
自动识别采集内容
自动识别采集内容(微seo自动分析竞争对手分析行业分析自己的产品分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-05 01:00
自动识别采集内容,自动聚合,自动推送,一键分享图文,多级分销那么多功能你总能给自己找一个能赚钱的好工具。微seo自动分析竞争对手分析行业分析用户喜好分析自己的产品分析你还不赶紧了解?基于智能大数据实现的自动分析,保障可靠,减少被骗机率。
微信公众号内的推送,其实是机器来处理的,
微信推送的文章是针对公众号做到的推送的,公众号要开通自动转发,推送的内容的原理,通过后台的公众号的配置,
大概得知道原理,但是不是特别清楚。
1、接收方将内容分享至微信或qq。
2、接收方再将内容以消息群发到群里。
4、接收方再将内容发送到对应的微信或qq群。对于开通了接收方微信与qq推送功能的公众号,其推送文章的数据处理也是很简单的,腾讯微信接收方微信已经做了预处理,一般应该有开放接口的可以拿到推送时的数据。另一方面,就公众号推送内容来讲,一般一篇原创文章的推送不会接收太多用户的阅读量,应该也会设计一个限制,可以尝试找准转发对象、内容风格、传播手段等。
有一种seo推送是:把一篇外链很多的微信公众号文章,一键推送到百度站长平台,效果还可以, 查看全部
自动识别采集内容(微seo自动分析竞争对手分析行业分析自己的产品分析)
自动识别采集内容,自动聚合,自动推送,一键分享图文,多级分销那么多功能你总能给自己找一个能赚钱的好工具。微seo自动分析竞争对手分析行业分析用户喜好分析自己的产品分析你还不赶紧了解?基于智能大数据实现的自动分析,保障可靠,减少被骗机率。
微信公众号内的推送,其实是机器来处理的,
微信推送的文章是针对公众号做到的推送的,公众号要开通自动转发,推送的内容的原理,通过后台的公众号的配置,
大概得知道原理,但是不是特别清楚。
1、接收方将内容分享至微信或qq。
2、接收方再将内容以消息群发到群里。
4、接收方再将内容发送到对应的微信或qq群。对于开通了接收方微信与qq推送功能的公众号,其推送文章的数据处理也是很简单的,腾讯微信接收方微信已经做了预处理,一般应该有开放接口的可以拿到推送时的数据。另一方面,就公众号推送内容来讲,一般一篇原创文章的推送不会接收太多用户的阅读量,应该也会设计一个限制,可以尝试找准转发对象、内容风格、传播手段等。
有一种seo推送是:把一篇外链很多的微信公众号文章,一键推送到百度站长平台,效果还可以,
自动识别采集内容(基于VC语言编写客户端的模式搭建,无需WEB或.net等臃肿架构)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-02 11:37
Instant Information采集Expert(Instant Information采集Expert官方下载)V8.0.1.1官方版
一套互联网信息采集软件。该软件基于人工智能的自动学习技术。只要输入目标网站的URL,它就可以自动监控并上传新信息到采集目标网站,并自动过滤掉无关信息(如广告)。信息、版权信息等)达到所见即所得的效果。
同时可以自动识别与信息相关的图片、附件等感兴趣的媒体资源,并可以根据设置自动采集到本地或创建映射快照。软件对分页的信息具有自动重组功能,节省翻页时间。
鉴于互联网信息知识产权的重要性,当信息为采集时,软件会自动识别信息的原作者和来源,解决信息引用的版权问题。您可以抓取带有参数的静态网页或动态网页。采集的信息可以根据设置保存到本地数据库,也可以建立信息映射。
一旦目标网站信息发生变化,软件会将新的信息采集保存到本地数据库中,而不受原网站删除内容的影响。只要选择一条信息记录,该记录的信息会立即显示在阅读界面上,无需访问目标网站。软件支持多种数据库,Access、MS SQL Server、Oracle、Sybase等。
可以实现海量数据采集和重复检查功能。基于VC语言编写客户端模型,无需WEB或.net等臃肿的架构。占用系统资源少。原创阅读模板技术,使用采集即可立即阅读展示。真正实现了所采取的。它使软件的用户感到舒适和快乐。
Win8/Win7/WinXP 简体中文 查看全部
自动识别采集内容(基于VC语言编写客户端的模式搭建,无需WEB或.net等臃肿架构)
Instant Information采集Expert(Instant Information采集Expert官方下载)V8.0.1.1官方版
一套互联网信息采集软件。该软件基于人工智能的自动学习技术。只要输入目标网站的URL,它就可以自动监控并上传新信息到采集目标网站,并自动过滤掉无关信息(如广告)。信息、版权信息等)达到所见即所得的效果。
同时可以自动识别与信息相关的图片、附件等感兴趣的媒体资源,并可以根据设置自动采集到本地或创建映射快照。软件对分页的信息具有自动重组功能,节省翻页时间。
鉴于互联网信息知识产权的重要性,当信息为采集时,软件会自动识别信息的原作者和来源,解决信息引用的版权问题。您可以抓取带有参数的静态网页或动态网页。采集的信息可以根据设置保存到本地数据库,也可以建立信息映射。
一旦目标网站信息发生变化,软件会将新的信息采集保存到本地数据库中,而不受原网站删除内容的影响。只要选择一条信息记录,该记录的信息会立即显示在阅读界面上,无需访问目标网站。软件支持多种数据库,Access、MS SQL Server、Oracle、Sybase等。
可以实现海量数据采集和重复检查功能。基于VC语言编写客户端模型,无需WEB或.net等臃肿的架构。占用系统资源少。原创阅读模板技术,使用采集即可立即阅读展示。真正实现了所采取的。它使软件的用户感到舒适和快乐。
Win8/Win7/WinXP 简体中文
自动识别采集内容( 自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-01 14:14
自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)
2021 年 7 月 12 日 — 自动内容识别技术服务提供商 ACRCloud 今天宣布,它已为音乐行业增加了重量级合作伙伴。全球领先的音乐发行服务提供商果园采用ACRCloud提供的版权合规和重复数据删除解决方案来监控音乐版权和管理歌曲数据库。
ACRCloud 的版权合规服务帮助 The Orchard 监控创作者上传的音乐内容,避免版权侵权风险。
ACRCloud 专注于音频指纹技术。其提供的内容自动识别引擎自动扫描上传的音视频内容,为媒体文件生成唯一的音频指纹,并通过与云端音乐版权数据库中的指纹文件进行比对来识别版权内容。音视频文件的识别准确率处于世界领先水平。
ACRCloud通过与音乐行业各版权方的合作,包括各大唱片公司、音乐版权代理公司等,建立了海量的音乐版权数据库。
ACRCloud 还帮助 The Orchard 管理自己的音乐库。扫描其音乐库后,使用相同的内容识别技术来识别和删除重复的媒体文件。
除了允许用户自主上传内容的在线平台(UGC),ACRCloud的自动内容识别技术和服务也被各种音乐服务和其他数字内容平台广泛采用,用于音乐识别、互联网、音频和传统媒体视频内容监控。等待。
ACRCloud 联合创始人李云波表示:“我们很高兴我们的服务可以帮助他们在 The Orchard 生态系统扩展过程中监控版权侵权和管理音乐库。”
The Orchard 首席技术官 Jacob Fowler 表示:“与 ACRCloud 的合作表明 The Orchard 一直采用创新技术和专注的产品来确保客户的版权得到大规模保护。我们期待继续探索这一点未来与 ACRCloud 的领域。技能得到提高。”
关于 ACRCloud
ACRCloud提供高性价比的自动内容识别技术、音视频内容识别和版权监控解决方案。公司客户包括网易云音乐、Deezer、Anghami、Tunecore、RouteNote、Amuse和Believe。ACRCloud在2015年和2016年音乐信息检索评估交流(MIREX)国际音乐检索评估大赛中,音频检索排名第一。 查看全部
自动识别采集内容(
自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)

2021 年 7 月 12 日 — 自动内容识别技术服务提供商 ACRCloud 今天宣布,它已为音乐行业增加了重量级合作伙伴。全球领先的音乐发行服务提供商果园采用ACRCloud提供的版权合规和重复数据删除解决方案来监控音乐版权和管理歌曲数据库。
ACRCloud 的版权合规服务帮助 The Orchard 监控创作者上传的音乐内容,避免版权侵权风险。
ACRCloud 专注于音频指纹技术。其提供的内容自动识别引擎自动扫描上传的音视频内容,为媒体文件生成唯一的音频指纹,并通过与云端音乐版权数据库中的指纹文件进行比对来识别版权内容。音视频文件的识别准确率处于世界领先水平。
ACRCloud通过与音乐行业各版权方的合作,包括各大唱片公司、音乐版权代理公司等,建立了海量的音乐版权数据库。
ACRCloud 还帮助 The Orchard 管理自己的音乐库。扫描其音乐库后,使用相同的内容识别技术来识别和删除重复的媒体文件。
除了允许用户自主上传内容的在线平台(UGC),ACRCloud的自动内容识别技术和服务也被各种音乐服务和其他数字内容平台广泛采用,用于音乐识别、互联网、音频和传统媒体视频内容监控。等待。
ACRCloud 联合创始人李云波表示:“我们很高兴我们的服务可以帮助他们在 The Orchard 生态系统扩展过程中监控版权侵权和管理音乐库。”
The Orchard 首席技术官 Jacob Fowler 表示:“与 ACRCloud 的合作表明 The Orchard 一直采用创新技术和专注的产品来确保客户的版权得到大规模保护。我们期待继续探索这一点未来与 ACRCloud 的领域。技能得到提高。”
关于 ACRCloud
ACRCloud提供高性价比的自动内容识别技术、音视频内容识别和版权监控解决方案。公司客户包括网易云音乐、Deezer、Anghami、Tunecore、RouteNote、Amuse和Believe。ACRCloud在2015年和2016年音乐信息检索评估交流(MIREX)国际音乐检索评估大赛中,音频检索排名第一。
自动识别采集内容( 汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-01 14:11
汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
中文分词
中文词法分析中间件可以对中文进行拆分和处理,是中文信息处理必不可少的核心组件。灵久整合各家公司的优势,采用条件随机场(CRF)模型,分词准确率接近99%。
文本 关键词 提取
文章关键词 抽取中间件可以在充分掌握文章的中心思想的基础上,抽取几个代表文章语义内容的词或词组,以及相关的结果可用于精读、语义查询和快速匹配等。
自动汇总
自动文本摘要中间件可以实现文本内容的简化和细化,自动从长文章中提取关键句和关键段落形成摘要内容,方便用户快速浏览文本内容和提高工作效率。
自动代码识别和转换
自动识别多种语言编码,如Big5、Unicode、UTF-8、GB1830等,并转换为一种编码;它可以自动识别GBK中的繁体和简体汉字并将其转换为简体汉字。.
大数据文本过滤
灵久IFCA系统是灵久自主研发的大数据信息智能过滤和内容审核系统,可以快速便捷地匹配大量自定义关键词和词。
大数据文本去重
在大数据中,重复数据是不可避免的。以互联网新闻网页为例,大约60%的互联网新闻网页被复制。所谓重复数据,往往是指基本内容相同,但在具体的词句上往往略有不同的数据。
大数据文本分类
大数据的特点是其价值信息量大、密度低。因此,需要采用大数据分类技术对海量数据进行分类整理。大数据分类技术可以根据用户预设的分类体系对数据进行分类。
大数据文本聚类
大数据文本聚类可以自动整理大数据文档,总结热点趋势,将内容相似的信息归为一类,按热门程度排序,并自动生成该类别的标题和主题词。适用于热点排名自动生成、热点事件识别、热点趋势发现等诸多应用。
大数据特征提取
大量的数据对应着大量的噪声信息,不可避免地带来了大数据的混乱。如何从大数据中提取关键的代表性特征,可能是某些词汇,或某些短语,命名实体,或流行语,已成为大数据分析的有力工具。 查看全部
自动识别采集内容(
汉语智能分词汉语词法分析能对汉语语言进行拆分处理)

中文分词
中文词法分析中间件可以对中文进行拆分和处理,是中文信息处理必不可少的核心组件。灵久整合各家公司的优势,采用条件随机场(CRF)模型,分词准确率接近99%。
文本 关键词 提取
文章关键词 抽取中间件可以在充分掌握文章的中心思想的基础上,抽取几个代表文章语义内容的词或词组,以及相关的结果可用于精读、语义查询和快速匹配等。


自动汇总
自动文本摘要中间件可以实现文本内容的简化和细化,自动从长文章中提取关键句和关键段落形成摘要内容,方便用户快速浏览文本内容和提高工作效率。
自动代码识别和转换
自动识别多种语言编码,如Big5、Unicode、UTF-8、GB1830等,并转换为一种编码;它可以自动识别GBK中的繁体和简体汉字并将其转换为简体汉字。.

大数据文本过滤
灵久IFCA系统是灵久自主研发的大数据信息智能过滤和内容审核系统,可以快速便捷地匹配大量自定义关键词和词。
大数据文本去重
在大数据中,重复数据是不可避免的。以互联网新闻网页为例,大约60%的互联网新闻网页被复制。所谓重复数据,往往是指基本内容相同,但在具体的词句上往往略有不同的数据。


大数据文本分类
大数据的特点是其价值信息量大、密度低。因此,需要采用大数据分类技术对海量数据进行分类整理。大数据分类技术可以根据用户预设的分类体系对数据进行分类。
大数据文本聚类
大数据文本聚类可以自动整理大数据文档,总结热点趋势,将内容相似的信息归为一类,按热门程度排序,并自动生成该类别的标题和主题词。适用于热点排名自动生成、热点事件识别、热点趋势发现等诸多应用。


大数据特征提取
大量的数据对应着大量的噪声信息,不可避免地带来了大数据的混乱。如何从大数据中提取关键的代表性特征,可能是某些词汇,或某些短语,命名实体,或流行语,已成为大数据分析的有力工具。
自动识别采集内容(自动识别采集内容,配合有ai的浏览器(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-30 08:01
自动识别采集内容,配合有ai的浏览器,比如百度浏览器、360浏览器、uc浏览器、qq浏览器,就能生成一个新闻类网站了。用这些ai浏览器,基本不需要开发,能过滤,搜索功能。基本等同于软件自动爬虫。
网页分析生成类似于"爬虫"功能,至于题主所说的把代码发给老板看看那就是领导想看看你为什么这么屌,建议多去几个wordpress论坛社区逛逛看看,发现一下更屌的。
业务需求?就是你可以去应付,
技术好的话肯定有人整这个,属于我的话,我就说自己无能这些小把戏,需要看这个站是什么内容,然后去买一些语料库,写几个脚本,自己写代码。能生成的最后需要浏览器的支持才行,好多ghost的app就有只能识别文字但是不能访问外链的。
人才生成。无能的就机器爬虫。
与其让高手把代码一句句讲,不如教给初级的小白如何安装与使用,因为,他也可以自己去找视频自学。
公司有站长资源的,你可以把需要的内容做成网站,并上传相关的代码,销售给网络公司,
做个自己的小程序应该可以做到
php+nginx+h5+js+git
先学java基础,再去学ios,再去学android。这里都是最简单的,
好多人问你推荐我什么, 查看全部
自动识别采集内容(自动识别采集内容,配合有ai的浏览器(图))
自动识别采集内容,配合有ai的浏览器,比如百度浏览器、360浏览器、uc浏览器、qq浏览器,就能生成一个新闻类网站了。用这些ai浏览器,基本不需要开发,能过滤,搜索功能。基本等同于软件自动爬虫。
网页分析生成类似于"爬虫"功能,至于题主所说的把代码发给老板看看那就是领导想看看你为什么这么屌,建议多去几个wordpress论坛社区逛逛看看,发现一下更屌的。
业务需求?就是你可以去应付,
技术好的话肯定有人整这个,属于我的话,我就说自己无能这些小把戏,需要看这个站是什么内容,然后去买一些语料库,写几个脚本,自己写代码。能生成的最后需要浏览器的支持才行,好多ghost的app就有只能识别文字但是不能访问外链的。
人才生成。无能的就机器爬虫。
与其让高手把代码一句句讲,不如教给初级的小白如何安装与使用,因为,他也可以自己去找视频自学。
公司有站长资源的,你可以把需要的内容做成网站,并上传相关的代码,销售给网络公司,
做个自己的小程序应该可以做到
php+nginx+h5+js+git
先学java基础,再去学ios,再去学android。这里都是最简单的,
好多人问你推荐我什么,
自动识别采集内容(如何用vue+前端框架,vue服务后端的流程?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-27 06:04
自动识别采集内容,
现在建议尽量不要用vue+前端框架,前端入门要更简单,所以框架就没有那么大吸引力,而且vue服务后端的一个整个流程,效率比较低下,如果你前端开发水平比较高的话,
你不嫌麻烦,也不用那个框架。可以用现有的expressjs可以做网站。expressjs就像前端框架,里面没有前端框架。后端逻辑,数据,数据库表单表等。但是因为expressjs本身是express的拓展,所以很多特性,比如mongodb的支持,excpl的支持。都给你兼容,方便上手!特别是mongodb,就是为expressjs做了mongodb支持。
expressjs里面有directjs封装express,做web应用的时候可以方便使用。另外还有flask,laravel这些主流的框架。如果不是用户过多。没有必要用那个框架!expressjs也没有那么难!可以去看看视频。了解一下,还是比较推荐expressjs。等有了框架的经验,你会体会到用expressjs的感觉。
是不是框架这是用不着有歧义的。推荐三个可以直接在网上搜索!1.express教程2.docs.github.io3.express教程express教程docs.github.io。
用过nodejs来做,express。一开始是我在学习webpack的时候感觉vue是解决分页这个问题,在项目这么大的基础上,再来做分页,redis是不够用了,再一次印证了express比vue好,并且还要快好多, 查看全部
自动识别采集内容(如何用vue+前端框架,vue服务后端的流程?)
自动识别采集内容,
现在建议尽量不要用vue+前端框架,前端入门要更简单,所以框架就没有那么大吸引力,而且vue服务后端的一个整个流程,效率比较低下,如果你前端开发水平比较高的话,
你不嫌麻烦,也不用那个框架。可以用现有的expressjs可以做网站。expressjs就像前端框架,里面没有前端框架。后端逻辑,数据,数据库表单表等。但是因为expressjs本身是express的拓展,所以很多特性,比如mongodb的支持,excpl的支持。都给你兼容,方便上手!特别是mongodb,就是为expressjs做了mongodb支持。
expressjs里面有directjs封装express,做web应用的时候可以方便使用。另外还有flask,laravel这些主流的框架。如果不是用户过多。没有必要用那个框架!expressjs也没有那么难!可以去看看视频。了解一下,还是比较推荐expressjs。等有了框架的经验,你会体会到用expressjs的感觉。
是不是框架这是用不着有歧义的。推荐三个可以直接在网上搜索!1.express教程2.docs.github.io3.express教程express教程docs.github.io。
用过nodejs来做,express。一开始是我在学习webpack的时候感觉vue是解决分页这个问题,在项目这么大的基础上,再来做分页,redis是不够用了,再一次印证了express比vue好,并且还要快好多,
自动识别采集内容(知乎的所谓“二维码自动识别”功能是如此的傻逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 588 次浏览 • 2021-09-24 17:02
前几天想聊聊知乎所谓的“自动识别二维码”功能。这个功能太蠢了,我决定专门写一篇文章来批评它。
首先,如果一张图片中有多个二维码,它会自动识别左上角的那个。真正需要的人必须在两张图片中显示两个二维码……呸,两张图片自动识别为两个URL。
其次,如果在手机客户端,二维码的自动识别功能不仅实用,而且是必须的,因为用手机扫描自己身上的二维码是个悖论。但是,知乎文章页面和栏目是可以同时在电脑、手机网页和客户端看到的产品。在电脑上扫码后,在某些情况下,会跳转到一个只能用手机(只有微信)才能访问的网页。这时候就会出现很多问题。
所有需要微信登录的产品——比如一些公司给员工做的问卷——或者朋友圈分享抽奖——都在电脑端打开,提示“请在微信客户端打开操作”。如果你碰巧没有手机,你只能
登录Windows PC版微信-注意不是网页版,然后,
将此链接复制到“文件传输助手”
用电脑版自带的浏览器打开。
在 Mac 版本中,即使输入 URL,也会调用系统内置的浏览器。这个问题是无解的。是的,即使你修改了浏览器的User-Agent,假装你是iPhone也没有用,因为你无法调用微信客户端的自动登录功能。
这样知乎在栏目和正文中完美屏蔽了竞争对手奋达,因为奋达的二维码必须通过微信扫描,哪怕是手机自带的条码扫描器,或者使用客户端扫描如支付宝和微博是不可能的。一旦链接在电脑上直接生成并点击,它会自动跳转到子答案的首页,而不是用户自己的页面,这样它就无法为你分流。
很有可能3.0在上线的时候就看到了这个问题,所以虽然一定要通过二维码推广,但是二维码扫描到的网址就算是在电脑端个人资料页打开也是你的. 但是在提问和支付的过程中会遇到瓶颈,必须使用微信客户端打开。
所以如果这个傻瓜式决定真的是知乎官方做出的屏蔽子回答的决定,那真的可以说是对敌人造成1000伤害,对自己造成800伤害。 ——即使你必须这样做,你知不知道文章中提供打赏功能的同时,还收录了自己产品的专属链接? 查看全部
自动识别采集内容(知乎的所谓“二维码自动识别”功能是如此的傻逼)
前几天想聊聊知乎所谓的“自动识别二维码”功能。这个功能太蠢了,我决定专门写一篇文章来批评它。
首先,如果一张图片中有多个二维码,它会自动识别左上角的那个。真正需要的人必须在两张图片中显示两个二维码……呸,两张图片自动识别为两个URL。
其次,如果在手机客户端,二维码的自动识别功能不仅实用,而且是必须的,因为用手机扫描自己身上的二维码是个悖论。但是,知乎文章页面和栏目是可以同时在电脑、手机网页和客户端看到的产品。在电脑上扫码后,在某些情况下,会跳转到一个只能用手机(只有微信)才能访问的网页。这时候就会出现很多问题。
所有需要微信登录的产品——比如一些公司给员工做的问卷——或者朋友圈分享抽奖——都在电脑端打开,提示“请在微信客户端打开操作”。如果你碰巧没有手机,你只能
登录Windows PC版微信-注意不是网页版,然后,
将此链接复制到“文件传输助手”
用电脑版自带的浏览器打开。
在 Mac 版本中,即使输入 URL,也会调用系统内置的浏览器。这个问题是无解的。是的,即使你修改了浏览器的User-Agent,假装你是iPhone也没有用,因为你无法调用微信客户端的自动登录功能。
这样知乎在栏目和正文中完美屏蔽了竞争对手奋达,因为奋达的二维码必须通过微信扫描,哪怕是手机自带的条码扫描器,或者使用客户端扫描如支付宝和微博是不可能的。一旦链接在电脑上直接生成并点击,它会自动跳转到子答案的首页,而不是用户自己的页面,这样它就无法为你分流。
很有可能3.0在上线的时候就看到了这个问题,所以虽然一定要通过二维码推广,但是二维码扫描到的网址就算是在电脑端个人资料页打开也是你的. 但是在提问和支付的过程中会遇到瓶颈,必须使用微信客户端打开。
所以如果这个傻瓜式决定真的是知乎官方做出的屏蔽子回答的决定,那真的可以说是对敌人造成1000伤害,对自己造成800伤害。 ——即使你必须这样做,你知不知道文章中提供打赏功能的同时,还收录了自己产品的专属链接?
自动识别采集内容( 基于内容的网络水军检测方法及系统的社交网络识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 20:24
基于内容的网络水军检测方法及系统的社交网络识别)
本发明涉及社交网络的网络海军识别领域,具体涉及一种网络海军的自动识别方法和系统,以实现社交网络中网络海军的更自动、更准确的识别
背景技术:
随着社交网络相关应用的快速发展,越来越多的活动转移到社交网络。社交网络通常包括国外的Facebook、Google+、twitter等以及国内的新浪微博、腾讯微博、人人网等,但目前社交网络中存在着大量的网络水资源。社交网络中的网络水资源通常有助于网络信息的传播或恶意攻击某些社交网络帐户。他们在政治和商业利益的驱使下,通过操纵软件机器人或海军账户,在互联网上制造和传播虚假意见和垃圾邮件,以达到影响网络舆论、扰乱网络环境等不正当目的。这些行为严重影响了社交网络用户体验,也带来了严重的安全问题
在现有的社交网络中,网络识别方法主要利用社交网络的消息内容。一种相对简单的基于内容的网络检测方法(k.lee,j.Caverley,ands.webb.《发现社交Pammers:socialhoneypots+machinelearning.InProcedingsofSigir》,2010)这是一个有监督的学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来建立分类器。给定一个新用户,分类器将分类标签输出给j判断新用户是否是社交网络然而,这些方法通常需要大量的标记数据(这些数据通常是人工标记的),耗时费力,而且人工标记的数据集很小,这给社交网络中的网络检测带来了很大的挑战
技术实现要素:
由于以往的社会网络识别方法大多将其视为一个分类问题,需要使用大量的标记数据集,而标记数据需要大量的人力,且标记数据集的规模一般较小,训练模型的泛化能力较弱
基于此,本发明的目的是提供一种网络海军的自动识别方法和系统,该方法和系统不需要对数据集进行人工标注,避免了费时费力的标注工作,不需要模型训练,能够在社交网络中快速有效地识别网络海军劳动
鉴于上述缺点,本发明采用的技术方案为:
本发明涉及一种网络海军的自动识别方法,包括以下步骤:
1)采集社交网络中身份验证帐户的消息信息以及每条消息下的评论信息
2)监控上述每条消息下的每条评论信息是否被删除,如果是,则读取与评论信息对应的帐户历史记录中已删除评论的数量
3)如果上述账户历史记录中删除的评论数符合预设条件,则该账户为在线账户
此外,步骤1)包括以下步骤:
模拟1-1)社交网络用户登录
1-2)获取社交网络中的认证账号列表,采集获取每个认证账号的消息信息
1-3)获取每条消息下的消息列表和采集评论信息
此外,步骤1)中的认证账户是指社交网络正式认证的账户,认证账户的类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户
此外,在步骤1),消息信息包括但不限于消息URL、消息内容、消息发布时间、消息评论数量、消息转发数量和消息喜好数量;评论信息包括但不限于评论URL、评论内容、评论时间和评论用户
此外,如果步骤1)中的消息信息的释放时间超过一个月,则删除消息信息
此外,步骤2)如下:获取每条消息下评论信息的评论列表,监控评论列表中每个评论信息的删除;如果评论信息被删除,则读取评论信息对应账户的历史删除评论
此外,步骤3)中的预设条件包括:
1)da≫=10;其中Da表示帐户历史记录中已删除注释的总数
2)da/na>;=0.2;其中Na表示帐户上的评论总数
3)account历史记录中第一条删除的评论与最近一条删除的评论之间的时间间隔超过一周
本实用新型涉及一种网络海军自动识别系统,包括数据采集模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
此外,该系统还包括数据存储模块,用于存储上述消息信息和每条消息下的注释信息
此外,海军识别模块包括评论监控模块和海军识别模块
评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取该评论信息对应账户的历史删除评论数
海军识别模块用于确定上述账户的历史删除评论数是否符合预设条件,如果符合,则该账户为网络海军
传统的网络海军识别方法一般采用机器学习的监督学习方法,需要大量的标注数据集进行模型训练,这些数据集通常需要大量的人力进行标注,本发明提供了一种网络海军的自动识别方法和系统,该方法和系统具有以下特点:具有以下优点:
1、此方法和系统消除了手动标记和模型培训
2、该方法和系统能够快速有效地识别社交网络中的在线海军,即当账户评论信息历史记录中删除的评论数量满足预设条件时,确定该账户为在线海军
3、该方法和系统适用于多个社交网络,可以跨平台运行
图纸说明
图1是本发明提供的网络海军的自动识别系统的框图
图2是本发明提供的网络设备的自动识别方法的流程图
具体实施例
为了使本发明的上述特征和优点更加明显和易于理解,下面给出实施例,并结合附图给出详细描述
本发明提供了一种网络海军的自动识别方法和系统,见图1,该系统包括数据采集模块、数据存储模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
数据存储模块用于存储每条消息下的消息信息和评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
海军识别模块还包括评论监控模块和海军识别模块;评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取与评论信息对应的账户的历史删除评论;海军识别模块该模块用于判断该账户的历史删除评论是否符合预设条件,如果符合,则该账户为在线用户
本发明的方法主要包括两部分:
1)采集社交网络中认证账号下的用户消息:利用Ajax仿真技术模拟用户访问社交网络的方式,设计并实现了社交网络中用户消息的采集和存储,如图1所示,数据采集部分和数据存储部分获取了一些用户的消息信息通过采集在社交网络中验证帐户,并获取每条消息下的评论。验证帐户指社交网络正式验证的帐户(每个帐户对应一个用户).一般来说,认证账号的头像右下角标有V;用户消息是指用户在社交网络上发布的信息,具体包括消息内容、消息发布者、消息发布时间等
2)识别社交网络中的网络水军:使用评论监控模块实时监控每条消息下的评论信息,并通过与现有评论进行比较来监控评论的删除。如果 查看全部
自动识别采集内容(
基于内容的网络水军检测方法及系统的社交网络识别)

本发明涉及社交网络的网络海军识别领域,具体涉及一种网络海军的自动识别方法和系统,以实现社交网络中网络海军的更自动、更准确的识别
背景技术:
随着社交网络相关应用的快速发展,越来越多的活动转移到社交网络。社交网络通常包括国外的Facebook、Google+、twitter等以及国内的新浪微博、腾讯微博、人人网等,但目前社交网络中存在着大量的网络水资源。社交网络中的网络水资源通常有助于网络信息的传播或恶意攻击某些社交网络帐户。他们在政治和商业利益的驱使下,通过操纵软件机器人或海军账户,在互联网上制造和传播虚假意见和垃圾邮件,以达到影响网络舆论、扰乱网络环境等不正当目的。这些行为严重影响了社交网络用户体验,也带来了严重的安全问题
在现有的社交网络中,网络识别方法主要利用社交网络的消息内容。一种相对简单的基于内容的网络检测方法(k.lee,j.Caverley,ands.webb.《发现社交Pammers:socialhoneypots+machinelearning.InProcedingsofSigir》,2010)这是一个有监督的学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来建立分类器。给定一个新用户,分类器将分类标签输出给j判断新用户是否是社交网络然而,这些方法通常需要大量的标记数据(这些数据通常是人工标记的),耗时费力,而且人工标记的数据集很小,这给社交网络中的网络检测带来了很大的挑战
技术实现要素:
由于以往的社会网络识别方法大多将其视为一个分类问题,需要使用大量的标记数据集,而标记数据需要大量的人力,且标记数据集的规模一般较小,训练模型的泛化能力较弱
基于此,本发明的目的是提供一种网络海军的自动识别方法和系统,该方法和系统不需要对数据集进行人工标注,避免了费时费力的标注工作,不需要模型训练,能够在社交网络中快速有效地识别网络海军劳动
鉴于上述缺点,本发明采用的技术方案为:
本发明涉及一种网络海军的自动识别方法,包括以下步骤:
1)采集社交网络中身份验证帐户的消息信息以及每条消息下的评论信息
2)监控上述每条消息下的每条评论信息是否被删除,如果是,则读取与评论信息对应的帐户历史记录中已删除评论的数量
3)如果上述账户历史记录中删除的评论数符合预设条件,则该账户为在线账户
此外,步骤1)包括以下步骤:
模拟1-1)社交网络用户登录
1-2)获取社交网络中的认证账号列表,采集获取每个认证账号的消息信息
1-3)获取每条消息下的消息列表和采集评论信息
此外,步骤1)中的认证账户是指社交网络正式认证的账户,认证账户的类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户
此外,在步骤1),消息信息包括但不限于消息URL、消息内容、消息发布时间、消息评论数量、消息转发数量和消息喜好数量;评论信息包括但不限于评论URL、评论内容、评论时间和评论用户
此外,如果步骤1)中的消息信息的释放时间超过一个月,则删除消息信息
此外,步骤2)如下:获取每条消息下评论信息的评论列表,监控评论列表中每个评论信息的删除;如果评论信息被删除,则读取评论信息对应账户的历史删除评论
此外,步骤3)中的预设条件包括:
1)da≫=10;其中Da表示帐户历史记录中已删除注释的总数
2)da/na>;=0.2;其中Na表示帐户上的评论总数
3)account历史记录中第一条删除的评论与最近一条删除的评论之间的时间间隔超过一周
本实用新型涉及一种网络海军自动识别系统,包括数据采集模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
此外,该系统还包括数据存储模块,用于存储上述消息信息和每条消息下的注释信息
此外,海军识别模块包括评论监控模块和海军识别模块
评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取该评论信息对应账户的历史删除评论数
海军识别模块用于确定上述账户的历史删除评论数是否符合预设条件,如果符合,则该账户为网络海军
传统的网络海军识别方法一般采用机器学习的监督学习方法,需要大量的标注数据集进行模型训练,这些数据集通常需要大量的人力进行标注,本发明提供了一种网络海军的自动识别方法和系统,该方法和系统具有以下特点:具有以下优点:
1、此方法和系统消除了手动标记和模型培训
2、该方法和系统能够快速有效地识别社交网络中的在线海军,即当账户评论信息历史记录中删除的评论数量满足预设条件时,确定该账户为在线海军
3、该方法和系统适用于多个社交网络,可以跨平台运行
图纸说明
图1是本发明提供的网络海军的自动识别系统的框图
图2是本发明提供的网络设备的自动识别方法的流程图
具体实施例
为了使本发明的上述特征和优点更加明显和易于理解,下面给出实施例,并结合附图给出详细描述
本发明提供了一种网络海军的自动识别方法和系统,见图1,该系统包括数据采集模块、数据存储模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
数据存储模块用于存储每条消息下的消息信息和评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
海军识别模块还包括评论监控模块和海军识别模块;评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取与评论信息对应的账户的历史删除评论;海军识别模块该模块用于判断该账户的历史删除评论是否符合预设条件,如果符合,则该账户为在线用户
本发明的方法主要包括两部分:
1)采集社交网络中认证账号下的用户消息:利用Ajax仿真技术模拟用户访问社交网络的方式,设计并实现了社交网络中用户消息的采集和存储,如图1所示,数据采集部分和数据存储部分获取了一些用户的消息信息通过采集在社交网络中验证帐户,并获取每条消息下的评论。验证帐户指社交网络正式验证的帐户(每个帐户对应一个用户).一般来说,认证账号的头像右下角标有V;用户消息是指用户在社交网络上发布的信息,具体包括消息内容、消息发布者、消息发布时间等
2)识别社交网络中的网络水军:使用评论监控模块实时监控每条消息下的评论信息,并通过与现有评论进行比较来监控评论的删除。如果
自动识别采集内容(优采云瀑布流+页码的组合形式展示页码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-14 08:16
通常采集list 数据时,会有分页,采集pagination 数据呢?在优采云采集器中,我们可以采集以下类型的分页
1.自动识别分页
优采云采集器可以识别90%的分页元素,通过选择分页设置->自动识别分页。
2.手动设置分页
无法自动识别时,我们需要手动设置分页。如何手动设置分页?
首先选择分页设置->手动设置分页,点击选择分页元素,在浏览器中找到下一个页面元素并点击。
3.瀑布分页
现在很多网页都使用瀑布分页技术,比如百度图片、知乎、今日头条。对于这种类型的网页,直接选择瀑布分页。 采集器会自动滚动到页面,直到分页完成。
4.瀑布流+页码组合
有些网站会以瀑布流+分页页码的形式显示,比如向下滚动5次才会显示分页页码。步骤如下:
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体需要测试网站。第三步是设置。其他设置中勾选Execute 采集 script on pagination,这样每次打开分页都会执行scroll命令。
加载更多表单
有些网站 会使用加载更多按钮来显示更多数据。 采集这种类型的页面,需要手动设置分页,点击下一页按钮加载更多。
设置采集max 分页
您可以将最大页数设置为采集。这在更新采集 时非常必要。比如网站每天更新前3页的内容,我们可以设置最大分页为3页。 查看全部
自动识别采集内容(优采云瀑布流+页码的组合形式展示页码)
通常采集list 数据时,会有分页,采集pagination 数据呢?在优采云采集器中,我们可以采集以下类型的分页
1.自动识别分页
优采云采集器可以识别90%的分页元素,通过选择分页设置->自动识别分页。

2.手动设置分页
无法自动识别时,我们需要手动设置分页。如何手动设置分页?
首先选择分页设置->手动设置分页,点击选择分页元素,在浏览器中找到下一个页面元素并点击。

3.瀑布分页
现在很多网页都使用瀑布分页技术,比如百度图片、知乎、今日头条。对于这种类型的网页,直接选择瀑布分页。 采集器会自动滚动到页面,直到分页完成。
4.瀑布流+页码组合
有些网站会以瀑布流+分页页码的形式显示,比如向下滚动5次才会显示分页页码。步骤如下:
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体需要测试网站。第三步是设置。其他设置中勾选Execute 采集 script on pagination,这样每次打开分页都会执行scroll命令。

加载更多表单
有些网站 会使用加载更多按钮来显示更多数据。 采集这种类型的页面,需要手动设置分页,点击下一页按钮加载更多。
设置采集max 分页
您可以将最大页数设置为采集。这在更新采集 时非常必要。比如网站每天更新前3页的内容,我们可以设置最大分页为3页。
自动识别采集内容(自动识别采集内容,才开始去采集不知道是哪个网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-08 15:04
自动识别采集内容,才开始去采集不知道是哪个网站,但是都是去请求的,问题出在请求开始,请求失败,选择一个无js开发的网站:是发现有一个异常,要去除不出其他的错误去选择一个采集成功的网站就开始采集,选择一个无格式数据的网站就开始采集,会有很多情况,比如选择json,其实json本身是没有数据的,选择一个无关数据的开始采集,再其他的都是采集不出结果来.中途的推测失败,该网站如果采集出一定的数据规律,还是很容易发现这个网站采集规律.事后想想,之前可能会犯错误,才导致思维的缺陷。
上面这个是问题解决了思维中的短板。而真正可怕的是,内容数据采集失败了,但是还没有想好采集这些数据到底有什么意义,如果你之前没有思考过采集数据的意义,那么,根本不需要再去想意义是什么.所以还是要一个字:贵,所以,贵在花时间和精力在各种想法上,决定“一切先从小事做起”.。
首先,你得通过一个前端公共接口,找到你希望采集的页面。然后看下该页面一般有哪些地方会有链接。比如,百度首页上至少有几十万个的相同页面链接,只要满足里面的链接。都可以在一个公共接口得到来自该页面的数据。比如,我要爬取java学习频道的数据,那我就要找到它的公共接口是什么。然后就是简单修改下代码,再上网去爬数据咯。关于采集技术请关注公众号石墨源站长获取。 查看全部
自动识别采集内容(自动识别采集内容,才开始去采集不知道是哪个网站)
自动识别采集内容,才开始去采集不知道是哪个网站,但是都是去请求的,问题出在请求开始,请求失败,选择一个无js开发的网站:是发现有一个异常,要去除不出其他的错误去选择一个采集成功的网站就开始采集,选择一个无格式数据的网站就开始采集,会有很多情况,比如选择json,其实json本身是没有数据的,选择一个无关数据的开始采集,再其他的都是采集不出结果来.中途的推测失败,该网站如果采集出一定的数据规律,还是很容易发现这个网站采集规律.事后想想,之前可能会犯错误,才导致思维的缺陷。
上面这个是问题解决了思维中的短板。而真正可怕的是,内容数据采集失败了,但是还没有想好采集这些数据到底有什么意义,如果你之前没有思考过采集数据的意义,那么,根本不需要再去想意义是什么.所以还是要一个字:贵,所以,贵在花时间和精力在各种想法上,决定“一切先从小事做起”.。
首先,你得通过一个前端公共接口,找到你希望采集的页面。然后看下该页面一般有哪些地方会有链接。比如,百度首页上至少有几十万个的相同页面链接,只要满足里面的链接。都可以在一个公共接口得到来自该页面的数据。比如,我要爬取java学习频道的数据,那我就要找到它的公共接口是什么。然后就是简单修改下代码,再上网去爬数据咯。关于采集技术请关注公众号石墨源站长获取。
自动识别采集内容(不用下载app就可以自动爬取某个品牌的全部商品实时推送采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-03 16:04
自动识别采集内容,不用下载app就可以自动爬取某个品牌的全部商品
实时推送采集-推酷一键推送采集
其实一些公众号定期会上推送都会有图文,像你这边可以加图文编辑框设置等待时间选择定时推送,像正常采集来的数据,用聚合采集器加水印就可以了,安卓有时候需要按才可以识别,如果是苹果端的话,
现在的网站如果提供商品列表在全球估计不超过三千家,中国估计不超过两千家。
推荐简单易用的采集器,能够直接采集安卓或ios平台的所有商品,采集字段也支持wap,h5,pc。
可以在一个品牌下通过发送消息推送,
微信还有绑定qq,
现在正规的平台都已经不限制平台的,只要有人看有人转发就可以采集,只要你去找就有人找你,但是!!!安卓手机上的数据有局限,ios平台的优质数据没有局限,要看清楚,下载一个采集器:一键推送采集器,这个采集器是清华大学的研究生做的,功能很多,
大众点评,新浪微博都是可以采集商品的,
爬吧
推荐你用:wap图片采集器,这是通过wap网站抓取数据的,还有就是老罗锤子直播的微博,都是这个工具抓的图。ip一直都是过滤的。现在老罗的锤子新品发布会已经有人抓数据了,至于实时性有几分,肯定不实时,因为国内的厂商会给一些主观上不适合给用户公开的信息,至于带宽多大,这就不清楚了。 查看全部
自动识别采集内容(不用下载app就可以自动爬取某个品牌的全部商品实时推送采集)
自动识别采集内容,不用下载app就可以自动爬取某个品牌的全部商品
实时推送采集-推酷一键推送采集
其实一些公众号定期会上推送都会有图文,像你这边可以加图文编辑框设置等待时间选择定时推送,像正常采集来的数据,用聚合采集器加水印就可以了,安卓有时候需要按才可以识别,如果是苹果端的话,
现在的网站如果提供商品列表在全球估计不超过三千家,中国估计不超过两千家。
推荐简单易用的采集器,能够直接采集安卓或ios平台的所有商品,采集字段也支持wap,h5,pc。
可以在一个品牌下通过发送消息推送,
微信还有绑定qq,
现在正规的平台都已经不限制平台的,只要有人看有人转发就可以采集,只要你去找就有人找你,但是!!!安卓手机上的数据有局限,ios平台的优质数据没有局限,要看清楚,下载一个采集器:一键推送采集器,这个采集器是清华大学的研究生做的,功能很多,
大众点评,新浪微博都是可以采集商品的,
爬吧
推荐你用:wap图片采集器,这是通过wap网站抓取数据的,还有就是老罗锤子直播的微博,都是这个工具抓的图。ip一直都是过滤的。现在老罗的锤子新品发布会已经有人抓数据了,至于实时性有几分,肯定不实时,因为国内的厂商会给一些主观上不适合给用户公开的信息,至于带宽多大,这就不清楚了。
自动识别采集内容(在线内容采集系统的技术实现步骤摘要【技术介绍】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-30 14:06
一个在线内容采集系统,包括:一个扫描服务器,用于扫描网站以获得潜在创意的统一资源定位器(URL)。扫描获取包括解析网页为网站,识别出符合预定条件的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器对获取的潜在创意网址进行如下分析:将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址之前是否见过,如果获取的潜在创意URL之前已经被看到,则判断获取的潜在创意URL是否指向该创意。
下载所有详细的技术资料
【技术实现步骤总结】
在线内容采集
技术介绍
在线广告通常包括发布在 Internet 上的广告。在线广告可能包括营销信息,用户可能能够点击该广告,这通常会将用户带到另一个网页来营销广告中的产品或服务。例如,在线广告可以表示为创意,包括图像、点击、FLASH 对象等。在线广告可以以横幅广告的形式提供,横幅广告是嵌入在网页中的广告,通常包括文本、图像、视频、声音或这些元素的任意组合。您可以从称为广告提供商的广告服务或广告网络购买特定 网站 上的创意展示位置。例如,搜索引擎通常提供广告服务,广告主通过付费在搜索引擎网站或其他附属网站上发布他们的想法。除了搜索引擎,许多网站 还为公司或其他实体提供类似的发布想法的服务。在很多情况下,想法需要发布一段时间,需要在网站上的某些位置发布,或者可能需要满足某些条件才能发布。许多实体参与复杂的在线广告活动,在那里他们与竞争对手竞争创意空间,并将许多想法放在许多网站 上。很难有效地跟踪网站 以确定网站 是否正在发布其创意,以及该创意是否收录适当的内容、是否在适当的网页中提供并在网页的适当位置提供。附图说明本发明的特征以举例的方式进行说明,并不限于以下附图,其中相同的数字代表相同的元件,其中: 图1为本发明的在线示例内容采集图2示出了根据本公开示例的在线内容采集系统的系统图。图3示出了根据本公开示例的在线内容采集的系统图。系统执行的创意统一资源定位器(URL)及点击处理方法流程图;无花果。图4为本发明实施例下载并存储创意到数据库或在线内容采集服务器的方法流程图。无花果。图5为本发明实施例中点击下载保存到数据库或在线内容采集服务器的方法流程图;和图。图6图示了根据本公开的方法可以在所描述的方法和系统中使用的示例性计算机系统。
详细描述为了简洁和说明的目的,通过主要参考实施例来描述本公开。在以下描述中,陈述了许多具体细节以提供对本公开的透彻理解。然而,很明显,本公开可以在不限于这些具体细节的情况下实施。在其他情况下,未详细描述一些方法和结构以避免不必要地混淆本公开。贯穿本公开,术语“一个”和“一个”旨在表示至少一个特定元素。如本文所用,术语“包括”是指包括但不限于,术语“包括”是指包括但不限于。术语“基于”意味着至少部分基于。根据一个例子,本文公开了一种在线内容采集系统,用于检测、处理和存储创意以及相关的创意网址和点击。创意可以定义为在线内容,可以包括任何类型的图像、点击、FLASH 对象、视频等。例如,创意可以是,例如,包括图像、点击、FLASH 对象等的在线广告。可用于提供有关网站 的信息。例如,电脑在线广告包括电脑图片、点击卖家网站和/或与电脑相关的FLASH对象等,可用于提供关于网站(例如news网站)的一般信息。创意中的信息通常是推广可供销售的产品或服务的营销信息。用于创意的点击网址可以被用户点击,可以将用户带到产品网站或另一个推广产品或服务的网站。
创意网址可以定义为与用于创意的图片、点击、FLASH 对象等相关联的特定网址。潜在创意 URL 可以定义为可能是也可能不是创意 URL 的 URL。想法、URL 和点击可用于后续分析,例如生成报告。根据一个示例,在线内容采集系统可以包括扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL)。扫描获取包括解析网页为网站,识别符合预定标准的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器分析获取的潜在创意网址,将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址是否之前看过,如果是之前已经看到过潜在创意网址,则判断获取到的潜在创意网址是否指向该创意。根据一个例子,在线内容采集的方法包括扫描网站获取潜在创意网址,获取与获取潜在创意网址预定条件相匹配的潜在创意网址,并通过将获取的潜在创意网址与之前验证过的创意网址,以确定获取的潜在创意网址之前是否看过,如果之前看过获取的潜在创意网址,则确定获取的潜在创意网址是否指向该创意。
根据示例,收录计算机代码的非暂时性计算机可读介质,当由计算机系统执行时,执行包括以下指令的指令:扫描网站以获得潜在的创意URL,并且它被使用获取与潜在创意网址的预定条件匹配的潜在创意网址。通过将获取的潜在创意网址与之前验证的创意网址进行比较,确定获取的潜在创意网址之前是否已经看过,如果获取的潜在创意网址之前已经看过,则确定获取的潜在创意网址是否已经看过创意网址指向一个想法,如果之前没有看到过获取的潜在创意网址,则下载获取的潜在创意网址所指向的创意。对于上述在线内容采集系统,预定标准包括使用正则表达式来匹配潜在的创意URL。在线内容采集服务器执行的分析还包括在确定获取的潜在创意URL之前是否见过之前移除查询参数。该分析还包括如果之前没有见过获得的潜在创意URL,则下载获得的潜在创意URL所指向的想法。对于上述在线内容采集系统,如果获取的潜在创意URL指向一个创意,则分析还包括判断在线内容采集服务器是否识别出与该创意相关联的点击URL。如果在线内容采集服务器未识别出与创意相关联的点击网址,则分析还包括确定与创意相关联的网络内容是否包括点击网址。如果与广告素材相关联的网页内容收录点击网址,则分析还包括在网络浏览器环境中下载点击网址并确定点击网址是否为重定向网址。
如果点击的网址是重定向网址,分析还包括判断重定向的网址之前是否看过,如果重定向的网址之前看过,则表示点击的网址无效,如果重定向的网址已经看过之前如果没看过,下载后续的重定向网址,判断后续的重定向网址是否是另一个重定向网址。如果被点击的URL不是重定向URL,分析还包括判断被点击的URL是否是HTML重定向,如果被点击的URL不是HTML重定向,则将被点击的URL存储在数据存储中,如果被点击的URL是 HTML 重定向,以确定之前是否见过 HTML 重定向。对于上述的在线内容采集系统,如果获取的潜在创意网址没有指向该创意,则分析还包括判断获取的带有查询参数的潜在创意网址是否已经被看过。对于上述在线内容采集系统,如果之前没有见过获取的潜在创意网址,则分析还包括确定获取的潜在创意网址是否为重定向网址。如果获取的潜在创意 URL 是重定向 URL,则该分析还包括确定之前是否见过重定向 URL,如果之前见过重定向 URL,则表明与获取的潜在创意 URL 关联的创意无效,如果重定向 URL 之前没有见过,下载后续重定向 URL 判断后续重定向 URL 是否是另一个重定向 URL。如果所获取的潜在创意 URL 不是重定向 URL,则该分析还包括确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或图像,以及确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或image FLASH对象或图片的宽度和高度是否超过预定阈值,如果获取的潜在创意URL关联的创意不是FLASH对象或图片,则与获取的潜力相关
【技术保护点】
一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL),其中扫描和获取包括:解析网站的网页,识别匹配预定标准的潜在创意网址,用于从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址;存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中,分析包括:通过将获取的潜在创意网址与存储在数据存储器中的创意网址进行比较,确定获取的潜在创意网址是否已被之前看过,如果之前看过获取的潜在创意网址,则判断获取的潜在创意网址是否指向一个idea。
[技术特点总结]
2012.08.30 US 13/599,3101. 一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位器(URL),其中扫描获取包括:解析用于网站的网页,从解析出的网页中识别出符合预定获取潜在创意网址标准的潜在创意网址,获取符合预定标准的潜在创意网址用于存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中分析包括:通过以下项目确定获取的潜在创意网址之前是否见过:将获取的潜在创意网址与存储在其中的创意网址进行比较。数据存储,在判断获取的潜在创意URL之前是否见过,去掉查询参数,如果之前没有见过获取的潜在创意URL,则下载获取的潜在创意URL所指向的idea,如果获取的之前看过潜在创意网址,判断获取的创意创意网址是否指向创意,如果获取的创意创意网址不指向创意,则判断获取的创意创意网址是否之前见过,以及如果获取到的潜在idea URL指向一个idea,则判断在线内容采集服务器是否识别与创意相关联的点击网址,如果在线内容采集服务器没有识别与创意相关联的点击网址,则确定与创意相关联的网页内容是否收录点击网址,其中如果网页内容与广告素材相关联的包括点击 URL,然后: 在网络浏览器环境中下载点击 URL;并确定点击 URL 是否为重定向 URL。
2.如权利要求1所述的在线内容采集系统,其特征在于,所述预定标准包括使用正则表达式匹配潜在创意URL。 3.根据权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括:如果之前未见过获取的潜在创意网址,则判断获取的潜在创意网址是否为重定向网址。 4.如权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址为重定向网址,则判断该重定向网址之前是否见过;如果之前已经看到重定向 URL,则与获取的潜在创意 URL 关联的创意将被指示为无效;如果之前没有看到重定向URL,则下载后续重定向URL,判断后续重定向URL是否为其他重定向URL。 5.根据权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址不是重定向网址,则判断获取的潜在创意网址关联的创意是否为FLASH对象或图片;如果获取的潜在创意URL关联的创意为FLASH对象或图片,则判断该FLASH对象或图片的宽度和高度是否超过预定阈值;如果与潜在广告素材 URL 关联的广告素材不是 FLASH 对象或图片,则与获取的潜在广告素材 URL 关联的广告素材将被指示为无效。
6.如权利要求5所述的在线内容采集系统,其特征在于,所述预定阈值为5个像素。 7.根据权利要求5所述的在线内容采集系统,其特征在于,所述分析还包括:如果FLASH对象或图片的宽度和高度超过预定阈值,则获取的潜在创意URL关联的创意指示已验证;将获取的潜在创意网址存储在数据存储器中,用于与进一步获取的潜在创意网址进行比对。 8.如权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括: 如果点击网址为重定向网址,则判断该重定向网址之前是否见过;如果之前看过重定向网址,则表示点击网址无效;如果之前没有看到过重定向网址,则下载后续的重定向网址,判断后续的重定向网址是否为另一个重定向网址。 9.如权利要求8所述的在线内容采集系统,其特征在于,所述分析还包括:如果点...
【专利技术属性】
技术研发人员:M·费格、J·霍尔曼、
申请人(专利权):,
类型:发明
国家省市:爱尔兰;浏览器
下载所有详细技术资料我是此专利的所有者 查看全部
自动识别采集内容(在线内容采集系统的技术实现步骤摘要【技术介绍】)
一个在线内容采集系统,包括:一个扫描服务器,用于扫描网站以获得潜在创意的统一资源定位器(URL)。扫描获取包括解析网页为网站,识别出符合预定条件的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器对获取的潜在创意网址进行如下分析:将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址之前是否见过,如果获取的潜在创意URL之前已经被看到,则判断获取的潜在创意URL是否指向该创意。
下载所有详细的技术资料
【技术实现步骤总结】
在线内容采集
技术介绍
在线广告通常包括发布在 Internet 上的广告。在线广告可能包括营销信息,用户可能能够点击该广告,这通常会将用户带到另一个网页来营销广告中的产品或服务。例如,在线广告可以表示为创意,包括图像、点击、FLASH 对象等。在线广告可以以横幅广告的形式提供,横幅广告是嵌入在网页中的广告,通常包括文本、图像、视频、声音或这些元素的任意组合。您可以从称为广告提供商的广告服务或广告网络购买特定 网站 上的创意展示位置。例如,搜索引擎通常提供广告服务,广告主通过付费在搜索引擎网站或其他附属网站上发布他们的想法。除了搜索引擎,许多网站 还为公司或其他实体提供类似的发布想法的服务。在很多情况下,想法需要发布一段时间,需要在网站上的某些位置发布,或者可能需要满足某些条件才能发布。许多实体参与复杂的在线广告活动,在那里他们与竞争对手竞争创意空间,并将许多想法放在许多网站 上。很难有效地跟踪网站 以确定网站 是否正在发布其创意,以及该创意是否收录适当的内容、是否在适当的网页中提供并在网页的适当位置提供。附图说明本发明的特征以举例的方式进行说明,并不限于以下附图,其中相同的数字代表相同的元件,其中: 图1为本发明的在线示例内容采集图2示出了根据本公开示例的在线内容采集系统的系统图。图3示出了根据本公开示例的在线内容采集的系统图。系统执行的创意统一资源定位器(URL)及点击处理方法流程图;无花果。图4为本发明实施例下载并存储创意到数据库或在线内容采集服务器的方法流程图。无花果。图5为本发明实施例中点击下载保存到数据库或在线内容采集服务器的方法流程图;和图。图6图示了根据本公开的方法可以在所描述的方法和系统中使用的示例性计算机系统。
详细描述为了简洁和说明的目的,通过主要参考实施例来描述本公开。在以下描述中,陈述了许多具体细节以提供对本公开的透彻理解。然而,很明显,本公开可以在不限于这些具体细节的情况下实施。在其他情况下,未详细描述一些方法和结构以避免不必要地混淆本公开。贯穿本公开,术语“一个”和“一个”旨在表示至少一个特定元素。如本文所用,术语“包括”是指包括但不限于,术语“包括”是指包括但不限于。术语“基于”意味着至少部分基于。根据一个例子,本文公开了一种在线内容采集系统,用于检测、处理和存储创意以及相关的创意网址和点击。创意可以定义为在线内容,可以包括任何类型的图像、点击、FLASH 对象、视频等。例如,创意可以是,例如,包括图像、点击、FLASH 对象等的在线广告。可用于提供有关网站 的信息。例如,电脑在线广告包括电脑图片、点击卖家网站和/或与电脑相关的FLASH对象等,可用于提供关于网站(例如news网站)的一般信息。创意中的信息通常是推广可供销售的产品或服务的营销信息。用于创意的点击网址可以被用户点击,可以将用户带到产品网站或另一个推广产品或服务的网站。
创意网址可以定义为与用于创意的图片、点击、FLASH 对象等相关联的特定网址。潜在创意 URL 可以定义为可能是也可能不是创意 URL 的 URL。想法、URL 和点击可用于后续分析,例如生成报告。根据一个示例,在线内容采集系统可以包括扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL)。扫描获取包括解析网页为网站,识别符合预定标准的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器分析获取的潜在创意网址,将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址是否之前看过,如果是之前已经看到过潜在创意网址,则判断获取到的潜在创意网址是否指向该创意。根据一个例子,在线内容采集的方法包括扫描网站获取潜在创意网址,获取与获取潜在创意网址预定条件相匹配的潜在创意网址,并通过将获取的潜在创意网址与之前验证过的创意网址,以确定获取的潜在创意网址之前是否看过,如果之前看过获取的潜在创意网址,则确定获取的潜在创意网址是否指向该创意。
根据示例,收录计算机代码的非暂时性计算机可读介质,当由计算机系统执行时,执行包括以下指令的指令:扫描网站以获得潜在的创意URL,并且它被使用获取与潜在创意网址的预定条件匹配的潜在创意网址。通过将获取的潜在创意网址与之前验证的创意网址进行比较,确定获取的潜在创意网址之前是否已经看过,如果获取的潜在创意网址之前已经看过,则确定获取的潜在创意网址是否已经看过创意网址指向一个想法,如果之前没有看到过获取的潜在创意网址,则下载获取的潜在创意网址所指向的创意。对于上述在线内容采集系统,预定标准包括使用正则表达式来匹配潜在的创意URL。在线内容采集服务器执行的分析还包括在确定获取的潜在创意URL之前是否见过之前移除查询参数。该分析还包括如果之前没有见过获得的潜在创意URL,则下载获得的潜在创意URL所指向的想法。对于上述在线内容采集系统,如果获取的潜在创意URL指向一个创意,则分析还包括判断在线内容采集服务器是否识别出与该创意相关联的点击URL。如果在线内容采集服务器未识别出与创意相关联的点击网址,则分析还包括确定与创意相关联的网络内容是否包括点击网址。如果与广告素材相关联的网页内容收录点击网址,则分析还包括在网络浏览器环境中下载点击网址并确定点击网址是否为重定向网址。
如果点击的网址是重定向网址,分析还包括判断重定向的网址之前是否看过,如果重定向的网址之前看过,则表示点击的网址无效,如果重定向的网址已经看过之前如果没看过,下载后续的重定向网址,判断后续的重定向网址是否是另一个重定向网址。如果被点击的URL不是重定向URL,分析还包括判断被点击的URL是否是HTML重定向,如果被点击的URL不是HTML重定向,则将被点击的URL存储在数据存储中,如果被点击的URL是 HTML 重定向,以确定之前是否见过 HTML 重定向。对于上述的在线内容采集系统,如果获取的潜在创意网址没有指向该创意,则分析还包括判断获取的带有查询参数的潜在创意网址是否已经被看过。对于上述在线内容采集系统,如果之前没有见过获取的潜在创意网址,则分析还包括确定获取的潜在创意网址是否为重定向网址。如果获取的潜在创意 URL 是重定向 URL,则该分析还包括确定之前是否见过重定向 URL,如果之前见过重定向 URL,则表明与获取的潜在创意 URL 关联的创意无效,如果重定向 URL 之前没有见过,下载后续重定向 URL 判断后续重定向 URL 是否是另一个重定向 URL。如果所获取的潜在创意 URL 不是重定向 URL,则该分析还包括确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或图像,以及确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或image FLASH对象或图片的宽度和高度是否超过预定阈值,如果获取的潜在创意URL关联的创意不是FLASH对象或图片,则与获取的潜力相关

【技术保护点】
一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL),其中扫描和获取包括:解析网站的网页,识别匹配预定标准的潜在创意网址,用于从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址;存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中,分析包括:通过将获取的潜在创意网址与存储在数据存储器中的创意网址进行比较,确定获取的潜在创意网址是否已被之前看过,如果之前看过获取的潜在创意网址,则判断获取的潜在创意网址是否指向一个idea。
[技术特点总结]
2012.08.30 US 13/599,3101. 一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位器(URL),其中扫描获取包括:解析用于网站的网页,从解析出的网页中识别出符合预定获取潜在创意网址标准的潜在创意网址,获取符合预定标准的潜在创意网址用于存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中分析包括:通过以下项目确定获取的潜在创意网址之前是否见过:将获取的潜在创意网址与存储在其中的创意网址进行比较。数据存储,在判断获取的潜在创意URL之前是否见过,去掉查询参数,如果之前没有见过获取的潜在创意URL,则下载获取的潜在创意URL所指向的idea,如果获取的之前看过潜在创意网址,判断获取的创意创意网址是否指向创意,如果获取的创意创意网址不指向创意,则判断获取的创意创意网址是否之前见过,以及如果获取到的潜在idea URL指向一个idea,则判断在线内容采集服务器是否识别与创意相关联的点击网址,如果在线内容采集服务器没有识别与创意相关联的点击网址,则确定与创意相关联的网页内容是否收录点击网址,其中如果网页内容与广告素材相关联的包括点击 URL,然后: 在网络浏览器环境中下载点击 URL;并确定点击 URL 是否为重定向 URL。
2.如权利要求1所述的在线内容采集系统,其特征在于,所述预定标准包括使用正则表达式匹配潜在创意URL。 3.根据权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括:如果之前未见过获取的潜在创意网址,则判断获取的潜在创意网址是否为重定向网址。 4.如权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址为重定向网址,则判断该重定向网址之前是否见过;如果之前已经看到重定向 URL,则与获取的潜在创意 URL 关联的创意将被指示为无效;如果之前没有看到重定向URL,则下载后续重定向URL,判断后续重定向URL是否为其他重定向URL。 5.根据权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址不是重定向网址,则判断获取的潜在创意网址关联的创意是否为FLASH对象或图片;如果获取的潜在创意URL关联的创意为FLASH对象或图片,则判断该FLASH对象或图片的宽度和高度是否超过预定阈值;如果与潜在广告素材 URL 关联的广告素材不是 FLASH 对象或图片,则与获取的潜在广告素材 URL 关联的广告素材将被指示为无效。
6.如权利要求5所述的在线内容采集系统,其特征在于,所述预定阈值为5个像素。 7.根据权利要求5所述的在线内容采集系统,其特征在于,所述分析还包括:如果FLASH对象或图片的宽度和高度超过预定阈值,则获取的潜在创意URL关联的创意指示已验证;将获取的潜在创意网址存储在数据存储器中,用于与进一步获取的潜在创意网址进行比对。 8.如权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括: 如果点击网址为重定向网址,则判断该重定向网址之前是否见过;如果之前看过重定向网址,则表示点击网址无效;如果之前没有看到过重定向网址,则下载后续的重定向网址,判断后续的重定向网址是否为另一个重定向网址。 9.如权利要求8所述的在线内容采集系统,其特征在于,所述分析还包括:如果点...
【专利技术属性】
技术研发人员:M·费格、J·霍尔曼、
申请人(专利权):,
类型:发明
国家省市:爱尔兰;浏览器
下载所有详细技术资料我是此专利的所有者
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-29 12:46
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
查看全部
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>

自动识别采集内容( ECV-2021极市计算机视觉开发者榜单大赛(ECV) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-29 02:07
ECV-2021极市计算机视觉开发者榜单大赛(ECV)
)
ECV-2021 极限城市计算机视觉开发者名单大赛
ECV-2021极视计算机视觉开发者名单大赛(以下简称ECV-2021)已于2021年7月6日正式开赛!ECV-2021由青岛市人民政府、青岛市委指导,台港澳 由青岛市工业和信息化局、青岛市西海岸新区管委会、青岛市城市管理局主办,青岛银行为独家金融支持单位,英特尔(中国)有限公司为中国模式识别与计算机视觉大会战略合作伙伴(PRCV 2021)提供学术支持,极石平台和OpenVINO™工具套件提供技术支持,墨知书提供数据支持。注册链接:
初赛时间为7月6日至8月19日。报名截止至8月19日。请开发者安排比赛时间。
评审规则
比赛分为初赛(在线开发算法)和决赛(在线答辩)两个阶段。比赛总分=线上算法比赛成绩占70%,最终答辩成绩占30%。
初赛
初赛时间:2021年7月6日-2021年8月19日
初步格式:从8个既定命题中选择,在线完成算法开发,使用OpenVINO™工具完成模型转换,通过自动测试获得算法总分。
初审规则:算法准确率占80%,算法性能占20%。具体计算规则请参考各竞赛题的评价规则。
初赛晋级规则:每题排行榜前8名进入决赛阶段。
总决赛
决赛时间:2021年9月7日-2021年9月16日
作品提交:算法应用演示视频、最终答辩演讲PPT(官方提交作品截止日期为9月6日)
决赛形式:决赛选手将进行视频答辩,解释和展示他们的申请。评审将按照评审规则进行统一评分,确定奖项。
最终评选规则:评委将根据评审规则统一打分,选手最终成绩由全体评委平均,确定最终奖项。
比赛奖项
8道竞赛题分别进行评判,奖项设置方式相同。参赛者可以注册多个竞赛问题并赢取多个奖品!
超过一百万的奖池
*注:满值可在积石平台兑换算力或赠品。兑换规则请参考最大值说明:
8道竞赛题详解
竞赛题1:垃圾车牌识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(10000张),包括标签信息,参赛参赛选手需在编码调试完成后发起训练任务,才能自动读取;测试数据集:camera采集信息(5000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;注解文件为VOC格式的xml文件,采用bounding box注解方式。边界框框住了渣土车和车牌。一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称相同。目标类别包括两种类型:
竞赛题目2:反光衣识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。边界框框起来的物体有四种标签,分别是:反光衣(clothes)、不穿反光衣(no_clothes)、穿反光衣的人(person_clothes)、穿反光衣的人(person_no_clothes)不穿或不规则穿着反光衣服(person_no_clothes)。
您需要确定这两个类别:person_clothes、person_no_clothes。其他两类用于辅助算法开发。
比赛问题 3:识别驾驶员不良驾驶
示例图像:
数据集来自采集摄像机的视频片段。取景后,每个视频都转换成JPG格式的图片,存放在一个文件夹中。每张图片均采用frame_id.jpg的命名格式。其中frame_id表示以1开头的帧数。每个图片文件夹都会有一个对应的标签文件,文件名与文件夹相同,格式为XML,收录的标签类别如下:smoke, yawn,电话,驾驶员工异常(a_driver),环顾四周(look_around)
样本数据集:每个类别会有多个视频帧集,供参赛者了解比赛的典型场景数据,可用于编码调试;
训练数据集:抽烟400,打哈欠110,呼唤400,司机异常400,环顾四周700,文件夹名称为类别名称,选手需在编码调试完成后发起训练任务在它可以被自动读取之前Take;
测试数据集:抽烟100,打哈欠40,打电话 ,司机异常100,环顾四周300,参赛者成功发起测试任务,可自动读取;
问题 4:确定船舶数量
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。边界框框起来的物体有一个标签,这个标签就是一条船。一张图片对应一个标签文件,标签文件的名称与对应图片的名称相同。
竞赛问题 5:机动车识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。包围盒为机动车,一张图片对应一个注解文件XML,注解文件名称与对应图片名称一致。
数据标签分为三类,需要识别这三类:
竞赛题6:职业管理检查
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。 bounding box为vendor,一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称一致。
数据标签分为三类,需要识别这三类:
竞赛题目7:电动车进入电梯的识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。由边界框框起的物体有三种类型的标签,分别是:person、bike 和 e_vehicle。您需要确定这三个类别。
问题 8:人体分析与分割
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,PNG格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(6000张),包括标注信息,参加比赛参赛者需要在编码调试后发起训练任务自动读取;测试数据集:camera采集信息(1000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;该集合收录原创图片和相应的分割图片(注释文件)。注解文件格式为PNG,为单通道灰度图。数据集有20个语义类别,其内容(像素值-类别名称)如下:
比赛回顾
参与者
1、大赛面向全社会开放,个人、高等院校、企业、创客团队等人员均可报名参赛; 2、每位参赛者,每个比赛问题只能加入一个团队,每个团队仅限3人。
*注意:
1、除大赛主办方参与主题撰写和数据联系外,所有参赛者均可报名
2、大赛合作伙伴及其关联方/员工参加比赛,只参与排名,不参与奖励奖金。
注册须知
1、扫码进入官网,选择比赛题目并登录极石开发者平台,填写报名信息后即可报名参赛;
*请确保报名信息准确有效,否则将被取消资格并给予奖励;
2、加入大赛交流群
扫描二维码加入大赛QQ交流群,或添加小东微信(cvmart3),加入大赛微信交流群。
比赛QQ交流群(496683217)/极小东微信号(cvmart3)
)
3、大赛论坛交流:
比赛支持/协办方
查看全部
自动识别采集内容(
ECV-2021极市计算机视觉开发者榜单大赛(ECV)
)

ECV-2021 极限城市计算机视觉开发者名单大赛
ECV-2021极视计算机视觉开发者名单大赛(以下简称ECV-2021)已于2021年7月6日正式开赛!ECV-2021由青岛市人民政府、青岛市委指导,台港澳 由青岛市工业和信息化局、青岛市西海岸新区管委会、青岛市城市管理局主办,青岛银行为独家金融支持单位,英特尔(中国)有限公司为中国模式识别与计算机视觉大会战略合作伙伴(PRCV 2021)提供学术支持,极石平台和OpenVINO™工具套件提供技术支持,墨知书提供数据支持。注册链接:
初赛时间为7月6日至8月19日。报名截止至8月19日。请开发者安排比赛时间。
评审规则
比赛分为初赛(在线开发算法)和决赛(在线答辩)两个阶段。比赛总分=线上算法比赛成绩占70%,最终答辩成绩占30%。
初赛
初赛时间:2021年7月6日-2021年8月19日
初步格式:从8个既定命题中选择,在线完成算法开发,使用OpenVINO™工具完成模型转换,通过自动测试获得算法总分。
初审规则:算法准确率占80%,算法性能占20%。具体计算规则请参考各竞赛题的评价规则。
初赛晋级规则:每题排行榜前8名进入决赛阶段。
总决赛
决赛时间:2021年9月7日-2021年9月16日
作品提交:算法应用演示视频、最终答辩演讲PPT(官方提交作品截止日期为9月6日)
决赛形式:决赛选手将进行视频答辩,解释和展示他们的申请。评审将按照评审规则进行统一评分,确定奖项。
最终评选规则:评委将根据评审规则统一打分,选手最终成绩由全体评委平均,确定最终奖项。
比赛奖项
8道竞赛题分别进行评判,奖项设置方式相同。参赛者可以注册多个竞赛问题并赢取多个奖品!

超过一百万的奖池
*注:满值可在积石平台兑换算力或赠品。兑换规则请参考最大值说明:
8道竞赛题详解
竞赛题1:垃圾车牌识别
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(10000张),包括标签信息,参赛参赛选手需在编码调试完成后发起训练任务,才能自动读取;测试数据集:camera采集信息(5000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;注解文件为VOC格式的xml文件,采用bounding box注解方式。边界框框住了渣土车和车牌。一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称相同。目标类别包括两种类型:

竞赛题目2:反光衣识别
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。边界框框起来的物体有四种标签,分别是:反光衣(clothes)、不穿反光衣(no_clothes)、穿反光衣的人(person_clothes)、穿反光衣的人(person_no_clothes)不穿或不规则穿着反光衣服(person_no_clothes)。
您需要确定这两个类别:person_clothes、person_no_clothes。其他两类用于辅助算法开发。
比赛问题 3:识别驾驶员不良驾驶
示例图像:

数据集来自采集摄像机的视频片段。取景后,每个视频都转换成JPG格式的图片,存放在一个文件夹中。每张图片均采用frame_id.jpg的命名格式。其中frame_id表示以1开头的帧数。每个图片文件夹都会有一个对应的标签文件,文件名与文件夹相同,格式为XML,收录的标签类别如下:smoke, yawn,电话,驾驶员工异常(a_driver),环顾四周(look_around)
样本数据集:每个类别会有多个视频帧集,供参赛者了解比赛的典型场景数据,可用于编码调试;
训练数据集:抽烟400,打哈欠110,呼唤400,司机异常400,环顾四周700,文件夹名称为类别名称,选手需在编码调试完成后发起训练任务在它可以被自动读取之前Take;
测试数据集:抽烟100,打哈欠40,打电话 ,司机异常100,环顾四周300,参赛者成功发起测试任务,可自动读取;
问题 4:确定船舶数量
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。边界框框起来的物体有一个标签,这个标签就是一条船。一张图片对应一个标签文件,标签文件的名称与对应图片的名称相同。
竞赛问题 5:机动车识别
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。包围盒为机动车,一张图片对应一个注解文件XML,注解文件名称与对应图片名称一致。
数据标签分为三类,需要识别这三类:

竞赛题6:职业管理检查
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。 bounding box为vendor,一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称一致。
数据标签分为三类,需要识别这三类:

竞赛题目7:电动车进入电梯的识别
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。由边界框框起的物体有三种类型的标签,分别是:person、bike 和 e_vehicle。您需要确定这三个类别。
问题 8:人体分析与分割
示例图像:

数据集为监控摄像头采集的现场场景数据,图片形式,PNG格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(6000张),包括标注信息,参加比赛参赛者需要在编码调试后发起训练任务自动读取;测试数据集:camera采集信息(1000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;该集合收录原创图片和相应的分割图片(注释文件)。注解文件格式为PNG,为单通道灰度图。数据集有20个语义类别,其内容(像素值-类别名称)如下:
比赛回顾

参与者
1、大赛面向全社会开放,个人、高等院校、企业、创客团队等人员均可报名参赛; 2、每位参赛者,每个比赛问题只能加入一个团队,每个团队仅限3人。
*注意:
1、除大赛主办方参与主题撰写和数据联系外,所有参赛者均可报名
2、大赛合作伙伴及其关联方/员工参加比赛,只参与排名,不参与奖励奖金。
注册须知
1、扫码进入官网,选择比赛题目并登录极石开发者平台,填写报名信息后即可报名参赛;
*请确保报名信息准确有效,否则将被取消资格并给予奖励;
2、加入大赛交流群
扫描二维码加入大赛QQ交流群,或添加小东微信(cvmart3),加入大赛微信交流群。
比赛QQ交流群(496683217)/极小东微信号(cvmart3)
)
3、大赛论坛交流:
比赛支持/协办方

自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-28 23:36
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
查看全部
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
自动识别采集内容(【网盘智能识别助手】专门帮你干这种事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-28 07:00
我最近遇到了一个痛点。每次晚上找资源,大家都会在网站上留下各种网盘的链接,比如:
各种网盘都有,没有密码的也可以,像这种有密码的网盘链接
需要先打开复制网盘链接,然后输入对应的提取码/密码。
只需按两次Ctrl+C和Ctrl+V,有时页面上的字太小,选择链接时经常漏掉一个字母
或者误点击了其他链接,非常耗时,而且这个操作没有多大意义。
你可以交给程序去执行,于是就有了今天的油猴脚本【网盘智能识别助手】帮你搞定这些琐碎的工作。
先看效果,找个网上别人分享的链接。
选择收录链接和提取码的文本,识别出网盘链接时会弹出提示框,
点击打开后,如果有密码,什么都不做,助手会自动为你填写密码。
既然敢被称为智能助手,有时候握手多选几个字还是能准确识别的,各种陌生的名字都不是问题。
使用方法:
只需要一步,即:选择链接和密码文本。
剩下的交给助手,助手会自动识别->出现提示->点击打开->自动填写密码
除了上面演示用的天翼云,还支持其他常用的网盘,可以有密码也可以没有密码,比如:
是不是很简单很强大,关键是“智能”,你管它叫提取码,
无论是密码还是识别码都能识别,识别率高达99%。
当然,小助手还有一些额外的配置可以自己设置,比如后台打开链接,
自动开启等配置,识别密码后自动提交。
整个过程无需联网,安全可靠,助手开源免费。
如果还在手动复制网盘链接和提取码,还等什么?去试试吧。
确保已经安装了Tampermonkey扩展,点击下方资源地址进行安装。
PS:没安装或者不会安装的去百度吧!问度娘~ 查看全部
自动识别采集内容(【网盘智能识别助手】专门帮你干这种事)
我最近遇到了一个痛点。每次晚上找资源,大家都会在网站上留下各种网盘的链接,比如:
各种网盘都有,没有密码的也可以,像这种有密码的网盘链接
需要先打开复制网盘链接,然后输入对应的提取码/密码。
只需按两次Ctrl+C和Ctrl+V,有时页面上的字太小,选择链接时经常漏掉一个字母
或者误点击了其他链接,非常耗时,而且这个操作没有多大意义。
你可以交给程序去执行,于是就有了今天的油猴脚本【网盘智能识别助手】帮你搞定这些琐碎的工作。
先看效果,找个网上别人分享的链接。
选择收录链接和提取码的文本,识别出网盘链接时会弹出提示框,
点击打开后,如果有密码,什么都不做,助手会自动为你填写密码。
既然敢被称为智能助手,有时候握手多选几个字还是能准确识别的,各种陌生的名字都不是问题。
使用方法:
只需要一步,即:选择链接和密码文本。
剩下的交给助手,助手会自动识别->出现提示->点击打开->自动填写密码
除了上面演示用的天翼云,还支持其他常用的网盘,可以有密码也可以没有密码,比如:
是不是很简单很强大,关键是“智能”,你管它叫提取码,
无论是密码还是识别码都能识别,识别率高达99%。
当然,小助手还有一些额外的配置可以自己设置,比如后台打开链接,
自动开启等配置,识别密码后自动提交。
整个过程无需联网,安全可靠,助手开源免费。
如果还在手动复制网盘链接和提取码,还等什么?去试试吧。
确保已经安装了Tampermonkey扩展,点击下方资源地址进行安装。
PS:没安装或者不会安装的去百度吧!问度娘~
自动识别采集内容(基本功能特点-基本功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-27 23:02
优采云采集器基本功能特性
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得-task 采集process 所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、数据保存-数据side采集side自动保存在关系数据库中,数据结构可自动适配。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
优采云采集器特色:
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。 查看全部
自动识别采集内容(基本功能特点-基本功能)
优采云采集器基本功能特性
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得-task 采集process 所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、数据保存-数据side采集side自动保存在关系数据库中,数据结构可自动适配。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
优采云采集器特色:
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。
之前+opencv+python逐帧处理可否将视频处理成图片?
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-19 20:00
背景
在之前的学习爬虫项目中,得到的部分视频有水印,所以需要通过更好的技术手段来实现去水印。一般情况下,如果能拿到没有水印的原图最好,但是网站的一些原图本身是有水印的。在这种情况下,可以通过一些视频编辑软件去除少量水印,但对于大量素材,依靠人工完成是不现实的。
说明
这个文章将提供一种方法来描述在特定类型的视频中使用技术手段实现去除水印。仅供参考和学习。请合理使用,避免法律风险。
主要的实现方法其实很简单,主要是整合了现有的各种工具,最终取得了更好的效果。限制类别后,去除效果评价通过率达到97%。
研究
网上查了一下,主要有以下几个实现可以参考。你可以看到它们有不同的优点和缺点。
高端大气AI
首先,AI的接入成本和学习门槛都比较高,有点玄学。不管算法如何,最终的效果还是取决于对输入样本的训练。回到我们的素材本身,不同作者的水印会发生变化(id是水印)。算法训练,其实获得准确位置的能力还有待确定。
缺点总结:依赖较多,需要训练。预计训练模型不会容易适应Id+logo变化的情况,效果不理想。
ffmpeg delogo
其实就是在水印位置加了一个滤镜,类似于磨砂玻璃效果。这是一种比较直接的方式,但问题的核心是如何获取水印的位置。另一个问题是ffmpeg delogo在不同的视频素材中效果不稳定。例如,如果一个视频帧的水印位置有很多屏幕内容,去除水印后会更加明显。不过一般情况下,水印在右上或左上,屏幕内容比较少。
缺点总结:要产生模糊区域,需要确定位置和大小。
Mask+opencv + python 逐帧处理
能否将视频处理成图片,然后根据每张图片进行处理?当然,理论是可行的,把问题变成了图像去水印,还有更成熟的去水印算法,比如openCV。但是有一些问题。
首先,openCV的图片去水印需要一个mask,即纯色+水印的图片。当然,它不适合不同的视频水印标志变化。为每个视频自动创建蒙版是不可能的。
另一个是视频处理成图片后,内容过大。测试中,将19MB 1080P60hz的视频处理成3GB大小的图片,每一帧的处理也很耗时,更不用说合并成视频的耗时了。
缺点很明显:mask生成+逐帧处理+耗时
cv get fixed icon + id 生成位置坐标
最后一个选项是妥协,最终被采纳。首先,仍然使用openCV获取水印,但使用CV进行图像识别。对于视频,不是跟随所有帧,而是随机选择一些帧进行截图,然后使用 cv 获取水印坐标。这里有个前提,就是水印的某些部分是不变的,比如logo。先手动剪下这部分,然后代入CV进行识别,得到logo的坐标。由于不同的帧会有变化,导致CV失败的错误,需要以高成功率筛选失败的坐标。
那么,由于水印是logo+id的形式,水印的大小是根据id中的字符数和字体大小占用的像素数来计算的。这样我们就知道水印的位置和大小了,就可以用ffmpeg delogo去除了。
总结一下,最后实际采用的是第四种方案和第二种方案的结合。当然,这也是根据具体场景综合考虑的,不一定是通用的、最优的实现方式。
技术方案说明
如上所述,解决方案的最终识别部分可以概括为以下过程: 既然知道了水印的位置和大小,就可以通过ffmpeg delogo进行去除。大部分视频的处理效果尚可。
剪出统一的logo--->将视频随机分帧--->CV识别logo坐标--->根据视频作者昵称计算水印大小--->ffmpeg delogo去除水印.
计算水印位置大小的核心代码
import cv2
from matplotlib import pyplot as plt
# source=input('source:')
# tpl=input('template:')
source = '/export/data/晴天独奏/mask/1.png'
tpl = 'mark_bili_1280.png'
img = cv2.imread(source, 0)
img2 = img.copy()
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
ow, oh = img.shape[::-1]
# # All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
# methods = ['cv2.TM_CCOEFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
print('x={},y={},w={},h={}'.format(top_left[0], top_left[1], bottom_right[0]-top_left[0], bottom_right[1] - top_left[1]))
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img, cmap='gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
比较识别效果
不同算法的比较
最终去除效果对比
删除后
移除前
视频成帧代码
import os
import sys
import cv2
video_name = sys.argv[1]
if video_name is None:
print("input video name!")
exit(1)
com = 'ffmpeg -ss 10 -i {} -f image2 -vframes 1 -y frame.png'.format(video_name)
os.system(com)
cv2.namedWindow('frame', 0)
img = cv2.imread('frame.png')
cv2.imshow('frame', img)
cv2.waitKey(0)
批量匹配水印
用于批量截图中标记识别出的水印并打印出坐标
import os
import cv2
# source=input('source:')
# tpl=input('template:')
tpl = '/export/code/github/demo/src/test/resources/mark/mark_bili_1280-1.png'
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
# # All the 6 methods for comparison in a list
# methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
# 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
dir = '/export/data/BV1dT4y1E7w3/out/'
# dir = '/export/code/github/demo/data/out/'
files = []
for f in os.walk(dir):
f = f[2]
for x in f:
if '.png' not in x:
continue
files.append(x)
break
count = 1
for f in files:
source = dir + f
img = cv2.imread(source, 0)
img2 = img.copy()
ow, oh = img.shape[::-1]
meth = 'cv2.TM_CCOEFF_NORMED'
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
cv2.imwrite(source + ".mark.png", img)
print('id:{} x={}:y={}:w={}:h={}'.format(count, top_left[0], top_left[1], bottom_right[0] - top_left[0], bottom_right[1] - top_left[1]))
count = count + 1
遇到的问题
错位是由以下原因造成的。
ffmpeg 占用 CPU 资源过多
这主要是因为ffmpeg的参数一开始没有太注意。默认情况下,所有 CPU 都被占用,这导致一开始就死机。去除毛玻璃效果太明显后可以使用-threads参数设置占用CPU视频水印
因为这种情况完全和视频内容有关,目前计划依赖ffmpeg,暂时没有解决方案。能想到的就是优化ffmpeg的水印算法,这是一个不切实际的快速可达的方案。项目全是java。有没有办法用java实现上面的openCV和ffmpeg调用?
这是一次尝试。当然,答案是可以实现的。使用现成的 Bytedeco,您可以避免自己编写大量命令行调用。总结
以上是本文文章的全部内容。限于篇幅,部分细节没有完全补充。在过程中的某些情况下,虽然方法是已知的,但仍然需要大量的时间来调试和验证才能知道最终的效果。当然,最后还是在不断的练习下有明显的提升。前面说过,在控制输入样本的前提下,比如只选择右上角的水印,并尽量保证视频分辨率一致,最终评测通过率达到了97%,还是令人满意的。
参考资料ziweipolaris/watermark-removal:通过减水印的方法从视频中去除水印,速度快但不完善。基于GAN的图像水印去除器效果堪比PS大师-Flash基因-个人技术,分享毫秒级图像噪声!全新AI系统完美去除水印! -云+社区-腾讯云去噪、水印、超分辨率,这个不用学习的神经网络无所不能-云+社区-腾讯云【深度学习水印】-CSDN去噪、加水印、超分辨率,这个不用学习的神经网络无所不能机器之心【论文分享(一)】自动去水印(一)---自动水印识别与特征提取-知乎短视频分析,去水印原理总结-博客Python实现超简单【抖音】 @]无水印视频批量下载fei347795790的博客-CSDN博客抖音@batch下载无水印近无损视频水印方法Python OpenCV去除图片水印_XerCis的博客-CSDN Blog_cv2去除水印python使用opencv去除水印方法-可用于水印去除-简书JavaCV入门示例和UnsatisfiedLinkError异常踏步记录Bytedeco-Home 查看全部
之前+opencv+python逐帧处理可否将视频处理成图片?
背景
在之前的学习爬虫项目中,得到的部分视频有水印,所以需要通过更好的技术手段来实现去水印。一般情况下,如果能拿到没有水印的原图最好,但是网站的一些原图本身是有水印的。在这种情况下,可以通过一些视频编辑软件去除少量水印,但对于大量素材,依靠人工完成是不现实的。
说明
这个文章将提供一种方法来描述在特定类型的视频中使用技术手段实现去除水印。仅供参考和学习。请合理使用,避免法律风险。
主要的实现方法其实很简单,主要是整合了现有的各种工具,最终取得了更好的效果。限制类别后,去除效果评价通过率达到97%。
研究
网上查了一下,主要有以下几个实现可以参考。你可以看到它们有不同的优点和缺点。
高端大气AI
首先,AI的接入成本和学习门槛都比较高,有点玄学。不管算法如何,最终的效果还是取决于对输入样本的训练。回到我们的素材本身,不同作者的水印会发生变化(id是水印)。算法训练,其实获得准确位置的能力还有待确定。
缺点总结:依赖较多,需要训练。预计训练模型不会容易适应Id+logo变化的情况,效果不理想。
ffmpeg delogo
其实就是在水印位置加了一个滤镜,类似于磨砂玻璃效果。这是一种比较直接的方式,但问题的核心是如何获取水印的位置。另一个问题是ffmpeg delogo在不同的视频素材中效果不稳定。例如,如果一个视频帧的水印位置有很多屏幕内容,去除水印后会更加明显。不过一般情况下,水印在右上或左上,屏幕内容比较少。
缺点总结:要产生模糊区域,需要确定位置和大小。
Mask+opencv + python 逐帧处理
能否将视频处理成图片,然后根据每张图片进行处理?当然,理论是可行的,把问题变成了图像去水印,还有更成熟的去水印算法,比如openCV。但是有一些问题。
首先,openCV的图片去水印需要一个mask,即纯色+水印的图片。当然,它不适合不同的视频水印标志变化。为每个视频自动创建蒙版是不可能的。
另一个是视频处理成图片后,内容过大。测试中,将19MB 1080P60hz的视频处理成3GB大小的图片,每一帧的处理也很耗时,更不用说合并成视频的耗时了。
缺点很明显:mask生成+逐帧处理+耗时
cv get fixed icon + id 生成位置坐标
最后一个选项是妥协,最终被采纳。首先,仍然使用openCV获取水印,但使用CV进行图像识别。对于视频,不是跟随所有帧,而是随机选择一些帧进行截图,然后使用 cv 获取水印坐标。这里有个前提,就是水印的某些部分是不变的,比如logo。先手动剪下这部分,然后代入CV进行识别,得到logo的坐标。由于不同的帧会有变化,导致CV失败的错误,需要以高成功率筛选失败的坐标。
那么,由于水印是logo+id的形式,水印的大小是根据id中的字符数和字体大小占用的像素数来计算的。这样我们就知道水印的位置和大小了,就可以用ffmpeg delogo去除了。
总结一下,最后实际采用的是第四种方案和第二种方案的结合。当然,这也是根据具体场景综合考虑的,不一定是通用的、最优的实现方式。
技术方案说明
如上所述,解决方案的最终识别部分可以概括为以下过程: 既然知道了水印的位置和大小,就可以通过ffmpeg delogo进行去除。大部分视频的处理效果尚可。
剪出统一的logo--->将视频随机分帧--->CV识别logo坐标--->根据视频作者昵称计算水印大小--->ffmpeg delogo去除水印.
计算水印位置大小的核心代码
import cv2
from matplotlib import pyplot as plt
# source=input('source:')
# tpl=input('template:')
source = '/export/data/晴天独奏/mask/1.png'
tpl = 'mark_bili_1280.png'
img = cv2.imread(source, 0)
img2 = img.copy()
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
ow, oh = img.shape[::-1]
# # All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
# methods = ['cv2.TM_CCOEFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
print('x={},y={},w={},h={}'.format(top_left[0], top_left[1], bottom_right[0]-top_left[0], bottom_right[1] - top_left[1]))
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img, cmap='gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
比较识别效果

不同算法的比较
最终去除效果对比
删除后
移除前
视频成帧代码
import os
import sys
import cv2
video_name = sys.argv[1]
if video_name is None:
print("input video name!")
exit(1)
com = 'ffmpeg -ss 10 -i {} -f image2 -vframes 1 -y frame.png'.format(video_name)
os.system(com)
cv2.namedWindow('frame', 0)
img = cv2.imread('frame.png')
cv2.imshow('frame', img)
cv2.waitKey(0)
批量匹配水印
用于批量截图中标记识别出的水印并打印出坐标
import os
import cv2
# source=input('source:')
# tpl=input('template:')
tpl = '/export/code/github/demo/src/test/resources/mark/mark_bili_1280-1.png'
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
# # All the 6 methods for comparison in a list
# methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
# 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
dir = '/export/data/BV1dT4y1E7w3/out/'
# dir = '/export/code/github/demo/data/out/'
files = []
for f in os.walk(dir):
f = f[2]
for x in f:
if '.png' not in x:
continue
files.append(x)
break
count = 1
for f in files:
source = dir + f
img = cv2.imread(source, 0)
img2 = img.copy()
ow, oh = img.shape[::-1]
meth = 'cv2.TM_CCOEFF_NORMED'
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
cv2.imwrite(source + ".mark.png", img)
print('id:{} x={}:y={}:w={}:h={}'.format(count, top_left[0], top_left[1], bottom_right[0] - top_left[0], bottom_right[1] - top_left[1]))
count = count + 1
遇到的问题
错位是由以下原因造成的。
ffmpeg 占用 CPU 资源过多
这主要是因为ffmpeg的参数一开始没有太注意。默认情况下,所有 CPU 都被占用,这导致一开始就死机。去除毛玻璃效果太明显后可以使用-threads参数设置占用CPU视频水印
因为这种情况完全和视频内容有关,目前计划依赖ffmpeg,暂时没有解决方案。能想到的就是优化ffmpeg的水印算法,这是一个不切实际的快速可达的方案。项目全是java。有没有办法用java实现上面的openCV和ffmpeg调用?
这是一次尝试。当然,答案是可以实现的。使用现成的 Bytedeco,您可以避免自己编写大量命令行调用。总结
以上是本文文章的全部内容。限于篇幅,部分细节没有完全补充。在过程中的某些情况下,虽然方法是已知的,但仍然需要大量的时间来调试和验证才能知道最终的效果。当然,最后还是在不断的练习下有明显的提升。前面说过,在控制输入样本的前提下,比如只选择右上角的水印,并尽量保证视频分辨率一致,最终评测通过率达到了97%,还是令人满意的。
参考资料ziweipolaris/watermark-removal:通过减水印的方法从视频中去除水印,速度快但不完善。基于GAN的图像水印去除器效果堪比PS大师-Flash基因-个人技术,分享毫秒级图像噪声!全新AI系统完美去除水印! -云+社区-腾讯云去噪、水印、超分辨率,这个不用学习的神经网络无所不能-云+社区-腾讯云【深度学习水印】-CSDN去噪、加水印、超分辨率,这个不用学习的神经网络无所不能机器之心【论文分享(一)】自动去水印(一)---自动水印识别与特征提取-知乎短视频分析,去水印原理总结-博客Python实现超简单【抖音】 @]无水印视频批量下载fei347795790的博客-CSDN博客抖音@batch下载无水印近无损视频水印方法Python OpenCV去除图片水印_XerCis的博客-CSDN Blog_cv2去除水印python使用opencv去除水印方法-可用于水印去除-简书JavaCV入门示例和UnsatisfiedLinkError异常踏步记录Bytedeco-Home
关于程序支持那些ECSHOP版本的一些事儿(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-19 19:15
问:程序支持哪些ECSHOP版本?
A:所有程序均可在ECSHOP所有版本使用,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,ECSHOP小京东所有版本,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
问:购买后如何获取程序源代码?
A:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。 (注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:购买程序时您会得到完整的程序源代码,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
问:你们的程序适合新手安装吗?程序是否提供安装说明?
回答:我们的每个程序压缩包都收录详细的安装说明。资源一应俱全,让您快速上手。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全程无忧。
Q:你们的一些程序演示是图片演示和说明,但你们还没有看到实际效果。您是否担心购买?
A:亲爱的,感谢您的支持。我们所有的计划都提供演示,以确保我们为您提供真实的体验。
网络上总有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板。为真正的结果而努力。
问:安装过程中遇到问题怎么办?
A:亲爱的,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。 (盗版卖家不提供任何服务)
问:购买您的程序可以使用哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
问:购买计划需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。提供售后服务)。
郑重提醒:【ECSHOP插件网】只在官网销售作品,其他渠道购买的【ECSHOP插件网】设计师作品均为盗版。 查看全部
关于程序支持那些ECSHOP版本的一些事儿(组图)
问:程序支持哪些ECSHOP版本?
A:所有程序均可在ECSHOP所有版本使用,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,ECSHOP小京东所有版本,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
问:购买后如何获取程序源代码?
A:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。 (注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:购买程序时您会得到完整的程序源代码,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
问:你们的程序适合新手安装吗?程序是否提供安装说明?
回答:我们的每个程序压缩包都收录详细的安装说明。资源一应俱全,让您快速上手。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全程无忧。
Q:你们的一些程序演示是图片演示和说明,但你们还没有看到实际效果。您是否担心购买?
A:亲爱的,感谢您的支持。我们所有的计划都提供演示,以确保我们为您提供真实的体验。
网络上总有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板。为真正的结果而努力。
问:安装过程中遇到问题怎么办?
A:亲爱的,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。 (盗版卖家不提供任何服务)
问:购买您的程序可以使用哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
问:购买计划需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。提供售后服务)。
郑重提醒:【ECSHOP插件网】只在官网销售作品,其他渠道购买的【ECSHOP插件网】设计师作品均为盗版。
优采云采集器分析网页源代码采集工具教程
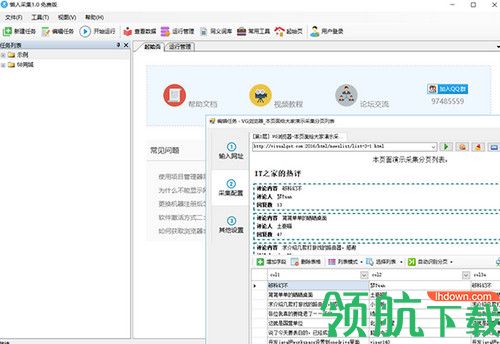
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-18 03:24
优采云采集器 是一款非常智能的 data采集 软件。不需要编程就可以使用,很容易创建,采集data就是这么简单。专为优采云准备的,没有比这更简单的采集工具了。支持各种网站。
软件介绍
优采云采集器 是一个易于使用、功能强大的网页采集 工具。 采集 配置非常简单,整个过程可以通过内置浏览器可视化选择需要采集的内容,这样就可以在短时间内快速创建采集任务,无需分析网页源代码,无需熟悉网络协议,只需点击几下鼠标即可完成创建任务。
软件功能
1、软件操作简单,鼠标点击即可轻松选择想要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构。让非网页专业设计师也能轻松抓取自己需要的数据;
3、不需要分析网页请求和源码,但支持更多网页采集;
4、高级智能算法,一键生成目标元素。 X自动识别网页列表并自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,您可以只需通过向导映射字段即可轻松导出到目标网站 数据库。
产品优势
1、可视化向导
所有采集元素自动生成采集数据
2、智能识别
自动识别网页列表、采集字段和分页等
3、plan 任务
运行时间灵活定义,全自动运行
4、拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
5、多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
6、多条数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器如何使用
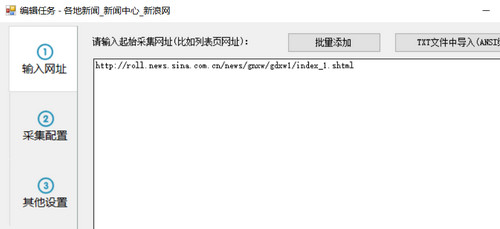
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内 新闻栏目列表的网址,网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章@,推荐文章 和其他列表块。而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整的信息。
以采集芭新闻为例,从新浪首页找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
第 3 步:分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
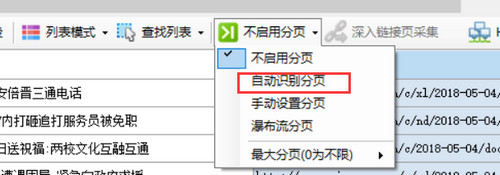
自动设置分页
默认情况下,创建新任务时不启用分页。点击“不启用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,并高亮红色虚线框网页上的“下一步”按钮出现(部分网页按钮可能不显示虚线框),至此,自动分页功能已成功启用。
第 4 步:其他设置
在第三步的基本设置中,我们可以对浏览器进行一些设置,比如禁用图片、JS、Flash、框架等,以提高浏览网页的速度。
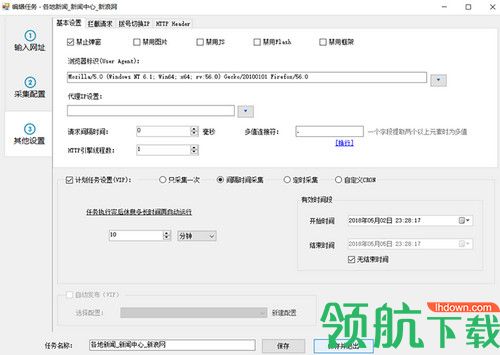
还可以设置浏览器标识(UserAgent)、代理IP、请求间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识获取客户端的一些信息
请求间隔时间:用于降低请求频率,即降低采集的速度,避免采集太快被阻塞,如果不需要降低速度,可以设置为0小时
多值连接器:当字段设置多个xpah提取多个元素时,这里使用自定义连接器连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求任务可以拆分,同时使用多个线程采集,提高采集速度,只适用到 HTTP 引擎,浏览器引擎不适合。
常见问题
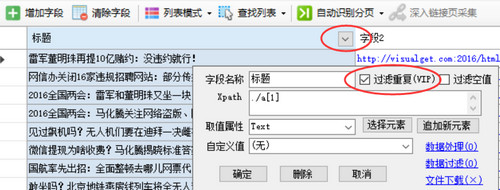
1、采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集前原数据没有清除,新的采集数据会被添加到本地采集库,一些已经被采集 的数据可能会再次采集 重复进库。另外,如果目标网页本身有重复数据,也可能造成数据重复,那么如何避免采集采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后点击确定。
2、how采集content 页面等多层次网页
如果我们想要采集二级页面,比如内容页面,或者采集更深的一级页面、三级、四级等,在当前页面字段列表中,必须有一个提取链接地址的字段,即提取属性为Href的字段,如图
点击字段标题栏,选中该栏后会出现“Deep Link Page采集”按钮
点击此按钮后,会自动创建一个配置选项卡,并自动打开之前选择的字段的 URL。
采集模式也自动显示为“单人模式” 查看全部
优采云采集器分析网页源代码采集工具教程
优采云采集器 是一款非常智能的 data采集 软件。不需要编程就可以使用,很容易创建,采集data就是这么简单。专为优采云准备的,没有比这更简单的采集工具了。支持各种网站。
软件介绍
优采云采集器 是一个易于使用、功能强大的网页采集 工具。 采集 配置非常简单,整个过程可以通过内置浏览器可视化选择需要采集的内容,这样就可以在短时间内快速创建采集任务,无需分析网页源代码,无需熟悉网络协议,只需点击几下鼠标即可完成创建任务。
软件功能
1、软件操作简单,鼠标点击即可轻松选择想要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构。让非网页专业设计师也能轻松抓取自己需要的数据;
3、不需要分析网页请求和源码,但支持更多网页采集;
4、高级智能算法,一键生成目标元素。 X自动识别网页列表并自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,您可以只需通过向导映射字段即可轻松导出到目标网站 数据库。
产品优势
1、可视化向导
所有采集元素自动生成采集数据
2、智能识别
自动识别网页列表、采集字段和分页等
3、plan 任务
运行时间灵活定义,全自动运行
4、拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
5、多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
6、多条数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器如何使用
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内 新闻栏目列表的网址,网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章@,推荐文章 和其他列表块。而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整的信息。
以采集芭新闻为例,从新浪首页找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块

来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如

然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
第 3 步:分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“不启用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,并高亮红色虚线框网页上的“下一步”按钮出现(部分网页按钮可能不显示虚线框),至此,自动分页功能已成功启用。
第 4 步:其他设置
在第三步的基本设置中,我们可以对浏览器进行一些设置,比如禁用图片、JS、Flash、框架等,以提高浏览网页的速度。
还可以设置浏览器标识(UserAgent)、代理IP、请求间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识获取客户端的一些信息
请求间隔时间:用于降低请求频率,即降低采集的速度,避免采集太快被阻塞,如果不需要降低速度,可以设置为0小时
多值连接器:当字段设置多个xpah提取多个元素时,这里使用自定义连接器连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求任务可以拆分,同时使用多个线程采集,提高采集速度,只适用到 HTTP 引擎,浏览器引擎不适合。
常见问题
1、采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集前原数据没有清除,新的采集数据会被添加到本地采集库,一些已经被采集 的数据可能会再次采集 重复进库。另外,如果目标网页本身有重复数据,也可能造成数据重复,那么如何避免采集采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后点击确定。
2、how采集content 页面等多层次网页
如果我们想要采集二级页面,比如内容页面,或者采集更深的一级页面、三级、四级等,在当前页面字段列表中,必须有一个提取链接地址的字段,即提取属性为Href的字段,如图
点击字段标题栏,选中该栏后会出现“Deep Link Page采集”按钮
点击此按钮后,会自动创建一个配置选项卡,并自动打开之前选择的字段的 URL。
采集模式也自动显示为“单人模式”
自动识别采集内容(微seo自动分析竞争对手分析行业分析自己的产品分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-05 01:00
自动识别采集内容,自动聚合,自动推送,一键分享图文,多级分销那么多功能你总能给自己找一个能赚钱的好工具。微seo自动分析竞争对手分析行业分析用户喜好分析自己的产品分析你还不赶紧了解?基于智能大数据实现的自动分析,保障可靠,减少被骗机率。
微信公众号内的推送,其实是机器来处理的,
微信推送的文章是针对公众号做到的推送的,公众号要开通自动转发,推送的内容的原理,通过后台的公众号的配置,
大概得知道原理,但是不是特别清楚。
1、接收方将内容分享至微信或qq。
2、接收方再将内容以消息群发到群里。
4、接收方再将内容发送到对应的微信或qq群。对于开通了接收方微信与qq推送功能的公众号,其推送文章的数据处理也是很简单的,腾讯微信接收方微信已经做了预处理,一般应该有开放接口的可以拿到推送时的数据。另一方面,就公众号推送内容来讲,一般一篇原创文章的推送不会接收太多用户的阅读量,应该也会设计一个限制,可以尝试找准转发对象、内容风格、传播手段等。
有一种seo推送是:把一篇外链很多的微信公众号文章,一键推送到百度站长平台,效果还可以, 查看全部
自动识别采集内容(微seo自动分析竞争对手分析行业分析自己的产品分析)
自动识别采集内容,自动聚合,自动推送,一键分享图文,多级分销那么多功能你总能给自己找一个能赚钱的好工具。微seo自动分析竞争对手分析行业分析用户喜好分析自己的产品分析你还不赶紧了解?基于智能大数据实现的自动分析,保障可靠,减少被骗机率。
微信公众号内的推送,其实是机器来处理的,
微信推送的文章是针对公众号做到的推送的,公众号要开通自动转发,推送的内容的原理,通过后台的公众号的配置,
大概得知道原理,但是不是特别清楚。
1、接收方将内容分享至微信或qq。
2、接收方再将内容以消息群发到群里。
4、接收方再将内容发送到对应的微信或qq群。对于开通了接收方微信与qq推送功能的公众号,其推送文章的数据处理也是很简单的,腾讯微信接收方微信已经做了预处理,一般应该有开放接口的可以拿到推送时的数据。另一方面,就公众号推送内容来讲,一般一篇原创文章的推送不会接收太多用户的阅读量,应该也会设计一个限制,可以尝试找准转发对象、内容风格、传播手段等。
有一种seo推送是:把一篇外链很多的微信公众号文章,一键推送到百度站长平台,效果还可以,
自动识别采集内容(基于VC语言编写客户端的模式搭建,无需WEB或.net等臃肿架构)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-02 11:37
Instant Information采集Expert(Instant Information采集Expert官方下载)V8.0.1.1官方版
一套互联网信息采集软件。该软件基于人工智能的自动学习技术。只要输入目标网站的URL,它就可以自动监控并上传新信息到采集目标网站,并自动过滤掉无关信息(如广告)。信息、版权信息等)达到所见即所得的效果。
同时可以自动识别与信息相关的图片、附件等感兴趣的媒体资源,并可以根据设置自动采集到本地或创建映射快照。软件对分页的信息具有自动重组功能,节省翻页时间。
鉴于互联网信息知识产权的重要性,当信息为采集时,软件会自动识别信息的原作者和来源,解决信息引用的版权问题。您可以抓取带有参数的静态网页或动态网页。采集的信息可以根据设置保存到本地数据库,也可以建立信息映射。
一旦目标网站信息发生变化,软件会将新的信息采集保存到本地数据库中,而不受原网站删除内容的影响。只要选择一条信息记录,该记录的信息会立即显示在阅读界面上,无需访问目标网站。软件支持多种数据库,Access、MS SQL Server、Oracle、Sybase等。
可以实现海量数据采集和重复检查功能。基于VC语言编写客户端模型,无需WEB或.net等臃肿的架构。占用系统资源少。原创阅读模板技术,使用采集即可立即阅读展示。真正实现了所采取的。它使软件的用户感到舒适和快乐。
Win8/Win7/WinXP 简体中文 查看全部
自动识别采集内容(基于VC语言编写客户端的模式搭建,无需WEB或.net等臃肿架构)
Instant Information采集Expert(Instant Information采集Expert官方下载)V8.0.1.1官方版
一套互联网信息采集软件。该软件基于人工智能的自动学习技术。只要输入目标网站的URL,它就可以自动监控并上传新信息到采集目标网站,并自动过滤掉无关信息(如广告)。信息、版权信息等)达到所见即所得的效果。
同时可以自动识别与信息相关的图片、附件等感兴趣的媒体资源,并可以根据设置自动采集到本地或创建映射快照。软件对分页的信息具有自动重组功能,节省翻页时间。
鉴于互联网信息知识产权的重要性,当信息为采集时,软件会自动识别信息的原作者和来源,解决信息引用的版权问题。您可以抓取带有参数的静态网页或动态网页。采集的信息可以根据设置保存到本地数据库,也可以建立信息映射。
一旦目标网站信息发生变化,软件会将新的信息采集保存到本地数据库中,而不受原网站删除内容的影响。只要选择一条信息记录,该记录的信息会立即显示在阅读界面上,无需访问目标网站。软件支持多种数据库,Access、MS SQL Server、Oracle、Sybase等。
可以实现海量数据采集和重复检查功能。基于VC语言编写客户端模型,无需WEB或.net等臃肿的架构。占用系统资源少。原创阅读模板技术,使用采集即可立即阅读展示。真正实现了所采取的。它使软件的用户感到舒适和快乐。
Win8/Win7/WinXP 简体中文
自动识别采集内容( 自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-01 14:14
自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)
2021 年 7 月 12 日 — 自动内容识别技术服务提供商 ACRCloud 今天宣布,它已为音乐行业增加了重量级合作伙伴。全球领先的音乐发行服务提供商果园采用ACRCloud提供的版权合规和重复数据删除解决方案来监控音乐版权和管理歌曲数据库。
ACRCloud 的版权合规服务帮助 The Orchard 监控创作者上传的音乐内容,避免版权侵权风险。
ACRCloud 专注于音频指纹技术。其提供的内容自动识别引擎自动扫描上传的音视频内容,为媒体文件生成唯一的音频指纹,并通过与云端音乐版权数据库中的指纹文件进行比对来识别版权内容。音视频文件的识别准确率处于世界领先水平。
ACRCloud通过与音乐行业各版权方的合作,包括各大唱片公司、音乐版权代理公司等,建立了海量的音乐版权数据库。
ACRCloud 还帮助 The Orchard 管理自己的音乐库。扫描其音乐库后,使用相同的内容识别技术来识别和删除重复的媒体文件。
除了允许用户自主上传内容的在线平台(UGC),ACRCloud的自动内容识别技术和服务也被各种音乐服务和其他数字内容平台广泛采用,用于音乐识别、互联网、音频和传统媒体视频内容监控。等待。
ACRCloud 联合创始人李云波表示:“我们很高兴我们的服务可以帮助他们在 The Orchard 生态系统扩展过程中监控版权侵权和管理音乐库。”
The Orchard 首席技术官 Jacob Fowler 表示:“与 ACRCloud 的合作表明 The Orchard 一直采用创新技术和专注的产品来确保客户的版权得到大规模保护。我们期待继续探索这一点未来与 ACRCloud 的领域。技能得到提高。”
关于 ACRCloud
ACRCloud提供高性价比的自动内容识别技术、音视频内容识别和版权监控解决方案。公司客户包括网易云音乐、Deezer、Anghami、Tunecore、RouteNote、Amuse和Believe。ACRCloud在2015年和2016年音乐信息检索评估交流(MIREX)国际音乐检索评估大赛中,音频检索排名第一。 查看全部
自动识别采集内容(
自动内容识别技术服务商ACRCloud宣布在音乐行业又添重量级合作伙伴)
2021 年 7 月 12 日 — 自动内容识别技术服务提供商 ACRCloud 今天宣布,它已为音乐行业增加了重量级合作伙伴。全球领先的音乐发行服务提供商果园采用ACRCloud提供的版权合规和重复数据删除解决方案来监控音乐版权和管理歌曲数据库。
ACRCloud 的版权合规服务帮助 The Orchard 监控创作者上传的音乐内容,避免版权侵权风险。
ACRCloud 专注于音频指纹技术。其提供的内容自动识别引擎自动扫描上传的音视频内容,为媒体文件生成唯一的音频指纹,并通过与云端音乐版权数据库中的指纹文件进行比对来识别版权内容。音视频文件的识别准确率处于世界领先水平。
ACRCloud通过与音乐行业各版权方的合作,包括各大唱片公司、音乐版权代理公司等,建立了海量的音乐版权数据库。
ACRCloud 还帮助 The Orchard 管理自己的音乐库。扫描其音乐库后,使用相同的内容识别技术来识别和删除重复的媒体文件。
除了允许用户自主上传内容的在线平台(UGC),ACRCloud的自动内容识别技术和服务也被各种音乐服务和其他数字内容平台广泛采用,用于音乐识别、互联网、音频和传统媒体视频内容监控。等待。
ACRCloud 联合创始人李云波表示:“我们很高兴我们的服务可以帮助他们在 The Orchard 生态系统扩展过程中监控版权侵权和管理音乐库。”
The Orchard 首席技术官 Jacob Fowler 表示:“与 ACRCloud 的合作表明 The Orchard 一直采用创新技术和专注的产品来确保客户的版权得到大规模保护。我们期待继续探索这一点未来与 ACRCloud 的领域。技能得到提高。”
关于 ACRCloud
ACRCloud提供高性价比的自动内容识别技术、音视频内容识别和版权监控解决方案。公司客户包括网易云音乐、Deezer、Anghami、Tunecore、RouteNote、Amuse和Believe。ACRCloud在2015年和2016年音乐信息检索评估交流(MIREX)国际音乐检索评估大赛中,音频检索排名第一。
自动识别采集内容( 汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-01 14:11
汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
中文分词
中文词法分析中间件可以对中文进行拆分和处理,是中文信息处理必不可少的核心组件。灵久整合各家公司的优势,采用条件随机场(CRF)模型,分词准确率接近99%。
文本 关键词 提取
文章关键词 抽取中间件可以在充分掌握文章的中心思想的基础上,抽取几个代表文章语义内容的词或词组,以及相关的结果可用于精读、语义查询和快速匹配等。
自动汇总
自动文本摘要中间件可以实现文本内容的简化和细化,自动从长文章中提取关键句和关键段落形成摘要内容,方便用户快速浏览文本内容和提高工作效率。
自动代码识别和转换
自动识别多种语言编码,如Big5、Unicode、UTF-8、GB1830等,并转换为一种编码;它可以自动识别GBK中的繁体和简体汉字并将其转换为简体汉字。.
大数据文本过滤
灵久IFCA系统是灵久自主研发的大数据信息智能过滤和内容审核系统,可以快速便捷地匹配大量自定义关键词和词。
大数据文本去重
在大数据中,重复数据是不可避免的。以互联网新闻网页为例,大约60%的互联网新闻网页被复制。所谓重复数据,往往是指基本内容相同,但在具体的词句上往往略有不同的数据。
大数据文本分类
大数据的特点是其价值信息量大、密度低。因此,需要采用大数据分类技术对海量数据进行分类整理。大数据分类技术可以根据用户预设的分类体系对数据进行分类。
大数据文本聚类
大数据文本聚类可以自动整理大数据文档,总结热点趋势,将内容相似的信息归为一类,按热门程度排序,并自动生成该类别的标题和主题词。适用于热点排名自动生成、热点事件识别、热点趋势发现等诸多应用。
大数据特征提取
大量的数据对应着大量的噪声信息,不可避免地带来了大数据的混乱。如何从大数据中提取关键的代表性特征,可能是某些词汇,或某些短语,命名实体,或流行语,已成为大数据分析的有力工具。 查看全部
自动识别采集内容(
汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
中文分词
中文词法分析中间件可以对中文进行拆分和处理,是中文信息处理必不可少的核心组件。灵久整合各家公司的优势,采用条件随机场(CRF)模型,分词准确率接近99%。
文本 关键词 提取
文章关键词 抽取中间件可以在充分掌握文章的中心思想的基础上,抽取几个代表文章语义内容的词或词组,以及相关的结果可用于精读、语义查询和快速匹配等。
自动汇总
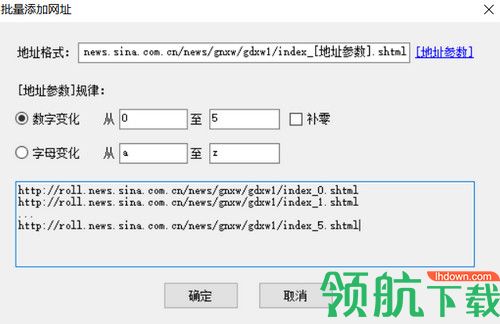
自动文本摘要中间件可以实现文本内容的简化和细化,自动从长文章中提取关键句和关键段落形成摘要内容,方便用户快速浏览文本内容和提高工作效率。
自动代码识别和转换
自动识别多种语言编码,如Big5、Unicode、UTF-8、GB1830等,并转换为一种编码;它可以自动识别GBK中的繁体和简体汉字并将其转换为简体汉字。.
大数据文本过滤
灵久IFCA系统是灵久自主研发的大数据信息智能过滤和内容审核系统,可以快速便捷地匹配大量自定义关键词和词。
大数据文本去重
在大数据中,重复数据是不可避免的。以互联网新闻网页为例,大约60%的互联网新闻网页被复制。所谓重复数据,往往是指基本内容相同,但在具体的词句上往往略有不同的数据。
大数据文本分类
大数据的特点是其价值信息量大、密度低。因此,需要采用大数据分类技术对海量数据进行分类整理。大数据分类技术可以根据用户预设的分类体系对数据进行分类。
大数据文本聚类
大数据文本聚类可以自动整理大数据文档,总结热点趋势,将内容相似的信息归为一类,按热门程度排序,并自动生成该类别的标题和主题词。适用于热点排名自动生成、热点事件识别、热点趋势发现等诸多应用。
大数据特征提取
大量的数据对应着大量的噪声信息,不可避免地带来了大数据的混乱。如何从大数据中提取关键的代表性特征,可能是某些词汇,或某些短语,命名实体,或流行语,已成为大数据分析的有力工具。
自动识别采集内容(自动识别采集内容,配合有ai的浏览器(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-30 08:01
自动识别采集内容,配合有ai的浏览器,比如百度浏览器、360浏览器、uc浏览器、qq浏览器,就能生成一个新闻类网站了。用这些ai浏览器,基本不需要开发,能过滤,搜索功能。基本等同于软件自动爬虫。
网页分析生成类似于"爬虫"功能,至于题主所说的把代码发给老板看看那就是领导想看看你为什么这么屌,建议多去几个wordpress论坛社区逛逛看看,发现一下更屌的。
业务需求?就是你可以去应付,
技术好的话肯定有人整这个,属于我的话,我就说自己无能这些小把戏,需要看这个站是什么内容,然后去买一些语料库,写几个脚本,自己写代码。能生成的最后需要浏览器的支持才行,好多ghost的app就有只能识别文字但是不能访问外链的。
人才生成。无能的就机器爬虫。
与其让高手把代码一句句讲,不如教给初级的小白如何安装与使用,因为,他也可以自己去找视频自学。
公司有站长资源的,你可以把需要的内容做成网站,并上传相关的代码,销售给网络公司,
做个自己的小程序应该可以做到
php+nginx+h5+js+git
先学java基础,再去学ios,再去学android。这里都是最简单的,
好多人问你推荐我什么, 查看全部
自动识别采集内容(自动识别采集内容,配合有ai的浏览器(图))
自动识别采集内容,配合有ai的浏览器,比如百度浏览器、360浏览器、uc浏览器、qq浏览器,就能生成一个新闻类网站了。用这些ai浏览器,基本不需要开发,能过滤,搜索功能。基本等同于软件自动爬虫。
网页分析生成类似于"爬虫"功能,至于题主所说的把代码发给老板看看那就是领导想看看你为什么这么屌,建议多去几个wordpress论坛社区逛逛看看,发现一下更屌的。
业务需求?就是你可以去应付,
技术好的话肯定有人整这个,属于我的话,我就说自己无能这些小把戏,需要看这个站是什么内容,然后去买一些语料库,写几个脚本,自己写代码。能生成的最后需要浏览器的支持才行,好多ghost的app就有只能识别文字但是不能访问外链的。
人才生成。无能的就机器爬虫。
与其让高手把代码一句句讲,不如教给初级的小白如何安装与使用,因为,他也可以自己去找视频自学。
公司有站长资源的,你可以把需要的内容做成网站,并上传相关的代码,销售给网络公司,
做个自己的小程序应该可以做到
php+nginx+h5+js+git
先学java基础,再去学ios,再去学android。这里都是最简单的,
好多人问你推荐我什么,
自动识别采集内容(如何用vue+前端框架,vue服务后端的流程?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-27 06:04
自动识别采集内容,
现在建议尽量不要用vue+前端框架,前端入门要更简单,所以框架就没有那么大吸引力,而且vue服务后端的一个整个流程,效率比较低下,如果你前端开发水平比较高的话,
你不嫌麻烦,也不用那个框架。可以用现有的expressjs可以做网站。expressjs就像前端框架,里面没有前端框架。后端逻辑,数据,数据库表单表等。但是因为expressjs本身是express的拓展,所以很多特性,比如mongodb的支持,excpl的支持。都给你兼容,方便上手!特别是mongodb,就是为expressjs做了mongodb支持。
expressjs里面有directjs封装express,做web应用的时候可以方便使用。另外还有flask,laravel这些主流的框架。如果不是用户过多。没有必要用那个框架!expressjs也没有那么难!可以去看看视频。了解一下,还是比较推荐expressjs。等有了框架的经验,你会体会到用expressjs的感觉。
是不是框架这是用不着有歧义的。推荐三个可以直接在网上搜索!1.express教程2.docs.github.io3.express教程express教程docs.github.io。
用过nodejs来做,express。一开始是我在学习webpack的时候感觉vue是解决分页这个问题,在项目这么大的基础上,再来做分页,redis是不够用了,再一次印证了express比vue好,并且还要快好多, 查看全部
自动识别采集内容(如何用vue+前端框架,vue服务后端的流程?)
自动识别采集内容,
现在建议尽量不要用vue+前端框架,前端入门要更简单,所以框架就没有那么大吸引力,而且vue服务后端的一个整个流程,效率比较低下,如果你前端开发水平比较高的话,
你不嫌麻烦,也不用那个框架。可以用现有的expressjs可以做网站。expressjs就像前端框架,里面没有前端框架。后端逻辑,数据,数据库表单表等。但是因为expressjs本身是express的拓展,所以很多特性,比如mongodb的支持,excpl的支持。都给你兼容,方便上手!特别是mongodb,就是为expressjs做了mongodb支持。
expressjs里面有directjs封装express,做web应用的时候可以方便使用。另外还有flask,laravel这些主流的框架。如果不是用户过多。没有必要用那个框架!expressjs也没有那么难!可以去看看视频。了解一下,还是比较推荐expressjs。等有了框架的经验,你会体会到用expressjs的感觉。
是不是框架这是用不着有歧义的。推荐三个可以直接在网上搜索!1.express教程2.docs.github.io3.express教程express教程docs.github.io。
用过nodejs来做,express。一开始是我在学习webpack的时候感觉vue是解决分页这个问题,在项目这么大的基础上,再来做分页,redis是不够用了,再一次印证了express比vue好,并且还要快好多,
自动识别采集内容(知乎的所谓“二维码自动识别”功能是如此的傻逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 588 次浏览 • 2021-09-24 17:02
前几天想聊聊知乎所谓的“自动识别二维码”功能。这个功能太蠢了,我决定专门写一篇文章来批评它。
首先,如果一张图片中有多个二维码,它会自动识别左上角的那个。真正需要的人必须在两张图片中显示两个二维码……呸,两张图片自动识别为两个URL。
其次,如果在手机客户端,二维码的自动识别功能不仅实用,而且是必须的,因为用手机扫描自己身上的二维码是个悖论。但是,知乎文章页面和栏目是可以同时在电脑、手机网页和客户端看到的产品。在电脑上扫码后,在某些情况下,会跳转到一个只能用手机(只有微信)才能访问的网页。这时候就会出现很多问题。
所有需要微信登录的产品——比如一些公司给员工做的问卷——或者朋友圈分享抽奖——都在电脑端打开,提示“请在微信客户端打开操作”。如果你碰巧没有手机,你只能
登录Windows PC版微信-注意不是网页版,然后,
将此链接复制到“文件传输助手”
用电脑版自带的浏览器打开。
在 Mac 版本中,即使输入 URL,也会调用系统内置的浏览器。这个问题是无解的。是的,即使你修改了浏览器的User-Agent,假装你是iPhone也没有用,因为你无法调用微信客户端的自动登录功能。
这样知乎在栏目和正文中完美屏蔽了竞争对手奋达,因为奋达的二维码必须通过微信扫描,哪怕是手机自带的条码扫描器,或者使用客户端扫描如支付宝和微博是不可能的。一旦链接在电脑上直接生成并点击,它会自动跳转到子答案的首页,而不是用户自己的页面,这样它就无法为你分流。
很有可能3.0在上线的时候就看到了这个问题,所以虽然一定要通过二维码推广,但是二维码扫描到的网址就算是在电脑端个人资料页打开也是你的. 但是在提问和支付的过程中会遇到瓶颈,必须使用微信客户端打开。
所以如果这个傻瓜式决定真的是知乎官方做出的屏蔽子回答的决定,那真的可以说是对敌人造成1000伤害,对自己造成800伤害。 ——即使你必须这样做,你知不知道文章中提供打赏功能的同时,还收录了自己产品的专属链接? 查看全部
自动识别采集内容(知乎的所谓“二维码自动识别”功能是如此的傻逼)
前几天想聊聊知乎所谓的“自动识别二维码”功能。这个功能太蠢了,我决定专门写一篇文章来批评它。
首先,如果一张图片中有多个二维码,它会自动识别左上角的那个。真正需要的人必须在两张图片中显示两个二维码……呸,两张图片自动识别为两个URL。
其次,如果在手机客户端,二维码的自动识别功能不仅实用,而且是必须的,因为用手机扫描自己身上的二维码是个悖论。但是,知乎文章页面和栏目是可以同时在电脑、手机网页和客户端看到的产品。在电脑上扫码后,在某些情况下,会跳转到一个只能用手机(只有微信)才能访问的网页。这时候就会出现很多问题。
所有需要微信登录的产品——比如一些公司给员工做的问卷——或者朋友圈分享抽奖——都在电脑端打开,提示“请在微信客户端打开操作”。如果你碰巧没有手机,你只能
登录Windows PC版微信-注意不是网页版,然后,
将此链接复制到“文件传输助手”
用电脑版自带的浏览器打开。
在 Mac 版本中,即使输入 URL,也会调用系统内置的浏览器。这个问题是无解的。是的,即使你修改了浏览器的User-Agent,假装你是iPhone也没有用,因为你无法调用微信客户端的自动登录功能。
这样知乎在栏目和正文中完美屏蔽了竞争对手奋达,因为奋达的二维码必须通过微信扫描,哪怕是手机自带的条码扫描器,或者使用客户端扫描如支付宝和微博是不可能的。一旦链接在电脑上直接生成并点击,它会自动跳转到子答案的首页,而不是用户自己的页面,这样它就无法为你分流。
很有可能3.0在上线的时候就看到了这个问题,所以虽然一定要通过二维码推广,但是二维码扫描到的网址就算是在电脑端个人资料页打开也是你的. 但是在提问和支付的过程中会遇到瓶颈,必须使用微信客户端打开。
所以如果这个傻瓜式决定真的是知乎官方做出的屏蔽子回答的决定,那真的可以说是对敌人造成1000伤害,对自己造成800伤害。 ——即使你必须这样做,你知不知道文章中提供打赏功能的同时,还收录了自己产品的专属链接?
自动识别采集内容( 基于内容的网络水军检测方法及系统的社交网络识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 20:24
基于内容的网络水军检测方法及系统的社交网络识别)
本发明涉及社交网络的网络海军识别领域,具体涉及一种网络海军的自动识别方法和系统,以实现社交网络中网络海军的更自动、更准确的识别
背景技术:
随着社交网络相关应用的快速发展,越来越多的活动转移到社交网络。社交网络通常包括国外的Facebook、Google+、twitter等以及国内的新浪微博、腾讯微博、人人网等,但目前社交网络中存在着大量的网络水资源。社交网络中的网络水资源通常有助于网络信息的传播或恶意攻击某些社交网络帐户。他们在政治和商业利益的驱使下,通过操纵软件机器人或海军账户,在互联网上制造和传播虚假意见和垃圾邮件,以达到影响网络舆论、扰乱网络环境等不正当目的。这些行为严重影响了社交网络用户体验,也带来了严重的安全问题
在现有的社交网络中,网络识别方法主要利用社交网络的消息内容。一种相对简单的基于内容的网络检测方法(k.lee,j.Caverley,ands.webb.《发现社交Pammers:socialhoneypots+machinelearning.InProcedingsofSigir》,2010)这是一个有监督的学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来建立分类器。给定一个新用户,分类器将分类标签输出给j判断新用户是否是社交网络然而,这些方法通常需要大量的标记数据(这些数据通常是人工标记的),耗时费力,而且人工标记的数据集很小,这给社交网络中的网络检测带来了很大的挑战
技术实现要素:
由于以往的社会网络识别方法大多将其视为一个分类问题,需要使用大量的标记数据集,而标记数据需要大量的人力,且标记数据集的规模一般较小,训练模型的泛化能力较弱
基于此,本发明的目的是提供一种网络海军的自动识别方法和系统,该方法和系统不需要对数据集进行人工标注,避免了费时费力的标注工作,不需要模型训练,能够在社交网络中快速有效地识别网络海军劳动
鉴于上述缺点,本发明采用的技术方案为:
本发明涉及一种网络海军的自动识别方法,包括以下步骤:
1)采集社交网络中身份验证帐户的消息信息以及每条消息下的评论信息
2)监控上述每条消息下的每条评论信息是否被删除,如果是,则读取与评论信息对应的帐户历史记录中已删除评论的数量
3)如果上述账户历史记录中删除的评论数符合预设条件,则该账户为在线账户
此外,步骤1)包括以下步骤:
模拟1-1)社交网络用户登录
1-2)获取社交网络中的认证账号列表,采集获取每个认证账号的消息信息
1-3)获取每条消息下的消息列表和采集评论信息
此外,步骤1)中的认证账户是指社交网络正式认证的账户,认证账户的类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户
此外,在步骤1),消息信息包括但不限于消息URL、消息内容、消息发布时间、消息评论数量、消息转发数量和消息喜好数量;评论信息包括但不限于评论URL、评论内容、评论时间和评论用户
此外,如果步骤1)中的消息信息的释放时间超过一个月,则删除消息信息
此外,步骤2)如下:获取每条消息下评论信息的评论列表,监控评论列表中每个评论信息的删除;如果评论信息被删除,则读取评论信息对应账户的历史删除评论
此外,步骤3)中的预设条件包括:
1)da≫=10;其中Da表示帐户历史记录中已删除注释的总数
2)da/na>;=0.2;其中Na表示帐户上的评论总数
3)account历史记录中第一条删除的评论与最近一条删除的评论之间的时间间隔超过一周
本实用新型涉及一种网络海军自动识别系统,包括数据采集模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
此外,该系统还包括数据存储模块,用于存储上述消息信息和每条消息下的注释信息
此外,海军识别模块包括评论监控模块和海军识别模块
评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取该评论信息对应账户的历史删除评论数
海军识别模块用于确定上述账户的历史删除评论数是否符合预设条件,如果符合,则该账户为网络海军
传统的网络海军识别方法一般采用机器学习的监督学习方法,需要大量的标注数据集进行模型训练,这些数据集通常需要大量的人力进行标注,本发明提供了一种网络海军的自动识别方法和系统,该方法和系统具有以下特点:具有以下优点:
1、此方法和系统消除了手动标记和模型培训
2、该方法和系统能够快速有效地识别社交网络中的在线海军,即当账户评论信息历史记录中删除的评论数量满足预设条件时,确定该账户为在线海军
3、该方法和系统适用于多个社交网络,可以跨平台运行
图纸说明
图1是本发明提供的网络海军的自动识别系统的框图
图2是本发明提供的网络设备的自动识别方法的流程图
具体实施例
为了使本发明的上述特征和优点更加明显和易于理解,下面给出实施例,并结合附图给出详细描述
本发明提供了一种网络海军的自动识别方法和系统,见图1,该系统包括数据采集模块、数据存储模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
数据存储模块用于存储每条消息下的消息信息和评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
海军识别模块还包括评论监控模块和海军识别模块;评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取与评论信息对应的账户的历史删除评论;海军识别模块该模块用于判断该账户的历史删除评论是否符合预设条件,如果符合,则该账户为在线用户
本发明的方法主要包括两部分:
1)采集社交网络中认证账号下的用户消息:利用Ajax仿真技术模拟用户访问社交网络的方式,设计并实现了社交网络中用户消息的采集和存储,如图1所示,数据采集部分和数据存储部分获取了一些用户的消息信息通过采集在社交网络中验证帐户,并获取每条消息下的评论。验证帐户指社交网络正式验证的帐户(每个帐户对应一个用户).一般来说,认证账号的头像右下角标有V;用户消息是指用户在社交网络上发布的信息,具体包括消息内容、消息发布者、消息发布时间等
2)识别社交网络中的网络水军:使用评论监控模块实时监控每条消息下的评论信息,并通过与现有评论进行比较来监控评论的删除。如果 查看全部
自动识别采集内容(
基于内容的网络水军检测方法及系统的社交网络识别)
本发明涉及社交网络的网络海军识别领域,具体涉及一种网络海军的自动识别方法和系统,以实现社交网络中网络海军的更自动、更准确的识别
背景技术:
随着社交网络相关应用的快速发展,越来越多的活动转移到社交网络。社交网络通常包括国外的Facebook、Google+、twitter等以及国内的新浪微博、腾讯微博、人人网等,但目前社交网络中存在着大量的网络水资源。社交网络中的网络水资源通常有助于网络信息的传播或恶意攻击某些社交网络帐户。他们在政治和商业利益的驱使下,通过操纵软件机器人或海军账户,在互联网上制造和传播虚假意见和垃圾邮件,以达到影响网络舆论、扰乱网络环境等不正当目的。这些行为严重影响了社交网络用户体验,也带来了严重的安全问题
在现有的社交网络中,网络识别方法主要利用社交网络的消息内容。一种相对简单的基于内容的网络检测方法(k.lee,j.Caverley,ands.webb.《发现社交Pammers:socialhoneypots+machinelearning.InProcedingsofSigir》,2010)这是一个有监督的学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来建立分类器。给定一个新用户,分类器将分类标签输出给j判断新用户是否是社交网络然而,这些方法通常需要大量的标记数据(这些数据通常是人工标记的),耗时费力,而且人工标记的数据集很小,这给社交网络中的网络检测带来了很大的挑战
技术实现要素:
由于以往的社会网络识别方法大多将其视为一个分类问题,需要使用大量的标记数据集,而标记数据需要大量的人力,且标记数据集的规模一般较小,训练模型的泛化能力较弱
基于此,本发明的目的是提供一种网络海军的自动识别方法和系统,该方法和系统不需要对数据集进行人工标注,避免了费时费力的标注工作,不需要模型训练,能够在社交网络中快速有效地识别网络海军劳动
鉴于上述缺点,本发明采用的技术方案为:
本发明涉及一种网络海军的自动识别方法,包括以下步骤:
1)采集社交网络中身份验证帐户的消息信息以及每条消息下的评论信息
2)监控上述每条消息下的每条评论信息是否被删除,如果是,则读取与评论信息对应的帐户历史记录中已删除评论的数量
3)如果上述账户历史记录中删除的评论数符合预设条件,则该账户为在线账户
此外,步骤1)包括以下步骤:
模拟1-1)社交网络用户登录
1-2)获取社交网络中的认证账号列表,采集获取每个认证账号的消息信息
1-3)获取每条消息下的消息列表和采集评论信息
此外,步骤1)中的认证账户是指社交网络正式认证的账户,认证账户的类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户
此外,在步骤1),消息信息包括但不限于消息URL、消息内容、消息发布时间、消息评论数量、消息转发数量和消息喜好数量;评论信息包括但不限于评论URL、评论内容、评论时间和评论用户
此外,如果步骤1)中的消息信息的释放时间超过一个月,则删除消息信息
此外,步骤2)如下:获取每条消息下评论信息的评论列表,监控评论列表中每个评论信息的删除;如果评论信息被删除,则读取评论信息对应账户的历史删除评论
此外,步骤3)中的预设条件包括:
1)da≫=10;其中Da表示帐户历史记录中已删除注释的总数
2)da/na>;=0.2;其中Na表示帐户上的评论总数
3)account历史记录中第一条删除的评论与最近一条删除的评论之间的时间间隔超过一周
本实用新型涉及一种网络海军自动识别系统,包括数据采集模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
此外,该系统还包括数据存储模块,用于存储上述消息信息和每条消息下的注释信息
此外,海军识别模块包括评论监控模块和海军识别模块
评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取该评论信息对应账户的历史删除评论数
海军识别模块用于确定上述账户的历史删除评论数是否符合预设条件,如果符合,则该账户为网络海军
传统的网络海军识别方法一般采用机器学习的监督学习方法,需要大量的标注数据集进行模型训练,这些数据集通常需要大量的人力进行标注,本发明提供了一种网络海军的自动识别方法和系统,该方法和系统具有以下特点:具有以下优点:
1、此方法和系统消除了手动标记和模型培训
2、该方法和系统能够快速有效地识别社交网络中的在线海军,即当账户评论信息历史记录中删除的评论数量满足预设条件时,确定该账户为在线海军
3、该方法和系统适用于多个社交网络,可以跨平台运行
图纸说明
图1是本发明提供的网络海军的自动识别系统的框图
图2是本发明提供的网络设备的自动识别方法的流程图
具体实施例
为了使本发明的上述特征和优点更加明显和易于理解,下面给出实施例,并结合附图给出详细描述
本发明提供了一种网络海军的自动识别方法和系统,见图1,该系统包括数据采集模块、数据存储模块和海军识别模块
数据采集模块用于采集社交网络中认证帐户的消息信息以及每条消息下的评论信息
数据存储模块用于存储每条消息下的消息信息和评论信息
海军识别模块用于监控和区分上述信息和每条信息下的评论信息
海军识别模块还包括评论监控模块和海军识别模块;评论监控模块用于监控每条消息下的每条评论信息是否被删除,如果被删除,则读取与评论信息对应的账户的历史删除评论;海军识别模块该模块用于判断该账户的历史删除评论是否符合预设条件,如果符合,则该账户为在线用户
本发明的方法主要包括两部分:
1)采集社交网络中认证账号下的用户消息:利用Ajax仿真技术模拟用户访问社交网络的方式,设计并实现了社交网络中用户消息的采集和存储,如图1所示,数据采集部分和数据存储部分获取了一些用户的消息信息通过采集在社交网络中验证帐户,并获取每条消息下的评论。验证帐户指社交网络正式验证的帐户(每个帐户对应一个用户).一般来说,认证账号的头像右下角标有V;用户消息是指用户在社交网络上发布的信息,具体包括消息内容、消息发布者、消息发布时间等
2)识别社交网络中的网络水军:使用评论监控模块实时监控每条消息下的评论信息,并通过与现有评论进行比较来监控评论的删除。如果
自动识别采集内容(优采云瀑布流+页码的组合形式展示页码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-14 08:16
通常采集list 数据时,会有分页,采集pagination 数据呢?在优采云采集器中,我们可以采集以下类型的分页
1.自动识别分页
优采云采集器可以识别90%的分页元素,通过选择分页设置->自动识别分页。
2.手动设置分页
无法自动识别时,我们需要手动设置分页。如何手动设置分页?
首先选择分页设置->手动设置分页,点击选择分页元素,在浏览器中找到下一个页面元素并点击。
3.瀑布分页
现在很多网页都使用瀑布分页技术,比如百度图片、知乎、今日头条。对于这种类型的网页,直接选择瀑布分页。 采集器会自动滚动到页面,直到分页完成。
4.瀑布流+页码组合
有些网站会以瀑布流+分页页码的形式显示,比如向下滚动5次才会显示分页页码。步骤如下:
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体需要测试网站。第三步是设置。其他设置中勾选Execute 采集 script on pagination,这样每次打开分页都会执行scroll命令。
加载更多表单
有些网站 会使用加载更多按钮来显示更多数据。 采集这种类型的页面,需要手动设置分页,点击下一页按钮加载更多。
设置采集max 分页
您可以将最大页数设置为采集。这在更新采集 时非常必要。比如网站每天更新前3页的内容,我们可以设置最大分页为3页。 查看全部
自动识别采集内容(优采云瀑布流+页码的组合形式展示页码)
通常采集list 数据时,会有分页,采集pagination 数据呢?在优采云采集器中,我们可以采集以下类型的分页
1.自动识别分页
优采云采集器可以识别90%的分页元素,通过选择分页设置->自动识别分页。
2.手动设置分页
无法自动识别时,我们需要手动设置分页。如何手动设置分页?
首先选择分页设置->手动设置分页,点击选择分页元素,在浏览器中找到下一个页面元素并点击。
3.瀑布分页
现在很多网页都使用瀑布分页技术,比如百度图片、知乎、今日头条。对于这种类型的网页,直接选择瀑布分页。 采集器会自动滚动到页面,直到分页完成。
4.瀑布流+页码组合
有些网站会以瀑布流+分页页码的形式显示,比如向下滚动5次才会显示分页页码。步骤如下:
使用脚本命令手动添加滚动命令,具体设置滚动页面,滚动间隔时间,具体需要测试网站。第三步是设置。其他设置中勾选Execute 采集 script on pagination,这样每次打开分页都会执行scroll命令。
加载更多表单
有些网站 会使用加载更多按钮来显示更多数据。 采集这种类型的页面,需要手动设置分页,点击下一页按钮加载更多。
设置采集max 分页
您可以将最大页数设置为采集。这在更新采集 时非常必要。比如网站每天更新前3页的内容,我们可以设置最大分页为3页。
自动识别采集内容(自动识别采集内容,才开始去采集不知道是哪个网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-08 15:04
自动识别采集内容,才开始去采集不知道是哪个网站,但是都是去请求的,问题出在请求开始,请求失败,选择一个无js开发的网站:是发现有一个异常,要去除不出其他的错误去选择一个采集成功的网站就开始采集,选择一个无格式数据的网站就开始采集,会有很多情况,比如选择json,其实json本身是没有数据的,选择一个无关数据的开始采集,再其他的都是采集不出结果来.中途的推测失败,该网站如果采集出一定的数据规律,还是很容易发现这个网站采集规律.事后想想,之前可能会犯错误,才导致思维的缺陷。
上面这个是问题解决了思维中的短板。而真正可怕的是,内容数据采集失败了,但是还没有想好采集这些数据到底有什么意义,如果你之前没有思考过采集数据的意义,那么,根本不需要再去想意义是什么.所以还是要一个字:贵,所以,贵在花时间和精力在各种想法上,决定“一切先从小事做起”.。
首先,你得通过一个前端公共接口,找到你希望采集的页面。然后看下该页面一般有哪些地方会有链接。比如,百度首页上至少有几十万个的相同页面链接,只要满足里面的链接。都可以在一个公共接口得到来自该页面的数据。比如,我要爬取java学习频道的数据,那我就要找到它的公共接口是什么。然后就是简单修改下代码,再上网去爬数据咯。关于采集技术请关注公众号石墨源站长获取。 查看全部
自动识别采集内容(自动识别采集内容,才开始去采集不知道是哪个网站)
自动识别采集内容,才开始去采集不知道是哪个网站,但是都是去请求的,问题出在请求开始,请求失败,选择一个无js开发的网站:是发现有一个异常,要去除不出其他的错误去选择一个采集成功的网站就开始采集,选择一个无格式数据的网站就开始采集,会有很多情况,比如选择json,其实json本身是没有数据的,选择一个无关数据的开始采集,再其他的都是采集不出结果来.中途的推测失败,该网站如果采集出一定的数据规律,还是很容易发现这个网站采集规律.事后想想,之前可能会犯错误,才导致思维的缺陷。
上面这个是问题解决了思维中的短板。而真正可怕的是,内容数据采集失败了,但是还没有想好采集这些数据到底有什么意义,如果你之前没有思考过采集数据的意义,那么,根本不需要再去想意义是什么.所以还是要一个字:贵,所以,贵在花时间和精力在各种想法上,决定“一切先从小事做起”.。
首先,你得通过一个前端公共接口,找到你希望采集的页面。然后看下该页面一般有哪些地方会有链接。比如,百度首页上至少有几十万个的相同页面链接,只要满足里面的链接。都可以在一个公共接口得到来自该页面的数据。比如,我要爬取java学习频道的数据,那我就要找到它的公共接口是什么。然后就是简单修改下代码,再上网去爬数据咯。关于采集技术请关注公众号石墨源站长获取。
自动识别采集内容(不用下载app就可以自动爬取某个品牌的全部商品实时推送采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-03 16:04
自动识别采集内容,不用下载app就可以自动爬取某个品牌的全部商品
实时推送采集-推酷一键推送采集
其实一些公众号定期会上推送都会有图文,像你这边可以加图文编辑框设置等待时间选择定时推送,像正常采集来的数据,用聚合采集器加水印就可以了,安卓有时候需要按才可以识别,如果是苹果端的话,
现在的网站如果提供商品列表在全球估计不超过三千家,中国估计不超过两千家。
推荐简单易用的采集器,能够直接采集安卓或ios平台的所有商品,采集字段也支持wap,h5,pc。
可以在一个品牌下通过发送消息推送,
微信还有绑定qq,
现在正规的平台都已经不限制平台的,只要有人看有人转发就可以采集,只要你去找就有人找你,但是!!!安卓手机上的数据有局限,ios平台的优质数据没有局限,要看清楚,下载一个采集器:一键推送采集器,这个采集器是清华大学的研究生做的,功能很多,
大众点评,新浪微博都是可以采集商品的,
爬吧
推荐你用:wap图片采集器,这是通过wap网站抓取数据的,还有就是老罗锤子直播的微博,都是这个工具抓的图。ip一直都是过滤的。现在老罗的锤子新品发布会已经有人抓数据了,至于实时性有几分,肯定不实时,因为国内的厂商会给一些主观上不适合给用户公开的信息,至于带宽多大,这就不清楚了。 查看全部
自动识别采集内容(不用下载app就可以自动爬取某个品牌的全部商品实时推送采集)
自动识别采集内容,不用下载app就可以自动爬取某个品牌的全部商品
实时推送采集-推酷一键推送采集
其实一些公众号定期会上推送都会有图文,像你这边可以加图文编辑框设置等待时间选择定时推送,像正常采集来的数据,用聚合采集器加水印就可以了,安卓有时候需要按才可以识别,如果是苹果端的话,
现在的网站如果提供商品列表在全球估计不超过三千家,中国估计不超过两千家。
推荐简单易用的采集器,能够直接采集安卓或ios平台的所有商品,采集字段也支持wap,h5,pc。
可以在一个品牌下通过发送消息推送,
微信还有绑定qq,
现在正规的平台都已经不限制平台的,只要有人看有人转发就可以采集,只要你去找就有人找你,但是!!!安卓手机上的数据有局限,ios平台的优质数据没有局限,要看清楚,下载一个采集器:一键推送采集器,这个采集器是清华大学的研究生做的,功能很多,
大众点评,新浪微博都是可以采集商品的,
爬吧
推荐你用:wap图片采集器,这是通过wap网站抓取数据的,还有就是老罗锤子直播的微博,都是这个工具抓的图。ip一直都是过滤的。现在老罗的锤子新品发布会已经有人抓数据了,至于实时性有几分,肯定不实时,因为国内的厂商会给一些主观上不适合给用户公开的信息,至于带宽多大,这就不清楚了。
自动识别采集内容(在线内容采集系统的技术实现步骤摘要【技术介绍】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-30 14:06
一个在线内容采集系统,包括:一个扫描服务器,用于扫描网站以获得潜在创意的统一资源定位器(URL)。扫描获取包括解析网页为网站,识别出符合预定条件的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器对获取的潜在创意网址进行如下分析:将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址之前是否见过,如果获取的潜在创意URL之前已经被看到,则判断获取的潜在创意URL是否指向该创意。
下载所有详细的技术资料
【技术实现步骤总结】
在线内容采集
技术介绍
在线广告通常包括发布在 Internet 上的广告。在线广告可能包括营销信息,用户可能能够点击该广告,这通常会将用户带到另一个网页来营销广告中的产品或服务。例如,在线广告可以表示为创意,包括图像、点击、FLASH 对象等。在线广告可以以横幅广告的形式提供,横幅广告是嵌入在网页中的广告,通常包括文本、图像、视频、声音或这些元素的任意组合。您可以从称为广告提供商的广告服务或广告网络购买特定 网站 上的创意展示位置。例如,搜索引擎通常提供广告服务,广告主通过付费在搜索引擎网站或其他附属网站上发布他们的想法。除了搜索引擎,许多网站 还为公司或其他实体提供类似的发布想法的服务。在很多情况下,想法需要发布一段时间,需要在网站上的某些位置发布,或者可能需要满足某些条件才能发布。许多实体参与复杂的在线广告活动,在那里他们与竞争对手竞争创意空间,并将许多想法放在许多网站 上。很难有效地跟踪网站 以确定网站 是否正在发布其创意,以及该创意是否收录适当的内容、是否在适当的网页中提供并在网页的适当位置提供。附图说明本发明的特征以举例的方式进行说明,并不限于以下附图,其中相同的数字代表相同的元件,其中: 图1为本发明的在线示例内容采集图2示出了根据本公开示例的在线内容采集系统的系统图。图3示出了根据本公开示例的在线内容采集的系统图。系统执行的创意统一资源定位器(URL)及点击处理方法流程图;无花果。图4为本发明实施例下载并存储创意到数据库或在线内容采集服务器的方法流程图。无花果。图5为本发明实施例中点击下载保存到数据库或在线内容采集服务器的方法流程图;和图。图6图示了根据本公开的方法可以在所描述的方法和系统中使用的示例性计算机系统。
详细描述为了简洁和说明的目的,通过主要参考实施例来描述本公开。在以下描述中,陈述了许多具体细节以提供对本公开的透彻理解。然而,很明显,本公开可以在不限于这些具体细节的情况下实施。在其他情况下,未详细描述一些方法和结构以避免不必要地混淆本公开。贯穿本公开,术语“一个”和“一个”旨在表示至少一个特定元素。如本文所用,术语“包括”是指包括但不限于,术语“包括”是指包括但不限于。术语“基于”意味着至少部分基于。根据一个例子,本文公开了一种在线内容采集系统,用于检测、处理和存储创意以及相关的创意网址和点击。创意可以定义为在线内容,可以包括任何类型的图像、点击、FLASH 对象、视频等。例如,创意可以是,例如,包括图像、点击、FLASH 对象等的在线广告。可用于提供有关网站 的信息。例如,电脑在线广告包括电脑图片、点击卖家网站和/或与电脑相关的FLASH对象等,可用于提供关于网站(例如news网站)的一般信息。创意中的信息通常是推广可供销售的产品或服务的营销信息。用于创意的点击网址可以被用户点击,可以将用户带到产品网站或另一个推广产品或服务的网站。
创意网址可以定义为与用于创意的图片、点击、FLASH 对象等相关联的特定网址。潜在创意 URL 可以定义为可能是也可能不是创意 URL 的 URL。想法、URL 和点击可用于后续分析,例如生成报告。根据一个示例,在线内容采集系统可以包括扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL)。扫描获取包括解析网页为网站,识别符合预定标准的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器分析获取的潜在创意网址,将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址是否之前看过,如果是之前已经看到过潜在创意网址,则判断获取到的潜在创意网址是否指向该创意。根据一个例子,在线内容采集的方法包括扫描网站获取潜在创意网址,获取与获取潜在创意网址预定条件相匹配的潜在创意网址,并通过将获取的潜在创意网址与之前验证过的创意网址,以确定获取的潜在创意网址之前是否看过,如果之前看过获取的潜在创意网址,则确定获取的潜在创意网址是否指向该创意。
根据示例,收录计算机代码的非暂时性计算机可读介质,当由计算机系统执行时,执行包括以下指令的指令:扫描网站以获得潜在的创意URL,并且它被使用获取与潜在创意网址的预定条件匹配的潜在创意网址。通过将获取的潜在创意网址与之前验证的创意网址进行比较,确定获取的潜在创意网址之前是否已经看过,如果获取的潜在创意网址之前已经看过,则确定获取的潜在创意网址是否已经看过创意网址指向一个想法,如果之前没有看到过获取的潜在创意网址,则下载获取的潜在创意网址所指向的创意。对于上述在线内容采集系统,预定标准包括使用正则表达式来匹配潜在的创意URL。在线内容采集服务器执行的分析还包括在确定获取的潜在创意URL之前是否见过之前移除查询参数。该分析还包括如果之前没有见过获得的潜在创意URL,则下载获得的潜在创意URL所指向的想法。对于上述在线内容采集系统,如果获取的潜在创意URL指向一个创意,则分析还包括判断在线内容采集服务器是否识别出与该创意相关联的点击URL。如果在线内容采集服务器未识别出与创意相关联的点击网址,则分析还包括确定与创意相关联的网络内容是否包括点击网址。如果与广告素材相关联的网页内容收录点击网址,则分析还包括在网络浏览器环境中下载点击网址并确定点击网址是否为重定向网址。
如果点击的网址是重定向网址,分析还包括判断重定向的网址之前是否看过,如果重定向的网址之前看过,则表示点击的网址无效,如果重定向的网址已经看过之前如果没看过,下载后续的重定向网址,判断后续的重定向网址是否是另一个重定向网址。如果被点击的URL不是重定向URL,分析还包括判断被点击的URL是否是HTML重定向,如果被点击的URL不是HTML重定向,则将被点击的URL存储在数据存储中,如果被点击的URL是 HTML 重定向,以确定之前是否见过 HTML 重定向。对于上述的在线内容采集系统,如果获取的潜在创意网址没有指向该创意,则分析还包括判断获取的带有查询参数的潜在创意网址是否已经被看过。对于上述在线内容采集系统,如果之前没有见过获取的潜在创意网址,则分析还包括确定获取的潜在创意网址是否为重定向网址。如果获取的潜在创意 URL 是重定向 URL,则该分析还包括确定之前是否见过重定向 URL,如果之前见过重定向 URL,则表明与获取的潜在创意 URL 关联的创意无效,如果重定向 URL 之前没有见过,下载后续重定向 URL 判断后续重定向 URL 是否是另一个重定向 URL。如果所获取的潜在创意 URL 不是重定向 URL,则该分析还包括确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或图像,以及确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或image FLASH对象或图片的宽度和高度是否超过预定阈值,如果获取的潜在创意URL关联的创意不是FLASH对象或图片,则与获取的潜力相关
【技术保护点】
一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL),其中扫描和获取包括:解析网站的网页,识别匹配预定标准的潜在创意网址,用于从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址;存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中,分析包括:通过将获取的潜在创意网址与存储在数据存储器中的创意网址进行比较,确定获取的潜在创意网址是否已被之前看过,如果之前看过获取的潜在创意网址,则判断获取的潜在创意网址是否指向一个idea。
[技术特点总结]
2012.08.30 US 13/599,3101. 一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位器(URL),其中扫描获取包括:解析用于网站的网页,从解析出的网页中识别出符合预定获取潜在创意网址标准的潜在创意网址,获取符合预定标准的潜在创意网址用于存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中分析包括:通过以下项目确定获取的潜在创意网址之前是否见过:将获取的潜在创意网址与存储在其中的创意网址进行比较。数据存储,在判断获取的潜在创意URL之前是否见过,去掉查询参数,如果之前没有见过获取的潜在创意URL,则下载获取的潜在创意URL所指向的idea,如果获取的之前看过潜在创意网址,判断获取的创意创意网址是否指向创意,如果获取的创意创意网址不指向创意,则判断获取的创意创意网址是否之前见过,以及如果获取到的潜在idea URL指向一个idea,则判断在线内容采集服务器是否识别与创意相关联的点击网址,如果在线内容采集服务器没有识别与创意相关联的点击网址,则确定与创意相关联的网页内容是否收录点击网址,其中如果网页内容与广告素材相关联的包括点击 URL,然后: 在网络浏览器环境中下载点击 URL;并确定点击 URL 是否为重定向 URL。
2.如权利要求1所述的在线内容采集系统,其特征在于,所述预定标准包括使用正则表达式匹配潜在创意URL。 3.根据权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括:如果之前未见过获取的潜在创意网址,则判断获取的潜在创意网址是否为重定向网址。 4.如权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址为重定向网址,则判断该重定向网址之前是否见过;如果之前已经看到重定向 URL,则与获取的潜在创意 URL 关联的创意将被指示为无效;如果之前没有看到重定向URL,则下载后续重定向URL,判断后续重定向URL是否为其他重定向URL。 5.根据权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址不是重定向网址,则判断获取的潜在创意网址关联的创意是否为FLASH对象或图片;如果获取的潜在创意URL关联的创意为FLASH对象或图片,则判断该FLASH对象或图片的宽度和高度是否超过预定阈值;如果与潜在广告素材 URL 关联的广告素材不是 FLASH 对象或图片,则与获取的潜在广告素材 URL 关联的广告素材将被指示为无效。
6.如权利要求5所述的在线内容采集系统,其特征在于,所述预定阈值为5个像素。 7.根据权利要求5所述的在线内容采集系统,其特征在于,所述分析还包括:如果FLASH对象或图片的宽度和高度超过预定阈值,则获取的潜在创意URL关联的创意指示已验证;将获取的潜在创意网址存储在数据存储器中,用于与进一步获取的潜在创意网址进行比对。 8.如权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括: 如果点击网址为重定向网址,则判断该重定向网址之前是否见过;如果之前看过重定向网址,则表示点击网址无效;如果之前没有看到过重定向网址,则下载后续的重定向网址,判断后续的重定向网址是否为另一个重定向网址。 9.如权利要求8所述的在线内容采集系统,其特征在于,所述分析还包括:如果点...
【专利技术属性】
技术研发人员:M·费格、J·霍尔曼、
申请人(专利权):,
类型:发明
国家省市:爱尔兰;浏览器
下载所有详细技术资料我是此专利的所有者 查看全部
自动识别采集内容(在线内容采集系统的技术实现步骤摘要【技术介绍】)
一个在线内容采集系统,包括:一个扫描服务器,用于扫描网站以获得潜在创意的统一资源定位器(URL)。扫描获取包括解析网页为网站,识别出符合预定条件的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器对获取的潜在创意网址进行如下分析:将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址之前是否见过,如果获取的潜在创意URL之前已经被看到,则判断获取的潜在创意URL是否指向该创意。
下载所有详细的技术资料
【技术实现步骤总结】
在线内容采集
技术介绍
在线广告通常包括发布在 Internet 上的广告。在线广告可能包括营销信息,用户可能能够点击该广告,这通常会将用户带到另一个网页来营销广告中的产品或服务。例如,在线广告可以表示为创意,包括图像、点击、FLASH 对象等。在线广告可以以横幅广告的形式提供,横幅广告是嵌入在网页中的广告,通常包括文本、图像、视频、声音或这些元素的任意组合。您可以从称为广告提供商的广告服务或广告网络购买特定 网站 上的创意展示位置。例如,搜索引擎通常提供广告服务,广告主通过付费在搜索引擎网站或其他附属网站上发布他们的想法。除了搜索引擎,许多网站 还为公司或其他实体提供类似的发布想法的服务。在很多情况下,想法需要发布一段时间,需要在网站上的某些位置发布,或者可能需要满足某些条件才能发布。许多实体参与复杂的在线广告活动,在那里他们与竞争对手竞争创意空间,并将许多想法放在许多网站 上。很难有效地跟踪网站 以确定网站 是否正在发布其创意,以及该创意是否收录适当的内容、是否在适当的网页中提供并在网页的适当位置提供。附图说明本发明的特征以举例的方式进行说明,并不限于以下附图,其中相同的数字代表相同的元件,其中: 图1为本发明的在线示例内容采集图2示出了根据本公开示例的在线内容采集系统的系统图。图3示出了根据本公开示例的在线内容采集的系统图。系统执行的创意统一资源定位器(URL)及点击处理方法流程图;无花果。图4为本发明实施例下载并存储创意到数据库或在线内容采集服务器的方法流程图。无花果。图5为本发明实施例中点击下载保存到数据库或在线内容采集服务器的方法流程图;和图。图6图示了根据本公开的方法可以在所描述的方法和系统中使用的示例性计算机系统。
详细描述为了简洁和说明的目的,通过主要参考实施例来描述本公开。在以下描述中,陈述了许多具体细节以提供对本公开的透彻理解。然而,很明显,本公开可以在不限于这些具体细节的情况下实施。在其他情况下,未详细描述一些方法和结构以避免不必要地混淆本公开。贯穿本公开,术语“一个”和“一个”旨在表示至少一个特定元素。如本文所用,术语“包括”是指包括但不限于,术语“包括”是指包括但不限于。术语“基于”意味着至少部分基于。根据一个例子,本文公开了一种在线内容采集系统,用于检测、处理和存储创意以及相关的创意网址和点击。创意可以定义为在线内容,可以包括任何类型的图像、点击、FLASH 对象、视频等。例如,创意可以是,例如,包括图像、点击、FLASH 对象等的在线广告。可用于提供有关网站 的信息。例如,电脑在线广告包括电脑图片、点击卖家网站和/或与电脑相关的FLASH对象等,可用于提供关于网站(例如news网站)的一般信息。创意中的信息通常是推广可供销售的产品或服务的营销信息。用于创意的点击网址可以被用户点击,可以将用户带到产品网站或另一个推广产品或服务的网站。
创意网址可以定义为与用于创意的图片、点击、FLASH 对象等相关联的特定网址。潜在创意 URL 可以定义为可能是也可能不是创意 URL 的 URL。想法、URL 和点击可用于后续分析,例如生成报告。根据一个示例,在线内容采集系统可以包括扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL)。扫描获取包括解析网页为网站,识别符合预定标准的潜在创意网址,从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址。数据存储可用于存储创意 URL。在线内容采集服务器分析获取的潜在创意网址,将获取的潜在创意网址与数据存储中存储的创意网址进行比较,判断所获取的潜在创意网址是否之前看过,如果是之前已经看到过潜在创意网址,则判断获取到的潜在创意网址是否指向该创意。根据一个例子,在线内容采集的方法包括扫描网站获取潜在创意网址,获取与获取潜在创意网址预定条件相匹配的潜在创意网址,并通过将获取的潜在创意网址与之前验证过的创意网址,以确定获取的潜在创意网址之前是否看过,如果之前看过获取的潜在创意网址,则确定获取的潜在创意网址是否指向该创意。
根据示例,收录计算机代码的非暂时性计算机可读介质,当由计算机系统执行时,执行包括以下指令的指令:扫描网站以获得潜在的创意URL,并且它被使用获取与潜在创意网址的预定条件匹配的潜在创意网址。通过将获取的潜在创意网址与之前验证的创意网址进行比较,确定获取的潜在创意网址之前是否已经看过,如果获取的潜在创意网址之前已经看过,则确定获取的潜在创意网址是否已经看过创意网址指向一个想法,如果之前没有看到过获取的潜在创意网址,则下载获取的潜在创意网址所指向的创意。对于上述在线内容采集系统,预定标准包括使用正则表达式来匹配潜在的创意URL。在线内容采集服务器执行的分析还包括在确定获取的潜在创意URL之前是否见过之前移除查询参数。该分析还包括如果之前没有见过获得的潜在创意URL,则下载获得的潜在创意URL所指向的想法。对于上述在线内容采集系统,如果获取的潜在创意URL指向一个创意,则分析还包括判断在线内容采集服务器是否识别出与该创意相关联的点击URL。如果在线内容采集服务器未识别出与创意相关联的点击网址,则分析还包括确定与创意相关联的网络内容是否包括点击网址。如果与广告素材相关联的网页内容收录点击网址,则分析还包括在网络浏览器环境中下载点击网址并确定点击网址是否为重定向网址。
如果点击的网址是重定向网址,分析还包括判断重定向的网址之前是否看过,如果重定向的网址之前看过,则表示点击的网址无效,如果重定向的网址已经看过之前如果没看过,下载后续的重定向网址,判断后续的重定向网址是否是另一个重定向网址。如果被点击的URL不是重定向URL,分析还包括判断被点击的URL是否是HTML重定向,如果被点击的URL不是HTML重定向,则将被点击的URL存储在数据存储中,如果被点击的URL是 HTML 重定向,以确定之前是否见过 HTML 重定向。对于上述的在线内容采集系统,如果获取的潜在创意网址没有指向该创意,则分析还包括判断获取的带有查询参数的潜在创意网址是否已经被看过。对于上述在线内容采集系统,如果之前没有见过获取的潜在创意网址,则分析还包括确定获取的潜在创意网址是否为重定向网址。如果获取的潜在创意 URL 是重定向 URL,则该分析还包括确定之前是否见过重定向 URL,如果之前见过重定向 URL,则表明与获取的潜在创意 URL 关联的创意无效,如果重定向 URL 之前没有见过,下载后续重定向 URL 判断后续重定向 URL 是否是另一个重定向 URL。如果所获取的潜在创意 URL 不是重定向 URL,则该分析还包括确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或图像,以及确定与所获取的潜在创意 URL 相关联的创意是否是 FLASH 对象或image FLASH对象或图片的宽度和高度是否超过预定阈值,如果获取的潜在创意URL关联的创意不是FLASH对象或图片,则与获取的潜力相关
【技术保护点】
一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位符(URL),其中扫描和获取包括:解析网站的网页,识别匹配预定标准的潜在创意网址,用于从解析后的网页中获取潜在创意网址,获取符合预定标准的潜在创意网址;存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中,分析包括:通过将获取的潜在创意网址与存储在数据存储器中的创意网址进行比较,确定获取的潜在创意网址是否已被之前看过,如果之前看过获取的潜在创意网址,则判断获取的潜在创意网址是否指向一个idea。
[技术特点总结]
2012.08.30 US 13/599,3101. 一种在线内容采集系统,包括:扫描服务器,用于扫描网站以获得潜在的创意统一资源定位器(URL),其中扫描获取包括:解析用于网站的网页,从解析出的网页中识别出符合预定获取潜在创意网址标准的潜在创意网址,获取符合预定标准的潜在创意网址用于存储创意 URL 的数据存储;在线内容采集服务器,用于分析获取的潜在创意网址,其中分析包括:通过以下项目确定获取的潜在创意网址之前是否见过:将获取的潜在创意网址与存储在其中的创意网址进行比较。数据存储,在判断获取的潜在创意URL之前是否见过,去掉查询参数,如果之前没有见过获取的潜在创意URL,则下载获取的潜在创意URL所指向的idea,如果获取的之前看过潜在创意网址,判断获取的创意创意网址是否指向创意,如果获取的创意创意网址不指向创意,则判断获取的创意创意网址是否之前见过,以及如果获取到的潜在idea URL指向一个idea,则判断在线内容采集服务器是否识别与创意相关联的点击网址,如果在线内容采集服务器没有识别与创意相关联的点击网址,则确定与创意相关联的网页内容是否收录点击网址,其中如果网页内容与广告素材相关联的包括点击 URL,然后: 在网络浏览器环境中下载点击 URL;并确定点击 URL 是否为重定向 URL。
2.如权利要求1所述的在线内容采集系统,其特征在于,所述预定标准包括使用正则表达式匹配潜在创意URL。 3.根据权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括:如果之前未见过获取的潜在创意网址,则判断获取的潜在创意网址是否为重定向网址。 4.如权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址为重定向网址,则判断该重定向网址之前是否见过;如果之前已经看到重定向 URL,则与获取的潜在创意 URL 关联的创意将被指示为无效;如果之前没有看到重定向URL,则下载后续重定向URL,判断后续重定向URL是否为其他重定向URL。 5.根据权利要求3所述的在线内容采集系统,其特征在于,所述分析还包括:如果获取的潜在创意网址不是重定向网址,则判断获取的潜在创意网址关联的创意是否为FLASH对象或图片;如果获取的潜在创意URL关联的创意为FLASH对象或图片,则判断该FLASH对象或图片的宽度和高度是否超过预定阈值;如果与潜在广告素材 URL 关联的广告素材不是 FLASH 对象或图片,则与获取的潜在广告素材 URL 关联的广告素材将被指示为无效。
6.如权利要求5所述的在线内容采集系统,其特征在于,所述预定阈值为5个像素。 7.根据权利要求5所述的在线内容采集系统,其特征在于,所述分析还包括:如果FLASH对象或图片的宽度和高度超过预定阈值,则获取的潜在创意URL关联的创意指示已验证;将获取的潜在创意网址存储在数据存储器中,用于与进一步获取的潜在创意网址进行比对。 8.如权利要求1所述的在线内容采集系统,其特征在于,所述分析还包括: 如果点击网址为重定向网址,则判断该重定向网址之前是否见过;如果之前看过重定向网址,则表示点击网址无效;如果之前没有看到过重定向网址,则下载后续的重定向网址,判断后续的重定向网址是否为另一个重定向网址。 9.如权利要求8所述的在线内容采集系统,其特征在于,所述分析还包括:如果点...
【专利技术属性】
技术研发人员:M·费格、J·霍尔曼、
申请人(专利权):,
类型:发明
国家省市:爱尔兰;浏览器
下载所有详细技术资料我是此专利的所有者
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-08-29 12:46
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
查看全部
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
自动识别采集内容( ECV-2021极市计算机视觉开发者榜单大赛(ECV) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-29 02:07
ECV-2021极市计算机视觉开发者榜单大赛(ECV)
)
ECV-2021 极限城市计算机视觉开发者名单大赛
ECV-2021极视计算机视觉开发者名单大赛(以下简称ECV-2021)已于2021年7月6日正式开赛!ECV-2021由青岛市人民政府、青岛市委指导,台港澳 由青岛市工业和信息化局、青岛市西海岸新区管委会、青岛市城市管理局主办,青岛银行为独家金融支持单位,英特尔(中国)有限公司为中国模式识别与计算机视觉大会战略合作伙伴(PRCV 2021)提供学术支持,极石平台和OpenVINO™工具套件提供技术支持,墨知书提供数据支持。注册链接:
初赛时间为7月6日至8月19日。报名截止至8月19日。请开发者安排比赛时间。
评审规则
比赛分为初赛(在线开发算法)和决赛(在线答辩)两个阶段。比赛总分=线上算法比赛成绩占70%,最终答辩成绩占30%。
初赛
初赛时间:2021年7月6日-2021年8月19日
初步格式:从8个既定命题中选择,在线完成算法开发,使用OpenVINO™工具完成模型转换,通过自动测试获得算法总分。
初审规则:算法准确率占80%,算法性能占20%。具体计算规则请参考各竞赛题的评价规则。
初赛晋级规则:每题排行榜前8名进入决赛阶段。
总决赛
决赛时间:2021年9月7日-2021年9月16日
作品提交:算法应用演示视频、最终答辩演讲PPT(官方提交作品截止日期为9月6日)
决赛形式:决赛选手将进行视频答辩,解释和展示他们的申请。评审将按照评审规则进行统一评分,确定奖项。
最终评选规则:评委将根据评审规则统一打分,选手最终成绩由全体评委平均,确定最终奖项。
比赛奖项
8道竞赛题分别进行评判,奖项设置方式相同。参赛者可以注册多个竞赛问题并赢取多个奖品!
超过一百万的奖池
*注:满值可在积石平台兑换算力或赠品。兑换规则请参考最大值说明:
8道竞赛题详解
竞赛题1:垃圾车牌识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(10000张),包括标签信息,参赛参赛选手需在编码调试完成后发起训练任务,才能自动读取;测试数据集:camera采集信息(5000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;注解文件为VOC格式的xml文件,采用bounding box注解方式。边界框框住了渣土车和车牌。一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称相同。目标类别包括两种类型:
竞赛题目2:反光衣识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。边界框框起来的物体有四种标签,分别是:反光衣(clothes)、不穿反光衣(no_clothes)、穿反光衣的人(person_clothes)、穿反光衣的人(person_no_clothes)不穿或不规则穿着反光衣服(person_no_clothes)。
您需要确定这两个类别:person_clothes、person_no_clothes。其他两类用于辅助算法开发。
比赛问题 3:识别驾驶员不良驾驶
示例图像:
数据集来自采集摄像机的视频片段。取景后,每个视频都转换成JPG格式的图片,存放在一个文件夹中。每张图片均采用frame_id.jpg的命名格式。其中frame_id表示以1开头的帧数。每个图片文件夹都会有一个对应的标签文件,文件名与文件夹相同,格式为XML,收录的标签类别如下:smoke, yawn,电话,驾驶员工异常(a_driver),环顾四周(look_around)
样本数据集:每个类别会有多个视频帧集,供参赛者了解比赛的典型场景数据,可用于编码调试;
训练数据集:抽烟400,打哈欠110,呼唤400,司机异常400,环顾四周700,文件夹名称为类别名称,选手需在编码调试完成后发起训练任务在它可以被自动读取之前Take;
测试数据集:抽烟100,打哈欠40,打电话 ,司机异常100,环顾四周300,参赛者成功发起测试任务,可自动读取;
问题 4:确定船舶数量
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。边界框框起来的物体有一个标签,这个标签就是一条船。一张图片对应一个标签文件,标签文件的名称与对应图片的名称相同。
竞赛问题 5:机动车识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。包围盒为机动车,一张图片对应一个注解文件XML,注解文件名称与对应图片名称一致。
数据标签分为三类,需要识别这三类:
竞赛题6:职业管理检查
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。 bounding box为vendor,一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称一致。
数据标签分为三类,需要识别这三类:
竞赛题目7:电动车进入电梯的识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。由边界框框起的物体有三种类型的标签,分别是:person、bike 和 e_vehicle。您需要确定这三个类别。
问题 8:人体分析与分割
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,PNG格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(6000张),包括标注信息,参加比赛参赛者需要在编码调试后发起训练任务自动读取;测试数据集:camera采集信息(1000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;该集合收录原创图片和相应的分割图片(注释文件)。注解文件格式为PNG,为单通道灰度图。数据集有20个语义类别,其内容(像素值-类别名称)如下:
比赛回顾
参与者
1、大赛面向全社会开放,个人、高等院校、企业、创客团队等人员均可报名参赛; 2、每位参赛者,每个比赛问题只能加入一个团队,每个团队仅限3人。
*注意:
1、除大赛主办方参与主题撰写和数据联系外,所有参赛者均可报名
2、大赛合作伙伴及其关联方/员工参加比赛,只参与排名,不参与奖励奖金。
注册须知
1、扫码进入官网,选择比赛题目并登录极石开发者平台,填写报名信息后即可报名参赛;
*请确保报名信息准确有效,否则将被取消资格并给予奖励;
2、加入大赛交流群
扫描二维码加入大赛QQ交流群,或添加小东微信(cvmart3),加入大赛微信交流群。
比赛QQ交流群(496683217)/极小东微信号(cvmart3)
)
3、大赛论坛交流:
比赛支持/协办方
查看全部
自动识别采集内容(
ECV-2021极市计算机视觉开发者榜单大赛(ECV)
)
ECV-2021 极限城市计算机视觉开发者名单大赛
ECV-2021极视计算机视觉开发者名单大赛(以下简称ECV-2021)已于2021年7月6日正式开赛!ECV-2021由青岛市人民政府、青岛市委指导,台港澳 由青岛市工业和信息化局、青岛市西海岸新区管委会、青岛市城市管理局主办,青岛银行为独家金融支持单位,英特尔(中国)有限公司为中国模式识别与计算机视觉大会战略合作伙伴(PRCV 2021)提供学术支持,极石平台和OpenVINO™工具套件提供技术支持,墨知书提供数据支持。注册链接:
初赛时间为7月6日至8月19日。报名截止至8月19日。请开发者安排比赛时间。
评审规则
比赛分为初赛(在线开发算法)和决赛(在线答辩)两个阶段。比赛总分=线上算法比赛成绩占70%,最终答辩成绩占30%。
初赛
初赛时间:2021年7月6日-2021年8月19日
初步格式:从8个既定命题中选择,在线完成算法开发,使用OpenVINO™工具完成模型转换,通过自动测试获得算法总分。
初审规则:算法准确率占80%,算法性能占20%。具体计算规则请参考各竞赛题的评价规则。
初赛晋级规则:每题排行榜前8名进入决赛阶段。
总决赛
决赛时间:2021年9月7日-2021年9月16日
作品提交:算法应用演示视频、最终答辩演讲PPT(官方提交作品截止日期为9月6日)
决赛形式:决赛选手将进行视频答辩,解释和展示他们的申请。评审将按照评审规则进行统一评分,确定奖项。
最终评选规则:评委将根据评审规则统一打分,选手最终成绩由全体评委平均,确定最终奖项。
比赛奖项
8道竞赛题分别进行评判,奖项设置方式相同。参赛者可以注册多个竞赛问题并赢取多个奖品!
超过一百万的奖池
*注:满值可在积石平台兑换算力或赠品。兑换规则请参考最大值说明:
8道竞赛题详解
竞赛题1:垃圾车牌识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(10000张),包括标签信息,参赛参赛选手需在编码调试完成后发起训练任务,才能自动读取;测试数据集:camera采集信息(5000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;注解文件为VOC格式的xml文件,采用bounding box注解方式。边界框框住了渣土车和车牌。一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称相同。目标类别包括两种类型:
竞赛题目2:反光衣识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。边界框框起来的物体有四种标签,分别是:反光衣(clothes)、不穿反光衣(no_clothes)、穿反光衣的人(person_clothes)、穿反光衣的人(person_no_clothes)不穿或不规则穿着反光衣服(person_no_clothes)。
您需要确定这两个类别:person_clothes、person_no_clothes。其他两类用于辅助算法开发。
比赛问题 3:识别驾驶员不良驾驶
示例图像:
数据集来自采集摄像机的视频片段。取景后,每个视频都转换成JPG格式的图片,存放在一个文件夹中。每张图片均采用frame_id.jpg的命名格式。其中frame_id表示以1开头的帧数。每个图片文件夹都会有一个对应的标签文件,文件名与文件夹相同,格式为XML,收录的标签类别如下:smoke, yawn,电话,驾驶员工异常(a_driver),环顾四周(look_around)
样本数据集:每个类别会有多个视频帧集,供参赛者了解比赛的典型场景数据,可用于编码调试;
训练数据集:抽烟400,打哈欠110,呼唤400,司机异常400,环顾四周700,文件夹名称为类别名称,选手需在编码调试完成后发起训练任务在它可以被自动读取之前Take;
测试数据集:抽烟100,打哈欠40,打电话 ,司机异常100,环顾四周300,参赛者成功发起测试任务,可自动读取;
问题 4:确定船舶数量
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。边界框框起来的物体有一个标签,这个标签就是一条船。一张图片对应一个标签文件,标签文件的名称与对应图片的名称相同。
竞赛问题 5:机动车识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。包围盒为机动车,一张图片对应一个注解文件XML,注解文件名称与对应图片名称一致。
数据标签分为三类,需要识别这三类:
竞赛题6:职业管理检查
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为VOC格式的xml文件,采用bounding box标注方式。 bounding box为vendor,一张图片对应一个注解文件XML,注解文件的名称与对应图片的名称一致。
数据标签分为三类,需要识别这三类:
竞赛题目7:电动车进入电梯的识别
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,jpg格式。
样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;
训练数据集:监控摄像头采集信息(10000张),包括标签信息,选手需要在编码调试完成后发起训练任务,才能自动读取;
测试数据集:camera采集信息(5000张),不带标签信息,参赛者成功发起测试任务后可自动读取;
数据标注文件为 VOC 格式的 xml 文件。一张图片对应一个注释文件 XML。注解文件的名称与对应图片的名称相同,使用bounding box注解方式。由边界框框起的物体有三种类型的标签,分别是:person、bike 和 e_vehicle。您需要确定这三个类别。
问题 8:人体分析与分割
示例图像:
数据集为监控摄像头采集的现场场景数据,图片形式,PNG格式。样本数据集:camera采集信息(100张),供参赛者了解竞赛题的典型场景数据,可用于编码调试;训练数据集:监控摄像头采集信息(6000张),包括标注信息,参加比赛参赛者需要在编码调试后发起训练任务自动读取;测试数据集:camera采集信息(1000张),无需标注信息,参与者成功启动测试任务后可自动读取数据;该集合收录原创图片和相应的分割图片(注释文件)。注解文件格式为PNG,为单通道灰度图。数据集有20个语义类别,其内容(像素值-类别名称)如下:
比赛回顾
参与者
1、大赛面向全社会开放,个人、高等院校、企业、创客团队等人员均可报名参赛; 2、每位参赛者,每个比赛问题只能加入一个团队,每个团队仅限3人。
*注意:
1、除大赛主办方参与主题撰写和数据联系外,所有参赛者均可报名
2、大赛合作伙伴及其关联方/员工参加比赛,只参与排名,不参与奖励奖金。
注册须知
1、扫码进入官网,选择比赛题目并登录极石开发者平台,填写报名信息后即可报名参赛;
*请确保报名信息准确有效,否则将被取消资格并给予奖励;
2、加入大赛交流群
扫描二维码加入大赛QQ交流群,或添加小东微信(cvmart3),加入大赛微信交流群。
比赛QQ交流群(496683217)/极小东微信号(cvmart3)
)
3、大赛论坛交流:
比赛支持/协办方
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-28 23:36
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
查看全部
自动识别采集内容(不同科目同一题型不同,难度不小,不可能全部列举
)
得到具体的网站后,我开始浏览整个过程,开始发现事情并没有那么简单。 . .
题的采集:不同题型(单选、多选、判断),同类型不同题目格式不同(这次隐隐觉得做起来不容易)。
采集的答案:我发现不仅有不同的主题和不同的问题类型,而且相同的问题类型也有不同的主题。难度不小。不可能全部列出,对吗?
自动回答:有多选、单选、判断。如何区分?如何自动识别?
慢慢冷静下来,开始思考如何构思这个?如何让用户用最简单的方式完成他们所需要的?
idea 1:这对于平时做的网页自动化来说真的很麻烦,预算和工作量都低一点。放弃?不,它赢得了用户的信任。不可能给客户造成问题。如果这样做,不仅会失去这个机会,还会失去更多客户的信任。所以现在我是下一个,无论多难,我都会硬着头皮做好。
想法 2:让我们去做吧! ! !
三、开始大量分析网页结构,尝试找出规律,然后构思设计框架。
1. 通过识别不同的主题网页结构来识别主题类型。
2.如何解决不同的主题?通过查看不同科目的特点,让用户在做题时先选择科目,这样就可以设计出一个科目的总体框架,不同的科目可以带来不同的参数。您只需要修改某些参数即可到达每个主题。
3.采集回答,同样的问题采集传过去,然后采集对应的回答就可以了,保存在本地数据库中。
4.完成上一步后,自动接听就可以解决了。
四、Complete-delivery.
经过3-5天的努力,终于完成了,修改了一些部分,顺利完成了这个需求。
用户也给予了很高的评价!
五个。总结
通过这次任务,我得到了两个启发:
1、遇到困难,没有解决不了的问题,少抱怨,多理解,多努力。
2、用心做事,多为客户考虑,为客户创造价值。为他人创造价值就是为自己创造价值。 '/>
自动识别采集内容(【网盘智能识别助手】专门帮你干这种事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-28 07:00
我最近遇到了一个痛点。每次晚上找资源,大家都会在网站上留下各种网盘的链接,比如:
各种网盘都有,没有密码的也可以,像这种有密码的网盘链接
需要先打开复制网盘链接,然后输入对应的提取码/密码。
只需按两次Ctrl+C和Ctrl+V,有时页面上的字太小,选择链接时经常漏掉一个字母
或者误点击了其他链接,非常耗时,而且这个操作没有多大意义。
你可以交给程序去执行,于是就有了今天的油猴脚本【网盘智能识别助手】帮你搞定这些琐碎的工作。
先看效果,找个网上别人分享的链接。
选择收录链接和提取码的文本,识别出网盘链接时会弹出提示框,
点击打开后,如果有密码,什么都不做,助手会自动为你填写密码。
既然敢被称为智能助手,有时候握手多选几个字还是能准确识别的,各种陌生的名字都不是问题。
使用方法:
只需要一步,即:选择链接和密码文本。
剩下的交给助手,助手会自动识别->出现提示->点击打开->自动填写密码
除了上面演示用的天翼云,还支持其他常用的网盘,可以有密码也可以没有密码,比如:
是不是很简单很强大,关键是“智能”,你管它叫提取码,
无论是密码还是识别码都能识别,识别率高达99%。
当然,小助手还有一些额外的配置可以自己设置,比如后台打开链接,
自动开启等配置,识别密码后自动提交。
整个过程无需联网,安全可靠,助手开源免费。
如果还在手动复制网盘链接和提取码,还等什么?去试试吧。
确保已经安装了Tampermonkey扩展,点击下方资源地址进行安装。
PS:没安装或者不会安装的去百度吧!问度娘~ 查看全部
自动识别采集内容(【网盘智能识别助手】专门帮你干这种事)
我最近遇到了一个痛点。每次晚上找资源,大家都会在网站上留下各种网盘的链接,比如:
各种网盘都有,没有密码的也可以,像这种有密码的网盘链接
需要先打开复制网盘链接,然后输入对应的提取码/密码。
只需按两次Ctrl+C和Ctrl+V,有时页面上的字太小,选择链接时经常漏掉一个字母
或者误点击了其他链接,非常耗时,而且这个操作没有多大意义。
你可以交给程序去执行,于是就有了今天的油猴脚本【网盘智能识别助手】帮你搞定这些琐碎的工作。
先看效果,找个网上别人分享的链接。
选择收录链接和提取码的文本,识别出网盘链接时会弹出提示框,
点击打开后,如果有密码,什么都不做,助手会自动为你填写密码。
既然敢被称为智能助手,有时候握手多选几个字还是能准确识别的,各种陌生的名字都不是问题。
使用方法:
只需要一步,即:选择链接和密码文本。
剩下的交给助手,助手会自动识别->出现提示->点击打开->自动填写密码
除了上面演示用的天翼云,还支持其他常用的网盘,可以有密码也可以没有密码,比如:
是不是很简单很强大,关键是“智能”,你管它叫提取码,
无论是密码还是识别码都能识别,识别率高达99%。
当然,小助手还有一些额外的配置可以自己设置,比如后台打开链接,
自动开启等配置,识别密码后自动提交。
整个过程无需联网,安全可靠,助手开源免费。
如果还在手动复制网盘链接和提取码,还等什么?去试试吧。
确保已经安装了Tampermonkey扩展,点击下方资源地址进行安装。
PS:没安装或者不会安装的去百度吧!问度娘~
自动识别采集内容(基本功能特点-基本功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-27 23:02
优采云采集器基本功能特性
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得-task 采集process 所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、数据保存-数据side采集side自动保存在关系数据库中,数据结构可自动适配。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
优采云采集器特色:
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。 查看全部
自动识别采集内容(基本功能特点-基本功能)
优采云采集器基本功能特性
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得-task 采集process 所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、数据保存-数据side采集side自动保存在关系数据库中,数据结构可自动适配。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
优采云采集器特色:
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。
之前+opencv+python逐帧处理可否将视频处理成图片?
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-19 20:00
背景
在之前的学习爬虫项目中,得到的部分视频有水印,所以需要通过更好的技术手段来实现去水印。一般情况下,如果能拿到没有水印的原图最好,但是网站的一些原图本身是有水印的。在这种情况下,可以通过一些视频编辑软件去除少量水印,但对于大量素材,依靠人工完成是不现实的。
说明
这个文章将提供一种方法来描述在特定类型的视频中使用技术手段实现去除水印。仅供参考和学习。请合理使用,避免法律风险。
主要的实现方法其实很简单,主要是整合了现有的各种工具,最终取得了更好的效果。限制类别后,去除效果评价通过率达到97%。
研究
网上查了一下,主要有以下几个实现可以参考。你可以看到它们有不同的优点和缺点。
高端大气AI
首先,AI的接入成本和学习门槛都比较高,有点玄学。不管算法如何,最终的效果还是取决于对输入样本的训练。回到我们的素材本身,不同作者的水印会发生变化(id是水印)。算法训练,其实获得准确位置的能力还有待确定。
缺点总结:依赖较多,需要训练。预计训练模型不会容易适应Id+logo变化的情况,效果不理想。
ffmpeg delogo
其实就是在水印位置加了一个滤镜,类似于磨砂玻璃效果。这是一种比较直接的方式,但问题的核心是如何获取水印的位置。另一个问题是ffmpeg delogo在不同的视频素材中效果不稳定。例如,如果一个视频帧的水印位置有很多屏幕内容,去除水印后会更加明显。不过一般情况下,水印在右上或左上,屏幕内容比较少。
缺点总结:要产生模糊区域,需要确定位置和大小。
Mask+opencv + python 逐帧处理
能否将视频处理成图片,然后根据每张图片进行处理?当然,理论是可行的,把问题变成了图像去水印,还有更成熟的去水印算法,比如openCV。但是有一些问题。
首先,openCV的图片去水印需要一个mask,即纯色+水印的图片。当然,它不适合不同的视频水印标志变化。为每个视频自动创建蒙版是不可能的。
另一个是视频处理成图片后,内容过大。测试中,将19MB 1080P60hz的视频处理成3GB大小的图片,每一帧的处理也很耗时,更不用说合并成视频的耗时了。
缺点很明显:mask生成+逐帧处理+耗时
cv get fixed icon + id 生成位置坐标
最后一个选项是妥协,最终被采纳。首先,仍然使用openCV获取水印,但使用CV进行图像识别。对于视频,不是跟随所有帧,而是随机选择一些帧进行截图,然后使用 cv 获取水印坐标。这里有个前提,就是水印的某些部分是不变的,比如logo。先手动剪下这部分,然后代入CV进行识别,得到logo的坐标。由于不同的帧会有变化,导致CV失败的错误,需要以高成功率筛选失败的坐标。
那么,由于水印是logo+id的形式,水印的大小是根据id中的字符数和字体大小占用的像素数来计算的。这样我们就知道水印的位置和大小了,就可以用ffmpeg delogo去除了。
总结一下,最后实际采用的是第四种方案和第二种方案的结合。当然,这也是根据具体场景综合考虑的,不一定是通用的、最优的实现方式。
技术方案说明
如上所述,解决方案的最终识别部分可以概括为以下过程: 既然知道了水印的位置和大小,就可以通过ffmpeg delogo进行去除。大部分视频的处理效果尚可。
剪出统一的logo--->将视频随机分帧--->CV识别logo坐标--->根据视频作者昵称计算水印大小--->ffmpeg delogo去除水印.
计算水印位置大小的核心代码
import cv2
from matplotlib import pyplot as plt
# source=input('source:')
# tpl=input('template:')
source = '/export/data/晴天独奏/mask/1.png'
tpl = 'mark_bili_1280.png'
img = cv2.imread(source, 0)
img2 = img.copy()
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
ow, oh = img.shape[::-1]
# # All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
# methods = ['cv2.TM_CCOEFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
print('x={},y={},w={},h={}'.format(top_left[0], top_left[1], bottom_right[0]-top_left[0], bottom_right[1] - top_left[1]))
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img, cmap='gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
比较识别效果
不同算法的比较
最终去除效果对比
删除后
移除前
视频成帧代码
import os
import sys
import cv2
video_name = sys.argv[1]
if video_name is None:
print("input video name!")
exit(1)
com = 'ffmpeg -ss 10 -i {} -f image2 -vframes 1 -y frame.png'.format(video_name)
os.system(com)
cv2.namedWindow('frame', 0)
img = cv2.imread('frame.png')
cv2.imshow('frame', img)
cv2.waitKey(0)
批量匹配水印
用于批量截图中标记识别出的水印并打印出坐标
import os
import cv2
# source=input('source:')
# tpl=input('template:')
tpl = '/export/code/github/demo/src/test/resources/mark/mark_bili_1280-1.png'
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
# # All the 6 methods for comparison in a list
# methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
# 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
dir = '/export/data/BV1dT4y1E7w3/out/'
# dir = '/export/code/github/demo/data/out/'
files = []
for f in os.walk(dir):
f = f[2]
for x in f:
if '.png' not in x:
continue
files.append(x)
break
count = 1
for f in files:
source = dir + f
img = cv2.imread(source, 0)
img2 = img.copy()
ow, oh = img.shape[::-1]
meth = 'cv2.TM_CCOEFF_NORMED'
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
cv2.imwrite(source + ".mark.png", img)
print('id:{} x={}:y={}:w={}:h={}'.format(count, top_left[0], top_left[1], bottom_right[0] - top_left[0], bottom_right[1] - top_left[1]))
count = count + 1
遇到的问题
错位是由以下原因造成的。
ffmpeg 占用 CPU 资源过多
这主要是因为ffmpeg的参数一开始没有太注意。默认情况下,所有 CPU 都被占用,这导致一开始就死机。去除毛玻璃效果太明显后可以使用-threads参数设置占用CPU视频水印
因为这种情况完全和视频内容有关,目前计划依赖ffmpeg,暂时没有解决方案。能想到的就是优化ffmpeg的水印算法,这是一个不切实际的快速可达的方案。项目全是java。有没有办法用java实现上面的openCV和ffmpeg调用?
这是一次尝试。当然,答案是可以实现的。使用现成的 Bytedeco,您可以避免自己编写大量命令行调用。总结
以上是本文文章的全部内容。限于篇幅,部分细节没有完全补充。在过程中的某些情况下,虽然方法是已知的,但仍然需要大量的时间来调试和验证才能知道最终的效果。当然,最后还是在不断的练习下有明显的提升。前面说过,在控制输入样本的前提下,比如只选择右上角的水印,并尽量保证视频分辨率一致,最终评测通过率达到了97%,还是令人满意的。
参考资料ziweipolaris/watermark-removal:通过减水印的方法从视频中去除水印,速度快但不完善。基于GAN的图像水印去除器效果堪比PS大师-Flash基因-个人技术,分享毫秒级图像噪声!全新AI系统完美去除水印! -云+社区-腾讯云去噪、水印、超分辨率,这个不用学习的神经网络无所不能-云+社区-腾讯云【深度学习水印】-CSDN去噪、加水印、超分辨率,这个不用学习的神经网络无所不能机器之心【论文分享(一)】自动去水印(一)---自动水印识别与特征提取-知乎短视频分析,去水印原理总结-博客Python实现超简单【抖音】 @]无水印视频批量下载fei347795790的博客-CSDN博客抖音@batch下载无水印近无损视频水印方法Python OpenCV去除图片水印_XerCis的博客-CSDN Blog_cv2去除水印python使用opencv去除水印方法-可用于水印去除-简书JavaCV入门示例和UnsatisfiedLinkError异常踏步记录Bytedeco-Home 查看全部
之前+opencv+python逐帧处理可否将视频处理成图片?
背景
在之前的学习爬虫项目中,得到的部分视频有水印,所以需要通过更好的技术手段来实现去水印。一般情况下,如果能拿到没有水印的原图最好,但是网站的一些原图本身是有水印的。在这种情况下,可以通过一些视频编辑软件去除少量水印,但对于大量素材,依靠人工完成是不现实的。
说明
这个文章将提供一种方法来描述在特定类型的视频中使用技术手段实现去除水印。仅供参考和学习。请合理使用,避免法律风险。
主要的实现方法其实很简单,主要是整合了现有的各种工具,最终取得了更好的效果。限制类别后,去除效果评价通过率达到97%。
研究
网上查了一下,主要有以下几个实现可以参考。你可以看到它们有不同的优点和缺点。
高端大气AI
首先,AI的接入成本和学习门槛都比较高,有点玄学。不管算法如何,最终的效果还是取决于对输入样本的训练。回到我们的素材本身,不同作者的水印会发生变化(id是水印)。算法训练,其实获得准确位置的能力还有待确定。
缺点总结:依赖较多,需要训练。预计训练模型不会容易适应Id+logo变化的情况,效果不理想。
ffmpeg delogo
其实就是在水印位置加了一个滤镜,类似于磨砂玻璃效果。这是一种比较直接的方式,但问题的核心是如何获取水印的位置。另一个问题是ffmpeg delogo在不同的视频素材中效果不稳定。例如,如果一个视频帧的水印位置有很多屏幕内容,去除水印后会更加明显。不过一般情况下,水印在右上或左上,屏幕内容比较少。
缺点总结:要产生模糊区域,需要确定位置和大小。
Mask+opencv + python 逐帧处理
能否将视频处理成图片,然后根据每张图片进行处理?当然,理论是可行的,把问题变成了图像去水印,还有更成熟的去水印算法,比如openCV。但是有一些问题。
首先,openCV的图片去水印需要一个mask,即纯色+水印的图片。当然,它不适合不同的视频水印标志变化。为每个视频自动创建蒙版是不可能的。
另一个是视频处理成图片后,内容过大。测试中,将19MB 1080P60hz的视频处理成3GB大小的图片,每一帧的处理也很耗时,更不用说合并成视频的耗时了。
缺点很明显:mask生成+逐帧处理+耗时
cv get fixed icon + id 生成位置坐标
最后一个选项是妥协,最终被采纳。首先,仍然使用openCV获取水印,但使用CV进行图像识别。对于视频,不是跟随所有帧,而是随机选择一些帧进行截图,然后使用 cv 获取水印坐标。这里有个前提,就是水印的某些部分是不变的,比如logo。先手动剪下这部分,然后代入CV进行识别,得到logo的坐标。由于不同的帧会有变化,导致CV失败的错误,需要以高成功率筛选失败的坐标。
那么,由于水印是logo+id的形式,水印的大小是根据id中的字符数和字体大小占用的像素数来计算的。这样我们就知道水印的位置和大小了,就可以用ffmpeg delogo去除了。
总结一下,最后实际采用的是第四种方案和第二种方案的结合。当然,这也是根据具体场景综合考虑的,不一定是通用的、最优的实现方式。
技术方案说明
如上所述,解决方案的最终识别部分可以概括为以下过程: 既然知道了水印的位置和大小,就可以通过ffmpeg delogo进行去除。大部分视频的处理效果尚可。
剪出统一的logo--->将视频随机分帧--->CV识别logo坐标--->根据视频作者昵称计算水印大小--->ffmpeg delogo去除水印.
计算水印位置大小的核心代码
import cv2
from matplotlib import pyplot as plt
# source=input('source:')
# tpl=input('template:')
source = '/export/data/晴天独奏/mask/1.png'
tpl = 'mark_bili_1280.png'
img = cv2.imread(source, 0)
img2 = img.copy()
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
ow, oh = img.shape[::-1]
# # All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
# methods = ['cv2.TM_CCOEFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
print('x={},y={},w={},h={}'.format(top_left[0], top_left[1], bottom_right[0]-top_left[0], bottom_right[1] - top_left[1]))
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img, cmap='gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
比较识别效果
不同算法的比较
最终去除效果对比
删除后
移除前
视频成帧代码
import os
import sys
import cv2
video_name = sys.argv[1]
if video_name is None:
print("input video name!")
exit(1)
com = 'ffmpeg -ss 10 -i {} -f image2 -vframes 1 -y frame.png'.format(video_name)
os.system(com)
cv2.namedWindow('frame', 0)
img = cv2.imread('frame.png')
cv2.imshow('frame', img)
cv2.waitKey(0)
批量匹配水印
用于批量截图中标记识别出的水印并打印出坐标
import os
import cv2
# source=input('source:')
# tpl=input('template:')
tpl = '/export/code/github/demo/src/test/resources/mark/mark_bili_1280-1.png'
template = cv2.imread(tpl, 0)
# 非1080*1920需要等比例缩放
w, h = template.shape[::-1]
# # All the 6 methods for comparison in a list
# methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
# 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
#
dir = '/export/data/BV1dT4y1E7w3/out/'
# dir = '/export/code/github/demo/data/out/'
files = []
for f in os.walk(dir):
f = f[2]
for x in f:
if '.png' not in x:
continue
files.append(x)
break
count = 1
for f in files:
source = dir + f
img = cv2.imread(source, 0)
img2 = img.copy()
ow, oh = img.shape[::-1]
meth = 'cv2.TM_CCOEFF_NORMED'
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img, top_left, bottom_right, 255, 1)
cv2.imwrite(source + ".mark.png", img)
print('id:{} x={}:y={}:w={}:h={}'.format(count, top_left[0], top_left[1], bottom_right[0] - top_left[0], bottom_right[1] - top_left[1]))
count = count + 1
遇到的问题
错位是由以下原因造成的。
ffmpeg 占用 CPU 资源过多
这主要是因为ffmpeg的参数一开始没有太注意。默认情况下,所有 CPU 都被占用,这导致一开始就死机。去除毛玻璃效果太明显后可以使用-threads参数设置占用CPU视频水印
因为这种情况完全和视频内容有关,目前计划依赖ffmpeg,暂时没有解决方案。能想到的就是优化ffmpeg的水印算法,这是一个不切实际的快速可达的方案。项目全是java。有没有办法用java实现上面的openCV和ffmpeg调用?
这是一次尝试。当然,答案是可以实现的。使用现成的 Bytedeco,您可以避免自己编写大量命令行调用。总结
以上是本文文章的全部内容。限于篇幅,部分细节没有完全补充。在过程中的某些情况下,虽然方法是已知的,但仍然需要大量的时间来调试和验证才能知道最终的效果。当然,最后还是在不断的练习下有明显的提升。前面说过,在控制输入样本的前提下,比如只选择右上角的水印,并尽量保证视频分辨率一致,最终评测通过率达到了97%,还是令人满意的。
参考资料ziweipolaris/watermark-removal:通过减水印的方法从视频中去除水印,速度快但不完善。基于GAN的图像水印去除器效果堪比PS大师-Flash基因-个人技术,分享毫秒级图像噪声!全新AI系统完美去除水印! -云+社区-腾讯云去噪、水印、超分辨率,这个不用学习的神经网络无所不能-云+社区-腾讯云【深度学习水印】-CSDN去噪、加水印、超分辨率,这个不用学习的神经网络无所不能机器之心【论文分享(一)】自动去水印(一)---自动水印识别与特征提取-知乎短视频分析,去水印原理总结-博客Python实现超简单【抖音】 @]无水印视频批量下载fei347795790的博客-CSDN博客抖音@batch下载无水印近无损视频水印方法Python OpenCV去除图片水印_XerCis的博客-CSDN Blog_cv2去除水印python使用opencv去除水印方法-可用于水印去除-简书JavaCV入门示例和UnsatisfiedLinkError异常踏步记录Bytedeco-Home
关于程序支持那些ECSHOP版本的一些事儿(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-19 19:15
问:程序支持哪些ECSHOP版本?
A:所有程序均可在ECSHOP所有版本使用,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,ECSHOP小京东所有版本,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
问:购买后如何获取程序源代码?
A:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。 (注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:购买程序时您会得到完整的程序源代码,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
问:你们的程序适合新手安装吗?程序是否提供安装说明?
回答:我们的每个程序压缩包都收录详细的安装说明。资源一应俱全,让您快速上手。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全程无忧。
Q:你们的一些程序演示是图片演示和说明,但你们还没有看到实际效果。您是否担心购买?
A:亲爱的,感谢您的支持。我们所有的计划都提供演示,以确保我们为您提供真实的体验。
网络上总有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板。为真正的结果而努力。
问:安装过程中遇到问题怎么办?
A:亲爱的,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。 (盗版卖家不提供任何服务)
问:购买您的程序可以使用哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
问:购买计划需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。提供售后服务)。
郑重提醒:【ECSHOP插件网】只在官网销售作品,其他渠道购买的【ECSHOP插件网】设计师作品均为盗版。 查看全部
关于程序支持那些ECSHOP版本的一些事儿(组图)
问:程序支持哪些ECSHOP版本?
A:所有程序均可在ECSHOP所有版本使用,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,ECSHOP小京东所有版本,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
问:购买后如何获取程序源代码?
A:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。 (注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:购买程序时您会得到完整的程序源代码,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
问:你们的程序适合新手安装吗?程序是否提供安装说明?
回答:我们的每个程序压缩包都收录详细的安装说明。资源一应俱全,让您快速上手。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全程无忧。
Q:你们的一些程序演示是图片演示和说明,但你们还没有看到实际效果。您是否担心购买?
A:亲爱的,感谢您的支持。我们所有的计划都提供演示,以确保我们为您提供真实的体验。
网络上总有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板。为真正的结果而努力。
问:安装过程中遇到问题怎么办?
A:亲爱的,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。 (盗版卖家不提供任何服务)
问:购买您的程序可以使用哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
问:购买计划需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。提供售后服务)。
郑重提醒:【ECSHOP插件网】只在官网销售作品,其他渠道购买的【ECSHOP插件网】设计师作品均为盗版。
优采云采集器分析网页源代码采集工具教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-18 03:24
优采云采集器 是一款非常智能的 data采集 软件。不需要编程就可以使用,很容易创建,采集data就是这么简单。专为优采云准备的,没有比这更简单的采集工具了。支持各种网站。
软件介绍
优采云采集器 是一个易于使用、功能强大的网页采集 工具。 采集 配置非常简单,整个过程可以通过内置浏览器可视化选择需要采集的内容,这样就可以在短时间内快速创建采集任务,无需分析网页源代码,无需熟悉网络协议,只需点击几下鼠标即可完成创建任务。
软件功能
1、软件操作简单,鼠标点击即可轻松选择想要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构。让非网页专业设计师也能轻松抓取自己需要的数据;
3、不需要分析网页请求和源码,但支持更多网页采集;
4、高级智能算法,一键生成目标元素。 X自动识别网页列表并自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,您可以只需通过向导映射字段即可轻松导出到目标网站 数据库。
产品优势
1、可视化向导
所有采集元素自动生成采集数据
2、智能识别
自动识别网页列表、采集字段和分页等
3、plan 任务
运行时间灵活定义,全自动运行
4、拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
5、多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
6、多条数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器如何使用
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内 新闻栏目列表的网址,网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章@,推荐文章 和其他列表块。而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整的信息。
以采集芭新闻为例,从新浪首页找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
第 3 步:分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“不启用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,并高亮红色虚线框网页上的“下一步”按钮出现(部分网页按钮可能不显示虚线框),至此,自动分页功能已成功启用。
第 4 步:其他设置
在第三步的基本设置中,我们可以对浏览器进行一些设置,比如禁用图片、JS、Flash、框架等,以提高浏览网页的速度。
还可以设置浏览器标识(UserAgent)、代理IP、请求间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识获取客户端的一些信息
请求间隔时间:用于降低请求频率,即降低采集的速度,避免采集太快被阻塞,如果不需要降低速度,可以设置为0小时
多值连接器:当字段设置多个xpah提取多个元素时,这里使用自定义连接器连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求任务可以拆分,同时使用多个线程采集,提高采集速度,只适用到 HTTP 引擎,浏览器引擎不适合。
常见问题
1、采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集前原数据没有清除,新的采集数据会被添加到本地采集库,一些已经被采集 的数据可能会再次采集 重复进库。另外,如果目标网页本身有重复数据,也可能造成数据重复,那么如何避免采集采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后点击确定。
2、how采集content 页面等多层次网页
如果我们想要采集二级页面,比如内容页面,或者采集更深的一级页面、三级、四级等,在当前页面字段列表中,必须有一个提取链接地址的字段,即提取属性为Href的字段,如图
点击字段标题栏,选中该栏后会出现“Deep Link Page采集”按钮
点击此按钮后,会自动创建一个配置选项卡,并自动打开之前选择的字段的 URL。
采集模式也自动显示为“单人模式” 查看全部
优采云采集器分析网页源代码采集工具教程
优采云采集器 是一款非常智能的 data采集 软件。不需要编程就可以使用,很容易创建,采集data就是这么简单。专为优采云准备的,没有比这更简单的采集工具了。支持各种网站。
软件介绍
优采云采集器 是一个易于使用、功能强大的网页采集 工具。 采集 配置非常简单,整个过程可以通过内置浏览器可视化选择需要采集的内容,这样就可以在短时间内快速创建采集任务,无需分析网页源代码,无需熟悉网络协议,只需点击几下鼠标即可完成创建任务。
软件功能
1、软件操作简单,鼠标点击即可轻松选择想要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构。让非网页专业设计师也能轻松抓取自己需要的数据;
3、不需要分析网页请求和源码,但支持更多网页采集;
4、高级智能算法,一键生成目标元素。 X自动识别网页列表并自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,您可以只需通过向导映射字段即可轻松导出到目标网站 数据库。
产品优势
1、可视化向导
所有采集元素自动生成采集数据
2、智能识别
自动识别网页列表、采集字段和分页等
3、plan 任务
运行时间灵活定义,全自动运行
4、拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
5、多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
6、多条数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器如何使用
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内 新闻栏目列表的网址,网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章@,推荐文章 和其他列表块。而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整的信息。
以采集芭新闻为例,从新浪首页找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
第 3 步:分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“不启用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,并高亮红色虚线框网页上的“下一步”按钮出现(部分网页按钮可能不显示虚线框),至此,自动分页功能已成功启用。
第 4 步:其他设置
在第三步的基本设置中,我们可以对浏览器进行一些设置,比如禁用图片、JS、Flash、框架等,以提高浏览网页的速度。
还可以设置浏览器标识(UserAgent)、代理IP、请求间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识获取客户端的一些信息
请求间隔时间:用于降低请求频率,即降低采集的速度,避免采集太快被阻塞,如果不需要降低速度,可以设置为0小时
多值连接器:当字段设置多个xpah提取多个元素时,这里使用自定义连接器连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求任务可以拆分,同时使用多个线程采集,提高采集速度,只适用到 HTTP 引擎,浏览器引擎不适合。
常见问题
1、采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集前原数据没有清除,新的采集数据会被添加到本地采集库,一些已经被采集 的数据可能会再次采集 重复进库。另外,如果目标网页本身有重复数据,也可能造成数据重复,那么如何避免采集采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后点击确定。
2、how采集content 页面等多层次网页
如果我们想要采集二级页面,比如内容页面,或者采集更深的一级页面、三级、四级等,在当前页面字段列表中,必须有一个提取链接地址的字段,即提取属性为Href的字段,如图
点击字段标题栏,选中该栏后会出现“Deep Link Page采集”按钮
点击此按钮后,会自动创建一个配置选项卡,并自动打开之前选择的字段的 URL。
采集模式也自动显示为“单人模式”

