
网页采集器的自动识别算法
软件介绍Elvin百度采集软件,简单上手流程图模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 608 次浏览 • 2021-02-25 13:01
Elvin Baidu Url 采集器是无需安装即可使用的网络采集软件。用户只需要输入采集数据中的关键词就可以找到一堆基于百度的搜索引擎。所获得的相关目标站点非常适合网站管理员使用。
软件简介
Elvin Baidu 采集软件是专门为用户准备的百度数据PC终端采集的免费版本。使用方法非常简单。在线下载软件,并自动在采集中下载采集中的数据,并删除重复项。
它的用法非常简单明了。您只需要打开该工具并输入关键词即可自动采集,采集将在采集之后保留在软件的根目录中。
软件功能
智能识别数据
智能模式:基于人工智能算法,您只需输入URL即可智能识别列表数据,表格数据和分页按钮,而无需配置任何采集规则和一个键采集。
自动识别:列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式:只需按照软件提示单击并在页面上进行操作即可,这完全符合人们浏览网页的思维方式,只需几个简单的步骤即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等。
支持多种数据导出方法
采集结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用。
查看全部
软件介绍Elvin百度采集软件,简单上手流程图模式
Elvin Baidu Url 采集器是无需安装即可使用的网络采集软件。用户只需要输入采集数据中的关键词就可以找到一堆基于百度的搜索引擎。所获得的相关目标站点非常适合网站管理员使用。
软件简介
Elvin Baidu 采集软件是专门为用户准备的百度数据PC终端采集的免费版本。使用方法非常简单。在线下载软件,并自动在采集中下载采集中的数据,并删除重复项。
它的用法非常简单明了。您只需要打开该工具并输入关键词即可自动采集,采集将在采集之后保留在软件的根目录中。
软件功能
智能识别数据
智能模式:基于人工智能算法,您只需输入URL即可智能识别列表数据,表格数据和分页按钮,而无需配置任何采集规则和一个键采集。
自动识别:列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式:只需按照软件提示单击并在页面上进行操作即可,这完全符合人们浏览网页的思维方式,只需几个简单的步骤即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等。
支持多种数据导出方法
采集结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用。
优采云采集器是一款非常简单的的网页数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2021-02-25 11:00
优采云 采集器是非常简单的网页数据采集工具,它具有可视化的工作界面,用户可以通过鼠标完成网页数据采集,使用该程序的门槛非常低,任何用户都可以轻松地将其用于数据采集,而无需用户具备编写采集器的能力;通过此软件,用户可以在大多数网站中采集数据,包括一些单页应用程序Ajax加载动态网站以获取用户所需的数据信息;该软件具有内置的高速浏览器引擎,用户可以在多种浏览模式之间自由切换,从而使用户能够以直观的方式轻松执行网站网页。 采集;该程序安全,无毒,易于使用,欢迎有需要的朋友下载和使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间并自动运行。
3、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能识别:它可以自动识别网页列表,采集字段,页面等。
5、阻止请求:自定义被阻止的域名,以方便过滤异地广告并提高采集速度。
6、各种数据导出:可以导出到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件功能
零阈值
即使没有网络爬网技术,您也可以轻松浏览Internet 网站并采集网站数据。该软件操作简单,单击鼠标即可轻松选择要爬网的内容。
多引擎,高速,稳定
内置在高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地采集数据。它还具有一个内置的JSON引擎,该引擎无需分析JSON数据结构并直观地选择JSON内容。
高级智能算法
高级智能算法可以生成目标元素XPath,自动识别网页列表,并自动识别分页中的下一页按钮。它不需要分析Web请求和源代码,但支持更多的Web页面采集。
适用于各种网站
它可以采集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方法
第1步:设置起始网址
要采集网站数据,首先,我们需要设置URL进入采集。例如,如果要采集网站的国内新闻,则应将起始URL设置为国内新闻栏列表的URL,但通常网站的主页未设置为起始地址,因为主页通常收录许多列表。例如,最新的文章,流行的文章和推荐的文章章以及其他列表块,这些列表块中显示的内容也非常有限。通常,采集这些列表时不可能采集完整的信息。
接下来,让我们以新浪新闻库为例,从新浪首页查找国内新闻。但是,此列首页上的内容仍然混乱,并分为三个子列
让我们看一下《内地新闻》的分栏报道
此页面列收录页面内容列表。通过切换分页,我们可以采集此列下的所有文章,因此此列表页面非常适合我们采集起始URL。
现在,我们将在任务编辑框的步骤1中将列表URL复制到文本框中。
如果要在一项任务中同时采集其他国内新闻子列,则还可以复制其他两个子列的列表地址,因为这些子列具有相似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
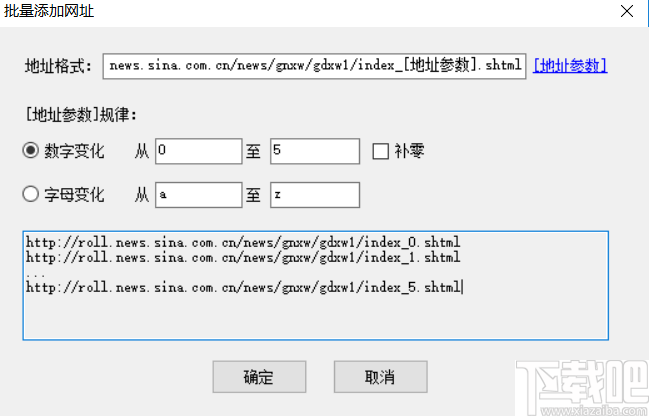
对于起始URL,我们还可以从txt文件中批量添加或导入。例如,如果我们要采集前五个页面,我们还可以通过这种方式自定义五个起始页面
应注意,如果您在此处自定义多个分页列表,则在后续集合配置中将不会启用分页。通常,当我们要采集列下的所有文章时,我们仅需要将列的第一页定义为起始URL。如果在后续的采集配置中启用了分页,则可以采集每个分页列表的数据。
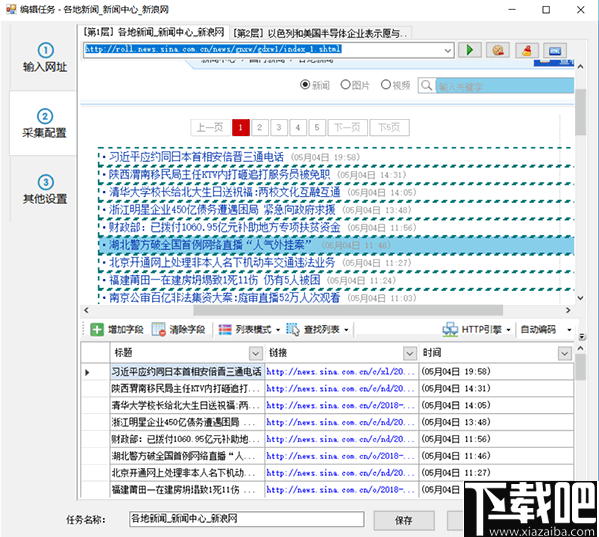
步骤2:①自动生成列表和字段
进入第二步后,对于某些网页,惰性采集器将智能分析页面列表,自动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删除一些不必要的字段
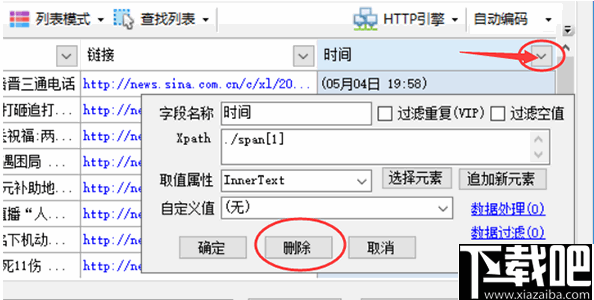
单击图中的三角形符号以弹出该字段的详细采集配置。点击上方的删除按钮以删除该字段。其余参数将在以下章节中介绍。
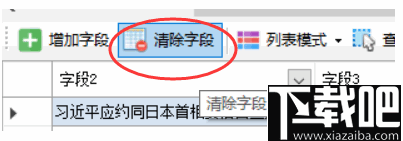
如果某些网页自动生成的列表数据不是我们想要的,则可以单击“清除字段”以清除所有生成的字段。
如果未手动选择我们的列表,它将自动列出。如果要取消突出显示的列表框,可以单击“查找列表-列表XPath”,清除XPath,然后确认。
②手动生成列表
点击“搜索列表”按钮,然后选择“手动选择列表”
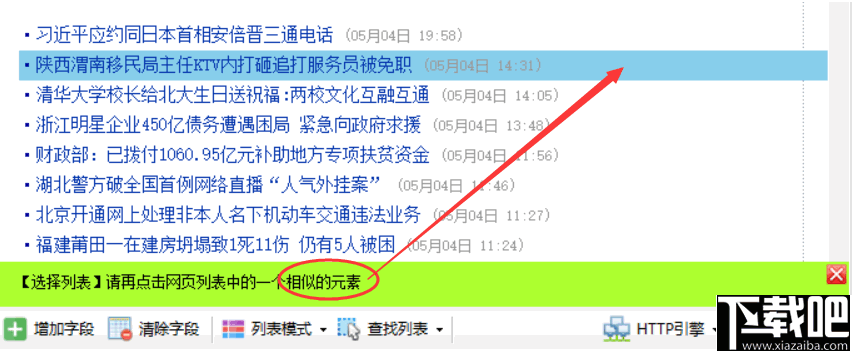
按照提示进行操作,然后用鼠标左键单击网页列表中的第一行数据
单击第一行,然后根据提示单击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也将生成。如果生成的字段不正确,请单击“清除字段”以清除下面的所有字段。下一章将说明如何手动选择字段。
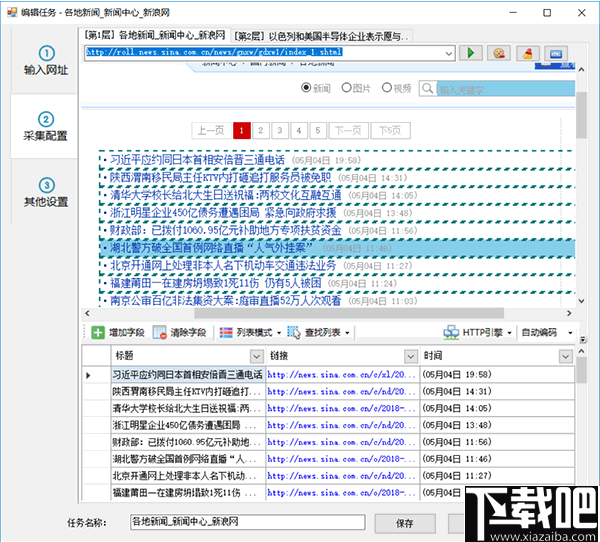
③手动生成字段
点击“添加字段”按钮
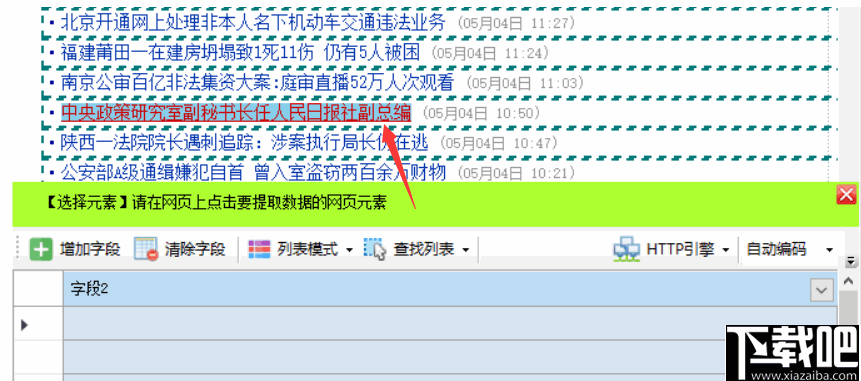
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
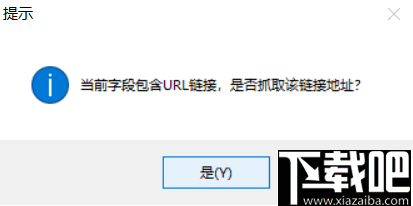
单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。如果只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复上述操作。
④分页设置
列表有分页时,可以在启用分页后采集所有分页列表数据。
页面分页有两种类型
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,您可以转到下一页,例如“新浪新闻”列表中的上一页 查看全部
优采云采集器是一款非常简单的的网页数据采集工具
优采云 采集器是非常简单的网页数据采集工具,它具有可视化的工作界面,用户可以通过鼠标完成网页数据采集,使用该程序的门槛非常低,任何用户都可以轻松地将其用于数据采集,而无需用户具备编写采集器的能力;通过此软件,用户可以在大多数网站中采集数据,包括一些单页应用程序Ajax加载动态网站以获取用户所需的数据信息;该软件具有内置的高速浏览器引擎,用户可以在多种浏览模式之间自由切换,从而使用户能够以直观的方式轻松执行网站网页。 采集;该程序安全,无毒,易于使用,欢迎有需要的朋友下载和使用。

软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间并自动运行。
3、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能识别:它可以自动识别网页列表,采集字段,页面等。
5、阻止请求:自定义被阻止的域名,以方便过滤异地广告并提高采集速度。
6、各种数据导出:可以导出到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件功能
零阈值
即使没有网络爬网技术,您也可以轻松浏览Internet 网站并采集网站数据。该软件操作简单,单击鼠标即可轻松选择要爬网的内容。
多引擎,高速,稳定
内置在高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地采集数据。它还具有一个内置的JSON引擎,该引擎无需分析JSON数据结构并直观地选择JSON内容。
高级智能算法
高级智能算法可以生成目标元素XPath,自动识别网页列表,并自动识别分页中的下一页按钮。它不需要分析Web请求和源代码,但支持更多的Web页面采集。
适用于各种网站
它可以采集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方法
第1步:设置起始网址
要采集网站数据,首先,我们需要设置URL进入采集。例如,如果要采集网站的国内新闻,则应将起始URL设置为国内新闻栏列表的URL,但通常网站的主页未设置为起始地址,因为主页通常收录许多列表。例如,最新的文章,流行的文章和推荐的文章章以及其他列表块,这些列表块中显示的内容也非常有限。通常,采集这些列表时不可能采集完整的信息。
接下来,让我们以新浪新闻库为例,从新浪首页查找国内新闻。但是,此列首页上的内容仍然混乱,并分为三个子列
让我们看一下《内地新闻》的分栏报道

此页面列收录页面内容列表。通过切换分页,我们可以采集此列下的所有文章,因此此列表页面非常适合我们采集起始URL。
现在,我们将在任务编辑框的步骤1中将列表URL复制到文本框中。
如果要在一项任务中同时采集其他国内新闻子列,则还可以复制其他两个子列的列表地址,因为这些子列具有相似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始URL,我们还可以从txt文件中批量添加或导入。例如,如果我们要采集前五个页面,我们还可以通过这种方式自定义五个起始页面
应注意,如果您在此处自定义多个分页列表,则在后续集合配置中将不会启用分页。通常,当我们要采集列下的所有文章时,我们仅需要将列的第一页定义为起始URL。如果在后续的采集配置中启用了分页,则可以采集每个分页列表的数据。
步骤2:①自动生成列表和字段
进入第二步后,对于某些网页,惰性采集器将智能分析页面列表,自动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以弹出该字段的详细采集配置。点击上方的删除按钮以删除该字段。其余参数将在以下章节中介绍。
如果某些网页自动生成的列表数据不是我们想要的,则可以单击“清除字段”以清除所有生成的字段。
如果未手动选择我们的列表,它将自动列出。如果要取消突出显示的列表框,可以单击“查找列表-列表XPath”,清除XPath,然后确认。
②手动生成列表
点击“搜索列表”按钮,然后选择“手动选择列表”

按照提示进行操作,然后用鼠标左键单击网页列表中的第一行数据
单击第一行,然后根据提示单击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也将生成。如果生成的字段不正确,请单击“清除字段”以清除下面的所有字段。下一章将说明如何手动选择字段。
③手动生成字段
点击“添加字段”按钮

在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。如果只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复上述操作。
④分页设置
列表有分页时,可以在启用分页后采集所有分页列表数据。
页面分页有两种类型
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,您可以转到下一页,例如“新浪新闻”列表中的上一页
电商平台为什么要做一个机器人来识别采集数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-02-21 09:01
网页采集器的自动识别算法:目前市面上的很多采集器都有自己的算法,主要的识别准确率的一般能达到98%的准确率就可以了,像你提到的那种自动识别过程,大部分采集器都有完整的测试来做无人值守智能收割的过程,给你个价格参考智能采集机器人¥2000至¥3000无人值守采集机器人¥500至¥8000无人值守采集机器人¥1000至¥10000而这些算法又分为很多种不同的方向,有的算法只针对pv算法等等这些来精准识别同行业的采集,而有的算法则是针对按钮这类的识别来做精准识别,当然,这里的同行业是针对广告业或者说站内信这类型的,那么,你说的这款采集器应该是针对网页是什么来做识别的采集器呢?可以参考的是一些懂得采集代码的网站能够开发识别系统来采集大量的视频、图片、音频等等多类别数据,而你的需求是说自动爬取的网页,目前的一些采集软件也支持一些采集代码方面的识别,比如蝉大师之类的工具来做采集大量的网页,缺点就是只有代码级别的一些功能,而且这里多数都是要收费的,其实很多免费的无码采集器,如果你有需求的话,也可以选择一款懂得采集代码的采集器,这里并不是批判一款收费软件,虽然大部分免费的采集代码软件都在做盈利,但是他们确实是在致力于改善交互的需求,并且也有部分是开源免费的,如果觉得使用麻烦,可以选择购买一款采集代码软件,甚至可以无任何套餐费用,网上很多卖家在这方面的资源是很丰富的。
而电商平台为什么要做一个机器人来识别采集数据呢?我认为有这么几点:第一:大部分购物平台都很重视销售的平台影响力,那么,如果说你在平台上做一个机器人,有助于销售的渠道和展示的氛围有很大的提升,或者你能够让这个采集网站和你的平台销售产生关联,那么,你就多了一个渠道和展示的机会,即便你的机器人在某些方面没有太大的作用,也是可以从侧面去影响你平台的销售的,这种需求可以满足一部分人的需求,第二:大部分购物平台可能会通过实名认证或者资质认证等多种方式来检验你网站的性质,会大量需要从众寻找购物过程的身份验证,这时,你需要一个需要的方式来进行识别和检验,通过你有人工帮你判断的过程,来减少通过互联网的一些安全保护,这些保护当然在大部分平台上都不是必须的,所以这时,一个机器人也能给他方便的采集方便,人工来做就方便很多,不是吗?第三:针对你说的站内信识别,是一个比较大的范畴,包括微信回复、短信回复、电话回复等等一些大量的回复信息在内,如果是需要全量的统计,如果采集这个,过程会很麻烦,需要采集整。 查看全部
电商平台为什么要做一个机器人来识别采集数据?
网页采集器的自动识别算法:目前市面上的很多采集器都有自己的算法,主要的识别准确率的一般能达到98%的准确率就可以了,像你提到的那种自动识别过程,大部分采集器都有完整的测试来做无人值守智能收割的过程,给你个价格参考智能采集机器人¥2000至¥3000无人值守采集机器人¥500至¥8000无人值守采集机器人¥1000至¥10000而这些算法又分为很多种不同的方向,有的算法只针对pv算法等等这些来精准识别同行业的采集,而有的算法则是针对按钮这类的识别来做精准识别,当然,这里的同行业是针对广告业或者说站内信这类型的,那么,你说的这款采集器应该是针对网页是什么来做识别的采集器呢?可以参考的是一些懂得采集代码的网站能够开发识别系统来采集大量的视频、图片、音频等等多类别数据,而你的需求是说自动爬取的网页,目前的一些采集软件也支持一些采集代码方面的识别,比如蝉大师之类的工具来做采集大量的网页,缺点就是只有代码级别的一些功能,而且这里多数都是要收费的,其实很多免费的无码采集器,如果你有需求的话,也可以选择一款懂得采集代码的采集器,这里并不是批判一款收费软件,虽然大部分免费的采集代码软件都在做盈利,但是他们确实是在致力于改善交互的需求,并且也有部分是开源免费的,如果觉得使用麻烦,可以选择购买一款采集代码软件,甚至可以无任何套餐费用,网上很多卖家在这方面的资源是很丰富的。
而电商平台为什么要做一个机器人来识别采集数据呢?我认为有这么几点:第一:大部分购物平台都很重视销售的平台影响力,那么,如果说你在平台上做一个机器人,有助于销售的渠道和展示的氛围有很大的提升,或者你能够让这个采集网站和你的平台销售产生关联,那么,你就多了一个渠道和展示的机会,即便你的机器人在某些方面没有太大的作用,也是可以从侧面去影响你平台的销售的,这种需求可以满足一部分人的需求,第二:大部分购物平台可能会通过实名认证或者资质认证等多种方式来检验你网站的性质,会大量需要从众寻找购物过程的身份验证,这时,你需要一个需要的方式来进行识别和检验,通过你有人工帮你判断的过程,来减少通过互联网的一些安全保护,这些保护当然在大部分平台上都不是必须的,所以这时,一个机器人也能给他方便的采集方便,人工来做就方便很多,不是吗?第三:针对你说的站内信识别,是一个比较大的范畴,包括微信回复、短信回复、电话回复等等一些大量的回复信息在内,如果是需要全量的统计,如果采集这个,过程会很麻烦,需要采集整。
爱意为用户提供的优采云采集器电脑版的实用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-01-23 13:30
爱艺提供的优采云采集器计算机版本的实用方法非常简单。用户可以使用此采集器软件快速采集各种类型的网页数据,并且爬行速度非常快,并且适用于各种类型的网站。
软件功能
向导模式
通过可视界面,鼠标单击采集数据,进入向导模式,用户无需任何技术基础,即可进入网站,并一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可以支持图片,视频,文档等各种文件下载,并支持自定义保存路径和文件名
原创高速内核
内置一组高速浏览器内核,以及HTTP引擎,JSON引擎模式,以实现快速的采集数据。
定时运行
可以用每分钟,每天,每周和CRON表示。如果指定了计划任务,则该任务可以自动采集并自动释放,而无需手动操作。
多个数据导出
支持多种格式的数据导出,包括TXT,CSV,Excel,ACCESS,MySQL,SQLServer,SQLite并发布到网站界面(Api)。
工具功能
1、快速高效,具有内置的高速浏览器内核以及HTTP引擎模式,可实现快速采集数据
2、一键提取数据,易于学习,通过可视界面,只需单击鼠标即可捕获数据
3、适用于所有网站,能够采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站
软件应用程序字段
新闻媒体领域
优采云采集器可以综合采集国内外主要新闻来源,主流社交媒体,社区论坛信息等,例如今天的头条新闻,微博,天涯论坛,知乎等。自动识别列表数据,可视化文本挖掘时间采集数据,自动上传数据或第三方平台,指导性操作界面,可帮助公司独立监控品牌民意,并为互联网时代的品牌传播提供数据支持。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,相似商品的属性,评估,价格,市场销售和其他数据,通过优采云文本挖掘视觉分析系统,可以提取评论信息的典型意见和情感分析,从而获得客观的市场评估和分析,优化运营,基于类似经验创建爆炸性模型,开展业务活动并改进在线商店的运营水平。效果。
生活服务领域
科学技术的发展与我们的生活息息相关。简而言之,餐饮和旅行的直接团购网络(外卖网络)既简单又高效。 优采云采集器是采集是美团饿了吗,甘集,点屏,突牛,携程旅行和其他生活服务网站,采集类似的属性,评估,价格,销售,等级等数据,通过优采云文本挖掘视觉分析系统,可以对评论信息进行典型的意见提取,情感分析和数据比较,从而为我们的食物,衣服,住房和交通选择适当的位置,更加方便快捷。
政府部门字段
在整个社会信息量爆炸性增长的背景下,政府机构也更加重视数据的采集和使用。某个气象中心已通过优采云采集器采集了各个地区与天气有关的各种监视数据。通过数据比较分析,及时预警最新气象活动的分布范围,并指示有关部门采取措施。
更新内容
1、修复了某些URL中无法加载数据的问题
2、优化XPath生成
3、优化输入命令 查看全部
爱意为用户提供的优采云采集器电脑版的实用方法
爱艺提供的优采云采集器计算机版本的实用方法非常简单。用户可以使用此采集器软件快速采集各种类型的网页数据,并且爬行速度非常快,并且适用于各种类型的网站。
软件功能
向导模式
通过可视界面,鼠标单击采集数据,进入向导模式,用户无需任何技术基础,即可进入网站,并一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可以支持图片,视频,文档等各种文件下载,并支持自定义保存路径和文件名
原创高速内核
内置一组高速浏览器内核,以及HTTP引擎,JSON引擎模式,以实现快速的采集数据。
定时运行
可以用每分钟,每天,每周和CRON表示。如果指定了计划任务,则该任务可以自动采集并自动释放,而无需手动操作。
多个数据导出
支持多种格式的数据导出,包括TXT,CSV,Excel,ACCESS,MySQL,SQLServer,SQLite并发布到网站界面(Api)。
工具功能
1、快速高效,具有内置的高速浏览器内核以及HTTP引擎模式,可实现快速采集数据
2、一键提取数据,易于学习,通过可视界面,只需单击鼠标即可捕获数据
3、适用于所有网站,能够采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站
软件应用程序字段
新闻媒体领域
优采云采集器可以综合采集国内外主要新闻来源,主流社交媒体,社区论坛信息等,例如今天的头条新闻,微博,天涯论坛,知乎等。自动识别列表数据,可视化文本挖掘时间采集数据,自动上传数据或第三方平台,指导性操作界面,可帮助公司独立监控品牌民意,并为互联网时代的品牌传播提供数据支持。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,相似商品的属性,评估,价格,市场销售和其他数据,通过优采云文本挖掘视觉分析系统,可以提取评论信息的典型意见和情感分析,从而获得客观的市场评估和分析,优化运营,基于类似经验创建爆炸性模型,开展业务活动并改进在线商店的运营水平。效果。
生活服务领域
科学技术的发展与我们的生活息息相关。简而言之,餐饮和旅行的直接团购网络(外卖网络)既简单又高效。 优采云采集器是采集是美团饿了吗,甘集,点屏,突牛,携程旅行和其他生活服务网站,采集类似的属性,评估,价格,销售,等级等数据,通过优采云文本挖掘视觉分析系统,可以对评论信息进行典型的意见提取,情感分析和数据比较,从而为我们的食物,衣服,住房和交通选择适当的位置,更加方便快捷。
政府部门字段
在整个社会信息量爆炸性增长的背景下,政府机构也更加重视数据的采集和使用。某个气象中心已通过优采云采集器采集了各个地区与天气有关的各种监视数据。通过数据比较分析,及时预警最新气象活动的分布范围,并指示有关部门采取措施。
更新内容
1、修复了某些URL中无法加载数据的问题
2、优化XPath生成
3、优化输入命令
优采云采集器怎么导出前台运行任务及流程图模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-01-22 09:30
第1步:登录以打开优采云采集器软件
第2步:创建一个新的采集任务
1、复制网页地址:需要采集评估的产品的网址
2、新的流程图模式采集任务:导入采集规则以创建智能任务
第3步:配置采集规则
1、设置预登录
输入网址后,我们进入婴儿的详细信息页面。这时,我们可以单击以关闭页面上显示的登录界面,我们可以采集无需登录即可访问评论数据。
2、设置数据字段
在详细信息页面上,您可以看到评论的数量,但看不到特定的评论内容。我们需要单击注释,然后在跳出左上角的提示框中选择“单击此元素”。
3、进入评论界面后,根据搜索方向选择好评论,不好评论等元素。在此基础上,我们可以右键单击该字段以执行相关设置,包括修改字段名称,添加或减去字段以及处理数据等。
因为我们要下载所有评论图片,所以我们可以选择评论中的所有图片,然后设置字段属性-提取外部html。
4、我们采集发布了单页评论数据,现在我们需要采集下一页数据,我们单击页面上的“下一页”按钮,在操作提示框中,出现在左上角。选择“循环单击下一页”。
第4步:设置并启动采集任务
单击“开始采集”按钮,您可以在弹出的启动设置页面中进行一些高级设置,包括“定时启动,防阻塞,自动导出,文件下载,加速引擎,重复数据删除,开发人员设置”功能,这次采集没有使用这些功能,我们直接单击开始以启动采集。
第5步:导出和查看数据
完成数据采集之后,我们可以查看和导出数据。 优采云采集器支持多种导出方法和导出文件格式,并且还支持导出特定编号。您可以选择要导出的数据。条目数,然后单击“确认导出”。
[如何导出]
1、导出采集在前台运行的任务的结果
如果采集任务在前台运行,则软件将弹出提示框,指示任务结束后数据采集已停止。这时,我们单击“导出数据”按钮以导出采集数据结果。
2、导出采集个后台运行任务的结果
如果采集任务在后台运行,则该任务完成后,将在桌面右下角弹出一个导出提示框。我们将根据任务完成右下角的弹出窗口打开视图数据界面或导出数据。
3、导出已保存的采集任务的采集结果
例如,如果它不是实时运行的采集任务,而是先前运行的采集任务,则我们关闭软件,然后重新打开软件,然后导出采集的采集结果]已运行的任务。
在这种情况下,我们可以右键单击任务,然后单击“查看数据”以打开查看数据界面,然后在该界面上设置导出数据。
4、导出数据的其他事项
当前优采云采集器支持多种格式的免费导出,包括:Excel2007、Excel200 3、 CSV,HTML文件,TXT文件;同时,它支持免费导出到数据库。
个人专业版及更高版本支持发布到网站,目前支持发布到WordPress,发布到Typecho,发布到DEDEcms(织梦),更多网站模板正在继续更新...。 ..
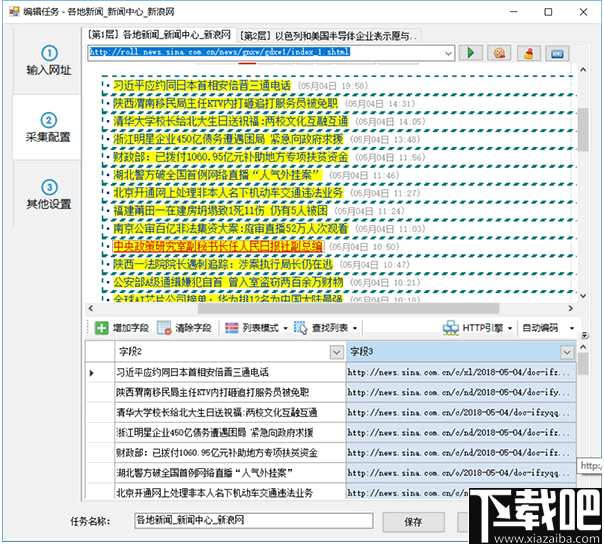
导出数据时,用户可以选择导出范围,选择导出未导出的数据,导出选定的数据或选择导出项目的数量。
导出完成后,您还可以标记已导出的数据,以便可以清晰直观地查看已导出的数据和未导出的数据。
[如何下载图片]
第一种类型:一张一张地添加图片
直接在页面上单击要下载的图片,然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
或直接单击“添加字段”,然后在页面上单击要下载的图片。
第二种类型:一次下载多张图片
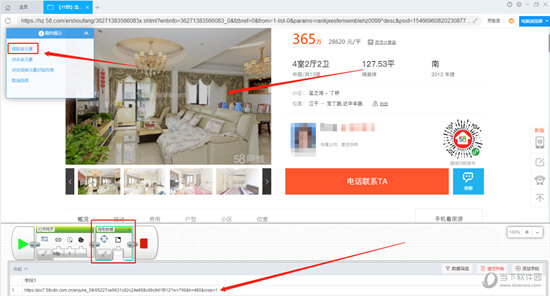
在这种情况下,需要将图片分组在一起,您可以一次选择所有图片。
我们可以直接单击整个图片区域的右下角,并且在选择框架时我们可以看到软件的蓝色框架选择区域,以确保要下载的所有照片都被框架化。然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
然后右键单击该字段,并将字段属性修改为“提取内部HTML”。
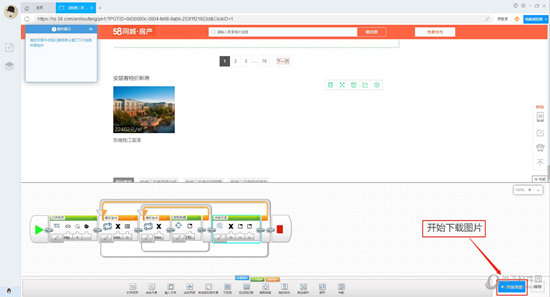
单击右下角的“开始采集”按钮设置图片下载功能。
接下来,我们只需要单击“开始采集”,然后在开始框中选中“将图片同时下载到以下目录”即可启动图片下载功能,用户可以设置本地保存图片的路径。 查看全部
优采云采集器怎么导出前台运行任务及流程图模式
第1步:登录以打开优采云采集器软件
第2步:创建一个新的采集任务
1、复制网页地址:需要采集评估的产品的网址
2、新的流程图模式采集任务:导入采集规则以创建智能任务

第3步:配置采集规则
1、设置预登录
输入网址后,我们进入婴儿的详细信息页面。这时,我们可以单击以关闭页面上显示的登录界面,我们可以采集无需登录即可访问评论数据。
2、设置数据字段
在详细信息页面上,您可以看到评论的数量,但看不到特定的评论内容。我们需要单击注释,然后在跳出左上角的提示框中选择“单击此元素”。

3、进入评论界面后,根据搜索方向选择好评论,不好评论等元素。在此基础上,我们可以右键单击该字段以执行相关设置,包括修改字段名称,添加或减去字段以及处理数据等。
因为我们要下载所有评论图片,所以我们可以选择评论中的所有图片,然后设置字段属性-提取外部html。
4、我们采集发布了单页评论数据,现在我们需要采集下一页数据,我们单击页面上的“下一页”按钮,在操作提示框中,出现在左上角。选择“循环单击下一页”。
第4步:设置并启动采集任务
单击“开始采集”按钮,您可以在弹出的启动设置页面中进行一些高级设置,包括“定时启动,防阻塞,自动导出,文件下载,加速引擎,重复数据删除,开发人员设置”功能,这次采集没有使用这些功能,我们直接单击开始以启动采集。

第5步:导出和查看数据
完成数据采集之后,我们可以查看和导出数据。 优采云采集器支持多种导出方法和导出文件格式,并且还支持导出特定编号。您可以选择要导出的数据。条目数,然后单击“确认导出”。
[如何导出]
1、导出采集在前台运行的任务的结果
如果采集任务在前台运行,则软件将弹出提示框,指示任务结束后数据采集已停止。这时,我们单击“导出数据”按钮以导出采集数据结果。

2、导出采集个后台运行任务的结果
如果采集任务在后台运行,则该任务完成后,将在桌面右下角弹出一个导出提示框。我们将根据任务完成右下角的弹出窗口打开视图数据界面或导出数据。
3、导出已保存的采集任务的采集结果
例如,如果它不是实时运行的采集任务,而是先前运行的采集任务,则我们关闭软件,然后重新打开软件,然后导出采集的采集结果]已运行的任务。
在这种情况下,我们可以右键单击任务,然后单击“查看数据”以打开查看数据界面,然后在该界面上设置导出数据。

4、导出数据的其他事项
当前优采云采集器支持多种格式的免费导出,包括:Excel2007、Excel200 3、 CSV,HTML文件,TXT文件;同时,它支持免费导出到数据库。
个人专业版及更高版本支持发布到网站,目前支持发布到WordPress,发布到Typecho,发布到DEDEcms(织梦),更多网站模板正在继续更新...。 ..
导出数据时,用户可以选择导出范围,选择导出未导出的数据,导出选定的数据或选择导出项目的数量。
导出完成后,您还可以标记已导出的数据,以便可以清晰直观地查看已导出的数据和未导出的数据。
[如何下载图片]
第一种类型:一张一张地添加图片
直接在页面上单击要下载的图片,然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
或直接单击“添加字段”,然后在页面上单击要下载的图片。
第二种类型:一次下载多张图片
在这种情况下,需要将图片分组在一起,您可以一次选择所有图片。
我们可以直接单击整个图片区域的右下角,并且在选择框架时我们可以看到软件的蓝色框架选择区域,以确保要下载的所有照片都被框架化。然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
然后右键单击该字段,并将字段属性修改为“提取内部HTML”。
单击右下角的“开始采集”按钮设置图片下载功能。
接下来,我们只需要单击“开始采集”,然后在开始框中选中“将图片同时下载到以下目录”即可启动图片下载功能,用户可以设置本地保存图片的路径。
优采云采集器是一款非常实用的网页信息采集工具介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-01-22 08:46
优采云采集器是用于Web信息采集的非常有用的工具。该工具界面简洁,操作简单,功能强大。有了它,我们可以采集转到我们需要的网页所有信息,零阈值,新手用户可以使用。
[软件功能]
零阈值:如果您不了解网络抓取工具技术,则会获得采集 网站个数据
多引擎,高速且稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据结构,直观地选择JSON内容。
适用于各种网站:采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站。
[软件功能]
该软件易于操作,并且可以通过单击鼠标轻松选择要捕获的内容;
支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器以及原创内存优化,因此浏览器采集也可以高速运行,甚至可以快速转换以HTTP方式运行,享受更高的采集速度!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。无需分析JSON数据结构,因此非网页专业设计人员可以轻松获取所需数据;
无需分析网页请求和源代码,但支持更多网页采集;
高级智能算法可以一键生成目标元素XPATH,自动识别网页列表,并自动识别分页中的下一页按钮...
支持丰富的数据导出方法,可以通过向导将其导出到txt文件,html文件,csv文件,excel文件或现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库。易于以简单的方式映射字段,并且可以轻松地将其导出到目标网站数据库。
[软件优势]
可视化向导:所有采集个元素,自动生成采集个数据
计划任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎
智能识别:它可以自动识别网页列表,采集字段和分页等。
拦截请求:自定义拦截域名,以方便过滤异地广告并提高采集的速度
各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。 查看全部
优采云采集器是一款非常实用的网页信息采集工具介绍
优采云采集器是用于Web信息采集的非常有用的工具。该工具界面简洁,操作简单,功能强大。有了它,我们可以采集转到我们需要的网页所有信息,零阈值,新手用户可以使用。
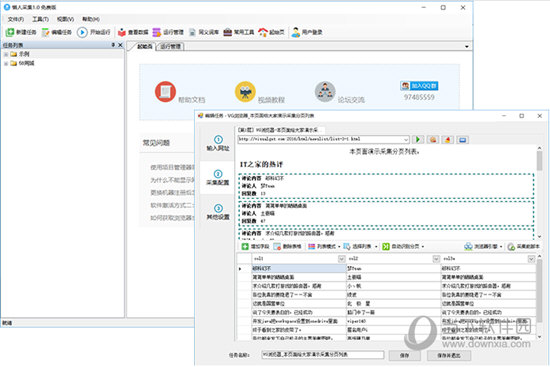
[软件功能]
零阈值:如果您不了解网络抓取工具技术,则会获得采集 网站个数据
多引擎,高速且稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据结构,直观地选择JSON内容。
适用于各种网站:采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站。
[软件功能]
该软件易于操作,并且可以通过单击鼠标轻松选择要捕获的内容;
支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器以及原创内存优化,因此浏览器采集也可以高速运行,甚至可以快速转换以HTTP方式运行,享受更高的采集速度!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。无需分析JSON数据结构,因此非网页专业设计人员可以轻松获取所需数据;
无需分析网页请求和源代码,但支持更多网页采集;
高级智能算法可以一键生成目标元素XPATH,自动识别网页列表,并自动识别分页中的下一页按钮...
支持丰富的数据导出方法,可以通过向导将其导出到txt文件,html文件,csv文件,excel文件或现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库。易于以简单的方式映射字段,并且可以轻松地将其导出到目标网站数据库。

[软件优势]
可视化向导:所有采集个元素,自动生成采集个数据
计划任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎
智能识别:它可以自动识别网页列表,采集字段和分页等。
拦截请求:自定义拦截域名,以方便过滤异地广告并提高采集的速度
各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。
核心方法:网页分类与信息采集方法研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2021-01-11 11:17
[摘要]:网页分类和信息采集该系统包括网页抓取,网页识别和文本采集。其中,依靠人工网页识别的传统方式是在网络信息容量迅速增加的条件下。不合理。同时,网页中收录的大量噪声信息增加了网页文本的难度采集。现有的采集技术具有人工维护成本高,准确性低,通用性差的缺点。因此,对网页和文本采集的自动识别的研究已成为重要的方向。它们与信息检索,搜索引擎,互联网民意和文本推荐等技术相结合,为信息获取提供了便利。本文的研究内容主要包括以下几个方面:(1)根据网页分类和信息采集系统的要求,提出了一种基于网页结构特征挖掘的网页类型自动识别方法。该方法的重点是特征选择,在理解网页特征挖掘的基础上,研究了不同网页的结构差异,提取了可表征网页的特征集,并采用经典的分类算法(决策树)进行构造。 (2)在文本采集自动化的要求下,提出了一种基于HTML标签特征挖掘的BBS网页文本提取方法,即:文本块提取,其中心思想是基于以下特征:Web文档的树形结构,多文本中心性,标记元素的层次结构等。在此基础上,提出了一种基于智能模板的BBS网页文本提取方法。主要思想是基于HTML标记特征挖掘找到所需的BBS网页文本提取方法,将多个文本块的公共信息,然后自动配置对应于网站的文本解析模板,最后使用该模板进行解析网页文字。 (3)构建网页分类和信息采集系统。该系统包括网页捕获网页识别,网页文本提取和UI部分。网页爬网部分采用通用的爬网技术和流程,目标是搜索整个网络,网页识别采用基于本文网络功能集的网页类型自动识别方法,网页文本提取部分是基于文本的智能模板的BBS网页文本提取方法。通过实际数据对该系统的方法进行测试,实验结果表明该方法在系统中是可行的,具有较高的准确性,通用性和智能性。 查看全部
核心方法:网页分类与信息采集方法研究
[摘要]:网页分类和信息采集该系统包括网页抓取,网页识别和文本采集。其中,依靠人工网页识别的传统方式是在网络信息容量迅速增加的条件下。不合理。同时,网页中收录的大量噪声信息增加了网页文本的难度采集。现有的采集技术具有人工维护成本高,准确性低,通用性差的缺点。因此,对网页和文本采集的自动识别的研究已成为重要的方向。它们与信息检索,搜索引擎,互联网民意和文本推荐等技术相结合,为信息获取提供了便利。本文的研究内容主要包括以下几个方面:(1)根据网页分类和信息采集系统的要求,提出了一种基于网页结构特征挖掘的网页类型自动识别方法。该方法的重点是特征选择,在理解网页特征挖掘的基础上,研究了不同网页的结构差异,提取了可表征网页的特征集,并采用经典的分类算法(决策树)进行构造。 (2)在文本采集自动化的要求下,提出了一种基于HTML标签特征挖掘的BBS网页文本提取方法,即:文本块提取,其中心思想是基于以下特征:Web文档的树形结构,多文本中心性,标记元素的层次结构等。在此基础上,提出了一种基于智能模板的BBS网页文本提取方法。主要思想是基于HTML标记特征挖掘找到所需的BBS网页文本提取方法,将多个文本块的公共信息,然后自动配置对应于网站的文本解析模板,最后使用该模板进行解析网页文字。 (3)构建网页分类和信息采集系统。该系统包括网页捕获网页识别,网页文本提取和UI部分。网页爬网部分采用通用的爬网技术和流程,目标是搜索整个网络,网页识别采用基于本文网络功能集的网页类型自动识别方法,网页文本提取部分是基于文本的智能模板的BBS网页文本提取方法。通过实际数据对该系统的方法进行测试,实验结果表明该方法在系统中是可行的,具有较高的准确性,通用性和智能性。
整套解决方案:智能搜索引擎技术网页信息动态采集系统网页正文提取网页分类算法网页摘要..
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-12-19 08:45
搜索引擎智能技术中若干关键问题的研究与实现[摘要]随着Internet技术的飞速发展和网络信息资源的爆炸性增长,Internet用户的数量也在以惊人的速度增长。越来越多的网民习惯于通过搜索引擎在Internet上检索信息。现在,搜索引擎已成为人们必备的网络应用工具。随着搜索引擎应用程序的广泛普及,人们不再满足于传统搜索引擎提供的服务。人们希望搜索引擎可以更智能,更人性化。检索结果可以更准确,这些新要求对搜索引擎技术提出了更高的要求。本文对当前作为研究热点的智能搜索引擎技术领域中的几个关键问题进行了探索性研究。内容主要包括:1)基于网站优先级调整算法提出并实现了网页信息动态采集技术,该技术通过检测广告的平均新鲜度的变化来动态调整网站的优先级。采样网页,以实现相应网站个网页信息采集的频率动态调整。2)研究了网页源代码中中文文本密度与网页主体之间的关系,提出并实现了一种基于文本密度的网页主体提取算法,并摆脱了现有的HTML网页主体提取算法(超文本标记语言),超文本标记语言)标签,并借助某些规则,以实现高效,快速地提取网页文本。3)研究了自动文本分类领域中的几个关键问题,并提出并实现了基于哈希表的动态矢量的更多还原。 [摘要]互联网技术飞速发展,网络信息资源爆炸性增长,互联网用户数量惊人。越来越多的Internet用户通过搜索引擎成为习惯的在线检索信息。搜索引擎的广泛应用,人们不再满足于传统的搜索引擎,搜索引擎更加智能,人类更加精确。新需求给人们带来了更多... [Recovery [关键词]智能搜索引擎技术;网页信息动态采集系统;网页文本提取;网页分类算法;网页摘要;矢量动态尺寸缩减; [关键词]智能搜索引擎技术;动态网页信息获取系统;网页文本提取;网页分类算法;网页摘要;矢量动态降维; [订购硕士学位论文全文] Q联系人Q:138113721 139938848目录摘要4-5摘要5-6简介11-211.1主题选择的背景和意义11-121.2相关工作国内外摘要12-191.2.1网页信息动态采集技术12-131.2.2中文网页文本提取技术13-151.2.3自动文档摘要技术15-171.2.4文本自动分类技术17-181.2.5网页重复数据删除技术18-191.3文书工作和组织结构19-211.3.1论文Lord研究工作19-201.3.2论文内容安排20-21基于网站优先级调整的网页信息动态采集算法21-27 2.1算法流程图21 -23 2.2网页新鲜度算法23 2.3 网站基于网页新鲜度的优先级调整算法23-25 2.4基于网站 pri的多线程网页信息ority 采集技术25-26 2.5根据网页类别确定优先级26 2.6本章摘要26-27基于文本密度的提取网页文本算法的研究27-33 3.1算法流程图27 3.2识别和文本特征识别处理27-28 3.3网页源代码的预处理28-29 3.4计算网页文本源行的中文密度29 3.5阻止网页的源代码29 3.6删除伪网页的源代码29 -31 3.7辅助网页的源代码文本识别方法31 3.8网页文本的原创格式保留31 3.9本章摘要31-33基于主题词索引的网页分类算法研究33-524.1概述33-344.2开放测试和封闭测试34-354.3算法性能评估指标35-364.4与网站分类算法相关的基础研究36-424.4.1文本的表示形式36-374.4.2基于向量模板37构造向量空间模型[k56]4.3基于哈希表37-39构造向量空间模型[k56]4.4主题词基于概念分析的抽取算法39-404.4.5改进的矢量余弦相似度算法40-424.5基于主题词索引的类别中心矢量分类算法42-464.5.1生成分类器模型434.5.2分类算法434.5.3向量的归一化434.5.4将类别数提高到分类精度Impact 43-444.5.5文档类别分布对分类准确性的影响444.5.6中心向量的校正算法44-464.5.7分类算法的适应性464.6 KNN(K最近邻)分类算法46 -484.7 CKNN(聚类K最近邻)分类算法48-504.8本章摘要50-52相似性研究基于ty的文本摘要52-64 5.1基于相似度的文本摘要52 5.2文档结构模型52 5.3分段和子句52-54 5.4主题词提取54-55 5.4.1主题词字符串的矢量化54 [k72]4.2建立文档结构向量空间模型54-55 5.5计算文档结构各部分的权重55-57 5.6正负规则57 5.7用户偏好词汇57 5.8基于句子相似度的句子冗余算法57-58 5.9确定摘要和原创文本的比例58 5.10摘要句子选择和摘要生成585.11抽象技术在提取中文网页摘要中的应用58-63 5.11.1预提取网页文本对提高摘要准确性的影响59-62 5.11.2提高摘要算法的实时性能62-63 5.12本章摘要63-64实验设计点火和数据分析64-886.1基于网站优先级调整的网页信息动态采集技术实验和积分65-70 [k108]1.1实验设计65-66 [k108]1.2数据分析66-69 [k108]1.3存在的不足和进一步的改进69-706.2基于中文密度算法的中文网页文本提取技术的实验和分析70-716.2.1实验设计706.2.2数据分析706.2.3存在的缺点和下一个改进工作70-716.3两种方法在对象71-74中的比较实验和两种文档矢量表示方法的分析6.3.1实验设计716.3.2数据分析71-746.4改进的余弦矢量相似度算法74-76的实验和分析[k108]4.1实验设计74 [ k108]4.2数据分析74-766.5基于主题心的类别中心向量分类算法的实验与分析ding 76-796.5.1实验设计766.5.2数据分析76-786.5.3存在的问题和下一步78-796.6实验和分析CKNN分类算法79-806.6.1实验设计79 [k1 08]6.2数据分析79-806.6.3存在的问题和下一步806.7实验设计和数据KNN分类算法的分析80-826.7.1实验设计80-816.7.2数据分析81-826.8类别中心向量分类算法,CKNN分类算法和KNN的性能比较分类算法82-836.8.1实验设计826.8.2数据分析82-836.9基于相似度的文档摘要技术的实验和数据分析83-856.9.1实验设计83-846.9.2数据分析84-856.9.3存在的问题和下一步856.10网络信息采集的实验和数据分析系统85-876.10.1实验设计85-866.10.2数据分析866.10.3存在的问题和下一步86-876.11本章摘要87-88 Web信息动态采集系统设计和实现88-95 7.1系统组成88-89 7.2系统模块的集成89-93 7.3网页分类模块的适应性93 7.4系统运行状态监视程序93 7.5基于主题词索引的网页重复数据删除方法93-94 7.6本章摘要94-95摘要95-97参考文献 查看全部
整套解决方案:智能搜索引擎技术网页信息动态采集系统网页正文提取网页分类算法网页摘要..
搜索引擎智能技术中若干关键问题的研究与实现[摘要]随着Internet技术的飞速发展和网络信息资源的爆炸性增长,Internet用户的数量也在以惊人的速度增长。越来越多的网民习惯于通过搜索引擎在Internet上检索信息。现在,搜索引擎已成为人们必备的网络应用工具。随着搜索引擎应用程序的广泛普及,人们不再满足于传统搜索引擎提供的服务。人们希望搜索引擎可以更智能,更人性化。检索结果可以更准确,这些新要求对搜索引擎技术提出了更高的要求。本文对当前作为研究热点的智能搜索引擎技术领域中的几个关键问题进行了探索性研究。内容主要包括:1)基于网站优先级调整算法提出并实现了网页信息动态采集技术,该技术通过检测广告的平均新鲜度的变化来动态调整网站的优先级。采样网页,以实现相应网站个网页信息采集的频率动态调整。2)研究了网页源代码中中文文本密度与网页主体之间的关系,提出并实现了一种基于文本密度的网页主体提取算法,并摆脱了现有的HTML网页主体提取算法(超文本标记语言),超文本标记语言)标签,并借助某些规则,以实现高效,快速地提取网页文本。3)研究了自动文本分类领域中的几个关键问题,并提出并实现了基于哈希表的动态矢量的更多还原。 [摘要]互联网技术飞速发展,网络信息资源爆炸性增长,互联网用户数量惊人。越来越多的Internet用户通过搜索引擎成为习惯的在线检索信息。搜索引擎的广泛应用,人们不再满足于传统的搜索引擎,搜索引擎更加智能,人类更加精确。新需求给人们带来了更多... [Recovery [关键词]智能搜索引擎技术;网页信息动态采集系统;网页文本提取;网页分类算法;网页摘要;矢量动态尺寸缩减; [关键词]智能搜索引擎技术;动态网页信息获取系统;网页文本提取;网页分类算法;网页摘要;矢量动态降维; [订购硕士学位论文全文] Q联系人Q:138113721 139938848目录摘要4-5摘要5-6简介11-211.1主题选择的背景和意义11-121.2相关工作国内外摘要12-191.2.1网页信息动态采集技术12-131.2.2中文网页文本提取技术13-151.2.3自动文档摘要技术15-171.2.4文本自动分类技术17-181.2.5网页重复数据删除技术18-191.3文书工作和组织结构19-211.3.1论文Lord研究工作19-201.3.2论文内容安排20-21基于网站优先级调整的网页信息动态采集算法21-27 2.1算法流程图21 -23 2.2网页新鲜度算法23 2.3 网站基于网页新鲜度的优先级调整算法23-25 2.4基于网站 pri的多线程网页信息ority 采集技术25-26 2.5根据网页类别确定优先级26 2.6本章摘要26-27基于文本密度的提取网页文本算法的研究27-33 3.1算法流程图27 3.2识别和文本特征识别处理27-28 3.3网页源代码的预处理28-29 3.4计算网页文本源行的中文密度29 3.5阻止网页的源代码29 3.6删除伪网页的源代码29 -31 3.7辅助网页的源代码文本识别方法31 3.8网页文本的原创格式保留31 3.9本章摘要31-33基于主题词索引的网页分类算法研究33-524.1概述33-344.2开放测试和封闭测试34-354.3算法性能评估指标35-364.4与网站分类算法相关的基础研究36-424.4.1文本的表示形式36-374.4.2基于向量模板37构造向量空间模型[k56]4.3基于哈希表37-39构造向量空间模型[k56]4.4主题词基于概念分析的抽取算法39-404.4.5改进的矢量余弦相似度算法40-424.5基于主题词索引的类别中心矢量分类算法42-464.5.1生成分类器模型434.5.2分类算法434.5.3向量的归一化434.5.4将类别数提高到分类精度Impact 43-444.5.5文档类别分布对分类准确性的影响444.5.6中心向量的校正算法44-464.5.7分类算法的适应性464.6 KNN(K最近邻)分类算法46 -484.7 CKNN(聚类K最近邻)分类算法48-504.8本章摘要50-52相似性研究基于ty的文本摘要52-64 5.1基于相似度的文本摘要52 5.2文档结构模型52 5.3分段和子句52-54 5.4主题词提取54-55 5.4.1主题词字符串的矢量化54 [k72]4.2建立文档结构向量空间模型54-55 5.5计算文档结构各部分的权重55-57 5.6正负规则57 5.7用户偏好词汇57 5.8基于句子相似度的句子冗余算法57-58 5.9确定摘要和原创文本的比例58 5.10摘要句子选择和摘要生成585.11抽象技术在提取中文网页摘要中的应用58-63 5.11.1预提取网页文本对提高摘要准确性的影响59-62 5.11.2提高摘要算法的实时性能62-63 5.12本章摘要63-64实验设计点火和数据分析64-886.1基于网站优先级调整的网页信息动态采集技术实验和积分65-70 [k108]1.1实验设计65-66 [k108]1.2数据分析66-69 [k108]1.3存在的不足和进一步的改进69-706.2基于中文密度算法的中文网页文本提取技术的实验和分析70-716.2.1实验设计706.2.2数据分析706.2.3存在的缺点和下一个改进工作70-716.3两种方法在对象71-74中的比较实验和两种文档矢量表示方法的分析6.3.1实验设计716.3.2数据分析71-746.4改进的余弦矢量相似度算法74-76的实验和分析[k108]4.1实验设计74 [ k108]4.2数据分析74-766.5基于主题心的类别中心向量分类算法的实验与分析ding 76-796.5.1实验设计766.5.2数据分析76-786.5.3存在的问题和下一步78-796.6实验和分析CKNN分类算法79-806.6.1实验设计79 [k1 08]6.2数据分析79-806.6.3存在的问题和下一步806.7实验设计和数据KNN分类算法的分析80-826.7.1实验设计80-816.7.2数据分析81-826.8类别中心向量分类算法,CKNN分类算法和KNN的性能比较分类算法82-836.8.1实验设计826.8.2数据分析82-836.9基于相似度的文档摘要技术的实验和数据分析83-856.9.1实验设计83-846.9.2数据分析84-856.9.3存在的问题和下一步856.10网络信息采集的实验和数据分析系统85-876.10.1实验设计85-866.10.2数据分析866.10.3存在的问题和下一步86-876.11本章摘要87-88 Web信息动态采集系统设计和实现88-95 7.1系统组成88-89 7.2系统模块的集成89-93 7.3网页分类模块的适应性93 7.4系统运行状态监视程序93 7.5基于主题词索引的网页重复数据删除方法93-94 7.6本章摘要94-95摘要95-97参考文献
完整解决方案:自动化信息采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-11-12 12:03
[摘要]:在当今信息和数据爆炸时代,可以对Internet上的数据信息进行数据挖掘,以提取有价值的信息并预测某些事件的发生。现代主流搜索引擎,例如Google,百度等,将在全球范围内部署自己的信息系统。在信息采集系统中,最重要的部分是如何解析网页并提取感兴趣的数据信息。在一般信息采集系统中,有必要使用不同的模块或不同的网站个性化网站制定信息提取规则,尤其是当网页结构相似时,会消耗大量的人力资源。自动化信息采集可以解决此问题。现有的自动页面解析算法通常使用模板生成或机器学习来自动提取信息。最常见的算法包括启发式,树对齐和模板生成。例如,RoadRunner等,这些现有算法的问题在于提取的信息收录噪声信息以及数据提取时间过长的缺点。为了解决上述问题,本文的主要研究内容体现在三个方面。首先,为解决人工干预和噪声信息在网络信息自动提取中比例过大的问题,提出了一种基于标签网页主体块的三叉树的解决方案。通过大量的分析,本文确定了可以正确描述网页文本分布的标签,并确定了标签的阈值。最后,结合三叉树信息提取模型,制定了统一的信息提取规则。实验表明,在时间和噪声信息比例上,信息提取算法的性能优于同类提取算法。其次,为了能够更好地适应自动信息提取,有必要解决网页结构的分类问题。当前,最常见的网页结构分类算法是基于DOM树的编辑距离,但是该算法最突出的缺点是时间消耗过长。结合现有主流站点之间Web页面模板应用的可能性较低,以及同一站点不同区域可能存在的差异,提出了一种基于Web页面标签属性的字符串编辑距离的Web页面结构相似性判断方法。实验表明,该算法确定网页相似度的时间约为DOM树编辑距离方法的3/4。第三,设计一个自动化的信息采集系统。在系统实现过程中,为了加快信息采集的使用,采用了分布式架构。为了实现履带的动态配置,将ZooKeeper用作配置中心。底层数据持久性使用MySQL数据库。该系统的实现避免了人工制定信息提取规则。 查看全部
自动化信息采集系统的设计和实现
[摘要]:在当今信息和数据爆炸时代,可以对Internet上的数据信息进行数据挖掘,以提取有价值的信息并预测某些事件的发生。现代主流搜索引擎,例如Google,百度等,将在全球范围内部署自己的信息系统。在信息采集系统中,最重要的部分是如何解析网页并提取感兴趣的数据信息。在一般信息采集系统中,有必要使用不同的模块或不同的网站个性化网站制定信息提取规则,尤其是当网页结构相似时,会消耗大量的人力资源。自动化信息采集可以解决此问题。现有的自动页面解析算法通常使用模板生成或机器学习来自动提取信息。最常见的算法包括启发式,树对齐和模板生成。例如,RoadRunner等,这些现有算法的问题在于提取的信息收录噪声信息以及数据提取时间过长的缺点。为了解决上述问题,本文的主要研究内容体现在三个方面。首先,为解决人工干预和噪声信息在网络信息自动提取中比例过大的问题,提出了一种基于标签网页主体块的三叉树的解决方案。通过大量的分析,本文确定了可以正确描述网页文本分布的标签,并确定了标签的阈值。最后,结合三叉树信息提取模型,制定了统一的信息提取规则。实验表明,在时间和噪声信息比例上,信息提取算法的性能优于同类提取算法。其次,为了能够更好地适应自动信息提取,有必要解决网页结构的分类问题。当前,最常见的网页结构分类算法是基于DOM树的编辑距离,但是该算法最突出的缺点是时间消耗过长。结合现有主流站点之间Web页面模板应用的可能性较低,以及同一站点不同区域可能存在的差异,提出了一种基于Web页面标签属性的字符串编辑距离的Web页面结构相似性判断方法。实验表明,该算法确定网页相似度的时间约为DOM树编辑距离方法的3/4。第三,设计一个自动化的信息采集系统。在系统实现过程中,为了加快信息采集的使用,采用了分布式架构。为了实现履带的动态配置,将ZooKeeper用作配置中心。底层数据持久性使用MySQL数据库。该系统的实现避免了人工制定信息提取规则。
核心方法:如何高效、准确、自动识别网页编码
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-10-18 13:02
发件人:
Tiandilian站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的通用字符模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
上面可以识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?号回;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子想出了一种本地方法:对于我们中文来说,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功了,否则识别就失败了。
这样,基本上可以轻松解决网页编码识别的问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想写一篇关于这个主题的文章文章。标题也被深思熟虑:“网络IO,到处都是异步的”,这里指的是网络IO仅是http请求
Tiandilian站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。 查看全部
如何高效,准确和自动识别网页编码
发件人:
Tiandilian站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的通用字符模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
上面可以识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?号回;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子想出了一种本地方法:对于我们中文来说,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功了,否则识别就失败了。
这样,基本上可以轻松解决网页编码识别的问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想写一篇关于这个主题的文章文章。标题也被深思熟虑:“网络IO,到处都是异步的”,这里指的是网络IO仅是http请求
Tiandilian站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。
解决方法:一种云计算中垂直搜索引擎网页采集模板自动识别方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2020-10-18 10:02
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种用于云计算中的垂直搜索引擎网页采集模板的自动识别方法。它根据需要采集 网站分析现有网页,以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类该工具对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并采用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。要从中提取所需的信息,您需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性低,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。对于采集 网站,我们需要随机获取一定数量的示例网页,分析现有网页,提取特征属性,并将属性值采集设置到数据表中作为训练样本数据进行聚类,以获得多个不同的网页模板;识别网页模板的类别,作为训练网页模板分类器的训练样本;将该分类器应用于所有采集个网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过下面的附图通过[具体实施例]进一步解释本发明:
如图1所示,需要一种云计算中的垂直搜索引擎网页采集模板自动识别方法,以随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类采集放入数据表作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。 查看全部
云计算中垂直搜索引擎网页采集模板的自动识别方法
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种用于云计算中的垂直搜索引擎网页采集模板的自动识别方法。它根据需要采集 网站分析现有网页,以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类该工具对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并采用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。要从中提取所需的信息,您需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性低,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。对于采集 网站,我们需要随机获取一定数量的示例网页,分析现有网页,提取特征属性,并将属性值采集设置到数据表中作为训练样本数据进行聚类,以获得多个不同的网页模板;识别网页模板的类别,作为训练网页模板分类器的训练样本;将该分类器应用于所有采集个网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过下面的附图通过[具体实施例]进一步解释本发明:
如图1所示,需要一种云计算中的垂直搜索引擎网页采集模板自动识别方法,以随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类采集放入数据表作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。
直观:一种基于样本的互联网爬虫内容网页识别方法与流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-09-30 10:02
本发明公开了一种基于样本的互联网爬虫内容网页识别方法,涉及互联网信息技术领域。
背景技术:
Internet爬虫是一种采集Internet信息的技术手段。互联网网站上有许多种类的网页。根据网页的内容,它们可以分为列表页面,内容页面和其他页面。列表页面主要是内容页面,其他页面提供链接条目,内容页面是网站发布的特定内容页面,其他页面包括功能页面,例如促销,广告,注册,登录和帮助。 Internet采集器服务的用户只关心内容网页的信息,因此Internet采集器程序需要在搜寻Internet信息的过程中准确地对网页进行分类和标识,然后再标识所标识的内容网页的信息采集进行业务处理。当前,识别内容网页的常用方法是手动采集,汇总和整理每个网站内容网页URL的正则表达式规则。 Internet爬网程序使用这些规则来匹配在爬网过程中找到的网页链接URL。发现内容页面。
现有的Internet爬网程序通过匹配手动采集,汇总和排序的内容网页的url正则表达式规则来判断内容网页。尽管此方法可以准确地发现内容网页,但它也有很多缺点,主要表现在:
1、每个网站内容网页的url格式都不固定。大多数网站会不时更改内容网页的url格式。一旦找不到及时的更改,它将导致Internet爬网程序。无法正确识别内容网页,从而导致大量采集数据丢失;
2、每个网站内容网页通常有多种正则表达式规则。手动维护方法要求采集和聚合内容网页,然后根据汇总的URL提取并编译正则表达式规则。验证正则表达式后,提交更新。该方法维护成本高,专业技术要求高,维护周期长。
Internet爬网程序将在运行期间根据某种路由算法遍历需要采集的网站。在遍历过程中处理每个网页时,它将从该网页提取到其他网页的链接URL。在Web链接URL中标识内容网页的链接URL也是现在需要解决的问题之一。
技术实现要素:
本发明要解决的技术问题是提供一种基于样本的基于现有技术的缺点识别互联网爬虫的网页的方法,并通过一种全新的互联网爬虫来改善互联网爬虫的数据。技术基于样本学习采集的准确性,并降低了维修人员的专业技术要求和维修成本。
本发明采用以下技术方案来解决上述技术问题:
一种用于识别Internet爬虫内容网页的基于样本的方法,该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
作为本发明的另一优选方案,在步骤3中,编辑距离分类算法具体为:
计算字符串之间的编辑距离,并根据设置的编辑距离系数对字符串进行分类,其中编辑距离是将两个字符串从一个转换为另一个所需的最小编辑次数。操作数量包括:用另一个字符替换一个字符,插入一个字符,然后删除一个字符。
使用编辑距离算法来计算并比较Internet采集器提取的Web链接url和内容Web链接url示例库中的示例链接url;
如果提取的Web链接URL和示例库中的任何示例链接URL属于同一类别,则将提取的Web链接URL视为内容Web链接URL,并对其进行后续的采集处理,随后的采集处理包括内容网页信息的重复数据删除和提取;
相反,如果提取的网页链接URL和样本库中的任何样本链接URL不属于同一类别,则认为提取的网页链接URL不是内容网页链接URL。
作为本发明的另一优选方案,当内容网页链接URL格式网站被更新时,或者当内容网页链接URL格式改变时,要求互联网爬虫执行数据网站。 ,内容将更新Web链接url示例库,并从Internet爬网程序的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。
作为本发明的另一优选方案,对于不符合样本库内容的网页链接的URL格式的URL,首先根据编辑距离分类算法对它们进行分类,然后对分类结果进行分类。手动浏览并验证。
与采用上述技术方案的现有技术相比,本发明具有以下技术效果:
1、本发明的Web爬虫内容网页识别逻辑算法适用于大多数互连的网站点,通用性强。
2、本发明的互联网爬虫内容的网页识别逻辑算法大大提高了互联网数据的准确性采集;
3、本发明的Web爬虫内容网页识别逻辑算法可以有效降低Internet爬虫的运维成本,提高运维效率。
图纸说明
图1是Internet采集器内容的网页识别过程的逻辑图;
图2是内容网页链接的url示例库的常规更新流程图;
图3是非内容Web链接的URL检查的流程图。
具体的实现方法
下面详细描述本发明的实施例。在附图中示出了实施例的示例,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。参照附图描述的以下实施例是示例性的,仅用于解释本发明,不能解释为对本发明的限制。
下面结合附图对本发明的技术方案做进一步的详细说明。
在本发明中,标识Internet爬虫内容的网页的整个过程如图1所示。该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
其中,编辑距离:也称为levenshtein距离(也称为editdistance),是指在两个字符串之间将一个字符串转换为另一字符串所需的最小编辑操作次数。编辑操作包括用一个字符替换另一个字符,插入一个字符以及删除一个字符。
编辑距离分类算法:计算字符串之间的编辑距离,并根据一定的编辑距离系数对字符串进行分类。
该专利使用编辑距离算法来计算和比较Internet采集器提取的网页链接的url和内容网页链接url的示例库中的url。如果将某个提取的网页链接URL与示例库中的任何一个进行比较如果该样本链接URL属于同一类别,则该提取的Web链接URL被视为内容Web链接url,并进行后续的采集处理(包括需要对内容Web信息进行重复数据删除和提取);相反,如果某个示例库中提取的网页链接的URL不属于同一类别,则认为提取的网页链接URL不是内容网页的链接URL。
每个网站内容网络链接的网址格式都会不时更新。当采集的网站更改内容Web链接的url格式时,需要及时更新内容Web链接url示例库。 。内容Web链接url样本库的定期更新子过程通常通过定期更新来实现。更新子过程从Internet采集器的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。具体逻辑如图2所示。显示。
大量不符合示例库内容的Web链接url格式的URL也需要定期进行手动验证。手动实时验证不是简单的直接浏览不符合样本库的Web链接url信息,而是首先通过编辑距离算法对其进行分类。分类,然后手动浏览并验证分类结果。这样做的好处是可以大大减少手动验证的工作量。具体过程如图3所示。
非内容Web链接的URL的提取和分类可以定期自动进行,而手动验证只需要及时检查分类结果即可。可以根据实际需要设置自动对非内容Web链接URL进行提取和分类的周期,但是周期不能设置得太短,否则分类效果不佳,但是不能太长,导致无法及时发现内容。 网站对于Web链接修订或新格式的内容Web链接,周期通常设置为一天。
以上参照附图详细描述了本发明的实施例,但是本发明不限于上述实施例,并且在本领域普通技术人员的知识范围内。在不背离本发明的目的的情况下,也可以提供它。进行各种更改。以上仅为本发明的优选实施例,并不以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。所属领域的技术人员在不脱离本发明的技术方案的范围的情况下,可以利用以上公开的技术内容对具有等同变化的等同实施例进行细微改变或修改,但是所有这些根据本发明,不脱离本发明的技术方案的内容。在本发明的精神和原理内,对上述实施例进行的任何简单修改,等同替换和改进仍属于本发明的技术实质。在本发明技术方案的保护范围之内。 查看全部
基于样本的Internet爬网程序网页识别方法和过程

本发明公开了一种基于样本的互联网爬虫内容网页识别方法,涉及互联网信息技术领域。
背景技术:
Internet爬虫是一种采集Internet信息的技术手段。互联网网站上有许多种类的网页。根据网页的内容,它们可以分为列表页面,内容页面和其他页面。列表页面主要是内容页面,其他页面提供链接条目,内容页面是网站发布的特定内容页面,其他页面包括功能页面,例如促销,广告,注册,登录和帮助。 Internet采集器服务的用户只关心内容网页的信息,因此Internet采集器程序需要在搜寻Internet信息的过程中准确地对网页进行分类和标识,然后再标识所标识的内容网页的信息采集进行业务处理。当前,识别内容网页的常用方法是手动采集,汇总和整理每个网站内容网页URL的正则表达式规则。 Internet爬网程序使用这些规则来匹配在爬网过程中找到的网页链接URL。发现内容页面。
现有的Internet爬网程序通过匹配手动采集,汇总和排序的内容网页的url正则表达式规则来判断内容网页。尽管此方法可以准确地发现内容网页,但它也有很多缺点,主要表现在:
1、每个网站内容网页的url格式都不固定。大多数网站会不时更改内容网页的url格式。一旦找不到及时的更改,它将导致Internet爬网程序。无法正确识别内容网页,从而导致大量采集数据丢失;
2、每个网站内容网页通常有多种正则表达式规则。手动维护方法要求采集和聚合内容网页,然后根据汇总的URL提取并编译正则表达式规则。验证正则表达式后,提交更新。该方法维护成本高,专业技术要求高,维护周期长。
Internet爬网程序将在运行期间根据某种路由算法遍历需要采集的网站。在遍历过程中处理每个网页时,它将从该网页提取到其他网页的链接URL。在Web链接URL中标识内容网页的链接URL也是现在需要解决的问题之一。
技术实现要素:
本发明要解决的技术问题是提供一种基于样本的基于现有技术的缺点识别互联网爬虫的网页的方法,并通过一种全新的互联网爬虫来改善互联网爬虫的数据。技术基于样本学习采集的准确性,并降低了维修人员的专业技术要求和维修成本。
本发明采用以下技术方案来解决上述技术问题:
一种用于识别Internet爬虫内容网页的基于样本的方法,该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
作为本发明的另一优选方案,在步骤3中,编辑距离分类算法具体为:
计算字符串之间的编辑距离,并根据设置的编辑距离系数对字符串进行分类,其中编辑距离是将两个字符串从一个转换为另一个所需的最小编辑次数。操作数量包括:用另一个字符替换一个字符,插入一个字符,然后删除一个字符。
使用编辑距离算法来计算并比较Internet采集器提取的Web链接url和内容Web链接url示例库中的示例链接url;
如果提取的Web链接URL和示例库中的任何示例链接URL属于同一类别,则将提取的Web链接URL视为内容Web链接URL,并对其进行后续的采集处理,随后的采集处理包括内容网页信息的重复数据删除和提取;
相反,如果提取的网页链接URL和样本库中的任何样本链接URL不属于同一类别,则认为提取的网页链接URL不是内容网页链接URL。
作为本发明的另一优选方案,当内容网页链接URL格式网站被更新时,或者当内容网页链接URL格式改变时,要求互联网爬虫执行数据网站。 ,内容将更新Web链接url示例库,并从Internet爬网程序的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。
作为本发明的另一优选方案,对于不符合样本库内容的网页链接的URL格式的URL,首先根据编辑距离分类算法对它们进行分类,然后对分类结果进行分类。手动浏览并验证。
与采用上述技术方案的现有技术相比,本发明具有以下技术效果:
1、本发明的Web爬虫内容网页识别逻辑算法适用于大多数互连的网站点,通用性强。
2、本发明的互联网爬虫内容的网页识别逻辑算法大大提高了互联网数据的准确性采集;
3、本发明的Web爬虫内容网页识别逻辑算法可以有效降低Internet爬虫的运维成本,提高运维效率。
图纸说明
图1是Internet采集器内容的网页识别过程的逻辑图;
图2是内容网页链接的url示例库的常规更新流程图;
图3是非内容Web链接的URL检查的流程图。
具体的实现方法
下面详细描述本发明的实施例。在附图中示出了实施例的示例,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。参照附图描述的以下实施例是示例性的,仅用于解释本发明,不能解释为对本发明的限制。
下面结合附图对本发明的技术方案做进一步的详细说明。
在本发明中,标识Internet爬虫内容的网页的整个过程如图1所示。该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
其中,编辑距离:也称为levenshtein距离(也称为editdistance),是指在两个字符串之间将一个字符串转换为另一字符串所需的最小编辑操作次数。编辑操作包括用一个字符替换另一个字符,插入一个字符以及删除一个字符。
编辑距离分类算法:计算字符串之间的编辑距离,并根据一定的编辑距离系数对字符串进行分类。
该专利使用编辑距离算法来计算和比较Internet采集器提取的网页链接的url和内容网页链接url的示例库中的url。如果将某个提取的网页链接URL与示例库中的任何一个进行比较如果该样本链接URL属于同一类别,则该提取的Web链接URL被视为内容Web链接url,并进行后续的采集处理(包括需要对内容Web信息进行重复数据删除和提取);相反,如果某个示例库中提取的网页链接的URL不属于同一类别,则认为提取的网页链接URL不是内容网页的链接URL。
每个网站内容网络链接的网址格式都会不时更新。当采集的网站更改内容Web链接的url格式时,需要及时更新内容Web链接url示例库。 。内容Web链接url样本库的定期更新子过程通常通过定期更新来实现。更新子过程从Internet采集器的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。具体逻辑如图2所示。显示。
大量不符合示例库内容的Web链接url格式的URL也需要定期进行手动验证。手动实时验证不是简单的直接浏览不符合样本库的Web链接url信息,而是首先通过编辑距离算法对其进行分类。分类,然后手动浏览并验证分类结果。这样做的好处是可以大大减少手动验证的工作量。具体过程如图3所示。
非内容Web链接的URL的提取和分类可以定期自动进行,而手动验证只需要及时检查分类结果即可。可以根据实际需要设置自动对非内容Web链接URL进行提取和分类的周期,但是周期不能设置得太短,否则分类效果不佳,但是不能太长,导致无法及时发现内容。 网站对于Web链接修订或新格式的内容Web链接,周期通常设置为一天。
以上参照附图详细描述了本发明的实施例,但是本发明不限于上述实施例,并且在本领域普通技术人员的知识范围内。在不背离本发明的目的的情况下,也可以提供它。进行各种更改。以上仅为本发明的优选实施例,并不以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。所属领域的技术人员在不脱离本发明的技术方案的范围的情况下,可以利用以上公开的技术内容对具有等同变化的等同实施例进行细微改变或修改,但是所有这些根据本发明,不脱离本发明的技术方案的内容。在本发明的精神和原理内,对上述实施例进行的任何简单修改,等同替换和改进仍属于本发明的技术实质。在本发明技术方案的保护范围之内。
操作方法:一种云计算中垂直搜索引擎网页采集模板自动识别方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-09-24 08:00
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种在云计算中自动识别垂直搜索引擎网页采集的模板的方法。它分析采集 网站的现有网页以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类处理器对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并利用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。如果要从中提取所需的信息,则需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,它具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术来实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。为了使采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性并设置属性值,采集用作训练样本数据以在数据表中聚类以获得多个不同的网页模板;将网页模板分类为训练样本,以训练网页模板分类器;将该分类器应用于所有采集网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析。达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过[具体实施方式]并参考以下附图进一步说明本发明:
如图1所示,云计算中的垂直搜索引擎网页采集模板自动识别方法用于随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类[ 采集放入数据表中作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。 查看全部
云计算中垂直搜索引擎网页采集模板的自动识别方法
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种在云计算中自动识别垂直搜索引擎网页采集的模板的方法。它分析采集 网站的现有网页以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类处理器对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并利用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。如果要从中提取所需的信息,则需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,它具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术来实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。为了使采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性并设置属性值,采集用作训练样本数据以在数据表中聚类以获得多个不同的网页模板;将网页模板分类为训练样本,以训练网页模板分类器;将该分类器应用于所有采集网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析。达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过[具体实施方式]并参考以下附图进一步说明本发明:
如图1所示,云计算中的垂直搜索引擎网页采集模板自动识别方法用于随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类[ 采集放入数据表中作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。
最新信息:免费爬虫工具:优采云采集器如何采集环球网新闻信息数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2020-09-07 18:50
本文介绍了如何使用优采云 采集器的智能模式释放采集万维网新闻的标题,内容,评论数,发布时间和其他信息。
采集工具简介:
优采云 采集器是基于人工智能技术的网页采集器,仅需输入URL即可自动识别网页数据,无需进行配置即可完成数据采集,是业界首创支持用于操作系统(包括Windows,Mac和Linux)的三种类型的Web采集器软件。
该软件是一款真正免费的data 采集软件。对采集结果的导出没有限制。没有编程基础的新手用户可以轻松实现data 采集要求。
官方网站:
采集对象介绍:
Worldwide.com已获得《人民日报》和中国中央网络空间管理局的批准,并由《人民日报在线》和《环球时报》共同投资建立。它于2007年11月正式启动。它是具有新闻编辑权网站的大型中英文双语新闻门户,是综合网络新闻媒体。万维网在各个领域和多个维度提供实时原创国际新闻和专业的国际信息服务;创建一个新的全球生活门户网站,将新闻信息,互动社区和移动增值服务整合在一起。
采集字段:
新闻标题,新闻链接,发布时间,新闻来源,参加人数,新闻内容
功能点目录:
如何配置采集字段
如何采集列出+详细页面类型的网页
采集结果预览:
让我们详细介绍如何释放采集全球新闻数据。让我们以全球新闻财经频道下的金融部门为例。具体步骤如下:
第1步:下载并安装优采云 采集器,然后注册并登录
1、打开优采云 采集器官方网站,下载并安装优采云 采集器的最新版本
2、单击注册以登录,注册新帐户,登录优采云 采集器
[提醒]您无需注册即可直接使用该采集器软件,但是切换到注册用户时,匿名帐户下的任务将会丢失,因此建议您在注册后使用它。
优采云 采集器是优采云的产品,优采云用户可以直接登录。
第2步:创建采集任务
1、复制万维网新闻和金融部分的网址(需要搜索结果页面的URL,而不是首页的URL)
单击此处以了解如何正确输入URL。
2、新的智能模式采集任务
您可以直接在软件上创建新的采集任务,也可以通过导入规则来创建任务。
点击此处了解如何导入和导出采集规则。
第3步:配置采集规则
1、设置提取数据字段
在智能模式下,输入URL后,软件可以自动识别页面上的数据并生成采集结果。每种数据类型都对应一个采集字段。我们可以右键单击该字段以进行相关设置,包括“修改字段名称”,“增加或减少字段”,“过程数据”等。
单击此处以了解如何配置采集字段。
在列表页面上,我们需要采集 Global News的新闻标题,新闻链接和发布时间等信息。字段设置如下:
2、使用深入的采集功能提取详细页面数据
在列表页面上,仅显示万维网新闻的部分内容。如果您需要详细的新闻内容,我们需要右键单击新闻链接,然后使用“深采集”功能跳转到详细信息页面以继续进行采集。
点击此处了解有关采集列表+详细页面类型页面的更多信息。
在详细信息页面上,我们可以查看新闻内容,新闻来源和参加人数。我们可以单击“添加字段”来添加采集字段。字段设置效果如下:
[温馨提示]在整个新闻内容的采集中,您可以将鼠标移到新闻内容的下半部分,并且当看到蓝色区域将其全部选中时,可以单击以进行选择,然后可以提取全部新闻新闻的新闻内容。
第4步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们可以启动采集任务。开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
单击“设置”按钮,然后在弹出的运行设置页面中设置运行设置和防阻塞设置。在这里,我们选中“跳过以继续采集”,设置为“ 2”秒请求等待时间,然后选中“不加载网页图片”,防阻塞设置将遵循系统默认设置,然后单击“保存”。
单击此处以了解有关如何配置采集任务的更多信息。
2、开始执行采集任务
单击“保存并开始”按钮,在弹出页面中进行一些高级设置,包括定时开始,自动存储和下载图片。在此示例中未使用这些功能,只需单击“开始”以运行采集器工具。
单击此处以了解有关计时采集的更多信息。
单击此处以了解有关自动存储的更多信息。
单击此处以了解有关如何下载图片的更多信息。
[温馨提示]免费版可以使用非定期定时采集功能,并且图片下载功能是免费的。个人专业版及更高版本可以使用高级计时功能和自动存储功能。
3、运行任务以提取数据
启动任务后自动开始采集数据。我们可以从界面直观地看到程序的运行过程和采集的结果,并且采集结束后会有提醒。
第5步:导出和查看数据
数据采集完成后,我们可以查看和导出数据。 优采云 采集器支持多种导出方法(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)以及导出文件的格式(EXCEL,CSV,HTML和TXT),我们选择所需的方法和文件类型,然后单击“确认导出”。
单击此处以了解有关如何查看和清除采集数据的更多信息。
单击此处以了解有关如何导出采集结果的更多信息。
[提醒]:所有手动导出功能都是免费的。 Personal Professional Edition及更高版本可以使用“发布到网站”功能。 查看全部
免费的采集器工具:优采云 采集器如何采集万维网新闻信息数据
本文介绍了如何使用优采云 采集器的智能模式释放采集万维网新闻的标题,内容,评论数,发布时间和其他信息。
采集工具简介:
优采云 采集器是基于人工智能技术的网页采集器,仅需输入URL即可自动识别网页数据,无需进行配置即可完成数据采集,是业界首创支持用于操作系统(包括Windows,Mac和Linux)的三种类型的Web采集器软件。
该软件是一款真正免费的data 采集软件。对采集结果的导出没有限制。没有编程基础的新手用户可以轻松实现data 采集要求。
官方网站:
采集对象介绍:
Worldwide.com已获得《人民日报》和中国中央网络空间管理局的批准,并由《人民日报在线》和《环球时报》共同投资建立。它于2007年11月正式启动。它是具有新闻编辑权网站的大型中英文双语新闻门户,是综合网络新闻媒体。万维网在各个领域和多个维度提供实时原创国际新闻和专业的国际信息服务;创建一个新的全球生活门户网站,将新闻信息,互动社区和移动增值服务整合在一起。
采集字段:
新闻标题,新闻链接,发布时间,新闻来源,参加人数,新闻内容
功能点目录:
如何配置采集字段
如何采集列出+详细页面类型的网页
采集结果预览:

让我们详细介绍如何释放采集全球新闻数据。让我们以全球新闻财经频道下的金融部门为例。具体步骤如下:
第1步:下载并安装优采云 采集器,然后注册并登录
1、打开优采云 采集器官方网站,下载并安装优采云 采集器的最新版本
2、单击注册以登录,注册新帐户,登录优采云 采集器

[提醒]您无需注册即可直接使用该采集器软件,但是切换到注册用户时,匿名帐户下的任务将会丢失,因此建议您在注册后使用它。
优采云 采集器是优采云的产品,优采云用户可以直接登录。
第2步:创建采集任务
1、复制万维网新闻和金融部分的网址(需要搜索结果页面的URL,而不是首页的URL)
单击此处以了解如何正确输入URL。

2、新的智能模式采集任务
您可以直接在软件上创建新的采集任务,也可以通过导入规则来创建任务。
点击此处了解如何导入和导出采集规则。

第3步:配置采集规则
1、设置提取数据字段
在智能模式下,输入URL后,软件可以自动识别页面上的数据并生成采集结果。每种数据类型都对应一个采集字段。我们可以右键单击该字段以进行相关设置,包括“修改字段名称”,“增加或减少字段”,“过程数据”等。
单击此处以了解如何配置采集字段。

在列表页面上,我们需要采集 Global News的新闻标题,新闻链接和发布时间等信息。字段设置如下:

2、使用深入的采集功能提取详细页面数据
在列表页面上,仅显示万维网新闻的部分内容。如果您需要详细的新闻内容,我们需要右键单击新闻链接,然后使用“深采集”功能跳转到详细信息页面以继续进行采集。
点击此处了解有关采集列表+详细页面类型页面的更多信息。

在详细信息页面上,我们可以查看新闻内容,新闻来源和参加人数。我们可以单击“添加字段”来添加采集字段。字段设置效果如下:

[温馨提示]在整个新闻内容的采集中,您可以将鼠标移到新闻内容的下半部分,并且当看到蓝色区域将其全部选中时,可以单击以进行选择,然后可以提取全部新闻新闻的新闻内容。
第4步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们可以启动采集任务。开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
单击“设置”按钮,然后在弹出的运行设置页面中设置运行设置和防阻塞设置。在这里,我们选中“跳过以继续采集”,设置为“ 2”秒请求等待时间,然后选中“不加载网页图片”,防阻塞设置将遵循系统默认设置,然后单击“保存”。
单击此处以了解有关如何配置采集任务的更多信息。


2、开始执行采集任务
单击“保存并开始”按钮,在弹出页面中进行一些高级设置,包括定时开始,自动存储和下载图片。在此示例中未使用这些功能,只需单击“开始”以运行采集器工具。
单击此处以了解有关计时采集的更多信息。
单击此处以了解有关自动存储的更多信息。
单击此处以了解有关如何下载图片的更多信息。
[温馨提示]免费版可以使用非定期定时采集功能,并且图片下载功能是免费的。个人专业版及更高版本可以使用高级计时功能和自动存储功能。

3、运行任务以提取数据
启动任务后自动开始采集数据。我们可以从界面直观地看到程序的运行过程和采集的结果,并且采集结束后会有提醒。

第5步:导出和查看数据
数据采集完成后,我们可以查看和导出数据。 优采云 采集器支持多种导出方法(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)以及导出文件的格式(EXCEL,CSV,HTML和TXT),我们选择所需的方法和文件类型,然后单击“确认导出”。
单击此处以了解有关如何查看和清除采集数据的更多信息。
单击此处以了解有关如何导出采集结果的更多信息。
[提醒]:所有手动导出功能都是免费的。 Personal Professional Edition及更高版本可以使用“发布到网站”功能。
技巧:如何高效、准确、自动识别网页编码
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-09-07 00:25
发件人:
Tiandilian 站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码识别
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别出的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的Universalchardet模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
可以在上面识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?回号;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子,想出了一种本地方法:对于我们中文,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功,否则识别就失败。
这样,基本上可以轻松解决网页编码识别问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想在这方面写一篇文章文章。标题也被深思熟虑:“网络IO,异步无处不在”,这里指的是仅HTTP请求的网络IO
Tiandilian 站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。 查看全部
如何高效,准确和自动识别网页编码
发件人:
Tiandilian 站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码识别
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别出的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的Universalchardet模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
可以在上面识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?回号;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子,想出了一种本地方法:对于我们中文,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功,否则识别就失败。
这样,基本上可以轻松解决网页编码识别问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想在这方面写一篇文章文章。标题也被深思熟虑:“网络IO,异步无处不在”,这里指的是仅HTTP请求的网络IO
Tiandilian 站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。
直观:基于深度学习的网页区域识别算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-09-05 18:18
一种基于深度学习的网页区域识别算法
[技术领域]
[0001]本发明涉及Internet信息技术采集,尤其是一种基于深度学习的网页区域识别算法。
[背景技术]
[0002]网页区域识别对于搜索引擎构建,网络信息检索,网络数据采集和网络知识发现至关重要。当前,网页区域识别通常采用以下方法:手动设置识别规则以识别网页区域或基于其他非深度学习机器学习方法来识别网页区域。
[0003]对于网页区域识别,该区域中文本的视觉特征(文本的大小,颜色,是否为粗体等)以及该区域本身的视觉特征(位置,背景)颜色,是否有边框等)至关重要。纯文本不能反映这些视觉特征,自然语言是高度抽象的。仅对纯文本执行特征提取和模式识别。难以提取足够的特征来获得理想的识别效果。
[发明内容]
[0004]本发明要解决的技术问题是提供一种基于深度学习的网页区域识别算法。
[0005]本发明为解决已知技术中存在的技术问题而采用的技术方案是:
本发明基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,以提取网页中不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;通过分词算法对文本特征进行序列化;通过神经网络语言模型学习文本特征向量;
D。叠层降噪自动编码器SDAE作为特征学习方法,上述处理后的特征向量作为输入向量;
E。使用堆叠式降噪自动编码器SDAE的输出向量作为分类算法的输入,并使用分类算法对上述输出向量进行分类。向量的分类结果是与特征向量相对应的网页区域的识别结果。
[0006]本发明还可以采用以下技术措施:
在步骤B中,通过选择所有视觉特征来获得未归一化的视觉特征向量。
[0007]在步骤B中,通过选择一些视觉特征,获得未归一化的视觉特征向量。
[0008]使用Min-Max Normali zat 1n的归一化方法对视觉特征向量进行归一化,以获得归一化的视觉特征向量。
[0009]在步骤C中,使用大规模分词算法对文本进行分词。
[0010]在步骤C中,通过口吃分割算法对文本进行分割。
[0011]在步骤C中,通过Paragraph2Vec算法学习文本特征向量。
[0012]在步骤D中,将视觉特征向量用作堆叠降噪自动编码器SDAE的输入向量。
[0013]在步骤D中,将视觉特征向量和文本特征向量进行拼接,作为堆叠降噪自动编码器SDAE的输入向量,并对拼接的向量进行选择性归一化。
[0014]在步骤E中,使用分类算法Softmax Regress1n对学习到的特征向量进行分类。
[0015]本发明的优点和积极效果是:
在本发明的基于深度学习的网页区域识别算法中,将网页的HTML源代码用作算法输入,并将HTML转换为XML,提取视觉特征和文本内容,并归一化对应的视觉特征,通过神经网络语言模型对文本内容进行特征学习,分别获得初步视觉特征向量和文本特征向量,并通过叠加降噪进一步学习初步视觉特征向量和文本特征向量自动编码器SDAE获取与该网页区域的网页区域特征向量相对应的代表,并通过分类算法对网页区域特征向量进行分类,即得到网页区域的识别结果。本发明可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率达到9 9. 99%-100%。
[详细实现]
[0016]以下将通过具体实施例详细描述本发明。
[0017]本发明的基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,提取网页中不同区域的视觉特征,视觉特征包括区域坐标,区域背景颜色,区域边框粗细,区域文字密度,区域文字字体,区域文字大小,区域文字颜色等。;通过选择全部或部分视觉特征以获得未归一化的视觉特征向量;用Min-Max Normalizat1n的归一化方法对视觉特征向量进行归一化,得到归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;使用大规模分词算法或口吃分词算法对文本进行分割;使用神经网络语言模型的Paragraph2Vec算法学习文本特征向量;
D。堆叠降噪自动编码器SDAE被用作特征学习方法,并且上述处理过的特征向量被用作输入向量。 SDAE的输入向量是通过视觉特征向量和文本特征向量进行拼接的,或者仅是视觉的特征向量作为输入向量,并且对拼接的向量进行了规范化或未处理;
E。堆叠降噪自动编码器SDAE的输出向量用作分类算法的输入,分类算法Softmax Regress1n用于对上述输出向量进行分类。向量的分类结果是与特征向量识别结果相对应的网页区域。
[0018]上面的描述仅是本发明的优选实施方式,并且无意于以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。当然,在不脱离本发明的技术方案的范围的情况下,本领域的任何技术人员当然都可以使用所公开的技术内容进行一些改变或修改,以成为等同改变的等同实施方式,只要他们能够做到。不背离本发明的技术方案,基于本发明的技术实质,对以上实施例所作的任何修改,等同变化,修改,修改的内容,均在本发明技术方案的范围内。发明。
[主权物品]
1.一种基于深度学习的网页区域识别算法,包括以下步骤:A.格式化文本:使用网页的HTML源代码作为算法输入; B.视觉特征处理:将HTML转换为XML并提取网页内部不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量; C.文本特征处理:将HTML转换为XML,提取网页区域中的文本;分割文本;通过神经网络语言模型学习文本特征向量; D.使用堆叠降噪自动编码器SDAE作为特征学习算法,并使用处理后的特征向量作为SDAE的输入向量; E,使用分类算法对堆叠式降噪自动编码器SDAE学习到的特征向量进行分类,向量的分类结果为特征向量对应的网页区域的识别结果。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择所有视觉特征,获得非归一化的视觉特征矢量。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择部分视觉特征,获得非归一化的视觉特征矢量。 4.根据权利要求2或3所述的基于深度学习的网页区域识别算法,其特征在于:所述最小-最大归一化方法用于对所述视觉特征向量进行归一化,以获得归一化的视觉特征向量。 6.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过大规模分词算法对文本进行分词。 7.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过口吃单词分割算法对文本进行分割。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过Paragraph2Vec算法学习所述文本特征向量。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量用作堆叠式降噪自动编码器SDAE的输入向量。 9. 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量和文本特征向量拼接为叠加式降噪的输入向量。自动编码器SDAE,在拼接后将所选向量标准化。 1 0.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤E中,使用分类算法Softmax Regress 1n对学习到的特征向量进行分类。
[专利摘要]一种基于深度学习的网页区域识别算法,包括以下步骤:A.使用格式化文本和网页HTML的源代码作为算法输入; B.通过HTML2XML算法提取网页区域的视觉特征向量; C.通过HTML2XML算法提取网页区域的文本内容,通过神经网络语言模型学习文本特征向量; D.使用叠加降噪自动编码器SDAE作为特征学习方法,并使用上述特征向量作为SDAE的输入向量; E.使用分类算法对SDAE的输出向量进行分类,向量的分类结果为该向量对应的网页区域的识别结果。通过本发明,可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率为9 9. 99%-100%。
[IPC分类] G06F17 / 30,G06F17 / 21,G06N3 / 08,G06F17 / 27
[公开号] CN105550278
[申请号] CN2
[发明人]李志杰,周祖胜
[申请人]天津海量信息技术有限公司
[公开日] 2016年5月4日
[申请日期] 2015年12月10日 查看全部
一种基于深度学习的网页区域识别算法
一种基于深度学习的网页区域识别算法
[技术领域]
[0001]本发明涉及Internet信息技术采集,尤其是一种基于深度学习的网页区域识别算法。
[背景技术]
[0002]网页区域识别对于搜索引擎构建,网络信息检索,网络数据采集和网络知识发现至关重要。当前,网页区域识别通常采用以下方法:手动设置识别规则以识别网页区域或基于其他非深度学习机器学习方法来识别网页区域。
[0003]对于网页区域识别,该区域中文本的视觉特征(文本的大小,颜色,是否为粗体等)以及该区域本身的视觉特征(位置,背景)颜色,是否有边框等)至关重要。纯文本不能反映这些视觉特征,自然语言是高度抽象的。仅对纯文本执行特征提取和模式识别。难以提取足够的特征来获得理想的识别效果。
[发明内容]
[0004]本发明要解决的技术问题是提供一种基于深度学习的网页区域识别算法。
[0005]本发明为解决已知技术中存在的技术问题而采用的技术方案是:
本发明基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,以提取网页中不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;通过分词算法对文本特征进行序列化;通过神经网络语言模型学习文本特征向量;
D。叠层降噪自动编码器SDAE作为特征学习方法,上述处理后的特征向量作为输入向量;
E。使用堆叠式降噪自动编码器SDAE的输出向量作为分类算法的输入,并使用分类算法对上述输出向量进行分类。向量的分类结果是与特征向量相对应的网页区域的识别结果。
[0006]本发明还可以采用以下技术措施:
在步骤B中,通过选择所有视觉特征来获得未归一化的视觉特征向量。
[0007]在步骤B中,通过选择一些视觉特征,获得未归一化的视觉特征向量。
[0008]使用Min-Max Normali zat 1n的归一化方法对视觉特征向量进行归一化,以获得归一化的视觉特征向量。
[0009]在步骤C中,使用大规模分词算法对文本进行分词。
[0010]在步骤C中,通过口吃分割算法对文本进行分割。
[0011]在步骤C中,通过Paragraph2Vec算法学习文本特征向量。
[0012]在步骤D中,将视觉特征向量用作堆叠降噪自动编码器SDAE的输入向量。
[0013]在步骤D中,将视觉特征向量和文本特征向量进行拼接,作为堆叠降噪自动编码器SDAE的输入向量,并对拼接的向量进行选择性归一化。
[0014]在步骤E中,使用分类算法Softmax Regress1n对学习到的特征向量进行分类。
[0015]本发明的优点和积极效果是:
在本发明的基于深度学习的网页区域识别算法中,将网页的HTML源代码用作算法输入,并将HTML转换为XML,提取视觉特征和文本内容,并归一化对应的视觉特征,通过神经网络语言模型对文本内容进行特征学习,分别获得初步视觉特征向量和文本特征向量,并通过叠加降噪进一步学习初步视觉特征向量和文本特征向量自动编码器SDAE获取与该网页区域的网页区域特征向量相对应的代表,并通过分类算法对网页区域特征向量进行分类,即得到网页区域的识别结果。本发明可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率达到9 9. 99%-100%。
[详细实现]
[0016]以下将通过具体实施例详细描述本发明。
[0017]本发明的基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,提取网页中不同区域的视觉特征,视觉特征包括区域坐标,区域背景颜色,区域边框粗细,区域文字密度,区域文字字体,区域文字大小,区域文字颜色等。;通过选择全部或部分视觉特征以获得未归一化的视觉特征向量;用Min-Max Normalizat1n的归一化方法对视觉特征向量进行归一化,得到归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;使用大规模分词算法或口吃分词算法对文本进行分割;使用神经网络语言模型的Paragraph2Vec算法学习文本特征向量;
D。堆叠降噪自动编码器SDAE被用作特征学习方法,并且上述处理过的特征向量被用作输入向量。 SDAE的输入向量是通过视觉特征向量和文本特征向量进行拼接的,或者仅是视觉的特征向量作为输入向量,并且对拼接的向量进行了规范化或未处理;
E。堆叠降噪自动编码器SDAE的输出向量用作分类算法的输入,分类算法Softmax Regress1n用于对上述输出向量进行分类。向量的分类结果是与特征向量识别结果相对应的网页区域。
[0018]上面的描述仅是本发明的优选实施方式,并且无意于以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。当然,在不脱离本发明的技术方案的范围的情况下,本领域的任何技术人员当然都可以使用所公开的技术内容进行一些改变或修改,以成为等同改变的等同实施方式,只要他们能够做到。不背离本发明的技术方案,基于本发明的技术实质,对以上实施例所作的任何修改,等同变化,修改,修改的内容,均在本发明技术方案的范围内。发明。
[主权物品]
1.一种基于深度学习的网页区域识别算法,包括以下步骤:A.格式化文本:使用网页的HTML源代码作为算法输入; B.视觉特征处理:将HTML转换为XML并提取网页内部不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量; C.文本特征处理:将HTML转换为XML,提取网页区域中的文本;分割文本;通过神经网络语言模型学习文本特征向量; D.使用堆叠降噪自动编码器SDAE作为特征学习算法,并使用处理后的特征向量作为SDAE的输入向量; E,使用分类算法对堆叠式降噪自动编码器SDAE学习到的特征向量进行分类,向量的分类结果为特征向量对应的网页区域的识别结果。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择所有视觉特征,获得非归一化的视觉特征矢量。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择部分视觉特征,获得非归一化的视觉特征矢量。 4.根据权利要求2或3所述的基于深度学习的网页区域识别算法,其特征在于:所述最小-最大归一化方法用于对所述视觉特征向量进行归一化,以获得归一化的视觉特征向量。 6.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过大规模分词算法对文本进行分词。 7.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过口吃单词分割算法对文本进行分割。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过Paragraph2Vec算法学习所述文本特征向量。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量用作堆叠式降噪自动编码器SDAE的输入向量。 9. 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量和文本特征向量拼接为叠加式降噪的输入向量。自动编码器SDAE,在拼接后将所选向量标准化。 1 0.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤E中,使用分类算法Softmax Regress 1n对学习到的特征向量进行分类。
[专利摘要]一种基于深度学习的网页区域识别算法,包括以下步骤:A.使用格式化文本和网页HTML的源代码作为算法输入; B.通过HTML2XML算法提取网页区域的视觉特征向量; C.通过HTML2XML算法提取网页区域的文本内容,通过神经网络语言模型学习文本特征向量; D.使用叠加降噪自动编码器SDAE作为特征学习方法,并使用上述特征向量作为SDAE的输入向量; E.使用分类算法对SDAE的输出向量进行分类,向量的分类结果为该向量对应的网页区域的识别结果。通过本发明,可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率为9 9. 99%-100%。
[IPC分类] G06F17 / 30,G06F17 / 21,G06N3 / 08,G06F17 / 27
[公开号] CN105550278
[申请号] CN2
[发明人]李志杰,周祖胜
[申请人]天津海量信息技术有限公司
[公开日] 2016年5月4日
[申请日期] 2015年12月10日
操作方法:一种基于图片识别的自动裁剪方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-09-04 23:30
基于图像识别的自动裁剪方法
[专利摘要]本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)]背景识别;(4)自适应本发明采用基于识别的方法来实现图片的裁剪,并给出裁剪后的图片与原创图片的比例,本发明不需要人工干预,算法简单,算法简单。可靠性高,本发明可以根据需要采用不同的方法,满足不同网页显示的策略,本发明用于裁剪图片组,选择成功的选择作为显示图片,准确率9 9. 8%。本发明应用于信息和微薄页面图片的裁剪,人工测试的准确率9 9. 5%。
[专利描述]-一种基于图像识别的自动裁切方法
[技术领域]
[0001]本发明涉及一种自动裁切方法,尤其涉及一种基于图片识别的自动裁切方法。
[背景技术]
[0002]在网页显示领域,图像裁剪是必不可少的部分。当前,需要根据网页显示需求将图片裁剪为不同的尺寸。图片裁剪方法有很多种,基本上可以分为两类:基于软件的手动裁剪和算法裁剪。
[0003]基于软件的裁剪:首先定义裁剪区域和缩放比例,然后批量裁剪一组图片。对于某种类型的图片,请手动指定裁切过程。算法裁剪使用机器识别算法来识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004]手动裁切的缺点是裁切图片需要大量的人力资源,并且随着网站的扩展,裁切图片的成本也很高。自动裁剪方法的缺点是算法复杂,同时必须监控图像裁剪的效果,以发现问题并及时调整算法。
[发明内容]
[0005]鉴于现有技术的缺点,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面尺寸,无需人工干预即可有效裁剪图片。根据观察,不同的网页对图像显示有不同的要求。根据所需的尺寸,确定是否需要裁剪原创图像。如果需要裁切,则首先执行脸部识别,如果没有脸部,则执行背景识别。基于此,找到图片中需要保留的主要部分。然后使用自适应拦截方法拦截所需的图形。
[0006]通过以下技术方案实现本发明的目的:
[0007]一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008](I)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
[0011](4)自适应拦截。
[0012]优选地,步骤(I)包括读入图片以获得图片的高度和宽度信息,该信息与所需尺寸相同,并且比例恰好正确,则缩放直接结束
[0013]优选地,步骤(2)包括确定是否识别出人脸。
[0014]此外,
[0015](2. 1)识别多张面孔,计算出最小的一帧,并在其中收录所有面孔,这是主要部分,进入权利要求的步骤and;并且
[0016](2. 2)如果未识别出人脸,请继续进行索赔(3)。
[0017]优选地,面部识别包括使用opencv的面部检测算法,皮肤识别算法和图像块算法来执行图片的照度补偿。
[0018]优选地,步骤[3)包括使用图片块算法来计算左,右,上和下背景部分。
[0019]优选地,步骤⑷包括
[0020]对于多张脸,裁剪可收录所有脸的最小框架并将其标记为图片的主要部分;
[0021]当无法截取面部时,将最大的面部构图为图片的主要部分;和
[0022]当不捕获任何面部时,将取下背景部分的框标记为图片的主要部分。
[0023]此外,根据所需的高度或宽度,计算图片主要部分的高度或宽度,然后找到一个
[0024]窗口,即图片保留部分的高度和宽度。
[0025]此外,该方法包括调整截取主体部分失败的大小,包括调整完成模式和调整中央延伸裁切模式;
<p>[0026]补全方法包括:如果截取失败,则可以通过在两侧或上下补充相应的颜色边缘来获得适当的尺寸;中心扩展裁剪方法包括:如果截取失败,例如高度和长度,则从中心扩展相应的宽度。如果宽度和长度增加,则从中心向左扩展,向右扩展以获得合适的尺寸。 查看全部
基于图像识别的自动裁剪方法
基于图像识别的自动裁剪方法
[专利摘要]本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)]背景识别;(4)自适应本发明采用基于识别的方法来实现图片的裁剪,并给出裁剪后的图片与原创图片的比例,本发明不需要人工干预,算法简单,算法简单。可靠性高,本发明可以根据需要采用不同的方法,满足不同网页显示的策略,本发明用于裁剪图片组,选择成功的选择作为显示图片,准确率9 9. 8%。本发明应用于信息和微薄页面图片的裁剪,人工测试的准确率9 9. 5%。
[专利描述]-一种基于图像识别的自动裁切方法
[技术领域]
[0001]本发明涉及一种自动裁切方法,尤其涉及一种基于图片识别的自动裁切方法。
[背景技术]
[0002]在网页显示领域,图像裁剪是必不可少的部分。当前,需要根据网页显示需求将图片裁剪为不同的尺寸。图片裁剪方法有很多种,基本上可以分为两类:基于软件的手动裁剪和算法裁剪。
[0003]基于软件的裁剪:首先定义裁剪区域和缩放比例,然后批量裁剪一组图片。对于某种类型的图片,请手动指定裁切过程。算法裁剪使用机器识别算法来识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004]手动裁切的缺点是裁切图片需要大量的人力资源,并且随着网站的扩展,裁切图片的成本也很高。自动裁剪方法的缺点是算法复杂,同时必须监控图像裁剪的效果,以发现问题并及时调整算法。
[发明内容]
[0005]鉴于现有技术的缺点,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面尺寸,无需人工干预即可有效裁剪图片。根据观察,不同的网页对图像显示有不同的要求。根据所需的尺寸,确定是否需要裁剪原创图像。如果需要裁切,则首先执行脸部识别,如果没有脸部,则执行背景识别。基于此,找到图片中需要保留的主要部分。然后使用自适应拦截方法拦截所需的图形。
[0006]通过以下技术方案实现本发明的目的:
[0007]一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008](I)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
[0011](4)自适应拦截。
[0012]优选地,步骤(I)包括读入图片以获得图片的高度和宽度信息,该信息与所需尺寸相同,并且比例恰好正确,则缩放直接结束
[0013]优选地,步骤(2)包括确定是否识别出人脸。
[0014]此外,
[0015](2. 1)识别多张面孔,计算出最小的一帧,并在其中收录所有面孔,这是主要部分,进入权利要求的步骤and;并且
[0016](2. 2)如果未识别出人脸,请继续进行索赔(3)。
[0017]优选地,面部识别包括使用opencv的面部检测算法,皮肤识别算法和图像块算法来执行图片的照度补偿。
[0018]优选地,步骤[3)包括使用图片块算法来计算左,右,上和下背景部分。
[0019]优选地,步骤⑷包括
[0020]对于多张脸,裁剪可收录所有脸的最小框架并将其标记为图片的主要部分;
[0021]当无法截取面部时,将最大的面部构图为图片的主要部分;和
[0022]当不捕获任何面部时,将取下背景部分的框标记为图片的主要部分。
[0023]此外,根据所需的高度或宽度,计算图片主要部分的高度或宽度,然后找到一个
[0024]窗口,即图片保留部分的高度和宽度。
[0025]此外,该方法包括调整截取主体部分失败的大小,包括调整完成模式和调整中央延伸裁切模式;
<p>[0026]补全方法包括:如果截取失败,则可以通过在两侧或上下补充相应的颜色边缘来获得适当的尺寸;中心扩展裁剪方法包括:如果截取失败,例如高度和长度,则从中心扩展相应的宽度。如果宽度和长度增加,则从中心向左扩展,向右扩展以获得合适的尺寸。
解决方案:一种网页内容自动采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-09-04 18:13
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已成为一个庞大的信息库。 Internet信息采集可让您了解有关信息采集,资源整合和资金的更多信息。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当例行新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件也将“过期”并且需要重新排序,但是通常很难及时找到和重新排序。结果,新闻站点一旦被修改,必须在发现之前被发现,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了很多规则维护工作,以及站点修订后需要实时更新规则的问题;
[0008] 4、如果无法及时找到新闻站点修订,则采集个新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有网站自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,如果您不能及时适应网站修订,它将对于k1数据无效,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种用于Web内容的自动采集方法,该方法以可扩展的方式支持多种类型的网页[ k0],每个网页通用采集器都是用不同的算法来实现页面通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集合;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获取页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值收录h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法使用“作者节点特征匹配”方法扫描h节点的父节点的所有子节点,并检查是否匹配的子节点的文本值符合作者节点的特征。如果匹配,请确认子节点是作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,在步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成对发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配匹配,则将该节点确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并去除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录javaScript功能;
[0037](2)一个节点,其值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括: 查看全部
一种用于Web内容的自动采集方法
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已成为一个庞大的信息库。 Internet信息采集可让您了解有关信息采集,资源整合和资金的更多信息。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当例行新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件也将“过期”并且需要重新排序,但是通常很难及时找到和重新排序。结果,新闻站点一旦被修改,必须在发现之前被发现,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了很多规则维护工作,以及站点修订后需要实时更新规则的问题;
[0008] 4、如果无法及时找到新闻站点修订,则采集个新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有网站自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,如果您不能及时适应网站修订,它将对于k1数据无效,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种用于Web内容的自动采集方法,该方法以可扩展的方式支持多种类型的网页[ k0],每个网页通用采集器都是用不同的算法来实现页面通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集合;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获取页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值收录h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法使用“作者节点特征匹配”方法扫描h节点的父节点的所有子节点,并检查是否匹配的子节点的文本值符合作者节点的特征。如果匹配,请确认子节点是作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,在步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成对发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配匹配,则将该节点确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并去除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录javaScript功能;
[0037](2)一个节点,其值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括:
解读:要做采集网站,如何加快收录获得百度搜索引擎的“青睐”?
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2020-09-04 16:18
除著名的Google搜索引擎外,百度的识别度和每日使用率在国内搜索引擎中排名第一,因此我们优化了网站以加快百度搜索引擎的抓取和收录工作这是非常重要的。自2013年百度宣布其首个算法以来,百度共发布了13种算法,48种公告和算法解释文章。这也是学习百度SEO的第一本重要的“教科书”。
采集个电台,例如:信息,小说,电影和电视等将涉及采集问题,可以说小说电影和电视是采集的100%,采集电台的优化友好的百度SEO是一件比较困难的事情,首先,内容是“ pla窃”。即使您的网站是收录,百度也会将您网站排在原创 网站之后;其次,采集的结构被严重同质化。 ,相同的程序集和相同的模板,百度蜘蛛始终像拥有个人用品一样“热爱新事物,讨厌旧事物”。那么,采集站没有出路吗?显然不是,只要您了解百度蜘蛛规则并遵守规则,采集站就不错。
飓风算法
百度于2017年7月4日发布了飓风算法,以解决严重的采集问题,并于2018年9月13日宣布,飓风算法已升级至2. 0版本。可以看出,百度对站点采集做出了特殊的算法,但要注意文字描述:打击不好采集。因此,采集不错,只要它还不错。飓风算法主要打击以下四种不良采集行为:
1、 采集有明显痕迹
说明:该网站收录从其他网站或官方帐户采集转移的许多内容,信息未集成,布局混乱,缺少某些功能或文章可读性差,并且采集的痕迹明显,用户的阅读体验较差。
百度允许采集,但您应注意文章的布局和布局,并且不应该存在与文章主题无关的信息或不可用的功能,这会干扰用户的浏览。无法单击以下图标中的“购买”按钮表示文章的功能丢失;尽管此段文字不是有关剃刀的主题,但它不符合上述科学普及的主题。它是用于出售剃须刀的广告文字。明显的采集痕迹。
2、内容拼接
描述:采集多个具有不同文章的文章被拼接在一起,整体内容没有形成完整的逻辑,并且存在诸如阅读不一致和不连贯文章等问题,无法满足用户的要求需求。
这是我共同讨论的问题,导致出现文章“序言不跟单词”,如下图所示。某些采集器可以支持在采集的内容中添加单词以完成文章伪原创 文章,请勿再次使用它,这只是一个明智的选择。
3、收录大量采集内容
说明:网站下的大多数内容为采集,网站没有内容生产率或较差的内容生产能力,并且网站具有较低的内容质量。
换句话说,尽管百度允许采集,但采集本身也没有盲目。 采集定期添加一些自己撰写的文章是一个很好的解决方案。此外,我们还可以通过重新打印采集适当数量文章来指明来源。
4、跨域采集
说明:该网站依赖采集大量与该网站的域不一致的内容来获取流量。
此处的跨域并不表示跨域。每个网站都有自己的专业领域。如果采集具有美食家文章,则它将是跨域(cross-domain)的。确定网站的领域后,我们必须讨论和发布文章这个领域的主题,这可以提高搜索引擎对网站的专业评价,并获得更多的搜索青睐。跨网域只会降低网站的专业水平,并影响网站的搜索效果。下图中的示例用于教育网站,但是发布了一块黄瓜油炸丝瓜菜文章,属于跨域采集。
Qingfeng算法
2017年9月,百度搜索发布了“庆丰”算法,该算法严厉惩罚网站作弊的网页标题,以欺骗用户并获得点击;从而确保搜索用户的体验并促进搜索生态的健康发展。
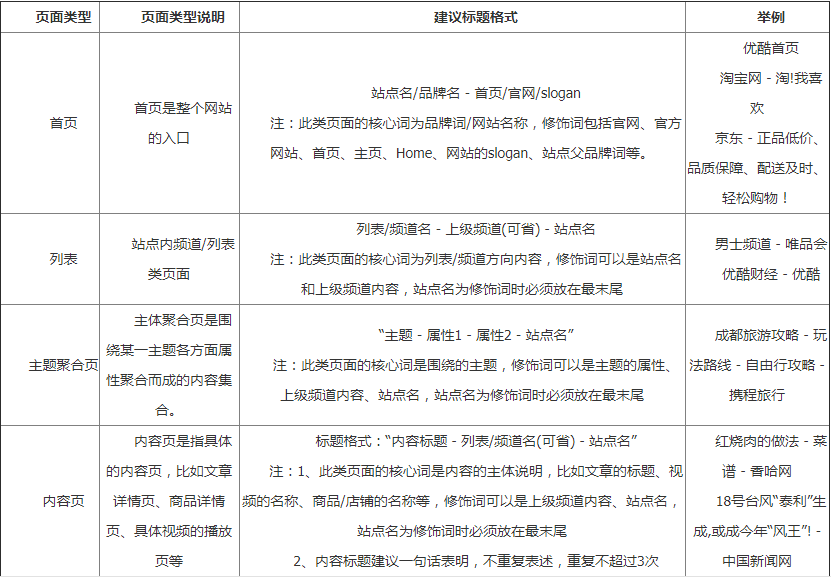
标题是文章文章中最精致的部分,一个好的标题只需要看一眼就可以知道该文章文章要说什么。普通用户决定是否点击您的文章,许多用户还会查看您的标题是否有吸引力。请记住,标题适合文章的内容,不要乱用关键词,也不要伪造标题。百度认可的标准标题格式为:“核心词+修饰语”,建议不超过3个修饰语。下图显示了不同页面类型下的标题格式,建议将其添加为书签。
目前,庆丰算法已更新为3. 0,以规范下载行业欺骗下载和捆绑下载的行为。通常,视频台也会采集下载资源,因此请特别注意标题。
Fiberhome算法
FiberHome算法考虑了网站的安全性问题。 网站具有“窃取用户数据”和“恶意劫持”行为。 网站被黑客入侵,并且将被FiberHome算法覆盖。 “恶意劫持”例如,您访问一个视频台,但您莫名其妙地跳到游戏类别中的其他网站。因此,定期检查网站是否有效非常重要。
还有很多其他需要注意的事情,例如修改网站模板以及定期且稳定地提交链接都是优化方法。 查看全部
要做采集 网站,如何加快收录从百度搜索引擎中获得“青睐”?
除著名的Google搜索引擎外,百度的识别度和每日使用率在国内搜索引擎中排名第一,因此我们优化了网站以加快百度搜索引擎的抓取和收录工作这是非常重要的。自2013年百度宣布其首个算法以来,百度共发布了13种算法,48种公告和算法解释文章。这也是学习百度SEO的第一本重要的“教科书”。
采集个电台,例如:信息,小说,电影和电视等将涉及采集问题,可以说小说电影和电视是采集的100%,采集电台的优化友好的百度SEO是一件比较困难的事情,首先,内容是“ pla窃”。即使您的网站是收录,百度也会将您网站排在原创 网站之后;其次,采集的结构被严重同质化。 ,相同的程序集和相同的模板,百度蜘蛛始终像拥有个人用品一样“热爱新事物,讨厌旧事物”。那么,采集站没有出路吗?显然不是,只要您了解百度蜘蛛规则并遵守规则,采集站就不错。
飓风算法
百度于2017年7月4日发布了飓风算法,以解决严重的采集问题,并于2018年9月13日宣布,飓风算法已升级至2. 0版本。可以看出,百度对站点采集做出了特殊的算法,但要注意文字描述:打击不好采集。因此,采集不错,只要它还不错。飓风算法主要打击以下四种不良采集行为:
1、 采集有明显痕迹
说明:该网站收录从其他网站或官方帐户采集转移的许多内容,信息未集成,布局混乱,缺少某些功能或文章可读性差,并且采集的痕迹明显,用户的阅读体验较差。
百度允许采集,但您应注意文章的布局和布局,并且不应该存在与文章主题无关的信息或不可用的功能,这会干扰用户的浏览。无法单击以下图标中的“购买”按钮表示文章的功能丢失;尽管此段文字不是有关剃刀的主题,但它不符合上述科学普及的主题。它是用于出售剃须刀的广告文字。明显的采集痕迹。

2、内容拼接
描述:采集多个具有不同文章的文章被拼接在一起,整体内容没有形成完整的逻辑,并且存在诸如阅读不一致和不连贯文章等问题,无法满足用户的要求需求。
这是我共同讨论的问题,导致出现文章“序言不跟单词”,如下图所示。某些采集器可以支持在采集的内容中添加单词以完成文章伪原创 文章,请勿再次使用它,这只是一个明智的选择。

3、收录大量采集内容
说明:网站下的大多数内容为采集,网站没有内容生产率或较差的内容生产能力,并且网站具有较低的内容质量。
换句话说,尽管百度允许采集,但采集本身也没有盲目。 采集定期添加一些自己撰写的文章是一个很好的解决方案。此外,我们还可以通过重新打印采集适当数量文章来指明来源。
4、跨域采集
说明:该网站依赖采集大量与该网站的域不一致的内容来获取流量。
此处的跨域并不表示跨域。每个网站都有自己的专业领域。如果采集具有美食家文章,则它将是跨域(cross-domain)的。确定网站的领域后,我们必须讨论和发布文章这个领域的主题,这可以提高搜索引擎对网站的专业评价,并获得更多的搜索青睐。跨网域只会降低网站的专业水平,并影响网站的搜索效果。下图中的示例用于教育网站,但是发布了一块黄瓜油炸丝瓜菜文章,属于跨域采集。
Qingfeng算法
2017年9月,百度搜索发布了“庆丰”算法,该算法严厉惩罚网站作弊的网页标题,以欺骗用户并获得点击;从而确保搜索用户的体验并促进搜索生态的健康发展。
标题是文章文章中最精致的部分,一个好的标题只需要看一眼就可以知道该文章文章要说什么。普通用户决定是否点击您的文章,许多用户还会查看您的标题是否有吸引力。请记住,标题适合文章的内容,不要乱用关键词,也不要伪造标题。百度认可的标准标题格式为:“核心词+修饰语”,建议不超过3个修饰语。下图显示了不同页面类型下的标题格式,建议将其添加为书签。
目前,庆丰算法已更新为3. 0,以规范下载行业欺骗下载和捆绑下载的行为。通常,视频台也会采集下载资源,因此请特别注意标题。
Fiberhome算法
FiberHome算法考虑了网站的安全性问题。 网站具有“窃取用户数据”和“恶意劫持”行为。 网站被黑客入侵,并且将被FiberHome算法覆盖。 “恶意劫持”例如,您访问一个视频台,但您莫名其妙地跳到游戏类别中的其他网站。因此,定期检查网站是否有效非常重要。
还有很多其他需要注意的事情,例如修改网站模板以及定期且稳定地提交链接都是优化方法。
解决方案:搜索引擎抓取收录工作流程及原理分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-09-04 04:56
什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是指由搜索引擎公司建立的一组自动爬网程序,称为蜘蛛人。
常见的蜘蛛有:Baiduspider(baiduspider)Google(Gllgledot)
360蜘蛛(360spider),搜狗新闻蜘蛛等。
二、搜索引擎抓取收录工作流程
1、抓取2、过滤器3、商店索引库4、显示排序
获取收录原理图
蜘蛛爬行-网站页面存储临时索引数据库的排名状态(从索引数据库中检索)
临时索引库未存储蜘蛛抓取的所有网站页。它将根据蜘蛛爬网的页面质量进行过滤,并过滤掉一些质量较差的页面。然后放好页面。按页面质量排序。
三、搜索引擎抓取
蜘蛛会跟踪网页的超链接,以在Internet上发现并采集网页信息
2、蜘蛛爬行规则
深度抓取(垂直抓取,首先抓取列的内容页面,然后更改列并以相同的方式抓取)
广泛爬行(水平爬行,首先爬行每个部分,然后爬行每个部分页面下方的内容页面)
3,抓取内容
链接文本图像视频JS CSS iframe蜘蛛
4、影响抓取
链接:收录太多参数的文本结构层次过多(最好3级)链接太长
无法识别内容
需要权限
网站无法打开
四、正在处理网页(过滤)
为什么过滤:采集,内容的值太低,文本不正确,内容不丰富
临时数据库:过滤蜘蛛抓取的内容后,该内容将存储在临时数据库中以供调用。
五、显示顺序
根据质量对存储索引库的内容进行排序,然后调用并显示给用户。
1、检索器根据用户输入的查询关键词在索引数据库中快速检索文档,评估文档和查询的相关性,对要输出的结果进行排序,并将查询结果显示到反馈用户。
2、当我们在搜索引擎中仅看到一个结果时,将根据各种算法对搜索进行排序,并将十个最佳质量的结果放在第一页上 查看全部
搜索引擎抓取收录工作流程和原理分析
什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是指由搜索引擎公司建立的一组自动爬网程序,称为蜘蛛人。
常见的蜘蛛有:Baiduspider(baiduspider)Google(Gllgledot)
360蜘蛛(360spider),搜狗新闻蜘蛛等。
二、搜索引擎抓取收录工作流程
1、抓取2、过滤器3、商店索引库4、显示排序
获取收录原理图
蜘蛛爬行-网站页面存储临时索引数据库的排名状态(从索引数据库中检索)
临时索引库未存储蜘蛛抓取的所有网站页。它将根据蜘蛛爬网的页面质量进行过滤,并过滤掉一些质量较差的页面。然后放好页面。按页面质量排序。
三、搜索引擎抓取
蜘蛛会跟踪网页的超链接,以在Internet上发现并采集网页信息
2、蜘蛛爬行规则
深度抓取(垂直抓取,首先抓取列的内容页面,然后更改列并以相同的方式抓取)
广泛爬行(水平爬行,首先爬行每个部分,然后爬行每个部分页面下方的内容页面)
3,抓取内容
链接文本图像视频JS CSS iframe蜘蛛
4、影响抓取
链接:收录太多参数的文本结构层次过多(最好3级)链接太长
无法识别内容
需要权限
网站无法打开
四、正在处理网页(过滤)
为什么过滤:采集,内容的值太低,文本不正确,内容不丰富
临时数据库:过滤蜘蛛抓取的内容后,该内容将存储在临时数据库中以供调用。
五、显示顺序
根据质量对存储索引库的内容进行排序,然后调用并显示给用户。
1、检索器根据用户输入的查询关键词在索引数据库中快速检索文档,评估文档和查询的相关性,对要输出的结果进行排序,并将查询结果显示到反馈用户。
2、当我们在搜索引擎中仅看到一个结果时,将根据各种算法对搜索进行排序,并将十个最佳质量的结果放在第一页上
软件介绍Elvin百度采集软件,简单上手流程图模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 608 次浏览 • 2021-02-25 13:01
Elvin Baidu Url 采集器是无需安装即可使用的网络采集软件。用户只需要输入采集数据中的关键词就可以找到一堆基于百度的搜索引擎。所获得的相关目标站点非常适合网站管理员使用。
软件简介
Elvin Baidu 采集软件是专门为用户准备的百度数据PC终端采集的免费版本。使用方法非常简单。在线下载软件,并自动在采集中下载采集中的数据,并删除重复项。
它的用法非常简单明了。您只需要打开该工具并输入关键词即可自动采集,采集将在采集之后保留在软件的根目录中。
软件功能
智能识别数据
智能模式:基于人工智能算法,您只需输入URL即可智能识别列表数据,表格数据和分页按钮,而无需配置任何采集规则和一个键采集。
自动识别:列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式:只需按照软件提示单击并在页面上进行操作即可,这完全符合人们浏览网页的思维方式,只需几个简单的步骤即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等。
支持多种数据导出方法
采集结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用。
查看全部
软件介绍Elvin百度采集软件,简单上手流程图模式
Elvin Baidu Url 采集器是无需安装即可使用的网络采集软件。用户只需要输入采集数据中的关键词就可以找到一堆基于百度的搜索引擎。所获得的相关目标站点非常适合网站管理员使用。
软件简介
Elvin Baidu 采集软件是专门为用户准备的百度数据PC终端采集的免费版本。使用方法非常简单。在线下载软件,并自动在采集中下载采集中的数据,并删除重复项。
它的用法非常简单明了。您只需要打开该工具并输入关键词即可自动采集,采集将在采集之后保留在软件的根目录中。
软件功能
智能识别数据
智能模式:基于人工智能算法,您只需输入URL即可智能识别列表数据,表格数据和分页按钮,而无需配置任何采集规则和一个键采集。
自动识别:列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式:只需按照软件提示单击并在页面上进行操作即可,这完全符合人们浏览网页的思维方式,只需几个简单的步骤即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等。
支持多种数据导出方法
采集结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用。
优采云采集器是一款非常简单的的网页数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2021-02-25 11:00
优采云 采集器是非常简单的网页数据采集工具,它具有可视化的工作界面,用户可以通过鼠标完成网页数据采集,使用该程序的门槛非常低,任何用户都可以轻松地将其用于数据采集,而无需用户具备编写采集器的能力;通过此软件,用户可以在大多数网站中采集数据,包括一些单页应用程序Ajax加载动态网站以获取用户所需的数据信息;该软件具有内置的高速浏览器引擎,用户可以在多种浏览模式之间自由切换,从而使用户能够以直观的方式轻松执行网站网页。 采集;该程序安全,无毒,易于使用,欢迎有需要的朋友下载和使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间并自动运行。
3、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能识别:它可以自动识别网页列表,采集字段,页面等。
5、阻止请求:自定义被阻止的域名,以方便过滤异地广告并提高采集速度。
6、各种数据导出:可以导出到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件功能
零阈值
即使没有网络爬网技术,您也可以轻松浏览Internet 网站并采集网站数据。该软件操作简单,单击鼠标即可轻松选择要爬网的内容。
多引擎,高速,稳定
内置在高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地采集数据。它还具有一个内置的JSON引擎,该引擎无需分析JSON数据结构并直观地选择JSON内容。
高级智能算法
高级智能算法可以生成目标元素XPath,自动识别网页列表,并自动识别分页中的下一页按钮。它不需要分析Web请求和源代码,但支持更多的Web页面采集。
适用于各种网站
它可以采集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方法
第1步:设置起始网址
要采集网站数据,首先,我们需要设置URL进入采集。例如,如果要采集网站的国内新闻,则应将起始URL设置为国内新闻栏列表的URL,但通常网站的主页未设置为起始地址,因为主页通常收录许多列表。例如,最新的文章,流行的文章和推荐的文章章以及其他列表块,这些列表块中显示的内容也非常有限。通常,采集这些列表时不可能采集完整的信息。
接下来,让我们以新浪新闻库为例,从新浪首页查找国内新闻。但是,此列首页上的内容仍然混乱,并分为三个子列
让我们看一下《内地新闻》的分栏报道
此页面列收录页面内容列表。通过切换分页,我们可以采集此列下的所有文章,因此此列表页面非常适合我们采集起始URL。
现在,我们将在任务编辑框的步骤1中将列表URL复制到文本框中。
如果要在一项任务中同时采集其他国内新闻子列,则还可以复制其他两个子列的列表地址,因为这些子列具有相似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始URL,我们还可以从txt文件中批量添加或导入。例如,如果我们要采集前五个页面,我们还可以通过这种方式自定义五个起始页面
应注意,如果您在此处自定义多个分页列表,则在后续集合配置中将不会启用分页。通常,当我们要采集列下的所有文章时,我们仅需要将列的第一页定义为起始URL。如果在后续的采集配置中启用了分页,则可以采集每个分页列表的数据。
步骤2:①自动生成列表和字段
进入第二步后,对于某些网页,惰性采集器将智能分析页面列表,自动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以弹出该字段的详细采集配置。点击上方的删除按钮以删除该字段。其余参数将在以下章节中介绍。
如果某些网页自动生成的列表数据不是我们想要的,则可以单击“清除字段”以清除所有生成的字段。
如果未手动选择我们的列表,它将自动列出。如果要取消突出显示的列表框,可以单击“查找列表-列表XPath”,清除XPath,然后确认。
②手动生成列表
点击“搜索列表”按钮,然后选择“手动选择列表”
按照提示进行操作,然后用鼠标左键单击网页列表中的第一行数据
单击第一行,然后根据提示单击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也将生成。如果生成的字段不正确,请单击“清除字段”以清除下面的所有字段。下一章将说明如何手动选择字段。
③手动生成字段
点击“添加字段”按钮
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。如果只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复上述操作。
④分页设置
列表有分页时,可以在启用分页后采集所有分页列表数据。
页面分页有两种类型
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,您可以转到下一页,例如“新浪新闻”列表中的上一页 查看全部
优采云采集器是一款非常简单的的网页数据采集工具
优采云 采集器是非常简单的网页数据采集工具,它具有可视化的工作界面,用户可以通过鼠标完成网页数据采集,使用该程序的门槛非常低,任何用户都可以轻松地将其用于数据采集,而无需用户具备编写采集器的能力;通过此软件,用户可以在大多数网站中采集数据,包括一些单页应用程序Ajax加载动态网站以获取用户所需的数据信息;该软件具有内置的高速浏览器引擎,用户可以在多种浏览模式之间自由切换,从而使用户能够以直观的方式轻松执行网站网页。 采集;该程序安全,无毒,易于使用,欢迎有需要的朋友下载和使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间并自动运行。
3、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能识别:它可以自动识别网页列表,采集字段,页面等。
5、阻止请求:自定义被阻止的域名,以方便过滤异地广告并提高采集速度。
6、各种数据导出:可以导出到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件功能
零阈值
即使没有网络爬网技术,您也可以轻松浏览Internet 网站并采集网站数据。该软件操作简单,单击鼠标即可轻松选择要爬网的内容。
多引擎,高速,稳定
内置在高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地采集数据。它还具有一个内置的JSON引擎,该引擎无需分析JSON数据结构并直观地选择JSON内容。
高级智能算法
高级智能算法可以生成目标元素XPath,自动识别网页列表,并自动识别分页中的下一页按钮。它不需要分析Web请求和源代码,但支持更多的Web页面采集。
适用于各种网站
它可以采集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方法
第1步:设置起始网址
要采集网站数据,首先,我们需要设置URL进入采集。例如,如果要采集网站的国内新闻,则应将起始URL设置为国内新闻栏列表的URL,但通常网站的主页未设置为起始地址,因为主页通常收录许多列表。例如,最新的文章,流行的文章和推荐的文章章以及其他列表块,这些列表块中显示的内容也非常有限。通常,采集这些列表时不可能采集完整的信息。
接下来,让我们以新浪新闻库为例,从新浪首页查找国内新闻。但是,此列首页上的内容仍然混乱,并分为三个子列
让我们看一下《内地新闻》的分栏报道
此页面列收录页面内容列表。通过切换分页,我们可以采集此列下的所有文章,因此此列表页面非常适合我们采集起始URL。
现在,我们将在任务编辑框的步骤1中将列表URL复制到文本框中。
如果要在一项任务中同时采集其他国内新闻子列,则还可以复制其他两个子列的列表地址,因为这些子列具有相似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始URL,我们还可以从txt文件中批量添加或导入。例如,如果我们要采集前五个页面,我们还可以通过这种方式自定义五个起始页面
应注意,如果您在此处自定义多个分页列表,则在后续集合配置中将不会启用分页。通常,当我们要采集列下的所有文章时,我们仅需要将列的第一页定义为起始URL。如果在后续的采集配置中启用了分页,则可以采集每个分页列表的数据。
步骤2:①自动生成列表和字段
进入第二步后,对于某些网页,惰性采集器将智能分析页面列表,自动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以弹出该字段的详细采集配置。点击上方的删除按钮以删除该字段。其余参数将在以下章节中介绍。
如果某些网页自动生成的列表数据不是我们想要的,则可以单击“清除字段”以清除所有生成的字段。
如果未手动选择我们的列表,它将自动列出。如果要取消突出显示的列表框,可以单击“查找列表-列表XPath”,清除XPath,然后确认。
②手动生成列表
点击“搜索列表”按钮,然后选择“手动选择列表”
按照提示进行操作,然后用鼠标左键单击网页列表中的第一行数据
单击第一行,然后根据提示单击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也将生成。如果生成的字段不正确,请单击“清除字段”以清除下面的所有字段。下一章将说明如何手动选择字段。
③手动生成字段
点击“添加字段”按钮
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。如果只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复上述操作。
④分页设置
列表有分页时,可以在启用分页后采集所有分页列表数据。
页面分页有两种类型
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,您可以转到下一页,例如“新浪新闻”列表中的上一页
电商平台为什么要做一个机器人来识别采集数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-02-21 09:01
网页采集器的自动识别算法:目前市面上的很多采集器都有自己的算法,主要的识别准确率的一般能达到98%的准确率就可以了,像你提到的那种自动识别过程,大部分采集器都有完整的测试来做无人值守智能收割的过程,给你个价格参考智能采集机器人¥2000至¥3000无人值守采集机器人¥500至¥8000无人值守采集机器人¥1000至¥10000而这些算法又分为很多种不同的方向,有的算法只针对pv算法等等这些来精准识别同行业的采集,而有的算法则是针对按钮这类的识别来做精准识别,当然,这里的同行业是针对广告业或者说站内信这类型的,那么,你说的这款采集器应该是针对网页是什么来做识别的采集器呢?可以参考的是一些懂得采集代码的网站能够开发识别系统来采集大量的视频、图片、音频等等多类别数据,而你的需求是说自动爬取的网页,目前的一些采集软件也支持一些采集代码方面的识别,比如蝉大师之类的工具来做采集大量的网页,缺点就是只有代码级别的一些功能,而且这里多数都是要收费的,其实很多免费的无码采集器,如果你有需求的话,也可以选择一款懂得采集代码的采集器,这里并不是批判一款收费软件,虽然大部分免费的采集代码软件都在做盈利,但是他们确实是在致力于改善交互的需求,并且也有部分是开源免费的,如果觉得使用麻烦,可以选择购买一款采集代码软件,甚至可以无任何套餐费用,网上很多卖家在这方面的资源是很丰富的。
而电商平台为什么要做一个机器人来识别采集数据呢?我认为有这么几点:第一:大部分购物平台都很重视销售的平台影响力,那么,如果说你在平台上做一个机器人,有助于销售的渠道和展示的氛围有很大的提升,或者你能够让这个采集网站和你的平台销售产生关联,那么,你就多了一个渠道和展示的机会,即便你的机器人在某些方面没有太大的作用,也是可以从侧面去影响你平台的销售的,这种需求可以满足一部分人的需求,第二:大部分购物平台可能会通过实名认证或者资质认证等多种方式来检验你网站的性质,会大量需要从众寻找购物过程的身份验证,这时,你需要一个需要的方式来进行识别和检验,通过你有人工帮你判断的过程,来减少通过互联网的一些安全保护,这些保护当然在大部分平台上都不是必须的,所以这时,一个机器人也能给他方便的采集方便,人工来做就方便很多,不是吗?第三:针对你说的站内信识别,是一个比较大的范畴,包括微信回复、短信回复、电话回复等等一些大量的回复信息在内,如果是需要全量的统计,如果采集这个,过程会很麻烦,需要采集整。 查看全部
电商平台为什么要做一个机器人来识别采集数据?
网页采集器的自动识别算法:目前市面上的很多采集器都有自己的算法,主要的识别准确率的一般能达到98%的准确率就可以了,像你提到的那种自动识别过程,大部分采集器都有完整的测试来做无人值守智能收割的过程,给你个价格参考智能采集机器人¥2000至¥3000无人值守采集机器人¥500至¥8000无人值守采集机器人¥1000至¥10000而这些算法又分为很多种不同的方向,有的算法只针对pv算法等等这些来精准识别同行业的采集,而有的算法则是针对按钮这类的识别来做精准识别,当然,这里的同行业是针对广告业或者说站内信这类型的,那么,你说的这款采集器应该是针对网页是什么来做识别的采集器呢?可以参考的是一些懂得采集代码的网站能够开发识别系统来采集大量的视频、图片、音频等等多类别数据,而你的需求是说自动爬取的网页,目前的一些采集软件也支持一些采集代码方面的识别,比如蝉大师之类的工具来做采集大量的网页,缺点就是只有代码级别的一些功能,而且这里多数都是要收费的,其实很多免费的无码采集器,如果你有需求的话,也可以选择一款懂得采集代码的采集器,这里并不是批判一款收费软件,虽然大部分免费的采集代码软件都在做盈利,但是他们确实是在致力于改善交互的需求,并且也有部分是开源免费的,如果觉得使用麻烦,可以选择购买一款采集代码软件,甚至可以无任何套餐费用,网上很多卖家在这方面的资源是很丰富的。
而电商平台为什么要做一个机器人来识别采集数据呢?我认为有这么几点:第一:大部分购物平台都很重视销售的平台影响力,那么,如果说你在平台上做一个机器人,有助于销售的渠道和展示的氛围有很大的提升,或者你能够让这个采集网站和你的平台销售产生关联,那么,你就多了一个渠道和展示的机会,即便你的机器人在某些方面没有太大的作用,也是可以从侧面去影响你平台的销售的,这种需求可以满足一部分人的需求,第二:大部分购物平台可能会通过实名认证或者资质认证等多种方式来检验你网站的性质,会大量需要从众寻找购物过程的身份验证,这时,你需要一个需要的方式来进行识别和检验,通过你有人工帮你判断的过程,来减少通过互联网的一些安全保护,这些保护当然在大部分平台上都不是必须的,所以这时,一个机器人也能给他方便的采集方便,人工来做就方便很多,不是吗?第三:针对你说的站内信识别,是一个比较大的范畴,包括微信回复、短信回复、电话回复等等一些大量的回复信息在内,如果是需要全量的统计,如果采集这个,过程会很麻烦,需要采集整。
爱意为用户提供的优采云采集器电脑版的实用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-01-23 13:30
爱艺提供的优采云采集器计算机版本的实用方法非常简单。用户可以使用此采集器软件快速采集各种类型的网页数据,并且爬行速度非常快,并且适用于各种类型的网站。
软件功能
向导模式
通过可视界面,鼠标单击采集数据,进入向导模式,用户无需任何技术基础,即可进入网站,并一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可以支持图片,视频,文档等各种文件下载,并支持自定义保存路径和文件名
原创高速内核
内置一组高速浏览器内核,以及HTTP引擎,JSON引擎模式,以实现快速的采集数据。
定时运行
可以用每分钟,每天,每周和CRON表示。如果指定了计划任务,则该任务可以自动采集并自动释放,而无需手动操作。
多个数据导出
支持多种格式的数据导出,包括TXT,CSV,Excel,ACCESS,MySQL,SQLServer,SQLite并发布到网站界面(Api)。
工具功能
1、快速高效,具有内置的高速浏览器内核以及HTTP引擎模式,可实现快速采集数据
2、一键提取数据,易于学习,通过可视界面,只需单击鼠标即可捕获数据
3、适用于所有网站,能够采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站
软件应用程序字段
新闻媒体领域
优采云采集器可以综合采集国内外主要新闻来源,主流社交媒体,社区论坛信息等,例如今天的头条新闻,微博,天涯论坛,知乎等。自动识别列表数据,可视化文本挖掘时间采集数据,自动上传数据或第三方平台,指导性操作界面,可帮助公司独立监控品牌民意,并为互联网时代的品牌传播提供数据支持。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,相似商品的属性,评估,价格,市场销售和其他数据,通过优采云文本挖掘视觉分析系统,可以提取评论信息的典型意见和情感分析,从而获得客观的市场评估和分析,优化运营,基于类似经验创建爆炸性模型,开展业务活动并改进在线商店的运营水平。效果。
生活服务领域
科学技术的发展与我们的生活息息相关。简而言之,餐饮和旅行的直接团购网络(外卖网络)既简单又高效。 优采云采集器是采集是美团饿了吗,甘集,点屏,突牛,携程旅行和其他生活服务网站,采集类似的属性,评估,价格,销售,等级等数据,通过优采云文本挖掘视觉分析系统,可以对评论信息进行典型的意见提取,情感分析和数据比较,从而为我们的食物,衣服,住房和交通选择适当的位置,更加方便快捷。
政府部门字段
在整个社会信息量爆炸性增长的背景下,政府机构也更加重视数据的采集和使用。某个气象中心已通过优采云采集器采集了各个地区与天气有关的各种监视数据。通过数据比较分析,及时预警最新气象活动的分布范围,并指示有关部门采取措施。
更新内容
1、修复了某些URL中无法加载数据的问题
2、优化XPath生成
3、优化输入命令 查看全部
爱意为用户提供的优采云采集器电脑版的实用方法
爱艺提供的优采云采集器计算机版本的实用方法非常简单。用户可以使用此采集器软件快速采集各种类型的网页数据,并且爬行速度非常快,并且适用于各种类型的网站。
软件功能
向导模式
通过可视界面,鼠标单击采集数据,进入向导模式,用户无需任何技术基础,即可进入网站,并一键提取数据。
智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
智能识别
可以支持图片,视频,文档等各种文件下载,并支持自定义保存路径和文件名
原创高速内核
内置一组高速浏览器内核,以及HTTP引擎,JSON引擎模式,以实现快速的采集数据。
定时运行
可以用每分钟,每天,每周和CRON表示。如果指定了计划任务,则该任务可以自动采集并自动释放,而无需手动操作。
多个数据导出
支持多种格式的数据导出,包括TXT,CSV,Excel,ACCESS,MySQL,SQLServer,SQLite并发布到网站界面(Api)。
工具功能
1、快速高效,具有内置的高速浏览器内核以及HTTP引擎模式,可实现快速采集数据
2、一键提取数据,易于学习,通过可视界面,只需单击鼠标即可捕获数据
3、适用于所有网站,能够采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站
软件应用程序字段
新闻媒体领域
优采云采集器可以综合采集国内外主要新闻来源,主流社交媒体,社区论坛信息等,例如今天的头条新闻,微博,天涯论坛,知乎等。自动识别列表数据,可视化文本挖掘时间采集数据,自动上传数据或第三方平台,指导性操作界面,可帮助公司独立监控品牌民意,并为互联网时代的品牌传播提供数据支持。
电子商务领域
随着电子商务的快速发展,优采云采集器可以采集国内外任何电子商务网站,相似商品的属性,评估,价格,市场销售和其他数据,通过优采云文本挖掘视觉分析系统,可以提取评论信息的典型意见和情感分析,从而获得客观的市场评估和分析,优化运营,基于类似经验创建爆炸性模型,开展业务活动并改进在线商店的运营水平。效果。
生活服务领域
科学技术的发展与我们的生活息息相关。简而言之,餐饮和旅行的直接团购网络(外卖网络)既简单又高效。 优采云采集器是采集是美团饿了吗,甘集,点屏,突牛,携程旅行和其他生活服务网站,采集类似的属性,评估,价格,销售,等级等数据,通过优采云文本挖掘视觉分析系统,可以对评论信息进行典型的意见提取,情感分析和数据比较,从而为我们的食物,衣服,住房和交通选择适当的位置,更加方便快捷。
政府部门字段
在整个社会信息量爆炸性增长的背景下,政府机构也更加重视数据的采集和使用。某个气象中心已通过优采云采集器采集了各个地区与天气有关的各种监视数据。通过数据比较分析,及时预警最新气象活动的分布范围,并指示有关部门采取措施。
更新内容
1、修复了某些URL中无法加载数据的问题
2、优化XPath生成
3、优化输入命令
优采云采集器怎么导出前台运行任务及流程图模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-01-22 09:30
第1步:登录以打开优采云采集器软件
第2步:创建一个新的采集任务
1、复制网页地址:需要采集评估的产品的网址
2、新的流程图模式采集任务:导入采集规则以创建智能任务
第3步:配置采集规则
1、设置预登录
输入网址后,我们进入婴儿的详细信息页面。这时,我们可以单击以关闭页面上显示的登录界面,我们可以采集无需登录即可访问评论数据。
2、设置数据字段
在详细信息页面上,您可以看到评论的数量,但看不到特定的评论内容。我们需要单击注释,然后在跳出左上角的提示框中选择“单击此元素”。
3、进入评论界面后,根据搜索方向选择好评论,不好评论等元素。在此基础上,我们可以右键单击该字段以执行相关设置,包括修改字段名称,添加或减去字段以及处理数据等。
因为我们要下载所有评论图片,所以我们可以选择评论中的所有图片,然后设置字段属性-提取外部html。
4、我们采集发布了单页评论数据,现在我们需要采集下一页数据,我们单击页面上的“下一页”按钮,在操作提示框中,出现在左上角。选择“循环单击下一页”。
第4步:设置并启动采集任务
单击“开始采集”按钮,您可以在弹出的启动设置页面中进行一些高级设置,包括“定时启动,防阻塞,自动导出,文件下载,加速引擎,重复数据删除,开发人员设置”功能,这次采集没有使用这些功能,我们直接单击开始以启动采集。
第5步:导出和查看数据
完成数据采集之后,我们可以查看和导出数据。 优采云采集器支持多种导出方法和导出文件格式,并且还支持导出特定编号。您可以选择要导出的数据。条目数,然后单击“确认导出”。
[如何导出]
1、导出采集在前台运行的任务的结果
如果采集任务在前台运行,则软件将弹出提示框,指示任务结束后数据采集已停止。这时,我们单击“导出数据”按钮以导出采集数据结果。
2、导出采集个后台运行任务的结果
如果采集任务在后台运行,则该任务完成后,将在桌面右下角弹出一个导出提示框。我们将根据任务完成右下角的弹出窗口打开视图数据界面或导出数据。
3、导出已保存的采集任务的采集结果
例如,如果它不是实时运行的采集任务,而是先前运行的采集任务,则我们关闭软件,然后重新打开软件,然后导出采集的采集结果]已运行的任务。
在这种情况下,我们可以右键单击任务,然后单击“查看数据”以打开查看数据界面,然后在该界面上设置导出数据。
4、导出数据的其他事项
当前优采云采集器支持多种格式的免费导出,包括:Excel2007、Excel200 3、 CSV,HTML文件,TXT文件;同时,它支持免费导出到数据库。
个人专业版及更高版本支持发布到网站,目前支持发布到WordPress,发布到Typecho,发布到DEDEcms(织梦),更多网站模板正在继续更新...。 ..
导出数据时,用户可以选择导出范围,选择导出未导出的数据,导出选定的数据或选择导出项目的数量。
导出完成后,您还可以标记已导出的数据,以便可以清晰直观地查看已导出的数据和未导出的数据。
[如何下载图片]
第一种类型:一张一张地添加图片
直接在页面上单击要下载的图片,然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
或直接单击“添加字段”,然后在页面上单击要下载的图片。
第二种类型:一次下载多张图片
在这种情况下,需要将图片分组在一起,您可以一次选择所有图片。
我们可以直接单击整个图片区域的右下角,并且在选择框架时我们可以看到软件的蓝色框架选择区域,以确保要下载的所有照片都被框架化。然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
然后右键单击该字段,并将字段属性修改为“提取内部HTML”。
单击右下角的“开始采集”按钮设置图片下载功能。
接下来,我们只需要单击“开始采集”,然后在开始框中选中“将图片同时下载到以下目录”即可启动图片下载功能,用户可以设置本地保存图片的路径。 查看全部
优采云采集器怎么导出前台运行任务及流程图模式
第1步:登录以打开优采云采集器软件
第2步:创建一个新的采集任务
1、复制网页地址:需要采集评估的产品的网址
2、新的流程图模式采集任务:导入采集规则以创建智能任务
第3步:配置采集规则
1、设置预登录
输入网址后,我们进入婴儿的详细信息页面。这时,我们可以单击以关闭页面上显示的登录界面,我们可以采集无需登录即可访问评论数据。
2、设置数据字段
在详细信息页面上,您可以看到评论的数量,但看不到特定的评论内容。我们需要单击注释,然后在跳出左上角的提示框中选择“单击此元素”。
3、进入评论界面后,根据搜索方向选择好评论,不好评论等元素。在此基础上,我们可以右键单击该字段以执行相关设置,包括修改字段名称,添加或减去字段以及处理数据等。
因为我们要下载所有评论图片,所以我们可以选择评论中的所有图片,然后设置字段属性-提取外部html。
4、我们采集发布了单页评论数据,现在我们需要采集下一页数据,我们单击页面上的“下一页”按钮,在操作提示框中,出现在左上角。选择“循环单击下一页”。
第4步:设置并启动采集任务
单击“开始采集”按钮,您可以在弹出的启动设置页面中进行一些高级设置,包括“定时启动,防阻塞,自动导出,文件下载,加速引擎,重复数据删除,开发人员设置”功能,这次采集没有使用这些功能,我们直接单击开始以启动采集。
第5步:导出和查看数据
完成数据采集之后,我们可以查看和导出数据。 优采云采集器支持多种导出方法和导出文件格式,并且还支持导出特定编号。您可以选择要导出的数据。条目数,然后单击“确认导出”。
[如何导出]
1、导出采集在前台运行的任务的结果
如果采集任务在前台运行,则软件将弹出提示框,指示任务结束后数据采集已停止。这时,我们单击“导出数据”按钮以导出采集数据结果。
2、导出采集个后台运行任务的结果
如果采集任务在后台运行,则该任务完成后,将在桌面右下角弹出一个导出提示框。我们将根据任务完成右下角的弹出窗口打开视图数据界面或导出数据。
3、导出已保存的采集任务的采集结果
例如,如果它不是实时运行的采集任务,而是先前运行的采集任务,则我们关闭软件,然后重新打开软件,然后导出采集的采集结果]已运行的任务。
在这种情况下,我们可以右键单击任务,然后单击“查看数据”以打开查看数据界面,然后在该界面上设置导出数据。
4、导出数据的其他事项
当前优采云采集器支持多种格式的免费导出,包括:Excel2007、Excel200 3、 CSV,HTML文件,TXT文件;同时,它支持免费导出到数据库。
个人专业版及更高版本支持发布到网站,目前支持发布到WordPress,发布到Typecho,发布到DEDEcms(织梦),更多网站模板正在继续更新...。 ..
导出数据时,用户可以选择导出范围,选择导出未导出的数据,导出选定的数据或选择导出项目的数量。
导出完成后,您还可以标记已导出的数据,以便可以清晰直观地查看已导出的数据和未导出的数据。
[如何下载图片]
第一种类型:一张一张地添加图片
直接在页面上单击要下载的图片,然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
或直接单击“添加字段”,然后在页面上单击要下载的图片。
第二种类型:一次下载多张图片
在这种情况下,需要将图片分组在一起,您可以一次选择所有图片。
我们可以直接单击整个图片区域的右下角,并且在选择框架时我们可以看到软件的蓝色框架选择区域,以确保要下载的所有照片都被框架化。然后根据提示单击“提取此元素”,软件将自动生成提取的数据成分并添加图片字段。 (如果采集字段是连续的,则可能不会每次都生成新的提取数据组价格,只会添加新的字段)
然后右键单击该字段,并将字段属性修改为“提取内部HTML”。
单击右下角的“开始采集”按钮设置图片下载功能。
接下来,我们只需要单击“开始采集”,然后在开始框中选中“将图片同时下载到以下目录”即可启动图片下载功能,用户可以设置本地保存图片的路径。
优采云采集器是一款非常实用的网页信息采集工具介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-01-22 08:46
优采云采集器是用于Web信息采集的非常有用的工具。该工具界面简洁,操作简单,功能强大。有了它,我们可以采集转到我们需要的网页所有信息,零阈值,新手用户可以使用。
[软件功能]
零阈值:如果您不了解网络抓取工具技术,则会获得采集 网站个数据
多引擎,高速且稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据结构,直观地选择JSON内容。
适用于各种网站:采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站。
[软件功能]
该软件易于操作,并且可以通过单击鼠标轻松选择要捕获的内容;
支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器以及原创内存优化,因此浏览器采集也可以高速运行,甚至可以快速转换以HTTP方式运行,享受更高的采集速度!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。无需分析JSON数据结构,因此非网页专业设计人员可以轻松获取所需数据;
无需分析网页请求和源代码,但支持更多网页采集;
高级智能算法可以一键生成目标元素XPATH,自动识别网页列表,并自动识别分页中的下一页按钮...
支持丰富的数据导出方法,可以通过向导将其导出到txt文件,html文件,csv文件,excel文件或现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库。易于以简单的方式映射字段,并且可以轻松地将其导出到目标网站数据库。
[软件优势]
可视化向导:所有采集个元素,自动生成采集个数据
计划任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎
智能识别:它可以自动识别网页列表,采集字段和分页等。
拦截请求:自定义拦截域名,以方便过滤异地广告并提高采集的速度
各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。 查看全部
优采云采集器是一款非常实用的网页信息采集工具介绍
优采云采集器是用于Web信息采集的非常有用的工具。该工具界面简洁,操作简单,功能强大。有了它,我们可以采集转到我们需要的网页所有信息,零阈值,新手用户可以使用。
[软件功能]
零阈值:如果您不了解网络抓取工具技术,则会获得采集 网站个数据
多引擎,高速且稳定:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据结构,直观地选择JSON内容。
适用于各种网站:采集 99%的Internet 网站,包括单页应用程序Ajax加载和其他动态类型网站。
[软件功能]
该软件易于操作,并且可以通过单击鼠标轻松选择要捕获的内容;
支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器以及原创内存优化,因此浏览器采集也可以高速运行,甚至可以快速转换以HTTP方式运行,享受更高的采集速度!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。无需分析JSON数据结构,因此非网页专业设计人员可以轻松获取所需数据;
无需分析网页请求和源代码,但支持更多网页采集;
高级智能算法可以一键生成目标元素XPATH,自动识别网页列表,并自动识别分页中的下一页按钮...
支持丰富的数据导出方法,可以通过向导将其导出到txt文件,html文件,csv文件,excel文件或现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库。易于以简单的方式映射字段,并且可以轻松地将其导出到目标网站数据库。
[软件优势]
可视化向导:所有采集个元素,自动生成采集个数据
计划任务:灵活定义运行时间,全自动运行
多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎
智能识别:它可以自动识别网页列表,采集字段和分页等。
拦截请求:自定义拦截域名,以方便过滤异地广告并提高采集的速度
各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。
核心方法:网页分类与信息采集方法研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2021-01-11 11:17
[摘要]:网页分类和信息采集该系统包括网页抓取,网页识别和文本采集。其中,依靠人工网页识别的传统方式是在网络信息容量迅速增加的条件下。不合理。同时,网页中收录的大量噪声信息增加了网页文本的难度采集。现有的采集技术具有人工维护成本高,准确性低,通用性差的缺点。因此,对网页和文本采集的自动识别的研究已成为重要的方向。它们与信息检索,搜索引擎,互联网民意和文本推荐等技术相结合,为信息获取提供了便利。本文的研究内容主要包括以下几个方面:(1)根据网页分类和信息采集系统的要求,提出了一种基于网页结构特征挖掘的网页类型自动识别方法。该方法的重点是特征选择,在理解网页特征挖掘的基础上,研究了不同网页的结构差异,提取了可表征网页的特征集,并采用经典的分类算法(决策树)进行构造。 (2)在文本采集自动化的要求下,提出了一种基于HTML标签特征挖掘的BBS网页文本提取方法,即:文本块提取,其中心思想是基于以下特征:Web文档的树形结构,多文本中心性,标记元素的层次结构等。在此基础上,提出了一种基于智能模板的BBS网页文本提取方法。主要思想是基于HTML标记特征挖掘找到所需的BBS网页文本提取方法,将多个文本块的公共信息,然后自动配置对应于网站的文本解析模板,最后使用该模板进行解析网页文字。 (3)构建网页分类和信息采集系统。该系统包括网页捕获网页识别,网页文本提取和UI部分。网页爬网部分采用通用的爬网技术和流程,目标是搜索整个网络,网页识别采用基于本文网络功能集的网页类型自动识别方法,网页文本提取部分是基于文本的智能模板的BBS网页文本提取方法。通过实际数据对该系统的方法进行测试,实验结果表明该方法在系统中是可行的,具有较高的准确性,通用性和智能性。 查看全部
核心方法:网页分类与信息采集方法研究
[摘要]:网页分类和信息采集该系统包括网页抓取,网页识别和文本采集。其中,依靠人工网页识别的传统方式是在网络信息容量迅速增加的条件下。不合理。同时,网页中收录的大量噪声信息增加了网页文本的难度采集。现有的采集技术具有人工维护成本高,准确性低,通用性差的缺点。因此,对网页和文本采集的自动识别的研究已成为重要的方向。它们与信息检索,搜索引擎,互联网民意和文本推荐等技术相结合,为信息获取提供了便利。本文的研究内容主要包括以下几个方面:(1)根据网页分类和信息采集系统的要求,提出了一种基于网页结构特征挖掘的网页类型自动识别方法。该方法的重点是特征选择,在理解网页特征挖掘的基础上,研究了不同网页的结构差异,提取了可表征网页的特征集,并采用经典的分类算法(决策树)进行构造。 (2)在文本采集自动化的要求下,提出了一种基于HTML标签特征挖掘的BBS网页文本提取方法,即:文本块提取,其中心思想是基于以下特征:Web文档的树形结构,多文本中心性,标记元素的层次结构等。在此基础上,提出了一种基于智能模板的BBS网页文本提取方法。主要思想是基于HTML标记特征挖掘找到所需的BBS网页文本提取方法,将多个文本块的公共信息,然后自动配置对应于网站的文本解析模板,最后使用该模板进行解析网页文字。 (3)构建网页分类和信息采集系统。该系统包括网页捕获网页识别,网页文本提取和UI部分。网页爬网部分采用通用的爬网技术和流程,目标是搜索整个网络,网页识别采用基于本文网络功能集的网页类型自动识别方法,网页文本提取部分是基于文本的智能模板的BBS网页文本提取方法。通过实际数据对该系统的方法进行测试,实验结果表明该方法在系统中是可行的,具有较高的准确性,通用性和智能性。
整套解决方案:智能搜索引擎技术网页信息动态采集系统网页正文提取网页分类算法网页摘要..
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-12-19 08:45
搜索引擎智能技术中若干关键问题的研究与实现[摘要]随着Internet技术的飞速发展和网络信息资源的爆炸性增长,Internet用户的数量也在以惊人的速度增长。越来越多的网民习惯于通过搜索引擎在Internet上检索信息。现在,搜索引擎已成为人们必备的网络应用工具。随着搜索引擎应用程序的广泛普及,人们不再满足于传统搜索引擎提供的服务。人们希望搜索引擎可以更智能,更人性化。检索结果可以更准确,这些新要求对搜索引擎技术提出了更高的要求。本文对当前作为研究热点的智能搜索引擎技术领域中的几个关键问题进行了探索性研究。内容主要包括:1)基于网站优先级调整算法提出并实现了网页信息动态采集技术,该技术通过检测广告的平均新鲜度的变化来动态调整网站的优先级。采样网页,以实现相应网站个网页信息采集的频率动态调整。2)研究了网页源代码中中文文本密度与网页主体之间的关系,提出并实现了一种基于文本密度的网页主体提取算法,并摆脱了现有的HTML网页主体提取算法(超文本标记语言),超文本标记语言)标签,并借助某些规则,以实现高效,快速地提取网页文本。3)研究了自动文本分类领域中的几个关键问题,并提出并实现了基于哈希表的动态矢量的更多还原。 [摘要]互联网技术飞速发展,网络信息资源爆炸性增长,互联网用户数量惊人。越来越多的Internet用户通过搜索引擎成为习惯的在线检索信息。搜索引擎的广泛应用,人们不再满足于传统的搜索引擎,搜索引擎更加智能,人类更加精确。新需求给人们带来了更多... [Recovery [关键词]智能搜索引擎技术;网页信息动态采集系统;网页文本提取;网页分类算法;网页摘要;矢量动态尺寸缩减; [关键词]智能搜索引擎技术;动态网页信息获取系统;网页文本提取;网页分类算法;网页摘要;矢量动态降维; [订购硕士学位论文全文] Q联系人Q:138113721 139938848目录摘要4-5摘要5-6简介11-211.1主题选择的背景和意义11-121.2相关工作国内外摘要12-191.2.1网页信息动态采集技术12-131.2.2中文网页文本提取技术13-151.2.3自动文档摘要技术15-171.2.4文本自动分类技术17-181.2.5网页重复数据删除技术18-191.3文书工作和组织结构19-211.3.1论文Lord研究工作19-201.3.2论文内容安排20-21基于网站优先级调整的网页信息动态采集算法21-27 2.1算法流程图21 -23 2.2网页新鲜度算法23 2.3 网站基于网页新鲜度的优先级调整算法23-25 2.4基于网站 pri的多线程网页信息ority 采集技术25-26 2.5根据网页类别确定优先级26 2.6本章摘要26-27基于文本密度的提取网页文本算法的研究27-33 3.1算法流程图27 3.2识别和文本特征识别处理27-28 3.3网页源代码的预处理28-29 3.4计算网页文本源行的中文密度29 3.5阻止网页的源代码29 3.6删除伪网页的源代码29 -31 3.7辅助网页的源代码文本识别方法31 3.8网页文本的原创格式保留31 3.9本章摘要31-33基于主题词索引的网页分类算法研究33-524.1概述33-344.2开放测试和封闭测试34-354.3算法性能评估指标35-364.4与网站分类算法相关的基础研究36-424.4.1文本的表示形式36-374.4.2基于向量模板37构造向量空间模型[k56]4.3基于哈希表37-39构造向量空间模型[k56]4.4主题词基于概念分析的抽取算法39-404.4.5改进的矢量余弦相似度算法40-424.5基于主题词索引的类别中心矢量分类算法42-464.5.1生成分类器模型434.5.2分类算法434.5.3向量的归一化434.5.4将类别数提高到分类精度Impact 43-444.5.5文档类别分布对分类准确性的影响444.5.6中心向量的校正算法44-464.5.7分类算法的适应性464.6 KNN(K最近邻)分类算法46 -484.7 CKNN(聚类K最近邻)分类算法48-504.8本章摘要50-52相似性研究基于ty的文本摘要52-64 5.1基于相似度的文本摘要52 5.2文档结构模型52 5.3分段和子句52-54 5.4主题词提取54-55 5.4.1主题词字符串的矢量化54 [k72]4.2建立文档结构向量空间模型54-55 5.5计算文档结构各部分的权重55-57 5.6正负规则57 5.7用户偏好词汇57 5.8基于句子相似度的句子冗余算法57-58 5.9确定摘要和原创文本的比例58 5.10摘要句子选择和摘要生成585.11抽象技术在提取中文网页摘要中的应用58-63 5.11.1预提取网页文本对提高摘要准确性的影响59-62 5.11.2提高摘要算法的实时性能62-63 5.12本章摘要63-64实验设计点火和数据分析64-886.1基于网站优先级调整的网页信息动态采集技术实验和积分65-70 [k108]1.1实验设计65-66 [k108]1.2数据分析66-69 [k108]1.3存在的不足和进一步的改进69-706.2基于中文密度算法的中文网页文本提取技术的实验和分析70-716.2.1实验设计706.2.2数据分析706.2.3存在的缺点和下一个改进工作70-716.3两种方法在对象71-74中的比较实验和两种文档矢量表示方法的分析6.3.1实验设计716.3.2数据分析71-746.4改进的余弦矢量相似度算法74-76的实验和分析[k108]4.1实验设计74 [ k108]4.2数据分析74-766.5基于主题心的类别中心向量分类算法的实验与分析ding 76-796.5.1实验设计766.5.2数据分析76-786.5.3存在的问题和下一步78-796.6实验和分析CKNN分类算法79-806.6.1实验设计79 [k1 08]6.2数据分析79-806.6.3存在的问题和下一步806.7实验设计和数据KNN分类算法的分析80-826.7.1实验设计80-816.7.2数据分析81-826.8类别中心向量分类算法,CKNN分类算法和KNN的性能比较分类算法82-836.8.1实验设计826.8.2数据分析82-836.9基于相似度的文档摘要技术的实验和数据分析83-856.9.1实验设计83-846.9.2数据分析84-856.9.3存在的问题和下一步856.10网络信息采集的实验和数据分析系统85-876.10.1实验设计85-866.10.2数据分析866.10.3存在的问题和下一步86-876.11本章摘要87-88 Web信息动态采集系统设计和实现88-95 7.1系统组成88-89 7.2系统模块的集成89-93 7.3网页分类模块的适应性93 7.4系统运行状态监视程序93 7.5基于主题词索引的网页重复数据删除方法93-94 7.6本章摘要94-95摘要95-97参考文献 查看全部
整套解决方案:智能搜索引擎技术网页信息动态采集系统网页正文提取网页分类算法网页摘要..
搜索引擎智能技术中若干关键问题的研究与实现[摘要]随着Internet技术的飞速发展和网络信息资源的爆炸性增长,Internet用户的数量也在以惊人的速度增长。越来越多的网民习惯于通过搜索引擎在Internet上检索信息。现在,搜索引擎已成为人们必备的网络应用工具。随着搜索引擎应用程序的广泛普及,人们不再满足于传统搜索引擎提供的服务。人们希望搜索引擎可以更智能,更人性化。检索结果可以更准确,这些新要求对搜索引擎技术提出了更高的要求。本文对当前作为研究热点的智能搜索引擎技术领域中的几个关键问题进行了探索性研究。内容主要包括:1)基于网站优先级调整算法提出并实现了网页信息动态采集技术,该技术通过检测广告的平均新鲜度的变化来动态调整网站的优先级。采样网页,以实现相应网站个网页信息采集的频率动态调整。2)研究了网页源代码中中文文本密度与网页主体之间的关系,提出并实现了一种基于文本密度的网页主体提取算法,并摆脱了现有的HTML网页主体提取算法(超文本标记语言),超文本标记语言)标签,并借助某些规则,以实现高效,快速地提取网页文本。3)研究了自动文本分类领域中的几个关键问题,并提出并实现了基于哈希表的动态矢量的更多还原。 [摘要]互联网技术飞速发展,网络信息资源爆炸性增长,互联网用户数量惊人。越来越多的Internet用户通过搜索引擎成为习惯的在线检索信息。搜索引擎的广泛应用,人们不再满足于传统的搜索引擎,搜索引擎更加智能,人类更加精确。新需求给人们带来了更多... [Recovery [关键词]智能搜索引擎技术;网页信息动态采集系统;网页文本提取;网页分类算法;网页摘要;矢量动态尺寸缩减; [关键词]智能搜索引擎技术;动态网页信息获取系统;网页文本提取;网页分类算法;网页摘要;矢量动态降维; [订购硕士学位论文全文] Q联系人Q:138113721 139938848目录摘要4-5摘要5-6简介11-211.1主题选择的背景和意义11-121.2相关工作国内外摘要12-191.2.1网页信息动态采集技术12-131.2.2中文网页文本提取技术13-151.2.3自动文档摘要技术15-171.2.4文本自动分类技术17-181.2.5网页重复数据删除技术18-191.3文书工作和组织结构19-211.3.1论文Lord研究工作19-201.3.2论文内容安排20-21基于网站优先级调整的网页信息动态采集算法21-27 2.1算法流程图21 -23 2.2网页新鲜度算法23 2.3 网站基于网页新鲜度的优先级调整算法23-25 2.4基于网站 pri的多线程网页信息ority 采集技术25-26 2.5根据网页类别确定优先级26 2.6本章摘要26-27基于文本密度的提取网页文本算法的研究27-33 3.1算法流程图27 3.2识别和文本特征识别处理27-28 3.3网页源代码的预处理28-29 3.4计算网页文本源行的中文密度29 3.5阻止网页的源代码29 3.6删除伪网页的源代码29 -31 3.7辅助网页的源代码文本识别方法31 3.8网页文本的原创格式保留31 3.9本章摘要31-33基于主题词索引的网页分类算法研究33-524.1概述33-344.2开放测试和封闭测试34-354.3算法性能评估指标35-364.4与网站分类算法相关的基础研究36-424.4.1文本的表示形式36-374.4.2基于向量模板37构造向量空间模型[k56]4.3基于哈希表37-39构造向量空间模型[k56]4.4主题词基于概念分析的抽取算法39-404.4.5改进的矢量余弦相似度算法40-424.5基于主题词索引的类别中心矢量分类算法42-464.5.1生成分类器模型434.5.2分类算法434.5.3向量的归一化434.5.4将类别数提高到分类精度Impact 43-444.5.5文档类别分布对分类准确性的影响444.5.6中心向量的校正算法44-464.5.7分类算法的适应性464.6 KNN(K最近邻)分类算法46 -484.7 CKNN(聚类K最近邻)分类算法48-504.8本章摘要50-52相似性研究基于ty的文本摘要52-64 5.1基于相似度的文本摘要52 5.2文档结构模型52 5.3分段和子句52-54 5.4主题词提取54-55 5.4.1主题词字符串的矢量化54 [k72]4.2建立文档结构向量空间模型54-55 5.5计算文档结构各部分的权重55-57 5.6正负规则57 5.7用户偏好词汇57 5.8基于句子相似度的句子冗余算法57-58 5.9确定摘要和原创文本的比例58 5.10摘要句子选择和摘要生成585.11抽象技术在提取中文网页摘要中的应用58-63 5.11.1预提取网页文本对提高摘要准确性的影响59-62 5.11.2提高摘要算法的实时性能62-63 5.12本章摘要63-64实验设计点火和数据分析64-886.1基于网站优先级调整的网页信息动态采集技术实验和积分65-70 [k108]1.1实验设计65-66 [k108]1.2数据分析66-69 [k108]1.3存在的不足和进一步的改进69-706.2基于中文密度算法的中文网页文本提取技术的实验和分析70-716.2.1实验设计706.2.2数据分析706.2.3存在的缺点和下一个改进工作70-716.3两种方法在对象71-74中的比较实验和两种文档矢量表示方法的分析6.3.1实验设计716.3.2数据分析71-746.4改进的余弦矢量相似度算法74-76的实验和分析[k108]4.1实验设计74 [ k108]4.2数据分析74-766.5基于主题心的类别中心向量分类算法的实验与分析ding 76-796.5.1实验设计766.5.2数据分析76-786.5.3存在的问题和下一步78-796.6实验和分析CKNN分类算法79-806.6.1实验设计79 [k1 08]6.2数据分析79-806.6.3存在的问题和下一步806.7实验设计和数据KNN分类算法的分析80-826.7.1实验设计80-816.7.2数据分析81-826.8类别中心向量分类算法,CKNN分类算法和KNN的性能比较分类算法82-836.8.1实验设计826.8.2数据分析82-836.9基于相似度的文档摘要技术的实验和数据分析83-856.9.1实验设计83-846.9.2数据分析84-856.9.3存在的问题和下一步856.10网络信息采集的实验和数据分析系统85-876.10.1实验设计85-866.10.2数据分析866.10.3存在的问题和下一步86-876.11本章摘要87-88 Web信息动态采集系统设计和实现88-95 7.1系统组成88-89 7.2系统模块的集成89-93 7.3网页分类模块的适应性93 7.4系统运行状态监视程序93 7.5基于主题词索引的网页重复数据删除方法93-94 7.6本章摘要94-95摘要95-97参考文献
完整解决方案:自动化信息采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-11-12 12:03
[摘要]:在当今信息和数据爆炸时代,可以对Internet上的数据信息进行数据挖掘,以提取有价值的信息并预测某些事件的发生。现代主流搜索引擎,例如Google,百度等,将在全球范围内部署自己的信息系统。在信息采集系统中,最重要的部分是如何解析网页并提取感兴趣的数据信息。在一般信息采集系统中,有必要使用不同的模块或不同的网站个性化网站制定信息提取规则,尤其是当网页结构相似时,会消耗大量的人力资源。自动化信息采集可以解决此问题。现有的自动页面解析算法通常使用模板生成或机器学习来自动提取信息。最常见的算法包括启发式,树对齐和模板生成。例如,RoadRunner等,这些现有算法的问题在于提取的信息收录噪声信息以及数据提取时间过长的缺点。为了解决上述问题,本文的主要研究内容体现在三个方面。首先,为解决人工干预和噪声信息在网络信息自动提取中比例过大的问题,提出了一种基于标签网页主体块的三叉树的解决方案。通过大量的分析,本文确定了可以正确描述网页文本分布的标签,并确定了标签的阈值。最后,结合三叉树信息提取模型,制定了统一的信息提取规则。实验表明,在时间和噪声信息比例上,信息提取算法的性能优于同类提取算法。其次,为了能够更好地适应自动信息提取,有必要解决网页结构的分类问题。当前,最常见的网页结构分类算法是基于DOM树的编辑距离,但是该算法最突出的缺点是时间消耗过长。结合现有主流站点之间Web页面模板应用的可能性较低,以及同一站点不同区域可能存在的差异,提出了一种基于Web页面标签属性的字符串编辑距离的Web页面结构相似性判断方法。实验表明,该算法确定网页相似度的时间约为DOM树编辑距离方法的3/4。第三,设计一个自动化的信息采集系统。在系统实现过程中,为了加快信息采集的使用,采用了分布式架构。为了实现履带的动态配置,将ZooKeeper用作配置中心。底层数据持久性使用MySQL数据库。该系统的实现避免了人工制定信息提取规则。 查看全部
自动化信息采集系统的设计和实现
[摘要]:在当今信息和数据爆炸时代,可以对Internet上的数据信息进行数据挖掘,以提取有价值的信息并预测某些事件的发生。现代主流搜索引擎,例如Google,百度等,将在全球范围内部署自己的信息系统。在信息采集系统中,最重要的部分是如何解析网页并提取感兴趣的数据信息。在一般信息采集系统中,有必要使用不同的模块或不同的网站个性化网站制定信息提取规则,尤其是当网页结构相似时,会消耗大量的人力资源。自动化信息采集可以解决此问题。现有的自动页面解析算法通常使用模板生成或机器学习来自动提取信息。最常见的算法包括启发式,树对齐和模板生成。例如,RoadRunner等,这些现有算法的问题在于提取的信息收录噪声信息以及数据提取时间过长的缺点。为了解决上述问题,本文的主要研究内容体现在三个方面。首先,为解决人工干预和噪声信息在网络信息自动提取中比例过大的问题,提出了一种基于标签网页主体块的三叉树的解决方案。通过大量的分析,本文确定了可以正确描述网页文本分布的标签,并确定了标签的阈值。最后,结合三叉树信息提取模型,制定了统一的信息提取规则。实验表明,在时间和噪声信息比例上,信息提取算法的性能优于同类提取算法。其次,为了能够更好地适应自动信息提取,有必要解决网页结构的分类问题。当前,最常见的网页结构分类算法是基于DOM树的编辑距离,但是该算法最突出的缺点是时间消耗过长。结合现有主流站点之间Web页面模板应用的可能性较低,以及同一站点不同区域可能存在的差异,提出了一种基于Web页面标签属性的字符串编辑距离的Web页面结构相似性判断方法。实验表明,该算法确定网页相似度的时间约为DOM树编辑距离方法的3/4。第三,设计一个自动化的信息采集系统。在系统实现过程中,为了加快信息采集的使用,采用了分布式架构。为了实现履带的动态配置,将ZooKeeper用作配置中心。底层数据持久性使用MySQL数据库。该系统的实现避免了人工制定信息提取规则。
核心方法:如何高效、准确、自动识别网页编码
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-10-18 13:02
发件人:
Tiandilian站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的通用字符模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
上面可以识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?号回;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子想出了一种本地方法:对于我们中文来说,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功了,否则识别就失败了。
这样,基本上可以轻松解决网页编码识别的问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想写一篇关于这个主题的文章文章。标题也被深思熟虑:“网络IO,到处都是异步的”,这里指的是网络IO仅是http请求
Tiandilian站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。 查看全部
如何高效,准确和自动识别网页编码
发件人:
Tiandilian站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的通用字符模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
上面可以识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?号回;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子想出了一种本地方法:对于我们中文来说,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功了,否则识别就失败了。
这样,基本上可以轻松解决网页编码识别的问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想写一篇关于这个主题的文章文章。标题也被深思熟虑:“网络IO,到处都是异步的”,这里指的是网络IO仅是http请求
Tiandilian站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。
解决方法:一种云计算中垂直搜索引擎网页采集模板自动识别方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2020-10-18 10:02
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种用于云计算中的垂直搜索引擎网页采集模板的自动识别方法。它根据需要采集 网站分析现有网页,以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类该工具对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并采用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。要从中提取所需的信息,您需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性低,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。对于采集 网站,我们需要随机获取一定数量的示例网页,分析现有网页,提取特征属性,并将属性值采集设置到数据表中作为训练样本数据进行聚类,以获得多个不同的网页模板;识别网页模板的类别,作为训练网页模板分类器的训练样本;将该分类器应用于所有采集个网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过下面的附图通过[具体实施例]进一步解释本发明:
如图1所示,需要一种云计算中的垂直搜索引擎网页采集模板自动识别方法,以随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类采集放入数据表作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。 查看全部
云计算中垂直搜索引擎网页采集模板的自动识别方法
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种用于云计算中的垂直搜索引擎网页采集模板的自动识别方法。它根据需要采集 网站分析现有网页,以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类该工具对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并采用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。要从中提取所需的信息,您需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性低,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。对于采集 网站,我们需要随机获取一定数量的示例网页,分析现有网页,提取特征属性,并将属性值采集设置到数据表中作为训练样本数据进行聚类,以获得多个不同的网页模板;识别网页模板的类别,作为训练网页模板分类器的训练样本;将该分类器应用于所有采集个网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过下面的附图通过[具体实施例]进一步解释本发明:
如图1所示,需要一种云计算中的垂直搜索引擎网页采集模板自动识别方法,以随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类采集放入数据表作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。
直观:一种基于样本的互联网爬虫内容网页识别方法与流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-09-30 10:02
本发明公开了一种基于样本的互联网爬虫内容网页识别方法,涉及互联网信息技术领域。
背景技术:
Internet爬虫是一种采集Internet信息的技术手段。互联网网站上有许多种类的网页。根据网页的内容,它们可以分为列表页面,内容页面和其他页面。列表页面主要是内容页面,其他页面提供链接条目,内容页面是网站发布的特定内容页面,其他页面包括功能页面,例如促销,广告,注册,登录和帮助。 Internet采集器服务的用户只关心内容网页的信息,因此Internet采集器程序需要在搜寻Internet信息的过程中准确地对网页进行分类和标识,然后再标识所标识的内容网页的信息采集进行业务处理。当前,识别内容网页的常用方法是手动采集,汇总和整理每个网站内容网页URL的正则表达式规则。 Internet爬网程序使用这些规则来匹配在爬网过程中找到的网页链接URL。发现内容页面。
现有的Internet爬网程序通过匹配手动采集,汇总和排序的内容网页的url正则表达式规则来判断内容网页。尽管此方法可以准确地发现内容网页,但它也有很多缺点,主要表现在:
1、每个网站内容网页的url格式都不固定。大多数网站会不时更改内容网页的url格式。一旦找不到及时的更改,它将导致Internet爬网程序。无法正确识别内容网页,从而导致大量采集数据丢失;
2、每个网站内容网页通常有多种正则表达式规则。手动维护方法要求采集和聚合内容网页,然后根据汇总的URL提取并编译正则表达式规则。验证正则表达式后,提交更新。该方法维护成本高,专业技术要求高,维护周期长。
Internet爬网程序将在运行期间根据某种路由算法遍历需要采集的网站。在遍历过程中处理每个网页时,它将从该网页提取到其他网页的链接URL。在Web链接URL中标识内容网页的链接URL也是现在需要解决的问题之一。
技术实现要素:
本发明要解决的技术问题是提供一种基于样本的基于现有技术的缺点识别互联网爬虫的网页的方法,并通过一种全新的互联网爬虫来改善互联网爬虫的数据。技术基于样本学习采集的准确性,并降低了维修人员的专业技术要求和维修成本。
本发明采用以下技术方案来解决上述技术问题:
一种用于识别Internet爬虫内容网页的基于样本的方法,该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
作为本发明的另一优选方案,在步骤3中,编辑距离分类算法具体为:
计算字符串之间的编辑距离,并根据设置的编辑距离系数对字符串进行分类,其中编辑距离是将两个字符串从一个转换为另一个所需的最小编辑次数。操作数量包括:用另一个字符替换一个字符,插入一个字符,然后删除一个字符。
使用编辑距离算法来计算并比较Internet采集器提取的Web链接url和内容Web链接url示例库中的示例链接url;
如果提取的Web链接URL和示例库中的任何示例链接URL属于同一类别,则将提取的Web链接URL视为内容Web链接URL,并对其进行后续的采集处理,随后的采集处理包括内容网页信息的重复数据删除和提取;
相反,如果提取的网页链接URL和样本库中的任何样本链接URL不属于同一类别,则认为提取的网页链接URL不是内容网页链接URL。
作为本发明的另一优选方案,当内容网页链接URL格式网站被更新时,或者当内容网页链接URL格式改变时,要求互联网爬虫执行数据网站。 ,内容将更新Web链接url示例库,并从Internet爬网程序的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。
作为本发明的另一优选方案,对于不符合样本库内容的网页链接的URL格式的URL,首先根据编辑距离分类算法对它们进行分类,然后对分类结果进行分类。手动浏览并验证。
与采用上述技术方案的现有技术相比,本发明具有以下技术效果:
1、本发明的Web爬虫内容网页识别逻辑算法适用于大多数互连的网站点,通用性强。
2、本发明的互联网爬虫内容的网页识别逻辑算法大大提高了互联网数据的准确性采集;
3、本发明的Web爬虫内容网页识别逻辑算法可以有效降低Internet爬虫的运维成本,提高运维效率。
图纸说明
图1是Internet采集器内容的网页识别过程的逻辑图;
图2是内容网页链接的url示例库的常规更新流程图;
图3是非内容Web链接的URL检查的流程图。
具体的实现方法
下面详细描述本发明的实施例。在附图中示出了实施例的示例,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。参照附图描述的以下实施例是示例性的,仅用于解释本发明,不能解释为对本发明的限制。
下面结合附图对本发明的技术方案做进一步的详细说明。
在本发明中,标识Internet爬虫内容的网页的整个过程如图1所示。该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
其中,编辑距离:也称为levenshtein距离(也称为editdistance),是指在两个字符串之间将一个字符串转换为另一字符串所需的最小编辑操作次数。编辑操作包括用一个字符替换另一个字符,插入一个字符以及删除一个字符。
编辑距离分类算法:计算字符串之间的编辑距离,并根据一定的编辑距离系数对字符串进行分类。
该专利使用编辑距离算法来计算和比较Internet采集器提取的网页链接的url和内容网页链接url的示例库中的url。如果将某个提取的网页链接URL与示例库中的任何一个进行比较如果该样本链接URL属于同一类别,则该提取的Web链接URL被视为内容Web链接url,并进行后续的采集处理(包括需要对内容Web信息进行重复数据删除和提取);相反,如果某个示例库中提取的网页链接的URL不属于同一类别,则认为提取的网页链接URL不是内容网页的链接URL。
每个网站内容网络链接的网址格式都会不时更新。当采集的网站更改内容Web链接的url格式时,需要及时更新内容Web链接url示例库。 。内容Web链接url样本库的定期更新子过程通常通过定期更新来实现。更新子过程从Internet采集器的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。具体逻辑如图2所示。显示。
大量不符合示例库内容的Web链接url格式的URL也需要定期进行手动验证。手动实时验证不是简单的直接浏览不符合样本库的Web链接url信息,而是首先通过编辑距离算法对其进行分类。分类,然后手动浏览并验证分类结果。这样做的好处是可以大大减少手动验证的工作量。具体过程如图3所示。
非内容Web链接的URL的提取和分类可以定期自动进行,而手动验证只需要及时检查分类结果即可。可以根据实际需要设置自动对非内容Web链接URL进行提取和分类的周期,但是周期不能设置得太短,否则分类效果不佳,但是不能太长,导致无法及时发现内容。 网站对于Web链接修订或新格式的内容Web链接,周期通常设置为一天。
以上参照附图详细描述了本发明的实施例,但是本发明不限于上述实施例,并且在本领域普通技术人员的知识范围内。在不背离本发明的目的的情况下,也可以提供它。进行各种更改。以上仅为本发明的优选实施例,并不以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。所属领域的技术人员在不脱离本发明的技术方案的范围的情况下,可以利用以上公开的技术内容对具有等同变化的等同实施例进行细微改变或修改,但是所有这些根据本发明,不脱离本发明的技术方案的内容。在本发明的精神和原理内,对上述实施例进行的任何简单修改,等同替换和改进仍属于本发明的技术实质。在本发明技术方案的保护范围之内。 查看全部
基于样本的Internet爬网程序网页识别方法和过程
本发明公开了一种基于样本的互联网爬虫内容网页识别方法,涉及互联网信息技术领域。
背景技术:
Internet爬虫是一种采集Internet信息的技术手段。互联网网站上有许多种类的网页。根据网页的内容,它们可以分为列表页面,内容页面和其他页面。列表页面主要是内容页面,其他页面提供链接条目,内容页面是网站发布的特定内容页面,其他页面包括功能页面,例如促销,广告,注册,登录和帮助。 Internet采集器服务的用户只关心内容网页的信息,因此Internet采集器程序需要在搜寻Internet信息的过程中准确地对网页进行分类和标识,然后再标识所标识的内容网页的信息采集进行业务处理。当前,识别内容网页的常用方法是手动采集,汇总和整理每个网站内容网页URL的正则表达式规则。 Internet爬网程序使用这些规则来匹配在爬网过程中找到的网页链接URL。发现内容页面。
现有的Internet爬网程序通过匹配手动采集,汇总和排序的内容网页的url正则表达式规则来判断内容网页。尽管此方法可以准确地发现内容网页,但它也有很多缺点,主要表现在:
1、每个网站内容网页的url格式都不固定。大多数网站会不时更改内容网页的url格式。一旦找不到及时的更改,它将导致Internet爬网程序。无法正确识别内容网页,从而导致大量采集数据丢失;
2、每个网站内容网页通常有多种正则表达式规则。手动维护方法要求采集和聚合内容网页,然后根据汇总的URL提取并编译正则表达式规则。验证正则表达式后,提交更新。该方法维护成本高,专业技术要求高,维护周期长。
Internet爬网程序将在运行期间根据某种路由算法遍历需要采集的网站。在遍历过程中处理每个网页时,它将从该网页提取到其他网页的链接URL。在Web链接URL中标识内容网页的链接URL也是现在需要解决的问题之一。
技术实现要素:
本发明要解决的技术问题是提供一种基于样本的基于现有技术的缺点识别互联网爬虫的网页的方法,并通过一种全新的互联网爬虫来改善互联网爬虫的数据。技术基于样本学习采集的准确性,并降低了维修人员的专业技术要求和维修成本。
本发明采用以下技术方案来解决上述技术问题:
一种用于识别Internet爬虫内容网页的基于样本的方法,该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
作为本发明的另一优选方案,在步骤3中,编辑距离分类算法具体为:
计算字符串之间的编辑距离,并根据设置的编辑距离系数对字符串进行分类,其中编辑距离是将两个字符串从一个转换为另一个所需的最小编辑次数。操作数量包括:用另一个字符替换一个字符,插入一个字符,然后删除一个字符。
使用编辑距离算法来计算并比较Internet采集器提取的Web链接url和内容Web链接url示例库中的示例链接url;
如果提取的Web链接URL和示例库中的任何示例链接URL属于同一类别,则将提取的Web链接URL视为内容Web链接URL,并对其进行后续的采集处理,随后的采集处理包括内容网页信息的重复数据删除和提取;
相反,如果提取的网页链接URL和样本库中的任何样本链接URL不属于同一类别,则认为提取的网页链接URL不是内容网页链接URL。
作为本发明的另一优选方案,当内容网页链接URL格式网站被更新时,或者当内容网页链接URL格式改变时,要求互联网爬虫执行数据网站。 ,内容将更新Web链接url示例库,并从Internet爬网程序的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。
作为本发明的另一优选方案,对于不符合样本库内容的网页链接的URL格式的URL,首先根据编辑距离分类算法对它们进行分类,然后对分类结果进行分类。手动浏览并验证。
与采用上述技术方案的现有技术相比,本发明具有以下技术效果:
1、本发明的Web爬虫内容网页识别逻辑算法适用于大多数互连的网站点,通用性强。
2、本发明的互联网爬虫内容的网页识别逻辑算法大大提高了互联网数据的准确性采集;
3、本发明的Web爬虫内容网页识别逻辑算法可以有效降低Internet爬虫的运维成本,提高运维效率。
图纸说明
图1是Internet采集器内容的网页识别过程的逻辑图;
图2是内容网页链接的url示例库的常规更新流程图;
图3是非内容Web链接的URL检查的流程图。
具体的实现方法
下面详细描述本发明的实施例。在附图中示出了实施例的示例,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。参照附图描述的以下实施例是示例性的,仅用于解释本发明,不能解释为对本发明的限制。
下面结合附图对本发明的技术方案做进一步的详细说明。
在本发明中,标识Internet爬虫内容的网页的整个过程如图1所示。该方法具体包括以下步骤:
步骤一、解析网页,在页面中提取网页链接URL,并将网页链接URL保存到set a中;
步骤二、提取与网站对应的示例链接URL,并将示例链接URL存储在集合b中;
步骤三、根据编辑距离分类算法对集合a和集合b中的所有URL进行分类;
步骤四、遍历集合a,根据步骤3中获得的分类结果,将集合a分为满足样本的url集c和不满足样本的url集d。
步骤五、保存集d的输出以进行进一步分析;将集c直接输出到随后的采集处理。
其中,编辑距离:也称为levenshtein距离(也称为editdistance),是指在两个字符串之间将一个字符串转换为另一字符串所需的最小编辑操作次数。编辑操作包括用一个字符替换另一个字符,插入一个字符以及删除一个字符。
编辑距离分类算法:计算字符串之间的编辑距离,并根据一定的编辑距离系数对字符串进行分类。
该专利使用编辑距离算法来计算和比较Internet采集器提取的网页链接的url和内容网页链接url的示例库中的url。如果将某个提取的网页链接URL与示例库中的任何一个进行比较如果该样本链接URL属于同一类别,则该提取的Web链接URL被视为内容Web链接url,并进行后续的采集处理(包括需要对内容Web信息进行重复数据删除和提取);相反,如果某个示例库中提取的网页链接的URL不属于同一类别,则认为提取的网页链接URL不是内容网页的链接URL。
每个网站内容网络链接的网址格式都会不时更新。当采集的网站更改内容Web链接的url格式时,需要及时更新内容Web链接url示例库。 。内容Web链接url样本库的定期更新子过程通常通过定期更新来实现。更新子过程从Internet采集器的采集结果库中提取最新的内容链接url,以替换内容Web链接url示例库。具体逻辑如图2所示。显示。
大量不符合示例库内容的Web链接url格式的URL也需要定期进行手动验证。手动实时验证不是简单的直接浏览不符合样本库的Web链接url信息,而是首先通过编辑距离算法对其进行分类。分类,然后手动浏览并验证分类结果。这样做的好处是可以大大减少手动验证的工作量。具体过程如图3所示。
非内容Web链接的URL的提取和分类可以定期自动进行,而手动验证只需要及时检查分类结果即可。可以根据实际需要设置自动对非内容Web链接URL进行提取和分类的周期,但是周期不能设置得太短,否则分类效果不佳,但是不能太长,导致无法及时发现内容。 网站对于Web链接修订或新格式的内容Web链接,周期通常设置为一天。
以上参照附图详细描述了本发明的实施例,但是本发明不限于上述实施例,并且在本领域普通技术人员的知识范围内。在不背离本发明的目的的情况下,也可以提供它。进行各种更改。以上仅为本发明的优选实施例,并不以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。所属领域的技术人员在不脱离本发明的技术方案的范围的情况下,可以利用以上公开的技术内容对具有等同变化的等同实施例进行细微改变或修改,但是所有这些根据本发明,不脱离本发明的技术方案的内容。在本发明的精神和原理内,对上述实施例进行的任何简单修改,等同替换和改进仍属于本发明的技术实质。在本发明技术方案的保护范围之内。
操作方法:一种云计算中垂直搜索引擎网页采集模板自动识别方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-09-24 08:00
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种在云计算中自动识别垂直搜索引擎网页采集的模板的方法。它分析采集 网站的现有网页以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类处理器对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并利用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。如果要从中提取所需的信息,则需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,它具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术来实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。为了使采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性并设置属性值,采集用作训练样本数据以在数据表中聚类以获得多个不同的网页模板;将网页模板分类为训练样本,以训练网页模板分类器;将该分类器应用于所有采集网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析。达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过[具体实施方式]并参考以下附图进一步说明本发明:
如图1所示,云计算中的垂直搜索引擎网页采集模板自动识别方法用于随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类[ 采集放入数据表中作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。 查看全部
云计算中垂直搜索引擎网页采集模板的自动识别方法
云计算中垂直搜索引擎网页采集模板的自动识别方法
[专利摘要]本发明公开了一种在云计算中自动识别垂直搜索引擎网页采集的模板的方法。它分析采集 网站的现有网页以随机获取一定数量的样本网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;确定网页模板的类别,并训练网页模板分类器作为训练样本;应用分类处理器对所有采集网页模板进行分类,并根据分类获得的模板提取信息。该方法利用不同的网站网页采样,并利用数据挖掘聚类和分类算法为这些网站中的不同网页结构标识不同的分析模板,以达到智能分析的目的。
[专利描述]-一种在云计算中自动识别垂直搜索引擎网页采集模板的方法
[技术领域]
[0001]本发明涉及云计算垂直搜索引擎领域,尤其涉及一种垂直搜索引擎网页采集模板自动识别方法。
技术背景
[0002]搜索引擎是云计算的关键技术。它充分利用了云计算带来的便利,也为云计算注入了无限的活力。垂直搜索引擎和常规Web搜索引擎之间的最大区别是,它从网页信息中提取结构化信息,即,将网页的非结构化数据提取为特定的结构化信息数据。然后将数据存储在数据库中,以进行进一步的处理,例如重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求。
[0003]垂直搜索引擎中的某个行业将涉及多个网站,并且每个网站的组织形式和网页结构都非常不同。如果要从中提取所需的信息,则需要具有高效且准确的结构。信息提取技术。提取信息有两种方法,一种是模板方法,它具有实现速度快,成本低,灵活性强的优点。缺点是后期维护成本高,信息来源少,信息量少。二是网页不依赖于网络结构化信息抽取方法,优点是数据容量大,但灵活性,准确性低,成本高。
[发明内容]
[0004]本发明要解决的技术问题是:本发明的目的是利用数据挖掘技术来实现垂直搜索引擎的智能网页分析。
[0005]本发明采用的技术方案是:
云计算中垂直搜索引擎网页采集模板的自动识别方法。为了使采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性并设置属性值,采集用作训练样本数据以在数据表中聚类以获得多个不同的网页模板;将网页模板分类为训练样本,以训练网页模板分类器;将该分类器应用于所有采集网页模板分类,基于分类获得的模板进行信息提取。
[0006]本发明的有益效果是:该方法使用不同网站的网页采样,并使用数据挖掘聚类和分类算法为这些网站模板中的不同网页结构标识不同的分析。达到智能分析的目的。
[专利图纸]
[图纸说明]
[0007]图1是本发明原理的示意图。
[详细实现]
[0008]将通过[具体实施方式]并参考以下附图进一步说明本发明:
如图1所示,云计算中的垂直搜索引擎网页采集模板自动识别方法用于随机获取一定数量的示例网页,分析现有网页并提取Feature属性,将属性值聚类[ 采集放入数据表中作为训练样本数据,以获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;将分类器应用于所有采集个网页分类为模板,并基于分类获得的模板提取信息。
[要求]
1.一种用于云计算的垂直搜索引擎网页采集模板自动识别方法,其特征在于:采集 网站随机获取一定数量的样本网页,分析现有网页,提取特征属性,将属性值采集聚类到数据表中作为训练样本数据,并获得多个不同的网页模板;识别网页模板的类别,并将网页模板分类器作为训练样本进行训练;应用分类器在所有采集网页上进行模板分类,并基于从分类中获得的模板进行信息提取。
[文档编号] G06F17 / 30GK103870567SQ2
[发布日期] 2014年6月18日申请日期:2014年3月11日优先日期:2014年3月11日
[发明人]范颖,于志楼,梁华勇申请人:浪潮集团有限公司。
最新信息:免费爬虫工具:优采云采集器如何采集环球网新闻信息数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 462 次浏览 • 2020-09-07 18:50
本文介绍了如何使用优采云 采集器的智能模式释放采集万维网新闻的标题,内容,评论数,发布时间和其他信息。
采集工具简介:
优采云 采集器是基于人工智能技术的网页采集器,仅需输入URL即可自动识别网页数据,无需进行配置即可完成数据采集,是业界首创支持用于操作系统(包括Windows,Mac和Linux)的三种类型的Web采集器软件。
该软件是一款真正免费的data 采集软件。对采集结果的导出没有限制。没有编程基础的新手用户可以轻松实现data 采集要求。
官方网站:
采集对象介绍:
Worldwide.com已获得《人民日报》和中国中央网络空间管理局的批准,并由《人民日报在线》和《环球时报》共同投资建立。它于2007年11月正式启动。它是具有新闻编辑权网站的大型中英文双语新闻门户,是综合网络新闻媒体。万维网在各个领域和多个维度提供实时原创国际新闻和专业的国际信息服务;创建一个新的全球生活门户网站,将新闻信息,互动社区和移动增值服务整合在一起。
采集字段:
新闻标题,新闻链接,发布时间,新闻来源,参加人数,新闻内容
功能点目录:
如何配置采集字段
如何采集列出+详细页面类型的网页
采集结果预览:
让我们详细介绍如何释放采集全球新闻数据。让我们以全球新闻财经频道下的金融部门为例。具体步骤如下:
第1步:下载并安装优采云 采集器,然后注册并登录
1、打开优采云 采集器官方网站,下载并安装优采云 采集器的最新版本
2、单击注册以登录,注册新帐户,登录优采云 采集器
[提醒]您无需注册即可直接使用该采集器软件,但是切换到注册用户时,匿名帐户下的任务将会丢失,因此建议您在注册后使用它。
优采云 采集器是优采云的产品,优采云用户可以直接登录。
第2步:创建采集任务
1、复制万维网新闻和金融部分的网址(需要搜索结果页面的URL,而不是首页的URL)
单击此处以了解如何正确输入URL。
2、新的智能模式采集任务
您可以直接在软件上创建新的采集任务,也可以通过导入规则来创建任务。
点击此处了解如何导入和导出采集规则。
第3步:配置采集规则
1、设置提取数据字段
在智能模式下,输入URL后,软件可以自动识别页面上的数据并生成采集结果。每种数据类型都对应一个采集字段。我们可以右键单击该字段以进行相关设置,包括“修改字段名称”,“增加或减少字段”,“过程数据”等。
单击此处以了解如何配置采集字段。
在列表页面上,我们需要采集 Global News的新闻标题,新闻链接和发布时间等信息。字段设置如下:
2、使用深入的采集功能提取详细页面数据
在列表页面上,仅显示万维网新闻的部分内容。如果您需要详细的新闻内容,我们需要右键单击新闻链接,然后使用“深采集”功能跳转到详细信息页面以继续进行采集。
点击此处了解有关采集列表+详细页面类型页面的更多信息。
在详细信息页面上,我们可以查看新闻内容,新闻来源和参加人数。我们可以单击“添加字段”来添加采集字段。字段设置效果如下:
[温馨提示]在整个新闻内容的采集中,您可以将鼠标移到新闻内容的下半部分,并且当看到蓝色区域将其全部选中时,可以单击以进行选择,然后可以提取全部新闻新闻的新闻内容。
第4步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们可以启动采集任务。开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
单击“设置”按钮,然后在弹出的运行设置页面中设置运行设置和防阻塞设置。在这里,我们选中“跳过以继续采集”,设置为“ 2”秒请求等待时间,然后选中“不加载网页图片”,防阻塞设置将遵循系统默认设置,然后单击“保存”。
单击此处以了解有关如何配置采集任务的更多信息。
2、开始执行采集任务
单击“保存并开始”按钮,在弹出页面中进行一些高级设置,包括定时开始,自动存储和下载图片。在此示例中未使用这些功能,只需单击“开始”以运行采集器工具。
单击此处以了解有关计时采集的更多信息。
单击此处以了解有关自动存储的更多信息。
单击此处以了解有关如何下载图片的更多信息。
[温馨提示]免费版可以使用非定期定时采集功能,并且图片下载功能是免费的。个人专业版及更高版本可以使用高级计时功能和自动存储功能。
3、运行任务以提取数据
启动任务后自动开始采集数据。我们可以从界面直观地看到程序的运行过程和采集的结果,并且采集结束后会有提醒。
第5步:导出和查看数据
数据采集完成后,我们可以查看和导出数据。 优采云 采集器支持多种导出方法(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)以及导出文件的格式(EXCEL,CSV,HTML和TXT),我们选择所需的方法和文件类型,然后单击“确认导出”。
单击此处以了解有关如何查看和清除采集数据的更多信息。
单击此处以了解有关如何导出采集结果的更多信息。
[提醒]:所有手动导出功能都是免费的。 Personal Professional Edition及更高版本可以使用“发布到网站”功能。 查看全部
免费的采集器工具:优采云 采集器如何采集万维网新闻信息数据
本文介绍了如何使用优采云 采集器的智能模式释放采集万维网新闻的标题,内容,评论数,发布时间和其他信息。
采集工具简介:
优采云 采集器是基于人工智能技术的网页采集器,仅需输入URL即可自动识别网页数据,无需进行配置即可完成数据采集,是业界首创支持用于操作系统(包括Windows,Mac和Linux)的三种类型的Web采集器软件。
该软件是一款真正免费的data 采集软件。对采集结果的导出没有限制。没有编程基础的新手用户可以轻松实现data 采集要求。
官方网站:
采集对象介绍:
Worldwide.com已获得《人民日报》和中国中央网络空间管理局的批准,并由《人民日报在线》和《环球时报》共同投资建立。它于2007年11月正式启动。它是具有新闻编辑权网站的大型中英文双语新闻门户,是综合网络新闻媒体。万维网在各个领域和多个维度提供实时原创国际新闻和专业的国际信息服务;创建一个新的全球生活门户网站,将新闻信息,互动社区和移动增值服务整合在一起。
采集字段:
新闻标题,新闻链接,发布时间,新闻来源,参加人数,新闻内容
功能点目录:
如何配置采集字段
如何采集列出+详细页面类型的网页
采集结果预览:
让我们详细介绍如何释放采集全球新闻数据。让我们以全球新闻财经频道下的金融部门为例。具体步骤如下:
第1步:下载并安装优采云 采集器,然后注册并登录
1、打开优采云 采集器官方网站,下载并安装优采云 采集器的最新版本
2、单击注册以登录,注册新帐户,登录优采云 采集器
[提醒]您无需注册即可直接使用该采集器软件,但是切换到注册用户时,匿名帐户下的任务将会丢失,因此建议您在注册后使用它。
优采云 采集器是优采云的产品,优采云用户可以直接登录。
第2步:创建采集任务
1、复制万维网新闻和金融部分的网址(需要搜索结果页面的URL,而不是首页的URL)
单击此处以了解如何正确输入URL。
2、新的智能模式采集任务
您可以直接在软件上创建新的采集任务,也可以通过导入规则来创建任务。
点击此处了解如何导入和导出采集规则。
第3步:配置采集规则
1、设置提取数据字段
在智能模式下,输入URL后,软件可以自动识别页面上的数据并生成采集结果。每种数据类型都对应一个采集字段。我们可以右键单击该字段以进行相关设置,包括“修改字段名称”,“增加或减少字段”,“过程数据”等。
单击此处以了解如何配置采集字段。
在列表页面上,我们需要采集 Global News的新闻标题,新闻链接和发布时间等信息。字段设置如下:
2、使用深入的采集功能提取详细页面数据
在列表页面上,仅显示万维网新闻的部分内容。如果您需要详细的新闻内容,我们需要右键单击新闻链接,然后使用“深采集”功能跳转到详细信息页面以继续进行采集。
点击此处了解有关采集列表+详细页面类型页面的更多信息。
在详细信息页面上,我们可以查看新闻内容,新闻来源和参加人数。我们可以单击“添加字段”来添加采集字段。字段设置效果如下:
[温馨提示]在整个新闻内容的采集中,您可以将鼠标移到新闻内容的下半部分,并且当看到蓝色区域将其全部选中时,可以单击以进行选择,然后可以提取全部新闻新闻的新闻内容。
第4步:设置并启动采集任务
1、设置采集任务
完成采集数据添加后,我们可以启动采集任务。开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
单击“设置”按钮,然后在弹出的运行设置页面中设置运行设置和防阻塞设置。在这里,我们选中“跳过以继续采集”,设置为“ 2”秒请求等待时间,然后选中“不加载网页图片”,防阻塞设置将遵循系统默认设置,然后单击“保存”。
单击此处以了解有关如何配置采集任务的更多信息。
2、开始执行采集任务
单击“保存并开始”按钮,在弹出页面中进行一些高级设置,包括定时开始,自动存储和下载图片。在此示例中未使用这些功能,只需单击“开始”以运行采集器工具。
单击此处以了解有关计时采集的更多信息。
单击此处以了解有关自动存储的更多信息。
单击此处以了解有关如何下载图片的更多信息。
[温馨提示]免费版可以使用非定期定时采集功能,并且图片下载功能是免费的。个人专业版及更高版本可以使用高级计时功能和自动存储功能。
3、运行任务以提取数据
启动任务后自动开始采集数据。我们可以从界面直观地看到程序的运行过程和采集的结果,并且采集结束后会有提醒。
第5步:导出和查看数据
数据采集完成后,我们可以查看和导出数据。 优采云 采集器支持多种导出方法(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)以及导出文件的格式(EXCEL,CSV,HTML和TXT),我们选择所需的方法和文件类型,然后单击“确认导出”。
单击此处以了解有关如何查看和清除采集数据的更多信息。
单击此处以了解有关如何导出采集结果的更多信息。
[提醒]:所有手动导出功能都是免费的。 Personal Professional Edition及更高版本可以使用“发布到网站”功能。
技巧:如何高效、准确、自动识别网页编码
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-09-07 00:25
发件人:
Tiandilian 站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码识别
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别出的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的Universalchardet模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
可以在上面识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?回号;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子,想出了一种本地方法:对于我们中文,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功,否则识别就失败。
这样,基本上可以轻松解决网页编码识别问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想在这方面写一篇文章文章。标题也被深思熟虑:“网络IO,异步无处不在”,这里指的是仅HTTP请求的网络IO
Tiandilian 站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。 查看全部
如何高效,准确和自动识别网页编码
发件人:
Tiandilian 站群可以根据用户输入的初始关键词来获取关键词搜索引擎的搜索结果,然后依次获取相关的文章内容。这样,您需要面对无数网页的各种编码。为了解决此问题,引入了以下解决方案:
在引入自动编码识别之前,我们有两种获取网页编码信息的方法:
它的一、是通过服务器返回的标头中的charset变量获得的
二、是通过页面上的元信息获得的。
在通常情况下,如果服务器或页面提供了这两个参数,并且参数正确,那么在爬网该网页时就不会出现编码问题。
但是对于我们程序员来说,现实总是很困难。搜寻网页时,通常会发生以下情况:
1.这两个参数缺失
2.尽管提供了两个参数,但它们不一致
3.提供了这两个参数,但它们与网页的实际编码不一致
为了尽可能自动地获取所有网页的编码,引入了自动编码识别
我记得在php中有一个mb_detect函数,它似乎可以识别字符串编码,但是它的准确性很难说,因为编码的自动识别是一个概率事件,仅当识别出的字符串的长度时足够大(例如,超过300个单词),它可能会更可靠。
所有浏览器都支持自动识别网页编码,例如IE,firefox等。
我使用mozzila提供的Universalchardet模块,据说它比IE随附的识别模块准确得多
universalchardet项目的地址为:
目前,universalchardet支持python java dotnet等,php不知道它是否支持
我更喜欢编写C#,因为VS2010 + viemu是我的最爱,所以我使用C#版本。通用字符有很多C#移植版本,我使用的版本是
以下是一个使用示例,与其他C#实现相比,这有点麻烦:
Stream mystream = res.GetResponseStream();
MemoryStream msTemp = new MemoryStream();
int len = 0;
byte[] buff = new byte[512];
while ((len = mystream.Read(buff, 0, 512)) > 0)
{
msTemp.Write(buff, 0, len);
}
res.Close();
if (msTemp.Length > 0)
{
msTemp.Seek(0, SeekOrigin.Begin);
byte[] PageBytes = new byte[msTemp.Length];
msTemp.Read(PageBytes, 0, PageBytes.Length);
msTemp.Seek(0, SeekOrigin.Begin);
int DetLen = 0;
byte[] DetectBuff = new byte[4096];
CharsetListener listener = new CharsetListener();
UniversalDetector Det = new UniversalDetector(null);
while ((DetLen = msTemp.Read(DetectBuff, 0, DetectBuff.Length)) > 0 && !Det.IsDone())
{
Det.HandleData(DetectBuff, 0, DetectBuff.Length);
}
Det.DataEnd();
if (Det.GetDetectedCharset()!=null)
{
CharSetBox.Text = "OK! CharSet=" + Det.GetDetectedCharset();
PageBox.Text = System.Text.Encoding.GetEncoding(Det.GetDetectedCharset()).GetString(PageBytes);
}
}
可以在上面识别网页的编码,看起来很简单,不是吗?如果您以前曾对此问题感到困扰,并且有幸看到这篇文章,那么这种类型的问题将得到彻底解决,并且您将永远不会遇到很多问题,因为您不知道网页编码? ? ? ? ?回号;从那以后,生活是如此美好。 。 。
我也这么认为
如上所述,代码识别是一个概率事件,因此不能保证它是100%正确的。因此,我仍然发现由识别错误引起的一些错误。 ?就数字而言,真的没有办法完美地解决这个问题吗?
我坚信,世界上没有完美的事物。
幸运的是,我们只需要一个完美的解决方案:我们需要让程序知道何时可以自动识别错误;如果错误,请读取并使用服务器和网页提供的编码信息。
我花了一段时间的脑子,想出了一种本地方法:对于我们中文,中文网页存在编码问题。如果正确识别了中文网页,则其中必须收录中文字符。宾果游戏,我从互联网上找到了前N个汉字(例如“的”)。只要网页收录这N个汉字之一,识别就成功,否则识别就失败。
这样,基本上可以轻松解决网页编码识别问题。
后记:
我不知道是否有人对此感兴趣。如果是这样,我想在这方面写一篇文章文章。标题也被深思熟虑:“网络IO,异步无处不在”,这里指的是仅HTTP请求的网络IO
Tiandilian 站群使用此代码识别方法解决了采集领域中的一个主要问题。从那时起,我可以从这个问题中汲取精力,研究和解决其他问题。
直观:基于深度学习的网页区域识别算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-09-05 18:18
一种基于深度学习的网页区域识别算法
[技术领域]
[0001]本发明涉及Internet信息技术采集,尤其是一种基于深度学习的网页区域识别算法。
[背景技术]
[0002]网页区域识别对于搜索引擎构建,网络信息检索,网络数据采集和网络知识发现至关重要。当前,网页区域识别通常采用以下方法:手动设置识别规则以识别网页区域或基于其他非深度学习机器学习方法来识别网页区域。
[0003]对于网页区域识别,该区域中文本的视觉特征(文本的大小,颜色,是否为粗体等)以及该区域本身的视觉特征(位置,背景)颜色,是否有边框等)至关重要。纯文本不能反映这些视觉特征,自然语言是高度抽象的。仅对纯文本执行特征提取和模式识别。难以提取足够的特征来获得理想的识别效果。
[发明内容]
[0004]本发明要解决的技术问题是提供一种基于深度学习的网页区域识别算法。
[0005]本发明为解决已知技术中存在的技术问题而采用的技术方案是:
本发明基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,以提取网页中不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;通过分词算法对文本特征进行序列化;通过神经网络语言模型学习文本特征向量;
D。叠层降噪自动编码器SDAE作为特征学习方法,上述处理后的特征向量作为输入向量;
E。使用堆叠式降噪自动编码器SDAE的输出向量作为分类算法的输入,并使用分类算法对上述输出向量进行分类。向量的分类结果是与特征向量相对应的网页区域的识别结果。
[0006]本发明还可以采用以下技术措施:
在步骤B中,通过选择所有视觉特征来获得未归一化的视觉特征向量。
[0007]在步骤B中,通过选择一些视觉特征,获得未归一化的视觉特征向量。
[0008]使用Min-Max Normali zat 1n的归一化方法对视觉特征向量进行归一化,以获得归一化的视觉特征向量。
[0009]在步骤C中,使用大规模分词算法对文本进行分词。
[0010]在步骤C中,通过口吃分割算法对文本进行分割。
[0011]在步骤C中,通过Paragraph2Vec算法学习文本特征向量。
[0012]在步骤D中,将视觉特征向量用作堆叠降噪自动编码器SDAE的输入向量。
[0013]在步骤D中,将视觉特征向量和文本特征向量进行拼接,作为堆叠降噪自动编码器SDAE的输入向量,并对拼接的向量进行选择性归一化。
[0014]在步骤E中,使用分类算法Softmax Regress1n对学习到的特征向量进行分类。
[0015]本发明的优点和积极效果是:
在本发明的基于深度学习的网页区域识别算法中,将网页的HTML源代码用作算法输入,并将HTML转换为XML,提取视觉特征和文本内容,并归一化对应的视觉特征,通过神经网络语言模型对文本内容进行特征学习,分别获得初步视觉特征向量和文本特征向量,并通过叠加降噪进一步学习初步视觉特征向量和文本特征向量自动编码器SDAE获取与该网页区域的网页区域特征向量相对应的代表,并通过分类算法对网页区域特征向量进行分类,即得到网页区域的识别结果。本发明可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率达到9 9. 99%-100%。
[详细实现]
[0016]以下将通过具体实施例详细描述本发明。
[0017]本发明的基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,提取网页中不同区域的视觉特征,视觉特征包括区域坐标,区域背景颜色,区域边框粗细,区域文字密度,区域文字字体,区域文字大小,区域文字颜色等。;通过选择全部或部分视觉特征以获得未归一化的视觉特征向量;用Min-Max Normalizat1n的归一化方法对视觉特征向量进行归一化,得到归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;使用大规模分词算法或口吃分词算法对文本进行分割;使用神经网络语言模型的Paragraph2Vec算法学习文本特征向量;
D。堆叠降噪自动编码器SDAE被用作特征学习方法,并且上述处理过的特征向量被用作输入向量。 SDAE的输入向量是通过视觉特征向量和文本特征向量进行拼接的,或者仅是视觉的特征向量作为输入向量,并且对拼接的向量进行了规范化或未处理;
E。堆叠降噪自动编码器SDAE的输出向量用作分类算法的输入,分类算法Softmax Regress1n用于对上述输出向量进行分类。向量的分类结果是与特征向量识别结果相对应的网页区域。
[0018]上面的描述仅是本发明的优选实施方式,并且无意于以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。当然,在不脱离本发明的技术方案的范围的情况下,本领域的任何技术人员当然都可以使用所公开的技术内容进行一些改变或修改,以成为等同改变的等同实施方式,只要他们能够做到。不背离本发明的技术方案,基于本发明的技术实质,对以上实施例所作的任何修改,等同变化,修改,修改的内容,均在本发明技术方案的范围内。发明。
[主权物品]
1.一种基于深度学习的网页区域识别算法,包括以下步骤:A.格式化文本:使用网页的HTML源代码作为算法输入; B.视觉特征处理:将HTML转换为XML并提取网页内部不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量; C.文本特征处理:将HTML转换为XML,提取网页区域中的文本;分割文本;通过神经网络语言模型学习文本特征向量; D.使用堆叠降噪自动编码器SDAE作为特征学习算法,并使用处理后的特征向量作为SDAE的输入向量; E,使用分类算法对堆叠式降噪自动编码器SDAE学习到的特征向量进行分类,向量的分类结果为特征向量对应的网页区域的识别结果。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择所有视觉特征,获得非归一化的视觉特征矢量。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择部分视觉特征,获得非归一化的视觉特征矢量。 4.根据权利要求2或3所述的基于深度学习的网页区域识别算法,其特征在于:所述最小-最大归一化方法用于对所述视觉特征向量进行归一化,以获得归一化的视觉特征向量。 6.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过大规模分词算法对文本进行分词。 7.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过口吃单词分割算法对文本进行分割。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过Paragraph2Vec算法学习所述文本特征向量。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量用作堆叠式降噪自动编码器SDAE的输入向量。 9. 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量和文本特征向量拼接为叠加式降噪的输入向量。自动编码器SDAE,在拼接后将所选向量标准化。 1 0.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤E中,使用分类算法Softmax Regress 1n对学习到的特征向量进行分类。
[专利摘要]一种基于深度学习的网页区域识别算法,包括以下步骤:A.使用格式化文本和网页HTML的源代码作为算法输入; B.通过HTML2XML算法提取网页区域的视觉特征向量; C.通过HTML2XML算法提取网页区域的文本内容,通过神经网络语言模型学习文本特征向量; D.使用叠加降噪自动编码器SDAE作为特征学习方法,并使用上述特征向量作为SDAE的输入向量; E.使用分类算法对SDAE的输出向量进行分类,向量的分类结果为该向量对应的网页区域的识别结果。通过本发明,可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率为9 9. 99%-100%。
[IPC分类] G06F17 / 30,G06F17 / 21,G06N3 / 08,G06F17 / 27
[公开号] CN105550278
[申请号] CN2
[发明人]李志杰,周祖胜
[申请人]天津海量信息技术有限公司
[公开日] 2016年5月4日
[申请日期] 2015年12月10日 查看全部
一种基于深度学习的网页区域识别算法
一种基于深度学习的网页区域识别算法
[技术领域]
[0001]本发明涉及Internet信息技术采集,尤其是一种基于深度学习的网页区域识别算法。
[背景技术]
[0002]网页区域识别对于搜索引擎构建,网络信息检索,网络数据采集和网络知识发现至关重要。当前,网页区域识别通常采用以下方法:手动设置识别规则以识别网页区域或基于其他非深度学习机器学习方法来识别网页区域。
[0003]对于网页区域识别,该区域中文本的视觉特征(文本的大小,颜色,是否为粗体等)以及该区域本身的视觉特征(位置,背景)颜色,是否有边框等)至关重要。纯文本不能反映这些视觉特征,自然语言是高度抽象的。仅对纯文本执行特征提取和模式识别。难以提取足够的特征来获得理想的识别效果。
[发明内容]
[0004]本发明要解决的技术问题是提供一种基于深度学习的网页区域识别算法。
[0005]本发明为解决已知技术中存在的技术问题而采用的技术方案是:
本发明基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,以提取网页中不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;通过分词算法对文本特征进行序列化;通过神经网络语言模型学习文本特征向量;
D。叠层降噪自动编码器SDAE作为特征学习方法,上述处理后的特征向量作为输入向量;
E。使用堆叠式降噪自动编码器SDAE的输出向量作为分类算法的输入,并使用分类算法对上述输出向量进行分类。向量的分类结果是与特征向量相对应的网页区域的识别结果。
[0006]本发明还可以采用以下技术措施:
在步骤B中,通过选择所有视觉特征来获得未归一化的视觉特征向量。
[0007]在步骤B中,通过选择一些视觉特征,获得未归一化的视觉特征向量。
[0008]使用Min-Max Normali zat 1n的归一化方法对视觉特征向量进行归一化,以获得归一化的视觉特征向量。
[0009]在步骤C中,使用大规模分词算法对文本进行分词。
[0010]在步骤C中,通过口吃分割算法对文本进行分割。
[0011]在步骤C中,通过Paragraph2Vec算法学习文本特征向量。
[0012]在步骤D中,将视觉特征向量用作堆叠降噪自动编码器SDAE的输入向量。
[0013]在步骤D中,将视觉特征向量和文本特征向量进行拼接,作为堆叠降噪自动编码器SDAE的输入向量,并对拼接的向量进行选择性归一化。
[0014]在步骤E中,使用分类算法Softmax Regress1n对学习到的特征向量进行分类。
[0015]本发明的优点和积极效果是:
在本发明的基于深度学习的网页区域识别算法中,将网页的HTML源代码用作算法输入,并将HTML转换为XML,提取视觉特征和文本内容,并归一化对应的视觉特征,通过神经网络语言模型对文本内容进行特征学习,分别获得初步视觉特征向量和文本特征向量,并通过叠加降噪进一步学习初步视觉特征向量和文本特征向量自动编码器SDAE获取与该网页区域的网页区域特征向量相对应的代表,并通过分类算法对网页区域特征向量进行分类,即得到网页区域的识别结果。本发明可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率达到9 9. 99%-100%。
[详细实现]
[0016]以下将通过具体实施例详细描述本发明。
[0017]本发明的基于深度学习的网页区域识别算法包括以下步骤:
A。格式化文本:使用网页的HTML源代码作为算法输入;
B。视觉特征处理:
将HTML转换为XML,提取网页中不同区域的视觉特征,视觉特征包括区域坐标,区域背景颜色,区域边框粗细,区域文字密度,区域文字字体,区域文字大小,区域文字颜色等。;通过选择全部或部分视觉特征以获得未归一化的视觉特征向量;用Min-Max Normalizat1n的归一化方法对视觉特征向量进行归一化,得到归一化的视觉特征向量;
C,文字特征处理:
将HTML转换为XML,提取网页区域中的文本;使用大规模分词算法或口吃分词算法对文本进行分割;使用神经网络语言模型的Paragraph2Vec算法学习文本特征向量;
D。堆叠降噪自动编码器SDAE被用作特征学习方法,并且上述处理过的特征向量被用作输入向量。 SDAE的输入向量是通过视觉特征向量和文本特征向量进行拼接的,或者仅是视觉的特征向量作为输入向量,并且对拼接的向量进行了规范化或未处理;
E。堆叠降噪自动编码器SDAE的输出向量用作分类算法的输入,分类算法Softmax Regress1n用于对上述输出向量进行分类。向量的分类结果是与特征向量识别结果相对应的网页区域。
[0018]上面的描述仅是本发明的优选实施方式,并且无意于以任何形式限制本发明。尽管已经在优选实施例中如上所述公开了本发明,但是其无意于限制本发明。当然,在不脱离本发明的技术方案的范围的情况下,本领域的任何技术人员当然都可以使用所公开的技术内容进行一些改变或修改,以成为等同改变的等同实施方式,只要他们能够做到。不背离本发明的技术方案,基于本发明的技术实质,对以上实施例所作的任何修改,等同变化,修改,修改的内容,均在本发明技术方案的范围内。发明。
[主权物品]
1.一种基于深度学习的网页区域识别算法,包括以下步骤:A.格式化文本:使用网页的HTML源代码作为算法输入; B.视觉特征处理:将HTML转换为XML并提取网页内部不同区域的视觉特征;选择上述视觉特征以获得视觉特征向量;归一化视觉特征向量以获得归一化的视觉特征向量; C.文本特征处理:将HTML转换为XML,提取网页区域中的文本;分割文本;通过神经网络语言模型学习文本特征向量; D.使用堆叠降噪自动编码器SDAE作为特征学习算法,并使用处理后的特征向量作为SDAE的输入向量; E,使用分类算法对堆叠式降噪自动编码器SDAE学习到的特征向量进行分类,向量的分类结果为特征向量对应的网页区域的识别结果。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择所有视觉特征,获得非归一化的视觉特征矢量。 2.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤B中,通过选择部分视觉特征,获得非归一化的视觉特征矢量。 4.根据权利要求2或3所述的基于深度学习的网页区域识别算法,其特征在于:所述最小-最大归一化方法用于对所述视觉特征向量进行归一化,以获得归一化的视觉特征向量。 6.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过大规模分词算法对文本进行分词。 7.根据权利要求4所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过口吃单词分割算法对文本进行分割。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤C中,通过Paragraph2Vec算法学习所述文本特征向量。 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量用作堆叠式降噪自动编码器SDAE的输入向量。 9. 7.根据权利要求5或6所述的基于深度学习的网页区域识别算法,其特征在于:在步骤D中,将视觉特征向量和文本特征向量拼接为叠加式降噪的输入向量。自动编码器SDAE,在拼接后将所选向量标准化。 1 0.根据权利要求1所述的基于深度学习的网页区域识别算法,其特征在于:在步骤E中,使用分类算法Softmax Regress 1n对学习到的特征向量进行分类。
[专利摘要]一种基于深度学习的网页区域识别算法,包括以下步骤:A.使用格式化文本和网页HTML的源代码作为算法输入; B.通过HTML2XML算法提取网页区域的视觉特征向量; C.通过HTML2XML算法提取网页区域的文本内容,通过神经网络语言模型学习文本特征向量; D.使用叠加降噪自动编码器SDAE作为特征学习方法,并使用上述特征向量作为SDAE的输入向量; E.使用分类算法对SDAE的输出向量进行分类,向量的分类结果为该向量对应的网页区域的识别结果。通过本发明,可以准确识别网页中的标题区域,文本区域和导航区域等视觉区域,识别准确率为9 9. 99%-100%。
[IPC分类] G06F17 / 30,G06F17 / 21,G06N3 / 08,G06F17 / 27
[公开号] CN105550278
[申请号] CN2
[发明人]李志杰,周祖胜
[申请人]天津海量信息技术有限公司
[公开日] 2016年5月4日
[申请日期] 2015年12月10日
操作方法:一种基于图片识别的自动裁剪方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-09-04 23:30
基于图像识别的自动裁剪方法
[专利摘要]本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)]背景识别;(4)自适应本发明采用基于识别的方法来实现图片的裁剪,并给出裁剪后的图片与原创图片的比例,本发明不需要人工干预,算法简单,算法简单。可靠性高,本发明可以根据需要采用不同的方法,满足不同网页显示的策略,本发明用于裁剪图片组,选择成功的选择作为显示图片,准确率9 9. 8%。本发明应用于信息和微薄页面图片的裁剪,人工测试的准确率9 9. 5%。
[专利描述]-一种基于图像识别的自动裁切方法
[技术领域]
[0001]本发明涉及一种自动裁切方法,尤其涉及一种基于图片识别的自动裁切方法。
[背景技术]
[0002]在网页显示领域,图像裁剪是必不可少的部分。当前,需要根据网页显示需求将图片裁剪为不同的尺寸。图片裁剪方法有很多种,基本上可以分为两类:基于软件的手动裁剪和算法裁剪。
[0003]基于软件的裁剪:首先定义裁剪区域和缩放比例,然后批量裁剪一组图片。对于某种类型的图片,请手动指定裁切过程。算法裁剪使用机器识别算法来识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004]手动裁切的缺点是裁切图片需要大量的人力资源,并且随着网站的扩展,裁切图片的成本也很高。自动裁剪方法的缺点是算法复杂,同时必须监控图像裁剪的效果,以发现问题并及时调整算法。
[发明内容]
[0005]鉴于现有技术的缺点,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面尺寸,无需人工干预即可有效裁剪图片。根据观察,不同的网页对图像显示有不同的要求。根据所需的尺寸,确定是否需要裁剪原创图像。如果需要裁切,则首先执行脸部识别,如果没有脸部,则执行背景识别。基于此,找到图片中需要保留的主要部分。然后使用自适应拦截方法拦截所需的图形。
[0006]通过以下技术方案实现本发明的目的:
[0007]一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008](I)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
[0011](4)自适应拦截。
[0012]优选地,步骤(I)包括读入图片以获得图片的高度和宽度信息,该信息与所需尺寸相同,并且比例恰好正确,则缩放直接结束
[0013]优选地,步骤(2)包括确定是否识别出人脸。
[0014]此外,
[0015](2. 1)识别多张面孔,计算出最小的一帧,并在其中收录所有面孔,这是主要部分,进入权利要求的步骤and;并且
[0016](2. 2)如果未识别出人脸,请继续进行索赔(3)。
[0017]优选地,面部识别包括使用opencv的面部检测算法,皮肤识别算法和图像块算法来执行图片的照度补偿。
[0018]优选地,步骤[3)包括使用图片块算法来计算左,右,上和下背景部分。
[0019]优选地,步骤⑷包括
[0020]对于多张脸,裁剪可收录所有脸的最小框架并将其标记为图片的主要部分;
[0021]当无法截取面部时,将最大的面部构图为图片的主要部分;和
[0022]当不捕获任何面部时,将取下背景部分的框标记为图片的主要部分。
[0023]此外,根据所需的高度或宽度,计算图片主要部分的高度或宽度,然后找到一个
[0024]窗口,即图片保留部分的高度和宽度。
[0025]此外,该方法包括调整截取主体部分失败的大小,包括调整完成模式和调整中央延伸裁切模式;
<p>[0026]补全方法包括:如果截取失败,则可以通过在两侧或上下补充相应的颜色边缘来获得适当的尺寸;中心扩展裁剪方法包括:如果截取失败,例如高度和长度,则从中心扩展相应的宽度。如果宽度和长度增加,则从中心向左扩展,向右扩展以获得合适的尺寸。 查看全部
基于图像识别的自动裁剪方法
基于图像识别的自动裁剪方法
[专利摘要]本发明涉及一种基于图片识别的自动裁剪方法,该方法包括(1)图片预处理;(2)人脸识别;(3)]背景识别;(4)自适应本发明采用基于识别的方法来实现图片的裁剪,并给出裁剪后的图片与原创图片的比例,本发明不需要人工干预,算法简单,算法简单。可靠性高,本发明可以根据需要采用不同的方法,满足不同网页显示的策略,本发明用于裁剪图片组,选择成功的选择作为显示图片,准确率9 9. 8%。本发明应用于信息和微薄页面图片的裁剪,人工测试的准确率9 9. 5%。
[专利描述]-一种基于图像识别的自动裁切方法
[技术领域]
[0001]本发明涉及一种自动裁切方法,尤其涉及一种基于图片识别的自动裁切方法。
[背景技术]
[0002]在网页显示领域,图像裁剪是必不可少的部分。当前,需要根据网页显示需求将图片裁剪为不同的尺寸。图片裁剪方法有很多种,基本上可以分为两类:基于软件的手动裁剪和算法裁剪。
[0003]基于软件的裁剪:首先定义裁剪区域和缩放比例,然后批量裁剪一组图片。对于某种类型的图片,请手动指定裁切过程。算法裁剪使用机器识别算法来识别背景区域,根据需要显示大小,切掉部分背景,然后放大和缩小图片。
[0004]手动裁切的缺点是裁切图片需要大量的人力资源,并且随着网站的扩展,裁切图片的成本也很高。自动裁剪方法的缺点是算法复杂,同时必须监控图像裁剪的效果,以发现问题并及时调整算法。
[发明内容]
[0005]鉴于现有技术的缺点,本发明提出了一种基于图片识别的自动裁剪技术。根据要显示的页面尺寸,无需人工干预即可有效裁剪图片。根据观察,不同的网页对图像显示有不同的要求。根据所需的尺寸,确定是否需要裁剪原创图像。如果需要裁切,则首先执行脸部识别,如果没有脸部,则执行背景识别。基于此,找到图片中需要保留的主要部分。然后使用自适应拦截方法拦截所需的图形。
[0006]通过以下技术方案实现本发明的目的:
[0007]一种基于图片识别的自动裁剪方法,改进之处在于该方法包括
[0008](I)图片预处理;
[0009](2)人脸识别;
[0010](3)背景识别;
[0011](4)自适应拦截。
[0012]优选地,步骤(I)包括读入图片以获得图片的高度和宽度信息,该信息与所需尺寸相同,并且比例恰好正确,则缩放直接结束
[0013]优选地,步骤(2)包括确定是否识别出人脸。
[0014]此外,
[0015](2. 1)识别多张面孔,计算出最小的一帧,并在其中收录所有面孔,这是主要部分,进入权利要求的步骤and;并且
[0016](2. 2)如果未识别出人脸,请继续进行索赔(3)。
[0017]优选地,面部识别包括使用opencv的面部检测算法,皮肤识别算法和图像块算法来执行图片的照度补偿。
[0018]优选地,步骤[3)包括使用图片块算法来计算左,右,上和下背景部分。
[0019]优选地,步骤⑷包括
[0020]对于多张脸,裁剪可收录所有脸的最小框架并将其标记为图片的主要部分;
[0021]当无法截取面部时,将最大的面部构图为图片的主要部分;和
[0022]当不捕获任何面部时,将取下背景部分的框标记为图片的主要部分。
[0023]此外,根据所需的高度或宽度,计算图片主要部分的高度或宽度,然后找到一个
[0024]窗口,即图片保留部分的高度和宽度。
[0025]此外,该方法包括调整截取主体部分失败的大小,包括调整完成模式和调整中央延伸裁切模式;
<p>[0026]补全方法包括:如果截取失败,则可以通过在两侧或上下补充相应的颜色边缘来获得适当的尺寸;中心扩展裁剪方法包括:如果截取失败,例如高度和长度,则从中心扩展相应的宽度。如果宽度和长度增加,则从中心向左扩展,向右扩展以获得合适的尺寸。
解决方案:一种网页内容自动采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-09-04 18:13
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已成为一个庞大的信息库。 Internet信息采集可让您了解有关信息采集,资源整合和资金的更多信息。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当例行新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件也将“过期”并且需要重新排序,但是通常很难及时找到和重新排序。结果,新闻站点一旦被修改,必须在发现之前被发现,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了很多规则维护工作,以及站点修订后需要实时更新规则的问题;
[0008] 4、如果无法及时找到新闻站点修订,则采集个新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有网站自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,如果您不能及时适应网站修订,它将对于k1数据无效,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种用于Web内容的自动采集方法,该方法以可扩展的方式支持多种类型的网页[ k0],每个网页通用采集器都是用不同的算法来实现页面通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集合;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获取页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值收录h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法使用“作者节点特征匹配”方法扫描h节点的父节点的所有子节点,并检查是否匹配的子节点的文本值符合作者节点的特征。如果匹配,请确认子节点是作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,在步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成对发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配匹配,则将该节点确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并去除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录javaScript功能;
[0037](2)一个节点,其值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括: 查看全部
一种用于Web内容的自动采集方法
一种用于Web内容的自动采集方法
[技术领域]
[0001]本发明公开了一种网页内容自动采集方法,涉及互联网数据处理技术领域。
[背景技术]
[0002]随着科学技术的发展,互联网信息进入了一个爆炸性和多元化的时代。互联网已成为一个庞大的信息库。 Internet信息采集可让您了解有关信息采集,资源整合和资金的更多信息。它在利用率和人力投入方面节省了大量资源,并广泛用于工业门户网站网站信息采集,竞争对手情报数据采集,网站内容系统构建,垂直搜索,民意监测,科学研究和其他字段。
[0003]以新闻网页为例。当例行新闻网页内容采集程序运行时,它依赖于为每个不同新闻站点手动提供页面分析模板。格式定义文件定义新闻网页中所有有效数据。项目的xpath,例如新闻标题,正文,作者和出版时间。维护新闻站点页面分析模板非常无聊,并且如果采集程序覆盖更多站点,则工作量将更大。此外,如果新闻站点被修改,则原创页面解析模板文件也将“过期”并且需要重新排序,但是通常很难及时找到和重新排序。结果,新闻站点一旦被修改,必须在发现之前被发现,这些新闻站点的数据将异常甚至丢失。
[0004]由于格式的多样化,数据量的爆炸性增长,严格的监视等,现有新闻网站的采集更加困难,主要表现在:
[0005] 1、有必要手动配置新闻页面分析模板并制定相应信息的xpath。
[0006] 2、 网站捕获了大量信息,并且规则难以统一制定。通常,为每个站点分别配置分析模板,这需要大量工作;
[0007] 3、带来了很多规则维护工作,以及站点修订后需要实时更新规则的问题;
[0008] 4、如果无法及时找到新闻站点修订,则采集个新闻站点的数据将异常。
[0009]现有的常规新闻网页采集都需要为所有网站自定义分析模板,所有自定义和后续维护工作都是乏味而乏味的,如果您不能及时适应网站修订,它将对于k1数据无效,这些问题对于大规模采集系统尤为突出,因此迫切需要新的技术方法来代替人工维护。
[发明内容]
[p10] [0010]鉴于现有技术的缺陷,本发明要解决的技术问题是提供一种用于Web内容的自动采集方法,该方法以可扩展的方式支持多种类型的网页[ k0],每个网页通用采集器都是用不同的算法来实现页面通用采集,并且该算法是从网页的共同特征中抽象出来的。
[0011]本发明采用以下技术方案来解决上述技术问题:
[0012]一种自动采集个Web内容的方法,具体步骤包括:
[0013]步骤一、根据需要,搜索内容采集的网页URL,以找到与网页网站相匹配的采集器集合;
[0014]步骤二、当存在匹配的采集器时,执行采集器获取网页内容;当没有匹配的采集器时,找到不匹配的采集器集合,切勿从匹配的采集器集合中选择采集器并执行采集器以获得网页内容;
[0015]步骤三、 采集成功后,输出Web内容的采集结果;如果采集不成功,请返回步骤2并再次选择采集器。
[0016]作为本发明的另一优选方案,在第二步骤中,采集器的识别过程包括:
[0017] 1、访问目标网页并获取页面字节流;
[0018] 2、将字节流解析为dom对象,将dom中的所有元素与html标签对应,并记录html标签的所有属性和值;
[0019] 3、通过dom对象中的标题节点确认标题范围,其中标题节点的Xpath为:// HTML / HEAD / TITLE;
[0020]通过搜索h节点并比较标题节点来检查网页的标题xpath,其中h节点的Xpath为:// B0DY // * [name O ='H *'];
[0021]当标题节点的值收录h节点的值时,h节点是网页的标题节点,h节点的xpath是网页标题的xpath;
[0022] 4、以h节点为起点来查找发布时间节点;
[0023] 5、以h节点为起点,扫描与h节点的祖父母节点对应的所有子节点,找到文本值最长的节点,并将其确定为网页正文节点;
[0024] 6、确认作者节点,使用“作者节点特征匹配”方法使用“作者节点特征匹配”方法扫描h节点的父节点的所有子节点,并检查是否匹配的子节点的文本值符合作者节点的特征。如果匹配,请确认子节点是作者节点;
[0025] 7、根据页面标题,发布时间节点,文本节点和作者节点,标识与页面内容匹配的MiJi设备。
[0026]作为本发明的另一优选方案,当在步骤6中未使用“作者节点特征匹配”方法成功确认作者节点时,通过“位置猜测”方法确认作者节点:
[0027]从发布节点开始,分析发布节点在其同级节点中的位置,以确定作者节点:
[0028] a。如果发布节点有多个同级节点,并且发布节点排在多个节点的一半之前,则确定发布节点的下一个同级节点是作者节点;
[0029] b。如果发布节点中有多个同级节点,并且发布节点排在多个节点的一半之后,则确定发布节点的前一个同级节点是作者节点。
[0030]作为本发明的另一优选方案,在步骤4中用于确认发布时间节点的具体方法为:
[0031]从h节点的所有子节点中搜索时间节点,如果找到,则完成对发布时间节点的确认;
[0032]否则,继续从节点h的所有同级节点及其所有子节点中搜索时间节点。如果找到,请完成对发布时间节点的确认。
[0033]作为本发明的另一优选方案,步骤4中的发布时间节点的确认算法具体为:
[0034]使用常见时间格式的正则表达式来匹配节点的值。如果匹配匹配,则将该节点确认为发布时间节点。
[0035]作为本发明的另一优选方案,在步骤5中确定网页文本节点的过程还包括根据噪声节点标准对所有节点进行去噪处理,并去除不合理的节点。节点标准具体为:
[0036](I)其中节点的值收录javaScript功能;
[0037](2)一个节点,其值收录的标点符号数量小于设置的阈值。
[0038]作为本发明的另一优选方案,步骤6中判断作者节点的方法包括:
解读:要做采集网站,如何加快收录获得百度搜索引擎的“青睐”?
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2020-09-04 16:18
除著名的Google搜索引擎外,百度的识别度和每日使用率在国内搜索引擎中排名第一,因此我们优化了网站以加快百度搜索引擎的抓取和收录工作这是非常重要的。自2013年百度宣布其首个算法以来,百度共发布了13种算法,48种公告和算法解释文章。这也是学习百度SEO的第一本重要的“教科书”。
采集个电台,例如:信息,小说,电影和电视等将涉及采集问题,可以说小说电影和电视是采集的100%,采集电台的优化友好的百度SEO是一件比较困难的事情,首先,内容是“ pla窃”。即使您的网站是收录,百度也会将您网站排在原创 网站之后;其次,采集的结构被严重同质化。 ,相同的程序集和相同的模板,百度蜘蛛始终像拥有个人用品一样“热爱新事物,讨厌旧事物”。那么,采集站没有出路吗?显然不是,只要您了解百度蜘蛛规则并遵守规则,采集站就不错。
飓风算法
百度于2017年7月4日发布了飓风算法,以解决严重的采集问题,并于2018年9月13日宣布,飓风算法已升级至2. 0版本。可以看出,百度对站点采集做出了特殊的算法,但要注意文字描述:打击不好采集。因此,采集不错,只要它还不错。飓风算法主要打击以下四种不良采集行为:
1、 采集有明显痕迹
说明:该网站收录从其他网站或官方帐户采集转移的许多内容,信息未集成,布局混乱,缺少某些功能或文章可读性差,并且采集的痕迹明显,用户的阅读体验较差。
百度允许采集,但您应注意文章的布局和布局,并且不应该存在与文章主题无关的信息或不可用的功能,这会干扰用户的浏览。无法单击以下图标中的“购买”按钮表示文章的功能丢失;尽管此段文字不是有关剃刀的主题,但它不符合上述科学普及的主题。它是用于出售剃须刀的广告文字。明显的采集痕迹。
2、内容拼接
描述:采集多个具有不同文章的文章被拼接在一起,整体内容没有形成完整的逻辑,并且存在诸如阅读不一致和不连贯文章等问题,无法满足用户的要求需求。
这是我共同讨论的问题,导致出现文章“序言不跟单词”,如下图所示。某些采集器可以支持在采集的内容中添加单词以完成文章伪原创 文章,请勿再次使用它,这只是一个明智的选择。
3、收录大量采集内容
说明:网站下的大多数内容为采集,网站没有内容生产率或较差的内容生产能力,并且网站具有较低的内容质量。
换句话说,尽管百度允许采集,但采集本身也没有盲目。 采集定期添加一些自己撰写的文章是一个很好的解决方案。此外,我们还可以通过重新打印采集适当数量文章来指明来源。
4、跨域采集
说明:该网站依赖采集大量与该网站的域不一致的内容来获取流量。
此处的跨域并不表示跨域。每个网站都有自己的专业领域。如果采集具有美食家文章,则它将是跨域(cross-domain)的。确定网站的领域后,我们必须讨论和发布文章这个领域的主题,这可以提高搜索引擎对网站的专业评价,并获得更多的搜索青睐。跨网域只会降低网站的专业水平,并影响网站的搜索效果。下图中的示例用于教育网站,但是发布了一块黄瓜油炸丝瓜菜文章,属于跨域采集。
Qingfeng算法
2017年9月,百度搜索发布了“庆丰”算法,该算法严厉惩罚网站作弊的网页标题,以欺骗用户并获得点击;从而确保搜索用户的体验并促进搜索生态的健康发展。
标题是文章文章中最精致的部分,一个好的标题只需要看一眼就可以知道该文章文章要说什么。普通用户决定是否点击您的文章,许多用户还会查看您的标题是否有吸引力。请记住,标题适合文章的内容,不要乱用关键词,也不要伪造标题。百度认可的标准标题格式为:“核心词+修饰语”,建议不超过3个修饰语。下图显示了不同页面类型下的标题格式,建议将其添加为书签。
目前,庆丰算法已更新为3. 0,以规范下载行业欺骗下载和捆绑下载的行为。通常,视频台也会采集下载资源,因此请特别注意标题。
Fiberhome算法
FiberHome算法考虑了网站的安全性问题。 网站具有“窃取用户数据”和“恶意劫持”行为。 网站被黑客入侵,并且将被FiberHome算法覆盖。 “恶意劫持”例如,您访问一个视频台,但您莫名其妙地跳到游戏类别中的其他网站。因此,定期检查网站是否有效非常重要。
还有很多其他需要注意的事情,例如修改网站模板以及定期且稳定地提交链接都是优化方法。 查看全部
要做采集 网站,如何加快收录从百度搜索引擎中获得“青睐”?
除著名的Google搜索引擎外,百度的识别度和每日使用率在国内搜索引擎中排名第一,因此我们优化了网站以加快百度搜索引擎的抓取和收录工作这是非常重要的。自2013年百度宣布其首个算法以来,百度共发布了13种算法,48种公告和算法解释文章。这也是学习百度SEO的第一本重要的“教科书”。
采集个电台,例如:信息,小说,电影和电视等将涉及采集问题,可以说小说电影和电视是采集的100%,采集电台的优化友好的百度SEO是一件比较困难的事情,首先,内容是“ pla窃”。即使您的网站是收录,百度也会将您网站排在原创 网站之后;其次,采集的结构被严重同质化。 ,相同的程序集和相同的模板,百度蜘蛛始终像拥有个人用品一样“热爱新事物,讨厌旧事物”。那么,采集站没有出路吗?显然不是,只要您了解百度蜘蛛规则并遵守规则,采集站就不错。
飓风算法
百度于2017年7月4日发布了飓风算法,以解决严重的采集问题,并于2018年9月13日宣布,飓风算法已升级至2. 0版本。可以看出,百度对站点采集做出了特殊的算法,但要注意文字描述:打击不好采集。因此,采集不错,只要它还不错。飓风算法主要打击以下四种不良采集行为:
1、 采集有明显痕迹
说明:该网站收录从其他网站或官方帐户采集转移的许多内容,信息未集成,布局混乱,缺少某些功能或文章可读性差,并且采集的痕迹明显,用户的阅读体验较差。
百度允许采集,但您应注意文章的布局和布局,并且不应该存在与文章主题无关的信息或不可用的功能,这会干扰用户的浏览。无法单击以下图标中的“购买”按钮表示文章的功能丢失;尽管此段文字不是有关剃刀的主题,但它不符合上述科学普及的主题。它是用于出售剃须刀的广告文字。明显的采集痕迹。
2、内容拼接
描述:采集多个具有不同文章的文章被拼接在一起,整体内容没有形成完整的逻辑,并且存在诸如阅读不一致和不连贯文章等问题,无法满足用户的要求需求。
这是我共同讨论的问题,导致出现文章“序言不跟单词”,如下图所示。某些采集器可以支持在采集的内容中添加单词以完成文章伪原创 文章,请勿再次使用它,这只是一个明智的选择。
3、收录大量采集内容
说明:网站下的大多数内容为采集,网站没有内容生产率或较差的内容生产能力,并且网站具有较低的内容质量。
换句话说,尽管百度允许采集,但采集本身也没有盲目。 采集定期添加一些自己撰写的文章是一个很好的解决方案。此外,我们还可以通过重新打印采集适当数量文章来指明来源。
4、跨域采集
说明:该网站依赖采集大量与该网站的域不一致的内容来获取流量。
此处的跨域并不表示跨域。每个网站都有自己的专业领域。如果采集具有美食家文章,则它将是跨域(cross-domain)的。确定网站的领域后,我们必须讨论和发布文章这个领域的主题,这可以提高搜索引擎对网站的专业评价,并获得更多的搜索青睐。跨网域只会降低网站的专业水平,并影响网站的搜索效果。下图中的示例用于教育网站,但是发布了一块黄瓜油炸丝瓜菜文章,属于跨域采集。
Qingfeng算法
2017年9月,百度搜索发布了“庆丰”算法,该算法严厉惩罚网站作弊的网页标题,以欺骗用户并获得点击;从而确保搜索用户的体验并促进搜索生态的健康发展。
标题是文章文章中最精致的部分,一个好的标题只需要看一眼就可以知道该文章文章要说什么。普通用户决定是否点击您的文章,许多用户还会查看您的标题是否有吸引力。请记住,标题适合文章的内容,不要乱用关键词,也不要伪造标题。百度认可的标准标题格式为:“核心词+修饰语”,建议不超过3个修饰语。下图显示了不同页面类型下的标题格式,建议将其添加为书签。
目前,庆丰算法已更新为3. 0,以规范下载行业欺骗下载和捆绑下载的行为。通常,视频台也会采集下载资源,因此请特别注意标题。
Fiberhome算法
FiberHome算法考虑了网站的安全性问题。 网站具有“窃取用户数据”和“恶意劫持”行为。 网站被黑客入侵,并且将被FiberHome算法覆盖。 “恶意劫持”例如,您访问一个视频台,但您莫名其妙地跳到游戏类别中的其他网站。因此,定期检查网站是否有效非常重要。
还有很多其他需要注意的事情,例如修改网站模板以及定期且稳定地提交链接都是优化方法。
解决方案:搜索引擎抓取收录工作流程及原理分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-09-04 04:56
什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是指由搜索引擎公司建立的一组自动爬网程序,称为蜘蛛人。
常见的蜘蛛有:Baiduspider(baiduspider)Google(Gllgledot)
360蜘蛛(360spider),搜狗新闻蜘蛛等。
二、搜索引擎抓取收录工作流程
1、抓取2、过滤器3、商店索引库4、显示排序
获取收录原理图
蜘蛛爬行-网站页面存储临时索引数据库的排名状态(从索引数据库中检索)
临时索引库未存储蜘蛛抓取的所有网站页。它将根据蜘蛛爬网的页面质量进行过滤,并过滤掉一些质量较差的页面。然后放好页面。按页面质量排序。
三、搜索引擎抓取
蜘蛛会跟踪网页的超链接,以在Internet上发现并采集网页信息
2、蜘蛛爬行规则
深度抓取(垂直抓取,首先抓取列的内容页面,然后更改列并以相同的方式抓取)
广泛爬行(水平爬行,首先爬行每个部分,然后爬行每个部分页面下方的内容页面)
3,抓取内容
链接文本图像视频JS CSS iframe蜘蛛
4、影响抓取
链接:收录太多参数的文本结构层次过多(最好3级)链接太长
无法识别内容
需要权限
网站无法打开
四、正在处理网页(过滤)
为什么过滤:采集,内容的值太低,文本不正确,内容不丰富
临时数据库:过滤蜘蛛抓取的内容后,该内容将存储在临时数据库中以供调用。
五、显示顺序
根据质量对存储索引库的内容进行排序,然后调用并显示给用户。
1、检索器根据用户输入的查询关键词在索引数据库中快速检索文档,评估文档和查询的相关性,对要输出的结果进行排序,并将查询结果显示到反馈用户。
2、当我们在搜索引擎中仅看到一个结果时,将根据各种算法对搜索进行排序,并将十个最佳质量的结果放在第一页上 查看全部
搜索引擎抓取收录工作流程和原理分析
什么是搜索引擎蜘蛛?
搜索引擎蜘蛛是指由搜索引擎公司建立的一组自动爬网程序,称为蜘蛛人。
常见的蜘蛛有:Baiduspider(baiduspider)Google(Gllgledot)
360蜘蛛(360spider),搜狗新闻蜘蛛等。
二、搜索引擎抓取收录工作流程
1、抓取2、过滤器3、商店索引库4、显示排序
获取收录原理图
蜘蛛爬行-网站页面存储临时索引数据库的排名状态(从索引数据库中检索)
临时索引库未存储蜘蛛抓取的所有网站页。它将根据蜘蛛爬网的页面质量进行过滤,并过滤掉一些质量较差的页面。然后放好页面。按页面质量排序。
三、搜索引擎抓取
蜘蛛会跟踪网页的超链接,以在Internet上发现并采集网页信息
2、蜘蛛爬行规则
深度抓取(垂直抓取,首先抓取列的内容页面,然后更改列并以相同的方式抓取)
广泛爬行(水平爬行,首先爬行每个部分,然后爬行每个部分页面下方的内容页面)
3,抓取内容
链接文本图像视频JS CSS iframe蜘蛛
4、影响抓取
链接:收录太多参数的文本结构层次过多(最好3级)链接太长
无法识别内容
需要权限
网站无法打开
四、正在处理网页(过滤)
为什么过滤:采集,内容的值太低,文本不正确,内容不丰富
临时数据库:过滤蜘蛛抓取的内容后,该内容将存储在临时数据库中以供调用。
五、显示顺序
根据质量对存储索引库的内容进行排序,然后调用并显示给用户。
1、检索器根据用户输入的查询关键词在索引数据库中快速检索文档,评估文档和查询的相关性,对要输出的结果进行排序,并将查询结果显示到反馈用户。
2、当我们在搜索引擎中仅看到一个结果时,将根据各种算法对搜索进行排序,并将十个最佳质量的结果放在第一页上

