自动识别采集内容( 汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
优采云 发布时间: 2021-10-01 14:11自动识别采集内容(
汉语智能分词汉语词法分析能对汉语语言进行拆分处理)
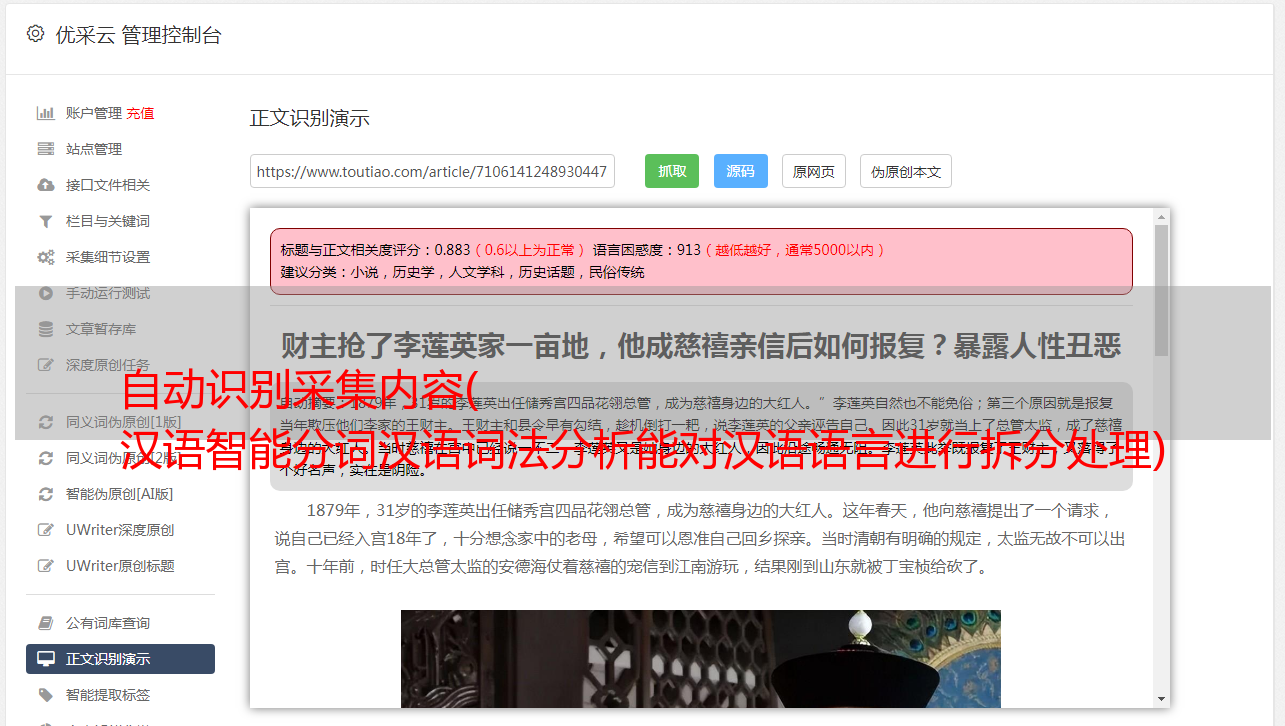
中文分词
中文词法分析中间件可以对中文进行拆分和处理,是中文信息处理必不可少的核心组件。灵久整合各家公司的优势,采用条件随机场(CRF)模型,分词准确率接近99%。
文本 关键词 提取
文章关键词 抽取中间件可以在充分掌握文章的中心思想的基础上,抽取几个代表文章语义内容的词或词组,以及相关的结果可用于精读、语义查询和快速匹配等。


自动汇总
自动文本摘要中间件可以实现文本内容的简化和细化,自动从长文章中提取关键句和关键段落形成摘要内容,方便用户快速浏览文本内容和提高工作效率。
自动代码识别和转换
自动识别多种语言编码,如Big5、Unicode、UTF-8、GB1830等,并转换为一种编码;它可以自动识别GBK中的繁体和简体汉字并将其转换为简体汉字。.
大数据文本过滤
灵久IFCA系统是灵久自主研发的大数据信息智能过滤和内容审核系统,可以快速便捷地匹配大量自定义关键词和词。
大数据文本去重
在大数据中,重复数据是不可避免的。以互联网新闻网页为例,大约60%的互联网新闻网页被复制。所谓重复数据,往往是指基本内容相同,但在具体的词句上往往略有不同的数据。

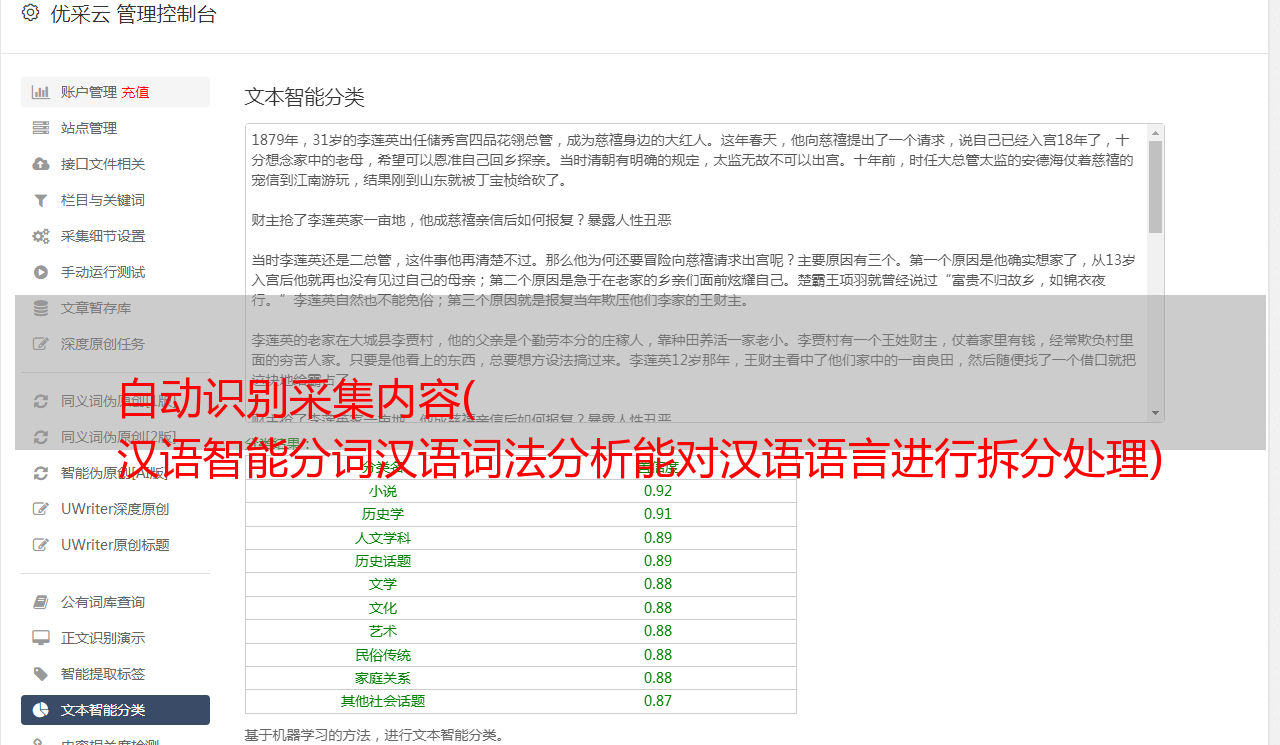
大数据文本分类
大数据的特点是其价值信息量大、密度低。因此,需要采用大数据分类技术对海量数据进行分类整理。大数据分类技术可以根据用户预设的分类体系对数据进行分类。
大数据文本聚类
大数据文本聚类可以自动整理大数据文档,总结热点趋势,将内容相似的信息归为一类,按热门程度排序,并自动生成该类别的标题和主题词。适用于热点排名自动生成、热点事件识别、热点趋势发现等诸多应用。
大数据特征提取
大量的数据对应着大量的噪声信息,不可避免地带来了大数据的混乱。如何从大数据中提取关键的代表性特征,可能是某些词汇,或某些短语,命名实体,或流行语,已成为大数据分析的有力工具。

