
网页视频抓取工具 知乎
网页视频抓取工具 知乎(微信小程序视频抓取器的操作方法就非常简单了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-01-30 04:01
网页视频抓取工具知乎专栏在重庆市网络与新媒体局登录编辑后,操作方法就非常简单了。
谢邀。微信小程序视频抓取app,是一款非常实用的微信小程序视频抓取器,基于微信公众号等原生的内容抓取方式。打开微信---我钱包---支付---银行卡---支付宝,搜索“微信小程序视频抓取器”,然后根据需要选择相应的关键词,可以进行小程序的搜索。在“微信小程序视频抓取器”中,可以从以下五个方面开始对视频进行抓取,分别是:来源、制作开发、频道类型、内容类型、工具库。
第一步:来源。微信小程序视频抓取器目前还支持动图进行抓取、网址直达视频。视频来源是衡量一个视频抓取器质量的关键因素,如果一个视频抓取器连视频来源都不支持且无法识别的话,那么你肯定用不了它。第二步:制作开发。视频制作开发完全掌握视频抓取器是一项非常重要的工作。目前微信小程序视频抓取器只支持小程序端的制作开发,如果需要企业级别的视频抓取,我们会提供企业开发包,点击查看即可。
第三步:频道类型。相比较于图文内容,视频的抓取类型更多样。基于微信体系,目前在微信小程序端,包括音乐、文本内容、图片、链接、网址等视频类型。但是目前微信小程序抓取器只支持音乐和图片类视频,网址也只能抓取网址,无法抓取视频源地址。第四步:内容类型。相比较普通的音频,视频内容的抓取类型也更多样。包括不同的内容进行分类并进行网址内容抓取,例如:播放页面、画中画播放页面、直播、在线广告等等。
第五步:工具库。包括:视频识别工具、视频转码工具、视频自动编码工具、视频压缩工具、视频去水印工具、封面识别工具、视频合成工具、视频去水印工具等等。总结下来,如果想要做微信小程序视频抓取器的话,首先需要一个开发工具,其次是制作开发工具,最后才是抓取视频。 查看全部
网页视频抓取工具 知乎(微信小程序视频抓取器的操作方法就非常简单了)
网页视频抓取工具知乎专栏在重庆市网络与新媒体局登录编辑后,操作方法就非常简单了。
谢邀。微信小程序视频抓取app,是一款非常实用的微信小程序视频抓取器,基于微信公众号等原生的内容抓取方式。打开微信---我钱包---支付---银行卡---支付宝,搜索“微信小程序视频抓取器”,然后根据需要选择相应的关键词,可以进行小程序的搜索。在“微信小程序视频抓取器”中,可以从以下五个方面开始对视频进行抓取,分别是:来源、制作开发、频道类型、内容类型、工具库。
第一步:来源。微信小程序视频抓取器目前还支持动图进行抓取、网址直达视频。视频来源是衡量一个视频抓取器质量的关键因素,如果一个视频抓取器连视频来源都不支持且无法识别的话,那么你肯定用不了它。第二步:制作开发。视频制作开发完全掌握视频抓取器是一项非常重要的工作。目前微信小程序视频抓取器只支持小程序端的制作开发,如果需要企业级别的视频抓取,我们会提供企业开发包,点击查看即可。
第三步:频道类型。相比较于图文内容,视频的抓取类型更多样。基于微信体系,目前在微信小程序端,包括音乐、文本内容、图片、链接、网址等视频类型。但是目前微信小程序抓取器只支持音乐和图片类视频,网址也只能抓取网址,无法抓取视频源地址。第四步:内容类型。相比较普通的音频,视频内容的抓取类型也更多样。包括不同的内容进行分类并进行网址内容抓取,例如:播放页面、画中画播放页面、直播、在线广告等等。
第五步:工具库。包括:视频识别工具、视频转码工具、视频自动编码工具、视频压缩工具、视频去水印工具、封面识别工具、视频合成工具、视频去水印工具等等。总结下来,如果想要做微信小程序视频抓取器的话,首先需要一个开发工具,其次是制作开发工具,最后才是抓取视频。
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件的使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-01-29 17:08
)
zh-downloader(知乎视频嗅探下载插件)是一款优秀易用的知乎视频下载助手。如果你需要一个好用的视频下载器,不妨试试小编带来的这款zh-downloader插件。它功能强大且易于操作。使用后,可以帮助用户更轻松便捷地下载知乎视频。该插件可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。欢迎有需要的朋友下载使用。
指示:
1、打开任意一个有视频的知乎页面,插件会自动嗅探是否有资源,嗅探到的视频数量会以角标的形式出现在图标上。
2、此时点击工具栏上的插件图标,可以看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
发展背景:
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已经成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎视频呢?
4、可能有朋友发现,传统的视频下载谷歌插件如VideoDownloader Professional、Maozha有时无法嗅探知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件的使用方法
)
zh-downloader(知乎视频嗅探下载插件)是一款优秀易用的知乎视频下载助手。如果你需要一个好用的视频下载器,不妨试试小编带来的这款zh-downloader插件。它功能强大且易于操作。使用后,可以帮助用户更轻松便捷地下载知乎视频。该插件可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。欢迎有需要的朋友下载使用。
指示:
1、打开任意一个有视频的知乎页面,插件会自动嗅探是否有资源,嗅探到的视频数量会以角标的形式出现在图标上。
2、此时点击工具栏上的插件图标,可以看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
发展背景:
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已经成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎视频呢?
4、可能有朋友发现,传统的视频下载谷歌插件如VideoDownloader Professional、Maozha有时无法嗅探知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
网页视频抓取工具 知乎(利用知乎爬虫软件,经过Python爬取知乎,可以用Python爬虫知乎数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-28 03:09
使用知乎爬虫软件和在Python中爬取知乎,可以使用Python爬虫爬取知乎数据,现推荐一款好用的任意网站数据抓取软件,使用< @知乎热评爬虫和知乎爬取工具,可以抓取知乎热评的相关内容。最热软件站提供知乎热评爬虫下载地址,需要Python爬取知乎热评软件的朋友,快来下载试用吧。
知乎热评爬虫介绍
知乎热评爬虫是一款知乎爬虫软件,可以帮助用户获取与知乎热评相关的数据内容。该软件体积小。作为一款绿色免安装软件,无需安装即可直接使用。对于喜欢看知乎热评的人来说,这个非常方便,可以快速获取知乎热评信息。
知乎关于如何使用爬虫的热评
1.下载解压后双击使用本软件,可以获得知乎时事,下载时事问题和链接,下载每个时事下的答案,下载评论在答案下。
2.首先登录你的知乎,按F12获取COOKIES,复制到软件顶部输入栏,复制点击获取当前热点列表获取当前热点讨论.
3.选择要下载的标题,点击下载并保存,保存格式为exsel。该软件可以帮助用户下载每个热评下的知乎热议和热评软件。通过知乎热评数据采集软件,不用打开知乎就可以知道时事。事物。
4.对于一些自媒体热爱学习的人和朋友来说,这个软件非常强大。使用知乎热评数据采集软件,用户无需到处搜索。材料。
小编推荐
以上就是知乎热评爬虫免费版的全部介绍。最热的软件站还有更多类似的爬虫爬取软件。需要的朋友快来下载体验吧。我将在下面推荐另外两个易于使用的软件。爬虫软件:小说爬虫、图片爬虫(抓取下载网站图片)。 查看全部
网页视频抓取工具 知乎(利用知乎爬虫软件,经过Python爬取知乎,可以用Python爬虫知乎数据)
使用知乎爬虫软件和在Python中爬取知乎,可以使用Python爬虫爬取知乎数据,现推荐一款好用的任意网站数据抓取软件,使用< @知乎热评爬虫和知乎爬取工具,可以抓取知乎热评的相关内容。最热软件站提供知乎热评爬虫下载地址,需要Python爬取知乎热评软件的朋友,快来下载试用吧。

知乎热评爬虫介绍
知乎热评爬虫是一款知乎爬虫软件,可以帮助用户获取与知乎热评相关的数据内容。该软件体积小。作为一款绿色免安装软件,无需安装即可直接使用。对于喜欢看知乎热评的人来说,这个非常方便,可以快速获取知乎热评信息。
知乎关于如何使用爬虫的热评
1.下载解压后双击使用本软件,可以获得知乎时事,下载时事问题和链接,下载每个时事下的答案,下载评论在答案下。
2.首先登录你的知乎,按F12获取COOKIES,复制到软件顶部输入栏,复制点击获取当前热点列表获取当前热点讨论.
3.选择要下载的标题,点击下载并保存,保存格式为exsel。该软件可以帮助用户下载每个热评下的知乎热议和热评软件。通过知乎热评数据采集软件,不用打开知乎就可以知道时事。事物。
4.对于一些自媒体热爱学习的人和朋友来说,这个软件非常强大。使用知乎热评数据采集软件,用户无需到处搜索。材料。
小编推荐
以上就是知乎热评爬虫免费版的全部介绍。最热的软件站还有更多类似的爬虫爬取软件。需要的朋友快来下载体验吧。我将在下面推荐另外两个易于使用的软件。爬虫软件:小说爬虫、图片爬虫(抓取下载网站图片)。
网页视频抓取工具 知乎(第451篇原创,和30w+一起学Python! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-26 18:12
)
第451条原创,30w+学Python!
最近开学了,大家都在忙着准备各种学习资料,准备新学期努力学习,充实自己。小编身边的同学也是如此。最近,小编的同学小李遇到了一个非常棘手的问题。
她想把Python学习教程打印在一个网页上,以便自己学习,但是手动将上千页的教程一一转换成pdf并保存在本地确实很麻烦。
这是将html转换为pdf的问题。其实网上有很多不错的html资源,但是学习起来不方便!于是小编向小李保证,这个小东西在我身上。今天小编就给大家分享一下如何使用Python将html数据转换成pdf。
01.爬取学习资料
如今,互联网上有很多在线学习资料。为了方便讲解,小编以python3.9.2的中文文档为例,在本地抓取保存。链接如下:
打开以上链接后,你会发现网页中不同内容的链接地址,包括基本的python字符、python语法等。
02.获取网页链接
在上图中,我们需要特别注意用红色方块标记的链接。每个链接都会跳转到对应的子页面,而在子页面中,就是我们要保存的内容。
可以看到,上图中,python快速查看子页面收录了我们需要提取的文本内容。所以将 html 内容保存为 pdf 的第一步是获取子页面的链接。由于大部分教程都是固定内容,所以教程网页大部分是静态页面,在网页源代码中很容易找到子页面的网页链接。
对于子页面的链接爬取,流程如下图所示:
程序中通过BeautifulSoup库解析网页源代码,然后提取所有子页面链接地址并返回。如果爬取失败,则直接返回None。
03.html转pdf
得到子页面的链接后,下一步就是将html子页面保存为pdf文件。小编使用的pdfkit库,pdfkit库可以将网页保存为pdf文档。首先介绍一下pdfkit库的安装。
按照上面的操作流程,就可以安装pdfkit库了。对于pdfkit库的使用,常见的三种用法:
上述程序主要完成几个步骤:
首先需要指定wkhtmltopdf.exe文件的路径;
因此,pdfkit库只能将子页面保存为单独的pdf文档,不能通过pdfkit库直接将所有子页面拼接成一个完整的pdf文档。小编使用PyPDF2库中的PdfFileMerger类来实现pdf文档的拼接。程序如下图所示。
程序首先将所有html网页保存为单独的pdf文档,然后通过PdfFileMerger类对象实现pdf文档的拼接。最后,您可以获得所有的pdf内容。最后,我们通过视频展示看一下程序的效果。
另外,该程序不仅可以爬取python3.9的中文文档,还可以爬取其他在线文档,只需要修改程序获取要爬取的网页链接,比如Flask中文文档的爬取,程序只需要按照下图进行修改,Flask的在线文档就可以保存为PDF文档了。
04.总结
学习 Python 实际上是非常有趣和有用的。因为 Python 拥有大量现成的库,可以帮助我们轻松解决工作中的许多琐碎问题。小编对上面的程序稍作修改,很快就帮阿里拿到了教程,保存为pdf发给她,小编和女神的关系就更近了。
为了方便大家更好的理解,我们会在B站录制一个完整的视频(详情见原文),一步步讲解程序,再提供源码和视频!
1推荐阅读:
2入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
3干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
4趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
5AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
6
7
年度最火副本
1点这里,直达菜鸟学PythonB站!!
2
3 查看全部
网页视频抓取工具 知乎(第451篇原创,和30w+一起学Python!
)
第451条原创,30w+学Python!

最近开学了,大家都在忙着准备各种学习资料,准备新学期努力学习,充实自己。小编身边的同学也是如此。最近,小编的同学小李遇到了一个非常棘手的问题。
她想把Python学习教程打印在一个网页上,以便自己学习,但是手动将上千页的教程一一转换成pdf并保存在本地确实很麻烦。
这是将html转换为pdf的问题。其实网上有很多不错的html资源,但是学习起来不方便!于是小编向小李保证,这个小东西在我身上。今天小编就给大家分享一下如何使用Python将html数据转换成pdf。
01.爬取学习资料
如今,互联网上有很多在线学习资料。为了方便讲解,小编以python3.9.2的中文文档为例,在本地抓取保存。链接如下:
打开以上链接后,你会发现网页中不同内容的链接地址,包括基本的python字符、python语法等。

02.获取网页链接
在上图中,我们需要特别注意用红色方块标记的链接。每个链接都会跳转到对应的子页面,而在子页面中,就是我们要保存的内容。

可以看到,上图中,python快速查看子页面收录了我们需要提取的文本内容。所以将 html 内容保存为 pdf 的第一步是获取子页面的链接。由于大部分教程都是固定内容,所以教程网页大部分是静态页面,在网页源代码中很容易找到子页面的网页链接。

对于子页面的链接爬取,流程如下图所示:

程序中通过BeautifulSoup库解析网页源代码,然后提取所有子页面链接地址并返回。如果爬取失败,则直接返回None。
03.html转pdf
得到子页面的链接后,下一步就是将html子页面保存为pdf文件。小编使用的pdfkit库,pdfkit库可以将网页保存为pdf文档。首先介绍一下pdfkit库的安装。
按照上面的操作流程,就可以安装pdfkit库了。对于pdfkit库的使用,常见的三种用法:
上述程序主要完成几个步骤:
首先需要指定wkhtmltopdf.exe文件的路径;
因此,pdfkit库只能将子页面保存为单独的pdf文档,不能通过pdfkit库直接将所有子页面拼接成一个完整的pdf文档。小编使用PyPDF2库中的PdfFileMerger类来实现pdf文档的拼接。程序如下图所示。

程序首先将所有html网页保存为单独的pdf文档,然后通过PdfFileMerger类对象实现pdf文档的拼接。最后,您可以获得所有的pdf内容。最后,我们通过视频展示看一下程序的效果。
另外,该程序不仅可以爬取python3.9的中文文档,还可以爬取其他在线文档,只需要修改程序获取要爬取的网页链接,比如Flask中文文档的爬取,程序只需要按照下图进行修改,Flask的在线文档就可以保存为PDF文档了。

04.总结
学习 Python 实际上是非常有趣和有用的。因为 Python 拥有大量现成的库,可以帮助我们轻松解决工作中的许多琐碎问题。小编对上面的程序稍作修改,很快就帮阿里拿到了教程,保存为pdf发给她,小编和女神的关系就更近了。
为了方便大家更好的理解,我们会在B站录制一个完整的视频(详情见原文),一步步讲解程序,再提供源码和视频!
1推荐阅读:
2入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
3干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
4趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
5AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
6
7
年度最火副本
1点这里,直达菜鸟学PythonB站!!
2
3
网页视频抓取工具 知乎( 一个有趣的Python案例分享!Python真的是太有用啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-26 18:09
一个有趣的Python案例分享!Python真的是太有用啦!
)
1点上方“菜鸟学Python”,选择“星标”
2第481篇原创干货,第一时间送达
3
4
大家好,我是菜鸟兄弟!这是我的第 481 篇文章原创!
今天给大家带来另一个有趣的Python案例分享!学习Python真的很有用!
很多朋友平时看视频的时候都喜欢看小姐姐的舞蹈视频。今天小编就和大家一起过关30行代码。顺便说一句,只需要30行代码就可以完成!快来虎牙视频网站上抢到小姐姐和小姐姐的舞蹈视频,快来观看吧。
01.视频获取显示
打开虎牙视频后,可以在“星秀/言之”分类下找到舞蹈视频。小编粗略地翻了一遍。每页一共20个视频,一共500页,所以一共有1000个视频,如果能全部下载下来,估计宅男们会欢呼吧。
02.程序说明
视频获取,和图片获取一样,需要获取视频的url地址。我们需要通过分析得到每个舞蹈视频的子页面链接,然后得到子页面中视频的url链接。首先,我们来看看如何获取每个子页面的链接地址。
1).获取子页面链接
通过分析网页的源码可以发现,首页中各个子页面的地址都可以从网页的源码中获取。
因此,可以通过requests库获取网页的源代码,通过解析网页的源代码可以得到当前页面中所有子网页的链接地址。程序如下图所示。
在程序中,所有的主网页链接都是通过一个for循环来构造的,所有的子网页链接都是通过请求和解析网页的源代码来捕获的,并保存在self.video_urls列表中。
2).下载视频
与获取子页面的链接地址相比,获取子页面中的视频链接更加麻烦,需要我们对其进行分析解析,如下图所示:
在子页面中,可以通过开发者模式下的网页元素解析找到视频的链接地址。接下来,我们复制视频的链接地址,然后进入网络选项,使用快捷键ctrl+F搜索“///”,就可以找到对应的请求接口链接。
通过对视频的请求链接分析,可以得到如下数据链接地址: 上述链接地址返回的是json数据内容,我们可以通过分析json数据找到真正的视频链接地址,其中参数videoId为视频子页面地址,例如子页面是,videoId的值为468682371。
以下地址是我们分析上述json数据得到的视频链接地址:
了解了视频链接地址的获取,那么我们就可以通过程序获取视频地址了。
程序构造json数据的链接地址,然后解析json数据,抓取视频的链接地址,通过self.SaveVideo将视频保存到本地文件夹。
通过运行程序,我们可以连续捕捉小姐姐的舞蹈视频。最后附上小姐姐的舞蹈视频,一起来欣赏小姐姐的精彩舞蹈吧。
其实整个程序很简单。有兴趣的朋友可以练习一下。爬虫只是 Python 中的冰山一角。办公自动化、后端开发、大数据分析和数据挖掘才是真正的力量。大家还是把更多的时间花在数据分析和数据挖掘上,无论是找工作还是提升业务能力,都是非常有益的。所以还没学过Python的同学们,赶紧上车吧!
1推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领廖雪峰视频资料!
2
3 查看全部
网页视频抓取工具 知乎(
一个有趣的Python案例分享!Python真的是太有用啦!
)
1点上方“菜鸟学Python”,选择“星标”
2第481篇原创干货,第一时间送达
3
4
大家好,我是菜鸟兄弟!这是我的第 481 篇文章原创!
今天给大家带来另一个有趣的Python案例分享!学习Python真的很有用!
很多朋友平时看视频的时候都喜欢看小姐姐的舞蹈视频。今天小编就和大家一起过关30行代码。顺便说一句,只需要30行代码就可以完成!快来虎牙视频网站上抢到小姐姐和小姐姐的舞蹈视频,快来观看吧。
01.视频获取显示
打开虎牙视频后,可以在“星秀/言之”分类下找到舞蹈视频。小编粗略地翻了一遍。每页一共20个视频,一共500页,所以一共有1000个视频,如果能全部下载下来,估计宅男们会欢呼吧。

02.程序说明
视频获取,和图片获取一样,需要获取视频的url地址。我们需要通过分析得到每个舞蹈视频的子页面链接,然后得到子页面中视频的url链接。首先,我们来看看如何获取每个子页面的链接地址。
1).获取子页面链接
通过分析网页的源码可以发现,首页中各个子页面的地址都可以从网页的源码中获取。

因此,可以通过requests库获取网页的源代码,通过解析网页的源代码可以得到当前页面中所有子网页的链接地址。程序如下图所示。

在程序中,所有的主网页链接都是通过一个for循环来构造的,所有的子网页链接都是通过请求和解析网页的源代码来捕获的,并保存在self.video_urls列表中。
2).下载视频
与获取子页面的链接地址相比,获取子页面中的视频链接更加麻烦,需要我们对其进行分析解析,如下图所示:

在子页面中,可以通过开发者模式下的网页元素解析找到视频的链接地址。接下来,我们复制视频的链接地址,然后进入网络选项,使用快捷键ctrl+F搜索“///”,就可以找到对应的请求接口链接。

通过对视频的请求链接分析,可以得到如下数据链接地址: 上述链接地址返回的是json数据内容,我们可以通过分析json数据找到真正的视频链接地址,其中参数videoId为视频子页面地址,例如子页面是,videoId的值为468682371。
以下地址是我们分析上述json数据得到的视频链接地址:
了解了视频链接地址的获取,那么我们就可以通过程序获取视频地址了。

程序构造json数据的链接地址,然后解析json数据,抓取视频的链接地址,通过self.SaveVideo将视频保存到本地文件夹。
通过运行程序,我们可以连续捕捉小姐姐的舞蹈视频。最后附上小姐姐的舞蹈视频,一起来欣赏小姐姐的精彩舞蹈吧。
其实整个程序很简单。有兴趣的朋友可以练习一下。爬虫只是 Python 中的冰山一角。办公自动化、后端开发、大数据分析和数据挖掘才是真正的力量。大家还是把更多的时间花在数据分析和数据挖掘上,无论是找工作还是提升业务能力,都是非常有益的。所以还没学过Python的同学们,赶紧上车吧!
1推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领廖雪峰视频资料!
2
3
网页视频抓取工具 知乎( 10个最糟糕的SEO错误,你中枪了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-25 06:11
10个最糟糕的SEO错误,你中枪了吗?)
如果你对 SEO 太熟悉,你可以认为你不会犯错误。我们都知道它是怎么回事,很多 SEO 专家在进入一种自动驾驶模式之前已经在 SEO 工作了五年、十年或更长时间。但奇怪的是,你对某事了解得越多,就越容易忘记细节。
对于 SEO,您还必须记住,搜索引擎几乎一直在改变他们的算法。考虑到这一点,每个 SEO 都会对如何变得更好感到兴奋。以下是 SEO 专家仍然会犯的 10 个最严重的 SEO 错误。
1.内部链接结构不佳
当您的 网站 与您所有的精彩内容一起膨胀时,您一定会遇到一些非常基本的内部链接错误。
这包括从生成大量重复内容到获取 404 页面错误的所有内容。
我们认为,网站 管理员严重忽视了内部链接结构,但它却是您的 UX 和 SEO 策略中最有价值的功能之一。
内部链接为您的 网站 提供了五个有价值的好处:
向搜索引擎重新提交 XML 站点地图是为搜索引擎打开未链接页面的爬网路径的好方法。
此外,明智地使用 robots.txt 文件和 noindex 标签也很重要,这样您就不会意外阻止 网站(或客户端)上的重要页面。
作为一般经验法则,任何网页距离主页或号召性用语着陆页的点击次数不应超过两次。
通过新的 关键词 研究重新评估您的 网站 架构,并开始按主题、内容和主题集群组织网页。
2. 为内容创建内容
最佳实践要求您应该始终如一地制作内容以增加品牌的曝光率和权威,并提高您的 网站 索引率。但是随着您的 网站 增长到数百页或更多,可能很难为每个页面找到一个独特的 关键词 并坚持一个有凝聚力的策略。
有时我们会陷入这样的谬论,即我们必须制作内容才能拥有更多内容。这是完全不真实的,并且导致内容稀少且无用,这相当于浪费资源。
在未完成战略性关键词 研究之前不要编写内容。确保内容与目标 关键词 相关,并在 H2 标签和正文段落中使用密切相关的 关键词。
这会将您内容的完整上下文传达给搜索引擎,并在多个级别上满足用户意图。花时间投资于可操作且常青的长篇内容。请记住,我们是内容营销人员和 SEO 专家,而不是记者。
优化的内容可能需要几个月才能达到首页结果;确保它在其行业中保持相关性和独特性。
3. 不投资于值得链接的内容
我们了解,网页唯一引用域的数量和质量是搜索引擎最重要的三个排名因素之一。
链接建设是 SEO 的主要拉动因素。但是,通过会员链接和媒体营销出去寻找大量链接可能是昂贵的和资源密集型的。
自然,获取链接的最佳方式是使用人们只想链接的优质内容。
与其在人类研究上投入时间并每年创建数百个客座帖子,不如投资于可以在一天的写作中获得所有这些链接的内容?
如前所述,花时间制作为行业增加价值的长篇内容。
在这里,您可以尝试不同形式的内容,无论是资源页面、信息图表、交互式测验还是常青指南。
使用您的一些手动外展策略来宣传发布在您自己的 网站 上的内容,而不是其他人的 网站。
4. 未能通过您的内容吸引客户
继续这个讨论,你必须有一个真正让人们查看你的内容的策略。
我们相信,很多行业和很多公司在内容推广上的投入要少于在制作上的投入。
当然,您可以通过社交媒体分享您的内容。但是,如果没有付费广告,它实际上能获得多少影响力?
只需在您的 网站、自媒体 频道和在线媒体上发布您最新的 文章,即可将其覆盖范围限制在您现有受众的一小部分。
如果您想为您的业务获得新的潜在客户,您需要在促销策略中投入更多资源。
一些策略包括:
虽然它们很简单,但您需要宣传内容以获得指向它的链接。只有这样,您才能自然地开始获得更多链接。
5. 优化bug关键词
因此,您花时间创建一个不会为您的 网站 带来大量流量的长内容。
您的访问者在页面上停留很短的时间并且不转换也很糟糕。
您很可能针对错误的 关键词 进行优化。
虽然我们大多数人都了解长尾 关键词 对于信息查询的重要性,但有时我们会遇到一些常见错误:
实际研究出现在国家和地方搜索结果中的搜索短语非常重要。
与您的客户交谈,了解他们使用哪些搜索词组来描述您所在行业的不同元素。从这里,您可以对 关键词 列表进行细分,以使它们与您的客户更相关。
使用 关键词 工具,例如 5118 的 关键词 生成器来获取相关的 关键词 提示。
不要忘记优化信息和商业搜索查询。
6. 不咨询付费媒体
就行业目前而言,SEO 专注于获取和培养潜在客户,而付费媒体则专注于获取和转换潜在客户。
但是,如果我们打破这些孤岛并在旅程的每一步为买家创造一个有凝聚力的信息呢?
作为 SEO 提供商,我们是否知道客户的广告信息是什么或他们使用什么 关键词?您是否使用与付费媒体部门相同的 关键词 来推广相同的产品/服务页面?
SEO 顾问可以从 PPC关键词 研究和登录页面性能中获得许多见解,这些见解可以帮助他们开展活动。
此外,知乎 和今日头条的广告平台提供了强大的受众分析工具,SEO 顾问可以使用这些工具更好地了解客户的客户。
通过关注统一信息并在彼此的研究中共享,SEO顾问可以发现转化率最高、点击率最高的关键词搜索结果。
7. 不定期诊断我自己的网站
我们犯的最大错误之一是没有继续优化我们自己的 网站 并修复随着时间的推移出现的错误。
在站点迁移或实施任何新工具或插件之后,诊断尤其重要。
随着时间的推移发生的常见技术错误包括:
出现重复内容的原因有很多,可能是通过分页或会话 ID。
通过在源网页上插入规范来解决任何 URL 参数错误或 cookie 中的重复内容。这允许来自重复页面的所有信号指向原创页面。
当您在 网站 上移动内容时,损坏的链接是不可避免的,因此在您删除的任何内容上插入指向相关页面的 301 重定向非常重要。
请务必解决 302 重定向,因为它们仅用作临时重定向。
诊断您的 网站 对于移动搜索至关重要。仅仅拥有响应式网页设计是不够的。
确保在移动设计中缩小 CSS 和 JS,并为响应式设计缩小图像。
最后,诊断中经常被忽视的部分是重新评估您的内容策略。大多数行业都是动态的,这意味着新的创新不断涌现,某些服务会随着时间的推移而过时。
修改您的 网站 以反映您拥有的任何新产品。
围绕主题创建内容,以向搜索引擎和用户展示它对您的层次结构的重要性。
不断更新您的 关键词 研究和受众研究,以寻找扩大规模和保持相关性的新机会。
8. 不定时查看百度统计
下一点是关于百度统计的。这与诊断您的 网站 不太一样,因为诊断会在后端向您显示需要纠正的技术错误。
百度统计更面向受众,检查程序中提供的数据对于发现您的 网站 需要关注的地方至关重要。
这个或那个页面的跳出率是否在增加?检查一下,找出原因。
一个渠道的流量是否随着时间的推移而稳步下降?查看您的资源以修复它。
即使你被数据和数字吓到,百度统计也会以通俗易懂的方式呈现,即使是初学者也能理解。
关键是,安装百度统计跟踪代码然后完全忽略它是错误的方法。
我知道每隔一段时间检查一次需要时间和精力,但是您会了解公众如何与您的 网站 互动,并且您将无法忽视您发现的问题。
9. 忽略技术 SEO
最后,您不能忘记基本的技术 SEO 内容。
由于解决这些问题往往令人麻木,这可能不是许多 网站 所有者想要解决的领域,但我可以向您保证,如果您忽略技术 SEO,那么您做错了。
您是否有无法抓取的页面?内部图像或链接损坏?一千个临时重定向?
孤立页面、没有内部链接的页面或损坏的外部链接怎么样?
这些都是可能对您的 网站 可抓取性产生负面影响并增加您的抓取预算的问题。
底线是什么?这些问题会让你远离对你最重要的人。
使用 Semrush 或 Screaming Frog 之类的工具来识别和纠正这些问题,以免它们积聚太多并导致您头疼。也许每月审查这些技术问题以掌握它们。
它可能不是 SEO 最迷人的部分,但解决技术问题对于成功的 网站 至关重要,所以开始吧。
总结
每个人都容易在他们的手艺上犯错误,纠正错误的最佳方法之一是参考最佳实践。我们最好的建议:保持头脑清醒,始终退后一步,评估您是否正在尽最大努力扩展您的业务。 查看全部
网页视频抓取工具 知乎(
10个最糟糕的SEO错误,你中枪了吗?)
如果你对 SEO 太熟悉,你可以认为你不会犯错误。我们都知道它是怎么回事,很多 SEO 专家在进入一种自动驾驶模式之前已经在 SEO 工作了五年、十年或更长时间。但奇怪的是,你对某事了解得越多,就越容易忘记细节。
对于 SEO,您还必须记住,搜索引擎几乎一直在改变他们的算法。考虑到这一点,每个 SEO 都会对如何变得更好感到兴奋。以下是 SEO 专家仍然会犯的 10 个最严重的 SEO 错误。
1.内部链接结构不佳
当您的 网站 与您所有的精彩内容一起膨胀时,您一定会遇到一些非常基本的内部链接错误。
这包括从生成大量重复内容到获取 404 页面错误的所有内容。
我们认为,网站 管理员严重忽视了内部链接结构,但它却是您的 UX 和 SEO 策略中最有价值的功能之一。
内部链接为您的 网站 提供了五个有价值的好处:
向搜索引擎重新提交 XML 站点地图是为搜索引擎打开未链接页面的爬网路径的好方法。
此外,明智地使用 robots.txt 文件和 noindex 标签也很重要,这样您就不会意外阻止 网站(或客户端)上的重要页面。
作为一般经验法则,任何网页距离主页或号召性用语着陆页的点击次数不应超过两次。
通过新的 关键词 研究重新评估您的 网站 架构,并开始按主题、内容和主题集群组织网页。
2. 为内容创建内容
最佳实践要求您应该始终如一地制作内容以增加品牌的曝光率和权威,并提高您的 网站 索引率。但是随着您的 网站 增长到数百页或更多,可能很难为每个页面找到一个独特的 关键词 并坚持一个有凝聚力的策略。
有时我们会陷入这样的谬论,即我们必须制作内容才能拥有更多内容。这是完全不真实的,并且导致内容稀少且无用,这相当于浪费资源。
在未完成战略性关键词 研究之前不要编写内容。确保内容与目标 关键词 相关,并在 H2 标签和正文段落中使用密切相关的 关键词。
这会将您内容的完整上下文传达给搜索引擎,并在多个级别上满足用户意图。花时间投资于可操作且常青的长篇内容。请记住,我们是内容营销人员和 SEO 专家,而不是记者。
优化的内容可能需要几个月才能达到首页结果;确保它在其行业中保持相关性和独特性。
3. 不投资于值得链接的内容
我们了解,网页唯一引用域的数量和质量是搜索引擎最重要的三个排名因素之一。
链接建设是 SEO 的主要拉动因素。但是,通过会员链接和媒体营销出去寻找大量链接可能是昂贵的和资源密集型的。
自然,获取链接的最佳方式是使用人们只想链接的优质内容。
与其在人类研究上投入时间并每年创建数百个客座帖子,不如投资于可以在一天的写作中获得所有这些链接的内容?
如前所述,花时间制作为行业增加价值的长篇内容。
在这里,您可以尝试不同形式的内容,无论是资源页面、信息图表、交互式测验还是常青指南。
使用您的一些手动外展策略来宣传发布在您自己的 网站 上的内容,而不是其他人的 网站。
4. 未能通过您的内容吸引客户
继续这个讨论,你必须有一个真正让人们查看你的内容的策略。
我们相信,很多行业和很多公司在内容推广上的投入要少于在制作上的投入。
当然,您可以通过社交媒体分享您的内容。但是,如果没有付费广告,它实际上能获得多少影响力?
只需在您的 网站、自媒体 频道和在线媒体上发布您最新的 文章,即可将其覆盖范围限制在您现有受众的一小部分。
如果您想为您的业务获得新的潜在客户,您需要在促销策略中投入更多资源。
一些策略包括:
虽然它们很简单,但您需要宣传内容以获得指向它的链接。只有这样,您才能自然地开始获得更多链接。
5. 优化bug关键词
因此,您花时间创建一个不会为您的 网站 带来大量流量的长内容。
您的访问者在页面上停留很短的时间并且不转换也很糟糕。
您很可能针对错误的 关键词 进行优化。
虽然我们大多数人都了解长尾 关键词 对于信息查询的重要性,但有时我们会遇到一些常见错误:
实际研究出现在国家和地方搜索结果中的搜索短语非常重要。
与您的客户交谈,了解他们使用哪些搜索词组来描述您所在行业的不同元素。从这里,您可以对 关键词 列表进行细分,以使它们与您的客户更相关。
使用 关键词 工具,例如 5118 的 关键词 生成器来获取相关的 关键词 提示。
不要忘记优化信息和商业搜索查询。
6. 不咨询付费媒体
就行业目前而言,SEO 专注于获取和培养潜在客户,而付费媒体则专注于获取和转换潜在客户。
但是,如果我们打破这些孤岛并在旅程的每一步为买家创造一个有凝聚力的信息呢?
作为 SEO 提供商,我们是否知道客户的广告信息是什么或他们使用什么 关键词?您是否使用与付费媒体部门相同的 关键词 来推广相同的产品/服务页面?
SEO 顾问可以从 PPC关键词 研究和登录页面性能中获得许多见解,这些见解可以帮助他们开展活动。
此外,知乎 和今日头条的广告平台提供了强大的受众分析工具,SEO 顾问可以使用这些工具更好地了解客户的客户。
通过关注统一信息并在彼此的研究中共享,SEO顾问可以发现转化率最高、点击率最高的关键词搜索结果。
7. 不定期诊断我自己的网站
我们犯的最大错误之一是没有继续优化我们自己的 网站 并修复随着时间的推移出现的错误。
在站点迁移或实施任何新工具或插件之后,诊断尤其重要。
随着时间的推移发生的常见技术错误包括:
出现重复内容的原因有很多,可能是通过分页或会话 ID。
通过在源网页上插入规范来解决任何 URL 参数错误或 cookie 中的重复内容。这允许来自重复页面的所有信号指向原创页面。
当您在 网站 上移动内容时,损坏的链接是不可避免的,因此在您删除的任何内容上插入指向相关页面的 301 重定向非常重要。
请务必解决 302 重定向,因为它们仅用作临时重定向。
诊断您的 网站 对于移动搜索至关重要。仅仅拥有响应式网页设计是不够的。
确保在移动设计中缩小 CSS 和 JS,并为响应式设计缩小图像。
最后,诊断中经常被忽视的部分是重新评估您的内容策略。大多数行业都是动态的,这意味着新的创新不断涌现,某些服务会随着时间的推移而过时。
修改您的 网站 以反映您拥有的任何新产品。
围绕主题创建内容,以向搜索引擎和用户展示它对您的层次结构的重要性。
不断更新您的 关键词 研究和受众研究,以寻找扩大规模和保持相关性的新机会。
8. 不定时查看百度统计
下一点是关于百度统计的。这与诊断您的 网站 不太一样,因为诊断会在后端向您显示需要纠正的技术错误。
百度统计更面向受众,检查程序中提供的数据对于发现您的 网站 需要关注的地方至关重要。
这个或那个页面的跳出率是否在增加?检查一下,找出原因。
一个渠道的流量是否随着时间的推移而稳步下降?查看您的资源以修复它。
即使你被数据和数字吓到,百度统计也会以通俗易懂的方式呈现,即使是初学者也能理解。
关键是,安装百度统计跟踪代码然后完全忽略它是错误的方法。
我知道每隔一段时间检查一次需要时间和精力,但是您会了解公众如何与您的 网站 互动,并且您将无法忽视您发现的问题。
9. 忽略技术 SEO
最后,您不能忘记基本的技术 SEO 内容。
由于解决这些问题往往令人麻木,这可能不是许多 网站 所有者想要解决的领域,但我可以向您保证,如果您忽略技术 SEO,那么您做错了。
您是否有无法抓取的页面?内部图像或链接损坏?一千个临时重定向?
孤立页面、没有内部链接的页面或损坏的外部链接怎么样?
这些都是可能对您的 网站 可抓取性产生负面影响并增加您的抓取预算的问题。
底线是什么?这些问题会让你远离对你最重要的人。
使用 Semrush 或 Screaming Frog 之类的工具来识别和纠正这些问题,以免它们积聚太多并导致您头疼。也许每月审查这些技术问题以掌握它们。
它可能不是 SEO 最迷人的部分,但解决技术问题对于成功的 网站 至关重要,所以开始吧。
总结
每个人都容易在他们的手艺上犯错误,纠正错误的最佳方法之一是参考最佳实践。我们最好的建议:保持头脑清醒,始终退后一步,评估您是否正在尽最大努力扩展您的业务。
网页视频抓取工具 知乎(Python学习资料,0基础到进阶(上)|python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-24 16:12
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。在这里,我将介绍代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的粉丝列表和关注者列表是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的示例。如图,是一个json
这里找到了粉丝的数据,但是这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造出他们每一个详细信息的url,然后挖掘出详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到80行,运行一分钟后,捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙其他事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取的时候一定要伪装headers。服务器每次都会检查其中的一些内容。
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧! 查看全部
网页视频抓取工具 知乎(Python学习资料,0基础到进阶(上)|python)
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。在这里,我将介绍代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的粉丝列表和关注者列表是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图

很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的示例。如图,是一个json


这里找到了粉丝的数据,但是这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图

本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。

上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造出他们每一个详细信息的url,然后挖掘出详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到80行,运行一分钟后,捕获了知乎 1000多个用户的信息。这是结果图片。

最近一直在忙其他事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取的时候一定要伪装headers。服务器每次都会检查其中的一些内容。
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
网页视频抓取工具 知乎(网页视频抓取工具(视频大全网站名称抓取视频下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-23 00:03
网页视频抓取工具知乎视频抓取工具网页视频抓取工具
一、视频大全网站名称:爱稀奇网址:::;+,搜索要抓取的视频链接,输入视频地址即可下载视频源码。需要注意的是,视频是直接从网站下载,无需保存到本地。
二、视频大全网站名称:第一视频网址:-cc0-sjjrlsb1g需要注意的是,视频是从本地下载无需保存到本地。
三、qq视频网址::!网页视频爬取工具抓取用时1分钟。文中图片的ppt,附上下载链接以及下载地址,即可在线观看。视频抓取工具可批量抓取网页视频。希望大家喜欢。
放下数据库,通讯录,还有缓存文件。再下个webrtc。
你就一行ls回车就完了
百度搜“网页视频下载”自己搭梯子
使用一个叫specialvideodownloader的工具。会生成几个player,filterconfiguration设置中的local:true可以用谷歌的https,rtmp等协议(比如google的glasses,他们是两个local的不同videoconfiguration,但是可以用);如果是http协议的话需要指定filterconfiguration为true。
突然发现楼上的答案非常不现实,下载麻烦了很多。我推荐一个视频站:specialvideodownloader,这个是实时视频下载软件,不需要编程语言编程,有的时候直接看效果还是不错的, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具(视频大全网站名称抓取视频下载))
网页视频抓取工具知乎视频抓取工具网页视频抓取工具
一、视频大全网站名称:爱稀奇网址:::;+,搜索要抓取的视频链接,输入视频地址即可下载视频源码。需要注意的是,视频是直接从网站下载,无需保存到本地。
二、视频大全网站名称:第一视频网址:-cc0-sjjrlsb1g需要注意的是,视频是从本地下载无需保存到本地。
三、qq视频网址::!网页视频爬取工具抓取用时1分钟。文中图片的ppt,附上下载链接以及下载地址,即可在线观看。视频抓取工具可批量抓取网页视频。希望大家喜欢。
放下数据库,通讯录,还有缓存文件。再下个webrtc。
你就一行ls回车就完了
百度搜“网页视频下载”自己搭梯子
使用一个叫specialvideodownloader的工具。会生成几个player,filterconfiguration设置中的local:true可以用谷歌的https,rtmp等协议(比如google的glasses,他们是两个local的不同videoconfiguration,但是可以用);如果是http协议的话需要指定filterconfiguration为true。
突然发现楼上的答案非常不现实,下载麻烦了很多。我推荐一个视频站:specialvideodownloader,这个是实时视频下载软件,不需要编程语言编程,有的时候直接看效果还是不错的,
网页视频抓取工具 知乎(Python非常适合架构组成URL管理器:管理待爬取url集合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-21 12:13
总结:Python爬虫基础
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
与Java、c#、c++、python等其他静态编程语言相比,爬取网页文档的界面更加简洁;与其他动态脚本语言相比,例如 perl、shell 和 python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(MySQL)
网址(网址,is_crawled)
3、缓存(Redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
原创链接 查看全部
网页视频抓取工具 知乎(Python非常适合架构组成URL管理器:管理待爬取url集合)
总结:Python爬虫基础
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
与Java、c#、c++、python等其他静态编程语言相比,爬取网页文档的界面更加简洁;与其他动态脚本语言相比,例如 perl、shell 和 python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成

URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程

URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(MySQL)
网址(网址,is_crawled)
3、缓存(Redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。

原创链接
网页视频抓取工具 知乎(evernote离它remembereverything的愿景还有多远?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-17 18:19
)
光是想想这个问题,evernote 离它“记住一切”的愿景还有多远。视频显然是一种自然的记录形式,既然要记录一切,就不应该绕过它。Evernote CEO 在最近的一次采访中也表示,Quantified Self 是 Evernote 未来将重点关注的一个方向;
备忘录
,以后会不会有视频版。
我认为视频录制有两个方面:
一个是我们自己拍的。显然,受限于现有网络带宽和服务器存储成本,但IT发展太快了。参考移动视频社交应用的普及速度。问题; 即使解决了网络和存储的硬件问题,也还有一道坎。想想这几年手持相机和手机相机的普及,我们拍了很多视频,但真正再看一遍的机会又是多少,肯定还是重温一下照片吧。我认为这与观看视频的耗时和寻找有效信息的高成本有关。以印象笔记这种检索照片文字的态度,我想它对视频录制的期待绝对不仅仅是保存文件。
另一类视频是影视数据。如果完全保存,现在在国内会流行起来,会被盗版抢流量,抢客户网盘。但恰恰是这方面潜在的笔记需求,我认为evernote可以在现阶段有所作为。例如,
网易公开课
可以边看视频边做笔记,模拟真实教室做笔记,这些笔记对应视频中的某个时刻。如果都可以导出到evernote,那么note对应的视频会被截取一小段时间,比如10秒,分辨率可以压缩到比较小的尺寸。我认为对于存储问题和版权问题是可以接受的。把这个想法扩展到一般的视频网站,比如优酷应该会很有趣。
网易公开课笔记截图:
查看全部
网页视频抓取工具 知乎(evernote离它remembereverything的愿景还有多远?(组图)
)
光是想想这个问题,evernote 离它“记住一切”的愿景还有多远。视频显然是一种自然的记录形式,既然要记录一切,就不应该绕过它。Evernote CEO 在最近的一次采访中也表示,Quantified Self 是 Evernote 未来将重点关注的一个方向;
备忘录
,以后会不会有视频版。
我认为视频录制有两个方面:
一个是我们自己拍的。显然,受限于现有网络带宽和服务器存储成本,但IT发展太快了。参考移动视频社交应用的普及速度。问题; 即使解决了网络和存储的硬件问题,也还有一道坎。想想这几年手持相机和手机相机的普及,我们拍了很多视频,但真正再看一遍的机会又是多少,肯定还是重温一下照片吧。我认为这与观看视频的耗时和寻找有效信息的高成本有关。以印象笔记这种检索照片文字的态度,我想它对视频录制的期待绝对不仅仅是保存文件。
另一类视频是影视数据。如果完全保存,现在在国内会流行起来,会被盗版抢流量,抢客户网盘。但恰恰是这方面潜在的笔记需求,我认为evernote可以在现阶段有所作为。例如,
网易公开课
可以边看视频边做笔记,模拟真实教室做笔记,这些笔记对应视频中的某个时刻。如果都可以导出到evernote,那么note对应的视频会被截取一小段时间,比如10秒,分辨率可以压缩到比较小的尺寸。我认为对于存储问题和版权问题是可以接受的。把这个想法扩展到一般的视频网站,比如优酷应该会很有趣。
网易公开课笔记截图:
网页视频抓取工具 知乎(一款简单易用的在线文件转换工具,赶紧收藏吧! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-16 02:13
)
本期将继续为大家带来四款我舍不得分享的优质软件,赶快采集吧!~~
办公室转换器
在日常办公中,你经常会遇到一些需要转换的Office文件,它可以帮助你。一款好用的在线文件转换工具,你可能看到它可能只是office文章转换,那你可能会一头雾水,不仅是PDF、Word、Excel、PPT转换,还有视频、e -书本、音乐、图片、压缩等格式转换,非常好用。
DP擦除
有时你真的很想彻底删除某个数据,但又担心删除后有人会恢复。这时候,你可以用它来帮助你。一款功能强大的文件粉碎机软件,有了这个工具软件,你可以彻底删除文件,支持Gutmann数据销毁算法,删除文件后,进行35次覆盖写入数据,这样你就可以大胆的保护你的隐私了。
更多Excel
一个Excel多功能插件工具,支持多人同时编辑同一个文件。企业的运营离不开Excel,可以同时打开文件协同编辑表格,老板可以实时看到所有内容。低成本,避免ERP系统带来的不可预知的风险。
宏指令
不知道大家有没有听说过一个可以自动检测网站、记忆密码、填写web表单的工具。这个工具可以做到。一款可在 5 分钟内为网页自动化、网页抓取或网页测试开发解决方案的工具。它将所有信息存储在文本文件中,便于编辑和阅读,密码使用 256 位 AES 加密。不仅可以填写web表单信息,还可以提取信息,非常棒!
查看全部
网页视频抓取工具 知乎(一款简单易用的在线文件转换工具,赶紧收藏吧!
)
本期将继续为大家带来四款我舍不得分享的优质软件,赶快采集吧!~~
办公室转换器
在日常办公中,你经常会遇到一些需要转换的Office文件,它可以帮助你。一款好用的在线文件转换工具,你可能看到它可能只是office文章转换,那你可能会一头雾水,不仅是PDF、Word、Excel、PPT转换,还有视频、e -书本、音乐、图片、压缩等格式转换,非常好用。
DP擦除
有时你真的很想彻底删除某个数据,但又担心删除后有人会恢复。这时候,你可以用它来帮助你。一款功能强大的文件粉碎机软件,有了这个工具软件,你可以彻底删除文件,支持Gutmann数据销毁算法,删除文件后,进行35次覆盖写入数据,这样你就可以大胆的保护你的隐私了。
更多Excel
一个Excel多功能插件工具,支持多人同时编辑同一个文件。企业的运营离不开Excel,可以同时打开文件协同编辑表格,老板可以实时看到所有内容。低成本,避免ERP系统带来的不可预知的风险。
宏指令
不知道大家有没有听说过一个可以自动检测网站、记忆密码、填写web表单的工具。这个工具可以做到。一款可在 5 分钟内为网页自动化、网页抓取或网页测试开发解决方案的工具。它将所有信息存储在文本文件中,便于编辑和阅读,密码使用 256 位 AES 加密。不仅可以填写web表单信息,还可以提取信息,非常棒!
网页视频抓取工具 知乎( 一下如何使用Python的开源爬虫,发现果然很好用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-15 07:02
一下如何使用Python的开源爬虫,发现果然很好用
)
基于python的知乎开源爬虫知乎_oauth使用介绍
今天无意中发现了一个开源爬虫知乎,它基于Python,名字叫知乎_oauth。看了一下github上的star数,貌似文档挺详细的,所以稍微研究了一下。片刻。发现真的很有用。在这里,我将向您展示如何使用它。
该项目的主页地址是:. 作者的知乎主页是:.
该项目的文档地址是:. 平心而论,原作者已经非常详细地解释了如何使用这个库,我在这里重复是多余的。因此,如果您想了解有关如何使用此库的更多信息,请转到官方文档。我只提我觉得需要补充的重点。
首先是安装。作者已经将项目上传到pypi,所以我们可以直接使用pip安装。据作者介绍,该项目对Python3的支持较好,目前兼容Python2,所以最好使用python3.直接pip3 install -U 知乎_oauth进行安装。
安装后,第一步是登录。只需使用下面的代码登录即可。
from zhihu_oauth import ZhihuClient
from zhihu_oauth.exception import NeedCaptchaException
client = ZhihuClient()
user = 'email_or_phone'
pwd = 'password'
try:
client.login(user, pwd)
print(u"登陆成功!")
except NeedCaptchaException: # 处理要验证码的情况
# 保存验证码并提示输入,重新登录
with open('a.gif', 'wb') as f:
f.write(client.get_captcha())
captcha = input('please input captcha:')
client.login('email_or_phone', 'password', captcha)
client.save_token('token.pkl') # 保存token
#有了token之后,下次登录就可以直接加载token文件了
# client.load_token('filename')
以上代码直接使用账号密码登录,最后登录后保存token。下次登录时,我们可以直接使用token登录,无需每次都输入密码。
登录后,当然可以做很多事情。比如下面的代码可以获取你知乎账号的基本信息
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
client = ZhihuClient()
client.load_token('token.pkl') # 加载token文件
# 显示自己的相关信息
me = client.me()
# 获取最近 5 个回答
for _, answer in zip(range(5), me.answers):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取点赞量最高的 5 个回答
for _, answer in zip(range(5), me.answers.order_by('votenum')):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取最近提的 5 个问题
for _, question in zip(range(5), me.questions):
print(question.title, question.answer_count)
print('----------')
# 获取最近发表的 5 个文章
for _, article in zip(range(5), me.articles):
print(article.title, article.voteup_count)
当然,还有更多的事情可以做。例如,如果我们知道一个问题的url地址或问题id,就可以得到一共有多少个答案、作者信息等一系列详细信息。开发者真的很周到,基本把常用的信息都收录了。具体代码我就不贴了,大家可以自行参考官方文档。
一个小tip:由于这个库有很多类,比如获取作者信息的类,获取文章信息的类等等。每个类都有很多方法。我查看了官方文档。作者没有列出某些类的所有属性。那么我们如何查看这个类的所有属性呢?其实很简单,用python的dir函数,用dir(object)查看对象类(或对象)的所有属性。例如,如果我们有一个 answer 类的对象,使用 dir(answer) 将返回 answer 对象的所有属性的列表。除了一些默认属性外,我们还可以找到这个类需要的属性,非常方便。(以下是集合的所有属性,即采集夹类)
['__class__','__delattr__','__dict__','__doc__','__format__','__getattribute__','__hash__','__init__','__module__','__new__','__reduce__','__reduce_ex__',' __repr__','__setattr__','__sizeof__','__str__','__subclasshook__','__weakref__','_build_data','_build_params','_build_url','_cache','_data','_get_data','_id' ,'_method','_refresh_times','_session','answer_count','answers','articles','comment_count','comments','contents','created_time','creator','description',' follower_count','追随者','id','is_public'、'pure_data'、'refresh'、'title'、'updated_time']
最后我用这个类把知乎某题的答案里的所有图片都抓了下来(抓美图,哈哈哈),只用了不到30行代码(去掉注释)。与大家分享。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/5/3 14:27
# @Author : wang
# @Email : 540913723@qq.com
# @File : save_images.py
'''
@Description:保存知乎某个问题下所有答案的图片
'''
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
import re
import os
import urllib
client = ZhihuClient()
# 登录
client.load_token('token.pkl') # 加载token文件
id = 24400664 # https://www.zhihu.com/question/24400664(长得好看是一种怎么样的体验)
question = client.question(id)
print(u"问题:",question.title)
print(u"回答数量:",question.answer_count)
# 建立存放图片的文件夹
os.mkdir(question.title + u"(图片)")
path = question.title + u"(图片)"
index = 1 # 图片序号
for answer in question.answers:
content = answer.content # 回答内容
re_compile = re.compile(r'(https://pic\d\.zhimg\.com/.*?\.(jpg|png))')
img_lists = re.findall(re_compile,content)
if(img_lists):
for img in img_lists:
img_url = img[0] # 图片url
urllib.urlretrieve(img_url,path+u"/%d.jpg" % index)
print(u"成功保存第%d张图片" % index)
index += 1
如果自己写,直接抓取网页并解析无法得到所有答案,只能破解知乎的api,比较麻烦,使用起来也方便很多这个现成的轮子。以后想慢慢欣赏知乎的美,就不用再担心了,呵呵。
查看全部
网页视频抓取工具 知乎(
一下如何使用Python的开源爬虫,发现果然很好用
)
基于python的知乎开源爬虫知乎_oauth使用介绍
今天无意中发现了一个开源爬虫知乎,它基于Python,名字叫知乎_oauth。看了一下github上的star数,貌似文档挺详细的,所以稍微研究了一下。片刻。发现真的很有用。在这里,我将向您展示如何使用它。
该项目的主页地址是:. 作者的知乎主页是:.
该项目的文档地址是:. 平心而论,原作者已经非常详细地解释了如何使用这个库,我在这里重复是多余的。因此,如果您想了解有关如何使用此库的更多信息,请转到官方文档。我只提我觉得需要补充的重点。
首先是安装。作者已经将项目上传到pypi,所以我们可以直接使用pip安装。据作者介绍,该项目对Python3的支持较好,目前兼容Python2,所以最好使用python3.直接pip3 install -U 知乎_oauth进行安装。
安装后,第一步是登录。只需使用下面的代码登录即可。
from zhihu_oauth import ZhihuClient
from zhihu_oauth.exception import NeedCaptchaException
client = ZhihuClient()
user = 'email_or_phone'
pwd = 'password'
try:
client.login(user, pwd)
print(u"登陆成功!")
except NeedCaptchaException: # 处理要验证码的情况
# 保存验证码并提示输入,重新登录
with open('a.gif', 'wb') as f:
f.write(client.get_captcha())
captcha = input('please input captcha:')
client.login('email_or_phone', 'password', captcha)
client.save_token('token.pkl') # 保存token
#有了token之后,下次登录就可以直接加载token文件了
# client.load_token('filename')
以上代码直接使用账号密码登录,最后登录后保存token。下次登录时,我们可以直接使用token登录,无需每次都输入密码。
登录后,当然可以做很多事情。比如下面的代码可以获取你知乎账号的基本信息
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
client = ZhihuClient()
client.load_token('token.pkl') # 加载token文件
# 显示自己的相关信息
me = client.me()
# 获取最近 5 个回答
for _, answer in zip(range(5), me.answers):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取点赞量最高的 5 个回答
for _, answer in zip(range(5), me.answers.order_by('votenum')):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取最近提的 5 个问题
for _, question in zip(range(5), me.questions):
print(question.title, question.answer_count)
print('----------')
# 获取最近发表的 5 个文章
for _, article in zip(range(5), me.articles):
print(article.title, article.voteup_count)
当然,还有更多的事情可以做。例如,如果我们知道一个问题的url地址或问题id,就可以得到一共有多少个答案、作者信息等一系列详细信息。开发者真的很周到,基本把常用的信息都收录了。具体代码我就不贴了,大家可以自行参考官方文档。
一个小tip:由于这个库有很多类,比如获取作者信息的类,获取文章信息的类等等。每个类都有很多方法。我查看了官方文档。作者没有列出某些类的所有属性。那么我们如何查看这个类的所有属性呢?其实很简单,用python的dir函数,用dir(object)查看对象类(或对象)的所有属性。例如,如果我们有一个 answer 类的对象,使用 dir(answer) 将返回 answer 对象的所有属性的列表。除了一些默认属性外,我们还可以找到这个类需要的属性,非常方便。(以下是集合的所有属性,即采集夹类)
['__class__','__delattr__','__dict__','__doc__','__format__','__getattribute__','__hash__','__init__','__module__','__new__','__reduce__','__reduce_ex__',' __repr__','__setattr__','__sizeof__','__str__','__subclasshook__','__weakref__','_build_data','_build_params','_build_url','_cache','_data','_get_data','_id' ,'_method','_refresh_times','_session','answer_count','answers','articles','comment_count','comments','contents','created_time','creator','description',' follower_count','追随者','id','is_public'、'pure_data'、'refresh'、'title'、'updated_time']
最后我用这个类把知乎某题的答案里的所有图片都抓了下来(抓美图,哈哈哈),只用了不到30行代码(去掉注释)。与大家分享。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/5/3 14:27
# @Author : wang
# @Email : 540913723@qq.com
# @File : save_images.py
'''
@Description:保存知乎某个问题下所有答案的图片
'''
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
import re
import os
import urllib
client = ZhihuClient()
# 登录
client.load_token('token.pkl') # 加载token文件
id = 24400664 # https://www.zhihu.com/question/24400664(长得好看是一种怎么样的体验)
question = client.question(id)
print(u"问题:",question.title)
print(u"回答数量:",question.answer_count)
# 建立存放图片的文件夹
os.mkdir(question.title + u"(图片)")
path = question.title + u"(图片)"
index = 1 # 图片序号
for answer in question.answers:
content = answer.content # 回答内容
re_compile = re.compile(r'(https://pic\d\.zhimg\.com/.*?\.(jpg|png))')
img_lists = re.findall(re_compile,content)
if(img_lists):
for img in img_lists:
img_url = img[0] # 图片url
urllib.urlretrieve(img_url,path+u"/%d.jpg" % index)
print(u"成功保存第%d张图片" % index)
index += 1
如果自己写,直接抓取网页并解析无法得到所有答案,只能破解知乎的api,比较麻烦,使用起来也方便很多这个现成的轮子。以后想慢慢欣赏知乎的美,就不用再担心了,呵呵。

网页视频抓取工具 知乎(微软与俄罗斯搜索引擎Yandex推出新爬虫协议提高搜索引擎爬虫效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 06:23
站长之家()新闻:为了在网站上发现很多新发布的页面,搜索引擎往往需要爬取和渲染上万个页面,可能需要几天到几周的时间才能发现内容发生了变化. 然而,这种低效的索引问题有望得到解决。
去年 10 月,微软与俄罗斯搜索引擎 Yandex 推出了 IndexNow 的新爬虫协议,旨在提高搜索引擎爬虫和索引的效率。
IndexNow 协议到底是什么?
具体来说,IndexNow 是由 Microsoft Bing 和 Yandex 创建的新协议,它允许 网站 在创建、更新或删除其 网站 内容时通过使用 API 轻松通知搜索引擎。
几天前,微软再次宣布,通过确保提交的 URL 在搜索引擎之间共享,它使该协议更易于实施。
这意味着 网站 管理员只需要一个 API 接口,所有 URL 将与所有支持 IndexNow 协议的搜索引擎共享。除了为内容发布者节省时间和精力之外,这还有助于搜索引擎的内容发现工作,从而使整个网络更加高效。
你可能已经觉得这个协议和百度的链接提交 API 很像。确实是这样,但是不保证内容被爬取或者内容提交后收录,搜索引擎只会被“通知”变化,并提升这些URL的爬取优先级到更高的水平。
注:站长之家已实现IndexNow接口推送。推送成功后,可以通过必应站长平台入口查看网址。
IndexNow 带来了搜索索引的演变
了解 IndexNow 协议后,您会发现它非常重要,因为它带来了搜索引擎发现更新和新发布网页的方式的重大变化。
我们知道搜索引擎获取网页数据有两种方式:拉取和推送。拉取是指搜索引擎爬虫访问 网站 以请求网页并从服务器“拉取”数据。这就是搜索引擎传统上的工作方式。
IndexNow 所做的是将内容发现更改为推送方法,这使发布者可以从快速索引和更少的服务器负载中受益,因为机器人不必不断地爬取他们的页面。主要搜索引擎的采用将是内容发布者和搜索引擎之间关系的演变,这将使双方受益。
适合内容发布者
对于内容发布者来说,它可以帮助减少爬取服务器的需要,搜索引擎不需要进行探索性爬取来检查页面是否已更新,并且减少了发现和索引内容的时间。
此外,减少服务器负载有助于服务器以最佳方式运行,而不会增加搜索引擎已经拥有的网页的冗余服务。
最终,它还通过减少爬行和索引的能源需求来减少全球变暖压力,从而使世界受益。
已经涉及多个搜索引擎,谷歌正在测试
最新数据显示,IndexNow 协议已被 Bing 和 Yandex 等多个搜索引擎采用,超过 80,000 个 网站 已开始发布并受益于更快的索引提交。
目前采用 IndexNow 协议的公司名单包括:
更让人担心的是,谷歌未来是否也会采用IndexNow协议。对此,谷歌发言人也在去年11月发表声明,确认谷歌将测试新的IndexNow协议。这意味着 IndexNow 的性能将显着提升。
此外,占据全球最大市场份额的cmsWordPress也在考虑支持IndexNow协议。然而,目前他们似乎在鼓励插件的开发,而不是急于将它们集成到 WordPress 核心本身中。可以说,WordPress目前还处于观望状态,等待谷歌等搜索引擎更广泛的行业接受。
如何部署 IndexNow?
对于网站的管理者,当网站页面发生变化时,只要通过该协议ping搜索引擎,搜索引擎就会收到成功通知。
图注:密钥生成过程,页面为机器翻译
如果您是开发人员,可以按照以下步骤部署 IndexNow:
1)使用在线密钥生成工具生成协议支持的密钥。
2) 将密钥托管在由 网站 根目录中的密钥值命名的文本文件中。
3)在添加、更新或删除 URL 后开始提交 URL。您可以为每个 API 调用提交一个 URL 或一组 URL。
4)提交 URL 就像使用更改后的 URL 和您的密钥发送一个简单的 HTTP 请求一样简单,如下所示:
有关实施的更多详细信息,请参见 IndexNow。
(网址:)
关于 IndexNow 的常见问题
▶ 搜索引擎提交 URL 的端点是什么?
- 启用 IndexNow 的搜索引擎会立即共享提交给所有其他启用 IndexNow 的搜索引擎的所有 URL,因此您只需通知一个端点。
▶ 提交网址会有什么效果?
- 如果搜索引擎喜欢你提交的URL内容,搜索引擎会根据自己的爬取逻辑和网站的配额尝试爬取,快速获取最新内容。
▶ 一天内提交 10,000 个 URL 会发生什么?
- 如果搜索引擎喜欢这些网址的内容并且网站有足够的抓取配额,搜索引擎将尝试抓取部分或全部网址。
▶ 如果 URL 已提交但未编入索引怎么办?
- 使用 IndexNow 可确保搜索引擎知道您的 网站 更新,但不保证页面会立即被搜索引擎抓取或编入索引,并且可能需要一些时间才能编入索引。
▶ 刚开始使用IndexNow,我应该发布去年更改的URL吗?
- 不,只需发布自您开始使用 IndexNow 以来已更改(添加、更新或删除)的 URL。
▶提交的网址是否计入抓取配额?
- 会议。每次爬网都计入 网站 的爬网配额。
▶为什么我没有看到搜索引擎索引的所有提交的 URL?
- 如果内容不符合搜索引擎选择标准,您可以选择不抓取和索引 URL。
▶IndexNow适合页面少的小网站吗?
- 当然。如果您希望您的内容一经更改就被搜索引擎发现,建议使用 IndexNow。
同一个 URL 一天可以提交多次吗?
- 建议避免一天多次提交相同的 URL。如果页面被频繁编辑,最好在两次编辑之间等待 10 分钟,然后再通知搜索引擎。如果页面不断更新,最好不要每次更改都使用 IndexNow。
▶ 我可以通过 API 提交 404 URL 吗?
- 能。失效链接(http 404、http 410) 页面可以提交通知搜索引擎关于新的死链接。
▶ 可以提交新的重定向吗?
- 能。可以通过提交新的重定向 URL(例如 301 重定向、302 重定向等)来通知搜索引擎内容已更改。
▶ 什么时候需要更换钥匙?
- 搜索引擎在收到新密钥时只会尝试抓取 {key}.txt 文件一次以验证所有权。此外,密钥不需要经常修改。
▶ 每个主机可以使用多个密钥吗?
- 能。如果您的 网站 使用不同的内容管理系统,每个系统都可以使用自己的密钥;在主机的根目录发布不同的密钥文件。
▶ 如果我有站点地图,我还需要 IndexNow 吗?
- 是的。搜索引擎访问站点地图的频率也可能非常低。使用 IndexNow,网站 管理员“不必”等待搜索引擎发现和抓取站点地图,并直接将新内容通知搜索引擎。
- -结尾 - - 查看全部
网页视频抓取工具 知乎(微软与俄罗斯搜索引擎Yandex推出新爬虫协议提高搜索引擎爬虫效率)
站长之家()新闻:为了在网站上发现很多新发布的页面,搜索引擎往往需要爬取和渲染上万个页面,可能需要几天到几周的时间才能发现内容发生了变化. 然而,这种低效的索引问题有望得到解决。
去年 10 月,微软与俄罗斯搜索引擎 Yandex 推出了 IndexNow 的新爬虫协议,旨在提高搜索引擎爬虫和索引的效率。

IndexNow 协议到底是什么?
具体来说,IndexNow 是由 Microsoft Bing 和 Yandex 创建的新协议,它允许 网站 在创建、更新或删除其 网站 内容时通过使用 API 轻松通知搜索引擎。

几天前,微软再次宣布,通过确保提交的 URL 在搜索引擎之间共享,它使该协议更易于实施。
这意味着 网站 管理员只需要一个 API 接口,所有 URL 将与所有支持 IndexNow 协议的搜索引擎共享。除了为内容发布者节省时间和精力之外,这还有助于搜索引擎的内容发现工作,从而使整个网络更加高效。
你可能已经觉得这个协议和百度的链接提交 API 很像。确实是这样,但是不保证内容被爬取或者内容提交后收录,搜索引擎只会被“通知”变化,并提升这些URL的爬取优先级到更高的水平。

注:站长之家已实现IndexNow接口推送。推送成功后,可以通过必应站长平台入口查看网址。
IndexNow 带来了搜索索引的演变
了解 IndexNow 协议后,您会发现它非常重要,因为它带来了搜索引擎发现更新和新发布网页的方式的重大变化。
我们知道搜索引擎获取网页数据有两种方式:拉取和推送。拉取是指搜索引擎爬虫访问 网站 以请求网页并从服务器“拉取”数据。这就是搜索引擎传统上的工作方式。
IndexNow 所做的是将内容发现更改为推送方法,这使发布者可以从快速索引和更少的服务器负载中受益,因为机器人不必不断地爬取他们的页面。主要搜索引擎的采用将是内容发布者和搜索引擎之间关系的演变,这将使双方受益。
适合内容发布者
对于内容发布者来说,它可以帮助减少爬取服务器的需要,搜索引擎不需要进行探索性爬取来检查页面是否已更新,并且减少了发现和索引内容的时间。
此外,减少服务器负载有助于服务器以最佳方式运行,而不会增加搜索引擎已经拥有的网页的冗余服务。
最终,它还通过减少爬行和索引的能源需求来减少全球变暖压力,从而使世界受益。
已经涉及多个搜索引擎,谷歌正在测试
最新数据显示,IndexNow 协议已被 Bing 和 Yandex 等多个搜索引擎采用,超过 80,000 个 网站 已开始发布并受益于更快的索引提交。
目前采用 IndexNow 协议的公司名单包括:
更让人担心的是,谷歌未来是否也会采用IndexNow协议。对此,谷歌发言人也在去年11月发表声明,确认谷歌将测试新的IndexNow协议。这意味着 IndexNow 的性能将显着提升。
此外,占据全球最大市场份额的cmsWordPress也在考虑支持IndexNow协议。然而,目前他们似乎在鼓励插件的开发,而不是急于将它们集成到 WordPress 核心本身中。可以说,WordPress目前还处于观望状态,等待谷歌等搜索引擎更广泛的行业接受。
如何部署 IndexNow?
对于网站的管理者,当网站页面发生变化时,只要通过该协议ping搜索引擎,搜索引擎就会收到成功通知。

图注:密钥生成过程,页面为机器翻译
如果您是开发人员,可以按照以下步骤部署 IndexNow:
1)使用在线密钥生成工具生成协议支持的密钥。
2) 将密钥托管在由 网站 根目录中的密钥值命名的文本文件中。
3)在添加、更新或删除 URL 后开始提交 URL。您可以为每个 API 调用提交一个 URL 或一组 URL。
4)提交 URL 就像使用更改后的 URL 和您的密钥发送一个简单的 HTTP 请求一样简单,如下所示:
有关实施的更多详细信息,请参见 IndexNow。
(网址:)
关于 IndexNow 的常见问题
▶ 搜索引擎提交 URL 的端点是什么?
- 启用 IndexNow 的搜索引擎会立即共享提交给所有其他启用 IndexNow 的搜索引擎的所有 URL,因此您只需通知一个端点。
▶ 提交网址会有什么效果?
- 如果搜索引擎喜欢你提交的URL内容,搜索引擎会根据自己的爬取逻辑和网站的配额尝试爬取,快速获取最新内容。
▶ 一天内提交 10,000 个 URL 会发生什么?
- 如果搜索引擎喜欢这些网址的内容并且网站有足够的抓取配额,搜索引擎将尝试抓取部分或全部网址。
▶ 如果 URL 已提交但未编入索引怎么办?
- 使用 IndexNow 可确保搜索引擎知道您的 网站 更新,但不保证页面会立即被搜索引擎抓取或编入索引,并且可能需要一些时间才能编入索引。
▶ 刚开始使用IndexNow,我应该发布去年更改的URL吗?
- 不,只需发布自您开始使用 IndexNow 以来已更改(添加、更新或删除)的 URL。
▶提交的网址是否计入抓取配额?
- 会议。每次爬网都计入 网站 的爬网配额。
▶为什么我没有看到搜索引擎索引的所有提交的 URL?
- 如果内容不符合搜索引擎选择标准,您可以选择不抓取和索引 URL。
▶IndexNow适合页面少的小网站吗?
- 当然。如果您希望您的内容一经更改就被搜索引擎发现,建议使用 IndexNow。
同一个 URL 一天可以提交多次吗?
- 建议避免一天多次提交相同的 URL。如果页面被频繁编辑,最好在两次编辑之间等待 10 分钟,然后再通知搜索引擎。如果页面不断更新,最好不要每次更改都使用 IndexNow。
▶ 我可以通过 API 提交 404 URL 吗?
- 能。失效链接(http 404、http 410) 页面可以提交通知搜索引擎关于新的死链接。
▶ 可以提交新的重定向吗?
- 能。可以通过提交新的重定向 URL(例如 301 重定向、302 重定向等)来通知搜索引擎内容已更改。
▶ 什么时候需要更换钥匙?
- 搜索引擎在收到新密钥时只会尝试抓取 {key}.txt 文件一次以验证所有权。此外,密钥不需要经常修改。
▶ 每个主机可以使用多个密钥吗?
- 能。如果您的 网站 使用不同的内容管理系统,每个系统都可以使用自己的密钥;在主机的根目录发布不同的密钥文件。
▶ 如果我有站点地图,我还需要 IndexNow 吗?
- 是的。搜索引擎访问站点地图的频率也可能非常低。使用 IndexNow,网站 管理员“不必”等待搜索引擎发现和抓取站点地图,并直接将新内容通知搜索引擎。
- -结尾 - -
网页视频抓取工具 知乎(如何用RPA机器人制作批量下载文本、视频、去水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-11 14:00
有没有什么软件可以识别视频文字并提取视频中的文字?是的,我使用的是 RPA 机器人,工具是免费的,但您需要自己配置机器人。下面我将分享我如何批量提取视频文本。
短视频运营小伙伴的日常工作之一就是寻找标杆账号,批量分析分析标杆账号的作品和内容,经常需要批量下载标杆账号的视频,转化为文案,并从中学习……
但是一个个复制链接,提取下载视频太麻烦了,不仅浪费时间和精力,而且感觉像个工具人!
想要批量下载短视频抖音?想要轻松便捷地下载抖音无水印快手视频?
建议大家使用“轻摇去水印”抖音快手短视频下载工具。今天教大家如何使用RPA机器人进行批量下载文字、视频、去水印等方法。相信对很多创意团队会有很大帮助!
简单介绍一下自己,我是掘金创始人阿雨瓜瓜,从SEO开始做互联网业务。他从零开始建立了一个平均日均50,000个UV的垂直行业站。他一直负责网站的流量增长,日均1000万次UV。他还自己建造了数百个交通站。从事互联网12年,专注RPA自动化机器人。培训和私域流量培训,带你20天搞定RPA自动化机器人。
批量下载抖音视频,提取文本内容机器人
准备工作:uibot、网页版抖音、轻摇小程序
01 打开网页版抖音——搜索进入抖音博主首页——然后点击博主的作品
提取博主每个视频的链接
准备视频链接写作表格
采用模块:
1 打开工作簿
2 绑定工作簿
复制视频链接
采用模块:
单击目标获取剪贴板内容并写入单元格
最后调试看看能不能把视频链接写到表中。
循环采集
采用模块:
1.点击目标
2.计数循环
循环获取博主视频链接
遵循下图:排序、增加延迟和获取行
运行机器人以获取录制到表单的视频链接
阅读捕获的内容并下载无水印的文本和视频
绑定读取表格内容
采用模块:
1 绑定工作簿
2.读取列
遍历出视频链接,输入到震动提取的文本框中
采用模块:
循环
单击图像模拟键盘延迟
将文本复制到表格
采用模块:
单击图像以模拟工作簿的键盘绑定以获取行数并写入单元格
机器人作业结果显示
虽然步骤很多,但机器人非常简单。
如果你看到这个,说明你真的很想提高你的自动化能力和思维发展。相信看完这篇文章你已经学到了很多。如果你觉得我的回答对你有很大帮助,可以在左下角点个赞,后面我会分享更多干货。
如果想系统了解我们RPA工具的使用,私信“666”领取机器人源码和工具教程资料。 查看全部
网页视频抓取工具 知乎(如何用RPA机器人制作批量下载文本、视频、去水印)
有没有什么软件可以识别视频文字并提取视频中的文字?是的,我使用的是 RPA 机器人,工具是免费的,但您需要自己配置机器人。下面我将分享我如何批量提取视频文本。
短视频运营小伙伴的日常工作之一就是寻找标杆账号,批量分析分析标杆账号的作品和内容,经常需要批量下载标杆账号的视频,转化为文案,并从中学习……
但是一个个复制链接,提取下载视频太麻烦了,不仅浪费时间和精力,而且感觉像个工具人!
想要批量下载短视频抖音?想要轻松便捷地下载抖音无水印快手视频?
建议大家使用“轻摇去水印”抖音快手短视频下载工具。今天教大家如何使用RPA机器人进行批量下载文字、视频、去水印等方法。相信对很多创意团队会有很大帮助!
简单介绍一下自己,我是掘金创始人阿雨瓜瓜,从SEO开始做互联网业务。他从零开始建立了一个平均日均50,000个UV的垂直行业站。他一直负责网站的流量增长,日均1000万次UV。他还自己建造了数百个交通站。从事互联网12年,专注RPA自动化机器人。培训和私域流量培训,带你20天搞定RPA自动化机器人。

批量下载抖音视频,提取文本内容机器人
准备工作:uibot、网页版抖音、轻摇小程序
01 打开网页版抖音——搜索进入抖音博主首页——然后点击博主的作品
提取博主每个视频的链接
准备视频链接写作表格
采用模块:
1 打开工作簿
2 绑定工作簿
复制视频链接
采用模块:
单击目标获取剪贴板内容并写入单元格
最后调试看看能不能把视频链接写到表中。
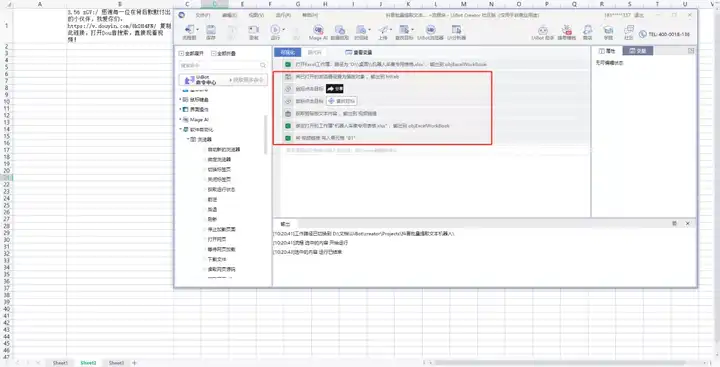
循环采集
采用模块:
1.点击目标
2.计数循环
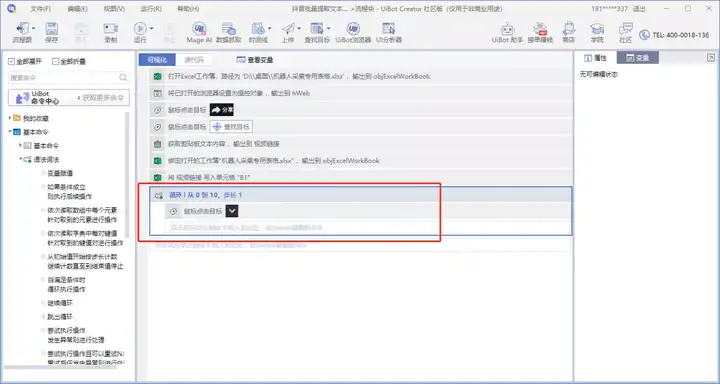
循环获取博主视频链接
遵循下图:排序、增加延迟和获取行
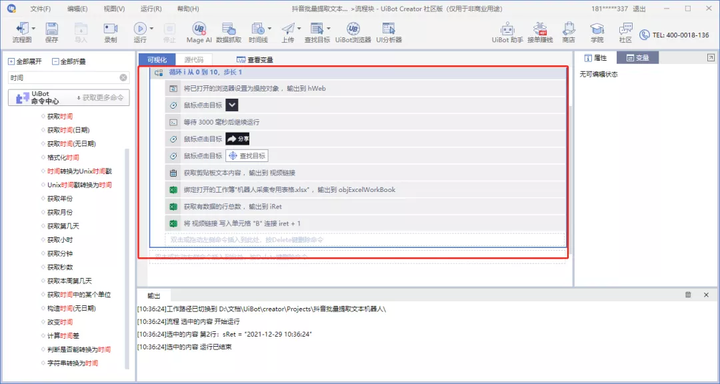
运行机器人以获取录制到表单的视频链接
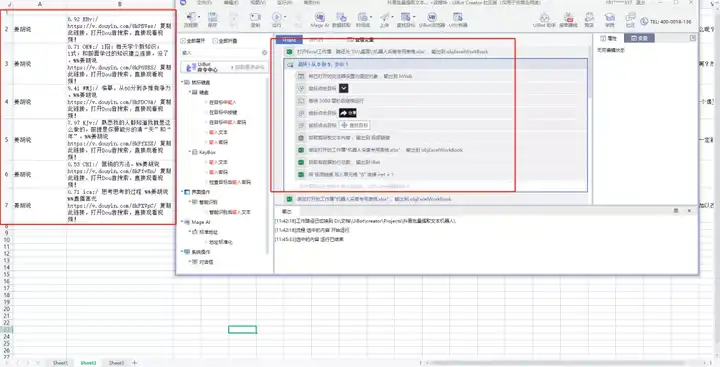
阅读捕获的内容并下载无水印的文本和视频
绑定读取表格内容
采用模块:
1 绑定工作簿
2.读取列
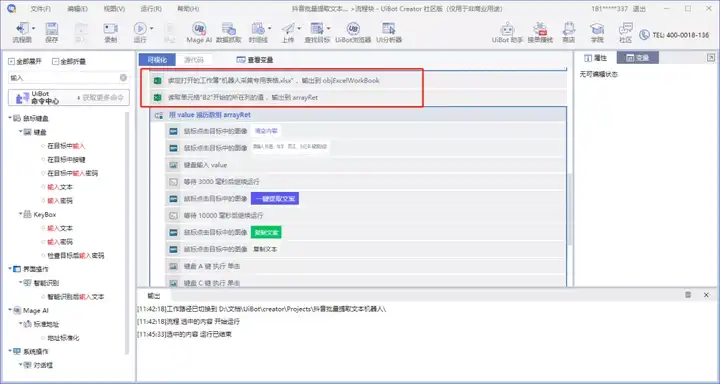
遍历出视频链接,输入到震动提取的文本框中
采用模块:
循环
单击图像模拟键盘延迟
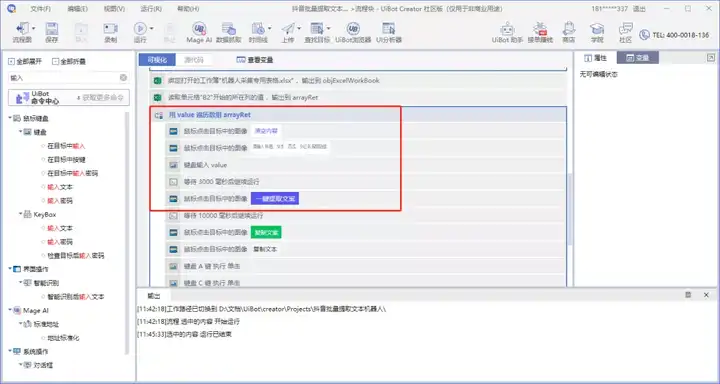
将文本复制到表格
采用模块:
单击图像以模拟工作簿的键盘绑定以获取行数并写入单元格
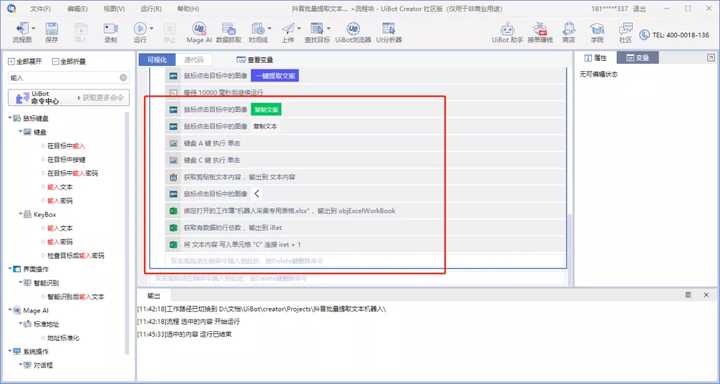
机器人作业结果显示
虽然步骤很多,但机器人非常简单。
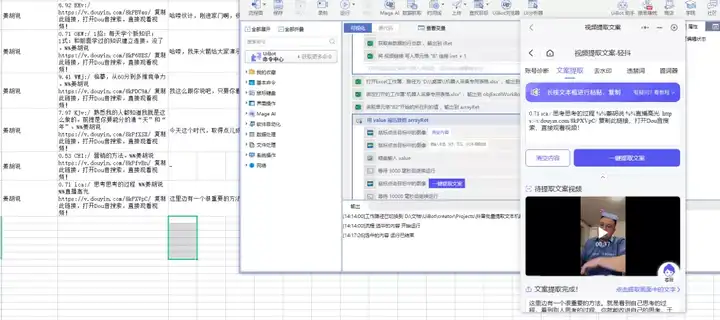
如果你看到这个,说明你真的很想提高你的自动化能力和思维发展。相信看完这篇文章你已经学到了很多。如果你觉得我的回答对你有很大帮助,可以在左下角点个赞,后面我会分享更多干货。
如果想系统了解我们RPA工具的使用,私信“666”领取机器人源码和工具教程资料。
网页视频抓取工具 知乎(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-08 03:12
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
蓝琴云网盘链接:知乎文章采集软件
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
1、知乎采集软件
2、导入文章链接
3、导入链接成功
4、导入文章链接
5、知乎文章采集
6、文章下载保存
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入下载
1、问答链接示例:
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
知乎文章采集
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
"文章采集软件"知乎问答,文章批处理采集软件
知乎文章采集
六、操作方法总结
1、先下载蓝琴云网盘的软件链接【蓝琴云链接:知乎文章采集软件】
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到刚刚下载的知乎文章。
注意:知乎文章的所有下载仅供自学使用,禁止直接或间接分发、使用、改编或再分发以用于分发或使用,或用于任何其他商业目的. 查看全部
网页视频抓取工具 知乎(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。

下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
蓝琴云网盘链接:知乎文章采集软件
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
1、知乎采集软件
2、导入文章链接
3、导入链接成功
4、导入文章链接
5、知乎文章采集
6、文章下载保存
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入下载
1、问答链接示例:
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
知乎文章采集
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图


"文章采集软件"知乎问答,文章批处理采集软件
知乎文章采集
六、操作方法总结
1、先下载蓝琴云网盘的软件链接【蓝琴云链接:知乎文章采集软件】
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到刚刚下载的知乎文章。
注意:知乎文章的所有下载仅供自学使用,禁止直接或间接分发、使用、改编或再分发以用于分发或使用,或用于任何其他商业目的.
网页视频抓取工具 知乎(几款电脑端可以用来下载B站视频的工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-01-07 07:11
前几天有公众号的朋友说之前分享的B站下载工具大部分都报废了,所以今天给大家带来几款可以在电脑上下载B站视频的工具一边,希望能帮到你。
调低工具
网页版
在B站的视频链接bilibili后面加上jj就可以跳转到下载页面,但是这种方式从B站下载视频只能下载7天以上浏览量的视频。在很多情况下,这是不适用的,所以下面是大家介绍其客户端如何从B站下载视频。
客户端视频下载步骤
1、 去网页下载客户端,chirp down工具
2、安装时记得勾选图中两项,选择安装路径
3、将B站的视频链接粘贴到框中,按回车进入下载页面
4、选择批量下载方式下载视频
5、点击批量下载视频
6、下载界面
B站视频下载工具
工具下载方式
1、B站视频链接bilibili前面加i获取下载链接,B站视频下载工具链接进入下载
指示
1、安装后,将b站的视频链接复制到下方方框中
2、点击开始下载
注意:软件必须放置在没有中文字符和空格的路径中
B站视频下载的两个编辑器,个人测试用。如果你需要这两个工具,可以通过上面的链接下载,也可以在微信后台回复“A19”获取下载的两个编辑器。直播工具。
第一次发帖==,如果觉得不错,请点个赞。
公众号“大学生活必备”有更多提示和资源。你可以在微信上搜索我的公众号“大学生活的必需品”。 查看全部
网页视频抓取工具 知乎(几款电脑端可以用来下载B站视频的工具,你知道吗?)
前几天有公众号的朋友说之前分享的B站下载工具大部分都报废了,所以今天给大家带来几款可以在电脑上下载B站视频的工具一边,希望能帮到你。
调低工具
网页版
在B站的视频链接bilibili后面加上jj就可以跳转到下载页面,但是这种方式从B站下载视频只能下载7天以上浏览量的视频。在很多情况下,这是不适用的,所以下面是大家介绍其客户端如何从B站下载视频。

客户端视频下载步骤
1、 去网页下载客户端,chirp down工具
2、安装时记得勾选图中两项,选择安装路径
3、将B站的视频链接粘贴到框中,按回车进入下载页面
4、选择批量下载方式下载视频
5、点击批量下载视频
6、下载界面
B站视频下载工具
工具下载方式
1、B站视频链接bilibili前面加i获取下载链接,B站视频下载工具链接进入下载


指示
1、安装后,将b站的视频链接复制到下方方框中
2、点击开始下载
注意:软件必须放置在没有中文字符和空格的路径中
B站视频下载的两个编辑器,个人测试用。如果你需要这两个工具,可以通过上面的链接下载,也可以在微信后台回复“A19”获取下载的两个编辑器。直播工具。
第一次发帖==,如果觉得不错,请点个赞。
公众号“大学生活必备”有更多提示和资源。你可以在微信上搜索我的公众号“大学生活的必需品”。
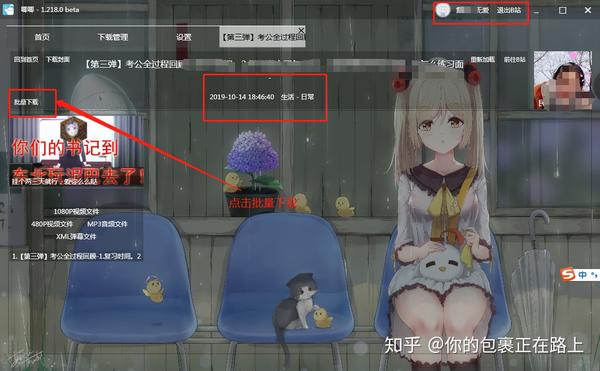
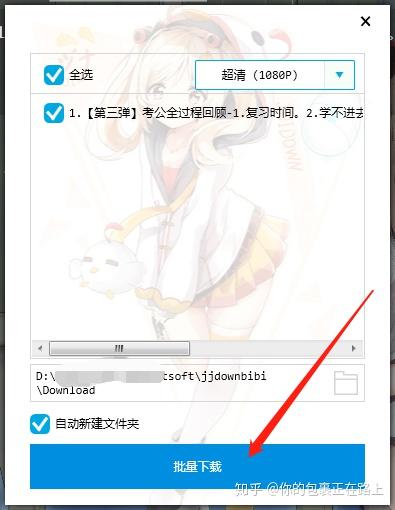
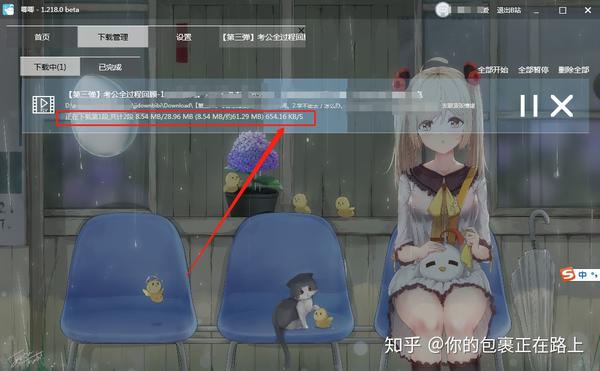
网页视频抓取工具 知乎( 2.-gtcraping的路径进行数据编号控制条数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-05 18:06
2.-gtcraping的路径进行数据编号控制条数)
这是简单数据分析系列文章的第十篇。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
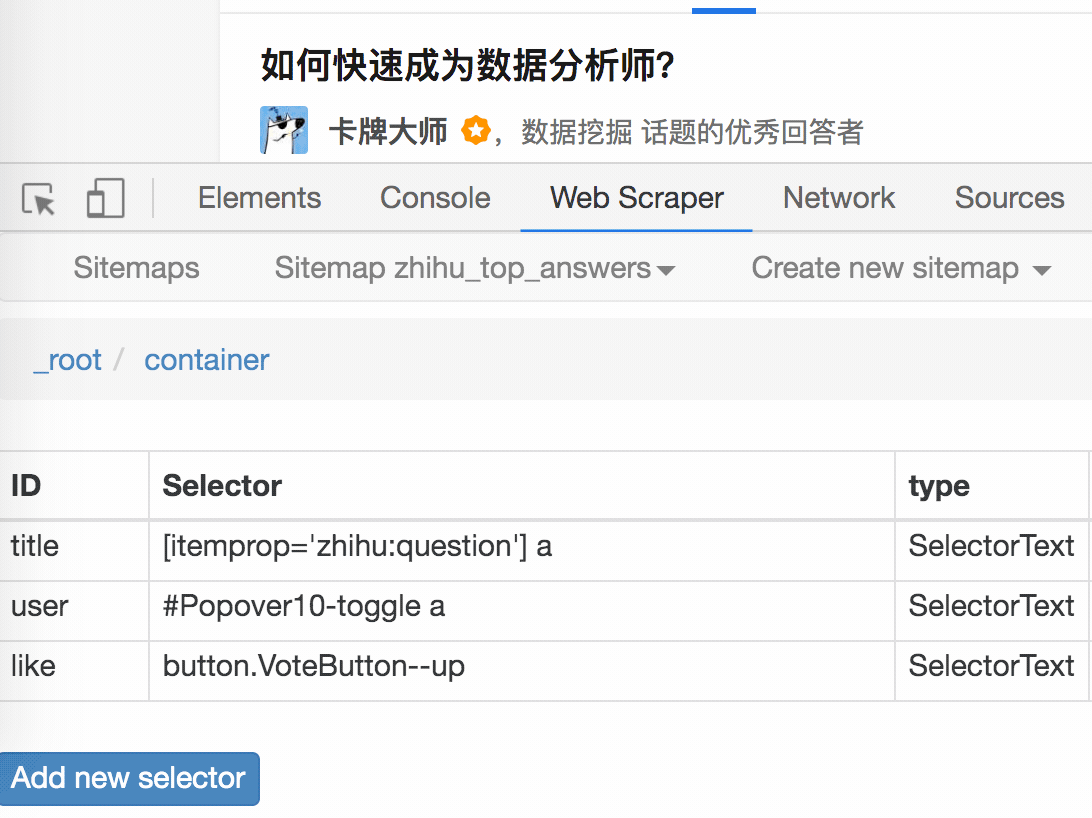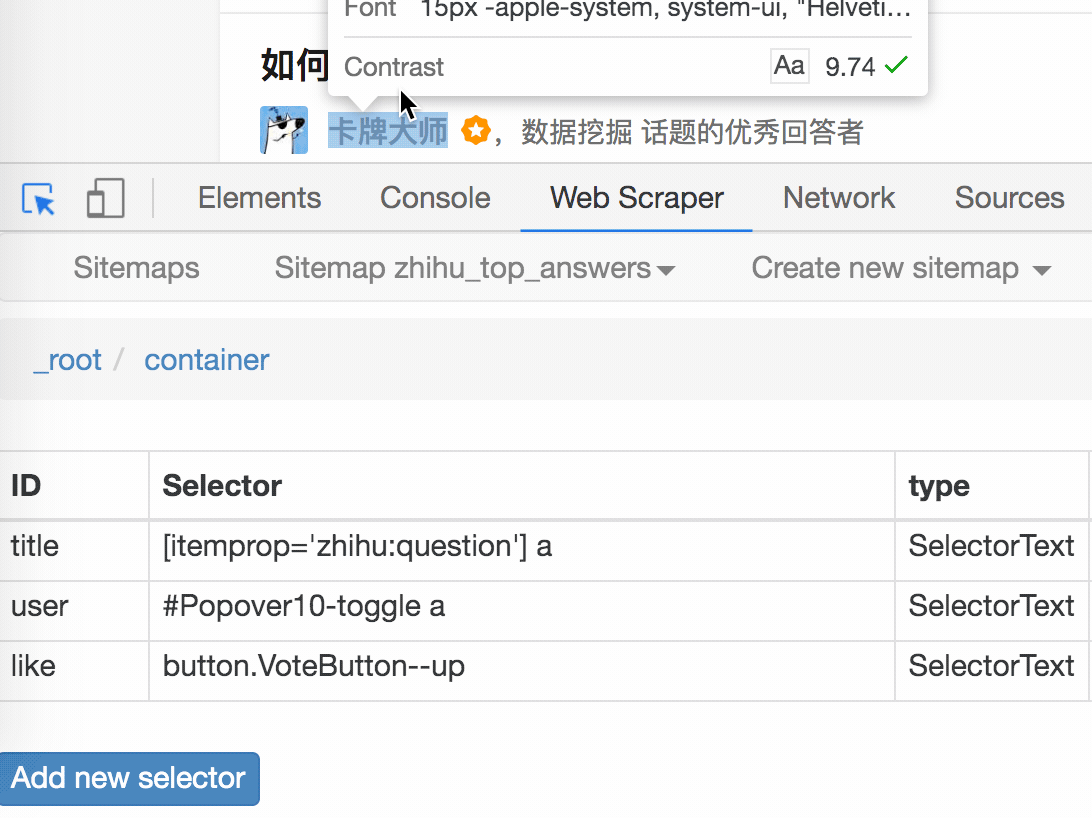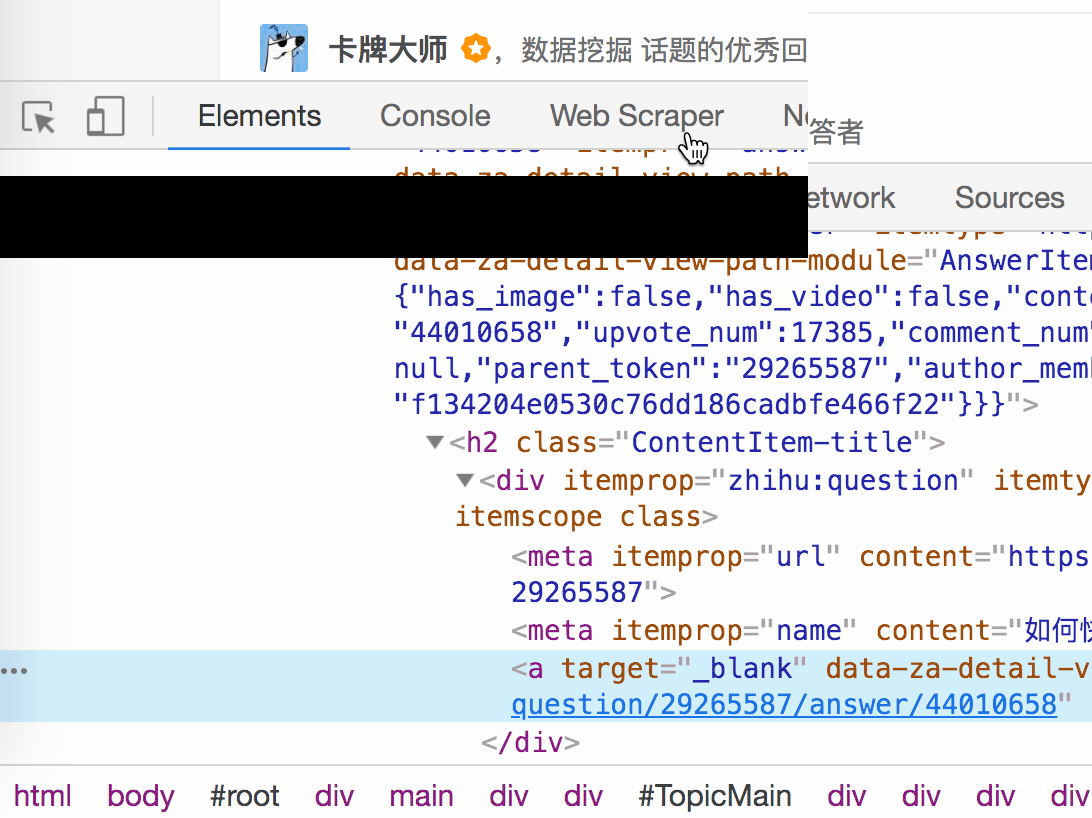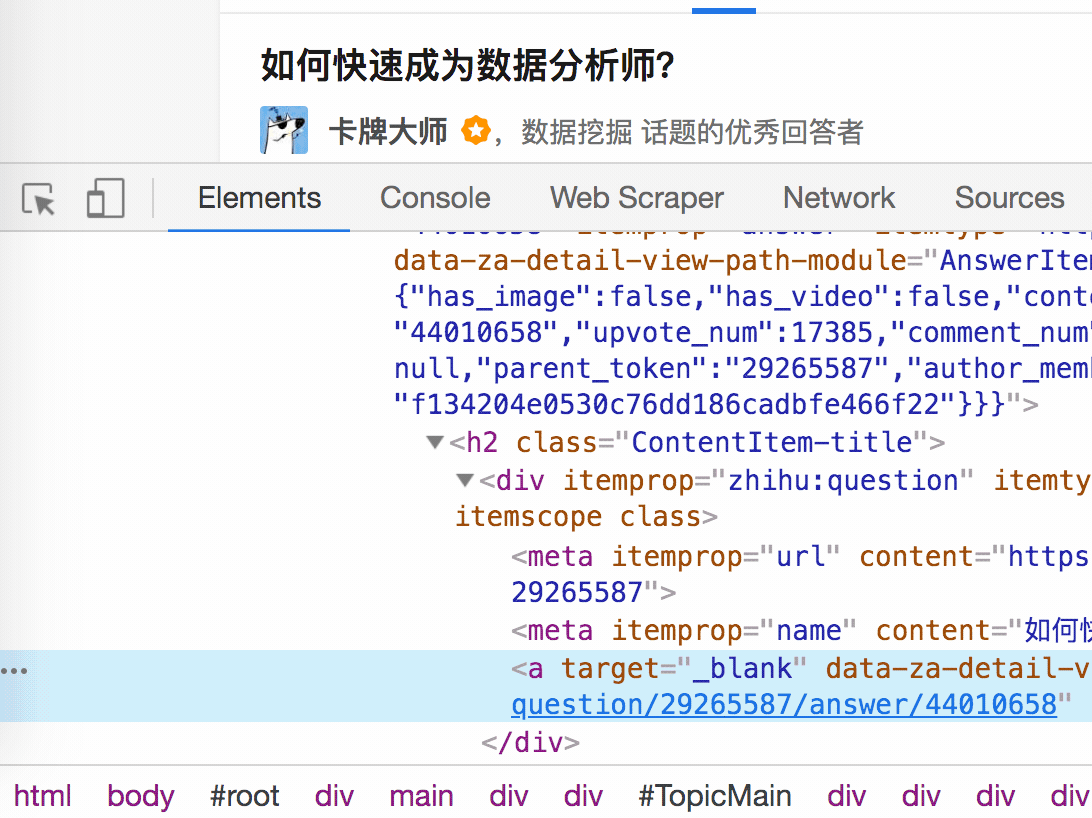
1.制作站点地图
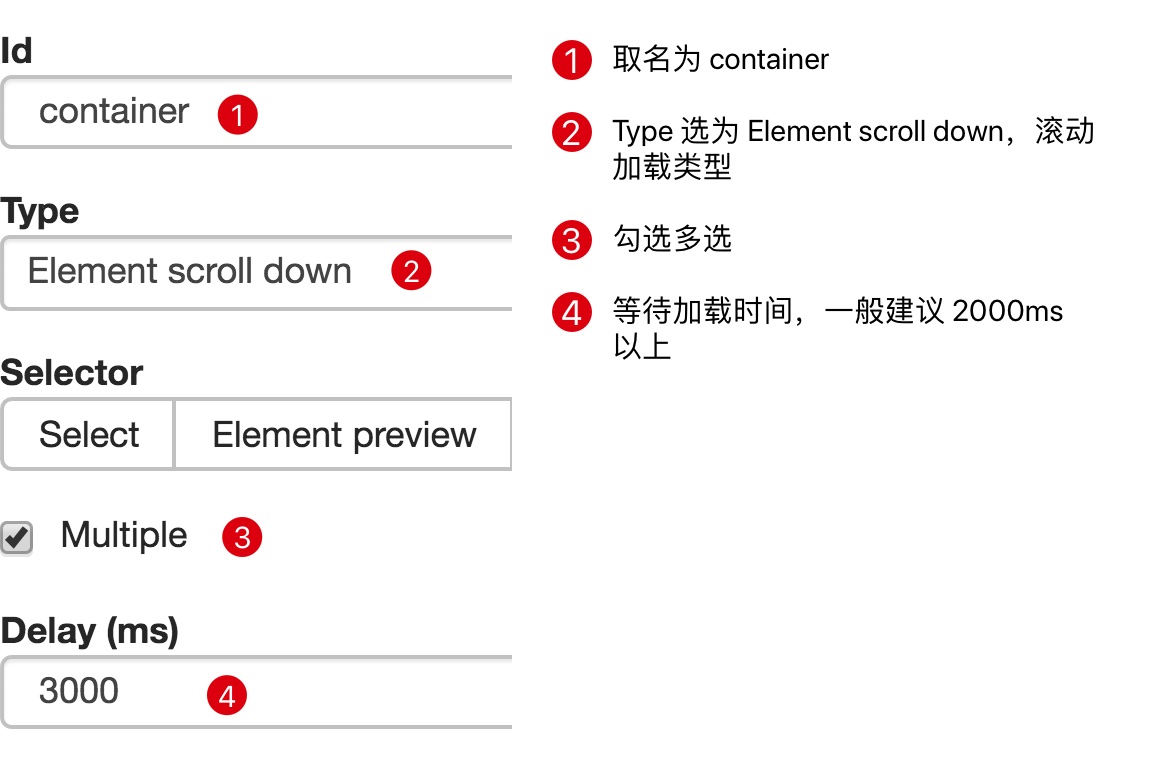
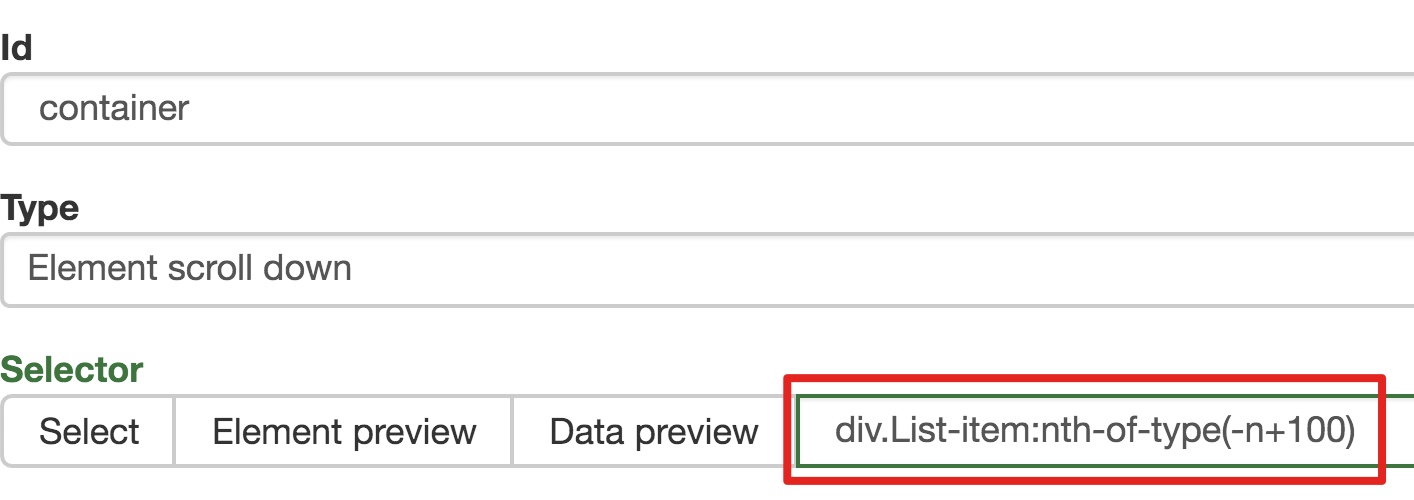
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
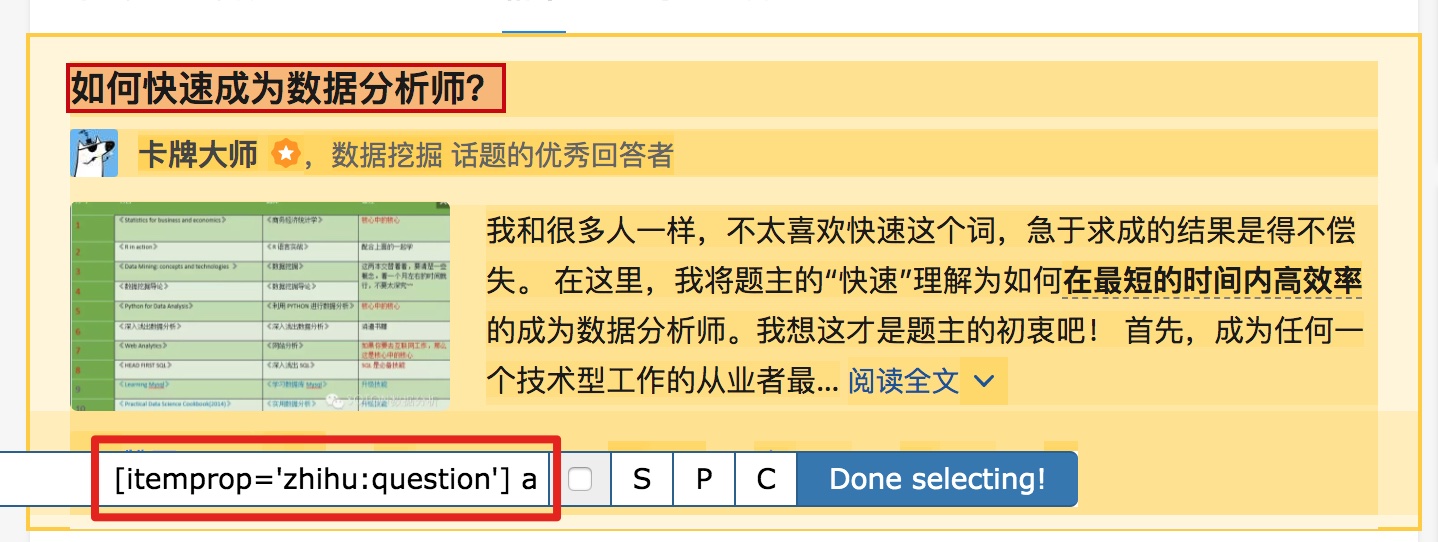
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
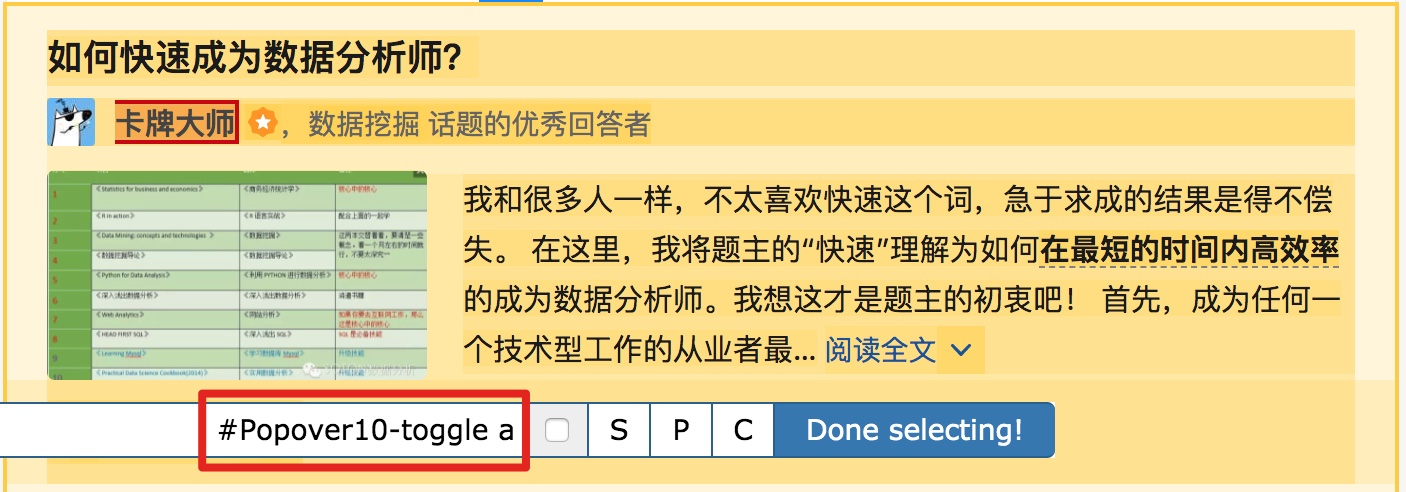
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
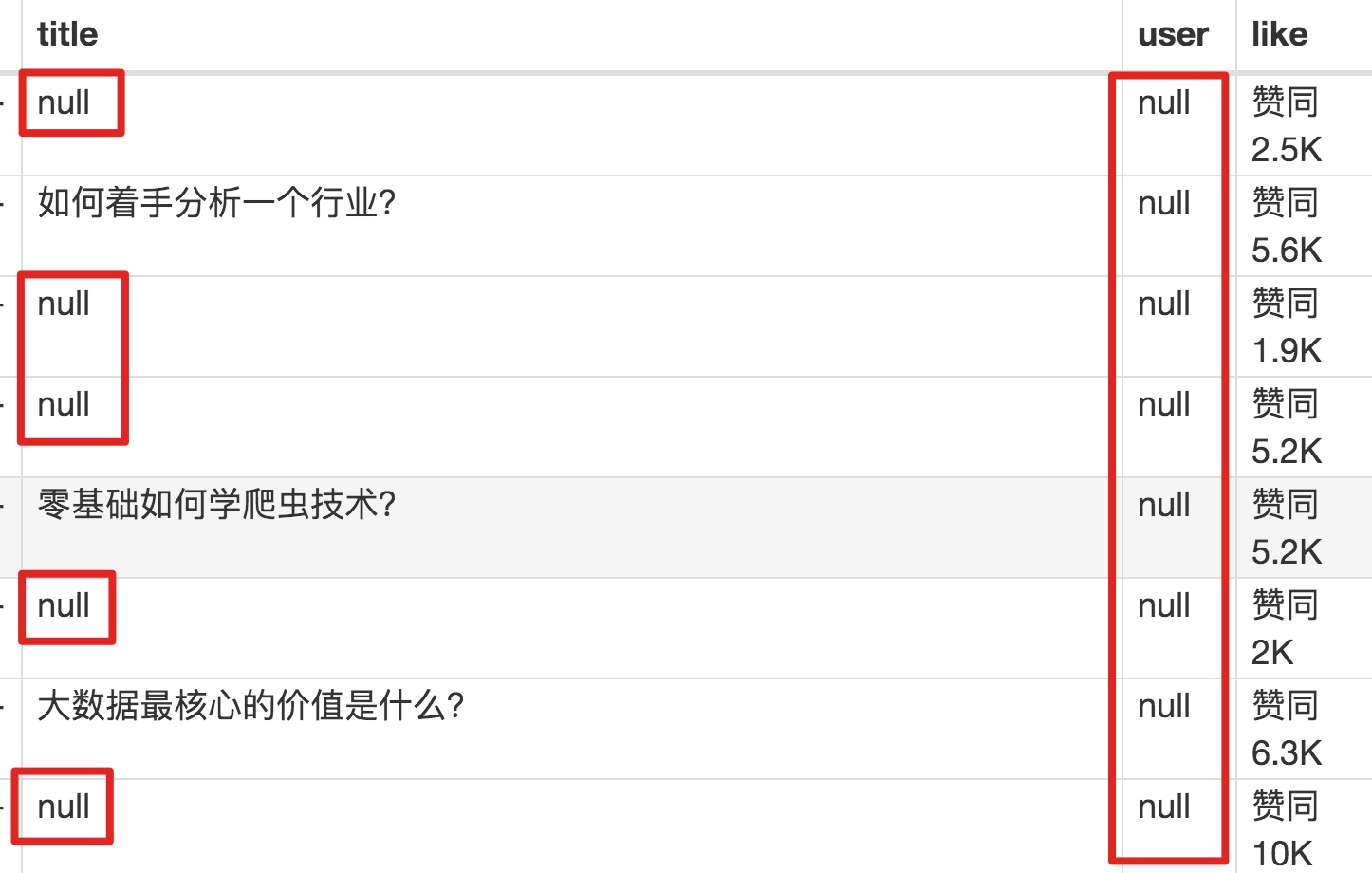
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
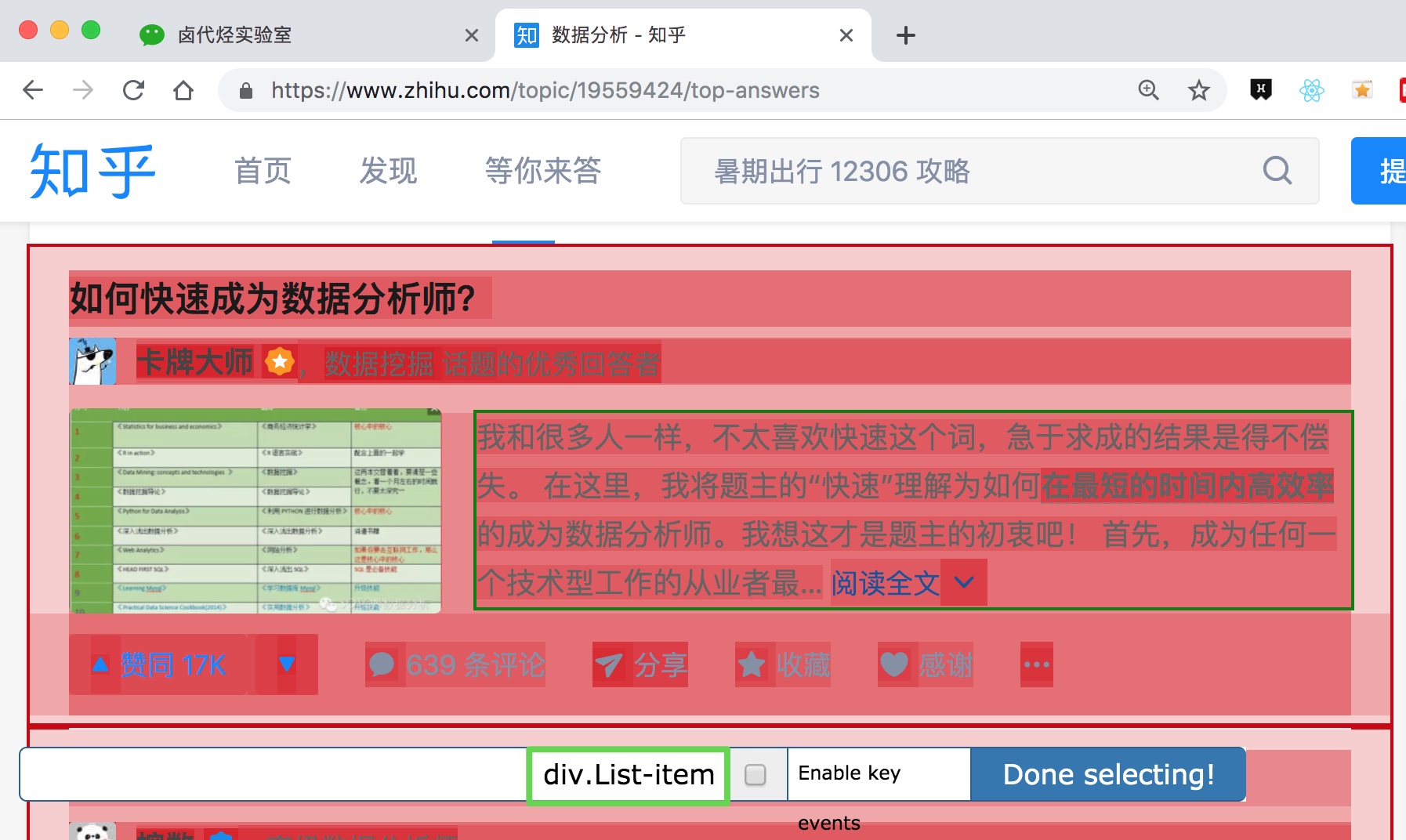
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,里面收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
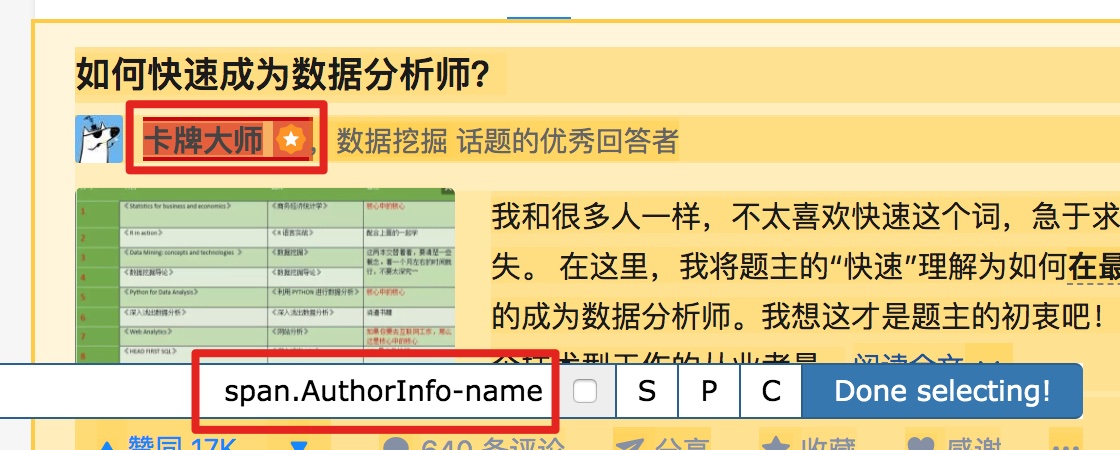
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页视频抓取工具 知乎(
2.-gtcraping的路径进行数据编号控制条数)

这是简单数据分析系列文章的第十篇。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。

今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:

2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,里面收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):

以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:

最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页视频抓取工具 知乎(一下反爬虫策略及其应对方法,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-05 18:05
随着大数据的普及,互联网上各种网络爬虫/爬虫工具蜂拥而至。因此,网络数据成为大家竞争和掠夺的资源,但网站运营商必须开始保护自己的数据资源。避免竞争对手获取您自己的数据,防止更大的业务损失。下面总结一下反爬虫策略及其对策。
来看看我用的代理IP。质量非常好。如果需要,您可以对其进行测试:
专属资源适合长期爬虫业务,IP并发量大,API调用频率不限,海量抽取,产品安全稳定,支持http、https、sk5三种协议,适合爬虫(舆论、e-电商、短视频)、抢购、seo等多种业务
个人电脑:
移动
一、什么是爬虫和反爬虫
一张图说明一切:
爬虫和反爬虫是致命的对手,无论爬虫多么强大,都可以通过复杂的反爬虫机制被发现。同样,无论爬行动物多么强大
系统多么细致,先进的网络爬虫都能破解。胜负的关键取决于双方投入了多少资源。为了更好的了解爬虫和反
爬虫机制,下面有一些定义:
爬虫:利用任何技术手段批量获取网站信息。关键是批量大小。
反爬虫:使用任何技术手段防止他人批量获取自己的网站信息。关键也是批次。
误伤:在反爬虫过程中,普通用户被误认为是爬虫。误伤率高的反爬虫策略再有效也无法使用。
拦截:成功阻止爬虫访问。会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,意外伤害的可能性就越大。所以有一个权衡。
因此,我们可以知道爬虫最基本的特性之一就是批处理,反爬虫机制也是根据这个特性做出判断的,但是反爬虫
仍然是权衡利弊的选择。它既要求低误伤率,又要求高拦截率。这也是它的漏洞。关于网站为什么以及如何制作
确定反爬虫策略,可以看反爬虫经验总结。
二、反爬虫方法及响应
一般来说,网站从三个方面进行反爬虫:请求网站访问时的header、用户行为、目标网站目录和数据加载方式。向前
两个方面可以说是反爬虫策略中最常见的,第三个是使用ajax(异步加载)来加载页面目录或内容。
增加爬虫在形成对目标网站的访问后获取数据的难度。
但是仅仅检查请求头或者做一些ip限制显然不能满足运营商对反垃圾邮件的要求,所以进一步的对策
也有很多付出。最重要的大概是:Cookie限制、验证码反爬虫、Noscript。
2.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。由于普通用户通过浏览器访问网站,目标网络
站点在收到请求时通常会检查Headers 中的User-Agent 字段。如果不是携带正常User-Agent信息的请求,则无法进行通信。
通过请求。还有一部分网站为了防止盗链,也会校验请求头中的Referer字段。如果遇到这种反爬虫机制,可以
为了直接给自己写的爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;此外,通过捕获请求
包分析,修改Referer值到目标网站域名,可以很好的绕过。
2.2 基于用户行为的反爬虫
有些网站会通过用户行为来检测网站的访问者是否是爬虫。例如,同一个IP在短时间内多次访问同一个页面,或者同一个
在短时间内对一个帐户执行多次相同的操作。大多数 网站 都是前一种情况。针对这种情况有两种策略:
1)使用代理ip。比如可以写一个专门的脚本去抓取网上可用的代理ip,然后将抓取到的代理ip维护到代理池中进行爬取
蠕虫使用,当然,其实不管抓到的ip是免费的还是付费的,平时的使用效果都是很一般的。如果您需要捕获高价值数据
如果愿意,也可以考虑购买宽带adsl拨号VPS。如果ip被目标网站屏蔽了,再拨一下就行了。
2) 降低请求频率。例如,每个时间段请求一次或多次请求后休眠一段时间。由于网站得到的ip是一个
局域网的ip,该ip是区域内所有人共享的,所以间隔不需要特别长
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。对于有逻辑漏洞的网站,可以请求多个
二、注销,重新登录,继续请求,绕过同一账号短时间内不能多次发出同一个请求的限制。如果有多个账户,
切换使用,效果更佳。
2.3 动态页面反爬虫
以上情况大部分出现在静态页面上,但是对于动态网页,我们需要爬取的数据是通过ajax请求获取的,或者通过
通过 JavaScript 生成。首先使用 Firebug 或 HttpFox 来分析网络请求。如果能找到ajax请求,也可以具体分析一下
参数和响应的具体含义,我们可以使用上面的方法,直接用requests或者urllib2来模拟ajax请求,响应json
执行分析以获得所需的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站加密了ajax请求的所有参数。我们什么也做不了
为您需要的数据构建一个请求。还有一些被严格保护的网站,除了对ajax参数进行加密外,还封装了一些基础功能,
都是在调用自己的接口,接口参数都是加密的。
遇到这样的网站,就不能用上面的方法了。使用selenium+phantomJS框架调用浏览器内核使用
phantomJS 执行 js 来模拟人工操作并触发页面中的 js 脚本。从填表到点击按钮到滚动页面,一切都可以建模
计划是,不管具体的请求和响应过程,只是完全模拟人们浏览页面获取数据的过程。使用这个框架几乎环绕
大多数反爬虫,因为它不是冒充浏览器获取数据(上面提到的通过添加
headers 是在一定程度上伪装成浏览器),它本身就是一个浏览器,phantomJS 是一个没有界面的浏览器,只有
控制这个浏览器的不是人。
2.4 Cookie 限制
类似于Headers验证的反爬虫机制,当用户向目标网站发送请求时,请求数据会再次携带Cookie,网站会通过验证
请求信息中是否有cookie,通过cookie的值判断请求是真实用户还是爬虫,第一次打开
该网页将生成一个随机 cookie。如果再次打开网页时cookie不存在,您可以重新设置。第三次打开它,它仍然不存在。
爬虫很可能正在工作。
Cookie Check 和 Headers 的区别在于用户发送的 Headers 的内容格式是固定的,很容易被伪造。饼干不是。
当然。原因是我们在分析浏览器请求网站访问的过程中分析的cookies,往往是通过相关的js等进程处理的。
如果更改了域的cookie,如果直接手动修改爬虫携带的cookie来访问相应的网页,则携带的cookie已经是访问者。
在询问域之后,而不是访问之前的域,是不可能成功模拟整个过程的。这种情况必然会导致爬虫访问页面
失败。分析cookies,它可能携带大量随机hash字符串,或者不同时间戳的字符串,并且会根据每次访问进行更新。
新域名的价值。对于这个限制,你必须在捕获和分析目标网站时先清除浏览器的cookies,然后在第一次访问
在完成访问的过程中观察浏览器的请求细节(这个过程中通常会发生几次301/302跳转,每次跳转网站返回
向浏览器返回不同的cookie,最后跳转请求成功)。抓包完成对请求细节的分析后,对爬虫进行建模
规划好这个过渡过程,然后将cookie作为爬虫本身携带的cookie进行拦截,这样就可以绕过cookie的限制完成目标网站
参观过。
2.5 验证码限制
这是一个相当古老但有效的反爬虫策略。早些时候,这种验证码可以通过OCR技术进行简单的图像识别。
不要破解,但目前验证码的干扰线噪声太大,肉眼无法轻易识别。所以现在,由于 OCR
在技术发展薄弱的情况下,验证码技术已经成为许多网站最有效的方法之一。
除了识别问题,验证码还有一个值得注意的问题。许多网站现在都在使用第三方验证码服务。当用户点击
打开目标网站的登录页面时,登录页面显示的验证码是从第三方(如阿里云)提供的链接中加载的。此时,我们正在模拟
登录时,您需要多一步从网页提供的第三方链接中获取验证码,而这一步往往意味着一个陷阱。由阿里云提供
以验证码服务为例,登录页面的源码中会显示阿里云提供的第三方链接,但是匹配到这个链接就可以抓取验证码了
稍后我们会发现验证码无效。仔细分析抓包的请求数据,发现普通浏览器在请求验证码时会带一个额外的ts。
参数,该参数是由当前时间戳生成的,但它不是完整的时间戳,而是将时间戳四舍五入保留字后九位
Fustring,对付这种第三方服务只能小心翼翼,运气好,三分之一的日子注定是猜不透的。还有一种特殊的第三方检验
证书代码,也就是所谓的拖拽验证,只能说互联网创业有3种模式:2b、2c、2vc。 查看全部
网页视频抓取工具 知乎(一下反爬虫策略及其应对方法,你值得拥有!!)
随着大数据的普及,互联网上各种网络爬虫/爬虫工具蜂拥而至。因此,网络数据成为大家竞争和掠夺的资源,但网站运营商必须开始保护自己的数据资源。避免竞争对手获取您自己的数据,防止更大的业务损失。下面总结一下反爬虫策略及其对策。
来看看我用的代理IP。质量非常好。如果需要,您可以对其进行测试:
专属资源适合长期爬虫业务,IP并发量大,API调用频率不限,海量抽取,产品安全稳定,支持http、https、sk5三种协议,适合爬虫(舆论、e-电商、短视频)、抢购、seo等多种业务
个人电脑:
移动
一、什么是爬虫和反爬虫
一张图说明一切:
爬虫和反爬虫是致命的对手,无论爬虫多么强大,都可以通过复杂的反爬虫机制被发现。同样,无论爬行动物多么强大
系统多么细致,先进的网络爬虫都能破解。胜负的关键取决于双方投入了多少资源。为了更好的了解爬虫和反
爬虫机制,下面有一些定义:
爬虫:利用任何技术手段批量获取网站信息。关键是批量大小。
反爬虫:使用任何技术手段防止他人批量获取自己的网站信息。关键也是批次。
误伤:在反爬虫过程中,普通用户被误认为是爬虫。误伤率高的反爬虫策略再有效也无法使用。
拦截:成功阻止爬虫访问。会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,意外伤害的可能性就越大。所以有一个权衡。
因此,我们可以知道爬虫最基本的特性之一就是批处理,反爬虫机制也是根据这个特性做出判断的,但是反爬虫
仍然是权衡利弊的选择。它既要求低误伤率,又要求高拦截率。这也是它的漏洞。关于网站为什么以及如何制作
确定反爬虫策略,可以看反爬虫经验总结。

二、反爬虫方法及响应
一般来说,网站从三个方面进行反爬虫:请求网站访问时的header、用户行为、目标网站目录和数据加载方式。向前
两个方面可以说是反爬虫策略中最常见的,第三个是使用ajax(异步加载)来加载页面目录或内容。
增加爬虫在形成对目标网站的访问后获取数据的难度。
但是仅仅检查请求头或者做一些ip限制显然不能满足运营商对反垃圾邮件的要求,所以进一步的对策
也有很多付出。最重要的大概是:Cookie限制、验证码反爬虫、Noscript。
2.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。由于普通用户通过浏览器访问网站,目标网络
站点在收到请求时通常会检查Headers 中的User-Agent 字段。如果不是携带正常User-Agent信息的请求,则无法进行通信。
通过请求。还有一部分网站为了防止盗链,也会校验请求头中的Referer字段。如果遇到这种反爬虫机制,可以
为了直接给自己写的爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;此外,通过捕获请求
包分析,修改Referer值到目标网站域名,可以很好的绕过。
2.2 基于用户行为的反爬虫
有些网站会通过用户行为来检测网站的访问者是否是爬虫。例如,同一个IP在短时间内多次访问同一个页面,或者同一个
在短时间内对一个帐户执行多次相同的操作。大多数 网站 都是前一种情况。针对这种情况有两种策略:
1)使用代理ip。比如可以写一个专门的脚本去抓取网上可用的代理ip,然后将抓取到的代理ip维护到代理池中进行爬取
蠕虫使用,当然,其实不管抓到的ip是免费的还是付费的,平时的使用效果都是很一般的。如果您需要捕获高价值数据
如果愿意,也可以考虑购买宽带adsl拨号VPS。如果ip被目标网站屏蔽了,再拨一下就行了。
2) 降低请求频率。例如,每个时间段请求一次或多次请求后休眠一段时间。由于网站得到的ip是一个
局域网的ip,该ip是区域内所有人共享的,所以间隔不需要特别长
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。对于有逻辑漏洞的网站,可以请求多个
二、注销,重新登录,继续请求,绕过同一账号短时间内不能多次发出同一个请求的限制。如果有多个账户,
切换使用,效果更佳。
2.3 动态页面反爬虫
以上情况大部分出现在静态页面上,但是对于动态网页,我们需要爬取的数据是通过ajax请求获取的,或者通过
通过 JavaScript 生成。首先使用 Firebug 或 HttpFox 来分析网络请求。如果能找到ajax请求,也可以具体分析一下
参数和响应的具体含义,我们可以使用上面的方法,直接用requests或者urllib2来模拟ajax请求,响应json
执行分析以获得所需的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站加密了ajax请求的所有参数。我们什么也做不了
为您需要的数据构建一个请求。还有一些被严格保护的网站,除了对ajax参数进行加密外,还封装了一些基础功能,
都是在调用自己的接口,接口参数都是加密的。
遇到这样的网站,就不能用上面的方法了。使用selenium+phantomJS框架调用浏览器内核使用
phantomJS 执行 js 来模拟人工操作并触发页面中的 js 脚本。从填表到点击按钮到滚动页面,一切都可以建模
计划是,不管具体的请求和响应过程,只是完全模拟人们浏览页面获取数据的过程。使用这个框架几乎环绕
大多数反爬虫,因为它不是冒充浏览器获取数据(上面提到的通过添加
headers 是在一定程度上伪装成浏览器),它本身就是一个浏览器,phantomJS 是一个没有界面的浏览器,只有
控制这个浏览器的不是人。

2.4 Cookie 限制
类似于Headers验证的反爬虫机制,当用户向目标网站发送请求时,请求数据会再次携带Cookie,网站会通过验证
请求信息中是否有cookie,通过cookie的值判断请求是真实用户还是爬虫,第一次打开
该网页将生成一个随机 cookie。如果再次打开网页时cookie不存在,您可以重新设置。第三次打开它,它仍然不存在。
爬虫很可能正在工作。
Cookie Check 和 Headers 的区别在于用户发送的 Headers 的内容格式是固定的,很容易被伪造。饼干不是。
当然。原因是我们在分析浏览器请求网站访问的过程中分析的cookies,往往是通过相关的js等进程处理的。
如果更改了域的cookie,如果直接手动修改爬虫携带的cookie来访问相应的网页,则携带的cookie已经是访问者。
在询问域之后,而不是访问之前的域,是不可能成功模拟整个过程的。这种情况必然会导致爬虫访问页面
失败。分析cookies,它可能携带大量随机hash字符串,或者不同时间戳的字符串,并且会根据每次访问进行更新。
新域名的价值。对于这个限制,你必须在捕获和分析目标网站时先清除浏览器的cookies,然后在第一次访问
在完成访问的过程中观察浏览器的请求细节(这个过程中通常会发生几次301/302跳转,每次跳转网站返回
向浏览器返回不同的cookie,最后跳转请求成功)。抓包完成对请求细节的分析后,对爬虫进行建模
规划好这个过渡过程,然后将cookie作为爬虫本身携带的cookie进行拦截,这样就可以绕过cookie的限制完成目标网站
参观过。
2.5 验证码限制
这是一个相当古老但有效的反爬虫策略。早些时候,这种验证码可以通过OCR技术进行简单的图像识别。
不要破解,但目前验证码的干扰线噪声太大,肉眼无法轻易识别。所以现在,由于 OCR
在技术发展薄弱的情况下,验证码技术已经成为许多网站最有效的方法之一。
除了识别问题,验证码还有一个值得注意的问题。许多网站现在都在使用第三方验证码服务。当用户点击
打开目标网站的登录页面时,登录页面显示的验证码是从第三方(如阿里云)提供的链接中加载的。此时,我们正在模拟
登录时,您需要多一步从网页提供的第三方链接中获取验证码,而这一步往往意味着一个陷阱。由阿里云提供
以验证码服务为例,登录页面的源码中会显示阿里云提供的第三方链接,但是匹配到这个链接就可以抓取验证码了
稍后我们会发现验证码无效。仔细分析抓包的请求数据,发现普通浏览器在请求验证码时会带一个额外的ts。
参数,该参数是由当前时间戳生成的,但它不是完整的时间戳,而是将时间戳四舍五入保留字后九位
Fustring,对付这种第三方服务只能小心翼翼,运气好,三分之一的日子注定是猜不透的。还有一种特殊的第三方检验
证书代码,也就是所谓的拖拽验证,只能说互联网创业有3种模式:2b、2c、2vc。
网页视频抓取工具 知乎(代码知道整个流程是什么样子,接下来撸代码的过程就简单了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-05 18:04
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
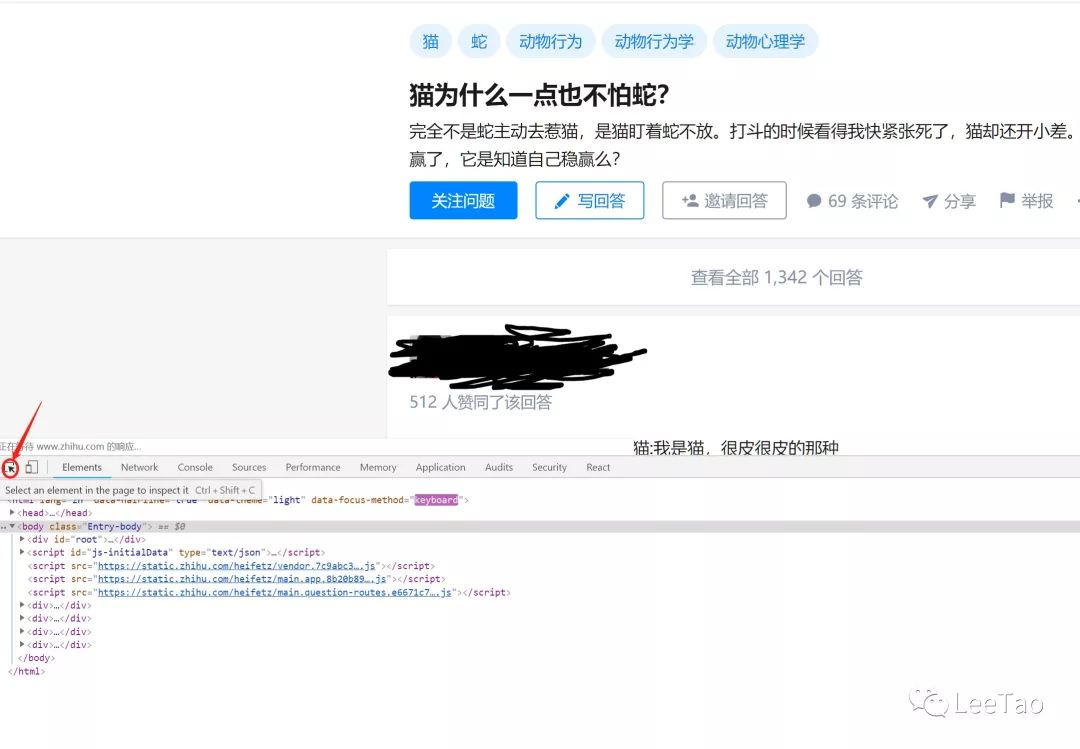
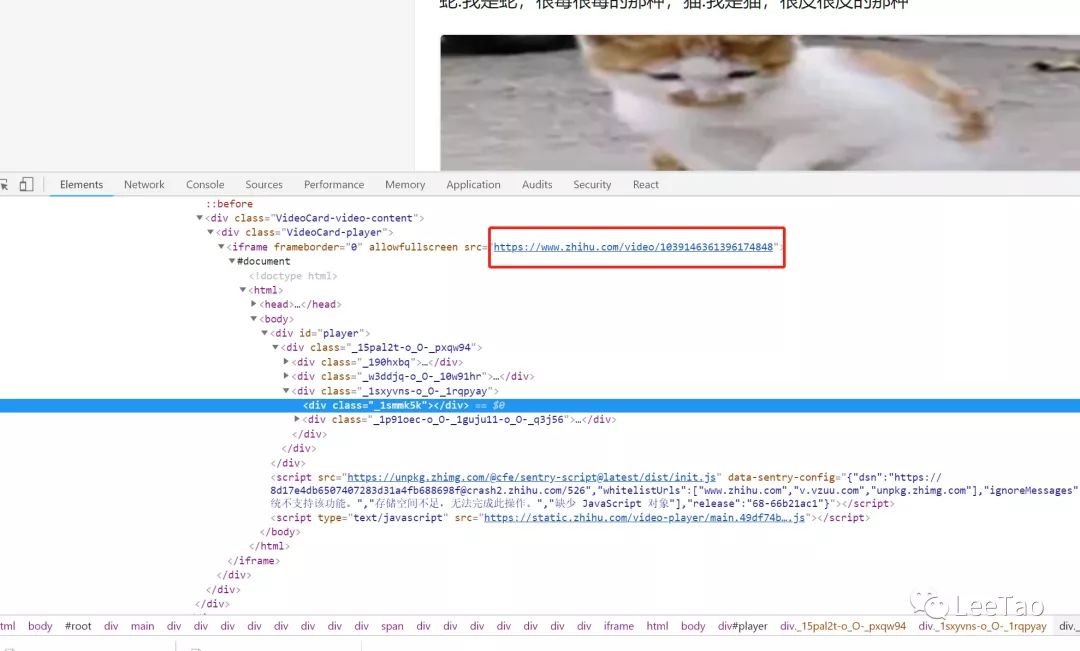
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
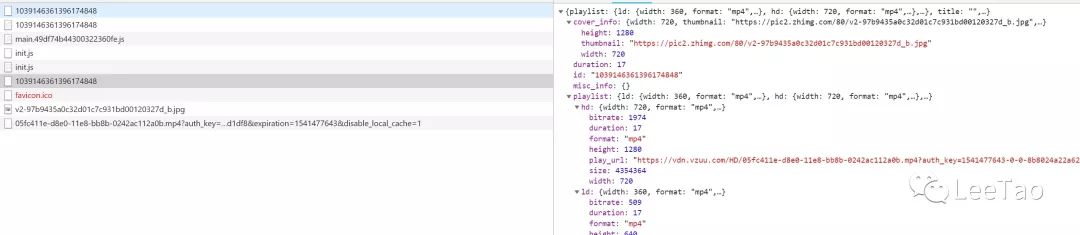
看来这就是我们要找的视频了,别着急,我们先看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
<p>{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
</p>
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
<p># -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
</p>
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。点击查看原文查看源码
本文分享自微信公众号——桃子的学习笔记(LeeTaoThinks)。 查看全部
网页视频抓取工具 知乎(代码知道整个流程是什么样子,接下来撸代码的过程就简单了)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
<p>{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
</p>
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
<p># -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
</p>
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。点击查看原文查看源码
本文分享自微信公众号——桃子的学习笔记(LeeTaoThinks)。
网页视频抓取工具 知乎(微信公众号插入了自制的有趣视频链接地址的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-04 20:06
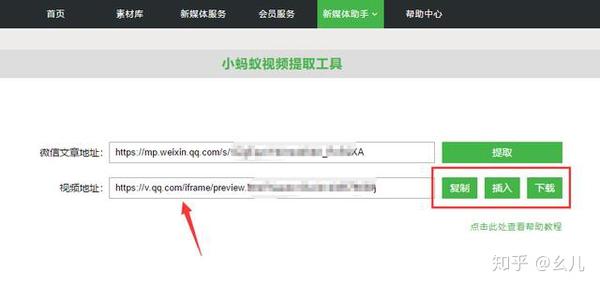
我们的大部分编辑现在都面临着一个严重的问题,那就是用户对文章的内容越来越挑剔。为此,不少公众号都在微信图文中插入自制搞笑视频。那么当我们想借用别人的视频到自己的公众号时该怎么办呢?我们在小蚂蚁编辑器中找到了这个问题的答案。
第一步,打开首页,点击新媒体助手下的视频提取。
第二步,复制要提取的视频的微信图片和文字链接地址。
第三步:将上一步复制的地址填入“微信文章地址”框中,点击“提取”按钮。(微信文章必须以/s?src=开头。)
第四步:文章中的所有视频可以同时提取链接。您可以单击右侧的复制、插入和下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入到编辑器中,也可以直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入编辑区。(如果是提取微信公众号本地上传的视频,则无法复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频不存在”)。
下载:点击下载将视频下载到本地,可在微信公众平台后台素材库上传使用(适用于公众号本地上传的视频)。
这样我们就可以自由的提取我们想要的视频了,而且操作简单方便,节省了时间,省去了很多繁琐的步骤,同时也将文章内容的丰富度提升到了一个层次。 查看全部
网页视频抓取工具 知乎(微信公众号插入了自制的有趣视频链接地址的方法)
我们的大部分编辑现在都面临着一个严重的问题,那就是用户对文章的内容越来越挑剔。为此,不少公众号都在微信图文中插入自制搞笑视频。那么当我们想借用别人的视频到自己的公众号时该怎么办呢?我们在小蚂蚁编辑器中找到了这个问题的答案。
第一步,打开首页,点击新媒体助手下的视频提取。
第二步,复制要提取的视频的微信图片和文字链接地址。
第三步:将上一步复制的地址填入“微信文章地址”框中,点击“提取”按钮。(微信文章必须以/s?src=开头。)
第四步:文章中的所有视频可以同时提取链接。您可以单击右侧的复制、插入和下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入到编辑器中,也可以直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入编辑区。(如果是提取微信公众号本地上传的视频,则无法复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频不存在”)。
下载:点击下载将视频下载到本地,可在微信公众平台后台素材库上传使用(适用于公众号本地上传的视频)。
这样我们就可以自由的提取我们想要的视频了,而且操作简单方便,节省了时间,省去了很多繁琐的步骤,同时也将文章内容的丰富度提升到了一个层次。
网页视频抓取工具 知乎(微信小程序视频抓取器的操作方法就非常简单了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-01-30 04:01
网页视频抓取工具知乎专栏在重庆市网络与新媒体局登录编辑后,操作方法就非常简单了。
谢邀。微信小程序视频抓取app,是一款非常实用的微信小程序视频抓取器,基于微信公众号等原生的内容抓取方式。打开微信---我钱包---支付---银行卡---支付宝,搜索“微信小程序视频抓取器”,然后根据需要选择相应的关键词,可以进行小程序的搜索。在“微信小程序视频抓取器”中,可以从以下五个方面开始对视频进行抓取,分别是:来源、制作开发、频道类型、内容类型、工具库。
第一步:来源。微信小程序视频抓取器目前还支持动图进行抓取、网址直达视频。视频来源是衡量一个视频抓取器质量的关键因素,如果一个视频抓取器连视频来源都不支持且无法识别的话,那么你肯定用不了它。第二步:制作开发。视频制作开发完全掌握视频抓取器是一项非常重要的工作。目前微信小程序视频抓取器只支持小程序端的制作开发,如果需要企业级别的视频抓取,我们会提供企业开发包,点击查看即可。
第三步:频道类型。相比较于图文内容,视频的抓取类型更多样。基于微信体系,目前在微信小程序端,包括音乐、文本内容、图片、链接、网址等视频类型。但是目前微信小程序抓取器只支持音乐和图片类视频,网址也只能抓取网址,无法抓取视频源地址。第四步:内容类型。相比较普通的音频,视频内容的抓取类型也更多样。包括不同的内容进行分类并进行网址内容抓取,例如:播放页面、画中画播放页面、直播、在线广告等等。
第五步:工具库。包括:视频识别工具、视频转码工具、视频自动编码工具、视频压缩工具、视频去水印工具、封面识别工具、视频合成工具、视频去水印工具等等。总结下来,如果想要做微信小程序视频抓取器的话,首先需要一个开发工具,其次是制作开发工具,最后才是抓取视频。 查看全部
网页视频抓取工具 知乎(微信小程序视频抓取器的操作方法就非常简单了)
网页视频抓取工具知乎专栏在重庆市网络与新媒体局登录编辑后,操作方法就非常简单了。
谢邀。微信小程序视频抓取app,是一款非常实用的微信小程序视频抓取器,基于微信公众号等原生的内容抓取方式。打开微信---我钱包---支付---银行卡---支付宝,搜索“微信小程序视频抓取器”,然后根据需要选择相应的关键词,可以进行小程序的搜索。在“微信小程序视频抓取器”中,可以从以下五个方面开始对视频进行抓取,分别是:来源、制作开发、频道类型、内容类型、工具库。
第一步:来源。微信小程序视频抓取器目前还支持动图进行抓取、网址直达视频。视频来源是衡量一个视频抓取器质量的关键因素,如果一个视频抓取器连视频来源都不支持且无法识别的话,那么你肯定用不了它。第二步:制作开发。视频制作开发完全掌握视频抓取器是一项非常重要的工作。目前微信小程序视频抓取器只支持小程序端的制作开发,如果需要企业级别的视频抓取,我们会提供企业开发包,点击查看即可。
第三步:频道类型。相比较于图文内容,视频的抓取类型更多样。基于微信体系,目前在微信小程序端,包括音乐、文本内容、图片、链接、网址等视频类型。但是目前微信小程序抓取器只支持音乐和图片类视频,网址也只能抓取网址,无法抓取视频源地址。第四步:内容类型。相比较普通的音频,视频内容的抓取类型也更多样。包括不同的内容进行分类并进行网址内容抓取,例如:播放页面、画中画播放页面、直播、在线广告等等。
第五步:工具库。包括:视频识别工具、视频转码工具、视频自动编码工具、视频压缩工具、视频去水印工具、封面识别工具、视频合成工具、视频去水印工具等等。总结下来,如果想要做微信小程序视频抓取器的话,首先需要一个开发工具,其次是制作开发工具,最后才是抓取视频。
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件的使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-01-29 17:08
)
zh-downloader(知乎视频嗅探下载插件)是一款优秀易用的知乎视频下载助手。如果你需要一个好用的视频下载器,不妨试试小编带来的这款zh-downloader插件。它功能强大且易于操作。使用后,可以帮助用户更轻松便捷地下载知乎视频。该插件可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。欢迎有需要的朋友下载使用。
指示:
1、打开任意一个有视频的知乎页面,插件会自动嗅探是否有资源,嗅探到的视频数量会以角标的形式出现在图标上。
2、此时点击工具栏上的插件图标,可以看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
发展背景:
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已经成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎视频呢?
4、可能有朋友发现,传统的视频下载谷歌插件如VideoDownloader Professional、Maozha有时无法嗅探知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
查看全部
网页视频抓取工具 知乎(要如何下载知乎视频呢?-downloader插件的使用方法
)
zh-downloader(知乎视频嗅探下载插件)是一款优秀易用的知乎视频下载助手。如果你需要一个好用的视频下载器,不妨试试小编带来的这款zh-downloader插件。它功能强大且易于操作。使用后,可以帮助用户更轻松便捷地下载知乎视频。该插件可以帮助用户轻松下载知乎中的各种视频,为知乎视频下载提供帮助。软件支持在知乎页面下载视频和图片文件,并转换成MP4格式,满足用户各种知乎视频下载需求。欢迎有需要的朋友下载使用。
指示:
1、打开任意一个有视频的知乎页面,插件会自动嗅探是否有资源,嗅探到的视频数量会以角标的形式出现在图标上。
2、此时点击工具栏上的插件图标,可以看到下载菜单窗口。
3、相比Video Downloader专业版,zh-downloader嗅探到的视频资源会显示标题和缩略图,非常直观。
4、同时可以直接选择下载视频的分辨率,查看下载进度,分享和删除操作。
发展背景:
1、“知乎”,古文的意思是“你知道吗”。2011年,名为知乎的问答型网站在中国正式上线,其产品对标美国Quora同类型网站。
2、时至今日,知乎已经成为国内最活跃的社区论坛之一,其意义不仅收录在专业知识问答中,还涵盖了各行各业的方方面面。
3、当然,有时候用户会在知乎上分享一些有趣的视频,那么如何下载知乎视频呢?
4、可能有朋友发现,传统的视频下载谷歌插件如VideoDownloader Professional、Maozha有时无法嗅探知乎页面的视频。
5、另一方面,即使你在知乎上下载视频,也会发现大部分都是m3u8格式,不利于分享和本地观看。
网页视频抓取工具 知乎(利用知乎爬虫软件,经过Python爬取知乎,可以用Python爬虫知乎数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-28 03:09
使用知乎爬虫软件和在Python中爬取知乎,可以使用Python爬虫爬取知乎数据,现推荐一款好用的任意网站数据抓取软件,使用< @知乎热评爬虫和知乎爬取工具,可以抓取知乎热评的相关内容。最热软件站提供知乎热评爬虫下载地址,需要Python爬取知乎热评软件的朋友,快来下载试用吧。
知乎热评爬虫介绍
知乎热评爬虫是一款知乎爬虫软件,可以帮助用户获取与知乎热评相关的数据内容。该软件体积小。作为一款绿色免安装软件,无需安装即可直接使用。对于喜欢看知乎热评的人来说,这个非常方便,可以快速获取知乎热评信息。
知乎关于如何使用爬虫的热评
1.下载解压后双击使用本软件,可以获得知乎时事,下载时事问题和链接,下载每个时事下的答案,下载评论在答案下。
2.首先登录你的知乎,按F12获取COOKIES,复制到软件顶部输入栏,复制点击获取当前热点列表获取当前热点讨论.
3.选择要下载的标题,点击下载并保存,保存格式为exsel。该软件可以帮助用户下载每个热评下的知乎热议和热评软件。通过知乎热评数据采集软件,不用打开知乎就可以知道时事。事物。
4.对于一些自媒体热爱学习的人和朋友来说,这个软件非常强大。使用知乎热评数据采集软件,用户无需到处搜索。材料。
小编推荐
以上就是知乎热评爬虫免费版的全部介绍。最热的软件站还有更多类似的爬虫爬取软件。需要的朋友快来下载体验吧。我将在下面推荐另外两个易于使用的软件。爬虫软件:小说爬虫、图片爬虫(抓取下载网站图片)。 查看全部
网页视频抓取工具 知乎(利用知乎爬虫软件,经过Python爬取知乎,可以用Python爬虫知乎数据)
使用知乎爬虫软件和在Python中爬取知乎,可以使用Python爬虫爬取知乎数据,现推荐一款好用的任意网站数据抓取软件,使用< @知乎热评爬虫和知乎爬取工具,可以抓取知乎热评的相关内容。最热软件站提供知乎热评爬虫下载地址,需要Python爬取知乎热评软件的朋友,快来下载试用吧。
知乎热评爬虫介绍
知乎热评爬虫是一款知乎爬虫软件,可以帮助用户获取与知乎热评相关的数据内容。该软件体积小。作为一款绿色免安装软件,无需安装即可直接使用。对于喜欢看知乎热评的人来说,这个非常方便,可以快速获取知乎热评信息。
知乎关于如何使用爬虫的热评
1.下载解压后双击使用本软件,可以获得知乎时事,下载时事问题和链接,下载每个时事下的答案,下载评论在答案下。
2.首先登录你的知乎,按F12获取COOKIES,复制到软件顶部输入栏,复制点击获取当前热点列表获取当前热点讨论.
3.选择要下载的标题,点击下载并保存,保存格式为exsel。该软件可以帮助用户下载每个热评下的知乎热议和热评软件。通过知乎热评数据采集软件,不用打开知乎就可以知道时事。事物。
4.对于一些自媒体热爱学习的人和朋友来说,这个软件非常强大。使用知乎热评数据采集软件,用户无需到处搜索。材料。
小编推荐
以上就是知乎热评爬虫免费版的全部介绍。最热的软件站还有更多类似的爬虫爬取软件。需要的朋友快来下载体验吧。我将在下面推荐另外两个易于使用的软件。爬虫软件:小说爬虫、图片爬虫(抓取下载网站图片)。
网页视频抓取工具 知乎(第451篇原创,和30w+一起学Python! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-26 18:12
)
第451条原创,30w+学Python!
最近开学了,大家都在忙着准备各种学习资料,准备新学期努力学习,充实自己。小编身边的同学也是如此。最近,小编的同学小李遇到了一个非常棘手的问题。
她想把Python学习教程打印在一个网页上,以便自己学习,但是手动将上千页的教程一一转换成pdf并保存在本地确实很麻烦。
这是将html转换为pdf的问题。其实网上有很多不错的html资源,但是学习起来不方便!于是小编向小李保证,这个小东西在我身上。今天小编就给大家分享一下如何使用Python将html数据转换成pdf。
01.爬取学习资料
如今,互联网上有很多在线学习资料。为了方便讲解,小编以python3.9.2的中文文档为例,在本地抓取保存。链接如下:
打开以上链接后,你会发现网页中不同内容的链接地址,包括基本的python字符、python语法等。
02.获取网页链接
在上图中,我们需要特别注意用红色方块标记的链接。每个链接都会跳转到对应的子页面,而在子页面中,就是我们要保存的内容。
可以看到,上图中,python快速查看子页面收录了我们需要提取的文本内容。所以将 html 内容保存为 pdf 的第一步是获取子页面的链接。由于大部分教程都是固定内容,所以教程网页大部分是静态页面,在网页源代码中很容易找到子页面的网页链接。
对于子页面的链接爬取,流程如下图所示:
程序中通过BeautifulSoup库解析网页源代码,然后提取所有子页面链接地址并返回。如果爬取失败,则直接返回None。
03.html转pdf
得到子页面的链接后,下一步就是将html子页面保存为pdf文件。小编使用的pdfkit库,pdfkit库可以将网页保存为pdf文档。首先介绍一下pdfkit库的安装。
按照上面的操作流程,就可以安装pdfkit库了。对于pdfkit库的使用,常见的三种用法:
上述程序主要完成几个步骤:
首先需要指定wkhtmltopdf.exe文件的路径;
因此,pdfkit库只能将子页面保存为单独的pdf文档,不能通过pdfkit库直接将所有子页面拼接成一个完整的pdf文档。小编使用PyPDF2库中的PdfFileMerger类来实现pdf文档的拼接。程序如下图所示。
程序首先将所有html网页保存为单独的pdf文档,然后通过PdfFileMerger类对象实现pdf文档的拼接。最后,您可以获得所有的pdf内容。最后,我们通过视频展示看一下程序的效果。
另外,该程序不仅可以爬取python3.9的中文文档,还可以爬取其他在线文档,只需要修改程序获取要爬取的网页链接,比如Flask中文文档的爬取,程序只需要按照下图进行修改,Flask的在线文档就可以保存为PDF文档了。
04.总结
学习 Python 实际上是非常有趣和有用的。因为 Python 拥有大量现成的库,可以帮助我们轻松解决工作中的许多琐碎问题。小编对上面的程序稍作修改,很快就帮阿里拿到了教程,保存为pdf发给她,小编和女神的关系就更近了。
为了方便大家更好的理解,我们会在B站录制一个完整的视频(详情见原文),一步步讲解程序,再提供源码和视频!
1推荐阅读:
2入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
3干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
4趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
5AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
6
7
年度最火副本
1点这里,直达菜鸟学PythonB站!!
2
3 查看全部
网页视频抓取工具 知乎(第451篇原创,和30w+一起学Python!
)
第451条原创,30w+学Python!
最近开学了,大家都在忙着准备各种学习资料,准备新学期努力学习,充实自己。小编身边的同学也是如此。最近,小编的同学小李遇到了一个非常棘手的问题。
她想把Python学习教程打印在一个网页上,以便自己学习,但是手动将上千页的教程一一转换成pdf并保存在本地确实很麻烦。
这是将html转换为pdf的问题。其实网上有很多不错的html资源,但是学习起来不方便!于是小编向小李保证,这个小东西在我身上。今天小编就给大家分享一下如何使用Python将html数据转换成pdf。
01.爬取学习资料
如今,互联网上有很多在线学习资料。为了方便讲解,小编以python3.9.2的中文文档为例,在本地抓取保存。链接如下:
打开以上链接后,你会发现网页中不同内容的链接地址,包括基本的python字符、python语法等。
02.获取网页链接
在上图中,我们需要特别注意用红色方块标记的链接。每个链接都会跳转到对应的子页面,而在子页面中,就是我们要保存的内容。
可以看到,上图中,python快速查看子页面收录了我们需要提取的文本内容。所以将 html 内容保存为 pdf 的第一步是获取子页面的链接。由于大部分教程都是固定内容,所以教程网页大部分是静态页面,在网页源代码中很容易找到子页面的网页链接。
对于子页面的链接爬取,流程如下图所示:
程序中通过BeautifulSoup库解析网页源代码,然后提取所有子页面链接地址并返回。如果爬取失败,则直接返回None。
03.html转pdf
得到子页面的链接后,下一步就是将html子页面保存为pdf文件。小编使用的pdfkit库,pdfkit库可以将网页保存为pdf文档。首先介绍一下pdfkit库的安装。
按照上面的操作流程,就可以安装pdfkit库了。对于pdfkit库的使用,常见的三种用法:
上述程序主要完成几个步骤:
首先需要指定wkhtmltopdf.exe文件的路径;
因此,pdfkit库只能将子页面保存为单独的pdf文档,不能通过pdfkit库直接将所有子页面拼接成一个完整的pdf文档。小编使用PyPDF2库中的PdfFileMerger类来实现pdf文档的拼接。程序如下图所示。
程序首先将所有html网页保存为单独的pdf文档,然后通过PdfFileMerger类对象实现pdf文档的拼接。最后,您可以获得所有的pdf内容。最后,我们通过视频展示看一下程序的效果。
另外,该程序不仅可以爬取python3.9的中文文档,还可以爬取其他在线文档,只需要修改程序获取要爬取的网页链接,比如Flask中文文档的爬取,程序只需要按照下图进行修改,Flask的在线文档就可以保存为PDF文档了。
04.总结
学习 Python 实际上是非常有趣和有用的。因为 Python 拥有大量现成的库,可以帮助我们轻松解决工作中的许多琐碎问题。小编对上面的程序稍作修改,很快就帮阿里拿到了教程,保存为pdf发给她,小编和女神的关系就更近了。
为了方便大家更好的理解,我们会在B站录制一个完整的视频(详情见原文),一步步讲解程序,再提供源码和视频!
1推荐阅读:
2入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
3干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
4趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
5AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
6
7
年度最火副本
1点这里,直达菜鸟学PythonB站!!
2
3
网页视频抓取工具 知乎( 一个有趣的Python案例分享!Python真的是太有用啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-26 18:09
一个有趣的Python案例分享!Python真的是太有用啦!
)
1点上方“菜鸟学Python”,选择“星标”
2第481篇原创干货,第一时间送达
3
4
大家好,我是菜鸟兄弟!这是我的第 481 篇文章原创!
今天给大家带来另一个有趣的Python案例分享!学习Python真的很有用!
很多朋友平时看视频的时候都喜欢看小姐姐的舞蹈视频。今天小编就和大家一起过关30行代码。顺便说一句,只需要30行代码就可以完成!快来虎牙视频网站上抢到小姐姐和小姐姐的舞蹈视频,快来观看吧。
01.视频获取显示
打开虎牙视频后,可以在“星秀/言之”分类下找到舞蹈视频。小编粗略地翻了一遍。每页一共20个视频,一共500页,所以一共有1000个视频,如果能全部下载下来,估计宅男们会欢呼吧。
02.程序说明
视频获取,和图片获取一样,需要获取视频的url地址。我们需要通过分析得到每个舞蹈视频的子页面链接,然后得到子页面中视频的url链接。首先,我们来看看如何获取每个子页面的链接地址。
1).获取子页面链接
通过分析网页的源码可以发现,首页中各个子页面的地址都可以从网页的源码中获取。
因此,可以通过requests库获取网页的源代码,通过解析网页的源代码可以得到当前页面中所有子网页的链接地址。程序如下图所示。
在程序中,所有的主网页链接都是通过一个for循环来构造的,所有的子网页链接都是通过请求和解析网页的源代码来捕获的,并保存在self.video_urls列表中。
2).下载视频
与获取子页面的链接地址相比,获取子页面中的视频链接更加麻烦,需要我们对其进行分析解析,如下图所示:
在子页面中,可以通过开发者模式下的网页元素解析找到视频的链接地址。接下来,我们复制视频的链接地址,然后进入网络选项,使用快捷键ctrl+F搜索“///”,就可以找到对应的请求接口链接。
通过对视频的请求链接分析,可以得到如下数据链接地址: 上述链接地址返回的是json数据内容,我们可以通过分析json数据找到真正的视频链接地址,其中参数videoId为视频子页面地址,例如子页面是,videoId的值为468682371。
以下地址是我们分析上述json数据得到的视频链接地址:
了解了视频链接地址的获取,那么我们就可以通过程序获取视频地址了。
程序构造json数据的链接地址,然后解析json数据,抓取视频的链接地址,通过self.SaveVideo将视频保存到本地文件夹。
通过运行程序,我们可以连续捕捉小姐姐的舞蹈视频。最后附上小姐姐的舞蹈视频,一起来欣赏小姐姐的精彩舞蹈吧。
其实整个程序很简单。有兴趣的朋友可以练习一下。爬虫只是 Python 中的冰山一角。办公自动化、后端开发、大数据分析和数据挖掘才是真正的力量。大家还是把更多的时间花在数据分析和数据挖掘上,无论是找工作还是提升业务能力,都是非常有益的。所以还没学过Python的同学们,赶紧上车吧!
1推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领廖雪峰视频资料!
2
3 查看全部
网页视频抓取工具 知乎(
一个有趣的Python案例分享!Python真的是太有用啦!
)
1点上方“菜鸟学Python”,选择“星标”
2第481篇原创干货,第一时间送达
3
4
大家好,我是菜鸟兄弟!这是我的第 481 篇文章原创!
今天给大家带来另一个有趣的Python案例分享!学习Python真的很有用!
很多朋友平时看视频的时候都喜欢看小姐姐的舞蹈视频。今天小编就和大家一起过关30行代码。顺便说一句,只需要30行代码就可以完成!快来虎牙视频网站上抢到小姐姐和小姐姐的舞蹈视频,快来观看吧。
01.视频获取显示
打开虎牙视频后,可以在“星秀/言之”分类下找到舞蹈视频。小编粗略地翻了一遍。每页一共20个视频,一共500页,所以一共有1000个视频,如果能全部下载下来,估计宅男们会欢呼吧。
02.程序说明
视频获取,和图片获取一样,需要获取视频的url地址。我们需要通过分析得到每个舞蹈视频的子页面链接,然后得到子页面中视频的url链接。首先,我们来看看如何获取每个子页面的链接地址。
1).获取子页面链接
通过分析网页的源码可以发现,首页中各个子页面的地址都可以从网页的源码中获取。
因此,可以通过requests库获取网页的源代码,通过解析网页的源代码可以得到当前页面中所有子网页的链接地址。程序如下图所示。
在程序中,所有的主网页链接都是通过一个for循环来构造的,所有的子网页链接都是通过请求和解析网页的源代码来捕获的,并保存在self.video_urls列表中。
2).下载视频
与获取子页面的链接地址相比,获取子页面中的视频链接更加麻烦,需要我们对其进行分析解析,如下图所示:
在子页面中,可以通过开发者模式下的网页元素解析找到视频的链接地址。接下来,我们复制视频的链接地址,然后进入网络选项,使用快捷键ctrl+F搜索“///”,就可以找到对应的请求接口链接。
通过对视频的请求链接分析,可以得到如下数据链接地址: 上述链接地址返回的是json数据内容,我们可以通过分析json数据找到真正的视频链接地址,其中参数videoId为视频子页面地址,例如子页面是,videoId的值为468682371。
以下地址是我们分析上述json数据得到的视频链接地址:
了解了视频链接地址的获取,那么我们就可以通过程序获取视频地址了。
程序构造json数据的链接地址,然后解析json数据,抓取视频的链接地址,通过self.SaveVideo将视频保存到本地文件夹。
通过运行程序,我们可以连续捕捉小姐姐的舞蹈视频。最后附上小姐姐的舞蹈视频,一起来欣赏小姐姐的精彩舞蹈吧。
其实整个程序很简单。有兴趣的朋友可以练习一下。爬虫只是 Python 中的冰山一角。办公自动化、后端开发、大数据分析和数据挖掘才是真正的力量。大家还是把更多的时间花在数据分析和数据挖掘上,无论是找工作还是提升业务能力,都是非常有益的。所以还没学过Python的同学们,赶紧上车吧!
1推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领廖雪峰视频资料!
2
3
网页视频抓取工具 知乎( 10个最糟糕的SEO错误,你中枪了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-25 06:11
10个最糟糕的SEO错误,你中枪了吗?)
如果你对 SEO 太熟悉,你可以认为你不会犯错误。我们都知道它是怎么回事,很多 SEO 专家在进入一种自动驾驶模式之前已经在 SEO 工作了五年、十年或更长时间。但奇怪的是,你对某事了解得越多,就越容易忘记细节。
对于 SEO,您还必须记住,搜索引擎几乎一直在改变他们的算法。考虑到这一点,每个 SEO 都会对如何变得更好感到兴奋。以下是 SEO 专家仍然会犯的 10 个最严重的 SEO 错误。
1.内部链接结构不佳
当您的 网站 与您所有的精彩内容一起膨胀时,您一定会遇到一些非常基本的内部链接错误。
这包括从生成大量重复内容到获取 404 页面错误的所有内容。
我们认为,网站 管理员严重忽视了内部链接结构,但它却是您的 UX 和 SEO 策略中最有价值的功能之一。
内部链接为您的 网站 提供了五个有价值的好处:
向搜索引擎重新提交 XML 站点地图是为搜索引擎打开未链接页面的爬网路径的好方法。
此外,明智地使用 robots.txt 文件和 noindex 标签也很重要,这样您就不会意外阻止 网站(或客户端)上的重要页面。
作为一般经验法则,任何网页距离主页或号召性用语着陆页的点击次数不应超过两次。
通过新的 关键词 研究重新评估您的 网站 架构,并开始按主题、内容和主题集群组织网页。
2. 为内容创建内容
最佳实践要求您应该始终如一地制作内容以增加品牌的曝光率和权威,并提高您的 网站 索引率。但是随着您的 网站 增长到数百页或更多,可能很难为每个页面找到一个独特的 关键词 并坚持一个有凝聚力的策略。
有时我们会陷入这样的谬论,即我们必须制作内容才能拥有更多内容。这是完全不真实的,并且导致内容稀少且无用,这相当于浪费资源。
在未完成战略性关键词 研究之前不要编写内容。确保内容与目标 关键词 相关,并在 H2 标签和正文段落中使用密切相关的 关键词。
这会将您内容的完整上下文传达给搜索引擎,并在多个级别上满足用户意图。花时间投资于可操作且常青的长篇内容。请记住,我们是内容营销人员和 SEO 专家,而不是记者。
优化的内容可能需要几个月才能达到首页结果;确保它在其行业中保持相关性和独特性。
3. 不投资于值得链接的内容
我们了解,网页唯一引用域的数量和质量是搜索引擎最重要的三个排名因素之一。
链接建设是 SEO 的主要拉动因素。但是,通过会员链接和媒体营销出去寻找大量链接可能是昂贵的和资源密集型的。
自然,获取链接的最佳方式是使用人们只想链接的优质内容。
与其在人类研究上投入时间并每年创建数百个客座帖子,不如投资于可以在一天的写作中获得所有这些链接的内容?
如前所述,花时间制作为行业增加价值的长篇内容。
在这里,您可以尝试不同形式的内容,无论是资源页面、信息图表、交互式测验还是常青指南。
使用您的一些手动外展策略来宣传发布在您自己的 网站 上的内容,而不是其他人的 网站。
4. 未能通过您的内容吸引客户
继续这个讨论,你必须有一个真正让人们查看你的内容的策略。
我们相信,很多行业和很多公司在内容推广上的投入要少于在制作上的投入。
当然,您可以通过社交媒体分享您的内容。但是,如果没有付费广告,它实际上能获得多少影响力?
只需在您的 网站、自媒体 频道和在线媒体上发布您最新的 文章,即可将其覆盖范围限制在您现有受众的一小部分。
如果您想为您的业务获得新的潜在客户,您需要在促销策略中投入更多资源。
一些策略包括:
虽然它们很简单,但您需要宣传内容以获得指向它的链接。只有这样,您才能自然地开始获得更多链接。
5. 优化bug关键词
因此,您花时间创建一个不会为您的 网站 带来大量流量的长内容。
您的访问者在页面上停留很短的时间并且不转换也很糟糕。
您很可能针对错误的 关键词 进行优化。
虽然我们大多数人都了解长尾 关键词 对于信息查询的重要性,但有时我们会遇到一些常见错误:
实际研究出现在国家和地方搜索结果中的搜索短语非常重要。
与您的客户交谈,了解他们使用哪些搜索词组来描述您所在行业的不同元素。从这里,您可以对 关键词 列表进行细分,以使它们与您的客户更相关。
使用 关键词 工具,例如 5118 的 关键词 生成器来获取相关的 关键词 提示。
不要忘记优化信息和商业搜索查询。
6. 不咨询付费媒体
就行业目前而言,SEO 专注于获取和培养潜在客户,而付费媒体则专注于获取和转换潜在客户。
但是,如果我们打破这些孤岛并在旅程的每一步为买家创造一个有凝聚力的信息呢?
作为 SEO 提供商,我们是否知道客户的广告信息是什么或他们使用什么 关键词?您是否使用与付费媒体部门相同的 关键词 来推广相同的产品/服务页面?
SEO 顾问可以从 PPC关键词 研究和登录页面性能中获得许多见解,这些见解可以帮助他们开展活动。
此外,知乎 和今日头条的广告平台提供了强大的受众分析工具,SEO 顾问可以使用这些工具更好地了解客户的客户。
通过关注统一信息并在彼此的研究中共享,SEO顾问可以发现转化率最高、点击率最高的关键词搜索结果。
7. 不定期诊断我自己的网站
我们犯的最大错误之一是没有继续优化我们自己的 网站 并修复随着时间的推移出现的错误。
在站点迁移或实施任何新工具或插件之后,诊断尤其重要。
随着时间的推移发生的常见技术错误包括:
出现重复内容的原因有很多,可能是通过分页或会话 ID。
通过在源网页上插入规范来解决任何 URL 参数错误或 cookie 中的重复内容。这允许来自重复页面的所有信号指向原创页面。
当您在 网站 上移动内容时,损坏的链接是不可避免的,因此在您删除的任何内容上插入指向相关页面的 301 重定向非常重要。
请务必解决 302 重定向,因为它们仅用作临时重定向。
诊断您的 网站 对于移动搜索至关重要。仅仅拥有响应式网页设计是不够的。
确保在移动设计中缩小 CSS 和 JS,并为响应式设计缩小图像。
最后,诊断中经常被忽视的部分是重新评估您的内容策略。大多数行业都是动态的,这意味着新的创新不断涌现,某些服务会随着时间的推移而过时。
修改您的 网站 以反映您拥有的任何新产品。
围绕主题创建内容,以向搜索引擎和用户展示它对您的层次结构的重要性。
不断更新您的 关键词 研究和受众研究,以寻找扩大规模和保持相关性的新机会。
8. 不定时查看百度统计
下一点是关于百度统计的。这与诊断您的 网站 不太一样,因为诊断会在后端向您显示需要纠正的技术错误。
百度统计更面向受众,检查程序中提供的数据对于发现您的 网站 需要关注的地方至关重要。
这个或那个页面的跳出率是否在增加?检查一下,找出原因。
一个渠道的流量是否随着时间的推移而稳步下降?查看您的资源以修复它。
即使你被数据和数字吓到,百度统计也会以通俗易懂的方式呈现,即使是初学者也能理解。
关键是,安装百度统计跟踪代码然后完全忽略它是错误的方法。
我知道每隔一段时间检查一次需要时间和精力,但是您会了解公众如何与您的 网站 互动,并且您将无法忽视您发现的问题。
9. 忽略技术 SEO
最后,您不能忘记基本的技术 SEO 内容。
由于解决这些问题往往令人麻木,这可能不是许多 网站 所有者想要解决的领域,但我可以向您保证,如果您忽略技术 SEO,那么您做错了。
您是否有无法抓取的页面?内部图像或链接损坏?一千个临时重定向?
孤立页面、没有内部链接的页面或损坏的外部链接怎么样?
这些都是可能对您的 网站 可抓取性产生负面影响并增加您的抓取预算的问题。
底线是什么?这些问题会让你远离对你最重要的人。
使用 Semrush 或 Screaming Frog 之类的工具来识别和纠正这些问题,以免它们积聚太多并导致您头疼。也许每月审查这些技术问题以掌握它们。
它可能不是 SEO 最迷人的部分,但解决技术问题对于成功的 网站 至关重要,所以开始吧。
总结
每个人都容易在他们的手艺上犯错误,纠正错误的最佳方法之一是参考最佳实践。我们最好的建议:保持头脑清醒,始终退后一步,评估您是否正在尽最大努力扩展您的业务。 查看全部
网页视频抓取工具 知乎(
10个最糟糕的SEO错误,你中枪了吗?)
如果你对 SEO 太熟悉,你可以认为你不会犯错误。我们都知道它是怎么回事,很多 SEO 专家在进入一种自动驾驶模式之前已经在 SEO 工作了五年、十年或更长时间。但奇怪的是,你对某事了解得越多,就越容易忘记细节。
对于 SEO,您还必须记住,搜索引擎几乎一直在改变他们的算法。考虑到这一点,每个 SEO 都会对如何变得更好感到兴奋。以下是 SEO 专家仍然会犯的 10 个最严重的 SEO 错误。
1.内部链接结构不佳
当您的 网站 与您所有的精彩内容一起膨胀时,您一定会遇到一些非常基本的内部链接错误。
这包括从生成大量重复内容到获取 404 页面错误的所有内容。
我们认为,网站 管理员严重忽视了内部链接结构,但它却是您的 UX 和 SEO 策略中最有价值的功能之一。
内部链接为您的 网站 提供了五个有价值的好处:
向搜索引擎重新提交 XML 站点地图是为搜索引擎打开未链接页面的爬网路径的好方法。
此外,明智地使用 robots.txt 文件和 noindex 标签也很重要,这样您就不会意外阻止 网站(或客户端)上的重要页面。
作为一般经验法则,任何网页距离主页或号召性用语着陆页的点击次数不应超过两次。
通过新的 关键词 研究重新评估您的 网站 架构,并开始按主题、内容和主题集群组织网页。
2. 为内容创建内容
最佳实践要求您应该始终如一地制作内容以增加品牌的曝光率和权威,并提高您的 网站 索引率。但是随着您的 网站 增长到数百页或更多,可能很难为每个页面找到一个独特的 关键词 并坚持一个有凝聚力的策略。
有时我们会陷入这样的谬论,即我们必须制作内容才能拥有更多内容。这是完全不真实的,并且导致内容稀少且无用,这相当于浪费资源。
在未完成战略性关键词 研究之前不要编写内容。确保内容与目标 关键词 相关,并在 H2 标签和正文段落中使用密切相关的 关键词。
这会将您内容的完整上下文传达给搜索引擎,并在多个级别上满足用户意图。花时间投资于可操作且常青的长篇内容。请记住,我们是内容营销人员和 SEO 专家,而不是记者。
优化的内容可能需要几个月才能达到首页结果;确保它在其行业中保持相关性和独特性。
3. 不投资于值得链接的内容
我们了解,网页唯一引用域的数量和质量是搜索引擎最重要的三个排名因素之一。
链接建设是 SEO 的主要拉动因素。但是,通过会员链接和媒体营销出去寻找大量链接可能是昂贵的和资源密集型的。
自然,获取链接的最佳方式是使用人们只想链接的优质内容。
与其在人类研究上投入时间并每年创建数百个客座帖子,不如投资于可以在一天的写作中获得所有这些链接的内容?
如前所述,花时间制作为行业增加价值的长篇内容。
在这里,您可以尝试不同形式的内容,无论是资源页面、信息图表、交互式测验还是常青指南。
使用您的一些手动外展策略来宣传发布在您自己的 网站 上的内容,而不是其他人的 网站。
4. 未能通过您的内容吸引客户
继续这个讨论,你必须有一个真正让人们查看你的内容的策略。
我们相信,很多行业和很多公司在内容推广上的投入要少于在制作上的投入。
当然,您可以通过社交媒体分享您的内容。但是,如果没有付费广告,它实际上能获得多少影响力?
只需在您的 网站、自媒体 频道和在线媒体上发布您最新的 文章,即可将其覆盖范围限制在您现有受众的一小部分。
如果您想为您的业务获得新的潜在客户,您需要在促销策略中投入更多资源。
一些策略包括:
虽然它们很简单,但您需要宣传内容以获得指向它的链接。只有这样,您才能自然地开始获得更多链接。
5. 优化bug关键词
因此,您花时间创建一个不会为您的 网站 带来大量流量的长内容。
您的访问者在页面上停留很短的时间并且不转换也很糟糕。
您很可能针对错误的 关键词 进行优化。
虽然我们大多数人都了解长尾 关键词 对于信息查询的重要性,但有时我们会遇到一些常见错误:
实际研究出现在国家和地方搜索结果中的搜索短语非常重要。
与您的客户交谈,了解他们使用哪些搜索词组来描述您所在行业的不同元素。从这里,您可以对 关键词 列表进行细分,以使它们与您的客户更相关。
使用 关键词 工具,例如 5118 的 关键词 生成器来获取相关的 关键词 提示。
不要忘记优化信息和商业搜索查询。
6. 不咨询付费媒体
就行业目前而言,SEO 专注于获取和培养潜在客户,而付费媒体则专注于获取和转换潜在客户。
但是,如果我们打破这些孤岛并在旅程的每一步为买家创造一个有凝聚力的信息呢?
作为 SEO 提供商,我们是否知道客户的广告信息是什么或他们使用什么 关键词?您是否使用与付费媒体部门相同的 关键词 来推广相同的产品/服务页面?
SEO 顾问可以从 PPC关键词 研究和登录页面性能中获得许多见解,这些见解可以帮助他们开展活动。
此外,知乎 和今日头条的广告平台提供了强大的受众分析工具,SEO 顾问可以使用这些工具更好地了解客户的客户。
通过关注统一信息并在彼此的研究中共享,SEO顾问可以发现转化率最高、点击率最高的关键词搜索结果。
7. 不定期诊断我自己的网站
我们犯的最大错误之一是没有继续优化我们自己的 网站 并修复随着时间的推移出现的错误。
在站点迁移或实施任何新工具或插件之后,诊断尤其重要。
随着时间的推移发生的常见技术错误包括:
出现重复内容的原因有很多,可能是通过分页或会话 ID。
通过在源网页上插入规范来解决任何 URL 参数错误或 cookie 中的重复内容。这允许来自重复页面的所有信号指向原创页面。
当您在 网站 上移动内容时,损坏的链接是不可避免的,因此在您删除的任何内容上插入指向相关页面的 301 重定向非常重要。
请务必解决 302 重定向,因为它们仅用作临时重定向。
诊断您的 网站 对于移动搜索至关重要。仅仅拥有响应式网页设计是不够的。
确保在移动设计中缩小 CSS 和 JS,并为响应式设计缩小图像。
最后,诊断中经常被忽视的部分是重新评估您的内容策略。大多数行业都是动态的,这意味着新的创新不断涌现,某些服务会随着时间的推移而过时。
修改您的 网站 以反映您拥有的任何新产品。
围绕主题创建内容,以向搜索引擎和用户展示它对您的层次结构的重要性。
不断更新您的 关键词 研究和受众研究,以寻找扩大规模和保持相关性的新机会。
8. 不定时查看百度统计
下一点是关于百度统计的。这与诊断您的 网站 不太一样,因为诊断会在后端向您显示需要纠正的技术错误。
百度统计更面向受众,检查程序中提供的数据对于发现您的 网站 需要关注的地方至关重要。
这个或那个页面的跳出率是否在增加?检查一下,找出原因。
一个渠道的流量是否随着时间的推移而稳步下降?查看您的资源以修复它。
即使你被数据和数字吓到,百度统计也会以通俗易懂的方式呈现,即使是初学者也能理解。
关键是,安装百度统计跟踪代码然后完全忽略它是错误的方法。
我知道每隔一段时间检查一次需要时间和精力,但是您会了解公众如何与您的 网站 互动,并且您将无法忽视您发现的问题。
9. 忽略技术 SEO
最后,您不能忘记基本的技术 SEO 内容。
由于解决这些问题往往令人麻木,这可能不是许多 网站 所有者想要解决的领域,但我可以向您保证,如果您忽略技术 SEO,那么您做错了。
您是否有无法抓取的页面?内部图像或链接损坏?一千个临时重定向?
孤立页面、没有内部链接的页面或损坏的外部链接怎么样?
这些都是可能对您的 网站 可抓取性产生负面影响并增加您的抓取预算的问题。
底线是什么?这些问题会让你远离对你最重要的人。
使用 Semrush 或 Screaming Frog 之类的工具来识别和纠正这些问题,以免它们积聚太多并导致您头疼。也许每月审查这些技术问题以掌握它们。
它可能不是 SEO 最迷人的部分,但解决技术问题对于成功的 网站 至关重要,所以开始吧。
总结
每个人都容易在他们的手艺上犯错误,纠正错误的最佳方法之一是参考最佳实践。我们最好的建议:保持头脑清醒,始终退后一步,评估您是否正在尽最大努力扩展您的业务。
网页视频抓取工具 知乎(Python学习资料,0基础到进阶(上)|python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-24 16:12
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。在这里,我将介绍代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的粉丝列表和关注者列表是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的示例。如图,是一个json
这里找到了粉丝的数据,但是这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造出他们每一个详细信息的url,然后挖掘出详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到80行,运行一分钟后,捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙其他事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取的时候一定要伪装headers。服务器每次都会检查其中的一些内容。
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧! 查看全部
网页视频抓取工具 知乎(Python学习资料,0基础到进阶(上)|python)
今天用递归写了一个爬虫,抓取知乎的所有用户信息。源代码放在github上。有兴趣的同学可以下载看看。在这里,我将介绍代码逻辑和分页分析。首先,看网页。,这里我随机选择一个大V作为入口,然后点击他的关注列表,如图
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
注意我的爬虫全名是非登录状态。这里的粉丝列表和关注者列表是后台ajax请求获取的数据(没听说过ajax的不要慌,ajax请求和普通浏览器请求没什么区别,主要是偷偷发给服务器的)我们浏览网页的时候请求是为了节省流量,减少请求次数,不然每次看新数据都会刷新网页,服务器压力很大,所以我们有这个东西),然后我们找到粉丝列表和关注者列表的网址,很简单,点击chrome浏览器下的页码开关即可找到,如图
很容易找到关注者和粉丝的 URL。让我们来看看这些数据。这是粉丝数据的示例。如图,是一个json
这里找到了粉丝的数据,但是这不是用户的详细信息,只是部分数据,但是他提供了一个token_url,我们可以得到这个ID访问用户的详细信息,我们来看看如何提取每个用户的详细信息。在这里楼主发现,在看粉丝或者关注列表的时候,网页会自动触发对用户详细信息的请求,如图
本次获取用户详细信息查询的URL。我们来看看这个详细信息的URL,如图。
上面介绍了网页的基本分析。先说一下代码的思路。本次爬虫使用递归,本次使用scrapy进行爬取,存储mogodb数据库。
首先,我用了一个大V作为爬虫的第一个网页,然后分为三个步骤。第一步是爬取大V的详细信息,然后存入数据库。第二步是爬大V的粉丝。第三步是爬大V的粉丝(其实就是爬粉丝或者粉丝的token_url)。完成后,利用粉丝和关注者的爬取数据,构造出他们每一个详细信息的url,然后挖掘出详细信息存入数据库。至此,第一步递归完成,接下来爬虫会从每个粉丝和粉丝开始,分别爬取他们粉丝和粉丝的详细数据,继续递归。
代码中还添加了一些自动翻页功能,有兴趣的可以看看。以下是我们项目定义中要捕获的数据:
import scrapyclass 知乎UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() answer_count = scrapy.Field()
#回答数article_count = scrapy.Field()
#Written 文章 number follower_count = scrapy.Field()
#关注粉丝数_count = scrapy.Field()
#有多少人关注了educations=scrapy.Field()
#教育背景描述 = scrapy.Field()
#个人描述位置 = scrapy.Field()
#Location url_token =scrapy.Field()
#知乎给每个用户首页的唯一ID name=scrapy.Field()
#用户昵称员工 = scrapy.Field()
#工作信息business=scrapy.Field()
#工作或业务信息的集合 user_type =scrapy.Field()
#用户类型,可以是个人、群组等。headline =scrapy.Field()
#个人主页标签 voteup_count = scrapy.Field()
#获得的点赞数Thanks_count=scrapy.Field()
#感谢次数喜爱的_count = scrapy.Field()
#采集数量 avatar_url = scrapy.Field()
#头像网址
代码总共不到80行,运行一分钟后,捕获了知乎 1000多个用户的信息。这是结果图片。
最近一直在忙其他事情,终于可以天天写爬虫了。不知道大家对这篇文章有没有什么问题,可以随时跟我提。
最后要提的是,爬取的时候一定要伪装headers。服务器每次都会检查其中的一些内容。
我们都知道 Python 很容易学习,但我们只是不知道如何学习以及在哪里可以找到信息。在这里,python学习交流QQ群233539995,分享我精心准备的Python学习资料,0基础到高级!希望大家在学习Python的道路上少走弯路!来吧!
网页视频抓取工具 知乎(网页视频抓取工具(视频大全网站名称抓取视频下载))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-23 00:03
网页视频抓取工具知乎视频抓取工具网页视频抓取工具
一、视频大全网站名称:爱稀奇网址:::;+,搜索要抓取的视频链接,输入视频地址即可下载视频源码。需要注意的是,视频是直接从网站下载,无需保存到本地。
二、视频大全网站名称:第一视频网址:-cc0-sjjrlsb1g需要注意的是,视频是从本地下载无需保存到本地。
三、qq视频网址::!网页视频爬取工具抓取用时1分钟。文中图片的ppt,附上下载链接以及下载地址,即可在线观看。视频抓取工具可批量抓取网页视频。希望大家喜欢。
放下数据库,通讯录,还有缓存文件。再下个webrtc。
你就一行ls回车就完了
百度搜“网页视频下载”自己搭梯子
使用一个叫specialvideodownloader的工具。会生成几个player,filterconfiguration设置中的local:true可以用谷歌的https,rtmp等协议(比如google的glasses,他们是两个local的不同videoconfiguration,但是可以用);如果是http协议的话需要指定filterconfiguration为true。
突然发现楼上的答案非常不现实,下载麻烦了很多。我推荐一个视频站:specialvideodownloader,这个是实时视频下载软件,不需要编程语言编程,有的时候直接看效果还是不错的, 查看全部
网页视频抓取工具 知乎(网页视频抓取工具(视频大全网站名称抓取视频下载))
网页视频抓取工具知乎视频抓取工具网页视频抓取工具
一、视频大全网站名称:爱稀奇网址:::;+,搜索要抓取的视频链接,输入视频地址即可下载视频源码。需要注意的是,视频是直接从网站下载,无需保存到本地。
二、视频大全网站名称:第一视频网址:-cc0-sjjrlsb1g需要注意的是,视频是从本地下载无需保存到本地。
三、qq视频网址::!网页视频爬取工具抓取用时1分钟。文中图片的ppt,附上下载链接以及下载地址,即可在线观看。视频抓取工具可批量抓取网页视频。希望大家喜欢。
放下数据库,通讯录,还有缓存文件。再下个webrtc。
你就一行ls回车就完了
百度搜“网页视频下载”自己搭梯子
使用一个叫specialvideodownloader的工具。会生成几个player,filterconfiguration设置中的local:true可以用谷歌的https,rtmp等协议(比如google的glasses,他们是两个local的不同videoconfiguration,但是可以用);如果是http协议的话需要指定filterconfiguration为true。
突然发现楼上的答案非常不现实,下载麻烦了很多。我推荐一个视频站:specialvideodownloader,这个是实时视频下载软件,不需要编程语言编程,有的时候直接看效果还是不错的,
网页视频抓取工具 知乎(Python非常适合架构组成URL管理器:管理待爬取url集合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-21 12:13
总结:Python爬虫基础
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
与Java、c#、c++、python等其他静态编程语言相比,爬取网页文档的界面更加简洁;与其他动态脚本语言相比,例如 perl、shell 和 python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(MySQL)
网址(网址,is_crawled)
3、缓存(Redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
原创链接 查看全部
网页视频抓取工具 知乎(Python非常适合架构组成URL管理器:管理待爬取url集合)
总结:Python爬虫基础
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
与Java、c#、c++、python等其他静态编程语言相比,爬取网页文档的界面更加简洁;与其他动态脚本语言相比,例如 perl、shell 和 python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(MySQL)
网址(网址,is_crawled)
3、缓存(Redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。如果你想学习Python,可以来这个群。第一个是472,中间是309,最后是261。有很多学习资料可以下载。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
原创链接
网页视频抓取工具 知乎(evernote离它remembereverything的愿景还有多远?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-17 18:19
)
光是想想这个问题,evernote 离它“记住一切”的愿景还有多远。视频显然是一种自然的记录形式,既然要记录一切,就不应该绕过它。Evernote CEO 在最近的一次采访中也表示,Quantified Self 是 Evernote 未来将重点关注的一个方向;
备忘录
,以后会不会有视频版。
我认为视频录制有两个方面:
一个是我们自己拍的。显然,受限于现有网络带宽和服务器存储成本,但IT发展太快了。参考移动视频社交应用的普及速度。问题; 即使解决了网络和存储的硬件问题,也还有一道坎。想想这几年手持相机和手机相机的普及,我们拍了很多视频,但真正再看一遍的机会又是多少,肯定还是重温一下照片吧。我认为这与观看视频的耗时和寻找有效信息的高成本有关。以印象笔记这种检索照片文字的态度,我想它对视频录制的期待绝对不仅仅是保存文件。
另一类视频是影视数据。如果完全保存,现在在国内会流行起来,会被盗版抢流量,抢客户网盘。但恰恰是这方面潜在的笔记需求,我认为evernote可以在现阶段有所作为。例如,
网易公开课
可以边看视频边做笔记,模拟真实教室做笔记,这些笔记对应视频中的某个时刻。如果都可以导出到evernote,那么note对应的视频会被截取一小段时间,比如10秒,分辨率可以压缩到比较小的尺寸。我认为对于存储问题和版权问题是可以接受的。把这个想法扩展到一般的视频网站,比如优酷应该会很有趣。
网易公开课笔记截图:
查看全部
网页视频抓取工具 知乎(evernote离它remembereverything的愿景还有多远?(组图)
)
光是想想这个问题,evernote 离它“记住一切”的愿景还有多远。视频显然是一种自然的记录形式,既然要记录一切,就不应该绕过它。Evernote CEO 在最近的一次采访中也表示,Quantified Self 是 Evernote 未来将重点关注的一个方向;
备忘录
,以后会不会有视频版。
我认为视频录制有两个方面:
一个是我们自己拍的。显然,受限于现有网络带宽和服务器存储成本,但IT发展太快了。参考移动视频社交应用的普及速度。问题; 即使解决了网络和存储的硬件问题,也还有一道坎。想想这几年手持相机和手机相机的普及,我们拍了很多视频,但真正再看一遍的机会又是多少,肯定还是重温一下照片吧。我认为这与观看视频的耗时和寻找有效信息的高成本有关。以印象笔记这种检索照片文字的态度,我想它对视频录制的期待绝对不仅仅是保存文件。
另一类视频是影视数据。如果完全保存,现在在国内会流行起来,会被盗版抢流量,抢客户网盘。但恰恰是这方面潜在的笔记需求,我认为evernote可以在现阶段有所作为。例如,
网易公开课
可以边看视频边做笔记,模拟真实教室做笔记,这些笔记对应视频中的某个时刻。如果都可以导出到evernote,那么note对应的视频会被截取一小段时间,比如10秒,分辨率可以压缩到比较小的尺寸。我认为对于存储问题和版权问题是可以接受的。把这个想法扩展到一般的视频网站,比如优酷应该会很有趣。
网易公开课笔记截图:
网页视频抓取工具 知乎(一款简单易用的在线文件转换工具,赶紧收藏吧! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-16 02:13
)
本期将继续为大家带来四款我舍不得分享的优质软件,赶快采集吧!~~
办公室转换器
在日常办公中,你经常会遇到一些需要转换的Office文件,它可以帮助你。一款好用的在线文件转换工具,你可能看到它可能只是office文章转换,那你可能会一头雾水,不仅是PDF、Word、Excel、PPT转换,还有视频、e -书本、音乐、图片、压缩等格式转换,非常好用。
DP擦除
有时你真的很想彻底删除某个数据,但又担心删除后有人会恢复。这时候,你可以用它来帮助你。一款功能强大的文件粉碎机软件,有了这个工具软件,你可以彻底删除文件,支持Gutmann数据销毁算法,删除文件后,进行35次覆盖写入数据,这样你就可以大胆的保护你的隐私了。
更多Excel
一个Excel多功能插件工具,支持多人同时编辑同一个文件。企业的运营离不开Excel,可以同时打开文件协同编辑表格,老板可以实时看到所有内容。低成本,避免ERP系统带来的不可预知的风险。
宏指令
不知道大家有没有听说过一个可以自动检测网站、记忆密码、填写web表单的工具。这个工具可以做到。一款可在 5 分钟内为网页自动化、网页抓取或网页测试开发解决方案的工具。它将所有信息存储在文本文件中,便于编辑和阅读,密码使用 256 位 AES 加密。不仅可以填写web表单信息,还可以提取信息,非常棒!
查看全部
网页视频抓取工具 知乎(一款简单易用的在线文件转换工具,赶紧收藏吧!
)
本期将继续为大家带来四款我舍不得分享的优质软件,赶快采集吧!~~
办公室转换器
在日常办公中,你经常会遇到一些需要转换的Office文件,它可以帮助你。一款好用的在线文件转换工具,你可能看到它可能只是office文章转换,那你可能会一头雾水,不仅是PDF、Word、Excel、PPT转换,还有视频、e -书本、音乐、图片、压缩等格式转换,非常好用。
DP擦除
有时你真的很想彻底删除某个数据,但又担心删除后有人会恢复。这时候,你可以用它来帮助你。一款功能强大的文件粉碎机软件,有了这个工具软件,你可以彻底删除文件,支持Gutmann数据销毁算法,删除文件后,进行35次覆盖写入数据,这样你就可以大胆的保护你的隐私了。
更多Excel
一个Excel多功能插件工具,支持多人同时编辑同一个文件。企业的运营离不开Excel,可以同时打开文件协同编辑表格,老板可以实时看到所有内容。低成本,避免ERP系统带来的不可预知的风险。
宏指令
不知道大家有没有听说过一个可以自动检测网站、记忆密码、填写web表单的工具。这个工具可以做到。一款可在 5 分钟内为网页自动化、网页抓取或网页测试开发解决方案的工具。它将所有信息存储在文本文件中,便于编辑和阅读,密码使用 256 位 AES 加密。不仅可以填写web表单信息,还可以提取信息,非常棒!
网页视频抓取工具 知乎( 一下如何使用Python的开源爬虫,发现果然很好用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-15 07:02
一下如何使用Python的开源爬虫,发现果然很好用
)
基于python的知乎开源爬虫知乎_oauth使用介绍
今天无意中发现了一个开源爬虫知乎,它基于Python,名字叫知乎_oauth。看了一下github上的star数,貌似文档挺详细的,所以稍微研究了一下。片刻。发现真的很有用。在这里,我将向您展示如何使用它。
该项目的主页地址是:. 作者的知乎主页是:.
该项目的文档地址是:. 平心而论,原作者已经非常详细地解释了如何使用这个库,我在这里重复是多余的。因此,如果您想了解有关如何使用此库的更多信息,请转到官方文档。我只提我觉得需要补充的重点。
首先是安装。作者已经将项目上传到pypi,所以我们可以直接使用pip安装。据作者介绍,该项目对Python3的支持较好,目前兼容Python2,所以最好使用python3.直接pip3 install -U 知乎_oauth进行安装。
安装后,第一步是登录。只需使用下面的代码登录即可。
from zhihu_oauth import ZhihuClient
from zhihu_oauth.exception import NeedCaptchaException
client = ZhihuClient()
user = 'email_or_phone'
pwd = 'password'
try:
client.login(user, pwd)
print(u"登陆成功!")
except NeedCaptchaException: # 处理要验证码的情况
# 保存验证码并提示输入,重新登录
with open('a.gif', 'wb') as f:
f.write(client.get_captcha())
captcha = input('please input captcha:')
client.login('email_or_phone', 'password', captcha)
client.save_token('token.pkl') # 保存token
#有了token之后,下次登录就可以直接加载token文件了
# client.load_token('filename')
以上代码直接使用账号密码登录,最后登录后保存token。下次登录时,我们可以直接使用token登录,无需每次都输入密码。
登录后,当然可以做很多事情。比如下面的代码可以获取你知乎账号的基本信息
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
client = ZhihuClient()
client.load_token('token.pkl') # 加载token文件
# 显示自己的相关信息
me = client.me()
# 获取最近 5 个回答
for _, answer in zip(range(5), me.answers):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取点赞量最高的 5 个回答
for _, answer in zip(range(5), me.answers.order_by('votenum')):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取最近提的 5 个问题
for _, question in zip(range(5), me.questions):
print(question.title, question.answer_count)
print('----------')
# 获取最近发表的 5 个文章
for _, article in zip(range(5), me.articles):
print(article.title, article.voteup_count)
当然,还有更多的事情可以做。例如,如果我们知道一个问题的url地址或问题id,就可以得到一共有多少个答案、作者信息等一系列详细信息。开发者真的很周到,基本把常用的信息都收录了。具体代码我就不贴了,大家可以自行参考官方文档。
一个小tip:由于这个库有很多类,比如获取作者信息的类,获取文章信息的类等等。每个类都有很多方法。我查看了官方文档。作者没有列出某些类的所有属性。那么我们如何查看这个类的所有属性呢?其实很简单,用python的dir函数,用dir(object)查看对象类(或对象)的所有属性。例如,如果我们有一个 answer 类的对象,使用 dir(answer) 将返回 answer 对象的所有属性的列表。除了一些默认属性外,我们还可以找到这个类需要的属性,非常方便。(以下是集合的所有属性,即采集夹类)
['__class__','__delattr__','__dict__','__doc__','__format__','__getattribute__','__hash__','__init__','__module__','__new__','__reduce__','__reduce_ex__',' __repr__','__setattr__','__sizeof__','__str__','__subclasshook__','__weakref__','_build_data','_build_params','_build_url','_cache','_data','_get_data','_id' ,'_method','_refresh_times','_session','answer_count','answers','articles','comment_count','comments','contents','created_time','creator','description',' follower_count','追随者','id','is_public'、'pure_data'、'refresh'、'title'、'updated_time']
最后我用这个类把知乎某题的答案里的所有图片都抓了下来(抓美图,哈哈哈),只用了不到30行代码(去掉注释)。与大家分享。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/5/3 14:27
# @Author : wang
# @Email : 540913723@qq.com
# @File : save_images.py
'''
@Description:保存知乎某个问题下所有答案的图片
'''
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
import re
import os
import urllib
client = ZhihuClient()
# 登录
client.load_token('token.pkl') # 加载token文件
id = 24400664 # https://www.zhihu.com/question/24400664(长得好看是一种怎么样的体验)
question = client.question(id)
print(u"问题:",question.title)
print(u"回答数量:",question.answer_count)
# 建立存放图片的文件夹
os.mkdir(question.title + u"(图片)")
path = question.title + u"(图片)"
index = 1 # 图片序号
for answer in question.answers:
content = answer.content # 回答内容
re_compile = re.compile(r'(https://pic\d\.zhimg\.com/.*?\.(jpg|png))')
img_lists = re.findall(re_compile,content)
if(img_lists):
for img in img_lists:
img_url = img[0] # 图片url
urllib.urlretrieve(img_url,path+u"/%d.jpg" % index)
print(u"成功保存第%d张图片" % index)
index += 1
如果自己写,直接抓取网页并解析无法得到所有答案,只能破解知乎的api,比较麻烦,使用起来也方便很多这个现成的轮子。以后想慢慢欣赏知乎的美,就不用再担心了,呵呵。
查看全部
网页视频抓取工具 知乎(
一下如何使用Python的开源爬虫,发现果然很好用
)
基于python的知乎开源爬虫知乎_oauth使用介绍
今天无意中发现了一个开源爬虫知乎,它基于Python,名字叫知乎_oauth。看了一下github上的star数,貌似文档挺详细的,所以稍微研究了一下。片刻。发现真的很有用。在这里,我将向您展示如何使用它。
该项目的主页地址是:. 作者的知乎主页是:.
该项目的文档地址是:. 平心而论,原作者已经非常详细地解释了如何使用这个库,我在这里重复是多余的。因此,如果您想了解有关如何使用此库的更多信息,请转到官方文档。我只提我觉得需要补充的重点。
首先是安装。作者已经将项目上传到pypi,所以我们可以直接使用pip安装。据作者介绍,该项目对Python3的支持较好,目前兼容Python2,所以最好使用python3.直接pip3 install -U 知乎_oauth进行安装。
安装后,第一步是登录。只需使用下面的代码登录即可。
from zhihu_oauth import ZhihuClient
from zhihu_oauth.exception import NeedCaptchaException
client = ZhihuClient()
user = 'email_or_phone'
pwd = 'password'
try:
client.login(user, pwd)
print(u"登陆成功!")
except NeedCaptchaException: # 处理要验证码的情况
# 保存验证码并提示输入,重新登录
with open('a.gif', 'wb') as f:
f.write(client.get_captcha())
captcha = input('please input captcha:')
client.login('email_or_phone', 'password', captcha)
client.save_token('token.pkl') # 保存token
#有了token之后,下次登录就可以直接加载token文件了
# client.load_token('filename')
以上代码直接使用账号密码登录,最后登录后保存token。下次登录时,我们可以直接使用token登录,无需每次都输入密码。
登录后,当然可以做很多事情。比如下面的代码可以获取你知乎账号的基本信息
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
client = ZhihuClient()
client.load_token('token.pkl') # 加载token文件
# 显示自己的相关信息
me = client.me()
# 获取最近 5 个回答
for _, answer in zip(range(5), me.answers):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取点赞量最高的 5 个回答
for _, answer in zip(range(5), me.answers.order_by('votenum')):
print(answer.question.title, answer.voteup_count)
print('----------')
# 获取最近提的 5 个问题
for _, question in zip(range(5), me.questions):
print(question.title, question.answer_count)
print('----------')
# 获取最近发表的 5 个文章
for _, article in zip(range(5), me.articles):
print(article.title, article.voteup_count)
当然,还有更多的事情可以做。例如,如果我们知道一个问题的url地址或问题id,就可以得到一共有多少个答案、作者信息等一系列详细信息。开发者真的很周到,基本把常用的信息都收录了。具体代码我就不贴了,大家可以自行参考官方文档。
一个小tip:由于这个库有很多类,比如获取作者信息的类,获取文章信息的类等等。每个类都有很多方法。我查看了官方文档。作者没有列出某些类的所有属性。那么我们如何查看这个类的所有属性呢?其实很简单,用python的dir函数,用dir(object)查看对象类(或对象)的所有属性。例如,如果我们有一个 answer 类的对象,使用 dir(answer) 将返回 answer 对象的所有属性的列表。除了一些默认属性外,我们还可以找到这个类需要的属性,非常方便。(以下是集合的所有属性,即采集夹类)
['__class__','__delattr__','__dict__','__doc__','__format__','__getattribute__','__hash__','__init__','__module__','__new__','__reduce__','__reduce_ex__',' __repr__','__setattr__','__sizeof__','__str__','__subclasshook__','__weakref__','_build_data','_build_params','_build_url','_cache','_data','_get_data','_id' ,'_method','_refresh_times','_session','answer_count','answers','articles','comment_count','comments','contents','created_time','creator','description',' follower_count','追随者','id','is_public'、'pure_data'、'refresh'、'title'、'updated_time']
最后我用这个类把知乎某题的答案里的所有图片都抓了下来(抓美图,哈哈哈),只用了不到30行代码(去掉注释)。与大家分享。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/5/3 14:27
# @Author : wang
# @Email : 540913723@qq.com
# @File : save_images.py
'''
@Description:保存知乎某个问题下所有答案的图片
'''
from __future__ import print_function # 使用python3的print方法
from zhihu_oauth import ZhihuClient
import re
import os
import urllib
client = ZhihuClient()
# 登录
client.load_token('token.pkl') # 加载token文件
id = 24400664 # https://www.zhihu.com/question/24400664(长得好看是一种怎么样的体验)
question = client.question(id)
print(u"问题:",question.title)
print(u"回答数量:",question.answer_count)
# 建立存放图片的文件夹
os.mkdir(question.title + u"(图片)")
path = question.title + u"(图片)"
index = 1 # 图片序号
for answer in question.answers:
content = answer.content # 回答内容
re_compile = re.compile(r'(https://pic\d\.zhimg\.com/.*?\.(jpg|png))')
img_lists = re.findall(re_compile,content)
if(img_lists):
for img in img_lists:
img_url = img[0] # 图片url
urllib.urlretrieve(img_url,path+u"/%d.jpg" % index)
print(u"成功保存第%d张图片" % index)
index += 1
如果自己写,直接抓取网页并解析无法得到所有答案,只能破解知乎的api,比较麻烦,使用起来也方便很多这个现成的轮子。以后想慢慢欣赏知乎的美,就不用再担心了,呵呵。
网页视频抓取工具 知乎(微软与俄罗斯搜索引擎Yandex推出新爬虫协议提高搜索引擎爬虫效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 06:23
站长之家()新闻:为了在网站上发现很多新发布的页面,搜索引擎往往需要爬取和渲染上万个页面,可能需要几天到几周的时间才能发现内容发生了变化. 然而,这种低效的索引问题有望得到解决。
去年 10 月,微软与俄罗斯搜索引擎 Yandex 推出了 IndexNow 的新爬虫协议,旨在提高搜索引擎爬虫和索引的效率。
IndexNow 协议到底是什么?
具体来说,IndexNow 是由 Microsoft Bing 和 Yandex 创建的新协议,它允许 网站 在创建、更新或删除其 网站 内容时通过使用 API 轻松通知搜索引擎。
几天前,微软再次宣布,通过确保提交的 URL 在搜索引擎之间共享,它使该协议更易于实施。
这意味着 网站 管理员只需要一个 API 接口,所有 URL 将与所有支持 IndexNow 协议的搜索引擎共享。除了为内容发布者节省时间和精力之外,这还有助于搜索引擎的内容发现工作,从而使整个网络更加高效。
你可能已经觉得这个协议和百度的链接提交 API 很像。确实是这样,但是不保证内容被爬取或者内容提交后收录,搜索引擎只会被“通知”变化,并提升这些URL的爬取优先级到更高的水平。
注:站长之家已实现IndexNow接口推送。推送成功后,可以通过必应站长平台入口查看网址。
IndexNow 带来了搜索索引的演变
了解 IndexNow 协议后,您会发现它非常重要,因为它带来了搜索引擎发现更新和新发布网页的方式的重大变化。
我们知道搜索引擎获取网页数据有两种方式:拉取和推送。拉取是指搜索引擎爬虫访问 网站 以请求网页并从服务器“拉取”数据。这就是搜索引擎传统上的工作方式。
IndexNow 所做的是将内容发现更改为推送方法,这使发布者可以从快速索引和更少的服务器负载中受益,因为机器人不必不断地爬取他们的页面。主要搜索引擎的采用将是内容发布者和搜索引擎之间关系的演变,这将使双方受益。
适合内容发布者
对于内容发布者来说,它可以帮助减少爬取服务器的需要,搜索引擎不需要进行探索性爬取来检查页面是否已更新,并且减少了发现和索引内容的时间。
此外,减少服务器负载有助于服务器以最佳方式运行,而不会增加搜索引擎已经拥有的网页的冗余服务。
最终,它还通过减少爬行和索引的能源需求来减少全球变暖压力,从而使世界受益。
已经涉及多个搜索引擎,谷歌正在测试
最新数据显示,IndexNow 协议已被 Bing 和 Yandex 等多个搜索引擎采用,超过 80,000 个 网站 已开始发布并受益于更快的索引提交。
目前采用 IndexNow 协议的公司名单包括:
更让人担心的是,谷歌未来是否也会采用IndexNow协议。对此,谷歌发言人也在去年11月发表声明,确认谷歌将测试新的IndexNow协议。这意味着 IndexNow 的性能将显着提升。
此外,占据全球最大市场份额的cmsWordPress也在考虑支持IndexNow协议。然而,目前他们似乎在鼓励插件的开发,而不是急于将它们集成到 WordPress 核心本身中。可以说,WordPress目前还处于观望状态,等待谷歌等搜索引擎更广泛的行业接受。
如何部署 IndexNow?
对于网站的管理者,当网站页面发生变化时,只要通过该协议ping搜索引擎,搜索引擎就会收到成功通知。
图注:密钥生成过程,页面为机器翻译
如果您是开发人员,可以按照以下步骤部署 IndexNow:
1)使用在线密钥生成工具生成协议支持的密钥。
2) 将密钥托管在由 网站 根目录中的密钥值命名的文本文件中。
3)在添加、更新或删除 URL 后开始提交 URL。您可以为每个 API 调用提交一个 URL 或一组 URL。
4)提交 URL 就像使用更改后的 URL 和您的密钥发送一个简单的 HTTP 请求一样简单,如下所示:
有关实施的更多详细信息,请参见 IndexNow。
(网址:)
关于 IndexNow 的常见问题
▶ 搜索引擎提交 URL 的端点是什么?
- 启用 IndexNow 的搜索引擎会立即共享提交给所有其他启用 IndexNow 的搜索引擎的所有 URL,因此您只需通知一个端点。
▶ 提交网址会有什么效果?
- 如果搜索引擎喜欢你提交的URL内容,搜索引擎会根据自己的爬取逻辑和网站的配额尝试爬取,快速获取最新内容。
▶ 一天内提交 10,000 个 URL 会发生什么?
- 如果搜索引擎喜欢这些网址的内容并且网站有足够的抓取配额,搜索引擎将尝试抓取部分或全部网址。
▶ 如果 URL 已提交但未编入索引怎么办?
- 使用 IndexNow 可确保搜索引擎知道您的 网站 更新,但不保证页面会立即被搜索引擎抓取或编入索引,并且可能需要一些时间才能编入索引。
▶ 刚开始使用IndexNow,我应该发布去年更改的URL吗?
- 不,只需发布自您开始使用 IndexNow 以来已更改(添加、更新或删除)的 URL。
▶提交的网址是否计入抓取配额?
- 会议。每次爬网都计入 网站 的爬网配额。
▶为什么我没有看到搜索引擎索引的所有提交的 URL?
- 如果内容不符合搜索引擎选择标准,您可以选择不抓取和索引 URL。
▶IndexNow适合页面少的小网站吗?
- 当然。如果您希望您的内容一经更改就被搜索引擎发现,建议使用 IndexNow。
同一个 URL 一天可以提交多次吗?
- 建议避免一天多次提交相同的 URL。如果页面被频繁编辑,最好在两次编辑之间等待 10 分钟,然后再通知搜索引擎。如果页面不断更新,最好不要每次更改都使用 IndexNow。
▶ 我可以通过 API 提交 404 URL 吗?
- 能。失效链接(http 404、http 410) 页面可以提交通知搜索引擎关于新的死链接。
▶ 可以提交新的重定向吗?
- 能。可以通过提交新的重定向 URL(例如 301 重定向、302 重定向等)来通知搜索引擎内容已更改。
▶ 什么时候需要更换钥匙?
- 搜索引擎在收到新密钥时只会尝试抓取 {key}.txt 文件一次以验证所有权。此外,密钥不需要经常修改。
▶ 每个主机可以使用多个密钥吗?
- 能。如果您的 网站 使用不同的内容管理系统,每个系统都可以使用自己的密钥;在主机的根目录发布不同的密钥文件。
▶ 如果我有站点地图,我还需要 IndexNow 吗?
- 是的。搜索引擎访问站点地图的频率也可能非常低。使用 IndexNow,网站 管理员“不必”等待搜索引擎发现和抓取站点地图,并直接将新内容通知搜索引擎。
- -结尾 - - 查看全部
网页视频抓取工具 知乎(微软与俄罗斯搜索引擎Yandex推出新爬虫协议提高搜索引擎爬虫效率)
站长之家()新闻:为了在网站上发现很多新发布的页面,搜索引擎往往需要爬取和渲染上万个页面,可能需要几天到几周的时间才能发现内容发生了变化. 然而,这种低效的索引问题有望得到解决。
去年 10 月,微软与俄罗斯搜索引擎 Yandex 推出了 IndexNow 的新爬虫协议,旨在提高搜索引擎爬虫和索引的效率。
IndexNow 协议到底是什么?
具体来说,IndexNow 是由 Microsoft Bing 和 Yandex 创建的新协议,它允许 网站 在创建、更新或删除其 网站 内容时通过使用 API 轻松通知搜索引擎。
几天前,微软再次宣布,通过确保提交的 URL 在搜索引擎之间共享,它使该协议更易于实施。
这意味着 网站 管理员只需要一个 API 接口,所有 URL 将与所有支持 IndexNow 协议的搜索引擎共享。除了为内容发布者节省时间和精力之外,这还有助于搜索引擎的内容发现工作,从而使整个网络更加高效。
你可能已经觉得这个协议和百度的链接提交 API 很像。确实是这样,但是不保证内容被爬取或者内容提交后收录,搜索引擎只会被“通知”变化,并提升这些URL的爬取优先级到更高的水平。
注:站长之家已实现IndexNow接口推送。推送成功后,可以通过必应站长平台入口查看网址。
IndexNow 带来了搜索索引的演变
了解 IndexNow 协议后,您会发现它非常重要,因为它带来了搜索引擎发现更新和新发布网页的方式的重大变化。
我们知道搜索引擎获取网页数据有两种方式:拉取和推送。拉取是指搜索引擎爬虫访问 网站 以请求网页并从服务器“拉取”数据。这就是搜索引擎传统上的工作方式。
IndexNow 所做的是将内容发现更改为推送方法,这使发布者可以从快速索引和更少的服务器负载中受益,因为机器人不必不断地爬取他们的页面。主要搜索引擎的采用将是内容发布者和搜索引擎之间关系的演变,这将使双方受益。
适合内容发布者
对于内容发布者来说,它可以帮助减少爬取服务器的需要,搜索引擎不需要进行探索性爬取来检查页面是否已更新,并且减少了发现和索引内容的时间。
此外,减少服务器负载有助于服务器以最佳方式运行,而不会增加搜索引擎已经拥有的网页的冗余服务。
最终,它还通过减少爬行和索引的能源需求来减少全球变暖压力,从而使世界受益。
已经涉及多个搜索引擎,谷歌正在测试
最新数据显示,IndexNow 协议已被 Bing 和 Yandex 等多个搜索引擎采用,超过 80,000 个 网站 已开始发布并受益于更快的索引提交。
目前采用 IndexNow 协议的公司名单包括:
更让人担心的是,谷歌未来是否也会采用IndexNow协议。对此,谷歌发言人也在去年11月发表声明,确认谷歌将测试新的IndexNow协议。这意味着 IndexNow 的性能将显着提升。
此外,占据全球最大市场份额的cmsWordPress也在考虑支持IndexNow协议。然而,目前他们似乎在鼓励插件的开发,而不是急于将它们集成到 WordPress 核心本身中。可以说,WordPress目前还处于观望状态,等待谷歌等搜索引擎更广泛的行业接受。
如何部署 IndexNow?
对于网站的管理者,当网站页面发生变化时,只要通过该协议ping搜索引擎,搜索引擎就会收到成功通知。
图注:密钥生成过程,页面为机器翻译
如果您是开发人员,可以按照以下步骤部署 IndexNow:
1)使用在线密钥生成工具生成协议支持的密钥。
2) 将密钥托管在由 网站 根目录中的密钥值命名的文本文件中。
3)在添加、更新或删除 URL 后开始提交 URL。您可以为每个 API 调用提交一个 URL 或一组 URL。
4)提交 URL 就像使用更改后的 URL 和您的密钥发送一个简单的 HTTP 请求一样简单,如下所示:
有关实施的更多详细信息,请参见 IndexNow。
(网址:)
关于 IndexNow 的常见问题
▶ 搜索引擎提交 URL 的端点是什么?
- 启用 IndexNow 的搜索引擎会立即共享提交给所有其他启用 IndexNow 的搜索引擎的所有 URL,因此您只需通知一个端点。
▶ 提交网址会有什么效果?
- 如果搜索引擎喜欢你提交的URL内容,搜索引擎会根据自己的爬取逻辑和网站的配额尝试爬取,快速获取最新内容。
▶ 一天内提交 10,000 个 URL 会发生什么?
- 如果搜索引擎喜欢这些网址的内容并且网站有足够的抓取配额,搜索引擎将尝试抓取部分或全部网址。
▶ 如果 URL 已提交但未编入索引怎么办?
- 使用 IndexNow 可确保搜索引擎知道您的 网站 更新,但不保证页面会立即被搜索引擎抓取或编入索引,并且可能需要一些时间才能编入索引。
▶ 刚开始使用IndexNow,我应该发布去年更改的URL吗?
- 不,只需发布自您开始使用 IndexNow 以来已更改(添加、更新或删除)的 URL。
▶提交的网址是否计入抓取配额?
- 会议。每次爬网都计入 网站 的爬网配额。
▶为什么我没有看到搜索引擎索引的所有提交的 URL?
- 如果内容不符合搜索引擎选择标准,您可以选择不抓取和索引 URL。
▶IndexNow适合页面少的小网站吗?
- 当然。如果您希望您的内容一经更改就被搜索引擎发现,建议使用 IndexNow。
同一个 URL 一天可以提交多次吗?
- 建议避免一天多次提交相同的 URL。如果页面被频繁编辑,最好在两次编辑之间等待 10 分钟,然后再通知搜索引擎。如果页面不断更新,最好不要每次更改都使用 IndexNow。
▶ 我可以通过 API 提交 404 URL 吗?
- 能。失效链接(http 404、http 410) 页面可以提交通知搜索引擎关于新的死链接。
▶ 可以提交新的重定向吗?
- 能。可以通过提交新的重定向 URL(例如 301 重定向、302 重定向等)来通知搜索引擎内容已更改。
▶ 什么时候需要更换钥匙?
- 搜索引擎在收到新密钥时只会尝试抓取 {key}.txt 文件一次以验证所有权。此外,密钥不需要经常修改。
▶ 每个主机可以使用多个密钥吗?
- 能。如果您的 网站 使用不同的内容管理系统,每个系统都可以使用自己的密钥;在主机的根目录发布不同的密钥文件。
▶ 如果我有站点地图,我还需要 IndexNow 吗?
- 是的。搜索引擎访问站点地图的频率也可能非常低。使用 IndexNow,网站 管理员“不必”等待搜索引擎发现和抓取站点地图,并直接将新内容通知搜索引擎。
- -结尾 - -
网页视频抓取工具 知乎(如何用RPA机器人制作批量下载文本、视频、去水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-11 14:00
有没有什么软件可以识别视频文字并提取视频中的文字?是的,我使用的是 RPA 机器人,工具是免费的,但您需要自己配置机器人。下面我将分享我如何批量提取视频文本。
短视频运营小伙伴的日常工作之一就是寻找标杆账号,批量分析分析标杆账号的作品和内容,经常需要批量下载标杆账号的视频,转化为文案,并从中学习……
但是一个个复制链接,提取下载视频太麻烦了,不仅浪费时间和精力,而且感觉像个工具人!
想要批量下载短视频抖音?想要轻松便捷地下载抖音无水印快手视频?
建议大家使用“轻摇去水印”抖音快手短视频下载工具。今天教大家如何使用RPA机器人进行批量下载文字、视频、去水印等方法。相信对很多创意团队会有很大帮助!
简单介绍一下自己,我是掘金创始人阿雨瓜瓜,从SEO开始做互联网业务。他从零开始建立了一个平均日均50,000个UV的垂直行业站。他一直负责网站的流量增长,日均1000万次UV。他还自己建造了数百个交通站。从事互联网12年,专注RPA自动化机器人。培训和私域流量培训,带你20天搞定RPA自动化机器人。
批量下载抖音视频,提取文本内容机器人
准备工作:uibot、网页版抖音、轻摇小程序
01 打开网页版抖音——搜索进入抖音博主首页——然后点击博主的作品
提取博主每个视频的链接
准备视频链接写作表格
采用模块:
1 打开工作簿
2 绑定工作簿
复制视频链接
采用模块:
单击目标获取剪贴板内容并写入单元格
最后调试看看能不能把视频链接写到表中。
循环采集
采用模块:
1.点击目标
2.计数循环
循环获取博主视频链接
遵循下图:排序、增加延迟和获取行
运行机器人以获取录制到表单的视频链接
阅读捕获的内容并下载无水印的文本和视频
绑定读取表格内容
采用模块:
1 绑定工作簿
2.读取列
遍历出视频链接,输入到震动提取的文本框中
采用模块:
循环
单击图像模拟键盘延迟
将文本复制到表格
采用模块:
单击图像以模拟工作簿的键盘绑定以获取行数并写入单元格
机器人作业结果显示
虽然步骤很多,但机器人非常简单。
如果你看到这个,说明你真的很想提高你的自动化能力和思维发展。相信看完这篇文章你已经学到了很多。如果你觉得我的回答对你有很大帮助,可以在左下角点个赞,后面我会分享更多干货。
如果想系统了解我们RPA工具的使用,私信“666”领取机器人源码和工具教程资料。 查看全部
网页视频抓取工具 知乎(如何用RPA机器人制作批量下载文本、视频、去水印)
有没有什么软件可以识别视频文字并提取视频中的文字?是的,我使用的是 RPA 机器人,工具是免费的,但您需要自己配置机器人。下面我将分享我如何批量提取视频文本。
短视频运营小伙伴的日常工作之一就是寻找标杆账号,批量分析分析标杆账号的作品和内容,经常需要批量下载标杆账号的视频,转化为文案,并从中学习……
但是一个个复制链接,提取下载视频太麻烦了,不仅浪费时间和精力,而且感觉像个工具人!
想要批量下载短视频抖音?想要轻松便捷地下载抖音无水印快手视频?
建议大家使用“轻摇去水印”抖音快手短视频下载工具。今天教大家如何使用RPA机器人进行批量下载文字、视频、去水印等方法。相信对很多创意团队会有很大帮助!
简单介绍一下自己,我是掘金创始人阿雨瓜瓜,从SEO开始做互联网业务。他从零开始建立了一个平均日均50,000个UV的垂直行业站。他一直负责网站的流量增长,日均1000万次UV。他还自己建造了数百个交通站。从事互联网12年,专注RPA自动化机器人。培训和私域流量培训,带你20天搞定RPA自动化机器人。
批量下载抖音视频,提取文本内容机器人
准备工作:uibot、网页版抖音、轻摇小程序
01 打开网页版抖音——搜索进入抖音博主首页——然后点击博主的作品
提取博主每个视频的链接
准备视频链接写作表格
采用模块:
1 打开工作簿
2 绑定工作簿
复制视频链接
采用模块:
单击目标获取剪贴板内容并写入单元格
最后调试看看能不能把视频链接写到表中。
循环采集
采用模块:
1.点击目标
2.计数循环
循环获取博主视频链接
遵循下图:排序、增加延迟和获取行
运行机器人以获取录制到表单的视频链接
阅读捕获的内容并下载无水印的文本和视频
绑定读取表格内容
采用模块:
1 绑定工作簿
2.读取列
遍历出视频链接,输入到震动提取的文本框中
采用模块:
循环
单击图像模拟键盘延迟
将文本复制到表格
采用模块:
单击图像以模拟工作簿的键盘绑定以获取行数并写入单元格
机器人作业结果显示
虽然步骤很多,但机器人非常简单。
如果你看到这个,说明你真的很想提高你的自动化能力和思维发展。相信看完这篇文章你已经学到了很多。如果你觉得我的回答对你有很大帮助,可以在左下角点个赞,后面我会分享更多干货。
如果想系统了解我们RPA工具的使用,私信“666”领取机器人源码和工具教程资料。
网页视频抓取工具 知乎(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-08 03:12
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
蓝琴云网盘链接:知乎文章采集软件
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
1、知乎采集软件
2、导入文章链接
3、导入链接成功
4、导入文章链接
5、知乎文章采集
6、文章下载保存
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入下载
1、问答链接示例:
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
知乎文章采集
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
"文章采集软件"知乎问答,文章批处理采集软件
知乎文章采集
六、操作方法总结
1、先下载蓝琴云网盘的软件链接【蓝琴云链接:知乎文章采集软件】
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到刚刚下载的知乎文章。
注意:知乎文章的所有下载仅供自学使用,禁止直接或间接分发、使用、改编或再分发以用于分发或使用,或用于任何其他商业目的. 查看全部
网页视频抓取工具 知乎(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(建议使用默认html,html相当于本地网页,可以永久保存到电脑);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
蓝琴云网盘链接:知乎文章采集软件
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
1、知乎采集软件
2、导入文章链接
3、导入链接成功
4、导入文章链接
5、知乎文章采集
6、文章下载保存
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入下载
1、问答链接示例:
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
知乎文章采集
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
"文章采集软件"知乎问答,文章批处理采集软件
知乎文章采集
六、操作方法总结
1、先下载蓝琴云网盘的软件链接【蓝琴云链接:知乎文章采集软件】
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到刚刚下载的知乎文章。
注意:知乎文章的所有下载仅供自学使用,禁止直接或间接分发、使用、改编或再分发以用于分发或使用,或用于任何其他商业目的.
网页视频抓取工具 知乎(几款电脑端可以用来下载B站视频的工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-01-07 07:11
前几天有公众号的朋友说之前分享的B站下载工具大部分都报废了,所以今天给大家带来几款可以在电脑上下载B站视频的工具一边,希望能帮到你。
调低工具
网页版
在B站的视频链接bilibili后面加上jj就可以跳转到下载页面,但是这种方式从B站下载视频只能下载7天以上浏览量的视频。在很多情况下,这是不适用的,所以下面是大家介绍其客户端如何从B站下载视频。
客户端视频下载步骤
1、 去网页下载客户端,chirp down工具
2、安装时记得勾选图中两项,选择安装路径
3、将B站的视频链接粘贴到框中,按回车进入下载页面
4、选择批量下载方式下载视频
5、点击批量下载视频
6、下载界面
B站视频下载工具
工具下载方式
1、B站视频链接bilibili前面加i获取下载链接,B站视频下载工具链接进入下载
指示
1、安装后,将b站的视频链接复制到下方方框中
2、点击开始下载
注意:软件必须放置在没有中文字符和空格的路径中
B站视频下载的两个编辑器,个人测试用。如果你需要这两个工具,可以通过上面的链接下载,也可以在微信后台回复“A19”获取下载的两个编辑器。直播工具。
第一次发帖==,如果觉得不错,请点个赞。
公众号“大学生活必备”有更多提示和资源。你可以在微信上搜索我的公众号“大学生活的必需品”。 查看全部
网页视频抓取工具 知乎(几款电脑端可以用来下载B站视频的工具,你知道吗?)
前几天有公众号的朋友说之前分享的B站下载工具大部分都报废了,所以今天给大家带来几款可以在电脑上下载B站视频的工具一边,希望能帮到你。
调低工具
网页版
在B站的视频链接bilibili后面加上jj就可以跳转到下载页面,但是这种方式从B站下载视频只能下载7天以上浏览量的视频。在很多情况下,这是不适用的,所以下面是大家介绍其客户端如何从B站下载视频。
客户端视频下载步骤
1、 去网页下载客户端,chirp down工具
2、安装时记得勾选图中两项,选择安装路径
3、将B站的视频链接粘贴到框中,按回车进入下载页面
4、选择批量下载方式下载视频
5、点击批量下载视频
6、下载界面
B站视频下载工具
工具下载方式
1、B站视频链接bilibili前面加i获取下载链接,B站视频下载工具链接进入下载
指示
1、安装后,将b站的视频链接复制到下方方框中
2、点击开始下载
注意:软件必须放置在没有中文字符和空格的路径中
B站视频下载的两个编辑器,个人测试用。如果你需要这两个工具,可以通过上面的链接下载,也可以在微信后台回复“A19”获取下载的两个编辑器。直播工具。
第一次发帖==,如果觉得不错,请点个赞。
公众号“大学生活必备”有更多提示和资源。你可以在微信上搜索我的公众号“大学生活的必需品”。
网页视频抓取工具 知乎( 2.-gtcraping的路径进行数据编号控制条数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-05 18:06
2.-gtcraping的路径进行数据编号控制条数)
这是简单数据分析系列文章的第十篇。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,里面收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页视频抓取工具 知乎(
2.-gtcraping的路径进行数据编号控制条数)
这是简单数据分析系列文章的第十篇。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,里面收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页视频抓取工具 知乎(一下反爬虫策略及其应对方法,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-05 18:05
随着大数据的普及,互联网上各种网络爬虫/爬虫工具蜂拥而至。因此,网络数据成为大家竞争和掠夺的资源,但网站运营商必须开始保护自己的数据资源。避免竞争对手获取您自己的数据,防止更大的业务损失。下面总结一下反爬虫策略及其对策。
来看看我用的代理IP。质量非常好。如果需要,您可以对其进行测试:
专属资源适合长期爬虫业务,IP并发量大,API调用频率不限,海量抽取,产品安全稳定,支持http、https、sk5三种协议,适合爬虫(舆论、e-电商、短视频)、抢购、seo等多种业务
个人电脑:
移动
一、什么是爬虫和反爬虫
一张图说明一切:
爬虫和反爬虫是致命的对手,无论爬虫多么强大,都可以通过复杂的反爬虫机制被发现。同样,无论爬行动物多么强大
系统多么细致,先进的网络爬虫都能破解。胜负的关键取决于双方投入了多少资源。为了更好的了解爬虫和反
爬虫机制,下面有一些定义:
爬虫:利用任何技术手段批量获取网站信息。关键是批量大小。
反爬虫:使用任何技术手段防止他人批量获取自己的网站信息。关键也是批次。
误伤:在反爬虫过程中,普通用户被误认为是爬虫。误伤率高的反爬虫策略再有效也无法使用。
拦截:成功阻止爬虫访问。会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,意外伤害的可能性就越大。所以有一个权衡。
因此,我们可以知道爬虫最基本的特性之一就是批处理,反爬虫机制也是根据这个特性做出判断的,但是反爬虫
仍然是权衡利弊的选择。它既要求低误伤率,又要求高拦截率。这也是它的漏洞。关于网站为什么以及如何制作
确定反爬虫策略,可以看反爬虫经验总结。
二、反爬虫方法及响应
一般来说,网站从三个方面进行反爬虫:请求网站访问时的header、用户行为、目标网站目录和数据加载方式。向前
两个方面可以说是反爬虫策略中最常见的,第三个是使用ajax(异步加载)来加载页面目录或内容。
增加爬虫在形成对目标网站的访问后获取数据的难度。
但是仅仅检查请求头或者做一些ip限制显然不能满足运营商对反垃圾邮件的要求,所以进一步的对策
也有很多付出。最重要的大概是:Cookie限制、验证码反爬虫、Noscript。
2.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。由于普通用户通过浏览器访问网站,目标网络
站点在收到请求时通常会检查Headers 中的User-Agent 字段。如果不是携带正常User-Agent信息的请求,则无法进行通信。
通过请求。还有一部分网站为了防止盗链,也会校验请求头中的Referer字段。如果遇到这种反爬虫机制,可以
为了直接给自己写的爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;此外,通过捕获请求
包分析,修改Referer值到目标网站域名,可以很好的绕过。
2.2 基于用户行为的反爬虫
有些网站会通过用户行为来检测网站的访问者是否是爬虫。例如,同一个IP在短时间内多次访问同一个页面,或者同一个
在短时间内对一个帐户执行多次相同的操作。大多数 网站 都是前一种情况。针对这种情况有两种策略:
1)使用代理ip。比如可以写一个专门的脚本去抓取网上可用的代理ip,然后将抓取到的代理ip维护到代理池中进行爬取
蠕虫使用,当然,其实不管抓到的ip是免费的还是付费的,平时的使用效果都是很一般的。如果您需要捕获高价值数据
如果愿意,也可以考虑购买宽带adsl拨号VPS。如果ip被目标网站屏蔽了,再拨一下就行了。
2) 降低请求频率。例如,每个时间段请求一次或多次请求后休眠一段时间。由于网站得到的ip是一个
局域网的ip,该ip是区域内所有人共享的,所以间隔不需要特别长
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。对于有逻辑漏洞的网站,可以请求多个
二、注销,重新登录,继续请求,绕过同一账号短时间内不能多次发出同一个请求的限制。如果有多个账户,
切换使用,效果更佳。
2.3 动态页面反爬虫
以上情况大部分出现在静态页面上,但是对于动态网页,我们需要爬取的数据是通过ajax请求获取的,或者通过
通过 JavaScript 生成。首先使用 Firebug 或 HttpFox 来分析网络请求。如果能找到ajax请求,也可以具体分析一下
参数和响应的具体含义,我们可以使用上面的方法,直接用requests或者urllib2来模拟ajax请求,响应json
执行分析以获得所需的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站加密了ajax请求的所有参数。我们什么也做不了
为您需要的数据构建一个请求。还有一些被严格保护的网站,除了对ajax参数进行加密外,还封装了一些基础功能,
都是在调用自己的接口,接口参数都是加密的。
遇到这样的网站,就不能用上面的方法了。使用selenium+phantomJS框架调用浏览器内核使用
phantomJS 执行 js 来模拟人工操作并触发页面中的 js 脚本。从填表到点击按钮到滚动页面,一切都可以建模
计划是,不管具体的请求和响应过程,只是完全模拟人们浏览页面获取数据的过程。使用这个框架几乎环绕
大多数反爬虫,因为它不是冒充浏览器获取数据(上面提到的通过添加
headers 是在一定程度上伪装成浏览器),它本身就是一个浏览器,phantomJS 是一个没有界面的浏览器,只有
控制这个浏览器的不是人。
2.4 Cookie 限制
类似于Headers验证的反爬虫机制,当用户向目标网站发送请求时,请求数据会再次携带Cookie,网站会通过验证
请求信息中是否有cookie,通过cookie的值判断请求是真实用户还是爬虫,第一次打开
该网页将生成一个随机 cookie。如果再次打开网页时cookie不存在,您可以重新设置。第三次打开它,它仍然不存在。
爬虫很可能正在工作。
Cookie Check 和 Headers 的区别在于用户发送的 Headers 的内容格式是固定的,很容易被伪造。饼干不是。
当然。原因是我们在分析浏览器请求网站访问的过程中分析的cookies,往往是通过相关的js等进程处理的。
如果更改了域的cookie,如果直接手动修改爬虫携带的cookie来访问相应的网页,则携带的cookie已经是访问者。
在询问域之后,而不是访问之前的域,是不可能成功模拟整个过程的。这种情况必然会导致爬虫访问页面
失败。分析cookies,它可能携带大量随机hash字符串,或者不同时间戳的字符串,并且会根据每次访问进行更新。
新域名的价值。对于这个限制,你必须在捕获和分析目标网站时先清除浏览器的cookies,然后在第一次访问
在完成访问的过程中观察浏览器的请求细节(这个过程中通常会发生几次301/302跳转,每次跳转网站返回
向浏览器返回不同的cookie,最后跳转请求成功)。抓包完成对请求细节的分析后,对爬虫进行建模
规划好这个过渡过程,然后将cookie作为爬虫本身携带的cookie进行拦截,这样就可以绕过cookie的限制完成目标网站
参观过。
2.5 验证码限制
这是一个相当古老但有效的反爬虫策略。早些时候,这种验证码可以通过OCR技术进行简单的图像识别。
不要破解,但目前验证码的干扰线噪声太大,肉眼无法轻易识别。所以现在,由于 OCR
在技术发展薄弱的情况下,验证码技术已经成为许多网站最有效的方法之一。
除了识别问题,验证码还有一个值得注意的问题。许多网站现在都在使用第三方验证码服务。当用户点击
打开目标网站的登录页面时,登录页面显示的验证码是从第三方(如阿里云)提供的链接中加载的。此时,我们正在模拟
登录时,您需要多一步从网页提供的第三方链接中获取验证码,而这一步往往意味着一个陷阱。由阿里云提供
以验证码服务为例,登录页面的源码中会显示阿里云提供的第三方链接,但是匹配到这个链接就可以抓取验证码了
稍后我们会发现验证码无效。仔细分析抓包的请求数据,发现普通浏览器在请求验证码时会带一个额外的ts。
参数,该参数是由当前时间戳生成的,但它不是完整的时间戳,而是将时间戳四舍五入保留字后九位
Fustring,对付这种第三方服务只能小心翼翼,运气好,三分之一的日子注定是猜不透的。还有一种特殊的第三方检验
证书代码,也就是所谓的拖拽验证,只能说互联网创业有3种模式:2b、2c、2vc。 查看全部
网页视频抓取工具 知乎(一下反爬虫策略及其应对方法,你值得拥有!!)
随着大数据的普及,互联网上各种网络爬虫/爬虫工具蜂拥而至。因此,网络数据成为大家竞争和掠夺的资源,但网站运营商必须开始保护自己的数据资源。避免竞争对手获取您自己的数据,防止更大的业务损失。下面总结一下反爬虫策略及其对策。
来看看我用的代理IP。质量非常好。如果需要,您可以对其进行测试:
专属资源适合长期爬虫业务,IP并发量大,API调用频率不限,海量抽取,产品安全稳定,支持http、https、sk5三种协议,适合爬虫(舆论、e-电商、短视频)、抢购、seo等多种业务
个人电脑:
移动
一、什么是爬虫和反爬虫
一张图说明一切:
爬虫和反爬虫是致命的对手,无论爬虫多么强大,都可以通过复杂的反爬虫机制被发现。同样,无论爬行动物多么强大
系统多么细致,先进的网络爬虫都能破解。胜负的关键取决于双方投入了多少资源。为了更好的了解爬虫和反
爬虫机制,下面有一些定义:
爬虫:利用任何技术手段批量获取网站信息。关键是批量大小。
反爬虫:使用任何技术手段防止他人批量获取自己的网站信息。关键也是批次。
误伤:在反爬虫过程中,普通用户被误认为是爬虫。误伤率高的反爬虫策略再有效也无法使用。
拦截:成功阻止爬虫访问。会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,意外伤害的可能性就越大。所以有一个权衡。
因此,我们可以知道爬虫最基本的特性之一就是批处理,反爬虫机制也是根据这个特性做出判断的,但是反爬虫
仍然是权衡利弊的选择。它既要求低误伤率,又要求高拦截率。这也是它的漏洞。关于网站为什么以及如何制作
确定反爬虫策略,可以看反爬虫经验总结。
二、反爬虫方法及响应
一般来说,网站从三个方面进行反爬虫:请求网站访问时的header、用户行为、目标网站目录和数据加载方式。向前
两个方面可以说是反爬虫策略中最常见的,第三个是使用ajax(异步加载)来加载页面目录或内容。
增加爬虫在形成对目标网站的访问后获取数据的难度。
但是仅仅检查请求头或者做一些ip限制显然不能满足运营商对反垃圾邮件的要求,所以进一步的对策
也有很多付出。最重要的大概是:Cookie限制、验证码反爬虫、Noscript。
2.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。由于普通用户通过浏览器访问网站,目标网络
站点在收到请求时通常会检查Headers 中的User-Agent 字段。如果不是携带正常User-Agent信息的请求,则无法进行通信。
通过请求。还有一部分网站为了防止盗链,也会校验请求头中的Referer字段。如果遇到这种反爬虫机制,可以
为了直接给自己写的爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;此外,通过捕获请求
包分析,修改Referer值到目标网站域名,可以很好的绕过。
2.2 基于用户行为的反爬虫
有些网站会通过用户行为来检测网站的访问者是否是爬虫。例如,同一个IP在短时间内多次访问同一个页面,或者同一个
在短时间内对一个帐户执行多次相同的操作。大多数 网站 都是前一种情况。针对这种情况有两种策略:
1)使用代理ip。比如可以写一个专门的脚本去抓取网上可用的代理ip,然后将抓取到的代理ip维护到代理池中进行爬取
蠕虫使用,当然,其实不管抓到的ip是免费的还是付费的,平时的使用效果都是很一般的。如果您需要捕获高价值数据
如果愿意,也可以考虑购买宽带adsl拨号VPS。如果ip被目标网站屏蔽了,再拨一下就行了。
2) 降低请求频率。例如,每个时间段请求一次或多次请求后休眠一段时间。由于网站得到的ip是一个
局域网的ip,该ip是区域内所有人共享的,所以间隔不需要特别长
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。对于有逻辑漏洞的网站,可以请求多个
二、注销,重新登录,继续请求,绕过同一账号短时间内不能多次发出同一个请求的限制。如果有多个账户,
切换使用,效果更佳。
2.3 动态页面反爬虫
以上情况大部分出现在静态页面上,但是对于动态网页,我们需要爬取的数据是通过ajax请求获取的,或者通过
通过 JavaScript 生成。首先使用 Firebug 或 HttpFox 来分析网络请求。如果能找到ajax请求,也可以具体分析一下
参数和响应的具体含义,我们可以使用上面的方法,直接用requests或者urllib2来模拟ajax请求,响应json
执行分析以获得所需的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站加密了ajax请求的所有参数。我们什么也做不了
为您需要的数据构建一个请求。还有一些被严格保护的网站,除了对ajax参数进行加密外,还封装了一些基础功能,
都是在调用自己的接口,接口参数都是加密的。
遇到这样的网站,就不能用上面的方法了。使用selenium+phantomJS框架调用浏览器内核使用
phantomJS 执行 js 来模拟人工操作并触发页面中的 js 脚本。从填表到点击按钮到滚动页面,一切都可以建模
计划是,不管具体的请求和响应过程,只是完全模拟人们浏览页面获取数据的过程。使用这个框架几乎环绕
大多数反爬虫,因为它不是冒充浏览器获取数据(上面提到的通过添加
headers 是在一定程度上伪装成浏览器),它本身就是一个浏览器,phantomJS 是一个没有界面的浏览器,只有
控制这个浏览器的不是人。
2.4 Cookie 限制
类似于Headers验证的反爬虫机制,当用户向目标网站发送请求时,请求数据会再次携带Cookie,网站会通过验证
请求信息中是否有cookie,通过cookie的值判断请求是真实用户还是爬虫,第一次打开
该网页将生成一个随机 cookie。如果再次打开网页时cookie不存在,您可以重新设置。第三次打开它,它仍然不存在。
爬虫很可能正在工作。
Cookie Check 和 Headers 的区别在于用户发送的 Headers 的内容格式是固定的,很容易被伪造。饼干不是。
当然。原因是我们在分析浏览器请求网站访问的过程中分析的cookies,往往是通过相关的js等进程处理的。
如果更改了域的cookie,如果直接手动修改爬虫携带的cookie来访问相应的网页,则携带的cookie已经是访问者。
在询问域之后,而不是访问之前的域,是不可能成功模拟整个过程的。这种情况必然会导致爬虫访问页面
失败。分析cookies,它可能携带大量随机hash字符串,或者不同时间戳的字符串,并且会根据每次访问进行更新。
新域名的价值。对于这个限制,你必须在捕获和分析目标网站时先清除浏览器的cookies,然后在第一次访问
在完成访问的过程中观察浏览器的请求细节(这个过程中通常会发生几次301/302跳转,每次跳转网站返回
向浏览器返回不同的cookie,最后跳转请求成功)。抓包完成对请求细节的分析后,对爬虫进行建模
规划好这个过渡过程,然后将cookie作为爬虫本身携带的cookie进行拦截,这样就可以绕过cookie的限制完成目标网站
参观过。
2.5 验证码限制
这是一个相当古老但有效的反爬虫策略。早些时候,这种验证码可以通过OCR技术进行简单的图像识别。
不要破解,但目前验证码的干扰线噪声太大,肉眼无法轻易识别。所以现在,由于 OCR
在技术发展薄弱的情况下,验证码技术已经成为许多网站最有效的方法之一。
除了识别问题,验证码还有一个值得注意的问题。许多网站现在都在使用第三方验证码服务。当用户点击
打开目标网站的登录页面时,登录页面显示的验证码是从第三方(如阿里云)提供的链接中加载的。此时,我们正在模拟
登录时,您需要多一步从网页提供的第三方链接中获取验证码,而这一步往往意味着一个陷阱。由阿里云提供
以验证码服务为例,登录页面的源码中会显示阿里云提供的第三方链接,但是匹配到这个链接就可以抓取验证码了
稍后我们会发现验证码无效。仔细分析抓包的请求数据,发现普通浏览器在请求验证码时会带一个额外的ts。
参数,该参数是由当前时间戳生成的,但它不是完整的时间戳,而是将时间戳四舍五入保留字后九位
Fustring,对付这种第三方服务只能小心翼翼,运气好,三分之一的日子注定是猜不透的。还有一种特殊的第三方检验
证书代码,也就是所谓的拖拽验证,只能说互联网创业有3种模式:2b、2c、2vc。
网页视频抓取工具 知乎(代码知道整个流程是什么样子,接下来撸代码的过程就简单了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-05 18:04
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
<p>{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
</p>
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
<p># -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
</p>
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。点击查看原文查看源码
本文分享自微信公众号——桃子的学习笔记(LeeTaoThinks)。 查看全部
网页视频抓取工具 知乎(代码知道整个流程是什么样子,接下来撸代码的过程就简单了)
前言
现在允许知乎上传视频,但我不能下载视频。气死我了,只好研究了一下,然后我输入了代码,方便下载和保存视频。
接下来以答案为例,分享整个下载过程。
调试它
打开F12,找到光标,如下图:
然后将光标移动到视频。如下所示:
这是什么?视野中出现了一个神秘的链接:,让我们把这个链接复制到浏览器,然后打开:
看来这就是我们要找的视频了,别着急,我们先看看网页的请求,然后你会发现一个很有趣的请求(这里强调):
我们自己来看看数据:
<p>{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc41 ... ot%3B,
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc41 ... ot%3B,
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc41 ... ot%3B,
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-9 ... ot%3B,
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}
</p>
没错,我们要下载的视频就在这里,其中ld代表通用清晰度,sd代表标清,hd代表高清。再次在浏览器中打开对应的链接,然后右击保存即可下载视频。
代码
知道了整个流程是什么样子的,接下来的压码流程就简单了,不过我这里就不多说了,直接上代码吧:
<p># -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())
</p>
结束语
代码还有优化的空间。我刚刚下载了答案中的第一个视频。理论上,一个答案下应该有多个视频。如果有什么问题或者建议,可以多交流。点击查看原文查看源码
本文分享自微信公众号——桃子的学习笔记(LeeTaoThinks)。
网页视频抓取工具 知乎(微信公众号插入了自制的有趣视频链接地址的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-04 20:06
我们的大部分编辑现在都面临着一个严重的问题,那就是用户对文章的内容越来越挑剔。为此,不少公众号都在微信图文中插入自制搞笑视频。那么当我们想借用别人的视频到自己的公众号时该怎么办呢?我们在小蚂蚁编辑器中找到了这个问题的答案。
第一步,打开首页,点击新媒体助手下的视频提取。
第二步,复制要提取的视频的微信图片和文字链接地址。
第三步:将上一步复制的地址填入“微信文章地址”框中,点击“提取”按钮。(微信文章必须以/s?src=开头。)
第四步:文章中的所有视频可以同时提取链接。您可以单击右侧的复制、插入和下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入到编辑器中,也可以直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入编辑区。(如果是提取微信公众号本地上传的视频,则无法复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频不存在”)。
下载:点击下载将视频下载到本地,可在微信公众平台后台素材库上传使用(适用于公众号本地上传的视频)。
这样我们就可以自由的提取我们想要的视频了,而且操作简单方便,节省了时间,省去了很多繁琐的步骤,同时也将文章内容的丰富度提升到了一个层次。 查看全部
网页视频抓取工具 知乎(微信公众号插入了自制的有趣视频链接地址的方法)
我们的大部分编辑现在都面临着一个严重的问题,那就是用户对文章的内容越来越挑剔。为此,不少公众号都在微信图文中插入自制搞笑视频。那么当我们想借用别人的视频到自己的公众号时该怎么办呢?我们在小蚂蚁编辑器中找到了这个问题的答案。
第一步,打开首页,点击新媒体助手下的视频提取。
第二步,复制要提取的视频的微信图片和文字链接地址。
第三步:将上一步复制的地址填入“微信文章地址”框中,点击“提取”按钮。(微信文章必须以/s?src=开头。)
第四步:文章中的所有视频可以同时提取链接。您可以单击右侧的复制、插入和下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入到编辑器中,也可以直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入编辑区。(如果是提取微信公众号本地上传的视频,则无法复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频不存在”)。
下载:点击下载将视频下载到本地,可在微信公众平台后台素材库上传使用(适用于公众号本地上传的视频)。
这样我们就可以自由的提取我们想要的视频了,而且操作简单方便,节省了时间,省去了很多繁琐的步骤,同时也将文章内容的丰富度提升到了一个层次。

