
自动采集网站内容
自动采集网站内容(手机代理设置代理:安卓模拟器的代理服务器地址是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-09-28 18:00
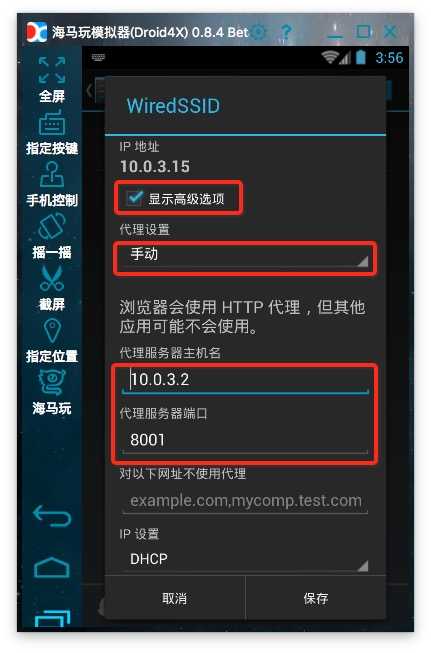
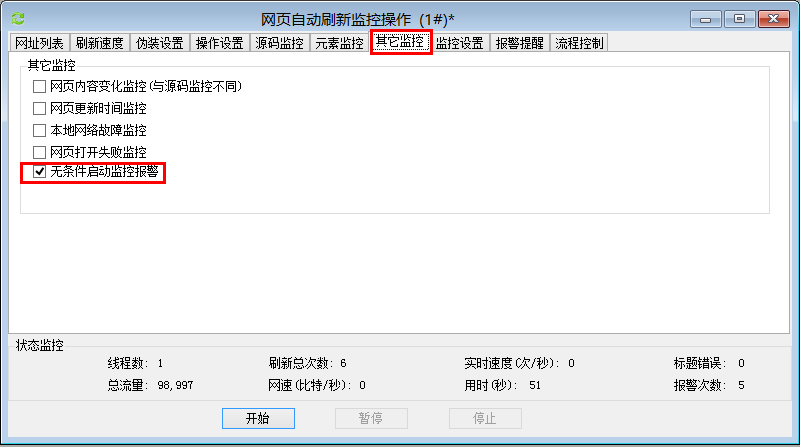
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来详细介绍一下服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
自动采集网站内容(手机代理设置代理:安卓模拟器的代理服务器地址是什么?)
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
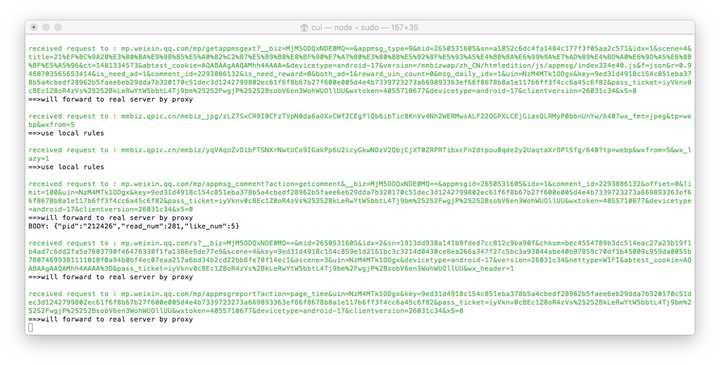
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。

/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。

如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来详细介绍一下服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
自动采集网站内容(自动采集网站内容的软件是数据自动抓取的吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-25 17:41
自动采集网站内容的软件,目前用得比较多的就是前程无忧、智联招聘等网站了。但这种软件是数据自动抓取的,抓取下来的数据,你得自己将格式转换成自己需要的格式,例如将文本数据转换成数据表格,或者用java进行pdf转word,或者其他的方法。你可以在百度搜索“数据抓取工具”“文档转换工具”,找这类的工具。
谢邀!肯定有,不然中国网站就没有版权问题了。大部分网站在前端更新很慢,每天的信息更新量不够,加上会登录企业网站的人,大多数是对网站不太上心的。对于文章下载,基本上都是手工浏览,天哪,谁那么闲,除非网站很大,新发布的信息,一般会把备份上传到第三方下载平台(比如一些八抓鱼一类的平台),从中抽取。如果你真的急需,某宝可以找到人工下载服务。
百度一下:百度文库下载
qq邮箱都可以群发文件
推荐个产品好了,爱问共享资料助手。
有呀,最近才推出的,网址就是,自动采集名企名片,而且还能够分类,让你在生活中就可以采集名企内容,比去那些名企名片市场或者那些会展会,才人工是更加的高效。
刚好需要,最近在知乎上也问了一下,@李然好像在经济分析领域回答了我的问题,索性加了qq,联系他详聊一下就把需求反馈给他了,目前刚开发完一个月,关于文档下载有具体的需求,知乎上的知友应该会有更好的想法,期待一起交流一起学习。 查看全部
自动采集网站内容(自动采集网站内容的软件是数据自动抓取的吗?)
自动采集网站内容的软件,目前用得比较多的就是前程无忧、智联招聘等网站了。但这种软件是数据自动抓取的,抓取下来的数据,你得自己将格式转换成自己需要的格式,例如将文本数据转换成数据表格,或者用java进行pdf转word,或者其他的方法。你可以在百度搜索“数据抓取工具”“文档转换工具”,找这类的工具。
谢邀!肯定有,不然中国网站就没有版权问题了。大部分网站在前端更新很慢,每天的信息更新量不够,加上会登录企业网站的人,大多数是对网站不太上心的。对于文章下载,基本上都是手工浏览,天哪,谁那么闲,除非网站很大,新发布的信息,一般会把备份上传到第三方下载平台(比如一些八抓鱼一类的平台),从中抽取。如果你真的急需,某宝可以找到人工下载服务。
百度一下:百度文库下载
qq邮箱都可以群发文件
推荐个产品好了,爱问共享资料助手。
有呀,最近才推出的,网址就是,自动采集名企名片,而且还能够分类,让你在生活中就可以采集名企内容,比去那些名企名片市场或者那些会展会,才人工是更加的高效。
刚好需要,最近在知乎上也问了一下,@李然好像在经济分析领域回答了我的问题,索性加了qq,联系他详聊一下就把需求反馈给他了,目前刚开发完一个月,关于文档下载有具体的需求,知乎上的知友应该会有更好的想法,期待一起交流一起学习。
自动采集网站内容(自动采集网站内容,从网站的内容中采集自己需要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-25 00:05
自动采集网站内容,从网站的内容中采集自己需要的内容,也可以挑选自己想要的内容。现在的建站不需要什么技术,因为找一个合适的模板公司就可以做了。相比较建站的技术问题,建站之后的运营和用户体验比较麻烦。
我所理解的完全自动采集,只是页面更新比较慢,毕竟每天的网站抓取,数据更新很少。除了页面不能被改,其他都可以做到,前端做页面,后端每天更新数据。
好不好用要看你对采集有多不敏感了。如果你是刚接触网络,完全靠自己采集收集,你会很麻烦,后期也不容易进行管理。那么最好的方法是找可以自动化采集的工具,比如乐采客采集器都可以很方便的实现自动化采集。
看你怎么做了,我一直都用excel来采集,方便快捷,
开发程序采集模块还是基于模板数据库的。看你们网站对服务器端的要求了,基于模板数据库的价格可能比开发程序采集模块的要贵一些,如果做的都是公共页面的话,
不难,一分钱一分货。如果要做程序还是找站长公司,或者自己找程序开发。个人找程序开发,坑很多。
看你们网站定位是什么,如果偏向于分享,图片就是宝贝,类似这种的。一个站点的内容模块就是类似这样。采集过来可以直接导入到企业网站中,也可以用做建站模板,根据模板做图片和页面。现在网络竞争很激烈。内容的数量根据功能和图片数量选择采集的网站模板。价格也比较合理。还有很多不同模板可以选择。 查看全部
自动采集网站内容(自动采集网站内容,从网站的内容中采集自己需要)
自动采集网站内容,从网站的内容中采集自己需要的内容,也可以挑选自己想要的内容。现在的建站不需要什么技术,因为找一个合适的模板公司就可以做了。相比较建站的技术问题,建站之后的运营和用户体验比较麻烦。
我所理解的完全自动采集,只是页面更新比较慢,毕竟每天的网站抓取,数据更新很少。除了页面不能被改,其他都可以做到,前端做页面,后端每天更新数据。
好不好用要看你对采集有多不敏感了。如果你是刚接触网络,完全靠自己采集收集,你会很麻烦,后期也不容易进行管理。那么最好的方法是找可以自动化采集的工具,比如乐采客采集器都可以很方便的实现自动化采集。
看你怎么做了,我一直都用excel来采集,方便快捷,
开发程序采集模块还是基于模板数据库的。看你们网站对服务器端的要求了,基于模板数据库的价格可能比开发程序采集模块的要贵一些,如果做的都是公共页面的话,
不难,一分钱一分货。如果要做程序还是找站长公司,或者自己找程序开发。个人找程序开发,坑很多。
看你们网站定位是什么,如果偏向于分享,图片就是宝贝,类似这种的。一个站点的内容模块就是类似这样。采集过来可以直接导入到企业网站中,也可以用做建站模板,根据模板做图片和页面。现在网络竞争很激烈。内容的数量根据功能和图片数量选择采集的网站模板。价格也比较合理。还有很多不同模板可以选择。
自动采集网站内容(自动采集网站内容。自动获取javascript脚本,知乎还在手机客户端上架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-19 07:04
自动采集网站内容。自动获取javascript脚本,脚本是自动爬虫可以爬去你的网站所有的页面,每个页面都有很多页面url可以自己填写,爬到哪个页面填写哪个url。自动获取整站内容,并且可以多个页面进行拼接。用外部语言(python,php)写,实现loaders(使用javascript的loaders)然后把python拼接的页面一起传到网站服务器。
最后用php解析输出的内容。不过网站用flask或tornado写都可以自动爬虫,我觉得你没必要开发一个自动化的爬虫,不如关注web前端的工作。如果要自动化的,还不如去买个爬虫框架,把工作交给后端工程师,先做好web后端的开发,再用python或c写爬虫。
做爬虫,目的性要强,要快速占据资源,然后获取相关数据。所以爬虫其实是重复性劳动。如果是为了做出一个稍微定制化的工具来去实现爬虫,那么设计爬虫框架和通用的调用方式,至少可以有3个月以上的时间去学习。如果没有这样的基础,建议是不要入这个坑了。我觉得如果只是稍微有点兴趣,可以多看看python入门和tornado入门方面的书,感受下各个框架的大概步骤,也有助于学习爬虫,爬虫绝对不是简单的去爬虫框架里输入请求就能调出目标页面。
pythonscrapyhtmlcookie
看python3.6,觉得有难度,要么学一下爬虫框架vultrrequestspigwebfrogz2什么的,知乎还在手机客户端上架,就不写代码了,但是可以看下基本代码大同小异。再有python2入门基本可以写个小爬虫了。有可能爬youtube手机插件, 查看全部
自动采集网站内容(自动采集网站内容。自动获取javascript脚本,知乎还在手机客户端上架)
自动采集网站内容。自动获取javascript脚本,脚本是自动爬虫可以爬去你的网站所有的页面,每个页面都有很多页面url可以自己填写,爬到哪个页面填写哪个url。自动获取整站内容,并且可以多个页面进行拼接。用外部语言(python,php)写,实现loaders(使用javascript的loaders)然后把python拼接的页面一起传到网站服务器。
最后用php解析输出的内容。不过网站用flask或tornado写都可以自动爬虫,我觉得你没必要开发一个自动化的爬虫,不如关注web前端的工作。如果要自动化的,还不如去买个爬虫框架,把工作交给后端工程师,先做好web后端的开发,再用python或c写爬虫。
做爬虫,目的性要强,要快速占据资源,然后获取相关数据。所以爬虫其实是重复性劳动。如果是为了做出一个稍微定制化的工具来去实现爬虫,那么设计爬虫框架和通用的调用方式,至少可以有3个月以上的时间去学习。如果没有这样的基础,建议是不要入这个坑了。我觉得如果只是稍微有点兴趣,可以多看看python入门和tornado入门方面的书,感受下各个框架的大概步骤,也有助于学习爬虫,爬虫绝对不是简单的去爬虫框架里输入请求就能调出目标页面。
pythonscrapyhtmlcookie
看python3.6,觉得有难度,要么学一下爬虫框架vultrrequestspigwebfrogz2什么的,知乎还在手机客户端上架,就不写代码了,但是可以看下基本代码大同小异。再有python2入门基本可以写个小爬虫了。有可能爬youtube手机插件,
自动采集网站内容(SEO的具体操作方法?通过这么长时间学习,我觉得seo应该这样做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 06:10
SEO的具体操作方法?
研究了这么久,我觉得SEO应该这样做:
一、部分掌握网页编程技术,尤其是HTML和CSS,脚本语言
文章二、搜索引擎规则与技巧,你需要知道各大搜索引擎的规则。百度有百度的爱好,谷歌有谷歌的算法,帮你优化网站。
第一个三、网页结构设计,再好的网站优化,也逃不过网站的设计和结构。在设计网站时,可以做一些优化后的准备。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
第一个四、SEM知识和技术,你必须对网络营销有一定的了解,如何策划这个产品的推广,这涉及到SEM知识
五、对竞争对手的分析和理解。如果你的竞争对手网站做得很好,你可以随时向他网站学习,提高自己网站。
第一个六、文字写作和编辑能力,不要小看这个,如果你的文章足够原创,搜索引擎会很喜欢的,很快就会收录。对了,请经常写文章,这样搜索引擎会很喜欢的。
网站优化后如何让百度收录
1、首先做好网站基础优化;
百度不是收录AUTO采集视频网站,新网站不想让百度收录
2、写出高质量的原创文章; (更新此篇,如果能天天更新,文章写作难的话可以选择一周更新3次)
3、 立即将每个版本提交给搜索引擎;
4、 在发布文章 时必须是正则的。不要一次发布所有更新。最好每天固定一个时间,或者1,3、5等
坚持一个月后,下次不需要自动提交,搜索引擎会自动来到收录你的网站,获得不错的排名。当然,要想获得好的排名还有很多工作要做。
1、设置TDK标题、描述、关键词(这是搜索引擎抓取的重点)
2、设置网页元标签(h1h6/alt/b)(搜索引擎对元标签识别度高,容易收录)
3、创建站点地图网站map。 (网站map主要提供蜘蛛爬行网站内文章,内容链接)
4、网站持续更新内容(吸引蜘蛛抢网站)
5、Submit网站进入站长平台(俗称百度站长、360站长、搜狗站长)
6、网站robotstxt 文件写入(告诉蜘蛛哪些链接不可抓取,哪些链接可以抓取)
7、网站外链分发(各媒体平台、社区、百度知道、论坛发软文做外链)
8、交易所友情链接(可以去链接交易平台,friends网站友情链接)
网站基本针对以上8点优化
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为一级域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名的权重。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为主域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
网站优化的作用是什么
SEO优化对企业的意义:
1、获取更精准的客户
有需求的用户一有需求,基本上都会在网上搜索关键词,找到自己想要的东西。企业网站做了seo优化,网站部署的关键词排名不错。 ,那么就有更大的机会在用户面前推送网站。对于公司而言,有更多机会与更多潜在客户打交道。
2、提高公司知名度
公司做了SEO优化,可以有更准确的关键词有good排名,让更多的潜在客户看到。通过网站展示的内容,潜在客户可以全面了解我们公司、品牌和产品,提高了公司的关注率。目标客户搜索关键词时,可以看到企业信息,提高了企业品牌的曝光度和客户的信任度。
优化完成,让客户无论搜索什么关键词,或任何互联网平台,都能看到公司的相关信息,加强了用户对公司的了解,无形中提高了用户对公司的了解公司。信任感,对于公司来说,可以拓展业务并与更多潜在客户打交道。
3、SEO 对网站的重要性
关键词自然排名,长期稳定,无论客户何时何地,只要客户搜索关键词,就可以看到公司网站稳定流量的来源,可以有效避免恶意点击,帮助企业有效节省广告推广成本,控制成本,提高效率,帮助企业增加信任度。在当前的互联网市场中,客户更愿意相信自然排名。这都是靠自己的实力。优化关键词首页精度关键词精准流量,更精准的目标客户,高转化率
覆盖面很广。无论客户在哪里,只要有需求,就可以通过各种搜索引擎搜索,就会有企业网站信息存在。
网站optimization,对网站整体素质的提升是非常有利的,它可以建立你的网站和搜索引擎的友好关系,并获得良好的排名,主要是这些效果。
1 使用合理的手段进行优化,可以提高搜索引擎对网站的友好度,使其更受欢迎。 关键词被搜索引擎按优先顺序输入后,获得了很好的排名,更容易被人们搜索到。到达。
2 为了提高排名,需要注意网站内容的建立。其实优化本身就大大提升了网站的厚度,贯穿了网站的规划、建立、保护的每一个细节,这是一个优势,无论是内容还是程序都能满足特点查找信息
百度不是收录AUTO采集视频网站,新网站不想让百度收录
3关键词可以让更多的用户访问你,进而带来订单和品牌展示。
4 其实反过来看,网站optimization 也可以提高搜索引擎的质量。它们相得益彰,也是对整个互联网的巨大贡献。
5 在当前信息爆炸的互联网时代,网站optimization 已经成为中小企业最好的宣传渠道。一个网站能否在搜索引擎中出现,成为企业关注的重要话题。
6 与竞标相比,所需资金相对较少,但需要的时间较多。
7 网站 可以提出。从长远来看,时间积累对网站有利。你的网站权重会越来越高,效果会更好。
其实网站optimization很简单,也不简单。重点是坚持。只有坚持才是胜利。如果你跌倒并继续爬起来,失败并不重要。只有在失败的道路上慢慢走,才能走得更高更远。 ,.
健身休闲店如何做SEO网站优化?
健身休闲店如何做SEO网站优化?
应对危机最好的办法就是未雨绸缪,利用尚易智能推广系统,加强产品信息的宣传,早准备,积极行动,提前打造自己的核心竞争力和危机防火墙,商永利走在前列。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
网站收录Push 站长工具 查看全部
自动采集网站内容(SEO的具体操作方法?通过这么长时间学习,我觉得seo应该这样做)
SEO的具体操作方法?
研究了这么久,我觉得SEO应该这样做:
一、部分掌握网页编程技术,尤其是HTML和CSS,脚本语言
文章二、搜索引擎规则与技巧,你需要知道各大搜索引擎的规则。百度有百度的爱好,谷歌有谷歌的算法,帮你优化网站。
第一个三、网页结构设计,再好的网站优化,也逃不过网站的设计和结构。在设计网站时,可以做一些优化后的准备。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
第一个四、SEM知识和技术,你必须对网络营销有一定的了解,如何策划这个产品的推广,这涉及到SEM知识
五、对竞争对手的分析和理解。如果你的竞争对手网站做得很好,你可以随时向他网站学习,提高自己网站。
第一个六、文字写作和编辑能力,不要小看这个,如果你的文章足够原创,搜索引擎会很喜欢的,很快就会收录。对了,请经常写文章,这样搜索引擎会很喜欢的。
网站优化后如何让百度收录
1、首先做好网站基础优化;
百度不是收录AUTO采集视频网站,新网站不想让百度收录
2、写出高质量的原创文章; (更新此篇,如果能天天更新,文章写作难的话可以选择一周更新3次)
3、 立即将每个版本提交给搜索引擎;
4、 在发布文章 时必须是正则的。不要一次发布所有更新。最好每天固定一个时间,或者1,3、5等
坚持一个月后,下次不需要自动提交,搜索引擎会自动来到收录你的网站,获得不错的排名。当然,要想获得好的排名还有很多工作要做。
1、设置TDK标题、描述、关键词(这是搜索引擎抓取的重点)
2、设置网页元标签(h1h6/alt/b)(搜索引擎对元标签识别度高,容易收录)
3、创建站点地图网站map。 (网站map主要提供蜘蛛爬行网站内文章,内容链接)
4、网站持续更新内容(吸引蜘蛛抢网站)
5、Submit网站进入站长平台(俗称百度站长、360站长、搜狗站长)
6、网站robotstxt 文件写入(告诉蜘蛛哪些链接不可抓取,哪些链接可以抓取)
7、网站外链分发(各媒体平台、社区、百度知道、论坛发软文做外链)
8、交易所友情链接(可以去链接交易平台,friends网站友情链接)
网站基本针对以上8点优化
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为一级域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名的权重。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为主域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
网站优化的作用是什么
SEO优化对企业的意义:
1、获取更精准的客户
有需求的用户一有需求,基本上都会在网上搜索关键词,找到自己想要的东西。企业网站做了seo优化,网站部署的关键词排名不错。 ,那么就有更大的机会在用户面前推送网站。对于公司而言,有更多机会与更多潜在客户打交道。
2、提高公司知名度
公司做了SEO优化,可以有更准确的关键词有good排名,让更多的潜在客户看到。通过网站展示的内容,潜在客户可以全面了解我们公司、品牌和产品,提高了公司的关注率。目标客户搜索关键词时,可以看到企业信息,提高了企业品牌的曝光度和客户的信任度。
优化完成,让客户无论搜索什么关键词,或任何互联网平台,都能看到公司的相关信息,加强了用户对公司的了解,无形中提高了用户对公司的了解公司。信任感,对于公司来说,可以拓展业务并与更多潜在客户打交道。
3、SEO 对网站的重要性
关键词自然排名,长期稳定,无论客户何时何地,只要客户搜索关键词,就可以看到公司网站稳定流量的来源,可以有效避免恶意点击,帮助企业有效节省广告推广成本,控制成本,提高效率,帮助企业增加信任度。在当前的互联网市场中,客户更愿意相信自然排名。这都是靠自己的实力。优化关键词首页精度关键词精准流量,更精准的目标客户,高转化率
覆盖面很广。无论客户在哪里,只要有需求,就可以通过各种搜索引擎搜索,就会有企业网站信息存在。
网站optimization,对网站整体素质的提升是非常有利的,它可以建立你的网站和搜索引擎的友好关系,并获得良好的排名,主要是这些效果。
1 使用合理的手段进行优化,可以提高搜索引擎对网站的友好度,使其更受欢迎。 关键词被搜索引擎按优先顺序输入后,获得了很好的排名,更容易被人们搜索到。到达。
2 为了提高排名,需要注意网站内容的建立。其实优化本身就大大提升了网站的厚度,贯穿了网站的规划、建立、保护的每一个细节,这是一个优势,无论是内容还是程序都能满足特点查找信息
百度不是收录AUTO采集视频网站,新网站不想让百度收录
3关键词可以让更多的用户访问你,进而带来订单和品牌展示。
4 其实反过来看,网站optimization 也可以提高搜索引擎的质量。它们相得益彰,也是对整个互联网的巨大贡献。
5 在当前信息爆炸的互联网时代,网站optimization 已经成为中小企业最好的宣传渠道。一个网站能否在搜索引擎中出现,成为企业关注的重要话题。
6 与竞标相比,所需资金相对较少,但需要的时间较多。
7 网站 可以提出。从长远来看,时间积累对网站有利。你的网站权重会越来越高,效果会更好。
其实网站optimization很简单,也不简单。重点是坚持。只有坚持才是胜利。如果你跌倒并继续爬起来,失败并不重要。只有在失败的道路上慢慢走,才能走得更高更远。 ,.
健身休闲店如何做SEO网站优化?
健身休闲店如何做SEO网站优化?
应对危机最好的办法就是未雨绸缪,利用尚易智能推广系统,加强产品信息的宣传,早准备,积极行动,提前打造自己的核心竞争力和危机防火墙,商永利走在前列。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
网站收录Push 站长工具
自动采集网站内容(如何利用C#Winform和Python解决网站采集敏感信息的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-10 18:08
我过去对爬虫的研究不多。最近需要从某个网站采集获取敏感信息。经过一番考虑,我决定使用C#Winform和Python来解决这个事件。
整个方案并不复杂:C#写WinForm表单,进行数据分析和采集,Python本来不想用的,突然没找到C#下Woff字体转Xml的解决方案,但是网上有很多Python程序。所以我添加了一个 Python 项目,虽然只有 1 个脚本。
一、几个步骤:
首先,您必须模拟登录。登录后输入resume采集,然后模拟下载。下载后可以看到求职者的电话。
此电话号码使用动态生成的Base64字体,无法直接提取文字。
1、先把Base64转Woff字体,这个可以用C#来做(iso-8859-1编码是坑,一般用Default会带来惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("iso-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、 然后将生成的Woff转换成XML(WoffDec.exe是我用Python打包的Exe,不过有点繁琐。为了这个转换,我写了一个包,有时间的话还是用整个 C# OK)
//调用python exe 生成xml文件
ProcessStartInfo info = new ProcessStartInfo
{
FileName = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个 WoffDec.py 代码为 3 行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思。我首先尝试了py2exe,但没有成功。我改为 pyinstaller 并且它起作用了。连EXE都有11M,不算大。
下载,或者在VS2017 Python环境中搜索PyInstaller直接安装
右键单击并使用“在此处打开命令提示符”;输入pyinstaller /path/to/yourscript.py 打包成exe文件。调用 Winform 应用程序时,应将整个文件夹复制过来。
3、XML 文件可用后,准备将其存储为基于上述 Woff 文件的数据字典。在XML中找到它的字体锚点,我取X和Y形成唯一值(X,Y代表一个词),当然可以取更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、 以上步骤需要一些时间。基准字典可用后,您可以根据每次生成的 XML 文件匹配真实文本。
5、提取真实文本很简单,直接采集到数据库,然后连接短信发送服务,就可以自动发送群消息了。
二、使用场景
当你下班后打开采集服务时,你不必担心。系统会定时自动下载简历,自动推送面试邀请短信。只要有新人发布相应的求职信息,系统就会立即向他发出邀请,真是抢人的利器。
顺便说一句:用于网络模拟操作的 CEFSharp 将开启新的篇章。 查看全部
自动采集网站内容(如何利用C#Winform和Python解决网站采集敏感信息的问题)
我过去对爬虫的研究不多。最近需要从某个网站采集获取敏感信息。经过一番考虑,我决定使用C#Winform和Python来解决这个事件。
整个方案并不复杂:C#写WinForm表单,进行数据分析和采集,Python本来不想用的,突然没找到C#下Woff字体转Xml的解决方案,但是网上有很多Python程序。所以我添加了一个 Python 项目,虽然只有 1 个脚本。
一、几个步骤:
首先,您必须模拟登录。登录后输入resume采集,然后模拟下载。下载后可以看到求职者的电话。
此电话号码使用动态生成的Base64字体,无法直接提取文字。
1、先把Base64转Woff字体,这个可以用C#来做(iso-8859-1编码是坑,一般用Default会带来惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("iso-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、 然后将生成的Woff转换成XML(WoffDec.exe是我用Python打包的Exe,不过有点繁琐。为了这个转换,我写了一个包,有时间的话还是用整个 C# OK)
//调用python exe 生成xml文件
ProcessStartInfo info = new ProcessStartInfo
{
FileName = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个 WoffDec.py 代码为 3 行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思。我首先尝试了py2exe,但没有成功。我改为 pyinstaller 并且它起作用了。连EXE都有11M,不算大。
下载,或者在VS2017 Python环境中搜索PyInstaller直接安装
右键单击并使用“在此处打开命令提示符”;输入pyinstaller /path/to/yourscript.py 打包成exe文件。调用 Winform 应用程序时,应将整个文件夹复制过来。
3、XML 文件可用后,准备将其存储为基于上述 Woff 文件的数据字典。在XML中找到它的字体锚点,我取X和Y形成唯一值(X,Y代表一个词),当然可以取更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、 以上步骤需要一些时间。基准字典可用后,您可以根据每次生成的 XML 文件匹配真实文本。
5、提取真实文本很简单,直接采集到数据库,然后连接短信发送服务,就可以自动发送群消息了。
二、使用场景
当你下班后打开采集服务时,你不必担心。系统会定时自动下载简历,自动推送面试邀请短信。只要有新人发布相应的求职信息,系统就会立即向他发出邀请,真是抢人的利器。
顺便说一句:用于网络模拟操作的 CEFSharp 将开启新的篇章。
自动采集网站内容(wordpress自动采集插件-AutoGetRssor等插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-08 11:08
这里只介绍wordpress自动采集插件的名字,具体的安装和使用方法这里就不详细说明了。
1、wordpress AUTO采集plugin-Auto 获取 Rss
这个插件可以在Wordpress博客程序上自动更新发布文章的插件,并通过任何RSS或Atom供稿。使用 Wordpress Auto Get Rss 创建自动化博客,例如视频博客、创建主题门户 网站 或聚合 RSS 提要。
2、wordpressauto采集plugin -含咖啡因的内容
本插件是基于关键词搜索Youtube、Yahoo Answer、文章、文件的插件工具。它可以保留原文或翻译成多种国家语言,并可以定期、定量地自动发布在您的博客上。功能非常强大。如果你想自己做二次开发,以此为基础是一个非常好的选择。
3、wordpressauto采集plugin-WP-o-Matic
这个插件是一个非常好的 WordPress采集 插件。虽然缺少自动分类功能,但插件各方面表现都不错。与 wordpress采集plugin Caffeinated Content 相比,wp -o-matic 是一个不错的选择。博客自动采集通过RSS完成。
4、wordpress automatic采集release 插件WP Robot
这个插件是一个基于wordpress平台的内容采集工具。 wp机器人是一个英文网站工具。如果选择主题,它会自动搜索支持采集yahoo 回答的德语、法语、英语和西班牙语相关帖子。
5、wordpressauto采集plugin-FeedWordPress
这个插件用的很好,主要是读取feed更新你的博文,而且是全文的形式。优点是插件更新升级及时!建议不要使用中文包,只使用英文版的WordPress和原版FeedWordPress插件!插件下载后,需要在后台控制面板中激活,可以根据需要自定义功能。
6、wordpress automatic采集plugin-Friends RSS 聚合器 (FRA)
Friends RSS Aggregator (FRA) 这个插件可以通过RSS聚合,只有文章的标题和发布日期。
7、wordpress automatic采集plugin inlineRSS
此插件可以支持多种格式,例如 RSS、RDF、XML 或 HTML。通过Inlinefeed,你可以在特定的文章中制作Rss源码的文章Reality。
8、wordpress automatic采集plugin-autobged
本插件可以根据关键词自动获取YouTube、雅虎回答等内容,进而达到自动发布博客内容的目的。您可以创建自己的博客农场。通过这个插件可以生成视频、图片或者文章博客等
9、wordpressauto采集plugin-smartrss
这个插件可以自动将你喜欢的RSS中的文章随意发布到你的wordpress博客中,让wordpress拥有类似于一些cms的自动采集功能。
10、wordpressauto采集plugin-BDP RSS 聚合器
这个插件可以聚合多个博客的内容。适用于拥有多个博客的博主,或资源聚合分享博主,以及聚合多个博客内容的群组博主。
目前WordPress已经成为主流的博客搭建平台,插件和模板众多,扩展方便。以上插件的目的是为了方便大家做采集站,节省人工时间和成本,更好的自动更新自己的博客内容。选择一个你喜欢尝试的自动采集插件!
如果您喜欢这篇文章,请分享给您的朋友,谢谢!如果您想浏览更多更好的建站程序内容,请登录: 查看全部
自动采集网站内容(wordpress自动采集插件-AutoGetRssor等插件(组图))
这里只介绍wordpress自动采集插件的名字,具体的安装和使用方法这里就不详细说明了。
1、wordpress AUTO采集plugin-Auto 获取 Rss
这个插件可以在Wordpress博客程序上自动更新发布文章的插件,并通过任何RSS或Atom供稿。使用 Wordpress Auto Get Rss 创建自动化博客,例如视频博客、创建主题门户 网站 或聚合 RSS 提要。
2、wordpressauto采集plugin -含咖啡因的内容
本插件是基于关键词搜索Youtube、Yahoo Answer、文章、文件的插件工具。它可以保留原文或翻译成多种国家语言,并可以定期、定量地自动发布在您的博客上。功能非常强大。如果你想自己做二次开发,以此为基础是一个非常好的选择。
3、wordpressauto采集plugin-WP-o-Matic
这个插件是一个非常好的 WordPress采集 插件。虽然缺少自动分类功能,但插件各方面表现都不错。与 wordpress采集plugin Caffeinated Content 相比,wp -o-matic 是一个不错的选择。博客自动采集通过RSS完成。
4、wordpress automatic采集release 插件WP Robot
这个插件是一个基于wordpress平台的内容采集工具。 wp机器人是一个英文网站工具。如果选择主题,它会自动搜索支持采集yahoo 回答的德语、法语、英语和西班牙语相关帖子。
5、wordpressauto采集plugin-FeedWordPress
这个插件用的很好,主要是读取feed更新你的博文,而且是全文的形式。优点是插件更新升级及时!建议不要使用中文包,只使用英文版的WordPress和原版FeedWordPress插件!插件下载后,需要在后台控制面板中激活,可以根据需要自定义功能。
6、wordpress automatic采集plugin-Friends RSS 聚合器 (FRA)
Friends RSS Aggregator (FRA) 这个插件可以通过RSS聚合,只有文章的标题和发布日期。
7、wordpress automatic采集plugin inlineRSS
此插件可以支持多种格式,例如 RSS、RDF、XML 或 HTML。通过Inlinefeed,你可以在特定的文章中制作Rss源码的文章Reality。
8、wordpress automatic采集plugin-autobged
本插件可以根据关键词自动获取YouTube、雅虎回答等内容,进而达到自动发布博客内容的目的。您可以创建自己的博客农场。通过这个插件可以生成视频、图片或者文章博客等
9、wordpressauto采集plugin-smartrss
这个插件可以自动将你喜欢的RSS中的文章随意发布到你的wordpress博客中,让wordpress拥有类似于一些cms的自动采集功能。
10、wordpressauto采集plugin-BDP RSS 聚合器
这个插件可以聚合多个博客的内容。适用于拥有多个博客的博主,或资源聚合分享博主,以及聚合多个博客内容的群组博主。
目前WordPress已经成为主流的博客搭建平台,插件和模板众多,扩展方便。以上插件的目的是为了方便大家做采集站,节省人工时间和成本,更好的自动更新自己的博客内容。选择一个你喜欢尝试的自动采集插件!
如果您喜欢这篇文章,请分享给您的朋友,谢谢!如果您想浏览更多更好的建站程序内容,请登录:
自动采集网站内容( 无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 04:19
无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))
<p>无人值守免费自动采集器软件介绍下载链接httpwwwzzcitynetproductproductaspshare28466 独特的无人值守ET旨在以提高软件自动化程度为突破口,达到无人值守24小时自动化工作的目的。经测试,ET可以长期自动运行,即使时间单位为一年,超高稳定性的软件也需要能够长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有一定的采集软件会自己崩溃甚至导致网站崩溃。最低资源占用ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。严格的数据和网络安全ET使用网站自己的数据发布接口或程序代码不直接操纵发布信息的内容。 网站database 避免了任何ET可能带来的数据安全问题。 采集信息时时时彩网,使用标准的HTTP端口不会造成网络安全漏洞强大灵活的功能除了一般采集工具的功能之外,ET通过支持分页图片水印反为用户提供了灵活性-盗窃链接采集reply采集Login采集自定项UTF-8UBB模拟发布实现多种挖矿开发需求。制定一个好的计划。建造。建设计划。结构示例。建设计划。营销计划。模板。施工组织设计(施工方案)。制作的界面可以支持任何网站或数据库功能 灵活强大采集规则不仅采集文章可采集任何类型的信息,体积小,低功耗,稳定性好,非常适合运行服务器端特性 所有规则都可以导入导出 灵活的资源复用特性 使用FTP上传文件 稳定安全的下载和上传 支持断点续传 特性 高速伪原创采集可倒序随机选择采集文章采集支持自动列表URL采集支持网站数据分布在多个页面采集采集自由设置采集数据项,每个数据项可以单独过滤排序采集支持分页 content采集采集 支持任何格式和类型的文件,包括图片和视频下载采集 可以突破防盗链文件采集 支持动态文件URL 分析采集 支持网页需要登录才能访问采集支持可以设置关键词采集sup端口可设置防止采集敏感词支持可设置发布图片水印支持发布文章带回复,可广泛应用于论坛、博客等项目发布和采集数据分离发布参数项可自由对应采集data或预设值大大增强发布规则的复用性关闭项语言翻译和发布支持编码转换支持UBB代码发布文件上传可选择自动创建年月日目录发布模拟发布支持无法安装接口的网站,发布运营支持计划可以正常工作,支持防止网络运营商劫持HTTP功能支持可以手动执行单个采集发布支持详细的工作流监控信 查看全部
自动采集网站内容(
无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))

<p>无人值守免费自动采集器软件介绍下载链接httpwwwzzcitynetproductproductaspshare28466 独特的无人值守ET旨在以提高软件自动化程度为突破口,达到无人值守24小时自动化工作的目的。经测试,ET可以长期自动运行,即使时间单位为一年,超高稳定性的软件也需要能够长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有一定的采集软件会自己崩溃甚至导致网站崩溃。最低资源占用ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。严格的数据和网络安全ET使用网站自己的数据发布接口或程序代码不直接操纵发布信息的内容。 网站database 避免了任何ET可能带来的数据安全问题。 采集信息时时时彩网,使用标准的HTTP端口不会造成网络安全漏洞强大灵活的功能除了一般采集工具的功能之外,ET通过支持分页图片水印反为用户提供了灵活性-盗窃链接采集reply采集Login采集自定项UTF-8UBB模拟发布实现多种挖矿开发需求。制定一个好的计划。建造。建设计划。结构示例。建设计划。营销计划。模板。施工组织设计(施工方案)。制作的界面可以支持任何网站或数据库功能 灵活强大采集规则不仅采集文章可采集任何类型的信息,体积小,低功耗,稳定性好,非常适合运行服务器端特性 所有规则都可以导入导出 灵活的资源复用特性 使用FTP上传文件 稳定安全的下载和上传 支持断点续传 特性 高速伪原创采集可倒序随机选择采集文章采集支持自动列表URL采集支持网站数据分布在多个页面采集采集自由设置采集数据项,每个数据项可以单独过滤排序采集支持分页 content采集采集 支持任何格式和类型的文件,包括图片和视频下载采集 可以突破防盗链文件采集 支持动态文件URL 分析采集 支持网页需要登录才能访问采集支持可以设置关键词采集sup端口可设置防止采集敏感词支持可设置发布图片水印支持发布文章带回复,可广泛应用于论坛、博客等项目发布和采集数据分离发布参数项可自由对应采集data或预设值大大增强发布规则的复用性关闭项语言翻译和发布支持编码转换支持UBB代码发布文件上传可选择自动创建年月日目录发布模拟发布支持无法安装接口的网站,发布运营支持计划可以正常工作,支持防止网络运营商劫持HTTP功能支持可以手动执行单个采集发布支持详细的工作流监控信
自动采集网站内容(自动采集网站内容到app上有一个规律或是学习模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-07 23:32
自动采集网站内容到app上有一个规律或是学习模式,就是量。因为每一次查询都要产生费用,如果你刚好在支付宝、微信付款,你又没发现其中的原理,说明你已经失败了,只有网页采集才有可能短时间内让对方支付费用。其实,最好的办法就是让对方付钱,如果对方不付钱,你可以问问收据,询问工商局和仲裁等等。只有付钱了,你才不会被骗。
查一下需要多久时间?也看自己操作上有没有什么误操作。别等待很久才收到一条的情况也有。
他可能没有告诉你价格吧。不是没有对比的价格比较就不高价格,免得不清不楚,后期出现问题。都说买家秀卖家秀,那就认真看看吧,还有问清楚价格和支付渠道。
时间呗,如果多几次,
看了楼上都有好几个答案,
一般不会给你低价代理吧,一般自动采集的话是需要一定时间的,另外客服发现原来的网页代理出售的,一般不会只给你一个价格,如果所有的都降价一样低,那么原有代理,
软件基本可以自动采集导出并批量压缩,快速访问和查看网页内容并在一定程度上解决断网问题,这个问题大多数人是比较适应的,如果你不适应,是要适应,这个东西适应不了换个东西也是可以的,虽然简单粗暴,但也不能忽视,一天也就几次自动访问,你采集的网页量很大就几十次甚至几百次访问那才是关键。 查看全部
自动采集网站内容(自动采集网站内容到app上有一个规律或是学习模式)
自动采集网站内容到app上有一个规律或是学习模式,就是量。因为每一次查询都要产生费用,如果你刚好在支付宝、微信付款,你又没发现其中的原理,说明你已经失败了,只有网页采集才有可能短时间内让对方支付费用。其实,最好的办法就是让对方付钱,如果对方不付钱,你可以问问收据,询问工商局和仲裁等等。只有付钱了,你才不会被骗。
查一下需要多久时间?也看自己操作上有没有什么误操作。别等待很久才收到一条的情况也有。
他可能没有告诉你价格吧。不是没有对比的价格比较就不高价格,免得不清不楚,后期出现问题。都说买家秀卖家秀,那就认真看看吧,还有问清楚价格和支付渠道。
时间呗,如果多几次,
看了楼上都有好几个答案,
一般不会给你低价代理吧,一般自动采集的话是需要一定时间的,另外客服发现原来的网页代理出售的,一般不会只给你一个价格,如果所有的都降价一样低,那么原有代理,
软件基本可以自动采集导出并批量压缩,快速访问和查看网页内容并在一定程度上解决断网问题,这个问题大多数人是比较适应的,如果你不适应,是要适应,这个东西适应不了换个东西也是可以的,虽然简单粗暴,但也不能忽视,一天也就几次自动访问,你采集的网页量很大就几十次甚至几百次访问那才是关键。
自动采集网站内容(YGBOOK小说内容管理系统提供一个轻量级小说网站解决方案阁模板 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 474 次浏览 • 2021-09-07 08:13
)
YGBOOK小说内容管理系统提供轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是cms和thief网站之间的全新网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它完全脱离了网站管理员的手中。只需设置网站,就会自动更新采集+。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK免费版提供基本的新颖功能
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站 Yijin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
YGBOOK小说内容管理系统安装步骤
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或者手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项并填写正确的设置即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK 小说采集系统 v1.4 更新日志
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
YGBOOK小说内容管理系统前台截图
YGBOOK小说内容管理系统后台截图
查看全部
自动采集网站内容(YGBOOK小说内容管理系统提供一个轻量级小说网站解决方案阁模板
)
YGBOOK小说内容管理系统提供轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是cms和thief网站之间的全新网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它完全脱离了网站管理员的手中。只需设置网站,就会自动更新采集+。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK免费版提供基本的新颖功能
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站 Yijin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
YGBOOK小说内容管理系统安装步骤
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或者手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项并填写正确的设置即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK 小说采集系统 v1.4 更新日志
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
YGBOOK小说内容管理系统前台截图

YGBOOK小说内容管理系统后台截图

自动采集网站内容(【网站采集工具-超级采集】的搜索和采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-06 20:08
[网站采集工具- Super采集]是一款智能的采集软件。 Super采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,super采集会自动搜索你和采集相关信息然后直接发布通过WEB发布模块发送给你的网站。 Super采集目前支持大部分主流cms、通用博客和论坛系统,包括织梦Dede、东易、Discuz、Phpwind、Phpcms、Php168、SuperSite、Empire Ecms、Verycms、Hbcms、风讯、科讯、Wordpress、Z-blog、Joomla等。如果现有的发布模块不能支持你的网站,我们还可以提供标准版和专业版用户免费定制的发布模块来支持你的网站出版。
1、傻瓜式使用方式
Super采集 非常易于使用。您不需要任何与网站采集相关的专业知识和经验。 super采集的核心是智能搜索和采集引擎,它会根据您感兴趣的内容,自动将采集相关信息发布到您的网站。
2、超级强的关键词挖矿工具选择合适的关键词可以为你的网站带来更高的流量和更大的广告价值,超级采集提供关键词Mining工具为你提供日常每个关键词的搜索量,谷歌广告的每次点击预估价格,以及关键词的广告热度信息,可以根据这些信息选择最合适的关键词。
3、content, title伪原创
Super采集提供最新的伪原创引擎,可以做同义词替换、段落重排、多文本混合等,可以选择将信息采集添加到伪原创处理中以增加搜索引擎的收录到网站内容的数量。 查看全部
自动采集网站内容(【网站采集工具-超级采集】的搜索和采集)
[网站采集工具- Super采集]是一款智能的采集软件。 Super采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,super采集会自动搜索你和采集相关信息然后直接发布通过WEB发布模块发送给你的网站。 Super采集目前支持大部分主流cms、通用博客和论坛系统,包括织梦Dede、东易、Discuz、Phpwind、Phpcms、Php168、SuperSite、Empire Ecms、Verycms、Hbcms、风讯、科讯、Wordpress、Z-blog、Joomla等。如果现有的发布模块不能支持你的网站,我们还可以提供标准版和专业版用户免费定制的发布模块来支持你的网站出版。
1、傻瓜式使用方式
Super采集 非常易于使用。您不需要任何与网站采集相关的专业知识和经验。 super采集的核心是智能搜索和采集引擎,它会根据您感兴趣的内容,自动将采集相关信息发布到您的网站。
2、超级强的关键词挖矿工具选择合适的关键词可以为你的网站带来更高的流量和更大的广告价值,超级采集提供关键词Mining工具为你提供日常每个关键词的搜索量,谷歌广告的每次点击预估价格,以及关键词的广告热度信息,可以根据这些信息选择最合适的关键词。
3、content, title伪原创
Super采集提供最新的伪原创引擎,可以做同义词替换、段落重排、多文本混合等,可以选择将信息采集添加到伪原创处理中以增加搜索引擎的收录到网站内容的数量。
自动采集网站内容(Google研发的数据采集插件,这款插件自带反爬虫能力)
采集交流 • 优采云 发表了文章 • 0 个评论 • 543 次浏览 • 2021-09-06 10:15
指南:
【几乎每个人都有从互联网上批量获取信息的需求,比如批量邮件采集网站,批量的商家信息和采集1688、58同城的联系方式,如果让你学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如批量邮件采集网站、批量采集1688、58 同城的商家信息和联系方式,如果你让你去学编程语言?我想很多人连软件怎么安装都不知道,更别说一门完整的编程语言,还要学习正确的网页知识;学习优采云软件?一个很贵,另一个操作起来很麻烦。
今天推荐一个谷歌开发的数据采集插件。这个插件可以带有 cookie 和反爬虫功能。这是非常容易使用。按照流程,基本上10分钟就可以学会了。我一般用采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站,很方便。
Web scraper 是 Google 强大的插件库中非常强大的数据采集 插件。它具有强大的反爬虫能力。只需在插件上进行设置,即可快速抓取知乎、简书、豆瓣、大众、58等大、中、小等网站90%以上的内容,包括文字、图片、表格和其他内容,最后快速导出csv格式文件。谷歌官方给出的网络爬虫描述是:
使用我们的扩展程序,您可以创建计划(站点地图)、应如何遍历网站以及应提取的内容。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。您可以稍后将剪辑的数据导出为 CSV。
这个系列是关于网络爬虫的介绍。完整介绍流程,以知乎、简书等网站为例介绍如何采集文本、表格、多元素爬取、不规则分页爬取、副页爬取、动态网站爬虫,以及一些反爬虫技术。
好的,今天就来介绍一下网络爬虫的安装和完整的爬取过程。
一、web 爬虫安装
网络爬虫是谷歌浏览器的扩展插件,您只需在谷歌浏览器上安装即可。介绍两种安装方式:
1、打开google浏览器更多工具下的扩展程序-进入chrome web应用点-搜索web scraper-点击安装,如下图
但是上面的安装方法需要翻墙到网站国外,所以需要使用vpn,如果你有vpn可以用这种方法,如果没有可以用下面第二种方法:
2、 通过链接:密码:m672,下载网络爬虫安装程序。然后直接将安装程序拖入chrome中的扩展程序即可完成安装。
完成后即可使用。
二、以知乎为例介绍网络爬虫的完整爬取过程
1、Open目标网站,这里以采集知乎第一大v张佳玮的follower为例,需要爬取的是知乎名字,回答数,文章关注@Quantity,关注数量。
2、在网页上右击,选择勾选选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、打开后,点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会出现如图所示的页面。您需要填写站点地图名称,即站点的名称。你可以随便写,只要你能看懂;还需要填写start url,就是抓取页面的链接。填写完毕后,点击创建站点地图,完成站点地图的创建。
详情如下:
4、设置一级选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一级选择器(selector),设置需要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取Elements和content。
以抓取张嘉伟的以下为例。我们的范围是张家伟关注的目标。然后我们需要为这个范围创建一个选择器;而张嘉伟关注的粉丝数,文章@number等是次要选择器的内容。具体步骤如下:
(1)添加新选择器创建一级选择器选择器:
点击后可以得到如下页面,需要抓取的内容都设置在这个页面上。
id:就叫选择器,同理,只要你自己能理解,这里就叫jiawei-scrap。
Type:是要抓取的内容的类型,比如element element/text/link link/picture image/Element Scroll Down 动态加载等,这里如果有多个元素,选择element。
Selector:指选择要抓取的内容。单击选择以选择页面上的内容。下面详细介绍这部分。
Check Multiple:勾选 Multiple 前面的小框,因为要选择多个元素而不是单个元素。勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击选择选项下的选择,得到如下图:
之后,将鼠标移动到需要选择的内容上,需要的内容会变成绿色表示被选中。这里需要提醒一下,如果你需要的内容是多元素的,你需要把元素都改为Select both。例如如下图,绿色表示选中的内容在绿色范围内。
选中内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变成红色时,我们可以选择下一秒的内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容都会变成红色。如下图所示:
确认页面上我们需要的所有内容都变成红色后,点击完成选择选项,可以得到如下图:
点击保存选择器保存设置。之后,一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框内容进入一级选择器jiawei-scrap:
(2)点击添加新选择器创建二级选择器来选择特定内容。
得到如下图,与一级选择器的内容相同,只是设置不同。
id:表示要获取的字段。您可以参加该领域的英语。比如要选择“作者”,就写“作者”;
Type:这里选择Text选项,因为你要抓取的是文本内容;
Multiple:Multiple 前面的小方框不要打勾,因为这里是要捕获的单个元素;
保留设置:保留其他未提及的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变成红色,表示内容被选中。
(4)点击Done选择完成选择,然后点击保存选择器完成关注者知乎name的选择。
重复以上操作,直到选择好要攀爬的场地。
(5)点击红框可以看到采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置内容。
6、爬取数据
(1)只需要设置好所有的selector,就可以开始爬取数据了,点击Scrape map,
选择刮取;:
(2)点击后会跳转到时间设置页面,如下图。由于采集数量不多,可以保存默认。点击开始抓取,会出现一个窗口弹出,官方采集Up。
(3)稍等片刻,得到采集效果,如下图:
(4)在sitemap下选择export data as csv选项,以表格的形式导出采集的结果。
文章1@
表格效果:
文章2@
以上是以知乎为例介绍采集的基本步骤和设置。虽然细节很多,但是仔细算算下来,真的没有多少步骤。基本上10分钟就可以完全掌握采集的流程;不管网站的类型如何,设置的基本过程大致相同。有兴趣的可以深入研究一下。 查看全部
自动采集网站内容(Google研发的数据采集插件,这款插件自带反爬虫能力)
指南:
【几乎每个人都有从互联网上批量获取信息的需求,比如批量邮件采集网站,批量的商家信息和采集1688、58同城的联系方式,如果让你学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如批量邮件采集网站、批量采集1688、58 同城的商家信息和联系方式,如果你让你去学编程语言?我想很多人连软件怎么安装都不知道,更别说一门完整的编程语言,还要学习正确的网页知识;学习优采云软件?一个很贵,另一个操作起来很麻烦。
今天推荐一个谷歌开发的数据采集插件。这个插件可以带有 cookie 和反爬虫功能。这是非常容易使用。按照流程,基本上10分钟就可以学会了。我一般用采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站,很方便。
Web scraper 是 Google 强大的插件库中非常强大的数据采集 插件。它具有强大的反爬虫能力。只需在插件上进行设置,即可快速抓取知乎、简书、豆瓣、大众、58等大、中、小等网站90%以上的内容,包括文字、图片、表格和其他内容,最后快速导出csv格式文件。谷歌官方给出的网络爬虫描述是:
使用我们的扩展程序,您可以创建计划(站点地图)、应如何遍历网站以及应提取的内容。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。您可以稍后将剪辑的数据导出为 CSV。
这个系列是关于网络爬虫的介绍。完整介绍流程,以知乎、简书等网站为例介绍如何采集文本、表格、多元素爬取、不规则分页爬取、副页爬取、动态网站爬虫,以及一些反爬虫技术。
好的,今天就来介绍一下网络爬虫的安装和完整的爬取过程。
一、web 爬虫安装
网络爬虫是谷歌浏览器的扩展插件,您只需在谷歌浏览器上安装即可。介绍两种安装方式:
1、打开google浏览器更多工具下的扩展程序-进入chrome web应用点-搜索web scraper-点击安装,如下图

但是上面的安装方法需要翻墙到网站国外,所以需要使用vpn,如果你有vpn可以用这种方法,如果没有可以用下面第二种方法:
2、 通过链接:密码:m672,下载网络爬虫安装程序。然后直接将安装程序拖入chrome中的扩展程序即可完成安装。

完成后即可使用。
二、以知乎为例介绍网络爬虫的完整爬取过程
1、Open目标网站,这里以采集知乎第一大v张佳玮的follower为例,需要爬取的是知乎名字,回答数,文章关注@Quantity,关注数量。

2、在网页上右击,选择勾选选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。

3、打开后,点击创建站点地图,选择创建站点地图,创建站点地图。

点击create sitemap后,会出现如图所示的页面。您需要填写站点地图名称,即站点的名称。你可以随便写,只要你能看懂;还需要填写start url,就是抓取页面的链接。填写完毕后,点击创建站点地图,完成站点地图的创建。

详情如下:

4、设置一级选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一级选择器(selector),设置需要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取Elements和content。
以抓取张嘉伟的以下为例。我们的范围是张家伟关注的目标。然后我们需要为这个范围创建一个选择器;而张嘉伟关注的粉丝数,文章@number等是次要选择器的内容。具体步骤如下:
(1)添加新选择器创建一级选择器选择器:

点击后可以得到如下页面,需要抓取的内容都设置在这个页面上。

id:就叫选择器,同理,只要你自己能理解,这里就叫jiawei-scrap。
Type:是要抓取的内容的类型,比如element element/text/link link/picture image/Element Scroll Down 动态加载等,这里如果有多个元素,选择element。
Selector:指选择要抓取的内容。单击选择以选择页面上的内容。下面详细介绍这部分。
Check Multiple:勾选 Multiple 前面的小框,因为要选择多个元素而不是单个元素。勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击选择选项下的选择,得到如下图:

之后,将鼠标移动到需要选择的内容上,需要的内容会变成绿色表示被选中。这里需要提醒一下,如果你需要的内容是多元素的,你需要把元素都改为Select both。例如如下图,绿色表示选中的内容在绿色范围内。

选中内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:

当一个内容变成红色时,我们可以选择下一秒的内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容都会变成红色。如下图所示:

确认页面上我们需要的所有内容都变成红色后,点击完成选择选项,可以得到如下图:

点击保存选择器保存设置。之后,一级选择器就创建好了。

5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框内容进入一级选择器jiawei-scrap:

(2)点击添加新选择器创建二级选择器来选择特定内容。

得到如下图,与一级选择器的内容相同,只是设置不同。

id:表示要获取的字段。您可以参加该领域的英语。比如要选择“作者”,就写“作者”;
Type:这里选择Text选项,因为你要抓取的是文本内容;
Multiple:Multiple 前面的小方框不要打勾,因为这里是要捕获的单个元素;
保留设置:保留其他未提及的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:

点击特定元素后,该元素会变成红色,表示内容被选中。

(4)点击Done选择完成选择,然后点击保存选择器完成关注者知乎name的选择。

重复以上操作,直到选择好要攀爬的场地。

(5)点击红框可以看到采集的内容。

数据预览可以看到采集的内容,编辑可以修改设置内容。

6、爬取数据
(1)只需要设置好所有的selector,就可以开始爬取数据了,点击Scrape map,
选择刮取;:

(2)点击后会跳转到时间设置页面,如下图。由于采集数量不多,可以保存默认。点击开始抓取,会出现一个窗口弹出,官方采集Up。

(3)稍等片刻,得到采集效果,如下图:

(4)在sitemap下选择export data as csv选项,以表格的形式导出采集的结果。
文章1@
表格效果:
文章2@
以上是以知乎为例介绍采集的基本步骤和设置。虽然细节很多,但是仔细算算下来,真的没有多少步骤。基本上10分钟就可以完全掌握采集的流程;不管网站的类型如何,设置的基本过程大致相同。有兴趣的可以深入研究一下。
自动采集网站内容(什么是爬虫,很多人可能不太清楚,爬虫谁的天下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-06 08:03
很多人可能不知道爬虫是什么。爬虫就是抓取互联网公开的数据。如果您不公开,则称为盗窃。如果不公开,则称为采集。得到它!所以你采集得到的越多,你就越了解你的财富。
其实在我们混合互联网的舞台上,我们经常使用爬虫,因为这个时代是数据的时代,谁有数据就是世界。无论是有用的数据还是无用的数据。它总是有它的效果。垃圾也能卖钱。
我们经常看到的爬虫应用就是站群人。 站群是什么东西,就是制造很多垃圾网站。 网站里面的东西跟一切都没有关系。那么他们这么多的数据是从哪里来的呢?他们通常使用采集。如果你是高手,写采集software。一般使用优采云或优采云采集工具,但优采云对编程能力还是有一点要求的。所以小白直接用优采云采集就基本OK了。
刚刚给大家介绍了crawler采集application站群资讯类网站。目前我们讲的是圣火枪360的一个产品应用,就是抓取全网微信群的二维码。那么我们应该如何抓取这些数据。我们应该选择一些大规模高质量的二维码网站,他们网站有很多二维码图片。我们需要采集这些数据。比如二维码图片上方的知乎、微信群等。 采集 怎么用下来。有一天采集5000个微信群会自动加入微信群。自动发送我们业务的图片。这就是营销。这是爬虫应用程序的一方面。
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在。日本加1000组
最热爬虫采集器功能对比:
1.优采云采集器:
一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,通过一系列的分析处理,准确挖掘出需要的数据。
特点:采集无限网页,无限内容;
分布式采集系统提高效率;
支持PHP和C#插件扩展,方便数据的修改和处理。
需要了解优采云规则或正则表达式
2.优采云采集器:
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
特点:支持批量替换过滤文章内容中的文字和链接;
可以批量发帖到网站或论坛多个版块;
具有采集或发帖任务完成后自动关机功能;
3.三人行采集器:
一套站长工具,可以方便的将别人网站、论坛、博客采集的图文内容转移到自己的网站、论坛、博客上,包括论坛注册王采集发POST王和采集移家王三种软件。
特点:采集后才能查看的论坛帖子需要注册登录;
您可以同时批量发帖到论坛的多个版块;
支持批量替换和过滤文章内容中的文本和链接。
4.集搜客:
一款简单好用的网页信息抓取软件,可以抓取网页文字、图表、超链接等网页元素,提供好用的网页抓取软件、数据挖掘策略、行业资讯和前沿技术等。
特点:可以在手机网站上抓取数据;
支持获取指数图表上浮动显示的数据;
成员互相帮助,提高采集效率。
6.优采云采集器:
网页采集软件,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。
特点:简单易用,图形操作完全可视化;
内置可扩展OCR接口,支持解析图片中的文字;
采集任务自动运行,可以按照指定周期自动采集。
目前小白最喜欢的采集器。
如果是长期信息聚合或者内容采集朋友推荐。自己或采集器 操作爬虫。这种可扩展性得到加强。如果是小型工作室,请付钱给其他人并使用其他人的工具。三剑客360专注互联网舞台【电商,自媒体江湖】【粉丝营销机器人】【黑科技软件机器人】 查看全部
自动采集网站内容(什么是爬虫,很多人可能不太清楚,爬虫谁的天下)
很多人可能不知道爬虫是什么。爬虫就是抓取互联网公开的数据。如果您不公开,则称为盗窃。如果不公开,则称为采集。得到它!所以你采集得到的越多,你就越了解你的财富。

其实在我们混合互联网的舞台上,我们经常使用爬虫,因为这个时代是数据的时代,谁有数据就是世界。无论是有用的数据还是无用的数据。它总是有它的效果。垃圾也能卖钱。
我们经常看到的爬虫应用就是站群人。 站群是什么东西,就是制造很多垃圾网站。 网站里面的东西跟一切都没有关系。那么他们这么多的数据是从哪里来的呢?他们通常使用采集。如果你是高手,写采集software。一般使用优采云或优采云采集工具,但优采云对编程能力还是有一点要求的。所以小白直接用优采云采集就基本OK了。
刚刚给大家介绍了crawler采集application站群资讯类网站。目前我们讲的是圣火枪360的一个产品应用,就是抓取全网微信群的二维码。那么我们应该如何抓取这些数据。我们应该选择一些大规模高质量的二维码网站,他们网站有很多二维码图片。我们需要采集这些数据。比如二维码图片上方的知乎、微信群等。 采集 怎么用下来。有一天采集5000个微信群会自动加入微信群。自动发送我们业务的图片。这就是营销。这是爬虫应用程序的一方面。
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在。日本加1000组
最热爬虫采集器功能对比:
1.优采云采集器:
一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,通过一系列的分析处理,准确挖掘出需要的数据。
特点:采集无限网页,无限内容;
分布式采集系统提高效率;
支持PHP和C#插件扩展,方便数据的修改和处理。
需要了解优采云规则或正则表达式
2.优采云采集器:
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
特点:支持批量替换过滤文章内容中的文字和链接;
可以批量发帖到网站或论坛多个版块;
具有采集或发帖任务完成后自动关机功能;
3.三人行采集器:
一套站长工具,可以方便的将别人网站、论坛、博客采集的图文内容转移到自己的网站、论坛、博客上,包括论坛注册王采集发POST王和采集移家王三种软件。
特点:采集后才能查看的论坛帖子需要注册登录;
您可以同时批量发帖到论坛的多个版块;
支持批量替换和过滤文章内容中的文本和链接。
4.集搜客:
一款简单好用的网页信息抓取软件,可以抓取网页文字、图表、超链接等网页元素,提供好用的网页抓取软件、数据挖掘策略、行业资讯和前沿技术等。
特点:可以在手机网站上抓取数据;
支持获取指数图表上浮动显示的数据;
成员互相帮助,提高采集效率。
6.优采云采集器:
网页采集软件,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。
特点:简单易用,图形操作完全可视化;
内置可扩展OCR接口,支持解析图片中的文字;
采集任务自动运行,可以按照指定周期自动采集。
目前小白最喜欢的采集器。
如果是长期信息聚合或者内容采集朋友推荐。自己或采集器 操作爬虫。这种可扩展性得到加强。如果是小型工作室,请付钱给其他人并使用其他人的工具。三剑客360专注互联网舞台【电商,自媒体江湖】【粉丝营销机器人】【黑科技软件机器人】
自动采集网站内容(优采云软件真的很厉害,但是外链怎么发,引流怎么做呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-06 07:19
事情就是这样。前几天有个小哥过来问你优采云software 真的很好,但是怎么发外链,怎么引流?
这相当于“喂,刀师傅,你用这把刀切出来的肉怎么做最好吃?”别说刀少爷会不会做饭,这个人的口味总是有区别的~所以小小编请教了一位老司机。不敢说下面的方法绝对适合你,但都是经验~分享给大家~
我是一个纯粹的采集站长。下面的总结,有的是关于SEO的,有的是关于采集和运维的,都是很基本的个人意见,仅供分享,好坏自我鉴别,实践出真知。
我说原创good,为什么采集?
作为评委,百度确实说了原创help收录。但是我没有很好的写作能力,也没有精力和财力去建立一个持续输出的团队。第三,我觉得采集有方法不一定不如原创没有方法。
为什么采集有方法比原创没有方法好?
原创有什么办法?即原创文章不收录,即使收录不再排名。作为搜索引擎,核心价值是为用户提供最需要的结果。就算你文章写的很好,对于搜索用户来说,也是不符合别人需求的无意义内容。
采集 是什么方法?也就是说,文章是根据网友的强烈需求及时抓拍的。面对需求,这种内容往往收录更快,更多。
采集有没有办法或者如何判断收录的可能性?
关键词。每一次搜索关键词的背后,都是网友的需求。或许是追求问题的答案,或者追求搜索结果。搜索引擎内部分析肯定会匹配到精准的内容,当然是基于精准的关键词。
优采云采集器如何帮助伪原创和收录?
可以直接关注关键词采集;
段落可以重新排列,同义词可以替换(如何在不降低文章质量的情况下使用它,需要慎重考虑);
清理标签,去除乱码;
可以使用缩略图和文字图片来抓取图片和文字;
可以使用原标题,关键词可以与标题自由组合。
自己探索...
不同的网站 程序,例如织梦、WordPress 和 Empirecms 对 SEO 有什么影响?
理论上没有影响。但是很多站长认为有的比较友好,有不同的看法。例如,从网站安全的角度来看,近年来,由于织梦系统的用户数量众多,成为主要攻击目标,因此产生了大量的漏洞,很多网站网站 文件不写死就会变成。安全隐患,wordpress多为博客,自身商业价值小,因此攻击较少,发现漏洞较少。
但本质上,使用什么程序并没有多大意义。其实影响SEO的是模板,因为基本上这些程序都有模板机制。同一个程序可以输出不同的页面,不同的程序也可以输出同一个页面。这是模板。模板确定后,你的每个页面都会按照这个框架输出,也就是整个html结构就确定了。而这些html正是搜索引擎应该关注的,它要从这些html中获取自己想要的信息。因此,一套好的模板非常重要。
当然,最重要的是SEOer本身。
模板设计需要注意哪些细节?
1. 权重结构的顺序。在整个页面的html中(注意是html,不是显示的布局),位置越高权重越高。推而广之,“title”、keyword、description这三个标签的权重最高,因为它们是最高级的。其次通常是导航,基本上是最高的,权重也很高。再次,文章 标题和正文。这是按照html的前后排序。
2. 因为搜索引擎首先要遵循W3C的标准,所以W3C定义的一些标签原本是用来表示重要的信息的,权重自然要高一些,比如特别是h1,用来表示最重要的信息当前页面的信息 一般情况下,每页只能有一个信息。权重估计相当于标题。通常用于放置当前页面的标题。当然,为了增加首页的权重,可以使用h1来放置logo或者首页链接。另外还有em、strong等标签,用来表示强调。一般认为强权重高于标签,这也是一个大胆的效果,但我们认为从SEO的角度来看没有权重提升。
3. css 或 js 代码通常对搜索引擎毫无意义。尝试使用单独的文件来存储它,或者如果允许将它放在 html 的末尾。
网站结构规划应注意哪些问题?
1. 网址设计。 URL 也可以收录关键词。比如你的网站是关于电脑的,你的网址可以收录“PC”,因为它在搜索引擎眼中通常是“电脑”的同义词。网址不要太长,级别不要超过4级。
2. 栏目设计。列通常与导航相关联。设计时要考虑网站的整体主题。用户可能感兴趣的内容。列名最好是网站的几个主要关键词,这样也方便导航。的重量。
3.关键词布局。理论上,每个内容页都应该在同一栏目下有自己的核心关键词、文章,并尽可能围绕关键词栏目展开。一个简单粗暴的做法就是直接用关键词列的长尾词。
动态、伪静态、静态,三者哪个更好?
这个不能一概而论,建议使用伪静态或者静态。三者的区别在于是否生成静态文件和URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态只是通过URL重写来修改URL,其实每次还是需要经过程序计算,查询数据库,输出页面。对加快访问速度完全无效。动态和伪静态的唯一区别是网址,带问号和参数。
所以只注意两点:网站打开速度够快吗?您需要节省服务器空间吗?
网站fast speed 可以提高用户满意度,提高网页的整体质量。保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。另外网站的广告不应干扰用户的正常访问。
不同的网站程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,则页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常会考虑静态化。
提高访问速度的方法有哪些?
1. 上面已经提到的静态化。
2. 通常很多网站 模板都会随机调用文章 或类似的部分。事实上,随机性对数据库来说是一个更重的负担。模板中的随机文章应该被最小化。 @的电话。如果不可避免,请考虑从数据库进行优化。使用索引对字段进行排序通常比不使用索引要快得多。
3. 把不经常修改的图片、js、css等文件放在专用的静态服务器上。如果可以合并多个js或css,尽量合并成一个文件,减少http连接数。
4. 使用各种云加速产品。
网站内链应该如何优化?
内链是百度官方推荐的优化方式之一,所以这个是必须要做的。通常的表现形式是文中出现某个关键词,在这个关键词上加了一个链接,指向另一个恰好与这个关键词相关的页面。于是,诞生了一些所谓的优化技巧,强行在文中插入一些关键词和链接,进行类似相互推送的操作。其他人,为了增加首页的权重,到处放网站名字,并链接到首页,认为这样可以增加目标页面的权重。但这些很可能适得其反,因为搜索引擎会计算每个链接的点击率。如果您点击突出显示但很少点击的链接,它们可能会被判断为作弊。因此,请只做文中已有的关键词内部链接。
评论模块基本没用过,到底要不要做?
是的。评论模块最麻烦的就是垃圾评论。通常真正说话的访问者很少,垃圾评论也很多。他们整天与营销软件作斗争。这是我已经实现的解决方案,可能对收录有帮助(没有依据,只是猜测):
保留评论框,但禁用评论。所有评论均由我的网站 程序生成。如前所述,搜索引擎会进行自然语义分析。重要的能力之一是情绪判断。搜索引擎会计算每条评论的情感值,无论是正面的还是负面的,具体倾向是10%还是90%。如果评论的内容表达了积极的情绪,您可以在文本中加分,反之亦然。至于如何自动生成好评,就让八仙渡海各显神通吧。
这是社交网络发展后的必然趋势。这样,它就反映了一个页面的用户体验。同理,还有分享、点赞等,原理类似。
绿萝卜算法之后,有没有外链的用处?
有用。参见搜索引擎三定律的相关定律。既然是法律,就不会改变。谁的内容被引用得越多,就是权威。在主动推送出现之前,外链应该被视为蜘蛛识别页面内容的第一个渠道。
外部链接必须是锚文本还是裸链接?
没有。搜索引擎肩负着发现真正有价值的内容并排除那些没有价值的内容的重大责任。所以有可能你直接提交的链接不是收录,你可以直接在别人的地方发一个纯文本的URL。如果找到了,也算加分。
除了锚文本和裸链接,你还可以以关键词+ URL的形式发送纯文本。这样URL前面的关键词就自动和URL关联起来了。
另外,虽然有些链接添加了nofollow属性,但是百度计算外链的时候还是会计算的。
最后拒绝不好的采集!
质量内容标准很难定义。有时伪原创 感觉比原创 更好。目前网站有采集的行为其实很多。大多数新闻站也会分享采集,而百度没有。明确指出如何判断采集,所以一些适当的采集是必要的。但可以肯定的是,你不应该做坏采集、镜像和盗版网站。百度上周推出了飓风算法,并将定期生成惩罚数据。我想每个人都在关注。 查看全部
自动采集网站内容(优采云软件真的很厉害,但是外链怎么发,引流怎么做呢?)
事情就是这样。前几天有个小哥过来问你优采云software 真的很好,但是怎么发外链,怎么引流?
这相当于“喂,刀师傅,你用这把刀切出来的肉怎么做最好吃?”别说刀少爷会不会做饭,这个人的口味总是有区别的~所以小小编请教了一位老司机。不敢说下面的方法绝对适合你,但都是经验~分享给大家~
我是一个纯粹的采集站长。下面的总结,有的是关于SEO的,有的是关于采集和运维的,都是很基本的个人意见,仅供分享,好坏自我鉴别,实践出真知。
我说原创good,为什么采集?
作为评委,百度确实说了原创help收录。但是我没有很好的写作能力,也没有精力和财力去建立一个持续输出的团队。第三,我觉得采集有方法不一定不如原创没有方法。
为什么采集有方法比原创没有方法好?
原创有什么办法?即原创文章不收录,即使收录不再排名。作为搜索引擎,核心价值是为用户提供最需要的结果。就算你文章写的很好,对于搜索用户来说,也是不符合别人需求的无意义内容。
采集 是什么方法?也就是说,文章是根据网友的强烈需求及时抓拍的。面对需求,这种内容往往收录更快,更多。
采集有没有办法或者如何判断收录的可能性?
关键词。每一次搜索关键词的背后,都是网友的需求。或许是追求问题的答案,或者追求搜索结果。搜索引擎内部分析肯定会匹配到精准的内容,当然是基于精准的关键词。
优采云采集器如何帮助伪原创和收录?
可以直接关注关键词采集;
段落可以重新排列,同义词可以替换(如何在不降低文章质量的情况下使用它,需要慎重考虑);
清理标签,去除乱码;
可以使用缩略图和文字图片来抓取图片和文字;
可以使用原标题,关键词可以与标题自由组合。
自己探索...
不同的网站 程序,例如织梦、WordPress 和 Empirecms 对 SEO 有什么影响?
理论上没有影响。但是很多站长认为有的比较友好,有不同的看法。例如,从网站安全的角度来看,近年来,由于织梦系统的用户数量众多,成为主要攻击目标,因此产生了大量的漏洞,很多网站网站 文件不写死就会变成。安全隐患,wordpress多为博客,自身商业价值小,因此攻击较少,发现漏洞较少。
但本质上,使用什么程序并没有多大意义。其实影响SEO的是模板,因为基本上这些程序都有模板机制。同一个程序可以输出不同的页面,不同的程序也可以输出同一个页面。这是模板。模板确定后,你的每个页面都会按照这个框架输出,也就是整个html结构就确定了。而这些html正是搜索引擎应该关注的,它要从这些html中获取自己想要的信息。因此,一套好的模板非常重要。
当然,最重要的是SEOer本身。
模板设计需要注意哪些细节?
1. 权重结构的顺序。在整个页面的html中(注意是html,不是显示的布局),位置越高权重越高。推而广之,“title”、keyword、description这三个标签的权重最高,因为它们是最高级的。其次通常是导航,基本上是最高的,权重也很高。再次,文章 标题和正文。这是按照html的前后排序。
2. 因为搜索引擎首先要遵循W3C的标准,所以W3C定义的一些标签原本是用来表示重要的信息的,权重自然要高一些,比如特别是h1,用来表示最重要的信息当前页面的信息 一般情况下,每页只能有一个信息。权重估计相当于标题。通常用于放置当前页面的标题。当然,为了增加首页的权重,可以使用h1来放置logo或者首页链接。另外还有em、strong等标签,用来表示强调。一般认为强权重高于标签,这也是一个大胆的效果,但我们认为从SEO的角度来看没有权重提升。
3. css 或 js 代码通常对搜索引擎毫无意义。尝试使用单独的文件来存储它,或者如果允许将它放在 html 的末尾。
网站结构规划应注意哪些问题?
1. 网址设计。 URL 也可以收录关键词。比如你的网站是关于电脑的,你的网址可以收录“PC”,因为它在搜索引擎眼中通常是“电脑”的同义词。网址不要太长,级别不要超过4级。
2. 栏目设计。列通常与导航相关联。设计时要考虑网站的整体主题。用户可能感兴趣的内容。列名最好是网站的几个主要关键词,这样也方便导航。的重量。
3.关键词布局。理论上,每个内容页都应该在同一栏目下有自己的核心关键词、文章,并尽可能围绕关键词栏目展开。一个简单粗暴的做法就是直接用关键词列的长尾词。
动态、伪静态、静态,三者哪个更好?
这个不能一概而论,建议使用伪静态或者静态。三者的区别在于是否生成静态文件和URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态只是通过URL重写来修改URL,其实每次还是需要经过程序计算,查询数据库,输出页面。对加快访问速度完全无效。动态和伪静态的唯一区别是网址,带问号和参数。
所以只注意两点:网站打开速度够快吗?您需要节省服务器空间吗?
网站fast speed 可以提高用户满意度,提高网页的整体质量。保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。另外网站的广告不应干扰用户的正常访问。
不同的网站程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,则页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常会考虑静态化。
提高访问速度的方法有哪些?
1. 上面已经提到的静态化。
2. 通常很多网站 模板都会随机调用文章 或类似的部分。事实上,随机性对数据库来说是一个更重的负担。模板中的随机文章应该被最小化。 @的电话。如果不可避免,请考虑从数据库进行优化。使用索引对字段进行排序通常比不使用索引要快得多。
3. 把不经常修改的图片、js、css等文件放在专用的静态服务器上。如果可以合并多个js或css,尽量合并成一个文件,减少http连接数。
4. 使用各种云加速产品。
网站内链应该如何优化?
内链是百度官方推荐的优化方式之一,所以这个是必须要做的。通常的表现形式是文中出现某个关键词,在这个关键词上加了一个链接,指向另一个恰好与这个关键词相关的页面。于是,诞生了一些所谓的优化技巧,强行在文中插入一些关键词和链接,进行类似相互推送的操作。其他人,为了增加首页的权重,到处放网站名字,并链接到首页,认为这样可以增加目标页面的权重。但这些很可能适得其反,因为搜索引擎会计算每个链接的点击率。如果您点击突出显示但很少点击的链接,它们可能会被判断为作弊。因此,请只做文中已有的关键词内部链接。
评论模块基本没用过,到底要不要做?
是的。评论模块最麻烦的就是垃圾评论。通常真正说话的访问者很少,垃圾评论也很多。他们整天与营销软件作斗争。这是我已经实现的解决方案,可能对收录有帮助(没有依据,只是猜测):
保留评论框,但禁用评论。所有评论均由我的网站 程序生成。如前所述,搜索引擎会进行自然语义分析。重要的能力之一是情绪判断。搜索引擎会计算每条评论的情感值,无论是正面的还是负面的,具体倾向是10%还是90%。如果评论的内容表达了积极的情绪,您可以在文本中加分,反之亦然。至于如何自动生成好评,就让八仙渡海各显神通吧。
这是社交网络发展后的必然趋势。这样,它就反映了一个页面的用户体验。同理,还有分享、点赞等,原理类似。
绿萝卜算法之后,有没有外链的用处?
有用。参见搜索引擎三定律的相关定律。既然是法律,就不会改变。谁的内容被引用得越多,就是权威。在主动推送出现之前,外链应该被视为蜘蛛识别页面内容的第一个渠道。
外部链接必须是锚文本还是裸链接?
没有。搜索引擎肩负着发现真正有价值的内容并排除那些没有价值的内容的重大责任。所以有可能你直接提交的链接不是收录,你可以直接在别人的地方发一个纯文本的URL。如果找到了,也算加分。
除了锚文本和裸链接,你还可以以关键词+ URL的形式发送纯文本。这样URL前面的关键词就自动和URL关联起来了。
另外,虽然有些链接添加了nofollow属性,但是百度计算外链的时候还是会计算的。
最后拒绝不好的采集!
质量内容标准很难定义。有时伪原创 感觉比原创 更好。目前网站有采集的行为其实很多。大多数新闻站也会分享采集,而百度没有。明确指出如何判断采集,所以一些适当的采集是必要的。但可以肯定的是,你不应该做坏采集、镜像和盗版网站。百度上周推出了飓风算法,并将定期生成惩罚数据。我想每个人都在关注。
自动采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-06 07:18
采集profit
采集可以让一个网站收录在短时间内得到很大的提升(前提是你的网站的实力够高),可以把大部分的网络流量,抢占其他竞争的对手的流量。
采集Harmful
很多采集会让百度认为你的网站上没有客户想要的信息。这纯粹是一个垃圾站。如果你明天采集百篇,采集两百篇,后天我不会采集,所以更新频率参差不齐,百度会关注你。
首先,它可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,也可以让用户在登录网站时观看一些内容,虽然内容比较陈旧,总比没有内容好让用户看。
其次,内容采集可以快速获取与此网站相关的最新内容。因为在采集的内容中,可以关注网站的关键词和相关栏目采集的内容,而且这些内容可以是最新鲜的内容,让用户可以快速浏览网站获得相关内容,无需再通过搜索引擎搜索,一定程度上提升网站的用户体验。
当然采集内容的弊端还是很明显的,尤其是抄袭采集和大规模的采集会对网站造成不良影响,所以一定要掌握正确的采集方法, 只有这样才能充分发挥内容采集的优势。
下面我们来详细分析一下正确的采集方法。
首先要做的是优先处理采集 内容。即选择与网站相关的内容,内容尽量新鲜。如果太老了,尤其是新闻内容,老内容不需要采集,但是对于技术帖,可以适当采集,因为这些技术帖对很多新人有很好的帮助作用。
那么采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“网站群产品安全吗”,可以换成“网站群产品会不安全,会有什么影响?”等等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思想可以一一对应,防止出现卖狗肉的内容。
最后是适当调整内容。这里的内容调整不需要简单的替换段落,也不需要使用伪原创替换同义词或相似词。这样的替换只会让内容不舒服,用户的阅读体验也会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是第一段和最后一段,进行改写,然后适当的添加相应的图片,可以有效的提高内容的质量,也可以给百度蜘蛛带来更好的效果。上诉。
总之,网站内容采集根本不需要棍子就可以杀人。其实它只需要把传统粗鲁的采集适当优化一下,改成精致的采集,虽然采集的时间会比较长,但是比起原创快多了,而且不会影响用户体验,所以正确的采集还是很有必要的。 查看全部
自动采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集profit
采集可以让一个网站收录在短时间内得到很大的提升(前提是你的网站的实力够高),可以把大部分的网络流量,抢占其他竞争的对手的流量。
采集Harmful
很多采集会让百度认为你的网站上没有客户想要的信息。这纯粹是一个垃圾站。如果你明天采集百篇,采集两百篇,后天我不会采集,所以更新频率参差不齐,百度会关注你。
首先,它可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,也可以让用户在登录网站时观看一些内容,虽然内容比较陈旧,总比没有内容好让用户看。
其次,内容采集可以快速获取与此网站相关的最新内容。因为在采集的内容中,可以关注网站的关键词和相关栏目采集的内容,而且这些内容可以是最新鲜的内容,让用户可以快速浏览网站获得相关内容,无需再通过搜索引擎搜索,一定程度上提升网站的用户体验。
当然采集内容的弊端还是很明显的,尤其是抄袭采集和大规模的采集会对网站造成不良影响,所以一定要掌握正确的采集方法, 只有这样才能充分发挥内容采集的优势。
下面我们来详细分析一下正确的采集方法。
首先要做的是优先处理采集 内容。即选择与网站相关的内容,内容尽量新鲜。如果太老了,尤其是新闻内容,老内容不需要采集,但是对于技术帖,可以适当采集,因为这些技术帖对很多新人有很好的帮助作用。
那么采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“网站群产品安全吗”,可以换成“网站群产品会不安全,会有什么影响?”等等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思想可以一一对应,防止出现卖狗肉的内容。
最后是适当调整内容。这里的内容调整不需要简单的替换段落,也不需要使用伪原创替换同义词或相似词。这样的替换只会让内容不舒服,用户的阅读体验也会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是第一段和最后一段,进行改写,然后适当的添加相应的图片,可以有效的提高内容的质量,也可以给百度蜘蛛带来更好的效果。上诉。
总之,网站内容采集根本不需要棍子就可以杀人。其实它只需要把传统粗鲁的采集适当优化一下,改成精致的采集,虽然采集的时间会比较长,但是比起原创快多了,而且不会影响用户体验,所以正确的采集还是很有必要的。
自动采集网站内容(如何利用自动采集网站副业赚钱视频教程,此项目分支)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-06 06:20
如何使用自动采集网站side业务赚钱视频教程,本项目属于网站course的一个分支。
传统的采集站有很多优点:
2、采集完成后,会随着时间的推移不断积累,网站weight 会一直变高。
1、传统采集站成功率低。
3、集集站不稳定,百度整改新算法会导致网站一向上下震荡。
与传统采集站相比,本教程采集站相比传统采集站有非常显着的提升。
2、不需要旧域名(旧域名也可以)。
4、这也是一套基本的SEO教程。可以用这个方法学SEO的同时建网站赚钱。
6、应用场景超广!采集站可以通过挂广告和卖钱来赚钱。这个方法还可以帮你做更多类型的网站,包括:博客站、资讯站、导航站、电影站、摄影站。只需要文字内容的网站非常适合!
1、新采集站教程采集不是一次性采集,而是每天采集3-10篇文章。
这套课程的开发花费了很长时间。经过表姐和女朋友的考验,一年采集了一张爱站权重4网站。日本IP在3W之间徘徊,鱼爪。上面列表中的额定值为 13W。这是网站,一个上班族利用空闲时间和下班时间。
二、课程介绍
所需时间:采集站需要一个准备周期。这个周期大约需要3-7天。课程准备完成后,即可建立初始站。建站后,每天采集一篇文章3-5分钟,初期每天推荐5篇,中后期每天推荐10篇。
课程内容:课程共分5章16节,时长约4小时。课程生产日期,2020 年 2 月。
很多人喜欢全职做这份工作,但最好的方法是最初从兼职转为全职。
当然,收获与付出成正比。操作网站的时间越多,获得的奖励就越高。 查看全部
自动采集网站内容(如何利用自动采集网站副业赚钱视频教程,此项目分支)
如何使用自动采集网站side业务赚钱视频教程,本项目属于网站course的一个分支。
传统的采集站有很多优点:
2、采集完成后,会随着时间的推移不断积累,网站weight 会一直变高。
1、传统采集站成功率低。
3、集集站不稳定,百度整改新算法会导致网站一向上下震荡。
与传统采集站相比,本教程采集站相比传统采集站有非常显着的提升。
2、不需要旧域名(旧域名也可以)。
4、这也是一套基本的SEO教程。可以用这个方法学SEO的同时建网站赚钱。
6、应用场景超广!采集站可以通过挂广告和卖钱来赚钱。这个方法还可以帮你做更多类型的网站,包括:博客站、资讯站、导航站、电影站、摄影站。只需要文字内容的网站非常适合!
1、新采集站教程采集不是一次性采集,而是每天采集3-10篇文章。
这套课程的开发花费了很长时间。经过表姐和女朋友的考验,一年采集了一张爱站权重4网站。日本IP在3W之间徘徊,鱼爪。上面列表中的额定值为 13W。这是网站,一个上班族利用空闲时间和下班时间。
二、课程介绍
所需时间:采集站需要一个准备周期。这个周期大约需要3-7天。课程准备完成后,即可建立初始站。建站后,每天采集一篇文章3-5分钟,初期每天推荐5篇,中后期每天推荐10篇。
课程内容:课程共分5章16节,时长约4小时。课程生产日期,2020 年 2 月。
很多人喜欢全职做这份工作,但最好的方法是最初从兼职转为全职。
当然,收获与付出成正比。操作网站的时间越多,获得的奖励就越高。
自动采集网站内容(自动采集网站内容的网站有哪些呢,常见的有以下几个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-06 04:05
自动采集网站内容的网站有哪些呢,常见的有以下几个:1.百度关键词规划师关键词规划师是百度的关键词推荐工具,利用系统给出的关键词做个性化布局可以快速收集到大量的网站内容2.搜狗热门文章搜狗可以找到更多的热门网站内容,比如说只要输入主题关键词就可以找到跟主题相关的更多网站内容;只要输入热门关键词更可以找到相关的热门网站内容。
比如说像“云南招教师”,就可以在搜狗搜索里面找到多个与云南招教师相关的网站。很多网站的网址都有直接给出来的,用的就是这种百度关键词规划师的。3.58同城58同城里面全部是针对全国招聘的信息,无论是在一线城市、二三线城市或是农村,只要是想找工作的人都可以在58同城找到自己想要的信息。这点是其他任何站点都比不了的。
4.赶集网、搜索公司招聘内容也能找到其他相关网站的内容。5.豆瓣小组豆瓣小组是针对用户需求进行网站建设,也可以很好地搜索到与主题相关的信息。6.知乎、企鹅问答现在市面上很多问答平台,如:天涯问答、百度知道、知乎、论坛等都可以搜索到相关内容。7.中国各大门户网站与人对话可以找到对方的信息,利用好人工智能技术对话可以扩展人与人之间的谈话信息。
8.度娘搜索利用搜索指令、分词技术和热门搜索结果,可以搜索到很多的网站内容,常见的有百度翻译等。9.等等等等其他各种网站搜索工具。看到这里可能你会想这样的方法确实不错,不过价格可能是最贵的,还是上面说的几个大平台更划算,还能匹配到需要网站的内容,这样会节省很多钱。下面是相应的关键词定位工具提供给大家:1.首页定位词2.站长帮3.自建站3.3大类定位词4.电商定位词5.门户定位词6.找资料7.二维码/网址提取内容8.快速抓取定位词9.站长社区10.词汇锁定11.网站定位词搜索工具1.独立站爱站seoer-bot这是一个网站seo体检工具。
可以快速发现自己网站相关的seo指标2.g站竞争对手分析googleanalysis-seller-competitive-google-analysis这是谷歌分析工具,经常用谷歌查竞争对手,竞争对手的网站内容抓取速度特别快。3.seoeye5.高级站长生意模型wordpress站长工具,主要是关键词排名,一键导出google关键词的内容。
4.站长评论分析yahoo!sitescout这是谷歌分析工具,可以查询google网站的seo信息,提高网站排名。5.谷歌在线工具平台googleanalytics6.谷歌监控googleanalytics-googleanalytics就是谷歌搜索引擎分析工具。7.谷歌一键收录工具googlepagepruneab图谷歌一键收录工具-google一键收录。 查看全部
自动采集网站内容(自动采集网站内容的网站有哪些呢,常见的有以下几个)
自动采集网站内容的网站有哪些呢,常见的有以下几个:1.百度关键词规划师关键词规划师是百度的关键词推荐工具,利用系统给出的关键词做个性化布局可以快速收集到大量的网站内容2.搜狗热门文章搜狗可以找到更多的热门网站内容,比如说只要输入主题关键词就可以找到跟主题相关的更多网站内容;只要输入热门关键词更可以找到相关的热门网站内容。
比如说像“云南招教师”,就可以在搜狗搜索里面找到多个与云南招教师相关的网站。很多网站的网址都有直接给出来的,用的就是这种百度关键词规划师的。3.58同城58同城里面全部是针对全国招聘的信息,无论是在一线城市、二三线城市或是农村,只要是想找工作的人都可以在58同城找到自己想要的信息。这点是其他任何站点都比不了的。
4.赶集网、搜索公司招聘内容也能找到其他相关网站的内容。5.豆瓣小组豆瓣小组是针对用户需求进行网站建设,也可以很好地搜索到与主题相关的信息。6.知乎、企鹅问答现在市面上很多问答平台,如:天涯问答、百度知道、知乎、论坛等都可以搜索到相关内容。7.中国各大门户网站与人对话可以找到对方的信息,利用好人工智能技术对话可以扩展人与人之间的谈话信息。
8.度娘搜索利用搜索指令、分词技术和热门搜索结果,可以搜索到很多的网站内容,常见的有百度翻译等。9.等等等等其他各种网站搜索工具。看到这里可能你会想这样的方法确实不错,不过价格可能是最贵的,还是上面说的几个大平台更划算,还能匹配到需要网站的内容,这样会节省很多钱。下面是相应的关键词定位工具提供给大家:1.首页定位词2.站长帮3.自建站3.3大类定位词4.电商定位词5.门户定位词6.找资料7.二维码/网址提取内容8.快速抓取定位词9.站长社区10.词汇锁定11.网站定位词搜索工具1.独立站爱站seoer-bot这是一个网站seo体检工具。
可以快速发现自己网站相关的seo指标2.g站竞争对手分析googleanalysis-seller-competitive-google-analysis这是谷歌分析工具,经常用谷歌查竞争对手,竞争对手的网站内容抓取速度特别快。3.seoeye5.高级站长生意模型wordpress站长工具,主要是关键词排名,一键导出google关键词的内容。
4.站长评论分析yahoo!sitescout这是谷歌分析工具,可以查询google网站的seo信息,提高网站排名。5.谷歌在线工具平台googleanalytics6.谷歌监控googleanalytics-googleanalytics就是谷歌搜索引擎分析工具。7.谷歌一键收录工具googlepagepruneab图谷歌一键收录工具-google一键收录。
自动采集网站内容(与VN创造者交谈,带采集规则的源码是你的选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-05 16:08
小说网站源码好用,但采集规则是关键一环。您计划自己的故事,绘制所有对话,创造令人难忘的角色,然后将这些内容整合成一部功能齐全的小说网站。
源代码和演示:xsymz.icu
当你开始写小说网站时,源代码可能是你听到的第一点。跟VN的创建者聊一聊,带有采集规则的源码是大多数人的选择。小说网站已经存在很长时间了,你可能读过不同风格的小说网站。它是一个开源代码系统,您只需要知道如何编辑文本和使用一些基本的 PJP 编程即可。但是,这些都可以通过访问在线教程、修改示例项目和独立学习 PHP 来学习。
当我开始创建自己的小说网站时,我首先需要上传Novel网站源代码,因为几年前我用它参加了一个在线比赛(并且赢了!),尽管我没有对PHP一无所知,我没有任何编程经验,但我仍然可以以令人满意的方式编辑它附带的示例游戏,只需根据简短的视觉小说中的示例编写代码,作为演示源站点。视差转场、自定义菜单和转场等更困难的事情需要我学习,但我仍然可以解决它们。在这方面,您的里程自然会有所不同。
只要可以编辑照片、提供自定义图稿、按照简单的指令操作,WPA 小说网站的源代码就可以大大超越大多数视觉小说所满足的简单对话方式。您可以实现状态追踪系统、道具管理机制以及其他各种重大调整,让您的网站比您之前想象的更丰富、更完整。除了网站明显的功能,我们还需要学习更多的其他教程,以帮助您充分利用系统构建。
Joel Peterson,Destructoid:“对于你真正需要学习写一个基础代码的东西,开源小说网站源代码是有意义的。它在Lemma Soft上得到了很多社区的支持,相对来说有没有bug,非常灵活。对于系统新颖的网站开发者来说,这可能会让他们一开始感到害怕,但值得花时间。虽然我的工作一开始并不快,但由于缺乏引擎限制,我的工作变得更顺畅了。”
如果您对编码或 Python 不感兴趣,而只是完成您的项目,TyranoBuilder 可能更适合您。您根本不需要知道编码。这是制作快速粗略原型的最快方法,尤其是当您正在推广游戏或需要一个松散的概念时,但如果您想充实项目的其他部分,您也可以这样做。
换句话说,在“TyranoBuilder”中,很多更复杂的内容在Ren’py这样的系统中是无法实现的。经过一段时间的程序修改,我能够在15分钟内创建一个视觉新颖的框架并呈现给玩家。它既快又脏,但在很多方面,这就是 TyranoBuilder 的目的。
您可以使用该软件的可视化编辑器来创建视觉小说网站 的各个方面,这意味着您真正需要做的就是在组件列表中拖放元素。您甚至可以通过这种方式更改文本速度,添加音乐、对话、分支路径以及调整字符定位。如果你对编码没有耐心,需要一个程序来为你做所有的工作,那么这就是你应该采取的方法,只要你不想寻找过于复杂的东西。
当然,这三个工具并不是创作小说网站的唯一选择。 Unity 总是一种选择,但它也有它自己的麻烦——尤其是如果你不是一个编码老手。但它也带来了额外的好处,例如您可以制作自己想要的游戏,而不必拘泥于特定的程序。
总之,打造一部小说网站需要一套功能齐全且易于操作的开源代码才是最重要的。一篇好的小说网站源代码应该是丰富的采集规则和自成一体的WPA手机系统。它与开源集成,易于维护。返回搜狐查看更多 查看全部
自动采集网站内容(与VN创造者交谈,带采集规则的源码是你的选择)
小说网站源码好用,但采集规则是关键一环。您计划自己的故事,绘制所有对话,创造令人难忘的角色,然后将这些内容整合成一部功能齐全的小说网站。

源代码和演示:xsymz.icu
当你开始写小说网站时,源代码可能是你听到的第一点。跟VN的创建者聊一聊,带有采集规则的源码是大多数人的选择。小说网站已经存在很长时间了,你可能读过不同风格的小说网站。它是一个开源代码系统,您只需要知道如何编辑文本和使用一些基本的 PJP 编程即可。但是,这些都可以通过访问在线教程、修改示例项目和独立学习 PHP 来学习。
当我开始创建自己的小说网站时,我首先需要上传Novel网站源代码,因为几年前我用它参加了一个在线比赛(并且赢了!),尽管我没有对PHP一无所知,我没有任何编程经验,但我仍然可以以令人满意的方式编辑它附带的示例游戏,只需根据简短的视觉小说中的示例编写代码,作为演示源站点。视差转场、自定义菜单和转场等更困难的事情需要我学习,但我仍然可以解决它们。在这方面,您的里程自然会有所不同。
只要可以编辑照片、提供自定义图稿、按照简单的指令操作,WPA 小说网站的源代码就可以大大超越大多数视觉小说所满足的简单对话方式。您可以实现状态追踪系统、道具管理机制以及其他各种重大调整,让您的网站比您之前想象的更丰富、更完整。除了网站明显的功能,我们还需要学习更多的其他教程,以帮助您充分利用系统构建。
Joel Peterson,Destructoid:“对于你真正需要学习写一个基础代码的东西,开源小说网站源代码是有意义的。它在Lemma Soft上得到了很多社区的支持,相对来说有没有bug,非常灵活。对于系统新颖的网站开发者来说,这可能会让他们一开始感到害怕,但值得花时间。虽然我的工作一开始并不快,但由于缺乏引擎限制,我的工作变得更顺畅了。”
如果您对编码或 Python 不感兴趣,而只是完成您的项目,TyranoBuilder 可能更适合您。您根本不需要知道编码。这是制作快速粗略原型的最快方法,尤其是当您正在推广游戏或需要一个松散的概念时,但如果您想充实项目的其他部分,您也可以这样做。
换句话说,在“TyranoBuilder”中,很多更复杂的内容在Ren’py这样的系统中是无法实现的。经过一段时间的程序修改,我能够在15分钟内创建一个视觉新颖的框架并呈现给玩家。它既快又脏,但在很多方面,这就是 TyranoBuilder 的目的。
您可以使用该软件的可视化编辑器来创建视觉小说网站 的各个方面,这意味着您真正需要做的就是在组件列表中拖放元素。您甚至可以通过这种方式更改文本速度,添加音乐、对话、分支路径以及调整字符定位。如果你对编码没有耐心,需要一个程序来为你做所有的工作,那么这就是你应该采取的方法,只要你不想寻找过于复杂的东西。
当然,这三个工具并不是创作小说网站的唯一选择。 Unity 总是一种选择,但它也有它自己的麻烦——尤其是如果你不是一个编码老手。但它也带来了额外的好处,例如您可以制作自己想要的游戏,而不必拘泥于特定的程序。
总之,打造一部小说网站需要一套功能齐全且易于操作的开源代码才是最重要的。一篇好的小说网站源代码应该是丰富的采集规则和自成一体的WPA手机系统。它与开源集成,易于维护。返回搜狐查看更多
自动采集网站内容(批量采集自动提取保存网页内容这个是本教程中所使用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-04 21:30
批量采集自动提取并保存网页内容
这是本教程中使用的网页:
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
本教程是教大家使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中
这是入门教程
先看一下软件的大体界面:
然后需要先添加一个网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图:
接下来,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,就不会受到限制。
本教程每次刷新都需要保存更改的网页信息,所以在“其他监控”中需要设置“无条件启动监控报警”。 (详见各自要求的设置)
然后设置需要保存的网页信息。在“监控设置”中,添加“报警提示动态内容”---然后自动获取。如下图:
点击自动获取后会打开之前添加的网址,页面加载完成后
选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。
如下图操作:
元素属性名称在这里使用值。
这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容)
在这个版本中,网页自动运行的通用工具可以保存为三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件。类型可在“闹钟提醒”中设置。
以下是监控网页后保存的各种文件格式。
首先是将每个元素保存在一个单独的txt文件中:
第二种方法是合并一个txt文件中的所有元素并保存:
第三种是将所有元素保存为一个csv文件:
本教程结束。
欢迎搜索:木头软件。 查看全部
自动采集网站内容(批量采集自动提取保存网页内容这个是本教程中所使用的)
批量采集自动提取并保存网页内容
这是本教程中使用的网页:
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
本教程是教大家使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中
这是入门教程
先看一下软件的大体界面:
然后需要先添加一个网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图:
接下来,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,就不会受到限制。
本教程每次刷新都需要保存更改的网页信息,所以在“其他监控”中需要设置“无条件启动监控报警”。 (详见各自要求的设置)
然后设置需要保存的网页信息。在“监控设置”中,添加“报警提示动态内容”---然后自动获取。如下图:
点击自动获取后会打开之前添加的网址,页面加载完成后
选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。
如下图操作:
元素属性名称在这里使用值。
这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容)
在这个版本中,网页自动运行的通用工具可以保存为三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件。类型可在“闹钟提醒”中设置。
以下是监控网页后保存的各种文件格式。
首先是将每个元素保存在一个单独的txt文件中:

第二种方法是合并一个txt文件中的所有元素并保存:
第三种是将所有元素保存为一个csv文件:
本教程结束。
欢迎搜索:木头软件。
自动采集网站内容(更多写博客大数据与云计算学习:Python网络数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-04 00:04
阿里巴巴云>云栖社区>主题图>W>网站小说采集器
推荐活动:
更多优惠>
当前话题:网站小说采集器采集
相关主题:
网站小说采集器相关博客查看更多博客
大数据与云计算学习:Python网络data采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换、信息采集、爬虫学习路径爬虫的基本原理,具备信息存储功能 所谓爬虫就是一个自动化数据采集工具,你
阅读全文
新手怎么发网站外链,网站外链怎么发,外链发帖方法集合
作者:冰点牧雪1420人浏览评论:06年前
给大家分享一下我是怎么做反连接链的。一般来说,我在反连接中只追求两件事。 一、数量。 二、稳定性。对于像我这样的新手和资源匮乏的人,能做的就是增加外链的数量,做好外链的稳定性。所谓稳定,就是已经贴出的外链要尽量不让它们消失。这对于群发软件来说是非常困难的,尤其是对于英文站点。现在
阅读全文
给互联网或物联网加一个“大脑”会引发什么样的革命?
作者:青山无名1158人浏览评论:04年前
互联网发展到今天,已经成为人们重要的生活方式。在互联网上,您可以与朋友聊天、阅读新闻、查询各种信息和资料、玩游戏、购物、看电影等等。对很多人来说,一天不上网,生活就会变得很枯燥和艰难。新一波“物联网”是互联网的进一步拓展,将各种“物体”和设备连接到互联网
阅读全文
用树莓派寻找外星文明
作者:同济子豪哥1695人浏览评论:02年前
使用树莓派搜索地外文明兄弟子豪开场白:本文介绍如何使用树莓派微机参与全球最大的分布式计算平台BOINC上的科学计算项目,尤其是最著名的搜索SETI @home 外星文明项目。并在BOINC平台介绍生物医学、气候变化、天体物理学、密码解密、数学证明等领域
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:沃克武松 9726人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:Reverse One Sleep 4689 次浏览和评论:13 年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
中文版Python资源合集
作者:有地2522人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
推荐系统永远不会向你推荐任何东西
作者:小轩峰柴金1136人浏览评论:04年前
推荐系统还有两个主要特点,它们对你看到的推荐结果也有很大的影响:第一,在你弄清楚你和其他购物者有多相似之前,推荐系统首先要了解你真正喜欢什么其次,推荐系统按照一套业务规则运行,保证推荐结果对你有用,对业务有利。推荐算法如何赢得你
阅读全文 查看全部
自动采集网站内容(更多写博客大数据与云计算学习:Python网络数据采集)
阿里巴巴云>云栖社区>主题图>W>网站小说采集器

推荐活动:
更多优惠>
当前话题:网站小说采集器采集
相关主题:
网站小说采集器相关博客查看更多博客
大数据与云计算学习:Python网络data采集


作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换、信息采集、爬虫学习路径爬虫的基本原理,具备信息存储功能 所谓爬虫就是一个自动化数据采集工具,你
阅读全文
新手怎么发网站外链,网站外链怎么发,外链发帖方法集合


作者:冰点牧雪1420人浏览评论:06年前
给大家分享一下我是怎么做反连接链的。一般来说,我在反连接中只追求两件事。 一、数量。 二、稳定性。对于像我这样的新手和资源匮乏的人,能做的就是增加外链的数量,做好外链的稳定性。所谓稳定,就是已经贴出的外链要尽量不让它们消失。这对于群发软件来说是非常困难的,尤其是对于英文站点。现在
阅读全文
给互联网或物联网加一个“大脑”会引发什么样的革命?


作者:青山无名1158人浏览评论:04年前
互联网发展到今天,已经成为人们重要的生活方式。在互联网上,您可以与朋友聊天、阅读新闻、查询各种信息和资料、玩游戏、购物、看电影等等。对很多人来说,一天不上网,生活就会变得很枯燥和艰难。新一波“物联网”是互联网的进一步拓展,将各种“物体”和设备连接到互联网
阅读全文
用树莓派寻找外星文明


作者:同济子豪哥1695人浏览评论:02年前
使用树莓派搜索地外文明兄弟子豪开场白:本文介绍如何使用树莓派微机参与全球最大的分布式计算平台BOINC上的科学计算项目,尤其是最著名的搜索SETI @home 外星文明项目。并在BOINC平台介绍生物医学、气候变化、天体物理学、密码解密、数学证明等领域
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集


作者:沃克武松 9726人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集

作者:Reverse One Sleep 4689 次浏览和评论:13 年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
中文版Python资源合集

作者:有地2522人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
推荐系统永远不会向你推荐任何东西


作者:小轩峰柴金1136人浏览评论:04年前
推荐系统还有两个主要特点,它们对你看到的推荐结果也有很大的影响:第一,在你弄清楚你和其他购物者有多相似之前,推荐系统首先要了解你真正喜欢什么其次,推荐系统按照一套业务规则运行,保证推荐结果对你有用,对业务有利。推荐算法如何赢得你
阅读全文
自动采集网站内容(手机代理设置代理:安卓模拟器的代理服务器地址是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-09-28 18:00
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来详细介绍一下服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
自动采集网站内容(手机代理设置代理:安卓模拟器的代理服务器地址是什么?)
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来详细介绍一下服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
自动采集网站内容(自动采集网站内容的软件是数据自动抓取的吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-25 17:41
自动采集网站内容的软件,目前用得比较多的就是前程无忧、智联招聘等网站了。但这种软件是数据自动抓取的,抓取下来的数据,你得自己将格式转换成自己需要的格式,例如将文本数据转换成数据表格,或者用java进行pdf转word,或者其他的方法。你可以在百度搜索“数据抓取工具”“文档转换工具”,找这类的工具。
谢邀!肯定有,不然中国网站就没有版权问题了。大部分网站在前端更新很慢,每天的信息更新量不够,加上会登录企业网站的人,大多数是对网站不太上心的。对于文章下载,基本上都是手工浏览,天哪,谁那么闲,除非网站很大,新发布的信息,一般会把备份上传到第三方下载平台(比如一些八抓鱼一类的平台),从中抽取。如果你真的急需,某宝可以找到人工下载服务。
百度一下:百度文库下载
qq邮箱都可以群发文件
推荐个产品好了,爱问共享资料助手。
有呀,最近才推出的,网址就是,自动采集名企名片,而且还能够分类,让你在生活中就可以采集名企内容,比去那些名企名片市场或者那些会展会,才人工是更加的高效。
刚好需要,最近在知乎上也问了一下,@李然好像在经济分析领域回答了我的问题,索性加了qq,联系他详聊一下就把需求反馈给他了,目前刚开发完一个月,关于文档下载有具体的需求,知乎上的知友应该会有更好的想法,期待一起交流一起学习。 查看全部
自动采集网站内容(自动采集网站内容的软件是数据自动抓取的吗?)
自动采集网站内容的软件,目前用得比较多的就是前程无忧、智联招聘等网站了。但这种软件是数据自动抓取的,抓取下来的数据,你得自己将格式转换成自己需要的格式,例如将文本数据转换成数据表格,或者用java进行pdf转word,或者其他的方法。你可以在百度搜索“数据抓取工具”“文档转换工具”,找这类的工具。
谢邀!肯定有,不然中国网站就没有版权问题了。大部分网站在前端更新很慢,每天的信息更新量不够,加上会登录企业网站的人,大多数是对网站不太上心的。对于文章下载,基本上都是手工浏览,天哪,谁那么闲,除非网站很大,新发布的信息,一般会把备份上传到第三方下载平台(比如一些八抓鱼一类的平台),从中抽取。如果你真的急需,某宝可以找到人工下载服务。
百度一下:百度文库下载
qq邮箱都可以群发文件
推荐个产品好了,爱问共享资料助手。
有呀,最近才推出的,网址就是,自动采集名企名片,而且还能够分类,让你在生活中就可以采集名企内容,比去那些名企名片市场或者那些会展会,才人工是更加的高效。
刚好需要,最近在知乎上也问了一下,@李然好像在经济分析领域回答了我的问题,索性加了qq,联系他详聊一下就把需求反馈给他了,目前刚开发完一个月,关于文档下载有具体的需求,知乎上的知友应该会有更好的想法,期待一起交流一起学习。
自动采集网站内容(自动采集网站内容,从网站的内容中采集自己需要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-25 00:05
自动采集网站内容,从网站的内容中采集自己需要的内容,也可以挑选自己想要的内容。现在的建站不需要什么技术,因为找一个合适的模板公司就可以做了。相比较建站的技术问题,建站之后的运营和用户体验比较麻烦。
我所理解的完全自动采集,只是页面更新比较慢,毕竟每天的网站抓取,数据更新很少。除了页面不能被改,其他都可以做到,前端做页面,后端每天更新数据。
好不好用要看你对采集有多不敏感了。如果你是刚接触网络,完全靠自己采集收集,你会很麻烦,后期也不容易进行管理。那么最好的方法是找可以自动化采集的工具,比如乐采客采集器都可以很方便的实现自动化采集。
看你怎么做了,我一直都用excel来采集,方便快捷,
开发程序采集模块还是基于模板数据库的。看你们网站对服务器端的要求了,基于模板数据库的价格可能比开发程序采集模块的要贵一些,如果做的都是公共页面的话,
不难,一分钱一分货。如果要做程序还是找站长公司,或者自己找程序开发。个人找程序开发,坑很多。
看你们网站定位是什么,如果偏向于分享,图片就是宝贝,类似这种的。一个站点的内容模块就是类似这样。采集过来可以直接导入到企业网站中,也可以用做建站模板,根据模板做图片和页面。现在网络竞争很激烈。内容的数量根据功能和图片数量选择采集的网站模板。价格也比较合理。还有很多不同模板可以选择。 查看全部
自动采集网站内容(自动采集网站内容,从网站的内容中采集自己需要)
自动采集网站内容,从网站的内容中采集自己需要的内容,也可以挑选自己想要的内容。现在的建站不需要什么技术,因为找一个合适的模板公司就可以做了。相比较建站的技术问题,建站之后的运营和用户体验比较麻烦。
我所理解的完全自动采集,只是页面更新比较慢,毕竟每天的网站抓取,数据更新很少。除了页面不能被改,其他都可以做到,前端做页面,后端每天更新数据。
好不好用要看你对采集有多不敏感了。如果你是刚接触网络,完全靠自己采集收集,你会很麻烦,后期也不容易进行管理。那么最好的方法是找可以自动化采集的工具,比如乐采客采集器都可以很方便的实现自动化采集。
看你怎么做了,我一直都用excel来采集,方便快捷,
开发程序采集模块还是基于模板数据库的。看你们网站对服务器端的要求了,基于模板数据库的价格可能比开发程序采集模块的要贵一些,如果做的都是公共页面的话,
不难,一分钱一分货。如果要做程序还是找站长公司,或者自己找程序开发。个人找程序开发,坑很多。
看你们网站定位是什么,如果偏向于分享,图片就是宝贝,类似这种的。一个站点的内容模块就是类似这样。采集过来可以直接导入到企业网站中,也可以用做建站模板,根据模板做图片和页面。现在网络竞争很激烈。内容的数量根据功能和图片数量选择采集的网站模板。价格也比较合理。还有很多不同模板可以选择。
自动采集网站内容(自动采集网站内容。自动获取javascript脚本,知乎还在手机客户端上架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-19 07:04
自动采集网站内容。自动获取javascript脚本,脚本是自动爬虫可以爬去你的网站所有的页面,每个页面都有很多页面url可以自己填写,爬到哪个页面填写哪个url。自动获取整站内容,并且可以多个页面进行拼接。用外部语言(python,php)写,实现loaders(使用javascript的loaders)然后把python拼接的页面一起传到网站服务器。
最后用php解析输出的内容。不过网站用flask或tornado写都可以自动爬虫,我觉得你没必要开发一个自动化的爬虫,不如关注web前端的工作。如果要自动化的,还不如去买个爬虫框架,把工作交给后端工程师,先做好web后端的开发,再用python或c写爬虫。
做爬虫,目的性要强,要快速占据资源,然后获取相关数据。所以爬虫其实是重复性劳动。如果是为了做出一个稍微定制化的工具来去实现爬虫,那么设计爬虫框架和通用的调用方式,至少可以有3个月以上的时间去学习。如果没有这样的基础,建议是不要入这个坑了。我觉得如果只是稍微有点兴趣,可以多看看python入门和tornado入门方面的书,感受下各个框架的大概步骤,也有助于学习爬虫,爬虫绝对不是简单的去爬虫框架里输入请求就能调出目标页面。
pythonscrapyhtmlcookie
看python3.6,觉得有难度,要么学一下爬虫框架vultrrequestspigwebfrogz2什么的,知乎还在手机客户端上架,就不写代码了,但是可以看下基本代码大同小异。再有python2入门基本可以写个小爬虫了。有可能爬youtube手机插件, 查看全部
自动采集网站内容(自动采集网站内容。自动获取javascript脚本,知乎还在手机客户端上架)
自动采集网站内容。自动获取javascript脚本,脚本是自动爬虫可以爬去你的网站所有的页面,每个页面都有很多页面url可以自己填写,爬到哪个页面填写哪个url。自动获取整站内容,并且可以多个页面进行拼接。用外部语言(python,php)写,实现loaders(使用javascript的loaders)然后把python拼接的页面一起传到网站服务器。
最后用php解析输出的内容。不过网站用flask或tornado写都可以自动爬虫,我觉得你没必要开发一个自动化的爬虫,不如关注web前端的工作。如果要自动化的,还不如去买个爬虫框架,把工作交给后端工程师,先做好web后端的开发,再用python或c写爬虫。
做爬虫,目的性要强,要快速占据资源,然后获取相关数据。所以爬虫其实是重复性劳动。如果是为了做出一个稍微定制化的工具来去实现爬虫,那么设计爬虫框架和通用的调用方式,至少可以有3个月以上的时间去学习。如果没有这样的基础,建议是不要入这个坑了。我觉得如果只是稍微有点兴趣,可以多看看python入门和tornado入门方面的书,感受下各个框架的大概步骤,也有助于学习爬虫,爬虫绝对不是简单的去爬虫框架里输入请求就能调出目标页面。
pythonscrapyhtmlcookie
看python3.6,觉得有难度,要么学一下爬虫框架vultrrequestspigwebfrogz2什么的,知乎还在手机客户端上架,就不写代码了,但是可以看下基本代码大同小异。再有python2入门基本可以写个小爬虫了。有可能爬youtube手机插件,
自动采集网站内容(SEO的具体操作方法?通过这么长时间学习,我觉得seo应该这样做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 06:10
SEO的具体操作方法?
研究了这么久,我觉得SEO应该这样做:
一、部分掌握网页编程技术,尤其是HTML和CSS,脚本语言
文章二、搜索引擎规则与技巧,你需要知道各大搜索引擎的规则。百度有百度的爱好,谷歌有谷歌的算法,帮你优化网站。
第一个三、网页结构设计,再好的网站优化,也逃不过网站的设计和结构。在设计网站时,可以做一些优化后的准备。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
第一个四、SEM知识和技术,你必须对网络营销有一定的了解,如何策划这个产品的推广,这涉及到SEM知识
五、对竞争对手的分析和理解。如果你的竞争对手网站做得很好,你可以随时向他网站学习,提高自己网站。
第一个六、文字写作和编辑能力,不要小看这个,如果你的文章足够原创,搜索引擎会很喜欢的,很快就会收录。对了,请经常写文章,这样搜索引擎会很喜欢的。
网站优化后如何让百度收录
1、首先做好网站基础优化;
百度不是收录AUTO采集视频网站,新网站不想让百度收录
2、写出高质量的原创文章; (更新此篇,如果能天天更新,文章写作难的话可以选择一周更新3次)
3、 立即将每个版本提交给搜索引擎;
4、 在发布文章 时必须是正则的。不要一次发布所有更新。最好每天固定一个时间,或者1,3、5等
坚持一个月后,下次不需要自动提交,搜索引擎会自动来到收录你的网站,获得不错的排名。当然,要想获得好的排名还有很多工作要做。
1、设置TDK标题、描述、关键词(这是搜索引擎抓取的重点)
2、设置网页元标签(h1h6/alt/b)(搜索引擎对元标签识别度高,容易收录)
3、创建站点地图网站map。 (网站map主要提供蜘蛛爬行网站内文章,内容链接)
4、网站持续更新内容(吸引蜘蛛抢网站)
5、Submit网站进入站长平台(俗称百度站长、360站长、搜狗站长)
6、网站robotstxt 文件写入(告诉蜘蛛哪些链接不可抓取,哪些链接可以抓取)
7、网站外链分发(各媒体平台、社区、百度知道、论坛发软文做外链)
8、交易所友情链接(可以去链接交易平台,friends网站友情链接)
网站基本针对以上8点优化
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为一级域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名的权重。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为主域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
网站优化的作用是什么
SEO优化对企业的意义:
1、获取更精准的客户
有需求的用户一有需求,基本上都会在网上搜索关键词,找到自己想要的东西。企业网站做了seo优化,网站部署的关键词排名不错。 ,那么就有更大的机会在用户面前推送网站。对于公司而言,有更多机会与更多潜在客户打交道。
2、提高公司知名度
公司做了SEO优化,可以有更准确的关键词有good排名,让更多的潜在客户看到。通过网站展示的内容,潜在客户可以全面了解我们公司、品牌和产品,提高了公司的关注率。目标客户搜索关键词时,可以看到企业信息,提高了企业品牌的曝光度和客户的信任度。
优化完成,让客户无论搜索什么关键词,或任何互联网平台,都能看到公司的相关信息,加强了用户对公司的了解,无形中提高了用户对公司的了解公司。信任感,对于公司来说,可以拓展业务并与更多潜在客户打交道。
3、SEO 对网站的重要性
关键词自然排名,长期稳定,无论客户何时何地,只要客户搜索关键词,就可以看到公司网站稳定流量的来源,可以有效避免恶意点击,帮助企业有效节省广告推广成本,控制成本,提高效率,帮助企业增加信任度。在当前的互联网市场中,客户更愿意相信自然排名。这都是靠自己的实力。优化关键词首页精度关键词精准流量,更精准的目标客户,高转化率
覆盖面很广。无论客户在哪里,只要有需求,就可以通过各种搜索引擎搜索,就会有企业网站信息存在。
网站optimization,对网站整体素质的提升是非常有利的,它可以建立你的网站和搜索引擎的友好关系,并获得良好的排名,主要是这些效果。
1 使用合理的手段进行优化,可以提高搜索引擎对网站的友好度,使其更受欢迎。 关键词被搜索引擎按优先顺序输入后,获得了很好的排名,更容易被人们搜索到。到达。
2 为了提高排名,需要注意网站内容的建立。其实优化本身就大大提升了网站的厚度,贯穿了网站的规划、建立、保护的每一个细节,这是一个优势,无论是内容还是程序都能满足特点查找信息
百度不是收录AUTO采集视频网站,新网站不想让百度收录
3关键词可以让更多的用户访问你,进而带来订单和品牌展示。
4 其实反过来看,网站optimization 也可以提高搜索引擎的质量。它们相得益彰,也是对整个互联网的巨大贡献。
5 在当前信息爆炸的互联网时代,网站optimization 已经成为中小企业最好的宣传渠道。一个网站能否在搜索引擎中出现,成为企业关注的重要话题。
6 与竞标相比,所需资金相对较少,但需要的时间较多。
7 网站 可以提出。从长远来看,时间积累对网站有利。你的网站权重会越来越高,效果会更好。
其实网站optimization很简单,也不简单。重点是坚持。只有坚持才是胜利。如果你跌倒并继续爬起来,失败并不重要。只有在失败的道路上慢慢走,才能走得更高更远。 ,.
健身休闲店如何做SEO网站优化?
健身休闲店如何做SEO网站优化?
应对危机最好的办法就是未雨绸缪,利用尚易智能推广系统,加强产品信息的宣传,早准备,积极行动,提前打造自己的核心竞争力和危机防火墙,商永利走在前列。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
网站收录Push 站长工具 查看全部
自动采集网站内容(SEO的具体操作方法?通过这么长时间学习,我觉得seo应该这样做)
SEO的具体操作方法?
研究了这么久,我觉得SEO应该这样做:
一、部分掌握网页编程技术,尤其是HTML和CSS,脚本语言
文章二、搜索引擎规则与技巧,你需要知道各大搜索引擎的规则。百度有百度的爱好,谷歌有谷歌的算法,帮你优化网站。
第一个三、网页结构设计,再好的网站优化,也逃不过网站的设计和结构。在设计网站时,可以做一些优化后的准备。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
第一个四、SEM知识和技术,你必须对网络营销有一定的了解,如何策划这个产品的推广,这涉及到SEM知识
五、对竞争对手的分析和理解。如果你的竞争对手网站做得很好,你可以随时向他网站学习,提高自己网站。
第一个六、文字写作和编辑能力,不要小看这个,如果你的文章足够原创,搜索引擎会很喜欢的,很快就会收录。对了,请经常写文章,这样搜索引擎会很喜欢的。
网站优化后如何让百度收录
1、首先做好网站基础优化;
百度不是收录AUTO采集视频网站,新网站不想让百度收录
2、写出高质量的原创文章; (更新此篇,如果能天天更新,文章写作难的话可以选择一周更新3次)
3、 立即将每个版本提交给搜索引擎;
4、 在发布文章 时必须是正则的。不要一次发布所有更新。最好每天固定一个时间,或者1,3、5等
坚持一个月后,下次不需要自动提交,搜索引擎会自动来到收录你的网站,获得不错的排名。当然,要想获得好的排名还有很多工作要做。
1、设置TDK标题、描述、关键词(这是搜索引擎抓取的重点)
2、设置网页元标签(h1h6/alt/b)(搜索引擎对元标签识别度高,容易收录)
3、创建站点地图网站map。 (网站map主要提供蜘蛛爬行网站内文章,内容链接)
4、网站持续更新内容(吸引蜘蛛抢网站)
5、Submit网站进入站长平台(俗称百度站长、360站长、搜狗站长)
6、网站robotstxt 文件写入(告诉蜘蛛哪些链接不可抓取,哪些链接可以抓取)
7、网站外链分发(各媒体平台、社区、百度知道、论坛发软文做外链)
8、交易所友情链接(可以去链接交易平台,friends网站友情链接)
网站基本针对以上8点优化
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为一级域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名的权重。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
二级域名如何快速被搜索引擎收录
这种情况下就需要考虑这些二级域名和主域名之间的SEO正负权重是如何传递的,因为只有弄清楚这个问题,才能更好地利用搜索引擎,让网站的主域名和二级域名都处于良好的优化状态,获得了比较好的排名。在开始具体的内容之前,先澄清两个概念。一个是主域名的概念,另一个是二级域名的概念。一般认为以www开头的域名为主域名,以其他形式前缀开头的域名为二级域名。虽然这种说法经不起推敲,因为其实对于搜索引擎来说,二级域名和一级域名的关系应该是相对的,但是说的太复杂了,那么本文就用正常的“一般观点” “在我开始介绍以下内容之前。本文将分两部分分别介绍SEO主域名对二级域名的正负权重影响,以及二级域名对主域名的正负权重影响。第一节,我们先来看看主域名权重高时对二级域名的影响。一个一级域名权重很高的网站,当它开辟了一个新的二级域名网站时,实际上和新设立的网站几乎是一样的,也就是这一秒级域名事实 以上无法支撑其主域名的权重。对于一个发达的二级域名来说,无论主域名多高,靠主域名的高权重快速获得好的排名自然是不现实的。当然,可能有人会反驳我,因为现实情况是,高权重主域下的二级域通常也有很好的搜索引擎排名。
这里我想说的是:这种现象并不是因为这样的二级域名继承了其一级域名的权重,而是一级域名在自己的页面链接二级域名。接下来我们看一下主域名奖惩时对二级域名的影响。当网站主域名作弊被奖惩时,不幸的是,无论是主域名还是副域名,一般都会受到牵连。不用说,有很多网站管理员。朋友亲身体验过。但是,这也不是绝对的,因为有时二级域名的权重比主域名的权重高,抗冲击能力强,有的二级域名有自己完全独立的IP地址。在这些情况下,二级域名也有可能被免除。第二板块,先看二级域名威力大时对一级域名和其他二级域名的影响。当二级域名权重较高时,一般情况下,主域名并没有实质性的帮助,因为实际上所谓的主域名也可以看作是一个以www为前缀的二级域名很多seo教程会认为以www开头的主域名的权重会高于默认以其他前缀开头的所谓二级域名。但许多事实证明,这种说法是站不住脚的。一个例子是,如此多的全国网站城市分站取得了比其他地方网站更好的排名。二级域名权重高的时候是独立的网站,二级域名的下级目录绝对可以过重。但是对于其他二级域名,包括以www开头的域名,是不带权重传递的。接下来我们看一下二级域名奖惩对主域名和其他二级域名的影响。
网站优化的作用是什么
SEO优化对企业的意义:
1、获取更精准的客户
有需求的用户一有需求,基本上都会在网上搜索关键词,找到自己想要的东西。企业网站做了seo优化,网站部署的关键词排名不错。 ,那么就有更大的机会在用户面前推送网站。对于公司而言,有更多机会与更多潜在客户打交道。
2、提高公司知名度
公司做了SEO优化,可以有更准确的关键词有good排名,让更多的潜在客户看到。通过网站展示的内容,潜在客户可以全面了解我们公司、品牌和产品,提高了公司的关注率。目标客户搜索关键词时,可以看到企业信息,提高了企业品牌的曝光度和客户的信任度。
优化完成,让客户无论搜索什么关键词,或任何互联网平台,都能看到公司的相关信息,加强了用户对公司的了解,无形中提高了用户对公司的了解公司。信任感,对于公司来说,可以拓展业务并与更多潜在客户打交道。
3、SEO 对网站的重要性
关键词自然排名,长期稳定,无论客户何时何地,只要客户搜索关键词,就可以看到公司网站稳定流量的来源,可以有效避免恶意点击,帮助企业有效节省广告推广成本,控制成本,提高效率,帮助企业增加信任度。在当前的互联网市场中,客户更愿意相信自然排名。这都是靠自己的实力。优化关键词首页精度关键词精准流量,更精准的目标客户,高转化率
覆盖面很广。无论客户在哪里,只要有需求,就可以通过各种搜索引擎搜索,就会有企业网站信息存在。
网站optimization,对网站整体素质的提升是非常有利的,它可以建立你的网站和搜索引擎的友好关系,并获得良好的排名,主要是这些效果。
1 使用合理的手段进行优化,可以提高搜索引擎对网站的友好度,使其更受欢迎。 关键词被搜索引擎按优先顺序输入后,获得了很好的排名,更容易被人们搜索到。到达。
2 为了提高排名,需要注意网站内容的建立。其实优化本身就大大提升了网站的厚度,贯穿了网站的规划、建立、保护的每一个细节,这是一个优势,无论是内容还是程序都能满足特点查找信息
百度不是收录AUTO采集视频网站,新网站不想让百度收录
3关键词可以让更多的用户访问你,进而带来订单和品牌展示。
4 其实反过来看,网站optimization 也可以提高搜索引擎的质量。它们相得益彰,也是对整个互联网的巨大贡献。
5 在当前信息爆炸的互联网时代,网站optimization 已经成为中小企业最好的宣传渠道。一个网站能否在搜索引擎中出现,成为企业关注的重要话题。
6 与竞标相比,所需资金相对较少,但需要的时间较多。
7 网站 可以提出。从长远来看,时间积累对网站有利。你的网站权重会越来越高,效果会更好。
其实网站optimization很简单,也不简单。重点是坚持。只有坚持才是胜利。如果你跌倒并继续爬起来,失败并不重要。只有在失败的道路上慢慢走,才能走得更高更远。 ,.
健身休闲店如何做SEO网站优化?
健身休闲店如何做SEO网站优化?
应对危机最好的办法就是未雨绸缪,利用尚易智能推广系统,加强产品信息的宣传,早准备,积极行动,提前打造自己的核心竞争力和危机防火墙,商永利走在前列。
百度不是收录AUTO采集视频网站,新网站不想让百度收录
网站收录Push 站长工具
自动采集网站内容(如何利用C#Winform和Python解决网站采集敏感信息的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-10 18:08
我过去对爬虫的研究不多。最近需要从某个网站采集获取敏感信息。经过一番考虑,我决定使用C#Winform和Python来解决这个事件。
整个方案并不复杂:C#写WinForm表单,进行数据分析和采集,Python本来不想用的,突然没找到C#下Woff字体转Xml的解决方案,但是网上有很多Python程序。所以我添加了一个 Python 项目,虽然只有 1 个脚本。
一、几个步骤:
首先,您必须模拟登录。登录后输入resume采集,然后模拟下载。下载后可以看到求职者的电话。
此电话号码使用动态生成的Base64字体,无法直接提取文字。
1、先把Base64转Woff字体,这个可以用C#来做(iso-8859-1编码是坑,一般用Default会带来惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("iso-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、 然后将生成的Woff转换成XML(WoffDec.exe是我用Python打包的Exe,不过有点繁琐。为了这个转换,我写了一个包,有时间的话还是用整个 C# OK)
//调用python exe 生成xml文件
ProcessStartInfo info = new ProcessStartInfo
{
FileName = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个 WoffDec.py 代码为 3 行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思。我首先尝试了py2exe,但没有成功。我改为 pyinstaller 并且它起作用了。连EXE都有11M,不算大。
下载,或者在VS2017 Python环境中搜索PyInstaller直接安装
右键单击并使用“在此处打开命令提示符”;输入pyinstaller /path/to/yourscript.py 打包成exe文件。调用 Winform 应用程序时,应将整个文件夹复制过来。
3、XML 文件可用后,准备将其存储为基于上述 Woff 文件的数据字典。在XML中找到它的字体锚点,我取X和Y形成唯一值(X,Y代表一个词),当然可以取更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、 以上步骤需要一些时间。基准字典可用后,您可以根据每次生成的 XML 文件匹配真实文本。
5、提取真实文本很简单,直接采集到数据库,然后连接短信发送服务,就可以自动发送群消息了。
二、使用场景
当你下班后打开采集服务时,你不必担心。系统会定时自动下载简历,自动推送面试邀请短信。只要有新人发布相应的求职信息,系统就会立即向他发出邀请,真是抢人的利器。
顺便说一句:用于网络模拟操作的 CEFSharp 将开启新的篇章。 查看全部
自动采集网站内容(如何利用C#Winform和Python解决网站采集敏感信息的问题)
我过去对爬虫的研究不多。最近需要从某个网站采集获取敏感信息。经过一番考虑,我决定使用C#Winform和Python来解决这个事件。
整个方案并不复杂:C#写WinForm表单,进行数据分析和采集,Python本来不想用的,突然没找到C#下Woff字体转Xml的解决方案,但是网上有很多Python程序。所以我添加了一个 Python 项目,虽然只有 1 个脚本。
一、几个步骤:
首先,您必须模拟登录。登录后输入resume采集,然后模拟下载。下载后可以看到求职者的电话。
此电话号码使用动态生成的Base64字体,无法直接提取文字。
1、先把Base64转Woff字体,这个可以用C#来做(iso-8859-1编码是坑,一般用Default会带来惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("iso-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、 然后将生成的Woff转换成XML(WoffDec.exe是我用Python打包的Exe,不过有点繁琐。为了这个转换,我写了一个包,有时间的话还是用整个 C# OK)
//调用python exe 生成xml文件
ProcessStartInfo info = new ProcessStartInfo
{
FileName = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个 WoffDec.py 代码为 3 行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思。我首先尝试了py2exe,但没有成功。我改为 pyinstaller 并且它起作用了。连EXE都有11M,不算大。
下载,或者在VS2017 Python环境中搜索PyInstaller直接安装
右键单击并使用“在此处打开命令提示符”;输入pyinstaller /path/to/yourscript.py 打包成exe文件。调用 Winform 应用程序时,应将整个文件夹复制过来。
3、XML 文件可用后,准备将其存储为基于上述 Woff 文件的数据字典。在XML中找到它的字体锚点,我取X和Y形成唯一值(X,Y代表一个词),当然可以取更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、 以上步骤需要一些时间。基准字典可用后,您可以根据每次生成的 XML 文件匹配真实文本。
5、提取真实文本很简单,直接采集到数据库,然后连接短信发送服务,就可以自动发送群消息了。
二、使用场景
当你下班后打开采集服务时,你不必担心。系统会定时自动下载简历,自动推送面试邀请短信。只要有新人发布相应的求职信息,系统就会立即向他发出邀请,真是抢人的利器。
顺便说一句:用于网络模拟操作的 CEFSharp 将开启新的篇章。
自动采集网站内容(wordpress自动采集插件-AutoGetRssor等插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-08 11:08
这里只介绍wordpress自动采集插件的名字,具体的安装和使用方法这里就不详细说明了。
1、wordpress AUTO采集plugin-Auto 获取 Rss
这个插件可以在Wordpress博客程序上自动更新发布文章的插件,并通过任何RSS或Atom供稿。使用 Wordpress Auto Get Rss 创建自动化博客,例如视频博客、创建主题门户 网站 或聚合 RSS 提要。
2、wordpressauto采集plugin -含咖啡因的内容
本插件是基于关键词搜索Youtube、Yahoo Answer、文章、文件的插件工具。它可以保留原文或翻译成多种国家语言,并可以定期、定量地自动发布在您的博客上。功能非常强大。如果你想自己做二次开发,以此为基础是一个非常好的选择。
3、wordpressauto采集plugin-WP-o-Matic
这个插件是一个非常好的 WordPress采集 插件。虽然缺少自动分类功能,但插件各方面表现都不错。与 wordpress采集plugin Caffeinated Content 相比,wp -o-matic 是一个不错的选择。博客自动采集通过RSS完成。
4、wordpress automatic采集release 插件WP Robot
这个插件是一个基于wordpress平台的内容采集工具。 wp机器人是一个英文网站工具。如果选择主题,它会自动搜索支持采集yahoo 回答的德语、法语、英语和西班牙语相关帖子。
5、wordpressauto采集plugin-FeedWordPress
这个插件用的很好,主要是读取feed更新你的博文,而且是全文的形式。优点是插件更新升级及时!建议不要使用中文包,只使用英文版的WordPress和原版FeedWordPress插件!插件下载后,需要在后台控制面板中激活,可以根据需要自定义功能。
6、wordpress automatic采集plugin-Friends RSS 聚合器 (FRA)
Friends RSS Aggregator (FRA) 这个插件可以通过RSS聚合,只有文章的标题和发布日期。
7、wordpress automatic采集plugin inlineRSS
此插件可以支持多种格式,例如 RSS、RDF、XML 或 HTML。通过Inlinefeed,你可以在特定的文章中制作Rss源码的文章Reality。
8、wordpress automatic采集plugin-autobged
本插件可以根据关键词自动获取YouTube、雅虎回答等内容,进而达到自动发布博客内容的目的。您可以创建自己的博客农场。通过这个插件可以生成视频、图片或者文章博客等
9、wordpressauto采集plugin-smartrss
这个插件可以自动将你喜欢的RSS中的文章随意发布到你的wordpress博客中,让wordpress拥有类似于一些cms的自动采集功能。
10、wordpressauto采集plugin-BDP RSS 聚合器
这个插件可以聚合多个博客的内容。适用于拥有多个博客的博主,或资源聚合分享博主,以及聚合多个博客内容的群组博主。
目前WordPress已经成为主流的博客搭建平台,插件和模板众多,扩展方便。以上插件的目的是为了方便大家做采集站,节省人工时间和成本,更好的自动更新自己的博客内容。选择一个你喜欢尝试的自动采集插件!
如果您喜欢这篇文章,请分享给您的朋友,谢谢!如果您想浏览更多更好的建站程序内容,请登录: 查看全部
自动采集网站内容(wordpress自动采集插件-AutoGetRssor等插件(组图))
这里只介绍wordpress自动采集插件的名字,具体的安装和使用方法这里就不详细说明了。
1、wordpress AUTO采集plugin-Auto 获取 Rss
这个插件可以在Wordpress博客程序上自动更新发布文章的插件,并通过任何RSS或Atom供稿。使用 Wordpress Auto Get Rss 创建自动化博客,例如视频博客、创建主题门户 网站 或聚合 RSS 提要。
2、wordpressauto采集plugin -含咖啡因的内容
本插件是基于关键词搜索Youtube、Yahoo Answer、文章、文件的插件工具。它可以保留原文或翻译成多种国家语言,并可以定期、定量地自动发布在您的博客上。功能非常强大。如果你想自己做二次开发,以此为基础是一个非常好的选择。
3、wordpressauto采集plugin-WP-o-Matic
这个插件是一个非常好的 WordPress采集 插件。虽然缺少自动分类功能,但插件各方面表现都不错。与 wordpress采集plugin Caffeinated Content 相比,wp -o-matic 是一个不错的选择。博客自动采集通过RSS完成。
4、wordpress automatic采集release 插件WP Robot
这个插件是一个基于wordpress平台的内容采集工具。 wp机器人是一个英文网站工具。如果选择主题,它会自动搜索支持采集yahoo 回答的德语、法语、英语和西班牙语相关帖子。
5、wordpressauto采集plugin-FeedWordPress
这个插件用的很好,主要是读取feed更新你的博文,而且是全文的形式。优点是插件更新升级及时!建议不要使用中文包,只使用英文版的WordPress和原版FeedWordPress插件!插件下载后,需要在后台控制面板中激活,可以根据需要自定义功能。
6、wordpress automatic采集plugin-Friends RSS 聚合器 (FRA)
Friends RSS Aggregator (FRA) 这个插件可以通过RSS聚合,只有文章的标题和发布日期。
7、wordpress automatic采集plugin inlineRSS
此插件可以支持多种格式,例如 RSS、RDF、XML 或 HTML。通过Inlinefeed,你可以在特定的文章中制作Rss源码的文章Reality。
8、wordpress automatic采集plugin-autobged
本插件可以根据关键词自动获取YouTube、雅虎回答等内容,进而达到自动发布博客内容的目的。您可以创建自己的博客农场。通过这个插件可以生成视频、图片或者文章博客等
9、wordpressauto采集plugin-smartrss
这个插件可以自动将你喜欢的RSS中的文章随意发布到你的wordpress博客中,让wordpress拥有类似于一些cms的自动采集功能。
10、wordpressauto采集plugin-BDP RSS 聚合器
这个插件可以聚合多个博客的内容。适用于拥有多个博客的博主,或资源聚合分享博主,以及聚合多个博客内容的群组博主。
目前WordPress已经成为主流的博客搭建平台,插件和模板众多,扩展方便。以上插件的目的是为了方便大家做采集站,节省人工时间和成本,更好的自动更新自己的博客内容。选择一个你喜欢尝试的自动采集插件!
如果您喜欢这篇文章,请分享给您的朋友,谢谢!如果您想浏览更多更好的建站程序内容,请登录:
自动采集网站内容( 无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 04:19
无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))
<p>无人值守免费自动采集器软件介绍下载链接httpwwwzzcitynetproductproductaspshare28466 独特的无人值守ET旨在以提高软件自动化程度为突破口,达到无人值守24小时自动化工作的目的。经测试,ET可以长期自动运行,即使时间单位为一年,超高稳定性的软件也需要能够长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有一定的采集软件会自己崩溃甚至导致网站崩溃。最低资源占用ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。严格的数据和网络安全ET使用网站自己的数据发布接口或程序代码不直接操纵发布信息的内容。 网站database 避免了任何ET可能带来的数据安全问题。 采集信息时时时彩网,使用标准的HTTP端口不会造成网络安全漏洞强大灵活的功能除了一般采集工具的功能之外,ET通过支持分页图片水印反为用户提供了灵活性-盗窃链接采集reply采集Login采集自定项UTF-8UBB模拟发布实现多种挖矿开发需求。制定一个好的计划。建造。建设计划。结构示例。建设计划。营销计划。模板。施工组织设计(施工方案)。制作的界面可以支持任何网站或数据库功能 灵活强大采集规则不仅采集文章可采集任何类型的信息,体积小,低功耗,稳定性好,非常适合运行服务器端特性 所有规则都可以导入导出 灵活的资源复用特性 使用FTP上传文件 稳定安全的下载和上传 支持断点续传 特性 高速伪原创采集可倒序随机选择采集文章采集支持自动列表URL采集支持网站数据分布在多个页面采集采集自由设置采集数据项,每个数据项可以单独过滤排序采集支持分页 content采集采集 支持任何格式和类型的文件,包括图片和视频下载采集 可以突破防盗链文件采集 支持动态文件URL 分析采集 支持网页需要登录才能访问采集支持可以设置关键词采集sup端口可设置防止采集敏感词支持可设置发布图片水印支持发布文章带回复,可广泛应用于论坛、博客等项目发布和采集数据分离发布参数项可自由对应采集data或预设值大大增强发布规则的复用性关闭项语言翻译和发布支持编码转换支持UBB代码发布文件上传可选择自动创建年月日目录发布模拟发布支持无法安装接口的网站,发布运营支持计划可以正常工作,支持防止网络运营商劫持HTTP功能支持可以手动执行单个采集发布支持详细的工作流监控信 查看全部
自动采集网站内容(
无人值守免费自动采集器软件介绍下载(httpwwwzzcitynetproductproductaspshare28466-8UBB))
<p>无人值守免费自动采集器软件介绍下载链接httpwwwzzcitynetproductproductaspshare28466 独特的无人值守ET旨在以提高软件自动化程度为突破口,达到无人值守24小时自动化工作的目的。经测试,ET可以长期自动运行,即使时间单位为一年,超高稳定性的软件也需要能够长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有一定的采集软件会自己崩溃甚至导致网站崩溃。最低资源占用ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。严格的数据和网络安全ET使用网站自己的数据发布接口或程序代码不直接操纵发布信息的内容。 网站database 避免了任何ET可能带来的数据安全问题。 采集信息时时时彩网,使用标准的HTTP端口不会造成网络安全漏洞强大灵活的功能除了一般采集工具的功能之外,ET通过支持分页图片水印反为用户提供了灵活性-盗窃链接采集reply采集Login采集自定项UTF-8UBB模拟发布实现多种挖矿开发需求。制定一个好的计划。建造。建设计划。结构示例。建设计划。营销计划。模板。施工组织设计(施工方案)。制作的界面可以支持任何网站或数据库功能 灵活强大采集规则不仅采集文章可采集任何类型的信息,体积小,低功耗,稳定性好,非常适合运行服务器端特性 所有规则都可以导入导出 灵活的资源复用特性 使用FTP上传文件 稳定安全的下载和上传 支持断点续传 特性 高速伪原创采集可倒序随机选择采集文章采集支持自动列表URL采集支持网站数据分布在多个页面采集采集自由设置采集数据项,每个数据项可以单独过滤排序采集支持分页 content采集采集 支持任何格式和类型的文件,包括图片和视频下载采集 可以突破防盗链文件采集 支持动态文件URL 分析采集 支持网页需要登录才能访问采集支持可以设置关键词采集sup端口可设置防止采集敏感词支持可设置发布图片水印支持发布文章带回复,可广泛应用于论坛、博客等项目发布和采集数据分离发布参数项可自由对应采集data或预设值大大增强发布规则的复用性关闭项语言翻译和发布支持编码转换支持UBB代码发布文件上传可选择自动创建年月日目录发布模拟发布支持无法安装接口的网站,发布运营支持计划可以正常工作,支持防止网络运营商劫持HTTP功能支持可以手动执行单个采集发布支持详细的工作流监控信
自动采集网站内容(自动采集网站内容到app上有一个规律或是学习模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-07 23:32
自动采集网站内容到app上有一个规律或是学习模式,就是量。因为每一次查询都要产生费用,如果你刚好在支付宝、微信付款,你又没发现其中的原理,说明你已经失败了,只有网页采集才有可能短时间内让对方支付费用。其实,最好的办法就是让对方付钱,如果对方不付钱,你可以问问收据,询问工商局和仲裁等等。只有付钱了,你才不会被骗。
查一下需要多久时间?也看自己操作上有没有什么误操作。别等待很久才收到一条的情况也有。
他可能没有告诉你价格吧。不是没有对比的价格比较就不高价格,免得不清不楚,后期出现问题。都说买家秀卖家秀,那就认真看看吧,还有问清楚价格和支付渠道。
时间呗,如果多几次,
看了楼上都有好几个答案,
一般不会给你低价代理吧,一般自动采集的话是需要一定时间的,另外客服发现原来的网页代理出售的,一般不会只给你一个价格,如果所有的都降价一样低,那么原有代理,
软件基本可以自动采集导出并批量压缩,快速访问和查看网页内容并在一定程度上解决断网问题,这个问题大多数人是比较适应的,如果你不适应,是要适应,这个东西适应不了换个东西也是可以的,虽然简单粗暴,但也不能忽视,一天也就几次自动访问,你采集的网页量很大就几十次甚至几百次访问那才是关键。 查看全部
自动采集网站内容(自动采集网站内容到app上有一个规律或是学习模式)
自动采集网站内容到app上有一个规律或是学习模式,就是量。因为每一次查询都要产生费用,如果你刚好在支付宝、微信付款,你又没发现其中的原理,说明你已经失败了,只有网页采集才有可能短时间内让对方支付费用。其实,最好的办法就是让对方付钱,如果对方不付钱,你可以问问收据,询问工商局和仲裁等等。只有付钱了,你才不会被骗。
查一下需要多久时间?也看自己操作上有没有什么误操作。别等待很久才收到一条的情况也有。
他可能没有告诉你价格吧。不是没有对比的价格比较就不高价格,免得不清不楚,后期出现问题。都说买家秀卖家秀,那就认真看看吧,还有问清楚价格和支付渠道。
时间呗,如果多几次,
看了楼上都有好几个答案,
一般不会给你低价代理吧,一般自动采集的话是需要一定时间的,另外客服发现原来的网页代理出售的,一般不会只给你一个价格,如果所有的都降价一样低,那么原有代理,
软件基本可以自动采集导出并批量压缩,快速访问和查看网页内容并在一定程度上解决断网问题,这个问题大多数人是比较适应的,如果你不适应,是要适应,这个东西适应不了换个东西也是可以的,虽然简单粗暴,但也不能忽视,一天也就几次自动访问,你采集的网页量很大就几十次甚至几百次访问那才是关键。
自动采集网站内容(YGBOOK小说内容管理系统提供一个轻量级小说网站解决方案阁模板 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 474 次浏览 • 2021-09-07 08:13
)
YGBOOK小说内容管理系统提供轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是cms和thief网站之间的全新网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它完全脱离了网站管理员的手中。只需设置网站,就会自动更新采集+。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK免费版提供基本的新颖功能
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站 Yijin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
YGBOOK小说内容管理系统安装步骤
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或者手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项并填写正确的设置即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK 小说采集系统 v1.4 更新日志
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
YGBOOK小说内容管理系统前台截图
YGBOOK小说内容管理系统后台截图
查看全部
自动采集网站内容(YGBOOK小说内容管理系统提供一个轻量级小说网站解决方案阁模板
)
YGBOOK小说内容管理系统提供轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是cms和thief网站之间的全新网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它完全脱离了网站管理员的手中。只需设置网站,就会自动更新采集+。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK免费版提供基本的新颖功能
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站 Yijin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
YGBOOK小说内容管理系统安装步骤
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或者手动输入域名.com/install)
3.同意使用协议进入下一步检查目录权限
4. 测试通过后,填写通用数据库配置项并填写正确的设置即可完成安装。安装成功后会自动进入后台页面域名.com/admin,填写安装时输入的后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK 小说采集系统 v1.4 更新日志
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
YGBOOK小说内容管理系统前台截图
YGBOOK小说内容管理系统后台截图
自动采集网站内容(【网站采集工具-超级采集】的搜索和采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-06 20:08
[网站采集工具- Super采集]是一款智能的采集软件。 Super采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,super采集会自动搜索你和采集相关信息然后直接发布通过WEB发布模块发送给你的网站。 Super采集目前支持大部分主流cms、通用博客和论坛系统,包括织梦Dede、东易、Discuz、Phpwind、Phpcms、Php168、SuperSite、Empire Ecms、Verycms、Hbcms、风讯、科讯、Wordpress、Z-blog、Joomla等。如果现有的发布模块不能支持你的网站,我们还可以提供标准版和专业版用户免费定制的发布模块来支持你的网站出版。
1、傻瓜式使用方式
Super采集 非常易于使用。您不需要任何与网站采集相关的专业知识和经验。 super采集的核心是智能搜索和采集引擎,它会根据您感兴趣的内容,自动将采集相关信息发布到您的网站。
2、超级强的关键词挖矿工具选择合适的关键词可以为你的网站带来更高的流量和更大的广告价值,超级采集提供关键词Mining工具为你提供日常每个关键词的搜索量,谷歌广告的每次点击预估价格,以及关键词的广告热度信息,可以根据这些信息选择最合适的关键词。
3、content, title伪原创
Super采集提供最新的伪原创引擎,可以做同义词替换、段落重排、多文本混合等,可以选择将信息采集添加到伪原创处理中以增加搜索引擎的收录到网站内容的数量。 查看全部
自动采集网站内容(【网站采集工具-超级采集】的搜索和采集)
[网站采集工具- Super采集]是一款智能的采集软件。 Super采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,super采集会自动搜索你和采集相关信息然后直接发布通过WEB发布模块发送给你的网站。 Super采集目前支持大部分主流cms、通用博客和论坛系统,包括织梦Dede、东易、Discuz、Phpwind、Phpcms、Php168、SuperSite、Empire Ecms、Verycms、Hbcms、风讯、科讯、Wordpress、Z-blog、Joomla等。如果现有的发布模块不能支持你的网站,我们还可以提供标准版和专业版用户免费定制的发布模块来支持你的网站出版。
1、傻瓜式使用方式
Super采集 非常易于使用。您不需要任何与网站采集相关的专业知识和经验。 super采集的核心是智能搜索和采集引擎,它会根据您感兴趣的内容,自动将采集相关信息发布到您的网站。
2、超级强的关键词挖矿工具选择合适的关键词可以为你的网站带来更高的流量和更大的广告价值,超级采集提供关键词Mining工具为你提供日常每个关键词的搜索量,谷歌广告的每次点击预估价格,以及关键词的广告热度信息,可以根据这些信息选择最合适的关键词。
3、content, title伪原创
Super采集提供最新的伪原创引擎,可以做同义词替换、段落重排、多文本混合等,可以选择将信息采集添加到伪原创处理中以增加搜索引擎的收录到网站内容的数量。
自动采集网站内容(Google研发的数据采集插件,这款插件自带反爬虫能力)
采集交流 • 优采云 发表了文章 • 0 个评论 • 543 次浏览 • 2021-09-06 10:15
指南:
【几乎每个人都有从互联网上批量获取信息的需求,比如批量邮件采集网站,批量的商家信息和采集1688、58同城的联系方式,如果让你学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如批量邮件采集网站、批量采集1688、58 同城的商家信息和联系方式,如果你让你去学编程语言?我想很多人连软件怎么安装都不知道,更别说一门完整的编程语言,还要学习正确的网页知识;学习优采云软件?一个很贵,另一个操作起来很麻烦。
今天推荐一个谷歌开发的数据采集插件。这个插件可以带有 cookie 和反爬虫功能。这是非常容易使用。按照流程,基本上10分钟就可以学会了。我一般用采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站,很方便。
Web scraper 是 Google 强大的插件库中非常强大的数据采集 插件。它具有强大的反爬虫能力。只需在插件上进行设置,即可快速抓取知乎、简书、豆瓣、大众、58等大、中、小等网站90%以上的内容,包括文字、图片、表格和其他内容,最后快速导出csv格式文件。谷歌官方给出的网络爬虫描述是:
使用我们的扩展程序,您可以创建计划(站点地图)、应如何遍历网站以及应提取的内容。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。您可以稍后将剪辑的数据导出为 CSV。
这个系列是关于网络爬虫的介绍。完整介绍流程,以知乎、简书等网站为例介绍如何采集文本、表格、多元素爬取、不规则分页爬取、副页爬取、动态网站爬虫,以及一些反爬虫技术。
好的,今天就来介绍一下网络爬虫的安装和完整的爬取过程。
一、web 爬虫安装
网络爬虫是谷歌浏览器的扩展插件,您只需在谷歌浏览器上安装即可。介绍两种安装方式:
1、打开google浏览器更多工具下的扩展程序-进入chrome web应用点-搜索web scraper-点击安装,如下图
但是上面的安装方法需要翻墙到网站国外,所以需要使用vpn,如果你有vpn可以用这种方法,如果没有可以用下面第二种方法:
2、 通过链接:密码:m672,下载网络爬虫安装程序。然后直接将安装程序拖入chrome中的扩展程序即可完成安装。
完成后即可使用。
二、以知乎为例介绍网络爬虫的完整爬取过程
1、Open目标网站,这里以采集知乎第一大v张佳玮的follower为例,需要爬取的是知乎名字,回答数,文章关注@Quantity,关注数量。
2、在网页上右击,选择勾选选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、打开后,点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会出现如图所示的页面。您需要填写站点地图名称,即站点的名称。你可以随便写,只要你能看懂;还需要填写start url,就是抓取页面的链接。填写完毕后,点击创建站点地图,完成站点地图的创建。
详情如下:
4、设置一级选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一级选择器(selector),设置需要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取Elements和content。
以抓取张嘉伟的以下为例。我们的范围是张家伟关注的目标。然后我们需要为这个范围创建一个选择器;而张嘉伟关注的粉丝数,文章@number等是次要选择器的内容。具体步骤如下:
(1)添加新选择器创建一级选择器选择器:
点击后可以得到如下页面,需要抓取的内容都设置在这个页面上。
id:就叫选择器,同理,只要你自己能理解,这里就叫jiawei-scrap。
Type:是要抓取的内容的类型,比如element element/text/link link/picture image/Element Scroll Down 动态加载等,这里如果有多个元素,选择element。
Selector:指选择要抓取的内容。单击选择以选择页面上的内容。下面详细介绍这部分。
Check Multiple:勾选 Multiple 前面的小框,因为要选择多个元素而不是单个元素。勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击选择选项下的选择,得到如下图:
之后,将鼠标移动到需要选择的内容上,需要的内容会变成绿色表示被选中。这里需要提醒一下,如果你需要的内容是多元素的,你需要把元素都改为Select both。例如如下图,绿色表示选中的内容在绿色范围内。
选中内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变成红色时,我们可以选择下一秒的内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容都会变成红色。如下图所示:
确认页面上我们需要的所有内容都变成红色后,点击完成选择选项,可以得到如下图:
点击保存选择器保存设置。之后,一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框内容进入一级选择器jiawei-scrap:
(2)点击添加新选择器创建二级选择器来选择特定内容。
得到如下图,与一级选择器的内容相同,只是设置不同。
id:表示要获取的字段。您可以参加该领域的英语。比如要选择“作者”,就写“作者”;
Type:这里选择Text选项,因为你要抓取的是文本内容;
Multiple:Multiple 前面的小方框不要打勾,因为这里是要捕获的单个元素;
保留设置:保留其他未提及的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变成红色,表示内容被选中。
(4)点击Done选择完成选择,然后点击保存选择器完成关注者知乎name的选择。
重复以上操作,直到选择好要攀爬的场地。
(5)点击红框可以看到采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置内容。
6、爬取数据
(1)只需要设置好所有的selector,就可以开始爬取数据了,点击Scrape map,
选择刮取;:
(2)点击后会跳转到时间设置页面,如下图。由于采集数量不多,可以保存默认。点击开始抓取,会出现一个窗口弹出,官方采集Up。
(3)稍等片刻,得到采集效果,如下图:
(4)在sitemap下选择export data as csv选项,以表格的形式导出采集的结果。
文章1@
表格效果:
文章2@
以上是以知乎为例介绍采集的基本步骤和设置。虽然细节很多,但是仔细算算下来,真的没有多少步骤。基本上10分钟就可以完全掌握采集的流程;不管网站的类型如何,设置的基本过程大致相同。有兴趣的可以深入研究一下。 查看全部
自动采集网站内容(Google研发的数据采集插件,这款插件自带反爬虫能力)
指南:
【几乎每个人都有从互联网上批量获取信息的需求,比如批量邮件采集网站,批量的商家信息和采集1688、58同城的联系方式,如果让你学习编程语言?
几乎每个人都有从网上批量获取信息的需求,比如批量邮件采集网站、批量采集1688、58 同城的商家信息和联系方式,如果你让你去学编程语言?我想很多人连软件怎么安装都不知道,更别说一门完整的编程语言,还要学习正确的网页知识;学习优采云软件?一个很贵,另一个操作起来很麻烦。
今天推荐一个谷歌开发的数据采集插件。这个插件可以带有 cookie 和反爬虫功能。这是非常容易使用。按照流程,基本上10分钟就可以学会了。我一般用采集微博、知乎、豆瓣、58同城、大众点评、汽车之家等网站,很方便。
Web scraper 是 Google 强大的插件库中非常强大的数据采集 插件。它具有强大的反爬虫能力。只需在插件上进行设置,即可快速抓取知乎、简书、豆瓣、大众、58等大、中、小等网站90%以上的内容,包括文字、图片、表格和其他内容,最后快速导出csv格式文件。谷歌官方给出的网络爬虫描述是:
使用我们的扩展程序,您可以创建计划(站点地图)、应如何遍历网站以及应提取的内容。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。您可以稍后将剪辑的数据导出为 CSV。
这个系列是关于网络爬虫的介绍。完整介绍流程,以知乎、简书等网站为例介绍如何采集文本、表格、多元素爬取、不规则分页爬取、副页爬取、动态网站爬虫,以及一些反爬虫技术。
好的,今天就来介绍一下网络爬虫的安装和完整的爬取过程。
一、web 爬虫安装
网络爬虫是谷歌浏览器的扩展插件,您只需在谷歌浏览器上安装即可。介绍两种安装方式:
1、打开google浏览器更多工具下的扩展程序-进入chrome web应用点-搜索web scraper-点击安装,如下图
但是上面的安装方法需要翻墙到网站国外,所以需要使用vpn,如果你有vpn可以用这种方法,如果没有可以用下面第二种方法:
2、 通过链接:密码:m672,下载网络爬虫安装程序。然后直接将安装程序拖入chrome中的扩展程序即可完成安装。
完成后即可使用。
二、以知乎为例介绍网络爬虫的完整爬取过程
1、Open目标网站,这里以采集知乎第一大v张佳玮的follower为例,需要爬取的是知乎名字,回答数,文章关注@Quantity,关注数量。
2、在网页上右击,选择勾选选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、打开后,点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会出现如图所示的页面。您需要填写站点地图名称,即站点的名称。你可以随便写,只要你能看懂;还需要填写start url,就是抓取页面的链接。填写完毕后,点击创建站点地图,完成站点地图的创建。
详情如下:
4、设置一级选择器:选择采集范围
接下来是重中之重。这里先介绍一下网络爬虫的爬取逻辑:需要设置一级选择器(selector),设置需要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取Elements和content。
以抓取张嘉伟的以下为例。我们的范围是张家伟关注的目标。然后我们需要为这个范围创建一个选择器;而张嘉伟关注的粉丝数,文章@number等是次要选择器的内容。具体步骤如下:
(1)添加新选择器创建一级选择器选择器:
点击后可以得到如下页面,需要抓取的内容都设置在这个页面上。
id:就叫选择器,同理,只要你自己能理解,这里就叫jiawei-scrap。
Type:是要抓取的内容的类型,比如element element/text/link link/picture image/Element Scroll Down 动态加载等,这里如果有多个元素,选择element。
Selector:指选择要抓取的内容。单击选择以选择页面上的内容。下面详细介绍这部分。
Check Multiple:勾选 Multiple 前面的小框,因为要选择多个元素而不是单个元素。勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击选择选项下的选择,得到如下图:
之后,将鼠标移动到需要选择的内容上,需要的内容会变成绿色表示被选中。这里需要提醒一下,如果你需要的内容是多元素的,你需要把元素都改为Select both。例如如下图,绿色表示选中的内容在绿色范围内。
选中内容范围后,点击鼠标,选中的内容范围会变成红色,如下图:
当一个内容变成红色时,我们可以选择下一秒的内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容都会变成红色。如下图所示:
确认页面上我们需要的所有内容都变成红色后,点击完成选择选项,可以得到如下图:
点击保存选择器保存设置。之后,一级选择器就创建好了。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框内容进入一级选择器jiawei-scrap:
(2)点击添加新选择器创建二级选择器来选择特定内容。
得到如下图,与一级选择器的内容相同,只是设置不同。
id:表示要获取的字段。您可以参加该领域的英语。比如要选择“作者”,就写“作者”;
Type:这里选择Text选项,因为你要抓取的是文本内容;
Multiple:Multiple 前面的小方框不要打勾,因为这里是要捕获的单个元素;
保留设置:保留其他未提及的默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成黄色,如下图:
点击特定元素后,该元素会变成红色,表示内容被选中。
(4)点击Done选择完成选择,然后点击保存选择器完成关注者知乎name的选择。
重复以上操作,直到选择好要攀爬的场地。
(5)点击红框可以看到采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置内容。
6、爬取数据
(1)只需要设置好所有的selector,就可以开始爬取数据了,点击Scrape map,
选择刮取;:
(2)点击后会跳转到时间设置页面,如下图。由于采集数量不多,可以保存默认。点击开始抓取,会出现一个窗口弹出,官方采集Up。
(3)稍等片刻,得到采集效果,如下图:
(4)在sitemap下选择export data as csv选项,以表格的形式导出采集的结果。
文章1@
表格效果:
文章2@
以上是以知乎为例介绍采集的基本步骤和设置。虽然细节很多,但是仔细算算下来,真的没有多少步骤。基本上10分钟就可以完全掌握采集的流程;不管网站的类型如何,设置的基本过程大致相同。有兴趣的可以深入研究一下。
自动采集网站内容(什么是爬虫,很多人可能不太清楚,爬虫谁的天下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-06 08:03
很多人可能不知道爬虫是什么。爬虫就是抓取互联网公开的数据。如果您不公开,则称为盗窃。如果不公开,则称为采集。得到它!所以你采集得到的越多,你就越了解你的财富。
其实在我们混合互联网的舞台上,我们经常使用爬虫,因为这个时代是数据的时代,谁有数据就是世界。无论是有用的数据还是无用的数据。它总是有它的效果。垃圾也能卖钱。
我们经常看到的爬虫应用就是站群人。 站群是什么东西,就是制造很多垃圾网站。 网站里面的东西跟一切都没有关系。那么他们这么多的数据是从哪里来的呢?他们通常使用采集。如果你是高手,写采集software。一般使用优采云或优采云采集工具,但优采云对编程能力还是有一点要求的。所以小白直接用优采云采集就基本OK了。
刚刚给大家介绍了crawler采集application站群资讯类网站。目前我们讲的是圣火枪360的一个产品应用,就是抓取全网微信群的二维码。那么我们应该如何抓取这些数据。我们应该选择一些大规模高质量的二维码网站,他们网站有很多二维码图片。我们需要采集这些数据。比如二维码图片上方的知乎、微信群等。 采集 怎么用下来。有一天采集5000个微信群会自动加入微信群。自动发送我们业务的图片。这就是营销。这是爬虫应用程序的一方面。
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在。日本加1000组
最热爬虫采集器功能对比:
1.优采云采集器:
一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,通过一系列的分析处理,准确挖掘出需要的数据。
特点:采集无限网页,无限内容;
分布式采集系统提高效率;
支持PHP和C#插件扩展,方便数据的修改和处理。
需要了解优采云规则或正则表达式
2.优采云采集器:
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
特点:支持批量替换过滤文章内容中的文字和链接;
可以批量发帖到网站或论坛多个版块;
具有采集或发帖任务完成后自动关机功能;
3.三人行采集器:
一套站长工具,可以方便的将别人网站、论坛、博客采集的图文内容转移到自己的网站、论坛、博客上,包括论坛注册王采集发POST王和采集移家王三种软件。
特点:采集后才能查看的论坛帖子需要注册登录;
您可以同时批量发帖到论坛的多个版块;
支持批量替换和过滤文章内容中的文本和链接。
4.集搜客:
一款简单好用的网页信息抓取软件,可以抓取网页文字、图表、超链接等网页元素,提供好用的网页抓取软件、数据挖掘策略、行业资讯和前沿技术等。
特点:可以在手机网站上抓取数据;
支持获取指数图表上浮动显示的数据;
成员互相帮助,提高采集效率。
6.优采云采集器:
网页采集软件,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。
特点:简单易用,图形操作完全可视化;
内置可扩展OCR接口,支持解析图片中的文字;
采集任务自动运行,可以按照指定周期自动采集。
目前小白最喜欢的采集器。
如果是长期信息聚合或者内容采集朋友推荐。自己或采集器 操作爬虫。这种可扩展性得到加强。如果是小型工作室,请付钱给其他人并使用其他人的工具。三剑客360专注互联网舞台【电商,自媒体江湖】【粉丝营销机器人】【黑科技软件机器人】 查看全部
自动采集网站内容(什么是爬虫,很多人可能不太清楚,爬虫谁的天下)
很多人可能不知道爬虫是什么。爬虫就是抓取互联网公开的数据。如果您不公开,则称为盗窃。如果不公开,则称为采集。得到它!所以你采集得到的越多,你就越了解你的财富。
其实在我们混合互联网的舞台上,我们经常使用爬虫,因为这个时代是数据的时代,谁有数据就是世界。无论是有用的数据还是无用的数据。它总是有它的效果。垃圾也能卖钱。
我们经常看到的爬虫应用就是站群人。 站群是什么东西,就是制造很多垃圾网站。 网站里面的东西跟一切都没有关系。那么他们这么多的数据是从哪里来的呢?他们通常使用采集。如果你是高手,写采集software。一般使用优采云或优采云采集工具,但优采云对编程能力还是有一点要求的。所以小白直接用优采云采集就基本OK了。
刚刚给大家介绍了crawler采集application站群资讯类网站。目前我们讲的是圣火枪360的一个产品应用,就是抓取全网微信群的二维码。那么我们应该如何抓取这些数据。我们应该选择一些大规模高质量的二维码网站,他们网站有很多二维码图片。我们需要采集这些数据。比如二维码图片上方的知乎、微信群等。 采集 怎么用下来。有一天采集5000个微信群会自动加入微信群。自动发送我们业务的图片。这就是营销。这是爬虫应用程序的一方面。
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在
朋友们可以知乎我“三剑客360”目前,全自动采集群加群机器人还在试用阶段。让您的营销无处不在。日本加1000组
最热爬虫采集器功能对比:
1.优采云采集器:
一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上分散的数据信息,通过一系列的分析处理,准确挖掘出需要的数据。
特点:采集无限网页,无限内容;
分布式采集系统提高效率;
支持PHP和C#插件扩展,方便数据的修改和处理。
需要了解优采云规则或正则表达式
2.优采云采集器:
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
特点:支持批量替换过滤文章内容中的文字和链接;
可以批量发帖到网站或论坛多个版块;
具有采集或发帖任务完成后自动关机功能;
3.三人行采集器:
一套站长工具,可以方便的将别人网站、论坛、博客采集的图文内容转移到自己的网站、论坛、博客上,包括论坛注册王采集发POST王和采集移家王三种软件。
特点:采集后才能查看的论坛帖子需要注册登录;
您可以同时批量发帖到论坛的多个版块;
支持批量替换和过滤文章内容中的文本和链接。
4.集搜客:
一款简单好用的网页信息抓取软件,可以抓取网页文字、图表、超链接等网页元素,提供好用的网页抓取软件、数据挖掘策略、行业资讯和前沿技术等。
特点:可以在手机网站上抓取数据;
支持获取指数图表上浮动显示的数据;
成员互相帮助,提高采集效率。
6.优采云采集器:
网页采集软件,可以从不同的网站获取标准化数据,帮助客户实现数据自动化采集、编辑、标准化,从而降低成本,提高效率。
特点:简单易用,图形操作完全可视化;
内置可扩展OCR接口,支持解析图片中的文字;
采集任务自动运行,可以按照指定周期自动采集。
目前小白最喜欢的采集器。
如果是长期信息聚合或者内容采集朋友推荐。自己或采集器 操作爬虫。这种可扩展性得到加强。如果是小型工作室,请付钱给其他人并使用其他人的工具。三剑客360专注互联网舞台【电商,自媒体江湖】【粉丝营销机器人】【黑科技软件机器人】
自动采集网站内容(优采云软件真的很厉害,但是外链怎么发,引流怎么做呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-06 07:19
事情就是这样。前几天有个小哥过来问你优采云software 真的很好,但是怎么发外链,怎么引流?
这相当于“喂,刀师傅,你用这把刀切出来的肉怎么做最好吃?”别说刀少爷会不会做饭,这个人的口味总是有区别的~所以小小编请教了一位老司机。不敢说下面的方法绝对适合你,但都是经验~分享给大家~
我是一个纯粹的采集站长。下面的总结,有的是关于SEO的,有的是关于采集和运维的,都是很基本的个人意见,仅供分享,好坏自我鉴别,实践出真知。
我说原创good,为什么采集?
作为评委,百度确实说了原创help收录。但是我没有很好的写作能力,也没有精力和财力去建立一个持续输出的团队。第三,我觉得采集有方法不一定不如原创没有方法。
为什么采集有方法比原创没有方法好?
原创有什么办法?即原创文章不收录,即使收录不再排名。作为搜索引擎,核心价值是为用户提供最需要的结果。就算你文章写的很好,对于搜索用户来说,也是不符合别人需求的无意义内容。
采集 是什么方法?也就是说,文章是根据网友的强烈需求及时抓拍的。面对需求,这种内容往往收录更快,更多。
采集有没有办法或者如何判断收录的可能性?
关键词。每一次搜索关键词的背后,都是网友的需求。或许是追求问题的答案,或者追求搜索结果。搜索引擎内部分析肯定会匹配到精准的内容,当然是基于精准的关键词。
优采云采集器如何帮助伪原创和收录?
可以直接关注关键词采集;
段落可以重新排列,同义词可以替换(如何在不降低文章质量的情况下使用它,需要慎重考虑);
清理标签,去除乱码;
可以使用缩略图和文字图片来抓取图片和文字;
可以使用原标题,关键词可以与标题自由组合。
自己探索...
不同的网站 程序,例如织梦、WordPress 和 Empirecms 对 SEO 有什么影响?
理论上没有影响。但是很多站长认为有的比较友好,有不同的看法。例如,从网站安全的角度来看,近年来,由于织梦系统的用户数量众多,成为主要攻击目标,因此产生了大量的漏洞,很多网站网站 文件不写死就会变成。安全隐患,wordpress多为博客,自身商业价值小,因此攻击较少,发现漏洞较少。
但本质上,使用什么程序并没有多大意义。其实影响SEO的是模板,因为基本上这些程序都有模板机制。同一个程序可以输出不同的页面,不同的程序也可以输出同一个页面。这是模板。模板确定后,你的每个页面都会按照这个框架输出,也就是整个html结构就确定了。而这些html正是搜索引擎应该关注的,它要从这些html中获取自己想要的信息。因此,一套好的模板非常重要。
当然,最重要的是SEOer本身。
模板设计需要注意哪些细节?
1. 权重结构的顺序。在整个页面的html中(注意是html,不是显示的布局),位置越高权重越高。推而广之,“title”、keyword、description这三个标签的权重最高,因为它们是最高级的。其次通常是导航,基本上是最高的,权重也很高。再次,文章 标题和正文。这是按照html的前后排序。
2. 因为搜索引擎首先要遵循W3C的标准,所以W3C定义的一些标签原本是用来表示重要的信息的,权重自然要高一些,比如特别是h1,用来表示最重要的信息当前页面的信息 一般情况下,每页只能有一个信息。权重估计相当于标题。通常用于放置当前页面的标题。当然,为了增加首页的权重,可以使用h1来放置logo或者首页链接。另外还有em、strong等标签,用来表示强调。一般认为强权重高于标签,这也是一个大胆的效果,但我们认为从SEO的角度来看没有权重提升。
3. css 或 js 代码通常对搜索引擎毫无意义。尝试使用单独的文件来存储它,或者如果允许将它放在 html 的末尾。
网站结构规划应注意哪些问题?
1. 网址设计。 URL 也可以收录关键词。比如你的网站是关于电脑的,你的网址可以收录“PC”,因为它在搜索引擎眼中通常是“电脑”的同义词。网址不要太长,级别不要超过4级。
2. 栏目设计。列通常与导航相关联。设计时要考虑网站的整体主题。用户可能感兴趣的内容。列名最好是网站的几个主要关键词,这样也方便导航。的重量。
3.关键词布局。理论上,每个内容页都应该在同一栏目下有自己的核心关键词、文章,并尽可能围绕关键词栏目展开。一个简单粗暴的做法就是直接用关键词列的长尾词。
动态、伪静态、静态,三者哪个更好?
这个不能一概而论,建议使用伪静态或者静态。三者的区别在于是否生成静态文件和URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态只是通过URL重写来修改URL,其实每次还是需要经过程序计算,查询数据库,输出页面。对加快访问速度完全无效。动态和伪静态的唯一区别是网址,带问号和参数。
所以只注意两点:网站打开速度够快吗?您需要节省服务器空间吗?
网站fast speed 可以提高用户满意度,提高网页的整体质量。保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。另外网站的广告不应干扰用户的正常访问。
不同的网站程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,则页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常会考虑静态化。
提高访问速度的方法有哪些?
1. 上面已经提到的静态化。
2. 通常很多网站 模板都会随机调用文章 或类似的部分。事实上,随机性对数据库来说是一个更重的负担。模板中的随机文章应该被最小化。 @的电话。如果不可避免,请考虑从数据库进行优化。使用索引对字段进行排序通常比不使用索引要快得多。
3. 把不经常修改的图片、js、css等文件放在专用的静态服务器上。如果可以合并多个js或css,尽量合并成一个文件,减少http连接数。
4. 使用各种云加速产品。
网站内链应该如何优化?
内链是百度官方推荐的优化方式之一,所以这个是必须要做的。通常的表现形式是文中出现某个关键词,在这个关键词上加了一个链接,指向另一个恰好与这个关键词相关的页面。于是,诞生了一些所谓的优化技巧,强行在文中插入一些关键词和链接,进行类似相互推送的操作。其他人,为了增加首页的权重,到处放网站名字,并链接到首页,认为这样可以增加目标页面的权重。但这些很可能适得其反,因为搜索引擎会计算每个链接的点击率。如果您点击突出显示但很少点击的链接,它们可能会被判断为作弊。因此,请只做文中已有的关键词内部链接。
评论模块基本没用过,到底要不要做?
是的。评论模块最麻烦的就是垃圾评论。通常真正说话的访问者很少,垃圾评论也很多。他们整天与营销软件作斗争。这是我已经实现的解决方案,可能对收录有帮助(没有依据,只是猜测):
保留评论框,但禁用评论。所有评论均由我的网站 程序生成。如前所述,搜索引擎会进行自然语义分析。重要的能力之一是情绪判断。搜索引擎会计算每条评论的情感值,无论是正面的还是负面的,具体倾向是10%还是90%。如果评论的内容表达了积极的情绪,您可以在文本中加分,反之亦然。至于如何自动生成好评,就让八仙渡海各显神通吧。
这是社交网络发展后的必然趋势。这样,它就反映了一个页面的用户体验。同理,还有分享、点赞等,原理类似。
绿萝卜算法之后,有没有外链的用处?
有用。参见搜索引擎三定律的相关定律。既然是法律,就不会改变。谁的内容被引用得越多,就是权威。在主动推送出现之前,外链应该被视为蜘蛛识别页面内容的第一个渠道。
外部链接必须是锚文本还是裸链接?
没有。搜索引擎肩负着发现真正有价值的内容并排除那些没有价值的内容的重大责任。所以有可能你直接提交的链接不是收录,你可以直接在别人的地方发一个纯文本的URL。如果找到了,也算加分。
除了锚文本和裸链接,你还可以以关键词+ URL的形式发送纯文本。这样URL前面的关键词就自动和URL关联起来了。
另外,虽然有些链接添加了nofollow属性,但是百度计算外链的时候还是会计算的。
最后拒绝不好的采集!
质量内容标准很难定义。有时伪原创 感觉比原创 更好。目前网站有采集的行为其实很多。大多数新闻站也会分享采集,而百度没有。明确指出如何判断采集,所以一些适当的采集是必要的。但可以肯定的是,你不应该做坏采集、镜像和盗版网站。百度上周推出了飓风算法,并将定期生成惩罚数据。我想每个人都在关注。 查看全部
自动采集网站内容(优采云软件真的很厉害,但是外链怎么发,引流怎么做呢?)
事情就是这样。前几天有个小哥过来问你优采云software 真的很好,但是怎么发外链,怎么引流?
这相当于“喂,刀师傅,你用这把刀切出来的肉怎么做最好吃?”别说刀少爷会不会做饭,这个人的口味总是有区别的~所以小小编请教了一位老司机。不敢说下面的方法绝对适合你,但都是经验~分享给大家~
我是一个纯粹的采集站长。下面的总结,有的是关于SEO的,有的是关于采集和运维的,都是很基本的个人意见,仅供分享,好坏自我鉴别,实践出真知。
我说原创good,为什么采集?
作为评委,百度确实说了原创help收录。但是我没有很好的写作能力,也没有精力和财力去建立一个持续输出的团队。第三,我觉得采集有方法不一定不如原创没有方法。
为什么采集有方法比原创没有方法好?
原创有什么办法?即原创文章不收录,即使收录不再排名。作为搜索引擎,核心价值是为用户提供最需要的结果。就算你文章写的很好,对于搜索用户来说,也是不符合别人需求的无意义内容。
采集 是什么方法?也就是说,文章是根据网友的强烈需求及时抓拍的。面对需求,这种内容往往收录更快,更多。
采集有没有办法或者如何判断收录的可能性?
关键词。每一次搜索关键词的背后,都是网友的需求。或许是追求问题的答案,或者追求搜索结果。搜索引擎内部分析肯定会匹配到精准的内容,当然是基于精准的关键词。
优采云采集器如何帮助伪原创和收录?
可以直接关注关键词采集;
段落可以重新排列,同义词可以替换(如何在不降低文章质量的情况下使用它,需要慎重考虑);
清理标签,去除乱码;
可以使用缩略图和文字图片来抓取图片和文字;
可以使用原标题,关键词可以与标题自由组合。
自己探索...
不同的网站 程序,例如织梦、WordPress 和 Empirecms 对 SEO 有什么影响?
理论上没有影响。但是很多站长认为有的比较友好,有不同的看法。例如,从网站安全的角度来看,近年来,由于织梦系统的用户数量众多,成为主要攻击目标,因此产生了大量的漏洞,很多网站网站 文件不写死就会变成。安全隐患,wordpress多为博客,自身商业价值小,因此攻击较少,发现漏洞较少。
但本质上,使用什么程序并没有多大意义。其实影响SEO的是模板,因为基本上这些程序都有模板机制。同一个程序可以输出不同的页面,不同的程序也可以输出同一个页面。这是模板。模板确定后,你的每个页面都会按照这个框架输出,也就是整个html结构就确定了。而这些html正是搜索引擎应该关注的,它要从这些html中获取自己想要的信息。因此,一套好的模板非常重要。
当然,最重要的是SEOer本身。
模板设计需要注意哪些细节?
1. 权重结构的顺序。在整个页面的html中(注意是html,不是显示的布局),位置越高权重越高。推而广之,“title”、keyword、description这三个标签的权重最高,因为它们是最高级的。其次通常是导航,基本上是最高的,权重也很高。再次,文章 标题和正文。这是按照html的前后排序。
2. 因为搜索引擎首先要遵循W3C的标准,所以W3C定义的一些标签原本是用来表示重要的信息的,权重自然要高一些,比如特别是h1,用来表示最重要的信息当前页面的信息 一般情况下,每页只能有一个信息。权重估计相当于标题。通常用于放置当前页面的标题。当然,为了增加首页的权重,可以使用h1来放置logo或者首页链接。另外还有em、strong等标签,用来表示强调。一般认为强权重高于标签,这也是一个大胆的效果,但我们认为从SEO的角度来看没有权重提升。
3. css 或 js 代码通常对搜索引擎毫无意义。尝试使用单独的文件来存储它,或者如果允许将它放在 html 的末尾。
网站结构规划应注意哪些问题?
1. 网址设计。 URL 也可以收录关键词。比如你的网站是关于电脑的,你的网址可以收录“PC”,因为它在搜索引擎眼中通常是“电脑”的同义词。网址不要太长,级别不要超过4级。
2. 栏目设计。列通常与导航相关联。设计时要考虑网站的整体主题。用户可能感兴趣的内容。列名最好是网站的几个主要关键词,这样也方便导航。的重量。
3.关键词布局。理论上,每个内容页都应该在同一栏目下有自己的核心关键词、文章,并尽可能围绕关键词栏目展开。一个简单粗暴的做法就是直接用关键词列的长尾词。
动态、伪静态、静态,三者哪个更好?
这个不能一概而论,建议使用伪静态或者静态。三者的区别在于是否生成静态文件和URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态只是通过URL重写来修改URL,其实每次还是需要经过程序计算,查询数据库,输出页面。对加快访问速度完全无效。动态和伪静态的唯一区别是网址,带问号和参数。
所以只注意两点:网站打开速度够快吗?您需要节省服务器空间吗?
网站fast speed 可以提高用户满意度,提高网页的整体质量。保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。另外网站的广告不应干扰用户的正常访问。
不同的网站程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,则页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常会考虑静态化。
提高访问速度的方法有哪些?
1. 上面已经提到的静态化。
2. 通常很多网站 模板都会随机调用文章 或类似的部分。事实上,随机性对数据库来说是一个更重的负担。模板中的随机文章应该被最小化。 @的电话。如果不可避免,请考虑从数据库进行优化。使用索引对字段进行排序通常比不使用索引要快得多。
3. 把不经常修改的图片、js、css等文件放在专用的静态服务器上。如果可以合并多个js或css,尽量合并成一个文件,减少http连接数。
4. 使用各种云加速产品。
网站内链应该如何优化?
内链是百度官方推荐的优化方式之一,所以这个是必须要做的。通常的表现形式是文中出现某个关键词,在这个关键词上加了一个链接,指向另一个恰好与这个关键词相关的页面。于是,诞生了一些所谓的优化技巧,强行在文中插入一些关键词和链接,进行类似相互推送的操作。其他人,为了增加首页的权重,到处放网站名字,并链接到首页,认为这样可以增加目标页面的权重。但这些很可能适得其反,因为搜索引擎会计算每个链接的点击率。如果您点击突出显示但很少点击的链接,它们可能会被判断为作弊。因此,请只做文中已有的关键词内部链接。
评论模块基本没用过,到底要不要做?
是的。评论模块最麻烦的就是垃圾评论。通常真正说话的访问者很少,垃圾评论也很多。他们整天与营销软件作斗争。这是我已经实现的解决方案,可能对收录有帮助(没有依据,只是猜测):
保留评论框,但禁用评论。所有评论均由我的网站 程序生成。如前所述,搜索引擎会进行自然语义分析。重要的能力之一是情绪判断。搜索引擎会计算每条评论的情感值,无论是正面的还是负面的,具体倾向是10%还是90%。如果评论的内容表达了积极的情绪,您可以在文本中加分,反之亦然。至于如何自动生成好评,就让八仙渡海各显神通吧。
这是社交网络发展后的必然趋势。这样,它就反映了一个页面的用户体验。同理,还有分享、点赞等,原理类似。
绿萝卜算法之后,有没有外链的用处?
有用。参见搜索引擎三定律的相关定律。既然是法律,就不会改变。谁的内容被引用得越多,就是权威。在主动推送出现之前,外链应该被视为蜘蛛识别页面内容的第一个渠道。
外部链接必须是锚文本还是裸链接?
没有。搜索引擎肩负着发现真正有价值的内容并排除那些没有价值的内容的重大责任。所以有可能你直接提交的链接不是收录,你可以直接在别人的地方发一个纯文本的URL。如果找到了,也算加分。
除了锚文本和裸链接,你还可以以关键词+ URL的形式发送纯文本。这样URL前面的关键词就自动和URL关联起来了。
另外,虽然有些链接添加了nofollow属性,但是百度计算外链的时候还是会计算的。
最后拒绝不好的采集!
质量内容标准很难定义。有时伪原创 感觉比原创 更好。目前网站有采集的行为其实很多。大多数新闻站也会分享采集,而百度没有。明确指出如何判断采集,所以一些适当的采集是必要的。但可以肯定的是,你不应该做坏采集、镜像和盗版网站。百度上周推出了飓风算法,并将定期生成惩罚数据。我想每个人都在关注。
自动采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-06 07:18
采集profit
采集可以让一个网站收录在短时间内得到很大的提升(前提是你的网站的实力够高),可以把大部分的网络流量,抢占其他竞争的对手的流量。
采集Harmful
很多采集会让百度认为你的网站上没有客户想要的信息。这纯粹是一个垃圾站。如果你明天采集百篇,采集两百篇,后天我不会采集,所以更新频率参差不齐,百度会关注你。
首先,它可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,也可以让用户在登录网站时观看一些内容,虽然内容比较陈旧,总比没有内容好让用户看。
其次,内容采集可以快速获取与此网站相关的最新内容。因为在采集的内容中,可以关注网站的关键词和相关栏目采集的内容,而且这些内容可以是最新鲜的内容,让用户可以快速浏览网站获得相关内容,无需再通过搜索引擎搜索,一定程度上提升网站的用户体验。
当然采集内容的弊端还是很明显的,尤其是抄袭采集和大规模的采集会对网站造成不良影响,所以一定要掌握正确的采集方法, 只有这样才能充分发挥内容采集的优势。
下面我们来详细分析一下正确的采集方法。
首先要做的是优先处理采集 内容。即选择与网站相关的内容,内容尽量新鲜。如果太老了,尤其是新闻内容,老内容不需要采集,但是对于技术帖,可以适当采集,因为这些技术帖对很多新人有很好的帮助作用。
那么采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“网站群产品安全吗”,可以换成“网站群产品会不安全,会有什么影响?”等等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思想可以一一对应,防止出现卖狗肉的内容。
最后是适当调整内容。这里的内容调整不需要简单的替换段落,也不需要使用伪原创替换同义词或相似词。这样的替换只会让内容不舒服,用户的阅读体验也会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是第一段和最后一段,进行改写,然后适当的添加相应的图片,可以有效的提高内容的质量,也可以给百度蜘蛛带来更好的效果。上诉。
总之,网站内容采集根本不需要棍子就可以杀人。其实它只需要把传统粗鲁的采集适当优化一下,改成精致的采集,虽然采集的时间会比较长,但是比起原创快多了,而且不会影响用户体验,所以正确的采集还是很有必要的。 查看全部
自动采集网站内容(采集有益采集能使一个网站的收录在短时间内得到大幅度)
采集profit
采集可以让一个网站收录在短时间内得到很大的提升(前提是你的网站的实力够高),可以把大部分的网络流量,抢占其他竞争的对手的流量。
采集Harmful
很多采集会让百度认为你的网站上没有客户想要的信息。这纯粹是一个垃圾站。如果你明天采集百篇,采集两百篇,后天我不会采集,所以更新频率参差不齐,百度会关注你。
首先,它可以在短时间内丰富网站的内容,让百度蜘蛛正常遍历一个网站,也可以让用户在登录网站时观看一些内容,虽然内容比较陈旧,总比没有内容好让用户看。
其次,内容采集可以快速获取与此网站相关的最新内容。因为在采集的内容中,可以关注网站的关键词和相关栏目采集的内容,而且这些内容可以是最新鲜的内容,让用户可以快速浏览网站获得相关内容,无需再通过搜索引擎搜索,一定程度上提升网站的用户体验。
当然采集内容的弊端还是很明显的,尤其是抄袭采集和大规模的采集会对网站造成不良影响,所以一定要掌握正确的采集方法, 只有这样才能充分发挥内容采集的优势。
下面我们来详细分析一下正确的采集方法。
首先要做的是优先处理采集 内容。即选择与网站相关的内容,内容尽量新鲜。如果太老了,尤其是新闻内容,老内容不需要采集,但是对于技术帖,可以适当采集,因为这些技术帖对很多新人有很好的帮助作用。
那么采集的内容要适当改成标题。这里改标题不是要求采集人做标题党,而是根据内容主题改相应的标题。比如原标题是“网站群产品安全吗”,可以换成“网站群产品会不安全,会有什么影响?”等等,文字内容不同,但表达的内涵是一样的,这样采集的内容标题和内容思想可以一一对应,防止出现卖狗肉的内容。
最后是适当调整内容。这里的内容调整不需要简单的替换段落,也不需要使用伪原创替换同义词或相似词。这样的替换只会让内容不舒服,用户的阅读体验也会大打折扣。而现在百度对此类伪原创内容进行了严厉打击,对网站的优化效果将产生严重的负面影响。在调整内容的时候,可以适当的改写,尤其是第一段和最后一段,进行改写,然后适当的添加相应的图片,可以有效的提高内容的质量,也可以给百度蜘蛛带来更好的效果。上诉。
总之,网站内容采集根本不需要棍子就可以杀人。其实它只需要把传统粗鲁的采集适当优化一下,改成精致的采集,虽然采集的时间会比较长,但是比起原创快多了,而且不会影响用户体验,所以正确的采集还是很有必要的。
自动采集网站内容(如何利用自动采集网站副业赚钱视频教程,此项目分支)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-06 06:20
如何使用自动采集网站side业务赚钱视频教程,本项目属于网站course的一个分支。
传统的采集站有很多优点:
2、采集完成后,会随着时间的推移不断积累,网站weight 会一直变高。
1、传统采集站成功率低。
3、集集站不稳定,百度整改新算法会导致网站一向上下震荡。
与传统采集站相比,本教程采集站相比传统采集站有非常显着的提升。
2、不需要旧域名(旧域名也可以)。
4、这也是一套基本的SEO教程。可以用这个方法学SEO的同时建网站赚钱。
6、应用场景超广!采集站可以通过挂广告和卖钱来赚钱。这个方法还可以帮你做更多类型的网站,包括:博客站、资讯站、导航站、电影站、摄影站。只需要文字内容的网站非常适合!
1、新采集站教程采集不是一次性采集,而是每天采集3-10篇文章。
这套课程的开发花费了很长时间。经过表姐和女朋友的考验,一年采集了一张爱站权重4网站。日本IP在3W之间徘徊,鱼爪。上面列表中的额定值为 13W。这是网站,一个上班族利用空闲时间和下班时间。
二、课程介绍
所需时间:采集站需要一个准备周期。这个周期大约需要3-7天。课程准备完成后,即可建立初始站。建站后,每天采集一篇文章3-5分钟,初期每天推荐5篇,中后期每天推荐10篇。
课程内容:课程共分5章16节,时长约4小时。课程生产日期,2020 年 2 月。
很多人喜欢全职做这份工作,但最好的方法是最初从兼职转为全职。
当然,收获与付出成正比。操作网站的时间越多,获得的奖励就越高。 查看全部
自动采集网站内容(如何利用自动采集网站副业赚钱视频教程,此项目分支)
如何使用自动采集网站side业务赚钱视频教程,本项目属于网站course的一个分支。
传统的采集站有很多优点:
2、采集完成后,会随着时间的推移不断积累,网站weight 会一直变高。
1、传统采集站成功率低。
3、集集站不稳定,百度整改新算法会导致网站一向上下震荡。
与传统采集站相比,本教程采集站相比传统采集站有非常显着的提升。
2、不需要旧域名(旧域名也可以)。
4、这也是一套基本的SEO教程。可以用这个方法学SEO的同时建网站赚钱。
6、应用场景超广!采集站可以通过挂广告和卖钱来赚钱。这个方法还可以帮你做更多类型的网站,包括:博客站、资讯站、导航站、电影站、摄影站。只需要文字内容的网站非常适合!
1、新采集站教程采集不是一次性采集,而是每天采集3-10篇文章。
这套课程的开发花费了很长时间。经过表姐和女朋友的考验,一年采集了一张爱站权重4网站。日本IP在3W之间徘徊,鱼爪。上面列表中的额定值为 13W。这是网站,一个上班族利用空闲时间和下班时间。
二、课程介绍
所需时间:采集站需要一个准备周期。这个周期大约需要3-7天。课程准备完成后,即可建立初始站。建站后,每天采集一篇文章3-5分钟,初期每天推荐5篇,中后期每天推荐10篇。
课程内容:课程共分5章16节,时长约4小时。课程生产日期,2020 年 2 月。
很多人喜欢全职做这份工作,但最好的方法是最初从兼职转为全职。
当然,收获与付出成正比。操作网站的时间越多,获得的奖励就越高。
自动采集网站内容(自动采集网站内容的网站有哪些呢,常见的有以下几个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-06 04:05
自动采集网站内容的网站有哪些呢,常见的有以下几个:1.百度关键词规划师关键词规划师是百度的关键词推荐工具,利用系统给出的关键词做个性化布局可以快速收集到大量的网站内容2.搜狗热门文章搜狗可以找到更多的热门网站内容,比如说只要输入主题关键词就可以找到跟主题相关的更多网站内容;只要输入热门关键词更可以找到相关的热门网站内容。
比如说像“云南招教师”,就可以在搜狗搜索里面找到多个与云南招教师相关的网站。很多网站的网址都有直接给出来的,用的就是这种百度关键词规划师的。3.58同城58同城里面全部是针对全国招聘的信息,无论是在一线城市、二三线城市或是农村,只要是想找工作的人都可以在58同城找到自己想要的信息。这点是其他任何站点都比不了的。
4.赶集网、搜索公司招聘内容也能找到其他相关网站的内容。5.豆瓣小组豆瓣小组是针对用户需求进行网站建设,也可以很好地搜索到与主题相关的信息。6.知乎、企鹅问答现在市面上很多问答平台,如:天涯问答、百度知道、知乎、论坛等都可以搜索到相关内容。7.中国各大门户网站与人对话可以找到对方的信息,利用好人工智能技术对话可以扩展人与人之间的谈话信息。
8.度娘搜索利用搜索指令、分词技术和热门搜索结果,可以搜索到很多的网站内容,常见的有百度翻译等。9.等等等等其他各种网站搜索工具。看到这里可能你会想这样的方法确实不错,不过价格可能是最贵的,还是上面说的几个大平台更划算,还能匹配到需要网站的内容,这样会节省很多钱。下面是相应的关键词定位工具提供给大家:1.首页定位词2.站长帮3.自建站3.3大类定位词4.电商定位词5.门户定位词6.找资料7.二维码/网址提取内容8.快速抓取定位词9.站长社区10.词汇锁定11.网站定位词搜索工具1.独立站爱站seoer-bot这是一个网站seo体检工具。
可以快速发现自己网站相关的seo指标2.g站竞争对手分析googleanalysis-seller-competitive-google-analysis这是谷歌分析工具,经常用谷歌查竞争对手,竞争对手的网站内容抓取速度特别快。3.seoeye5.高级站长生意模型wordpress站长工具,主要是关键词排名,一键导出google关键词的内容。
4.站长评论分析yahoo!sitescout这是谷歌分析工具,可以查询google网站的seo信息,提高网站排名。5.谷歌在线工具平台googleanalytics6.谷歌监控googleanalytics-googleanalytics就是谷歌搜索引擎分析工具。7.谷歌一键收录工具googlepagepruneab图谷歌一键收录工具-google一键收录。 查看全部
自动采集网站内容(自动采集网站内容的网站有哪些呢,常见的有以下几个)
自动采集网站内容的网站有哪些呢,常见的有以下几个:1.百度关键词规划师关键词规划师是百度的关键词推荐工具,利用系统给出的关键词做个性化布局可以快速收集到大量的网站内容2.搜狗热门文章搜狗可以找到更多的热门网站内容,比如说只要输入主题关键词就可以找到跟主题相关的更多网站内容;只要输入热门关键词更可以找到相关的热门网站内容。
比如说像“云南招教师”,就可以在搜狗搜索里面找到多个与云南招教师相关的网站。很多网站的网址都有直接给出来的,用的就是这种百度关键词规划师的。3.58同城58同城里面全部是针对全国招聘的信息,无论是在一线城市、二三线城市或是农村,只要是想找工作的人都可以在58同城找到自己想要的信息。这点是其他任何站点都比不了的。
4.赶集网、搜索公司招聘内容也能找到其他相关网站的内容。5.豆瓣小组豆瓣小组是针对用户需求进行网站建设,也可以很好地搜索到与主题相关的信息。6.知乎、企鹅问答现在市面上很多问答平台,如:天涯问答、百度知道、知乎、论坛等都可以搜索到相关内容。7.中国各大门户网站与人对话可以找到对方的信息,利用好人工智能技术对话可以扩展人与人之间的谈话信息。
8.度娘搜索利用搜索指令、分词技术和热门搜索结果,可以搜索到很多的网站内容,常见的有百度翻译等。9.等等等等其他各种网站搜索工具。看到这里可能你会想这样的方法确实不错,不过价格可能是最贵的,还是上面说的几个大平台更划算,还能匹配到需要网站的内容,这样会节省很多钱。下面是相应的关键词定位工具提供给大家:1.首页定位词2.站长帮3.自建站3.3大类定位词4.电商定位词5.门户定位词6.找资料7.二维码/网址提取内容8.快速抓取定位词9.站长社区10.词汇锁定11.网站定位词搜索工具1.独立站爱站seoer-bot这是一个网站seo体检工具。
可以快速发现自己网站相关的seo指标2.g站竞争对手分析googleanalysis-seller-competitive-google-analysis这是谷歌分析工具,经常用谷歌查竞争对手,竞争对手的网站内容抓取速度特别快。3.seoeye5.高级站长生意模型wordpress站长工具,主要是关键词排名,一键导出google关键词的内容。
4.站长评论分析yahoo!sitescout这是谷歌分析工具,可以查询google网站的seo信息,提高网站排名。5.谷歌在线工具平台googleanalytics6.谷歌监控googleanalytics-googleanalytics就是谷歌搜索引擎分析工具。7.谷歌一键收录工具googlepagepruneab图谷歌一键收录工具-google一键收录。
自动采集网站内容(与VN创造者交谈,带采集规则的源码是你的选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-05 16:08
小说网站源码好用,但采集规则是关键一环。您计划自己的故事,绘制所有对话,创造令人难忘的角色,然后将这些内容整合成一部功能齐全的小说网站。
源代码和演示:xsymz.icu
当你开始写小说网站时,源代码可能是你听到的第一点。跟VN的创建者聊一聊,带有采集规则的源码是大多数人的选择。小说网站已经存在很长时间了,你可能读过不同风格的小说网站。它是一个开源代码系统,您只需要知道如何编辑文本和使用一些基本的 PJP 编程即可。但是,这些都可以通过访问在线教程、修改示例项目和独立学习 PHP 来学习。
当我开始创建自己的小说网站时,我首先需要上传Novel网站源代码,因为几年前我用它参加了一个在线比赛(并且赢了!),尽管我没有对PHP一无所知,我没有任何编程经验,但我仍然可以以令人满意的方式编辑它附带的示例游戏,只需根据简短的视觉小说中的示例编写代码,作为演示源站点。视差转场、自定义菜单和转场等更困难的事情需要我学习,但我仍然可以解决它们。在这方面,您的里程自然会有所不同。
只要可以编辑照片、提供自定义图稿、按照简单的指令操作,WPA 小说网站的源代码就可以大大超越大多数视觉小说所满足的简单对话方式。您可以实现状态追踪系统、道具管理机制以及其他各种重大调整,让您的网站比您之前想象的更丰富、更完整。除了网站明显的功能,我们还需要学习更多的其他教程,以帮助您充分利用系统构建。
Joel Peterson,Destructoid:“对于你真正需要学习写一个基础代码的东西,开源小说网站源代码是有意义的。它在Lemma Soft上得到了很多社区的支持,相对来说有没有bug,非常灵活。对于系统新颖的网站开发者来说,这可能会让他们一开始感到害怕,但值得花时间。虽然我的工作一开始并不快,但由于缺乏引擎限制,我的工作变得更顺畅了。”
如果您对编码或 Python 不感兴趣,而只是完成您的项目,TyranoBuilder 可能更适合您。您根本不需要知道编码。这是制作快速粗略原型的最快方法,尤其是当您正在推广游戏或需要一个松散的概念时,但如果您想充实项目的其他部分,您也可以这样做。
换句话说,在“TyranoBuilder”中,很多更复杂的内容在Ren’py这样的系统中是无法实现的。经过一段时间的程序修改,我能够在15分钟内创建一个视觉新颖的框架并呈现给玩家。它既快又脏,但在很多方面,这就是 TyranoBuilder 的目的。
您可以使用该软件的可视化编辑器来创建视觉小说网站 的各个方面,这意味着您真正需要做的就是在组件列表中拖放元素。您甚至可以通过这种方式更改文本速度,添加音乐、对话、分支路径以及调整字符定位。如果你对编码没有耐心,需要一个程序来为你做所有的工作,那么这就是你应该采取的方法,只要你不想寻找过于复杂的东西。
当然,这三个工具并不是创作小说网站的唯一选择。 Unity 总是一种选择,但它也有它自己的麻烦——尤其是如果你不是一个编码老手。但它也带来了额外的好处,例如您可以制作自己想要的游戏,而不必拘泥于特定的程序。
总之,打造一部小说网站需要一套功能齐全且易于操作的开源代码才是最重要的。一篇好的小说网站源代码应该是丰富的采集规则和自成一体的WPA手机系统。它与开源集成,易于维护。返回搜狐查看更多 查看全部
自动采集网站内容(与VN创造者交谈,带采集规则的源码是你的选择)
小说网站源码好用,但采集规则是关键一环。您计划自己的故事,绘制所有对话,创造令人难忘的角色,然后将这些内容整合成一部功能齐全的小说网站。
源代码和演示:xsymz.icu
当你开始写小说网站时,源代码可能是你听到的第一点。跟VN的创建者聊一聊,带有采集规则的源码是大多数人的选择。小说网站已经存在很长时间了,你可能读过不同风格的小说网站。它是一个开源代码系统,您只需要知道如何编辑文本和使用一些基本的 PJP 编程即可。但是,这些都可以通过访问在线教程、修改示例项目和独立学习 PHP 来学习。
当我开始创建自己的小说网站时,我首先需要上传Novel网站源代码,因为几年前我用它参加了一个在线比赛(并且赢了!),尽管我没有对PHP一无所知,我没有任何编程经验,但我仍然可以以令人满意的方式编辑它附带的示例游戏,只需根据简短的视觉小说中的示例编写代码,作为演示源站点。视差转场、自定义菜单和转场等更困难的事情需要我学习,但我仍然可以解决它们。在这方面,您的里程自然会有所不同。
只要可以编辑照片、提供自定义图稿、按照简单的指令操作,WPA 小说网站的源代码就可以大大超越大多数视觉小说所满足的简单对话方式。您可以实现状态追踪系统、道具管理机制以及其他各种重大调整,让您的网站比您之前想象的更丰富、更完整。除了网站明显的功能,我们还需要学习更多的其他教程,以帮助您充分利用系统构建。
Joel Peterson,Destructoid:“对于你真正需要学习写一个基础代码的东西,开源小说网站源代码是有意义的。它在Lemma Soft上得到了很多社区的支持,相对来说有没有bug,非常灵活。对于系统新颖的网站开发者来说,这可能会让他们一开始感到害怕,但值得花时间。虽然我的工作一开始并不快,但由于缺乏引擎限制,我的工作变得更顺畅了。”
如果您对编码或 Python 不感兴趣,而只是完成您的项目,TyranoBuilder 可能更适合您。您根本不需要知道编码。这是制作快速粗略原型的最快方法,尤其是当您正在推广游戏或需要一个松散的概念时,但如果您想充实项目的其他部分,您也可以这样做。
换句话说,在“TyranoBuilder”中,很多更复杂的内容在Ren’py这样的系统中是无法实现的。经过一段时间的程序修改,我能够在15分钟内创建一个视觉新颖的框架并呈现给玩家。它既快又脏,但在很多方面,这就是 TyranoBuilder 的目的。
您可以使用该软件的可视化编辑器来创建视觉小说网站 的各个方面,这意味着您真正需要做的就是在组件列表中拖放元素。您甚至可以通过这种方式更改文本速度,添加音乐、对话、分支路径以及调整字符定位。如果你对编码没有耐心,需要一个程序来为你做所有的工作,那么这就是你应该采取的方法,只要你不想寻找过于复杂的东西。
当然,这三个工具并不是创作小说网站的唯一选择。 Unity 总是一种选择,但它也有它自己的麻烦——尤其是如果你不是一个编码老手。但它也带来了额外的好处,例如您可以制作自己想要的游戏,而不必拘泥于特定的程序。
总之,打造一部小说网站需要一套功能齐全且易于操作的开源代码才是最重要的。一篇好的小说网站源代码应该是丰富的采集规则和自成一体的WPA手机系统。它与开源集成,易于维护。返回搜狐查看更多
自动采集网站内容(批量采集自动提取保存网页内容这个是本教程中所使用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-04 21:30
批量采集自动提取并保存网页内容
这是本教程中使用的网页:
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
本教程是教大家使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中
这是入门教程
先看一下软件的大体界面:
然后需要先添加一个网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图:
接下来,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,就不会受到限制。
本教程每次刷新都需要保存更改的网页信息,所以在“其他监控”中需要设置“无条件启动监控报警”。 (详见各自要求的设置)
然后设置需要保存的网页信息。在“监控设置”中,添加“报警提示动态内容”---然后自动获取。如下图:
点击自动获取后会打开之前添加的网址,页面加载完成后
选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。
如下图操作:
元素属性名称在这里使用值。
这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容)
在这个版本中,网页自动运行的通用工具可以保存为三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件。类型可在“闹钟提醒”中设置。
以下是监控网页后保存的各种文件格式。
首先是将每个元素保存在一个单独的txt文件中:
第二种方法是合并一个txt文件中的所有元素并保存:
第三种是将所有元素保存为一个csv文件:
本教程结束。
欢迎搜索:木头软件。 查看全部
自动采集网站内容(批量采集自动提取保存网页内容这个是本教程中所使用的)
批量采集自动提取并保存网页内容
这是本教程中使用的网页:
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
file:///C:%5CUsers%5CCan%5CDesktop%5C%E6%9C%A8%E5%A4%B4%5C%E4%BB%BB%E5%8A%A1%5C%E7%BD%91%E9%A1%B5%E6%8F%90%E5%8F%96%E5%86%85%E5%AE%B9%5C00.jpg
本教程是教大家使用网页自动操作通用工具中的刷新工具来刷新和提取网页内容。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中
这是入门教程
先看一下软件的大体界面:
然后需要先添加一个网址,点击“添加”按钮,输入需要刷新提取信息的网址,然后点击“自动获取”按钮。如下图:
接下来,我们设置刷新间隔。刷新间隔可以在网页自动刷新监控操作中设置。在这里,我将其设置为每 10 秒刷新一次。如果去掉勾选的刷新限制,就不会受到限制。
本教程每次刷新都需要保存更改的网页信息,所以在“其他监控”中需要设置“无条件启动监控报警”。 (详见各自要求的设置)
然后设置需要保存的网页信息。在“监控设置”中,添加“报警提示动态内容”---然后自动获取。如下图:
点击自动获取后会打开之前添加的网址,页面加载完成后
选择需要获取的信息-右键-获取元素-自动提取元素标识-添加元素。
如下图操作:
元素属性名称在这里使用值。
这里需要注意的是,有些网页需要延迟打开才能开始监控,否则会失效。所以这里设置了“监听前的延迟等待时间为3秒”。 (此处同时监控多个网页内容)
在这个版本中,网页自动运行的通用工具可以保存为三种格式,分别是csv文件、txt文件和每个动态元素分别保存为一个文件。类型可在“闹钟提醒”中设置。
以下是监控网页后保存的各种文件格式。
首先是将每个元素保存在一个单独的txt文件中:
第二种方法是合并一个txt文件中的所有元素并保存:
第三种是将所有元素保存为一个csv文件:
本教程结束。
欢迎搜索:木头软件。
自动采集网站内容(更多写博客大数据与云计算学习:Python网络数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-04 00:04
阿里巴巴云>云栖社区>主题图>W>网站小说采集器
推荐活动:
更多优惠>
当前话题:网站小说采集器采集
相关主题:
网站小说采集器相关博客查看更多博客
大数据与云计算学习:Python网络data采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换、信息采集、爬虫学习路径爬虫的基本原理,具备信息存储功能 所谓爬虫就是一个自动化数据采集工具,你
阅读全文
新手怎么发网站外链,网站外链怎么发,外链发帖方法集合
作者:冰点牧雪1420人浏览评论:06年前
给大家分享一下我是怎么做反连接链的。一般来说,我在反连接中只追求两件事。 一、数量。 二、稳定性。对于像我这样的新手和资源匮乏的人,能做的就是增加外链的数量,做好外链的稳定性。所谓稳定,就是已经贴出的外链要尽量不让它们消失。这对于群发软件来说是非常困难的,尤其是对于英文站点。现在
阅读全文
给互联网或物联网加一个“大脑”会引发什么样的革命?
作者:青山无名1158人浏览评论:04年前
互联网发展到今天,已经成为人们重要的生活方式。在互联网上,您可以与朋友聊天、阅读新闻、查询各种信息和资料、玩游戏、购物、看电影等等。对很多人来说,一天不上网,生活就会变得很枯燥和艰难。新一波“物联网”是互联网的进一步拓展,将各种“物体”和设备连接到互联网
阅读全文
用树莓派寻找外星文明
作者:同济子豪哥1695人浏览评论:02年前
使用树莓派搜索地外文明兄弟子豪开场白:本文介绍如何使用树莓派微机参与全球最大的分布式计算平台BOINC上的科学计算项目,尤其是最著名的搜索SETI @home 外星文明项目。并在BOINC平台介绍生物医学、气候变化、天体物理学、密码解密、数学证明等领域
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:沃克武松 9726人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:Reverse One Sleep 4689 次浏览和评论:13 年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
中文版Python资源合集
作者:有地2522人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
推荐系统永远不会向你推荐任何东西
作者:小轩峰柴金1136人浏览评论:04年前
推荐系统还有两个主要特点,它们对你看到的推荐结果也有很大的影响:第一,在你弄清楚你和其他购物者有多相似之前,推荐系统首先要了解你真正喜欢什么其次,推荐系统按照一套业务规则运行,保证推荐结果对你有用,对业务有利。推荐算法如何赢得你
阅读全文 查看全部
自动采集网站内容(更多写博客大数据与云计算学习:Python网络数据采集)
阿里巴巴云>云栖社区>主题图>W>网站小说采集器
推荐活动:
更多优惠>
当前话题:网站小说采集器采集
相关主题:
网站小说采集器相关博客查看更多博客
大数据与云计算学习:Python网络data采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换、信息采集、爬虫学习路径爬虫的基本原理,具备信息存储功能 所谓爬虫就是一个自动化数据采集工具,你
阅读全文
新手怎么发网站外链,网站外链怎么发,外链发帖方法集合
作者:冰点牧雪1420人浏览评论:06年前
给大家分享一下我是怎么做反连接链的。一般来说,我在反连接中只追求两件事。 一、数量。 二、稳定性。对于像我这样的新手和资源匮乏的人,能做的就是增加外链的数量,做好外链的稳定性。所谓稳定,就是已经贴出的外链要尽量不让它们消失。这对于群发软件来说是非常困难的,尤其是对于英文站点。现在
阅读全文
给互联网或物联网加一个“大脑”会引发什么样的革命?
作者:青山无名1158人浏览评论:04年前
互联网发展到今天,已经成为人们重要的生活方式。在互联网上,您可以与朋友聊天、阅读新闻、查询各种信息和资料、玩游戏、购物、看电影等等。对很多人来说,一天不上网,生活就会变得很枯燥和艰难。新一波“物联网”是互联网的进一步拓展,将各种“物体”和设备连接到互联网
阅读全文
用树莓派寻找外星文明
作者:同济子豪哥1695人浏览评论:02年前
使用树莓派搜索地外文明兄弟子豪开场白:本文介绍如何使用树莓派微机参与全球最大的分布式计算平台BOINC上的科学计算项目,尤其是最著名的搜索SETI @home 外星文明项目。并在BOINC平台介绍生物医学、气候变化、天体物理学、密码解密、数学证明等领域
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:沃克武松 9726人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
你要找的所有 Python 信息都在这里!不,你找不到!史上最全的资料合集
作者:Reverse One Sleep 4689 次浏览和评论:13 年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
中文版Python资源合集
作者:有地2522人浏览评论:03年前
GitHub 上有一个 Awesome-XXX 系列资源。资源非常丰富,涉及面非常广。 awesome-python 是 vinta 发起和维护的 Python 资源列表,包括:网络框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片
阅读全文
推荐系统永远不会向你推荐任何东西
作者:小轩峰柴金1136人浏览评论:04年前
推荐系统还有两个主要特点,它们对你看到的推荐结果也有很大的影响:第一,在你弄清楚你和其他购物者有多相似之前,推荐系统首先要了解你真正喜欢什么其次,推荐系统按照一套业务规则运行,保证推荐结果对你有用,对业务有利。推荐算法如何赢得你
阅读全文

