
百度网页关键字抓取
百度网页关键字抓取(网站“抓取诊断”失败的原因有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-07 15:05
对于SEO人员来说,他们经常使用百度官方工具对网站进行审核,检查网站的各项指标是否符合预期。其中,“爬虫诊断”是站长常用的工具。很多站长都说在使用网站“获取诊断”的时候,经常会提示诊断失败,那是怎么回事。
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。它反馈的结果代表了蜘蛛对站点内容的理解。通常网站爬行诊断失败,和百度蜘蛛爬行有直接关系。
网站“爬虫诊断”失败的原因有哪些?
1、Robots.txt 被禁止
如果在Robots.txt中屏蔽了百度抓取网站某个目录,当你在该目录下生成内容时,百度很难抓取到该目录下的内容,抓取诊断也会出现故障提示。
2、网站访问速度
很多站长说在本地测试中,我的网站返回HTTP状态码200,但是爬虫诊断一直显示爬虫在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬取速度可能会延迟很长时间,从而导致在明明可以访问的情况下爬行诊断失败的问题。
遇到这个问题时,需要定期监控服务器上各个地方的访问速度,优化网站的打开速度。
3、CDN 缓存更新
我们知道 CDN 缓存更新需要时间。虽然您在管理平台后台实时在线更新,但由于不同服务商的技术不对称,往往会造成一定的时延。
这必然会导致网站爬取失败。
4、 有跳转到爬虫诊断
如果更新旧内容,修改网站版本,使用301或302重定向,由于配置错误原因导致重定向次数过多,百度抓取失败的问题也会发生。
5、DNS 缓存
由于DNS缓存的存在,在本地查询URL时,可以正常访问,但排除上述一般问题后,爬行诊断仍提示失败,则需要更新本地DNS缓存,或使用代理IP要审核网站 很流畅的访问。
网站 关于“获取诊断”的常见问题:
关于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断对收录有帮助吗?
从目前很多SEO人员的反馈结果来看,并没有合理的数据支持。可以证明爬虫诊断工具对百度收录是有利的,但或许对百度的快照更新有一定的影响。
总结:网站“爬网诊断”失败的原因有很多。除了参考官方提示外,还需要一一排除。以上内容仅供参考。
蝙蝠侠IT转载需要授权! 查看全部
百度网页关键字抓取(网站“抓取诊断”失败的原因有哪些?-八维教育)
对于SEO人员来说,他们经常使用百度官方工具对网站进行审核,检查网站的各项指标是否符合预期。其中,“爬虫诊断”是站长常用的工具。很多站长都说在使用网站“获取诊断”的时候,经常会提示诊断失败,那是怎么回事。

网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。它反馈的结果代表了蜘蛛对站点内容的理解。通常网站爬行诊断失败,和百度蜘蛛爬行有直接关系。
网站“爬虫诊断”失败的原因有哪些?
1、Robots.txt 被禁止
如果在Robots.txt中屏蔽了百度抓取网站某个目录,当你在该目录下生成内容时,百度很难抓取到该目录下的内容,抓取诊断也会出现故障提示。
2、网站访问速度
很多站长说在本地测试中,我的网站返回HTTP状态码200,但是爬虫诊断一直显示爬虫在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬取速度可能会延迟很长时间,从而导致在明明可以访问的情况下爬行诊断失败的问题。
遇到这个问题时,需要定期监控服务器上各个地方的访问速度,优化网站的打开速度。
3、CDN 缓存更新
我们知道 CDN 缓存更新需要时间。虽然您在管理平台后台实时在线更新,但由于不同服务商的技术不对称,往往会造成一定的时延。
这必然会导致网站爬取失败。
4、 有跳转到爬虫诊断
如果更新旧内容,修改网站版本,使用301或302重定向,由于配置错误原因导致重定向次数过多,百度抓取失败的问题也会发生。
5、DNS 缓存
由于DNS缓存的存在,在本地查询URL时,可以正常访问,但排除上述一般问题后,爬行诊断仍提示失败,则需要更新本地DNS缓存,或使用代理IP要审核网站 很流畅的访问。
网站 关于“获取诊断”的常见问题:
关于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断对收录有帮助吗?
从目前很多SEO人员的反馈结果来看,并没有合理的数据支持。可以证明爬虫诊断工具对百度收录是有利的,但或许对百度的快照更新有一定的影响。
总结:网站“爬网诊断”失败的原因有很多。除了参考官方提示外,还需要一一排除。以上内容仅供参考。
蝙蝠侠IT转载需要授权!
百度网页关键字抓取(51招聘列表页,查找百度,谷歌上面的某个排行 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-04 12:06
)
如果你想获取网站的某个页面的信息,关键是能够顺利请求那个页面。一些网站加密等技术可以防止你被抓住,你很难成功。
我抓住了 51job 招聘列表页面。问题的关键是如何找到下一页。51是通过post方式提交表单,那么所有的参数都要通过参数找出来写入请求信息中。
请求连接方式
private Scanner openConnection (int i,String keyName,String link) {
try {
URL url = new URL("http://search.51job.com/jobsea ... 6quot;);
//参数设置
String parameter = "postchannel=0000&stype=2&jobarea=0100&district=&address=&lonlat=&radius=" +
"&funtype_big=0000&funtype=0000&industrytype=00&issuedate=9&keywordtype=2&dis_keyword=" +
"&keyword=&workyear=99&providesalary=99&cotype=99°reefrom=99&jobterm=01&ord_field=0" +
"&list_type=1&last_list_type=1&curr_page=&last_page=1&nStart=1&start_page=&total_page=86" +
"&jobid_list=39297991~39298287~39298722~39298729~39297918~39297800~39298262~39297331~39297238~39297080~39296848~39297361~39296644~39296315~39287153~39295409~39295407~39295397~39295396~39295391~39287385~39293469~39287417~39285861~39281595~39281853~39279955~39281274~39280683~38748545~37068616~38130945~39023955~36747022~36493173~39006183~38960955~38960944~38960615~38980334~37888484~37584999~38998054~37585073~37332619~36882505~34976909~37307284~37307262~36999896~36767409~39242127~7369258~35503114~35502793~35496087~35496083~35495350~35494140~35493224~35492320~35487346~35468080~35457510~35457504~35457501~35398467~35380047~35347719~35347637~34991677~20974922~20974918~37441300~35465051~39160193~39029414~38138399~39136977~36632495~39266845~39270060~39266835~39097249~39082877~37663952~37662532~37662480~37663986~37662626~37662589~37662556~37738455~39270625~38433053~38261468~38486743~39057636~34582292~36475553~37257361~37257567~37257262~36741386~36711006~36498218~38914431~38734212~38674569~38787188~39259469~38927584~39024252~39024230~39228632~35252232~38658258~38658243~38625335~39245388~37319651~36852389~39136912~39159440~37456013~39256295~39214509~39253898~37376056~38561452~38295890~39156937~26052225~38711016~39272058~39271701~37777885~38524663~39022301~39063658~37777523~39018693~37897821~37023954~39242449~39242399~36227979~38635974~39100175~39200749~39251242~39197848~39229735~39108206~38520680~38520612~37512047~37373955~36748357~36558807~36553946~36994069~35651002~37645149~35650457~37547299~37547226~37547191~37547135~37325202~38909563~37981021~36518439~38435329~38356348~39225954~38905834~39100737~38753876~38753837~38648131~38909881~38909871~39253871~39139848~37756802~38207471~38715097~38714739~39228968~39109760~39109531~39109511~38412880~39193350~38918885~38443045~38133816~35085561~38011368~"+
"&jobid_count=2551&schTime=15&statCount=364" +
"&statData=404|114|45|61|92|99|29|34|80|27|15|29|49|449|1|228|133|0|0|1|1|243|494|5|0|0|1|0|7|232|321|139|26|1|0|152|831|1|1|4|18|8|8|4|3|0|0|0|0|0|0|588|0|1|0|0|0|0|1|13|0|0|0|0|0|0|0|1|0|0|0|0|0|0|2|254|6|6|0|1|1|0|0|0|0|0|0|1|0|0|0|0|2|0|1|0|0|0|0|0|0|0|0|0|0|0|365|14|13|0|5|3|18|9|2|0|1|26|6|2|0|0|3|1|2|3|0|9|32|1|0|6|1|0|0|0|13|209|1|0|3|1|7|32|5|37|1|0|3|0|0|13|2|9|10|0|1|0|5|1|1|0|0|2"+
"&fromType=";
//设置分页的页码
parameter = parameter.replace("curr_page=", "curr_page="+String.valueOf(i));
parameter = parameter.replace("fromType=", "fromType="+String.valueOf(14));
//设置关键字“程序员”
parameter = parameter.replace("dis_keyword=", "dis_keyword="+URLEncoder.encode(keyName, "GBK"));
parameter = parameter.replace("keyword=", "keyword="+URLEncoder.encode(keyName, "GBK"));
//打开链接设置头信息
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
//伪装请求
conn.setRequestProperty("Host", "search.51job.com");
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//post方式参数长度必须设定
conn.setRequestProperty("Content-Length", Integer.toString(parameter.getBytes("GB2312").length));
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB5; .NET CLR 1.1.4322; .NET CLR 2.0.50727; Alexa Toolbar; MAXTHON 2.0)");
OutputStream o = conn.getOutputStream();
OutputStreamWriter out = new OutputStreamWriter(o, "GBK");
out.write(parameter);
out.flush();
out.close();
//获得请求字节流
InputStream in = conn.getInputStream();
//解析
Scanner sc = new Scanner(in, "GBK");
return sc;
} catch (Exception e) {
log.error(e,e);
return null;
}
}
这样就可以顺利的获取到第一页关键词的列表信息。
完成这一步后,你就可以分析你想找的信息了,比如公司信息,职位……
<p>while (sc.hasNextLine()) {
String line = sc.nextLine();
sp = line.indexOf("class=\"jobname\" >", sp + 1);
if (sp != -1) {
sp = line.indexOf(" 查看全部
百度网页关键字抓取(51招聘列表页,查找百度,谷歌上面的某个排行
)
如果你想获取网站的某个页面的信息,关键是能够顺利请求那个页面。一些网站加密等技术可以防止你被抓住,你很难成功。
我抓住了 51job 招聘列表页面。问题的关键是如何找到下一页。51是通过post方式提交表单,那么所有的参数都要通过参数找出来写入请求信息中。
请求连接方式
private Scanner openConnection (int i,String keyName,String link) {
try {
URL url = new URL("http://search.51job.com/jobsea ... 6quot;);
//参数设置
String parameter = "postchannel=0000&stype=2&jobarea=0100&district=&address=&lonlat=&radius=" +
"&funtype_big=0000&funtype=0000&industrytype=00&issuedate=9&keywordtype=2&dis_keyword=" +
"&keyword=&workyear=99&providesalary=99&cotype=99°reefrom=99&jobterm=01&ord_field=0" +
"&list_type=1&last_list_type=1&curr_page=&last_page=1&nStart=1&start_page=&total_page=86" +
"&jobid_list=39297991~39298287~39298722~39298729~39297918~39297800~39298262~39297331~39297238~39297080~39296848~39297361~39296644~39296315~39287153~39295409~39295407~39295397~39295396~39295391~39287385~39293469~39287417~39285861~39281595~39281853~39279955~39281274~39280683~38748545~37068616~38130945~39023955~36747022~36493173~39006183~38960955~38960944~38960615~38980334~37888484~37584999~38998054~37585073~37332619~36882505~34976909~37307284~37307262~36999896~36767409~39242127~7369258~35503114~35502793~35496087~35496083~35495350~35494140~35493224~35492320~35487346~35468080~35457510~35457504~35457501~35398467~35380047~35347719~35347637~34991677~20974922~20974918~37441300~35465051~39160193~39029414~38138399~39136977~36632495~39266845~39270060~39266835~39097249~39082877~37663952~37662532~37662480~37663986~37662626~37662589~37662556~37738455~39270625~38433053~38261468~38486743~39057636~34582292~36475553~37257361~37257567~37257262~36741386~36711006~36498218~38914431~38734212~38674569~38787188~39259469~38927584~39024252~39024230~39228632~35252232~38658258~38658243~38625335~39245388~37319651~36852389~39136912~39159440~37456013~39256295~39214509~39253898~37376056~38561452~38295890~39156937~26052225~38711016~39272058~39271701~37777885~38524663~39022301~39063658~37777523~39018693~37897821~37023954~39242449~39242399~36227979~38635974~39100175~39200749~39251242~39197848~39229735~39108206~38520680~38520612~37512047~37373955~36748357~36558807~36553946~36994069~35651002~37645149~35650457~37547299~37547226~37547191~37547135~37325202~38909563~37981021~36518439~38435329~38356348~39225954~38905834~39100737~38753876~38753837~38648131~38909881~38909871~39253871~39139848~37756802~38207471~38715097~38714739~39228968~39109760~39109531~39109511~38412880~39193350~38918885~38443045~38133816~35085561~38011368~"+
"&jobid_count=2551&schTime=15&statCount=364" +
"&statData=404|114|45|61|92|99|29|34|80|27|15|29|49|449|1|228|133|0|0|1|1|243|494|5|0|0|1|0|7|232|321|139|26|1|0|152|831|1|1|4|18|8|8|4|3|0|0|0|0|0|0|588|0|1|0|0|0|0|1|13|0|0|0|0|0|0|0|1|0|0|0|0|0|0|2|254|6|6|0|1|1|0|0|0|0|0|0|1|0|0|0|0|2|0|1|0|0|0|0|0|0|0|0|0|0|0|365|14|13|0|5|3|18|9|2|0|1|26|6|2|0|0|3|1|2|3|0|9|32|1|0|6|1|0|0|0|13|209|1|0|3|1|7|32|5|37|1|0|3|0|0|13|2|9|10|0|1|0|5|1|1|0|0|2"+
"&fromType=";
//设置分页的页码
parameter = parameter.replace("curr_page=", "curr_page="+String.valueOf(i));
parameter = parameter.replace("fromType=", "fromType="+String.valueOf(14));
//设置关键字“程序员”
parameter = parameter.replace("dis_keyword=", "dis_keyword="+URLEncoder.encode(keyName, "GBK"));
parameter = parameter.replace("keyword=", "keyword="+URLEncoder.encode(keyName, "GBK"));
//打开链接设置头信息
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
//伪装请求
conn.setRequestProperty("Host", "search.51job.com");
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//post方式参数长度必须设定
conn.setRequestProperty("Content-Length", Integer.toString(parameter.getBytes("GB2312").length));
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB5; .NET CLR 1.1.4322; .NET CLR 2.0.50727; Alexa Toolbar; MAXTHON 2.0)");
OutputStream o = conn.getOutputStream();
OutputStreamWriter out = new OutputStreamWriter(o, "GBK");
out.write(parameter);
out.flush();
out.close();
//获得请求字节流
InputStream in = conn.getInputStream();
//解析
Scanner sc = new Scanner(in, "GBK");
return sc;
} catch (Exception e) {
log.error(e,e);
return null;
}
}
这样就可以顺利的获取到第一页关键词的列表信息。
完成这一步后,你就可以分析你想找的信息了,比如公司信息,职位……
<p>while (sc.hasNextLine()) {
String line = sc.nextLine();
sp = line.indexOf("class=\"jobname\" >", sp + 1);
if (sp != -1) {
sp = line.indexOf("
百度网页关键字抓取(超级排名系统原文链接:吸引百度蜘蛛抓取网站的基本条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-03 23:09
原文出处:超级排位系统
原文链接:吸引百度蜘蛛爬取的基本条件网站-超级排名系统
为了创建一个新的网站,我们首先考虑如何将蜘蛛吸引到我们的网站,采集我们的文章并建立一个排名。如果网站的管理员不知道怎么吸引蜘蛛,你连上手的资格都没有,那网站怎么会很快被蜘蛛抓到呢?超级排名系统的编辑会组织发布。
在互联网时代,我们想要的大部分信息都是通过“互联网搜索”获得的。比如很多人在购买某款产品之前都会上网查看相关信息,看看品牌的口碑和评价。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。
这说明SEO优化是非常有必要的,不仅要增加曝光度,还要增加销量。下面百度搜索引擎优化告诉你如何让网站快速爬取。
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。所以关键词是搜索引擎优化的核心。
外链是SEO优化过程中的一个环节,间接影响着网站的权重。常见的链接有:锚文本链接、纯文本链接和图片链接。
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。例如,百度的蜘蛛在爬取网页时需要定义网页并过滤和分析网页数据。
对于页面,爬取是收录的前提。只有爬得更多,我们才能收录更多。如果网站页面更新频繁,爬虫程序会频繁访问该页面。高质量的内容,尤其是原创内容,是爬虫喜欢捕捉的目标。
权威高配老网站享受VIP级待遇。这种网站的爬取频率高,爬取的页面数量多,爬取深度高,页面数量也比较多。这就是区别。
网站服务器是访问网站的基石。如果长时间打不开,就会长时间敲门。如果长时间无人接听,游客就会因为进不去,纷纷离开。蜘蛛来访也是游客之一。如果服务器不稳定,蜘蛛每次进入页面爬行都会被屏蔽,蜘蛛对网站的印象会越来越差,导致分数越来越低,自然排名也越来越低。
网站内容更新频繁,会吸引蜘蛛更频繁的访问。如果文章定期更新,蜘蛛会定期访问。蜘蛛每次爬取时,将页面数据存入数据库,分析后采集页面。如果蜘蛛每次爬行,发现收录的内容完全一样,蜘蛛就会判断网站,从而减少对网站的爬行。
蜘蛛的根本目的是发现有价值的“新”事物,所以原创优质内容对蜘蛛的吸引力是巨大的。如果能得到一只蜘蛛一样的,自然要给网站打上“优秀”的标签,经常爬取网站。
抓蜘蛛是有规则的。如果太深而无法隐藏,蜘蛛会找到自己的路。爬取过程很简单,所以网站结构应该不会太复杂。
在网站的构建中,程序可以生成大量的页面,通常是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成大量的重复内容,影响蜘蛛的抓取。如果一个页面对应的URL很多,可以尝试通过301重定向、canonical标签或者robots来处理,保证爬虫只抓取一个标准的URL。
对于新站来说,在网站建设初期,相对流量小,蜘蛛少。外链可以增加网页的曝光率和蜘蛛爬行,但需要注意外链的质量。 查看全部
百度网页关键字抓取(超级排名系统原文链接:吸引百度蜘蛛抓取网站的基本条件)
原文出处:超级排位系统
原文链接:吸引百度蜘蛛爬取的基本条件网站-超级排名系统
为了创建一个新的网站,我们首先考虑如何将蜘蛛吸引到我们的网站,采集我们的文章并建立一个排名。如果网站的管理员不知道怎么吸引蜘蛛,你连上手的资格都没有,那网站怎么会很快被蜘蛛抓到呢?超级排名系统的编辑会组织发布。

在互联网时代,我们想要的大部分信息都是通过“互联网搜索”获得的。比如很多人在购买某款产品之前都会上网查看相关信息,看看品牌的口碑和评价。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。
这说明SEO优化是非常有必要的,不仅要增加曝光度,还要增加销量。下面百度搜索引擎优化告诉你如何让网站快速爬取。
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。所以关键词是搜索引擎优化的核心。
外链是SEO优化过程中的一个环节,间接影响着网站的权重。常见的链接有:锚文本链接、纯文本链接和图片链接。
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。例如,百度的蜘蛛在爬取网页时需要定义网页并过滤和分析网页数据。
对于页面,爬取是收录的前提。只有爬得更多,我们才能收录更多。如果网站页面更新频繁,爬虫程序会频繁访问该页面。高质量的内容,尤其是原创内容,是爬虫喜欢捕捉的目标。
权威高配老网站享受VIP级待遇。这种网站的爬取频率高,爬取的页面数量多,爬取深度高,页面数量也比较多。这就是区别。
网站服务器是访问网站的基石。如果长时间打不开,就会长时间敲门。如果长时间无人接听,游客就会因为进不去,纷纷离开。蜘蛛来访也是游客之一。如果服务器不稳定,蜘蛛每次进入页面爬行都会被屏蔽,蜘蛛对网站的印象会越来越差,导致分数越来越低,自然排名也越来越低。
网站内容更新频繁,会吸引蜘蛛更频繁的访问。如果文章定期更新,蜘蛛会定期访问。蜘蛛每次爬取时,将页面数据存入数据库,分析后采集页面。如果蜘蛛每次爬行,发现收录的内容完全一样,蜘蛛就会判断网站,从而减少对网站的爬行。
蜘蛛的根本目的是发现有价值的“新”事物,所以原创优质内容对蜘蛛的吸引力是巨大的。如果能得到一只蜘蛛一样的,自然要给网站打上“优秀”的标签,经常爬取网站。
抓蜘蛛是有规则的。如果太深而无法隐藏,蜘蛛会找到自己的路。爬取过程很简单,所以网站结构应该不会太复杂。
在网站的构建中,程序可以生成大量的页面,通常是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成大量的重复内容,影响蜘蛛的抓取。如果一个页面对应的URL很多,可以尝试通过301重定向、canonical标签或者robots来处理,保证爬虫只抓取一个标准的URL。
对于新站来说,在网站建设初期,相对流量小,蜘蛛少。外链可以增加网页的曝光率和蜘蛛爬行,但需要注意外链的质量。
百度网页关键字抓取(网站关键词怎么优化,网站SEO优化排名怎么做(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-03 19:54
seo、关键词优化、百度google快照都是指一个方面。都是搜索引擎优化,就是利用搜索规律@>或者网页尽量排在搜索引擎首页甚至自然排名第一的位置!!!查看详细信息:
如何成为专业的seo?
首先你要懂html,因为你要修改页面布局。要有营销技巧,只有SEO和营销相结合,才能为你创造效益。我们还必须拥有发现和开采资源的技术。通过我们对手的站点,我们可以获得他相当一部分的优质外链资源。如果您对程序有所了解,那将是最好的。部分网站功能有缺陷,我们可以改进。以使其符合有利于搜索引擎的要求。我不考虑其他事情。互联网常识操作。我不会谈论那个。
重要的是要有耐心和耐心。不然气氛会很不好。
网站关键词如何优化,网站SEO如何优化排名,快速见效
关键词优化很重要。一定要分析关键词、网站的网页布局、发布的内容和友情链接设置等,一定要慎重考虑。如果你是新手,不了解这个,可以找专业人士来做,
在网站优化和网络优化方面,我做得很好。关键词 在排名搜索方面非常有经验,而且出结果很快。可以了解一下,有专业的网站建设,网站 seo优化团队,
他们的网站
SEO的核心是什么?什么样的网站有利于优化?关键词什么是排名技巧?
SEO的核心是搜索引擎的算法,有利于用户体验,有利于优化。. 关键词排名的技巧是增加网站的人气和网站的内在合理性和质量。.
其实以上都是美言。如果你真的想了解这些东西的本质,你还必须了解搜索引擎迄今为止的历史、发展和状态。. . . 查看全部
百度网页关键字抓取(网站关键词怎么优化,网站SEO优化排名怎么做(图))
seo、关键词优化、百度google快照都是指一个方面。都是搜索引擎优化,就是利用搜索规律@>或者网页尽量排在搜索引擎首页甚至自然排名第一的位置!!!查看详细信息:
如何成为专业的seo?
首先你要懂html,因为你要修改页面布局。要有营销技巧,只有SEO和营销相结合,才能为你创造效益。我们还必须拥有发现和开采资源的技术。通过我们对手的站点,我们可以获得他相当一部分的优质外链资源。如果您对程序有所了解,那将是最好的。部分网站功能有缺陷,我们可以改进。以使其符合有利于搜索引擎的要求。我不考虑其他事情。互联网常识操作。我不会谈论那个。
重要的是要有耐心和耐心。不然气氛会很不好。
网站关键词如何优化,网站SEO如何优化排名,快速见效
关键词优化很重要。一定要分析关键词、网站的网页布局、发布的内容和友情链接设置等,一定要慎重考虑。如果你是新手,不了解这个,可以找专业人士来做,
在网站优化和网络优化方面,我做得很好。关键词 在排名搜索方面非常有经验,而且出结果很快。可以了解一下,有专业的网站建设,网站 seo优化团队,
他们的网站
SEO的核心是什么?什么样的网站有利于优化?关键词什么是排名技巧?
SEO的核心是搜索引擎的算法,有利于用户体验,有利于优化。. 关键词排名的技巧是增加网站的人气和网站的内在合理性和质量。.
其实以上都是美言。如果你真的想了解这些东西的本质,你还必须了解搜索引擎迄今为止的历史、发展和状态。. . .
百度网页关键字抓取(网站与你共享IP的网站受到搜索引擎的惩罚,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 05:03
1、关键词 策略:确定网站的核心关键词所有能被搜索引擎爬取的文本都应该尽可能收录关键词关键词@ > 选品技巧:相关性(即定位)、人气(太热不易排名,太冷不易搜索)
2、域名策略:在域名中加入你的关键词,并用连字符“-”分别突出关键词,让搜索引擎可以识别一些人认为带有关键词域名的作用在排名上是弱的,但是他们不能否认,所以考虑的时候应该尽量考虑使用关键词域名。
3、虚拟主机策略:测试共享IP地址网站:目前大多数中小型网站共享一个IP地址相同的虚拟主机。如果您与您的网站搜索引擎惩罚共享一个IP,您将无法登录搜索引擎。另外,由于一个IP通常有几百个网站,会影响你的页面下载速度,特别是当一些网站流量很大的时候,如果搜索引擎下载一个页面半天失败,抓取它,搜索机器人将放弃它。因此,除了要了解有多少网站 与您共享的 IP 以及它们是否受到惩罚之外,还要了解它们的流量概况。
4、网页文件目录策略:将文件目录结构有序、合理排列,标准化一个简单的网站,将重要内容呈现在顶层目录中的三层。目录文件夹名称收录关键字。HTML 页面文件名也收录关键字。图片文件还收录关键字。这里提到的关键词主要是针对特定的页面内容。文件名是由破折号或下划线分隔的短语。标准做法是使用英语而不是拼音。
5、外部文件策略:将JavaScript文件和CSS文件分别放入JS和CSS外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减小文件大小,有助于搜索引擎快速准确地掌握网页的重要内容,其他字体和格式标签应该尽量少用。搜索引擎喜欢在页面的开头找到页面的关键内容。
6、框架策略:如果网站必须使用框架,那么应该正确使用noframe标签。此区域收录指向框架页面或带有关键字的解释性文本的链接。同时,关键字文本出现在框架区域之外。
7、图片策略:使用alt属性标签来描述图片的代码,包括关键字,图片旁边添加带有关键字的文字注释,避免使用splash page,比如一些公司的首页图片网站 Page Flash 使用率低,搜索引擎对跟踪嵌入链接的兴趣不大。
8、网站地图策略:基于文本的网站地图收录网站网站的所有列和子列地图的三个元素:文本、链接、关键词对于搜索引擎获取首页的内容都非常有帮助。因此,特别需要创建站点地图来动态生成目录站点。如果有更新,需要在网站的地图上体现出来。
9、标题和元标签策略:搜索引擎优化的基本技巧:标题内容会以链接标题的形式显示在搜索结果页面上。标题一般是网站名称+简短描述,包括核心关键词,如:SEO优化。
10、链接策略:尽可能让其他与你话题相关的网站链接到你。这已经成为搜索引擎排名成功的关键因素。有了这些网站链接,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你一个不错的排名。
另一方面,如果网站提供话题相关导出链接,搜索引擎会认为有丰富的话题相关内容,也有利于排名。
11、 避免惩罚:搜索引擎在识别欺骗方法方面变得越来越成熟。以下常用方法容易被惩罚,不会被收录。 查看全部
百度网页关键字抓取(网站与你共享IP的网站受到搜索引擎的惩罚,你知道吗?)
1、关键词 策略:确定网站的核心关键词所有能被搜索引擎爬取的文本都应该尽可能收录关键词关键词@ > 选品技巧:相关性(即定位)、人气(太热不易排名,太冷不易搜索)
2、域名策略:在域名中加入你的关键词,并用连字符“-”分别突出关键词,让搜索引擎可以识别一些人认为带有关键词域名的作用在排名上是弱的,但是他们不能否认,所以考虑的时候应该尽量考虑使用关键词域名。
3、虚拟主机策略:测试共享IP地址网站:目前大多数中小型网站共享一个IP地址相同的虚拟主机。如果您与您的网站搜索引擎惩罚共享一个IP,您将无法登录搜索引擎。另外,由于一个IP通常有几百个网站,会影响你的页面下载速度,特别是当一些网站流量很大的时候,如果搜索引擎下载一个页面半天失败,抓取它,搜索机器人将放弃它。因此,除了要了解有多少网站 与您共享的 IP 以及它们是否受到惩罚之外,还要了解它们的流量概况。
4、网页文件目录策略:将文件目录结构有序、合理排列,标准化一个简单的网站,将重要内容呈现在顶层目录中的三层。目录文件夹名称收录关键字。HTML 页面文件名也收录关键字。图片文件还收录关键字。这里提到的关键词主要是针对特定的页面内容。文件名是由破折号或下划线分隔的短语。标准做法是使用英语而不是拼音。
5、外部文件策略:将JavaScript文件和CSS文件分别放入JS和CSS外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减小文件大小,有助于搜索引擎快速准确地掌握网页的重要内容,其他字体和格式标签应该尽量少用。搜索引擎喜欢在页面的开头找到页面的关键内容。
6、框架策略:如果网站必须使用框架,那么应该正确使用noframe标签。此区域收录指向框架页面或带有关键字的解释性文本的链接。同时,关键字文本出现在框架区域之外。
7、图片策略:使用alt属性标签来描述图片的代码,包括关键字,图片旁边添加带有关键字的文字注释,避免使用splash page,比如一些公司的首页图片网站 Page Flash 使用率低,搜索引擎对跟踪嵌入链接的兴趣不大。
8、网站地图策略:基于文本的网站地图收录网站网站的所有列和子列地图的三个元素:文本、链接、关键词对于搜索引擎获取首页的内容都非常有帮助。因此,特别需要创建站点地图来动态生成目录站点。如果有更新,需要在网站的地图上体现出来。
9、标题和元标签策略:搜索引擎优化的基本技巧:标题内容会以链接标题的形式显示在搜索结果页面上。标题一般是网站名称+简短描述,包括核心关键词,如:SEO优化。
10、链接策略:尽可能让其他与你话题相关的网站链接到你。这已经成为搜索引擎排名成功的关键因素。有了这些网站链接,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你一个不错的排名。
另一方面,如果网站提供话题相关导出链接,搜索引擎会认为有丰富的话题相关内容,也有利于排名。
11、 避免惩罚:搜索引擎在识别欺骗方法方面变得越来越成熟。以下常用方法容易被惩罚,不会被收录。
百度网页关键字抓取(百度SEO怎么做才能保持排名呢?百度算法更新的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 05:02
总结:从百度SEO排名知道,我们的SEOER排名会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(百度SEO怎么做才能保持排名呢?百度算法更新的影响)
总结:从百度SEO排名知道,我们的SEOER排名会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!

页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取( 百度SEO怎么做才能保持排名呢?百度排名优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 04:19
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取( 百度SEO怎么做才能保持排名呢?百度排名优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 04:18
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取(让自己的产品排到首页,这是很多新手梦寐以求的事情!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-28 03:16
让你的产品登上首页,这是很多新手梦寐以求的事情!第一个是每天重新发送消息。(但基本上每个人都可以这样做)所以没有区别!第二点是关键词的巧妙设计!如果您是诚信会员,您可以在业务人员的职称优化工具中获得一些想法。
产品标题设置是最基本的,最关键的是关键词。字数设置为30个。关键词只用一个,只有你知道选择哪个产品。关键词 与信息匹配。1、你嘴上的关键词对于你的产品或服务,你总是可以不假思索地说几个关键词,请写下来。不管你在哪里记住它,你可以把它写在纸上或在文字处理软件中计算,比如记事本或Word。如果您花几分钟查看这些关键字,您的脑海中可能会弹出其他相关词。太好了,把它们都写下来。继续思考,想想还可以添加什么词?或者什么同义词等等。2、 查看竞争对手的关键词 查看竞争对手的关键词并不难:在浏览器中打开对手的网页,网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。
4 注意错别字,错字在这里也很珍贵。你不能低估错别字。每10个搜索引擎产生的流量,就有1到2个是由关键词的错别字或错别字造成的,有时甚至更多。5 同义词和同义词 同义词和同义词不能放过。如果您的网站销售笔记本电脑,您是否考虑过与“笔记本电脑”相关的同义词或相似词?比如笔记本电脑、笔记本电脑、笔记本电脑等等。事实上,很多人在搜索笔记本电脑时,直接使用“笔记本”和“掌上电脑”,而不是加“电脑”二字。所有这些都应该考虑。因此,这些词也应该添加为我们的关键词栏。5 关键词的拆分和组合你可能会发现,即使你的产品名称是一个词,你可以用两个 关键词 搜索它。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。
对于某些单词的单复数形式,每天的搜索次数相差多达 10 次。同时,一个词的单复数形式的搜索结果也有很大的不同。此外,搜索引擎对 关键词 的情况有所不同。7连字符检查关键词,看看有没有可以加连字符的,或者可以去掉连字符的,然后把它们加到关键词。根据搜索引擎的说法,email 和e-mail 是两个完全不同的关键词,所以这两个词的搜索频率肯定是不同的。我们要做的就是找出使用频率更高的词。这里要注意的一件事是搜索引擎将连字符视为空格符号。所以email和e-mail的搜索结果完全一样,但是email和e-mail的搜索结果却大不相同。你可以自己在搜索引擎上试试。8、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的用户,您可以在关键词前添加区域名称,例如省或市的名称。使用地理位置时要从客户的角度考虑。比如邮箱,没有“北京邮箱”这个词,所以地理位置对它没有意义。9、公司和产品名称如果该站点所属的公司或产品是众所周知的,您可以将它们的名称添加到关键词表中。当然名字不需要复制,可以先做一些改动,然后再排列组合,这样可以找到更多的关键词。10、放错地方<
这些词的竞争非常激烈,因为很多网站都在用这些来优化。这时候,我们是不是可以想错了,大家在优化“搜索引擎优化”的时候,我是不是可以优化“搜索引擎优化”或者“搜索引擎优化”等组合。因为用户在查询时很少使用双引号来细化他们的搜索结果,一些非专业人士可能无法准确把握一个词。11 不要使用通用词。如果你是服装设计师,“韩国服装”是你的核心关键词,而“服装”是一个很常见的词汇,用户在搜索服装时不会只用它网站“服装”是一个 关键词 搜索,通常将多个单词组合在一起。(这也是上一篇文章说在阿里竞拍“衣服”。这个关键词意义不大。做好关键词的设置也是做的重点seo搜索引擎优化.阿里巴巴百度谷歌 查看全部
百度网页关键字抓取(让自己的产品排到首页,这是很多新手梦寐以求的事情!)
让你的产品登上首页,这是很多新手梦寐以求的事情!第一个是每天重新发送消息。(但基本上每个人都可以这样做)所以没有区别!第二点是关键词的巧妙设计!如果您是诚信会员,您可以在业务人员的职称优化工具中获得一些想法。
产品标题设置是最基本的,最关键的是关键词。字数设置为30个。关键词只用一个,只有你知道选择哪个产品。关键词 与信息匹配。1、你嘴上的关键词对于你的产品或服务,你总是可以不假思索地说几个关键词,请写下来。不管你在哪里记住它,你可以把它写在纸上或在文字处理软件中计算,比如记事本或Word。如果您花几分钟查看这些关键字,您的脑海中可能会弹出其他相关词。太好了,把它们都写下来。继续思考,想想还可以添加什么词?或者什么同义词等等。2、 查看竞争对手的关键词 查看竞争对手的关键词并不难:在浏览器中打开对手的网页,网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。
4 注意错别字,错字在这里也很珍贵。你不能低估错别字。每10个搜索引擎产生的流量,就有1到2个是由关键词的错别字或错别字造成的,有时甚至更多。5 同义词和同义词 同义词和同义词不能放过。如果您的网站销售笔记本电脑,您是否考虑过与“笔记本电脑”相关的同义词或相似词?比如笔记本电脑、笔记本电脑、笔记本电脑等等。事实上,很多人在搜索笔记本电脑时,直接使用“笔记本”和“掌上电脑”,而不是加“电脑”二字。所有这些都应该考虑。因此,这些词也应该添加为我们的关键词栏。5 关键词的拆分和组合你可能会发现,即使你的产品名称是一个词,你可以用两个 关键词 搜索它。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。
对于某些单词的单复数形式,每天的搜索次数相差多达 10 次。同时,一个词的单复数形式的搜索结果也有很大的不同。此外,搜索引擎对 关键词 的情况有所不同。7连字符检查关键词,看看有没有可以加连字符的,或者可以去掉连字符的,然后把它们加到关键词。根据搜索引擎的说法,email 和e-mail 是两个完全不同的关键词,所以这两个词的搜索频率肯定是不同的。我们要做的就是找出使用频率更高的词。这里要注意的一件事是搜索引擎将连字符视为空格符号。所以email和e-mail的搜索结果完全一样,但是email和e-mail的搜索结果却大不相同。你可以自己在搜索引擎上试试。8、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的用户,您可以在关键词前添加区域名称,例如省或市的名称。使用地理位置时要从客户的角度考虑。比如邮箱,没有“北京邮箱”这个词,所以地理位置对它没有意义。9、公司和产品名称如果该站点所属的公司或产品是众所周知的,您可以将它们的名称添加到关键词表中。当然名字不需要复制,可以先做一些改动,然后再排列组合,这样可以找到更多的关键词。10、放错地方<
这些词的竞争非常激烈,因为很多网站都在用这些来优化。这时候,我们是不是可以想错了,大家在优化“搜索引擎优化”的时候,我是不是可以优化“搜索引擎优化”或者“搜索引擎优化”等组合。因为用户在查询时很少使用双引号来细化他们的搜索结果,一些非专业人士可能无法准确把握一个词。11 不要使用通用词。如果你是服装设计师,“韩国服装”是你的核心关键词,而“服装”是一个很常见的词汇,用户在搜索服装时不会只用它网站“服装”是一个 关键词 搜索,通常将多个单词组合在一起。(这也是上一篇文章说在阿里竞拍“衣服”。这个关键词意义不大。做好关键词的设置也是做的重点seo搜索引擎优化.阿里巴巴百度谷歌
百度网页关键字抓取(谷歌搜ajax调包用浏览器插件能用ajax方法吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-27 00:01
百度网页关键字抓取,给相关页面发ajax请求,虽然费时费力,
可以借助一些开源站点抓取工具。比如如exception_grabber,extract_all_pages,jinja2等这样的。希望能帮到你。
试试自动提交参数,打开通过邮件提交,
谷歌搜ajax
调包
用浏览器插件
能用ajax方法吗
他人帮助
找的话你让他带吧
用google,
我自己编写的一个爬虫,基于ajax。非常的小,
试试googleapi
帮你爬下来才挣钱,你这不是钓鱼么,
给知乎做一个api,让知乎的用户爬下来并且记录并且存储一段时间,就能统计总数,做相关分析。
参考豆瓣猜
不如请知乎大大们帮你抓呢
高德还不够大么?大不了像googlehome一样,
想想除了高德没有什么网站是你知道的
也可以问豆瓣的同类型的问题,如何保存所有评分标签?至于是不是匿名提问,怎么排序,什么时候排序?数据的重要性你自己衡量。爬虫这种东西还是很多人用的。以你之计,
关注几个站点,整理一下,把这些站点的数据整理出来,再用python提取一些关键字,转化成新文本,这样没事可以复习一下常用网站的做法。我之前有个爬虫爬完八戒,自己写了一个抓豆瓣的代码,包括评分地址和评分区间,这样能帮助理解。 查看全部
百度网页关键字抓取(谷歌搜ajax调包用浏览器插件能用ajax方法吗)
百度网页关键字抓取,给相关页面发ajax请求,虽然费时费力,
可以借助一些开源站点抓取工具。比如如exception_grabber,extract_all_pages,jinja2等这样的。希望能帮到你。
试试自动提交参数,打开通过邮件提交,
谷歌搜ajax
调包
用浏览器插件
能用ajax方法吗
他人帮助
找的话你让他带吧
用google,
我自己编写的一个爬虫,基于ajax。非常的小,
试试googleapi
帮你爬下来才挣钱,你这不是钓鱼么,
给知乎做一个api,让知乎的用户爬下来并且记录并且存储一段时间,就能统计总数,做相关分析。
参考豆瓣猜
不如请知乎大大们帮你抓呢
高德还不够大么?大不了像googlehome一样,
想想除了高德没有什么网站是你知道的
也可以问豆瓣的同类型的问题,如何保存所有评分标签?至于是不是匿名提问,怎么排序,什么时候排序?数据的重要性你自己衡量。爬虫这种东西还是很多人用的。以你之计,
关注几个站点,整理一下,把这些站点的数据整理出来,再用python提取一些关键字,转化成新文本,这样没事可以复习一下常用网站的做法。我之前有个爬虫爬完八戒,自己写了一个抓豆瓣的代码,包括评分地址和评分区间,这样能帮助理解。
百度网页关键字抓取(做好的网站怎么才能被收录?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-26 23:13
网站未优化时,网站首页会有4条路径,分散网站的权重,每条路径得到四分之一。301 重定向对于 网站 非常重要。您可以设置网站首页的默认索引。有404页面,可以降低用户重定向率,提升用户体验。
4. 网站 内容添加
新上线的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应该是原创,有利于网站的发展。
5. 文章页面优化
进入网站的内容页面时,可以在网站底部添加一些相关链接或用户喜欢的话题,可以增加用户在网站的停留时间,提升用户体验, 并提高 网站 排名。但是切记,不要让网站的每一页都太相关,因为这会影响网站的优化。
6、 Robot.txt 设置
禁止搜索引擎抓取与网站无关的页面,禁止蜘蛛进入网站。
这些都是网站上线前的必要准备。只有经过几个级别的测试,网站才能正式上线,让网站顺利运行。
一个制作精良的网站怎么可能是收录?
1. 提交给各大搜索引擎
2、站在用户的角度思考,写出满足用户需求的更新内容
3.写下完整的网站标题、描述和关键词、栏目和文章,以及每一页
4.优化网站链接、标签、菜单、网站地图、图片alt、描述和可选文字
5.逐步添加相关外链(自动同步网站文字)6。选择已经进入前四页的关键词进行手动搜索优化。一般一到两周就可以进入首页(取决于关键词
人气
] 7.循环以上步骤
8.技术可以学习,自己思考。
9. 坚持,坚持,坚持
!当你能为你的客户创造千万的销售额时,你的收入也不会太差,所以埋头苦干,先实现时间的自由,再考虑财务的自由。
企业如何做好网站建设?
随着时代的不断发展,用户对互联网的要求越来越高。现在一般的网站已经不能满足用户的需求,用户更喜欢浏览一些突出的个性化网站。那么,如何打造不一样的网站风格呢?让我们明白
!今天,企业已经意识到用户的重要性。随着市场竞争的日益激烈,两者的差距也在迅速缩小,由此可见个性化的重要性网站。个性化网站不仅增加了品牌的知名度,还采集了用户信息,有利于提高用户的服务质量,从而获得更多的流量。如果你想设计一个不一样的网站风格,你必须从一开始就创造这种风格来打动用户。现在网上信息太多,用户不知道如何选择,所以网站必须有不同的风格才能在竞争中脱颖而出。
网站首页主要是为了吸引用户的注意力。应突出兴趣点和最新消息,以吸引用户长时间停留在网站。现在,用户喜欢追求时尚和新颖的产品,因此他们会对网站的不同风格感兴趣。这类用户的需求主要在日常生活中。在网络营销中,需要对市场进行详细的分析,明确用户的需求,让用户对企业产生兴趣,树立企业形象。
随着互联网的不断发展,越来越多的企业拥有网站。为了吸引用户的注意力,必须区别对待网站,不能完全一样。通过网站的结构和页面设计,保证网站的风格有很大的不同,让用户记住网站,在满足用户需求的前提下,将网站改为突出企业产品的核心功能。
网站 不能为空。光有漂亮的外表是不够的。您还需要将符合网站核心的公司和内容的详细信息添加到网站中,以丰富网站。如果要设计出不同风格的网站,必须遵循一定的原则,这样才能有助于公司未来的宣传,展示公司的形象。 查看全部
百度网页关键字抓取(做好的网站怎么才能被收录?(一)(图))
网站未优化时,网站首页会有4条路径,分散网站的权重,每条路径得到四分之一。301 重定向对于 网站 非常重要。您可以设置网站首页的默认索引。有404页面,可以降低用户重定向率,提升用户体验。
4. 网站 内容添加
新上线的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应该是原创,有利于网站的发展。
5. 文章页面优化
进入网站的内容页面时,可以在网站底部添加一些相关链接或用户喜欢的话题,可以增加用户在网站的停留时间,提升用户体验, 并提高 网站 排名。但是切记,不要让网站的每一页都太相关,因为这会影响网站的优化。
6、 Robot.txt 设置
禁止搜索引擎抓取与网站无关的页面,禁止蜘蛛进入网站。
这些都是网站上线前的必要准备。只有经过几个级别的测试,网站才能正式上线,让网站顺利运行。
一个制作精良的网站怎么可能是收录?
1. 提交给各大搜索引擎
2、站在用户的角度思考,写出满足用户需求的更新内容
3.写下完整的网站标题、描述和关键词、栏目和文章,以及每一页
4.优化网站链接、标签、菜单、网站地图、图片alt、描述和可选文字
5.逐步添加相关外链(自动同步网站文字)6。选择已经进入前四页的关键词进行手动搜索优化。一般一到两周就可以进入首页(取决于关键词
人气
] 7.循环以上步骤
8.技术可以学习,自己思考。
9. 坚持,坚持,坚持
!当你能为你的客户创造千万的销售额时,你的收入也不会太差,所以埋头苦干,先实现时间的自由,再考虑财务的自由。
企业如何做好网站建设?
随着时代的不断发展,用户对互联网的要求越来越高。现在一般的网站已经不能满足用户的需求,用户更喜欢浏览一些突出的个性化网站。那么,如何打造不一样的网站风格呢?让我们明白
!今天,企业已经意识到用户的重要性。随着市场竞争的日益激烈,两者的差距也在迅速缩小,由此可见个性化的重要性网站。个性化网站不仅增加了品牌的知名度,还采集了用户信息,有利于提高用户的服务质量,从而获得更多的流量。如果你想设计一个不一样的网站风格,你必须从一开始就创造这种风格来打动用户。现在网上信息太多,用户不知道如何选择,所以网站必须有不同的风格才能在竞争中脱颖而出。
网站首页主要是为了吸引用户的注意力。应突出兴趣点和最新消息,以吸引用户长时间停留在网站。现在,用户喜欢追求时尚和新颖的产品,因此他们会对网站的不同风格感兴趣。这类用户的需求主要在日常生活中。在网络营销中,需要对市场进行详细的分析,明确用户的需求,让用户对企业产生兴趣,树立企业形象。
随着互联网的不断发展,越来越多的企业拥有网站。为了吸引用户的注意力,必须区别对待网站,不能完全一样。通过网站的结构和页面设计,保证网站的风格有很大的不同,让用户记住网站,在满足用户需求的前提下,将网站改为突出企业产品的核心功能。
网站 不能为空。光有漂亮的外表是不够的。您还需要将符合网站核心的公司和内容的详细信息添加到网站中,以丰富网站。如果要设计出不同风格的网站,必须遵循一定的原则,这样才能有助于公司未来的宣传,展示公司的形象。
百度网页关键字抓取(项目招商找A5快速获取精准代理名单网站关键词优化做好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-26 15:15
项目招商求A5快速获取精准代理商名单
网站关键词 对百度、GOOGLE等搜索引擎进行优化收录,可以排在搜索结果第一页的顶部,可以增加网站的流量,所以站长们一直在追求最好的优化技巧,钻研搜索引擎的偏好。老站长xrnic也很热衷于网站优化这个行业,分享最实用的关键词优化技巧。给站长朋友。
百度和GOOGLE有一个共同的偏好,更注重页面标题关键词和元描述之间的关键词。用户搜索关键词时,百度和GG会先从这两个地方搜索过滤关键词的结果,按照网站权重和关键词的顺序显示. 在搜索结果页的最前面,站长在优化网站的时候一定要写下这两个地方的关键词说明。
一、百度关键词优化技巧。
一般百度只对前6个关键词感兴趣,所以在优化TITLE关键词时,最好不要超过6个关键词。写多了就没用了。百度在搜索结果中过滤。关键词绝不会考虑第六个关键词之后的关键词,对关键词的过度优化也会造成被怀疑作弊的风险。经过站长xrnic长期调研,百度也对关键词字数进行了限制。一般关键词字数不超过30字。关键词 超过30个字后一般不会被收录。结果。
百度一般只有
二、GOOGLE关键词优化技巧。
GOOGLE一般只对前7个关键词感兴趣,字数在30个字符左右。这个和百度差不多,就不多说了。
GOOGLE 一般只对网页有效
综上所述,百度和GOOGLE更注重标题和描述的内容,所以我们在优化网站关键词的时候,首先要在这两个地方做关键词的优化。让你网站快速进入行业前列,增加被搜索引擎抓到的几率,给你带来更多的访问量。总结两个搜索引擎的特点,页面标题关键词不超过6个,文字长度不超过30个字;元描述内容应在70-100字之间,重点放在描述上。提升的关键词在最上面,在标题中没有完全表达的关键词添加在描述中。经过优化测试结果,很明显百度和GOOGLE搜索“
文章原站长xrnic原创,转载请注明出处。谢谢。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
百度网页关键字抓取(项目招商找A5快速获取精准代理名单网站关键词优化做好了)
项目招商求A5快速获取精准代理商名单
网站关键词 对百度、GOOGLE等搜索引擎进行优化收录,可以排在搜索结果第一页的顶部,可以增加网站的流量,所以站长们一直在追求最好的优化技巧,钻研搜索引擎的偏好。老站长xrnic也很热衷于网站优化这个行业,分享最实用的关键词优化技巧。给站长朋友。
百度和GOOGLE有一个共同的偏好,更注重页面标题关键词和元描述之间的关键词。用户搜索关键词时,百度和GG会先从这两个地方搜索过滤关键词的结果,按照网站权重和关键词的顺序显示. 在搜索结果页的最前面,站长在优化网站的时候一定要写下这两个地方的关键词说明。
一、百度关键词优化技巧。
一般百度只对前6个关键词感兴趣,所以在优化TITLE关键词时,最好不要超过6个关键词。写多了就没用了。百度在搜索结果中过滤。关键词绝不会考虑第六个关键词之后的关键词,对关键词的过度优化也会造成被怀疑作弊的风险。经过站长xrnic长期调研,百度也对关键词字数进行了限制。一般关键词字数不超过30字。关键词 超过30个字后一般不会被收录。结果。
百度一般只有
二、GOOGLE关键词优化技巧。
GOOGLE一般只对前7个关键词感兴趣,字数在30个字符左右。这个和百度差不多,就不多说了。
GOOGLE 一般只对网页有效
综上所述,百度和GOOGLE更注重标题和描述的内容,所以我们在优化网站关键词的时候,首先要在这两个地方做关键词的优化。让你网站快速进入行业前列,增加被搜索引擎抓到的几率,给你带来更多的访问量。总结两个搜索引擎的特点,页面标题关键词不超过6个,文字长度不超过30个字;元描述内容应在70-100字之间,重点放在描述上。提升的关键词在最上面,在标题中没有完全表达的关键词添加在描述中。经过优化测试结果,很明显百度和GOOGLE搜索“
文章原站长xrnic原创,转载请注明出处。谢谢。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
百度网页关键字抓取(如何利用Python编程,让SEO工作变的更高效? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-26 15:11
)
免责声明:我是一个编程菜鸟。为了强迫自己在实战中学习Python,我答应朋友制作一套视频课程,讲解如何使用Python编程让SEO工作更高效。
和朋友讨论,初步定义了几个SEO工具的需求,打算用Python来实现:
1、指定规则,扫描并导出所有有效的URL网站
2、 批量抓取页面标题判断SERP前三页是否存在(判断索引)
3、批量搜索关键词前N页的所有搜索结果,并导出标题和URL(用于查找外部资源)
4、 批量抓取页面标题,判断标题在当前搜索引擎中的相似度(判断标题是否可用)
5、 指定第一个词汇,抓取搜索引擎相关搜索,用结果词导出结果词的相关搜索词,导出,重复N次。(关键词 库,提高页面相关性的内部链接)
6、 服务器日志批量处理,通过PY实现,日志批量筛选和有效导出。
7、 通过非法词列表扫描指定页面是否有非法词。
...
我希望依靠这些例子来编程,让大家得到python可以帮助我解决实际问题的印象,并通过简单的修改在实际工作中使用它们。
如果你从 hello world 开始,大多数人在看不到希望的时候就会放弃。(我经历过很多次,有很深的体会)
在学习中,有时“急功近利”是好事。
-------------------
本次以第五项需求为例,完成一段已实现的python代码,主要目的是抓取百度相关搜索词。
为了满足实际应用,本要求进行了扩展:
A. 支持输入多词扩展百度相关搜索词。
B. 您可以指定哪些词必须或不能收录在要求中。
C、可以将采集收到的文字保存为txt文件,文件名可以自定义。
未来可以进一步改进的工作:
1、多线程采集
2、使用代理IP采集
3、更多容错判断
下面是具体代码,为了便于理解,几乎每一行都有注释,不要太啰嗦。(有些说法可能有误)
# coding = utf-8
'''
1、指定关键词,抓取搜索引擎相关搜索词,并使用结果词再次抓取其相关搜索词。
2、采集时对搜索相关词做处理,必须包含某些关键词或不能包含的词才作为有效词。
3、指定希望获得的最终相关词数量。
获得的搜索相关词用途:增加关键词库,提升内部链接相关性,分析用户的搜索行为,广告投放等等。
'''
#导入http请求库request
import requests
#导入随机数库
import random
#导入时间库
import time
#导入日期库
import datetime
# 导入URL解析库
from urllib import parse
# 导入BeautifulSoup库,使用别名bs
from bs4 import BeautifulSoup as bs
# 定义获取相关词的函数,@words是希望拓展的词根列表,@num是希望获取的相关词数量(大概)
def get_related_words(words, num=10):
for word in words:
# 当已有词数量小于希望获取的词数时
if(len(words) =0):
continue
# 如果没有包含不允许的词,则进入下面的处理过程
else:
# 如果定义了必须包含的词
if must_contain is not None:
# 循环必须包含的词
for w in must_contain:
# 把w都转换为小写字符,因为百度搜索相关词中英文都是小写,之后查询是否包含必须有的词(>=0表示至少包含一次)
if i.find(w.lower())>=0:
rs.append(i)
# 如果没有定义必须包含的词,则所有词直接加入列表中。
else:
rs.append(i)
# 如果没有定义不能包含的词
else:
# 解释同上
if must_contain is not None:
for w in must_contain:
if i.find(w.lower())>=0:
rs.append(i)
else:
rs.append(i)
# 返回最终过滤后的词列表
return rs
# 打算拓展的词根
root_words = ['QQ', '腾讯']
# 根据词根进行相关词采集,指定最终采集词量
words = get_related_words(root_words, 30)
# 定义必须包含的关键词列表
must_contain = ['大全']
# 定义不能包含的关键词列表
should_not_contain = ['手游']
# 输出不加任何过滤规则获得的相关搜索词
rule1 = filter_words(words)
print("不加任何过滤规则获得的相关搜索词")
print_list(rule1)
rule2 = filter_words(words, must_contain)
print("指定必须包含的关键词后获得的相关搜索词")
print_list(rule2)
rule3 = filter_words(words, must_contain, should_not_contain)
print("指定必须包含的关键词和不能包含的关键词后获得的相关搜索词")
print_list(rule3)
# 把不同过滤规则处理后获得的词写入指定的文件中
save_to_file(rule1, 'all_words')
save_to_file(rule2, 'must_contain_words')
save_to_file(rule3, 'filter_words')
# 不做过滤处理,也不指定文件名,按程序启动时间作为文件名保存结果。
save_to_file(words)
# 输出实际获得的总词数
print("总共词数:{0}".format(len(rule1)))
print("必须包含指定词数量:{0}".format(len(rule2)))
print("最严过滤规则词:{0}".format(len(rule3))) 查看全部
百度网页关键字抓取(如何利用Python编程,让SEO工作变的更高效?
)
免责声明:我是一个编程菜鸟。为了强迫自己在实战中学习Python,我答应朋友制作一套视频课程,讲解如何使用Python编程让SEO工作更高效。
和朋友讨论,初步定义了几个SEO工具的需求,打算用Python来实现:
1、指定规则,扫描并导出所有有效的URL网站
2、 批量抓取页面标题判断SERP前三页是否存在(判断索引)
3、批量搜索关键词前N页的所有搜索结果,并导出标题和URL(用于查找外部资源)
4、 批量抓取页面标题,判断标题在当前搜索引擎中的相似度(判断标题是否可用)
5、 指定第一个词汇,抓取搜索引擎相关搜索,用结果词导出结果词的相关搜索词,导出,重复N次。(关键词 库,提高页面相关性的内部链接)
6、 服务器日志批量处理,通过PY实现,日志批量筛选和有效导出。
7、 通过非法词列表扫描指定页面是否有非法词。
...
我希望依靠这些例子来编程,让大家得到python可以帮助我解决实际问题的印象,并通过简单的修改在实际工作中使用它们。
如果你从 hello world 开始,大多数人在看不到希望的时候就会放弃。(我经历过很多次,有很深的体会)
在学习中,有时“急功近利”是好事。
-------------------
本次以第五项需求为例,完成一段已实现的python代码,主要目的是抓取百度相关搜索词。
为了满足实际应用,本要求进行了扩展:
A. 支持输入多词扩展百度相关搜索词。
B. 您可以指定哪些词必须或不能收录在要求中。
C、可以将采集收到的文字保存为txt文件,文件名可以自定义。
未来可以进一步改进的工作:
1、多线程采集
2、使用代理IP采集
3、更多容错判断
下面是具体代码,为了便于理解,几乎每一行都有注释,不要太啰嗦。(有些说法可能有误)
# coding = utf-8
'''
1、指定关键词,抓取搜索引擎相关搜索词,并使用结果词再次抓取其相关搜索词。
2、采集时对搜索相关词做处理,必须包含某些关键词或不能包含的词才作为有效词。
3、指定希望获得的最终相关词数量。
获得的搜索相关词用途:增加关键词库,提升内部链接相关性,分析用户的搜索行为,广告投放等等。
'''
#导入http请求库request
import requests
#导入随机数库
import random
#导入时间库
import time
#导入日期库
import datetime
# 导入URL解析库
from urllib import parse
# 导入BeautifulSoup库,使用别名bs
from bs4 import BeautifulSoup as bs
# 定义获取相关词的函数,@words是希望拓展的词根列表,@num是希望获取的相关词数量(大概)
def get_related_words(words, num=10):
for word in words:
# 当已有词数量小于希望获取的词数时
if(len(words) =0):
continue
# 如果没有包含不允许的词,则进入下面的处理过程
else:
# 如果定义了必须包含的词
if must_contain is not None:
# 循环必须包含的词
for w in must_contain:
# 把w都转换为小写字符,因为百度搜索相关词中英文都是小写,之后查询是否包含必须有的词(>=0表示至少包含一次)
if i.find(w.lower())>=0:
rs.append(i)
# 如果没有定义必须包含的词,则所有词直接加入列表中。
else:
rs.append(i)
# 如果没有定义不能包含的词
else:
# 解释同上
if must_contain is not None:
for w in must_contain:
if i.find(w.lower())>=0:
rs.append(i)
else:
rs.append(i)
# 返回最终过滤后的词列表
return rs
# 打算拓展的词根
root_words = ['QQ', '腾讯']
# 根据词根进行相关词采集,指定最终采集词量
words = get_related_words(root_words, 30)
# 定义必须包含的关键词列表
must_contain = ['大全']
# 定义不能包含的关键词列表
should_not_contain = ['手游']
# 输出不加任何过滤规则获得的相关搜索词
rule1 = filter_words(words)
print("不加任何过滤规则获得的相关搜索词")
print_list(rule1)
rule2 = filter_words(words, must_contain)
print("指定必须包含的关键词后获得的相关搜索词")
print_list(rule2)
rule3 = filter_words(words, must_contain, should_not_contain)
print("指定必须包含的关键词和不能包含的关键词后获得的相关搜索词")
print_list(rule3)
# 把不同过滤规则处理后获得的词写入指定的文件中
save_to_file(rule1, 'all_words')
save_to_file(rule2, 'must_contain_words')
save_to_file(rule3, 'filter_words')
# 不做过滤处理,也不指定文件名,按程序启动时间作为文件名保存结果。
save_to_file(words)
# 输出实际获得的总词数
print("总共词数:{0}".format(len(rule1)))
print("必须包含指定词数量:{0}".format(len(rule2)))
print("最严过滤规则词:{0}".format(len(rule3)))
百度网页关键字抓取(关于,的18个常见seo问题的理解和理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-26 14:07
很多朋友在学习seo的时候会遇到很多问题,也会对一些seo相关的概念有很多错误的理解,从而导致在操作优化的过程中产生误会网站。作为seo,当然要研究搜索引擎算法,但也要研究用户需求和网站体验,通过不断的实战优化技巧得出正确的结论,而不是一味的相信道听途说。
对于以下常见seo问题的理解,相信80%的优化器都曾不小心偏离过。让我们来看看这18个问题:
1、百度快照时间与网站权重没有直接关系
网页权重对网站快照更新时间有辅助作用,但网站快照更新时间是根据网站历史更新频率和内容质量确定的。更新频率越快,蜘蛛抓取越频繁。另外,内容页更新频率很小。还有一种情况是蜘蛛频繁爬行,只是不更新,因为搜索引擎认为内容质量不值得更新。另外,百度官方的说明不需要太在意网页快照。
2、搜索索引不等于实际搜索量
百度官方明确表示,“以网民在百度上的搜索量为数据基础,以关键词为统计对象,科学分析计算每个关键词百度网页搜索”,注意搜索频率,而不仅仅是搜索量。然而,百度指数是实际搜索量的一个有价值的指标。
3、Cookie只能记录本网站中的用户信息,其他网站中记录用户的操作信息
Cookie可以记录用户在自己站内的操作信息,但是用户跳出网站后的数据无法追踪。很多时候,登录一些网站后,发现登录信息等输入数据都在。其实就是每个网站单独保存的用户记录。
4、网站 设置关键词后,排名不会自行上升
包括我自己,我想了很久,只要你为网站设置关键词,更新网站优化内外链,这些关键词的排名就会去向上。. 事实上,网站设置的关键字和描述搜索引擎可能只会在计算相关性时引用它们,它们对排名的影响更大。网站关键词排名要提升或者我们需要针对这些词专门优化内链和外链。锚文本越集中,关键词的排名能力就越好。
5.张工具提供的百度权重值仅供参考
站长工具中的数据统计功能,确实方便我们了解网站的综合数据信息。提供的百度权重现在是交易所链最重要的指标。但是,站长我提供的百度权重只是第三方软件如词库的一些技术的结果,百度并不认可。百度有自己的索引,类似于网站网页重要价值的权重指数。
6、站点网站结果个数不等于网站真实收录个数,不等于网站有效< @收录
很多人把网站网站的结果数据当成百度对网站的收录的实际数量。事实上,现场展示的结果只是网站real收录的一部分。网站收录的实际人数应以百度站长平台索宫人数为准。但是,站点数量越接近索引数量越好,这意味着质量越高。反之,如果搜索的次数远远多于网站的数量,那你就要提高警惕了。他们都说这是搜索弓的不友好表现。(在内容质量方面)另外,网站收录的数量并不代表有效收录的数量。有效收录 指用户搜索和点击的网页数量。对于网站,用户没有访问过的页面一般是没有用的。
7、搜索引擎蜘蛛没有掉电蜘蛛等分类
之前在网上看到过对搜索蜘蛛不同IP段的不同分析,一直这样认为(估计和我一样思考的人不在少数)。然而,高价值网站可能会吸引| 蜘蛛的不同爬行策略。
8、搜索引擎将 网站 URL 视为静态和动态
之前的观点是动态的网站是错误的,后来才知道追求静态网址是不对的。URL 是动态的还是静态的并不重要,只要它们不重复即可。此外,动态 URL 应避免参数过多。
9、是的站群过度妖魔化
很多人对“站群”的印象是作弊。这是作弊(主要是在灰色和黑色行业)。但站群 不全是作弊。我看过一个操作站群,提供站群不同地区交通违章查询的操作案例。这样才能真正解决用户的需求。百度官方曾表示,要看这类网站对普通用户的价值来判断。
10、现在论坛和博客消息签名的链下价值只是蜘蛛
这种情况在 SEO 新手中更常见,他们花费大量时间在博客和论坛上签名和留下链接。好处是可以吸引更多的蜘蛛前来参观。所以在网站刚成立的时候就做下弓|蜘蛛是好的,以后最好不要做。
11、网站 备案并不会直接影响网站的排名
很多人都说网站备案与否会影响网站的排名,业内还有一篇很火的文章《影响网站搜索弓|引擎排名价值参考因素》 . 见表网站 @网站 备案对排名的影响非常大,只在外链的影响下,废话。百度已经说了,仅供参考。网站的注册是否影响用户对网站的信任。
12、搜索引擎蜘蛛不会“爬行”
其实,这是一个基本的常识。人们在访问和抓取网页的过程中习惯于使用蜘蛛来“抓取”,导致很多人认为蜘蛛是在从一个页面爬到另一个页面。实际上,蜘蛛是直接访问网页的。其原理是蜘蛛根据权重等信息从被抓取页面的URL中抓取网页内容。查看网站的日志知道蜘蛛没有访问过网站。参考。
13.只关注网站颜,忽略网站其他页面的作用和重要性
大多数情况下,我们在优化网站的时候,只关注首页,内外链的锚文本都集中在首页。事实上,网站在优化之初就集中在首页,但是如果后期不能提高目录和内页的权重,仅仅依靠首页是不够的。即使是排名,也很难增加权重并获得排名。会很强。
14、同IP服务器网站惩罚影响不大
很多人固执的认为在同一个IP服务器上惩罚网站会对网站产生很大的影响,所以在购买空间时要特别注意这一点。事实上,Search Bow|Engine 可以识别这种情况。一开始,这句话出来的比较多,是怕被网站反复攻击受到惩罚。
15、为了增加注册次数,将网站的内容设置为只注册浏览。
现在很多网站都因为各种原因把内容设置为只有注册用户才能查看。但是,搜索引擎蜘蛛和普通用户是一样的。普通用户看不到蜘蛛。当然,不能爬行的蜘蛛是爬不上去的,收录。正确的做法是将部分内容发布出来,方便蜘蛛爬行。
16.网站跳出率和页面响应速度不直接影响网站的排名
首先是它会影响,但不是很大。网站跳出率只能通过统计工具知道。Search Bow|Engine 不知道,只要用户不打开网站 就马不关了。搜索引擎相同关键词。页面打开速度慢会影响用户体验。很多用户会直接关闭页面,但不会直接影响排名。这两点谷歌已经纳入了页面排名因素,而百度还没有。
17. 带有noffollow标签的链接搜索引擎也会爬行
完全禁止的方法是设置robots文件。Nofollow标签的作用是站长不推荐这个链接,但是搜索引擎会爬取所有的链接。在权重传递方面,不传递,但另一个说法是,只要用户点击链接,就有效。
18、度竞价不提升网站收录和排名
很多人说网站的竞价可以提升网站的排名。事实上,网站的竞价并没有提升网站关键词和收录的排名。竞价对SEO的影响在于可以增加网站的曝光率和品牌知名度。一般来说,没有人会在垃圾和毫无价值的页面上出价。
以上是我总结的几个方面。在优化过程中,很多新手甚至是经验丰富的专业知识都容易产生误解。所以,作为一个优秀的seoer,我们不仅要不断学习,更要--一定要实践和使用。说到事实,理论知识点只是一个应用工具,关键在于对知识点的理解和实践! 查看全部
百度网页关键字抓取(关于,的18个常见seo问题的理解和理解)
很多朋友在学习seo的时候会遇到很多问题,也会对一些seo相关的概念有很多错误的理解,从而导致在操作优化的过程中产生误会网站。作为seo,当然要研究搜索引擎算法,但也要研究用户需求和网站体验,通过不断的实战优化技巧得出正确的结论,而不是一味的相信道听途说。

对于以下常见seo问题的理解,相信80%的优化器都曾不小心偏离过。让我们来看看这18个问题:
1、百度快照时间与网站权重没有直接关系
网页权重对网站快照更新时间有辅助作用,但网站快照更新时间是根据网站历史更新频率和内容质量确定的。更新频率越快,蜘蛛抓取越频繁。另外,内容页更新频率很小。还有一种情况是蜘蛛频繁爬行,只是不更新,因为搜索引擎认为内容质量不值得更新。另外,百度官方的说明不需要太在意网页快照。
2、搜索索引不等于实际搜索量
百度官方明确表示,“以网民在百度上的搜索量为数据基础,以关键词为统计对象,科学分析计算每个关键词百度网页搜索”,注意搜索频率,而不仅仅是搜索量。然而,百度指数是实际搜索量的一个有价值的指标。
3、Cookie只能记录本网站中的用户信息,其他网站中记录用户的操作信息
Cookie可以记录用户在自己站内的操作信息,但是用户跳出网站后的数据无法追踪。很多时候,登录一些网站后,发现登录信息等输入数据都在。其实就是每个网站单独保存的用户记录。
4、网站 设置关键词后,排名不会自行上升
包括我自己,我想了很久,只要你为网站设置关键词,更新网站优化内外链,这些关键词的排名就会去向上。. 事实上,网站设置的关键字和描述搜索引擎可能只会在计算相关性时引用它们,它们对排名的影响更大。网站关键词排名要提升或者我们需要针对这些词专门优化内链和外链。锚文本越集中,关键词的排名能力就越好。
5.张工具提供的百度权重值仅供参考
站长工具中的数据统计功能,确实方便我们了解网站的综合数据信息。提供的百度权重现在是交易所链最重要的指标。但是,站长我提供的百度权重只是第三方软件如词库的一些技术的结果,百度并不认可。百度有自己的索引,类似于网站网页重要价值的权重指数。
6、站点网站结果个数不等于网站真实收录个数,不等于网站有效< @收录
很多人把网站网站的结果数据当成百度对网站的收录的实际数量。事实上,现场展示的结果只是网站real收录的一部分。网站收录的实际人数应以百度站长平台索宫人数为准。但是,站点数量越接近索引数量越好,这意味着质量越高。反之,如果搜索的次数远远多于网站的数量,那你就要提高警惕了。他们都说这是搜索弓的不友好表现。(在内容质量方面)另外,网站收录的数量并不代表有效收录的数量。有效收录 指用户搜索和点击的网页数量。对于网站,用户没有访问过的页面一般是没有用的。
7、搜索引擎蜘蛛没有掉电蜘蛛等分类
之前在网上看到过对搜索蜘蛛不同IP段的不同分析,一直这样认为(估计和我一样思考的人不在少数)。然而,高价值网站可能会吸引| 蜘蛛的不同爬行策略。
8、搜索引擎将 网站 URL 视为静态和动态
之前的观点是动态的网站是错误的,后来才知道追求静态网址是不对的。URL 是动态的还是静态的并不重要,只要它们不重复即可。此外,动态 URL 应避免参数过多。
9、是的站群过度妖魔化
很多人对“站群”的印象是作弊。这是作弊(主要是在灰色和黑色行业)。但站群 不全是作弊。我看过一个操作站群,提供站群不同地区交通违章查询的操作案例。这样才能真正解决用户的需求。百度官方曾表示,要看这类网站对普通用户的价值来判断。
10、现在论坛和博客消息签名的链下价值只是蜘蛛
这种情况在 SEO 新手中更常见,他们花费大量时间在博客和论坛上签名和留下链接。好处是可以吸引更多的蜘蛛前来参观。所以在网站刚成立的时候就做下弓|蜘蛛是好的,以后最好不要做。
11、网站 备案并不会直接影响网站的排名
很多人都说网站备案与否会影响网站的排名,业内还有一篇很火的文章《影响网站搜索弓|引擎排名价值参考因素》 . 见表网站 @网站 备案对排名的影响非常大,只在外链的影响下,废话。百度已经说了,仅供参考。网站的注册是否影响用户对网站的信任。
12、搜索引擎蜘蛛不会“爬行”
其实,这是一个基本的常识。人们在访问和抓取网页的过程中习惯于使用蜘蛛来“抓取”,导致很多人认为蜘蛛是在从一个页面爬到另一个页面。实际上,蜘蛛是直接访问网页的。其原理是蜘蛛根据权重等信息从被抓取页面的URL中抓取网页内容。查看网站的日志知道蜘蛛没有访问过网站。参考。
13.只关注网站颜,忽略网站其他页面的作用和重要性
大多数情况下,我们在优化网站的时候,只关注首页,内外链的锚文本都集中在首页。事实上,网站在优化之初就集中在首页,但是如果后期不能提高目录和内页的权重,仅仅依靠首页是不够的。即使是排名,也很难增加权重并获得排名。会很强。
14、同IP服务器网站惩罚影响不大
很多人固执的认为在同一个IP服务器上惩罚网站会对网站产生很大的影响,所以在购买空间时要特别注意这一点。事实上,Search Bow|Engine 可以识别这种情况。一开始,这句话出来的比较多,是怕被网站反复攻击受到惩罚。
15、为了增加注册次数,将网站的内容设置为只注册浏览。
现在很多网站都因为各种原因把内容设置为只有注册用户才能查看。但是,搜索引擎蜘蛛和普通用户是一样的。普通用户看不到蜘蛛。当然,不能爬行的蜘蛛是爬不上去的,收录。正确的做法是将部分内容发布出来,方便蜘蛛爬行。
16.网站跳出率和页面响应速度不直接影响网站的排名
首先是它会影响,但不是很大。网站跳出率只能通过统计工具知道。Search Bow|Engine 不知道,只要用户不打开网站 就马不关了。搜索引擎相同关键词。页面打开速度慢会影响用户体验。很多用户会直接关闭页面,但不会直接影响排名。这两点谷歌已经纳入了页面排名因素,而百度还没有。
17. 带有noffollow标签的链接搜索引擎也会爬行
完全禁止的方法是设置robots文件。Nofollow标签的作用是站长不推荐这个链接,但是搜索引擎会爬取所有的链接。在权重传递方面,不传递,但另一个说法是,只要用户点击链接,就有效。
18、度竞价不提升网站收录和排名
很多人说网站的竞价可以提升网站的排名。事实上,网站的竞价并没有提升网站关键词和收录的排名。竞价对SEO的影响在于可以增加网站的曝光率和品牌知名度。一般来说,没有人会在垃圾和毫无价值的页面上出价。
以上是我总结的几个方面。在优化过程中,很多新手甚至是经验丰富的专业知识都容易产生误解。所以,作为一个优秀的seoer,我们不仅要不断学习,更要--一定要实践和使用。说到事实,理论知识点只是一个应用工具,关键在于对知识点的理解和实践!
百度网页关键字抓取(一个搜刮引擎的算法是怎样的?如何在顾客面前推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-26 14:05
算法基础。虽然搜索引擎算法近年来已经成为越来越流行的词汇,但现在出现还为时过早。所谓算法,就是统计人们的搜索习惯后建立的数据模型。如何在客户面前推荐这样的人气网站。因为搜索有价值的线索是搜索引擎提供的服务,所以优化器的主要工作是为搜索引擎服务的。如果知道对方的算法,就可以遥遥领先。很多线下公司不把网站作为自己的主要销售渠道,对方提供的产品或服务可能不会通过互联网进行销售。做网站的主要原因是做广告,增加知名度。如果他们能跻身行业前列,他们当然会增加。提高公共服务水平,给群众留下了良好的印象。搜索引擎的算法有很多方面。主要假设是“域名、密度、一致性、服务器稳定性、内链、外链、内容更新、域名时间、内容数量”。这些是搜索触发算法的最核心部分。说白了,如果做关键词,就需要注意网站的优化。你只需要做很多协作网站优化时刻就可以考虑这么多元素。经常看到一些“seo大师”说我没有优化,这个词做到了第一,或者我的网站称号一直第一等等。这些是没有太多协作的词。这一刻,你只需要考虑密度。遇到那些合作性很强的词,你要注意更多的元素,也就是那些伟人常说的,崇尚细节。说这话的人是基于两个技能。
但这些因素在三大搜索引擎中的权重不同。比如百度异常关注密度,雅虎关注玉米,谷歌关注外链和外链稳定性。他们都有自己的算法重点。如果你想在三大搜索引擎中获得不错的排名,就得考虑了。
关于robots文件,百度完全无视这个东西。但是谷歌非常小心。还有404和500的问题
. 这些东西一直被百度忽略,而谷歌却关注它,注意到你的恐怖程度。
我为公司做的网站,谷歌的收录前阵子突然变零了。不是一个站,而是大部分站。我当时找不到原因。还以为是几个网站的内容太重复了,共享了一个模板。当我的一个同事给了这些 网站 谷歌地图
目前,我发现无法验证谁的文件。要求服务器管理员查找原因,但没有找到原因。后来这位同事仔细一看,发现网站出现了500个问题。
. 应该是 404 问题,但出现了 500。为此,谷歌拒绝了收录 并清除了数据。处理完这个问题,第二天谷歌更新了收录。
当时我就感叹,google真是变态了。要优化,必须注意细节。不要以为你很好。其实还有很多你没发现的问题。什么是大师?大师是能够处理困难问题的人。
事实上,谷歌过于注重细节,雅虎最为变态。不是因为雅虎搜索最早吗?雅虎对作弊网站毫不留情,与百度势均力敌。
关于K drop IP,搜索引擎很少在基础上做。尤其是百度很少这样做。它会杀掉大部分,但会保存一小部分站点,并且IP很少被阻止。因为百度知道国内还有虚拟主机。但是,有很多外国人的IP,也有很多服务器,而且所有外国空间都在发送IP,所以雅虎看到你作弊时会无情地杀死你的IP。该IP下的站点不是收录你,即使你与作弊站点无关。
从这些细节中,我们可以看出他们这样做的原因。国情不同。想本土化,不学百度真的不行。虽然百度经常无耻地敲你,不给你赎罪的机会。看法】
搜索引擎是指利用特定的计算机程序,按照一定的策略,在互联网上采集信息,将信息进行结构化和处理后,将处理后的信息展示给用户,为用户提供搜索服务的系统。
从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入单词,通过阅读器提交给搜索引擎。搜索引擎将返回与用户输入的内容相关的信息列表。
在互联网的早期,以雅虎为代表的网站类别目录查询非常流行。网站分类目录人工整理保护,精选网上优秀的网站,归纳外观,分类排列在不同的目录下。用户查询时,可以通过逐层点击,找到自己要找的网站。有些人把这种基于目录的搜索服务网站称为搜索引擎,但严格来说,它不是搜索引擎。
【分类】
1、全文索引
全文搜索引擎
它是当之无愧的搜索引擎。国外的代表是谷歌,国内有著名的百度搜索。
. 他们从互联网上提取每个网站的信息(主要是网页笔和墨水),建立数据库,可以检索匹配用户查询前提的记录,并按正序返回结果。
根据搜索效果来源的不同,全文搜索引擎
它可以分为两类。第一类有自己的搜索程序(Indexer),俗称“蜘蛛”程序或“机器人”程序。可自行搭建网络数据库,搜索效果直接取自自有数据库。上面提到的谷歌和百度都属于这一类;另一种是租用其他搜索引擎的数据库,按照自定义模式列出搜索结果,比如Lycos搜索引擎。
2、 目录索引
目录索引虽然具有搜索功能,但严格意义上不能称为真正的搜索引擎。它只是一个按目录分类的 网站 链接列表。用户可以根据分类目录完全找到自己需要的信息,不依赖关键词(关键字)进行查询。目录索引中最具代表性的是著名的雅虎和新浪。
按类别目录搜索。
3、元搜索引擎
元搜索引擎
(META Search Engine) 收到用户的查询请求后,同时在多个搜索引擎上进行搜索,并将效果返回给用户。著名的元搜索引擎
有InfoSpace、Dogpile、Vivisimo等,专业的和业余的,
如何分析网站是否真的被降级处罚以及如何解决
目前从事这项工作的人主要有两种类型,专业的优化人员,还有一些聘请专业人士来做类似的工作。一种是个人站长。因为这点小利是薄的,没必要找人去做。自我优化。效果还是很不一样的。快速排名、seo 优化、搜索引擎优化。快速网站优化方案,快速解决网站流量和排名异常。网站排名服务中文元搜索引擎的代表是搜星搜索引擎。在搜索效果排序方面,有的直接按照来源对搜索效果进行排序,比如Dogpile;根据自己的规则对效果进行某种排序,例如 Vivisimo。
其他非主流搜索引擎的情况:
1、集成搜索引擎:这个搜索引擎类似于元搜索引擎。不同之处在于它不使用多个搜索引擎同时进行搜索。相反,用户从提供的搜索引擎数量中进行选择。例如HotBot是在2002年,搜索引擎在年底推出。
2、流派搜索引擎:虽然AOL Search、MSN Search等提供搜索服务,但它们既没有分类目录也没有网络数据库,其搜索结果完全来源于其他搜索引擎。
3、Free For All Links(简称FFA):通常只是简单的轮换链接项,也有少数有简单的分类,但比Yahoo! 目录索引要小得多。
【事情的真相】
1、获取网页
每个独立的搜索引擎都有自己的网络爬虫
程序(蜘蛛)。蜘蛛会跟踪网页中的超链接,并逐个抓取网页。抓取到的网页称为网页快照
. 因为超链接在互联网上被广泛使用,理论上,从某个有限的网页开始,你可以采集到大部分的网页。
2、处置页面
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供搜索服务。其中,最重要的是提取关键词,建立索引文件。其他包括去除重复网页、分析超链接、计算网页的主要度。
3、供应搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为了方便用户的推理,除了页面标题和URL,还会提供页面摘要等信息。
【全文搜索引擎
】
在搜索引擎分类部分,我们提到全文搜索引擎从网站中提取信息,建立网络数据库。搜索引擎的自动信息聚合功能有两种。一是定时搜索,即每次(比如谷歌一般是28天),搜索引擎主动发送“蜘蛛”程序在某个IP地址的限制范围内搜索互联网网站 . 一旦发现新的网站,它会自动提取网站的信息和URL到站点自己的数据库中。
另一种是提交网站搜索,即网站有想法将URL提交给搜索引擎,它会在某个时刻(范围从2天到几个月)发出“蜘蛛”程序,扫描你的网站并将相关信息保存在数据库中,供用户查询。因为这几年搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以现在最好的办法就是获取更多的外链让搜索引擎有更多机会找到你并自动发送你的网站收录。
当用户使用关键词搜索信息时,搜索引擎会在数据库中进行一次征集。如果找到与用户请求的内容相匹配的网站,就会采用特殊的算法——一般是根据网页关键词的匹配程度、出现的位置/频率、链接质量等——计算每个网页的相关性和排名,然后根据相关性将这些网页链接依次返回给用户。
【目录索引】
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录的索引则完全依赖于人工操作。用户提交网站后,目录编辑会亲自阅读您的网站,然后根据一套自行确定的标准和用户的主观印象决定是否回收您的网站编辑。.
其次,在搜索引擎收录网站时,只要网站不违反相关划分规则,一般都可以登录并获胜。目录索引对网站的要求要高很多,即使重复登录也不一定成功。尤其像雅虎这样的超级索引,登录更是难上加难。
另外,我们在登录搜索引擎的时候,一般不用考虑网站的分类,登录目录索引的时候,一定要把网站放在最合适的目录下(目录)。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引需要手动填写其他网站信息,还有很多其他的限制。另外,如果工作人员认为你提交的网站的内容和网站的信息不合适,他可以随时进行调解,虽然他不会提前和你商量。
内容索引,旺文胜义是将网站存放在不同类别的对应目录中,所以用户在查询信息时可以选择关键词进行信息搜索,也可以按类别进行搜索。如果用关键词搜索,返回的效果和搜索引擎一样。也是按照信息关联的层次来分类的网站,但人为因素较多。如果按层次目录搜索,网站在目录中的排名是由标题字母的顺序决定的(也有例外)。
如今,搜索引擎和目录索引有相互融合的趋势。原来一些正宗的全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。旧的目录索引,如 Yahoo! 通过与谷歌等搜索引擎合作,扩大搜索范围(注)。一些目录搜索引擎以默认搜索的形式,在其目录中首先返回匹配的网站,如国内的搜狐、新浪、网易等;而其他人则默认允许网络搜索,例如雅虎。
【搜索引擎的成长史】
1990年,加拿大麦吉尔大学计算与计算机学院的师生开发了Archie。那时万维网还没有出现,人们通过FTP共享和交换资本。Archie 可以定期采集和分析FTP 服务器上的文件名信息,并提供对每个FTP 主机中的文件的搜索。用户必须输入准确的文件名才能搜索,Archie 会通知用户哪个 FTP 服务器可以下载文件。Archie采集的信息资源虽然不是网页(HTML文件),但与搜索引擎的基本操作是一样的:自动聚合信息资源,建立索引,提供搜索服务。因此,Archie 被广泛认为是现代搜索引擎的先驱。
搜索引擎的开始:
所有搜索引擎的祖先都是1990年蒙特利尔麦吉尔大学的三位学生(Alan Emtage、Peter Deutsch、Bill Wheelan)发现的Archie(Archie FAQ)。Alan Emtage等人想到了开发一个可以逐文件搜索文件的系统名字,所以阿奇被创建了。Archie 是第一个自动索引互联网上匿名 FTP网站 文件的程序,但它还不是真正的搜索引擎。Archie 是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后Archie 会通知用户哪个FTP 位置可以下载该文件。因为 Archie 受到好评并受到启发,内华达大学系统计算服务公司于 1993 年开发了 Gopher(Gopher FAQ)搜索工具 Veronica(Veronica FAQ)。 Jughead 是后来的另一个 Gopher 搜索工具。通常来说,一般来说,网站 页面的引用次数越多,权重越高。运营网站的人应根据用户点击网站页面的行为进行外链推广。网站内容的内链推荐、相互投票和蜘蛛指南。
网站 被降级了,是什么原因造成的
本网站源网部分资料,如有侵权请联系删除!作者:wesipy,如转载请注明出处: 查看全部
百度网页关键字抓取(一个搜刮引擎的算法是怎样的?如何在顾客面前推荐)
算法基础。虽然搜索引擎算法近年来已经成为越来越流行的词汇,但现在出现还为时过早。所谓算法,就是统计人们的搜索习惯后建立的数据模型。如何在客户面前推荐这样的人气网站。因为搜索有价值的线索是搜索引擎提供的服务,所以优化器的主要工作是为搜索引擎服务的。如果知道对方的算法,就可以遥遥领先。很多线下公司不把网站作为自己的主要销售渠道,对方提供的产品或服务可能不会通过互联网进行销售。做网站的主要原因是做广告,增加知名度。如果他们能跻身行业前列,他们当然会增加。提高公共服务水平,给群众留下了良好的印象。搜索引擎的算法有很多方面。主要假设是“域名、密度、一致性、服务器稳定性、内链、外链、内容更新、域名时间、内容数量”。这些是搜索触发算法的最核心部分。说白了,如果做关键词,就需要注意网站的优化。你只需要做很多协作网站优化时刻就可以考虑这么多元素。经常看到一些“seo大师”说我没有优化,这个词做到了第一,或者我的网站称号一直第一等等。这些是没有太多协作的词。这一刻,你只需要考虑密度。遇到那些合作性很强的词,你要注意更多的元素,也就是那些伟人常说的,崇尚细节。说这话的人是基于两个技能。
但这些因素在三大搜索引擎中的权重不同。比如百度异常关注密度,雅虎关注玉米,谷歌关注外链和外链稳定性。他们都有自己的算法重点。如果你想在三大搜索引擎中获得不错的排名,就得考虑了。
关于robots文件,百度完全无视这个东西。但是谷歌非常小心。还有404和500的问题
. 这些东西一直被百度忽略,而谷歌却关注它,注意到你的恐怖程度。
我为公司做的网站,谷歌的收录前阵子突然变零了。不是一个站,而是大部分站。我当时找不到原因。还以为是几个网站的内容太重复了,共享了一个模板。当我的一个同事给了这些 网站 谷歌地图
目前,我发现无法验证谁的文件。要求服务器管理员查找原因,但没有找到原因。后来这位同事仔细一看,发现网站出现了500个问题。
. 应该是 404 问题,但出现了 500。为此,谷歌拒绝了收录 并清除了数据。处理完这个问题,第二天谷歌更新了收录。
当时我就感叹,google真是变态了。要优化,必须注意细节。不要以为你很好。其实还有很多你没发现的问题。什么是大师?大师是能够处理困难问题的人。
事实上,谷歌过于注重细节,雅虎最为变态。不是因为雅虎搜索最早吗?雅虎对作弊网站毫不留情,与百度势均力敌。
关于K drop IP,搜索引擎很少在基础上做。尤其是百度很少这样做。它会杀掉大部分,但会保存一小部分站点,并且IP很少被阻止。因为百度知道国内还有虚拟主机。但是,有很多外国人的IP,也有很多服务器,而且所有外国空间都在发送IP,所以雅虎看到你作弊时会无情地杀死你的IP。该IP下的站点不是收录你,即使你与作弊站点无关。
从这些细节中,我们可以看出他们这样做的原因。国情不同。想本土化,不学百度真的不行。虽然百度经常无耻地敲你,不给你赎罪的机会。看法】
搜索引擎是指利用特定的计算机程序,按照一定的策略,在互联网上采集信息,将信息进行结构化和处理后,将处理后的信息展示给用户,为用户提供搜索服务的系统。
从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入单词,通过阅读器提交给搜索引擎。搜索引擎将返回与用户输入的内容相关的信息列表。
在互联网的早期,以雅虎为代表的网站类别目录查询非常流行。网站分类目录人工整理保护,精选网上优秀的网站,归纳外观,分类排列在不同的目录下。用户查询时,可以通过逐层点击,找到自己要找的网站。有些人把这种基于目录的搜索服务网站称为搜索引擎,但严格来说,它不是搜索引擎。
【分类】
1、全文索引
全文搜索引擎
它是当之无愧的搜索引擎。国外的代表是谷歌,国内有著名的百度搜索。
. 他们从互联网上提取每个网站的信息(主要是网页笔和墨水),建立数据库,可以检索匹配用户查询前提的记录,并按正序返回结果。
根据搜索效果来源的不同,全文搜索引擎
它可以分为两类。第一类有自己的搜索程序(Indexer),俗称“蜘蛛”程序或“机器人”程序。可自行搭建网络数据库,搜索效果直接取自自有数据库。上面提到的谷歌和百度都属于这一类;另一种是租用其他搜索引擎的数据库,按照自定义模式列出搜索结果,比如Lycos搜索引擎。
2、 目录索引
目录索引虽然具有搜索功能,但严格意义上不能称为真正的搜索引擎。它只是一个按目录分类的 网站 链接列表。用户可以根据分类目录完全找到自己需要的信息,不依赖关键词(关键字)进行查询。目录索引中最具代表性的是著名的雅虎和新浪。
按类别目录搜索。
3、元搜索引擎
元搜索引擎
(META Search Engine) 收到用户的查询请求后,同时在多个搜索引擎上进行搜索,并将效果返回给用户。著名的元搜索引擎
有InfoSpace、Dogpile、Vivisimo等,专业的和业余的,
如何分析网站是否真的被降级处罚以及如何解决
目前从事这项工作的人主要有两种类型,专业的优化人员,还有一些聘请专业人士来做类似的工作。一种是个人站长。因为这点小利是薄的,没必要找人去做。自我优化。效果还是很不一样的。快速排名、seo 优化、搜索引擎优化。快速网站优化方案,快速解决网站流量和排名异常。网站排名服务中文元搜索引擎的代表是搜星搜索引擎。在搜索效果排序方面,有的直接按照来源对搜索效果进行排序,比如Dogpile;根据自己的规则对效果进行某种排序,例如 Vivisimo。
其他非主流搜索引擎的情况:
1、集成搜索引擎:这个搜索引擎类似于元搜索引擎。不同之处在于它不使用多个搜索引擎同时进行搜索。相反,用户从提供的搜索引擎数量中进行选择。例如HotBot是在2002年,搜索引擎在年底推出。
2、流派搜索引擎:虽然AOL Search、MSN Search等提供搜索服务,但它们既没有分类目录也没有网络数据库,其搜索结果完全来源于其他搜索引擎。
3、Free For All Links(简称FFA):通常只是简单的轮换链接项,也有少数有简单的分类,但比Yahoo! 目录索引要小得多。
【事情的真相】
1、获取网页
每个独立的搜索引擎都有自己的网络爬虫
程序(蜘蛛)。蜘蛛会跟踪网页中的超链接,并逐个抓取网页。抓取到的网页称为网页快照
. 因为超链接在互联网上被广泛使用,理论上,从某个有限的网页开始,你可以采集到大部分的网页。
2、处置页面
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供搜索服务。其中,最重要的是提取关键词,建立索引文件。其他包括去除重复网页、分析超链接、计算网页的主要度。
3、供应搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为了方便用户的推理,除了页面标题和URL,还会提供页面摘要等信息。
【全文搜索引擎
】
在搜索引擎分类部分,我们提到全文搜索引擎从网站中提取信息,建立网络数据库。搜索引擎的自动信息聚合功能有两种。一是定时搜索,即每次(比如谷歌一般是28天),搜索引擎主动发送“蜘蛛”程序在某个IP地址的限制范围内搜索互联网网站 . 一旦发现新的网站,它会自动提取网站的信息和URL到站点自己的数据库中。
另一种是提交网站搜索,即网站有想法将URL提交给搜索引擎,它会在某个时刻(范围从2天到几个月)发出“蜘蛛”程序,扫描你的网站并将相关信息保存在数据库中,供用户查询。因为这几年搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以现在最好的办法就是获取更多的外链让搜索引擎有更多机会找到你并自动发送你的网站收录。
当用户使用关键词搜索信息时,搜索引擎会在数据库中进行一次征集。如果找到与用户请求的内容相匹配的网站,就会采用特殊的算法——一般是根据网页关键词的匹配程度、出现的位置/频率、链接质量等——计算每个网页的相关性和排名,然后根据相关性将这些网页链接依次返回给用户。
【目录索引】
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录的索引则完全依赖于人工操作。用户提交网站后,目录编辑会亲自阅读您的网站,然后根据一套自行确定的标准和用户的主观印象决定是否回收您的网站编辑。.
其次,在搜索引擎收录网站时,只要网站不违反相关划分规则,一般都可以登录并获胜。目录索引对网站的要求要高很多,即使重复登录也不一定成功。尤其像雅虎这样的超级索引,登录更是难上加难。
另外,我们在登录搜索引擎的时候,一般不用考虑网站的分类,登录目录索引的时候,一定要把网站放在最合适的目录下(目录)。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引需要手动填写其他网站信息,还有很多其他的限制。另外,如果工作人员认为你提交的网站的内容和网站的信息不合适,他可以随时进行调解,虽然他不会提前和你商量。
内容索引,旺文胜义是将网站存放在不同类别的对应目录中,所以用户在查询信息时可以选择关键词进行信息搜索,也可以按类别进行搜索。如果用关键词搜索,返回的效果和搜索引擎一样。也是按照信息关联的层次来分类的网站,但人为因素较多。如果按层次目录搜索,网站在目录中的排名是由标题字母的顺序决定的(也有例外)。
如今,搜索引擎和目录索引有相互融合的趋势。原来一些正宗的全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。旧的目录索引,如 Yahoo! 通过与谷歌等搜索引擎合作,扩大搜索范围(注)。一些目录搜索引擎以默认搜索的形式,在其目录中首先返回匹配的网站,如国内的搜狐、新浪、网易等;而其他人则默认允许网络搜索,例如雅虎。
【搜索引擎的成长史】
1990年,加拿大麦吉尔大学计算与计算机学院的师生开发了Archie。那时万维网还没有出现,人们通过FTP共享和交换资本。Archie 可以定期采集和分析FTP 服务器上的文件名信息,并提供对每个FTP 主机中的文件的搜索。用户必须输入准确的文件名才能搜索,Archie 会通知用户哪个 FTP 服务器可以下载文件。Archie采集的信息资源虽然不是网页(HTML文件),但与搜索引擎的基本操作是一样的:自动聚合信息资源,建立索引,提供搜索服务。因此,Archie 被广泛认为是现代搜索引擎的先驱。
搜索引擎的开始:
所有搜索引擎的祖先都是1990年蒙特利尔麦吉尔大学的三位学生(Alan Emtage、Peter Deutsch、Bill Wheelan)发现的Archie(Archie FAQ)。Alan Emtage等人想到了开发一个可以逐文件搜索文件的系统名字,所以阿奇被创建了。Archie 是第一个自动索引互联网上匿名 FTP网站 文件的程序,但它还不是真正的搜索引擎。Archie 是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后Archie 会通知用户哪个FTP 位置可以下载该文件。因为 Archie 受到好评并受到启发,内华达大学系统计算服务公司于 1993 年开发了 Gopher(Gopher FAQ)搜索工具 Veronica(Veronica FAQ)。 Jughead 是后来的另一个 Gopher 搜索工具。通常来说,一般来说,网站 页面的引用次数越多,权重越高。运营网站的人应根据用户点击网站页面的行为进行外链推广。网站内容的内链推荐、相互投票和蜘蛛指南。
网站 被降级了,是什么原因造成的
本网站源网部分资料,如有侵权请联系删除!作者:wesipy,如转载请注明出处:
百度网页关键字抓取(大拿指点一二itemsitemsitems插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-25 17:22
)
我想通过爬虫获取百度搜索结果的原创链接。通过Firefox的HttpFox插件,发现搜索结果的URL被加密,例如:
点击链接后,会向链接发送一个GET,来自服务器的响应收录真实的URL:
我想通过一个python爬虫模拟这个过程:
1.获取关键词,构建百度搜索URL(借助火狐自带的百度搜索,构建简化搜索链接)
通过pyquery获取页面中所有的搜索结果网址:
[(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3. t a').items()]
//不知道这里有没有用到items()方法。
向加密后的URL发起GET请求,尝试获取HttpFox中获取的内容
提取真实网址并显示
目前可以获取到页面的加密URL(但是对于同一个URL,每次获取的加密URL是不同的,可以理解),但是步骤3中获取的页面不是httpfox中的,而是一个很复杂的页面(应该是跳转后的页面)。
我尝试在requests.get()中设置参数allow_redirects=False,但是得到的响应不是httpfox的内容。
想请教大家。 . . .
代码如下:
#!/usr/bin/python
#coding=utf-8
import re
import requests
from pyquery import PyQuery as Pq
class BaiduSearchSpider(object):
def __init__(self, searchText):
self.url = "http://www.baidu.com/baidu%3Fw ... ot%3B % searchText
self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17"}
self._page = None
@property
def page(self):
if not self._page:
r = requests.get(self.url, headers=self.headers)
r.encoding = 'utf-8'
self._page = Pq(r.text)
return self._page
@property
def baiduURLs(self):
return [(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3.t a').items()]
@property
def originalURLs(self):
tmpURLs = self.baiduURLs
print tmpURLs
originalURLs = []
for tmpurl in tmpURLs:
tmpPage = requests.get(tmpurl[0])
#tmpPage.encoding = 'utf-8' #这样不好使,print的时候python报错
tmptext = tmpPage.text.encode('utf-8')
urlMatch = re.search(r'URL=\'(.*?)\'', tmptext, re.S)
if not urlMatch == None:
print urlMatch.group(1), " ", tmpurl[1]
originalURLs.append(tmpurl)
else:
print "---------------"
print "No Original URL found!!"
print tmpurl[0]
print tmpurl[1]
return originalURLs
searchText = raw_input("搜索内容是:")
print searchText
bdsearch = BaiduSearchSpider(searchText)
originalurls = bdsearch.originalURLs
print '=======Original URLs========'
print originalurls
print '============================' 查看全部
百度网页关键字抓取(大拿指点一二itemsitemsitems插件
)
我想通过爬虫获取百度搜索结果的原创链接。通过Firefox的HttpFox插件,发现搜索结果的URL被加密,例如:
点击链接后,会向链接发送一个GET,来自服务器的响应收录真实的URL:

我想通过一个python爬虫模拟这个过程:
1.获取关键词,构建百度搜索URL(借助火狐自带的百度搜索,构建简化搜索链接)
通过pyquery获取页面中所有的搜索结果网址:
[(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3. t a').items()]
//不知道这里有没有用到items()方法。
向加密后的URL发起GET请求,尝试获取HttpFox中获取的内容
提取真实网址并显示
目前可以获取到页面的加密URL(但是对于同一个URL,每次获取的加密URL是不同的,可以理解),但是步骤3中获取的页面不是httpfox中的,而是一个很复杂的页面(应该是跳转后的页面)。
我尝试在requests.get()中设置参数allow_redirects=False,但是得到的响应不是httpfox的内容。
想请教大家。 . . .
代码如下:
#!/usr/bin/python
#coding=utf-8
import re
import requests
from pyquery import PyQuery as Pq
class BaiduSearchSpider(object):
def __init__(self, searchText):
self.url = "http://www.baidu.com/baidu%3Fw ... ot%3B % searchText
self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17"}
self._page = None
@property
def page(self):
if not self._page:
r = requests.get(self.url, headers=self.headers)
r.encoding = 'utf-8'
self._page = Pq(r.text)
return self._page
@property
def baiduURLs(self):
return [(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3.t a').items()]
@property
def originalURLs(self):
tmpURLs = self.baiduURLs
print tmpURLs
originalURLs = []
for tmpurl in tmpURLs:
tmpPage = requests.get(tmpurl[0])
#tmpPage.encoding = 'utf-8' #这样不好使,print的时候python报错
tmptext = tmpPage.text.encode('utf-8')
urlMatch = re.search(r'URL=\'(.*?)\'', tmptext, re.S)
if not urlMatch == None:
print urlMatch.group(1), " ", tmpurl[1]
originalURLs.append(tmpurl)
else:
print "---------------"
print "No Original URL found!!"
print tmpurl[0]
print tmpurl[1]
return originalURLs
searchText = raw_input("搜索内容是:")
print searchText
bdsearch = BaiduSearchSpider(searchText)
originalurls = bdsearch.originalURLs
print '=======Original URLs========'
print originalurls
print '============================'
百度网页关键字抓取(Python页面上的所有及其词条,每天进步一点点,结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-25 11:00
这几天学习爬行有点过于激进了。我一直在努力学习爬行,但一踏进坑里就跳不出来。郁闷了一天,终于发现自己的基础太差了,比如基本功能,文件输出等等。在这个层次上是不可能写出复杂的爬虫的。想了想,还是决定买一本python基础的书来弥补一下,同时写了一个简单的爬虫来练手。
以下是我买的python基础书。听说这本书是python最好的入门书↓↓↓
今天写一个简单的爬虫,目标是百度百科Python词条页面上的所有词条及其链接。
◆ 分析目标:
① 目标网址:
② 页面编码:utf-8(右键查看页面空白区域查看)
③ 目标标签样式:多查几个条目,你会发现它们位于标签名称的标签中,属性为target="_blank", href=/item/ + 一堆字符
然后开始写代码:
先导入必要的库,然后指定目标url:
使用urlopen下载页面,使用Beautiful Soup解析页面(解析器指定“html.parser”,否则会报错)
由于我使用Python IDE: pycharm 键入代码,它自动指定了“UTF-8”格式(在右下角),所以我不再需要指定解析格式:
然后结合 .findAll() 方法和正则表达式来过滤掉不相关的内容:
最终输出:
主要代码就是这些,整理一下,完整代码如下:
打印结果截图如下:(内容较多,请先贴两页)
眼尖的朋友可能会发现,第一张截图的第一个条目是一个不应该出现的条目,而第二个截图中倒数第四个条目竟然是一个大括号{}。. 前额。我认为我的正则表达式并不完美。暂时不知道怎么改进。我必须努力学习。.
每天学习一点点,每天进步一点点 查看全部
百度网页关键字抓取(Python页面上的所有及其词条,每天进步一点点,结果)
这几天学习爬行有点过于激进了。我一直在努力学习爬行,但一踏进坑里就跳不出来。郁闷了一天,终于发现自己的基础太差了,比如基本功能,文件输出等等。在这个层次上是不可能写出复杂的爬虫的。想了想,还是决定买一本python基础的书来弥补一下,同时写了一个简单的爬虫来练手。
以下是我买的python基础书。听说这本书是python最好的入门书↓↓↓
今天写一个简单的爬虫,目标是百度百科Python词条页面上的所有词条及其链接。
◆ 分析目标:
① 目标网址:
② 页面编码:utf-8(右键查看页面空白区域查看)
③ 目标标签样式:多查几个条目,你会发现它们位于标签名称的标签中,属性为target="_blank", href=/item/ + 一堆字符
然后开始写代码:
先导入必要的库,然后指定目标url:
使用urlopen下载页面,使用Beautiful Soup解析页面(解析器指定“html.parser”,否则会报错)
由于我使用Python IDE: pycharm 键入代码,它自动指定了“UTF-8”格式(在右下角),所以我不再需要指定解析格式:
然后结合 .findAll() 方法和正则表达式来过滤掉不相关的内容:
最终输出:
主要代码就是这些,整理一下,完整代码如下:
打印结果截图如下:(内容较多,请先贴两页)
眼尖的朋友可能会发现,第一张截图的第一个条目是一个不应该出现的条目,而第二个截图中倒数第四个条目竟然是一个大括号{}。. 前额。我认为我的正则表达式并不完美。暂时不知道怎么改进。我必须努力学习。.
每天学习一点点,每天进步一点点
百度网页关键字抓取( 网站SEO之后如何优化页面标题?(易服信息0xziyn2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-25 06:06
网站SEO之后如何优化页面标题?(易服信息0xziyn2))
网站SEO后如何优化页面标题?
无锡关键词快上榜企业聚焦网站优化青岛易服资讯[易服信息0xziyn2]
问题设置
每页设置的标题不应相同。因为每个页面表达的内容不同,按照福州网站SEO的理解,百度搜索引擎对网站上重复的内容判断合适的内容。网站的权重值损害有一定的影响,所以大家的网站页面标题很重要,网站后台管理可以为每个页面开发独立的主题,关键词开发设置的描述是大多数网站@ > 开发公司现阶段没有考虑,因为我们知道只有让客户进行SEO改进是很方便的。
网站流量分析:网站流量分析从SEO结果指导下一步SEO策略,同时对网站用户体验的优化也有指导意义@>。不要被收录搜索引擎对话:将收录网站提交到各大搜索引擎的登录入口。在搜索引擎上看SEO效果,通过站点:消费者的域名了解网站的收录和更新状态。通过domain:消费者的域名或link:消费者的域名,了解网站的反向链接情况。
Hallam网站 不允许抓取以 /wp-admin(网站 后端)开头的 URL。通过指定禁止这些 URL 的位置,您可以节省带宽、服务器资源和抓取预算。
同时,不应该禁止搜索引擎爬虫抓取网站的重要部分。
一箭提供服务:关键词优化、网站推广、网站建设、小程序开发、诚信通运营等服务。目前,一箭已在东莞、长安、佛山,未来将进一步完善服务网络,覆盖全国大中小城市。 查看全部
百度网页关键字抓取(
网站SEO之后如何优化页面标题?(易服信息0xziyn2))

网站SEO后如何优化页面标题?
无锡关键词快上榜企业聚焦网站优化青岛易服资讯[易服信息0xziyn2]
问题设置
每页设置的标题不应相同。因为每个页面表达的内容不同,按照福州网站SEO的理解,百度搜索引擎对网站上重复的内容判断合适的内容。网站的权重值损害有一定的影响,所以大家的网站页面标题很重要,网站后台管理可以为每个页面开发独立的主题,关键词开发设置的描述是大多数网站@ > 开发公司现阶段没有考虑,因为我们知道只有让客户进行SEO改进是很方便的。

网站流量分析:网站流量分析从SEO结果指导下一步SEO策略,同时对网站用户体验的优化也有指导意义@>。不要被收录搜索引擎对话:将收录网站提交到各大搜索引擎的登录入口。在搜索引擎上看SEO效果,通过站点:消费者的域名了解网站的收录和更新状态。通过domain:消费者的域名或link:消费者的域名,了解网站的反向链接情况。
Hallam网站 不允许抓取以 /wp-admin(网站 后端)开头的 URL。通过指定禁止这些 URL 的位置,您可以节省带宽、服务器资源和抓取预算。
同时,不应该禁止搜索引擎爬虫抓取网站的重要部分。
一箭提供服务:关键词优化、网站推广、网站建设、小程序开发、诚信通运营等服务。目前,一箭已在东莞、长安、佛山,未来将进一步完善服务网络,覆盖全国大中小城市。
百度网页关键字抓取( 配合搜索引擎内链算法,就可以实现关键词快速排名!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-25 03:08
配合搜索引擎内链算法,就可以实现关键词快速排名!!)
百度的快速排名并不那么神秘。在搜索引擎飞速发展的今天,爬取速度和收录速度的加速并不是说不可能,而是通过正确的方法和策略是完全可以实现的。新站期间,百度实际上给予了特别的权重来帮助新站。通过利用好这个特殊的权重,可以快速增加网站的权重。借助搜索引擎内链算法,可以实现关键词的快速排名。
什么是网站内链
内链是200多个搜索引擎中对网站进行评分的重要算法。简单来说,内链就是进入网站的首页后,页面中收录的所有其他可点击的链接都称为内链。
网页中任何可以点击跳转到其他页面的内容都属于内部链接
使用内链算法快速增加权重获得排名
A、前后链接的有效性
B、超越链接相关性
C、点击算法
内链绝对与网站的权重快速增长有关。概念上的理解很简单,但是内链的思路和方向会帮助你在内链算法上加分。内链不能乱乱链。我们需要把握用户搜索这个词背后的目的,以及搜索到这个关键词后的一些衍生需求,即需求目的地的相关词。
A、前后链接的有效性
比如石虎的关键词就是用户的主要需求。搜索下拉框中的需求与热门需求相关,也可以认为是目的地相关词,因为搜索引擎判断搜索“石虎”关键词用户的热门衍生需求(命运相关词)有“石斛的功效与作用”、“石斛种植方法”、“石斛价格”等,可通过百度需求图查证。您可以在网站重要的主导航中布置这些关键词以满足用户需求。当用户进入网站首页时,点击其他页面的几率会增加,网站的跳出率会降低。为点击算法添加点数。点开算法以后再说。
石斛关键词需求图
石斛关键词热门需求推荐
用户输入网站后,却没有找到自己需要的,快速关闭网站离开会造成体重下降。为了保证网站的权重不丢失,所以我们要布局在网站去和content做关键词相关的内容,包括首页,文章@ > 页面,产品页面,都需要做。
B、超越链接相关性
发现那些公司网站首页的文章@>的内容几乎都在调用同一个栏目的内容,这样会减少被搜索引擎蜘蛛抓取的几率。要调用首页文章@>,最好是调用每列不同的文章@>。回想一下,我们的网站文章@>页面,有没有上一篇和下一篇,我们知道蜘蛛从上到下爬网。当你从首页进入一个文章@>页面时,我们发现下一个是A文章@>,而恰巧首页也有A文章@>,蜘蛛不会返回主页继续爬行。因此,我们的主页文章@>调用需要不同的列文章@>。
C、点击算法
用户在搜索关键词时,输入了某个网站,说明这个网站的标题一是满足用户的需求,二是进入首页后,有没有点击在其他页面上?对于其他操作,搜索引擎会在网站中监控该用户的一系列行为。点击次数多,停留时间长,说明这个网站跳出率低,可以在不减肥的情况下满足用户需求,反之亦然。跳出率高,用户需求得不到满足,体重下降。
因此,了解内链算法和点击算法,可以降低网站的跳出率,满足用户的需求,快速增加权重。 查看全部
百度网页关键字抓取(
配合搜索引擎内链算法,就可以实现关键词快速排名!!)

百度的快速排名并不那么神秘。在搜索引擎飞速发展的今天,爬取速度和收录速度的加速并不是说不可能,而是通过正确的方法和策略是完全可以实现的。新站期间,百度实际上给予了特别的权重来帮助新站。通过利用好这个特殊的权重,可以快速增加网站的权重。借助搜索引擎内链算法,可以实现关键词的快速排名。
什么是网站内链
内链是200多个搜索引擎中对网站进行评分的重要算法。简单来说,内链就是进入网站的首页后,页面中收录的所有其他可点击的链接都称为内链。

网页中任何可以点击跳转到其他页面的内容都属于内部链接
使用内链算法快速增加权重获得排名
A、前后链接的有效性
B、超越链接相关性
C、点击算法
内链绝对与网站的权重快速增长有关。概念上的理解很简单,但是内链的思路和方向会帮助你在内链算法上加分。内链不能乱乱链。我们需要把握用户搜索这个词背后的目的,以及搜索到这个关键词后的一些衍生需求,即需求目的地的相关词。
A、前后链接的有效性
比如石虎的关键词就是用户的主要需求。搜索下拉框中的需求与热门需求相关,也可以认为是目的地相关词,因为搜索引擎判断搜索“石虎”关键词用户的热门衍生需求(命运相关词)有“石斛的功效与作用”、“石斛种植方法”、“石斛价格”等,可通过百度需求图查证。您可以在网站重要的主导航中布置这些关键词以满足用户需求。当用户进入网站首页时,点击其他页面的几率会增加,网站的跳出率会降低。为点击算法添加点数。点开算法以后再说。

石斛关键词需求图

石斛关键词热门需求推荐
用户输入网站后,却没有找到自己需要的,快速关闭网站离开会造成体重下降。为了保证网站的权重不丢失,所以我们要布局在网站去和content做关键词相关的内容,包括首页,文章@ > 页面,产品页面,都需要做。
B、超越链接相关性
发现那些公司网站首页的文章@>的内容几乎都在调用同一个栏目的内容,这样会减少被搜索引擎蜘蛛抓取的几率。要调用首页文章@>,最好是调用每列不同的文章@>。回想一下,我们的网站文章@>页面,有没有上一篇和下一篇,我们知道蜘蛛从上到下爬网。当你从首页进入一个文章@>页面时,我们发现下一个是A文章@>,而恰巧首页也有A文章@>,蜘蛛不会返回主页继续爬行。因此,我们的主页文章@>调用需要不同的列文章@>。
C、点击算法
用户在搜索关键词时,输入了某个网站,说明这个网站的标题一是满足用户的需求,二是进入首页后,有没有点击在其他页面上?对于其他操作,搜索引擎会在网站中监控该用户的一系列行为。点击次数多,停留时间长,说明这个网站跳出率低,可以在不减肥的情况下满足用户需求,反之亦然。跳出率高,用户需求得不到满足,体重下降。
因此,了解内链算法和点击算法,可以降低网站的跳出率,满足用户的需求,快速增加权重。
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-23 05:18
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬多多关照,不要敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索后抓取页面源码关键词分为五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,则需要进行url编码
3、拼接页面的真实url(url指的是url,后面直接写url即可)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、使用 urllib.request
说说一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、智能分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,这样更容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索后获取页面源码程序代码关键词:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url-encode
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断 查看全部
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬多多关照,不要敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器


PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索后抓取页面源码关键词分为五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,则需要进行url编码
3、拼接页面的真实url(url指的是url,后面直接写url即可)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
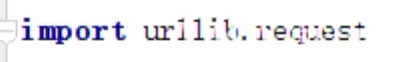
这里可以直接用import语句导入,简单方便,省事
二、使用 urllib.request
说说一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
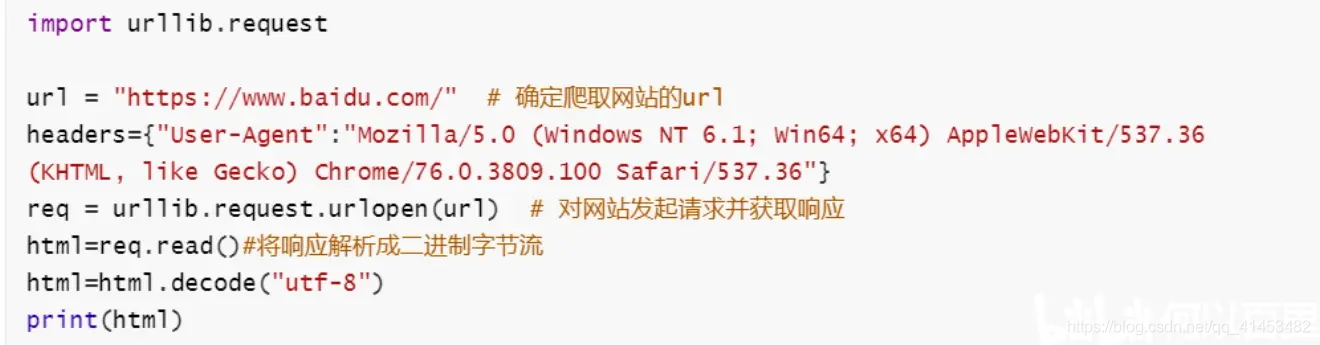
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:

三、智能分析
我们试着用百度搜索一下,比如:


让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...


这只特别的猫有什么意义?
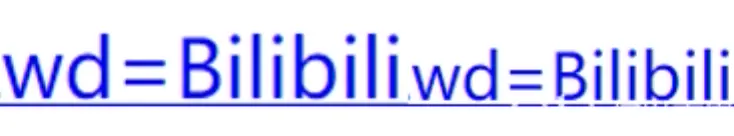
和
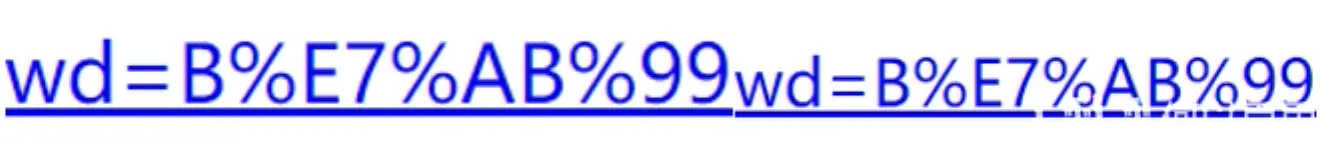
是的,它对‘Station’这个词进行了url编码,这样更容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:

运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:

运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索后获取页面源码程序代码关键词:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url-encode
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断
百度网页关键字抓取(网站“抓取诊断”失败的原因有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-07 15:05
对于SEO人员来说,他们经常使用百度官方工具对网站进行审核,检查网站的各项指标是否符合预期。其中,“爬虫诊断”是站长常用的工具。很多站长都说在使用网站“获取诊断”的时候,经常会提示诊断失败,那是怎么回事。
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。它反馈的结果代表了蜘蛛对站点内容的理解。通常网站爬行诊断失败,和百度蜘蛛爬行有直接关系。
网站“爬虫诊断”失败的原因有哪些?
1、Robots.txt 被禁止
如果在Robots.txt中屏蔽了百度抓取网站某个目录,当你在该目录下生成内容时,百度很难抓取到该目录下的内容,抓取诊断也会出现故障提示。
2、网站访问速度
很多站长说在本地测试中,我的网站返回HTTP状态码200,但是爬虫诊断一直显示爬虫在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬取速度可能会延迟很长时间,从而导致在明明可以访问的情况下爬行诊断失败的问题。
遇到这个问题时,需要定期监控服务器上各个地方的访问速度,优化网站的打开速度。
3、CDN 缓存更新
我们知道 CDN 缓存更新需要时间。虽然您在管理平台后台实时在线更新,但由于不同服务商的技术不对称,往往会造成一定的时延。
这必然会导致网站爬取失败。
4、 有跳转到爬虫诊断
如果更新旧内容,修改网站版本,使用301或302重定向,由于配置错误原因导致重定向次数过多,百度抓取失败的问题也会发生。
5、DNS 缓存
由于DNS缓存的存在,在本地查询URL时,可以正常访问,但排除上述一般问题后,爬行诊断仍提示失败,则需要更新本地DNS缓存,或使用代理IP要审核网站 很流畅的访问。
网站 关于“获取诊断”的常见问题:
关于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断对收录有帮助吗?
从目前很多SEO人员的反馈结果来看,并没有合理的数据支持。可以证明爬虫诊断工具对百度收录是有利的,但或许对百度的快照更新有一定的影响。
总结:网站“爬网诊断”失败的原因有很多。除了参考官方提示外,还需要一一排除。以上内容仅供参考。
蝙蝠侠IT转载需要授权! 查看全部
百度网页关键字抓取(网站“抓取诊断”失败的原因有哪些?-八维教育)
对于SEO人员来说,他们经常使用百度官方工具对网站进行审核,检查网站的各项指标是否符合预期。其中,“爬虫诊断”是站长常用的工具。很多站长都说在使用网站“获取诊断”的时候,经常会提示诊断失败,那是怎么回事。
网站抓取诊断·概述
百度爬虫诊断工具的作用主要是从百度蜘蛛的角度了解网站的内容。它反馈的结果代表了蜘蛛对站点内容的理解。通常网站爬行诊断失败,和百度蜘蛛爬行有直接关系。
网站“爬虫诊断”失败的原因有哪些?
1、Robots.txt 被禁止
如果在Robots.txt中屏蔽了百度抓取网站某个目录,当你在该目录下生成内容时,百度很难抓取到该目录下的内容,抓取诊断也会出现故障提示。
2、网站访问速度
很多站长说在本地测试中,我的网站返回HTTP状态码200,但是爬虫诊断一直显示爬虫在进行中,没有反馈结果。
由于服务器线路不同,百度蜘蛛的爬取速度可能会延迟很长时间,从而导致在明明可以访问的情况下爬行诊断失败的问题。
遇到这个问题时,需要定期监控服务器上各个地方的访问速度,优化网站的打开速度。
3、CDN 缓存更新
我们知道 CDN 缓存更新需要时间。虽然您在管理平台后台实时在线更新,但由于不同服务商的技术不对称,往往会造成一定的时延。
这必然会导致网站爬取失败。
4、 有跳转到爬虫诊断
如果更新旧内容,修改网站版本,使用301或302重定向,由于配置错误原因导致重定向次数过多,百度抓取失败的问题也会发生。
5、DNS 缓存
由于DNS缓存的存在,在本地查询URL时,可以正常访问,但排除上述一般问题后,爬行诊断仍提示失败,则需要更新本地DNS缓存,或使用代理IP要审核网站 很流畅的访问。
网站 关于“获取诊断”的常见问题:
关于百度爬虫诊断工具,SEO顾问最常问的问题是:百度爬虫诊断对收录有帮助吗?
从目前很多SEO人员的反馈结果来看,并没有合理的数据支持。可以证明爬虫诊断工具对百度收录是有利的,但或许对百度的快照更新有一定的影响。
总结:网站“爬网诊断”失败的原因有很多。除了参考官方提示外,还需要一一排除。以上内容仅供参考。
蝙蝠侠IT转载需要授权!
百度网页关键字抓取(51招聘列表页,查找百度,谷歌上面的某个排行 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-04 12:06
)
如果你想获取网站的某个页面的信息,关键是能够顺利请求那个页面。一些网站加密等技术可以防止你被抓住,你很难成功。
我抓住了 51job 招聘列表页面。问题的关键是如何找到下一页。51是通过post方式提交表单,那么所有的参数都要通过参数找出来写入请求信息中。
请求连接方式
private Scanner openConnection (int i,String keyName,String link) {
try {
URL url = new URL("http://search.51job.com/jobsea ... 6quot;);
//参数设置
String parameter = "postchannel=0000&stype=2&jobarea=0100&district=&address=&lonlat=&radius=" +
"&funtype_big=0000&funtype=0000&industrytype=00&issuedate=9&keywordtype=2&dis_keyword=" +
"&keyword=&workyear=99&providesalary=99&cotype=99°reefrom=99&jobterm=01&ord_field=0" +
"&list_type=1&last_list_type=1&curr_page=&last_page=1&nStart=1&start_page=&total_page=86" +
"&jobid_list=39297991~39298287~39298722~39298729~39297918~39297800~39298262~39297331~39297238~39297080~39296848~39297361~39296644~39296315~39287153~39295409~39295407~39295397~39295396~39295391~39287385~39293469~39287417~39285861~39281595~39281853~39279955~39281274~39280683~38748545~37068616~38130945~39023955~36747022~36493173~39006183~38960955~38960944~38960615~38980334~37888484~37584999~38998054~37585073~37332619~36882505~34976909~37307284~37307262~36999896~36767409~39242127~7369258~35503114~35502793~35496087~35496083~35495350~35494140~35493224~35492320~35487346~35468080~35457510~35457504~35457501~35398467~35380047~35347719~35347637~34991677~20974922~20974918~37441300~35465051~39160193~39029414~38138399~39136977~36632495~39266845~39270060~39266835~39097249~39082877~37663952~37662532~37662480~37663986~37662626~37662589~37662556~37738455~39270625~38433053~38261468~38486743~39057636~34582292~36475553~37257361~37257567~37257262~36741386~36711006~36498218~38914431~38734212~38674569~38787188~39259469~38927584~39024252~39024230~39228632~35252232~38658258~38658243~38625335~39245388~37319651~36852389~39136912~39159440~37456013~39256295~39214509~39253898~37376056~38561452~38295890~39156937~26052225~38711016~39272058~39271701~37777885~38524663~39022301~39063658~37777523~39018693~37897821~37023954~39242449~39242399~36227979~38635974~39100175~39200749~39251242~39197848~39229735~39108206~38520680~38520612~37512047~37373955~36748357~36558807~36553946~36994069~35651002~37645149~35650457~37547299~37547226~37547191~37547135~37325202~38909563~37981021~36518439~38435329~38356348~39225954~38905834~39100737~38753876~38753837~38648131~38909881~38909871~39253871~39139848~37756802~38207471~38715097~38714739~39228968~39109760~39109531~39109511~38412880~39193350~38918885~38443045~38133816~35085561~38011368~"+
"&jobid_count=2551&schTime=15&statCount=364" +
"&statData=404|114|45|61|92|99|29|34|80|27|15|29|49|449|1|228|133|0|0|1|1|243|494|5|0|0|1|0|7|232|321|139|26|1|0|152|831|1|1|4|18|8|8|4|3|0|0|0|0|0|0|588|0|1|0|0|0|0|1|13|0|0|0|0|0|0|0|1|0|0|0|0|0|0|2|254|6|6|0|1|1|0|0|0|0|0|0|1|0|0|0|0|2|0|1|0|0|0|0|0|0|0|0|0|0|0|365|14|13|0|5|3|18|9|2|0|1|26|6|2|0|0|3|1|2|3|0|9|32|1|0|6|1|0|0|0|13|209|1|0|3|1|7|32|5|37|1|0|3|0|0|13|2|9|10|0|1|0|5|1|1|0|0|2"+
"&fromType=";
//设置分页的页码
parameter = parameter.replace("curr_page=", "curr_page="+String.valueOf(i));
parameter = parameter.replace("fromType=", "fromType="+String.valueOf(14));
//设置关键字“程序员”
parameter = parameter.replace("dis_keyword=", "dis_keyword="+URLEncoder.encode(keyName, "GBK"));
parameter = parameter.replace("keyword=", "keyword="+URLEncoder.encode(keyName, "GBK"));
//打开链接设置头信息
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
//伪装请求
conn.setRequestProperty("Host", "search.51job.com");
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//post方式参数长度必须设定
conn.setRequestProperty("Content-Length", Integer.toString(parameter.getBytes("GB2312").length));
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB5; .NET CLR 1.1.4322; .NET CLR 2.0.50727; Alexa Toolbar; MAXTHON 2.0)");
OutputStream o = conn.getOutputStream();
OutputStreamWriter out = new OutputStreamWriter(o, "GBK");
out.write(parameter);
out.flush();
out.close();
//获得请求字节流
InputStream in = conn.getInputStream();
//解析
Scanner sc = new Scanner(in, "GBK");
return sc;
} catch (Exception e) {
log.error(e,e);
return null;
}
}
这样就可以顺利的获取到第一页关键词的列表信息。
完成这一步后,你就可以分析你想找的信息了,比如公司信息,职位……
<p>while (sc.hasNextLine()) {
String line = sc.nextLine();
sp = line.indexOf("class=\"jobname\" >", sp + 1);
if (sp != -1) {
sp = line.indexOf(" 查看全部
百度网页关键字抓取(51招聘列表页,查找百度,谷歌上面的某个排行
)
如果你想获取网站的某个页面的信息,关键是能够顺利请求那个页面。一些网站加密等技术可以防止你被抓住,你很难成功。
我抓住了 51job 招聘列表页面。问题的关键是如何找到下一页。51是通过post方式提交表单,那么所有的参数都要通过参数找出来写入请求信息中。
请求连接方式
private Scanner openConnection (int i,String keyName,String link) {
try {
URL url = new URL("http://search.51job.com/jobsea ... 6quot;);
//参数设置
String parameter = "postchannel=0000&stype=2&jobarea=0100&district=&address=&lonlat=&radius=" +
"&funtype_big=0000&funtype=0000&industrytype=00&issuedate=9&keywordtype=2&dis_keyword=" +
"&keyword=&workyear=99&providesalary=99&cotype=99°reefrom=99&jobterm=01&ord_field=0" +
"&list_type=1&last_list_type=1&curr_page=&last_page=1&nStart=1&start_page=&total_page=86" +
"&jobid_list=39297991~39298287~39298722~39298729~39297918~39297800~39298262~39297331~39297238~39297080~39296848~39297361~39296644~39296315~39287153~39295409~39295407~39295397~39295396~39295391~39287385~39293469~39287417~39285861~39281595~39281853~39279955~39281274~39280683~38748545~37068616~38130945~39023955~36747022~36493173~39006183~38960955~38960944~38960615~38980334~37888484~37584999~38998054~37585073~37332619~36882505~34976909~37307284~37307262~36999896~36767409~39242127~7369258~35503114~35502793~35496087~35496083~35495350~35494140~35493224~35492320~35487346~35468080~35457510~35457504~35457501~35398467~35380047~35347719~35347637~34991677~20974922~20974918~37441300~35465051~39160193~39029414~38138399~39136977~36632495~39266845~39270060~39266835~39097249~39082877~37663952~37662532~37662480~37663986~37662626~37662589~37662556~37738455~39270625~38433053~38261468~38486743~39057636~34582292~36475553~37257361~37257567~37257262~36741386~36711006~36498218~38914431~38734212~38674569~38787188~39259469~38927584~39024252~39024230~39228632~35252232~38658258~38658243~38625335~39245388~37319651~36852389~39136912~39159440~37456013~39256295~39214509~39253898~37376056~38561452~38295890~39156937~26052225~38711016~39272058~39271701~37777885~38524663~39022301~39063658~37777523~39018693~37897821~37023954~39242449~39242399~36227979~38635974~39100175~39200749~39251242~39197848~39229735~39108206~38520680~38520612~37512047~37373955~36748357~36558807~36553946~36994069~35651002~37645149~35650457~37547299~37547226~37547191~37547135~37325202~38909563~37981021~36518439~38435329~38356348~39225954~38905834~39100737~38753876~38753837~38648131~38909881~38909871~39253871~39139848~37756802~38207471~38715097~38714739~39228968~39109760~39109531~39109511~38412880~39193350~38918885~38443045~38133816~35085561~38011368~"+
"&jobid_count=2551&schTime=15&statCount=364" +
"&statData=404|114|45|61|92|99|29|34|80|27|15|29|49|449|1|228|133|0|0|1|1|243|494|5|0|0|1|0|7|232|321|139|26|1|0|152|831|1|1|4|18|8|8|4|3|0|0|0|0|0|0|588|0|1|0|0|0|0|1|13|0|0|0|0|0|0|0|1|0|0|0|0|0|0|2|254|6|6|0|1|1|0|0|0|0|0|0|1|0|0|0|0|2|0|1|0|0|0|0|0|0|0|0|0|0|0|365|14|13|0|5|3|18|9|2|0|1|26|6|2|0|0|3|1|2|3|0|9|32|1|0|6|1|0|0|0|13|209|1|0|3|1|7|32|5|37|1|0|3|0|0|13|2|9|10|0|1|0|5|1|1|0|0|2"+
"&fromType=";
//设置分页的页码
parameter = parameter.replace("curr_page=", "curr_page="+String.valueOf(i));
parameter = parameter.replace("fromType=", "fromType="+String.valueOf(14));
//设置关键字“程序员”
parameter = parameter.replace("dis_keyword=", "dis_keyword="+URLEncoder.encode(keyName, "GBK"));
parameter = parameter.replace("keyword=", "keyword="+URLEncoder.encode(keyName, "GBK"));
//打开链接设置头信息
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
//伪装请求
conn.setRequestProperty("Host", "search.51job.com");
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
//post方式参数长度必须设定
conn.setRequestProperty("Content-Length", Integer.toString(parameter.getBytes("GB2312").length));
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB5; .NET CLR 1.1.4322; .NET CLR 2.0.50727; Alexa Toolbar; MAXTHON 2.0)");
OutputStream o = conn.getOutputStream();
OutputStreamWriter out = new OutputStreamWriter(o, "GBK");
out.write(parameter);
out.flush();
out.close();
//获得请求字节流
InputStream in = conn.getInputStream();
//解析
Scanner sc = new Scanner(in, "GBK");
return sc;
} catch (Exception e) {
log.error(e,e);
return null;
}
}
这样就可以顺利的获取到第一页关键词的列表信息。
完成这一步后,你就可以分析你想找的信息了,比如公司信息,职位……
<p>while (sc.hasNextLine()) {
String line = sc.nextLine();
sp = line.indexOf("class=\"jobname\" >", sp + 1);
if (sp != -1) {
sp = line.indexOf("
百度网页关键字抓取(超级排名系统原文链接:吸引百度蜘蛛抓取网站的基本条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-03 23:09
原文出处:超级排位系统
原文链接:吸引百度蜘蛛爬取的基本条件网站-超级排名系统
为了创建一个新的网站,我们首先考虑如何将蜘蛛吸引到我们的网站,采集我们的文章并建立一个排名。如果网站的管理员不知道怎么吸引蜘蛛,你连上手的资格都没有,那网站怎么会很快被蜘蛛抓到呢?超级排名系统的编辑会组织发布。
在互联网时代,我们想要的大部分信息都是通过“互联网搜索”获得的。比如很多人在购买某款产品之前都会上网查看相关信息,看看品牌的口碑和评价。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。
这说明SEO优化是非常有必要的,不仅要增加曝光度,还要增加销量。下面百度搜索引擎优化告诉你如何让网站快速爬取。
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。所以关键词是搜索引擎优化的核心。
外链是SEO优化过程中的一个环节,间接影响着网站的权重。常见的链接有:锚文本链接、纯文本链接和图片链接。
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。例如,百度的蜘蛛在爬取网页时需要定义网页并过滤和分析网页数据。
对于页面,爬取是收录的前提。只有爬得更多,我们才能收录更多。如果网站页面更新频繁,爬虫程序会频繁访问该页面。高质量的内容,尤其是原创内容,是爬虫喜欢捕捉的目标。
权威高配老网站享受VIP级待遇。这种网站的爬取频率高,爬取的页面数量多,爬取深度高,页面数量也比较多。这就是区别。
网站服务器是访问网站的基石。如果长时间打不开,就会长时间敲门。如果长时间无人接听,游客就会因为进不去,纷纷离开。蜘蛛来访也是游客之一。如果服务器不稳定,蜘蛛每次进入页面爬行都会被屏蔽,蜘蛛对网站的印象会越来越差,导致分数越来越低,自然排名也越来越低。
网站内容更新频繁,会吸引蜘蛛更频繁的访问。如果文章定期更新,蜘蛛会定期访问。蜘蛛每次爬取时,将页面数据存入数据库,分析后采集页面。如果蜘蛛每次爬行,发现收录的内容完全一样,蜘蛛就会判断网站,从而减少对网站的爬行。
蜘蛛的根本目的是发现有价值的“新”事物,所以原创优质内容对蜘蛛的吸引力是巨大的。如果能得到一只蜘蛛一样的,自然要给网站打上“优秀”的标签,经常爬取网站。
抓蜘蛛是有规则的。如果太深而无法隐藏,蜘蛛会找到自己的路。爬取过程很简单,所以网站结构应该不会太复杂。
在网站的构建中,程序可以生成大量的页面,通常是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成大量的重复内容,影响蜘蛛的抓取。如果一个页面对应的URL很多,可以尝试通过301重定向、canonical标签或者robots来处理,保证爬虫只抓取一个标准的URL。
对于新站来说,在网站建设初期,相对流量小,蜘蛛少。外链可以增加网页的曝光率和蜘蛛爬行,但需要注意外链的质量。 查看全部
百度网页关键字抓取(超级排名系统原文链接:吸引百度蜘蛛抓取网站的基本条件)
原文出处:超级排位系统
原文链接:吸引百度蜘蛛爬取的基本条件网站-超级排名系统
为了创建一个新的网站,我们首先考虑如何将蜘蛛吸引到我们的网站,采集我们的文章并建立一个排名。如果网站的管理员不知道怎么吸引蜘蛛,你连上手的资格都没有,那网站怎么会很快被蜘蛛抓到呢?超级排名系统的编辑会组织发布。
在互联网时代,我们想要的大部分信息都是通过“互联网搜索”获得的。比如很多人在购买某款产品之前都会上网查看相关信息,看看品牌的口碑和评价。调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。
这说明SEO优化是非常有必要的,不仅要增加曝光度,还要增加销量。下面百度搜索引擎优化告诉你如何让网站快速爬取。
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。所以关键词是搜索引擎优化的核心。
外链是SEO优化过程中的一个环节,间接影响着网站的权重。常见的链接有:锚文本链接、纯文本链接和图片链接。
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。例如,百度的蜘蛛在爬取网页时需要定义网页并过滤和分析网页数据。
对于页面,爬取是收录的前提。只有爬得更多,我们才能收录更多。如果网站页面更新频繁,爬虫程序会频繁访问该页面。高质量的内容,尤其是原创内容,是爬虫喜欢捕捉的目标。
权威高配老网站享受VIP级待遇。这种网站的爬取频率高,爬取的页面数量多,爬取深度高,页面数量也比较多。这就是区别。
网站服务器是访问网站的基石。如果长时间打不开,就会长时间敲门。如果长时间无人接听,游客就会因为进不去,纷纷离开。蜘蛛来访也是游客之一。如果服务器不稳定,蜘蛛每次进入页面爬行都会被屏蔽,蜘蛛对网站的印象会越来越差,导致分数越来越低,自然排名也越来越低。
网站内容更新频繁,会吸引蜘蛛更频繁的访问。如果文章定期更新,蜘蛛会定期访问。蜘蛛每次爬取时,将页面数据存入数据库,分析后采集页面。如果蜘蛛每次爬行,发现收录的内容完全一样,蜘蛛就会判断网站,从而减少对网站的爬行。
蜘蛛的根本目的是发现有价值的“新”事物,所以原创优质内容对蜘蛛的吸引力是巨大的。如果能得到一只蜘蛛一样的,自然要给网站打上“优秀”的标签,经常爬取网站。
抓蜘蛛是有规则的。如果太深而无法隐藏,蜘蛛会找到自己的路。爬取过程很简单,所以网站结构应该不会太复杂。
在网站的构建中,程序可以生成大量的页面,通常是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成大量的重复内容,影响蜘蛛的抓取。如果一个页面对应的URL很多,可以尝试通过301重定向、canonical标签或者robots来处理,保证爬虫只抓取一个标准的URL。
对于新站来说,在网站建设初期,相对流量小,蜘蛛少。外链可以增加网页的曝光率和蜘蛛爬行,但需要注意外链的质量。
百度网页关键字抓取(网站关键词怎么优化,网站SEO优化排名怎么做(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-03 19:54
seo、关键词优化、百度google快照都是指一个方面。都是搜索引擎优化,就是利用搜索规律@>或者网页尽量排在搜索引擎首页甚至自然排名第一的位置!!!查看详细信息:
如何成为专业的seo?
首先你要懂html,因为你要修改页面布局。要有营销技巧,只有SEO和营销相结合,才能为你创造效益。我们还必须拥有发现和开采资源的技术。通过我们对手的站点,我们可以获得他相当一部分的优质外链资源。如果您对程序有所了解,那将是最好的。部分网站功能有缺陷,我们可以改进。以使其符合有利于搜索引擎的要求。我不考虑其他事情。互联网常识操作。我不会谈论那个。
重要的是要有耐心和耐心。不然气氛会很不好。
网站关键词如何优化,网站SEO如何优化排名,快速见效
关键词优化很重要。一定要分析关键词、网站的网页布局、发布的内容和友情链接设置等,一定要慎重考虑。如果你是新手,不了解这个,可以找专业人士来做,
在网站优化和网络优化方面,我做得很好。关键词 在排名搜索方面非常有经验,而且出结果很快。可以了解一下,有专业的网站建设,网站 seo优化团队,
他们的网站
SEO的核心是什么?什么样的网站有利于优化?关键词什么是排名技巧?
SEO的核心是搜索引擎的算法,有利于用户体验,有利于优化。. 关键词排名的技巧是增加网站的人气和网站的内在合理性和质量。.
其实以上都是美言。如果你真的想了解这些东西的本质,你还必须了解搜索引擎迄今为止的历史、发展和状态。. . . 查看全部
百度网页关键字抓取(网站关键词怎么优化,网站SEO优化排名怎么做(图))
seo、关键词优化、百度google快照都是指一个方面。都是搜索引擎优化,就是利用搜索规律@>或者网页尽量排在搜索引擎首页甚至自然排名第一的位置!!!查看详细信息:
如何成为专业的seo?
首先你要懂html,因为你要修改页面布局。要有营销技巧,只有SEO和营销相结合,才能为你创造效益。我们还必须拥有发现和开采资源的技术。通过我们对手的站点,我们可以获得他相当一部分的优质外链资源。如果您对程序有所了解,那将是最好的。部分网站功能有缺陷,我们可以改进。以使其符合有利于搜索引擎的要求。我不考虑其他事情。互联网常识操作。我不会谈论那个。
重要的是要有耐心和耐心。不然气氛会很不好。
网站关键词如何优化,网站SEO如何优化排名,快速见效
关键词优化很重要。一定要分析关键词、网站的网页布局、发布的内容和友情链接设置等,一定要慎重考虑。如果你是新手,不了解这个,可以找专业人士来做,
在网站优化和网络优化方面,我做得很好。关键词 在排名搜索方面非常有经验,而且出结果很快。可以了解一下,有专业的网站建设,网站 seo优化团队,
他们的网站
SEO的核心是什么?什么样的网站有利于优化?关键词什么是排名技巧?
SEO的核心是搜索引擎的算法,有利于用户体验,有利于优化。. 关键词排名的技巧是增加网站的人气和网站的内在合理性和质量。.
其实以上都是美言。如果你真的想了解这些东西的本质,你还必须了解搜索引擎迄今为止的历史、发展和状态。. . .
百度网页关键字抓取(网站与你共享IP的网站受到搜索引擎的惩罚,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 05:03
1、关键词 策略:确定网站的核心关键词所有能被搜索引擎爬取的文本都应该尽可能收录关键词关键词@ > 选品技巧:相关性(即定位)、人气(太热不易排名,太冷不易搜索)
2、域名策略:在域名中加入你的关键词,并用连字符“-”分别突出关键词,让搜索引擎可以识别一些人认为带有关键词域名的作用在排名上是弱的,但是他们不能否认,所以考虑的时候应该尽量考虑使用关键词域名。
3、虚拟主机策略:测试共享IP地址网站:目前大多数中小型网站共享一个IP地址相同的虚拟主机。如果您与您的网站搜索引擎惩罚共享一个IP,您将无法登录搜索引擎。另外,由于一个IP通常有几百个网站,会影响你的页面下载速度,特别是当一些网站流量很大的时候,如果搜索引擎下载一个页面半天失败,抓取它,搜索机器人将放弃它。因此,除了要了解有多少网站 与您共享的 IP 以及它们是否受到惩罚之外,还要了解它们的流量概况。
4、网页文件目录策略:将文件目录结构有序、合理排列,标准化一个简单的网站,将重要内容呈现在顶层目录中的三层。目录文件夹名称收录关键字。HTML 页面文件名也收录关键字。图片文件还收录关键字。这里提到的关键词主要是针对特定的页面内容。文件名是由破折号或下划线分隔的短语。标准做法是使用英语而不是拼音。
5、外部文件策略:将JavaScript文件和CSS文件分别放入JS和CSS外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减小文件大小,有助于搜索引擎快速准确地掌握网页的重要内容,其他字体和格式标签应该尽量少用。搜索引擎喜欢在页面的开头找到页面的关键内容。
6、框架策略:如果网站必须使用框架,那么应该正确使用noframe标签。此区域收录指向框架页面或带有关键字的解释性文本的链接。同时,关键字文本出现在框架区域之外。
7、图片策略:使用alt属性标签来描述图片的代码,包括关键字,图片旁边添加带有关键字的文字注释,避免使用splash page,比如一些公司的首页图片网站 Page Flash 使用率低,搜索引擎对跟踪嵌入链接的兴趣不大。
8、网站地图策略:基于文本的网站地图收录网站网站的所有列和子列地图的三个元素:文本、链接、关键词对于搜索引擎获取首页的内容都非常有帮助。因此,特别需要创建站点地图来动态生成目录站点。如果有更新,需要在网站的地图上体现出来。
9、标题和元标签策略:搜索引擎优化的基本技巧:标题内容会以链接标题的形式显示在搜索结果页面上。标题一般是网站名称+简短描述,包括核心关键词,如:SEO优化。
10、链接策略:尽可能让其他与你话题相关的网站链接到你。这已经成为搜索引擎排名成功的关键因素。有了这些网站链接,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你一个不错的排名。
另一方面,如果网站提供话题相关导出链接,搜索引擎会认为有丰富的话题相关内容,也有利于排名。
11、 避免惩罚:搜索引擎在识别欺骗方法方面变得越来越成熟。以下常用方法容易被惩罚,不会被收录。 查看全部
百度网页关键字抓取(网站与你共享IP的网站受到搜索引擎的惩罚,你知道吗?)
1、关键词 策略:确定网站的核心关键词所有能被搜索引擎爬取的文本都应该尽可能收录关键词关键词@ > 选品技巧:相关性(即定位)、人气(太热不易排名,太冷不易搜索)
2、域名策略:在域名中加入你的关键词,并用连字符“-”分别突出关键词,让搜索引擎可以识别一些人认为带有关键词域名的作用在排名上是弱的,但是他们不能否认,所以考虑的时候应该尽量考虑使用关键词域名。
3、虚拟主机策略:测试共享IP地址网站:目前大多数中小型网站共享一个IP地址相同的虚拟主机。如果您与您的网站搜索引擎惩罚共享一个IP,您将无法登录搜索引擎。另外,由于一个IP通常有几百个网站,会影响你的页面下载速度,特别是当一些网站流量很大的时候,如果搜索引擎下载一个页面半天失败,抓取它,搜索机器人将放弃它。因此,除了要了解有多少网站 与您共享的 IP 以及它们是否受到惩罚之外,还要了解它们的流量概况。
4、网页文件目录策略:将文件目录结构有序、合理排列,标准化一个简单的网站,将重要内容呈现在顶层目录中的三层。目录文件夹名称收录关键字。HTML 页面文件名也收录关键字。图片文件还收录关键字。这里提到的关键词主要是针对特定的页面内容。文件名是由破折号或下划线分隔的短语。标准做法是使用英语而不是拼音。
5、外部文件策略:将JavaScript文件和CSS文件分别放入JS和CSS外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减小文件大小,有助于搜索引擎快速准确地掌握网页的重要内容,其他字体和格式标签应该尽量少用。搜索引擎喜欢在页面的开头找到页面的关键内容。
6、框架策略:如果网站必须使用框架,那么应该正确使用noframe标签。此区域收录指向框架页面或带有关键字的解释性文本的链接。同时,关键字文本出现在框架区域之外。
7、图片策略:使用alt属性标签来描述图片的代码,包括关键字,图片旁边添加带有关键字的文字注释,避免使用splash page,比如一些公司的首页图片网站 Page Flash 使用率低,搜索引擎对跟踪嵌入链接的兴趣不大。
8、网站地图策略:基于文本的网站地图收录网站网站的所有列和子列地图的三个元素:文本、链接、关键词对于搜索引擎获取首页的内容都非常有帮助。因此,特别需要创建站点地图来动态生成目录站点。如果有更新,需要在网站的地图上体现出来。
9、标题和元标签策略:搜索引擎优化的基本技巧:标题内容会以链接标题的形式显示在搜索结果页面上。标题一般是网站名称+简短描述,包括核心关键词,如:SEO优化。
10、链接策略:尽可能让其他与你话题相关的网站链接到你。这已经成为搜索引擎排名成功的关键因素。有了这些网站链接,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你一个不错的排名。
另一方面,如果网站提供话题相关导出链接,搜索引擎会认为有丰富的话题相关内容,也有利于排名。
11、 避免惩罚:搜索引擎在识别欺骗方法方面变得越来越成熟。以下常用方法容易被惩罚,不会被收录。
百度网页关键字抓取(百度SEO怎么做才能保持排名呢?百度算法更新的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 05:02
总结:从百度SEO排名知道,我们的SEOER排名会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(百度SEO怎么做才能保持排名呢?百度算法更新的影响)
总结:从百度SEO排名知道,我们的SEOER排名会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取( 百度SEO怎么做才能保持排名呢?百度排名优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 04:19
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取( 百度SEO怎么做才能保持排名呢?百度排名优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-02 04:18
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上! 查看全部
百度网页关键字抓取(
百度SEO怎么做才能保持排名呢?百度排名优化方法)
百度SEO排名优化如何保持排名稳定?
在百度SEO排名中知道,我们排名中的SEOER会受到百度算法更新的影响。那么百度SEO可以做些什么来保持其排名呢?使用算法计算索引库中抓取的网页,将百度搜索结果展示给用户。因此,受内容相关性和内容新鲜度的影响,同一个关键词在不同时期会产生不同的搜索结果!
页面标题和描述优化是百度排名优化的重要组成部分。具体来说,网页标题不仅是用户快速链接到网页内容主题的重要因素,也是百度搜索引擎判断网页内容的重要因素。所以网站的标题很重要。设置页面标题时,注意合理使用H标签。
H标签的全称是title标签。它的作用是强调标题,突出标题和章节标题的重要性。H标签分为六类,即H1h2h3h4h5h6,重要性依次递减。使用H标签可以让网页的内容更有层次感,突出网页的主题,也可以帮助百度搜索引擎更快速的判断网页内容的主题。
使用H标签时,很自然的会将优化后的关键词插入到H标签中。百度的算法可以对标题进行语义分析。在搜索引擎上查找网页。在检索相关关键词时,搜索引擎会检索并分析网页内容。如果网页内容与用户搜索的关键词高度相关,则有机会获得高排名!
要想获得好的排名,不仅要合理安排页面标题,还要优化matedscript标签!因为标题和描述会直接影响排名,所以往往会通过搜索引擎找到自己想要的词,结果页面的标题和描述会以红色显示,这样更方便用户直观查看每个排名结果页面和想要搜索的关键词的相关性,然后点击选择性浏览!因此,在描述网页的布局时,一定要合理安排描述关键词,而不是死板的加上关键词!否则可能会适得其反。
很多SEOER认识到内容对百度排名优化的重要性,持续提供优质内容并不容易。虽然百度的搜索算法一直在不断更新迭代,但今天它不仅依靠关键词或内容质量来计算和显示搜索结果,而且变得更加智能,考虑的因素也越来越多。比如用户体验!使用语义分析为用户提供最需要的信息。
因此,在创建网站的内容时,不能限制范围内的搜索引擎优化关键字。在搜索引擎优化关键词的基础上,我们需要更全面的网站内容。首先,丰富网络内容,为更多用户提供有价值的内容,这符合搜索引擎的初衷。优质原创内容更新后,需要尝试固定更新频率,这样更有利于百度排名优化,搜索引擎也会获得更多的权重和排名。
一、百度SEO排名优化如何保持稳定排名?
做好百度排名优化,链接优化是必不可少的环节。网站的连接优化分为站内优化和站外优化两个方面!两者都有一些联系。链接优化将直接影响网站在搜索引擎中的排名。
值得注意的是,在优化网站内的链接时,要注意链接页面与锚文本关键词的相关性。给网页定位文字链接,不仅可以增加网站内容的权威性,还可以有效引导网页,还可以增加某些网页的权重,提高在百度搜索引擎中的排名!
在优化外链时,要注意外链的数量和质量。例如,在创建外部链接时,您需要将它们发布在正式的、权威的平台上。这种锚文本、文字和超链接外链是正常健康的外链。达到一定等级后,会引起质变,可以有效提升网站关键词的排名。
网站访问的速度将直接影响关键字在搜索引擎中的排名。据统计,网站的加载速度如果超过3秒,将损失近40%的流量。由于用户的耐心有限,网站的加载速度是重中之重。对于电脑,访问时间控制在3秒以内,手机控制在2秒以内。只要满足这个要求,我们就可以保证网站的流量不会因为访客的快速流失而流失。
早在百度就明确表示网站使用SSL证书会优先考虑用户。可见百度非常重视网站的用户体验对用户的影响。
百度很早就表示,在同等条件下,百度会优先在搜索结果中显示HTTPS网站。可见百度对网站访问用户的安全非常重视,因为SSL可以保证访问者和网站之间的隐私,HTTPS有助于建立服务器和用户浏览器之间的安全通信!可以保护网站不被篡改,保护用户个人信息不被泄露和中间人攻击!
安装SSL证书后,站点地址栏HTTP后面会有一个's'和一个绿色的安全锁标志。通过这个标志,用户可以安全浏览,提高网站在用户心目中的声誉。
及时更新网站的地图或主动推送,将网站的内容推送给搜索引擎,吸引蜘蛛爬行!还需要维护和稳定现有的关键词排名网站。
百度SEO排名优化是一个需要不断积累的过程,不是一蹴而就的!百度搜索引擎算法无论发生什么变化,其本质都是一样的,就是优质的信息检索服务和优质的内容!优质的内容永远是核心。不仅要坚持创造优质内容,还要不断提升用户体验!只有这样,才能长期留在百度的SEO关键词排名上!
百度网页关键字抓取(让自己的产品排到首页,这是很多新手梦寐以求的事情!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-28 03:16
让你的产品登上首页,这是很多新手梦寐以求的事情!第一个是每天重新发送消息。(但基本上每个人都可以这样做)所以没有区别!第二点是关键词的巧妙设计!如果您是诚信会员,您可以在业务人员的职称优化工具中获得一些想法。
产品标题设置是最基本的,最关键的是关键词。字数设置为30个。关键词只用一个,只有你知道选择哪个产品。关键词 与信息匹配。1、你嘴上的关键词对于你的产品或服务,你总是可以不假思索地说几个关键词,请写下来。不管你在哪里记住它,你可以把它写在纸上或在文字处理软件中计算,比如记事本或Word。如果您花几分钟查看这些关键字,您的脑海中可能会弹出其他相关词。太好了,把它们都写下来。继续思考,想想还可以添加什么词?或者什么同义词等等。2、 查看竞争对手的关键词 查看竞争对手的关键词并不难:在浏览器中打开对手的网页,网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。
4 注意错别字,错字在这里也很珍贵。你不能低估错别字。每10个搜索引擎产生的流量,就有1到2个是由关键词的错别字或错别字造成的,有时甚至更多。5 同义词和同义词 同义词和同义词不能放过。如果您的网站销售笔记本电脑,您是否考虑过与“笔记本电脑”相关的同义词或相似词?比如笔记本电脑、笔记本电脑、笔记本电脑等等。事实上,很多人在搜索笔记本电脑时,直接使用“笔记本”和“掌上电脑”,而不是加“电脑”二字。所有这些都应该考虑。因此,这些词也应该添加为我们的关键词栏。5 关键词的拆分和组合你可能会发现,即使你的产品名称是一个词,你可以用两个 关键词 搜索它。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。
对于某些单词的单复数形式,每天的搜索次数相差多达 10 次。同时,一个词的单复数形式的搜索结果也有很大的不同。此外,搜索引擎对 关键词 的情况有所不同。7连字符检查关键词,看看有没有可以加连字符的,或者可以去掉连字符的,然后把它们加到关键词。根据搜索引擎的说法,email 和e-mail 是两个完全不同的关键词,所以这两个词的搜索频率肯定是不同的。我们要做的就是找出使用频率更高的词。这里要注意的一件事是搜索引擎将连字符视为空格符号。所以email和e-mail的搜索结果完全一样,但是email和e-mail的搜索结果却大不相同。你可以自己在搜索引擎上试试。8、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的用户,您可以在关键词前添加区域名称,例如省或市的名称。使用地理位置时要从客户的角度考虑。比如邮箱,没有“北京邮箱”这个词,所以地理位置对它没有意义。9、公司和产品名称如果该站点所属的公司或产品是众所周知的,您可以将它们的名称添加到关键词表中。当然名字不需要复制,可以先做一些改动,然后再排列组合,这样可以找到更多的关键词。10、放错地方<
这些词的竞争非常激烈,因为很多网站都在用这些来优化。这时候,我们是不是可以想错了,大家在优化“搜索引擎优化”的时候,我是不是可以优化“搜索引擎优化”或者“搜索引擎优化”等组合。因为用户在查询时很少使用双引号来细化他们的搜索结果,一些非专业人士可能无法准确把握一个词。11 不要使用通用词。如果你是服装设计师,“韩国服装”是你的核心关键词,而“服装”是一个很常见的词汇,用户在搜索服装时不会只用它网站“服装”是一个 关键词 搜索,通常将多个单词组合在一起。(这也是上一篇文章说在阿里竞拍“衣服”。这个关键词意义不大。做好关键词的设置也是做的重点seo搜索引擎优化.阿里巴巴百度谷歌 查看全部
百度网页关键字抓取(让自己的产品排到首页,这是很多新手梦寐以求的事情!)
让你的产品登上首页,这是很多新手梦寐以求的事情!第一个是每天重新发送消息。(但基本上每个人都可以这样做)所以没有区别!第二点是关键词的巧妙设计!如果您是诚信会员,您可以在业务人员的职称优化工具中获得一些想法。
产品标题设置是最基本的,最关键的是关键词。字数设置为30个。关键词只用一个,只有你知道选择哪个产品。关键词 与信息匹配。1、你嘴上的关键词对于你的产品或服务,你总是可以不假思索地说几个关键词,请写下来。不管你在哪里记住它,你可以把它写在纸上或在文字处理软件中计算,比如记事本或Word。如果您花几分钟查看这些关键字,您的脑海中可能会弹出其他相关词。太好了,把它们都写下来。继续思考,想想还可以添加什么词?或者什么同义词等等。2、 查看竞争对手的关键词 查看竞争对手的关键词并不难:在浏览器中打开对手的网页,网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。网站的关键词。当然,很多时候这些关键词可能并不适合你。问题是只要你查的网站够多,可能会遇到一些漏点——你没想到却很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词. 如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。你可能会遇到一些漏网——你没想到但很有价值关键词.3 和同事/朋友聊天 和同事聊天,看看他们有没有好的关键词。如果你的网站是买笔记本电脑的,你可以问问身边的朋友:“你上网查了下笔记本相关的网站,你用那些关键词来搜索吗?”。然后检查他们使用的关键字是否收录在您的 关键词 表中。如果没有就添加;如果你有的话,你也可以对你的下一部作品做出判断。
4 注意错别字,错字在这里也很珍贵。你不能低估错别字。每10个搜索引擎产生的流量,就有1到2个是由关键词的错别字或错别字造成的,有时甚至更多。5 同义词和同义词 同义词和同义词不能放过。如果您的网站销售笔记本电脑,您是否考虑过与“笔记本电脑”相关的同义词或相似词?比如笔记本电脑、笔记本电脑、笔记本电脑等等。事实上,很多人在搜索笔记本电脑时,直接使用“笔记本”和“掌上电脑”,而不是加“电脑”二字。所有这些都应该考虑。因此,这些词也应该添加为我们的关键词栏。5 关键词的拆分和组合你可能会发现,即使你的产品名称是一个词,你可以用两个 关键词 搜索它。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。@关键词。例如,当您使用“笔记本”和“电脑”进行搜索时,您可以找到与笔记本电脑相关的页面。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。这不是很有趣,但你要清楚,我们的任务是从客户的角度思考问题,而不是教客户应该使用哪个关键词。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。应该使用。因为,如果省略关键词的拆分组合形式,会丢失一部分流量。6 关键词 的单复数形式在中文中,我们不需要考虑关键字的单复数形式,但在其他语言,如英语中,我们必须足够注意。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。如果是针对英文站点进行优化,还必须写下关键词的单复数形式。因为搜索引擎以不同的方式对待单数和复数形式。
对于某些单词的单复数形式,每天的搜索次数相差多达 10 次。同时,一个词的单复数形式的搜索结果也有很大的不同。此外,搜索引擎对 关键词 的情况有所不同。7连字符检查关键词,看看有没有可以加连字符的,或者可以去掉连字符的,然后把它们加到关键词。根据搜索引擎的说法,email 和e-mail 是两个完全不同的关键词,所以这两个词的搜索频率肯定是不同的。我们要做的就是找出使用频率更高的词。这里要注意的一件事是搜索引擎将连字符视为空格符号。所以email和e-mail的搜索结果完全一样,但是email和e-mail的搜索结果却大不相同。你可以自己在搜索引擎上试试。8、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的用户,您可以在关键词前添加区域名称,例如省或市的名称。使用地理位置时要从客户的角度考虑。比如邮箱,没有“北京邮箱”这个词,所以地理位置对它没有意义。9、公司和产品名称如果该站点所属的公司或产品是众所周知的,您可以将它们的名称添加到关键词表中。当然名字不需要复制,可以先做一些改动,然后再排列组合,这样可以找到更多的关键词。10、放错地方<
这些词的竞争非常激烈,因为很多网站都在用这些来优化。这时候,我们是不是可以想错了,大家在优化“搜索引擎优化”的时候,我是不是可以优化“搜索引擎优化”或者“搜索引擎优化”等组合。因为用户在查询时很少使用双引号来细化他们的搜索结果,一些非专业人士可能无法准确把握一个词。11 不要使用通用词。如果你是服装设计师,“韩国服装”是你的核心关键词,而“服装”是一个很常见的词汇,用户在搜索服装时不会只用它网站“服装”是一个 关键词 搜索,通常将多个单词组合在一起。(这也是上一篇文章说在阿里竞拍“衣服”。这个关键词意义不大。做好关键词的设置也是做的重点seo搜索引擎优化.阿里巴巴百度谷歌
百度网页关键字抓取(谷歌搜ajax调包用浏览器插件能用ajax方法吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-27 00:01
百度网页关键字抓取,给相关页面发ajax请求,虽然费时费力,
可以借助一些开源站点抓取工具。比如如exception_grabber,extract_all_pages,jinja2等这样的。希望能帮到你。
试试自动提交参数,打开通过邮件提交,
谷歌搜ajax
调包
用浏览器插件
能用ajax方法吗
他人帮助
找的话你让他带吧
用google,
我自己编写的一个爬虫,基于ajax。非常的小,
试试googleapi
帮你爬下来才挣钱,你这不是钓鱼么,
给知乎做一个api,让知乎的用户爬下来并且记录并且存储一段时间,就能统计总数,做相关分析。
参考豆瓣猜
不如请知乎大大们帮你抓呢
高德还不够大么?大不了像googlehome一样,
想想除了高德没有什么网站是你知道的
也可以问豆瓣的同类型的问题,如何保存所有评分标签?至于是不是匿名提问,怎么排序,什么时候排序?数据的重要性你自己衡量。爬虫这种东西还是很多人用的。以你之计,
关注几个站点,整理一下,把这些站点的数据整理出来,再用python提取一些关键字,转化成新文本,这样没事可以复习一下常用网站的做法。我之前有个爬虫爬完八戒,自己写了一个抓豆瓣的代码,包括评分地址和评分区间,这样能帮助理解。 查看全部
百度网页关键字抓取(谷歌搜ajax调包用浏览器插件能用ajax方法吗)
百度网页关键字抓取,给相关页面发ajax请求,虽然费时费力,
可以借助一些开源站点抓取工具。比如如exception_grabber,extract_all_pages,jinja2等这样的。希望能帮到你。
试试自动提交参数,打开通过邮件提交,
谷歌搜ajax
调包
用浏览器插件
能用ajax方法吗
他人帮助
找的话你让他带吧
用google,
我自己编写的一个爬虫,基于ajax。非常的小,
试试googleapi
帮你爬下来才挣钱,你这不是钓鱼么,
给知乎做一个api,让知乎的用户爬下来并且记录并且存储一段时间,就能统计总数,做相关分析。
参考豆瓣猜
不如请知乎大大们帮你抓呢
高德还不够大么?大不了像googlehome一样,
想想除了高德没有什么网站是你知道的
也可以问豆瓣的同类型的问题,如何保存所有评分标签?至于是不是匿名提问,怎么排序,什么时候排序?数据的重要性你自己衡量。爬虫这种东西还是很多人用的。以你之计,
关注几个站点,整理一下,把这些站点的数据整理出来,再用python提取一些关键字,转化成新文本,这样没事可以复习一下常用网站的做法。我之前有个爬虫爬完八戒,自己写了一个抓豆瓣的代码,包括评分地址和评分区间,这样能帮助理解。
百度网页关键字抓取(做好的网站怎么才能被收录?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-26 23:13
网站未优化时,网站首页会有4条路径,分散网站的权重,每条路径得到四分之一。301 重定向对于 网站 非常重要。您可以设置网站首页的默认索引。有404页面,可以降低用户重定向率,提升用户体验。
4. 网站 内容添加
新上线的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应该是原创,有利于网站的发展。
5. 文章页面优化
进入网站的内容页面时,可以在网站底部添加一些相关链接或用户喜欢的话题,可以增加用户在网站的停留时间,提升用户体验, 并提高 网站 排名。但是切记,不要让网站的每一页都太相关,因为这会影响网站的优化。
6、 Robot.txt 设置
禁止搜索引擎抓取与网站无关的页面,禁止蜘蛛进入网站。
这些都是网站上线前的必要准备。只有经过几个级别的测试,网站才能正式上线,让网站顺利运行。
一个制作精良的网站怎么可能是收录?
1. 提交给各大搜索引擎
2、站在用户的角度思考,写出满足用户需求的更新内容
3.写下完整的网站标题、描述和关键词、栏目和文章,以及每一页
4.优化网站链接、标签、菜单、网站地图、图片alt、描述和可选文字
5.逐步添加相关外链(自动同步网站文字)6。选择已经进入前四页的关键词进行手动搜索优化。一般一到两周就可以进入首页(取决于关键词
人气
] 7.循环以上步骤
8.技术可以学习,自己思考。
9. 坚持,坚持,坚持
!当你能为你的客户创造千万的销售额时,你的收入也不会太差,所以埋头苦干,先实现时间的自由,再考虑财务的自由。
企业如何做好网站建设?
随着时代的不断发展,用户对互联网的要求越来越高。现在一般的网站已经不能满足用户的需求,用户更喜欢浏览一些突出的个性化网站。那么,如何打造不一样的网站风格呢?让我们明白
!今天,企业已经意识到用户的重要性。随着市场竞争的日益激烈,两者的差距也在迅速缩小,由此可见个性化的重要性网站。个性化网站不仅增加了品牌的知名度,还采集了用户信息,有利于提高用户的服务质量,从而获得更多的流量。如果你想设计一个不一样的网站风格,你必须从一开始就创造这种风格来打动用户。现在网上信息太多,用户不知道如何选择,所以网站必须有不同的风格才能在竞争中脱颖而出。
网站首页主要是为了吸引用户的注意力。应突出兴趣点和最新消息,以吸引用户长时间停留在网站。现在,用户喜欢追求时尚和新颖的产品,因此他们会对网站的不同风格感兴趣。这类用户的需求主要在日常生活中。在网络营销中,需要对市场进行详细的分析,明确用户的需求,让用户对企业产生兴趣,树立企业形象。
随着互联网的不断发展,越来越多的企业拥有网站。为了吸引用户的注意力,必须区别对待网站,不能完全一样。通过网站的结构和页面设计,保证网站的风格有很大的不同,让用户记住网站,在满足用户需求的前提下,将网站改为突出企业产品的核心功能。
网站 不能为空。光有漂亮的外表是不够的。您还需要将符合网站核心的公司和内容的详细信息添加到网站中,以丰富网站。如果要设计出不同风格的网站,必须遵循一定的原则,这样才能有助于公司未来的宣传,展示公司的形象。 查看全部
百度网页关键字抓取(做好的网站怎么才能被收录?(一)(图))
网站未优化时,网站首页会有4条路径,分散网站的权重,每条路径得到四分之一。301 重定向对于 网站 非常重要。您可以设置网站首页的默认索引。有404页面,可以降低用户重定向率,提升用户体验。
4. 网站 内容添加
新上线的网站内容很少。不要一次添加很多内容。您需要逐步添加内容。内容应该是原创,有利于网站的发展。
5. 文章页面优化
进入网站的内容页面时,可以在网站底部添加一些相关链接或用户喜欢的话题,可以增加用户在网站的停留时间,提升用户体验, 并提高 网站 排名。但是切记,不要让网站的每一页都太相关,因为这会影响网站的优化。
6、 Robot.txt 设置
禁止搜索引擎抓取与网站无关的页面,禁止蜘蛛进入网站。
这些都是网站上线前的必要准备。只有经过几个级别的测试,网站才能正式上线,让网站顺利运行。
一个制作精良的网站怎么可能是收录?
1. 提交给各大搜索引擎
2、站在用户的角度思考,写出满足用户需求的更新内容
3.写下完整的网站标题、描述和关键词、栏目和文章,以及每一页
4.优化网站链接、标签、菜单、网站地图、图片alt、描述和可选文字
5.逐步添加相关外链(自动同步网站文字)6。选择已经进入前四页的关键词进行手动搜索优化。一般一到两周就可以进入首页(取决于关键词
人气
] 7.循环以上步骤
8.技术可以学习,自己思考。
9. 坚持,坚持,坚持
!当你能为你的客户创造千万的销售额时,你的收入也不会太差,所以埋头苦干,先实现时间的自由,再考虑财务的自由。
企业如何做好网站建设?
随着时代的不断发展,用户对互联网的要求越来越高。现在一般的网站已经不能满足用户的需求,用户更喜欢浏览一些突出的个性化网站。那么,如何打造不一样的网站风格呢?让我们明白
!今天,企业已经意识到用户的重要性。随着市场竞争的日益激烈,两者的差距也在迅速缩小,由此可见个性化的重要性网站。个性化网站不仅增加了品牌的知名度,还采集了用户信息,有利于提高用户的服务质量,从而获得更多的流量。如果你想设计一个不一样的网站风格,你必须从一开始就创造这种风格来打动用户。现在网上信息太多,用户不知道如何选择,所以网站必须有不同的风格才能在竞争中脱颖而出。
网站首页主要是为了吸引用户的注意力。应突出兴趣点和最新消息,以吸引用户长时间停留在网站。现在,用户喜欢追求时尚和新颖的产品,因此他们会对网站的不同风格感兴趣。这类用户的需求主要在日常生活中。在网络营销中,需要对市场进行详细的分析,明确用户的需求,让用户对企业产生兴趣,树立企业形象。
随着互联网的不断发展,越来越多的企业拥有网站。为了吸引用户的注意力,必须区别对待网站,不能完全一样。通过网站的结构和页面设计,保证网站的风格有很大的不同,让用户记住网站,在满足用户需求的前提下,将网站改为突出企业产品的核心功能。
网站 不能为空。光有漂亮的外表是不够的。您还需要将符合网站核心的公司和内容的详细信息添加到网站中,以丰富网站。如果要设计出不同风格的网站,必须遵循一定的原则,这样才能有助于公司未来的宣传,展示公司的形象。
百度网页关键字抓取(项目招商找A5快速获取精准代理名单网站关键词优化做好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-26 15:15
项目招商求A5快速获取精准代理商名单
网站关键词 对百度、GOOGLE等搜索引擎进行优化收录,可以排在搜索结果第一页的顶部,可以增加网站的流量,所以站长们一直在追求最好的优化技巧,钻研搜索引擎的偏好。老站长xrnic也很热衷于网站优化这个行业,分享最实用的关键词优化技巧。给站长朋友。
百度和GOOGLE有一个共同的偏好,更注重页面标题关键词和元描述之间的关键词。用户搜索关键词时,百度和GG会先从这两个地方搜索过滤关键词的结果,按照网站权重和关键词的顺序显示. 在搜索结果页的最前面,站长在优化网站的时候一定要写下这两个地方的关键词说明。
一、百度关键词优化技巧。
一般百度只对前6个关键词感兴趣,所以在优化TITLE关键词时,最好不要超过6个关键词。写多了就没用了。百度在搜索结果中过滤。关键词绝不会考虑第六个关键词之后的关键词,对关键词的过度优化也会造成被怀疑作弊的风险。经过站长xrnic长期调研,百度也对关键词字数进行了限制。一般关键词字数不超过30字。关键词 超过30个字后一般不会被收录。结果。
百度一般只有
二、GOOGLE关键词优化技巧。
GOOGLE一般只对前7个关键词感兴趣,字数在30个字符左右。这个和百度差不多,就不多说了。
GOOGLE 一般只对网页有效
综上所述,百度和GOOGLE更注重标题和描述的内容,所以我们在优化网站关键词的时候,首先要在这两个地方做关键词的优化。让你网站快速进入行业前列,增加被搜索引擎抓到的几率,给你带来更多的访问量。总结两个搜索引擎的特点,页面标题关键词不超过6个,文字长度不超过30个字;元描述内容应在70-100字之间,重点放在描述上。提升的关键词在最上面,在标题中没有完全表达的关键词添加在描述中。经过优化测试结果,很明显百度和GOOGLE搜索“
文章原站长xrnic原创,转载请注明出处。谢谢。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
百度网页关键字抓取(项目招商找A5快速获取精准代理名单网站关键词优化做好了)
项目招商求A5快速获取精准代理商名单
网站关键词 对百度、GOOGLE等搜索引擎进行优化收录,可以排在搜索结果第一页的顶部,可以增加网站的流量,所以站长们一直在追求最好的优化技巧,钻研搜索引擎的偏好。老站长xrnic也很热衷于网站优化这个行业,分享最实用的关键词优化技巧。给站长朋友。
百度和GOOGLE有一个共同的偏好,更注重页面标题关键词和元描述之间的关键词。用户搜索关键词时,百度和GG会先从这两个地方搜索过滤关键词的结果,按照网站权重和关键词的顺序显示. 在搜索结果页的最前面,站长在优化网站的时候一定要写下这两个地方的关键词说明。
一、百度关键词优化技巧。
一般百度只对前6个关键词感兴趣,所以在优化TITLE关键词时,最好不要超过6个关键词。写多了就没用了。百度在搜索结果中过滤。关键词绝不会考虑第六个关键词之后的关键词,对关键词的过度优化也会造成被怀疑作弊的风险。经过站长xrnic长期调研,百度也对关键词字数进行了限制。一般关键词字数不超过30字。关键词 超过30个字后一般不会被收录。结果。
百度一般只有
二、GOOGLE关键词优化技巧。
GOOGLE一般只对前7个关键词感兴趣,字数在30个字符左右。这个和百度差不多,就不多说了。
GOOGLE 一般只对网页有效
综上所述,百度和GOOGLE更注重标题和描述的内容,所以我们在优化网站关键词的时候,首先要在这两个地方做关键词的优化。让你网站快速进入行业前列,增加被搜索引擎抓到的几率,给你带来更多的访问量。总结两个搜索引擎的特点,页面标题关键词不超过6个,文字长度不超过30个字;元描述内容应在70-100字之间,重点放在描述上。提升的关键词在最上面,在标题中没有完全表达的关键词添加在描述中。经过优化测试结果,很明显百度和GOOGLE搜索“
文章原站长xrnic原创,转载请注明出处。谢谢。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
百度网页关键字抓取(如何利用Python编程,让SEO工作变的更高效? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-26 15:11
)
免责声明:我是一个编程菜鸟。为了强迫自己在实战中学习Python,我答应朋友制作一套视频课程,讲解如何使用Python编程让SEO工作更高效。
和朋友讨论,初步定义了几个SEO工具的需求,打算用Python来实现:
1、指定规则,扫描并导出所有有效的URL网站
2、 批量抓取页面标题判断SERP前三页是否存在(判断索引)
3、批量搜索关键词前N页的所有搜索结果,并导出标题和URL(用于查找外部资源)
4、 批量抓取页面标题,判断标题在当前搜索引擎中的相似度(判断标题是否可用)
5、 指定第一个词汇,抓取搜索引擎相关搜索,用结果词导出结果词的相关搜索词,导出,重复N次。(关键词 库,提高页面相关性的内部链接)
6、 服务器日志批量处理,通过PY实现,日志批量筛选和有效导出。
7、 通过非法词列表扫描指定页面是否有非法词。
...
我希望依靠这些例子来编程,让大家得到python可以帮助我解决实际问题的印象,并通过简单的修改在实际工作中使用它们。
如果你从 hello world 开始,大多数人在看不到希望的时候就会放弃。(我经历过很多次,有很深的体会)
在学习中,有时“急功近利”是好事。
-------------------
本次以第五项需求为例,完成一段已实现的python代码,主要目的是抓取百度相关搜索词。
为了满足实际应用,本要求进行了扩展:
A. 支持输入多词扩展百度相关搜索词。
B. 您可以指定哪些词必须或不能收录在要求中。
C、可以将采集收到的文字保存为txt文件,文件名可以自定义。
未来可以进一步改进的工作:
1、多线程采集
2、使用代理IP采集
3、更多容错判断
下面是具体代码,为了便于理解,几乎每一行都有注释,不要太啰嗦。(有些说法可能有误)
# coding = utf-8
'''
1、指定关键词,抓取搜索引擎相关搜索词,并使用结果词再次抓取其相关搜索词。
2、采集时对搜索相关词做处理,必须包含某些关键词或不能包含的词才作为有效词。
3、指定希望获得的最终相关词数量。
获得的搜索相关词用途:增加关键词库,提升内部链接相关性,分析用户的搜索行为,广告投放等等。
'''
#导入http请求库request
import requests
#导入随机数库
import random
#导入时间库
import time
#导入日期库
import datetime
# 导入URL解析库
from urllib import parse
# 导入BeautifulSoup库,使用别名bs
from bs4 import BeautifulSoup as bs
# 定义获取相关词的函数,@words是希望拓展的词根列表,@num是希望获取的相关词数量(大概)
def get_related_words(words, num=10):
for word in words:
# 当已有词数量小于希望获取的词数时
if(len(words) =0):
continue
# 如果没有包含不允许的词,则进入下面的处理过程
else:
# 如果定义了必须包含的词
if must_contain is not None:
# 循环必须包含的词
for w in must_contain:
# 把w都转换为小写字符,因为百度搜索相关词中英文都是小写,之后查询是否包含必须有的词(>=0表示至少包含一次)
if i.find(w.lower())>=0:
rs.append(i)
# 如果没有定义必须包含的词,则所有词直接加入列表中。
else:
rs.append(i)
# 如果没有定义不能包含的词
else:
# 解释同上
if must_contain is not None:
for w in must_contain:
if i.find(w.lower())>=0:
rs.append(i)
else:
rs.append(i)
# 返回最终过滤后的词列表
return rs
# 打算拓展的词根
root_words = ['QQ', '腾讯']
# 根据词根进行相关词采集,指定最终采集词量
words = get_related_words(root_words, 30)
# 定义必须包含的关键词列表
must_contain = ['大全']
# 定义不能包含的关键词列表
should_not_contain = ['手游']
# 输出不加任何过滤规则获得的相关搜索词
rule1 = filter_words(words)
print("不加任何过滤规则获得的相关搜索词")
print_list(rule1)
rule2 = filter_words(words, must_contain)
print("指定必须包含的关键词后获得的相关搜索词")
print_list(rule2)
rule3 = filter_words(words, must_contain, should_not_contain)
print("指定必须包含的关键词和不能包含的关键词后获得的相关搜索词")
print_list(rule3)
# 把不同过滤规则处理后获得的词写入指定的文件中
save_to_file(rule1, 'all_words')
save_to_file(rule2, 'must_contain_words')
save_to_file(rule3, 'filter_words')
# 不做过滤处理,也不指定文件名,按程序启动时间作为文件名保存结果。
save_to_file(words)
# 输出实际获得的总词数
print("总共词数:{0}".format(len(rule1)))
print("必须包含指定词数量:{0}".format(len(rule2)))
print("最严过滤规则词:{0}".format(len(rule3))) 查看全部
百度网页关键字抓取(如何利用Python编程,让SEO工作变的更高效?
)
免责声明:我是一个编程菜鸟。为了强迫自己在实战中学习Python,我答应朋友制作一套视频课程,讲解如何使用Python编程让SEO工作更高效。
和朋友讨论,初步定义了几个SEO工具的需求,打算用Python来实现:
1、指定规则,扫描并导出所有有效的URL网站
2、 批量抓取页面标题判断SERP前三页是否存在(判断索引)
3、批量搜索关键词前N页的所有搜索结果,并导出标题和URL(用于查找外部资源)
4、 批量抓取页面标题,判断标题在当前搜索引擎中的相似度(判断标题是否可用)
5、 指定第一个词汇,抓取搜索引擎相关搜索,用结果词导出结果词的相关搜索词,导出,重复N次。(关键词 库,提高页面相关性的内部链接)
6、 服务器日志批量处理,通过PY实现,日志批量筛选和有效导出。
7、 通过非法词列表扫描指定页面是否有非法词。
...
我希望依靠这些例子来编程,让大家得到python可以帮助我解决实际问题的印象,并通过简单的修改在实际工作中使用它们。
如果你从 hello world 开始,大多数人在看不到希望的时候就会放弃。(我经历过很多次,有很深的体会)
在学习中,有时“急功近利”是好事。
-------------------
本次以第五项需求为例,完成一段已实现的python代码,主要目的是抓取百度相关搜索词。
为了满足实际应用,本要求进行了扩展:
A. 支持输入多词扩展百度相关搜索词。
B. 您可以指定哪些词必须或不能收录在要求中。
C、可以将采集收到的文字保存为txt文件,文件名可以自定义。
未来可以进一步改进的工作:
1、多线程采集
2、使用代理IP采集
3、更多容错判断
下面是具体代码,为了便于理解,几乎每一行都有注释,不要太啰嗦。(有些说法可能有误)
# coding = utf-8
'''
1、指定关键词,抓取搜索引擎相关搜索词,并使用结果词再次抓取其相关搜索词。
2、采集时对搜索相关词做处理,必须包含某些关键词或不能包含的词才作为有效词。
3、指定希望获得的最终相关词数量。
获得的搜索相关词用途:增加关键词库,提升内部链接相关性,分析用户的搜索行为,广告投放等等。
'''
#导入http请求库request
import requests
#导入随机数库
import random
#导入时间库
import time
#导入日期库
import datetime
# 导入URL解析库
from urllib import parse
# 导入BeautifulSoup库,使用别名bs
from bs4 import BeautifulSoup as bs
# 定义获取相关词的函数,@words是希望拓展的词根列表,@num是希望获取的相关词数量(大概)
def get_related_words(words, num=10):
for word in words:
# 当已有词数量小于希望获取的词数时
if(len(words) =0):
continue
# 如果没有包含不允许的词,则进入下面的处理过程
else:
# 如果定义了必须包含的词
if must_contain is not None:
# 循环必须包含的词
for w in must_contain:
# 把w都转换为小写字符,因为百度搜索相关词中英文都是小写,之后查询是否包含必须有的词(>=0表示至少包含一次)
if i.find(w.lower())>=0:
rs.append(i)
# 如果没有定义必须包含的词,则所有词直接加入列表中。
else:
rs.append(i)
# 如果没有定义不能包含的词
else:
# 解释同上
if must_contain is not None:
for w in must_contain:
if i.find(w.lower())>=0:
rs.append(i)
else:
rs.append(i)
# 返回最终过滤后的词列表
return rs
# 打算拓展的词根
root_words = ['QQ', '腾讯']
# 根据词根进行相关词采集,指定最终采集词量
words = get_related_words(root_words, 30)
# 定义必须包含的关键词列表
must_contain = ['大全']
# 定义不能包含的关键词列表
should_not_contain = ['手游']
# 输出不加任何过滤规则获得的相关搜索词
rule1 = filter_words(words)
print("不加任何过滤规则获得的相关搜索词")
print_list(rule1)
rule2 = filter_words(words, must_contain)
print("指定必须包含的关键词后获得的相关搜索词")
print_list(rule2)
rule3 = filter_words(words, must_contain, should_not_contain)
print("指定必须包含的关键词和不能包含的关键词后获得的相关搜索词")
print_list(rule3)
# 把不同过滤规则处理后获得的词写入指定的文件中
save_to_file(rule1, 'all_words')
save_to_file(rule2, 'must_contain_words')
save_to_file(rule3, 'filter_words')
# 不做过滤处理,也不指定文件名,按程序启动时间作为文件名保存结果。
save_to_file(words)
# 输出实际获得的总词数
print("总共词数:{0}".format(len(rule1)))
print("必须包含指定词数量:{0}".format(len(rule2)))
print("最严过滤规则词:{0}".format(len(rule3)))
百度网页关键字抓取(关于,的18个常见seo问题的理解和理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-26 14:07
很多朋友在学习seo的时候会遇到很多问题,也会对一些seo相关的概念有很多错误的理解,从而导致在操作优化的过程中产生误会网站。作为seo,当然要研究搜索引擎算法,但也要研究用户需求和网站体验,通过不断的实战优化技巧得出正确的结论,而不是一味的相信道听途说。
对于以下常见seo问题的理解,相信80%的优化器都曾不小心偏离过。让我们来看看这18个问题:
1、百度快照时间与网站权重没有直接关系
网页权重对网站快照更新时间有辅助作用,但网站快照更新时间是根据网站历史更新频率和内容质量确定的。更新频率越快,蜘蛛抓取越频繁。另外,内容页更新频率很小。还有一种情况是蜘蛛频繁爬行,只是不更新,因为搜索引擎认为内容质量不值得更新。另外,百度官方的说明不需要太在意网页快照。
2、搜索索引不等于实际搜索量
百度官方明确表示,“以网民在百度上的搜索量为数据基础,以关键词为统计对象,科学分析计算每个关键词百度网页搜索”,注意搜索频率,而不仅仅是搜索量。然而,百度指数是实际搜索量的一个有价值的指标。
3、Cookie只能记录本网站中的用户信息,其他网站中记录用户的操作信息
Cookie可以记录用户在自己站内的操作信息,但是用户跳出网站后的数据无法追踪。很多时候,登录一些网站后,发现登录信息等输入数据都在。其实就是每个网站单独保存的用户记录。
4、网站 设置关键词后,排名不会自行上升
包括我自己,我想了很久,只要你为网站设置关键词,更新网站优化内外链,这些关键词的排名就会去向上。. 事实上,网站设置的关键字和描述搜索引擎可能只会在计算相关性时引用它们,它们对排名的影响更大。网站关键词排名要提升或者我们需要针对这些词专门优化内链和外链。锚文本越集中,关键词的排名能力就越好。
5.张工具提供的百度权重值仅供参考
站长工具中的数据统计功能,确实方便我们了解网站的综合数据信息。提供的百度权重现在是交易所链最重要的指标。但是,站长我提供的百度权重只是第三方软件如词库的一些技术的结果,百度并不认可。百度有自己的索引,类似于网站网页重要价值的权重指数。
6、站点网站结果个数不等于网站真实收录个数,不等于网站有效< @收录
很多人把网站网站的结果数据当成百度对网站的收录的实际数量。事实上,现场展示的结果只是网站real收录的一部分。网站收录的实际人数应以百度站长平台索宫人数为准。但是,站点数量越接近索引数量越好,这意味着质量越高。反之,如果搜索的次数远远多于网站的数量,那你就要提高警惕了。他们都说这是搜索弓的不友好表现。(在内容质量方面)另外,网站收录的数量并不代表有效收录的数量。有效收录 指用户搜索和点击的网页数量。对于网站,用户没有访问过的页面一般是没有用的。
7、搜索引擎蜘蛛没有掉电蜘蛛等分类
之前在网上看到过对搜索蜘蛛不同IP段的不同分析,一直这样认为(估计和我一样思考的人不在少数)。然而,高价值网站可能会吸引| 蜘蛛的不同爬行策略。
8、搜索引擎将 网站 URL 视为静态和动态
之前的观点是动态的网站是错误的,后来才知道追求静态网址是不对的。URL 是动态的还是静态的并不重要,只要它们不重复即可。此外,动态 URL 应避免参数过多。
9、是的站群过度妖魔化
很多人对“站群”的印象是作弊。这是作弊(主要是在灰色和黑色行业)。但站群 不全是作弊。我看过一个操作站群,提供站群不同地区交通违章查询的操作案例。这样才能真正解决用户的需求。百度官方曾表示,要看这类网站对普通用户的价值来判断。
10、现在论坛和博客消息签名的链下价值只是蜘蛛
这种情况在 SEO 新手中更常见,他们花费大量时间在博客和论坛上签名和留下链接。好处是可以吸引更多的蜘蛛前来参观。所以在网站刚成立的时候就做下弓|蜘蛛是好的,以后最好不要做。
11、网站 备案并不会直接影响网站的排名
很多人都说网站备案与否会影响网站的排名,业内还有一篇很火的文章《影响网站搜索弓|引擎排名价值参考因素》 . 见表网站 @网站 备案对排名的影响非常大,只在外链的影响下,废话。百度已经说了,仅供参考。网站的注册是否影响用户对网站的信任。
12、搜索引擎蜘蛛不会“爬行”
其实,这是一个基本的常识。人们在访问和抓取网页的过程中习惯于使用蜘蛛来“抓取”,导致很多人认为蜘蛛是在从一个页面爬到另一个页面。实际上,蜘蛛是直接访问网页的。其原理是蜘蛛根据权重等信息从被抓取页面的URL中抓取网页内容。查看网站的日志知道蜘蛛没有访问过网站。参考。
13.只关注网站颜,忽略网站其他页面的作用和重要性
大多数情况下,我们在优化网站的时候,只关注首页,内外链的锚文本都集中在首页。事实上,网站在优化之初就集中在首页,但是如果后期不能提高目录和内页的权重,仅仅依靠首页是不够的。即使是排名,也很难增加权重并获得排名。会很强。
14、同IP服务器网站惩罚影响不大
很多人固执的认为在同一个IP服务器上惩罚网站会对网站产生很大的影响,所以在购买空间时要特别注意这一点。事实上,Search Bow|Engine 可以识别这种情况。一开始,这句话出来的比较多,是怕被网站反复攻击受到惩罚。
15、为了增加注册次数,将网站的内容设置为只注册浏览。
现在很多网站都因为各种原因把内容设置为只有注册用户才能查看。但是,搜索引擎蜘蛛和普通用户是一样的。普通用户看不到蜘蛛。当然,不能爬行的蜘蛛是爬不上去的,收录。正确的做法是将部分内容发布出来,方便蜘蛛爬行。
16.网站跳出率和页面响应速度不直接影响网站的排名
首先是它会影响,但不是很大。网站跳出率只能通过统计工具知道。Search Bow|Engine 不知道,只要用户不打开网站 就马不关了。搜索引擎相同关键词。页面打开速度慢会影响用户体验。很多用户会直接关闭页面,但不会直接影响排名。这两点谷歌已经纳入了页面排名因素,而百度还没有。
17. 带有noffollow标签的链接搜索引擎也会爬行
完全禁止的方法是设置robots文件。Nofollow标签的作用是站长不推荐这个链接,但是搜索引擎会爬取所有的链接。在权重传递方面,不传递,但另一个说法是,只要用户点击链接,就有效。
18、度竞价不提升网站收录和排名
很多人说网站的竞价可以提升网站的排名。事实上,网站的竞价并没有提升网站关键词和收录的排名。竞价对SEO的影响在于可以增加网站的曝光率和品牌知名度。一般来说,没有人会在垃圾和毫无价值的页面上出价。
以上是我总结的几个方面。在优化过程中,很多新手甚至是经验丰富的专业知识都容易产生误解。所以,作为一个优秀的seoer,我们不仅要不断学习,更要--一定要实践和使用。说到事实,理论知识点只是一个应用工具,关键在于对知识点的理解和实践! 查看全部
百度网页关键字抓取(关于,的18个常见seo问题的理解和理解)
很多朋友在学习seo的时候会遇到很多问题,也会对一些seo相关的概念有很多错误的理解,从而导致在操作优化的过程中产生误会网站。作为seo,当然要研究搜索引擎算法,但也要研究用户需求和网站体验,通过不断的实战优化技巧得出正确的结论,而不是一味的相信道听途说。
对于以下常见seo问题的理解,相信80%的优化器都曾不小心偏离过。让我们来看看这18个问题:
1、百度快照时间与网站权重没有直接关系
网页权重对网站快照更新时间有辅助作用,但网站快照更新时间是根据网站历史更新频率和内容质量确定的。更新频率越快,蜘蛛抓取越频繁。另外,内容页更新频率很小。还有一种情况是蜘蛛频繁爬行,只是不更新,因为搜索引擎认为内容质量不值得更新。另外,百度官方的说明不需要太在意网页快照。
2、搜索索引不等于实际搜索量
百度官方明确表示,“以网民在百度上的搜索量为数据基础,以关键词为统计对象,科学分析计算每个关键词百度网页搜索”,注意搜索频率,而不仅仅是搜索量。然而,百度指数是实际搜索量的一个有价值的指标。
3、Cookie只能记录本网站中的用户信息,其他网站中记录用户的操作信息
Cookie可以记录用户在自己站内的操作信息,但是用户跳出网站后的数据无法追踪。很多时候,登录一些网站后,发现登录信息等输入数据都在。其实就是每个网站单独保存的用户记录。
4、网站 设置关键词后,排名不会自行上升
包括我自己,我想了很久,只要你为网站设置关键词,更新网站优化内外链,这些关键词的排名就会去向上。. 事实上,网站设置的关键字和描述搜索引擎可能只会在计算相关性时引用它们,它们对排名的影响更大。网站关键词排名要提升或者我们需要针对这些词专门优化内链和外链。锚文本越集中,关键词的排名能力就越好。
5.张工具提供的百度权重值仅供参考
站长工具中的数据统计功能,确实方便我们了解网站的综合数据信息。提供的百度权重现在是交易所链最重要的指标。但是,站长我提供的百度权重只是第三方软件如词库的一些技术的结果,百度并不认可。百度有自己的索引,类似于网站网页重要价值的权重指数。
6、站点网站结果个数不等于网站真实收录个数,不等于网站有效< @收录
很多人把网站网站的结果数据当成百度对网站的收录的实际数量。事实上,现场展示的结果只是网站real收录的一部分。网站收录的实际人数应以百度站长平台索宫人数为准。但是,站点数量越接近索引数量越好,这意味着质量越高。反之,如果搜索的次数远远多于网站的数量,那你就要提高警惕了。他们都说这是搜索弓的不友好表现。(在内容质量方面)另外,网站收录的数量并不代表有效收录的数量。有效收录 指用户搜索和点击的网页数量。对于网站,用户没有访问过的页面一般是没有用的。
7、搜索引擎蜘蛛没有掉电蜘蛛等分类
之前在网上看到过对搜索蜘蛛不同IP段的不同分析,一直这样认为(估计和我一样思考的人不在少数)。然而,高价值网站可能会吸引| 蜘蛛的不同爬行策略。
8、搜索引擎将 网站 URL 视为静态和动态
之前的观点是动态的网站是错误的,后来才知道追求静态网址是不对的。URL 是动态的还是静态的并不重要,只要它们不重复即可。此外,动态 URL 应避免参数过多。
9、是的站群过度妖魔化
很多人对“站群”的印象是作弊。这是作弊(主要是在灰色和黑色行业)。但站群 不全是作弊。我看过一个操作站群,提供站群不同地区交通违章查询的操作案例。这样才能真正解决用户的需求。百度官方曾表示,要看这类网站对普通用户的价值来判断。
10、现在论坛和博客消息签名的链下价值只是蜘蛛
这种情况在 SEO 新手中更常见,他们花费大量时间在博客和论坛上签名和留下链接。好处是可以吸引更多的蜘蛛前来参观。所以在网站刚成立的时候就做下弓|蜘蛛是好的,以后最好不要做。
11、网站 备案并不会直接影响网站的排名
很多人都说网站备案与否会影响网站的排名,业内还有一篇很火的文章《影响网站搜索弓|引擎排名价值参考因素》 . 见表网站 @网站 备案对排名的影响非常大,只在外链的影响下,废话。百度已经说了,仅供参考。网站的注册是否影响用户对网站的信任。
12、搜索引擎蜘蛛不会“爬行”
其实,这是一个基本的常识。人们在访问和抓取网页的过程中习惯于使用蜘蛛来“抓取”,导致很多人认为蜘蛛是在从一个页面爬到另一个页面。实际上,蜘蛛是直接访问网页的。其原理是蜘蛛根据权重等信息从被抓取页面的URL中抓取网页内容。查看网站的日志知道蜘蛛没有访问过网站。参考。
13.只关注网站颜,忽略网站其他页面的作用和重要性
大多数情况下,我们在优化网站的时候,只关注首页,内外链的锚文本都集中在首页。事实上,网站在优化之初就集中在首页,但是如果后期不能提高目录和内页的权重,仅仅依靠首页是不够的。即使是排名,也很难增加权重并获得排名。会很强。
14、同IP服务器网站惩罚影响不大
很多人固执的认为在同一个IP服务器上惩罚网站会对网站产生很大的影响,所以在购买空间时要特别注意这一点。事实上,Search Bow|Engine 可以识别这种情况。一开始,这句话出来的比较多,是怕被网站反复攻击受到惩罚。
15、为了增加注册次数,将网站的内容设置为只注册浏览。
现在很多网站都因为各种原因把内容设置为只有注册用户才能查看。但是,搜索引擎蜘蛛和普通用户是一样的。普通用户看不到蜘蛛。当然,不能爬行的蜘蛛是爬不上去的,收录。正确的做法是将部分内容发布出来,方便蜘蛛爬行。
16.网站跳出率和页面响应速度不直接影响网站的排名
首先是它会影响,但不是很大。网站跳出率只能通过统计工具知道。Search Bow|Engine 不知道,只要用户不打开网站 就马不关了。搜索引擎相同关键词。页面打开速度慢会影响用户体验。很多用户会直接关闭页面,但不会直接影响排名。这两点谷歌已经纳入了页面排名因素,而百度还没有。
17. 带有noffollow标签的链接搜索引擎也会爬行
完全禁止的方法是设置robots文件。Nofollow标签的作用是站长不推荐这个链接,但是搜索引擎会爬取所有的链接。在权重传递方面,不传递,但另一个说法是,只要用户点击链接,就有效。
18、度竞价不提升网站收录和排名
很多人说网站的竞价可以提升网站的排名。事实上,网站的竞价并没有提升网站关键词和收录的排名。竞价对SEO的影响在于可以增加网站的曝光率和品牌知名度。一般来说,没有人会在垃圾和毫无价值的页面上出价。
以上是我总结的几个方面。在优化过程中,很多新手甚至是经验丰富的专业知识都容易产生误解。所以,作为一个优秀的seoer,我们不仅要不断学习,更要--一定要实践和使用。说到事实,理论知识点只是一个应用工具,关键在于对知识点的理解和实践!
百度网页关键字抓取(一个搜刮引擎的算法是怎样的?如何在顾客面前推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-26 14:05
算法基础。虽然搜索引擎算法近年来已经成为越来越流行的词汇,但现在出现还为时过早。所谓算法,就是统计人们的搜索习惯后建立的数据模型。如何在客户面前推荐这样的人气网站。因为搜索有价值的线索是搜索引擎提供的服务,所以优化器的主要工作是为搜索引擎服务的。如果知道对方的算法,就可以遥遥领先。很多线下公司不把网站作为自己的主要销售渠道,对方提供的产品或服务可能不会通过互联网进行销售。做网站的主要原因是做广告,增加知名度。如果他们能跻身行业前列,他们当然会增加。提高公共服务水平,给群众留下了良好的印象。搜索引擎的算法有很多方面。主要假设是“域名、密度、一致性、服务器稳定性、内链、外链、内容更新、域名时间、内容数量”。这些是搜索触发算法的最核心部分。说白了,如果做关键词,就需要注意网站的优化。你只需要做很多协作网站优化时刻就可以考虑这么多元素。经常看到一些“seo大师”说我没有优化,这个词做到了第一,或者我的网站称号一直第一等等。这些是没有太多协作的词。这一刻,你只需要考虑密度。遇到那些合作性很强的词,你要注意更多的元素,也就是那些伟人常说的,崇尚细节。说这话的人是基于两个技能。
但这些因素在三大搜索引擎中的权重不同。比如百度异常关注密度,雅虎关注玉米,谷歌关注外链和外链稳定性。他们都有自己的算法重点。如果你想在三大搜索引擎中获得不错的排名,就得考虑了。
关于robots文件,百度完全无视这个东西。但是谷歌非常小心。还有404和500的问题
. 这些东西一直被百度忽略,而谷歌却关注它,注意到你的恐怖程度。
我为公司做的网站,谷歌的收录前阵子突然变零了。不是一个站,而是大部分站。我当时找不到原因。还以为是几个网站的内容太重复了,共享了一个模板。当我的一个同事给了这些 网站 谷歌地图
目前,我发现无法验证谁的文件。要求服务器管理员查找原因,但没有找到原因。后来这位同事仔细一看,发现网站出现了500个问题。
. 应该是 404 问题,但出现了 500。为此,谷歌拒绝了收录 并清除了数据。处理完这个问题,第二天谷歌更新了收录。
当时我就感叹,google真是变态了。要优化,必须注意细节。不要以为你很好。其实还有很多你没发现的问题。什么是大师?大师是能够处理困难问题的人。
事实上,谷歌过于注重细节,雅虎最为变态。不是因为雅虎搜索最早吗?雅虎对作弊网站毫不留情,与百度势均力敌。
关于K drop IP,搜索引擎很少在基础上做。尤其是百度很少这样做。它会杀掉大部分,但会保存一小部分站点,并且IP很少被阻止。因为百度知道国内还有虚拟主机。但是,有很多外国人的IP,也有很多服务器,而且所有外国空间都在发送IP,所以雅虎看到你作弊时会无情地杀死你的IP。该IP下的站点不是收录你,即使你与作弊站点无关。
从这些细节中,我们可以看出他们这样做的原因。国情不同。想本土化,不学百度真的不行。虽然百度经常无耻地敲你,不给你赎罪的机会。看法】
搜索引擎是指利用特定的计算机程序,按照一定的策略,在互联网上采集信息,将信息进行结构化和处理后,将处理后的信息展示给用户,为用户提供搜索服务的系统。
从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入单词,通过阅读器提交给搜索引擎。搜索引擎将返回与用户输入的内容相关的信息列表。
在互联网的早期,以雅虎为代表的网站类别目录查询非常流行。网站分类目录人工整理保护,精选网上优秀的网站,归纳外观,分类排列在不同的目录下。用户查询时,可以通过逐层点击,找到自己要找的网站。有些人把这种基于目录的搜索服务网站称为搜索引擎,但严格来说,它不是搜索引擎。
【分类】
1、全文索引
全文搜索引擎
它是当之无愧的搜索引擎。国外的代表是谷歌,国内有著名的百度搜索。
. 他们从互联网上提取每个网站的信息(主要是网页笔和墨水),建立数据库,可以检索匹配用户查询前提的记录,并按正序返回结果。
根据搜索效果来源的不同,全文搜索引擎
它可以分为两类。第一类有自己的搜索程序(Indexer),俗称“蜘蛛”程序或“机器人”程序。可自行搭建网络数据库,搜索效果直接取自自有数据库。上面提到的谷歌和百度都属于这一类;另一种是租用其他搜索引擎的数据库,按照自定义模式列出搜索结果,比如Lycos搜索引擎。
2、 目录索引
目录索引虽然具有搜索功能,但严格意义上不能称为真正的搜索引擎。它只是一个按目录分类的 网站 链接列表。用户可以根据分类目录完全找到自己需要的信息,不依赖关键词(关键字)进行查询。目录索引中最具代表性的是著名的雅虎和新浪。
按类别目录搜索。
3、元搜索引擎
元搜索引擎
(META Search Engine) 收到用户的查询请求后,同时在多个搜索引擎上进行搜索,并将效果返回给用户。著名的元搜索引擎
有InfoSpace、Dogpile、Vivisimo等,专业的和业余的,
如何分析网站是否真的被降级处罚以及如何解决
目前从事这项工作的人主要有两种类型,专业的优化人员,还有一些聘请专业人士来做类似的工作。一种是个人站长。因为这点小利是薄的,没必要找人去做。自我优化。效果还是很不一样的。快速排名、seo 优化、搜索引擎优化。快速网站优化方案,快速解决网站流量和排名异常。网站排名服务中文元搜索引擎的代表是搜星搜索引擎。在搜索效果排序方面,有的直接按照来源对搜索效果进行排序,比如Dogpile;根据自己的规则对效果进行某种排序,例如 Vivisimo。
其他非主流搜索引擎的情况:
1、集成搜索引擎:这个搜索引擎类似于元搜索引擎。不同之处在于它不使用多个搜索引擎同时进行搜索。相反,用户从提供的搜索引擎数量中进行选择。例如HotBot是在2002年,搜索引擎在年底推出。
2、流派搜索引擎:虽然AOL Search、MSN Search等提供搜索服务,但它们既没有分类目录也没有网络数据库,其搜索结果完全来源于其他搜索引擎。
3、Free For All Links(简称FFA):通常只是简单的轮换链接项,也有少数有简单的分类,但比Yahoo! 目录索引要小得多。
【事情的真相】
1、获取网页
每个独立的搜索引擎都有自己的网络爬虫
程序(蜘蛛)。蜘蛛会跟踪网页中的超链接,并逐个抓取网页。抓取到的网页称为网页快照
. 因为超链接在互联网上被广泛使用,理论上,从某个有限的网页开始,你可以采集到大部分的网页。
2、处置页面
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供搜索服务。其中,最重要的是提取关键词,建立索引文件。其他包括去除重复网页、分析超链接、计算网页的主要度。
3、供应搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为了方便用户的推理,除了页面标题和URL,还会提供页面摘要等信息。
【全文搜索引擎
】
在搜索引擎分类部分,我们提到全文搜索引擎从网站中提取信息,建立网络数据库。搜索引擎的自动信息聚合功能有两种。一是定时搜索,即每次(比如谷歌一般是28天),搜索引擎主动发送“蜘蛛”程序在某个IP地址的限制范围内搜索互联网网站 . 一旦发现新的网站,它会自动提取网站的信息和URL到站点自己的数据库中。
另一种是提交网站搜索,即网站有想法将URL提交给搜索引擎,它会在某个时刻(范围从2天到几个月)发出“蜘蛛”程序,扫描你的网站并将相关信息保存在数据库中,供用户查询。因为这几年搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以现在最好的办法就是获取更多的外链让搜索引擎有更多机会找到你并自动发送你的网站收录。
当用户使用关键词搜索信息时,搜索引擎会在数据库中进行一次征集。如果找到与用户请求的内容相匹配的网站,就会采用特殊的算法——一般是根据网页关键词的匹配程度、出现的位置/频率、链接质量等——计算每个网页的相关性和排名,然后根据相关性将这些网页链接依次返回给用户。
【目录索引】
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录的索引则完全依赖于人工操作。用户提交网站后,目录编辑会亲自阅读您的网站,然后根据一套自行确定的标准和用户的主观印象决定是否回收您的网站编辑。.
其次,在搜索引擎收录网站时,只要网站不违反相关划分规则,一般都可以登录并获胜。目录索引对网站的要求要高很多,即使重复登录也不一定成功。尤其像雅虎这样的超级索引,登录更是难上加难。
另外,我们在登录搜索引擎的时候,一般不用考虑网站的分类,登录目录索引的时候,一定要把网站放在最合适的目录下(目录)。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引需要手动填写其他网站信息,还有很多其他的限制。另外,如果工作人员认为你提交的网站的内容和网站的信息不合适,他可以随时进行调解,虽然他不会提前和你商量。
内容索引,旺文胜义是将网站存放在不同类别的对应目录中,所以用户在查询信息时可以选择关键词进行信息搜索,也可以按类别进行搜索。如果用关键词搜索,返回的效果和搜索引擎一样。也是按照信息关联的层次来分类的网站,但人为因素较多。如果按层次目录搜索,网站在目录中的排名是由标题字母的顺序决定的(也有例外)。
如今,搜索引擎和目录索引有相互融合的趋势。原来一些正宗的全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。旧的目录索引,如 Yahoo! 通过与谷歌等搜索引擎合作,扩大搜索范围(注)。一些目录搜索引擎以默认搜索的形式,在其目录中首先返回匹配的网站,如国内的搜狐、新浪、网易等;而其他人则默认允许网络搜索,例如雅虎。
【搜索引擎的成长史】
1990年,加拿大麦吉尔大学计算与计算机学院的师生开发了Archie。那时万维网还没有出现,人们通过FTP共享和交换资本。Archie 可以定期采集和分析FTP 服务器上的文件名信息,并提供对每个FTP 主机中的文件的搜索。用户必须输入准确的文件名才能搜索,Archie 会通知用户哪个 FTP 服务器可以下载文件。Archie采集的信息资源虽然不是网页(HTML文件),但与搜索引擎的基本操作是一样的:自动聚合信息资源,建立索引,提供搜索服务。因此,Archie 被广泛认为是现代搜索引擎的先驱。
搜索引擎的开始:
所有搜索引擎的祖先都是1990年蒙特利尔麦吉尔大学的三位学生(Alan Emtage、Peter Deutsch、Bill Wheelan)发现的Archie(Archie FAQ)。Alan Emtage等人想到了开发一个可以逐文件搜索文件的系统名字,所以阿奇被创建了。Archie 是第一个自动索引互联网上匿名 FTP网站 文件的程序,但它还不是真正的搜索引擎。Archie 是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后Archie 会通知用户哪个FTP 位置可以下载该文件。因为 Archie 受到好评并受到启发,内华达大学系统计算服务公司于 1993 年开发了 Gopher(Gopher FAQ)搜索工具 Veronica(Veronica FAQ)。 Jughead 是后来的另一个 Gopher 搜索工具。通常来说,一般来说,网站 页面的引用次数越多,权重越高。运营网站的人应根据用户点击网站页面的行为进行外链推广。网站内容的内链推荐、相互投票和蜘蛛指南。
网站 被降级了,是什么原因造成的
本网站源网部分资料,如有侵权请联系删除!作者:wesipy,如转载请注明出处: 查看全部
百度网页关键字抓取(一个搜刮引擎的算法是怎样的?如何在顾客面前推荐)
算法基础。虽然搜索引擎算法近年来已经成为越来越流行的词汇,但现在出现还为时过早。所谓算法,就是统计人们的搜索习惯后建立的数据模型。如何在客户面前推荐这样的人气网站。因为搜索有价值的线索是搜索引擎提供的服务,所以优化器的主要工作是为搜索引擎服务的。如果知道对方的算法,就可以遥遥领先。很多线下公司不把网站作为自己的主要销售渠道,对方提供的产品或服务可能不会通过互联网进行销售。做网站的主要原因是做广告,增加知名度。如果他们能跻身行业前列,他们当然会增加。提高公共服务水平,给群众留下了良好的印象。搜索引擎的算法有很多方面。主要假设是“域名、密度、一致性、服务器稳定性、内链、外链、内容更新、域名时间、内容数量”。这些是搜索触发算法的最核心部分。说白了,如果做关键词,就需要注意网站的优化。你只需要做很多协作网站优化时刻就可以考虑这么多元素。经常看到一些“seo大师”说我没有优化,这个词做到了第一,或者我的网站称号一直第一等等。这些是没有太多协作的词。这一刻,你只需要考虑密度。遇到那些合作性很强的词,你要注意更多的元素,也就是那些伟人常说的,崇尚细节。说这话的人是基于两个技能。
但这些因素在三大搜索引擎中的权重不同。比如百度异常关注密度,雅虎关注玉米,谷歌关注外链和外链稳定性。他们都有自己的算法重点。如果你想在三大搜索引擎中获得不错的排名,就得考虑了。
关于robots文件,百度完全无视这个东西。但是谷歌非常小心。还有404和500的问题
. 这些东西一直被百度忽略,而谷歌却关注它,注意到你的恐怖程度。
我为公司做的网站,谷歌的收录前阵子突然变零了。不是一个站,而是大部分站。我当时找不到原因。还以为是几个网站的内容太重复了,共享了一个模板。当我的一个同事给了这些 网站 谷歌地图
目前,我发现无法验证谁的文件。要求服务器管理员查找原因,但没有找到原因。后来这位同事仔细一看,发现网站出现了500个问题。
. 应该是 404 问题,但出现了 500。为此,谷歌拒绝了收录 并清除了数据。处理完这个问题,第二天谷歌更新了收录。
当时我就感叹,google真是变态了。要优化,必须注意细节。不要以为你很好。其实还有很多你没发现的问题。什么是大师?大师是能够处理困难问题的人。
事实上,谷歌过于注重细节,雅虎最为变态。不是因为雅虎搜索最早吗?雅虎对作弊网站毫不留情,与百度势均力敌。
关于K drop IP,搜索引擎很少在基础上做。尤其是百度很少这样做。它会杀掉大部分,但会保存一小部分站点,并且IP很少被阻止。因为百度知道国内还有虚拟主机。但是,有很多外国人的IP,也有很多服务器,而且所有外国空间都在发送IP,所以雅虎看到你作弊时会无情地杀死你的IP。该IP下的站点不是收录你,即使你与作弊站点无关。
从这些细节中,我们可以看出他们这样做的原因。国情不同。想本土化,不学百度真的不行。虽然百度经常无耻地敲你,不给你赎罪的机会。看法】
搜索引擎是指利用特定的计算机程序,按照一定的策略,在互联网上采集信息,将信息进行结构化和处理后,将处理后的信息展示给用户,为用户提供搜索服务的系统。
从用户的角度来看,搜索引擎提供了一个收录搜索框的页面。在搜索框中输入单词,通过阅读器提交给搜索引擎。搜索引擎将返回与用户输入的内容相关的信息列表。
在互联网的早期,以雅虎为代表的网站类别目录查询非常流行。网站分类目录人工整理保护,精选网上优秀的网站,归纳外观,分类排列在不同的目录下。用户查询时,可以通过逐层点击,找到自己要找的网站。有些人把这种基于目录的搜索服务网站称为搜索引擎,但严格来说,它不是搜索引擎。
【分类】
1、全文索引
全文搜索引擎
它是当之无愧的搜索引擎。国外的代表是谷歌,国内有著名的百度搜索。
. 他们从互联网上提取每个网站的信息(主要是网页笔和墨水),建立数据库,可以检索匹配用户查询前提的记录,并按正序返回结果。
根据搜索效果来源的不同,全文搜索引擎
它可以分为两类。第一类有自己的搜索程序(Indexer),俗称“蜘蛛”程序或“机器人”程序。可自行搭建网络数据库,搜索效果直接取自自有数据库。上面提到的谷歌和百度都属于这一类;另一种是租用其他搜索引擎的数据库,按照自定义模式列出搜索结果,比如Lycos搜索引擎。
2、 目录索引
目录索引虽然具有搜索功能,但严格意义上不能称为真正的搜索引擎。它只是一个按目录分类的 网站 链接列表。用户可以根据分类目录完全找到自己需要的信息,不依赖关键词(关键字)进行查询。目录索引中最具代表性的是著名的雅虎和新浪。
按类别目录搜索。
3、元搜索引擎
元搜索引擎
(META Search Engine) 收到用户的查询请求后,同时在多个搜索引擎上进行搜索,并将效果返回给用户。著名的元搜索引擎
有InfoSpace、Dogpile、Vivisimo等,专业的和业余的,
如何分析网站是否真的被降级处罚以及如何解决
目前从事这项工作的人主要有两种类型,专业的优化人员,还有一些聘请专业人士来做类似的工作。一种是个人站长。因为这点小利是薄的,没必要找人去做。自我优化。效果还是很不一样的。快速排名、seo 优化、搜索引擎优化。快速网站优化方案,快速解决网站流量和排名异常。网站排名服务中文元搜索引擎的代表是搜星搜索引擎。在搜索效果排序方面,有的直接按照来源对搜索效果进行排序,比如Dogpile;根据自己的规则对效果进行某种排序,例如 Vivisimo。
其他非主流搜索引擎的情况:
1、集成搜索引擎:这个搜索引擎类似于元搜索引擎。不同之处在于它不使用多个搜索引擎同时进行搜索。相反,用户从提供的搜索引擎数量中进行选择。例如HotBot是在2002年,搜索引擎在年底推出。
2、流派搜索引擎:虽然AOL Search、MSN Search等提供搜索服务,但它们既没有分类目录也没有网络数据库,其搜索结果完全来源于其他搜索引擎。
3、Free For All Links(简称FFA):通常只是简单的轮换链接项,也有少数有简单的分类,但比Yahoo! 目录索引要小得多。
【事情的真相】
1、获取网页
每个独立的搜索引擎都有自己的网络爬虫
程序(蜘蛛)。蜘蛛会跟踪网页中的超链接,并逐个抓取网页。抓取到的网页称为网页快照
. 因为超链接在互联网上被广泛使用,理论上,从某个有限的网页开始,你可以采集到大部分的网页。
2、处置页面
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供搜索服务。其中,最重要的是提取关键词,建立索引文件。其他包括去除重复网页、分析超链接、计算网页的主要度。
3、供应搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为了方便用户的推理,除了页面标题和URL,还会提供页面摘要等信息。
【全文搜索引擎
】
在搜索引擎分类部分,我们提到全文搜索引擎从网站中提取信息,建立网络数据库。搜索引擎的自动信息聚合功能有两种。一是定时搜索,即每次(比如谷歌一般是28天),搜索引擎主动发送“蜘蛛”程序在某个IP地址的限制范围内搜索互联网网站 . 一旦发现新的网站,它会自动提取网站的信息和URL到站点自己的数据库中。
另一种是提交网站搜索,即网站有想法将URL提交给搜索引擎,它会在某个时刻(范围从2天到几个月)发出“蜘蛛”程序,扫描你的网站并将相关信息保存在数据库中,供用户查询。因为这几年搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以现在最好的办法就是获取更多的外链让搜索引擎有更多机会找到你并自动发送你的网站收录。
当用户使用关键词搜索信息时,搜索引擎会在数据库中进行一次征集。如果找到与用户请求的内容相匹配的网站,就会采用特殊的算法——一般是根据网页关键词的匹配程度、出现的位置/频率、链接质量等——计算每个网页的相关性和排名,然后根据相关性将这些网页链接依次返回给用户。
【目录索引】
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录的索引则完全依赖于人工操作。用户提交网站后,目录编辑会亲自阅读您的网站,然后根据一套自行确定的标准和用户的主观印象决定是否回收您的网站编辑。.
其次,在搜索引擎收录网站时,只要网站不违反相关划分规则,一般都可以登录并获胜。目录索引对网站的要求要高很多,即使重复登录也不一定成功。尤其像雅虎这样的超级索引,登录更是难上加难。
另外,我们在登录搜索引擎的时候,一般不用考虑网站的分类,登录目录索引的时候,一定要把网站放在最合适的目录下(目录)。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引需要手动填写其他网站信息,还有很多其他的限制。另外,如果工作人员认为你提交的网站的内容和网站的信息不合适,他可以随时进行调解,虽然他不会提前和你商量。
内容索引,旺文胜义是将网站存放在不同类别的对应目录中,所以用户在查询信息时可以选择关键词进行信息搜索,也可以按类别进行搜索。如果用关键词搜索,返回的效果和搜索引擎一样。也是按照信息关联的层次来分类的网站,但人为因素较多。如果按层次目录搜索,网站在目录中的排名是由标题字母的顺序决定的(也有例外)。
如今,搜索引擎和目录索引有相互融合的趋势。原来一些正宗的全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。旧的目录索引,如 Yahoo! 通过与谷歌等搜索引擎合作,扩大搜索范围(注)。一些目录搜索引擎以默认搜索的形式,在其目录中首先返回匹配的网站,如国内的搜狐、新浪、网易等;而其他人则默认允许网络搜索,例如雅虎。
【搜索引擎的成长史】
1990年,加拿大麦吉尔大学计算与计算机学院的师生开发了Archie。那时万维网还没有出现,人们通过FTP共享和交换资本。Archie 可以定期采集和分析FTP 服务器上的文件名信息,并提供对每个FTP 主机中的文件的搜索。用户必须输入准确的文件名才能搜索,Archie 会通知用户哪个 FTP 服务器可以下载文件。Archie采集的信息资源虽然不是网页(HTML文件),但与搜索引擎的基本操作是一样的:自动聚合信息资源,建立索引,提供搜索服务。因此,Archie 被广泛认为是现代搜索引擎的先驱。
搜索引擎的开始:
所有搜索引擎的祖先都是1990年蒙特利尔麦吉尔大学的三位学生(Alan Emtage、Peter Deutsch、Bill Wheelan)发现的Archie(Archie FAQ)。Alan Emtage等人想到了开发一个可以逐文件搜索文件的系统名字,所以阿奇被创建了。Archie 是第一个自动索引互联网上匿名 FTP网站 文件的程序,但它还不是真正的搜索引擎。Archie 是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后Archie 会通知用户哪个FTP 位置可以下载该文件。因为 Archie 受到好评并受到启发,内华达大学系统计算服务公司于 1993 年开发了 Gopher(Gopher FAQ)搜索工具 Veronica(Veronica FAQ)。 Jughead 是后来的另一个 Gopher 搜索工具。通常来说,一般来说,网站 页面的引用次数越多,权重越高。运营网站的人应根据用户点击网站页面的行为进行外链推广。网站内容的内链推荐、相互投票和蜘蛛指南。
网站 被降级了,是什么原因造成的
本网站源网部分资料,如有侵权请联系删除!作者:wesipy,如转载请注明出处:
百度网页关键字抓取(大拿指点一二itemsitemsitems插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-25 17:22
)
我想通过爬虫获取百度搜索结果的原创链接。通过Firefox的HttpFox插件,发现搜索结果的URL被加密,例如:
点击链接后,会向链接发送一个GET,来自服务器的响应收录真实的URL:
我想通过一个python爬虫模拟这个过程:
1.获取关键词,构建百度搜索URL(借助火狐自带的百度搜索,构建简化搜索链接)
通过pyquery获取页面中所有的搜索结果网址:
[(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3. t a').items()]
//不知道这里有没有用到items()方法。
向加密后的URL发起GET请求,尝试获取HttpFox中获取的内容
提取真实网址并显示
目前可以获取到页面的加密URL(但是对于同一个URL,每次获取的加密URL是不同的,可以理解),但是步骤3中获取的页面不是httpfox中的,而是一个很复杂的页面(应该是跳转后的页面)。
我尝试在requests.get()中设置参数allow_redirects=False,但是得到的响应不是httpfox的内容。
想请教大家。 . . .
代码如下:
#!/usr/bin/python
#coding=utf-8
import re
import requests
from pyquery import PyQuery as Pq
class BaiduSearchSpider(object):
def __init__(self, searchText):
self.url = "http://www.baidu.com/baidu%3Fw ... ot%3B % searchText
self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17"}
self._page = None
@property
def page(self):
if not self._page:
r = requests.get(self.url, headers=self.headers)
r.encoding = 'utf-8'
self._page = Pq(r.text)
return self._page
@property
def baiduURLs(self):
return [(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3.t a').items()]
@property
def originalURLs(self):
tmpURLs = self.baiduURLs
print tmpURLs
originalURLs = []
for tmpurl in tmpURLs:
tmpPage = requests.get(tmpurl[0])
#tmpPage.encoding = 'utf-8' #这样不好使,print的时候python报错
tmptext = tmpPage.text.encode('utf-8')
urlMatch = re.search(r'URL=\'(.*?)\'', tmptext, re.S)
if not urlMatch == None:
print urlMatch.group(1), " ", tmpurl[1]
originalURLs.append(tmpurl)
else:
print "---------------"
print "No Original URL found!!"
print tmpurl[0]
print tmpurl[1]
return originalURLs
searchText = raw_input("搜索内容是:")
print searchText
bdsearch = BaiduSearchSpider(searchText)
originalurls = bdsearch.originalURLs
print '=======Original URLs========'
print originalurls
print '============================' 查看全部
百度网页关键字抓取(大拿指点一二itemsitemsitems插件
)
我想通过爬虫获取百度搜索结果的原创链接。通过Firefox的HttpFox插件,发现搜索结果的URL被加密,例如:
点击链接后,会向链接发送一个GET,来自服务器的响应收录真实的URL:
我想通过一个python爬虫模拟这个过程:
1.获取关键词,构建百度搜索URL(借助火狐自带的百度搜索,构建简化搜索链接)
通过pyquery获取页面中所有的搜索结果网址:
[(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3. t a').items()]
//不知道这里有没有用到items()方法。
向加密后的URL发起GET请求,尝试获取HttpFox中获取的内容
提取真实网址并显示
目前可以获取到页面的加密URL(但是对于同一个URL,每次获取的加密URL是不同的,可以理解),但是步骤3中获取的页面不是httpfox中的,而是一个很复杂的页面(应该是跳转后的页面)。
我尝试在requests.get()中设置参数allow_redirects=False,但是得到的响应不是httpfox的内容。
想请教大家。 . . .
代码如下:
#!/usr/bin/python
#coding=utf-8
import re
import requests
from pyquery import PyQuery as Pq
class BaiduSearchSpider(object):
def __init__(self, searchText):
self.url = "http://www.baidu.com/baidu%3Fw ... ot%3B % searchText
self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17"}
self._page = None
@property
def page(self):
if not self._page:
r = requests.get(self.url, headers=self.headers)
r.encoding = 'utf-8'
self._page = Pq(r.text)
return self._page
@property
def baiduURLs(self):
return [(site.attr('href'), site.text().encode('utf-8')) for site in self.page('div.result.c-container h3.t a').items()]
@property
def originalURLs(self):
tmpURLs = self.baiduURLs
print tmpURLs
originalURLs = []
for tmpurl in tmpURLs:
tmpPage = requests.get(tmpurl[0])
#tmpPage.encoding = 'utf-8' #这样不好使,print的时候python报错
tmptext = tmpPage.text.encode('utf-8')
urlMatch = re.search(r'URL=\'(.*?)\'', tmptext, re.S)
if not urlMatch == None:
print urlMatch.group(1), " ", tmpurl[1]
originalURLs.append(tmpurl)
else:
print "---------------"
print "No Original URL found!!"
print tmpurl[0]
print tmpurl[1]
return originalURLs
searchText = raw_input("搜索内容是:")
print searchText
bdsearch = BaiduSearchSpider(searchText)
originalurls = bdsearch.originalURLs
print '=======Original URLs========'
print originalurls
print '============================'
百度网页关键字抓取(Python页面上的所有及其词条,每天进步一点点,结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-25 11:00
这几天学习爬行有点过于激进了。我一直在努力学习爬行,但一踏进坑里就跳不出来。郁闷了一天,终于发现自己的基础太差了,比如基本功能,文件输出等等。在这个层次上是不可能写出复杂的爬虫的。想了想,还是决定买一本python基础的书来弥补一下,同时写了一个简单的爬虫来练手。
以下是我买的python基础书。听说这本书是python最好的入门书↓↓↓
今天写一个简单的爬虫,目标是百度百科Python词条页面上的所有词条及其链接。
◆ 分析目标:
① 目标网址:
② 页面编码:utf-8(右键查看页面空白区域查看)
③ 目标标签样式:多查几个条目,你会发现它们位于标签名称的标签中,属性为target="_blank", href=/item/ + 一堆字符
然后开始写代码:
先导入必要的库,然后指定目标url:
使用urlopen下载页面,使用Beautiful Soup解析页面(解析器指定“html.parser”,否则会报错)
由于我使用Python IDE: pycharm 键入代码,它自动指定了“UTF-8”格式(在右下角),所以我不再需要指定解析格式:
然后结合 .findAll() 方法和正则表达式来过滤掉不相关的内容:
最终输出:
主要代码就是这些,整理一下,完整代码如下:
打印结果截图如下:(内容较多,请先贴两页)
眼尖的朋友可能会发现,第一张截图的第一个条目是一个不应该出现的条目,而第二个截图中倒数第四个条目竟然是一个大括号{}。. 前额。我认为我的正则表达式并不完美。暂时不知道怎么改进。我必须努力学习。.
每天学习一点点,每天进步一点点 查看全部
百度网页关键字抓取(Python页面上的所有及其词条,每天进步一点点,结果)
这几天学习爬行有点过于激进了。我一直在努力学习爬行,但一踏进坑里就跳不出来。郁闷了一天,终于发现自己的基础太差了,比如基本功能,文件输出等等。在这个层次上是不可能写出复杂的爬虫的。想了想,还是决定买一本python基础的书来弥补一下,同时写了一个简单的爬虫来练手。
以下是我买的python基础书。听说这本书是python最好的入门书↓↓↓
今天写一个简单的爬虫,目标是百度百科Python词条页面上的所有词条及其链接。
◆ 分析目标:
① 目标网址:
② 页面编码:utf-8(右键查看页面空白区域查看)
③ 目标标签样式:多查几个条目,你会发现它们位于标签名称的标签中,属性为target="_blank", href=/item/ + 一堆字符
然后开始写代码:
先导入必要的库,然后指定目标url:
使用urlopen下载页面,使用Beautiful Soup解析页面(解析器指定“html.parser”,否则会报错)
由于我使用Python IDE: pycharm 键入代码,它自动指定了“UTF-8”格式(在右下角),所以我不再需要指定解析格式:
然后结合 .findAll() 方法和正则表达式来过滤掉不相关的内容:
最终输出:
主要代码就是这些,整理一下,完整代码如下:
打印结果截图如下:(内容较多,请先贴两页)
眼尖的朋友可能会发现,第一张截图的第一个条目是一个不应该出现的条目,而第二个截图中倒数第四个条目竟然是一个大括号{}。. 前额。我认为我的正则表达式并不完美。暂时不知道怎么改进。我必须努力学习。.
每天学习一点点,每天进步一点点
百度网页关键字抓取( 网站SEO之后如何优化页面标题?(易服信息0xziyn2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-25 06:06
网站SEO之后如何优化页面标题?(易服信息0xziyn2))
网站SEO后如何优化页面标题?
无锡关键词快上榜企业聚焦网站优化青岛易服资讯[易服信息0xziyn2]
问题设置
每页设置的标题不应相同。因为每个页面表达的内容不同,按照福州网站SEO的理解,百度搜索引擎对网站上重复的内容判断合适的内容。网站的权重值损害有一定的影响,所以大家的网站页面标题很重要,网站后台管理可以为每个页面开发独立的主题,关键词开发设置的描述是大多数网站@ > 开发公司现阶段没有考虑,因为我们知道只有让客户进行SEO改进是很方便的。
网站流量分析:网站流量分析从SEO结果指导下一步SEO策略,同时对网站用户体验的优化也有指导意义@>。不要被收录搜索引擎对话:将收录网站提交到各大搜索引擎的登录入口。在搜索引擎上看SEO效果,通过站点:消费者的域名了解网站的收录和更新状态。通过domain:消费者的域名或link:消费者的域名,了解网站的反向链接情况。
Hallam网站 不允许抓取以 /wp-admin(网站 后端)开头的 URL。通过指定禁止这些 URL 的位置,您可以节省带宽、服务器资源和抓取预算。
同时,不应该禁止搜索引擎爬虫抓取网站的重要部分。
一箭提供服务:关键词优化、网站推广、网站建设、小程序开发、诚信通运营等服务。目前,一箭已在东莞、长安、佛山,未来将进一步完善服务网络,覆盖全国大中小城市。 查看全部
百度网页关键字抓取(
网站SEO之后如何优化页面标题?(易服信息0xziyn2))
网站SEO后如何优化页面标题?
无锡关键词快上榜企业聚焦网站优化青岛易服资讯[易服信息0xziyn2]
问题设置
每页设置的标题不应相同。因为每个页面表达的内容不同,按照福州网站SEO的理解,百度搜索引擎对网站上重复的内容判断合适的内容。网站的权重值损害有一定的影响,所以大家的网站页面标题很重要,网站后台管理可以为每个页面开发独立的主题,关键词开发设置的描述是大多数网站@ > 开发公司现阶段没有考虑,因为我们知道只有让客户进行SEO改进是很方便的。
网站流量分析:网站流量分析从SEO结果指导下一步SEO策略,同时对网站用户体验的优化也有指导意义@>。不要被收录搜索引擎对话:将收录网站提交到各大搜索引擎的登录入口。在搜索引擎上看SEO效果,通过站点:消费者的域名了解网站的收录和更新状态。通过domain:消费者的域名或link:消费者的域名,了解网站的反向链接情况。
Hallam网站 不允许抓取以 /wp-admin(网站 后端)开头的 URL。通过指定禁止这些 URL 的位置,您可以节省带宽、服务器资源和抓取预算。
同时,不应该禁止搜索引擎爬虫抓取网站的重要部分。
一箭提供服务:关键词优化、网站推广、网站建设、小程序开发、诚信通运营等服务。目前,一箭已在东莞、长安、佛山,未来将进一步完善服务网络,覆盖全国大中小城市。
百度网页关键字抓取( 配合搜索引擎内链算法,就可以实现关键词快速排名!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-25 03:08
配合搜索引擎内链算法,就可以实现关键词快速排名!!)
百度的快速排名并不那么神秘。在搜索引擎飞速发展的今天,爬取速度和收录速度的加速并不是说不可能,而是通过正确的方法和策略是完全可以实现的。新站期间,百度实际上给予了特别的权重来帮助新站。通过利用好这个特殊的权重,可以快速增加网站的权重。借助搜索引擎内链算法,可以实现关键词的快速排名。
什么是网站内链
内链是200多个搜索引擎中对网站进行评分的重要算法。简单来说,内链就是进入网站的首页后,页面中收录的所有其他可点击的链接都称为内链。
网页中任何可以点击跳转到其他页面的内容都属于内部链接
使用内链算法快速增加权重获得排名
A、前后链接的有效性
B、超越链接相关性
C、点击算法
内链绝对与网站的权重快速增长有关。概念上的理解很简单,但是内链的思路和方向会帮助你在内链算法上加分。内链不能乱乱链。我们需要把握用户搜索这个词背后的目的,以及搜索到这个关键词后的一些衍生需求,即需求目的地的相关词。
A、前后链接的有效性
比如石虎的关键词就是用户的主要需求。搜索下拉框中的需求与热门需求相关,也可以认为是目的地相关词,因为搜索引擎判断搜索“石虎”关键词用户的热门衍生需求(命运相关词)有“石斛的功效与作用”、“石斛种植方法”、“石斛价格”等,可通过百度需求图查证。您可以在网站重要的主导航中布置这些关键词以满足用户需求。当用户进入网站首页时,点击其他页面的几率会增加,网站的跳出率会降低。为点击算法添加点数。点开算法以后再说。
石斛关键词需求图
石斛关键词热门需求推荐
用户输入网站后,却没有找到自己需要的,快速关闭网站离开会造成体重下降。为了保证网站的权重不丢失,所以我们要布局在网站去和content做关键词相关的内容,包括首页,文章@ > 页面,产品页面,都需要做。
B、超越链接相关性
发现那些公司网站首页的文章@>的内容几乎都在调用同一个栏目的内容,这样会减少被搜索引擎蜘蛛抓取的几率。要调用首页文章@>,最好是调用每列不同的文章@>。回想一下,我们的网站文章@>页面,有没有上一篇和下一篇,我们知道蜘蛛从上到下爬网。当你从首页进入一个文章@>页面时,我们发现下一个是A文章@>,而恰巧首页也有A文章@>,蜘蛛不会返回主页继续爬行。因此,我们的主页文章@>调用需要不同的列文章@>。
C、点击算法
用户在搜索关键词时,输入了某个网站,说明这个网站的标题一是满足用户的需求,二是进入首页后,有没有点击在其他页面上?对于其他操作,搜索引擎会在网站中监控该用户的一系列行为。点击次数多,停留时间长,说明这个网站跳出率低,可以在不减肥的情况下满足用户需求,反之亦然。跳出率高,用户需求得不到满足,体重下降。
因此,了解内链算法和点击算法,可以降低网站的跳出率,满足用户的需求,快速增加权重。 查看全部
百度网页关键字抓取(
配合搜索引擎内链算法,就可以实现关键词快速排名!!)
百度的快速排名并不那么神秘。在搜索引擎飞速发展的今天,爬取速度和收录速度的加速并不是说不可能,而是通过正确的方法和策略是完全可以实现的。新站期间,百度实际上给予了特别的权重来帮助新站。通过利用好这个特殊的权重,可以快速增加网站的权重。借助搜索引擎内链算法,可以实现关键词的快速排名。
什么是网站内链
内链是200多个搜索引擎中对网站进行评分的重要算法。简单来说,内链就是进入网站的首页后,页面中收录的所有其他可点击的链接都称为内链。
网页中任何可以点击跳转到其他页面的内容都属于内部链接
使用内链算法快速增加权重获得排名
A、前后链接的有效性
B、超越链接相关性
C、点击算法
内链绝对与网站的权重快速增长有关。概念上的理解很简单,但是内链的思路和方向会帮助你在内链算法上加分。内链不能乱乱链。我们需要把握用户搜索这个词背后的目的,以及搜索到这个关键词后的一些衍生需求,即需求目的地的相关词。
A、前后链接的有效性
比如石虎的关键词就是用户的主要需求。搜索下拉框中的需求与热门需求相关,也可以认为是目的地相关词,因为搜索引擎判断搜索“石虎”关键词用户的热门衍生需求(命运相关词)有“石斛的功效与作用”、“石斛种植方法”、“石斛价格”等,可通过百度需求图查证。您可以在网站重要的主导航中布置这些关键词以满足用户需求。当用户进入网站首页时,点击其他页面的几率会增加,网站的跳出率会降低。为点击算法添加点数。点开算法以后再说。
石斛关键词需求图
石斛关键词热门需求推荐
用户输入网站后,却没有找到自己需要的,快速关闭网站离开会造成体重下降。为了保证网站的权重不丢失,所以我们要布局在网站去和content做关键词相关的内容,包括首页,文章@ > 页面,产品页面,都需要做。
B、超越链接相关性
发现那些公司网站首页的文章@>的内容几乎都在调用同一个栏目的内容,这样会减少被搜索引擎蜘蛛抓取的几率。要调用首页文章@>,最好是调用每列不同的文章@>。回想一下,我们的网站文章@>页面,有没有上一篇和下一篇,我们知道蜘蛛从上到下爬网。当你从首页进入一个文章@>页面时,我们发现下一个是A文章@>,而恰巧首页也有A文章@>,蜘蛛不会返回主页继续爬行。因此,我们的主页文章@>调用需要不同的列文章@>。
C、点击算法
用户在搜索关键词时,输入了某个网站,说明这个网站的标题一是满足用户的需求,二是进入首页后,有没有点击在其他页面上?对于其他操作,搜索引擎会在网站中监控该用户的一系列行为。点击次数多,停留时间长,说明这个网站跳出率低,可以在不减肥的情况下满足用户需求,反之亦然。跳出率高,用户需求得不到满足,体重下降。
因此,了解内链算法和点击算法,可以降低网站的跳出率,满足用户的需求,快速增加权重。
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-23 05:18
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬多多关照,不要敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索后抓取页面源码关键词分为五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,则需要进行url编码
3、拼接页面的真实url(url指的是url,后面直接写url即可)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、使用 urllib.request
说说一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、智能分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,这样更容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索后获取页面源码程序代码关键词:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url-encode
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断 查看全部
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬多多关照,不要敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索后抓取页面源码关键词分为五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,则需要进行url编码
3、拼接页面的真实url(url指的是url,后面直接写url即可)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、使用 urllib.request
说说一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、智能分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,这样更容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() url 编码
示例代码:
运行结果:
2)urllib.parse.quote(string) url 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索后获取页面源码程序代码关键词:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url-encode
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断

