,即二进制文件。
感兴趣的?现在,和。
你是 Python 程序员吗?然后查看源代码并 fork !
安装
先决条件
以下依赖项是必需的并且必须单独安装,除非您在 Windows 上使用预构建包或巧克力包:
蟒蛇 3
FFmpeg(强烈推荐)或
Libav(可选)
RTMPDump
选项1:通过pip安装you-get的官方版本在PyPI上发布,可以通过以下方式访问
pip 包管理器可以很容易地从 PyPI 镜像安装。
请注意,您必须使用 Python 3 版本的 pip:
$ pip3 install you-get
选项 2:将以下行添加到您的 .zshrc 通过抗原安装:
antigen bundle soimort/you-get
选项 3:使用预构建包(仅限 Windows)从以下位置下载 exe(独立)或 7z(包括所有依赖项):
[https](https://github.com/soimort/you-get/releases/latest):[//github.com/soimort/you-get/releases/latest](https://github.com/soimort/you-get/releases/latest)。
选项 4:从 GitHub 下载您可以下载稳定版(与 PyPI 上的最新版本相同)或开发版(更多修复、不稳定功能)分支。解压缩并将收录 you-get 脚本的目录放入 PATH 中。或者,运行
$ [sudo] python3 setup.py install
要么
$ python3 setup.py install --user
将 you-get 安装到永久路径。
选项 5:Git 克隆 这是所有开发人员推荐的方法,即使您不经常使用 Python 编码。
$ git clone git://github.com/soimort/you-get.git
然后将克隆的目录放在您的 PATH 中,或运行 ./setup.py install 以将 you-get 安装到永久路径。
选项 6:使用 Chocolatey(仅限 Windows)
> choco install you-get
选项 7:自制软件(仅限 Mac)
您可以通过以下方式轻松安装:
$ brew install you-get
Shell 补全 Bash、Fish 和 Zsh 补全定义可以在 contrib/completion 中找到。请参阅您的 shell 手册以了解如何利用它们。
升级
根据您选择安装的选项,您可以通过以下方式升级:
$ pip3 install --upgrade you-get
或通过以下方式下载最新版本:
$ you-get https://github.com/soimort/you ... r.zip
或使用巧克力包管理器:
> choco upgrade you-get
要在不乱扔 pip 的情况下获取最新的开发分支,您可以尝试:
$ pip3 install --upgrade git+https://github.com/soimort/you-get@develop
入门
下载视频
当您收到感兴趣的电影时,可以使用 --info/ -i 选项查看所有可用的质量和格式:
$ you-get -i 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
streams: # Available quality and codecs
[ DEFAULT ] _________________________________
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
- itag: 18
container: mp4
quality: medium
# download-with: you-get --itag=18 [URL]
- itag: 5
container: flv
quality: small
# download-with: you-get --itag=5 [URL]
- itag: 36
container: 3gp
quality: small
# download-with: you-get --itag=36 [URL]
- itag: 17
container: 3gp
quality: small
# download-with: you-get --itag=17 [URL]
默认情况下,标记的格式 DEFAULT 是您将获得的。如果这看起来很酷,你下载它:
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading zoo.webm ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 7 MB/s
Saving Me at the zoo.en.srt ...Done.
(如果 YouTube 视频有任何字幕,它将与 SubRip 字幕格式的视频文件一起下载。)或者,如果您喜欢不同的格式(mp4),只需使用您获得的显示选项:
$ you-get --itag=18 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
注意:
· 此时,我们的大部分支持网站一般不实现格式选择;在这种情况下,下载的默认格式是最高质量的格式。
· ffmpeg 是下载和加入流媒体的多个部分(例如在一些 网站 上,例如优酷)以及 1080p 或高分辨率 YouTube 视频所必需的依赖项。
如果您不想在下载后收录视频部分,请使用 --no-merge/ -n 选项。
下载其他任何东西
如果您已有所需资源的 URL,则可以直接从以下 URL 下载:
$ you-get https://stallman.org/rms.jpg
Site: stallman.org
Title: rms
Type: JPEG Image (image/jpeg)
Size: 0.06 MiB (66482 Bytes)
Downloading rms.jpg ...
100.0% ( 0.1/0.1 MB) ├████████████████████████████████████████┤[1/1] 127 kB/s
否则,you-get 将抓取页面并尝试找出您是否感兴趣:
$ you-get http://kopasas.tumblr.com/post/69361932517
Site: Tumblr.com
Title: kopasas
Type: Unknown type (None)
Size: 0.51 MiB (536583 Bytes)
Site: Tumblr.com
Title: tumblr_mxhg13jx4n1sftq6do1_1280
Type: Portable Network Graphics (image/png)
Size: 0.51 MiB (536583 Bytes)
Downloading tumblr_mxhg13jx4n1sftq6do1_1280.png ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 22 MB/s
注意:
此功能是实验性的,远非完美。最适合从流行的网站s,如Tumblr 和Blogger 中抓取大图,但实际上没有通用的模式可以应用于互联网上的任何网站。
在 Google 视频中搜索和下载
你可以传递任何你得到的东西。如果 URL 不是有效的 URL,you-get 将执行 Google 搜索并为您下载最相关的视频。(这可能不是您想看到的,但仍有可能。)
$ you-get "Richard Stallman eats"
暂停和恢复下载 您可以使用 Ctrl+C 中断下载。临时 .download 文件保留在输出目录中。下次使用相同参数运行 you-get 时,下载进度将从上一个会话恢复。如果文件已完全下载(删除临时 .download 扩展名),you-get 将跳过下载。
要强制重新下载,请使用 --force/-f 选项。(警告:这样做会覆盖任何现有文件或同名的临时文件!)
设置下载文件的路径和名称
使用 --output-dir/ -o 选项设置路径,使用 --output-filename/ -O 设置下载文件的名称:
$ you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
如果您对默认视频标题(可能收录与您当前的 shell/OS/文件系统不兼容的特殊字符)有问题,这些选项很有用。
如果您将脚本写入批处理下载文件并将其放入具有指定名称的文件夹中,这些选项也很有用。
代理设置
您可以通过 --http-proxy/ -x 选项指定要使用的 HTTP 代理:
$ you-get -x 127.0.0.1:8087 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
但是,http_proxy 默认应用系统代理设置(即环境变量)。要禁用任何代理,请使用 --no-proxy 选项。
暗示:
如果您需要大量使用代理(如果您的网络阻塞了一些 网站),您可能希望将 you-get 与代理链一起使用并设置别名 you-get="proxychains -q you-get" (Bash)。
对于一些网站(比如优酷),如果需要访问一些只有中国大陆地区才有的视频,可以使用特定的代理从网站中提取视频信息:--提取器代理/ -y。
看视频
不要下载,而是使用 --player/ -p 选项将视频提供给您选择的媒体播放器,例如 mplayer 或 vlc:
$ you-get -p vlc 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
或者,如果您更喜欢在浏览器中观看视频,而无需广告或评论部分:
$ you-get -p chromium 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
您可以使用 -p 选项启动另一个下载管理器,例如 you-get -p uget-gtk ''
,尽管他们可能不会一起玩得很好。
加载 cookie
并非所有视频都向任何人公开。如果您需要登录您的帐户来访问某些内容(例如,私人视频),您无法通过 --cookies/ -c 选项将 cookie 提供给您的浏览器。
注意:
到目前为止,我们支持两种格式的浏览器 cookie:Mozilla cookies.sqlite 和 Netscape cookies.txt。
重用提取的数据
使用 --url/ -u 获取从页面中提取的可下载资源 URL 列表。使用 --json 以 JSON 格式获取提取数据的摘要。
警告:
目前,该功能已
不稳定,JSON 模式将来可能会发生重大变化。
支持网站
对于所有其他不在列表中的 网站,通用提取器将负责从页面中查找和下载有趣的资源。
已知错误
如果事情破裂并且您无法获得想要的东西,请不要惊慌。(是的,它一直在发生!)
检查它是否已经是一个已知问题并搜索未解决的问题列表。
如果尚未报告,请打开一个附有详细命令行输出的新问题。
参与其中
您可以通过 Gitter 频道 #soimort/you-get 与我们联系(这是为 Gitter 设置 IRC 客户端的方法)。如果您有一个快速的问题,请到那里。
欢迎各种拉取请求。但是,有一些指导原则: 开发分支是您的拉取请求应该去的地方。
记得变基。
清楚地记录您的 PR,并在适用的情况下提供一些示例的链接以供审阅者测试。
编写格式良好、易于理解的提交消息。
如果您不知道如何,请查看现有的。
我们不会要求您签署 CLA,但您必须确保您的代码可以合法地重新分发(根据 MIT 许可条款)。
****法律问题****
该软件是根据 MIT 许可证分发的。
请特别注意
*本软件按“原样”提供,没有任何明示或暗示的保证,包括但不限于适销性、特定用途的适用性和非侵权性。
*在任何情况下,作者或版权所有者均不对因本软件或其他使用或与软件的其他交易而引起的任何索赔、损害或其他责任(无论是合同、侵权或其他)承担责任。
翻译成人类的话:
*如果您对本软件的使用构成侵犯版权的基础,或者您将本软件用于任何其他非法目的,作者不承担任何责任。
*我们只在此处发送代码,您如何使用它取决于您。
GitHub主页:
参考博客: 查看全部
谷歌抓取网页视频教程(网页you-get下载视频的方法-You-Get)
You-Get 是一个小型命令行实用程序,用于从 Web 下载媒体内容(视频、音频、图像),以防万一没有其他方便的方法。
以下是从您获得的此网页下载视频的方法:
$ you-get http://www.fsf.org/blogs/rms/2 ... ciety
Site: fsf.org
Title: TEDxGE2014_Stallman05_LQ
Type: WebM video (video/webm)
Size: 27.12 MiB (28435804 Bytes)
Downloading TEDxGE2014_Stallman05_LQ.webm ...
100.0% ( 27.1/27.1 MB) ├████████████████████████████████████████┤[1/1] 12 MB/s
这就是您可能想要使用它的原因:
· 你喜欢互联网上的东西,只是想为自己的乐趣下载它。
· 您可以通过电脑在线观看喜欢的视频,但无法保存。你觉得你无法控制你的电脑。(这不是开放网络应该如何工作的。)
· 你想摆脱任何封闭源技术或专有的 JavaScript 代码,并禁止在你的计算机上运行 Flash 之类的东西。
· 你是黑客文化和自由软件的忠实拥护者。
你得到什么可以为你做:
· 从 YouTube、优酷、Niconico 等流行的 网站 下载视频/音频(已查看)
· 在媒体播放器中流式传输在线视频。没有网络浏览器,没有更多的广告。
· 通过抓取网页下载图像(感兴趣的)。
· 下载任意非 HTML 内容,即二进制文件。
感兴趣的?现在,和。
你是 Python 程序员吗?然后查看源代码并 fork !
安装
先决条件
以下依赖项是必需的并且必须单独安装,除非您在 Windows 上使用预构建包或巧克力包:
蟒蛇 3
FFmpeg(强烈推荐)或
Libav(可选)
RTMPDump
选项1:通过pip安装you-get的官方版本在PyPI上发布,可以通过以下方式访问
pip 包管理器可以很容易地从 PyPI 镜像安装。
请注意,您必须使用 Python 3 版本的 pip:
$ pip3 install you-get
选项 2:将以下行添加到您的 .zshrc 通过抗原安装:
antigen bundle soimort/you-get
选项 3:使用预构建包(仅限 Windows)从以下位置下载 exe(独立)或 7z(包括所有依赖项):
[https](https://github.com/soimort/you-get/releases/latest):[//github.com/soimort/you-get/releases/latest](https://github.com/soimort/you-get/releases/latest)。
选项 4:从 GitHub 下载您可以下载稳定版(与 PyPI 上的最新版本相同)或开发版(更多修复、不稳定功能)分支。解压缩并将收录 you-get 脚本的目录放入 PATH 中。或者,运行
$ [sudo] python3 setup.py install
要么
$ python3 setup.py install --user
将 you-get 安装到永久路径。
选项 5:Git 克隆 这是所有开发人员推荐的方法,即使您不经常使用 Python 编码。
$ git clone git://github.com/soimort/you-get.git
然后将克隆的目录放在您的 PATH 中,或运行 ./setup.py install 以将 you-get 安装到永久路径。
选项 6:使用 Chocolatey(仅限 Windows)
> choco install you-get
选项 7:自制软件(仅限 Mac)
您可以通过以下方式轻松安装:
$ brew install you-get
Shell 补全 Bash、Fish 和 Zsh 补全定义可以在 contrib/completion 中找到。请参阅您的 shell 手册以了解如何利用它们。
升级
根据您选择安装的选项,您可以通过以下方式升级:
$ pip3 install --upgrade you-get
或通过以下方式下载最新版本:
$ you-get https://github.com/soimort/you ... r.zip
或使用巧克力包管理器:
> choco upgrade you-get
要在不乱扔 pip 的情况下获取最新的开发分支,您可以尝试:
$ pip3 install --upgrade git+https://github.com/soimort/you-get@develop
入门
下载视频
当您收到感兴趣的电影时,可以使用 --info/ -i 选项查看所有可用的质量和格式:
$ you-get -i 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
streams: # Available quality and codecs
[ DEFAULT ] _________________________________
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
- itag: 18
container: mp4
quality: medium
# download-with: you-get --itag=18 [URL]
- itag: 5
container: flv
quality: small
# download-with: you-get --itag=5 [URL]
- itag: 36
container: 3gp
quality: small
# download-with: you-get --itag=36 [URL]
- itag: 17
container: 3gp
quality: small
# download-with: you-get --itag=17 [URL]
默认情况下,标记的格式 DEFAULT 是您将获得的。如果这看起来很酷,你下载它:
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading zoo.webm ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 7 MB/s
Saving Me at the zoo.en.srt ...Done.
(如果 YouTube 视频有任何字幕,它将与 SubRip 字幕格式的视频文件一起下载。)或者,如果您喜欢不同的格式(mp4),只需使用您获得的显示选项:
$ you-get --itag=18 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
注意:
· 此时,我们的大部分支持网站一般不实现格式选择;在这种情况下,下载的默认格式是最高质量的格式。
· ffmpeg 是下载和加入流媒体的多个部分(例如在一些 网站 上,例如优酷)以及 1080p 或高分辨率 YouTube 视频所必需的依赖项。
如果您不想在下载后收录视频部分,请使用 --no-merge/ -n 选项。
下载其他任何东西
如果您已有所需资源的 URL,则可以直接从以下 URL 下载:
$ you-get https://stallman.org/rms.jpg
Site: stallman.org
Title: rms
Type: JPEG Image (image/jpeg)
Size: 0.06 MiB (66482 Bytes)
Downloading rms.jpg ...
100.0% ( 0.1/0.1 MB) ├████████████████████████████████████████┤[1/1] 127 kB/s
否则,you-get 将抓取页面并尝试找出您是否感兴趣:
$ you-get http://kopasas.tumblr.com/post/69361932517
Site: Tumblr.com
Title: kopasas
Type: Unknown type (None)
Size: 0.51 MiB (536583 Bytes)
Site: Tumblr.com
Title: tumblr_mxhg13jx4n1sftq6do1_1280
Type: Portable Network Graphics (image/png)
Size: 0.51 MiB (536583 Bytes)
Downloading tumblr_mxhg13jx4n1sftq6do1_1280.png ...
100.0% ( 0.5/0.5 MB) ├████████████████████████████████████████┤[1/1] 22 MB/s
注意:
此功能是实验性的,远非完美。最适合从流行的网站s,如Tumblr 和Blogger 中抓取大图,但实际上没有通用的模式可以应用于互联网上的任何网站。
在 Google 视频中搜索和下载
你可以传递任何你得到的东西。如果 URL 不是有效的 URL,you-get 将执行 Google 搜索并为您下载最相关的视频。(这可能不是您想看到的,但仍有可能。)
$ you-get "Richard Stallman eats"
暂停和恢复下载 您可以使用 Ctrl+C 中断下载。临时 .download 文件保留在输出目录中。下次使用相同参数运行 you-get 时,下载进度将从上一个会话恢复。如果文件已完全下载(删除临时 .download 扩展名),you-get 将跳过下载。
要强制重新下载,请使用 --force/-f 选项。(警告:这样做会覆盖任何现有文件或同名的临时文件!)
设置下载文件的路径和名称
使用 --output-dir/ -o 选项设置路径,使用 --output-filename/ -O 设置下载文件的名称:
$ you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
如果您对默认视频标题(可能收录与您当前的 shell/OS/文件系统不兼容的特殊字符)有问题,这些选项很有用。
如果您将脚本写入批处理下载文件并将其放入具有指定名称的文件夹中,这些选项也很有用。
代理设置
您可以通过 --http-proxy/ -x 选项指定要使用的 HTTP 代理:
$ you-get -x 127.0.0.1:8087 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
但是,http_proxy 默认应用系统代理设置(即环境变量)。要禁用任何代理,请使用 --no-proxy 选项。
暗示:
如果您需要大量使用代理(如果您的网络阻塞了一些 网站),您可能希望将 you-get 与代理链一起使用并设置别名 you-get="proxychains -q you-get" (Bash)。
对于一些网站(比如优酷),如果需要访问一些只有中国大陆地区才有的视频,可以使用特定的代理从网站中提取视频信息:--提取器代理/ -y。
看视频
不要下载,而是使用 --player/ -p 选项将视频提供给您选择的媒体播放器,例如 mplayer 或 vlc:
$ you-get -p vlc 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
或者,如果您更喜欢在浏览器中观看视频,而无需广告或评论部分:
$ you-get -p chromium 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
暗示:
您可以使用 -p 选项启动另一个下载管理器,例如 you-get -p uget-gtk ''
,尽管他们可能不会一起玩得很好。
加载 cookie
并非所有视频都向任何人公开。如果您需要登录您的帐户来访问某些内容(例如,私人视频),您无法通过 --cookies/ -c 选项将 cookie 提供给您的浏览器。
注意:
到目前为止,我们支持两种格式的浏览器 cookie:Mozilla cookies.sqlite 和 Netscape cookies.txt。
重用提取的数据
使用 --url/ -u 获取从页面中提取的可下载资源 URL 列表。使用 --json 以 JSON 格式获取提取数据的摘要。
警告:
目前,该功能已
不稳定,JSON 模式将来可能会发生重大变化。
支持网站
对于所有其他不在列表中的 网站,通用提取器将负责从页面中查找和下载有趣的资源。
已知错误
如果事情破裂并且您无法获得想要的东西,请不要惊慌。(是的,它一直在发生!)
检查它是否已经是一个已知问题并搜索未解决的问题列表。
如果尚未报告,请打开一个附有详细命令行输出的新问题。
参与其中
您可以通过 Gitter 频道 #soimort/you-get 与我们联系(这是为 Gitter 设置 IRC 客户端的方法)。如果您有一个快速的问题,请到那里。
欢迎各种拉取请求。但是,有一些指导原则: 开发分支是您的拉取请求应该去的地方。
记得变基。
清楚地记录您的 PR,并在适用的情况下提供一些示例的链接以供审阅者测试。
编写格式良好、易于理解的提交消息。
如果您不知道如何,请查看现有的。
我们不会要求您签署 CLA,但您必须确保您的代码可以合法地重新分发(根据 MIT 许可条款)。
****法律问题****
该软件是根据 MIT 许可证分发的。
请特别注意
*本软件按“原样”提供,没有任何明示或暗示的保证,包括但不限于适销性、特定用途的适用性和非侵权性。
*在任何情况下,作者或版权所有者均不对因本软件或其他使用或与软件的其他交易而引起的任何索赔、损害或其他责任(无论是合同、侵权或其他)承担责任。
翻译成人类的话:
*如果您对本软件的使用构成侵犯版权的基础,或者您将本软件用于任何其他非法目的,作者不承担任何责任。
*我们只在此处发送代码,您如何使用它取决于您。
GitHub主页:
参考博客:
谷歌抓取网页视频教程(谷歌搜索网站各个页面的情况统计信息统计及应用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-18 23:05
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以在此处检查网页中的一些小错误;
1、HTML 建议
1)点击左侧导航栏中的“疑难解答-HTML推荐”;
2)在右侧显示 HTML 建议;
3)点击“Duplicate Meta Description”链接,显示收录重复网页描述元描述的网页链接;
4)点击链接查看重复的网页链接,根据情况修改;
5)点击返回查看“Short Meta Description”链接,根据情况修改;
6)点击返回查看“缺少标题标签”,并为列出的页面添加标题标签(title);
7)点击返回查看“重复的标题标签”,其中列出了重复的网页标题;
8)点击进入查看哪些页面收录相同的标题,根据实际情况修改;
本节学习了 HTML 建议的基础知识,如果您成功完成了练习,请继续下一课; 查看全部
谷歌抓取网页视频教程(谷歌搜索网站各个页面的情况统计信息统计及应用技巧)
在下一课中,您可以手动将自己的链接页面提交到 Google 搜索引擎;
1、 像 Googlebot 一样抓取
1)点击左侧导航栏中的“疑难解答-像Googlebot一样抓取”;
2)右侧显示一个文本框,在里面输入正确的网页相对地址,然后点击右侧的抓取;
3) 下拉查看爬取链接的处理。如果提示“找不到”,请检查链接是否正确;
4)提交完成后,等待谷歌处理结果,当显示“成功”时,点击右侧“提交索引”;
5)会出现一个对话框。如果是单独的页面,直接点击提交。如果是目录页面,选择第二个“URL和所有链接页面”,然后点击“提交”;
6)过一会会提示“URL已提交索引”;
7)每周手动提交500个链接地址,“URL和所有链接页面”每月10个;
本节学习了像Googlebot一样爬行的基础知识,如果您成功完成了练习,请继续下一课;
下一课可以查看谷歌搜索抓取的统计数据网站;
1、 爬取统计
1)点击左侧导航栏中的“疑难解答-爬取统计”;
2)右侧会显示网站爬取的概况,包括每日爬取量,提交站点地图时会有峰值;
3)每天下载的数据量也会出现波峰和波谷,可以在sitemap中告诉谷歌,网站每个页面的更新频率,避免重复爬取没有更新的页面;
4)页面下载时间,可以查看网站的访问速度;
本节学习了爬取统计的基础知识,如果你成功完成了练习,请继续下一课;
在下一课中,您可以在此处检查网页中的一些小错误;
1、HTML 建议
1)点击左侧导航栏中的“疑难解答-HTML推荐”;
2)在右侧显示 HTML 建议;
3)点击“Duplicate Meta Description”链接,显示收录重复网页描述元描述的网页链接;
4)点击链接查看重复的网页链接,根据情况修改;
5)点击返回查看“Short Meta Description”链接,根据情况修改;
6)点击返回查看“缺少标题标签”,并为列出的页面添加标题标签(title);
7)点击返回查看“重复的标题标签”,其中列出了重复的网页标题;
8)点击进入查看哪些页面收录相同的标题,根据实际情况修改;
本节学习了 HTML 建议的基础知识,如果您成功完成了练习,请继续下一课;
谷歌抓取网页视频教程(WordPressSEO搜索优化1.设置Google搜索控制台至关重要插件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-16 22:19
对于WordPress外贸网站的用户,如果没有被索引,谷歌就不会显示?这就是网站索引的重要性!这是推动 网站 访问量和实现有机增长的关键。它是 网站 的 SEO 旅程的起点,也是与 Google 建立重要关系的起点。当搜索引擎通过使用称为蜘蛛的自动发现程序抓取页面来识别 网站 页面时,就会发生索引。它对 Google 中的 网站 页面进行分类,并通过在用户输入特定 关键词 时出现在搜索结果中的 URL 为它们提供身份。将索引视为政府机构登记或婴儿出生证明上分配给新车的名称。索引确保对 网站 的识别,
现在,让我们详细了解如何让 网站 快速被 Google 收录!
WordPress SEO 搜索优化
1. 设置 Google Search Console
为了跟踪 网站 的索引,必须安装 Google Search Console。本质上,它是任何与 Google 搜索相关的管理面板,可用于监控 网站 的流量,了解 Google 抓取 网站 的频率,并专注于 网站 的索引。
控制台的设置过程非常简单。登录 Google Search Console网站,输入您要管理的域名,并按照以下步骤确认您是该域的所有者。
完成此操作后,可以提交 网站 中的各个 URL 以供 Google 编制索引。当您提交它们时,Google 会抓取它们并将内容添加到索引中。
可能想知道如何为所有页面提交 网站 URL。通过 Google Search Console 提交站点地图是一个过程,接下来我们将介绍该主题!
2. 创建站点地图并将其提交给 Google 进行索引
站点地图是 Google 可以在其索引中使用的 网站 的全面、高级视图。
在提交站点地图之前,您必须创建一个。事实上,它非常简单——您需要做的就是安装一个像 Google XML Sitemaps 插件这样的工具。这是 Google 制作的一个很棒的插件,用于确保搜索结果中的 网站 索引是最新的。提交站点地图不仅可以让 Google 刷新网站内容,还可以让 Google 更轻松地抓取网站。
站点地图跟踪 网站 上的所有页面,是向 Google 提供所有内容快照的最佳方式。这是让 网站 被索引的更主动的方法,因此请创建一个站点地图并定期将其提交给 Google。
生成站点地图时,通过控制台获取站点地图的 URL。只需将此 URL 提交给 Google。格式为[/sitemap.xml];确保以所需的格式提交您的站点地图!
您还可以使用 网站 之类的东西来创建站点地图。
无论是使用 Google 的插件还是这个 网站,站点地图都会定期创建并提交给 Google。这有助于搜索引擎抓取 网站 上的页面并生成准确的内容索引。
3. 制定内容营销策略
为了让 Google 更频繁地索引 网站,需要产生流量。让人们访问 网站 的最佳方式之一是发布他们喜欢消费的内容!
制定可靠的内容营销策略将帮助您更好地定期在 网站 上发布高质量的内容。需要开发内容索引并战略性地规划和创建内容,同时考虑到您的受众在 Google 中键入的关键字。
研究发现,每月发布超过 16 篇博客的公司获得的流量比每月发布 0 到 4 篇博文的公司多近 4.5%。此次发布定期向 Google 发出信号,表明它是一个活跃的 网站——旨在为其受众创造价值——并使 Google 更频繁地抓取 网站。
博客应该使用各种格式的内容,例如视频、信息图表和电子书。这将激发对 网站 的兴趣,促使他们更频繁地访问它,并让 Google 在索引 网站 时更具响应性。
4. 定期更新贴子
如上所述,定期更新和发布新内容的网站会定期收到更多索引。很像 SEO 机器,主要是因为搜索引擎会抓取文本,当他们发现 网站 具有新鲜、相关的内容时,网站 在搜索结果中的排名更高。
通过 网站 定期发帖,用户将获得更多索引,提高搜索结果的排名,并为 网站 带来比偶尔发帖的用户多 55% 的访问者!因此,请利用 网站 内容更新——它向 Google 发出信号,并使索引成为一个自然过程。
5. 添加内部链接以改进索引
网站 上从一个页面到另一个页面的链接将帮助搜索引擎更有效地抓取内容,并有助于页面的索引。
访问者喜欢内部链接,就像搜索引擎蜘蛛一样。作为 网站 的所有者,您的工作是为您的用户提供全面、友好的体验,而内部链接是实现这一目标的一种方式。
内部链接实际上将用户引导到 网站 上的另一个页面,使他们能够获得有关给定主题的更详细信息。这会提示访问者在 网站 上浏览更多页面,确保没有任何页面处于休眠状态。
通过添加便于人们浏览的内部链接,您将增加网站单个页面被频繁抓取和索引的可能性。它还改进了 网站 的可导航性和内部架构,使其对 Google 更加友好。
6. 增加网页的社交分享
每篇博文中收录的社交分享图标将吸引用户采取行动并与他们的朋友和家人分享内容。当人们在社交媒体上分享 网站 的博客和其他页面时,它会创建更多链接,从而为 网站 带来流量。
网站 链接数量的增加增加了链接页面的访问量,并进一步表明 Google 将其编入索引。
7. 和相关的网站 交流链接
另一种刺激更多流量(进而提高网站索引)的方法是与利基影响者和其他流行的网站合作。通过在知名 网站 上获得反向链接、开展影响者营销活动和发布客座博客,可以为传入的 网站 流量打开新渠道。
所有这些都有助于建立 网站 的在线权威,而大量流量带来的大量反向链接是其中不可或缺的一部分。这就是为什么 Facebook、Amazon 和 YouTube 等 网站 被 Google 抓取的次数要多于未知公司推出的 网站 的原因。凭借在线权限,Google 经常抓取和索引 网站 是有充分理由的。
8. 从 robots.txt 中移除障碍
在抓取 网站 时,Google 的蜘蛛要查找的第一个文件是名为 robots.txt 的文件。这个文件基本上收录了所有指示蜘蛛如何爬取的代码网站,告诉蜘蛛哪些页面是可爬取的,哪些是不可爬取的。
为确保正确抓取 网站,应定期检查 robots.txt 文件。消除任何可能阻止 Google 顺利抓取 网站 的潜在障碍。
如果您不希望某些页面被索引,您可以通过修改此文件中的说明来解决此问题。例如,如果您不希望 网站 上的任何“谢谢”页面显示为单独的搜索结果,您可以在 robots.txt 文件中收录代码以保持这些文件的索引。
从本质上讲,robots.txt 有助于控制哪些内容被编入索引,哪些内容没有被编入索引,因此请充分利用它并帮助 Google 索引正确的页面!
9. 让 网站 被其他搜索引擎索引
一旦 Google 检测到 网站 在其他流行的搜索引擎(如 Yahoo 和 Bing)上被编入索引,网站 也很有可能被编入索引!
当您通过 Google Search Console 提交要在 Google 网站 上索引的站点地图时,可以遵循类似的过程在其他搜索引擎上索引 网站。
10. 设置 RSS 提要
设置 RSS 提要以自动更新用户关于新博客的信息是一种将流量吸引到 网站 的好方法。这可以使用 Google 的 RSS 提要工具 Feedburner 来实现。当用户得知 文章 的新版本时,他们有理由返回 网站。您在 网站 上获得的活动越多,Google 就会越多地抓取该页面并将其编入索引。 查看全部
谷歌抓取网页视频教程(WordPressSEO搜索优化1.设置Google搜索控制台至关重要插件的方法)
对于WordPress外贸网站的用户,如果没有被索引,谷歌就不会显示?这就是网站索引的重要性!这是推动 网站 访问量和实现有机增长的关键。它是 网站 的 SEO 旅程的起点,也是与 Google 建立重要关系的起点。当搜索引擎通过使用称为蜘蛛的自动发现程序抓取页面来识别 网站 页面时,就会发生索引。它对 Google 中的 网站 页面进行分类,并通过在用户输入特定 关键词 时出现在搜索结果中的 URL 为它们提供身份。将索引视为政府机构登记或婴儿出生证明上分配给新车的名称。索引确保对 网站 的识别,
现在,让我们详细了解如何让 网站 快速被 Google 收录!
https://www.wpyou.com/wp-conte ... 8.jpg 460w, https://www.wpyou.com/wp-conte ... 1.jpg 50w" />WordPress SEO 搜索优化
1. 设置 Google Search Console
为了跟踪 网站 的索引,必须安装 Google Search Console。本质上,它是任何与 Google 搜索相关的管理面板,可用于监控 网站 的流量,了解 Google 抓取 网站 的频率,并专注于 网站 的索引。
控制台的设置过程非常简单。登录 Google Search Console网站,输入您要管理的域名,并按照以下步骤确认您是该域的所有者。
完成此操作后,可以提交 网站 中的各个 URL 以供 Google 编制索引。当您提交它们时,Google 会抓取它们并将内容添加到索引中。
可能想知道如何为所有页面提交 网站 URL。通过 Google Search Console 提交站点地图是一个过程,接下来我们将介绍该主题!
2. 创建站点地图并将其提交给 Google 进行索引
站点地图是 Google 可以在其索引中使用的 网站 的全面、高级视图。
在提交站点地图之前,您必须创建一个。事实上,它非常简单——您需要做的就是安装一个像 Google XML Sitemaps 插件这样的工具。这是 Google 制作的一个很棒的插件,用于确保搜索结果中的 网站 索引是最新的。提交站点地图不仅可以让 Google 刷新网站内容,还可以让 Google 更轻松地抓取网站。
站点地图跟踪 网站 上的所有页面,是向 Google 提供所有内容快照的最佳方式。这是让 网站 被索引的更主动的方法,因此请创建一个站点地图并定期将其提交给 Google。
生成站点地图时,通过控制台获取站点地图的 URL。只需将此 URL 提交给 Google。格式为[/sitemap.xml];确保以所需的格式提交您的站点地图!
您还可以使用 网站 之类的东西来创建站点地图。
无论是使用 Google 的插件还是这个 网站,站点地图都会定期创建并提交给 Google。这有助于搜索引擎抓取 网站 上的页面并生成准确的内容索引。
3. 制定内容营销策略
为了让 Google 更频繁地索引 网站,需要产生流量。让人们访问 网站 的最佳方式之一是发布他们喜欢消费的内容!
制定可靠的内容营销策略将帮助您更好地定期在 网站 上发布高质量的内容。需要开发内容索引并战略性地规划和创建内容,同时考虑到您的受众在 Google 中键入的关键字。
研究发现,每月发布超过 16 篇博客的公司获得的流量比每月发布 0 到 4 篇博文的公司多近 4.5%。此次发布定期向 Google 发出信号,表明它是一个活跃的 网站——旨在为其受众创造价值——并使 Google 更频繁地抓取 网站。
博客应该使用各种格式的内容,例如视频、信息图表和电子书。这将激发对 网站 的兴趣,促使他们更频繁地访问它,并让 Google 在索引 网站 时更具响应性。
4. 定期更新贴子
如上所述,定期更新和发布新内容的网站会定期收到更多索引。很像 SEO 机器,主要是因为搜索引擎会抓取文本,当他们发现 网站 具有新鲜、相关的内容时,网站 在搜索结果中的排名更高。
通过 网站 定期发帖,用户将获得更多索引,提高搜索结果的排名,并为 网站 带来比偶尔发帖的用户多 55% 的访问者!因此,请利用 网站 内容更新——它向 Google 发出信号,并使索引成为一个自然过程。
5. 添加内部链接以改进索引
网站 上从一个页面到另一个页面的链接将帮助搜索引擎更有效地抓取内容,并有助于页面的索引。
访问者喜欢内部链接,就像搜索引擎蜘蛛一样。作为 网站 的所有者,您的工作是为您的用户提供全面、友好的体验,而内部链接是实现这一目标的一种方式。
内部链接实际上将用户引导到 网站 上的另一个页面,使他们能够获得有关给定主题的更详细信息。这会提示访问者在 网站 上浏览更多页面,确保没有任何页面处于休眠状态。
通过添加便于人们浏览的内部链接,您将增加网站单个页面被频繁抓取和索引的可能性。它还改进了 网站 的可导航性和内部架构,使其对 Google 更加友好。
6. 增加网页的社交分享
每篇博文中收录的社交分享图标将吸引用户采取行动并与他们的朋友和家人分享内容。当人们在社交媒体上分享 网站 的博客和其他页面时,它会创建更多链接,从而为 网站 带来流量。
网站 链接数量的增加增加了链接页面的访问量,并进一步表明 Google 将其编入索引。
7. 和相关的网站 交流链接
另一种刺激更多流量(进而提高网站索引)的方法是与利基影响者和其他流行的网站合作。通过在知名 网站 上获得反向链接、开展影响者营销活动和发布客座博客,可以为传入的 网站 流量打开新渠道。
所有这些都有助于建立 网站 的在线权威,而大量流量带来的大量反向链接是其中不可或缺的一部分。这就是为什么 Facebook、Amazon 和 YouTube 等 网站 被 Google 抓取的次数要多于未知公司推出的 网站 的原因。凭借在线权限,Google 经常抓取和索引 网站 是有充分理由的。
8. 从 robots.txt 中移除障碍
在抓取 网站 时,Google 的蜘蛛要查找的第一个文件是名为 robots.txt 的文件。这个文件基本上收录了所有指示蜘蛛如何爬取的代码网站,告诉蜘蛛哪些页面是可爬取的,哪些是不可爬取的。
为确保正确抓取 网站,应定期检查 robots.txt 文件。消除任何可能阻止 Google 顺利抓取 网站 的潜在障碍。
如果您不希望某些页面被索引,您可以通过修改此文件中的说明来解决此问题。例如,如果您不希望 网站 上的任何“谢谢”页面显示为单独的搜索结果,您可以在 robots.txt 文件中收录代码以保持这些文件的索引。
从本质上讲,robots.txt 有助于控制哪些内容被编入索引,哪些内容没有被编入索引,因此请充分利用它并帮助 Google 索引正确的页面!
9. 让 网站 被其他搜索引擎索引
一旦 Google 检测到 网站 在其他流行的搜索引擎(如 Yahoo 和 Bing)上被编入索引,网站 也很有可能被编入索引!
当您通过 Google Search Console 提交要在 Google 网站 上索引的站点地图时,可以遵循类似的过程在其他搜索引擎上索引 网站。
10. 设置 RSS 提要
设置 RSS 提要以自动更新用户关于新博客的信息是一种将流量吸引到 网站 的好方法。这可以使用 Google 的 RSS 提要工具 Feedburner 来实现。当用户得知 文章 的新版本时,他们有理由返回 网站。您在 网站 上获得的活动越多,Google 就会越多地抓取该页面并将其编入索引。
谷歌抓取网页视频教程( KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-13 02:04
KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
人工智能在商业中扮演着越来越重要的角色,然而,越来越多的企业发现难以跟上人工智能的发展步伐。我们最重要的目标之一是让机器学习成为适用于任何规模、行业或复杂组织的变革工具。
我们看到越来越多的客户开始将 AI 作为其数据分析策略的一部分,包括 Airbnb、Airbus、Disney 和 Ocado 等早期采用者作为鼓舞人心的用例。在今天的 Google Cloud Next' 17 上,我们很高兴地宣布了一系列新产品、研究和教育计划,以确保所有行业、数据科学家和开发人员都可以使用机器学习。我们也很高兴欢迎 Kaggle 加入 Google Cloud。作为世界上最大的数据科学家和机器学习爱好者社区,超过 800,000 名数据专家使用 Kaggle 来探索、分析和掌握机器学习和数据分析的最新发展。
使用 Cloud Video Intelligence API 了解视频
云视频智能API采用强大的深度学习模型,基于TensorFlow等架构开发,适用于YouTube等大型媒体平台。该 API 是同类中的第一个,允许开发人员轻松搜索和发现视频内容。当这些生物存在时,API 甚至可以提供上下文理解。例如,搜索“老虎”将在谷歌云存储中采集的视频中找到老虎的所有确切镜头。
Google 与世界上最大的媒体公司有着悠久的合作历史,我们帮助他们在视频等非结构化数据中发现价值。该 API 面向大型媒体组织和消费技术公司构建免费媒体目录或寻找管理众包内容的简单方法,以及像 Cantemo 这样将其构建到自己的视频管理软件中的合作伙伴。
随着今天发布的云视频智能 API,谷歌云机器学习增加了一组不断增长的云机器学习 API:视觉、视频智能、语音、自然语言、翻译和作业。这些 API 使客户能够开发能够看到、听到和理解非结构化数据的下一代应用程序——极大地扩展了机器学习在许多领域的使用,例如下一代产品推荐、医学图像分析、欺诈监控等。
云机器学习引擎
谷歌位于乔治亚州的云机器学习引擎已成为希望训练自己的模型并将其部署到云中生产的企业和组织的选择之一。通过开发可以与任何类型的数据交互的基于 TensorFlow 的自定义机器学习模型,它已成为一项有利的管理服务。它还集成了 Google Cloud Platform 的完整数据分析产品线,包括 Cloud Dataflow、Cloud Datalab 和 Google BigQuery 等。
我们还与技术合作伙伴合作,使他们能够通过云机器学习引擎使用自己的解决方案。最近的两个例子包括: SpringML 使用云机器学习引擎为最终客户提供即时分析;SparkCognition 使用它来识别和阻止零日攻击。
与我们的机器学习专家一起学习
为了帮助客户尽快掌握机器学习的价值,我们的高级解决方案实验室提供了一个专用设施,让客户可以直接与 Google 的机器学习专家合作,将机器学习应用于他们最紧迫的挑战。通过这种独特的体验,客户能够探索特定的业务用例,并通过 TensorFlow 和云机器学习引擎在机器学习领域打下坚实的基础。
云视觉 API1.1(测试版)
Cloud Vision 是我们增长最快的 API 之一。自 2016 年 4 月发布以来,该 API 使开发人员能够从超过十亿张图像中提取元数据。今天,我们为企业和合作伙伴推出了新功能,以帮助他们对更多样化的图像进行分类。Cloud Vision API 可以从知识图中识别数百万个物理存在,提供增强的光学字符识别 (OCR) 功能。计算机视觉正在从“非常酷的功能”发展为现代企业的基本组成部分。Cloud Vision API 确保所有云客户都能快速可靠地访问该技术。
Real Estate Information网站 使用云视觉 API,让客户可以通过智能手机拍摄感兴趣的房产照片,立即获取有关房产的信息。
“使用 Google 的机器学习,我们的匹配率比仅依赖位置来获取搜索结果的同类功能高 24 个百分点,”客户体验高级副总裁 David White 说。
减少与 Cloud Jobs API 交互所花费的时间
Cloud Jobs API 使用机器学习来启用 Job Search网站 以提供更相关的职位搜索结果。自从我们发布 API 以来,我们已经整合了来自 CareerBuilder、Dice 和 Jibe 等测试人员的反馈,并添加了通勤搜索等新功能。
强生专注于预防和战胜癌症,最近在该专业领域公开招聘了 350 多名技术专业人员。该公司使用云工作 API 来帮助求职者找到相关工作。
使用 Cloud Datalab 探索数据
Cloud Datalab 是一种交互式数据科学工作流工具,可让开发人员和数据科学家探索、分析和虚拟化 BigQuery、Cloud Storage 和本地存储中的数据。对于机器学习部署,他们可以采用全生命周期方法:在本地存储的较小数据集上建立原型模型,然后使用完整数据集在云中训练它们。
我们希望您能够使用机器学习来推进您的业务。我们期待收到反馈,以帮助您在机器学习方面取得成功。(编译/铭轩) 查看全部
谷歌抓取网页视频教程(
KaggleKaggle:用云视频智能应用程序接口理解视频云视频)
人工智能在商业中扮演着越来越重要的角色,然而,越来越多的企业发现难以跟上人工智能的发展步伐。我们最重要的目标之一是让机器学习成为适用于任何规模、行业或复杂组织的变革工具。
我们看到越来越多的客户开始将 AI 作为其数据分析策略的一部分,包括 Airbnb、Airbus、Disney 和 Ocado 等早期采用者作为鼓舞人心的用例。在今天的 Google Cloud Next' 17 上,我们很高兴地宣布了一系列新产品、研究和教育计划,以确保所有行业、数据科学家和开发人员都可以使用机器学习。我们也很高兴欢迎 Kaggle 加入 Google Cloud。作为世界上最大的数据科学家和机器学习爱好者社区,超过 800,000 名数据专家使用 Kaggle 来探索、分析和掌握机器学习和数据分析的最新发展。
使用 Cloud Video Intelligence API 了解视频
云视频智能API采用强大的深度学习模型,基于TensorFlow等架构开发,适用于YouTube等大型媒体平台。该 API 是同类中的第一个,允许开发人员轻松搜索和发现视频内容。当这些生物存在时,API 甚至可以提供上下文理解。例如,搜索“老虎”将在谷歌云存储中采集的视频中找到老虎的所有确切镜头。
Google 与世界上最大的媒体公司有着悠久的合作历史,我们帮助他们在视频等非结构化数据中发现价值。该 API 面向大型媒体组织和消费技术公司构建免费媒体目录或寻找管理众包内容的简单方法,以及像 Cantemo 这样将其构建到自己的视频管理软件中的合作伙伴。
随着今天发布的云视频智能 API,谷歌云机器学习增加了一组不断增长的云机器学习 API:视觉、视频智能、语音、自然语言、翻译和作业。这些 API 使客户能够开发能够看到、听到和理解非结构化数据的下一代应用程序——极大地扩展了机器学习在许多领域的使用,例如下一代产品推荐、医学图像分析、欺诈监控等。
云机器学习引擎
谷歌位于乔治亚州的云机器学习引擎已成为希望训练自己的模型并将其部署到云中生产的企业和组织的选择之一。通过开发可以与任何类型的数据交互的基于 TensorFlow 的自定义机器学习模型,它已成为一项有利的管理服务。它还集成了 Google Cloud Platform 的完整数据分析产品线,包括 Cloud Dataflow、Cloud Datalab 和 Google BigQuery 等。
我们还与技术合作伙伴合作,使他们能够通过云机器学习引擎使用自己的解决方案。最近的两个例子包括: SpringML 使用云机器学习引擎为最终客户提供即时分析;SparkCognition 使用它来识别和阻止零日攻击。
与我们的机器学习专家一起学习
为了帮助客户尽快掌握机器学习的价值,我们的高级解决方案实验室提供了一个专用设施,让客户可以直接与 Google 的机器学习专家合作,将机器学习应用于他们最紧迫的挑战。通过这种独特的体验,客户能够探索特定的业务用例,并通过 TensorFlow 和云机器学习引擎在机器学习领域打下坚实的基础。
云视觉 API1.1(测试版)
Cloud Vision 是我们增长最快的 API 之一。自 2016 年 4 月发布以来,该 API 使开发人员能够从超过十亿张图像中提取元数据。今天,我们为企业和合作伙伴推出了新功能,以帮助他们对更多样化的图像进行分类。Cloud Vision API 可以从知识图中识别数百万个物理存在,提供增强的光学字符识别 (OCR) 功能。计算机视觉正在从“非常酷的功能”发展为现代企业的基本组成部分。Cloud Vision API 确保所有云客户都能快速可靠地访问该技术。
Real Estate Information网站 使用云视觉 API,让客户可以通过智能手机拍摄感兴趣的房产照片,立即获取有关房产的信息。
“使用 Google 的机器学习,我们的匹配率比仅依赖位置来获取搜索结果的同类功能高 24 个百分点,”客户体验高级副总裁 David White 说。
减少与 Cloud Jobs API 交互所花费的时间
Cloud Jobs API 使用机器学习来启用 Job Search网站 以提供更相关的职位搜索结果。自从我们发布 API 以来,我们已经整合了来自 CareerBuilder、Dice 和 Jibe 等测试人员的反馈,并添加了通勤搜索等新功能。
强生专注于预防和战胜癌症,最近在该专业领域公开招聘了 350 多名技术专业人员。该公司使用云工作 API 来帮助求职者找到相关工作。
使用 Cloud Datalab 探索数据
Cloud Datalab 是一种交互式数据科学工作流工具,可让开发人员和数据科学家探索、分析和虚拟化 BigQuery、Cloud Storage 和本地存储中的数据。对于机器学习部署,他们可以采用全生命周期方法:在本地存储的较小数据集上建立原型模型,然后使用完整数据集在云中训练它们。
我们希望您能够使用机器学习来推进您的业务。我们期待收到反馈,以帮助您在机器学习方面取得成功。(编译/铭轩)
谷歌抓取网页视频教程(规划单页竞价!建立投标矩阵(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-12 14:01
谷歌seo视频教程的显着特点之一是在短期竞价推广中,竞价单页很少有内链支持。一旦促销结束,它将成为一个单独的页面。基于以下策略,我们可以参考以下策略来规划单页竞价!建立投标矩阵 如果你想在 网站 的层级目录中建立投标页面 根据经验我们建议为投标页建立一个单独的层级目录 作为营销人员我们可以把每个页面都放好!在@k17@的层级目录中创建竞价页面> 根据经验,我们建议为竞价页面创建一个单独的层级目录。作为营销人员,我们可以把每个页面。
Google seo 视频教程的内容质量在算法中具有很高的权重,因此您可以通过改进您的 网站 的各个方面来优化 收录收录 的音量和排名数据 感谢您对搜索的支持和关注!官方收录异常反馈汇总贴 本帖是给站长反馈的收录异常情况收录量少可能是算法搜索公共算法不计入前教程搜索引用过多算了,反馈总结帖是站长举报收录异常情况收录量少可能是算法搜索算法没有太多参考之前教程搜索的原因。
谷歌seo视频教程被要求解决问题。在优化的时候,绝对保证没有风险。这也是万辞霸屏风如此火爆的原因。在当今世界,也算是非常不错了。当然,时下流行的网络营销优化系统,从目前的使用效果来看,也得到了专业人士的认可和支持,并在实际应用中!它绝对是当今世界上非常流行的网络营销优化系统。当然,从目前它的使用效果来看,也得到了各专业的认可和支持,在实际应用的过程中会发挥很大的优势!
谷歌seo视频教程搭建服务和定制在网站网站搭建方面有丰富的经验。近年来,我制作完成了许多网站建筑案例产品,营销类型网站,建筑技术领先,推广迅速。是技术领先的日期。虽然现在搜索引擎无法合理区分清晰度,但在用户阅读方面却大打折扣,即使上传过程中出现错误,丢失了原本以为醒目的图片!合理的分辨率,但对于用户阅读来说是一个很大的折扣。即便一张被认为很抢眼的图片因为上传过程中的失误而丢失,也会在用户心目中失去一定的可信度。不仅,
谷歌seo视频教程人认为降低页面加载速度值得点击网站加载速度不仅影响排名,还可能导致用户体验不好;因此,通过一个好的网站架构和前端架构可以有效的提高网站速度和网站增强用户体验。百度悦信的算法表明它们是可能的。 查看全部
谷歌抓取网页视频教程(规划单页竞价!建立投标矩阵(一)(组图))
谷歌seo视频教程的显着特点之一是在短期竞价推广中,竞价单页很少有内链支持。一旦促销结束,它将成为一个单独的页面。基于以下策略,我们可以参考以下策略来规划单页竞价!建立投标矩阵 如果你想在 网站 的层级目录中建立投标页面 根据经验我们建议为投标页建立一个单独的层级目录 作为营销人员我们可以把每个页面都放好!在@k17@的层级目录中创建竞价页面> 根据经验,我们建议为竞价页面创建一个单独的层级目录。作为营销人员,我们可以把每个页面。
Google seo 视频教程的内容质量在算法中具有很高的权重,因此您可以通过改进您的 网站 的各个方面来优化 收录收录 的音量和排名数据 感谢您对搜索的支持和关注!官方收录异常反馈汇总贴 本帖是给站长反馈的收录异常情况收录量少可能是算法搜索公共算法不计入前教程搜索引用过多算了,反馈总结帖是站长举报收录异常情况收录量少可能是算法搜索算法没有太多参考之前教程搜索的原因。
谷歌seo视频教程被要求解决问题。在优化的时候,绝对保证没有风险。这也是万辞霸屏风如此火爆的原因。在当今世界,也算是非常不错了。当然,时下流行的网络营销优化系统,从目前的使用效果来看,也得到了专业人士的认可和支持,并在实际应用中!它绝对是当今世界上非常流行的网络营销优化系统。当然,从目前它的使用效果来看,也得到了各专业的认可和支持,在实际应用的过程中会发挥很大的优势!
谷歌seo视频教程搭建服务和定制在网站网站搭建方面有丰富的经验。近年来,我制作完成了许多网站建筑案例产品,营销类型网站,建筑技术领先,推广迅速。是技术领先的日期。虽然现在搜索引擎无法合理区分清晰度,但在用户阅读方面却大打折扣,即使上传过程中出现错误,丢失了原本以为醒目的图片!合理的分辨率,但对于用户阅读来说是一个很大的折扣。即便一张被认为很抢眼的图片因为上传过程中的失误而丢失,也会在用户心目中失去一定的可信度。不仅,
谷歌seo视频教程人认为降低页面加载速度值得点击网站加载速度不仅影响排名,还可能导致用户体验不好;因此,通过一个好的网站架构和前端架构可以有效的提高网站速度和网站增强用户体验。百度悦信的算法表明它们是可能的。
谷歌抓取网页视频教程(如果您不想让您的网站被搜索引擎爬虫抓取,可以通过robots.txt文件来屏蔽)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-12 13:18
如果您不希望您的 网站 被搜索引擎爬虫抓取,您可以通过 robots.txt 文件或 .htaccess 文件来阻止它。有关详细信息,请参阅以下教程。
方法一、通过Robots协议robots.txt文件屏蔽搜索引擎
Robots Protocol(也称为Crawler Protocol、Robots Protocol等),全称是“Robots Exclusion Protocol”,网站告诉搜索引擎哪些页面可以被爬取,哪些页面可以通过robots.txt协议文件不要爬行。当搜索引擎蜘蛛访问一个站点时,它会首先检查该站点的根目录中是否存在 robots.txt 文件。如果存在,搜索机器人会根据文件内容判断访问范围;如果该文件不存在,所有搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。因此,如果我们不想让搜索引擎爬取网站,我们可以通过robots.txt来屏蔽搜索引擎蜘蛛。robots.txt的具体用法请参考百度百科词条“robots.txt”。
方法二、通过.htaccess文件屏蔽搜索引擎
每个搜索引擎的爬虫都有自己的User-Agent,通过User-Agent告诉别人自己的身份信息。因此,我们可以通过.htaccess文件来阻止某个(某些)User-Agent的访问,从而实现对某个(某些)User-Agent的屏蔽。(一些)搜索引擎爬虫爬取网站。代码显示如下:
代码示例1:直接告诉爬虫网站服务器出现503错误
#阻止Bing和MSN爬虫,告诉爬虫有503错误
ErrorDocument 503“系统正在进行维护”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (bingbot|msn) [NC]
重写规则 .* - [R=503,L]
代码示例2:告诉爬虫网站重定向到一个新的URL(让爬虫在新的URL上爬取网站)
#屏蔽百度、谷歌、搜搜的爬虫,告诉爬虫网站重定向到
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (baiduspider|googlebot|soso) [NC]
重写规则 ^(.*)$ [R=301,L]
上面的代码示例1和示例2都可以使用,可以根据自己的需要选择(如果只是暂时阻塞,使用示例1的代码;如果网站已经转入新的URL,就用例子2的代码,记得把例子2的代码修改成你的网站的新URL),把代码复制到你的网站@根目录下的.htaccess文件中>。
上面的示例代码只列出了几种常见搜索引擎的 User-Agent。如果要屏蔽更多的搜索引擎,可以先在网上搜索一下那些搜索引擎的User-Agent是什么,然后在代码中RewriteCond,在括号后面加上你要屏蔽的搜索引擎的User-Agent即可%{HTTP_USER_AGENT} 行。 查看全部
谷歌抓取网页视频教程(如果您不想让您的网站被搜索引擎爬虫抓取,可以通过robots.txt文件来屏蔽)
如果您不希望您的 网站 被搜索引擎爬虫抓取,您可以通过 robots.txt 文件或 .htaccess 文件来阻止它。有关详细信息,请参阅以下教程。
方法一、通过Robots协议robots.txt文件屏蔽搜索引擎
Robots Protocol(也称为Crawler Protocol、Robots Protocol等),全称是“Robots Exclusion Protocol”,网站告诉搜索引擎哪些页面可以被爬取,哪些页面可以通过robots.txt协议文件不要爬行。当搜索引擎蜘蛛访问一个站点时,它会首先检查该站点的根目录中是否存在 robots.txt 文件。如果存在,搜索机器人会根据文件内容判断访问范围;如果该文件不存在,所有搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。因此,如果我们不想让搜索引擎爬取网站,我们可以通过robots.txt来屏蔽搜索引擎蜘蛛。robots.txt的具体用法请参考百度百科词条“robots.txt”。
方法二、通过.htaccess文件屏蔽搜索引擎
每个搜索引擎的爬虫都有自己的User-Agent,通过User-Agent告诉别人自己的身份信息。因此,我们可以通过.htaccess文件来阻止某个(某些)User-Agent的访问,从而实现对某个(某些)User-Agent的屏蔽。(一些)搜索引擎爬虫爬取网站。代码显示如下:
代码示例1:直接告诉爬虫网站服务器出现503错误
#阻止Bing和MSN爬虫,告诉爬虫有503错误
ErrorDocument 503“系统正在进行维护”
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (bingbot|msn) [NC]
重写规则 .* - [R=503,L]
代码示例2:告诉爬虫网站重定向到一个新的URL(让爬虫在新的URL上爬取网站)
#屏蔽百度、谷歌、搜搜的爬虫,告诉爬虫网站重定向到
重写引擎开启
RewriteCond %{HTTP_USER_AGENT} (baiduspider|googlebot|soso) [NC]
重写规则 ^(.*)$ [R=301,L]
上面的代码示例1和示例2都可以使用,可以根据自己的需要选择(如果只是暂时阻塞,使用示例1的代码;如果网站已经转入新的URL,就用例子2的代码,记得把例子2的代码修改成你的网站的新URL),把代码复制到你的网站@根目录下的.htaccess文件中>。
上面的示例代码只列出了几种常见搜索引擎的 User-Agent。如果要屏蔽更多的搜索引擎,可以先在网上搜索一下那些搜索引擎的User-Agent是什么,然后在代码中RewriteCond,在括号后面加上你要屏蔽的搜索引擎的User-Agent即可%{HTTP_USER_AGENT} 行。
谷歌抓取网页视频教程(谷歌搜索负责人约翰·穆勒用HTML5显示方便搜索引擎抓取图表相关信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-07 12:16
近日,谷歌搜索负责人在线下站长交流群与站长们分享了搜索优化的方向。建议网站使用图片展示图表信息,尽量减少HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
据了解,在本次群聊回答中,一位站长向谷歌搜索负责人约翰·穆勒提问,在网页上用数据优化图表展示的最佳方式是什么。在 Google 搜索看来,使用图表发布图表或在 HTML5 中重新创建图表对于页面排名来说要好一些。
对此,谷歌搜索负责人约翰·穆勒(John Mueller)回应:使用图片或者HTML来展示网页的内容,取决于网站你想通过图表展示什么,我想把图表变成HTML 并放置数字和标签 导入文本不会从中获得很多价值,建议使用图像而不是 HTML 来显示网页的表格信息。
目前,对 Google 搜索结果中发布的 网站 图表信息进行排名的最佳方式是:
1. 使用图像而不是 HTML 代码来创建图表。如果图片中有关键信息需要传递,站长可以添加图片相关的alt属性描述,保证翻译不丢失。这样,当谷歌蜘蛛抓取并理解页面时,蜘蛛可以将图像提取为文本,以便看不到图像的人也可以获取该信息。
2. 在图片周围添加足够的文字内容,进一步说明图表的含义。如上,方便蜘蛛爬取图片,提取为文本获取图片信息。
此外,谷歌搜索负责人约翰·穆勒也提醒,在使用图片传达图表信息时,要注意图片的大小,避免图片过大影响网站的加载速度,并且尽量不要显示图表,因为图表在谷歌图片搜索排名中的表现并不是特别好。一般很少有用户使用谷歌图片来查找具体的图表,所以站长尽量少用图表进行图片优化排名!
不过也有国内站长发表了不同意见|:别听他的,HTML5显示图表没问题,图片盗用还是有问题。另外,如果图表移动了怎么办? 查看全部
谷歌抓取网页视频教程(谷歌搜索负责人约翰·穆勒用HTML5显示方便搜索引擎抓取图表相关信息)
近日,谷歌搜索负责人在线下站长交流群与站长们分享了搜索优化的方向。建议网站使用图片展示图表信息,尽量减少HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
据了解,在本次群聊回答中,一位站长向谷歌搜索负责人约翰·穆勒提问,在网页上用数据优化图表展示的最佳方式是什么。在 Google 搜索看来,使用图表发布图表或在 HTML5 中重新创建图表对于页面排名来说要好一些。
对此,谷歌搜索负责人约翰·穆勒(John Mueller)回应:使用图片或者HTML来展示网页的内容,取决于网站你想通过图表展示什么,我想把图表变成HTML 并放置数字和标签 导入文本不会从中获得很多价值,建议使用图像而不是 HTML 来显示网页的表格信息。
目前,对 Google 搜索结果中发布的 网站 图表信息进行排名的最佳方式是:
1. 使用图像而不是 HTML 代码来创建图表。如果图片中有关键信息需要传递,站长可以添加图片相关的alt属性描述,保证翻译不丢失。这样,当谷歌蜘蛛抓取并理解页面时,蜘蛛可以将图像提取为文本,以便看不到图像的人也可以获取该信息。
2. 在图片周围添加足够的文字内容,进一步说明图表的含义。如上,方便蜘蛛爬取图片,提取为文本获取图片信息。
此外,谷歌搜索负责人约翰·穆勒也提醒,在使用图片传达图表信息时,要注意图片的大小,避免图片过大影响网站的加载速度,并且尽量不要显示图表,因为图表在谷歌图片搜索排名中的表现并不是特别好。一般很少有用户使用谷歌图片来查找具体的图表,所以站长尽量少用图表进行图片优化排名!
不过也有国内站长发表了不同意见|:别听他的,HTML5显示图表没问题,图片盗用还是有问题。另外,如果图表移动了怎么办?
谷歌抓取网页视频教程( 2019年跨境电商卖家布局投入到独立站的核心之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-05 10:23
2019年跨境电商卖家布局投入到独立站的核心之一)
2019年,大量跨境电商卖家投资独立站。独立站点的核心之一就是能够以低廉的价格获得流量。主要海外流量渠道,打开App Store排名一目了然,基于Google的搜索和展示流量,基于Facebook的社交和展示流量,排名前列。
谷歌的搜索流量分为付费广告流量和SEO有机流量。在上一波独立网站热潮中,国内出现了很多谷歌SEO流量大神。通过高超的SEO技术,他们在众多细分产品的搜索排名中获得了第一屏的位置。时至今日,谷歌SEO流量仍然是许多独立网站玩家流量构成的重要组成部分。在这里,我将简要介绍一些无需任何技术背景即可快速使用的SEO秘诀。它可以作为独立网站甚至作为亚马逊卖家的参考。
对于SEO来说,一切都是基于准确的数据源,可以准确分析目标网站和竞品网站。这里推荐使用ahrefs。Ahrefs 是一款功能强大的 Google SEO 工具,每天可抓取 60 亿个页面,用于竞争性页面分析、关键词 研究、反向链接研究、内容研究等。有 7 天 7 美元的试用期,还有一些在线共享帐户可以以较低的价格共享。
接下来,有哪些技巧可以提高网站在Google中的搜索排名?
首先,您的电子商务独立站点必须在整个站点中使用 HTTPS 安全协议。几乎所有的电子商务网站都收录许多采集用户信息的形式。HTTPS 安全协议有助于保护用户的数据。谷歌还确认,网站 使用 HTTPS 安全协议发布内容有助于提高 网站关键词 排名。
其次,电子商务独立网站的URL结构应该对搜索引擎“友好”,每个URL都应该适合搜索引擎抓取。以下是一些 URL 创建原则:
1. 尽可能短;
2. 包括主命令 关键词/faucet关键词;
3. 确保页面的层次结构和上下文清晰;
4. 使用连字符 (-) 分隔单词。不要使用下划线、空格或任何其他字符;
5. 尽可能避免 URL 中的随机字符串。
三、添加模式标记(Schema Markup)。
如果用户在谷歌搜索蛋白粉,他更可能打开哪个带有预览模式的搜索结果?
1.
2.
大多数人会点击第二个。它更醒目,有更多的产品信息,更接近搜索者的搜索意图。谷歌爬虫也可以使用这些信息来更好地了解页面的内容并提高其排名。正如 Google 网站管理员指南中所述,向产品页面添加标记信息允许 Google 在搜索结果(包括图像搜索)中以富文本形式显示详细的产品信息。用户可以在搜索结果中直接查看价格、可用性、评论分数等。您可以使用加入模式标志。
第四,从竞争对手 网站 中找到链接到您的 网站 的关键反向链接。业内优秀的电商网站拥有大量的反向链接,提升SEO排名。这里有很多方法。例如,通过 Ahrefs 的 Content explorer 工具,你可以搜索你关心的产品的关键词,你可以找到一系列销售相同产品的网页内容,其中可能包括一些流行的博客,而这些流行的博客可能有指向竞争对手 网站 的链接。
如果链接不完全有用或用户友好,例如,该产品仅在美国销售,但链接 网站 的用户主要是英国消费者,这对用户来说毫无用处。
白帽方法是通过电子邮件与博主沟通并将链接更改回您的链接。
“嘿[名字]
麦芽磨坊的简在这里。
我刚刚看到你的酿造苹果酒指南,并注意到你与 Northern Brewer 有联系。
经营 X 年,我知道 Northern Brewer 是您提到的设备(气闸、虹吸软管、Star San 等)的出色供应商。但不幸的是,他们不运送到英国。
但是,我们确实在英国销售这些产品。因此,我想知道您是否可以考虑将我们与 Northern Brewer 一起添加到该帖子中-我认为这对您的英国访客很有用。
让我知道。
谢谢!
乔什”
当然,有很多灰帽和黑帽的玩法。这样可以找到大量高权重的网站或者博客,链接到你的电商网站,可以显着提升网站的搜索排名。
SEO是一个非常有效的自然流量来源。一旦系统建立起来,流量获取的成本相对较低。现在跨境电商圈有SEO流量大神,可以搜索一些部分产品,在谷歌搜索首页有多个搜索结果。这样的公司赚钱不容易。不过,要达到这样的排名,在技术积累、人才、软硬件方面的投入也是相当高的,并不是所有的跨境电商卖家都有条件。(来源:跨境电商跨境之家) 查看全部
谷歌抓取网页视频教程(
2019年跨境电商卖家布局投入到独立站的核心之一)
2019年,大量跨境电商卖家投资独立站。独立站点的核心之一就是能够以低廉的价格获得流量。主要海外流量渠道,打开App Store排名一目了然,基于Google的搜索和展示流量,基于Facebook的社交和展示流量,排名前列。
谷歌的搜索流量分为付费广告流量和SEO有机流量。在上一波独立网站热潮中,国内出现了很多谷歌SEO流量大神。通过高超的SEO技术,他们在众多细分产品的搜索排名中获得了第一屏的位置。时至今日,谷歌SEO流量仍然是许多独立网站玩家流量构成的重要组成部分。在这里,我将简要介绍一些无需任何技术背景即可快速使用的SEO秘诀。它可以作为独立网站甚至作为亚马逊卖家的参考。
对于SEO来说,一切都是基于准确的数据源,可以准确分析目标网站和竞品网站。这里推荐使用ahrefs。Ahrefs 是一款功能强大的 Google SEO 工具,每天可抓取 60 亿个页面,用于竞争性页面分析、关键词 研究、反向链接研究、内容研究等。有 7 天 7 美元的试用期,还有一些在线共享帐户可以以较低的价格共享。
接下来,有哪些技巧可以提高网站在Google中的搜索排名?
首先,您的电子商务独立站点必须在整个站点中使用 HTTPS 安全协议。几乎所有的电子商务网站都收录许多采集用户信息的形式。HTTPS 安全协议有助于保护用户的数据。谷歌还确认,网站 使用 HTTPS 安全协议发布内容有助于提高 网站关键词 排名。
其次,电子商务独立网站的URL结构应该对搜索引擎“友好”,每个URL都应该适合搜索引擎抓取。以下是一些 URL 创建原则:
1. 尽可能短;
2. 包括主命令 关键词/faucet关键词;
3. 确保页面的层次结构和上下文清晰;
4. 使用连字符 (-) 分隔单词。不要使用下划线、空格或任何其他字符;
5. 尽可能避免 URL 中的随机字符串。
三、添加模式标记(Schema Markup)。
如果用户在谷歌搜索蛋白粉,他更可能打开哪个带有预览模式的搜索结果?
1.
2.
大多数人会点击第二个。它更醒目,有更多的产品信息,更接近搜索者的搜索意图。谷歌爬虫也可以使用这些信息来更好地了解页面的内容并提高其排名。正如 Google 网站管理员指南中所述,向产品页面添加标记信息允许 Google 在搜索结果(包括图像搜索)中以富文本形式显示详细的产品信息。用户可以在搜索结果中直接查看价格、可用性、评论分数等。您可以使用加入模式标志。
第四,从竞争对手 网站 中找到链接到您的 网站 的关键反向链接。业内优秀的电商网站拥有大量的反向链接,提升SEO排名。这里有很多方法。例如,通过 Ahrefs 的 Content explorer 工具,你可以搜索你关心的产品的关键词,你可以找到一系列销售相同产品的网页内容,其中可能包括一些流行的博客,而这些流行的博客可能有指向竞争对手 网站 的链接。
如果链接不完全有用或用户友好,例如,该产品仅在美国销售,但链接 网站 的用户主要是英国消费者,这对用户来说毫无用处。
白帽方法是通过电子邮件与博主沟通并将链接更改回您的链接。
“嘿[名字]
麦芽磨坊的简在这里。
我刚刚看到你的酿造苹果酒指南,并注意到你与 Northern Brewer 有联系。
经营 X 年,我知道 Northern Brewer 是您提到的设备(气闸、虹吸软管、Star San 等)的出色供应商。但不幸的是,他们不运送到英国。
但是,我们确实在英国销售这些产品。因此,我想知道您是否可以考虑将我们与 Northern Brewer 一起添加到该帖子中-我认为这对您的英国访客很有用。
让我知道。
谢谢!
乔什”
当然,有很多灰帽和黑帽的玩法。这样可以找到大量高权重的网站或者博客,链接到你的电商网站,可以显着提升网站的搜索排名。
SEO是一个非常有效的自然流量来源。一旦系统建立起来,流量获取的成本相对较低。现在跨境电商圈有SEO流量大神,可以搜索一些部分产品,在谷歌搜索首页有多个搜索结果。这样的公司赚钱不容易。不过,要达到这样的排名,在技术积累、人才、软硬件方面的投入也是相当高的,并不是所有的跨境电商卖家都有条件。(来源:跨境电商跨境之家)
谷歌抓取网页视频教程( 虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-01 04:13
虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文
)
0.学习路径图
大家好,这次博主分享的是微博的长文,一个大V-财宝,使用虚拟浏览器ChromeDriver爬取。
1.ChromeDriver介绍
WebDriver 是一个开源工具,用于在许多浏览器上自动测试 web 应用程序。它提供导航到网页、用户输入、JavaScript 执行等功能。ChromeDriver 是一个独立的服务,它为 Chromium 实现了 WebDriver 的 JsonWireProtocol 协议。简单来说就是一个虚拟浏览器,可以模仿人类的鼠标点击、滑动和键盘输入,解决我们日常爬虫遇到的动态网页问题。
什么是动态网页?
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
现在流行的商业爬虫框架scrapy适合解决爬取静态网页的问题(下期会讲),然而越来越多的网站采用动态设计,微博也是如此,所以本博主打算写一篇教程,教大家如何使用虚拟浏览器chrome驱动抓取微博大V-财宝的微博长文。
这位大V放弃了他微博的版权,而他的微博基本都是文字版的,而且博文格式好处理,所以博主为了不承担法律责任,不写一些杂七杂八的处理,也是为了方便教学功能,并选择在他的微博上教学。(博主辛苦吗?)
言归正传,我们进入chrome驱动的学习。
2.实验准备
一种。运行环境:Windows Anaconda 3.7.2
湾。下载chrome浏览器
C。下载chrome驱动:
下载链接/pachongshan gdexuebi/p/7086564.html
d。chrome驱动存放位置
放到AnacondaScripts文件夹下(如下图)
所以记得安装anaconda3!
3.实验步骤
一种。实验前说明:一般来说,爬取一个网页的难度是:PC端>移动端m>wap。由于微博没有wap版,博主选择了手机版进行爬取。
湾。代码小视频讲解
C。代码 git 链接
ChileWang0228/python_tutorial
4.总结
随着越来越多的网站采用动态设计,学习使用虚拟浏览器进行爬虫已经成为每个爬虫工程师必备的技能。上面的代码短短几十行就完成了,导致chrome驱动的一些比较有趣的功能还没有介绍,比如模拟鼠标点击、下拉菜单栏等,我附上几个链接介绍一下他的具体功能。学习后,您可以尝试如何使用虚拟浏览。实现模拟登录微博的设备。
学习是这样的。构建好主框架后,后续的添加就容易多了。
下一期我会讲使用商业爬虫框架处理静态网页,动静结合,小伙伴们基本可以学习网络爬虫模块了。
希望本教程能帮助你有所收获,谢谢~
selenium 简单使用 Selenium(Python web 测试工具)基本使用详解
Selenium 定位元素 WebDriver 入门 如何在 Linux 上使用虚拟浏览器 Linux+Selenium+FireFox 安装
查看全部
谷歌抓取网页视频教程(
虚拟浏览器chrome去爬取微博大V-财宝宝的微博长文
)
0.学习路径图
大家好,这次博主分享的是微博的长文,一个大V-财宝,使用虚拟浏览器ChromeDriver爬取。
1.ChromeDriver介绍
WebDriver 是一个开源工具,用于在许多浏览器上自动测试 web 应用程序。它提供导航到网页、用户输入、JavaScript 执行等功能。ChromeDriver 是一个独立的服务,它为 Chromium 实现了 WebDriver 的 JsonWireProtocol 协议。简单来说就是一个虚拟浏览器,可以模仿人类的鼠标点击、滑动和键盘输入,解决我们日常爬虫遇到的动态网页问题。
什么是动态网页?
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
现在流行的商业爬虫框架scrapy适合解决爬取静态网页的问题(下期会讲),然而越来越多的网站采用动态设计,微博也是如此,所以本博主打算写一篇教程,教大家如何使用虚拟浏览器chrome驱动抓取微博大V-财宝的微博长文。
这位大V放弃了他微博的版权,而他的微博基本都是文字版的,而且博文格式好处理,所以博主为了不承担法律责任,不写一些杂七杂八的处理,也是为了方便教学功能,并选择在他的微博上教学。(博主辛苦吗?)
言归正传,我们进入chrome驱动的学习。
2.实验准备
一种。运行环境:Windows Anaconda 3.7.2
湾。下载chrome浏览器
C。下载chrome驱动:
下载链接/pachongshan gdexuebi/p/7086564.html
d。chrome驱动存放位置
放到AnacondaScripts文件夹下(如下图)
所以记得安装anaconda3!
3.实验步骤
一种。实验前说明:一般来说,爬取一个网页的难度是:PC端>移动端m>wap。由于微博没有wap版,博主选择了手机版进行爬取。
湾。代码小视频讲解
C。代码 git 链接
ChileWang0228/python_tutorial
4.总结
随着越来越多的网站采用动态设计,学习使用虚拟浏览器进行爬虫已经成为每个爬虫工程师必备的技能。上面的代码短短几十行就完成了,导致chrome驱动的一些比较有趣的功能还没有介绍,比如模拟鼠标点击、下拉菜单栏等,我附上几个链接介绍一下他的具体功能。学习后,您可以尝试如何使用虚拟浏览。实现模拟登录微博的设备。
学习是这样的。构建好主框架后,后续的添加就容易多了。
下一期我会讲使用商业爬虫框架处理静态网页,动静结合,小伙伴们基本可以学习网络爬虫模块了。
希望本教程能帮助你有所收获,谢谢~
selenium 简单使用 Selenium(Python web 测试工具)基本使用详解
Selenium 定位元素 WebDriver 入门 如何在 Linux 上使用虚拟浏览器 Linux+Selenium+FireFox 安装
谷歌抓取网页视频教程(Google是如何查找与您的查询匹配的网页的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-01 03:21
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
为您提供搜索结果的三个主要流程如下:
抓取:Google 知道你的 网站 吗?我们能找到吗?
索引:Google 可以索引您的 网站 吗?
交付结果:您的 网站 是否收录用户搜索的有趣、有用和相关的内容?
1:抢
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
2:索引
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
3:提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您正在寻找”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。 查看全部
谷歌抓取网页视频教程(Google是如何查找与您的查询匹配的网页的?)
当你坐在电脑前进行谷歌搜索时,来自整个网络的一系列搜索结果几乎会立即出现在你的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?
简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序会搜索索引以确定最相关的搜索结果以返回(提供)给您。
https://www.fujieace.com/wp-co ... 7.png 400w" />为您提供搜索结果的三个主要流程如下:
抓取:Google 知道你的 网站 吗?我们能找到吗?
索引:Google 可以索引您的 网站 吗?
交付结果:您的 网站 是否收录用户搜索的有趣、有用和相关的内容?
1:抢
抓取是 Googlebot 查找要添加到 Google 索引的新页面和更新页面的过程。
我们使用大量计算机来摄取(或“抓取”)网络上的大量网页。执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。
谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。
Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。
2:索引
Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个庞大的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。
3:提供结果
当用户输入查询时,我们的计算机会在索引中搜索匹配的网页,并返回我们认为与用户搜索最相关的结果。相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。
为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并提高您的网站排名。
Google 的“您正在寻找”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。与我们的搜索结果类似,这些功能中使用的关键字是由我们的网络爬虫和搜索算法自动生成的。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。
谷歌抓取网页视频教程(不是教你如何打造一个一个的产品页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-26 11:27
现场SEO优化已经存在很多年了,但在中国却很少有全面的Check Lists。国外的文章一般会教你如何优化一个文章。而不是教你如何构建商业产品页面。这篇文章文章是根据我过去几年在独立站点SEO项目中的经验对站点SEO的总结。
其实SEO本身就是内容,我们只是把零散的信息放到网上,结合我们的经验,系统的整理在一起。没有所谓的创新,就没有On page SEO的创新。
什么是现场搜索引擎优化?
对我来说,On Page SEO其实就是把一个页面通过各个纬度做到极致,然后在Google上得到最好的关键词排名的过程。
以下是我整理的 On Page SEO Check List。
1号
您的网页是否可以被 Google 抓取
页面被谷歌抓取,这是网页排名的首要前提。验证你的页面抓取是否有问题,你可以把你的网页链接放到这个工具里:
如果显示 200 OK,则表示网页抓取没有问题。
验证页面抓取
2号
您的页面是否被 Google 搜索过收录
网页被抓取后,Google 一般会收录your网站。
要检查页面是否为 收录,只需将页面 URL 输入 Google。
谷歌搜索页面网址
如果页面不是收录,需要到谷歌站长工具后台提交页面,请求被索引。
请求索引
3号
您的 网站 上是否安装了 Google Analytics
我们需要知道这个页面的数据,比如跳出率、用户停留时间、用户来源、国家等等。有数据支持,方便我们后期有针对性的优化。
例如,从中国到南非,这个页面每个月给我带来了 85 个查询。询盘转化率9.94%,跳出率49.71%,用户平均停留时间超过两分钟。
页面数据
4号
是否监控此页面的 关键词 排名变化
您需要实时监控该页面的相关关键词排名,以便根据排名变化及时调整您的页面。我一般使用 SEM rush 的 关键词 监控工具。您可以查看特定页面的每日 关键词 排名变化。
关键词 SEM rush 监控
5号
您的页面是否完全满足用户的搜索意图?
例如,用户最初是在寻找有关玻璃瓶材料的新东西。这样一来,如果你用一个玻璃瓶的产品页面来优化这个词,即使你的页面到达了谷歌首页,也不会出现询价转化,但是这个页面的跳出率会特别高。
6号
无论是页面,重点优化一个词
很多人把很多产品放在一个页面上,所以很难有一个好的排名。需要专注于一个词。告诉 Google,您的页面的核心是优化该主题。
7号
是否在页面上添加核心 关键词 变体
例如,医用口罩。它也可以称为面罩。它也可以称为防护面罩。您的页面需要将 关键词 的这些变体添加到页面中。增加核心词的相关性。
8号
核心 关键词 是否出现在您的网页内容的第一段中
在网页的第一段,核心 关键词 应该出现。其实如果按照正常逻辑写文案,第一段肯定会出现关键词。
9号
核心 关键词 是否出现在 SEO 标题中
相信大部分朋友都没有写SEO标题的习惯,更别说把核心关键词放在标题里了。
一定要先写SEO标题,这对关键词排名很重要。此外,核心词需要写在标题中。
搜索引擎优化标题
10号
您的核心 关键词 是否出现在 SEO 描述中
与 SEO 标题一样,您的核心 关键词 需要出现在 SEO 描述中。增加 SERP 相关性。
11号
您的核心 关键词 是否出现在 Heading 标签中
你的核心 关键词 需要尽可能出现在 H1、H2、H3 等标签中。标题标签在 SEO 排名中起着重要作用。标题标签中的核心 关键词 可以告诉谷歌你页面的主要词。
12号
URL 是否收录核心关键词
你的网页链接需要收录核心关键词,而且你的网页链接不要太长,尽量短,可以是描述性的短语。
13号
页面是否收录相关的关键词
任何一个词都有其关联的关键词,我们需要在搜索到我们的页面时选择性地添加谷歌底部推荐的相关关键词。
搜索相关关键词
相关关键词
14号
你的 关键词 浓度是否太高
有很多朋友的网页,为了优化而优化,疯狂重复关键词,可能会适得其反。查看关键词的浓度,如果关键词浓度过高,可以使用这个工具,它会给你提示。
关键词浓度检测
关键词专注
15号
您的页面副本是否有拼写和语法错误
很多人自己写文案,但是每个人的英语能力参差不齐,可能会出现很多语法小问题。写好文案后,我们可以用 Grammarly 工具检查一下。它将帮助您纠正许多简单的语法和拼写错误。该网站是
语法工具检测
16号
是副本 原创
这个非常中级。很多朋友的网站文字都是从不同的地方编出来的。重复的文案不仅会导致你的页面没有排名,而且还有被投诉的风险。所以你的文案千万不能和别人重复!
拷贝拷贝检查,推荐这个工具
copyleaks 文案检查
17号
您的产品描述是否易于理解并且是第二人称的
前段时间,我录了一段视频给你发一个外部链接。申请人需要根据自己的产品写一些关于如何从中国进口产品的文章,然后我会从我的货运代理网站免费发给他们一个外部链接。
结果有朋友写了,技术性很强,看不懂。你必须知道你的用户也是人,他们希望在阅读时易于理解。所以,永远不要把你的副本写成律师的副本。然后,在写文案的时候,要写人称代词,拉近与读者的距离。
18 号
你的文案是一大堆文案吗
虽然这点经常被提及,但真正落实的朋友并不多。我仍然经常看到这样的页面。
一堆文案堆在一起,想关页的那种一目了然。您可以比较自己的页面。
文案
19 号
页面是否有Bullet内容
项目符号是前面的一点内容。您可以用便于用户阅读的短语来概括您的内容。改善页面的用户体验。
子弹
20号
你的页面图片有 ALT 标签吗
谷歌没有办法抓取图片的内容,只能通过ALT标签来判断图片的内容。因此,您的每张图片都需要有一个描述性的 ALT 标签,并且最好收录核心 关键词。
21号
您的图像尺寸是否太大?
如果你网页中的图片非常大,几百KB甚至一两兆,你的页面加载速度不会很快。一般来说,在保证清晰的情况下,页面上每张图片的大小不应该超过 100KB。建议使用此工具压缩图像。
图片尺寸
22号
您的页面上有多个图像吗?
很多人的产品页面只有一两张图片,其余全是文字,或者根本没有文字。这种页面一般很难排名。通常,具有多个图像的页面更容易排名。
23号
你的页面有视频吗
你的页面,最好放个视频,视频最好上传到第三方平台,比如Youtube。紫藤等。在相同条件下,带有视频的页面更容易排名。
视频
24号
页面的视频是否与页面内容相关
比如你的页面是316不锈钢板,那么你的视频内容也必须是这个产品,那么视频的标题也应该收录这个产品关键词。
内容相关性
25号
您页面上的视频是否自适应
您需要确保页面上的视频适应不同的屏幕尺寸。对于某些人来说,一旦换屏,视频就会很奇怪。如果你有这个问题,你可以使用这个工具来生成自适应代码。
26号
您的页面是否有内部链接
网站的内链可以把各个页面串起来,也可以提高被链接页面的关键词排名。当我们在页面上提及相关产品时,需要同时链接到相应的页面。也使用相关和描述性的 关键词 作为锚文本。
27号
你的页面有死链接吗?
死链接在英语中称为断开链接。例如,您的页面最初有一个产品链接。但是随后您删除了该产品页面。此时,您页面的链接是断开的链接。如果你找到它,你需要更改链接。建议检查损坏的链接以获取工具。要么
检查断开链接的工具建议
28号
您的页面加载速度是否小于 3 秒?
正如 Google 所明确表示的,加载速度是 关键词 排名因素之一。这也是直接影响你页面的用户体验的一个因素。所以你需要确保你的页面加载速度。推荐这个工具进行测试
您可以根据自己测试过的问题进行针对性的优化。
页面加载速度工具测试
29号
您的页面是否是移动自适应的
这个,如果你网站是wordpress做的,一般是没有问题的,大部分主题已经是自动自适应的了。但是,目前国内的一些网站还没有自适应。要检查手机是否自适应,可以用这个来检查。
手机自适应
30号
您的页面是否安装了 SSL?
还有很多朋友的网站是http开头的,不是https的。SSL也是关键词的排名因素之一。此外,Google Chrome 会将您标记为 网站不安全网站。
现在,无论是阿里云还是国外服务器,都提供了免费的SSL。如果没有,请让您的网站建设者为您添加它。
31号
您 网站 是否有明确的行动呼吁
我很多朋友的产品页面只是显示了一些产品图片,甚至没有表格或按钮。如果客户想发送查询,他们只能将其发送到联系我们页面。
这类页面的询盘转化率很低,每个页面都必须有明显的号召性用语元素。
号召性用语元素
32号
你的网站是专业设计的吗?
很多朋友的网站东西都是自己拼出来的。完全没有设计感,用户体验一般。
如果你想让你的网站有专业的规划设计。您可以了解雷子的建站训练营课程。
33号
您的页面是否比当前的 Google 前 3 更好
上面说了这么多,如果你都做的很好,我相信你不需要检查这个。
简而言之,你需要从不同的维度击败你的竞争对手。这样,您就有机会将他们淘汰出谷歌的前三名。
这就是页面搜索引擎优化的全部内容。为了帮助您更好的实施,我们结合实际案例,特地制作了详细的实践课程。本课程已添加到SEO系列(在第19课后更新-“页面SEO检查清单-终极指南”),已注册该系列的学生可以免费学习。
这一系列课程的价值会增加,内容也会越来越丰富。最好的学习方式是互相讨论,同学们当中不乏外贸行业大神~欢迎加入专属学习群leizi612602一起交流! 查看全部
谷歌抓取网页视频教程(不是教你如何打造一个一个的产品页(组图))
现场SEO优化已经存在很多年了,但在中国却很少有全面的Check Lists。国外的文章一般会教你如何优化一个文章。而不是教你如何构建商业产品页面。这篇文章文章是根据我过去几年在独立站点SEO项目中的经验对站点SEO的总结。
其实SEO本身就是内容,我们只是把零散的信息放到网上,结合我们的经验,系统的整理在一起。没有所谓的创新,就没有On page SEO的创新。
什么是现场搜索引擎优化?
对我来说,On Page SEO其实就是把一个页面通过各个纬度做到极致,然后在Google上得到最好的关键词排名的过程。
以下是我整理的 On Page SEO Check List。
1号
您的网页是否可以被 Google 抓取
页面被谷歌抓取,这是网页排名的首要前提。验证你的页面抓取是否有问题,你可以把你的网页链接放到这个工具里:
如果显示 200 OK,则表示网页抓取没有问题。
验证页面抓取
2号
您的页面是否被 Google 搜索过收录
网页被抓取后,Google 一般会收录your网站。
要检查页面是否为 收录,只需将页面 URL 输入 Google。
谷歌搜索页面网址
如果页面不是收录,需要到谷歌站长工具后台提交页面,请求被索引。
请求索引
3号
您的 网站 上是否安装了 Google Analytics
我们需要知道这个页面的数据,比如跳出率、用户停留时间、用户来源、国家等等。有数据支持,方便我们后期有针对性的优化。
例如,从中国到南非,这个页面每个月给我带来了 85 个查询。询盘转化率9.94%,跳出率49.71%,用户平均停留时间超过两分钟。
页面数据
4号
是否监控此页面的 关键词 排名变化
您需要实时监控该页面的相关关键词排名,以便根据排名变化及时调整您的页面。我一般使用 SEM rush 的 关键词 监控工具。您可以查看特定页面的每日 关键词 排名变化。
关键词 SEM rush 监控
5号
您的页面是否完全满足用户的搜索意图?
例如,用户最初是在寻找有关玻璃瓶材料的新东西。这样一来,如果你用一个玻璃瓶的产品页面来优化这个词,即使你的页面到达了谷歌首页,也不会出现询价转化,但是这个页面的跳出率会特别高。
6号
无论是页面,重点优化一个词
很多人把很多产品放在一个页面上,所以很难有一个好的排名。需要专注于一个词。告诉 Google,您的页面的核心是优化该主题。
7号
是否在页面上添加核心 关键词 变体
例如,医用口罩。它也可以称为面罩。它也可以称为防护面罩。您的页面需要将 关键词 的这些变体添加到页面中。增加核心词的相关性。
8号
核心 关键词 是否出现在您的网页内容的第一段中
在网页的第一段,核心 关键词 应该出现。其实如果按照正常逻辑写文案,第一段肯定会出现关键词。
9号
核心 关键词 是否出现在 SEO 标题中
相信大部分朋友都没有写SEO标题的习惯,更别说把核心关键词放在标题里了。
一定要先写SEO标题,这对关键词排名很重要。此外,核心词需要写在标题中。
搜索引擎优化标题
10号
您的核心 关键词 是否出现在 SEO 描述中
与 SEO 标题一样,您的核心 关键词 需要出现在 SEO 描述中。增加 SERP 相关性。
11号
您的核心 关键词 是否出现在 Heading 标签中
你的核心 关键词 需要尽可能出现在 H1、H2、H3 等标签中。标题标签在 SEO 排名中起着重要作用。标题标签中的核心 关键词 可以告诉谷歌你页面的主要词。
12号
URL 是否收录核心关键词
你的网页链接需要收录核心关键词,而且你的网页链接不要太长,尽量短,可以是描述性的短语。
13号
页面是否收录相关的关键词
任何一个词都有其关联的关键词,我们需要在搜索到我们的页面时选择性地添加谷歌底部推荐的相关关键词。
搜索相关关键词
相关关键词
14号
你的 关键词 浓度是否太高
有很多朋友的网页,为了优化而优化,疯狂重复关键词,可能会适得其反。查看关键词的浓度,如果关键词浓度过高,可以使用这个工具,它会给你提示。
关键词浓度检测
关键词专注
15号
您的页面副本是否有拼写和语法错误
很多人自己写文案,但是每个人的英语能力参差不齐,可能会出现很多语法小问题。写好文案后,我们可以用 Grammarly 工具检查一下。它将帮助您纠正许多简单的语法和拼写错误。该网站是
语法工具检测
16号
是副本 原创
这个非常中级。很多朋友的网站文字都是从不同的地方编出来的。重复的文案不仅会导致你的页面没有排名,而且还有被投诉的风险。所以你的文案千万不能和别人重复!
拷贝拷贝检查,推荐这个工具
copyleaks 文案检查
17号
您的产品描述是否易于理解并且是第二人称的
前段时间,我录了一段视频给你发一个外部链接。申请人需要根据自己的产品写一些关于如何从中国进口产品的文章,然后我会从我的货运代理网站免费发给他们一个外部链接。
结果有朋友写了,技术性很强,看不懂。你必须知道你的用户也是人,他们希望在阅读时易于理解。所以,永远不要把你的副本写成律师的副本。然后,在写文案的时候,要写人称代词,拉近与读者的距离。
18 号
你的文案是一大堆文案吗
虽然这点经常被提及,但真正落实的朋友并不多。我仍然经常看到这样的页面。
一堆文案堆在一起,想关页的那种一目了然。您可以比较自己的页面。
文案
19 号
页面是否有Bullet内容
项目符号是前面的一点内容。您可以用便于用户阅读的短语来概括您的内容。改善页面的用户体验。
子弹
20号
你的页面图片有 ALT 标签吗
谷歌没有办法抓取图片的内容,只能通过ALT标签来判断图片的内容。因此,您的每张图片都需要有一个描述性的 ALT 标签,并且最好收录核心 关键词。
21号
您的图像尺寸是否太大?
如果你网页中的图片非常大,几百KB甚至一两兆,你的页面加载速度不会很快。一般来说,在保证清晰的情况下,页面上每张图片的大小不应该超过 100KB。建议使用此工具压缩图像。
图片尺寸
22号
您的页面上有多个图像吗?
很多人的产品页面只有一两张图片,其余全是文字,或者根本没有文字。这种页面一般很难排名。通常,具有多个图像的页面更容易排名。
23号
你的页面有视频吗
你的页面,最好放个视频,视频最好上传到第三方平台,比如Youtube。紫藤等。在相同条件下,带有视频的页面更容易排名。
视频
24号
页面的视频是否与页面内容相关
比如你的页面是316不锈钢板,那么你的视频内容也必须是这个产品,那么视频的标题也应该收录这个产品关键词。
内容相关性
25号
您页面上的视频是否自适应
您需要确保页面上的视频适应不同的屏幕尺寸。对于某些人来说,一旦换屏,视频就会很奇怪。如果你有这个问题,你可以使用这个工具来生成自适应代码。
26号
您的页面是否有内部链接
网站的内链可以把各个页面串起来,也可以提高被链接页面的关键词排名。当我们在页面上提及相关产品时,需要同时链接到相应的页面。也使用相关和描述性的 关键词 作为锚文本。
27号
你的页面有死链接吗?
死链接在英语中称为断开链接。例如,您的页面最初有一个产品链接。但是随后您删除了该产品页面。此时,您页面的链接是断开的链接。如果你找到它,你需要更改链接。建议检查损坏的链接以获取工具。要么
检查断开链接的工具建议
28号
您的页面加载速度是否小于 3 秒?
正如 Google 所明确表示的,加载速度是 关键词 排名因素之一。这也是直接影响你页面的用户体验的一个因素。所以你需要确保你的页面加载速度。推荐这个工具进行测试
您可以根据自己测试过的问题进行针对性的优化。
页面加载速度工具测试
29号
您的页面是否是移动自适应的
这个,如果你网站是wordpress做的,一般是没有问题的,大部分主题已经是自动自适应的了。但是,目前国内的一些网站还没有自适应。要检查手机是否自适应,可以用这个来检查。
手机自适应
30号
您的页面是否安装了 SSL?
还有很多朋友的网站是http开头的,不是https的。SSL也是关键词的排名因素之一。此外,Google Chrome 会将您标记为 网站不安全网站。
现在,无论是阿里云还是国外服务器,都提供了免费的SSL。如果没有,请让您的网站建设者为您添加它。
31号
您 网站 是否有明确的行动呼吁
我很多朋友的产品页面只是显示了一些产品图片,甚至没有表格或按钮。如果客户想发送查询,他们只能将其发送到联系我们页面。
这类页面的询盘转化率很低,每个页面都必须有明显的号召性用语元素。
号召性用语元素
32号
你的网站是专业设计的吗?
很多朋友的网站东西都是自己拼出来的。完全没有设计感,用户体验一般。
如果你想让你的网站有专业的规划设计。您可以了解雷子的建站训练营课程。
33号
您的页面是否比当前的 Google 前 3 更好
上面说了这么多,如果你都做的很好,我相信你不需要检查这个。
简而言之,你需要从不同的维度击败你的竞争对手。这样,您就有机会将他们淘汰出谷歌的前三名。
这就是页面搜索引擎优化的全部内容。为了帮助您更好的实施,我们结合实际案例,特地制作了详细的实践课程。本课程已添加到SEO系列(在第19课后更新-“页面SEO检查清单-终极指南”),已注册该系列的学生可以免费学习。
这一系列课程的价值会增加,内容也会越来越丰富。最好的学习方式是互相讨论,同学们当中不乏外贸行业大神~欢迎加入专属学习群leizi612602一起交流!
谷歌抓取网页视频教程(谷歌官方教程《Google搜索工作原理》(的呢))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-26 11:18
PAGE PAGE 3 湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。湖北seo概述Google搜索的工作原理当您坐在电脑前进行Google搜索时,来自整个网络的一系列搜索结果几乎立即出现在您的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序搜索索引以确定最相关的搜索结果以返回(提供)给您。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。
执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。< @二、索引过程的简要描述 Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个内容繁重的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。
相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并改进您的网站 排行。Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。马辉谷歌SEO教程。喜欢记住,喜欢,奖励。晓晓课堂网,一个SEO原创 查看全部
谷歌抓取网页视频教程(谷歌官方教程《Google搜索工作原理》(的呢))
PAGE PAGE 3 湖北seo:搜索引擎的工作其实就是信息检索的过程。谷歌搜索引擎的工作原理是什么?今天,小课堂为大家带来了谷歌官方教程《谷歌搜索的工作原理》。湖北seo希望对大家有所帮助。湖北seo概述Google搜索的工作原理当您坐在电脑前进行Google搜索时,来自整个网络的一系列搜索结果几乎立即出现在您的眼前。Google 如何找到与您的查询匹配的页面,以及它如何确定搜索结果的排名顺序?简单来说,您可以将在网络上搜索视为查找一本大书,其中海量索引会告诉您各种内容的位置。当您执行 Google 搜索时,我们的程序搜索索引以确定最相关的搜索结果以返回(提供)给您。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。为您提供搜索结果的三个主要过程如下: 1、 抓取 Google 知道您的 网站 吗?我们能找到吗?2、索引 Google 可以索引您的 网站 吗?3、提供结果 您的 网站 是否收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。收录与用户搜索相关的有趣、有用和相关的内容?一、抓取过程的简要说明 抓取是 Googlebot 查找新的和更新的页面以添加到 Google 索引的过程。(湖北seo百度搜索称它为百度蜘蛛)我们使用大量的计算机来提取(或“爬取”)互联网上的海量网页。
执行抓取任务的程序称为 Googlebot(也称为机器人或“蜘蛛”)。Googlebot 使用算法进行抓取:计算机程序确定要抓取哪个 网站、多久抓取一次以及从每个 网站 抓取多少页面。谷歌从一个网页 URL 列表开始其抓取过程,该列表是在之前的抓取过程中形成的,并且随着 网站 网站管理员提供更多站点地图数据而增长。当 Googlebot 访问每个 网站 时,它会检测每个页面上的链接并将这些链接添加到其要抓取的页面列表中。新创建的 网站s、对现有 网站s 的更改以及损坏的链接都会被记录下来并用于更新 Google 的索引。Google 不会收取任何费用来提高 网站 的抓取速度。我们区分搜索业务和营利性 AdWords 服务。< @二、索引过程的简要描述 Googlebot 处理它抓取的每个页面,将它找到的所有单词以及这些单词在每个页面上的位置编译成一个内容繁重的索引。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。此外,我们处理关键内容标签和属性中的信息,例如标题标签和 Alt 属性。Googlebot 可以处理多种类型的内容,但不能处理所有类型的内容。例如,我们无法处理某些富媒体文件或动态网页的内容。三、交付结果摘要当用户输入查询时,我们的计算机会搜索索引以查找匹配的网页,并返回我们认为与用户搜索最相关的结果。
相关性由 200 多个因素决定,其中之一是特定网页的 PageRank。PageRank 是一个网页的重要性,通过来自其他网页的链接来衡量。简单地说,从其他 网站 到您的 网站 页面的单个链接会提升您的 网站 PageRank。并非所有链接都具有同等价值:Google 致力于通过识别垃圾链接和其他对搜索结果产生负面影响的行为来不断改善用户体验。根据您的内容质量分配的链接是最佳链接。为了让您的 网站 在搜索结果页面中排名靠前,您必须确保 Google 可以正确抓取您的 网站 并将其编入索引。我们的网站网站管理员指南概述了一些最佳实践,可帮助您避免常见的潜在问题并改进您的网站 排行。Google 的“您在寻找什么”功能和 Google 自动完成功能旨在通过显示相关搜索字词、常见拼写错误和热门查询来帮助用户节省时间。用我们的谷歌。com 搜索结果,这些功能使用由我们的网络爬虫和搜索算法自动生成的关键字。只有当我们相信预测会节省用户时间时,才会显示这些内容。如果 网站 在关键字搜索中排名很高,那是因为我们通过算法确定其内容与用户的查询高度相关。以上是小小课堂为大家带来的谷歌官方教程《谷歌搜索的工作原理》。湖北seo感谢收看。马辉谷歌SEO教程。喜欢记住,喜欢,奖励。晓晓课堂网,一个SEO原创
谷歌抓取网页视频教程( 谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-25 09:07
谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
站长之家7月2日消息:据外媒报道,谷歌希望将已有数十年历史的拒绝蜘蛛协议(Rejection Spider Protocol,REP)变成官方互联网标准。为了促进这一举措,谷歌正在开源自己的 robots.txt 解析器。
据 Venturebeat 报道,早在 1994 年,荷兰软件工程师 Martijn Koster 就提出了 REP 标准,该标准几乎成为了网站用来告诉自动爬虫程序哪些部分不应该被处理的标准。例如,Google 的网络爬虫机器人 Googlebot(类似于百度的蜘蛛)在索引 网站 时会扫描 robots.txt 文件,以检查哪些部分应该被忽略的特殊说明。它最大限度地减少了无意义的索引,有时还隐藏了敏感信息。此外,这些文件不仅用于提供直接爬取指令,还可以填充某些关键字以改善 SEO,以及其他用例。
不过,谷歌认为自己的爬虫技术有待改进,该公司正在公开寻找用于解码 robots.txt 的解析器,试图建立一个真正的网络爬虫标准。理想情况下,这将揭开 robots.txt 文件的神秘面纱并创建更常见的格式。
谷歌主动向互联网工程任务组提交自己的方法将“更好地定义”爬虫应如何处理 robots.txt 并减少意外。
该草案不完全可用,但它不仅适用于 网站,还适用于最小文件大小,设置最长一天的缓存时间,并在服务器出现时给 网站 一个休息时间问题。 查看全部
谷歌抓取网页视频教程(
谷歌希望将几十年前的拒绝蜘蛛协议变成官方互联网标准)
站长之家7月2日消息:据外媒报道,谷歌希望将已有数十年历史的拒绝蜘蛛协议(Rejection Spider Protocol,REP)变成官方互联网标准。为了促进这一举措,谷歌正在开源自己的 robots.txt 解析器。
据 Venturebeat 报道,早在 1994 年,荷兰软件工程师 Martijn Koster 就提出了 REP 标准,该标准几乎成为了网站用来告诉自动爬虫程序哪些部分不应该被处理的标准。例如,Google 的网络爬虫机器人 Googlebot(类似于百度的蜘蛛)在索引 网站 时会扫描 robots.txt 文件,以检查哪些部分应该被忽略的特殊说明。它最大限度地减少了无意义的索引,有时还隐藏了敏感信息。此外,这些文件不仅用于提供直接爬取指令,还可以填充某些关键字以改善 SEO,以及其他用例。
不过,谷歌认为自己的爬虫技术有待改进,该公司正在公开寻找用于解码 robots.txt 的解析器,试图建立一个真正的网络爬虫标准。理想情况下,这将揭开 robots.txt 文件的神秘面纱并创建更常见的格式。
谷歌主动向互联网工程任务组提交自己的方法将“更好地定义”爬虫应如何处理 robots.txt 并减少意外。
该草案不完全可用,但它不仅适用于 网站,还适用于最小文件大小,设置最长一天的缓存时间,并在服务器出现时给 网站 一个休息时间问题。

