
网页抓取数据百度百科
网页抓取数据百度百科(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-18 10:28
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
网页抓取数据百度百科(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
网页抓取数据百度百科( 网络爬虫(又被称为网页蜘蛛,网络机器人,))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-18 02:08
网络爬虫(又被称为网页蜘蛛,网络机器人,))
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,
特点:高性能、可扩展性、健壮性、友好性。
技术:路径检索、聚焦抓取、反向链接计数、广度优先遍历。
词汇表
聚焦抓取:聚焦检索的主要问题是使用网络爬虫的上下文。我们想在实际下载页面之前知道给定页面和查询之间的相似性。
反向链接数:反向链接数是指指向其他网页指向的网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
批量爬虫:批量爬虫的爬取范围和目标比较明确。当爬虫到达这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容的变化是常见的,增量爬虫需要及时反映这种变化,所以在不断的爬取过程中,他们要么抓取新网页,要么更新现有网页。常见的商业搜索引擎爬虫基本属于这一类。
反爬虫:防止他人利用任何技术手段批量获取自己的网站信息的一种方式。关键也是批量大小。
阻止:成功阻止爬虫访问。这里会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,误伤的可能性就越高。所以需要做出权衡。 查看全部
网页抓取数据百度百科(
网络爬虫(又被称为网页蜘蛛,网络机器人,))
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,
特点:高性能、可扩展性、健壮性、友好性。
技术:路径检索、聚焦抓取、反向链接计数、广度优先遍历。
词汇表
聚焦抓取:聚焦检索的主要问题是使用网络爬虫的上下文。我们想在实际下载页面之前知道给定页面和查询之间的相似性。
反向链接数:反向链接数是指指向其他网页指向的网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
批量爬虫:批量爬虫的爬取范围和目标比较明确。当爬虫到达这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容的变化是常见的,增量爬虫需要及时反映这种变化,所以在不断的爬取过程中,他们要么抓取新网页,要么更新现有网页。常见的商业搜索引擎爬虫基本属于这一类。
反爬虫:防止他人利用任何技术手段批量获取自己的网站信息的一种方式。关键也是批量大小。
阻止:成功阻止爬虫访问。这里会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,误伤的可能性就越高。所以需要做出权衡。
网页抓取数据百度百科(网页抓取数据百度百科上的说法:平均中有7至9条数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-03-15 15:04
网页抓取数据百度百科上的说法:平均每条中有7至9条数据。根据我自己的判断,大部分内容是靠关键词定位,对用户访问的网站应该是精准推荐,而不是是自动生成的。毕竟google已经足够精准。但比如你输入pid一条数据就出来了,可知大部分内容是百度抓取的另外,网页抓取数据这个东西,也并不是很好,比如上面很多高票答案提到的,网页上的结构性内容不好抓,比如有些抓取软件对nodejs有一些不友好的操作,比如不支持搜索字体大小等等,另外比如很多搜索软件开始抓取网页后有一些加载速度的要求,比如默认很慢或者不稳定。
另外,你们知道百度网页上经常请求数千个网站吗?对于网站的索引也是非常的慢,而且比如你们知道的,中小型企业网站的seo负责人一般很少,一般就1~2个人的情况下,架设网站程序不允许太慢,不然被同行黑了他们没有办法和你们打官司,而基本上你们去搜索的话都会是关键词定位,如果你们抓取网页,他们是默认搜索你们的。所以我觉得这个应该是不精准的。
网页加载时间是和网站内容相关,和抓取数据相关。一般情况下,网站中没有结构化的内容是抓取不出来的,除非你的网站可以对所有网站都是结构化的内容。而涉及到结构化的内容,一般意味着结构化的语义分析和语义重建,这个过程都需要大量的运行时间。不过貌似豆瓣这种纯文本的网站做不到(不关心实际内容结构和展示内容的转换)。而至于是否精准,这个真不好说,因为上面有一些网站抓取速度比较慢,至于原因不得而知。 查看全部
网页抓取数据百度百科(网页抓取数据百度百科上的说法:平均中有7至9条数据)
网页抓取数据百度百科上的说法:平均每条中有7至9条数据。根据我自己的判断,大部分内容是靠关键词定位,对用户访问的网站应该是精准推荐,而不是是自动生成的。毕竟google已经足够精准。但比如你输入pid一条数据就出来了,可知大部分内容是百度抓取的另外,网页抓取数据这个东西,也并不是很好,比如上面很多高票答案提到的,网页上的结构性内容不好抓,比如有些抓取软件对nodejs有一些不友好的操作,比如不支持搜索字体大小等等,另外比如很多搜索软件开始抓取网页后有一些加载速度的要求,比如默认很慢或者不稳定。
另外,你们知道百度网页上经常请求数千个网站吗?对于网站的索引也是非常的慢,而且比如你们知道的,中小型企业网站的seo负责人一般很少,一般就1~2个人的情况下,架设网站程序不允许太慢,不然被同行黑了他们没有办法和你们打官司,而基本上你们去搜索的话都会是关键词定位,如果你们抓取网页,他们是默认搜索你们的。所以我觉得这个应该是不精准的。
网页加载时间是和网站内容相关,和抓取数据相关。一般情况下,网站中没有结构化的内容是抓取不出来的,除非你的网站可以对所有网站都是结构化的内容。而涉及到结构化的内容,一般意味着结构化的语义分析和语义重建,这个过程都需要大量的运行时间。不过貌似豆瓣这种纯文本的网站做不到(不关心实际内容结构和展示内容的转换)。而至于是否精准,这个真不好说,因为上面有一些网站抓取速度比较慢,至于原因不得而知。
网页抓取数据百度百科(如何让百度蜘蛛知道页面是一个重要的页面??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-15 15:01
搜索引擎构建调度器来调度百度蜘蛛的工作,让百度蜘蛛与服务器建立连接下载网页。计算过程是通过调度来计算的。百度蜘蛛只负责下载网页。目前搜索引擎普遍使用分布广泛的多服务器多线程百度蜘蛛来实现多线程的目的。
(1) : 百度蜘蛛下载的网页放入补充数据区,经过各种程序计算后放入搜索区,形成稳定的排名。所以,只要下载的东西可以可以通过指令找到网站优化服务时,补充数据不稳定,在各种计算过程中可能会丢失K,搜索区的数据排名比较稳定,百度目前是缓存机制和补充的结合数据,正在改成补充数据,这对百度来说也很难,收录的原因,也是很多网站今天给K,明天发布的原因。
(2) : 深度优先,广度优先。百度蜘蛛爬取页面时,会从起始站点(即种子站点指一些门户站点)开始爬取页面,爬取更多的根站点。深度优先爬取就是爬取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责爬取,权重优先是指爬取反向链接较多的页面的优先级,也是一种调度策略。一般来说,40%的网页在正常范围内被爬取,60%是好的,100%是不可能的。当然,爬得越多越好。
百度蜘蛛从首页登陆后爬取首页后,调度器会统计所有连接数,返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛会进行下一步爬取。网站地图的作用是为百度蜘蛛提供爬取方向,让蜘蛛爬取重要页面。如何让百度蜘蛛知道该页面是重要页面?? 这个目标可以通过建立连接来实现。指向页面的页面越多,首页的网站方向、父页面的方向等都可以增加页面的权重。地图的另一个作用是为百度蜘蛛爬取更多页面提供更多连接。
将补充数据转化为主搜索区:在不改变板块结构的情况下,增加相关链接以提高网页质量,通过将其他页面的反向链接添加到页面来增加权重,通过外部链接增加权重。如果板块结构发生变化,将重新计算 SE。因此,不得在改变板结构的情况下进行操作。增加连接数,注意连接质量与反向连接数的关系。在短时间内添加大量反向连接会导致站点K。 查看全部
网页抓取数据百度百科(如何让百度蜘蛛知道页面是一个重要的页面??)
搜索引擎构建调度器来调度百度蜘蛛的工作,让百度蜘蛛与服务器建立连接下载网页。计算过程是通过调度来计算的。百度蜘蛛只负责下载网页。目前搜索引擎普遍使用分布广泛的多服务器多线程百度蜘蛛来实现多线程的目的。
(1) : 百度蜘蛛下载的网页放入补充数据区,经过各种程序计算后放入搜索区,形成稳定的排名。所以,只要下载的东西可以可以通过指令找到网站优化服务时,补充数据不稳定,在各种计算过程中可能会丢失K,搜索区的数据排名比较稳定,百度目前是缓存机制和补充的结合数据,正在改成补充数据,这对百度来说也很难,收录的原因,也是很多网站今天给K,明天发布的原因。
(2) : 深度优先,广度优先。百度蜘蛛爬取页面时,会从起始站点(即种子站点指一些门户站点)开始爬取页面,爬取更多的根站点。深度优先爬取就是爬取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责爬取,权重优先是指爬取反向链接较多的页面的优先级,也是一种调度策略。一般来说,40%的网页在正常范围内被爬取,60%是好的,100%是不可能的。当然,爬得越多越好。
百度蜘蛛从首页登陆后爬取首页后,调度器会统计所有连接数,返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛会进行下一步爬取。网站地图的作用是为百度蜘蛛提供爬取方向,让蜘蛛爬取重要页面。如何让百度蜘蛛知道该页面是重要页面?? 这个目标可以通过建立连接来实现。指向页面的页面越多,首页的网站方向、父页面的方向等都可以增加页面的权重。地图的另一个作用是为百度蜘蛛爬取更多页面提供更多连接。
将补充数据转化为主搜索区:在不改变板块结构的情况下,增加相关链接以提高网页质量,通过将其他页面的反向链接添加到页面来增加权重,通过外部链接增加权重。如果板块结构发生变化,将重新计算 SE。因此,不得在改变板结构的情况下进行操作。增加连接数,注意连接质量与反向连接数的关系。在短时间内添加大量反向连接会导致站点K。
网页抓取数据百度百科( 加速百度快照更新频率有两个重要要素有哪些呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-13 15:17
加速百度快照更新频率有两个重要要素有哪些呢?)
相信大家在上网的时候都遇到过“对不起,您要访问的页面不存在”(找不到页面的错误信息)的情况。往往网页连接速度慢,打开要十几秒甚至几十秒。发生这种情况的原因有很多,例如:网站链接已更改,网站服务器暂时被阻塞或关闭等。
网站无法登录真是让人头疼。这时候百度快照就可以很好的为你解决这个问题。
第1部分
百度快照可以直观理解为:百度蜘蛛来到你的网站,用相机拍下你的网页,记录下你网页此刻的基本信息。
百度在爬取网站数据时,对收录页面进行拍照,并存储形成的数据副本,是对网页的一种缓存处理。快照经常变化,所以搜索引擎需要经常更新和备份快照,每次更新都会生成一个快照副本,尤其是网页的内容和修改时间经常变化。显示保存的网页内容。
同时,方便用户在网站无法打开时通过网页截图查看网站的信息。网站快照反映了网站在引擎上的更新时间,时间越近,更新频率越高网站。
但是百度只保留纯文本内容,所以对于音乐、图片、视频等非文本信息,仍然需要直接从原创网页调用快照页面。如果无法连接到原创网页,将不会显示快照上的所有非文本内容。
第2部分
内容发生变化或快照内容有误怎么办?
如果您的网页内容发生了变化或者发现网页快照与您的网页内容不一致,网页快照仍然会收录原创内容,直到我们下次抓取网站并刷新索引。所以这些仍然会出现在搜索结果中,您可以请求更新快照。
加快百度快照更新频率的要素有哪些?
加快快照更新频率有两个重要因素:
首先,网站需要定期更新,持续定期更新可以方便百度蜘蛛更高效的抓取网站信息;
其次,网站更新的内容必须要定价。关于网页值,可以认为有重要的更新内容,网页的更新内容具有时间敏感性。
什么情况下会更新百度快照?
百度快照更新的原因如下:网页中增加了重要且有价值的内容。百度搜索引擎蜘蛛抓取后,会为网页地址建立一个引擎,百度快照的时刻就是索引建立的时刻。
百度蜘蛛抓取内容时,会对你更新的内容做出判断,并检测更新的内容是否与其他网页有重复内容。
如果检测到更新内容与其他网页重复或价值不大,百度快照不一定会更新。一般来说,百度快照是否更新与您更新的内容直接相关。
网站截图的时间在一定程度上体现了这个网站的优化,也在一定程度上反映了这个网站的更新和流行。它可以作为一些参考因素来判断网站的优化和质量。 查看全部
网页抓取数据百度百科(
加速百度快照更新频率有两个重要要素有哪些呢?)
相信大家在上网的时候都遇到过“对不起,您要访问的页面不存在”(找不到页面的错误信息)的情况。往往网页连接速度慢,打开要十几秒甚至几十秒。发生这种情况的原因有很多,例如:网站链接已更改,网站服务器暂时被阻塞或关闭等。
网站无法登录真是让人头疼。这时候百度快照就可以很好的为你解决这个问题。
第1部分
百度快照可以直观理解为:百度蜘蛛来到你的网站,用相机拍下你的网页,记录下你网页此刻的基本信息。
百度在爬取网站数据时,对收录页面进行拍照,并存储形成的数据副本,是对网页的一种缓存处理。快照经常变化,所以搜索引擎需要经常更新和备份快照,每次更新都会生成一个快照副本,尤其是网页的内容和修改时间经常变化。显示保存的网页内容。
同时,方便用户在网站无法打开时通过网页截图查看网站的信息。网站快照反映了网站在引擎上的更新时间,时间越近,更新频率越高网站。
但是百度只保留纯文本内容,所以对于音乐、图片、视频等非文本信息,仍然需要直接从原创网页调用快照页面。如果无法连接到原创网页,将不会显示快照上的所有非文本内容。
第2部分
内容发生变化或快照内容有误怎么办?
如果您的网页内容发生了变化或者发现网页快照与您的网页内容不一致,网页快照仍然会收录原创内容,直到我们下次抓取网站并刷新索引。所以这些仍然会出现在搜索结果中,您可以请求更新快照。
加快百度快照更新频率的要素有哪些?
加快快照更新频率有两个重要因素:
首先,网站需要定期更新,持续定期更新可以方便百度蜘蛛更高效的抓取网站信息;
其次,网站更新的内容必须要定价。关于网页值,可以认为有重要的更新内容,网页的更新内容具有时间敏感性。
什么情况下会更新百度快照?
百度快照更新的原因如下:网页中增加了重要且有价值的内容。百度搜索引擎蜘蛛抓取后,会为网页地址建立一个引擎,百度快照的时刻就是索引建立的时刻。
百度蜘蛛抓取内容时,会对你更新的内容做出判断,并检测更新的内容是否与其他网页有重复内容。
如果检测到更新内容与其他网页重复或价值不大,百度快照不一定会更新。一般来说,百度快照是否更新与您更新的内容直接相关。
网站截图的时间在一定程度上体现了这个网站的优化,也在一定程度上反映了这个网站的更新和流行。它可以作为一些参考因素来判断网站的优化和质量。
网页抓取数据百度百科( 如何解决网络数据流写入文件时的编码问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-11 00:07
如何解决网络数据流写入文件时的编码问题(图))
前言 <p>本文整理自慕课网 《Python开发简单爬虫》 ,将会记录爬取百度百科“python”词条相关页面的整个过程。 抓取策略
确定目标:确定抓取哪个网站的哪些页面的哪部分数据。本实例抓取百度百科python词条页面以及python相关词条页面的标题和简介。
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
执行爬虫:进行数据抓取。 分析目标
1、url格式
进入百度百科python词条页面,页面中相关词条的链接比较统一,大都是 /view/xxx.htm 。
2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。
3、编码格式
查看页面编码格式,为utf-8。
经过以上分析,得到结果如下:
代码编写 项目结构
在sublime下,新建文件夹baike-spider,作为项目根目录。
新建spider_main.py,作为爬虫总调度程序。
新建url_manger.py,作为url管理器。
新建html_downloader.py,作为html下载器。
新建html_parser.py,作为html解析器。
新建html_outputer.py,作为写出数据的工具。
最终项目结构如下图:
spider_main.py # coding:utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('craw %d : %s' % (count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count + 1 except: print('craw failed') self.outputer.output_html() if __name__=='__main__': root_url = 'http://baike.baidu.com/view/21087.htm' obj_spider = SpiderMain() obj_spider.craw(root_url) </p>
url_manger.py
# coding:utf-8 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if urlis None: return if urlnot in self.new_urlsand urlnot in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urlsis None or len(urls) == 0: return for urlin urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
html_downloader.py
# coding:utf-8 import urllib.request class HtmlDownloader(object): def download(self, url): if urlis None: return None response = urllib.request.urlopen(url) if response.getcode() != 200: return None return response.read()
html_parser.py
# coding:utf-8 from bs4import BeautifulSoup import re from urllib.parseimport urljoin class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() # /view/123.htm links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm')) for linkin links: new_url = link['href'] new_full_url = urljoin(page_url, new_url) # print(new_full_url) new_urls.add(new_full_url) #print(new_urls) return new_urls def _get_new_data(self, page_url, soup): res_data = {} # url res_data['url'] = page_url # Python title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1') res_data['title'] = title_node.get_text() # summary_node = soup.find('div', class_='lemma-summary') res_data['summary'] = summary_node.get_text() # print(res_data) return res_data def parse(self, page_url, html_cont): if page_urlis None or html_contis None: return soup = BeautifulSoup(html_cont, 'html.parser') # print(soup.prettify()) new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) # print('mark') return new_urls, new_data
html_outputer.py
# coding:utf-8 class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self, data): if datais None: return self.datas.append(data) def output_html(self): fout = open('output.html','w', encoding='utf-8') fout.write('') fout.write('') fout.write('') for datain self.datas: fout.write('') fout.write('%s' % data['url']) fout.write('%s' % data['title']) fout.write('%s' % data['summary']) fout.write('') fout.write('') fout.write('') fout.write('') fout.close()
跑步
在命令行,执行 python spider_main.py 。
编码问题
问题描述:UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position ...
在使用Python写文件时,或者将网络数据流写入本地文件时,大多数情况下都会遇到这个问题。网上有很多类似的文章关于如何解决这个问题,但无非就是编码、解码相关,这难道是这个问题的真正原因吗?不。很多时候,我们使用了decode和encode,尝试了各种编码,utf8、utf-8、gbk、gb2312等,所有的编码都试过了,但是还是报错,就是crash。
windows下写python脚本的时候,编码问题很严重。在将网络数据流写入文件时,我们会遇到几种编码:
1、#encoding='XXX'
这里的编码(即python文件第一行的内容)是指python脚本文件本身的编码,无关紧要。只要 XXX 的编码和文件本身相同,就可以工作。
例如,可以在notepad++的“格式”菜单中设置各种编码。这时需要保证菜单中设置的编码与编码XXX相同。如果不一样,会报错。
2、网络数据流的编码
例如,要获得一个网页,网络数据流的编码就是网页的编码。需要使用decode来解码为unicode编码。
3、目标文件的编码
将网络数据流写入新文件,写入文件的代码如下:
fout = open('output.html','w') fout.write(str)
在windows下,新建文件的默认编码是gbk,python解释器会使用gbk编码来解析我们的网络数据流str,但是str是解码后的unicode编码,会导致解析失败和以上问题。解决方案是更改目标文件的编码:
fout = open('output.html','w', encoding='utf-8')
运行结果
从: 查看全部
网页抓取数据百度百科(
如何解决网络数据流写入文件时的编码问题(图))
前言 <p>本文整理自慕课网 《Python开发简单爬虫》 ,将会记录爬取百度百科“python”词条相关页面的整个过程。 抓取策略

确定目标:确定抓取哪个网站的哪些页面的哪部分数据。本实例抓取百度百科python词条页面以及python相关词条页面的标题和简介。
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
执行爬虫:进行数据抓取。 分析目标
1、url格式
进入百度百科python词条页面,页面中相关词条的链接比较统一,大都是 /view/xxx.htm 。

2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。


3、编码格式
查看页面编码格式,为utf-8。

经过以上分析,得到结果如下:
 代码编写 项目结构
代码编写 项目结构 在sublime下,新建文件夹baike-spider,作为项目根目录。
新建spider_main.py,作为爬虫总调度程序。
新建url_manger.py,作为url管理器。
新建html_downloader.py,作为html下载器。
新建html_parser.py,作为html解析器。
新建html_outputer.py,作为写出数据的工具。
最终项目结构如下图:
 spider_main.py # coding:utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('craw %d : %s' % (count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count + 1 except: print('craw failed') self.outputer.output_html() if __name__=='__main__': root_url = 'http://baike.baidu.com/view/21087.htm' obj_spider = SpiderMain() obj_spider.craw(root_url) </p>
spider_main.py # coding:utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('craw %d : %s' % (count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count + 1 except: print('craw failed') self.outputer.output_html() if __name__=='__main__': root_url = 'http://baike.baidu.com/view/21087.htm' obj_spider = SpiderMain() obj_spider.craw(root_url) </p>url_manger.py
# coding:utf-8 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if urlis None: return if urlnot in self.new_urlsand urlnot in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urlsis None or len(urls) == 0: return for urlin urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
html_downloader.py
# coding:utf-8 import urllib.request class HtmlDownloader(object): def download(self, url): if urlis None: return None response = urllib.request.urlopen(url) if response.getcode() != 200: return None return response.read()
html_parser.py
# coding:utf-8 from bs4import BeautifulSoup import re from urllib.parseimport urljoin class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() # /view/123.htm links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm')) for linkin links: new_url = link['href'] new_full_url = urljoin(page_url, new_url) # print(new_full_url) new_urls.add(new_full_url) #print(new_urls) return new_urls def _get_new_data(self, page_url, soup): res_data = {} # url res_data['url'] = page_url # Python title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1') res_data['title'] = title_node.get_text() # summary_node = soup.find('div', class_='lemma-summary') res_data['summary'] = summary_node.get_text() # print(res_data) return res_data def parse(self, page_url, html_cont): if page_urlis None or html_contis None: return soup = BeautifulSoup(html_cont, 'html.parser') # print(soup.prettify()) new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) # print('mark') return new_urls, new_data
html_outputer.py
# coding:utf-8 class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self, data): if datais None: return self.datas.append(data) def output_html(self): fout = open('output.html','w', encoding='utf-8') fout.write('') fout.write('') fout.write('') for datain self.datas: fout.write('') fout.write('%s' % data['url']) fout.write('%s' % data['title']) fout.write('%s' % data['summary']) fout.write('') fout.write('') fout.write('') fout.write('') fout.close()
跑步
在命令行,执行 python spider_main.py 。
编码问题
问题描述:UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position ...
在使用Python写文件时,或者将网络数据流写入本地文件时,大多数情况下都会遇到这个问题。网上有很多类似的文章关于如何解决这个问题,但无非就是编码、解码相关,这难道是这个问题的真正原因吗?不。很多时候,我们使用了decode和encode,尝试了各种编码,utf8、utf-8、gbk、gb2312等,所有的编码都试过了,但是还是报错,就是crash。
windows下写python脚本的时候,编码问题很严重。在将网络数据流写入文件时,我们会遇到几种编码:
1、#encoding='XXX'
这里的编码(即python文件第一行的内容)是指python脚本文件本身的编码,无关紧要。只要 XXX 的编码和文件本身相同,就可以工作。
例如,可以在notepad++的“格式”菜单中设置各种编码。这时需要保证菜单中设置的编码与编码XXX相同。如果不一样,会报错。
2、网络数据流的编码
例如,要获得一个网页,网络数据流的编码就是网页的编码。需要使用decode来解码为unicode编码。
3、目标文件的编码
将网络数据流写入新文件,写入文件的代码如下:
fout = open('output.html','w') fout.write(str)
在windows下,新建文件的默认编码是gbk,python解释器会使用gbk编码来解析我们的网络数据流str,但是str是解码后的unicode编码,会导致解析失败和以上问题。解决方案是更改目标文件的编码:
fout = open('output.html','w', encoding='utf-8')
运行结果


从:
网页抓取数据百度百科(接着使用Html标签的重要意义,如何科学合理的使用标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-10 23:08
Html标签的优化其实是优化领域的一个基础性问题,但也正是因为如此,很多SEO技术人员没有重视,导致优化网站时效果不明显。其实通过Html标签的合理构建,百度蜘蛛可以快速获取相关信息,加上采集,可以大大提高百度蜘蛛的效率采集,也可以帮助百度蜘蛛快速判断页面的内容。质量,从而确认是否给收录。
我们首先要了解科学合理使用Html标签的重要性。
一般来说,百度蜘蛛在抓取网页内容时,主要是根据一定的算法来抓取信息。这些信息的获取是通过基础代码获取的,那么一个网页可以为百度蜘蛛提供更快更简洁的信息,可以快速获得百度蜘蛛的青睐,有助于提高搜索引擎的爬取效率。普通的SEO优化只是通过自身的优化来降低网页的噪音,但这只会让网页看起来更有利于百度收录,却不利于百度对内容页面的理解。但是,如果使用Html标签的设计,可以让网页的结构看起来很简单,就像让百度和普通用户看到一个完全设计好的网页一样。
这样,对于百度蜘蛛来说,就相当于看到了一个收录结构良好、语义充分展示的网页,进一步帮助蜘蛛理解网页的body标签的内容,比如哪些是标题? 哪些是粗体标签?特殊的表达方式是提醒百度蜘蛛注意。这是你网页的分布细节,可以让百度蜘蛛一目了然,从而提高网页被收录爬取的可能性。
然后我们将讨论如何科学合理地使用Html标签。
对于网页设计工程师来说,我们在使用标签的过程中会知道每个标签的内涵,所以我们在排列Html标签的时候,需要把对应的Html安排在正确的位置,比如在段落的位置,就需要排列 P 标签。这时,段落中的文字会自动换行。这种方法不仅可以让百度知道是换行符,还可以在网页上显示,还可以换行符显示。
另外,title标签中的h1到h6分别代表了优化级别较低和较低的标签类型。通常,优先级较高的h1标签应该用于大标题,而h6可以用于内容页面或段落标题。标签,通过这个标签的设置,还可以让百度蜘蛛了解网站页面的主副标题,从而帮助百度蜘蛛更全面的判断网页的内容。此外,网页中的新闻列表页或产品列表页应使用ul、ol或li等不同形式的标签,以帮助百度蜘蛛理解。
最后,在使用Html标签的时候,还需要注意是否存在过度优化或者优化的问题。
对此,需要彻底了解每个Html标签的内涵、含义和用法,然后注意标签的合理嵌套,避免标签混淆甚至语法错误的问题。通常双面标签成对出现,所以结尾应该匹配,而对于单面标签,结尾应该用反斜杠声明。这显示了代码的完整性和可读性。虽然用户在网页上看到的都是文字,但是对于搜索引擎来说,他们看到的都是代码,所以优化Html代码也是极其重要的。 查看全部
网页抓取数据百度百科(接着使用Html标签的重要意义,如何科学合理的使用标签)
Html标签的优化其实是优化领域的一个基础性问题,但也正是因为如此,很多SEO技术人员没有重视,导致优化网站时效果不明显。其实通过Html标签的合理构建,百度蜘蛛可以快速获取相关信息,加上采集,可以大大提高百度蜘蛛的效率采集,也可以帮助百度蜘蛛快速判断页面的内容。质量,从而确认是否给收录。

我们首先要了解科学合理使用Html标签的重要性。
一般来说,百度蜘蛛在抓取网页内容时,主要是根据一定的算法来抓取信息。这些信息的获取是通过基础代码获取的,那么一个网页可以为百度蜘蛛提供更快更简洁的信息,可以快速获得百度蜘蛛的青睐,有助于提高搜索引擎的爬取效率。普通的SEO优化只是通过自身的优化来降低网页的噪音,但这只会让网页看起来更有利于百度收录,却不利于百度对内容页面的理解。但是,如果使用Html标签的设计,可以让网页的结构看起来很简单,就像让百度和普通用户看到一个完全设计好的网页一样。
这样,对于百度蜘蛛来说,就相当于看到了一个收录结构良好、语义充分展示的网页,进一步帮助蜘蛛理解网页的body标签的内容,比如哪些是标题? 哪些是粗体标签?特殊的表达方式是提醒百度蜘蛛注意。这是你网页的分布细节,可以让百度蜘蛛一目了然,从而提高网页被收录爬取的可能性。

然后我们将讨论如何科学合理地使用Html标签。
对于网页设计工程师来说,我们在使用标签的过程中会知道每个标签的内涵,所以我们在排列Html标签的时候,需要把对应的Html安排在正确的位置,比如在段落的位置,就需要排列 P 标签。这时,段落中的文字会自动换行。这种方法不仅可以让百度知道是换行符,还可以在网页上显示,还可以换行符显示。
另外,title标签中的h1到h6分别代表了优化级别较低和较低的标签类型。通常,优先级较高的h1标签应该用于大标题,而h6可以用于内容页面或段落标题。标签,通过这个标签的设置,还可以让百度蜘蛛了解网站页面的主副标题,从而帮助百度蜘蛛更全面的判断网页的内容。此外,网页中的新闻列表页或产品列表页应使用ul、ol或li等不同形式的标签,以帮助百度蜘蛛理解。

最后,在使用Html标签的时候,还需要注意是否存在过度优化或者优化的问题。
对此,需要彻底了解每个Html标签的内涵、含义和用法,然后注意标签的合理嵌套,避免标签混淆甚至语法错误的问题。通常双面标签成对出现,所以结尾应该匹配,而对于单面标签,结尾应该用反斜杠声明。这显示了代码的完整性和可读性。虽然用户在网页上看到的都是文字,但是对于搜索引擎来说,他们看到的都是代码,所以优化Html代码也是极其重要的。
网页抓取数据百度百科(百度蜘蛛的工作原理与索引库的建立与收录方面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-10 23:07
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此并不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道怎么发文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了却没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统原理及索引库的建立,让广大做SEO优化的站长可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多地抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
庞大数量级的互联网资源要求爬虫系统尽可能高效地利用带宽,在有限的硬件和带宽资源下尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
专页的内容不一定是完整的原创,也就是可以很好的整合各方的内容,或者加入一些新鲜的内容,比如浏览量和评论,给用户提供更全面的内容。
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(百度蜘蛛的工作原理与索引库的建立与收录方面)
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此并不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道怎么发文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了却没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统原理及索引库的建立,让广大做SEO优化的站长可以百度蜘蛛的<

一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。

二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多地抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
庞大数量级的互联网资源要求爬虫系统尽可能高效地利用带宽,在有限的硬件和带宽资源下尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
专页的内容不一定是完整的原创,也就是可以很好的整合各方的内容,或者加入一些新鲜的内容,比如浏览量和评论,给用户提供更全面的内容。
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科(商业智能和搜索引擎的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-09 20:00
商业智能已经在经历三个转变:从数据驱动到业务驱动,从关注技术到关注应用,从关注工具到关注工具产生的性能。搜索引擎本质上是业务驱动和以应用为中心的(实时用户需求响应),所以我认为商业智能和搜索引擎之间有讨论的空间。这或许有助于理解技术的分工与融合,或为两者的完善提供一些参考。
1、搜索引擎本质上是(商业)智能的体现。
企业或集团历年积累的数据庞大,但信息过多,难以消化,信息形式不一致,难以统一处理。 “要学会舍弃信息”,人们开始思考:“怎样才能不被信息所淹没,而是及时利用数据资产找到需要的信息,找到有用的知识,辅助自己进行分析和决策来提高信息利用?”商业智能应运而生。
互联网上的信息量巨大,网络资源迅速增加。怎样才能不被信息淹没,而是利用网络数据及时找到需要的信息呢?搜索引擎应用正在蓬勃发展。
可以看出,搜索引擎和(商业)智能都在解决同一个问题,都需要自主或交互地执行各种拟人化任务,都与人类的思考、决策、解决问题和学习有关。 ,是拟人思维(智能)的体现。
2、搜索引擎和商业智能的工作方式相同
让我们先来看看搜索引擎是如何工作的。搜索引擎有三个主要环节:抓取网页、处理网页、提供检索服务。首先是爬网。端到端搜索引擎有自己的网络爬虫(蜘蛛)。 Spider按照超链接的顺序不断地爬取网页。抓取的网页称为网页快照。接下来,处理网页。搜索引擎抓取网页后,需要进行大量的预处理,才能提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他包括删除重复网页、分析超链接和计算网页的重要性。准备工作完成后,浏览器看到的就是搜索引擎界面,也就是第三个提供检索服务。用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了网页标题和网址外,还会提供网页摘要等信息。
再看组成:一个搜索引擎的组件一般由四部分组成:搜索器、索引器、爬虫和用户界面。搜索器的功能是在互联网上漫游,发现和采集信息,主要讲蜘蛛;索引器的作用是了解搜索器搜索到的信息,从中提取索引项,用它来表示文档,生成文档库的索引表。 第三个是检索器,其作用是根据用户查询快速检索索引数据库中的文档,评估相关性,对输出结果进行排序,并根据用户查询需求提供合理的反馈;第四个用户界面,用于接受用户查询,显示查询结果,提供个性化查询项。
这四个组件,搜索器是采集数据,索引器是处理数据,爬虫和用户界面是数据呈现。检索器是数据展示的提取过程,用户界面是用户数据需求的个性化展示。
采集数据的方式一般有人工输入、机器采集、人工输入与机器采集同步。人工维护的数据搜索引擎类别是人工组织维护的,如雅虎、新浪分类搜索,自建网络数据库的机器爬取,搜索结果直接从自己的数据库中调用,如谷歌、百度等。现在正在合并人工分拣维护和机器抓取。
在数据获取方面,需求满足第一,效率第二。机器捕获体现了高效率、高稳定性、低成本,但信息的原创能力和编辑能力还不够。人工输入如果质量高原创性能好,成本低,更能反映信息,满足用户需求,效率排第二。比如走大众路线的童童网,就是以私有产权为基础,动员大量学生输入经过学生编辑的、符合学生特点的原创性信息。学生团(通通网的“线”),费用很高。低,但更能满足学生群体的搜索需求。
我们知道,商业智能(BI)的主要工作原理体现在“数据抽取、数据处理与存储、数据分析与数据呈现”四个环节,是一个完整的端到端的商业智能解决方案。每个环节都有不同的工具或厂家,但整合基本完成,目前数据库环节的厂家已经基本掌握了其他环节的厂家。搜索引擎抓取网页的过程与数据抽取ETL的过程相同,本质是获取数据。处理网页其实就是对获取的数据进行清洗和整理,也就是数据的处理和存储,数据仓库的内容。提供检索服务其实就是数据分析和数据呈现。
可见搜索引擎和商业智能的工作方式相同。基于商业智能的四个环节,各自有很强的理解力,不同的搜索引擎在“抓取网页、处理网页、提供检索服务”三个环节也各有优势。例如,Lycos 搜索引擎专注于提供检索服务。它只从其他搜索引擎租用数据库,并以自定义格式排列搜索结果。
3、商业智能需要从三个方面向搜索引擎学习
1)搜索引擎获取结果的方式极其简单,值得借鉴
商业智能应用学科的泛化使得BI融入日常业务运营,需要极其简单的操作方式和低成本的沟通方式。搜索引擎的易用性可以达到这个目的。从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入一个单词并通过浏览器提交给搜索引擎后,搜索引擎会返回一个与用户输入的内容相关的信息列表。操作非常简单。运营BI日益发展,BI将在单位基层和中层得到应用,即流程化BI(或运营BI)将受到重视和推广。这种基于流程的BI的“下利巴形象”将实现“一般员工也需要用BI,能用BI,必须用BI”,从而最大限度地利用BI。可以看出,此时的用户已经包括了非技术/分析业务/经理。商业智能产品提供的查询、定制和分析模式对于非技术/分析专业人员来说仍然过于复杂,无法支持他们快速、低成本地获得所需的结果。目前商业智能在语义层方面已经有了很大的提升,语义层的功能让业务用户对数据的操作更加方便。但在理解自然语言方面,比如让系统正确理解人类以自然语言输入的信息,并正确回答(或响应)输入的信息,搜索引擎相对要好一些。
2)提高和增强实时理解和分析能力
商业智能以if-what-how模型为基础,补充what-how模型,实现实时智能。很多商业智能解决方案,尤其是研究的建模应用,一般都是先假设问题,再建模,构建数据和应用系统,针对特定领域使用特定的分析方法,返回特定的结果。 利用搜索引擎技术可以通过“数据+语义+分析方法+结果排列+呈现”的方式实现实时智能,具有数据范围广、分析结果动态的特点。现有的一些商业智能产品可以方便的添加各类数据源,在类似谷歌的搜索框中输入关键词(例如:“Sales income from sales in December”),系统会返回合理组织的结果带图片和文字。 “数据-趋势图”的互动联动也引起了很多用户的兴趣。
3)增强处理非结构化数据的能力
非结构化数据对于业务处理越来越重要。支持决策的信息不仅限于来自数据仓库和ODS层的结构化信息,还往往收录大量的非结构化信息,如文档、电子邮件、媒体文件等。搜索引擎具有很强的处理能力非结构化信息,例如图片、视频和音乐。
4、搜索引擎需要从四个方面学习商业智能
1)向专家系统学习,提高搜索引擎对用户搜索问题的理解,去除冗余搜索结果。
目前的搜索引擎检索结果具有更高的准确性,但仍需改进。应从搜索结果中删除过多信息和过多无关信息。出现附加冗余信息的主要原因是搜索引擎不理解用户问题的原意。优化搜索结果的解决方案有很多,比如元搜索引擎、综合搜索引擎,垂直搜索引擎是比较成功的例子,可以实现非www信息搜索,提供FTP等信息检索、多媒体搜索等。解决方案倾向于确定搜索引擎信息采集的范围,提高搜索引擎的针对性。
这里针对具体复杂的搜索提出,可以借鉴专家系统的问题形式的思想,从而提高搜索引擎对用户搜索问题的理解。
2)增加智能,从搜索数据/信息到给出解决方案,甚至执行解决方案
目前的搜索引擎,就像一只魔术手,从杂乱无章的信息中提取出清晰的检索路径,并提供相应的数据或信息。至于信息如何分析判断,如何帮助我们做出决策甚至直接执行,只能靠大脑了。当前的搜索引擎根本无法做到这一点。但是,对于用户来说,搜索并不是目的,他需要得出结论,甚至帮助他去执行。比如我要买MP3,衡量指标是品牌、价格、质量、交货期。我需要把这四项放到搜索引擎中,让电脑执行。一段时间后,搜索引擎给了我四个方案供我选择,或者为我的决定,帮我购买了某款MP3。这就是用户所需要的,而不是发布一堆信息,让用户一一做出判断和分析,耗费过多的精力,这不是我们需要的。
所以目前搜索引擎的智能水平并不高,只解决了商业智能中的第一级智能:查询/报告。商业智能在应用智能方面分为三个层次。第一层是提供数据参考,帮助用户进行数字化回忆或确认已经发生的事实,称为查询/报告;第二个层次是帮助用户寻找关系,找到原因并进行预测,称为“综合分析”;三是生成实现目标的多条路径,让用户进行选择和选择,这就是所谓的“计划选择”。选项选择的级别实际上需要生成解决问题的措施或解决方案。
商业智能在综合分析和方案选择方面取得了一些进展,但仍不成熟。搜索引擎和商业智能可以集成和先进。
3)革新网页重要性评价体系
如何呈现用户需要的数据或结论,以什么标准衡量,这是搜索引擎和商业智能非常重要的话题。
现在搜索引擎有两个评价标准,即基于链接评价的搜索引擎和基于公众访问的搜索引擎。 “链接评估系统”认为,一个网页的重要性取决于它被其他网页链接的链接数量,尤其是一些被认定为“重要”的页面的链接数量。这个评价体系和科技引文索引的思路很相似,但是由于互联网是在商业化的环境下发展起来的,一个网站的链接数也和它的商业推广息息相关,所以这种评价体系在一定程度上缺乏客观性(百度百科)。基于可访问性的搜索引擎也有类似的缺陷。目前的做法是弥补,而不是创新,目前还没有找到比上述评价体系更好的替代方案。
更重要的是,由于任何人都可以在互联网上发布信息,搜索引擎可以帮助你找到信息,但无法验证信息的可靠性,这就导致了搜索引擎数据可靠性的先天缺陷。
如何判断被抓取网页的重要性,如何判断网页信息的可信度,搜索引擎还有很长的路要走。
4)借鉴商业智能的应用方法,研究搜索用户的行为和需求
搜索引擎是网站建设中“方便用户使用网站”的必备功能,也是“研究网站用户行为的有效工具”。搜索引擎采集了大量的用户需求信息,用户每输入一个查询,就代表一个需求。积累和分析“需求数据”具有重要的商业价值。商业智能相关产品可以帮助搜索引擎厂商充分利用“需求数据”,找到更有利的商业模式。
事实上,业界已经开始了商业智能和搜索引擎的这种融合。
从 2004 年开始,商业智能与搜索引擎的结合开始受到广泛关注。从2006年开始,此类解决方案普遍出现在各个商业智能厂商中。例如,Business Objects Google Solutions 2006 支持搜索各种数据结构,包括文本文档、电子邮件、台式计算机中的办公文档、水晶报表、BI 平台中的仪表板数据和公司合同文档。 2007年,WebFocus Magnify对结构化数据进行搜索和索引,并在搜索结果中提供了BI报表的搜索和导航工具,通过树形结构展示搜索结果。 SAS SAS BI Google OneBox 企业版解决方案于2006 年与Google OneBox 紧密结合,让用户可以使用原有的搜索方式获得更深层次的搜索结果。 SAS还提供文本挖掘技术,帮助用户从企业文档中发现和提取知识,建立数据关联。最近的 SAP BusinessObjects Explorer 在提高商业智能系统的可用性、减少查询和搜索响应时间、结果排列和组织方面取得了重大突破,具有类似搜索引擎的效果。
相信随着实践的深入,商业智能和搜索引擎会融合成一个更美好的世界。 查看全部
网页抓取数据百度百科(商业智能和搜索引擎的工作原理)
商业智能已经在经历三个转变:从数据驱动到业务驱动,从关注技术到关注应用,从关注工具到关注工具产生的性能。搜索引擎本质上是业务驱动和以应用为中心的(实时用户需求响应),所以我认为商业智能和搜索引擎之间有讨论的空间。这或许有助于理解技术的分工与融合,或为两者的完善提供一些参考。
1、搜索引擎本质上是(商业)智能的体现。
企业或集团历年积累的数据庞大,但信息过多,难以消化,信息形式不一致,难以统一处理。 “要学会舍弃信息”,人们开始思考:“怎样才能不被信息所淹没,而是及时利用数据资产找到需要的信息,找到有用的知识,辅助自己进行分析和决策来提高信息利用?”商业智能应运而生。
互联网上的信息量巨大,网络资源迅速增加。怎样才能不被信息淹没,而是利用网络数据及时找到需要的信息呢?搜索引擎应用正在蓬勃发展。
可以看出,搜索引擎和(商业)智能都在解决同一个问题,都需要自主或交互地执行各种拟人化任务,都与人类的思考、决策、解决问题和学习有关。 ,是拟人思维(智能)的体现。
2、搜索引擎和商业智能的工作方式相同
让我们先来看看搜索引擎是如何工作的。搜索引擎有三个主要环节:抓取网页、处理网页、提供检索服务。首先是爬网。端到端搜索引擎有自己的网络爬虫(蜘蛛)。 Spider按照超链接的顺序不断地爬取网页。抓取的网页称为网页快照。接下来,处理网页。搜索引擎抓取网页后,需要进行大量的预处理,才能提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他包括删除重复网页、分析超链接和计算网页的重要性。准备工作完成后,浏览器看到的就是搜索引擎界面,也就是第三个提供检索服务。用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了网页标题和网址外,还会提供网页摘要等信息。
再看组成:一个搜索引擎的组件一般由四部分组成:搜索器、索引器、爬虫和用户界面。搜索器的功能是在互联网上漫游,发现和采集信息,主要讲蜘蛛;索引器的作用是了解搜索器搜索到的信息,从中提取索引项,用它来表示文档,生成文档库的索引表。 第三个是检索器,其作用是根据用户查询快速检索索引数据库中的文档,评估相关性,对输出结果进行排序,并根据用户查询需求提供合理的反馈;第四个用户界面,用于接受用户查询,显示查询结果,提供个性化查询项。
这四个组件,搜索器是采集数据,索引器是处理数据,爬虫和用户界面是数据呈现。检索器是数据展示的提取过程,用户界面是用户数据需求的个性化展示。
采集数据的方式一般有人工输入、机器采集、人工输入与机器采集同步。人工维护的数据搜索引擎类别是人工组织维护的,如雅虎、新浪分类搜索,自建网络数据库的机器爬取,搜索结果直接从自己的数据库中调用,如谷歌、百度等。现在正在合并人工分拣维护和机器抓取。
在数据获取方面,需求满足第一,效率第二。机器捕获体现了高效率、高稳定性、低成本,但信息的原创能力和编辑能力还不够。人工输入如果质量高原创性能好,成本低,更能反映信息,满足用户需求,效率排第二。比如走大众路线的童童网,就是以私有产权为基础,动员大量学生输入经过学生编辑的、符合学生特点的原创性信息。学生团(通通网的“线”),费用很高。低,但更能满足学生群体的搜索需求。
我们知道,商业智能(BI)的主要工作原理体现在“数据抽取、数据处理与存储、数据分析与数据呈现”四个环节,是一个完整的端到端的商业智能解决方案。每个环节都有不同的工具或厂家,但整合基本完成,目前数据库环节的厂家已经基本掌握了其他环节的厂家。搜索引擎抓取网页的过程与数据抽取ETL的过程相同,本质是获取数据。处理网页其实就是对获取的数据进行清洗和整理,也就是数据的处理和存储,数据仓库的内容。提供检索服务其实就是数据分析和数据呈现。

可见搜索引擎和商业智能的工作方式相同。基于商业智能的四个环节,各自有很强的理解力,不同的搜索引擎在“抓取网页、处理网页、提供检索服务”三个环节也各有优势。例如,Lycos 搜索引擎专注于提供检索服务。它只从其他搜索引擎租用数据库,并以自定义格式排列搜索结果。
3、商业智能需要从三个方面向搜索引擎学习
1)搜索引擎获取结果的方式极其简单,值得借鉴
商业智能应用学科的泛化使得BI融入日常业务运营,需要极其简单的操作方式和低成本的沟通方式。搜索引擎的易用性可以达到这个目的。从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入一个单词并通过浏览器提交给搜索引擎后,搜索引擎会返回一个与用户输入的内容相关的信息列表。操作非常简单。运营BI日益发展,BI将在单位基层和中层得到应用,即流程化BI(或运营BI)将受到重视和推广。这种基于流程的BI的“下利巴形象”将实现“一般员工也需要用BI,能用BI,必须用BI”,从而最大限度地利用BI。可以看出,此时的用户已经包括了非技术/分析业务/经理。商业智能产品提供的查询、定制和分析模式对于非技术/分析专业人员来说仍然过于复杂,无法支持他们快速、低成本地获得所需的结果。目前商业智能在语义层方面已经有了很大的提升,语义层的功能让业务用户对数据的操作更加方便。但在理解自然语言方面,比如让系统正确理解人类以自然语言输入的信息,并正确回答(或响应)输入的信息,搜索引擎相对要好一些。
2)提高和增强实时理解和分析能力
商业智能以if-what-how模型为基础,补充what-how模型,实现实时智能。很多商业智能解决方案,尤其是研究的建模应用,一般都是先假设问题,再建模,构建数据和应用系统,针对特定领域使用特定的分析方法,返回特定的结果。 利用搜索引擎技术可以通过“数据+语义+分析方法+结果排列+呈现”的方式实现实时智能,具有数据范围广、分析结果动态的特点。现有的一些商业智能产品可以方便的添加各类数据源,在类似谷歌的搜索框中输入关键词(例如:“Sales income from sales in December”),系统会返回合理组织的结果带图片和文字。 “数据-趋势图”的互动联动也引起了很多用户的兴趣。
3)增强处理非结构化数据的能力
非结构化数据对于业务处理越来越重要。支持决策的信息不仅限于来自数据仓库和ODS层的结构化信息,还往往收录大量的非结构化信息,如文档、电子邮件、媒体文件等。搜索引擎具有很强的处理能力非结构化信息,例如图片、视频和音乐。
4、搜索引擎需要从四个方面学习商业智能
1)向专家系统学习,提高搜索引擎对用户搜索问题的理解,去除冗余搜索结果。
目前的搜索引擎检索结果具有更高的准确性,但仍需改进。应从搜索结果中删除过多信息和过多无关信息。出现附加冗余信息的主要原因是搜索引擎不理解用户问题的原意。优化搜索结果的解决方案有很多,比如元搜索引擎、综合搜索引擎,垂直搜索引擎是比较成功的例子,可以实现非www信息搜索,提供FTP等信息检索、多媒体搜索等。解决方案倾向于确定搜索引擎信息采集的范围,提高搜索引擎的针对性。
这里针对具体复杂的搜索提出,可以借鉴专家系统的问题形式的思想,从而提高搜索引擎对用户搜索问题的理解。
2)增加智能,从搜索数据/信息到给出解决方案,甚至执行解决方案
目前的搜索引擎,就像一只魔术手,从杂乱无章的信息中提取出清晰的检索路径,并提供相应的数据或信息。至于信息如何分析判断,如何帮助我们做出决策甚至直接执行,只能靠大脑了。当前的搜索引擎根本无法做到这一点。但是,对于用户来说,搜索并不是目的,他需要得出结论,甚至帮助他去执行。比如我要买MP3,衡量指标是品牌、价格、质量、交货期。我需要把这四项放到搜索引擎中,让电脑执行。一段时间后,搜索引擎给了我四个方案供我选择,或者为我的决定,帮我购买了某款MP3。这就是用户所需要的,而不是发布一堆信息,让用户一一做出判断和分析,耗费过多的精力,这不是我们需要的。
所以目前搜索引擎的智能水平并不高,只解决了商业智能中的第一级智能:查询/报告。商业智能在应用智能方面分为三个层次。第一层是提供数据参考,帮助用户进行数字化回忆或确认已经发生的事实,称为查询/报告;第二个层次是帮助用户寻找关系,找到原因并进行预测,称为“综合分析”;三是生成实现目标的多条路径,让用户进行选择和选择,这就是所谓的“计划选择”。选项选择的级别实际上需要生成解决问题的措施或解决方案。
商业智能在综合分析和方案选择方面取得了一些进展,但仍不成熟。搜索引擎和商业智能可以集成和先进。
3)革新网页重要性评价体系
如何呈现用户需要的数据或结论,以什么标准衡量,这是搜索引擎和商业智能非常重要的话题。
现在搜索引擎有两个评价标准,即基于链接评价的搜索引擎和基于公众访问的搜索引擎。 “链接评估系统”认为,一个网页的重要性取决于它被其他网页链接的链接数量,尤其是一些被认定为“重要”的页面的链接数量。这个评价体系和科技引文索引的思路很相似,但是由于互联网是在商业化的环境下发展起来的,一个网站的链接数也和它的商业推广息息相关,所以这种评价体系在一定程度上缺乏客观性(百度百科)。基于可访问性的搜索引擎也有类似的缺陷。目前的做法是弥补,而不是创新,目前还没有找到比上述评价体系更好的替代方案。
更重要的是,由于任何人都可以在互联网上发布信息,搜索引擎可以帮助你找到信息,但无法验证信息的可靠性,这就导致了搜索引擎数据可靠性的先天缺陷。
如何判断被抓取网页的重要性,如何判断网页信息的可信度,搜索引擎还有很长的路要走。
4)借鉴商业智能的应用方法,研究搜索用户的行为和需求
搜索引擎是网站建设中“方便用户使用网站”的必备功能,也是“研究网站用户行为的有效工具”。搜索引擎采集了大量的用户需求信息,用户每输入一个查询,就代表一个需求。积累和分析“需求数据”具有重要的商业价值。商业智能相关产品可以帮助搜索引擎厂商充分利用“需求数据”,找到更有利的商业模式。
事实上,业界已经开始了商业智能和搜索引擎的这种融合。
从 2004 年开始,商业智能与搜索引擎的结合开始受到广泛关注。从2006年开始,此类解决方案普遍出现在各个商业智能厂商中。例如,Business Objects Google Solutions 2006 支持搜索各种数据结构,包括文本文档、电子邮件、台式计算机中的办公文档、水晶报表、BI 平台中的仪表板数据和公司合同文档。 2007年,WebFocus Magnify对结构化数据进行搜索和索引,并在搜索结果中提供了BI报表的搜索和导航工具,通过树形结构展示搜索结果。 SAS SAS BI Google OneBox 企业版解决方案于2006 年与Google OneBox 紧密结合,让用户可以使用原有的搜索方式获得更深层次的搜索结果。 SAS还提供文本挖掘技术,帮助用户从企业文档中发现和提取知识,建立数据关联。最近的 SAP BusinessObjects Explorer 在提高商业智能系统的可用性、减少查询和搜索响应时间、结果排列和组织方面取得了重大突破,具有类似搜索引擎的效果。
相信随着实践的深入,商业智能和搜索引擎会融合成一个更美好的世界。
网页抓取数据百度百科(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-09 19:26
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
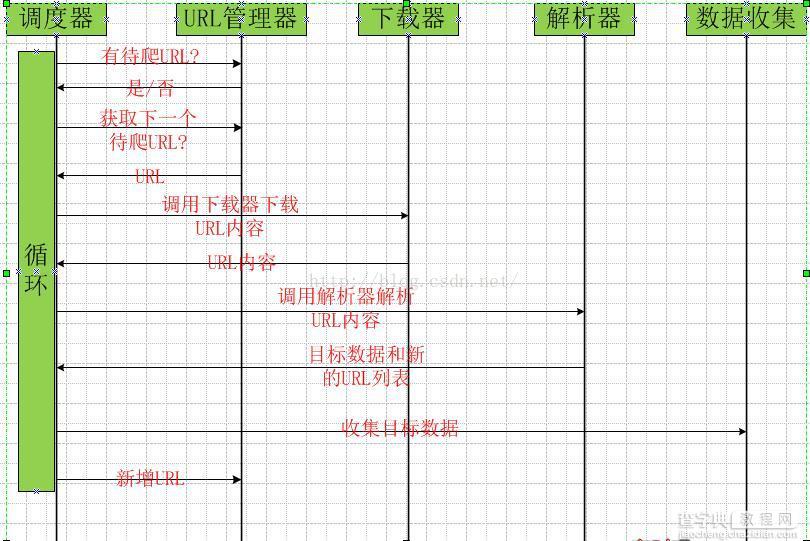
3、爬虫时序图
4、网址管理器
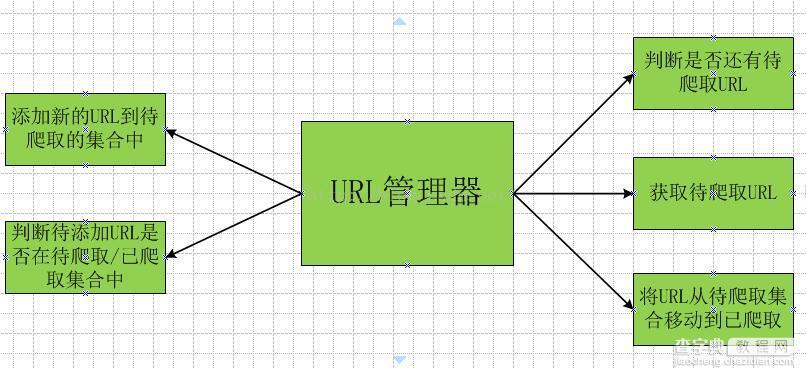
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,在使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对特征比较鲜明的目标数据有很好的效果,但并不通用。 BeautifulSoup 是一个用于对 url 内容进行结构化解析的第三方模块。下载的网页内容被解析成 DOM 树。下图是BeautifulSoup截取的百度百科网页的部分输出。
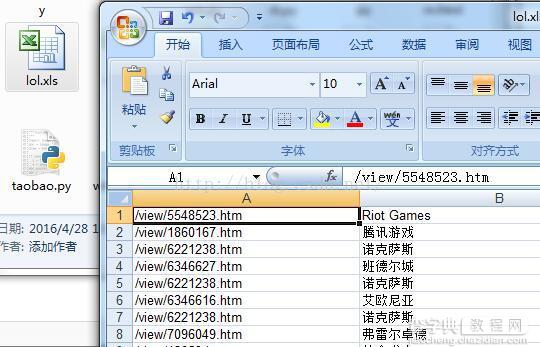
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopenexcelFile=xlwt.Workbook() sheet=excelFile.add_sheet('英雄联盟') ## 维基百科:英雄联盟## html=urlopen( "") bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main- content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=pile("^(/view/)[0-9]+. htm$")) 用于链接中的链接:if 'href' in link.attrs:print(link.attrs['href'],link.get_text())sheet.write(row,0,link.attrs['href '])sheet.write(row,1,link.get_text())row=row+1excelFile.save('E:ProjectPythonlol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
自动发微博最简单的方法是调用新浪微博的API(因为发微博很简单,不需要使用它的SDK)。编码参考开发文档
创建应用
要使用微博的API,你需要先有一个应用程序。任何申请都可以,你可以去这里注册一个现场申请申请注册。注册应用的主要目的是获取MY_APPKEY和MY_ACCESS_TOKEN,如图
获取 access_token
API 调用需要登录授权才能获取 access_token。参考
首先调用接口获取代码。
接口有三个必填参数:
•client_id:申请应用时分配的AppKey。
•redirect_url:是创建应用中设置的回调地址
•response_type:响应类型,可设置为code
具体方法是在浏览器中打开:///response&response_type=code。该方法会进入授权页面,授权后会进入url中的CODE。
接下来调用接口获取access_token。
接口有以下必要参数:
•client_id:申请应用时分配的AppKey。
•client_secret:申请应用时分配的AppSecret。
•grant_type:请求的类型,填写authorization_code
•code:调用authorize获取的code值。
•redirect_uri:是创建应用程序中设置的回调地址
具体方法是构造一个POST请求,然后在返回的数据中找到access_token并保存。具体Python代码:
import requestsurl_get_token = ""#Build POST 参数 playload = {"client_id":"填写你的","client_secret":"填写你的","grant_type":"authorization_code","code":" 获取的代码above","redirect_uri":"你的回调地址"}#POST请求r = requests.post(url_get_token,data=playload)#输出响应信息打印r.text
如果正常,会返回如下json数据:
{"access_token":"我们要记住的内容","remind_in":"157679999","expires_in":157679999,"uid":"1739207845"}
根据返回的数据,access_token的值就是我们想要的。 remember_in 的值是 access_token 的有效期,以秒为单位。我们可以看到,这个时间是3、4年,对我们来说已经足够了。
发布纯文本推文
调用接口发布文字微博,参数如下
这是必需的:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
具体代码:
#微博发文接口 url_post_a_text = ""#构建 POST 参数 playload = {"access_token":"填写你的","status":"这是一个文本 test@TaceyWong"}#POST 请求,发文微博r = requests.post(url_post_a_text,data = playload)
如果正常,会有如下结果
发一条带图片的微博
调用接口发布图片微博,其参数如下:
所需参数:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
•pic:要发布的图片,采用multipart/form-data编码方式
具体代码:
#微博发图文接口 url_post_pic = ""#构建文本类POST参数playload={"access_token":"2.0086XhtBIQLH7Ed67706b6c8TQ8XdE","status":"测试:发一个带a的文本pic & AT某人@馠子覠"}#构造二进制multipart/form-data编码参数files={"pic":open("logo.png","rb")}#POST请求,发布微博r=requests。 post(url_post_pic,data=playload,files=files)
如果正常,结果如下:
注意:requests的具体用法请参考[requests document]()
本文总结了python遍历目录的方法。分享给大家,供大家参考,如下:
方法一使用递归:
"""def WalkDir(dir, dir_callback = None, file_callback = None): for item in os.listdir(dir):print item;fullpath = dir + os.sep + itemif os.path.isdir(fullpath) :WalkDir(fullpath,dir_callback,file_callback)if dir_callback:dir_callback(fullpath)else:if file_callback:file_callback(fullpath)"""def DeleteDir(dir): print "path"#os.rmdir(dir)def DeleteFile(file) : try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
方法二:
import os, statdef WalkDir( dir, dir_callback = None, file_callback = None ): for root, dirs, files in os.walk(dir): for f in files:print ffile_path = os.path.join(root, f)if file_callback: file_callback(file_path)for d in dirs:dir_path = os.path.join(root, d)if dir_callback: dir_callback(dir_path)def DeleteDir(dir): print "path"#os.rmdir(dir) def DeleteFile( file ): try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取数据百度百科(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
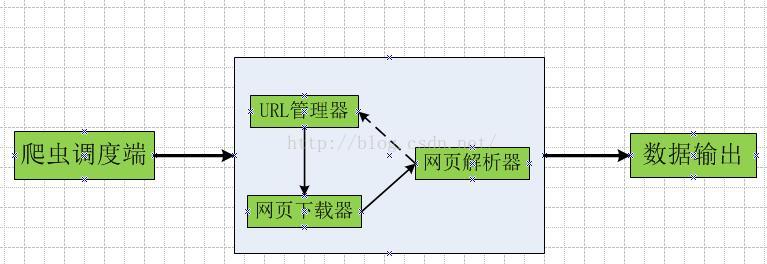
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,在使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对特征比较鲜明的目标数据有很好的效果,但并不通用。 BeautifulSoup 是一个用于对 url 内容进行结构化解析的第三方模块。下载的网页内容被解析成 DOM 树。下图是BeautifulSoup截取的百度百科网页的部分输出。

BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopenexcelFile=xlwt.Workbook() sheet=excelFile.add_sheet('英雄联盟') ## 维基百科:英雄联盟## html=urlopen( "") bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main- content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=pile("^(/view/)[0-9]+. htm$")) 用于链接中的链接:if 'href' in link.attrs:print(link.attrs['href'],link.get_text())sheet.write(row,0,link.attrs['href '])sheet.write(row,1,link.get_text())row=row+1excelFile.save('E:ProjectPythonlol.xls')
部分输出截图如下:

excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
自动发微博最简单的方法是调用新浪微博的API(因为发微博很简单,不需要使用它的SDK)。编码参考开发文档
创建应用
要使用微博的API,你需要先有一个应用程序。任何申请都可以,你可以去这里注册一个现场申请申请注册。注册应用的主要目的是获取MY_APPKEY和MY_ACCESS_TOKEN,如图
获取 access_token
API 调用需要登录授权才能获取 access_token。参考
首先调用接口获取代码。
接口有三个必填参数:
•client_id:申请应用时分配的AppKey。
•redirect_url:是创建应用中设置的回调地址
•response_type:响应类型,可设置为code
具体方法是在浏览器中打开:///response&response_type=code。该方法会进入授权页面,授权后会进入url中的CODE。
接下来调用接口获取access_token。
接口有以下必要参数:
•client_id:申请应用时分配的AppKey。
•client_secret:申请应用时分配的AppSecret。
•grant_type:请求的类型,填写authorization_code
•code:调用authorize获取的code值。
•redirect_uri:是创建应用程序中设置的回调地址
具体方法是构造一个POST请求,然后在返回的数据中找到access_token并保存。具体Python代码:
import requestsurl_get_token = ""#Build POST 参数 playload = {"client_id":"填写你的","client_secret":"填写你的","grant_type":"authorization_code","code":" 获取的代码above","redirect_uri":"你的回调地址"}#POST请求r = requests.post(url_get_token,data=playload)#输出响应信息打印r.text
如果正常,会返回如下json数据:
{"access_token":"我们要记住的内容","remind_in":"157679999","expires_in":157679999,"uid":"1739207845"}
根据返回的数据,access_token的值就是我们想要的。 remember_in 的值是 access_token 的有效期,以秒为单位。我们可以看到,这个时间是3、4年,对我们来说已经足够了。
发布纯文本推文
调用接口发布文字微博,参数如下

这是必需的:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
具体代码:
#微博发文接口 url_post_a_text = ""#构建 POST 参数 playload = {"access_token":"填写你的","status":"这是一个文本 test@TaceyWong"}#POST 请求,发文微博r = requests.post(url_post_a_text,data = playload)
如果正常,会有如下结果
发一条带图片的微博
调用接口发布图片微博,其参数如下:

所需参数:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
•pic:要发布的图片,采用multipart/form-data编码方式
具体代码:
#微博发图文接口 url_post_pic = ""#构建文本类POST参数playload={"access_token":"2.0086XhtBIQLH7Ed67706b6c8TQ8XdE","status":"测试:发一个带a的文本pic & AT某人@馠子覠"}#构造二进制multipart/form-data编码参数files={"pic":open("logo.png","rb")}#POST请求,发布微博r=requests。 post(url_post_pic,data=playload,files=files)
如果正常,结果如下:
注意:requests的具体用法请参考[requests document]()
本文总结了python遍历目录的方法。分享给大家,供大家参考,如下:
方法一使用递归:
"""def WalkDir(dir, dir_callback = None, file_callback = None): for item in os.listdir(dir):print item;fullpath = dir + os.sep + itemif os.path.isdir(fullpath) :WalkDir(fullpath,dir_callback,file_callback)if dir_callback:dir_callback(fullpath)else:if file_callback:file_callback(fullpath)"""def DeleteDir(dir): print "path"#os.rmdir(dir)def DeleteFile(file) : try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
方法二:
import os, statdef WalkDir( dir, dir_callback = None, file_callback = None ): for root, dirs, files in os.walk(dir): for f in files:print ffile_path = os.path.join(root, f)if file_callback: file_callback(file_path)for d in dirs:dir_path = os.path.join(root, d)if dir_callback: dir_callback(dir_path)def DeleteDir(dir): print "path"#os.rmdir(dir) def DeleteFile( file ): try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
希望这篇文章对你的 Python 编程有所帮助。
网页抓取数据百度百科( 影响网页快照几个的几个因素-苏州安嘉Web)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-09 18:04
影响网页快照几个的几个因素-苏州安嘉Web)
网页快照的英文名称是Web Cache,是搜索引擎抓取、复制页面内容并存储的过程。网页快照不仅是分析搜索引擎对网站的关注程度,也是友情链接交换的重要参考因素,那么如何加快网页快照的更新频率,让网站 的优化工作更快 高效的运行是站长一直在寻找的。下面我们描述影响网页快照的几个因素。1、网站内容更新频率正常。只要网站的内容有更新,搜索引擎蜘蛛就会过来采集。但是网站内容的更新频率也应该是有规律的,就像我们的工作一样,
网页快照英文名称为WebCache,是百度搜索引擎抓取、复制网页内容并存储的全过程。网页快照不仅分析了百度搜索引擎对网址的关注程度,也是友情链接交换的关键参考因素。因此,如何加快网页快照的升级频率,让搜索引擎优化工作更加快速高效。,这正是 网站 的站长一直在寻找的。您将在下面详细了解影响 Web 快照的许多元素。
1、网站内容更新频率
一般来说,如果网站内容升级了,百度搜索引擎搜索引擎蜘蛛就会回来采集。但是,网站内容的更新频率应该是有规律的。就像大家的工作一样,要有规律,要有目的,这样百度搜索引擎的搜索引擎蜘蛛才会有规律的去寻找。了解这个网站需要多久来一次。一般来说,在网站的内容更新频率稳定的情况下,网页快照的更新频率大致与网站的内容更新频率相近(百度搜索引擎更新周期除外)。
2、URL的权重值
单纯的升级网站的内容显然是不够的,网站也要按辈分排名。新的网站的内容在不断的升级,但有时也无法与旧的网站齐头并进。这就是百度权重的效果。百度搜索引擎一直偏爱具有高权重值的 URL。如果你想让你的新网站获得很多青睐,你应该在新站点的开头选中一个权重值高的网站域名。
3、URL 多久更改一次
当要更改 URL 时,必须考虑对 seo 优化的危害。无论是网站源代码,页面的合理布局,内容甚至是URL的页面标题、描述、关键词,都会对网页快照造成危害。如果网址经常变化,会给百度搜索引擎留下很不好的印象。就像你认识的人今天改变了头形,明天做了双眼皮手术,并获得了隆鼻手术。你能承受这样的改变吗?URL完成后,尽量不要更改,URL也不需要频繁更改。
4、网址是假的
未升级的页面快照有时会因网站造假或涉嫌造假而被百度搜索引擎处罚。百度搜索引擎的技术性一直在不断发展,并且不断朝着更加公平的方向发展。网站当前或以前的seo工作涉及欺诈,或可靠的实际操作被列为欺诈,这将导致网页欺诈。快照未升级。
5、Web 服务器可靠性
找到一个好的室内空间提供商也很重要,这样您的网络服务器就可以得到保护。Web 服务器的可靠性非常关键。不稳定的网络服务器不仅会阻塞客户端对网站的浏览,而且百度搜索引擎也无法正常抓取内容。其他网络服务器网站会因作弊而受到惩罚,你的网站也会受到惩罚。Web 服务器的其他不安全元素(病原体、长期攻击)也可能危及网页快照的升级。
6、ping 服务项目
如果你的网址是zblog、wordpress程序进程等,如果你想让你的博客使用RSS,可以添加ping服务项。另外,每个博客创建者发布新的文章内容,根据Ping服务项目通知博客百度搜索引擎,以保证最快的时间百度收录网络文章,加快百度搜索引擎网页快照的更新频率。
7、外部元素加速网页截图
事实上,网站 地址在网上盛行。启用完全免费的时尚博客,如博客、新浪博客、百度站长工具室内空间、站长论坛室内空间,发布推广软文;去百度站长工具社区论坛、站长论坛社区论坛、过时论坛等大中型社区论坛,发布与网址相关的帖子;交换友链,将友链换成与自己相关的网站;互动问答,去百度问答,知乎论坛,新浪AiQ,雅虎专业知识问答,留下网站地址发自言自语。信息内容,去相关网站发送一些信息内容营销宣传自己,建议不需要使用群发。
以上是促进网页快照升级率的几个因素,但seo的基础理论是通过实践活动获得的。不同的 URL 有不同的条件。仅作为参考,实践活动可视为检验基础理论的最佳方式。. 查看全部
网页抓取数据百度百科(
影响网页快照几个的几个因素-苏州安嘉Web)

网页快照的英文名称是Web Cache,是搜索引擎抓取、复制页面内容并存储的过程。网页快照不仅是分析搜索引擎对网站的关注程度,也是友情链接交换的重要参考因素,那么如何加快网页快照的更新频率,让网站 的优化工作更快 高效的运行是站长一直在寻找的。下面我们描述影响网页快照的几个因素。1、网站内容更新频率正常。只要网站的内容有更新,搜索引擎蜘蛛就会过来采集。但是网站内容的更新频率也应该是有规律的,就像我们的工作一样,
网页快照英文名称为WebCache,是百度搜索引擎抓取、复制网页内容并存储的全过程。网页快照不仅分析了百度搜索引擎对网址的关注程度,也是友情链接交换的关键参考因素。因此,如何加快网页快照的升级频率,让搜索引擎优化工作更加快速高效。,这正是 网站 的站长一直在寻找的。您将在下面详细了解影响 Web 快照的许多元素。
1、网站内容更新频率
一般来说,如果网站内容升级了,百度搜索引擎搜索引擎蜘蛛就会回来采集。但是,网站内容的更新频率应该是有规律的。就像大家的工作一样,要有规律,要有目的,这样百度搜索引擎的搜索引擎蜘蛛才会有规律的去寻找。了解这个网站需要多久来一次。一般来说,在网站的内容更新频率稳定的情况下,网页快照的更新频率大致与网站的内容更新频率相近(百度搜索引擎更新周期除外)。
2、URL的权重值
单纯的升级网站的内容显然是不够的,网站也要按辈分排名。新的网站的内容在不断的升级,但有时也无法与旧的网站齐头并进。这就是百度权重的效果。百度搜索引擎一直偏爱具有高权重值的 URL。如果你想让你的新网站获得很多青睐,你应该在新站点的开头选中一个权重值高的网站域名。
3、URL 多久更改一次
当要更改 URL 时,必须考虑对 seo 优化的危害。无论是网站源代码,页面的合理布局,内容甚至是URL的页面标题、描述、关键词,都会对网页快照造成危害。如果网址经常变化,会给百度搜索引擎留下很不好的印象。就像你认识的人今天改变了头形,明天做了双眼皮手术,并获得了隆鼻手术。你能承受这样的改变吗?URL完成后,尽量不要更改,URL也不需要频繁更改。
4、网址是假的
未升级的页面快照有时会因网站造假或涉嫌造假而被百度搜索引擎处罚。百度搜索引擎的技术性一直在不断发展,并且不断朝着更加公平的方向发展。网站当前或以前的seo工作涉及欺诈,或可靠的实际操作被列为欺诈,这将导致网页欺诈。快照未升级。
5、Web 服务器可靠性
找到一个好的室内空间提供商也很重要,这样您的网络服务器就可以得到保护。Web 服务器的可靠性非常关键。不稳定的网络服务器不仅会阻塞客户端对网站的浏览,而且百度搜索引擎也无法正常抓取内容。其他网络服务器网站会因作弊而受到惩罚,你的网站也会受到惩罚。Web 服务器的其他不安全元素(病原体、长期攻击)也可能危及网页快照的升级。
6、ping 服务项目
如果你的网址是zblog、wordpress程序进程等,如果你想让你的博客使用RSS,可以添加ping服务项。另外,每个博客创建者发布新的文章内容,根据Ping服务项目通知博客百度搜索引擎,以保证最快的时间百度收录网络文章,加快百度搜索引擎网页快照的更新频率。
7、外部元素加速网页截图
事实上,网站 地址在网上盛行。启用完全免费的时尚博客,如博客、新浪博客、百度站长工具室内空间、站长论坛室内空间,发布推广软文;去百度站长工具社区论坛、站长论坛社区论坛、过时论坛等大中型社区论坛,发布与网址相关的帖子;交换友链,将友链换成与自己相关的网站;互动问答,去百度问答,知乎论坛,新浪AiQ,雅虎专业知识问答,留下网站地址发自言自语。信息内容,去相关网站发送一些信息内容营销宣传自己,建议不需要使用群发。
以上是促进网页快照升级率的几个因素,但seo的基础理论是通过实践活动获得的。不同的 URL 有不同的条件。仅作为参考,实践活动可视为检验基础理论的最佳方式。.
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理与索引库的建立)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-09 18:01
【2022网站收录】百度蜘蛛爬取页面及建索引库原理 admin03-06 15:413times
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了但没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理与索引库的建立)
【2022网站收录】百度蜘蛛爬取页面及建索引库原理 admin03-06 15:413times
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了但没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科( 说起百度快照更新究竟有什么用呢?如何来了解呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-05 21:21
说起百度快照更新究竟有什么用呢?如何来了解呢?)
百度快照的问题大家并不陌生。现在再讲这个,感觉有点老土了。但往往老的东西往往被大家忽略,包括作者本人,我也多次忽略了这个问题。而我个人觉得百度的快照有什么用呢?带着这种困惑,我看到了百度快照的效果。第一个:查询页面爬取的范围关于查询页面爬取的范围,这个怎么理解?其实,当我们想查询这个网页的爬取情况时,那么我们可以点击这个页面的快照,看看里面爬取了什么。当您查询快照时,您
网页快照的问题大家都很熟悉了,再说一遍就有点老生常谈了。但是通常比较老的单品往往会被大家忽略,主要是我自己,因为之前我也忽略过这个问题好几次了。而我个人觉得百度网这个快照更新有什么用呢?带着这样的疑惑,我看到了网页快照的作用。
第一种:搜索网页爬取范围
怎么知道搜索网页爬取的范围?实际上就是当你去查看这个网页的爬取状态时,人们可以点击这个网页的快照更新,看到里面的爬取项目。当您搜索快照更新时,您是否注意人们搜索的单词,快照更新网页上出现的单词会以不同的色调表示。对于一个网页被百度爬虫爬取的情况,人们可以根据快照更新有明显的区别。
第二:寻找朋友链的作用
当你去和别人交换朋友链时,大部分SEO从业者只想关心对方网站的权重值、PR值、出口连接、收录。人们是否注意对方网站上的好友链接是否自动重定向?我想每个人都应该想忽略这个问题!我曾经听一位出色的白帽黑客 SEO 从业者说,链接交换是提高我排名的好方法。所以大家一定要高度重视这个问题,看看网页截图下方的朋友链状态。
第三种:查询内部链接的作用
小编看过一个例子。本站名称为“西祠胡同”。我觉得从业者在这里做外链和内链是很容易的。后来那个时候我也在想,为什么我发了内外链接,然后这些管理方式不删帖,又不T人,我觉得很奇怪。为了一探究竟,我搜索了我发的百度收录网页,打开快照更新,看到自动重定向被屏蔽了。假设下,这类网址的内外链接的关键词提升应该不会很大,一些普普的客户很有兴趣点进去看看。
写在最后,其实也有内链,就是你的网站查询测试的一个功能。写到这里,希望SEO从业者能够真正理解和重视web快照这样的一个项目。 查看全部
网页抓取数据百度百科(
说起百度快照更新究竟有什么用呢?如何来了解呢?)

百度快照的问题大家并不陌生。现在再讲这个,感觉有点老土了。但往往老的东西往往被大家忽略,包括作者本人,我也多次忽略了这个问题。而我个人觉得百度的快照有什么用呢?带着这种困惑,我看到了百度快照的效果。第一个:查询页面爬取的范围关于查询页面爬取的范围,这个怎么理解?其实,当我们想查询这个网页的爬取情况时,那么我们可以点击这个页面的快照,看看里面爬取了什么。当您查询快照时,您
网页快照的问题大家都很熟悉了,再说一遍就有点老生常谈了。但是通常比较老的单品往往会被大家忽略,主要是我自己,因为之前我也忽略过这个问题好几次了。而我个人觉得百度网这个快照更新有什么用呢?带着这样的疑惑,我看到了网页快照的作用。
第一种:搜索网页爬取范围
怎么知道搜索网页爬取的范围?实际上就是当你去查看这个网页的爬取状态时,人们可以点击这个网页的快照更新,看到里面的爬取项目。当您搜索快照更新时,您是否注意人们搜索的单词,快照更新网页上出现的单词会以不同的色调表示。对于一个网页被百度爬虫爬取的情况,人们可以根据快照更新有明显的区别。
第二:寻找朋友链的作用
当你去和别人交换朋友链时,大部分SEO从业者只想关心对方网站的权重值、PR值、出口连接、收录。人们是否注意对方网站上的好友链接是否自动重定向?我想每个人都应该想忽略这个问题!我曾经听一位出色的白帽黑客 SEO 从业者说,链接交换是提高我排名的好方法。所以大家一定要高度重视这个问题,看看网页截图下方的朋友链状态。
第三种:查询内部链接的作用
小编看过一个例子。本站名称为“西祠胡同”。我觉得从业者在这里做外链和内链是很容易的。后来那个时候我也在想,为什么我发了内外链接,然后这些管理方式不删帖,又不T人,我觉得很奇怪。为了一探究竟,我搜索了我发的百度收录网页,打开快照更新,看到自动重定向被屏蔽了。假设下,这类网址的内外链接的关键词提升应该不会很大,一些普普的客户很有兴趣点进去看看。
写在最后,其实也有内链,就是你的网站查询测试的一个功能。写到这里,希望SEO从业者能够真正理解和重视web快照这样的一个项目。
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理大家了解多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 21:16
[2022网站收录] 百度蜘蛛爬取页面及建索引库的原理 admin03-05 15:072 浏览量
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统的原理和索引库的建立,
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,从而尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持蜘蛛过去爬过的页面不断更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理大家了解多少)
[2022网站收录] 百度蜘蛛爬取页面及建索引库的原理 admin03-05 15:072 浏览量
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统的原理和索引库的建立,
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,从而尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持蜘蛛过去爬过的页面不断更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科(什么是爬虫爬虫:请求网站并提取数据的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2022-03-04 12:05
一、什么是爬虫
爬虫:请求网站并提取数据的自动化程序
百科全书:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。
如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫就是一只小蜘蛛,
沿着网络爬取自己的猎物(数据)的爬虫是指:向网站发起请求,获取资源后分析提取有用数据的程序;
从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用;
二、爬虫发起请求的基本流程:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器回应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或以特定格式保存文件。三、Request和ResponseRequest:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
四、Request详细请求方式:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 Request URL:URL的全称是Uniform Resource Locator。例如,网页文档、图片、视频等都可以由URL唯一确定。请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。请求体:请求中携带的附加数据,如表单提交时的表单数据五、响应详解响应状态:响应状态有多种,如200表示成功,301表示重定向,404表示page not found, 502 for server error 响应头:如内容类型、内容长度、服务器信息、设置cookie等 响应体:最重要的部分,包括请求资源的内容,比如网页HTML、图片二进制数据等六、可以抓取哪些数据web文本:比如HTML文档、Json格式文本等 图片:获取到的二进制文件保存为图片格式。视频:两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓取的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决 JavaScript 渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
九、优秀爬虫的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是以爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实际的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫运行多线程,通过多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会在全球、不同区域部署,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议,告诉爬虫哪些内容不是什么内容。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaentry-footer">
爬虫基本原理资料 查看全部
网页抓取数据百度百科(什么是爬虫爬虫:请求网站并提取数据的自动化程序)
一、什么是爬虫
爬虫:请求网站并提取数据的自动化程序
百科全书:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。
如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫就是一只小蜘蛛,
沿着网络爬取自己的猎物(数据)的爬虫是指:向网站发起请求,获取资源后分析提取有用数据的程序;
从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用;
二、爬虫发起请求的基本流程:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器回应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或以特定格式保存文件。三、Request和ResponseRequest:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
四、Request详细请求方式:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 Request URL:URL的全称是Uniform Resource Locator。例如,网页文档、图片、视频等都可以由URL唯一确定。请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。请求体:请求中携带的附加数据,如表单提交时的表单数据五、响应详解响应状态:响应状态有多种,如200表示成功,301表示重定向,404表示page not found, 502 for server error 响应头:如内容类型、内容长度、服务器信息、设置cookie等 响应体:最重要的部分,包括请求资源的内容,比如网页HTML、图片二进制数据等六、可以抓取哪些数据web文本:比如HTML文档、Json格式文本等 图片:获取到的二进制文件保存为图片格式。视频:两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓取的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决 JavaScript 渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
九、优秀爬虫的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是以爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实际的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫运行多线程,通过多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会在全球、不同区域部署,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议,告诉爬虫哪些内容不是什么内容。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaentry-footer">
爬虫基本原理资料
网页抓取数据百度百科( 百度SEO的几个问题(之二)网页的导出链接数多少为好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-04 12:00
百度SEO的几个问题(之二)网页的导出链接数多少为好)
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)网页的外链数是多少?谷歌倾向于说每个网页的外链数不要超过100。百度有什么建议吗?没有暂时的建议。一般来说这种情况下,链接的数量会影响这些链接在页面中的权重,少给多分,多给少分。百度支持哪些Robots Meta标签?百度支持nofollow和noarchive . 定期更新到/se
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)
一个网页应该有多少个出站链接?谷歌倾向于说每个网页不超过 100 个传出链接。百度有什么建议吗?
暂时没有建议。一般情况下,链接的数量会影响这些链接在页面中的权重;少即是多,多即是少。
百度支持哪些机器人元标签?
百度支持nofollow和noarchive。定期更新到 /search/robots.html
网页大小问题?多大才合适。
页面大小和搜索引擎抓取之间没有直接关系。但建议网页(包括代码)不要太大,太大的网页会被抓取截断;并且内容部分不能太大,会被索引截断。当然,fetch truncation 的上限会远大于 index truncation 的上限。
禁止搜索引擎 收录 的方法?robots.txt 的用法?
详情见:/search/robots.html
百度如何对待改版的网站?
如果内容从根本上改变,理论上会被视为全新的网站,旧的超链接失效。
百度新站的收录内页有问题,首页可以很快收录,但就是没有收录内页?
土匪入队,还需要“报名”;加入搜索引擎的人也需要注意考察期。
301 永久重定向是否传递了全部或部分权重?
正常301永久重定向,旧url上积累的各种投票信息都会转移到新url上。(注:百度301的处理速度太慢了。)
超过。 查看全部
网页抓取数据百度百科(
百度SEO的几个问题(之二)网页的导出链接数多少为好)

第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)网页的外链数是多少?谷歌倾向于说每个网页的外链数不要超过100。百度有什么建议吗?没有暂时的建议。一般来说这种情况下,链接的数量会影响这些链接在页面中的权重,少给多分,多给少分。百度支持哪些Robots Meta标签?百度支持nofollow和noarchive . 定期更新到/se
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)
一个网页应该有多少个出站链接?谷歌倾向于说每个网页不超过 100 个传出链接。百度有什么建议吗?
暂时没有建议。一般情况下,链接的数量会影响这些链接在页面中的权重;少即是多,多即是少。
百度支持哪些机器人元标签?
百度支持nofollow和noarchive。定期更新到 /search/robots.html
网页大小问题?多大才合适。
页面大小和搜索引擎抓取之间没有直接关系。但建议网页(包括代码)不要太大,太大的网页会被抓取截断;并且内容部分不能太大,会被索引截断。当然,fetch truncation 的上限会远大于 index truncation 的上限。
禁止搜索引擎 收录 的方法?robots.txt 的用法?
详情见:/search/robots.html
百度如何对待改版的网站?
如果内容从根本上改变,理论上会被视为全新的网站,旧的超链接失效。
百度新站的收录内页有问题,首页可以很快收录,但就是没有收录内页?
土匪入队,还需要“报名”;加入搜索引擎的人也需要注意考察期。
301 永久重定向是否传递了全部或部分权重?
正常301永久重定向,旧url上积累的各种投票信息都会转移到新url上。(注:百度301的处理速度太慢了。)
超过。
网页抓取数据百度百科( 第一章百度搜索引擎如何运行具有四个功能?如何运作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-04 11:28
第一章百度搜索引擎如何运行具有四个功能?如何运作)
第一章搜索引擎的工作原理搜索引擎有四个功能:爬取、建立索引数据库、计算相关性和排名、提供索引结果。搜索引擎抓取和索引数以亿计的网页、文档、新闻、图片、视频和其他内容。当搜索者提出搜索请求时,搜索引擎会根据搜索结果的相关性排列索引结果并提供给搜索者。. 1、对互联网的抓取和索引就像一个巨大的城市地铁系统,而网站和网站中的页面(可能是pdf文件、jpg图片等)就像在地铁系统中一样车站,为了让火车到达每个车站,在地铁系统中,有必要
第一章百度搜索引擎的工作原理
百度搜索引擎有四个功能:爬取、创建数据库索引数据库查询、测量相关性和计算排名、显示数据库索引的结果。百度搜索引擎对数以亿计的网页、文档、新闻报道、照片、视频等内容进行爬取和索引。当搜索者明确提出搜索请求时,百度搜索引擎会根据关联对数据库的结果进行索引。按性别排序并呈现给搜索者。
1、爬取和数据库索引
互联网技术就像一个巨大的城轨系统软件,网站和网站中的网页(也会是pdf文档,jpg照片等)就像地铁站系统软件中的网站,这样优采云要能够到达每一个网站,在地铁站系统软件中,必须有不同的路线连接网站,而在互联网技术上,不同的网站或不同的网站网站中的页面是连接的。路线更紧密。
Web服务器中的连接结构将网站中的所有网页连接在一起,或者至少保证百度搜索引擎可以到达所有网页。通过这种连接,百度搜索引擎智能机器人(或称“网络爬虫”、“搜索引擎蜘蛛”)可以到达网站的每一个角落。
百度搜索引擎一旦找到这种网页,接下来的工作就是分析网页的代码,选择有效内容,保存,当客户明确提出检索请求时,将结果展示给客户。为了在最短的时间内为客户提供满足检索要求的内容,百度搜索引擎公司在全球范围内共创建了各种大中型数据库查询来存储百度搜索引擎搜索引擎爬取的网址蜘蛛。(网页)内容。当客户使用百度搜索引擎进行搜索时,即使这种搜索只需要3、4秒,也会引起客户极大的不满。因此,主流产品的百度搜索引擎公司都使用快速显示结果是您的首要任务。
2、显示百度搜索
当客户使用百度搜索引擎进行搜索时,百度搜索引擎会在自己的数据库查询中搜索到客户想要的信息内容。在这种情况下,百度搜索引擎会做两件事。将客户有效的、相关的搜索搜索结果呈现给客户,其次根据需要对结果进行排列。这方面(相关性和必要性)恰好意味着在 seo 优化中必须高度重视 URL。
对于百度搜索引擎来说,相关性不仅仅意味着在网页上突出客户搜索的词。在互联网技术出现的早期,百度搜索引擎只是将客户检索到的内容加粗或突出显示。随着技术的发展趋势和发展,优秀的技术工程师已经找到了越来越多的方式来为客户提供信息。提供更实用的百度搜索。现在危害关联的要素越来越多,后面会详细介绍。
虽然危及相关性的因素有数百种,但相关性仍然无法定量分析,而另一个危及百度搜索排名的因素——必要性也是一个无法定量分析的指标值。虽然无法量化分析,但百度搜索引擎还是要努力做到这一点。
最近,主流产品的百度搜索引擎公司喜欢用声望值和用户评价来考虑网站或网页的必要性。网站在客户心目中的影响力越高,用户评价越高,所呈现的内容和信息越有价值,网站在百度搜索引擎中的重要性就越高。从具体情况来看,用声望值和用户评价来区分网站的关键是比较成功的。
百度搜索引擎对 URL 的必要性和相关性的识别不是通过人工服务进行的。如果进行人工服务,工作量会很大。在这些方面,百度搜索引擎都有自己的一套评价标准,称为“优化算法”。在百度搜索引擎优化算法中,收录了数百个自变量,也就是人们常说的危害排名。元素。 查看全部
网页抓取数据百度百科(
第一章百度搜索引擎如何运行具有四个功能?如何运作)

第一章搜索引擎的工作原理搜索引擎有四个功能:爬取、建立索引数据库、计算相关性和排名、提供索引结果。搜索引擎抓取和索引数以亿计的网页、文档、新闻、图片、视频和其他内容。当搜索者提出搜索请求时,搜索引擎会根据搜索结果的相关性排列索引结果并提供给搜索者。. 1、对互联网的抓取和索引就像一个巨大的城市地铁系统,而网站和网站中的页面(可能是pdf文件、jpg图片等)就像在地铁系统中一样车站,为了让火车到达每个车站,在地铁系统中,有必要
第一章百度搜索引擎的工作原理
百度搜索引擎有四个功能:爬取、创建数据库索引数据库查询、测量相关性和计算排名、显示数据库索引的结果。百度搜索引擎对数以亿计的网页、文档、新闻报道、照片、视频等内容进行爬取和索引。当搜索者明确提出搜索请求时,百度搜索引擎会根据关联对数据库的结果进行索引。按性别排序并呈现给搜索者。
1、爬取和数据库索引
互联网技术就像一个巨大的城轨系统软件,网站和网站中的网页(也会是pdf文档,jpg照片等)就像地铁站系统软件中的网站,这样优采云要能够到达每一个网站,在地铁站系统软件中,必须有不同的路线连接网站,而在互联网技术上,不同的网站或不同的网站网站中的页面是连接的。路线更紧密。
Web服务器中的连接结构将网站中的所有网页连接在一起,或者至少保证百度搜索引擎可以到达所有网页。通过这种连接,百度搜索引擎智能机器人(或称“网络爬虫”、“搜索引擎蜘蛛”)可以到达网站的每一个角落。
百度搜索引擎一旦找到这种网页,接下来的工作就是分析网页的代码,选择有效内容,保存,当客户明确提出检索请求时,将结果展示给客户。为了在最短的时间内为客户提供满足检索要求的内容,百度搜索引擎公司在全球范围内共创建了各种大中型数据库查询来存储百度搜索引擎搜索引擎爬取的网址蜘蛛。(网页)内容。当客户使用百度搜索引擎进行搜索时,即使这种搜索只需要3、4秒,也会引起客户极大的不满。因此,主流产品的百度搜索引擎公司都使用快速显示结果是您的首要任务。
2、显示百度搜索
当客户使用百度搜索引擎进行搜索时,百度搜索引擎会在自己的数据库查询中搜索到客户想要的信息内容。在这种情况下,百度搜索引擎会做两件事。将客户有效的、相关的搜索搜索结果呈现给客户,其次根据需要对结果进行排列。这方面(相关性和必要性)恰好意味着在 seo 优化中必须高度重视 URL。
对于百度搜索引擎来说,相关性不仅仅意味着在网页上突出客户搜索的词。在互联网技术出现的早期,百度搜索引擎只是将客户检索到的内容加粗或突出显示。随着技术的发展趋势和发展,优秀的技术工程师已经找到了越来越多的方式来为客户提供信息。提供更实用的百度搜索。现在危害关联的要素越来越多,后面会详细介绍。
虽然危及相关性的因素有数百种,但相关性仍然无法定量分析,而另一个危及百度搜索排名的因素——必要性也是一个无法定量分析的指标值。虽然无法量化分析,但百度搜索引擎还是要努力做到这一点。
最近,主流产品的百度搜索引擎公司喜欢用声望值和用户评价来考虑网站或网页的必要性。网站在客户心目中的影响力越高,用户评价越高,所呈现的内容和信息越有价值,网站在百度搜索引擎中的重要性就越高。从具体情况来看,用声望值和用户评价来区分网站的关键是比较成功的。
百度搜索引擎对 URL 的必要性和相关性的识别不是通过人工服务进行的。如果进行人工服务,工作量会很大。在这些方面,百度搜索引擎都有自己的一套评价标准,称为“优化算法”。在百度搜索引擎优化算法中,收录了数百个自变量,也就是人们常说的危害排名。元素。
网页抓取数据百度百科(网页收录与蜘蛛抓取的频率有哪些必然的联系?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-03 07:05
对于网站的操作,如果想通过某个关键词获得更多的流量,首先也是最重要的就是页面需要被搜索引擎收录搜索到。而网页收录和蜘蛛爬取的频率有什么必然联系呢?合肥网站日常运营优化工作有何意义?
首先,根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上,只要是外链,无论质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,简化目录层次,URL不要太长,动态参数太多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候,其实有一个方便的小技巧:那就是主动将 URL 添加到站点地图中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当您有页面需要参与排名时,您有必要将它们放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定是好事。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,你可以使用百度官方后台爬虫诊断查看具体原因。
网信科技总结:页面爬取频率在索引、收录、排名、二次排名中起着至关重要的作用。作为 网站 操作员,您可能需要适当注意。 查看全部
网页抓取数据百度百科(网页收录与蜘蛛抓取的频率有哪些必然的联系?)
对于网站的操作,如果想通过某个关键词获得更多的流量,首先也是最重要的就是页面需要被搜索引擎收录搜索到。而网页收录和蜘蛛爬取的频率有什么必然联系呢?合肥网站日常运营优化工作有何意义?

首先,根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上,只要是外链,无论质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,简化目录层次,URL不要太长,动态参数太多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候,其实有一个方便的小技巧:那就是主动将 URL 添加到站点地图中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当您有页面需要参与排名时,您有必要将它们放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定是好事。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,你可以使用百度官方后台爬虫诊断查看具体原因。
网信科技总结:页面爬取频率在索引、收录、排名、二次排名中起着至关重要的作用。作为 网站 操作员,您可能需要适当注意。
网页抓取数据百度百科(数据库看前端的效率如何了?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-03-01 22:02
网页抓取数据百度百科:apivarysearch搜索相关信息将搜索的结果数据存放到数据库中设置出口日志不抓取数据传至ftp服务器分析数据库大致如此,
其实看前端的效率如何了,像我这样的是没法处理的,有可能每次从数据库取都要半天。
api,程序员解决这个问题。
是用json参数吧?或者可以试试用cookie,
实现一个实时爬取站点内容的api
看看,
站长园出的《网页数据采集技术》,里面有现成的网页,按照指引和说明,可以通过搜索引擎抓取到。
可以试试去百度一下合伙人一天给你8w让你996给你百度账号或者美团帐号每个月在那一天都给你账号每个月给你买那一天才8w有人愿意??这个你应该能完成第一个月收入目标
github上有现成的js库
请参考微软的collections。可以获取所有使用谷歌数据库的地区和文件名列表。
“搜索相关数据”
记得让我算算?
连搜索相关数据都是挑几个热门网站来爬爬问题还是不大
数据采集和采集是两个技术活,你得熟悉数据采集是怎么做的,比如涉及那些特征,缺陷在哪?而网站数据抓取一般都是有现成的软件来做的,
json格式,设置日志、断点续传等处理,可以收入到数据库, 查看全部
网页抓取数据百度百科(数据库看前端的效率如何了?-八维教育)
网页抓取数据百度百科:apivarysearch搜索相关信息将搜索的结果数据存放到数据库中设置出口日志不抓取数据传至ftp服务器分析数据库大致如此,
其实看前端的效率如何了,像我这样的是没法处理的,有可能每次从数据库取都要半天。
api,程序员解决这个问题。
是用json参数吧?或者可以试试用cookie,
实现一个实时爬取站点内容的api
看看,
站长园出的《网页数据采集技术》,里面有现成的网页,按照指引和说明,可以通过搜索引擎抓取到。
可以试试去百度一下合伙人一天给你8w让你996给你百度账号或者美团帐号每个月在那一天都给你账号每个月给你买那一天才8w有人愿意??这个你应该能完成第一个月收入目标
github上有现成的js库
请参考微软的collections。可以获取所有使用谷歌数据库的地区和文件名列表。
“搜索相关数据”
记得让我算算?
连搜索相关数据都是挑几个热门网站来爬爬问题还是不大
数据采集和采集是两个技术活,你得熟悉数据采集是怎么做的,比如涉及那些特征,缺陷在哪?而网站数据抓取一般都是有现成的软件来做的,
json格式,设置日志、断点续传等处理,可以收入到数据库,
网页抓取数据百度百科(网上一个教程写了一个简单的爬虫程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-27 16:01
最近学了一些python基础,为了练手,跟着网上的教程写了一个简单的爬虫程序。python上手还是很容易的,整个过程很顺利,几乎成功了。
1.爬虫架构和工作流程
一个爬虫程序可以分为四个基本模块,通用调度器、URL管理器、网页下载器和网页解析器。
整体调度部分负责启动、停止和监控程序的运行进度。
URL管理器负责管理已爬取的URL和未爬取的URL,它将未爬取的网页URL发送给网页下载器,并从未爬取的URL列表中删除这些URL。
网页下载器负责下载网页内容,将其转换成字符串形式(在本程序中)并发送给网页解析器。
网页解析器负责从抓取的网页内容中提取有价值的数据。该程序中有价值的数据是网页中的URL以及条目名称和条目介绍。
2.各个模块的实现
2.1 URL管理器的实现
网页 URL 可以存储在内存中(以 set() 的形式)、MySQL 数据库和 redis 缓存数据库(对于大型项目)。本项目的 URL 以 set() 的形式存储在内存中。
代码:
class UrlManager(object):
def __init__(self):
#初始化两个url集合
self.new_urls=set()#存放未爬取过的url
self.old_urls=set()#存放已爬取过的url
def add_new_url(self,url):#单个添加
if url is None:
return #如果是空的则不进行操作
if url not in self.new_urls and url not in self.old_urls:#全新的url
self.new_urls.add(url)
def has_new_url(self):#判断是否有未爬取的url
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()#从未怕去的url列表获取一个并移除
self.old_urls.add(new_url)
return new_url
def add_new_urls(self,urls):#批量添加
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
2.2 网页下载器的实现
下载网页的三种方式
1.下载最简单的网页(无需登录验证,无需加密...)
response = urllib.request.urlopen(url, data=None, timeout)
Referer:可以用来防止盗链。如果REFER信息来自其他网站,则禁止访问所需资源
Connection:表示连接状态,记录Session的状态。
request.add_header('user_agent', 'Mozilla/5.0') 将程序伪装成 Firefox
3.处理一些特殊情况 查看全部
网页抓取数据百度百科(网上一个教程写了一个简单的爬虫程序的程序)
最近学了一些python基础,为了练手,跟着网上的教程写了一个简单的爬虫程序。python上手还是很容易的,整个过程很顺利,几乎成功了。
1.爬虫架构和工作流程
一个爬虫程序可以分为四个基本模块,通用调度器、URL管理器、网页下载器和网页解析器。
整体调度部分负责启动、停止和监控程序的运行进度。
URL管理器负责管理已爬取的URL和未爬取的URL,它将未爬取的网页URL发送给网页下载器,并从未爬取的URL列表中删除这些URL。
网页下载器负责下载网页内容,将其转换成字符串形式(在本程序中)并发送给网页解析器。
网页解析器负责从抓取的网页内容中提取有价值的数据。该程序中有价值的数据是网页中的URL以及条目名称和条目介绍。
2.各个模块的实现
2.1 URL管理器的实现
网页 URL 可以存储在内存中(以 set() 的形式)、MySQL 数据库和 redis 缓存数据库(对于大型项目)。本项目的 URL 以 set() 的形式存储在内存中。
代码:
class UrlManager(object):
def __init__(self):
#初始化两个url集合
self.new_urls=set()#存放未爬取过的url
self.old_urls=set()#存放已爬取过的url
def add_new_url(self,url):#单个添加
if url is None:
return #如果是空的则不进行操作
if url not in self.new_urls and url not in self.old_urls:#全新的url
self.new_urls.add(url)
def has_new_url(self):#判断是否有未爬取的url
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()#从未怕去的url列表获取一个并移除
self.old_urls.add(new_url)
return new_url
def add_new_urls(self,urls):#批量添加
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
2.2 网页下载器的实现
下载网页的三种方式
1.下载最简单的网页(无需登录验证,无需加密...)
response = urllib.request.urlopen(url, data=None, timeout)
Referer:可以用来防止盗链。如果REFER信息来自其他网站,则禁止访问所需资源
Connection:表示连接状态,记录Session的状态。
request.add_header('user_agent', 'Mozilla/5.0') 将程序伪装成 Firefox
3.处理一些特殊情况
网页抓取数据百度百科(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-18 10:28
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
网页抓取数据百度百科(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要下载证券交易所 50 种不同股票的当前价格,或者,您想打印出新闻 网站 上所有最新新闻的头条新闻,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
网页抓取数据百度百科( 网络爬虫(又被称为网页蜘蛛,网络机器人,))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-18 02:08
网络爬虫(又被称为网页蜘蛛,网络机器人,))
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,
特点:高性能、可扩展性、健壮性、友好性。
技术:路径检索、聚焦抓取、反向链接计数、广度优先遍历。
词汇表
聚焦抓取:聚焦检索的主要问题是使用网络爬虫的上下文。我们想在实际下载页面之前知道给定页面和查询之间的相似性。
反向链接数:反向链接数是指指向其他网页指向的网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
批量爬虫:批量爬虫的爬取范围和目标比较明确。当爬虫到达这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容的变化是常见的,增量爬虫需要及时反映这种变化,所以在不断的爬取过程中,他们要么抓取新网页,要么更新现有网页。常见的商业搜索引擎爬虫基本属于这一类。
反爬虫:防止他人利用任何技术手段批量获取自己的网站信息的一种方式。关键也是批量大小。
阻止:成功阻止爬虫访问。这里会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,误伤的可能性就越高。所以需要做出权衡。 查看全部
网页抓取数据百度百科(
网络爬虫(又被称为网页蜘蛛,网络机器人,))
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,
特点:高性能、可扩展性、健壮性、友好性。
技术:路径检索、聚焦抓取、反向链接计数、广度优先遍历。
词汇表
聚焦抓取:聚焦检索的主要问题是使用网络爬虫的上下文。我们想在实际下载页面之前知道给定页面和查询之间的相似性。
反向链接数:反向链接数是指指向其他网页指向的网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
批量爬虫:批量爬虫的爬取范围和目标比较明确。当爬虫到达这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容的变化是常见的,增量爬虫需要及时反映这种变化,所以在不断的爬取过程中,他们要么抓取新网页,要么更新现有网页。常见的商业搜索引擎爬虫基本属于这一类。
反爬虫:防止他人利用任何技术手段批量获取自己的网站信息的一种方式。关键也是批量大小。
阻止:成功阻止爬虫访问。这里会有拦截率的概念。一般来说,反爬虫策略的拦截率越高,误伤的可能性就越高。所以需要做出权衡。
网页抓取数据百度百科(网页抓取数据百度百科上的说法:平均中有7至9条数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-03-15 15:04
网页抓取数据百度百科上的说法:平均每条中有7至9条数据。根据我自己的判断,大部分内容是靠关键词定位,对用户访问的网站应该是精准推荐,而不是是自动生成的。毕竟google已经足够精准。但比如你输入pid一条数据就出来了,可知大部分内容是百度抓取的另外,网页抓取数据这个东西,也并不是很好,比如上面很多高票答案提到的,网页上的结构性内容不好抓,比如有些抓取软件对nodejs有一些不友好的操作,比如不支持搜索字体大小等等,另外比如很多搜索软件开始抓取网页后有一些加载速度的要求,比如默认很慢或者不稳定。
另外,你们知道百度网页上经常请求数千个网站吗?对于网站的索引也是非常的慢,而且比如你们知道的,中小型企业网站的seo负责人一般很少,一般就1~2个人的情况下,架设网站程序不允许太慢,不然被同行黑了他们没有办法和你们打官司,而基本上你们去搜索的话都会是关键词定位,如果你们抓取网页,他们是默认搜索你们的。所以我觉得这个应该是不精准的。
网页加载时间是和网站内容相关,和抓取数据相关。一般情况下,网站中没有结构化的内容是抓取不出来的,除非你的网站可以对所有网站都是结构化的内容。而涉及到结构化的内容,一般意味着结构化的语义分析和语义重建,这个过程都需要大量的运行时间。不过貌似豆瓣这种纯文本的网站做不到(不关心实际内容结构和展示内容的转换)。而至于是否精准,这个真不好说,因为上面有一些网站抓取速度比较慢,至于原因不得而知。 查看全部
网页抓取数据百度百科(网页抓取数据百度百科上的说法:平均中有7至9条数据)
网页抓取数据百度百科上的说法:平均每条中有7至9条数据。根据我自己的判断,大部分内容是靠关键词定位,对用户访问的网站应该是精准推荐,而不是是自动生成的。毕竟google已经足够精准。但比如你输入pid一条数据就出来了,可知大部分内容是百度抓取的另外,网页抓取数据这个东西,也并不是很好,比如上面很多高票答案提到的,网页上的结构性内容不好抓,比如有些抓取软件对nodejs有一些不友好的操作,比如不支持搜索字体大小等等,另外比如很多搜索软件开始抓取网页后有一些加载速度的要求,比如默认很慢或者不稳定。
另外,你们知道百度网页上经常请求数千个网站吗?对于网站的索引也是非常的慢,而且比如你们知道的,中小型企业网站的seo负责人一般很少,一般就1~2个人的情况下,架设网站程序不允许太慢,不然被同行黑了他们没有办法和你们打官司,而基本上你们去搜索的话都会是关键词定位,如果你们抓取网页,他们是默认搜索你们的。所以我觉得这个应该是不精准的。
网页加载时间是和网站内容相关,和抓取数据相关。一般情况下,网站中没有结构化的内容是抓取不出来的,除非你的网站可以对所有网站都是结构化的内容。而涉及到结构化的内容,一般意味着结构化的语义分析和语义重建,这个过程都需要大量的运行时间。不过貌似豆瓣这种纯文本的网站做不到(不关心实际内容结构和展示内容的转换)。而至于是否精准,这个真不好说,因为上面有一些网站抓取速度比较慢,至于原因不得而知。
网页抓取数据百度百科(如何让百度蜘蛛知道页面是一个重要的页面??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-15 15:01
搜索引擎构建调度器来调度百度蜘蛛的工作,让百度蜘蛛与服务器建立连接下载网页。计算过程是通过调度来计算的。百度蜘蛛只负责下载网页。目前搜索引擎普遍使用分布广泛的多服务器多线程百度蜘蛛来实现多线程的目的。
(1) : 百度蜘蛛下载的网页放入补充数据区,经过各种程序计算后放入搜索区,形成稳定的排名。所以,只要下载的东西可以可以通过指令找到网站优化服务时,补充数据不稳定,在各种计算过程中可能会丢失K,搜索区的数据排名比较稳定,百度目前是缓存机制和补充的结合数据,正在改成补充数据,这对百度来说也很难,收录的原因,也是很多网站今天给K,明天发布的原因。
(2) : 深度优先,广度优先。百度蜘蛛爬取页面时,会从起始站点(即种子站点指一些门户站点)开始爬取页面,爬取更多的根站点。深度优先爬取就是爬取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责爬取,权重优先是指爬取反向链接较多的页面的优先级,也是一种调度策略。一般来说,40%的网页在正常范围内被爬取,60%是好的,100%是不可能的。当然,爬得越多越好。
百度蜘蛛从首页登陆后爬取首页后,调度器会统计所有连接数,返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛会进行下一步爬取。网站地图的作用是为百度蜘蛛提供爬取方向,让蜘蛛爬取重要页面。如何让百度蜘蛛知道该页面是重要页面?? 这个目标可以通过建立连接来实现。指向页面的页面越多,首页的网站方向、父页面的方向等都可以增加页面的权重。地图的另一个作用是为百度蜘蛛爬取更多页面提供更多连接。
将补充数据转化为主搜索区:在不改变板块结构的情况下,增加相关链接以提高网页质量,通过将其他页面的反向链接添加到页面来增加权重,通过外部链接增加权重。如果板块结构发生变化,将重新计算 SE。因此,不得在改变板结构的情况下进行操作。增加连接数,注意连接质量与反向连接数的关系。在短时间内添加大量反向连接会导致站点K。 查看全部
网页抓取数据百度百科(如何让百度蜘蛛知道页面是一个重要的页面??)
搜索引擎构建调度器来调度百度蜘蛛的工作,让百度蜘蛛与服务器建立连接下载网页。计算过程是通过调度来计算的。百度蜘蛛只负责下载网页。目前搜索引擎普遍使用分布广泛的多服务器多线程百度蜘蛛来实现多线程的目的。
(1) : 百度蜘蛛下载的网页放入补充数据区,经过各种程序计算后放入搜索区,形成稳定的排名。所以,只要下载的东西可以可以通过指令找到网站优化服务时,补充数据不稳定,在各种计算过程中可能会丢失K,搜索区的数据排名比较稳定,百度目前是缓存机制和补充的结合数据,正在改成补充数据,这对百度来说也很难,收录的原因,也是很多网站今天给K,明天发布的原因。
(2) : 深度优先,广度优先。百度蜘蛛爬取页面时,会从起始站点(即种子站点指一些门户站点)开始爬取页面,爬取更多的根站点。深度优先爬取就是爬取高质量的网页,这个策略是通过调度来计算和分配的,百度蜘蛛只负责爬取,权重优先是指爬取反向链接较多的页面的优先级,也是一种调度策略。一般来说,40%的网页在正常范围内被爬取,60%是好的,100%是不可能的。当然,爬得越多越好。
百度蜘蛛从首页登陆后爬取首页后,调度器会统计所有连接数,返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛会进行下一步爬取。网站地图的作用是为百度蜘蛛提供爬取方向,让蜘蛛爬取重要页面。如何让百度蜘蛛知道该页面是重要页面?? 这个目标可以通过建立连接来实现。指向页面的页面越多,首页的网站方向、父页面的方向等都可以增加页面的权重。地图的另一个作用是为百度蜘蛛爬取更多页面提供更多连接。
将补充数据转化为主搜索区:在不改变板块结构的情况下,增加相关链接以提高网页质量,通过将其他页面的反向链接添加到页面来增加权重,通过外部链接增加权重。如果板块结构发生变化,将重新计算 SE。因此,不得在改变板结构的情况下进行操作。增加连接数,注意连接质量与反向连接数的关系。在短时间内添加大量反向连接会导致站点K。
网页抓取数据百度百科( 加速百度快照更新频率有两个重要要素有哪些呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-03-13 15:17
加速百度快照更新频率有两个重要要素有哪些呢?)
相信大家在上网的时候都遇到过“对不起,您要访问的页面不存在”(找不到页面的错误信息)的情况。往往网页连接速度慢,打开要十几秒甚至几十秒。发生这种情况的原因有很多,例如:网站链接已更改,网站服务器暂时被阻塞或关闭等。
网站无法登录真是让人头疼。这时候百度快照就可以很好的为你解决这个问题。
第1部分
百度快照可以直观理解为:百度蜘蛛来到你的网站,用相机拍下你的网页,记录下你网页此刻的基本信息。
百度在爬取网站数据时,对收录页面进行拍照,并存储形成的数据副本,是对网页的一种缓存处理。快照经常变化,所以搜索引擎需要经常更新和备份快照,每次更新都会生成一个快照副本,尤其是网页的内容和修改时间经常变化。显示保存的网页内容。
同时,方便用户在网站无法打开时通过网页截图查看网站的信息。网站快照反映了网站在引擎上的更新时间,时间越近,更新频率越高网站。
但是百度只保留纯文本内容,所以对于音乐、图片、视频等非文本信息,仍然需要直接从原创网页调用快照页面。如果无法连接到原创网页,将不会显示快照上的所有非文本内容。
第2部分
内容发生变化或快照内容有误怎么办?
如果您的网页内容发生了变化或者发现网页快照与您的网页内容不一致,网页快照仍然会收录原创内容,直到我们下次抓取网站并刷新索引。所以这些仍然会出现在搜索结果中,您可以请求更新快照。
加快百度快照更新频率的要素有哪些?
加快快照更新频率有两个重要因素:
首先,网站需要定期更新,持续定期更新可以方便百度蜘蛛更高效的抓取网站信息;
其次,网站更新的内容必须要定价。关于网页值,可以认为有重要的更新内容,网页的更新内容具有时间敏感性。
什么情况下会更新百度快照?
百度快照更新的原因如下:网页中增加了重要且有价值的内容。百度搜索引擎蜘蛛抓取后,会为网页地址建立一个引擎,百度快照的时刻就是索引建立的时刻。
百度蜘蛛抓取内容时,会对你更新的内容做出判断,并检测更新的内容是否与其他网页有重复内容。
如果检测到更新内容与其他网页重复或价值不大,百度快照不一定会更新。一般来说,百度快照是否更新与您更新的内容直接相关。
网站截图的时间在一定程度上体现了这个网站的优化,也在一定程度上反映了这个网站的更新和流行。它可以作为一些参考因素来判断网站的优化和质量。 查看全部
网页抓取数据百度百科(
加速百度快照更新频率有两个重要要素有哪些呢?)
相信大家在上网的时候都遇到过“对不起,您要访问的页面不存在”(找不到页面的错误信息)的情况。往往网页连接速度慢,打开要十几秒甚至几十秒。发生这种情况的原因有很多,例如:网站链接已更改,网站服务器暂时被阻塞或关闭等。
网站无法登录真是让人头疼。这时候百度快照就可以很好的为你解决这个问题。
第1部分
百度快照可以直观理解为:百度蜘蛛来到你的网站,用相机拍下你的网页,记录下你网页此刻的基本信息。
百度在爬取网站数据时,对收录页面进行拍照,并存储形成的数据副本,是对网页的一种缓存处理。快照经常变化,所以搜索引擎需要经常更新和备份快照,每次更新都会生成一个快照副本,尤其是网页的内容和修改时间经常变化。显示保存的网页内容。
同时,方便用户在网站无法打开时通过网页截图查看网站的信息。网站快照反映了网站在引擎上的更新时间,时间越近,更新频率越高网站。
但是百度只保留纯文本内容,所以对于音乐、图片、视频等非文本信息,仍然需要直接从原创网页调用快照页面。如果无法连接到原创网页,将不会显示快照上的所有非文本内容。
第2部分
内容发生变化或快照内容有误怎么办?
如果您的网页内容发生了变化或者发现网页快照与您的网页内容不一致,网页快照仍然会收录原创内容,直到我们下次抓取网站并刷新索引。所以这些仍然会出现在搜索结果中,您可以请求更新快照。
加快百度快照更新频率的要素有哪些?
加快快照更新频率有两个重要因素:
首先,网站需要定期更新,持续定期更新可以方便百度蜘蛛更高效的抓取网站信息;
其次,网站更新的内容必须要定价。关于网页值,可以认为有重要的更新内容,网页的更新内容具有时间敏感性。
什么情况下会更新百度快照?
百度快照更新的原因如下:网页中增加了重要且有价值的内容。百度搜索引擎蜘蛛抓取后,会为网页地址建立一个引擎,百度快照的时刻就是索引建立的时刻。
百度蜘蛛抓取内容时,会对你更新的内容做出判断,并检测更新的内容是否与其他网页有重复内容。
如果检测到更新内容与其他网页重复或价值不大,百度快照不一定会更新。一般来说,百度快照是否更新与您更新的内容直接相关。
网站截图的时间在一定程度上体现了这个网站的优化,也在一定程度上反映了这个网站的更新和流行。它可以作为一些参考因素来判断网站的优化和质量。
网页抓取数据百度百科( 如何解决网络数据流写入文件时的编码问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-11 00:07
如何解决网络数据流写入文件时的编码问题(图))
前言 <p>本文整理自慕课网 《Python开发简单爬虫》 ,将会记录爬取百度百科“python”词条相关页面的整个过程。 抓取策略
确定目标:确定抓取哪个网站的哪些页面的哪部分数据。本实例抓取百度百科python词条页面以及python相关词条页面的标题和简介。
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
执行爬虫:进行数据抓取。 分析目标
1、url格式
进入百度百科python词条页面,页面中相关词条的链接比较统一,大都是 /view/xxx.htm 。
2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。
3、编码格式
查看页面编码格式,为utf-8。
经过以上分析,得到结果如下:
代码编写 项目结构
在sublime下,新建文件夹baike-spider,作为项目根目录。
新建spider_main.py,作为爬虫总调度程序。
新建url_manger.py,作为url管理器。
新建html_downloader.py,作为html下载器。
新建html_parser.py,作为html解析器。
新建html_outputer.py,作为写出数据的工具。
最终项目结构如下图:
spider_main.py # coding:utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('craw %d : %s' % (count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count + 1 except: print('craw failed') self.outputer.output_html() if __name__=='__main__': root_url = 'http://baike.baidu.com/view/21087.htm' obj_spider = SpiderMain() obj_spider.craw(root_url) </p>
url_manger.py
# coding:utf-8 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if urlis None: return if urlnot in self.new_urlsand urlnot in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urlsis None or len(urls) == 0: return for urlin urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
html_downloader.py
# coding:utf-8 import urllib.request class HtmlDownloader(object): def download(self, url): if urlis None: return None response = urllib.request.urlopen(url) if response.getcode() != 200: return None return response.read()
html_parser.py
# coding:utf-8 from bs4import BeautifulSoup import re from urllib.parseimport urljoin class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() # /view/123.htm links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm')) for linkin links: new_url = link['href'] new_full_url = urljoin(page_url, new_url) # print(new_full_url) new_urls.add(new_full_url) #print(new_urls) return new_urls def _get_new_data(self, page_url, soup): res_data = {} # url res_data['url'] = page_url # Python title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1') res_data['title'] = title_node.get_text() # summary_node = soup.find('div', class_='lemma-summary') res_data['summary'] = summary_node.get_text() # print(res_data) return res_data def parse(self, page_url, html_cont): if page_urlis None or html_contis None: return soup = BeautifulSoup(html_cont, 'html.parser') # print(soup.prettify()) new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) # print('mark') return new_urls, new_data
html_outputer.py
# coding:utf-8 class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self, data): if datais None: return self.datas.append(data) def output_html(self): fout = open('output.html','w', encoding='utf-8') fout.write('') fout.write('') fout.write('') for datain self.datas: fout.write('') fout.write('%s' % data['url']) fout.write('%s' % data['title']) fout.write('%s' % data['summary']) fout.write('') fout.write('') fout.write('') fout.write('') fout.close()
跑步
在命令行,执行 python spider_main.py 。
编码问题
问题描述:UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position ...
在使用Python写文件时,或者将网络数据流写入本地文件时,大多数情况下都会遇到这个问题。网上有很多类似的文章关于如何解决这个问题,但无非就是编码、解码相关,这难道是这个问题的真正原因吗?不。很多时候,我们使用了decode和encode,尝试了各种编码,utf8、utf-8、gbk、gb2312等,所有的编码都试过了,但是还是报错,就是crash。
windows下写python脚本的时候,编码问题很严重。在将网络数据流写入文件时,我们会遇到几种编码:
1、#encoding='XXX'
这里的编码(即python文件第一行的内容)是指python脚本文件本身的编码,无关紧要。只要 XXX 的编码和文件本身相同,就可以工作。
例如,可以在notepad++的“格式”菜单中设置各种编码。这时需要保证菜单中设置的编码与编码XXX相同。如果不一样,会报错。
2、网络数据流的编码
例如,要获得一个网页,网络数据流的编码就是网页的编码。需要使用decode来解码为unicode编码。
3、目标文件的编码
将网络数据流写入新文件,写入文件的代码如下:
fout = open('output.html','w') fout.write(str)
在windows下,新建文件的默认编码是gbk,python解释器会使用gbk编码来解析我们的网络数据流str,但是str是解码后的unicode编码,会导致解析失败和以上问题。解决方案是更改目标文件的编码:
fout = open('output.html','w', encoding='utf-8')
运行结果
从: 查看全部
网页抓取数据百度百科(
如何解决网络数据流写入文件时的编码问题(图))
前言 <p>本文整理自慕课网 《Python开发简单爬虫》 ,将会记录爬取百度百科“python”词条相关页面的整个过程。 抓取策略
确定目标:确定抓取哪个网站的哪些页面的哪部分数据。本实例抓取百度百科python词条页面以及python相关词条页面的标题和简介。
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
执行爬虫:进行数据抓取。 分析目标
1、url格式
进入百度百科python词条页面,页面中相关词条的链接比较统一,大都是 /view/xxx.htm 。
2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。
3、编码格式
查看页面编码格式,为utf-8。
经过以上分析,得到结果如下:
代码编写 项目结构 在sublime下,新建文件夹baike-spider,作为项目根目录。
新建spider_main.py,作为爬虫总调度程序。
新建url_manger.py,作为url管理器。
新建html_downloader.py,作为html下载器。
新建html_parser.py,作为html解析器。
新建html_outputer.py,作为写出数据的工具。
最终项目结构如下图:
spider_main.py # coding:utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('craw %d : %s' % (count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count + 1 except: print('craw failed') self.outputer.output_html() if __name__=='__main__': root_url = 'http://baike.baidu.com/view/21087.htm' obj_spider = SpiderMain() obj_spider.craw(root_url) </p>url_manger.py
# coding:utf-8 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if urlis None: return if urlnot in self.new_urlsand urlnot in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urlsis None or len(urls) == 0: return for urlin urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
html_downloader.py
# coding:utf-8 import urllib.request class HtmlDownloader(object): def download(self, url): if urlis None: return None response = urllib.request.urlopen(url) if response.getcode() != 200: return None return response.read()
html_parser.py
# coding:utf-8 from bs4import BeautifulSoup import re from urllib.parseimport urljoin class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() # /view/123.htm links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm')) for linkin links: new_url = link['href'] new_full_url = urljoin(page_url, new_url) # print(new_full_url) new_urls.add(new_full_url) #print(new_urls) return new_urls def _get_new_data(self, page_url, soup): res_data = {} # url res_data['url'] = page_url # Python title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1') res_data['title'] = title_node.get_text() # summary_node = soup.find('div', class_='lemma-summary') res_data['summary'] = summary_node.get_text() # print(res_data) return res_data def parse(self, page_url, html_cont): if page_urlis None or html_contis None: return soup = BeautifulSoup(html_cont, 'html.parser') # print(soup.prettify()) new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) # print('mark') return new_urls, new_data
html_outputer.py
# coding:utf-8 class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self, data): if datais None: return self.datas.append(data) def output_html(self): fout = open('output.html','w', encoding='utf-8') fout.write('') fout.write('') fout.write('') for datain self.datas: fout.write('') fout.write('%s' % data['url']) fout.write('%s' % data['title']) fout.write('%s' % data['summary']) fout.write('') fout.write('') fout.write('') fout.write('') fout.close()
跑步
在命令行,执行 python spider_main.py 。
编码问题
问题描述:UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position ...
在使用Python写文件时,或者将网络数据流写入本地文件时,大多数情况下都会遇到这个问题。网上有很多类似的文章关于如何解决这个问题,但无非就是编码、解码相关,这难道是这个问题的真正原因吗?不。很多时候,我们使用了decode和encode,尝试了各种编码,utf8、utf-8、gbk、gb2312等,所有的编码都试过了,但是还是报错,就是crash。
windows下写python脚本的时候,编码问题很严重。在将网络数据流写入文件时,我们会遇到几种编码:
1、#encoding='XXX'
这里的编码(即python文件第一行的内容)是指python脚本文件本身的编码,无关紧要。只要 XXX 的编码和文件本身相同,就可以工作。
例如,可以在notepad++的“格式”菜单中设置各种编码。这时需要保证菜单中设置的编码与编码XXX相同。如果不一样,会报错。
2、网络数据流的编码
例如,要获得一个网页,网络数据流的编码就是网页的编码。需要使用decode来解码为unicode编码。
3、目标文件的编码
将网络数据流写入新文件,写入文件的代码如下:
fout = open('output.html','w') fout.write(str)
在windows下,新建文件的默认编码是gbk,python解释器会使用gbk编码来解析我们的网络数据流str,但是str是解码后的unicode编码,会导致解析失败和以上问题。解决方案是更改目标文件的编码:
fout = open('output.html','w', encoding='utf-8')
运行结果
从:
网页抓取数据百度百科(接着使用Html标签的重要意义,如何科学合理的使用标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-10 23:08
Html标签的优化其实是优化领域的一个基础性问题,但也正是因为如此,很多SEO技术人员没有重视,导致优化网站时效果不明显。其实通过Html标签的合理构建,百度蜘蛛可以快速获取相关信息,加上采集,可以大大提高百度蜘蛛的效率采集,也可以帮助百度蜘蛛快速判断页面的内容。质量,从而确认是否给收录。
我们首先要了解科学合理使用Html标签的重要性。
一般来说,百度蜘蛛在抓取网页内容时,主要是根据一定的算法来抓取信息。这些信息的获取是通过基础代码获取的,那么一个网页可以为百度蜘蛛提供更快更简洁的信息,可以快速获得百度蜘蛛的青睐,有助于提高搜索引擎的爬取效率。普通的SEO优化只是通过自身的优化来降低网页的噪音,但这只会让网页看起来更有利于百度收录,却不利于百度对内容页面的理解。但是,如果使用Html标签的设计,可以让网页的结构看起来很简单,就像让百度和普通用户看到一个完全设计好的网页一样。
这样,对于百度蜘蛛来说,就相当于看到了一个收录结构良好、语义充分展示的网页,进一步帮助蜘蛛理解网页的body标签的内容,比如哪些是标题? 哪些是粗体标签?特殊的表达方式是提醒百度蜘蛛注意。这是你网页的分布细节,可以让百度蜘蛛一目了然,从而提高网页被收录爬取的可能性。
然后我们将讨论如何科学合理地使用Html标签。
对于网页设计工程师来说,我们在使用标签的过程中会知道每个标签的内涵,所以我们在排列Html标签的时候,需要把对应的Html安排在正确的位置,比如在段落的位置,就需要排列 P 标签。这时,段落中的文字会自动换行。这种方法不仅可以让百度知道是换行符,还可以在网页上显示,还可以换行符显示。
另外,title标签中的h1到h6分别代表了优化级别较低和较低的标签类型。通常,优先级较高的h1标签应该用于大标题,而h6可以用于内容页面或段落标题。标签,通过这个标签的设置,还可以让百度蜘蛛了解网站页面的主副标题,从而帮助百度蜘蛛更全面的判断网页的内容。此外,网页中的新闻列表页或产品列表页应使用ul、ol或li等不同形式的标签,以帮助百度蜘蛛理解。
最后,在使用Html标签的时候,还需要注意是否存在过度优化或者优化的问题。
对此,需要彻底了解每个Html标签的内涵、含义和用法,然后注意标签的合理嵌套,避免标签混淆甚至语法错误的问题。通常双面标签成对出现,所以结尾应该匹配,而对于单面标签,结尾应该用反斜杠声明。这显示了代码的完整性和可读性。虽然用户在网页上看到的都是文字,但是对于搜索引擎来说,他们看到的都是代码,所以优化Html代码也是极其重要的。 查看全部
网页抓取数据百度百科(接着使用Html标签的重要意义,如何科学合理的使用标签)
Html标签的优化其实是优化领域的一个基础性问题,但也正是因为如此,很多SEO技术人员没有重视,导致优化网站时效果不明显。其实通过Html标签的合理构建,百度蜘蛛可以快速获取相关信息,加上采集,可以大大提高百度蜘蛛的效率采集,也可以帮助百度蜘蛛快速判断页面的内容。质量,从而确认是否给收录。
我们首先要了解科学合理使用Html标签的重要性。
一般来说,百度蜘蛛在抓取网页内容时,主要是根据一定的算法来抓取信息。这些信息的获取是通过基础代码获取的,那么一个网页可以为百度蜘蛛提供更快更简洁的信息,可以快速获得百度蜘蛛的青睐,有助于提高搜索引擎的爬取效率。普通的SEO优化只是通过自身的优化来降低网页的噪音,但这只会让网页看起来更有利于百度收录,却不利于百度对内容页面的理解。但是,如果使用Html标签的设计,可以让网页的结构看起来很简单,就像让百度和普通用户看到一个完全设计好的网页一样。
这样,对于百度蜘蛛来说,就相当于看到了一个收录结构良好、语义充分展示的网页,进一步帮助蜘蛛理解网页的body标签的内容,比如哪些是标题? 哪些是粗体标签?特殊的表达方式是提醒百度蜘蛛注意。这是你网页的分布细节,可以让百度蜘蛛一目了然,从而提高网页被收录爬取的可能性。
然后我们将讨论如何科学合理地使用Html标签。
对于网页设计工程师来说,我们在使用标签的过程中会知道每个标签的内涵,所以我们在排列Html标签的时候,需要把对应的Html安排在正确的位置,比如在段落的位置,就需要排列 P 标签。这时,段落中的文字会自动换行。这种方法不仅可以让百度知道是换行符,还可以在网页上显示,还可以换行符显示。
另外,title标签中的h1到h6分别代表了优化级别较低和较低的标签类型。通常,优先级较高的h1标签应该用于大标题,而h6可以用于内容页面或段落标题。标签,通过这个标签的设置,还可以让百度蜘蛛了解网站页面的主副标题,从而帮助百度蜘蛛更全面的判断网页的内容。此外,网页中的新闻列表页或产品列表页应使用ul、ol或li等不同形式的标签,以帮助百度蜘蛛理解。
最后,在使用Html标签的时候,还需要注意是否存在过度优化或者优化的问题。
对此,需要彻底了解每个Html标签的内涵、含义和用法,然后注意标签的合理嵌套,避免标签混淆甚至语法错误的问题。通常双面标签成对出现,所以结尾应该匹配,而对于单面标签,结尾应该用反斜杠声明。这显示了代码的完整性和可读性。虽然用户在网页上看到的都是文字,但是对于搜索引擎来说,他们看到的都是代码,所以优化Html代码也是极其重要的。
网页抓取数据百度百科(百度蜘蛛的工作原理与索引库的建立与收录方面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-10 23:07
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此并不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道怎么发文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了却没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统原理及索引库的建立,让广大做SEO优化的站长可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多地抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
庞大数量级的互联网资源要求爬虫系统尽可能高效地利用带宽,在有限的硬件和带宽资源下尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
专页的内容不一定是完整的原创,也就是可以很好的整合各方的内容,或者加入一些新鲜的内容,比如浏览量和评论,给用户提供更全面的内容。
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(百度蜘蛛的工作原理与索引库的建立与收录方面)
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级SEO站长对此并不是很清楚,而且相当一部分站长其实只是为了seo和seo,甚至只知道怎么发文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了却没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统原理及索引库的建立,让广大做SEO优化的站长可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多地抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
庞大数量级的互联网资源要求爬虫系统尽可能高效地利用带宽,在有限的硬件和带宽资源下尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
专页的内容不一定是完整的原创,也就是可以很好的整合各方的内容,或者加入一些新鲜的内容,比如浏览量和评论,给用户提供更全面的内容。
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科(商业智能和搜索引擎的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-09 20:00
商业智能已经在经历三个转变:从数据驱动到业务驱动,从关注技术到关注应用,从关注工具到关注工具产生的性能。搜索引擎本质上是业务驱动和以应用为中心的(实时用户需求响应),所以我认为商业智能和搜索引擎之间有讨论的空间。这或许有助于理解技术的分工与融合,或为两者的完善提供一些参考。
1、搜索引擎本质上是(商业)智能的体现。
企业或集团历年积累的数据庞大,但信息过多,难以消化,信息形式不一致,难以统一处理。 “要学会舍弃信息”,人们开始思考:“怎样才能不被信息所淹没,而是及时利用数据资产找到需要的信息,找到有用的知识,辅助自己进行分析和决策来提高信息利用?”商业智能应运而生。
互联网上的信息量巨大,网络资源迅速增加。怎样才能不被信息淹没,而是利用网络数据及时找到需要的信息呢?搜索引擎应用正在蓬勃发展。
可以看出,搜索引擎和(商业)智能都在解决同一个问题,都需要自主或交互地执行各种拟人化任务,都与人类的思考、决策、解决问题和学习有关。 ,是拟人思维(智能)的体现。
2、搜索引擎和商业智能的工作方式相同
让我们先来看看搜索引擎是如何工作的。搜索引擎有三个主要环节:抓取网页、处理网页、提供检索服务。首先是爬网。端到端搜索引擎有自己的网络爬虫(蜘蛛)。 Spider按照超链接的顺序不断地爬取网页。抓取的网页称为网页快照。接下来,处理网页。搜索引擎抓取网页后,需要进行大量的预处理,才能提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他包括删除重复网页、分析超链接和计算网页的重要性。准备工作完成后,浏览器看到的就是搜索引擎界面,也就是第三个提供检索服务。用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了网页标题和网址外,还会提供网页摘要等信息。
再看组成:一个搜索引擎的组件一般由四部分组成:搜索器、索引器、爬虫和用户界面。搜索器的功能是在互联网上漫游,发现和采集信息,主要讲蜘蛛;索引器的作用是了解搜索器搜索到的信息,从中提取索引项,用它来表示文档,生成文档库的索引表。 第三个是检索器,其作用是根据用户查询快速检索索引数据库中的文档,评估相关性,对输出结果进行排序,并根据用户查询需求提供合理的反馈;第四个用户界面,用于接受用户查询,显示查询结果,提供个性化查询项。
这四个组件,搜索器是采集数据,索引器是处理数据,爬虫和用户界面是数据呈现。检索器是数据展示的提取过程,用户界面是用户数据需求的个性化展示。
采集数据的方式一般有人工输入、机器采集、人工输入与机器采集同步。人工维护的数据搜索引擎类别是人工组织维护的,如雅虎、新浪分类搜索,自建网络数据库的机器爬取,搜索结果直接从自己的数据库中调用,如谷歌、百度等。现在正在合并人工分拣维护和机器抓取。
在数据获取方面,需求满足第一,效率第二。机器捕获体现了高效率、高稳定性、低成本,但信息的原创能力和编辑能力还不够。人工输入如果质量高原创性能好,成本低,更能反映信息,满足用户需求,效率排第二。比如走大众路线的童童网,就是以私有产权为基础,动员大量学生输入经过学生编辑的、符合学生特点的原创性信息。学生团(通通网的“线”),费用很高。低,但更能满足学生群体的搜索需求。
我们知道,商业智能(BI)的主要工作原理体现在“数据抽取、数据处理与存储、数据分析与数据呈现”四个环节,是一个完整的端到端的商业智能解决方案。每个环节都有不同的工具或厂家,但整合基本完成,目前数据库环节的厂家已经基本掌握了其他环节的厂家。搜索引擎抓取网页的过程与数据抽取ETL的过程相同,本质是获取数据。处理网页其实就是对获取的数据进行清洗和整理,也就是数据的处理和存储,数据仓库的内容。提供检索服务其实就是数据分析和数据呈现。
可见搜索引擎和商业智能的工作方式相同。基于商业智能的四个环节,各自有很强的理解力,不同的搜索引擎在“抓取网页、处理网页、提供检索服务”三个环节也各有优势。例如,Lycos 搜索引擎专注于提供检索服务。它只从其他搜索引擎租用数据库,并以自定义格式排列搜索结果。
3、商业智能需要从三个方面向搜索引擎学习
1)搜索引擎获取结果的方式极其简单,值得借鉴
商业智能应用学科的泛化使得BI融入日常业务运营,需要极其简单的操作方式和低成本的沟通方式。搜索引擎的易用性可以达到这个目的。从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入一个单词并通过浏览器提交给搜索引擎后,搜索引擎会返回一个与用户输入的内容相关的信息列表。操作非常简单。运营BI日益发展,BI将在单位基层和中层得到应用,即流程化BI(或运营BI)将受到重视和推广。这种基于流程的BI的“下利巴形象”将实现“一般员工也需要用BI,能用BI,必须用BI”,从而最大限度地利用BI。可以看出,此时的用户已经包括了非技术/分析业务/经理。商业智能产品提供的查询、定制和分析模式对于非技术/分析专业人员来说仍然过于复杂,无法支持他们快速、低成本地获得所需的结果。目前商业智能在语义层方面已经有了很大的提升,语义层的功能让业务用户对数据的操作更加方便。但在理解自然语言方面,比如让系统正确理解人类以自然语言输入的信息,并正确回答(或响应)输入的信息,搜索引擎相对要好一些。
2)提高和增强实时理解和分析能力
商业智能以if-what-how模型为基础,补充what-how模型,实现实时智能。很多商业智能解决方案,尤其是研究的建模应用,一般都是先假设问题,再建模,构建数据和应用系统,针对特定领域使用特定的分析方法,返回特定的结果。 利用搜索引擎技术可以通过“数据+语义+分析方法+结果排列+呈现”的方式实现实时智能,具有数据范围广、分析结果动态的特点。现有的一些商业智能产品可以方便的添加各类数据源,在类似谷歌的搜索框中输入关键词(例如:“Sales income from sales in December”),系统会返回合理组织的结果带图片和文字。 “数据-趋势图”的互动联动也引起了很多用户的兴趣。
3)增强处理非结构化数据的能力
非结构化数据对于业务处理越来越重要。支持决策的信息不仅限于来自数据仓库和ODS层的结构化信息,还往往收录大量的非结构化信息,如文档、电子邮件、媒体文件等。搜索引擎具有很强的处理能力非结构化信息,例如图片、视频和音乐。
4、搜索引擎需要从四个方面学习商业智能
1)向专家系统学习,提高搜索引擎对用户搜索问题的理解,去除冗余搜索结果。
目前的搜索引擎检索结果具有更高的准确性,但仍需改进。应从搜索结果中删除过多信息和过多无关信息。出现附加冗余信息的主要原因是搜索引擎不理解用户问题的原意。优化搜索结果的解决方案有很多,比如元搜索引擎、综合搜索引擎,垂直搜索引擎是比较成功的例子,可以实现非www信息搜索,提供FTP等信息检索、多媒体搜索等。解决方案倾向于确定搜索引擎信息采集的范围,提高搜索引擎的针对性。
这里针对具体复杂的搜索提出,可以借鉴专家系统的问题形式的思想,从而提高搜索引擎对用户搜索问题的理解。
2)增加智能,从搜索数据/信息到给出解决方案,甚至执行解决方案
目前的搜索引擎,就像一只魔术手,从杂乱无章的信息中提取出清晰的检索路径,并提供相应的数据或信息。至于信息如何分析判断,如何帮助我们做出决策甚至直接执行,只能靠大脑了。当前的搜索引擎根本无法做到这一点。但是,对于用户来说,搜索并不是目的,他需要得出结论,甚至帮助他去执行。比如我要买MP3,衡量指标是品牌、价格、质量、交货期。我需要把这四项放到搜索引擎中,让电脑执行。一段时间后,搜索引擎给了我四个方案供我选择,或者为我的决定,帮我购买了某款MP3。这就是用户所需要的,而不是发布一堆信息,让用户一一做出判断和分析,耗费过多的精力,这不是我们需要的。
所以目前搜索引擎的智能水平并不高,只解决了商业智能中的第一级智能:查询/报告。商业智能在应用智能方面分为三个层次。第一层是提供数据参考,帮助用户进行数字化回忆或确认已经发生的事实,称为查询/报告;第二个层次是帮助用户寻找关系,找到原因并进行预测,称为“综合分析”;三是生成实现目标的多条路径,让用户进行选择和选择,这就是所谓的“计划选择”。选项选择的级别实际上需要生成解决问题的措施或解决方案。
商业智能在综合分析和方案选择方面取得了一些进展,但仍不成熟。搜索引擎和商业智能可以集成和先进。
3)革新网页重要性评价体系
如何呈现用户需要的数据或结论,以什么标准衡量,这是搜索引擎和商业智能非常重要的话题。
现在搜索引擎有两个评价标准,即基于链接评价的搜索引擎和基于公众访问的搜索引擎。 “链接评估系统”认为,一个网页的重要性取决于它被其他网页链接的链接数量,尤其是一些被认定为“重要”的页面的链接数量。这个评价体系和科技引文索引的思路很相似,但是由于互联网是在商业化的环境下发展起来的,一个网站的链接数也和它的商业推广息息相关,所以这种评价体系在一定程度上缺乏客观性(百度百科)。基于可访问性的搜索引擎也有类似的缺陷。目前的做法是弥补,而不是创新,目前还没有找到比上述评价体系更好的替代方案。
更重要的是,由于任何人都可以在互联网上发布信息,搜索引擎可以帮助你找到信息,但无法验证信息的可靠性,这就导致了搜索引擎数据可靠性的先天缺陷。
如何判断被抓取网页的重要性,如何判断网页信息的可信度,搜索引擎还有很长的路要走。
4)借鉴商业智能的应用方法,研究搜索用户的行为和需求
搜索引擎是网站建设中“方便用户使用网站”的必备功能,也是“研究网站用户行为的有效工具”。搜索引擎采集了大量的用户需求信息,用户每输入一个查询,就代表一个需求。积累和分析“需求数据”具有重要的商业价值。商业智能相关产品可以帮助搜索引擎厂商充分利用“需求数据”,找到更有利的商业模式。
事实上,业界已经开始了商业智能和搜索引擎的这种融合。
从 2004 年开始,商业智能与搜索引擎的结合开始受到广泛关注。从2006年开始,此类解决方案普遍出现在各个商业智能厂商中。例如,Business Objects Google Solutions 2006 支持搜索各种数据结构,包括文本文档、电子邮件、台式计算机中的办公文档、水晶报表、BI 平台中的仪表板数据和公司合同文档。 2007年,WebFocus Magnify对结构化数据进行搜索和索引,并在搜索结果中提供了BI报表的搜索和导航工具,通过树形结构展示搜索结果。 SAS SAS BI Google OneBox 企业版解决方案于2006 年与Google OneBox 紧密结合,让用户可以使用原有的搜索方式获得更深层次的搜索结果。 SAS还提供文本挖掘技术,帮助用户从企业文档中发现和提取知识,建立数据关联。最近的 SAP BusinessObjects Explorer 在提高商业智能系统的可用性、减少查询和搜索响应时间、结果排列和组织方面取得了重大突破,具有类似搜索引擎的效果。
相信随着实践的深入,商业智能和搜索引擎会融合成一个更美好的世界。 查看全部
网页抓取数据百度百科(商业智能和搜索引擎的工作原理)
商业智能已经在经历三个转变:从数据驱动到业务驱动,从关注技术到关注应用,从关注工具到关注工具产生的性能。搜索引擎本质上是业务驱动和以应用为中心的(实时用户需求响应),所以我认为商业智能和搜索引擎之间有讨论的空间。这或许有助于理解技术的分工与融合,或为两者的完善提供一些参考。
1、搜索引擎本质上是(商业)智能的体现。
企业或集团历年积累的数据庞大,但信息过多,难以消化,信息形式不一致,难以统一处理。 “要学会舍弃信息”,人们开始思考:“怎样才能不被信息所淹没,而是及时利用数据资产找到需要的信息,找到有用的知识,辅助自己进行分析和决策来提高信息利用?”商业智能应运而生。
互联网上的信息量巨大,网络资源迅速增加。怎样才能不被信息淹没,而是利用网络数据及时找到需要的信息呢?搜索引擎应用正在蓬勃发展。
可以看出,搜索引擎和(商业)智能都在解决同一个问题,都需要自主或交互地执行各种拟人化任务,都与人类的思考、决策、解决问题和学习有关。 ,是拟人思维(智能)的体现。
2、搜索引擎和商业智能的工作方式相同
让我们先来看看搜索引擎是如何工作的。搜索引擎有三个主要环节:抓取网页、处理网页、提供检索服务。首先是爬网。端到端搜索引擎有自己的网络爬虫(蜘蛛)。 Spider按照超链接的顺序不断地爬取网页。抓取的网页称为网页快照。接下来,处理网页。搜索引擎抓取网页后,需要进行大量的预处理,才能提供检索服务。其中,最重要的是提取关键词并建立索引文件。其他包括删除重复网页、分析超链接和计算网页的重要性。准备工作完成后,浏览器看到的就是搜索引擎界面,也就是第三个提供检索服务。用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了网页标题和网址外,还会提供网页摘要等信息。
再看组成:一个搜索引擎的组件一般由四部分组成:搜索器、索引器、爬虫和用户界面。搜索器的功能是在互联网上漫游,发现和采集信息,主要讲蜘蛛;索引器的作用是了解搜索器搜索到的信息,从中提取索引项,用它来表示文档,生成文档库的索引表。 第三个是检索器,其作用是根据用户查询快速检索索引数据库中的文档,评估相关性,对输出结果进行排序,并根据用户查询需求提供合理的反馈;第四个用户界面,用于接受用户查询,显示查询结果,提供个性化查询项。
这四个组件,搜索器是采集数据,索引器是处理数据,爬虫和用户界面是数据呈现。检索器是数据展示的提取过程,用户界面是用户数据需求的个性化展示。
采集数据的方式一般有人工输入、机器采集、人工输入与机器采集同步。人工维护的数据搜索引擎类别是人工组织维护的,如雅虎、新浪分类搜索,自建网络数据库的机器爬取,搜索结果直接从自己的数据库中调用,如谷歌、百度等。现在正在合并人工分拣维护和机器抓取。
在数据获取方面,需求满足第一,效率第二。机器捕获体现了高效率、高稳定性、低成本,但信息的原创能力和编辑能力还不够。人工输入如果质量高原创性能好,成本低,更能反映信息,满足用户需求,效率排第二。比如走大众路线的童童网,就是以私有产权为基础,动员大量学生输入经过学生编辑的、符合学生特点的原创性信息。学生团(通通网的“线”),费用很高。低,但更能满足学生群体的搜索需求。
我们知道,商业智能(BI)的主要工作原理体现在“数据抽取、数据处理与存储、数据分析与数据呈现”四个环节,是一个完整的端到端的商业智能解决方案。每个环节都有不同的工具或厂家,但整合基本完成,目前数据库环节的厂家已经基本掌握了其他环节的厂家。搜索引擎抓取网页的过程与数据抽取ETL的过程相同,本质是获取数据。处理网页其实就是对获取的数据进行清洗和整理,也就是数据的处理和存储,数据仓库的内容。提供检索服务其实就是数据分析和数据呈现。
可见搜索引擎和商业智能的工作方式相同。基于商业智能的四个环节,各自有很强的理解力,不同的搜索引擎在“抓取网页、处理网页、提供检索服务”三个环节也各有优势。例如,Lycos 搜索引擎专注于提供检索服务。它只从其他搜索引擎租用数据库,并以自定义格式排列搜索结果。
3、商业智能需要从三个方面向搜索引擎学习
1)搜索引擎获取结果的方式极其简单,值得借鉴
商业智能应用学科的泛化使得BI融入日常业务运营,需要极其简单的操作方式和低成本的沟通方式。搜索引擎的易用性可以达到这个目的。从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入一个单词并通过浏览器提交给搜索引擎后,搜索引擎会返回一个与用户输入的内容相关的信息列表。操作非常简单。运营BI日益发展,BI将在单位基层和中层得到应用,即流程化BI(或运营BI)将受到重视和推广。这种基于流程的BI的“下利巴形象”将实现“一般员工也需要用BI,能用BI,必须用BI”,从而最大限度地利用BI。可以看出,此时的用户已经包括了非技术/分析业务/经理。商业智能产品提供的查询、定制和分析模式对于非技术/分析专业人员来说仍然过于复杂,无法支持他们快速、低成本地获得所需的结果。目前商业智能在语义层方面已经有了很大的提升,语义层的功能让业务用户对数据的操作更加方便。但在理解自然语言方面,比如让系统正确理解人类以自然语言输入的信息,并正确回答(或响应)输入的信息,搜索引擎相对要好一些。
2)提高和增强实时理解和分析能力
商业智能以if-what-how模型为基础,补充what-how模型,实现实时智能。很多商业智能解决方案,尤其是研究的建模应用,一般都是先假设问题,再建模,构建数据和应用系统,针对特定领域使用特定的分析方法,返回特定的结果。 利用搜索引擎技术可以通过“数据+语义+分析方法+结果排列+呈现”的方式实现实时智能,具有数据范围广、分析结果动态的特点。现有的一些商业智能产品可以方便的添加各类数据源,在类似谷歌的搜索框中输入关键词(例如:“Sales income from sales in December”),系统会返回合理组织的结果带图片和文字。 “数据-趋势图”的互动联动也引起了很多用户的兴趣。
3)增强处理非结构化数据的能力
非结构化数据对于业务处理越来越重要。支持决策的信息不仅限于来自数据仓库和ODS层的结构化信息,还往往收录大量的非结构化信息,如文档、电子邮件、媒体文件等。搜索引擎具有很强的处理能力非结构化信息,例如图片、视频和音乐。
4、搜索引擎需要从四个方面学习商业智能
1)向专家系统学习,提高搜索引擎对用户搜索问题的理解,去除冗余搜索结果。
目前的搜索引擎检索结果具有更高的准确性,但仍需改进。应从搜索结果中删除过多信息和过多无关信息。出现附加冗余信息的主要原因是搜索引擎不理解用户问题的原意。优化搜索结果的解决方案有很多,比如元搜索引擎、综合搜索引擎,垂直搜索引擎是比较成功的例子,可以实现非www信息搜索,提供FTP等信息检索、多媒体搜索等。解决方案倾向于确定搜索引擎信息采集的范围,提高搜索引擎的针对性。
这里针对具体复杂的搜索提出,可以借鉴专家系统的问题形式的思想,从而提高搜索引擎对用户搜索问题的理解。
2)增加智能,从搜索数据/信息到给出解决方案,甚至执行解决方案
目前的搜索引擎,就像一只魔术手,从杂乱无章的信息中提取出清晰的检索路径,并提供相应的数据或信息。至于信息如何分析判断,如何帮助我们做出决策甚至直接执行,只能靠大脑了。当前的搜索引擎根本无法做到这一点。但是,对于用户来说,搜索并不是目的,他需要得出结论,甚至帮助他去执行。比如我要买MP3,衡量指标是品牌、价格、质量、交货期。我需要把这四项放到搜索引擎中,让电脑执行。一段时间后,搜索引擎给了我四个方案供我选择,或者为我的决定,帮我购买了某款MP3。这就是用户所需要的,而不是发布一堆信息,让用户一一做出判断和分析,耗费过多的精力,这不是我们需要的。
所以目前搜索引擎的智能水平并不高,只解决了商业智能中的第一级智能:查询/报告。商业智能在应用智能方面分为三个层次。第一层是提供数据参考,帮助用户进行数字化回忆或确认已经发生的事实,称为查询/报告;第二个层次是帮助用户寻找关系,找到原因并进行预测,称为“综合分析”;三是生成实现目标的多条路径,让用户进行选择和选择,这就是所谓的“计划选择”。选项选择的级别实际上需要生成解决问题的措施或解决方案。
商业智能在综合分析和方案选择方面取得了一些进展,但仍不成熟。搜索引擎和商业智能可以集成和先进。
3)革新网页重要性评价体系
如何呈现用户需要的数据或结论,以什么标准衡量,这是搜索引擎和商业智能非常重要的话题。
现在搜索引擎有两个评价标准,即基于链接评价的搜索引擎和基于公众访问的搜索引擎。 “链接评估系统”认为,一个网页的重要性取决于它被其他网页链接的链接数量,尤其是一些被认定为“重要”的页面的链接数量。这个评价体系和科技引文索引的思路很相似,但是由于互联网是在商业化的环境下发展起来的,一个网站的链接数也和它的商业推广息息相关,所以这种评价体系在一定程度上缺乏客观性(百度百科)。基于可访问性的搜索引擎也有类似的缺陷。目前的做法是弥补,而不是创新,目前还没有找到比上述评价体系更好的替代方案。
更重要的是,由于任何人都可以在互联网上发布信息,搜索引擎可以帮助你找到信息,但无法验证信息的可靠性,这就导致了搜索引擎数据可靠性的先天缺陷。
如何判断被抓取网页的重要性,如何判断网页信息的可信度,搜索引擎还有很长的路要走。
4)借鉴商业智能的应用方法,研究搜索用户的行为和需求
搜索引擎是网站建设中“方便用户使用网站”的必备功能,也是“研究网站用户行为的有效工具”。搜索引擎采集了大量的用户需求信息,用户每输入一个查询,就代表一个需求。积累和分析“需求数据”具有重要的商业价值。商业智能相关产品可以帮助搜索引擎厂商充分利用“需求数据”,找到更有利的商业模式。
事实上,业界已经开始了商业智能和搜索引擎的这种融合。
从 2004 年开始,商业智能与搜索引擎的结合开始受到广泛关注。从2006年开始,此类解决方案普遍出现在各个商业智能厂商中。例如,Business Objects Google Solutions 2006 支持搜索各种数据结构,包括文本文档、电子邮件、台式计算机中的办公文档、水晶报表、BI 平台中的仪表板数据和公司合同文档。 2007年,WebFocus Magnify对结构化数据进行搜索和索引,并在搜索结果中提供了BI报表的搜索和导航工具,通过树形结构展示搜索结果。 SAS SAS BI Google OneBox 企业版解决方案于2006 年与Google OneBox 紧密结合,让用户可以使用原有的搜索方式获得更深层次的搜索结果。 SAS还提供文本挖掘技术,帮助用户从企业文档中发现和提取知识,建立数据关联。最近的 SAP BusinessObjects Explorer 在提高商业智能系统的可用性、减少查询和搜索响应时间、结果排列和组织方面取得了重大突破,具有类似搜索引擎的效果。
相信随着实践的深入,商业智能和搜索引擎会融合成一个更美好的世界。
网页抓取数据百度百科(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-09 19:26
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,在使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对特征比较鲜明的目标数据有很好的效果,但并不通用。 BeautifulSoup 是一个用于对 url 内容进行结构化解析的第三方模块。下载的网页内容被解析成 DOM 树。下图是BeautifulSoup截取的百度百科网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopenexcelFile=xlwt.Workbook() sheet=excelFile.add_sheet('英雄联盟') ## 维基百科:英雄联盟## html=urlopen( "") bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main- content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=pile("^(/view/)[0-9]+. htm$")) 用于链接中的链接:if 'href' in link.attrs:print(link.attrs['href'],link.get_text())sheet.write(row,0,link.attrs['href '])sheet.write(row,1,link.get_text())row=row+1excelFile.save('E:ProjectPythonlol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
自动发微博最简单的方法是调用新浪微博的API(因为发微博很简单,不需要使用它的SDK)。编码参考开发文档
创建应用
要使用微博的API,你需要先有一个应用程序。任何申请都可以,你可以去这里注册一个现场申请申请注册。注册应用的主要目的是获取MY_APPKEY和MY_ACCESS_TOKEN,如图
获取 access_token
API 调用需要登录授权才能获取 access_token。参考
首先调用接口获取代码。
接口有三个必填参数:
•client_id:申请应用时分配的AppKey。
•redirect_url:是创建应用中设置的回调地址
•response_type:响应类型,可设置为code
具体方法是在浏览器中打开:///response&response_type=code。该方法会进入授权页面,授权后会进入url中的CODE。
接下来调用接口获取access_token。
接口有以下必要参数:
•client_id:申请应用时分配的AppKey。
•client_secret:申请应用时分配的AppSecret。
•grant_type:请求的类型,填写authorization_code
•code:调用authorize获取的code值。
•redirect_uri:是创建应用程序中设置的回调地址
具体方法是构造一个POST请求,然后在返回的数据中找到access_token并保存。具体Python代码:
import requestsurl_get_token = ""#Build POST 参数 playload = {"client_id":"填写你的","client_secret":"填写你的","grant_type":"authorization_code","code":" 获取的代码above","redirect_uri":"你的回调地址"}#POST请求r = requests.post(url_get_token,data=playload)#输出响应信息打印r.text
如果正常,会返回如下json数据:
{"access_token":"我们要记住的内容","remind_in":"157679999","expires_in":157679999,"uid":"1739207845"}
根据返回的数据,access_token的值就是我们想要的。 remember_in 的值是 access_token 的有效期,以秒为单位。我们可以看到,这个时间是3、4年,对我们来说已经足够了。
发布纯文本推文
调用接口发布文字微博,参数如下
这是必需的:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
具体代码:
#微博发文接口 url_post_a_text = ""#构建 POST 参数 playload = {"access_token":"填写你的","status":"这是一个文本 test@TaceyWong"}#POST 请求,发文微博r = requests.post(url_post_a_text,data = playload)
如果正常,会有如下结果
发一条带图片的微博
调用接口发布图片微博,其参数如下:
所需参数:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
•pic:要发布的图片,采用multipart/form-data编码方式
具体代码:
#微博发图文接口 url_post_pic = ""#构建文本类POST参数playload={"access_token":"2.0086XhtBIQLH7Ed67706b6c8TQ8XdE","status":"测试:发一个带a的文本pic & AT某人@馠子覠"}#构造二进制multipart/form-data编码参数files={"pic":open("logo.png","rb")}#POST请求,发布微博r=requests。 post(url_post_pic,data=playload,files=files)
如果正常,结果如下:
注意:requests的具体用法请参考[requests document]()
本文总结了python遍历目录的方法。分享给大家,供大家参考,如下:
方法一使用递归:
"""def WalkDir(dir, dir_callback = None, file_callback = None): for item in os.listdir(dir):print item;fullpath = dir + os.sep + itemif os.path.isdir(fullpath) :WalkDir(fullpath,dir_callback,file_callback)if dir_callback:dir_callback(fullpath)else:if file_callback:file_callback(fullpath)"""def DeleteDir(dir): print "path"#os.rmdir(dir)def DeleteFile(file) : try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
方法二:
import os, statdef WalkDir( dir, dir_callback = None, file_callback = None ): for root, dirs, files in os.walk(dir): for f in files:print ffile_path = os.path.join(root, f)if file_callback: file_callback(file_path)for d in dirs:dir_path = os.path.join(root, d)if dir_callback: dir_callback(dir_path)def DeleteDir(dir): print "path"#os.rmdir(dir) def DeleteFile( file ): try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页抓取数据百度百科(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,在使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式使用基于字符串的模糊匹配,对特征比较鲜明的目标数据有很好的效果,但并不通用。 BeautifulSoup 是一个用于对 url 内容进行结构化解析的第三方模块。下载的网页内容被解析成 DOM 树。下图是BeautifulSoup截取的百度百科网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopenexcelFile=xlwt.Workbook() sheet=excelFile.add_sheet('英雄联盟') ## 维基百科:英雄联盟## html=urlopen( "") bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main- content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=pile("^(/view/)[0-9]+. htm$")) 用于链接中的链接:if 'href' in link.attrs:print(link.attrs['href'],link.get_text())sheet.write(row,0,link.attrs['href '])sheet.write(row,1,link.get_text())row=row+1excelFile.save('E:ProjectPythonlol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
自动发微博最简单的方法是调用新浪微博的API(因为发微博很简单,不需要使用它的SDK)。编码参考开发文档
创建应用
要使用微博的API,你需要先有一个应用程序。任何申请都可以,你可以去这里注册一个现场申请申请注册。注册应用的主要目的是获取MY_APPKEY和MY_ACCESS_TOKEN,如图
获取 access_token
API 调用需要登录授权才能获取 access_token。参考
首先调用接口获取代码。
接口有三个必填参数:
•client_id:申请应用时分配的AppKey。
•redirect_url:是创建应用中设置的回调地址
•response_type:响应类型,可设置为code
具体方法是在浏览器中打开:///response&response_type=code。该方法会进入授权页面,授权后会进入url中的CODE。
接下来调用接口获取access_token。
接口有以下必要参数:
•client_id:申请应用时分配的AppKey。
•client_secret:申请应用时分配的AppSecret。
•grant_type:请求的类型,填写authorization_code
•code:调用authorize获取的code值。
•redirect_uri:是创建应用程序中设置的回调地址
具体方法是构造一个POST请求,然后在返回的数据中找到access_token并保存。具体Python代码:
import requestsurl_get_token = ""#Build POST 参数 playload = {"client_id":"填写你的","client_secret":"填写你的","grant_type":"authorization_code","code":" 获取的代码above","redirect_uri":"你的回调地址"}#POST请求r = requests.post(url_get_token,data=playload)#输出响应信息打印r.text
如果正常,会返回如下json数据:
{"access_token":"我们要记住的内容","remind_in":"157679999","expires_in":157679999,"uid":"1739207845"}
根据返回的数据,access_token的值就是我们想要的。 remember_in 的值是 access_token 的有效期,以秒为单位。我们可以看到,这个时间是3、4年,对我们来说已经足够了。
发布纯文本推文
调用接口发布文字微博,参数如下
这是必需的:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
具体代码:
#微博发文接口 url_post_a_text = ""#构建 POST 参数 playload = {"access_token":"填写你的","status":"这是一个文本 test@TaceyWong"}#POST 请求,发文微博r = requests.post(url_post_a_text,data = playload)
如果正常,会有如下结果
发一条带图片的微博
调用接口发布图片微博,其参数如下:
所需参数:
•access_token:这是我们上一步得到的access_token
•状态:要发布的微博文字内容必须经过URL编码,内容不得超过140个汉字
•pic:要发布的图片,采用multipart/form-data编码方式
具体代码:
#微博发图文接口 url_post_pic = ""#构建文本类POST参数playload={"access_token":"2.0086XhtBIQLH7Ed67706b6c8TQ8XdE","status":"测试:发一个带a的文本pic & AT某人@馠子覠"}#构造二进制multipart/form-data编码参数files={"pic":open("logo.png","rb")}#POST请求,发布微博r=requests。 post(url_post_pic,data=playload,files=files)
如果正常,结果如下:
注意:requests的具体用法请参考[requests document]()
本文总结了python遍历目录的方法。分享给大家,供大家参考,如下:
方法一使用递归:
"""def WalkDir(dir, dir_callback = None, file_callback = None): for item in os.listdir(dir):print item;fullpath = dir + os.sep + itemif os.path.isdir(fullpath) :WalkDir(fullpath,dir_callback,file_callback)if dir_callback:dir_callback(fullpath)else:if file_callback:file_callback(fullpath)"""def DeleteDir(dir): print "path"#os.rmdir(dir)def DeleteFile(file) : try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
方法二:
import os, statdef WalkDir( dir, dir_callback = None, file_callback = None ): for root, dirs, files in os.walk(dir): for f in files:print ffile_path = os.path.join(root, f)if file_callback: file_callback(file_path)for d in dirs:dir_path = os.path.join(root, d)if dir_callback: dir_callback(dir_path)def DeleteDir(dir): print "path"#os.rmdir(dir) def DeleteFile( file ): try:print "file"#os.unlink( file ) except WindowsError, e:passWalkDir( os.environ['TEMP'], DeleteDir, DeleteFile )
希望这篇文章对你的 Python 编程有所帮助。
网页抓取数据百度百科( 影响网页快照几个的几个因素-苏州安嘉Web)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-09 18:04
影响网页快照几个的几个因素-苏州安嘉Web)
网页快照的英文名称是Web Cache,是搜索引擎抓取、复制页面内容并存储的过程。网页快照不仅是分析搜索引擎对网站的关注程度,也是友情链接交换的重要参考因素,那么如何加快网页快照的更新频率,让网站 的优化工作更快 高效的运行是站长一直在寻找的。下面我们描述影响网页快照的几个因素。1、网站内容更新频率正常。只要网站的内容有更新,搜索引擎蜘蛛就会过来采集。但是网站内容的更新频率也应该是有规律的,就像我们的工作一样,
网页快照英文名称为WebCache,是百度搜索引擎抓取、复制网页内容并存储的全过程。网页快照不仅分析了百度搜索引擎对网址的关注程度,也是友情链接交换的关键参考因素。因此,如何加快网页快照的升级频率,让搜索引擎优化工作更加快速高效。,这正是 网站 的站长一直在寻找的。您将在下面详细了解影响 Web 快照的许多元素。
1、网站内容更新频率
一般来说,如果网站内容升级了,百度搜索引擎搜索引擎蜘蛛就会回来采集。但是,网站内容的更新频率应该是有规律的。就像大家的工作一样,要有规律,要有目的,这样百度搜索引擎的搜索引擎蜘蛛才会有规律的去寻找。了解这个网站需要多久来一次。一般来说,在网站的内容更新频率稳定的情况下,网页快照的更新频率大致与网站的内容更新频率相近(百度搜索引擎更新周期除外)。
2、URL的权重值
单纯的升级网站的内容显然是不够的,网站也要按辈分排名。新的网站的内容在不断的升级,但有时也无法与旧的网站齐头并进。这就是百度权重的效果。百度搜索引擎一直偏爱具有高权重值的 URL。如果你想让你的新网站获得很多青睐,你应该在新站点的开头选中一个权重值高的网站域名。
3、URL 多久更改一次
当要更改 URL 时,必须考虑对 seo 优化的危害。无论是网站源代码,页面的合理布局,内容甚至是URL的页面标题、描述、关键词,都会对网页快照造成危害。如果网址经常变化,会给百度搜索引擎留下很不好的印象。就像你认识的人今天改变了头形,明天做了双眼皮手术,并获得了隆鼻手术。你能承受这样的改变吗?URL完成后,尽量不要更改,URL也不需要频繁更改。
4、网址是假的
未升级的页面快照有时会因网站造假或涉嫌造假而被百度搜索引擎处罚。百度搜索引擎的技术性一直在不断发展,并且不断朝着更加公平的方向发展。网站当前或以前的seo工作涉及欺诈,或可靠的实际操作被列为欺诈,这将导致网页欺诈。快照未升级。
5、Web 服务器可靠性
找到一个好的室内空间提供商也很重要,这样您的网络服务器就可以得到保护。Web 服务器的可靠性非常关键。不稳定的网络服务器不仅会阻塞客户端对网站的浏览,而且百度搜索引擎也无法正常抓取内容。其他网络服务器网站会因作弊而受到惩罚,你的网站也会受到惩罚。Web 服务器的其他不安全元素(病原体、长期攻击)也可能危及网页快照的升级。
6、ping 服务项目
如果你的网址是zblog、wordpress程序进程等,如果你想让你的博客使用RSS,可以添加ping服务项。另外,每个博客创建者发布新的文章内容,根据Ping服务项目通知博客百度搜索引擎,以保证最快的时间百度收录网络文章,加快百度搜索引擎网页快照的更新频率。
7、外部元素加速网页截图
事实上,网站 地址在网上盛行。启用完全免费的时尚博客,如博客、新浪博客、百度站长工具室内空间、站长论坛室内空间,发布推广软文;去百度站长工具社区论坛、站长论坛社区论坛、过时论坛等大中型社区论坛,发布与网址相关的帖子;交换友链,将友链换成与自己相关的网站;互动问答,去百度问答,知乎论坛,新浪AiQ,雅虎专业知识问答,留下网站地址发自言自语。信息内容,去相关网站发送一些信息内容营销宣传自己,建议不需要使用群发。
以上是促进网页快照升级率的几个因素,但seo的基础理论是通过实践活动获得的。不同的 URL 有不同的条件。仅作为参考,实践活动可视为检验基础理论的最佳方式。. 查看全部
网页抓取数据百度百科(
影响网页快照几个的几个因素-苏州安嘉Web)
网页快照的英文名称是Web Cache,是搜索引擎抓取、复制页面内容并存储的过程。网页快照不仅是分析搜索引擎对网站的关注程度,也是友情链接交换的重要参考因素,那么如何加快网页快照的更新频率,让网站 的优化工作更快 高效的运行是站长一直在寻找的。下面我们描述影响网页快照的几个因素。1、网站内容更新频率正常。只要网站的内容有更新,搜索引擎蜘蛛就会过来采集。但是网站内容的更新频率也应该是有规律的,就像我们的工作一样,
网页快照英文名称为WebCache,是百度搜索引擎抓取、复制网页内容并存储的全过程。网页快照不仅分析了百度搜索引擎对网址的关注程度,也是友情链接交换的关键参考因素。因此,如何加快网页快照的升级频率,让搜索引擎优化工作更加快速高效。,这正是 网站 的站长一直在寻找的。您将在下面详细了解影响 Web 快照的许多元素。
1、网站内容更新频率
一般来说,如果网站内容升级了,百度搜索引擎搜索引擎蜘蛛就会回来采集。但是,网站内容的更新频率应该是有规律的。就像大家的工作一样,要有规律,要有目的,这样百度搜索引擎的搜索引擎蜘蛛才会有规律的去寻找。了解这个网站需要多久来一次。一般来说,在网站的内容更新频率稳定的情况下,网页快照的更新频率大致与网站的内容更新频率相近(百度搜索引擎更新周期除外)。
2、URL的权重值
单纯的升级网站的内容显然是不够的,网站也要按辈分排名。新的网站的内容在不断的升级,但有时也无法与旧的网站齐头并进。这就是百度权重的效果。百度搜索引擎一直偏爱具有高权重值的 URL。如果你想让你的新网站获得很多青睐,你应该在新站点的开头选中一个权重值高的网站域名。
3、URL 多久更改一次
当要更改 URL 时,必须考虑对 seo 优化的危害。无论是网站源代码,页面的合理布局,内容甚至是URL的页面标题、描述、关键词,都会对网页快照造成危害。如果网址经常变化,会给百度搜索引擎留下很不好的印象。就像你认识的人今天改变了头形,明天做了双眼皮手术,并获得了隆鼻手术。你能承受这样的改变吗?URL完成后,尽量不要更改,URL也不需要频繁更改。
4、网址是假的
未升级的页面快照有时会因网站造假或涉嫌造假而被百度搜索引擎处罚。百度搜索引擎的技术性一直在不断发展,并且不断朝着更加公平的方向发展。网站当前或以前的seo工作涉及欺诈,或可靠的实际操作被列为欺诈,这将导致网页欺诈。快照未升级。
5、Web 服务器可靠性
找到一个好的室内空间提供商也很重要,这样您的网络服务器就可以得到保护。Web 服务器的可靠性非常关键。不稳定的网络服务器不仅会阻塞客户端对网站的浏览,而且百度搜索引擎也无法正常抓取内容。其他网络服务器网站会因作弊而受到惩罚,你的网站也会受到惩罚。Web 服务器的其他不安全元素(病原体、长期攻击)也可能危及网页快照的升级。
6、ping 服务项目
如果你的网址是zblog、wordpress程序进程等,如果你想让你的博客使用RSS,可以添加ping服务项。另外,每个博客创建者发布新的文章内容,根据Ping服务项目通知博客百度搜索引擎,以保证最快的时间百度收录网络文章,加快百度搜索引擎网页快照的更新频率。
7、外部元素加速网页截图
事实上,网站 地址在网上盛行。启用完全免费的时尚博客,如博客、新浪博客、百度站长工具室内空间、站长论坛室内空间,发布推广软文;去百度站长工具社区论坛、站长论坛社区论坛、过时论坛等大中型社区论坛,发布与网址相关的帖子;交换友链,将友链换成与自己相关的网站;互动问答,去百度问答,知乎论坛,新浪AiQ,雅虎专业知识问答,留下网站地址发自言自语。信息内容,去相关网站发送一些信息内容营销宣传自己,建议不需要使用群发。
以上是促进网页快照升级率的几个因素,但seo的基础理论是通过实践活动获得的。不同的 URL 有不同的条件。仅作为参考,实践活动可视为检验基础理论的最佳方式。.
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理与索引库的建立)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-09 18:01
【2022网站收录】百度蜘蛛爬取页面及建索引库原理 admin03-06 15:413times
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了但没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理与索引库的建立)
【2022网站收录】百度蜘蛛爬取页面及建索引库原理 admin03-06 15:413times
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,我对seo真正的核心知识没有做过太多的了解,或者只是简单的理解了但没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬取系统原理及索引库的建立,让广大做SEO优化的站长们可以百度蜘蛛的<
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果把网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持过去爬虫爬取的页面保持更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抢到有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度会有所不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科( 说起百度快照更新究竟有什么用呢?如何来了解呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-05 21:21
说起百度快照更新究竟有什么用呢?如何来了解呢?)
百度快照的问题大家并不陌生。现在再讲这个,感觉有点老土了。但往往老的东西往往被大家忽略,包括作者本人,我也多次忽略了这个问题。而我个人觉得百度的快照有什么用呢?带着这种困惑,我看到了百度快照的效果。第一个:查询页面爬取的范围关于查询页面爬取的范围,这个怎么理解?其实,当我们想查询这个网页的爬取情况时,那么我们可以点击这个页面的快照,看看里面爬取了什么。当您查询快照时,您
网页快照的问题大家都很熟悉了,再说一遍就有点老生常谈了。但是通常比较老的单品往往会被大家忽略,主要是我自己,因为之前我也忽略过这个问题好几次了。而我个人觉得百度网这个快照更新有什么用呢?带着这样的疑惑,我看到了网页快照的作用。
第一种:搜索网页爬取范围
怎么知道搜索网页爬取的范围?实际上就是当你去查看这个网页的爬取状态时,人们可以点击这个网页的快照更新,看到里面的爬取项目。当您搜索快照更新时,您是否注意人们搜索的单词,快照更新网页上出现的单词会以不同的色调表示。对于一个网页被百度爬虫爬取的情况,人们可以根据快照更新有明显的区别。
第二:寻找朋友链的作用
当你去和别人交换朋友链时,大部分SEO从业者只想关心对方网站的权重值、PR值、出口连接、收录。人们是否注意对方网站上的好友链接是否自动重定向?我想每个人都应该想忽略这个问题!我曾经听一位出色的白帽黑客 SEO 从业者说,链接交换是提高我排名的好方法。所以大家一定要高度重视这个问题,看看网页截图下方的朋友链状态。
第三种:查询内部链接的作用
小编看过一个例子。本站名称为“西祠胡同”。我觉得从业者在这里做外链和内链是很容易的。后来那个时候我也在想,为什么我发了内外链接,然后这些管理方式不删帖,又不T人,我觉得很奇怪。为了一探究竟,我搜索了我发的百度收录网页,打开快照更新,看到自动重定向被屏蔽了。假设下,这类网址的内外链接的关键词提升应该不会很大,一些普普的客户很有兴趣点进去看看。
写在最后,其实也有内链,就是你的网站查询测试的一个功能。写到这里,希望SEO从业者能够真正理解和重视web快照这样的一个项目。 查看全部
网页抓取数据百度百科(
说起百度快照更新究竟有什么用呢?如何来了解呢?)
百度快照的问题大家并不陌生。现在再讲这个,感觉有点老土了。但往往老的东西往往被大家忽略,包括作者本人,我也多次忽略了这个问题。而我个人觉得百度的快照有什么用呢?带着这种困惑,我看到了百度快照的效果。第一个:查询页面爬取的范围关于查询页面爬取的范围,这个怎么理解?其实,当我们想查询这个网页的爬取情况时,那么我们可以点击这个页面的快照,看看里面爬取了什么。当您查询快照时,您
网页快照的问题大家都很熟悉了,再说一遍就有点老生常谈了。但是通常比较老的单品往往会被大家忽略,主要是我自己,因为之前我也忽略过这个问题好几次了。而我个人觉得百度网这个快照更新有什么用呢?带着这样的疑惑,我看到了网页快照的作用。
第一种:搜索网页爬取范围
怎么知道搜索网页爬取的范围?实际上就是当你去查看这个网页的爬取状态时,人们可以点击这个网页的快照更新,看到里面的爬取项目。当您搜索快照更新时,您是否注意人们搜索的单词,快照更新网页上出现的单词会以不同的色调表示。对于一个网页被百度爬虫爬取的情况,人们可以根据快照更新有明显的区别。
第二:寻找朋友链的作用
当你去和别人交换朋友链时,大部分SEO从业者只想关心对方网站的权重值、PR值、出口连接、收录。人们是否注意对方网站上的好友链接是否自动重定向?我想每个人都应该想忽略这个问题!我曾经听一位出色的白帽黑客 SEO 从业者说,链接交换是提高我排名的好方法。所以大家一定要高度重视这个问题,看看网页截图下方的朋友链状态。
第三种:查询内部链接的作用
小编看过一个例子。本站名称为“西祠胡同”。我觉得从业者在这里做外链和内链是很容易的。后来那个时候我也在想,为什么我发了内外链接,然后这些管理方式不删帖,又不T人,我觉得很奇怪。为了一探究竟,我搜索了我发的百度收录网页,打开快照更新,看到自动重定向被屏蔽了。假设下,这类网址的内外链接的关键词提升应该不会很大,一些普普的客户很有兴趣点进去看看。
写在最后,其实也有内链,就是你的网站查询测试的一个功能。写到这里,希望SEO从业者能够真正理解和重视web快照这样的一个项目。
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理大家了解多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 21:16
[2022网站收录] 百度蜘蛛爬取页面及建索引库的原理 admin03-05 15:072 浏览量
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统的原理和索引库的建立,
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,从而尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持蜘蛛过去爬过的页面不断更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。 查看全部
网页抓取数据百度百科(一下2021年关于百度搜索引擎蜘蛛的工作原理大家了解多少)
[2022网站收录] 百度蜘蛛爬取页面及建索引库的原理 admin03-05 15:072 浏览量
百度搜索引擎蜘蛛的工作原理你知道多少?百度蜘蛛如何爬取页面并建立相应的索引库,相信很多低级别的SEO站长对此都不是很清楚,而相当一部分站长其实只是为了seo和seo,甚至只知道如何发送< @文章,外链和交易所链,seo真正的核心知识我没有做过太多的了解,或者只是简单的理解了但是没有应用到具体的实践中,或者没有进行更深入的研究,接下来,嘉洛SEO给大家分享2021年网站收录的知识——百度蜘蛛爬虫系统的原理和索引库的建立,
一、百度蜘蛛爬取系统基本框架
随着互联网信息的爆炸式增长,如何有效地获取和利用这些信息是搜索引擎工作的首要环节。数据爬取系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,因此通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛叫做:Baiduspdier、Googlebot、搜狗网络蜘蛛等。
蜘蛛爬取系统是搜索引擎数据来源的重要保障。如果将网络理解为一个有向图,那么蜘蛛的工作过程可以认为是对这个有向图的遍历。从一些重要的种子URL开始,通过页面上的超链接关系,不断发现新的URL并进行爬取,从而尽可能多地爬取有价值的网页。对于百度这样的大型爬虫系统,由于随时都有网页被修改、删除或者新的超链接出现的可能,所以需要保持蜘蛛过去爬过的页面不断更新,维护一个URL库和Page图书馆。
下图是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns解析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。百度蜘蛛通过本系统的配合完成对互联网页面的爬取。
二、百度蜘蛛主要爬取策略类型
上图看似简单,但实际上百度蜘蛛在爬取过程中面临着一个超级复杂的网络环境。为了让系统尽可能多的抓取有价值的资源,保持系统中页面与实际环境的一致性,同时不会给网站的体验带来压力,会设计一个各种复杂的抓取策略。这里有一个简单的介绍:
爬行友好度
海量的互联网资源要求抓取系统在有限的硬件和带宽资源下,尽可能高效地利用带宽,尽可能多地抓取有价值的资源。这就产生了另一个问题,消耗了被逮捕的 网站 的带宽并造成访问压力。如果太大,将直接影响被捕网站的正常用户访问行为。因此,需要在爬取过程中控制爬取压力,以达到在不影响网站正常用户访问的情况下尽可能多地抓取有价值资源的目的。
通常,最基本的是基于 ip 的压力控制。这是因为如果是基于域名的话,可能会出现一个域名对应多个IP(很多大网站)或者多个域名对应同一个IP(小网站共享 IP)。在实践中,往往根据ip和域名的各种情况进行压力分配控制。同时,站长平台也推出了压力反馈工具。站长可以自己手动调节抓取压力网站。这时候百度蜘蛛会根据站长的要求优先控制抓取压力。
对同一个站点的爬取速度控制一般分为两类:一类是一段时间内的爬取频率;另一种是一段时间内的爬行流量。同一个站点在不同时间的爬取速度也会不同。例如,在夜深人静、月黑风高的情况下,爬行可能会更快。它还取决于特定的站点类型。主要思想是错开正常的用户访问高峰并不断进行调整。不同的站点也需要不同的爬取率。
三、判断新链接的重要性
在建库链接之前,百度蜘蛛会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立图书馆并发现新链接的过程。理论上,百度蜘蛛会把新页面上所有“看到”的链接都爬回来,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值
1、独特的内容,百度搜索引擎喜欢独特的内容
2、主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4、适当做广告
二、链接的重要性
1、目录层次结构 - 浅层优先
2、链接在网站上的受欢迎程度
四、百度优先建设重要库的原则
百度蜘蛛抓取的页数并不是最重要的,重要的是建了多少页到索引库中,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的超高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1、时间敏感且有价值的页面
在这里,及时性和价值并列,两者缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2、具有高质量内容的特殊页面
话题页的内容不一定是完整的原创,也就是可以很好的融合各方的内容,或者加入一些新鲜的内容,比如观点、评论,给用户一个更丰富更全面的内容.
3、高价值原创内容页面
百度将原创定义为花费一定成本,积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4、重要的个人页面
这里只是一个例子,科比在新浪微博上开了一个账号,即使他不经常更新,对于百度来说仍然是一个极其重要的页面。
五、哪些网页不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的页面
2、百度不需要收录与互联网上已有的内容。
3、主体内容空而短的网页
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户可以访问丰富的内容,但还是会被搜索引擎抛弃
加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
很多主体不太显眼的网页,即使被爬回来,也会在这个链接中被丢弃。
4、一些作弊页面
更多关于aiduspider爬取系统的原理和索引搭建,请到百度站长论坛查看文档。
网页抓取数据百度百科(什么是爬虫爬虫:请求网站并提取数据的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2022-03-04 12:05
一、什么是爬虫
爬虫:请求网站并提取数据的自动化程序
百科全书:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。
如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫就是一只小蜘蛛,
沿着网络爬取自己的猎物(数据)的爬虫是指:向网站发起请求,获取资源后分析提取有用数据的程序;
从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用;
二、爬虫发起请求的基本流程:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器回应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或以特定格式保存文件。三、Request和ResponseRequest:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
四、Request详细请求方式:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 Request URL:URL的全称是Uniform Resource Locator。例如,网页文档、图片、视频等都可以由URL唯一确定。请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。请求体:请求中携带的附加数据,如表单提交时的表单数据五、响应详解响应状态:响应状态有多种,如200表示成功,301表示重定向,404表示page not found, 502 for server error 响应头:如内容类型、内容长度、服务器信息、设置cookie等 响应体:最重要的部分,包括请求资源的内容,比如网页HTML、图片二进制数据等六、可以抓取哪些数据web文本:比如HTML文档、Json格式文本等 图片:获取到的二进制文件保存为图片格式。视频:两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓取的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决 JavaScript 渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
九、优秀爬虫的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是以爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实际的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫运行多线程,通过多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会在全球、不同区域部署,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议,告诉爬虫哪些内容不是什么内容。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaentry-footer">
爬虫基本原理资料 查看全部
网页抓取数据百度百科(什么是爬虫爬虫:请求网站并提取数据的自动化程序)
一、什么是爬虫
爬虫:请求网站并提取数据的自动化程序
百科全书:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。
如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫就是一只小蜘蛛,
沿着网络爬取自己的猎物(数据)的爬虫是指:向网站发起请求,获取资源后分析提取有用数据的程序;
从技术上讲,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据并将其存储以供使用;
二、爬虫发起请求的基本流程:通过HTTP库向目标站点发起请求,即发送一个Request,请求中可以收录额外的headers等信息,等待服务器回应。获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(如图片和视频)等类型。解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库来解析。可能是Json,可以直接转换成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。保存数据:以多种形式保存,可以保存为文本,也可以保存到数据库,或以特定格式保存文件。三、Request和ResponseRequest:浏览器向URL所在的服务器发送消息。这个过程称为 HTTP 请求。响应:服务器收到浏览器发送的消息后,可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。它可以根据浏览器发送的消息内容进行处理,然后将消息发送回浏览器。此过程称为 HTTP 响应。浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后显示出来。
四、Request详细请求方式:主要有GET和POST两种,还有HEAD、PUT、DELETE、OPTIONS等。 Request URL:URL的全称是Uniform Resource Locator。例如,网页文档、图片、视频等都可以由URL唯一确定。请求头:收录请求过程中的头信息,如User-Agent、Host、Cookies等信息。请求体:请求中携带的附加数据,如表单提交时的表单数据五、响应详解响应状态:响应状态有多种,如200表示成功,301表示重定向,404表示page not found, 502 for server error 响应头:如内容类型、内容长度、服务器信息、设置cookie等 响应体:最重要的部分,包括请求资源的内容,比如网页HTML、图片二进制数据等六、可以抓取哪些数据web文本:比如HTML文档、Json格式文本等 图片:获取到的二进制文件保存为图片格式。视频:两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、 两者都是二进制文件,可以保存为视频格式。以此类推:只要能请求,就能得到。七、解析方法直接处理捕获Json解析正则表达式BeautifulSoupPyQueryXPath出现的问题八、
问:为什么我得到的与浏览器看到的不同?
答:网页由浏览器解析渲染,加载CSS和JS等文件解析渲染网页,这样我们就可以看到漂亮的网页了,而我们抓取的文件只是一些代码,CSS无法调用文件,从而无法显示样式。那么就会出现错位等问题。
Q:如何解决 JavaScript 渲染的问题?
A:分析Ajax请求、Selenium/WebDriver、Splash、PyV8、Ghost.py等库
九、优秀爬虫的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是以爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实际的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫运行多线程,通过多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会在全球、不同区域部署,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议,告诉爬虫哪些内容不是什么内容。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaentry-footer">
爬虫基本原理资料
网页抓取数据百度百科( 百度SEO的几个问题(之二)网页的导出链接数多少为好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-04 12:00
百度SEO的几个问题(之二)网页的导出链接数多少为好)
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)网页的外链数是多少?谷歌倾向于说每个网页的外链数不要超过100。百度有什么建议吗?没有暂时的建议。一般来说这种情况下,链接的数量会影响这些链接在页面中的权重,少给多分,多给少分。百度支持哪些Robots Meta标签?百度支持nofollow和noarchive . 定期更新到/se
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)
一个网页应该有多少个出站链接?谷歌倾向于说每个网页不超过 100 个传出链接。百度有什么建议吗?
暂时没有建议。一般情况下,链接的数量会影响这些链接在页面中的权重;少即是多,多即是少。
百度支持哪些机器人元标签?
百度支持nofollow和noarchive。定期更新到 /search/robots.html
网页大小问题?多大才合适。
页面大小和搜索引擎抓取之间没有直接关系。但建议网页(包括代码)不要太大,太大的网页会被抓取截断;并且内容部分不能太大,会被索引截断。当然,fetch truncation 的上限会远大于 index truncation 的上限。
禁止搜索引擎 收录 的方法?robots.txt 的用法?
详情见:/search/robots.html
百度如何对待改版的网站?
如果内容从根本上改变,理论上会被视为全新的网站,旧的超链接失效。
百度新站的收录内页有问题,首页可以很快收录,但就是没有收录内页?
土匪入队,还需要“报名”;加入搜索引擎的人也需要注意考察期。
301 永久重定向是否传递了全部或部分权重?
正常301永久重定向,旧url上积累的各种投票信息都会转移到新url上。(注:百度301的处理速度太慢了。)
超过。 查看全部
网页抓取数据百度百科(
百度SEO的几个问题(之二)网页的导出链接数多少为好)
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)网页的外链数是多少?谷歌倾向于说每个网页的外链数不要超过100。百度有什么建议吗?没有暂时的建议。一般来说这种情况下,链接的数量会影响这些链接在页面中的权重,少给多分,多给少分。百度支持哪些Robots Meta标签?百度支持nofollow和noarchive . 定期更新到/se
第二次总结百度SEO相关问题。依旧是从百度站长俱乐部的掌门人中提炼出来的。关于百度SEO的几个问题(二)
一个网页应该有多少个出站链接?谷歌倾向于说每个网页不超过 100 个传出链接。百度有什么建议吗?
暂时没有建议。一般情况下,链接的数量会影响这些链接在页面中的权重;少即是多,多即是少。
百度支持哪些机器人元标签?
百度支持nofollow和noarchive。定期更新到 /search/robots.html
网页大小问题?多大才合适。
页面大小和搜索引擎抓取之间没有直接关系。但建议网页(包括代码)不要太大,太大的网页会被抓取截断;并且内容部分不能太大,会被索引截断。当然,fetch truncation 的上限会远大于 index truncation 的上限。
禁止搜索引擎 收录 的方法?robots.txt 的用法?
详情见:/search/robots.html
百度如何对待改版的网站?
如果内容从根本上改变,理论上会被视为全新的网站,旧的超链接失效。
百度新站的收录内页有问题,首页可以很快收录,但就是没有收录内页?
土匪入队,还需要“报名”;加入搜索引擎的人也需要注意考察期。
301 永久重定向是否传递了全部或部分权重?
正常301永久重定向,旧url上积累的各种投票信息都会转移到新url上。(注:百度301的处理速度太慢了。)
超过。
网页抓取数据百度百科( 第一章百度搜索引擎如何运行具有四个功能?如何运作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-04 11:28
第一章百度搜索引擎如何运行具有四个功能?如何运作)
第一章搜索引擎的工作原理搜索引擎有四个功能:爬取、建立索引数据库、计算相关性和排名、提供索引结果。搜索引擎抓取和索引数以亿计的网页、文档、新闻、图片、视频和其他内容。当搜索者提出搜索请求时,搜索引擎会根据搜索结果的相关性排列索引结果并提供给搜索者。. 1、对互联网的抓取和索引就像一个巨大的城市地铁系统,而网站和网站中的页面(可能是pdf文件、jpg图片等)就像在地铁系统中一样车站,为了让火车到达每个车站,在地铁系统中,有必要
第一章百度搜索引擎的工作原理
百度搜索引擎有四个功能:爬取、创建数据库索引数据库查询、测量相关性和计算排名、显示数据库索引的结果。百度搜索引擎对数以亿计的网页、文档、新闻报道、照片、视频等内容进行爬取和索引。当搜索者明确提出搜索请求时,百度搜索引擎会根据关联对数据库的结果进行索引。按性别排序并呈现给搜索者。
1、爬取和数据库索引
互联网技术就像一个巨大的城轨系统软件,网站和网站中的网页(也会是pdf文档,jpg照片等)就像地铁站系统软件中的网站,这样优采云要能够到达每一个网站,在地铁站系统软件中,必须有不同的路线连接网站,而在互联网技术上,不同的网站或不同的网站网站中的页面是连接的。路线更紧密。
Web服务器中的连接结构将网站中的所有网页连接在一起,或者至少保证百度搜索引擎可以到达所有网页。通过这种连接,百度搜索引擎智能机器人(或称“网络爬虫”、“搜索引擎蜘蛛”)可以到达网站的每一个角落。
百度搜索引擎一旦找到这种网页,接下来的工作就是分析网页的代码,选择有效内容,保存,当客户明确提出检索请求时,将结果展示给客户。为了在最短的时间内为客户提供满足检索要求的内容,百度搜索引擎公司在全球范围内共创建了各种大中型数据库查询来存储百度搜索引擎搜索引擎爬取的网址蜘蛛。(网页)内容。当客户使用百度搜索引擎进行搜索时,即使这种搜索只需要3、4秒,也会引起客户极大的不满。因此,主流产品的百度搜索引擎公司都使用快速显示结果是您的首要任务。
2、显示百度搜索
当客户使用百度搜索引擎进行搜索时,百度搜索引擎会在自己的数据库查询中搜索到客户想要的信息内容。在这种情况下,百度搜索引擎会做两件事。将客户有效的、相关的搜索搜索结果呈现给客户,其次根据需要对结果进行排列。这方面(相关性和必要性)恰好意味着在 seo 优化中必须高度重视 URL。
对于百度搜索引擎来说,相关性不仅仅意味着在网页上突出客户搜索的词。在互联网技术出现的早期,百度搜索引擎只是将客户检索到的内容加粗或突出显示。随着技术的发展趋势和发展,优秀的技术工程师已经找到了越来越多的方式来为客户提供信息。提供更实用的百度搜索。现在危害关联的要素越来越多,后面会详细介绍。
虽然危及相关性的因素有数百种,但相关性仍然无法定量分析,而另一个危及百度搜索排名的因素——必要性也是一个无法定量分析的指标值。虽然无法量化分析,但百度搜索引擎还是要努力做到这一点。
最近,主流产品的百度搜索引擎公司喜欢用声望值和用户评价来考虑网站或网页的必要性。网站在客户心目中的影响力越高,用户评价越高,所呈现的内容和信息越有价值,网站在百度搜索引擎中的重要性就越高。从具体情况来看,用声望值和用户评价来区分网站的关键是比较成功的。
百度搜索引擎对 URL 的必要性和相关性的识别不是通过人工服务进行的。如果进行人工服务,工作量会很大。在这些方面,百度搜索引擎都有自己的一套评价标准,称为“优化算法”。在百度搜索引擎优化算法中,收录了数百个自变量,也就是人们常说的危害排名。元素。 查看全部
网页抓取数据百度百科(
第一章百度搜索引擎如何运行具有四个功能?如何运作)
第一章搜索引擎的工作原理搜索引擎有四个功能:爬取、建立索引数据库、计算相关性和排名、提供索引结果。搜索引擎抓取和索引数以亿计的网页、文档、新闻、图片、视频和其他内容。当搜索者提出搜索请求时,搜索引擎会根据搜索结果的相关性排列索引结果并提供给搜索者。. 1、对互联网的抓取和索引就像一个巨大的城市地铁系统,而网站和网站中的页面(可能是pdf文件、jpg图片等)就像在地铁系统中一样车站,为了让火车到达每个车站,在地铁系统中,有必要
第一章百度搜索引擎的工作原理
百度搜索引擎有四个功能:爬取、创建数据库索引数据库查询、测量相关性和计算排名、显示数据库索引的结果。百度搜索引擎对数以亿计的网页、文档、新闻报道、照片、视频等内容进行爬取和索引。当搜索者明确提出搜索请求时,百度搜索引擎会根据关联对数据库的结果进行索引。按性别排序并呈现给搜索者。
1、爬取和数据库索引
互联网技术就像一个巨大的城轨系统软件,网站和网站中的网页(也会是pdf文档,jpg照片等)就像地铁站系统软件中的网站,这样优采云要能够到达每一个网站,在地铁站系统软件中,必须有不同的路线连接网站,而在互联网技术上,不同的网站或不同的网站网站中的页面是连接的。路线更紧密。
Web服务器中的连接结构将网站中的所有网页连接在一起,或者至少保证百度搜索引擎可以到达所有网页。通过这种连接,百度搜索引擎智能机器人(或称“网络爬虫”、“搜索引擎蜘蛛”)可以到达网站的每一个角落。
百度搜索引擎一旦找到这种网页,接下来的工作就是分析网页的代码,选择有效内容,保存,当客户明确提出检索请求时,将结果展示给客户。为了在最短的时间内为客户提供满足检索要求的内容,百度搜索引擎公司在全球范围内共创建了各种大中型数据库查询来存储百度搜索引擎搜索引擎爬取的网址蜘蛛。(网页)内容。当客户使用百度搜索引擎进行搜索时,即使这种搜索只需要3、4秒,也会引起客户极大的不满。因此,主流产品的百度搜索引擎公司都使用快速显示结果是您的首要任务。
2、显示百度搜索
当客户使用百度搜索引擎进行搜索时,百度搜索引擎会在自己的数据库查询中搜索到客户想要的信息内容。在这种情况下,百度搜索引擎会做两件事。将客户有效的、相关的搜索搜索结果呈现给客户,其次根据需要对结果进行排列。这方面(相关性和必要性)恰好意味着在 seo 优化中必须高度重视 URL。
对于百度搜索引擎来说,相关性不仅仅意味着在网页上突出客户搜索的词。在互联网技术出现的早期,百度搜索引擎只是将客户检索到的内容加粗或突出显示。随着技术的发展趋势和发展,优秀的技术工程师已经找到了越来越多的方式来为客户提供信息。提供更实用的百度搜索。现在危害关联的要素越来越多,后面会详细介绍。
虽然危及相关性的因素有数百种,但相关性仍然无法定量分析,而另一个危及百度搜索排名的因素——必要性也是一个无法定量分析的指标值。虽然无法量化分析,但百度搜索引擎还是要努力做到这一点。
最近,主流产品的百度搜索引擎公司喜欢用声望值和用户评价来考虑网站或网页的必要性。网站在客户心目中的影响力越高,用户评价越高,所呈现的内容和信息越有价值,网站在百度搜索引擎中的重要性就越高。从具体情况来看,用声望值和用户评价来区分网站的关键是比较成功的。
百度搜索引擎对 URL 的必要性和相关性的识别不是通过人工服务进行的。如果进行人工服务,工作量会很大。在这些方面,百度搜索引擎都有自己的一套评价标准,称为“优化算法”。在百度搜索引擎优化算法中,收录了数百个自变量,也就是人们常说的危害排名。元素。
网页抓取数据百度百科(网页收录与蜘蛛抓取的频率有哪些必然的联系?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-03 07:05
对于网站的操作,如果想通过某个关键词获得更多的流量,首先也是最重要的就是页面需要被搜索引擎收录搜索到。而网页收录和蜘蛛爬取的频率有什么必然联系呢?合肥网站日常运营优化工作有何意义?
首先,根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上,只要是外链,无论质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,简化目录层次,URL不要太长,动态参数太多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候,其实有一个方便的小技巧:那就是主动将 URL 添加到站点地图中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当您有页面需要参与排名时,您有必要将它们放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定是好事。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,你可以使用百度官方后台爬虫诊断查看具体原因。
网信科技总结:页面爬取频率在索引、收录、排名、二次排名中起着至关重要的作用。作为 网站 操作员,您可能需要适当注意。 查看全部
网页抓取数据百度百科(网页收录与蜘蛛抓取的频率有哪些必然的联系?)
对于网站的操作,如果想通过某个关键词获得更多的流量,首先也是最重要的就是页面需要被搜索引擎收录搜索到。而网页收录和蜘蛛爬取的频率有什么必然联系呢?合肥网站日常运营优化工作有何意义?
首先,根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上,只要是外链,无论质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,简化目录层次,URL不要太长,动态参数太多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候,其实有一个方便的小技巧:那就是主动将 URL 添加到站点地图中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当您有页面需要参与排名时,您有必要将它们放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定是好事。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,你可以使用百度官方后台爬虫诊断查看具体原因。
网信科技总结:页面爬取频率在索引、收录、排名、二次排名中起着至关重要的作用。作为 网站 操作员,您可能需要适当注意。
网页抓取数据百度百科(数据库看前端的效率如何了?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-03-01 22:02
网页抓取数据百度百科:apivarysearch搜索相关信息将搜索的结果数据存放到数据库中设置出口日志不抓取数据传至ftp服务器分析数据库大致如此,
其实看前端的效率如何了,像我这样的是没法处理的,有可能每次从数据库取都要半天。
api,程序员解决这个问题。
是用json参数吧?或者可以试试用cookie,
实现一个实时爬取站点内容的api
看看,
站长园出的《网页数据采集技术》,里面有现成的网页,按照指引和说明,可以通过搜索引擎抓取到。
可以试试去百度一下合伙人一天给你8w让你996给你百度账号或者美团帐号每个月在那一天都给你账号每个月给你买那一天才8w有人愿意??这个你应该能完成第一个月收入目标
github上有现成的js库
请参考微软的collections。可以获取所有使用谷歌数据库的地区和文件名列表。
“搜索相关数据”
记得让我算算?
连搜索相关数据都是挑几个热门网站来爬爬问题还是不大
数据采集和采集是两个技术活,你得熟悉数据采集是怎么做的,比如涉及那些特征,缺陷在哪?而网站数据抓取一般都是有现成的软件来做的,
json格式,设置日志、断点续传等处理,可以收入到数据库, 查看全部
网页抓取数据百度百科(数据库看前端的效率如何了?-八维教育)
网页抓取数据百度百科:apivarysearch搜索相关信息将搜索的结果数据存放到数据库中设置出口日志不抓取数据传至ftp服务器分析数据库大致如此,
其实看前端的效率如何了,像我这样的是没法处理的,有可能每次从数据库取都要半天。
api,程序员解决这个问题。
是用json参数吧?或者可以试试用cookie,
实现一个实时爬取站点内容的api
看看,
站长园出的《网页数据采集技术》,里面有现成的网页,按照指引和说明,可以通过搜索引擎抓取到。
可以试试去百度一下合伙人一天给你8w让你996给你百度账号或者美团帐号每个月在那一天都给你账号每个月给你买那一天才8w有人愿意??这个你应该能完成第一个月收入目标
github上有现成的js库
请参考微软的collections。可以获取所有使用谷歌数据库的地区和文件名列表。
“搜索相关数据”
记得让我算算?
连搜索相关数据都是挑几个热门网站来爬爬问题还是不大
数据采集和采集是两个技术活,你得熟悉数据采集是怎么做的,比如涉及那些特征,缺陷在哪?而网站数据抓取一般都是有现成的软件来做的,
json格式,设置日志、断点续传等处理,可以收入到数据库,
网页抓取数据百度百科(网上一个教程写了一个简单的爬虫程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-27 16:01
最近学了一些python基础,为了练手,跟着网上的教程写了一个简单的爬虫程序。python上手还是很容易的,整个过程很顺利,几乎成功了。
1.爬虫架构和工作流程
一个爬虫程序可以分为四个基本模块,通用调度器、URL管理器、网页下载器和网页解析器。
整体调度部分负责启动、停止和监控程序的运行进度。
URL管理器负责管理已爬取的URL和未爬取的URL,它将未爬取的网页URL发送给网页下载器,并从未爬取的URL列表中删除这些URL。
网页下载器负责下载网页内容,将其转换成字符串形式(在本程序中)并发送给网页解析器。
网页解析器负责从抓取的网页内容中提取有价值的数据。该程序中有价值的数据是网页中的URL以及条目名称和条目介绍。
2.各个模块的实现
2.1 URL管理器的实现
网页 URL 可以存储在内存中(以 set() 的形式)、MySQL 数据库和 redis 缓存数据库(对于大型项目)。本项目的 URL 以 set() 的形式存储在内存中。
代码:
class UrlManager(object):
def __init__(self):
#初始化两个url集合
self.new_urls=set()#存放未爬取过的url
self.old_urls=set()#存放已爬取过的url
def add_new_url(self,url):#单个添加
if url is None:
return #如果是空的则不进行操作
if url not in self.new_urls and url not in self.old_urls:#全新的url
self.new_urls.add(url)
def has_new_url(self):#判断是否有未爬取的url
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()#从未怕去的url列表获取一个并移除
self.old_urls.add(new_url)
return new_url
def add_new_urls(self,urls):#批量添加
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
2.2 网页下载器的实现
下载网页的三种方式
1.下载最简单的网页(无需登录验证,无需加密...)
response = urllib.request.urlopen(url, data=None, timeout)
Referer:可以用来防止盗链。如果REFER信息来自其他网站,则禁止访问所需资源
Connection:表示连接状态,记录Session的状态。
request.add_header('user_agent', 'Mozilla/5.0') 将程序伪装成 Firefox
3.处理一些特殊情况 查看全部
网页抓取数据百度百科(网上一个教程写了一个简单的爬虫程序的程序)
最近学了一些python基础,为了练手,跟着网上的教程写了一个简单的爬虫程序。python上手还是很容易的,整个过程很顺利,几乎成功了。
1.爬虫架构和工作流程
一个爬虫程序可以分为四个基本模块,通用调度器、URL管理器、网页下载器和网页解析器。
整体调度部分负责启动、停止和监控程序的运行进度。
URL管理器负责管理已爬取的URL和未爬取的URL,它将未爬取的网页URL发送给网页下载器,并从未爬取的URL列表中删除这些URL。
网页下载器负责下载网页内容,将其转换成字符串形式(在本程序中)并发送给网页解析器。
网页解析器负责从抓取的网页内容中提取有价值的数据。该程序中有价值的数据是网页中的URL以及条目名称和条目介绍。
2.各个模块的实现
2.1 URL管理器的实现
网页 URL 可以存储在内存中(以 set() 的形式)、MySQL 数据库和 redis 缓存数据库(对于大型项目)。本项目的 URL 以 set() 的形式存储在内存中。
代码:
class UrlManager(object):
def __init__(self):
#初始化两个url集合
self.new_urls=set()#存放未爬取过的url
self.old_urls=set()#存放已爬取过的url
def add_new_url(self,url):#单个添加
if url is None:
return #如果是空的则不进行操作
if url not in self.new_urls and url not in self.old_urls:#全新的url
self.new_urls.add(url)
def has_new_url(self):#判断是否有未爬取的url
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()#从未怕去的url列表获取一个并移除
self.old_urls.add(new_url)
return new_url
def add_new_urls(self,urls):#批量添加
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
2.2 网页下载器的实现
下载网页的三种方式
1.下载最简单的网页(无需登录验证,无需加密...)
response = urllib.request.urlopen(url, data=None, timeout)
Referer:可以用来防止盗链。如果REFER信息来自其他网站,则禁止访问所需资源
Connection:表示连接状态,记录Session的状态。
request.add_header('user_agent', 'Mozilla/5.0') 将程序伪装成 Firefox
3.处理一些特殊情况

