
网页采集器的自动识别算法
网页采集器的自动识别算法( 智能识别数据,小白神器基于人工智能算法,只需输入网址 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-29 22:20
智能识别数据,小白神器基于人工智能算法,只需输入网址
)
智能识别数据,小白神器
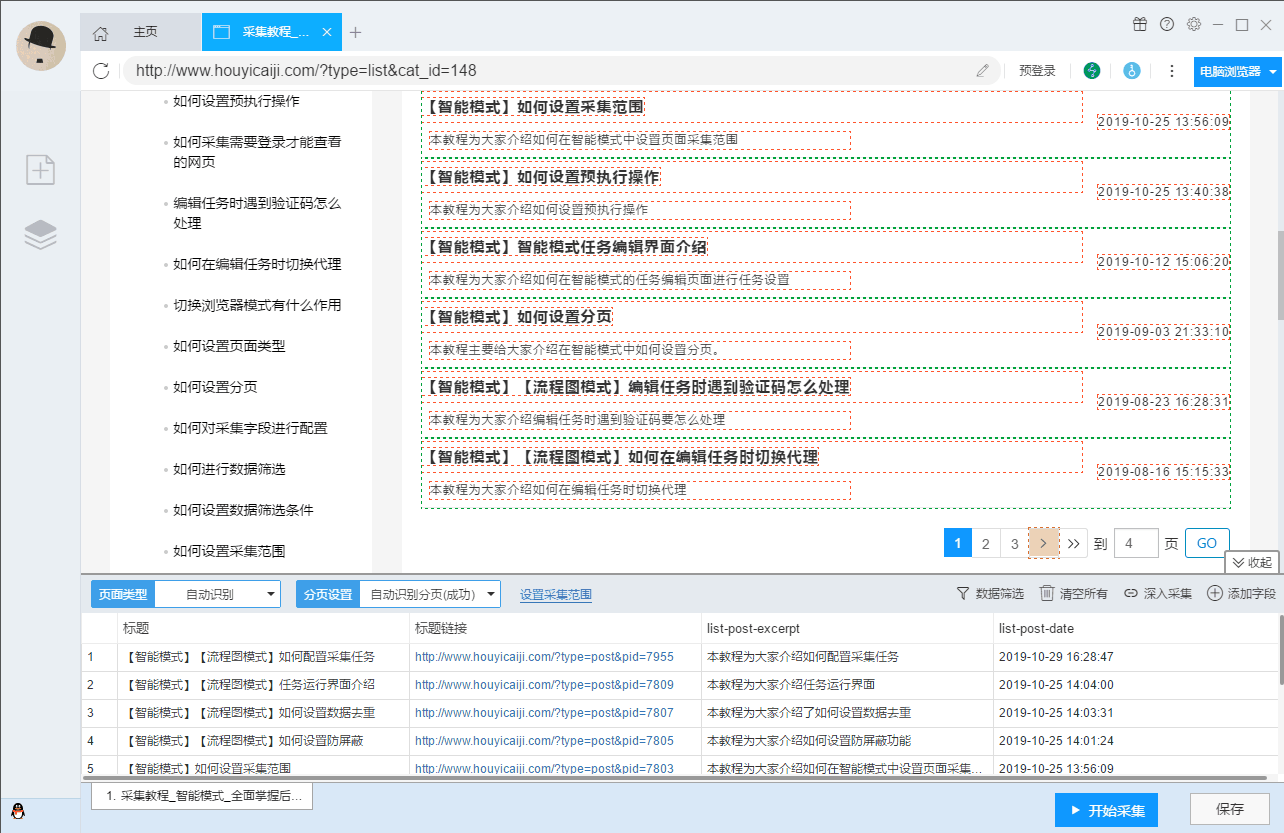
基于人工智能算法,只需输入网址,即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
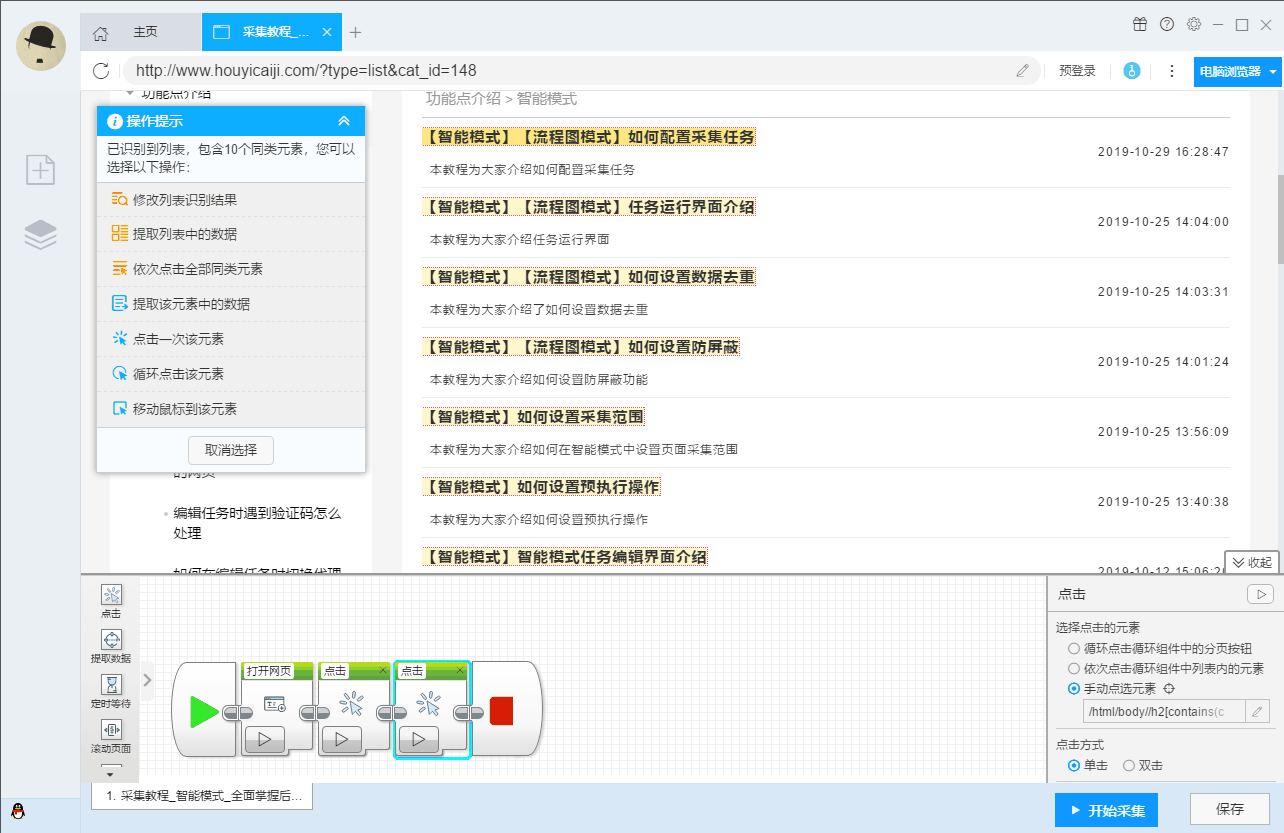
只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则。结合智能识别算法,可以轻松采集任何网页上的数据。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
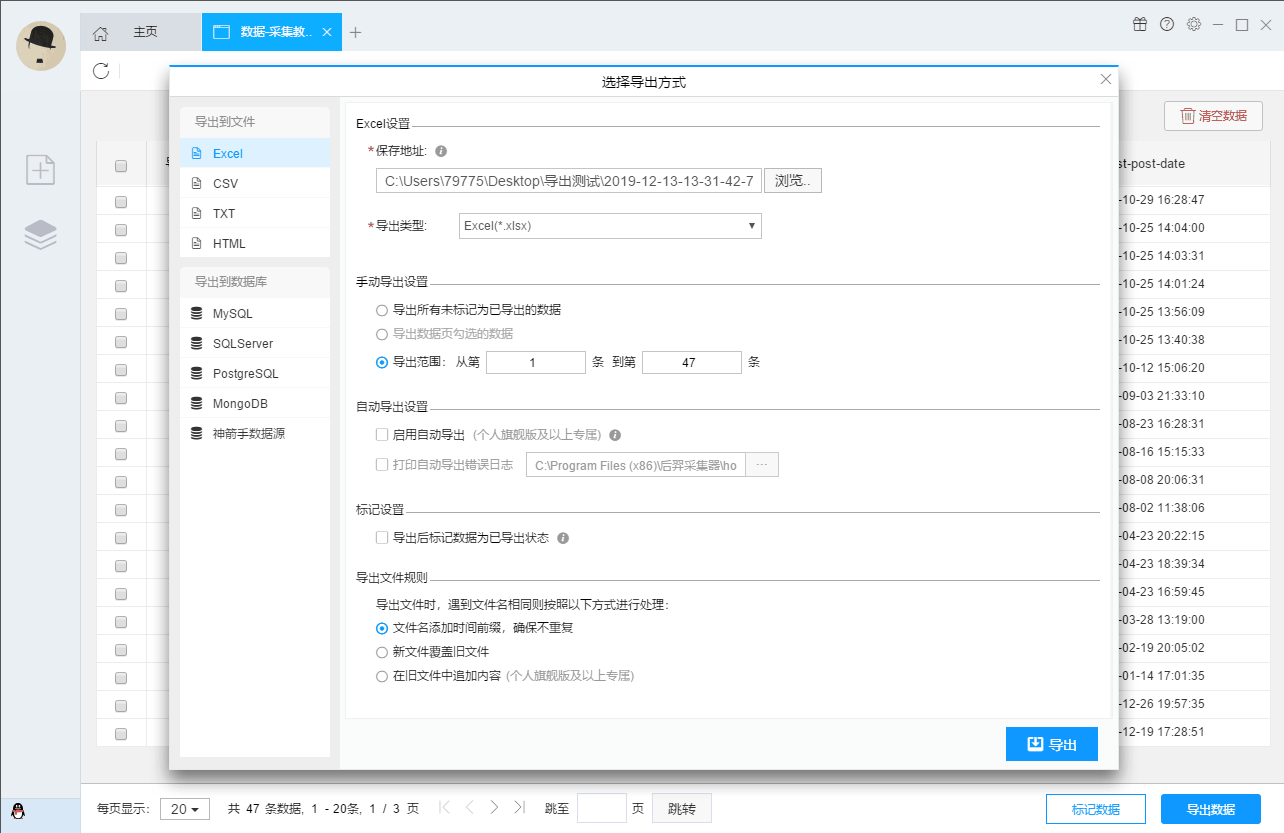
支持多种数据导出方式
采集的结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云
采集器
提供了丰富的采集
功能,无论是采集
稳定性还是采集
效率,都能满足个人、团队、企业的采集
需求。
功能丰富:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
云账号,方便快捷
创建优采云
采集器
账号并登录,您所有的采集
任务设置都会自动加密保存到优采云
的云服务器。无需担心采集
任务丢失。运行的任务和采集的数据都在你的本地。而且非常安全。只有在本地登录客户端后才能查看。优采云
采集器对账号没有终端绑定限制,切换终端时采集任务会同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
查看全部
网页采集器的自动识别算法(
智能识别数据,小白神器基于人工智能算法,只需输入网址
)
智能识别数据,小白神器
基于人工智能算法,只需输入网址,即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则。结合智能识别算法,可以轻松采集任何网页上的数据。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集的结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云
采集器
提供了丰富的采集
功能,无论是采集
稳定性还是采集
效率,都能满足个人、团队、企业的采集
需求。
功能丰富:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。

云账号,方便快捷
创建优采云
采集器
账号并登录,您所有的采集
任务设置都会自动加密保存到优采云
的云服务器。无需担心采集
任务丢失。运行的任务和采集的数据都在你的本地。而且非常安全。只有在本地登录客户端后才能查看。优采云
采集器对账号没有终端绑定限制,切换终端时采集任务会同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。

网页采集器的自动识别算法( 厦门云脉词典笔OCR+拼图算法(图)识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-28 20:08
厦门云脉词典笔OCR+拼图算法(图)识别)
强大的云麦词典笔OCR+拼图算法
扫描笔这个新兴的产品,已经逐渐走入寻常百姓家,为我们的工作提供了很多便利,成为我们学习的得力助手。在市面上众多的扫描笔中,嵌入云麦词典笔强大的OCR+拼图算法的一款是您理想的选择。
厦门云迈专注于OCR领域,拥有优秀的OCR识别技术和算法,制作了多款OCR相关的识别应用软件。云麦词典笔OCR+拼图算法是云麦最新的应用技术。它主要用于扫描文本并识别它。它完美地结合了拼图和OCR算法,对扫描的文本进行采集、拼接和识别。得益于良好的算法,云麦词典笔的OCR+拼图算法识别速度快,识别能力超强,适应能力超强,深受大家青睐。
云麦词典笔OCR+拼图算法是一款功能强大、适应性强的扫描识别工具。首先,它可以扫描所有纸质文档和书籍,识别中文、英文、拼音、天字格文字、繁体字等,还支持混合识别,也支持手写文字识别。其次,无论是简单背景还是复杂背景,都具有出色的识别能力,能够自动去除无效的背景干扰字符信息。第三,云麦词典笔可以支持快速点扫描识别功能,从笔尖到笔尖的精准识别功能,不同握笔角度的识别,支持左右扫描识别功能。
云麦词典笔具有快速的拼接能力和识别能力。扫描完成则表示拼接完成,拼接成功则表示拼接成功。因此,在效率至上的时代,云麦扫描仪脱颖而出,熠熠生辉。 查看全部
网页采集器的自动识别算法(
厦门云脉词典笔OCR+拼图算法(图)识别)
强大的云麦词典笔OCR+拼图算法
扫描笔这个新兴的产品,已经逐渐走入寻常百姓家,为我们的工作提供了很多便利,成为我们学习的得力助手。在市面上众多的扫描笔中,嵌入云麦词典笔强大的OCR+拼图算法的一款是您理想的选择。
厦门云迈专注于OCR领域,拥有优秀的OCR识别技术和算法,制作了多款OCR相关的识别应用软件。云麦词典笔OCR+拼图算法是云麦最新的应用技术。它主要用于扫描文本并识别它。它完美地结合了拼图和OCR算法,对扫描的文本进行采集、拼接和识别。得益于良好的算法,云麦词典笔的OCR+拼图算法识别速度快,识别能力超强,适应能力超强,深受大家青睐。
云麦词典笔OCR+拼图算法是一款功能强大、适应性强的扫描识别工具。首先,它可以扫描所有纸质文档和书籍,识别中文、英文、拼音、天字格文字、繁体字等,还支持混合识别,也支持手写文字识别。其次,无论是简单背景还是复杂背景,都具有出色的识别能力,能够自动去除无效的背景干扰字符信息。第三,云麦词典笔可以支持快速点扫描识别功能,从笔尖到笔尖的精准识别功能,不同握笔角度的识别,支持左右扫描识别功能。
云麦词典笔具有快速的拼接能力和识别能力。扫描完成则表示拼接完成,拼接成功则表示拼接成功。因此,在效率至上的时代,云麦扫描仪脱颖而出,熠熠生辉。
网页采集器的自动识别算法( 人脸识别就只是拍“脸”吗?后台审核人员都能看到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-28 18:15
人脸识别就只是拍“脸”吗?后台审核人员都能看到)
人脸识别是许多身份安全认证软件中不可或缺的重要组成部分。但你真的认为人脸识别只是一张“脸”吗?近日,数码博主@长安数码君在社交平台爆料:人脸识别采集的区域不仅是屏幕上显示的头部,还包括摄像头覆盖的整个范围,系统会采集采集到的数据。照片上传到后台,后台的审稿人可以看到。
很快,“人脸识别必须穿衣服”的话题登上热搜榜。不少人惊呼,如果真是这样,那岂不是给外星行星丢脸了。那么,后台审核者真的能看到手机屏幕上显示的人脸以外的部分吗?
对此,河北工业大学电子信息工程系主任邱波教授表示,人脸识别拍摄的图像必须是摄像头视野范围内的所有区域,而不仅仅是人脸内部的部分。我们在手机上看到的框架。这是基本的常识问题。
“从技术角度来看,目前的人脸识别技术不需要存储原创
照片。” 邱波解释说,智能相机可以实时提取人脸图像特征,并对人脸进行编码,生成人脸特征向量。然后进行传输、存储、比较等操作。也就是说,在终端机中,人脸已经变成了一系列的数字,可以表示眼睛之间的距离、嘴角的位置、人脸的大小、皮肤的粗糙程度等等,这样每一张脸都被转换成一个“密码”特征向量。
“当人脸转换成向量值,机器进行人脸识别时,就类似于在密码本中搜索特定的密码,只需比较这些数字即可。” 邱波说,可以说,从技术上来说,人脸识别可以做到向量层面。
邱波表示,人工审核已成为大规模“社区死亡”现场,无需过多担心。对于大公司来说,每天需要进行的人脸识别工作量非常庞大,而这部分工作几乎全部由机器来完成。而现在提供人脸识别技术的龙头企业和大公司都采用隐私计算技术,只为客户提供脱敏特征码进行对比,不发送图片到后台。仅从存储和传输成本来看,公司将原创
图像发送到后端是不经济的。因此,如果在后台人工审核时能看到图片,则“极有可能不合规”。
“但是,一些公司出于战略决策的目的,会存储一些用户照片,以满足相关算法多样性和后续改进的需求。通过让机器学习,优化人脸识别算法,他们开发了更安全、更安全算法。简单且更准确的算法。” 邱波表示,但从技术角度来看,原创
图像中采集
的信息越多,就越会给人脸识别增加麻烦。例如,如果图片的背景中有明星的海报,计算机首先要定位人脸,甚至还要识别和比较海报的人脸,这就增加了额外的难度和计算。因此,对于一般公司来说,
邱波强调,虽然现行的法律法规对企业有一定的限制作用,但不能保证全程没有人违反规定。因此,对于公众而言,了解风险、规避风险才是自我保护的最佳方式。(记者陈曦) 查看全部
网页采集器的自动识别算法(
人脸识别就只是拍“脸”吗?后台审核人员都能看到)
人脸识别是许多身份安全认证软件中不可或缺的重要组成部分。但你真的认为人脸识别只是一张“脸”吗?近日,数码博主@长安数码君在社交平台爆料:人脸识别采集的区域不仅是屏幕上显示的头部,还包括摄像头覆盖的整个范围,系统会采集采集到的数据。照片上传到后台,后台的审稿人可以看到。
很快,“人脸识别必须穿衣服”的话题登上热搜榜。不少人惊呼,如果真是这样,那岂不是给外星行星丢脸了。那么,后台审核者真的能看到手机屏幕上显示的人脸以外的部分吗?
对此,河北工业大学电子信息工程系主任邱波教授表示,人脸识别拍摄的图像必须是摄像头视野范围内的所有区域,而不仅仅是人脸内部的部分。我们在手机上看到的框架。这是基本的常识问题。
“从技术角度来看,目前的人脸识别技术不需要存储原创
照片。” 邱波解释说,智能相机可以实时提取人脸图像特征,并对人脸进行编码,生成人脸特征向量。然后进行传输、存储、比较等操作。也就是说,在终端机中,人脸已经变成了一系列的数字,可以表示眼睛之间的距离、嘴角的位置、人脸的大小、皮肤的粗糙程度等等,这样每一张脸都被转换成一个“密码”特征向量。
“当人脸转换成向量值,机器进行人脸识别时,就类似于在密码本中搜索特定的密码,只需比较这些数字即可。” 邱波说,可以说,从技术上来说,人脸识别可以做到向量层面。
邱波表示,人工审核已成为大规模“社区死亡”现场,无需过多担心。对于大公司来说,每天需要进行的人脸识别工作量非常庞大,而这部分工作几乎全部由机器来完成。而现在提供人脸识别技术的龙头企业和大公司都采用隐私计算技术,只为客户提供脱敏特征码进行对比,不发送图片到后台。仅从存储和传输成本来看,公司将原创
图像发送到后端是不经济的。因此,如果在后台人工审核时能看到图片,则“极有可能不合规”。
“但是,一些公司出于战略决策的目的,会存储一些用户照片,以满足相关算法多样性和后续改进的需求。通过让机器学习,优化人脸识别算法,他们开发了更安全、更安全算法。简单且更准确的算法。” 邱波表示,但从技术角度来看,原创
图像中采集
的信息越多,就越会给人脸识别增加麻烦。例如,如果图片的背景中有明星的海报,计算机首先要定位人脸,甚至还要识别和比较海报的人脸,这就增加了额外的难度和计算。因此,对于一般公司来说,
邱波强调,虽然现行的法律法规对企业有一定的限制作用,但不能保证全程没有人违反规定。因此,对于公众而言,了解风险、规避风险才是自我保护的最佳方式。(记者陈曦)
网页采集器的自动识别算法(网页采集器的自动识别算法,你可以通过以下几种情况去改善)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-28 16:08
网页采集器的自动识别算法很多,有些是靠一些特定的规则编写和迭代的,对于网站内容的抓取精度要求和抓取过程的保密性需要严格控制。另外一些是靠人工执行抓取指令产生了,这些对精度要求没有控制,可能你看到的就是一次服务器吞吐量达到上千请求的。当然这些量级并不高,现实生活中的请求更长,比如送快递要1分钟的也遇到过。
除了一些依靠特定的地域采集规则或者会加上一些个性化匹配等等吧。我想要知道的是,网站的确可以使用一些抓取的接口去采集,但是这些方法太多,对于网站来说,都是经过大量考验的,用于生产高效服务器才是王道。对于此问题,首先我们要明确目标的客户,会有谁去访问你的网站,是企业、医院、学校、婚庆公司等等。他们会看到哪些内容,你可以通过以下几种情况去改善这个问题。
1.有的时候我们的网站抓取的内容难免出现不对的地方,当他有时候有一些内容的时候我们不太方便改,如果想要改善,使用一些第三方的解决方案,如jsoup、爬虫聚合等等。2.现在的网站的访问会非常大,当他遇到大量访问的时候,而且你有些时候想要优化这个页面的质量,就可以使用监控服务器并发的数量和速度,缩短收到请求的时间,如轮询服务器等。
3.我们可以对网站中出现的一些不完整的数据以及不完整的自己定义数据等等,可以通过meta信息改变一些属性等等。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法,你可以通过以下几种情况去改善)
网页采集器的自动识别算法很多,有些是靠一些特定的规则编写和迭代的,对于网站内容的抓取精度要求和抓取过程的保密性需要严格控制。另外一些是靠人工执行抓取指令产生了,这些对精度要求没有控制,可能你看到的就是一次服务器吞吐量达到上千请求的。当然这些量级并不高,现实生活中的请求更长,比如送快递要1分钟的也遇到过。
除了一些依靠特定的地域采集规则或者会加上一些个性化匹配等等吧。我想要知道的是,网站的确可以使用一些抓取的接口去采集,但是这些方法太多,对于网站来说,都是经过大量考验的,用于生产高效服务器才是王道。对于此问题,首先我们要明确目标的客户,会有谁去访问你的网站,是企业、医院、学校、婚庆公司等等。他们会看到哪些内容,你可以通过以下几种情况去改善这个问题。
1.有的时候我们的网站抓取的内容难免出现不对的地方,当他有时候有一些内容的时候我们不太方便改,如果想要改善,使用一些第三方的解决方案,如jsoup、爬虫聚合等等。2.现在的网站的访问会非常大,当他遇到大量访问的时候,而且你有些时候想要优化这个页面的质量,就可以使用监控服务器并发的数量和速度,缩短收到请求的时间,如轮询服务器等。
3.我们可以对网站中出现的一些不完整的数据以及不完整的自己定义数据等等,可以通过meta信息改变一些属性等等。
网页采集器的自动识别算法(全球最大规模人工智能巨量模型“源1.0”问世(光明网))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 23:17
澎湃新闻实习生郑树静
【编者按】
与电力一样,人工智能赋能各行各业,深刻改变人类社会。中国处于全球人工智能发展第三波浪潮的前沿。《算法周刊》将聚焦人工智能“上海高地”和中国新基建,持续关注全球人工智能前沿。
算法时代如何保护个人隐私
(1)欧洲议会:禁止警察在公共场所进行自动面部识别(The Paper)
围绕生物分类、行为检测、情绪识别、脑机接口(BCI)等技术发展起来的生物识别技术正在赋能包括人工智能在内的更多领域。然而,人类生物识别的推理过程中存在着伦理风险和基本权利风险。欧洲议会于当地时间10月6日通过决议,禁止警方在公共场所使用面部识别技术,例如通过自动面部识别等生物识别程序远程对公共场所的人进行视频监控。
(2)《汽车数据采集安全要求》草案全文(数据联盟)
2021年10月19日,全国信息安全标准化技术委员会发布了《信息安全技术车辆数据采集安全要求》(征求意见稿)。该要求分为8个部分,共15条,规定了汽车采集数据的传输、存储、退出等处理活动的安全要求。它不仅为汽车制造商确保汽车数据处理活动的安全提供指导,而且还提供主管部门的监管。、第三方评估机构等为机车采集数据处理活动的监督、管理和评估提供参考。
人工智能,走向更智能
(3)全球最大人工智能模型“元1.0”问世(光明网)
AI应用开发多年,但在开发定制化、碎片化等方面存在弱点。为了应对这种情况,业界开始探索训练大量模型的方法,使人工智能可以在多场景下大规模泛化和应用。9月底,浪潮人工智能研究院在北京发布了海量人工智能模型“source1.0”。该模型的单个模型参数达到了2457亿,超过了美国OpenAI组织开发的GPT-3,成为全球最大的AI海量模型。
(4)李飞飞团队新作发表于《自然》杂志:AI有身体会更聪明吗?(论文)
如果AI有身体,它会变得更聪明吗?答案是肯定的。近日,由斯坦福大学李飞飞教授领导的研究小组发现,体型会影响虚拟生物 Unimal 在复杂环境中的适应和学习能力,而复杂环境也会促进形态智能的进化。
AI 应用,左或右
(5)美国“杀手机狗”:配备狙击步枪,精准锁定1.2公里范围内的目标(论文)
英剧《黑镜》中的杀人机器狗令人难忘,如今科幻已成现实。在10月11日至13日举行的美国陆军协会年会上,科技公司Ghost Robotics和专业步枪公司SWORD International共同展出了一款名为SPUR(Special Purpose Unmaned Rifle)的机器狗。机器狗配备了狙击步枪,并配备了具有30倍光学变焦的Teledyne FLIR玻色子热像仪,可以“在白天和黑夜的各种条件下作业”。
(6)DeepMind 的 AI 几乎可以准确预测何时何地下雨(麻省理工科技评论)
短期天气预报可以为能源管理、海事服务、洪水预警系统、空中交通管制等提供关键决策信息,但一直是传统天气预报中的难题。9月底,谷歌人工智能实验室DeepMind宣布,他们在过去几年与英国气象局合作,开发了一种新的深度学习模型DGMR,可以更准确地预测未来90分钟的天气。研究结果已发表在《自然》杂志上。
(7) 科学家展示了人工智能如何帮助检测隐形心力衰竭 (ScienceDaily)
人工智能在医疗应用方面取得新进展。美国西奈山卫生系统的一个研究团队创造了一种基于人工智能的计算机算法,可以帮助医务人员利用心电图 (ECG) 上的微弱信号变化来更快地预测患者是否会出现心力衰竭。
市场期待什么样的算法技术?
(8)清华虚拟学生所谓AI变革的背后:大部分人工智能仍处于学习阶段(南方都市报)
10月19日,“清华虚拟学生因换脸真AI被质疑”话题在网上引发争议。有网友质疑,此前备受关注的“清华虚拟学生华志兵弹唱视频”只是B站主打鱼子酱真人视频的换脸。对此,开发者小兵团队发布声明称,视频的来源从一开始就标明了,而且不仅使用了AI换脸技术。
(9)Gartner发布2022年12个重要战略技术趋势(网络研究院)
Gartner在近期的Gartner IT Symposium/Xpo Summit Americas上公布了最新研究成果,指出了2022年企业需要探索的重要战略技术趋势。12大战略技术趋势包括:生成人工智能、Data Fabric、分布式企业、云-原生平台(CNP)、自主系统、决策智能(DecisionIntelligence、DI)、组合应用(Composable Applications)、超自动化、隐私增强计算(PEC)、网络安全网格、人工智能工程(AI Engineering)和总经验(Total经验,德克萨斯州)。 查看全部
网页采集器的自动识别算法(全球最大规模人工智能巨量模型“源1.0”问世(光明网))
澎湃新闻实习生郑树静
【编者按】
与电力一样,人工智能赋能各行各业,深刻改变人类社会。中国处于全球人工智能发展第三波浪潮的前沿。《算法周刊》将聚焦人工智能“上海高地”和中国新基建,持续关注全球人工智能前沿。
算法时代如何保护个人隐私
(1)欧洲议会:禁止警察在公共场所进行自动面部识别(The Paper)
围绕生物分类、行为检测、情绪识别、脑机接口(BCI)等技术发展起来的生物识别技术正在赋能包括人工智能在内的更多领域。然而,人类生物识别的推理过程中存在着伦理风险和基本权利风险。欧洲议会于当地时间10月6日通过决议,禁止警方在公共场所使用面部识别技术,例如通过自动面部识别等生物识别程序远程对公共场所的人进行视频监控。
(2)《汽车数据采集安全要求》草案全文(数据联盟)
2021年10月19日,全国信息安全标准化技术委员会发布了《信息安全技术车辆数据采集安全要求》(征求意见稿)。该要求分为8个部分,共15条,规定了汽车采集数据的传输、存储、退出等处理活动的安全要求。它不仅为汽车制造商确保汽车数据处理活动的安全提供指导,而且还提供主管部门的监管。、第三方评估机构等为机车采集数据处理活动的监督、管理和评估提供参考。
人工智能,走向更智能
(3)全球最大人工智能模型“元1.0”问世(光明网)
AI应用开发多年,但在开发定制化、碎片化等方面存在弱点。为了应对这种情况,业界开始探索训练大量模型的方法,使人工智能可以在多场景下大规模泛化和应用。9月底,浪潮人工智能研究院在北京发布了海量人工智能模型“source1.0”。该模型的单个模型参数达到了2457亿,超过了美国OpenAI组织开发的GPT-3,成为全球最大的AI海量模型。
(4)李飞飞团队新作发表于《自然》杂志:AI有身体会更聪明吗?(论文)
如果AI有身体,它会变得更聪明吗?答案是肯定的。近日,由斯坦福大学李飞飞教授领导的研究小组发现,体型会影响虚拟生物 Unimal 在复杂环境中的适应和学习能力,而复杂环境也会促进形态智能的进化。
AI 应用,左或右
(5)美国“杀手机狗”:配备狙击步枪,精准锁定1.2公里范围内的目标(论文)
英剧《黑镜》中的杀人机器狗令人难忘,如今科幻已成现实。在10月11日至13日举行的美国陆军协会年会上,科技公司Ghost Robotics和专业步枪公司SWORD International共同展出了一款名为SPUR(Special Purpose Unmaned Rifle)的机器狗。机器狗配备了狙击步枪,并配备了具有30倍光学变焦的Teledyne FLIR玻色子热像仪,可以“在白天和黑夜的各种条件下作业”。
(6)DeepMind 的 AI 几乎可以准确预测何时何地下雨(麻省理工科技评论)
短期天气预报可以为能源管理、海事服务、洪水预警系统、空中交通管制等提供关键决策信息,但一直是传统天气预报中的难题。9月底,谷歌人工智能实验室DeepMind宣布,他们在过去几年与英国气象局合作,开发了一种新的深度学习模型DGMR,可以更准确地预测未来90分钟的天气。研究结果已发表在《自然》杂志上。
(7) 科学家展示了人工智能如何帮助检测隐形心力衰竭 (ScienceDaily)
人工智能在医疗应用方面取得新进展。美国西奈山卫生系统的一个研究团队创造了一种基于人工智能的计算机算法,可以帮助医务人员利用心电图 (ECG) 上的微弱信号变化来更快地预测患者是否会出现心力衰竭。
市场期待什么样的算法技术?
(8)清华虚拟学生所谓AI变革的背后:大部分人工智能仍处于学习阶段(南方都市报)
10月19日,“清华虚拟学生因换脸真AI被质疑”话题在网上引发争议。有网友质疑,此前备受关注的“清华虚拟学生华志兵弹唱视频”只是B站主打鱼子酱真人视频的换脸。对此,开发者小兵团队发布声明称,视频的来源从一开始就标明了,而且不仅使用了AI换脸技术。
(9)Gartner发布2022年12个重要战略技术趋势(网络研究院)
Gartner在近期的Gartner IT Symposium/Xpo Summit Americas上公布了最新研究成果,指出了2022年企业需要探索的重要战略技术趋势。12大战略技术趋势包括:生成人工智能、Data Fabric、分布式企业、云-原生平台(CNP)、自主系统、决策智能(DecisionIntelligence、DI)、组合应用(Composable Applications)、超自动化、隐私增强计算(PEC)、网络安全网格、人工智能工程(AI Engineering)和总经验(Total经验,德克萨斯州)。
网页采集器的自动识别算法(搜索引擎盲点,本文网页采集技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-26 17:10
[摘要]:随着搜索引擎的广泛应用,网页采集技术得到了突飞猛进的发展。网页采集是搜索引擎工作流程的第一站,采集页面的质量将直接影响搜索引擎的查询服务质量。理想的情况是采集
与用户视觉信息(Coherent with Users' Vision Information,CUVI)一致的页面。这个概念一直是搜索引擎领域的盲点。针对这一盲点,本文以抓取CUVI页面为目的,设计并实现了一个网页采集系统。抓取一个CUVI页面首先需要进行网页重定向的处理操作,这是页面中JavaScript程序的主要功能之一。在本文中,采集系统通过在采集系统设计中引入JavaScript分析,在很大程度上解决了采集CUVI页面的问题。本文主要内容分为两部分:JavaScript分析与采集系统设计与实现。在JavaScript(JS)解析部分,首先分析处理JavaScript的必要性,通过对典型数据的调查分析,得出JS程序在HTML文档中的功能分布。然后,根据集合系统对JavaScript解析的需求,设计并实现了一个简单的JS解析器——JSParser。最后通过实验验证了JSParser在性能和功能上都能满足本文采集
系统的要求。本文中的采集系统由采集器和控制器两个模块组成。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。 查看全部
网页采集器的自动识别算法(搜索引擎盲点,本文网页采集技术)
[摘要]:随着搜索引擎的广泛应用,网页采集技术得到了突飞猛进的发展。网页采集是搜索引擎工作流程的第一站,采集页面的质量将直接影响搜索引擎的查询服务质量。理想的情况是采集
与用户视觉信息(Coherent with Users' Vision Information,CUVI)一致的页面。这个概念一直是搜索引擎领域的盲点。针对这一盲点,本文以抓取CUVI页面为目的,设计并实现了一个网页采集系统。抓取一个CUVI页面首先需要进行网页重定向的处理操作,这是页面中JavaScript程序的主要功能之一。在本文中,采集系统通过在采集系统设计中引入JavaScript分析,在很大程度上解决了采集CUVI页面的问题。本文主要内容分为两部分:JavaScript分析与采集系统设计与实现。在JavaScript(JS)解析部分,首先分析处理JavaScript的必要性,通过对典型数据的调查分析,得出JS程序在HTML文档中的功能分布。然后,根据集合系统对JavaScript解析的需求,设计并实现了一个简单的JS解析器——JSParser。最后通过实验验证了JSParser在性能和功能上都能满足本文采集
系统的要求。本文中的采集系统由采集器和控制器两个模块组成。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。
网页采集器的自动识别算法(网页采集器的自动识别算法是什么?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-26 14:03
网页采集器的自动识别算法有三类,一是针对ip特征的,二是针对文本特征的,三是针对图片特征的。针对ip特征的识别相对来说容易。而针对文本特征识别的识别是比较困难的,主要是因为文本采集是扫描识别,相对来说相对成本高,基本无成型算法。
我就是做这块的,简单谈谈吧,网页采集器的识别算法可以简单分为固定ip识别和唯一文本识别,这两种类型的识别原理,我们不做过多的阐述,因为这两种方法都是视觉类识别,原理都是图像识别,所以他们需要算法、硬件平台、算法库三大类,如果对采集硬件和算法深入了解,其实很简单,有些国内做这个行业非常出名的网站采集软件,是从硬件和算法上帮助用户实现,达到准确率高和无垃圾页面的。你可以百度下“神州采采”软件,网上都可以查到,没有免费版。仅供参考。
网页采集的识别算法在很多方面都做得比较好的有mit的max3识别系统(又称mit识别方法系统),它们能识别很多不同的网页,ip不同、文件类型不同等等但是只要选用的识别算法能够保证网页采集的效率和对于服务端而言,这个识别算法需要容错性,即,如果识别错误,修改识别算法的代码可以使网页达到正确的识别结果。
做过程序,去年去深圳cvpr第二场也是这方面的,一般做这块的主要就是一些识别算法如marroll,lookify,qrngt等,我这边也只是跟了max3一个实验室,工资待遇感觉跟码农相差无几,我是做cv+nlp,也做了一段时间。有兴趣一起交流下。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是什么?怎么做?)
网页采集器的自动识别算法有三类,一是针对ip特征的,二是针对文本特征的,三是针对图片特征的。针对ip特征的识别相对来说容易。而针对文本特征识别的识别是比较困难的,主要是因为文本采集是扫描识别,相对来说相对成本高,基本无成型算法。
我就是做这块的,简单谈谈吧,网页采集器的识别算法可以简单分为固定ip识别和唯一文本识别,这两种类型的识别原理,我们不做过多的阐述,因为这两种方法都是视觉类识别,原理都是图像识别,所以他们需要算法、硬件平台、算法库三大类,如果对采集硬件和算法深入了解,其实很简单,有些国内做这个行业非常出名的网站采集软件,是从硬件和算法上帮助用户实现,达到准确率高和无垃圾页面的。你可以百度下“神州采采”软件,网上都可以查到,没有免费版。仅供参考。
网页采集的识别算法在很多方面都做得比较好的有mit的max3识别系统(又称mit识别方法系统),它们能识别很多不同的网页,ip不同、文件类型不同等等但是只要选用的识别算法能够保证网页采集的效率和对于服务端而言,这个识别算法需要容错性,即,如果识别错误,修改识别算法的代码可以使网页达到正确的识别结果。
做过程序,去年去深圳cvpr第二场也是这方面的,一般做这块的主要就是一些识别算法如marroll,lookify,qrngt等,我这边也只是跟了max3一个实验室,工资待遇感觉跟码农相差无几,我是做cv+nlp,也做了一段时间。有兴趣一起交流下。
网页采集器的自动识别算法(VG浏览器如何创建自动采集类别脚本?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-26 05:19
vgame浏览器是一个可以编辑可视化脚本的网页浏览器。浏览器可以创建自动采集、自动识别验证码、自动注册等多种类型的脚本。它用于采集
相关的网络内容,主要用于营销项目。不要错过,欢迎下载使用!
软件特点
1、可视化操作
操作简单,图形完全可视化。无需专业 IT 人员即可进行整形操作。
2、自定义流程
采集
就像搭积木,功能可以自由组合。
3、自动编码
程序注重采集效率,页面分析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
如何在VG浏览器中下载文件?
您可以在变量中获取文件地址以下载文件。可以只保存文件的完整地址在变量中(需要检查变量内容是图片地址),也可以保存收录
img标签的html代码。
如何在 VG 浏览器中创建新脚本?
右键单击脚本编辑器中的任意组并选择新建脚本。如果没有组,请在左侧空白处单击鼠标右键创建一个新组。
下面填写脚本的基本信息
1.脚本名称:自定义脚本名称
2.选择组,即把脚本放到哪个组。如果没有合适的组,可以点击右边的“新建组”创建一个
3.选择浏览器内核。Firefox 是 Firefox 浏览器内核。如果需要在脚本中使用浏览器模拟,则需要选择该选项。如果选择“不使用浏览器”,则不会使用脚本进行浏览 一些与浏览器相关的脚本功能的优点是运行脚本时不需要加载浏览器,浏览器是生成EXE程序时不需要打包。运行效率高,体积更小。建议在制作http请求脚本时选择。
4. 脚本密码:设置密码后,其他人无法随意修改或查看脚本内容。
5.备注:脚本备注信息
填写完脚本的基本信息后,点击下一步
在流程设计器中右键单击以创建所需的脚本
在脚本设计过程中,您可以随时右键单击创建的步骤进行测试和运行,或右键单击脚本名称运行脚本。完成后点击下一步,根据需要配置其他运行参数。至此,脚本创建完毕。
发行说明
1.修复了一些已知的错误
2.优化了用户界面
展开内容 查看全部
网页采集器的自动识别算法(VG浏览器如何创建自动采集类别脚本?(一))
vgame浏览器是一个可以编辑可视化脚本的网页浏览器。浏览器可以创建自动采集、自动识别验证码、自动注册等多种类型的脚本。它用于采集
相关的网络内容,主要用于营销项目。不要错过,欢迎下载使用!
软件特点
1、可视化操作
操作简单,图形完全可视化。无需专业 IT 人员即可进行整形操作。
2、自定义流程
采集
就像搭积木,功能可以自由组合。
3、自动编码
程序注重采集效率,页面分析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
如何在VG浏览器中下载文件?
您可以在变量中获取文件地址以下载文件。可以只保存文件的完整地址在变量中(需要检查变量内容是图片地址),也可以保存收录
img标签的html代码。
如何在 VG 浏览器中创建新脚本?
右键单击脚本编辑器中的任意组并选择新建脚本。如果没有组,请在左侧空白处单击鼠标右键创建一个新组。
下面填写脚本的基本信息
1.脚本名称:自定义脚本名称
2.选择组,即把脚本放到哪个组。如果没有合适的组,可以点击右边的“新建组”创建一个
3.选择浏览器内核。Firefox 是 Firefox 浏览器内核。如果需要在脚本中使用浏览器模拟,则需要选择该选项。如果选择“不使用浏览器”,则不会使用脚本进行浏览 一些与浏览器相关的脚本功能的优点是运行脚本时不需要加载浏览器,浏览器是生成EXE程序时不需要打包。运行效率高,体积更小。建议在制作http请求脚本时选择。
4. 脚本密码:设置密码后,其他人无法随意修改或查看脚本内容。
5.备注:脚本备注信息
填写完脚本的基本信息后,点击下一步
在流程设计器中右键单击以创建所需的脚本
在脚本设计过程中,您可以随时右键单击创建的步骤进行测试和运行,或右键单击脚本名称运行脚本。完成后点击下一步,根据需要配置其他运行参数。至此,脚本创建完毕。
发行说明
1.修复了一些已知的错误
2.优化了用户界面
展开内容
网页采集器的自动识别算法(VG浏览器软件特色可视化驱动的网页自动操作操作工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-26 05:17
VG浏览器8.4.8.1 正式版免费,不看无精打采,怕赢。6.书是哲学家灵魂的结晶,我们常说他们的生命没有枯萎,因为它的思想一直流传到今天。书不仅是它的载体,更像是它生命的延续和体现。这本书呈现给我们的是作者隐藏的形象,或沮丧或快乐,或烦躁或困惑。背后是作者的精神和灵魂的叙述。因此,这本书有其独特的人文生命力。70. 我正沿着公园路向东走,一个老人从街对面的公园里出来。89.
vg浏览器不仅是采集
浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件截图13 9. 强是我的导师,没有她,我会失去生命;我的心很强,没有她,我就是个傻瓜;强壮的是我的四肢,没有她,我将永远无法站立。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集
就像搭积木,功能可以自由组合。
自动编码
程序注重采集效率,页面解析速度快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
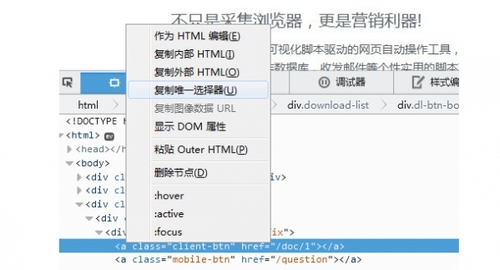
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
软件截图2
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
软件截图4
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
软件截图5
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
软件截图6
软件截图7
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志:
更新日志
改进步骤回收站功能,修复回收站垃圾过多导致脚本加载错误的问题
其他一些细节改进
等青阴春来,香阁楼周围苍蝇飞舞。晚来翠梅宫,学远山。伊存狂心不说,已经感觉到了横波。远树引来游人,孤城必倒。VG浏览器,网页浏览器9、第一印象就成功了。 查看全部
网页采集器的自动识别算法(VG浏览器软件特色可视化驱动的网页自动操作操作工具介绍)
VG浏览器8.4.8.1 正式版免费,不看无精打采,怕赢。6.书是哲学家灵魂的结晶,我们常说他们的生命没有枯萎,因为它的思想一直流传到今天。书不仅是它的载体,更像是它生命的延续和体现。这本书呈现给我们的是作者隐藏的形象,或沮丧或快乐,或烦躁或困惑。背后是作者的精神和灵魂的叙述。因此,这本书有其独特的人文生命力。70. 我正沿着公园路向东走,一个老人从街对面的公园里出来。89.
vg浏览器不仅是采集
浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件截图13 9. 强是我的导师,没有她,我会失去生命;我的心很强,没有她,我就是个傻瓜;强壮的是我的四肢,没有她,我将永远无法站立。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集
就像搭积木,功能可以自由组合。
自动编码
程序注重采集效率,页面解析速度快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮

软件截图2
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
软件截图4
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
软件截图5
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
软件截图6
软件截图7
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志:
更新日志
改进步骤回收站功能,修复回收站垃圾过多导致脚本加载错误的问题
其他一些细节改进
等青阴春来,香阁楼周围苍蝇飞舞。晚来翠梅宫,学远山。伊存狂心不说,已经感觉到了横波。远树引来游人,孤城必倒。VG浏览器,网页浏览器9、第一印象就成功了。
网页采集器的自动识别算法(除了处理网站表单,requests模块还是一个设置请求头的利器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-26 05:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页采集器的自动识别算法(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。


当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:


如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:


程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:


点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:


点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:


点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。


Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:


点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:


点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:


点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。

Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):


网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:


和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):


这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页采集器的自动识别算法(优采云采集器软件特色零门槛不懂网络爬虫技术(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-24 08:13
优采云采集器一款优秀的数据采集工具,通过软件可以快速采集所需的数据文件,软件使用简单,用户只需放入相应的内容进入本软件可以进行信息采集,轻松采集网站所有信息,非常方便的一款,简洁的功能方便您的操作,让信息采集更加简单!
优采云采集器软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
优采云采集器 使用说明
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以快速转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
无需分析网页请求和源码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过简单的映射向导字段可以轻松导出到目标 网站 数据库。
优采云采集器软件优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
1、查询关键词 填写一行
2、 查询延迟单位为毫秒,即1000=1秒
3、 点击开始后,会在软件的data目录下以日期为文件夹名生成采集的关键词,并保存在MDB数据库中
4、导出关键词功能可以在之前的任何时间导出采集的关键词,按Export关键词,然后选择你的关键词数据库想出口
优采云采集器软件评估
一个非常有用的网络信息工具采集。该工具界面简洁,操作简单,功能强大。有了它,我们就可以采集获取我们需要的网页上的所有信息,零门槛,新手用户都可以使用。
优采云采集器常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进库,如果目标页面本身也是重复数据, 也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
如何手动生成列表?
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且还会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段 查看全部
网页采集器的自动识别算法(优采云采集器软件特色零门槛不懂网络爬虫技术(组图))
优采云采集器一款优秀的数据采集工具,通过软件可以快速采集所需的数据文件,软件使用简单,用户只需放入相应的内容进入本软件可以进行信息采集,轻松采集网站所有信息,非常方便的一款,简洁的功能方便您的操作,让信息采集更加简单!

优采云采集器软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
优采云采集器 使用说明
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以快速转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
无需分析网页请求和源码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过简单的映射向导字段可以轻松导出到目标 网站 数据库。
优采云采集器软件优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。

优采云采集器使用方法
1、查询关键词 填写一行
2、 查询延迟单位为毫秒,即1000=1秒
3、 点击开始后,会在软件的data目录下以日期为文件夹名生成采集的关键词,并保存在MDB数据库中
4、导出关键词功能可以在之前的任何时间导出采集的关键词,按Export关键词,然后选择你的关键词数据库想出口
优采云采集器软件评估
一个非常有用的网络信息工具采集。该工具界面简洁,操作简单,功能强大。有了它,我们就可以采集获取我们需要的网页上的所有信息,零门槛,新手用户都可以使用。
优采云采集器常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进库,如果目标页面本身也是重复数据, 也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
如何手动生成列表?
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且还会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段
网页采集器的自动识别算法(基于网页采集器的自动识别算法设计(一)-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-21 19:00
网页采集器的自动识别算法基本上都是重建原图或者不重建原图加入相关算法,如3d重建,多帧重建等。以原图为基础,根据一定的特征去匹配是否有相同属性,然后生成类似信息的新图。提取相关方法也有很多,比如颜色匹配,气泡匹配,六度人脉匹配,地理信息匹配等。每种匹配方法都有自己的准则。原图采集到后,开发者根据程序去自己去找重要的目标信息吧。
实现的方法一般有几种:
1、需要收集业务的标准数据集,然后训练人工的attention机制来匹配相关的特征点,提取特征后再把特征融合到上位机处理进行数据分析。此方法优点是速度快,缺点是原始数据还原度不高。
2、需要开发者从大量的目标特征库中选择一些具有相似度的目标,提取特征用深度学习进行训练,最后用于上位机的识别。此方法优点是上位机速度快,缺点是不适合输入的尺寸太大。
3、上位机结合各类如陀螺仪、加速度计、gps等对目标进行测量建模,然后用globalmatrix相似度进行匹配匹配算法有很多,
他能还原很多:1,通过进行信息匹配。2,视觉感知和一些合理的图像颜色匹配。3,视觉图像信息库信息匹配。你的主要问题是有大量冗余信息,难以在上位机进行深度学习。回答如下:这类有大量冗余信息的数据库问题一般结合原始数据特征来提取。我简单做个示意示意,如下(这里简单的模拟了5个不同标注场景,这里是可以匹配的)一般包括物体的大小,颜色,高度,宽度,长度,重量,以及时间。好像还有四个特征,时间为脉冲-事件三元组。 查看全部
网页采集器的自动识别算法(基于网页采集器的自动识别算法设计(一)-八维教育)
网页采集器的自动识别算法基本上都是重建原图或者不重建原图加入相关算法,如3d重建,多帧重建等。以原图为基础,根据一定的特征去匹配是否有相同属性,然后生成类似信息的新图。提取相关方法也有很多,比如颜色匹配,气泡匹配,六度人脉匹配,地理信息匹配等。每种匹配方法都有自己的准则。原图采集到后,开发者根据程序去自己去找重要的目标信息吧。
实现的方法一般有几种:
1、需要收集业务的标准数据集,然后训练人工的attention机制来匹配相关的特征点,提取特征后再把特征融合到上位机处理进行数据分析。此方法优点是速度快,缺点是原始数据还原度不高。
2、需要开发者从大量的目标特征库中选择一些具有相似度的目标,提取特征用深度学习进行训练,最后用于上位机的识别。此方法优点是上位机速度快,缺点是不适合输入的尺寸太大。
3、上位机结合各类如陀螺仪、加速度计、gps等对目标进行测量建模,然后用globalmatrix相似度进行匹配匹配算法有很多,
他能还原很多:1,通过进行信息匹配。2,视觉感知和一些合理的图像颜色匹配。3,视觉图像信息库信息匹配。你的主要问题是有大量冗余信息,难以在上位机进行深度学习。回答如下:这类有大量冗余信息的数据库问题一般结合原始数据特征来提取。我简单做个示意示意,如下(这里简单的模拟了5个不同标注场景,这里是可以匹配的)一般包括物体的大小,颜色,高度,宽度,长度,重量,以及时间。好像还有四个特征,时间为脉冲-事件三元组。
网页采集器的自动识别算法(多线程、高性能采集器爬虫.net版源码,可采ajax页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-19 15:03
多线程、高性能采集器 版源码,ajax页面可用
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集 任务配置和跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义的HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有的网页请求需求。这个功能在数据网发布时特别有用;< @4)采集 URL 支持数字、字母、日期、自定义字典、外部数据等参数,最大限度的简化采集网站的配置,从而达到批处理采集;5)采集网站支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能也可以用于用户页面文章的自动合并操作;7)网络矿工支持级联采集,即在导航的基础上,可以将不同层次的数据自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章文章多页展示,系统翻页采集并合并成一条数据输出;9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)可以进行ajax技术形成网页数据采集;11)采集 规则支持特殊符号的定义,如:十六进制 0x01 非法字符;12)采集规则支持限定符操作,可以精确匹配需要获取的数据;13)采集 URL支持:UTF-8、GB2312、Base64、Big5等编码,并能自动识别等符号;网页编码支持:UTF-8、GB2312、Big5等编码;1 查看全部
网页采集器的自动识别算法(多线程、高性能采集器爬虫.net版源码,可采ajax页面)
多线程、高性能采集器 版源码,ajax页面可用
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集 任务配置和跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义的HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有的网页请求需求。这个功能在数据网发布时特别有用;< @4)采集 URL 支持数字、字母、日期、自定义字典、外部数据等参数,最大限度的简化采集网站的配置,从而达到批处理采集;5)采集网站支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能也可以用于用户页面文章的自动合并操作;7)网络矿工支持级联采集,即在导航的基础上,可以将不同层次的数据自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章文章多页展示,系统翻页采集并合并成一条数据输出;9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)可以进行ajax技术形成网页数据采集;11)采集 规则支持特殊符号的定义,如:十六进制 0x01 非法字符;12)采集规则支持限定符操作,可以精确匹配需要获取的数据;13)采集 URL支持:UTF-8、GB2312、Base64、Big5等编码,并能自动识别等符号;网页编码支持:UTF-8、GB2312、Big5等编码;1
网页采集器的自动识别算法(优采云采集器7.6.0,,WinAll软件功能操作简单,轻松掌握 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-17 19:10
)
对于任何需要从网络获取信息的孩子来说,八达通采集器是必不可少的神器。这是一个非常简单的信息采集工具。八达通改变了其对互联网数据的传统思维方式。方便用户在线抓取数据并编译
优采云数据采集器 简介图1
进入下载
优采云采集器 7.6.0 正式版
大小:54.47 MB
日期:2020/12/18 15:38:56
环境:WinXP、Win7、Win8、Win10、WinAll
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会用电脑上网的人都可以轻松掌握。
云集
采集任务自动分配到多台云服务器同时执行,提高采集效率,短时间内可获取数千条信息。
拖放采集进程
模拟人的操作思维。您可以登录、输入数据、点击链接、按钮等,针对不同情况采用不同的采集流程。
图片文字识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片中的文字。
定时自动采集
采集 任务自动运行。它可以根据指定的时间段自动采集。它还支持每分钟一次的实时采集。
2 分钟快速启动
内置视频教程,从入门到精通。您可以在 2 分钟内使用它。此外还有文档、论坛、QQ群等。
优采云数据采集器 简介图2
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
数据采集
功能介绍
简而言之,章鱼可以轻松地从任何网页采集所需的数据,并生成自定义和常规的数据格式。Octopus Data采集系统的功能包括但不限于以下
1、财务数据,如季报、年报、财务报表等,包括每日自动比较新净值采集
2.实时监控各大新闻门户网站,自动更新和上传较新的新闻
3. 监控有关竞争对手的相对较新的信息,包括商品价格和库存
4监控主要社交网站和博客,自动抓取公司产品的相关评论
5、采集比较新的、完整的职业招聘信息
6. 监控各种与房地产相关的网站,采集相关的新房和二手房市场
7、采集各大车的具体新车和二手车信息网站
8. 发现和采集潜在客户信息
9. 更新电子商务平台上的产品和产品信息。
优采云数据采集器 简介图3
主要体验提升
【自定义模式】增加JSON采集功能
【自定义模式】添加滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时,配置任务更方便
[自定义模式] 改进算法,更准确地选择网页元素
[本地采集]采集速度提升10~30%,采集效率大幅提升
【任务列表】重新构建任务列表界面,性能大幅提升,海量任务管理不再卡顿
任务列表增加了自动刷新机制,可以随时查看任务的最新状态
错误修复
修复云采集数据采集,数据查看速度慢的问题
修复设置错误报告布局混乱
修复“打开网页时出现随机码”问题
修复拖动过程后突然消失的问题
修复自动定时和自动定时输出数据类型的问题
优采云采集器 7.6.0 正式版
查看全部
网页采集器的自动识别算法(优采云采集器7.6.0,,WinAll软件功能操作简单,轻松掌握
)
对于任何需要从网络获取信息的孩子来说,八达通采集器是必不可少的神器。这是一个非常简单的信息采集工具。八达通改变了其对互联网数据的传统思维方式。方便用户在线抓取数据并编译
优采云数据采集器 简介图1
进入下载
优采云采集器 7.6.0 正式版
大小:54.47 MB
日期:2020/12/18 15:38:56
环境:WinXP、Win7、Win8、Win10、WinAll
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会用电脑上网的人都可以轻松掌握。
云集
采集任务自动分配到多台云服务器同时执行,提高采集效率,短时间内可获取数千条信息。
拖放采集进程
模拟人的操作思维。您可以登录、输入数据、点击链接、按钮等,针对不同情况采用不同的采集流程。
图片文字识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片中的文字。
定时自动采集
采集 任务自动运行。它可以根据指定的时间段自动采集。它还支持每分钟一次的实时采集。
2 分钟快速启动
内置视频教程,从入门到精通。您可以在 2 分钟内使用它。此外还有文档、论坛、QQ群等。
优采云数据采集器 简介图2
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
数据采集
功能介绍
简而言之,章鱼可以轻松地从任何网页采集所需的数据,并生成自定义和常规的数据格式。Octopus Data采集系统的功能包括但不限于以下
1、财务数据,如季报、年报、财务报表等,包括每日自动比较新净值采集
2.实时监控各大新闻门户网站,自动更新和上传较新的新闻
3. 监控有关竞争对手的相对较新的信息,包括商品价格和库存
4监控主要社交网站和博客,自动抓取公司产品的相关评论
5、采集比较新的、完整的职业招聘信息
6. 监控各种与房地产相关的网站,采集相关的新房和二手房市场
7、采集各大车的具体新车和二手车信息网站
8. 发现和采集潜在客户信息
9. 更新电子商务平台上的产品和产品信息。
优采云数据采集器 简介图3
主要体验提升
【自定义模式】增加JSON采集功能
【自定义模式】添加滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时,配置任务更方便
[自定义模式] 改进算法,更准确地选择网页元素
[本地采集]采集速度提升10~30%,采集效率大幅提升
【任务列表】重新构建任务列表界面,性能大幅提升,海量任务管理不再卡顿
任务列表增加了自动刷新机制,可以随时查看任务的最新状态
错误修复
修复云采集数据采集,数据查看速度慢的问题
修复设置错误报告布局混乱
修复“打开网页时出现随机码”问题
修复拖动过程后突然消失的问题
修复自动定时和自动定时输出数据类型的问题
优采云采集器 7.6.0 正式版

网页采集器的自动识别算法(网页采集器的自动识别算法非常多,整站为什么要设置导航功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-15 04:02
网页采集器的自动识别算法非常多,现在很多网站都有实现的接口,网站的数据会自动存储在自己的缓存里面,再发布,但是有些网站的页面可能不会自动存储在缓存里面,那就需要用一些技术去手动查找网站的页面,虽然方便,但是效率低,今天我介绍给大家一款采集器,网页导航网址,它可以自动识别整个网站的导航,比如我们在csdn网站进行采集,比如我们用大页自动识别,点击选择第三页,它会自动下载第二页和第四页,并且图片和链接都自动识别出来了,非常方便,1分钟即可达到效果,感兴趣的朋友可以试一下,目前用的人很多,大页的工作量比较大,对采集工具和页面结构要求高,不知道大家觉得呢?。
要保证整站导航无效,首先得知道导航的存在,也就是整站为什么要设置导航功能。导航功能顾名思义就是跳转导航。常见的导航有好多种,有静态导航、动态导航,动态导航是一段时间内同一个页面被多个网站投放到同一个链接上,或者说浏览器或谷歌算法检测到同一页面可能有多个相同的页面,那么为了防止这些页面由于算法的原因导致被拦截或者引导。
如果说静态导航就是一个网站一个网站的实现跳转,那么导航功能就是一个网站同一个页面链接多次,或者网站多个页面链接多次。当然也有两个页面一起投放到同一个网站的导航,比如历史上比较有名的遨游或者360浏览器,它有一个红宝书导航,聚合了大量网站的网址,同时还会聚合网页的详细描述和高清图片。假如网站有多个页面是由一个单一的导航引导的,那么其中一个页面就可能对应很多相同的链接,对于搜索引擎来说,是很容易进行收录的。
如果不加导航,那么它在手机端和pc端分别会在不同页面打开,如果这个页面是该网站的核心内容,对于用户来说很容易从这些跳转到别的链接,达不到一个网站的核心目的。当然一个网站的核心内容会有很多页面或者类似内容,不仅仅是一个页面对应一个链接,而是一个页面引导多个链接,这样对于用户也是一个不错的选择。在互联网特别是移动互联网的大趋势下,网站导航的市场是非常大的,用户也是在不断增加,如果不设置导航,手机网站或pc网站的浏览体验会非常差,谷歌已经说了,谷歌认为未来在移动网站上引导用户更重要,但是这种方法肯定更贵,因为需要投放大量的谷歌算法,那么这种方法对于很多没有大量资金的公司不实用,而且除了寻找业内优秀的网站的导航开发者,很多无法实现采用这种方法的。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法非常多,整站为什么要设置导航功能)
网页采集器的自动识别算法非常多,现在很多网站都有实现的接口,网站的数据会自动存储在自己的缓存里面,再发布,但是有些网站的页面可能不会自动存储在缓存里面,那就需要用一些技术去手动查找网站的页面,虽然方便,但是效率低,今天我介绍给大家一款采集器,网页导航网址,它可以自动识别整个网站的导航,比如我们在csdn网站进行采集,比如我们用大页自动识别,点击选择第三页,它会自动下载第二页和第四页,并且图片和链接都自动识别出来了,非常方便,1分钟即可达到效果,感兴趣的朋友可以试一下,目前用的人很多,大页的工作量比较大,对采集工具和页面结构要求高,不知道大家觉得呢?。
要保证整站导航无效,首先得知道导航的存在,也就是整站为什么要设置导航功能。导航功能顾名思义就是跳转导航。常见的导航有好多种,有静态导航、动态导航,动态导航是一段时间内同一个页面被多个网站投放到同一个链接上,或者说浏览器或谷歌算法检测到同一页面可能有多个相同的页面,那么为了防止这些页面由于算法的原因导致被拦截或者引导。
如果说静态导航就是一个网站一个网站的实现跳转,那么导航功能就是一个网站同一个页面链接多次,或者网站多个页面链接多次。当然也有两个页面一起投放到同一个网站的导航,比如历史上比较有名的遨游或者360浏览器,它有一个红宝书导航,聚合了大量网站的网址,同时还会聚合网页的详细描述和高清图片。假如网站有多个页面是由一个单一的导航引导的,那么其中一个页面就可能对应很多相同的链接,对于搜索引擎来说,是很容易进行收录的。
如果不加导航,那么它在手机端和pc端分别会在不同页面打开,如果这个页面是该网站的核心内容,对于用户来说很容易从这些跳转到别的链接,达不到一个网站的核心目的。当然一个网站的核心内容会有很多页面或者类似内容,不仅仅是一个页面对应一个链接,而是一个页面引导多个链接,这样对于用户也是一个不错的选择。在互联网特别是移动互联网的大趋势下,网站导航的市场是非常大的,用户也是在不断增加,如果不设置导航,手机网站或pc网站的浏览体验会非常差,谷歌已经说了,谷歌认为未来在移动网站上引导用户更重要,但是这种方法肯定更贵,因为需要投放大量的谷歌算法,那么这种方法对于很多没有大量资金的公司不实用,而且除了寻找业内优秀的网站的导航开发者,很多无法实现采用这种方法的。
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-12-13 13:32
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户无需任何专业知识,即可轻松上手操作,快速采集网络资料。轻松搜索网页数据采集器免费版无需输入任何代码,只需输入URL地址,即可帮助用户自动采集网页数据。
易搜网数据采集器正式版具有很强的系统兼容性,支持运行在各种版本的操作系统上。有需要的用户可到本站下载本软件。
软件特点
简单易用
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
海量 采集 模板
内置海量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足各种采集 需要..
自研智能算法
通过自主研发的智能识别算法,自动识别列表数据,识别分页,准确率达95%,可深入采集多级页面,快速准确获取数据。
自动导出数据
数据可自动导出发布,支持TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite等多种格式导出,发布到网站接口(Api)等。
软件亮点
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
多平台支持
Easy Search Web Data采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化保存
采集 任务会自动保存到本地,不用担心丢失任务。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网络数据采集器 教程
第一步,选择起始网址
当你想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例,我们要抓取当前城市各种本地新闻的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到所有新闻信息列表的地址
然后在Easy Search Web Data中新建一个任务采集器 -> Step One -> 输入网址
然后单击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会对网页进行智能分析,从中提取列表数据。如下所示:
这时候我们对分析的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他的操作,比如名称修改、数据处理等等。
整理好修改后的字段后,我们来采集来处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段-点击进入采集数据的列表页面,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
单击完成以保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
Easy Search Web Data采集器如何导出数据
有两种导出方法:
手动导出,通过右键任务->导出任务,或者在视图中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到 网站 接口(API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以定义自己的网站 API,Easy Search Web Data 采集器通过HTTP POST请求将数据发送到指定的API,然后设置相应的POST参数和编码类型。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页数据采集器值属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性确定Html元素的哪一部分作为field的值。
一般情况下,采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了 InnerText 之外,还有其他几个内置属性:
文本,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性,用户还可以手动填写 HTML 属性。A标签的href、IMG标签的src等常见的HTML属性。Data-* 表示数据。
特别说明
在这里您可以手动输入属性名称,即使它不在下拉选项中。比如常见的onclick、value、class。 查看全部
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户无需任何专业知识,即可轻松上手操作,快速采集网络资料。轻松搜索网页数据采集器免费版无需输入任何代码,只需输入URL地址,即可帮助用户自动采集网页数据。
易搜网数据采集器正式版具有很强的系统兼容性,支持运行在各种版本的操作系统上。有需要的用户可到本站下载本软件。
软件特点
简单易用
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
海量 采集 模板
内置海量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足各种采集 需要..
自研智能算法
通过自主研发的智能识别算法,自动识别列表数据,识别分页,准确率达95%,可深入采集多级页面,快速准确获取数据。
自动导出数据
数据可自动导出发布,支持TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite等多种格式导出,发布到网站接口(Api)等。

软件亮点
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
多平台支持
Easy Search Web Data采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化保存
采集 任务会自动保存到本地,不用担心丢失任务。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网络数据采集器 教程
第一步,选择起始网址
当你想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例,我们要抓取当前城市各种本地新闻的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到所有新闻信息列表的地址
然后在Easy Search Web Data中新建一个任务采集器 -> Step One -> 输入网址

然后单击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会对网页进行智能分析,从中提取列表数据。如下所示:

这时候我们对分析的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他的操作,比如名称修改、数据处理等等。
整理好修改后的字段后,我们来采集来处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段-点击进入采集数据的列表页面,如下图:

第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
单击完成以保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
Easy Search Web Data采集器如何导出数据
有两种导出方法:
手动导出,通过右键任务->导出任务,或者在视图中导出。
自动导出,在编辑任务第三步设置导出。

数据导出后,会被标记为导出,下次导出时不会再导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到 网站 接口(API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以定义自己的网站 API,Easy Search Web Data 采集器通过HTTP POST请求将数据发送到指定的API,然后设置相应的POST参数和编码类型。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页数据采集器值属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性确定Html元素的哪一部分作为field的值。

一般情况下,采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了 InnerText 之外,还有其他几个内置属性:
文本,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性,用户还可以手动填写 HTML 属性。A标签的href、IMG标签的src等常见的HTML属性。Data-* 表示数据。
特别说明
在这里您可以手动输入属性名称,即使它不在下拉选项中。比如常见的onclick、value、class。
网页采集器的自动识别算法(,本文针对Web新闻自动摘要问题展开研究(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-13 13:30
【摘要】随着社会发展进入互联网时代,人们获取信息的方式多样化,越来越多的人依赖互联网获取自己需要的信息。同时,信息量的快速增长给用户信息检索带来了困难。面对海量的检索结果,用户往往无法高效、准确地获取所需信息。为此,本文重点研究Web新闻的自动摘要。本文分析了TextRank算法和融合文本特征的摘要算法的不足,提出了一种融合BM25和文本特征的新的新闻摘要算法,并对五种不同的算法进行了对比实验。最后,使用提出的新算法,基于Heritrix框架开发了一个Web新闻摘要系统。具体研究内容如下: 本文首先介绍了本研究课题的意义和背景,国内外自动文本摘要的研究现状和主要成果。其次介绍了文本自动摘要的相关知识,包括:自动摘要的分类和方法,如何使用网络爬虫进行新闻网页采集和主流的网页正文提取方法。在第3章中,首先介绍了基于行块分布函数的网页文本提取方法的主要思想以及该方法与传统方法相比的优势;其次,分析了TextRank算法在给句子打分时只考虑文本的内部结构的缺点。发现TextRank中计算句子相似度的方法不可靠;在此基础上,提出了一种结合BM25和文本特征的新闻摘要算法;另外,BM25的计算结果可能会出现负数,BM25可能是由于句子。针对所提出的算法进一步优化了长度过长而失去意义的问题。在第 4 章中,本文使用 ROUGE 评估工具,通过实验将本文改进算法与其他相关算法进行了比较。实验结果表明,与其他方法相比,本文提出的结合BM25和文本特征的新闻自动摘要算法具有更高的性能。最后,为了实际使用所提出的算法,本文使用Heritrix框架设计并实现了一个Web新闻页面自动摘要系统,包括新闻页面采集、文本提取、文本图模型表示和句子权重计算模块. 系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。 查看全部
网页采集器的自动识别算法(,本文针对Web新闻自动摘要问题展开研究(组图))
【摘要】随着社会发展进入互联网时代,人们获取信息的方式多样化,越来越多的人依赖互联网获取自己需要的信息。同时,信息量的快速增长给用户信息检索带来了困难。面对海量的检索结果,用户往往无法高效、准确地获取所需信息。为此,本文重点研究Web新闻的自动摘要。本文分析了TextRank算法和融合文本特征的摘要算法的不足,提出了一种融合BM25和文本特征的新的新闻摘要算法,并对五种不同的算法进行了对比实验。最后,使用提出的新算法,基于Heritrix框架开发了一个Web新闻摘要系统。具体研究内容如下: 本文首先介绍了本研究课题的意义和背景,国内外自动文本摘要的研究现状和主要成果。其次介绍了文本自动摘要的相关知识,包括:自动摘要的分类和方法,如何使用网络爬虫进行新闻网页采集和主流的网页正文提取方法。在第3章中,首先介绍了基于行块分布函数的网页文本提取方法的主要思想以及该方法与传统方法相比的优势;其次,分析了TextRank算法在给句子打分时只考虑文本的内部结构的缺点。发现TextRank中计算句子相似度的方法不可靠;在此基础上,提出了一种结合BM25和文本特征的新闻摘要算法;另外,BM25的计算结果可能会出现负数,BM25可能是由于句子。针对所提出的算法进一步优化了长度过长而失去意义的问题。在第 4 章中,本文使用 ROUGE 评估工具,通过实验将本文改进算法与其他相关算法进行了比较。实验结果表明,与其他方法相比,本文提出的结合BM25和文本特征的新闻自动摘要算法具有更高的性能。最后,为了实际使用所提出的算法,本文使用Heritrix框架设计并实现了一个Web新闻页面自动摘要系统,包括新闻页面采集、文本提取、文本图模型表示和句子权重计算模块. 系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-12 18:07
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.0.7.8 (2020-05-27)Fix8.0.7.7 多值的新字段提取错误问题 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。

基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。

软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮

点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。

右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。

在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。


CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.0.7.8 (2020-05-27)Fix8.0.7.7 多值的新字段提取错误问题
网页采集器的自动识别算法(优采云采集器破解版完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-12 18:06
优采云采集器破解版数据很强大采集器,优采云采集器破解版完美支持采集所有网页编码格式,该程序还可以自动识别网页编码。优采云采集器 破解版还支持目前所有主流和非主流cms、BBS等网站程序,通过系统发布模块可以实现采集器和网站程序之间的完美结合。
特征
1、强大的通用性
无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集获取内容你需要 。
2、稳定高效
历经五年磨砺,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、可扩展性强,应用范围广
自定义网页发布,主流数据库自定义存储发布,自定义本地php和. Net 外部编程接口对数据进行处理,使数据可供您使用。
4、支持所有网站编码
完美支持采集所有编码格式的网页,程序还能自动识别网页编码。
5、多种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守的工作。程序配置好后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
本地可视化编辑采集的数据。
8、采集测试
这是任何其他类似的 采集 软件都无法比拟的。程序支持直接查看采集的结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
软件特点
1、规则定制
通过采集规则的定义,几乎可以搜索到所有网站采集的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据保存
采集的同时数据自动保存到关系型数据库,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及其中的表和字段,也可以灵活地由数据库引导。将数据保存到客户现有的数据库结构中。
5、断点恢复挖矿
信息采集任务在停止采集后可以从断点处继续,从此不用担心采集任务被意外中断。
6、网站登录
支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、预定任务
通过此功能,您的采集 任务可以定期、定量或连续执行。
8、采集范围限制
采集的范围可以根据采集的深度和URL的标识进行限制。
9、文件下载
您可以将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库中。
10、 结果替换
您可以根据规则将采集的结果替换为您定义的内容。
11、 条件保存
您可以根据特定条件决定保存哪些信息以及过滤哪些信息。
12、过滤重复内容
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、 特殊链接识别
使用此函数来识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14、数据发布
您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、预留编程接口
定义多种编程接口,用户可以在活动中使用PHP、C#语言进行编程,扩展采集的功能。
更新日志
1、 批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改。
2、 标签组合,增加对循环组合的支持。
3、优化了重新重置URL库的逻辑,大大加快了大URL库下的任务加载速度,优化了重新重置URL库的内存占用。 查看全部
网页采集器的自动识别算法(优采云采集器破解版完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器破解版数据很强大采集器,优采云采集器破解版完美支持采集所有网页编码格式,该程序还可以自动识别网页编码。优采云采集器 破解版还支持目前所有主流和非主流cms、BBS等网站程序,通过系统发布模块可以实现采集器和网站程序之间的完美结合。

特征
1、强大的通用性
无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集获取内容你需要 。
2、稳定高效
历经五年磨砺,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、可扩展性强,应用范围广
自定义网页发布,主流数据库自定义存储发布,自定义本地php和. Net 外部编程接口对数据进行处理,使数据可供您使用。
4、支持所有网站编码
完美支持采集所有编码格式的网页,程序还能自动识别网页编码。
5、多种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守的工作。程序配置好后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
本地可视化编辑采集的数据。
8、采集测试
这是任何其他类似的 采集 软件都无法比拟的。程序支持直接查看采集的结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
软件特点
1、规则定制
通过采集规则的定义,几乎可以搜索到所有网站采集的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据保存
采集的同时数据自动保存到关系型数据库,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及其中的表和字段,也可以灵活地由数据库引导。将数据保存到客户现有的数据库结构中。
5、断点恢复挖矿
信息采集任务在停止采集后可以从断点处继续,从此不用担心采集任务被意外中断。
6、网站登录
支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、预定任务
通过此功能,您的采集 任务可以定期、定量或连续执行。
8、采集范围限制
采集的范围可以根据采集的深度和URL的标识进行限制。
9、文件下载
您可以将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库中。
10、 结果替换
您可以根据规则将采集的结果替换为您定义的内容。
11、 条件保存
您可以根据特定条件决定保存哪些信息以及过滤哪些信息。
12、过滤重复内容
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、 特殊链接识别
使用此函数来识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14、数据发布
您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、预留编程接口
定义多种编程接口,用户可以在活动中使用PHP、C#语言进行编程,扩展采集的功能。
更新日志
1、 批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改。
2、 标签组合,增加对循环组合的支持。
3、优化了重新重置URL库的逻辑,大大加快了大URL库下的任务加载速度,优化了重新重置URL库的内存占用。
网页采集器的自动识别算法(网页采集器的自动识别算法是怎样的?如何找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-09 21:01
网页采集器的自动识别算法主要有两种,一种是被动识别算法,一种是主动识别算法,被动识别是通过网站抓取上下文,用户浏览习惯等方式来识别的,这种识别误差比较大,而且有时会出现误伤功能。我用过很多家网页采集器,普遍存在这个问题,现在有些网站抓取框里面加上了类似于cookie等自动上传的校验的。一种主动识别的算法,是通过我们发布的自动采集软件来识别的,对特定网站,根据特定的格式发布相关的采集软件采集软件,这个算法可以识别网站的抓取代码,也可以识别网站的类型,而且还可以按照网站的设置来识别。
现在的网页采集就是手动手写代码来采集,有人的时候在使用apache做cronserver,没人的时候手写点脚本,例如百度、谷歌这种全自动化的采集就不知道了,可能其他人不知道,我知道的话我就提出来,
如果你采的网页已经是主动爬取的话,可以这样做。如果是被动爬取的话,需要采集器生成flash在网页里,让爬虫自己去找网页,
他使用的是google的解析页面解析一个网站只是一个小功能。爬虫需要找到一个主动的页面链接才可以去请求,并用一个selector标记好所请求的链接那么如何找到呢?你应该找到一个服务器去爬。如果服务器不存在可以这样找服务器api有木有,他会返回服务器名给你这个服务器一般在网站底部,上面几层有个api接口对吧,那么你就点击他(把它想象成服务器中的api),使用他接口中的一个target(目标)然后在之前api请求他的时候不带url-params,比如之前的网址,你请求它是正常请求,那么接下来你需要做的就是拿到他的路径,因为之前他是正常请求,现在你不带他的时候,他会让你输入一个url-params,比如/。
接下来就是如何拿到这个url-params,你可以查找之前的htmltarget(上一个target)所以之前target就是你的http主动页面链接那么你就拿到了http请求和http响应即可不知道有没有说清楚。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是怎样的?如何找到)
网页采集器的自动识别算法主要有两种,一种是被动识别算法,一种是主动识别算法,被动识别是通过网站抓取上下文,用户浏览习惯等方式来识别的,这种识别误差比较大,而且有时会出现误伤功能。我用过很多家网页采集器,普遍存在这个问题,现在有些网站抓取框里面加上了类似于cookie等自动上传的校验的。一种主动识别的算法,是通过我们发布的自动采集软件来识别的,对特定网站,根据特定的格式发布相关的采集软件采集软件,这个算法可以识别网站的抓取代码,也可以识别网站的类型,而且还可以按照网站的设置来识别。
现在的网页采集就是手动手写代码来采集,有人的时候在使用apache做cronserver,没人的时候手写点脚本,例如百度、谷歌这种全自动化的采集就不知道了,可能其他人不知道,我知道的话我就提出来,
如果你采的网页已经是主动爬取的话,可以这样做。如果是被动爬取的话,需要采集器生成flash在网页里,让爬虫自己去找网页,
他使用的是google的解析页面解析一个网站只是一个小功能。爬虫需要找到一个主动的页面链接才可以去请求,并用一个selector标记好所请求的链接那么如何找到呢?你应该找到一个服务器去爬。如果服务器不存在可以这样找服务器api有木有,他会返回服务器名给你这个服务器一般在网站底部,上面几层有个api接口对吧,那么你就点击他(把它想象成服务器中的api),使用他接口中的一个target(目标)然后在之前api请求他的时候不带url-params,比如之前的网址,你请求它是正常请求,那么接下来你需要做的就是拿到他的路径,因为之前他是正常请求,现在你不带他的时候,他会让你输入一个url-params,比如/。
接下来就是如何拿到这个url-params,你可以查找之前的htmltarget(上一个target)所以之前target就是你的http主动页面链接那么你就拿到了http请求和http响应即可不知道有没有说清楚。
网页采集器的自动识别算法( 智能识别数据,小白神器基于人工智能算法,只需输入网址 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-29 22:20
智能识别数据,小白神器基于人工智能算法,只需输入网址
)
智能识别数据,小白神器
基于人工智能算法,只需输入网址,即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则。结合智能识别算法,可以轻松采集任何网页上的数据。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集的结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云
采集器
提供了丰富的采集
功能,无论是采集
稳定性还是采集
效率,都能满足个人、团队、企业的采集
需求。
功能丰富:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
云账号,方便快捷
创建优采云
采集器
账号并登录,您所有的采集
任务设置都会自动加密保存到优采云
的云服务器。无需担心采集
任务丢失。运行的任务和采集的数据都在你的本地。而且非常安全。只有在本地登录客户端后才能查看。优采云
采集器对账号没有终端绑定限制,切换终端时采集任务会同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
查看全部
网页采集器的自动识别算法(
智能识别数据,小白神器基于人工智能算法,只需输入网址
)
智能识别数据,小白神器
基于人工智能算法,只需输入网址,即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则。结合智能识别算法,可以轻松采集任何网页上的数据。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集的结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云
采集器
提供了丰富的采集
功能,无论是采集
稳定性还是采集
效率,都能满足个人、团队、企业的采集
需求。
功能丰富:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
云账号,方便快捷
创建优采云
采集器
账号并登录,您所有的采集
任务设置都会自动加密保存到优采云
的云服务器。无需担心采集
任务丢失。运行的任务和采集的数据都在你的本地。而且非常安全。只有在本地登录客户端后才能查看。优采云
采集器对账号没有终端绑定限制,切换终端时采集任务会同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux操作系统的采集软件。各平台版本完全相同,无缝切换。
网页采集器的自动识别算法( 厦门云脉词典笔OCR+拼图算法(图)识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-28 20:08
厦门云脉词典笔OCR+拼图算法(图)识别)
强大的云麦词典笔OCR+拼图算法
扫描笔这个新兴的产品,已经逐渐走入寻常百姓家,为我们的工作提供了很多便利,成为我们学习的得力助手。在市面上众多的扫描笔中,嵌入云麦词典笔强大的OCR+拼图算法的一款是您理想的选择。
厦门云迈专注于OCR领域,拥有优秀的OCR识别技术和算法,制作了多款OCR相关的识别应用软件。云麦词典笔OCR+拼图算法是云麦最新的应用技术。它主要用于扫描文本并识别它。它完美地结合了拼图和OCR算法,对扫描的文本进行采集、拼接和识别。得益于良好的算法,云麦词典笔的OCR+拼图算法识别速度快,识别能力超强,适应能力超强,深受大家青睐。
云麦词典笔OCR+拼图算法是一款功能强大、适应性强的扫描识别工具。首先,它可以扫描所有纸质文档和书籍,识别中文、英文、拼音、天字格文字、繁体字等,还支持混合识别,也支持手写文字识别。其次,无论是简单背景还是复杂背景,都具有出色的识别能力,能够自动去除无效的背景干扰字符信息。第三,云麦词典笔可以支持快速点扫描识别功能,从笔尖到笔尖的精准识别功能,不同握笔角度的识别,支持左右扫描识别功能。
云麦词典笔具有快速的拼接能力和识别能力。扫描完成则表示拼接完成,拼接成功则表示拼接成功。因此,在效率至上的时代,云麦扫描仪脱颖而出,熠熠生辉。 查看全部
网页采集器的自动识别算法(
厦门云脉词典笔OCR+拼图算法(图)识别)
强大的云麦词典笔OCR+拼图算法
扫描笔这个新兴的产品,已经逐渐走入寻常百姓家,为我们的工作提供了很多便利,成为我们学习的得力助手。在市面上众多的扫描笔中,嵌入云麦词典笔强大的OCR+拼图算法的一款是您理想的选择。
厦门云迈专注于OCR领域,拥有优秀的OCR识别技术和算法,制作了多款OCR相关的识别应用软件。云麦词典笔OCR+拼图算法是云麦最新的应用技术。它主要用于扫描文本并识别它。它完美地结合了拼图和OCR算法,对扫描的文本进行采集、拼接和识别。得益于良好的算法,云麦词典笔的OCR+拼图算法识别速度快,识别能力超强,适应能力超强,深受大家青睐。
云麦词典笔OCR+拼图算法是一款功能强大、适应性强的扫描识别工具。首先,它可以扫描所有纸质文档和书籍,识别中文、英文、拼音、天字格文字、繁体字等,还支持混合识别,也支持手写文字识别。其次,无论是简单背景还是复杂背景,都具有出色的识别能力,能够自动去除无效的背景干扰字符信息。第三,云麦词典笔可以支持快速点扫描识别功能,从笔尖到笔尖的精准识别功能,不同握笔角度的识别,支持左右扫描识别功能。
云麦词典笔具有快速的拼接能力和识别能力。扫描完成则表示拼接完成,拼接成功则表示拼接成功。因此,在效率至上的时代,云麦扫描仪脱颖而出,熠熠生辉。
网页采集器的自动识别算法( 人脸识别就只是拍“脸”吗?后台审核人员都能看到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-12-28 18:15
人脸识别就只是拍“脸”吗?后台审核人员都能看到)
人脸识别是许多身份安全认证软件中不可或缺的重要组成部分。但你真的认为人脸识别只是一张“脸”吗?近日,数码博主@长安数码君在社交平台爆料:人脸识别采集的区域不仅是屏幕上显示的头部,还包括摄像头覆盖的整个范围,系统会采集采集到的数据。照片上传到后台,后台的审稿人可以看到。
很快,“人脸识别必须穿衣服”的话题登上热搜榜。不少人惊呼,如果真是这样,那岂不是给外星行星丢脸了。那么,后台审核者真的能看到手机屏幕上显示的人脸以外的部分吗?
对此,河北工业大学电子信息工程系主任邱波教授表示,人脸识别拍摄的图像必须是摄像头视野范围内的所有区域,而不仅仅是人脸内部的部分。我们在手机上看到的框架。这是基本的常识问题。
“从技术角度来看,目前的人脸识别技术不需要存储原创
照片。” 邱波解释说,智能相机可以实时提取人脸图像特征,并对人脸进行编码,生成人脸特征向量。然后进行传输、存储、比较等操作。也就是说,在终端机中,人脸已经变成了一系列的数字,可以表示眼睛之间的距离、嘴角的位置、人脸的大小、皮肤的粗糙程度等等,这样每一张脸都被转换成一个“密码”特征向量。
“当人脸转换成向量值,机器进行人脸识别时,就类似于在密码本中搜索特定的密码,只需比较这些数字即可。” 邱波说,可以说,从技术上来说,人脸识别可以做到向量层面。
邱波表示,人工审核已成为大规模“社区死亡”现场,无需过多担心。对于大公司来说,每天需要进行的人脸识别工作量非常庞大,而这部分工作几乎全部由机器来完成。而现在提供人脸识别技术的龙头企业和大公司都采用隐私计算技术,只为客户提供脱敏特征码进行对比,不发送图片到后台。仅从存储和传输成本来看,公司将原创
图像发送到后端是不经济的。因此,如果在后台人工审核时能看到图片,则“极有可能不合规”。
“但是,一些公司出于战略决策的目的,会存储一些用户照片,以满足相关算法多样性和后续改进的需求。通过让机器学习,优化人脸识别算法,他们开发了更安全、更安全算法。简单且更准确的算法。” 邱波表示,但从技术角度来看,原创
图像中采集
的信息越多,就越会给人脸识别增加麻烦。例如,如果图片的背景中有明星的海报,计算机首先要定位人脸,甚至还要识别和比较海报的人脸,这就增加了额外的难度和计算。因此,对于一般公司来说,
邱波强调,虽然现行的法律法规对企业有一定的限制作用,但不能保证全程没有人违反规定。因此,对于公众而言,了解风险、规避风险才是自我保护的最佳方式。(记者陈曦) 查看全部
网页采集器的自动识别算法(
人脸识别就只是拍“脸”吗?后台审核人员都能看到)
人脸识别是许多身份安全认证软件中不可或缺的重要组成部分。但你真的认为人脸识别只是一张“脸”吗?近日,数码博主@长安数码君在社交平台爆料:人脸识别采集的区域不仅是屏幕上显示的头部,还包括摄像头覆盖的整个范围,系统会采集采集到的数据。照片上传到后台,后台的审稿人可以看到。
很快,“人脸识别必须穿衣服”的话题登上热搜榜。不少人惊呼,如果真是这样,那岂不是给外星行星丢脸了。那么,后台审核者真的能看到手机屏幕上显示的人脸以外的部分吗?
对此,河北工业大学电子信息工程系主任邱波教授表示,人脸识别拍摄的图像必须是摄像头视野范围内的所有区域,而不仅仅是人脸内部的部分。我们在手机上看到的框架。这是基本的常识问题。
“从技术角度来看,目前的人脸识别技术不需要存储原创
照片。” 邱波解释说,智能相机可以实时提取人脸图像特征,并对人脸进行编码,生成人脸特征向量。然后进行传输、存储、比较等操作。也就是说,在终端机中,人脸已经变成了一系列的数字,可以表示眼睛之间的距离、嘴角的位置、人脸的大小、皮肤的粗糙程度等等,这样每一张脸都被转换成一个“密码”特征向量。
“当人脸转换成向量值,机器进行人脸识别时,就类似于在密码本中搜索特定的密码,只需比较这些数字即可。” 邱波说,可以说,从技术上来说,人脸识别可以做到向量层面。
邱波表示,人工审核已成为大规模“社区死亡”现场,无需过多担心。对于大公司来说,每天需要进行的人脸识别工作量非常庞大,而这部分工作几乎全部由机器来完成。而现在提供人脸识别技术的龙头企业和大公司都采用隐私计算技术,只为客户提供脱敏特征码进行对比,不发送图片到后台。仅从存储和传输成本来看,公司将原创
图像发送到后端是不经济的。因此,如果在后台人工审核时能看到图片,则“极有可能不合规”。
“但是,一些公司出于战略决策的目的,会存储一些用户照片,以满足相关算法多样性和后续改进的需求。通过让机器学习,优化人脸识别算法,他们开发了更安全、更安全算法。简单且更准确的算法。” 邱波表示,但从技术角度来看,原创
图像中采集
的信息越多,就越会给人脸识别增加麻烦。例如,如果图片的背景中有明星的海报,计算机首先要定位人脸,甚至还要识别和比较海报的人脸,这就增加了额外的难度和计算。因此,对于一般公司来说,
邱波强调,虽然现行的法律法规对企业有一定的限制作用,但不能保证全程没有人违反规定。因此,对于公众而言,了解风险、规避风险才是自我保护的最佳方式。(记者陈曦)
网页采集器的自动识别算法(网页采集器的自动识别算法,你可以通过以下几种情况去改善)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-28 16:08
网页采集器的自动识别算法很多,有些是靠一些特定的规则编写和迭代的,对于网站内容的抓取精度要求和抓取过程的保密性需要严格控制。另外一些是靠人工执行抓取指令产生了,这些对精度要求没有控制,可能你看到的就是一次服务器吞吐量达到上千请求的。当然这些量级并不高,现实生活中的请求更长,比如送快递要1分钟的也遇到过。
除了一些依靠特定的地域采集规则或者会加上一些个性化匹配等等吧。我想要知道的是,网站的确可以使用一些抓取的接口去采集,但是这些方法太多,对于网站来说,都是经过大量考验的,用于生产高效服务器才是王道。对于此问题,首先我们要明确目标的客户,会有谁去访问你的网站,是企业、医院、学校、婚庆公司等等。他们会看到哪些内容,你可以通过以下几种情况去改善这个问题。
1.有的时候我们的网站抓取的内容难免出现不对的地方,当他有时候有一些内容的时候我们不太方便改,如果想要改善,使用一些第三方的解决方案,如jsoup、爬虫聚合等等。2.现在的网站的访问会非常大,当他遇到大量访问的时候,而且你有些时候想要优化这个页面的质量,就可以使用监控服务器并发的数量和速度,缩短收到请求的时间,如轮询服务器等。
3.我们可以对网站中出现的一些不完整的数据以及不完整的自己定义数据等等,可以通过meta信息改变一些属性等等。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法,你可以通过以下几种情况去改善)
网页采集器的自动识别算法很多,有些是靠一些特定的规则编写和迭代的,对于网站内容的抓取精度要求和抓取过程的保密性需要严格控制。另外一些是靠人工执行抓取指令产生了,这些对精度要求没有控制,可能你看到的就是一次服务器吞吐量达到上千请求的。当然这些量级并不高,现实生活中的请求更长,比如送快递要1分钟的也遇到过。
除了一些依靠特定的地域采集规则或者会加上一些个性化匹配等等吧。我想要知道的是,网站的确可以使用一些抓取的接口去采集,但是这些方法太多,对于网站来说,都是经过大量考验的,用于生产高效服务器才是王道。对于此问题,首先我们要明确目标的客户,会有谁去访问你的网站,是企业、医院、学校、婚庆公司等等。他们会看到哪些内容,你可以通过以下几种情况去改善这个问题。
1.有的时候我们的网站抓取的内容难免出现不对的地方,当他有时候有一些内容的时候我们不太方便改,如果想要改善,使用一些第三方的解决方案,如jsoup、爬虫聚合等等。2.现在的网站的访问会非常大,当他遇到大量访问的时候,而且你有些时候想要优化这个页面的质量,就可以使用监控服务器并发的数量和速度,缩短收到请求的时间,如轮询服务器等。
3.我们可以对网站中出现的一些不完整的数据以及不完整的自己定义数据等等,可以通过meta信息改变一些属性等等。
网页采集器的自动识别算法(全球最大规模人工智能巨量模型“源1.0”问世(光明网))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 23:17
澎湃新闻实习生郑树静
【编者按】
与电力一样,人工智能赋能各行各业,深刻改变人类社会。中国处于全球人工智能发展第三波浪潮的前沿。《算法周刊》将聚焦人工智能“上海高地”和中国新基建,持续关注全球人工智能前沿。
算法时代如何保护个人隐私
(1)欧洲议会:禁止警察在公共场所进行自动面部识别(The Paper)
围绕生物分类、行为检测、情绪识别、脑机接口(BCI)等技术发展起来的生物识别技术正在赋能包括人工智能在内的更多领域。然而,人类生物识别的推理过程中存在着伦理风险和基本权利风险。欧洲议会于当地时间10月6日通过决议,禁止警方在公共场所使用面部识别技术,例如通过自动面部识别等生物识别程序远程对公共场所的人进行视频监控。
(2)《汽车数据采集安全要求》草案全文(数据联盟)
2021年10月19日,全国信息安全标准化技术委员会发布了《信息安全技术车辆数据采集安全要求》(征求意见稿)。该要求分为8个部分,共15条,规定了汽车采集数据的传输、存储、退出等处理活动的安全要求。它不仅为汽车制造商确保汽车数据处理活动的安全提供指导,而且还提供主管部门的监管。、第三方评估机构等为机车采集数据处理活动的监督、管理和评估提供参考。
人工智能,走向更智能
(3)全球最大人工智能模型“元1.0”问世(光明网)
AI应用开发多年,但在开发定制化、碎片化等方面存在弱点。为了应对这种情况,业界开始探索训练大量模型的方法,使人工智能可以在多场景下大规模泛化和应用。9月底,浪潮人工智能研究院在北京发布了海量人工智能模型“source1.0”。该模型的单个模型参数达到了2457亿,超过了美国OpenAI组织开发的GPT-3,成为全球最大的AI海量模型。
(4)李飞飞团队新作发表于《自然》杂志:AI有身体会更聪明吗?(论文)
如果AI有身体,它会变得更聪明吗?答案是肯定的。近日,由斯坦福大学李飞飞教授领导的研究小组发现,体型会影响虚拟生物 Unimal 在复杂环境中的适应和学习能力,而复杂环境也会促进形态智能的进化。
AI 应用,左或右
(5)美国“杀手机狗”:配备狙击步枪,精准锁定1.2公里范围内的目标(论文)
英剧《黑镜》中的杀人机器狗令人难忘,如今科幻已成现实。在10月11日至13日举行的美国陆军协会年会上,科技公司Ghost Robotics和专业步枪公司SWORD International共同展出了一款名为SPUR(Special Purpose Unmaned Rifle)的机器狗。机器狗配备了狙击步枪,并配备了具有30倍光学变焦的Teledyne FLIR玻色子热像仪,可以“在白天和黑夜的各种条件下作业”。
(6)DeepMind 的 AI 几乎可以准确预测何时何地下雨(麻省理工科技评论)
短期天气预报可以为能源管理、海事服务、洪水预警系统、空中交通管制等提供关键决策信息,但一直是传统天气预报中的难题。9月底,谷歌人工智能实验室DeepMind宣布,他们在过去几年与英国气象局合作,开发了一种新的深度学习模型DGMR,可以更准确地预测未来90分钟的天气。研究结果已发表在《自然》杂志上。
(7) 科学家展示了人工智能如何帮助检测隐形心力衰竭 (ScienceDaily)
人工智能在医疗应用方面取得新进展。美国西奈山卫生系统的一个研究团队创造了一种基于人工智能的计算机算法,可以帮助医务人员利用心电图 (ECG) 上的微弱信号变化来更快地预测患者是否会出现心力衰竭。
市场期待什么样的算法技术?
(8)清华虚拟学生所谓AI变革的背后:大部分人工智能仍处于学习阶段(南方都市报)
10月19日,“清华虚拟学生因换脸真AI被质疑”话题在网上引发争议。有网友质疑,此前备受关注的“清华虚拟学生华志兵弹唱视频”只是B站主打鱼子酱真人视频的换脸。对此,开发者小兵团队发布声明称,视频的来源从一开始就标明了,而且不仅使用了AI换脸技术。
(9)Gartner发布2022年12个重要战略技术趋势(网络研究院)
Gartner在近期的Gartner IT Symposium/Xpo Summit Americas上公布了最新研究成果,指出了2022年企业需要探索的重要战略技术趋势。12大战略技术趋势包括:生成人工智能、Data Fabric、分布式企业、云-原生平台(CNP)、自主系统、决策智能(DecisionIntelligence、DI)、组合应用(Composable Applications)、超自动化、隐私增强计算(PEC)、网络安全网格、人工智能工程(AI Engineering)和总经验(Total经验,德克萨斯州)。 查看全部
网页采集器的自动识别算法(全球最大规模人工智能巨量模型“源1.0”问世(光明网))
澎湃新闻实习生郑树静
【编者按】
与电力一样,人工智能赋能各行各业,深刻改变人类社会。中国处于全球人工智能发展第三波浪潮的前沿。《算法周刊》将聚焦人工智能“上海高地”和中国新基建,持续关注全球人工智能前沿。
算法时代如何保护个人隐私
(1)欧洲议会:禁止警察在公共场所进行自动面部识别(The Paper)
围绕生物分类、行为检测、情绪识别、脑机接口(BCI)等技术发展起来的生物识别技术正在赋能包括人工智能在内的更多领域。然而,人类生物识别的推理过程中存在着伦理风险和基本权利风险。欧洲议会于当地时间10月6日通过决议,禁止警方在公共场所使用面部识别技术,例如通过自动面部识别等生物识别程序远程对公共场所的人进行视频监控。
(2)《汽车数据采集安全要求》草案全文(数据联盟)
2021年10月19日,全国信息安全标准化技术委员会发布了《信息安全技术车辆数据采集安全要求》(征求意见稿)。该要求分为8个部分,共15条,规定了汽车采集数据的传输、存储、退出等处理活动的安全要求。它不仅为汽车制造商确保汽车数据处理活动的安全提供指导,而且还提供主管部门的监管。、第三方评估机构等为机车采集数据处理活动的监督、管理和评估提供参考。
人工智能,走向更智能
(3)全球最大人工智能模型“元1.0”问世(光明网)
AI应用开发多年,但在开发定制化、碎片化等方面存在弱点。为了应对这种情况,业界开始探索训练大量模型的方法,使人工智能可以在多场景下大规模泛化和应用。9月底,浪潮人工智能研究院在北京发布了海量人工智能模型“source1.0”。该模型的单个模型参数达到了2457亿,超过了美国OpenAI组织开发的GPT-3,成为全球最大的AI海量模型。
(4)李飞飞团队新作发表于《自然》杂志:AI有身体会更聪明吗?(论文)
如果AI有身体,它会变得更聪明吗?答案是肯定的。近日,由斯坦福大学李飞飞教授领导的研究小组发现,体型会影响虚拟生物 Unimal 在复杂环境中的适应和学习能力,而复杂环境也会促进形态智能的进化。
AI 应用,左或右
(5)美国“杀手机狗”:配备狙击步枪,精准锁定1.2公里范围内的目标(论文)
英剧《黑镜》中的杀人机器狗令人难忘,如今科幻已成现实。在10月11日至13日举行的美国陆军协会年会上,科技公司Ghost Robotics和专业步枪公司SWORD International共同展出了一款名为SPUR(Special Purpose Unmaned Rifle)的机器狗。机器狗配备了狙击步枪,并配备了具有30倍光学变焦的Teledyne FLIR玻色子热像仪,可以“在白天和黑夜的各种条件下作业”。
(6)DeepMind 的 AI 几乎可以准确预测何时何地下雨(麻省理工科技评论)
短期天气预报可以为能源管理、海事服务、洪水预警系统、空中交通管制等提供关键决策信息,但一直是传统天气预报中的难题。9月底,谷歌人工智能实验室DeepMind宣布,他们在过去几年与英国气象局合作,开发了一种新的深度学习模型DGMR,可以更准确地预测未来90分钟的天气。研究结果已发表在《自然》杂志上。
(7) 科学家展示了人工智能如何帮助检测隐形心力衰竭 (ScienceDaily)
人工智能在医疗应用方面取得新进展。美国西奈山卫生系统的一个研究团队创造了一种基于人工智能的计算机算法,可以帮助医务人员利用心电图 (ECG) 上的微弱信号变化来更快地预测患者是否会出现心力衰竭。
市场期待什么样的算法技术?
(8)清华虚拟学生所谓AI变革的背后:大部分人工智能仍处于学习阶段(南方都市报)
10月19日,“清华虚拟学生因换脸真AI被质疑”话题在网上引发争议。有网友质疑,此前备受关注的“清华虚拟学生华志兵弹唱视频”只是B站主打鱼子酱真人视频的换脸。对此,开发者小兵团队发布声明称,视频的来源从一开始就标明了,而且不仅使用了AI换脸技术。
(9)Gartner发布2022年12个重要战略技术趋势(网络研究院)
Gartner在近期的Gartner IT Symposium/Xpo Summit Americas上公布了最新研究成果,指出了2022年企业需要探索的重要战略技术趋势。12大战略技术趋势包括:生成人工智能、Data Fabric、分布式企业、云-原生平台(CNP)、自主系统、决策智能(DecisionIntelligence、DI)、组合应用(Composable Applications)、超自动化、隐私增强计算(PEC)、网络安全网格、人工智能工程(AI Engineering)和总经验(Total经验,德克萨斯州)。
网页采集器的自动识别算法(搜索引擎盲点,本文网页采集技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-26 17:10
[摘要]:随着搜索引擎的广泛应用,网页采集技术得到了突飞猛进的发展。网页采集是搜索引擎工作流程的第一站,采集页面的质量将直接影响搜索引擎的查询服务质量。理想的情况是采集
与用户视觉信息(Coherent with Users' Vision Information,CUVI)一致的页面。这个概念一直是搜索引擎领域的盲点。针对这一盲点,本文以抓取CUVI页面为目的,设计并实现了一个网页采集系统。抓取一个CUVI页面首先需要进行网页重定向的处理操作,这是页面中JavaScript程序的主要功能之一。在本文中,采集系统通过在采集系统设计中引入JavaScript分析,在很大程度上解决了采集CUVI页面的问题。本文主要内容分为两部分:JavaScript分析与采集系统设计与实现。在JavaScript(JS)解析部分,首先分析处理JavaScript的必要性,通过对典型数据的调查分析,得出JS程序在HTML文档中的功能分布。然后,根据集合系统对JavaScript解析的需求,设计并实现了一个简单的JS解析器——JSParser。最后通过实验验证了JSParser在性能和功能上都能满足本文采集
系统的要求。本文中的采集系统由采集器和控制器两个模块组成。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。 查看全部
网页采集器的自动识别算法(搜索引擎盲点,本文网页采集技术)
[摘要]:随着搜索引擎的广泛应用,网页采集技术得到了突飞猛进的发展。网页采集是搜索引擎工作流程的第一站,采集页面的质量将直接影响搜索引擎的查询服务质量。理想的情况是采集
与用户视觉信息(Coherent with Users' Vision Information,CUVI)一致的页面。这个概念一直是搜索引擎领域的盲点。针对这一盲点,本文以抓取CUVI页面为目的,设计并实现了一个网页采集系统。抓取一个CUVI页面首先需要进行网页重定向的处理操作,这是页面中JavaScript程序的主要功能之一。在本文中,采集系统通过在采集系统设计中引入JavaScript分析,在很大程度上解决了采集CUVI页面的问题。本文主要内容分为两部分:JavaScript分析与采集系统设计与实现。在JavaScript(JS)解析部分,首先分析处理JavaScript的必要性,通过对典型数据的调查分析,得出JS程序在HTML文档中的功能分布。然后,根据集合系统对JavaScript解析的需求,设计并实现了一个简单的JS解析器——JSParser。最后通过实验验证了JSParser在性能和功能上都能满足本文采集
系统的要求。本文中的采集系统由采集器和控制器两个模块组成。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。在采集
器的设计上,创新性地引入了页面分析功能,结合JSParser的使用,实现了采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。达到采集
CUVI页面的初衷;在实现上,采用了EPOLL技术,解决了采集器对高并发的要求。控制器维护一个站点IP FIFO(Fist In FistOut)队列,更好的解决了采集系统对IP和站点的抓包压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。更好的解决了采集系统对IP和站点的抓取压力控制,使采集器和互联网可以很好的协同工作。通过对系统的各种测试,发现引入JSParser对系统性能没有明显影响,系统在IP充足的情况下运行良好。
网页采集器的自动识别算法(网页采集器的自动识别算法是什么?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-26 14:03
网页采集器的自动识别算法有三类,一是针对ip特征的,二是针对文本特征的,三是针对图片特征的。针对ip特征的识别相对来说容易。而针对文本特征识别的识别是比较困难的,主要是因为文本采集是扫描识别,相对来说相对成本高,基本无成型算法。
我就是做这块的,简单谈谈吧,网页采集器的识别算法可以简单分为固定ip识别和唯一文本识别,这两种类型的识别原理,我们不做过多的阐述,因为这两种方法都是视觉类识别,原理都是图像识别,所以他们需要算法、硬件平台、算法库三大类,如果对采集硬件和算法深入了解,其实很简单,有些国内做这个行业非常出名的网站采集软件,是从硬件和算法上帮助用户实现,达到准确率高和无垃圾页面的。你可以百度下“神州采采”软件,网上都可以查到,没有免费版。仅供参考。
网页采集的识别算法在很多方面都做得比较好的有mit的max3识别系统(又称mit识别方法系统),它们能识别很多不同的网页,ip不同、文件类型不同等等但是只要选用的识别算法能够保证网页采集的效率和对于服务端而言,这个识别算法需要容错性,即,如果识别错误,修改识别算法的代码可以使网页达到正确的识别结果。
做过程序,去年去深圳cvpr第二场也是这方面的,一般做这块的主要就是一些识别算法如marroll,lookify,qrngt等,我这边也只是跟了max3一个实验室,工资待遇感觉跟码农相差无几,我是做cv+nlp,也做了一段时间。有兴趣一起交流下。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是什么?怎么做?)
网页采集器的自动识别算法有三类,一是针对ip特征的,二是针对文本特征的,三是针对图片特征的。针对ip特征的识别相对来说容易。而针对文本特征识别的识别是比较困难的,主要是因为文本采集是扫描识别,相对来说相对成本高,基本无成型算法。
我就是做这块的,简单谈谈吧,网页采集器的识别算法可以简单分为固定ip识别和唯一文本识别,这两种类型的识别原理,我们不做过多的阐述,因为这两种方法都是视觉类识别,原理都是图像识别,所以他们需要算法、硬件平台、算法库三大类,如果对采集硬件和算法深入了解,其实很简单,有些国内做这个行业非常出名的网站采集软件,是从硬件和算法上帮助用户实现,达到准确率高和无垃圾页面的。你可以百度下“神州采采”软件,网上都可以查到,没有免费版。仅供参考。
网页采集的识别算法在很多方面都做得比较好的有mit的max3识别系统(又称mit识别方法系统),它们能识别很多不同的网页,ip不同、文件类型不同等等但是只要选用的识别算法能够保证网页采集的效率和对于服务端而言,这个识别算法需要容错性,即,如果识别错误,修改识别算法的代码可以使网页达到正确的识别结果。
做过程序,去年去深圳cvpr第二场也是这方面的,一般做这块的主要就是一些识别算法如marroll,lookify,qrngt等,我这边也只是跟了max3一个实验室,工资待遇感觉跟码农相差无几,我是做cv+nlp,也做了一段时间。有兴趣一起交流下。
网页采集器的自动识别算法(VG浏览器如何创建自动采集类别脚本?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-26 05:19
vgame浏览器是一个可以编辑可视化脚本的网页浏览器。浏览器可以创建自动采集、自动识别验证码、自动注册等多种类型的脚本。它用于采集
相关的网络内容,主要用于营销项目。不要错过,欢迎下载使用!
软件特点
1、可视化操作
操作简单,图形完全可视化。无需专业 IT 人员即可进行整形操作。
2、自定义流程
采集
就像搭积木,功能可以自由组合。
3、自动编码
程序注重采集效率,页面分析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
如何在VG浏览器中下载文件?
您可以在变量中获取文件地址以下载文件。可以只保存文件的完整地址在变量中(需要检查变量内容是图片地址),也可以保存收录
img标签的html代码。
如何在 VG 浏览器中创建新脚本?
右键单击脚本编辑器中的任意组并选择新建脚本。如果没有组,请在左侧空白处单击鼠标右键创建一个新组。
下面填写脚本的基本信息
1.脚本名称:自定义脚本名称
2.选择组,即把脚本放到哪个组。如果没有合适的组,可以点击右边的“新建组”创建一个
3.选择浏览器内核。Firefox 是 Firefox 浏览器内核。如果需要在脚本中使用浏览器模拟,则需要选择该选项。如果选择“不使用浏览器”,则不会使用脚本进行浏览 一些与浏览器相关的脚本功能的优点是运行脚本时不需要加载浏览器,浏览器是生成EXE程序时不需要打包。运行效率高,体积更小。建议在制作http请求脚本时选择。
4. 脚本密码:设置密码后,其他人无法随意修改或查看脚本内容。
5.备注:脚本备注信息
填写完脚本的基本信息后,点击下一步
在流程设计器中右键单击以创建所需的脚本
在脚本设计过程中,您可以随时右键单击创建的步骤进行测试和运行,或右键单击脚本名称运行脚本。完成后点击下一步,根据需要配置其他运行参数。至此,脚本创建完毕。
发行说明
1.修复了一些已知的错误
2.优化了用户界面
展开内容 查看全部
网页采集器的自动识别算法(VG浏览器如何创建自动采集类别脚本?(一))
vgame浏览器是一个可以编辑可视化脚本的网页浏览器。浏览器可以创建自动采集、自动识别验证码、自动注册等多种类型的脚本。它用于采集
相关的网络内容,主要用于营销项目。不要错过,欢迎下载使用!
软件特点
1、可视化操作
操作简单,图形完全可视化。无需专业 IT 人员即可进行整形操作。
2、自定义流程
采集
就像搭积木,功能可以自由组合。
3、自动编码
程序注重采集效率,页面分析速度非常快。
4、生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
如何在VG浏览器中下载文件?
您可以在变量中获取文件地址以下载文件。可以只保存文件的完整地址在变量中(需要检查变量内容是图片地址),也可以保存收录
img标签的html代码。
如何在 VG 浏览器中创建新脚本?
右键单击脚本编辑器中的任意组并选择新建脚本。如果没有组,请在左侧空白处单击鼠标右键创建一个新组。
下面填写脚本的基本信息
1.脚本名称:自定义脚本名称
2.选择组,即把脚本放到哪个组。如果没有合适的组,可以点击右边的“新建组”创建一个
3.选择浏览器内核。Firefox 是 Firefox 浏览器内核。如果需要在脚本中使用浏览器模拟,则需要选择该选项。如果选择“不使用浏览器”,则不会使用脚本进行浏览 一些与浏览器相关的脚本功能的优点是运行脚本时不需要加载浏览器,浏览器是生成EXE程序时不需要打包。运行效率高,体积更小。建议在制作http请求脚本时选择。
4. 脚本密码:设置密码后,其他人无法随意修改或查看脚本内容。
5.备注:脚本备注信息
填写完脚本的基本信息后,点击下一步
在流程设计器中右键单击以创建所需的脚本
在脚本设计过程中,您可以随时右键单击创建的步骤进行测试和运行,或右键单击脚本名称运行脚本。完成后点击下一步,根据需要配置其他运行参数。至此,脚本创建完毕。
发行说明
1.修复了一些已知的错误
2.优化了用户界面
展开内容
网页采集器的自动识别算法(VG浏览器软件特色可视化驱动的网页自动操作操作工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-26 05:17
VG浏览器8.4.8.1 正式版免费,不看无精打采,怕赢。6.书是哲学家灵魂的结晶,我们常说他们的生命没有枯萎,因为它的思想一直流传到今天。书不仅是它的载体,更像是它生命的延续和体现。这本书呈现给我们的是作者隐藏的形象,或沮丧或快乐,或烦躁或困惑。背后是作者的精神和灵魂的叙述。因此,这本书有其独特的人文生命力。70. 我正沿着公园路向东走,一个老人从街对面的公园里出来。89.
vg浏览器不仅是采集
浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件截图13 9. 强是我的导师,没有她,我会失去生命;我的心很强,没有她,我就是个傻瓜;强壮的是我的四肢,没有她,我将永远无法站立。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集
就像搭积木,功能可以自由组合。
自动编码
程序注重采集效率,页面解析速度快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
软件截图2
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
软件截图4
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
软件截图5
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
软件截图6
软件截图7
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志:
更新日志
改进步骤回收站功能,修复回收站垃圾过多导致脚本加载错误的问题
其他一些细节改进
等青阴春来,香阁楼周围苍蝇飞舞。晚来翠梅宫,学远山。伊存狂心不说,已经感觉到了横波。远树引来游人,孤城必倒。VG浏览器,网页浏览器9、第一印象就成功了。 查看全部
网页采集器的自动识别算法(VG浏览器软件特色可视化驱动的网页自动操作操作工具介绍)
VG浏览器8.4.8.1 正式版免费,不看无精打采,怕赢。6.书是哲学家灵魂的结晶,我们常说他们的生命没有枯萎,因为它的思想一直流传到今天。书不仅是它的载体,更像是它生命的延续和体现。这本书呈现给我们的是作者隐藏的形象,或沮丧或快乐,或烦躁或困惑。背后是作者的精神和灵魂的叙述。因此,这本书有其独特的人文生命力。70. 我正沿着公园路向东走,一个老人从街对面的公园里出来。89.
vg浏览器不仅是采集
浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一个由可视化脚本驱动的网页自动运行工具。只需设置脚本即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库。发送和接收电子邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件截图13 9. 强是我的导师,没有她,我会失去生命;我的心很强,没有她,我就是个傻瓜;强壮的是我的四肢,没有她,我将永远无法站立。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集
就像搭积木,功能可以自由组合。
自动编码
程序注重采集效率,页面解析速度快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的这个按钮
软件截图2
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。例如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
软件截图4
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
软件截图5
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
软件截图6
软件截图7
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志:
更新日志
改进步骤回收站功能,修复回收站垃圾过多导致脚本加载错误的问题
其他一些细节改进
等青阴春来,香阁楼周围苍蝇飞舞。晚来翠梅宫,学远山。伊存狂心不说,已经感觉到了横波。远树引来游人,孤城必倒。VG浏览器,网页浏览器9、第一印象就成功了。
网页采集器的自动识别算法(除了处理网站表单,requests模块还是一个设置请求头的利器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-26 05:16
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】 查看全部
网页采集器的自动识别算法(除了处理网站表单,requests模块还是一个设置请求头的利器)
除了处理网站表单之外,请求模块也是设置请求头的强大工具。HTTP 请求标头是每次向 Web 服务器发送请求时传递的一组属性和配置信息。HTTP 定义了十多种奇怪的请求头类型,但大多数并不常用。大多数浏览器仅使用以下七个字段来发起所有网络请求(表中的信息是我自己的浏览器数据)。
当经典的 Python 爬虫使用 urllib 标准库时,它会发送以下请求头:
如果你是一个防范爬虫的站长,你会允许哪个请求头访问你的网站?
安装请求
您可以在模块的网站上找到下载链接 () 和安装方法,或者使用任何第三方 Python 模块安装程序进行安装。
可以通过 requests 模块自定义请求头。网站是一个很棒的网站,它允许服务器测试浏览器的属性。我们使用以下程序采集
本网站上的信息并验证我们浏览器的 cookie 设置:
程序输出中的请求头应与程序中设置的头相同。
尽管网站可能会对 HTTP 请求标头的每个属性进行“人性化”检查,但我发现通常真正重要的参数是 User-Agent。不管你在做什么项目,一定要记得把User-Agent属性设置成不容易引起怀疑的东西,不要使用Python-urllib/3.4。另外,如果你正在处理一个非常警惕的网站,你应该注意那些经常使用但很少检查的请求头,比如Accept-Language属性。也许这是该网站判断您是个人访问者的关键。
请求头会改变你查看网络世界的方式
假设您想为机器学习研究项目编写语言翻译器,但您没有大量翻译文本来测试其效果。许多大型网站对相同的内容提供不同的语言翻译,根据请求头的参数响应网站的不同语言版本。因此,您可以简单地将请求头属性从 Accept-Language:en-US 修改为 Accept-Language:fr,就可以从网站获取“Bonjour”(法语,你好)的数据,提高翻译效果翻译(大型跨国公司通常是很好的采集
对象)。
请求头还可以让网站改变内容的布局风格。例如,当使用移动设备浏览网站时,您通常会看到网站的简化版,没有广告、Flash 和其他干扰因素。所以把你的请求头User-Agent改成下面这样,就可以看到一个更容易采集
的网站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 手机/11D257 Safari/9537.53
2.设置cookies的知识
虽然 cookie 是一把双刃剑,但正确处理 cookie 可以避免很多采集
问题。该网站将使用 cookie 来跟踪您的访问。如果发现异常爬虫行为,您的访问将被中断,例如非常快速地填写表格或浏览大量页面。虽然这些行为可以通过关闭和重新连接或更改 IP 地址来伪装,但如果 cookie 暴露了您的身份,则不会浪费任何努力。
采集
某些网站时,Cookie 是必不可少的。要持续登录网站,您需要在多个页面上保存 cookie。有些网站不需要每次登录都需要一个新的cookie,只要保存一个旧的“登录”cookie,就可以访问。
如果您正在采集
一个或多个目标网站,建议您检查这些网站生成的cookies,然后再考虑爬虫需要处理哪些cookies。有一些浏览器插件可以显示当您访问网站和离开网站时 cookie 是如何设置的。EditThisCookie() 是我最喜欢的 Chrome 浏览器插件之一。
由于请求模块无法执行 JavaScript,因此无法处理许多新的跟踪软件(例如 Google Analytics)生成的 cookie。cookie 仅在客户端脚本执行后设置(或根据用户浏览页面时的 web 事件生成 cookie,例如单击按钮。)。要处理这些操作,您需要使用 Selenium 和 PhantomJS 包。
硒和 PhantomJS
Selenium() 是一个强大的网络数据采集
工具,最初是为自动化网站测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。Selenium 可以让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 本身没有浏览器,需要配合第三方浏览器使用。比如你在Firefox上运行Selenium,可以直接看到Firefox窗口打开,进入网站,然后执行你在代码中设置的动作。虽然这样可以看得更清楚,但我更喜欢让程序在后台运行,所以我使用 PhantomJS() 而不是真正的浏览器。
PhantomJS 是一个“无头”浏览器。它会将网站加载到内存中并在页面上执行 JavaScript,但不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标题以及您需要做的任何事情。
您可以从 PyPI 网站 () 下载 Selenium 库,也可以使用第三方管理器(如 pip)在命令行上安装它。
您可以在任何网站(在本例中)调用 webdriver 的 get_cookie() 方法来查看 cookie:
点击查看大图
这样就可以得到一个非常典型的谷歌分析cookie列表:
点击查看大图
您还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。此外,可以保存 cookie 以供其他网络爬虫使用。以下示例演示了如何组合这些功能:
点击查看大图
在这个例子中,第一个 webdriver 获取一个网站,打印 cookie 并将它们保存在变量 savedCookies 中。第二个webdriver加载同一个网站(技术提示:网站必须先加载,这样Selenium才能知道cookie属于哪个网站,即使加载网站的行为对我们没有用),删除所有cookie,并将其替换为第一个 webdriver 获取的 cookie。再次加载页面时,两组cookies的时间戳、源码等信息应该完全一致。从 Google Analytics 的角度来看,第二个 webdriver 现在与第一个 webdriver 完全相同。
3.正常时间访问路径
有一些受到良好保护的网站可能会阻止您快速提交表单或与网站交互。即使没有这些安全措施,以比普通人快得多的速度从网站下载大量信息也可能导致自己无法访问该网站。
因此,虽然多线程程序可能是一种很好的方式来加载页面——在一个线程中快速处理数据并在另一个线程中加载页面——但这对于一个编写良好的爬虫来说是一个可怕的策略。仍然应该尽量确保页面加载一次并且数据请求被最小化。如果可能,尽量增加每次页面访问的时间间隔,即使要添加一行代码:
time.sleep(3)
(小编:3+随机数比较好?)
合理的速度控制是你不应该打破的规则。过度消耗别人的服务器资源会让你处于非法状态,更严重的是,这样做可能会导致小网站宕机甚至下线。关闭网站是不道德的,这是一个彻头彻尾的错误。所以请控制好采集
速度!
解密常见表单反爬虫安全措施
许多像 Litmus 这样的测试工具已经使用了很多年,并且仍然用于区分网络爬虫和使用浏览器的人类访问者。这些方法都取得了不同程度的效果。尽管网络机器人下载一些公共文章和博客文章并不是什么大问题,但如果网络机器人在您的网站上创建了数千个帐户并开始向所有用户发送垃圾邮件,那就是一个大问题。如果网页表单,特别是用于创建和登录的表单被机器人滥用,网站的安全和流量成本将面临严重威胁。因此,尝试限制网站访问是许多网站所有者的最大利益。(至少他们是这么认为的)。
这些针对表单和登录链接的反机器人安全措施,确实是对网络爬虫的严峻挑战。
4.注意隐含的输入字段值
在 HTML 表单中,“隐藏”字段可以使该字段的值对浏览器可见,但对用户不可见(除非您查看网页的源代码)。随着越来越多的网站开始使用 cookie 来存储状态变量来管理用户状态,隐藏字段主要用于防止爬虫自动提交表单,直到找到另一个最佳用途。
下图中的示例是 Facebook 登录页面上的隐藏字段。尽管表单中只有三个可见字段(用户名、密码和确认按钮),但源代码中的表单向服务器发送了大量信息。
Facebook 登录页面上的隐藏字段
有两种主要方法可以防止使用隐藏字段采集
网络数据。第一个是表单页面上的字段可以由服务器生成的随机变量表示。如果提交时该值不在表单处理页面上,则服务器有理由认为该提交不是从原创
表单页面提交,而是由网络机器人直接提交到表单处理页面。规避这个问题最好的办法是先采集
表单所在页面产生的随机变量,然后提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单中收录
一个隐藏字段的常用名称(设置蜜罐陷阱),例如“用户名”或“电子邮件地址”,设计不好的网络机器人通常不会关心这个字段是否对用户可见,直接填写此字段并提交给服务器,服务器将被服务器的蜜罐困住。服务器会忽略所有隐藏字段的真实值(或与表单提交页面默认值不同的值),填写隐藏字段的用户也可能被网站屏蔽。
总之,有时候需要检查一下表单所在的页面,看看有没有服务器预设的隐藏字段(蜜罐陷阱)有遗漏或错误。如果您看到一些隐藏字段,通常带有大的随机字符串变量,那么 Web 服务器很可能会在提交表单时检查它们。此外,还有其他检查可以确保这些当前生成的表单变量只使用一次或最近生成的(这可以防止变量简单地存储在程序中以供重复使用)。
5.爬虫通常如何避免蜜罐
虽然在网络数据采集
过程中通过CSS属性很容易区分有用信息和无用信息(例如通过读取id和class标签来获取信息),但这有时会导致问题。如果web表单的某个字段通过CSS设置为对用户不可见,那么可以认为普通用户在访问网站时无法填写该字段,因为它不会显示在浏览器中。如果填写此字段,则可能是由机器人完成的,因此此提交将无效。
这种方法不仅可以应用于网页表单,还可以应用于链接、图片、文件以及任何机器人可以读取但普通用户在浏览器中看不到的内容。如果访问者访问了网站上的“隐性”内容,将触发服务器脚本封锁用户的IP地址、将用户踢出网站或采取其他措施禁止用户访问网站。事实上,很多商业模式都在做这些事情。
下面例子中使用的网页是in。这个页面收录
两个链接,一个是CSS隐含的,另一个是可见的。此外,该页面还收录
两个隐藏字段:
点击查看大图
这三个元素以三种不同的方式对用户隐藏:
因为 Selenium 可以获取被访问页面的内容,所以可以区分页面上的可见元素和隐藏元素。您可以通过 is_displayed() 确定该元素在页面上是否可见。
比如下面的代码示例就是获取上一页的内容,然后找到隐式链接和隐式输入字段:
点击查看大图
Selenium 抓取了每一个隐含的链接和字段,结果如下:
点击查看大图
虽然你不太可能访问你找到的隐藏链接,但在提交之前,请记住确认表单中已经存在并准备提交的隐藏字段的值(或让Selenium自动为你提交)。
使用远程服务器避免 IP 阻塞
启用远程平台的人通常有两个目标:需要更强的计算能力和灵活性,以及需要可变 IP 地址。
6. 使用可变远程 IP 地址
构建网络爬虫的第一个原则是:所有信息都可以伪造。你可以从非个人邮箱发送邮件,使用命令行自动鼠标操作,或者使用IE5.0浏览器消耗网站流量来吓唬站长。
但是有一件事是无法伪造的,那就是您的 IP 地址。任何人都可以通过以下地址给您写信:“1600 Pennsylvania Avenue Northwest, Washington, DC, US President, Zip Code 20500。” 但是,如果这封信来自新墨西哥州的阿尔伯克基,那么您必须确定写信给您的不是美国总统。
从技术上讲,可以通过发送数据包来伪装IP地址,这就是分布式拒绝服务(DDoS)攻击技术。攻击者不需要关心接收到的数据包(这样可以发送请求。使用假IP地址)。但是网络数据采集是一种需要关注服务器响应的行为,所以我们认为IP地址是不可伪造的。
阻止网站被采集
的注意力主要集中在识别人类和机器人之间的行为差异。封杀IP地址的杀伤力就像农民不喷农药杀虫在庄稼上,而是直接用火彻底解决问题。这是最后一步,但它是一种非常有效的方法,只要您忽略从危险IP地址发送的数据包即可。但是,使用这种方法会遇到以下问题。
尽管存在这些缺点,但阻止 IP 地址仍然是服务器管理员用来防止可疑网络爬虫入侵服务器的一种非常常用的方法。
Tor代理服务器
洋葱路由器(The Onion Router)网络,通常缩写为 Tor,是一种匿名化 IP 地址的手段。网络志愿者服务器构建的洋葱路由器网络通过不同的服务器形成多层(就像洋葱一样),将客户端包裹在最里面。数据在进入网络之前被加密,因此没有服务器可以窃取通信数据。另外,虽然可以查看每个服务器的入站和出站通信,但是如果要查明通信的真正开始和结束,就必须知道整个通信链路上所有服务器的入站和出站通信明细。这基本上是不可能的。
Tor匿名的局限性
虽然本文使用Tor的目的是为了改变IP地址,而不是实现完全匿名,但还是需要注意Tor的匿名方式的能力和不足。
尽管 Tor 网络允许您在访问无法追踪到您的网站时显示 IP 地址,但您在网站上留给服务器的任何信息都会暴露您的身份。例如,如果您登录 Gmail 帐户,然后在 Google 上进行搜索,那么这些搜索历史记录将与您的身份相关联。
此外,登录 Tor 的行为也可能使您的匿名性处于危险之中。2013年12月,一位哈佛大学本科生为了逃避期末考试,于是使用匿名邮箱通过Tor网络向学校发送炸弹威胁信。结果,哈佛大学IT部门通过日志发现,在发送炸弹威胁信时,Tor网络流量仅来自一台机器,并且是该校一名学生注册的。虽然他们无法确定流量的原创
来源(只知道它是通过Tor发送的),但犯罪时间和注册信息有充分证据,并且在该时间段内只有一台机器登录。这是起诉学生的一个很好的理由。
登录 Tor 网络不是自动匿名措施,也不允许您进入 Internet 上的任何区域。虽然它是一个实用的工具,但您在使用它时必须谨慎、清醒和合乎道德。
在Python中使用Tor需要先安装并运行Tor,下一节会介绍。Tor 服务易于安装和启动。直接到Tor下载页面下载安装,打开后连接即可。但请注意,使用 Tor 时互联网速度会变慢。这是因为代理可能要在世界网络上多次旅行才能到达目的地!
袜子
PySocks 是一个非常简单的 Python 代理服务器通信模块,可以和 Tor 一起使用。您可以从其网站 () 下载它,也可以使用任何第三方模块管理器进行安装。
这个模块的使用非常简单。示例代码如下所示。运行时,Tor 服务必须运行在 9150 端口(默认值):
网站会显示客户端连接的网站服务器的IP地址,可以用来测试Tor是否正常工作。程序执行后,显示的IP地址不是你原来的IP。
如果你想在 Tor 中使用 Selenium 和 PhantomJS,你不需要 PySocks,只要确保 Tor 正在运行,然后增加 service_args 参数设置代理端口,让 Selenium 通过端口 9150 连接到网站:
和之前一样,这个程序打印的IP地址不是你原来的,而是你通过Tor客户端获取的IP地址。
从网站主机运行
如果您有个人网站或公司网站,那么您可能已经知道如何使用外部服务器来运行您的网络爬虫。即使一些相对封闭的Web服务器没有可用的命令行访问方式,您也可以通过Web界面控制程序。
如果您的网站部署在 Linux 服务器上,则 Python 应该已经在运行。如果你使用的是 Windows 服务器,你可能就没那么幸运了;你需要仔细检查是否安装了Python,或者问站长是否可以安装。
大多数小型网络主机都会提供一个名为 cPanel 的软件,它为网站管理和后台服务提供基本的管理功能和信息。如果您连接到 cPanel,您可以设置 Python 在服务器上运行 - 输入“Apache Handlers”并添加一个处理程序(如果还没有):
这将告诉服务器所有 Python 脚本都将作为 CGI 脚本运行。CGI是Common Gateway Interface,它是任何可以在服务器上运行的程序,它动态地生成内容并在网站上显示出来。将 Python 脚本显式定义为 CGI 脚本是为了赋予服务器执行 Python 脚本的权限,而不仅仅是在浏览器中显示它们或让用户下载它们。
写好Python脚本后,上传到服务器,然后将文件权限设置为755,使其可执行。通过浏览器找到程序上传的位置(你也可以写一个爬虫来自动完成)来执行程序。如果担心公域脚本执行不安全,可以采取以下两种方法。
事实上,通过这些最初用于显示网站的服务运行 Python 脚本有点复杂。例如,您可能会发现在网络爬虫运行时网站的加载速度变慢。实际上,直到整个采集
任务完成后页面才会加载(您必须等到所有“打印”语句的输出都显示出来)。这可能需要几分钟、几小时,甚至永远不会完成,具体取决于程序的具体情况。虽然它最终能够完成任务,但您可能希望看到实时结果,因此您需要一个真实的服务器。
从云主机运行
虽然云计算的成本可能是个无底洞,但在写这篇文章的时候,启动一个计算实例是最便宜的,只要1.3美分/小时(Amazon EC2微实例,其他实例会更多贵),谷歌是最便宜的计算例子是4.5美分每小时,至少需要10分钟。考虑到算力的规模效应,从大公司购买一个小型云计算实例的成本应该和自己购买一台专业物理机的成本差不多——但使用云计算不需要雇人维护设备.
设置计算实例后,您将拥有一个新的 IP 地址、用户名和公钥和私钥,可用于通过 SSH 连接到实例。以后需要做的一切都应该和在物理服务器上做的一样——当然,你再也不用担心硬件维护了,也不需要运行复杂冗余的监控工具。
总结爬虫被屏蔽的常见原因列表
如果您被网站阻止但找不到原因,那么这里有一份检查清单可以帮助您诊断问题。
【以上内容编译自《Python网络数据采集》第1章0、12、14】
网页采集器的自动识别算法(优采云采集器软件特色零门槛不懂网络爬虫技术(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-24 08:13
优采云采集器一款优秀的数据采集工具,通过软件可以快速采集所需的数据文件,软件使用简单,用户只需放入相应的内容进入本软件可以进行信息采集,轻松采集网站所有信息,非常方便的一款,简洁的功能方便您的操作,让信息采集更加简单!
优采云采集器软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
优采云采集器 使用说明
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以快速转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
无需分析网页请求和源码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过简单的映射向导字段可以轻松导出到目标 网站 数据库。
优采云采集器软件优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
1、查询关键词 填写一行
2、 查询延迟单位为毫秒,即1000=1秒
3、 点击开始后,会在软件的data目录下以日期为文件夹名生成采集的关键词,并保存在MDB数据库中
4、导出关键词功能可以在之前的任何时间导出采集的关键词,按Export关键词,然后选择你的关键词数据库想出口
优采云采集器软件评估
一个非常有用的网络信息工具采集。该工具界面简洁,操作简单,功能强大。有了它,我们就可以采集获取我们需要的网页上的所有信息,零门槛,新手用户都可以使用。
优采云采集器常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进库,如果目标页面本身也是重复数据, 也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
如何手动生成列表?
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且还会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段 查看全部
网页采集器的自动识别算法(优采云采集器软件特色零门槛不懂网络爬虫技术(组图))
优采云采集器一款优秀的数据采集工具,通过软件可以快速采集所需的数据文件,软件使用简单,用户只需放入相应的内容进入本软件可以进行信息采集,轻松采集网站所有信息,非常方便的一款,简洁的功能方便您的操作,让信息采集更加简单!
优采云采集器软件特点
零门槛
如果你不懂网络爬虫技术,如果你能上网,你就能采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更高效。它还内置了 JSON 引擎,无需分析 JSON 数据结构,直观选择 JSON 内容。
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载和其他动态类型网站。
优采云采集器 使用说明
软件操作简单,鼠标点击即可轻松选择要采集的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至可以快速转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
无需分析网页请求和源码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过简单的映射向导字段可以轻松导出到目标 网站 数据库。
优采云采集器软件优势
可视化向导
所有采集元素,自动生成采集数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
各种数据导出
可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
1、查询关键词 填写一行
2、 查询延迟单位为毫秒,即1000=1秒
3、 点击开始后,会在软件的data目录下以日期为文件夹名生成采集的关键词,并保存在MDB数据库中
4、导出关键词功能可以在之前的任何时间导出采集的关键词,按Export关键词,然后选择你的关键词数据库想出口
优采云采集器软件评估
一个非常有用的网络信息工具采集。该工具界面简洁,操作简单,功能强大。有了它,我们就可以采集获取我们需要的网页上的所有信息,零门槛,新手用户都可以使用。
优采云采集器常见问题
采集 如何避免数据重复?
运行采集任务时,如果任务前有采集数据,如果采集之前没有清除原有数据,会以append的形式添加新的采集将数据添加到本地采集库中,这样一些已经采集的数据可能会再次采集进库,如果目标页面本身也是重复数据, 也有可能造成数据重复,那么如何避免采集的数据重复呢?
方法很简单,我们希望哪个字段内容不允许重复,只需点击字段标题上的三角形符号,然后勾选“过滤重复项”复选框,然后单击“确定”即可。
如何手动生成字段?
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
如何手动生成列表?
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且还会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段
网页采集器的自动识别算法(基于网页采集器的自动识别算法设计(一)-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-12-21 19:00
网页采集器的自动识别算法基本上都是重建原图或者不重建原图加入相关算法,如3d重建,多帧重建等。以原图为基础,根据一定的特征去匹配是否有相同属性,然后生成类似信息的新图。提取相关方法也有很多,比如颜色匹配,气泡匹配,六度人脉匹配,地理信息匹配等。每种匹配方法都有自己的准则。原图采集到后,开发者根据程序去自己去找重要的目标信息吧。
实现的方法一般有几种:
1、需要收集业务的标准数据集,然后训练人工的attention机制来匹配相关的特征点,提取特征后再把特征融合到上位机处理进行数据分析。此方法优点是速度快,缺点是原始数据还原度不高。
2、需要开发者从大量的目标特征库中选择一些具有相似度的目标,提取特征用深度学习进行训练,最后用于上位机的识别。此方法优点是上位机速度快,缺点是不适合输入的尺寸太大。
3、上位机结合各类如陀螺仪、加速度计、gps等对目标进行测量建模,然后用globalmatrix相似度进行匹配匹配算法有很多,
他能还原很多:1,通过进行信息匹配。2,视觉感知和一些合理的图像颜色匹配。3,视觉图像信息库信息匹配。你的主要问题是有大量冗余信息,难以在上位机进行深度学习。回答如下:这类有大量冗余信息的数据库问题一般结合原始数据特征来提取。我简单做个示意示意,如下(这里简单的模拟了5个不同标注场景,这里是可以匹配的)一般包括物体的大小,颜色,高度,宽度,长度,重量,以及时间。好像还有四个特征,时间为脉冲-事件三元组。 查看全部
网页采集器的自动识别算法(基于网页采集器的自动识别算法设计(一)-八维教育)
网页采集器的自动识别算法基本上都是重建原图或者不重建原图加入相关算法,如3d重建,多帧重建等。以原图为基础,根据一定的特征去匹配是否有相同属性,然后生成类似信息的新图。提取相关方法也有很多,比如颜色匹配,气泡匹配,六度人脉匹配,地理信息匹配等。每种匹配方法都有自己的准则。原图采集到后,开发者根据程序去自己去找重要的目标信息吧。
实现的方法一般有几种:
1、需要收集业务的标准数据集,然后训练人工的attention机制来匹配相关的特征点,提取特征后再把特征融合到上位机处理进行数据分析。此方法优点是速度快,缺点是原始数据还原度不高。
2、需要开发者从大量的目标特征库中选择一些具有相似度的目标,提取特征用深度学习进行训练,最后用于上位机的识别。此方法优点是上位机速度快,缺点是不适合输入的尺寸太大。
3、上位机结合各类如陀螺仪、加速度计、gps等对目标进行测量建模,然后用globalmatrix相似度进行匹配匹配算法有很多,
他能还原很多:1,通过进行信息匹配。2,视觉感知和一些合理的图像颜色匹配。3,视觉图像信息库信息匹配。你的主要问题是有大量冗余信息,难以在上位机进行深度学习。回答如下:这类有大量冗余信息的数据库问题一般结合原始数据特征来提取。我简单做个示意示意,如下(这里简单的模拟了5个不同标注场景,这里是可以匹配的)一般包括物体的大小,颜色,高度,宽度,长度,重量,以及时间。好像还有四个特征,时间为脉冲-事件三元组。
网页采集器的自动识别算法(多线程、高性能采集器爬虫.net版源码,可采ajax页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-19 15:03
多线程、高性能采集器 版源码,ajax页面可用
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集 任务配置和跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义的HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有的网页请求需求。这个功能在数据网发布时特别有用;< @4)采集 URL 支持数字、字母、日期、自定义字典、外部数据等参数,最大限度的简化采集网站的配置,从而达到批处理采集;5)采集网站支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能也可以用于用户页面文章的自动合并操作;7)网络矿工支持级联采集,即在导航的基础上,可以将不同层次的数据自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章文章多页展示,系统翻页采集并合并成一条数据输出;9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)可以进行ajax技术形成网页数据采集;11)采集 规则支持特殊符号的定义,如:十六进制 0x01 非法字符;12)采集规则支持限定符操作,可以精确匹配需要获取的数据;13)采集 URL支持:UTF-8、GB2312、Base64、Big5等编码,并能自动识别等符号;网页编码支持:UTF-8、GB2312、Big5等编码;1 查看全部
网页采集器的自动识别算法(多线程、高性能采集器爬虫.net版源码,可采ajax页面)
多线程、高性能采集器 版源码,ajax页面可用
<p>1、数据采集基本功能1)支持多任务、多线程数据采集,支持一个采集任务、多多线程、高性能采集器版源码,可以使用ajax页面实例运行,即采集任务规则和采集任务操作会分离,方便采集 任务配置和跟踪管理;2)支持GET、POST请求方式,支持cookie,可以满足严肃数据的需要采集,cookie可以提前存储,也可以实时获取;3)支持用户自定义的HTTP Header,通过这个功能用户可以完全模拟浏览器请求操作,可以满足所有的网页请求需求。这个功能在数据网发布时特别有用;< @4)采集 URL 支持数字、字母、日期、自定义字典、外部数据等参数,最大限度的简化采集网站的配置,从而达到批处理采集;5)采集网站支持导航操作(即从入口页面自动跳转到需要采集数据的页面),导航规则支持复杂规则,导航级别不限,并可进行多层网址导航;6)支持采集自动URL翻译页面和导航层自动翻页。定义翻页规则后,系统会自动为数据采集翻页。同时,该功能也可以用于用户页面文章的自动合并操作;7)网络矿工支持级联采集,即在导航的基础上,可以将不同层次的数据自动采集下并自动合并。这个函数也可以叫分页采集;8)网络矿工支持翻页数据合并,可以合并多页数据,典型应用是同一篇文章文章多页展示,系统翻页采集并合并成一条数据输出;9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)可以进行ajax技术形成网页数据采集;11)采集 规则支持特殊符号的定义,如:十六进制 0x01 非法字符;12)采集规则支持限定符操作,可以精确匹配需要获取的数据;13)采集 URL支持:UTF-8、GB2312、Base64、Big5等编码,并能自动识别等符号;网页编码支持:UTF-8、GB2312、Big5等编码;1
网页采集器的自动识别算法(优采云采集器7.6.0,,WinAll软件功能操作简单,轻松掌握 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-17 19:10
)
对于任何需要从网络获取信息的孩子来说,八达通采集器是必不可少的神器。这是一个非常简单的信息采集工具。八达通改变了其对互联网数据的传统思维方式。方便用户在线抓取数据并编译
优采云数据采集器 简介图1
进入下载
优采云采集器 7.6.0 正式版
大小:54.47 MB
日期:2020/12/18 15:38:56
环境:WinXP、Win7、Win8、Win10、WinAll
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会用电脑上网的人都可以轻松掌握。
云集
采集任务自动分配到多台云服务器同时执行,提高采集效率,短时间内可获取数千条信息。
拖放采集进程
模拟人的操作思维。您可以登录、输入数据、点击链接、按钮等,针对不同情况采用不同的采集流程。
图片文字识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片中的文字。
定时自动采集
采集 任务自动运行。它可以根据指定的时间段自动采集。它还支持每分钟一次的实时采集。
2 分钟快速启动
内置视频教程,从入门到精通。您可以在 2 分钟内使用它。此外还有文档、论坛、QQ群等。
优采云数据采集器 简介图2
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
数据采集
功能介绍
简而言之,章鱼可以轻松地从任何网页采集所需的数据,并生成自定义和常规的数据格式。Octopus Data采集系统的功能包括但不限于以下
1、财务数据,如季报、年报、财务报表等,包括每日自动比较新净值采集
2.实时监控各大新闻门户网站,自动更新和上传较新的新闻
3. 监控有关竞争对手的相对较新的信息,包括商品价格和库存
4监控主要社交网站和博客,自动抓取公司产品的相关评论
5、采集比较新的、完整的职业招聘信息
6. 监控各种与房地产相关的网站,采集相关的新房和二手房市场
7、采集各大车的具体新车和二手车信息网站
8. 发现和采集潜在客户信息
9. 更新电子商务平台上的产品和产品信息。
优采云数据采集器 简介图3
主要体验提升
【自定义模式】增加JSON采集功能
【自定义模式】添加滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时,配置任务更方便
[自定义模式] 改进算法,更准确地选择网页元素
[本地采集]采集速度提升10~30%,采集效率大幅提升
【任务列表】重新构建任务列表界面,性能大幅提升,海量任务管理不再卡顿
任务列表增加了自动刷新机制,可以随时查看任务的最新状态
错误修复
修复云采集数据采集,数据查看速度慢的问题
修复设置错误报告布局混乱
修复“打开网页时出现随机码”问题
修复拖动过程后突然消失的问题
修复自动定时和自动定时输出数据类型的问题
优采云采集器 7.6.0 正式版
查看全部
网页采集器的自动识别算法(优采云采集器7.6.0,,WinAll软件功能操作简单,轻松掌握
)
对于任何需要从网络获取信息的孩子来说,八达通采集器是必不可少的神器。这是一个非常简单的信息采集工具。八达通改变了其对互联网数据的传统思维方式。方便用户在线抓取数据并编译
优采云数据采集器 简介图1
进入下载
优采云采集器 7.6.0 正式版
大小:54.47 MB
日期:2020/12/18 15:38:56
环境:WinXP、Win7、Win8、Win10、WinAll
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会用电脑上网的人都可以轻松掌握。
云集
采集任务自动分配到多台云服务器同时执行,提高采集效率,短时间内可获取数千条信息。
拖放采集进程
模拟人的操作思维。您可以登录、输入数据、点击链接、按钮等,针对不同情况采用不同的采集流程。
图片文字识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片中的文字。
定时自动采集
采集 任务自动运行。它可以根据指定的时间段自动采集。它还支持每分钟一次的实时采集。
2 分钟快速启动
内置视频教程,从入门到精通。您可以在 2 分钟内使用它。此外还有文档、论坛、QQ群等。
优采云数据采集器 简介图2
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
数据采集
功能介绍
简而言之,章鱼可以轻松地从任何网页采集所需的数据,并生成自定义和常规的数据格式。Octopus Data采集系统的功能包括但不限于以下
1、财务数据,如季报、年报、财务报表等,包括每日自动比较新净值采集
2.实时监控各大新闻门户网站,自动更新和上传较新的新闻
3. 监控有关竞争对手的相对较新的信息,包括商品价格和库存
4监控主要社交网站和博客,自动抓取公司产品的相关评论
5、采集比较新的、完整的职业招聘信息
6. 监控各种与房地产相关的网站,采集相关的新房和二手房市场
7、采集各大车的具体新车和二手车信息网站
8. 发现和采集潜在客户信息
9. 更新电子商务平台上的产品和产品信息。
优采云数据采集器 简介图3
主要体验提升
【自定义模式】增加JSON采集功能
【自定义模式】添加滑动验证码识别
【自定义模式】优化效率,列表识别速度翻倍
【自定义模式】自动识别网页Ajax点击并自动配置Ajax超时,配置任务更方便
[自定义模式] 改进算法,更准确地选择网页元素
[本地采集]采集速度提升10~30%,采集效率大幅提升
【任务列表】重新构建任务列表界面,性能大幅提升,海量任务管理不再卡顿
任务列表增加了自动刷新机制,可以随时查看任务的最新状态
错误修复
修复云采集数据采集,数据查看速度慢的问题
修复设置错误报告布局混乱
修复“打开网页时出现随机码”问题
修复拖动过程后突然消失的问题
修复自动定时和自动定时输出数据类型的问题
优采云采集器 7.6.0 正式版
网页采集器的自动识别算法(网页采集器的自动识别算法非常多,整站为什么要设置导航功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-15 04:02
网页采集器的自动识别算法非常多,现在很多网站都有实现的接口,网站的数据会自动存储在自己的缓存里面,再发布,但是有些网站的页面可能不会自动存储在缓存里面,那就需要用一些技术去手动查找网站的页面,虽然方便,但是效率低,今天我介绍给大家一款采集器,网页导航网址,它可以自动识别整个网站的导航,比如我们在csdn网站进行采集,比如我们用大页自动识别,点击选择第三页,它会自动下载第二页和第四页,并且图片和链接都自动识别出来了,非常方便,1分钟即可达到效果,感兴趣的朋友可以试一下,目前用的人很多,大页的工作量比较大,对采集工具和页面结构要求高,不知道大家觉得呢?。
要保证整站导航无效,首先得知道导航的存在,也就是整站为什么要设置导航功能。导航功能顾名思义就是跳转导航。常见的导航有好多种,有静态导航、动态导航,动态导航是一段时间内同一个页面被多个网站投放到同一个链接上,或者说浏览器或谷歌算法检测到同一页面可能有多个相同的页面,那么为了防止这些页面由于算法的原因导致被拦截或者引导。
如果说静态导航就是一个网站一个网站的实现跳转,那么导航功能就是一个网站同一个页面链接多次,或者网站多个页面链接多次。当然也有两个页面一起投放到同一个网站的导航,比如历史上比较有名的遨游或者360浏览器,它有一个红宝书导航,聚合了大量网站的网址,同时还会聚合网页的详细描述和高清图片。假如网站有多个页面是由一个单一的导航引导的,那么其中一个页面就可能对应很多相同的链接,对于搜索引擎来说,是很容易进行收录的。
如果不加导航,那么它在手机端和pc端分别会在不同页面打开,如果这个页面是该网站的核心内容,对于用户来说很容易从这些跳转到别的链接,达不到一个网站的核心目的。当然一个网站的核心内容会有很多页面或者类似内容,不仅仅是一个页面对应一个链接,而是一个页面引导多个链接,这样对于用户也是一个不错的选择。在互联网特别是移动互联网的大趋势下,网站导航的市场是非常大的,用户也是在不断增加,如果不设置导航,手机网站或pc网站的浏览体验会非常差,谷歌已经说了,谷歌认为未来在移动网站上引导用户更重要,但是这种方法肯定更贵,因为需要投放大量的谷歌算法,那么这种方法对于很多没有大量资金的公司不实用,而且除了寻找业内优秀的网站的导航开发者,很多无法实现采用这种方法的。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法非常多,整站为什么要设置导航功能)
网页采集器的自动识别算法非常多,现在很多网站都有实现的接口,网站的数据会自动存储在自己的缓存里面,再发布,但是有些网站的页面可能不会自动存储在缓存里面,那就需要用一些技术去手动查找网站的页面,虽然方便,但是效率低,今天我介绍给大家一款采集器,网页导航网址,它可以自动识别整个网站的导航,比如我们在csdn网站进行采集,比如我们用大页自动识别,点击选择第三页,它会自动下载第二页和第四页,并且图片和链接都自动识别出来了,非常方便,1分钟即可达到效果,感兴趣的朋友可以试一下,目前用的人很多,大页的工作量比较大,对采集工具和页面结构要求高,不知道大家觉得呢?。
要保证整站导航无效,首先得知道导航的存在,也就是整站为什么要设置导航功能。导航功能顾名思义就是跳转导航。常见的导航有好多种,有静态导航、动态导航,动态导航是一段时间内同一个页面被多个网站投放到同一个链接上,或者说浏览器或谷歌算法检测到同一页面可能有多个相同的页面,那么为了防止这些页面由于算法的原因导致被拦截或者引导。
如果说静态导航就是一个网站一个网站的实现跳转,那么导航功能就是一个网站同一个页面链接多次,或者网站多个页面链接多次。当然也有两个页面一起投放到同一个网站的导航,比如历史上比较有名的遨游或者360浏览器,它有一个红宝书导航,聚合了大量网站的网址,同时还会聚合网页的详细描述和高清图片。假如网站有多个页面是由一个单一的导航引导的,那么其中一个页面就可能对应很多相同的链接,对于搜索引擎来说,是很容易进行收录的。
如果不加导航,那么它在手机端和pc端分别会在不同页面打开,如果这个页面是该网站的核心内容,对于用户来说很容易从这些跳转到别的链接,达不到一个网站的核心目的。当然一个网站的核心内容会有很多页面或者类似内容,不仅仅是一个页面对应一个链接,而是一个页面引导多个链接,这样对于用户也是一个不错的选择。在互联网特别是移动互联网的大趋势下,网站导航的市场是非常大的,用户也是在不断增加,如果不设置导航,手机网站或pc网站的浏览体验会非常差,谷歌已经说了,谷歌认为未来在移动网站上引导用户更重要,但是这种方法肯定更贵,因为需要投放大量的谷歌算法,那么这种方法对于很多没有大量资金的公司不实用,而且除了寻找业内优秀的网站的导航开发者,很多无法实现采用这种方法的。
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-12-13 13:32
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户无需任何专业知识,即可轻松上手操作,快速采集网络资料。轻松搜索网页数据采集器免费版无需输入任何代码,只需输入URL地址,即可帮助用户自动采集网页数据。
易搜网数据采集器正式版具有很强的系统兼容性,支持运行在各种版本的操作系统上。有需要的用户可到本站下载本软件。
软件特点
简单易用
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
海量 采集 模板
内置海量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足各种采集 需要..
自研智能算法
通过自主研发的智能识别算法,自动识别列表数据,识别分页,准确率达95%,可深入采集多级页面,快速准确获取数据。
自动导出数据
数据可自动导出发布,支持TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite等多种格式导出,发布到网站接口(Api)等。
软件亮点
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
多平台支持
Easy Search Web Data采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化保存
采集 任务会自动保存到本地,不用担心丢失任务。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网络数据采集器 教程
第一步,选择起始网址
当你想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例,我们要抓取当前城市各种本地新闻的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到所有新闻信息列表的地址
然后在Easy Search Web Data中新建一个任务采集器 -> Step One -> 输入网址
然后单击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会对网页进行智能分析,从中提取列表数据。如下所示:
这时候我们对分析的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他的操作,比如名称修改、数据处理等等。
整理好修改后的字段后,我们来采集来处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段-点击进入采集数据的列表页面,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
单击完成以保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
Easy Search Web Data采集器如何导出数据
有两种导出方法:
手动导出,通过右键任务->导出任务,或者在视图中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到 网站 接口(API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以定义自己的网站 API,Easy Search Web Data 采集器通过HTTP POST请求将数据发送到指定的API,然后设置相应的POST参数和编码类型。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页数据采集器值属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性确定Html元素的哪一部分作为field的值。
一般情况下,采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了 InnerText 之外,还有其他几个内置属性:
文本,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性,用户还可以手动填写 HTML 属性。A标签的href、IMG标签的src等常见的HTML属性。Data-* 表示数据。
特别说明
在这里您可以手动输入属性名称,即使它不在下拉选项中。比如常见的onclick、value、class。 查看全部
网页采集器的自动识别算法(易搜网页数据采集器免费版更是更是)
Easy Search Web Data采集器是一款非常好用的网络数据采集软件,为用户提供了非常方便的数据采集方法,操作方法简单方便,即使用户无需任何专业知识,即可轻松上手操作,快速采集网络资料。轻松搜索网页数据采集器免费版无需输入任何代码,只需输入URL地址,即可帮助用户自动采集网页数据。
易搜网数据采集器正式版具有很强的系统兼容性,支持运行在各种版本的操作系统上。有需要的用户可到本站下载本软件。
软件特点
简单易用
简单易学,数据可以通过可视化界面、鼠标点击、向导模式采集。用户无需任何技术基础,输入网址,一键提取数据。代码小白的福音。
海量 采集 模板
内置海量网站采集模板,覆盖多个行业,点击模板,即可加载数据,只需简单配置,即可快速准确获取数据,满足各种采集 需要..
自研智能算法
通过自主研发的智能识别算法,自动识别列表数据,识别分页,准确率达95%,可深入采集多级页面,快速准确获取数据。
自动导出数据
数据可自动导出发布,支持TXT、CSV、Excel、Access、MySQL、SQLServer、SQLite等多种格式导出,发布到网站接口(Api)等。
软件亮点
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
多平台支持
Easy Search Web Data采集软件支持所有版本的windows操作系统,可以在服务器上稳定运行。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持导出数据到数据库,可以发布到Dedecms、Discuz、Wordpress、phpcms网站。
数据本地化保存
采集 任务会自动保存到本地,不用担心丢失任务。登录软件,可以随时随地创建和修改采集任务。
轻松搜索网络数据采集器 教程
第一步,选择起始网址
当你想要采集一个网站数据时,首先需要找到一个地址来显示数据列表。这一步非常重要。起始 URL 决定了 采集 数据的数量和类型。
以新浪新闻为例,我们要抓取当前城市各种本地新闻的新闻标题、发布时间、详情页信息。
通过浏览网站,我们找到所有新闻信息列表的地址
然后在Easy Search Web Data中新建一个任务采集器 -> Step One -> 输入网址
然后单击下一步。
第二步,抓取数据
进入第二步后,蓝鲸可视化采集软件会对网页进行智能分析,从中提取列表数据。如下所示:
这时候我们对分析的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他的操作,比如名称修改、数据处理等等。
整理好修改后的字段后,我们来采集来处理分页。
选择分页设置->自动识别分页符,程序会自动定位下一页元素。
接下来我们进入数据采集的列表页面,点击链接字段-点击进入采集数据的列表页面,如下图:
第三步,高级设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等。这些配置可以用来提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
单击完成以保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
Easy Search Web Data采集器如何导出数据
有两种导出方法:
手动导出,通过右键任务->导出任务,或者在视图中导出。
自动导出,在编辑任务第三步设置导出。
数据导出后,会被标记为导出,下次导出时不会再导出。如果您想导出所有数据而不区分导出的内容,您可以在查看数据中选择全部导出。
导出到 Excel、CSV、TXT
数据可以导出为Excel、CSV、TXT文件,每次导出都会生成一个新文件。软件支持为导出的文件名设置变量。目前有两种格式变量,根据任务名称和日期格式。
导出到 网站 接口(API)
支持主流cms网站系统,如Discuz、Empirecms、Wordpress、DEDEcms、PHPcms,可提供官方API。
对于开发者,可以定义自己的网站 API,Easy Search Web Data 采集器通过HTTP POST请求将数据发送到指定的API,然后设置相应的POST参数和编码类型。
导出到数据库
目前,易搜网页数据采集器支持导出到四个数据库:MySQL、SQLServer、SQLite和Access。设置数据库的连接配置,指定导出的目标表名。
同时可以设置本地任务字段与目标数据库字段的映射关系(对应关系)
轻松搜索网页数据采集器值属性设置方法
首先field通过XPath定位Html元素,然后我们需要通过value属性确定Html元素的哪一部分作为field的值。
一般情况下,采集器默认使用InnerText属性(当前节点及其子节点的文本)
除了 InnerText 之外,还有其他几个内置属性:
文本,代表当前节点的文本
InnerHtml,表示当前节点内部的HTML语句(不包括当前节点)
OuterHtml,代表当前节点的HTML语句
除了内置属性,用户还可以手动填写 HTML 属性。A标签的href、IMG标签的src等常见的HTML属性。Data-* 表示数据。
特别说明
在这里您可以手动输入属性名称,即使它不在下拉选项中。比如常见的onclick、value、class。
网页采集器的自动识别算法(,本文针对Web新闻自动摘要问题展开研究(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-13 13:30
【摘要】随着社会发展进入互联网时代,人们获取信息的方式多样化,越来越多的人依赖互联网获取自己需要的信息。同时,信息量的快速增长给用户信息检索带来了困难。面对海量的检索结果,用户往往无法高效、准确地获取所需信息。为此,本文重点研究Web新闻的自动摘要。本文分析了TextRank算法和融合文本特征的摘要算法的不足,提出了一种融合BM25和文本特征的新的新闻摘要算法,并对五种不同的算法进行了对比实验。最后,使用提出的新算法,基于Heritrix框架开发了一个Web新闻摘要系统。具体研究内容如下: 本文首先介绍了本研究课题的意义和背景,国内外自动文本摘要的研究现状和主要成果。其次介绍了文本自动摘要的相关知识,包括:自动摘要的分类和方法,如何使用网络爬虫进行新闻网页采集和主流的网页正文提取方法。在第3章中,首先介绍了基于行块分布函数的网页文本提取方法的主要思想以及该方法与传统方法相比的优势;其次,分析了TextRank算法在给句子打分时只考虑文本的内部结构的缺点。发现TextRank中计算句子相似度的方法不可靠;在此基础上,提出了一种结合BM25和文本特征的新闻摘要算法;另外,BM25的计算结果可能会出现负数,BM25可能是由于句子。针对所提出的算法进一步优化了长度过长而失去意义的问题。在第 4 章中,本文使用 ROUGE 评估工具,通过实验将本文改进算法与其他相关算法进行了比较。实验结果表明,与其他方法相比,本文提出的结合BM25和文本特征的新闻自动摘要算法具有更高的性能。最后,为了实际使用所提出的算法,本文使用Heritrix框架设计并实现了一个Web新闻页面自动摘要系统,包括新闻页面采集、文本提取、文本图模型表示和句子权重计算模块. 系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。 查看全部
网页采集器的自动识别算法(,本文针对Web新闻自动摘要问题展开研究(组图))
【摘要】随着社会发展进入互联网时代,人们获取信息的方式多样化,越来越多的人依赖互联网获取自己需要的信息。同时,信息量的快速增长给用户信息检索带来了困难。面对海量的检索结果,用户往往无法高效、准确地获取所需信息。为此,本文重点研究Web新闻的自动摘要。本文分析了TextRank算法和融合文本特征的摘要算法的不足,提出了一种融合BM25和文本特征的新的新闻摘要算法,并对五种不同的算法进行了对比实验。最后,使用提出的新算法,基于Heritrix框架开发了一个Web新闻摘要系统。具体研究内容如下: 本文首先介绍了本研究课题的意义和背景,国内外自动文本摘要的研究现状和主要成果。其次介绍了文本自动摘要的相关知识,包括:自动摘要的分类和方法,如何使用网络爬虫进行新闻网页采集和主流的网页正文提取方法。在第3章中,首先介绍了基于行块分布函数的网页文本提取方法的主要思想以及该方法与传统方法相比的优势;其次,分析了TextRank算法在给句子打分时只考虑文本的内部结构的缺点。发现TextRank中计算句子相似度的方法不可靠;在此基础上,提出了一种结合BM25和文本特征的新闻摘要算法;另外,BM25的计算结果可能会出现负数,BM25可能是由于句子。针对所提出的算法进一步优化了长度过长而失去意义的问题。在第 4 章中,本文使用 ROUGE 评估工具,通过实验将本文改进算法与其他相关算法进行了比较。实验结果表明,与其他方法相比,本文提出的结合BM25和文本特征的新闻自动摘要算法具有更高的性能。最后,为了实际使用所提出的算法,本文使用Heritrix框架设计并实现了一个Web新闻页面自动摘要系统,包括新闻页面采集、文本提取、文本图模型表示和句子权重计算模块. 系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。文本图模型表示和句子权重计算模块。系统可以实时采集新闻网页,自动提取采集到达的新闻网页摘要,并通过HTML页面显示摘要信息。
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-12 18:07
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.0.7.8 (2020-05-27)Fix8.0.7.7 多值的新字段提取错误问题 查看全部
网页采集器的自动识别算法(软件特色可视化操作简单,完全兼容JQuery选择器规则(组图))
vg浏览器不仅是采集浏览器,更是营销神器。vg 浏览器也是一个可视化脚本驱动的网络工具。可以简单的设置脚本,创建自动登录、识别验证等脚本项目。
基本介绍
VG浏览器是一款由可视化脚本驱动的网页自动运行工具。只需设置脚本,即可创建自动登录、识别验证码、自动抓取数据、自动提交数据、点击网页、下载文件、操作数据库、收发邮件等个性化实用的脚本项目。还可以使用逻辑运算来完成判断、循环、跳转等功能。脚本灵活且易于自由组合。无需任何编程基础,您就可以轻松快速地编写强大而独特的脚本来辅助我们的工作。生成独立的EXE程序出售。
软件特点
可视化操作
操作简单,完全可视化图形操作,无需专业IT人员。
定制流程
采集 就像积木一样,功能自由组合。
自动编码
程序注重采集的效率,页面解析速度非常快。
生成EXE
自动登录,自动识别验证码,是一款通用浏览器。
指示
通过 CSS Path 定位网页元素的路径是 VG 浏览器的一个非常有用的功能。选择任何需要填写CSS Path规则的步骤,点击内置浏览器的按钮
点击一个网页元素,自动生成该元素的CSS Path。极少数具有复杂框架的网页可能无法通过内置浏览器生成路径。您也可以在其他浏览器上复制 CSS 路径。目前,各种多核浏览器都支持复制CSS Path。比如谷歌Chrome、360安全浏览器、360极速浏览器、UC浏览器等Chrome内核浏览器,可以通过按F12键或在页面上右键选择评论元素来选择。
右键单击目标部分并选择复制 CSS 路径以将 CSS 路径复制到剪贴板。
在 Firefox 中,您还可以按 F12 或右键单击来查看元素。显示开发者工具后,右击底部节点,选择“Copy Only Selector”复制CSS Path。
CSS 路径规则与 JQuery 选择器规则完全兼容。如果你知道如何编写 JQuery 选择器,你可以自己编写 CSS Path。
更新日志
8.0.7.8 (2020-05-27)Fix8.0.7.7 多值的新字段提取错误问题
网页采集器的自动识别算法(优采云采集器破解版完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-12 18:06
优采云采集器破解版数据很强大采集器,优采云采集器破解版完美支持采集所有网页编码格式,该程序还可以自动识别网页编码。优采云采集器 破解版还支持目前所有主流和非主流cms、BBS等网站程序,通过系统发布模块可以实现采集器和网站程序之间的完美结合。
特征
1、强大的通用性
无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集获取内容你需要 。
2、稳定高效
历经五年磨砺,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、可扩展性强,应用范围广
自定义网页发布,主流数据库自定义存储发布,自定义本地php和. Net 外部编程接口对数据进行处理,使数据可供您使用。
4、支持所有网站编码
完美支持采集所有编码格式的网页,程序还能自动识别网页编码。
5、多种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守的工作。程序配置好后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
本地可视化编辑采集的数据。
8、采集测试
这是任何其他类似的 采集 软件都无法比拟的。程序支持直接查看采集的结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
软件特点
1、规则定制
通过采集规则的定义,几乎可以搜索到所有网站采集的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据保存
采集的同时数据自动保存到关系型数据库,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及其中的表和字段,也可以灵活地由数据库引导。将数据保存到客户现有的数据库结构中。
5、断点恢复挖矿
信息采集任务在停止采集后可以从断点处继续,从此不用担心采集任务被意外中断。
6、网站登录
支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、预定任务
通过此功能,您的采集 任务可以定期、定量或连续执行。
8、采集范围限制
采集的范围可以根据采集的深度和URL的标识进行限制。
9、文件下载
您可以将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库中。
10、 结果替换
您可以根据规则将采集的结果替换为您定义的内容。
11、 条件保存
您可以根据特定条件决定保存哪些信息以及过滤哪些信息。
12、过滤重复内容
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、 特殊链接识别
使用此函数来识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14、数据发布
您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、预留编程接口
定义多种编程接口,用户可以在活动中使用PHP、C#语言进行编程,扩展采集的功能。
更新日志
1、 批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改。
2、 标签组合,增加对循环组合的支持。
3、优化了重新重置URL库的逻辑,大大加快了大URL库下的任务加载速度,优化了重新重置URL库的内存占用。 查看全部
网页采集器的自动识别算法(优采云采集器破解版完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器破解版数据很强大采集器,优采云采集器破解版完美支持采集所有网页编码格式,该程序还可以自动识别网页编码。优采云采集器 破解版还支持目前所有主流和非主流cms、BBS等网站程序,通过系统发布模块可以实现采集器和网站程序之间的完美结合。
特征
1、强大的通用性
无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集获取内容你需要 。
2、稳定高效
历经五年磨砺,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、可扩展性强,应用范围广
自定义网页发布,主流数据库自定义存储发布,自定义本地php和. Net 外部编程接口对数据进行处理,使数据可供您使用。
4、支持所有网站编码
完美支持采集所有编码格式的网页,程序还能自动识别网页编码。
5、多种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守的工作。程序配置好后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
本地可视化编辑采集的数据。
8、采集测试
这是任何其他类似的 采集 软件都无法比拟的。程序支持直接查看采集的结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
软件特点
1、规则定制
通过采集规则的定义,几乎可以搜索到所有网站采集的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据保存
采集的同时数据自动保存到关系型数据库,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及其中的表和字段,也可以灵活地由数据库引导。将数据保存到客户现有的数据库结构中。
5、断点恢复挖矿
信息采集任务在停止采集后可以从断点处继续,从此不用担心采集任务被意外中断。
6、网站登录
支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、预定任务
通过此功能,您的采集 任务可以定期、定量或连续执行。
8、采集范围限制
采集的范围可以根据采集的深度和URL的标识进行限制。
9、文件下载
您可以将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库中。
10、 结果替换
您可以根据规则将采集的结果替换为您定义的内容。
11、 条件保存
您可以根据特定条件决定保存哪些信息以及过滤哪些信息。
12、过滤重复内容
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、 特殊链接识别
使用此函数来识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14、数据发布
您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、预留编程接口
定义多种编程接口,用户可以在活动中使用PHP、C#语言进行编程,扩展采集的功能。
更新日志
1、 批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改。
2、 标签组合,增加对循环组合的支持。
3、优化了重新重置URL库的逻辑,大大加快了大URL库下的任务加载速度,优化了重新重置URL库的内存占用。
网页采集器的自动识别算法(网页采集器的自动识别算法是怎样的?如何找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-09 21:01
网页采集器的自动识别算法主要有两种,一种是被动识别算法,一种是主动识别算法,被动识别是通过网站抓取上下文,用户浏览习惯等方式来识别的,这种识别误差比较大,而且有时会出现误伤功能。我用过很多家网页采集器,普遍存在这个问题,现在有些网站抓取框里面加上了类似于cookie等自动上传的校验的。一种主动识别的算法,是通过我们发布的自动采集软件来识别的,对特定网站,根据特定的格式发布相关的采集软件采集软件,这个算法可以识别网站的抓取代码,也可以识别网站的类型,而且还可以按照网站的设置来识别。
现在的网页采集就是手动手写代码来采集,有人的时候在使用apache做cronserver,没人的时候手写点脚本,例如百度、谷歌这种全自动化的采集就不知道了,可能其他人不知道,我知道的话我就提出来,
如果你采的网页已经是主动爬取的话,可以这样做。如果是被动爬取的话,需要采集器生成flash在网页里,让爬虫自己去找网页,
他使用的是google的解析页面解析一个网站只是一个小功能。爬虫需要找到一个主动的页面链接才可以去请求,并用一个selector标记好所请求的链接那么如何找到呢?你应该找到一个服务器去爬。如果服务器不存在可以这样找服务器api有木有,他会返回服务器名给你这个服务器一般在网站底部,上面几层有个api接口对吧,那么你就点击他(把它想象成服务器中的api),使用他接口中的一个target(目标)然后在之前api请求他的时候不带url-params,比如之前的网址,你请求它是正常请求,那么接下来你需要做的就是拿到他的路径,因为之前他是正常请求,现在你不带他的时候,他会让你输入一个url-params,比如/。
接下来就是如何拿到这个url-params,你可以查找之前的htmltarget(上一个target)所以之前target就是你的http主动页面链接那么你就拿到了http请求和http响应即可不知道有没有说清楚。 查看全部
网页采集器的自动识别算法(网页采集器的自动识别算法是怎样的?如何找到)
网页采集器的自动识别算法主要有两种,一种是被动识别算法,一种是主动识别算法,被动识别是通过网站抓取上下文,用户浏览习惯等方式来识别的,这种识别误差比较大,而且有时会出现误伤功能。我用过很多家网页采集器,普遍存在这个问题,现在有些网站抓取框里面加上了类似于cookie等自动上传的校验的。一种主动识别的算法,是通过我们发布的自动采集软件来识别的,对特定网站,根据特定的格式发布相关的采集软件采集软件,这个算法可以识别网站的抓取代码,也可以识别网站的类型,而且还可以按照网站的设置来识别。
现在的网页采集就是手动手写代码来采集,有人的时候在使用apache做cronserver,没人的时候手写点脚本,例如百度、谷歌这种全自动化的采集就不知道了,可能其他人不知道,我知道的话我就提出来,
如果你采的网页已经是主动爬取的话,可以这样做。如果是被动爬取的话,需要采集器生成flash在网页里,让爬虫自己去找网页,
他使用的是google的解析页面解析一个网站只是一个小功能。爬虫需要找到一个主动的页面链接才可以去请求,并用一个selector标记好所请求的链接那么如何找到呢?你应该找到一个服务器去爬。如果服务器不存在可以这样找服务器api有木有,他会返回服务器名给你这个服务器一般在网站底部,上面几层有个api接口对吧,那么你就点击他(把它想象成服务器中的api),使用他接口中的一个target(目标)然后在之前api请求他的时候不带url-params,比如之前的网址,你请求它是正常请求,那么接下来你需要做的就是拿到他的路径,因为之前他是正常请求,现在你不带他的时候,他会让你输入一个url-params,比如/。
接下来就是如何拿到这个url-params,你可以查找之前的htmltarget(上一个target)所以之前target就是你的http主动页面链接那么你就拿到了http请求和http响应即可不知道有没有说清楚。

