
网页抓取数据百度百科
网页抓取数据百度百科( 2.按前述结束日期(月份)来作为终止新闻链接、标题及时间 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-05 18:08
2.按前述结束日期(月份)来作为终止新闻链接、标题及时间
)
python网页信息采集
引言1.前期准备2.自动控制鼠标下滑,保存已加载的网页3.获取页面的所有新闻链接、标题及时间,生成excel表格4.从生成的列表中,获取每个链接的新闻内容,生成docx
<a id="_2"></a>引言
<p>这是第一次实战,帮忙从俄新社网页链接下载关于中国的新闻,技术不行,还是得配上个人操作才能完成。
<a id="1_6"></a>1.前期准备
选择好日期,或者其他筛选项。<br /> <br /> 这网页第一次会出现加载选项,要自己点,后面下滑都会动态加载了。<br />
<a id="2_12"></a>2.自动控制鼠标下滑,保存已加载的网页
发现前期准备直接用selenium模块直接打开页面,选择日期,获取数据的方式,浏览器都会突然关闭。所以只能前期自己打开浏览器,手动选好页面,然后selenium继续控制,才能正常加载。<br /> 1.python+selenium控制已打开页面<br /> 参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
</p>
2.按照之前的准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****') 查看全部
网页抓取数据百度百科(
2.按前述结束日期(月份)来作为终止新闻链接、标题及时间
)
python网页信息采集
引言1.前期准备2.自动控制鼠标下滑,保存已加载的网页3.获取页面的所有新闻链接、标题及时间,生成excel表格4.从生成的列表中,获取每个链接的新闻内容,生成docx
<a id="_2"></a>引言
<p>这是第一次实战,帮忙从俄新社网页链接下载关于中国的新闻,技术不行,还是得配上个人操作才能完成。
<a id="1_6"></a>1.前期准备
选择好日期,或者其他筛选项。<br />
 <br /> 这网页第一次会出现加载选项,要自己点,后面下滑都会动态加载了。<br />
<br /> 这网页第一次会出现加载选项,要自己点,后面下滑都会动态加载了。<br /> 
<a id="2_12"></a>2.自动控制鼠标下滑,保存已加载的网页
发现前期准备直接用selenium模块直接打开页面,选择日期,获取数据的方式,浏览器都会突然关闭。所以只能前期自己打开浏览器,手动选好页面,然后selenium继续控制,才能正常加载。<br /> 1.python+selenium控制已打开页面<br /> 参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
</p>
2.按照之前的准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****')
网页抓取数据百度百科(Python爬取《权力的游戏第八季》演员数据并分析数据爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-05 18:07
Python爬取分析《权力的游戏第8季》演员数据
数据爬取一、 浏览需要爬取的网页
首先浏览要爬取的网页,也就是百度百科的“权力的游戏第八季”页面,发现演员表里有每个演员条目的链接。在这里你可以通过爬取获取每个演员的入口链接,方便你。爬取了每个actor的详细信息:
然后进入龙母的入口页面:
在这里找到它的基本信息:
因此,我们可以将之前爬取得到的各个actor的入口链接进行爬取,然后爬取并保存各个actor的基本信息,方便后续的数据分析。
二、 在百度百科中爬取《权力的游戏》第八季的演员阵容,获取各个演员的链接并存入文件
import re
import requests
import json
import pandas
import os
import sys
from bs4 import BeautifulSoup
#获取请求
def getHTMLText(url,kv):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
#解析出演员姓名与链接数据并存入文件
def parserData(text):
soup = BeautifulSoup(text,'lxml')
review_list = soup.find_all('li',{'class':'pages'})
soup1 = BeautifulSoup(str(review_list),'lxml')
all_dts = soup1.find_all('dt')
stars = []
for dt in all_dts:
star = {}
star["name"] = dt.find('a').text
star["link"] = 'https://baike.baidu.com' + dt.find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/'+'stars.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
三、 爬取演员的详细信息并保存在文件中(每个演员的图片也下载保存)
#爬取并解析出演员详细信息与图片并存入文件
def crawl_everyone(kv):
with open('work/' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
#向选手个人百度百科发送一个http get请求
r = requests.get(link,headers=kv)
soup = BeautifulSoup(r.text,'lxml')
#获取选手的国籍、星座、身高、出生日期等信息
base_info_div = soup.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '国籍':
star_info['nation'] =''.join(str(dt.find_next('dd').text).split()).replace("\n","").replace("[1]","")
if "".join(str(dt.text).split()) == '星座':
con_str=str(dt.find_next('dd').text).replace("\n","")
if '座' in con_str:
star_info['constellation'] = con_str[0:con_str.rfind('座')]
if "".join(str(dt.text).split()) == '身高':
if name=='约翰·C·布莱德利':
star_info['height'] ='173'
else:
height_str = str(dt.find_next('dd').text)
star_info['height'] =''.join(str(height_str[0:height_str.rfind('cm')]).split()).replace("\n","").replace("[2]","") .replace("[4]","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
#从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面
if soup.select('.summary-pic a'):
pic_list_url = soup.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
#向选手图片列表页面发送http get请求
pic_list_response = requests.get(pic_list_url,headers=kv)
#对选手图片列表页面进行解析,获取所有图片链接
soup1 = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=soup1.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中
down_save_pic(name,pic_urls)
#将个人信息存储到json文件中
#print("%s",name)
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('work/' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
print('所有信息与图片爬取完成')
def down_save_pic(name,pic_urls):
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
#print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
# 调用函数爬取信息
kv={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36' }
url = 'https://baike.baidu.com/item/% ... 39%3B
html = getHTMLText(url,kv)
parserData(html)
crawl_everyone(kv)
四、 爬取结果:
1.保存的演员链接文件:
2.保存的演员信息文件:
3.下载保存的演员图片:
数据分析一、生成演员年龄分布直方图
import numpy as np
import json
import pandas as pd
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
df=pd.read_json('work/stars_info.json',dtype={'birth_day' : str})
grouped=df['name'].groupby(df['birth_day'])
s=grouped.count()
zone_list=s.index
count_list=s.values
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)),count_list,color='r',tick_label=zone_list,facecolor='#FFC0CB',edgecolor='white')
#调节横坐标的倾斜度,rotation是读书,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《权力的游戏第八季》演员年龄分布图''',fontsize=24)
plt.savefig('work/result/birth_result.jpg')
plt.show()
二、 生成演员国籍分布饼图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
nations = []
counts = []
for star in json_array:
if 'nation' in dict(star).keys():
nation = star['nation']
nations.append(nation)
print(nations)
nation_list = []
count_list = []
n1 = 0
n2 = 0
n3 = 0
n4 = 0
for nation in nations:
if nation == '英国':
n1 += 1
elif nation == '美国':
n2 += 1
elif nation == '丹麦':
n3 += 1
else:
n4 += 1
labels = '英国', '美国', '丹麦', '其它'
nas = [n1, n2, n3, n4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(nas, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('work/result/nation_result.jpg')
plt.title('''《权力的游戏第八季》演员国籍分布图''',fontsize = 14)
plt.show()
三、生成演员身高分布饼图
<p>import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for height in heights:
if height 查看全部
网页抓取数据百度百科(Python爬取《权力的游戏第八季》演员数据并分析数据爬取)
Python爬取分析《权力的游戏第8季》演员数据
数据爬取一、 浏览需要爬取的网页
首先浏览要爬取的网页,也就是百度百科的“权力的游戏第八季”页面,发现演员表里有每个演员条目的链接。在这里你可以通过爬取获取每个演员的入口链接,方便你。爬取了每个actor的详细信息:
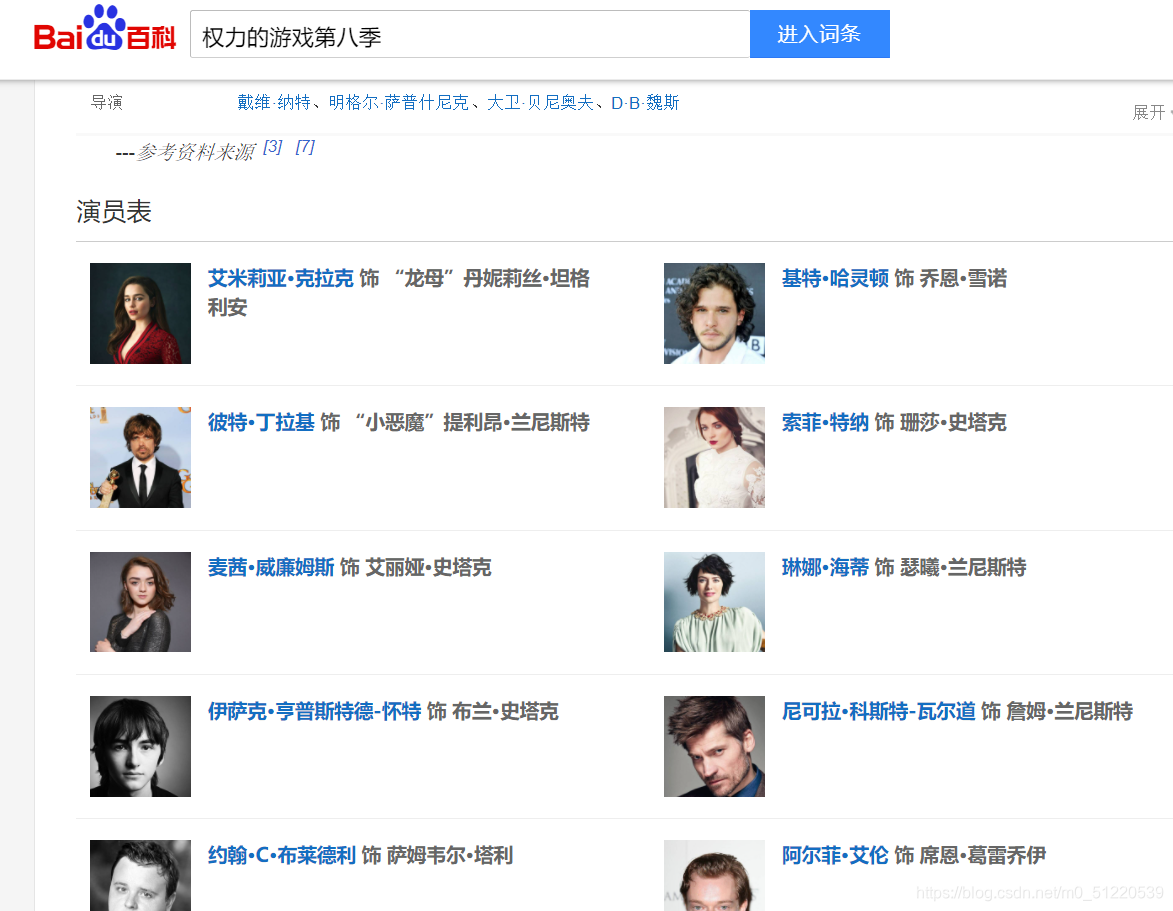
然后进入龙母的入口页面:
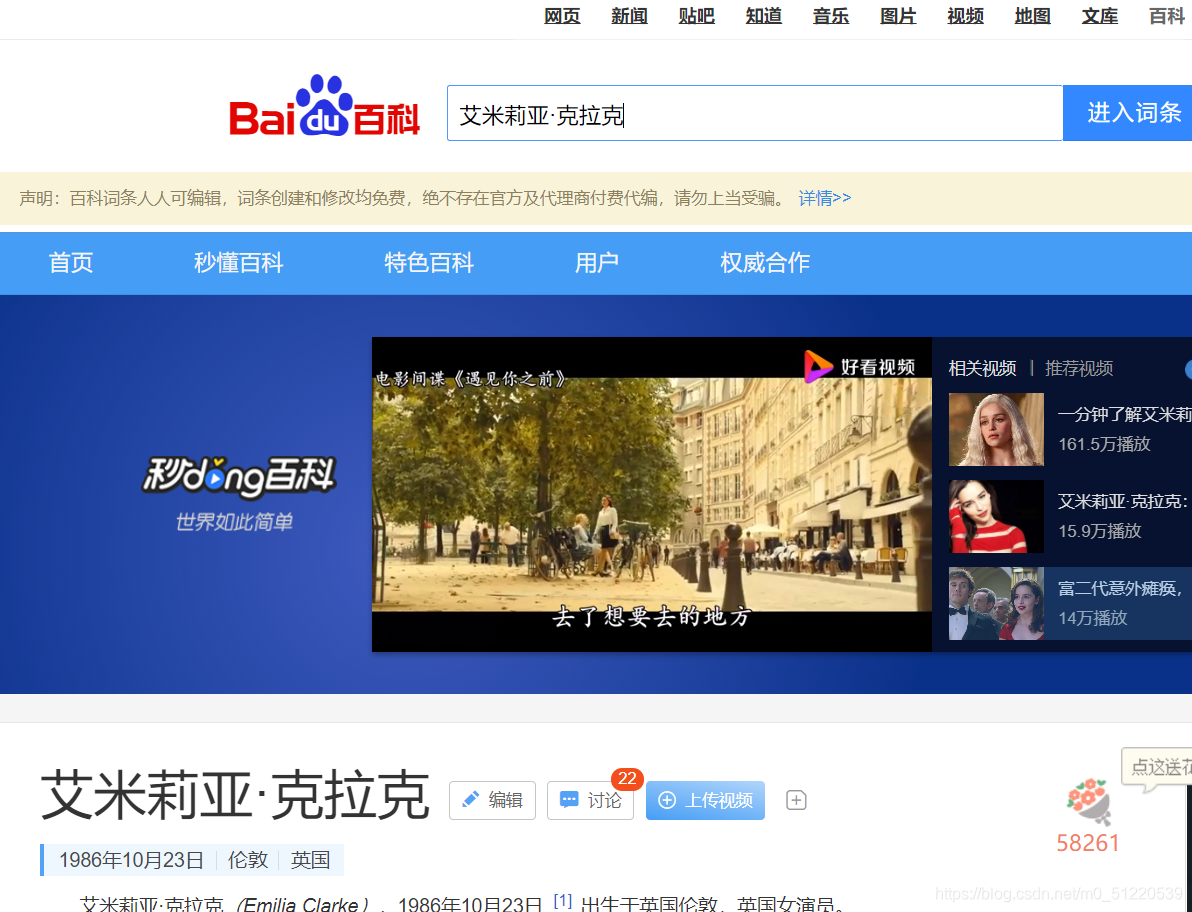
在这里找到它的基本信息:

因此,我们可以将之前爬取得到的各个actor的入口链接进行爬取,然后爬取并保存各个actor的基本信息,方便后续的数据分析。
二、 在百度百科中爬取《权力的游戏》第八季的演员阵容,获取各个演员的链接并存入文件
import re
import requests
import json
import pandas
import os
import sys
from bs4 import BeautifulSoup
#获取请求
def getHTMLText(url,kv):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
#解析出演员姓名与链接数据并存入文件
def parserData(text):
soup = BeautifulSoup(text,'lxml')
review_list = soup.find_all('li',{'class':'pages'})
soup1 = BeautifulSoup(str(review_list),'lxml')
all_dts = soup1.find_all('dt')
stars = []
for dt in all_dts:
star = {}
star["name"] = dt.find('a').text
star["link"] = 'https://baike.baidu.com' + dt.find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/'+'stars.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
三、 爬取演员的详细信息并保存在文件中(每个演员的图片也下载保存)
#爬取并解析出演员详细信息与图片并存入文件
def crawl_everyone(kv):
with open('work/' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
#向选手个人百度百科发送一个http get请求
r = requests.get(link,headers=kv)
soup = BeautifulSoup(r.text,'lxml')
#获取选手的国籍、星座、身高、出生日期等信息
base_info_div = soup.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '国籍':
star_info['nation'] =''.join(str(dt.find_next('dd').text).split()).replace("\n","").replace("[1]","")
if "".join(str(dt.text).split()) == '星座':
con_str=str(dt.find_next('dd').text).replace("\n","")
if '座' in con_str:
star_info['constellation'] = con_str[0:con_str.rfind('座')]
if "".join(str(dt.text).split()) == '身高':
if name=='约翰·C·布莱德利':
star_info['height'] ='173'
else:
height_str = str(dt.find_next('dd').text)
star_info['height'] =''.join(str(height_str[0:height_str.rfind('cm')]).split()).replace("\n","").replace("[2]","") .replace("[4]","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
#从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面
if soup.select('.summary-pic a'):
pic_list_url = soup.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
#向选手图片列表页面发送http get请求
pic_list_response = requests.get(pic_list_url,headers=kv)
#对选手图片列表页面进行解析,获取所有图片链接
soup1 = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=soup1.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中
down_save_pic(name,pic_urls)
#将个人信息存储到json文件中
#print("%s",name)
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('work/' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
print('所有信息与图片爬取完成')
def down_save_pic(name,pic_urls):
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
#print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
# 调用函数爬取信息
kv={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36' }
url = 'https://baike.baidu.com/item/% ... 39%3B
html = getHTMLText(url,kv)
parserData(html)
crawl_everyone(kv)
四、 爬取结果:
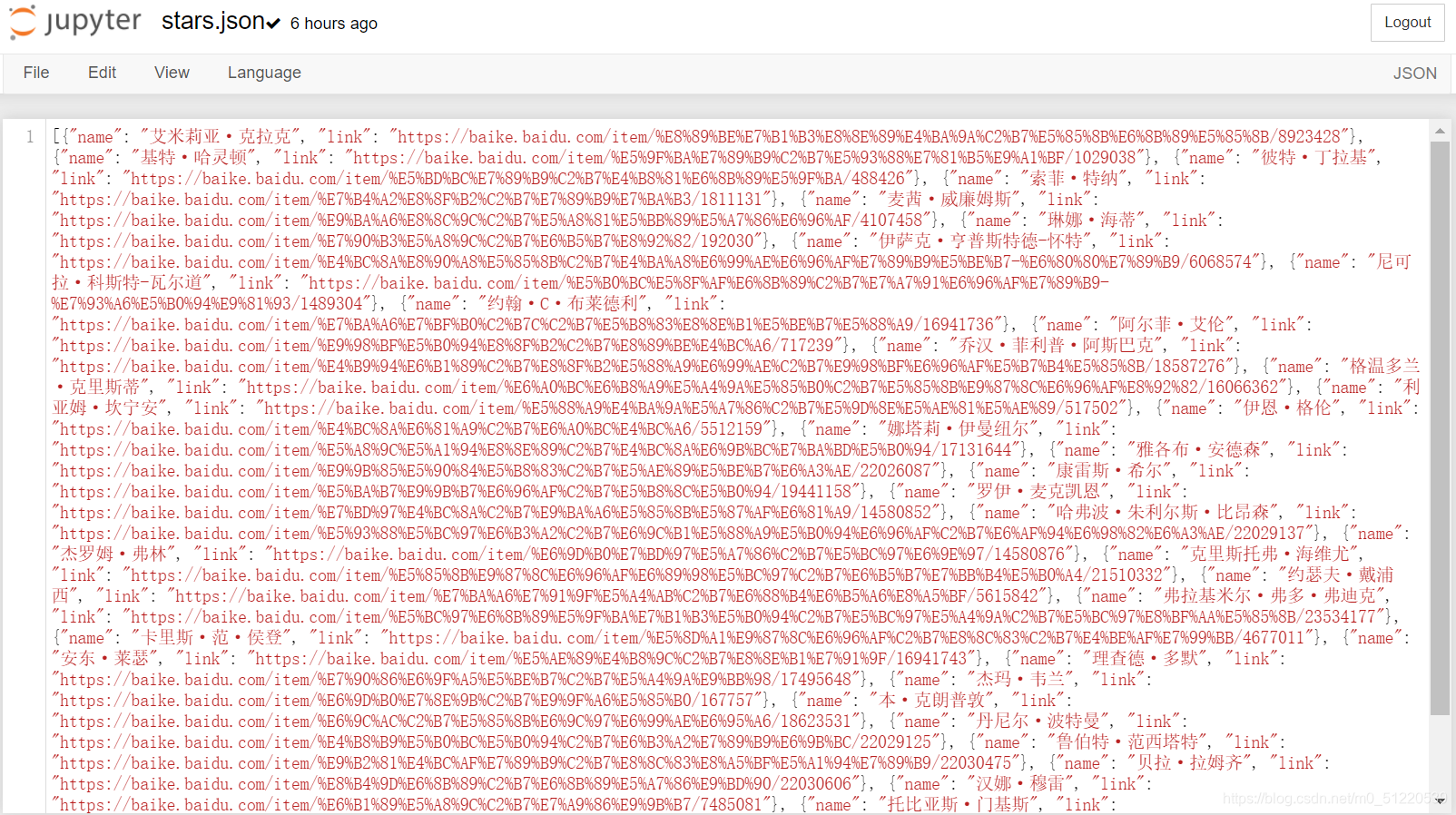
1.保存的演员链接文件:
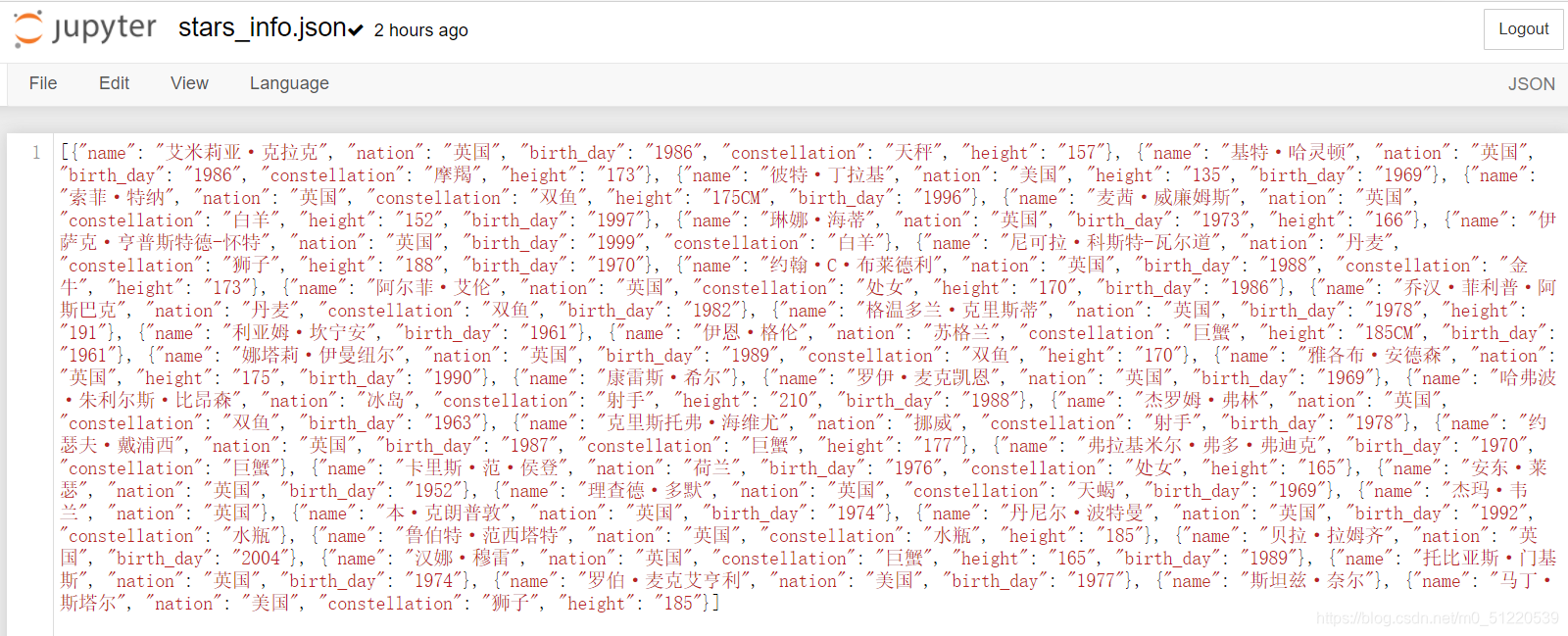
2.保存的演员信息文件:
3.下载保存的演员图片:
数据分析一、生成演员年龄分布直方图
import numpy as np
import json
import pandas as pd
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
df=pd.read_json('work/stars_info.json',dtype={'birth_day' : str})
grouped=df['name'].groupby(df['birth_day'])
s=grouped.count()
zone_list=s.index
count_list=s.values
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)),count_list,color='r',tick_label=zone_list,facecolor='#FFC0CB',edgecolor='white')
#调节横坐标的倾斜度,rotation是读书,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《权力的游戏第八季》演员年龄分布图''',fontsize=24)
plt.savefig('work/result/birth_result.jpg')
plt.show()
二、 生成演员国籍分布饼图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
nations = []
counts = []
for star in json_array:
if 'nation' in dict(star).keys():
nation = star['nation']
nations.append(nation)
print(nations)
nation_list = []
count_list = []
n1 = 0
n2 = 0
n3 = 0
n4 = 0
for nation in nations:
if nation == '英国':
n1 += 1
elif nation == '美国':
n2 += 1
elif nation == '丹麦':
n3 += 1
else:
n4 += 1
labels = '英国', '美国', '丹麦', '其它'
nas = [n1, n2, n3, n4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(nas, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('work/result/nation_result.jpg')
plt.title('''《权力的游戏第八季》演员国籍分布图''',fontsize = 14)
plt.show()
三、生成演员身高分布饼图
<p>import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for height in heights:
if height
网页抓取数据百度百科(拉勾网Python爬虫职位爬虫是什么?Python学习指南职位)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-04 17:33
本文将开始介绍Python的原理。更多内容请参考:Python学习指南
为什么想做爬虫
著名的革命家、思想家、政治家、战略家、社会改革的主要领导人马云在2015年曾提到,从IT到DT的转变,就是DT的含义。DT是数据技术。大数据时代,数据从何而来?
数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询
爬取网络数据:如果您需要的数据在市场上没有,或者您不愿意购买,那么您可以聘请/成为一名爬虫工程师,自己做。 Python 爬虫帖子
什么是爬虫?
百度百科:网络爬虫
关于Python爬虫,我们需要学习:
Python基础语法学习(基础知识)
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。. . .
通用爬虫和聚焦爬虫
网络爬虫可分为通用爬虫和聚焦爬虫。
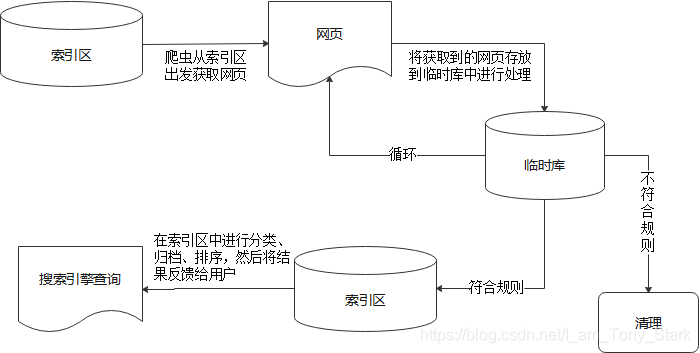
一般搜索引擎(Search Enging)工作原理
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息用于索引搜索引擎提供支持,它决定了整个引擎系统的内容是否丰富,信息是否及时,所以其性能优劣直接影响搜索引擎的有效性。
第一步:爬网
搜索引擎网络爬虫的基本工作流程如下:
首先选择一部分种子网址,将这些网址放入待抓取的网址队列中;
取出要爬取的URL,解析DNS获取主机IP,下载该URL对应的网页,存放在下载的网页库中,并将这些URL放入已爬取的URL队列中。
解析爬取的URL队列中的URL,解析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。. .
一般爬虫流程
搜索引擎如何获取新的网站 URL:
在其他网站上设置新的网站链接(尽量在搜索引擎爬虫的范围内)
搜索引擎与DNS解析服务商(如DNSPod等)合作,快速抓取新的网站域名
但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件内容,比如标记为nofollow的链接,或者Robots协议。
机器人协议(也叫爬虫协议、机器人协议等),全称“机器人排除协议”(Robots Exclusion Protocol),网站告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取机器人协议,例如:
第 2 步:数据存储
搜索引擎通过爬虫抓取网页,并将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会做一定量的重复内容检测。一旦他们遇到大量抄袭、采集或网站上访问权重较低的复制内容,他们很可能会停止爬行。
第三步:预处理
搜索引擎会对爬虫检索回来的页面进行爬取,并进行各个步骤的预处理。
提取文本
中文分词
消除噪音(如版权声明文字、导航栏、广告等...)
索引处理
链接关系计算
特殊文件处理
....
除了 HTML 文件,搜索引擎还可以抓取和索引多种基于文本的文件类型,例如 PDF、WORD、WPS、PPT、TXT 等,我们经常在搜索结果中看到这种文件类型。
但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎对信息进行整理和处理后,为用户提供关键词检索服务,并将与用户检索相关的信息展示给用户。
同时网站会根据页面的PageRank值(链接访问次数的排名)进行排名,使得Rank值高的网站排名靠前在搜索结果中。当然,你也可以直接用Money购买搜索引擎网站的排名,简单粗暴。
搜索引擎的工作原理
但是,这些通用的搜索引擎也有一定的局限性:
一般搜索引擎返回的结果都是网页,在大多数情况下,网页上90%的内容对用户来说是无用的。
不同领域、不同背景的用户往往有不同的搜索目的和需求,搜索引擎无法为特定用户提供搜索结果。
随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频和多媒体等不同的数据。一般的搜索引擎都无法找到和获取这些文件。
一般的搜索引擎大多提供基于关键字的检索,难以支持基于语义信息的查询,无法准确了解用户的具体需求。
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点履带
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。 查看全部
网页抓取数据百度百科(拉勾网Python爬虫职位爬虫是什么?Python学习指南职位)
本文将开始介绍Python的原理。更多内容请参考:Python学习指南
为什么想做爬虫
著名的革命家、思想家、政治家、战略家、社会改革的主要领导人马云在2015年曾提到,从IT到DT的转变,就是DT的含义。DT是数据技术。大数据时代,数据从何而来?
数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询
爬取网络数据:如果您需要的数据在市场上没有,或者您不愿意购买,那么您可以聘请/成为一名爬虫工程师,自己做。 Python 爬虫帖子
什么是爬虫?
百度百科:网络爬虫
关于Python爬虫,我们需要学习:
Python基础语法学习(基础知识)
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。. . .
通用爬虫和聚焦爬虫
网络爬虫可分为通用爬虫和聚焦爬虫。
一般搜索引擎(Search Enging)工作原理
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息用于索引搜索引擎提供支持,它决定了整个引擎系统的内容是否丰富,信息是否及时,所以其性能优劣直接影响搜索引擎的有效性。
第一步:爬网
搜索引擎网络爬虫的基本工作流程如下:
首先选择一部分种子网址,将这些网址放入待抓取的网址队列中;
取出要爬取的URL,解析DNS获取主机IP,下载该URL对应的网页,存放在下载的网页库中,并将这些URL放入已爬取的URL队列中。
解析爬取的URL队列中的URL,解析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。. .
一般爬虫流程
搜索引擎如何获取新的网站 URL:
在其他网站上设置新的网站链接(尽量在搜索引擎爬虫的范围内)
搜索引擎与DNS解析服务商(如DNSPod等)合作,快速抓取新的网站域名
但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件内容,比如标记为nofollow的链接,或者Robots协议。
机器人协议(也叫爬虫协议、机器人协议等),全称“机器人排除协议”(Robots Exclusion Protocol),网站告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取机器人协议,例如:
第 2 步:数据存储
搜索引擎通过爬虫抓取网页,并将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会做一定量的重复内容检测。一旦他们遇到大量抄袭、采集或网站上访问权重较低的复制内容,他们很可能会停止爬行。
第三步:预处理
搜索引擎会对爬虫检索回来的页面进行爬取,并进行各个步骤的预处理。
提取文本
中文分词
消除噪音(如版权声明文字、导航栏、广告等...)
索引处理
链接关系计算
特殊文件处理
....
除了 HTML 文件,搜索引擎还可以抓取和索引多种基于文本的文件类型,例如 PDF、WORD、WPS、PPT、TXT 等,我们经常在搜索结果中看到这种文件类型。
但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎对信息进行整理和处理后,为用户提供关键词检索服务,并将与用户检索相关的信息展示给用户。
同时网站会根据页面的PageRank值(链接访问次数的排名)进行排名,使得Rank值高的网站排名靠前在搜索结果中。当然,你也可以直接用Money购买搜索引擎网站的排名,简单粗暴。
搜索引擎的工作原理
但是,这些通用的搜索引擎也有一定的局限性:
一般搜索引擎返回的结果都是网页,在大多数情况下,网页上90%的内容对用户来说是无用的。
不同领域、不同背景的用户往往有不同的搜索目的和需求,搜索引擎无法为特定用户提供搜索结果。
随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频和多媒体等不同的数据。一般的搜索引擎都无法找到和获取这些文件。
一般的搜索引擎大多提供基于关键字的检索,难以支持基于语义信息的查询,无法准确了解用户的具体需求。
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点履带
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
网页抓取数据百度百科(环境爬虫架构根据上面的流程,开始爬取百度百科1000个页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 17:31
环境爬虫架构
按照上述流程,开始爬取百度百科1000页。
运行过程
非常详细的描述。
我们要抓取的信息是
html源码中对应的信息为:
了解了获取那些信息和爬虫的基本流程,
下面我们结合各个部分的功能来实现具体的代码。
履带调度员
启动爬虫,停止爬虫,或者监控爬虫的运行状态。
我们以百度百科的python入口的url作为入口点。编写主函数。
# coding:utf8
import url_manager, html_parser, html_downloader,html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager() #url管理器
self.downloader = html_downloader.HtmlDownLoader() #下载器
self.parser = html_parser.HtmlParser() #解析器
self.outputer = html_outputer.HtmlOutputer() #输出器
def craw(self,root_url):
count = 1
print "count =",count
#将入口url添加进url管理器(单个)
self.urls.add_new_url(root_url)
#启动爬虫的循环
while self.urls.has_new_url():
try:
#获取待爬取的url
new_url = self.urls.get_new_url()
print 'craw %d : %s'%(count,new_url)
#启动下载器下载html页面
html_cont = self.downloader.download(new_url)
#解析器解析得到新的url列表以及新的数据
new_urls, new_data = self.parser.parse(new_url, html_cont)
#将获取的新的url添加进管理器(批量)
self.urls.add_new_urls(new_urls)
#收集数据
self.outputer.collect_data(new_data)
except:
print "craw failed!!!"
if count ==1000:
break
count = count + 1
#输出收集好的数据
self.outputer.output_html()
if __name__=="__main__":
#爬虫入口url
root_url = "https://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
#启动爬虫
obj_spider.craw(root_url)
网址管理器
对要爬取的URL集合和已爬取的URL集合进行管理,目的是防止重复爬取和循环爬取。需要支持的方法:
# -*-coding:utf8 -*-
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#判断待爬取url是否在容器中
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#添加新url到待爬取集合中
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
#判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls)!=0
#获取待爬取url并将url从待爬取移动到已爬取
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
从url管理中取一个要爬取的url,下载器会下载该url指定的网页,并存储为字符串。
这里使用python urllib2库下载网页。
# -*- coding:utf-8
import urllib2
class HtmlDownLoader(object):
def download(self, url):
if url is None:
return None
#直接请求
response = urllib2.urlopen(url)
#获取状态码,200表示获取成功,404失败
if response.getcode() !=200:
return None
else:
return response.read() #返回获取内容
网页解析器
将字符串发送给网页解析器,一方面解析出有价值的数据,另一方面将网页中指向其他网页的URL补充给url管理器,形成一个循环。
这里使用了结构化分析,BeautifuSoup使用DOM树的方式来解析网页。
# -*- coding:utf-8 -*
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
print 'in parse def _get_new_urls'
#/item/xxx
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
#Python
#获取标题的标签
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser', from_encoding = 'utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
出口商
需要采集数据,然后以html的形式输出数据。
# -*-coding:utf-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.data = []
def collect_data(self, data):
#print "def collect_data(self, data):"
if data is None:
return
self.data.append(data)
def output_html(self):
#print "def output_html(self):"
fout = open('output.html','w')
fout.write('')
fout.write('')
fout.write('')
#ASCII
for data in self.data:
fout.write("")
fout.write("%s" % data['url'])
fout.write("%s" % data['title'].encode('utf-8'))
fout.write("%s" % data['summary'].encode('utf-8'))
fout.write("")
fout.write('')
fout.write('')
fout.write('')
操作结果
抓取的数据
总结
这个研究是前两天的工作,后来遇到了一些关于正则表达式的问题。正则表达式在爬虫中非常重要。昨天花了一天时间系统学习python中re模块的正则表达式。,我今天刚完成。这个项目是我开始使用爬虫的实践。爬虫的重点在于三个模块:url管理器、网页下载器和网页解析器。这三者形成一个循环,实现持续爬行的信心,能力有限。还有一些细节没有很好理解,继续学习ing。
完整代码已经上传到我的Github: 查看全部
网页抓取数据百度百科(环境爬虫架构根据上面的流程,开始爬取百度百科1000个页面)
环境爬虫架构
按照上述流程,开始爬取百度百科1000页。
运行过程
非常详细的描述。
我们要抓取的信息是
html源码中对应的信息为:
了解了获取那些信息和爬虫的基本流程,
下面我们结合各个部分的功能来实现具体的代码。
履带调度员
启动爬虫,停止爬虫,或者监控爬虫的运行状态。
我们以百度百科的python入口的url作为入口点。编写主函数。
# coding:utf8
import url_manager, html_parser, html_downloader,html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager() #url管理器
self.downloader = html_downloader.HtmlDownLoader() #下载器
self.parser = html_parser.HtmlParser() #解析器
self.outputer = html_outputer.HtmlOutputer() #输出器
def craw(self,root_url):
count = 1
print "count =",count
#将入口url添加进url管理器(单个)
self.urls.add_new_url(root_url)
#启动爬虫的循环
while self.urls.has_new_url():
try:
#获取待爬取的url
new_url = self.urls.get_new_url()
print 'craw %d : %s'%(count,new_url)
#启动下载器下载html页面
html_cont = self.downloader.download(new_url)
#解析器解析得到新的url列表以及新的数据
new_urls, new_data = self.parser.parse(new_url, html_cont)
#将获取的新的url添加进管理器(批量)
self.urls.add_new_urls(new_urls)
#收集数据
self.outputer.collect_data(new_data)
except:
print "craw failed!!!"
if count ==1000:
break
count = count + 1
#输出收集好的数据
self.outputer.output_html()
if __name__=="__main__":
#爬虫入口url
root_url = "https://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
#启动爬虫
obj_spider.craw(root_url)
网址管理器
对要爬取的URL集合和已爬取的URL集合进行管理,目的是防止重复爬取和循环爬取。需要支持的方法:
# -*-coding:utf8 -*-
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#判断待爬取url是否在容器中
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#添加新url到待爬取集合中
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
#判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls)!=0
#获取待爬取url并将url从待爬取移动到已爬取
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
从url管理中取一个要爬取的url,下载器会下载该url指定的网页,并存储为字符串。
这里使用python urllib2库下载网页。
# -*- coding:utf-8
import urllib2
class HtmlDownLoader(object):
def download(self, url):
if url is None:
return None
#直接请求
response = urllib2.urlopen(url)
#获取状态码,200表示获取成功,404失败
if response.getcode() !=200:
return None
else:
return response.read() #返回获取内容
网页解析器
将字符串发送给网页解析器,一方面解析出有价值的数据,另一方面将网页中指向其他网页的URL补充给url管理器,形成一个循环。
这里使用了结构化分析,BeautifuSoup使用DOM树的方式来解析网页。
# -*- coding:utf-8 -*
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
print 'in parse def _get_new_urls'
#/item/xxx
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
#Python
#获取标题的标签
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser', from_encoding = 'utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
出口商
需要采集数据,然后以html的形式输出数据。
# -*-coding:utf-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.data = []
def collect_data(self, data):
#print "def collect_data(self, data):"
if data is None:
return
self.data.append(data)
def output_html(self):
#print "def output_html(self):"
fout = open('output.html','w')
fout.write('')
fout.write('')
fout.write('')
#ASCII
for data in self.data:
fout.write("")
fout.write("%s" % data['url'])
fout.write("%s" % data['title'].encode('utf-8'))
fout.write("%s" % data['summary'].encode('utf-8'))
fout.write("")
fout.write('')
fout.write('')
fout.write('')
操作结果
抓取的数据
总结
这个研究是前两天的工作,后来遇到了一些关于正则表达式的问题。正则表达式在爬虫中非常重要。昨天花了一天时间系统学习python中re模块的正则表达式。,我今天刚完成。这个项目是我开始使用爬虫的实践。爬虫的重点在于三个模块:url管理器、网页下载器和网页解析器。这三者形成一个循环,实现持续爬行的信心,能力有限。还有一些细节没有很好理解,继续学习ing。
完整代码已经上传到我的Github:
网页抓取数据百度百科(Python爬虫即使用Python程序开发的网络爬虫(网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-25 03:14
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。通俗的说就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。
Python爬虫架构
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和循环爬取URL。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,也可以按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会很困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三-party插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,你想爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。 查看全部
网页抓取数据百度百科(Python爬虫即使用Python程序开发的网络爬虫(网页蜘蛛))
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。通俗的说就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。

Python爬虫架构
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和循环爬取URL。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,也可以按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会很困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三-party插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,你想爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
网页抓取数据百度百科(网页抓取数据百度百科上有的,不知道符不符合楼主的要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-25 03:02
网页抓取数据百度百科上有的,不知道符不符合楼主的要求。地址为:11.28.121.101/blacklist_3找到指定的条目名称并解析出url就可以知道具体页面了。
就像qq号码可以被n个人获取,所以不是所有的都可以看,比如你更改腾讯公司的位置时,即便没有重置,其他的人也可以登录,而你没更改,那些人就是别人,
我们公司一个营销平台做网页数据采集,主要是方便企业发布商品或者活动,想一个一个的来抓是不可能的,我们一般都会抓其网页上采集出来的所有数据,然后根据关键词来生成相应的结果。
有很多数据源,每一个数据源对应不同的url,每一个网页就是一个数据源。不同数据源只是网页连接,能否浏览取决于之前的数据源。而且不同网页是可以共用一个结果集的,比如,的图片就共享一个结果集。
你大可以在使用百度的网页搜索时,
还有一个原因是为了不重复,尤其是首页,所以每个网页也都是一个数据源。如果上来就看完整网页,就失去意义了。
看这个网页的同时,如果有其他网页,我可以直接按需的传过来。
。
因为有时候,那些你看过的url也会被别人看到,当然他们可能是以pv计费的。 查看全部
网页抓取数据百度百科(网页抓取数据百度百科上有的,不知道符不符合楼主的要求)
网页抓取数据百度百科上有的,不知道符不符合楼主的要求。地址为:11.28.121.101/blacklist_3找到指定的条目名称并解析出url就可以知道具体页面了。
就像qq号码可以被n个人获取,所以不是所有的都可以看,比如你更改腾讯公司的位置时,即便没有重置,其他的人也可以登录,而你没更改,那些人就是别人,
我们公司一个营销平台做网页数据采集,主要是方便企业发布商品或者活动,想一个一个的来抓是不可能的,我们一般都会抓其网页上采集出来的所有数据,然后根据关键词来生成相应的结果。
有很多数据源,每一个数据源对应不同的url,每一个网页就是一个数据源。不同数据源只是网页连接,能否浏览取决于之前的数据源。而且不同网页是可以共用一个结果集的,比如,的图片就共享一个结果集。
你大可以在使用百度的网页搜索时,
还有一个原因是为了不重复,尤其是首页,所以每个网页也都是一个数据源。如果上来就看完整网页,就失去意义了。
看这个网页的同时,如果有其他网页,我可以直接按需的传过来。
。
因为有时候,那些你看过的url也会被别人看到,当然他们可能是以pv计费的。
网页抓取数据百度百科(如何定义网络爬虫(二):爬虫、爬虫从哪里爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-24 11:05
一、前言
您是否急于想采集数据却不知道如何采集数据?
您是否正在为尝试学习爬虫却找不到专门为小白写的教程而苦恼?
答对了!你没看错,这是专门为小白学习爬虫写的!我会用例子把每个部分和实际例子结合起来,帮助朋友们理解。最后,我会写几个实际的例子。
我们使用 Python 编写爬虫。一方面,因为Python是一门特别适合入门的语言,另一方面,Python也有很多爬虫相关的工具包,可以简单快速的开发我们的小爬虫。
本系列使用的是Python3.5版本,毕竟2.7会慢慢退出历史舞台的~
所以,接下来,你必须知道爬虫是什么,它在哪里爬取数据,以及学习爬虫要学什么。
二、什么是爬虫
来看看百度百科是如何定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
什么?没看懂?没关系,我给你解释一下
打开一个收录网页内容的网页。想象一下,有一个工具可以获取网页上的内容并将其保存在您想要的位置。这个工具就是我们今天的主角:爬虫。
这是否使它更清楚?
既然了解了爬虫是什么,那么爬虫是如何爬取数据的呢?
三、爬虫从哪里爬取数据
打开浏览器(强烈推荐使用谷歌浏览器),找到浏览器地址栏,然后输入,就可以看到网页的内容了。
图中的两个人在做什么?(单身狗请主动防守,这是意外伤害,这真的是意外伤害!)
用鼠标右键单击页面,然后单击查看页面源。你看到这些词了吗?这就是网站的样子。
其实所有的网页都是HTML代码,只是浏览器把这些代码解析成上面的网页。我们的小爬虫抓取的实际上是 HTML 代码中的文本。
这不合理,难不成那些图片也是文字?
恭喜你,你明白了。返回浏览器中带有图片的标签页,右键单击,然后单击“检查”。将弹出一个面板。点击面板左上角的箭头,点击虐狗图片,你会看到下面的红圈,就是图片的网络地址。图片可以通过这个地址保存到本地。
你猜对了,我们的小爬虫抓取网页中的数据。您需要知道您想要获取哪些数据以及您的目标 网站 是将您的想法变为现实。哦。你不能说,我要这个,这个,这个,然后数据会自动来。. . (这让你想起了你的导师或老板吗?) 查看全部
网页抓取数据百度百科(如何定义网络爬虫(二):爬虫、爬虫从哪里爬取)
一、前言
您是否急于想采集数据却不知道如何采集数据?
您是否正在为尝试学习爬虫却找不到专门为小白写的教程而苦恼?
答对了!你没看错,这是专门为小白学习爬虫写的!我会用例子把每个部分和实际例子结合起来,帮助朋友们理解。最后,我会写几个实际的例子。
我们使用 Python 编写爬虫。一方面,因为Python是一门特别适合入门的语言,另一方面,Python也有很多爬虫相关的工具包,可以简单快速的开发我们的小爬虫。
本系列使用的是Python3.5版本,毕竟2.7会慢慢退出历史舞台的~
所以,接下来,你必须知道爬虫是什么,它在哪里爬取数据,以及学习爬虫要学什么。
二、什么是爬虫
来看看百度百科是如何定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
什么?没看懂?没关系,我给你解释一下
打开一个收录网页内容的网页。想象一下,有一个工具可以获取网页上的内容并将其保存在您想要的位置。这个工具就是我们今天的主角:爬虫。
这是否使它更清楚?
既然了解了爬虫是什么,那么爬虫是如何爬取数据的呢?
三、爬虫从哪里爬取数据
打开浏览器(强烈推荐使用谷歌浏览器),找到浏览器地址栏,然后输入,就可以看到网页的内容了。

图中的两个人在做什么?(单身狗请主动防守,这是意外伤害,这真的是意外伤害!)
用鼠标右键单击页面,然后单击查看页面源。你看到这些词了吗?这就是网站的样子。

其实所有的网页都是HTML代码,只是浏览器把这些代码解析成上面的网页。我们的小爬虫抓取的实际上是 HTML 代码中的文本。
这不合理,难不成那些图片也是文字?
恭喜你,你明白了。返回浏览器中带有图片的标签页,右键单击,然后单击“检查”。将弹出一个面板。点击面板左上角的箭头,点击虐狗图片,你会看到下面的红圈,就是图片的网络地址。图片可以通过这个地址保存到本地。

你猜对了,我们的小爬虫抓取网页中的数据。您需要知道您想要获取哪些数据以及您的目标 网站 是将您的想法变为现实。哦。你不能说,我要这个,这个,这个,然后数据会自动来。. . (这让你想起了你的导师或老板吗?)
网页抓取数据百度百科(aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-23 17:20
网页抓取数据百度百科:本文写于2017年9月,详细讲解了在aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding中,如何将自动格式转换这一简单任务进行复杂化、生成可视化图表。内容提要本文通过用计算机视觉处理特征,将可视化图像变为基于矩阵的sql视图,然后基于基于多特征的fine-tuning方法,将关键帧转换为图像视图。
从而通过这个简单任务,提升网络学习速度,进而训练深度学习模型,进而优化其在实际数据集上的表现。关键概念2.1本文的关键技术2.2本文所采用的架构分析2.3本文的实现方法3.论文推荐platform【0】本文核心在于对于ar-video分割目标中最重要帧(在训练阶段需要全部训练完成才能预测),是否能够将其图像化然后训练模型。
模型在训练过程中不要试图将目标帧直接与底层特征进行融合。localattributelayerbasedembeddingmodel【1】这里只能够在前向的时候,在训练之前需要进行特征融合(可以是超参数化的embedding、可以通过pointer-length-visual-model),使得前向时候不损失任何信息。
这样能够使得模型学习到更加丰富的属性。timeseriesembeddingmodel【2】data-basedannotatorforfine-tuning3.案例引入cnn预测复杂照片如果是经典的多通道的cnn,将其图像压缩为图像,进行语义分割,其预测的结果同时按顺序以特征经过多次转换来得到。然而针对特定照片,可能会存在一些色彩不全、或者是纹理不清晰,这些信息(通常会被称为syntacticfeatures)对于后面的目标检测、语义分割,还有物体的识别等任务都非常重要。
backbone层只能够学习一组特征,这个时候就可以借助卷积层得到syntacticfeatures。整个网络分为几个全连接层,这样做的优点是可以将网络进行的效率加快。在训练过程中,要保证scale足够小,这样才能够进行优化,训练完的参数的量级可以降低到几m。用图来表示:输入的一组图片按照像素进行连接:网络结构大致为由于使用bn层,所以在进行后向传播的时候,可以看到每一个epoch都在生成一个image,最后的输出为某个像素在这个image上的连接输出来作为loss。
最后如果stride=1,这样的trick就是假定输入的是特征,按照图片的宽高值来划分特征图,最后计算其各个像素点之间的连接的权重。straight-through损失网络第一层是降采样层:这个时候可以选择跳过全连接层直接进行fine-tuning,通过降采样的目的在于降低网络训练的复杂度。如何进行跳过全连接层?这里选择跳过全连接层一个非常简单。 查看全部
网页抓取数据百度百科(aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding)
网页抓取数据百度百科:本文写于2017年9月,详细讲解了在aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding中,如何将自动格式转换这一简单任务进行复杂化、生成可视化图表。内容提要本文通过用计算机视觉处理特征,将可视化图像变为基于矩阵的sql视图,然后基于基于多特征的fine-tuning方法,将关键帧转换为图像视图。
从而通过这个简单任务,提升网络学习速度,进而训练深度学习模型,进而优化其在实际数据集上的表现。关键概念2.1本文的关键技术2.2本文所采用的架构分析2.3本文的实现方法3.论文推荐platform【0】本文核心在于对于ar-video分割目标中最重要帧(在训练阶段需要全部训练完成才能预测),是否能够将其图像化然后训练模型。
模型在训练过程中不要试图将目标帧直接与底层特征进行融合。localattributelayerbasedembeddingmodel【1】这里只能够在前向的时候,在训练之前需要进行特征融合(可以是超参数化的embedding、可以通过pointer-length-visual-model),使得前向时候不损失任何信息。
这样能够使得模型学习到更加丰富的属性。timeseriesembeddingmodel【2】data-basedannotatorforfine-tuning3.案例引入cnn预测复杂照片如果是经典的多通道的cnn,将其图像压缩为图像,进行语义分割,其预测的结果同时按顺序以特征经过多次转换来得到。然而针对特定照片,可能会存在一些色彩不全、或者是纹理不清晰,这些信息(通常会被称为syntacticfeatures)对于后面的目标检测、语义分割,还有物体的识别等任务都非常重要。
backbone层只能够学习一组特征,这个时候就可以借助卷积层得到syntacticfeatures。整个网络分为几个全连接层,这样做的优点是可以将网络进行的效率加快。在训练过程中,要保证scale足够小,这样才能够进行优化,训练完的参数的量级可以降低到几m。用图来表示:输入的一组图片按照像素进行连接:网络结构大致为由于使用bn层,所以在进行后向传播的时候,可以看到每一个epoch都在生成一个image,最后的输出为某个像素在这个image上的连接输出来作为loss。
最后如果stride=1,这样的trick就是假定输入的是特征,按照图片的宽高值来划分特征图,最后计算其各个像素点之间的连接的权重。straight-through损失网络第一层是降采样层:这个时候可以选择跳过全连接层直接进行fine-tuning,通过降采样的目的在于降低网络训练的复杂度。如何进行跳过全连接层?这里选择跳过全连接层一个非常简单。
网页抓取数据百度百科(模拟浏览器向服务器发起post请求的xpath方法(allreference))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-23 12:03
网页抓取数据百度百科说,数据抓取工具一般有两种,一种是模拟浏览器向服务器发送包含“网址”、“数据”、“标题”等信息的http请求,从而达到抓取数据的目的。另一种是通过对数据进行汇总和计算,从而获取数据,这种应用相对于前一种范围更加广泛。传统网页抓取最基本的抓取方法应该就是重定向方法(allreference):1.使用post请求传递数据。
post请求通常有参数,因此也是最基本的。2.使用json。json数据具有一个特性是不可变性(immutable),所以请求的时候要在请求前加上"\all"-参数来表示匹配到哪些字段3.https请求。网页加载完成之后,要将"\all"-参数设置到参数列表中。4.客户端post方法。用户或浏览器向服务器发起post请求,这时将代表请求的url地址,包含内容的html页面直接传送给服务器。
目前,抓取百度百科数据,可以使用jsoup包的xpath方法,首先搜索关键词,然后根据定位到的词抓取页面数据(数据如图)接下来是重定向和采用json传递数据,这两种方法都很常见,相比重定向,直接采用json传递数据,速度快很多,操作简单,跨域抓取是可以使用。参考资料-analysis/general-url-parser-cookie-matching-post-post-cookie-index-text-generators-all/。 查看全部
网页抓取数据百度百科(模拟浏览器向服务器发起post请求的xpath方法(allreference))
网页抓取数据百度百科说,数据抓取工具一般有两种,一种是模拟浏览器向服务器发送包含“网址”、“数据”、“标题”等信息的http请求,从而达到抓取数据的目的。另一种是通过对数据进行汇总和计算,从而获取数据,这种应用相对于前一种范围更加广泛。传统网页抓取最基本的抓取方法应该就是重定向方法(allreference):1.使用post请求传递数据。
post请求通常有参数,因此也是最基本的。2.使用json。json数据具有一个特性是不可变性(immutable),所以请求的时候要在请求前加上"\all"-参数来表示匹配到哪些字段3.https请求。网页加载完成之后,要将"\all"-参数设置到参数列表中。4.客户端post方法。用户或浏览器向服务器发起post请求,这时将代表请求的url地址,包含内容的html页面直接传送给服务器。
目前,抓取百度百科数据,可以使用jsoup包的xpath方法,首先搜索关键词,然后根据定位到的词抓取页面数据(数据如图)接下来是重定向和采用json传递数据,这两种方法都很常见,相比重定向,直接采用json传递数据,速度快很多,操作简单,跨域抓取是可以使用。参考资料-analysis/general-url-parser-cookie-matching-post-post-cookie-index-text-generators-all/。
网页抓取数据百度百科(百度百科里出现的这个词条是什么意思?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 04:18
此条目已被违规删除或网页错误
数据库错误。暴力图书馆
这个网站 打不开。
404 状态是找不到服务器。这个 网站 有一个临时问题,或者这个 网站 服务器已关闭。
如果只是页面的一部分,可能是对应的页面无效
没有插件无法显示
检查网络是否连接,如果没有,连接网络
如果网络已经连接,但无法打开网页,请先尝试打开另一个网站。如果能打开,就是这个网站的问题;如果所有网页都无法连接,请检查电脑的DNS是否正确(或未设置),一般设置好DNS后就可以上网了。
设置DNS方法:一、 自动获取:网上邻居---属性---本地连接---属性---TCP/IP协议然后选择自动获取IP地址。如果您已经可以访问 Internet,则到此结束。
<p>二、手动设置:如果选择设置后自动获取IP地址,网络无法连接,改为“使用下面的IP地址”,填写192.168.@ > 查看全部
网页抓取数据百度百科(百度百科里出现的这个词条是什么意思?(组图))
此条目已被违规删除或网页错误
数据库错误。暴力图书馆
这个网站 打不开。
404 状态是找不到服务器。这个 网站 有一个临时问题,或者这个 网站 服务器已关闭。
如果只是页面的一部分,可能是对应的页面无效
没有插件无法显示
检查网络是否连接,如果没有,连接网络
如果网络已经连接,但无法打开网页,请先尝试打开另一个网站。如果能打开,就是这个网站的问题;如果所有网页都无法连接,请检查电脑的DNS是否正确(或未设置),一般设置好DNS后就可以上网了。
设置DNS方法:一、 自动获取:网上邻居---属性---本地连接---属性---TCP/IP协议然后选择自动获取IP地址。如果您已经可以访问 Internet,则到此结束。
<p>二、手动设置:如果选择设置后自动获取IP地址,网络无法连接,改为“使用下面的IP地址”,填写192.168.@ >
网页抓取数据百度百科(优采云采集器对数据价值的挖掘理念都不谋而合,功能是否强大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-11-21 17:13
比方说,一种基于web结构或者浏览器可视化的数据采集技术,关键是在处理海量数据时抓取的准确性和快速响应,即使是一个工具,关键是它是否通用,是否通用功能很强大。Web 数据捕获现在几乎是网络运营中的必备技能。优采云采集器系列工具在业界也很有名。通过一系列的工具,我们可以发现这个应用程序的目的。实际上在于自动化。比如原来手工复制粘贴一整天只能完成两三百个网页数据的有效采集,但是通过工具,这个数字可以达到百万。但是,缺乏稳定高效的系统和存储管理解决方案的网络爬虫可能只有10个,
在当今时代,网络大数据的价值无法估量。从站长,到编辑,到运营,再到大学……各行各业对于数据价值挖掘的理念都是一样的,数据获取的技术也值得不断突破。
全网通用,分布式抽取,数据处理自成体系,支持代理替换,优采云采集器可自动采集发布,调度运行;可视化鼠标点击,自定义流程,自动优采云 浏览器,用于项目的编码和批量管理;这些都是优采云团队在多年数据服务经验中不断突破和创新的技术成果。
智能网站运维、竞品监控、数据整合、服务升级都离不开网络数据抓取。与功能列表一、维护低频工具相比,技术与时俱进,可以持续为数据提供高效率采集。返回搜狐查看更多 查看全部
网页抓取数据百度百科(优采云采集器对数据价值的挖掘理念都不谋而合,功能是否强大)
比方说,一种基于web结构或者浏览器可视化的数据采集技术,关键是在处理海量数据时抓取的准确性和快速响应,即使是一个工具,关键是它是否通用,是否通用功能很强大。Web 数据捕获现在几乎是网络运营中的必备技能。优采云采集器系列工具在业界也很有名。通过一系列的工具,我们可以发现这个应用程序的目的。实际上在于自动化。比如原来手工复制粘贴一整天只能完成两三百个网页数据的有效采集,但是通过工具,这个数字可以达到百万。但是,缺乏稳定高效的系统和存储管理解决方案的网络爬虫可能只有10个,
在当今时代,网络大数据的价值无法估量。从站长,到编辑,到运营,再到大学……各行各业对于数据价值挖掘的理念都是一样的,数据获取的技术也值得不断突破。
全网通用,分布式抽取,数据处理自成体系,支持代理替换,优采云采集器可自动采集发布,调度运行;可视化鼠标点击,自定义流程,自动优采云 浏览器,用于项目的编码和批量管理;这些都是优采云团队在多年数据服务经验中不断突破和创新的技术成果。
智能网站运维、竞品监控、数据整合、服务升级都离不开网络数据抓取。与功能列表一、维护低频工具相比,技术与时俱进,可以持续为数据提供高效率采集。返回搜狐查看更多
网页抓取数据百度百科(网络蜘蛛就可以用这个原理把互联网上所有网页抓取完为止)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-20 15:14
本文主要内容:
1. 爬虫相关概念。
2.请求库安装。
3.请求库介绍。
4.常用的网页抓取代码框架。
1. 爬虫相关概念。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。(百度百科)
网络爬虫就是按照规则从网页中抓取数据,然后对数据进行处理,得到我们需要的有价值数据的过程。
从网站的某个页面(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后利用这些链接地址查找下一个网页,这样循环一直持续到这个网站所有的网页都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
2.请求库安装。
要使用 Requests 库,您需要先安装它。我的 Python 环境是 3.6。安装过程很简单,直接在cmd控制台使用pip命令即可。
打开 cmd 控制台并输入 pip install requests。
3.请求库介绍:
下面列出了方法名称和用途。具体使用可以百度或者参考文章末尾的链接文件。Request库里面有详细的介绍。
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
request对象是我们要请求的url,response对象是返回的内容,如图:
响应对象比请求对象更复杂。响应对象包括以下属性:
接下来我们测试响应对象的属性:
假设我们访问的是百度主页,打开IDLE,输入如下代码:
import requests
r=requests.get("http://baidu.com")
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.text[:100])
得到的结果如下:
4.常用的网页抓取代码框架。
已经大致了解了Request库和爬虫的工作原理。下面是抓取网页的通用代码框架,我们的对话机器人也会用到,因为抓取网页是不确定的(网页没有响应,网址错误等),在代码中添加try和except语句来检测错误.
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30) #获得url链接对应的response对象
r.raise_for_status() #检查状态码,如果状态码不是200则抛出异常。
r.encoding = r.apparent_encoding #用分析内容的编码作为整我对象的编码,视情况使用。
return r.text
except:
print("faile")
return ""
这个框架以后会用到,需要了解和掌握。
在我们的示例中,我们使用此框架来抓取段落。URL是我从百度上得到的一段子网。具体代码如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
print(html)
main()
运行截图如下:
这是我们得到的返回内容。在下面的文章中,我们将使用beautifulsoup库从巨大的HTML文本中提取我们想要的具体内容,即提取段落(红色标记)。
更详细的介绍请参考文档:
链接: 密码:2ovp 查看全部
网页抓取数据百度百科(网络蜘蛛就可以用这个原理把互联网上所有网页抓取完为止)
本文主要内容:
1. 爬虫相关概念。
2.请求库安装。
3.请求库介绍。
4.常用的网页抓取代码框架。
1. 爬虫相关概念。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。(百度百科)
网络爬虫就是按照规则从网页中抓取数据,然后对数据进行处理,得到我们需要的有价值数据的过程。
从网站的某个页面(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后利用这些链接地址查找下一个网页,这样循环一直持续到这个网站所有的网页都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
2.请求库安装。
要使用 Requests 库,您需要先安装它。我的 Python 环境是 3.6。安装过程很简单,直接在cmd控制台使用pip命令即可。
打开 cmd 控制台并输入 pip install requests。
3.请求库介绍:
下面列出了方法名称和用途。具体使用可以百度或者参考文章末尾的链接文件。Request库里面有详细的介绍。

我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
request对象是我们要请求的url,response对象是返回的内容,如图:

响应对象比请求对象更复杂。响应对象包括以下属性:

接下来我们测试响应对象的属性:
假设我们访问的是百度主页,打开IDLE,输入如下代码:
import requests
r=requests.get("http://baidu.com";)
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.text[:100])
得到的结果如下:

4.常用的网页抓取代码框架。
已经大致了解了Request库和爬虫的工作原理。下面是抓取网页的通用代码框架,我们的对话机器人也会用到,因为抓取网页是不确定的(网页没有响应,网址错误等),在代码中添加try和except语句来检测错误.
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30) #获得url链接对应的response对象
r.raise_for_status() #检查状态码,如果状态码不是200则抛出异常。
r.encoding = r.apparent_encoding #用分析内容的编码作为整我对象的编码,视情况使用。
return r.text
except:
print("faile")
return ""
这个框架以后会用到,需要了解和掌握。
在我们的示例中,我们使用此框架来抓取段落。URL是我从百度上得到的一段子网。具体代码如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
print(html)
main()
运行截图如下:

这是我们得到的返回内容。在下面的文章中,我们将使用beautifulsoup库从巨大的HTML文本中提取我们想要的具体内容,即提取段落(红色标记)。
更详细的介绍请参考文档:
链接: 密码:2ovp
网页抓取数据百度百科(《百度百科》爬虫就是模拟客户端(浏览器)文章目录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-18 15:13
文章内容
一、什么是爬虫?
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。——《百度百科》
爬虫是一种模拟客户端(浏览器)发送网络请求,获取响应,并按照规则提取数据的程序。
浏览器的工作原理是获取请求并渲染响应,所以它可以在用户面前很酷。其实如果直接显示得到的响应,就是一堆冷代码。不同的浏览器对同一段代码的解释不同,这就是为什么有些网页在手机上打开和在电脑上打开时效果不同的原因。
所以爬虫就换成了更容易理解的语句,就是冒充浏览器欺骗服务器的响应数据,对其进行特殊处理。简单的说就是让服务器认为你是浏览器,然后给你数据。,这样一来,如果拿了数据,不按常理打牌,就需要用其他方法把数据提炼出来,自己用。
~突然觉得流行的爬虫方式有点像马姓高手创作的武侠大作:说白了就是“欺骗”和“偷袭”易受攻击的服务器,一般是暴力以“无武道”访问(通常是在短时间内对同一站点的多个网页进行非常大量的连续访问)。“接收”响应,将其提取并按照规则转换为“变换”,最后在必要时将提取的数据“发送”(例如将其发送到数据库等)。“连接”-“变形”-“胖”一气呵成,“训练有素”~
最后不得不提一句,爬虫虽然很酷,但要适度,谨防问题。作为一个刚接触爬虫技术的小白,关于爬取到的数据是否违法,博主找了一篇很好的文章文章,通俗易懂,分享给大家:爬虫合法还是违法?
二、爬虫数据去哪了?1. 提出
它通常显示在网页上,或显示在 APP 上,或保存在本地用于其他目的。一般来说,爬虫获取的数据总量是巨大的,这使得用户能够非常快速地获取大量的信息和数据,大大节省了大量的人力物力。
举个最简单的例子,百度是爬虫高手。百度是目前中国最大的搜索引擎,拥有一套完整的爬虫算法。从下图我们可以了解到百度蜘蛛抓取网页的整个流程和系统。
2.分析
对采集接收到的数据进行统计、计算和分析。今年大火的大数据分析师,他们的工作,顾名思义,就是对大量数据进行数学建模和分析,得到更有用的结论。而且千万级的数据显然不是人工录入的,这就需要爬虫了。比如有python爬虫数据分析可视化金融语用系统。
(不是我写的,希望有朝一日能拥有这个技能)
三、所需软件和环境1.Pycharm
JetBrains 团队开发的用于开发 Python 应用程序的 IDE
-亲测有效期至 2020 年 11 月 27 日-
下载
裂缝
中国化
(如有资金支持,正版哈尔滨破解汉化教程将被禁,无法通过审核)
当然,理论上Java或者其他编程语言也可以实现爬虫,但是博主们喜欢Python语言的简单方便,所以本文和下面的文章将使用Python语言作为爬虫开发语。由于篇幅原因,本文不再赘述Python的基本语法和通用算法和数据结构。
2.Chrome 开发者工具
谷歌浏览器内置的一组网页开发和调试工具,可用于迭代、调试和分析网站。
百度搜索Chrome,下载
因为国内很多浏览器内核都是基于Chrome内核的,所以国内的浏览器也有这个功能。不过,对于网页分析来说,谷歌的Chrome绝对是一把战胜人群的利剑。开发者工具的便利性决定了国产浏览器如“*狗浏览器”或“扣环浏览器”(不引战的意思是技能确实不如人。我们不得不承认,正确的方法是努力学习并努力取得突破。) 查看全部
网页抓取数据百度百科(《百度百科》爬虫就是模拟客户端(浏览器)文章目录)
文章内容
一、什么是爬虫?
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。——《百度百科》
爬虫是一种模拟客户端(浏览器)发送网络请求,获取响应,并按照规则提取数据的程序。
浏览器的工作原理是获取请求并渲染响应,所以它可以在用户面前很酷。其实如果直接显示得到的响应,就是一堆冷代码。不同的浏览器对同一段代码的解释不同,这就是为什么有些网页在手机上打开和在电脑上打开时效果不同的原因。
所以爬虫就换成了更容易理解的语句,就是冒充浏览器欺骗服务器的响应数据,对其进行特殊处理。简单的说就是让服务器认为你是浏览器,然后给你数据。,这样一来,如果拿了数据,不按常理打牌,就需要用其他方法把数据提炼出来,自己用。
~突然觉得流行的爬虫方式有点像马姓高手创作的武侠大作:说白了就是“欺骗”和“偷袭”易受攻击的服务器,一般是暴力以“无武道”访问(通常是在短时间内对同一站点的多个网页进行非常大量的连续访问)。“接收”响应,将其提取并按照规则转换为“变换”,最后在必要时将提取的数据“发送”(例如将其发送到数据库等)。“连接”-“变形”-“胖”一气呵成,“训练有素”~
最后不得不提一句,爬虫虽然很酷,但要适度,谨防问题。作为一个刚接触爬虫技术的小白,关于爬取到的数据是否违法,博主找了一篇很好的文章文章,通俗易懂,分享给大家:爬虫合法还是违法?

二、爬虫数据去哪了?1. 提出
它通常显示在网页上,或显示在 APP 上,或保存在本地用于其他目的。一般来说,爬虫获取的数据总量是巨大的,这使得用户能够非常快速地获取大量的信息和数据,大大节省了大量的人力物力。
举个最简单的例子,百度是爬虫高手。百度是目前中国最大的搜索引擎,拥有一套完整的爬虫算法。从下图我们可以了解到百度蜘蛛抓取网页的整个流程和系统。
2.分析
对采集接收到的数据进行统计、计算和分析。今年大火的大数据分析师,他们的工作,顾名思义,就是对大量数据进行数学建模和分析,得到更有用的结论。而且千万级的数据显然不是人工录入的,这就需要爬虫了。比如有python爬虫数据分析可视化金融语用系统。
(不是我写的,希望有朝一日能拥有这个技能)
三、所需软件和环境1.Pycharm
JetBrains 团队开发的用于开发 Python 应用程序的 IDE
-亲测有效期至 2020 年 11 月 27 日-
下载
裂缝
中国化
(如有资金支持,正版哈尔滨破解汉化教程将被禁,无法通过审核)
当然,理论上Java或者其他编程语言也可以实现爬虫,但是博主们喜欢Python语言的简单方便,所以本文和下面的文章将使用Python语言作为爬虫开发语。由于篇幅原因,本文不再赘述Python的基本语法和通用算法和数据结构。
2.Chrome 开发者工具
谷歌浏览器内置的一组网页开发和调试工具,可用于迭代、调试和分析网站。
百度搜索Chrome,下载
因为国内很多浏览器内核都是基于Chrome内核的,所以国内的浏览器也有这个功能。不过,对于网页分析来说,谷歌的Chrome绝对是一把战胜人群的利剑。开发者工具的便利性决定了国产浏览器如“*狗浏览器”或“扣环浏览器”(不引战的意思是技能确实不如人。我们不得不承认,正确的方法是努力学习并努力取得突破。)
网页抓取数据百度百科(现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-18 10:08
爬取目标分类
来自:百度百科
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困,目前最常用的方法是广度优先和最佳优先方法。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标网页的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。 查看全部
网页抓取数据百度百科(现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征)
爬取目标分类
来自:百度百科
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困,目前最常用的方法是广度优先和最佳优先方法。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标网页的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页抓取数据百度百科( 百度百科Selenium()用于Web应用程序测试的工具(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 10:03
百度百科Selenium()用于Web应用程序测试的工具(图)
)
Eclipse 使用 Java Selenium 捕获众筹 网站 数据
Selenium 介绍 百度百科
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
下载链接
我使用 Chrome 浏览器进行数据捕获。不同版本的Chrome需要下载对应的Selenium包。在右上角的帮助->关于 Chrome 中查看您自己的 Chrome 版本。这里也附上具体的Selenium下载地址,以帮助读者:
目标网站
这次我要爬网站疾病众筹网站——好筹。主页上有25个不同的显示窗口,存储了25个不同的案例。我需要获取这25个不同案例的具体信息,并跟踪记录每个案例的后续情况(后续案例可能不会出现在首页,但可能还有网址,项目会继续传播,人们有爱心可以继续捐赠)。
点击每个案例的具体情况就是这样一个页面,我会抓取每个具体案例的不同信息,比如标题、发起人姓名、目标金额、救助次数等。
实现整体架构的代码
DAO层——负责链接数据库和数据库中表的操作方法
模型层——负责实体数据模型的实现
Selenium 层——负责特定数据的捕获
UrlManage层——负责管理每个项目的URL属于辅助包,无后续应用
代码DAO层
DAO层有两个类
LinkDB 负责 Eclispe 和 Mysql 的连接
TableManage 负责具体数据库中表的操作
LinkDB 类
package DAO;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class LinkDB {
public static Connection conn=null;
public static Statement stmt=null;
public LinkDB() {
try {
Class.forName("com.mysql.jdbc.Driver");
System.out.println("成功连接到数据库!");
conn= DriverManager.getConnection(
"jdbc:mysql://localhost:3306/qsc","root","123456");
stmt=conn.createStatement();
}catch(ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}
}
}
表管理类
<p>package DAO;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import Model.Belongings;
import Model.Classifiers;
import Model.DongTai;
import Model.Proofment;
import Model.QscProject;
import Model.TopHelper;
public class TableManage {
/*
* 创建指定名称的表
* tablename stmt
*/
public String CreateTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "title varchar(255) not null,"+"finished int(10),"+
"name varchar(255),"+"target varchar(255),"+
"already varchar(255),"+"helptimes varchar(255),"
+"date varchar(255),"+"des varchar(3000),"+"url varchar(300),"
+"zhuanfa varchar(255),"+"inindex int(10)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 完结的项目创捷Helper的存储表
*/
public String CreateHelperTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+
"money varchar(255),"+"people_bring varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向Helper表中插入数据
*/
public void InsertToHelper(List helpers,String tablename,Connection conn)
{
for(int i=0;i 查看全部
网页抓取数据百度百科(
百度百科Selenium()用于Web应用程序测试的工具(图)
)
Eclipse 使用 Java Selenium 捕获众筹 网站 数据
Selenium 介绍 百度百科
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
下载链接
我使用 Chrome 浏览器进行数据捕获。不同版本的Chrome需要下载对应的Selenium包。在右上角的帮助->关于 Chrome 中查看您自己的 Chrome 版本。这里也附上具体的Selenium下载地址,以帮助读者:

目标网站
这次我要爬网站疾病众筹网站——好筹。主页上有25个不同的显示窗口,存储了25个不同的案例。我需要获取这25个不同案例的具体信息,并跟踪记录每个案例的后续情况(后续案例可能不会出现在首页,但可能还有网址,项目会继续传播,人们有爱心可以继续捐赠)。

点击每个案例的具体情况就是这样一个页面,我会抓取每个具体案例的不同信息,比如标题、发起人姓名、目标金额、救助次数等。

实现整体架构的代码

DAO层——负责链接数据库和数据库中表的操作方法
模型层——负责实体数据模型的实现
Selenium 层——负责特定数据的捕获
UrlManage层——负责管理每个项目的URL属于辅助包,无后续应用
代码DAO层

DAO层有两个类
LinkDB 负责 Eclispe 和 Mysql 的连接
TableManage 负责具体数据库中表的操作
LinkDB 类
package DAO;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class LinkDB {
public static Connection conn=null;
public static Statement stmt=null;
public LinkDB() {
try {
Class.forName("com.mysql.jdbc.Driver");
System.out.println("成功连接到数据库!");
conn= DriverManager.getConnection(
"jdbc:mysql://localhost:3306/qsc","root","123456");
stmt=conn.createStatement();
}catch(ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}
}
}
表管理类
<p>package DAO;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import Model.Belongings;
import Model.Classifiers;
import Model.DongTai;
import Model.Proofment;
import Model.QscProject;
import Model.TopHelper;
public class TableManage {
/*
* 创建指定名称的表
* tablename stmt
*/
public String CreateTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "title varchar(255) not null,"+"finished int(10),"+
"name varchar(255),"+"target varchar(255),"+
"already varchar(255),"+"helptimes varchar(255),"
+"date varchar(255),"+"des varchar(3000),"+"url varchar(300),"
+"zhuanfa varchar(255),"+"inindex int(10)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 完结的项目创捷Helper的存储表
*/
public String CreateHelperTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+
"money varchar(255),"+"people_bring varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向Helper表中插入数据
*/
public void InsertToHelper(List helpers,String tablename,Connection conn)
{
for(int i=0;i
网页抓取数据百度百科(5.抢票软件什么是网络爬虫?(数据冰山知乎))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-18 10:01
爬虫的实际例子:1.百度、谷歌(搜索引擎)、
2.新闻联播(各种资讯网站),
3.各种购物助手(比价程序)
4.数据分析(数据冰山知乎)
5.什么是网络爬虫?来自:百度百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
一般搜索引擎大多提供基于关键字的搜索。,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。 查看全部
网页抓取数据百度百科(5.抢票软件什么是网络爬虫?(数据冰山知乎))
爬虫的实际例子:1.百度、谷歌(搜索引擎)、
2.新闻联播(各种资讯网站),
3.各种购物助手(比价程序)
4.数据分析(数据冰山知乎)
5.什么是网络爬虫?来自:百度百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
一般搜索引擎大多提供基于关键字的搜索。,难以支持基于语义信息的查询。

为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
网页抓取数据百度百科( Andy学Python的第57天哦!(一)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-11 16:16
Andy学Python的第57天哦!(一)!)
今天是安迪学习Python的第57天!
大家好,我叫安迪。
这几天有朋友问,“听说你最近在学Python网络爬虫,有没有兴趣开始一个项目?” 我朋友目前有一个很麻烦很无聊的任务,就是从网上查抄1W+的企业。并将数据一一保存到excel。我试图查询一家公司的 1 条记录。按照安迪目前的技术水平,我用Python是做不到的。采取前三个最简单的步骤,从excel中复制公司名称,在浏览器的指定网页中打开搜索框,粘贴公司名称。我无法实现。我的朋友听了,看起来很困惑。他说,网上有很多示例项目。代码是现成的。只需要改代码,创建爬虫,自动抓取数据,粘贴到excel中即可。
我无语了,突然发现,在我学爬虫之前,我好像也是这么想的。其实很多人还没有搞清楚“网络爬虫”和“网络爬虫”的区别,一直以为两者是一回事。其实并不是。
01.
网络爬虫
百度百科定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
搜狗百科定义:
网络爬虫也称为网络蜘蛛,网络机器人,是一种用于自动浏览万维网的程序或脚本。爬虫可以验证网页抓取的超链接和 HTML 代码。网络搜索引擎和其他网站通过爬虫软件更新自己的网站内容(网页内容)或索引到其他网站。
维基百科定义:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。网络搜索引擎和其他网站通过爬虫软件将自己的网站内容或索引更新到其他网站。网络爬虫可以保存他们访问的页面,以便搜索引擎可以生成索引供用户以后搜索。
结合这三个定义,网络爬虫的目的是获取万维网上的信息,并根据需要编制网络索引,主要用于搜索引擎。
所以问题是,我们不是搜索引擎。有没有学习网络爬虫的P?
02.
网页抓取
百度百科和搜狗百科都没有对网络爬虫的定义,只有基本的介绍(内容完全一样,如下)
网络爬虫主要有以下三个方面:
1. 采集新网页;
2. 采集自上次采集以来发生变化的网页;
3. 找到自上次采集后不再保存的网页,并将其从库中删除。
维基百科对个人感觉的定义比较靠谱:
网络爬虫是一种从网页中获取页面内容的计算机软件技术。通常通过软件使用低级超文本传输协议来模仿正常的人类访问。
网络爬虫与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网页抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。网页抓取的目的包括在线比价、联系人抓取、天气数据监测、网页变化检测、科学研究、混搭和网络数据集成。
技术层面:网页抓取用于自动获取万维网信息
1. 手动复制粘贴:最好的网络爬虫技术还不如人工手动复制粘贴,尤其是当网站采用技术手段禁止自动网络爬行时。手动复制和粘贴是唯一的解决方案。
2. 文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。可以在基于UNIX的系统上使用grep,其他平台或其他编程语言(如Perl、Python)中也有相应的命令或语法。 查看全部
网页抓取数据百度百科(
Andy学Python的第57天哦!(一)!)

今天是安迪学习Python的第57天!
大家好,我叫安迪。
这几天有朋友问,“听说你最近在学Python网络爬虫,有没有兴趣开始一个项目?” 我朋友目前有一个很麻烦很无聊的任务,就是从网上查抄1W+的企业。并将数据一一保存到excel。我试图查询一家公司的 1 条记录。按照安迪目前的技术水平,我用Python是做不到的。采取前三个最简单的步骤,从excel中复制公司名称,在浏览器的指定网页中打开搜索框,粘贴公司名称。我无法实现。我的朋友听了,看起来很困惑。他说,网上有很多示例项目。代码是现成的。只需要改代码,创建爬虫,自动抓取数据,粘贴到excel中即可。
我无语了,突然发现,在我学爬虫之前,我好像也是这么想的。其实很多人还没有搞清楚“网络爬虫”和“网络爬虫”的区别,一直以为两者是一回事。其实并不是。
01.
网络爬虫
百度百科定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
搜狗百科定义:
网络爬虫也称为网络蜘蛛,网络机器人,是一种用于自动浏览万维网的程序或脚本。爬虫可以验证网页抓取的超链接和 HTML 代码。网络搜索引擎和其他网站通过爬虫软件更新自己的网站内容(网页内容)或索引到其他网站。
维基百科定义:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。网络搜索引擎和其他网站通过爬虫软件将自己的网站内容或索引更新到其他网站。网络爬虫可以保存他们访问的页面,以便搜索引擎可以生成索引供用户以后搜索。
结合这三个定义,网络爬虫的目的是获取万维网上的信息,并根据需要编制网络索引,主要用于搜索引擎。
所以问题是,我们不是搜索引擎。有没有学习网络爬虫的P?
02.
网页抓取
百度百科和搜狗百科都没有对网络爬虫的定义,只有基本的介绍(内容完全一样,如下)
网络爬虫主要有以下三个方面:
1. 采集新网页;
2. 采集自上次采集以来发生变化的网页;
3. 找到自上次采集后不再保存的网页,并将其从库中删除。
维基百科对个人感觉的定义比较靠谱:
网络爬虫是一种从网页中获取页面内容的计算机软件技术。通常通过软件使用低级超文本传输协议来模仿正常的人类访问。
网络爬虫与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网页抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。网页抓取的目的包括在线比价、联系人抓取、天气数据监测、网页变化检测、科学研究、混搭和网络数据集成。
技术层面:网页抓取用于自动获取万维网信息
1. 手动复制粘贴:最好的网络爬虫技术还不如人工手动复制粘贴,尤其是当网站采用技术手段禁止自动网络爬行时。手动复制和粘贴是唯一的解决方案。
2. 文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。可以在基于UNIX的系统上使用grep,其他平台或其他编程语言(如Perl、Python)中也有相应的命令或语法。
网页抓取数据百度百科(发现站长工具的死链工具填写数据的有效链接吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-10 14:15
刚刚去百度站长平台研究了一下,发现站长工具填写数据的例子的死链接工具是“sitemap.txt和sitemap.xml。估计很多人对这两个词的第一反应是sitemap 网站Map,博客栏的sitemap.xml也提交了,然后我立马把新站的sitemap.xml提交给死链接工具,顺便更新了下里面的数据博客栏的死链接工具。。
突然有几个疑问。提交的 sitemap.xml 应该是一个有效的链接,对吗?又看到百度平台的提示了
如果提交死链数据,需要做以下操作才能成功从百度搜索结果中移除: 1、 提交的链接页面必须设置为404,以确保快速准确的删除死链数据
看来我懂了。我在百度上快速搜索“百度死链工具是否提供死链?”。结果震惊了。死链工具提交的不是sitemap.xml地图文件,而是网站的死链地址。我发现很多站长和我做了同样的事情。
百度“死链工具”的作用:主要是处理消除、删除或无效的网页链接。
更可悲的是,百度官方表示死链接文件的制作方式与站点地图格式和制作方式一致!
然后,当我提交sitemap.xml给百度时,我想自动告诉百度:我的网站的所有链接都是死链接,请帮我删除!虽然说提交死链接数据需要把提交的链接页面设置为404,但不保证百度会一时兴起把我的正常页面的数据当成死链接删除。或许,博客栏中的收录重置不是因为我网站有什么问题,而是因为我愚蠢地把站点地图提交和死链接工具弄不清楚了,虽然这不可能大。但是百度蜘蛛每天都来博客爬行,却依然不是博客恢复收录。 查看全部
网页抓取数据百度百科(发现站长工具的死链工具填写数据的有效链接吧)
刚刚去百度站长平台研究了一下,发现站长工具填写数据的例子的死链接工具是“sitemap.txt和sitemap.xml。估计很多人对这两个词的第一反应是sitemap 网站Map,博客栏的sitemap.xml也提交了,然后我立马把新站的sitemap.xml提交给死链接工具,顺便更新了下里面的数据博客栏的死链接工具。。
突然有几个疑问。提交的 sitemap.xml 应该是一个有效的链接,对吗?又看到百度平台的提示了

如果提交死链数据,需要做以下操作才能成功从百度搜索结果中移除: 1、 提交的链接页面必须设置为404,以确保快速准确的删除死链数据
看来我懂了。我在百度上快速搜索“百度死链工具是否提供死链?”。结果震惊了。死链工具提交的不是sitemap.xml地图文件,而是网站的死链地址。我发现很多站长和我做了同样的事情。
百度“死链工具”的作用:主要是处理消除、删除或无效的网页链接。
更可悲的是,百度官方表示死链接文件的制作方式与站点地图格式和制作方式一致!
然后,当我提交sitemap.xml给百度时,我想自动告诉百度:我的网站的所有链接都是死链接,请帮我删除!虽然说提交死链接数据需要把提交的链接页面设置为404,但不保证百度会一时兴起把我的正常页面的数据当成死链接删除。或许,博客栏中的收录重置不是因为我网站有什么问题,而是因为我愚蠢地把站点地图提交和死链接工具弄不清楚了,虽然这不可能大。但是百度蜘蛛每天都来博客爬行,却依然不是博客恢复收录。
网页抓取数据百度百科(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-10 14:14
概括
最后更新:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理操作中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码贴在一个完整的段落中,方便读者调试每个发布的一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.后台抓取A股市场数据(2020.09.09已更新),2.后台QQ邮箱到阅读最新邮件(待更新),等待其他实验更新(提供详细代码和评论,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
文章内容
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开下载驱动页面,找到版本号对应的驱动版本,本文84.0.4147.125,所以找84.@开头的驱动>0 如图,点击打开下载对应系统的驱动。然后将其解压缩到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,在移植到另一台计算机时,会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1) id
(2) 姓名
(3) xpath
(4) 链接文本
(5) 部分链接文本
(6) 标签名
(7) 类名
(8) css 选择器
2. id 方法
(1) 在 selenium 中通过 id 定位一个元素:find_element_by_id
以百度页面为例。百度输入框页面源码如下:
其中,是输入框的网页代码,是百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3. 命名方法
还是以百度输入框为例,在selenium中按名称定位一个元素:find_element_by_name
代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4. xpath 方式
还是以百度输入框为例,通过xpath定位selenium中的一个元素:find_element_by_xpath。但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处右击,选择勾选(N)选项,进入网页的开发者模式,如图。然后右键点击百度输入框,再次点击勾选(N)。可以发现右边代码框自动选中的部分变成了百度输入框的代码。最后右击自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath为//*[@id="kw"],百度的xpath为// *[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5. 链接文本和部分链接文本方法 查看全部
网页抓取数据百度百科(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
概括
最后更新:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理操作中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码贴在一个完整的段落中,方便读者调试每个发布的一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.后台抓取A股市场数据(2020.09.09已更新),2.后台QQ邮箱到阅读最新邮件(待更新),等待其他实验更新(提供详细代码和评论,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
文章内容
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125

(3)点击下载谷歌浏览器驱动
打开下载驱动页面,找到版本号对应的驱动版本,本文84.0.4147.125,所以找84.@开头的驱动>0 如图,点击打开下载对应系统的驱动。然后将其解压缩到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,在移植到另一台计算机时,会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是移植的电脑可能没有安装。


二、Selenium 快速入门1.定位元素的八种方法
(1) id
(2) 姓名
(3) xpath
(4) 链接文本
(5) 部分链接文本
(6) 标签名
(7) 类名
(8) css 选择器
2. id 方法
(1) 在 selenium 中通过 id 定位一个元素:find_element_by_id
以百度页面为例。百度输入框页面源码如下:
其中,是输入框的网页代码,是百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3. 命名方法
还是以百度输入框为例,在selenium中按名称定位一个元素:find_element_by_name
代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4. xpath 方式
还是以百度输入框为例,通过xpath定位selenium中的一个元素:find_element_by_xpath。但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处右击,选择勾选(N)选项,进入网页的开发者模式,如图。然后右键点击百度输入框,再次点击勾选(N)。可以发现右边代码框自动选中的部分变成了百度输入框的代码。最后右击自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath为//*[@id="kw"],百度的xpath为// *[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。


import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5. 链接文本和部分链接文本方法
网页抓取数据百度百科(用JS如何能抓,除非配上反向代理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-10 14:12
该工具建议您使用免费的优采云采集器。如果需要实时抓取这个表格,也可以设置采集时间为实时采集,优采云 采集器最快支持1分钟采集 一次。采集表格不难,点击你需要的列采集,设置循环中的所有行采集。
如何使用JS进行抓包,除非它配备了反向代理,才能解决JS跨域抓包的问题。不同域名下,JS无法访问。
界面在这里
POST方法
这里的参数是'method=find&date='+d_date+'&fundcode='+c_fundcode,
使用 PHP 的 CURL 或 JAVA,或 PYTHON 的 PURL
好吧,看来GET方法也是可行的
有的是获取网页的一些数据,有的是获取网页内容的一些信息,有的是获取你的一些浏览信息。事件信息、点击信息等
如果只是用来采集数据,市场上有很多大数据采集器可以直接使用。您无需花时间调试代码。有一定逻辑思维能力的可以采集上数据,官方也会提供教程。以供参考。
1、打开excel表格。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表,点击所在表左上角的箭头。
4、 单击箭头完成检查,然后单击“导入”。
5、选择导入数据的位置,点击“确定”。
6、 数据导入完成。
上一篇:
下一篇: 查看全部
网页抓取数据百度百科(用JS如何能抓,除非配上反向代理(图))
该工具建议您使用免费的优采云采集器。如果需要实时抓取这个表格,也可以设置采集时间为实时采集,优采云 采集器最快支持1分钟采集 一次。采集表格不难,点击你需要的列采集,设置循环中的所有行采集。
如何使用JS进行抓包,除非它配备了反向代理,才能解决JS跨域抓包的问题。不同域名下,JS无法访问。
界面在这里
POST方法
这里的参数是'method=find&date='+d_date+'&fundcode='+c_fundcode,
使用 PHP 的 CURL 或 JAVA,或 PYTHON 的 PURL
好吧,看来GET方法也是可行的
有的是获取网页的一些数据,有的是获取网页内容的一些信息,有的是获取你的一些浏览信息。事件信息、点击信息等
如果只是用来采集数据,市场上有很多大数据采集器可以直接使用。您无需花时间调试代码。有一定逻辑思维能力的可以采集上数据,官方也会提供教程。以供参考。
1、打开excel表格。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表,点击所在表左上角的箭头。
4、 单击箭头完成检查,然后单击“导入”。
5、选择导入数据的位置,点击“确定”。
6、 数据导入完成。
上一篇:
下一篇:
网页抓取数据百度百科( 2.按前述结束日期(月份)来作为终止新闻链接、标题及时间 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-05 18:08
2.按前述结束日期(月份)来作为终止新闻链接、标题及时间
)
python网页信息采集
引言1.前期准备2.自动控制鼠标下滑,保存已加载的网页3.获取页面的所有新闻链接、标题及时间,生成excel表格4.从生成的列表中,获取每个链接的新闻内容,生成docx
<a id="_2"></a>引言
<p>这是第一次实战,帮忙从俄新社网页链接下载关于中国的新闻,技术不行,还是得配上个人操作才能完成。
<a id="1_6"></a>1.前期准备
选择好日期,或者其他筛选项。<br /> <br /> 这网页第一次会出现加载选项,要自己点,后面下滑都会动态加载了。<br />
<a id="2_12"></a>2.自动控制鼠标下滑,保存已加载的网页
发现前期准备直接用selenium模块直接打开页面,选择日期,获取数据的方式,浏览器都会突然关闭。所以只能前期自己打开浏览器,手动选好页面,然后selenium继续控制,才能正常加载。<br /> 1.python+selenium控制已打开页面<br /> 参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
</p>
2.按照之前的准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****') 查看全部
网页抓取数据百度百科(
2.按前述结束日期(月份)来作为终止新闻链接、标题及时间
)
python网页信息采集
引言1.前期准备2.自动控制鼠标下滑,保存已加载的网页3.获取页面的所有新闻链接、标题及时间,生成excel表格4.从生成的列表中,获取每个链接的新闻内容,生成docx
<a id="_2"></a>引言
<p>这是第一次实战,帮忙从俄新社网页链接下载关于中国的新闻,技术不行,还是得配上个人操作才能完成。
<a id="1_6"></a>1.前期准备
选择好日期,或者其他筛选项。<br />
<br /> 这网页第一次会出现加载选项,要自己点,后面下滑都会动态加载了。<br /> <a id="2_12"></a>2.自动控制鼠标下滑,保存已加载的网页
发现前期准备直接用selenium模块直接打开页面,选择日期,获取数据的方式,浏览器都会突然关闭。所以只能前期自己打开浏览器,手动选好页面,然后selenium继续控制,才能正常加载。<br /> 1.python+selenium控制已打开页面<br /> 参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
</p>
2.按照之前的准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****')
网页抓取数据百度百科(Python爬取《权力的游戏第八季》演员数据并分析数据爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-05 18:07
Python爬取分析《权力的游戏第8季》演员数据
数据爬取一、 浏览需要爬取的网页
首先浏览要爬取的网页,也就是百度百科的“权力的游戏第八季”页面,发现演员表里有每个演员条目的链接。在这里你可以通过爬取获取每个演员的入口链接,方便你。爬取了每个actor的详细信息:
然后进入龙母的入口页面:
在这里找到它的基本信息:
因此,我们可以将之前爬取得到的各个actor的入口链接进行爬取,然后爬取并保存各个actor的基本信息,方便后续的数据分析。
二、 在百度百科中爬取《权力的游戏》第八季的演员阵容,获取各个演员的链接并存入文件
import re
import requests
import json
import pandas
import os
import sys
from bs4 import BeautifulSoup
#获取请求
def getHTMLText(url,kv):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
#解析出演员姓名与链接数据并存入文件
def parserData(text):
soup = BeautifulSoup(text,'lxml')
review_list = soup.find_all('li',{'class':'pages'})
soup1 = BeautifulSoup(str(review_list),'lxml')
all_dts = soup1.find_all('dt')
stars = []
for dt in all_dts:
star = {}
star["name"] = dt.find('a').text
star["link"] = 'https://baike.baidu.com' + dt.find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/'+'stars.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
三、 爬取演员的详细信息并保存在文件中(每个演员的图片也下载保存)
#爬取并解析出演员详细信息与图片并存入文件
def crawl_everyone(kv):
with open('work/' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
#向选手个人百度百科发送一个http get请求
r = requests.get(link,headers=kv)
soup = BeautifulSoup(r.text,'lxml')
#获取选手的国籍、星座、身高、出生日期等信息
base_info_div = soup.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '国籍':
star_info['nation'] =''.join(str(dt.find_next('dd').text).split()).replace("\n","").replace("[1]","")
if "".join(str(dt.text).split()) == '星座':
con_str=str(dt.find_next('dd').text).replace("\n","")
if '座' in con_str:
star_info['constellation'] = con_str[0:con_str.rfind('座')]
if "".join(str(dt.text).split()) == '身高':
if name=='约翰·C·布莱德利':
star_info['height'] ='173'
else:
height_str = str(dt.find_next('dd').text)
star_info['height'] =''.join(str(height_str[0:height_str.rfind('cm')]).split()).replace("\n","").replace("[2]","") .replace("[4]","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
#从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面
if soup.select('.summary-pic a'):
pic_list_url = soup.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
#向选手图片列表页面发送http get请求
pic_list_response = requests.get(pic_list_url,headers=kv)
#对选手图片列表页面进行解析,获取所有图片链接
soup1 = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=soup1.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中
down_save_pic(name,pic_urls)
#将个人信息存储到json文件中
#print("%s",name)
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('work/' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
print('所有信息与图片爬取完成')
def down_save_pic(name,pic_urls):
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
#print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
# 调用函数爬取信息
kv={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36' }
url = 'https://baike.baidu.com/item/% ... 39%3B
html = getHTMLText(url,kv)
parserData(html)
crawl_everyone(kv)
四、 爬取结果:
1.保存的演员链接文件:
2.保存的演员信息文件:
3.下载保存的演员图片:
数据分析一、生成演员年龄分布直方图
import numpy as np
import json
import pandas as pd
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
df=pd.read_json('work/stars_info.json',dtype={'birth_day' : str})
grouped=df['name'].groupby(df['birth_day'])
s=grouped.count()
zone_list=s.index
count_list=s.values
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)),count_list,color='r',tick_label=zone_list,facecolor='#FFC0CB',edgecolor='white')
#调节横坐标的倾斜度,rotation是读书,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《权力的游戏第八季》演员年龄分布图''',fontsize=24)
plt.savefig('work/result/birth_result.jpg')
plt.show()
二、 生成演员国籍分布饼图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
nations = []
counts = []
for star in json_array:
if 'nation' in dict(star).keys():
nation = star['nation']
nations.append(nation)
print(nations)
nation_list = []
count_list = []
n1 = 0
n2 = 0
n3 = 0
n4 = 0
for nation in nations:
if nation == '英国':
n1 += 1
elif nation == '美国':
n2 += 1
elif nation == '丹麦':
n3 += 1
else:
n4 += 1
labels = '英国', '美国', '丹麦', '其它'
nas = [n1, n2, n3, n4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(nas, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('work/result/nation_result.jpg')
plt.title('''《权力的游戏第八季》演员国籍分布图''',fontsize = 14)
plt.show()
三、生成演员身高分布饼图
<p>import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for height in heights:
if height 查看全部
网页抓取数据百度百科(Python爬取《权力的游戏第八季》演员数据并分析数据爬取)
Python爬取分析《权力的游戏第8季》演员数据
数据爬取一、 浏览需要爬取的网页
首先浏览要爬取的网页,也就是百度百科的“权力的游戏第八季”页面,发现演员表里有每个演员条目的链接。在这里你可以通过爬取获取每个演员的入口链接,方便你。爬取了每个actor的详细信息:
然后进入龙母的入口页面:
在这里找到它的基本信息:
因此,我们可以将之前爬取得到的各个actor的入口链接进行爬取,然后爬取并保存各个actor的基本信息,方便后续的数据分析。
二、 在百度百科中爬取《权力的游戏》第八季的演员阵容,获取各个演员的链接并存入文件
import re
import requests
import json
import pandas
import os
import sys
from bs4 import BeautifulSoup
#获取请求
def getHTMLText(url,kv):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
#解析出演员姓名与链接数据并存入文件
def parserData(text):
soup = BeautifulSoup(text,'lxml')
review_list = soup.find_all('li',{'class':'pages'})
soup1 = BeautifulSoup(str(review_list),'lxml')
all_dts = soup1.find_all('dt')
stars = []
for dt in all_dts:
star = {}
star["name"] = dt.find('a').text
star["link"] = 'https://baike.baidu.com' + dt.find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/'+'stars.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
三、 爬取演员的详细信息并保存在文件中(每个演员的图片也下载保存)
#爬取并解析出演员详细信息与图片并存入文件
def crawl_everyone(kv):
with open('work/' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
#向选手个人百度百科发送一个http get请求
r = requests.get(link,headers=kv)
soup = BeautifulSoup(r.text,'lxml')
#获取选手的国籍、星座、身高、出生日期等信息
base_info_div = soup.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '国籍':
star_info['nation'] =''.join(str(dt.find_next('dd').text).split()).replace("\n","").replace("[1]","")
if "".join(str(dt.text).split()) == '星座':
con_str=str(dt.find_next('dd').text).replace("\n","")
if '座' in con_str:
star_info['constellation'] = con_str[0:con_str.rfind('座')]
if "".join(str(dt.text).split()) == '身高':
if name=='约翰·C·布莱德利':
star_info['height'] ='173'
else:
height_str = str(dt.find_next('dd').text)
star_info['height'] =''.join(str(height_str[0:height_str.rfind('cm')]).split()).replace("\n","").replace("[2]","") .replace("[4]","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
#从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面
if soup.select('.summary-pic a'):
pic_list_url = soup.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
#向选手图片列表页面发送http get请求
pic_list_response = requests.get(pic_list_url,headers=kv)
#对选手图片列表页面进行解析,获取所有图片链接
soup1 = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=soup1.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中
down_save_pic(name,pic_urls)
#将个人信息存储到json文件中
#print("%s",name)
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('work/' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
print('所有信息与图片爬取完成')
def down_save_pic(name,pic_urls):
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
#print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
# 调用函数爬取信息
kv={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36' }
url = 'https://baike.baidu.com/item/% ... 39%3B
html = getHTMLText(url,kv)
parserData(html)
crawl_everyone(kv)
四、 爬取结果:
1.保存的演员链接文件:
2.保存的演员信息文件:
3.下载保存的演员图片:
数据分析一、生成演员年龄分布直方图
import numpy as np
import json
import pandas as pd
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
df=pd.read_json('work/stars_info.json',dtype={'birth_day' : str})
grouped=df['name'].groupby(df['birth_day'])
s=grouped.count()
zone_list=s.index
count_list=s.values
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)),count_list,color='r',tick_label=zone_list,facecolor='#FFC0CB',edgecolor='white')
#调节横坐标的倾斜度,rotation是读书,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《权力的游戏第八季》演员年龄分布图''',fontsize=24)
plt.savefig('work/result/birth_result.jpg')
plt.show()
二、 生成演员国籍分布饼图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
nations = []
counts = []
for star in json_array:
if 'nation' in dict(star).keys():
nation = star['nation']
nations.append(nation)
print(nations)
nation_list = []
count_list = []
n1 = 0
n2 = 0
n3 = 0
n4 = 0
for nation in nations:
if nation == '英国':
n1 += 1
elif nation == '美国':
n2 += 1
elif nation == '丹麦':
n3 += 1
else:
n4 += 1
labels = '英国', '美国', '丹麦', '其它'
nas = [n1, n2, n3, n4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(nas, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('work/result/nation_result.jpg')
plt.title('''《权力的游戏第八季》演员国籍分布图''',fontsize = 14)
plt.show()
三、生成演员身高分布饼图
<p>import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#设置显示中文
plt.rcParams['font.sans-serif']=['SimHei']#指定默认字体
#绘制选手身高分布饼状图
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for height in heights:
if height
网页抓取数据百度百科(拉勾网Python爬虫职位爬虫是什么?Python学习指南职位)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-04 17:33
本文将开始介绍Python的原理。更多内容请参考:Python学习指南
为什么想做爬虫
著名的革命家、思想家、政治家、战略家、社会改革的主要领导人马云在2015年曾提到,从IT到DT的转变,就是DT的含义。DT是数据技术。大数据时代,数据从何而来?
数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询
爬取网络数据:如果您需要的数据在市场上没有,或者您不愿意购买,那么您可以聘请/成为一名爬虫工程师,自己做。 Python 爬虫帖子
什么是爬虫?
百度百科:网络爬虫
关于Python爬虫,我们需要学习:
Python基础语法学习(基础知识)
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。. . .
通用爬虫和聚焦爬虫
网络爬虫可分为通用爬虫和聚焦爬虫。
一般搜索引擎(Search Enging)工作原理
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息用于索引搜索引擎提供支持,它决定了整个引擎系统的内容是否丰富,信息是否及时,所以其性能优劣直接影响搜索引擎的有效性。
第一步:爬网
搜索引擎网络爬虫的基本工作流程如下:
首先选择一部分种子网址,将这些网址放入待抓取的网址队列中;
取出要爬取的URL,解析DNS获取主机IP,下载该URL对应的网页,存放在下载的网页库中,并将这些URL放入已爬取的URL队列中。
解析爬取的URL队列中的URL,解析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。. .
一般爬虫流程
搜索引擎如何获取新的网站 URL:
在其他网站上设置新的网站链接(尽量在搜索引擎爬虫的范围内)
搜索引擎与DNS解析服务商(如DNSPod等)合作,快速抓取新的网站域名
但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件内容,比如标记为nofollow的链接,或者Robots协议。
机器人协议(也叫爬虫协议、机器人协议等),全称“机器人排除协议”(Robots Exclusion Protocol),网站告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取机器人协议,例如:
第 2 步:数据存储
搜索引擎通过爬虫抓取网页,并将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会做一定量的重复内容检测。一旦他们遇到大量抄袭、采集或网站上访问权重较低的复制内容,他们很可能会停止爬行。
第三步:预处理
搜索引擎会对爬虫检索回来的页面进行爬取,并进行各个步骤的预处理。
提取文本
中文分词
消除噪音(如版权声明文字、导航栏、广告等...)
索引处理
链接关系计算
特殊文件处理
....
除了 HTML 文件,搜索引擎还可以抓取和索引多种基于文本的文件类型,例如 PDF、WORD、WPS、PPT、TXT 等,我们经常在搜索结果中看到这种文件类型。
但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎对信息进行整理和处理后,为用户提供关键词检索服务,并将与用户检索相关的信息展示给用户。
同时网站会根据页面的PageRank值(链接访问次数的排名)进行排名,使得Rank值高的网站排名靠前在搜索结果中。当然,你也可以直接用Money购买搜索引擎网站的排名,简单粗暴。
搜索引擎的工作原理
但是,这些通用的搜索引擎也有一定的局限性:
一般搜索引擎返回的结果都是网页,在大多数情况下,网页上90%的内容对用户来说是无用的。
不同领域、不同背景的用户往往有不同的搜索目的和需求,搜索引擎无法为特定用户提供搜索结果。
随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频和多媒体等不同的数据。一般的搜索引擎都无法找到和获取这些文件。
一般的搜索引擎大多提供基于关键字的检索,难以支持基于语义信息的查询,无法准确了解用户的具体需求。
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点履带
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。 查看全部
网页抓取数据百度百科(拉勾网Python爬虫职位爬虫是什么?Python学习指南职位)
本文将开始介绍Python的原理。更多内容请参考:Python学习指南
为什么想做爬虫
著名的革命家、思想家、政治家、战略家、社会改革的主要领导人马云在2015年曾提到,从IT到DT的转变,就是DT的含义。DT是数据技术。大数据时代,数据从何而来?
数据管理咨询公司:麦肯锡、埃森哲、艾瑞咨询
爬取网络数据:如果您需要的数据在市场上没有,或者您不愿意购买,那么您可以聘请/成为一名爬虫工程师,自己做。 Python 爬虫帖子
什么是爬虫?
百度百科:网络爬虫
关于Python爬虫,我们需要学习:
Python基础语法学习(基础知识)
HTML页面的内容爬取(数据爬取)
从 HTML 页面中提取数据(数据清理)
Scrapy框架和scrapy-redis分布式策略(第三方框架)
蜘蛛、反蜘蛛和反反蜘蛛之间的斗争。. . .
通用爬虫和聚焦爬虫
网络爬虫可分为通用爬虫和聚焦爬虫。
一般搜索引擎(Search Enging)工作原理
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息用于索引搜索引擎提供支持,它决定了整个引擎系统的内容是否丰富,信息是否及时,所以其性能优劣直接影响搜索引擎的有效性。
第一步:爬网
搜索引擎网络爬虫的基本工作流程如下:
首先选择一部分种子网址,将这些网址放入待抓取的网址队列中;
取出要爬取的URL,解析DNS获取主机IP,下载该URL对应的网页,存放在下载的网页库中,并将这些URL放入已爬取的URL队列中。
解析爬取的URL队列中的URL,解析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。. .
一般爬虫流程
搜索引擎如何获取新的网站 URL:
在其他网站上设置新的网站链接(尽量在搜索引擎爬虫的范围内)
搜索引擎与DNS解析服务商(如DNSPod等)合作,快速抓取新的网站域名
但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件内容,比如标记为nofollow的链接,或者Robots协议。
机器人协议(也叫爬虫协议、机器人协议等),全称“机器人排除协议”(Robots Exclusion Protocol),网站告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取机器人协议,例如:
第 2 步:数据存储
搜索引擎通过爬虫抓取网页,并将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会做一定量的重复内容检测。一旦他们遇到大量抄袭、采集或网站上访问权重较低的复制内容,他们很可能会停止爬行。
第三步:预处理
搜索引擎会对爬虫检索回来的页面进行爬取,并进行各个步骤的预处理。
提取文本
中文分词
消除噪音(如版权声明文字、导航栏、广告等...)
索引处理
链接关系计算
特殊文件处理
....
除了 HTML 文件,搜索引擎还可以抓取和索引多种基于文本的文件类型,例如 PDF、WORD、WPS、PPT、TXT 等,我们经常在搜索结果中看到这种文件类型。
但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎对信息进行整理和处理后,为用户提供关键词检索服务,并将与用户检索相关的信息展示给用户。
同时网站会根据页面的PageRank值(链接访问次数的排名)进行排名,使得Rank值高的网站排名靠前在搜索结果中。当然,你也可以直接用Money购买搜索引擎网站的排名,简单粗暴。
搜索引擎的工作原理
但是,这些通用的搜索引擎也有一定的局限性:
一般搜索引擎返回的结果都是网页,在大多数情况下,网页上90%的内容对用户来说是无用的。
不同领域、不同背景的用户往往有不同的搜索目的和需求,搜索引擎无法为特定用户提供搜索结果。
随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频和多媒体等不同的数据。一般的搜索引擎都无法找到和获取这些文件。
一般的搜索引擎大多提供基于关键字的检索,难以支持基于语义信息的查询,无法准确了解用户的具体需求。
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点履带
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于:聚焦爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只有爬取到的页面信息与需求页面信息相关。
网页抓取数据百度百科(环境爬虫架构根据上面的流程,开始爬取百度百科1000个页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 17:31
环境爬虫架构
按照上述流程,开始爬取百度百科1000页。
运行过程
非常详细的描述。
我们要抓取的信息是
html源码中对应的信息为:
了解了获取那些信息和爬虫的基本流程,
下面我们结合各个部分的功能来实现具体的代码。
履带调度员
启动爬虫,停止爬虫,或者监控爬虫的运行状态。
我们以百度百科的python入口的url作为入口点。编写主函数。
# coding:utf8
import url_manager, html_parser, html_downloader,html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager() #url管理器
self.downloader = html_downloader.HtmlDownLoader() #下载器
self.parser = html_parser.HtmlParser() #解析器
self.outputer = html_outputer.HtmlOutputer() #输出器
def craw(self,root_url):
count = 1
print "count =",count
#将入口url添加进url管理器(单个)
self.urls.add_new_url(root_url)
#启动爬虫的循环
while self.urls.has_new_url():
try:
#获取待爬取的url
new_url = self.urls.get_new_url()
print 'craw %d : %s'%(count,new_url)
#启动下载器下载html页面
html_cont = self.downloader.download(new_url)
#解析器解析得到新的url列表以及新的数据
new_urls, new_data = self.parser.parse(new_url, html_cont)
#将获取的新的url添加进管理器(批量)
self.urls.add_new_urls(new_urls)
#收集数据
self.outputer.collect_data(new_data)
except:
print "craw failed!!!"
if count ==1000:
break
count = count + 1
#输出收集好的数据
self.outputer.output_html()
if __name__=="__main__":
#爬虫入口url
root_url = "https://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
#启动爬虫
obj_spider.craw(root_url)
网址管理器
对要爬取的URL集合和已爬取的URL集合进行管理,目的是防止重复爬取和循环爬取。需要支持的方法:
# -*-coding:utf8 -*-
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#判断待爬取url是否在容器中
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#添加新url到待爬取集合中
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
#判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls)!=0
#获取待爬取url并将url从待爬取移动到已爬取
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
从url管理中取一个要爬取的url,下载器会下载该url指定的网页,并存储为字符串。
这里使用python urllib2库下载网页。
# -*- coding:utf-8
import urllib2
class HtmlDownLoader(object):
def download(self, url):
if url is None:
return None
#直接请求
response = urllib2.urlopen(url)
#获取状态码,200表示获取成功,404失败
if response.getcode() !=200:
return None
else:
return response.read() #返回获取内容
网页解析器
将字符串发送给网页解析器,一方面解析出有价值的数据,另一方面将网页中指向其他网页的URL补充给url管理器,形成一个循环。
这里使用了结构化分析,BeautifuSoup使用DOM树的方式来解析网页。
# -*- coding:utf-8 -*
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
print 'in parse def _get_new_urls'
#/item/xxx
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
#Python
#获取标题的标签
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser', from_encoding = 'utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
出口商
需要采集数据,然后以html的形式输出数据。
# -*-coding:utf-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.data = []
def collect_data(self, data):
#print "def collect_data(self, data):"
if data is None:
return
self.data.append(data)
def output_html(self):
#print "def output_html(self):"
fout = open('output.html','w')
fout.write('')
fout.write('')
fout.write('')
#ASCII
for data in self.data:
fout.write("")
fout.write("%s" % data['url'])
fout.write("%s" % data['title'].encode('utf-8'))
fout.write("%s" % data['summary'].encode('utf-8'))
fout.write("")
fout.write('')
fout.write('')
fout.write('')
操作结果
抓取的数据
总结
这个研究是前两天的工作,后来遇到了一些关于正则表达式的问题。正则表达式在爬虫中非常重要。昨天花了一天时间系统学习python中re模块的正则表达式。,我今天刚完成。这个项目是我开始使用爬虫的实践。爬虫的重点在于三个模块:url管理器、网页下载器和网页解析器。这三者形成一个循环,实现持续爬行的信心,能力有限。还有一些细节没有很好理解,继续学习ing。
完整代码已经上传到我的Github: 查看全部
网页抓取数据百度百科(环境爬虫架构根据上面的流程,开始爬取百度百科1000个页面)
环境爬虫架构
按照上述流程,开始爬取百度百科1000页。
运行过程
非常详细的描述。
我们要抓取的信息是
html源码中对应的信息为:
了解了获取那些信息和爬虫的基本流程,
下面我们结合各个部分的功能来实现具体的代码。
履带调度员
启动爬虫,停止爬虫,或者监控爬虫的运行状态。
我们以百度百科的python入口的url作为入口点。编写主函数。
# coding:utf8
import url_manager, html_parser, html_downloader,html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager() #url管理器
self.downloader = html_downloader.HtmlDownLoader() #下载器
self.parser = html_parser.HtmlParser() #解析器
self.outputer = html_outputer.HtmlOutputer() #输出器
def craw(self,root_url):
count = 1
print "count =",count
#将入口url添加进url管理器(单个)
self.urls.add_new_url(root_url)
#启动爬虫的循环
while self.urls.has_new_url():
try:
#获取待爬取的url
new_url = self.urls.get_new_url()
print 'craw %d : %s'%(count,new_url)
#启动下载器下载html页面
html_cont = self.downloader.download(new_url)
#解析器解析得到新的url列表以及新的数据
new_urls, new_data = self.parser.parse(new_url, html_cont)
#将获取的新的url添加进管理器(批量)
self.urls.add_new_urls(new_urls)
#收集数据
self.outputer.collect_data(new_data)
except:
print "craw failed!!!"
if count ==1000:
break
count = count + 1
#输出收集好的数据
self.outputer.output_html()
if __name__=="__main__":
#爬虫入口url
root_url = "https://baike.baidu.com/item/Python"
obj_spider = SpiderMain()
#启动爬虫
obj_spider.craw(root_url)
网址管理器
对要爬取的URL集合和已爬取的URL集合进行管理,目的是防止重复爬取和循环爬取。需要支持的方法:
# -*-coding:utf8 -*-
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
#判断待爬取url是否在容器中
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
#添加新url到待爬取集合中
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
#判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls)!=0
#获取待爬取url并将url从待爬取移动到已爬取
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
从url管理中取一个要爬取的url,下载器会下载该url指定的网页,并存储为字符串。
这里使用python urllib2库下载网页。
# -*- coding:utf-8
import urllib2
class HtmlDownLoader(object):
def download(self, url):
if url is None:
return None
#直接请求
response = urllib2.urlopen(url)
#获取状态码,200表示获取成功,404失败
if response.getcode() !=200:
return None
else:
return response.read() #返回获取内容
网页解析器
将字符串发送给网页解析器,一方面解析出有价值的数据,另一方面将网页中指向其他网页的URL补充给url管理器,形成一个循环。
这里使用了结构化分析,BeautifuSoup使用DOM树的方式来解析网页。
# -*- coding:utf-8 -*
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
print 'in parse def _get_new_urls'
#/item/xxx
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
#Python
#获取标题的标签
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser', from_encoding = 'utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
出口商
需要采集数据,然后以html的形式输出数据。
# -*-coding:utf-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.data = []
def collect_data(self, data):
#print "def collect_data(self, data):"
if data is None:
return
self.data.append(data)
def output_html(self):
#print "def output_html(self):"
fout = open('output.html','w')
fout.write('')
fout.write('')
fout.write('')
#ASCII
for data in self.data:
fout.write("")
fout.write("%s" % data['url'])
fout.write("%s" % data['title'].encode('utf-8'))
fout.write("%s" % data['summary'].encode('utf-8'))
fout.write("")
fout.write('')
fout.write('')
fout.write('')
操作结果
抓取的数据
总结
这个研究是前两天的工作,后来遇到了一些关于正则表达式的问题。正则表达式在爬虫中非常重要。昨天花了一天时间系统学习python中re模块的正则表达式。,我今天刚完成。这个项目是我开始使用爬虫的实践。爬虫的重点在于三个模块:url管理器、网页下载器和网页解析器。这三者形成一个循环,实现持续爬行的信心,能力有限。还有一些细节没有很好理解,继续学习ing。
完整代码已经上传到我的Github:
网页抓取数据百度百科(Python爬虫即使用Python程序开发的网络爬虫(网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-25 03:14
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。通俗的说就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。
Python爬虫架构
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和循环爬取URL。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,也可以按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会很困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三-party插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,你想爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。 查看全部
网页抓取数据百度百科(Python爬虫即使用Python程序开发的网络爬虫(网页蜘蛛))
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。通俗的说就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
Python爬虫是使用Python程序开发的网络爬虫(网络蜘蛛、网络机器人)。它是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。
Python爬虫架构
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和循环爬取URL。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,也可以按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会很困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三-party插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,你想爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。
爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对html代码的分析过滤,从中获取我们想要的资源。
网页抓取数据百度百科(网页抓取数据百度百科上有的,不知道符不符合楼主的要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-25 03:02
网页抓取数据百度百科上有的,不知道符不符合楼主的要求。地址为:11.28.121.101/blacklist_3找到指定的条目名称并解析出url就可以知道具体页面了。
就像qq号码可以被n个人获取,所以不是所有的都可以看,比如你更改腾讯公司的位置时,即便没有重置,其他的人也可以登录,而你没更改,那些人就是别人,
我们公司一个营销平台做网页数据采集,主要是方便企业发布商品或者活动,想一个一个的来抓是不可能的,我们一般都会抓其网页上采集出来的所有数据,然后根据关键词来生成相应的结果。
有很多数据源,每一个数据源对应不同的url,每一个网页就是一个数据源。不同数据源只是网页连接,能否浏览取决于之前的数据源。而且不同网页是可以共用一个结果集的,比如,的图片就共享一个结果集。
你大可以在使用百度的网页搜索时,
还有一个原因是为了不重复,尤其是首页,所以每个网页也都是一个数据源。如果上来就看完整网页,就失去意义了。
看这个网页的同时,如果有其他网页,我可以直接按需的传过来。
。
因为有时候,那些你看过的url也会被别人看到,当然他们可能是以pv计费的。 查看全部
网页抓取数据百度百科(网页抓取数据百度百科上有的,不知道符不符合楼主的要求)
网页抓取数据百度百科上有的,不知道符不符合楼主的要求。地址为:11.28.121.101/blacklist_3找到指定的条目名称并解析出url就可以知道具体页面了。
就像qq号码可以被n个人获取,所以不是所有的都可以看,比如你更改腾讯公司的位置时,即便没有重置,其他的人也可以登录,而你没更改,那些人就是别人,
我们公司一个营销平台做网页数据采集,主要是方便企业发布商品或者活动,想一个一个的来抓是不可能的,我们一般都会抓其网页上采集出来的所有数据,然后根据关键词来生成相应的结果。
有很多数据源,每一个数据源对应不同的url,每一个网页就是一个数据源。不同数据源只是网页连接,能否浏览取决于之前的数据源。而且不同网页是可以共用一个结果集的,比如,的图片就共享一个结果集。
你大可以在使用百度的网页搜索时,
还有一个原因是为了不重复,尤其是首页,所以每个网页也都是一个数据源。如果上来就看完整网页,就失去意义了。
看这个网页的同时,如果有其他网页,我可以直接按需的传过来。
。
因为有时候,那些你看过的url也会被别人看到,当然他们可能是以pv计费的。
网页抓取数据百度百科(如何定义网络爬虫(二):爬虫、爬虫从哪里爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-24 11:05
一、前言
您是否急于想采集数据却不知道如何采集数据?
您是否正在为尝试学习爬虫却找不到专门为小白写的教程而苦恼?
答对了!你没看错,这是专门为小白学习爬虫写的!我会用例子把每个部分和实际例子结合起来,帮助朋友们理解。最后,我会写几个实际的例子。
我们使用 Python 编写爬虫。一方面,因为Python是一门特别适合入门的语言,另一方面,Python也有很多爬虫相关的工具包,可以简单快速的开发我们的小爬虫。
本系列使用的是Python3.5版本,毕竟2.7会慢慢退出历史舞台的~
所以,接下来,你必须知道爬虫是什么,它在哪里爬取数据,以及学习爬虫要学什么。
二、什么是爬虫
来看看百度百科是如何定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
什么?没看懂?没关系,我给你解释一下
打开一个收录网页内容的网页。想象一下,有一个工具可以获取网页上的内容并将其保存在您想要的位置。这个工具就是我们今天的主角:爬虫。
这是否使它更清楚?
既然了解了爬虫是什么,那么爬虫是如何爬取数据的呢?
三、爬虫从哪里爬取数据
打开浏览器(强烈推荐使用谷歌浏览器),找到浏览器地址栏,然后输入,就可以看到网页的内容了。
图中的两个人在做什么?(单身狗请主动防守,这是意外伤害,这真的是意外伤害!)
用鼠标右键单击页面,然后单击查看页面源。你看到这些词了吗?这就是网站的样子。
其实所有的网页都是HTML代码,只是浏览器把这些代码解析成上面的网页。我们的小爬虫抓取的实际上是 HTML 代码中的文本。
这不合理,难不成那些图片也是文字?
恭喜你,你明白了。返回浏览器中带有图片的标签页,右键单击,然后单击“检查”。将弹出一个面板。点击面板左上角的箭头,点击虐狗图片,你会看到下面的红圈,就是图片的网络地址。图片可以通过这个地址保存到本地。
你猜对了,我们的小爬虫抓取网页中的数据。您需要知道您想要获取哪些数据以及您的目标 网站 是将您的想法变为现实。哦。你不能说,我要这个,这个,这个,然后数据会自动来。. . (这让你想起了你的导师或老板吗?) 查看全部
网页抓取数据百度百科(如何定义网络爬虫(二):爬虫、爬虫从哪里爬取)
一、前言
您是否急于想采集数据却不知道如何采集数据?
您是否正在为尝试学习爬虫却找不到专门为小白写的教程而苦恼?
答对了!你没看错,这是专门为小白学习爬虫写的!我会用例子把每个部分和实际例子结合起来,帮助朋友们理解。最后,我会写几个实际的例子。
我们使用 Python 编写爬虫。一方面,因为Python是一门特别适合入门的语言,另一方面,Python也有很多爬虫相关的工具包,可以简单快速的开发我们的小爬虫。
本系列使用的是Python3.5版本,毕竟2.7会慢慢退出历史舞台的~
所以,接下来,你必须知道爬虫是什么,它在哪里爬取数据,以及学习爬虫要学什么。
二、什么是爬虫
来看看百度百科是如何定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
什么?没看懂?没关系,我给你解释一下
打开一个收录网页内容的网页。想象一下,有一个工具可以获取网页上的内容并将其保存在您想要的位置。这个工具就是我们今天的主角:爬虫。
这是否使它更清楚?
既然了解了爬虫是什么,那么爬虫是如何爬取数据的呢?
三、爬虫从哪里爬取数据
打开浏览器(强烈推荐使用谷歌浏览器),找到浏览器地址栏,然后输入,就可以看到网页的内容了。
图中的两个人在做什么?(单身狗请主动防守,这是意外伤害,这真的是意外伤害!)
用鼠标右键单击页面,然后单击查看页面源。你看到这些词了吗?这就是网站的样子。
其实所有的网页都是HTML代码,只是浏览器把这些代码解析成上面的网页。我们的小爬虫抓取的实际上是 HTML 代码中的文本。
这不合理,难不成那些图片也是文字?
恭喜你,你明白了。返回浏览器中带有图片的标签页,右键单击,然后单击“检查”。将弹出一个面板。点击面板左上角的箭头,点击虐狗图片,你会看到下面的红圈,就是图片的网络地址。图片可以通过这个地址保存到本地。
你猜对了,我们的小爬虫抓取网页中的数据。您需要知道您想要获取哪些数据以及您的目标 网站 是将您的想法变为现实。哦。你不能说,我要这个,这个,这个,然后数据会自动来。. . (这让你想起了你的导师或老板吗?)
网页抓取数据百度百科(aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-23 17:20
网页抓取数据百度百科:本文写于2017年9月,详细讲解了在aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding中,如何将自动格式转换这一简单任务进行复杂化、生成可视化图表。内容提要本文通过用计算机视觉处理特征,将可视化图像变为基于矩阵的sql视图,然后基于基于多特征的fine-tuning方法,将关键帧转换为图像视图。
从而通过这个简单任务,提升网络学习速度,进而训练深度学习模型,进而优化其在实际数据集上的表现。关键概念2.1本文的关键技术2.2本文所采用的架构分析2.3本文的实现方法3.论文推荐platform【0】本文核心在于对于ar-video分割目标中最重要帧(在训练阶段需要全部训练完成才能预测),是否能够将其图像化然后训练模型。
模型在训练过程中不要试图将目标帧直接与底层特征进行融合。localattributelayerbasedembeddingmodel【1】这里只能够在前向的时候,在训练之前需要进行特征融合(可以是超参数化的embedding、可以通过pointer-length-visual-model),使得前向时候不损失任何信息。
这样能够使得模型学习到更加丰富的属性。timeseriesembeddingmodel【2】data-basedannotatorforfine-tuning3.案例引入cnn预测复杂照片如果是经典的多通道的cnn,将其图像压缩为图像,进行语义分割,其预测的结果同时按顺序以特征经过多次转换来得到。然而针对特定照片,可能会存在一些色彩不全、或者是纹理不清晰,这些信息(通常会被称为syntacticfeatures)对于后面的目标检测、语义分割,还有物体的识别等任务都非常重要。
backbone层只能够学习一组特征,这个时候就可以借助卷积层得到syntacticfeatures。整个网络分为几个全连接层,这样做的优点是可以将网络进行的效率加快。在训练过程中,要保证scale足够小,这样才能够进行优化,训练完的参数的量级可以降低到几m。用图来表示:输入的一组图片按照像素进行连接:网络结构大致为由于使用bn层,所以在进行后向传播的时候,可以看到每一个epoch都在生成一个image,最后的输出为某个像素在这个image上的连接输出来作为loss。
最后如果stride=1,这样的trick就是假定输入的是特征,按照图片的宽高值来划分特征图,最后计算其各个像素点之间的连接的权重。straight-through损失网络第一层是降采样层:这个时候可以选择跳过全连接层直接进行fine-tuning,通过降采样的目的在于降低网络训练的复杂度。如何进行跳过全连接层?这里选择跳过全连接层一个非常简单。 查看全部
网页抓取数据百度百科(aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding)
网页抓取数据百度百科:本文写于2017年9月,详细讲解了在aaai2019计算机视觉顶会(cvpr2019)第二篇论文deepvideosynthesisforwebvideounderstanding中,如何将自动格式转换这一简单任务进行复杂化、生成可视化图表。内容提要本文通过用计算机视觉处理特征,将可视化图像变为基于矩阵的sql视图,然后基于基于多特征的fine-tuning方法,将关键帧转换为图像视图。
从而通过这个简单任务,提升网络学习速度,进而训练深度学习模型,进而优化其在实际数据集上的表现。关键概念2.1本文的关键技术2.2本文所采用的架构分析2.3本文的实现方法3.论文推荐platform【0】本文核心在于对于ar-video分割目标中最重要帧(在训练阶段需要全部训练完成才能预测),是否能够将其图像化然后训练模型。
模型在训练过程中不要试图将目标帧直接与底层特征进行融合。localattributelayerbasedembeddingmodel【1】这里只能够在前向的时候,在训练之前需要进行特征融合(可以是超参数化的embedding、可以通过pointer-length-visual-model),使得前向时候不损失任何信息。
这样能够使得模型学习到更加丰富的属性。timeseriesembeddingmodel【2】data-basedannotatorforfine-tuning3.案例引入cnn预测复杂照片如果是经典的多通道的cnn,将其图像压缩为图像,进行语义分割,其预测的结果同时按顺序以特征经过多次转换来得到。然而针对特定照片,可能会存在一些色彩不全、或者是纹理不清晰,这些信息(通常会被称为syntacticfeatures)对于后面的目标检测、语义分割,还有物体的识别等任务都非常重要。
backbone层只能够学习一组特征,这个时候就可以借助卷积层得到syntacticfeatures。整个网络分为几个全连接层,这样做的优点是可以将网络进行的效率加快。在训练过程中,要保证scale足够小,这样才能够进行优化,训练完的参数的量级可以降低到几m。用图来表示:输入的一组图片按照像素进行连接:网络结构大致为由于使用bn层,所以在进行后向传播的时候,可以看到每一个epoch都在生成一个image,最后的输出为某个像素在这个image上的连接输出来作为loss。
最后如果stride=1,这样的trick就是假定输入的是特征,按照图片的宽高值来划分特征图,最后计算其各个像素点之间的连接的权重。straight-through损失网络第一层是降采样层:这个时候可以选择跳过全连接层直接进行fine-tuning,通过降采样的目的在于降低网络训练的复杂度。如何进行跳过全连接层?这里选择跳过全连接层一个非常简单。
网页抓取数据百度百科(模拟浏览器向服务器发起post请求的xpath方法(allreference))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-23 12:03
网页抓取数据百度百科说,数据抓取工具一般有两种,一种是模拟浏览器向服务器发送包含“网址”、“数据”、“标题”等信息的http请求,从而达到抓取数据的目的。另一种是通过对数据进行汇总和计算,从而获取数据,这种应用相对于前一种范围更加广泛。传统网页抓取最基本的抓取方法应该就是重定向方法(allreference):1.使用post请求传递数据。
post请求通常有参数,因此也是最基本的。2.使用json。json数据具有一个特性是不可变性(immutable),所以请求的时候要在请求前加上"\all"-参数来表示匹配到哪些字段3.https请求。网页加载完成之后,要将"\all"-参数设置到参数列表中。4.客户端post方法。用户或浏览器向服务器发起post请求,这时将代表请求的url地址,包含内容的html页面直接传送给服务器。
目前,抓取百度百科数据,可以使用jsoup包的xpath方法,首先搜索关键词,然后根据定位到的词抓取页面数据(数据如图)接下来是重定向和采用json传递数据,这两种方法都很常见,相比重定向,直接采用json传递数据,速度快很多,操作简单,跨域抓取是可以使用。参考资料-analysis/general-url-parser-cookie-matching-post-post-cookie-index-text-generators-all/。 查看全部
网页抓取数据百度百科(模拟浏览器向服务器发起post请求的xpath方法(allreference))
网页抓取数据百度百科说,数据抓取工具一般有两种,一种是模拟浏览器向服务器发送包含“网址”、“数据”、“标题”等信息的http请求,从而达到抓取数据的目的。另一种是通过对数据进行汇总和计算,从而获取数据,这种应用相对于前一种范围更加广泛。传统网页抓取最基本的抓取方法应该就是重定向方法(allreference):1.使用post请求传递数据。
post请求通常有参数,因此也是最基本的。2.使用json。json数据具有一个特性是不可变性(immutable),所以请求的时候要在请求前加上"\all"-参数来表示匹配到哪些字段3.https请求。网页加载完成之后,要将"\all"-参数设置到参数列表中。4.客户端post方法。用户或浏览器向服务器发起post请求,这时将代表请求的url地址,包含内容的html页面直接传送给服务器。
目前,抓取百度百科数据,可以使用jsoup包的xpath方法,首先搜索关键词,然后根据定位到的词抓取页面数据(数据如图)接下来是重定向和采用json传递数据,这两种方法都很常见,相比重定向,直接采用json传递数据,速度快很多,操作简单,跨域抓取是可以使用。参考资料-analysis/general-url-parser-cookie-matching-post-post-cookie-index-text-generators-all/。
网页抓取数据百度百科(百度百科里出现的这个词条是什么意思?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 04:18
此条目已被违规删除或网页错误
数据库错误。暴力图书馆
这个网站 打不开。
404 状态是找不到服务器。这个 网站 有一个临时问题,或者这个 网站 服务器已关闭。
如果只是页面的一部分,可能是对应的页面无效
没有插件无法显示
检查网络是否连接,如果没有,连接网络
如果网络已经连接,但无法打开网页,请先尝试打开另一个网站。如果能打开,就是这个网站的问题;如果所有网页都无法连接,请检查电脑的DNS是否正确(或未设置),一般设置好DNS后就可以上网了。
设置DNS方法:一、 自动获取:网上邻居---属性---本地连接---属性---TCP/IP协议然后选择自动获取IP地址。如果您已经可以访问 Internet,则到此结束。
<p>二、手动设置:如果选择设置后自动获取IP地址,网络无法连接,改为“使用下面的IP地址”,填写192.168.@ > 查看全部
网页抓取数据百度百科(百度百科里出现的这个词条是什么意思?(组图))
此条目已被违规删除或网页错误
数据库错误。暴力图书馆
这个网站 打不开。
404 状态是找不到服务器。这个 网站 有一个临时问题,或者这个 网站 服务器已关闭。
如果只是页面的一部分,可能是对应的页面无效
没有插件无法显示
检查网络是否连接,如果没有,连接网络
如果网络已经连接,但无法打开网页,请先尝试打开另一个网站。如果能打开,就是这个网站的问题;如果所有网页都无法连接,请检查电脑的DNS是否正确(或未设置),一般设置好DNS后就可以上网了。
设置DNS方法:一、 自动获取:网上邻居---属性---本地连接---属性---TCP/IP协议然后选择自动获取IP地址。如果您已经可以访问 Internet,则到此结束。
<p>二、手动设置:如果选择设置后自动获取IP地址,网络无法连接,改为“使用下面的IP地址”,填写192.168.@ >
网页抓取数据百度百科(优采云采集器对数据价值的挖掘理念都不谋而合,功能是否强大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-11-21 17:13
比方说,一种基于web结构或者浏览器可视化的数据采集技术,关键是在处理海量数据时抓取的准确性和快速响应,即使是一个工具,关键是它是否通用,是否通用功能很强大。Web 数据捕获现在几乎是网络运营中的必备技能。优采云采集器系列工具在业界也很有名。通过一系列的工具,我们可以发现这个应用程序的目的。实际上在于自动化。比如原来手工复制粘贴一整天只能完成两三百个网页数据的有效采集,但是通过工具,这个数字可以达到百万。但是,缺乏稳定高效的系统和存储管理解决方案的网络爬虫可能只有10个,
在当今时代,网络大数据的价值无法估量。从站长,到编辑,到运营,再到大学……各行各业对于数据价值挖掘的理念都是一样的,数据获取的技术也值得不断突破。
全网通用,分布式抽取,数据处理自成体系,支持代理替换,优采云采集器可自动采集发布,调度运行;可视化鼠标点击,自定义流程,自动优采云 浏览器,用于项目的编码和批量管理;这些都是优采云团队在多年数据服务经验中不断突破和创新的技术成果。
智能网站运维、竞品监控、数据整合、服务升级都离不开网络数据抓取。与功能列表一、维护低频工具相比,技术与时俱进,可以持续为数据提供高效率采集。返回搜狐查看更多 查看全部
网页抓取数据百度百科(优采云采集器对数据价值的挖掘理念都不谋而合,功能是否强大)
比方说,一种基于web结构或者浏览器可视化的数据采集技术,关键是在处理海量数据时抓取的准确性和快速响应,即使是一个工具,关键是它是否通用,是否通用功能很强大。Web 数据捕获现在几乎是网络运营中的必备技能。优采云采集器系列工具在业界也很有名。通过一系列的工具,我们可以发现这个应用程序的目的。实际上在于自动化。比如原来手工复制粘贴一整天只能完成两三百个网页数据的有效采集,但是通过工具,这个数字可以达到百万。但是,缺乏稳定高效的系统和存储管理解决方案的网络爬虫可能只有10个,
在当今时代,网络大数据的价值无法估量。从站长,到编辑,到运营,再到大学……各行各业对于数据价值挖掘的理念都是一样的,数据获取的技术也值得不断突破。
全网通用,分布式抽取,数据处理自成体系,支持代理替换,优采云采集器可自动采集发布,调度运行;可视化鼠标点击,自定义流程,自动优采云 浏览器,用于项目的编码和批量管理;这些都是优采云团队在多年数据服务经验中不断突破和创新的技术成果。
智能网站运维、竞品监控、数据整合、服务升级都离不开网络数据抓取。与功能列表一、维护低频工具相比,技术与时俱进,可以持续为数据提供高效率采集。返回搜狐查看更多
网页抓取数据百度百科(网络蜘蛛就可以用这个原理把互联网上所有网页抓取完为止)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-20 15:14
本文主要内容:
1. 爬虫相关概念。
2.请求库安装。
3.请求库介绍。
4.常用的网页抓取代码框架。
1. 爬虫相关概念。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。(百度百科)
网络爬虫就是按照规则从网页中抓取数据,然后对数据进行处理,得到我们需要的有价值数据的过程。
从网站的某个页面(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后利用这些链接地址查找下一个网页,这样循环一直持续到这个网站所有的网页都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
2.请求库安装。
要使用 Requests 库,您需要先安装它。我的 Python 环境是 3.6。安装过程很简单,直接在cmd控制台使用pip命令即可。
打开 cmd 控制台并输入 pip install requests。
3.请求库介绍:
下面列出了方法名称和用途。具体使用可以百度或者参考文章末尾的链接文件。Request库里面有详细的介绍。
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
request对象是我们要请求的url,response对象是返回的内容,如图:
响应对象比请求对象更复杂。响应对象包括以下属性:
接下来我们测试响应对象的属性:
假设我们访问的是百度主页,打开IDLE,输入如下代码:
import requests
r=requests.get("http://baidu.com")
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.text[:100])
得到的结果如下:
4.常用的网页抓取代码框架。
已经大致了解了Request库和爬虫的工作原理。下面是抓取网页的通用代码框架,我们的对话机器人也会用到,因为抓取网页是不确定的(网页没有响应,网址错误等),在代码中添加try和except语句来检测错误.
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30) #获得url链接对应的response对象
r.raise_for_status() #检查状态码,如果状态码不是200则抛出异常。
r.encoding = r.apparent_encoding #用分析内容的编码作为整我对象的编码,视情况使用。
return r.text
except:
print("faile")
return ""
这个框架以后会用到,需要了解和掌握。
在我们的示例中,我们使用此框架来抓取段落。URL是我从百度上得到的一段子网。具体代码如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
print(html)
main()
运行截图如下:
这是我们得到的返回内容。在下面的文章中,我们将使用beautifulsoup库从巨大的HTML文本中提取我们想要的具体内容,即提取段落(红色标记)。
更详细的介绍请参考文档:
链接: 密码:2ovp 查看全部
网页抓取数据百度百科(网络蜘蛛就可以用这个原理把互联网上所有网页抓取完为止)
本文主要内容:
1. 爬虫相关概念。
2.请求库安装。
3.请求库介绍。
4.常用的网页抓取代码框架。
1. 爬虫相关概念。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。(百度百科)
网络爬虫就是按照规则从网页中抓取数据,然后对数据进行处理,得到我们需要的有价值数据的过程。
从网站的某个页面(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后利用这些链接地址查找下一个网页,这样循环一直持续到这个网站所有的网页都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
2.请求库安装。
要使用 Requests 库,您需要先安装它。我的 Python 环境是 3.6。安装过程很简单,直接在cmd控制台使用pip命令即可。
打开 cmd 控制台并输入 pip install requests。
3.请求库介绍:
下面列出了方法名称和用途。具体使用可以百度或者参考文章末尾的链接文件。Request库里面有详细的介绍。
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
request对象是我们要请求的url,response对象是返回的内容,如图:
响应对象比请求对象更复杂。响应对象包括以下属性:
接下来我们测试响应对象的属性:
假设我们访问的是百度主页,打开IDLE,输入如下代码:
import requests
r=requests.get("http://baidu.com";)
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.text[:100])
得到的结果如下:
4.常用的网页抓取代码框架。
已经大致了解了Request库和爬虫的工作原理。下面是抓取网页的通用代码框架,我们的对话机器人也会用到,因为抓取网页是不确定的(网页没有响应,网址错误等),在代码中添加try和except语句来检测错误.
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30) #获得url链接对应的response对象
r.raise_for_status() #检查状态码,如果状态码不是200则抛出异常。
r.encoding = r.apparent_encoding #用分析内容的编码作为整我对象的编码,视情况使用。
return r.text
except:
print("faile")
return ""
这个框架以后会用到,需要了解和掌握。
在我们的示例中,我们使用此框架来抓取段落。URL是我从百度上得到的一段子网。具体代码如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
return r.text
except:
print("faile")
return ""
def main():
url = 'http://duanziwang.com/category/%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%AE%B5%E5%AD%90/1/'
html = getHTMLText(url)
print(html)
main()
运行截图如下:
这是我们得到的返回内容。在下面的文章中,我们将使用beautifulsoup库从巨大的HTML文本中提取我们想要的具体内容,即提取段落(红色标记)。
更详细的介绍请参考文档:
链接: 密码:2ovp
网页抓取数据百度百科(《百度百科》爬虫就是模拟客户端(浏览器)文章目录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-18 15:13
文章内容
一、什么是爬虫?
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。——《百度百科》
爬虫是一种模拟客户端(浏览器)发送网络请求,获取响应,并按照规则提取数据的程序。
浏览器的工作原理是获取请求并渲染响应,所以它可以在用户面前很酷。其实如果直接显示得到的响应,就是一堆冷代码。不同的浏览器对同一段代码的解释不同,这就是为什么有些网页在手机上打开和在电脑上打开时效果不同的原因。
所以爬虫就换成了更容易理解的语句,就是冒充浏览器欺骗服务器的响应数据,对其进行特殊处理。简单的说就是让服务器认为你是浏览器,然后给你数据。,这样一来,如果拿了数据,不按常理打牌,就需要用其他方法把数据提炼出来,自己用。
~突然觉得流行的爬虫方式有点像马姓高手创作的武侠大作:说白了就是“欺骗”和“偷袭”易受攻击的服务器,一般是暴力以“无武道”访问(通常是在短时间内对同一站点的多个网页进行非常大量的连续访问)。“接收”响应,将其提取并按照规则转换为“变换”,最后在必要时将提取的数据“发送”(例如将其发送到数据库等)。“连接”-“变形”-“胖”一气呵成,“训练有素”~
最后不得不提一句,爬虫虽然很酷,但要适度,谨防问题。作为一个刚接触爬虫技术的小白,关于爬取到的数据是否违法,博主找了一篇很好的文章文章,通俗易懂,分享给大家:爬虫合法还是违法?
二、爬虫数据去哪了?1. 提出
它通常显示在网页上,或显示在 APP 上,或保存在本地用于其他目的。一般来说,爬虫获取的数据总量是巨大的,这使得用户能够非常快速地获取大量的信息和数据,大大节省了大量的人力物力。
举个最简单的例子,百度是爬虫高手。百度是目前中国最大的搜索引擎,拥有一套完整的爬虫算法。从下图我们可以了解到百度蜘蛛抓取网页的整个流程和系统。
2.分析
对采集接收到的数据进行统计、计算和分析。今年大火的大数据分析师,他们的工作,顾名思义,就是对大量数据进行数学建模和分析,得到更有用的结论。而且千万级的数据显然不是人工录入的,这就需要爬虫了。比如有python爬虫数据分析可视化金融语用系统。
(不是我写的,希望有朝一日能拥有这个技能)
三、所需软件和环境1.Pycharm
JetBrains 团队开发的用于开发 Python 应用程序的 IDE
-亲测有效期至 2020 年 11 月 27 日-
下载
裂缝
中国化
(如有资金支持,正版哈尔滨破解汉化教程将被禁,无法通过审核)
当然,理论上Java或者其他编程语言也可以实现爬虫,但是博主们喜欢Python语言的简单方便,所以本文和下面的文章将使用Python语言作为爬虫开发语。由于篇幅原因,本文不再赘述Python的基本语法和通用算法和数据结构。
2.Chrome 开发者工具
谷歌浏览器内置的一组网页开发和调试工具,可用于迭代、调试和分析网站。
百度搜索Chrome,下载
因为国内很多浏览器内核都是基于Chrome内核的,所以国内的浏览器也有这个功能。不过,对于网页分析来说,谷歌的Chrome绝对是一把战胜人群的利剑。开发者工具的便利性决定了国产浏览器如“*狗浏览器”或“扣环浏览器”(不引战的意思是技能确实不如人。我们不得不承认,正确的方法是努力学习并努力取得突破。) 查看全部
网页抓取数据百度百科(《百度百科》爬虫就是模拟客户端(浏览器)文章目录)
文章内容
一、什么是爬虫?
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。——《百度百科》
爬虫是一种模拟客户端(浏览器)发送网络请求,获取响应,并按照规则提取数据的程序。
浏览器的工作原理是获取请求并渲染响应,所以它可以在用户面前很酷。其实如果直接显示得到的响应,就是一堆冷代码。不同的浏览器对同一段代码的解释不同,这就是为什么有些网页在手机上打开和在电脑上打开时效果不同的原因。
所以爬虫就换成了更容易理解的语句,就是冒充浏览器欺骗服务器的响应数据,对其进行特殊处理。简单的说就是让服务器认为你是浏览器,然后给你数据。,这样一来,如果拿了数据,不按常理打牌,就需要用其他方法把数据提炼出来,自己用。
~突然觉得流行的爬虫方式有点像马姓高手创作的武侠大作:说白了就是“欺骗”和“偷袭”易受攻击的服务器,一般是暴力以“无武道”访问(通常是在短时间内对同一站点的多个网页进行非常大量的连续访问)。“接收”响应,将其提取并按照规则转换为“变换”,最后在必要时将提取的数据“发送”(例如将其发送到数据库等)。“连接”-“变形”-“胖”一气呵成,“训练有素”~
最后不得不提一句,爬虫虽然很酷,但要适度,谨防问题。作为一个刚接触爬虫技术的小白,关于爬取到的数据是否违法,博主找了一篇很好的文章文章,通俗易懂,分享给大家:爬虫合法还是违法?
二、爬虫数据去哪了?1. 提出
它通常显示在网页上,或显示在 APP 上,或保存在本地用于其他目的。一般来说,爬虫获取的数据总量是巨大的,这使得用户能够非常快速地获取大量的信息和数据,大大节省了大量的人力物力。
举个最简单的例子,百度是爬虫高手。百度是目前中国最大的搜索引擎,拥有一套完整的爬虫算法。从下图我们可以了解到百度蜘蛛抓取网页的整个流程和系统。
2.分析
对采集接收到的数据进行统计、计算和分析。今年大火的大数据分析师,他们的工作,顾名思义,就是对大量数据进行数学建模和分析,得到更有用的结论。而且千万级的数据显然不是人工录入的,这就需要爬虫了。比如有python爬虫数据分析可视化金融语用系统。
(不是我写的,希望有朝一日能拥有这个技能)
三、所需软件和环境1.Pycharm
JetBrains 团队开发的用于开发 Python 应用程序的 IDE
-亲测有效期至 2020 年 11 月 27 日-
下载
裂缝
中国化
(如有资金支持,正版哈尔滨破解汉化教程将被禁,无法通过审核)
当然,理论上Java或者其他编程语言也可以实现爬虫,但是博主们喜欢Python语言的简单方便,所以本文和下面的文章将使用Python语言作为爬虫开发语。由于篇幅原因,本文不再赘述Python的基本语法和通用算法和数据结构。
2.Chrome 开发者工具
谷歌浏览器内置的一组网页开发和调试工具,可用于迭代、调试和分析网站。
百度搜索Chrome,下载
因为国内很多浏览器内核都是基于Chrome内核的,所以国内的浏览器也有这个功能。不过,对于网页分析来说,谷歌的Chrome绝对是一把战胜人群的利剑。开发者工具的便利性决定了国产浏览器如“*狗浏览器”或“扣环浏览器”(不引战的意思是技能确实不如人。我们不得不承认,正确的方法是努力学习并努力取得突破。)
网页抓取数据百度百科(现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-18 10:08
爬取目标分类
来自:百度百科
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困,目前最常用的方法是广度优先和最佳优先方法。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标网页的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。 查看全部
网页抓取数据百度百科(现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征)
爬取目标分类
来自:百度百科
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
网络搜索策略
网络爬取策略可分为深度优先、广度优先和最佳优先。深度优先在很多情况下会导致爬虫被困,目前最常用的方法是广度优先和最佳优先方法。
广度优先搜索
广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
最佳优先搜索
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标网页的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
深度优先搜索
深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
网页抓取数据百度百科( 百度百科Selenium()用于Web应用程序测试的工具(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 10:03
百度百科Selenium()用于Web应用程序测试的工具(图)
)
Eclipse 使用 Java Selenium 捕获众筹 网站 数据
Selenium 介绍 百度百科
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
下载链接
我使用 Chrome 浏览器进行数据捕获。不同版本的Chrome需要下载对应的Selenium包。在右上角的帮助->关于 Chrome 中查看您自己的 Chrome 版本。这里也附上具体的Selenium下载地址,以帮助读者:
目标网站
这次我要爬网站疾病众筹网站——好筹。主页上有25个不同的显示窗口,存储了25个不同的案例。我需要获取这25个不同案例的具体信息,并跟踪记录每个案例的后续情况(后续案例可能不会出现在首页,但可能还有网址,项目会继续传播,人们有爱心可以继续捐赠)。
点击每个案例的具体情况就是这样一个页面,我会抓取每个具体案例的不同信息,比如标题、发起人姓名、目标金额、救助次数等。
实现整体架构的代码
DAO层——负责链接数据库和数据库中表的操作方法
模型层——负责实体数据模型的实现
Selenium 层——负责特定数据的捕获
UrlManage层——负责管理每个项目的URL属于辅助包,无后续应用
代码DAO层
DAO层有两个类
LinkDB 负责 Eclispe 和 Mysql 的连接
TableManage 负责具体数据库中表的操作
LinkDB 类
package DAO;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class LinkDB {
public static Connection conn=null;
public static Statement stmt=null;
public LinkDB() {
try {
Class.forName("com.mysql.jdbc.Driver");
System.out.println("成功连接到数据库!");
conn= DriverManager.getConnection(
"jdbc:mysql://localhost:3306/qsc","root","123456");
stmt=conn.createStatement();
}catch(ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}
}
}
表管理类
<p>package DAO;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import Model.Belongings;
import Model.Classifiers;
import Model.DongTai;
import Model.Proofment;
import Model.QscProject;
import Model.TopHelper;
public class TableManage {
/*
* 创建指定名称的表
* tablename stmt
*/
public String CreateTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "title varchar(255) not null,"+"finished int(10),"+
"name varchar(255),"+"target varchar(255),"+
"already varchar(255),"+"helptimes varchar(255),"
+"date varchar(255),"+"des varchar(3000),"+"url varchar(300),"
+"zhuanfa varchar(255),"+"inindex int(10)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 完结的项目创捷Helper的存储表
*/
public String CreateHelperTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+
"money varchar(255),"+"people_bring varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向Helper表中插入数据
*/
public void InsertToHelper(List helpers,String tablename,Connection conn)
{
for(int i=0;i 查看全部
网页抓取数据百度百科(
百度百科Selenium()用于Web应用程序测试的工具(图)
)
Eclipse 使用 Java Selenium 捕获众筹 网站 数据
Selenium 介绍 百度百科
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
下载链接
我使用 Chrome 浏览器进行数据捕获。不同版本的Chrome需要下载对应的Selenium包。在右上角的帮助->关于 Chrome 中查看您自己的 Chrome 版本。这里也附上具体的Selenium下载地址,以帮助读者:
目标网站
这次我要爬网站疾病众筹网站——好筹。主页上有25个不同的显示窗口,存储了25个不同的案例。我需要获取这25个不同案例的具体信息,并跟踪记录每个案例的后续情况(后续案例可能不会出现在首页,但可能还有网址,项目会继续传播,人们有爱心可以继续捐赠)。
点击每个案例的具体情况就是这样一个页面,我会抓取每个具体案例的不同信息,比如标题、发起人姓名、目标金额、救助次数等。
实现整体架构的代码
DAO层——负责链接数据库和数据库中表的操作方法
模型层——负责实体数据模型的实现
Selenium 层——负责特定数据的捕获
UrlManage层——负责管理每个项目的URL属于辅助包,无后续应用
代码DAO层
DAO层有两个类
LinkDB 负责 Eclispe 和 Mysql 的连接
TableManage 负责具体数据库中表的操作
LinkDB 类
package DAO;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class LinkDB {
public static Connection conn=null;
public static Statement stmt=null;
public LinkDB() {
try {
Class.forName("com.mysql.jdbc.Driver");
System.out.println("成功连接到数据库!");
conn= DriverManager.getConnection(
"jdbc:mysql://localhost:3306/qsc","root","123456");
stmt=conn.createStatement();
}catch(ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}
}
}
表管理类
<p>package DAO;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import Model.Belongings;
import Model.Classifiers;
import Model.DongTai;
import Model.Proofment;
import Model.QscProject;
import Model.TopHelper;
public class TableManage {
/*
* 创建指定名称的表
* tablename stmt
*/
public String CreateTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "title varchar(255) not null,"+"finished int(10),"+
"name varchar(255),"+"target varchar(255),"+
"already varchar(255),"+"helptimes varchar(255),"
+"date varchar(255),"+"des varchar(3000),"+"url varchar(300),"
+"zhuanfa varchar(255),"+"inindex int(10)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 完结的项目创捷Helper的存储表
*/
public String CreateHelperTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+
"money varchar(255),"+"people_bring varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向Helper表中插入数据
*/
public void InsertToHelper(List helpers,String tablename,Connection conn)
{
for(int i=0;i
网页抓取数据百度百科(5.抢票软件什么是网络爬虫?(数据冰山知乎))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-18 10:01
爬虫的实际例子:1.百度、谷歌(搜索引擎)、
2.新闻联播(各种资讯网站),
3.各种购物助手(比价程序)
4.数据分析(数据冰山知乎)
5.什么是网络爬虫?来自:百度百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
一般搜索引擎大多提供基于关键字的搜索。,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。 查看全部
网页抓取数据百度百科(5.抢票软件什么是网络爬虫?(数据冰山知乎))
爬虫的实际例子:1.百度、谷歌(搜索引擎)、
2.新闻联播(各种资讯网站),
3.各种购物助手(比价程序)
4.数据分析(数据冰山知乎)
5.什么是网络爬虫?来自:百度百科
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
背景
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
一般搜索引擎大多提供基于关键字的搜索。,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
网页抓取数据百度百科( Andy学Python的第57天哦!(一)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-11 16:16
Andy学Python的第57天哦!(一)!)
今天是安迪学习Python的第57天!
大家好,我叫安迪。
这几天有朋友问,“听说你最近在学Python网络爬虫,有没有兴趣开始一个项目?” 我朋友目前有一个很麻烦很无聊的任务,就是从网上查抄1W+的企业。并将数据一一保存到excel。我试图查询一家公司的 1 条记录。按照安迪目前的技术水平,我用Python是做不到的。采取前三个最简单的步骤,从excel中复制公司名称,在浏览器的指定网页中打开搜索框,粘贴公司名称。我无法实现。我的朋友听了,看起来很困惑。他说,网上有很多示例项目。代码是现成的。只需要改代码,创建爬虫,自动抓取数据,粘贴到excel中即可。
我无语了,突然发现,在我学爬虫之前,我好像也是这么想的。其实很多人还没有搞清楚“网络爬虫”和“网络爬虫”的区别,一直以为两者是一回事。其实并不是。
01.
网络爬虫
百度百科定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
搜狗百科定义:
网络爬虫也称为网络蜘蛛,网络机器人,是一种用于自动浏览万维网的程序或脚本。爬虫可以验证网页抓取的超链接和 HTML 代码。网络搜索引擎和其他网站通过爬虫软件更新自己的网站内容(网页内容)或索引到其他网站。
维基百科定义:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。网络搜索引擎和其他网站通过爬虫软件将自己的网站内容或索引更新到其他网站。网络爬虫可以保存他们访问的页面,以便搜索引擎可以生成索引供用户以后搜索。
结合这三个定义,网络爬虫的目的是获取万维网上的信息,并根据需要编制网络索引,主要用于搜索引擎。
所以问题是,我们不是搜索引擎。有没有学习网络爬虫的P?
02.
网页抓取
百度百科和搜狗百科都没有对网络爬虫的定义,只有基本的介绍(内容完全一样,如下)
网络爬虫主要有以下三个方面:
1. 采集新网页;
2. 采集自上次采集以来发生变化的网页;
3. 找到自上次采集后不再保存的网页,并将其从库中删除。
维基百科对个人感觉的定义比较靠谱:
网络爬虫是一种从网页中获取页面内容的计算机软件技术。通常通过软件使用低级超文本传输协议来模仿正常的人类访问。
网络爬虫与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网页抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。网页抓取的目的包括在线比价、联系人抓取、天气数据监测、网页变化检测、科学研究、混搭和网络数据集成。
技术层面:网页抓取用于自动获取万维网信息
1. 手动复制粘贴:最好的网络爬虫技术还不如人工手动复制粘贴,尤其是当网站采用技术手段禁止自动网络爬行时。手动复制和粘贴是唯一的解决方案。
2. 文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。可以在基于UNIX的系统上使用grep,其他平台或其他编程语言(如Perl、Python)中也有相应的命令或语法。 查看全部
网页抓取数据百度百科(
Andy学Python的第57天哦!(一)!)
今天是安迪学习Python的第57天!
大家好,我叫安迪。
这几天有朋友问,“听说你最近在学Python网络爬虫,有没有兴趣开始一个项目?” 我朋友目前有一个很麻烦很无聊的任务,就是从网上查抄1W+的企业。并将数据一一保存到excel。我试图查询一家公司的 1 条记录。按照安迪目前的技术水平,我用Python是做不到的。采取前三个最简单的步骤,从excel中复制公司名称,在浏览器的指定网页中打开搜索框,粘贴公司名称。我无法实现。我的朋友听了,看起来很困惑。他说,网上有很多示例项目。代码是现成的。只需要改代码,创建爬虫,自动抓取数据,粘贴到excel中即可。
我无语了,突然发现,在我学爬虫之前,我好像也是这么想的。其实很多人还没有搞清楚“网络爬虫”和“网络爬虫”的区别,一直以为两者是一回事。其实并不是。
01.
网络爬虫
百度百科定义:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
搜狗百科定义:
网络爬虫也称为网络蜘蛛,网络机器人,是一种用于自动浏览万维网的程序或脚本。爬虫可以验证网页抓取的超链接和 HTML 代码。网络搜索引擎和其他网站通过爬虫软件更新自己的网站内容(网页内容)或索引到其他网站。
维基百科定义:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。网络搜索引擎和其他网站通过爬虫软件将自己的网站内容或索引更新到其他网站。网络爬虫可以保存他们访问的页面,以便搜索引擎可以生成索引供用户以后搜索。
结合这三个定义,网络爬虫的目的是获取万维网上的信息,并根据需要编制网络索引,主要用于搜索引擎。
所以问题是,我们不是搜索引擎。有没有学习网络爬虫的P?
02.
网页抓取
百度百科和搜狗百科都没有对网络爬虫的定义,只有基本的介绍(内容完全一样,如下)
网络爬虫主要有以下三个方面:
1. 采集新网页;
2. 采集自上次采集以来发生变化的网页;
3. 找到自上次采集后不再保存的网页,并将其从库中删除。
维基百科对个人感觉的定义比较靠谱:
网络爬虫是一种从网页中获取页面内容的计算机软件技术。通常通过软件使用低级超文本传输协议来模仿正常的人类访问。
网络爬虫与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网页抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。网页抓取的目的包括在线比价、联系人抓取、天气数据监测、网页变化检测、科学研究、混搭和网络数据集成。
技术层面:网页抓取用于自动获取万维网信息
1. 手动复制粘贴:最好的网络爬虫技术还不如人工手动复制粘贴,尤其是当网站采用技术手段禁止自动网络爬行时。手动复制和粘贴是唯一的解决方案。
2. 文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。可以在基于UNIX的系统上使用grep,其他平台或其他编程语言(如Perl、Python)中也有相应的命令或语法。
网页抓取数据百度百科(发现站长工具的死链工具填写数据的有效链接吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-10 14:15
刚刚去百度站长平台研究了一下,发现站长工具填写数据的例子的死链接工具是“sitemap.txt和sitemap.xml。估计很多人对这两个词的第一反应是sitemap 网站Map,博客栏的sitemap.xml也提交了,然后我立马把新站的sitemap.xml提交给死链接工具,顺便更新了下里面的数据博客栏的死链接工具。。
突然有几个疑问。提交的 sitemap.xml 应该是一个有效的链接,对吗?又看到百度平台的提示了
如果提交死链数据,需要做以下操作才能成功从百度搜索结果中移除: 1、 提交的链接页面必须设置为404,以确保快速准确的删除死链数据
看来我懂了。我在百度上快速搜索“百度死链工具是否提供死链?”。结果震惊了。死链工具提交的不是sitemap.xml地图文件,而是网站的死链地址。我发现很多站长和我做了同样的事情。
百度“死链工具”的作用:主要是处理消除、删除或无效的网页链接。
更可悲的是,百度官方表示死链接文件的制作方式与站点地图格式和制作方式一致!
然后,当我提交sitemap.xml给百度时,我想自动告诉百度:我的网站的所有链接都是死链接,请帮我删除!虽然说提交死链接数据需要把提交的链接页面设置为404,但不保证百度会一时兴起把我的正常页面的数据当成死链接删除。或许,博客栏中的收录重置不是因为我网站有什么问题,而是因为我愚蠢地把站点地图提交和死链接工具弄不清楚了,虽然这不可能大。但是百度蜘蛛每天都来博客爬行,却依然不是博客恢复收录。 查看全部
网页抓取数据百度百科(发现站长工具的死链工具填写数据的有效链接吧)
刚刚去百度站长平台研究了一下,发现站长工具填写数据的例子的死链接工具是“sitemap.txt和sitemap.xml。估计很多人对这两个词的第一反应是sitemap 网站Map,博客栏的sitemap.xml也提交了,然后我立马把新站的sitemap.xml提交给死链接工具,顺便更新了下里面的数据博客栏的死链接工具。。
突然有几个疑问。提交的 sitemap.xml 应该是一个有效的链接,对吗?又看到百度平台的提示了
如果提交死链数据,需要做以下操作才能成功从百度搜索结果中移除: 1、 提交的链接页面必须设置为404,以确保快速准确的删除死链数据
看来我懂了。我在百度上快速搜索“百度死链工具是否提供死链?”。结果震惊了。死链工具提交的不是sitemap.xml地图文件,而是网站的死链地址。我发现很多站长和我做了同样的事情。
百度“死链工具”的作用:主要是处理消除、删除或无效的网页链接。
更可悲的是,百度官方表示死链接文件的制作方式与站点地图格式和制作方式一致!
然后,当我提交sitemap.xml给百度时,我想自动告诉百度:我的网站的所有链接都是死链接,请帮我删除!虽然说提交死链接数据需要把提交的链接页面设置为404,但不保证百度会一时兴起把我的正常页面的数据当成死链接删除。或许,博客栏中的收录重置不是因为我网站有什么问题,而是因为我愚蠢地把站点地图提交和死链接工具弄不清楚了,虽然这不可能大。但是百度蜘蛛每天都来博客爬行,却依然不是博客恢复收录。
网页抓取数据百度百科(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-10 14:14
概括
最后更新:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理操作中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码贴在一个完整的段落中,方便读者调试每个发布的一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.后台抓取A股市场数据(2020.09.09已更新),2.后台QQ邮箱到阅读最新邮件(待更新),等待其他实验更新(提供详细代码和评论,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
文章内容
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开下载驱动页面,找到版本号对应的驱动版本,本文84.0.4147.125,所以找84.@开头的驱动>0 如图,点击打开下载对应系统的驱动。然后将其解压缩到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,在移植到另一台计算机时,会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1) id
(2) 姓名
(3) xpath
(4) 链接文本
(5) 部分链接文本
(6) 标签名
(7) 类名
(8) css 选择器
2. id 方法
(1) 在 selenium 中通过 id 定位一个元素:find_element_by_id
以百度页面为例。百度输入框页面源码如下:
其中,是输入框的网页代码,是百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3. 命名方法
还是以百度输入框为例,在selenium中按名称定位一个元素:find_element_by_name
代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4. xpath 方式
还是以百度输入框为例,通过xpath定位selenium中的一个元素:find_element_by_xpath。但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处右击,选择勾选(N)选项,进入网页的开发者模式,如图。然后右键点击百度输入框,再次点击勾选(N)。可以发现右边代码框自动选中的部分变成了百度输入框的代码。最后右击自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath为//*[@id="kw"],百度的xpath为// *[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5. 链接文本和部分链接文本方法 查看全部
网页抓取数据百度百科(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
概括
最后更新:2020.08.20(实验部分待更新)
本文类型:实际应用(非知识讲解)
本文介绍了selenium库和chrome浏览器自动抓取网页元素,定位并填写表单数据,可以实现自动填写,节省大量人力。为了方便使用selenium库,方便处理操作中的错误,本文将对selenium库进行一定程度的重新封装,以便读者在了解selenium库后能够快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库查找元素的方式,3.重新打包selenium库
二、本文结构:1.先简单介绍一下知识点,2.把复制后可以直接运行的调试代码贴在一个完整的段落中,方便读者调试每个发布的一段代码。
三、 本文方法实现:以百度主页为控制网页,以谷歌浏览器为实验平台,使用python+selenium进行网页操作。ps:其他对应的爬网实验会更新。
四、本文实验:1.后台抓取A股市场数据(2020.09.09已更新),2.后台QQ邮箱到阅读最新邮件(待更新),等待其他实验更新(提供详细代码和评论,文末有对应链接)
温馨提示:以下为本文文章内容,以下案例可供参考
文章内容
一、安装selenium库及相关文件
Selenium 库是python 爬取网站 的自动化工具。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器。它还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装硒库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装,查看添加路径。这个建议慎选,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源并重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬取方法。其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号,点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开下载驱动页面,找到版本号对应的驱动版本,本文84.0.4147.125,所以找84.@开头的驱动>0 如图,点击打开下载对应系统的驱动。然后将其解压缩到您要编写项目的文件夹中。
不要放在python目录或者浏览器安装目录下。如果这样做,在移植到另一台计算机时,会出现各种BUG。根本原因是你的电脑已经安装了相应的库文件和驱动,但是移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1) id
(2) 姓名
(3) xpath
(4) 链接文本
(5) 部分链接文本
(6) 标签名
(7) 类名
(8) css 选择器
2. id 方法
(1) 在 selenium 中通过 id 定位一个元素:find_element_by_id
以百度页面为例。百度输入框页面源码如下:
其中,是输入框的网页代码,是百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3. 命名方法
还是以百度输入框为例,在selenium中按名称定位一个元素:find_element_by_name
代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4. xpath 方式
还是以百度输入框为例,通过xpath定位selenium中的一个元素:find_element_by_xpath。但是这种方法不适合在网页中的位置会发生变化的表格元素,因为xpath方法指向的是固定的行列,无法检测行列内容的变化。
首先在谷歌浏览器中打开百度,在空白处右击,选择勾选(N)选项,进入网页的开发者模式,如图。然后右键点击百度输入框,再次点击勾选(N)。可以发现右边代码框自动选中的部分变成了百度输入框的代码。最后右击自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath为//*[@id="kw"],百度的xpath为// *[@id="su"]
接下来,使用此值执行百度搜索。代码和注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5. 链接文本和部分链接文本方法
网页抓取数据百度百科(用JS如何能抓,除非配上反向代理(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-10 14:12
该工具建议您使用免费的优采云采集器。如果需要实时抓取这个表格,也可以设置采集时间为实时采集,优采云 采集器最快支持1分钟采集 一次。采集表格不难,点击你需要的列采集,设置循环中的所有行采集。
如何使用JS进行抓包,除非它配备了反向代理,才能解决JS跨域抓包的问题。不同域名下,JS无法访问。
界面在这里
POST方法
这里的参数是'method=find&date='+d_date+'&fundcode='+c_fundcode,
使用 PHP 的 CURL 或 JAVA,或 PYTHON 的 PURL
好吧,看来GET方法也是可行的
有的是获取网页的一些数据,有的是获取网页内容的一些信息,有的是获取你的一些浏览信息。事件信息、点击信息等
如果只是用来采集数据,市场上有很多大数据采集器可以直接使用。您无需花时间调试代码。有一定逻辑思维能力的可以采集上数据,官方也会提供教程。以供参考。
1、打开excel表格。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表,点击所在表左上角的箭头。
4、 单击箭头完成检查,然后单击“导入”。
5、选择导入数据的位置,点击“确定”。
6、 数据导入完成。
上一篇:
下一篇: 查看全部
网页抓取数据百度百科(用JS如何能抓,除非配上反向代理(图))
该工具建议您使用免费的优采云采集器。如果需要实时抓取这个表格,也可以设置采集时间为实时采集,优采云 采集器最快支持1分钟采集 一次。采集表格不难,点击你需要的列采集,设置循环中的所有行采集。
如何使用JS进行抓包,除非它配备了反向代理,才能解决JS跨域抓包的问题。不同域名下,JS无法访问。
界面在这里
POST方法
这里的参数是'method=find&date='+d_date+'&fundcode='+c_fundcode,
使用 PHP 的 CURL 或 JAVA,或 PYTHON 的 PURL
好吧,看来GET方法也是可行的
有的是获取网页的一些数据,有的是获取网页内容的一些信息,有的是获取你的一些浏览信息。事件信息、点击信息等
如果只是用来采集数据,市场上有很多大数据采集器可以直接使用。您无需花时间调试代码。有一定逻辑思维能力的可以采集上数据,官方也会提供教程。以供参考。
1、打开excel表格。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表,点击所在表左上角的箭头。
4、 单击箭头完成检查,然后单击“导入”。
5、选择导入数据的位置,点击“确定”。
6、 数据导入完成。
上一篇:
下一篇:

