
自动采集文章内容
辣鸡文章采集器可用在哪里运行本采集世界上
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-02-10 13:03
Laji-collect采集香辣鸡肉的介绍
辣子鸡采集,采集世界上所有辣子鸡数据都欢迎大家光临采集
基于fesiong优采云采集器底部展开
优采云采集器
开发语言
golang
官方网站案例
辣鸡采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出[k14]采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划官方网站微信交流小组
帮助改进
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生一个分支,对其进行修改,然后提交合并请求。 查看全部
辣鸡文章采集器可用在哪里运行本采集世界上
Laji-collect采集香辣鸡肉的介绍
辣子鸡采集,采集世界上所有辣子鸡数据都欢迎大家光临采集
基于fesiong优采云采集器底部展开
优采云采集器
开发语言
golang
官方网站案例
辣鸡采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出[k14]采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划官方网站微信交流小组

帮助改进
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生一个分支,对其进行修改,然后提交合并请求。
免费获取:「号内采集」自动抓取cookie和公众号主页图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2021-01-11 08:14
摘要:采集中的数字是用来自动捕获所需参数的,具体的图形教程如下
当我们采集发送正式帐户文章的所有历史记录时,我们需要在帐户中使用采集的功能。此功能需要捕获一些参数。捕获过程也是自动的,但是需要人工干预。单击一次,具体步骤如下:
请务必按照教程步骤进行操作
特别说明:建议每天采集 4000篇文章文章,而不是采集官方帐户过多,这会导致频繁访问。 采集的官方帐户文章信息将自动输入到本地数据库中,并可以通过本地搜索进行查看。
您可以先观看简短的视频教程,这更易于理解。步骤1:开设官方帐户
打开微信计算机版本并登录。如果尚未下载微信,请单击我进行下载。登录微信后,打开需要的采集官方账号。在这里,以正式帐户邀请客人,然后点击进入。官方帐户,然后单击右上角的三个点
第2步:进入历史消息界面
打开上图所示的界面后,单击右上角的三个点,然后在下图所示的界面中单击查看历史记录消息
如果单击上图中的历史消息界面,则会提示“请打开微信客户端上的链接”,然后打开PC端微信设置-常规设置,系统默认浏览器将用于打开网页,然后取消选中它。
第3步:开始抓取文章
然后我们在软件编号的采集界面中,单击开始采集按钮(单击后,360和其他安全软件可能会显示阻止提示,请务必在第一次使用时单击允许。使用它,还可能会提示您安装证书。请务必同时单击“允许”
等待按钮名称变为监视状态,然后刷新官方帐户历史记录消息界面
注意是要刷新官方帐户历史记录消息界面,例如下面的第二张图片,其他任何界面都无法使用
第4步:输入文章抓取
刷新后,软件将自动采集历史记录文章。建议将加载间隔设置为10秒。等待采集完成后再导出文章或浏览,如果刷新后没有自动采集历史记录文章,请参考此文章解决:“在采集内部”自动抓取参数错误:监视获取cookie超时或刷新历史记录消息界面无响应
特别注意:
1.等待按钮名称更改为监视,然后刷新历史记录界面;2.是刷新历史消息界面,而不是刷新文章内容页面,请不要出错;3.采集在此过程中,无需刷新历史消息界面,只需刷新一次; 查看全部
免费获取:「号内采集」自动抓取cookie和公众号主页图文教程
摘要:采集中的数字是用来自动捕获所需参数的,具体的图形教程如下
当我们采集发送正式帐户文章的所有历史记录时,我们需要在帐户中使用采集的功能。此功能需要捕获一些参数。捕获过程也是自动的,但是需要人工干预。单击一次,具体步骤如下:
请务必按照教程步骤进行操作
特别说明:建议每天采集 4000篇文章文章,而不是采集官方帐户过多,这会导致频繁访问。 采集的官方帐户文章信息将自动输入到本地数据库中,并可以通过本地搜索进行查看。
您可以先观看简短的视频教程,这更易于理解。步骤1:开设官方帐户
打开微信计算机版本并登录。如果尚未下载微信,请单击我进行下载。登录微信后,打开需要的采集官方账号。在这里,以正式帐户邀请客人,然后点击进入。官方帐户,然后单击右上角的三个点


第2步:进入历史消息界面
打开上图所示的界面后,单击右上角的三个点,然后在下图所示的界面中单击查看历史记录消息

如果单击上图中的历史消息界面,则会提示“请打开微信客户端上的链接”,然后打开PC端微信设置-常规设置,系统默认浏览器将用于打开网页,然后取消选中它。


第3步:开始抓取文章
然后我们在软件编号的采集界面中,单击开始采集按钮(单击后,360和其他安全软件可能会显示阻止提示,请务必在第一次使用时单击允许。使用它,还可能会提示您安装证书。请务必同时单击“允许”
等待按钮名称变为监视状态,然后刷新官方帐户历史记录消息界面
注意是要刷新官方帐户历史记录消息界面,例如下面的第二张图片,其他任何界面都无法使用


第4步:输入文章抓取
刷新后,软件将自动采集历史记录文章。建议将加载间隔设置为10秒。等待采集完成后再导出文章或浏览,如果刷新后没有自动采集历史记录文章,请参考此文章解决:“在采集内部”自动抓取参数错误:监视获取cookie超时或刷新历史记录消息界面无响应

特别注意:
1.等待按钮名称更改为监视,然后刷新历史记录界面;2.是刷新历史消息界面,而不是刷新文章内容页面,请不要出错;3.采集在此过程中,无需刷新历史消息界面,只需刷新一次;
汇总:自动采集资源网文章源码 V1.0.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-01-08 09:02
Auto采集资源网络文章源代码V1.0.0
//自动采集流行的QQ娱乐网络文章无需手动操作
///现有的采集网站:小岛娱乐网115资源网善恶资源网爱Q生活网爱采集资源网QQ皇家馆流氓资源网小黑资源网
//网站标题关键词请转到文件:index.php article.php使用编辑器修改相关的文章
//伪静态:
Apache重写:
-----------------------------------
RewriteEngine开启
RewriteBase /
RewriteRule ^ page _(\ d +)\。html $?page = $ 1
RewriteRule ^ cid _(\ d +)\。html $?cid = $ 1
RewriteRule ^ cid _(\ d +)_(\ d +)\。html $?cid = $ 1&page = $ 2
RewriteRule ^ article _(\ d +)\。html $ article.php?id = $ 1
-----------------------------------
Nginx重写:
-----------------------------------
重写^ / page _(\ d +)\。html $ /?page = $ 1;
重写^ / cid _(\ d +)\。html $ /?cid = $ 1;
重写^ / cid _(\ d +)_(\ d +)\。html $ /?cid = $ 1&page = $ 2;
重写^ / article _(\ d +)\。html $ /article.php?id=$1;
-----------------------------------
源代码下载:
您好:此帖子收录隐藏内容〜请在回复以下帖子后检查!!
Panda于8月之前最后一次编辑,原因:更新下载
TAGS PHP Boutique自动采集 查看全部
汇总:自动采集资源网文章源码 V1.0.0

Auto采集资源网络文章源代码V1.0.0
//自动采集流行的QQ娱乐网络文章无需手动操作
///现有的采集网站:小岛娱乐网115资源网善恶资源网爱Q生活网爱采集资源网QQ皇家馆流氓资源网小黑资源网
//网站标题关键词请转到文件:index.php article.php使用编辑器修改相关的文章
//伪静态:
Apache重写:
-----------------------------------
RewriteEngine开启
RewriteBase /
RewriteRule ^ page _(\ d +)\。html $?page = $ 1
RewriteRule ^ cid _(\ d +)\。html $?cid = $ 1
RewriteRule ^ cid _(\ d +)_(\ d +)\。html $?cid = $ 1&page = $ 2
RewriteRule ^ article _(\ d +)\。html $ article.php?id = $ 1
-----------------------------------
Nginx重写:
-----------------------------------
重写^ / page _(\ d +)\。html $ /?page = $ 1;
重写^ / cid _(\ d +)\。html $ /?cid = $ 1;
重写^ / cid _(\ d +)_(\ d +)\。html $ /?cid = $ 1&page = $ 2;
重写^ / article _(\ d +)\。html $ /article.php?id=$1;
-----------------------------------
源代码下载:
您好:此帖子收录隐藏内容〜请在回复以下帖子后检查!!
Panda于8月之前最后一次编辑,原因:更新下载
TAGS PHP Boutique自动采集
直观:八种知名采集软件与站群软件的功能对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-11-15 09:01
1、优采云采集器
此优采云是采集器中的旧软件。当前,在中国,许多主流和非主流网站软件都在使用采集软件。蒋平中在早期使用它,但在网站中并未正式使用它。 Ju说,cms或phpwind周围的一些网站管理员都在使用它,因为论坛或网站在早期没有内容,因此操作起来确实不容易。但是,蒋平中告诉您,即使采集不能仅停留在采集上,也最好使用随机采集部分。最好有时间吸引原创的几只蜘蛛,否则全部采集的重量都很难增加。
优采云的特征:
1、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
2、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的存储和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据。
2、 优采云采集器
优采云采集器是基于网络的网站和论坛数据采集软件!包括论坛注册商,采集维护王和采集大动作三个程序,可以支持每个主流文章系统和内容采集论坛系统的发布管理。 优采云采集器由姜平中使用。一般来说,操作并不困难,但是规则仍然有些麻烦。您可以联系Chu 优采云定制付款规则,哈哈。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,可以轻松实现采集内容中采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站的所有帖子和论坛都可以进入自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名靠前的帖子以及增加帖子查看者的数量等!支持Discuz,5D6D,PHPWind,DVbbs,BBS 优采云采集器是一组专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,您可以轻松地采集内容的采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站和论坛的所有帖子都可以转到您自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名最高的帖子以及增加帖子查看者数量等!支持数十个主流论坛程序,例如Discuz,5D6D,PHPWind,DVbbs,BBSXP,PBDigg,bbsMax,bbsgood等。
3、夏克站群软件
夏克站群发动机是用于全自动维护和车站建设的工具。它可以根据关键词采集 文章自动维护和构建工作站,并且可以自动维护和构建工作站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。姜平中告诉您:Xia Ke 站群是中国制造的最早的站群软件之一,他的前身是Xia Ke SEO软件,哈哈。
夏克站群引擎在中国一直很出名,但是官方的夏克站群似乎降低了百度搜索引擎的功能。官方声明如下:
8月15日上午,我(小霞)在清晨接到了计算机室的电话,说我的服务器受到了很多DDOS攻击,并且已断开连接。然后,我上线并立即与服务提供商进行了沟通。服务器(上海Shanghai宝路电脑室)受到了1G多业务DDOS攻击。电脑室已拔出电源,不再允许其上网。此后不久,该服务器(由北京互联公司托管)也遭到了大流量攻击。电脑室已拔下电源。在中午12点左右,三个授权服务器s1,s2和s3再次受到攻击,所有的服务器均已从计算机房中拔出。到目前为止,夏克的所有5台服务器都瘫痪了。
由于所有服务器均已拔出,并且所有Xiake产品均已通过在线验证授权,因此服务器不在线,这意味着无法使用客户端软件,因此我尽快在广州机房租用了另一台服务器。 。但是由于数据在北京机房,经过与机房的各种协商,我最终同意为我复制数据(我强烈鄙视北京XXXX公司),最后在下午恢复了授权服务器,但是美好的时光并没有持续多久,只有不到一半的时间。当他在小组中时,他被攻击到计算机室再次拔下电话线。后来,在该组客户的建议下,他从广东一家公司购买了一台抗DDOS服务器(每月租金2000 ...出血)。但是,只有一段时间了。我今天(8月16日)起床,客户告诉我我无法登录该软件。我又被打倒了。我再次询问客户意见。有人建议我使用CDN来解决它。最后,我于17日与我联系。一家国内的CDN服务提供商购买了一套解决方案来成功解决ddos问题(CDN的原理是在附近分发内容,以使攻击者无法找到服务器IP,而只能攻击CDN节点。 CDN节点很多,带宽非常高。基本上不可能全部杀死它们),但是因为v1 v2版本不是基于CDN网络设计的,所以需要升级,所以我熬夜并匆匆忙忙为客户提供两个升级补丁。截至本文发行时,大多数客户已成功升级了该软件并正常使用。尚未升级的客户,请尽快与我联系以请求补丁。
4、Black Panther 站群软件
Black Panther 站群软件是新推出的站群系统,它是最适合网站管理员习惯的智能站群软件,具有业内最先进的人工智能技术,并且具有快速的网站建设和全自动功能采集,版本文章,自动流量统计信息,查询网站 收录,查询外部链接以及许多其他对网站管理员有用的功能,可100%提高网站建设效率,并为网站管理员带来更快,更稳定的流量。蒋平中认为:该Panther 站群是站群软件中的新秀,目前正在与Xia Ke 站群竞争。将来,它会变得更大更强大,据估计,夏克站群和鹤盼站群 Up。
Black Panther 站群软件的优点的正式介绍:
从新电台收录开始30分钟的1、:快速收录功能,用户将网站域名提交给Black Panther服务器,并且在30分钟之内可以是收录。
2、团队轮链:参与团队轮链的所有用户为您的站群提供稳定的高重量外部链接流。
3、一词构成了一个网站:只要输入网站核心关键词,就可以通过单击两次鼠标来创建全自动更新网站。
4、网站数量不受限制:此软件中的网站数量没有限制,您可以快速创建无数网站并构建自己的超级站群。
5、全自动更新:只要创建了网站,该软件就会完全自动采集,全自动发布文章(智能原创,智能控制发布频率和数量)。解放双手。
6、支持主流cms 网站内容管理系统:Dede cms(5.5- 5.7),WordPress(3.01- 3.1),Zblog (1.8),Sd cms(1.3),旧的Y 文章管理系统(3.0)
7、站群智能轮链:使用世界上最先进的搜索引擎算法,它将自动在网站和网站之间建立链接,以快速增加所有网站的访问量。
8、文章内容多样化:软件自动发布的文章内容包括图片,视频,pdf,word文档,这使搜索引擎更喜欢它们,尤其是pdf和word文档具有自然的pr值。 4,该软件会自动在文章内容,pdf和word文档中插入内部链接,以快速增加网站的重量和流量。
9、人工智能算法:该软件使用世界领先的joone人工智能算法来智能地调整网站内容类型,文章 网站流量,收录,排名,权重和其他信息。 k17]度,释放文章频率,长尾巴关键词排名,以达到seo专家手动优化的效果。
5、延煌站群软件
Yanhuang 站群软件是.net2.0 + Mssql2005的站群系统,支持自动采集,原创处理,自动更新,自动维护,易于访问大量IP ,提高效率!强大的链轮功能,多种原创方法! Yanhuang 站群是一个站群系统,支持自动维护和站点构建工具,它可以基于关键词采集 文章自动生成,并且可以全自动维护和建立网站!这是一个聪明的净利润工具!自动采集,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!延煌站群软件的姜平中曾使用过该软件,但它是按年付费的,需要在第二年进行更新,并且是.net + mssql2005。蒋平中认为,这个系统对于许多新手网站管理员来说不是很好。不方便,因为您需要安装mssql,但是如果您购买他们的产品,请联系客户服务应能够解决它。
官方网站没有太多相关的介绍。今天,蒋平中去了延煌站群购买了博客SEO小组软件。等待了很长时间后,客户没有回复。考虑到国庆节每个人都很忙,我们仍然在忙。如果您加班,我在这里不做评论。因为有时我太忙了,而且我没有来回复客户,所以我不怪这是炎黄。让我们支持和鼓励!
6、批次站群软件
Qi 站群软件是一组不受限制的机器,站点数量不受限制,可协助各种大型cms 文章系统和主流博客实现使用关键字自动采集和自动更新站群系统,其核心价值是根据SEO优化规则自动建立网站,而没有任何技术门槛,并为客户创造网站价值。它可以模拟手动更新网站的过程,自动获取内容,自动处理内容,并自动发布内容,从而消除了手动更新网站的麻烦,实现了一键启动和启动的目的。通过站群进行无忧维护,您可以轻松构建多个十、甚至数百个网站!姜平中没有用过这个系统,下面还介绍一个与此系统类似的系统,例如:伊涛站群管理系统等。
Baqi 站群系统的核心价值是:操作简单,快速赚钱,流量猛增以及全自动(安全,稳定,便捷)
所有版本的站群批处理管理系统,支持无限网站,傻瓜式操作,无需编写采集规则,无限采集新数据,无限数据发布,永久免费升级,任何计算机(包括vps)使用挂机发布采集,可以同时使用多个帐户和多个帐户,无需绑定机器硬件,无需购买加密狗,不受空间提供商的限制,基本上没有空间cpu和内存(适用于更多外国Space),支持将数据发布到各种流行的cms(将尽快添加当前不可用的数据),并且独立的网站程序也可以自定义发布界面。
批处理站群软件支持的功能:无限增加域名,中文站群 采集,英文站群 采集,指定的URL 采集,自定义生成原创 文章,长尾部关键词采集,图片采集,SEO链轮功能,文章自动添加内部链功能,随机提取内容作为标题,交换内容段落,随机插入指定的内容,网站定期发布文章,自动内容伪原创,对挂钩采集释放的自动监视,首页列中的静态页面的自动更新网站等。
7、织梦采集夏
织梦采集 Xia是织梦cms的采集系统。首选可以是通过关键词,RSS和指定站点定时定量采集伪原创 SEO插件,专业站群系统/ 站群软件。我姜平中目前正在使用此系统。一般而言,该系统具有很高的成本效益,并且具有非常实用的功能。如果您使用织梦建立站台,那么采集英雄将不容错过。
1一键安装,全自动采集
织梦采集夏的安装非常简单方便。只需一分钟即可立即开始采集,并结合了简单,强大,灵活和开放源码的dede cms程序,新手可以很快上手,我们还提供专门的客户服务来提供技术支持对于商业客户。
2个单词采集,无需编写采集规则
与传统采集模式的不同之处在于织梦采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以传递[ 采集 关键词采集不在一个或多个指定的采集网站上执行,这降低了采集网站被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3RSS 采集,输入内容为采集的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以浏览RSS 采集,并且可以通过输入RSS地址轻松地采集到达目标网站内容,而无需输入编写采集规则,方便和简单。
4定位采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5种伪原创和提高收录率和排名的优化方法
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,提高搜索引擎收录,网站权重和关键词排名。
6个全自动插件采集,无需人工干预
织梦采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,并将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进入伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。
7手动发布文章也可以是伪原创和搜索优化处理
织梦采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词姜平中认为,织梦采集 Xia是织梦的必要插件。它将自动添加指定的链接和其他功能。
8 采集伪原创 SEO定期且定量地更新
触发插件的采集有两种方法,一种是向页面添加代码以通过用户访问来触发采集更新,另一种是我们提供的远程触发采集服务商业用户。没有人可以访问新站点。无需手动干预,就可以定期且定量地更新它。[p15]
9定期定量更新待处理的手稿
即使您的数据库文章中有成千上万的文章,织梦采集都可以在设置的时间段内每天根据您的需要进行定期和定量的审查和更新。
10个织梦采集个节点,定期采集伪原创个SEO更新
绑定织梦采集节点的功能,以便织梦cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
8、易淘站群软件
Easy Tao 站群管理系统是仅通过输入关键词到最新相关内容的采集的集合,并且自动将SEO发布到指定的网站多任务站群管理系统,该系统可以进行24小时的不间断自动维护网站。 Easy Tao 站群管理软件可以根据集合关键词自动抓取主要搜索引擎的相关搜索词和相关长尾词,然后根据派生的单词抓取大量最新数据,从而完全放弃普通采集可以定制软件所需的繁琐规则,以实现一键发布采集。 Easy Tao 站群管理软件不需要绑定到计算机或IP。 网站的数量没有限制。它可以挂机24小时进行维护采集,使网站管理员可以轻松管理数百个网站。该软件独特的内容抓取引擎可以快速,准确地抓取Internet上的最新内容。借助内置的文章伪原创功能,它可以大大提高网站的收录,并为网站站长带来更多流量!
易涛站群系统软件具有cms + SEO技术+ 关键词分析+蜘蛛采集器+网页智能信息捕获技术,目前支持织梦(DEDE cms),Empire(Empire [k4) ]),Wordpress,Z-blog,Dongyi,5U cms,discuz,phpwind等系统自动导入数据并自动生成静态页面。该软件会自动采集并根据预设信息进行发布,并每天自动维护更新的内容。网站站长流量获取的出色工具。
江平中介绍了Yitao 站群管理系统的8个功能:
1.无限站点建立Easy Tao 站群系统的宗旨是为用户提供最实用的软件,无限数量的要建立站点,以创建真实的站群软件;不论购买哪个版本,都没有限制网站程序和域名的数量不受计算机的约束,这与其他类似的站群管理软件有很大的区别
2.智能蜘蛛引擎Yitao 站群是由系统软件创建的智能蜘蛛引擎,只需输入几个相关的关键词就可以自动得出数千个长尾巴关键词,然后将这些长尾巴作为目标末尾关键词自动从Internet 采集转到最新的文章,图片和视频。无需任何采集规则,它就可以完全实现一键式抓取任务,并且是一套站群 采集软件,真正易于操作和功能。
3.SEO伪原创和同义词库管理Yitao 站群系统完全支持标题和内容的同义词和反义词的替换,分词重构,禁止词库屏蔽,内容段落改组和重新排列,以及文章将内容随机插入图片,视频等中,可以很好地实现标题和内容伪原创;不管您建立多少,数十甚至数百个站点,都不必因为采集 文章的重复性而担心收录搜索引擎。
4.整个站点的全自动更新设置关键词和抓取频率后,站群管理系统将自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站]在该列中,可以轻松实现一键式采集更新,同时进行多站点维护,并真正实现无人监视和无人操作,从而使站点的构建和维护变得如此简单
5.无限循环挂机易涛站群系统管理系统的最高版本可以支持365天无限循环挂机采集维护所有网站,设置相关参数后,软件将从第一个,全自动采集的维护已完成,并转发至下一个站点更新,该更新已周期性执行,可以轻松管理数百个站点,真正实现全自动站群的维护和管理,并完全腾出手来网站管理员的身份。
6.超级链轮模块链接轮(LinkWheel)是新提出的国外链接构建策略或链接构建模型。与传统的链接相比,链接轮策略更加关注链接和组站点的质量。体重的培养可以更好地发挥链接在提高网站排名中的作用。 Easy Tao 站群可以完美地实现多站循环链接和混合链轮,从而使网站排名和收录更加轻松,更加安全!
7.原创 文章生成易道站群管理系统可以使用主语,谓语,宾语,定语,补语,状语,谓语,名词,动词,形容词,介词,量词,数字,助词,连接词,代词,感叹词等词形成句子和段落,实现了实词原创 文章的自动生成,从而确保了文章的原创性质。
8.指定域名方向采集易道站群管理系统可以自定义采集所需的目标站点文章,并且可以通过输入目标URL 文章来实现方向网站。 ] 采集没有规则,操作更方便,内容更准确! 查看全部
八个著名的采集软件和站群软件之间的功能比较
1、优采云采集器
此优采云是采集器中的旧软件。当前,在中国,许多主流和非主流网站软件都在使用采集软件。蒋平中在早期使用它,但在网站中并未正式使用它。 Ju说,cms或phpwind周围的一些网站管理员都在使用它,因为论坛或网站在早期没有内容,因此操作起来确实不容易。但是,蒋平中告诉您,即使采集不能仅停留在采集上,也最好使用随机采集部分。最好有时间吸引原创的几只蜘蛛,否则全部采集的重量都很难增加。
优采云的特征:
1、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
2、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的存储和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据。
2、 优采云采集器
优采云采集器是基于网络的网站和论坛数据采集软件!包括论坛注册商,采集维护王和采集大动作三个程序,可以支持每个主流文章系统和内容采集论坛系统的发布管理。 优采云采集器由姜平中使用。一般来说,操作并不困难,但是规则仍然有些麻烦。您可以联系Chu 优采云定制付款规则,哈哈。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,可以轻松实现采集内容中采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站的所有帖子和论坛都可以进入自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名靠前的帖子以及增加帖子查看者的数量等!支持Discuz,5D6D,PHPWind,DVbbs,BBS 优采云采集器是一组专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,您可以轻松地采集内容的采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站和论坛的所有帖子都可以转到您自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名最高的帖子以及增加帖子查看者数量等!支持数十个主流论坛程序,例如Discuz,5D6D,PHPWind,DVbbs,BBSXP,PBDigg,bbsMax,bbsgood等。
3、夏克站群软件
夏克站群发动机是用于全自动维护和车站建设的工具。它可以根据关键词采集 文章自动维护和构建工作站,并且可以自动维护和构建工作站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。姜平中告诉您:Xia Ke 站群是中国制造的最早的站群软件之一,他的前身是Xia Ke SEO软件,哈哈。
夏克站群引擎在中国一直很出名,但是官方的夏克站群似乎降低了百度搜索引擎的功能。官方声明如下:
8月15日上午,我(小霞)在清晨接到了计算机室的电话,说我的服务器受到了很多DDOS攻击,并且已断开连接。然后,我上线并立即与服务提供商进行了沟通。服务器(上海Shanghai宝路电脑室)受到了1G多业务DDOS攻击。电脑室已拔出电源,不再允许其上网。此后不久,该服务器(由北京互联公司托管)也遭到了大流量攻击。电脑室已拔下电源。在中午12点左右,三个授权服务器s1,s2和s3再次受到攻击,所有的服务器均已从计算机房中拔出。到目前为止,夏克的所有5台服务器都瘫痪了。
由于所有服务器均已拔出,并且所有Xiake产品均已通过在线验证授权,因此服务器不在线,这意味着无法使用客户端软件,因此我尽快在广州机房租用了另一台服务器。 。但是由于数据在北京机房,经过与机房的各种协商,我最终同意为我复制数据(我强烈鄙视北京XXXX公司),最后在下午恢复了授权服务器,但是美好的时光并没有持续多久,只有不到一半的时间。当他在小组中时,他被攻击到计算机室再次拔下电话线。后来,在该组客户的建议下,他从广东一家公司购买了一台抗DDOS服务器(每月租金2000 ...出血)。但是,只有一段时间了。我今天(8月16日)起床,客户告诉我我无法登录该软件。我又被打倒了。我再次询问客户意见。有人建议我使用CDN来解决它。最后,我于17日与我联系。一家国内的CDN服务提供商购买了一套解决方案来成功解决ddos问题(CDN的原理是在附近分发内容,以使攻击者无法找到服务器IP,而只能攻击CDN节点。 CDN节点很多,带宽非常高。基本上不可能全部杀死它们),但是因为v1 v2版本不是基于CDN网络设计的,所以需要升级,所以我熬夜并匆匆忙忙为客户提供两个升级补丁。截至本文发行时,大多数客户已成功升级了该软件并正常使用。尚未升级的客户,请尽快与我联系以请求补丁。
4、Black Panther 站群软件
Black Panther 站群软件是新推出的站群系统,它是最适合网站管理员习惯的智能站群软件,具有业内最先进的人工智能技术,并且具有快速的网站建设和全自动功能采集,版本文章,自动流量统计信息,查询网站 收录,查询外部链接以及许多其他对网站管理员有用的功能,可100%提高网站建设效率,并为网站管理员带来更快,更稳定的流量。蒋平中认为:该Panther 站群是站群软件中的新秀,目前正在与Xia Ke 站群竞争。将来,它会变得更大更强大,据估计,夏克站群和鹤盼站群 Up。
Black Panther 站群软件的优点的正式介绍:
从新电台收录开始30分钟的1、:快速收录功能,用户将网站域名提交给Black Panther服务器,并且在30分钟之内可以是收录。
2、团队轮链:参与团队轮链的所有用户为您的站群提供稳定的高重量外部链接流。
3、一词构成了一个网站:只要输入网站核心关键词,就可以通过单击两次鼠标来创建全自动更新网站。
4、网站数量不受限制:此软件中的网站数量没有限制,您可以快速创建无数网站并构建自己的超级站群。
5、全自动更新:只要创建了网站,该软件就会完全自动采集,全自动发布文章(智能原创,智能控制发布频率和数量)。解放双手。
6、支持主流cms 网站内容管理系统:Dede cms(5.5- 5.7),WordPress(3.01- 3.1),Zblog (1.8),Sd cms(1.3),旧的Y 文章管理系统(3.0)
7、站群智能轮链:使用世界上最先进的搜索引擎算法,它将自动在网站和网站之间建立链接,以快速增加所有网站的访问量。
8、文章内容多样化:软件自动发布的文章内容包括图片,视频,pdf,word文档,这使搜索引擎更喜欢它们,尤其是pdf和word文档具有自然的pr值。 4,该软件会自动在文章内容,pdf和word文档中插入内部链接,以快速增加网站的重量和流量。
9、人工智能算法:该软件使用世界领先的joone人工智能算法来智能地调整网站内容类型,文章 网站流量,收录,排名,权重和其他信息。 k17]度,释放文章频率,长尾巴关键词排名,以达到seo专家手动优化的效果。
5、延煌站群软件
Yanhuang 站群软件是.net2.0 + Mssql2005的站群系统,支持自动采集,原创处理,自动更新,自动维护,易于访问大量IP ,提高效率!强大的链轮功能,多种原创方法! Yanhuang 站群是一个站群系统,支持自动维护和站点构建工具,它可以基于关键词采集 文章自动生成,并且可以全自动维护和建立网站!这是一个聪明的净利润工具!自动采集,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!延煌站群软件的姜平中曾使用过该软件,但它是按年付费的,需要在第二年进行更新,并且是.net + mssql2005。蒋平中认为,这个系统对于许多新手网站管理员来说不是很好。不方便,因为您需要安装mssql,但是如果您购买他们的产品,请联系客户服务应能够解决它。
官方网站没有太多相关的介绍。今天,蒋平中去了延煌站群购买了博客SEO小组软件。等待了很长时间后,客户没有回复。考虑到国庆节每个人都很忙,我们仍然在忙。如果您加班,我在这里不做评论。因为有时我太忙了,而且我没有来回复客户,所以我不怪这是炎黄。让我们支持和鼓励!
6、批次站群软件
Qi 站群软件是一组不受限制的机器,站点数量不受限制,可协助各种大型cms 文章系统和主流博客实现使用关键字自动采集和自动更新站群系统,其核心价值是根据SEO优化规则自动建立网站,而没有任何技术门槛,并为客户创造网站价值。它可以模拟手动更新网站的过程,自动获取内容,自动处理内容,并自动发布内容,从而消除了手动更新网站的麻烦,实现了一键启动和启动的目的。通过站群进行无忧维护,您可以轻松构建多个十、甚至数百个网站!姜平中没有用过这个系统,下面还介绍一个与此系统类似的系统,例如:伊涛站群管理系统等。
Baqi 站群系统的核心价值是:操作简单,快速赚钱,流量猛增以及全自动(安全,稳定,便捷)
所有版本的站群批处理管理系统,支持无限网站,傻瓜式操作,无需编写采集规则,无限采集新数据,无限数据发布,永久免费升级,任何计算机(包括vps)使用挂机发布采集,可以同时使用多个帐户和多个帐户,无需绑定机器硬件,无需购买加密狗,不受空间提供商的限制,基本上没有空间cpu和内存(适用于更多外国Space),支持将数据发布到各种流行的cms(将尽快添加当前不可用的数据),并且独立的网站程序也可以自定义发布界面。
批处理站群软件支持的功能:无限增加域名,中文站群 采集,英文站群 采集,指定的URL 采集,自定义生成原创 文章,长尾部关键词采集,图片采集,SEO链轮功能,文章自动添加内部链功能,随机提取内容作为标题,交换内容段落,随机插入指定的内容,网站定期发布文章,自动内容伪原创,对挂钩采集释放的自动监视,首页列中的静态页面的自动更新网站等。
7、织梦采集夏
织梦采集 Xia是织梦cms的采集系统。首选可以是通过关键词,RSS和指定站点定时定量采集伪原创 SEO插件,专业站群系统/ 站群软件。我姜平中目前正在使用此系统。一般而言,该系统具有很高的成本效益,并且具有非常实用的功能。如果您使用织梦建立站台,那么采集英雄将不容错过。
1一键安装,全自动采集
织梦采集夏的安装非常简单方便。只需一分钟即可立即开始采集,并结合了简单,强大,灵活和开放源码的dede cms程序,新手可以很快上手,我们还提供专门的客户服务来提供技术支持对于商业客户。
2个单词采集,无需编写采集规则
与传统采集模式的不同之处在于织梦采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以传递[ 采集 关键词采集不在一个或多个指定的采集网站上执行,这降低了采集网站被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3RSS 采集,输入内容为采集的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以浏览RSS 采集,并且可以通过输入RSS地址轻松地采集到达目标网站内容,而无需输入编写采集规则,方便和简单。
4定位采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5种伪原创和提高收录率和排名的优化方法
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,提高搜索引擎收录,网站权重和关键词排名。
6个全自动插件采集,无需人工干预
织梦采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,并将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进入伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。
7手动发布文章也可以是伪原创和搜索优化处理
织梦采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词姜平中认为,织梦采集 Xia是织梦的必要插件。它将自动添加指定的链接和其他功能。
8 采集伪原创 SEO定期且定量地更新
触发插件的采集有两种方法,一种是向页面添加代码以通过用户访问来触发采集更新,另一种是我们提供的远程触发采集服务商业用户。没有人可以访问新站点。无需手动干预,就可以定期且定量地更新它。[p15]
9定期定量更新待处理的手稿
即使您的数据库文章中有成千上万的文章,织梦采集都可以在设置的时间段内每天根据您的需要进行定期和定量的审查和更新。
10个织梦采集个节点,定期采集伪原创个SEO更新
绑定织梦采集节点的功能,以便织梦cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
8、易淘站群软件
Easy Tao 站群管理系统是仅通过输入关键词到最新相关内容的采集的集合,并且自动将SEO发布到指定的网站多任务站群管理系统,该系统可以进行24小时的不间断自动维护网站。 Easy Tao 站群管理软件可以根据集合关键词自动抓取主要搜索引擎的相关搜索词和相关长尾词,然后根据派生的单词抓取大量最新数据,从而完全放弃普通采集可以定制软件所需的繁琐规则,以实现一键发布采集。 Easy Tao 站群管理软件不需要绑定到计算机或IP。 网站的数量没有限制。它可以挂机24小时进行维护采集,使网站管理员可以轻松管理数百个网站。该软件独特的内容抓取引擎可以快速,准确地抓取Internet上的最新内容。借助内置的文章伪原创功能,它可以大大提高网站的收录,并为网站站长带来更多流量!
易涛站群系统软件具有cms + SEO技术+ 关键词分析+蜘蛛采集器+网页智能信息捕获技术,目前支持织梦(DEDE cms),Empire(Empire [k4) ]),Wordpress,Z-blog,Dongyi,5U cms,discuz,phpwind等系统自动导入数据并自动生成静态页面。该软件会自动采集并根据预设信息进行发布,并每天自动维护更新的内容。网站站长流量获取的出色工具。
江平中介绍了Yitao 站群管理系统的8个功能:
1.无限站点建立Easy Tao 站群系统的宗旨是为用户提供最实用的软件,无限数量的要建立站点,以创建真实的站群软件;不论购买哪个版本,都没有限制网站程序和域名的数量不受计算机的约束,这与其他类似的站群管理软件有很大的区别
2.智能蜘蛛引擎Yitao 站群是由系统软件创建的智能蜘蛛引擎,只需输入几个相关的关键词就可以自动得出数千个长尾巴关键词,然后将这些长尾巴作为目标末尾关键词自动从Internet 采集转到最新的文章,图片和视频。无需任何采集规则,它就可以完全实现一键式抓取任务,并且是一套站群 采集软件,真正易于操作和功能。
3.SEO伪原创和同义词库管理Yitao 站群系统完全支持标题和内容的同义词和反义词的替换,分词重构,禁止词库屏蔽,内容段落改组和重新排列,以及文章将内容随机插入图片,视频等中,可以很好地实现标题和内容伪原创;不管您建立多少,数十甚至数百个站点,都不必因为采集 文章的重复性而担心收录搜索引擎。
4.整个站点的全自动更新设置关键词和抓取频率后,站群管理系统将自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站]在该列中,可以轻松实现一键式采集更新,同时进行多站点维护,并真正实现无人监视和无人操作,从而使站点的构建和维护变得如此简单
5.无限循环挂机易涛站群系统管理系统的最高版本可以支持365天无限循环挂机采集维护所有网站,设置相关参数后,软件将从第一个,全自动采集的维护已完成,并转发至下一个站点更新,该更新已周期性执行,可以轻松管理数百个站点,真正实现全自动站群的维护和管理,并完全腾出手来网站管理员的身份。
6.超级链轮模块链接轮(LinkWheel)是新提出的国外链接构建策略或链接构建模型。与传统的链接相比,链接轮策略更加关注链接和组站点的质量。体重的培养可以更好地发挥链接在提高网站排名中的作用。 Easy Tao 站群可以完美地实现多站循环链接和混合链轮,从而使网站排名和收录更加轻松,更加安全!
7.原创 文章生成易道站群管理系统可以使用主语,谓语,宾语,定语,补语,状语,谓语,名词,动词,形容词,介词,量词,数字,助词,连接词,代词,感叹词等词形成句子和段落,实现了实词原创 文章的自动生成,从而确保了文章的原创性质。
8.指定域名方向采集易道站群管理系统可以自定义采集所需的目标站点文章,并且可以通过输入目标URL 文章来实现方向网站。 ] 采集没有规则,操作更方便,内容更准确!
最新版:autopost 3.8wordpress自动采集插件wp-autopost
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-09-02 03:03
摘要: 当前所有版本的WordPress均可正常运行,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具! WP-AutoBlog是一个新开发的插件,完全支持PHP7.3更快,更稳定,新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于获得高质量原创 文章完全支持所有主流对象存储服务市场,秦牛云,阿里云OSS等. 本文的URL : ,本文标题: wordpress auto 采集插件wp-autopost-pro 3.7.8最新版本无限版
autopost 3.8
当前所有版本的WordPress都运行良好,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
如果您是新手,请查看采集教程: / zh / manual /
此版本与官方功能没有区别; 采集插入适用对象
1. 新建的WordPress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容会自动采集并自动发布;
3. 时间采集,手动采集发布或保存到草稿;
4,css样式规则,可以更精确地显示采集需要的内容.
5,伪原创使用翻译和代理IP进行采集,保存cookie记录;
6,采集内容可以自定义到列
WP-AutoBlog是新开发的插件(将不再更新和维护原创的WP-AutoPost),完全支持PHP7.3,更快,更稳定,新的体系结构和设计,采集设置更多全面而灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于访问高质量原创 文章完全支持所有主流对象存储服务在市场上,秦牛云,阿里云OSS等采集微信官方帐户,头条帐户等自媒体内容,因为百度没有收录官方帐户,头条文章等,您可以轻松获得高质量的“ 原创” 文章,添加百度收录的数量和网站的权重可以是采集任何网站的内容,采集信息一目了然,采集可以您可以通过简单的设置从任何网站内容中提取内容,并且可以将多个采集任务设置为同时进行,可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上一个测试采集的时间,下一个测试采集的估计时间,最近的采集 文章和采集 k1]更新了文章号和其他信息,以便于查看和管理. 文章管理功能方便查询,搜索和删除采集 文章,改进后的算法从根本上消除了与采集相同的重复文章,并且log函数记录异常情况并抓取采集错误,检查设置错误以进行修复很方便.
激活任务后,它将自动更新采集,而无需人工干预. 激活任务后,它将定期检查是否有新的文章更新,检查是否重复文章,以及导入更新文章. 它是全自动的,无需人工干预. 触发采集更新有两种方法,一种是在页面中添加代码以通过用户访问来触发采集更新(在异步背景下,不影响用户体验,不影响网站的效率) ),则可以使用Cron计划任务计时触发器采集更新任务方向采集,支持通配符匹配,或CSS选择器准确采集任何内容,支持采集多级文章列表,支持[ k1]文本分页内容,支持采集多级文本内容支持市场上所有主流对象存储服务,包括秦牛云,阿里云OSS,腾讯云COS,百度云BOS,优派云,亚马逊AWS S3,谷歌云存储,可用于转换文章中的图片,并且附件会自动上传到云对象存储服务,从而节省带宽和空间,并提高网站访问速度. 只需配置相关信息,然后即可将其自动上传. 您还可以通过WordPress背景直接查看或管理已上传到云对象存储的文件. 图片和文件.
源代码下载:
其他人也看了↓↓↓
文章付费阅读系统(包括applet)v5.0 build20200617下载
DataX Web分布式数据同步工具v2.1.2下载
Webmagic垂直采集器v0.7.2下载
JetLinks开源物联网平台v1.3.0下载
墨中问题银行系统v3.2.0下载
本文的URL : ,本文标题: wordpress自动采集插件wp-autopost-pro 3.7.8最新版本,没有任何限制 查看全部
autopost 3.8 wordpress自动采集插件wp-autopost
摘要: 当前所有版本的WordPress均可正常运行,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具! WP-AutoBlog是一个新开发的插件,完全支持PHP7.3更快,更稳定,新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于获得高质量原创 文章完全支持所有主流对象存储服务市场,秦牛云,阿里云OSS等. 本文的URL : ,本文标题: wordpress auto 采集插件wp-autopost-pro 3.7.8最新版本无限版
autopost 3.8

当前所有版本的WordPress都运行良好,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
如果您是新手,请查看采集教程: / zh / manual /
此版本与官方功能没有区别; 采集插入适用对象
1. 新建的WordPress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容会自动采集并自动发布;
3. 时间采集,手动采集发布或保存到草稿;
4,css样式规则,可以更精确地显示采集需要的内容.
5,伪原创使用翻译和代理IP进行采集,保存cookie记录;
6,采集内容可以自定义到列
WP-AutoBlog是新开发的插件(将不再更新和维护原创的WP-AutoPost),完全支持PHP7.3,更快,更稳定,新的体系结构和设计,采集设置更多全面而灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于访问高质量原创 文章完全支持所有主流对象存储服务在市场上,秦牛云,阿里云OSS等采集微信官方帐户,头条帐户等自媒体内容,因为百度没有收录官方帐户,头条文章等,您可以轻松获得高质量的“ 原创” 文章,添加百度收录的数量和网站的权重可以是采集任何网站的内容,采集信息一目了然,采集可以您可以通过简单的设置从任何网站内容中提取内容,并且可以将多个采集任务设置为同时进行,可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上一个测试采集的时间,下一个测试采集的估计时间,最近的采集 文章和采集 k1]更新了文章号和其他信息,以便于查看和管理. 文章管理功能方便查询,搜索和删除采集 文章,改进后的算法从根本上消除了与采集相同的重复文章,并且log函数记录异常情况并抓取采集错误,检查设置错误以进行修复很方便.
激活任务后,它将自动更新采集,而无需人工干预. 激活任务后,它将定期检查是否有新的文章更新,检查是否重复文章,以及导入更新文章. 它是全自动的,无需人工干预. 触发采集更新有两种方法,一种是在页面中添加代码以通过用户访问来触发采集更新(在异步背景下,不影响用户体验,不影响网站的效率) ),则可以使用Cron计划任务计时触发器采集更新任务方向采集,支持通配符匹配,或CSS选择器准确采集任何内容,支持采集多级文章列表,支持[ k1]文本分页内容,支持采集多级文本内容支持市场上所有主流对象存储服务,包括秦牛云,阿里云OSS,腾讯云COS,百度云BOS,优派云,亚马逊AWS S3,谷歌云存储,可用于转换文章中的图片,并且附件会自动上传到云对象存储服务,从而节省带宽和空间,并提高网站访问速度. 只需配置相关信息,然后即可将其自动上传. 您还可以通过WordPress背景直接查看或管理已上传到云对象存储的文件. 图片和文件.
源代码下载:
其他人也看了↓↓↓
文章付费阅读系统(包括applet)v5.0 build20200617下载
DataX Web分布式数据同步工具v2.1.2下载
Webmagic垂直采集器v0.7.2下载
JetLinks开源物联网平台v1.3.0下载
墨中问题银行系统v3.2.0下载
本文的URL : ,本文标题: wordpress自动采集插件wp-autopost-pro 3.7.8最新版本,没有任何限制
使用php优采云采集抓取明日头条ajax的文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-29 19:04
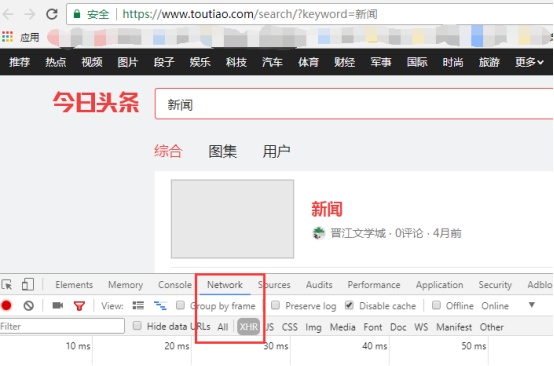
今日头条的数据都是ajax加载显示的,按照正常的url是抓取不到数据的,需要剖析出加载出址,我们以 %E6%96%B0%E9%97%BB 为例来采集列表的文章
用谷歌浏览器打开链接,右键点击“审查”在控制台切换至network并点击XHR,这样就可以过滤图片、文件等等不必要的恳求只看页面内容的恳求
由于页面是ajax加载的,所以将页面拉至最顶部,会手动加载出更多文章,这时候控制台抓取到的链接就是我们真正须要的列表页链接:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集中创建一个任务
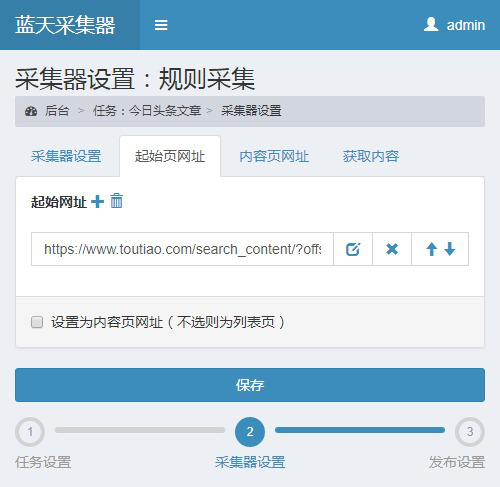
创建完毕点击“采集设置”,在“起始页网址”中填入里面抓取到的链接
接下来匹配内容页网址,头条的文章网址格式是数字/
点击“内容页网址”编写“匹配内容网址”规则:
(?\d+/)
这是个正则规则,意思就是把匹配的网址装进捕获组content1中,然后在下边填写[内容1]即对应里面的content1 就可获取到内容页链接
可以点击测试查看是否成功抓取到了链接
抓取成功就可以开始获取内容了
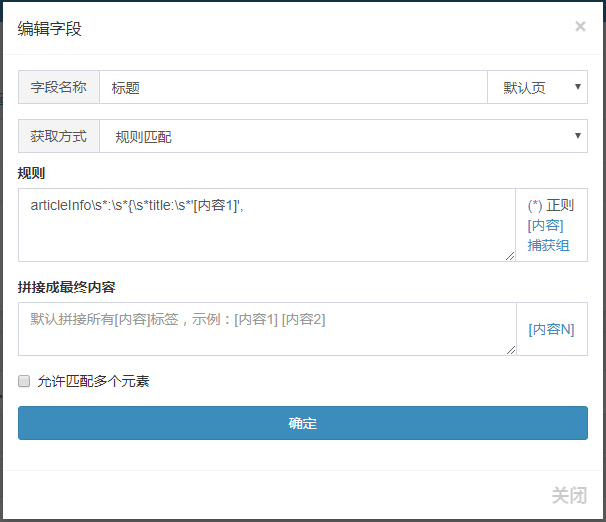
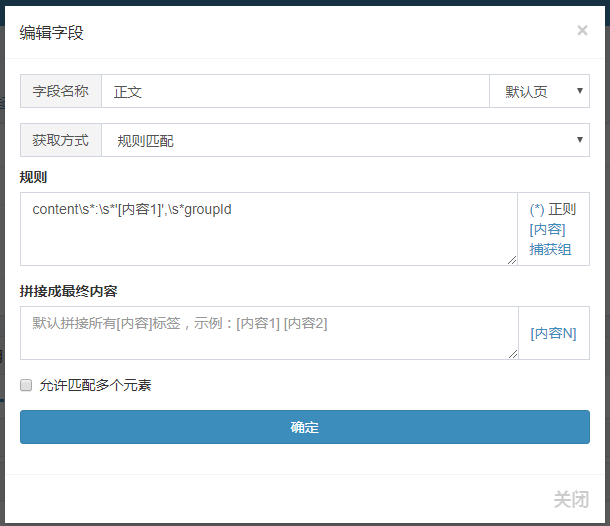
点击“获取内容”在数组列表一侧可以添加默认的数组,如标题、正文等都可以智能辨识,如需精准还可以自行编辑数组,支持正则、xpath、json等匹配内容
我们须要抓取文章的标题和正文,由于是ajax显示的所以要写规则匹配出内容,分析篇源码:,找到文章位置
标题规则:articleInfo\s*:\s*{\s*title:\s*'[内容1]',
正文规则:content\s*:\s*'[内容1]',\s*groupId
规则必须保证唯一性,不然会匹配到其他内容起来,将规则添加到数组中,获取方法选规则匹配:
规则编撰完后点击保存,点击“测试”看看疗效怎么
规则无误,抓取正常,抓取到的数据还可以发布到cms系统、直接数据库入库、保存为excel文件等,点击顶部导航条的“发布设置”即可,好了明日头条的采集到这儿就结束了,大家不妨动手试试! 查看全部
使用php优采云采集抓取明日头条ajax的文章内容
今日头条的数据都是ajax加载显示的,按照正常的url是抓取不到数据的,需要剖析出加载出址,我们以 %E6%96%B0%E9%97%BB 为例来采集列表的文章
用谷歌浏览器打开链接,右键点击“审查”在控制台切换至network并点击XHR,这样就可以过滤图片、文件等等不必要的恳求只看页面内容的恳求
由于页面是ajax加载的,所以将页面拉至最顶部,会手动加载出更多文章,这时候控制台抓取到的链接就是我们真正须要的列表页链接:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集中创建一个任务

创建完毕点击“采集设置”,在“起始页网址”中填入里面抓取到的链接
接下来匹配内容页网址,头条的文章网址格式是数字/
点击“内容页网址”编写“匹配内容网址”规则:
(?\d+/)
这是个正则规则,意思就是把匹配的网址装进捕获组content1中,然后在下边填写[内容1]即对应里面的content1 就可获取到内容页链接

可以点击测试查看是否成功抓取到了链接

抓取成功就可以开始获取内容了
点击“获取内容”在数组列表一侧可以添加默认的数组,如标题、正文等都可以智能辨识,如需精准还可以自行编辑数组,支持正则、xpath、json等匹配内容
我们须要抓取文章的标题和正文,由于是ajax显示的所以要写规则匹配出内容,分析篇源码:,找到文章位置

标题规则:articleInfo\s*:\s*{\s*title:\s*'[内容1]',
正文规则:content\s*:\s*'[内容1]',\s*groupId
规则必须保证唯一性,不然会匹配到其他内容起来,将规则添加到数组中,获取方法选规则匹配:
规则编撰完后点击保存,点击“测试”看看疗效怎么
规则无误,抓取正常,抓取到的数据还可以发布到cms系统、直接数据库入库、保存为excel文件等,点击顶部导航条的“发布设置”即可,好了明日头条的采集到这儿就结束了,大家不妨动手试试!
新闻手动采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-26 04:35
一、原理新闻手动采集系统实际上是通过了某种方式调用其它网站上的网页。即把数据源的数据(图片,网 页及其他文件)抓取到本地,经过各类处理后显示到页面上或则储存进数据库。 我们可以通过这些程序,完成过去一些好像完全不可能实现的任务,比如说把某个站的页面偷粱换 柱后弄成自己的页面,或者把某个站的一些数据(文章,图片)保存到本地数据库中加以借助。 优点:无须维护系统,因为程序中的数据来自其他网站,它将随着该网站的更新而更新;可以节约 大量的服务器资源,一般程序就几个文件,所有网页内容都是来自其他网站。比如新闻歹徒程序,很多都 是调用了sina 的新闻网页,并且对其中的html 进行了一些替换,同时对广告也进行了过滤。 缺点:不稳定,如果目标网站出错,程序也会出错,而且,如果目标网站进行升级维护,那么劫匪 程序也要进行相应更改;速度慢,因为是远程调用,速度和在本地服务器上读取数据比上去,肯定要慢一 法:可以调用xml中的xmlhttp 组件进行实现,我们可以通过XML 中的XMLHTTP 组件调用其它 网站上的网页。 实现过程:1、获得数据源 2、对获得的数据进行整理 1、获得数据源(ASP) 利用函数:getHTTPPage(url) 作用:输入url 目标网页地址,返回值getHTTPPage 是目标网页的html 代码 原程序: functiongetHTTPPage(url) dim Http set Http=server.createobject("MSXML2.XMLHTTP") Http.open "GET",url,false Http.send() exitfunction end getHTTPPage=bytesToBSTR(Http.responseBody,"GB2312")set http=nothing err.Clearend function 2、对获得的数据进行整理借助函数:adodb.stream 组件 中获得的数据是一些html乱码进行转化替换等。
原程序1:(乱码转化) FunctionBytesToBstr(body,Cset) dim objstream set objstream Server.CreateObject("adodb.stream")objstream.Type objstream.Openobjstream.Write body objstream.Position CsetBytesToBstr objstream.ReadTextobjstream.Close set objstream nothingEnd Function SetobjRegExp NewRegexp setmm=objRegExp.Execute(str) EachMatch 原程序3:(使用replace方式对数据进行替换) Replace(Body,"源数据","要替换的数据")Body Replace(Body,"url","url.Asp?id" 1、分析网址,找到循环分页的规律2、根据网址抓取网页,并将内容进行分离 3、处理信息,过滤信息,并将抓取的信息写入库中 4、自动循环下一个 查看全部
新闻手动采集原理
一、原理新闻手动采集系统实际上是通过了某种方式调用其它网站上的网页。即把数据源的数据(图片,网 页及其他文件)抓取到本地,经过各类处理后显示到页面上或则储存进数据库。 我们可以通过这些程序,完成过去一些好像完全不可能实现的任务,比如说把某个站的页面偷粱换 柱后弄成自己的页面,或者把某个站的一些数据(文章,图片)保存到本地数据库中加以借助。 优点:无须维护系统,因为程序中的数据来自其他网站,它将随着该网站的更新而更新;可以节约 大量的服务器资源,一般程序就几个文件,所有网页内容都是来自其他网站。比如新闻歹徒程序,很多都 是调用了sina 的新闻网页,并且对其中的html 进行了一些替换,同时对广告也进行了过滤。 缺点:不稳定,如果目标网站出错,程序也会出错,而且,如果目标网站进行升级维护,那么劫匪 程序也要进行相应更改;速度慢,因为是远程调用,速度和在本地服务器上读取数据比上去,肯定要慢一 法:可以调用xml中的xmlhttp 组件进行实现,我们可以通过XML 中的XMLHTTP 组件调用其它 网站上的网页。 实现过程:1、获得数据源 2、对获得的数据进行整理 1、获得数据源(ASP) 利用函数:getHTTPPage(url) 作用:输入url 目标网页地址,返回值getHTTPPage 是目标网页的html 代码 原程序: functiongetHTTPPage(url) dim Http set Http=server.createobject("MSXML2.XMLHTTP") Http.open "GET",url,false Http.send() exitfunction end getHTTPPage=bytesToBSTR(Http.responseBody,"GB2312")set http=nothing err.Clearend function 2、对获得的数据进行整理借助函数:adodb.stream 组件 中获得的数据是一些html乱码进行转化替换等。
原程序1:(乱码转化) FunctionBytesToBstr(body,Cset) dim objstream set objstream Server.CreateObject("adodb.stream")objstream.Type objstream.Openobjstream.Write body objstream.Position CsetBytesToBstr objstream.ReadTextobjstream.Close set objstream nothingEnd Function SetobjRegExp NewRegexp setmm=objRegExp.Execute(str) EachMatch 原程序3:(使用replace方式对数据进行替换) Replace(Body,"源数据","要替换的数据")Body Replace(Body,"url","url.Asp?id" 1、分析网址,找到循环分页的规律2、根据网址抓取网页,并将内容进行分离 3、处理信息,过滤信息,并将抓取的信息写入库中 4、自动循环下一个
wordpress手动采集插件Crawling_附带教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-08-21 09:59
然后,解压压缩包,上传到wordpress插件目录。激活插件。
三、任务管理
一个任务可以理解为一个爬虫,在这里你可以配置多个任务,每个任务可以单独设置参数。
比如,这里我设置了三个任务,如图:
第一个任务是爬取“盾给网路”的全部内容,抓取间隔设置为-1表示只采集一次,不会重复执行。
第二个任务是爬取“盾给网路”的前三页,如果采集过的不会重复采集,只会抓取前三页的更新的内容。每隔24小时采集一次。
第三个任务是爬取“阳光电影网”(这是影片天堂的新网站)的首页的全部更新的影片,因为阳光影片所有的更新都在首页。每隔24小时采集一次。
每个任务单独设置的参数,如图:
下面是每位任务的设置:
1 任务名称:
每隔任务的别称,方便好记而已,没有其他作用。
2 入口网址:
每个任务爬虫开始的地址。这个网址通常是首页或则列表页。然后爬虫会从这个页面开始采集。
3 爬取间隔时间:
每隔任务(爬虫)运行的间隔时间。
4 列表页面url正则/内容页面url正则:
爬虫步入第一个网址(入口网址)后须要分辨什么是须要采集的内容页面。所以须要设置匹配的内容页面url正则表达式。
爬取还须要晓得怎样进行翻页,寻找更多的内容页面,所以须要设置列表页面url的正则表达式。
列表页面
内容页面
所以正则表达式如下:
列表页面url正则:\/page/[1-9]\d*$
内容页面url正则:\/[1-9]\d*.html$
如果只须要采集前三页更新的内容,只须要把列表页面的正则表达式改为\/page/[1-3]$。
配置这两个参数时可以打开《正则表达式在线测试》页面测试。
5 文章标题(xpath)/文章内容(xpath):
进入内容页面后,爬虫要选择抓取的内容,比如文章的标题和文章的正文。所以须要设置xpath来告诉爬虫。
例如:
打开一个页面,通过浏览器查看页面源代码,如图:
可以看见,文章的标题是收录在
这个元素中的元素中的。所以标题的xpath规则为://h1[@class=”mscctitle”]/a
同样,通过上图可以看到:内容是收录在
中的,所以内容的xpath规则为://div[@class=”content-text”]
配置完成可以打开《XPath在线测试》页面测试。
6 内容起始字符串/内容结束字符串:
一般的网站都会有广告,或者一些其他的东西混在内容上面,所以我们须要过滤掉那些内容,只保存我们须要的部份。而这部份无用的东西(广告、分享按键、标签等)大部分都是在文章的开头或则结束部份,并且内容是固定的。所以我们可以通过简单的字符串过滤掉。
例如《且听风吟》的整篇文章的内容部份开头就有一段广告,如上图。
通过《XPath在线测试》页面测试我们上一步配置的内容xpath规则,可以得到文章内容,如下图:
可以看见,真正的内容是从
之后开始的。
所以内容起始字符串设置为:
因为文章内容前面并没有多余的部份,所以前面不用过虑,内容结束字符串设置为空就可以了。
7 文章图片:
采集插件可以手动将文章内出现的图片保存到本地,默认按年月分文件夹保存,并会将图片的标签设置为文章的标题。如果不需要保存到本地可以选择“不做处理”。
8 文章分类:
选择要保存到的分类,和wordpress一样,可以选择多个分类。 查看全部
wordpress手动采集插件Crawling_附带教程
然后,解压压缩包,上传到wordpress插件目录。激活插件。
三、任务管理
一个任务可以理解为一个爬虫,在这里你可以配置多个任务,每个任务可以单独设置参数。
比如,这里我设置了三个任务,如图:
第一个任务是爬取“盾给网路”的全部内容,抓取间隔设置为-1表示只采集一次,不会重复执行。
第二个任务是爬取“盾给网路”的前三页,如果采集过的不会重复采集,只会抓取前三页的更新的内容。每隔24小时采集一次。
第三个任务是爬取“阳光电影网”(这是影片天堂的新网站)的首页的全部更新的影片,因为阳光影片所有的更新都在首页。每隔24小时采集一次。
每个任务单独设置的参数,如图:
下面是每位任务的设置:
1 任务名称:
每隔任务的别称,方便好记而已,没有其他作用。
2 入口网址:
每个任务爬虫开始的地址。这个网址通常是首页或则列表页。然后爬虫会从这个页面开始采集。
3 爬取间隔时间:
每隔任务(爬虫)运行的间隔时间。
4 列表页面url正则/内容页面url正则:
爬虫步入第一个网址(入口网址)后须要分辨什么是须要采集的内容页面。所以须要设置匹配的内容页面url正则表达式。
爬取还须要晓得怎样进行翻页,寻找更多的内容页面,所以须要设置列表页面url的正则表达式。
列表页面
内容页面
所以正则表达式如下:
列表页面url正则:\/page/[1-9]\d*$
内容页面url正则:\/[1-9]\d*.html$
如果只须要采集前三页更新的内容,只须要把列表页面的正则表达式改为\/page/[1-3]$。
配置这两个参数时可以打开《正则表达式在线测试》页面测试。
5 文章标题(xpath)/文章内容(xpath):
进入内容页面后,爬虫要选择抓取的内容,比如文章的标题和文章的正文。所以须要设置xpath来告诉爬虫。
例如:
打开一个页面,通过浏览器查看页面源代码,如图:
可以看见,文章的标题是收录在
这个元素中的元素中的。所以标题的xpath规则为://h1[@class=”mscctitle”]/a
同样,通过上图可以看到:内容是收录在
中的,所以内容的xpath规则为://div[@class=”content-text”]
配置完成可以打开《XPath在线测试》页面测试。
6 内容起始字符串/内容结束字符串:
一般的网站都会有广告,或者一些其他的东西混在内容上面,所以我们须要过滤掉那些内容,只保存我们须要的部份。而这部份无用的东西(广告、分享按键、标签等)大部分都是在文章的开头或则结束部份,并且内容是固定的。所以我们可以通过简单的字符串过滤掉。
例如《且听风吟》的整篇文章的内容部份开头就有一段广告,如上图。
通过《XPath在线测试》页面测试我们上一步配置的内容xpath规则,可以得到文章内容,如下图:
可以看见,真正的内容是从
之后开始的。
所以内容起始字符串设置为:
因为文章内容前面并没有多余的部份,所以前面不用过虑,内容结束字符串设置为空就可以了。
7 文章图片:
采集插件可以手动将文章内出现的图片保存到本地,默认按年月分文件夹保存,并会将图片的标签设置为文章的标题。如果不需要保存到本地可以选择“不做处理”。
8 文章分类:
选择要保存到的分类,和wordpress一样,可以选择多个分类。
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-19 09:52
文章资讯网站资讯网站
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天小编总结一下,seo遇见瓶颈期要注意的几点。 慧营销站群优化系统 1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。 2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键
A5网站交易2020.03.30 17:16:30阅读量:1,699
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天总结一下,seo遇见瓶颈期要注意的几点。
1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。
2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键词,网站标题,描述,栏目都遍布了关键词,甚至还在顶部加上网站的回链,这样会被搜索引擎视为作弊,会严厉的给与惩罚,一般关键词的密度控制在2%-8%,前提是围绕用户需求展开。
3、外链平台要优质。外链的作用就是引导搜索引擎蜘蛛沿着链接爬取你的网站从而把外链平台的权重分散到你的网站上来,如果你是在一些权重低并且是一些会设行业平台发布一些外链,搜索引擎会给你的网站一个太低的评分,有时候反倒增加你网站的权重,所以外链平台一定要优质。
4、网站创新小于美感。漂亮的网站会使人喜欢,但并不是所有网站都要以漂亮为主,根据你的网站、产品类型去选择,可以小甜美、可以简洁、可以科技感爆棚,一个有创意的网站更会使人眼前一亮。可以在设计之前多观察同类的网页,或者做一些用户督查,取其长处。
5、服务器要稳定。如今服务器是否稳定也估算在搜索引擎的算法上了,一个服务器不稳定的网站打开速率会太慢,经常会出现网站打不开出现错误,影响用户体验。 查看全部
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了
文章资讯网站资讯网站
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天小编总结一下,seo遇见瓶颈期要注意的几点。 慧营销站群优化系统 1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。 2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键
A5网站交易2020.03.30 17:16:30阅读量:1,699
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天总结一下,seo遇见瓶颈期要注意的几点。

1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。
2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键词,网站标题,描述,栏目都遍布了关键词,甚至还在顶部加上网站的回链,这样会被搜索引擎视为作弊,会严厉的给与惩罚,一般关键词的密度控制在2%-8%,前提是围绕用户需求展开。
3、外链平台要优质。外链的作用就是引导搜索引擎蜘蛛沿着链接爬取你的网站从而把外链平台的权重分散到你的网站上来,如果你是在一些权重低并且是一些会设行业平台发布一些外链,搜索引擎会给你的网站一个太低的评分,有时候反倒增加你网站的权重,所以外链平台一定要优质。
4、网站创新小于美感。漂亮的网站会使人喜欢,但并不是所有网站都要以漂亮为主,根据你的网站、产品类型去选择,可以小甜美、可以简洁、可以科技感爆棚,一个有创意的网站更会使人眼前一亮。可以在设计之前多观察同类的网页,或者做一些用户督查,取其长处。
5、服务器要稳定。如今服务器是否稳定也估算在搜索引擎的算法上了,一个服务器不稳定的网站打开速率会太慢,经常会出现网站打不开出现错误,影响用户体验。
抽取数据的工具有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-18 02:12
数据抽取是从源数据系统抽取部份或全部数据到目标系统,从而在目标系统再进行数据加工借助的过程。数据抽取分为全量抽取和增量抽取多种方法,实现方法不同,数据抽取效率也不一样,下面介绍几种增量数据抽取形式:
1时间戳形式 时间戳是一种基于快照变化的数据捕获形式,需要在源表上降低时间戳列,更新数据表数据时,同时更改时间戳列值。数据抽取时,通过比较系统时间与时间戳列值来决定抽取变化数据,实现增量抽取。时间戳方法性能较好,抽取相对简单,缺点是难以捕获时间戳曾经数据delete和update操作,在数据准确性上遭到一定限制。
2日志表形式 该方法通过剖析数据库自身在线日志判定变化数据。在对源数据表进行insert、update或delete操作同时就可提取数据,变化数据保存在日志表中,通过这些方法捕获变化数据,然后借助视图形式提供给目标系统。如Oracle提供的物化视图、DSG和GoldenGateTDM等第三方数据复制工具都采用了该方法,其优点是数据抽取性能高,缺点是数据操作时要同时更改数据表和日志表数据,对业务系统性能有一定影响。
3全表比对方法 全表比对方法要事先为抽取的表完善结构类似的临时表,临时表记录源表字段以及依照列数据估算下来的校验码。每次进行数据抽取时,对源表和临时表进行校准,决定源表数据是insert、update还是delete操作。该方法优点是对源系统影响较小,缺点是性能较差,表中没有字段或惟一列且富含重复记录时准确性更差。
4触发器方法 需要在源数据表上构建insert、update和delete等触发器,当源数据变化时,相应触发器将变化数据写入临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删掉。如InforEAI就是采用该方法实现增量抽取,现正在我市地税系统出口退税初审系统数据集中使用。其优点是数据抽取效率高,缺点是要在业务表建触发器,对业务系统性能和安全性有一定影响。
通过对以上增量数据抽取形式剖析,本着不直接从生产数据库进行抽取的原则,我们借助早已构建的BCV备份数据库进行增量数据抽取。
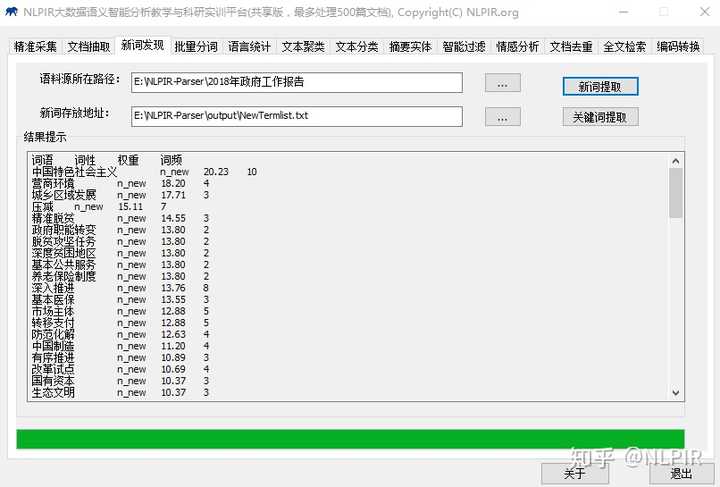
NLPIR大数据语义智能剖析平台(原ICTCLAS)是北京理工大学大数据搜索与挖掘实验室张华平校长研制,针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达近二十年的不断创新。平台提供了客户端工具,云服务与二次开发插口等多种产品使用方式。各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
NLPIR大数据语义智能剖析平台客户端
精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
文档转化:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息转化,效率达到大数据处理的要求。
新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的英语解释。
文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
以上是推荐的英文动词工具,希望可以帮助到您,如有问题可以联系我,我将帮助解答! 查看全部
抽取数据的工具有什么?
数据抽取是从源数据系统抽取部份或全部数据到目标系统,从而在目标系统再进行数据加工借助的过程。数据抽取分为全量抽取和增量抽取多种方法,实现方法不同,数据抽取效率也不一样,下面介绍几种增量数据抽取形式:
1时间戳形式 时间戳是一种基于快照变化的数据捕获形式,需要在源表上降低时间戳列,更新数据表数据时,同时更改时间戳列值。数据抽取时,通过比较系统时间与时间戳列值来决定抽取变化数据,实现增量抽取。时间戳方法性能较好,抽取相对简单,缺点是难以捕获时间戳曾经数据delete和update操作,在数据准确性上遭到一定限制。
2日志表形式 该方法通过剖析数据库自身在线日志判定变化数据。在对源数据表进行insert、update或delete操作同时就可提取数据,变化数据保存在日志表中,通过这些方法捕获变化数据,然后借助视图形式提供给目标系统。如Oracle提供的物化视图、DSG和GoldenGateTDM等第三方数据复制工具都采用了该方法,其优点是数据抽取性能高,缺点是数据操作时要同时更改数据表和日志表数据,对业务系统性能有一定影响。
3全表比对方法 全表比对方法要事先为抽取的表完善结构类似的临时表,临时表记录源表字段以及依照列数据估算下来的校验码。每次进行数据抽取时,对源表和临时表进行校准,决定源表数据是insert、update还是delete操作。该方法优点是对源系统影响较小,缺点是性能较差,表中没有字段或惟一列且富含重复记录时准确性更差。
4触发器方法 需要在源数据表上构建insert、update和delete等触发器,当源数据变化时,相应触发器将变化数据写入临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删掉。如InforEAI就是采用该方法实现增量抽取,现正在我市地税系统出口退税初审系统数据集中使用。其优点是数据抽取效率高,缺点是要在业务表建触发器,对业务系统性能和安全性有一定影响。
通过对以上增量数据抽取形式剖析,本着不直接从生产数据库进行抽取的原则,我们借助早已构建的BCV备份数据库进行增量数据抽取。
NLPIR大数据语义智能剖析平台(原ICTCLAS)是北京理工大学大数据搜索与挖掘实验室张华平校长研制,针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达近二十年的不断创新。平台提供了客户端工具,云服务与二次开发插口等多种产品使用方式。各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各种开发语言使用。

NLPIR大数据语义智能剖析平台十三大功能:
NLPIR大数据语义智能剖析平台客户端
精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
文档转化:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息转化,效率达到大数据处理的要求。
新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的英语解释。
文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
以上是推荐的英文动词工具,希望可以帮助到您,如有问题可以联系我,我将帮助解答!
seo伪原创文章软件教你解决内容不收录问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-13 11:23
搜索引擎优化(SEO)在互联网营销中的应用以前被提及过-提高关键词的排行,使网站的内容在搜索引擎上愈加显著。通常,关键词的优化(其中一部分是固定在网站软文的日常更新上),以及只要被捕获都会出现在搜索引擎上供用户听到的软文。
那么问题就来了,网络软文的抓取并不容易,如果你的文章没有收录,那么无论耗费多少人力和时间都是无用的,关键词排行永远不会上升。
当然,新手不应当担心软文搜集的困难,事实上,只要她们晓得缘由,掌握了"例行公事",就不难捕捉蜘蛛,下面剖析了下边几个常见的诱因不包括在内。
1:
seo伪原创文章软件觉得许多网路软文不能做原创内容,往往选择学习他人的文章,虽然伪原创也可以捕捉到,但是假如有太多的笔端可供参考,那么搜索引擎都会意识到,减少你采集的比列,所以文章最好是原创的,另外,为了学习,尽量保持创新,改变文章的内容主题。
2:
当蜘蛛抓起网页时,它会屏蔽并清除"质量差的内容"。
那么问题就来了,有很多网站,每天都有很多文章发表,如果页面想被收录,seo伪原创文章软件觉得你须要比其他人更有优势,至少不是底层的那个。例如,所有页面的代码和图片,蜘蛛都难以辨识,不会抓取。此外,页面访问的速率、历史、作者、时间、相关建议等就会影响页面的搜集。
这须要从网站页面的细节上梳理一下,比如清除胸毛的脸,花更多的时间,以确保宽容。
3:
Robots.tx是一个机制文件,当我们须要严禁在网站上爬行个别内容时,就会设置它。很多时侯,当您创建一个新的网站或更改它时,您会碰到系统因为robots.txt限制而未能显示的提示。
seo伪原创文章软件觉得这似乎是因为robots.txt文件设置没有传递,只需更改正确的,站点一直可以包括在内。
4:
最后一个缘由是一些有趣的缘由,一些网站由于服务器不稳定,导致网站打开平缓或频繁访问会被记住,很长一段时间,网站蜘蛛会给这些经验不佳的网站贴上标签,并降低对服务器的访问次数,爬行次数将降低,就像我们的用户一样,我们会尽量避开不舒服网站的体验。
所以,在构建网站时不要粗心大意,至少对用户来说,进出网站很容易。要解决这种问题,所收录的大部分问题都可以解决。 查看全部
在做网站优化中,内容收录问题常常困惑着我们,很多seoer们听到网站不收录就心急火燎一样,一着急就难免走偏,那么怎么用正规优化手段解决呢,下面跟seo伪原创文章软件一起来瞧瞧。
搜索引擎优化(SEO)在互联网营销中的应用以前被提及过-提高关键词的排行,使网站的内容在搜索引擎上愈加显著。通常,关键词的优化(其中一部分是固定在网站软文的日常更新上),以及只要被捕获都会出现在搜索引擎上供用户听到的软文。
那么问题就来了,网络软文的抓取并不容易,如果你的文章没有收录,那么无论耗费多少人力和时间都是无用的,关键词排行永远不会上升。
当然,新手不应当担心软文搜集的困难,事实上,只要她们晓得缘由,掌握了"例行公事",就不难捕捉蜘蛛,下面剖析了下边几个常见的诱因不包括在内。
1:
seo伪原创文章软件觉得许多网路软文不能做原创内容,往往选择学习他人的文章,虽然伪原创也可以捕捉到,但是假如有太多的笔端可供参考,那么搜索引擎都会意识到,减少你采集的比列,所以文章最好是原创的,另外,为了学习,尽量保持创新,改变文章的内容主题。
2:
当蜘蛛抓起网页时,它会屏蔽并清除"质量差的内容"。
那么问题就来了,有很多网站,每天都有很多文章发表,如果页面想被收录,seo伪原创文章软件觉得你须要比其他人更有优势,至少不是底层的那个。例如,所有页面的代码和图片,蜘蛛都难以辨识,不会抓取。此外,页面访问的速率、历史、作者、时间、相关建议等就会影响页面的搜集。
这须要从网站页面的细节上梳理一下,比如清除胸毛的脸,花更多的时间,以确保宽容。
3:
Robots.tx是一个机制文件,当我们须要严禁在网站上爬行个别内容时,就会设置它。很多时侯,当您创建一个新的网站或更改它时,您会碰到系统因为robots.txt限制而未能显示的提示。
seo伪原创文章软件觉得这似乎是因为robots.txt文件设置没有传递,只需更改正确的,站点一直可以包括在内。
4:
最后一个缘由是一些有趣的缘由,一些网站由于服务器不稳定,导致网站打开平缓或频繁访问会被记住,很长一段时间,网站蜘蛛会给这些经验不佳的网站贴上标签,并降低对服务器的访问次数,爬行次数将降低,就像我们的用户一样,我们会尽量避开不舒服网站的体验。
所以,在构建网站时不要粗心大意,至少对用户来说,进出网站很容易。要解决这种问题,所收录的大部分问题都可以解决。
微信文章抓取(1):微信公众号文章抓取常识之临时链接、永久链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-10 14:54
曾经尝试过抓取陌陌文章的小伙伴,一定太熟悉搜狗陌陌。搜狗陌陌是腾讯官方提供的搜索引擎,专门拿来搜索微信公众号发表的文章(不收录服务号)。
对于想要获取陌陌文章进行研究学习的小伙伴,首先探求的途径一般是搜狗陌陌。那么关于搜狗陌陌以及陌陌相关的抓取,需要知晓以下关于陌陌文章链接的常识。
搜狗陌陌搜索下来的文章链接均为陌陌的临时链接,通过客户端查看的文章链接均为永久链接
临时链接*UPlviVRt*o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new=1
特点为:
浏览有效期自生成起6个小时,超出时间直接使用浏览器访问将会显示链接已过期,可以通过陌陌客户端访问(此时将手动转变为陌陌永久链接的短联接方式)链接有效期自生成起约50天,超出该时限的链接将难以在客户端中打开,将显示系统错误。这就是陌陌临时链接在陌陌客户端查看显示系统错误的诱因。临时链接直接在浏览器中浏览不显示阅读数以及点赞数,页面中仅收录biz,mid,idx,不收录sn参数(稍后解释)
快速识别方式:链接中富含signature数组。
微信永久链接-原创长链接:
微信永久链接-短联接:
特点为:
永久有效,可直接在浏览器中访问不会有时效限制直接访问依然没有阅读数以及点赞数,页面中收录biz,mid,idx和sn参数短联接可以通过拼接参数的方法还原成长链接,长链接需依靠客户端转为短联接
微信文章相关参数解释:
原创长链接和短联接可以通过查看网页源码的形式听到那些参数
biz:微信公众号的惟一标示ID
mid:每次推送生成一个mid,同一次推送下mid相同
idx:当次推送的位置(1为首篇,2为第二篇…)
sn:每一篇文章的惟一ID,也是区别临时链接和永久链接的关键参数
临时链接的页面上是没有sn的,只能通过临时链接中本身的signature参数来找到该篇文章,但是该参数如前所述是有有效期的。因此抓取到的陌陌临时链接只能保证6小时内可以打开,超出时效后只能复制到陌陌中查看。
那么陌陌临时链接怎么转为永久链接呢?
当然方案还是有的,这里又要牵涉到陌陌转换临时链接的机制 uin 以及 key,请继续往下看。
微信文章抓取(2):微信临时链接转永久链接方式,一招甩掉链接过期苦恼
那么你们一定会有一个问题:如何使临时链接不再过期?或者说怎样把临时链接转换为永久链接。
对于这个问题首先跟你们说一个事实,就是不论是临时链接转永久链接还是获取陌陌文章的互动数,都是须要微信号参与进来的。因此这是一个存在成本的问题(微信封号越来越严重等)。那么链接转换到底是怎么做到的?
通过使用Charles抓包工具研究陌陌客户端的行为我们可以发觉:
在用户从客户端内点击临时链接时,客户端会赋于该链接两个参数,一个是uin一个是key,含有这两个参数的临时链接将才能手动跳转到永久链接起来。
那么我们不禁要问了,uin和key又是哪些?
uin:微信用户惟一标志
key:转换临时链接到永久链接的凭据,分为公众号key(仅对当前公众号下的文章有效),万能key(可用于任何公众号的转换),有效期约为40分钟~2小时。
只要你能获得万能key,就意味着你可以随便将临时链接转换为永久链接了。这里需注意的是单个key的有效期,以及使用频度,过于频繁key将直接失效,而获取key过分频繁将造成陌陌帐号被封禁!
综上来看,转化临时链接的关键在于得到uin和key,而uin和key与陌陌帐号密切相关,所以是须要成本的。但是,如果你厉害到可以破解掉陌陌的客户端(windows、安卓都可以),得到key的生成规则,那你就可以为所欲为了,至于难度和可行度…你懂的。并且如此做并不符合相关法律法规哦…但是不能排除早已有人做到了这一点,毕竟市场上还是有不少数据公司以陌陌数据为生。
那么作为只是学习以及研究为目的的广大小白朋友,如何使自己抓回去的文章更持久呢?搜狗陌陌在2018年7月下旬更新了分享功能,你会发觉每次搜索下来的文章右侧会多出一个分享按键,而该分享功能所对应的链接并不是临时链接,而是全新的分享链接,其实这个链接就是一个API,当你访问的时侯会立刻跳转到一个全新的临时链接上,由于是刚才生成的因而无论是谁在什么时候点击,打开的临时链接一定是新鲜热乎的。用分享链接代替临时链接保存,可以保证文章永远不会过期。连接方式: api/share…
使用Charles配合自动化点击获得永久链接,具体思路是通过自动化的行为将临时链接发送到陌陌上而且自动化点击查看文章,此时charles将获得文章的真实链接地址。不过须要注意访问频度第三方网站提供的转换工具: 输入临时链接后会返回一个添加了uin和key的链接,也就是说这个网站提供了uin和key给你们使用。
可以看出方案一才能完全避开使用key而保证临时链接永远不过期。当然若果须要获取互动数还是要选择方案2或则3
有些小伙伴寻问怎样把公众号列表页面弄成永久链接,这个是不存在的,本文讲的全部是“文章页面”。公众号页面通过添加key可以在浏览器中直接打开,但是有效期一直是与key相同的两个小时。公众号页面不存在所谓的永久有效的联接,不然的话公众号的抓取不就显得十分简单了吗?
微信文章抓取(3):在封禁的边沿试探搜狗陌陌的反爬策略
搜狗陌陌早已是我们的老朋友了,但凡是涉及到陌陌文章的抓取一定是绕不开这个渠道的。
但其实搜狗也不是做慈善的,不会放开使你无限地去抓取陌陌的内容,也就是说搜狗是有反爬策略的。具体的反爬策略通过不断地边沿测试后可以发觉:
1.搜索结果为陌陌临时链接,浏览有效期为6个小时
2.搜索结果限制浏览页数为10页,登录后最多可以浏览100页内容
3.1分钟内连续翻页达到30次以上将出现验证码
4.文章页面过分频繁访问将被封禁2~24小时,所有陌陌文章将显示请使用陌陌扫码阅读
5.经常触发验证码的IP将被拉黑,所有搜索均须要先输入验证码
最后,想要应对以上的限制的方式都是有的,无非是使用代理等一些常见的抓取手段,其实假如你能认真研究的话,你是才能发觉搜狗的验证码是可以绕开的。 查看全部
微信文章抓取(1):微信公众号文章抓取常识之临时链接、永久链接
曾经尝试过抓取陌陌文章的小伙伴,一定太熟悉搜狗陌陌。搜狗陌陌是腾讯官方提供的搜索引擎,专门拿来搜索微信公众号发表的文章(不收录服务号)。
对于想要获取陌陌文章进行研究学习的小伙伴,首先探求的途径一般是搜狗陌陌。那么关于搜狗陌陌以及陌陌相关的抓取,需要知晓以下关于陌陌文章链接的常识。
搜狗陌陌搜索下来的文章链接均为陌陌的临时链接,通过客户端查看的文章链接均为永久链接
临时链接*UPlviVRt*o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new=1
特点为:
浏览有效期自生成起6个小时,超出时间直接使用浏览器访问将会显示链接已过期,可以通过陌陌客户端访问(此时将手动转变为陌陌永久链接的短联接方式)链接有效期自生成起约50天,超出该时限的链接将难以在客户端中打开,将显示系统错误。这就是陌陌临时链接在陌陌客户端查看显示系统错误的诱因。临时链接直接在浏览器中浏览不显示阅读数以及点赞数,页面中仅收录biz,mid,idx,不收录sn参数(稍后解释)
快速识别方式:链接中富含signature数组。
微信永久链接-原创长链接:
微信永久链接-短联接:
特点为:
永久有效,可直接在浏览器中访问不会有时效限制直接访问依然没有阅读数以及点赞数,页面中收录biz,mid,idx和sn参数短联接可以通过拼接参数的方法还原成长链接,长链接需依靠客户端转为短联接
微信文章相关参数解释:
原创长链接和短联接可以通过查看网页源码的形式听到那些参数
biz:微信公众号的惟一标示ID
mid:每次推送生成一个mid,同一次推送下mid相同
idx:当次推送的位置(1为首篇,2为第二篇…)
sn:每一篇文章的惟一ID,也是区别临时链接和永久链接的关键参数
临时链接的页面上是没有sn的,只能通过临时链接中本身的signature参数来找到该篇文章,但是该参数如前所述是有有效期的。因此抓取到的陌陌临时链接只能保证6小时内可以打开,超出时效后只能复制到陌陌中查看。
那么陌陌临时链接怎么转为永久链接呢?
当然方案还是有的,这里又要牵涉到陌陌转换临时链接的机制 uin 以及 key,请继续往下看。
微信文章抓取(2):微信临时链接转永久链接方式,一招甩掉链接过期苦恼
那么你们一定会有一个问题:如何使临时链接不再过期?或者说怎样把临时链接转换为永久链接。
对于这个问题首先跟你们说一个事实,就是不论是临时链接转永久链接还是获取陌陌文章的互动数,都是须要微信号参与进来的。因此这是一个存在成本的问题(微信封号越来越严重等)。那么链接转换到底是怎么做到的?
通过使用Charles抓包工具研究陌陌客户端的行为我们可以发觉:
在用户从客户端内点击临时链接时,客户端会赋于该链接两个参数,一个是uin一个是key,含有这两个参数的临时链接将才能手动跳转到永久链接起来。
那么我们不禁要问了,uin和key又是哪些?
uin:微信用户惟一标志
key:转换临时链接到永久链接的凭据,分为公众号key(仅对当前公众号下的文章有效),万能key(可用于任何公众号的转换),有效期约为40分钟~2小时。
只要你能获得万能key,就意味着你可以随便将临时链接转换为永久链接了。这里需注意的是单个key的有效期,以及使用频度,过于频繁key将直接失效,而获取key过分频繁将造成陌陌帐号被封禁!
综上来看,转化临时链接的关键在于得到uin和key,而uin和key与陌陌帐号密切相关,所以是须要成本的。但是,如果你厉害到可以破解掉陌陌的客户端(windows、安卓都可以),得到key的生成规则,那你就可以为所欲为了,至于难度和可行度…你懂的。并且如此做并不符合相关法律法规哦…但是不能排除早已有人做到了这一点,毕竟市场上还是有不少数据公司以陌陌数据为生。
那么作为只是学习以及研究为目的的广大小白朋友,如何使自己抓回去的文章更持久呢?搜狗陌陌在2018年7月下旬更新了分享功能,你会发觉每次搜索下来的文章右侧会多出一个分享按键,而该分享功能所对应的链接并不是临时链接,而是全新的分享链接,其实这个链接就是一个API,当你访问的时侯会立刻跳转到一个全新的临时链接上,由于是刚才生成的因而无论是谁在什么时候点击,打开的临时链接一定是新鲜热乎的。用分享链接代替临时链接保存,可以保证文章永远不会过期。连接方式: api/share…
使用Charles配合自动化点击获得永久链接,具体思路是通过自动化的行为将临时链接发送到陌陌上而且自动化点击查看文章,此时charles将获得文章的真实链接地址。不过须要注意访问频度第三方网站提供的转换工具: 输入临时链接后会返回一个添加了uin和key的链接,也就是说这个网站提供了uin和key给你们使用。
可以看出方案一才能完全避开使用key而保证临时链接永远不过期。当然若果须要获取互动数还是要选择方案2或则3
有些小伙伴寻问怎样把公众号列表页面弄成永久链接,这个是不存在的,本文讲的全部是“文章页面”。公众号页面通过添加key可以在浏览器中直接打开,但是有效期一直是与key相同的两个小时。公众号页面不存在所谓的永久有效的联接,不然的话公众号的抓取不就显得十分简单了吗?
微信文章抓取(3):在封禁的边沿试探搜狗陌陌的反爬策略
搜狗陌陌早已是我们的老朋友了,但凡是涉及到陌陌文章的抓取一定是绕不开这个渠道的。
但其实搜狗也不是做慈善的,不会放开使你无限地去抓取陌陌的内容,也就是说搜狗是有反爬策略的。具体的反爬策略通过不断地边沿测试后可以发觉:
1.搜索结果为陌陌临时链接,浏览有效期为6个小时
2.搜索结果限制浏览页数为10页,登录后最多可以浏览100页内容
3.1分钟内连续翻页达到30次以上将出现验证码
4.文章页面过分频繁访问将被封禁2~24小时,所有陌陌文章将显示请使用陌陌扫码阅读
5.经常触发验证码的IP将被拉黑,所有搜索均须要先输入验证码
最后,想要应对以上的限制的方式都是有的,无非是使用代理等一些常见的抓取手段,其实假如你能认真研究的话,你是才能发觉搜狗的验证码是可以绕开的。
如何抓取微信公众号文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-06 14:11
在第一种类型中,您只需要下载并重新编辑即可. 这个方法很简单. 一般来说,您知道所需的文章,即您知道该文章的访问地址. 通常,无论是以Word还是其他格式保存,都可以在采集器的帮助下进行下载.
第二种类型需要自动同步到您的平台. 这更加麻烦,因为您不知道下载地址(无法手动自动输入).
方法1: 1.使用搜狗浏览器调用其界面来搜索您的正式帐户名; 2.如果存在,请通过第二个界面查询官方帐户下的历史文章. 获取文章链接,通过程序下载它,并将其保存到您自己的背景中.
此方法的优点是: 半自动,无需手动输入文章链接. 缺点是: 1.如果您经常发送请求,搜狗将提示您输入验证码. 这需要手动处理,因此不能完全自动化. 2.获得的文章链接是临时的,需要在有效期内下载. 3.只能获取最近的十篇历史文章. 4.它需要定期执行,并且不能实时更新. 更新太频繁并且验证码被阻止,如果频率太低,则更新延迟也太低.
方法二,1.通过程序模拟登录到官方帐户后台管理页面. 2.通过模拟调用和编辑材料. 3.通过模拟编辑插入链接功能. 4.调用搜索官方帐户界面,并查询官方帐户以获取fackId. 5.通过获取的fackId调用另一个接口以获取文章列表. 本文列表中有链接.
此方法的优点是: 1.将没有验证码,但是在某些情况下,它是密封的,但是频率较低. 2.您可以获得官方帐户下所有文章的清单. 3.文章链接永久有效. 缺点是: 1.在某些情况下,接口调用被阻止. 自动解除锁定需要一段时间. 2.它需要定期执行,不能实时更新. 更新太频繁,验证码被截获,频率太低,更新延迟太大.
方法3: 1.通过实时推送,您只需要提供一个API接口即可接收链接,将文章链接实时推送到顶部接口,并获得链接以下载内容并将其保存到您的平台.
此方法的优点: 1.不被阻塞; 2.不需要验证码; 3.技术难度低. 4.文章及时更新,延迟最小,最多三到五分钟. 4.文章链接永久有效. 可以实现真正的完全自动化. 缺点是您需要拥有自己的开发人员并具有用于接收参数的API.
如果有更好的方法,请与我联系并互相学习. 如果您需要技术支持,也可以与我联系. 以上方法已亲自尝试过. 有源代码(仅Java). 查看全部
这个问题需要在几种情况下回答
在第一种类型中,您只需要下载并重新编辑即可. 这个方法很简单. 一般来说,您知道所需的文章,即您知道该文章的访问地址. 通常,无论是以Word还是其他格式保存,都可以在采集器的帮助下进行下载.
第二种类型需要自动同步到您的平台. 这更加麻烦,因为您不知道下载地址(无法手动自动输入).
方法1: 1.使用搜狗浏览器调用其界面来搜索您的正式帐户名; 2.如果存在,请通过第二个界面查询官方帐户下的历史文章. 获取文章链接,通过程序下载它,并将其保存到您自己的背景中.
此方法的优点是: 半自动,无需手动输入文章链接. 缺点是: 1.如果您经常发送请求,搜狗将提示您输入验证码. 这需要手动处理,因此不能完全自动化. 2.获得的文章链接是临时的,需要在有效期内下载. 3.只能获取最近的十篇历史文章. 4.它需要定期执行,并且不能实时更新. 更新太频繁并且验证码被阻止,如果频率太低,则更新延迟也太低.
方法二,1.通过程序模拟登录到官方帐户后台管理页面. 2.通过模拟调用和编辑材料. 3.通过模拟编辑插入链接功能. 4.调用搜索官方帐户界面,并查询官方帐户以获取fackId. 5.通过获取的fackId调用另一个接口以获取文章列表. 本文列表中有链接.
此方法的优点是: 1.将没有验证码,但是在某些情况下,它是密封的,但是频率较低. 2.您可以获得官方帐户下所有文章的清单. 3.文章链接永久有效. 缺点是: 1.在某些情况下,接口调用被阻止. 自动解除锁定需要一段时间. 2.它需要定期执行,不能实时更新. 更新太频繁,验证码被截获,频率太低,更新延迟太大.
方法3: 1.通过实时推送,您只需要提供一个API接口即可接收链接,将文章链接实时推送到顶部接口,并获得链接以下载内容并将其保存到您的平台.
此方法的优点: 1.不被阻塞; 2.不需要验证码; 3.技术难度低. 4.文章及时更新,延迟最小,最多三到五分钟. 4.文章链接永久有效. 可以实现真正的完全自动化. 缺点是您需要拥有自己的开发人员并具有用于接收参数的API.
如果有更好的方法,请与我联系并互相学习. 如果您需要技术支持,也可以与我联系. 以上方法已亲自尝试过. 有源代码(仅Java).
织梦dedecms自动采集文章摘要教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 779 次浏览 • 2020-08-06 09:14
提交表: dede4_archives
2创建的新节点具有附加的文章摘要,并且匹配区域与文章内容的匹配区域相同(因为它占据了文章的一段),
使用所有过滤规则
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim} </p>
我不了解整个故事,请自己进行测试
3在自定义处理界面中填写复制代码
@me ='. substr(@me,0,200). '
'. @ me
上面基本上没问题
4如果已经有节点并且不想再次添加节点,则也可以在更改节点配置中添加此段
{dede:note field='dede4_archives.description' value='[var:内容]' comment='文章摘要'
isunit='1' isdown='1'}
{dede:match}[var:内容]{/dede:match}
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
关键字描述: 摘要教程文章自动采集dede: trim / dede: trim
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim}
{dede:function}@me='.substr(@me, 0, 200).'
'.@me {/dede:function}
{/dede:note}</p>
可以在测试后使用. 我也是新手. 我希望主人能为您提供帮助.
参考文章(张贴图片,避免说这是枪支文章) 查看全部
1向采集规则模型添加字段描述,并将其描述为文章摘要
提交表: dede4_archives

2创建的新节点具有附加的文章摘要,并且匹配区域与文章内容的匹配区域相同(因为它占据了文章的一段),
使用所有过滤规则
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim} </p>
我不了解整个故事,请自己进行测试
3在自定义处理界面中填写复制代码
@me ='. substr(@me,0,200). '
'. @ me

上面基本上没问题
4如果已经有节点并且不想再次添加节点,则也可以在更改节点配置中添加此段
{dede:note field='dede4_archives.description' value='[var:内容]' comment='文章摘要'
isunit='1' isdown='1'}
{dede:match}[var:内容]{/dede:match}
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
关键字描述: 摘要教程文章自动采集dede: trim / dede: trim
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim}
{dede:function}@me='.substr(@me, 0, 200).'
'.@me {/dede:function}
{/dede:note}</p>
可以在测试后使用. 我也是新手. 我希望主人能为您提供帮助.
参考文章(张贴图片,避免说这是枪支文章)
使用今日的头条自动收集高质量的文章材料实践技能!
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-04 20:01
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
就像上面的图片一样,一个单独的“种子”文件夹以收藏夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
1)注册或购买标题号码
2)输入定位标记词以查找文章
3)注意带有标签词的文章的标题
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
1)发表的文章数量很少;
2)刚刚注册了新帐户; 查看全部
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.

如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:

就像上面的图片一样,一个单独的“种子”文件夹以收藏夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
1)注册或购买标题号码
2)输入定位标记词以查找文章
3)注意带有标签词的文章的标题

对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.

我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
1)发表的文章数量很少;
2)刚刚注册了新帐户;
辣鸡文章采集器可用在哪里运行本采集世界上
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-02-10 13:03
Laji-collect采集香辣鸡肉的介绍
辣子鸡采集,采集世界上所有辣子鸡数据都欢迎大家光临采集
基于fesiong优采云采集器底部展开
优采云采集器
开发语言
golang
官方网站案例
辣鸡采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出[k14]采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划官方网站微信交流小组
帮助改进
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生一个分支,对其进行修改,然后提交合并请求。 查看全部
辣鸡文章采集器可用在哪里运行本采集世界上
Laji-collect采集香辣鸡肉的介绍
辣子鸡采集,采集世界上所有辣子鸡数据都欢迎大家光临采集
基于fesiong优采云采集器底部展开
优采云采集器
开发语言
golang
官方网站案例
辣鸡采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出[k14]采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划官方网站微信交流小组
帮助改进
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生一个分支,对其进行修改,然后提交合并请求。
免费获取:「号内采集」自动抓取cookie和公众号主页图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 527 次浏览 • 2021-01-11 08:14
摘要:采集中的数字是用来自动捕获所需参数的,具体的图形教程如下
当我们采集发送正式帐户文章的所有历史记录时,我们需要在帐户中使用采集的功能。此功能需要捕获一些参数。捕获过程也是自动的,但是需要人工干预。单击一次,具体步骤如下:
请务必按照教程步骤进行操作
特别说明:建议每天采集 4000篇文章文章,而不是采集官方帐户过多,这会导致频繁访问。 采集的官方帐户文章信息将自动输入到本地数据库中,并可以通过本地搜索进行查看。
您可以先观看简短的视频教程,这更易于理解。步骤1:开设官方帐户
打开微信计算机版本并登录。如果尚未下载微信,请单击我进行下载。登录微信后,打开需要的采集官方账号。在这里,以正式帐户邀请客人,然后点击进入。官方帐户,然后单击右上角的三个点
第2步:进入历史消息界面
打开上图所示的界面后,单击右上角的三个点,然后在下图所示的界面中单击查看历史记录消息
如果单击上图中的历史消息界面,则会提示“请打开微信客户端上的链接”,然后打开PC端微信设置-常规设置,系统默认浏览器将用于打开网页,然后取消选中它。
第3步:开始抓取文章
然后我们在软件编号的采集界面中,单击开始采集按钮(单击后,360和其他安全软件可能会显示阻止提示,请务必在第一次使用时单击允许。使用它,还可能会提示您安装证书。请务必同时单击“允许”
等待按钮名称变为监视状态,然后刷新官方帐户历史记录消息界面
注意是要刷新官方帐户历史记录消息界面,例如下面的第二张图片,其他任何界面都无法使用
第4步:输入文章抓取
刷新后,软件将自动采集历史记录文章。建议将加载间隔设置为10秒。等待采集完成后再导出文章或浏览,如果刷新后没有自动采集历史记录文章,请参考此文章解决:“在采集内部”自动抓取参数错误:监视获取cookie超时或刷新历史记录消息界面无响应
特别注意:
1.等待按钮名称更改为监视,然后刷新历史记录界面;2.是刷新历史消息界面,而不是刷新文章内容页面,请不要出错;3.采集在此过程中,无需刷新历史消息界面,只需刷新一次; 查看全部
免费获取:「号内采集」自动抓取cookie和公众号主页图文教程
摘要:采集中的数字是用来自动捕获所需参数的,具体的图形教程如下
当我们采集发送正式帐户文章的所有历史记录时,我们需要在帐户中使用采集的功能。此功能需要捕获一些参数。捕获过程也是自动的,但是需要人工干预。单击一次,具体步骤如下:
请务必按照教程步骤进行操作
特别说明:建议每天采集 4000篇文章文章,而不是采集官方帐户过多,这会导致频繁访问。 采集的官方帐户文章信息将自动输入到本地数据库中,并可以通过本地搜索进行查看。
您可以先观看简短的视频教程,这更易于理解。步骤1:开设官方帐户
打开微信计算机版本并登录。如果尚未下载微信,请单击我进行下载。登录微信后,打开需要的采集官方账号。在这里,以正式帐户邀请客人,然后点击进入。官方帐户,然后单击右上角的三个点
第2步:进入历史消息界面
打开上图所示的界面后,单击右上角的三个点,然后在下图所示的界面中单击查看历史记录消息
如果单击上图中的历史消息界面,则会提示“请打开微信客户端上的链接”,然后打开PC端微信设置-常规设置,系统默认浏览器将用于打开网页,然后取消选中它。
第3步:开始抓取文章
然后我们在软件编号的采集界面中,单击开始采集按钮(单击后,360和其他安全软件可能会显示阻止提示,请务必在第一次使用时单击允许。使用它,还可能会提示您安装证书。请务必同时单击“允许”
等待按钮名称变为监视状态,然后刷新官方帐户历史记录消息界面
注意是要刷新官方帐户历史记录消息界面,例如下面的第二张图片,其他任何界面都无法使用
第4步:输入文章抓取
刷新后,软件将自动采集历史记录文章。建议将加载间隔设置为10秒。等待采集完成后再导出文章或浏览,如果刷新后没有自动采集历史记录文章,请参考此文章解决:“在采集内部”自动抓取参数错误:监视获取cookie超时或刷新历史记录消息界面无响应
特别注意:
1.等待按钮名称更改为监视,然后刷新历史记录界面;2.是刷新历史消息界面,而不是刷新文章内容页面,请不要出错;3.采集在此过程中,无需刷新历史消息界面,只需刷新一次;
汇总:自动采集资源网文章源码 V1.0.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-01-08 09:02
Auto采集资源网络文章源代码V1.0.0
//自动采集流行的QQ娱乐网络文章无需手动操作
///现有的采集网站:小岛娱乐网115资源网善恶资源网爱Q生活网爱采集资源网QQ皇家馆流氓资源网小黑资源网
//网站标题关键词请转到文件:index.php article.php使用编辑器修改相关的文章
//伪静态:
Apache重写:
-----------------------------------
RewriteEngine开启
RewriteBase /
RewriteRule ^ page _(\ d +)\。html $?page = $ 1
RewriteRule ^ cid _(\ d +)\。html $?cid = $ 1
RewriteRule ^ cid _(\ d +)_(\ d +)\。html $?cid = $ 1&page = $ 2
RewriteRule ^ article _(\ d +)\。html $ article.php?id = $ 1
-----------------------------------
Nginx重写:
-----------------------------------
重写^ / page _(\ d +)\。html $ /?page = $ 1;
重写^ / cid _(\ d +)\。html $ /?cid = $ 1;
重写^ / cid _(\ d +)_(\ d +)\。html $ /?cid = $ 1&page = $ 2;
重写^ / article _(\ d +)\。html $ /article.php?id=$1;
-----------------------------------
源代码下载:
您好:此帖子收录隐藏内容〜请在回复以下帖子后检查!!
Panda于8月之前最后一次编辑,原因:更新下载
TAGS PHP Boutique自动采集 查看全部
汇总:自动采集资源网文章源码 V1.0.0
Auto采集资源网络文章源代码V1.0.0
//自动采集流行的QQ娱乐网络文章无需手动操作
///现有的采集网站:小岛娱乐网115资源网善恶资源网爱Q生活网爱采集资源网QQ皇家馆流氓资源网小黑资源网
//网站标题关键词请转到文件:index.php article.php使用编辑器修改相关的文章
//伪静态:
Apache重写:
-----------------------------------
RewriteEngine开启
RewriteBase /
RewriteRule ^ page _(\ d +)\。html $?page = $ 1
RewriteRule ^ cid _(\ d +)\。html $?cid = $ 1
RewriteRule ^ cid _(\ d +)_(\ d +)\。html $?cid = $ 1&page = $ 2
RewriteRule ^ article _(\ d +)\。html $ article.php?id = $ 1
-----------------------------------
Nginx重写:
-----------------------------------
重写^ / page _(\ d +)\。html $ /?page = $ 1;
重写^ / cid _(\ d +)\。html $ /?cid = $ 1;
重写^ / cid _(\ d +)_(\ d +)\。html $ /?cid = $ 1&page = $ 2;
重写^ / article _(\ d +)\。html $ /article.php?id=$1;
-----------------------------------
源代码下载:
您好:此帖子收录隐藏内容〜请在回复以下帖子后检查!!
Panda于8月之前最后一次编辑,原因:更新下载
TAGS PHP Boutique自动采集
直观:八种知名采集软件与站群软件的功能对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-11-15 09:01
1、优采云采集器
此优采云是采集器中的旧软件。当前,在中国,许多主流和非主流网站软件都在使用采集软件。蒋平中在早期使用它,但在网站中并未正式使用它。 Ju说,cms或phpwind周围的一些网站管理员都在使用它,因为论坛或网站在早期没有内容,因此操作起来确实不容易。但是,蒋平中告诉您,即使采集不能仅停留在采集上,也最好使用随机采集部分。最好有时间吸引原创的几只蜘蛛,否则全部采集的重量都很难增加。
优采云的特征:
1、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
2、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的存储和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据。
2、 优采云采集器
优采云采集器是基于网络的网站和论坛数据采集软件!包括论坛注册商,采集维护王和采集大动作三个程序,可以支持每个主流文章系统和内容采集论坛系统的发布管理。 优采云采集器由姜平中使用。一般来说,操作并不困难,但是规则仍然有些麻烦。您可以联系Chu 优采云定制付款规则,哈哈。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,可以轻松实现采集内容中采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站的所有帖子和论坛都可以进入自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名靠前的帖子以及增加帖子查看者的数量等!支持Discuz,5D6D,PHPWind,DVbbs,BBS 优采云采集器是一组专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,您可以轻松地采集内容的采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站和论坛的所有帖子都可以转到您自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名最高的帖子以及增加帖子查看者数量等!支持数十个主流论坛程序,例如Discuz,5D6D,PHPWind,DVbbs,BBSXP,PBDigg,bbsMax,bbsgood等。
3、夏克站群软件
夏克站群发动机是用于全自动维护和车站建设的工具。它可以根据关键词采集 文章自动维护和构建工作站,并且可以自动维护和构建工作站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。姜平中告诉您:Xia Ke 站群是中国制造的最早的站群软件之一,他的前身是Xia Ke SEO软件,哈哈。
夏克站群引擎在中国一直很出名,但是官方的夏克站群似乎降低了百度搜索引擎的功能。官方声明如下:
8月15日上午,我(小霞)在清晨接到了计算机室的电话,说我的服务器受到了很多DDOS攻击,并且已断开连接。然后,我上线并立即与服务提供商进行了沟通。服务器(上海Shanghai宝路电脑室)受到了1G多业务DDOS攻击。电脑室已拔出电源,不再允许其上网。此后不久,该服务器(由北京互联公司托管)也遭到了大流量攻击。电脑室已拔下电源。在中午12点左右,三个授权服务器s1,s2和s3再次受到攻击,所有的服务器均已从计算机房中拔出。到目前为止,夏克的所有5台服务器都瘫痪了。
由于所有服务器均已拔出,并且所有Xiake产品均已通过在线验证授权,因此服务器不在线,这意味着无法使用客户端软件,因此我尽快在广州机房租用了另一台服务器。 。但是由于数据在北京机房,经过与机房的各种协商,我最终同意为我复制数据(我强烈鄙视北京XXXX公司),最后在下午恢复了授权服务器,但是美好的时光并没有持续多久,只有不到一半的时间。当他在小组中时,他被攻击到计算机室再次拔下电话线。后来,在该组客户的建议下,他从广东一家公司购买了一台抗DDOS服务器(每月租金2000 ...出血)。但是,只有一段时间了。我今天(8月16日)起床,客户告诉我我无法登录该软件。我又被打倒了。我再次询问客户意见。有人建议我使用CDN来解决它。最后,我于17日与我联系。一家国内的CDN服务提供商购买了一套解决方案来成功解决ddos问题(CDN的原理是在附近分发内容,以使攻击者无法找到服务器IP,而只能攻击CDN节点。 CDN节点很多,带宽非常高。基本上不可能全部杀死它们),但是因为v1 v2版本不是基于CDN网络设计的,所以需要升级,所以我熬夜并匆匆忙忙为客户提供两个升级补丁。截至本文发行时,大多数客户已成功升级了该软件并正常使用。尚未升级的客户,请尽快与我联系以请求补丁。
4、Black Panther 站群软件
Black Panther 站群软件是新推出的站群系统,它是最适合网站管理员习惯的智能站群软件,具有业内最先进的人工智能技术,并且具有快速的网站建设和全自动功能采集,版本文章,自动流量统计信息,查询网站 收录,查询外部链接以及许多其他对网站管理员有用的功能,可100%提高网站建设效率,并为网站管理员带来更快,更稳定的流量。蒋平中认为:该Panther 站群是站群软件中的新秀,目前正在与Xia Ke 站群竞争。将来,它会变得更大更强大,据估计,夏克站群和鹤盼站群 Up。
Black Panther 站群软件的优点的正式介绍:
从新电台收录开始30分钟的1、:快速收录功能,用户将网站域名提交给Black Panther服务器,并且在30分钟之内可以是收录。
2、团队轮链:参与团队轮链的所有用户为您的站群提供稳定的高重量外部链接流。
3、一词构成了一个网站:只要输入网站核心关键词,就可以通过单击两次鼠标来创建全自动更新网站。
4、网站数量不受限制:此软件中的网站数量没有限制,您可以快速创建无数网站并构建自己的超级站群。
5、全自动更新:只要创建了网站,该软件就会完全自动采集,全自动发布文章(智能原创,智能控制发布频率和数量)。解放双手。
6、支持主流cms 网站内容管理系统:Dede cms(5.5- 5.7),WordPress(3.01- 3.1),Zblog (1.8),Sd cms(1.3),旧的Y 文章管理系统(3.0)
7、站群智能轮链:使用世界上最先进的搜索引擎算法,它将自动在网站和网站之间建立链接,以快速增加所有网站的访问量。
8、文章内容多样化:软件自动发布的文章内容包括图片,视频,pdf,word文档,这使搜索引擎更喜欢它们,尤其是pdf和word文档具有自然的pr值。 4,该软件会自动在文章内容,pdf和word文档中插入内部链接,以快速增加网站的重量和流量。
9、人工智能算法:该软件使用世界领先的joone人工智能算法来智能地调整网站内容类型,文章 网站流量,收录,排名,权重和其他信息。 k17]度,释放文章频率,长尾巴关键词排名,以达到seo专家手动优化的效果。
5、延煌站群软件
Yanhuang 站群软件是.net2.0 + Mssql2005的站群系统,支持自动采集,原创处理,自动更新,自动维护,易于访问大量IP ,提高效率!强大的链轮功能,多种原创方法! Yanhuang 站群是一个站群系统,支持自动维护和站点构建工具,它可以基于关键词采集 文章自动生成,并且可以全自动维护和建立网站!这是一个聪明的净利润工具!自动采集,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!延煌站群软件的姜平中曾使用过该软件,但它是按年付费的,需要在第二年进行更新,并且是.net + mssql2005。蒋平中认为,这个系统对于许多新手网站管理员来说不是很好。不方便,因为您需要安装mssql,但是如果您购买他们的产品,请联系客户服务应能够解决它。
官方网站没有太多相关的介绍。今天,蒋平中去了延煌站群购买了博客SEO小组软件。等待了很长时间后,客户没有回复。考虑到国庆节每个人都很忙,我们仍然在忙。如果您加班,我在这里不做评论。因为有时我太忙了,而且我没有来回复客户,所以我不怪这是炎黄。让我们支持和鼓励!
6、批次站群软件
Qi 站群软件是一组不受限制的机器,站点数量不受限制,可协助各种大型cms 文章系统和主流博客实现使用关键字自动采集和自动更新站群系统,其核心价值是根据SEO优化规则自动建立网站,而没有任何技术门槛,并为客户创造网站价值。它可以模拟手动更新网站的过程,自动获取内容,自动处理内容,并自动发布内容,从而消除了手动更新网站的麻烦,实现了一键启动和启动的目的。通过站群进行无忧维护,您可以轻松构建多个十、甚至数百个网站!姜平中没有用过这个系统,下面还介绍一个与此系统类似的系统,例如:伊涛站群管理系统等。
Baqi 站群系统的核心价值是:操作简单,快速赚钱,流量猛增以及全自动(安全,稳定,便捷)
所有版本的站群批处理管理系统,支持无限网站,傻瓜式操作,无需编写采集规则,无限采集新数据,无限数据发布,永久免费升级,任何计算机(包括vps)使用挂机发布采集,可以同时使用多个帐户和多个帐户,无需绑定机器硬件,无需购买加密狗,不受空间提供商的限制,基本上没有空间cpu和内存(适用于更多外国Space),支持将数据发布到各种流行的cms(将尽快添加当前不可用的数据),并且独立的网站程序也可以自定义发布界面。
批处理站群软件支持的功能:无限增加域名,中文站群 采集,英文站群 采集,指定的URL 采集,自定义生成原创 文章,长尾部关键词采集,图片采集,SEO链轮功能,文章自动添加内部链功能,随机提取内容作为标题,交换内容段落,随机插入指定的内容,网站定期发布文章,自动内容伪原创,对挂钩采集释放的自动监视,首页列中的静态页面的自动更新网站等。
7、织梦采集夏
织梦采集 Xia是织梦cms的采集系统。首选可以是通过关键词,RSS和指定站点定时定量采集伪原创 SEO插件,专业站群系统/ 站群软件。我姜平中目前正在使用此系统。一般而言,该系统具有很高的成本效益,并且具有非常实用的功能。如果您使用织梦建立站台,那么采集英雄将不容错过。
1一键安装,全自动采集
织梦采集夏的安装非常简单方便。只需一分钟即可立即开始采集,并结合了简单,强大,灵活和开放源码的dede cms程序,新手可以很快上手,我们还提供专门的客户服务来提供技术支持对于商业客户。
2个单词采集,无需编写采集规则
与传统采集模式的不同之处在于织梦采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以传递[ 采集 关键词采集不在一个或多个指定的采集网站上执行,这降低了采集网站被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3RSS 采集,输入内容为采集的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以浏览RSS 采集,并且可以通过输入RSS地址轻松地采集到达目标网站内容,而无需输入编写采集规则,方便和简单。
4定位采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5种伪原创和提高收录率和排名的优化方法
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,提高搜索引擎收录,网站权重和关键词排名。
6个全自动插件采集,无需人工干预
织梦采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,并将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进入伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。
7手动发布文章也可以是伪原创和搜索优化处理
织梦采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词姜平中认为,织梦采集 Xia是织梦的必要插件。它将自动添加指定的链接和其他功能。
8 采集伪原创 SEO定期且定量地更新
触发插件的采集有两种方法,一种是向页面添加代码以通过用户访问来触发采集更新,另一种是我们提供的远程触发采集服务商业用户。没有人可以访问新站点。无需手动干预,就可以定期且定量地更新它。[p15]
9定期定量更新待处理的手稿
即使您的数据库文章中有成千上万的文章,织梦采集都可以在设置的时间段内每天根据您的需要进行定期和定量的审查和更新。
10个织梦采集个节点,定期采集伪原创个SEO更新
绑定织梦采集节点的功能,以便织梦cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
8、易淘站群软件
Easy Tao 站群管理系统是仅通过输入关键词到最新相关内容的采集的集合,并且自动将SEO发布到指定的网站多任务站群管理系统,该系统可以进行24小时的不间断自动维护网站。 Easy Tao 站群管理软件可以根据集合关键词自动抓取主要搜索引擎的相关搜索词和相关长尾词,然后根据派生的单词抓取大量最新数据,从而完全放弃普通采集可以定制软件所需的繁琐规则,以实现一键发布采集。 Easy Tao 站群管理软件不需要绑定到计算机或IP。 网站的数量没有限制。它可以挂机24小时进行维护采集,使网站管理员可以轻松管理数百个网站。该软件独特的内容抓取引擎可以快速,准确地抓取Internet上的最新内容。借助内置的文章伪原创功能,它可以大大提高网站的收录,并为网站站长带来更多流量!
易涛站群系统软件具有cms + SEO技术+ 关键词分析+蜘蛛采集器+网页智能信息捕获技术,目前支持织梦(DEDE cms),Empire(Empire [k4) ]),Wordpress,Z-blog,Dongyi,5U cms,discuz,phpwind等系统自动导入数据并自动生成静态页面。该软件会自动采集并根据预设信息进行发布,并每天自动维护更新的内容。网站站长流量获取的出色工具。
江平中介绍了Yitao 站群管理系统的8个功能:
1.无限站点建立Easy Tao 站群系统的宗旨是为用户提供最实用的软件,无限数量的要建立站点,以创建真实的站群软件;不论购买哪个版本,都没有限制网站程序和域名的数量不受计算机的约束,这与其他类似的站群管理软件有很大的区别
2.智能蜘蛛引擎Yitao 站群是由系统软件创建的智能蜘蛛引擎,只需输入几个相关的关键词就可以自动得出数千个长尾巴关键词,然后将这些长尾巴作为目标末尾关键词自动从Internet 采集转到最新的文章,图片和视频。无需任何采集规则,它就可以完全实现一键式抓取任务,并且是一套站群 采集软件,真正易于操作和功能。
3.SEO伪原创和同义词库管理Yitao 站群系统完全支持标题和内容的同义词和反义词的替换,分词重构,禁止词库屏蔽,内容段落改组和重新排列,以及文章将内容随机插入图片,视频等中,可以很好地实现标题和内容伪原创;不管您建立多少,数十甚至数百个站点,都不必因为采集 文章的重复性而担心收录搜索引擎。
4.整个站点的全自动更新设置关键词和抓取频率后,站群管理系统将自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站]在该列中,可以轻松实现一键式采集更新,同时进行多站点维护,并真正实现无人监视和无人操作,从而使站点的构建和维护变得如此简单
5.无限循环挂机易涛站群系统管理系统的最高版本可以支持365天无限循环挂机采集维护所有网站,设置相关参数后,软件将从第一个,全自动采集的维护已完成,并转发至下一个站点更新,该更新已周期性执行,可以轻松管理数百个站点,真正实现全自动站群的维护和管理,并完全腾出手来网站管理员的身份。
6.超级链轮模块链接轮(LinkWheel)是新提出的国外链接构建策略或链接构建模型。与传统的链接相比,链接轮策略更加关注链接和组站点的质量。体重的培养可以更好地发挥链接在提高网站排名中的作用。 Easy Tao 站群可以完美地实现多站循环链接和混合链轮,从而使网站排名和收录更加轻松,更加安全!
7.原创 文章生成易道站群管理系统可以使用主语,谓语,宾语,定语,补语,状语,谓语,名词,动词,形容词,介词,量词,数字,助词,连接词,代词,感叹词等词形成句子和段落,实现了实词原创 文章的自动生成,从而确保了文章的原创性质。
8.指定域名方向采集易道站群管理系统可以自定义采集所需的目标站点文章,并且可以通过输入目标URL 文章来实现方向网站。 ] 采集没有规则,操作更方便,内容更准确! 查看全部
八个著名的采集软件和站群软件之间的功能比较
1、优采云采集器
此优采云是采集器中的旧软件。当前,在中国,许多主流和非主流网站软件都在使用采集软件。蒋平中在早期使用它,但在网站中并未正式使用它。 Ju说,cms或phpwind周围的一些网站管理员都在使用它,因为论坛或网站在早期没有内容,因此操作起来确实不容易。但是,蒋平中告诉您,即使采集不能仅停留在采集上,也最好使用随机采集部分。最好有时间吸引原创的几只蜘蛛,否则全部采集的重量都很难增加。
优采云的特征:
1、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
2、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的存储和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据。
2、 优采云采集器
优采云采集器是基于网络的网站和论坛数据采集软件!包括论坛注册商,采集维护王和采集大动作三个程序,可以支持每个主流文章系统和内容采集论坛系统的发布管理。 优采云采集器由姜平中使用。一般来说,操作并不困难,但是规则仍然有些麻烦。您可以联系Chu 优采云定制付款规则,哈哈。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,可以轻松实现采集内容中采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站的所有帖子和论坛都可以进入自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名靠前的帖子以及增加帖子查看者的数量等!支持Discuz,5D6D,PHPWind,DVbbs,BBS 优采云采集器是一组专业的网站内容采集软件,支持各种论坛帖子和回复采集,网站和博客文章内容捕获,通过相关配置,您可以轻松地采集内容的采集 80%供您自己使用。根据网站建设计划之间的差异,优采云采集器子论坛采集器,cms 采集器和博客采集器三类,它们支持近40个主流网站建设计划和数百个版本数据采集和发布任务,支持图像本地化,支持网站登录采集,页面抓取,完全模拟的手动登录发布,24小时挂机操作,自动过滤重复发布,在断点处恢复,快速,安全,稳定的软件操作!论坛采集器还支持论坛成员的无限注册,自动增加帖子查看者,自动排名最高的帖子等。优采云采集器内置的超级SEO伪原创模块,同义词替换,英汉翻译,简体和繁体翻译,使您的采集功能更强大!
优采云采集器当前分为三个系列,即论坛采集器系列,cms 采集器系列和博客采集器系列,它们基本涵盖了一些主流网站建设程序,这些程序非常符合各种用户的需求。
优采云论坛采集器当前包括四套软件:论坛注册商,论坛维护王,论坛移动和同步更新王。通过使用该软件,您可以增加论坛的注册成员数。您可以呼吸采集其他人网站和论坛的所有帖子都可以转到您自己的论坛,您可以每天自动挂断采集最新的帖子文章并执行文章伪原创处理,以及自动维护论坛中的帖子数量,自动排名最高的帖子以及增加帖子查看者数量等!支持数十个主流论坛程序,例如Discuz,5D6D,PHPWind,DVbbs,BBSXP,PBDigg,bbsMax,bbsgood等。
3、夏克站群软件
夏克站群发动机是用于全自动维护和车站建设的工具。它可以根据关键词采集 文章自动维护和构建工作站,并且可以自动维护和构建工作站!这是一个智能的在线赚钱工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。姜平中告诉您:Xia Ke 站群是中国制造的最早的站群软件之一,他的前身是Xia Ke SEO软件,哈哈。
夏克站群引擎在中国一直很出名,但是官方的夏克站群似乎降低了百度搜索引擎的功能。官方声明如下:
8月15日上午,我(小霞)在清晨接到了计算机室的电话,说我的服务器受到了很多DDOS攻击,并且已断开连接。然后,我上线并立即与服务提供商进行了沟通。服务器(上海Shanghai宝路电脑室)受到了1G多业务DDOS攻击。电脑室已拔出电源,不再允许其上网。此后不久,该服务器(由北京互联公司托管)也遭到了大流量攻击。电脑室已拔下电源。在中午12点左右,三个授权服务器s1,s2和s3再次受到攻击,所有的服务器均已从计算机房中拔出。到目前为止,夏克的所有5台服务器都瘫痪了。
由于所有服务器均已拔出,并且所有Xiake产品均已通过在线验证授权,因此服务器不在线,这意味着无法使用客户端软件,因此我尽快在广州机房租用了另一台服务器。 。但是由于数据在北京机房,经过与机房的各种协商,我最终同意为我复制数据(我强烈鄙视北京XXXX公司),最后在下午恢复了授权服务器,但是美好的时光并没有持续多久,只有不到一半的时间。当他在小组中时,他被攻击到计算机室再次拔下电话线。后来,在该组客户的建议下,他从广东一家公司购买了一台抗DDOS服务器(每月租金2000 ...出血)。但是,只有一段时间了。我今天(8月16日)起床,客户告诉我我无法登录该软件。我又被打倒了。我再次询问客户意见。有人建议我使用CDN来解决它。最后,我于17日与我联系。一家国内的CDN服务提供商购买了一套解决方案来成功解决ddos问题(CDN的原理是在附近分发内容,以使攻击者无法找到服务器IP,而只能攻击CDN节点。 CDN节点很多,带宽非常高。基本上不可能全部杀死它们),但是因为v1 v2版本不是基于CDN网络设计的,所以需要升级,所以我熬夜并匆匆忙忙为客户提供两个升级补丁。截至本文发行时,大多数客户已成功升级了该软件并正常使用。尚未升级的客户,请尽快与我联系以请求补丁。
4、Black Panther 站群软件
Black Panther 站群软件是新推出的站群系统,它是最适合网站管理员习惯的智能站群软件,具有业内最先进的人工智能技术,并且具有快速的网站建设和全自动功能采集,版本文章,自动流量统计信息,查询网站 收录,查询外部链接以及许多其他对网站管理员有用的功能,可100%提高网站建设效率,并为网站管理员带来更快,更稳定的流量。蒋平中认为:该Panther 站群是站群软件中的新秀,目前正在与Xia Ke 站群竞争。将来,它会变得更大更强大,据估计,夏克站群和鹤盼站群 Up。
Black Panther 站群软件的优点的正式介绍:
从新电台收录开始30分钟的1、:快速收录功能,用户将网站域名提交给Black Panther服务器,并且在30分钟之内可以是收录。
2、团队轮链:参与团队轮链的所有用户为您的站群提供稳定的高重量外部链接流。
3、一词构成了一个网站:只要输入网站核心关键词,就可以通过单击两次鼠标来创建全自动更新网站。
4、网站数量不受限制:此软件中的网站数量没有限制,您可以快速创建无数网站并构建自己的超级站群。
5、全自动更新:只要创建了网站,该软件就会完全自动采集,全自动发布文章(智能原创,智能控制发布频率和数量)。解放双手。
6、支持主流cms 网站内容管理系统:Dede cms(5.5- 5.7),WordPress(3.01- 3.1),Zblog (1.8),Sd cms(1.3),旧的Y 文章管理系统(3.0)
7、站群智能轮链:使用世界上最先进的搜索引擎算法,它将自动在网站和网站之间建立链接,以快速增加所有网站的访问量。
8、文章内容多样化:软件自动发布的文章内容包括图片,视频,pdf,word文档,这使搜索引擎更喜欢它们,尤其是pdf和word文档具有自然的pr值。 4,该软件会自动在文章内容,pdf和word文档中插入内部链接,以快速增加网站的重量和流量。
9、人工智能算法:该软件使用世界领先的joone人工智能算法来智能地调整网站内容类型,文章 网站流量,收录,排名,权重和其他信息。 k17]度,释放文章频率,长尾巴关键词排名,以达到seo专家手动优化的效果。
5、延煌站群软件
Yanhuang 站群软件是.net2.0 + Mssql2005的站群系统,支持自动采集,原创处理,自动更新,自动维护,易于访问大量IP ,提高效率!强大的链轮功能,多种原创方法! Yanhuang 站群是一个站群系统,支持自动维护和站点构建工具,它可以基于关键词采集 文章自动生成,并且可以全自动维护和建立网站!这是一个聪明的净利润工具!自动采集,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!延煌站群软件的姜平中曾使用过该软件,但它是按年付费的,需要在第二年进行更新,并且是.net + mssql2005。蒋平中认为,这个系统对于许多新手网站管理员来说不是很好。不方便,因为您需要安装mssql,但是如果您购买他们的产品,请联系客户服务应能够解决它。
官方网站没有太多相关的介绍。今天,蒋平中去了延煌站群购买了博客SEO小组软件。等待了很长时间后,客户没有回复。考虑到国庆节每个人都很忙,我们仍然在忙。如果您加班,我在这里不做评论。因为有时我太忙了,而且我没有来回复客户,所以我不怪这是炎黄。让我们支持和鼓励!
6、批次站群软件
Qi 站群软件是一组不受限制的机器,站点数量不受限制,可协助各种大型cms 文章系统和主流博客实现使用关键字自动采集和自动更新站群系统,其核心价值是根据SEO优化规则自动建立网站,而没有任何技术门槛,并为客户创造网站价值。它可以模拟手动更新网站的过程,自动获取内容,自动处理内容,并自动发布内容,从而消除了手动更新网站的麻烦,实现了一键启动和启动的目的。通过站群进行无忧维护,您可以轻松构建多个十、甚至数百个网站!姜平中没有用过这个系统,下面还介绍一个与此系统类似的系统,例如:伊涛站群管理系统等。
Baqi 站群系统的核心价值是:操作简单,快速赚钱,流量猛增以及全自动(安全,稳定,便捷)
所有版本的站群批处理管理系统,支持无限网站,傻瓜式操作,无需编写采集规则,无限采集新数据,无限数据发布,永久免费升级,任何计算机(包括vps)使用挂机发布采集,可以同时使用多个帐户和多个帐户,无需绑定机器硬件,无需购买加密狗,不受空间提供商的限制,基本上没有空间cpu和内存(适用于更多外国Space),支持将数据发布到各种流行的cms(将尽快添加当前不可用的数据),并且独立的网站程序也可以自定义发布界面。
批处理站群软件支持的功能:无限增加域名,中文站群 采集,英文站群 采集,指定的URL 采集,自定义生成原创 文章,长尾部关键词采集,图片采集,SEO链轮功能,文章自动添加内部链功能,随机提取内容作为标题,交换内容段落,随机插入指定的内容,网站定期发布文章,自动内容伪原创,对挂钩采集释放的自动监视,首页列中的静态页面的自动更新网站等。
7、织梦采集夏
织梦采集 Xia是织梦cms的采集系统。首选可以是通过关键词,RSS和指定站点定时定量采集伪原创 SEO插件,专业站群系统/ 站群软件。我姜平中目前正在使用此系统。一般而言,该系统具有很高的成本效益,并且具有非常实用的功能。如果您使用织梦建立站台,那么采集英雄将不容错过。
1一键安装,全自动采集
织梦采集夏的安装非常简单方便。只需一分钟即可立即开始采集,并结合了简单,强大,灵活和开放源码的dede cms程序,新手可以很快上手,我们还提供专门的客户服务来提供技术支持对于商业客户。
2个单词采集,无需编写采集规则
与传统采集模式的不同之处在于织梦采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以传递[ 采集 关键词采集不在一个或多个指定的采集网站上执行,这降低了采集网站被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3RSS 采集,输入内容为采集的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以浏览RSS 采集,并且可以通过输入RSS地址轻松地采集到达目标网站内容,而无需输入编写采集规则,方便和简单。
4定位采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5种伪原创和提高收录率和排名的优化方法
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,提高搜索引擎收录,网站权重和关键词排名。
6个全自动插件采集,无需人工干预
织梦采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,并将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进入伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。
7手动发布文章也可以是伪原创和搜索优化处理
织梦采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词姜平中认为,织梦采集 Xia是织梦的必要插件。它将自动添加指定的链接和其他功能。
8 采集伪原创 SEO定期且定量地更新
触发插件的采集有两种方法,一种是向页面添加代码以通过用户访问来触发采集更新,另一种是我们提供的远程触发采集服务商业用户。没有人可以访问新站点。无需手动干预,就可以定期且定量地更新它。[p15]
9定期定量更新待处理的手稿
即使您的数据库文章中有成千上万的文章,织梦采集都可以在设置的时间段内每天根据您的需要进行定期和定量的审查和更新。
10个织梦采集个节点,定期采集伪原创个SEO更新
绑定织梦采集节点的功能,以便织梦cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
8、易淘站群软件
Easy Tao 站群管理系统是仅通过输入关键词到最新相关内容的采集的集合,并且自动将SEO发布到指定的网站多任务站群管理系统,该系统可以进行24小时的不间断自动维护网站。 Easy Tao 站群管理软件可以根据集合关键词自动抓取主要搜索引擎的相关搜索词和相关长尾词,然后根据派生的单词抓取大量最新数据,从而完全放弃普通采集可以定制软件所需的繁琐规则,以实现一键发布采集。 Easy Tao 站群管理软件不需要绑定到计算机或IP。 网站的数量没有限制。它可以挂机24小时进行维护采集,使网站管理员可以轻松管理数百个网站。该软件独特的内容抓取引擎可以快速,准确地抓取Internet上的最新内容。借助内置的文章伪原创功能,它可以大大提高网站的收录,并为网站站长带来更多流量!
易涛站群系统软件具有cms + SEO技术+ 关键词分析+蜘蛛采集器+网页智能信息捕获技术,目前支持织梦(DEDE cms),Empire(Empire [k4) ]),Wordpress,Z-blog,Dongyi,5U cms,discuz,phpwind等系统自动导入数据并自动生成静态页面。该软件会自动采集并根据预设信息进行发布,并每天自动维护更新的内容。网站站长流量获取的出色工具。
江平中介绍了Yitao 站群管理系统的8个功能:
1.无限站点建立Easy Tao 站群系统的宗旨是为用户提供最实用的软件,无限数量的要建立站点,以创建真实的站群软件;不论购买哪个版本,都没有限制网站程序和域名的数量不受计算机的约束,这与其他类似的站群管理软件有很大的区别
2.智能蜘蛛引擎Yitao 站群是由系统软件创建的智能蜘蛛引擎,只需输入几个相关的关键词就可以自动得出数千个长尾巴关键词,然后将这些长尾巴作为目标末尾关键词自动从Internet 采集转到最新的文章,图片和视频。无需任何采集规则,它就可以完全实现一键式抓取任务,并且是一套站群 采集软件,真正易于操作和功能。
3.SEO伪原创和同义词库管理Yitao 站群系统完全支持标题和内容的同义词和反义词的替换,分词重构,禁止词库屏蔽,内容段落改组和重新排列,以及文章将内容随机插入图片,视频等中,可以很好地实现标题和内容伪原创;不管您建立多少,数十甚至数百个站点,都不必因为采集 文章的重复性而担心收录搜索引擎。
4.整个站点的全自动更新设置关键词和抓取频率后,站群管理系统将自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站]在该列中,可以轻松实现一键式采集更新,同时进行多站点维护,并真正实现无人监视和无人操作,从而使站点的构建和维护变得如此简单
5.无限循环挂机易涛站群系统管理系统的最高版本可以支持365天无限循环挂机采集维护所有网站,设置相关参数后,软件将从第一个,全自动采集的维护已完成,并转发至下一个站点更新,该更新已周期性执行,可以轻松管理数百个站点,真正实现全自动站群的维护和管理,并完全腾出手来网站管理员的身份。
6.超级链轮模块链接轮(LinkWheel)是新提出的国外链接构建策略或链接构建模型。与传统的链接相比,链接轮策略更加关注链接和组站点的质量。体重的培养可以更好地发挥链接在提高网站排名中的作用。 Easy Tao 站群可以完美地实现多站循环链接和混合链轮,从而使网站排名和收录更加轻松,更加安全!
7.原创 文章生成易道站群管理系统可以使用主语,谓语,宾语,定语,补语,状语,谓语,名词,动词,形容词,介词,量词,数字,助词,连接词,代词,感叹词等词形成句子和段落,实现了实词原创 文章的自动生成,从而确保了文章的原创性质。
8.指定域名方向采集易道站群管理系统可以自定义采集所需的目标站点文章,并且可以通过输入目标URL 文章来实现方向网站。 ] 采集没有规则,操作更方便,内容更准确!
最新版:autopost 3.8wordpress自动采集插件wp-autopost
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-09-02 03:03
摘要: 当前所有版本的WordPress均可正常运行,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具! WP-AutoBlog是一个新开发的插件,完全支持PHP7.3更快,更稳定,新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于获得高质量原创 文章完全支持所有主流对象存储服务市场,秦牛云,阿里云OSS等. 本文的URL : ,本文标题: wordpress auto 采集插件wp-autopost-pro 3.7.8最新版本无限版
autopost 3.8
当前所有版本的WordPress都运行良好,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
如果您是新手,请查看采集教程: / zh / manual /
此版本与官方功能没有区别; 采集插入适用对象
1. 新建的WordPress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容会自动采集并自动发布;
3. 时间采集,手动采集发布或保存到草稿;
4,css样式规则,可以更精确地显示采集需要的内容.
5,伪原创使用翻译和代理IP进行采集,保存cookie记录;
6,采集内容可以自定义到列
WP-AutoBlog是新开发的插件(将不再更新和维护原创的WP-AutoPost),完全支持PHP7.3,更快,更稳定,新的体系结构和设计,采集设置更多全面而灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于访问高质量原创 文章完全支持所有主流对象存储服务在市场上,秦牛云,阿里云OSS等采集微信官方帐户,头条帐户等自媒体内容,因为百度没有收录官方帐户,头条文章等,您可以轻松获得高质量的“ 原创” 文章,添加百度收录的数量和网站的权重可以是采集任何网站的内容,采集信息一目了然,采集可以您可以通过简单的设置从任何网站内容中提取内容,并且可以将多个采集任务设置为同时进行,可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上一个测试采集的时间,下一个测试采集的估计时间,最近的采集 文章和采集 k1]更新了文章号和其他信息,以便于查看和管理. 文章管理功能方便查询,搜索和删除采集 文章,改进后的算法从根本上消除了与采集相同的重复文章,并且log函数记录异常情况并抓取采集错误,检查设置错误以进行修复很方便.
激活任务后,它将自动更新采集,而无需人工干预. 激活任务后,它将定期检查是否有新的文章更新,检查是否重复文章,以及导入更新文章. 它是全自动的,无需人工干预. 触发采集更新有两种方法,一种是在页面中添加代码以通过用户访问来触发采集更新(在异步背景下,不影响用户体验,不影响网站的效率) ),则可以使用Cron计划任务计时触发器采集更新任务方向采集,支持通配符匹配,或CSS选择器准确采集任何内容,支持采集多级文章列表,支持[ k1]文本分页内容,支持采集多级文本内容支持市场上所有主流对象存储服务,包括秦牛云,阿里云OSS,腾讯云COS,百度云BOS,优派云,亚马逊AWS S3,谷歌云存储,可用于转换文章中的图片,并且附件会自动上传到云对象存储服务,从而节省带宽和空间,并提高网站访问速度. 只需配置相关信息,然后即可将其自动上传. 您还可以通过WordPress背景直接查看或管理已上传到云对象存储的文件. 图片和文件.
源代码下载:
其他人也看了↓↓↓
文章付费阅读系统(包括applet)v5.0 build20200617下载
DataX Web分布式数据同步工具v2.1.2下载
Webmagic垂直采集器v0.7.2下载
JetLinks开源物联网平台v1.3.0下载
墨中问题银行系统v3.2.0下载
本文的URL : ,本文标题: wordpress自动采集插件wp-autopost-pro 3.7.8最新版本,没有任何限制 查看全部
autopost 3.8 wordpress自动采集插件wp-autopost
摘要: 当前所有版本的WordPress均可正常运行,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具! WP-AutoBlog是一个新开发的插件,完全支持PHP7.3更快,更稳定,新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于获得高质量原创 文章完全支持所有主流对象存储服务市场,秦牛云,阿里云OSS等. 本文的URL : ,本文标题: wordpress auto 采集插件wp-autopost-pro 3.7.8最新版本无限版
autopost 3.8
当前所有版本的WordPress都运行良好,请随时使用它们. WP-AutoPost-Pro是一个出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
如果您是新手,请查看采集教程: / zh / manual /
此版本与官方功能没有区别; 采集插入适用对象
1. 新建的WordPress网站的内容相对较小,希望尽快拥有更丰富的内容;
2. 热门内容会自动采集并自动发布;
3. 时间采集,手动采集发布或保存到草稿;
4,css样式规则,可以更精确地显示采集需要的内容.
5,伪原创使用翻译和代理IP进行采集,保存cookie记录;
6,采集内容可以自定义到列
WP-AutoBlog是新开发的插件(将不再更新和维护原创的WP-AutoPost),完全支持PHP7.3,更快,更稳定,新的体系结构和设计,采集设置更多全面而灵活;支持多级文章列表,多级文章内容采集新支持Google神经网络翻译,有道神经网络翻译,易于访问高质量原创 文章完全支持所有主流对象存储服务在市场上,秦牛云,阿里云OSS等采集微信官方帐户,头条帐户等自媒体内容,因为百度没有收录官方帐户,头条文章等,您可以轻松获得高质量的“ 原创” 文章,添加百度收录的数量和网站的权重可以是采集任何网站的内容,采集信息一目了然,采集可以您可以通过简单的设置从任何网站内容中提取内容,并且可以将多个采集任务设置为同时进行,可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上一个测试采集的时间,下一个测试采集的估计时间,最近的采集 文章和采集 k1]更新了文章号和其他信息,以便于查看和管理. 文章管理功能方便查询,搜索和删除采集 文章,改进后的算法从根本上消除了与采集相同的重复文章,并且log函数记录异常情况并抓取采集错误,检查设置错误以进行修复很方便.
激活任务后,它将自动更新采集,而无需人工干预. 激活任务后,它将定期检查是否有新的文章更新,检查是否重复文章,以及导入更新文章. 它是全自动的,无需人工干预. 触发采集更新有两种方法,一种是在页面中添加代码以通过用户访问来触发采集更新(在异步背景下,不影响用户体验,不影响网站的效率) ),则可以使用Cron计划任务计时触发器采集更新任务方向采集,支持通配符匹配,或CSS选择器准确采集任何内容,支持采集多级文章列表,支持[ k1]文本分页内容,支持采集多级文本内容支持市场上所有主流对象存储服务,包括秦牛云,阿里云OSS,腾讯云COS,百度云BOS,优派云,亚马逊AWS S3,谷歌云存储,可用于转换文章中的图片,并且附件会自动上传到云对象存储服务,从而节省带宽和空间,并提高网站访问速度. 只需配置相关信息,然后即可将其自动上传. 您还可以通过WordPress背景直接查看或管理已上传到云对象存储的文件. 图片和文件.
源代码下载:
其他人也看了↓↓↓
文章付费阅读系统(包括applet)v5.0 build20200617下载
DataX Web分布式数据同步工具v2.1.2下载
Webmagic垂直采集器v0.7.2下载
JetLinks开源物联网平台v1.3.0下载
墨中问题银行系统v3.2.0下载
本文的URL : ,本文标题: wordpress自动采集插件wp-autopost-pro 3.7.8最新版本,没有任何限制
使用php优采云采集抓取明日头条ajax的文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-29 19:04
今日头条的数据都是ajax加载显示的,按照正常的url是抓取不到数据的,需要剖析出加载出址,我们以 %E6%96%B0%E9%97%BB 为例来采集列表的文章
用谷歌浏览器打开链接,右键点击“审查”在控制台切换至network并点击XHR,这样就可以过滤图片、文件等等不必要的恳求只看页面内容的恳求
由于页面是ajax加载的,所以将页面拉至最顶部,会手动加载出更多文章,这时候控制台抓取到的链接就是我们真正须要的列表页链接:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集中创建一个任务
创建完毕点击“采集设置”,在“起始页网址”中填入里面抓取到的链接
接下来匹配内容页网址,头条的文章网址格式是数字/
点击“内容页网址”编写“匹配内容网址”规则:
(?\d+/)
这是个正则规则,意思就是把匹配的网址装进捕获组content1中,然后在下边填写[内容1]即对应里面的content1 就可获取到内容页链接
可以点击测试查看是否成功抓取到了链接
抓取成功就可以开始获取内容了
点击“获取内容”在数组列表一侧可以添加默认的数组,如标题、正文等都可以智能辨识,如需精准还可以自行编辑数组,支持正则、xpath、json等匹配内容
我们须要抓取文章的标题和正文,由于是ajax显示的所以要写规则匹配出内容,分析篇源码:,找到文章位置
标题规则:articleInfo\s*:\s*{\s*title:\s*'[内容1]',
正文规则:content\s*:\s*'[内容1]',\s*groupId
规则必须保证唯一性,不然会匹配到其他内容起来,将规则添加到数组中,获取方法选规则匹配:
规则编撰完后点击保存,点击“测试”看看疗效怎么
规则无误,抓取正常,抓取到的数据还可以发布到cms系统、直接数据库入库、保存为excel文件等,点击顶部导航条的“发布设置”即可,好了明日头条的采集到这儿就结束了,大家不妨动手试试! 查看全部
使用php优采云采集抓取明日头条ajax的文章内容
今日头条的数据都是ajax加载显示的,按照正常的url是抓取不到数据的,需要剖析出加载出址,我们以 %E6%96%B0%E9%97%BB 为例来采集列表的文章
用谷歌浏览器打开链接,右键点击“审查”在控制台切换至network并点击XHR,这样就可以过滤图片、文件等等不必要的恳求只看页面内容的恳求
由于页面是ajax加载的,所以将页面拉至最顶部,会手动加载出更多文章,这时候控制台抓取到的链接就是我们真正须要的列表页链接:
%E6%96%B0%E9%97%BB&autoload=true&count=20&cur_tab=1&from=search_tab
在优采云采集中创建一个任务
创建完毕点击“采集设置”,在“起始页网址”中填入里面抓取到的链接
接下来匹配内容页网址,头条的文章网址格式是数字/
点击“内容页网址”编写“匹配内容网址”规则:
(?\d+/)
这是个正则规则,意思就是把匹配的网址装进捕获组content1中,然后在下边填写[内容1]即对应里面的content1 就可获取到内容页链接
可以点击测试查看是否成功抓取到了链接
抓取成功就可以开始获取内容了
点击“获取内容”在数组列表一侧可以添加默认的数组,如标题、正文等都可以智能辨识,如需精准还可以自行编辑数组,支持正则、xpath、json等匹配内容
我们须要抓取文章的标题和正文,由于是ajax显示的所以要写规则匹配出内容,分析篇源码:,找到文章位置
标题规则:articleInfo\s*:\s*{\s*title:\s*'[内容1]',
正文规则:content\s*:\s*'[内容1]',\s*groupId
规则必须保证唯一性,不然会匹配到其他内容起来,将规则添加到数组中,获取方法选规则匹配:
规则编撰完后点击保存,点击“测试”看看疗效怎么
规则无误,抓取正常,抓取到的数据还可以发布到cms系统、直接数据库入库、保存为excel文件等,点击顶部导航条的“发布设置”即可,好了明日头条的采集到这儿就结束了,大家不妨动手试试!
新闻手动采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-26 04:35
一、原理新闻手动采集系统实际上是通过了某种方式调用其它网站上的网页。即把数据源的数据(图片,网 页及其他文件)抓取到本地,经过各类处理后显示到页面上或则储存进数据库。 我们可以通过这些程序,完成过去一些好像完全不可能实现的任务,比如说把某个站的页面偷粱换 柱后弄成自己的页面,或者把某个站的一些数据(文章,图片)保存到本地数据库中加以借助。 优点:无须维护系统,因为程序中的数据来自其他网站,它将随着该网站的更新而更新;可以节约 大量的服务器资源,一般程序就几个文件,所有网页内容都是来自其他网站。比如新闻歹徒程序,很多都 是调用了sina 的新闻网页,并且对其中的html 进行了一些替换,同时对广告也进行了过滤。 缺点:不稳定,如果目标网站出错,程序也会出错,而且,如果目标网站进行升级维护,那么劫匪 程序也要进行相应更改;速度慢,因为是远程调用,速度和在本地服务器上读取数据比上去,肯定要慢一 法:可以调用xml中的xmlhttp 组件进行实现,我们可以通过XML 中的XMLHTTP 组件调用其它 网站上的网页。 实现过程:1、获得数据源 2、对获得的数据进行整理 1、获得数据源(ASP) 利用函数:getHTTPPage(url) 作用:输入url 目标网页地址,返回值getHTTPPage 是目标网页的html 代码 原程序: functiongetHTTPPage(url) dim Http set Http=server.createobject("MSXML2.XMLHTTP") Http.open "GET",url,false Http.send() exitfunction end getHTTPPage=bytesToBSTR(Http.responseBody,"GB2312")set http=nothing err.Clearend function 2、对获得的数据进行整理借助函数:adodb.stream 组件 中获得的数据是一些html乱码进行转化替换等。
原程序1:(乱码转化) FunctionBytesToBstr(body,Cset) dim objstream set objstream Server.CreateObject("adodb.stream")objstream.Type objstream.Openobjstream.Write body objstream.Position CsetBytesToBstr objstream.ReadTextobjstream.Close set objstream nothingEnd Function SetobjRegExp NewRegexp setmm=objRegExp.Execute(str) EachMatch 原程序3:(使用replace方式对数据进行替换) Replace(Body,"源数据","要替换的数据")Body Replace(Body,"url","url.Asp?id" 1、分析网址,找到循环分页的规律2、根据网址抓取网页,并将内容进行分离 3、处理信息,过滤信息,并将抓取的信息写入库中 4、自动循环下一个 查看全部
新闻手动采集原理
一、原理新闻手动采集系统实际上是通过了某种方式调用其它网站上的网页。即把数据源的数据(图片,网 页及其他文件)抓取到本地,经过各类处理后显示到页面上或则储存进数据库。 我们可以通过这些程序,完成过去一些好像完全不可能实现的任务,比如说把某个站的页面偷粱换 柱后弄成自己的页面,或者把某个站的一些数据(文章,图片)保存到本地数据库中加以借助。 优点:无须维护系统,因为程序中的数据来自其他网站,它将随着该网站的更新而更新;可以节约 大量的服务器资源,一般程序就几个文件,所有网页内容都是来自其他网站。比如新闻歹徒程序,很多都 是调用了sina 的新闻网页,并且对其中的html 进行了一些替换,同时对广告也进行了过滤。 缺点:不稳定,如果目标网站出错,程序也会出错,而且,如果目标网站进行升级维护,那么劫匪 程序也要进行相应更改;速度慢,因为是远程调用,速度和在本地服务器上读取数据比上去,肯定要慢一 法:可以调用xml中的xmlhttp 组件进行实现,我们可以通过XML 中的XMLHTTP 组件调用其它 网站上的网页。 实现过程:1、获得数据源 2、对获得的数据进行整理 1、获得数据源(ASP) 利用函数:getHTTPPage(url) 作用:输入url 目标网页地址,返回值getHTTPPage 是目标网页的html 代码 原程序: functiongetHTTPPage(url) dim Http set Http=server.createobject("MSXML2.XMLHTTP") Http.open "GET",url,false Http.send() exitfunction end getHTTPPage=bytesToBSTR(Http.responseBody,"GB2312")set http=nothing err.Clearend function 2、对获得的数据进行整理借助函数:adodb.stream 组件 中获得的数据是一些html乱码进行转化替换等。
原程序1:(乱码转化) FunctionBytesToBstr(body,Cset) dim objstream set objstream Server.CreateObject("adodb.stream")objstream.Type objstream.Openobjstream.Write body objstream.Position CsetBytesToBstr objstream.ReadTextobjstream.Close set objstream nothingEnd Function SetobjRegExp NewRegexp setmm=objRegExp.Execute(str) EachMatch 原程序3:(使用replace方式对数据进行替换) Replace(Body,"源数据","要替换的数据")Body Replace(Body,"url","url.Asp?id" 1、分析网址,找到循环分页的规律2、根据网址抓取网页,并将内容进行分离 3、处理信息,过滤信息,并将抓取的信息写入库中 4、自动循环下一个
wordpress手动采集插件Crawling_附带教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-08-21 09:59
然后,解压压缩包,上传到wordpress插件目录。激活插件。
三、任务管理
一个任务可以理解为一个爬虫,在这里你可以配置多个任务,每个任务可以单独设置参数。
比如,这里我设置了三个任务,如图:
第一个任务是爬取“盾给网路”的全部内容,抓取间隔设置为-1表示只采集一次,不会重复执行。
第二个任务是爬取“盾给网路”的前三页,如果采集过的不会重复采集,只会抓取前三页的更新的内容。每隔24小时采集一次。
第三个任务是爬取“阳光电影网”(这是影片天堂的新网站)的首页的全部更新的影片,因为阳光影片所有的更新都在首页。每隔24小时采集一次。
每个任务单独设置的参数,如图:
下面是每位任务的设置:
1 任务名称:
每隔任务的别称,方便好记而已,没有其他作用。
2 入口网址:
每个任务爬虫开始的地址。这个网址通常是首页或则列表页。然后爬虫会从这个页面开始采集。
3 爬取间隔时间:
每隔任务(爬虫)运行的间隔时间。
4 列表页面url正则/内容页面url正则:
爬虫步入第一个网址(入口网址)后须要分辨什么是须要采集的内容页面。所以须要设置匹配的内容页面url正则表达式。
爬取还须要晓得怎样进行翻页,寻找更多的内容页面,所以须要设置列表页面url的正则表达式。
列表页面
内容页面
所以正则表达式如下:
列表页面url正则:\/page/[1-9]\d*$
内容页面url正则:\/[1-9]\d*.html$
如果只须要采集前三页更新的内容,只须要把列表页面的正则表达式改为\/page/[1-3]$。
配置这两个参数时可以打开《正则表达式在线测试》页面测试。
5 文章标题(xpath)/文章内容(xpath):
进入内容页面后,爬虫要选择抓取的内容,比如文章的标题和文章的正文。所以须要设置xpath来告诉爬虫。
例如:
打开一个页面,通过浏览器查看页面源代码,如图:
可以看见,文章的标题是收录在
这个元素中的元素中的。所以标题的xpath规则为://h1[@class=”mscctitle”]/a
同样,通过上图可以看到:内容是收录在
中的,所以内容的xpath规则为://div[@class=”content-text”]
配置完成可以打开《XPath在线测试》页面测试。
6 内容起始字符串/内容结束字符串:
一般的网站都会有广告,或者一些其他的东西混在内容上面,所以我们须要过滤掉那些内容,只保存我们须要的部份。而这部份无用的东西(广告、分享按键、标签等)大部分都是在文章的开头或则结束部份,并且内容是固定的。所以我们可以通过简单的字符串过滤掉。
例如《且听风吟》的整篇文章的内容部份开头就有一段广告,如上图。
通过《XPath在线测试》页面测试我们上一步配置的内容xpath规则,可以得到文章内容,如下图:
可以看见,真正的内容是从
之后开始的。
所以内容起始字符串设置为:
因为文章内容前面并没有多余的部份,所以前面不用过虑,内容结束字符串设置为空就可以了。
7 文章图片:
采集插件可以手动将文章内出现的图片保存到本地,默认按年月分文件夹保存,并会将图片的标签设置为文章的标题。如果不需要保存到本地可以选择“不做处理”。
8 文章分类:
选择要保存到的分类,和wordpress一样,可以选择多个分类。 查看全部
wordpress手动采集插件Crawling_附带教程
然后,解压压缩包,上传到wordpress插件目录。激活插件。
三、任务管理
一个任务可以理解为一个爬虫,在这里你可以配置多个任务,每个任务可以单独设置参数。
比如,这里我设置了三个任务,如图:
第一个任务是爬取“盾给网路”的全部内容,抓取间隔设置为-1表示只采集一次,不会重复执行。
第二个任务是爬取“盾给网路”的前三页,如果采集过的不会重复采集,只会抓取前三页的更新的内容。每隔24小时采集一次。
第三个任务是爬取“阳光电影网”(这是影片天堂的新网站)的首页的全部更新的影片,因为阳光影片所有的更新都在首页。每隔24小时采集一次。
每个任务单独设置的参数,如图:
下面是每位任务的设置:
1 任务名称:
每隔任务的别称,方便好记而已,没有其他作用。
2 入口网址:
每个任务爬虫开始的地址。这个网址通常是首页或则列表页。然后爬虫会从这个页面开始采集。
3 爬取间隔时间:
每隔任务(爬虫)运行的间隔时间。
4 列表页面url正则/内容页面url正则:
爬虫步入第一个网址(入口网址)后须要分辨什么是须要采集的内容页面。所以须要设置匹配的内容页面url正则表达式。
爬取还须要晓得怎样进行翻页,寻找更多的内容页面,所以须要设置列表页面url的正则表达式。
列表页面
内容页面
所以正则表达式如下:
列表页面url正则:\/page/[1-9]\d*$
内容页面url正则:\/[1-9]\d*.html$
如果只须要采集前三页更新的内容,只须要把列表页面的正则表达式改为\/page/[1-3]$。
配置这两个参数时可以打开《正则表达式在线测试》页面测试。
5 文章标题(xpath)/文章内容(xpath):
进入内容页面后,爬虫要选择抓取的内容,比如文章的标题和文章的正文。所以须要设置xpath来告诉爬虫。
例如:
打开一个页面,通过浏览器查看页面源代码,如图:
可以看见,文章的标题是收录在
这个元素中的元素中的。所以标题的xpath规则为://h1[@class=”mscctitle”]/a
同样,通过上图可以看到:内容是收录在
中的,所以内容的xpath规则为://div[@class=”content-text”]
配置完成可以打开《XPath在线测试》页面测试。
6 内容起始字符串/内容结束字符串:
一般的网站都会有广告,或者一些其他的东西混在内容上面,所以我们须要过滤掉那些内容,只保存我们须要的部份。而这部份无用的东西(广告、分享按键、标签等)大部分都是在文章的开头或则结束部份,并且内容是固定的。所以我们可以通过简单的字符串过滤掉。
例如《且听风吟》的整篇文章的内容部份开头就有一段广告,如上图。
通过《XPath在线测试》页面测试我们上一步配置的内容xpath规则,可以得到文章内容,如下图:
可以看见,真正的内容是从
之后开始的。
所以内容起始字符串设置为:
因为文章内容前面并没有多余的部份,所以前面不用过虑,内容结束字符串设置为空就可以了。
7 文章图片:
采集插件可以手动将文章内出现的图片保存到本地,默认按年月分文件夹保存,并会将图片的标签设置为文章的标题。如果不需要保存到本地可以选择“不做处理”。
8 文章分类:
选择要保存到的分类,和wordpress一样,可以选择多个分类。
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-19 09:52
文章资讯网站资讯网站
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天小编总结一下,seo遇见瓶颈期要注意的几点。 慧营销站群优化系统 1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。 2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键
A5网站交易2020.03.30 17:16:30阅读量:1,699
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天总结一下,seo遇见瓶颈期要注意的几点。
1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。
2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键词,网站标题,描述,栏目都遍布了关键词,甚至还在顶部加上网站的回链,这样会被搜索引擎视为作弊,会严厉的给与惩罚,一般关键词的密度控制在2%-8%,前提是围绕用户需求展开。
3、外链平台要优质。外链的作用就是引导搜索引擎蜘蛛沿着链接爬取你的网站从而把外链平台的权重分散到你的网站上来,如果你是在一些权重低并且是一些会设行业平台发布一些外链,搜索引擎会给你的网站一个太低的评分,有时候反倒增加你网站的权重,所以外链平台一定要优质。
4、网站创新小于美感。漂亮的网站会使人喜欢,但并不是所有网站都要以漂亮为主,根据你的网站、产品类型去选择,可以小甜美、可以简洁、可以科技感爆棚,一个有创意的网站更会使人眼前一亮。可以在设计之前多观察同类的网页,或者做一些用户督查,取其长处。
5、服务器要稳定。如今服务器是否稳定也估算在搜索引擎的算法上了,一个服务器不稳定的网站打开速率会太慢,经常会出现网站打不开出现错误,影响用户体验。 查看全部
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了
文章资讯网站资讯网站
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天小编总结一下,seo遇见瓶颈期要注意的几点。 慧营销站群优化系统 1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。 2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键
A5网站交易2020.03.30 17:16:30阅读量:1,699
有些SEO初学者做了一段时间SEO优化,会遇上瓶颈期,发现自己优化不动了,不好使哪些办法优化,网站的排行和权重就是仍然上不去,有些甚至还升高了,这对SEO初学者来说是一个沉重的严打。今天总结一下,seo遇见瓶颈期要注意的几点。
1、提高文章质量。有些优化人员采用野蛮的采集手段,只追求量,不保证质。建议网站多采用原创文章,不要使用采集或伪原创的作弊方式,只有重视文章质量才有出路,只在乎文章数量是没有意义的。
2、不要堆积关键词。有的SEO初学者为了提升网站的相关性,大肆堆积关键词,网站标题,描述,栏目都遍布了关键词,甚至还在顶部加上网站的回链,这样会被搜索引擎视为作弊,会严厉的给与惩罚,一般关键词的密度控制在2%-8%,前提是围绕用户需求展开。
3、外链平台要优质。外链的作用就是引导搜索引擎蜘蛛沿着链接爬取你的网站从而把外链平台的权重分散到你的网站上来,如果你是在一些权重低并且是一些会设行业平台发布一些外链,搜索引擎会给你的网站一个太低的评分,有时候反倒增加你网站的权重,所以外链平台一定要优质。
4、网站创新小于美感。漂亮的网站会使人喜欢,但并不是所有网站都要以漂亮为主,根据你的网站、产品类型去选择,可以小甜美、可以简洁、可以科技感爆棚,一个有创意的网站更会使人眼前一亮。可以在设计之前多观察同类的网页,或者做一些用户督查,取其长处。
5、服务器要稳定。如今服务器是否稳定也估算在搜索引擎的算法上了,一个服务器不稳定的网站打开速率会太慢,经常会出现网站打不开出现错误,影响用户体验。
抽取数据的工具有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-18 02:12
数据抽取是从源数据系统抽取部份或全部数据到目标系统,从而在目标系统再进行数据加工借助的过程。数据抽取分为全量抽取和增量抽取多种方法,实现方法不同,数据抽取效率也不一样,下面介绍几种增量数据抽取形式:
1时间戳形式 时间戳是一种基于快照变化的数据捕获形式,需要在源表上降低时间戳列,更新数据表数据时,同时更改时间戳列值。数据抽取时,通过比较系统时间与时间戳列值来决定抽取变化数据,实现增量抽取。时间戳方法性能较好,抽取相对简单,缺点是难以捕获时间戳曾经数据delete和update操作,在数据准确性上遭到一定限制。
2日志表形式 该方法通过剖析数据库自身在线日志判定变化数据。在对源数据表进行insert、update或delete操作同时就可提取数据,变化数据保存在日志表中,通过这些方法捕获变化数据,然后借助视图形式提供给目标系统。如Oracle提供的物化视图、DSG和GoldenGateTDM等第三方数据复制工具都采用了该方法,其优点是数据抽取性能高,缺点是数据操作时要同时更改数据表和日志表数据,对业务系统性能有一定影响。
3全表比对方法 全表比对方法要事先为抽取的表完善结构类似的临时表,临时表记录源表字段以及依照列数据估算下来的校验码。每次进行数据抽取时,对源表和临时表进行校准,决定源表数据是insert、update还是delete操作。该方法优点是对源系统影响较小,缺点是性能较差,表中没有字段或惟一列且富含重复记录时准确性更差。
4触发器方法 需要在源数据表上构建insert、update和delete等触发器,当源数据变化时,相应触发器将变化数据写入临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删掉。如InforEAI就是采用该方法实现增量抽取,现正在我市地税系统出口退税初审系统数据集中使用。其优点是数据抽取效率高,缺点是要在业务表建触发器,对业务系统性能和安全性有一定影响。
通过对以上增量数据抽取形式剖析,本着不直接从生产数据库进行抽取的原则,我们借助早已构建的BCV备份数据库进行增量数据抽取。
NLPIR大数据语义智能剖析平台(原ICTCLAS)是北京理工大学大数据搜索与挖掘实验室张华平校长研制,针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达近二十年的不断创新。平台提供了客户端工具,云服务与二次开发插口等多种产品使用方式。各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
NLPIR大数据语义智能剖析平台客户端
精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
文档转化:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息转化,效率达到大数据处理的要求。
新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的英语解释。
文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
以上是推荐的英文动词工具,希望可以帮助到您,如有问题可以联系我,我将帮助解答! 查看全部
抽取数据的工具有什么?
数据抽取是从源数据系统抽取部份或全部数据到目标系统,从而在目标系统再进行数据加工借助的过程。数据抽取分为全量抽取和增量抽取多种方法,实现方法不同,数据抽取效率也不一样,下面介绍几种增量数据抽取形式:
1时间戳形式 时间戳是一种基于快照变化的数据捕获形式,需要在源表上降低时间戳列,更新数据表数据时,同时更改时间戳列值。数据抽取时,通过比较系统时间与时间戳列值来决定抽取变化数据,实现增量抽取。时间戳方法性能较好,抽取相对简单,缺点是难以捕获时间戳曾经数据delete和update操作,在数据准确性上遭到一定限制。
2日志表形式 该方法通过剖析数据库自身在线日志判定变化数据。在对源数据表进行insert、update或delete操作同时就可提取数据,变化数据保存在日志表中,通过这些方法捕获变化数据,然后借助视图形式提供给目标系统。如Oracle提供的物化视图、DSG和GoldenGateTDM等第三方数据复制工具都采用了该方法,其优点是数据抽取性能高,缺点是数据操作时要同时更改数据表和日志表数据,对业务系统性能有一定影响。
3全表比对方法 全表比对方法要事先为抽取的表完善结构类似的临时表,临时表记录源表字段以及依照列数据估算下来的校验码。每次进行数据抽取时,对源表和临时表进行校准,决定源表数据是insert、update还是delete操作。该方法优点是对源系统影响较小,缺点是性能较差,表中没有字段或惟一列且富含重复记录时准确性更差。
4触发器方法 需要在源数据表上构建insert、update和delete等触发器,当源数据变化时,相应触发器将变化数据写入临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删掉。如InforEAI就是采用该方法实现增量抽取,现正在我市地税系统出口退税初审系统数据集中使用。其优点是数据抽取效率高,缺点是要在业务表建触发器,对业务系统性能和安全性有一定影响。
通过对以上增量数据抽取形式剖析,本着不直接从生产数据库进行抽取的原则,我们借助早已构建的BCV备份数据库进行增量数据抽取。
NLPIR大数据语义智能剖析平台(原ICTCLAS)是北京理工大学大数据搜索与挖掘实验室张华平校长研制,针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达近二十年的不断创新。平台提供了客户端工具,云服务与二次开发插口等多种产品使用方式。各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
NLPIR大数据语义智能剖析平台客户端
精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
文档转化:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息转化,效率达到大数据处理的要求。
新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的英语解释。
文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
以上是推荐的英文动词工具,希望可以帮助到您,如有问题可以联系我,我将帮助解答!
seo伪原创文章软件教你解决内容不收录问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-13 11:23
搜索引擎优化(SEO)在互联网营销中的应用以前被提及过-提高关键词的排行,使网站的内容在搜索引擎上愈加显著。通常,关键词的优化(其中一部分是固定在网站软文的日常更新上),以及只要被捕获都会出现在搜索引擎上供用户听到的软文。
那么问题就来了,网络软文的抓取并不容易,如果你的文章没有收录,那么无论耗费多少人力和时间都是无用的,关键词排行永远不会上升。
当然,新手不应当担心软文搜集的困难,事实上,只要她们晓得缘由,掌握了"例行公事",就不难捕捉蜘蛛,下面剖析了下边几个常见的诱因不包括在内。
1:
seo伪原创文章软件觉得许多网路软文不能做原创内容,往往选择学习他人的文章,虽然伪原创也可以捕捉到,但是假如有太多的笔端可供参考,那么搜索引擎都会意识到,减少你采集的比列,所以文章最好是原创的,另外,为了学习,尽量保持创新,改变文章的内容主题。
2:
当蜘蛛抓起网页时,它会屏蔽并清除"质量差的内容"。
那么问题就来了,有很多网站,每天都有很多文章发表,如果页面想被收录,seo伪原创文章软件觉得你须要比其他人更有优势,至少不是底层的那个。例如,所有页面的代码和图片,蜘蛛都难以辨识,不会抓取。此外,页面访问的速率、历史、作者、时间、相关建议等就会影响页面的搜集。
这须要从网站页面的细节上梳理一下,比如清除胸毛的脸,花更多的时间,以确保宽容。
3:
Robots.tx是一个机制文件,当我们须要严禁在网站上爬行个别内容时,就会设置它。很多时侯,当您创建一个新的网站或更改它时,您会碰到系统因为robots.txt限制而未能显示的提示。
seo伪原创文章软件觉得这似乎是因为robots.txt文件设置没有传递,只需更改正确的,站点一直可以包括在内。
4:
最后一个缘由是一些有趣的缘由,一些网站由于服务器不稳定,导致网站打开平缓或频繁访问会被记住,很长一段时间,网站蜘蛛会给这些经验不佳的网站贴上标签,并降低对服务器的访问次数,爬行次数将降低,就像我们的用户一样,我们会尽量避开不舒服网站的体验。
所以,在构建网站时不要粗心大意,至少对用户来说,进出网站很容易。要解决这种问题,所收录的大部分问题都可以解决。 查看全部
在做网站优化中,内容收录问题常常困惑着我们,很多seoer们听到网站不收录就心急火燎一样,一着急就难免走偏,那么怎么用正规优化手段解决呢,下面跟seo伪原创文章软件一起来瞧瞧。
搜索引擎优化(SEO)在互联网营销中的应用以前被提及过-提高关键词的排行,使网站的内容在搜索引擎上愈加显著。通常,关键词的优化(其中一部分是固定在网站软文的日常更新上),以及只要被捕获都会出现在搜索引擎上供用户听到的软文。
那么问题就来了,网络软文的抓取并不容易,如果你的文章没有收录,那么无论耗费多少人力和时间都是无用的,关键词排行永远不会上升。
当然,新手不应当担心软文搜集的困难,事实上,只要她们晓得缘由,掌握了"例行公事",就不难捕捉蜘蛛,下面剖析了下边几个常见的诱因不包括在内。
1:
seo伪原创文章软件觉得许多网路软文不能做原创内容,往往选择学习他人的文章,虽然伪原创也可以捕捉到,但是假如有太多的笔端可供参考,那么搜索引擎都会意识到,减少你采集的比列,所以文章最好是原创的,另外,为了学习,尽量保持创新,改变文章的内容主题。
2:
当蜘蛛抓起网页时,它会屏蔽并清除"质量差的内容"。
那么问题就来了,有很多网站,每天都有很多文章发表,如果页面想被收录,seo伪原创文章软件觉得你须要比其他人更有优势,至少不是底层的那个。例如,所有页面的代码和图片,蜘蛛都难以辨识,不会抓取。此外,页面访问的速率、历史、作者、时间、相关建议等就会影响页面的搜集。
这须要从网站页面的细节上梳理一下,比如清除胸毛的脸,花更多的时间,以确保宽容。
3:
Robots.tx是一个机制文件,当我们须要严禁在网站上爬行个别内容时,就会设置它。很多时侯,当您创建一个新的网站或更改它时,您会碰到系统因为robots.txt限制而未能显示的提示。
seo伪原创文章软件觉得这似乎是因为robots.txt文件设置没有传递,只需更改正确的,站点一直可以包括在内。
4:
最后一个缘由是一些有趣的缘由,一些网站由于服务器不稳定,导致网站打开平缓或频繁访问会被记住,很长一段时间,网站蜘蛛会给这些经验不佳的网站贴上标签,并降低对服务器的访问次数,爬行次数将降低,就像我们的用户一样,我们会尽量避开不舒服网站的体验。
所以,在构建网站时不要粗心大意,至少对用户来说,进出网站很容易。要解决这种问题,所收录的大部分问题都可以解决。
微信文章抓取(1):微信公众号文章抓取常识之临时链接、永久链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-10 14:54
曾经尝试过抓取陌陌文章的小伙伴,一定太熟悉搜狗陌陌。搜狗陌陌是腾讯官方提供的搜索引擎,专门拿来搜索微信公众号发表的文章(不收录服务号)。
对于想要获取陌陌文章进行研究学习的小伙伴,首先探求的途径一般是搜狗陌陌。那么关于搜狗陌陌以及陌陌相关的抓取,需要知晓以下关于陌陌文章链接的常识。
搜狗陌陌搜索下来的文章链接均为陌陌的临时链接,通过客户端查看的文章链接均为永久链接
临时链接*UPlviVRt*o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new=1
特点为:
浏览有效期自生成起6个小时,超出时间直接使用浏览器访问将会显示链接已过期,可以通过陌陌客户端访问(此时将手动转变为陌陌永久链接的短联接方式)链接有效期自生成起约50天,超出该时限的链接将难以在客户端中打开,将显示系统错误。这就是陌陌临时链接在陌陌客户端查看显示系统错误的诱因。临时链接直接在浏览器中浏览不显示阅读数以及点赞数,页面中仅收录biz,mid,idx,不收录sn参数(稍后解释)
快速识别方式:链接中富含signature数组。
微信永久链接-原创长链接:
微信永久链接-短联接:
特点为:
永久有效,可直接在浏览器中访问不会有时效限制直接访问依然没有阅读数以及点赞数,页面中收录biz,mid,idx和sn参数短联接可以通过拼接参数的方法还原成长链接,长链接需依靠客户端转为短联接
微信文章相关参数解释:
原创长链接和短联接可以通过查看网页源码的形式听到那些参数
biz:微信公众号的惟一标示ID
mid:每次推送生成一个mid,同一次推送下mid相同
idx:当次推送的位置(1为首篇,2为第二篇…)
sn:每一篇文章的惟一ID,也是区别临时链接和永久链接的关键参数
临时链接的页面上是没有sn的,只能通过临时链接中本身的signature参数来找到该篇文章,但是该参数如前所述是有有效期的。因此抓取到的陌陌临时链接只能保证6小时内可以打开,超出时效后只能复制到陌陌中查看。
那么陌陌临时链接怎么转为永久链接呢?
当然方案还是有的,这里又要牵涉到陌陌转换临时链接的机制 uin 以及 key,请继续往下看。
微信文章抓取(2):微信临时链接转永久链接方式,一招甩掉链接过期苦恼
那么你们一定会有一个问题:如何使临时链接不再过期?或者说怎样把临时链接转换为永久链接。
对于这个问题首先跟你们说一个事实,就是不论是临时链接转永久链接还是获取陌陌文章的互动数,都是须要微信号参与进来的。因此这是一个存在成本的问题(微信封号越来越严重等)。那么链接转换到底是怎么做到的?
通过使用Charles抓包工具研究陌陌客户端的行为我们可以发觉:
在用户从客户端内点击临时链接时,客户端会赋于该链接两个参数,一个是uin一个是key,含有这两个参数的临时链接将才能手动跳转到永久链接起来。
那么我们不禁要问了,uin和key又是哪些?
uin:微信用户惟一标志
key:转换临时链接到永久链接的凭据,分为公众号key(仅对当前公众号下的文章有效),万能key(可用于任何公众号的转换),有效期约为40分钟~2小时。
只要你能获得万能key,就意味着你可以随便将临时链接转换为永久链接了。这里需注意的是单个key的有效期,以及使用频度,过于频繁key将直接失效,而获取key过分频繁将造成陌陌帐号被封禁!
综上来看,转化临时链接的关键在于得到uin和key,而uin和key与陌陌帐号密切相关,所以是须要成本的。但是,如果你厉害到可以破解掉陌陌的客户端(windows、安卓都可以),得到key的生成规则,那你就可以为所欲为了,至于难度和可行度…你懂的。并且如此做并不符合相关法律法规哦…但是不能排除早已有人做到了这一点,毕竟市场上还是有不少数据公司以陌陌数据为生。
那么作为只是学习以及研究为目的的广大小白朋友,如何使自己抓回去的文章更持久呢?搜狗陌陌在2018年7月下旬更新了分享功能,你会发觉每次搜索下来的文章右侧会多出一个分享按键,而该分享功能所对应的链接并不是临时链接,而是全新的分享链接,其实这个链接就是一个API,当你访问的时侯会立刻跳转到一个全新的临时链接上,由于是刚才生成的因而无论是谁在什么时候点击,打开的临时链接一定是新鲜热乎的。用分享链接代替临时链接保存,可以保证文章永远不会过期。连接方式: api/share…
使用Charles配合自动化点击获得永久链接,具体思路是通过自动化的行为将临时链接发送到陌陌上而且自动化点击查看文章,此时charles将获得文章的真实链接地址。不过须要注意访问频度第三方网站提供的转换工具: 输入临时链接后会返回一个添加了uin和key的链接,也就是说这个网站提供了uin和key给你们使用。
可以看出方案一才能完全避开使用key而保证临时链接永远不过期。当然若果须要获取互动数还是要选择方案2或则3
有些小伙伴寻问怎样把公众号列表页面弄成永久链接,这个是不存在的,本文讲的全部是“文章页面”。公众号页面通过添加key可以在浏览器中直接打开,但是有效期一直是与key相同的两个小时。公众号页面不存在所谓的永久有效的联接,不然的话公众号的抓取不就显得十分简单了吗?
微信文章抓取(3):在封禁的边沿试探搜狗陌陌的反爬策略
搜狗陌陌早已是我们的老朋友了,但凡是涉及到陌陌文章的抓取一定是绕不开这个渠道的。
但其实搜狗也不是做慈善的,不会放开使你无限地去抓取陌陌的内容,也就是说搜狗是有反爬策略的。具体的反爬策略通过不断地边沿测试后可以发觉:
1.搜索结果为陌陌临时链接,浏览有效期为6个小时
2.搜索结果限制浏览页数为10页,登录后最多可以浏览100页内容
3.1分钟内连续翻页达到30次以上将出现验证码
4.文章页面过分频繁访问将被封禁2~24小时,所有陌陌文章将显示请使用陌陌扫码阅读
5.经常触发验证码的IP将被拉黑,所有搜索均须要先输入验证码
最后,想要应对以上的限制的方式都是有的,无非是使用代理等一些常见的抓取手段,其实假如你能认真研究的话,你是才能发觉搜狗的验证码是可以绕开的。 查看全部
微信文章抓取(1):微信公众号文章抓取常识之临时链接、永久链接
曾经尝试过抓取陌陌文章的小伙伴,一定太熟悉搜狗陌陌。搜狗陌陌是腾讯官方提供的搜索引擎,专门拿来搜索微信公众号发表的文章(不收录服务号)。
对于想要获取陌陌文章进行研究学习的小伙伴,首先探求的途径一般是搜狗陌陌。那么关于搜狗陌陌以及陌陌相关的抓取,需要知晓以下关于陌陌文章链接的常识。
搜狗陌陌搜索下来的文章链接均为陌陌的临时链接,通过客户端查看的文章链接均为永久链接
临时链接*UPlviVRt*o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new=1
特点为:
浏览有效期自生成起6个小时,超出时间直接使用浏览器访问将会显示链接已过期,可以通过陌陌客户端访问(此时将手动转变为陌陌永久链接的短联接方式)链接有效期自生成起约50天,超出该时限的链接将难以在客户端中打开,将显示系统错误。这就是陌陌临时链接在陌陌客户端查看显示系统错误的诱因。临时链接直接在浏览器中浏览不显示阅读数以及点赞数,页面中仅收录biz,mid,idx,不收录sn参数(稍后解释)
快速识别方式:链接中富含signature数组。
微信永久链接-原创长链接:
微信永久链接-短联接:
特点为:
永久有效,可直接在浏览器中访问不会有时效限制直接访问依然没有阅读数以及点赞数,页面中收录biz,mid,idx和sn参数短联接可以通过拼接参数的方法还原成长链接,长链接需依靠客户端转为短联接
微信文章相关参数解释:
原创长链接和短联接可以通过查看网页源码的形式听到那些参数
biz:微信公众号的惟一标示ID
mid:每次推送生成一个mid,同一次推送下mid相同
idx:当次推送的位置(1为首篇,2为第二篇…)
sn:每一篇文章的惟一ID,也是区别临时链接和永久链接的关键参数
临时链接的页面上是没有sn的,只能通过临时链接中本身的signature参数来找到该篇文章,但是该参数如前所述是有有效期的。因此抓取到的陌陌临时链接只能保证6小时内可以打开,超出时效后只能复制到陌陌中查看。
那么陌陌临时链接怎么转为永久链接呢?
当然方案还是有的,这里又要牵涉到陌陌转换临时链接的机制 uin 以及 key,请继续往下看。
微信文章抓取(2):微信临时链接转永久链接方式,一招甩掉链接过期苦恼
那么你们一定会有一个问题:如何使临时链接不再过期?或者说怎样把临时链接转换为永久链接。
对于这个问题首先跟你们说一个事实,就是不论是临时链接转永久链接还是获取陌陌文章的互动数,都是须要微信号参与进来的。因此这是一个存在成本的问题(微信封号越来越严重等)。那么链接转换到底是怎么做到的?
通过使用Charles抓包工具研究陌陌客户端的行为我们可以发觉:
在用户从客户端内点击临时链接时,客户端会赋于该链接两个参数,一个是uin一个是key,含有这两个参数的临时链接将才能手动跳转到永久链接起来。
那么我们不禁要问了,uin和key又是哪些?
uin:微信用户惟一标志
key:转换临时链接到永久链接的凭据,分为公众号key(仅对当前公众号下的文章有效),万能key(可用于任何公众号的转换),有效期约为40分钟~2小时。
只要你能获得万能key,就意味着你可以随便将临时链接转换为永久链接了。这里需注意的是单个key的有效期,以及使用频度,过于频繁key将直接失效,而获取key过分频繁将造成陌陌帐号被封禁!
综上来看,转化临时链接的关键在于得到uin和key,而uin和key与陌陌帐号密切相关,所以是须要成本的。但是,如果你厉害到可以破解掉陌陌的客户端(windows、安卓都可以),得到key的生成规则,那你就可以为所欲为了,至于难度和可行度…你懂的。并且如此做并不符合相关法律法规哦…但是不能排除早已有人做到了这一点,毕竟市场上还是有不少数据公司以陌陌数据为生。
那么作为只是学习以及研究为目的的广大小白朋友,如何使自己抓回去的文章更持久呢?搜狗陌陌在2018年7月下旬更新了分享功能,你会发觉每次搜索下来的文章右侧会多出一个分享按键,而该分享功能所对应的链接并不是临时链接,而是全新的分享链接,其实这个链接就是一个API,当你访问的时侯会立刻跳转到一个全新的临时链接上,由于是刚才生成的因而无论是谁在什么时候点击,打开的临时链接一定是新鲜热乎的。用分享链接代替临时链接保存,可以保证文章永远不会过期。连接方式: api/share…
使用Charles配合自动化点击获得永久链接,具体思路是通过自动化的行为将临时链接发送到陌陌上而且自动化点击查看文章,此时charles将获得文章的真实链接地址。不过须要注意访问频度第三方网站提供的转换工具: 输入临时链接后会返回一个添加了uin和key的链接,也就是说这个网站提供了uin和key给你们使用。
可以看出方案一才能完全避开使用key而保证临时链接永远不过期。当然若果须要获取互动数还是要选择方案2或则3
有些小伙伴寻问怎样把公众号列表页面弄成永久链接,这个是不存在的,本文讲的全部是“文章页面”。公众号页面通过添加key可以在浏览器中直接打开,但是有效期一直是与key相同的两个小时。公众号页面不存在所谓的永久有效的联接,不然的话公众号的抓取不就显得十分简单了吗?
微信文章抓取(3):在封禁的边沿试探搜狗陌陌的反爬策略
搜狗陌陌早已是我们的老朋友了,但凡是涉及到陌陌文章的抓取一定是绕不开这个渠道的。
但其实搜狗也不是做慈善的,不会放开使你无限地去抓取陌陌的内容,也就是说搜狗是有反爬策略的。具体的反爬策略通过不断地边沿测试后可以发觉:
1.搜索结果为陌陌临时链接,浏览有效期为6个小时
2.搜索结果限制浏览页数为10页,登录后最多可以浏览100页内容
3.1分钟内连续翻页达到30次以上将出现验证码
4.文章页面过分频繁访问将被封禁2~24小时,所有陌陌文章将显示请使用陌陌扫码阅读
5.经常触发验证码的IP将被拉黑,所有搜索均须要先输入验证码
最后,想要应对以上的限制的方式都是有的,无非是使用代理等一些常见的抓取手段,其实假如你能认真研究的话,你是才能发觉搜狗的验证码是可以绕开的。
如何抓取微信公众号文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-06 14:11
在第一种类型中,您只需要下载并重新编辑即可. 这个方法很简单. 一般来说,您知道所需的文章,即您知道该文章的访问地址. 通常,无论是以Word还是其他格式保存,都可以在采集器的帮助下进行下载.
第二种类型需要自动同步到您的平台. 这更加麻烦,因为您不知道下载地址(无法手动自动输入).
方法1: 1.使用搜狗浏览器调用其界面来搜索您的正式帐户名; 2.如果存在,请通过第二个界面查询官方帐户下的历史文章. 获取文章链接,通过程序下载它,并将其保存到您自己的背景中.
此方法的优点是: 半自动,无需手动输入文章链接. 缺点是: 1.如果您经常发送请求,搜狗将提示您输入验证码. 这需要手动处理,因此不能完全自动化. 2.获得的文章链接是临时的,需要在有效期内下载. 3.只能获取最近的十篇历史文章. 4.它需要定期执行,并且不能实时更新. 更新太频繁并且验证码被阻止,如果频率太低,则更新延迟也太低.
方法二,1.通过程序模拟登录到官方帐户后台管理页面. 2.通过模拟调用和编辑材料. 3.通过模拟编辑插入链接功能. 4.调用搜索官方帐户界面,并查询官方帐户以获取fackId. 5.通过获取的fackId调用另一个接口以获取文章列表. 本文列表中有链接.
此方法的优点是: 1.将没有验证码,但是在某些情况下,它是密封的,但是频率较低. 2.您可以获得官方帐户下所有文章的清单. 3.文章链接永久有效. 缺点是: 1.在某些情况下,接口调用被阻止. 自动解除锁定需要一段时间. 2.它需要定期执行,不能实时更新. 更新太频繁,验证码被截获,频率太低,更新延迟太大.
方法3: 1.通过实时推送,您只需要提供一个API接口即可接收链接,将文章链接实时推送到顶部接口,并获得链接以下载内容并将其保存到您的平台.
此方法的优点: 1.不被阻塞; 2.不需要验证码; 3.技术难度低. 4.文章及时更新,延迟最小,最多三到五分钟. 4.文章链接永久有效. 可以实现真正的完全自动化. 缺点是您需要拥有自己的开发人员并具有用于接收参数的API.
如果有更好的方法,请与我联系并互相学习. 如果您需要技术支持,也可以与我联系. 以上方法已亲自尝试过. 有源代码(仅Java). 查看全部
这个问题需要在几种情况下回答
在第一种类型中,您只需要下载并重新编辑即可. 这个方法很简单. 一般来说,您知道所需的文章,即您知道该文章的访问地址. 通常,无论是以Word还是其他格式保存,都可以在采集器的帮助下进行下载.
第二种类型需要自动同步到您的平台. 这更加麻烦,因为您不知道下载地址(无法手动自动输入).
方法1: 1.使用搜狗浏览器调用其界面来搜索您的正式帐户名; 2.如果存在,请通过第二个界面查询官方帐户下的历史文章. 获取文章链接,通过程序下载它,并将其保存到您自己的背景中.
此方法的优点是: 半自动,无需手动输入文章链接. 缺点是: 1.如果您经常发送请求,搜狗将提示您输入验证码. 这需要手动处理,因此不能完全自动化. 2.获得的文章链接是临时的,需要在有效期内下载. 3.只能获取最近的十篇历史文章. 4.它需要定期执行,并且不能实时更新. 更新太频繁并且验证码被阻止,如果频率太低,则更新延迟也太低.
方法二,1.通过程序模拟登录到官方帐户后台管理页面. 2.通过模拟调用和编辑材料. 3.通过模拟编辑插入链接功能. 4.调用搜索官方帐户界面,并查询官方帐户以获取fackId. 5.通过获取的fackId调用另一个接口以获取文章列表. 本文列表中有链接.
此方法的优点是: 1.将没有验证码,但是在某些情况下,它是密封的,但是频率较低. 2.您可以获得官方帐户下所有文章的清单. 3.文章链接永久有效. 缺点是: 1.在某些情况下,接口调用被阻止. 自动解除锁定需要一段时间. 2.它需要定期执行,不能实时更新. 更新太频繁,验证码被截获,频率太低,更新延迟太大.
方法3: 1.通过实时推送,您只需要提供一个API接口即可接收链接,将文章链接实时推送到顶部接口,并获得链接以下载内容并将其保存到您的平台.
此方法的优点: 1.不被阻塞; 2.不需要验证码; 3.技术难度低. 4.文章及时更新,延迟最小,最多三到五分钟. 4.文章链接永久有效. 可以实现真正的完全自动化. 缺点是您需要拥有自己的开发人员并具有用于接收参数的API.
如果有更好的方法,请与我联系并互相学习. 如果您需要技术支持,也可以与我联系. 以上方法已亲自尝试过. 有源代码(仅Java).
织梦dedecms自动采集文章摘要教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 779 次浏览 • 2020-08-06 09:14
提交表: dede4_archives
2创建的新节点具有附加的文章摘要,并且匹配区域与文章内容的匹配区域相同(因为它占据了文章的一段),
使用所有过滤规则
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim} </p>
我不了解整个故事,请自己进行测试
3在自定义处理界面中填写复制代码
@me ='. substr(@me,0,200). '
'. @ me
上面基本上没问题
4如果已经有节点并且不想再次添加节点,则也可以在更改节点配置中添加此段
{dede:note field='dede4_archives.description' value='[var:内容]' comment='文章摘要'
isunit='1' isdown='1'}
{dede:match}[var:内容]{/dede:match}
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
关键字描述: 摘要教程文章自动采集dede: trim / dede: trim
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim}
{dede:function}@me='.substr(@me, 0, 200).'
'.@me {/dede:function}
{/dede:note}</p>
可以在测试后使用. 我也是新手. 我希望主人能为您提供帮助.
参考文章(张贴图片,避免说这是枪支文章) 查看全部
1向采集规则模型添加字段描述,并将其描述为文章摘要
提交表: dede4_archives
2创建的新节点具有附加的文章摘要,并且匹配区域与文章内容的匹配区域相同(因为它占据了文章的一段),
使用所有过滤规则
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim} </p>
我不了解整个故事,请自己进行测试
3在自定义处理界面中填写复制代码
@me ='. substr(@me,0,200). '
'. @ me
上面基本上没问题
4如果已经有节点并且不想再次添加节点,则也可以在更改节点配置中添加此段
{dede:note field='dede4_archives.description' value='[var:内容]' comment='文章摘要'
isunit='1' isdown='1'}
{dede:match}[var:内容]{/dede:match}
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
关键字描述: 摘要教程文章自动采集dede: trim / dede: trim
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}*{/dede:trim}
{dede:trim} {/dede:trim}
{dede:function}@me='.substr(@me, 0, 200).'
'.@me {/dede:function}
{/dede:note}</p>
可以在测试后使用. 我也是新手. 我希望主人能为您提供帮助.
参考文章(张贴图片,避免说这是枪支文章)
使用今日的头条自动收集高质量的文章材料实践技能!
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-04 20:01
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
就像上面的图片一样,一个单独的“种子”文件夹以收藏夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
1)注册或购买标题号码
2)输入定位标记词以查找文章
3)注意带有标签词的文章的标题
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
1)发表的文章数量很少;
2)刚刚注册了新帐户; 查看全部
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
就像上面的图片一样,一个单独的“种子”文件夹以收藏夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
1)注册或购买标题号码
2)输入定位标记词以查找文章
3)注意带有标签词的文章的标题
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
1)发表的文章数量很少;
2)刚刚注册了新帐户;

