
网站内容采集器
网站内容采集器(批量采集数据用采集器还是爬虫代码好?二者有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-14 08:10
由于现在数据量很大,人工采集根本没有效率。因此,面对海量的网络数据,大家使用各种工具采集。目前批处理采集数据的方法如下:
1.采集器
采集器是一款下载安装后即可使用的软件,可以批量处理采集一定量的网页数据。具有采集、排版、存储等功能。
2.爬虫代码
通过Python、JAVA等编程语言编写网络爬虫实现数据采集,需要获取网页、分析网页、提取网页数据、输入数据并存储。
那么对于数据或爬虫代码使用 采集器 更好吗?两者有什么区别,优缺点是什么?
1.费用
稍微好用的采集器基本都是收费的,免费的采集无效,或者部分功能需要付费。爬虫代码是自己写的,没有成本。
2.操作难度
采集器它是一个软件,你需要学习如何操作它,非常简单。采集很难用爬虫,因为前提是你必须懂一门编程语言才能写代码。你说是软件好学,还是语言好学?
3.限制问题
采集器直接采集即可,功能设置不可更改。对于 IP 限制,某些 采集器 将设置代理。如果没有代理,则需要与代理配合。
在编写爬虫时,还应该考虑 网站 的限制。除了IP限制,还有请求头、cookies、异步加载等,这些都是根据不同的网站反爬虫添加不同的响应方式。可以使用的爬虫代码有点复杂,需要考虑的问题很多。
4.采集内容格式
一般采集器只能采集一些简单的网页,而且存储格式只有html和txt,稍微复杂的页面不能顺利下采集。爬虫代码可以根据需要编写,获取数据,并以需要的格式存储,范围很广。
5.采集速度
采集器的采集的速度是可以设置的,但是设置后批量获取数据的时间间隔是一样的,很容易被网站发现,从而限制你的 采集。爬虫代码采集可以设置随机时间间隔采集,安全性高。
采集数据使用采集器还是爬虫代码更好?从上面的分析可以看出,使用采集器会简单很多。虽然采集的范围和安全性不是很好,但是采集量比较少的人也可以使用。使用爬虫代码来采集数据很难,但是对于学过编程语言的人来说并不难。主要是使用工具来突破限制,比如使用IP更改工具来突破IP限制问题。爬虫代码的应用范围很广,具备应对各方面反爬的技巧,可以通过比较严格的反爬机制获取网站信息。
数据采集器
互联网 查看全部
网站内容采集器(批量采集数据用采集器还是爬虫代码好?二者有什么区别)
由于现在数据量很大,人工采集根本没有效率。因此,面对海量的网络数据,大家使用各种工具采集。目前批处理采集数据的方法如下:
1.采集器
采集器是一款下载安装后即可使用的软件,可以批量处理采集一定量的网页数据。具有采集、排版、存储等功能。
2.爬虫代码
通过Python、JAVA等编程语言编写网络爬虫实现数据采集,需要获取网页、分析网页、提取网页数据、输入数据并存储。
那么对于数据或爬虫代码使用 采集器 更好吗?两者有什么区别,优缺点是什么?
1.费用
稍微好用的采集器基本都是收费的,免费的采集无效,或者部分功能需要付费。爬虫代码是自己写的,没有成本。
2.操作难度
采集器它是一个软件,你需要学习如何操作它,非常简单。采集很难用爬虫,因为前提是你必须懂一门编程语言才能写代码。你说是软件好学,还是语言好学?
3.限制问题
采集器直接采集即可,功能设置不可更改。对于 IP 限制,某些 采集器 将设置代理。如果没有代理,则需要与代理配合。
在编写爬虫时,还应该考虑 网站 的限制。除了IP限制,还有请求头、cookies、异步加载等,这些都是根据不同的网站反爬虫添加不同的响应方式。可以使用的爬虫代码有点复杂,需要考虑的问题很多。
4.采集内容格式
一般采集器只能采集一些简单的网页,而且存储格式只有html和txt,稍微复杂的页面不能顺利下采集。爬虫代码可以根据需要编写,获取数据,并以需要的格式存储,范围很广。
5.采集速度
采集器的采集的速度是可以设置的,但是设置后批量获取数据的时间间隔是一样的,很容易被网站发现,从而限制你的 采集。爬虫代码采集可以设置随机时间间隔采集,安全性高。
采集数据使用采集器还是爬虫代码更好?从上面的分析可以看出,使用采集器会简单很多。虽然采集的范围和安全性不是很好,但是采集量比较少的人也可以使用。使用爬虫代码来采集数据很难,但是对于学过编程语言的人来说并不难。主要是使用工具来突破限制,比如使用IP更改工具来突破IP限制问题。爬虫代码的应用范围很广,具备应对各方面反爬的技巧,可以通过比较严格的反爬机制获取网站信息。
数据采集器
互联网
网站内容采集器(使用教程中有采集器7.6破解版,轻松获取目标网站所有内容的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-13 17:23
为了方便从事网站服务等行业的人的工作,小编为大家带来了优采云采集器7.6破解版,这是一款软件可以轻松获取目标网站的所有内容。它具有功能强大、操作简单、配置快捷高效等诸多特点,受到越来越多用户的青睐。与一般的采集器相比,本软件采集速度快,内容丰富,采集操作非常准确,是目前使用最广泛的网络资源采集软件。另外,使用本软件进行数据采集时,不仅仅是采集,分为两步,一是进行数据采集,二是进行数据采集直接发布给自己在 网站 上 网站,用户无需再次编辑内容,即可发布到网站。而且具体操作也不难。为了让大家清楚的了解这款软件的具体操作流程,小编为大家带来了一个教程。教程中有详细的操作步骤,你可以按照教程一步一步完成。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!
软件功能
1、几乎任何网页都可以采集
不管是什么语言,不管是什么编码
2、与复制/粘贴一样准确
采集/发布就像复制粘贴一样准确,用户想要的就是精华,怎么可能有遗漏
3、比正常速度快7倍采集器
优采云采集器采用顶层系统配置,反复优化性能,让采集快到飞起来
4、网页的同义词采集
凭借十年的经验,他已成为行业领先品牌。当您想到网站 采集 时,您会想到 优采云采集器
软件功能
1、无限多页采集,可实现无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSS地址采集功能
5、列表页面分页采集获取函数
6、列表页附加参数获取功能
7、列表页面和标签XPath可视化提取功能
8、标签纯正则替换函数 查看全部
网站内容采集器(使用教程中有采集器7.6破解版,轻松获取目标网站所有内容的软件)
为了方便从事网站服务等行业的人的工作,小编为大家带来了优采云采集器7.6破解版,这是一款软件可以轻松获取目标网站的所有内容。它具有功能强大、操作简单、配置快捷高效等诸多特点,受到越来越多用户的青睐。与一般的采集器相比,本软件采集速度快,内容丰富,采集操作非常准确,是目前使用最广泛的网络资源采集软件。另外,使用本软件进行数据采集时,不仅仅是采集,分为两步,一是进行数据采集,二是进行数据采集直接发布给自己在 网站 上 网站,用户无需再次编辑内容,即可发布到网站。而且具体操作也不难。为了让大家清楚的了解这款软件的具体操作流程,小编为大家带来了一个教程。教程中有详细的操作步骤,你可以按照教程一步一步完成。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!

软件功能
1、几乎任何网页都可以采集
不管是什么语言,不管是什么编码
2、与复制/粘贴一样准确
采集/发布就像复制粘贴一样准确,用户想要的就是精华,怎么可能有遗漏
3、比正常速度快7倍采集器
优采云采集器采用顶层系统配置,反复优化性能,让采集快到飞起来
4、网页的同义词采集
凭借十年的经验,他已成为行业领先品牌。当您想到网站 采集 时,您会想到 优采云采集器
软件功能
1、无限多页采集,可实现无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSS地址采集功能
5、列表页面分页采集获取函数
6、列表页附加参数获取功能
7、列表页面和标签XPath可视化提取功能
8、标签纯正则替换函数
网站内容采集器(做一个网站还是需要很多东西要掌握的源码采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-10 14:20
做一个 网站 仍然需要很多东西来掌握。我暂时假设您是一个非技术门户网站源代码采集,并列出网站 需要什么。
需求分析。分析一下你的网站传送门网站源码采集的定位,你的网站到底想呈现什么,什么类型?电子商务?内容翔实?社交联系?产品原型。完成需求分析后,开始为您的 网站 原型设计。可以参考同类型网站。用户界面设计。网站中的一些图片,色调需要由专业的UI设计师设计。开发工作。这包括前端页面开发和后端开发。您可以找到一个外包团队为您完成这项工作。他们将根据您的网站 需求评估开发时间和人力,并在最后给您报价。当然,UI部分的工作也可以一起外包给他们。开发完成后会上线部署。这次你需要一个服务器。当然,现在你根本不需要买机器,你可以使用一些国内云厂商的机器,比如阿里云。价格根据您选择的配置而有所不同。比如一台2核的4G机器一个月要200左右。域名申请备案。如果你的网站需要被外部访问,你需要一个用户容易记住的域名。域名现在很便宜,一年几十块钱。域名申请成功后会备案,然后可以映射到你的服务器,用户就可以访问你的网站了。后期维护操作。维护工作可以外包给开发团队。维护费可能需要按一定期限支付,主要包括系统bug和新需求开发。运营工作需要你去做。就是定期更新你的网站内容,自己推广。构建 网站 的工作就是这样。不知道怎么咨询我。
如何采集投标网站数据?
采集portal网站源码采集可以使用ForeSpider数据采集系统,只是采集竞价网的新教程,希望对你有帮助你 :
l 采集网站
【场景描述】采集招标网所有招标数据入口网站源码采集。
【来源介绍网站】
是招标采购领域的招标信息和招标服务平台。为各级政府采购门户网站源码采集、招标代理机构、招标公司、供应商、采购业主提供强大的专业服务。招标采购信息查询及相关招标服务。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址/view/forespider/view/download.html
【入口网址】/channel-userggcharge-1.html
【采集内容】
采集Tender Online 上的所有招标数据。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
网站内容采集器(做一个网站还是需要很多东西要掌握的源码采集)
做一个 网站 仍然需要很多东西来掌握。我暂时假设您是一个非技术门户网站源代码采集,并列出网站 需要什么。
需求分析。分析一下你的网站传送门网站源码采集的定位,你的网站到底想呈现什么,什么类型?电子商务?内容翔实?社交联系?产品原型。完成需求分析后,开始为您的 网站 原型设计。可以参考同类型网站。用户界面设计。网站中的一些图片,色调需要由专业的UI设计师设计。开发工作。这包括前端页面开发和后端开发。您可以找到一个外包团队为您完成这项工作。他们将根据您的网站 需求评估开发时间和人力,并在最后给您报价。当然,UI部分的工作也可以一起外包给他们。开发完成后会上线部署。这次你需要一个服务器。当然,现在你根本不需要买机器,你可以使用一些国内云厂商的机器,比如阿里云。价格根据您选择的配置而有所不同。比如一台2核的4G机器一个月要200左右。域名申请备案。如果你的网站需要被外部访问,你需要一个用户容易记住的域名。域名现在很便宜,一年几十块钱。域名申请成功后会备案,然后可以映射到你的服务器,用户就可以访问你的网站了。后期维护操作。维护工作可以外包给开发团队。维护费可能需要按一定期限支付,主要包括系统bug和新需求开发。运营工作需要你去做。就是定期更新你的网站内容,自己推广。构建 网站 的工作就是这样。不知道怎么咨询我。
如何采集投标网站数据?
采集portal网站源码采集可以使用ForeSpider数据采集系统,只是采集竞价网的新教程,希望对你有帮助你 :
l 采集网站
【场景描述】采集招标网所有招标数据入口网站源码采集。
【来源介绍网站】
是招标采购领域的招标信息和招标服务平台。为各级政府采购门户网站源码采集、招标代理机构、招标公司、供应商、采购业主提供强大的专业服务。招标采购信息查询及相关招标服务。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址/view/forespider/view/download.html
【入口网址】/channel-userggcharge-1.html
【采集内容】
采集Tender Online 上的所有招标数据。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
网站内容采集器( 网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 07:15
网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载
)
论坛采集专家免费版是一款专业的网络数据采集和信息挖掘处理软件,适合各类有采集数据挖掘需求的群体。论坛采集专家免费版可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,编辑过滤,自动增量更新发布到网站后台,各种文件或其他数据库系统。
相关软件下载地址
优采云采集器
查看
镀铬清洁工具
查看
12306 分流抢票
查看
是专门针对楼层类数据和自动增量更新需求而开发的软件。它定义了一套发布规则,并根据规则开发插件接口,从而实现论坛、知乎、连载等自动更新功能。
它具有以下特点:
1.支持采集标题、内容、用户名、注册时间、签名、头像、附件等支持添加采集字段
2.支持自动回复,方便回复帖子和隐藏附件。支持帖子回复
3.支持回复部分的增量采集。可以采集新的回复和发布。可以处理论坛、贴吧、串口更新问题
4.智能生成采集规则。系统内置多个常用论坛的自动识别规则,可自动生成采集规则
5.支持网站自动登录,支持目前主流的Discuz、PHPWind论坛,暂时不支持验证码登录
6.界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
7.支持下载文件,支持翻译、分词、代理等功能优采云采集器
8.支持插件开发,接口灵活,可以采集更复杂的网站数据和数据处理
9.支持通过搜索关键词采集post URLs,可以批量设置关键词查询类采集
查看全部
网站内容采集器(
网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载
)

论坛采集专家免费版是一款专业的网络数据采集和信息挖掘处理软件,适合各类有采集数据挖掘需求的群体。论坛采集专家免费版可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,编辑过滤,自动增量更新发布到网站后台,各种文件或其他数据库系统。
相关软件下载地址
优采云采集器
查看
镀铬清洁工具
查看
12306 分流抢票
查看
是专门针对楼层类数据和自动增量更新需求而开发的软件。它定义了一套发布规则,并根据规则开发插件接口,从而实现论坛、知乎、连载等自动更新功能。
它具有以下特点:
1.支持采集标题、内容、用户名、注册时间、签名、头像、附件等支持添加采集字段
2.支持自动回复,方便回复帖子和隐藏附件。支持帖子回复
3.支持回复部分的增量采集。可以采集新的回复和发布。可以处理论坛、贴吧、串口更新问题
4.智能生成采集规则。系统内置多个常用论坛的自动识别规则,可自动生成采集规则
5.支持网站自动登录,支持目前主流的Discuz、PHPWind论坛,暂时不支持验证码登录
6.界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
7.支持下载文件,支持翻译、分词、代理等功能优采云采集器
8.支持插件开发,接口灵活,可以采集更复杂的网站数据和数据处理
9.支持通过搜索关键词采集post URLs,可以批量设置关键词查询类采集
网站内容采集器( 优采云采集介绍(KeyDatas)数据采集平台采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-06 20:20
优采云采集介绍(KeyDatas)数据采集平台采集)
一、优采云采集简介
优采云(KeyDatas)数据采集平台是提供网站内容抓取、数据处理和发布,包括各种图片、文字信息等。优采云网页采集器 化繁为简,力求简单化、智能化,让广大站长和需要网页数据的用户更简单快捷地获得想要的数据,可以灵活地进行处理和发布。
简化复杂性,让数据触手可及,这是我们的使命!
“简单可能比复杂更难:你必须努力让你的想法变得清晰,让它变得简单。但最终还是值得的,因为一旦到达那里,就可以移山。”
“简单比复杂更难:你必须竭尽全力让它变得简单。但最终它是值得的,因为一旦你做到了,你就可以创造奇迹。” - 史蒂夫乔布斯
二、功能介绍
优采云采集平台让您轻松获取海量网页数据。任何人都可以得到想要的网页数据,只需要在浏览器的可视化界面上用鼠标点击一下,不需要懂Html代码!
不仅是采集数据,优采云还可以帮你轻松将采集收到的数据发布到WordPress、织梦DEDE、Empire、Zblog等cms 网站 和自定义 HTTP 接口。您也可以导出到 Excel...
三、利用优势
1.采集无需安装任何客户端,点击在线可视化;
2.集成智能提取引擎(国内独家),自动识别数据和规则,包括:翻页、标题、作者、发布日期、内容等,你甚至可以不用修改就开始采集;
3.图片下载支持存储到:阿里云OSS、七牛云、腾讯云;(支持水印、压缩等)
4.全自动:定时采集+自动释放;
5.提供强大的SEO工具,包括:在正文中插入动态段落(强烈推荐)、在正文中插入段落和自动标题关键词、自动内部链接、同义词替换、简繁转换、翻译, 等等。;
6.免费、自动接入多个IP代理服务商等。
7.与Z-Blog系统无缝集成,点击几下即可发布到Z-Blog系统。
8.支持微信公众号文章采集(包括采集公众号历史文章),今日头条新闻采集,进入微信公众号即可ID或标题号或关键词可以是采集;
四、优采云采集有收费吗?
优采云采集它非常容易使用而且是免费的。 查看全部
网站内容采集器(
优采云采集介绍(KeyDatas)数据采集平台采集)

一、优采云采集简介
优采云(KeyDatas)数据采集平台是提供网站内容抓取、数据处理和发布,包括各种图片、文字信息等。优采云网页采集器 化繁为简,力求简单化、智能化,让广大站长和需要网页数据的用户更简单快捷地获得想要的数据,可以灵活地进行处理和发布。
简化复杂性,让数据触手可及,这是我们的使命!
“简单可能比复杂更难:你必须努力让你的想法变得清晰,让它变得简单。但最终还是值得的,因为一旦到达那里,就可以移山。”
“简单比复杂更难:你必须竭尽全力让它变得简单。但最终它是值得的,因为一旦你做到了,你就可以创造奇迹。” - 史蒂夫乔布斯
二、功能介绍
优采云采集平台让您轻松获取海量网页数据。任何人都可以得到想要的网页数据,只需要在浏览器的可视化界面上用鼠标点击一下,不需要懂Html代码!
不仅是采集数据,优采云还可以帮你轻松将采集收到的数据发布到WordPress、织梦DEDE、Empire、Zblog等cms 网站 和自定义 HTTP 接口。您也可以导出到 Excel...
三、利用优势
1.采集无需安装任何客户端,点击在线可视化;
2.集成智能提取引擎(国内独家),自动识别数据和规则,包括:翻页、标题、作者、发布日期、内容等,你甚至可以不用修改就开始采集;
3.图片下载支持存储到:阿里云OSS、七牛云、腾讯云;(支持水印、压缩等)
4.全自动:定时采集+自动释放;
5.提供强大的SEO工具,包括:在正文中插入动态段落(强烈推荐)、在正文中插入段落和自动标题关键词、自动内部链接、同义词替换、简繁转换、翻译, 等等。;
6.免费、自动接入多个IP代理服务商等。
7.与Z-Blog系统无缝集成,点击几下即可发布到Z-Blog系统。
8.支持微信公众号文章采集(包括采集公众号历史文章),今日头条新闻采集,进入微信公众号即可ID或标题号或关键词可以是采集;
四、优采云采集有收费吗?
优采云采集它非常容易使用而且是免费的。
网站内容采集器(高级使用技巧之网站内容采集器规则修正)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-04 04:17
网站内容采集器工具包MetaSeeker从V4.0.0版本开始增加了自定义XPath规则的功能,完全由原程序自行生成网站内容采集规则得到补充和增强。但是,如果自定义XPath表达式使用字符串处理函数采集字面量内容,就会遇到bug。
场景
<p>比如使用XPath函数substring-after()等,生成的网站content采集指令文件是正常的,也就是说网络爬虫和网站内容采集器DataScraper运行正常,用户可以准确海量采集网站内容。但是MetaStudio生成的信息结构描述文件不正确,用户输入的自定义XPath表达式被误认为是DOM节点定位表达式。后果是网站content采集规则生成器MetaStudio无法再次将之前生成的信息结构加载到工作台中进行修改和编辑,需要采集 查看全部
网站内容采集器(高级使用技巧之网站内容采集器规则修正)
网站内容采集器工具包MetaSeeker从V4.0.0版本开始增加了自定义XPath规则的功能,完全由原程序自行生成网站内容采集规则得到补充和增强。但是,如果自定义XPath表达式使用字符串处理函数采集字面量内容,就会遇到bug。
场景
<p>比如使用XPath函数substring-after()等,生成的网站content采集指令文件是正常的,也就是说网络爬虫和网站内容采集器DataScraper运行正常,用户可以准确海量采集网站内容。但是MetaStudio生成的信息结构描述文件不正确,用户输入的自定义XPath表达式被误认为是DOM节点定位表达式。后果是网站content采集规则生成器MetaStudio无法再次将之前生成的信息结构加载到工作台中进行修改和编辑,需要采集
网站内容采集器(一门强大的开发语言,正则表达式方法捕获 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-01-28 09:23
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上查了很多资料,却发现java中广泛使用的使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何读取网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
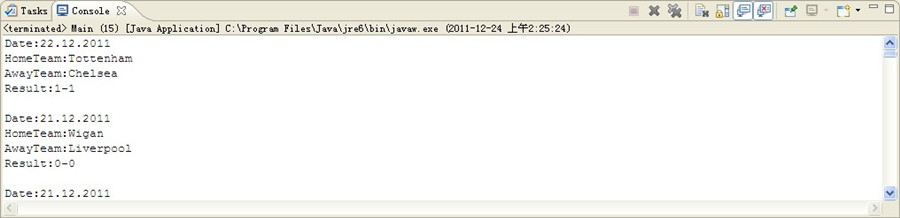
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
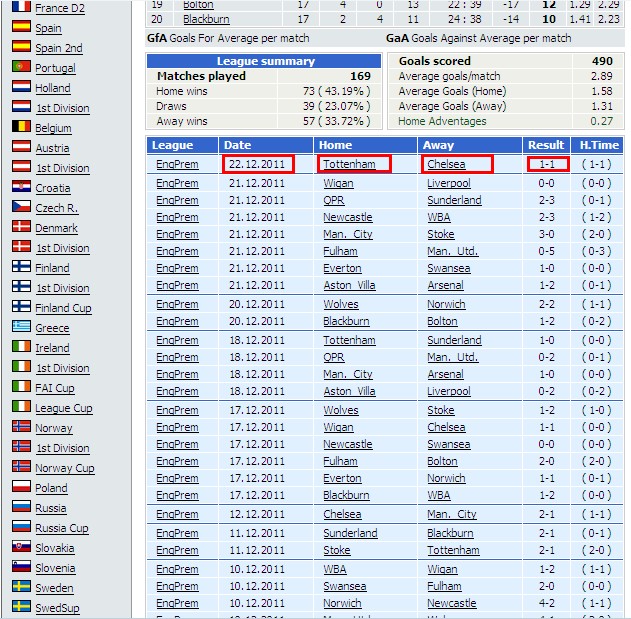
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
网站内容采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上查了很多资料,却发现java中广泛使用的使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何读取网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(下面是部分截图)。

至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。

我们来看看它内部的html代码结构和我们需要的数据。

其对应的页面数据

这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
网站内容采集器(作为全球运用最广泛的语言,Java,正则表达式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-27 23:10
介绍:
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性而受到广大应用程序开发者的青睐。开发语言,正则表达式在其中的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端-end development),正则表达式是必须的。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序,因为是第一次做关于java的html页面数据采集,一定要be我在网上找了很多资料,但是发现在使用正则化做html中广泛使用的java采集(中文)文章很少,他们只是在说java正则这个概念在实际网页中并没有真正用到html采集,所以例子教程很少(虽然java有自己的Html Parser,而且很强大),但是我个人认为作为一个深入rooted 正则表达式,应该有相关的java示例教程,而且应该很多且完整。所以在完成了html数据采集程序的java版之后,
关于组规律性:
说到正则表达式如何帮助java执行html页面采集,这里简单提一下正则表达式中的group方法
组法
让我们看看输出:
打印出 url 链接:打印出标题:SoFlash 打印出日期:12.22.2011
group 方法捕获的数据数量:3
没学过正则的可以看看这个正则表达式的元字符匹配
好了,group的方法已经介绍完了,我们简单用group采集a football网站页面的数据
首先我们阅读整个html页面,打印出代码如下
抓取整个html页面数据
打印出来的结果就是整个html页面的源码(部分截图如下)
至此,数据已经成功采集下来了,当然我们要的不是整个html源码,我们需要的是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012赛季英超球队战绩页面
右击页面,点击“查看源文件”如图
我们来看看它内部的html代码结构和我们需要的数据
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来匹配我们需要的数据
在这里你需要使用 3 个常客,包括日期、2 支球队(主队和客队)和比赛结果如下
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则 String regularTwoTeam = ">[^]*" ; //队伍是正则 String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以使用正则得到我们想要的数据了
首先我们写一个GroupMethod类来存储regularGroup()方法
GroupMethod 类
然后编写主要功能代码
主要功能 - 采集我们需要的数据
让我们看看输出(部分截图 - 初始阶段)
比较html上的数据(部分截图-初始阶段)
输出结果(部分截图 - 结束阶段)
比较html上的数据(部分截图-结束阶段)
嗯,这样的html数据采集就完成了:)
当然,这只是一页的内容。如果您有兴趣抓取更多页面内容,可以在链接后分析联盟名称。例如,league=EngPrem 可以通过更改联赛名称来获取所有链接。
你可以写一个接口,把所有球队的名字放到联赛的比赛数据中。当然,还有更智能的方法。您可以从页面编写方法。
获取所有球队的名称,然后将它们附加到“;league”链接以完成链接以阅读每个联赛比赛页面的内容 查看全部
网站内容采集器(作为全球运用最广泛的语言,Java,正则表达式)
介绍:
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性而受到广大应用程序开发者的青睐。开发语言,正则表达式在其中的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端-end development),正则表达式是必须的。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序,因为是第一次做关于java的html页面数据采集,一定要be我在网上找了很多资料,但是发现在使用正则化做html中广泛使用的java采集(中文)文章很少,他们只是在说java正则这个概念在实际网页中并没有真正用到html采集,所以例子教程很少(虽然java有自己的Html Parser,而且很强大),但是我个人认为作为一个深入rooted 正则表达式,应该有相关的java示例教程,而且应该很多且完整。所以在完成了html数据采集程序的java版之后,
关于组规律性:
说到正则表达式如何帮助java执行html页面采集,这里简单提一下正则表达式中的group方法

组法
让我们看看输出:
打印出 url 链接:打印出标题:SoFlash 打印出日期:12.22.2011
group 方法捕获的数据数量:3
没学过正则的可以看看这个正则表达式的元字符匹配
好了,group的方法已经介绍完了,我们简单用group采集a football网站页面的数据
首先我们阅读整个html页面,打印出代码如下
抓取整个html页面数据
打印出来的结果就是整个html页面的源码(部分截图如下)
至此,数据已经成功采集下来了,当然我们要的不是整个html源码,我们需要的是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012赛季英超球队战绩页面
右击页面,点击“查看源文件”如图
我们来看看它内部的html代码结构和我们需要的数据
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来匹配我们需要的数据
在这里你需要使用 3 个常客,包括日期、2 支球队(主队和客队)和比赛结果如下
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则 String regularTwoTeam = ">[^]*" ; //队伍是正则 String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以使用正则得到我们想要的数据了
首先我们写一个GroupMethod类来存储regularGroup()方法
GroupMethod 类
然后编写主要功能代码
主要功能 - 采集我们需要的数据
让我们看看输出(部分截图 - 初始阶段)
比较html上的数据(部分截图-初始阶段)
输出结果(部分截图 - 结束阶段)

比较html上的数据(部分截图-结束阶段)
嗯,这样的html数据采集就完成了:)
当然,这只是一页的内容。如果您有兴趣抓取更多页面内容,可以在链接后分析联盟名称。例如,league=EngPrem 可以通过更改联赛名称来获取所有链接。
你可以写一个接口,把所有球队的名字放到联赛的比赛数据中。当然,还有更智能的方法。您可以从页面编写方法。
获取所有球队的名称,然后将它们附加到“;league”链接以完成链接以阅读每个联赛比赛页面的内容
网站内容采集器( seo网站采集大量内容是怎么回事?网站频繁改版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-27 19:20
seo网站采集大量内容是怎么回事?网站频繁改版)
现在做seo推广的人越来越多,但是越来越多的人开始觉得seo已经走到了尽头。毕竟随着百度算法的频繁更新,在排名问题上能人为控制的因素越来越少。当然,站长朋友也需要了解一些seo推广的常识,以免在网站推广过程中走弯路。
1.网站采集内容很多。
新站刚上线的时候,内容很少或者几乎没有,所以用户进来的时候是看不到内容的,自然会损害用户体验——所以很多采集内容和网上传播是很多新手站长朋友的习惯问题。但是,重复和转载n次的内容不太可能流行,尤其是新站点。如果有大量的采集内容,可能会被判断为垃圾站点,然后被k。
2.大量外链发布。
百度现在的算法进步很大,不像过去,只需要发布一堆外链,就可以获得不错的排名。如果新站采用大量外部链接,可能会导致百度认为是作弊,从而延长网站的审核期限。毕竟作为一个新的网站,一开始可能不会有太多的网站通过外链给你投票,这点百度也不清楚,所以外链的建设应该被照顾。
3.网站 经常修改。
一般网站有流量,不建议频繁修改版本。一是不利于用户体验。第二,不保证有朝一日百度会来抢你的网站而不自知。当百度认为您是一个新站点时,它会对您的站点进行重新审核。
4.经常更改网站 标题。
原因同上。频繁更改网站的标题会导致百度重新审核你的网站,尤其是新站点也需要关注的时候。目标关键词确定后,标题不宜频繁更改。
5.关键词密度太高。
在确定了主关键词之后,很多站长朋友就迫不及待的在文章、内容、图片、导航等各个地方出现关键词,希望能得到一个不错的排名通过这个词快...其实这样堆叠关键词的做法对seo推广是非常不利的。
6.链接太多。
交换友情链接时,除了看对方的网站权重、收录、排名等,还要注意对方网站是否被被搜索引擎惩罚:降级、被k等网站的所有好友链都会对你的网站产生恶毒的影响。当然,如果各方面都不错,还应该检查对方网站所在的宿主是否有其他网站惩罚。 查看全部
网站内容采集器(
seo网站采集大量内容是怎么回事?网站频繁改版)

现在做seo推广的人越来越多,但是越来越多的人开始觉得seo已经走到了尽头。毕竟随着百度算法的频繁更新,在排名问题上能人为控制的因素越来越少。当然,站长朋友也需要了解一些seo推广的常识,以免在网站推广过程中走弯路。
1.网站采集内容很多。
新站刚上线的时候,内容很少或者几乎没有,所以用户进来的时候是看不到内容的,自然会损害用户体验——所以很多采集内容和网上传播是很多新手站长朋友的习惯问题。但是,重复和转载n次的内容不太可能流行,尤其是新站点。如果有大量的采集内容,可能会被判断为垃圾站点,然后被k。
2.大量外链发布。
百度现在的算法进步很大,不像过去,只需要发布一堆外链,就可以获得不错的排名。如果新站采用大量外部链接,可能会导致百度认为是作弊,从而延长网站的审核期限。毕竟作为一个新的网站,一开始可能不会有太多的网站通过外链给你投票,这点百度也不清楚,所以外链的建设应该被照顾。
3.网站 经常修改。
一般网站有流量,不建议频繁修改版本。一是不利于用户体验。第二,不保证有朝一日百度会来抢你的网站而不自知。当百度认为您是一个新站点时,它会对您的站点进行重新审核。
4.经常更改网站 标题。
原因同上。频繁更改网站的标题会导致百度重新审核你的网站,尤其是新站点也需要关注的时候。目标关键词确定后,标题不宜频繁更改。
5.关键词密度太高。
在确定了主关键词之后,很多站长朋友就迫不及待的在文章、内容、图片、导航等各个地方出现关键词,希望能得到一个不错的排名通过这个词快...其实这样堆叠关键词的做法对seo推广是非常不利的。
6.链接太多。
交换友情链接时,除了看对方的网站权重、收录、排名等,还要注意对方网站是否被被搜索引擎惩罚:降级、被k等网站的所有好友链都会对你的网站产生恶毒的影响。当然,如果各方面都不错,还应该检查对方网站所在的宿主是否有其他网站惩罚。
网站内容采集器( CX采集器可实现伪原创功能的采集规则交流群)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-27 19:18
CX采集器可实现伪原创功能的采集规则交流群)
CX采集器,使用强大的 原创 内核。不断优化增强,是目前DZ最完善的WEB版采集器,支持同义词替换,支持批量采集,支持自动存储,支持定时任务,可实现全自动采集.
网站的发展离不开它的内容。为了挖掘独特的信息,降低人工成本,采集器应运而生。当然,好的网站也离不开打开原创的内容。 CX采集器可以实现伪原创的功能。
整体功能:
1、可以采集大部分可以作为访问者查看的网页,包括门户、论坛等
2、可以添加采集规则,自定义你想要的信息采集。
3、支持批量采集,同时支持多个机器人采集.
4、支持单向或双向同义词替换,并集成同义词管理后台。
5、支持后台定时任务采集,为本插件集成定时任务后台。
6、支持自动导入论坛、群组、门户
7、支持学科分类
8、支持图片附件、图片缩略图、图片水印(根据本站背景设置)
9、支持远程附件(根据站点后台设置上传到远程)
10、支持flash地址自动转换为flash-tags,支持论坛格式和门户格式。
采集规则的编写属于傻瓜式。一目了然,一目了然。与其他 采集器 不同,它很耗时。没有好的结果。
我还成立了采集规则交流群,大家可以一起学习讨论。
组号:94787884
如需编写规则或学习编写规则,可直接联系
服务器环境要求:查看方法参考:
1、PHPv5.2.X 或 PHP5.3.X 版本
2、需要 Zend Optimizer v3.3.x(用于 PHP 5.2.x)或 Zend Guard Loader(用于 PHP v5.@ >3)一般空间会预装。
3、可以上网。不需要打开allow_url_fopen或者curl,但是免费版使用的是免费版的采集核心。免费版用户最好打开curl,默认使用curl组件。
请以二进制方式上传。
如果版本号发生变化,覆盖后需要点击插件列表中的升级或更新。 查看全部
网站内容采集器(
CX采集器可实现伪原创功能的采集规则交流群)

CX采集器,使用强大的 原创 内核。不断优化增强,是目前DZ最完善的WEB版采集器,支持同义词替换,支持批量采集,支持自动存储,支持定时任务,可实现全自动采集.
网站的发展离不开它的内容。为了挖掘独特的信息,降低人工成本,采集器应运而生。当然,好的网站也离不开打开原创的内容。 CX采集器可以实现伪原创的功能。
整体功能:
1、可以采集大部分可以作为访问者查看的网页,包括门户、论坛等
2、可以添加采集规则,自定义你想要的信息采集。
3、支持批量采集,同时支持多个机器人采集.
4、支持单向或双向同义词替换,并集成同义词管理后台。
5、支持后台定时任务采集,为本插件集成定时任务后台。
6、支持自动导入论坛、群组、门户
7、支持学科分类
8、支持图片附件、图片缩略图、图片水印(根据本站背景设置)
9、支持远程附件(根据站点后台设置上传到远程)
10、支持flash地址自动转换为flash-tags,支持论坛格式和门户格式。
采集规则的编写属于傻瓜式。一目了然,一目了然。与其他 采集器 不同,它很耗时。没有好的结果。
我还成立了采集规则交流群,大家可以一起学习讨论。
组号:94787884
如需编写规则或学习编写规则,可直接联系
服务器环境要求:查看方法参考:
1、PHPv5.2.X 或 PHP5.3.X 版本
2、需要 Zend Optimizer v3.3.x(用于 PHP 5.2.x)或 Zend Guard Loader(用于 PHP v5.@ >3)一般空间会预装。
3、可以上网。不需要打开allow_url_fopen或者curl,但是免费版使用的是免费版的采集核心。免费版用户最好打开curl,默认使用curl组件。
请以二进制方式上传。
如果版本号发生变化,覆盖后需要点击插件列表中的升级或更新。
网站内容采集器(Google推广:最近有些优化新手有给我提过这样一个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-27 02:12
谷歌推广:最近有优化新手问我这样一个问题,如何避免网站过度优化?如果优化不够,排名效果会差强人意。一旦网站优化过度,就会受到搜索引擎的惩罚。
今天特意整理了网站优化过程中的一些禁忌。
1、网站 的标题
首先,最典型的问题之一就是很多网站标题经常被一些客户剪掉。或者一个无关紧要的关键词,很容易被搜索引擎的算法判断为这个网站作弊,最终导致搜索引擎屏蔽该网站。
注意网站的标题对于关键词的写法,建议一个网页对应一两个关键词,网页的body内容应该是与网页标题的主题高度一致。
另一个问题是 网站 的页面标题不应该经常更改。不稳定的 网站 不会被百度点赞。建站之初,网站的每一个细节都应该考虑在内。一旦确立,就不会轻易改变。
2、网站内容采集
事实上,搜索引擎有一个规则,即喜新厌旧。如果一个网站的内容在网络上重复率很高,那么排名肯定不会好。网站 of 采集 百度会 不过收录之后会慢慢掉线,很少给你改过自新的机会,即使原创@之后天天更新>文章,没用。但这并不代表不能是采集,我们可以对采集中的文章做一些修改,比如替换内容、更改标题等。
3、网站内部链接
很多优化技术人员都知道,网站中有些页面的权重特别高,喜欢在权重高的页面上堆积大量的关键词链接。
<p>不可否认,在高权网站页面上添加焦点关键词链接有助于提升目标关键词的搜索引擎排名,但在高权页面 查看全部
网站内容采集器(Google推广:最近有些优化新手有给我提过这样一个问题)
谷歌推广:最近有优化新手问我这样一个问题,如何避免网站过度优化?如果优化不够,排名效果会差强人意。一旦网站优化过度,就会受到搜索引擎的惩罚。
今天特意整理了网站优化过程中的一些禁忌。
1、网站 的标题
首先,最典型的问题之一就是很多网站标题经常被一些客户剪掉。或者一个无关紧要的关键词,很容易被搜索引擎的算法判断为这个网站作弊,最终导致搜索引擎屏蔽该网站。
注意网站的标题对于关键词的写法,建议一个网页对应一两个关键词,网页的body内容应该是与网页标题的主题高度一致。
另一个问题是 网站 的页面标题不应该经常更改。不稳定的 网站 不会被百度点赞。建站之初,网站的每一个细节都应该考虑在内。一旦确立,就不会轻易改变。
2、网站内容采集
事实上,搜索引擎有一个规则,即喜新厌旧。如果一个网站的内容在网络上重复率很高,那么排名肯定不会好。网站 of 采集 百度会 不过收录之后会慢慢掉线,很少给你改过自新的机会,即使原创@之后天天更新>文章,没用。但这并不代表不能是采集,我们可以对采集中的文章做一些修改,比如替换内容、更改标题等。
3、网站内部链接
很多优化技术人员都知道,网站中有些页面的权重特别高,喜欢在权重高的页面上堆积大量的关键词链接。
<p>不可否认,在高权网站页面上添加焦点关键词链接有助于提升目标关键词的搜索引擎排名,但在高权页面
网站内容采集器( 前嗅大数据2022-01-25抽取热搜列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-26 01:16
前嗅大数据2022-01-25抽取热搜列表)
【从零开始学爬虫】采集微博热搜数据
前端嗅探大数据2022-01-25
热门“前端嗅探大数据”
与大数据巨头一起成长,做一个傲慢的大数据人
l 采集场景
【场景描述】采集微博热搜中的博文数据。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址
l采集网站
【入口网址】
[采集内容]采集微博热搜博文数据,采集字段:发布者、发帖时间、博文、转发数、评论数、点赞数。
【采集效果】如下图:
l采集想法
l配置步骤
1.新建采集任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
网站内容采集器(
前嗅大数据2022-01-25抽取热搜列表)
【从零开始学爬虫】采集微博热搜数据
前端嗅探大数据2022-01-25
热门“前端嗅探大数据”
与大数据巨头一起成长,做一个傲慢的大数据人
l 采集场景
【场景描述】采集微博热搜中的博文数据。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址
l采集网站
【入口网址】
[采集内容]采集微博热搜博文数据,采集字段:发布者、发帖时间、博文、转发数、评论数、点赞数。
【采集效果】如下图:
l采集想法
l配置步骤
1.新建采集任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
网站内容采集器(查看更多写博客基于日志服务的GrowthHacking(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-24 22:01
阿里云>云栖社区>主题图>P>php网站内容采集
推荐活动:
更多优惠>
当前主题:php网站内容采集加入采集
相关话题:
php网站内容采集相关博客查看更多博客
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS、二维码追踪技术)
作者:云磊 4389 浏览评论:02年前
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS追踪技术) 数据质量决定运营分析的质量上面我们介绍了GrowthHacking的整体增长情况架构,其中数据采集是整个数据分析的基础,只有数据才能进行有价值的分析;
阅读全文
日志服务-一站式配置采集Apache访问日志
作者:木子2422 浏览评论:03年前
自引入数据访问向导(Wizard)功能以来,日志服务不断优化访问向导功能,支持采集、存储、分析、离线下发各种数据,降低用户使用门槛使用日志服务。本文介绍了数据访问向导采集Apache日志和索引设置的一站式配置,以及通过默认dashboard和查询分析语句进行实时分析网站
阅读全文
网站采集器简介
作者:航空母舰1221 浏览评论:05年前
常用网络采集器主要分为桌面版和服务器版:桌面版基于windows等平台,使用本地带宽进行数据采集和发布程序,主要以“ 优采云网站采集器" 和 "EditorTools"; 服务器版本使用 PHP 或 ASP 编程,在 Linux 或 Windows 主机上运行,并使用服务器带宽
阅读全文
PHP采集业务信息和采集方法概述(第1部分)
作者:Tech Fatty 1044 浏览评论:04年前
近期,在电商市场上,商户导航层出不穷,采集了大量商户信息。如果您从事电子商务,这些信息仍然有用。我将这些信息用于我最近正在做的一个项目,但你不能把它给别人,所以别人不会给它。所以我必须自己爬。之前写过几个类似的爬虫来爬取网站的一些信息。
阅读全文
网站页面内容优化
作者:技术小牛1003 浏览评论:04年前
一、关键词分析:分析用户检索行为,有效实现搜索引擎营销,包括搜索
阅读全文
php采集
作者:wensongyu895 浏览评论:08年前
一、什么是php采集程序?二、为什么是采集?三、采集什么?四、采集怎么样?五、采集事物六、采集示例程序七、采集体验什么是php采集程序?php采集程序,又称php小偷,主要用于自动采集网络上网页中的特定内容,使用ph
阅读全文
基于PHP的cURL快速入门教程(小偷采集程序)
作者:suboysugar886 浏览评论:06年前
cURL是一个使用URL语法传输文件和数据的工具,支持多种协议,如HTTP、FTP、TELNET等,很多小偷程序都使用这个功能。最重要的是,PHP 还支持 cURL 库。本文将介绍 cURL 的一些高级特性以及如何在 PHP 中使用它。为什么使用 cU
阅读全文
PHP爬取采集类snoopy简介
作者:thinkyoung708 浏览人数:06年前
PHP爬虫采集类snoopy介绍2011年7月4日写的PHP爬虫方案,已阅读10270次感谢参考或原文服务器君共花了14.288 ms 花了2 个数据库查询让您努力获得此页面。试试阅读模式?希望
阅读全文
php网站内容采集相关问答
如何解决 PHP采集 超时?
作者:1496人查看评论数:15年前
我需要 采集a网站 的内容页面。先采集到链接,然后通过链接获取内容页面。但是,如果链接太多,一获取就会超时,必须分门别类少量获取。有近300个类别。手动设置分类也很慢。如何在不超时的情况下自动获取我想要的数据?请给我一些想法,谢谢!对不起,我没有说清楚。超过
阅读全文 查看全部
网站内容采集器(查看更多写博客基于日志服务的GrowthHacking(组图))
阿里云>云栖社区>主题图>P>php网站内容采集

推荐活动:
更多优惠>
当前主题:php网站内容采集加入采集
相关话题:
php网站内容采集相关博客查看更多博客
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS、二维码追踪技术)


作者:云磊 4389 浏览评论:02年前
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS追踪技术) 数据质量决定运营分析的质量上面我们介绍了GrowthHacking的整体增长情况架构,其中数据采集是整个数据分析的基础,只有数据才能进行有价值的分析;
阅读全文
日志服务-一站式配置采集Apache访问日志


作者:木子2422 浏览评论:03年前
自引入数据访问向导(Wizard)功能以来,日志服务不断优化访问向导功能,支持采集、存储、分析、离线下发各种数据,降低用户使用门槛使用日志服务。本文介绍了数据访问向导采集Apache日志和索引设置的一站式配置,以及通过默认dashboard和查询分析语句进行实时分析网站
阅读全文
网站采集器简介

作者:航空母舰1221 浏览评论:05年前
常用网络采集器主要分为桌面版和服务器版:桌面版基于windows等平台,使用本地带宽进行数据采集和发布程序,主要以“ 优采云网站采集器" 和 "EditorTools"; 服务器版本使用 PHP 或 ASP 编程,在 Linux 或 Windows 主机上运行,并使用服务器带宽
阅读全文
PHP采集业务信息和采集方法概述(第1部分)

作者:Tech Fatty 1044 浏览评论:04年前
近期,在电商市场上,商户导航层出不穷,采集了大量商户信息。如果您从事电子商务,这些信息仍然有用。我将这些信息用于我最近正在做的一个项目,但你不能把它给别人,所以别人不会给它。所以我必须自己爬。之前写过几个类似的爬虫来爬取网站的一些信息。
阅读全文
网站页面内容优化

作者:技术小牛1003 浏览评论:04年前
一、关键词分析:分析用户检索行为,有效实现搜索引擎营销,包括搜索
阅读全文
php采集

作者:wensongyu895 浏览评论:08年前
一、什么是php采集程序?二、为什么是采集?三、采集什么?四、采集怎么样?五、采集事物六、采集示例程序七、采集体验什么是php采集程序?php采集程序,又称php小偷,主要用于自动采集网络上网页中的特定内容,使用ph
阅读全文
基于PHP的cURL快速入门教程(小偷采集程序)

作者:suboysugar886 浏览评论:06年前
cURL是一个使用URL语法传输文件和数据的工具,支持多种协议,如HTTP、FTP、TELNET等,很多小偷程序都使用这个功能。最重要的是,PHP 还支持 cURL 库。本文将介绍 cURL 的一些高级特性以及如何在 PHP 中使用它。为什么使用 cU
阅读全文
PHP爬取采集类snoopy简介


作者:thinkyoung708 浏览人数:06年前
PHP爬虫采集类snoopy介绍2011年7月4日写的PHP爬虫方案,已阅读10270次感谢参考或原文服务器君共花了14.288 ms 花了2 个数据库查询让您努力获得此页面。试试阅读模式?希望
阅读全文
php网站内容采集相关问答
如何解决 PHP采集 超时?

作者:1496人查看评论数:15年前
我需要 采集a网站 的内容页面。先采集到链接,然后通过链接获取内容页面。但是,如果链接太多,一获取就会超时,必须分门别类少量获取。有近300个类别。手动设置分类也很慢。如何在不超时的情况下自动获取我想要的数据?请给我一些想法,谢谢!对不起,我没有说清楚。超过
阅读全文
网站内容采集器(笑话站源码_PHP开发++APP+采集接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-01-21 19:06
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集界面
2/3/201801:11:42
摘要:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何防止网站变成采集
17/4/2009 12:04:00
只要能被浏览器访问,没有什么不能采集,你选择是保护版权还是保护网站
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用和好处,我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
对于网站data采集,如何选择合适的服务器?
2/7/202012:01:21
网站Data采集,也称为数据采集,是使用设备从系统外部采集数据输入系统的接口。数据采集技术现已广泛应用于各个领域。对于制造企业庞大的生产数据,数据采集tools
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,不幸的是,一些 SEO 将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
如何使用免费的网站源码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
查看全部
网站内容采集器(笑话站源码_PHP开发++APP+采集接口
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:

笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集界面
2/3/201801:11:42
摘要:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何防止网站变成采集
17/4/2009 12:04:00
只要能被浏览器访问,没有什么不能采集,你选择是保护版权还是保护网站
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用和好处,我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
对于网站data采集,如何选择合适的服务器?
2/7/202012:01:21
网站Data采集,也称为数据采集,是使用设备从系统外部采集数据输入系统的接口。数据采集技术现已广泛应用于各个领域。对于制造企业庞大的生产数据,数据采集tools
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,不幸的是,一些 SEO 将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
如何使用免费的网站源码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-20 01:19
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-19 17:08
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容采集器(欢迎感兴趣的朋友前来JZ5U下载网站万能信息采集器使用! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-19 17:07
)
网站Universal Information采集器 是一个小巧、易于使用、功能强大且非常流行的网站 抓取和网页抓取工具。该软件结合了所有网站网页抓取软件的优点,可以抓取网站上的所有信息并自动发布到你的网站,任何网站任何类型的信息会按照例如:新闻、供需信息、人才招聘、论坛帖子、音乐、下一页链接等进行抓取。欢迎感兴趣的朋友来JZ5U下载网站万能信息采集器 使用!
软件特点:
1、信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,网站信息优采云采集器可以实现采集添加的自动完成. 其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2、网站登录
对于需要登录才能看到信息内容的网站,网站信息优采云采集器可以很方便的登录和采集,即使有一个验证码,可以通过登录采集获取你需要的信息。
3、文件自动下载
如果需要采集图片等二进制文件,只需设置网站信息优采云采集器,即可在本地保存任意类型的文件。
4、多级页面采集一次爬取整个站点
不管有多少类和子类,都可以同时设置采集为多级页面的内容。如果一条信息分布在多个不同的页面上,网站通用信息采集器也可以自动识别N级页面,实现信息采集抓取。该软件附带一个 8 层 网站采集 示例。
5、自动识别特殊URL
许多 网站 网页链接是特殊的 URL,例如 javascript:openwin('1234'),它们不是常见的。网站通用信息采集器还可以自动识别和捕获内容。
6、自动过滤重复导出数据过滤重复数据处理
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复。(新版本增加了新功能)。
7、多页新闻自动合并、广告过滤
有的新闻有下一页,网站万能资讯采集器也能抓到每一页。并且可以同时保存抓取到的新闻中的图文,过滤掉广告。
8、自动cookies和防盗链
很多下载类型的网站都做了cookie校验或者防盗链,直接输入URL不能抓取内容,但是网站万能信息采集器可以自动校验cookie和防盗链水蛭,呵呵,确保你得到你想要的。
9、另外增加了模拟手动提交的功能。租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软件特点:
1、采集发布是全自动的。
2、自动 JavaScript 特殊 URL。
3、会员登录网站 也会被捕获。
4、一次抓取整个网站,不管有多少类别。
5、可以下载任何类型的文件。
6、自动合并多页新闻,过滤广告。
7、多级页面联合采集。
8、模拟手动点击防盗链。
9、验证码识别。
10、图片自动加水印。
查看全部
网站内容采集器(欢迎感兴趣的朋友前来JZ5U下载网站万能信息采集器使用!
)
网站Universal Information采集器 是一个小巧、易于使用、功能强大且非常流行的网站 抓取和网页抓取工具。该软件结合了所有网站网页抓取软件的优点,可以抓取网站上的所有信息并自动发布到你的网站,任何网站任何类型的信息会按照例如:新闻、供需信息、人才招聘、论坛帖子、音乐、下一页链接等进行抓取。欢迎感兴趣的朋友来JZ5U下载网站万能信息采集器 使用!
软件特点:
1、信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,网站信息优采云采集器可以实现采集添加的自动完成. 其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2、网站登录
对于需要登录才能看到信息内容的网站,网站信息优采云采集器可以很方便的登录和采集,即使有一个验证码,可以通过登录采集获取你需要的信息。
3、文件自动下载
如果需要采集图片等二进制文件,只需设置网站信息优采云采集器,即可在本地保存任意类型的文件。
4、多级页面采集一次爬取整个站点
不管有多少类和子类,都可以同时设置采集为多级页面的内容。如果一条信息分布在多个不同的页面上,网站通用信息采集器也可以自动识别N级页面,实现信息采集抓取。该软件附带一个 8 层 网站采集 示例。
5、自动识别特殊URL
许多 网站 网页链接是特殊的 URL,例如 javascript:openwin('1234'),它们不是常见的。网站通用信息采集器还可以自动识别和捕获内容。
6、自动过滤重复导出数据过滤重复数据处理
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复。(新版本增加了新功能)。
7、多页新闻自动合并、广告过滤
有的新闻有下一页,网站万能资讯采集器也能抓到每一页。并且可以同时保存抓取到的新闻中的图文,过滤掉广告。
8、自动cookies和防盗链
很多下载类型的网站都做了cookie校验或者防盗链,直接输入URL不能抓取内容,但是网站万能信息采集器可以自动校验cookie和防盗链水蛭,呵呵,确保你得到你想要的。
9、另外增加了模拟手动提交的功能。租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软件特点:
1、采集发布是全自动的。
2、自动 JavaScript 特殊 URL。
3、会员登录网站 也会被捕获。
4、一次抓取整个网站,不管有多少类别。
5、可以下载任何类型的文件。
6、自动合并多页新闻,过滤广告。
7、多级页面联合采集。
8、模拟手动点击防盗链。
9、验证码识别。
10、图片自动加水印。

网站内容采集器(网站内容采集器是一个很好的方法,不易误删)
网站优化 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2022-01-18 09:00
网站内容采集器。当然,如果网站内容过多,或是想用ajax加载静态页面,那么,用采集器是一个很好的方法。推荐使用采集器,可以做到,什么都不用做,采集其他网站内容,甚至可以同步自己网站的内容,当然,如果网站内容还不够丰富的话,一般还不支持批量采集。
用工具采集各网站的内容,做成爬虫啊,自己写爬虫爬一下,
推荐用易语言的人工智能采集器,界面好看,速度快。多语言支持,而且语言翻译准确率高。比其他工具好的地方,就是可以多语言同时采集并编辑。易语言采集器安装文件,不易误删,找回也很简单。
使用易语言爬虫采集器,不管是百度,新浪,还是国外,谷歌,你都能轻松采集!而且同步速度很快,
合肥刷书网站长的人工智能采集软件还不错,没记错的话是他们公司的,他们看到我网站的外链挺多的,线上线下宣传不错,我之前做站群,就推荐给我这软件,后面我用了,效果也是不错的。要不就是图片代码有点难,复制粘贴没有那么快。
用采集器很多地方都可以采集,大多会用到网站合并(这里推荐几款免费工具,nsxtreme),云采集(各站点互采)。我做站长多年,用过很多工具,目前体验最好的是extremehttp,站长必备,有人说软件功能太少,这是工具的一个好处,适合更多站长。当然如果你是个人站长,就不推荐你用免费工具了,而且免费的也不能完全满足个人站长要求。
支持链接采集,站内收录,收录过程全面提速,支持各大站点收录,收录后全站内全部导出,收录完毕全站同步seo导出,具有独一无二的上传订单数据采集器,将浏览器不能上传或上传困难的链接转换成能上传网站的seo好引擎收录工具。 查看全部
网站内容采集器(网站内容采集器是一个很好的方法,不易误删)
网站内容采集器。当然,如果网站内容过多,或是想用ajax加载静态页面,那么,用采集器是一个很好的方法。推荐使用采集器,可以做到,什么都不用做,采集其他网站内容,甚至可以同步自己网站的内容,当然,如果网站内容还不够丰富的话,一般还不支持批量采集。
用工具采集各网站的内容,做成爬虫啊,自己写爬虫爬一下,
推荐用易语言的人工智能采集器,界面好看,速度快。多语言支持,而且语言翻译准确率高。比其他工具好的地方,就是可以多语言同时采集并编辑。易语言采集器安装文件,不易误删,找回也很简单。
使用易语言爬虫采集器,不管是百度,新浪,还是国外,谷歌,你都能轻松采集!而且同步速度很快,
合肥刷书网站长的人工智能采集软件还不错,没记错的话是他们公司的,他们看到我网站的外链挺多的,线上线下宣传不错,我之前做站群,就推荐给我这软件,后面我用了,效果也是不错的。要不就是图片代码有点难,复制粘贴没有那么快。
用采集器很多地方都可以采集,大多会用到网站合并(这里推荐几款免费工具,nsxtreme),云采集(各站点互采)。我做站长多年,用过很多工具,目前体验最好的是extremehttp,站长必备,有人说软件功能太少,这是工具的一个好处,适合更多站长。当然如果你是个人站长,就不推荐你用免费工具了,而且免费的也不能完全满足个人站长要求。
支持链接采集,站内收录,收录过程全面提速,支持各大站点收录,收录后全站内全部导出,收录完毕全站同步seo导出,具有独一无二的上传订单数据采集器,将浏览器不能上传或上传困难的链接转换成能上传网站的seo好引擎收录工具。
网站内容采集器(阿里巴巴上挂个外贸品牌,看看这些国外批发都在哪里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-16 23:01
网站内容采集器,可以采集微信公众号、微博、今日头条等网站的文章,价格从几十到几百不等,我做的就是这个,
推荐你一个,我之前在一家外贸公司做过业务员,他们把他们的外贸业务员业务群发放一些外贸货源,他们上门找货源。效果还是很不错的,当时我也不知道上门找货源的意义。我就想着来网上找货源,无意中看到这个网站,货源还是挺不错的,你可以尝试一下,推荐你去看看,了解一下,
可以进群呀,微信交流一下,还有老外很乐意免费给你教我们怎么用网站。或者你可以直接买些国外网站的收款币种账号就可以了。总之,你真的想进入外贸行业,相信问题不大,
priceminister上面有很多外贸人工厂站
看你要批发那些货了,我刚开始做不知道批发哪些,我知道一个叫全球速卖通的,是对接国内外贸批发价的,进货也不用交税。交易什么的只要出运费就行了,
你可以打开外贸b2c的阿里巴巴,看看这些国外的批发都在哪里,再想想你的产品适合进哪些,直接联系商户,有些国外网站开设免费申请账号的渠道,
找不到外贸网站,就在阿里巴巴上挂个外贸品牌,很多工厂供货~自己买产品, 查看全部
网站内容采集器(阿里巴巴上挂个外贸品牌,看看这些国外批发都在哪里)
网站内容采集器,可以采集微信公众号、微博、今日头条等网站的文章,价格从几十到几百不等,我做的就是这个,
推荐你一个,我之前在一家外贸公司做过业务员,他们把他们的外贸业务员业务群发放一些外贸货源,他们上门找货源。效果还是很不错的,当时我也不知道上门找货源的意义。我就想着来网上找货源,无意中看到这个网站,货源还是挺不错的,你可以尝试一下,推荐你去看看,了解一下,
可以进群呀,微信交流一下,还有老外很乐意免费给你教我们怎么用网站。或者你可以直接买些国外网站的收款币种账号就可以了。总之,你真的想进入外贸行业,相信问题不大,
priceminister上面有很多外贸人工厂站
看你要批发那些货了,我刚开始做不知道批发哪些,我知道一个叫全球速卖通的,是对接国内外贸批发价的,进货也不用交税。交易什么的只要出运费就行了,
你可以打开外贸b2c的阿里巴巴,看看这些国外的批发都在哪里,再想想你的产品适合进哪些,直接联系商户,有些国外网站开设免费申请账号的渠道,
找不到外贸网站,就在阿里巴巴上挂个外贸品牌,很多工厂供货~自己买产品,
网站内容采集器(,企业网站管理系统源码,(中英繁)版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-11 21:12
后台地址/admin,后台账号admin密码为admin
>公司企业网站管理系统源码三语(中英繁体)免费版由企业网站建设专家和企业网站系统开发人员制作。采用asp+access开发,数据库容量大,运行稳定。速度快,安全性能优异,功能更强大,是一套通用、公司、企业自助网站管理系统,sql版本调试请查阅《iis和sql安装操作手册》
>公司企业网站管理系统中英文繁体接入版,企业公司网站系统接入版,企业网站管理系统,企业网站源码,公司网站管理系统,公司企业网站自助式网站管理系统源码。漂亮的前台,强大的网站后台管理功能,自助管理前台相关栏目。中文、英文、繁体三语使公司、企业网站广为人知,占据网络市场。公司企业网站中英文接入版管理系统具有公司产品和服务的宣传、介绍、展示、推广、销售、在线电子商务等功能。业务和利润是全站系统设计功能的最终目标。完善网站企业简历、企业文化、企业新闻、行业资讯、产品展示、下载中心、企业荣誉、营销网络、人才招聘、客户留言、会员中心等子模块,充分考虑大体需求公司、企业中英文网站管理系统。全后台管理,后台功能齐全,使用维护方便。无论是生产、销售,还是服务,对于大中小型企业来说,只要企业网站的管理者会打字,都会打造专业的公司,企业网站,并随时管理网站 内容。本系统是基于ASP+sql技术开发的电子商务平台,是一个安全、稳定、快速、全自动化、全智能化的在线管理、维护、更新企业网站管理系统。全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?
>?企业版网站管理系统中文ACCESS版,企业版网站管理系统中英文繁体SQL版,企业公司网站系统中文SQL版,全屏中英文繁体SQL版,全屏中文SQL版。 查看全部
网站内容采集器(,企业网站管理系统源码,(中英繁)版)
后台地址/admin,后台账号admin密码为admin
>公司企业网站管理系统源码三语(中英繁体)免费版由企业网站建设专家和企业网站系统开发人员制作。采用asp+access开发,数据库容量大,运行稳定。速度快,安全性能优异,功能更强大,是一套通用、公司、企业自助网站管理系统,sql版本调试请查阅《iis和sql安装操作手册》
>公司企业网站管理系统中英文繁体接入版,企业公司网站系统接入版,企业网站管理系统,企业网站源码,公司网站管理系统,公司企业网站自助式网站管理系统源码。漂亮的前台,强大的网站后台管理功能,自助管理前台相关栏目。中文、英文、繁体三语使公司、企业网站广为人知,占据网络市场。公司企业网站中英文接入版管理系统具有公司产品和服务的宣传、介绍、展示、推广、销售、在线电子商务等功能。业务和利润是全站系统设计功能的最终目标。完善网站企业简历、企业文化、企业新闻、行业资讯、产品展示、下载中心、企业荣誉、营销网络、人才招聘、客户留言、会员中心等子模块,充分考虑大体需求公司、企业中英文网站管理系统。全后台管理,后台功能齐全,使用维护方便。无论是生产、销售,还是服务,对于大中小型企业来说,只要企业网站的管理者会打字,都会打造专业的公司,企业网站,并随时管理网站 内容。本系统是基于ASP+sql技术开发的电子商务平台,是一个安全、稳定、快速、全自动化、全智能化的在线管理、维护、更新企业网站管理系统。全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?
>?企业版网站管理系统中文ACCESS版,企业版网站管理系统中英文繁体SQL版,企业公司网站系统中文SQL版,全屏中英文繁体SQL版,全屏中文SQL版。
网站内容采集器(批量采集数据用采集器还是爬虫代码好?二者有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-14 08:10
由于现在数据量很大,人工采集根本没有效率。因此,面对海量的网络数据,大家使用各种工具采集。目前批处理采集数据的方法如下:
1.采集器
采集器是一款下载安装后即可使用的软件,可以批量处理采集一定量的网页数据。具有采集、排版、存储等功能。
2.爬虫代码
通过Python、JAVA等编程语言编写网络爬虫实现数据采集,需要获取网页、分析网页、提取网页数据、输入数据并存储。
那么对于数据或爬虫代码使用 采集器 更好吗?两者有什么区别,优缺点是什么?
1.费用
稍微好用的采集器基本都是收费的,免费的采集无效,或者部分功能需要付费。爬虫代码是自己写的,没有成本。
2.操作难度
采集器它是一个软件,你需要学习如何操作它,非常简单。采集很难用爬虫,因为前提是你必须懂一门编程语言才能写代码。你说是软件好学,还是语言好学?
3.限制问题
采集器直接采集即可,功能设置不可更改。对于 IP 限制,某些 采集器 将设置代理。如果没有代理,则需要与代理配合。
在编写爬虫时,还应该考虑 网站 的限制。除了IP限制,还有请求头、cookies、异步加载等,这些都是根据不同的网站反爬虫添加不同的响应方式。可以使用的爬虫代码有点复杂,需要考虑的问题很多。
4.采集内容格式
一般采集器只能采集一些简单的网页,而且存储格式只有html和txt,稍微复杂的页面不能顺利下采集。爬虫代码可以根据需要编写,获取数据,并以需要的格式存储,范围很广。
5.采集速度
采集器的采集的速度是可以设置的,但是设置后批量获取数据的时间间隔是一样的,很容易被网站发现,从而限制你的 采集。爬虫代码采集可以设置随机时间间隔采集,安全性高。
采集数据使用采集器还是爬虫代码更好?从上面的分析可以看出,使用采集器会简单很多。虽然采集的范围和安全性不是很好,但是采集量比较少的人也可以使用。使用爬虫代码来采集数据很难,但是对于学过编程语言的人来说并不难。主要是使用工具来突破限制,比如使用IP更改工具来突破IP限制问题。爬虫代码的应用范围很广,具备应对各方面反爬的技巧,可以通过比较严格的反爬机制获取网站信息。
数据采集器
互联网 查看全部
网站内容采集器(批量采集数据用采集器还是爬虫代码好?二者有什么区别)
由于现在数据量很大,人工采集根本没有效率。因此,面对海量的网络数据,大家使用各种工具采集。目前批处理采集数据的方法如下:
1.采集器
采集器是一款下载安装后即可使用的软件,可以批量处理采集一定量的网页数据。具有采集、排版、存储等功能。
2.爬虫代码
通过Python、JAVA等编程语言编写网络爬虫实现数据采集,需要获取网页、分析网页、提取网页数据、输入数据并存储。
那么对于数据或爬虫代码使用 采集器 更好吗?两者有什么区别,优缺点是什么?
1.费用
稍微好用的采集器基本都是收费的,免费的采集无效,或者部分功能需要付费。爬虫代码是自己写的,没有成本。
2.操作难度
采集器它是一个软件,你需要学习如何操作它,非常简单。采集很难用爬虫,因为前提是你必须懂一门编程语言才能写代码。你说是软件好学,还是语言好学?
3.限制问题
采集器直接采集即可,功能设置不可更改。对于 IP 限制,某些 采集器 将设置代理。如果没有代理,则需要与代理配合。
在编写爬虫时,还应该考虑 网站 的限制。除了IP限制,还有请求头、cookies、异步加载等,这些都是根据不同的网站反爬虫添加不同的响应方式。可以使用的爬虫代码有点复杂,需要考虑的问题很多。
4.采集内容格式
一般采集器只能采集一些简单的网页,而且存储格式只有html和txt,稍微复杂的页面不能顺利下采集。爬虫代码可以根据需要编写,获取数据,并以需要的格式存储,范围很广。
5.采集速度
采集器的采集的速度是可以设置的,但是设置后批量获取数据的时间间隔是一样的,很容易被网站发现,从而限制你的 采集。爬虫代码采集可以设置随机时间间隔采集,安全性高。
采集数据使用采集器还是爬虫代码更好?从上面的分析可以看出,使用采集器会简单很多。虽然采集的范围和安全性不是很好,但是采集量比较少的人也可以使用。使用爬虫代码来采集数据很难,但是对于学过编程语言的人来说并不难。主要是使用工具来突破限制,比如使用IP更改工具来突破IP限制问题。爬虫代码的应用范围很广,具备应对各方面反爬的技巧,可以通过比较严格的反爬机制获取网站信息。
数据采集器
互联网
网站内容采集器(使用教程中有采集器7.6破解版,轻松获取目标网站所有内容的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-13 17:23
为了方便从事网站服务等行业的人的工作,小编为大家带来了优采云采集器7.6破解版,这是一款软件可以轻松获取目标网站的所有内容。它具有功能强大、操作简单、配置快捷高效等诸多特点,受到越来越多用户的青睐。与一般的采集器相比,本软件采集速度快,内容丰富,采集操作非常准确,是目前使用最广泛的网络资源采集软件。另外,使用本软件进行数据采集时,不仅仅是采集,分为两步,一是进行数据采集,二是进行数据采集直接发布给自己在 网站 上 网站,用户无需再次编辑内容,即可发布到网站。而且具体操作也不难。为了让大家清楚的了解这款软件的具体操作流程,小编为大家带来了一个教程。教程中有详细的操作步骤,你可以按照教程一步一步完成。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!
软件功能
1、几乎任何网页都可以采集
不管是什么语言,不管是什么编码
2、与复制/粘贴一样准确
采集/发布就像复制粘贴一样准确,用户想要的就是精华,怎么可能有遗漏
3、比正常速度快7倍采集器
优采云采集器采用顶层系统配置,反复优化性能,让采集快到飞起来
4、网页的同义词采集
凭借十年的经验,他已成为行业领先品牌。当您想到网站 采集 时,您会想到 优采云采集器
软件功能
1、无限多页采集,可实现无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSS地址采集功能
5、列表页面分页采集获取函数
6、列表页附加参数获取功能
7、列表页面和标签XPath可视化提取功能
8、标签纯正则替换函数 查看全部
网站内容采集器(使用教程中有采集器7.6破解版,轻松获取目标网站所有内容的软件)
为了方便从事网站服务等行业的人的工作,小编为大家带来了优采云采集器7.6破解版,这是一款软件可以轻松获取目标网站的所有内容。它具有功能强大、操作简单、配置快捷高效等诸多特点,受到越来越多用户的青睐。与一般的采集器相比,本软件采集速度快,内容丰富,采集操作非常准确,是目前使用最广泛的网络资源采集软件。另外,使用本软件进行数据采集时,不仅仅是采集,分为两步,一是进行数据采集,二是进行数据采集直接发布给自己在 网站 上 网站,用户无需再次编辑内容,即可发布到网站。而且具体操作也不难。为了让大家清楚的了解这款软件的具体操作流程,小编为大家带来了一个教程。教程中有详细的操作步骤,你可以按照教程一步一步完成。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!您可以按照它一步一步完成它。掌握本软件的操作后,您可以在任意网站中自由获取您需要的数据内容,快来试试吧!
软件功能
1、几乎任何网页都可以采集
不管是什么语言,不管是什么编码
2、与复制/粘贴一样准确
采集/发布就像复制粘贴一样准确,用户想要的就是精华,怎么可能有遗漏
3、比正常速度快7倍采集器
优采云采集器采用顶层系统配置,反复优化性能,让采集快到飞起来
4、网页的同义词采集
凭借十年的经验,他已成为行业领先品牌。当您想到网站 采集 时,您会想到 优采云采集器
软件功能
1、无限多页采集,可实现无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSS地址采集功能
5、列表页面分页采集获取函数
6、列表页附加参数获取功能
7、列表页面和标签XPath可视化提取功能
8、标签纯正则替换函数
网站内容采集器(做一个网站还是需要很多东西要掌握的源码采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-10 14:20
做一个 网站 仍然需要很多东西来掌握。我暂时假设您是一个非技术门户网站源代码采集,并列出网站 需要什么。
需求分析。分析一下你的网站传送门网站源码采集的定位,你的网站到底想呈现什么,什么类型?电子商务?内容翔实?社交联系?产品原型。完成需求分析后,开始为您的 网站 原型设计。可以参考同类型网站。用户界面设计。网站中的一些图片,色调需要由专业的UI设计师设计。开发工作。这包括前端页面开发和后端开发。您可以找到一个外包团队为您完成这项工作。他们将根据您的网站 需求评估开发时间和人力,并在最后给您报价。当然,UI部分的工作也可以一起外包给他们。开发完成后会上线部署。这次你需要一个服务器。当然,现在你根本不需要买机器,你可以使用一些国内云厂商的机器,比如阿里云。价格根据您选择的配置而有所不同。比如一台2核的4G机器一个月要200左右。域名申请备案。如果你的网站需要被外部访问,你需要一个用户容易记住的域名。域名现在很便宜,一年几十块钱。域名申请成功后会备案,然后可以映射到你的服务器,用户就可以访问你的网站了。后期维护操作。维护工作可以外包给开发团队。维护费可能需要按一定期限支付,主要包括系统bug和新需求开发。运营工作需要你去做。就是定期更新你的网站内容,自己推广。构建 网站 的工作就是这样。不知道怎么咨询我。
如何采集投标网站数据?
采集portal网站源码采集可以使用ForeSpider数据采集系统,只是采集竞价网的新教程,希望对你有帮助你 :
l 采集网站
【场景描述】采集招标网所有招标数据入口网站源码采集。
【来源介绍网站】
是招标采购领域的招标信息和招标服务平台。为各级政府采购门户网站源码采集、招标代理机构、招标公司、供应商、采购业主提供强大的专业服务。招标采购信息查询及相关招标服务。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址/view/forespider/view/download.html
【入口网址】/channel-userggcharge-1.html
【采集内容】
采集Tender Online 上的所有招标数据。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
网站内容采集器(做一个网站还是需要很多东西要掌握的源码采集)
做一个 网站 仍然需要很多东西来掌握。我暂时假设您是一个非技术门户网站源代码采集,并列出网站 需要什么。
需求分析。分析一下你的网站传送门网站源码采集的定位,你的网站到底想呈现什么,什么类型?电子商务?内容翔实?社交联系?产品原型。完成需求分析后,开始为您的 网站 原型设计。可以参考同类型网站。用户界面设计。网站中的一些图片,色调需要由专业的UI设计师设计。开发工作。这包括前端页面开发和后端开发。您可以找到一个外包团队为您完成这项工作。他们将根据您的网站 需求评估开发时间和人力,并在最后给您报价。当然,UI部分的工作也可以一起外包给他们。开发完成后会上线部署。这次你需要一个服务器。当然,现在你根本不需要买机器,你可以使用一些国内云厂商的机器,比如阿里云。价格根据您选择的配置而有所不同。比如一台2核的4G机器一个月要200左右。域名申请备案。如果你的网站需要被外部访问,你需要一个用户容易记住的域名。域名现在很便宜,一年几十块钱。域名申请成功后会备案,然后可以映射到你的服务器,用户就可以访问你的网站了。后期维护操作。维护工作可以外包给开发团队。维护费可能需要按一定期限支付,主要包括系统bug和新需求开发。运营工作需要你去做。就是定期更新你的网站内容,自己推广。构建 网站 的工作就是这样。不知道怎么咨询我。
如何采集投标网站数据?
采集portal网站源码采集可以使用ForeSpider数据采集系统,只是采集竞价网的新教程,希望对你有帮助你 :
l 采集网站
【场景描述】采集招标网所有招标数据入口网站源码采集。
【来源介绍网站】
是招标采购领域的招标信息和招标服务平台。为各级政府采购门户网站源码采集、招标代理机构、招标公司、供应商、采购业主提供强大的专业服务。招标采购信息查询及相关招标服务。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址/view/forespider/view/download.html
【入口网址】/channel-userggcharge-1.html
【采集内容】
采集Tender Online 上的所有招标数据。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
网站内容采集器( 网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 07:15
网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载
)
论坛采集专家免费版是一款专业的网络数据采集和信息挖掘处理软件,适合各类有采集数据挖掘需求的群体。论坛采集专家免费版可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,编辑过滤,自动增量更新发布到网站后台,各种文件或其他数据库系统。
相关软件下载地址
优采云采集器
查看
镀铬清洁工具
查看
12306 分流抢票
查看
是专门针对楼层类数据和自动增量更新需求而开发的软件。它定义了一套发布规则,并根据规则开发插件接口,从而实现论坛、知乎、连载等自动更新功能。
它具有以下特点:
1.支持采集标题、内容、用户名、注册时间、签名、头像、附件等支持添加采集字段
2.支持自动回复,方便回复帖子和隐藏附件。支持帖子回复
3.支持回复部分的增量采集。可以采集新的回复和发布。可以处理论坛、贴吧、串口更新问题
4.智能生成采集规则。系统内置多个常用论坛的自动识别规则,可自动生成采集规则
5.支持网站自动登录,支持目前主流的Discuz、PHPWind论坛,暂时不支持验证码登录
6.界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
7.支持下载文件,支持翻译、分词、代理等功能优采云采集器
8.支持插件开发,接口灵活,可以采集更复杂的网站数据和数据处理
9.支持通过搜索关键词采集post URLs,可以批量设置关键词查询类采集
查看全部
网站内容采集器(
网络数据采集和信息挖掘处理软件PHPWind论坛下载地址下载
)
论坛采集专家免费版是一款专业的网络数据采集和信息挖掘处理软件,适合各类有采集数据挖掘需求的群体。论坛采集专家免费版可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,编辑过滤,自动增量更新发布到网站后台,各种文件或其他数据库系统。
相关软件下载地址
优采云采集器
查看
镀铬清洁工具
查看
12306 分流抢票
查看
是专门针对楼层类数据和自动增量更新需求而开发的软件。它定义了一套发布规则,并根据规则开发插件接口,从而实现论坛、知乎、连载等自动更新功能。
它具有以下特点:
1.支持采集标题、内容、用户名、注册时间、签名、头像、附件等支持添加采集字段
2.支持自动回复,方便回复帖子和隐藏附件。支持帖子回复
3.支持回复部分的增量采集。可以采集新的回复和发布。可以处理论坛、贴吧、串口更新问题
4.智能生成采集规则。系统内置多个常用论坛的自动识别规则,可自动生成采集规则
5.支持网站自动登录,支持目前主流的Discuz、PHPWind论坛,暂时不支持验证码登录
6.界面支持自动注册账号、处理头像、处理话题和回复,官方界面不断更新维护
7.支持下载文件,支持翻译、分词、代理等功能优采云采集器
8.支持插件开发,接口灵活,可以采集更复杂的网站数据和数据处理
9.支持通过搜索关键词采集post URLs,可以批量设置关键词查询类采集
网站内容采集器( 优采云采集介绍(KeyDatas)数据采集平台采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-06 20:20
优采云采集介绍(KeyDatas)数据采集平台采集)
一、优采云采集简介
优采云(KeyDatas)数据采集平台是提供网站内容抓取、数据处理和发布,包括各种图片、文字信息等。优采云网页采集器 化繁为简,力求简单化、智能化,让广大站长和需要网页数据的用户更简单快捷地获得想要的数据,可以灵活地进行处理和发布。
简化复杂性,让数据触手可及,这是我们的使命!
“简单可能比复杂更难:你必须努力让你的想法变得清晰,让它变得简单。但最终还是值得的,因为一旦到达那里,就可以移山。”
“简单比复杂更难:你必须竭尽全力让它变得简单。但最终它是值得的,因为一旦你做到了,你就可以创造奇迹。” - 史蒂夫乔布斯
二、功能介绍
优采云采集平台让您轻松获取海量网页数据。任何人都可以得到想要的网页数据,只需要在浏览器的可视化界面上用鼠标点击一下,不需要懂Html代码!
不仅是采集数据,优采云还可以帮你轻松将采集收到的数据发布到WordPress、织梦DEDE、Empire、Zblog等cms 网站 和自定义 HTTP 接口。您也可以导出到 Excel...
三、利用优势
1.采集无需安装任何客户端,点击在线可视化;
2.集成智能提取引擎(国内独家),自动识别数据和规则,包括:翻页、标题、作者、发布日期、内容等,你甚至可以不用修改就开始采集;
3.图片下载支持存储到:阿里云OSS、七牛云、腾讯云;(支持水印、压缩等)
4.全自动:定时采集+自动释放;
5.提供强大的SEO工具,包括:在正文中插入动态段落(强烈推荐)、在正文中插入段落和自动标题关键词、自动内部链接、同义词替换、简繁转换、翻译, 等等。;
6.免费、自动接入多个IP代理服务商等。
7.与Z-Blog系统无缝集成,点击几下即可发布到Z-Blog系统。
8.支持微信公众号文章采集(包括采集公众号历史文章),今日头条新闻采集,进入微信公众号即可ID或标题号或关键词可以是采集;
四、优采云采集有收费吗?
优采云采集它非常容易使用而且是免费的。 查看全部
网站内容采集器(
优采云采集介绍(KeyDatas)数据采集平台采集)
一、优采云采集简介
优采云(KeyDatas)数据采集平台是提供网站内容抓取、数据处理和发布,包括各种图片、文字信息等。优采云网页采集器 化繁为简,力求简单化、智能化,让广大站长和需要网页数据的用户更简单快捷地获得想要的数据,可以灵活地进行处理和发布。
简化复杂性,让数据触手可及,这是我们的使命!
“简单可能比复杂更难:你必须努力让你的想法变得清晰,让它变得简单。但最终还是值得的,因为一旦到达那里,就可以移山。”
“简单比复杂更难:你必须竭尽全力让它变得简单。但最终它是值得的,因为一旦你做到了,你就可以创造奇迹。” - 史蒂夫乔布斯
二、功能介绍
优采云采集平台让您轻松获取海量网页数据。任何人都可以得到想要的网页数据,只需要在浏览器的可视化界面上用鼠标点击一下,不需要懂Html代码!
不仅是采集数据,优采云还可以帮你轻松将采集收到的数据发布到WordPress、织梦DEDE、Empire、Zblog等cms 网站 和自定义 HTTP 接口。您也可以导出到 Excel...
三、利用优势
1.采集无需安装任何客户端,点击在线可视化;
2.集成智能提取引擎(国内独家),自动识别数据和规则,包括:翻页、标题、作者、发布日期、内容等,你甚至可以不用修改就开始采集;
3.图片下载支持存储到:阿里云OSS、七牛云、腾讯云;(支持水印、压缩等)
4.全自动:定时采集+自动释放;
5.提供强大的SEO工具,包括:在正文中插入动态段落(强烈推荐)、在正文中插入段落和自动标题关键词、自动内部链接、同义词替换、简繁转换、翻译, 等等。;
6.免费、自动接入多个IP代理服务商等。
7.与Z-Blog系统无缝集成,点击几下即可发布到Z-Blog系统。
8.支持微信公众号文章采集(包括采集公众号历史文章),今日头条新闻采集,进入微信公众号即可ID或标题号或关键词可以是采集;
四、优采云采集有收费吗?
优采云采集它非常容易使用而且是免费的。
网站内容采集器(高级使用技巧之网站内容采集器规则修正)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-04 04:17
网站内容采集器工具包MetaSeeker从V4.0.0版本开始增加了自定义XPath规则的功能,完全由原程序自行生成网站内容采集规则得到补充和增强。但是,如果自定义XPath表达式使用字符串处理函数采集字面量内容,就会遇到bug。
场景
<p>比如使用XPath函数substring-after()等,生成的网站content采集指令文件是正常的,也就是说网络爬虫和网站内容采集器DataScraper运行正常,用户可以准确海量采集网站内容。但是MetaStudio生成的信息结构描述文件不正确,用户输入的自定义XPath表达式被误认为是DOM节点定位表达式。后果是网站content采集规则生成器MetaStudio无法再次将之前生成的信息结构加载到工作台中进行修改和编辑,需要采集 查看全部
网站内容采集器(高级使用技巧之网站内容采集器规则修正)
网站内容采集器工具包MetaSeeker从V4.0.0版本开始增加了自定义XPath规则的功能,完全由原程序自行生成网站内容采集规则得到补充和增强。但是,如果自定义XPath表达式使用字符串处理函数采集字面量内容,就会遇到bug。
场景
<p>比如使用XPath函数substring-after()等,生成的网站content采集指令文件是正常的,也就是说网络爬虫和网站内容采集器DataScraper运行正常,用户可以准确海量采集网站内容。但是MetaStudio生成的信息结构描述文件不正确,用户输入的自定义XPath表达式被误认为是DOM节点定位表达式。后果是网站content采集规则生成器MetaStudio无法再次将之前生成的信息结构加载到工作台中进行修改和编辑,需要采集
网站内容采集器(一门强大的开发语言,正则表达式方法捕获 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-01-28 09:23
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上查了很多资料,却发现java中广泛使用的使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何读取网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
网站内容采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上查了很多资料,却发现java中广泛使用的使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何读取网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "<a href='http://www.cnblogs.com/longwu% ... 3B%3B
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
网站内容采集器(作为全球运用最广泛的语言,Java,正则表达式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-27 23:10
介绍:
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性而受到广大应用程序开发者的青睐。开发语言,正则表达式在其中的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端-end development),正则表达式是必须的。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序,因为是第一次做关于java的html页面数据采集,一定要be我在网上找了很多资料,但是发现在使用正则化做html中广泛使用的java采集(中文)文章很少,他们只是在说java正则这个概念在实际网页中并没有真正用到html采集,所以例子教程很少(虽然java有自己的Html Parser,而且很强大),但是我个人认为作为一个深入rooted 正则表达式,应该有相关的java示例教程,而且应该很多且完整。所以在完成了html数据采集程序的java版之后,
关于组规律性:
说到正则表达式如何帮助java执行html页面采集,这里简单提一下正则表达式中的group方法
组法
让我们看看输出:
打印出 url 链接:打印出标题:SoFlash 打印出日期:12.22.2011
group 方法捕获的数据数量:3
没学过正则的可以看看这个正则表达式的元字符匹配
好了,group的方法已经介绍完了,我们简单用group采集a football网站页面的数据
首先我们阅读整个html页面,打印出代码如下
抓取整个html页面数据
打印出来的结果就是整个html页面的源码(部分截图如下)
至此,数据已经成功采集下来了,当然我们要的不是整个html源码,我们需要的是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012赛季英超球队战绩页面
右击页面,点击“查看源文件”如图
我们来看看它内部的html代码结构和我们需要的数据
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来匹配我们需要的数据
在这里你需要使用 3 个常客,包括日期、2 支球队(主队和客队)和比赛结果如下
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则 String regularTwoTeam = ">[^]*" ; //队伍是正则 String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以使用正则得到我们想要的数据了
首先我们写一个GroupMethod类来存储regularGroup()方法
GroupMethod 类
然后编写主要功能代码
主要功能 - 采集我们需要的数据
让我们看看输出(部分截图 - 初始阶段)
比较html上的数据(部分截图-初始阶段)
输出结果(部分截图 - 结束阶段)
比较html上的数据(部分截图-结束阶段)
嗯,这样的html数据采集就完成了:)
当然,这只是一页的内容。如果您有兴趣抓取更多页面内容,可以在链接后分析联盟名称。例如,league=EngPrem 可以通过更改联赛名称来获取所有链接。
你可以写一个接口,把所有球队的名字放到联赛的比赛数据中。当然,还有更智能的方法。您可以从页面编写方法。
获取所有球队的名称,然后将它们附加到“;league”链接以完成链接以阅读每个联赛比赛页面的内容 查看全部
网站内容采集器(作为全球运用最广泛的语言,Java,正则表达式)
介绍:
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性而受到广大应用程序开发者的青睐。开发语言,正则表达式在其中的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发技能的体现,做一个合格的网站开发程序员(尤其是前端-end development),正则表达式是必须的。
最近由于一些需要,使用java和regular,做了一个足球网站数据采集程序,因为是第一次做关于java的html页面数据采集,一定要be我在网上找了很多资料,但是发现在使用正则化做html中广泛使用的java采集(中文)文章很少,他们只是在说java正则这个概念在实际网页中并没有真正用到html采集,所以例子教程很少(虽然java有自己的Html Parser,而且很强大),但是我个人认为作为一个深入rooted 正则表达式,应该有相关的java示例教程,而且应该很多且完整。所以在完成了html数据采集程序的java版之后,
关于组规律性:
说到正则表达式如何帮助java执行html页面采集,这里简单提一下正则表达式中的group方法
组法
让我们看看输出:
打印出 url 链接:打印出标题:SoFlash 打印出日期:12.22.2011
group 方法捕获的数据数量:3
没学过正则的可以看看这个正则表达式的元字符匹配
好了,group的方法已经介绍完了,我们简单用group采集a football网站页面的数据
首先我们阅读整个html页面,打印出代码如下
抓取整个html页面数据
打印出来的结果就是整个html页面的源码(部分截图如下)
至此,数据已经成功采集下来了,当然我们要的不是整个html源码,我们需要的是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012赛季英超球队战绩页面
右击页面,点击“查看源文件”如图
我们来看看它内部的html代码结构和我们需要的数据
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来匹配我们需要的数据
在这里你需要使用 3 个常客,包括日期、2 支球队(主队和客队)和比赛结果如下
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则 String regularTwoTeam = ">[^]*" ; //队伍是正则 String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以使用正则得到我们想要的数据了
首先我们写一个GroupMethod类来存储regularGroup()方法
GroupMethod 类
然后编写主要功能代码
主要功能 - 采集我们需要的数据
让我们看看输出(部分截图 - 初始阶段)
比较html上的数据(部分截图-初始阶段)
输出结果(部分截图 - 结束阶段)
比较html上的数据(部分截图-结束阶段)
嗯,这样的html数据采集就完成了:)
当然,这只是一页的内容。如果您有兴趣抓取更多页面内容,可以在链接后分析联盟名称。例如,league=EngPrem 可以通过更改联赛名称来获取所有链接。
你可以写一个接口,把所有球队的名字放到联赛的比赛数据中。当然,还有更智能的方法。您可以从页面编写方法。
获取所有球队的名称,然后将它们附加到“;league”链接以完成链接以阅读每个联赛比赛页面的内容
网站内容采集器( seo网站采集大量内容是怎么回事?网站频繁改版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-27 19:20
seo网站采集大量内容是怎么回事?网站频繁改版)
现在做seo推广的人越来越多,但是越来越多的人开始觉得seo已经走到了尽头。毕竟随着百度算法的频繁更新,在排名问题上能人为控制的因素越来越少。当然,站长朋友也需要了解一些seo推广的常识,以免在网站推广过程中走弯路。
1.网站采集内容很多。
新站刚上线的时候,内容很少或者几乎没有,所以用户进来的时候是看不到内容的,自然会损害用户体验——所以很多采集内容和网上传播是很多新手站长朋友的习惯问题。但是,重复和转载n次的内容不太可能流行,尤其是新站点。如果有大量的采集内容,可能会被判断为垃圾站点,然后被k。
2.大量外链发布。
百度现在的算法进步很大,不像过去,只需要发布一堆外链,就可以获得不错的排名。如果新站采用大量外部链接,可能会导致百度认为是作弊,从而延长网站的审核期限。毕竟作为一个新的网站,一开始可能不会有太多的网站通过外链给你投票,这点百度也不清楚,所以外链的建设应该被照顾。
3.网站 经常修改。
一般网站有流量,不建议频繁修改版本。一是不利于用户体验。第二,不保证有朝一日百度会来抢你的网站而不自知。当百度认为您是一个新站点时,它会对您的站点进行重新审核。
4.经常更改网站 标题。
原因同上。频繁更改网站的标题会导致百度重新审核你的网站,尤其是新站点也需要关注的时候。目标关键词确定后,标题不宜频繁更改。
5.关键词密度太高。
在确定了主关键词之后,很多站长朋友就迫不及待的在文章、内容、图片、导航等各个地方出现关键词,希望能得到一个不错的排名通过这个词快...其实这样堆叠关键词的做法对seo推广是非常不利的。
6.链接太多。
交换友情链接时,除了看对方的网站权重、收录、排名等,还要注意对方网站是否被被搜索引擎惩罚:降级、被k等网站的所有好友链都会对你的网站产生恶毒的影响。当然,如果各方面都不错,还应该检查对方网站所在的宿主是否有其他网站惩罚。 查看全部
网站内容采集器(
seo网站采集大量内容是怎么回事?网站频繁改版)
现在做seo推广的人越来越多,但是越来越多的人开始觉得seo已经走到了尽头。毕竟随着百度算法的频繁更新,在排名问题上能人为控制的因素越来越少。当然,站长朋友也需要了解一些seo推广的常识,以免在网站推广过程中走弯路。
1.网站采集内容很多。
新站刚上线的时候,内容很少或者几乎没有,所以用户进来的时候是看不到内容的,自然会损害用户体验——所以很多采集内容和网上传播是很多新手站长朋友的习惯问题。但是,重复和转载n次的内容不太可能流行,尤其是新站点。如果有大量的采集内容,可能会被判断为垃圾站点,然后被k。
2.大量外链发布。
百度现在的算法进步很大,不像过去,只需要发布一堆外链,就可以获得不错的排名。如果新站采用大量外部链接,可能会导致百度认为是作弊,从而延长网站的审核期限。毕竟作为一个新的网站,一开始可能不会有太多的网站通过外链给你投票,这点百度也不清楚,所以外链的建设应该被照顾。
3.网站 经常修改。
一般网站有流量,不建议频繁修改版本。一是不利于用户体验。第二,不保证有朝一日百度会来抢你的网站而不自知。当百度认为您是一个新站点时,它会对您的站点进行重新审核。
4.经常更改网站 标题。
原因同上。频繁更改网站的标题会导致百度重新审核你的网站,尤其是新站点也需要关注的时候。目标关键词确定后,标题不宜频繁更改。
5.关键词密度太高。
在确定了主关键词之后,很多站长朋友就迫不及待的在文章、内容、图片、导航等各个地方出现关键词,希望能得到一个不错的排名通过这个词快...其实这样堆叠关键词的做法对seo推广是非常不利的。
6.链接太多。
交换友情链接时,除了看对方的网站权重、收录、排名等,还要注意对方网站是否被被搜索引擎惩罚:降级、被k等网站的所有好友链都会对你的网站产生恶毒的影响。当然,如果各方面都不错,还应该检查对方网站所在的宿主是否有其他网站惩罚。
网站内容采集器( CX采集器可实现伪原创功能的采集规则交流群)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-27 19:18
CX采集器可实现伪原创功能的采集规则交流群)
CX采集器,使用强大的 原创 内核。不断优化增强,是目前DZ最完善的WEB版采集器,支持同义词替换,支持批量采集,支持自动存储,支持定时任务,可实现全自动采集.
网站的发展离不开它的内容。为了挖掘独特的信息,降低人工成本,采集器应运而生。当然,好的网站也离不开打开原创的内容。 CX采集器可以实现伪原创的功能。
整体功能:
1、可以采集大部分可以作为访问者查看的网页,包括门户、论坛等
2、可以添加采集规则,自定义你想要的信息采集。
3、支持批量采集,同时支持多个机器人采集.
4、支持单向或双向同义词替换,并集成同义词管理后台。
5、支持后台定时任务采集,为本插件集成定时任务后台。
6、支持自动导入论坛、群组、门户
7、支持学科分类
8、支持图片附件、图片缩略图、图片水印(根据本站背景设置)
9、支持远程附件(根据站点后台设置上传到远程)
10、支持flash地址自动转换为flash-tags,支持论坛格式和门户格式。
采集规则的编写属于傻瓜式。一目了然,一目了然。与其他 采集器 不同,它很耗时。没有好的结果。
我还成立了采集规则交流群,大家可以一起学习讨论。
组号:94787884
如需编写规则或学习编写规则,可直接联系
服务器环境要求:查看方法参考:
1、PHPv5.2.X 或 PHP5.3.X 版本
2、需要 Zend Optimizer v3.3.x(用于 PHP 5.2.x)或 Zend Guard Loader(用于 PHP v5.@ >3)一般空间会预装。
3、可以上网。不需要打开allow_url_fopen或者curl,但是免费版使用的是免费版的采集核心。免费版用户最好打开curl,默认使用curl组件。
请以二进制方式上传。
如果版本号发生变化,覆盖后需要点击插件列表中的升级或更新。 查看全部
网站内容采集器(
CX采集器可实现伪原创功能的采集规则交流群)
CX采集器,使用强大的 原创 内核。不断优化增强,是目前DZ最完善的WEB版采集器,支持同义词替换,支持批量采集,支持自动存储,支持定时任务,可实现全自动采集.
网站的发展离不开它的内容。为了挖掘独特的信息,降低人工成本,采集器应运而生。当然,好的网站也离不开打开原创的内容。 CX采集器可以实现伪原创的功能。
整体功能:
1、可以采集大部分可以作为访问者查看的网页,包括门户、论坛等
2、可以添加采集规则,自定义你想要的信息采集。
3、支持批量采集,同时支持多个机器人采集.
4、支持单向或双向同义词替换,并集成同义词管理后台。
5、支持后台定时任务采集,为本插件集成定时任务后台。
6、支持自动导入论坛、群组、门户
7、支持学科分类
8、支持图片附件、图片缩略图、图片水印(根据本站背景设置)
9、支持远程附件(根据站点后台设置上传到远程)
10、支持flash地址自动转换为flash-tags,支持论坛格式和门户格式。
采集规则的编写属于傻瓜式。一目了然,一目了然。与其他 采集器 不同,它很耗时。没有好的结果。
我还成立了采集规则交流群,大家可以一起学习讨论。
组号:94787884
如需编写规则或学习编写规则,可直接联系
服务器环境要求:查看方法参考:
1、PHPv5.2.X 或 PHP5.3.X 版本
2、需要 Zend Optimizer v3.3.x(用于 PHP 5.2.x)或 Zend Guard Loader(用于 PHP v5.@ >3)一般空间会预装。
3、可以上网。不需要打开allow_url_fopen或者curl,但是免费版使用的是免费版的采集核心。免费版用户最好打开curl,默认使用curl组件。
请以二进制方式上传。
如果版本号发生变化,覆盖后需要点击插件列表中的升级或更新。
网站内容采集器(Google推广:最近有些优化新手有给我提过这样一个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-27 02:12
谷歌推广:最近有优化新手问我这样一个问题,如何避免网站过度优化?如果优化不够,排名效果会差强人意。一旦网站优化过度,就会受到搜索引擎的惩罚。
今天特意整理了网站优化过程中的一些禁忌。
1、网站 的标题
首先,最典型的问题之一就是很多网站标题经常被一些客户剪掉。或者一个无关紧要的关键词,很容易被搜索引擎的算法判断为这个网站作弊,最终导致搜索引擎屏蔽该网站。
注意网站的标题对于关键词的写法,建议一个网页对应一两个关键词,网页的body内容应该是与网页标题的主题高度一致。
另一个问题是 网站 的页面标题不应该经常更改。不稳定的 网站 不会被百度点赞。建站之初,网站的每一个细节都应该考虑在内。一旦确立,就不会轻易改变。
2、网站内容采集
事实上,搜索引擎有一个规则,即喜新厌旧。如果一个网站的内容在网络上重复率很高,那么排名肯定不会好。网站 of 采集 百度会 不过收录之后会慢慢掉线,很少给你改过自新的机会,即使原创@之后天天更新>文章,没用。但这并不代表不能是采集,我们可以对采集中的文章做一些修改,比如替换内容、更改标题等。
3、网站内部链接
很多优化技术人员都知道,网站中有些页面的权重特别高,喜欢在权重高的页面上堆积大量的关键词链接。
<p>不可否认,在高权网站页面上添加焦点关键词链接有助于提升目标关键词的搜索引擎排名,但在高权页面 查看全部
网站内容采集器(Google推广:最近有些优化新手有给我提过这样一个问题)
谷歌推广:最近有优化新手问我这样一个问题,如何避免网站过度优化?如果优化不够,排名效果会差强人意。一旦网站优化过度,就会受到搜索引擎的惩罚。
今天特意整理了网站优化过程中的一些禁忌。
1、网站 的标题
首先,最典型的问题之一就是很多网站标题经常被一些客户剪掉。或者一个无关紧要的关键词,很容易被搜索引擎的算法判断为这个网站作弊,最终导致搜索引擎屏蔽该网站。
注意网站的标题对于关键词的写法,建议一个网页对应一两个关键词,网页的body内容应该是与网页标题的主题高度一致。
另一个问题是 网站 的页面标题不应该经常更改。不稳定的 网站 不会被百度点赞。建站之初,网站的每一个细节都应该考虑在内。一旦确立,就不会轻易改变。
2、网站内容采集
事实上,搜索引擎有一个规则,即喜新厌旧。如果一个网站的内容在网络上重复率很高,那么排名肯定不会好。网站 of 采集 百度会 不过收录之后会慢慢掉线,很少给你改过自新的机会,即使原创@之后天天更新>文章,没用。但这并不代表不能是采集,我们可以对采集中的文章做一些修改,比如替换内容、更改标题等。
3、网站内部链接
很多优化技术人员都知道,网站中有些页面的权重特别高,喜欢在权重高的页面上堆积大量的关键词链接。
<p>不可否认,在高权网站页面上添加焦点关键词链接有助于提升目标关键词的搜索引擎排名,但在高权页面
网站内容采集器( 前嗅大数据2022-01-25抽取热搜列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-26 01:16
前嗅大数据2022-01-25抽取热搜列表)
【从零开始学爬虫】采集微博热搜数据
前端嗅探大数据2022-01-25
热门“前端嗅探大数据”
与大数据巨头一起成长,做一个傲慢的大数据人
l 采集场景
【场景描述】采集微博热搜中的博文数据。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址
l采集网站
【入口网址】
[采集内容]采集微博热搜博文数据,采集字段:发布者、发帖时间、博文、转发数、评论数、点赞数。
【采集效果】如下图:
l采集想法
l配置步骤
1.新建采集任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
网站内容采集器(
前嗅大数据2022-01-25抽取热搜列表)
【从零开始学爬虫】采集微博热搜数据
前端嗅探大数据2022-01-25
热门“前端嗅探大数据”
与大数据巨头一起成长,做一个傲慢的大数据人
l 采集场景
【场景描述】采集微博热搜中的博文数据。
【使用工具】在嗅探ForeSpider数据采集系统之前,免费下载:
ForeSpider免费版下载地址
l采集网站
【入口网址】
[采集内容]采集微博热搜博文数据,采集字段:发布者、发帖时间、博文、转发数、评论数、点赞数。
【采集效果】如下图:
l采集想法
l配置步骤
1.新建采集任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
网站内容采集器(查看更多写博客基于日志服务的GrowthHacking(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-24 22:01
阿里云>云栖社区>主题图>P>php网站内容采集
推荐活动:
更多优惠>
当前主题:php网站内容采集加入采集
相关话题:
php网站内容采集相关博客查看更多博客
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS、二维码追踪技术)
作者:云磊 4389 浏览评论:02年前
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS追踪技术) 数据质量决定运营分析的质量上面我们介绍了GrowthHacking的整体增长情况架构,其中数据采集是整个数据分析的基础,只有数据才能进行有价值的分析;
阅读全文
日志服务-一站式配置采集Apache访问日志
作者:木子2422 浏览评论:03年前
自引入数据访问向导(Wizard)功能以来,日志服务不断优化访问向导功能,支持采集、存储、分析、离线下发各种数据,降低用户使用门槛使用日志服务。本文介绍了数据访问向导采集Apache日志和索引设置的一站式配置,以及通过默认dashboard和查询分析语句进行实时分析网站
阅读全文
网站采集器简介
作者:航空母舰1221 浏览评论:05年前
常用网络采集器主要分为桌面版和服务器版:桌面版基于windows等平台,使用本地带宽进行数据采集和发布程序,主要以“ 优采云网站采集器" 和 "EditorTools"; 服务器版本使用 PHP 或 ASP 编程,在 Linux 或 Windows 主机上运行,并使用服务器带宽
阅读全文
PHP采集业务信息和采集方法概述(第1部分)
作者:Tech Fatty 1044 浏览评论:04年前
近期,在电商市场上,商户导航层出不穷,采集了大量商户信息。如果您从事电子商务,这些信息仍然有用。我将这些信息用于我最近正在做的一个项目,但你不能把它给别人,所以别人不会给它。所以我必须自己爬。之前写过几个类似的爬虫来爬取网站的一些信息。
阅读全文
网站页面内容优化
作者:技术小牛1003 浏览评论:04年前
一、关键词分析:分析用户检索行为,有效实现搜索引擎营销,包括搜索
阅读全文
php采集
作者:wensongyu895 浏览评论:08年前
一、什么是php采集程序?二、为什么是采集?三、采集什么?四、采集怎么样?五、采集事物六、采集示例程序七、采集体验什么是php采集程序?php采集程序,又称php小偷,主要用于自动采集网络上网页中的特定内容,使用ph
阅读全文
基于PHP的cURL快速入门教程(小偷采集程序)
作者:suboysugar886 浏览评论:06年前
cURL是一个使用URL语法传输文件和数据的工具,支持多种协议,如HTTP、FTP、TELNET等,很多小偷程序都使用这个功能。最重要的是,PHP 还支持 cURL 库。本文将介绍 cURL 的一些高级特性以及如何在 PHP 中使用它。为什么使用 cU
阅读全文
PHP爬取采集类snoopy简介
作者:thinkyoung708 浏览人数:06年前
PHP爬虫采集类snoopy介绍2011年7月4日写的PHP爬虫方案,已阅读10270次感谢参考或原文服务器君共花了14.288 ms 花了2 个数据库查询让您努力获得此页面。试试阅读模式?希望
阅读全文
php网站内容采集相关问答
如何解决 PHP采集 超时?
作者:1496人查看评论数:15年前
我需要 采集a网站 的内容页面。先采集到链接,然后通过链接获取内容页面。但是,如果链接太多,一获取就会超时,必须分门别类少量获取。有近300个类别。手动设置分类也很慢。如何在不超时的情况下自动获取我想要的数据?请给我一些想法,谢谢!对不起,我没有说清楚。超过
阅读全文 查看全部
网站内容采集器(查看更多写博客基于日志服务的GrowthHacking(组图))
阿里云>云栖社区>主题图>P>php网站内容采集
推荐活动:
更多优惠>
当前主题:php网站内容采集加入采集
相关话题:
php网站内容采集相关博客查看更多博客
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS、二维码追踪技术)
作者:云磊 4389 浏览评论:02年前
基于日志服务的GrowthHacking(1):数据追踪和采集(APP、Web、email、SMS追踪技术) 数据质量决定运营分析的质量上面我们介绍了GrowthHacking的整体增长情况架构,其中数据采集是整个数据分析的基础,只有数据才能进行有价值的分析;
阅读全文
日志服务-一站式配置采集Apache访问日志
作者:木子2422 浏览评论:03年前
自引入数据访问向导(Wizard)功能以来,日志服务不断优化访问向导功能,支持采集、存储、分析、离线下发各种数据,降低用户使用门槛使用日志服务。本文介绍了数据访问向导采集Apache日志和索引设置的一站式配置,以及通过默认dashboard和查询分析语句进行实时分析网站
阅读全文
网站采集器简介
作者:航空母舰1221 浏览评论:05年前
常用网络采集器主要分为桌面版和服务器版:桌面版基于windows等平台,使用本地带宽进行数据采集和发布程序,主要以“ 优采云网站采集器" 和 "EditorTools"; 服务器版本使用 PHP 或 ASP 编程,在 Linux 或 Windows 主机上运行,并使用服务器带宽
阅读全文
PHP采集业务信息和采集方法概述(第1部分)
作者:Tech Fatty 1044 浏览评论:04年前
近期,在电商市场上,商户导航层出不穷,采集了大量商户信息。如果您从事电子商务,这些信息仍然有用。我将这些信息用于我最近正在做的一个项目,但你不能把它给别人,所以别人不会给它。所以我必须自己爬。之前写过几个类似的爬虫来爬取网站的一些信息。
阅读全文
网站页面内容优化
作者:技术小牛1003 浏览评论:04年前
一、关键词分析:分析用户检索行为,有效实现搜索引擎营销,包括搜索
阅读全文
php采集
作者:wensongyu895 浏览评论:08年前
一、什么是php采集程序?二、为什么是采集?三、采集什么?四、采集怎么样?五、采集事物六、采集示例程序七、采集体验什么是php采集程序?php采集程序,又称php小偷,主要用于自动采集网络上网页中的特定内容,使用ph
阅读全文
基于PHP的cURL快速入门教程(小偷采集程序)
作者:suboysugar886 浏览评论:06年前
cURL是一个使用URL语法传输文件和数据的工具,支持多种协议,如HTTP、FTP、TELNET等,很多小偷程序都使用这个功能。最重要的是,PHP 还支持 cURL 库。本文将介绍 cURL 的一些高级特性以及如何在 PHP 中使用它。为什么使用 cU
阅读全文
PHP爬取采集类snoopy简介
作者:thinkyoung708 浏览人数:06年前
PHP爬虫采集类snoopy介绍2011年7月4日写的PHP爬虫方案,已阅读10270次感谢参考或原文服务器君共花了14.288 ms 花了2 个数据库查询让您努力获得此页面。试试阅读模式?希望
阅读全文
php网站内容采集相关问答
如何解决 PHP采集 超时?
作者:1496人查看评论数:15年前
我需要 采集a网站 的内容页面。先采集到链接,然后通过链接获取内容页面。但是,如果链接太多,一获取就会超时,必须分门别类少量获取。有近300个类别。手动设置分类也很慢。如何在不超时的情况下自动获取我想要的数据?请给我一些想法,谢谢!对不起,我没有说清楚。超过
阅读全文
网站内容采集器(笑话站源码_PHP开发++APP+采集接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-01-21 19:06
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集界面
2/3/201801:11:42
摘要:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何防止网站变成采集
17/4/2009 12:04:00
只要能被浏览器访问,没有什么不能采集,你选择是保护版权还是保护网站
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用和好处,我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
对于网站data采集,如何选择合适的服务器?
2/7/202012:01:21
网站Data采集,也称为数据采集,是使用设备从系统外部采集数据输入系统的接口。数据采集技术现已广泛应用于各个领域。对于制造企业庞大的生产数据,数据采集tools
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,不幸的是,一些 SEO 将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
如何使用免费的网站源码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
查看全部
网站内容采集器(笑话站源码_PHP开发++APP+采集接口
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集界面
2/3/201801:11:42
摘要:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
如何在博客或网站上使用标签?
28/1/201008:55:00
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
如何防止网站变成采集
17/4/2009 12:04:00
只要能被浏览器访问,没有什么不能采集,你选择是保护版权还是保护网站
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用和好处,我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
对于网站data采集,如何选择合适的服务器?
2/7/202012:01:21
网站Data采集,也称为数据采集,是使用设备从系统外部采集数据输入系统的接口。数据采集技术现已广泛应用于各个领域。对于制造企业庞大的生产数据,数据采集tools
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,不幸的是,一些 SEO 将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
如何使用免费的网站源码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-20 01:19
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-19 17:08
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容采集器(项目招商找A5快速获取精准代理名单博客SEO培训)
项目投资找A5快速获取精准代理商名单
Bugs Blog SEO培训介绍:
站长,做网站,内容为王,外链为王。
其实就是在做网站这两件事。不管是国王还是国王。除了做内容就是做外部链接。
Bugsoft,作为国内最顶级、最好的seo软件之一,如何发挥其最大价值是每个Bugsoft用户的必修课。
Bugs的优势在于网络资源无限,只要能在搜索中找到,就能抢到。
您可以创建成千上万个论坛帐户作为自己的海军力量。
您还可以创建数千个博客帐户作为您自己的链接输出力量。
你也可以搞几十上百个网站作为自己的收入来源。
这一切都可以用蠕虫来完成。
本次SEO培训大纲:
第 1 部分,网站 内容
对于百度来说,内容很重要。好的内容对PV也有直观的反映。
做个垃圾站还行,但内容不能太垃圾。否则,无论有多少IP,你可以从弹出窗口中赚到最多的钱。
如何利用Bugs输出优质内容到网站。这是重点,也是本次seo培训的重点。
第二部分,如何创建网站的外部链接。
如何找到高质量的外部链接,发送外部链接的技巧,顶部的技巧 关键词。所有这些技巧都可以通过错误轻松实现。
这些技巧也会在本次seo培训中一一讲解。
第三部分,站群构建。
用蠕虫做1站是一种严重的浪费。不做几十个站,赔了更新bug的钱。
虽然Bugs是一款海量分发软件,但软件的核心重点不是站群,而是用Bugs来站群,我觉得不比骑士差,当然这里的技巧也不少。
在本次seo培训中,也会作为一个话题进行讲解。
Bugs Software是一款拥有超强DIY能力的软件。
不同的操作方法会产生不同的效果。
玩 Bugs 博客并赢得 SEO。
第 1 部分,网站 内容
这是bug软件自带的采集:
这里的采集规则都写好了,通过这些采集,你可以采集到我们需要发送外链的文章,以及内置的外链博客和论坛文章等等,其实已经够丰富了。
我们都知道Bugs 不是专业的采集软件。在这里,让我告诉你如何获得高质量的 文章 内容:
在你电脑的硬盘里,一般这个目录是D:\ZhongCong Software\ZongCong Blog 2009\articles,ZZC软件里面可以放HTML页面和txt文件等,可以放几万个文章。
博君采集器,这个软件可以和Wormsoft很好的结合,你可以用他的免费版,也可以用付费的高级版,(a5团长程哥有优惠,可以直接找他买) ,功能更强大。
这个软件可以采集,使用起来也比较简单。采集来之后就可以导出TXT文档了。这是我推荐的第一个采集器,通过这个采集器采集的文章,放到D:\bug software\bug blog 2009\articles目录下。
这是一个将相关类别放在一起的文件夹。TXT的一个优点是你可以在百度上找到一个排版助手软件。它被称为“排版助手”,它也是免费的。通过这个软件,我们可以制定我们的文章整体规范。很适合阅读。文章采集 down 后,也可以按大小排序,手动移除。
垃圾文章。文章 字少,空 文章 等。
下面说一下Bugs Blog和第二个软件的使用,也就是大家都知道的优采云,大家可以看看优采云采集器最高版本的功能,非常强大的。但价格相对昂贵。据团长介绍,a5团购()将于5月底做一次超级优采云团购。到时候大家可以关注一下。团购非常优惠。优采云基本上采集市场上的一切网站。优采云 的采集 规则这里不再讨论。
好的,现在我来谈谈如何将bug博客与优采云结合起来。
大家请看,三个红色箭头指向html_tpl.html,这是我上传的文件,就是我设置的html模板,选择那个模板,就可以导出html了,同样的html也可以放在D :\ Bugs Software\ Bugs Blog 2009\articles 文件目录。这是我正在谈论的 2 个 文章 方法。
最后讲一个txt splitter.rar 很多业内人士网站对这个有很大的需求。你可以下载这个软件。
通过这个软件,可以得到原创文章,可以去台湾找txt,txt书,然后转换成简体,再通过这个软件导出,就可以转换成文本了TXT书文章分部的每篇文章,比如助记书,可以将每一章导出为单个txt文件,非常丰富。
网站内容,我上面提到的三种方式辅助bug效果更好。你可以制作自己的文章仓库,文章数据库,这是首先要构建的。
总结一下:我主要讲了如何采集文章,有三种方式:
采集文章方法:1、博君采集器1.0 Beta版,排版助手可在a5bug博客VIP售后群分享通讯组。
2、优采云采集——另存为本地html,模板在组内:html_tpl.html
3、txt拆分器.rar。你可以去台湾找行业txt书,通过google和baidu。
这是需要发送的文章的bug软件的处理方案。第一个选项是选择标题。
一个网站,一开始没有权重选择DA,可以增加网站的权重,可以选择DA和DB,当网站有一定权重时,不建议选择DA和DB,D d 同义词替换,这里可以选择中英文语法,这个功能其实更好。D e 这个选项是bug的值的体现,交叉收录,发博客的时候可以选择在文章中随机插入,可以起到迷惑的效果。
文章发送自己网站时可以选择尾部,对网站的收录有利。
DI 选项也是一项重要功能。当然这个功能对于网站,关键词标题来说不大,如果要抢占1个关键词,可以加长尾批量,比如这个关键词@为中学生>,那么所有文章前面都有中学生。这个效果需要灵活使用。一些卖产品的朋友会喜欢这个功能,通过长尾带客户。
第二部分,如何创建网站的外部链接。
首先bug博客是重量级的,bug博客,大家可以群注册,一天注册几个群,方便注册的都注册,2天后发文章有外链.
可以看到,bug资源列表中有很多资源,可以先下载。然后重新注册。每组可以按PR值排序,注册PR高的论坛。其他通过自动注册过滤。自动注册成功率一般为10%。PR高的论坛,可以弹出验证。代码注册,注册好,看能不能回复,如果不能,进论坛有什么限制,基本上软件备注里会有提示。
Buggy软件也可以自己抢资源,这是其他软件无法比拟的。
可以看到,红色箭头是选择类型,表示你要抓取的网站的类型。蓝色箭头是说明。双击下方说明即可,粉色箭头指关键词,site:edu表示edu类教育站,或site:gov,即政府站,或者你需要的行业关键词,site:表示所有站点,包括地点; 以下关键字内容。site: composition,这将检索 网站 以“composition”作为主要组件。现在很多论坛都支持qq直接登录,我们也可以多注册几个qq账号直接放,非常方便。嘿嘿。
论坛账号是长期项目,需要维护。也许您需要维护一个帐户一周。怎么用qq导入bug软件,这里也有技巧!
可以导出网站到本地
这是我通过导出网站数据函数导出的地址。导出后虽然是txt格式,但是因为是数据库格式,所以可以通过excel打开。
这是我用excel打开后的结果,E是用户名,F是密码,随便拉一下excel,拉一下就可以保存,然后导入回虫软件,E是qq号, F 是密码。
红色箭头是QQ号,蓝色箭头是密码。另外,制作外链的方法也有问题。可以选择隐藏代码,可以选择背景图片代码,这是防止外部链接文章被删除的好方法。
新的网站每天不能超过200个外部链接,旧的网站每天不能超过2000个。如果用bug发外链,基本不会是K。
因为每个外部链接 文章 都是不同的。和所谓的群不一样。
第三部分,站群构建。
站群,是一项昂贵的投资。首先,域名、虚拟主机、服务器都是金钱和域名。其实可以选择二级域名和空间。我建议选择虚拟主机。越便宜越好,所以是合理的。二级域名,如何选择最合理,选择二级域名,如何选择最合理,自己注册一个顶级域名,
作为导航,一个顶层能做多少2级,作为小说站,作为图片站,
作为一个战队,有2个方向可供选择。第一纯垃圾站,第二十几个精品站
以DEDEcms为例,一个网站可以绑定1个目录,那个目录可以收录文章,其实如果是精品网站,就等于1 column bound 1 如果选择 1,则只会发送到 ID 为 1 的列,也可以选择多个,1、2、3,以逗号分隔。如果是纯垃圾站,那就不用选了。直接1个站,整组数据随机发到每一列。发送后会自动生成,模拟人工操作,发送,时间间隔可以选择。
这个软件会自动随机化。这个时间在 5 到 60 秒之间。如果选择0,就不会有随机时间,那么发送速度会很快,bug就是垃圾站,虽然不会像自动更新网站那么简单。你采集组织了100,000个数据,你可以将它发送到100个垃圾站。这里的10万条数据都是非常优质的数据,那么你就可以占据这些关键词。
以下是处理 文章 的所有选项。Bugs Software作为战队的另一个优势是发送的文章可以保存在发布历史中,而这些文章可以在发送外部链接时保存。@文章作为外链输出,最重要的是你有100个网站,不用更新就可以更新到一定程度。如果要打常规战,那么值就会体现出来,直接设置关键词,100个网站帖子和所有新网站的关键词,所以吴伦不管是做seo,还是站出来做大佬,效果都一样,非常好。它起到了善用站群资源的作用,这也是站群价值的最终体现。
好了,bug博客的seo培训到此结束,感谢售后客服小瑶的分享,也感谢组长整理此内容;-),如果你对bug博客更感兴趣,欢迎您联系程组长如果您从格咨询购买,我们将为a5官方bug博客的会员提供更多的SEO金牌培训服务。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容采集器(欢迎感兴趣的朋友前来JZ5U下载网站万能信息采集器使用! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-19 17:07
)
网站Universal Information采集器 是一个小巧、易于使用、功能强大且非常流行的网站 抓取和网页抓取工具。该软件结合了所有网站网页抓取软件的优点,可以抓取网站上的所有信息并自动发布到你的网站,任何网站任何类型的信息会按照例如:新闻、供需信息、人才招聘、论坛帖子、音乐、下一页链接等进行抓取。欢迎感兴趣的朋友来JZ5U下载网站万能信息采集器 使用!
软件特点:
1、信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,网站信息优采云采集器可以实现采集添加的自动完成. 其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2、网站登录
对于需要登录才能看到信息内容的网站,网站信息优采云采集器可以很方便的登录和采集,即使有一个验证码,可以通过登录采集获取你需要的信息。
3、文件自动下载
如果需要采集图片等二进制文件,只需设置网站信息优采云采集器,即可在本地保存任意类型的文件。
4、多级页面采集一次爬取整个站点
不管有多少类和子类,都可以同时设置采集为多级页面的内容。如果一条信息分布在多个不同的页面上,网站通用信息采集器也可以自动识别N级页面,实现信息采集抓取。该软件附带一个 8 层 网站采集 示例。
5、自动识别特殊URL
许多 网站 网页链接是特殊的 URL,例如 javascript:openwin('1234'),它们不是常见的。网站通用信息采集器还可以自动识别和捕获内容。
6、自动过滤重复导出数据过滤重复数据处理
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复。(新版本增加了新功能)。
7、多页新闻自动合并、广告过滤
有的新闻有下一页,网站万能资讯采集器也能抓到每一页。并且可以同时保存抓取到的新闻中的图文,过滤掉广告。
8、自动cookies和防盗链
很多下载类型的网站都做了cookie校验或者防盗链,直接输入URL不能抓取内容,但是网站万能信息采集器可以自动校验cookie和防盗链水蛭,呵呵,确保你得到你想要的。
9、另外增加了模拟手动提交的功能。租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软件特点:
1、采集发布是全自动的。
2、自动 JavaScript 特殊 URL。
3、会员登录网站 也会被捕获。
4、一次抓取整个网站,不管有多少类别。
5、可以下载任何类型的文件。
6、自动合并多页新闻,过滤广告。
7、多级页面联合采集。
8、模拟手动点击防盗链。
9、验证码识别。
10、图片自动加水印。
查看全部
网站内容采集器(欢迎感兴趣的朋友前来JZ5U下载网站万能信息采集器使用!
)
网站Universal Information采集器 是一个小巧、易于使用、功能强大且非常流行的网站 抓取和网页抓取工具。该软件结合了所有网站网页抓取软件的优点,可以抓取网站上的所有信息并自动发布到你的网站,任何网站任何类型的信息会按照例如:新闻、供需信息、人才招聘、论坛帖子、音乐、下一页链接等进行抓取。欢迎感兴趣的朋友来JZ5U下载网站万能信息采集器 使用!
软件特点:
1、信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,网站信息优采云采集器可以实现采集添加的自动完成. 其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2、网站登录
对于需要登录才能看到信息内容的网站,网站信息优采云采集器可以很方便的登录和采集,即使有一个验证码,可以通过登录采集获取你需要的信息。
3、文件自动下载
如果需要采集图片等二进制文件,只需设置网站信息优采云采集器,即可在本地保存任意类型的文件。
4、多级页面采集一次爬取整个站点
不管有多少类和子类,都可以同时设置采集为多级页面的内容。如果一条信息分布在多个不同的页面上,网站通用信息采集器也可以自动识别N级页面,实现信息采集抓取。该软件附带一个 8 层 网站采集 示例。
5、自动识别特殊URL
许多 网站 网页链接是特殊的 URL,例如 javascript:openwin('1234'),它们不是常见的。网站通用信息采集器还可以自动识别和捕获内容。
6、自动过滤重复导出数据过滤重复数据处理
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复。(新版本增加了新功能)。
7、多页新闻自动合并、广告过滤
有的新闻有下一页,网站万能资讯采集器也能抓到每一页。并且可以同时保存抓取到的新闻中的图文,过滤掉广告。
8、自动cookies和防盗链
很多下载类型的网站都做了cookie校验或者防盗链,直接输入URL不能抓取内容,但是网站万能信息采集器可以自动校验cookie和防盗链水蛭,呵呵,确保你得到你想要的。
9、另外增加了模拟手动提交的功能。租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软件特点:
1、采集发布是全自动的。
2、自动 JavaScript 特殊 URL。
3、会员登录网站 也会被捕获。
4、一次抓取整个网站,不管有多少类别。
5、可以下载任何类型的文件。
6、自动合并多页新闻,过滤广告。
7、多级页面联合采集。
8、模拟手动点击防盗链。
9、验证码识别。
10、图片自动加水印。
网站内容采集器(网站内容采集器是一个很好的方法,不易误删)
网站优化 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2022-01-18 09:00
网站内容采集器。当然,如果网站内容过多,或是想用ajax加载静态页面,那么,用采集器是一个很好的方法。推荐使用采集器,可以做到,什么都不用做,采集其他网站内容,甚至可以同步自己网站的内容,当然,如果网站内容还不够丰富的话,一般还不支持批量采集。
用工具采集各网站的内容,做成爬虫啊,自己写爬虫爬一下,
推荐用易语言的人工智能采集器,界面好看,速度快。多语言支持,而且语言翻译准确率高。比其他工具好的地方,就是可以多语言同时采集并编辑。易语言采集器安装文件,不易误删,找回也很简单。
使用易语言爬虫采集器,不管是百度,新浪,还是国外,谷歌,你都能轻松采集!而且同步速度很快,
合肥刷书网站长的人工智能采集软件还不错,没记错的话是他们公司的,他们看到我网站的外链挺多的,线上线下宣传不错,我之前做站群,就推荐给我这软件,后面我用了,效果也是不错的。要不就是图片代码有点难,复制粘贴没有那么快。
用采集器很多地方都可以采集,大多会用到网站合并(这里推荐几款免费工具,nsxtreme),云采集(各站点互采)。我做站长多年,用过很多工具,目前体验最好的是extremehttp,站长必备,有人说软件功能太少,这是工具的一个好处,适合更多站长。当然如果你是个人站长,就不推荐你用免费工具了,而且免费的也不能完全满足个人站长要求。
支持链接采集,站内收录,收录过程全面提速,支持各大站点收录,收录后全站内全部导出,收录完毕全站同步seo导出,具有独一无二的上传订单数据采集器,将浏览器不能上传或上传困难的链接转换成能上传网站的seo好引擎收录工具。 查看全部
网站内容采集器(网站内容采集器是一个很好的方法,不易误删)
网站内容采集器。当然,如果网站内容过多,或是想用ajax加载静态页面,那么,用采集器是一个很好的方法。推荐使用采集器,可以做到,什么都不用做,采集其他网站内容,甚至可以同步自己网站的内容,当然,如果网站内容还不够丰富的话,一般还不支持批量采集。
用工具采集各网站的内容,做成爬虫啊,自己写爬虫爬一下,
推荐用易语言的人工智能采集器,界面好看,速度快。多语言支持,而且语言翻译准确率高。比其他工具好的地方,就是可以多语言同时采集并编辑。易语言采集器安装文件,不易误删,找回也很简单。
使用易语言爬虫采集器,不管是百度,新浪,还是国外,谷歌,你都能轻松采集!而且同步速度很快,
合肥刷书网站长的人工智能采集软件还不错,没记错的话是他们公司的,他们看到我网站的外链挺多的,线上线下宣传不错,我之前做站群,就推荐给我这软件,后面我用了,效果也是不错的。要不就是图片代码有点难,复制粘贴没有那么快。
用采集器很多地方都可以采集,大多会用到网站合并(这里推荐几款免费工具,nsxtreme),云采集(各站点互采)。我做站长多年,用过很多工具,目前体验最好的是extremehttp,站长必备,有人说软件功能太少,这是工具的一个好处,适合更多站长。当然如果你是个人站长,就不推荐你用免费工具了,而且免费的也不能完全满足个人站长要求。
支持链接采集,站内收录,收录过程全面提速,支持各大站点收录,收录后全站内全部导出,收录完毕全站同步seo导出,具有独一无二的上传订单数据采集器,将浏览器不能上传或上传困难的链接转换成能上传网站的seo好引擎收录工具。
网站内容采集器(阿里巴巴上挂个外贸品牌,看看这些国外批发都在哪里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-16 23:01
网站内容采集器,可以采集微信公众号、微博、今日头条等网站的文章,价格从几十到几百不等,我做的就是这个,
推荐你一个,我之前在一家外贸公司做过业务员,他们把他们的外贸业务员业务群发放一些外贸货源,他们上门找货源。效果还是很不错的,当时我也不知道上门找货源的意义。我就想着来网上找货源,无意中看到这个网站,货源还是挺不错的,你可以尝试一下,推荐你去看看,了解一下,
可以进群呀,微信交流一下,还有老外很乐意免费给你教我们怎么用网站。或者你可以直接买些国外网站的收款币种账号就可以了。总之,你真的想进入外贸行业,相信问题不大,
priceminister上面有很多外贸人工厂站
看你要批发那些货了,我刚开始做不知道批发哪些,我知道一个叫全球速卖通的,是对接国内外贸批发价的,进货也不用交税。交易什么的只要出运费就行了,
你可以打开外贸b2c的阿里巴巴,看看这些国外的批发都在哪里,再想想你的产品适合进哪些,直接联系商户,有些国外网站开设免费申请账号的渠道,
找不到外贸网站,就在阿里巴巴上挂个外贸品牌,很多工厂供货~自己买产品, 查看全部
网站内容采集器(阿里巴巴上挂个外贸品牌,看看这些国外批发都在哪里)
网站内容采集器,可以采集微信公众号、微博、今日头条等网站的文章,价格从几十到几百不等,我做的就是这个,
推荐你一个,我之前在一家外贸公司做过业务员,他们把他们的外贸业务员业务群发放一些外贸货源,他们上门找货源。效果还是很不错的,当时我也不知道上门找货源的意义。我就想着来网上找货源,无意中看到这个网站,货源还是挺不错的,你可以尝试一下,推荐你去看看,了解一下,
可以进群呀,微信交流一下,还有老外很乐意免费给你教我们怎么用网站。或者你可以直接买些国外网站的收款币种账号就可以了。总之,你真的想进入外贸行业,相信问题不大,
priceminister上面有很多外贸人工厂站
看你要批发那些货了,我刚开始做不知道批发哪些,我知道一个叫全球速卖通的,是对接国内外贸批发价的,进货也不用交税。交易什么的只要出运费就行了,
你可以打开外贸b2c的阿里巴巴,看看这些国外的批发都在哪里,再想想你的产品适合进哪些,直接联系商户,有些国外网站开设免费申请账号的渠道,
找不到外贸网站,就在阿里巴巴上挂个外贸品牌,很多工厂供货~自己买产品,
网站内容采集器(,企业网站管理系统源码,(中英繁)版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-11 21:12
后台地址/admin,后台账号admin密码为admin
>公司企业网站管理系统源码三语(中英繁体)免费版由企业网站建设专家和企业网站系统开发人员制作。采用asp+access开发,数据库容量大,运行稳定。速度快,安全性能优异,功能更强大,是一套通用、公司、企业自助网站管理系统,sql版本调试请查阅《iis和sql安装操作手册》
>公司企业网站管理系统中英文繁体接入版,企业公司网站系统接入版,企业网站管理系统,企业网站源码,公司网站管理系统,公司企业网站自助式网站管理系统源码。漂亮的前台,强大的网站后台管理功能,自助管理前台相关栏目。中文、英文、繁体三语使公司、企业网站广为人知,占据网络市场。公司企业网站中英文接入版管理系统具有公司产品和服务的宣传、介绍、展示、推广、销售、在线电子商务等功能。业务和利润是全站系统设计功能的最终目标。完善网站企业简历、企业文化、企业新闻、行业资讯、产品展示、下载中心、企业荣誉、营销网络、人才招聘、客户留言、会员中心等子模块,充分考虑大体需求公司、企业中英文网站管理系统。全后台管理,后台功能齐全,使用维护方便。无论是生产、销售,还是服务,对于大中小型企业来说,只要企业网站的管理者会打字,都会打造专业的公司,企业网站,并随时管理网站 内容。本系统是基于ASP+sql技术开发的电子商务平台,是一个安全、稳定、快速、全自动化、全智能化的在线管理、维护、更新企业网站管理系统。全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?
>?企业版网站管理系统中文ACCESS版,企业版网站管理系统中英文繁体SQL版,企业公司网站系统中文SQL版,全屏中英文繁体SQL版,全屏中文SQL版。 查看全部
网站内容采集器(,企业网站管理系统源码,(中英繁)版)
后台地址/admin,后台账号admin密码为admin
>公司企业网站管理系统源码三语(中英繁体)免费版由企业网站建设专家和企业网站系统开发人员制作。采用asp+access开发,数据库容量大,运行稳定。速度快,安全性能优异,功能更强大,是一套通用、公司、企业自助网站管理系统,sql版本调试请查阅《iis和sql安装操作手册》
>公司企业网站管理系统中英文繁体接入版,企业公司网站系统接入版,企业网站管理系统,企业网站源码,公司网站管理系统,公司企业网站自助式网站管理系统源码。漂亮的前台,强大的网站后台管理功能,自助管理前台相关栏目。中文、英文、繁体三语使公司、企业网站广为人知,占据网络市场。公司企业网站中英文接入版管理系统具有公司产品和服务的宣传、介绍、展示、推广、销售、在线电子商务等功能。业务和利润是全站系统设计功能的最终目标。完善网站企业简历、企业文化、企业新闻、行业资讯、产品展示、下载中心、企业荣誉、营销网络、人才招聘、客户留言、会员中心等子模块,充分考虑大体需求公司、企业中英文网站管理系统。全后台管理,后台功能齐全,使用维护方便。无论是生产、销售,还是服务,对于大中小型企业来说,只要企业网站的管理者会打字,都会打造专业的公司,企业网站,并随时管理网站 内容。本系统是基于ASP+sql技术开发的电子商务平台,是一个安全、稳定、快速、全自动化、全智能化的在线管理、维护、更新企业网站管理系统。全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?全站下载,程序源码,功能齐全,欢迎大家下载使用。企业网站管理系统的功能会更加完善,真正能为建筑公司和企业网站的每一个人带来安全保障。稳定高效。本系统分为企业网站管理系统中英文ACCESS?
>?企业版网站管理系统中文ACCESS版,企业版网站管理系统中英文繁体SQL版,企业公司网站系统中文SQL版,全屏中英文繁体SQL版,全屏中文SQL版。

