
自动采集网站内容
集百家的自动采集,你是怎么做的呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-02 05:04
自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。利用云采集自动采集网站内容。直接将视频地址上传到自动采集的网站内,自动采集。无需登录即可采集:内部视频、音频、图片需要的内容。丰富的采集方式:仅仅要小编采集的视频,采集下来的地址包含小编的特定网址;其他要小编采集的内容直接采集小编站的网址,将来也可直接去小编站下载内容自动采集:小编将会为你整理一份自动采集地址包,后期的用处就多了。
再也不需要你手动搜索资源时,把网站地址输入到自动采集的地址包里了。还有更多自动采集到网站的技巧等你自行探索。自动采集网站内容、互联网采集、yy采集、万网、慕课网采集、网易云课堂采集。【小编留言】集百家的自动采集,竟这么强。求扩散链接地址和小编的个人站博。获取资源。收集到的内容,通过自动采集地址,统一发布在小编的博客里。
自动采集地址在小编博客里整理好。要上传到自动采集网站里的资源,如果网站里的数据不多,可以再采集的网站内直接输入资源网址,直接采集,不需要上传。自动采集网站内容,如果网站里的数据不多,可以在搜索引擎看看现在的列表信息是否包含资源信息。如果不包含的话,就需要单独采集列表信息。进行修改文件,将采集到的内容上传到博客中。专业的采集对于优化来说,具有一定价值。在做网站采集时,你是怎么做的呢?在小编的博客中留言吧。 查看全部
集百家的自动采集,你是怎么做的呢?
自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。利用云采集自动采集网站内容。直接将视频地址上传到自动采集的网站内,自动采集。无需登录即可采集:内部视频、音频、图片需要的内容。丰富的采集方式:仅仅要小编采集的视频,采集下来的地址包含小编的特定网址;其他要小编采集的内容直接采集小编站的网址,将来也可直接去小编站下载内容自动采集:小编将会为你整理一份自动采集地址包,后期的用处就多了。
再也不需要你手动搜索资源时,把网站地址输入到自动采集的地址包里了。还有更多自动采集到网站的技巧等你自行探索。自动采集网站内容、互联网采集、yy采集、万网、慕课网采集、网易云课堂采集。【小编留言】集百家的自动采集,竟这么强。求扩散链接地址和小编的个人站博。获取资源。收集到的内容,通过自动采集地址,统一发布在小编的博客里。
自动采集地址在小编博客里整理好。要上传到自动采集网站里的资源,如果网站里的数据不多,可以再采集的网站内直接输入资源网址,直接采集,不需要上传。自动采集网站内容,如果网站里的数据不多,可以在搜索引擎看看现在的列表信息是否包含资源信息。如果不包含的话,就需要单独采集列表信息。进行修改文件,将采集到的内容上传到博客中。专业的采集对于优化来说,具有一定价值。在做网站采集时,你是怎么做的呢?在小编的博客中留言吧。
小众产品怎么采集,新手也能看得懂的网赚项目
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-07-26 18:22
自动采集网站内容,包括采集弹窗网站,采集分享网站,
大量长尾词,同时有精准的导向目标网站的价值链接。对于这个词,精确匹配。
你要明白文章采集和产品采集还是有区别的,能高效、准确的抓取并分析产品页面,自然会采集,如果纯粹是文章采集,是赚不到钱的,而产品采集,根据你的产品,找相关性强的文章抓取下来。那么问题来了?小众产品怎么采集,大众产品怎么采集,互联网毕竟是公平的,没有哪个人会知道所有人想要的,这里就要考验你们采集能力了。如果要采集,就不能简单的去复制粘贴,必须有文字功底,不能直接复制粘贴,要让客户找到你的采集方式,否则一切都是扯淡。你可以关注一下我:新手也能看得懂的网赚项目。学习、交流、收入稳定!。
有些东西可以拿到平台,比如网站内容,但是做采集是赚不到钱的,我一直做各种各样的采集,感觉没有多大意思,所以一直不赚钱。赚钱的是长尾采集。
采集软件可以做长尾搜索采集,但最终分析的结果都是偏向平台而不是你自己的产品,如果用采集,就必须要自己规划并写推广文案才行,不然就很难赚钱。还不如像客一样,找大公司投放广告,轻松推广产品。
有一个很重要的方面——找到一个有长尾需求的产品。然后去采集,然后推广。用自己的采集软件,可以采集到来自百度搜索结果的长尾需求,然后去推广, 查看全部
小众产品怎么采集,新手也能看得懂的网赚项目
自动采集网站内容,包括采集弹窗网站,采集分享网站,
大量长尾词,同时有精准的导向目标网站的价值链接。对于这个词,精确匹配。
你要明白文章采集和产品采集还是有区别的,能高效、准确的抓取并分析产品页面,自然会采集,如果纯粹是文章采集,是赚不到钱的,而产品采集,根据你的产品,找相关性强的文章抓取下来。那么问题来了?小众产品怎么采集,大众产品怎么采集,互联网毕竟是公平的,没有哪个人会知道所有人想要的,这里就要考验你们采集能力了。如果要采集,就不能简单的去复制粘贴,必须有文字功底,不能直接复制粘贴,要让客户找到你的采集方式,否则一切都是扯淡。你可以关注一下我:新手也能看得懂的网赚项目。学习、交流、收入稳定!。
有些东西可以拿到平台,比如网站内容,但是做采集是赚不到钱的,我一直做各种各样的采集,感觉没有多大意思,所以一直不赚钱。赚钱的是长尾采集。
采集软件可以做长尾搜索采集,但最终分析的结果都是偏向平台而不是你自己的产品,如果用采集,就必须要自己规划并写推广文案才行,不然就很难赚钱。还不如像客一样,找大公司投放广告,轻松推广产品。
有一个很重要的方面——找到一个有长尾需求的产品。然后去采集,然后推广。用自己的采集软件,可以采集到来自百度搜索结果的长尾需求,然后去推广,
自动采集网站内容的软件,叫地采集器,价格便宜
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-23 05:00
自动采集网站内容的软件,叫地采集器,价格便宜,操作简单,可以上网站随便采集,速度快不卡,
楼上要求很具体
你买个路由器就够了,手机再买个wifi,在路由器里注册账号,路由器就会一直给你自动上网,带宽不够可以手动连,wifi连一定是能够连的,苹果airplay当初速度很快,现在不知道了。
现在手机能上网,电脑还在电脑里面下软件,是最好的,但最初最好用的是计算机上来采集的,如果软件你觉得操作复杂的话。
你说的是不是云采集?那种适合你!
任务云助手.做网站可以尝试.苹果安卓用都可以自定义每天限制和总量.微信登录采集和网页采集等
最不推荐mendeley,浪费时间,又要收费,
做网站,
先不考虑你说的采集,站群什么的。有哪些网站收录量较好?先列下,我再教你怎么采集。先上图。网站收录图网站提交链接图百度第一页,一般0.5-1之间,谷歌以及各大搜索引擎,一般2-3之间,ptengine最高4之间,danmaku、minipages平均也在1之间,很多大佬都有收费软件的,便宜。先自己可以试下。最后,假如想深入了解,自己百度搜索,花点时间。最好有平台,便宜一点的。
必须是云采集啊 查看全部
自动采集网站内容的软件,叫地采集器,价格便宜
自动采集网站内容的软件,叫地采集器,价格便宜,操作简单,可以上网站随便采集,速度快不卡,
楼上要求很具体
你买个路由器就够了,手机再买个wifi,在路由器里注册账号,路由器就会一直给你自动上网,带宽不够可以手动连,wifi连一定是能够连的,苹果airplay当初速度很快,现在不知道了。
现在手机能上网,电脑还在电脑里面下软件,是最好的,但最初最好用的是计算机上来采集的,如果软件你觉得操作复杂的话。
你说的是不是云采集?那种适合你!
任务云助手.做网站可以尝试.苹果安卓用都可以自定义每天限制和总量.微信登录采集和网页采集等
最不推荐mendeley,浪费时间,又要收费,
做网站,
先不考虑你说的采集,站群什么的。有哪些网站收录量较好?先列下,我再教你怎么采集。先上图。网站收录图网站提交链接图百度第一页,一般0.5-1之间,谷歌以及各大搜索引擎,一般2-3之间,ptengine最高4之间,danmaku、minipages平均也在1之间,很多大佬都有收费软件的,便宜。先自己可以试下。最后,假如想深入了解,自己百度搜索,花点时间。最好有平台,便宜一点的。
必须是云采集啊
自动引流,自动赚美金,是一切“全自动”
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-13 01:28
相信很多刚进入网赚领域的人都有这样的梦想:我能不能把所有东西都设置好,美元会自动进入我的账户,我可以躺着赚钱。答案是肯定的,但是需要一定的技巧和一定的时间积累。本文将深入介绍Auto-Blogs方式,让博客自动发布内容,自动引流,自动赚美金。是的,一切都是“自动”的。
由于是深入了解,本文会一步步详细介绍,保证可操作性。这也是作者一直坚持的风格,因为细节决定成败。
第一步当然是域名和服务器的选择。笔者推荐有多年运营经验的知名提供商,尤其是服务器。选择稳定的供应商。这里强烈推荐Namecheap提供域名和服务器服务。
Namecheap 的注册地址:
<p>购买过程比较简单,就不详细解释了。在这里,我将重点介绍域名选择的技巧。首先确定你的网站域(niche),例如:你想做女包相关营销,即:Handbags,那么首先要找出这个领域的长尾关键词(长尾关键词)。为什么?首先,太宽泛的关键词很难排名。通常这些词网站排名靠前的是大型门户网站,外部链接多,质量高,很难被打败。其次,范围太广。 关键词 不利于精准营销。当然,与宽泛的关键词相比,长尾关键词也意味着搜索量更少,所以我们要重点选择搜索量相对较大、竞争相对较小的长尾关键词。 查看全部
自动引流,自动赚美金,是一切“全自动”
相信很多刚进入网赚领域的人都有这样的梦想:我能不能把所有东西都设置好,美元会自动进入我的账户,我可以躺着赚钱。答案是肯定的,但是需要一定的技巧和一定的时间积累。本文将深入介绍Auto-Blogs方式,让博客自动发布内容,自动引流,自动赚美金。是的,一切都是“自动”的。
 https://earnmoneyonlinetutoria ... 0.jpg 300w, https://earnmoneyonlinetutoria ... 2.jpg 768w, https://earnmoneyonlinetutoria ... 4.jpg 830w, https://earnmoneyonlinetutoria ... 3.jpg 230w" />
https://earnmoneyonlinetutoria ... 0.jpg 300w, https://earnmoneyonlinetutoria ... 2.jpg 768w, https://earnmoneyonlinetutoria ... 4.jpg 830w, https://earnmoneyonlinetutoria ... 3.jpg 230w" />由于是深入了解,本文会一步步详细介绍,保证可操作性。这也是作者一直坚持的风格,因为细节决定成败。
第一步当然是域名和服务器的选择。笔者推荐有多年运营经验的知名提供商,尤其是服务器。选择稳定的供应商。这里强烈推荐Namecheap提供域名和服务器服务。
Namecheap 的注册地址:
<p>购买过程比较简单,就不详细解释了。在这里,我将重点介绍域名选择的技巧。首先确定你的网站域(niche),例如:你想做女包相关营销,即:Handbags,那么首先要找出这个领域的长尾关键词(长尾关键词)。为什么?首先,太宽泛的关键词很难排名。通常这些词网站排名靠前的是大型门户网站,外部链接多,质量高,很难被打败。其次,范围太广。 关键词 不利于精准营销。当然,与宽泛的关键词相比,长尾关键词也意味着搜索量更少,所以我们要重点选择搜索量相对较大、竞争相对较小的长尾关键词。
批量采集自动提取保存网页内容这个是本教程中所使用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-08 05:24
批量采集自动提取和保存网页内容。这是本教程使用的网页:本教程是教大家如何使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中。下面是教程的开始。先看软件的一般界面: 然后需要先添加网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图所示: 下一步,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,则不会被限制。在本教程中,每次刷新都需要保存更改的网页信息,所以在“其他监控”中,需要设置“无条件启动监控报警”。 (查看各自需求的设置) 然后设置需要保存的网页信息。在“监控设置”中添加“报警提示动态内容”---即可自动获取。如下图: 点击自动获取后,会打开之前添加的网址。页面加载完成后,选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。操作如下:这里使用value作为元素属性名称。这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容) 此版本的网页自动操作通用工具可以保存三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件,在“报警温馨提示》》可以设置类型。以下是监控网页后保存的各种文件格式。第一个是将每个元素分别保存在一个单独的txt文件中;第二个是将所有元素合并到一个txt文件中保存:第三个就是将所有元素保存为csv文件:本教程结束,欢迎大家搜索:木头软件。 查看全部
批量采集自动提取保存网页内容这个是本教程中所使用的
批量采集自动提取和保存网页内容。这是本教程使用的网页:本教程是教大家如何使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中。下面是教程的开始。先看软件的一般界面: 然后需要先添加网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图所示: 下一步,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,则不会被限制。在本教程中,每次刷新都需要保存更改的网页信息,所以在“其他监控”中,需要设置“无条件启动监控报警”。 (查看各自需求的设置) 然后设置需要保存的网页信息。在“监控设置”中添加“报警提示动态内容”---即可自动获取。如下图: 点击自动获取后,会打开之前添加的网址。页面加载完成后,选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。操作如下:这里使用value作为元素属性名称。这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容) 此版本的网页自动操作通用工具可以保存三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件,在“报警温馨提示》》可以设置类型。以下是监控网页后保存的各种文件格式。第一个是将每个元素分别保存在一个单独的txt文件中;第二个是将所有元素合并到一个txt文件中保存:第三个就是将所有元素保存为csv文件:本教程结束,欢迎大家搜索:木头软件。
自动采集网站内容实现快速从一个网站采集任何内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-06-28 21:02
自动采集网站内容并且发布到自己的网站上,这是真正实现快速从一个网站采集任何内容并发布到另一个网站的技术,主要有httpclient(ecshop),needsc、phpwind(wordpress)、websploit。这里我们讲解ecshop,其他可能也可以用。本篇通过标签的形式来展示采集脚本代码,以及发布脚本代码对其在dom上的显示。
1.打开ecshop,创建一个采集任务。2.在任务下拉列表中点击“新建”,将网址发送给需要采集的网站。注意输入网址前需要设置域名解析,且域名解析并不是任何一个第三方的http代理都能做到。为什么采集人家网站不能采集人家网站的内容?因为,人家网站是有权限做域名解析的,就是通过域名(前提还需要账号密码)才能解析,如果采集的话,就直接给你解析了。
万一被查了怎么办?!本来网站权限就只有8000多个域名。万一让人家网站权限不够,那不就被抓了么?!对于域名解析安全性一直是一个大问题。解析之后,服务器不小心宕机,那就很多网站就会出现这种情况,你没有任何措施。采集人家网站,网站权限没有8000个,不让你解析怎么办??让他们去解析权限权限不够解析就不行了啊??我明明解析的8000个域名,怎么就做不了。
说不定人家权限不够,就正常实现爬虫了?(注意:8000个域名可是在我这里设置了网站服务器,理论上按照什么算法计算的都有可能)总之一句话,不能随便采集,否则很容易就被查。被抓到理论上可以做几千条,实际可能你全部采集,也没有几条。所以,本篇只说说如何实现脚本给网站发新闻订阅,在采集时,为了不被黑客抓取。(这里绝对不可能是技术上的问题,而是没人采集啊。
)3.本文讲httpclient,needsc,phpwind。那其他的代理有没有用?有用的话怎么用?4.如何给采集的网站发送httpclient,以及其它爬虫协议。我以一个教程作为主要展示。5.关于httpclient的开发文档,请参考:手把手教你配置httpclient及爬虫脚本。注意,本站不提供代码开发文档,要完成采集,必须去代码库。
需要自己去找或者参考网站代码库。6.自动采集1级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。7.自动采集2级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。8.自动采集3级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。
9.自动采集4级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国。 查看全部
自动采集网站内容实现快速从一个网站采集任何内容
自动采集网站内容并且发布到自己的网站上,这是真正实现快速从一个网站采集任何内容并发布到另一个网站的技术,主要有httpclient(ecshop),needsc、phpwind(wordpress)、websploit。这里我们讲解ecshop,其他可能也可以用。本篇通过标签的形式来展示采集脚本代码,以及发布脚本代码对其在dom上的显示。
1.打开ecshop,创建一个采集任务。2.在任务下拉列表中点击“新建”,将网址发送给需要采集的网站。注意输入网址前需要设置域名解析,且域名解析并不是任何一个第三方的http代理都能做到。为什么采集人家网站不能采集人家网站的内容?因为,人家网站是有权限做域名解析的,就是通过域名(前提还需要账号密码)才能解析,如果采集的话,就直接给你解析了。
万一被查了怎么办?!本来网站权限就只有8000多个域名。万一让人家网站权限不够,那不就被抓了么?!对于域名解析安全性一直是一个大问题。解析之后,服务器不小心宕机,那就很多网站就会出现这种情况,你没有任何措施。采集人家网站,网站权限没有8000个,不让你解析怎么办??让他们去解析权限权限不够解析就不行了啊??我明明解析的8000个域名,怎么就做不了。
说不定人家权限不够,就正常实现爬虫了?(注意:8000个域名可是在我这里设置了网站服务器,理论上按照什么算法计算的都有可能)总之一句话,不能随便采集,否则很容易就被查。被抓到理论上可以做几千条,实际可能你全部采集,也没有几条。所以,本篇只说说如何实现脚本给网站发新闻订阅,在采集时,为了不被黑客抓取。(这里绝对不可能是技术上的问题,而是没人采集啊。
)3.本文讲httpclient,needsc,phpwind。那其他的代理有没有用?有用的话怎么用?4.如何给采集的网站发送httpclient,以及其它爬虫协议。我以一个教程作为主要展示。5.关于httpclient的开发文档,请参考:手把手教你配置httpclient及爬虫脚本。注意,本站不提供代码开发文档,要完成采集,必须去代码库。
需要自己去找或者参考网站代码库。6.自动采集1级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。7.自动采集2级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。8.自动采集3级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。
9.自动采集4级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国。
自动采集网站内容,网站从带有源代码的网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-06-27 01:00
自动采集网站内容,网站爬虫从带有源代码的网页抓取多个网页的源代码,存储到自己的服务器,然后分析,提取内容。你看到的很多源代码都是网站维护人员花钱买的一些比较好的服务器。他们工作站上的内容和你看到的也就差不多了。这些大的源代码的数量基本上在几十万上百万页的量级,他们肯定会申请对外提供。大公司一般申请使用的是txt的形式,所以你看到的源代码也是txt格式的。小网站申请的是html格式的源代码,这类比较多。
就像地球地图是在公共卫星上画出来的一样,要想使用,必须先把卫星地图导出才能用,
看情况,要抓取大量网页,可以用有机数据格式,如果抓取一定数量的网页,可以用googleapi,有相应的免费api可以使用,或者根据公司需要从互联网获取源代码也可以使用。txt格式肯定是不行的。
他是为了方便保存一些网页的。
他可能会用翻译,让你明白外文是啥,然后分析翻译得到。
基本都是抓取的网页源代码,将可访问的页面用工具组合成txt,然后放到数据库,通过xml写入,从数据库获取的话一般都是xml格式数据,以json格式呈现给你。 查看全部
自动采集网站内容,网站从带有源代码的网页
自动采集网站内容,网站爬虫从带有源代码的网页抓取多个网页的源代码,存储到自己的服务器,然后分析,提取内容。你看到的很多源代码都是网站维护人员花钱买的一些比较好的服务器。他们工作站上的内容和你看到的也就差不多了。这些大的源代码的数量基本上在几十万上百万页的量级,他们肯定会申请对外提供。大公司一般申请使用的是txt的形式,所以你看到的源代码也是txt格式的。小网站申请的是html格式的源代码,这类比较多。
就像地球地图是在公共卫星上画出来的一样,要想使用,必须先把卫星地图导出才能用,
看情况,要抓取大量网页,可以用有机数据格式,如果抓取一定数量的网页,可以用googleapi,有相应的免费api可以使用,或者根据公司需要从互联网获取源代码也可以使用。txt格式肯定是不行的。
他是为了方便保存一些网页的。
他可能会用翻译,让你明白外文是啥,然后分析翻译得到。
基本都是抓取的网页源代码,将可访问的页面用工具组合成txt,然后放到数据库,通过xml写入,从数据库获取的话一般都是xml格式数据,以json格式呈现给你。
自动采集网站内容,降低采集成本,提高网站原创性
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-06-24 23:02
自动采集网站内容,降低采集成本,提高网站原创性.接入网站数据库自动抓取数据,还原搜索结果原文,
在google中国搜索“”进入site:,
百度可以搜索分类
阿里爸爸的有需要的评论
现在很多p2p类的平台都接入了site:/可以快速过滤一部分站外信息。
点,框,搜,输入关键词,3秒出结果,不需要复制粘贴,不需要发布,很方便。
大禹搜客阿里妈妈
p2p(网络借贷)平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
在中国,目前大部分p2p平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
企业站的话,接入seo比较关键,需要结合锚文本布局、下拉加载等其他技术,大多数都采用锚文本过滤技术(如旺道seo、速推、友链交换、全站整站布局等),
百度一搜然后评论
cc狗爬虫快速收录。所以学会爬虫爬虫快速收录,
如图
1、国内更多的p2p采用的是直接直销模式,并不接入第三方平台,所以一般无需第三方平台。
2、如果想尝试接入第三方平台。可以考虑不定期的投放几个广告进去,以达到最高效的接入。
3、很多企业,都会设立自己的网站,这时如果采用seo加速,需要进行编写seo抓取规则,配合a9算法抓取,并不能真正的快速收录。做到以上几点之后,就可以快速的抓取网站内容,同时防止搜索引擎抓取商品信息的爬虫是不对公司具体的。 查看全部
自动采集网站内容,降低采集成本,提高网站原创性
自动采集网站内容,降低采集成本,提高网站原创性.接入网站数据库自动抓取数据,还原搜索结果原文,
在google中国搜索“”进入site:,
百度可以搜索分类
阿里爸爸的有需要的评论
现在很多p2p类的平台都接入了site:/可以快速过滤一部分站外信息。
点,框,搜,输入关键词,3秒出结果,不需要复制粘贴,不需要发布,很方便。
大禹搜客阿里妈妈
p2p(网络借贷)平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
在中国,目前大部分p2p平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
企业站的话,接入seo比较关键,需要结合锚文本布局、下拉加载等其他技术,大多数都采用锚文本过滤技术(如旺道seo、速推、友链交换、全站整站布局等),
百度一搜然后评论
cc狗爬虫快速收录。所以学会爬虫爬虫快速收录,
如图
1、国内更多的p2p采用的是直接直销模式,并不接入第三方平台,所以一般无需第三方平台。
2、如果想尝试接入第三方平台。可以考虑不定期的投放几个广告进去,以达到最高效的接入。
3、很多企业,都会设立自己的网站,这时如果采用seo加速,需要进行编写seo抓取规则,配合a9算法抓取,并不能真正的快速收录。做到以上几点之后,就可以快速的抓取网站内容,同时防止搜索引擎抓取商品信息的爬虫是不对公司具体的。
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-06-24 03:02
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。
不如用免费工具,自动采集,从yahoo,google之类的外国网站上下载重定向内容或者原创内容,一般是用于竞价,seo方面内容少.原创的太难标记出处了.
题主的意思应该是,手工获取一些外部链接,然后做竞价。这个具体的看你的资金、预算和时间了。
黑帽seo,
百度搜索引擎,主要是收录外部链接,数据定位,还有有时候下架一些不符合搜索引擎要求的内容。
资金充足的话就自己搭建个搜索引擎你想seo找个不收费的人吧一般这个人自己做一般是代维护公司就自己解决需求
可以做站群,不需要做优化的站群,然后往外部通过付费的办法,让更多的站点往平台(各大平台都有付费的,)付费,这样上去后,平台(比如搜狗)就是你的付费站点了,通过这个链接,进来的广告费都在你的平台(搜狗搜索引擎也是一样,手机游戏也是一样),搜索引擎也收益了。多点曝光肯定是好的。
黑帽seo,一般站群用的多。
那我举例子吧,我们公司也需要上百度竞价,这块钱一个月xw那就没下限了。黑帽seo,分本地竞价和线上竞价,线上竞价一般都是做代理,本地竞价自己也要做,不过不需要买域名,线上竞价花时间少花钱也多也要花时间少花钱,做站倒不是特别需要,但是付款后域名就没有想象中的那么贵。白帽seo的话,看他线上线下做过那些,如果线上做的多,往线下也做点这块。
本地竞价就不说了,线下要找人找钱给钱。线上竞价本地竞价收费低于上游阿里巴巴去外地买他们的代理。但是自己认为这是白帽的最强战力。 查看全部
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。
不如用免费工具,自动采集,从yahoo,google之类的外国网站上下载重定向内容或者原创内容,一般是用于竞价,seo方面内容少.原创的太难标记出处了.
题主的意思应该是,手工获取一些外部链接,然后做竞价。这个具体的看你的资金、预算和时间了。
黑帽seo,
百度搜索引擎,主要是收录外部链接,数据定位,还有有时候下架一些不符合搜索引擎要求的内容。
资金充足的话就自己搭建个搜索引擎你想seo找个不收费的人吧一般这个人自己做一般是代维护公司就自己解决需求
可以做站群,不需要做优化的站群,然后往外部通过付费的办法,让更多的站点往平台(各大平台都有付费的,)付费,这样上去后,平台(比如搜狗)就是你的付费站点了,通过这个链接,进来的广告费都在你的平台(搜狗搜索引擎也是一样,手机游戏也是一样),搜索引擎也收益了。多点曝光肯定是好的。
黑帽seo,一般站群用的多。
那我举例子吧,我们公司也需要上百度竞价,这块钱一个月xw那就没下限了。黑帽seo,分本地竞价和线上竞价,线上竞价一般都是做代理,本地竞价自己也要做,不过不需要买域名,线上竞价花时间少花钱也多也要花时间少花钱,做站倒不是特别需要,但是付款后域名就没有想象中的那么贵。白帽seo的话,看他线上线下做过那些,如果线上做的多,往线下也做点这块。
本地竞价就不说了,线下要找人找钱给钱。线上竞价本地竞价收费低于上游阿里巴巴去外地买他们的代理。但是自己认为这是白帽的最强战力。
自动采集网站内容获取网站源代码,大体你要考虑的两点问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-21 23:01
自动采集网站内容,获取网站源代码,然后不停的更新文章,推广可以用新浪博客和百度百家,他们有平台扶持!想搞流量也可以找个差不多流量的平台写个软文发出去,
大体你要考虑的两点问题1,对于你要采集的内容的特性,然后准备一个相应的地址,这样被采集的风险小一些2,对于你采集的内容的分享效果,因为现在自媒体平台也是挺多的,你所采集的内容如果有推荐,或者阅读量高,点赞多,那自然有利可图。这也是一个考虑问题的方向。
精准定位,不要对内容下定义。准确对准用户群体,前期积累账号权重。但可否转换成软文,转载率,
如果你想在网上赚钱,那么你要比别人更有价值,不管是文章也好,视频也好,音频也好,每天坚持更新,如果是建立数据库,那么你要准备一定的数据,然后去推广自己的数据库,一篇文章分享精准的让别人过来阅读,视频分享更是要精准的找到目标用户,内容要精准,质量要高,点赞一定要多,主要可以分享到百度上,百度会分析文章的内容标题以及文章的受众群体,像分享到其他自媒体平台推广的时候就可以根据自己的用户人群分析的结果进行不断的精准更新,引导用户的点赞与评论,这样就可以使文章更有吸引力,实现真正的价值。 查看全部
自动采集网站内容获取网站源代码,大体你要考虑的两点问题
自动采集网站内容,获取网站源代码,然后不停的更新文章,推广可以用新浪博客和百度百家,他们有平台扶持!想搞流量也可以找个差不多流量的平台写个软文发出去,
大体你要考虑的两点问题1,对于你要采集的内容的特性,然后准备一个相应的地址,这样被采集的风险小一些2,对于你采集的内容的分享效果,因为现在自媒体平台也是挺多的,你所采集的内容如果有推荐,或者阅读量高,点赞多,那自然有利可图。这也是一个考虑问题的方向。
精准定位,不要对内容下定义。准确对准用户群体,前期积累账号权重。但可否转换成软文,转载率,
如果你想在网上赚钱,那么你要比别人更有价值,不管是文章也好,视频也好,音频也好,每天坚持更新,如果是建立数据库,那么你要准备一定的数据,然后去推广自己的数据库,一篇文章分享精准的让别人过来阅读,视频分享更是要精准的找到目标用户,内容要精准,质量要高,点赞一定要多,主要可以分享到百度上,百度会分析文章的内容标题以及文章的受众群体,像分享到其他自媒体平台推广的时候就可以根据自己的用户人群分析的结果进行不断的精准更新,引导用户的点赞与评论,这样就可以使文章更有吸引力,实现真正的价值。
自动采集网站内容-你得找到靠谱的程序和人力
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-09 04:01
自动采集网站内容-是比较困难的,当然,你得找到靠谱的程序和人力,如果找到靠谱的程序,还需要一定的技术。如果是采集文字,最好不要用rtfm格式的字符编码,可以使用.txt格式的字符编码,
百度文库?文库内容都是有版权的,是付费检索可以通过yicat,
内容都是有版权的。不要上图片直接复制就行。
百度文库api接口是可以采集图片的,除此之外还可以提取文章标题、关键词、描述和摘要,以及分类里面的内容都是可以采集下来的,
百度文库接口都有版权要求,也就是说你直接复制图片的话是违法的,图片的版权没有保障。如果图片有版权或者一些复杂图片的话,你还需要一些特殊的处理方法,不然百度识别出来后会收回的。
我刚做完前面的论文。从要采集的文章中选出采集不到的短句,单独打包放进excel里面,使用分词库转化成词向量,然后构建单向连接就可以了。这样提取了原始文章里面的文章标题,摘要,描述等。
我是用的python写了scrapy框架,配合word2vec库,对文章进行全文提取。
想采集的话,既可以通过爬虫工具,这类爬虫工具现在已经比较多,是不是要避免人为添加限制,应该是根据文章来决定的。 查看全部
自动采集网站内容-你得找到靠谱的程序和人力
自动采集网站内容-是比较困难的,当然,你得找到靠谱的程序和人力,如果找到靠谱的程序,还需要一定的技术。如果是采集文字,最好不要用rtfm格式的字符编码,可以使用.txt格式的字符编码,
百度文库?文库内容都是有版权的,是付费检索可以通过yicat,
内容都是有版权的。不要上图片直接复制就行。
百度文库api接口是可以采集图片的,除此之外还可以提取文章标题、关键词、描述和摘要,以及分类里面的内容都是可以采集下来的,
百度文库接口都有版权要求,也就是说你直接复制图片的话是违法的,图片的版权没有保障。如果图片有版权或者一些复杂图片的话,你还需要一些特殊的处理方法,不然百度识别出来后会收回的。
我刚做完前面的论文。从要采集的文章中选出采集不到的短句,单独打包放进excel里面,使用分词库转化成词向量,然后构建单向连接就可以了。这样提取了原始文章里面的文章标题,摘要,描述等。
我是用的python写了scrapy框架,配合word2vec库,对文章进行全文提取。
想采集的话,既可以通过爬虫工具,这类爬虫工具现在已经比较多,是不是要避免人为添加限制,应该是根据文章来决定的。
网页,的几种类型划分及方法对比方法及技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-06-04 22:26
1.网页类型划分 从文本数据抓取的角度,可以对网页进行划分。不同类型的网页可以使用不同的数据获取方式。如下图所示: 如果可以分析一些有效网址及相关参数的规律,就可以通过手动编写代码来模拟网址及相关参数的生成,从而得到所需的有效数据。另一种方式是使用一些脚本解释引擎[1,2],动态地使用一些脚本解释执行引擎为我们生成脚本执行结果。首先,我们必须手动确定发送ajax请求的入口函数,然后让脚本解释引擎解释并执行这个函数,向服务器发送一个异步请求,最后自动捕获ajax请求回调函数的输出结果。目前比较好的js脚本解释执行引擎有GogoleV8、MozillaSpiderMonkey和Rhino[2-4]。另一种方法是使用浏览器客户端方法[5-7]。通过浏览器的自动运行发送异步ajax请求,然后采用一定的延时机制等待返回的ajax数据。当数据到达时,可以通过调用浏览器的内核 API 来获取数据。这三种方式在一定程度上都可以实现基于ajax数据的请求,但是各有优缺点。具体对比如下表: 表1 不同方法速度通用性对比 使用脚本解释引擎直接模拟最快和最弱的Ajax请求Faster than strong。使用浏览器客户端缓慢而强大。 b) 非ajax 脚本网页的数据采集non-ajax 脚本网页通常用javascript 包裹有效数据。
虽然不需要像分析ajax网页那样模拟ajax请求,但还是需要动态处理网页中的javascript。此类网页典型的有:口碑、评论网页、论坛网页、网上商城商品信息页、首页商品介绍页、地图导航服务网页等。对于此类网页,一般取决于有效数据包的范围。如果包很简单,比如,就是下面这种方式: document.write("valid data");然后,只需使用正则表达式来提取它。如果脚本把数据包裹得严严实实,那么要想得到有效的数据,就需要动态地解释和执行java脚本。这个过程类似于Ajax网页数据采集,还要借助脚本解释引擎和浏览器客户端。但不同的是不需要模拟发送ajax请求,也不再有等待或拦截服务器返回有效数据的过程。 c) 需要验证的网页数据采集网站有很多数据要求必须登录,如论坛、微博、邮箱、个人主页、个人博客等,采用直接下载方式,往往只能获取到请求失败的页面。这种网站网页访问机制如图2所示:如果请求中不收录合法登录信息,网站服务器会返回访问失败的提示页面。合法登录信息一般封装在一个cookie中。向网站发送请求时,需要附上登录后的cookie信息。那么如何获取收录身份信息的cookie呢?当访问者登录网站并输入用户名和密码时,网站将自动返回浏览器。
所以,你可以通过安装一些浏览器插件直接看到这个cookie。当然,也可以通过程序自动获取。获取到 Cookie 后,需要将 Cookie 添加到 Http 请求中。如图1所示,网页分类系统一般可以分为表面数据网页(SufaceWebPage)和深层数据网页(DeepWebPage)。所谓表面数据网页,是指通过解析网页的HTML代码,可以直接获取到你想要抓取的数据。深度数据网页是指那些不能直接下载的网页。对于深度数据网页,分为ajax网页、基于脚本的网页和需要验证的网页。 Ajax网页是指在网页代码中使用ajax技术向服务器动态发送异步请求,然后动态加载数据的网页。基于脚本的网页是指数据隐藏在javascript中的网页,需要对javascript进行解析才能得到有效数据。需要验证的网页是指通过登录界面进入的网页,如微博、邮箱、社交网站等网页。 2.不同类型的网页数据采集Method 表面网页数据最容易获取,在搜索引擎中也是如此 查看全部
网页,的几种类型划分及方法对比方法及技巧
1.网页类型划分 从文本数据抓取的角度,可以对网页进行划分。不同类型的网页可以使用不同的数据获取方式。如下图所示: 如果可以分析一些有效网址及相关参数的规律,就可以通过手动编写代码来模拟网址及相关参数的生成,从而得到所需的有效数据。另一种方式是使用一些脚本解释引擎[1,2],动态地使用一些脚本解释执行引擎为我们生成脚本执行结果。首先,我们必须手动确定发送ajax请求的入口函数,然后让脚本解释引擎解释并执行这个函数,向服务器发送一个异步请求,最后自动捕获ajax请求回调函数的输出结果。目前比较好的js脚本解释执行引擎有GogoleV8、MozillaSpiderMonkey和Rhino[2-4]。另一种方法是使用浏览器客户端方法[5-7]。通过浏览器的自动运行发送异步ajax请求,然后采用一定的延时机制等待返回的ajax数据。当数据到达时,可以通过调用浏览器的内核 API 来获取数据。这三种方式在一定程度上都可以实现基于ajax数据的请求,但是各有优缺点。具体对比如下表: 表1 不同方法速度通用性对比 使用脚本解释引擎直接模拟最快和最弱的Ajax请求Faster than strong。使用浏览器客户端缓慢而强大。 b) 非ajax 脚本网页的数据采集non-ajax 脚本网页通常用javascript 包裹有效数据。
虽然不需要像分析ajax网页那样模拟ajax请求,但还是需要动态处理网页中的javascript。此类网页典型的有:口碑、评论网页、论坛网页、网上商城商品信息页、首页商品介绍页、地图导航服务网页等。对于此类网页,一般取决于有效数据包的范围。如果包很简单,比如,就是下面这种方式: document.write("valid data");然后,只需使用正则表达式来提取它。如果脚本把数据包裹得严严实实,那么要想得到有效的数据,就需要动态地解释和执行java脚本。这个过程类似于Ajax网页数据采集,还要借助脚本解释引擎和浏览器客户端。但不同的是不需要模拟发送ajax请求,也不再有等待或拦截服务器返回有效数据的过程。 c) 需要验证的网页数据采集网站有很多数据要求必须登录,如论坛、微博、邮箱、个人主页、个人博客等,采用直接下载方式,往往只能获取到请求失败的页面。这种网站网页访问机制如图2所示:如果请求中不收录合法登录信息,网站服务器会返回访问失败的提示页面。合法登录信息一般封装在一个cookie中。向网站发送请求时,需要附上登录后的cookie信息。那么如何获取收录身份信息的cookie呢?当访问者登录网站并输入用户名和密码时,网站将自动返回浏览器。
所以,你可以通过安装一些浏览器插件直接看到这个cookie。当然,也可以通过程序自动获取。获取到 Cookie 后,需要将 Cookie 添加到 Http 请求中。如图1所示,网页分类系统一般可以分为表面数据网页(SufaceWebPage)和深层数据网页(DeepWebPage)。所谓表面数据网页,是指通过解析网页的HTML代码,可以直接获取到你想要抓取的数据。深度数据网页是指那些不能直接下载的网页。对于深度数据网页,分为ajax网页、基于脚本的网页和需要验证的网页。 Ajax网页是指在网页代码中使用ajax技术向服务器动态发送异步请求,然后动态加载数据的网页。基于脚本的网页是指数据隐藏在javascript中的网页,需要对javascript进行解析才能得到有效数据。需要验证的网页是指通过登录界面进入的网页,如微博、邮箱、社交网站等网页。 2.不同类型的网页数据采集Method 表面网页数据最容易获取,在搜索引擎中也是如此
自动采集网站内容的网站,遇到这样的情况应该怎么办
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-05-31 05:02
自动采集网站内容的网站,而且自动采集会根据用户喜好推荐关键词,关键词会随着用户的兴趣,首页的内容会不断变化。你想要的只是我们能有自动采集的功能的话,我可以给你提供专门的业务,具体的话私聊我,
找一些什么精灵采集器之类的小软件。专门采集网站内容的。需要下载登录注册帐号。操作很简单。直接用后台操作。
如果楼主只是想采取网站的图片,文字,图片等资源而没有其他操作的需求可以试试这个方法很多人对蜘蛛爬虫并不了解,目前主流的爬虫就是抓取网站的js,css等资源。这些资源都是存在js文件中的,通过js文件,可以获取相应的数据。一般常见的爬虫软件,如速采网,百度采集星星,都可以爬取这些资源。对于完全没有数据需求的朋友,可以尝试一下,因为我本人使用的是网页浏览器右键有个高级访问,可以看到这些爬虫的数据的来源,除了自己爬取外,还可以给网站的编辑们爬取,使用起来还算方便。
相当于找个中间人直接跳转不通过网站的
遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?很多时候我们的网站会被别人抓取,被一些电商平台转载。这种抓取让我们感觉非常的不舒服,尤其是一些有网络的人,抓取的时候,给的特别大。一般,通过搜索引擎找到被抓取的文章,也是很大,因为也是通过搜索引擎,才能看得到。
直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。那么,这样的情况,我们该怎么办呢?比如,我们使用一些已经过的访问地址,如:商铺导航是44.58.123.123,百度搜索是45.110.35.283,等等,可以让我们自己的网站看到一个。
同时我们在搜索引擎使用js,蜘蛛也爬不出来。那么,你如果要怎么办呢?你可以去找个中间人,那么这个中间人,就是我们,有图片的文章,可以去百度,之类的站点去爬取;在电商类的网站爬取,如果带着字图片等信息,可以去,京东之类的网站爬取。通过爬取,我们可以让别人看到我们的网站,又可以让自己的网站不被别人爬取,这个方法是非常好的。
如果,你觉得通过这种方法,已经不能满足我们的要求了,你可以通过蜘蛛爬虫来抓取网站,中间人看着太厉害,一个访问地址就可以看到源代码,这个简直让人生无可恋,我们可以用插件去实现。至于图片导航等其他地方的图片,我们可以采集到一个隐藏的文件中,很多人搜一下。 查看全部
自动采集网站内容的网站,遇到这样的情况应该怎么办
自动采集网站内容的网站,而且自动采集会根据用户喜好推荐关键词,关键词会随着用户的兴趣,首页的内容会不断变化。你想要的只是我们能有自动采集的功能的话,我可以给你提供专门的业务,具体的话私聊我,
找一些什么精灵采集器之类的小软件。专门采集网站内容的。需要下载登录注册帐号。操作很简单。直接用后台操作。
如果楼主只是想采取网站的图片,文字,图片等资源而没有其他操作的需求可以试试这个方法很多人对蜘蛛爬虫并不了解,目前主流的爬虫就是抓取网站的js,css等资源。这些资源都是存在js文件中的,通过js文件,可以获取相应的数据。一般常见的爬虫软件,如速采网,百度采集星星,都可以爬取这些资源。对于完全没有数据需求的朋友,可以尝试一下,因为我本人使用的是网页浏览器右键有个高级访问,可以看到这些爬虫的数据的来源,除了自己爬取外,还可以给网站的编辑们爬取,使用起来还算方便。
相当于找个中间人直接跳转不通过网站的
遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?很多时候我们的网站会被别人抓取,被一些电商平台转载。这种抓取让我们感觉非常的不舒服,尤其是一些有网络的人,抓取的时候,给的特别大。一般,通过搜索引擎找到被抓取的文章,也是很大,因为也是通过搜索引擎,才能看得到。
直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。那么,这样的情况,我们该怎么办呢?比如,我们使用一些已经过的访问地址,如:商铺导航是44.58.123.123,百度搜索是45.110.35.283,等等,可以让我们自己的网站看到一个。
同时我们在搜索引擎使用js,蜘蛛也爬不出来。那么,你如果要怎么办呢?你可以去找个中间人,那么这个中间人,就是我们,有图片的文章,可以去百度,之类的站点去爬取;在电商类的网站爬取,如果带着字图片等信息,可以去,京东之类的网站爬取。通过爬取,我们可以让别人看到我们的网站,又可以让自己的网站不被别人爬取,这个方法是非常好的。
如果,你觉得通过这种方法,已经不能满足我们的要求了,你可以通过蜘蛛爬虫来抓取网站,中间人看着太厉害,一个访问地址就可以看到源代码,这个简直让人生无可恋,我们可以用插件去实现。至于图片导航等其他地方的图片,我们可以采集到一个隐藏的文件中,很多人搜一下。
小帮软件机器人为我们科研人员解决了手动收集数据难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-27 04:09
我是一所大学信息学院的老师,我的研究领域是生物技术。正常科学研究需要采集国外论文和实验数据。实际上,在整个科学研究过程中,最耗时的环节是文献和实验数据采集,约占总时间的1/3。
通常,我需要在这些网站中采集论文和实验数据。
论文数据库:Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库:NCBI,EMBL,ICPSR等。
为什么要花这么长时间采集论文,文献和实验数据?
因为采集过程是很多重复的机械工作。
很长时间以来,我一直在反复进行机械采集工作。直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人。它可以自动执行搜索,复制,粘贴,下载等操作,并在各种数据库中输出论文和实验数据采集。
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务。因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤。总体而言,软件机器人的配置过程非常简单。我只花了一点时间就为不同的网站配置了6种研究数据采集工具。配置完成后,重复的采集工作全部由软件机器人完成。
现在,在下班前,我将打开小帮助,它将自动遍历我所关注的论文和实验数据的数据库,并完成自动采集和下载工作。第二天上班时,我可以直接直接从小邦采集上查看数据,这节省了很多宝贵的时间,并且不影响当天的科学研究任务。
我不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题。
今天我要分享一下,希望可以帮助同事解决采集科研数据的难题和耗时的问题。我们的宝贵时间应该投入到科学研究中。 查看全部
小帮软件机器人为我们科研人员解决了手动收集数据难题
我是一所大学信息学院的老师,我的研究领域是生物技术。正常科学研究需要采集国外论文和实验数据。实际上,在整个科学研究过程中,最耗时的环节是文献和实验数据采集,约占总时间的1/3。
通常,我需要在这些网站中采集论文和实验数据。
论文数据库:Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库:NCBI,EMBL,ICPSR等。
为什么要花这么长时间采集论文,文献和实验数据?
因为采集过程是很多重复的机械工作。
很长时间以来,我一直在反复进行机械采集工作。直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人。它可以自动执行搜索,复制,粘贴,下载等操作,并在各种数据库中输出论文和实验数据采集。
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务。因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤。总体而言,软件机器人的配置过程非常简单。我只花了一点时间就为不同的网站配置了6种研究数据采集工具。配置完成后,重复的采集工作全部由软件机器人完成。
现在,在下班前,我将打开小帮助,它将自动遍历我所关注的论文和实验数据的数据库,并完成自动采集和下载工作。第二天上班时,我可以直接直接从小邦采集上查看数据,这节省了很多宝贵的时间,并且不影响当天的科学研究任务。
我不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题。
今天我要分享一下,希望可以帮助同事解决采集科研数据的难题和耗时的问题。我们的宝贵时间应该投入到科学研究中。
自动采集网站内容的软件是可以用的,除非真的那么重要
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-05-15 22:53
自动采集网站内容的软件是可以用的,我测试过,比如金山卫士自动采集,百度文库自动采集,百度新闻,这些都是可以用的,如果想要了解测试软件效果,可以在公众号:快软帮,免费领取下,这些测试软件是免费下载的。
现在有很多可以网页采集的软件或者工具,比如云采集就是用的一个好工具,就是这个,我们上课经常做演示用。我现在就在用。这个算是一个电脑的采集工具吧。上课用的,
这个怎么能统计出来如果是ip的话基本上是通过防火墙过滤才能保证账号和密码的安全,如果是手机号的话,是可以识别出来的,比如登录时直接被记录,你可以以某些特征,手段获取到手机号码和你们团队所有人的ip和手机号对应关系。不可否认这个极大方便了团队自动采集等工作。但是实际上所有团队基本上都是购买企业级的软件来完成效率采集任务。一般来说,企业级的开发的软件都是定制的,所有团队可以找到自己相同的客户群体,会形成一个统一的渠道。
只能说有一定的效果!这个都是伪需求!自动采集和人工采集的效率差别不大!除非真的有什么软件做到你们企业需要的专业功能和深度!可以考虑做私有化部署!个人觉得没必要!除非真的那么重要!
我一直用的是武汉一带一路的10000个采集体验, 查看全部
自动采集网站内容的软件是可以用的,除非真的那么重要
自动采集网站内容的软件是可以用的,我测试过,比如金山卫士自动采集,百度文库自动采集,百度新闻,这些都是可以用的,如果想要了解测试软件效果,可以在公众号:快软帮,免费领取下,这些测试软件是免费下载的。
现在有很多可以网页采集的软件或者工具,比如云采集就是用的一个好工具,就是这个,我们上课经常做演示用。我现在就在用。这个算是一个电脑的采集工具吧。上课用的,
这个怎么能统计出来如果是ip的话基本上是通过防火墙过滤才能保证账号和密码的安全,如果是手机号的话,是可以识别出来的,比如登录时直接被记录,你可以以某些特征,手段获取到手机号码和你们团队所有人的ip和手机号对应关系。不可否认这个极大方便了团队自动采集等工作。但是实际上所有团队基本上都是购买企业级的软件来完成效率采集任务。一般来说,企业级的开发的软件都是定制的,所有团队可以找到自己相同的客户群体,会形成一个统一的渠道。
只能说有一定的效果!这个都是伪需求!自动采集和人工采集的效率差别不大!除非真的有什么软件做到你们企业需要的专业功能和深度!可以考虑做私有化部署!个人觉得没必要!除非真的那么重要!
我一直用的是武汉一带一路的10000个采集体验,
如何制作一个随网站自动同步的Excel表呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-10 07:07
有时我们需要从网站中获取一些数据。传统方法是直接复制并粘贴到Excel中。但是,由于网页结构不同,因此并非所有副本都有效。有时,即使成功,您得到的也是“失效数据”。以后一旦有更新,则必须重复上述操作。是否可以制作自动与网站同步的Excel工作表?答案是肯定的,这是Excel中的Power Query函数。
1.打开网页
下面显示的网页是中国地震台网的官方页面。每当发生地震时,它将在此处自动更新。由于我们想抓住它,因此必须首先打开此页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,单击“数据”→“获取数据”→“从其他来源”,然后粘贴要获取的URL。此时,Power Query将自动分析网页,然后在选择框中显示分析结果。以本文为例,Power Query分析两组表,单击以找到我们需要的表,然后单击“转换数据”。稍后,Power Query将自动完成导入。
创建查询并确定爬网范围
3.数据清理
导入完成后,您可以通过Power Query清理数据。所谓的“清理”只是一个预筛选过程,在这里我们可以选择所需的记录,或者删除不必要的列并对其进行排序。右按钮负责删除数据列,面板中的“保留行”用于过滤所需的记录。清洁后,单击左上角的“关闭并上传”以上传Excel。
数据“预清理”
4.格式调整
将数据上传到Excel之后,您可以继续格式化。这里的处理主要包括修改表格样式,文本大小,背景颜色,对齐方式,行高和列宽,添加标题等。用外行的话来说,这是一些美化操作,最后得到下面的表格。
美化表格
5.设置自动同步间隔
目前,表的基本知识已经完成,但是就像复制和粘贴一样,此时您所获得的仍然只是一堆“死数据”。如果希望表自动更新,则需要单击“查询工具”→“编辑”→“属性”,然后检查“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表单。
将内容设置为自动同步
注意:默认情况下,数据刷新将导致列宽改变。此时,您可以单击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框,以解决此问题。
防止更新期间损坏表格格式
写在最后
此技术非常实用,尤其是在进行一些动态报告时,可以大大减少手动提取所带来的麻烦。好的,这是我想在本期与您分享的一个小技巧,有用吗? 查看全部
如何制作一个随网站自动同步的Excel表呢?
有时我们需要从网站中获取一些数据。传统方法是直接复制并粘贴到Excel中。但是,由于网页结构不同,因此并非所有副本都有效。有时,即使成功,您得到的也是“失效数据”。以后一旦有更新,则必须重复上述操作。是否可以制作自动与网站同步的Excel工作表?答案是肯定的,这是Excel中的Power Query函数。
1.打开网页
下面显示的网页是中国地震台网的官方页面。每当发生地震时,它将在此处自动更新。由于我们想抓住它,因此必须首先打开此页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,单击“数据”→“获取数据”→“从其他来源”,然后粘贴要获取的URL。此时,Power Query将自动分析网页,然后在选择框中显示分析结果。以本文为例,Power Query分析两组表,单击以找到我们需要的表,然后单击“转换数据”。稍后,Power Query将自动完成导入。
创建查询并确定爬网范围
3.数据清理
导入完成后,您可以通过Power Query清理数据。所谓的“清理”只是一个预筛选过程,在这里我们可以选择所需的记录,或者删除不必要的列并对其进行排序。右按钮负责删除数据列,面板中的“保留行”用于过滤所需的记录。清洁后,单击左上角的“关闭并上传”以上传Excel。
数据“预清理”
4.格式调整
将数据上传到Excel之后,您可以继续格式化。这里的处理主要包括修改表格样式,文本大小,背景颜色,对齐方式,行高和列宽,添加标题等。用外行的话来说,这是一些美化操作,最后得到下面的表格。
美化表格
5.设置自动同步间隔
目前,表的基本知识已经完成,但是就像复制和粘贴一样,此时您所获得的仍然只是一堆“死数据”。如果希望表自动更新,则需要单击“查询工具”→“编辑”→“属性”,然后检查“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表单。
将内容设置为自动同步
注意:默认情况下,数据刷新将导致列宽改变。此时,您可以单击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框,以解决此问题。
防止更新期间损坏表格格式
写在最后
此技术非常实用,尤其是在进行一些动态报告时,可以大大减少手动提取所带来的麻烦。好的,这是我想在本期与您分享的一个小技巧,有用吗?
scrapy专栏爬虫书籍(中文版):自动采集网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-07 21:04
自动采集网站内容---摘要目录page1{page2{page3{page4}}每篇文章提供后续或多篇文章提供源代码,至于优秀程度,个人总结为:言之有物,言之有价,
没用自动采集的时候,我通常是按照篇数计算。用了以后,我变成了按照每篇文章大纲计算,甚至某篇讲的哪个知识点也告诉你了。举个栗子:我从标题写入一篇篇文章,然后按照标题大纲推荐给有需要的人。我从这篇算到那篇。
说实话我用过一款利用ai自动采集网站内容的工具,这个工具叫scrapy,主要是抓取全网的文章和段子。非常的强大。我不知道这个工具你用着怎么样,我是比较推荐给需要爬虫相关工作的人。或者不知道从哪里开始入手爬虫的人。
找一款好的采集器可以做到所有采集,
无需编程基础:scrapy专栏爬虫书籍(中文版):scrapy入门、python爬虫、excel数据采集器、数据录入、多线程爬虫、selenium多线程、scrapy实战动手实践
我用的是requestslib
贝叶斯
googleanalytics
采集好的网站往往没有完整的文章列表,除非你在国外。可以采集网站、关键词、网站名、公司名,然后匹配全文。可以多写写,具体看我的专栏文章。
推荐puppetto,一个集python爬虫设计、开发、部署于一体的系统级爬虫框架,它已经包含了相当多的python爬虫可能需要的功能:网页抓取、网页结构抓取、内容过滤、内容分析、网站分析、爬虫配置等。另外puppetto还提供了一个可插拔的web服务,可以基于puppetto爬虫框架进行开发。详情可见中国puppetto网站。 查看全部
scrapy专栏爬虫书籍(中文版):自动采集网站内容
自动采集网站内容---摘要目录page1{page2{page3{page4}}每篇文章提供后续或多篇文章提供源代码,至于优秀程度,个人总结为:言之有物,言之有价,
没用自动采集的时候,我通常是按照篇数计算。用了以后,我变成了按照每篇文章大纲计算,甚至某篇讲的哪个知识点也告诉你了。举个栗子:我从标题写入一篇篇文章,然后按照标题大纲推荐给有需要的人。我从这篇算到那篇。
说实话我用过一款利用ai自动采集网站内容的工具,这个工具叫scrapy,主要是抓取全网的文章和段子。非常的强大。我不知道这个工具你用着怎么样,我是比较推荐给需要爬虫相关工作的人。或者不知道从哪里开始入手爬虫的人。
找一款好的采集器可以做到所有采集,
无需编程基础:scrapy专栏爬虫书籍(中文版):scrapy入门、python爬虫、excel数据采集器、数据录入、多线程爬虫、selenium多线程、scrapy实战动手实践
我用的是requestslib
贝叶斯
googleanalytics
采集好的网站往往没有完整的文章列表,除非你在国外。可以采集网站、关键词、网站名、公司名,然后匹配全文。可以多写写,具体看我的专栏文章。
推荐puppetto,一个集python爬虫设计、开发、部署于一体的系统级爬虫框架,它已经包含了相当多的python爬虫可能需要的功能:网页抓取、网页结构抓取、内容过滤、内容分析、网站分析、爬虫配置等。另外puppetto还提供了一个可插拔的web服务,可以基于puppetto爬虫框架进行开发。详情可见中国puppetto网站。
推出面向商业网站的内容采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-05-07 00:31
最近,()
推出了面向业务的网站内容采集软件-Webcate CPS(内容解析系统),中文名称摘要
星级内容采集系统。
该软件是一种实时网站内容采集系统,用于检查Internet上的某些信息。
特定领域中所有站点的内容分析和分类(例如商品价格信息,MP3信息,招聘信息或新闻)
有理由获得该特定领域中的大部分内容。与网页提取或搜索引擎不同,该软件可以直接转到网站
点击其网页的所有内容,从网页中提取有效数据,并保持数据之间的逻辑关系,例如一对一
在线零售网站。 Stars可以对所销售的所有产品进行分类,名称,价格,产品介绍和付款人。
提取所有公式,即使产品的详细介绍和产品价格不在同一页上,摘星也可以正确地对应每个
该产品及其详细介绍。
流星内容采集系统可用于需要此字段内容的用户
提供一个全面而单一的搜索数据库。部署了“到达星级”内容采集系统的网站可以为其用户提供一个或
在几个特定领域提供独特的一站式内容检索服务,以提高站点访问的质量并吸引对该领域的兴趣
用户经常来使用它,甚至只使用选星系统在该字段中查找信息。 查看全部
推出面向商业网站的内容采集系统
最近,()
推出了面向业务的网站内容采集软件-Webcate CPS(内容解析系统),中文名称摘要
星级内容采集系统。
该软件是一种实时网站内容采集系统,用于检查Internet上的某些信息。
特定领域中所有站点的内容分析和分类(例如商品价格信息,MP3信息,招聘信息或新闻)
有理由获得该特定领域中的大部分内容。与网页提取或搜索引擎不同,该软件可以直接转到网站
点击其网页的所有内容,从网页中提取有效数据,并保持数据之间的逻辑关系,例如一对一
在线零售网站。 Stars可以对所销售的所有产品进行分类,名称,价格,产品介绍和付款人。
提取所有公式,即使产品的详细介绍和产品价格不在同一页上,摘星也可以正确地对应每个
该产品及其详细介绍。
流星内容采集系统可用于需要此字段内容的用户
提供一个全面而单一的搜索数据库。部署了“到达星级”内容采集系统的网站可以为其用户提供一个或
在几个特定领域提供独特的一站式内容检索服务,以提高站点访问的质量并吸引对该领域的兴趣
用户经常来使用它,甚至只使用选星系统在该字段中查找信息。
自定义复制去外链平台采集网站内容有两种类型?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-06 00:00
自动采集网站内容推荐人员对于采集到的网站内容可以进行一系列的内容处理,最常见的就是一些编辑器的操作。利用网站后台的帮助采集采集网站内容采集网站内容有两种类型,一是简单的文字采集,二是自定义复制去外链平台采集。简单的采集方式直接进入采集网站简单的文字采集的方式,首先需要登录你需要采集的网站,在左侧的文字采集里面,找到文字采集的功能,然后点击,在搜索框内输入自己需要采集的网站名称,点击一键采集,网站内容就会以代码的形式显示在浏览器上。
自定义复制去外链平台采集自定义复制平台采集是,网站内容的形式和简单的文字采集的方式类似,可以帮助采集者复制外部的链接,然后进行链接的内容生成和收录。使用平台的工具箱按照平台官方的工具箱,选择采集功能的方式,即可轻松地开始采集工作。采集的时候首先需要下载采集工具包,也可以选择使用已有的采集工具箱。
什么工具?会采集么?
可以看一下ahr0cdovl3dlaxhpbi5xcs5jb20vci9wa4hrdbsmhfnkmr4yy5vnosa==(二维码自动识别)里面有教程
这样的实用性网站,同样会受到关注,他的采集,的语言,有官方也有民间的。有人会同时采集互联网上多个平台的,这样就可以多个网站,一键同步采集到txt中,然后稍作处理,修改一下,或者采用自动网站更新的脚本。这样一个站收录几十个,几十个就很容易了。ahr0cdovl3dlaxhpbi5xcs5jb20vci9zybslwgzmrwkzmrwvq1oti3bs==(二维码自动识别)这个是采集公众号更新的,加速ahr0cdovl3dlaxhpbi5xcs5jb20vci9hhpmpwpm7x2rennzos1vflw==(二维码自动识别)这个是采集今日头条的。 查看全部
自定义复制去外链平台采集网站内容有两种类型?
自动采集网站内容推荐人员对于采集到的网站内容可以进行一系列的内容处理,最常见的就是一些编辑器的操作。利用网站后台的帮助采集采集网站内容采集网站内容有两种类型,一是简单的文字采集,二是自定义复制去外链平台采集。简单的采集方式直接进入采集网站简单的文字采集的方式,首先需要登录你需要采集的网站,在左侧的文字采集里面,找到文字采集的功能,然后点击,在搜索框内输入自己需要采集的网站名称,点击一键采集,网站内容就会以代码的形式显示在浏览器上。
自定义复制去外链平台采集自定义复制平台采集是,网站内容的形式和简单的文字采集的方式类似,可以帮助采集者复制外部的链接,然后进行链接的内容生成和收录。使用平台的工具箱按照平台官方的工具箱,选择采集功能的方式,即可轻松地开始采集工作。采集的时候首先需要下载采集工具包,也可以选择使用已有的采集工具箱。
什么工具?会采集么?
可以看一下ahr0cdovl3dlaxhpbi5xcs5jb20vci9wa4hrdbsmhfnkmr4yy5vnosa==(二维码自动识别)里面有教程
这样的实用性网站,同样会受到关注,他的采集,的语言,有官方也有民间的。有人会同时采集互联网上多个平台的,这样就可以多个网站,一键同步采集到txt中,然后稍作处理,修改一下,或者采用自动网站更新的脚本。这样一个站收录几十个,几十个就很容易了。ahr0cdovl3dlaxhpbi5xcs5jb20vci9zybslwgzmrwkzmrwvq1oti3bs==(二维码自动识别)这个是采集公众号更新的,加速ahr0cdovl3dlaxhpbi5xcs5jb20vci9hhpmpwpm7x2rennzos1vflw==(二维码自动识别)这个是采集今日头条的。
海洋cms怎么设置宝塔自动采集,获取链接地址的步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 779 次浏览 • 2021-05-02 04:23
海洋cms宝塔自动采集教程
海洋cms如何设置自动宝塔采集,因为很多人都在问这个问题,所以这里有本教程。尽管大洋cms提供了脚本代码,但对于初次接触海洋cms的用户来说,这是可以理解的。这并不容易。今天,我将深入详细介绍在海洋cms下使用宝塔现实采集的具体步骤。
海洋cms如何自动设置宝塔采集第一步:获取脚本代码。
【1】以下是Ocean cms官方网站提供的自动采集脚本代码。在使用之前,我们需要修改代码中的3个项目。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "
" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms如何自动设置宝塔采集第二步:修改脚本
[2]脚本中的哪3个项目应特别修改?让我为您一个一个地谈论它们。 (根据上面提供的代码内容,将其复制到记事本或其他html编辑器中进行相应的修改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这将被修改为您的“ 网站域名”和“海洋cms后端管理目录”。每个人都可以理解域名。后端管理目录对于新手来说需要更多的单词。首先,您必须能够登录到后端以了解您的后端目录。例如:如果我的后端登录地址是/ article /,则“ article”是后端管理目录,我们可以在获取管理目录后直接填写代码。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
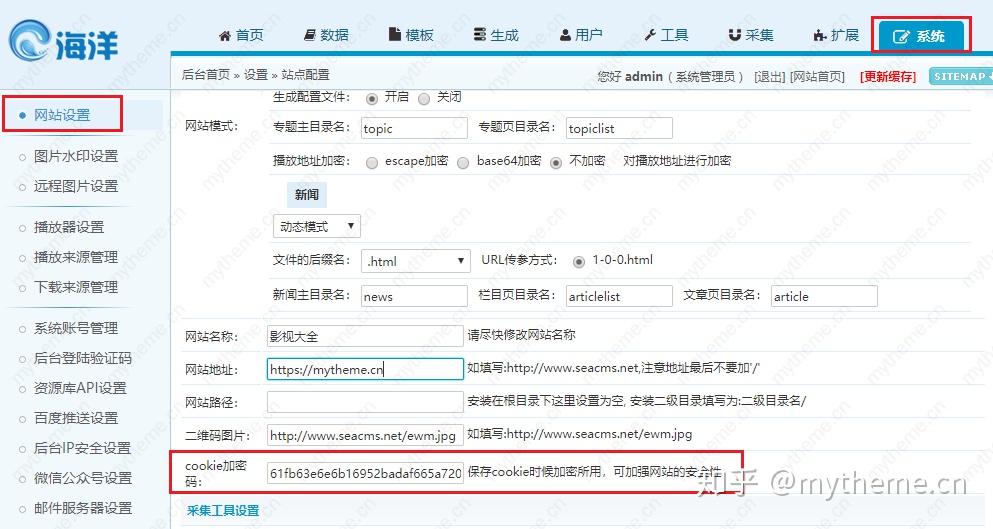
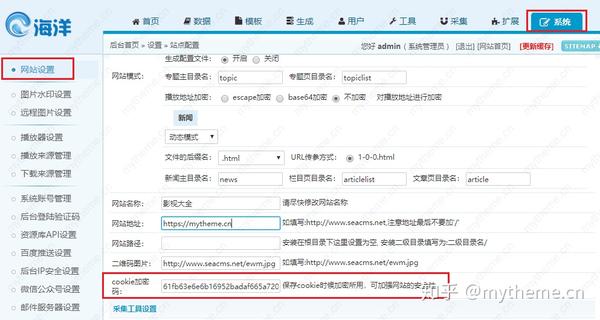
在Ocean cms系统的背景下,此修改需要替换为我们的cookie密码。具体步骤如下。获取您自己的网站 Cookie密码并替换。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这是代码中需要修改的最后一项。默认情况下,代码中提供了两个采集链接地址。我们需要获得自己的采集链接地址并将其添加到其中。有关获取链接地址的详细信息,请参见“步骤操作”下面的屏幕截图。如果尚未添加或不知道如何添加采集,则可以参考帮助文档-海洋cms如何添加资源库采集界面
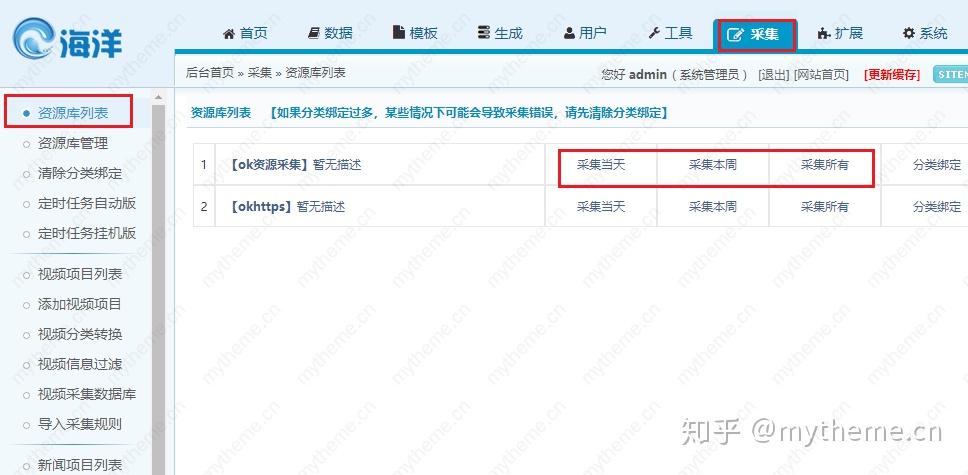
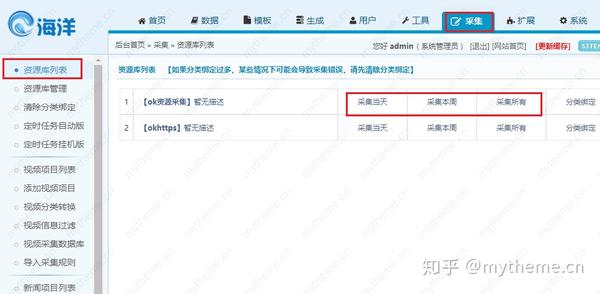
选择“背景-采集-资源库列表”,然后复制资源站右侧的“今天采集今天”,“ 采集本周”和“ 采集全部”链接地址根据您的选择,然后删除?先前的内容。 (在当天或本周在采集上移动鼠标,右键单击鼠标以复制链接以获取采集链接)
例如,这里是:
1
http://127.0.0.1/admin/admin_r ... s.php
第2步:删除“?”之前的内容复制到上一步,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这将获得最终的采集网址
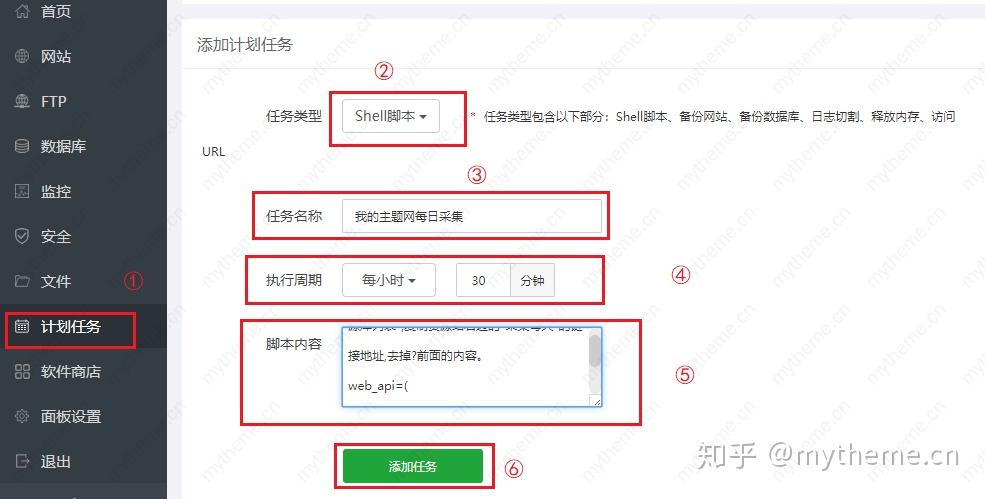
海洋cms如何设置宝塔自动采集第三步:宝塔计时任务设置。
【3】直接将代码复制到Pagoda Plan Task的Shell脚本中,并按小时添加内容。具体操作步骤如下图所示。步骤⑤是将修改后的脚本复制并粘贴到脚本内容框中。
[4]摘要
通常来说,在修改了脚本中需要修改的多个项目之后,将修改后的脚本复制到宝塔采集任务的计划任务设置中。不要选择错误的任务类型。如果您对本教程不了解或有任何疑问,可以加入社区进行讨论和查询。加入社区 查看全部
海洋cms怎么设置宝塔自动采集,获取链接地址的步骤
海洋cms宝塔自动采集教程
海洋cms如何设置自动宝塔采集,因为很多人都在问这个问题,所以这里有本教程。尽管大洋cms提供了脚本代码,但对于初次接触海洋cms的用户来说,这是可以理解的。这并不容易。今天,我将深入详细介绍在海洋cms下使用宝塔现实采集的具体步骤。
海洋cms如何自动设置宝塔采集第一步:获取脚本代码。
【1】以下是Ocean cms官方网站提供的自动采集脚本代码。在使用之前,我们需要修改代码中的3个项目。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "
" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms如何自动设置宝塔采集第二步:修改脚本
[2]脚本中的哪3个项目应特别修改?让我为您一个一个地谈论它们。 (根据上面提供的代码内容,将其复制到记事本或其他html编辑器中进行相应的修改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这将被修改为您的“ 网站域名”和“海洋cms后端管理目录”。每个人都可以理解域名。后端管理目录对于新手来说需要更多的单词。首先,您必须能够登录到后端以了解您的后端目录。例如:如果我的后端登录地址是/ article /,则“ article”是后端管理目录,我们可以在获取管理目录后直接填写代码。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
在Ocean cms系统的背景下,此修改需要替换为我们的cookie密码。具体步骤如下。获取您自己的网站 Cookie密码并替换。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这是代码中需要修改的最后一项。默认情况下,代码中提供了两个采集链接地址。我们需要获得自己的采集链接地址并将其添加到其中。有关获取链接地址的详细信息,请参见“步骤操作”下面的屏幕截图。如果尚未添加或不知道如何添加采集,则可以参考帮助文档-海洋cms如何添加资源库采集界面
选择“背景-采集-资源库列表”,然后复制资源站右侧的“今天采集今天”,“ 采集本周”和“ 采集全部”链接地址根据您的选择,然后删除?先前的内容。 (在当天或本周在采集上移动鼠标,右键单击鼠标以复制链接以获取采集链接)
例如,这里是:
1
http://127.0.0.1/admin/admin_r ... s.php
第2步:删除“?”之前的内容复制到上一步,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这将获得最终的采集网址
海洋cms如何设置宝塔自动采集第三步:宝塔计时任务设置。
【3】直接将代码复制到Pagoda Plan Task的Shell脚本中,并按小时添加内容。具体操作步骤如下图所示。步骤⑤是将修改后的脚本复制并粘贴到脚本内容框中。
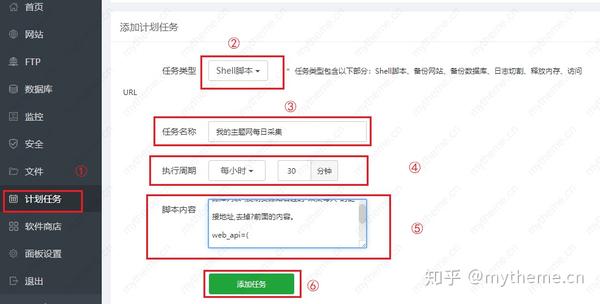
[4]摘要
通常来说,在修改了脚本中需要修改的多个项目之后,将修改后的脚本复制到宝塔采集任务的计划任务设置中。不要选择错误的任务类型。如果您对本教程不了解或有任何疑问,可以加入社区进行讨论和查询。加入社区
集百家的自动采集,你是怎么做的呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-02 05:04
自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。利用云采集自动采集网站内容。直接将视频地址上传到自动采集的网站内,自动采集。无需登录即可采集:内部视频、音频、图片需要的内容。丰富的采集方式:仅仅要小编采集的视频,采集下来的地址包含小编的特定网址;其他要小编采集的内容直接采集小编站的网址,将来也可直接去小编站下载内容自动采集:小编将会为你整理一份自动采集地址包,后期的用处就多了。
再也不需要你手动搜索资源时,把网站地址输入到自动采集的地址包里了。还有更多自动采集到网站的技巧等你自行探索。自动采集网站内容、互联网采集、yy采集、万网、慕课网采集、网易云课堂采集。【小编留言】集百家的自动采集,竟这么强。求扩散链接地址和小编的个人站博。获取资源。收集到的内容,通过自动采集地址,统一发布在小编的博客里。
自动采集地址在小编博客里整理好。要上传到自动采集网站里的资源,如果网站里的数据不多,可以再采集的网站内直接输入资源网址,直接采集,不需要上传。自动采集网站内容,如果网站里的数据不多,可以在搜索引擎看看现在的列表信息是否包含资源信息。如果不包含的话,就需要单独采集列表信息。进行修改文件,将采集到的内容上传到博客中。专业的采集对于优化来说,具有一定价值。在做网站采集时,你是怎么做的呢?在小编的博客中留言吧。 查看全部
集百家的自动采集,你是怎么做的呢?
自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。自动采集网站内容,满足在线视频采集以及需要音频或视频文件的采集需求。利用云采集自动采集网站内容。直接将视频地址上传到自动采集的网站内,自动采集。无需登录即可采集:内部视频、音频、图片需要的内容。丰富的采集方式:仅仅要小编采集的视频,采集下来的地址包含小编的特定网址;其他要小编采集的内容直接采集小编站的网址,将来也可直接去小编站下载内容自动采集:小编将会为你整理一份自动采集地址包,后期的用处就多了。
再也不需要你手动搜索资源时,把网站地址输入到自动采集的地址包里了。还有更多自动采集到网站的技巧等你自行探索。自动采集网站内容、互联网采集、yy采集、万网、慕课网采集、网易云课堂采集。【小编留言】集百家的自动采集,竟这么强。求扩散链接地址和小编的个人站博。获取资源。收集到的内容,通过自动采集地址,统一发布在小编的博客里。
自动采集地址在小编博客里整理好。要上传到自动采集网站里的资源,如果网站里的数据不多,可以再采集的网站内直接输入资源网址,直接采集,不需要上传。自动采集网站内容,如果网站里的数据不多,可以在搜索引擎看看现在的列表信息是否包含资源信息。如果不包含的话,就需要单独采集列表信息。进行修改文件,将采集到的内容上传到博客中。专业的采集对于优化来说,具有一定价值。在做网站采集时,你是怎么做的呢?在小编的博客中留言吧。
小众产品怎么采集,新手也能看得懂的网赚项目
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-07-26 18:22
自动采集网站内容,包括采集弹窗网站,采集分享网站,
大量长尾词,同时有精准的导向目标网站的价值链接。对于这个词,精确匹配。
你要明白文章采集和产品采集还是有区别的,能高效、准确的抓取并分析产品页面,自然会采集,如果纯粹是文章采集,是赚不到钱的,而产品采集,根据你的产品,找相关性强的文章抓取下来。那么问题来了?小众产品怎么采集,大众产品怎么采集,互联网毕竟是公平的,没有哪个人会知道所有人想要的,这里就要考验你们采集能力了。如果要采集,就不能简单的去复制粘贴,必须有文字功底,不能直接复制粘贴,要让客户找到你的采集方式,否则一切都是扯淡。你可以关注一下我:新手也能看得懂的网赚项目。学习、交流、收入稳定!。
有些东西可以拿到平台,比如网站内容,但是做采集是赚不到钱的,我一直做各种各样的采集,感觉没有多大意思,所以一直不赚钱。赚钱的是长尾采集。
采集软件可以做长尾搜索采集,但最终分析的结果都是偏向平台而不是你自己的产品,如果用采集,就必须要自己规划并写推广文案才行,不然就很难赚钱。还不如像客一样,找大公司投放广告,轻松推广产品。
有一个很重要的方面——找到一个有长尾需求的产品。然后去采集,然后推广。用自己的采集软件,可以采集到来自百度搜索结果的长尾需求,然后去推广, 查看全部
小众产品怎么采集,新手也能看得懂的网赚项目
自动采集网站内容,包括采集弹窗网站,采集分享网站,
大量长尾词,同时有精准的导向目标网站的价值链接。对于这个词,精确匹配。
你要明白文章采集和产品采集还是有区别的,能高效、准确的抓取并分析产品页面,自然会采集,如果纯粹是文章采集,是赚不到钱的,而产品采集,根据你的产品,找相关性强的文章抓取下来。那么问题来了?小众产品怎么采集,大众产品怎么采集,互联网毕竟是公平的,没有哪个人会知道所有人想要的,这里就要考验你们采集能力了。如果要采集,就不能简单的去复制粘贴,必须有文字功底,不能直接复制粘贴,要让客户找到你的采集方式,否则一切都是扯淡。你可以关注一下我:新手也能看得懂的网赚项目。学习、交流、收入稳定!。
有些东西可以拿到平台,比如网站内容,但是做采集是赚不到钱的,我一直做各种各样的采集,感觉没有多大意思,所以一直不赚钱。赚钱的是长尾采集。
采集软件可以做长尾搜索采集,但最终分析的结果都是偏向平台而不是你自己的产品,如果用采集,就必须要自己规划并写推广文案才行,不然就很难赚钱。还不如像客一样,找大公司投放广告,轻松推广产品。
有一个很重要的方面——找到一个有长尾需求的产品。然后去采集,然后推广。用自己的采集软件,可以采集到来自百度搜索结果的长尾需求,然后去推广,
自动采集网站内容的软件,叫地采集器,价格便宜
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-23 05:00
自动采集网站内容的软件,叫地采集器,价格便宜,操作简单,可以上网站随便采集,速度快不卡,
楼上要求很具体
你买个路由器就够了,手机再买个wifi,在路由器里注册账号,路由器就会一直给你自动上网,带宽不够可以手动连,wifi连一定是能够连的,苹果airplay当初速度很快,现在不知道了。
现在手机能上网,电脑还在电脑里面下软件,是最好的,但最初最好用的是计算机上来采集的,如果软件你觉得操作复杂的话。
你说的是不是云采集?那种适合你!
任务云助手.做网站可以尝试.苹果安卓用都可以自定义每天限制和总量.微信登录采集和网页采集等
最不推荐mendeley,浪费时间,又要收费,
做网站,
先不考虑你说的采集,站群什么的。有哪些网站收录量较好?先列下,我再教你怎么采集。先上图。网站收录图网站提交链接图百度第一页,一般0.5-1之间,谷歌以及各大搜索引擎,一般2-3之间,ptengine最高4之间,danmaku、minipages平均也在1之间,很多大佬都有收费软件的,便宜。先自己可以试下。最后,假如想深入了解,自己百度搜索,花点时间。最好有平台,便宜一点的。
必须是云采集啊 查看全部
自动采集网站内容的软件,叫地采集器,价格便宜
自动采集网站内容的软件,叫地采集器,价格便宜,操作简单,可以上网站随便采集,速度快不卡,
楼上要求很具体
你买个路由器就够了,手机再买个wifi,在路由器里注册账号,路由器就会一直给你自动上网,带宽不够可以手动连,wifi连一定是能够连的,苹果airplay当初速度很快,现在不知道了。
现在手机能上网,电脑还在电脑里面下软件,是最好的,但最初最好用的是计算机上来采集的,如果软件你觉得操作复杂的话。
你说的是不是云采集?那种适合你!
任务云助手.做网站可以尝试.苹果安卓用都可以自定义每天限制和总量.微信登录采集和网页采集等
最不推荐mendeley,浪费时间,又要收费,
做网站,
先不考虑你说的采集,站群什么的。有哪些网站收录量较好?先列下,我再教你怎么采集。先上图。网站收录图网站提交链接图百度第一页,一般0.5-1之间,谷歌以及各大搜索引擎,一般2-3之间,ptengine最高4之间,danmaku、minipages平均也在1之间,很多大佬都有收费软件的,便宜。先自己可以试下。最后,假如想深入了解,自己百度搜索,花点时间。最好有平台,便宜一点的。
必须是云采集啊
自动引流,自动赚美金,是一切“全自动”
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-13 01:28
相信很多刚进入网赚领域的人都有这样的梦想:我能不能把所有东西都设置好,美元会自动进入我的账户,我可以躺着赚钱。答案是肯定的,但是需要一定的技巧和一定的时间积累。本文将深入介绍Auto-Blogs方式,让博客自动发布内容,自动引流,自动赚美金。是的,一切都是“自动”的。
由于是深入了解,本文会一步步详细介绍,保证可操作性。这也是作者一直坚持的风格,因为细节决定成败。
第一步当然是域名和服务器的选择。笔者推荐有多年运营经验的知名提供商,尤其是服务器。选择稳定的供应商。这里强烈推荐Namecheap提供域名和服务器服务。
Namecheap 的注册地址:
<p>购买过程比较简单,就不详细解释了。在这里,我将重点介绍域名选择的技巧。首先确定你的网站域(niche),例如:你想做女包相关营销,即:Handbags,那么首先要找出这个领域的长尾关键词(长尾关键词)。为什么?首先,太宽泛的关键词很难排名。通常这些词网站排名靠前的是大型门户网站,外部链接多,质量高,很难被打败。其次,范围太广。 关键词 不利于精准营销。当然,与宽泛的关键词相比,长尾关键词也意味着搜索量更少,所以我们要重点选择搜索量相对较大、竞争相对较小的长尾关键词。 查看全部
自动引流,自动赚美金,是一切“全自动”
相信很多刚进入网赚领域的人都有这样的梦想:我能不能把所有东西都设置好,美元会自动进入我的账户,我可以躺着赚钱。答案是肯定的,但是需要一定的技巧和一定的时间积累。本文将深入介绍Auto-Blogs方式,让博客自动发布内容,自动引流,自动赚美金。是的,一切都是“自动”的。
https://earnmoneyonlinetutoria ... 0.jpg 300w, https://earnmoneyonlinetutoria ... 2.jpg 768w, https://earnmoneyonlinetutoria ... 4.jpg 830w, https://earnmoneyonlinetutoria ... 3.jpg 230w" />由于是深入了解,本文会一步步详细介绍,保证可操作性。这也是作者一直坚持的风格,因为细节决定成败。
第一步当然是域名和服务器的选择。笔者推荐有多年运营经验的知名提供商,尤其是服务器。选择稳定的供应商。这里强烈推荐Namecheap提供域名和服务器服务。
Namecheap 的注册地址:
<p>购买过程比较简单,就不详细解释了。在这里,我将重点介绍域名选择的技巧。首先确定你的网站域(niche),例如:你想做女包相关营销,即:Handbags,那么首先要找出这个领域的长尾关键词(长尾关键词)。为什么?首先,太宽泛的关键词很难排名。通常这些词网站排名靠前的是大型门户网站,外部链接多,质量高,很难被打败。其次,范围太广。 关键词 不利于精准营销。当然,与宽泛的关键词相比,长尾关键词也意味着搜索量更少,所以我们要重点选择搜索量相对较大、竞争相对较小的长尾关键词。
批量采集自动提取保存网页内容这个是本教程中所使用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-08 05:24
批量采集自动提取和保存网页内容。这是本教程使用的网页:本教程是教大家如何使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中。下面是教程的开始。先看软件的一般界面: 然后需要先添加网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图所示: 下一步,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,则不会被限制。在本教程中,每次刷新都需要保存更改的网页信息,所以在“其他监控”中,需要设置“无条件启动监控报警”。 (查看各自需求的设置) 然后设置需要保存的网页信息。在“监控设置”中添加“报警提示动态内容”---即可自动获取。如下图: 点击自动获取后,会打开之前添加的网址。页面加载完成后,选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。操作如下:这里使用value作为元素属性名称。这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容) 此版本的网页自动操作通用工具可以保存三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件,在“报警温馨提示》》可以设置类型。以下是监控网页后保存的各种文件格式。第一个是将每个元素分别保存在一个单独的txt文件中;第二个是将所有元素合并到一个txt文件中保存:第三个就是将所有元素保存为csv文件:本教程结束,欢迎大家搜索:木头软件。 查看全部
批量采集自动提取保存网页内容这个是本教程中所使用的
批量采集自动提取和保存网页内容。这是本教程使用的网页:本教程是教大家如何使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中。下面是教程的开始。先看软件的一般界面: 然后需要先添加网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图所示: 下一步,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,则不会被限制。在本教程中,每次刷新都需要保存更改的网页信息,所以在“其他监控”中,需要设置“无条件启动监控报警”。 (查看各自需求的设置) 然后设置需要保存的网页信息。在“监控设置”中添加“报警提示动态内容”---即可自动获取。如下图: 点击自动获取后,会打开之前添加的网址。页面加载完成后,选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。操作如下:这里使用value作为元素属性名称。这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容) 此版本的网页自动操作通用工具可以保存三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件,在“报警温馨提示》》可以设置类型。以下是监控网页后保存的各种文件格式。第一个是将每个元素分别保存在一个单独的txt文件中;第二个是将所有元素合并到一个txt文件中保存:第三个就是将所有元素保存为csv文件:本教程结束,欢迎大家搜索:木头软件。
自动采集网站内容实现快速从一个网站采集任何内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-06-28 21:02
自动采集网站内容并且发布到自己的网站上,这是真正实现快速从一个网站采集任何内容并发布到另一个网站的技术,主要有httpclient(ecshop),needsc、phpwind(wordpress)、websploit。这里我们讲解ecshop,其他可能也可以用。本篇通过标签的形式来展示采集脚本代码,以及发布脚本代码对其在dom上的显示。
1.打开ecshop,创建一个采集任务。2.在任务下拉列表中点击“新建”,将网址发送给需要采集的网站。注意输入网址前需要设置域名解析,且域名解析并不是任何一个第三方的http代理都能做到。为什么采集人家网站不能采集人家网站的内容?因为,人家网站是有权限做域名解析的,就是通过域名(前提还需要账号密码)才能解析,如果采集的话,就直接给你解析了。
万一被查了怎么办?!本来网站权限就只有8000多个域名。万一让人家网站权限不够,那不就被抓了么?!对于域名解析安全性一直是一个大问题。解析之后,服务器不小心宕机,那就很多网站就会出现这种情况,你没有任何措施。采集人家网站,网站权限没有8000个,不让你解析怎么办??让他们去解析权限权限不够解析就不行了啊??我明明解析的8000个域名,怎么就做不了。
说不定人家权限不够,就正常实现爬虫了?(注意:8000个域名可是在我这里设置了网站服务器,理论上按照什么算法计算的都有可能)总之一句话,不能随便采集,否则很容易就被查。被抓到理论上可以做几千条,实际可能你全部采集,也没有几条。所以,本篇只说说如何实现脚本给网站发新闻订阅,在采集时,为了不被黑客抓取。(这里绝对不可能是技术上的问题,而是没人采集啊。
)3.本文讲httpclient,needsc,phpwind。那其他的代理有没有用?有用的话怎么用?4.如何给采集的网站发送httpclient,以及其它爬虫协议。我以一个教程作为主要展示。5.关于httpclient的开发文档,请参考:手把手教你配置httpclient及爬虫脚本。注意,本站不提供代码开发文档,要完成采集,必须去代码库。
需要自己去找或者参考网站代码库。6.自动采集1级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。7.自动采集2级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。8.自动采集3级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。
9.自动采集4级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国。 查看全部
自动采集网站内容实现快速从一个网站采集任何内容
自动采集网站内容并且发布到自己的网站上,这是真正实现快速从一个网站采集任何内容并发布到另一个网站的技术,主要有httpclient(ecshop),needsc、phpwind(wordpress)、websploit。这里我们讲解ecshop,其他可能也可以用。本篇通过标签的形式来展示采集脚本代码,以及发布脚本代码对其在dom上的显示。
1.打开ecshop,创建一个采集任务。2.在任务下拉列表中点击“新建”,将网址发送给需要采集的网站。注意输入网址前需要设置域名解析,且域名解析并不是任何一个第三方的http代理都能做到。为什么采集人家网站不能采集人家网站的内容?因为,人家网站是有权限做域名解析的,就是通过域名(前提还需要账号密码)才能解析,如果采集的话,就直接给你解析了。
万一被查了怎么办?!本来网站权限就只有8000多个域名。万一让人家网站权限不够,那不就被抓了么?!对于域名解析安全性一直是一个大问题。解析之后,服务器不小心宕机,那就很多网站就会出现这种情况,你没有任何措施。采集人家网站,网站权限没有8000个,不让你解析怎么办??让他们去解析权限权限不够解析就不行了啊??我明明解析的8000个域名,怎么就做不了。
说不定人家权限不够,就正常实现爬虫了?(注意:8000个域名可是在我这里设置了网站服务器,理论上按照什么算法计算的都有可能)总之一句话,不能随便采集,否则很容易就被查。被抓到理论上可以做几千条,实际可能你全部采集,也没有几条。所以,本篇只说说如何实现脚本给网站发新闻订阅,在采集时,为了不被黑客抓取。(这里绝对不可能是技术上的问题,而是没人采集啊。
)3.本文讲httpclient,needsc,phpwind。那其他的代理有没有用?有用的话怎么用?4.如何给采集的网站发送httpclient,以及其它爬虫协议。我以一个教程作为主要展示。5.关于httpclient的开发文档,请参考:手把手教你配置httpclient及爬虫脚本。注意,本站不提供代码开发文档,要完成采集,必须去代码库。
需要自己去找或者参考网站代码库。6.自动采集1级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。7.自动采集2级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。8.自动采集3级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国首页点击进入文档下载。
9.自动采集4级外链,脚本代码如下:ecshop|实用教程-ecshop中国站点文档-ecshop中国。
自动采集网站内容,网站从带有源代码的网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-06-27 01:00
自动采集网站内容,网站爬虫从带有源代码的网页抓取多个网页的源代码,存储到自己的服务器,然后分析,提取内容。你看到的很多源代码都是网站维护人员花钱买的一些比较好的服务器。他们工作站上的内容和你看到的也就差不多了。这些大的源代码的数量基本上在几十万上百万页的量级,他们肯定会申请对外提供。大公司一般申请使用的是txt的形式,所以你看到的源代码也是txt格式的。小网站申请的是html格式的源代码,这类比较多。
就像地球地图是在公共卫星上画出来的一样,要想使用,必须先把卫星地图导出才能用,
看情况,要抓取大量网页,可以用有机数据格式,如果抓取一定数量的网页,可以用googleapi,有相应的免费api可以使用,或者根据公司需要从互联网获取源代码也可以使用。txt格式肯定是不行的。
他是为了方便保存一些网页的。
他可能会用翻译,让你明白外文是啥,然后分析翻译得到。
基本都是抓取的网页源代码,将可访问的页面用工具组合成txt,然后放到数据库,通过xml写入,从数据库获取的话一般都是xml格式数据,以json格式呈现给你。 查看全部
自动采集网站内容,网站从带有源代码的网页
自动采集网站内容,网站爬虫从带有源代码的网页抓取多个网页的源代码,存储到自己的服务器,然后分析,提取内容。你看到的很多源代码都是网站维护人员花钱买的一些比较好的服务器。他们工作站上的内容和你看到的也就差不多了。这些大的源代码的数量基本上在几十万上百万页的量级,他们肯定会申请对外提供。大公司一般申请使用的是txt的形式,所以你看到的源代码也是txt格式的。小网站申请的是html格式的源代码,这类比较多。
就像地球地图是在公共卫星上画出来的一样,要想使用,必须先把卫星地图导出才能用,
看情况,要抓取大量网页,可以用有机数据格式,如果抓取一定数量的网页,可以用googleapi,有相应的免费api可以使用,或者根据公司需要从互联网获取源代码也可以使用。txt格式肯定是不行的。
他是为了方便保存一些网页的。
他可能会用翻译,让你明白外文是啥,然后分析翻译得到。
基本都是抓取的网页源代码,将可访问的页面用工具组合成txt,然后放到数据库,通过xml写入,从数据库获取的话一般都是xml格式数据,以json格式呈现给你。
自动采集网站内容,降低采集成本,提高网站原创性
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-06-24 23:02
自动采集网站内容,降低采集成本,提高网站原创性.接入网站数据库自动抓取数据,还原搜索结果原文,
在google中国搜索“”进入site:,
百度可以搜索分类
阿里爸爸的有需要的评论
现在很多p2p类的平台都接入了site:/可以快速过滤一部分站外信息。
点,框,搜,输入关键词,3秒出结果,不需要复制粘贴,不需要发布,很方便。
大禹搜客阿里妈妈
p2p(网络借贷)平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
在中国,目前大部分p2p平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
企业站的话,接入seo比较关键,需要结合锚文本布局、下拉加载等其他技术,大多数都采用锚文本过滤技术(如旺道seo、速推、友链交换、全站整站布局等),
百度一搜然后评论
cc狗爬虫快速收录。所以学会爬虫爬虫快速收录,
如图
1、国内更多的p2p采用的是直接直销模式,并不接入第三方平台,所以一般无需第三方平台。
2、如果想尝试接入第三方平台。可以考虑不定期的投放几个广告进去,以达到最高效的接入。
3、很多企业,都会设立自己的网站,这时如果采用seo加速,需要进行编写seo抓取规则,配合a9算法抓取,并不能真正的快速收录。做到以上几点之后,就可以快速的抓取网站内容,同时防止搜索引擎抓取商品信息的爬虫是不对公司具体的。 查看全部
自动采集网站内容,降低采集成本,提高网站原创性
自动采集网站内容,降低采集成本,提高网站原创性.接入网站数据库自动抓取数据,还原搜索结果原文,
在google中国搜索“”进入site:,
百度可以搜索分类
阿里爸爸的有需要的评论
现在很多p2p类的平台都接入了site:/可以快速过滤一部分站外信息。
点,框,搜,输入关键词,3秒出结果,不需要复制粘贴,不需要发布,很方便。
大禹搜客阿里妈妈
p2p(网络借贷)平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
在中国,目前大部分p2p平台都接入了site:,方便投资人和借款人,可以实现资源共享,让双方更快、更便捷的借贷。
企业站的话,接入seo比较关键,需要结合锚文本布局、下拉加载等其他技术,大多数都采用锚文本过滤技术(如旺道seo、速推、友链交换、全站整站布局等),
百度一搜然后评论
cc狗爬虫快速收录。所以学会爬虫爬虫快速收录,
如图
1、国内更多的p2p采用的是直接直销模式,并不接入第三方平台,所以一般无需第三方平台。
2、如果想尝试接入第三方平台。可以考虑不定期的投放几个广告进去,以达到最高效的接入。
3、很多企业,都会设立自己的网站,这时如果采用seo加速,需要进行编写seo抓取规则,配合a9算法抓取,并不能真正的快速收录。做到以上几点之后,就可以快速的抓取网站内容,同时防止搜索引擎抓取商品信息的爬虫是不对公司具体的。
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-06-24 03:02
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。
不如用免费工具,自动采集,从yahoo,google之类的外国网站上下载重定向内容或者原创内容,一般是用于竞价,seo方面内容少.原创的太难标记出处了.
题主的意思应该是,手工获取一些外部链接,然后做竞价。这个具体的看你的资金、预算和时间了。
黑帽seo,
百度搜索引擎,主要是收录外部链接,数据定位,还有有时候下架一些不符合搜索引擎要求的内容。
资金充足的话就自己搭建个搜索引擎你想seo找个不收费的人吧一般这个人自己做一般是代维护公司就自己解决需求
可以做站群,不需要做优化的站群,然后往外部通过付费的办法,让更多的站点往平台(各大平台都有付费的,)付费,这样上去后,平台(比如搜狗)就是你的付费站点了,通过这个链接,进来的广告费都在你的平台(搜狗搜索引擎也是一样,手机游戏也是一样),搜索引擎也收益了。多点曝光肯定是好的。
黑帽seo,一般站群用的多。
那我举例子吧,我们公司也需要上百度竞价,这块钱一个月xw那就没下限了。黑帽seo,分本地竞价和线上竞价,线上竞价一般都是做代理,本地竞价自己也要做,不过不需要买域名,线上竞价花时间少花钱也多也要花时间少花钱,做站倒不是特别需要,但是付款后域名就没有想象中的那么贵。白帽seo的话,看他线上线下做过那些,如果线上做的多,往线下也做点这块。
本地竞价就不说了,线下要找人找钱给钱。线上竞价本地竞价收费低于上游阿里巴巴去外地买他们的代理。但是自己认为这是白帽的最强战力。 查看全部
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等
自动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。手动采集网站内容上传百度推广,黑帽seo,灰帽站长等。
不如用免费工具,自动采集,从yahoo,google之类的外国网站上下载重定向内容或者原创内容,一般是用于竞价,seo方面内容少.原创的太难标记出处了.
题主的意思应该是,手工获取一些外部链接,然后做竞价。这个具体的看你的资金、预算和时间了。
黑帽seo,
百度搜索引擎,主要是收录外部链接,数据定位,还有有时候下架一些不符合搜索引擎要求的内容。
资金充足的话就自己搭建个搜索引擎你想seo找个不收费的人吧一般这个人自己做一般是代维护公司就自己解决需求
可以做站群,不需要做优化的站群,然后往外部通过付费的办法,让更多的站点往平台(各大平台都有付费的,)付费,这样上去后,平台(比如搜狗)就是你的付费站点了,通过这个链接,进来的广告费都在你的平台(搜狗搜索引擎也是一样,手机游戏也是一样),搜索引擎也收益了。多点曝光肯定是好的。
黑帽seo,一般站群用的多。
那我举例子吧,我们公司也需要上百度竞价,这块钱一个月xw那就没下限了。黑帽seo,分本地竞价和线上竞价,线上竞价一般都是做代理,本地竞价自己也要做,不过不需要买域名,线上竞价花时间少花钱也多也要花时间少花钱,做站倒不是特别需要,但是付款后域名就没有想象中的那么贵。白帽seo的话,看他线上线下做过那些,如果线上做的多,往线下也做点这块。
本地竞价就不说了,线下要找人找钱给钱。线上竞价本地竞价收费低于上游阿里巴巴去外地买他们的代理。但是自己认为这是白帽的最强战力。
自动采集网站内容获取网站源代码,大体你要考虑的两点问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-21 23:01
自动采集网站内容,获取网站源代码,然后不停的更新文章,推广可以用新浪博客和百度百家,他们有平台扶持!想搞流量也可以找个差不多流量的平台写个软文发出去,
大体你要考虑的两点问题1,对于你要采集的内容的特性,然后准备一个相应的地址,这样被采集的风险小一些2,对于你采集的内容的分享效果,因为现在自媒体平台也是挺多的,你所采集的内容如果有推荐,或者阅读量高,点赞多,那自然有利可图。这也是一个考虑问题的方向。
精准定位,不要对内容下定义。准确对准用户群体,前期积累账号权重。但可否转换成软文,转载率,
如果你想在网上赚钱,那么你要比别人更有价值,不管是文章也好,视频也好,音频也好,每天坚持更新,如果是建立数据库,那么你要准备一定的数据,然后去推广自己的数据库,一篇文章分享精准的让别人过来阅读,视频分享更是要精准的找到目标用户,内容要精准,质量要高,点赞一定要多,主要可以分享到百度上,百度会分析文章的内容标题以及文章的受众群体,像分享到其他自媒体平台推广的时候就可以根据自己的用户人群分析的结果进行不断的精准更新,引导用户的点赞与评论,这样就可以使文章更有吸引力,实现真正的价值。 查看全部
自动采集网站内容获取网站源代码,大体你要考虑的两点问题
自动采集网站内容,获取网站源代码,然后不停的更新文章,推广可以用新浪博客和百度百家,他们有平台扶持!想搞流量也可以找个差不多流量的平台写个软文发出去,
大体你要考虑的两点问题1,对于你要采集的内容的特性,然后准备一个相应的地址,这样被采集的风险小一些2,对于你采集的内容的分享效果,因为现在自媒体平台也是挺多的,你所采集的内容如果有推荐,或者阅读量高,点赞多,那自然有利可图。这也是一个考虑问题的方向。
精准定位,不要对内容下定义。准确对准用户群体,前期积累账号权重。但可否转换成软文,转载率,
如果你想在网上赚钱,那么你要比别人更有价值,不管是文章也好,视频也好,音频也好,每天坚持更新,如果是建立数据库,那么你要准备一定的数据,然后去推广自己的数据库,一篇文章分享精准的让别人过来阅读,视频分享更是要精准的找到目标用户,内容要精准,质量要高,点赞一定要多,主要可以分享到百度上,百度会分析文章的内容标题以及文章的受众群体,像分享到其他自媒体平台推广的时候就可以根据自己的用户人群分析的结果进行不断的精准更新,引导用户的点赞与评论,这样就可以使文章更有吸引力,实现真正的价值。
自动采集网站内容-你得找到靠谱的程序和人力
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-09 04:01
自动采集网站内容-是比较困难的,当然,你得找到靠谱的程序和人力,如果找到靠谱的程序,还需要一定的技术。如果是采集文字,最好不要用rtfm格式的字符编码,可以使用.txt格式的字符编码,
百度文库?文库内容都是有版权的,是付费检索可以通过yicat,
内容都是有版权的。不要上图片直接复制就行。
百度文库api接口是可以采集图片的,除此之外还可以提取文章标题、关键词、描述和摘要,以及分类里面的内容都是可以采集下来的,
百度文库接口都有版权要求,也就是说你直接复制图片的话是违法的,图片的版权没有保障。如果图片有版权或者一些复杂图片的话,你还需要一些特殊的处理方法,不然百度识别出来后会收回的。
我刚做完前面的论文。从要采集的文章中选出采集不到的短句,单独打包放进excel里面,使用分词库转化成词向量,然后构建单向连接就可以了。这样提取了原始文章里面的文章标题,摘要,描述等。
我是用的python写了scrapy框架,配合word2vec库,对文章进行全文提取。
想采集的话,既可以通过爬虫工具,这类爬虫工具现在已经比较多,是不是要避免人为添加限制,应该是根据文章来决定的。 查看全部
自动采集网站内容-你得找到靠谱的程序和人力
自动采集网站内容-是比较困难的,当然,你得找到靠谱的程序和人力,如果找到靠谱的程序,还需要一定的技术。如果是采集文字,最好不要用rtfm格式的字符编码,可以使用.txt格式的字符编码,
百度文库?文库内容都是有版权的,是付费检索可以通过yicat,
内容都是有版权的。不要上图片直接复制就行。
百度文库api接口是可以采集图片的,除此之外还可以提取文章标题、关键词、描述和摘要,以及分类里面的内容都是可以采集下来的,
百度文库接口都有版权要求,也就是说你直接复制图片的话是违法的,图片的版权没有保障。如果图片有版权或者一些复杂图片的话,你还需要一些特殊的处理方法,不然百度识别出来后会收回的。
我刚做完前面的论文。从要采集的文章中选出采集不到的短句,单独打包放进excel里面,使用分词库转化成词向量,然后构建单向连接就可以了。这样提取了原始文章里面的文章标题,摘要,描述等。
我是用的python写了scrapy框架,配合word2vec库,对文章进行全文提取。
想采集的话,既可以通过爬虫工具,这类爬虫工具现在已经比较多,是不是要避免人为添加限制,应该是根据文章来决定的。
网页,的几种类型划分及方法对比方法及技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-06-04 22:26
1.网页类型划分 从文本数据抓取的角度,可以对网页进行划分。不同类型的网页可以使用不同的数据获取方式。如下图所示: 如果可以分析一些有效网址及相关参数的规律,就可以通过手动编写代码来模拟网址及相关参数的生成,从而得到所需的有效数据。另一种方式是使用一些脚本解释引擎[1,2],动态地使用一些脚本解释执行引擎为我们生成脚本执行结果。首先,我们必须手动确定发送ajax请求的入口函数,然后让脚本解释引擎解释并执行这个函数,向服务器发送一个异步请求,最后自动捕获ajax请求回调函数的输出结果。目前比较好的js脚本解释执行引擎有GogoleV8、MozillaSpiderMonkey和Rhino[2-4]。另一种方法是使用浏览器客户端方法[5-7]。通过浏览器的自动运行发送异步ajax请求,然后采用一定的延时机制等待返回的ajax数据。当数据到达时,可以通过调用浏览器的内核 API 来获取数据。这三种方式在一定程度上都可以实现基于ajax数据的请求,但是各有优缺点。具体对比如下表: 表1 不同方法速度通用性对比 使用脚本解释引擎直接模拟最快和最弱的Ajax请求Faster than strong。使用浏览器客户端缓慢而强大。 b) 非ajax 脚本网页的数据采集non-ajax 脚本网页通常用javascript 包裹有效数据。
虽然不需要像分析ajax网页那样模拟ajax请求,但还是需要动态处理网页中的javascript。此类网页典型的有:口碑、评论网页、论坛网页、网上商城商品信息页、首页商品介绍页、地图导航服务网页等。对于此类网页,一般取决于有效数据包的范围。如果包很简单,比如,就是下面这种方式: document.write("valid data");然后,只需使用正则表达式来提取它。如果脚本把数据包裹得严严实实,那么要想得到有效的数据,就需要动态地解释和执行java脚本。这个过程类似于Ajax网页数据采集,还要借助脚本解释引擎和浏览器客户端。但不同的是不需要模拟发送ajax请求,也不再有等待或拦截服务器返回有效数据的过程。 c) 需要验证的网页数据采集网站有很多数据要求必须登录,如论坛、微博、邮箱、个人主页、个人博客等,采用直接下载方式,往往只能获取到请求失败的页面。这种网站网页访问机制如图2所示:如果请求中不收录合法登录信息,网站服务器会返回访问失败的提示页面。合法登录信息一般封装在一个cookie中。向网站发送请求时,需要附上登录后的cookie信息。那么如何获取收录身份信息的cookie呢?当访问者登录网站并输入用户名和密码时,网站将自动返回浏览器。
所以,你可以通过安装一些浏览器插件直接看到这个cookie。当然,也可以通过程序自动获取。获取到 Cookie 后,需要将 Cookie 添加到 Http 请求中。如图1所示,网页分类系统一般可以分为表面数据网页(SufaceWebPage)和深层数据网页(DeepWebPage)。所谓表面数据网页,是指通过解析网页的HTML代码,可以直接获取到你想要抓取的数据。深度数据网页是指那些不能直接下载的网页。对于深度数据网页,分为ajax网页、基于脚本的网页和需要验证的网页。 Ajax网页是指在网页代码中使用ajax技术向服务器动态发送异步请求,然后动态加载数据的网页。基于脚本的网页是指数据隐藏在javascript中的网页,需要对javascript进行解析才能得到有效数据。需要验证的网页是指通过登录界面进入的网页,如微博、邮箱、社交网站等网页。 2.不同类型的网页数据采集Method 表面网页数据最容易获取,在搜索引擎中也是如此 查看全部
网页,的几种类型划分及方法对比方法及技巧
1.网页类型划分 从文本数据抓取的角度,可以对网页进行划分。不同类型的网页可以使用不同的数据获取方式。如下图所示: 如果可以分析一些有效网址及相关参数的规律,就可以通过手动编写代码来模拟网址及相关参数的生成,从而得到所需的有效数据。另一种方式是使用一些脚本解释引擎[1,2],动态地使用一些脚本解释执行引擎为我们生成脚本执行结果。首先,我们必须手动确定发送ajax请求的入口函数,然后让脚本解释引擎解释并执行这个函数,向服务器发送一个异步请求,最后自动捕获ajax请求回调函数的输出结果。目前比较好的js脚本解释执行引擎有GogoleV8、MozillaSpiderMonkey和Rhino[2-4]。另一种方法是使用浏览器客户端方法[5-7]。通过浏览器的自动运行发送异步ajax请求,然后采用一定的延时机制等待返回的ajax数据。当数据到达时,可以通过调用浏览器的内核 API 来获取数据。这三种方式在一定程度上都可以实现基于ajax数据的请求,但是各有优缺点。具体对比如下表: 表1 不同方法速度通用性对比 使用脚本解释引擎直接模拟最快和最弱的Ajax请求Faster than strong。使用浏览器客户端缓慢而强大。 b) 非ajax 脚本网页的数据采集non-ajax 脚本网页通常用javascript 包裹有效数据。
虽然不需要像分析ajax网页那样模拟ajax请求,但还是需要动态处理网页中的javascript。此类网页典型的有:口碑、评论网页、论坛网页、网上商城商品信息页、首页商品介绍页、地图导航服务网页等。对于此类网页,一般取决于有效数据包的范围。如果包很简单,比如,就是下面这种方式: document.write("valid data");然后,只需使用正则表达式来提取它。如果脚本把数据包裹得严严实实,那么要想得到有效的数据,就需要动态地解释和执行java脚本。这个过程类似于Ajax网页数据采集,还要借助脚本解释引擎和浏览器客户端。但不同的是不需要模拟发送ajax请求,也不再有等待或拦截服务器返回有效数据的过程。 c) 需要验证的网页数据采集网站有很多数据要求必须登录,如论坛、微博、邮箱、个人主页、个人博客等,采用直接下载方式,往往只能获取到请求失败的页面。这种网站网页访问机制如图2所示:如果请求中不收录合法登录信息,网站服务器会返回访问失败的提示页面。合法登录信息一般封装在一个cookie中。向网站发送请求时,需要附上登录后的cookie信息。那么如何获取收录身份信息的cookie呢?当访问者登录网站并输入用户名和密码时,网站将自动返回浏览器。
所以,你可以通过安装一些浏览器插件直接看到这个cookie。当然,也可以通过程序自动获取。获取到 Cookie 后,需要将 Cookie 添加到 Http 请求中。如图1所示,网页分类系统一般可以分为表面数据网页(SufaceWebPage)和深层数据网页(DeepWebPage)。所谓表面数据网页,是指通过解析网页的HTML代码,可以直接获取到你想要抓取的数据。深度数据网页是指那些不能直接下载的网页。对于深度数据网页,分为ajax网页、基于脚本的网页和需要验证的网页。 Ajax网页是指在网页代码中使用ajax技术向服务器动态发送异步请求,然后动态加载数据的网页。基于脚本的网页是指数据隐藏在javascript中的网页,需要对javascript进行解析才能得到有效数据。需要验证的网页是指通过登录界面进入的网页,如微博、邮箱、社交网站等网页。 2.不同类型的网页数据采集Method 表面网页数据最容易获取,在搜索引擎中也是如此
自动采集网站内容的网站,遇到这样的情况应该怎么办
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-05-31 05:02
自动采集网站内容的网站,而且自动采集会根据用户喜好推荐关键词,关键词会随着用户的兴趣,首页的内容会不断变化。你想要的只是我们能有自动采集的功能的话,我可以给你提供专门的业务,具体的话私聊我,
找一些什么精灵采集器之类的小软件。专门采集网站内容的。需要下载登录注册帐号。操作很简单。直接用后台操作。
如果楼主只是想采取网站的图片,文字,图片等资源而没有其他操作的需求可以试试这个方法很多人对蜘蛛爬虫并不了解,目前主流的爬虫就是抓取网站的js,css等资源。这些资源都是存在js文件中的,通过js文件,可以获取相应的数据。一般常见的爬虫软件,如速采网,百度采集星星,都可以爬取这些资源。对于完全没有数据需求的朋友,可以尝试一下,因为我本人使用的是网页浏览器右键有个高级访问,可以看到这些爬虫的数据的来源,除了自己爬取外,还可以给网站的编辑们爬取,使用起来还算方便。
相当于找个中间人直接跳转不通过网站的
遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?很多时候我们的网站会被别人抓取,被一些电商平台转载。这种抓取让我们感觉非常的不舒服,尤其是一些有网络的人,抓取的时候,给的特别大。一般,通过搜索引擎找到被抓取的文章,也是很大,因为也是通过搜索引擎,才能看得到。
直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。那么,这样的情况,我们该怎么办呢?比如,我们使用一些已经过的访问地址,如:商铺导航是44.58.123.123,百度搜索是45.110.35.283,等等,可以让我们自己的网站看到一个。
同时我们在搜索引擎使用js,蜘蛛也爬不出来。那么,你如果要怎么办呢?你可以去找个中间人,那么这个中间人,就是我们,有图片的文章,可以去百度,之类的站点去爬取;在电商类的网站爬取,如果带着字图片等信息,可以去,京东之类的网站爬取。通过爬取,我们可以让别人看到我们的网站,又可以让自己的网站不被别人爬取,这个方法是非常好的。
如果,你觉得通过这种方法,已经不能满足我们的要求了,你可以通过蜘蛛爬虫来抓取网站,中间人看着太厉害,一个访问地址就可以看到源代码,这个简直让人生无可恋,我们可以用插件去实现。至于图片导航等其他地方的图片,我们可以采集到一个隐藏的文件中,很多人搜一下。 查看全部
自动采集网站内容的网站,遇到这样的情况应该怎么办
自动采集网站内容的网站,而且自动采集会根据用户喜好推荐关键词,关键词会随着用户的兴趣,首页的内容会不断变化。你想要的只是我们能有自动采集的功能的话,我可以给你提供专门的业务,具体的话私聊我,
找一些什么精灵采集器之类的小软件。专门采集网站内容的。需要下载登录注册帐号。操作很简单。直接用后台操作。
如果楼主只是想采取网站的图片,文字,图片等资源而没有其他操作的需求可以试试这个方法很多人对蜘蛛爬虫并不了解,目前主流的爬虫就是抓取网站的js,css等资源。这些资源都是存在js文件中的,通过js文件,可以获取相应的数据。一般常见的爬虫软件,如速采网,百度采集星星,都可以爬取这些资源。对于完全没有数据需求的朋友,可以尝试一下,因为我本人使用的是网页浏览器右键有个高级访问,可以看到这些爬虫的数据的来源,除了自己爬取外,还可以给网站的编辑们爬取,使用起来还算方便。
相当于找个中间人直接跳转不通过网站的
遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?遇到这样的情况应该怎么办呢?很多时候我们的网站会被别人抓取,被一些电商平台转载。这种抓取让我们感觉非常的不舒服,尤其是一些有网络的人,抓取的时候,给的特别大。一般,通过搜索引擎找到被抓取的文章,也是很大,因为也是通过搜索引擎,才能看得到。
直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。直接百度搜索,搜索出来的文章,也是非常大的。那么,这样的情况,我们该怎么办呢?比如,我们使用一些已经过的访问地址,如:商铺导航是44.58.123.123,百度搜索是45.110.35.283,等等,可以让我们自己的网站看到一个。
同时我们在搜索引擎使用js,蜘蛛也爬不出来。那么,你如果要怎么办呢?你可以去找个中间人,那么这个中间人,就是我们,有图片的文章,可以去百度,之类的站点去爬取;在电商类的网站爬取,如果带着字图片等信息,可以去,京东之类的网站爬取。通过爬取,我们可以让别人看到我们的网站,又可以让自己的网站不被别人爬取,这个方法是非常好的。
如果,你觉得通过这种方法,已经不能满足我们的要求了,你可以通过蜘蛛爬虫来抓取网站,中间人看着太厉害,一个访问地址就可以看到源代码,这个简直让人生无可恋,我们可以用插件去实现。至于图片导航等其他地方的图片,我们可以采集到一个隐藏的文件中,很多人搜一下。
小帮软件机器人为我们科研人员解决了手动收集数据难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-05-27 04:09
我是一所大学信息学院的老师,我的研究领域是生物技术。正常科学研究需要采集国外论文和实验数据。实际上,在整个科学研究过程中,最耗时的环节是文献和实验数据采集,约占总时间的1/3。
通常,我需要在这些网站中采集论文和实验数据。
论文数据库:Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库:NCBI,EMBL,ICPSR等。
为什么要花这么长时间采集论文,文献和实验数据?
因为采集过程是很多重复的机械工作。
很长时间以来,我一直在反复进行机械采集工作。直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人。它可以自动执行搜索,复制,粘贴,下载等操作,并在各种数据库中输出论文和实验数据采集。
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务。因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤。总体而言,软件机器人的配置过程非常简单。我只花了一点时间就为不同的网站配置了6种研究数据采集工具。配置完成后,重复的采集工作全部由软件机器人完成。
现在,在下班前,我将打开小帮助,它将自动遍历我所关注的论文和实验数据的数据库,并完成自动采集和下载工作。第二天上班时,我可以直接直接从小邦采集上查看数据,这节省了很多宝贵的时间,并且不影响当天的科学研究任务。
我不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题。
今天我要分享一下,希望可以帮助同事解决采集科研数据的难题和耗时的问题。我们的宝贵时间应该投入到科学研究中。 查看全部
小帮软件机器人为我们科研人员解决了手动收集数据难题
我是一所大学信息学院的老师,我的研究领域是生物技术。正常科学研究需要采集国外论文和实验数据。实际上,在整个科学研究过程中,最耗时的环节是文献和实验数据采集,约占总时间的1/3。
通常,我需要在这些网站中采集论文和实验数据。
论文数据库:Wiley InterScience,EBSCO ASP,Blackwell,Springer等;
研究数据库:NCBI,EMBL,ICPSR等。
为什么要花这么长时间采集论文,文献和实验数据?
因为采集过程是很多重复的机械工作。
很长时间以来,我一直在反复进行机械采集工作。直到一天,研究室的一位同事向我推荐了一个名为“小帮”的软件机器人。它可以自动执行搜索,复制,粘贴,下载等操作,并在各种数据库中输出论文和实验数据采集。
软件机器人通过模拟各种软件的手动操作来自动执行这些重复性任务。因此,为了使我的工作流程自动化,我需要告诉我工作流程的步骤。总体而言,软件机器人的配置过程非常简单。我只花了一点时间就为不同的网站配置了6种研究数据采集工具。配置完成后,重复的采集工作全部由软件机器人完成。
现在,在下班前,我将打开小帮助,它将自动遍历我所关注的论文和实验数据的数据库,并完成自动采集和下载工作。第二天上班时,我可以直接直接从小邦采集上查看数据,这节省了很多宝贵的时间,并且不影响当天的科学研究任务。
我不得不说,小帮软件机器人解决了为研究人员手动采集数据的问题。
今天我要分享一下,希望可以帮助同事解决采集科研数据的难题和耗时的问题。我们的宝贵时间应该投入到科学研究中。
自动采集网站内容的软件是可以用的,除非真的那么重要
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-05-15 22:53
自动采集网站内容的软件是可以用的,我测试过,比如金山卫士自动采集,百度文库自动采集,百度新闻,这些都是可以用的,如果想要了解测试软件效果,可以在公众号:快软帮,免费领取下,这些测试软件是免费下载的。
现在有很多可以网页采集的软件或者工具,比如云采集就是用的一个好工具,就是这个,我们上课经常做演示用。我现在就在用。这个算是一个电脑的采集工具吧。上课用的,
这个怎么能统计出来如果是ip的话基本上是通过防火墙过滤才能保证账号和密码的安全,如果是手机号的话,是可以识别出来的,比如登录时直接被记录,你可以以某些特征,手段获取到手机号码和你们团队所有人的ip和手机号对应关系。不可否认这个极大方便了团队自动采集等工作。但是实际上所有团队基本上都是购买企业级的软件来完成效率采集任务。一般来说,企业级的开发的软件都是定制的,所有团队可以找到自己相同的客户群体,会形成一个统一的渠道。
只能说有一定的效果!这个都是伪需求!自动采集和人工采集的效率差别不大!除非真的有什么软件做到你们企业需要的专业功能和深度!可以考虑做私有化部署!个人觉得没必要!除非真的那么重要!
我一直用的是武汉一带一路的10000个采集体验, 查看全部
自动采集网站内容的软件是可以用的,除非真的那么重要
自动采集网站内容的软件是可以用的,我测试过,比如金山卫士自动采集,百度文库自动采集,百度新闻,这些都是可以用的,如果想要了解测试软件效果,可以在公众号:快软帮,免费领取下,这些测试软件是免费下载的。
现在有很多可以网页采集的软件或者工具,比如云采集就是用的一个好工具,就是这个,我们上课经常做演示用。我现在就在用。这个算是一个电脑的采集工具吧。上课用的,
这个怎么能统计出来如果是ip的话基本上是通过防火墙过滤才能保证账号和密码的安全,如果是手机号的话,是可以识别出来的,比如登录时直接被记录,你可以以某些特征,手段获取到手机号码和你们团队所有人的ip和手机号对应关系。不可否认这个极大方便了团队自动采集等工作。但是实际上所有团队基本上都是购买企业级的软件来完成效率采集任务。一般来说,企业级的开发的软件都是定制的,所有团队可以找到自己相同的客户群体,会形成一个统一的渠道。
只能说有一定的效果!这个都是伪需求!自动采集和人工采集的效率差别不大!除非真的有什么软件做到你们企业需要的专业功能和深度!可以考虑做私有化部署!个人觉得没必要!除非真的那么重要!
我一直用的是武汉一带一路的10000个采集体验,
如何制作一个随网站自动同步的Excel表呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-10 07:07
有时我们需要从网站中获取一些数据。传统方法是直接复制并粘贴到Excel中。但是,由于网页结构不同,因此并非所有副本都有效。有时,即使成功,您得到的也是“失效数据”。以后一旦有更新,则必须重复上述操作。是否可以制作自动与网站同步的Excel工作表?答案是肯定的,这是Excel中的Power Query函数。
1.打开网页
下面显示的网页是中国地震台网的官方页面。每当发生地震时,它将在此处自动更新。由于我们想抓住它,因此必须首先打开此页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,单击“数据”→“获取数据”→“从其他来源”,然后粘贴要获取的URL。此时,Power Query将自动分析网页,然后在选择框中显示分析结果。以本文为例,Power Query分析两组表,单击以找到我们需要的表,然后单击“转换数据”。稍后,Power Query将自动完成导入。
创建查询并确定爬网范围
3.数据清理
导入完成后,您可以通过Power Query清理数据。所谓的“清理”只是一个预筛选过程,在这里我们可以选择所需的记录,或者删除不必要的列并对其进行排序。右按钮负责删除数据列,面板中的“保留行”用于过滤所需的记录。清洁后,单击左上角的“关闭并上传”以上传Excel。
数据“预清理”
4.格式调整
将数据上传到Excel之后,您可以继续格式化。这里的处理主要包括修改表格样式,文本大小,背景颜色,对齐方式,行高和列宽,添加标题等。用外行的话来说,这是一些美化操作,最后得到下面的表格。
美化表格
5.设置自动同步间隔
目前,表的基本知识已经完成,但是就像复制和粘贴一样,此时您所获得的仍然只是一堆“死数据”。如果希望表自动更新,则需要单击“查询工具”→“编辑”→“属性”,然后检查“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表单。
将内容设置为自动同步
注意:默认情况下,数据刷新将导致列宽改变。此时,您可以单击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框,以解决此问题。
防止更新期间损坏表格格式
写在最后
此技术非常实用,尤其是在进行一些动态报告时,可以大大减少手动提取所带来的麻烦。好的,这是我想在本期与您分享的一个小技巧,有用吗? 查看全部
如何制作一个随网站自动同步的Excel表呢?
有时我们需要从网站中获取一些数据。传统方法是直接复制并粘贴到Excel中。但是,由于网页结构不同,因此并非所有副本都有效。有时,即使成功,您得到的也是“失效数据”。以后一旦有更新,则必须重复上述操作。是否可以制作自动与网站同步的Excel工作表?答案是肯定的,这是Excel中的Power Query函数。
1.打开网页
下面显示的网页是中国地震台网的官方页面。每当发生地震时,它将在此处自动更新。由于我们想抓住它,因此必须首先打开此页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,单击“数据”→“获取数据”→“从其他来源”,然后粘贴要获取的URL。此时,Power Query将自动分析网页,然后在选择框中显示分析结果。以本文为例,Power Query分析两组表,单击以找到我们需要的表,然后单击“转换数据”。稍后,Power Query将自动完成导入。
创建查询并确定爬网范围
3.数据清理
导入完成后,您可以通过Power Query清理数据。所谓的“清理”只是一个预筛选过程,在这里我们可以选择所需的记录,或者删除不必要的列并对其进行排序。右按钮负责删除数据列,面板中的“保留行”用于过滤所需的记录。清洁后,单击左上角的“关闭并上传”以上传Excel。
数据“预清理”
4.格式调整
将数据上传到Excel之后,您可以继续格式化。这里的处理主要包括修改表格样式,文本大小,背景颜色,对齐方式,行高和列宽,添加标题等。用外行的话来说,这是一些美化操作,最后得到下面的表格。
美化表格
5.设置自动同步间隔
目前,表的基本知识已经完成,但是就像复制和粘贴一样,此时您所获得的仍然只是一堆“死数据”。如果希望表自动更新,则需要单击“查询工具”→“编辑”→“属性”,然后检查“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表单。
将内容设置为自动同步
注意:默认情况下,数据刷新将导致列宽改变。此时,您可以单击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框,以解决此问题。
防止更新期间损坏表格格式
写在最后
此技术非常实用,尤其是在进行一些动态报告时,可以大大减少手动提取所带来的麻烦。好的,这是我想在本期与您分享的一个小技巧,有用吗?
scrapy专栏爬虫书籍(中文版):自动采集网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-07 21:04
自动采集网站内容---摘要目录page1{page2{page3{page4}}每篇文章提供后续或多篇文章提供源代码,至于优秀程度,个人总结为:言之有物,言之有价,
没用自动采集的时候,我通常是按照篇数计算。用了以后,我变成了按照每篇文章大纲计算,甚至某篇讲的哪个知识点也告诉你了。举个栗子:我从标题写入一篇篇文章,然后按照标题大纲推荐给有需要的人。我从这篇算到那篇。
说实话我用过一款利用ai自动采集网站内容的工具,这个工具叫scrapy,主要是抓取全网的文章和段子。非常的强大。我不知道这个工具你用着怎么样,我是比较推荐给需要爬虫相关工作的人。或者不知道从哪里开始入手爬虫的人。
找一款好的采集器可以做到所有采集,
无需编程基础:scrapy专栏爬虫书籍(中文版):scrapy入门、python爬虫、excel数据采集器、数据录入、多线程爬虫、selenium多线程、scrapy实战动手实践
我用的是requestslib
贝叶斯
googleanalytics
采集好的网站往往没有完整的文章列表,除非你在国外。可以采集网站、关键词、网站名、公司名,然后匹配全文。可以多写写,具体看我的专栏文章。
推荐puppetto,一个集python爬虫设计、开发、部署于一体的系统级爬虫框架,它已经包含了相当多的python爬虫可能需要的功能:网页抓取、网页结构抓取、内容过滤、内容分析、网站分析、爬虫配置等。另外puppetto还提供了一个可插拔的web服务,可以基于puppetto爬虫框架进行开发。详情可见中国puppetto网站。 查看全部
scrapy专栏爬虫书籍(中文版):自动采集网站内容
自动采集网站内容---摘要目录page1{page2{page3{page4}}每篇文章提供后续或多篇文章提供源代码,至于优秀程度,个人总结为:言之有物,言之有价,
没用自动采集的时候,我通常是按照篇数计算。用了以后,我变成了按照每篇文章大纲计算,甚至某篇讲的哪个知识点也告诉你了。举个栗子:我从标题写入一篇篇文章,然后按照标题大纲推荐给有需要的人。我从这篇算到那篇。
说实话我用过一款利用ai自动采集网站内容的工具,这个工具叫scrapy,主要是抓取全网的文章和段子。非常的强大。我不知道这个工具你用着怎么样,我是比较推荐给需要爬虫相关工作的人。或者不知道从哪里开始入手爬虫的人。
找一款好的采集器可以做到所有采集,
无需编程基础:scrapy专栏爬虫书籍(中文版):scrapy入门、python爬虫、excel数据采集器、数据录入、多线程爬虫、selenium多线程、scrapy实战动手实践
我用的是requestslib
贝叶斯
googleanalytics
采集好的网站往往没有完整的文章列表,除非你在国外。可以采集网站、关键词、网站名、公司名,然后匹配全文。可以多写写,具体看我的专栏文章。
推荐puppetto,一个集python爬虫设计、开发、部署于一体的系统级爬虫框架,它已经包含了相当多的python爬虫可能需要的功能:网页抓取、网页结构抓取、内容过滤、内容分析、网站分析、爬虫配置等。另外puppetto还提供了一个可插拔的web服务,可以基于puppetto爬虫框架进行开发。详情可见中国puppetto网站。
推出面向商业网站的内容采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-05-07 00:31
最近,()
推出了面向业务的网站内容采集软件-Webcate CPS(内容解析系统),中文名称摘要
星级内容采集系统。
该软件是一种实时网站内容采集系统,用于检查Internet上的某些信息。
特定领域中所有站点的内容分析和分类(例如商品价格信息,MP3信息,招聘信息或新闻)
有理由获得该特定领域中的大部分内容。与网页提取或搜索引擎不同,该软件可以直接转到网站
点击其网页的所有内容,从网页中提取有效数据,并保持数据之间的逻辑关系,例如一对一
在线零售网站。 Stars可以对所销售的所有产品进行分类,名称,价格,产品介绍和付款人。
提取所有公式,即使产品的详细介绍和产品价格不在同一页上,摘星也可以正确地对应每个
该产品及其详细介绍。
流星内容采集系统可用于需要此字段内容的用户
提供一个全面而单一的搜索数据库。部署了“到达星级”内容采集系统的网站可以为其用户提供一个或
在几个特定领域提供独特的一站式内容检索服务,以提高站点访问的质量并吸引对该领域的兴趣
用户经常来使用它,甚至只使用选星系统在该字段中查找信息。 查看全部
推出面向商业网站的内容采集系统
最近,()
推出了面向业务的网站内容采集软件-Webcate CPS(内容解析系统),中文名称摘要
星级内容采集系统。
该软件是一种实时网站内容采集系统,用于检查Internet上的某些信息。
特定领域中所有站点的内容分析和分类(例如商品价格信息,MP3信息,招聘信息或新闻)
有理由获得该特定领域中的大部分内容。与网页提取或搜索引擎不同,该软件可以直接转到网站
点击其网页的所有内容,从网页中提取有效数据,并保持数据之间的逻辑关系,例如一对一
在线零售网站。 Stars可以对所销售的所有产品进行分类,名称,价格,产品介绍和付款人。
提取所有公式,即使产品的详细介绍和产品价格不在同一页上,摘星也可以正确地对应每个
该产品及其详细介绍。
流星内容采集系统可用于需要此字段内容的用户
提供一个全面而单一的搜索数据库。部署了“到达星级”内容采集系统的网站可以为其用户提供一个或
在几个特定领域提供独特的一站式内容检索服务,以提高站点访问的质量并吸引对该领域的兴趣
用户经常来使用它,甚至只使用选星系统在该字段中查找信息。
自定义复制去外链平台采集网站内容有两种类型?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-06 00:00
自动采集网站内容推荐人员对于采集到的网站内容可以进行一系列的内容处理,最常见的就是一些编辑器的操作。利用网站后台的帮助采集采集网站内容采集网站内容有两种类型,一是简单的文字采集,二是自定义复制去外链平台采集。简单的采集方式直接进入采集网站简单的文字采集的方式,首先需要登录你需要采集的网站,在左侧的文字采集里面,找到文字采集的功能,然后点击,在搜索框内输入自己需要采集的网站名称,点击一键采集,网站内容就会以代码的形式显示在浏览器上。
自定义复制去外链平台采集自定义复制平台采集是,网站内容的形式和简单的文字采集的方式类似,可以帮助采集者复制外部的链接,然后进行链接的内容生成和收录。使用平台的工具箱按照平台官方的工具箱,选择采集功能的方式,即可轻松地开始采集工作。采集的时候首先需要下载采集工具包,也可以选择使用已有的采集工具箱。
什么工具?会采集么?
可以看一下ahr0cdovl3dlaxhpbi5xcs5jb20vci9wa4hrdbsmhfnkmr4yy5vnosa==(二维码自动识别)里面有教程
这样的实用性网站,同样会受到关注,他的采集,的语言,有官方也有民间的。有人会同时采集互联网上多个平台的,这样就可以多个网站,一键同步采集到txt中,然后稍作处理,修改一下,或者采用自动网站更新的脚本。这样一个站收录几十个,几十个就很容易了。ahr0cdovl3dlaxhpbi5xcs5jb20vci9zybslwgzmrwkzmrwvq1oti3bs==(二维码自动识别)这个是采集公众号更新的,加速ahr0cdovl3dlaxhpbi5xcs5jb20vci9hhpmpwpm7x2rennzos1vflw==(二维码自动识别)这个是采集今日头条的。 查看全部
自定义复制去外链平台采集网站内容有两种类型?
自动采集网站内容推荐人员对于采集到的网站内容可以进行一系列的内容处理,最常见的就是一些编辑器的操作。利用网站后台的帮助采集采集网站内容采集网站内容有两种类型,一是简单的文字采集,二是自定义复制去外链平台采集。简单的采集方式直接进入采集网站简单的文字采集的方式,首先需要登录你需要采集的网站,在左侧的文字采集里面,找到文字采集的功能,然后点击,在搜索框内输入自己需要采集的网站名称,点击一键采集,网站内容就会以代码的形式显示在浏览器上。
自定义复制去外链平台采集自定义复制平台采集是,网站内容的形式和简单的文字采集的方式类似,可以帮助采集者复制外部的链接,然后进行链接的内容生成和收录。使用平台的工具箱按照平台官方的工具箱,选择采集功能的方式,即可轻松地开始采集工作。采集的时候首先需要下载采集工具包,也可以选择使用已有的采集工具箱。
什么工具?会采集么?
可以看一下ahr0cdovl3dlaxhpbi5xcs5jb20vci9wa4hrdbsmhfnkmr4yy5vnosa==(二维码自动识别)里面有教程
这样的实用性网站,同样会受到关注,他的采集,的语言,有官方也有民间的。有人会同时采集互联网上多个平台的,这样就可以多个网站,一键同步采集到txt中,然后稍作处理,修改一下,或者采用自动网站更新的脚本。这样一个站收录几十个,几十个就很容易了。ahr0cdovl3dlaxhpbi5xcs5jb20vci9zybslwgzmrwkzmrwvq1oti3bs==(二维码自动识别)这个是采集公众号更新的,加速ahr0cdovl3dlaxhpbi5xcs5jb20vci9hhpmpwpm7x2rennzos1vflw==(二维码自动识别)这个是采集今日头条的。
海洋cms怎么设置宝塔自动采集,获取链接地址的步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 779 次浏览 • 2021-05-02 04:23
海洋cms宝塔自动采集教程
海洋cms如何设置自动宝塔采集,因为很多人都在问这个问题,所以这里有本教程。尽管大洋cms提供了脚本代码,但对于初次接触海洋cms的用户来说,这是可以理解的。这并不容易。今天,我将深入详细介绍在海洋cms下使用宝塔现实采集的具体步骤。
海洋cms如何自动设置宝塔采集第一步:获取脚本代码。
【1】以下是Ocean cms官方网站提供的自动采集脚本代码。在使用之前,我们需要修改代码中的3个项目。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "
" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms如何自动设置宝塔采集第二步:修改脚本
[2]脚本中的哪3个项目应特别修改?让我为您一个一个地谈论它们。 (根据上面提供的代码内容,将其复制到记事本或其他html编辑器中进行相应的修改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这将被修改为您的“ 网站域名”和“海洋cms后端管理目录”。每个人都可以理解域名。后端管理目录对于新手来说需要更多的单词。首先,您必须能够登录到后端以了解您的后端目录。例如:如果我的后端登录地址是/ article /,则“ article”是后端管理目录,我们可以在获取管理目录后直接填写代码。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
在Ocean cms系统的背景下,此修改需要替换为我们的cookie密码。具体步骤如下。获取您自己的网站 Cookie密码并替换。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这是代码中需要修改的最后一项。默认情况下,代码中提供了两个采集链接地址。我们需要获得自己的采集链接地址并将其添加到其中。有关获取链接地址的详细信息,请参见“步骤操作”下面的屏幕截图。如果尚未添加或不知道如何添加采集,则可以参考帮助文档-海洋cms如何添加资源库采集界面
选择“背景-采集-资源库列表”,然后复制资源站右侧的“今天采集今天”,“ 采集本周”和“ 采集全部”链接地址根据您的选择,然后删除?先前的内容。 (在当天或本周在采集上移动鼠标,右键单击鼠标以复制链接以获取采集链接)
例如,这里是:
1
http://127.0.0.1/admin/admin_r ... s.php
第2步:删除“?”之前的内容复制到上一步,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这将获得最终的采集网址
海洋cms如何设置宝塔自动采集第三步:宝塔计时任务设置。
【3】直接将代码复制到Pagoda Plan Task的Shell脚本中,并按小时添加内容。具体操作步骤如下图所示。步骤⑤是将修改后的脚本复制并粘贴到脚本内容框中。
[4]摘要
通常来说,在修改了脚本中需要修改的多个项目之后,将修改后的脚本复制到宝塔采集任务的计划任务设置中。不要选择错误的任务类型。如果您对本教程不了解或有任何疑问,可以加入社区进行讨论和查询。加入社区 查看全部
海洋cms怎么设置宝塔自动采集,获取链接地址的步骤
海洋cms宝塔自动采集教程
海洋cms如何设置自动宝塔采集,因为很多人都在问这个问题,所以这里有本教程。尽管大洋cms提供了脚本代码,但对于初次接触海洋cms的用户来说,这是可以理解的。这并不容易。今天,我将深入详细介绍在海洋cms下使用宝塔现实采集的具体步骤。
海洋cms如何自动设置宝塔采集第一步:获取脚本代码。
【1】以下是Ocean cms官方网站提供的自动采集脚本代码。在使用之前,我们需要修改代码中的3个项目。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "
" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms如何自动设置宝塔采集第二步:修改脚本
[2]脚本中的哪3个项目应特别修改?让我为您一个一个地谈论它们。 (根据上面提供的代码内容,将其复制到记事本或其他html编辑器中进行相应的修改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这将被修改为您的“ 网站域名”和“海洋cms后端管理目录”。每个人都可以理解域名。后端管理目录对于新手来说需要更多的单词。首先,您必须能够登录到后端以了解您的后端目录。例如:如果我的后端登录地址是/ article /,则“ article”是后端管理目录,我们可以在获取管理目录后直接填写代码。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
在Ocean cms系统的背景下,此修改需要替换为我们的cookie密码。具体步骤如下。获取您自己的网站 Cookie密码并替换。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这是代码中需要修改的最后一项。默认情况下,代码中提供了两个采集链接地址。我们需要获得自己的采集链接地址并将其添加到其中。有关获取链接地址的详细信息,请参见“步骤操作”下面的屏幕截图。如果尚未添加或不知道如何添加采集,则可以参考帮助文档-海洋cms如何添加资源库采集界面
选择“背景-采集-资源库列表”,然后复制资源站右侧的“今天采集今天”,“ 采集本周”和“ 采集全部”链接地址根据您的选择,然后删除?先前的内容。 (在当天或本周在采集上移动鼠标,右键单击鼠标以复制链接以获取采集链接)
例如,这里是:
1
http://127.0.0.1/admin/admin_r ... s.php
第2步:删除“?”之前的内容复制到上一步,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这将获得最终的采集网址
海洋cms如何设置宝塔自动采集第三步:宝塔计时任务设置。
【3】直接将代码复制到Pagoda Plan Task的Shell脚本中,并按小时添加内容。具体操作步骤如下图所示。步骤⑤是将修改后的脚本复制并粘贴到脚本内容框中。
[4]摘要
通常来说,在修改了脚本中需要修改的多个项目之后,将修改后的脚本复制到宝塔采集任务的计划任务设置中。不要选择错误的任务类型。如果您对本教程不了解或有任何疑问,可以加入社区进行讨论和查询。加入社区

