
网页表格抓取
网页表格抓取(Python快速的抓取表格的思路和方法(4-7行))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-18 14:11
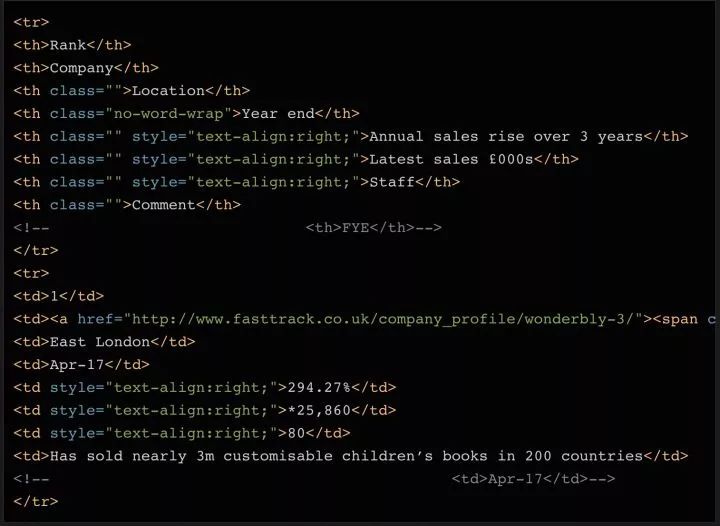
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
页面内容过多时会变慢,给人一种导出失败的错觉
除了表格中的数据,页面上的其他所有内容也会导入EXCEL,需要后期整理
虽然,没有技术要求。但是如果要处理大量的页面,就需要一一操作,相当繁琐
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
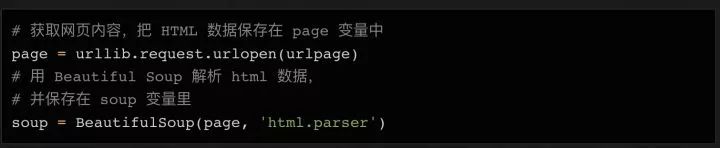
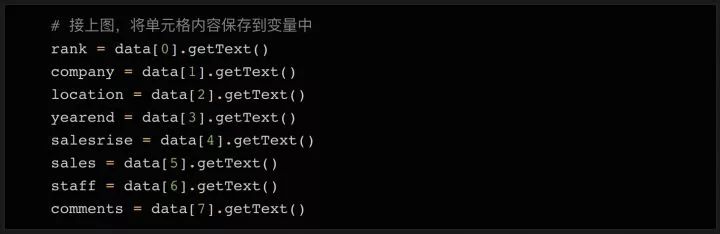
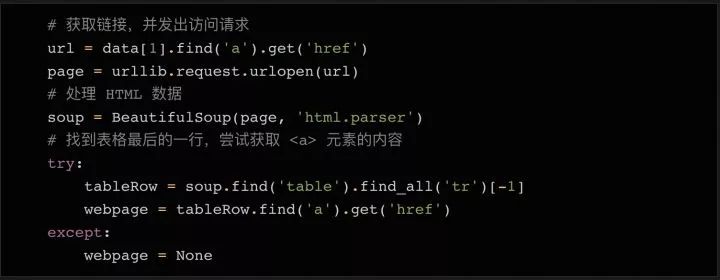
主要用到三个库:requests、BeautifulSoup和pandas(第1-3行)
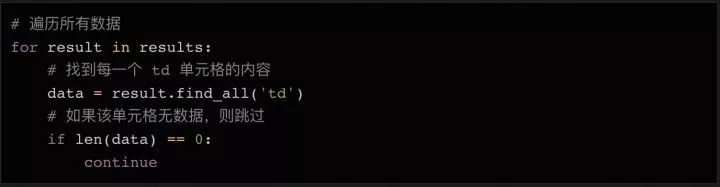
使用 BeautifulSoup 获取 table 标签下的表格内容(第 4-7 行)
使用 pd.read_html 直接读取 HTML 中的内容作为 DataFrame(第 8-11 行)
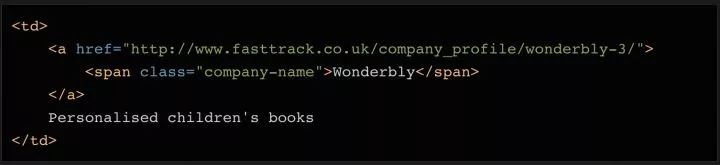
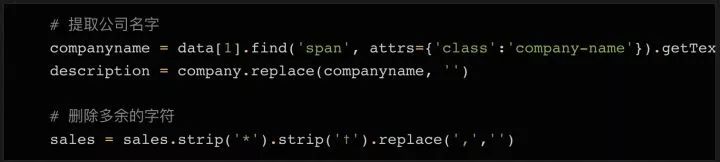
这一步是关键。pd.read_html 方法省去了很多解析HTML的步骤,否则用BeautifulSoup一一抓取表格内容会很麻烦。它还使用了prettify()方法,可以把BeautifulSoup对象变成字符串,因为pd.read_html处理的是字符串对象
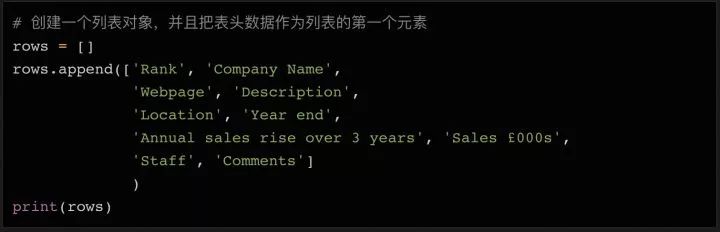
最后将DataFrame导出为EXCEL(12行)
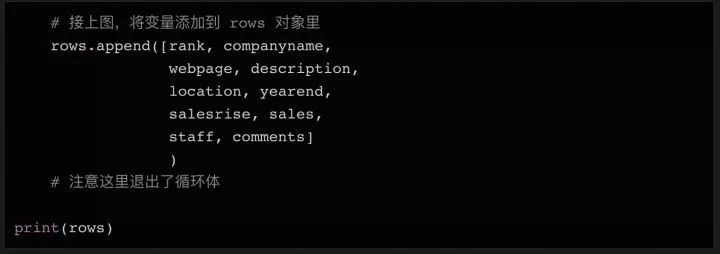
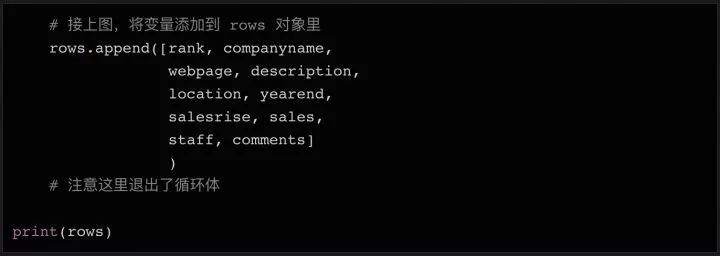
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。 查看全部
网页表格抓取(Python快速的抓取表格的思路和方法(4-7行))
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
页面内容过多时会变慢,给人一种导出失败的错觉
除了表格中的数据,页面上的其他所有内容也会导入EXCEL,需要后期整理
虽然,没有技术要求。但是如果要处理大量的页面,就需要一一操作,相当繁琐
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
主要用到三个库:requests、BeautifulSoup和pandas(第1-3行)
使用 BeautifulSoup 获取 table 标签下的表格内容(第 4-7 行)
使用 pd.read_html 直接读取 HTML 中的内容作为 DataFrame(第 8-11 行)
这一步是关键。pd.read_html 方法省去了很多解析HTML的步骤,否则用BeautifulSoup一一抓取表格内容会很麻烦。它还使用了prettify()方法,可以把BeautifulSoup对象变成字符串,因为pd.read_html处理的是字符串对象
最后将DataFrame导出为EXCEL(12行)
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
网页表格抓取(Python中的网络爬虫库用于从网站中提取数据的程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-18 03:13
)
在本章中,我们将学习网络爬虫,包括学习 Python 中的 BeautifulSoup 库,该库用于从 网站 中提取数据。
本章收录以下主题。
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或 Web 浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化的过程。
抓取网页的过程分为获取网页和提取数据。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析、保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests$ pip3 install beautifulsoup4
2.1Requests 库
使用 Requests 库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。Requests 库收录不同类型的请求,这里使用 GET 请求。GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,您必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。这里我们将解析一个来自百度网站的新闻网页。创建一个脚本,将其命名为 parse_web_page.py,并在其中写入以下代码。
import requestsfrom bs4 import BeautifulSouppage_result = requests.get('https://www.news.baidu.com')parse_obj = BeautifulSoup(page_result.content, 'html.parser')print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.pyOutput:Top News - IMDb 查看全部
网页表格抓取(Python中的网络爬虫库用于从网站中提取数据的程序
)
在本章中,我们将学习网络爬虫,包括学习 Python 中的 BeautifulSoup 库,该库用于从 网站 中提取数据。
本章收录以下主题。
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或 Web 浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化的过程。
抓取网页的过程分为获取网页和提取数据。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析、保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests$ pip3 install beautifulsoup4
2.1Requests 库
使用 Requests 库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。Requests 库收录不同类型的请求,这里使用 GET 请求。GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,您必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。这里我们将解析一个来自百度网站的新闻网页。创建一个脚本,将其命名为 parse_web_page.py,并在其中写入以下代码。
import requestsfrom bs4 import BeautifulSouppage_result = requests.get('https://www.news.baidu.com')parse_obj = BeautifulSoup(page_result.content, 'html.parser')print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.pyOutput:Top News - IMDb
网页表格抓取(利用Xpath+GoogleSheet对网页描述的自动以下查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-18 03:12
我们都遇到过在某些时候必须从 网站 中提取数据的情况。例如,当您制作新的购物广告系列时,您可能没有可用于快速制作广告的产品 Feed(产品信息集)。
理想情况下,我们将以易于导入的文件格式(例如 Excel 或 Google 表格)提供我们需要的内容,例如登录页面、产品名称等。但对于大多数不知道如何进行数据抓取的人来说,广告商可能不得不手动复制粘贴成百上千的产品信息。
在最近的一份工作中,我被要求从客户 网站 的 15 个页面中下载大约 150 个新产品数据,并将每个产品的名称和着陆页 URL 复制并粘贴到电子表格中。
手动完成这项工作需要多少时间?这不仅费时,手动浏览这么多内容,而且一一复制粘贴,出错的概率也非常高。这无疑会增加更多的时间来审查文件。
在这里,SEJ工作人员分享了使用ImportXML结合Google Sheet轻松完成这项工作。
文章内容
什么是 ImportXML?
根据 Google 的解释,ImportXML 可以从以下各种结构化数据类型中的任何一种导入数据:包括 XML、HTML、CSV、TSV、RSS 和 ATOM XML 提要。
本质上,IMPORTXML 是一个功能,可以让你从网页中抓取结构化数据,例如段落文本、TDK 信息等。过程简单,不需要任何编码基础。
ImportXML 如何帮助抓取网页元素?
函数本身非常简单,只需要两个值:
例如,要从中提取页面标题,我们只需要将以下内容复制并粘贴到 Google Sheet 单元格中:
==IMPORTXML(“”, “//title”, “en_US”)
然后单元格将显示:登月 - 维基百科
或者,如果我们正在寻找网页的描述,我们可以尝试以下操作:
=IMPORTXML("","//meta[@name='description']/@content")
使用Xpath + Google Sheet 自动抓取网页描述
以下是一些较常见的 XPath 查询参考:
Google Sheet + ImportXML 案例演示
自从将 IMPORTXML 添加到 Google Sheets 以来,它一直是我们处理许多日常任务的秘密武器。
此外,该功能还可以结合其他公式来完成一些更高级的数据分析任务。如果没有Google Sheets的ImportXML,可能需要使用Python等方式进行程序抓取。
在下面的例子中,我们将演示 IMPORTXML 最基本的用法:从网页中获取数据。
想象一下,我们被要求创建一个内容广告活动。他们希望我们在文章 分类下的最新30 篇文章文章 上投放动态搜索广告。您可能会说这是一项非常简单的任务。不幸的是,网站编辑器无法给我们发送页面数据,并希望我们参考网站页面的内容来制作广告。
正如我们在文章开头提到的,一种方法是手动打开页面获取并在广告平台中填写,另一种是手动采集信息并将其放入Google Sheets和Excel。需要一一打开网页,复制粘贴信息。但是通过在 Google Sheets 中使用 IMPORTXML,我们可以在很短的时间内实现相同的操作而不会出错。
第 1 步:创建新的 Google 表格
首先,我们打开一个空白的 Google Sheets 文档:
从一个空白的 Google Sheets 文档开始。第二步:添加需要爬取的页面地址
添加我们要从中获取信息的页面(或多个页面)的 URL。在我们的例子中,我们需要抓取内容。
添加要爬取的页面的URL。第 3 步:查找 XPath
找到要抓取的元素,复制XPath 路径并在ImportXML 函数的第二个参数中使用它。在我们的示例中,我们需要找到 文章 的 30 个最近更新的标题。我们只需要将鼠标悬停在 文章 之一的标题上,右键单击并单击检查。
打开 Chrome WebDev 工具。
这将打开 Google Chrome 浏览器的开发者工具窗口:
查找并复制要提取的 XPath 元素。
确保 文章 标题仍处于选中状态并突出显示,然后再次右键单击并选择 Copy> 以复制 XPath。
第 4 步:将数据提取到 Google 表格中
返回到您的 Google Sheets 文档并输入 IMPORTXML 函数,如下所示:
=IMPORTXML(B1,”///*[starts-with(@id,'title')]”)
有几点需要注意:
首先,在我们的公式中,我们引用单元格 B1 的第一个参数,而 B1 我们输入要提取数据的网页地址。
其次,我们从 Chrome 开发者面板复制的 XPath 放在第二个参数中时会用双引号括起来。但是复制的XPath也有双引号,如下:
(///*[@id="title_1"])
为了保证前后双引号不会混淆,我们需要将Xpath中的双引号改为单引号,然后放入ImportXML函数中。
(///*[@id='title_1'])
请注意,在这个例子中,由于每个文章的页面ID标题都会发生变化(title_1、title_2等),所以我们要稍微修改一下XPath,然后需要使用starts- with函数获取页面上ID名称收录'title'的所有元素。
以下是 Google Sheets 文档的内容:
IMPORTXML 的一个例子。
输入后,文章的所有标题很快就会返回:
在 Google 表格中导入的标题。
您也可以使用此方法抓取其他网页上的元素信息。比如抓取文章姓名、文章 URL、摘要、作者姓名等。
如果要抓取网址,我们需要调整查询,使用/@抓取元素的属性。那么完整的Xpath查询如下:
=IMPORTXML(B1,”//*[starts-with(@id,'title')]/@href”)
导入 文章 链接
输入后:
文章 和 Google 表格中导入的 URL
添加摘要和作者姓名后:
包括摘要和作者姓名在内的所有数据都被抓取并导入到 Google 表格中。结论
无论是需要爬取文章,还是其他页面元素,包括产品价格或运费等数据,都可以使用Xpath自动获取,出错的可能性很小。
该工具不仅可用于 PPC 构建广告活动,还可用于需要批量网页数据分析和采集的其他任务,例如 SEO。
当然,相比Python的数据爬取,Google Sheet爬取数据有一定的局限性。谷歌会给每个Sheet一定比例的抓取,抓取的数量会有一定的限制。Google 这样做的主要目的是避免恶意使用服务器。另外这个功能是免费的,谷歌也会考虑运维成本。 查看全部
网页表格抓取(利用Xpath+GoogleSheet对网页描述的自动以下查询)
我们都遇到过在某些时候必须从 网站 中提取数据的情况。例如,当您制作新的购物广告系列时,您可能没有可用于快速制作广告的产品 Feed(产品信息集)。
理想情况下,我们将以易于导入的文件格式(例如 Excel 或 Google 表格)提供我们需要的内容,例如登录页面、产品名称等。但对于大多数不知道如何进行数据抓取的人来说,广告商可能不得不手动复制粘贴成百上千的产品信息。
在最近的一份工作中,我被要求从客户 网站 的 15 个页面中下载大约 150 个新产品数据,并将每个产品的名称和着陆页 URL 复制并粘贴到电子表格中。
手动完成这项工作需要多少时间?这不仅费时,手动浏览这么多内容,而且一一复制粘贴,出错的概率也非常高。这无疑会增加更多的时间来审查文件。
在这里,SEJ工作人员分享了使用ImportXML结合Google Sheet轻松完成这项工作。
文章内容
什么是 ImportXML?
根据 Google 的解释,ImportXML 可以从以下各种结构化数据类型中的任何一种导入数据:包括 XML、HTML、CSV、TSV、RSS 和 ATOM XML 提要。
本质上,IMPORTXML 是一个功能,可以让你从网页中抓取结构化数据,例如段落文本、TDK 信息等。过程简单,不需要任何编码基础。
ImportXML 如何帮助抓取网页元素?
函数本身非常简单,只需要两个值:
例如,要从中提取页面标题,我们只需要将以下内容复制并粘贴到 Google Sheet 单元格中:
==IMPORTXML(“”, “//title”, “en_US”)
然后单元格将显示:登月 - 维基百科
或者,如果我们正在寻找网页的描述,我们可以尝试以下操作:
=IMPORTXML("","//meta[@name='description']/@content")
使用Xpath + Google Sheet 自动抓取网页描述
以下是一些较常见的 XPath 查询参考:
Google Sheet + ImportXML 案例演示
自从将 IMPORTXML 添加到 Google Sheets 以来,它一直是我们处理许多日常任务的秘密武器。
此外,该功能还可以结合其他公式来完成一些更高级的数据分析任务。如果没有Google Sheets的ImportXML,可能需要使用Python等方式进行程序抓取。
在下面的例子中,我们将演示 IMPORTXML 最基本的用法:从网页中获取数据。
想象一下,我们被要求创建一个内容广告活动。他们希望我们在文章 分类下的最新30 篇文章文章 上投放动态搜索广告。您可能会说这是一项非常简单的任务。不幸的是,网站编辑器无法给我们发送页面数据,并希望我们参考网站页面的内容来制作广告。
正如我们在文章开头提到的,一种方法是手动打开页面获取并在广告平台中填写,另一种是手动采集信息并将其放入Google Sheets和Excel。需要一一打开网页,复制粘贴信息。但是通过在 Google Sheets 中使用 IMPORTXML,我们可以在很短的时间内实现相同的操作而不会出错。
第 1 步:创建新的 Google 表格
首先,我们打开一个空白的 Google Sheets 文档:
从一个空白的 Google Sheets 文档开始。第二步:添加需要爬取的页面地址
添加我们要从中获取信息的页面(或多个页面)的 URL。在我们的例子中,我们需要抓取内容。
添加要爬取的页面的URL。第 3 步:查找 XPath
找到要抓取的元素,复制XPath 路径并在ImportXML 函数的第二个参数中使用它。在我们的示例中,我们需要找到 文章 的 30 个最近更新的标题。我们只需要将鼠标悬停在 文章 之一的标题上,右键单击并单击检查。
打开 Chrome WebDev 工具。
这将打开 Google Chrome 浏览器的开发者工具窗口:
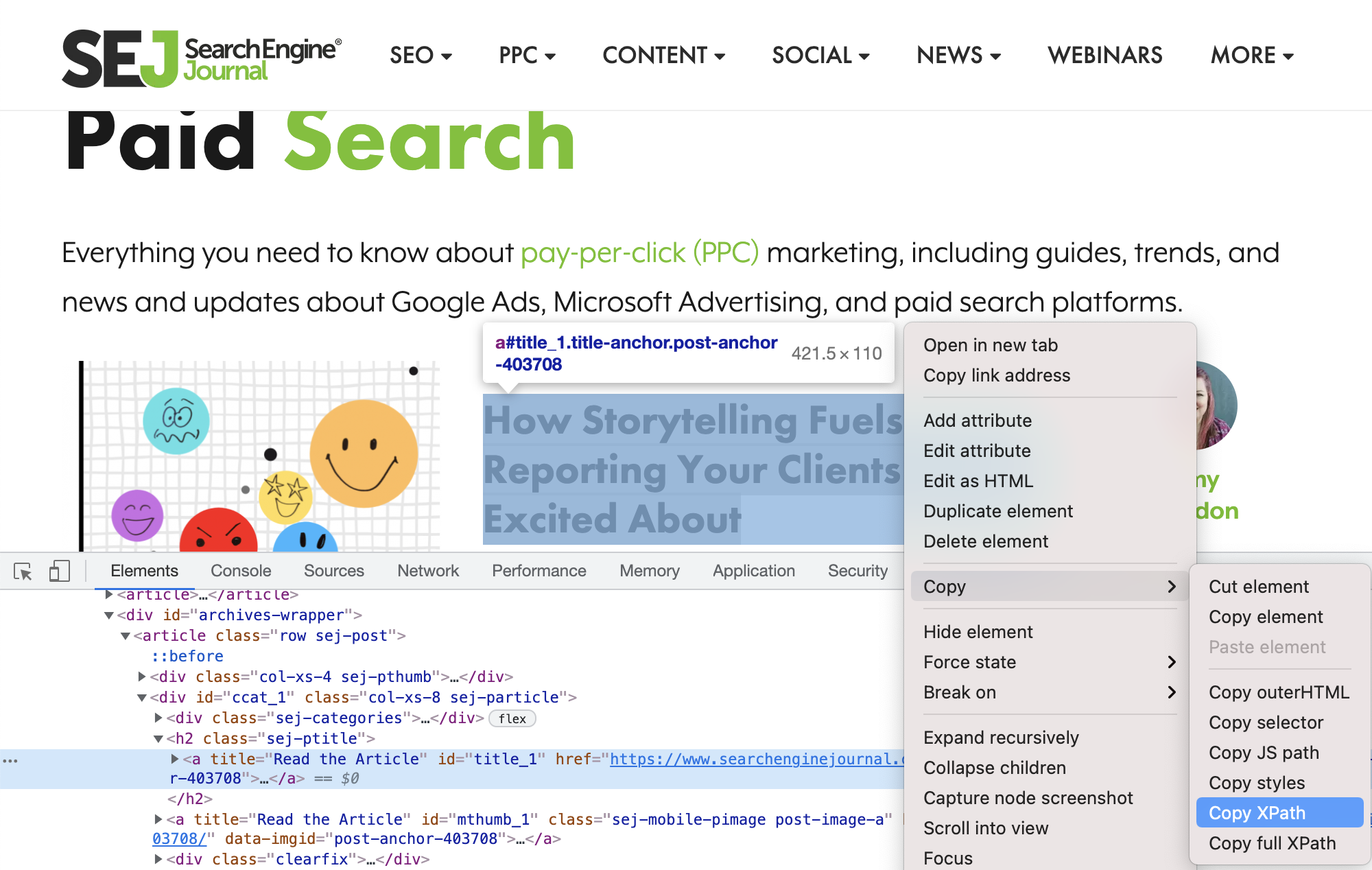
查找并复制要提取的 XPath 元素。
确保 文章 标题仍处于选中状态并突出显示,然后再次右键单击并选择 Copy> 以复制 XPath。
第 4 步:将数据提取到 Google 表格中
返回到您的 Google Sheets 文档并输入 IMPORTXML 函数,如下所示:
=IMPORTXML(B1,”///*[starts-with(@id,'title')]”)
有几点需要注意:
首先,在我们的公式中,我们引用单元格 B1 的第一个参数,而 B1 我们输入要提取数据的网页地址。
其次,我们从 Chrome 开发者面板复制的 XPath 放在第二个参数中时会用双引号括起来。但是复制的XPath也有双引号,如下:
(///*[@id="title_1"])
为了保证前后双引号不会混淆,我们需要将Xpath中的双引号改为单引号,然后放入ImportXML函数中。
(///*[@id='title_1'])
请注意,在这个例子中,由于每个文章的页面ID标题都会发生变化(title_1、title_2等),所以我们要稍微修改一下XPath,然后需要使用starts- with函数获取页面上ID名称收录'title'的所有元素。
以下是 Google Sheets 文档的内容:
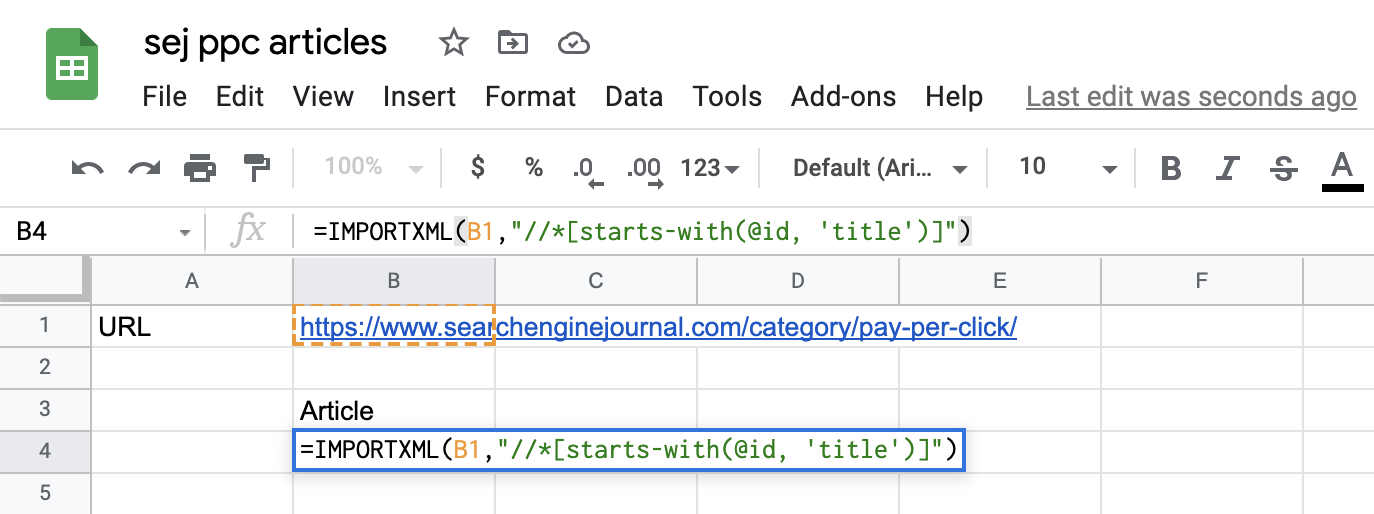
IMPORTXML 的一个例子。
输入后,文章的所有标题很快就会返回:

在 Google 表格中导入的标题。
您也可以使用此方法抓取其他网页上的元素信息。比如抓取文章姓名、文章 URL、摘要、作者姓名等。
如果要抓取网址,我们需要调整查询,使用/@抓取元素的属性。那么完整的Xpath查询如下:
=IMPORTXML(B1,”//*[starts-with(@id,'title')]/@href”)
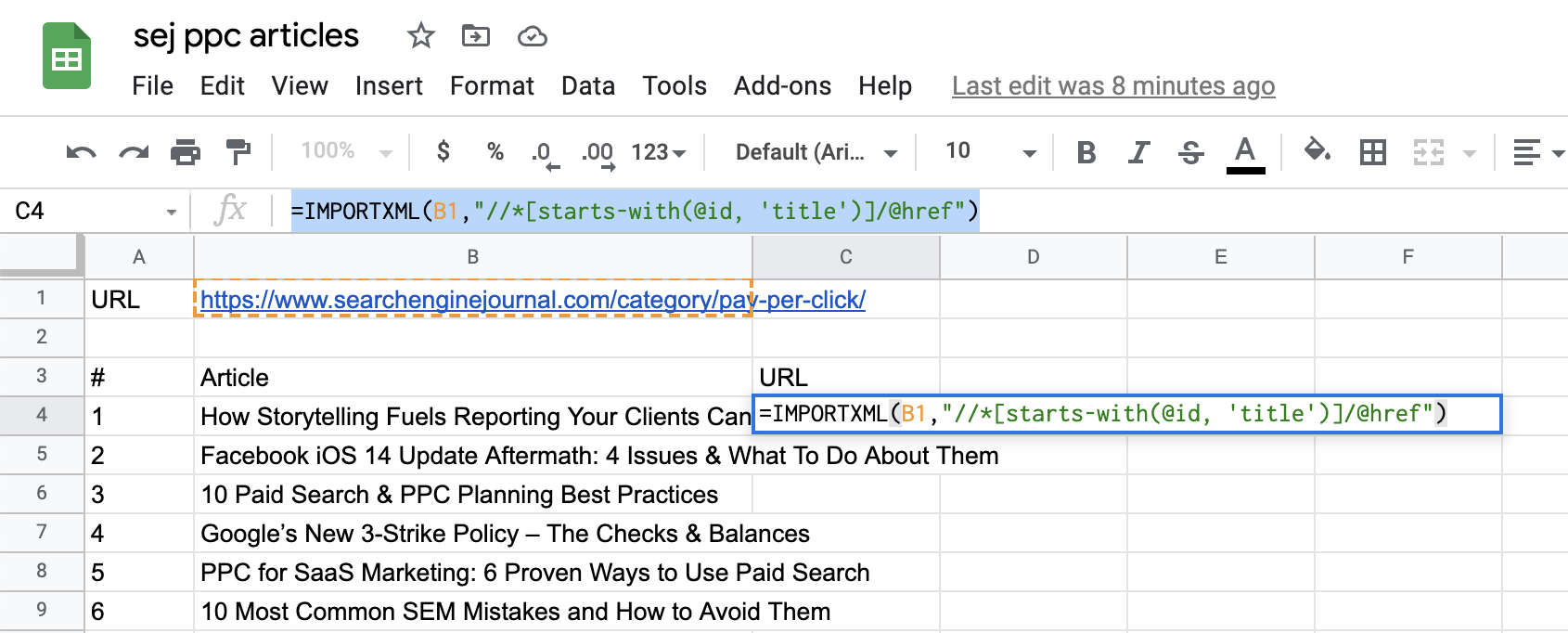
导入 文章 链接
输入后:
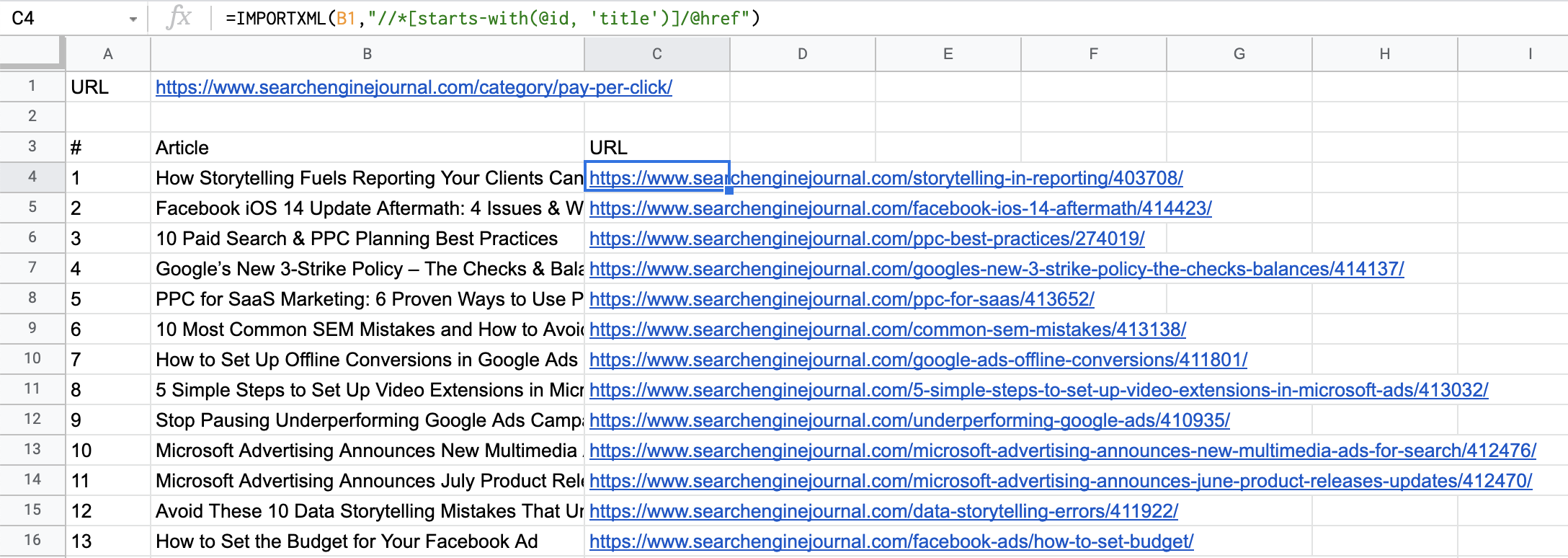
文章 和 Google 表格中导入的 URL
添加摘要和作者姓名后:
包括摘要和作者姓名在内的所有数据都被抓取并导入到 Google 表格中。结论
无论是需要爬取文章,还是其他页面元素,包括产品价格或运费等数据,都可以使用Xpath自动获取,出错的可能性很小。
该工具不仅可用于 PPC 构建广告活动,还可用于需要批量网页数据分析和采集的其他任务,例如 SEO。
当然,相比Python的数据爬取,Google Sheet爬取数据有一定的局限性。谷歌会给每个Sheet一定比例的抓取,抓取的数量会有一定的限制。Google 这样做的主要目的是避免恶意使用服务器。另外这个功能是免费的,谷歌也会考虑运维成本。
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 03:11
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
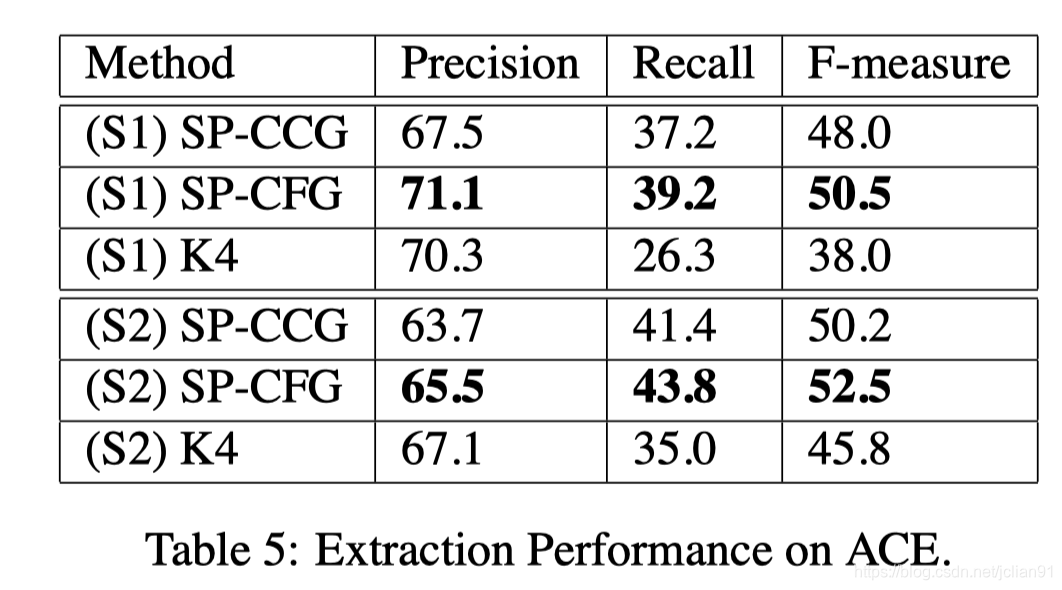
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
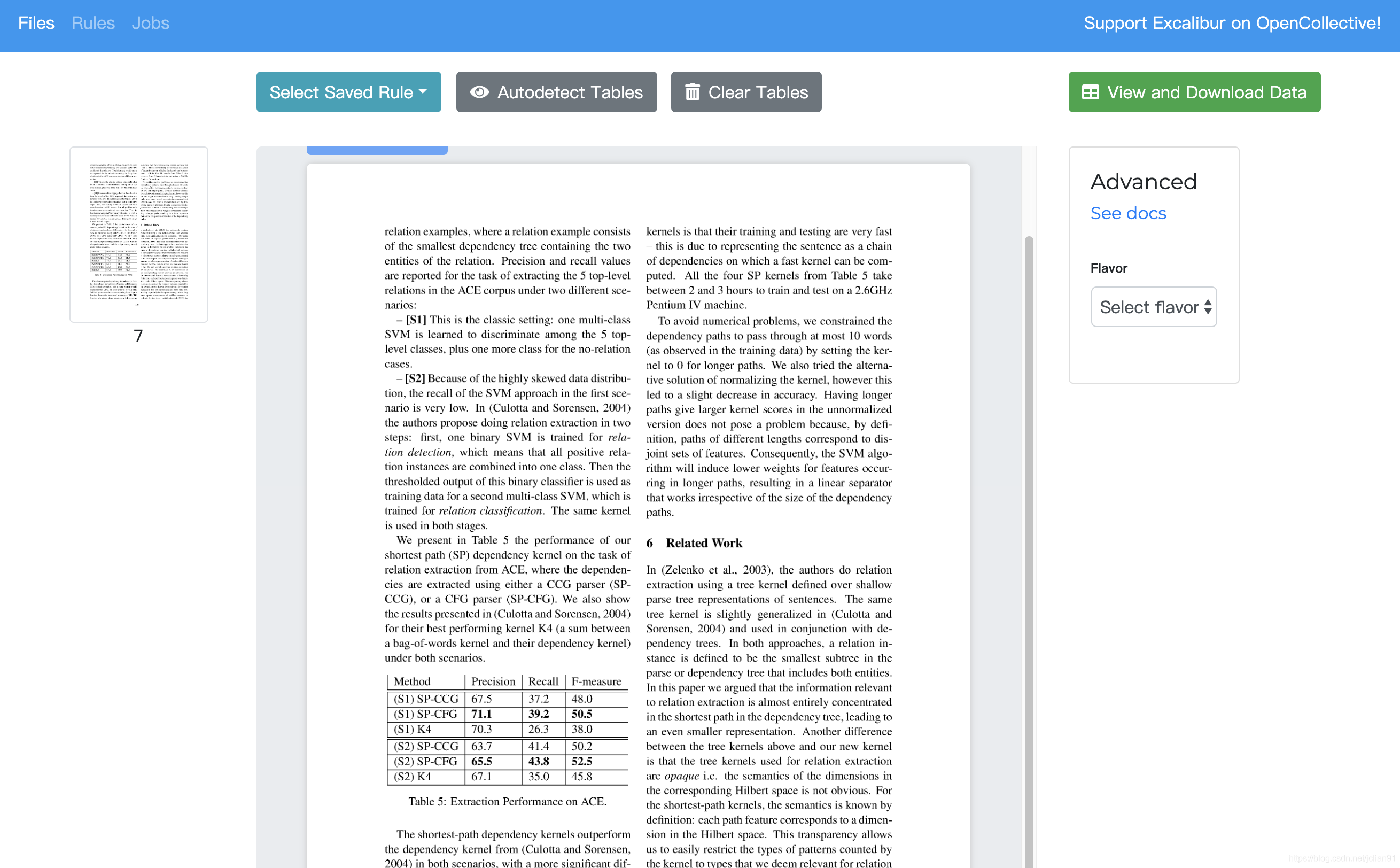
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
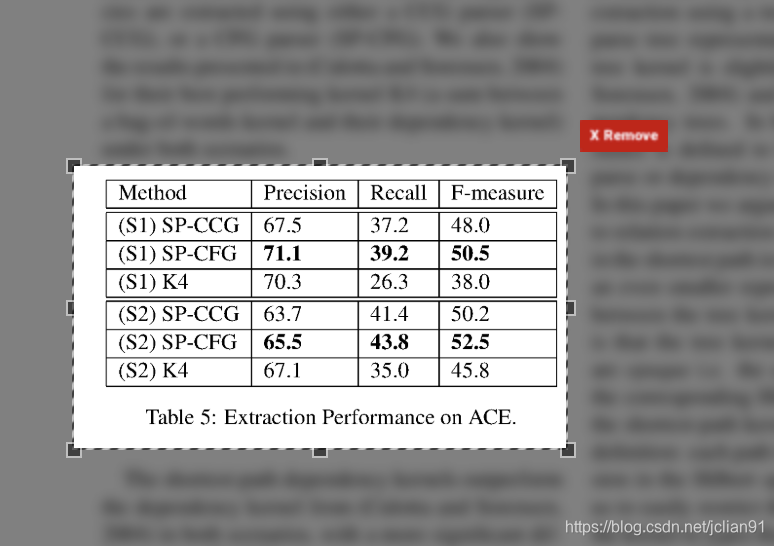
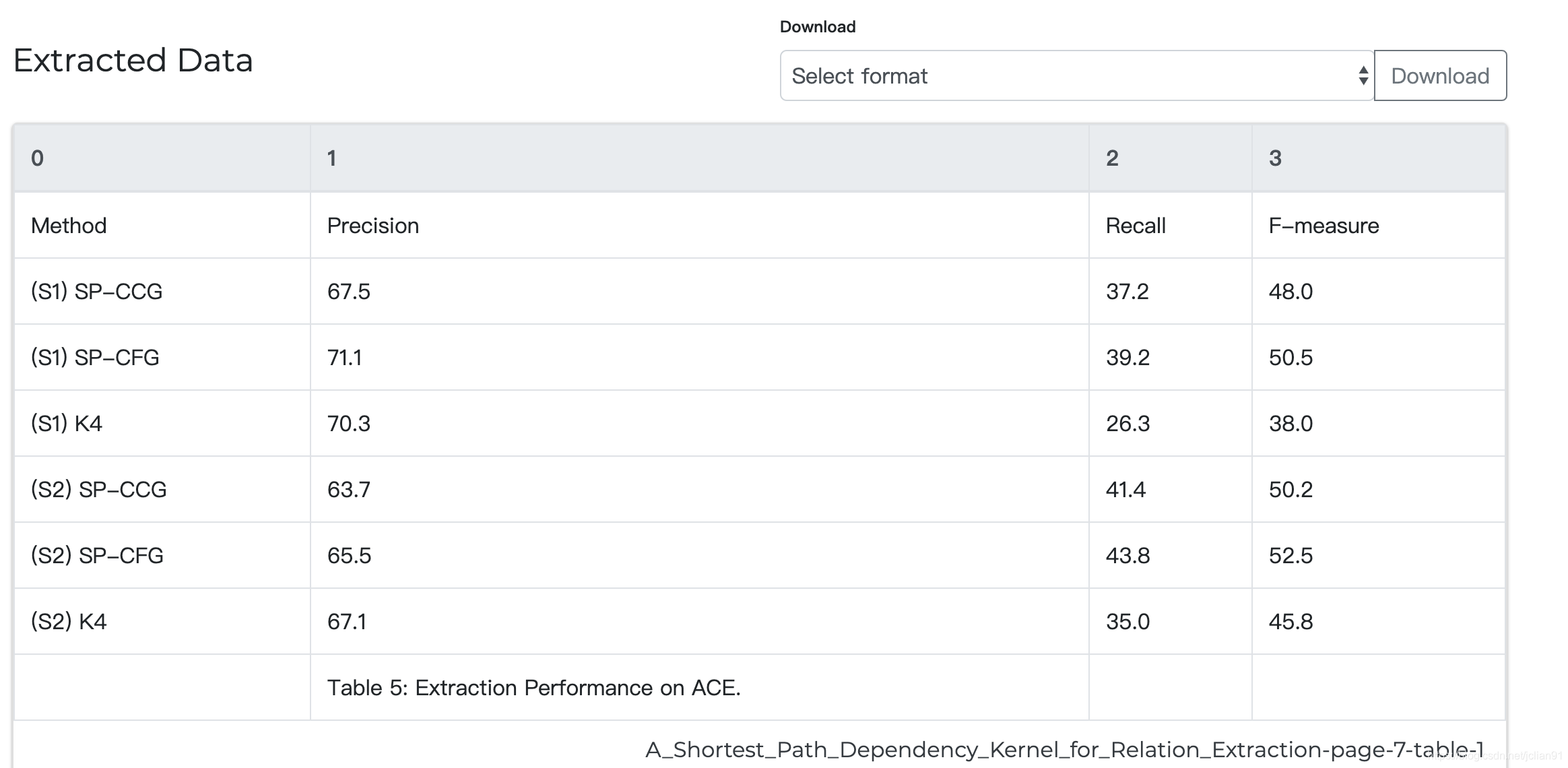
然后点击“查看和下载数据”按钮,即可获取从PDF分析表中获取的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
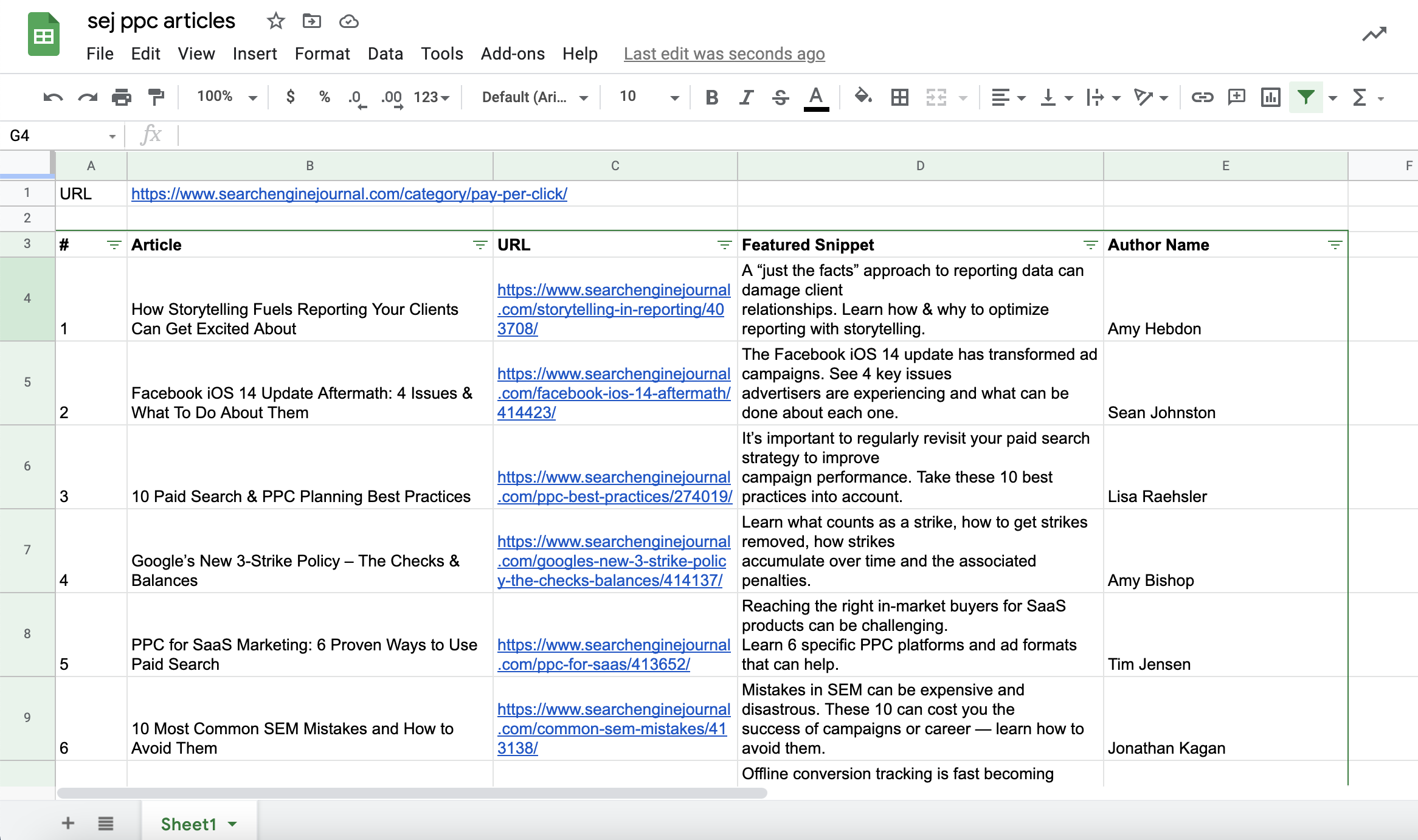
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~ 查看全部
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:

作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,即可获取从PDF分析表中获取的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~
网页表格抓取(如何才能高效提取出pdf文件中的表格数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-16 11:30
在实际研究中,我们往往需要获取大量的数据,而这些数据很大一部分是以pdf形式呈现的,比如公司年报、发行上市公告等。 面对如此多的数据表格,显然不建议手动复制和粘贴它们。那么如何才能高效的提取pdf文件中的表格数据呢?
Python提供了很多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等,总体来说pdfplumber库的性能更好,可以提取完整且相对规范的表格。所以,这条推文也主要介绍了pdfplumber库在pdf表提取中的作用。
pdfplumber库作为强大的pdf文件解析工具,可以快速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页码、页码等信息,还可以进行页面可视化操作。在使用pdfplumber库之前,需要先安装,即在cmd命令行中输入:
pip 安装 pdfplumber
pdfplumber库提供了两个pdf表提取函数,分别是.extract_tables()和.extract_table(),这两个函数的提取结果是不同的。为了演示,我们在网站上下载了一份pdf格式的短期融资券主体信用评级报告。任意选择一张表,其界面如下:
Python骚操作,提取pdf文件中的表数据!
关于如何快速学习python,可以加小编的python学习群:611+530+101,不管你是新手还是大牛,欢迎小编不定期分享干货。
每天晚上20:00会有直播分享python学习知识和路线方法。群里会不定期更新最新的教程和学习方法。大家都在学习python,或者转行,或者大学生,打工,如果想提升自己的能力,如果你是正在学习python的小伙伴,都可以加入学习。最后,祝所有程序员都能走上人生的巅峰,让代码将梦想照进现实
接下来,我们简单分析一下两种提取模式的结果差异。
(1).extract_tables()
它可以输出页面中的所有表,并返回一个嵌套列表,其结构级别为表→行→单元格。这时,页面上的整个表被放入一个大列表中,原表中的每一行构成了大列表中的每个子列表。如果您需要输出单个外部列表元素,您得到的是由原创表中的同一行元素组成的列表。例如,我们执行以下过程:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
(2).extract_table()
返回多个独立列表,其结构级别为row→cell。如果页面中有多个行数相同的表,默认会输出最上面的表;否则只输出行数最多的表。此时,表格的每一行都作为一个单独的列表,列表中的每个元素都是原创表格每个单元格的内容。如果你需要输出一个元素,你会得到一个特定的值或字符串。如下:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
在此基础上,我们详细介绍了如何从pdf文件中提取表格数据。一种思路是把提取的列表当成字符串,结合Python的正则表达式re模块进行处理,保存为Excel可以识别的标准逗号分隔的csv文件。即,按以下步骤进行:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
虽然可以获得完整的表格数据,但是这种方法比较难理解,在处理结构不规则的表格时容易出错。因为pdfplumber库提取的表格数据是整洁的列表结构,收录数字、字符串等数据类型。因此,我们可以调用pandas库下的DataFrame()函数,将列表转换为可以直接输出到Excel的DataFrame数据结构。DataFrame的基本构造函数如下:
数据帧([数据,索引,列])
三个参数data、index、columns分别代表创建对象、行索引、列索引。DataFrame类型可以通过二维的ndarray对象、列表、字典、元组等来创建,本推文中的数据是指整个pdf表格,提取过程如下:
Python骚操作,提取pdf文件中的表数据!
其中table[1:]表示选择整个表进行DataFrame对象创建,columns=table[0]表示使用表的第一行元素作为列变量名,不创建行索引. 输出Excel表格如下:
Python骚操作,提取pdf文件中的表数据!
通过上面的简单程序,我们已经提取了完整的pdf表格。但是需要注意的是,面对不规则的表数据提取,DataFrame对象的创建方法可能还是错误的,需要在实际操作中进行检查。 查看全部
网页表格抓取(如何才能高效提取出pdf文件中的表格数据呢?)
在实际研究中,我们往往需要获取大量的数据,而这些数据很大一部分是以pdf形式呈现的,比如公司年报、发行上市公告等。 面对如此多的数据表格,显然不建议手动复制和粘贴它们。那么如何才能高效的提取pdf文件中的表格数据呢?

Python提供了很多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等,总体来说pdfplumber库的性能更好,可以提取完整且相对规范的表格。所以,这条推文也主要介绍了pdfplumber库在pdf表提取中的作用。
pdfplumber库作为强大的pdf文件解析工具,可以快速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页码、页码等信息,还可以进行页面可视化操作。在使用pdfplumber库之前,需要先安装,即在cmd命令行中输入:
pip 安装 pdfplumber
pdfplumber库提供了两个pdf表提取函数,分别是.extract_tables()和.extract_table(),这两个函数的提取结果是不同的。为了演示,我们在网站上下载了一份pdf格式的短期融资券主体信用评级报告。任意选择一张表,其界面如下:

Python骚操作,提取pdf文件中的表数据!
关于如何快速学习python,可以加小编的python学习群:611+530+101,不管你是新手还是大牛,欢迎小编不定期分享干货。
每天晚上20:00会有直播分享python学习知识和路线方法。群里会不定期更新最新的教程和学习方法。大家都在学习python,或者转行,或者大学生,打工,如果想提升自己的能力,如果你是正在学习python的小伙伴,都可以加入学习。最后,祝所有程序员都能走上人生的巅峰,让代码将梦想照进现实
接下来,我们简单分析一下两种提取模式的结果差异。
(1).extract_tables()
它可以输出页面中的所有表,并返回一个嵌套列表,其结构级别为表→行→单元格。这时,页面上的整个表被放入一个大列表中,原表中的每一行构成了大列表中的每个子列表。如果您需要输出单个外部列表元素,您得到的是由原创表中的同一行元素组成的列表。例如,我们执行以下过程:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
(2).extract_table()
返回多个独立列表,其结构级别为row→cell。如果页面中有多个行数相同的表,默认会输出最上面的表;否则只输出行数最多的表。此时,表格的每一行都作为一个单独的列表,列表中的每个元素都是原创表格每个单元格的内容。如果你需要输出一个元素,你会得到一个特定的值或字符串。如下:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
在此基础上,我们详细介绍了如何从pdf文件中提取表格数据。一种思路是把提取的列表当成字符串,结合Python的正则表达式re模块进行处理,保存为Excel可以识别的标准逗号分隔的csv文件。即,按以下步骤进行:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
虽然可以获得完整的表格数据,但是这种方法比较难理解,在处理结构不规则的表格时容易出错。因为pdfplumber库提取的表格数据是整洁的列表结构,收录数字、字符串等数据类型。因此,我们可以调用pandas库下的DataFrame()函数,将列表转换为可以直接输出到Excel的DataFrame数据结构。DataFrame的基本构造函数如下:
数据帧([数据,索引,列])
三个参数data、index、columns分别代表创建对象、行索引、列索引。DataFrame类型可以通过二维的ndarray对象、列表、字典、元组等来创建,本推文中的数据是指整个pdf表格,提取过程如下:
Python骚操作,提取pdf文件中的表数据!
其中table[1:]表示选择整个表进行DataFrame对象创建,columns=table[0]表示使用表的第一行元素作为列变量名,不创建行索引. 输出Excel表格如下:
Python骚操作,提取pdf文件中的表数据!
通过上面的简单程序,我们已经提取了完整的pdf表格。但是需要注意的是,面对不规则的表数据提取,DataFrame对象的创建方法可能还是错误的,需要在实际操作中进行检查。
网页表格抓取(本文以爬取东方财富网CPI数据[1],讲解如何使用Stata)
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2021-10-15 15:15
本文以东方财富网[1]的CPI数据为例,讲解如何使用Stata抓取web表数据。
Stata虽然不是数据爬取工具,但是可以轻松解决一些小的数据爬取任务。数据爬取的本质无非是数据请求和数据处理,所以熟练使用Stata进行数据爬取往往是良好数据处理能力的标志。在实际应用中,我们经常需要爬取一些公共数据。显示这些数据的一种常见方式是通过 HTML 呈现。一个简单的 HTML 表格示例如下:
1
2
3
1
2
3
东方财富网CPI数据表是这样的:
下面我将一步步解释如何爬取这张表。
准备工作Stata14.0或以上;
Chrome浏览器;
想要爬下数据的你。
网络分析
先解释一下如何爬取一个页面的表单。这个页面的网址是:
在页面上右击,选择显示网页的源代码。很多浏览器都有查看网页源代码的功能,但我还是最喜欢谷歌浏览器。点击跳转到页面源码界面:
也就是说,你刚才看到的网页的本质其实就是源代码。我们之所以能看到各种五颜六色的页面,是因为浏览器已经为我们翻译了源代码。
接下来我们要做的就是找出这张表在源码中的位置,然后分析这张表的特征,方便后面Stata处理源码的时候过滤。
一种经常用于查找目标的方法是使用搜索功能。Ctr+F(Mac 的 Command + F)可以打开搜索框。我们注意到表中有两个词,所以我们用月份来搜索。
我们第一次发现这个词是在1987行,仔细一看,这里附近的代码就是表的代码。
下一步就是分析这部分代码的特点:表中的所有数据都位于源代码中的一行,所以我们不能从它所在的行开始;
表数据的前一行要么有一个字符串
经过上面的网页分析后,我们就可以开始爬取网页表单了。
开始爬行
总的来说,Stata 抓取网页表单分为 3 个步骤:请求:下载收录所需数据的源代码;
转码:许多网页不使用 UTF-8 编码。直接读入Stata会造成乱码,所以可以提前进行UTF-8转码;
处理:主要是处理字符串。常见的操作包括拆分、转置(sxpose)、提取(正则表达式或直接字符串提取)等。
问
由于本网页没有防爬机制,可以直接使用copy命令下载。copy命令不仅可以下载网页,还可以下载文件(当然,网页其实就是一个html文件)。更多的使用可以帮助复制。这里我们将要抓取的页面保存为一个名为temp.txt的txt文件。为什么会有这个名字,因为爬完之后会被删除,所以它只是一个临时文件。其实Stata也可以创建临时文件,运行结束会自动删除,不过我觉得没有这个必要,因为通常需要打开temp.txt文件分析一下内容。
清除所有
* 设置工作目录
cd'你自己的工作目录(文件夹的路径)'
复制'#39; temp.txt,替换
转码
在我的Stata命令package-finance包中,我写了一个简单的转码命令。这个命令包的安装方法是: * 首先需要安装github命令,这个命令用于在GitHub上安装命令
* net install github, from('#39;)
* 然后你可以安装这个命令
* github 安装 czxa/finance,替换
安装成功后,使用以下命令直接对temp.txt文件进行转码:
utrans temp.txt
如果返回的结果是转码成功,说明转码成功!(感觉像是在胡说八道……)
如果由于各种原因不幸安装这个小命令失败,可以直接使用以下三个命令进行转码:unicode encoding set gb18030
unicode 翻译 temp.txt
unicode 擦除备份,badidea
读
接下来我们将temp.txt文件读入Stata进行处理。一个很常见的读取方法是使用中缀命令:
使用 temp.txt 中缀 strL v 1-20000,清除
* 将变量 v 的显示格式更改为 %60s(使其看起来更宽)
格式 v %60s
这个命令的意思是创建一个strL格式的变量v,然后读取temp.txt文件每一行的前1-20000个字符(因为我们注意到temp.txt的每一行不超过20000字符)输入变量 v 的每个观测值,读入后如下所示:
处理
首先,根据我们在上面网页分析中发现的结论,我们保留上一行匹配表数据或有字符串'
* 再次删除空观察
删除如果 v ==''
* 删除一些明显不是表中数据的观察,这些无用的观察都收录斜线
删除如果索引(v,'/')
这一步的结果:
其实到这里,我们已经把表格组织的很干净了,但是这不像一个表格,我们需要进行这样的操作:我们注意到第1-13行实际上是表格的第一行,14- 26 该行实际上是表的第二行。我们怎样才能完成这样的操作呢?一个非常有用的命令是 post 命令。这个命令的功能就像它的名字-邮局一样。它可以将v的每个观察值发送到我们想要获取的表的指定位置。
* 第一步是在postfile中创建一个“邮局”,并设置“收件人”(变量日期,v1-v12):
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 cpi.dta,替换
* 然后循环发送v的值给每个接收者
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
* 关闭邮局 mypost
关闭我的帖子
* 打开 cpi.dta 查看整理后的数据
使用 cpi,清除
在这个“邮局操作”之后,数据现在是这样的:
至此,我们其实已经完成了对这张表的爬取,但是接下来我们会将数据组织成更正规的Stata数据。* 组织日期变量
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
* date() 函数将字符串日期转换为Stata日期
gen date1 = date(date,'YM')
* 格式很容易让我们人类理解
格式日期1 %tdCY-N
* 将 date1 变量放在第一列
订单日期1
* 删除日期
下车日期
* 将 date1 重命名为 date
ren date1 日期
* 循环所有变量并删除%
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
* 将所有可以转换为数字变量的字符串变量转换为数字变量
解串,替换
* 循环所有变量,如果变量名不是日期,将显示格式改为%6.2f
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
排序后的数据集如下所示:
就这样,我们爬上了单页表单。此外,我们还注意到完整的表格有 8 页。我们可以点击下一页,看到第二页的网址是:
显然url中的最后一个参数是页数。每个页面的结构都是一样的,所以你可以循环刚才的代码,爬下剩下的6个页面的表格,合并它们。
多页面抓取
垂直拼接示例
举个例子,我们试着用刚才的代码爬取第二页:clear
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
运行这些代码后,可以得到一个类似于第一页爬取结果的表,然后可以使用append命令将该表垂直拼接到第一页爬取的数据集CPI_final.dta上:
使用 CPI_final 追加
保存 CPI_final,替换
环缝
为了一致性,我重写了上面的代码,因为有些代码可以在循环后运行,比如变量标签、变量名等。 *==================== ============*
* 东方财富消费者物价指数爬行
*================================*
* 下载第一页
清除所有
cd'~/桌面'
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
保存 CPI_final,替换
* 下一个循环从第 2 页到第 8 页并垂直缝合每一页
forval i = 2/8{
清除
复制'`i'' temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
使用 CPI_final 追加
保存 CPI_final,替换
}
使用 CPI_final,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
爬取结果:
至此,我们就完成了这个爬取任务。下面我们进行一个简单的应用-数据展示。
数据呈现
如果我想观察CPI的走势,我需要画一个折线图:
使用 CPI_final,清除
排序日期
* 画画
* 推荐使用我最喜欢的绘画主题plotplain
* 安装方法
ssc 安装百叶窗方案,替换所有
* 永久设置情节主题为plotplain
设置计划情节,永久
* 查看2018年6月对应的Stata日期
di date('2018-06','YM')
* /// 表示代码换行,注意下面几行绘制代码一起运行
tw ///
行 cpi_all 日期, ///
lc(blue*0.6) lp(solid) ///
xline(21336) || ///
行 cpi_city 日期, lc(dkorange) ///
lp(实心) || ///
行 cpi_village 日期, lc(orange_red) ||, ///
ti('图:消费物价指数走势', size(*1.2)) || ///
scatteri 101.90 21336 (12)'June 2018' ||, ///
leg(pos(6) row(1) order(1'全国CPI' 2'城市CPI' 3'农村CPI'))
* 以png格式导出图片
gr 导出 20181004a1.png,替换
以上一些选项的含义: ||:用于分隔图层。
line:用于绘制折线图
tw:全称twoway,用于组合多个图层
lc:全称lcolor(),控制折线图的颜色
lp:全称lpattern(),控制线型
yline:在指定位置画一条水平线
xline:在指定位置画一条垂直线
ti:全称title(),控制标题,size用来控制标题文字的大小,这里是1.2次
leg:全称是legend(),控制图例。pos 用于控制图例的位置。这是一个 6 点方向,排列成一行。
scatteri:用于在指定坐标处绘制一个点。'June 2018'是这个点的标签,(12)用于指定这个标签在该点所在的方向,指定为12点钟方向。❝
欢迎加入 TidyFriday 知识星球,获取更多学习资源:❞
参考文献[1]
东方财富网CPI数据: 查看全部
网页表格抓取(本文以爬取东方财富网CPI数据[1],讲解如何使用Stata)
本文以东方财富网[1]的CPI数据为例,讲解如何使用Stata抓取web表数据。
Stata虽然不是数据爬取工具,但是可以轻松解决一些小的数据爬取任务。数据爬取的本质无非是数据请求和数据处理,所以熟练使用Stata进行数据爬取往往是良好数据处理能力的标志。在实际应用中,我们经常需要爬取一些公共数据。显示这些数据的一种常见方式是通过 HTML 呈现。一个简单的 HTML 表格示例如下:
1
2
3
1
2
3
东方财富网CPI数据表是这样的:

下面我将一步步解释如何爬取这张表。
准备工作Stata14.0或以上;
Chrome浏览器;
想要爬下数据的你。
网络分析
先解释一下如何爬取一个页面的表单。这个页面的网址是:

在页面上右击,选择显示网页的源代码。很多浏览器都有查看网页源代码的功能,但我还是最喜欢谷歌浏览器。点击跳转到页面源码界面:

也就是说,你刚才看到的网页的本质其实就是源代码。我们之所以能看到各种五颜六色的页面,是因为浏览器已经为我们翻译了源代码。
接下来我们要做的就是找出这张表在源码中的位置,然后分析这张表的特征,方便后面Stata处理源码的时候过滤。
一种经常用于查找目标的方法是使用搜索功能。Ctr+F(Mac 的 Command + F)可以打开搜索框。我们注意到表中有两个词,所以我们用月份来搜索。

我们第一次发现这个词是在1987行,仔细一看,这里附近的代码就是表的代码。
下一步就是分析这部分代码的特点:表中的所有数据都位于源代码中的一行,所以我们不能从它所在的行开始;
表数据的前一行要么有一个字符串
经过上面的网页分析后,我们就可以开始爬取网页表单了。
开始爬行
总的来说,Stata 抓取网页表单分为 3 个步骤:请求:下载收录所需数据的源代码;
转码:许多网页不使用 UTF-8 编码。直接读入Stata会造成乱码,所以可以提前进行UTF-8转码;
处理:主要是处理字符串。常见的操作包括拆分、转置(sxpose)、提取(正则表达式或直接字符串提取)等。
问
由于本网页没有防爬机制,可以直接使用copy命令下载。copy命令不仅可以下载网页,还可以下载文件(当然,网页其实就是一个html文件)。更多的使用可以帮助复制。这里我们将要抓取的页面保存为一个名为temp.txt的txt文件。为什么会有这个名字,因为爬完之后会被删除,所以它只是一个临时文件。其实Stata也可以创建临时文件,运行结束会自动删除,不过我觉得没有这个必要,因为通常需要打开temp.txt文件分析一下内容。
清除所有
* 设置工作目录
cd'你自己的工作目录(文件夹的路径)'
复制'#39; temp.txt,替换
转码
在我的Stata命令package-finance包中,我写了一个简单的转码命令。这个命令包的安装方法是: * 首先需要安装github命令,这个命令用于在GitHub上安装命令
* net install github, from('#39;)
* 然后你可以安装这个命令
* github 安装 czxa/finance,替换
安装成功后,使用以下命令直接对temp.txt文件进行转码:
utrans temp.txt
如果返回的结果是转码成功,说明转码成功!(感觉像是在胡说八道……)
如果由于各种原因不幸安装这个小命令失败,可以直接使用以下三个命令进行转码:unicode encoding set gb18030
unicode 翻译 temp.txt
unicode 擦除备份,badidea
读
接下来我们将temp.txt文件读入Stata进行处理。一个很常见的读取方法是使用中缀命令:
使用 temp.txt 中缀 strL v 1-20000,清除
* 将变量 v 的显示格式更改为 %60s(使其看起来更宽)
格式 v %60s
这个命令的意思是创建一个strL格式的变量v,然后读取temp.txt文件每一行的前1-20000个字符(因为我们注意到temp.txt的每一行不超过20000字符)输入变量 v 的每个观测值,读入后如下所示:

处理
首先,根据我们在上面网页分析中发现的结论,我们保留上一行匹配表数据或有字符串'
* 再次删除空观察
删除如果 v ==''
* 删除一些明显不是表中数据的观察,这些无用的观察都收录斜线
删除如果索引(v,'/')
这一步的结果:

其实到这里,我们已经把表格组织的很干净了,但是这不像一个表格,我们需要进行这样的操作:我们注意到第1-13行实际上是表格的第一行,14- 26 该行实际上是表的第二行。我们怎样才能完成这样的操作呢?一个非常有用的命令是 post 命令。这个命令的功能就像它的名字-邮局一样。它可以将v的每个观察值发送到我们想要获取的表的指定位置。
* 第一步是在postfile中创建一个“邮局”,并设置“收件人”(变量日期,v1-v12):
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 cpi.dta,替换
* 然后循环发送v的值给每个接收者
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
* 关闭邮局 mypost
关闭我的帖子
* 打开 cpi.dta 查看整理后的数据
使用 cpi,清除
在这个“邮局操作”之后,数据现在是这样的:

至此,我们其实已经完成了对这张表的爬取,但是接下来我们会将数据组织成更正规的Stata数据。* 组织日期变量
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
* date() 函数将字符串日期转换为Stata日期
gen date1 = date(date,'YM')
* 格式很容易让我们人类理解
格式日期1 %tdCY-N
* 将 date1 变量放在第一列
订单日期1
* 删除日期
下车日期
* 将 date1 重命名为 date
ren date1 日期
* 循环所有变量并删除%
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
* 将所有可以转换为数字变量的字符串变量转换为数字变量
解串,替换
* 循环所有变量,如果变量名不是日期,将显示格式改为%6.2f
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
排序后的数据集如下所示:

就这样,我们爬上了单页表单。此外,我们还注意到完整的表格有 8 页。我们可以点击下一页,看到第二页的网址是:
显然url中的最后一个参数是页数。每个页面的结构都是一样的,所以你可以循环刚才的代码,爬下剩下的6个页面的表格,合并它们。
多页面抓取
垂直拼接示例
举个例子,我们试着用刚才的代码爬取第二页:clear
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
运行这些代码后,可以得到一个类似于第一页爬取结果的表,然后可以使用append命令将该表垂直拼接到第一页爬取的数据集CPI_final.dta上:
使用 CPI_final 追加
保存 CPI_final,替换
环缝
为了一致性,我重写了上面的代码,因为有些代码可以在循环后运行,比如变量标签、变量名等。 *==================== ============*
* 东方财富消费者物价指数爬行
*================================*
* 下载第一页
清除所有
cd'~/桌面'
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
保存 CPI_final,替换
* 下一个循环从第 2 页到第 8 页并垂直缝合每一页
forval i = 2/8{
清除
复制'`i'' temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
使用 CPI_final 追加
保存 CPI_final,替换
}
使用 CPI_final,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
爬取结果:

至此,我们就完成了这个爬取任务。下面我们进行一个简单的应用-数据展示。
数据呈现
如果我想观察CPI的走势,我需要画一个折线图:
使用 CPI_final,清除
排序日期
* 画画
* 推荐使用我最喜欢的绘画主题plotplain
* 安装方法
ssc 安装百叶窗方案,替换所有
* 永久设置情节主题为plotplain
设置计划情节,永久
* 查看2018年6月对应的Stata日期
di date('2018-06','YM')
* /// 表示代码换行,注意下面几行绘制代码一起运行
tw ///
行 cpi_all 日期, ///
lc(blue*0.6) lp(solid) ///
xline(21336) || ///
行 cpi_city 日期, lc(dkorange) ///
lp(实心) || ///
行 cpi_village 日期, lc(orange_red) ||, ///
ti('图:消费物价指数走势', size(*1.2)) || ///
scatteri 101.90 21336 (12)'June 2018' ||, ///
leg(pos(6) row(1) order(1'全国CPI' 2'城市CPI' 3'农村CPI'))
* 以png格式导出图片
gr 导出 20181004a1.png,替换

以上一些选项的含义: ||:用于分隔图层。
line:用于绘制折线图
tw:全称twoway,用于组合多个图层
lc:全称lcolor(),控制折线图的颜色
lp:全称lpattern(),控制线型
yline:在指定位置画一条水平线
xline:在指定位置画一条垂直线
ti:全称title(),控制标题,size用来控制标题文字的大小,这里是1.2次
leg:全称是legend(),控制图例。pos 用于控制图例的位置。这是一个 6 点方向,排列成一行。
scatteri:用于在指定坐标处绘制一个点。'June 2018'是这个点的标签,(12)用于指定这个标签在该点所在的方向,指定为12点钟方向。❝
欢迎加入 TidyFriday 知识星球,获取更多学习资源:❞
参考文献[1]
东方财富网CPI数据:
网页表格抓取(在ASP.NET中表格的显式方法,表格数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-15 15:13
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键。考虑实际情况,我们应该隐藏主键,使用隐藏属性)对应的列是)。在后台只需要将Repeater绑定到对应的数据源上即可,这里我们使用class来标记按钮,这样在JS中就可以将所有相同class的按钮作为一组取出。从而在JS中监听和选择设置对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。
转载于: 查看全部
网页表格抓取(在ASP.NET中表格的显式方法,表格数据的方法)
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键。考虑实际情况,我们应该隐藏主键,使用隐藏属性)对应的列是)。在后台只需要将Repeater绑定到对应的数据源上即可,这里我们使用class来标记按钮,这样在JS中就可以将所有相同class的按钮作为一组取出。从而在JS中监听和选择设置对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。
转载于:
网页表格抓取(如何采集网页中的表格数据到Excel中推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-15 15:12
如何将网页中的表格数据采集转Excel
<p>推荐使用网页表单数据工具搜索上传到采集,简单方便快捷。web表单数据采集器是一种可以采集单页规则和不规则表单的表单,也可以是连续的采集多页表单,可以指定 查看全部
网页表格抓取( 有你想要的精彩作者|東不归出品|Python知识学堂 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-15 15:08
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
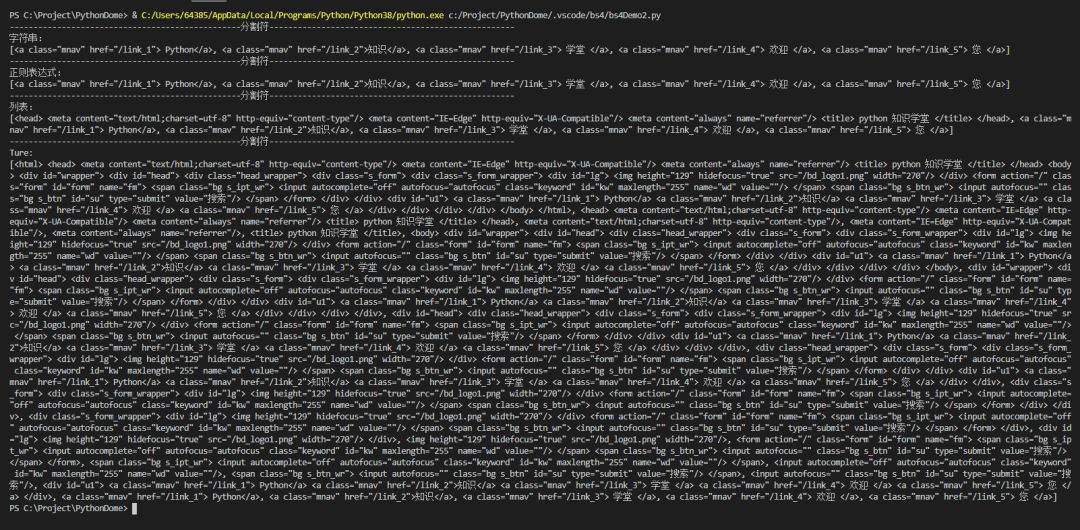
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
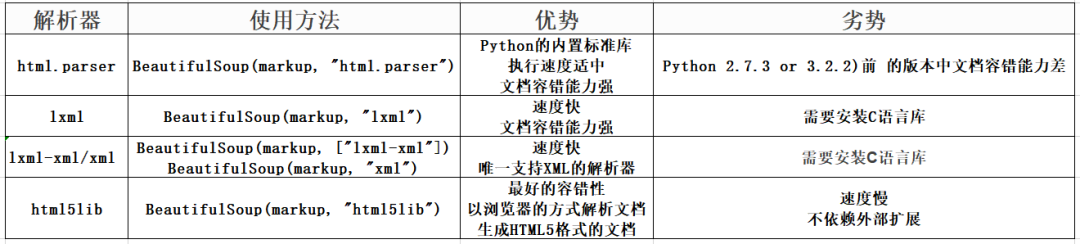
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一段 HTML 或者 XML 文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml 结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果可以得出结论,如果不指定解析器,他会给出系统中最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
Python 知识学院,欢迎您!
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先大致了解一下,后面会有遍历文档和搜索文档的说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:可以通过字符串参数搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
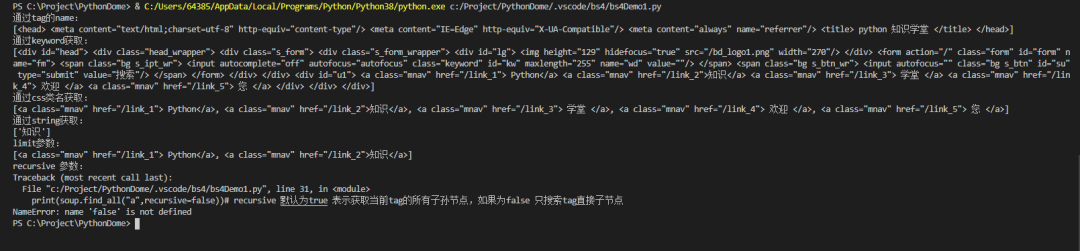
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 方法基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再贴一下官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
查看全部
网页表格抓取(
有你想要的精彩作者|東不归出品|Python知识学堂
)

有你想要的

作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果

xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果

lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果

可以看到,这些解析器解析出来的记录基本相同,但是如果一段 HTML 或者 XML 文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml 结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果

可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
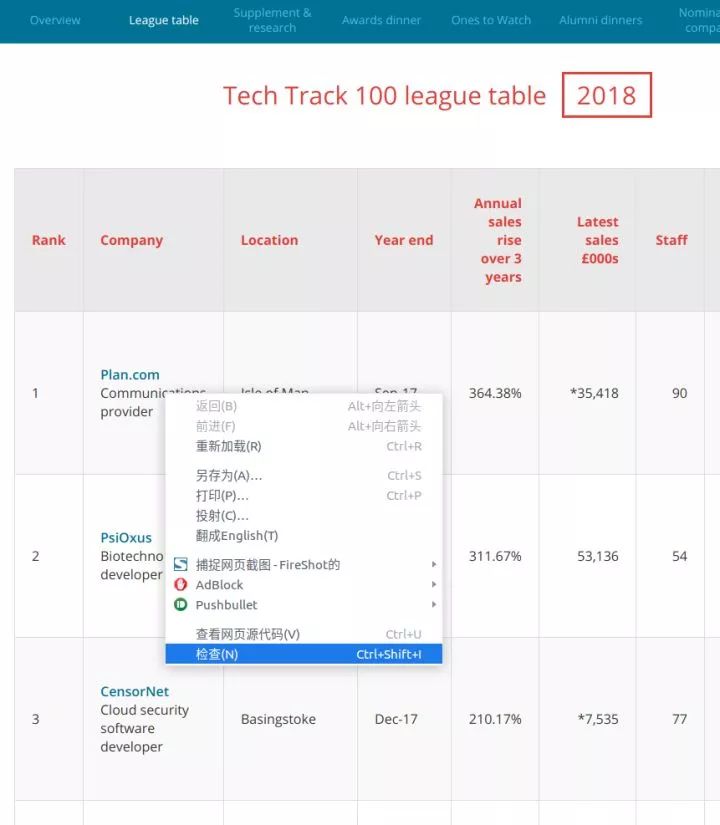
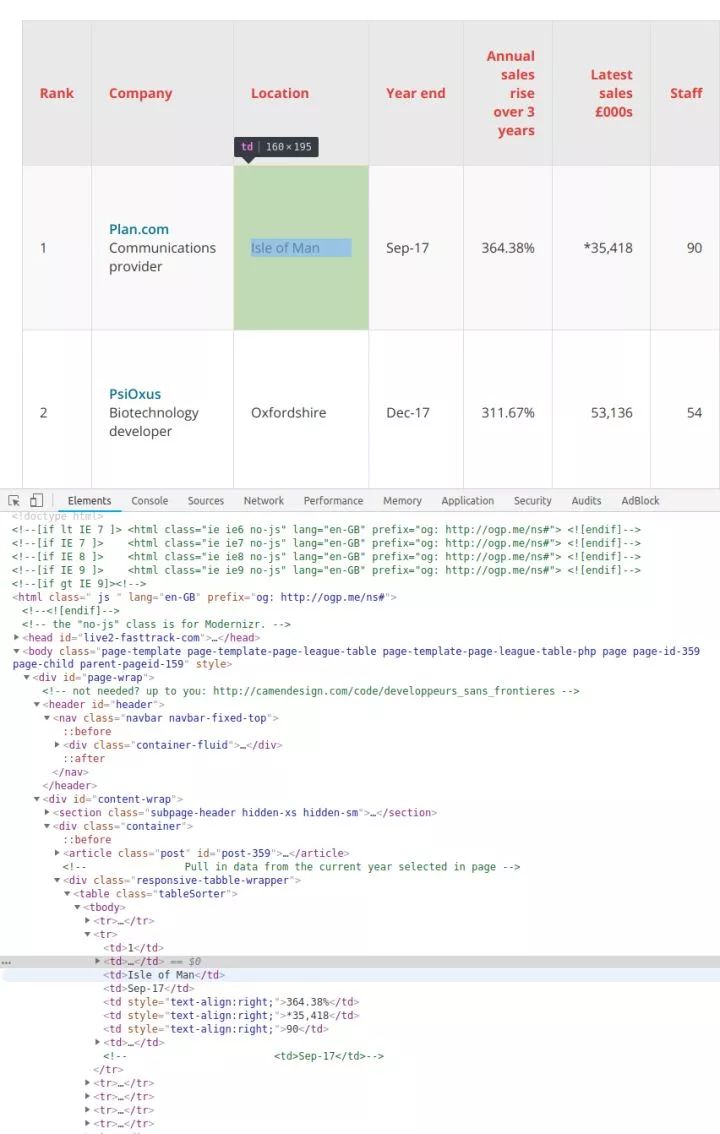
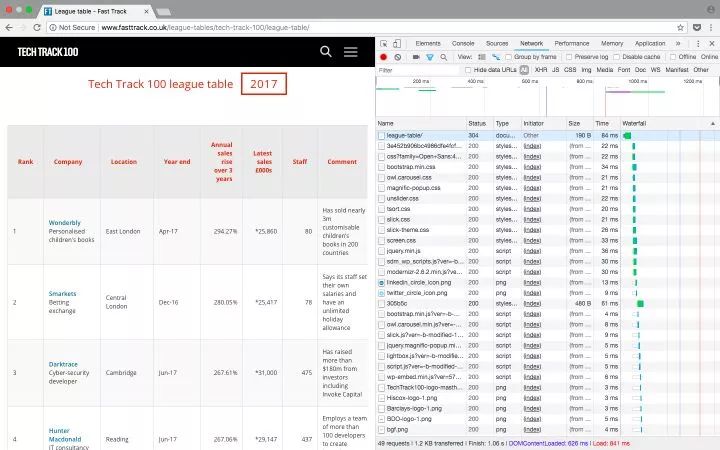
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果

从结果可以得出结论,如果不指定解析器,他会给出系统中最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果

上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:

如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:

导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
Python 知识学院,欢迎您!
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:

这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先大致了解一下,后面会有遍历文档和搜索文档的说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果

但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果

可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:

上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:可以通过字符串参数搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 方法基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再贴一下官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!

过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30

Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看

网页表格抓取( 网页信息提取的方式从网页中提取信息的需求日益剧增)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 15:06
网页信息提取的方式从网页中提取信息的需求日益剧增)
关于转载授权
欢迎个人将大数据文摘作品转发至朋友圈、自媒体、媒体、机构需申请授权,后台留言“机构名称+转载”。已经申请授权的不需要再次申请,只要按照约定转载即可,但文章末尾必须放置大数据摘要二维码。
编译|丁雪黄年程序笔记|席雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。这是一个问题或产品,它的功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
从网页中提取信息的方法
有多种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如Twitter、Facebook、Google、Twitter、StackOverflow,都提供了API,以更加结构化的方式访问网站数据。如果可以通过API直接获取所需信息,那么这种方式几乎总是比网络爬取方式要好。因为如果你可以从数据提供者那里得到结构化的数据,那为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并非所有 网站 都提供 API。一些网站不愿意让读者以结构化的方式抓取大量信息,一些网站由于缺乏相关技术知识而无法提供API。遇到这种情况我该怎么办?那么,我们需要通过网络爬虫来获取数据。
当然还有一些其他的方式,比如RSS订阅,但是由于使用限制,这里就不展开讨论了。
什么是网络爬虫?
网页抓取是一种从网站获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转换为结构化数据(数据库或电子表格)。
网络爬虫可以通过不同的方式实现,包括从 Google Docs 到几乎所有的编程语言。由于 Python 的易用性和丰富的生态系统,我会选择使用 Python。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将使用 Python 编程语言向您展示学习网页抓取的最简单方法。
对于需要通过非编程方式从网页中提取数据的读者,可以去import.io看看。有基于图形用户界面的基本操作来运行网页抓取。电脑迷可以继续看这篇文章!
网络爬虫所需的库
我们都知道 Python 是一种开源编程语言。您可能会找到许多库来实现一个功能。因此,有必要找到最好的库。我倾向于使用 BeautifulSoup(Python 库),因为它使用起来简单直观。准确地说,我将使用两个 Python 模块来抓取数据:
· Urllib2:它是一个用于获取URL 的Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关更多详细信息,请参阅文档页面。
· BeautifulSoup:它是一种用于从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表和段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。您可以在其文档页面查看安装指南。
BeautifulSoup 并不能帮助我们获取网页,这就是我将 urllib2 和 BeautifulSoup 库一起使用的原因。除了 BeautifulSoup,Python 还有其他的 HTML 抓取方法。喜欢:
·机械化
·刮痕
·Scrapy
基础 - 熟悉 HTML(标签)
在做网页爬虫的时候,我们需要处理html标签。因此,我们首先要了解标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
语法的各个标签的解释如下:
1.:html文档必须以类型声明开头
2.html文档写在and标签之间
3.html文档的可见部分写在and标签之间
4.HTML header 使用标签定义
5.html 段落用法
标签定义
其他有用的 HTML 标签是:
1.html 链接使用标签定义,“这是一个测试”
2.html表用法定义,行用法的意思,行用法分为数据
3.html 列表 查看全部
网页表格抓取(
网页信息提取的方式从网页中提取信息的需求日益剧增)

关于转载授权
欢迎个人将大数据文摘作品转发至朋友圈、自媒体、媒体、机构需申请授权,后台留言“机构名称+转载”。已经申请授权的不需要再次申请,只要按照约定转载即可,但文章末尾必须放置大数据摘要二维码。
编译|丁雪黄年程序笔记|席雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。这是一个问题或产品,它的功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
从网页中提取信息的方法
有多种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如Twitter、Facebook、Google、Twitter、StackOverflow,都提供了API,以更加结构化的方式访问网站数据。如果可以通过API直接获取所需信息,那么这种方式几乎总是比网络爬取方式要好。因为如果你可以从数据提供者那里得到结构化的数据,那为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并非所有 网站 都提供 API。一些网站不愿意让读者以结构化的方式抓取大量信息,一些网站由于缺乏相关技术知识而无法提供API。遇到这种情况我该怎么办?那么,我们需要通过网络爬虫来获取数据。
当然还有一些其他的方式,比如RSS订阅,但是由于使用限制,这里就不展开讨论了。

什么是网络爬虫?
网页抓取是一种从网站获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转换为结构化数据(数据库或电子表格)。
网络爬虫可以通过不同的方式实现,包括从 Google Docs 到几乎所有的编程语言。由于 Python 的易用性和丰富的生态系统,我会选择使用 Python。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将使用 Python 编程语言向您展示学习网页抓取的最简单方法。
对于需要通过非编程方式从网页中提取数据的读者,可以去import.io看看。有基于图形用户界面的基本操作来运行网页抓取。电脑迷可以继续看这篇文章!
网络爬虫所需的库
我们都知道 Python 是一种开源编程语言。您可能会找到许多库来实现一个功能。因此,有必要找到最好的库。我倾向于使用 BeautifulSoup(Python 库),因为它使用起来简单直观。准确地说,我将使用两个 Python 模块来抓取数据:
· Urllib2:它是一个用于获取URL 的Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关更多详细信息,请参阅文档页面。
· BeautifulSoup:它是一种用于从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表和段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。您可以在其文档页面查看安装指南。
BeautifulSoup 并不能帮助我们获取网页,这就是我将 urllib2 和 BeautifulSoup 库一起使用的原因。除了 BeautifulSoup,Python 还有其他的 HTML 抓取方法。喜欢:
·机械化
·刮痕
·Scrapy
基础 - 熟悉 HTML(标签)
在做网页爬虫的时候,我们需要处理html标签。因此,我们首先要了解标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:

语法的各个标签的解释如下:
1.:html文档必须以类型声明开头
2.html文档写在and标签之间
3.html文档的可见部分写在and标签之间
4.HTML header 使用标签定义
5.html 段落用法
标签定义
其他有用的 HTML 标签是:
1.html 链接使用标签定义,“这是一个测试”
2.html表用法定义,行用法的意思,行用法分为数据

3.html 列表
网页表格抓取(1.网页展示的表格如下获取网页表格的后话了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-14 15:31
文章内容
文章 仅用于学习和交流。使用 python 模块 pandas 获取 Web 表单。
有时我想在看到它时将表单保存在网页上。有办法吗?答案是肯定的。
主要有两个步骤,
一种是读取表格内容,另一种是读取后保存内容。
我只解释最简单的获取网页表单的方式,即网页是纯粹的表单。
如果网页中混有其他非表格的数据,则需要定位表格,然后进行表格获取。当然,这是后来的事情。1.网页展示
网页上显示的表格如下。
2.阅读表格
运行以下代码。
怎么样,读出来的代码和网页上的一样吗?既然已经读出,下一步就是保存。
3.保存表格
这一步添加了一行代码。执行代码后,可以看到多了一个table_.csv文件。
打开保存的table_.csv文件看看
您可以看到保存的文件与您在网页上看到的完全相同。好了,结束工作。
完整代码
# read_html,用来读取网页表格
# to_csv,用来保存为csv格式的文档
# 网页需要是纯表格才能用此代码,否则还需要定位到网页表格位置
import pandas as pd
url = 'http://quote.cfi.cn/cache_image/node233.js'
html_data = pd.read_html(url)
for i in html_data:
table_data = pd.DataFrame(i)
table_data.to_csv('table_.csv') # 文件名称
print(table_data)
不禁感受到python语言的强大。 查看全部
网页表格抓取(1.网页展示的表格如下获取网页表格的后话了)
文章内容
文章 仅用于学习和交流。使用 python 模块 pandas 获取 Web 表单。
有时我想在看到它时将表单保存在网页上。有办法吗?答案是肯定的。
主要有两个步骤,
一种是读取表格内容,另一种是读取后保存内容。
我只解释最简单的获取网页表单的方式,即网页是纯粹的表单。
如果网页中混有其他非表格的数据,则需要定位表格,然后进行表格获取。当然,这是后来的事情。1.网页展示
网页上显示的表格如下。

2.阅读表格
运行以下代码。
怎么样,读出来的代码和网页上的一样吗?既然已经读出,下一步就是保存。

3.保存表格
这一步添加了一行代码。执行代码后,可以看到多了一个table_.csv文件。

打开保存的table_.csv文件看看

您可以看到保存的文件与您在网页上看到的完全相同。好了,结束工作。
完整代码
# read_html,用来读取网页表格
# to_csv,用来保存为csv格式的文档
# 网页需要是纯表格才能用此代码,否则还需要定位到网页表格位置
import pandas as pd
url = 'http://quote.cfi.cn/cache_image/node233.js'
html_data = pd.read_html(url)
for i in html_data:
table_data = pd.DataFrame(i)
table_data.to_csv('table_.csv') # 文件名称
print(table_data)
不禁感受到python语言的强大。
网页表格抓取(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-13 06:04
编译:欧莎
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和说明。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为数据的第一行是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些需要清除的字符,比如备注。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中的额外字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
编译源:
●输入m获取文章目录
推荐↓↓↓
人工智能与大数据技术 查看全部
网页表格抓取(用脚本将获取信息上获取2018年100强企业的信息)
编译:欧莎
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:

安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:

每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。

下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:

接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:

如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。

看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和说明。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为数据的第一行是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些需要清除的字符,比如备注。

我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中的额外字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
编译源:
●输入m获取文章目录
推荐↓↓↓

人工智能与大数据技术
网页表格抓取(如何把网页数据直接抓取成Excel表格有多好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2021-10-13 01:37
在购物网站、酒店机票网站中,搜索一大堆需要比价和研究的产品。也许你需要在工作中列出竞品清单,也许你需要抓取数据与朋友讨论旅行计划。这时候有没有什么有效的方法让我不用手动把数据一一复制整理,直接把网页数据抓取到Excel表格里,那该有多好?
或者你正在搜索“软件下载”文章的某个话题(网站右上角有搜索功能!),发现一堆你想要的文章搜索结果阅读,有没有 方法直接将搜索结果中的一打或二十个文章 自动转换成表格列表。在类似的百科、资料、学习网站中,可以更快的整理出你需要的参考资料。
今天,我将介绍一个可以帮助您更快完成上述操作的工具:“Listly”。该工具可以通过输入网页网址,自动将网页上的项目列表和数据内容下载并转换成Excel表格。而且在我的实际测试中,可以支持中文内容网站和数据网站的购物,免费账号也有一定的使用。
1. “Listly”网页自动转Excel效果演示:
首先我们来看看“Listly”将网页转成Excel的效果。
下图是我在 Google Play 电影中的“愿望清单”。
使用“Listly”,我可以自动将愿望清单网页的内容抓取到以下数据库表中。
而且只要按下抓取按钮,它就会从网页中抓取各种数据格式,如下图所示。
然后我可以一键下载捕获的数据并下载Excel数据表,如下图。
不同的网站,把“Listly”抢到一张桌子上的效果未必100%完美。例如,在 Google Play 电影的愿望清单中,某些“Play Books”的名称字段在转换过程中变为空白。或者运行版本。
但是,如果您最初必须手动完成,从头到尾需要很多时间,“Listly”会先帮助您制作 80% 正确的表格,然后我们可以从这里进行修复和调整,这将节省很多时间。
2.《Listly》超简单操作教程:
如何操作“Listly”?它比我们想象的要简单得多,基本上任何人都可以立即开始。
我们可以输入“Listly”网站,输入我们要爬取的网址。也可以安装“Listly Chrome Plugin”,在想要抓取的网页上按抓取按钮。
例如,让我们再次演示一个示例。我在购物网站中搜索某类商品,在搜索结果页面点击“Listly”抓取按钮。
就这样!几秒钟后,您将看到以下成功捕获屏幕。
“Listly”会抓取网页上的各种数据组织,因此它会抓取多种类型的内容。我们可以使用 [page] 在我们捕捉到的不同内容之间切换。例如,此页面是已捕获搜索结果的产品列表。, 其他页面可能会捕捉到左侧的项目类别列表。
要查看您需要哪种信息,只需切换到该选项卡即可。
确认好你想要的数据的分页后,点击上方的【下载为Excel】按钮,就可以得到如下图的Excel表格了!可以看到产品名称、网址、价格等一应俱全。
是不是真的很简单。
当然,如前所述,抓取的表中可能有一些您不需要的数据。我们只需要转到 Excel 并手动调整它。
3. “Listly”抓取搜索结果并定期跟踪它们:
有时,我们的目的是跟踪和研究一些将要更新的信息。此时,“Listly”还提供了“定时自动爬取内容”服务。
比如下图中,我在小园搜索了某个话题的文章信息。同样,在搜索结果页面上,按“Listly”抓取按钮。
这时候就抓到了搜索结果相同的文章列表结构。如果您注册了“Listly”帐户,您可以将捕获的结果保存在您的仪表板中。
并使用【添加日程】设置自动爬取周期,比如一个月爬一次,看看有没有添加更多相关话题文章。
同样,捕获的文章列表也可以导出到Excel表格中,节省您手动复制标题和URL的时间。
相信大家在搜索信息的过程中,经常需要“将所有数据整理成一个list”,而此时“Listly”确实可以节省不少时间。
此外,“Listly”免费账号提供“每月抓取10个网页”的额度,跟踪1个网页更新。对于免费用户偶尔使用,应该足够了。当然,如果您是出于商业目的,可以考虑“Listly”付费账户。
记得之前有人问过我,有没有办法把网页数据转成Excel,看来“Listly”是个不错的解决方案。
文章 链接:
文章标题:Listly自动抓取网页并转换成Excel表格!支持中文购物和数据网站 查看全部
网页表格抓取(如何把网页数据直接抓取成Excel表格有多好?)
在购物网站、酒店机票网站中,搜索一大堆需要比价和研究的产品。也许你需要在工作中列出竞品清单,也许你需要抓取数据与朋友讨论旅行计划。这时候有没有什么有效的方法让我不用手动把数据一一复制整理,直接把网页数据抓取到Excel表格里,那该有多好?
或者你正在搜索“软件下载”文章的某个话题(网站右上角有搜索功能!),发现一堆你想要的文章搜索结果阅读,有没有 方法直接将搜索结果中的一打或二十个文章 自动转换成表格列表。在类似的百科、资料、学习网站中,可以更快的整理出你需要的参考资料。
今天,我将介绍一个可以帮助您更快完成上述操作的工具:“Listly”。该工具可以通过输入网页网址,自动将网页上的项目列表和数据内容下载并转换成Excel表格。而且在我的实际测试中,可以支持中文内容网站和数据网站的购物,免费账号也有一定的使用。
1. “Listly”网页自动转Excel效果演示:
首先我们来看看“Listly”将网页转成Excel的效果。
下图是我在 Google Play 电影中的“愿望清单”。

使用“Listly”,我可以自动将愿望清单网页的内容抓取到以下数据库表中。
而且只要按下抓取按钮,它就会从网页中抓取各种数据格式,如下图所示。

然后我可以一键下载捕获的数据并下载Excel数据表,如下图。
不同的网站,把“Listly”抢到一张桌子上的效果未必100%完美。例如,在 Google Play 电影的愿望清单中,某些“Play Books”的名称字段在转换过程中变为空白。或者运行版本。
但是,如果您最初必须手动完成,从头到尾需要很多时间,“Listly”会先帮助您制作 80% 正确的表格,然后我们可以从这里进行修复和调整,这将节省很多时间。

2.《Listly》超简单操作教程:
如何操作“Listly”?它比我们想象的要简单得多,基本上任何人都可以立即开始。
我们可以输入“Listly”网站,输入我们要爬取的网址。也可以安装“Listly Chrome Plugin”,在想要抓取的网页上按抓取按钮。
例如,让我们再次演示一个示例。我在购物网站中搜索某类商品,在搜索结果页面点击“Listly”抓取按钮。

就这样!几秒钟后,您将看到以下成功捕获屏幕。
“Listly”会抓取网页上的各种数据组织,因此它会抓取多种类型的内容。我们可以使用 [page] 在我们捕捉到的不同内容之间切换。例如,此页面是已捕获搜索结果的产品列表。, 其他页面可能会捕捉到左侧的项目类别列表。
要查看您需要哪种信息,只需切换到该选项卡即可。


确认好你想要的数据的分页后,点击上方的【下载为Excel】按钮,就可以得到如下图的Excel表格了!可以看到产品名称、网址、价格等一应俱全。
是不是真的很简单。
当然,如前所述,抓取的表中可能有一些您不需要的数据。我们只需要转到 Excel 并手动调整它。
3. “Listly”抓取搜索结果并定期跟踪它们:
有时,我们的目的是跟踪和研究一些将要更新的信息。此时,“Listly”还提供了“定时自动爬取内容”服务。
比如下图中,我在小园搜索了某个话题的文章信息。同样,在搜索结果页面上,按“Listly”抓取按钮。

这时候就抓到了搜索结果相同的文章列表结构。如果您注册了“Listly”帐户,您可以将捕获的结果保存在您的仪表板中。

并使用【添加日程】设置自动爬取周期,比如一个月爬一次,看看有没有添加更多相关话题文章。

同样,捕获的文章列表也可以导出到Excel表格中,节省您手动复制标题和URL的时间。

相信大家在搜索信息的过程中,经常需要“将所有数据整理成一个list”,而此时“Listly”确实可以节省不少时间。
此外,“Listly”免费账号提供“每月抓取10个网页”的额度,跟踪1个网页更新。对于免费用户偶尔使用,应该足够了。当然,如果您是出于商业目的,可以考虑“Listly”付费账户。
记得之前有人问过我,有没有办法把网页数据转成Excel,看来“Listly”是个不错的解决方案。
文章 链接:
文章标题:Listly自动抓取网页并转换成Excel表格!支持中文购物和数据网站
网页表格抓取(小白表示R语言太有用了!(附案例分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-12 07:22
今天,R语言对我帮助很大。几行简单的代码几乎为我节省了一天的时间。小白说R语言好用!
问题如下:
我想获取网页上表格中的数据,网页表格如下图
但是,这张表无法复制和粘贴,这是非常作弊的。Ctrl+C 和 Ctrl+V 之后,只有 URL 出来了。估计是禁用了复制粘贴功能。而且一一敲的话,工作量会很大,估计最后会瞎的……
整个数据量如下,/aspx/1/NewData/Stat_Data.aspx?state=1&next=2¤cy=usd&year=2016
从2014年到2017年有四年,每年有7个项目,每个项目分12个月,共336张表,有的表内容特别大,数量特别多,如下图:
按照这个工作量,如果你一一数数,输入Excel,一天不吃不喝可能做不完。
幸运的是,我最近才开始使用 R ......
听说R语言也有爬取数据的功能,于是在网上简单搜索了一些帖子,使用XML包,成功将这个网页中的336表保存为Excel格式。
代码显示如下:
>install.packages("XML")#安装 XML 包
>library(XML) #加载XML包
>/aspx/1/NewData/Stat_Class.aspx?state=1&t=2&guid=7146" #写表所在的URL
>tblsR语言网页数据抓取示例
>流行
>write.csv(pop,file="d:/pop.csv") #将pop存储为D盘的CSV文件
这样就快速实现了网页中的数据爬取。第一次用R语言工作,往往很有成就感~不过毕竟有336个网页,最后还要跑336次代码,工作量也是肯定。童鞋们,如果有更好更快的导出数据的方法,欢迎提供~ 查看全部
网页表格抓取(小白表示R语言太有用了!(附案例分析))
今天,R语言对我帮助很大。几行简单的代码几乎为我节省了一天的时间。小白说R语言好用!
问题如下:
我想获取网页上表格中的数据,网页表格如下图
但是,这张表无法复制和粘贴,这是非常作弊的。Ctrl+C 和 Ctrl+V 之后,只有 URL 出来了。估计是禁用了复制粘贴功能。而且一一敲的话,工作量会很大,估计最后会瞎的……
整个数据量如下,/aspx/1/NewData/Stat_Data.aspx?state=1&next=2¤cy=usd&year=2016
从2014年到2017年有四年,每年有7个项目,每个项目分12个月,共336张表,有的表内容特别大,数量特别多,如下图:
按照这个工作量,如果你一一数数,输入Excel,一天不吃不喝可能做不完。
幸运的是,我最近才开始使用 R ......
听说R语言也有爬取数据的功能,于是在网上简单搜索了一些帖子,使用XML包,成功将这个网页中的336表保存为Excel格式。
代码显示如下:
>install.packages("XML")#安装 XML 包
>library(XML) #加载XML包
>/aspx/1/NewData/Stat_Class.aspx?state=1&t=2&guid=7146" #写表所在的URL
>tblsR语言网页数据抓取示例
>流行
>write.csv(pop,file="d:/pop.csv") #将pop存储为D盘的CSV文件
这样就快速实现了网页中的数据爬取。第一次用R语言工作,往往很有成就感~不过毕竟有336个网页,最后还要跑336次代码,工作量也是肯定。童鞋们,如果有更好更快的导出数据的方法,欢迎提供~
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-11 16:39
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取( image如何抓取网页表格里的数据?Datapreview预览一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-11 08:20
image如何抓取网页表格里的数据?Datapreview预览一下)
图片
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
图片
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
图片
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
图片
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
图片
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
图片
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
图片
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
图片
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
图片
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
图片
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
image如何抓取网页表格里的数据?Datapreview预览一下)
图片
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
图片
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
图片
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
图片
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
图片
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:

图片
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
图片
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
图片
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
图片
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
图片
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(我想从使用Python2.7+Windows保存的HTML网页中提取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-09 22:24
我想从使用 Python 2.7 + Windows 保存的 HTML 网页中提取数据。 Python BeautifulSoup 从保存的 HTML 页面中提取表格
有多个保存的 HTML 页面,它们是相似的,每个页面都收录一个 5 列的表格。行数不固定。
源码如下:
text = '''
/DXR.axd?r=1_19-RPSupplier Code (Count=6, Record Count:86) (next page)
 3617GermanEU20122013
 3617BelgiumEU20142015
…
…
…
…
…
'''
我想要的是将表格的内容放入 .xls 文件中。
我所要做的就是:
soup = BeautifulSoup(text)
aa = soup.find_all('table')[0].tbody.find_all('tr')
for a in aa:
print a.text
它提供了所有内容,但都在第一行。
我认为:
aa = soup.find_all(id = 'MainTable')
for a in aa:
for b in a.find_all(id = 'Row2'):
print b.text
它给出了特定行的内容,但仍然在第 1 行。
3617BelgiumEU20142015
这还不够,HTML文件行数的不确定性也是一个问题。
我想要的是“3617”、“比利时”、“欧盟”、“2014”和“2015”,以便我可以将它们保存在 .xls 文件中。
提取表格的最佳方法是什么?
来源
2015-07-22Mark K 查看全部
网页表格抓取(我想从使用Python2.7+Windows保存的HTML网页中提取数据)
我想从使用 Python 2.7 + Windows 保存的 HTML 网页中提取数据。 Python BeautifulSoup 从保存的 HTML 页面中提取表格
有多个保存的 HTML 页面,它们是相似的,每个页面都收录一个 5 列的表格。行数不固定。
源码如下:
text = '''
/DXR.axd?r=1_19-RPSupplier Code (Count=6, Record Count:86) (next page)
 3617GermanEU20122013
 3617BelgiumEU20142015
…
…
…
…
…
'''
我想要的是将表格的内容放入 .xls 文件中。
我所要做的就是:
soup = BeautifulSoup(text)
aa = soup.find_all('table')[0].tbody.find_all('tr')
for a in aa:
print a.text
它提供了所有内容,但都在第一行。
我认为:
aa = soup.find_all(id = 'MainTable')
for a in aa:
for b in a.find_all(id = 'Row2'):
print b.text
它给出了特定行的内容,但仍然在第 1 行。
3617BelgiumEU20142015
这还不够,HTML文件行数的不确定性也是一个问题。
我想要的是“3617”、“比利时”、“欧盟”、“2014”和“2015”,以便我可以将它们保存在 .xls 文件中。
提取表格的最佳方法是什么?
来源
2015-07-22Mark K
网页表格抓取(本文本文实例讲述Python实现抓取网页生成Excel文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-09 21:13
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
Python抓取网页生成Excel文件 查看全部
网页表格抓取(本文本文实例讲述Python实现抓取网页生成Excel文件的方法)
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
Python抓取网页生成Excel文件
网页表格抓取(爬虫所要通用的表格函数应对方法,对你非常有帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-09 16:44
如果你的爬虫想要爬取的内容存在于页面的table标签中,那么本文探讨的方法对你很有帮助。
下面两个网址有非常规范的表格数据
前者是北京500强名单,后者是中国500强名单
对于常规爬取,需要对页面进行分析,准确找到这部分内容的标签位置,然后进行定点爬取。分析了几个页面,发现这些表中的数据非常相似。
它们存储在 table 标记中。第一个tr是第一行的标题,数据内容从第二个tr开始。
排名
公司名称(中英文)
营业收入(百万美元)
2
国家电网公司(STATE GRID)
348903.1
3
中国石油化工集团公司(SINOPEC GROUP)
326953
4
中国石油天然气集团公司(CHINA NATIONAL PETROLEUM)
326007.6
既然都长得一样,何不写一个通用的表单爬取功能,这样当你遇到这种页面时,可以快速爬取。之所以不写一般的表单爬虫,是因为不同的页面获取方式不同,但是只要获取到html,其余的分析提取过程都是一样的。
如果你想让一个函数处理所有情况,你需要对表格有特殊的理解,这样这个函数才能覆盖大部分情况。至于一些特殊的页面,则不在此功能范围之内。
第一个tr是标题行,内部标签可以是th或td。对于tbody中的tr,内部是td。编写程序时应注意这一点。在获取td内容时,我只关心实际的文本内容。至于加粗的标签或者链接,不是我想要的。因此,代码中只需要提取td下的文本内容即可。
思路确定了,代码就容易写了
import pprint
import requests
from lxml import etree
def get_table_from_html(html):
tree = etree.HTML(html)
# 寻找所有的table标签
table_lst = tree.xpath("//table")
table_data_lst = []
for table in table_lst:
table_data_lst.append(get_table(table))
return table_data_lst
def get_table(table_ele):
"""
获取table数据
:param table_ele:
:return:
"""
tr_lst = table_ele.xpath(".//tr")
# 第一行通常来说都是标题
title_data = get_title(tr_lst[0])
# 第一行后面都是数据
data = get_data(tr_lst[1:])
return {
'title': title_data,
'data': data
}
def get_title(tr_ele):
"""
获取标题
标题可能用th 标签,也可能用td标签
:param tr_ele:
:return:
"""
# 先寻找th标签
title_lst = get_tr_data_by_tag(tr_ele, 'th')
if not title_lst:
title_lst = get_tr_data_by_tag(tr_ele, 'td')
return title_lst
def get_data(tr_lst):
"""
获取数据
:param tr_lst:
:return:
"""
datas = []
for tr in tr_lst:
tr_data = get_tr_data_by_tag(tr, 'td')
datas.append(tr_data)
return datas
def get_tr_data_by_tag(tr, tag):
"""
获取一行数据
:param tr:
:param tag:
:return:
"""
datas = []
nodes = tr.xpath(".//{tag}".format(tag=tag))
for node in nodes:
text = node.xpath('string(.)').strip()
datas.append(text)
return datas
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
return res.text
def run():
url = 'https://baike.baidu.com/item/% ... 39%3B
# url = "https://www.phb123.com/qiye/35109.html"
html = get_html(url)
table_lst = get_table_from_html(html)
pprint.pprint(table_lst)
if __name__ == '__main__':
run()
目前只有少数几个网页被用于测试。如果遇到无法通过此方法准确抓取的页面,可以给我留言,我会根据页面内容改进此表单的抓取方法 查看全部
网页表格抓取(爬虫所要通用的表格函数应对方法,对你非常有帮助)
如果你的爬虫想要爬取的内容存在于页面的table标签中,那么本文探讨的方法对你很有帮助。
下面两个网址有非常规范的表格数据
前者是北京500强名单,后者是中国500强名单
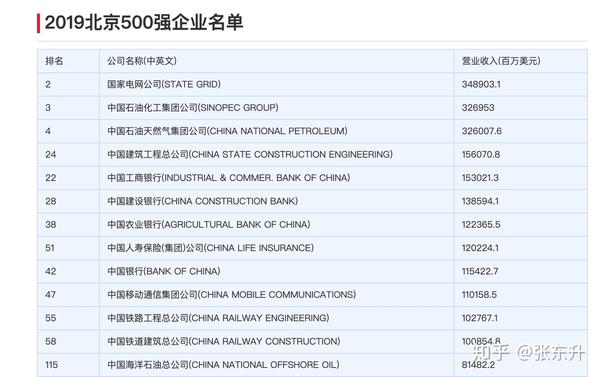
对于常规爬取,需要对页面进行分析,准确找到这部分内容的标签位置,然后进行定点爬取。分析了几个页面,发现这些表中的数据非常相似。
它们存储在 table 标记中。第一个tr是第一行的标题,数据内容从第二个tr开始。
排名
公司名称(中英文)
营业收入(百万美元)
2
国家电网公司(STATE GRID)
348903.1
3
中国石油化工集团公司(SINOPEC GROUP)
326953
4
中国石油天然气集团公司(CHINA NATIONAL PETROLEUM)
326007.6
既然都长得一样,何不写一个通用的表单爬取功能,这样当你遇到这种页面时,可以快速爬取。之所以不写一般的表单爬虫,是因为不同的页面获取方式不同,但是只要获取到html,其余的分析提取过程都是一样的。
如果你想让一个函数处理所有情况,你需要对表格有特殊的理解,这样这个函数才能覆盖大部分情况。至于一些特殊的页面,则不在此功能范围之内。
第一个tr是标题行,内部标签可以是th或td。对于tbody中的tr,内部是td。编写程序时应注意这一点。在获取td内容时,我只关心实际的文本内容。至于加粗的标签或者链接,不是我想要的。因此,代码中只需要提取td下的文本内容即可。
思路确定了,代码就容易写了
import pprint
import requests
from lxml import etree
def get_table_from_html(html):
tree = etree.HTML(html)
# 寻找所有的table标签
table_lst = tree.xpath("//table")
table_data_lst = []
for table in table_lst:
table_data_lst.append(get_table(table))
return table_data_lst
def get_table(table_ele):
"""
获取table数据
:param table_ele:
:return:
"""
tr_lst = table_ele.xpath(".//tr")
# 第一行通常来说都是标题
title_data = get_title(tr_lst[0])
# 第一行后面都是数据
data = get_data(tr_lst[1:])
return {
'title': title_data,
'data': data
}
def get_title(tr_ele):
"""
获取标题
标题可能用th 标签,也可能用td标签
:param tr_ele:
:return:
"""
# 先寻找th标签
title_lst = get_tr_data_by_tag(tr_ele, 'th')
if not title_lst:
title_lst = get_tr_data_by_tag(tr_ele, 'td')
return title_lst
def get_data(tr_lst):
"""
获取数据
:param tr_lst:
:return:
"""
datas = []
for tr in tr_lst:
tr_data = get_tr_data_by_tag(tr, 'td')
datas.append(tr_data)
return datas
def get_tr_data_by_tag(tr, tag):
"""
获取一行数据
:param tr:
:param tag:
:return:
"""
datas = []
nodes = tr.xpath(".//{tag}".format(tag=tag))
for node in nodes:
text = node.xpath('string(.)').strip()
datas.append(text)
return datas
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
return res.text
def run():
url = 'https://baike.baidu.com/item/% ... 39%3B
# url = "https://www.phb123.com/qiye/35109.html"
html = get_html(url)
table_lst = get_table_from_html(html)
pprint.pprint(table_lst)
if __name__ == '__main__':
run()
目前只有少数几个网页被用于测试。如果遇到无法通过此方法准确抓取的页面,可以给我留言,我会根据页面内容改进此表单的抓取方法
网页表格抓取(第4课中如何采集多个列表中的数据?课 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-07 18:08
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,比如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环-提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以单击多次直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
查看全部
网页表格抓取(第4课中如何采集多个列表中的数据?课
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,比如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
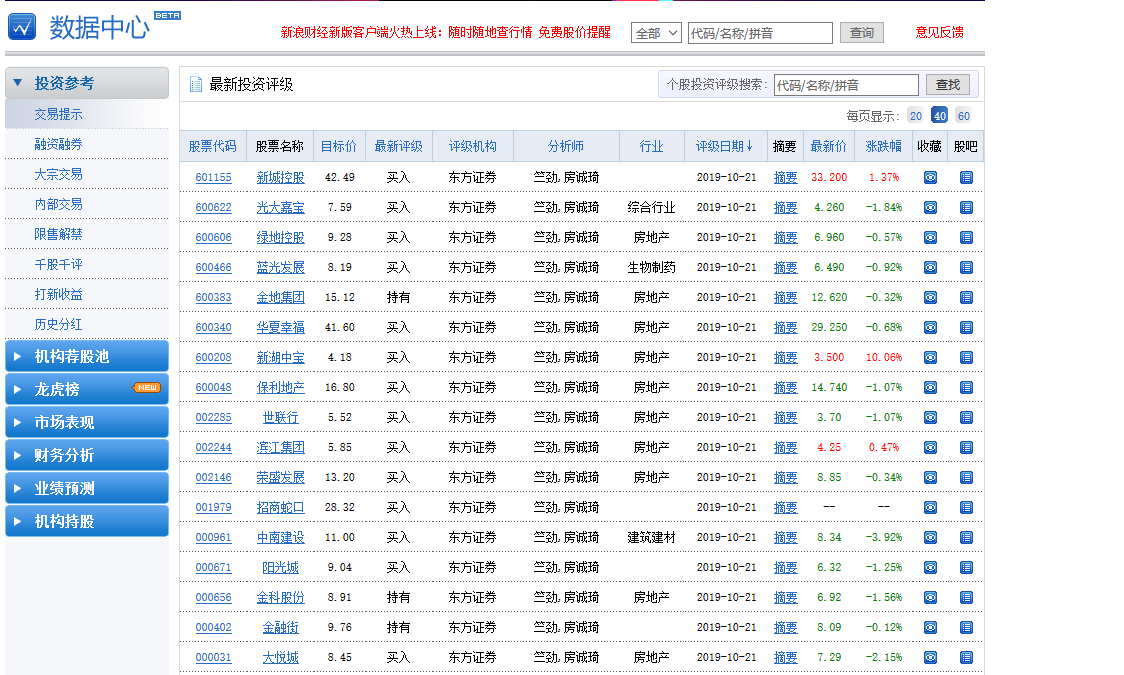
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
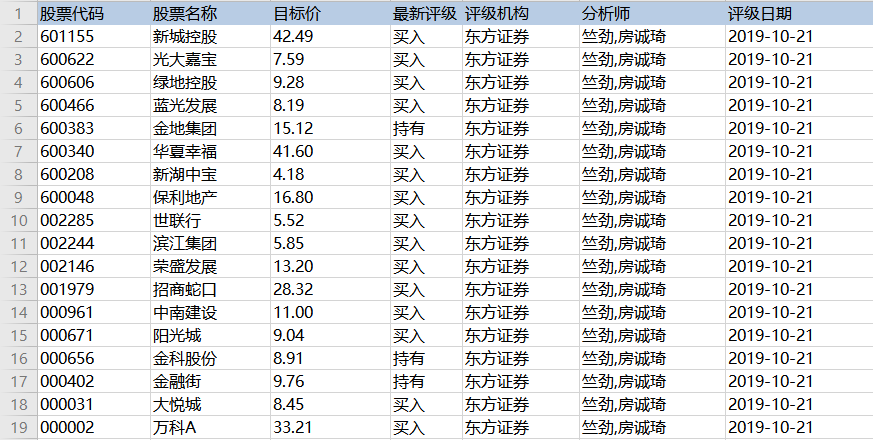
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。

步骤二、建立【循环-提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
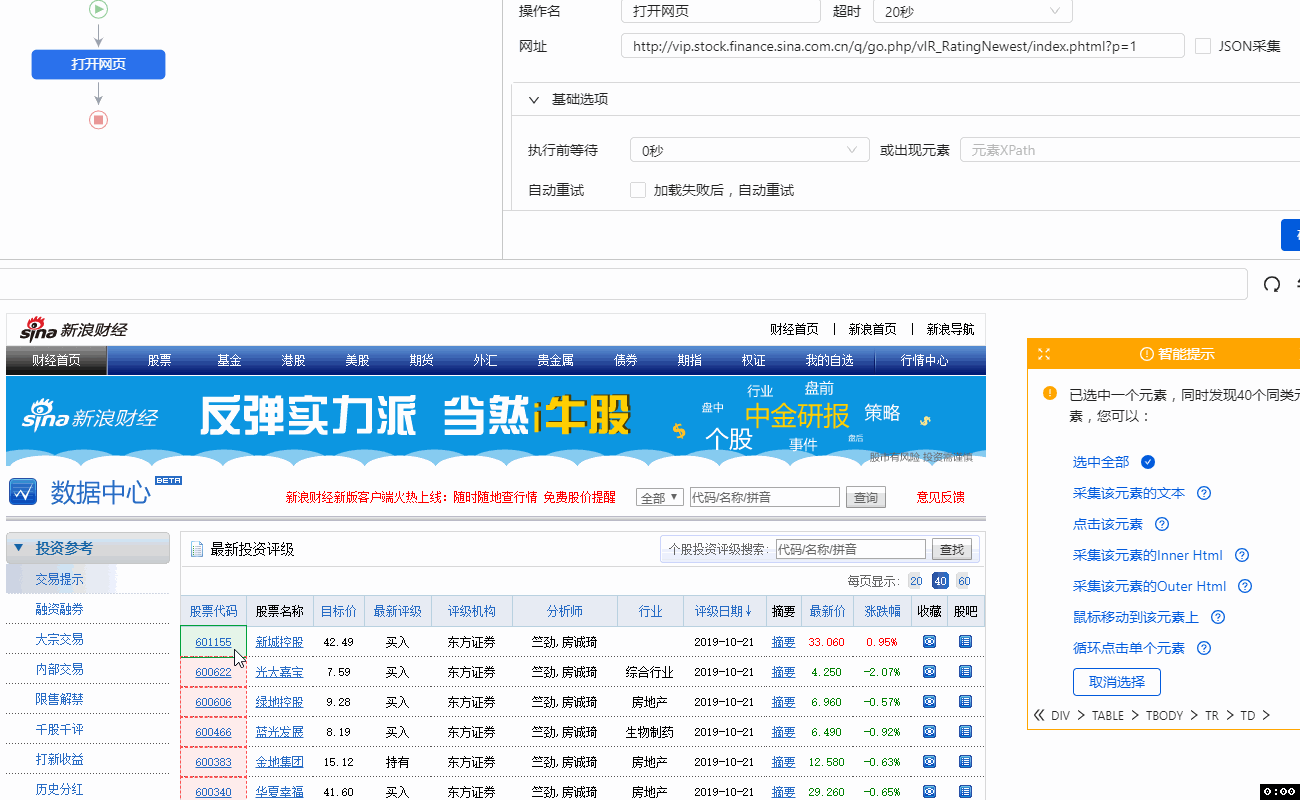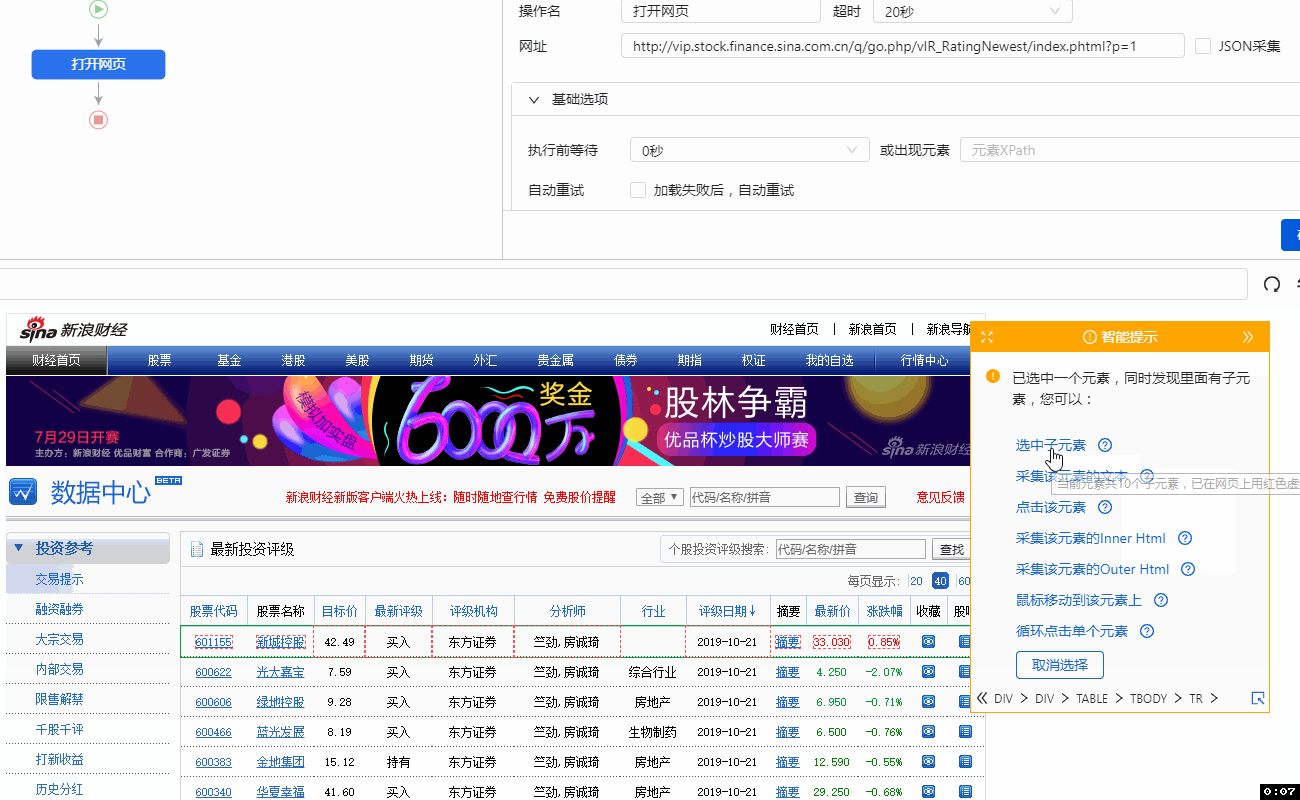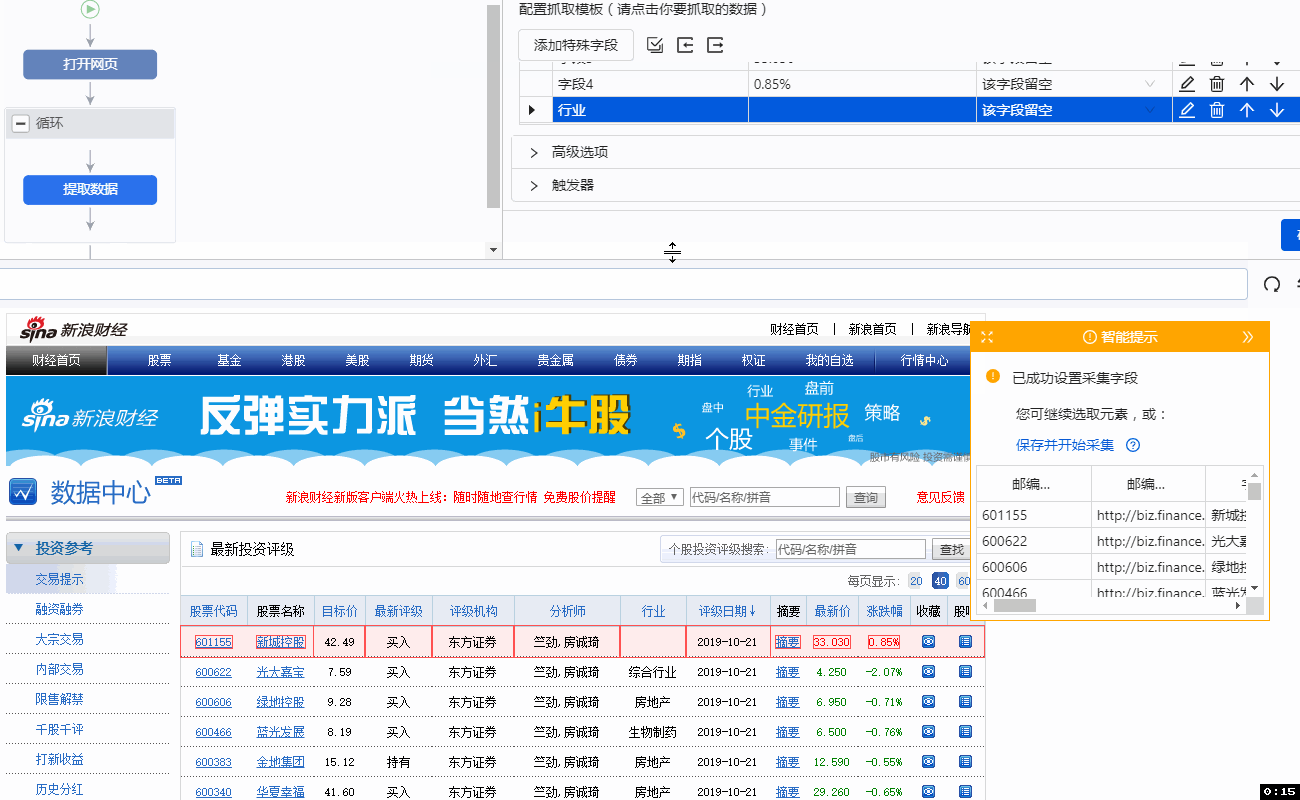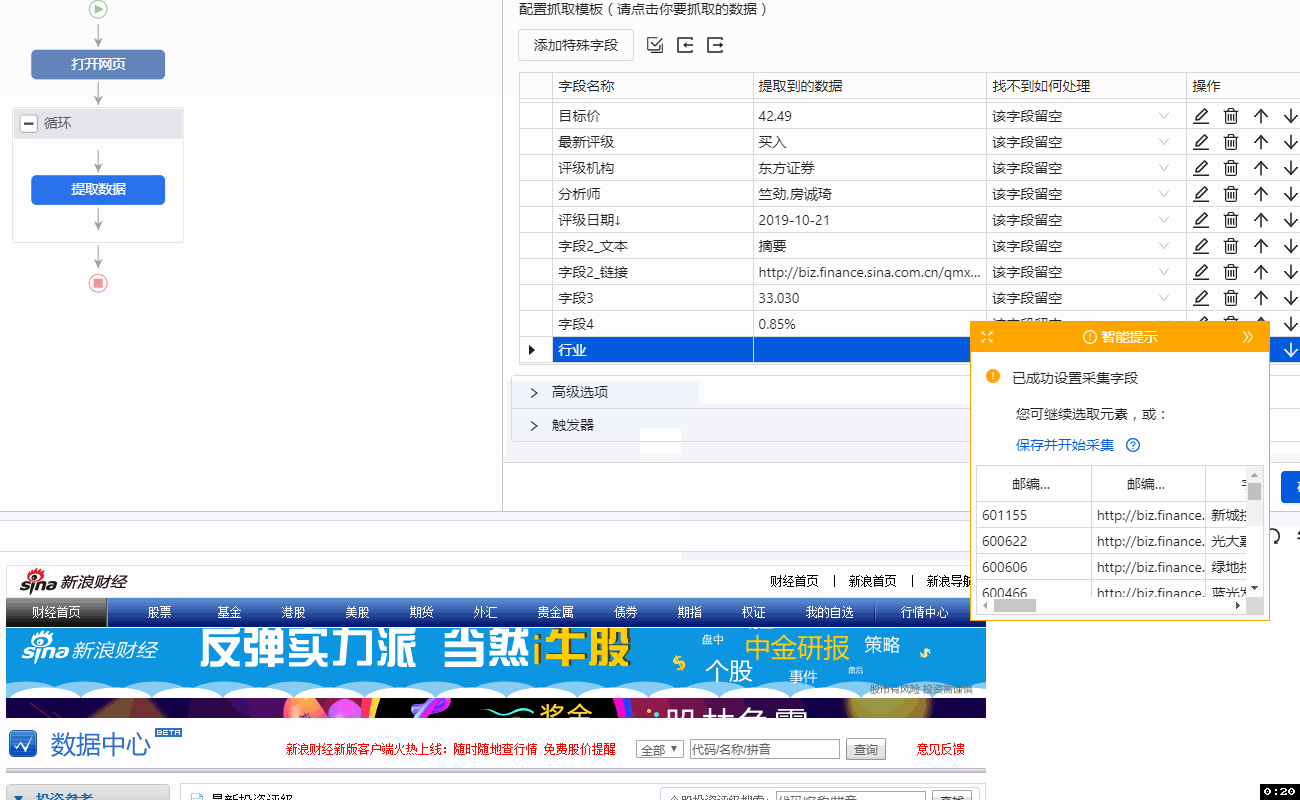
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】

用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
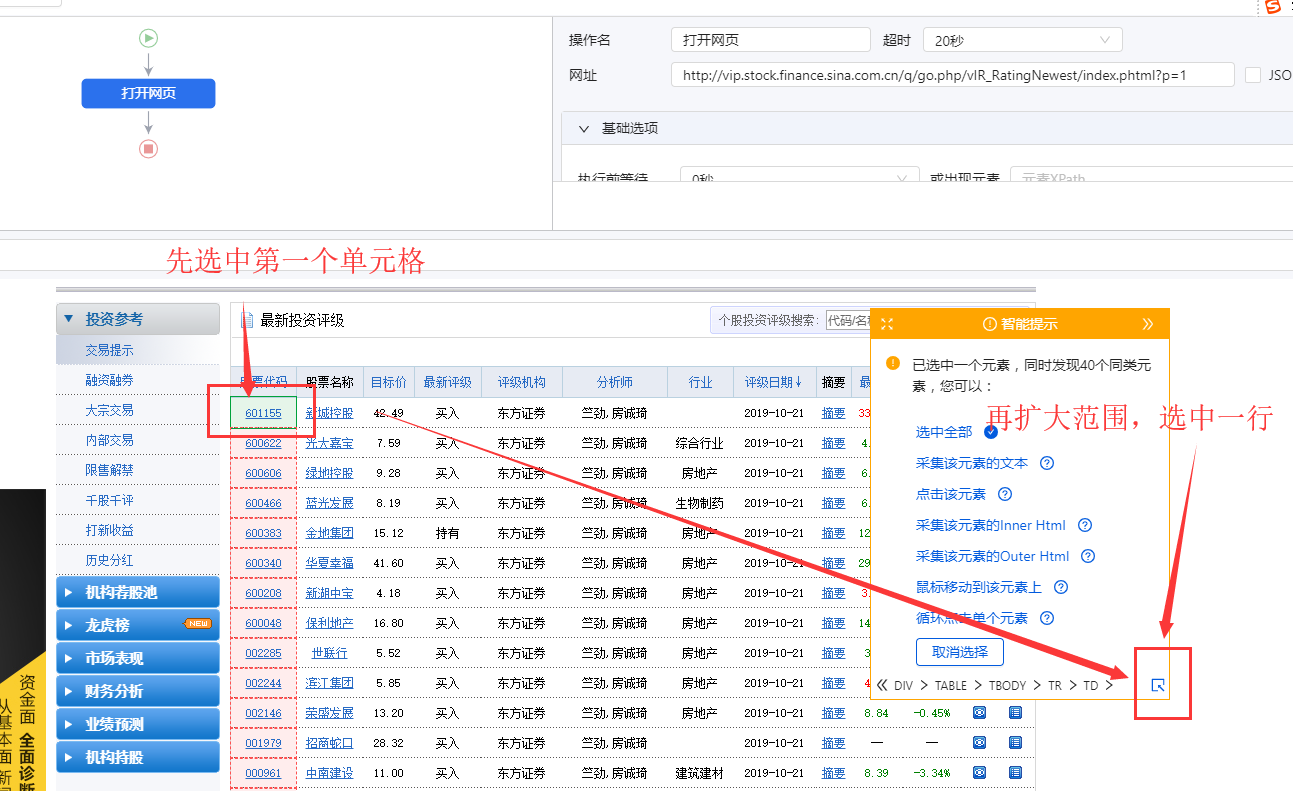
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
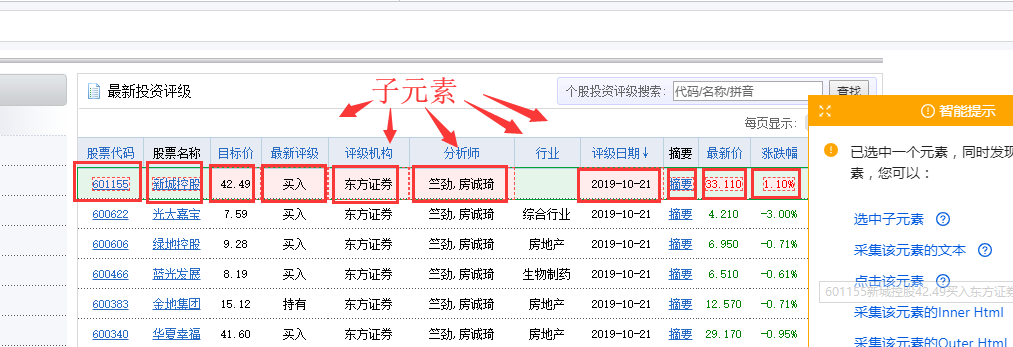
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以单击多次直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)

2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
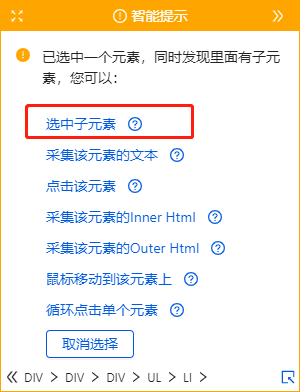
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
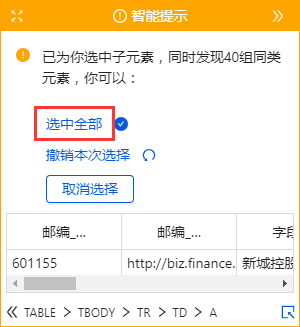
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
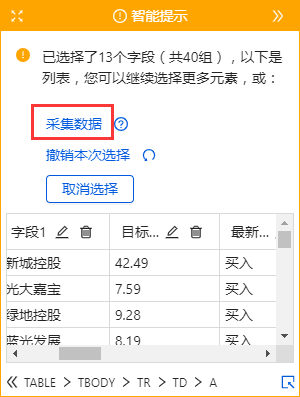
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
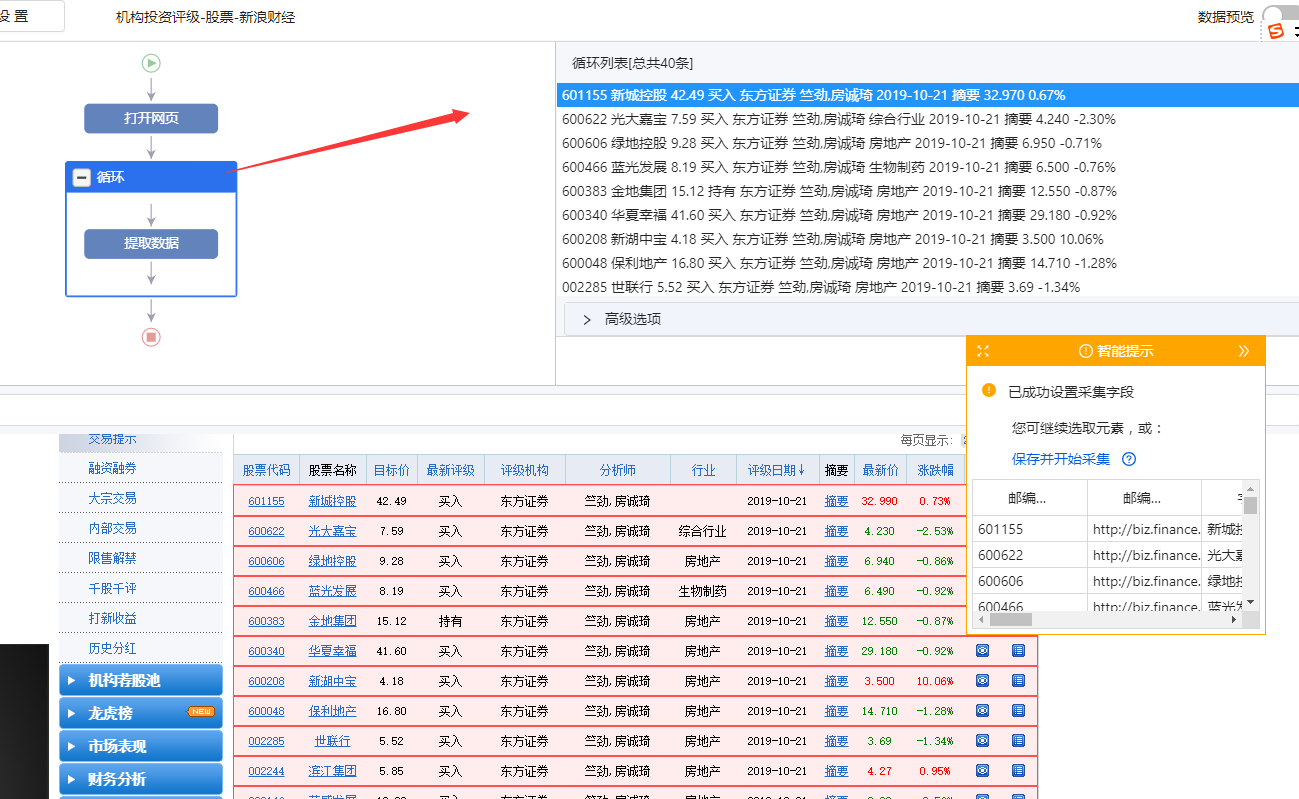
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、修改字段名称。更改为字段的相应名称。
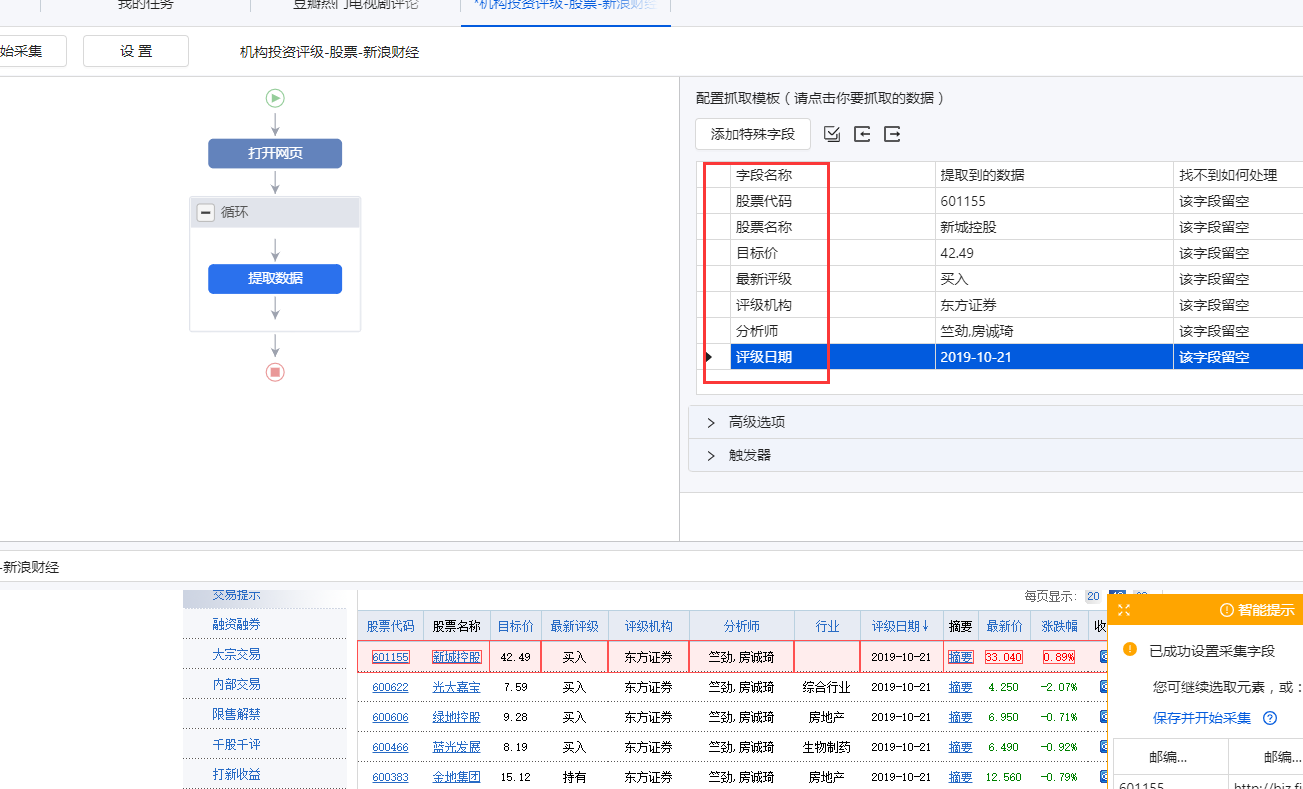
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
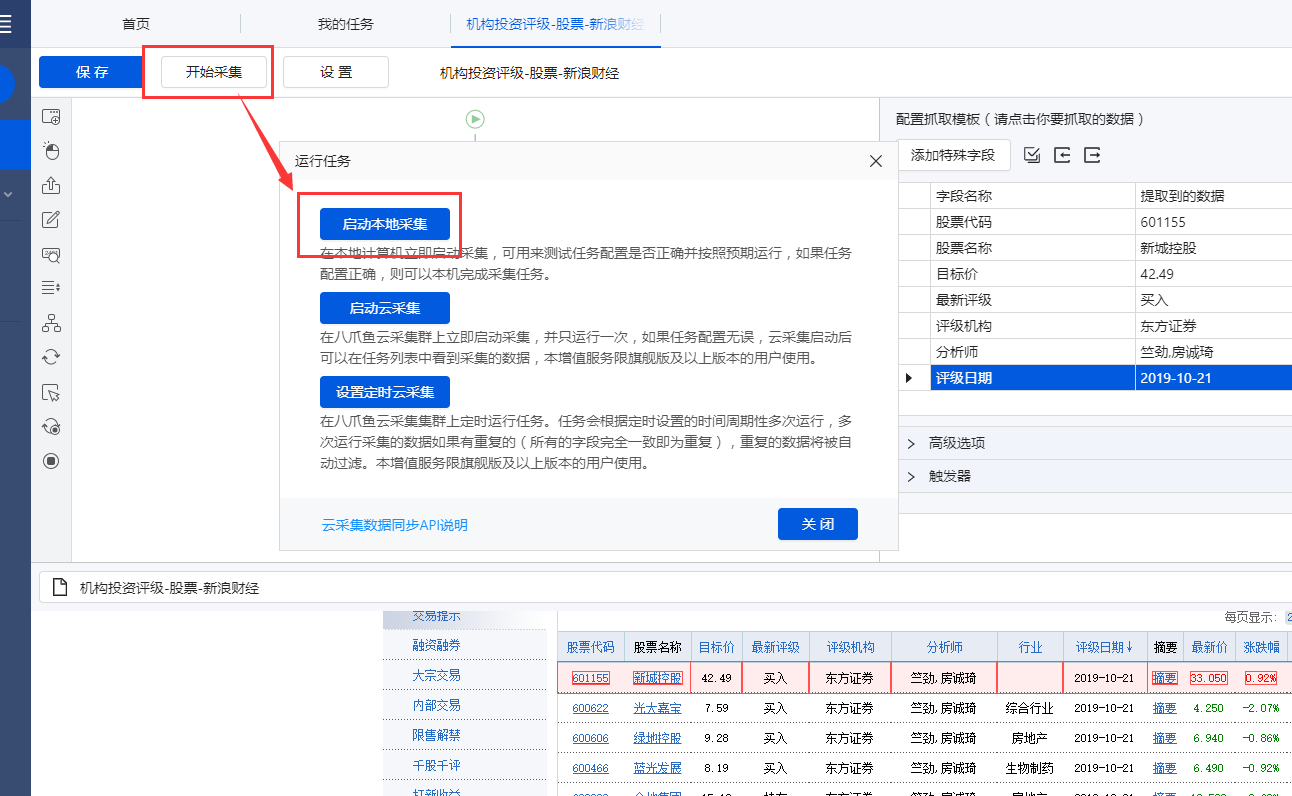
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
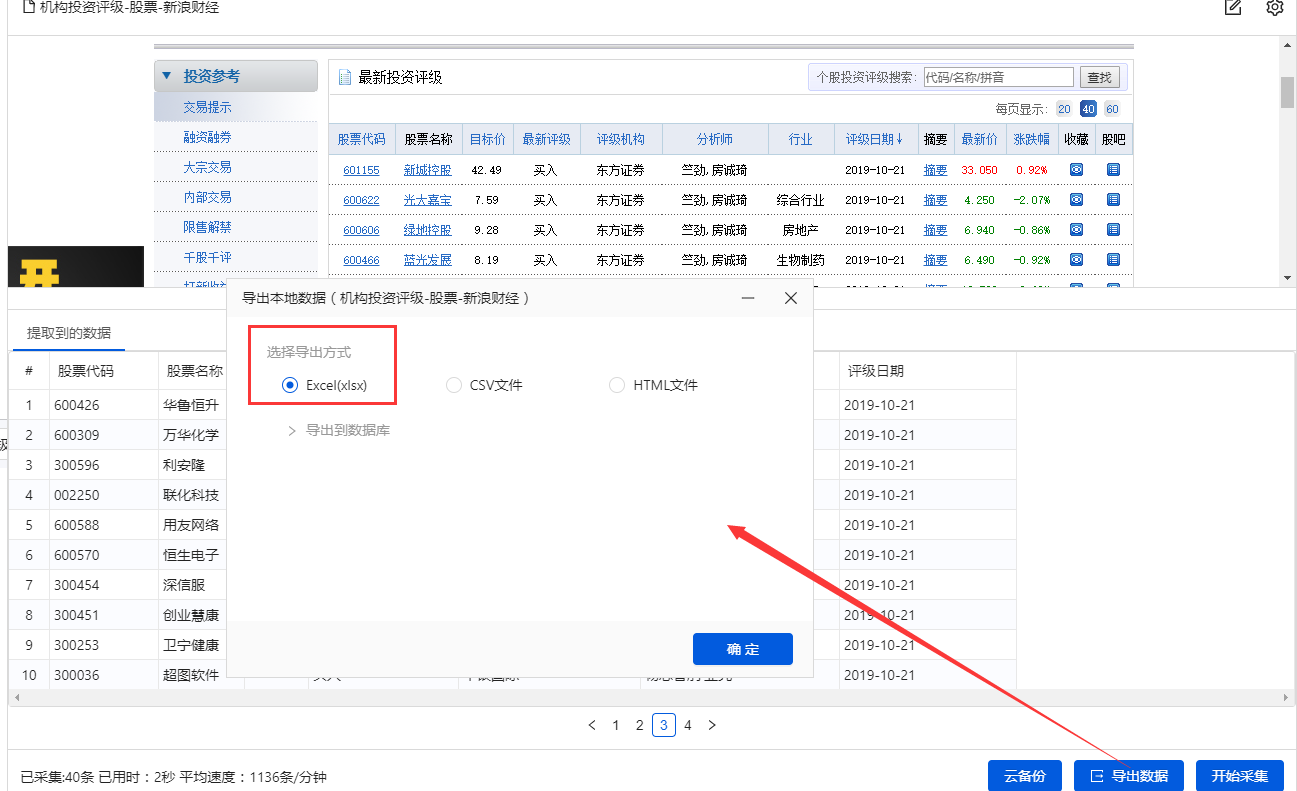
数据示例:
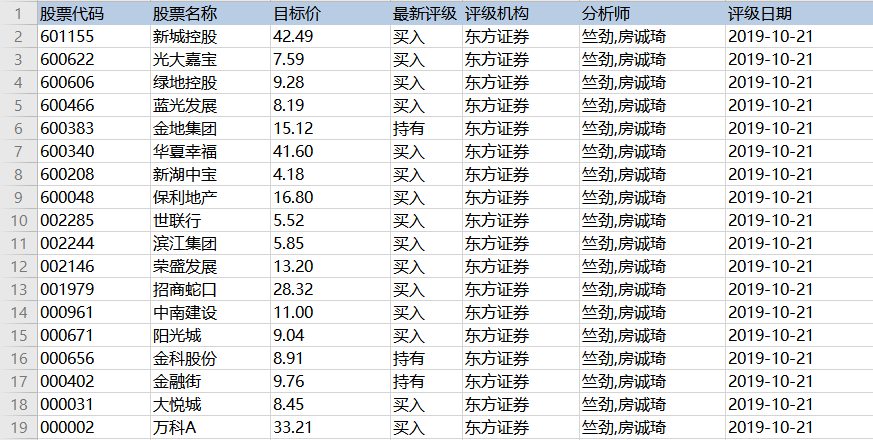
网页表格抓取(Python快速的抓取表格的思路和方法(4-7行))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-18 14:11
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
页面内容过多时会变慢,给人一种导出失败的错觉
除了表格中的数据,页面上的其他所有内容也会导入EXCEL,需要后期整理
虽然,没有技术要求。但是如果要处理大量的页面,就需要一一操作,相当繁琐
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
主要用到三个库:requests、BeautifulSoup和pandas(第1-3行)
使用 BeautifulSoup 获取 table 标签下的表格内容(第 4-7 行)
使用 pd.read_html 直接读取 HTML 中的内容作为 DataFrame(第 8-11 行)
这一步是关键。pd.read_html 方法省去了很多解析HTML的步骤,否则用BeautifulSoup一一抓取表格内容会很麻烦。它还使用了prettify()方法,可以把BeautifulSoup对象变成字符串,因为pd.read_html处理的是字符串对象
最后将DataFrame导出为EXCEL(12行)
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。 查看全部
网页表格抓取(Python快速的抓取表格的思路和方法(4-7行))
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
页面内容过多时会变慢,给人一种导出失败的错觉
除了表格中的数据,页面上的其他所有内容也会导入EXCEL,需要后期整理
虽然,没有技术要求。但是如果要处理大量的页面,就需要一一操作,相当繁琐
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
主要用到三个库:requests、BeautifulSoup和pandas(第1-3行)
使用 BeautifulSoup 获取 table 标签下的表格内容(第 4-7 行)
使用 pd.read_html 直接读取 HTML 中的内容作为 DataFrame(第 8-11 行)
这一步是关键。pd.read_html 方法省去了很多解析HTML的步骤,否则用BeautifulSoup一一抓取表格内容会很麻烦。它还使用了prettify()方法,可以把BeautifulSoup对象变成字符串,因为pd.read_html处理的是字符串对象
最后将DataFrame导出为EXCEL(12行)
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样,我们就可以把精力集中在学习vscode快捷键的操作上,而不是学习这张表的获取方法。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
网页表格抓取(Python中的网络爬虫库用于从网站中提取数据的程序 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-18 03:13
)
在本章中,我们将学习网络爬虫,包括学习 Python 中的 BeautifulSoup 库,该库用于从 网站 中提取数据。
本章收录以下主题。
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或 Web 浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化的过程。
抓取网页的过程分为获取网页和提取数据。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析、保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests$ pip3 install beautifulsoup4
2.1Requests 库
使用 Requests 库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。Requests 库收录不同类型的请求,这里使用 GET 请求。GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,您必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。这里我们将解析一个来自百度网站的新闻网页。创建一个脚本,将其命名为 parse_web_page.py,并在其中写入以下代码。
import requestsfrom bs4 import BeautifulSouppage_result = requests.get('https://www.news.baidu.com')parse_obj = BeautifulSoup(page_result.content, 'html.parser')print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.pyOutput:Top News - IMDb 查看全部
网页表格抓取(Python中的网络爬虫库用于从网站中提取数据的程序
)
在本章中,我们将学习网络爬虫,包括学习 Python 中的 BeautifulSoup 库,该库用于从 网站 中提取数据。
本章收录以下主题。
1 什么是网络爬虫
网络爬虫是指从网站中提取数据的技术,可以将非结构化数据转化为结构化数据。
网络爬虫的目的是从网站中提取数据。提取的数据可以存储在本地文件中并保存在系统中,也可以以表格的形式存储在数据库中。网络爬虫使用 HTTP 或 Web 浏览器直接访问万维网 (WWW)。网络爬虫或机器人抓取网页的过程是一个自动化的过程。
抓取网页的过程分为获取网页和提取数据。网络爬虫可以抓取网页,是网络爬虫的必备组件。获取网页后,需要提取网页数据。我们可以对提取的数据进行搜索、解析、保存在表格中,然后重新排列格式。
2 数据提取
在本节中,我们将了解数据提取。我们可以使用 Python 的 BeautifulSoup 库进行数据提取。这里还需要 Python 库的 Requests 模块。
运行以下命令来安装 Requests 和 BeautifulSoup 库。
$ pip3 install requests$ pip3 install beautifulsoup4
2.1Requests 库
使用 Requests 库以易于理解的格式在 Python 脚本中使用 HTTP。在这里,使用 Python 中的 Requests 库来获取网页。Requests 库收录不同类型的请求,这里使用 GET 请求。GET请求用于从Web服务器获取信息,通过GET请求可以获取指定网页的HTML内容。每个请求对应一个状态码,从服务器返回。这些状态码为我们提供了相应请求执行结果的相关信息。以下是一些状态代码。
2.2BeautifulSoup 库
BeautifulSoup 也是一个 Python 库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包。
要在脚本中使用 Requests 和 BeautifulSoup 模块,您必须使用 import 语句导入这两个模块。现在让我们看一个用于解析网页的示例程序。这里我们将解析一个来自百度网站的新闻网页。创建一个脚本,将其命名为 parse_web_page.py,并在其中写入以下代码。
import requestsfrom bs4 import BeautifulSouppage_result = requests.get('https://www.news.baidu.com')parse_obj = BeautifulSoup(page_result.content, 'html.parser')print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.pyOutput:Top News - IMDb
网页表格抓取(利用Xpath+GoogleSheet对网页描述的自动以下查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-18 03:12
我们都遇到过在某些时候必须从 网站 中提取数据的情况。例如,当您制作新的购物广告系列时,您可能没有可用于快速制作广告的产品 Feed(产品信息集)。
理想情况下,我们将以易于导入的文件格式(例如 Excel 或 Google 表格)提供我们需要的内容,例如登录页面、产品名称等。但对于大多数不知道如何进行数据抓取的人来说,广告商可能不得不手动复制粘贴成百上千的产品信息。
在最近的一份工作中,我被要求从客户 网站 的 15 个页面中下载大约 150 个新产品数据,并将每个产品的名称和着陆页 URL 复制并粘贴到电子表格中。
手动完成这项工作需要多少时间?这不仅费时,手动浏览这么多内容,而且一一复制粘贴,出错的概率也非常高。这无疑会增加更多的时间来审查文件。
在这里,SEJ工作人员分享了使用ImportXML结合Google Sheet轻松完成这项工作。
文章内容
什么是 ImportXML?
根据 Google 的解释,ImportXML 可以从以下各种结构化数据类型中的任何一种导入数据:包括 XML、HTML、CSV、TSV、RSS 和 ATOM XML 提要。
本质上,IMPORTXML 是一个功能,可以让你从网页中抓取结构化数据,例如段落文本、TDK 信息等。过程简单,不需要任何编码基础。
ImportXML 如何帮助抓取网页元素?
函数本身非常简单,只需要两个值:
例如,要从中提取页面标题,我们只需要将以下内容复制并粘贴到 Google Sheet 单元格中:
==IMPORTXML(“”, “//title”, “en_US”)
然后单元格将显示:登月 - 维基百科
或者,如果我们正在寻找网页的描述,我们可以尝试以下操作:
=IMPORTXML("","//meta[@name='description']/@content")
使用Xpath + Google Sheet 自动抓取网页描述
以下是一些较常见的 XPath 查询参考:
Google Sheet + ImportXML 案例演示
自从将 IMPORTXML 添加到 Google Sheets 以来,它一直是我们处理许多日常任务的秘密武器。
此外,该功能还可以结合其他公式来完成一些更高级的数据分析任务。如果没有Google Sheets的ImportXML,可能需要使用Python等方式进行程序抓取。
在下面的例子中,我们将演示 IMPORTXML 最基本的用法:从网页中获取数据。
想象一下,我们被要求创建一个内容广告活动。他们希望我们在文章 分类下的最新30 篇文章文章 上投放动态搜索广告。您可能会说这是一项非常简单的任务。不幸的是,网站编辑器无法给我们发送页面数据,并希望我们参考网站页面的内容来制作广告。
正如我们在文章开头提到的,一种方法是手动打开页面获取并在广告平台中填写,另一种是手动采集信息并将其放入Google Sheets和Excel。需要一一打开网页,复制粘贴信息。但是通过在 Google Sheets 中使用 IMPORTXML,我们可以在很短的时间内实现相同的操作而不会出错。
第 1 步:创建新的 Google 表格
首先,我们打开一个空白的 Google Sheets 文档:
从一个空白的 Google Sheets 文档开始。第二步:添加需要爬取的页面地址
添加我们要从中获取信息的页面(或多个页面)的 URL。在我们的例子中,我们需要抓取内容。
添加要爬取的页面的URL。第 3 步:查找 XPath
找到要抓取的元素,复制XPath 路径并在ImportXML 函数的第二个参数中使用它。在我们的示例中,我们需要找到 文章 的 30 个最近更新的标题。我们只需要将鼠标悬停在 文章 之一的标题上,右键单击并单击检查。
打开 Chrome WebDev 工具。
这将打开 Google Chrome 浏览器的开发者工具窗口:
查找并复制要提取的 XPath 元素。
确保 文章 标题仍处于选中状态并突出显示,然后再次右键单击并选择 Copy> 以复制 XPath。
第 4 步:将数据提取到 Google 表格中
返回到您的 Google Sheets 文档并输入 IMPORTXML 函数,如下所示:
=IMPORTXML(B1,”///*[starts-with(@id,'title')]”)
有几点需要注意:
首先,在我们的公式中,我们引用单元格 B1 的第一个参数,而 B1 我们输入要提取数据的网页地址。
其次,我们从 Chrome 开发者面板复制的 XPath 放在第二个参数中时会用双引号括起来。但是复制的XPath也有双引号,如下:
(///*[@id="title_1"])
为了保证前后双引号不会混淆,我们需要将Xpath中的双引号改为单引号,然后放入ImportXML函数中。
(///*[@id='title_1'])
请注意,在这个例子中,由于每个文章的页面ID标题都会发生变化(title_1、title_2等),所以我们要稍微修改一下XPath,然后需要使用starts- with函数获取页面上ID名称收录'title'的所有元素。
以下是 Google Sheets 文档的内容:
IMPORTXML 的一个例子。
输入后,文章的所有标题很快就会返回:
在 Google 表格中导入的标题。
您也可以使用此方法抓取其他网页上的元素信息。比如抓取文章姓名、文章 URL、摘要、作者姓名等。
如果要抓取网址,我们需要调整查询,使用/@抓取元素的属性。那么完整的Xpath查询如下:
=IMPORTXML(B1,”//*[starts-with(@id,'title')]/@href”)
导入 文章 链接
输入后:
文章 和 Google 表格中导入的 URL
添加摘要和作者姓名后:
包括摘要和作者姓名在内的所有数据都被抓取并导入到 Google 表格中。结论
无论是需要爬取文章,还是其他页面元素,包括产品价格或运费等数据,都可以使用Xpath自动获取,出错的可能性很小。
该工具不仅可用于 PPC 构建广告活动,还可用于需要批量网页数据分析和采集的其他任务,例如 SEO。
当然,相比Python的数据爬取,Google Sheet爬取数据有一定的局限性。谷歌会给每个Sheet一定比例的抓取,抓取的数量会有一定的限制。Google 这样做的主要目的是避免恶意使用服务器。另外这个功能是免费的,谷歌也会考虑运维成本。 查看全部
网页表格抓取(利用Xpath+GoogleSheet对网页描述的自动以下查询)
我们都遇到过在某些时候必须从 网站 中提取数据的情况。例如,当您制作新的购物广告系列时,您可能没有可用于快速制作广告的产品 Feed(产品信息集)。
理想情况下,我们将以易于导入的文件格式(例如 Excel 或 Google 表格)提供我们需要的内容,例如登录页面、产品名称等。但对于大多数不知道如何进行数据抓取的人来说,广告商可能不得不手动复制粘贴成百上千的产品信息。
在最近的一份工作中,我被要求从客户 网站 的 15 个页面中下载大约 150 个新产品数据,并将每个产品的名称和着陆页 URL 复制并粘贴到电子表格中。
手动完成这项工作需要多少时间?这不仅费时,手动浏览这么多内容,而且一一复制粘贴,出错的概率也非常高。这无疑会增加更多的时间来审查文件。
在这里,SEJ工作人员分享了使用ImportXML结合Google Sheet轻松完成这项工作。
文章内容
什么是 ImportXML?
根据 Google 的解释,ImportXML 可以从以下各种结构化数据类型中的任何一种导入数据:包括 XML、HTML、CSV、TSV、RSS 和 ATOM XML 提要。
本质上,IMPORTXML 是一个功能,可以让你从网页中抓取结构化数据,例如段落文本、TDK 信息等。过程简单,不需要任何编码基础。
ImportXML 如何帮助抓取网页元素?
函数本身非常简单,只需要两个值:
例如,要从中提取页面标题,我们只需要将以下内容复制并粘贴到 Google Sheet 单元格中:
==IMPORTXML(“”, “//title”, “en_US”)
然后单元格将显示:登月 - 维基百科
或者,如果我们正在寻找网页的描述,我们可以尝试以下操作:
=IMPORTXML("","//meta[@name='description']/@content")
使用Xpath + Google Sheet 自动抓取网页描述
以下是一些较常见的 XPath 查询参考:
Google Sheet + ImportXML 案例演示
自从将 IMPORTXML 添加到 Google Sheets 以来,它一直是我们处理许多日常任务的秘密武器。
此外,该功能还可以结合其他公式来完成一些更高级的数据分析任务。如果没有Google Sheets的ImportXML,可能需要使用Python等方式进行程序抓取。
在下面的例子中,我们将演示 IMPORTXML 最基本的用法:从网页中获取数据。
想象一下,我们被要求创建一个内容广告活动。他们希望我们在文章 分类下的最新30 篇文章文章 上投放动态搜索广告。您可能会说这是一项非常简单的任务。不幸的是,网站编辑器无法给我们发送页面数据,并希望我们参考网站页面的内容来制作广告。
正如我们在文章开头提到的,一种方法是手动打开页面获取并在广告平台中填写,另一种是手动采集信息并将其放入Google Sheets和Excel。需要一一打开网页,复制粘贴信息。但是通过在 Google Sheets 中使用 IMPORTXML,我们可以在很短的时间内实现相同的操作而不会出错。
第 1 步:创建新的 Google 表格
首先,我们打开一个空白的 Google Sheets 文档:
从一个空白的 Google Sheets 文档开始。第二步:添加需要爬取的页面地址
添加我们要从中获取信息的页面(或多个页面)的 URL。在我们的例子中,我们需要抓取内容。
添加要爬取的页面的URL。第 3 步:查找 XPath
找到要抓取的元素,复制XPath 路径并在ImportXML 函数的第二个参数中使用它。在我们的示例中,我们需要找到 文章 的 30 个最近更新的标题。我们只需要将鼠标悬停在 文章 之一的标题上,右键单击并单击检查。
打开 Chrome WebDev 工具。
这将打开 Google Chrome 浏览器的开发者工具窗口:
查找并复制要提取的 XPath 元素。
确保 文章 标题仍处于选中状态并突出显示,然后再次右键单击并选择 Copy> 以复制 XPath。
第 4 步:将数据提取到 Google 表格中
返回到您的 Google Sheets 文档并输入 IMPORTXML 函数,如下所示:
=IMPORTXML(B1,”///*[starts-with(@id,'title')]”)
有几点需要注意:
首先,在我们的公式中,我们引用单元格 B1 的第一个参数,而 B1 我们输入要提取数据的网页地址。
其次,我们从 Chrome 开发者面板复制的 XPath 放在第二个参数中时会用双引号括起来。但是复制的XPath也有双引号,如下:
(///*[@id="title_1"])
为了保证前后双引号不会混淆,我们需要将Xpath中的双引号改为单引号,然后放入ImportXML函数中。
(///*[@id='title_1'])
请注意,在这个例子中,由于每个文章的页面ID标题都会发生变化(title_1、title_2等),所以我们要稍微修改一下XPath,然后需要使用starts- with函数获取页面上ID名称收录'title'的所有元素。
以下是 Google Sheets 文档的内容:
IMPORTXML 的一个例子。
输入后,文章的所有标题很快就会返回:
在 Google 表格中导入的标题。
您也可以使用此方法抓取其他网页上的元素信息。比如抓取文章姓名、文章 URL、摘要、作者姓名等。
如果要抓取网址,我们需要调整查询,使用/@抓取元素的属性。那么完整的Xpath查询如下:
=IMPORTXML(B1,”//*[starts-with(@id,'title')]/@href”)
导入 文章 链接
输入后:
文章 和 Google 表格中导入的 URL
添加摘要和作者姓名后:
包括摘要和作者姓名在内的所有数据都被抓取并导入到 Google 表格中。结论
无论是需要爬取文章,还是其他页面元素,包括产品价格或运费等数据,都可以使用Xpath自动获取,出错的可能性很小。
该工具不仅可用于 PPC 构建广告活动,还可用于需要批量网页数据分析和采集的其他任务,例如 SEO。
当然,相比Python的数据爬取,Google Sheet爬取数据有一定的局限性。谷歌会给每个Sheet一定比例的抓取,抓取的数量会有一定的限制。Google 这样做的主要目的是避免恶意使用服务器。另外这个功能是免费的,谷歌也会考虑运维成本。
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 03:11
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,即可获取从PDF分析表中获取的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~ 查看全部
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,即可获取从PDF分析表中获取的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~
网页表格抓取(如何才能高效提取出pdf文件中的表格数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-16 11:30
在实际研究中,我们往往需要获取大量的数据,而这些数据很大一部分是以pdf形式呈现的,比如公司年报、发行上市公告等。 面对如此多的数据表格,显然不建议手动复制和粘贴它们。那么如何才能高效的提取pdf文件中的表格数据呢?
Python提供了很多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等,总体来说pdfplumber库的性能更好,可以提取完整且相对规范的表格。所以,这条推文也主要介绍了pdfplumber库在pdf表提取中的作用。
pdfplumber库作为强大的pdf文件解析工具,可以快速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页码、页码等信息,还可以进行页面可视化操作。在使用pdfplumber库之前,需要先安装,即在cmd命令行中输入:
pip 安装 pdfplumber
pdfplumber库提供了两个pdf表提取函数,分别是.extract_tables()和.extract_table(),这两个函数的提取结果是不同的。为了演示,我们在网站上下载了一份pdf格式的短期融资券主体信用评级报告。任意选择一张表,其界面如下:
Python骚操作,提取pdf文件中的表数据!
关于如何快速学习python,可以加小编的python学习群:611+530+101,不管你是新手还是大牛,欢迎小编不定期分享干货。
每天晚上20:00会有直播分享python学习知识和路线方法。群里会不定期更新最新的教程和学习方法。大家都在学习python,或者转行,或者大学生,打工,如果想提升自己的能力,如果你是正在学习python的小伙伴,都可以加入学习。最后,祝所有程序员都能走上人生的巅峰,让代码将梦想照进现实
接下来,我们简单分析一下两种提取模式的结果差异。
(1).extract_tables()
它可以输出页面中的所有表,并返回一个嵌套列表,其结构级别为表→行→单元格。这时,页面上的整个表被放入一个大列表中,原表中的每一行构成了大列表中的每个子列表。如果您需要输出单个外部列表元素,您得到的是由原创表中的同一行元素组成的列表。例如,我们执行以下过程:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
(2).extract_table()
返回多个独立列表,其结构级别为row→cell。如果页面中有多个行数相同的表,默认会输出最上面的表;否则只输出行数最多的表。此时,表格的每一行都作为一个单独的列表,列表中的每个元素都是原创表格每个单元格的内容。如果你需要输出一个元素,你会得到一个特定的值或字符串。如下:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
在此基础上,我们详细介绍了如何从pdf文件中提取表格数据。一种思路是把提取的列表当成字符串,结合Python的正则表达式re模块进行处理,保存为Excel可以识别的标准逗号分隔的csv文件。即,按以下步骤进行:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
虽然可以获得完整的表格数据,但是这种方法比较难理解,在处理结构不规则的表格时容易出错。因为pdfplumber库提取的表格数据是整洁的列表结构,收录数字、字符串等数据类型。因此,我们可以调用pandas库下的DataFrame()函数,将列表转换为可以直接输出到Excel的DataFrame数据结构。DataFrame的基本构造函数如下:
数据帧([数据,索引,列])
三个参数data、index、columns分别代表创建对象、行索引、列索引。DataFrame类型可以通过二维的ndarray对象、列表、字典、元组等来创建,本推文中的数据是指整个pdf表格,提取过程如下:
Python骚操作,提取pdf文件中的表数据!
其中table[1:]表示选择整个表进行DataFrame对象创建,columns=table[0]表示使用表的第一行元素作为列变量名,不创建行索引. 输出Excel表格如下:
Python骚操作,提取pdf文件中的表数据!
通过上面的简单程序,我们已经提取了完整的pdf表格。但是需要注意的是,面对不规则的表数据提取,DataFrame对象的创建方法可能还是错误的,需要在实际操作中进行检查。 查看全部
网页表格抓取(如何才能高效提取出pdf文件中的表格数据呢?)
在实际研究中,我们往往需要获取大量的数据,而这些数据很大一部分是以pdf形式呈现的,比如公司年报、发行上市公告等。 面对如此多的数据表格,显然不建议手动复制和粘贴它们。那么如何才能高效的提取pdf文件中的表格数据呢?
Python提供了很多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等,总体来说pdfplumber库的性能更好,可以提取完整且相对规范的表格。所以,这条推文也主要介绍了pdfplumber库在pdf表提取中的作用。
pdfplumber库作为强大的pdf文件解析工具,可以快速将pdf文档转换为易于处理的txt文档,并输出pdf文档的字符、页码、页码等信息,还可以进行页面可视化操作。在使用pdfplumber库之前,需要先安装,即在cmd命令行中输入:
pip 安装 pdfplumber
pdfplumber库提供了两个pdf表提取函数,分别是.extract_tables()和.extract_table(),这两个函数的提取结果是不同的。为了演示,我们在网站上下载了一份pdf格式的短期融资券主体信用评级报告。任意选择一张表,其界面如下:
Python骚操作,提取pdf文件中的表数据!
关于如何快速学习python,可以加小编的python学习群:611+530+101,不管你是新手还是大牛,欢迎小编不定期分享干货。
每天晚上20:00会有直播分享python学习知识和路线方法。群里会不定期更新最新的教程和学习方法。大家都在学习python,或者转行,或者大学生,打工,如果想提升自己的能力,如果你是正在学习python的小伙伴,都可以加入学习。最后,祝所有程序员都能走上人生的巅峰,让代码将梦想照进现实
接下来,我们简单分析一下两种提取模式的结果差异。
(1).extract_tables()
它可以输出页面中的所有表,并返回一个嵌套列表,其结构级别为表→行→单元格。这时,页面上的整个表被放入一个大列表中,原表中的每一行构成了大列表中的每个子列表。如果您需要输出单个外部列表元素,您得到的是由原创表中的同一行元素组成的列表。例如,我们执行以下过程:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
(2).extract_table()
返回多个独立列表,其结构级别为row→cell。如果页面中有多个行数相同的表,默认会输出最上面的表;否则只输出行数最多的表。此时,表格的每一行都作为一个单独的列表,列表中的每个元素都是原创表格每个单元格的内容。如果你需要输出一个元素,你会得到一个特定的值或字符串。如下:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
在此基础上,我们详细介绍了如何从pdf文件中提取表格数据。一种思路是把提取的列表当成字符串,结合Python的正则表达式re模块进行处理,保存为Excel可以识别的标准逗号分隔的csv文件。即,按以下步骤进行:
Python骚操作,提取pdf文件中的表数据!
输出结果:
Python骚操作,提取pdf文件中的表数据!
虽然可以获得完整的表格数据,但是这种方法比较难理解,在处理结构不规则的表格时容易出错。因为pdfplumber库提取的表格数据是整洁的列表结构,收录数字、字符串等数据类型。因此,我们可以调用pandas库下的DataFrame()函数,将列表转换为可以直接输出到Excel的DataFrame数据结构。DataFrame的基本构造函数如下:
数据帧([数据,索引,列])
三个参数data、index、columns分别代表创建对象、行索引、列索引。DataFrame类型可以通过二维的ndarray对象、列表、字典、元组等来创建,本推文中的数据是指整个pdf表格,提取过程如下:
Python骚操作,提取pdf文件中的表数据!
其中table[1:]表示选择整个表进行DataFrame对象创建,columns=table[0]表示使用表的第一行元素作为列变量名,不创建行索引. 输出Excel表格如下:
Python骚操作,提取pdf文件中的表数据!
通过上面的简单程序,我们已经提取了完整的pdf表格。但是需要注意的是,面对不规则的表数据提取,DataFrame对象的创建方法可能还是错误的,需要在实际操作中进行检查。
网页表格抓取(本文以爬取东方财富网CPI数据[1],讲解如何使用Stata)
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2021-10-15 15:15
本文以东方财富网[1]的CPI数据为例,讲解如何使用Stata抓取web表数据。
Stata虽然不是数据爬取工具,但是可以轻松解决一些小的数据爬取任务。数据爬取的本质无非是数据请求和数据处理,所以熟练使用Stata进行数据爬取往往是良好数据处理能力的标志。在实际应用中,我们经常需要爬取一些公共数据。显示这些数据的一种常见方式是通过 HTML 呈现。一个简单的 HTML 表格示例如下:
1
2
3
1
2
3
东方财富网CPI数据表是这样的:
下面我将一步步解释如何爬取这张表。
准备工作Stata14.0或以上;
Chrome浏览器;
想要爬下数据的你。
网络分析
先解释一下如何爬取一个页面的表单。这个页面的网址是:
在页面上右击,选择显示网页的源代码。很多浏览器都有查看网页源代码的功能,但我还是最喜欢谷歌浏览器。点击跳转到页面源码界面:
也就是说,你刚才看到的网页的本质其实就是源代码。我们之所以能看到各种五颜六色的页面,是因为浏览器已经为我们翻译了源代码。
接下来我们要做的就是找出这张表在源码中的位置,然后分析这张表的特征,方便后面Stata处理源码的时候过滤。
一种经常用于查找目标的方法是使用搜索功能。Ctr+F(Mac 的 Command + F)可以打开搜索框。我们注意到表中有两个词,所以我们用月份来搜索。
我们第一次发现这个词是在1987行,仔细一看,这里附近的代码就是表的代码。
下一步就是分析这部分代码的特点:表中的所有数据都位于源代码中的一行,所以我们不能从它所在的行开始;
表数据的前一行要么有一个字符串
经过上面的网页分析后,我们就可以开始爬取网页表单了。
开始爬行
总的来说,Stata 抓取网页表单分为 3 个步骤:请求:下载收录所需数据的源代码;
转码:许多网页不使用 UTF-8 编码。直接读入Stata会造成乱码,所以可以提前进行UTF-8转码;
处理:主要是处理字符串。常见的操作包括拆分、转置(sxpose)、提取(正则表达式或直接字符串提取)等。
问
由于本网页没有防爬机制,可以直接使用copy命令下载。copy命令不仅可以下载网页,还可以下载文件(当然,网页其实就是一个html文件)。更多的使用可以帮助复制。这里我们将要抓取的页面保存为一个名为temp.txt的txt文件。为什么会有这个名字,因为爬完之后会被删除,所以它只是一个临时文件。其实Stata也可以创建临时文件,运行结束会自动删除,不过我觉得没有这个必要,因为通常需要打开temp.txt文件分析一下内容。
清除所有
* 设置工作目录
cd'你自己的工作目录(文件夹的路径)'
复制'#39; temp.txt,替换
转码
在我的Stata命令package-finance包中,我写了一个简单的转码命令。这个命令包的安装方法是: * 首先需要安装github命令,这个命令用于在GitHub上安装命令
* net install github, from('#39;)
* 然后你可以安装这个命令
* github 安装 czxa/finance,替换
安装成功后,使用以下命令直接对temp.txt文件进行转码:
utrans temp.txt
如果返回的结果是转码成功,说明转码成功!(感觉像是在胡说八道……)
如果由于各种原因不幸安装这个小命令失败,可以直接使用以下三个命令进行转码:unicode encoding set gb18030
unicode 翻译 temp.txt
unicode 擦除备份,badidea
读
接下来我们将temp.txt文件读入Stata进行处理。一个很常见的读取方法是使用中缀命令:
使用 temp.txt 中缀 strL v 1-20000,清除
* 将变量 v 的显示格式更改为 %60s(使其看起来更宽)
格式 v %60s
这个命令的意思是创建一个strL格式的变量v,然后读取temp.txt文件每一行的前1-20000个字符(因为我们注意到temp.txt的每一行不超过20000字符)输入变量 v 的每个观测值,读入后如下所示:
处理
首先,根据我们在上面网页分析中发现的结论,我们保留上一行匹配表数据或有字符串'
* 再次删除空观察
删除如果 v ==''
* 删除一些明显不是表中数据的观察,这些无用的观察都收录斜线
删除如果索引(v,'/')
这一步的结果:
其实到这里,我们已经把表格组织的很干净了,但是这不像一个表格,我们需要进行这样的操作:我们注意到第1-13行实际上是表格的第一行,14- 26 该行实际上是表的第二行。我们怎样才能完成这样的操作呢?一个非常有用的命令是 post 命令。这个命令的功能就像它的名字-邮局一样。它可以将v的每个观察值发送到我们想要获取的表的指定位置。
* 第一步是在postfile中创建一个“邮局”,并设置“收件人”(变量日期,v1-v12):
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 cpi.dta,替换
* 然后循环发送v的值给每个接收者
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
* 关闭邮局 mypost
关闭我的帖子
* 打开 cpi.dta 查看整理后的数据
使用 cpi,清除
在这个“邮局操作”之后,数据现在是这样的:
至此,我们其实已经完成了对这张表的爬取,但是接下来我们会将数据组织成更正规的Stata数据。* 组织日期变量
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
* date() 函数将字符串日期转换为Stata日期
gen date1 = date(date,'YM')
* 格式很容易让我们人类理解
格式日期1 %tdCY-N
* 将 date1 变量放在第一列
订单日期1
* 删除日期
下车日期
* 将 date1 重命名为 date
ren date1 日期
* 循环所有变量并删除%
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
* 将所有可以转换为数字变量的字符串变量转换为数字变量
解串,替换
* 循环所有变量,如果变量名不是日期,将显示格式改为%6.2f
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
排序后的数据集如下所示:
就这样,我们爬上了单页表单。此外,我们还注意到完整的表格有 8 页。我们可以点击下一页,看到第二页的网址是:
显然url中的最后一个参数是页数。每个页面的结构都是一样的,所以你可以循环刚才的代码,爬下剩下的6个页面的表格,合并它们。
多页面抓取
垂直拼接示例
举个例子,我们试着用刚才的代码爬取第二页:clear
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
运行这些代码后,可以得到一个类似于第一页爬取结果的表,然后可以使用append命令将该表垂直拼接到第一页爬取的数据集CPI_final.dta上:
使用 CPI_final 追加
保存 CPI_final,替换
环缝
为了一致性,我重写了上面的代码,因为有些代码可以在循环后运行,比如变量标签、变量名等。 *==================== ============*
* 东方财富消费者物价指数爬行
*================================*
* 下载第一页
清除所有
cd'~/桌面'
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
保存 CPI_final,替换
* 下一个循环从第 2 页到第 8 页并垂直缝合每一页
forval i = 2/8{
清除
复制'`i'' temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
使用 CPI_final 追加
保存 CPI_final,替换
}
使用 CPI_final,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
爬取结果:
至此,我们就完成了这个爬取任务。下面我们进行一个简单的应用-数据展示。
数据呈现
如果我想观察CPI的走势,我需要画一个折线图:
使用 CPI_final,清除
排序日期
* 画画
* 推荐使用我最喜欢的绘画主题plotplain
* 安装方法
ssc 安装百叶窗方案,替换所有
* 永久设置情节主题为plotplain
设置计划情节,永久
* 查看2018年6月对应的Stata日期
di date('2018-06','YM')
* /// 表示代码换行,注意下面几行绘制代码一起运行
tw ///
行 cpi_all 日期, ///
lc(blue*0.6) lp(solid) ///
xline(21336) || ///
行 cpi_city 日期, lc(dkorange) ///
lp(实心) || ///
行 cpi_village 日期, lc(orange_red) ||, ///
ti('图:消费物价指数走势', size(*1.2)) || ///
scatteri 101.90 21336 (12)'June 2018' ||, ///
leg(pos(6) row(1) order(1'全国CPI' 2'城市CPI' 3'农村CPI'))
* 以png格式导出图片
gr 导出 20181004a1.png,替换
以上一些选项的含义: ||:用于分隔图层。
line:用于绘制折线图
tw:全称twoway,用于组合多个图层
lc:全称lcolor(),控制折线图的颜色
lp:全称lpattern(),控制线型
yline:在指定位置画一条水平线
xline:在指定位置画一条垂直线
ti:全称title(),控制标题,size用来控制标题文字的大小,这里是1.2次
leg:全称是legend(),控制图例。pos 用于控制图例的位置。这是一个 6 点方向,排列成一行。
scatteri:用于在指定坐标处绘制一个点。'June 2018'是这个点的标签,(12)用于指定这个标签在该点所在的方向,指定为12点钟方向。❝
欢迎加入 TidyFriday 知识星球,获取更多学习资源:❞
参考文献[1]
东方财富网CPI数据: 查看全部
网页表格抓取(本文以爬取东方财富网CPI数据[1],讲解如何使用Stata)
本文以东方财富网[1]的CPI数据为例,讲解如何使用Stata抓取web表数据。
Stata虽然不是数据爬取工具,但是可以轻松解决一些小的数据爬取任务。数据爬取的本质无非是数据请求和数据处理,所以熟练使用Stata进行数据爬取往往是良好数据处理能力的标志。在实际应用中,我们经常需要爬取一些公共数据。显示这些数据的一种常见方式是通过 HTML 呈现。一个简单的 HTML 表格示例如下:
1
2
3
1
2
3
东方财富网CPI数据表是这样的:
下面我将一步步解释如何爬取这张表。
准备工作Stata14.0或以上;
Chrome浏览器;
想要爬下数据的你。
网络分析
先解释一下如何爬取一个页面的表单。这个页面的网址是:
在页面上右击,选择显示网页的源代码。很多浏览器都有查看网页源代码的功能,但我还是最喜欢谷歌浏览器。点击跳转到页面源码界面:
也就是说,你刚才看到的网页的本质其实就是源代码。我们之所以能看到各种五颜六色的页面,是因为浏览器已经为我们翻译了源代码。
接下来我们要做的就是找出这张表在源码中的位置,然后分析这张表的特征,方便后面Stata处理源码的时候过滤。
一种经常用于查找目标的方法是使用搜索功能。Ctr+F(Mac 的 Command + F)可以打开搜索框。我们注意到表中有两个词,所以我们用月份来搜索。
我们第一次发现这个词是在1987行,仔细一看,这里附近的代码就是表的代码。
下一步就是分析这部分代码的特点:表中的所有数据都位于源代码中的一行,所以我们不能从它所在的行开始;
表数据的前一行要么有一个字符串
经过上面的网页分析后,我们就可以开始爬取网页表单了。
开始爬行
总的来说,Stata 抓取网页表单分为 3 个步骤:请求:下载收录所需数据的源代码;
转码:许多网页不使用 UTF-8 编码。直接读入Stata会造成乱码,所以可以提前进行UTF-8转码;
处理:主要是处理字符串。常见的操作包括拆分、转置(sxpose)、提取(正则表达式或直接字符串提取)等。
问
由于本网页没有防爬机制,可以直接使用copy命令下载。copy命令不仅可以下载网页,还可以下载文件(当然,网页其实就是一个html文件)。更多的使用可以帮助复制。这里我们将要抓取的页面保存为一个名为temp.txt的txt文件。为什么会有这个名字,因为爬完之后会被删除,所以它只是一个临时文件。其实Stata也可以创建临时文件,运行结束会自动删除,不过我觉得没有这个必要,因为通常需要打开temp.txt文件分析一下内容。
清除所有
* 设置工作目录
cd'你自己的工作目录(文件夹的路径)'
复制'#39; temp.txt,替换
转码
在我的Stata命令package-finance包中,我写了一个简单的转码命令。这个命令包的安装方法是: * 首先需要安装github命令,这个命令用于在GitHub上安装命令
* net install github, from('#39;)
* 然后你可以安装这个命令
* github 安装 czxa/finance,替换
安装成功后,使用以下命令直接对temp.txt文件进行转码:
utrans temp.txt
如果返回的结果是转码成功,说明转码成功!(感觉像是在胡说八道……)
如果由于各种原因不幸安装这个小命令失败,可以直接使用以下三个命令进行转码:unicode encoding set gb18030
unicode 翻译 temp.txt
unicode 擦除备份,badidea
读
接下来我们将temp.txt文件读入Stata进行处理。一个很常见的读取方法是使用中缀命令:
使用 temp.txt 中缀 strL v 1-20000,清除
* 将变量 v 的显示格式更改为 %60s(使其看起来更宽)
格式 v %60s
这个命令的意思是创建一个strL格式的变量v,然后读取temp.txt文件每一行的前1-20000个字符(因为我们注意到temp.txt的每一行不超过20000字符)输入变量 v 的每个观测值,读入后如下所示:
处理
首先,根据我们在上面网页分析中发现的结论,我们保留上一行匹配表数据或有字符串'
* 再次删除空观察
删除如果 v ==''
* 删除一些明显不是表中数据的观察,这些无用的观察都收录斜线
删除如果索引(v,'/')
这一步的结果:
其实到这里,我们已经把表格组织的很干净了,但是这不像一个表格,我们需要进行这样的操作:我们注意到第1-13行实际上是表格的第一行,14- 26 该行实际上是表的第二行。我们怎样才能完成这样的操作呢?一个非常有用的命令是 post 命令。这个命令的功能就像它的名字-邮局一样。它可以将v的每个观察值发送到我们想要获取的表的指定位置。
* 第一步是在postfile中创建一个“邮局”,并设置“收件人”(变量日期,v1-v12):
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 cpi.dta,替换
* 然后循环发送v的值给每个接收者
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
* 关闭邮局 mypost
关闭我的帖子
* 打开 cpi.dta 查看整理后的数据
使用 cpi,清除
在这个“邮局操作”之后,数据现在是这样的:
至此,我们其实已经完成了对这张表的爬取,但是接下来我们会将数据组织成更正规的Stata数据。* 组织日期变量
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
* date() 函数将字符串日期转换为Stata日期
gen date1 = date(date,'YM')
* 格式很容易让我们人类理解
格式日期1 %tdCY-N
* 将 date1 变量放在第一列
订单日期1
* 删除日期
下车日期
* 将 date1 重命名为 date
ren date1 日期
* 循环所有变量并删除%
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
* 将所有可以转换为数字变量的字符串变量转换为数字变量
解串,替换
* 循环所有变量,如果变量名不是日期,将显示格式改为%6.2f
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
排序后的数据集如下所示:
就这样,我们爬上了单页表单。此外,我们还注意到完整的表格有 8 页。我们可以点击下一页,看到第二页的网址是:
显然url中的最后一个参数是页数。每个页面的结构都是一样的,所以你可以循环刚才的代码,爬下剩下的6个页面的表格,合并它们。
多页面抓取
垂直拼接示例
举个例子,我们试着用刚才的代码爬取第二页:clear
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
运行这些代码后,可以得到一个类似于第一页爬取结果的表,然后可以使用append命令将该表垂直拼接到第一页爬取的数据集CPI_final.dta上:
使用 CPI_final 追加
保存 CPI_final,替换
环缝
为了一致性,我重写了上面的代码,因为有些代码可以在循环后运行,比如变量标签、变量名等。 *==================== ============*
* 东方财富消费者物价指数爬行
*================================*
* 下载第一页
清除所有
cd'~/桌面'
复制'#39; temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
保存 CPI_final,替换
* 下一个循环从第 2 页到第 8 页并垂直缝合每一页
forval i = 2/8{
清除
复制'`i'' temp.txt,替换
utrans temp.txt
使用 temp.txt 中缀 strL v 1-20000,清除
保持如果索引(v [_n-1],'
删除如果 v ==''
删除如果索引(v,'/')
postfile mypost str20 日期 str20 v1 str20 v2 str20 v3 ///
str20 v4 str20 v5 str20 v6 str20 v7 str20 v8 str20 v9 ///
str20 v10 str20 v11 str20 v12 使用 CPI_temp.dta,替换
forval i = 1(13)`=_N'{
post mypost (v[`i']) (v[`i' + 1]) (v[`i' + 2]) (v[`i' + 3]) ///
(v[`i' + 4]) (v[`i' + 5]) (v[`i' + 6]) (v[`i' + 7]) ///
(v[`i' + 8]) (v[`i' + 9]) (v[`i' + 10]) (v[`i' + 11]) ///
(v[`i' + 12])
}
关闭我的帖子
使用 CPI_temp,清除
使用 CPI_final 追加
保存 CPI_final,替换
}
使用 CPI_final,清除
替换日期 = subinstr(date,'year','', .)
替换日期 = subinstr(date,'month','', .)
gen date1 = date(date,'YM')
格式日期1 %tdCY-N
订单日期1
下车日期
ren date1 日期
foreach i 的 varlist _all{
cap 替换 `i' = subinstr(`i','%','', .)
}
解串,替换
foreach i 的 varlist _all{
如果'`i'' !='date' {
格式`i' %6.2f
}
}
* 添加变量标签
标签 var date'month'
标签 var v1'National CPI'
标签 var v2'全国 CPI 年率'
标签 var v3'全国 CPI 月率'
标签 var v4'National CPI Cumulative'
标签 var v5'City CPI'
标签 var v6'城市 CPI 年率'
标签 var v7'城市 CPI 月率'
label var v8'City CPI Cumulative'
标签 var v9'农村居民消费价格指数'
label var v10'农村CPI年率'
label var v11'农村CPI月率'
标签 var v12'农村 CPI 累积'
* 数据集标签
标签数据'消费者价格指数'
* 变量重命名
ren v1 cpi_all
ren v2 cpi_all_year_rate
ren v3 cpi_all_month_rate
ren v4 cpi_all_accum
ren v5 cpi_city
ren v6 cpi_city_year_rate
ren v7 cpi_city_month_rate
ren v8 cpi_city_accum
ren v9 cpi_village
ren v10 cpi_village_year_rate
ren v11 cpi_village_month_rate
ren v12 cpi_village_accum
保存 CPI_final,替换
爬取结果:
至此,我们就完成了这个爬取任务。下面我们进行一个简单的应用-数据展示。
数据呈现
如果我想观察CPI的走势,我需要画一个折线图:
使用 CPI_final,清除
排序日期
* 画画
* 推荐使用我最喜欢的绘画主题plotplain
* 安装方法
ssc 安装百叶窗方案,替换所有
* 永久设置情节主题为plotplain
设置计划情节,永久
* 查看2018年6月对应的Stata日期
di date('2018-06','YM')
* /// 表示代码换行,注意下面几行绘制代码一起运行
tw ///
行 cpi_all 日期, ///
lc(blue*0.6) lp(solid) ///
xline(21336) || ///
行 cpi_city 日期, lc(dkorange) ///
lp(实心) || ///
行 cpi_village 日期, lc(orange_red) ||, ///
ti('图:消费物价指数走势', size(*1.2)) || ///
scatteri 101.90 21336 (12)'June 2018' ||, ///
leg(pos(6) row(1) order(1'全国CPI' 2'城市CPI' 3'农村CPI'))
* 以png格式导出图片
gr 导出 20181004a1.png,替换
以上一些选项的含义: ||:用于分隔图层。
line:用于绘制折线图
tw:全称twoway,用于组合多个图层
lc:全称lcolor(),控制折线图的颜色
lp:全称lpattern(),控制线型
yline:在指定位置画一条水平线
xline:在指定位置画一条垂直线
ti:全称title(),控制标题,size用来控制标题文字的大小,这里是1.2次
leg:全称是legend(),控制图例。pos 用于控制图例的位置。这是一个 6 点方向,排列成一行。
scatteri:用于在指定坐标处绘制一个点。'June 2018'是这个点的标签,(12)用于指定这个标签在该点所在的方向,指定为12点钟方向。❝
欢迎加入 TidyFriday 知识星球,获取更多学习资源:❞
参考文献[1]
东方财富网CPI数据:
网页表格抓取(在ASP.NET中表格的显式方法,表格数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-15 15:13
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键。考虑实际情况,我们应该隐藏主键,使用隐藏属性)对应的列是)。在后台只需要将Repeater绑定到对应的数据源上即可,这里我们使用class来标记按钮,这样在JS中就可以将所有相同class的按钮作为一组取出。从而在JS中监听和选择设置对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。
转载于: 查看全部
网页表格抓取(在ASP.NET中表格的显式方法,表格数据的方法)
ASP.NET 中有多种表的显式方法。有html标签、asp服务器控件GridView、Repeater控件等,可以帮助我们在页面上显示表格信息。GridView 控件更强大,它有自己的属性和方法,可用于对显式表数据执行各种操作。但是如果使用传统的html标签或者Repeater控件来显示数据,如何获取选中行的数据呢?这里介绍一下使用JS获取页表数据的方法。
如图,我们需要对表中的数据进行编辑和删除。
以中继器控件为例:
(1)页表:定义表头,设置数据绑定(有些操作需要获取数据的主键。考虑实际情况,我们应该隐藏主键,使用隐藏属性)对应的列是)。在后台只需要将Repeater绑定到对应的数据源上即可,这里我们使用class来标记按钮,这样在JS中就可以将所有相同class的按钮作为一组取出。从而在JS中监听和选择设置对应的行。
1 出货单单头:
2
3
4
5
6 ID
7 客户ID
8 出货人员
9 创建时间
10 更新时间
11 编辑
12 删除
13 新增子信息
14
15
16
17
18
19
20
21
22
23
24 编辑
25
26
27 删除
28
29
30 新增子信息
31
32
33
34
35
(2)JS部分:通过class获取对应的一组按钮并设置监听。然后通过标签名获取选中行,通过标签名获取选中行的所有列数据的集合,转换对应的数据通过DOM操作显示在前台指定位置。
1 /*编辑单头信息*/
2 var Top_Edit = document.getElementsByClassName("Top_Edit");
3
4 for (var i = 0; i < Top_Edit.length; i++) {
5
6 Top_Edit[i].index = i;
7
8 Top_Edit[i].onclick = function () {
9
10 var table = document.getElementById("Top_Table");
11
12 /*获取选中的行 */
13 var child = table.getElementsByTagName("tr")[this.index + 1];
14
15 /*获取选择行的所有列*/
16 var SZ_col = child.getElementsByTagName("td");
17
18 document.getElementById("Edit_id").value = SZ_col[0].innerHTML;
19 document.getElementById("edit_customer").value = SZ_col[1].innerHTML;
20 document.getElementById("edit_man").value = SZ_col[2].innerHTML;
21 document.getElementById("Top_Creat_Time").value = SZ_col[3].innerHTML;
22 document.getElementById("Top_Update_Time").value = SZ_col[4].innerHTML;
23
24 }
25 }
JS 只需简单几步即可获取表格数据。还有其他获取表格数据的方法,比如jQuery,大家可以多尝试,然后比较总结,这也是对程序员自己的一种改进。
转载于:
网页表格抓取(如何采集网页中的表格数据到Excel中推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-15 15:12
如何将网页中的表格数据采集转Excel
<p>推荐使用网页表单数据工具搜索上传到采集,简单方便快捷。web表单数据采集器是一种可以采集单页规则和不规则表单的表单,也可以是连续的采集多页表单,可以指定 查看全部
网页表格抓取( 有你想要的精彩作者|東不归出品|Python知识学堂 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-15 15:08
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一段 HTML 或者 XML 文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml 结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果可以得出结论,如果不指定解析器,他会给出系统中最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
Python 知识学院,欢迎您!
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先大致了解一下,后面会有遍历文档和搜索文档的说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:可以通过字符串参数搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 方法基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再贴一下官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
查看全部
网页表格抓取(
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一段 HTML 或者 XML 文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml 结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果可以得出结论,如果不指定解析器,他会给出系统中最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
Python 知识学院,欢迎您!
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先大致了解一下,后面会有遍历文档和搜索文档的说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:可以通过字符串参数搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 方法基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/t ... %3Bbr /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再贴一下官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看
网页表格抓取( 网页信息提取的方式从网页中提取信息的需求日益剧增)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 15:06
网页信息提取的方式从网页中提取信息的需求日益剧增)
关于转载授权
欢迎个人将大数据文摘作品转发至朋友圈、自媒体、媒体、机构需申请授权,后台留言“机构名称+转载”。已经申请授权的不需要再次申请,只要按照约定转载即可,但文章末尾必须放置大数据摘要二维码。
编译|丁雪黄年程序笔记|席雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。这是一个问题或产品,它的功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
从网页中提取信息的方法
有多种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如Twitter、Facebook、Google、Twitter、StackOverflow,都提供了API,以更加结构化的方式访问网站数据。如果可以通过API直接获取所需信息,那么这种方式几乎总是比网络爬取方式要好。因为如果你可以从数据提供者那里得到结构化的数据,那为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并非所有 网站 都提供 API。一些网站不愿意让读者以结构化的方式抓取大量信息,一些网站由于缺乏相关技术知识而无法提供API。遇到这种情况我该怎么办?那么,我们需要通过网络爬虫来获取数据。
当然还有一些其他的方式,比如RSS订阅,但是由于使用限制,这里就不展开讨论了。
什么是网络爬虫?
网页抓取是一种从网站获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转换为结构化数据(数据库或电子表格)。
网络爬虫可以通过不同的方式实现,包括从 Google Docs 到几乎所有的编程语言。由于 Python 的易用性和丰富的生态系统,我会选择使用 Python。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将使用 Python 编程语言向您展示学习网页抓取的最简单方法。
对于需要通过非编程方式从网页中提取数据的读者,可以去import.io看看。有基于图形用户界面的基本操作来运行网页抓取。电脑迷可以继续看这篇文章!
网络爬虫所需的库
我们都知道 Python 是一种开源编程语言。您可能会找到许多库来实现一个功能。因此,有必要找到最好的库。我倾向于使用 BeautifulSoup(Python 库),因为它使用起来简单直观。准确地说,我将使用两个 Python 模块来抓取数据:
· Urllib2:它是一个用于获取URL 的Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关更多详细信息,请参阅文档页面。
· BeautifulSoup:它是一种用于从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表和段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。您可以在其文档页面查看安装指南。
BeautifulSoup 并不能帮助我们获取网页,这就是我将 urllib2 和 BeautifulSoup 库一起使用的原因。除了 BeautifulSoup,Python 还有其他的 HTML 抓取方法。喜欢:
·机械化
·刮痕
·Scrapy
基础 - 熟悉 HTML(标签)
在做网页爬虫的时候,我们需要处理html标签。因此,我们首先要了解标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
语法的各个标签的解释如下:
1.:html文档必须以类型声明开头
2.html文档写在and标签之间
3.html文档的可见部分写在and标签之间
4.HTML header 使用标签定义
5.html 段落用法
标签定义
其他有用的 HTML 标签是:
1.html 链接使用标签定义,“这是一个测试”
2.html表用法定义,行用法的意思,行用法分为数据
3.html 列表 查看全部
网页表格抓取(
网页信息提取的方式从网页中提取信息的需求日益剧增)
关于转载授权
欢迎个人将大数据文摘作品转发至朋友圈、自媒体、媒体、机构需申请授权,后台留言“机构名称+转载”。已经申请授权的不需要再次申请,只要按照约定转载即可,但文章末尾必须放置大数据摘要二维码。
编译|丁雪黄年程序笔记|席雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。这是一个问题或产品,它的功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
从网页中提取信息的方法
有多种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如Twitter、Facebook、Google、Twitter、StackOverflow,都提供了API,以更加结构化的方式访问网站数据。如果可以通过API直接获取所需信息,那么这种方式几乎总是比网络爬取方式要好。因为如果你可以从数据提供者那里得到结构化的数据,那为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并非所有 网站 都提供 API。一些网站不愿意让读者以结构化的方式抓取大量信息,一些网站由于缺乏相关技术知识而无法提供API。遇到这种情况我该怎么办?那么,我们需要通过网络爬虫来获取数据。
当然还有一些其他的方式,比如RSS订阅,但是由于使用限制,这里就不展开讨论了。
什么是网络爬虫?
网页抓取是一种从网站获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转换为结构化数据(数据库或电子表格)。
网络爬虫可以通过不同的方式实现,包括从 Google Docs 到几乎所有的编程语言。由于 Python 的易用性和丰富的生态系统,我会选择使用 Python。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将使用 Python 编程语言向您展示学习网页抓取的最简单方法。
对于需要通过非编程方式从网页中提取数据的读者,可以去import.io看看。有基于图形用户界面的基本操作来运行网页抓取。电脑迷可以继续看这篇文章!
网络爬虫所需的库
我们都知道 Python 是一种开源编程语言。您可能会找到许多库来实现一个功能。因此,有必要找到最好的库。我倾向于使用 BeautifulSoup(Python 库),因为它使用起来简单直观。准确地说,我将使用两个 Python 模块来抓取数据:
· Urllib2:它是一个用于获取URL 的Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关更多详细信息,请参阅文档页面。
· BeautifulSoup:它是一种用于从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表和段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。您可以在其文档页面查看安装指南。
BeautifulSoup 并不能帮助我们获取网页,这就是我将 urllib2 和 BeautifulSoup 库一起使用的原因。除了 BeautifulSoup,Python 还有其他的 HTML 抓取方法。喜欢:
·机械化
·刮痕
·Scrapy
基础 - 熟悉 HTML(标签)
在做网页爬虫的时候,我们需要处理html标签。因此,我们首先要了解标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
语法的各个标签的解释如下:
1.:html文档必须以类型声明开头
2.html文档写在and标签之间
3.html文档的可见部分写在and标签之间
4.HTML header 使用标签定义
5.html 段落用法
标签定义
其他有用的 HTML 标签是:
1.html 链接使用标签定义,“这是一个测试”
2.html表用法定义,行用法的意思,行用法分为数据
3.html 列表
网页表格抓取(1.网页展示的表格如下获取网页表格的后话了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-14 15:31
文章内容
文章 仅用于学习和交流。使用 python 模块 pandas 获取 Web 表单。
有时我想在看到它时将表单保存在网页上。有办法吗?答案是肯定的。
主要有两个步骤,
一种是读取表格内容,另一种是读取后保存内容。
我只解释最简单的获取网页表单的方式,即网页是纯粹的表单。
如果网页中混有其他非表格的数据,则需要定位表格,然后进行表格获取。当然,这是后来的事情。1.网页展示
网页上显示的表格如下。
2.阅读表格
运行以下代码。
怎么样,读出来的代码和网页上的一样吗?既然已经读出,下一步就是保存。
3.保存表格
这一步添加了一行代码。执行代码后,可以看到多了一个table_.csv文件。
打开保存的table_.csv文件看看
您可以看到保存的文件与您在网页上看到的完全相同。好了,结束工作。
完整代码
# read_html,用来读取网页表格
# to_csv,用来保存为csv格式的文档
# 网页需要是纯表格才能用此代码,否则还需要定位到网页表格位置
import pandas as pd
url = 'http://quote.cfi.cn/cache_image/node233.js'
html_data = pd.read_html(url)
for i in html_data:
table_data = pd.DataFrame(i)
table_data.to_csv('table_.csv') # 文件名称
print(table_data)
不禁感受到python语言的强大。 查看全部
网页表格抓取(1.网页展示的表格如下获取网页表格的后话了)
文章内容
文章 仅用于学习和交流。使用 python 模块 pandas 获取 Web 表单。
有时我想在看到它时将表单保存在网页上。有办法吗?答案是肯定的。
主要有两个步骤,
一种是读取表格内容,另一种是读取后保存内容。
我只解释最简单的获取网页表单的方式,即网页是纯粹的表单。
如果网页中混有其他非表格的数据,则需要定位表格,然后进行表格获取。当然,这是后来的事情。1.网页展示
网页上显示的表格如下。
2.阅读表格
运行以下代码。
怎么样,读出来的代码和网页上的一样吗?既然已经读出,下一步就是保存。
3.保存表格
这一步添加了一行代码。执行代码后,可以看到多了一个table_.csv文件。
打开保存的table_.csv文件看看
您可以看到保存的文件与您在网页上看到的完全相同。好了,结束工作。
完整代码
# read_html,用来读取网页表格
# to_csv,用来保存为csv格式的文档
# 网页需要是纯表格才能用此代码,否则还需要定位到网页表格位置
import pandas as pd
url = 'http://quote.cfi.cn/cache_image/node233.js'
html_data = pd.read_html(url)
for i in html_data:
table_data = pd.DataFrame(i)
table_data.to_csv('table_.csv') # 文件名称
print(table_data)
不禁感受到python语言的强大。
网页表格抓取(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-13 06:04
编译:欧莎
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和说明。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为数据的第一行是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些需要清除的字符,比如备注。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中的额外字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
编译源:
●输入m获取文章目录
推荐↓↓↓
人工智能与大数据技术 查看全部
网页表格抓取(用脚本将获取信息上获取2018年100强企业的信息)
编译:欧莎
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和说明。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为数据的第一行是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些需要清除的字符,比如备注。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中的额外字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
编译源:
●输入m获取文章目录
推荐↓↓↓
人工智能与大数据技术
网页表格抓取(如何把网页数据直接抓取成Excel表格有多好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2021-10-13 01:37
在购物网站、酒店机票网站中,搜索一大堆需要比价和研究的产品。也许你需要在工作中列出竞品清单,也许你需要抓取数据与朋友讨论旅行计划。这时候有没有什么有效的方法让我不用手动把数据一一复制整理,直接把网页数据抓取到Excel表格里,那该有多好?
或者你正在搜索“软件下载”文章的某个话题(网站右上角有搜索功能!),发现一堆你想要的文章搜索结果阅读,有没有 方法直接将搜索结果中的一打或二十个文章 自动转换成表格列表。在类似的百科、资料、学习网站中,可以更快的整理出你需要的参考资料。
今天,我将介绍一个可以帮助您更快完成上述操作的工具:“Listly”。该工具可以通过输入网页网址,自动将网页上的项目列表和数据内容下载并转换成Excel表格。而且在我的实际测试中,可以支持中文内容网站和数据网站的购物,免费账号也有一定的使用。
1. “Listly”网页自动转Excel效果演示:
首先我们来看看“Listly”将网页转成Excel的效果。
下图是我在 Google Play 电影中的“愿望清单”。
使用“Listly”,我可以自动将愿望清单网页的内容抓取到以下数据库表中。
而且只要按下抓取按钮,它就会从网页中抓取各种数据格式,如下图所示。
然后我可以一键下载捕获的数据并下载Excel数据表,如下图。
不同的网站,把“Listly”抢到一张桌子上的效果未必100%完美。例如,在 Google Play 电影的愿望清单中,某些“Play Books”的名称字段在转换过程中变为空白。或者运行版本。
但是,如果您最初必须手动完成,从头到尾需要很多时间,“Listly”会先帮助您制作 80% 正确的表格,然后我们可以从这里进行修复和调整,这将节省很多时间。
2.《Listly》超简单操作教程:
如何操作“Listly”?它比我们想象的要简单得多,基本上任何人都可以立即开始。
我们可以输入“Listly”网站,输入我们要爬取的网址。也可以安装“Listly Chrome Plugin”,在想要抓取的网页上按抓取按钮。
例如,让我们再次演示一个示例。我在购物网站中搜索某类商品,在搜索结果页面点击“Listly”抓取按钮。
就这样!几秒钟后,您将看到以下成功捕获屏幕。
“Listly”会抓取网页上的各种数据组织,因此它会抓取多种类型的内容。我们可以使用 [page] 在我们捕捉到的不同内容之间切换。例如,此页面是已捕获搜索结果的产品列表。, 其他页面可能会捕捉到左侧的项目类别列表。
要查看您需要哪种信息,只需切换到该选项卡即可。
确认好你想要的数据的分页后,点击上方的【下载为Excel】按钮,就可以得到如下图的Excel表格了!可以看到产品名称、网址、价格等一应俱全。
是不是真的很简单。
当然,如前所述,抓取的表中可能有一些您不需要的数据。我们只需要转到 Excel 并手动调整它。
3. “Listly”抓取搜索结果并定期跟踪它们:
有时,我们的目的是跟踪和研究一些将要更新的信息。此时,“Listly”还提供了“定时自动爬取内容”服务。
比如下图中,我在小园搜索了某个话题的文章信息。同样,在搜索结果页面上,按“Listly”抓取按钮。
这时候就抓到了搜索结果相同的文章列表结构。如果您注册了“Listly”帐户,您可以将捕获的结果保存在您的仪表板中。
并使用【添加日程】设置自动爬取周期,比如一个月爬一次,看看有没有添加更多相关话题文章。
同样,捕获的文章列表也可以导出到Excel表格中,节省您手动复制标题和URL的时间。
相信大家在搜索信息的过程中,经常需要“将所有数据整理成一个list”,而此时“Listly”确实可以节省不少时间。
此外,“Listly”免费账号提供“每月抓取10个网页”的额度,跟踪1个网页更新。对于免费用户偶尔使用,应该足够了。当然,如果您是出于商业目的,可以考虑“Listly”付费账户。
记得之前有人问过我,有没有办法把网页数据转成Excel,看来“Listly”是个不错的解决方案。
文章 链接:
文章标题:Listly自动抓取网页并转换成Excel表格!支持中文购物和数据网站 查看全部
网页表格抓取(如何把网页数据直接抓取成Excel表格有多好?)
在购物网站、酒店机票网站中,搜索一大堆需要比价和研究的产品。也许你需要在工作中列出竞品清单,也许你需要抓取数据与朋友讨论旅行计划。这时候有没有什么有效的方法让我不用手动把数据一一复制整理,直接把网页数据抓取到Excel表格里,那该有多好?
或者你正在搜索“软件下载”文章的某个话题(网站右上角有搜索功能!),发现一堆你想要的文章搜索结果阅读,有没有 方法直接将搜索结果中的一打或二十个文章 自动转换成表格列表。在类似的百科、资料、学习网站中,可以更快的整理出你需要的参考资料。
今天,我将介绍一个可以帮助您更快完成上述操作的工具:“Listly”。该工具可以通过输入网页网址,自动将网页上的项目列表和数据内容下载并转换成Excel表格。而且在我的实际测试中,可以支持中文内容网站和数据网站的购物,免费账号也有一定的使用。
1. “Listly”网页自动转Excel效果演示:
首先我们来看看“Listly”将网页转成Excel的效果。
下图是我在 Google Play 电影中的“愿望清单”。
使用“Listly”,我可以自动将愿望清单网页的内容抓取到以下数据库表中。
而且只要按下抓取按钮,它就会从网页中抓取各种数据格式,如下图所示。
然后我可以一键下载捕获的数据并下载Excel数据表,如下图。
不同的网站,把“Listly”抢到一张桌子上的效果未必100%完美。例如,在 Google Play 电影的愿望清单中,某些“Play Books”的名称字段在转换过程中变为空白。或者运行版本。
但是,如果您最初必须手动完成,从头到尾需要很多时间,“Listly”会先帮助您制作 80% 正确的表格,然后我们可以从这里进行修复和调整,这将节省很多时间。
2.《Listly》超简单操作教程:
如何操作“Listly”?它比我们想象的要简单得多,基本上任何人都可以立即开始。
我们可以输入“Listly”网站,输入我们要爬取的网址。也可以安装“Listly Chrome Plugin”,在想要抓取的网页上按抓取按钮。
例如,让我们再次演示一个示例。我在购物网站中搜索某类商品,在搜索结果页面点击“Listly”抓取按钮。
就这样!几秒钟后,您将看到以下成功捕获屏幕。
“Listly”会抓取网页上的各种数据组织,因此它会抓取多种类型的内容。我们可以使用 [page] 在我们捕捉到的不同内容之间切换。例如,此页面是已捕获搜索结果的产品列表。, 其他页面可能会捕捉到左侧的项目类别列表。
要查看您需要哪种信息,只需切换到该选项卡即可。
确认好你想要的数据的分页后,点击上方的【下载为Excel】按钮,就可以得到如下图的Excel表格了!可以看到产品名称、网址、价格等一应俱全。
是不是真的很简单。
当然,如前所述,抓取的表中可能有一些您不需要的数据。我们只需要转到 Excel 并手动调整它。
3. “Listly”抓取搜索结果并定期跟踪它们:
有时,我们的目的是跟踪和研究一些将要更新的信息。此时,“Listly”还提供了“定时自动爬取内容”服务。
比如下图中,我在小园搜索了某个话题的文章信息。同样,在搜索结果页面上,按“Listly”抓取按钮。
这时候就抓到了搜索结果相同的文章列表结构。如果您注册了“Listly”帐户,您可以将捕获的结果保存在您的仪表板中。
并使用【添加日程】设置自动爬取周期,比如一个月爬一次,看看有没有添加更多相关话题文章。
同样,捕获的文章列表也可以导出到Excel表格中,节省您手动复制标题和URL的时间。
相信大家在搜索信息的过程中,经常需要“将所有数据整理成一个list”,而此时“Listly”确实可以节省不少时间。
此外,“Listly”免费账号提供“每月抓取10个网页”的额度,跟踪1个网页更新。对于免费用户偶尔使用,应该足够了。当然,如果您是出于商业目的,可以考虑“Listly”付费账户。
记得之前有人问过我,有没有办法把网页数据转成Excel,看来“Listly”是个不错的解决方案。
文章 链接:
文章标题:Listly自动抓取网页并转换成Excel表格!支持中文购物和数据网站
网页表格抓取(小白表示R语言太有用了!(附案例分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-12 07:22
今天,R语言对我帮助很大。几行简单的代码几乎为我节省了一天的时间。小白说R语言好用!
问题如下:
我想获取网页上表格中的数据,网页表格如下图
但是,这张表无法复制和粘贴,这是非常作弊的。Ctrl+C 和 Ctrl+V 之后,只有 URL 出来了。估计是禁用了复制粘贴功能。而且一一敲的话,工作量会很大,估计最后会瞎的……
整个数据量如下,/aspx/1/NewData/Stat_Data.aspx?state=1&next=2¤cy=usd&year=2016
从2014年到2017年有四年,每年有7个项目,每个项目分12个月,共336张表,有的表内容特别大,数量特别多,如下图:
按照这个工作量,如果你一一数数,输入Excel,一天不吃不喝可能做不完。
幸运的是,我最近才开始使用 R ......
听说R语言也有爬取数据的功能,于是在网上简单搜索了一些帖子,使用XML包,成功将这个网页中的336表保存为Excel格式。
代码显示如下:
>install.packages("XML")#安装 XML 包
>library(XML) #加载XML包
>/aspx/1/NewData/Stat_Class.aspx?state=1&t=2&guid=7146" #写表所在的URL
>tblsR语言网页数据抓取示例
>流行
>write.csv(pop,file="d:/pop.csv") #将pop存储为D盘的CSV文件
这样就快速实现了网页中的数据爬取。第一次用R语言工作,往往很有成就感~不过毕竟有336个网页,最后还要跑336次代码,工作量也是肯定。童鞋们,如果有更好更快的导出数据的方法,欢迎提供~ 查看全部
网页表格抓取(小白表示R语言太有用了!(附案例分析))
今天,R语言对我帮助很大。几行简单的代码几乎为我节省了一天的时间。小白说R语言好用!
问题如下:
我想获取网页上表格中的数据,网页表格如下图
但是,这张表无法复制和粘贴,这是非常作弊的。Ctrl+C 和 Ctrl+V 之后,只有 URL 出来了。估计是禁用了复制粘贴功能。而且一一敲的话,工作量会很大,估计最后会瞎的……
整个数据量如下,/aspx/1/NewData/Stat_Data.aspx?state=1&next=2¤cy=usd&year=2016
从2014年到2017年有四年,每年有7个项目,每个项目分12个月,共336张表,有的表内容特别大,数量特别多,如下图:
按照这个工作量,如果你一一数数,输入Excel,一天不吃不喝可能做不完。
幸运的是,我最近才开始使用 R ......
听说R语言也有爬取数据的功能,于是在网上简单搜索了一些帖子,使用XML包,成功将这个网页中的336表保存为Excel格式。
代码显示如下:
>install.packages("XML")#安装 XML 包
>library(XML) #加载XML包
>/aspx/1/NewData/Stat_Class.aspx?state=1&t=2&guid=7146" #写表所在的URL
>tblsR语言网页数据抓取示例
>流行
>write.csv(pop,file="d:/pop.csv") #将pop存储为D盘的CSV文件
这样就快速实现了网页中的数据爬取。第一次用R语言工作,往往很有成就感~不过毕竟有336个网页,最后还要跑336次代码,工作量也是肯定。童鞋们,如果有更好更快的导出数据的方法,欢迎提供~
网页表格抓取( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-11 16:39
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。我以前这样做过,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取( image如何抓取网页表格里的数据?Datapreview预览一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-11 08:20
image如何抓取网页表格里的数据?Datapreview预览一下)
图片
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
图片
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
图片
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
图片
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
图片
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
图片
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
图片
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
图片
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
图片
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
图片
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
image如何抓取网页表格里的数据?Datapreview预览一下)
图片
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
图片
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
图片
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
图片
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容会被默认捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
图片
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
图片
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
图片
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
图片
我们把抓到的CSV文件下载下来,在预览器中打开后,会发现出现了车次的数据,但是出发站的数据又为空了!
图片
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
图片
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是原装正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,也不太适合现代网页的匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(我想从使用Python2.7+Windows保存的HTML网页中提取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-09 22:24
我想从使用 Python 2.7 + Windows 保存的 HTML 网页中提取数据。 Python BeautifulSoup 从保存的 HTML 页面中提取表格
有多个保存的 HTML 页面,它们是相似的,每个页面都收录一个 5 列的表格。行数不固定。
源码如下:
text = '''
/DXR.axd?r=1_19-RPSupplier Code (Count=6, Record Count:86) (next page)
 3617GermanEU20122013
 3617BelgiumEU20142015
…
…
…
…
…
'''
我想要的是将表格的内容放入 .xls 文件中。
我所要做的就是:
soup = BeautifulSoup(text)
aa = soup.find_all('table')[0].tbody.find_all('tr')
for a in aa:
print a.text
它提供了所有内容,但都在第一行。
我认为:
aa = soup.find_all(id = 'MainTable')
for a in aa:
for b in a.find_all(id = 'Row2'):
print b.text
它给出了特定行的内容,但仍然在第 1 行。
3617BelgiumEU20142015
这还不够,HTML文件行数的不确定性也是一个问题。
我想要的是“3617”、“比利时”、“欧盟”、“2014”和“2015”,以便我可以将它们保存在 .xls 文件中。
提取表格的最佳方法是什么?
来源
2015-07-22Mark K 查看全部
网页表格抓取(我想从使用Python2.7+Windows保存的HTML网页中提取数据)
我想从使用 Python 2.7 + Windows 保存的 HTML 网页中提取数据。 Python BeautifulSoup 从保存的 HTML 页面中提取表格
有多个保存的 HTML 页面,它们是相似的,每个页面都收录一个 5 列的表格。行数不固定。
源码如下:
text = '''
/DXR.axd?r=1_19-RPSupplier Code (Count=6, Record Count:86) (next page)
 3617GermanEU20122013
 3617BelgiumEU20142015
…
…
…
…
…
'''
我想要的是将表格的内容放入 .xls 文件中。
我所要做的就是:
soup = BeautifulSoup(text)
aa = soup.find_all('table')[0].tbody.find_all('tr')
for a in aa:
print a.text
它提供了所有内容,但都在第一行。
我认为:
aa = soup.find_all(id = 'MainTable')
for a in aa:
for b in a.find_all(id = 'Row2'):
print b.text
它给出了特定行的内容,但仍然在第 1 行。
3617BelgiumEU20142015
这还不够,HTML文件行数的不确定性也是一个问题。
我想要的是“3617”、“比利时”、“欧盟”、“2014”和“2015”,以便我可以将它们保存在 .xls 文件中。
提取表格的最佳方法是什么?
来源
2015-07-22Mark K
网页表格抓取(本文本文实例讲述Python实现抓取网页生成Excel文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-09 21:13
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
Python抓取网页生成Excel文件 查看全部
网页表格抓取(本文本文实例讲述Python实现抓取网页生成Excel文件的方法)
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下
本文介绍如何使用 Python 抓取网页生成 Excel 文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
Python抓取网页生成Excel文件
网页表格抓取(爬虫所要通用的表格函数应对方法,对你非常有帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-09 16:44
如果你的爬虫想要爬取的内容存在于页面的table标签中,那么本文探讨的方法对你很有帮助。
下面两个网址有非常规范的表格数据
前者是北京500强名单,后者是中国500强名单
对于常规爬取,需要对页面进行分析,准确找到这部分内容的标签位置,然后进行定点爬取。分析了几个页面,发现这些表中的数据非常相似。
它们存储在 table 标记中。第一个tr是第一行的标题,数据内容从第二个tr开始。
排名
公司名称(中英文)
营业收入(百万美元)
2
国家电网公司(STATE GRID)
348903.1
3
中国石油化工集团公司(SINOPEC GROUP)
326953
4
中国石油天然气集团公司(CHINA NATIONAL PETROLEUM)
326007.6
既然都长得一样,何不写一个通用的表单爬取功能,这样当你遇到这种页面时,可以快速爬取。之所以不写一般的表单爬虫,是因为不同的页面获取方式不同,但是只要获取到html,其余的分析提取过程都是一样的。
如果你想让一个函数处理所有情况,你需要对表格有特殊的理解,这样这个函数才能覆盖大部分情况。至于一些特殊的页面,则不在此功能范围之内。
第一个tr是标题行,内部标签可以是th或td。对于tbody中的tr,内部是td。编写程序时应注意这一点。在获取td内容时,我只关心实际的文本内容。至于加粗的标签或者链接,不是我想要的。因此,代码中只需要提取td下的文本内容即可。
思路确定了,代码就容易写了
import pprint
import requests
from lxml import etree
def get_table_from_html(html):
tree = etree.HTML(html)
# 寻找所有的table标签
table_lst = tree.xpath("//table")
table_data_lst = []
for table in table_lst:
table_data_lst.append(get_table(table))
return table_data_lst
def get_table(table_ele):
"""
获取table数据
:param table_ele:
:return:
"""
tr_lst = table_ele.xpath(".//tr")
# 第一行通常来说都是标题
title_data = get_title(tr_lst[0])
# 第一行后面都是数据
data = get_data(tr_lst[1:])
return {
'title': title_data,
'data': data
}
def get_title(tr_ele):
"""
获取标题
标题可能用th 标签,也可能用td标签
:param tr_ele:
:return:
"""
# 先寻找th标签
title_lst = get_tr_data_by_tag(tr_ele, 'th')
if not title_lst:
title_lst = get_tr_data_by_tag(tr_ele, 'td')
return title_lst
def get_data(tr_lst):
"""
获取数据
:param tr_lst:
:return:
"""
datas = []
for tr in tr_lst:
tr_data = get_tr_data_by_tag(tr, 'td')
datas.append(tr_data)
return datas
def get_tr_data_by_tag(tr, tag):
"""
获取一行数据
:param tr:
:param tag:
:return:
"""
datas = []
nodes = tr.xpath(".//{tag}".format(tag=tag))
for node in nodes:
text = node.xpath('string(.)').strip()
datas.append(text)
return datas
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
return res.text
def run():
url = 'https://baike.baidu.com/item/% ... 39%3B
# url = "https://www.phb123.com/qiye/35109.html"
html = get_html(url)
table_lst = get_table_from_html(html)
pprint.pprint(table_lst)
if __name__ == '__main__':
run()
目前只有少数几个网页被用于测试。如果遇到无法通过此方法准确抓取的页面,可以给我留言,我会根据页面内容改进此表单的抓取方法 查看全部
网页表格抓取(爬虫所要通用的表格函数应对方法,对你非常有帮助)
如果你的爬虫想要爬取的内容存在于页面的table标签中,那么本文探讨的方法对你很有帮助。
下面两个网址有非常规范的表格数据
前者是北京500强名单,后者是中国500强名单
对于常规爬取,需要对页面进行分析,准确找到这部分内容的标签位置,然后进行定点爬取。分析了几个页面,发现这些表中的数据非常相似。
它们存储在 table 标记中。第一个tr是第一行的标题,数据内容从第二个tr开始。
排名
公司名称(中英文)
营业收入(百万美元)
2
国家电网公司(STATE GRID)
348903.1
3
中国石油化工集团公司(SINOPEC GROUP)
326953
4
中国石油天然气集团公司(CHINA NATIONAL PETROLEUM)
326007.6
既然都长得一样,何不写一个通用的表单爬取功能,这样当你遇到这种页面时,可以快速爬取。之所以不写一般的表单爬虫,是因为不同的页面获取方式不同,但是只要获取到html,其余的分析提取过程都是一样的。
如果你想让一个函数处理所有情况,你需要对表格有特殊的理解,这样这个函数才能覆盖大部分情况。至于一些特殊的页面,则不在此功能范围之内。
第一个tr是标题行,内部标签可以是th或td。对于tbody中的tr,内部是td。编写程序时应注意这一点。在获取td内容时,我只关心实际的文本内容。至于加粗的标签或者链接,不是我想要的。因此,代码中只需要提取td下的文本内容即可。
思路确定了,代码就容易写了
import pprint
import requests
from lxml import etree
def get_table_from_html(html):
tree = etree.HTML(html)
# 寻找所有的table标签
table_lst = tree.xpath("//table")
table_data_lst = []
for table in table_lst:
table_data_lst.append(get_table(table))
return table_data_lst
def get_table(table_ele):
"""
获取table数据
:param table_ele:
:return:
"""
tr_lst = table_ele.xpath(".//tr")
# 第一行通常来说都是标题
title_data = get_title(tr_lst[0])
# 第一行后面都是数据
data = get_data(tr_lst[1:])
return {
'title': title_data,
'data': data
}
def get_title(tr_ele):
"""
获取标题
标题可能用th 标签,也可能用td标签
:param tr_ele:
:return:
"""
# 先寻找th标签
title_lst = get_tr_data_by_tag(tr_ele, 'th')
if not title_lst:
title_lst = get_tr_data_by_tag(tr_ele, 'td')
return title_lst
def get_data(tr_lst):
"""
获取数据
:param tr_lst:
:return:
"""
datas = []
for tr in tr_lst:
tr_data = get_tr_data_by_tag(tr, 'td')
datas.append(tr_data)
return datas
def get_tr_data_by_tag(tr, tag):
"""
获取一行数据
:param tr:
:param tag:
:return:
"""
datas = []
nodes = tr.xpath(".//{tag}".format(tag=tag))
for node in nodes:
text = node.xpath('string(.)').strip()
datas.append(text)
return datas
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
return res.text
def run():
url = 'https://baike.baidu.com/item/% ... 39%3B
# url = "https://www.phb123.com/qiye/35109.html"
html = get_html(url)
table_lst = get_table_from_html(html)
pprint.pprint(table_lst)
if __name__ == '__main__':
run()
目前只有少数几个网页被用于测试。如果遇到无法通过此方法准确抓取的页面,可以给我留言,我会根据页面内容改进此表单的抓取方法
网页表格抓取(第4课中如何采集多个列表中的数据?课 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-07 18:08
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,比如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环-提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以单击多次直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
查看全部
网页表格抓取(第4课中如何采集多个列表中的数据?课
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,比如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环-提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以单击多次直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:

