
网页表格抓取
网页表格抓取(Python使用Web抓取有助于的步骤寻找您想要的抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-08 23:06
前言
爬虫是一种从 网站 抓取大量数据的自动化方法。甚至在 网站 上复制和粘贴您最喜欢的引用或台词也是一种网络抓取形式。大多数 网站 不允许您将他们的数据保存在 网站 上供您使用。因此,唯一的选择是手动复制数据,这会消耗大量时间,甚至可能需要几天才能完成。
网站 上的大部分数据都是非结构化的。网页抓取有助于将这些非结构化数据以自定义和结构化的形式在本地或数据库中存储。如果您出于学习目的抓取网页,则不太可能遇到任何问题。在不违反服务条款的情况下自己进行一些网络爬行以提高您的技能是一个很好的做法。.
履带步数
为什么使用 Python 进行网页抓取?
Python 非常快,而且网页抓取更容易。因为代码太容易了,你可以用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页爬取代码,将请求发送到我们要爬取的网站的URL。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Web 抓取使用 Python 提取数据的步骤
找到你要爬取的URL,分析网站找到要提取的数据,编写代码,运行代码,从网站中提取数据,将数据按照需要的格式存储在电脑中,用于网络爬取图书馆
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象。
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供用于导航、搜索和修改解析树的惯用方法。它专为快速且高度可靠的数据提取而设计。
pandas 是一个开源库,它允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察数据行和变量列中存储和操作表数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(可迭代)包装任何可迭代的。
演示:抓住一个 网站
Step 1. 找到你要抓取的网址
为了演示,我们将抓取网页以提取手机的详细信息。我用一个例子()来演示这个过程。
Stpe 2. 分析 网站
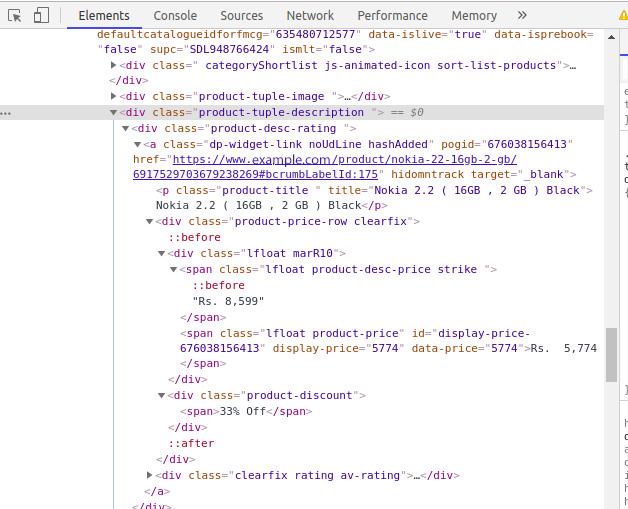
数据通常嵌套在标签中。分析并检查我们要获取的数据是否在其嵌套的页面上进行了标记。要查看页面,只需右键单击该元素并单击“检查”。将打开一个小的检查元件框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则控制台选项卡中将突出显示特定产品区域的代码。
我们应该做的第一件事是回顾和理解HTML的结构,因为从网站中获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标签。
步骤3.找到要提取的数据
我们会提取手机数据,如产品名称、实际价格、折扣价等,您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标签。
通过检查元素的区域打开控制台。单击左上角的箭头,然后单击产品。您现在可以看到我们点击的产品的具体代码。
步骤4. 写代码
现在我们必须找出数据和链接在哪里。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了网站的URL并访问了网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你就成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印soup,那么我们就能看到整个网站 页面的HTML 内容。我们现在要做的是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
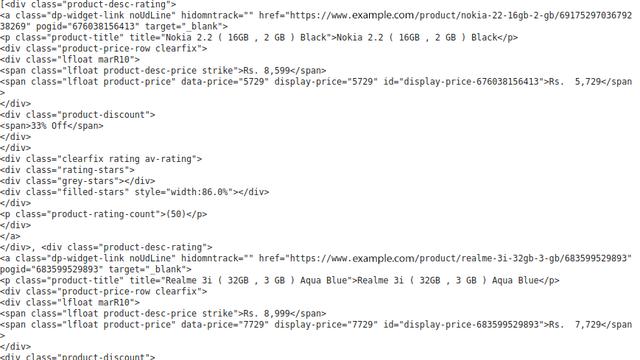
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在div的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到该列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,而 product_url 出现在锚标签下。
HTML 锚标记定义了一个将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页和文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,两者都出现在 span 标签中。标签用于对内联元素进行分组。并且标签本身不提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一种通用的容器标签。它用于 HTML 的各种标记组,以便您可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
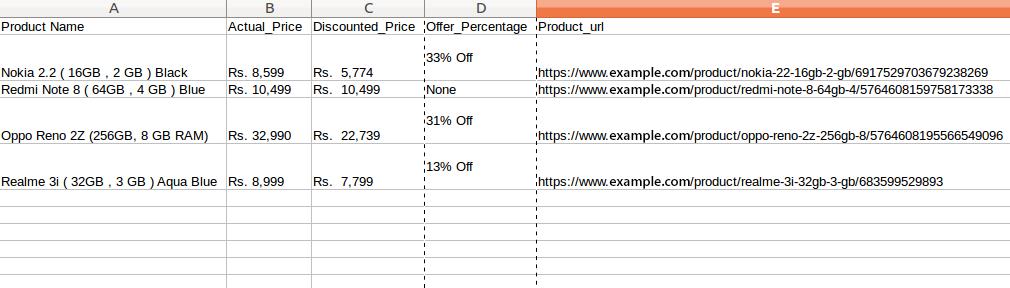
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储在文件或数据库中。您可以按所需格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
参考: 查看全部
网页表格抓取(Python使用Web抓取有助于的步骤寻找您想要的抓取数据)
前言
爬虫是一种从 网站 抓取大量数据的自动化方法。甚至在 网站 上复制和粘贴您最喜欢的引用或台词也是一种网络抓取形式。大多数 网站 不允许您将他们的数据保存在 网站 上供您使用。因此,唯一的选择是手动复制数据,这会消耗大量时间,甚至可能需要几天才能完成。
网站 上的大部分数据都是非结构化的。网页抓取有助于将这些非结构化数据以自定义和结构化的形式在本地或数据库中存储。如果您出于学习目的抓取网页,则不太可能遇到任何问题。在不违反服务条款的情况下自己进行一些网络爬行以提高您的技能是一个很好的做法。.
履带步数
为什么使用 Python 进行网页抓取?
Python 非常快,而且网页抓取更容易。因为代码太容易了,你可以用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页爬取代码,将请求发送到我们要爬取的网站的URL。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Web 抓取使用 Python 提取数据的步骤
找到你要爬取的URL,分析网站找到要提取的数据,编写代码,运行代码,从网站中提取数据,将数据按照需要的格式存储在电脑中,用于网络爬取图书馆
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象。
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供用于导航、搜索和修改解析树的惯用方法。它专为快速且高度可靠的数据提取而设计。
pandas 是一个开源库,它允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察数据行和变量列中存储和操作表数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(可迭代)包装任何可迭代的。
演示:抓住一个 网站
Step 1. 找到你要抓取的网址
为了演示,我们将抓取网页以提取手机的详细信息。我用一个例子()来演示这个过程。
Stpe 2. 分析 网站
数据通常嵌套在标签中。分析并检查我们要获取的数据是否在其嵌套的页面上进行了标记。要查看页面,只需右键单击该元素并单击“检查”。将打开一个小的检查元件框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则控制台选项卡中将突出显示特定产品区域的代码。
我们应该做的第一件事是回顾和理解HTML的结构,因为从网站中获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标签。
步骤3.找到要提取的数据
我们会提取手机数据,如产品名称、实际价格、折扣价等,您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标签。
通过检查元素的区域打开控制台。单击左上角的箭头,然后单击产品。您现在可以看到我们点击的产品的具体代码。
步骤4. 写代码
现在我们必须找出数据和链接在哪里。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了网站的URL并访问了网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你就成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印soup,那么我们就能看到整个网站 页面的HTML 内容。我们现在要做的是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在div的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到该列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,而 product_url 出现在锚标签下。
HTML 锚标记定义了一个将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页和文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,两者都出现在 span 标签中。标签用于对内联元素进行分组。并且标签本身不提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一种通用的容器标签。它用于 HTML 的各种标记组,以便您可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储在文件或数据库中。您可以按所需格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
参考:
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-08 23:02
这是简单数据分析系列文章的第十一篇。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果我们真的要抓取表格数据,可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果我们真的要抓取表格数据,可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(Python编程语言Excel爬虫函数学起来容易些什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-08 23:00
近年来,Python编程语言非常流行,很多人使用Python来开发网络爬虫工具。Python虽然简单,但学起来并不容易,需要一定的基础。今天小编就给大家介绍一个Excel爬虫功能,比较简单易学,可以满足特定场景下数据采集的需求。
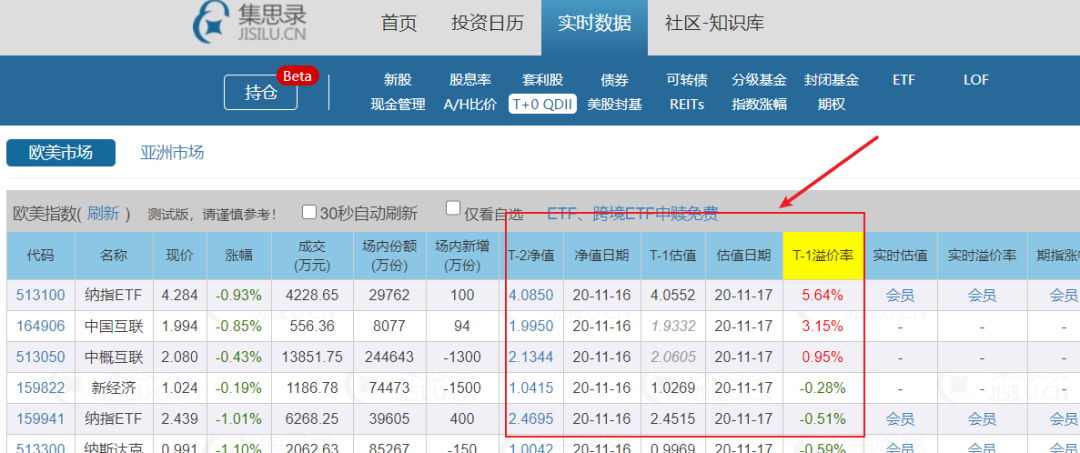
有一个基金网页#qdiie,网页上有一个数据表,如下图所示,需要将红框中标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步,使用Firefox或Chrome打开目标网页,右键查看代码,找到表的id。如果 table 没有 id,则可以使用 table 类样式代替。
第二步编写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要抓取的URL,"flex_qdiie"指的是网页中table元素的id号。函数名中的 W 表示当前函数需要 Excel 浏览器的帮助。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或HttpPost()方法无法读取完整的网页,需要使用浏览器读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。由于网页数据需要定期更新,需要Excel浏览器循环抓取网页。
第四步是刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表中的所有数据。这是一长串文本。可以发现每一列之间用分号隔开,每一行之间用两个分号隔开。. 找到规则后,我们可以使用 Split2Array() 函数对数据进行拆分和提取。
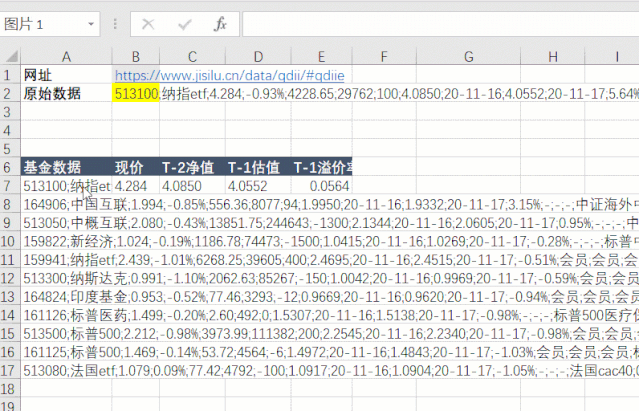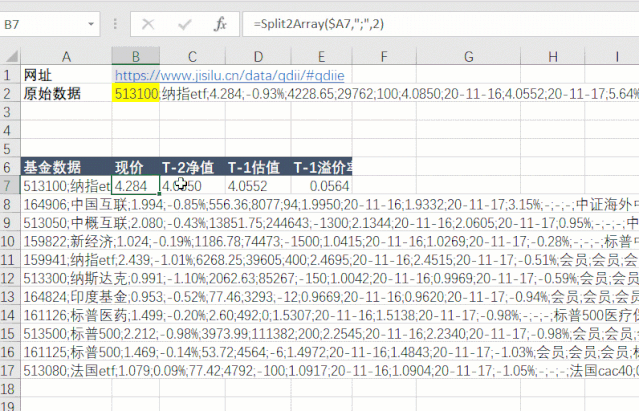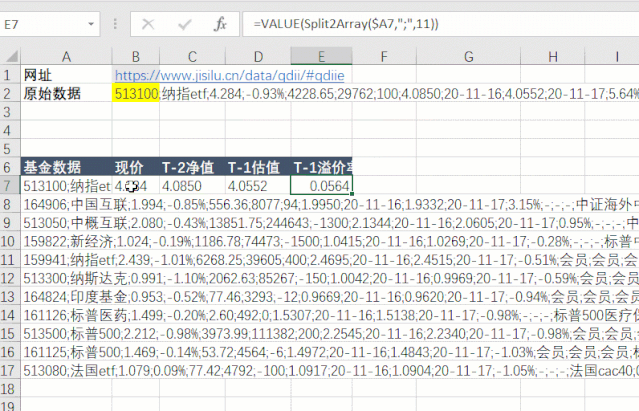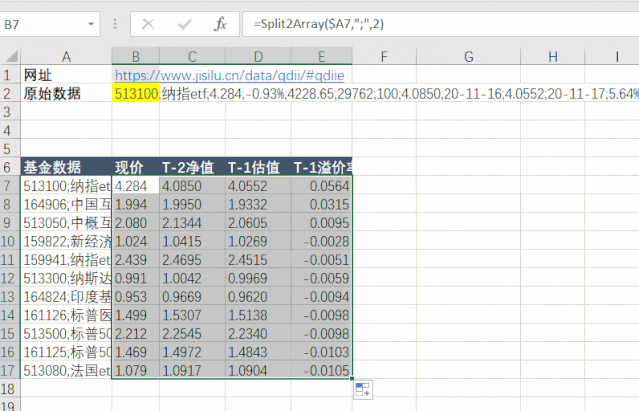
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是对数据进行拆分和提取。先拆分每一行的数据,然后拆分每列的数据。
第六步,使用公式=AutoRefresh(120)设置定时刷新任务,每120秒自动刷新一次表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,就可以对数据进行处理和计算,达到监测预警的目的。怎么样,还算简单,写个公式就可以做网页数据采集。
如果你觉得这个技巧很实用,请帮忙转发给你的朋友 查看全部
网页表格抓取(Python编程语言Excel爬虫函数学起来容易些什么?(图))
近年来,Python编程语言非常流行,很多人使用Python来开发网络爬虫工具。Python虽然简单,但学起来并不容易,需要一定的基础。今天小编就给大家介绍一个Excel爬虫功能,比较简单易学,可以满足特定场景下数据采集的需求。

有一个基金网页#qdiie,网页上有一个数据表,如下图所示,需要将红框中标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步,使用Firefox或Chrome打开目标网页,右键查看代码,找到表的id。如果 table 没有 id,则可以使用 table 类样式代替。
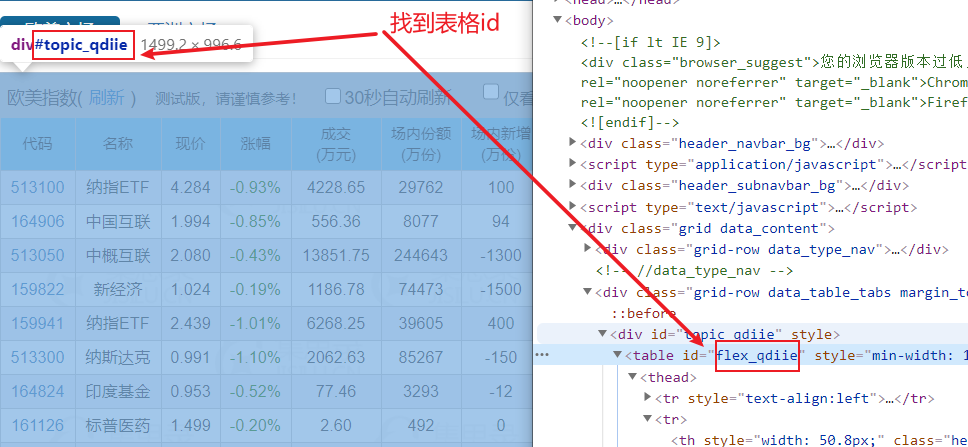
第二步编写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要抓取的URL,"flex_qdiie"指的是网页中table元素的id号。函数名中的 W 表示当前函数需要 Excel 浏览器的帮助。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或HttpPost()方法无法读取完整的网页,需要使用浏览器读取所有的网页数据。
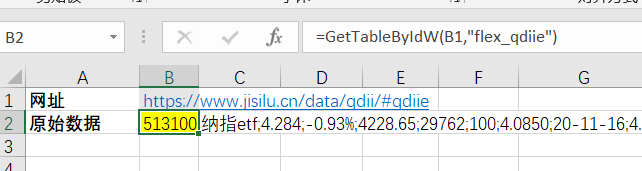
第三步,打开Excel浏览器,设置网页循环爬取任务。由于网页数据需要定期更新,需要Excel浏览器循环抓取网页。

第四步是刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表中的所有数据。这是一长串文本。可以发现每一列之间用分号隔开,每一行之间用两个分号隔开。. 找到规则后,我们可以使用 Split2Array() 函数对数据进行拆分和提取。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是对数据进行拆分和提取。先拆分每一行的数据,然后拆分每列的数据。
第六步,使用公式=AutoRefresh(120)设置定时刷新任务,每120秒自动刷新一次表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,就可以对数据进行处理和计算,达到监测预警的目的。怎么样,还算简单,写个公式就可以做网页数据采集。
如果你觉得这个技巧很实用,请帮忙转发给你的朋友
网页表格抓取(这是一个用来更新公园信息的数据管理系统,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-04 12:11
这是一个用于更新园区信息的数据管理系统,本页面截图主要用于更新站点信息。幸运的是,这个页面的每个元素都可以通过 ID 来定位。它收录三种形式的信息:文本框、下拉列表和复选按钮。我的实现思路是将id对应的定位信息放在excel表中,通过抓取excel表中提供的定位信息和需要更新的对应值来更新数据。
这里分别封装了文本框信息输入、下拉列表选择和勾选按钮勾选,然后将相应的方法统一到update方法中来实现。这消除了对每个字段进行单独处理的需要。
包装代码:
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import traceback
import time
class BasePage:
def __init__(self, driver):
self.driver = driver
# 对查找单个页面元素进行封装。
def find_element(self, by, locator):
by = by.lower()
element = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
element = self.driver.find_element_by_id(locator)
elif by == 'name':
element = self.driver.find_element_by_name(locator)
elif by == 'xpath':
element = self.driver.find_element_by_xpath(locator)
elif by == 'class':
element = self.driver.find_element_by_class_name(locator)
elif by == 'tag':
element = self.driver.find_element_by_tag_name(locator)
elif by == 'link':
element = self.driver.find_element_by_link_text(locator)
elif by == 'plink':
element = self.driver.find_element_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return element
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 对查找多个页面元素进行封装。
def find_elements(self, by, locator):
by = by.lower()
elements = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
elements = self.driver.find_elements_by_id(locator)
elif by == 'name':
elements = self.driver.find_elements_by_name(locator)
elif by == 'xpath':
elements = self.driver.find_elements_by_xpath(locator)
elif by == 'class':
elements = self.driver.find_elements_by_class_name(locator)
elif by == 'tag':
elements = self.driver.find_elements_by_tag_name(locator)
elif by == 'link':
elements = self.driver.find_elements_by_link_text(locator)
elif by == 'plink':
elements = self.driver.find_elements_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return elements
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 点击页面元素
def click(self, by, locator):
element = self.find_element(by, locator)
element.click()
# 输入框输入新信息
def type(self, by, locator, value):
y = [x for x in value if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element.clear()
element.send_keys(value.strip())
else:
pass
# 下拉菜单通过可见文本进行选择
def select(self, by, locator, text):
y = [x for x in text if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element_element = Select(element)
element_element.select_by_visible_text(text.strip())
else:
pass
# 复选按钮勾选时我们需要首先勾掉已选选项
def uncheck(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
elements = self.find_elements(by, locator)
for element in elements:
element.click()
else:
pass
# 选择excel表格所提供的选项进行勾选
def check(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
be_options = options.split(',')
for option in be_options:
element = self.find_element(by, locator.format(option.strip()))
element.click()
else:
pass
# def input(self, left_title, excel_title, by, locator, values):
# y = [x for x in values if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.type(by, locator, values)
# else:
# pass
# 根据excel表格提供标题所包含的关键字来决定进行哪种数据操作
def update(self, title, by, values):
y = [x for x in values if x != '']
if len(y) > 0:
if '_Text' in title: # 文本框
field = title.strip().split('_')
locator = field[0]
self.type(by, locator, values)
elif '_Select' in title: # 下拉列表
field = title.strip().split('_')
locator = field[0]
self.select(by, locator, values)
elif '_Option' in title: # 复选按钮
field = title.strip().split('_')
locator = field[0]
self.uncheck('xpath', '//input[@checked="" and contains(@id, "{}__")]'.format(locator), values)
self.check('id', '%s__{}'%locator, values)
else:
print('Please indicate the data type for the title "{}" in Excel!!!'.format(title))
else:
pass
# def set(self, left_title, excel_title, by, locator, text):
# y = [x for x in text if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.select(by, locator, text)
# else:
# pass
# 登录系统进行封装方便以后重用
def login_orms(self, url, username, password):
# driver = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
self.driver.delete_all_cookies()
self.driver.get(url)
self.driver.maximize_window()
time.sleep(2)
self.type('id', 'userName', username)
self.type('id', 'password', password)
self.click('id', 'okBtnAnchor')
time.sleep(2)
# 登录系统后选择Contract
def goto_manager_page(self, url, username, password, contract, page):
self.login_orms(url, username, password)
time.sleep(2)
self.click('xpath', "//option[text()='" + contract + " Contract']") # 通过click也可以对下拉列表进行选择
time.sleep(2)
self.click('link', page)
time.sleep(2)
下面是实现代码(没有对操作excel表的封装)
from Orms.BasePage import *
import xlrd
""""""
url = 'reserveamerica.com/xxxx'
account_user = 'xxx'
account_password = 'xxx'
wb = xlrd.open_workbook('D://SiteandLoopSetUp.xls')
""""""
sheet1 = wb.sheet_by_index(0)
sheet2 = wb.sheet_by_index(1)
# read provided information in Excel.
contract = sheet1.col_values(0)[1].strip()
park_name = sheet1.col_values(1)[1].strip()
search_ids = sheet1.col_values(2)[1:]
check_in_times = sheet1.col_values(3)[1:]
check_out_times = sheet1.col_values(4)[1:]
cols_num = sheet1.ncols
print('There will be "{}" fields need to update as following:'.format(cols_num))
left_titles = sheet1.row_values(0)[5:cols_num]
print(left_titles)
browser = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
driver = BasePage(browser)
driver.goto_manager_page(url=url, username=account_user, password=account_password, contract=contract, page='Inventory Manager')
# Input park name and search
driver.type('id', 'FacilitySearchCriteria.facilityName', park_name)
driver.click('xpath', '//a[@aria-label="Search"]')
time.sleep(3)
# Click facility id in search results to facility details page
driver.click('xpath', '//tr[@name="e_Glow"]/td/a')
time.sleep(2)
# Choose Loop/Site Set-up for Facility Details drop-down list
driver.select('id', 'page_name', 'Loop/Site Set-up')
time.sleep(2)
driver.click('xpath', '//a[@tabindex="-1" and @accesskey="S"]')
time.sleep(2)
for x in range(len(search_ids)):
try:
driver.select('id', 'search_type', 'Site ID')
time.sleep(2)
driver.type('id', 'search_value', search_ids[x])
driver.click('id', 'goAnchor')
time.sleep(2)
driver.click('xpath', '//tr[@name="e_Glow"]/td[2]/a')
time.sleep(2)
# in_time and out_time are required fields, need to handle separately.
in_time = check_in_times[x].strip().split(' ')
y = [x for x in in_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkin Time', in_time[0])
driver.select('id', 'Checkin Time_ispm', in_time[1])
else:
pass
out_time = check_out_times[x].strip().split(' ')
y = [x for x in out_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkout Time', out_time[0])
driver.select('id', 'Checkout Time_ispm', out_time[1])
else:
pass
# update left information in excel.
for i in range(len(left_titles)):
title = left_titles[i]
excel_values = sheet1.col_values(5+i)[1:]
driver.update(title, 'id', excel_values[x])
except Exception as e:
raise Exception
else:
driver.click('xpath', '//a[@aria-label="OK"]')
以上是我模拟手动操作自动填写页面表单的方法。虽然每次做的时候都需要找到需要更新信息的页面元素ID的值,复制到excel中,但是对于几十种合同和几十种形式的网站类型,还有上千个字段需要单独处理的,就简单多了。
当然,肯定有一些不完善的地方,比如强制等待而不是隐形等待。必须有更好的方法来实现这一目标。请指正~~~ 查看全部
网页表格抓取(这是一个用来更新公园信息的数据管理系统,怎么办?)
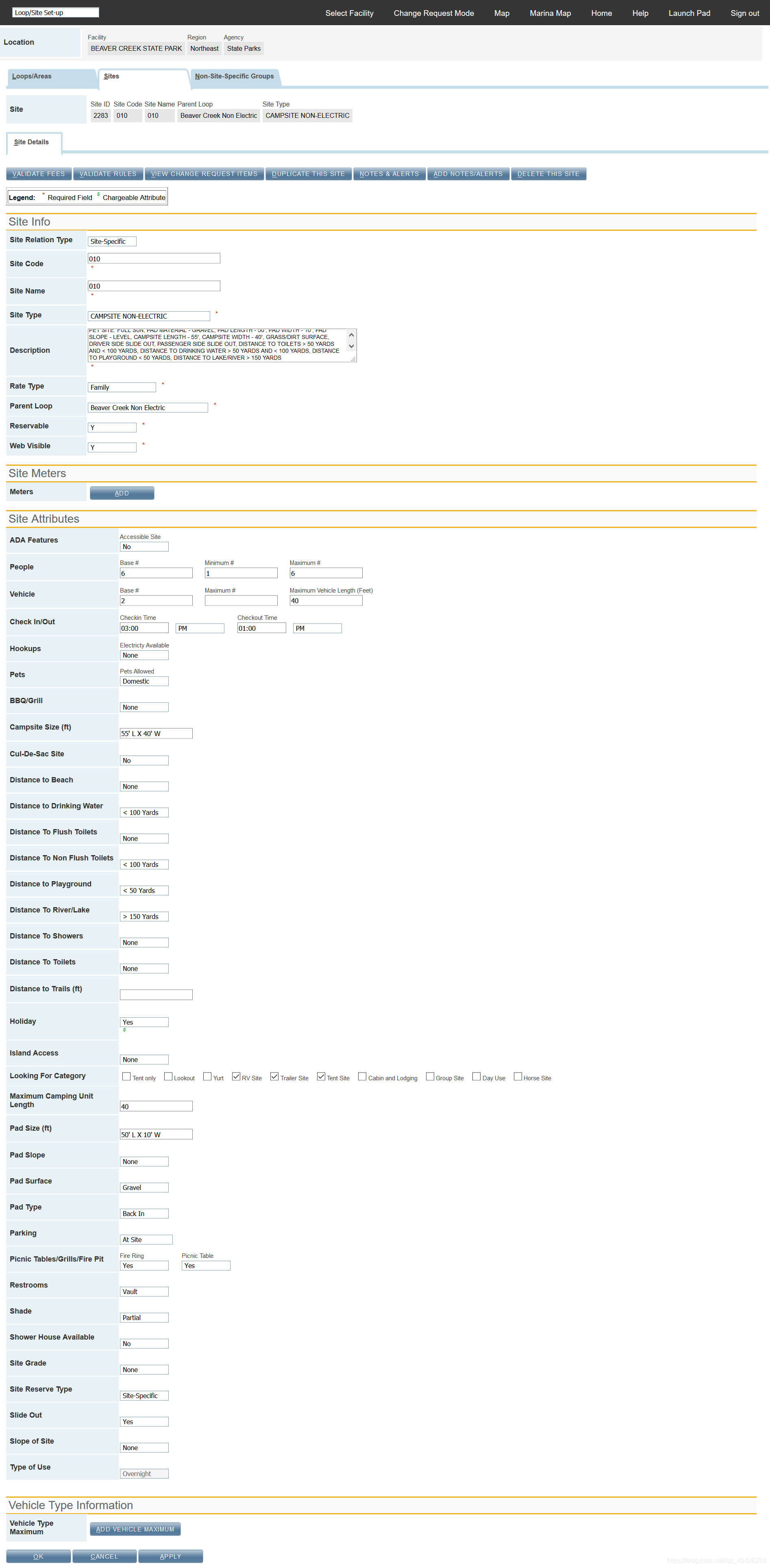
这是一个用于更新园区信息的数据管理系统,本页面截图主要用于更新站点信息。幸运的是,这个页面的每个元素都可以通过 ID 来定位。它收录三种形式的信息:文本框、下拉列表和复选按钮。我的实现思路是将id对应的定位信息放在excel表中,通过抓取excel表中提供的定位信息和需要更新的对应值来更新数据。
这里分别封装了文本框信息输入、下拉列表选择和勾选按钮勾选,然后将相应的方法统一到update方法中来实现。这消除了对每个字段进行单独处理的需要。
包装代码:
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import traceback
import time
class BasePage:
def __init__(self, driver):
self.driver = driver
# 对查找单个页面元素进行封装。
def find_element(self, by, locator):
by = by.lower()
element = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
element = self.driver.find_element_by_id(locator)
elif by == 'name':
element = self.driver.find_element_by_name(locator)
elif by == 'xpath':
element = self.driver.find_element_by_xpath(locator)
elif by == 'class':
element = self.driver.find_element_by_class_name(locator)
elif by == 'tag':
element = self.driver.find_element_by_tag_name(locator)
elif by == 'link':
element = self.driver.find_element_by_link_text(locator)
elif by == 'plink':
element = self.driver.find_element_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return element
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 对查找多个页面元素进行封装。
def find_elements(self, by, locator):
by = by.lower()
elements = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
elements = self.driver.find_elements_by_id(locator)
elif by == 'name':
elements = self.driver.find_elements_by_name(locator)
elif by == 'xpath':
elements = self.driver.find_elements_by_xpath(locator)
elif by == 'class':
elements = self.driver.find_elements_by_class_name(locator)
elif by == 'tag':
elements = self.driver.find_elements_by_tag_name(locator)
elif by == 'link':
elements = self.driver.find_elements_by_link_text(locator)
elif by == 'plink':
elements = self.driver.find_elements_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return elements
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 点击页面元素
def click(self, by, locator):
element = self.find_element(by, locator)
element.click()
# 输入框输入新信息
def type(self, by, locator, value):
y = [x for x in value if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element.clear()
element.send_keys(value.strip())
else:
pass
# 下拉菜单通过可见文本进行选择
def select(self, by, locator, text):
y = [x for x in text if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element_element = Select(element)
element_element.select_by_visible_text(text.strip())
else:
pass
# 复选按钮勾选时我们需要首先勾掉已选选项
def uncheck(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
elements = self.find_elements(by, locator)
for element in elements:
element.click()
else:
pass
# 选择excel表格所提供的选项进行勾选
def check(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
be_options = options.split(',')
for option in be_options:
element = self.find_element(by, locator.format(option.strip()))
element.click()
else:
pass
# def input(self, left_title, excel_title, by, locator, values):
# y = [x for x in values if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.type(by, locator, values)
# else:
# pass
# 根据excel表格提供标题所包含的关键字来决定进行哪种数据操作
def update(self, title, by, values):
y = [x for x in values if x != '']
if len(y) > 0:
if '_Text' in title: # 文本框
field = title.strip().split('_')
locator = field[0]
self.type(by, locator, values)
elif '_Select' in title: # 下拉列表
field = title.strip().split('_')
locator = field[0]
self.select(by, locator, values)
elif '_Option' in title: # 复选按钮
field = title.strip().split('_')
locator = field[0]
self.uncheck('xpath', '//input[@checked="" and contains(@id, "{}__")]'.format(locator), values)
self.check('id', '%s__{}'%locator, values)
else:
print('Please indicate the data type for the title "{}" in Excel!!!'.format(title))
else:
pass
# def set(self, left_title, excel_title, by, locator, text):
# y = [x for x in text if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.select(by, locator, text)
# else:
# pass
# 登录系统进行封装方便以后重用
def login_orms(self, url, username, password):
# driver = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
self.driver.delete_all_cookies()
self.driver.get(url)
self.driver.maximize_window()
time.sleep(2)
self.type('id', 'userName', username)
self.type('id', 'password', password)
self.click('id', 'okBtnAnchor')
time.sleep(2)
# 登录系统后选择Contract
def goto_manager_page(self, url, username, password, contract, page):
self.login_orms(url, username, password)
time.sleep(2)
self.click('xpath', "//option[text()='" + contract + " Contract']") # 通过click也可以对下拉列表进行选择
time.sleep(2)
self.click('link', page)
time.sleep(2)
下面是实现代码(没有对操作excel表的封装)
from Orms.BasePage import *
import xlrd
""""""
url = 'reserveamerica.com/xxxx'
account_user = 'xxx'
account_password = 'xxx'
wb = xlrd.open_workbook('D://SiteandLoopSetUp.xls')
""""""
sheet1 = wb.sheet_by_index(0)
sheet2 = wb.sheet_by_index(1)
# read provided information in Excel.
contract = sheet1.col_values(0)[1].strip()
park_name = sheet1.col_values(1)[1].strip()
search_ids = sheet1.col_values(2)[1:]
check_in_times = sheet1.col_values(3)[1:]
check_out_times = sheet1.col_values(4)[1:]
cols_num = sheet1.ncols
print('There will be "{}" fields need to update as following:'.format(cols_num))
left_titles = sheet1.row_values(0)[5:cols_num]
print(left_titles)
browser = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
driver = BasePage(browser)
driver.goto_manager_page(url=url, username=account_user, password=account_password, contract=contract, page='Inventory Manager')
# Input park name and search
driver.type('id', 'FacilitySearchCriteria.facilityName', park_name)
driver.click('xpath', '//a[@aria-label="Search"]')
time.sleep(3)
# Click facility id in search results to facility details page
driver.click('xpath', '//tr[@name="e_Glow"]/td/a')
time.sleep(2)
# Choose Loop/Site Set-up for Facility Details drop-down list
driver.select('id', 'page_name', 'Loop/Site Set-up')
time.sleep(2)
driver.click('xpath', '//a[@tabindex="-1" and @accesskey="S"]')
time.sleep(2)
for x in range(len(search_ids)):
try:
driver.select('id', 'search_type', 'Site ID')
time.sleep(2)
driver.type('id', 'search_value', search_ids[x])
driver.click('id', 'goAnchor')
time.sleep(2)
driver.click('xpath', '//tr[@name="e_Glow"]/td[2]/a')
time.sleep(2)
# in_time and out_time are required fields, need to handle separately.
in_time = check_in_times[x].strip().split(' ')
y = [x for x in in_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkin Time', in_time[0])
driver.select('id', 'Checkin Time_ispm', in_time[1])
else:
pass
out_time = check_out_times[x].strip().split(' ')
y = [x for x in out_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkout Time', out_time[0])
driver.select('id', 'Checkout Time_ispm', out_time[1])
else:
pass
# update left information in excel.
for i in range(len(left_titles)):
title = left_titles[i]
excel_values = sheet1.col_values(5+i)[1:]
driver.update(title, 'id', excel_values[x])
except Exception as e:
raise Exception
else:
driver.click('xpath', '//a[@aria-label="OK"]')
以上是我模拟手动操作自动填写页面表单的方法。虽然每次做的时候都需要找到需要更新信息的页面元素ID的值,复制到excel中,但是对于几十种合同和几十种形式的网站类型,还有上千个字段需要单独处理的,就简单多了。
当然,肯定有一些不完善的地方,比如强制等待而不是隐形等待。必须有更好的方法来实现这一目标。请指正~~~
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-02 21:29
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不会再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
} 查看全部
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不会再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
}
网页表格抓取(totowiththisthis.宽恕,今天才开始使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-30 22:29
请原谅,今天才开始用beautifulSoup来解决这个问题。
我设法通过拖入网站上的 URL 使其工作,该网站上的每个产品页面都有一个如下所示的表格: URL 使其工作。此网站 上的每个产品页面都有一个类似于下表的表格:
YYF Shutter Stats:
Diameter:
56 mm / 2.20 inches
Width:
44.40 mm / 1.74 inches
Gap Width:
4.75 mm / .18 inches
Weight:
67.8 grams
Bearing Size:
Size C (.250 x .500 x .187)
CBC SPEC Bearing
Response:
CBC Silicone Slim Pad (19mm)
我正在尝试将该表提取为我可以在 web 应用程序中使用的某种形式的数据。
我将如何从每个网页中提取此内容,该网站有大约 400 个收录此表格的产品页面,我最好从页面中获取每个表格并将其放入数据库条目或文本文件中与产品名称。我将如何从每个网页中提取内容,大约有400个产品页面收录此表,我最好从页面中获取每个表并将其放入 名称是数据库的条目或文本文件中的产品
如您所见,该表格的格式并不准确,但它是页面上唯一标有 p>
的表格
class="product-feature-table"
我刚刚尝试编辑一个 URL 抓取脚本,但我开始觉得我正在尝试这样做是错误的。就我尝试这样做而言,一切都是错误的。
我的url脚本如下: 我的url脚本如下:
import urllib2
from bs4 import BeautifulSoup
url = raw_input('Web-Address: ')
html = urllib2.urlopen('http://' +url).read()
soup = BeautifulSoup(html)
soup.prettify()
for anchor in soup.findAll('a', href=True):
print anchor['href']
我可以将所有这些 URL 放入一个文本文件中,但更喜欢使用 Sqlite 或 Postgresql,是否有任何在线文章可以帮助我更好地理解这些概念,而不会淹没新手? URL 都输入到一个文本文件中,但我更喜欢使用 Sqlite 或 Postgresql。有没有在线文章 可以帮助我更好地理解这些概念而不会让新手感到不知所措? 查看全部
网页表格抓取(totowiththisthis.宽恕,今天才开始使用)
请原谅,今天才开始用beautifulSoup来解决这个问题。
我设法通过拖入网站上的 URL 使其工作,该网站上的每个产品页面都有一个如下所示的表格: URL 使其工作。此网站 上的每个产品页面都有一个类似于下表的表格:
YYF Shutter Stats:
Diameter:
56 mm / 2.20 inches
Width:
44.40 mm / 1.74 inches
Gap Width:
4.75 mm / .18 inches
Weight:
67.8 grams
Bearing Size:
Size C (.250 x .500 x .187)
CBC SPEC Bearing
Response:
CBC Silicone Slim Pad (19mm)
我正在尝试将该表提取为我可以在 web 应用程序中使用的某种形式的数据。
我将如何从每个网页中提取此内容,该网站有大约 400 个收录此表格的产品页面,我最好从页面中获取每个表格并将其放入数据库条目或文本文件中与产品名称。我将如何从每个网页中提取内容,大约有400个产品页面收录此表,我最好从页面中获取每个表并将其放入 名称是数据库的条目或文本文件中的产品
如您所见,该表格的格式并不准确,但它是页面上唯一标有 p>
的表格
class="product-feature-table"
我刚刚尝试编辑一个 URL 抓取脚本,但我开始觉得我正在尝试这样做是错误的。就我尝试这样做而言,一切都是错误的。
我的url脚本如下: 我的url脚本如下:
import urllib2
from bs4 import BeautifulSoup
url = raw_input('Web-Address: ')
html = urllib2.urlopen('http://' +url).read()
soup = BeautifulSoup(html)
soup.prettify()
for anchor in soup.findAll('a', href=True):
print anchor['href']
我可以将所有这些 URL 放入一个文本文件中,但更喜欢使用 Sqlite 或 Postgresql,是否有任何在线文章可以帮助我更好地理解这些概念,而不会淹没新手? URL 都输入到一个文本文件中,但我更喜欢使用 Sqlite 或 Postgresql。有没有在线文章 可以帮助我更好地理解这些概念而不会让新手感到不知所措?
网页表格抓取(和数据挖掘项目的表格中提取文本和数字数据介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 22:23
作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。和数字数据。
要处理的 PDF 文档数量超过 80,000 个,每个文档可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。我已经成功地使用 PDFMiner 来处理页面并从中采集最相关的数据,但是,在尝试不同的技术数周后,我未能从表格中获取完美的数据。相关数据,但是在尝试了几个星期不同的技术后,我未能从表中得到完美的数据。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐在单词之间添加空格),一些单元格有很多行,整个表格的行距不同,还有多列单元格。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐会在单词之间增加空格),一些单元格有很多行,整个表格的行距不一样,并且有多个单元格列。
对普通页面产生最佳性能的字符边距、行边距和字边距参数在应用于表格处理时会产生混乱的结果。当应用于表处理时,参数可能会产生令人困惑的结果。幸运的是,3/4 的表格具有垂直和水平线,可用于将其区域划分为单元格并找到每个单元格的坐标。幸运的是,3/4 的表格都有垂直和水平线,可以用来划分它们的区域为单元格并找到每个单元格的坐标。但是pdfminer.pdfinterp.PDFPageInterpreter和pdfminer.converter.PDFPageAggregator带来的LTText实例往往不尊重每个单元格的边界。细胞边界。
我花了很多天尝试不同的技术,包括对 laparams 和字符串解释和拆分的更改,以获取和使用整个页面处理生成的 LTText 实例。并通过字符串解释和拆分更改获取并使用整个页面处理生成的 LTText 实例。真正有用的东西会用 interpreter.process_cell(page, xmin, ymin, xmax, ymax) xmax, ymax) 替换 interpreter.process_page(page)
我相信如果有一些方法使用 PDFMiner 函数和方法来获取收录在单元格边界内的对象,使用保守的 laparameters 来避免混乱的结果,我相信可能存在解决方案。我相信如果有一些方法使用PDFMiner函数和方法来获取单元格边界内收录的对象,使用保守的laparameters来避免混淆结果,我相信可能会有解决方案。理想的方法应该足够快,因为它必须多次应用。在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域中提取文本?在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域提取文本? ,这是相似的,但没有回答。
我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,它们使用了其他库和技术。我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,这使用了其他库和技术。我不想混合不同的库和它们的对象来解决这个问题,因为 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。有没有人有建议?有人有建议吗? 查看全部
网页表格抓取(和数据挖掘项目的表格中提取文本和数字数据介绍)
作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。和数字数据。
要处理的 PDF 文档数量超过 80,000 个,每个文档可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。我已经成功地使用 PDFMiner 来处理页面并从中采集最相关的数据,但是,在尝试不同的技术数周后,我未能从表格中获取完美的数据。相关数据,但是在尝试了几个星期不同的技术后,我未能从表中得到完美的数据。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐在单词之间添加空格),一些单元格有很多行,整个表格的行距不同,还有多列单元格。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐会在单词之间增加空格),一些单元格有很多行,整个表格的行距不一样,并且有多个单元格列。
对普通页面产生最佳性能的字符边距、行边距和字边距参数在应用于表格处理时会产生混乱的结果。当应用于表处理时,参数可能会产生令人困惑的结果。幸运的是,3/4 的表格具有垂直和水平线,可用于将其区域划分为单元格并找到每个单元格的坐标。幸运的是,3/4 的表格都有垂直和水平线,可以用来划分它们的区域为单元格并找到每个单元格的坐标。但是pdfminer.pdfinterp.PDFPageInterpreter和pdfminer.converter.PDFPageAggregator带来的LTText实例往往不尊重每个单元格的边界。细胞边界。
我花了很多天尝试不同的技术,包括对 laparams 和字符串解释和拆分的更改,以获取和使用整个页面处理生成的 LTText 实例。并通过字符串解释和拆分更改获取并使用整个页面处理生成的 LTText 实例。真正有用的东西会用 interpreter.process_cell(page, xmin, ymin, xmax, ymax) xmax, ymax) 替换 interpreter.process_page(page)
我相信如果有一些方法使用 PDFMiner 函数和方法来获取收录在单元格边界内的对象,使用保守的 laparameters 来避免混乱的结果,我相信可能存在解决方案。我相信如果有一些方法使用PDFMiner函数和方法来获取单元格边界内收录的对象,使用保守的laparameters来避免混淆结果,我相信可能会有解决方案。理想的方法应该足够快,因为它必须多次应用。在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域中提取文本?在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域提取文本? ,这是相似的,但没有回答。
我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,它们使用了其他库和技术。我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,这使用了其他库和技术。我不想混合不同的库和它们的对象来解决这个问题,因为 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。有没有人有建议?有人有建议吗?
网页表格抓取(用Perl网页和提交表格这里简单的模块介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-30 22:21
本文文章主要介绍如何使用Perl抓取网页和提交表单。有一定的参考价值。有兴趣的朋友可以参考一下。希望大家看完这篇文章收获,带你一探究竟。
使用 Perl 抓取网页并提交表单
这里简单介绍一下使用Perl捕获网页源代码,以及使用POST方法提交表单并返回结果。我不能说难的,只说简单的。
这里提到的 Perl 模块是:
useLWP::Simple;useLWP::UserAgent;使用 Perldoc 查看详细用法。
1、使用Perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my$url='http://freshair.npr.org/dayFA. ... 39%3B useLWP::Simple; my$content=get$url; die"Couldn'tget$url"unlessdefined$content;
#$content 是网页的内容,这里是对这个内容的一些分析:
if($content=~m/jazz/i){ print"They'retalkingaboutjazztodayonFreshAir!\n"; }else{ print"FreshAirisapparentlyjazzlesstoday.\n"; }
非常简单易懂。获取一个网页的内容很容易,但难的是有规律地过滤出需要的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTMLPOST 向服务器提交数据,您可以在这里这样做:
$response=$browser->post($url, [ formkey1=>value1, formkey2=>value2, ... ], );
案例分析:比如提交一个序列并返回结果,使用Perl来实现。代码如下:
#!/usr/bin/Perl useLWP::UserAgent; my$browser=LWP::UserAgent->new; $protein="MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI"; my$SUSUI_URL="http://www.enzim.hu/hmmtop/ser ... 3B%3B my$response=$browser->post($SUSUI_URL,['if'=>$protein,]); if($response->is_success){ print$response->content; }else{ print"Badluckthistime\n"; }
通过分析页面,我们可以看到只有一个input需要提交,就是name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
感谢您仔细阅读这篇文章,也希望文章编者分享的《如何使用Perl抓取网页和提交表单》对大家有所帮助,也希望大家全部支持易速云,关注易速云行业资讯频道,更多相关知识等你学习! 查看全部
网页表格抓取(用Perl网页和提交表格这里简单的模块介绍)
本文文章主要介绍如何使用Perl抓取网页和提交表单。有一定的参考价值。有兴趣的朋友可以参考一下。希望大家看完这篇文章收获,带你一探究竟。
使用 Perl 抓取网页并提交表单
这里简单介绍一下使用Perl捕获网页源代码,以及使用POST方法提交表单并返回结果。我不能说难的,只说简单的。
这里提到的 Perl 模块是:
useLWP::Simple;useLWP::UserAgent;使用 Perldoc 查看详细用法。
1、使用Perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my$url='http://freshair.npr.org/dayFA. ... 39%3B useLWP::Simple; my$content=get$url; die"Couldn'tget$url"unlessdefined$content;
#$content 是网页的内容,这里是对这个内容的一些分析:
if($content=~m/jazz/i){ print"They'retalkingaboutjazztodayonFreshAir!\n"; }else{ print"FreshAirisapparentlyjazzlesstoday.\n"; }
非常简单易懂。获取一个网页的内容很容易,但难的是有规律地过滤出需要的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTMLPOST 向服务器提交数据,您可以在这里这样做:
$response=$browser->post($url, [ formkey1=>value1, formkey2=>value2, ... ], );
案例分析:比如提交一个序列并返回结果,使用Perl来实现。代码如下:
#!/usr/bin/Perl useLWP::UserAgent; my$browser=LWP::UserAgent->new; $protein="MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI"; my$SUSUI_URL="http://www.enzim.hu/hmmtop/ser ... 3B%3B my$response=$browser->post($SUSUI_URL,['if'=>$protein,]); if($response->is_success){ print$response->content; }else{ print"Badluckthistime\n"; }
通过分析页面,我们可以看到只有一个input需要提交,就是name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
感谢您仔细阅读这篇文章,也希望文章编者分享的《如何使用Perl抓取网页和提交表单》对大家有所帮助,也希望大家全部支持易速云,关注易速云行业资讯频道,更多相关知识等你学习!
网页表格抓取(利用pandas库中的read_html方法快速抓取网页中常见的表格型数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-27 19:00
使用pandas库中的read_html方法快速抓取网页中常见的表格数据
表格形式
我们在网上经常会看到这样的表格,比如:
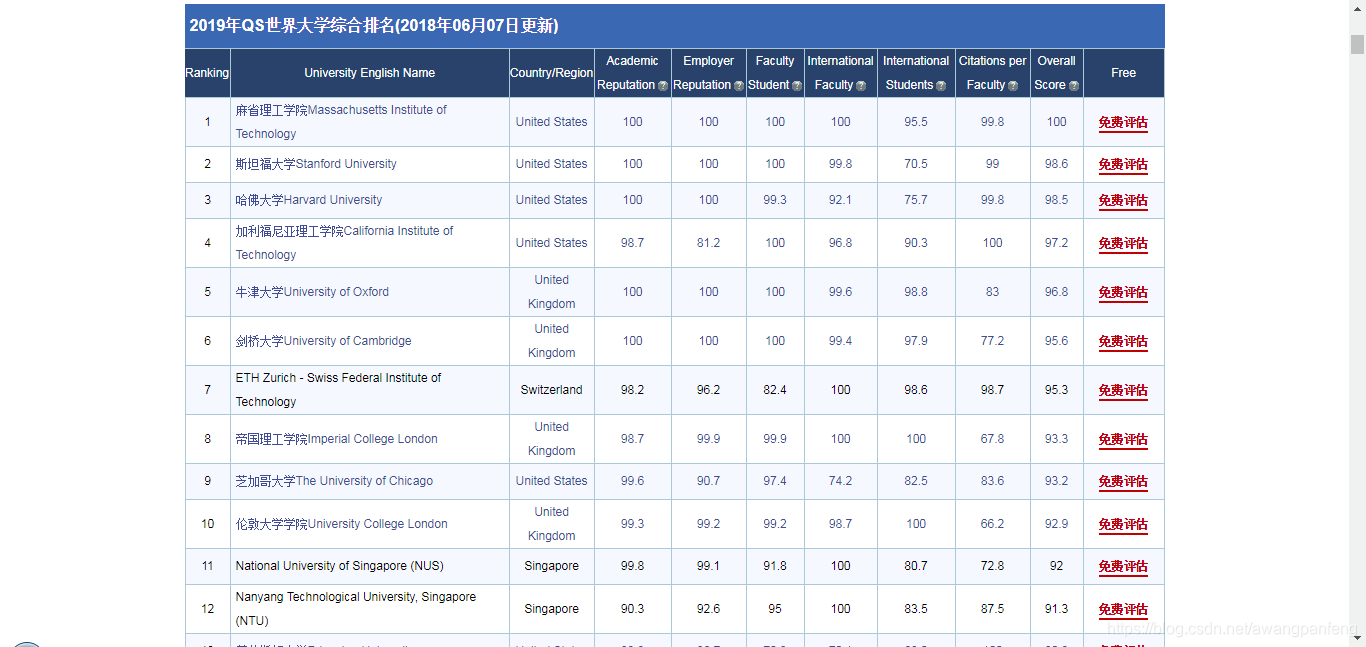
QS2018世界大学排名:
可以看出表格类型的表格页结构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
...
...
...
...
...
...
...
...
...
...
...
首先简单解释一下上面出现的几个标签的含义:
1
2
3
4
5
6
: 定义表格
: 定义表格的页眉
: 定义表格的主体
: 定义表格的行
: 定义表格的表头
: 定义表格单元
使用 pandas 模块中的 read_html 函数可以轻松快速地捕获此类表格数据。下面就来做吧。
我们以中国上市公司信息页面上的表格为例,感受一下read_html函数的威力。
1
2
3
4
5
6
7
8
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
之前买房的时候爬上实时登记情况~ 查看全部
网页表格抓取(利用pandas库中的read_html方法快速抓取网页中常见的表格型数据)
使用pandas库中的read_html方法快速抓取网页中常见的表格数据
表格形式
我们在网上经常会看到这样的表格,比如:
QS2018世界大学排名:
可以看出表格类型的表格页结构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
...
...
...
...
...
...
...
...
...
...
...
首先简单解释一下上面出现的几个标签的含义:
1
2
3
4
5
6
: 定义表格
: 定义表格的页眉
: 定义表格的主体
: 定义表格的行
: 定义表格的表头
: 定义表格单元
使用 pandas 模块中的 read_html 函数可以轻松快速地捕获此类表格数据。下面就来做吧。
我们以中国上市公司信息页面上的表格为例,感受一下read_html函数的威力。
1
2
3
4
5
6
7
8
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
之前买房的时候爬上实时登记情况~
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-26 22:10
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,就可以得到从PDF分析表中得到的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~ 查看全部
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:

作者测试的PDF收录以下表格:

我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:

选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:

然后点击“查看和下载数据”按钮,就可以得到从PDF分析表中得到的数据。截图如下:

如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~
网页表格抓取(网页表格数据采集助手的使用方法及使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2021-11-24 20:08
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,并且您可以指定采集 所需字段的内容。
相关软件软件大小版本说明下载地址
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,此外,您可以指定采集 所需字段的内容。采集后的内容既可以保存为EXCEL软件可以读取的文件格式,也可以保存为保留原格式的纯文本格式,绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,则软件URL列表
这个地址会自动添加,你只需要下拉选择它,它就会打开。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。
页面收录的表格数量和页眉信息显示在软件左上角的列表框中。
3、从表号列表中选择要抓取的表,在软件表左上角第一个框中会显示该表左上角的第一个文本
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果网页表单中有带有链接的字段,您可以选择是否
包括链接地址。如果你有并且想要采集它的链接地址,那么你不能同时选择收录标题行。
6、如果你想让采集只有一个网页的表格数据,那么你可以点击抓取表格直接抓取,如果之前没有选择收录表格
网格、表格数据会以CVS格式保存,这种格式可以直接用微软EXCEL软件打开转换成EXCEL表格,如果之前选择收录表格
网格线和表格数据会以TXT格式保存,可以用记事本软件打开查看,表格线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后
继续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您查看页面并找到它。
只要输入它。如果网页没有下一页的链接,但是URL中收录了页数,那么您也可以根据URL中的页数选择打开,您可以
要从前到后选择,例如从第 1 页到第 10 页,或从后到前,例如从第 10 页到第 1 页,请在页码输入框中输入,但此时
URL中代表页数的位置应该用“(*)”代替,否则程序将无法识别。
8、 然后选择定时采集 或者等待网页打开加载采集后立即加载,定时采集是程序设置的一个很小的时间间隔
判断打开的页面中是否有你想要的表单,采集如果有,采集页面加载后,只要采集的页面已经打开,
程序会立即进行采集,两者各有特点,视需要选择。
9、最后,你只需要点击抢表按钮,你就可以泡杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的一
一些信息后,直接点击抓取表格,无需经过爬取测试等操作。 查看全部
网页表格抓取(网页表格数据采集助手的使用方法及使用方法介绍)
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,并且您可以指定采集 所需字段的内容。
相关软件软件大小版本说明下载地址
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,此外,您可以指定采集 所需字段的内容。采集后的内容既可以保存为EXCEL软件可以读取的文件格式,也可以保存为保留原格式的纯文本格式,绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。

指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,则软件URL列表
这个地址会自动添加,你只需要下拉选择它,它就会打开。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。
页面收录的表格数量和页眉信息显示在软件左上角的列表框中。
3、从表号列表中选择要抓取的表,在软件表左上角第一个框中会显示该表左上角的第一个文本
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果网页表单中有带有链接的字段,您可以选择是否
包括链接地址。如果你有并且想要采集它的链接地址,那么你不能同时选择收录标题行。
6、如果你想让采集只有一个网页的表格数据,那么你可以点击抓取表格直接抓取,如果之前没有选择收录表格
网格、表格数据会以CVS格式保存,这种格式可以直接用微软EXCEL软件打开转换成EXCEL表格,如果之前选择收录表格
网格线和表格数据会以TXT格式保存,可以用记事本软件打开查看,表格线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后
继续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您查看页面并找到它。
只要输入它。如果网页没有下一页的链接,但是URL中收录了页数,那么您也可以根据URL中的页数选择打开,您可以
要从前到后选择,例如从第 1 页到第 10 页,或从后到前,例如从第 10 页到第 1 页,请在页码输入框中输入,但此时
URL中代表页数的位置应该用“(*)”代替,否则程序将无法识别。
8、 然后选择定时采集 或者等待网页打开加载采集后立即加载,定时采集是程序设置的一个很小的时间间隔
判断打开的页面中是否有你想要的表单,采集如果有,采集页面加载后,只要采集的页面已经打开,
程序会立即进行采集,两者各有特点,视需要选择。
9、最后,你只需要点击抢表按钮,你就可以泡杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的一
一些信息后,直接点击抓取表格,无需经过爬取测试等操作。
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-24 08:12
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
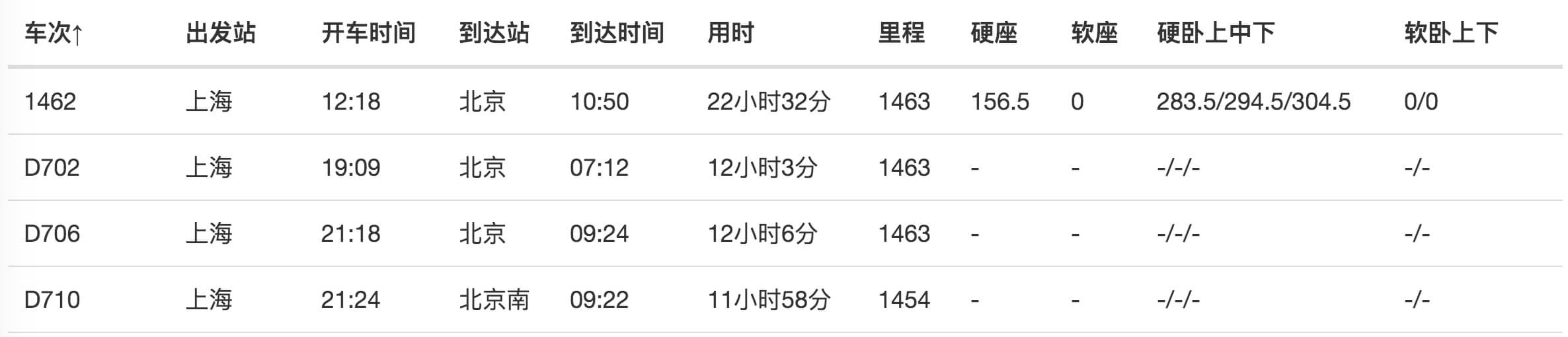
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
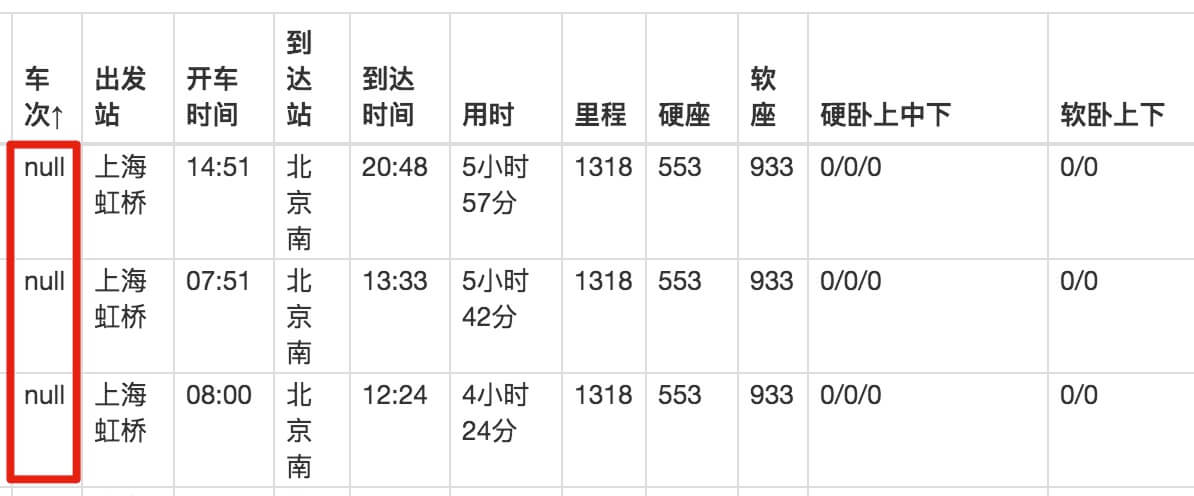
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-23 04:17
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/119 ... 39%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/119 ... 39%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取( Google通过提交表入党积极分子考察与毫米对照表教师职称级别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-19 06:13
Google通过提交表入党积极分子考察与毫米对照表教师职称级别)
谷歌通过提交入党人数调查条目数和毫米对照表、教师职称等级表、员工考核评分表、普通年金现值系数表、普通年金现值系数表爬取新页面,爬取新页面. 虽然谷歌已经是抓取页面最多的搜索引擎,但它仍然不满足,因为有很多网页和信息很难找到和抓取。这就是为什么你在做网站的时候一定要注意搜索引擎的友好性。现在谷歌已经开始提供提交表单了。我发现下面的网页我想写一个详细的说明。看到幻灭写完了,下面直接引述主要内容。我们已经知道,除了文字,视频、音频、Flash 等类型的内容,Googlebot 还可以通过 JS 代码抓取链接。未来,Googlebot 也有望直接识别图片和视频。为了进一步抓取互联网的内容,谷歌宣布Googlebot已经可以通过提交表单来抓取更多的内容。据 Google 称,Googlebot 目前正在试验少量高质量的 网站 表单提交。当Googlebot发现这些网站上有HTML表单时,当检测到时,它会自动从网站中选择一些词进入表单的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表单。提交表单 稍后,一旦 Googlebot 认为出现的新内容是合法的、有趣的和独特的,
<p>在引文数据库中,这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。同时,谷歌还强调,如果网站的robotstxt文件中禁止使用该表单,您不希望该表单后生成的链接被抓取。那么 Googlebot 将不会抓取。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要输入用户个人信息,如密码、用户名、联系人等时,Googlebot 会自动跳过这些表单。这种表单爬取目前只是一个小表单。测试范围谷歌表示不会影响网站,也不会影响网站的PR值,也不会影响网站的正常爬取排名。MattCutts 还写了一篇文章说明了这样做的好处。< @网站首页只是以表格的形式列出了公司下属的站,并没有以链接的形式列出各个站。这种类型的网站之前无法深入。网站 @收录因为Google在不提交表单的情况下无法找到隐藏在表单后面的URL存在一定的安全风险。网站如果某部分不想成为 查看全部
网页表格抓取(
Google通过提交表入党积极分子考察与毫米对照表教师职称级别)

谷歌通过提交入党人数调查条目数和毫米对照表、教师职称等级表、员工考核评分表、普通年金现值系数表、普通年金现值系数表爬取新页面,爬取新页面. 虽然谷歌已经是抓取页面最多的搜索引擎,但它仍然不满足,因为有很多网页和信息很难找到和抓取。这就是为什么你在做网站的时候一定要注意搜索引擎的友好性。现在谷歌已经开始提供提交表单了。我发现下面的网页我想写一个详细的说明。看到幻灭写完了,下面直接引述主要内容。我们已经知道,除了文字,视频、音频、Flash 等类型的内容,Googlebot 还可以通过 JS 代码抓取链接。未来,Googlebot 也有望直接识别图片和视频。为了进一步抓取互联网的内容,谷歌宣布Googlebot已经可以通过提交表单来抓取更多的内容。据 Google 称,Googlebot 目前正在试验少量高质量的 网站 表单提交。当Googlebot发现这些网站上有HTML表单时,当检测到时,它会自动从网站中选择一些词进入表单的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表单。提交表单 稍后,一旦 Googlebot 认为出现的新内容是合法的、有趣的和独特的,

<p>在引文数据库中,这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。同时,谷歌还强调,如果网站的robotstxt文件中禁止使用该表单,您不希望该表单后生成的链接被抓取。那么 Googlebot 将不会抓取。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要输入用户个人信息,如密码、用户名、联系人等时,Googlebot 会自动跳过这些表单。这种表单爬取目前只是一个小表单。测试范围谷歌表示不会影响网站,也不会影响网站的PR值,也不会影响网站的正常爬取排名。MattCutts 还写了一篇文章说明了这样做的好处。< @网站首页只是以表格的形式列出了公司下属的站,并没有以链接的形式列出各个站。这种类型的网站之前无法深入。网站 @收录因为Google在不提交表单的情况下无法找到隐藏在表单后面的URL存在一定的安全风险。网站如果某部分不想成为
网页表格抓取(Python将表格转换为CSV文件?你是否曾经想从网页中自动提取Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-11-19 04:04
使用requests和beautiful Soup提取HTML表格,然后将其保存为CSV文件或任何其他格式的Python。
Python 将 HTML 表格转换为 CSV 文件?您是否曾经想从网页中自动提取 HTML 表格并将它们以适当的格式保存在您的计算机上?如果是这种情况,那么您来对地方了。在本教程中,我们将使用 requests 和 BeautifulSoup 库来转换任何网页中的任何表格并将其保存在我们的磁盘上。
Python 如何将 HTML 表格转换为 CSV?我们还将使用 Pandas 轻松转换为 CSV 格式(或 Pandas 支持的任何格式)。如果您还没有安装 requests、BeautifulSoup 和 pandas,请使用以下命令安装它们:
pip3 install requests bs4 pandas
Python 将HTML 表格转为CSV 示例介绍——打开一个新的Python 文件并继续,让我们导入库:
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
我们需要一个函数来接受目标 URL 并为我们提供正确的汤对象:
USER_AGENT = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"
def get_soup(url):
"""Constructs and returns a soup using the HTML content of `url` passed"""
# initialize a session
session = requests.Session()
# set the User-Agent as a regular browser
session.headers['User-Agent'] = USER_AGENT
# request for english content (optional)
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
# make the request
html = session.get(url)
# return the soup
return bs(html.content, "html.parser")
Python 如何将 HTML 表格转换为 CSV?我们首先初始化了一个请求会话,我们使用 User-Agent 头来表明我们只是一个普通浏览器而不是机器人(一些网站 阻止了他们),然后我们使用 session.get() 方法来获取 HTML 内容。之后,我们使用 html.parser 来构造一个 BeautifulSoup 对象。
相关教程:如何在 Python 中制作电子邮件提取器。
Python 将 HTML 表格转换为 CSV 文件?由于我们要提取任何页面中的每个表格,因此我们需要找到表格 HTML 标记并将其返回。以下函数正是这样做的:
def get_all_tables(soup):
"""Extracts and returns all tables in a soup object"""
return soup.find_all("table")
现在我们需要一种方法来获取标题、列名或任何您想称呼它们的内容:
def get_table_headers(table):
"""Given a table soup, returns all the headers"""
headers = []
for th in table.find("tr").find_all("th"):
headers.append(th.text.strip())
return headers
上述函数查找表的第一行并提取所有第 th 个标签(标题)。
现在我们知道如何提取表头,剩下的就是提取所有表行:
def get_table_rows(table):
"""Given a table, returns all its rows"""
rows = []
for tr in table.find_all("tr")[1:]:
cells = []
# grab all td tags in this table row
tds = tr.find_all("td")
if len(tds) == 0:
# if no td tags, search for th tags
# can be found especially in wikipedia tables below the table
ths = tr.find_all("th")
for th in ths:
cells.append(th.text.strip())
else:
# use regular td tags
for td in tds:
cells.append(td.text.strip())
rows.append(cells)
return rows
上面的所有函数都是这样做的,即找到tr标签(表行)并提取td元素,然后将它们附加到列表中。我们之所以使用table.find_all("tr")[1:]而不是所有的tr标签,是因为第一个tr标签对应的是表头,我们不想在这里添加。
Python 将 HTML 表格转换为 CSV 文件?以下函数获取表名、标题和所有行,并将它们保存为 CSV 格式:
def save_as_csv(table_name, headers, rows):
pd.DataFrame(rows, columns=headers).to_csv(f"{table_name}.csv")
现在我们有了所有的核心函数,让我们把它们放在一个主函数中:
def main(url):
# get the soup
soup = get_soup(url)
# extract all the tables from the web page
tables = get_all_tables(soup)
print(f"[+] Found a total of {len(tables)} tables.")
# iterate over all tables
for i, table in enumerate(tables, start=1):
# get the table headers
headers = get_table_headers(table)
# get all the rows of the table
rows = get_table_rows(table)
# save table as csv file
table_name = f"table-{i}"
print(f"[+] Saving {table_name}")
save_as_csv(table_name, headers, rows)
Python 如何将 HTML 表格转换为 CSV?上述函数执行以下操作:
Python 将 HTML 表格转换为 CSV 的例子——最后,我们调用 main 函数:
if __name__ == "__main__":
import sys
try:
url = sys.argv[1]
except IndexError:
print("Please specify a URL.\nUsage: python html_table_extractor.py [URL]")
exit(1)
main(url)
这将接受来自命令行参数的 URL,让我们试试这是否有效:
C:\pythoncode-tutorials\web-scraping\html-table-extractor>python html_table_extractor.py https://en.wikipedia.org/wiki/ ... ation
[+] Found a total of 2 tables.
[+] Saving table-1
[+] Saving table-2
很好,我当前目录下出现了两个CSV文件,它们对应维基百科页面中的两个表,它们是提取表之一的一部分:
如何在 Python 中将 HTML 表格转换为 CSV
惊人!我们已经成功构建了一个 Python 脚本来从任何 网站 中提取任何表,尝试传递其他 URL 并查看它是否有效。
Python 将 HTML 表格转换为 CSV 文件?对于Javascript驱动的网站(使用Javascript动态加载网站数据),请尽量使用requests-html库或selenium。让我们看看你在下面的评论中做了什么!
您还可以制作一个从整个 网站 下载所有表单的网络爬虫,您可以通过提取所有 网站 链接并在从它们获得的每个 URL 上运行此脚本来实现此目的。
另外,如果你正在爬取的网站由于某种原因阻塞了你的IP地址,你需要使用一些代理服务器作为对策。 查看全部
网页表格抓取(Python将表格转换为CSV文件?你是否曾经想从网页中自动提取Python)
使用requests和beautiful Soup提取HTML表格,然后将其保存为CSV文件或任何其他格式的Python。
Python 将 HTML 表格转换为 CSV 文件?您是否曾经想从网页中自动提取 HTML 表格并将它们以适当的格式保存在您的计算机上?如果是这种情况,那么您来对地方了。在本教程中,我们将使用 requests 和 BeautifulSoup 库来转换任何网页中的任何表格并将其保存在我们的磁盘上。
Python 如何将 HTML 表格转换为 CSV?我们还将使用 Pandas 轻松转换为 CSV 格式(或 Pandas 支持的任何格式)。如果您还没有安装 requests、BeautifulSoup 和 pandas,请使用以下命令安装它们:
pip3 install requests bs4 pandas
Python 将HTML 表格转为CSV 示例介绍——打开一个新的Python 文件并继续,让我们导入库:
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
我们需要一个函数来接受目标 URL 并为我们提供正确的汤对象:
USER_AGENT = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"
def get_soup(url):
"""Constructs and returns a soup using the HTML content of `url` passed"""
# initialize a session
session = requests.Session()
# set the User-Agent as a regular browser
session.headers['User-Agent'] = USER_AGENT
# request for english content (optional)
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
# make the request
html = session.get(url)
# return the soup
return bs(html.content, "html.parser")
Python 如何将 HTML 表格转换为 CSV?我们首先初始化了一个请求会话,我们使用 User-Agent 头来表明我们只是一个普通浏览器而不是机器人(一些网站 阻止了他们),然后我们使用 session.get() 方法来获取 HTML 内容。之后,我们使用 html.parser 来构造一个 BeautifulSoup 对象。
相关教程:如何在 Python 中制作电子邮件提取器。
Python 将 HTML 表格转换为 CSV 文件?由于我们要提取任何页面中的每个表格,因此我们需要找到表格 HTML 标记并将其返回。以下函数正是这样做的:
def get_all_tables(soup):
"""Extracts and returns all tables in a soup object"""
return soup.find_all("table")
现在我们需要一种方法来获取标题、列名或任何您想称呼它们的内容:
def get_table_headers(table):
"""Given a table soup, returns all the headers"""
headers = []
for th in table.find("tr").find_all("th"):
headers.append(th.text.strip())
return headers
上述函数查找表的第一行并提取所有第 th 个标签(标题)。
现在我们知道如何提取表头,剩下的就是提取所有表行:
def get_table_rows(table):
"""Given a table, returns all its rows"""
rows = []
for tr in table.find_all("tr")[1:]:
cells = []
# grab all td tags in this table row
tds = tr.find_all("td")
if len(tds) == 0:
# if no td tags, search for th tags
# can be found especially in wikipedia tables below the table
ths = tr.find_all("th")
for th in ths:
cells.append(th.text.strip())
else:
# use regular td tags
for td in tds:
cells.append(td.text.strip())
rows.append(cells)
return rows
上面的所有函数都是这样做的,即找到tr标签(表行)并提取td元素,然后将它们附加到列表中。我们之所以使用table.find_all("tr")[1:]而不是所有的tr标签,是因为第一个tr标签对应的是表头,我们不想在这里添加。
Python 将 HTML 表格转换为 CSV 文件?以下函数获取表名、标题和所有行,并将它们保存为 CSV 格式:
def save_as_csv(table_name, headers, rows):
pd.DataFrame(rows, columns=headers).to_csv(f"{table_name}.csv")
现在我们有了所有的核心函数,让我们把它们放在一个主函数中:
def main(url):
# get the soup
soup = get_soup(url)
# extract all the tables from the web page
tables = get_all_tables(soup)
print(f"[+] Found a total of {len(tables)} tables.")
# iterate over all tables
for i, table in enumerate(tables, start=1):
# get the table headers
headers = get_table_headers(table)
# get all the rows of the table
rows = get_table_rows(table)
# save table as csv file
table_name = f"table-{i}"
print(f"[+] Saving {table_name}")
save_as_csv(table_name, headers, rows)
Python 如何将 HTML 表格转换为 CSV?上述函数执行以下操作:
Python 将 HTML 表格转换为 CSV 的例子——最后,我们调用 main 函数:
if __name__ == "__main__":
import sys
try:
url = sys.argv[1]
except IndexError:
print("Please specify a URL.\nUsage: python html_table_extractor.py [URL]")
exit(1)
main(url)
这将接受来自命令行参数的 URL,让我们试试这是否有效:
C:\pythoncode-tutorials\web-scraping\html-table-extractor>python html_table_extractor.py https://en.wikipedia.org/wiki/ ... ation
[+] Found a total of 2 tables.
[+] Saving table-1
[+] Saving table-2
很好,我当前目录下出现了两个CSV文件,它们对应维基百科页面中的两个表,它们是提取表之一的一部分:
 https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />
https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />如何在 Python 中将 HTML 表格转换为 CSV
惊人!我们已经成功构建了一个 Python 脚本来从任何 网站 中提取任何表,尝试传递其他 URL 并查看它是否有效。
Python 将 HTML 表格转换为 CSV 文件?对于Javascript驱动的网站(使用Javascript动态加载网站数据),请尽量使用requests-html库或selenium。让我们看看你在下面的评论中做了什么!
您还可以制作一个从整个 网站 下载所有表单的网络爬虫,您可以通过提取所有 网站 链接并在从它们获得的每个 URL 上运行此脚本来实现此目的。
另外,如果你正在爬取的网站由于某种原因阻塞了你的IP地址,你需要使用一些代理服务器作为对策。
网页表格抓取( 《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-18 12:05
《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
抓取网页生成Excel文件的方法的python实现
时间:2019-03-31
本文章给大家介绍了爬取网页生成Excel文件的Python实现。主要包括爬取网页生成Excel文件的Python实现。用例举例、应用技巧、基础知识点总结和注意事项有一定的参考价值,有需要的朋友可以参考。
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开csv文件,另存为Excel文件
对Python相关内容感兴趣的读者可以查看本站专题:《Python操作Excel表格技巧总结》、《Python文件及目录操作技巧总结》、《Python文本文件操作技巧总结》、 《Python数据结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》
我希望这篇文章能对你的 Python 编程有所帮助。 查看全部
网页表格抓取(
《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
抓取网页生成Excel文件的方法的python实现
时间:2019-03-31
本文章给大家介绍了爬取网页生成Excel文件的Python实现。主要包括爬取网页生成Excel文件的Python实现。用例举例、应用技巧、基础知识点总结和注意事项有一定的参考价值,有需要的朋友可以参考。
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开csv文件,另存为Excel文件
对Python相关内容感兴趣的读者可以查看本站专题:《Python操作Excel表格技巧总结》、《Python文件及目录操作技巧总结》、《Python文本文件操作技巧总结》、 《Python数据结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》
我希望这篇文章能对你的 Python 编程有所帮助。
网页表格抓取(rainfall:有什么方法可以让我在上面得到我想要的数据帧吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 11:01
我想从嵌套的 URL 链接中抓取和解析表,并创建一个 Pandas 数据框并将其导出。我想出了如何抓取页面是否有表格,然后从 HTML 页面中删除表格,但现在我需要从父链接中的子链接抓取并解析表格,我想我需要循环通过所有子链接解析它的表,我很感兴趣。我想知道是否有任何有效的方法可以制作这个BeautifulSoup。谁能告诉我如何做到这一点?
我的尝试
这是我目前从 HTML 页面抓取和解析单个表的尝试,但我不知道如何从嵌套的 HTML 页面中抓取和解析具有唯一表名的表,并在最后创建一个 Pandas 数据框.
def scrape_table(url):
response = requests.get(url, timeout=10)
bs= BeautifulSoup(response.content, 'html.parser')
table = bs.find('table')
list_of_rows = []
for row in table.findAll('tr'):
list_of_cells =[]
for cell in row.findAll('td'):
text = cell.text
list_of_cells.append(text)
list_of_rows.append(list_of_cells)
x= list_of_rows[1:]
df = pd.DataFrame(x, index=None)
df.to_csv("output.csv")
但这就是我想要做的:
main_entry_html = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_1= "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
...
以此类推,我需要访问 2015-01 到 2020-07 的所有月度汇总链接,以及标题为 Area-averagerain 的陡峭和分析表,最后创建一个数据框作为我想要的输出。
我想我可以使用for循环遍历每个子URL链接(即月份摘要链接),然后通过查看其表名来解析我想要的表。我不确定如何在 python 中实现这一点?谁能告诉我如何做到这一点?有什么可能的想法吗?
预期输出
下面是我想从所有子 URL 链接中抓取和解析所有表的数据框。以下是具有虚拟值的示例数据框:
有什么办法可以获得我想要的数据框吗?如何从嵌套的 url-link 中抓取和解析表?谁能给我一些可能的想法并告诉我如何实现预期的输出?谢谢 查看全部
网页表格抓取(rainfall:有什么方法可以让我在上面得到我想要的数据帧吗)
我想从嵌套的 URL 链接中抓取和解析表,并创建一个 Pandas 数据框并将其导出。我想出了如何抓取页面是否有表格,然后从 HTML 页面中删除表格,但现在我需要从父链接中的子链接抓取并解析表格,我想我需要循环通过所有子链接解析它的表,我很感兴趣。我想知道是否有任何有效的方法可以制作这个BeautifulSoup。谁能告诉我如何做到这一点?
我的尝试
这是我目前从 HTML 页面抓取和解析单个表的尝试,但我不知道如何从嵌套的 HTML 页面中抓取和解析具有唯一表名的表,并在最后创建一个 Pandas 数据框.
def scrape_table(url):
response = requests.get(url, timeout=10)
bs= BeautifulSoup(response.content, 'html.parser')
table = bs.find('table')
list_of_rows = []
for row in table.findAll('tr'):
list_of_cells =[]
for cell in row.findAll('td'):
text = cell.text
list_of_cells.append(text)
list_of_rows.append(list_of_cells)
x= list_of_rows[1:]
df = pd.DataFrame(x, index=None)
df.to_csv("output.csv")
但这就是我想要做的:
main_entry_html = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_1= "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
...
以此类推,我需要访问 2015-01 到 2020-07 的所有月度汇总链接,以及标题为 Area-averagerain 的陡峭和分析表,最后创建一个数据框作为我想要的输出。
我想我可以使用for循环遍历每个子URL链接(即月份摘要链接),然后通过查看其表名来解析我想要的表。我不确定如何在 python 中实现这一点?谁能告诉我如何做到这一点?有什么可能的想法吗?
预期输出
下面是我想从所有子 URL 链接中抓取和解析所有表的数据框。以下是具有虚拟值的示例数据框:

有什么办法可以获得我想要的数据框吗?如何从嵌套的 url-link 中抓取和解析表?谁能给我一些可能的想法并告诉我如何实现预期的输出?谢谢
网页表格抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-17 08:16
1.首先在网页获取表单时,首先需要添加NPOI引用:
2. 添加引用后,首先要获取网页的数据源。作者的数据源是一个数据库查询返回的List。下面是具体的编码过程。
3.代码如下:
1 public void exportExcel(List movie_list)
2 {
3
4
5 ClientScript.RegisterStartupScript(this.GetType(), "message", "alert('111111111');");
6
7
8 if (movie_list == null || movie_list.Count == 0)
9 {
10
11 Response.Write("alert('没有数据要导出!');");
12 return;
13 }
14
15 //定义表头数组
16 string[] excelHead = { "序号","名称", "地点", "票房" };
17
18 //自定义表头
19 var workBook = new HSSFWorkbook();
20 var sheet = workBook.CreateSheet("电影数据");
21 var col = sheet.CreateRow(0);
22 //遍历表头在exal表格中
23 for (int i = 0; i < excelHead.Length; i++)
24 {
25 //报表的头部
26 col.CreateCell(i).SetCellValue(excelHead[i]);
27 }
28 int a = 1;
29 //遍历表数据
30 foreach (var item in movie_list)
31 {
32 var row = sheet.CreateRow(a);
33 row.CreateCell(0).SetCellValue(a);
34 row.CreateCell(1).SetCellValue(item.MovieName);
35 row.CreateCell(2).SetCellValue(item.MovieLocat);
36 row.CreateCell(3).SetCellValue(item.MoviePrice);
37 a++;
38 }
39
40 string File_name = "电影统计-"+DateTime.Now.ToString("yyMMddHHmmss")+".xls";
41 var file = new FileStream(AppDomain.CurrentDomain.BaseDirectory + "Exports\\" + File_name, FileMode.Create);
42 workBook.Write(file);
43 file.Close();
44 /*
45 * 最后重定向到项目下的Export文件夹内的Excel文件,
46 * 网页会直接提示我们下载。如果是想要在网页生成超链接,
47 * 也可以这样写:Response.Write(file);
48 */
49 Response.Redirect("/Exports/" + File_name);
50
51 }
52 }
4.最后在网页上下载文件截图:
5. 一个完整的Excel电子表格导出过程基本实现了,是不是很简单?我希望你能从中学到你想学到的东西。 查看全部
网页表格抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
1.首先在网页获取表单时,首先需要添加NPOI引用:
2. 添加引用后,首先要获取网页的数据源。作者的数据源是一个数据库查询返回的List。下面是具体的编码过程。
3.代码如下:
1 public void exportExcel(List movie_list)
2 {
3
4
5 ClientScript.RegisterStartupScript(this.GetType(), "message", "alert('111111111');");
6
7
8 if (movie_list == null || movie_list.Count == 0)
9 {
10
11 Response.Write("alert('没有数据要导出!');");
12 return;
13 }
14
15 //定义表头数组
16 string[] excelHead = { "序号","名称", "地点", "票房" };
17
18 //自定义表头
19 var workBook = new HSSFWorkbook();
20 var sheet = workBook.CreateSheet("电影数据");
21 var col = sheet.CreateRow(0);
22 //遍历表头在exal表格中
23 for (int i = 0; i < excelHead.Length; i++)
24 {
25 //报表的头部
26 col.CreateCell(i).SetCellValue(excelHead[i]);
27 }
28 int a = 1;
29 //遍历表数据
30 foreach (var item in movie_list)
31 {
32 var row = sheet.CreateRow(a);
33 row.CreateCell(0).SetCellValue(a);
34 row.CreateCell(1).SetCellValue(item.MovieName);
35 row.CreateCell(2).SetCellValue(item.MovieLocat);
36 row.CreateCell(3).SetCellValue(item.MoviePrice);
37 a++;
38 }
39
40 string File_name = "电影统计-"+DateTime.Now.ToString("yyMMddHHmmss")+".xls";
41 var file = new FileStream(AppDomain.CurrentDomain.BaseDirectory + "Exports\\" + File_name, FileMode.Create);
42 workBook.Write(file);
43 file.Close();
44 /*
45 * 最后重定向到项目下的Export文件夹内的Excel文件,
46 * 网页会直接提示我们下载。如果是想要在网页生成超链接,
47 * 也可以这样写:Response.Write(file);
48 */
49 Response.Redirect("/Exports/" + File_name);
50
51 }
52 }
4.最后在网页上下载文件截图:

5. 一个完整的Excel电子表格导出过程基本实现了,是不是很简单?我希望你能从中学到你想学到的东西。
网页表格抓取( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-17 08:15
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容将默认被捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列第11篇文章(图)Datapreview)

这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。

具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。

在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容将默认被捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:

解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:

解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!

这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:

为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(如何用perl提交表格部分表格使用HTMLPOST抓取网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-12 07:22
1、使用perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current'
use LWP::Simple;
my $content = get $url;
die "Couldn't get $url" unless defined $content;
# $content 里是网页内容,下面是对此内容作些分析:
if($content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
非常简单易懂。获取网页内容很容易,但难的是有规律地过滤所需的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTML POST 向服务器提交数据,您可以在此处执行此操作:
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
);
示例分析:比如在()中提交一个序列并返回结果,使用perl来实现。代码如下:
#!/usr/bin/perl
use LWP::UserAgent;
my $browser = LWP::UserAgent->new;
$protein = "MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI";
my $SUSUI_URL = "http://www.enzim.hu/hmmtop/ser ... 3B%3B
my $response = $browser->post( $SUSUI_URL, [ 'if' => $protein, ] );
if ($response->is_success) {
print $response->content;
} else {
print "Bad luck this time\n";
}
通过分析页面,我们可以看到只有一个输入要提交,即name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
有点相关文章 查看全部
网页表格抓取(如何用perl提交表格部分表格使用HTMLPOST抓取网页?)
1、使用perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current'
use LWP::Simple;
my $content = get $url;
die "Couldn't get $url" unless defined $content;
# $content 里是网页内容,下面是对此内容作些分析:
if($content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
非常简单易懂。获取网页内容很容易,但难的是有规律地过滤所需的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTML POST 向服务器提交数据,您可以在此处执行此操作:
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
);
示例分析:比如在()中提交一个序列并返回结果,使用perl来实现。代码如下:
#!/usr/bin/perl
use LWP::UserAgent;
my $browser = LWP::UserAgent->new;
$protein = "MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI";
my $SUSUI_URL = "http://www.enzim.hu/hmmtop/ser ... 3B%3B
my $response = $browser->post( $SUSUI_URL, [ 'if' => $protein, ] );
if ($response->is_success) {
print $response->content;
} else {
print "Bad luck this time\n";
}
通过分析页面,我们可以看到只有一个输入要提交,即name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
有点相关文章
网页表格抓取(Python使用Web抓取有助于的步骤寻找您想要的抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-08 23:06
前言
爬虫是一种从 网站 抓取大量数据的自动化方法。甚至在 网站 上复制和粘贴您最喜欢的引用或台词也是一种网络抓取形式。大多数 网站 不允许您将他们的数据保存在 网站 上供您使用。因此,唯一的选择是手动复制数据,这会消耗大量时间,甚至可能需要几天才能完成。
网站 上的大部分数据都是非结构化的。网页抓取有助于将这些非结构化数据以自定义和结构化的形式在本地或数据库中存储。如果您出于学习目的抓取网页,则不太可能遇到任何问题。在不违反服务条款的情况下自己进行一些网络爬行以提高您的技能是一个很好的做法。.
履带步数
为什么使用 Python 进行网页抓取?
Python 非常快,而且网页抓取更容易。因为代码太容易了,你可以用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页爬取代码,将请求发送到我们要爬取的网站的URL。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Web 抓取使用 Python 提取数据的步骤
找到你要爬取的URL,分析网站找到要提取的数据,编写代码,运行代码,从网站中提取数据,将数据按照需要的格式存储在电脑中,用于网络爬取图书馆
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象。
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供用于导航、搜索和修改解析树的惯用方法。它专为快速且高度可靠的数据提取而设计。
pandas 是一个开源库,它允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察数据行和变量列中存储和操作表数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(可迭代)包装任何可迭代的。
演示:抓住一个 网站
Step 1. 找到你要抓取的网址
为了演示,我们将抓取网页以提取手机的详细信息。我用一个例子()来演示这个过程。
Stpe 2. 分析 网站
数据通常嵌套在标签中。分析并检查我们要获取的数据是否在其嵌套的页面上进行了标记。要查看页面,只需右键单击该元素并单击“检查”。将打开一个小的检查元件框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则控制台选项卡中将突出显示特定产品区域的代码。
我们应该做的第一件事是回顾和理解HTML的结构,因为从网站中获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标签。
步骤3.找到要提取的数据
我们会提取手机数据,如产品名称、实际价格、折扣价等,您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标签。
通过检查元素的区域打开控制台。单击左上角的箭头,然后单击产品。您现在可以看到我们点击的产品的具体代码。
步骤4. 写代码
现在我们必须找出数据和链接在哪里。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了网站的URL并访问了网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你就成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印soup,那么我们就能看到整个网站 页面的HTML 内容。我们现在要做的是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在div的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到该列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,而 product_url 出现在锚标签下。
HTML 锚标记定义了一个将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页和文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,两者都出现在 span 标签中。标签用于对内联元素进行分组。并且标签本身不提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一种通用的容器标签。它用于 HTML 的各种标记组,以便您可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储在文件或数据库中。您可以按所需格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
参考: 查看全部
网页表格抓取(Python使用Web抓取有助于的步骤寻找您想要的抓取数据)
前言
爬虫是一种从 网站 抓取大量数据的自动化方法。甚至在 网站 上复制和粘贴您最喜欢的引用或台词也是一种网络抓取形式。大多数 网站 不允许您将他们的数据保存在 网站 上供您使用。因此,唯一的选择是手动复制数据,这会消耗大量时间,甚至可能需要几天才能完成。
网站 上的大部分数据都是非结构化的。网页抓取有助于将这些非结构化数据以自定义和结构化的形式在本地或数据库中存储。如果您出于学习目的抓取网页,则不太可能遇到任何问题。在不违反服务条款的情况下自己进行一些网络爬行以提高您的技能是一个很好的做法。.
履带步数
为什么使用 Python 进行网页抓取?
Python 非常快,而且网页抓取更容易。因为代码太容易了,你可以用简单的小代码来执行大任务。
如何进行网页抓取?
我们需要运行网页爬取代码,将请求发送到我们要爬取的网站的URL。服务器发送数据并允许我们读取 HTML 或 XML 页面作为响应。该代码解析 HTML 或 XML 页面,查找数据并提取它们。
以下是使用 Web 抓取使用 Python 提取数据的步骤
找到你要爬取的URL,分析网站找到要提取的数据,编写代码,运行代码,从网站中提取数据,将数据按照需要的格式存储在电脑中,用于网络爬取图书馆
Requests 是一个允许使用 Python 发送 HTTP 请求的模块。HTTP请求用于返回一个收录所有响应数据(如编码、状态、内容等)的响应对象。
BeautifulSoup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。这适用于您最喜欢的解析器,以提供用于导航、搜索和修改解析树的惯用方法。它专为快速且高度可靠的数据提取而设计。
pandas 是一个开源库,它允许我们在 Python Web 开发中执行数据操作。它建立在 Numpy 包之上,其关键数据结构称为 DataFrame。DataFrames 允许我们在观察数据行和变量列中存储和操作表数据。
Tqdm 是另一个 python 库,它可以快速让你的循环显示一个智能进度表——你所要做的就是用 Tqdm(可迭代)包装任何可迭代的。
演示:抓住一个 网站
Step 1. 找到你要抓取的网址
为了演示,我们将抓取网页以提取手机的详细信息。我用一个例子()来演示这个过程。
Stpe 2. 分析 网站
数据通常嵌套在标签中。分析并检查我们要获取的数据是否在其嵌套的页面上进行了标记。要查看页面,只需右键单击该元素并单击“检查”。将打开一个小的检查元件框。你可以看到网站背后的原创代码。现在您可以找到要抓取的详细信息标签。
您可以在控制台的左上角找到一个箭头符号。如果单击箭头,然后单击产品区域,则控制台选项卡中将突出显示特定产品区域的代码。
我们应该做的第一件事是回顾和理解HTML的结构,因为从网站中获取数据非常重要。网站 页面上会有很多代码,我们需要收录我们数据的代码。学习 HTML 的基础知识将帮助您熟悉 HTML 标签。
步骤3.找到要提取的数据
我们会提取手机数据,如产品名称、实际价格、折扣价等,您可以提取任何类型的数据。为此,我们必须找到收录我们数据的标签。
通过检查元素的区域打开控制台。单击左上角的箭头,然后单击产品。您现在可以看到我们点击的产品的具体代码。
步骤4. 写代码
现在我们必须找出数据和链接在哪里。让我们开始编码。
创建一个名为 scrap.py 的文件并在您选择的任何编辑器中打开它。我们将使用 pip 安装上面提到的四个 Python 库。
第一个也是主要的过程是访问站点数据。我们已经设置了网站的URL并访问了网站。
url = 'https://www.example.com/produc ... aders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/64.0.3282.167 Safari/537.36' }result = requests.get(url, headers=headers,verify=True)Print(result)
输出:
如果你看到上面的结果,那么你就成功访问了这个网站。
步骤 5. 运行代码并从 网站 中提取数据
现在,我们将使用 Beautifulsoup 来解析 HTML。
soup = BeautifulSoup(result.content, 'html.parser')
如果我们打印soup,那么我们就能看到整个网站 页面的HTML 内容。我们现在要做的是过滤收录数据的部分。因此,我们将从汤中提取部分标签。
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})Print(section)
结果如下:
现在,我们可以在div的“product-desc-rating”类中提取手机的详细信息。我为手机的每个列详细信息创建了一个列表,并使用 for 循环将其附加到该列表中。
Products = []url = []Actual_Price = []Discounted_Price = []Discount = []
产品名称出现在 HTML 中的 p 标签(段落标签)下,而 product_url 出现在锚标签下。
HTML 锚标记定义了一个将一个页面链接到另一个页面的超链接。它可以创建指向另一个网页和文件、位置或任何 URL 的超链接。“href”属性是 HTML 标签最重要的属性。以及指向目标页面或 URL 的链接。
然后我们将提取实际价格和折扣价格,两者都出现在 span 标签中。标签用于对内联元素进行分组。并且标签本身不提供任何视觉变化。最后,我们将从 div 标签中提取报价百分比。div 标签是块级标签。它是一种通用的容器标签。它用于 HTML 的各种标记组,以便您可以创建部分并将样式应用于它们。
for t in tqdm(section): product_name = t.p.text Products.append(product_name) product_url = t.a['href'] url.append(product_url) original_price = t.span.getText() Actual_Price.append(original_price) discounted_price = t.find('span', class_ = 'lfloat product-price').getText() Discounted_Price.append(discounted_price) try: product_discount = t.find('div', class_ = 'product-discount') Discount.append(product_discount.text) except Exception as e: product_discount = None Discount.append(product_discount)
步骤 6. 以所需格式存储数据
我们已经提取了数据。我们现在要做的就是将数据存储在文件或数据库中。您可以按所需格式存储数据。这取决于您的要求。在这里,我们将以 CSV(逗号分隔值)格式存储提取的数据。
= pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url}) df.to_csv(' products.csv', index=False, encoding='utf-8')
参考:
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-08 23:02
这是简单数据分析系列文章的第十一篇。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果我们真的要抓取表格数据,可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的。您只需要添加一个空格和一个标点符号。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果我们真的要抓取表格数据,可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(Python编程语言Excel爬虫函数学起来容易些什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-08 23:00
近年来,Python编程语言非常流行,很多人使用Python来开发网络爬虫工具。Python虽然简单,但学起来并不容易,需要一定的基础。今天小编就给大家介绍一个Excel爬虫功能,比较简单易学,可以满足特定场景下数据采集的需求。
有一个基金网页#qdiie,网页上有一个数据表,如下图所示,需要将红框中标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步,使用Firefox或Chrome打开目标网页,右键查看代码,找到表的id。如果 table 没有 id,则可以使用 table 类样式代替。
第二步编写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要抓取的URL,"flex_qdiie"指的是网页中table元素的id号。函数名中的 W 表示当前函数需要 Excel 浏览器的帮助。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或HttpPost()方法无法读取完整的网页,需要使用浏览器读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。由于网页数据需要定期更新,需要Excel浏览器循环抓取网页。
第四步是刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表中的所有数据。这是一长串文本。可以发现每一列之间用分号隔开,每一行之间用两个分号隔开。. 找到规则后,我们可以使用 Split2Array() 函数对数据进行拆分和提取。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是对数据进行拆分和提取。先拆分每一行的数据,然后拆分每列的数据。
第六步,使用公式=AutoRefresh(120)设置定时刷新任务,每120秒自动刷新一次表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,就可以对数据进行处理和计算,达到监测预警的目的。怎么样,还算简单,写个公式就可以做网页数据采集。
如果你觉得这个技巧很实用,请帮忙转发给你的朋友 查看全部
网页表格抓取(Python编程语言Excel爬虫函数学起来容易些什么?(图))
近年来,Python编程语言非常流行,很多人使用Python来开发网络爬虫工具。Python虽然简单,但学起来并不容易,需要一定的基础。今天小编就给大家介绍一个Excel爬虫功能,比较简单易学,可以满足特定场景下数据采集的需求。
有一个基金网页#qdiie,网页上有一个数据表,如下图所示,需要将红框中标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步,使用Firefox或Chrome打开目标网页,右键查看代码,找到表的id。如果 table 没有 id,则可以使用 table 类样式代替。
第二步编写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要抓取的URL,"flex_qdiie"指的是网页中table元素的id号。函数名中的 W 表示当前函数需要 Excel 浏览器的帮助。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或HttpPost()方法无法读取完整的网页,需要使用浏览器读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。由于网页数据需要定期更新,需要Excel浏览器循环抓取网页。
第四步是刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表中的所有数据。这是一长串文本。可以发现每一列之间用分号隔开,每一行之间用两个分号隔开。. 找到规则后,我们可以使用 Split2Array() 函数对数据进行拆分和提取。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是对数据进行拆分和提取。先拆分每一行的数据,然后拆分每列的数据。
第六步,使用公式=AutoRefresh(120)设置定时刷新任务,每120秒自动刷新一次表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,就可以对数据进行处理和计算,达到监测预警的目的。怎么样,还算简单,写个公式就可以做网页数据采集。
如果你觉得这个技巧很实用,请帮忙转发给你的朋友
网页表格抓取(这是一个用来更新公园信息的数据管理系统,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-04 12:11
这是一个用于更新园区信息的数据管理系统,本页面截图主要用于更新站点信息。幸运的是,这个页面的每个元素都可以通过 ID 来定位。它收录三种形式的信息:文本框、下拉列表和复选按钮。我的实现思路是将id对应的定位信息放在excel表中,通过抓取excel表中提供的定位信息和需要更新的对应值来更新数据。
这里分别封装了文本框信息输入、下拉列表选择和勾选按钮勾选,然后将相应的方法统一到update方法中来实现。这消除了对每个字段进行单独处理的需要。
包装代码:
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import traceback
import time
class BasePage:
def __init__(self, driver):
self.driver = driver
# 对查找单个页面元素进行封装。
def find_element(self, by, locator):
by = by.lower()
element = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
element = self.driver.find_element_by_id(locator)
elif by == 'name':
element = self.driver.find_element_by_name(locator)
elif by == 'xpath':
element = self.driver.find_element_by_xpath(locator)
elif by == 'class':
element = self.driver.find_element_by_class_name(locator)
elif by == 'tag':
element = self.driver.find_element_by_tag_name(locator)
elif by == 'link':
element = self.driver.find_element_by_link_text(locator)
elif by == 'plink':
element = self.driver.find_element_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return element
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 对查找多个页面元素进行封装。
def find_elements(self, by, locator):
by = by.lower()
elements = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
elements = self.driver.find_elements_by_id(locator)
elif by == 'name':
elements = self.driver.find_elements_by_name(locator)
elif by == 'xpath':
elements = self.driver.find_elements_by_xpath(locator)
elif by == 'class':
elements = self.driver.find_elements_by_class_name(locator)
elif by == 'tag':
elements = self.driver.find_elements_by_tag_name(locator)
elif by == 'link':
elements = self.driver.find_elements_by_link_text(locator)
elif by == 'plink':
elements = self.driver.find_elements_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return elements
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 点击页面元素
def click(self, by, locator):
element = self.find_element(by, locator)
element.click()
# 输入框输入新信息
def type(self, by, locator, value):
y = [x for x in value if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element.clear()
element.send_keys(value.strip())
else:
pass
# 下拉菜单通过可见文本进行选择
def select(self, by, locator, text):
y = [x for x in text if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element_element = Select(element)
element_element.select_by_visible_text(text.strip())
else:
pass
# 复选按钮勾选时我们需要首先勾掉已选选项
def uncheck(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
elements = self.find_elements(by, locator)
for element in elements:
element.click()
else:
pass
# 选择excel表格所提供的选项进行勾选
def check(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
be_options = options.split(',')
for option in be_options:
element = self.find_element(by, locator.format(option.strip()))
element.click()
else:
pass
# def input(self, left_title, excel_title, by, locator, values):
# y = [x for x in values if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.type(by, locator, values)
# else:
# pass
# 根据excel表格提供标题所包含的关键字来决定进行哪种数据操作
def update(self, title, by, values):
y = [x for x in values if x != '']
if len(y) > 0:
if '_Text' in title: # 文本框
field = title.strip().split('_')
locator = field[0]
self.type(by, locator, values)
elif '_Select' in title: # 下拉列表
field = title.strip().split('_')
locator = field[0]
self.select(by, locator, values)
elif '_Option' in title: # 复选按钮
field = title.strip().split('_')
locator = field[0]
self.uncheck('xpath', '//input[@checked="" and contains(@id, "{}__")]'.format(locator), values)
self.check('id', '%s__{}'%locator, values)
else:
print('Please indicate the data type for the title "{}" in Excel!!!'.format(title))
else:
pass
# def set(self, left_title, excel_title, by, locator, text):
# y = [x for x in text if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.select(by, locator, text)
# else:
# pass
# 登录系统进行封装方便以后重用
def login_orms(self, url, username, password):
# driver = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
self.driver.delete_all_cookies()
self.driver.get(url)
self.driver.maximize_window()
time.sleep(2)
self.type('id', 'userName', username)
self.type('id', 'password', password)
self.click('id', 'okBtnAnchor')
time.sleep(2)
# 登录系统后选择Contract
def goto_manager_page(self, url, username, password, contract, page):
self.login_orms(url, username, password)
time.sleep(2)
self.click('xpath', "//option[text()='" + contract + " Contract']") # 通过click也可以对下拉列表进行选择
time.sleep(2)
self.click('link', page)
time.sleep(2)
下面是实现代码(没有对操作excel表的封装)
from Orms.BasePage import *
import xlrd
""""""
url = 'reserveamerica.com/xxxx'
account_user = 'xxx'
account_password = 'xxx'
wb = xlrd.open_workbook('D://SiteandLoopSetUp.xls')
""""""
sheet1 = wb.sheet_by_index(0)
sheet2 = wb.sheet_by_index(1)
# read provided information in Excel.
contract = sheet1.col_values(0)[1].strip()
park_name = sheet1.col_values(1)[1].strip()
search_ids = sheet1.col_values(2)[1:]
check_in_times = sheet1.col_values(3)[1:]
check_out_times = sheet1.col_values(4)[1:]
cols_num = sheet1.ncols
print('There will be "{}" fields need to update as following:'.format(cols_num))
left_titles = sheet1.row_values(0)[5:cols_num]
print(left_titles)
browser = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
driver = BasePage(browser)
driver.goto_manager_page(url=url, username=account_user, password=account_password, contract=contract, page='Inventory Manager')
# Input park name and search
driver.type('id', 'FacilitySearchCriteria.facilityName', park_name)
driver.click('xpath', '//a[@aria-label="Search"]')
time.sleep(3)
# Click facility id in search results to facility details page
driver.click('xpath', '//tr[@name="e_Glow"]/td/a')
time.sleep(2)
# Choose Loop/Site Set-up for Facility Details drop-down list
driver.select('id', 'page_name', 'Loop/Site Set-up')
time.sleep(2)
driver.click('xpath', '//a[@tabindex="-1" and @accesskey="S"]')
time.sleep(2)
for x in range(len(search_ids)):
try:
driver.select('id', 'search_type', 'Site ID')
time.sleep(2)
driver.type('id', 'search_value', search_ids[x])
driver.click('id', 'goAnchor')
time.sleep(2)
driver.click('xpath', '//tr[@name="e_Glow"]/td[2]/a')
time.sleep(2)
# in_time and out_time are required fields, need to handle separately.
in_time = check_in_times[x].strip().split(' ')
y = [x for x in in_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkin Time', in_time[0])
driver.select('id', 'Checkin Time_ispm', in_time[1])
else:
pass
out_time = check_out_times[x].strip().split(' ')
y = [x for x in out_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkout Time', out_time[0])
driver.select('id', 'Checkout Time_ispm', out_time[1])
else:
pass
# update left information in excel.
for i in range(len(left_titles)):
title = left_titles[i]
excel_values = sheet1.col_values(5+i)[1:]
driver.update(title, 'id', excel_values[x])
except Exception as e:
raise Exception
else:
driver.click('xpath', '//a[@aria-label="OK"]')
以上是我模拟手动操作自动填写页面表单的方法。虽然每次做的时候都需要找到需要更新信息的页面元素ID的值,复制到excel中,但是对于几十种合同和几十种形式的网站类型,还有上千个字段需要单独处理的,就简单多了。
当然,肯定有一些不完善的地方,比如强制等待而不是隐形等待。必须有更好的方法来实现这一目标。请指正~~~ 查看全部
网页表格抓取(这是一个用来更新公园信息的数据管理系统,怎么办?)
这是一个用于更新园区信息的数据管理系统,本页面截图主要用于更新站点信息。幸运的是,这个页面的每个元素都可以通过 ID 来定位。它收录三种形式的信息:文本框、下拉列表和复选按钮。我的实现思路是将id对应的定位信息放在excel表中,通过抓取excel表中提供的定位信息和需要更新的对应值来更新数据。
这里分别封装了文本框信息输入、下拉列表选择和勾选按钮勾选,然后将相应的方法统一到update方法中来实现。这消除了对每个字段进行单独处理的需要。
包装代码:
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import traceback
import time
class BasePage:
def __init__(self, driver):
self.driver = driver
# 对查找单个页面元素进行封装。
def find_element(self, by, locator):
by = by.lower()
element = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
element = self.driver.find_element_by_id(locator)
elif by == 'name':
element = self.driver.find_element_by_name(locator)
elif by == 'xpath':
element = self.driver.find_element_by_xpath(locator)
elif by == 'class':
element = self.driver.find_element_by_class_name(locator)
elif by == 'tag':
element = self.driver.find_element_by_tag_name(locator)
elif by == 'link':
element = self.driver.find_element_by_link_text(locator)
elif by == 'plink':
element = self.driver.find_element_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return element
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 对查找多个页面元素进行封装。
def find_elements(self, by, locator):
by = by.lower()
elements = None
if by in ['id', 'name', 'xpath', 'class', 'tag', 'link', 'plink']:
try:
if by == 'id':
elements = self.driver.find_elements_by_id(locator)
elif by == 'name':
elements = self.driver.find_elements_by_name(locator)
elif by == 'xpath':
elements = self.driver.find_elements_by_xpath(locator)
elif by == 'class':
elements = self.driver.find_elements_by_class_name(locator)
elif by == 'tag':
elements = self.driver.find_elements_by_tag_name(locator)
elif by == 'link':
elements = self.driver.find_elements_by_link_text(locator)
elif by == 'plink':
elements = self.driver.find_elements_by_partial_link_text(locator)
else:
print('Not find the element "{}"!'.format(locator))
return elements
except NoSuchElementException as e:
print(traceback.print_exc())
else:
print('Provided a wrong locator "{}"!'.format(locator))
# 点击页面元素
def click(self, by, locator):
element = self.find_element(by, locator)
element.click()
# 输入框输入新信息
def type(self, by, locator, value):
y = [x for x in value if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element.clear()
element.send_keys(value.strip())
else:
pass
# 下拉菜单通过可见文本进行选择
def select(self, by, locator, text):
y = [x for x in text if x != '']
if len(y) > 0:
element = self.find_element(by, locator)
element_element = Select(element)
element_element.select_by_visible_text(text.strip())
else:
pass
# 复选按钮勾选时我们需要首先勾掉已选选项
def uncheck(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
elements = self.find_elements(by, locator)
for element in elements:
element.click()
else:
pass
# 选择excel表格所提供的选项进行勾选
def check(self, by, locator, options):
y = [x for x in options if x != '']
if len(y) > 0:
be_options = options.split(',')
for option in be_options:
element = self.find_element(by, locator.format(option.strip()))
element.click()
else:
pass
# def input(self, left_title, excel_title, by, locator, values):
# y = [x for x in values if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.type(by, locator, values)
# else:
# pass
# 根据excel表格提供标题所包含的关键字来决定进行哪种数据操作
def update(self, title, by, values):
y = [x for x in values if x != '']
if len(y) > 0:
if '_Text' in title: # 文本框
field = title.strip().split('_')
locator = field[0]
self.type(by, locator, values)
elif '_Select' in title: # 下拉列表
field = title.strip().split('_')
locator = field[0]
self.select(by, locator, values)
elif '_Option' in title: # 复选按钮
field = title.strip().split('_')
locator = field[0]
self.uncheck('xpath', '//input[@checked="" and contains(@id, "{}__")]'.format(locator), values)
self.check('id', '%s__{}'%locator, values)
else:
print('Please indicate the data type for the title "{}" in Excel!!!'.format(title))
else:
pass
# def set(self, left_title, excel_title, by, locator, text):
# y = [x for x in text if x != '']
# if len(y) > 0:
# if left_title == excel_title:
# self.select(by, locator, text)
# else:
# pass
# 登录系统进行封装方便以后重用
def login_orms(self, url, username, password):
# driver = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
self.driver.delete_all_cookies()
self.driver.get(url)
self.driver.maximize_window()
time.sleep(2)
self.type('id', 'userName', username)
self.type('id', 'password', password)
self.click('id', 'okBtnAnchor')
time.sleep(2)
# 登录系统后选择Contract
def goto_manager_page(self, url, username, password, contract, page):
self.login_orms(url, username, password)
time.sleep(2)
self.click('xpath', "//option[text()='" + contract + " Contract']") # 通过click也可以对下拉列表进行选择
time.sleep(2)
self.click('link', page)
time.sleep(2)
下面是实现代码(没有对操作excel表的封装)
from Orms.BasePage import *
import xlrd
""""""
url = 'reserveamerica.com/xxxx'
account_user = 'xxx'
account_password = 'xxx'
wb = xlrd.open_workbook('D://SiteandLoopSetUp.xls')
""""""
sheet1 = wb.sheet_by_index(0)
sheet2 = wb.sheet_by_index(1)
# read provided information in Excel.
contract = sheet1.col_values(0)[1].strip()
park_name = sheet1.col_values(1)[1].strip()
search_ids = sheet1.col_values(2)[1:]
check_in_times = sheet1.col_values(3)[1:]
check_out_times = sheet1.col_values(4)[1:]
cols_num = sheet1.ncols
print('There will be "{}" fields need to update as following:'.format(cols_num))
left_titles = sheet1.row_values(0)[5:cols_num]
print(left_titles)
browser = webdriver.Firefox(executable_path='D:\\Selenium 3.14\\geckodriver.exe')
driver = BasePage(browser)
driver.goto_manager_page(url=url, username=account_user, password=account_password, contract=contract, page='Inventory Manager')
# Input park name and search
driver.type('id', 'FacilitySearchCriteria.facilityName', park_name)
driver.click('xpath', '//a[@aria-label="Search"]')
time.sleep(3)
# Click facility id in search results to facility details page
driver.click('xpath', '//tr[@name="e_Glow"]/td/a')
time.sleep(2)
# Choose Loop/Site Set-up for Facility Details drop-down list
driver.select('id', 'page_name', 'Loop/Site Set-up')
time.sleep(2)
driver.click('xpath', '//a[@tabindex="-1" and @accesskey="S"]')
time.sleep(2)
for x in range(len(search_ids)):
try:
driver.select('id', 'search_type', 'Site ID')
time.sleep(2)
driver.type('id', 'search_value', search_ids[x])
driver.click('id', 'goAnchor')
time.sleep(2)
driver.click('xpath', '//tr[@name="e_Glow"]/td[2]/a')
time.sleep(2)
# in_time and out_time are required fields, need to handle separately.
in_time = check_in_times[x].strip().split(' ')
y = [x for x in in_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkin Time', in_time[0])
driver.select('id', 'Checkin Time_ispm', in_time[1])
else:
pass
out_time = check_out_times[x].strip().split(' ')
y = [x for x in out_time if x != '']
if len(y) > 0:
driver.type('id', 'Checkout Time', out_time[0])
driver.select('id', 'Checkout Time_ispm', out_time[1])
else:
pass
# update left information in excel.
for i in range(len(left_titles)):
title = left_titles[i]
excel_values = sheet1.col_values(5+i)[1:]
driver.update(title, 'id', excel_values[x])
except Exception as e:
raise Exception
else:
driver.click('xpath', '//a[@aria-label="OK"]')
以上是我模拟手动操作自动填写页面表单的方法。虽然每次做的时候都需要找到需要更新信息的页面元素ID的值,复制到excel中,但是对于几十种合同和几十种形式的网站类型,还有上千个字段需要单独处理的,就简单多了。
当然,肯定有一些不完善的地方,比如强制等待而不是隐形等待。必须有更好的方法来实现这一目标。请指正~~~
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-02 21:29
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不会再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
} 查看全部
网页表格抓取(网页上只有一个表格的数据如何获取?(一))
首先下载jsoup的jar包,自己在网上搜索这个,有很多,然后导入到程序中方便使用。
接下来先获取你想要获取的网页内容,Document doc = Jsoup.connect(url).timeout(5000).get();
这里的网址就是你要爬取的网址。timeout(5000) 设置你抓取网页的最长时间,超过时间后不会再尝试。一般网站不需要设置,只需要Document doc = Jsoup.connect(url).get(); 获取网页内容并转换为文档格式。
下一步是找到您想要获取的数据。这里我们主要讲一下如何获取网页表格中的数据。其他类似。
你需要了解你想要获取的网页的html标签的结构,按F12进入开发者模式,寻找你想要获取的数据信息。
如果网页上只有一张表格,很简单: Elements elements1 = doc.select("table").select("tr"); 这行代码获取网页上表格中的行,返回的元素是表格有多少行。如果是多个表,那么select()就是表的标签,比如它的class和其他属性,来决定你选择哪个表。
for (int i = 0; i <elements1.size()-1; i++) {
//获取每一行的列
元素 tds = 元素1.get(i).select("td");
{
//处理每一行你需要的一些列
//获取第i行第j列的值
字符串 oldClose = tds.get(j).text()
//接下来,继续你的操作
………………
}
}
网页表格抓取(totowiththisthis.宽恕,今天才开始使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-30 22:29
请原谅,今天才开始用beautifulSoup来解决这个问题。
我设法通过拖入网站上的 URL 使其工作,该网站上的每个产品页面都有一个如下所示的表格: URL 使其工作。此网站 上的每个产品页面都有一个类似于下表的表格:
YYF Shutter Stats:
Diameter:
56 mm / 2.20 inches
Width:
44.40 mm / 1.74 inches
Gap Width:
4.75 mm / .18 inches
Weight:
67.8 grams
Bearing Size:
Size C (.250 x .500 x .187)
CBC SPEC Bearing
Response:
CBC Silicone Slim Pad (19mm)
我正在尝试将该表提取为我可以在 web 应用程序中使用的某种形式的数据。
我将如何从每个网页中提取此内容,该网站有大约 400 个收录此表格的产品页面,我最好从页面中获取每个表格并将其放入数据库条目或文本文件中与产品名称。我将如何从每个网页中提取内容,大约有400个产品页面收录此表,我最好从页面中获取每个表并将其放入 名称是数据库的条目或文本文件中的产品
如您所见,该表格的格式并不准确,但它是页面上唯一标有 p>
的表格
class="product-feature-table"
我刚刚尝试编辑一个 URL 抓取脚本,但我开始觉得我正在尝试这样做是错误的。就我尝试这样做而言,一切都是错误的。
我的url脚本如下: 我的url脚本如下:
import urllib2
from bs4 import BeautifulSoup
url = raw_input('Web-Address: ')
html = urllib2.urlopen('http://' +url).read()
soup = BeautifulSoup(html)
soup.prettify()
for anchor in soup.findAll('a', href=True):
print anchor['href']
我可以将所有这些 URL 放入一个文本文件中,但更喜欢使用 Sqlite 或 Postgresql,是否有任何在线文章可以帮助我更好地理解这些概念,而不会淹没新手? URL 都输入到一个文本文件中,但我更喜欢使用 Sqlite 或 Postgresql。有没有在线文章 可以帮助我更好地理解这些概念而不会让新手感到不知所措? 查看全部
网页表格抓取(totowiththisthis.宽恕,今天才开始使用)
请原谅,今天才开始用beautifulSoup来解决这个问题。
我设法通过拖入网站上的 URL 使其工作,该网站上的每个产品页面都有一个如下所示的表格: URL 使其工作。此网站 上的每个产品页面都有一个类似于下表的表格:
YYF Shutter Stats:
Diameter:
56 mm / 2.20 inches
Width:
44.40 mm / 1.74 inches
Gap Width:
4.75 mm / .18 inches
Weight:
67.8 grams
Bearing Size:
Size C (.250 x .500 x .187)
CBC SPEC Bearing
Response:
CBC Silicone Slim Pad (19mm)
我正在尝试将该表提取为我可以在 web 应用程序中使用的某种形式的数据。
我将如何从每个网页中提取此内容,该网站有大约 400 个收录此表格的产品页面,我最好从页面中获取每个表格并将其放入数据库条目或文本文件中与产品名称。我将如何从每个网页中提取内容,大约有400个产品页面收录此表,我最好从页面中获取每个表并将其放入 名称是数据库的条目或文本文件中的产品
如您所见,该表格的格式并不准确,但它是页面上唯一标有 p>
的表格
class="product-feature-table"
我刚刚尝试编辑一个 URL 抓取脚本,但我开始觉得我正在尝试这样做是错误的。就我尝试这样做而言,一切都是错误的。
我的url脚本如下: 我的url脚本如下:
import urllib2
from bs4 import BeautifulSoup
url = raw_input('Web-Address: ')
html = urllib2.urlopen('http://' +url).read()
soup = BeautifulSoup(html)
soup.prettify()
for anchor in soup.findAll('a', href=True):
print anchor['href']
我可以将所有这些 URL 放入一个文本文件中,但更喜欢使用 Sqlite 或 Postgresql,是否有任何在线文章可以帮助我更好地理解这些概念,而不会淹没新手? URL 都输入到一个文本文件中,但我更喜欢使用 Sqlite 或 Postgresql。有没有在线文章 可以帮助我更好地理解这些概念而不会让新手感到不知所措?
网页表格抓取(和数据挖掘项目的表格中提取文本和数字数据介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 22:23
作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。和数字数据。
要处理的 PDF 文档数量超过 80,000 个,每个文档可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。我已经成功地使用 PDFMiner 来处理页面并从中采集最相关的数据,但是,在尝试不同的技术数周后,我未能从表格中获取完美的数据。相关数据,但是在尝试了几个星期不同的技术后,我未能从表中得到完美的数据。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐在单词之间添加空格),一些单元格有很多行,整个表格的行距不同,还有多列单元格。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐会在单词之间增加空格),一些单元格有很多行,整个表格的行距不一样,并且有多个单元格列。
对普通页面产生最佳性能的字符边距、行边距和字边距参数在应用于表格处理时会产生混乱的结果。当应用于表处理时,参数可能会产生令人困惑的结果。幸运的是,3/4 的表格具有垂直和水平线,可用于将其区域划分为单元格并找到每个单元格的坐标。幸运的是,3/4 的表格都有垂直和水平线,可以用来划分它们的区域为单元格并找到每个单元格的坐标。但是pdfminer.pdfinterp.PDFPageInterpreter和pdfminer.converter.PDFPageAggregator带来的LTText实例往往不尊重每个单元格的边界。细胞边界。
我花了很多天尝试不同的技术,包括对 laparams 和字符串解释和拆分的更改,以获取和使用整个页面处理生成的 LTText 实例。并通过字符串解释和拆分更改获取并使用整个页面处理生成的 LTText 实例。真正有用的东西会用 interpreter.process_cell(page, xmin, ymin, xmax, ymax) xmax, ymax) 替换 interpreter.process_page(page)
我相信如果有一些方法使用 PDFMiner 函数和方法来获取收录在单元格边界内的对象,使用保守的 laparameters 来避免混乱的结果,我相信可能存在解决方案。我相信如果有一些方法使用PDFMiner函数和方法来获取单元格边界内收录的对象,使用保守的laparameters来避免混淆结果,我相信可能会有解决方案。理想的方法应该足够快,因为它必须多次应用。在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域中提取文本?在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域提取文本? ,这是相似的,但没有回答。
我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,它们使用了其他库和技术。我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,这使用了其他库和技术。我不想混合不同的库和它们的对象来解决这个问题,因为 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。有没有人有建议?有人有建议吗? 查看全部
网页表格抓取(和数据挖掘项目的表格中提取文本和数字数据介绍)
作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。作为数字化和数据挖掘项目的一部分,我正在尝试从 PDF 页面中的表格中提取文本和数字数据。和数字数据。
要处理的 PDF 文档数量超过 80,000 个,每个文档可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。可能有 4 到 80 页,结合了图像、文本、注释和多种类型的表格。我已经成功地使用 PDFMiner 来处理页面并从中采集最相关的数据,但是,在尝试不同的技术数周后,我未能从表格中获取完美的数据。相关数据,但是在尝试了几个星期不同的技术后,我未能从表中得到完美的数据。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐在单词之间添加空格),一些单元格有很多行,整个表格的行距不同,还有多列单元格。不幸的是,这些表格有几种布局:它们的一些列是对齐的(对齐会在单词之间增加空格),一些单元格有很多行,整个表格的行距不一样,并且有多个单元格列。
对普通页面产生最佳性能的字符边距、行边距和字边距参数在应用于表格处理时会产生混乱的结果。当应用于表处理时,参数可能会产生令人困惑的结果。幸运的是,3/4 的表格具有垂直和水平线,可用于将其区域划分为单元格并找到每个单元格的坐标。幸运的是,3/4 的表格都有垂直和水平线,可以用来划分它们的区域为单元格并找到每个单元格的坐标。但是pdfminer.pdfinterp.PDFPageInterpreter和pdfminer.converter.PDFPageAggregator带来的LTText实例往往不尊重每个单元格的边界。细胞边界。
我花了很多天尝试不同的技术,包括对 laparams 和字符串解释和拆分的更改,以获取和使用整个页面处理生成的 LTText 实例。并通过字符串解释和拆分更改获取并使用整个页面处理生成的 LTText 实例。真正有用的东西会用 interpreter.process_cell(page, xmin, ymin, xmax, ymax) xmax, ymax) 替换 interpreter.process_page(page)
我相信如果有一些方法使用 PDFMiner 函数和方法来获取收录在单元格边界内的对象,使用保守的 laparameters 来避免混乱的结果,我相信可能存在解决方案。我相信如果有一些方法使用PDFMiner函数和方法来获取单元格边界内收录的对象,使用保守的laparameters来避免混淆结果,我相信可能会有解决方案。理想的方法应该足够快,因为它必须多次应用。在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域中提取文本?在 StackOverflow 中搜索时,我发现从 PDF 页面的某些区域提取文本? ,这是相似的,但没有回答。
我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,它们使用了其他库和技术。我还发现从 pdf 中提取区域和按坐标提取 PDF 文本,这使用了其他库和技术。我不想混合不同的库和它们的对象来解决这个问题,因为 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。 PDFMiner 在恢复除表格之外的所有信息方面确实非常有效。有没有人有建议?有人有建议吗?
网页表格抓取(用Perl网页和提交表格这里简单的模块介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-30 22:21
本文文章主要介绍如何使用Perl抓取网页和提交表单。有一定的参考价值。有兴趣的朋友可以参考一下。希望大家看完这篇文章收获,带你一探究竟。
使用 Perl 抓取网页并提交表单
这里简单介绍一下使用Perl捕获网页源代码,以及使用POST方法提交表单并返回结果。我不能说难的,只说简单的。
这里提到的 Perl 模块是:
useLWP::Simple;useLWP::UserAgent;使用 Perldoc 查看详细用法。
1、使用Perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my$url='http://freshair.npr.org/dayFA. ... 39%3B useLWP::Simple; my$content=get$url; die"Couldn'tget$url"unlessdefined$content;
#$content 是网页的内容,这里是对这个内容的一些分析:
if($content=~m/jazz/i){ print"They'retalkingaboutjazztodayonFreshAir!\n"; }else{ print"FreshAirisapparentlyjazzlesstoday.\n"; }
非常简单易懂。获取一个网页的内容很容易,但难的是有规律地过滤出需要的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTMLPOST 向服务器提交数据,您可以在这里这样做:
$response=$browser->post($url, [ formkey1=>value1, formkey2=>value2, ... ], );
案例分析:比如提交一个序列并返回结果,使用Perl来实现。代码如下:
#!/usr/bin/Perl useLWP::UserAgent; my$browser=LWP::UserAgent->new; $protein="MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI"; my$SUSUI_URL="http://www.enzim.hu/hmmtop/ser ... 3B%3B my$response=$browser->post($SUSUI_URL,['if'=>$protein,]); if($response->is_success){ print$response->content; }else{ print"Badluckthistime\n"; }
通过分析页面,我们可以看到只有一个input需要提交,就是name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
感谢您仔细阅读这篇文章,也希望文章编者分享的《如何使用Perl抓取网页和提交表单》对大家有所帮助,也希望大家全部支持易速云,关注易速云行业资讯频道,更多相关知识等你学习! 查看全部
网页表格抓取(用Perl网页和提交表格这里简单的模块介绍)
本文文章主要介绍如何使用Perl抓取网页和提交表单。有一定的参考价值。有兴趣的朋友可以参考一下。希望大家看完这篇文章收获,带你一探究竟。
使用 Perl 抓取网页并提交表单
这里简单介绍一下使用Perl捕获网页源代码,以及使用POST方法提交表单并返回结果。我不能说难的,只说简单的。
这里提到的 Perl 模块是:
useLWP::Simple;useLWP::UserAgent;使用 Perldoc 查看详细用法。
1、使用Perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my$url='http://freshair.npr.org/dayFA. ... 39%3B useLWP::Simple; my$content=get$url; die"Couldn'tget$url"unlessdefined$content;
#$content 是网页的内容,这里是对这个内容的一些分析:
if($content=~m/jazz/i){ print"They'retalkingaboutjazztodayonFreshAir!\n"; }else{ print"FreshAirisapparentlyjazzlesstoday.\n"; }
非常简单易懂。获取一个网页的内容很容易,但难的是有规律地过滤出需要的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTMLPOST 向服务器提交数据,您可以在这里这样做:
$response=$browser->post($url, [ formkey1=>value1, formkey2=>value2, ... ], );
案例分析:比如提交一个序列并返回结果,使用Perl来实现。代码如下:
#!/usr/bin/Perl useLWP::UserAgent; my$browser=LWP::UserAgent->new; $protein="MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI"; my$SUSUI_URL="http://www.enzim.hu/hmmtop/ser ... 3B%3B my$response=$browser->post($SUSUI_URL,['if'=>$protein,]); if($response->is_success){ print$response->content; }else{ print"Badluckthistime\n"; }
通过分析页面,我们可以看到只有一个input需要提交,就是name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
感谢您仔细阅读这篇文章,也希望文章编者分享的《如何使用Perl抓取网页和提交表单》对大家有所帮助,也希望大家全部支持易速云,关注易速云行业资讯频道,更多相关知识等你学习!
网页表格抓取(利用pandas库中的read_html方法快速抓取网页中常见的表格型数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-27 19:00
使用pandas库中的read_html方法快速抓取网页中常见的表格数据
表格形式
我们在网上经常会看到这样的表格,比如:
QS2018世界大学排名:
可以看出表格类型的表格页结构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
...
...
...
...
...
...
...
...
...
...
...
首先简单解释一下上面出现的几个标签的含义:
1
2
3
4
5
6
: 定义表格
: 定义表格的页眉
: 定义表格的主体
: 定义表格的行
: 定义表格的表头
: 定义表格单元
使用 pandas 模块中的 read_html 函数可以轻松快速地捕获此类表格数据。下面就来做吧。
我们以中国上市公司信息页面上的表格为例,感受一下read_html函数的威力。
1
2
3
4
5
6
7
8
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
之前买房的时候爬上实时登记情况~ 查看全部
网页表格抓取(利用pandas库中的read_html方法快速抓取网页中常见的表格型数据)
使用pandas库中的read_html方法快速抓取网页中常见的表格数据
表格形式
我们在网上经常会看到这样的表格,比如:
QS2018世界大学排名:
可以看出表格类型的表格页结构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
...
...
...
...
...
...
...
...
...
...
...
首先简单解释一下上面出现的几个标签的含义:
1
2
3
4
5
6
: 定义表格
: 定义表格的页眉
: 定义表格的主体
: 定义表格的行
: 定义表格的表头
: 定义表格单元
使用 pandas 模块中的 read_html 函数可以轻松快速地捕获此类表格数据。下面就来做吧。
我们以中国上市公司信息页面上的表格为例,感受一下read_html函数的威力。
1
2
3
4
5
6
7
8
import pandas as pd
import csv
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/%3F ... 39%3B % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
之前买房的时候爬上实时登记情况~
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-26 22:10
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,就可以得到从PDF分析表中得到的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~ 查看全部
网页表格抓取(Python爬虫与使用Excalibur运行下面的命令启动(图))
启动和使用 Excalibur
运行以下命令启动 Excalibur:
$ excalibur initdb
$ excalibur webserver
前一个命令是初始化数据库,后一个命令是运行服务器服务。在浏览器中输入::5050 使用平台。
进入PDF表单提取平台,首页如下:
作者测试的PDF收录以下表格:
我们将PDF文档上传到上述平台,点击“上传PDF”按钮,然后选择对应的PDF文档和表格所在的页码。PDF上传后,表单所在页面如下图所示:
选择右边的Flavor中的“lattice”,用鼠标选择table所在的区域,如下图:
然后点击“查看和下载数据”按钮,就可以得到从PDF分析表中得到的数据。截图如下:
如果我们还想将这个表的解析结果保存为文件,我们可以在Download旁边的下拉框中选择一种保存格式,然后点击Download按钮。比如作者选择保存为csv文件,下载的文件如下:
"Method","Precision","Recall","F-measure"
"(S1) SP-CCG","67.5","37.2","48.0"
"(S1) SP-CFG","71.1","39.2","50.5"
"(S1) K4","70.3","26.3","38.0"
"(S2) SP-CCG","63.7","41.4","50.2"
"(S2) SP-CFG","65.5","43.8","52.5"
"(S2) K4","67.1","35.0","45.8"
"","Table 5: Extraction Performance on ACE.","",""
我们可以发现,表的分析结果还是相当漂亮的。
本次分享到此结束,感谢阅读。
注:本人已开通微信公众号:Python爬虫与算法(微信ID:easy_web_scrape),欢迎大家关注~~
网页表格抓取(网页表格数据采集助手的使用方法及使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2021-11-24 20:08
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,并且您可以指定采集 所需字段的内容。
相关软件软件大小版本说明下载地址
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,此外,您可以指定采集 所需字段的内容。采集后的内容既可以保存为EXCEL软件可以读取的文件格式,也可以保存为保留原格式的纯文本格式,绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,则软件URL列表
这个地址会自动添加,你只需要下拉选择它,它就会打开。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。
页面收录的表格数量和页眉信息显示在软件左上角的列表框中。
3、从表号列表中选择要抓取的表,在软件表左上角第一个框中会显示该表左上角的第一个文本
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果网页表单中有带有链接的字段,您可以选择是否
包括链接地址。如果你有并且想要采集它的链接地址,那么你不能同时选择收录标题行。
6、如果你想让采集只有一个网页的表格数据,那么你可以点击抓取表格直接抓取,如果之前没有选择收录表格
网格、表格数据会以CVS格式保存,这种格式可以直接用微软EXCEL软件打开转换成EXCEL表格,如果之前选择收录表格
网格线和表格数据会以TXT格式保存,可以用记事本软件打开查看,表格线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后
继续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您查看页面并找到它。
只要输入它。如果网页没有下一页的链接,但是URL中收录了页数,那么您也可以根据URL中的页数选择打开,您可以
要从前到后选择,例如从第 1 页到第 10 页,或从后到前,例如从第 10 页到第 1 页,请在页码输入框中输入,但此时
URL中代表页数的位置应该用“(*)”代替,否则程序将无法识别。
8、 然后选择定时采集 或者等待网页打开加载采集后立即加载,定时采集是程序设置的一个很小的时间间隔
判断打开的页面中是否有你想要的表单,采集如果有,采集页面加载后,只要采集的页面已经打开,
程序会立即进行采集,两者各有特点,视需要选择。
9、最后,你只需要点击抢表按钮,你就可以泡杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的一
一些信息后,直接点击抓取表格,无需经过爬取测试等操作。 查看全部
网页表格抓取(网页表格数据采集助手的使用方法及使用方法介绍)
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,并且您可以指定采集 所需字段的内容。
相关软件软件大小版本说明下载地址
网页表单数据采集助手是一种可以采集单页规则和不规则表单的表单,也可以自动连续采集指定网站的表单,此外,您可以指定采集 所需字段的内容。采集后的内容既可以保存为EXCEL软件可以读取的文件格式,也可以保存为保留原格式的纯文本格式,绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,则软件URL列表
这个地址会自动添加,你只需要下拉选择它,它就会打开。
2、 然后点击爬虫测试按钮,可以看到网页的源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。
页面收录的表格数量和页眉信息显示在软件左上角的列表框中。
3、从表号列表中选择要抓取的表,在软件表左上角第一个框中会显示该表左上角的第一个文本
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果网页表单中有带有链接的字段,您可以选择是否
包括链接地址。如果你有并且想要采集它的链接地址,那么你不能同时选择收录标题行。
6、如果你想让采集只有一个网页的表格数据,那么你可以点击抓取表格直接抓取,如果之前没有选择收录表格
网格、表格数据会以CVS格式保存,这种格式可以直接用微软EXCEL软件打开转换成EXCEL表格,如果之前选择收录表格
网格线和表格数据会以TXT格式保存,可以用记事本软件打开查看,表格线直接可用,也很清晰。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后
继续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您查看页面并找到它。
只要输入它。如果网页没有下一页的链接,但是URL中收录了页数,那么您也可以根据URL中的页数选择打开,您可以
要从前到后选择,例如从第 1 页到第 10 页,或从后到前,例如从第 10 页到第 1 页,请在页码输入框中输入,但此时
URL中代表页数的位置应该用“(*)”代替,否则程序将无法识别。
8、 然后选择定时采集 或者等待网页打开加载采集后立即加载,定时采集是程序设置的一个很小的时间间隔
判断打开的页面中是否有你想要的表单,采集如果有,采集页面加载后,只要采集的页面已经打开,
程序会立即进行采集,两者各有特点,视需要选择。
9、最后,你只需要点击抢表按钮,你就可以泡杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的一
一些信息后,直接点击抓取表格,无需经过爬取测试等操作。
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-24 08:12
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(这是简易数据分析系列的第11篇文章(图)制作)
这是简单数据分析系列文章的第十一篇。
今天我们讲讲如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
Ϻ &txtDaoDa=
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,即默认会抓取这些列的内容。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,,等标签,这些标签提供默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本不是正品,自然是无法识别的.
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-23 04:17
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/119 ... 39%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
网页表格抓取(如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是很人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/119 ... 39%3B
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格最好的方法就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
网页表格抓取( Google通过提交表入党积极分子考察与毫米对照表教师职称级别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-19 06:13
Google通过提交表入党积极分子考察与毫米对照表教师职称级别)
谷歌通过提交入党人数调查条目数和毫米对照表、教师职称等级表、员工考核评分表、普通年金现值系数表、普通年金现值系数表爬取新页面,爬取新页面. 虽然谷歌已经是抓取页面最多的搜索引擎,但它仍然不满足,因为有很多网页和信息很难找到和抓取。这就是为什么你在做网站的时候一定要注意搜索引擎的友好性。现在谷歌已经开始提供提交表单了。我发现下面的网页我想写一个详细的说明。看到幻灭写完了,下面直接引述主要内容。我们已经知道,除了文字,视频、音频、Flash 等类型的内容,Googlebot 还可以通过 JS 代码抓取链接。未来,Googlebot 也有望直接识别图片和视频。为了进一步抓取互联网的内容,谷歌宣布Googlebot已经可以通过提交表单来抓取更多的内容。据 Google 称,Googlebot 目前正在试验少量高质量的 网站 表单提交。当Googlebot发现这些网站上有HTML表单时,当检测到时,它会自动从网站中选择一些词进入表单的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表单。提交表单 稍后,一旦 Googlebot 认为出现的新内容是合法的、有趣的和独特的,
<p>在引文数据库中,这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。同时,谷歌还强调,如果网站的robotstxt文件中禁止使用该表单,您不希望该表单后生成的链接被抓取。那么 Googlebot 将不会抓取。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要输入用户个人信息,如密码、用户名、联系人等时,Googlebot 会自动跳过这些表单。这种表单爬取目前只是一个小表单。测试范围谷歌表示不会影响网站,也不会影响网站的PR值,也不会影响网站的正常爬取排名。MattCutts 还写了一篇文章说明了这样做的好处。< @网站首页只是以表格的形式列出了公司下属的站,并没有以链接的形式列出各个站。这种类型的网站之前无法深入。网站 @收录因为Google在不提交表单的情况下无法找到隐藏在表单后面的URL存在一定的安全风险。网站如果某部分不想成为 查看全部
网页表格抓取(
Google通过提交表入党积极分子考察与毫米对照表教师职称级别)
谷歌通过提交入党人数调查条目数和毫米对照表、教师职称等级表、员工考核评分表、普通年金现值系数表、普通年金现值系数表爬取新页面,爬取新页面. 虽然谷歌已经是抓取页面最多的搜索引擎,但它仍然不满足,因为有很多网页和信息很难找到和抓取。这就是为什么你在做网站的时候一定要注意搜索引擎的友好性。现在谷歌已经开始提供提交表单了。我发现下面的网页我想写一个详细的说明。看到幻灭写完了,下面直接引述主要内容。我们已经知道,除了文字,视频、音频、Flash 等类型的内容,Googlebot 还可以通过 JS 代码抓取链接。未来,Googlebot 也有望直接识别图片和视频。为了进一步抓取互联网的内容,谷歌宣布Googlebot已经可以通过提交表单来抓取更多的内容。据 Google 称,Googlebot 目前正在试验少量高质量的 网站 表单提交。当Googlebot发现这些网站上有HTML表单时,当检测到时,它会自动从网站中选择一些词进入表单的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表单。提交表单 稍后,一旦 Googlebot 认为出现的新内容是合法的、有趣的和独特的,
<p>在引文数据库中,这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。同时,谷歌还强调,如果网站的robotstxt文件中禁止使用该表单,您不希望该表单后生成的链接被抓取。那么 Googlebot 将不会抓取。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要输入用户个人信息,如密码、用户名、联系人等时,Googlebot 会自动跳过这些表单。这种表单爬取目前只是一个小表单。测试范围谷歌表示不会影响网站,也不会影响网站的PR值,也不会影响网站的正常爬取排名。MattCutts 还写了一篇文章说明了这样做的好处。< @网站首页只是以表格的形式列出了公司下属的站,并没有以链接的形式列出各个站。这种类型的网站之前无法深入。网站 @收录因为Google在不提交表单的情况下无法找到隐藏在表单后面的URL存在一定的安全风险。网站如果某部分不想成为
网页表格抓取(Python将表格转换为CSV文件?你是否曾经想从网页中自动提取Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-11-19 04:04
使用requests和beautiful Soup提取HTML表格,然后将其保存为CSV文件或任何其他格式的Python。
Python 将 HTML 表格转换为 CSV 文件?您是否曾经想从网页中自动提取 HTML 表格并将它们以适当的格式保存在您的计算机上?如果是这种情况,那么您来对地方了。在本教程中,我们将使用 requests 和 BeautifulSoup 库来转换任何网页中的任何表格并将其保存在我们的磁盘上。
Python 如何将 HTML 表格转换为 CSV?我们还将使用 Pandas 轻松转换为 CSV 格式(或 Pandas 支持的任何格式)。如果您还没有安装 requests、BeautifulSoup 和 pandas,请使用以下命令安装它们:
pip3 install requests bs4 pandas
Python 将HTML 表格转为CSV 示例介绍——打开一个新的Python 文件并继续,让我们导入库:
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
我们需要一个函数来接受目标 URL 并为我们提供正确的汤对象:
USER_AGENT = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"
def get_soup(url):
"""Constructs and returns a soup using the HTML content of `url` passed"""
# initialize a session
session = requests.Session()
# set the User-Agent as a regular browser
session.headers['User-Agent'] = USER_AGENT
# request for english content (optional)
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
# make the request
html = session.get(url)
# return the soup
return bs(html.content, "html.parser")
Python 如何将 HTML 表格转换为 CSV?我们首先初始化了一个请求会话,我们使用 User-Agent 头来表明我们只是一个普通浏览器而不是机器人(一些网站 阻止了他们),然后我们使用 session.get() 方法来获取 HTML 内容。之后,我们使用 html.parser 来构造一个 BeautifulSoup 对象。
相关教程:如何在 Python 中制作电子邮件提取器。
Python 将 HTML 表格转换为 CSV 文件?由于我们要提取任何页面中的每个表格,因此我们需要找到表格 HTML 标记并将其返回。以下函数正是这样做的:
def get_all_tables(soup):
"""Extracts and returns all tables in a soup object"""
return soup.find_all("table")
现在我们需要一种方法来获取标题、列名或任何您想称呼它们的内容:
def get_table_headers(table):
"""Given a table soup, returns all the headers"""
headers = []
for th in table.find("tr").find_all("th"):
headers.append(th.text.strip())
return headers
上述函数查找表的第一行并提取所有第 th 个标签(标题)。
现在我们知道如何提取表头,剩下的就是提取所有表行:
def get_table_rows(table):
"""Given a table, returns all its rows"""
rows = []
for tr in table.find_all("tr")[1:]:
cells = []
# grab all td tags in this table row
tds = tr.find_all("td")
if len(tds) == 0:
# if no td tags, search for th tags
# can be found especially in wikipedia tables below the table
ths = tr.find_all("th")
for th in ths:
cells.append(th.text.strip())
else:
# use regular td tags
for td in tds:
cells.append(td.text.strip())
rows.append(cells)
return rows
上面的所有函数都是这样做的,即找到tr标签(表行)并提取td元素,然后将它们附加到列表中。我们之所以使用table.find_all("tr")[1:]而不是所有的tr标签,是因为第一个tr标签对应的是表头,我们不想在这里添加。
Python 将 HTML 表格转换为 CSV 文件?以下函数获取表名、标题和所有行,并将它们保存为 CSV 格式:
def save_as_csv(table_name, headers, rows):
pd.DataFrame(rows, columns=headers).to_csv(f"{table_name}.csv")
现在我们有了所有的核心函数,让我们把它们放在一个主函数中:
def main(url):
# get the soup
soup = get_soup(url)
# extract all the tables from the web page
tables = get_all_tables(soup)
print(f"[+] Found a total of {len(tables)} tables.")
# iterate over all tables
for i, table in enumerate(tables, start=1):
# get the table headers
headers = get_table_headers(table)
# get all the rows of the table
rows = get_table_rows(table)
# save table as csv file
table_name = f"table-{i}"
print(f"[+] Saving {table_name}")
save_as_csv(table_name, headers, rows)
Python 如何将 HTML 表格转换为 CSV?上述函数执行以下操作:
Python 将 HTML 表格转换为 CSV 的例子——最后,我们调用 main 函数:
if __name__ == "__main__":
import sys
try:
url = sys.argv[1]
except IndexError:
print("Please specify a URL.\nUsage: python html_table_extractor.py [URL]")
exit(1)
main(url)
这将接受来自命令行参数的 URL,让我们试试这是否有效:
C:\pythoncode-tutorials\web-scraping\html-table-extractor>python html_table_extractor.py https://en.wikipedia.org/wiki/ ... ation
[+] Found a total of 2 tables.
[+] Saving table-1
[+] Saving table-2
很好,我当前目录下出现了两个CSV文件,它们对应维基百科页面中的两个表,它们是提取表之一的一部分:
如何在 Python 中将 HTML 表格转换为 CSV
惊人!我们已经成功构建了一个 Python 脚本来从任何 网站 中提取任何表,尝试传递其他 URL 并查看它是否有效。
Python 将 HTML 表格转换为 CSV 文件?对于Javascript驱动的网站(使用Javascript动态加载网站数据),请尽量使用requests-html库或selenium。让我们看看你在下面的评论中做了什么!
您还可以制作一个从整个 网站 下载所有表单的网络爬虫,您可以通过提取所有 网站 链接并在从它们获得的每个 URL 上运行此脚本来实现此目的。
另外,如果你正在爬取的网站由于某种原因阻塞了你的IP地址,你需要使用一些代理服务器作为对策。 查看全部
网页表格抓取(Python将表格转换为CSV文件?你是否曾经想从网页中自动提取Python)
使用requests和beautiful Soup提取HTML表格,然后将其保存为CSV文件或任何其他格式的Python。
Python 将 HTML 表格转换为 CSV 文件?您是否曾经想从网页中自动提取 HTML 表格并将它们以适当的格式保存在您的计算机上?如果是这种情况,那么您来对地方了。在本教程中,我们将使用 requests 和 BeautifulSoup 库来转换任何网页中的任何表格并将其保存在我们的磁盘上。
Python 如何将 HTML 表格转换为 CSV?我们还将使用 Pandas 轻松转换为 CSV 格式(或 Pandas 支持的任何格式)。如果您还没有安装 requests、BeautifulSoup 和 pandas,请使用以下命令安装它们:
pip3 install requests bs4 pandas
Python 将HTML 表格转为CSV 示例介绍——打开一个新的Python 文件并继续,让我们导入库:
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
我们需要一个函数来接受目标 URL 并为我们提供正确的汤对象:
USER_AGENT = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
# US english
LANGUAGE = "en-US,en;q=0.5"
def get_soup(url):
"""Constructs and returns a soup using the HTML content of `url` passed"""
# initialize a session
session = requests.Session()
# set the User-Agent as a regular browser
session.headers['User-Agent'] = USER_AGENT
# request for english content (optional)
session.headers['Accept-Language'] = LANGUAGE
session.headers['Content-Language'] = LANGUAGE
# make the request
html = session.get(url)
# return the soup
return bs(html.content, "html.parser")
Python 如何将 HTML 表格转换为 CSV?我们首先初始化了一个请求会话,我们使用 User-Agent 头来表明我们只是一个普通浏览器而不是机器人(一些网站 阻止了他们),然后我们使用 session.get() 方法来获取 HTML 内容。之后,我们使用 html.parser 来构造一个 BeautifulSoup 对象。
相关教程:如何在 Python 中制作电子邮件提取器。
Python 将 HTML 表格转换为 CSV 文件?由于我们要提取任何页面中的每个表格,因此我们需要找到表格 HTML 标记并将其返回。以下函数正是这样做的:
def get_all_tables(soup):
"""Extracts and returns all tables in a soup object"""
return soup.find_all("table")
现在我们需要一种方法来获取标题、列名或任何您想称呼它们的内容:
def get_table_headers(table):
"""Given a table soup, returns all the headers"""
headers = []
for th in table.find("tr").find_all("th"):
headers.append(th.text.strip())
return headers
上述函数查找表的第一行并提取所有第 th 个标签(标题)。
现在我们知道如何提取表头,剩下的就是提取所有表行:
def get_table_rows(table):
"""Given a table, returns all its rows"""
rows = []
for tr in table.find_all("tr")[1:]:
cells = []
# grab all td tags in this table row
tds = tr.find_all("td")
if len(tds) == 0:
# if no td tags, search for th tags
# can be found especially in wikipedia tables below the table
ths = tr.find_all("th")
for th in ths:
cells.append(th.text.strip())
else:
# use regular td tags
for td in tds:
cells.append(td.text.strip())
rows.append(cells)
return rows
上面的所有函数都是这样做的,即找到tr标签(表行)并提取td元素,然后将它们附加到列表中。我们之所以使用table.find_all("tr")[1:]而不是所有的tr标签,是因为第一个tr标签对应的是表头,我们不想在这里添加。
Python 将 HTML 表格转换为 CSV 文件?以下函数获取表名、标题和所有行,并将它们保存为 CSV 格式:
def save_as_csv(table_name, headers, rows):
pd.DataFrame(rows, columns=headers).to_csv(f"{table_name}.csv")
现在我们有了所有的核心函数,让我们把它们放在一个主函数中:
def main(url):
# get the soup
soup = get_soup(url)
# extract all the tables from the web page
tables = get_all_tables(soup)
print(f"[+] Found a total of {len(tables)} tables.")
# iterate over all tables
for i, table in enumerate(tables, start=1):
# get the table headers
headers = get_table_headers(table)
# get all the rows of the table
rows = get_table_rows(table)
# save table as csv file
table_name = f"table-{i}"
print(f"[+] Saving {table_name}")
save_as_csv(table_name, headers, rows)
Python 如何将 HTML 表格转换为 CSV?上述函数执行以下操作:
Python 将 HTML 表格转换为 CSV 的例子——最后,我们调用 main 函数:
if __name__ == "__main__":
import sys
try:
url = sys.argv[1]
except IndexError:
print("Please specify a URL.\nUsage: python html_table_extractor.py [URL]")
exit(1)
main(url)
这将接受来自命令行参数的 URL,让我们试试这是否有效:
C:\pythoncode-tutorials\web-scraping\html-table-extractor>python html_table_extractor.py https://en.wikipedia.org/wiki/ ... ation
[+] Found a total of 2 tables.
[+] Saving table-1
[+] Saving table-2
很好,我当前目录下出现了两个CSV文件,它们对应维基百科页面中的两个表,它们是提取表之一的一部分:
https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />如何在 Python 中将 HTML 表格转换为 CSV
惊人!我们已经成功构建了一个 Python 脚本来从任何 网站 中提取任何表,尝试传递其他 URL 并查看它是否有效。
Python 将 HTML 表格转换为 CSV 文件?对于Javascript驱动的网站(使用Javascript动态加载网站数据),请尽量使用requests-html库或selenium。让我们看看你在下面的评论中做了什么!
您还可以制作一个从整个 网站 下载所有表单的网络爬虫,您可以通过提取所有 网站 链接并在从它们获得的每个 URL 上运行此脚本来实现此目的。
另外,如果你正在爬取的网站由于某种原因阻塞了你的IP地址,你需要使用一些代理服务器作为对策。
网页表格抓取( 《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-18 12:05
《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
抓取网页生成Excel文件的方法的python实现
时间:2019-03-31
本文章给大家介绍了爬取网页生成Excel文件的Python实现。主要包括爬取网页生成Excel文件的Python实现。用例举例、应用技巧、基础知识点总结和注意事项有一定的参考价值,有需要的朋友可以参考。
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开csv文件,另存为Excel文件
对Python相关内容感兴趣的读者可以查看本站专题:《Python操作Excel表格技巧总结》、《Python文件及目录操作技巧总结》、《Python文本文件操作技巧总结》、 《Python数据结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》
我希望这篇文章能对你的 Python 编程有所帮助。 查看全部
网页表格抓取(
《Python操作Excel表格技巧总结》及Python抓网页生成Excel文件)
抓取网页生成Excel文件的方法的python实现
时间:2019-03-31
本文章给大家介绍了爬取网页生成Excel文件的Python实现。主要包括爬取网页生成Excel文件的Python实现。用例举例、应用技巧、基础知识点总结和注意事项有一定的参考价值,有需要的朋友可以参考。
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开csv文件,另存为Excel文件
对Python相关内容感兴趣的读者可以查看本站专题:《Python操作Excel表格技巧总结》、《Python文件及目录操作技巧总结》、《Python文本文件操作技巧总结》、 《Python数据结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》
我希望这篇文章能对你的 Python 编程有所帮助。
网页表格抓取(rainfall:有什么方法可以让我在上面得到我想要的数据帧吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-17 11:01
我想从嵌套的 URL 链接中抓取和解析表,并创建一个 Pandas 数据框并将其导出。我想出了如何抓取页面是否有表格,然后从 HTML 页面中删除表格,但现在我需要从父链接中的子链接抓取并解析表格,我想我需要循环通过所有子链接解析它的表,我很感兴趣。我想知道是否有任何有效的方法可以制作这个BeautifulSoup。谁能告诉我如何做到这一点?
我的尝试
这是我目前从 HTML 页面抓取和解析单个表的尝试,但我不知道如何从嵌套的 HTML 页面中抓取和解析具有唯一表名的表,并在最后创建一个 Pandas 数据框.
def scrape_table(url):
response = requests.get(url, timeout=10)
bs= BeautifulSoup(response.content, 'html.parser')
table = bs.find('table')
list_of_rows = []
for row in table.findAll('tr'):
list_of_cells =[]
for cell in row.findAll('td'):
text = cell.text
list_of_cells.append(text)
list_of_rows.append(list_of_cells)
x= list_of_rows[1:]
df = pd.DataFrame(x, index=None)
df.to_csv("output.csv")
但这就是我想要做的:
main_entry_html = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_1= "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
...
以此类推,我需要访问 2015-01 到 2020-07 的所有月度汇总链接,以及标题为 Area-averagerain 的陡峭和分析表,最后创建一个数据框作为我想要的输出。
我想我可以使用for循环遍历每个子URL链接(即月份摘要链接),然后通过查看其表名来解析我想要的表。我不确定如何在 python 中实现这一点?谁能告诉我如何做到这一点?有什么可能的想法吗?
预期输出
下面是我想从所有子 URL 链接中抓取和解析所有表的数据框。以下是具有虚拟值的示例数据框:
有什么办法可以获得我想要的数据框吗?如何从嵌套的 url-link 中抓取和解析表?谁能给我一些可能的想法并告诉我如何实现预期的输出?谢谢 查看全部
网页表格抓取(rainfall:有什么方法可以让我在上面得到我想要的数据帧吗)
我想从嵌套的 URL 链接中抓取和解析表,并创建一个 Pandas 数据框并将其导出。我想出了如何抓取页面是否有表格,然后从 HTML 页面中删除表格,但现在我需要从父链接中的子链接抓取并解析表格,我想我需要循环通过所有子链接解析它的表,我很感兴趣。我想知道是否有任何有效的方法可以制作这个BeautifulSoup。谁能告诉我如何做到这一点?
我的尝试
这是我目前从 HTML 页面抓取和解析单个表的尝试,但我不知道如何从嵌套的 HTML 页面中抓取和解析具有唯一表名的表,并在最后创建一个 Pandas 数据框.
def scrape_table(url):
response = requests.get(url, timeout=10)
bs= BeautifulSoup(response.content, 'html.parser')
table = bs.find('table')
list_of_rows = []
for row in table.findAll('tr'):
list_of_cells =[]
for cell in row.findAll('td'):
text = cell.text
list_of_cells.append(text)
list_of_rows.append(list_of_cells)
x= list_of_rows[1:]
df = pd.DataFrame(x, index=None)
df.to_csv("output.csv")
但这就是我想要做的:
main_entry_html = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_1= "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
child_url_2 = "http://www.bom.gov.au/climate/ ... ot%3B
...
以此类推,我需要访问 2015-01 到 2020-07 的所有月度汇总链接,以及标题为 Area-averagerain 的陡峭和分析表,最后创建一个数据框作为我想要的输出。
我想我可以使用for循环遍历每个子URL链接(即月份摘要链接),然后通过查看其表名来解析我想要的表。我不确定如何在 python 中实现这一点?谁能告诉我如何做到这一点?有什么可能的想法吗?
预期输出
下面是我想从所有子 URL 链接中抓取和解析所有表的数据框。以下是具有虚拟值的示例数据框:
有什么办法可以获得我想要的数据框吗?如何从嵌套的 url-link 中抓取和解析表?谁能给我一些可能的想法并告诉我如何实现预期的输出?谢谢
网页表格抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-17 08:16
1.首先在网页获取表单时,首先需要添加NPOI引用:
2. 添加引用后,首先要获取网页的数据源。作者的数据源是一个数据库查询返回的List。下面是具体的编码过程。
3.代码如下:
1 public void exportExcel(List movie_list)
2 {
3
4
5 ClientScript.RegisterStartupScript(this.GetType(), "message", "alert('111111111');");
6
7
8 if (movie_list == null || movie_list.Count == 0)
9 {
10
11 Response.Write("alert('没有数据要导出!');");
12 return;
13 }
14
15 //定义表头数组
16 string[] excelHead = { "序号","名称", "地点", "票房" };
17
18 //自定义表头
19 var workBook = new HSSFWorkbook();
20 var sheet = workBook.CreateSheet("电影数据");
21 var col = sheet.CreateRow(0);
22 //遍历表头在exal表格中
23 for (int i = 0; i < excelHead.Length; i++)
24 {
25 //报表的头部
26 col.CreateCell(i).SetCellValue(excelHead[i]);
27 }
28 int a = 1;
29 //遍历表数据
30 foreach (var item in movie_list)
31 {
32 var row = sheet.CreateRow(a);
33 row.CreateCell(0).SetCellValue(a);
34 row.CreateCell(1).SetCellValue(item.MovieName);
35 row.CreateCell(2).SetCellValue(item.MovieLocat);
36 row.CreateCell(3).SetCellValue(item.MoviePrice);
37 a++;
38 }
39
40 string File_name = "电影统计-"+DateTime.Now.ToString("yyMMddHHmmss")+".xls";
41 var file = new FileStream(AppDomain.CurrentDomain.BaseDirectory + "Exports\\" + File_name, FileMode.Create);
42 workBook.Write(file);
43 file.Close();
44 /*
45 * 最后重定向到项目下的Export文件夹内的Excel文件,
46 * 网页会直接提示我们下载。如果是想要在网页生成超链接,
47 * 也可以这样写:Response.Write(file);
48 */
49 Response.Redirect("/Exports/" + File_name);
50
51 }
52 }
4.最后在网页上下载文件截图:
5. 一个完整的Excel电子表格导出过程基本实现了,是不是很简单?我希望你能从中学到你想学到的东西。 查看全部
网页表格抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
1.首先在网页获取表单时,首先需要添加NPOI引用:
2. 添加引用后,首先要获取网页的数据源。作者的数据源是一个数据库查询返回的List。下面是具体的编码过程。
3.代码如下:
1 public void exportExcel(List movie_list)
2 {
3
4
5 ClientScript.RegisterStartupScript(this.GetType(), "message", "alert('111111111');");
6
7
8 if (movie_list == null || movie_list.Count == 0)
9 {
10
11 Response.Write("alert('没有数据要导出!');");
12 return;
13 }
14
15 //定义表头数组
16 string[] excelHead = { "序号","名称", "地点", "票房" };
17
18 //自定义表头
19 var workBook = new HSSFWorkbook();
20 var sheet = workBook.CreateSheet("电影数据");
21 var col = sheet.CreateRow(0);
22 //遍历表头在exal表格中
23 for (int i = 0; i < excelHead.Length; i++)
24 {
25 //报表的头部
26 col.CreateCell(i).SetCellValue(excelHead[i]);
27 }
28 int a = 1;
29 //遍历表数据
30 foreach (var item in movie_list)
31 {
32 var row = sheet.CreateRow(a);
33 row.CreateCell(0).SetCellValue(a);
34 row.CreateCell(1).SetCellValue(item.MovieName);
35 row.CreateCell(2).SetCellValue(item.MovieLocat);
36 row.CreateCell(3).SetCellValue(item.MoviePrice);
37 a++;
38 }
39
40 string File_name = "电影统计-"+DateTime.Now.ToString("yyMMddHHmmss")+".xls";
41 var file = new FileStream(AppDomain.CurrentDomain.BaseDirectory + "Exports\\" + File_name, FileMode.Create);
42 workBook.Write(file);
43 file.Close();
44 /*
45 * 最后重定向到项目下的Export文件夹内的Excel文件,
46 * 网页会直接提示我们下载。如果是想要在网页生成超链接,
47 * 也可以这样写:Response.Write(file);
48 */
49 Response.Redirect("/Exports/" + File_name);
50
51 }
52 }
4.最后在网页上下载文件截图:
5. 一个完整的Excel电子表格导出过程基本实现了,是不是很简单?我希望你能从中学到你想学到的东西。
网页表格抓取( 这是简易数据分析系列第11篇文章(图)Datapreview)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-17 08:15
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容将默认被捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。 查看全部
网页表格抓取(
这是简易数据分析系列第11篇文章(图)Datapreview)
这是简单数据分析系列文章的第十一篇。
原文首发于博客园。
今天我们讲的是如何抓取web表单中的数据。首先,我们来分析一下网页上的经典表格是如何组成的。
经典表就是这些知识点,不多说了。下面我们写一个简单的表单Web Scraper爬虫。
1.制作站点地图
我们今天的做法网站是
%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们首先创建一个收录整个表的容器,Type选为Table,表示我们要抓取表。
具体参数如上图所示,因为比较简单,就不多说了。
在此面板下向下滚动,您会发现一个不同的面板。仔细看就会发现,这些数据其实就是表数据类型的分类。在这种情况下,他列出了列车号、出发站和行驶时间的分类。
在Table列的类别中,每行内容旁边的选择按钮默认是打勾的,这意味着这些列的内容将默认被捕获。如果您不想抓取某种类型的内容,只需取消选中相应的复选框即可。
当你点击保存选择器按钮时,你会发现Result键的一些选项报错,说invalid format无效:
解决这个错误非常简单。一般来说,Result键名的长度是不够的,加一个空格和一个标点符号就可以了。如果还是报错,尝试改成英文名:
解决错误并保存成功后,我们就可以按照Web Scraper的爬取例程爬取数据了。
2.我为什么不建议你使用Web Scraper的Table Selector?
如果按照刚才的教程,你会觉得很流畅,但是查看数据的时候你会傻眼。
刚开始爬的时候,我们先用Data preview预览数据,会发现数据很完美:
取完数据后,在浏览器的预览面板中预览,会发现车号一栏的数据为空,表示没有取到相关内容:
我们下载抓到的CSV文件后,在预览器中打开,会发现出现了车次数据,但是出发站数据又为空了!
这不是作弊!
我一直在研究这个问题很长时间。应该是Web Scraper对中文关键字索引的支持不友好,所以会抛出一些奇怪的bug,所以不建议大家使用它的Table功能。
如果真的要抓取表格数据,我们可以使用之前的方案,先创建一个Element类型的容器,然后在容器中手动创建子选择器,这样我们就可以避免这个问题。
以上只是原因之一。另一个原因是在现代 网站 中,很少有人使用 HTML 原创表单。
HTML 提供了表格的基本标签,例如,和其他标签,这些标签提供了默认样式。优点是在互联网刚刚发展的时候,可以提供开箱即用的表格;缺点是款式太单一,不易定制。后来很多网站用其他标签来模拟表格,就像PPT把各种大小的立方体组合成一个表格,方便定制:
为此,当你使用Table Selector来匹配一个表时,可能生死不匹配,因为从Web Scraper的角度来看,你看到的表是高仿的,根本就不是真品,所以自然不是。认可。
3.总结
我们不建议直接使用Web Scraper的Table Selector,因为它对中文支持不是很友好,对现代网页也不太好匹配。如果需要抓取表格,可以使用前面创建父子选择器的方法。
网页表格抓取(如何用perl提交表格部分表格使用HTMLPOST抓取网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-12 07:22
1、使用perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current'
use LWP::Simple;
my $content = get $url;
die "Couldn't get $url" unless defined $content;
# $content 里是网页内容,下面是对此内容作些分析:
if($content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
非常简单易懂。获取网页内容很容易,但难的是有规律地过滤所需的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTML POST 向服务器提交数据,您可以在此处执行此操作:
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
);
示例分析:比如在()中提交一个序列并返回结果,使用perl来实现。代码如下:
#!/usr/bin/perl
use LWP::UserAgent;
my $browser = LWP::UserAgent->new;
$protein = "MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI";
my $SUSUI_URL = "http://www.enzim.hu/hmmtop/ser ... 3B%3B
my $response = $browser->post( $SUSUI_URL, [ 'if' => $protein, ] );
if ($response->is_success) {
print $response->content;
} else {
print "Bad luck this time\n";
}
通过分析页面,我们可以看到只有一个输入要提交,即name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
有点相关文章 查看全部
网页表格抓取(如何用perl提交表格部分表格使用HTMLPOST抓取网页?)
1、使用perl抓取网页
如果你只是想获取某个网页,使用LWP::Simple中的功能是最简单的。通过调用get($url)函数,可以获得相关URL的内容。
my $url = 'http://freshair.npr.org/dayFA.cfm?todayDate=current'
use LWP::Simple;
my $content = get $url;
die "Couldn't get $url" unless defined $content;
# $content 里是网页内容,下面是对此内容作些分析:
if($content =~ m/jazz/i) {
print "They're talking about jazz today on Fresh Air!\n";
} else {
print "Fresh Air is apparently jazzless today.\n";
}
非常简单易懂。获取网页内容很容易,但难的是有规律地过滤所需的内容。
2、通过POST提交表单
某些 HTML 表单使用 HTML POST 向服务器提交数据,您可以在此处执行此操作:
$response = $browser->post( $url,
[
formkey1 => value1,
formkey2 => value2,
...
],
);
示例分析:比如在()中提交一个序列并返回结果,使用perl来实现。代码如下:
#!/usr/bin/perl
use LWP::UserAgent;
my $browser = LWP::UserAgent->new;
$protein = "MSSSTPFDPYALSEHDEERPQNVQSKSRTAELQAEIDDTVGIMRDNINKVAERGERLTSI";
my $SUSUI_URL = "http://www.enzim.hu/hmmtop/ser ... 3B%3B
my $response = $browser->post( $SUSUI_URL, [ 'if' => $protein, ] );
if ($response->is_success) {
print $response->content;
} else {
print "Bad luck this time\n";
}
通过分析页面,我们可以看到只有一个输入要提交,即name="if"。 $protein 是要提交的序列。 $response->content 是返回结果。
有点相关文章

