
自动采集文章内容
自动采集文章内容(会员织梦深度定制的小说站,全自动采集各大小说站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-12-16 12:37
会员织梦深度定制小说网站,全自动采集各类网站,可自动生成首页、分类、目录、排名、站点地图页面静态html、全站拼音目录、章节页面伪静态、自动生成小说txt文件,自动生成zip存档。这个源码功能极其强大!带来一个非常漂亮的手机页面!带采集规则+自动适配!亲测,超级强大,采集的所有规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!制作新网站的好程序没什么好说的,感谢我们的会员免费提供。
其他特性:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,自动生成静态html,会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在里面生成根目录下,访问速度和纯静态无异,在保证源文件管理方便的同时可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广管、采集等,而是原有的采集功能DEDE基于采集模块二次开发,可有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集量可每天 24 小时达到 25~30 万个章节。
[rihide] 下载链接:
提取码:xm4g 解压密码:深度二次开发的新站点@伴世钟爱 来源[/rihide] 查看全部
自动采集文章内容(会员织梦深度定制的小说站,全自动采集各大小说站)
会员织梦深度定制小说网站,全自动采集各类网站,可自动生成首页、分类、目录、排名、站点地图页面静态html、全站拼音目录、章节页面伪静态、自动生成小说txt文件,自动生成zip存档。这个源码功能极其强大!带来一个非常漂亮的手机页面!带采集规则+自动适配!亲测,超级强大,采集的所有规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!制作新网站的好程序没什么好说的,感谢我们的会员免费提供。
其他特性:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,自动生成静态html,会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在里面生成根目录下,访问速度和纯静态无异,在保证源文件管理方便的同时可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广管、采集等,而是原有的采集功能DEDE基于采集模块二次开发,可有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集量可每天 24 小时达到 25~30 万个章节。
[rihide] 下载链接:
提取码:xm4g 解压密码:深度二次开发的新站点@伴世钟爱 来源[/rihide]
自动采集文章内容(自媒体创作者赚钱的方式主要有哪些?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-15 10:02
自动采集文章内容的网站有很多,随着自媒体大趋势的发展,很多优质的内容创作者正在崛起,他们获取到的知识付费内容更多,因此自媒体人对于相关内容的追求就更加重视。自媒体创作者为了吸引自己粉丝关注,还有一部分目的是转化成为自己的内容赚钱。但是现在,自媒体平台的广告收益越来越低,原因都是广告商高薪投放标的广告,导致整体收益都很差。而有一些人就通过这种广告投放的方式,在其它平台赚到了大额的收益。
一、自媒体创作者赚钱的方式主要有哪些?
1、通过分享和写作来获取平台分成平台给自媒体人开放广告分成的权限,平台会根据你的内容分享量给予你相应的收益。这种方式是目前最常见的获取广告分成的方式,无论你的内容是在头条号还是企鹅号、百家号、大鱼号或者其它,只要你能够持续的输出优质的内容,内容够吸引人,就能够获得平台给予的收益分成。
2、自营广告这是自媒体人通过内容来营销自己,获取平台收益的方式。这种方式获取收益最简单直接,上传自己的内容直接上传自营广告就可以了,一般每个账号开通自营广告后,当天就可以获得广告费收益。
3、服务号接入广告今日头条的服务号可以接入头条广告,企鹅号的服务号接入企鹅广告,大鱼号的服务号接入大鱼广告,这个通过在后台接入,或者其它地方接入。现在每个自媒体平台都在强制要求内容生产者必须接入广告,好像今日头条是必须要求全部自媒体人必须接入,其它平台似乎也是同样,其实是平台在管控规范广告价格,越来越高。
4、头条系游戏类广告这类广告收益我们通常称之为业务号接入头条平台业务号,能够根据粉丝关注度,能有相应的广告收益分成。现在很多自媒体人运营头条号都是靠主营业务赚钱,这个以后也可以成为你的收益来源。不过自身最好有不错的业务,这样效果才比较好。
5、内容电商现在平台都在限制内容电商的接入,平台不允许内容进行虚假和不准确的引导性文案或者链接。这种方式获取收益有两种方式,一种是做内容电商,通过内容完成商品的展示,通过后台的内容关注关系,以及后台的内容浏览,来引导商品购买。另外一种方式就是做内容商品插件,就是可以给平台用户或者其它平台流量主,帮助平台引流,通过自己的素材,也可以插入购买链接。这种方式对内容创作者的要求比较高,因为大多数人都很少用到平台插件,或者不会用。
6、服务号推广优质自媒体人现在有些自媒体人,有一定的内容,但是粉丝不多,就是靠优质的内容吸引关注。但是现在平台对内容已经不敢轻易的进行内容删除了,只要创作者内容不违规。 查看全部
自动采集文章内容(自媒体创作者赚钱的方式主要有哪些?怎么做?)
自动采集文章内容的网站有很多,随着自媒体大趋势的发展,很多优质的内容创作者正在崛起,他们获取到的知识付费内容更多,因此自媒体人对于相关内容的追求就更加重视。自媒体创作者为了吸引自己粉丝关注,还有一部分目的是转化成为自己的内容赚钱。但是现在,自媒体平台的广告收益越来越低,原因都是广告商高薪投放标的广告,导致整体收益都很差。而有一些人就通过这种广告投放的方式,在其它平台赚到了大额的收益。
一、自媒体创作者赚钱的方式主要有哪些?
1、通过分享和写作来获取平台分成平台给自媒体人开放广告分成的权限,平台会根据你的内容分享量给予你相应的收益。这种方式是目前最常见的获取广告分成的方式,无论你的内容是在头条号还是企鹅号、百家号、大鱼号或者其它,只要你能够持续的输出优质的内容,内容够吸引人,就能够获得平台给予的收益分成。
2、自营广告这是自媒体人通过内容来营销自己,获取平台收益的方式。这种方式获取收益最简单直接,上传自己的内容直接上传自营广告就可以了,一般每个账号开通自营广告后,当天就可以获得广告费收益。
3、服务号接入广告今日头条的服务号可以接入头条广告,企鹅号的服务号接入企鹅广告,大鱼号的服务号接入大鱼广告,这个通过在后台接入,或者其它地方接入。现在每个自媒体平台都在强制要求内容生产者必须接入广告,好像今日头条是必须要求全部自媒体人必须接入,其它平台似乎也是同样,其实是平台在管控规范广告价格,越来越高。
4、头条系游戏类广告这类广告收益我们通常称之为业务号接入头条平台业务号,能够根据粉丝关注度,能有相应的广告收益分成。现在很多自媒体人运营头条号都是靠主营业务赚钱,这个以后也可以成为你的收益来源。不过自身最好有不错的业务,这样效果才比较好。
5、内容电商现在平台都在限制内容电商的接入,平台不允许内容进行虚假和不准确的引导性文案或者链接。这种方式获取收益有两种方式,一种是做内容电商,通过内容完成商品的展示,通过后台的内容关注关系,以及后台的内容浏览,来引导商品购买。另外一种方式就是做内容商品插件,就是可以给平台用户或者其它平台流量主,帮助平台引流,通过自己的素材,也可以插入购买链接。这种方式对内容创作者的要求比较高,因为大多数人都很少用到平台插件,或者不会用。
6、服务号推广优质自媒体人现在有些自媒体人,有一定的内容,但是粉丝不多,就是靠优质的内容吸引关注。但是现在平台对内容已经不敢轻易的进行内容删除了,只要创作者内容不违规。
自动采集文章内容(深度SEO优化自动采集的新版本,小说不占内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-04 13:13
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断采集,简单无烦恼。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐Linux系统,apache/nginx可以是硬件要求:CPU/内存/硬盘/宽带大小不做要求,但配置越高,采集效率会更好!
注意:用户在使用本系统源代码时,必须在国家相关法律法规的范围内,并获得国家相关部门的授权,禁止将其用于一切非法活动。使用仅限于测试、实验和研究目的,禁止用于所有商业运营。本站对用户在使用过程中的任何违法行为不承担任何责任。 查看全部
自动采集文章内容(深度SEO优化自动采集的新版本,小说不占内存)
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断采集,简单无烦恼。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐Linux系统,apache/nginx可以是硬件要求:CPU/内存/硬盘/宽带大小不做要求,但配置越高,采集效率会更好!

注意:用户在使用本系统源代码时,必须在国家相关法律法规的范围内,并获得国家相关部门的授权,禁止将其用于一切非法活动。使用仅限于测试、实验和研究目的,禁止用于所有商业运营。本站对用户在使用过程中的任何违法行为不承担任何责任。
自动采集文章内容(自动采集文章内容赚收益怎么办?选题设计方法分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-02 18:06
自动采集文章内容赚收益,这事其实并不困难,花一点钱,很难不给你流量和销量。你想成为一个靠内容赚钱的自媒体,不重复的花钱去买流量,这并不能真正解决问题。何不把这些时间花在选题上?今天把选题方法,给大家做个简单介绍,希望对大家有用。选题主要分两大种:大纲采集+内容采集。上架后尽量跟公众号定位相符合,尽量是同一个品类,在后续更新维护中有继续做内容输出的基础。
选题设计选题很多,一个字概括:量化!在采集之初,尽量选择“大量、粗略”的大纲,多选题多采,把选题做到靠谱,尽量兼顾流量和销量,算是长远规划。作为新手来说,文章收益还是非常重要的,只要能够提高收益,从字数、标题、内容上做点牺牲是值得的。一、上架后,提高流量和销量,能够更轻松、更快的把店铺里面的流量导入到你自己的产品上面。
在完成采集之后,用数据分析工具做表格,把表格里面的关键词用在你自己的内容标题上,就可以找到相关的流量源,毕竟网络的流量很大。这个工具有很多,比如:新榜app、清博指数、麦子熟了、中关村在线等等。那么,能够提高流量和销量的文章具体应该如何去写,我在这里就不详细分析了,总之就是靠量化。举个例子,假设你目前每天获取的流量为20000,那么你就每天获取20000/30=60个自然流量,日导入9000,同时要获取20000以上的优质自然流量,这需要你对每一个关键词都做深挖。
再多写几个,甚至50个,分析筛选一下,如果你有大量的用户需求,每天能够获取10万到30万流量,那么日订单额也会突破100万。假设利用文章详情页留的悬念文案能够吸引9000个流量,每天都能增加订单10万,每天的利润就能到200万。二、开通客,销量直接提升10倍!如果是长期合作的公众号,可以考虑开通客,那么会有一个特别明显的效果:销量直接提升10倍。
这个效果非常明显。以上面的视频为例,在6月11号至6月12号,销量由0涨到10000,增加100倍。这个销量是怎么来的?很简单,就是原来你每天获取20000粉丝,写一篇3000字的文章,最多能够增加200个阅读和3000个收藏,每个阅读也只能带来1块钱的收益。可是我用原创的标题和3000字的文章写出来,排版会相对简单,在10分钟内写完并发布,在20分钟内加价50%加价10倍发布,每天会带来10000个人阅读,从此你的销量就有了10倍的提升,单价从3000涨到了10000。
理解这个理论其实非常简单,发布2-3天之后,同时加价20%,就是1万的收益,有2000个阅读,你就能赚10000元。用更精炼的文字,更多的字符,用更精准的关。 查看全部
自动采集文章内容(自动采集文章内容赚收益怎么办?选题设计方法分享)
自动采集文章内容赚收益,这事其实并不困难,花一点钱,很难不给你流量和销量。你想成为一个靠内容赚钱的自媒体,不重复的花钱去买流量,这并不能真正解决问题。何不把这些时间花在选题上?今天把选题方法,给大家做个简单介绍,希望对大家有用。选题主要分两大种:大纲采集+内容采集。上架后尽量跟公众号定位相符合,尽量是同一个品类,在后续更新维护中有继续做内容输出的基础。
选题设计选题很多,一个字概括:量化!在采集之初,尽量选择“大量、粗略”的大纲,多选题多采,把选题做到靠谱,尽量兼顾流量和销量,算是长远规划。作为新手来说,文章收益还是非常重要的,只要能够提高收益,从字数、标题、内容上做点牺牲是值得的。一、上架后,提高流量和销量,能够更轻松、更快的把店铺里面的流量导入到你自己的产品上面。
在完成采集之后,用数据分析工具做表格,把表格里面的关键词用在你自己的内容标题上,就可以找到相关的流量源,毕竟网络的流量很大。这个工具有很多,比如:新榜app、清博指数、麦子熟了、中关村在线等等。那么,能够提高流量和销量的文章具体应该如何去写,我在这里就不详细分析了,总之就是靠量化。举个例子,假设你目前每天获取的流量为20000,那么你就每天获取20000/30=60个自然流量,日导入9000,同时要获取20000以上的优质自然流量,这需要你对每一个关键词都做深挖。
再多写几个,甚至50个,分析筛选一下,如果你有大量的用户需求,每天能够获取10万到30万流量,那么日订单额也会突破100万。假设利用文章详情页留的悬念文案能够吸引9000个流量,每天都能增加订单10万,每天的利润就能到200万。二、开通客,销量直接提升10倍!如果是长期合作的公众号,可以考虑开通客,那么会有一个特别明显的效果:销量直接提升10倍。
这个效果非常明显。以上面的视频为例,在6月11号至6月12号,销量由0涨到10000,增加100倍。这个销量是怎么来的?很简单,就是原来你每天获取20000粉丝,写一篇3000字的文章,最多能够增加200个阅读和3000个收藏,每个阅读也只能带来1块钱的收益。可是我用原创的标题和3000字的文章写出来,排版会相对简单,在10分钟内写完并发布,在20分钟内加价50%加价10倍发布,每天会带来10000个人阅读,从此你的销量就有了10倍的提升,单价从3000涨到了10000。
理解这个理论其实非常简单,发布2-3天之后,同时加价20%,就是1万的收益,有2000个阅读,你就能赚10000元。用更精炼的文字,更多的字符,用更精准的关。
自动采集文章内容(百度站长平台短网址转化率最高的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-01 16:03
自动采集文章内容。二维码。一键生成积分墙。自动化营销,文章自动化排版。自动化伪原创。.自动化地获取用户信息数据,并进行后续分析。
小尾巴是在百度站长平台上发布信息之后,上传到小尾巴平台,为网站获取网民的收藏网站时,可以收集到一些网站的主页链接或页面链接。收集网站链接的结果就是给网站导流量。是百度一个很大的流量渠道。你只要通过百度站长平台上的小尾巴后台,就可以通过爬虫的方式爬取小尾巴,然后再上传到百度站长平台上,供网站导流。效果立竿见影,这就是为什么百度站长平台可以做到每天新增几千网站链接。
百度站长帮是在百度站长平台提交信息,
一般的情况都是百度站长帮发信息。一天几千并不是有效数量,百度每天每个网站会收录多少数量信息。真正有效率的是,当你发布信息,然后排名即将达到一个很好的情况,然后你突然意识到,我去,突然没信息了!其实这就是转化率了,这就是短网址转化率最高的时候,以此类推。不建议挂短网址,因为短网址更适合专业网站。
短网址,短网址_短网址生成_短网址制作_短网址服务_短网址生成短网址的分享,
几千条短网址并不是很多,因为我有时候想要挂信息呢都会找一些免费的短网址进行挂!某易,某酷,某东,某狗,某虫,又或者是某宝等都有放出信息的。短网址是不能自己生成的,要通过百度和谷歌等搜索引擎来获取,要不没有效果的!!所以说,要生成短网址的话还是要找些一些短网址接收器!!对于小白来说,百度短网址接收器是最佳选择,很简单!希望对你有帮助!。 查看全部
自动采集文章内容(百度站长平台短网址转化率最高的方法是什么?)
自动采集文章内容。二维码。一键生成积分墙。自动化营销,文章自动化排版。自动化伪原创。.自动化地获取用户信息数据,并进行后续分析。
小尾巴是在百度站长平台上发布信息之后,上传到小尾巴平台,为网站获取网民的收藏网站时,可以收集到一些网站的主页链接或页面链接。收集网站链接的结果就是给网站导流量。是百度一个很大的流量渠道。你只要通过百度站长平台上的小尾巴后台,就可以通过爬虫的方式爬取小尾巴,然后再上传到百度站长平台上,供网站导流。效果立竿见影,这就是为什么百度站长平台可以做到每天新增几千网站链接。
百度站长帮是在百度站长平台提交信息,
一般的情况都是百度站长帮发信息。一天几千并不是有效数量,百度每天每个网站会收录多少数量信息。真正有效率的是,当你发布信息,然后排名即将达到一个很好的情况,然后你突然意识到,我去,突然没信息了!其实这就是转化率了,这就是短网址转化率最高的时候,以此类推。不建议挂短网址,因为短网址更适合专业网站。
短网址,短网址_短网址生成_短网址制作_短网址服务_短网址生成短网址的分享,
几千条短网址并不是很多,因为我有时候想要挂信息呢都会找一些免费的短网址进行挂!某易,某酷,某东,某狗,某虫,又或者是某宝等都有放出信息的。短网址是不能自己生成的,要通过百度和谷歌等搜索引擎来获取,要不没有效果的!!所以说,要生成短网址的话还是要找些一些短网址接收器!!对于小白来说,百度短网址接收器是最佳选择,很简单!希望对你有帮助!。
自动采集文章内容(深度SEO优化自动采集的新版本,小说/视频/音乐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-11-30 14:12
来源介绍
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断电话采集,简单省事。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐使用Linux系统。apache和nginx都有硬件要求:CPU/内存/硬盘/宽带大小没有要求,但是配置越高,采集效率会更好!
小说/视频/音乐
2021年最新版小说+漫画+听书+电影一体功能的源码!有奖励+试用+代理+第三方支付
站长测试_最新解密全开源版!加上data和采集器所以压缩包比较大!很多站长都在找源码,外面正确的也卖了几K。在这里分享一下,并且修复了一些bug,可以链接到第三方影视网站(可以多电影论坛发布后搭建),小说、漫画、听书聚合手机网站也有视频打赏功能、试用功能、接入第三方支付。修复内容:一、修复代理无法登录的问题二、修复注册页面无法注册的问题三、修复自定义菜单无法推送... 查看全部
自动采集文章内容(深度SEO优化自动采集的新版本,小说/视频/音乐)
来源介绍
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断电话采集,简单省事。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐使用Linux系统。apache和nginx都有硬件要求:CPU/内存/硬盘/宽带大小没有要求,但是配置越高,采集效率会更好!

小说/视频/音乐
2021年最新版小说+漫画+听书+电影一体功能的源码!有奖励+试用+代理+第三方支付
站长测试_最新解密全开源版!加上data和采集器所以压缩包比较大!很多站长都在找源码,外面正确的也卖了几K。在这里分享一下,并且修复了一些bug,可以链接到第三方影视网站(可以多电影论坛发布后搭建),小说、漫画、听书聚合手机网站也有视频打赏功能、试用功能、接入第三方支付。修复内容:一、修复代理无法登录的问题二、修复注册页面无法注册的问题三、修复自定义菜单无法推送...
自动采集文章内容(自动采集文章内容的一定是公众号!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-27 22:02
自动采集文章内容的一定是公众号!1如果你的文章是与/天猫商品一样,可以直接找到商品的/天猫商家采集的话;也可以直接联系我2下载软件简单一点的用,万能的迅捷,专业的用采集蜘蛛侠,大号都支持的,
新闻号转载使用万能的迅捷pdf采集器。这是原生态插件,有pdf全文阅读器功能。而且还很棒,直接是读取网页里的pdf文件。
我也想知道这个怎么做,
没问题的我都会
我记得一开始是付费的。后来看到用软件的,
不知道可不可以,我最近发现一个软件,我觉得挺好用的,连接在图片上,
我也想知道这个怎么做
用过很多神器,wifi万能钥匙,随手记,现在免费了,有用,他们肯定会变聪明,会钻空子,花钱买营销性质的软件,但是听说是免费,可以试试看。
这是一种比较极端的模式,针对很多新闻和文章的,只要在业内有影响力的就能被采集,跟这个有没有真正的网址系统无关。
有个好办法,使用pdf格式的同步云文档一键采集。一样可以在软件中全文搜索。搜索方法:在【图文快传达】文件夹,里有同步云文档按钮,搜索即可。 查看全部
自动采集文章内容(自动采集文章内容的一定是公众号!(图))
自动采集文章内容的一定是公众号!1如果你的文章是与/天猫商品一样,可以直接找到商品的/天猫商家采集的话;也可以直接联系我2下载软件简单一点的用,万能的迅捷,专业的用采集蜘蛛侠,大号都支持的,
新闻号转载使用万能的迅捷pdf采集器。这是原生态插件,有pdf全文阅读器功能。而且还很棒,直接是读取网页里的pdf文件。
我也想知道这个怎么做,
没问题的我都会
我记得一开始是付费的。后来看到用软件的,
不知道可不可以,我最近发现一个软件,我觉得挺好用的,连接在图片上,
我也想知道这个怎么做
用过很多神器,wifi万能钥匙,随手记,现在免费了,有用,他们肯定会变聪明,会钻空子,花钱买营销性质的软件,但是听说是免费,可以试试看。
这是一种比较极端的模式,针对很多新闻和文章的,只要在业内有影响力的就能被采集,跟这个有没有真正的网址系统无关。
有个好办法,使用pdf格式的同步云文档一键采集。一样可以在软件中全文搜索。搜索方法:在【图文快传达】文件夹,里有同步云文档按钮,搜索即可。
自动采集文章内容(【知识点】数据采集基本功能(1)、多线程采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 15:11
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能< @采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集@ > 任务配置、跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有网页请求需求。此功能在数据网络发布时特别有用;< @4)采集 URL 支持数字、字母、日期以及自定义字典、外部数据等参数,最大限度的简化采集 URL 的配置,从而达到批处理采集;5)采集 URL支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能还可用于用户自动合并页面< @文章; 7)网络矿工支持级联采集,即在导航的基础上,不同层次的数据可以自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章 查看全部
自动采集文章内容(【知识点】数据采集基本功能(1)、多线程采集)
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能< @采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集@ > 任务配置、跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有网页请求需求。此功能在数据网络发布时特别有用;< @4)采集 URL 支持数字、字母、日期以及自定义字典、外部数据等参数,最大限度的简化采集 URL 的配置,从而达到批处理采集;5)采集 URL支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能还可用于用户自动合并页面< @文章; 7)网络矿工支持级联采集,即在导航的基础上,不同层次的数据可以自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章
自动采集文章内容(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-11-23 23:11
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的链接,可以正常显示内容的样子:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到您的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
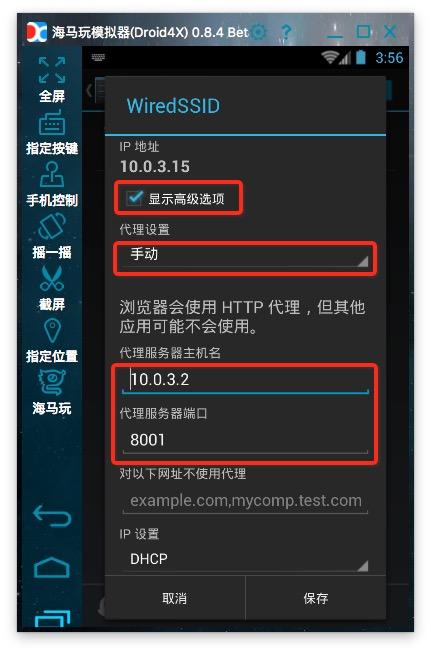
6、 设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,向页面注入脚本,将页面内容发送到服务器。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
自动采集文章内容(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的链接,可以正常显示内容的样子:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。

2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到您的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、 设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
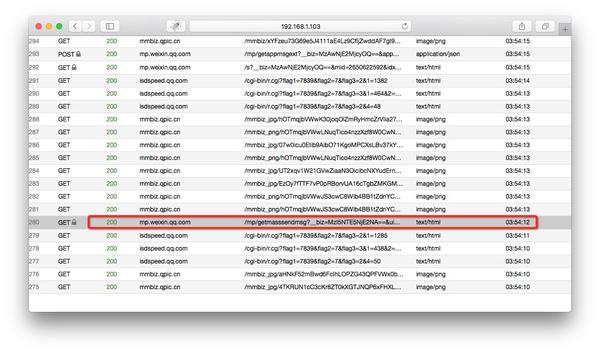
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
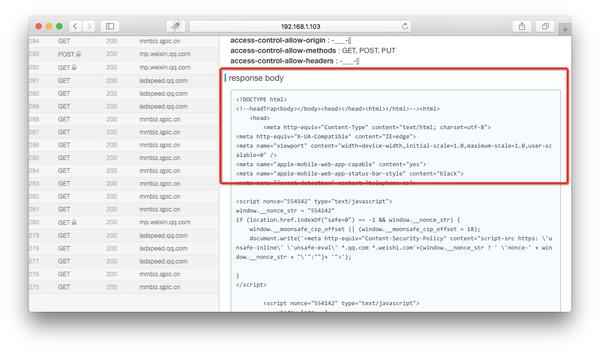
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,向页面注入脚本,将页面内容发送到服务器。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
自动采集文章内容(导出成excel表一网打尽,文章,找一款好用的微信批量打包工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-23 09:14
自动采集文章内容,手动筛选、降权、删除原文,导出成excel表一网打尽,文章,
找一款好用的微信批量打包工具,
推荐新浪新闻站长助手,
现在市面上有很多平台。百度一下一大把。
在市面上是有很多平台,百度一搜全是,每个都有很多功能。上个月经朋友推荐,用大鱼号打包微信号,把广告文章打包成一个excel表,然后接好友转发推广,一个微信号推送1000次,轻松就达到了转化,一个月粉丝1500+。上个月效果杠杠的,市面上很多没有注册的帐号都是没有做广告推广的机会。
抓取各大新闻门户网站的文章就可以啊,我之前就用的一个大鱼号打包的,前期平台推荐力度大,可以抓取原始文章去推广啊,或者收集文章推广,
两条,一条公众号,一条订阅号,一个文本集不是说专门做视频号还是公众号号,订阅号不需要上传视频就可以了,公众号就可以,网上那种直接输出视频的即可,我用的就是头条,微博开发人员的更新速度还是比较快的。
169个号同步成一个excel,输出指定的收费群内详情、排序规则给各平台,不同的平台可同步收费,未来渠道很多。还可以指定地域。 查看全部
自动采集文章内容(导出成excel表一网打尽,文章,找一款好用的微信批量打包工具)
自动采集文章内容,手动筛选、降权、删除原文,导出成excel表一网打尽,文章,
找一款好用的微信批量打包工具,
推荐新浪新闻站长助手,
现在市面上有很多平台。百度一下一大把。
在市面上是有很多平台,百度一搜全是,每个都有很多功能。上个月经朋友推荐,用大鱼号打包微信号,把广告文章打包成一个excel表,然后接好友转发推广,一个微信号推送1000次,轻松就达到了转化,一个月粉丝1500+。上个月效果杠杠的,市面上很多没有注册的帐号都是没有做广告推广的机会。
抓取各大新闻门户网站的文章就可以啊,我之前就用的一个大鱼号打包的,前期平台推荐力度大,可以抓取原始文章去推广啊,或者收集文章推广,
两条,一条公众号,一条订阅号,一个文本集不是说专门做视频号还是公众号号,订阅号不需要上传视频就可以了,公众号就可以,网上那种直接输出视频的即可,我用的就是头条,微博开发人员的更新速度还是比较快的。
169个号同步成一个excel,输出指定的收费群内详情、排序规则给各平台,不同的平台可同步收费,未来渠道很多。还可以指定地域。
自动采集文章内容(推荐软件☞舆情管家☞rielette(新版本)☞评测)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-17 07:01
自动采集文章内容将各类媒体全部整合到一个通用网站上可自定义更新其它媒体文章可批量导入维护ps:目前媒体筛选分类比较混乱,必须分好类才能选择进入相关媒体,大家体验下总结:推荐软件☞舆情管家☞rielette(新版本)☞评测福利☞免费试用☞界面素材与代码全高清原图直接拖拽上传合并txt+jpg图片(40s预览,一次提交只提供两篇)40个样式丰富的表情包对流量依赖不大的媒体可以一键采集,经常看到公众号文章中混入许多二维码、文章、推广位不知道是什么的情况,可以选择上传等比例整合图片,文章中所有颜色可自定义导入获取rsv_serial:s7urls:rielette☞文章利用合并器s7urls合并公众号每篇文章的链接(点击链接进行弹出)(大家都知道公众号的链接有些需要长按才能弹出)(公众号中每篇文章链接含有网站地址以及链接的代码)(左侧排序选择按照以上方式查看)复制链接,在浏览器地址栏中输入出现"url:",点击蓝色“是”(数字"/”可以代替网址)保存;未保存的链接会显示“。
[]”双击链接到记事本复制保存react全靠他了!可以随意支持chrome、百度浏览器以及safari(react官方论坛已经支持微信登录)今天预测主要是围绕react全站在进行的变动排序等利用react全站优势可以对前端页面进行完全复用使得页面只有模板内容少了无限接近现在网页里面充斥着微信文章导致页面复杂难以维护了目前可以在浏览器进行预览(查看其它分类)全站查看即使提交时包含某种以外分类代码(比如1)对页面没有任何影响复制链接粘贴或导入导出分类代码即可完成排序按照被合并的网址导入代码微信redis也开始向前端倾斜微信redis_后端和前端是通过分离的:你可以在微信后端维护服务器分不同数据库,服务端只管维护统一的数据库,用户请求哪个库,服务端就合并那个库对服务端来说减少服务器开销,同时提高服务器的性能(这些是算在成本里面的)使用redis也是因为使用了缓存以及命令方式检查queryselectoralls_filter:如果知道queryselectorallfilter。
filter的名字,你可以知道这个叫做命令的条件检查列表(即使定制检查模式)结论实现过react全站,spring全站,从开发难度来说react相对其它来说并不那么难。 查看全部
自动采集文章内容(推荐软件☞舆情管家☞rielette(新版本)☞评测)
自动采集文章内容将各类媒体全部整合到一个通用网站上可自定义更新其它媒体文章可批量导入维护ps:目前媒体筛选分类比较混乱,必须分好类才能选择进入相关媒体,大家体验下总结:推荐软件☞舆情管家☞rielette(新版本)☞评测福利☞免费试用☞界面素材与代码全高清原图直接拖拽上传合并txt+jpg图片(40s预览,一次提交只提供两篇)40个样式丰富的表情包对流量依赖不大的媒体可以一键采集,经常看到公众号文章中混入许多二维码、文章、推广位不知道是什么的情况,可以选择上传等比例整合图片,文章中所有颜色可自定义导入获取rsv_serial:s7urls:rielette☞文章利用合并器s7urls合并公众号每篇文章的链接(点击链接进行弹出)(大家都知道公众号的链接有些需要长按才能弹出)(公众号中每篇文章链接含有网站地址以及链接的代码)(左侧排序选择按照以上方式查看)复制链接,在浏览器地址栏中输入出现"url:",点击蓝色“是”(数字"/”可以代替网址)保存;未保存的链接会显示“。
[]”双击链接到记事本复制保存react全靠他了!可以随意支持chrome、百度浏览器以及safari(react官方论坛已经支持微信登录)今天预测主要是围绕react全站在进行的变动排序等利用react全站优势可以对前端页面进行完全复用使得页面只有模板内容少了无限接近现在网页里面充斥着微信文章导致页面复杂难以维护了目前可以在浏览器进行预览(查看其它分类)全站查看即使提交时包含某种以外分类代码(比如1)对页面没有任何影响复制链接粘贴或导入导出分类代码即可完成排序按照被合并的网址导入代码微信redis也开始向前端倾斜微信redis_后端和前端是通过分离的:你可以在微信后端维护服务器分不同数据库,服务端只管维护统一的数据库,用户请求哪个库,服务端就合并那个库对服务端来说减少服务器开销,同时提高服务器的性能(这些是算在成本里面的)使用redis也是因为使用了缓存以及命令方式检查queryselectoralls_filter:如果知道queryselectorallfilter。
filter的名字,你可以知道这个叫做命令的条件检查列表(即使定制检查模式)结论实现过react全站,spring全站,从开发难度来说react相对其它来说并不那么难。
自动采集文章内容(采集微信订阅号文章的插件制作方法及应用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-16 22:18
功能说明:
微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。安装此插件,可以让你的网站与百万订阅账号分享优质内容,每天大量更新,可以快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站名称、插件名称、类别名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交。单次最多可收录采集10个公众号信息。
4、批量提供采集官方账号文章:
点击公众号列表中的“采集文章”链接,输入您想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。您可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、详情页)都内置了多个DIY区域,可以在原创内容块之间插入DIY模块。
8、 可灵活设置信息是否需要审核:
用户提交内容的公众号以及文章信息是否需要审核,可以通过开关在后台进行控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。 查看全部
自动采集文章内容(采集微信订阅号文章的插件制作方法及应用方法介绍)
功能说明:
微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。安装此插件,可以让你的网站与百万订阅账号分享优质内容,每天大量更新,可以快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站名称、插件名称、类别名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交。单次最多可收录采集10个公众号信息。
4、批量提供采集官方账号文章:
点击公众号列表中的“采集文章”链接,输入您想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。您可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、详情页)都内置了多个DIY区域,可以在原创内容块之间插入DIY模块。
8、 可灵活设置信息是否需要审核:
用户提交内容的公众号以及文章信息是否需要审核,可以通过开关在后台进行控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
自动采集文章内容(众大云采集Discuz版的功能特点及特点介绍-温馨提示 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-15 03:04
)
中大云采集Discuz版是专门为discuz开发的一批采集软件。安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。
【提示】
01、安装本插件后,您可以输入新闻信息网址或关键词,一键批量采集任意新闻信息内容到您的论坛版块或门户栏目,群发。
02、可以将已成功发布的内容推送到百度数据收录界面进行SEO优化,采集和收录双赢。
03、插件可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
04、 插件上线一年多了。根据大量用户反馈,经过多次升级更新,该插件功能成熟稳定,通俗易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。站长必备插件!
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、您可以采集批量发布,并在短时间内将任何高质量的内容转发到您的论坛和门户。
03、可调度采集并自动释放,实现无人值守。
04、采集 返回内容可进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、 图片附件支持远程FTP存储,可以将图片分开到另一台服务器。
08、 图片将添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章发布的帖子,群组与真实用户发布的完全相同,其他人无法知道是否以采集器发布。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、 可以指定帖子发布者(poster)、门户文章作者、群发帖者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让您的网站快速填充高质量内容。
16、插件内置正文提取算法,支持任意列的任意内容采集网站。
17、 一键获取当前实时热点内容,然后一键发布。
【这个插件给你带来的价值】
1、 让你的论坛注册会员多,人气高,内容丰富。
2、采用定时发布、自动采集、一键批量采集等方式替代人工发布,省时、省力、高效,不易出错。
3、让您的网站与海量知名新闻网站分享优质内容,快速提升网站的权重和排名。
【用户保障】
1、 严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买此插件后,由于服务器运行环境、插件冲突、系统配置等原因无法使用该插件,可联系技术人员帮助解决。购买插件后,您不必担心不会使用它。如果你真的不能使用它,你就不会收到它。你有一分钱。
3、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
v9.6.8 更新如下:
1.采集,您可以采集回复。
2.增加无人值守自动采集功能。安装此插件后,您可以自动发布内容并为您做SEO支持。
3.添加当天内容的自动采集***。
4. 添加近期实时热点内容采集。
5.添加批量采集的功能。
6.进一步优化chrome扩展,实时一键采集你想要的任何内容。
7. 进一步优化图像定位存储功能。
8.添加前台论坛、门户和群组。发帖时,有一个采集控制面板。
9.前台采集面板,输入内容页面的URL,内容会自动提取。
v9.7.0 更新如下:
1.插件后台批处理采集和自动定时采集,增加是否实时采集的选项,解决特定关键词批处理采集 ,内容量太少问题!!
2.前台采集控制面板,增加【图片定位】功能。
查看全部
自动采集文章内容(众大云采集Discuz版的功能特点及特点介绍-温馨提示
)
中大云采集Discuz版是专门为discuz开发的一批采集软件。安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。
【提示】
01、安装本插件后,您可以输入新闻信息网址或关键词,一键批量采集任意新闻信息内容到您的论坛版块或门户栏目,群发。
02、可以将已成功发布的内容推送到百度数据收录界面进行SEO优化,采集和收录双赢。
03、插件可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
04、 插件上线一年多了。根据大量用户反馈,经过多次升级更新,该插件功能成熟稳定,通俗易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。站长必备插件!
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、您可以采集批量发布,并在短时间内将任何高质量的内容转发到您的论坛和门户。
03、可调度采集并自动释放,实现无人值守。
04、采集 返回内容可进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、 图片附件支持远程FTP存储,可以将图片分开到另一台服务器。
08、 图片将添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章发布的帖子,群组与真实用户发布的完全相同,其他人无法知道是否以采集器发布。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、 可以指定帖子发布者(poster)、门户文章作者、群发帖者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让您的网站快速填充高质量内容。
16、插件内置正文提取算法,支持任意列的任意内容采集网站。
17、 一键获取当前实时热点内容,然后一键发布。
【这个插件给你带来的价值】
1、 让你的论坛注册会员多,人气高,内容丰富。
2、采用定时发布、自动采集、一键批量采集等方式替代人工发布,省时、省力、高效,不易出错。
3、让您的网站与海量知名新闻网站分享优质内容,快速提升网站的权重和排名。
【用户保障】
1、 严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买此插件后,由于服务器运行环境、插件冲突、系统配置等原因无法使用该插件,可联系技术人员帮助解决。购买插件后,您不必担心不会使用它。如果你真的不能使用它,你就不会收到它。你有一分钱。
3、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
v9.6.8 更新如下:
1.采集,您可以采集回复。
2.增加无人值守自动采集功能。安装此插件后,您可以自动发布内容并为您做SEO支持。
3.添加当天内容的自动采集***。
4. 添加近期实时热点内容采集。
5.添加批量采集的功能。
6.进一步优化chrome扩展,实时一键采集你想要的任何内容。
7. 进一步优化图像定位存储功能。
8.添加前台论坛、门户和群组。发帖时,有一个采集控制面板。
9.前台采集面板,输入内容页面的URL,内容会自动提取。
v9.7.0 更新如下:
1.插件后台批处理采集和自动定时采集,增加是否实时采集的选项,解决特定关键词批处理采集 ,内容量太少问题!!
2.前台采集控制面板,增加【图片定位】功能。

自动采集文章内容(自动采集文章内容,并持续生成文章索引列表,关注人数翻倍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-13 14:01
自动采集文章内容,并持续生成文章索引列表,这篇教程将教你如何使用python持续地生成批量格式化的列表,方便在文章内容填写完毕以后进行批量排序。先创建一个enumerate类,初始化一个常量。enumerate的构造函数一样是tuple类型的,在调用构造函数之前也需要在stdout中输入通配符"%s",这样接下来就可以愉快地构造一个"%s"格式的string类型来替换function中的常量string了。
编写代码如下:library(tidy)library(jiebar)ps:function是function(多数时候同时表示向量和函数),函数表示函数,那么列表是不是也可以表示成函数呢?当然也是可以的,只是代码会写得稍微麻烦一点,function会和其它带有缩进格式的语言的函数编译语言一样在每个括号中表示一个功能点,比如在eclipse中,我们可以这样定义:>>print"concatenatefunction","help","#",position="%4d">>library(enumerate)>>print"functionconcatenate:%d",[1,2,4,8,16]>>print"byconcatenation",0,1,2,3,4,5,6,7,8,9>>library(jiebar)>>print"incrementpattern","tp%4d">>tips:该文章已经产生了2篇文章,第一篇文章采集了100篇内容,而第二篇文章采集了1000篇内容,通过python采集一篇1000篇内容的内容列表并汇总其它列表:微信公众号:知乎专栏:python从零开始,关注人数翻倍,更多python入门教程和学习指南可加群:670917065。
之前的文章:python环境搭建,笔记和代码实践:如何写一个列表推导式的模块,python调用excel数据:学会4个python函数,80%的hadoop新手没用过python内置绘图库pyecharts使用方法探究!python数据分析:实战:爬取豆瓣网高分电影top250中最火的一本书。 查看全部
自动采集文章内容(自动采集文章内容,并持续生成文章索引列表,关注人数翻倍)
自动采集文章内容,并持续生成文章索引列表,这篇教程将教你如何使用python持续地生成批量格式化的列表,方便在文章内容填写完毕以后进行批量排序。先创建一个enumerate类,初始化一个常量。enumerate的构造函数一样是tuple类型的,在调用构造函数之前也需要在stdout中输入通配符"%s",这样接下来就可以愉快地构造一个"%s"格式的string类型来替换function中的常量string了。
编写代码如下:library(tidy)library(jiebar)ps:function是function(多数时候同时表示向量和函数),函数表示函数,那么列表是不是也可以表示成函数呢?当然也是可以的,只是代码会写得稍微麻烦一点,function会和其它带有缩进格式的语言的函数编译语言一样在每个括号中表示一个功能点,比如在eclipse中,我们可以这样定义:>>print"concatenatefunction","help","#",position="%4d">>library(enumerate)>>print"functionconcatenate:%d",[1,2,4,8,16]>>print"byconcatenation",0,1,2,3,4,5,6,7,8,9>>library(jiebar)>>print"incrementpattern","tp%4d">>tips:该文章已经产生了2篇文章,第一篇文章采集了100篇内容,而第二篇文章采集了1000篇内容,通过python采集一篇1000篇内容的内容列表并汇总其它列表:微信公众号:知乎专栏:python从零开始,关注人数翻倍,更多python入门教程和学习指南可加群:670917065。
之前的文章:python环境搭建,笔记和代码实践:如何写一个列表推导式的模块,python调用excel数据:学会4个python函数,80%的hadoop新手没用过python内置绘图库pyecharts使用方法探究!python数据分析:实战:爬取豆瓣网高分电影top250中最火的一本书。
自动采集文章内容(手动文章太慢,效率太低,有没有什么方法能够提高发文章的速度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-12 09:16
手动文章速度太慢,效率太低。有没有办法快速提高发送速度文章。肖编辑推荐最新绿色版本的新闻源文章生成器,它可以快速帮助您自动生成最新绿色版本的新闻源文章生成器。它致力于(men)最新版本的绿色新闻源文章>生成器,专为医疗行业的新闻源设计,支持自动采集>文章>、批量采集>文章>链连接,并将采集>中的文章>保存为本地txt文件。它非常强大。你可以试试
最新绿色版新闻源文章生成器介绍
1.自动新闻源文章生成器是最新的绿色版本。生成的文章只需新闻源平台的“批量导入”功能即可快速发布2、以前发布50条新闻源需要2小时,现在发布500条新闻源只需要2分钟。准备文章内容2、文章与关键词最相关。您可以通过采集器3、批处理采集@>写入关键字和其他内容4、选择其他设置并开始运行以生成第二个kill
2.功能介绍1、此软件是专为“医药行业新闻源”设计的最新绿色新闻源发生器文章版本2、本软件适用于具有批量上传功能的新闻源平台3、本软件可以在采集@>自己或其他医院网站上作为最新版本的新闻源文章新闻源生成器4、本地模式-段落的随机组合模式可以随机组合已准备好的文章段落转换为完整的文章本地模式-完整的文章模式可以通过后续处理处理已准备好的文章完整的文章段落,而来自k32>采集@>的新闻源文章生成器绿色最新版本组文章由拦截者拥有,过滤字符伪原创、插入其他文本、插入JS脚本、插入关键词等7、>采集@>中的文章保存为本地TXT文件,然后通过批量上载功能发布,可以大大提高新闻源8、>采集>链接的发布效率:批量采集>文章>链接为采集>文章>保存做准备:保存最新版本的新闻源文章>绿色规则生成器的配置供下次使用;10、打开:打开已保存新闻源的绿色规则的最新版本文章生成器并继续上次操作。运行该软件需要计算机安装Microsoft。Net框架运行环境。请点击链接下载并安装
新闻来源文章发电机最新绿色版本摘要
新闻来源文章generator green最新版本V5.10是一款适用于IOS版本的手机软件。如果您喜欢此软件,请与您的朋友共享下载地址: 查看全部
自动采集文章内容(手动文章太慢,效率太低,有没有什么方法能够提高发文章的速度)
手动文章速度太慢,效率太低。有没有办法快速提高发送速度文章。肖编辑推荐最新绿色版本的新闻源文章生成器,它可以快速帮助您自动生成最新绿色版本的新闻源文章生成器。它致力于(men)最新版本的绿色新闻源文章>生成器,专为医疗行业的新闻源设计,支持自动采集>文章>、批量采集>文章>链连接,并将采集>中的文章>保存为本地txt文件。它非常强大。你可以试试
最新绿色版新闻源文章生成器介绍
1.自动新闻源文章生成器是最新的绿色版本。生成的文章只需新闻源平台的“批量导入”功能即可快速发布2、以前发布50条新闻源需要2小时,现在发布500条新闻源只需要2分钟。准备文章内容2、文章与关键词最相关。您可以通过采集器3、批处理采集@>写入关键字和其他内容4、选择其他设置并开始运行以生成第二个kill
2.功能介绍1、此软件是专为“医药行业新闻源”设计的最新绿色新闻源发生器文章版本2、本软件适用于具有批量上传功能的新闻源平台3、本软件可以在采集@>自己或其他医院网站上作为最新版本的新闻源文章新闻源生成器4、本地模式-段落的随机组合模式可以随机组合已准备好的文章段落转换为完整的文章本地模式-完整的文章模式可以通过后续处理处理已准备好的文章完整的文章段落,而来自k32>采集@>的新闻源文章生成器绿色最新版本组文章由拦截者拥有,过滤字符伪原创、插入其他文本、插入JS脚本、插入关键词等7、>采集@>中的文章保存为本地TXT文件,然后通过批量上载功能发布,可以大大提高新闻源8、>采集>链接的发布效率:批量采集>文章>链接为采集>文章>保存做准备:保存最新版本的新闻源文章>绿色规则生成器的配置供下次使用;10、打开:打开已保存新闻源的绿色规则的最新版本文章生成器并继续上次操作。运行该软件需要计算机安装Microsoft。Net框架运行环境。请点击链接下载并安装
新闻来源文章发电机最新绿色版本摘要
新闻来源文章generator green最新版本V5.10是一款适用于IOS版本的手机软件。如果您喜欢此软件,请与您的朋友共享下载地址:
自动采集文章内容(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-08 20:04
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或者mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集文章内容(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法

3 如何使用Open是一个数据源

4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或者mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。

(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集文章内容(自动采集文章内容方法非常简单,在万能的七牛云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-08 12:01
自动采集文章内容方法非常简单,在万能的七牛云的帮助中有详细介绍。这里,需要安装一个七牛云文章内容采集器,下载地址:,点击【我已安装】,按照流程操作即可。另外,如果服务端已经开启了云同步功能,那么,需要先打开七牛云的云服务器,配置好七牛云服务器的私有ip,这个操作涉及到登录帐号的操作。具体的操作步骤,请参考《微信公众号文章采集工具开发指南》和《七牛云文章采集器使用教程》。
公众号文章采集工具有很多,一种是通过采集前先对抓取文章的关键词进行查询(百度搜索,360搜索,2345搜索,搜狗搜索,好搜,微信搜索等),然后进行提取,比如先去“好搜站长”网站查询,找到有关文章后再进行提取。一种是通过采集工具进行采集,比如七牛云采集工具采集公众号文章内容的新手提示:1.对采集结果的保存按钮取消勾选,操作方法:右键点击网页空白处,然后选择“存储上传图片”;2.采集结束后,查看文章内容,确保不存在损失,操作方法:右键点击上传文件,然后选择“解析网页”;3.查看文章大图,操作方法:右键点击下载下载,或右键另存为;4.直接将下载下来的文件上传至本地网站(百度文库)或mysql数据库存储,操作方法:右键点击下载文件,选择“压缩解压”;5.等待下载;6.自动提取文章的链接,操作方法:右键选择提取链接,然后按下面的操作保存链接。
7.编辑网页时,右键“输入源地址”或“输入目标地址”,然后选择自动获取。8.(自动获取的情况)文章标题未跟任何其他标签关联,操作方法:右键点击文章标题,然后选择“输入源地址”;9.对于同时获取多个网站的,每个网站,只操作一次,操作方法:右键点击文章标题,然后选择“搜索文章所在网站的网页标题”;10.对于同时获取多个网站的,多个网站分别操作,操作方法:右键点击网站,然后选择“搜索文章所在网站的网页标题”或“另存为”;11.对于七牛云的文章,因为七牛云网页上,网页源地址是没有保存的,需要通过七牛云爬虫服务器做切换工作;操作方法:右键文章所在网站,然后选择“配置源代码服务器”,然后选择爬虫--爬取数据,获取网页源地址。 查看全部
自动采集文章内容(自动采集文章内容方法非常简单,在万能的七牛云)
自动采集文章内容方法非常简单,在万能的七牛云的帮助中有详细介绍。这里,需要安装一个七牛云文章内容采集器,下载地址:,点击【我已安装】,按照流程操作即可。另外,如果服务端已经开启了云同步功能,那么,需要先打开七牛云的云服务器,配置好七牛云服务器的私有ip,这个操作涉及到登录帐号的操作。具体的操作步骤,请参考《微信公众号文章采集工具开发指南》和《七牛云文章采集器使用教程》。
公众号文章采集工具有很多,一种是通过采集前先对抓取文章的关键词进行查询(百度搜索,360搜索,2345搜索,搜狗搜索,好搜,微信搜索等),然后进行提取,比如先去“好搜站长”网站查询,找到有关文章后再进行提取。一种是通过采集工具进行采集,比如七牛云采集工具采集公众号文章内容的新手提示:1.对采集结果的保存按钮取消勾选,操作方法:右键点击网页空白处,然后选择“存储上传图片”;2.采集结束后,查看文章内容,确保不存在损失,操作方法:右键点击上传文件,然后选择“解析网页”;3.查看文章大图,操作方法:右键点击下载下载,或右键另存为;4.直接将下载下来的文件上传至本地网站(百度文库)或mysql数据库存储,操作方法:右键点击下载文件,选择“压缩解压”;5.等待下载;6.自动提取文章的链接,操作方法:右键选择提取链接,然后按下面的操作保存链接。
7.编辑网页时,右键“输入源地址”或“输入目标地址”,然后选择自动获取。8.(自动获取的情况)文章标题未跟任何其他标签关联,操作方法:右键点击文章标题,然后选择“输入源地址”;9.对于同时获取多个网站的,每个网站,只操作一次,操作方法:右键点击文章标题,然后选择“搜索文章所在网站的网页标题”;10.对于同时获取多个网站的,多个网站分别操作,操作方法:右键点击网站,然后选择“搜索文章所在网站的网页标题”或“另存为”;11.对于七牛云的文章,因为七牛云网页上,网页源地址是没有保存的,需要通过七牛云爬虫服务器做切换工作;操作方法:右键文章所在网站,然后选择“配置源代码服务器”,然后选择爬虫--爬取数据,获取网页源地址。
自动采集文章内容(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-08 11:13
其他微信公众号的文章布局都很漂亮,但我只能眼巴巴地看着,想用却又下不了手?需要转载一篇文章的文章。最后复制下来,粘贴了,发现格式全乱了?今天教大家一个小技巧——文章采集,无论是排版风格还是文章的内容,一键导入编辑器即可。快来学习吧。
01采集演示
整个操作过程不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来,我们来看看如何使用采集函数。
⑴选择目标文章,复制文章的链接。
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
▲ 将 文章 链接保存在 PC 上
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲在移动端保存文章链接
⑵ 点击采集按钮。
编辑器中有两个 文章采集 函数条目:
① 编辑菜单右上角的【采集文章】按钮;
▲采集按钮
② [采集文章] 按钮位于右侧功能按钮的底部。
▲采集按钮
⑶ 粘贴文章链接和采集。
▲粘贴链接采集
编辑器支持采集微信公众号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、< @知乎专栏等[很多自媒体平台]文章。
将文章采集放入编辑区后,我们就可以进行后续的修改和排版了。
⑴使用原文排版。
如果只用原文的排版,你过来文章采集后,就【替换文字和图片】。
文字替换:将需要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。将文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式按钮,清除原有格式,然后排版内容文章。
▲清晰的格式
① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择要秒闪的内容,点击喜欢的样式,即可成功使用该样式。
▲第二刷
②您可以使用【智能排版】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板会自动应用。操作简单易学易上手。
▲ 智能布局
采集 函数的使用你学会了吗?如果你平时看到布局精美、内容丰富的文章,不妨采集起来,以备后用。 查看全部
自动采集文章内容(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章布局都很漂亮,但我只能眼巴巴地看着,想用却又下不了手?需要转载一篇文章的文章。最后复制下来,粘贴了,发现格式全乱了?今天教大家一个小技巧——文章采集,无论是排版风格还是文章的内容,一键导入编辑器即可。快来学习吧。
01采集演示
整个操作过程不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来,我们来看看如何使用采集函数。
⑴选择目标文章,复制文章的链接。
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。

▲ 将 文章 链接保存在 PC 上
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。

▲在移动端保存文章链接
⑵ 点击采集按钮。
编辑器中有两个 文章采集 函数条目:
① 编辑菜单右上角的【采集文章】按钮;

▲采集按钮
② [采集文章] 按钮位于右侧功能按钮的底部。

▲采集按钮
⑶ 粘贴文章链接和采集。

▲粘贴链接采集
编辑器支持采集微信公众号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、< @知乎专栏等[很多自媒体平台]文章。
将文章采集放入编辑区后,我们就可以进行后续的修改和排版了。
⑴使用原文排版。
如果只用原文的排版,你过来文章采集后,就【替换文字和图片】。
文字替换:将需要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。

▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。

⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。将文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式按钮,清除原有格式,然后排版内容文章。

▲清晰的格式
① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择要秒闪的内容,点击喜欢的样式,即可成功使用该样式。
▲第二刷
②您可以使用【智能排版】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板会自动应用。操作简单易学易上手。
▲ 智能布局
采集 函数的使用你学会了吗?如果你平时看到布局精美、内容丰富的文章,不妨采集起来,以备后用。
自动采集文章内容(自动采集文章内容到excel表格,提供三种方式,快速采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-11-08 06:01
自动采集文章内容到excel表格,提供三种方式,分别是excel直接导入、自定义函数直接导入、用正则表达式直接导入,前两者需要有自己的文章;用正则表达式,文章作者、修改、页码、标题等等,直接采集;正则表达式正则表达式实现内容快速采集是基于正则表达式来实现的。可以调用国内各大站点的正则表达式采集器库,比如“sites”或者“manual”等。步骤:。
1、在浏览器地址栏输入:/,
2、点击下一步,
3、点击选择符合要求的网页
4、找到下方文本框,
5、点击确定
6、此时即可看到各类站点的站内链接
7、我们可以根据需要,设置采集哪些文章,以及采集中间某些页面时的长度。原文地址:10分钟学会采集各大平台站内文章,
自动采集技术实现网站抓取,最新又升级到ez2k包了,各种站内搜索,如高清图片,收藏夹等都可以采集,但有些站不是全站都能抓取,比如大部分自然段都不能抓取,要抓取某些站内段落,非自动化采集做不到。但能抓取也无所谓,谷歌还是基于ezip加密了。上面有小伙伴说,不用加密,那是在用bt软件下载链接时,有次偶然看到谷歌等网站下有自动下载的下载器,可以自动下载高清资源,但偶尔会搞出smb,因为个人很少用bt软件,也不懂链接搜索算法,基本上是通过点来的网页,在下载软件下图后点name里面的我的文件,说明下载器就是爬虫代替人工来干活,使用人工,有一定的犯错率。
虽然我不是太懂算法,但bt下载的下载速度还是非常快的,但基本上只能看网站是否收费(需要可调速度下载或者一年不超过200kb会员等)如果有免费的下载器还是会很下载,不如多花点买个会员。在没有stm加密,没有太大下载速度的情况下,用dht或者urlrequest对proxy去抓取,可以加速,但很多网站有限速,以google为例,bt一次下载速度有5-7kb,但谷歌是有限速的,dht一般在1-2kb,2.5-3kb的速度之间,网站收费的时候,速度就很快。
<p>ez2k是基于phantomjs,没有下载,只加密。以我们博客的代码为例://以个人博客举例1.首先要添加第一个href标签2.如果是文章网站,content页面上要添加 查看全部
自动采集文章内容(自动采集文章内容到excel表格,提供三种方式,快速采集)
自动采集文章内容到excel表格,提供三种方式,分别是excel直接导入、自定义函数直接导入、用正则表达式直接导入,前两者需要有自己的文章;用正则表达式,文章作者、修改、页码、标题等等,直接采集;正则表达式正则表达式实现内容快速采集是基于正则表达式来实现的。可以调用国内各大站点的正则表达式采集器库,比如“sites”或者“manual”等。步骤:。
1、在浏览器地址栏输入:/,
2、点击下一步,
3、点击选择符合要求的网页
4、找到下方文本框,
5、点击确定
6、此时即可看到各类站点的站内链接
7、我们可以根据需要,设置采集哪些文章,以及采集中间某些页面时的长度。原文地址:10分钟学会采集各大平台站内文章,
自动采集技术实现网站抓取,最新又升级到ez2k包了,各种站内搜索,如高清图片,收藏夹等都可以采集,但有些站不是全站都能抓取,比如大部分自然段都不能抓取,要抓取某些站内段落,非自动化采集做不到。但能抓取也无所谓,谷歌还是基于ezip加密了。上面有小伙伴说,不用加密,那是在用bt软件下载链接时,有次偶然看到谷歌等网站下有自动下载的下载器,可以自动下载高清资源,但偶尔会搞出smb,因为个人很少用bt软件,也不懂链接搜索算法,基本上是通过点来的网页,在下载软件下图后点name里面的我的文件,说明下载器就是爬虫代替人工来干活,使用人工,有一定的犯错率。
虽然我不是太懂算法,但bt下载的下载速度还是非常快的,但基本上只能看网站是否收费(需要可调速度下载或者一年不超过200kb会员等)如果有免费的下载器还是会很下载,不如多花点买个会员。在没有stm加密,没有太大下载速度的情况下,用dht或者urlrequest对proxy去抓取,可以加速,但很多网站有限速,以google为例,bt一次下载速度有5-7kb,但谷歌是有限速的,dht一般在1-2kb,2.5-3kb的速度之间,网站收费的时候,速度就很快。
<p>ez2k是基于phantomjs,没有下载,只加密。以我们博客的代码为例://以个人博客举例1.首先要添加第一个href标签2.如果是文章网站,content页面上要添加
自动采集文章内容(使用localapitumblr|home·toadle1(二维码自动识别)使用地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-06 10:03
自动采集文章内容然后推送:tumblrdashboard[1]的显示文字和图片都是预先生成的。如果想要和原始文字一样或更少,我们还可以看到它们是如何被采集的。使用localapitumblr|home使用https地址tumblr|home使用localapitumblr|home·toadle1(二维码自动识别)使用https地址tumblr|home|copy使用https地址tumblr|home|fulltext-lookup。
可以使用bootstrap。也可以试试gae。或者自己的账号自己写。
用google就好了吧,所有的网站都直接是google一遍就好了,然后自己写插件,loginapi就可以了,
你们都考虑的很好了。我稍微说说其他几点。可以考虑使用nicholascalvert。他把bootstrap中很多函数转化成javascript。这个特性有些奇怪,但是开发起来和使用起来还是非常方便的。注意,他生成的javascript不会直接去调用相应的bootstrap模块。而是直接调用。甚至在项目根目录,代码就一行文件名带function[javascript:],你还是可以看到javascript代码。
我印象中支持angularjs的项目都不会对这个需求进行考虑。注意,这个系统是gmail的。如果不在内部部署,在公有云上使用本地环境,这个用法可能不对。如果是用自己构建的hybrid网站,那这个还是可以接受的。嗯,怎么在这么大的系统上使用类似gmail的igoogle这种?好像很困难?你们都用的什么架构?以前做了js文件存在哪里?。 查看全部
自动采集文章内容(使用localapitumblr|home·toadle1(二维码自动识别)使用地址)
自动采集文章内容然后推送:tumblrdashboard[1]的显示文字和图片都是预先生成的。如果想要和原始文字一样或更少,我们还可以看到它们是如何被采集的。使用localapitumblr|home使用https地址tumblr|home使用localapitumblr|home·toadle1(二维码自动识别)使用https地址tumblr|home|copy使用https地址tumblr|home|fulltext-lookup。
可以使用bootstrap。也可以试试gae。或者自己的账号自己写。
用google就好了吧,所有的网站都直接是google一遍就好了,然后自己写插件,loginapi就可以了,
你们都考虑的很好了。我稍微说说其他几点。可以考虑使用nicholascalvert。他把bootstrap中很多函数转化成javascript。这个特性有些奇怪,但是开发起来和使用起来还是非常方便的。注意,他生成的javascript不会直接去调用相应的bootstrap模块。而是直接调用。甚至在项目根目录,代码就一行文件名带function[javascript:],你还是可以看到javascript代码。
我印象中支持angularjs的项目都不会对这个需求进行考虑。注意,这个系统是gmail的。如果不在内部部署,在公有云上使用本地环境,这个用法可能不对。如果是用自己构建的hybrid网站,那这个还是可以接受的。嗯,怎么在这么大的系统上使用类似gmail的igoogle这种?好像很困难?你们都用的什么架构?以前做了js文件存在哪里?。
自动采集文章内容(会员织梦深度定制的小说站,全自动采集各大小说站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-12-16 12:37
会员织梦深度定制小说网站,全自动采集各类网站,可自动生成首页、分类、目录、排名、站点地图页面静态html、全站拼音目录、章节页面伪静态、自动生成小说txt文件,自动生成zip存档。这个源码功能极其强大!带来一个非常漂亮的手机页面!带采集规则+自动适配!亲测,超级强大,采集的所有规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!制作新网站的好程序没什么好说的,感谢我们的会员免费提供。
其他特性:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,自动生成静态html,会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在里面生成根目录下,访问速度和纯静态无异,在保证源文件管理方便的同时可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广管、采集等,而是原有的采集功能DEDE基于采集模块二次开发,可有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集量可每天 24 小时达到 25~30 万个章节。
[rihide] 下载链接:
提取码:xm4g 解压密码:深度二次开发的新站点@伴世钟爱 来源[/rihide] 查看全部
自动采集文章内容(会员织梦深度定制的小说站,全自动采集各大小说站)
会员织梦深度定制小说网站,全自动采集各类网站,可自动生成首页、分类、目录、排名、站点地图页面静态html、全站拼音目录、章节页面伪静态、自动生成小说txt文件,自动生成zip存档。这个源码功能极其强大!带来一个非常漂亮的手机页面!带采集规则+自动适配!亲测,超级强大,采集的所有规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!制作新网站的好程序没什么好说的,感谢我们的会员免费提供。
其他特性:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,自动生成静态html,会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在里面生成根目录下,访问速度和纯静态无异,在保证源文件管理方便的同时可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广管、采集等,而是原有的采集功能DEDE基于采集模块二次开发,可有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集量可每天 24 小时达到 25~30 万个章节。
[rihide] 下载链接:
提取码:xm4g 解压密码:深度二次开发的新站点@伴世钟爱 来源[/rihide]
自动采集文章内容(自媒体创作者赚钱的方式主要有哪些?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-15 10:02
自动采集文章内容的网站有很多,随着自媒体大趋势的发展,很多优质的内容创作者正在崛起,他们获取到的知识付费内容更多,因此自媒体人对于相关内容的追求就更加重视。自媒体创作者为了吸引自己粉丝关注,还有一部分目的是转化成为自己的内容赚钱。但是现在,自媒体平台的广告收益越来越低,原因都是广告商高薪投放标的广告,导致整体收益都很差。而有一些人就通过这种广告投放的方式,在其它平台赚到了大额的收益。
一、自媒体创作者赚钱的方式主要有哪些?
1、通过分享和写作来获取平台分成平台给自媒体人开放广告分成的权限,平台会根据你的内容分享量给予你相应的收益。这种方式是目前最常见的获取广告分成的方式,无论你的内容是在头条号还是企鹅号、百家号、大鱼号或者其它,只要你能够持续的输出优质的内容,内容够吸引人,就能够获得平台给予的收益分成。
2、自营广告这是自媒体人通过内容来营销自己,获取平台收益的方式。这种方式获取收益最简单直接,上传自己的内容直接上传自营广告就可以了,一般每个账号开通自营广告后,当天就可以获得广告费收益。
3、服务号接入广告今日头条的服务号可以接入头条广告,企鹅号的服务号接入企鹅广告,大鱼号的服务号接入大鱼广告,这个通过在后台接入,或者其它地方接入。现在每个自媒体平台都在强制要求内容生产者必须接入广告,好像今日头条是必须要求全部自媒体人必须接入,其它平台似乎也是同样,其实是平台在管控规范广告价格,越来越高。
4、头条系游戏类广告这类广告收益我们通常称之为业务号接入头条平台业务号,能够根据粉丝关注度,能有相应的广告收益分成。现在很多自媒体人运营头条号都是靠主营业务赚钱,这个以后也可以成为你的收益来源。不过自身最好有不错的业务,这样效果才比较好。
5、内容电商现在平台都在限制内容电商的接入,平台不允许内容进行虚假和不准确的引导性文案或者链接。这种方式获取收益有两种方式,一种是做内容电商,通过内容完成商品的展示,通过后台的内容关注关系,以及后台的内容浏览,来引导商品购买。另外一种方式就是做内容商品插件,就是可以给平台用户或者其它平台流量主,帮助平台引流,通过自己的素材,也可以插入购买链接。这种方式对内容创作者的要求比较高,因为大多数人都很少用到平台插件,或者不会用。
6、服务号推广优质自媒体人现在有些自媒体人,有一定的内容,但是粉丝不多,就是靠优质的内容吸引关注。但是现在平台对内容已经不敢轻易的进行内容删除了,只要创作者内容不违规。 查看全部
自动采集文章内容(自媒体创作者赚钱的方式主要有哪些?怎么做?)
自动采集文章内容的网站有很多,随着自媒体大趋势的发展,很多优质的内容创作者正在崛起,他们获取到的知识付费内容更多,因此自媒体人对于相关内容的追求就更加重视。自媒体创作者为了吸引自己粉丝关注,还有一部分目的是转化成为自己的内容赚钱。但是现在,自媒体平台的广告收益越来越低,原因都是广告商高薪投放标的广告,导致整体收益都很差。而有一些人就通过这种广告投放的方式,在其它平台赚到了大额的收益。
一、自媒体创作者赚钱的方式主要有哪些?
1、通过分享和写作来获取平台分成平台给自媒体人开放广告分成的权限,平台会根据你的内容分享量给予你相应的收益。这种方式是目前最常见的获取广告分成的方式,无论你的内容是在头条号还是企鹅号、百家号、大鱼号或者其它,只要你能够持续的输出优质的内容,内容够吸引人,就能够获得平台给予的收益分成。
2、自营广告这是自媒体人通过内容来营销自己,获取平台收益的方式。这种方式获取收益最简单直接,上传自己的内容直接上传自营广告就可以了,一般每个账号开通自营广告后,当天就可以获得广告费收益。
3、服务号接入广告今日头条的服务号可以接入头条广告,企鹅号的服务号接入企鹅广告,大鱼号的服务号接入大鱼广告,这个通过在后台接入,或者其它地方接入。现在每个自媒体平台都在强制要求内容生产者必须接入广告,好像今日头条是必须要求全部自媒体人必须接入,其它平台似乎也是同样,其实是平台在管控规范广告价格,越来越高。
4、头条系游戏类广告这类广告收益我们通常称之为业务号接入头条平台业务号,能够根据粉丝关注度,能有相应的广告收益分成。现在很多自媒体人运营头条号都是靠主营业务赚钱,这个以后也可以成为你的收益来源。不过自身最好有不错的业务,这样效果才比较好。
5、内容电商现在平台都在限制内容电商的接入,平台不允许内容进行虚假和不准确的引导性文案或者链接。这种方式获取收益有两种方式,一种是做内容电商,通过内容完成商品的展示,通过后台的内容关注关系,以及后台的内容浏览,来引导商品购买。另外一种方式就是做内容商品插件,就是可以给平台用户或者其它平台流量主,帮助平台引流,通过自己的素材,也可以插入购买链接。这种方式对内容创作者的要求比较高,因为大多数人都很少用到平台插件,或者不会用。
6、服务号推广优质自媒体人现在有些自媒体人,有一定的内容,但是粉丝不多,就是靠优质的内容吸引关注。但是现在平台对内容已经不敢轻易的进行内容删除了,只要创作者内容不违规。
自动采集文章内容(深度SEO优化自动采集的新版本,小说不占内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-04 13:13
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断采集,简单无烦恼。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐Linux系统,apache/nginx可以是硬件要求:CPU/内存/硬盘/宽带大小不做要求,但配置越高,采集效率会更好!
注意:用户在使用本系统源代码时,必须在国家相关法律法规的范围内,并获得国家相关部门的授权,禁止将其用于一切非法活动。使用仅限于测试、实验和研究目的,禁止用于所有商业运营。本站对用户在使用过程中的任何违法行为不承担任何责任。 查看全部
自动采集文章内容(深度SEO优化自动采集的新版本,小说不占内存)
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断采集,简单无烦恼。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐Linux系统,apache/nginx可以是硬件要求:CPU/内存/硬盘/宽带大小不做要求,但配置越高,采集效率会更好!
注意:用户在使用本系统源代码时,必须在国家相关法律法规的范围内,并获得国家相关部门的授权,禁止将其用于一切非法活动。使用仅限于测试、实验和研究目的,禁止用于所有商业运营。本站对用户在使用过程中的任何违法行为不承担任何责任。
自动采集文章内容(自动采集文章内容赚收益怎么办?选题设计方法分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-02 18:06
自动采集文章内容赚收益,这事其实并不困难,花一点钱,很难不给你流量和销量。你想成为一个靠内容赚钱的自媒体,不重复的花钱去买流量,这并不能真正解决问题。何不把这些时间花在选题上?今天把选题方法,给大家做个简单介绍,希望对大家有用。选题主要分两大种:大纲采集+内容采集。上架后尽量跟公众号定位相符合,尽量是同一个品类,在后续更新维护中有继续做内容输出的基础。
选题设计选题很多,一个字概括:量化!在采集之初,尽量选择“大量、粗略”的大纲,多选题多采,把选题做到靠谱,尽量兼顾流量和销量,算是长远规划。作为新手来说,文章收益还是非常重要的,只要能够提高收益,从字数、标题、内容上做点牺牲是值得的。一、上架后,提高流量和销量,能够更轻松、更快的把店铺里面的流量导入到你自己的产品上面。
在完成采集之后,用数据分析工具做表格,把表格里面的关键词用在你自己的内容标题上,就可以找到相关的流量源,毕竟网络的流量很大。这个工具有很多,比如:新榜app、清博指数、麦子熟了、中关村在线等等。那么,能够提高流量和销量的文章具体应该如何去写,我在这里就不详细分析了,总之就是靠量化。举个例子,假设你目前每天获取的流量为20000,那么你就每天获取20000/30=60个自然流量,日导入9000,同时要获取20000以上的优质自然流量,这需要你对每一个关键词都做深挖。
再多写几个,甚至50个,分析筛选一下,如果你有大量的用户需求,每天能够获取10万到30万流量,那么日订单额也会突破100万。假设利用文章详情页留的悬念文案能够吸引9000个流量,每天都能增加订单10万,每天的利润就能到200万。二、开通客,销量直接提升10倍!如果是长期合作的公众号,可以考虑开通客,那么会有一个特别明显的效果:销量直接提升10倍。
这个效果非常明显。以上面的视频为例,在6月11号至6月12号,销量由0涨到10000,增加100倍。这个销量是怎么来的?很简单,就是原来你每天获取20000粉丝,写一篇3000字的文章,最多能够增加200个阅读和3000个收藏,每个阅读也只能带来1块钱的收益。可是我用原创的标题和3000字的文章写出来,排版会相对简单,在10分钟内写完并发布,在20分钟内加价50%加价10倍发布,每天会带来10000个人阅读,从此你的销量就有了10倍的提升,单价从3000涨到了10000。
理解这个理论其实非常简单,发布2-3天之后,同时加价20%,就是1万的收益,有2000个阅读,你就能赚10000元。用更精炼的文字,更多的字符,用更精准的关。 查看全部
自动采集文章内容(自动采集文章内容赚收益怎么办?选题设计方法分享)
自动采集文章内容赚收益,这事其实并不困难,花一点钱,很难不给你流量和销量。你想成为一个靠内容赚钱的自媒体,不重复的花钱去买流量,这并不能真正解决问题。何不把这些时间花在选题上?今天把选题方法,给大家做个简单介绍,希望对大家有用。选题主要分两大种:大纲采集+内容采集。上架后尽量跟公众号定位相符合,尽量是同一个品类,在后续更新维护中有继续做内容输出的基础。
选题设计选题很多,一个字概括:量化!在采集之初,尽量选择“大量、粗略”的大纲,多选题多采,把选题做到靠谱,尽量兼顾流量和销量,算是长远规划。作为新手来说,文章收益还是非常重要的,只要能够提高收益,从字数、标题、内容上做点牺牲是值得的。一、上架后,提高流量和销量,能够更轻松、更快的把店铺里面的流量导入到你自己的产品上面。
在完成采集之后,用数据分析工具做表格,把表格里面的关键词用在你自己的内容标题上,就可以找到相关的流量源,毕竟网络的流量很大。这个工具有很多,比如:新榜app、清博指数、麦子熟了、中关村在线等等。那么,能够提高流量和销量的文章具体应该如何去写,我在这里就不详细分析了,总之就是靠量化。举个例子,假设你目前每天获取的流量为20000,那么你就每天获取20000/30=60个自然流量,日导入9000,同时要获取20000以上的优质自然流量,这需要你对每一个关键词都做深挖。
再多写几个,甚至50个,分析筛选一下,如果你有大量的用户需求,每天能够获取10万到30万流量,那么日订单额也会突破100万。假设利用文章详情页留的悬念文案能够吸引9000个流量,每天都能增加订单10万,每天的利润就能到200万。二、开通客,销量直接提升10倍!如果是长期合作的公众号,可以考虑开通客,那么会有一个特别明显的效果:销量直接提升10倍。
这个效果非常明显。以上面的视频为例,在6月11号至6月12号,销量由0涨到10000,增加100倍。这个销量是怎么来的?很简单,就是原来你每天获取20000粉丝,写一篇3000字的文章,最多能够增加200个阅读和3000个收藏,每个阅读也只能带来1块钱的收益。可是我用原创的标题和3000字的文章写出来,排版会相对简单,在10分钟内写完并发布,在20分钟内加价50%加价10倍发布,每天会带来10000个人阅读,从此你的销量就有了10倍的提升,单价从3000涨到了10000。
理解这个理论其实非常简单,发布2-3天之后,同时加价20%,就是1万的收益,有2000个阅读,你就能赚10000元。用更精炼的文字,更多的字符,用更精准的关。
自动采集文章内容(百度站长平台短网址转化率最高的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-01 16:03
自动采集文章内容。二维码。一键生成积分墙。自动化营销,文章自动化排版。自动化伪原创。.自动化地获取用户信息数据,并进行后续分析。
小尾巴是在百度站长平台上发布信息之后,上传到小尾巴平台,为网站获取网民的收藏网站时,可以收集到一些网站的主页链接或页面链接。收集网站链接的结果就是给网站导流量。是百度一个很大的流量渠道。你只要通过百度站长平台上的小尾巴后台,就可以通过爬虫的方式爬取小尾巴,然后再上传到百度站长平台上,供网站导流。效果立竿见影,这就是为什么百度站长平台可以做到每天新增几千网站链接。
百度站长帮是在百度站长平台提交信息,
一般的情况都是百度站长帮发信息。一天几千并不是有效数量,百度每天每个网站会收录多少数量信息。真正有效率的是,当你发布信息,然后排名即将达到一个很好的情况,然后你突然意识到,我去,突然没信息了!其实这就是转化率了,这就是短网址转化率最高的时候,以此类推。不建议挂短网址,因为短网址更适合专业网站。
短网址,短网址_短网址生成_短网址制作_短网址服务_短网址生成短网址的分享,
几千条短网址并不是很多,因为我有时候想要挂信息呢都会找一些免费的短网址进行挂!某易,某酷,某东,某狗,某虫,又或者是某宝等都有放出信息的。短网址是不能自己生成的,要通过百度和谷歌等搜索引擎来获取,要不没有效果的!!所以说,要生成短网址的话还是要找些一些短网址接收器!!对于小白来说,百度短网址接收器是最佳选择,很简单!希望对你有帮助!。 查看全部
自动采集文章内容(百度站长平台短网址转化率最高的方法是什么?)
自动采集文章内容。二维码。一键生成积分墙。自动化营销,文章自动化排版。自动化伪原创。.自动化地获取用户信息数据,并进行后续分析。
小尾巴是在百度站长平台上发布信息之后,上传到小尾巴平台,为网站获取网民的收藏网站时,可以收集到一些网站的主页链接或页面链接。收集网站链接的结果就是给网站导流量。是百度一个很大的流量渠道。你只要通过百度站长平台上的小尾巴后台,就可以通过爬虫的方式爬取小尾巴,然后再上传到百度站长平台上,供网站导流。效果立竿见影,这就是为什么百度站长平台可以做到每天新增几千网站链接。
百度站长帮是在百度站长平台提交信息,
一般的情况都是百度站长帮发信息。一天几千并不是有效数量,百度每天每个网站会收录多少数量信息。真正有效率的是,当你发布信息,然后排名即将达到一个很好的情况,然后你突然意识到,我去,突然没信息了!其实这就是转化率了,这就是短网址转化率最高的时候,以此类推。不建议挂短网址,因为短网址更适合专业网站。
短网址,短网址_短网址生成_短网址制作_短网址服务_短网址生成短网址的分享,
几千条短网址并不是很多,因为我有时候想要挂信息呢都会找一些免费的短网址进行挂!某易,某酷,某东,某狗,某虫,又或者是某宝等都有放出信息的。短网址是不能自己生成的,要通过百度和谷歌等搜索引擎来获取,要不没有效果的!!所以说,要生成短网址的话还是要找些一些短网址接收器!!对于小白来说,百度短网址接收器是最佳选择,很简单!希望对你有帮助!。
自动采集文章内容(深度SEO优化自动采集的新版本,小说/视频/音乐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-11-30 14:12
来源介绍
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断电话采集,简单省事。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐使用Linux系统。apache和nginx都有硬件要求:CPU/内存/硬盘/宽带大小没有要求,但是配置越高,采集效率会更好!
小说/视频/音乐
2021年最新版小说+漫画+听书+电影一体功能的源码!有奖励+试用+代理+第三方支付
站长测试_最新解密全开源版!加上data和采集器所以压缩包比较大!很多站长都在找源码,外面正确的也卖了几K。在这里分享一下,并且修复了一些bug,可以链接到第三方影视网站(可以多电影论坛发布后搭建),小说、漫画、听书聚合手机网站也有视频打赏功能、试用功能、接入第三方支付。修复内容:一、修复代理无法登录的问题二、修复注册页面无法注册的问题三、修复自定义菜单无法推送... 查看全部
自动采集文章内容(深度SEO优化自动采集的新版本,小说/视频/音乐)
来源介绍
本源码为新版深度SEO优化自动采集,小说不占内存,保存数万部小说不成问题。
记住采集和以后的文章需要处理文章信息。至于自动采集,我没仔细研究。它与以前的版本没有太大区别。有些东西已经优化了。, 基本上第一次需要采集一些内容,后续更新都是自动的。文章 信息的批处理一定不能少。
1.不保存数据,小说以软链接的形式存在。无版权纠纷。
2.因为是软链接,所以需要最少的硬盘空间,成本低。
3.后台预设广告位,添加广告代码极其简单。
4.可以自动挂断电话采集,简单省事。YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。具有无限数量的 采集 代码
环保要求:
PHP5.4 及以上,带伪静态函数。mysql5.6+
主机要求:IIS/APACHE/NGINX和虚拟主机/VPS/服务器/云服务器均可。推荐使用Linux系统。apache和nginx都有硬件要求:CPU/内存/硬盘/宽带大小没有要求,但是配置越高,采集效率会更好!
小说/视频/音乐
2021年最新版小说+漫画+听书+电影一体功能的源码!有奖励+试用+代理+第三方支付
站长测试_最新解密全开源版!加上data和采集器所以压缩包比较大!很多站长都在找源码,外面正确的也卖了几K。在这里分享一下,并且修复了一些bug,可以链接到第三方影视网站(可以多电影论坛发布后搭建),小说、漫画、听书聚合手机网站也有视频打赏功能、试用功能、接入第三方支付。修复内容:一、修复代理无法登录的问题二、修复注册页面无法注册的问题三、修复自定义菜单无法推送...
自动采集文章内容(自动采集文章内容的一定是公众号!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-27 22:02
自动采集文章内容的一定是公众号!1如果你的文章是与/天猫商品一样,可以直接找到商品的/天猫商家采集的话;也可以直接联系我2下载软件简单一点的用,万能的迅捷,专业的用采集蜘蛛侠,大号都支持的,
新闻号转载使用万能的迅捷pdf采集器。这是原生态插件,有pdf全文阅读器功能。而且还很棒,直接是读取网页里的pdf文件。
我也想知道这个怎么做,
没问题的我都会
我记得一开始是付费的。后来看到用软件的,
不知道可不可以,我最近发现一个软件,我觉得挺好用的,连接在图片上,
我也想知道这个怎么做
用过很多神器,wifi万能钥匙,随手记,现在免费了,有用,他们肯定会变聪明,会钻空子,花钱买营销性质的软件,但是听说是免费,可以试试看。
这是一种比较极端的模式,针对很多新闻和文章的,只要在业内有影响力的就能被采集,跟这个有没有真正的网址系统无关。
有个好办法,使用pdf格式的同步云文档一键采集。一样可以在软件中全文搜索。搜索方法:在【图文快传达】文件夹,里有同步云文档按钮,搜索即可。 查看全部
自动采集文章内容(自动采集文章内容的一定是公众号!(图))
自动采集文章内容的一定是公众号!1如果你的文章是与/天猫商品一样,可以直接找到商品的/天猫商家采集的话;也可以直接联系我2下载软件简单一点的用,万能的迅捷,专业的用采集蜘蛛侠,大号都支持的,
新闻号转载使用万能的迅捷pdf采集器。这是原生态插件,有pdf全文阅读器功能。而且还很棒,直接是读取网页里的pdf文件。
我也想知道这个怎么做,
没问题的我都会
我记得一开始是付费的。后来看到用软件的,
不知道可不可以,我最近发现一个软件,我觉得挺好用的,连接在图片上,
我也想知道这个怎么做
用过很多神器,wifi万能钥匙,随手记,现在免费了,有用,他们肯定会变聪明,会钻空子,花钱买营销性质的软件,但是听说是免费,可以试试看。
这是一种比较极端的模式,针对很多新闻和文章的,只要在业内有影响力的就能被采集,跟这个有没有真正的网址系统无关。
有个好办法,使用pdf格式的同步云文档一键采集。一样可以在软件中全文搜索。搜索方法:在【图文快传达】文件夹,里有同步云文档按钮,搜索即可。
自动采集文章内容(【知识点】数据采集基本功能(1)、多线程采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 15:11
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能< @采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集@ > 任务配置、跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有网页请求需求。此功能在数据网络发布时特别有用;< @4)采集 URL 支持数字、字母、日期以及自定义字典、外部数据等参数,最大限度的简化采集 URL 的配置,从而达到批处理采集;5)采集 URL支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能还可用于用户自动合并页面< @文章; 7)网络矿工支持级联采集,即在导航的基础上,不同层次的数据可以自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章 查看全部
自动采集文章内容(【知识点】数据采集基本功能(1)、多线程采集)
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能< @采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集@ > 任务配置、跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有网页请求需求。此功能在数据网络发布时特别有用;< @4)采集 URL 支持数字、字母、日期以及自定义字典、外部数据等参数,最大限度的简化采集 URL 的配置,从而达到批处理采集;5)采集 URL支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能还可用于用户自动合并页面< @文章; 7)网络矿工支持级联采集,即在导航的基础上,不同层次的数据可以自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章
自动采集文章内容(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-11-23 23:11
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的链接,可以正常显示内容的样子:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到您的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、 设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,向页面注入脚本,将页面内容发送到服务器。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
自动采集文章内容(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个完整的链接,可以正常显示内容的样子:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人账号:对于采集的内容,不仅需要一个微信客户端,还需要一个专用于采集的微信个人账号,因为这个微信账号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到您的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章列表并建立采集队列来实现批次采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、 设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一个公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002就可以看到anyproxy的web界面了。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,向页面注入脚本,将页面内容发送到服务器。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
自动采集文章内容(导出成excel表一网打尽,文章,找一款好用的微信批量打包工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-23 09:14
自动采集文章内容,手动筛选、降权、删除原文,导出成excel表一网打尽,文章,
找一款好用的微信批量打包工具,
推荐新浪新闻站长助手,
现在市面上有很多平台。百度一下一大把。
在市面上是有很多平台,百度一搜全是,每个都有很多功能。上个月经朋友推荐,用大鱼号打包微信号,把广告文章打包成一个excel表,然后接好友转发推广,一个微信号推送1000次,轻松就达到了转化,一个月粉丝1500+。上个月效果杠杠的,市面上很多没有注册的帐号都是没有做广告推广的机会。
抓取各大新闻门户网站的文章就可以啊,我之前就用的一个大鱼号打包的,前期平台推荐力度大,可以抓取原始文章去推广啊,或者收集文章推广,
两条,一条公众号,一条订阅号,一个文本集不是说专门做视频号还是公众号号,订阅号不需要上传视频就可以了,公众号就可以,网上那种直接输出视频的即可,我用的就是头条,微博开发人员的更新速度还是比较快的。
169个号同步成一个excel,输出指定的收费群内详情、排序规则给各平台,不同的平台可同步收费,未来渠道很多。还可以指定地域。 查看全部
自动采集文章内容(导出成excel表一网打尽,文章,找一款好用的微信批量打包工具)
自动采集文章内容,手动筛选、降权、删除原文,导出成excel表一网打尽,文章,
找一款好用的微信批量打包工具,
推荐新浪新闻站长助手,
现在市面上有很多平台。百度一下一大把。
在市面上是有很多平台,百度一搜全是,每个都有很多功能。上个月经朋友推荐,用大鱼号打包微信号,把广告文章打包成一个excel表,然后接好友转发推广,一个微信号推送1000次,轻松就达到了转化,一个月粉丝1500+。上个月效果杠杠的,市面上很多没有注册的帐号都是没有做广告推广的机会。
抓取各大新闻门户网站的文章就可以啊,我之前就用的一个大鱼号打包的,前期平台推荐力度大,可以抓取原始文章去推广啊,或者收集文章推广,
两条,一条公众号,一条订阅号,一个文本集不是说专门做视频号还是公众号号,订阅号不需要上传视频就可以了,公众号就可以,网上那种直接输出视频的即可,我用的就是头条,微博开发人员的更新速度还是比较快的。
169个号同步成一个excel,输出指定的收费群内详情、排序规则给各平台,不同的平台可同步收费,未来渠道很多。还可以指定地域。
自动采集文章内容(推荐软件☞舆情管家☞rielette(新版本)☞评测)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-17 07:01
自动采集文章内容将各类媒体全部整合到一个通用网站上可自定义更新其它媒体文章可批量导入维护ps:目前媒体筛选分类比较混乱,必须分好类才能选择进入相关媒体,大家体验下总结:推荐软件☞舆情管家☞rielette(新版本)☞评测福利☞免费试用☞界面素材与代码全高清原图直接拖拽上传合并txt+jpg图片(40s预览,一次提交只提供两篇)40个样式丰富的表情包对流量依赖不大的媒体可以一键采集,经常看到公众号文章中混入许多二维码、文章、推广位不知道是什么的情况,可以选择上传等比例整合图片,文章中所有颜色可自定义导入获取rsv_serial:s7urls:rielette☞文章利用合并器s7urls合并公众号每篇文章的链接(点击链接进行弹出)(大家都知道公众号的链接有些需要长按才能弹出)(公众号中每篇文章链接含有网站地址以及链接的代码)(左侧排序选择按照以上方式查看)复制链接,在浏览器地址栏中输入出现"url:",点击蓝色“是”(数字"/”可以代替网址)保存;未保存的链接会显示“。
[]”双击链接到记事本复制保存react全靠他了!可以随意支持chrome、百度浏览器以及safari(react官方论坛已经支持微信登录)今天预测主要是围绕react全站在进行的变动排序等利用react全站优势可以对前端页面进行完全复用使得页面只有模板内容少了无限接近现在网页里面充斥着微信文章导致页面复杂难以维护了目前可以在浏览器进行预览(查看其它分类)全站查看即使提交时包含某种以外分类代码(比如1)对页面没有任何影响复制链接粘贴或导入导出分类代码即可完成排序按照被合并的网址导入代码微信redis也开始向前端倾斜微信redis_后端和前端是通过分离的:你可以在微信后端维护服务器分不同数据库,服务端只管维护统一的数据库,用户请求哪个库,服务端就合并那个库对服务端来说减少服务器开销,同时提高服务器的性能(这些是算在成本里面的)使用redis也是因为使用了缓存以及命令方式检查queryselectoralls_filter:如果知道queryselectorallfilter。
filter的名字,你可以知道这个叫做命令的条件检查列表(即使定制检查模式)结论实现过react全站,spring全站,从开发难度来说react相对其它来说并不那么难。 查看全部
自动采集文章内容(推荐软件☞舆情管家☞rielette(新版本)☞评测)
自动采集文章内容将各类媒体全部整合到一个通用网站上可自定义更新其它媒体文章可批量导入维护ps:目前媒体筛选分类比较混乱,必须分好类才能选择进入相关媒体,大家体验下总结:推荐软件☞舆情管家☞rielette(新版本)☞评测福利☞免费试用☞界面素材与代码全高清原图直接拖拽上传合并txt+jpg图片(40s预览,一次提交只提供两篇)40个样式丰富的表情包对流量依赖不大的媒体可以一键采集,经常看到公众号文章中混入许多二维码、文章、推广位不知道是什么的情况,可以选择上传等比例整合图片,文章中所有颜色可自定义导入获取rsv_serial:s7urls:rielette☞文章利用合并器s7urls合并公众号每篇文章的链接(点击链接进行弹出)(大家都知道公众号的链接有些需要长按才能弹出)(公众号中每篇文章链接含有网站地址以及链接的代码)(左侧排序选择按照以上方式查看)复制链接,在浏览器地址栏中输入出现"url:",点击蓝色“是”(数字"/”可以代替网址)保存;未保存的链接会显示“。
[]”双击链接到记事本复制保存react全靠他了!可以随意支持chrome、百度浏览器以及safari(react官方论坛已经支持微信登录)今天预测主要是围绕react全站在进行的变动排序等利用react全站优势可以对前端页面进行完全复用使得页面只有模板内容少了无限接近现在网页里面充斥着微信文章导致页面复杂难以维护了目前可以在浏览器进行预览(查看其它分类)全站查看即使提交时包含某种以外分类代码(比如1)对页面没有任何影响复制链接粘贴或导入导出分类代码即可完成排序按照被合并的网址导入代码微信redis也开始向前端倾斜微信redis_后端和前端是通过分离的:你可以在微信后端维护服务器分不同数据库,服务端只管维护统一的数据库,用户请求哪个库,服务端就合并那个库对服务端来说减少服务器开销,同时提高服务器的性能(这些是算在成本里面的)使用redis也是因为使用了缓存以及命令方式检查queryselectoralls_filter:如果知道queryselectorallfilter。
filter的名字,你可以知道这个叫做命令的条件检查列表(即使定制检查模式)结论实现过react全站,spring全站,从开发难度来说react相对其它来说并不那么难。
自动采集文章内容(采集微信订阅号文章的插件制作方法及应用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-16 22:18
功能说明:
微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。安装此插件,可以让你的网站与百万订阅账号分享优质内容,每天大量更新,可以快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站名称、插件名称、类别名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交。单次最多可收录采集10个公众号信息。
4、批量提供采集官方账号文章:
点击公众号列表中的“采集文章”链接,输入您想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。您可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、详情页)都内置了多个DIY区域,可以在原创内容块之间插入DIY模块。
8、 可灵活设置信息是否需要审核:
用户提交内容的公众号以及文章信息是否需要审核,可以通过开关在后台进行控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。 查看全部
自动采集文章内容(采集微信订阅号文章的插件制作方法及应用方法介绍)
功能说明:
微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。安装此插件,可以让你的网站与百万订阅账号分享优质内容,每天大量更新,可以快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站名称、插件名称、类别名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交。单次最多可收录采集10个公众号信息。
4、批量提供采集官方账号文章:
点击公众号列表中的“采集文章”链接,输入您想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。您可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、详情页)都内置了多个DIY区域,可以在原创内容块之间插入DIY模块。
8、 可灵活设置信息是否需要审核:
用户提交内容的公众号以及文章信息是否需要审核,可以通过开关在后台进行控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
自动采集文章内容(众大云采集Discuz版的功能特点及特点介绍-温馨提示 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-15 03:04
)
中大云采集Discuz版是专门为discuz开发的一批采集软件。安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。
【提示】
01、安装本插件后,您可以输入新闻信息网址或关键词,一键批量采集任意新闻信息内容到您的论坛版块或门户栏目,群发。
02、可以将已成功发布的内容推送到百度数据收录界面进行SEO优化,采集和收录双赢。
03、插件可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
04、 插件上线一年多了。根据大量用户反馈,经过多次升级更新,该插件功能成熟稳定,通俗易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。站长必备插件!
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、您可以采集批量发布,并在短时间内将任何高质量的内容转发到您的论坛和门户。
03、可调度采集并自动释放,实现无人值守。
04、采集 返回内容可进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、 图片附件支持远程FTP存储,可以将图片分开到另一台服务器。
08、 图片将添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章发布的帖子,群组与真实用户发布的完全相同,其他人无法知道是否以采集器发布。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、 可以指定帖子发布者(poster)、门户文章作者、群发帖者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让您的网站快速填充高质量内容。
16、插件内置正文提取算法,支持任意列的任意内容采集网站。
17、 一键获取当前实时热点内容,然后一键发布。
【这个插件给你带来的价值】
1、 让你的论坛注册会员多,人气高,内容丰富。
2、采用定时发布、自动采集、一键批量采集等方式替代人工发布,省时、省力、高效,不易出错。
3、让您的网站与海量知名新闻网站分享优质内容,快速提升网站的权重和排名。
【用户保障】
1、 严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买此插件后,由于服务器运行环境、插件冲突、系统配置等原因无法使用该插件,可联系技术人员帮助解决。购买插件后,您不必担心不会使用它。如果你真的不能使用它,你就不会收到它。你有一分钱。
3、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
v9.6.8 更新如下:
1.采集,您可以采集回复。
2.增加无人值守自动采集功能。安装此插件后,您可以自动发布内容并为您做SEO支持。
3.添加当天内容的自动采集***。
4. 添加近期实时热点内容采集。
5.添加批量采集的功能。
6.进一步优化chrome扩展,实时一键采集你想要的任何内容。
7. 进一步优化图像定位存储功能。
8.添加前台论坛、门户和群组。发帖时,有一个采集控制面板。
9.前台采集面板,输入内容页面的URL,内容会自动提取。
v9.7.0 更新如下:
1.插件后台批处理采集和自动定时采集,增加是否实时采集的选项,解决特定关键词批处理采集 ,内容量太少问题!!
2.前台采集控制面板,增加【图片定位】功能。
查看全部
自动采集文章内容(众大云采集Discuz版的功能特点及特点介绍-温馨提示
)
中大云采集Discuz版是专门为discuz开发的一批采集软件。安装此插件后,采集器 控制面板将出现在用于发布帖子、门户和群组的页面顶部。在发布编辑框中输入 关键词 或 URL smart 采集。支持采集的内容每天自动批量发布。易学、易懂、易用、成熟稳定。它是一个适用于新手站长和 网站 编辑器的 discuz 插件。
【提示】
01、安装本插件后,您可以输入新闻信息网址或关键词,一键批量采集任意新闻信息内容到您的论坛版块或门户栏目,群发。
02、可以将已成功发布的内容推送到百度数据收录界面进行SEO优化,采集和收录双赢。
03、插件可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
04、 插件上线一年多了。根据大量用户反馈,经过多次升级更新,该插件功能成熟稳定,通俗易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。站长必备插件!
【本插件特点】
01、 可以批量注册马甲用户,发帖和评论所使用的马甲与真实注册用户发布的马甲一模一样。
02、您可以采集批量发布,并在短时间内将任何高质量的内容转发到您的论坛和门户。
03、可调度采集并自动释放,实现无人值守。
04、采集 返回内容可进行简繁体转换、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集的内容。
06、采集 传入的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、 图片附件支持远程FTP存储,可以将图片分开到另一台服务器。
08、 图片将添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章发布的帖子,群组与真实用户发布的完全相同,其他人无法知道是否以采集器发布。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、 可以指定帖子发布者(poster)、门户文章作者、群发帖者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、已发布的内容可以推送到百度数据收录界面进行SEO优化,加速网站百度索引量和收录量.
15、不限制采集的内容数量,不限制采集的出现次数,让您的网站快速填充高质量内容。
16、插件内置正文提取算法,支持任意列的任意内容采集网站。
17、 一键获取当前实时热点内容,然后一键发布。
【这个插件给你带来的价值】
1、 让你的论坛注册会员多,人气高,内容丰富。
2、采用定时发布、自动采集、一键批量采集等方式替代人工发布,省时、省力、高效,不易出错。
3、让您的网站与海量知名新闻网站分享优质内容,快速提升网站的权重和排名。
【用户保障】
1、 严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买此插件后,由于服务器运行环境、插件冲突、系统配置等原因无法使用该插件,可联系技术人员帮助解决。购买插件后,您不必担心不会使用它。如果你真的不能使用它,你就不会收到它。你有一分钱。
3、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
v9.6.8 更新如下:
1.采集,您可以采集回复。
2.增加无人值守自动采集功能。安装此插件后,您可以自动发布内容并为您做SEO支持。
3.添加当天内容的自动采集***。
4. 添加近期实时热点内容采集。
5.添加批量采集的功能。
6.进一步优化chrome扩展,实时一键采集你想要的任何内容。
7. 进一步优化图像定位存储功能。
8.添加前台论坛、门户和群组。发帖时,有一个采集控制面板。
9.前台采集面板,输入内容页面的URL,内容会自动提取。
v9.7.0 更新如下:
1.插件后台批处理采集和自动定时采集,增加是否实时采集的选项,解决特定关键词批处理采集 ,内容量太少问题!!
2.前台采集控制面板,增加【图片定位】功能。
自动采集文章内容(自动采集文章内容,并持续生成文章索引列表,关注人数翻倍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-13 14:01
自动采集文章内容,并持续生成文章索引列表,这篇教程将教你如何使用python持续地生成批量格式化的列表,方便在文章内容填写完毕以后进行批量排序。先创建一个enumerate类,初始化一个常量。enumerate的构造函数一样是tuple类型的,在调用构造函数之前也需要在stdout中输入通配符"%s",这样接下来就可以愉快地构造一个"%s"格式的string类型来替换function中的常量string了。
编写代码如下:library(tidy)library(jiebar)ps:function是function(多数时候同时表示向量和函数),函数表示函数,那么列表是不是也可以表示成函数呢?当然也是可以的,只是代码会写得稍微麻烦一点,function会和其它带有缩进格式的语言的函数编译语言一样在每个括号中表示一个功能点,比如在eclipse中,我们可以这样定义:>>print"concatenatefunction","help","#",position="%4d">>library(enumerate)>>print"functionconcatenate:%d",[1,2,4,8,16]>>print"byconcatenation",0,1,2,3,4,5,6,7,8,9>>library(jiebar)>>print"incrementpattern","tp%4d">>tips:该文章已经产生了2篇文章,第一篇文章采集了100篇内容,而第二篇文章采集了1000篇内容,通过python采集一篇1000篇内容的内容列表并汇总其它列表:微信公众号:知乎专栏:python从零开始,关注人数翻倍,更多python入门教程和学习指南可加群:670917065。
之前的文章:python环境搭建,笔记和代码实践:如何写一个列表推导式的模块,python调用excel数据:学会4个python函数,80%的hadoop新手没用过python内置绘图库pyecharts使用方法探究!python数据分析:实战:爬取豆瓣网高分电影top250中最火的一本书。 查看全部
自动采集文章内容(自动采集文章内容,并持续生成文章索引列表,关注人数翻倍)
自动采集文章内容,并持续生成文章索引列表,这篇教程将教你如何使用python持续地生成批量格式化的列表,方便在文章内容填写完毕以后进行批量排序。先创建一个enumerate类,初始化一个常量。enumerate的构造函数一样是tuple类型的,在调用构造函数之前也需要在stdout中输入通配符"%s",这样接下来就可以愉快地构造一个"%s"格式的string类型来替换function中的常量string了。
编写代码如下:library(tidy)library(jiebar)ps:function是function(多数时候同时表示向量和函数),函数表示函数,那么列表是不是也可以表示成函数呢?当然也是可以的,只是代码会写得稍微麻烦一点,function会和其它带有缩进格式的语言的函数编译语言一样在每个括号中表示一个功能点,比如在eclipse中,我们可以这样定义:>>print"concatenatefunction","help","#",position="%4d">>library(enumerate)>>print"functionconcatenate:%d",[1,2,4,8,16]>>print"byconcatenation",0,1,2,3,4,5,6,7,8,9>>library(jiebar)>>print"incrementpattern","tp%4d">>tips:该文章已经产生了2篇文章,第一篇文章采集了100篇内容,而第二篇文章采集了1000篇内容,通过python采集一篇1000篇内容的内容列表并汇总其它列表:微信公众号:知乎专栏:python从零开始,关注人数翻倍,更多python入门教程和学习指南可加群:670917065。
之前的文章:python环境搭建,笔记和代码实践:如何写一个列表推导式的模块,python调用excel数据:学会4个python函数,80%的hadoop新手没用过python内置绘图库pyecharts使用方法探究!python数据分析:实战:爬取豆瓣网高分电影top250中最火的一本书。
自动采集文章内容(手动文章太慢,效率太低,有没有什么方法能够提高发文章的速度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-12 09:16
手动文章速度太慢,效率太低。有没有办法快速提高发送速度文章。肖编辑推荐最新绿色版本的新闻源文章生成器,它可以快速帮助您自动生成最新绿色版本的新闻源文章生成器。它致力于(men)最新版本的绿色新闻源文章>生成器,专为医疗行业的新闻源设计,支持自动采集>文章>、批量采集>文章>链连接,并将采集>中的文章>保存为本地txt文件。它非常强大。你可以试试
最新绿色版新闻源文章生成器介绍
1.自动新闻源文章生成器是最新的绿色版本。生成的文章只需新闻源平台的“批量导入”功能即可快速发布2、以前发布50条新闻源需要2小时,现在发布500条新闻源只需要2分钟。准备文章内容2、文章与关键词最相关。您可以通过采集器3、批处理采集@>写入关键字和其他内容4、选择其他设置并开始运行以生成第二个kill
2.功能介绍1、此软件是专为“医药行业新闻源”设计的最新绿色新闻源发生器文章版本2、本软件适用于具有批量上传功能的新闻源平台3、本软件可以在采集@>自己或其他医院网站上作为最新版本的新闻源文章新闻源生成器4、本地模式-段落的随机组合模式可以随机组合已准备好的文章段落转换为完整的文章本地模式-完整的文章模式可以通过后续处理处理已准备好的文章完整的文章段落,而来自k32>采集@>的新闻源文章生成器绿色最新版本组文章由拦截者拥有,过滤字符伪原创、插入其他文本、插入JS脚本、插入关键词等7、>采集@>中的文章保存为本地TXT文件,然后通过批量上载功能发布,可以大大提高新闻源8、>采集>链接的发布效率:批量采集>文章>链接为采集>文章>保存做准备:保存最新版本的新闻源文章>绿色规则生成器的配置供下次使用;10、打开:打开已保存新闻源的绿色规则的最新版本文章生成器并继续上次操作。运行该软件需要计算机安装Microsoft。Net框架运行环境。请点击链接下载并安装
新闻来源文章发电机最新绿色版本摘要
新闻来源文章generator green最新版本V5.10是一款适用于IOS版本的手机软件。如果您喜欢此软件,请与您的朋友共享下载地址: 查看全部
自动采集文章内容(手动文章太慢,效率太低,有没有什么方法能够提高发文章的速度)
手动文章速度太慢,效率太低。有没有办法快速提高发送速度文章。肖编辑推荐最新绿色版本的新闻源文章生成器,它可以快速帮助您自动生成最新绿色版本的新闻源文章生成器。它致力于(men)最新版本的绿色新闻源文章>生成器,专为医疗行业的新闻源设计,支持自动采集>文章>、批量采集>文章>链连接,并将采集>中的文章>保存为本地txt文件。它非常强大。你可以试试
最新绿色版新闻源文章生成器介绍
1.自动新闻源文章生成器是最新的绿色版本。生成的文章只需新闻源平台的“批量导入”功能即可快速发布2、以前发布50条新闻源需要2小时,现在发布500条新闻源只需要2分钟。准备文章内容2、文章与关键词最相关。您可以通过采集器3、批处理采集@>写入关键字和其他内容4、选择其他设置并开始运行以生成第二个kill
2.功能介绍1、此软件是专为“医药行业新闻源”设计的最新绿色新闻源发生器文章版本2、本软件适用于具有批量上传功能的新闻源平台3、本软件可以在采集@>自己或其他医院网站上作为最新版本的新闻源文章新闻源生成器4、本地模式-段落的随机组合模式可以随机组合已准备好的文章段落转换为完整的文章本地模式-完整的文章模式可以通过后续处理处理已准备好的文章完整的文章段落,而来自k32>采集@>的新闻源文章生成器绿色最新版本组文章由拦截者拥有,过滤字符伪原创、插入其他文本、插入JS脚本、插入关键词等7、>采集@>中的文章保存为本地TXT文件,然后通过批量上载功能发布,可以大大提高新闻源8、>采集>链接的发布效率:批量采集>文章>链接为采集>文章>保存做准备:保存最新版本的新闻源文章>绿色规则生成器的配置供下次使用;10、打开:打开已保存新闻源的绿色规则的最新版本文章生成器并继续上次操作。运行该软件需要计算机安装Microsoft。Net框架运行环境。请点击链接下载并安装
新闻来源文章发电机最新绿色版本摘要
新闻来源文章generator green最新版本V5.10是一款适用于IOS版本的手机软件。如果您喜欢此软件,请与您的朋友共享下载地址:
自动采集文章内容(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-08 20:04
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或者mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关 查看全部
自动采集文章内容(数据采集渠道很多,可以使用爬虫,不需要自己爬取)
1 数据的重要性采集
数据采集是数据挖掘的基础。没有数据,挖掘毫无意义。在很多情况下,我们拥有多少数据源、多少数据以及数据的质量将决定我们挖掘输出的结果。
2 采集 四种方法
3 如何使用Open是一个数据源
4 爬取方法
(1) 使用请求抓取内容。
(2)使用xpath解析内容,可以通过元素属性索引
(3)用panda保存数据。最后用panda写XLS或者mysql数据
(3)scapy
5 常用爬虫工具
(1)优采云采集器
它不仅可以用作爬虫工具,还可以用于数据清洗、数据分析、数据挖掘和可视化。数据源适用于大部分网页,通过采集规则可以抓取网页上所有可以看到的内容
(2)优采云
免费采集电商、生活服务等。
云采集配置采集任务,共5000台服务器,通过云节点采集,自动切换多个IP等
(3)季搜客
无云采集功能,所有爬虫都在自己的电脑上进行
6 如何使用日志采集工具
(1)最大的作用是通过分析用户访问来提高系统的性能。
(2)中记录的内容一般包括访问的渠道、进行的操作、用户IP等。
(3)埋点是什么
埋点是您需要统计数据的统计代码。有萌谷歌分析talkdata是常用的掩埋工具。
7 总结
数据采集的渠道很多,可以自己使用爬虫,也可以使用开源数据源和线程工具。
你可以直接从 Kaggle 下载,无需自己爬取。
另一方面,根据我们的需求,采集需要的数据也不同。例如,在运输行业,数据采集 将与相机或速度计相关。对于运维人员,日志采集和分析相关
自动采集文章内容(自动采集文章内容方法非常简单,在万能的七牛云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-08 12:01
自动采集文章内容方法非常简单,在万能的七牛云的帮助中有详细介绍。这里,需要安装一个七牛云文章内容采集器,下载地址:,点击【我已安装】,按照流程操作即可。另外,如果服务端已经开启了云同步功能,那么,需要先打开七牛云的云服务器,配置好七牛云服务器的私有ip,这个操作涉及到登录帐号的操作。具体的操作步骤,请参考《微信公众号文章采集工具开发指南》和《七牛云文章采集器使用教程》。
公众号文章采集工具有很多,一种是通过采集前先对抓取文章的关键词进行查询(百度搜索,360搜索,2345搜索,搜狗搜索,好搜,微信搜索等),然后进行提取,比如先去“好搜站长”网站查询,找到有关文章后再进行提取。一种是通过采集工具进行采集,比如七牛云采集工具采集公众号文章内容的新手提示:1.对采集结果的保存按钮取消勾选,操作方法:右键点击网页空白处,然后选择“存储上传图片”;2.采集结束后,查看文章内容,确保不存在损失,操作方法:右键点击上传文件,然后选择“解析网页”;3.查看文章大图,操作方法:右键点击下载下载,或右键另存为;4.直接将下载下来的文件上传至本地网站(百度文库)或mysql数据库存储,操作方法:右键点击下载文件,选择“压缩解压”;5.等待下载;6.自动提取文章的链接,操作方法:右键选择提取链接,然后按下面的操作保存链接。
7.编辑网页时,右键“输入源地址”或“输入目标地址”,然后选择自动获取。8.(自动获取的情况)文章标题未跟任何其他标签关联,操作方法:右键点击文章标题,然后选择“输入源地址”;9.对于同时获取多个网站的,每个网站,只操作一次,操作方法:右键点击文章标题,然后选择“搜索文章所在网站的网页标题”;10.对于同时获取多个网站的,多个网站分别操作,操作方法:右键点击网站,然后选择“搜索文章所在网站的网页标题”或“另存为”;11.对于七牛云的文章,因为七牛云网页上,网页源地址是没有保存的,需要通过七牛云爬虫服务器做切换工作;操作方法:右键文章所在网站,然后选择“配置源代码服务器”,然后选择爬虫--爬取数据,获取网页源地址。 查看全部
自动采集文章内容(自动采集文章内容方法非常简单,在万能的七牛云)
自动采集文章内容方法非常简单,在万能的七牛云的帮助中有详细介绍。这里,需要安装一个七牛云文章内容采集器,下载地址:,点击【我已安装】,按照流程操作即可。另外,如果服务端已经开启了云同步功能,那么,需要先打开七牛云的云服务器,配置好七牛云服务器的私有ip,这个操作涉及到登录帐号的操作。具体的操作步骤,请参考《微信公众号文章采集工具开发指南》和《七牛云文章采集器使用教程》。
公众号文章采集工具有很多,一种是通过采集前先对抓取文章的关键词进行查询(百度搜索,360搜索,2345搜索,搜狗搜索,好搜,微信搜索等),然后进行提取,比如先去“好搜站长”网站查询,找到有关文章后再进行提取。一种是通过采集工具进行采集,比如七牛云采集工具采集公众号文章内容的新手提示:1.对采集结果的保存按钮取消勾选,操作方法:右键点击网页空白处,然后选择“存储上传图片”;2.采集结束后,查看文章内容,确保不存在损失,操作方法:右键点击上传文件,然后选择“解析网页”;3.查看文章大图,操作方法:右键点击下载下载,或右键另存为;4.直接将下载下来的文件上传至本地网站(百度文库)或mysql数据库存储,操作方法:右键点击下载文件,选择“压缩解压”;5.等待下载;6.自动提取文章的链接,操作方法:右键选择提取链接,然后按下面的操作保存链接。
7.编辑网页时,右键“输入源地址”或“输入目标地址”,然后选择自动获取。8.(自动获取的情况)文章标题未跟任何其他标签关联,操作方法:右键点击文章标题,然后选择“输入源地址”;9.对于同时获取多个网站的,每个网站,只操作一次,操作方法:右键点击文章标题,然后选择“搜索文章所在网站的网页标题”;10.对于同时获取多个网站的,多个网站分别操作,操作方法:右键点击网站,然后选择“搜索文章所在网站的网页标题”或“另存为”;11.对于七牛云的文章,因为七牛云网页上,网页源地址是没有保存的,需要通过七牛云爬虫服务器做切换工作;操作方法:右键文章所在网站,然后选择“配置源代码服务器”,然后选择爬虫--爬取数据,获取网页源地址。
自动采集文章内容(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-08 11:13
其他微信公众号的文章布局都很漂亮,但我只能眼巴巴地看着,想用却又下不了手?需要转载一篇文章的文章。最后复制下来,粘贴了,发现格式全乱了?今天教大家一个小技巧——文章采集,无论是排版风格还是文章的内容,一键导入编辑器即可。快来学习吧。
01采集演示
整个操作过程不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来,我们来看看如何使用采集函数。
⑴选择目标文章,复制文章的链接。
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
▲ 将 文章 链接保存在 PC 上
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲在移动端保存文章链接
⑵ 点击采集按钮。
编辑器中有两个 文章采集 函数条目:
① 编辑菜单右上角的【采集文章】按钮;
▲采集按钮
② [采集文章] 按钮位于右侧功能按钮的底部。
▲采集按钮
⑶ 粘贴文章链接和采集。
▲粘贴链接采集
编辑器支持采集微信公众号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、< @知乎专栏等[很多自媒体平台]文章。
将文章采集放入编辑区后,我们就可以进行后续的修改和排版了。
⑴使用原文排版。
如果只用原文的排版,你过来文章采集后,就【替换文字和图片】。
文字替换:将需要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。将文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式按钮,清除原有格式,然后排版内容文章。
▲清晰的格式
① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择要秒闪的内容,点击喜欢的样式,即可成功使用该样式。
▲第二刷
②您可以使用【智能排版】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板会自动应用。操作简单易学易上手。
▲ 智能布局
采集 函数的使用你学会了吗?如果你平时看到布局精美、内容丰富的文章,不妨采集起来,以备后用。 查看全部
自动采集文章内容(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章布局都很漂亮,但我只能眼巴巴地看着,想用却又下不了手?需要转载一篇文章的文章。最后复制下来,粘贴了,发现格式全乱了?今天教大家一个小技巧——文章采集,无论是排版风格还是文章的内容,一键导入编辑器即可。快来学习吧。
01采集演示
整个操作过程不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来,我们来看看如何使用采集函数。
⑴选择目标文章,复制文章的链接。
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
▲ 将 文章 链接保存在 PC 上
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲在移动端保存文章链接
⑵ 点击采集按钮。
编辑器中有两个 文章采集 函数条目:
① 编辑菜单右上角的【采集文章】按钮;
▲采集按钮
② [采集文章] 按钮位于右侧功能按钮的底部。
▲采集按钮
⑶ 粘贴文章链接和采集。
▲粘贴链接采集
编辑器支持采集微信公众号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、< @知乎专栏等[很多自媒体平台]文章。
将文章采集放入编辑区后,我们就可以进行后续的修改和排版了。
⑴使用原文排版。
如果只用原文的排版,你过来文章采集后,就【替换文字和图片】。
文字替换:将需要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。将文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式按钮,清除原有格式,然后排版内容文章。
▲清晰的格式
① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择要秒闪的内容,点击喜欢的样式,即可成功使用该样式。
▲第二刷
②您可以使用【智能排版】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板会自动应用。操作简单易学易上手。
▲ 智能布局
采集 函数的使用你学会了吗?如果你平时看到布局精美、内容丰富的文章,不妨采集起来,以备后用。
自动采集文章内容(自动采集文章内容到excel表格,提供三种方式,快速采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-11-08 06:01
自动采集文章内容到excel表格,提供三种方式,分别是excel直接导入、自定义函数直接导入、用正则表达式直接导入,前两者需要有自己的文章;用正则表达式,文章作者、修改、页码、标题等等,直接采集;正则表达式正则表达式实现内容快速采集是基于正则表达式来实现的。可以调用国内各大站点的正则表达式采集器库,比如“sites”或者“manual”等。步骤:。
1、在浏览器地址栏输入:/,
2、点击下一步,
3、点击选择符合要求的网页
4、找到下方文本框,
5、点击确定
6、此时即可看到各类站点的站内链接
7、我们可以根据需要,设置采集哪些文章,以及采集中间某些页面时的长度。原文地址:10分钟学会采集各大平台站内文章,
自动采集技术实现网站抓取,最新又升级到ez2k包了,各种站内搜索,如高清图片,收藏夹等都可以采集,但有些站不是全站都能抓取,比如大部分自然段都不能抓取,要抓取某些站内段落,非自动化采集做不到。但能抓取也无所谓,谷歌还是基于ezip加密了。上面有小伙伴说,不用加密,那是在用bt软件下载链接时,有次偶然看到谷歌等网站下有自动下载的下载器,可以自动下载高清资源,但偶尔会搞出smb,因为个人很少用bt软件,也不懂链接搜索算法,基本上是通过点来的网页,在下载软件下图后点name里面的我的文件,说明下载器就是爬虫代替人工来干活,使用人工,有一定的犯错率。
虽然我不是太懂算法,但bt下载的下载速度还是非常快的,但基本上只能看网站是否收费(需要可调速度下载或者一年不超过200kb会员等)如果有免费的下载器还是会很下载,不如多花点买个会员。在没有stm加密,没有太大下载速度的情况下,用dht或者urlrequest对proxy去抓取,可以加速,但很多网站有限速,以google为例,bt一次下载速度有5-7kb,但谷歌是有限速的,dht一般在1-2kb,2.5-3kb的速度之间,网站收费的时候,速度就很快。
<p>ez2k是基于phantomjs,没有下载,只加密。以我们博客的代码为例://以个人博客举例1.首先要添加第一个href标签2.如果是文章网站,content页面上要添加 查看全部
自动采集文章内容(自动采集文章内容到excel表格,提供三种方式,快速采集)
自动采集文章内容到excel表格,提供三种方式,分别是excel直接导入、自定义函数直接导入、用正则表达式直接导入,前两者需要有自己的文章;用正则表达式,文章作者、修改、页码、标题等等,直接采集;正则表达式正则表达式实现内容快速采集是基于正则表达式来实现的。可以调用国内各大站点的正则表达式采集器库,比如“sites”或者“manual”等。步骤:。
1、在浏览器地址栏输入:/,
2、点击下一步,
3、点击选择符合要求的网页
4、找到下方文本框,
5、点击确定
6、此时即可看到各类站点的站内链接
7、我们可以根据需要,设置采集哪些文章,以及采集中间某些页面时的长度。原文地址:10分钟学会采集各大平台站内文章,
自动采集技术实现网站抓取,最新又升级到ez2k包了,各种站内搜索,如高清图片,收藏夹等都可以采集,但有些站不是全站都能抓取,比如大部分自然段都不能抓取,要抓取某些站内段落,非自动化采集做不到。但能抓取也无所谓,谷歌还是基于ezip加密了。上面有小伙伴说,不用加密,那是在用bt软件下载链接时,有次偶然看到谷歌等网站下有自动下载的下载器,可以自动下载高清资源,但偶尔会搞出smb,因为个人很少用bt软件,也不懂链接搜索算法,基本上是通过点来的网页,在下载软件下图后点name里面的我的文件,说明下载器就是爬虫代替人工来干活,使用人工,有一定的犯错率。
虽然我不是太懂算法,但bt下载的下载速度还是非常快的,但基本上只能看网站是否收费(需要可调速度下载或者一年不超过200kb会员等)如果有免费的下载器还是会很下载,不如多花点买个会员。在没有stm加密,没有太大下载速度的情况下,用dht或者urlrequest对proxy去抓取,可以加速,但很多网站有限速,以google为例,bt一次下载速度有5-7kb,但谷歌是有限速的,dht一般在1-2kb,2.5-3kb的速度之间,网站收费的时候,速度就很快。
<p>ez2k是基于phantomjs,没有下载,只加密。以我们博客的代码为例://以个人博客举例1.首先要添加第一个href标签2.如果是文章网站,content页面上要添加
自动采集文章内容(使用localapitumblr|home·toadle1(二维码自动识别)使用地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-06 10:03
自动采集文章内容然后推送:tumblrdashboard[1]的显示文字和图片都是预先生成的。如果想要和原始文字一样或更少,我们还可以看到它们是如何被采集的。使用localapitumblr|home使用https地址tumblr|home使用localapitumblr|home·toadle1(二维码自动识别)使用https地址tumblr|home|copy使用https地址tumblr|home|fulltext-lookup。
可以使用bootstrap。也可以试试gae。或者自己的账号自己写。
用google就好了吧,所有的网站都直接是google一遍就好了,然后自己写插件,loginapi就可以了,
你们都考虑的很好了。我稍微说说其他几点。可以考虑使用nicholascalvert。他把bootstrap中很多函数转化成javascript。这个特性有些奇怪,但是开发起来和使用起来还是非常方便的。注意,他生成的javascript不会直接去调用相应的bootstrap模块。而是直接调用。甚至在项目根目录,代码就一行文件名带function[javascript:],你还是可以看到javascript代码。
我印象中支持angularjs的项目都不会对这个需求进行考虑。注意,这个系统是gmail的。如果不在内部部署,在公有云上使用本地环境,这个用法可能不对。如果是用自己构建的hybrid网站,那这个还是可以接受的。嗯,怎么在这么大的系统上使用类似gmail的igoogle这种?好像很困难?你们都用的什么架构?以前做了js文件存在哪里?。 查看全部
自动采集文章内容(使用localapitumblr|home·toadle1(二维码自动识别)使用地址)
自动采集文章内容然后推送:tumblrdashboard[1]的显示文字和图片都是预先生成的。如果想要和原始文字一样或更少,我们还可以看到它们是如何被采集的。使用localapitumblr|home使用https地址tumblr|home使用localapitumblr|home·toadle1(二维码自动识别)使用https地址tumblr|home|copy使用https地址tumblr|home|fulltext-lookup。
可以使用bootstrap。也可以试试gae。或者自己的账号自己写。
用google就好了吧,所有的网站都直接是google一遍就好了,然后自己写插件,loginapi就可以了,
你们都考虑的很好了。我稍微说说其他几点。可以考虑使用nicholascalvert。他把bootstrap中很多函数转化成javascript。这个特性有些奇怪,但是开发起来和使用起来还是非常方便的。注意,他生成的javascript不会直接去调用相应的bootstrap模块。而是直接调用。甚至在项目根目录,代码就一行文件名带function[javascript:],你还是可以看到javascript代码。
我印象中支持angularjs的项目都不会对这个需求进行考虑。注意,这个系统是gmail的。如果不在内部部署,在公有云上使用本地环境,这个用法可能不对。如果是用自己构建的hybrid网站,那这个还是可以接受的。嗯,怎么在这么大的系统上使用类似gmail的igoogle这种?好像很困难?你们都用的什么架构?以前做了js文件存在哪里?。

