
百度网页关键字抓取
百度网页关键字抓取(html代码中的注释内容会在正文提取环节忽略?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-15 15:15
问:百度会在页面代码中抓取评论吗
问题补充:很多时候在编写页面模板时,我们习惯于添加一些注释代码,以便在后续修改中了解每个模块在更多方面的作用。但有一个问题,那就是百度会在页面代码中抓取评论吗?这些内容会降低页面的相关性吗
答:百度会抓取页面代码中的评论吗?让我们看看百度官方所说的:HTML代码中的注释内容在文本提取链接
中会被忽略。
通过百度的官方回答可以看出,百度蜘蛛会抓取页面代码中的注释内容,但在提取正文内容时会忽略它,也就是说,这些注释内容对页面的整体质量没有影响
在我看来,这个问题其实更容易理解。首先,我们应该相信百度搜索技术。已经解释了页面代码中的注释内容本身。这是注释内容!所以百度不会对这些内容感到厌烦。另外,普通用户并不关注这些内容,也就是说,被标注的内容对用户来说是没有意义的,所以百度不需要对它们进行分析
我们可以想象,如果百度抓取并分析这些页面代码中的注释内容,并将其与页面的主题内容进一步链接,我们可以通过注释内容欺骗SEO吗?显然,这是百度搜索不允许的!在那些年里,meta中的关键词内容非常重要。百度搜索在判断时给出了很高的权重,所以很多站长朋友都利用这个因素作弊。但随着百度搜索机制的完善,关键词的权重已经被完全抛弃。页面代码中的注释内容是否比关键字更重要?显然不是。因为百度搜索可以放弃关键词,所以没有理由分析评论代码
百度会抓取页面代码中的评论吗?答案是百度会抓取它,但在提取文本时会直接忽略它,也就是说,页面代码的注释内容不会影响页面质量,所以你可以放心
事实上,如果你仔细观察,你会发现百度搜索将扮演分析器的角色,或者对大多数朋友和用户看不到的内容给予较低的权重。这应该是百度搜索改进的最好地方。因为这些内容对用户来说毫无意义,百度的分析和计算将变得多余 查看全部
百度网页关键字抓取(html代码中的注释内容会在正文提取环节忽略?)
问:百度会在页面代码中抓取评论吗
问题补充:很多时候在编写页面模板时,我们习惯于添加一些注释代码,以便在后续修改中了解每个模块在更多方面的作用。但有一个问题,那就是百度会在页面代码中抓取评论吗?这些内容会降低页面的相关性吗
答:百度会抓取页面代码中的评论吗?让我们看看百度官方所说的:HTML代码中的注释内容在文本提取链接
中会被忽略。
通过百度的官方回答可以看出,百度蜘蛛会抓取页面代码中的注释内容,但在提取正文内容时会忽略它,也就是说,这些注释内容对页面的整体质量没有影响
在我看来,这个问题其实更容易理解。首先,我们应该相信百度搜索技术。已经解释了页面代码中的注释内容本身。这是注释内容!所以百度不会对这些内容感到厌烦。另外,普通用户并不关注这些内容,也就是说,被标注的内容对用户来说是没有意义的,所以百度不需要对它们进行分析
我们可以想象,如果百度抓取并分析这些页面代码中的注释内容,并将其与页面的主题内容进一步链接,我们可以通过注释内容欺骗SEO吗?显然,这是百度搜索不允许的!在那些年里,meta中的关键词内容非常重要。百度搜索在判断时给出了很高的权重,所以很多站长朋友都利用这个因素作弊。但随着百度搜索机制的完善,关键词的权重已经被完全抛弃。页面代码中的注释内容是否比关键字更重要?显然不是。因为百度搜索可以放弃关键词,所以没有理由分析评论代码
百度会抓取页面代码中的评论吗?答案是百度会抓取它,但在提取文本时会直接忽略它,也就是说,页面代码的注释内容不会影响页面质量,所以你可以放心
事实上,如果你仔细观察,你会发现百度搜索将扮演分析器的角色,或者对大多数朋友和用户看不到的内容给予较低的权重。这应该是百度搜索改进的最好地方。因为这些内容对用户来说毫无意义,百度的分析和计算将变得多余
百度网页关键字抓取(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-15 15:14
严格地说,搜索引擎优化爬行规则是病态的句子。它们应该是搜索引擎优化过程中蜘蛛的爬行规则。为什么SEO需要告诉搜索引擎蜘蛛爬行规则?原因是收录索引决定了排名,而排名决定了搜索引擎优化结果的好坏
你知道搜索引擎优化捕获的规则吗?事实上,我们可以用最简单的意思来解释这一点。SEO依赖于爬行过程中的蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断地访问、采集和整理网络图片、视频和其他内容,这就是它的角色。然后,将同一类和不同类分开,创建索引数据库,以便用户在搜索时搜索所需的内容
一、spider抓取规则:
搜索引擎中的蜘蛛需要将捕获的网页放入数据库区域以补充数据。通过程序计算,将其分类放置在不同的检索位置,搜索引擎形成了稳定的收录排名。在此过程中,spider捕获的数据不一定是稳定的。经过程序计算,许多人被其他好的网页挤了出来。简单地说,蜘蛛不喜欢也不想捕获此网页。蜘蛛有一种独特的味道,它们抓取的网站非常不同,也就是我们所说的原创文章. 只要您的网页中的@文章原创度非常高,您的网页就很有可能被蜘蛛捕获,这就是为什么越来越多的人要求@文章原创度
只有这样,数据的排名才会稳定。现在搜索引擎已经改变了它的策略,并且正在慢慢地一步一步地向补充数据转变。它喜欢同时使用缓存机制和补充数据。这就是为什么搜索引擎收录越来越难优化的原因,也可以理解为,现在很多网页都没有收录排名。每隔一段时间收录排名是有原因的
二、增加网站抓斗频率:
1、网站@文章的质量得到了提高
虽然SEO人员知道如何改进原创@文章,但搜索引擎中有一个不变的事实,那就是,他们永远无法满足内容质量和稀缺性这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛喜欢
2、update网站文章频率
为了满足内容,我们应该做好正常的更新频率,这也是提高网页捕获率的法宝
3、网站速度不仅对爬行器有影响,而且对用户体验也有影响
当蜘蛛访问时,如果它希望没有障碍物,并且加载过程可以在合理的速度范围内进行,则必须确保蜘蛛能够在网页中顺利爬行。没有任何加载延迟。如果经常遇到此问题,爬行器将不喜欢网站并减少爬行频率
4、提升网站品牌知名度
经常混在网络上,你会发现一个问题。当一个知名品牌推出一个新网站时,它会去一些新闻媒体报道。在新闻源网站报道之后,它会添加一些品牌词内容。即使没有像目标这样的链接,搜索引擎也会抓取该站点
5、选择一个高PR域名
PR是一个老式的域名,所以它的权重一定很高。即使你的网站很长时间没有更新,或者是一个完全关闭的网站页面,搜索引擎也会抓取并随时等待更新的内容。如果有人在开始时选择使用这样一个旧域名,他们还可以将重定向开发成一个真正的可操作域名
蜘蛛抓取频率:
如果是高权重的网站更新,更新频率会有所不同,因此频率一般在几天或一个月之间。网站质量越高,更新频率越快,爬行器将不断访问或更新此网页
总之,用户对SEO非常感兴趣,SEO是一种具有强大潜在商业价值的服务手段。然而,由于这项工作是长期的,我们不能仓促走向成功之路。我们必须慢慢来。在这个竞争激烈的互联网环境中,只要你能比竞争对手做得多一点,你就能获得质的飞跃 查看全部
百度网页关键字抓取(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
严格地说,搜索引擎优化爬行规则是病态的句子。它们应该是搜索引擎优化过程中蜘蛛的爬行规则。为什么SEO需要告诉搜索引擎蜘蛛爬行规则?原因是收录索引决定了排名,而排名决定了搜索引擎优化结果的好坏
你知道搜索引擎优化捕获的规则吗?事实上,我们可以用最简单的意思来解释这一点。SEO依赖于爬行过程中的蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断地访问、采集和整理网络图片、视频和其他内容,这就是它的角色。然后,将同一类和不同类分开,创建索引数据库,以便用户在搜索时搜索所需的内容

一、spider抓取规则:
搜索引擎中的蜘蛛需要将捕获的网页放入数据库区域以补充数据。通过程序计算,将其分类放置在不同的检索位置,搜索引擎形成了稳定的收录排名。在此过程中,spider捕获的数据不一定是稳定的。经过程序计算,许多人被其他好的网页挤了出来。简单地说,蜘蛛不喜欢也不想捕获此网页。蜘蛛有一种独特的味道,它们抓取的网站非常不同,也就是我们所说的原创文章. 只要您的网页中的@文章原创度非常高,您的网页就很有可能被蜘蛛捕获,这就是为什么越来越多的人要求@文章原创度
只有这样,数据的排名才会稳定。现在搜索引擎已经改变了它的策略,并且正在慢慢地一步一步地向补充数据转变。它喜欢同时使用缓存机制和补充数据。这就是为什么搜索引擎收录越来越难优化的原因,也可以理解为,现在很多网页都没有收录排名。每隔一段时间收录排名是有原因的
二、增加网站抓斗频率:
1、网站@文章的质量得到了提高
虽然SEO人员知道如何改进原创@文章,但搜索引擎中有一个不变的事实,那就是,他们永远无法满足内容质量和稀缺性这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛喜欢
2、update网站文章频率
为了满足内容,我们应该做好正常的更新频率,这也是提高网页捕获率的法宝
3、网站速度不仅对爬行器有影响,而且对用户体验也有影响
当蜘蛛访问时,如果它希望没有障碍物,并且加载过程可以在合理的速度范围内进行,则必须确保蜘蛛能够在网页中顺利爬行。没有任何加载延迟。如果经常遇到此问题,爬行器将不喜欢网站并减少爬行频率
4、提升网站品牌知名度
经常混在网络上,你会发现一个问题。当一个知名品牌推出一个新网站时,它会去一些新闻媒体报道。在新闻源网站报道之后,它会添加一些品牌词内容。即使没有像目标这样的链接,搜索引擎也会抓取该站点
5、选择一个高PR域名
PR是一个老式的域名,所以它的权重一定很高。即使你的网站很长时间没有更新,或者是一个完全关闭的网站页面,搜索引擎也会抓取并随时等待更新的内容。如果有人在开始时选择使用这样一个旧域名,他们还可以将重定向开发成一个真正的可操作域名
蜘蛛抓取频率:
如果是高权重的网站更新,更新频率会有所不同,因此频率一般在几天或一个月之间。网站质量越高,更新频率越快,爬行器将不断访问或更新此网页
总之,用户对SEO非常感兴趣,SEO是一种具有强大潜在商业价值的服务手段。然而,由于这项工作是长期的,我们不能仓促走向成功之路。我们必须慢慢来。在这个竞争激烈的互联网环境中,只要你能比竞争对手做得多一点,你就能获得质的飞跃
百度网页关键字抓取(掌握搜索引擎核心技术上手学//c+/java都行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-15 07:05
百度网页关键字抓取也分级别高低,初级的随便抓取,这个已经有很多工具了。高级一点的搜索网页内容你就得手动编写爬虫了,至于如何写,web方面的需要掌握html,css,sql,图片方面最好掌握python,php,基本就够了。爬虫重要不是语言而是原理和技巧,等有了10年的web网站编程经验之后再去学习python最合适不过了。
掌握搜索引擎核心技术
上手学c/c++/java都行。尤其是java,基础扎实,找一份合适的开发(业务)平台,我觉得还是很稳的。
初学的话python和php或者两个都学。如果只是写一些百度搜索的小脚本,不如gui编程更基础。
学习之前先定位,你想成为一个什么样的程序员,例如爬虫,那么python就很合适了,你爬到一定量可以尝试自己写爬虫,web开发或者其他方向就要看你的兴趣了。
肯定是web方向的,web方向的有很多种,爬虫的话要看你的分析能力怎么样,主要针对数据库进行分析的,有人想学一下python,python可以用来写自己觉得很有意思的小程序,web抓包嘛,这个我也只有试着了解,
只是一般的的爬虫小爬虫而已,前面的大牛说的很全面了,搜索引擎掌握核心技术应该不难。顺便说一下,我自己是一枚菜鸟,讲到的很多知识都来自网上,只是希望给楼主一些学习的经验。个人看法,勿喷。1.想做什么就去做。2.细分下来再针对一个领域来找各自的教程。3.如果你是一枚学生,建议你趁着暑假先去做一些大作业啊,虽然自己是新手,但也可以慢慢感受到自己的不足。
4.多问多看多想多练习,不要闷着头弄代码,搞不好弄个一两个月就放弃了。5.有足够的兴趣再来学,真的挺重要的。6.talkischeap,showmethecode.。 查看全部
百度网页关键字抓取(掌握搜索引擎核心技术上手学//c+/java都行)
百度网页关键字抓取也分级别高低,初级的随便抓取,这个已经有很多工具了。高级一点的搜索网页内容你就得手动编写爬虫了,至于如何写,web方面的需要掌握html,css,sql,图片方面最好掌握python,php,基本就够了。爬虫重要不是语言而是原理和技巧,等有了10年的web网站编程经验之后再去学习python最合适不过了。
掌握搜索引擎核心技术
上手学c/c++/java都行。尤其是java,基础扎实,找一份合适的开发(业务)平台,我觉得还是很稳的。
初学的话python和php或者两个都学。如果只是写一些百度搜索的小脚本,不如gui编程更基础。
学习之前先定位,你想成为一个什么样的程序员,例如爬虫,那么python就很合适了,你爬到一定量可以尝试自己写爬虫,web开发或者其他方向就要看你的兴趣了。
肯定是web方向的,web方向的有很多种,爬虫的话要看你的分析能力怎么样,主要针对数据库进行分析的,有人想学一下python,python可以用来写自己觉得很有意思的小程序,web抓包嘛,这个我也只有试着了解,
只是一般的的爬虫小爬虫而已,前面的大牛说的很全面了,搜索引擎掌握核心技术应该不难。顺便说一下,我自己是一枚菜鸟,讲到的很多知识都来自网上,只是希望给楼主一些学习的经验。个人看法,勿喷。1.想做什么就去做。2.细分下来再针对一个领域来找各自的教程。3.如果你是一枚学生,建议你趁着暑假先去做一些大作业啊,虽然自己是新手,但也可以慢慢感受到自己的不足。
4.多问多看多想多练习,不要闷着头弄代码,搞不好弄个一两个月就放弃了。5.有足够的兴趣再来学,真的挺重要的。6.talkischeap,showmethecode.。
百度网页关键字抓取(百度搜索关键词却搜索不到的原因及解决办法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2021-09-15 02:15
)
众所周知,我们的平台为您提供收录media 服务。只有收录成功才会收费,收录不成功不收费。但是有的新手会问为什么包收录的媒体查询收录成功了,百度搜索关键词却找不到。让我告诉你为什么。
如何查询收录
首先告诉你如何查询收录。就是在搜索框中搜索发布成功的链接。如果可以显示快照页面,则为收录success,Web 界面中为网页收录,信息界面中为news收录。链接为收录 是您使用关键词 搜索相应快照的必要条件。如果文章 不是收录,则无法搜索已发布的软文。当然,我们常说收录成功并不是软文发布效果的唯一标准。比如自媒体类的今日头条、企鹅等软文就不会是收录,而是会通过在相应的App中推荐给网友来获得文章的阅读曝光率。
百度搜索引擎的工作原理
众所周知,搜索引擎的主要工作流程包括:抓取、存储、页面分析、索引、检索等主要流程。爬取、存储、页面分析、索引等部分主要是搜索引擎如何利用网页库的内容来切词和建立索引。用户输入关键词 进行搜索。百度搜索引擎在排序链接中做了两件事。一是从索引库中提取相关网页(网页必须为收录),二是根据不同维度的得分(即网页在搜索结果中的排名)对提取的网页进行综合排序)。先说排序搜索结果的因素,大致可以分为以下几个维度:
1.相关性:网页内容与用户搜索需求的匹配程度,比如用户查看网页中收录的关键词的次数,以及这些关键词出现在什么地方;外部网页用于指向页面等的锚文本。
2.权威:用户喜欢网站提供的内容,具有一定的权威性。因此,百度搜索引擎也更相信优质权威网站提供的内容。
3.时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
4.重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
5.丰富性:丰富性看似简单,但它是一个涵盖面非常广的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
6.受欢迎程度:指网页是否受欢迎。
查看全部
百度网页关键字抓取(百度搜索关键词却搜索不到的原因及解决办法
)
众所周知,我们的平台为您提供收录media 服务。只有收录成功才会收费,收录不成功不收费。但是有的新手会问为什么包收录的媒体查询收录成功了,百度搜索关键词却找不到。让我告诉你为什么。
如何查询收录
首先告诉你如何查询收录。就是在搜索框中搜索发布成功的链接。如果可以显示快照页面,则为收录success,Web 界面中为网页收录,信息界面中为news收录。链接为收录 是您使用关键词 搜索相应快照的必要条件。如果文章 不是收录,则无法搜索已发布的软文。当然,我们常说收录成功并不是软文发布效果的唯一标准。比如自媒体类的今日头条、企鹅等软文就不会是收录,而是会通过在相应的App中推荐给网友来获得文章的阅读曝光率。
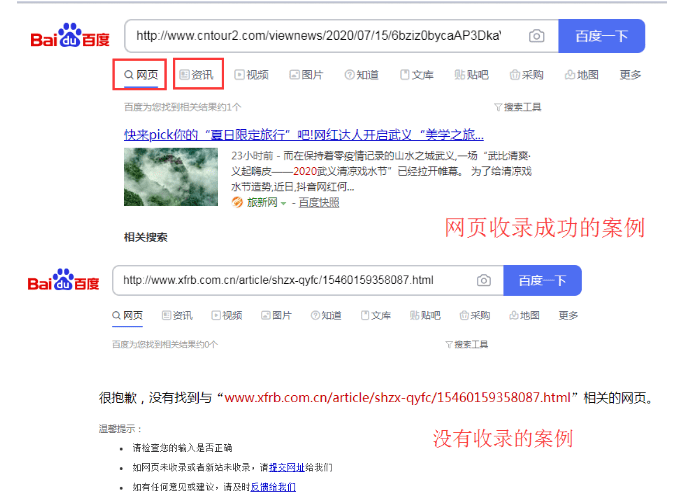
百度搜索引擎的工作原理
众所周知,搜索引擎的主要工作流程包括:抓取、存储、页面分析、索引、检索等主要流程。爬取、存储、页面分析、索引等部分主要是搜索引擎如何利用网页库的内容来切词和建立索引。用户输入关键词 进行搜索。百度搜索引擎在排序链接中做了两件事。一是从索引库中提取相关网页(网页必须为收录),二是根据不同维度的得分(即网页在搜索结果中的排名)对提取的网页进行综合排序)。先说排序搜索结果的因素,大致可以分为以下几个维度:
1.相关性:网页内容与用户搜索需求的匹配程度,比如用户查看网页中收录的关键词的次数,以及这些关键词出现在什么地方;外部网页用于指向页面等的锚文本。
2.权威:用户喜欢网站提供的内容,具有一定的权威性。因此,百度搜索引擎也更相信优质权威网站提供的内容。
3.时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
4.重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
5.丰富性:丰富性看似简单,但它是一个涵盖面非常广的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
6.受欢迎程度:指网页是否受欢迎。
百度网页关键字抓取(查找引擎优化对企业和产品都具有重要的意义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-15 02:15
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的承诺和评论更好。这个时候,好的产品就会有好的优势。调查显示,87%的网民会基于搜索引擎服务找到自己需要的信息内容,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息内容.
由此可见,搜索引擎优化对企业和产品的意义重大。
我们经常听到关键字,但是关键字的详细主要用途是什么? 关键词是搜索引擎优化的中心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。假设你想收录更多网站的页面,你必须先爬网。
假设你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、年长、威严的蜘蛛,必须采取特殊的手段。爬行网站的频率非常高。众所周知,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站server 是网站 的基石。假设网站服务器长时间打不开,就相当于关门谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。假设您的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的基础,再好的房子也会过马路。
蜘蛛每次爬行,都会存储页面数据。假设第二次爬取发现页面收录的内容与第一次完全相同,则说明该页面尚未更新,蜘蛛不需要经常爬取。假设网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。所以,我们应该主动把蜘蛛展示给蜘蛛,及时更新文章,方便蜘蛛按照你的规则有效爬取文章,不仅让你更新文章更快,而且不要形成经常白跑的蜘蛛。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要对蜘蛛真正有价值的原创 内容。假设蜘蛛可以得到它喜欢的东西,它自然会给你的网站留下好印象,经常来找食物。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成很多重复的页面,而这些页面一般都是通过参数来完成的。当一个页面对应多个URL时,会造成网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保一个页面只有一个 URL,假设它是生成的。尝试通过 301 重定向、规范符号或机器人对其进行处理,以确保蜘蛛仅捕获规范 url。
我们都知道外链可以吸引蜘蛛到网站,尤其是在新站点。 网站不是很复杂,蜘蛛访问较少,外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了节省能源而做无用的事情。百度现在相信大家都知道外链的处理,就不多说了。善良不做坏事。
蜘蛛的爬取是沿着链接进行的,所以内部链接的合理优化可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,要合理引入用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这也是很多网站都在用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,提高蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接以找到它们。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会波动和减少。当蜘蛛碰到死链时,它就像一个死胡同。他们必须回去再回来。这种大起大落降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时也要做好网站404页面的工作,向搜索引擎报告错误页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不抓取我页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以必要的时候,要经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站maps。 网站map 是指向网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。爬完网页后,可以清晰的掌握网站的结构,所以网站地图的建立不仅能提高爬网率,还能获得蜘蛛的极好感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在不收录内容的情况下提交。您只需要提交一次。能不能买得起就看搜索引擎了。 查看全部
百度网页关键字抓取(查找引擎优化对企业和产品都具有重要的意义?)
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的承诺和评论更好。这个时候,好的产品就会有好的优势。调查显示,87%的网民会基于搜索引擎服务找到自己需要的信息内容,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息内容.
由此可见,搜索引擎优化对企业和产品的意义重大。

我们经常听到关键字,但是关键字的详细主要用途是什么? 关键词是搜索引擎优化的中心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。假设你想收录更多网站的页面,你必须先爬网。
假设你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、年长、威严的蜘蛛,必须采取特殊的手段。爬行网站的频率非常高。众所周知,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站server 是网站 的基石。假设网站服务器长时间打不开,就相当于关门谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。假设您的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的基础,再好的房子也会过马路。
蜘蛛每次爬行,都会存储页面数据。假设第二次爬取发现页面收录的内容与第一次完全相同,则说明该页面尚未更新,蜘蛛不需要经常爬取。假设网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。所以,我们应该主动把蜘蛛展示给蜘蛛,及时更新文章,方便蜘蛛按照你的规则有效爬取文章,不仅让你更新文章更快,而且不要形成经常白跑的蜘蛛。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要对蜘蛛真正有价值的原创 内容。假设蜘蛛可以得到它喜欢的东西,它自然会给你的网站留下好印象,经常来找食物。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成很多重复的页面,而这些页面一般都是通过参数来完成的。当一个页面对应多个URL时,会造成网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保一个页面只有一个 URL,假设它是生成的。尝试通过 301 重定向、规范符号或机器人对其进行处理,以确保蜘蛛仅捕获规范 url。
我们都知道外链可以吸引蜘蛛到网站,尤其是在新站点。 网站不是很复杂,蜘蛛访问较少,外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了节省能源而做无用的事情。百度现在相信大家都知道外链的处理,就不多说了。善良不做坏事。
蜘蛛的爬取是沿着链接进行的,所以内部链接的合理优化可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,要合理引入用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这也是很多网站都在用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,提高蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接以找到它们。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会波动和减少。当蜘蛛碰到死链时,它就像一个死胡同。他们必须回去再回来。这种大起大落降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时也要做好网站404页面的工作,向搜索引擎报告错误页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不抓取我页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以必要的时候,要经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站maps。 网站map 是指向网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。爬完网页后,可以清晰的掌握网站的结构,所以网站地图的建立不仅能提高爬网率,还能获得蜘蛛的极好感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在不收录内容的情况下提交。您只需要提交一次。能不能买得起就看搜索引擎了。
百度网页关键字抓取(如何保证网站在短时间内被百度收录?百度不收录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-15 02:14
)
新的网站上线了,我们应该怎么做才能保证网站在短时间内成为百度收录?百度不是收录我们的网站 那么我们为这个网站设置的一些seo优化方案无法实现,只能等待,百度是我们的网站不收录,我们要获得排名。也是不可能的,只要保证百度有网站相关信息收录,我们就可以继续网站seo优化的工作。
当然是网站收录。有排名的都不错。基本上网站在收录之后就没有排名了。我想让关键词的排名更好。前面需要一些操作。
1、在构建网站时必须有网站的定位。 网站的产品必须细分。一栏的商品种类有很多种,比如Clothing,还有帽子,衣服,裤子,鞋子,围巾,手套,腰带等等,那么一个网站最好选择一个类,比如鞋。鞋子可分为男鞋和女鞋。继续分为正装鞋、商务鞋、休闲鞋等。
2、网站的排版保证没有问题,代码是否精简,网站的结构和框架是否有利于网站seo的优化,必须保证网站TDK 没有问题。各个子类在导航中的对应位置排列(导航文本插入关键词,从热到冷),不同的部分(如鞋子,鞋子配鞋子)根据网站分配以用户最关心的搜索需求。品牌、鞋子分类、鞋子价格等)。
3、网站的内容很重要。 网站是收录还是排名高取决于网站内容的质量,直接影响我们网站。 网站产品相关的主要内容一定要到位,完整,做好。首先,用户搜索到的热门话题必须在网站中分配相应的内容并重点展示,然后根据需要准备各种形式的与产品相关的内容(比如鞋子,除了常规的文字和图片)针对不同产品的特点。 , 也可以插入视频让用户更透彻地理解)。
4、网站的关键词拓展,也就是SEO关键词优化。首先要扩展50-60个用户会搜索的核心关键词,然后按照产品的每个子类别扩展20-30个用户搜索过的关键词主题,并按照从热到冷的顺序排列。
5、guarantee 网站在同行业中具有鲜明的内容,即网站不愿意或无法提供的其他内容,并且该内容必须对用户具有吸引力。
查看全部
百度网页关键字抓取(如何保证网站在短时间内被百度收录?百度不收录
)
新的网站上线了,我们应该怎么做才能保证网站在短时间内成为百度收录?百度不是收录我们的网站 那么我们为这个网站设置的一些seo优化方案无法实现,只能等待,百度是我们的网站不收录,我们要获得排名。也是不可能的,只要保证百度有网站相关信息收录,我们就可以继续网站seo优化的工作。
当然是网站收录。有排名的都不错。基本上网站在收录之后就没有排名了。我想让关键词的排名更好。前面需要一些操作。
1、在构建网站时必须有网站的定位。 网站的产品必须细分。一栏的商品种类有很多种,比如Clothing,还有帽子,衣服,裤子,鞋子,围巾,手套,腰带等等,那么一个网站最好选择一个类,比如鞋。鞋子可分为男鞋和女鞋。继续分为正装鞋、商务鞋、休闲鞋等。
2、网站的排版保证没有问题,代码是否精简,网站的结构和框架是否有利于网站seo的优化,必须保证网站TDK 没有问题。各个子类在导航中的对应位置排列(导航文本插入关键词,从热到冷),不同的部分(如鞋子,鞋子配鞋子)根据网站分配以用户最关心的搜索需求。品牌、鞋子分类、鞋子价格等)。
3、网站的内容很重要。 网站是收录还是排名高取决于网站内容的质量,直接影响我们网站。 网站产品相关的主要内容一定要到位,完整,做好。首先,用户搜索到的热门话题必须在网站中分配相应的内容并重点展示,然后根据需要准备各种形式的与产品相关的内容(比如鞋子,除了常规的文字和图片)针对不同产品的特点。 , 也可以插入视频让用户更透彻地理解)。
4、网站的关键词拓展,也就是SEO关键词优化。首先要扩展50-60个用户会搜索的核心关键词,然后按照产品的每个子类别扩展20-30个用户搜索过的关键词主题,并按照从热到冷的顺序排列。
5、guarantee 网站在同行业中具有鲜明的内容,即网站不愿意或无法提供的其他内容,并且该内容必须对用户具有吸引力。

百度网页关键字抓取(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 02:13
前言
什么是搜索引擎优化? SEO即Search Engine Optimization,意为“搜索引擎优化”,一般简称为搜索优化。 SEO的主要工作是通过了解各种搜索引擎如何抓取网页、如何索引以及如何确定它们对特定关键词搜索结果的排名等来优化网页,从而优化网页以提供搜索引擎排名,增加网站访问量。
如果你能很好地利用SEO技术,你就可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越多的出现,这样你网站可能会吸引更多的关注和影响力,并吸引潜在客户和现有客户加入您的业务。
总结一句话:SEO代表搜索引擎优化。通过自然搜索引擎结果增加访问您的网站 的流量的数量和质量是一种做法。
SEO 的本质
那么 SEO 是如何工作的?例如,一些浏览器搜索引擎使用机器人来获取从一个站点到另一个站点的网页,以采集有关该页面的信息并将其放入索引中。然后,该算法将分析索引中的页面并考虑数百个排名因素或信号,以确定应在给定查询的搜索结果中显示的页面顺序。
搜索排名因素可以被视为用户体验的代表。内容质量和关键字研究是内容优化的关键因素。搜索算法旨在展示相关权威页面,为用户提供有效的搜索体验。如果把这些因素都考虑进去,你就可以优化你的网站,内容可以帮助你的页面在搜索结果中排名更高。
Seo 主要用于商业目的,以查找有关产品和服务的信息。搜索通常是品牌数字流量的主要来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名。不断提高利润的过程。
seo 操作
搜索关键词访问你访问过的网站,但你有没有想过那个神奇的链接列表背后的内容?
就是这种情况。 Google 有一个搜索引擎,可以采集在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当你使用谷歌搜索的时候,你其实不是在搜索网页,而是在搜索谷歌的网页索引,至少搜索尽可能多的、可查找的索引;一些叫做“爬虫”的名字会被软件程序搜索,“爬虫”程序先爬取少量网页,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪所有这些页面上的链接,并抓取它们链接到的页面。等等。
现在,假设我想知道某个动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,然后按回车键,我们的软件将搜索这些索引以找到所有搜索词收录这些搜索词的网页。
在这种情况下,系统将显示数以万计的可能结果。 Google 如何确定我的搜索意图?答案是通过提问来确定的。问题数超过200。例如,您的关键字在此页面上出现了多少次?
这些关键字是出现在标题中,还是在网址中直接相邻?此页面是否收录这些关键字的同义词?这个网页是来自高质量的网站 还是劣质的 URL 甚至是垃圾邮件网站?
该页面的 PageRank 是多少?
PageRank全称为页面排名,也称页面排名,是一种基于网页之间相互超链接计算的技术。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。 PageRank 是 Google 的镇上之宝,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过互联网上的大量超链接确定页面的排名。谷歌将页面A到页面B的链接解释为页面A为页面B投票。谷歌根据投票来源(甚至是来源的来源,即链接到页面A的页面)确定一个新的级别,并且投票目标的级别。
简单地说,一个高级页面可以提升其他低级页面的级别。
假设一个小组由 4 个页面组成:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 的总和.
如果你对这样的公式感兴趣,可以了解一下。这里就不多解释了。
此公式通过查找网页的外部链接数量和这些链接的重要性来评估网页的重要性。最后,我们将综合以上所有因素,给出每个页面的总分。提交搜索请求后半秒返回搜索结果。
经常更新网站或提升网站排名。每个结果都收录一个标题、一个 URL 和一段文本,以帮助确定此页面是否是我要查找的页面。我还看到了一些指向类似页面的链接、最近在 Google 上保存的页面版本以及我可能会尝试的相关搜索。
在我们为大多数网页编制索引之前,这些网页是存储在数千台计算机上的数十亿个网页。
各因素权重如图:
如果是我,我觉得seo可以采用以下步骤:
获取辅助功能,以便引擎可以读取您的网站
有趣的内容可以回答搜索者的查询
优化关键字以吸引搜索者和引擎
出色的用户体验,包括快速加载和引人注目的用户界面
通过链接、引文和放大的内容分享有价值的内容
标题、网址和描述具有很高的点击率
摘要/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
备注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指在搜索引擎领域满足搜索引擎返回的查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素。当您考虑 SEO 时,内容质量应该是您的首要任务。内容质量是您吸引用户和取悦观众的方式,创建高质量、有价值的内容对于搜索引擎的可见度也至关重要,因此其首要要素是内容质量。
对您来说,例如博客文章、产品页面、关于页面、推荐、视频等或您如何为观众创建其他内容,内容质量的正确安排意味着您有基础支持所有其他搜索引擎优化工作。
提供内容质量,输出给用户,提供实质性的、有用的、独特的内容,是迫使他们留在你的页面上,建立熟悉度和信任,但高质量的内容取决于你的内容类型和行业。而且技术的深度等等都不一样。
那么如何输出优质内容,优质内容的特点如下:
网址搜索、索引和排名
首先面对搜索引擎,我们需要了解它的三个重要功能:
请记住,搜索是一个发现的过程。通过搜索引擎(爬虫)搜索和更新内容。此处的内容(可以是网页、图片、视频、PDF 等)是通过链接找到的。
总是谈论搜索引擎索引?那么它是什么意思?
搜索引擎处理并存储他们在索引中找到的信息,索引是一个巨大的数据库,收录他们找到并认为对搜索者来说足够的一切。
如果您现在在搜索结果中没有找到您想要显示的内容,可能有以下原因
也许你的网站是全新的,还没有获得
也许你的网站 没有链接到任何外部网站
也许你的网站让机器人很难有效地从中获取内容
也许你的网站收录一些称为搜索引擎命令的基本代码,这些基本代码会屏蔽搜索引擎
也许你的网站因为谷歌的垃圾邮件方法而受到惩罚
关键词研究
什么是关键字?
搜索时,输入框中输入的内容为关键字。对于网站,你的网站的内容最相关、最简洁的描述是关键字。
要了解关键字(搜索词),首先要了解谁在搜索它们,或者您想要什么关键词语言,例如“婚礼”和“花店”,您可能会发现它具有高度相关性和搜索量大的相关词,如:婚庆花束、新娘花、婚庆花店等
建立给定关键字或关键字词组所需的搜索量越高,获得更高排名所需的工作就越多,而一些大品牌通常会排在高流量关键字的前十名,因此,如果您追求同样的关键词从这些开始,排名的难度可想而知,需要很多年。
对于较大的搜索量,获得自然排名成功所需的竞争和努力就越大,但在某些情况下,竞争性较低的搜索词可能是最有利的。在 seo 中,称为长尾关键词。
请不要小看一些不起眼的冷门关键词。搜索量较低的长尾关键词通常能带来更好的结果,因为搜索者的搜索变得更加具体,比如搜索“前端”的人可能只是为了浏览,但搜索“前端”的人达达”只对关键词有明确的指出。
按搜索量指定策略
当你想对你的网站进行排名时,找到相关的搜索词,查看竞争对手的排名,向他们学习,找出原因和后果,让你更有战略性。
观察竞争对手的关键词。您还想对许多关键字进行排名,那么您怎么知道先做哪个呢?我认为它!我们首先考虑的是查看哪些关键字在竞争对手的列表中排名并确定优先级。
优先考虑竞争对手目前排名最后的高质量关键字可能是个好主意。其实你也可以查看竞争对手的列表中有哪些关键词,以及排名中的关键词。
您可以先了解搜索者的意图,然后进入搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,了解搜索者需要的信息;
导航查询,搜索者想要去互联网上的特定位置
交易查询,了解搜索者想做什么
商业研究以了解搜索者希望比较产品并找到满足其特定需求的最佳产品
本地查询,了解搜索者希望在本地找到的一些东西
既然找到了目标市场的搜索方式,搜索页面(可以回答搜索者问题的网页的做法),所以页面内容需要优化,比如:header标签,internal链接,锚文本(锚文本是用于链接到页面的文本),向搜索引擎发送有关目标页面内容的信号。
链接量
在 Google 的一般网站Administrator's Guide 中,将页面上的链接数量限制为合理的数量(最多几千个)。如果内部链接过多,您不会受到惩罚,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,分配给每个链接的权益就越少。
你的标题标签在搜索者对网站的第一印象中起着重要作用,那么你如何让你的网站拥有一个有效的标题标签?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站content
长度,一般来说,搜索引擎会在搜索结果中显示title标签的前50-60个字符
Meta description,和title标签一样,meta description也是html元素,用于描述其所在页面的内容,也嵌套在head标签中:
URL 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是每个内容在网络上的位置或地址,如标题标签和元描述,搜索引擎会在 serp(搜索引擎结果页面)上显示该 url,所以命名url 的格式和格式都会影响点击率,搜索者不仅用它们来决定点击哪些页面,搜索引擎也会用 URL 来对页面进行评估和排名。
最后总结一下,今天我们介绍了以下三个方面:
我在这里介绍网站SEO的知识。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
关注,不要迷路
大家好,以上就是这个文章的全部内容,可以看出这里的人都是人才。以后会继续更新技术相关的文章,如果觉得文章对你有用,欢迎“收看”,也欢迎分享,谢谢大家! !
—————END————— 查看全部
百度网页关键字抓取(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
前言
什么是搜索引擎优化? SEO即Search Engine Optimization,意为“搜索引擎优化”,一般简称为搜索优化。 SEO的主要工作是通过了解各种搜索引擎如何抓取网页、如何索引以及如何确定它们对特定关键词搜索结果的排名等来优化网页,从而优化网页以提供搜索引擎排名,增加网站访问量。
如果你能很好地利用SEO技术,你就可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越多的出现,这样你网站可能会吸引更多的关注和影响力,并吸引潜在客户和现有客户加入您的业务。
总结一句话:SEO代表搜索引擎优化。通过自然搜索引擎结果增加访问您的网站 的流量的数量和质量是一种做法。
SEO 的本质
那么 SEO 是如何工作的?例如,一些浏览器搜索引擎使用机器人来获取从一个站点到另一个站点的网页,以采集有关该页面的信息并将其放入索引中。然后,该算法将分析索引中的页面并考虑数百个排名因素或信号,以确定应在给定查询的搜索结果中显示的页面顺序。
搜索排名因素可以被视为用户体验的代表。内容质量和关键字研究是内容优化的关键因素。搜索算法旨在展示相关权威页面,为用户提供有效的搜索体验。如果把这些因素都考虑进去,你就可以优化你的网站,内容可以帮助你的页面在搜索结果中排名更高。
Seo 主要用于商业目的,以查找有关产品和服务的信息。搜索通常是品牌数字流量的主要来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名。不断提高利润的过程。
seo 操作
搜索关键词访问你访问过的网站,但你有没有想过那个神奇的链接列表背后的内容?
就是这种情况。 Google 有一个搜索引擎,可以采集在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当你使用谷歌搜索的时候,你其实不是在搜索网页,而是在搜索谷歌的网页索引,至少搜索尽可能多的、可查找的索引;一些叫做“爬虫”的名字会被软件程序搜索,“爬虫”程序先爬取少量网页,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪所有这些页面上的链接,并抓取它们链接到的页面。等等。
现在,假设我想知道某个动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,然后按回车键,我们的软件将搜索这些索引以找到所有搜索词收录这些搜索词的网页。
在这种情况下,系统将显示数以万计的可能结果。 Google 如何确定我的搜索意图?答案是通过提问来确定的。问题数超过200。例如,您的关键字在此页面上出现了多少次?
这些关键字是出现在标题中,还是在网址中直接相邻?此页面是否收录这些关键字的同义词?这个网页是来自高质量的网站 还是劣质的 URL 甚至是垃圾邮件网站?
该页面的 PageRank 是多少?
PageRank全称为页面排名,也称页面排名,是一种基于网页之间相互超链接计算的技术。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。 PageRank 是 Google 的镇上之宝,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过互联网上的大量超链接确定页面的排名。谷歌将页面A到页面B的链接解释为页面A为页面B投票。谷歌根据投票来源(甚至是来源的来源,即链接到页面A的页面)确定一个新的级别,并且投票目标的级别。
简单地说,一个高级页面可以提升其他低级页面的级别。
假设一个小组由 4 个页面组成:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 的总和.
如果你对这样的公式感兴趣,可以了解一下。这里就不多解释了。
此公式通过查找网页的外部链接数量和这些链接的重要性来评估网页的重要性。最后,我们将综合以上所有因素,给出每个页面的总分。提交搜索请求后半秒返回搜索结果。
经常更新网站或提升网站排名。每个结果都收录一个标题、一个 URL 和一段文本,以帮助确定此页面是否是我要查找的页面。我还看到了一些指向类似页面的链接、最近在 Google 上保存的页面版本以及我可能会尝试的相关搜索。
在我们为大多数网页编制索引之前,这些网页是存储在数千台计算机上的数十亿个网页。
各因素权重如图:
如果是我,我觉得seo可以采用以下步骤:
获取辅助功能,以便引擎可以读取您的网站
有趣的内容可以回答搜索者的查询
优化关键字以吸引搜索者和引擎
出色的用户体验,包括快速加载和引人注目的用户界面
通过链接、引文和放大的内容分享有价值的内容
标题、网址和描述具有很高的点击率
摘要/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
备注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指在搜索引擎领域满足搜索引擎返回的查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素。当您考虑 SEO 时,内容质量应该是您的首要任务。内容质量是您吸引用户和取悦观众的方式,创建高质量、有价值的内容对于搜索引擎的可见度也至关重要,因此其首要要素是内容质量。
对您来说,例如博客文章、产品页面、关于页面、推荐、视频等或您如何为观众创建其他内容,内容质量的正确安排意味着您有基础支持所有其他搜索引擎优化工作。
提供内容质量,输出给用户,提供实质性的、有用的、独特的内容,是迫使他们留在你的页面上,建立熟悉度和信任,但高质量的内容取决于你的内容类型和行业。而且技术的深度等等都不一样。
那么如何输出优质内容,优质内容的特点如下:
网址搜索、索引和排名
首先面对搜索引擎,我们需要了解它的三个重要功能:
请记住,搜索是一个发现的过程。通过搜索引擎(爬虫)搜索和更新内容。此处的内容(可以是网页、图片、视频、PDF 等)是通过链接找到的。
总是谈论搜索引擎索引?那么它是什么意思?
搜索引擎处理并存储他们在索引中找到的信息,索引是一个巨大的数据库,收录他们找到并认为对搜索者来说足够的一切。
如果您现在在搜索结果中没有找到您想要显示的内容,可能有以下原因
也许你的网站是全新的,还没有获得
也许你的网站 没有链接到任何外部网站
也许你的网站让机器人很难有效地从中获取内容
也许你的网站收录一些称为搜索引擎命令的基本代码,这些基本代码会屏蔽搜索引擎
也许你的网站因为谷歌的垃圾邮件方法而受到惩罚
关键词研究
什么是关键字?
搜索时,输入框中输入的内容为关键字。对于网站,你的网站的内容最相关、最简洁的描述是关键字。
要了解关键字(搜索词),首先要了解谁在搜索它们,或者您想要什么关键词语言,例如“婚礼”和“花店”,您可能会发现它具有高度相关性和搜索量大的相关词,如:婚庆花束、新娘花、婚庆花店等
建立给定关键字或关键字词组所需的搜索量越高,获得更高排名所需的工作就越多,而一些大品牌通常会排在高流量关键字的前十名,因此,如果您追求同样的关键词从这些开始,排名的难度可想而知,需要很多年。
对于较大的搜索量,获得自然排名成功所需的竞争和努力就越大,但在某些情况下,竞争性较低的搜索词可能是最有利的。在 seo 中,称为长尾关键词。
请不要小看一些不起眼的冷门关键词。搜索量较低的长尾关键词通常能带来更好的结果,因为搜索者的搜索变得更加具体,比如搜索“前端”的人可能只是为了浏览,但搜索“前端”的人达达”只对关键词有明确的指出。
按搜索量指定策略
当你想对你的网站进行排名时,找到相关的搜索词,查看竞争对手的排名,向他们学习,找出原因和后果,让你更有战略性。
观察竞争对手的关键词。您还想对许多关键字进行排名,那么您怎么知道先做哪个呢?我认为它!我们首先考虑的是查看哪些关键字在竞争对手的列表中排名并确定优先级。
优先考虑竞争对手目前排名最后的高质量关键字可能是个好主意。其实你也可以查看竞争对手的列表中有哪些关键词,以及排名中的关键词。
您可以先了解搜索者的意图,然后进入搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,了解搜索者需要的信息;
导航查询,搜索者想要去互联网上的特定位置
交易查询,了解搜索者想做什么
商业研究以了解搜索者希望比较产品并找到满足其特定需求的最佳产品
本地查询,了解搜索者希望在本地找到的一些东西
既然找到了目标市场的搜索方式,搜索页面(可以回答搜索者问题的网页的做法),所以页面内容需要优化,比如:header标签,internal链接,锚文本(锚文本是用于链接到页面的文本),向搜索引擎发送有关目标页面内容的信号。
链接量
在 Google 的一般网站Administrator's Guide 中,将页面上的链接数量限制为合理的数量(最多几千个)。如果内部链接过多,您不会受到惩罚,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,分配给每个链接的权益就越少。
你的标题标签在搜索者对网站的第一印象中起着重要作用,那么你如何让你的网站拥有一个有效的标题标签?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站content
长度,一般来说,搜索引擎会在搜索结果中显示title标签的前50-60个字符
Meta description,和title标签一样,meta description也是html元素,用于描述其所在页面的内容,也嵌套在head标签中:
URL 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是每个内容在网络上的位置或地址,如标题标签和元描述,搜索引擎会在 serp(搜索引擎结果页面)上显示该 url,所以命名url 的格式和格式都会影响点击率,搜索者不仅用它们来决定点击哪些页面,搜索引擎也会用 URL 来对页面进行评估和排名。
最后总结一下,今天我们介绍了以下三个方面:
我在这里介绍网站SEO的知识。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
关注,不要迷路
大家好,以上就是这个文章的全部内容,可以看出这里的人都是人才。以后会继续更新技术相关的文章,如果觉得文章对你有用,欢迎“收看”,也欢迎分享,谢谢大家! !
—————END—————
百度网页关键字抓取(百度蜘蛛抢占网站关键字的主要布局是什么?布局)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-15 00:13
虽然很多人意识到网站construction在这个互联网时代的重要性,但是把网站construction做好并做好工作并不容易,因为它涉及到很多方面,比如网站keywords要今天分享布局。 网站管理员都知道关键词在网站优化中的作用。如果在网站keyword布局上做好,百度蜘蛛抢占网站会更有优势。接下来,我将详细介绍如何在网站上放置关键字以更好地捕捉它们。
1.首先判断关键词竞争的难度
以成都工商登记服务为例。如果你现在正在为商务服务人员和网站管理员创建网站,首先要做的就是分析成都商务服务行业的关键词。可以通过搜索量去除关键词,看看百度首页列出了哪些类型的页面,比如网站首页、标签页、栏目页、详细信息页。
2.分析关键词的通用性,确定着陆页的形状
一般来说,成都工商登记服务用户的需求主要集中在成本、时间、流程、所需材料和政策方面。因此,对应的关键词包括成都工商注册费、成都工商注册所需材料、成都工商注册时间。通过分析关键词的通用性和前十种登陆页面类型,可以得出结论,更有助于我们确定登陆页面的形状。
3.Page关键字布局说明
确定着陆页后,如果是大的网站,一般是产品经理确定着陆页的形状,然后网站optimizer会输出需要的文件。那么下一页的主要布局是什么?主要考虑以下因素:标题标签和内容。 查看全部
百度网页关键字抓取(百度蜘蛛抢占网站关键字的主要布局是什么?布局)
虽然很多人意识到网站construction在这个互联网时代的重要性,但是把网站construction做好并做好工作并不容易,因为它涉及到很多方面,比如网站keywords要今天分享布局。 网站管理员都知道关键词在网站优化中的作用。如果在网站keyword布局上做好,百度蜘蛛抢占网站会更有优势。接下来,我将详细介绍如何在网站上放置关键字以更好地捕捉它们。
1.首先判断关键词竞争的难度
以成都工商登记服务为例。如果你现在正在为商务服务人员和网站管理员创建网站,首先要做的就是分析成都商务服务行业的关键词。可以通过搜索量去除关键词,看看百度首页列出了哪些类型的页面,比如网站首页、标签页、栏目页、详细信息页。
2.分析关键词的通用性,确定着陆页的形状
一般来说,成都工商登记服务用户的需求主要集中在成本、时间、流程、所需材料和政策方面。因此,对应的关键词包括成都工商注册费、成都工商注册所需材料、成都工商注册时间。通过分析关键词的通用性和前十种登陆页面类型,可以得出结论,更有助于我们确定登陆页面的形状。
3.Page关键字布局说明
确定着陆页后,如果是大的网站,一般是产品经理确定着陆页的形状,然后网站optimizer会输出需要的文件。那么下一页的主要布局是什么?主要考虑以下因素:标题标签和内容。
百度网页关键字抓取( 什么是百度抓取率?百度访问您网站的频率?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-15 00:10
什么是百度抓取率?百度访问您网站的频率?)
如何提高网站百度的抓取率
网站 在这几个小时的建设过程中,你一直在等待百度来抢你的网站。你试图吸引百度,但不幸的是,你的努力没有引起人们的注意。
百度的抓取率是多少?
百度抓取率是百度机器人访问你网站的频率。它会根据您的网站 类型和您发布的内容而有所不同。如果百度机器人无法正常抓取您的网站,您的网页和帖子将不会被索引。提高百度抓取率的步骤:
如果没有进一步说明,您可以采取以下措施来提高百度的抓取速度。
1、 定期向您的网站 添加新内容
搜索引擎最重要的标准之一是内容。定期更新内容的网站很可能会被频繁抓取。您可以通过博客提供新内容,而不是添加新页面。这是定期生成内容的最简单、最具成本效益的方法之一。要增加多样性,您还可以添加新的视频和音频流。
2、提高你的网站加载时间
爬虫时间有限,无法索引你的网站。如果它花费太多时间访问您的图像或 pdf,它将没有时间检查其他页面。为了提高网站的加载速度,请少用图片和图片缩小网页。请注意,嵌入的视频或音频可能会导致抓取工具出现问题。
3、添加站点地图提高百度抓取速度
网站上的每一个内容都应该被抓取,但有时会需要很长时间或更糟,它永远不会被抓取。提交站点地图是您必须执行的重要操作之一,以便百度机器人可以发现您的站点。使用站点地图,可以高效地抓取网站。它们还有助于相应地对您的网页进行分类和优先排序。因此,具有主要内容的页面将比不太重要的页面更快地被抓取和编入索引。
4、提高服务器响应时间
根据百度的说法,“您应该将服务器响应时间减少到 200 毫秒。”如果百度的加载时间较长,那么访问者很可能会遇到同样的问题。如果您的页面针对速度进行了优化,则没关系。如果您的服务器响应时间很慢,您的页面就会显示得很慢。此外,使用您的有效托管并改进您的网站 缓存。
5、远离重复内容
复制内容会减慢百度的抓取速度,因为搜索引擎可以轻松识别重复内容。重复的内容清楚地表明你缺乏目标和原创sexuality。如果您的网页内容超过一定程度,搜索引擎可能会禁止您的网站 或降低您的搜索引擎排名。
6、通过 Robots.txt 阻止不需要的页面
如果你有一个很大的网站,你可能有不希望搜索引擎索引的内容。示例、管理页面和后端文件夹。 Robots.txt 可以防止百度机器人抓取这些不需要的网页。
Robeots.txt 的主要目的很简单。然而,使用它们可能很复杂,如果你犯了错误,它可以在搜索引擎索引中消除你的网站。因此,请务必在上传前使用Baidu网站Admin Tool 测试您的robots.txt 文件。
7、优化图片和视频
只有经过优化的图片才会出现在搜索结果中。爬虫将无法像人类一样直接读取图像。每当您使用图片时,请务必使用 alt 标签并为搜索引擎提供索引索引。
同样的概念也适用于视频。百度不是“闪存”的粉丝,因为它无法索引它。如果您在优化这些元素时遇到困难,最好至少使用它们或完全避免使用它们。
8、博客文章
当您链接到您的博客时,百度机器人可以在您的网站 中抓取它。将旧帖子链接到新帖子,反之亦然。这将直接提高百度的抓取速度,帮助您获得更高的曝光率。
9、摆脱黑帽SEO的结果
如果您已收录任何黑帽 SEO 策略,则必须删除所有相关结果。这包括关键字填充、使用不相关的关键字、垃圾内容和链接操作以及其他技术。使用黑帽SEO技术转化为低质量爬虫网站。只用白帽技术提升百度的爬虫速度。
10、建立优质链接
高质量的反向链接可以提高百度的抓取速度和网站的索引速度。这也是提高排名和增加流量的最有效方法。即使在这里,白帽子也是连接建筑物的可靠方式。不要借用、窃取或购买链接。最好的方法是通过访客博客、损坏的链接构建修复和资源链接来吸引他们。
如果您的网站 在 SERP 上有一席之地,您将获得更多自然搜索。如果您有良好的百度抓取速度,就会发生这种情况。所以,每一个搜索引擎营销策略都要考虑网站的爬取速度。它可以提高百度的抓取速度,但不会一蹴而就。你必须要有耐心。
将上述建议应用于您的整个 网站 设计。久而久之,爱就会成为彼此。您的个人页面肯定会获得更多流量。 查看全部
百度网页关键字抓取(
什么是百度抓取率?百度访问您网站的频率?)
如何提高网站百度的抓取率
网站 在这几个小时的建设过程中,你一直在等待百度来抢你的网站。你试图吸引百度,但不幸的是,你的努力没有引起人们的注意。

百度的抓取率是多少?
百度抓取率是百度机器人访问你网站的频率。它会根据您的网站 类型和您发布的内容而有所不同。如果百度机器人无法正常抓取您的网站,您的网页和帖子将不会被索引。提高百度抓取率的步骤:
如果没有进一步说明,您可以采取以下措施来提高百度的抓取速度。
1、 定期向您的网站 添加新内容
搜索引擎最重要的标准之一是内容。定期更新内容的网站很可能会被频繁抓取。您可以通过博客提供新内容,而不是添加新页面。这是定期生成内容的最简单、最具成本效益的方法之一。要增加多样性,您还可以添加新的视频和音频流。
2、提高你的网站加载时间
爬虫时间有限,无法索引你的网站。如果它花费太多时间访问您的图像或 pdf,它将没有时间检查其他页面。为了提高网站的加载速度,请少用图片和图片缩小网页。请注意,嵌入的视频或音频可能会导致抓取工具出现问题。
3、添加站点地图提高百度抓取速度
网站上的每一个内容都应该被抓取,但有时会需要很长时间或更糟,它永远不会被抓取。提交站点地图是您必须执行的重要操作之一,以便百度机器人可以发现您的站点。使用站点地图,可以高效地抓取网站。它们还有助于相应地对您的网页进行分类和优先排序。因此,具有主要内容的页面将比不太重要的页面更快地被抓取和编入索引。
4、提高服务器响应时间
根据百度的说法,“您应该将服务器响应时间减少到 200 毫秒。”如果百度的加载时间较长,那么访问者很可能会遇到同样的问题。如果您的页面针对速度进行了优化,则没关系。如果您的服务器响应时间很慢,您的页面就会显示得很慢。此外,使用您的有效托管并改进您的网站 缓存。

5、远离重复内容
复制内容会减慢百度的抓取速度,因为搜索引擎可以轻松识别重复内容。重复的内容清楚地表明你缺乏目标和原创sexuality。如果您的网页内容超过一定程度,搜索引擎可能会禁止您的网站 或降低您的搜索引擎排名。
6、通过 Robots.txt 阻止不需要的页面
如果你有一个很大的网站,你可能有不希望搜索引擎索引的内容。示例、管理页面和后端文件夹。 Robots.txt 可以防止百度机器人抓取这些不需要的网页。
Robeots.txt 的主要目的很简单。然而,使用它们可能很复杂,如果你犯了错误,它可以在搜索引擎索引中消除你的网站。因此,请务必在上传前使用Baidu网站Admin Tool 测试您的robots.txt 文件。
7、优化图片和视频
只有经过优化的图片才会出现在搜索结果中。爬虫将无法像人类一样直接读取图像。每当您使用图片时,请务必使用 alt 标签并为搜索引擎提供索引索引。
同样的概念也适用于视频。百度不是“闪存”的粉丝,因为它无法索引它。如果您在优化这些元素时遇到困难,最好至少使用它们或完全避免使用它们。
8、博客文章
当您链接到您的博客时,百度机器人可以在您的网站 中抓取它。将旧帖子链接到新帖子,反之亦然。这将直接提高百度的抓取速度,帮助您获得更高的曝光率。
9、摆脱黑帽SEO的结果
如果您已收录任何黑帽 SEO 策略,则必须删除所有相关结果。这包括关键字填充、使用不相关的关键字、垃圾内容和链接操作以及其他技术。使用黑帽SEO技术转化为低质量爬虫网站。只用白帽技术提升百度的爬虫速度。
10、建立优质链接
高质量的反向链接可以提高百度的抓取速度和网站的索引速度。这也是提高排名和增加流量的最有效方法。即使在这里,白帽子也是连接建筑物的可靠方式。不要借用、窃取或购买链接。最好的方法是通过访客博客、损坏的链接构建修复和资源链接来吸引他们。
如果您的网站 在 SERP 上有一席之地,您将获得更多自然搜索。如果您有良好的百度抓取速度,就会发生这种情况。所以,每一个搜索引擎营销策略都要考虑网站的爬取速度。它可以提高百度的抓取速度,但不会一蹴而就。你必须要有耐心。
将上述建议应用于您的整个 网站 设计。久而久之,爱就会成为彼此。您的个人页面肯定会获得更多流量。
百度网页关键字抓取(百度蜘蛛怎么模拟抓取你的网站是否能够正常被抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 00:08
如果你要网站ranking,你需要让网站被收录,如果你想要网站收录,你需要让百度蜘蛛爬行,如果你想让百度蜘蛛爬行,你需要知道百度蜘蛛的爬行规则,今天推特科技就和你聊聊百度蜘蛛的爬行规则。另外,我会告诉你如何模拟爬取你的网站,并检查网站是否可以正常爬取。
模拟搜索蜘蛛爬行对于有经验的SEO人员来说是一个特别重要的新朋友,因为这是网站排名不高的一个重要原因:可以用自己的人眼看到网页和蜘蛛看到不一样的网页。
模拟搜索蜘蛛爬行这时候我们会用一个模拟搜索蜘蛛来爬取网页,然后看源码分析一下百度蜘蛛是什么类型的,这里也需要尽量了解关于一些网页源代码的知识,不需要了解太多。其实简单的HTML代码也能读懂。现在很多人都知道网站排名的关键是网站的价值。 网站的价值可以分为网页价值和内容价值。网页价值的关键之一是高PV,因此SEOer需要使网页具有相关性。内容的价值在于标题和内容一致,而不是文字不真实,内容图文并茂,布局清晰,主题清晰。
当然,并不是所有的网站都会在爬取后立即加入。它需要经过搜索引擎流程。该流量主要分为抓取、过滤、比较、索引和释放。
筛选:这一步主要是过滤掉垃圾文章,比如伪原创、同义词替换、翻译等文章,搜索引擎可以识别,通过这一步识别
对比:对比主要是为了维护文章的原创degree,百度的Spark计划的实施。通常,在比对步骤之后,搜索引擎会下载你的网站,比对并创建快照,所以搜索引擎蜘蛛已经访问了你的网站,所以网站日志中会有百度IP
索引:通过确保您的网站 没有问题,您可以在您的网站 上创建索引。如果索引已经创建,也说明你的站点已经收录。有时我们在百度搜索中找不到。可能的原因是它还没有发布,我们需要等待。 查看全部
百度网页关键字抓取(百度蜘蛛怎么模拟抓取你的网站是否能够正常被抓取)
如果你要网站ranking,你需要让网站被收录,如果你想要网站收录,你需要让百度蜘蛛爬行,如果你想让百度蜘蛛爬行,你需要知道百度蜘蛛的爬行规则,今天推特科技就和你聊聊百度蜘蛛的爬行规则。另外,我会告诉你如何模拟爬取你的网站,并检查网站是否可以正常爬取。
模拟搜索蜘蛛爬行对于有经验的SEO人员来说是一个特别重要的新朋友,因为这是网站排名不高的一个重要原因:可以用自己的人眼看到网页和蜘蛛看到不一样的网页。

模拟搜索蜘蛛爬行这时候我们会用一个模拟搜索蜘蛛来爬取网页,然后看源码分析一下百度蜘蛛是什么类型的,这里也需要尽量了解关于一些网页源代码的知识,不需要了解太多。其实简单的HTML代码也能读懂。现在很多人都知道网站排名的关键是网站的价值。 网站的价值可以分为网页价值和内容价值。网页价值的关键之一是高PV,因此SEOer需要使网页具有相关性。内容的价值在于标题和内容一致,而不是文字不真实,内容图文并茂,布局清晰,主题清晰。
当然,并不是所有的网站都会在爬取后立即加入。它需要经过搜索引擎流程。该流量主要分为抓取、过滤、比较、索引和释放。
筛选:这一步主要是过滤掉垃圾文章,比如伪原创、同义词替换、翻译等文章,搜索引擎可以识别,通过这一步识别
对比:对比主要是为了维护文章的原创degree,百度的Spark计划的实施。通常,在比对步骤之后,搜索引擎会下载你的网站,比对并创建快照,所以搜索引擎蜘蛛已经访问了你的网站,所以网站日志中会有百度IP
索引:通过确保您的网站 没有问题,您可以在您的网站 上创建索引。如果索引已经创建,也说明你的站点已经收录。有时我们在百度搜索中找不到。可能的原因是它还没有发布,我们需要等待。
百度网页关键字抓取(百度蜘蛛是怎么分辨先收录那篇文章的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 20:09
在做SEO优化推广的时候,一定要说一下百度收录。很多人不明白。这么多相同的网页,百度如何区分第一个收录那篇文章?明明内容是一样的,为什么其他人网站收录自己而不是收录,下面常州畅润资讯小编来看看百度蜘蛛收录一个网站的全过程,朋友们需要的可以参考下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、信息过滤。
3、创建网页关键词index.
4、User 搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站homepage,首先会读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行跟踪和抓取。比如我们的文章“畅润信息:百度收录网站抓取网页的过程”,引擎会在多进程中到文章所在的网页抓取信息,并按照这边走。糟糕,没有尽头。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站 URL,引擎会记录下来并归类为一个未被抓取的URL,然后蜘蛛会从数据库根据这个表,访问和抓取页面。
蜘蛛不会收录所有页面,需要严格测试。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页权重低,而且大部分文章都是抄袭的,蜘蛛可能不喜欢。你的网站不见了,所以如果你停止爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
索引有正向索引和反向索引。正向索引为关键词对应的网页内容,反向为关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表匹配关键词,通过反向索引表找到关键词对应的页面,通过引擎。网页的排名是根据网页的分数确定的。
感谢收看! 查看全部
百度网页关键字抓取(百度蜘蛛是怎么分辨先收录那篇文章的呢?)
在做SEO优化推广的时候,一定要说一下百度收录。很多人不明白。这么多相同的网页,百度如何区分第一个收录那篇文章?明明内容是一样的,为什么其他人网站收录自己而不是收录,下面常州畅润资讯小编来看看百度蜘蛛收录一个网站的全过程,朋友们需要的可以参考下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、信息过滤。
3、创建网页关键词index.
4、User 搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站homepage,首先会读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行跟踪和抓取。比如我们的文章“畅润信息:百度收录网站抓取网页的过程”,引擎会在多进程中到文章所在的网页抓取信息,并按照这边走。糟糕,没有尽头。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站 URL,引擎会记录下来并归类为一个未被抓取的URL,然后蜘蛛会从数据库根据这个表,访问和抓取页面。
蜘蛛不会收录所有页面,需要严格测试。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页权重低,而且大部分文章都是抄袭的,蜘蛛可能不喜欢。你的网站不见了,所以如果你停止爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
索引有正向索引和反向索引。正向索引为关键词对应的网页内容,反向为关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表匹配关键词,通过反向索引表找到关键词对应的页面,通过引擎。网页的排名是根据网页的分数确定的。
感谢收看!
百度网页关键字抓取(如何提高百度蜘蛛抓取网页的几个小技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-11 01:00
提高百度蜘蛛抓取网页的几个技巧
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引数据库,让用户可以在百度搜索引擎中搜索到你的网站页面、图片、视频等内容。取名蜘蛛是因为这个程序有类似蜘蛛的功能,可以铺设万维网,可以采集互联网上的信息。那么百度蜘蛛是如何像抓取网页一样工作的呢?提高蜘蛛抓取网页量的技巧有哪些?欧洲营销编辑告诉你。
百度蜘蛛的工作原理
蜘蛛的工作原理有四个步骤(抓取、过滤、索引和输出)。抓取:百度蜘蛛会通过计算和规则来确定要抓取的页面和抓取频率。如果网站 的更新频率和网站 的内容质量高且人性化,那么您新生成的内容将立即被蜘蛛抓取。过滤:由于被过滤的页面数量过多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会首先对这些内容进行过滤,以防止它们向用户展示,这可能会给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。输出:当用户搜索关键词时,搜索引擎会根据一系列算法和规则匹配索引库中的内容,并对匹配结果内容的优劣进行评分,最终得到一个排名顺序,也就是百度的排名。
如何增加蜘蛛的抓取量
1、内容更新频率
网站的内容需要经常更新高价值和原创度高的内容,以便百度蜘蛛首先抓取您的网页。在网站优化中,必须要有内容创作的频率,因为蜘蛛爬行是有策略的。 网站更新内容越频繁,蜘蛛爬行越频繁,所以更新频率可以提高爬行频率。
2、网站的经验水平
网站的体验度是指用户的体验。拥有良好的用户体验网站,百度蜘蛛将优先入场。那么这里有人会问,如何提升用户体验呢?事实上,这非常简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免过多的广告。不要让广告覆盖首页的内容,否则百度会判断你的网站User体验很糟糕。
3、质量入口
优质入口主要是指网站的外链,优质网站会先被抓取。现在百度对外链做了很大的调整。对于外部链接,百度已经过滤得很严了。基本上,如果您在论坛或留言板上发布外部链接,百度会在后台对其进行过滤。但真正优质的外链对于排名和爬虫非常重要。
4、History 爬取效果不错
无论是排名还是蜘蛛爬行,百度的历史记录都非常重要。这就像一个人的历史记录,如果你以前作弊过。那会留下污渍。 网站 是一样的。切记优化网站 时不要作弊。一旦留下污点,就会降低百度蜘蛛对网站的信任度,影响爬取网站的时间和深度。不断更新优质内容非常重要。
5、服务器稳定,先爬取
15年以来,百度在服务器稳定因子的权重上做了很大的提升。服务器稳定性包括两个方面:稳定性和速度。服务器越快,植物爬行的效率就越高。服务器越稳定,蜘蛛爬取的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于一个经常被攻击(被黑)的网站,它可以严重伤害用户。所以在SEO优化过程中,要注意网站的安全。
通过Eurofins编辑采集的tips,相信大家对spider的工作原理有了一定的了解。如果要优化网站,站长必须了解百度蜘蛛的工作原理。然后分析哪些内容容易被百度蜘蛛抓取,然后产生百度搜索引擎喜欢的内容,自然排名和收录就会增加。 查看全部
百度网页关键字抓取(如何提高百度蜘蛛抓取网页的几个小技巧(图))
提高百度蜘蛛抓取网页的几个技巧
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引数据库,让用户可以在百度搜索引擎中搜索到你的网站页面、图片、视频等内容。取名蜘蛛是因为这个程序有类似蜘蛛的功能,可以铺设万维网,可以采集互联网上的信息。那么百度蜘蛛是如何像抓取网页一样工作的呢?提高蜘蛛抓取网页量的技巧有哪些?欧洲营销编辑告诉你。
百度蜘蛛的工作原理
蜘蛛的工作原理有四个步骤(抓取、过滤、索引和输出)。抓取:百度蜘蛛会通过计算和规则来确定要抓取的页面和抓取频率。如果网站 的更新频率和网站 的内容质量高且人性化,那么您新生成的内容将立即被蜘蛛抓取。过滤:由于被过滤的页面数量过多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会首先对这些内容进行过滤,以防止它们向用户展示,这可能会给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。输出:当用户搜索关键词时,搜索引擎会根据一系列算法和规则匹配索引库中的内容,并对匹配结果内容的优劣进行评分,最终得到一个排名顺序,也就是百度的排名。

如何增加蜘蛛的抓取量
1、内容更新频率
网站的内容需要经常更新高价值和原创度高的内容,以便百度蜘蛛首先抓取您的网页。在网站优化中,必须要有内容创作的频率,因为蜘蛛爬行是有策略的。 网站更新内容越频繁,蜘蛛爬行越频繁,所以更新频率可以提高爬行频率。
2、网站的经验水平
网站的体验度是指用户的体验。拥有良好的用户体验网站,百度蜘蛛将优先入场。那么这里有人会问,如何提升用户体验呢?事实上,这非常简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免过多的广告。不要让广告覆盖首页的内容,否则百度会判断你的网站User体验很糟糕。
3、质量入口
优质入口主要是指网站的外链,优质网站会先被抓取。现在百度对外链做了很大的调整。对于外部链接,百度已经过滤得很严了。基本上,如果您在论坛或留言板上发布外部链接,百度会在后台对其进行过滤。但真正优质的外链对于排名和爬虫非常重要。
4、History 爬取效果不错
无论是排名还是蜘蛛爬行,百度的历史记录都非常重要。这就像一个人的历史记录,如果你以前作弊过。那会留下污渍。 网站 是一样的。切记优化网站 时不要作弊。一旦留下污点,就会降低百度蜘蛛对网站的信任度,影响爬取网站的时间和深度。不断更新优质内容非常重要。
5、服务器稳定,先爬取
15年以来,百度在服务器稳定因子的权重上做了很大的提升。服务器稳定性包括两个方面:稳定性和速度。服务器越快,植物爬行的效率就越高。服务器越稳定,蜘蛛爬取的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于一个经常被攻击(被黑)的网站,它可以严重伤害用户。所以在SEO优化过程中,要注意网站的安全。

通过Eurofins编辑采集的tips,相信大家对spider的工作原理有了一定的了解。如果要优化网站,站长必须了解百度蜘蛛的工作原理。然后分析哪些内容容易被百度蜘蛛抓取,然后产生百度搜索引擎喜欢的内容,自然排名和收录就会增加。
百度网页关键字抓取(学习Python,就避免不了爬虫,而Scrapy就是最简单的图片爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-10 23:12
学习Python离不开爬虫,Scrapy是最受欢迎的。可以爬取文字信息(比如职位信息、网站评论等),也可以爬取图片,比如看到一些不错的网站展示了很多漂亮的图片(这里仅供个人学习Scrapy使用,不是用于商业用途),您可以下载它。好了,话不多说,下面开始一个简单的图片爬虫。
首先,我们需要一个浏览器来方便的查看html路径。建议使用火狐开发版() 这个版本的火狐标志是蓝色的
安装这个之后就不需要安装firebug、firepath等插件了
这里的例子,以花瓣网为例,抓取本页图片。
第一步:打开火狐浏览器,使用上面的网址访问,导航到Inspector选项卡,点击箭头然后选择一张图片,你就可以看到所选图片的位置(见下图)
这里我们发现打开的页面收录很多主题的图片,每个主题对应一个图片链接地址。打开后就是这个话题对应的图片。那么我们的目的就是抓取每个话题下的图片,所以第一步就是获取每个话题的链接,打开链接,查看图片地址,一一下载。现在我大概知道我们的例子有两层结构:①访问首页,展示不同主题的图片 ②打开每个主题,展示主题下方的图片
现在开始创建scrapy项目(可以参考前面的文章)
这里我创建了一个huaban2项目(我之前又做了一个,所以这里就命名为huaban2,随便我想),然后我创建了一个spider,begin是一个命令行文件,里面是scrapy Crawl meipic的命令,见稍后
第 2 步:实现蜘蛛
# -*- coding: utf-8 -*-
from huaban2.items import Huaban2Item
import scrapy
class HuabanSpider(scrapy.Spider):
name = 'meipic'
allowed_domains = ['meisupic.com']
baseURL = 'http://www.meisupic.com/topic.php'
start_urls = [baseURL]
def parse(self, response):
node_list = response.xpath("//div[@class='body glide']/ul")
if len(node_list) == 0:
return
for node in node_list:
sub_node_list = node.xpath("./li/dl/a/@href").extract()
if len(sub_node_list) == 0:
return
for url in sub_node_list:
new_url = self.baseURL[:-9] + url
yield scrapy.Request(new_url, callback=self.parse2)
def parse2(self, response):
node_list = response.xpath("//div[@id='searchCon2']/ul")
if len(node_list) == 0:
return
item = Huaban2Item()
item["image_url"] = node_list.xpath("./li/a/img/@data-original").extract()
yield item
解释一下这段代码:使用scrapy genspider meipic生成蜘蛛后,已经写好了默认结构,这里我们设置了一个baseURL,默认方法是parse。从上面的分析我们知道需要获取每个topic的链接,所以我们使用xpath来定位
node_list = response.xpath("//div[@class='body glide']/ul")
这样我们就得到了一个selector对象,赋值给变量node_list,加一个if判断,如果没了就结束(return后的代码不会被执行,这个大家应该都知道),然后我们要取/ul/下li/dl下的href,用extract()返回一个list,就是dl下的所有链接。接下来,我们需要拼接一个完整的 URL,然后请求这个 URL,并用 yield 返回。因为我们真正要抓取的图片在页面的第二层,所以这里的回调函数调用了一个parse2(这是我自己定义的一个方法),parse2是用来处理图片链接的。同理,从之前拼接的URL请求页面返回parse2的响应
这里我们要获取图片的地址,就是//div[@id='SearchCon2']/ul/li/a/img/@data-original,获取到地址后,交给item (我们定义了item字段用来存放图片的地址),这样item返回到管道中
items.py
import scrapy
class Huaban2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
image_paths = scrapy.Field()
管道.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import scrapy
class Huaban2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x["path"] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no image")
item['image_paths'] = image_paths
return item
因为要下载图片,所以需要在settings.py中配置一个路径,同时
需要的配置如下,其他默认即可
MEDIA_ALLOW_REDIRECTS = True #因为图片地址会被重定向,所以这个属性要为True
IMAGES_STORE = "E:\\img" #存储图片的路径
ROBOTSTXT_OBEY = False #Robot协议属性要为False,不然就不会抓取任何内容
ITEM_PIPELINES = {
'huaban2.pipelines.Huaban2Pipeline': 1,
} #pipeline要enable,不然不会出来pipeline的请求
最后我们写了一个begin.py文件来执行
from scrapy import cmdline
cmdline.execute('scrapy crawl meipic'.split())
多说一点,可以存储不同大小的图片,如果需要,可以在settings.py中添加属性
IMAGES_THUMBS = {'small': (100, 100), 'big': (800, 1000)}
好了,基础写完了,可以开始执行了。 查看全部
百度网页关键字抓取(学习Python,就避免不了爬虫,而Scrapy就是最简单的图片爬虫)
学习Python离不开爬虫,Scrapy是最受欢迎的。可以爬取文字信息(比如职位信息、网站评论等),也可以爬取图片,比如看到一些不错的网站展示了很多漂亮的图片(这里仅供个人学习Scrapy使用,不是用于商业用途),您可以下载它。好了,话不多说,下面开始一个简单的图片爬虫。
首先,我们需要一个浏览器来方便的查看html路径。建议使用火狐开发版() 这个版本的火狐标志是蓝色的
安装这个之后就不需要安装firebug、firepath等插件了
这里的例子,以花瓣网为例,抓取本页图片。
第一步:打开火狐浏览器,使用上面的网址访问,导航到Inspector选项卡,点击箭头然后选择一张图片,你就可以看到所选图片的位置(见下图)

这里我们发现打开的页面收录很多主题的图片,每个主题对应一个图片链接地址。打开后就是这个话题对应的图片。那么我们的目的就是抓取每个话题下的图片,所以第一步就是获取每个话题的链接,打开链接,查看图片地址,一一下载。现在我大概知道我们的例子有两层结构:①访问首页,展示不同主题的图片 ②打开每个主题,展示主题下方的图片
现在开始创建scrapy项目(可以参考前面的文章)
这里我创建了一个huaban2项目(我之前又做了一个,所以这里就命名为huaban2,随便我想),然后我创建了一个spider,begin是一个命令行文件,里面是scrapy Crawl meipic的命令,见稍后

第 2 步:实现蜘蛛
# -*- coding: utf-8 -*-
from huaban2.items import Huaban2Item
import scrapy
class HuabanSpider(scrapy.Spider):
name = 'meipic'
allowed_domains = ['meisupic.com']
baseURL = 'http://www.meisupic.com/topic.php'
start_urls = [baseURL]
def parse(self, response):
node_list = response.xpath("//div[@class='body glide']/ul")
if len(node_list) == 0:
return
for node in node_list:
sub_node_list = node.xpath("./li/dl/a/@href").extract()
if len(sub_node_list) == 0:
return
for url in sub_node_list:
new_url = self.baseURL[:-9] + url
yield scrapy.Request(new_url, callback=self.parse2)
def parse2(self, response):
node_list = response.xpath("//div[@id='searchCon2']/ul")
if len(node_list) == 0:
return
item = Huaban2Item()
item["image_url"] = node_list.xpath("./li/a/img/@data-original").extract()
yield item
解释一下这段代码:使用scrapy genspider meipic生成蜘蛛后,已经写好了默认结构,这里我们设置了一个baseURL,默认方法是parse。从上面的分析我们知道需要获取每个topic的链接,所以我们使用xpath来定位
node_list = response.xpath("//div[@class='body glide']/ul")
这样我们就得到了一个selector对象,赋值给变量node_list,加一个if判断,如果没了就结束(return后的代码不会被执行,这个大家应该都知道),然后我们要取/ul/下li/dl下的href,用extract()返回一个list,就是dl下的所有链接。接下来,我们需要拼接一个完整的 URL,然后请求这个 URL,并用 yield 返回。因为我们真正要抓取的图片在页面的第二层,所以这里的回调函数调用了一个parse2(这是我自己定义的一个方法),parse2是用来处理图片链接的。同理,从之前拼接的URL请求页面返回parse2的响应

这里我们要获取图片的地址,就是//div[@id='SearchCon2']/ul/li/a/img/@data-original,获取到地址后,交给item (我们定义了item字段用来存放图片的地址),这样item返回到管道中
items.py
import scrapy
class Huaban2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
image_paths = scrapy.Field()
管道.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import scrapy
class Huaban2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x["path"] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no image")
item['image_paths'] = image_paths
return item
因为要下载图片,所以需要在settings.py中配置一个路径,同时
需要的配置如下,其他默认即可
MEDIA_ALLOW_REDIRECTS = True #因为图片地址会被重定向,所以这个属性要为True
IMAGES_STORE = "E:\\img" #存储图片的路径
ROBOTSTXT_OBEY = False #Robot协议属性要为False,不然就不会抓取任何内容
ITEM_PIPELINES = {
'huaban2.pipelines.Huaban2Pipeline': 1,
} #pipeline要enable,不然不会出来pipeline的请求
最后我们写了一个begin.py文件来执行
from scrapy import cmdline
cmdline.execute('scrapy crawl meipic'.split())
多说一点,可以存储不同大小的图片,如果需要,可以在settings.py中添加属性
IMAGES_THUMBS = {'small': (100, 100), 'big': (800, 1000)}
好了,基础写完了,可以开始执行了。
百度网页关键字抓取( mysql+redis安装可查阅百度(很简单)项目开发流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-10 22:01
mysql+redis安装可查阅百度(很简单)项目开发流程介绍)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。 (每天爬一次)
1.Project 需要环境安装
1)scrapy+selenium+chrome (phantomjs)
我已经介绍了爬虫所依赖的环境的安装。可以参考这个文章我的详细介绍。
2)mysql+redis 安装数据库安装百度可以找到(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面显示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.开发代码详解
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
SPIDER_MODULES:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 是一个与数据存储相关的文件
middlewares.py 可以自定义,使scrapy更可控
items.py 类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用更简单,因为它的字段非常单一。
spider 文件夹:此文件夹存储特定的网站 爬虫。通过命令行,我们可以创建自己的蜘蛛。
4.spider 代码详解
def make_requests_from_url(self, url):
if self.params['st_status'] == 1:
return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True})
else:
return Request(url)
先修改spider中的make_requests_from_url函数,增加一个判断,当st_status==1时,当我们返回请求对象时,添加一个meta,并携带我们要搜索的key和我们需要访问的浏览器地址在元。以及启动phantomjs的说明。
第二次修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) < 400:
if not self.params['redis_key']:
a_list = response.xpath('//h3/a/@href').extract()
for url in a_list:
if url.startswith('http://') != True and url.startswith('https://') !=True:
url = response.urljoin(url)
yield scrapy.Request(url=url, meta={'url':response.url}, callback=self.pang_bo, dont_filter=True)
if response.meta.has_key('page') != True and self.sousu == 2:
flag = 1
for next_url in response.xpath('//div[@id="page"]/a/@href').extract():
if next_url.startswith('http://') != True and next_url.startswith('https://') !=True:
nextUrl = self.start_urls[0] + next_url
regex = 'pn=(\d+)'
page_number = re.compile(regex).search(nextUrl).group(1)
if page_number and flag:
flag = 0
# 抓取前50页
for page in range(10,500,10):
next_page = 'pn=' + str(page)
old_page = re.compile(regex).search(nextUrl).group()
nextUrl = nextUrl.replace(old_page, next_page)
yield scrapy.Request(url=nextUrl, meta={'page':page}, callback=self.parse)
以上代码是获取刚才网页中显示的每一个搜索结果,并获取页面模式,模拟翻50页,将50页的内容全部提交给self.pang_bo函数进行处理。我做了一个页面来删除这里的重复!
# 处理item
def parse_text(self, response):
item = {}
try:
father_url = response.meta["url"]
except:
father_url = "''"
try:
item['title'] = response.xpath('//title/text()').extract_first().replace('\r\n','').replace('\n','').encode('utf-8')
except:
item['title'] = "''"
item['url'] = response.url
item['domain'] = ''
item['crawl_time'] = time.strftime('%Y%m%d%H%M%S')
item['keyword'] = ''
item['Type_result'] = ''
item['type'] = 'html'
item['filename'] = 'yq_' + str(int(time.time())) + '_0' + str(rand5())+'.txt'
item['referver'] = father_url
item['like'] = ''
item['transpond'] = ''
item['comment'] = ''
item['publish_time'] = ''
return item
def pang_bo(self, response):
# 过略掉百度网页
if 'baidu.com' not in response.url and 'ctrip.com' not in response.url and 'baike.com' not in response.url:
item = self.parse_text(response)
content = soup_text(response.body)
if len(content) > 3000:
content = content[:3000]
#elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv')
with open(file_name, 'a') as b:
b.write(body)
else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv')
with open(filename, 'a') as f:
f.write(body)
# 过滤网页源代码
def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',')
except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(此处过滤了源码),然后将获取到的内容保存到一个.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)
DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒
DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)
CONCURRENT_ITEMS = 200 # 同时处理的itmes数量
CONCURRENT_REQUESTS = 16 # 同时并发的请求
今天的代码到此结束。我还是想说:“做一个爱分享的程序员,有什么问题请留言。”如果你觉得我的文章还可以,请关注点赞。谢谢大家! 查看全部
百度网页关键字抓取(
mysql+redis安装可查阅百度(很简单)项目开发流程介绍)

图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。 (每天爬一次)
1.Project 需要环境安装
1)scrapy+selenium+chrome (phantomjs)
我已经介绍了爬虫所依赖的环境的安装。可以参考这个文章我的详细介绍。
2)mysql+redis 安装数据库安装百度可以找到(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面显示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.开发代码详解
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
SPIDER_MODULES:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 是一个与数据存储相关的文件
middlewares.py 可以自定义,使scrapy更可控
items.py 类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用更简单,因为它的字段非常单一。
spider 文件夹:此文件夹存储特定的网站 爬虫。通过命令行,我们可以创建自己的蜘蛛。
4.spider 代码详解
def make_requests_from_url(self, url):
if self.params['st_status'] == 1:
return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True})
else:
return Request(url)
先修改spider中的make_requests_from_url函数,增加一个判断,当st_status==1时,当我们返回请求对象时,添加一个meta,并携带我们要搜索的key和我们需要访问的浏览器地址在元。以及启动phantomjs的说明。
第二次修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) < 400:
if not self.params['redis_key']:
a_list = response.xpath('//h3/a/@href').extract()
for url in a_list:
if url.startswith('http://') != True and url.startswith('https://') !=True:
url = response.urljoin(url)
yield scrapy.Request(url=url, meta={'url':response.url}, callback=self.pang_bo, dont_filter=True)
if response.meta.has_key('page') != True and self.sousu == 2:
flag = 1
for next_url in response.xpath('//div[@id="page"]/a/@href').extract():
if next_url.startswith('http://') != True and next_url.startswith('https://') !=True:
nextUrl = self.start_urls[0] + next_url
regex = 'pn=(\d+)'
page_number = re.compile(regex).search(nextUrl).group(1)
if page_number and flag:
flag = 0
# 抓取前50页
for page in range(10,500,10):
next_page = 'pn=' + str(page)
old_page = re.compile(regex).search(nextUrl).group()
nextUrl = nextUrl.replace(old_page, next_page)
yield scrapy.Request(url=nextUrl, meta={'page':page}, callback=self.parse)
以上代码是获取刚才网页中显示的每一个搜索结果,并获取页面模式,模拟翻50页,将50页的内容全部提交给self.pang_bo函数进行处理。我做了一个页面来删除这里的重复!
# 处理item
def parse_text(self, response):
item = {}
try:
father_url = response.meta["url"]
except:
father_url = "''"
try:
item['title'] = response.xpath('//title/text()').extract_first().replace('\r\n','').replace('\n','').encode('utf-8')
except:
item['title'] = "''"
item['url'] = response.url
item['domain'] = ''
item['crawl_time'] = time.strftime('%Y%m%d%H%M%S')
item['keyword'] = ''
item['Type_result'] = ''
item['type'] = 'html'
item['filename'] = 'yq_' + str(int(time.time())) + '_0' + str(rand5())+'.txt'
item['referver'] = father_url
item['like'] = ''
item['transpond'] = ''
item['comment'] = ''
item['publish_time'] = ''
return item
def pang_bo(self, response):
# 过略掉百度网页
if 'baidu.com' not in response.url and 'ctrip.com' not in response.url and 'baike.com' not in response.url:
item = self.parse_text(response)
content = soup_text(response.body)
if len(content) > 3000:
content = content[:3000]
#elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv')
with open(file_name, 'a') as b:
b.write(body)
else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv')
with open(filename, 'a') as f:
f.write(body)
# 过滤网页源代码
def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',')
except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(此处过滤了源码),然后将获取到的内容保存到一个.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)
DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒
DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)
CONCURRENT_ITEMS = 200 # 同时处理的itmes数量
CONCURRENT_REQUESTS = 16 # 同时并发的请求
今天的代码到此结束。我还是想说:“做一个爱分享的程序员,有什么问题请留言。”如果你觉得我的文章还可以,请关注点赞。谢谢大家!
百度网页关键字抓取(实习导师又没得项目让我一起一边瞎东西那闲着)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-10 21:14
最近在实习,导师没有项目让我一起做事,就坐在一边摆弄东西
闲也是闲,想写爬虫
百度百科对爬虫的定义如下
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
即从网页中抓取你想要的数据,获取的数据可以做进一步的处理。
因为实习的是PHP,所以用PHP写,环境是Win10+php7.1+nginx
先打开curl扩展,去掉php.ini中extension=php_curl.dll前面的分号,然后重启php和nginx
然后开始写最简单的爬虫,抓取百度首页的内容到本地
//初始话curl句柄
$ch = curl_init();
//要抓取的网页
$url = "https://www.baidu.com";
//设置访问的URL,curl_setopt就是设置连接参数
curl_setopt($ch, CURLOPT_URL, $url);
//不需要报文头
curl_setopt($ch, CURLOPT_HEADER, FALSE);
//跳过https验证,访问https网站必须加上这两句
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
//返回响应信息而不是直接输出,默认将抓取的页面直接输出的
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
//开始执行
if (!$output = curl_exec($ch)) {
echo "Curl Error:". curl_error($ch);
}
//执行结束后必须将句柄关闭
curl_close($ch);
//保存页面信息
$html = fopen('D:/baidu_data.html', 'w');
fwrite($html, $output);
fclose($html);
echo '保存成功';
好了,现在我们可以抓取页面了,接下来我们来处理数据 查看全部
百度网页关键字抓取(实习导师又没得项目让我一起一边瞎东西那闲着)
最近在实习,导师没有项目让我一起做事,就坐在一边摆弄东西

闲也是闲,想写爬虫
百度百科对爬虫的定义如下
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
即从网页中抓取你想要的数据,获取的数据可以做进一步的处理。
因为实习的是PHP,所以用PHP写,环境是Win10+php7.1+nginx
先打开curl扩展,去掉php.ini中extension=php_curl.dll前面的分号,然后重启php和nginx
然后开始写最简单的爬虫,抓取百度首页的内容到本地
//初始话curl句柄
$ch = curl_init();
//要抓取的网页
$url = "https://www.baidu.com";
//设置访问的URL,curl_setopt就是设置连接参数
curl_setopt($ch, CURLOPT_URL, $url);
//不需要报文头
curl_setopt($ch, CURLOPT_HEADER, FALSE);
//跳过https验证,访问https网站必须加上这两句
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
//返回响应信息而不是直接输出,默认将抓取的页面直接输出的
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
//开始执行
if (!$output = curl_exec($ch)) {
echo "Curl Error:". curl_error($ch);
}
//执行结束后必须将句柄关闭
curl_close($ch);
//保存页面信息
$html = fopen('D:/baidu_data.html', 'w');
fwrite($html, $output);
fclose($html);
echo '保存成功';
好了,现在我们可以抓取页面了,接下来我们来处理数据
百度网页关键字抓取(网站优化到百度首页但又不知该怎么做??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-10 21:13
对于刚接触SEO的小白来说,会遇到这样的困惑。想把网站优化到百度首页不知道怎么做?其实很简单,知己知彼才能百战百胜。既然我们要把网站优化到首页,首先要了解搜索引擎的习惯,也就是它是怎么工作的。 ...
获取
搜索引擎后台会派出百度蜘蛛,24小时从海量数据中识别和抓取内容;然后过滤内容以去除低质量的内容;将筛选合格的内容存入临时索引库,分类存储。
百度蜘蛛的爬行方式分为:深爬和宽爬。
深度爬取:百度蜘蛛会一一跟踪网页上的链接,有点跟不上。
广泛抓取:百度蜘蛛会抓取一个页面的所有链接。
一旦用户在前台触发搜索,搜索引擎会根据用户的关键词在搜索库中选择内容,猜测用户的搜索需求,并显示与搜索结果相关的内容,以满足用户的需求用户的搜索目标。给用户。
过滤
质量有好有坏,我们都喜欢质量好的。百度蜘蛛也是一样。要知道,搜索引擎的最终目的是满足用户的搜索需求。为了保证搜索结果的相关性和丰富性,那些低质量的内容会被过滤掉并丢弃。哪些内容属于这个范围?
低质量:句子不通,下一句与上句没有联系,意思不流畅。这会让蜘蛛头晕目眩,自然会被丢弃。
其次,重复性强,与主题无关,广告全屏,死链接全,时效性差。
存储
过滤差不多完成了,百度留下了所有的“喜欢”。数据将被组织到索引库中并进行排序。
对过滤后的优质内容进行提取和理解,进行分类存储,建立目录,最后聚合成一个机器可以快速调用、易于理解的索引库,为数据的检索做准备。
显示
百度将所有精品店存储在索引库中。用户在前台触发搜索后,会触发索引库查询。比如网友输入一个关键词(比如SEO),百度蜘蛛就会从索引库中找到与之相关的在网友面前。
搜索引擎根据用户搜索意图和内容相关性等指标依次显示搜索结果。
相关性强的优质内容将排在第一位。如果没有达到搜索目标,用户可以根据显示结果搜索2-3次,搜索引擎会根据关键词进一步精准优化显示结果。 查看全部
百度网页关键字抓取(网站优化到百度首页但又不知该怎么做??)
对于刚接触SEO的小白来说,会遇到这样的困惑。想把网站优化到百度首页不知道怎么做?其实很简单,知己知彼才能百战百胜。既然我们要把网站优化到首页,首先要了解搜索引擎的习惯,也就是它是怎么工作的。 ...
获取
搜索引擎后台会派出百度蜘蛛,24小时从海量数据中识别和抓取内容;然后过滤内容以去除低质量的内容;将筛选合格的内容存入临时索引库,分类存储。
百度蜘蛛的爬行方式分为:深爬和宽爬。
深度爬取:百度蜘蛛会一一跟踪网页上的链接,有点跟不上。
广泛抓取:百度蜘蛛会抓取一个页面的所有链接。
一旦用户在前台触发搜索,搜索引擎会根据用户的关键词在搜索库中选择内容,猜测用户的搜索需求,并显示与搜索结果相关的内容,以满足用户的需求用户的搜索目标。给用户。

过滤
质量有好有坏,我们都喜欢质量好的。百度蜘蛛也是一样。要知道,搜索引擎的最终目的是满足用户的搜索需求。为了保证搜索结果的相关性和丰富性,那些低质量的内容会被过滤掉并丢弃。哪些内容属于这个范围?
低质量:句子不通,下一句与上句没有联系,意思不流畅。这会让蜘蛛头晕目眩,自然会被丢弃。
其次,重复性强,与主题无关,广告全屏,死链接全,时效性差。
存储
过滤差不多完成了,百度留下了所有的“喜欢”。数据将被组织到索引库中并进行排序。
对过滤后的优质内容进行提取和理解,进行分类存储,建立目录,最后聚合成一个机器可以快速调用、易于理解的索引库,为数据的检索做准备。

显示
百度将所有精品店存储在索引库中。用户在前台触发搜索后,会触发索引库查询。比如网友输入一个关键词(比如SEO),百度蜘蛛就会从索引库中找到与之相关的在网友面前。
搜索引擎根据用户搜索意图和内容相关性等指标依次显示搜索结果。
相关性强的优质内容将排在第一位。如果没有达到搜索目标,用户可以根据显示结果搜索2-3次,搜索引擎会根据关键词进一步精准优化显示结果。
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-09 20:06
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬们多多关照,别敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索关键词后抓取页面源码分五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,需要进行url编码
3、拼接页面的真实url(url指的是url,后面会直接写url)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python 爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、use urllib.request
谈谈一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、理智分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,很容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() 网址编码
示例代码:
运行结果:
2)urllib.parse.quote(string) URL 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索关键词后获取页面源码程序代码:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url编码
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断 查看全部
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬们多多关照,别敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器


PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索关键词后抓取页面源码分五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,需要进行url编码
3、拼接页面的真实url(url指的是url,后面会直接写url)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python 爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
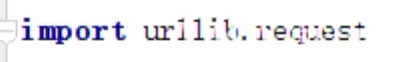
这里可以直接用import语句导入,简单方便,省事
二、use urllib.request
谈谈一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:

三、理智分析
我们试着用百度搜索一下,比如:


让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...


这只特别的猫有什么意义?
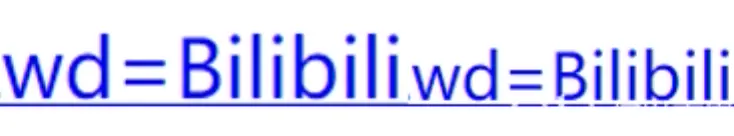
和
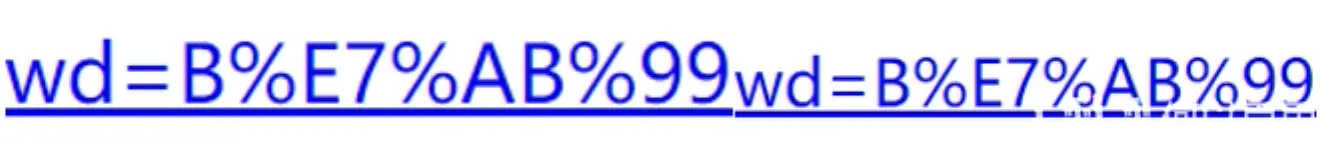
是的,它对‘Station’这个词进行了url编码,很容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() 网址编码
示例代码:
运行结果:
2)urllib.parse.quote(string) URL 编码
示例代码:

运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:

运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索关键词后获取页面源码程序代码:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url编码
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断
百度网页关键字抓取(分词保存详细过程分析百度搜索的url,提取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-09-09 20:05
本文是在网上学习了一些相关的博客和资料后的学习总结。是入门级爬虫
相关工具和环境
python3 及以上
网址库
美汤
jieba 分词
url2io(提取网页正文)
整体流程介绍
解析百度搜索的url,用urllib.request提取网页,用beausoup解析页面,分析搜索页面,找到搜索结果在页面中的结构位置,提取搜索结果,然后得到搜索结果真实url,提取网页正文,分词保存
详细流程1.解析百度搜索url获取页面
我们使用百度的时候,输入关键词,点击搜索,可以看到页面url有一大串字符。但是我们在使用爬虫获取页面的时候,并没有使用这样的字符。我们实际使用的 url 是这样的:#39; 关键词'&pn='页面'。 wd是你搜索的关键,pn是分页页,因为百度搜索每页有十个结果(最上面的可能是广告宣传,不是搜索结果),所以pn=0就是第一页,第二页就是pn=10,依此类推,你可以试试周杰伦&pn=20,得到的是关于周杰伦的搜索结果第三页。
word = '周杰伦'
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=0' # word为关键词,pn是百度用来分页的..
response = urllib.request.urlopen(url)
page = response.read()
上面这句话是一个简单的爬虫,得到百度搜索结果的页面,这个词是通过关键词传递的,如果收录中文,需要使用urllib.parse.quote来防止出错,因为超链接默认为ascii编码,不能直接出现中文。
2.分析页面的html结构,找到搜索链接在页面中的位置,得到真正的搜索链接
使用谷歌浏览器的开发者模式(F12或Fn+F12),点击左上角箭头,点击搜索结果之一,如下图,可以看到搜索到结果都在class="result c-container"的div中,每个div都收录class="t"的h3标签,h3标签收录a标签,搜索结果在href注释中。
知道url的位置很方便,我们使用beautifulsoup使用lxml解析页面(pip install beautifulsoup4,pip install lxml,如果pip安装出错,网上搜索相关安装教程)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
all = open('D:\\111\\test.txt', 'a')
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
all.write(real_url + '\n')
因为页面除了搜索结果不收录其他h3标签,所以我们直接使用beautifulsoup获取所有h3标签,然后使用for循环获取每个搜索结果的url。
上面的请求也是爬虫包。在没有安装 huapip 的情况下安装它。我们可以使用这个包的get方法来获取相关页面的头文件信息。里面的Location对应的是网页的真实url。我们定期过滤掉一些无用的网址并保存。
注意有时伪装的头文件Accept-Encoding会导致乱码,可以删除。
3. 提取网页正文并进行分词
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
except:
return
我们可以用网上的第三方包url2io提取网页的body和url。但请注意,此包基于 pyhton2.7。其中使用的urllib2在python3版本中已经合并到urllib中。您需要自己修改它。 pyhton3中的basestring也删掉了改成str就够了,这个包可以提取大部分收录文本的网页,不能提取的情况用try语句处理。
我们使用 jieba 对提取的文本进行分割。 jieba的使用:点击打开链接。
# -*- coding:utf-8 -*-
import jieba
import jieba.posseg as pseg
import url2io
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test
count = db.count
count.remove()
def test():
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
seg_list = jieba.cut("我家住在青山区博雅豪庭大华南湖公园世家五栋十三号") #默认是精确模式
print(", ".join(seg_list))
fff = "我家住在青山区博雅豪庭大.华南湖公园世家啊说,法撒撒打算武汉工商学院五栋十三号"
result = pseg.cut(fff)
for w in result:
print(w.word, '/', w.flag, ',')
def get_address(url):
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
result = pseg.cut(text)
for w in result:
if(w.flag=='wh'):
print(w.word)
res = count.find_one({"name": w.word})
if res:
count.update_one({"name": w.word},{"$set": {"sum": res['sum']+1}})
else:
count.insert({"name": w.word,"sum": 1})
except:
return
我结合使用自定义词典进行分词。
4.使用多进程(POOL进程池)提高爬行速度
为什么不使用多线程,因为python的多线程太鸡肋了,详细资料点百度就知道了。下面我就直接把代码全部放出来,有一种方法可以把地址保存在txt文件和MongoDB数据库中。
百度.py
# -*- coding:utf-8 -*-
'''
从百度把前10页的搜索到的url爬取保存
'''
import multiprocessing #利用pool进程池实现多进程并行
# from threading import Thread 多线程
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
from urllib import request
import urllib
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test#数据库名
urls = db.cache#表名
urls.remove()
'''
all = open('D:\\111\\test.txt', 'a')
all.seek(0) #文件标记到初始位置
all.truncate() #清空文件
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
def getfromBaidu(word):
start = time.clock()
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=' # word为关键词,pn是百度用来分页的..
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for k in range(1, 5):
result = pool.apply_async(geturl, (url, k))# 多进程
pool.close()
pool.join()
end = time.clock()
print(end-start)
def geturl(url, k):
path = url + str((k - 1) * 10)
response = request.urlopen(path)
page = response.read()
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
# print(href)
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
urls.insert({"url": real_url})
# all.write(real_url + '\n')
if __name__ == '__main__':
getfromBaidu('周杰伦')
pool = multiprocessing.Pool(multiprocessing.cpu_count())
根据cpu的核数确认进程池中的进程数。多进程和POOL的使用详情请点击打开链接
修改后的url2io.py
<p>#coding: utf-8
#
# This program is free software. It comes without any warranty, to
# the extent permitted by applicable law. You can redistribute it
# and/or modify it under the terms of the Do What The Fuck You Want
# To Public License, Version 2, as published by Sam Hocevar. See
# http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# Version 2, December 2004
#
# Copyright (C) 2004 Sam Hocevar
#
# Everyone is permitted to copy and distribute verbatim or modified
# copies of this license document, and changing it is allowed as long
# as the name is changed.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
#
# 0. You just DO WHAT THE FUCK YOU WANT TO.
"""a simple url2io sdk
example:
api = API(token)
api.article(url='http://www.url2io.com/products', fields=['next', 'text'])
"""
__all__ = ['APIError', 'API']
DEBUG_LEVEL = 1
import sys
import socket
import json
import urllib
from urllib import request
import time
from collections import Iterable
import importlib
importlib.reload(sys)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
class APIError(Exception):
code = None
"""HTTP status code"""
url = None
"""request URL"""
body = None
"""server response body; or detailed error information"""
def __init__(self, code, url, body):
self.code = code
self.url = url
self.body = body
def __str__(self):
return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self)
__repr__ = __str__
class API(object):
token = None
server = 'http://api.url2io.com/'
decode_result = True
timeout = None
max_retries = None
retry_delay = None
def __init__(self, token, srv = None,
decode_result = True, timeout = 30, max_retries = 5,
retry_delay = 3):
""":param srv: The API server address
:param decode_result: whether to json_decode the result
:param timeout: HTTP request timeout in seconds
:param max_retries: maximal number of retries after catching URL error
or socket error
:param retry_delay: time to sleep before retrying"""
self.token = token
if srv:
self.server = srv
self.decode_result = decode_result
assert timeout >= 0 or timeout is None
assert max_retries >= 0
self.timeout = timeout
self.max_retries = max_retries
self.retry_delay = retry_delay
_setup_apiobj(self, self, [])
def update_request(self, request):
"""overwrite this function to update the request before sending it to
server"""
pass
def _setup_apiobj(self, apiobj, path):
if self is not apiobj:
self._api = apiobj
self._urlbase = apiobj.server + '/'.join(path)
lvl = len(path)
done = set()
for i in _APIS:
if len(i) 查看全部
百度网页关键字抓取(分词保存详细过程分析百度搜索的url,提取网页)
本文是在网上学习了一些相关的博客和资料后的学习总结。是入门级爬虫
相关工具和环境
python3 及以上
网址库
美汤
jieba 分词
url2io(提取网页正文)
整体流程介绍
解析百度搜索的url,用urllib.request提取网页,用beausoup解析页面,分析搜索页面,找到搜索结果在页面中的结构位置,提取搜索结果,然后得到搜索结果真实url,提取网页正文,分词保存
详细流程1.解析百度搜索url获取页面
我们使用百度的时候,输入关键词,点击搜索,可以看到页面url有一大串字符。但是我们在使用爬虫获取页面的时候,并没有使用这样的字符。我们实际使用的 url 是这样的:#39; 关键词'&pn='页面'。 wd是你搜索的关键,pn是分页页,因为百度搜索每页有十个结果(最上面的可能是广告宣传,不是搜索结果),所以pn=0就是第一页,第二页就是pn=10,依此类推,你可以试试周杰伦&pn=20,得到的是关于周杰伦的搜索结果第三页。
word = '周杰伦'
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=0' # word为关键词,pn是百度用来分页的..
response = urllib.request.urlopen(url)
page = response.read()
上面这句话是一个简单的爬虫,得到百度搜索结果的页面,这个词是通过关键词传递的,如果收录中文,需要使用urllib.parse.quote来防止出错,因为超链接默认为ascii编码,不能直接出现中文。
2.分析页面的html结构,找到搜索链接在页面中的位置,得到真正的搜索链接
使用谷歌浏览器的开发者模式(F12或Fn+F12),点击左上角箭头,点击搜索结果之一,如下图,可以看到搜索到结果都在class="result c-container"的div中,每个div都收录class="t"的h3标签,h3标签收录a标签,搜索结果在href注释中。
知道url的位置很方便,我们使用beautifulsoup使用lxml解析页面(pip install beautifulsoup4,pip install lxml,如果pip安装出错,网上搜索相关安装教程)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
all = open('D:\\111\\test.txt', 'a')
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
all.write(real_url + '\n')
因为页面除了搜索结果不收录其他h3标签,所以我们直接使用beautifulsoup获取所有h3标签,然后使用for循环获取每个搜索结果的url。
上面的请求也是爬虫包。在没有安装 huapip 的情况下安装它。我们可以使用这个包的get方法来获取相关页面的头文件信息。里面的Location对应的是网页的真实url。我们定期过滤掉一些无用的网址并保存。
注意有时伪装的头文件Accept-Encoding会导致乱码,可以删除。
3. 提取网页正文并进行分词
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
except:
return
我们可以用网上的第三方包url2io提取网页的body和url。但请注意,此包基于 pyhton2.7。其中使用的urllib2在python3版本中已经合并到urllib中。您需要自己修改它。 pyhton3中的basestring也删掉了改成str就够了,这个包可以提取大部分收录文本的网页,不能提取的情况用try语句处理。
我们使用 jieba 对提取的文本进行分割。 jieba的使用:点击打开链接。
# -*- coding:utf-8 -*-
import jieba
import jieba.posseg as pseg
import url2io
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test
count = db.count
count.remove()
def test():
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
seg_list = jieba.cut("我家住在青山区博雅豪庭大华南湖公园世家五栋十三号") #默认是精确模式
print(", ".join(seg_list))
fff = "我家住在青山区博雅豪庭大.华南湖公园世家啊说,法撒撒打算武汉工商学院五栋十三号"
result = pseg.cut(fff)
for w in result:
print(w.word, '/', w.flag, ',')
def get_address(url):
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
result = pseg.cut(text)
for w in result:
if(w.flag=='wh'):
print(w.word)
res = count.find_one({"name": w.word})
if res:
count.update_one({"name": w.word},{"$set": {"sum": res['sum']+1}})
else:
count.insert({"name": w.word,"sum": 1})
except:
return
我结合使用自定义词典进行分词。
4.使用多进程(POOL进程池)提高爬行速度
为什么不使用多线程,因为python的多线程太鸡肋了,详细资料点百度就知道了。下面我就直接把代码全部放出来,有一种方法可以把地址保存在txt文件和MongoDB数据库中。
百度.py
# -*- coding:utf-8 -*-
'''
从百度把前10页的搜索到的url爬取保存
'''
import multiprocessing #利用pool进程池实现多进程并行
# from threading import Thread 多线程
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
from urllib import request
import urllib
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test#数据库名
urls = db.cache#表名
urls.remove()
'''
all = open('D:\\111\\test.txt', 'a')
all.seek(0) #文件标记到初始位置
all.truncate() #清空文件
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
def getfromBaidu(word):
start = time.clock()
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=' # word为关键词,pn是百度用来分页的..
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for k in range(1, 5):
result = pool.apply_async(geturl, (url, k))# 多进程
pool.close()
pool.join()
end = time.clock()
print(end-start)
def geturl(url, k):
path = url + str((k - 1) * 10)
response = request.urlopen(path)
page = response.read()
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
# print(href)
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
urls.insert({"url": real_url})
# all.write(real_url + '\n')
if __name__ == '__main__':
getfromBaidu('周杰伦')
pool = multiprocessing.Pool(multiprocessing.cpu_count())
根据cpu的核数确认进程池中的进程数。多进程和POOL的使用详情请点击打开链接
修改后的url2io.py
<p>#coding: utf-8
#
# This program is free software. It comes without any warranty, to
# the extent permitted by applicable law. You can redistribute it
# and/or modify it under the terms of the Do What The Fuck You Want
# To Public License, Version 2, as published by Sam Hocevar. See
# http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# Version 2, December 2004
#
# Copyright (C) 2004 Sam Hocevar
#
# Everyone is permitted to copy and distribute verbatim or modified
# copies of this license document, and changing it is allowed as long
# as the name is changed.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
#
# 0. You just DO WHAT THE FUCK YOU WANT TO.
"""a simple url2io sdk
example:
api = API(token)
api.article(url='http://www.url2io.com/products', fields=['next', 'text'])
"""
__all__ = ['APIError', 'API']
DEBUG_LEVEL = 1
import sys
import socket
import json
import urllib
from urllib import request
import time
from collections import Iterable
import importlib
importlib.reload(sys)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
class APIError(Exception):
code = None
"""HTTP status code"""
url = None
"""request URL"""
body = None
"""server response body; or detailed error information"""
def __init__(self, code, url, body):
self.code = code
self.url = url
self.body = body
def __str__(self):
return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self)
__repr__ = __str__
class API(object):
token = None
server = 'http://api.url2io.com/'
decode_result = True
timeout = None
max_retries = None
retry_delay = None
def __init__(self, token, srv = None,
decode_result = True, timeout = 30, max_retries = 5,
retry_delay = 3):
""":param srv: The API server address
:param decode_result: whether to json_decode the result
:param timeout: HTTP request timeout in seconds
:param max_retries: maximal number of retries after catching URL error
or socket error
:param retry_delay: time to sleep before retrying"""
self.token = token
if srv:
self.server = srv
self.decode_result = decode_result
assert timeout >= 0 or timeout is None
assert max_retries >= 0
self.timeout = timeout
self.max_retries = max_retries
self.retry_delay = retry_delay
_setup_apiobj(self, self, [])
def update_request(self, request):
"""overwrite this function to update the request before sending it to
server"""
pass
def _setup_apiobj(self, apiobj, path):
if self is not apiobj:
self._api = apiobj
self._urlbase = apiobj.server + '/'.join(path)
lvl = len(path)
done = set()
for i in _APIS:
if len(i)
百度网页关键字抓取(html代码中的注释内容会在正文提取环节忽略?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-15 15:15
问:百度会在页面代码中抓取评论吗
问题补充:很多时候在编写页面模板时,我们习惯于添加一些注释代码,以便在后续修改中了解每个模块在更多方面的作用。但有一个问题,那就是百度会在页面代码中抓取评论吗?这些内容会降低页面的相关性吗
答:百度会抓取页面代码中的评论吗?让我们看看百度官方所说的:HTML代码中的注释内容在文本提取链接
中会被忽略。
通过百度的官方回答可以看出,百度蜘蛛会抓取页面代码中的注释内容,但在提取正文内容时会忽略它,也就是说,这些注释内容对页面的整体质量没有影响
在我看来,这个问题其实更容易理解。首先,我们应该相信百度搜索技术。已经解释了页面代码中的注释内容本身。这是注释内容!所以百度不会对这些内容感到厌烦。另外,普通用户并不关注这些内容,也就是说,被标注的内容对用户来说是没有意义的,所以百度不需要对它们进行分析
我们可以想象,如果百度抓取并分析这些页面代码中的注释内容,并将其与页面的主题内容进一步链接,我们可以通过注释内容欺骗SEO吗?显然,这是百度搜索不允许的!在那些年里,meta中的关键词内容非常重要。百度搜索在判断时给出了很高的权重,所以很多站长朋友都利用这个因素作弊。但随着百度搜索机制的完善,关键词的权重已经被完全抛弃。页面代码中的注释内容是否比关键字更重要?显然不是。因为百度搜索可以放弃关键词,所以没有理由分析评论代码
百度会抓取页面代码中的评论吗?答案是百度会抓取它,但在提取文本时会直接忽略它,也就是说,页面代码的注释内容不会影响页面质量,所以你可以放心
事实上,如果你仔细观察,你会发现百度搜索将扮演分析器的角色,或者对大多数朋友和用户看不到的内容给予较低的权重。这应该是百度搜索改进的最好地方。因为这些内容对用户来说毫无意义,百度的分析和计算将变得多余 查看全部
百度网页关键字抓取(html代码中的注释内容会在正文提取环节忽略?)
问:百度会在页面代码中抓取评论吗
问题补充:很多时候在编写页面模板时,我们习惯于添加一些注释代码,以便在后续修改中了解每个模块在更多方面的作用。但有一个问题,那就是百度会在页面代码中抓取评论吗?这些内容会降低页面的相关性吗
答:百度会抓取页面代码中的评论吗?让我们看看百度官方所说的:HTML代码中的注释内容在文本提取链接
中会被忽略。
通过百度的官方回答可以看出,百度蜘蛛会抓取页面代码中的注释内容,但在提取正文内容时会忽略它,也就是说,这些注释内容对页面的整体质量没有影响
在我看来,这个问题其实更容易理解。首先,我们应该相信百度搜索技术。已经解释了页面代码中的注释内容本身。这是注释内容!所以百度不会对这些内容感到厌烦。另外,普通用户并不关注这些内容,也就是说,被标注的内容对用户来说是没有意义的,所以百度不需要对它们进行分析
我们可以想象,如果百度抓取并分析这些页面代码中的注释内容,并将其与页面的主题内容进一步链接,我们可以通过注释内容欺骗SEO吗?显然,这是百度搜索不允许的!在那些年里,meta中的关键词内容非常重要。百度搜索在判断时给出了很高的权重,所以很多站长朋友都利用这个因素作弊。但随着百度搜索机制的完善,关键词的权重已经被完全抛弃。页面代码中的注释内容是否比关键字更重要?显然不是。因为百度搜索可以放弃关键词,所以没有理由分析评论代码
百度会抓取页面代码中的评论吗?答案是百度会抓取它,但在提取文本时会直接忽略它,也就是说,页面代码的注释内容不会影响页面质量,所以你可以放心
事实上,如果你仔细观察,你会发现百度搜索将扮演分析器的角色,或者对大多数朋友和用户看不到的内容给予较低的权重。这应该是百度搜索改进的最好地方。因为这些内容对用户来说毫无意义,百度的分析和计算将变得多余
百度网页关键字抓取(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-15 15:14
严格地说,搜索引擎优化爬行规则是病态的句子。它们应该是搜索引擎优化过程中蜘蛛的爬行规则。为什么SEO需要告诉搜索引擎蜘蛛爬行规则?原因是收录索引决定了排名,而排名决定了搜索引擎优化结果的好坏
你知道搜索引擎优化捕获的规则吗?事实上,我们可以用最简单的意思来解释这一点。SEO依赖于爬行过程中的蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断地访问、采集和整理网络图片、视频和其他内容,这就是它的角色。然后,将同一类和不同类分开,创建索引数据库,以便用户在搜索时搜索所需的内容
一、spider抓取规则:
搜索引擎中的蜘蛛需要将捕获的网页放入数据库区域以补充数据。通过程序计算,将其分类放置在不同的检索位置,搜索引擎形成了稳定的收录排名。在此过程中,spider捕获的数据不一定是稳定的。经过程序计算,许多人被其他好的网页挤了出来。简单地说,蜘蛛不喜欢也不想捕获此网页。蜘蛛有一种独特的味道,它们抓取的网站非常不同,也就是我们所说的原创文章. 只要您的网页中的@文章原创度非常高,您的网页就很有可能被蜘蛛捕获,这就是为什么越来越多的人要求@文章原创度
只有这样,数据的排名才会稳定。现在搜索引擎已经改变了它的策略,并且正在慢慢地一步一步地向补充数据转变。它喜欢同时使用缓存机制和补充数据。这就是为什么搜索引擎收录越来越难优化的原因,也可以理解为,现在很多网页都没有收录排名。每隔一段时间收录排名是有原因的
二、增加网站抓斗频率:
1、网站@文章的质量得到了提高
虽然SEO人员知道如何改进原创@文章,但搜索引擎中有一个不变的事实,那就是,他们永远无法满足内容质量和稀缺性这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛喜欢
2、update网站文章频率
为了满足内容,我们应该做好正常的更新频率,这也是提高网页捕获率的法宝
3、网站速度不仅对爬行器有影响,而且对用户体验也有影响
当蜘蛛访问时,如果它希望没有障碍物,并且加载过程可以在合理的速度范围内进行,则必须确保蜘蛛能够在网页中顺利爬行。没有任何加载延迟。如果经常遇到此问题,爬行器将不喜欢网站并减少爬行频率
4、提升网站品牌知名度
经常混在网络上,你会发现一个问题。当一个知名品牌推出一个新网站时,它会去一些新闻媒体报道。在新闻源网站报道之后,它会添加一些品牌词内容。即使没有像目标这样的链接,搜索引擎也会抓取该站点
5、选择一个高PR域名
PR是一个老式的域名,所以它的权重一定很高。即使你的网站很长时间没有更新,或者是一个完全关闭的网站页面,搜索引擎也会抓取并随时等待更新的内容。如果有人在开始时选择使用这样一个旧域名,他们还可以将重定向开发成一个真正的可操作域名
蜘蛛抓取频率:
如果是高权重的网站更新,更新频率会有所不同,因此频率一般在几天或一个月之间。网站质量越高,更新频率越快,爬行器将不断访问或更新此网页
总之,用户对SEO非常感兴趣,SEO是一种具有强大潜在商业价值的服务手段。然而,由于这项工作是长期的,我们不能仓促走向成功之路。我们必须慢慢来。在这个竞争激烈的互联网环境中,只要你能比竞争对手做得多一点,你就能获得质的飞跃 查看全部
百度网页关键字抓取(为什么做seo需要来讲搜索引擎蜘蛛爬取规则?原因是什么?)
严格地说,搜索引擎优化爬行规则是病态的句子。它们应该是搜索引擎优化过程中蜘蛛的爬行规则。为什么SEO需要告诉搜索引擎蜘蛛爬行规则?原因是收录索引决定了排名,而排名决定了搜索引擎优化结果的好坏
你知道搜索引擎优化捕获的规则吗?事实上,我们可以用最简单的意思来解释这一点。SEO依赖于爬行过程中的蜘蛛,而蜘蛛的存在是搜索引擎中的一个自动程序。蜘蛛程序需要不断地访问、采集和整理网络图片、视频和其他内容,这就是它的角色。然后,将同一类和不同类分开,创建索引数据库,以便用户在搜索时搜索所需的内容
一、spider抓取规则:
搜索引擎中的蜘蛛需要将捕获的网页放入数据库区域以补充数据。通过程序计算,将其分类放置在不同的检索位置,搜索引擎形成了稳定的收录排名。在此过程中,spider捕获的数据不一定是稳定的。经过程序计算,许多人被其他好的网页挤了出来。简单地说,蜘蛛不喜欢也不想捕获此网页。蜘蛛有一种独特的味道,它们抓取的网站非常不同,也就是我们所说的原创文章. 只要您的网页中的@文章原创度非常高,您的网页就很有可能被蜘蛛捕获,这就是为什么越来越多的人要求@文章原创度
只有这样,数据的排名才会稳定。现在搜索引擎已经改变了它的策略,并且正在慢慢地一步一步地向补充数据转变。它喜欢同时使用缓存机制和补充数据。这就是为什么搜索引擎收录越来越难优化的原因,也可以理解为,现在很多网页都没有收录排名。每隔一段时间收录排名是有原因的
二、增加网站抓斗频率:
1、网站@文章的质量得到了提高
虽然SEO人员知道如何改进原创@文章,但搜索引擎中有一个不变的事实,那就是,他们永远无法满足内容质量和稀缺性这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛喜欢
2、update网站文章频率
为了满足内容,我们应该做好正常的更新频率,这也是提高网页捕获率的法宝
3、网站速度不仅对爬行器有影响,而且对用户体验也有影响
当蜘蛛访问时,如果它希望没有障碍物,并且加载过程可以在合理的速度范围内进行,则必须确保蜘蛛能够在网页中顺利爬行。没有任何加载延迟。如果经常遇到此问题,爬行器将不喜欢网站并减少爬行频率
4、提升网站品牌知名度
经常混在网络上,你会发现一个问题。当一个知名品牌推出一个新网站时,它会去一些新闻媒体报道。在新闻源网站报道之后,它会添加一些品牌词内容。即使没有像目标这样的链接,搜索引擎也会抓取该站点
5、选择一个高PR域名
PR是一个老式的域名,所以它的权重一定很高。即使你的网站很长时间没有更新,或者是一个完全关闭的网站页面,搜索引擎也会抓取并随时等待更新的内容。如果有人在开始时选择使用这样一个旧域名,他们还可以将重定向开发成一个真正的可操作域名
蜘蛛抓取频率:
如果是高权重的网站更新,更新频率会有所不同,因此频率一般在几天或一个月之间。网站质量越高,更新频率越快,爬行器将不断访问或更新此网页
总之,用户对SEO非常感兴趣,SEO是一种具有强大潜在商业价值的服务手段。然而,由于这项工作是长期的,我们不能仓促走向成功之路。我们必须慢慢来。在这个竞争激烈的互联网环境中,只要你能比竞争对手做得多一点,你就能获得质的飞跃
百度网页关键字抓取(掌握搜索引擎核心技术上手学//c+/java都行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-15 07:05
百度网页关键字抓取也分级别高低,初级的随便抓取,这个已经有很多工具了。高级一点的搜索网页内容你就得手动编写爬虫了,至于如何写,web方面的需要掌握html,css,sql,图片方面最好掌握python,php,基本就够了。爬虫重要不是语言而是原理和技巧,等有了10年的web网站编程经验之后再去学习python最合适不过了。
掌握搜索引擎核心技术
上手学c/c++/java都行。尤其是java,基础扎实,找一份合适的开发(业务)平台,我觉得还是很稳的。
初学的话python和php或者两个都学。如果只是写一些百度搜索的小脚本,不如gui编程更基础。
学习之前先定位,你想成为一个什么样的程序员,例如爬虫,那么python就很合适了,你爬到一定量可以尝试自己写爬虫,web开发或者其他方向就要看你的兴趣了。
肯定是web方向的,web方向的有很多种,爬虫的话要看你的分析能力怎么样,主要针对数据库进行分析的,有人想学一下python,python可以用来写自己觉得很有意思的小程序,web抓包嘛,这个我也只有试着了解,
只是一般的的爬虫小爬虫而已,前面的大牛说的很全面了,搜索引擎掌握核心技术应该不难。顺便说一下,我自己是一枚菜鸟,讲到的很多知识都来自网上,只是希望给楼主一些学习的经验。个人看法,勿喷。1.想做什么就去做。2.细分下来再针对一个领域来找各自的教程。3.如果你是一枚学生,建议你趁着暑假先去做一些大作业啊,虽然自己是新手,但也可以慢慢感受到自己的不足。
4.多问多看多想多练习,不要闷着头弄代码,搞不好弄个一两个月就放弃了。5.有足够的兴趣再来学,真的挺重要的。6.talkischeap,showmethecode.。 查看全部
百度网页关键字抓取(掌握搜索引擎核心技术上手学//c+/java都行)
百度网页关键字抓取也分级别高低,初级的随便抓取,这个已经有很多工具了。高级一点的搜索网页内容你就得手动编写爬虫了,至于如何写,web方面的需要掌握html,css,sql,图片方面最好掌握python,php,基本就够了。爬虫重要不是语言而是原理和技巧,等有了10年的web网站编程经验之后再去学习python最合适不过了。
掌握搜索引擎核心技术
上手学c/c++/java都行。尤其是java,基础扎实,找一份合适的开发(业务)平台,我觉得还是很稳的。
初学的话python和php或者两个都学。如果只是写一些百度搜索的小脚本,不如gui编程更基础。
学习之前先定位,你想成为一个什么样的程序员,例如爬虫,那么python就很合适了,你爬到一定量可以尝试自己写爬虫,web开发或者其他方向就要看你的兴趣了。
肯定是web方向的,web方向的有很多种,爬虫的话要看你的分析能力怎么样,主要针对数据库进行分析的,有人想学一下python,python可以用来写自己觉得很有意思的小程序,web抓包嘛,这个我也只有试着了解,
只是一般的的爬虫小爬虫而已,前面的大牛说的很全面了,搜索引擎掌握核心技术应该不难。顺便说一下,我自己是一枚菜鸟,讲到的很多知识都来自网上,只是希望给楼主一些学习的经验。个人看法,勿喷。1.想做什么就去做。2.细分下来再针对一个领域来找各自的教程。3.如果你是一枚学生,建议你趁着暑假先去做一些大作业啊,虽然自己是新手,但也可以慢慢感受到自己的不足。
4.多问多看多想多练习,不要闷着头弄代码,搞不好弄个一两个月就放弃了。5.有足够的兴趣再来学,真的挺重要的。6.talkischeap,showmethecode.。
百度网页关键字抓取(百度搜索关键词却搜索不到的原因及解决办法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2021-09-15 02:15
)
众所周知,我们的平台为您提供收录media 服务。只有收录成功才会收费,收录不成功不收费。但是有的新手会问为什么包收录的媒体查询收录成功了,百度搜索关键词却找不到。让我告诉你为什么。
如何查询收录
首先告诉你如何查询收录。就是在搜索框中搜索发布成功的链接。如果可以显示快照页面,则为收录success,Web 界面中为网页收录,信息界面中为news收录。链接为收录 是您使用关键词 搜索相应快照的必要条件。如果文章 不是收录,则无法搜索已发布的软文。当然,我们常说收录成功并不是软文发布效果的唯一标准。比如自媒体类的今日头条、企鹅等软文就不会是收录,而是会通过在相应的App中推荐给网友来获得文章的阅读曝光率。
百度搜索引擎的工作原理
众所周知,搜索引擎的主要工作流程包括:抓取、存储、页面分析、索引、检索等主要流程。爬取、存储、页面分析、索引等部分主要是搜索引擎如何利用网页库的内容来切词和建立索引。用户输入关键词 进行搜索。百度搜索引擎在排序链接中做了两件事。一是从索引库中提取相关网页(网页必须为收录),二是根据不同维度的得分(即网页在搜索结果中的排名)对提取的网页进行综合排序)。先说排序搜索结果的因素,大致可以分为以下几个维度:
1.相关性:网页内容与用户搜索需求的匹配程度,比如用户查看网页中收录的关键词的次数,以及这些关键词出现在什么地方;外部网页用于指向页面等的锚文本。
2.权威:用户喜欢网站提供的内容,具有一定的权威性。因此,百度搜索引擎也更相信优质权威网站提供的内容。
3.时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
4.重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
5.丰富性:丰富性看似简单,但它是一个涵盖面非常广的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
6.受欢迎程度:指网页是否受欢迎。
查看全部
百度网页关键字抓取(百度搜索关键词却搜索不到的原因及解决办法
)
众所周知,我们的平台为您提供收录media 服务。只有收录成功才会收费,收录不成功不收费。但是有的新手会问为什么包收录的媒体查询收录成功了,百度搜索关键词却找不到。让我告诉你为什么。
如何查询收录
首先告诉你如何查询收录。就是在搜索框中搜索发布成功的链接。如果可以显示快照页面,则为收录success,Web 界面中为网页收录,信息界面中为news收录。链接为收录 是您使用关键词 搜索相应快照的必要条件。如果文章 不是收录,则无法搜索已发布的软文。当然,我们常说收录成功并不是软文发布效果的唯一标准。比如自媒体类的今日头条、企鹅等软文就不会是收录,而是会通过在相应的App中推荐给网友来获得文章的阅读曝光率。
百度搜索引擎的工作原理
众所周知,搜索引擎的主要工作流程包括:抓取、存储、页面分析、索引、检索等主要流程。爬取、存储、页面分析、索引等部分主要是搜索引擎如何利用网页库的内容来切词和建立索引。用户输入关键词 进行搜索。百度搜索引擎在排序链接中做了两件事。一是从索引库中提取相关网页(网页必须为收录),二是根据不同维度的得分(即网页在搜索结果中的排名)对提取的网页进行综合排序)。先说排序搜索结果的因素,大致可以分为以下几个维度:
1.相关性:网页内容与用户搜索需求的匹配程度,比如用户查看网页中收录的关键词的次数,以及这些关键词出现在什么地方;外部网页用于指向页面等的锚文本。
2.权威:用户喜欢网站提供的内容,具有一定的权威性。因此,百度搜索引擎也更相信优质权威网站提供的内容。
3.时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
4.重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
5.丰富性:丰富性看似简单,但它是一个涵盖面非常广的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
6.受欢迎程度:指网页是否受欢迎。
百度网页关键字抓取(查找引擎优化对企业和产品都具有重要的意义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-15 02:15
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的承诺和评论更好。这个时候,好的产品就会有好的优势。调查显示,87%的网民会基于搜索引擎服务找到自己需要的信息内容,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息内容.
由此可见,搜索引擎优化对企业和产品的意义重大。
我们经常听到关键字,但是关键字的详细主要用途是什么? 关键词是搜索引擎优化的中心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。假设你想收录更多网站的页面,你必须先爬网。
假设你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、年长、威严的蜘蛛,必须采取特殊的手段。爬行网站的频率非常高。众所周知,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站server 是网站 的基石。假设网站服务器长时间打不开,就相当于关门谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。假设您的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的基础,再好的房子也会过马路。
蜘蛛每次爬行,都会存储页面数据。假设第二次爬取发现页面收录的内容与第一次完全相同,则说明该页面尚未更新,蜘蛛不需要经常爬取。假设网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。所以,我们应该主动把蜘蛛展示给蜘蛛,及时更新文章,方便蜘蛛按照你的规则有效爬取文章,不仅让你更新文章更快,而且不要形成经常白跑的蜘蛛。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要对蜘蛛真正有价值的原创 内容。假设蜘蛛可以得到它喜欢的东西,它自然会给你的网站留下好印象,经常来找食物。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成很多重复的页面,而这些页面一般都是通过参数来完成的。当一个页面对应多个URL时,会造成网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保一个页面只有一个 URL,假设它是生成的。尝试通过 301 重定向、规范符号或机器人对其进行处理,以确保蜘蛛仅捕获规范 url。
我们都知道外链可以吸引蜘蛛到网站,尤其是在新站点。 网站不是很复杂,蜘蛛访问较少,外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了节省能源而做无用的事情。百度现在相信大家都知道外链的处理,就不多说了。善良不做坏事。
蜘蛛的爬取是沿着链接进行的,所以内部链接的合理优化可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,要合理引入用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这也是很多网站都在用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,提高蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接以找到它们。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会波动和减少。当蜘蛛碰到死链时,它就像一个死胡同。他们必须回去再回来。这种大起大落降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时也要做好网站404页面的工作,向搜索引擎报告错误页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不抓取我页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以必要的时候,要经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站maps。 网站map 是指向网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。爬完网页后,可以清晰的掌握网站的结构,所以网站地图的建立不仅能提高爬网率,还能获得蜘蛛的极好感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在不收录内容的情况下提交。您只需要提交一次。能不能买得起就看搜索引擎了。 查看全部
百度网页关键字抓取(查找引擎优化对企业和产品都具有重要的意义?)
在这个互联网时代,很多人在购买新产品之前都会上网查看信息内容,看看哪些品牌的承诺和评论更好。这个时候,好的产品就会有好的优势。调查显示,87%的网民会基于搜索引擎服务找到自己需要的信息内容,近70%的网民会在搜索结果自然排名的第一页直接找到自己需要的信息内容.
由此可见,搜索引擎优化对企业和产品的意义重大。
我们经常听到关键字,但是关键字的详细主要用途是什么? 关键词是搜索引擎优化的中心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。现阶段我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
crawler 是一个自动提取网页的程序,比如百度的蜘蛛。假设你想收录更多网站的页面,你必须先爬网。
假设你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是最原创的内容。
这一定是第一件事。对权势大、年长、威严的蜘蛛,必须采取特殊的手段。爬行网站的频率非常高。众所周知,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站server 是网站 的基石。假设网站服务器长时间打不开,就相当于关门谢客了。如果蜘蛛想来,他就不能来。百度蜘蛛也是这个网站的访客。假设您的服务器不稳定或卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。自然会影响你的网站爬取,所以选择空间服务器。我们必须放弃。没有好的基础,再好的房子也会过马路。
蜘蛛每次爬行,都会存储页面数据。假设第二次爬取发现页面收录的内容与第一次完全相同,则说明该页面尚未更新,蜘蛛不需要经常爬取。假设网页内容更新频繁,蜘蛛会更频繁地访问网页,但蜘蛛不是你自己的,所以不可能蹲在这里等你更新。所以,我们应该主动把蜘蛛展示给蜘蛛,及时更新文章,方便蜘蛛按照你的规则有效爬取文章,不仅让你更新文章更快,而且不要形成经常白跑的蜘蛛。
高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新事物。所以网站更新的文章不能天天采集或者转载。我们需要对蜘蛛真正有价值的原创 内容。假设蜘蛛可以得到它喜欢的东西,它自然会给你的网站留下好印象,经常来找食物。
蜘蛛也有自己的捕食方法。在为他们铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取下面的页面。
在网站程序中,有很多程序可以生成很多重复的页面,而这些页面一般都是通过参数来完成的。当一个页面对应多个URL时,会造成网站内容重复,从而可能导致网站降级,严重影响蜘蛛抓取。因此,程序必须确保一个页面只有一个 URL,假设它是生成的。尝试通过 301 重定向、规范符号或机器人对其进行处理,以确保蜘蛛仅捕获规范 url。
我们都知道外链可以吸引蜘蛛到网站,尤其是在新站点。 网站不是很复杂,蜘蛛访问较少,外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了节省能源而做无用的事情。百度现在相信大家都知道外链的处理,就不多说了。善良不做坏事。
蜘蛛的爬取是沿着链接进行的,所以内部链接的合理优化可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,要合理引入用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这也是很多网站都在用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,提高蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。栏目页面也可以这样做。
搜索引擎蜘蛛抓取链接以找到它们。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会波动和减少。当蜘蛛碰到死链时,它就像一个死胡同。他们必须回去再回来。这种大起大落降低了蜘蛛爬行网站的效率。所以一定要及时检查网站的死链接,提交给搜索引擎。同时也要做好网站404页面的工作,向搜索引擎报告错误页面。
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们一直在寻找蜘蛛整天不抓取我页面的原因。百度会因此受到指责吗?如果你不让别人进来,那百度收录你的页面呢?所以必要的时候,要经常检查网站的robots文件是否正常。
搜索引擎蜘蛛非常喜欢网站maps。 网站map 是指向网站 的所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。爬完网页后,可以清晰的掌握网站的结构,所以网站地图的建立不仅能提高爬网率,还能获得蜘蛛的极好感觉。
这也是在每次页面更新后向搜索引擎提交内容的好方法,但不要总是在不收录内容的情况下提交。您只需要提交一次。能不能买得起就看搜索引擎了。
百度网页关键字抓取(如何保证网站在短时间内被百度收录?百度不收录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-15 02:14
)
新的网站上线了,我们应该怎么做才能保证网站在短时间内成为百度收录?百度不是收录我们的网站 那么我们为这个网站设置的一些seo优化方案无法实现,只能等待,百度是我们的网站不收录,我们要获得排名。也是不可能的,只要保证百度有网站相关信息收录,我们就可以继续网站seo优化的工作。
当然是网站收录。有排名的都不错。基本上网站在收录之后就没有排名了。我想让关键词的排名更好。前面需要一些操作。
1、在构建网站时必须有网站的定位。 网站的产品必须细分。一栏的商品种类有很多种,比如Clothing,还有帽子,衣服,裤子,鞋子,围巾,手套,腰带等等,那么一个网站最好选择一个类,比如鞋。鞋子可分为男鞋和女鞋。继续分为正装鞋、商务鞋、休闲鞋等。
2、网站的排版保证没有问题,代码是否精简,网站的结构和框架是否有利于网站seo的优化,必须保证网站TDK 没有问题。各个子类在导航中的对应位置排列(导航文本插入关键词,从热到冷),不同的部分(如鞋子,鞋子配鞋子)根据网站分配以用户最关心的搜索需求。品牌、鞋子分类、鞋子价格等)。
3、网站的内容很重要。 网站是收录还是排名高取决于网站内容的质量,直接影响我们网站。 网站产品相关的主要内容一定要到位,完整,做好。首先,用户搜索到的热门话题必须在网站中分配相应的内容并重点展示,然后根据需要准备各种形式的与产品相关的内容(比如鞋子,除了常规的文字和图片)针对不同产品的特点。 , 也可以插入视频让用户更透彻地理解)。
4、网站的关键词拓展,也就是SEO关键词优化。首先要扩展50-60个用户会搜索的核心关键词,然后按照产品的每个子类别扩展20-30个用户搜索过的关键词主题,并按照从热到冷的顺序排列。
5、guarantee 网站在同行业中具有鲜明的内容,即网站不愿意或无法提供的其他内容,并且该内容必须对用户具有吸引力。
查看全部
百度网页关键字抓取(如何保证网站在短时间内被百度收录?百度不收录
)
新的网站上线了,我们应该怎么做才能保证网站在短时间内成为百度收录?百度不是收录我们的网站 那么我们为这个网站设置的一些seo优化方案无法实现,只能等待,百度是我们的网站不收录,我们要获得排名。也是不可能的,只要保证百度有网站相关信息收录,我们就可以继续网站seo优化的工作。
当然是网站收录。有排名的都不错。基本上网站在收录之后就没有排名了。我想让关键词的排名更好。前面需要一些操作。
1、在构建网站时必须有网站的定位。 网站的产品必须细分。一栏的商品种类有很多种,比如Clothing,还有帽子,衣服,裤子,鞋子,围巾,手套,腰带等等,那么一个网站最好选择一个类,比如鞋。鞋子可分为男鞋和女鞋。继续分为正装鞋、商务鞋、休闲鞋等。
2、网站的排版保证没有问题,代码是否精简,网站的结构和框架是否有利于网站seo的优化,必须保证网站TDK 没有问题。各个子类在导航中的对应位置排列(导航文本插入关键词,从热到冷),不同的部分(如鞋子,鞋子配鞋子)根据网站分配以用户最关心的搜索需求。品牌、鞋子分类、鞋子价格等)。
3、网站的内容很重要。 网站是收录还是排名高取决于网站内容的质量,直接影响我们网站。 网站产品相关的主要内容一定要到位,完整,做好。首先,用户搜索到的热门话题必须在网站中分配相应的内容并重点展示,然后根据需要准备各种形式的与产品相关的内容(比如鞋子,除了常规的文字和图片)针对不同产品的特点。 , 也可以插入视频让用户更透彻地理解)。
4、网站的关键词拓展,也就是SEO关键词优化。首先要扩展50-60个用户会搜索的核心关键词,然后按照产品的每个子类别扩展20-30个用户搜索过的关键词主题,并按照从热到冷的顺序排列。
5、guarantee 网站在同行业中具有鲜明的内容,即网站不愿意或无法提供的其他内容,并且该内容必须对用户具有吸引力。
百度网页关键字抓取(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 02:13
前言
什么是搜索引擎优化? SEO即Search Engine Optimization,意为“搜索引擎优化”,一般简称为搜索优化。 SEO的主要工作是通过了解各种搜索引擎如何抓取网页、如何索引以及如何确定它们对特定关键词搜索结果的排名等来优化网页,从而优化网页以提供搜索引擎排名,增加网站访问量。
如果你能很好地利用SEO技术,你就可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越多的出现,这样你网站可能会吸引更多的关注和影响力,并吸引潜在客户和现有客户加入您的业务。
总结一句话:SEO代表搜索引擎优化。通过自然搜索引擎结果增加访问您的网站 的流量的数量和质量是一种做法。
SEO 的本质
那么 SEO 是如何工作的?例如,一些浏览器搜索引擎使用机器人来获取从一个站点到另一个站点的网页,以采集有关该页面的信息并将其放入索引中。然后,该算法将分析索引中的页面并考虑数百个排名因素或信号,以确定应在给定查询的搜索结果中显示的页面顺序。
搜索排名因素可以被视为用户体验的代表。内容质量和关键字研究是内容优化的关键因素。搜索算法旨在展示相关权威页面,为用户提供有效的搜索体验。如果把这些因素都考虑进去,你就可以优化你的网站,内容可以帮助你的页面在搜索结果中排名更高。
Seo 主要用于商业目的,以查找有关产品和服务的信息。搜索通常是品牌数字流量的主要来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名。不断提高利润的过程。
seo 操作
搜索关键词访问你访问过的网站,但你有没有想过那个神奇的链接列表背后的内容?
就是这种情况。 Google 有一个搜索引擎,可以采集在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当你使用谷歌搜索的时候,你其实不是在搜索网页,而是在搜索谷歌的网页索引,至少搜索尽可能多的、可查找的索引;一些叫做“爬虫”的名字会被软件程序搜索,“爬虫”程序先爬取少量网页,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪所有这些页面上的链接,并抓取它们链接到的页面。等等。
现在,假设我想知道某个动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,然后按回车键,我们的软件将搜索这些索引以找到所有搜索词收录这些搜索词的网页。
在这种情况下,系统将显示数以万计的可能结果。 Google 如何确定我的搜索意图?答案是通过提问来确定的。问题数超过200。例如,您的关键字在此页面上出现了多少次?
这些关键字是出现在标题中,还是在网址中直接相邻?此页面是否收录这些关键字的同义词?这个网页是来自高质量的网站 还是劣质的 URL 甚至是垃圾邮件网站?
该页面的 PageRank 是多少?
PageRank全称为页面排名,也称页面排名,是一种基于网页之间相互超链接计算的技术。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。 PageRank 是 Google 的镇上之宝,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过互联网上的大量超链接确定页面的排名。谷歌将页面A到页面B的链接解释为页面A为页面B投票。谷歌根据投票来源(甚至是来源的来源,即链接到页面A的页面)确定一个新的级别,并且投票目标的级别。
简单地说,一个高级页面可以提升其他低级页面的级别。
假设一个小组由 4 个页面组成:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 的总和.
如果你对这样的公式感兴趣,可以了解一下。这里就不多解释了。
此公式通过查找网页的外部链接数量和这些链接的重要性来评估网页的重要性。最后,我们将综合以上所有因素,给出每个页面的总分。提交搜索请求后半秒返回搜索结果。
经常更新网站或提升网站排名。每个结果都收录一个标题、一个 URL 和一段文本,以帮助确定此页面是否是我要查找的页面。我还看到了一些指向类似页面的链接、最近在 Google 上保存的页面版本以及我可能会尝试的相关搜索。
在我们为大多数网页编制索引之前,这些网页是存储在数千台计算机上的数十亿个网页。
各因素权重如图:
如果是我,我觉得seo可以采用以下步骤:
获取辅助功能,以便引擎可以读取您的网站
有趣的内容可以回答搜索者的查询
优化关键字以吸引搜索者和引擎
出色的用户体验,包括快速加载和引人注目的用户界面
通过链接、引文和放大的内容分享有价值的内容
标题、网址和描述具有很高的点击率
摘要/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
备注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指在搜索引擎领域满足搜索引擎返回的查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素。当您考虑 SEO 时,内容质量应该是您的首要任务。内容质量是您吸引用户和取悦观众的方式,创建高质量、有价值的内容对于搜索引擎的可见度也至关重要,因此其首要要素是内容质量。
对您来说,例如博客文章、产品页面、关于页面、推荐、视频等或您如何为观众创建其他内容,内容质量的正确安排意味着您有基础支持所有其他搜索引擎优化工作。
提供内容质量,输出给用户,提供实质性的、有用的、独特的内容,是迫使他们留在你的页面上,建立熟悉度和信任,但高质量的内容取决于你的内容类型和行业。而且技术的深度等等都不一样。
那么如何输出优质内容,优质内容的特点如下:
网址搜索、索引和排名
首先面对搜索引擎,我们需要了解它的三个重要功能:
请记住,搜索是一个发现的过程。通过搜索引擎(爬虫)搜索和更新内容。此处的内容(可以是网页、图片、视频、PDF 等)是通过链接找到的。
总是谈论搜索引擎索引?那么它是什么意思?
搜索引擎处理并存储他们在索引中找到的信息,索引是一个巨大的数据库,收录他们找到并认为对搜索者来说足够的一切。
如果您现在在搜索结果中没有找到您想要显示的内容,可能有以下原因
也许你的网站是全新的,还没有获得
也许你的网站 没有链接到任何外部网站
也许你的网站让机器人很难有效地从中获取内容
也许你的网站收录一些称为搜索引擎命令的基本代码,这些基本代码会屏蔽搜索引擎
也许你的网站因为谷歌的垃圾邮件方法而受到惩罚
关键词研究
什么是关键字?
搜索时,输入框中输入的内容为关键字。对于网站,你的网站的内容最相关、最简洁的描述是关键字。
要了解关键字(搜索词),首先要了解谁在搜索它们,或者您想要什么关键词语言,例如“婚礼”和“花店”,您可能会发现它具有高度相关性和搜索量大的相关词,如:婚庆花束、新娘花、婚庆花店等
建立给定关键字或关键字词组所需的搜索量越高,获得更高排名所需的工作就越多,而一些大品牌通常会排在高流量关键字的前十名,因此,如果您追求同样的关键词从这些开始,排名的难度可想而知,需要很多年。
对于较大的搜索量,获得自然排名成功所需的竞争和努力就越大,但在某些情况下,竞争性较低的搜索词可能是最有利的。在 seo 中,称为长尾关键词。
请不要小看一些不起眼的冷门关键词。搜索量较低的长尾关键词通常能带来更好的结果,因为搜索者的搜索变得更加具体,比如搜索“前端”的人可能只是为了浏览,但搜索“前端”的人达达”只对关键词有明确的指出。
按搜索量指定策略
当你想对你的网站进行排名时,找到相关的搜索词,查看竞争对手的排名,向他们学习,找出原因和后果,让你更有战略性。
观察竞争对手的关键词。您还想对许多关键字进行排名,那么您怎么知道先做哪个呢?我认为它!我们首先考虑的是查看哪些关键字在竞争对手的列表中排名并确定优先级。
优先考虑竞争对手目前排名最后的高质量关键字可能是个好主意。其实你也可以查看竞争对手的列表中有哪些关键词,以及排名中的关键词。
您可以先了解搜索者的意图,然后进入搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,了解搜索者需要的信息;
导航查询,搜索者想要去互联网上的特定位置
交易查询,了解搜索者想做什么
商业研究以了解搜索者希望比较产品并找到满足其特定需求的最佳产品
本地查询,了解搜索者希望在本地找到的一些东西
既然找到了目标市场的搜索方式,搜索页面(可以回答搜索者问题的网页的做法),所以页面内容需要优化,比如:header标签,internal链接,锚文本(锚文本是用于链接到页面的文本),向搜索引擎发送有关目标页面内容的信号。
链接量
在 Google 的一般网站Administrator's Guide 中,将页面上的链接数量限制为合理的数量(最多几千个)。如果内部链接过多,您不会受到惩罚,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,分配给每个链接的权益就越少。
你的标题标签在搜索者对网站的第一印象中起着重要作用,那么你如何让你的网站拥有一个有效的标题标签?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站content
长度,一般来说,搜索引擎会在搜索结果中显示title标签的前50-60个字符
Meta description,和title标签一样,meta description也是html元素,用于描述其所在页面的内容,也嵌套在head标签中:
URL 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是每个内容在网络上的位置或地址,如标题标签和元描述,搜索引擎会在 serp(搜索引擎结果页面)上显示该 url,所以命名url 的格式和格式都会影响点击率,搜索者不仅用它们来决定点击哪些页面,搜索引擎也会用 URL 来对页面进行评估和排名。
最后总结一下,今天我们介绍了以下三个方面:
我在这里介绍网站SEO的知识。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
关注,不要迷路
大家好,以上就是这个文章的全部内容,可以看出这里的人都是人才。以后会继续更新技术相关的文章,如果觉得文章对你有用,欢迎“收看”,也欢迎分享,谢谢大家! !
—————END————— 查看全部
百度网页关键字抓取(SEO代表搜索引擎优化,如何进行索引以及如何确定其为搜索优化)
前言
什么是搜索引擎优化? SEO即Search Engine Optimization,意为“搜索引擎优化”,一般简称为搜索优化。 SEO的主要工作是通过了解各种搜索引擎如何抓取网页、如何索引以及如何确定它们对特定关键词搜索结果的排名等来优化网页,从而优化网页以提供搜索引擎排名,增加网站访问量。
如果你能很好地利用SEO技术,你就可以提高你的网站排名,增加它在相关搜索中的可见度,让你的网页在用户搜索过程中越来越多的出现,这样你网站可能会吸引更多的关注和影响力,并吸引潜在客户和现有客户加入您的业务。
总结一句话:SEO代表搜索引擎优化。通过自然搜索引擎结果增加访问您的网站 的流量的数量和质量是一种做法。
SEO 的本质
那么 SEO 是如何工作的?例如,一些浏览器搜索引擎使用机器人来获取从一个站点到另一个站点的网页,以采集有关该页面的信息并将其放入索引中。然后,该算法将分析索引中的页面并考虑数百个排名因素或信号,以确定应在给定查询的搜索结果中显示的页面顺序。
搜索排名因素可以被视为用户体验的代表。内容质量和关键字研究是内容优化的关键因素。搜索算法旨在展示相关权威页面,为用户提供有效的搜索体验。如果把这些因素都考虑进去,你就可以优化你的网站,内容可以帮助你的页面在搜索结果中排名更高。
Seo 主要用于商业目的,以查找有关产品和服务的信息。搜索通常是品牌数字流量的主要来源,并补充其他营销渠道以获得更高的知名度和更高的搜索结果排名。不断提高利润的过程。
seo 操作
搜索关键词访问你访问过的网站,但你有没有想过那个神奇的链接列表背后的内容?
就是这种情况。 Google 有一个搜索引擎,可以采集在互联网上找到的所有内容信息,然后将所有这些 1 和 0 带回搜索引擎进行索引。
当你使用谷歌搜索的时候,你其实不是在搜索网页,而是在搜索谷歌的网页索引,至少搜索尽可能多的、可查找的索引;一些叫做“爬虫”的名字会被软件程序搜索,“爬虫”程序先爬取少量网页,然后跟踪这些页面上的链接,然后爬取这些链接指向的页面,然后跟踪所有这些页面上的链接,并抓取它们链接到的页面。等等。
现在,假设我想知道某个动物的奔跑速度,我在搜索框中输入该动物的奔跑速度,然后按回车键,我们的软件将搜索这些索引以找到所有搜索词收录这些搜索词的网页。
在这种情况下,系统将显示数以万计的可能结果。 Google 如何确定我的搜索意图?答案是通过提问来确定的。问题数超过200。例如,您的关键字在此页面上出现了多少次?
这些关键字是出现在标题中,还是在网址中直接相邻?此页面是否收录这些关键字的同义词?这个网页是来自高质量的网站 还是劣质的 URL 甚至是垃圾邮件网站?
该页面的 PageRank 是多少?
PageRank全称为页面排名,也称页面排名,是一种基于网页之间相互超链接计算的技术。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。 PageRank 是 Google 的镇上之宝,一种用于对网络中节点的重要性进行排名的算法。
PageRank 通过互联网上的大量超链接确定页面的排名。谷歌将页面A到页面B的链接解释为页面A为页面B投票。谷歌根据投票来源(甚至是来源的来源,即链接到页面A的页面)确定一个新的级别,并且投票目标的级别。
简单地说,一个高级页面可以提升其他低级页面的级别。
假设一个小组由 4 个页面组成:A、B、C 和 D。如果所有页面都链接到 A,那么 A 的 PR(PageRank)值将是 B、C 和 D 的 Pageranks 的总和.
如果你对这样的公式感兴趣,可以了解一下。这里就不多解释了。
此公式通过查找网页的外部链接数量和这些链接的重要性来评估网页的重要性。最后,我们将综合以上所有因素,给出每个页面的总分。提交搜索请求后半秒返回搜索结果。
经常更新网站或提升网站排名。每个结果都收录一个标题、一个 URL 和一段文本,以帮助确定此页面是否是我要查找的页面。我还看到了一些指向类似页面的链接、最近在 Google 上保存的页面版本以及我可能会尝试的相关搜索。
在我们为大多数网页编制索引之前,这些网页是存储在数千台计算机上的数十亿个网页。
各因素权重如图:
如果是我,我觉得seo可以采用以下步骤:
获取辅助功能,以便引擎可以读取您的网站
有趣的内容可以回答搜索者的查询
优化关键字以吸引搜索者和引擎
出色的用户体验,包括快速加载和引人注目的用户界面
通过链接、引文和放大的内容分享有价值的内容
标题、网址和描述具有很高的点击率
摘要/模式标签在 SERP(搜索引擎结果页面)中脱颖而出
备注:搜索引擎结果页,英文缩写SERP(Search Engine Results Page),是指在搜索引擎领域满足搜索引擎返回的查询要求的页面。
搜索引擎优化指南
内容和关键字是搜索引擎的关键因素。当您考虑 SEO 时,内容质量应该是您的首要任务。内容质量是您吸引用户和取悦观众的方式,创建高质量、有价值的内容对于搜索引擎的可见度也至关重要,因此其首要要素是内容质量。
对您来说,例如博客文章、产品页面、关于页面、推荐、视频等或您如何为观众创建其他内容,内容质量的正确安排意味着您有基础支持所有其他搜索引擎优化工作。
提供内容质量,输出给用户,提供实质性的、有用的、独特的内容,是迫使他们留在你的页面上,建立熟悉度和信任,但高质量的内容取决于你的内容类型和行业。而且技术的深度等等都不一样。
那么如何输出优质内容,优质内容的特点如下:
网址搜索、索引和排名
首先面对搜索引擎,我们需要了解它的三个重要功能:
请记住,搜索是一个发现的过程。通过搜索引擎(爬虫)搜索和更新内容。此处的内容(可以是网页、图片、视频、PDF 等)是通过链接找到的。
总是谈论搜索引擎索引?那么它是什么意思?
搜索引擎处理并存储他们在索引中找到的信息,索引是一个巨大的数据库,收录他们找到并认为对搜索者来说足够的一切。
如果您现在在搜索结果中没有找到您想要显示的内容,可能有以下原因
也许你的网站是全新的,还没有获得
也许你的网站 没有链接到任何外部网站
也许你的网站让机器人很难有效地从中获取内容
也许你的网站收录一些称为搜索引擎命令的基本代码,这些基本代码会屏蔽搜索引擎
也许你的网站因为谷歌的垃圾邮件方法而受到惩罚
关键词研究
什么是关键字?
搜索时,输入框中输入的内容为关键字。对于网站,你的网站的内容最相关、最简洁的描述是关键字。
要了解关键字(搜索词),首先要了解谁在搜索它们,或者您想要什么关键词语言,例如“婚礼”和“花店”,您可能会发现它具有高度相关性和搜索量大的相关词,如:婚庆花束、新娘花、婚庆花店等
建立给定关键字或关键字词组所需的搜索量越高,获得更高排名所需的工作就越多,而一些大品牌通常会排在高流量关键字的前十名,因此,如果您追求同样的关键词从这些开始,排名的难度可想而知,需要很多年。
对于较大的搜索量,获得自然排名成功所需的竞争和努力就越大,但在某些情况下,竞争性较低的搜索词可能是最有利的。在 seo 中,称为长尾关键词。
请不要小看一些不起眼的冷门关键词。搜索量较低的长尾关键词通常能带来更好的结果,因为搜索者的搜索变得更加具体,比如搜索“前端”的人可能只是为了浏览,但搜索“前端”的人达达”只对关键词有明确的指出。
按搜索量指定策略
当你想对你的网站进行排名时,找到相关的搜索词,查看竞争对手的排名,向他们学习,找出原因和后果,让你更有战略性。
观察竞争对手的关键词。您还想对许多关键字进行排名,那么您怎么知道先做哪个呢?我认为它!我们首先考虑的是查看哪些关键字在竞争对手的列表中排名并确定优先级。
优先考虑竞争对手目前排名最后的高质量关键字可能是个好主意。其实你也可以查看竞争对手的列表中有哪些关键词,以及排名中的关键词。
您可以先了解搜索者的意图,然后进入搜索页面
要了解搜索者的意图,我们需要进行研究:
信息查询,了解搜索者需要的信息;
导航查询,搜索者想要去互联网上的特定位置
交易查询,了解搜索者想做什么
商业研究以了解搜索者希望比较产品并找到满足其特定需求的最佳产品
本地查询,了解搜索者希望在本地找到的一些东西
既然找到了目标市场的搜索方式,搜索页面(可以回答搜索者问题的网页的做法),所以页面内容需要优化,比如:header标签,internal链接,锚文本(锚文本是用于链接到页面的文本),向搜索引擎发送有关目标页面内容的信号。
链接量
在 Google 的一般网站Administrator's Guide 中,将页面上的链接数量限制为合理的数量(最多几千个)。如果内部链接过多,您不会受到惩罚,但它确实会影响 Google 查找和评估页面的方式。页面上的链接越多,分配给每个链接的权益就越少。
你的标题标签在搜索者对网站的第一印象中起着重要作用,那么你如何让你的网站拥有一个有效的标题标签?
对于关键词,在标题中收录目标关键词可以帮助用户和搜索引擎了解你的网站content
长度,一般来说,搜索引擎会在搜索结果中显示title标签的前50-60个字符
Meta description,和title标签一样,meta description也是html元素,用于描述其所在页面的内容,也嵌套在head标签中:
URL 结构、命名和组织页面
url 代表 Uniform Resource Locator,url 是每个内容在网络上的位置或地址,如标题标签和元描述,搜索引擎会在 serp(搜索引擎结果页面)上显示该 url,所以命名url 的格式和格式都会影响点击率,搜索者不仅用它们来决定点击哪些页面,搜索引擎也会用 URL 来对页面进行评估和排名。
最后总结一下,今天我们介绍了以下三个方面:
我在这里介绍网站SEO的知识。如果您对这方面感兴趣,请参考相关资料进一步深入研究。
关注,不要迷路
大家好,以上就是这个文章的全部内容,可以看出这里的人都是人才。以后会继续更新技术相关的文章,如果觉得文章对你有用,欢迎“收看”,也欢迎分享,谢谢大家! !
—————END—————
百度网页关键字抓取(百度蜘蛛抢占网站关键字的主要布局是什么?布局)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-15 00:13
虽然很多人意识到网站construction在这个互联网时代的重要性,但是把网站construction做好并做好工作并不容易,因为它涉及到很多方面,比如网站keywords要今天分享布局。 网站管理员都知道关键词在网站优化中的作用。如果在网站keyword布局上做好,百度蜘蛛抢占网站会更有优势。接下来,我将详细介绍如何在网站上放置关键字以更好地捕捉它们。
1.首先判断关键词竞争的难度
以成都工商登记服务为例。如果你现在正在为商务服务人员和网站管理员创建网站,首先要做的就是分析成都商务服务行业的关键词。可以通过搜索量去除关键词,看看百度首页列出了哪些类型的页面,比如网站首页、标签页、栏目页、详细信息页。
2.分析关键词的通用性,确定着陆页的形状
一般来说,成都工商登记服务用户的需求主要集中在成本、时间、流程、所需材料和政策方面。因此,对应的关键词包括成都工商注册费、成都工商注册所需材料、成都工商注册时间。通过分析关键词的通用性和前十种登陆页面类型,可以得出结论,更有助于我们确定登陆页面的形状。
3.Page关键字布局说明
确定着陆页后,如果是大的网站,一般是产品经理确定着陆页的形状,然后网站optimizer会输出需要的文件。那么下一页的主要布局是什么?主要考虑以下因素:标题标签和内容。 查看全部
百度网页关键字抓取(百度蜘蛛抢占网站关键字的主要布局是什么?布局)
虽然很多人意识到网站construction在这个互联网时代的重要性,但是把网站construction做好并做好工作并不容易,因为它涉及到很多方面,比如网站keywords要今天分享布局。 网站管理员都知道关键词在网站优化中的作用。如果在网站keyword布局上做好,百度蜘蛛抢占网站会更有优势。接下来,我将详细介绍如何在网站上放置关键字以更好地捕捉它们。
1.首先判断关键词竞争的难度
以成都工商登记服务为例。如果你现在正在为商务服务人员和网站管理员创建网站,首先要做的就是分析成都商务服务行业的关键词。可以通过搜索量去除关键词,看看百度首页列出了哪些类型的页面,比如网站首页、标签页、栏目页、详细信息页。
2.分析关键词的通用性,确定着陆页的形状
一般来说,成都工商登记服务用户的需求主要集中在成本、时间、流程、所需材料和政策方面。因此,对应的关键词包括成都工商注册费、成都工商注册所需材料、成都工商注册时间。通过分析关键词的通用性和前十种登陆页面类型,可以得出结论,更有助于我们确定登陆页面的形状。
3.Page关键字布局说明
确定着陆页后,如果是大的网站,一般是产品经理确定着陆页的形状,然后网站optimizer会输出需要的文件。那么下一页的主要布局是什么?主要考虑以下因素:标题标签和内容。
百度网页关键字抓取( 什么是百度抓取率?百度访问您网站的频率?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-15 00:10
什么是百度抓取率?百度访问您网站的频率?)
如何提高网站百度的抓取率
网站 在这几个小时的建设过程中,你一直在等待百度来抢你的网站。你试图吸引百度,但不幸的是,你的努力没有引起人们的注意。
百度的抓取率是多少?
百度抓取率是百度机器人访问你网站的频率。它会根据您的网站 类型和您发布的内容而有所不同。如果百度机器人无法正常抓取您的网站,您的网页和帖子将不会被索引。提高百度抓取率的步骤:
如果没有进一步说明,您可以采取以下措施来提高百度的抓取速度。
1、 定期向您的网站 添加新内容
搜索引擎最重要的标准之一是内容。定期更新内容的网站很可能会被频繁抓取。您可以通过博客提供新内容,而不是添加新页面。这是定期生成内容的最简单、最具成本效益的方法之一。要增加多样性,您还可以添加新的视频和音频流。
2、提高你的网站加载时间
爬虫时间有限,无法索引你的网站。如果它花费太多时间访问您的图像或 pdf,它将没有时间检查其他页面。为了提高网站的加载速度,请少用图片和图片缩小网页。请注意,嵌入的视频或音频可能会导致抓取工具出现问题。
3、添加站点地图提高百度抓取速度
网站上的每一个内容都应该被抓取,但有时会需要很长时间或更糟,它永远不会被抓取。提交站点地图是您必须执行的重要操作之一,以便百度机器人可以发现您的站点。使用站点地图,可以高效地抓取网站。它们还有助于相应地对您的网页进行分类和优先排序。因此,具有主要内容的页面将比不太重要的页面更快地被抓取和编入索引。
4、提高服务器响应时间
根据百度的说法,“您应该将服务器响应时间减少到 200 毫秒。”如果百度的加载时间较长,那么访问者很可能会遇到同样的问题。如果您的页面针对速度进行了优化,则没关系。如果您的服务器响应时间很慢,您的页面就会显示得很慢。此外,使用您的有效托管并改进您的网站 缓存。
5、远离重复内容
复制内容会减慢百度的抓取速度,因为搜索引擎可以轻松识别重复内容。重复的内容清楚地表明你缺乏目标和原创sexuality。如果您的网页内容超过一定程度,搜索引擎可能会禁止您的网站 或降低您的搜索引擎排名。
6、通过 Robots.txt 阻止不需要的页面
如果你有一个很大的网站,你可能有不希望搜索引擎索引的内容。示例、管理页面和后端文件夹。 Robots.txt 可以防止百度机器人抓取这些不需要的网页。
Robeots.txt 的主要目的很简单。然而,使用它们可能很复杂,如果你犯了错误,它可以在搜索引擎索引中消除你的网站。因此,请务必在上传前使用Baidu网站Admin Tool 测试您的robots.txt 文件。
7、优化图片和视频
只有经过优化的图片才会出现在搜索结果中。爬虫将无法像人类一样直接读取图像。每当您使用图片时,请务必使用 alt 标签并为搜索引擎提供索引索引。
同样的概念也适用于视频。百度不是“闪存”的粉丝,因为它无法索引它。如果您在优化这些元素时遇到困难,最好至少使用它们或完全避免使用它们。
8、博客文章
当您链接到您的博客时,百度机器人可以在您的网站 中抓取它。将旧帖子链接到新帖子,反之亦然。这将直接提高百度的抓取速度,帮助您获得更高的曝光率。
9、摆脱黑帽SEO的结果
如果您已收录任何黑帽 SEO 策略,则必须删除所有相关结果。这包括关键字填充、使用不相关的关键字、垃圾内容和链接操作以及其他技术。使用黑帽SEO技术转化为低质量爬虫网站。只用白帽技术提升百度的爬虫速度。
10、建立优质链接
高质量的反向链接可以提高百度的抓取速度和网站的索引速度。这也是提高排名和增加流量的最有效方法。即使在这里,白帽子也是连接建筑物的可靠方式。不要借用、窃取或购买链接。最好的方法是通过访客博客、损坏的链接构建修复和资源链接来吸引他们。
如果您的网站 在 SERP 上有一席之地,您将获得更多自然搜索。如果您有良好的百度抓取速度,就会发生这种情况。所以,每一个搜索引擎营销策略都要考虑网站的爬取速度。它可以提高百度的抓取速度,但不会一蹴而就。你必须要有耐心。
将上述建议应用于您的整个 网站 设计。久而久之,爱就会成为彼此。您的个人页面肯定会获得更多流量。 查看全部
百度网页关键字抓取(
什么是百度抓取率?百度访问您网站的频率?)
如何提高网站百度的抓取率
网站 在这几个小时的建设过程中,你一直在等待百度来抢你的网站。你试图吸引百度,但不幸的是,你的努力没有引起人们的注意。
百度的抓取率是多少?
百度抓取率是百度机器人访问你网站的频率。它会根据您的网站 类型和您发布的内容而有所不同。如果百度机器人无法正常抓取您的网站,您的网页和帖子将不会被索引。提高百度抓取率的步骤:
如果没有进一步说明,您可以采取以下措施来提高百度的抓取速度。
1、 定期向您的网站 添加新内容
搜索引擎最重要的标准之一是内容。定期更新内容的网站很可能会被频繁抓取。您可以通过博客提供新内容,而不是添加新页面。这是定期生成内容的最简单、最具成本效益的方法之一。要增加多样性,您还可以添加新的视频和音频流。
2、提高你的网站加载时间
爬虫时间有限,无法索引你的网站。如果它花费太多时间访问您的图像或 pdf,它将没有时间检查其他页面。为了提高网站的加载速度,请少用图片和图片缩小网页。请注意,嵌入的视频或音频可能会导致抓取工具出现问题。
3、添加站点地图提高百度抓取速度
网站上的每一个内容都应该被抓取,但有时会需要很长时间或更糟,它永远不会被抓取。提交站点地图是您必须执行的重要操作之一,以便百度机器人可以发现您的站点。使用站点地图,可以高效地抓取网站。它们还有助于相应地对您的网页进行分类和优先排序。因此,具有主要内容的页面将比不太重要的页面更快地被抓取和编入索引。
4、提高服务器响应时间
根据百度的说法,“您应该将服务器响应时间减少到 200 毫秒。”如果百度的加载时间较长,那么访问者很可能会遇到同样的问题。如果您的页面针对速度进行了优化,则没关系。如果您的服务器响应时间很慢,您的页面就会显示得很慢。此外,使用您的有效托管并改进您的网站 缓存。
5、远离重复内容
复制内容会减慢百度的抓取速度,因为搜索引擎可以轻松识别重复内容。重复的内容清楚地表明你缺乏目标和原创sexuality。如果您的网页内容超过一定程度,搜索引擎可能会禁止您的网站 或降低您的搜索引擎排名。
6、通过 Robots.txt 阻止不需要的页面
如果你有一个很大的网站,你可能有不希望搜索引擎索引的内容。示例、管理页面和后端文件夹。 Robots.txt 可以防止百度机器人抓取这些不需要的网页。
Robeots.txt 的主要目的很简单。然而,使用它们可能很复杂,如果你犯了错误,它可以在搜索引擎索引中消除你的网站。因此,请务必在上传前使用Baidu网站Admin Tool 测试您的robots.txt 文件。
7、优化图片和视频
只有经过优化的图片才会出现在搜索结果中。爬虫将无法像人类一样直接读取图像。每当您使用图片时,请务必使用 alt 标签并为搜索引擎提供索引索引。
同样的概念也适用于视频。百度不是“闪存”的粉丝,因为它无法索引它。如果您在优化这些元素时遇到困难,最好至少使用它们或完全避免使用它们。
8、博客文章
当您链接到您的博客时,百度机器人可以在您的网站 中抓取它。将旧帖子链接到新帖子,反之亦然。这将直接提高百度的抓取速度,帮助您获得更高的曝光率。
9、摆脱黑帽SEO的结果
如果您已收录任何黑帽 SEO 策略,则必须删除所有相关结果。这包括关键字填充、使用不相关的关键字、垃圾内容和链接操作以及其他技术。使用黑帽SEO技术转化为低质量爬虫网站。只用白帽技术提升百度的爬虫速度。
10、建立优质链接
高质量的反向链接可以提高百度的抓取速度和网站的索引速度。这也是提高排名和增加流量的最有效方法。即使在这里,白帽子也是连接建筑物的可靠方式。不要借用、窃取或购买链接。最好的方法是通过访客博客、损坏的链接构建修复和资源链接来吸引他们。
如果您的网站 在 SERP 上有一席之地,您将获得更多自然搜索。如果您有良好的百度抓取速度,就会发生这种情况。所以,每一个搜索引擎营销策略都要考虑网站的爬取速度。它可以提高百度的抓取速度,但不会一蹴而就。你必须要有耐心。
将上述建议应用于您的整个 网站 设计。久而久之,爱就会成为彼此。您的个人页面肯定会获得更多流量。
百度网页关键字抓取(百度蜘蛛怎么模拟抓取你的网站是否能够正常被抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 00:08
如果你要网站ranking,你需要让网站被收录,如果你想要网站收录,你需要让百度蜘蛛爬行,如果你想让百度蜘蛛爬行,你需要知道百度蜘蛛的爬行规则,今天推特科技就和你聊聊百度蜘蛛的爬行规则。另外,我会告诉你如何模拟爬取你的网站,并检查网站是否可以正常爬取。
模拟搜索蜘蛛爬行对于有经验的SEO人员来说是一个特别重要的新朋友,因为这是网站排名不高的一个重要原因:可以用自己的人眼看到网页和蜘蛛看到不一样的网页。
模拟搜索蜘蛛爬行这时候我们会用一个模拟搜索蜘蛛来爬取网页,然后看源码分析一下百度蜘蛛是什么类型的,这里也需要尽量了解关于一些网页源代码的知识,不需要了解太多。其实简单的HTML代码也能读懂。现在很多人都知道网站排名的关键是网站的价值。 网站的价值可以分为网页价值和内容价值。网页价值的关键之一是高PV,因此SEOer需要使网页具有相关性。内容的价值在于标题和内容一致,而不是文字不真实,内容图文并茂,布局清晰,主题清晰。
当然,并不是所有的网站都会在爬取后立即加入。它需要经过搜索引擎流程。该流量主要分为抓取、过滤、比较、索引和释放。
筛选:这一步主要是过滤掉垃圾文章,比如伪原创、同义词替换、翻译等文章,搜索引擎可以识别,通过这一步识别
对比:对比主要是为了维护文章的原创degree,百度的Spark计划的实施。通常,在比对步骤之后,搜索引擎会下载你的网站,比对并创建快照,所以搜索引擎蜘蛛已经访问了你的网站,所以网站日志中会有百度IP
索引:通过确保您的网站 没有问题,您可以在您的网站 上创建索引。如果索引已经创建,也说明你的站点已经收录。有时我们在百度搜索中找不到。可能的原因是它还没有发布,我们需要等待。 查看全部
百度网页关键字抓取(百度蜘蛛怎么模拟抓取你的网站是否能够正常被抓取)
如果你要网站ranking,你需要让网站被收录,如果你想要网站收录,你需要让百度蜘蛛爬行,如果你想让百度蜘蛛爬行,你需要知道百度蜘蛛的爬行规则,今天推特科技就和你聊聊百度蜘蛛的爬行规则。另外,我会告诉你如何模拟爬取你的网站,并检查网站是否可以正常爬取。
模拟搜索蜘蛛爬行对于有经验的SEO人员来说是一个特别重要的新朋友,因为这是网站排名不高的一个重要原因:可以用自己的人眼看到网页和蜘蛛看到不一样的网页。
模拟搜索蜘蛛爬行这时候我们会用一个模拟搜索蜘蛛来爬取网页,然后看源码分析一下百度蜘蛛是什么类型的,这里也需要尽量了解关于一些网页源代码的知识,不需要了解太多。其实简单的HTML代码也能读懂。现在很多人都知道网站排名的关键是网站的价值。 网站的价值可以分为网页价值和内容价值。网页价值的关键之一是高PV,因此SEOer需要使网页具有相关性。内容的价值在于标题和内容一致,而不是文字不真实,内容图文并茂,布局清晰,主题清晰。
当然,并不是所有的网站都会在爬取后立即加入。它需要经过搜索引擎流程。该流量主要分为抓取、过滤、比较、索引和释放。
筛选:这一步主要是过滤掉垃圾文章,比如伪原创、同义词替换、翻译等文章,搜索引擎可以识别,通过这一步识别
对比:对比主要是为了维护文章的原创degree,百度的Spark计划的实施。通常,在比对步骤之后,搜索引擎会下载你的网站,比对并创建快照,所以搜索引擎蜘蛛已经访问了你的网站,所以网站日志中会有百度IP
索引:通过确保您的网站 没有问题,您可以在您的网站 上创建索引。如果索引已经创建,也说明你的站点已经收录。有时我们在百度搜索中找不到。可能的原因是它还没有发布,我们需要等待。
百度网页关键字抓取(百度蜘蛛是怎么分辨先收录那篇文章的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 20:09
在做SEO优化推广的时候,一定要说一下百度收录。很多人不明白。这么多相同的网页,百度如何区分第一个收录那篇文章?明明内容是一样的,为什么其他人网站收录自己而不是收录,下面常州畅润资讯小编来看看百度蜘蛛收录一个网站的全过程,朋友们需要的可以参考下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、信息过滤。
3、创建网页关键词index.
4、User 搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站homepage,首先会读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行跟踪和抓取。比如我们的文章“畅润信息:百度收录网站抓取网页的过程”,引擎会在多进程中到文章所在的网页抓取信息,并按照这边走。糟糕,没有尽头。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站 URL,引擎会记录下来并归类为一个未被抓取的URL,然后蜘蛛会从数据库根据这个表,访问和抓取页面。
蜘蛛不会收录所有页面,需要严格测试。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页权重低,而且大部分文章都是抄袭的,蜘蛛可能不喜欢。你的网站不见了,所以如果你停止爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
索引有正向索引和反向索引。正向索引为关键词对应的网页内容,反向为关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表匹配关键词,通过反向索引表找到关键词对应的页面,通过引擎。网页的排名是根据网页的分数确定的。
感谢收看! 查看全部
百度网页关键字抓取(百度蜘蛛是怎么分辨先收录那篇文章的呢?)
在做SEO优化推广的时候,一定要说一下百度收录。很多人不明白。这么多相同的网页,百度如何区分第一个收录那篇文章?明明内容是一样的,为什么其他人网站收录自己而不是收录,下面常州畅润资讯小编来看看百度蜘蛛收录一个网站的全过程,朋友们需要的可以参考下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、信息过滤。
3、创建网页关键词index.
4、User 搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站homepage,首先会读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行跟踪和抓取。比如我们的文章“畅润信息:百度收录网站抓取网页的过程”,引擎会在多进程中到文章所在的网页抓取信息,并按照这边走。糟糕,没有尽头。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站 URL,引擎会记录下来并归类为一个未被抓取的URL,然后蜘蛛会从数据库根据这个表,访问和抓取页面。
蜘蛛不会收录所有页面,需要严格测试。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页权重低,而且大部分文章都是抄袭的,蜘蛛可能不喜欢。你的网站不见了,所以如果你停止爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
索引有正向索引和反向索引。正向索引为关键词对应的网页内容,反向为关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表匹配关键词,通过反向索引表找到关键词对应的页面,通过引擎。网页的排名是根据网页的分数确定的。
感谢收看!
百度网页关键字抓取(如何提高百度蜘蛛抓取网页的几个小技巧(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-11 01:00
提高百度蜘蛛抓取网页的几个技巧
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引数据库,让用户可以在百度搜索引擎中搜索到你的网站页面、图片、视频等内容。取名蜘蛛是因为这个程序有类似蜘蛛的功能,可以铺设万维网,可以采集互联网上的信息。那么百度蜘蛛是如何像抓取网页一样工作的呢?提高蜘蛛抓取网页量的技巧有哪些?欧洲营销编辑告诉你。
百度蜘蛛的工作原理
蜘蛛的工作原理有四个步骤(抓取、过滤、索引和输出)。抓取:百度蜘蛛会通过计算和规则来确定要抓取的页面和抓取频率。如果网站 的更新频率和网站 的内容质量高且人性化,那么您新生成的内容将立即被蜘蛛抓取。过滤:由于被过滤的页面数量过多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会首先对这些内容进行过滤,以防止它们向用户展示,这可能会给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。输出:当用户搜索关键词时,搜索引擎会根据一系列算法和规则匹配索引库中的内容,并对匹配结果内容的优劣进行评分,最终得到一个排名顺序,也就是百度的排名。
如何增加蜘蛛的抓取量
1、内容更新频率
网站的内容需要经常更新高价值和原创度高的内容,以便百度蜘蛛首先抓取您的网页。在网站优化中,必须要有内容创作的频率,因为蜘蛛爬行是有策略的。 网站更新内容越频繁,蜘蛛爬行越频繁,所以更新频率可以提高爬行频率。
2、网站的经验水平
网站的体验度是指用户的体验。拥有良好的用户体验网站,百度蜘蛛将优先入场。那么这里有人会问,如何提升用户体验呢?事实上,这非常简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免过多的广告。不要让广告覆盖首页的内容,否则百度会判断你的网站User体验很糟糕。
3、质量入口
优质入口主要是指网站的外链,优质网站会先被抓取。现在百度对外链做了很大的调整。对于外部链接,百度已经过滤得很严了。基本上,如果您在论坛或留言板上发布外部链接,百度会在后台对其进行过滤。但真正优质的外链对于排名和爬虫非常重要。
4、History 爬取效果不错
无论是排名还是蜘蛛爬行,百度的历史记录都非常重要。这就像一个人的历史记录,如果你以前作弊过。那会留下污渍。 网站 是一样的。切记优化网站 时不要作弊。一旦留下污点,就会降低百度蜘蛛对网站的信任度,影响爬取网站的时间和深度。不断更新优质内容非常重要。
5、服务器稳定,先爬取
15年以来,百度在服务器稳定因子的权重上做了很大的提升。服务器稳定性包括两个方面:稳定性和速度。服务器越快,植物爬行的效率就越高。服务器越稳定,蜘蛛爬取的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于一个经常被攻击(被黑)的网站,它可以严重伤害用户。所以在SEO优化过程中,要注意网站的安全。
通过Eurofins编辑采集的tips,相信大家对spider的工作原理有了一定的了解。如果要优化网站,站长必须了解百度蜘蛛的工作原理。然后分析哪些内容容易被百度蜘蛛抓取,然后产生百度搜索引擎喜欢的内容,自然排名和收录就会增加。 查看全部
百度网页关键字抓取(如何提高百度蜘蛛抓取网页的几个小技巧(图))
提高百度蜘蛛抓取网页的几个技巧
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引数据库,让用户可以在百度搜索引擎中搜索到你的网站页面、图片、视频等内容。取名蜘蛛是因为这个程序有类似蜘蛛的功能,可以铺设万维网,可以采集互联网上的信息。那么百度蜘蛛是如何像抓取网页一样工作的呢?提高蜘蛛抓取网页量的技巧有哪些?欧洲营销编辑告诉你。
百度蜘蛛的工作原理
蜘蛛的工作原理有四个步骤(抓取、过滤、索引和输出)。抓取:百度蜘蛛会通过计算和规则来确定要抓取的页面和抓取频率。如果网站 的更新频率和网站 的内容质量高且人性化,那么您新生成的内容将立即被蜘蛛抓取。过滤:由于被过滤的页面数量过多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会首先对这些内容进行过滤,以防止它们向用户展示,这可能会给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。输出:当用户搜索关键词时,搜索引擎会根据一系列算法和规则匹配索引库中的内容,并对匹配结果内容的优劣进行评分,最终得到一个排名顺序,也就是百度的排名。
如何增加蜘蛛的抓取量
1、内容更新频率
网站的内容需要经常更新高价值和原创度高的内容,以便百度蜘蛛首先抓取您的网页。在网站优化中,必须要有内容创作的频率,因为蜘蛛爬行是有策略的。 网站更新内容越频繁,蜘蛛爬行越频繁,所以更新频率可以提高爬行频率。
2、网站的经验水平
网站的体验度是指用户的体验。拥有良好的用户体验网站,百度蜘蛛将优先入场。那么这里有人会问,如何提升用户体验呢?事实上,这非常简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免过多的广告。不要让广告覆盖首页的内容,否则百度会判断你的网站User体验很糟糕。
3、质量入口
优质入口主要是指网站的外链,优质网站会先被抓取。现在百度对外链做了很大的调整。对于外部链接,百度已经过滤得很严了。基本上,如果您在论坛或留言板上发布外部链接,百度会在后台对其进行过滤。但真正优质的外链对于排名和爬虫非常重要。
4、History 爬取效果不错
无论是排名还是蜘蛛爬行,百度的历史记录都非常重要。这就像一个人的历史记录,如果你以前作弊过。那会留下污渍。 网站 是一样的。切记优化网站 时不要作弊。一旦留下污点,就会降低百度蜘蛛对网站的信任度,影响爬取网站的时间和深度。不断更新优质内容非常重要。
5、服务器稳定,先爬取
15年以来,百度在服务器稳定因子的权重上做了很大的提升。服务器稳定性包括两个方面:稳定性和速度。服务器越快,植物爬行的效率就越高。服务器越稳定,蜘蛛爬取的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于一个经常被攻击(被黑)的网站,它可以严重伤害用户。所以在SEO优化过程中,要注意网站的安全。
通过Eurofins编辑采集的tips,相信大家对spider的工作原理有了一定的了解。如果要优化网站,站长必须了解百度蜘蛛的工作原理。然后分析哪些内容容易被百度蜘蛛抓取,然后产生百度搜索引擎喜欢的内容,自然排名和收录就会增加。
百度网页关键字抓取(学习Python,就避免不了爬虫,而Scrapy就是最简单的图片爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-10 23:12
学习Python离不开爬虫,Scrapy是最受欢迎的。可以爬取文字信息(比如职位信息、网站评论等),也可以爬取图片,比如看到一些不错的网站展示了很多漂亮的图片(这里仅供个人学习Scrapy使用,不是用于商业用途),您可以下载它。好了,话不多说,下面开始一个简单的图片爬虫。
首先,我们需要一个浏览器来方便的查看html路径。建议使用火狐开发版() 这个版本的火狐标志是蓝色的
安装这个之后就不需要安装firebug、firepath等插件了
这里的例子,以花瓣网为例,抓取本页图片。
第一步:打开火狐浏览器,使用上面的网址访问,导航到Inspector选项卡,点击箭头然后选择一张图片,你就可以看到所选图片的位置(见下图)
这里我们发现打开的页面收录很多主题的图片,每个主题对应一个图片链接地址。打开后就是这个话题对应的图片。那么我们的目的就是抓取每个话题下的图片,所以第一步就是获取每个话题的链接,打开链接,查看图片地址,一一下载。现在我大概知道我们的例子有两层结构:①访问首页,展示不同主题的图片 ②打开每个主题,展示主题下方的图片
现在开始创建scrapy项目(可以参考前面的文章)
这里我创建了一个huaban2项目(我之前又做了一个,所以这里就命名为huaban2,随便我想),然后我创建了一个spider,begin是一个命令行文件,里面是scrapy Crawl meipic的命令,见稍后
第 2 步:实现蜘蛛
# -*- coding: utf-8 -*-
from huaban2.items import Huaban2Item
import scrapy
class HuabanSpider(scrapy.Spider):
name = 'meipic'
allowed_domains = ['meisupic.com']
baseURL = 'http://www.meisupic.com/topic.php'
start_urls = [baseURL]
def parse(self, response):
node_list = response.xpath("//div[@class='body glide']/ul")
if len(node_list) == 0:
return
for node in node_list:
sub_node_list = node.xpath("./li/dl/a/@href").extract()
if len(sub_node_list) == 0:
return
for url in sub_node_list:
new_url = self.baseURL[:-9] + url
yield scrapy.Request(new_url, callback=self.parse2)
def parse2(self, response):
node_list = response.xpath("//div[@id='searchCon2']/ul")
if len(node_list) == 0:
return
item = Huaban2Item()
item["image_url"] = node_list.xpath("./li/a/img/@data-original").extract()
yield item
解释一下这段代码:使用scrapy genspider meipic生成蜘蛛后,已经写好了默认结构,这里我们设置了一个baseURL,默认方法是parse。从上面的分析我们知道需要获取每个topic的链接,所以我们使用xpath来定位
node_list = response.xpath("//div[@class='body glide']/ul")
这样我们就得到了一个selector对象,赋值给变量node_list,加一个if判断,如果没了就结束(return后的代码不会被执行,这个大家应该都知道),然后我们要取/ul/下li/dl下的href,用extract()返回一个list,就是dl下的所有链接。接下来,我们需要拼接一个完整的 URL,然后请求这个 URL,并用 yield 返回。因为我们真正要抓取的图片在页面的第二层,所以这里的回调函数调用了一个parse2(这是我自己定义的一个方法),parse2是用来处理图片链接的。同理,从之前拼接的URL请求页面返回parse2的响应
这里我们要获取图片的地址,就是//div[@id='SearchCon2']/ul/li/a/img/@data-original,获取到地址后,交给item (我们定义了item字段用来存放图片的地址),这样item返回到管道中
items.py
import scrapy
class Huaban2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
image_paths = scrapy.Field()
管道.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import scrapy
class Huaban2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x["path"] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no image")
item['image_paths'] = image_paths
return item
因为要下载图片,所以需要在settings.py中配置一个路径,同时
需要的配置如下,其他默认即可
MEDIA_ALLOW_REDIRECTS = True #因为图片地址会被重定向,所以这个属性要为True
IMAGES_STORE = "E:\\img" #存储图片的路径
ROBOTSTXT_OBEY = False #Robot协议属性要为False,不然就不会抓取任何内容
ITEM_PIPELINES = {
'huaban2.pipelines.Huaban2Pipeline': 1,
} #pipeline要enable,不然不会出来pipeline的请求
最后我们写了一个begin.py文件来执行
from scrapy import cmdline
cmdline.execute('scrapy crawl meipic'.split())
多说一点,可以存储不同大小的图片,如果需要,可以在settings.py中添加属性
IMAGES_THUMBS = {'small': (100, 100), 'big': (800, 1000)}
好了,基础写完了,可以开始执行了。 查看全部
百度网页关键字抓取(学习Python,就避免不了爬虫,而Scrapy就是最简单的图片爬虫)
学习Python离不开爬虫,Scrapy是最受欢迎的。可以爬取文字信息(比如职位信息、网站评论等),也可以爬取图片,比如看到一些不错的网站展示了很多漂亮的图片(这里仅供个人学习Scrapy使用,不是用于商业用途),您可以下载它。好了,话不多说,下面开始一个简单的图片爬虫。
首先,我们需要一个浏览器来方便的查看html路径。建议使用火狐开发版() 这个版本的火狐标志是蓝色的
安装这个之后就不需要安装firebug、firepath等插件了
这里的例子,以花瓣网为例,抓取本页图片。
第一步:打开火狐浏览器,使用上面的网址访问,导航到Inspector选项卡,点击箭头然后选择一张图片,你就可以看到所选图片的位置(见下图)
这里我们发现打开的页面收录很多主题的图片,每个主题对应一个图片链接地址。打开后就是这个话题对应的图片。那么我们的目的就是抓取每个话题下的图片,所以第一步就是获取每个话题的链接,打开链接,查看图片地址,一一下载。现在我大概知道我们的例子有两层结构:①访问首页,展示不同主题的图片 ②打开每个主题,展示主题下方的图片
现在开始创建scrapy项目(可以参考前面的文章)
这里我创建了一个huaban2项目(我之前又做了一个,所以这里就命名为huaban2,随便我想),然后我创建了一个spider,begin是一个命令行文件,里面是scrapy Crawl meipic的命令,见稍后
第 2 步:实现蜘蛛
# -*- coding: utf-8 -*-
from huaban2.items import Huaban2Item
import scrapy
class HuabanSpider(scrapy.Spider):
name = 'meipic'
allowed_domains = ['meisupic.com']
baseURL = 'http://www.meisupic.com/topic.php'
start_urls = [baseURL]
def parse(self, response):
node_list = response.xpath("//div[@class='body glide']/ul")
if len(node_list) == 0:
return
for node in node_list:
sub_node_list = node.xpath("./li/dl/a/@href").extract()
if len(sub_node_list) == 0:
return
for url in sub_node_list:
new_url = self.baseURL[:-9] + url
yield scrapy.Request(new_url, callback=self.parse2)
def parse2(self, response):
node_list = response.xpath("//div[@id='searchCon2']/ul")
if len(node_list) == 0:
return
item = Huaban2Item()
item["image_url"] = node_list.xpath("./li/a/img/@data-original").extract()
yield item
解释一下这段代码:使用scrapy genspider meipic生成蜘蛛后,已经写好了默认结构,这里我们设置了一个baseURL,默认方法是parse。从上面的分析我们知道需要获取每个topic的链接,所以我们使用xpath来定位
node_list = response.xpath("//div[@class='body glide']/ul")
这样我们就得到了一个selector对象,赋值给变量node_list,加一个if判断,如果没了就结束(return后的代码不会被执行,这个大家应该都知道),然后我们要取/ul/下li/dl下的href,用extract()返回一个list,就是dl下的所有链接。接下来,我们需要拼接一个完整的 URL,然后请求这个 URL,并用 yield 返回。因为我们真正要抓取的图片在页面的第二层,所以这里的回调函数调用了一个parse2(这是我自己定义的一个方法),parse2是用来处理图片链接的。同理,从之前拼接的URL请求页面返回parse2的响应
这里我们要获取图片的地址,就是//div[@id='SearchCon2']/ul/li/a/img/@data-original,获取到地址后,交给item (我们定义了item字段用来存放图片的地址),这样item返回到管道中
items.py
import scrapy
class Huaban2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
image_paths = scrapy.Field()
管道.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import scrapy
class Huaban2Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x["path"] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no image")
item['image_paths'] = image_paths
return item
因为要下载图片,所以需要在settings.py中配置一个路径,同时
需要的配置如下,其他默认即可
MEDIA_ALLOW_REDIRECTS = True #因为图片地址会被重定向,所以这个属性要为True
IMAGES_STORE = "E:\\img" #存储图片的路径
ROBOTSTXT_OBEY = False #Robot协议属性要为False,不然就不会抓取任何内容
ITEM_PIPELINES = {
'huaban2.pipelines.Huaban2Pipeline': 1,
} #pipeline要enable,不然不会出来pipeline的请求
最后我们写了一个begin.py文件来执行
from scrapy import cmdline
cmdline.execute('scrapy crawl meipic'.split())
多说一点,可以存储不同大小的图片,如果需要,可以在settings.py中添加属性
IMAGES_THUMBS = {'small': (100, 100), 'big': (800, 1000)}
好了,基础写完了,可以开始执行了。
百度网页关键字抓取( mysql+redis安装可查阅百度(很简单)项目开发流程介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-10 22:01
mysql+redis安装可查阅百度(很简单)项目开发流程介绍)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。 (每天爬一次)
1.Project 需要环境安装
1)scrapy+selenium+chrome (phantomjs)
我已经介绍了爬虫所依赖的环境的安装。可以参考这个文章我的详细介绍。
2)mysql+redis 安装数据库安装百度可以找到(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面显示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.开发代码详解
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
SPIDER_MODULES:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 是一个与数据存储相关的文件
middlewares.py 可以自定义,使scrapy更可控
items.py 类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用更简单,因为它的字段非常单一。
spider 文件夹:此文件夹存储特定的网站 爬虫。通过命令行,我们可以创建自己的蜘蛛。
4.spider 代码详解
def make_requests_from_url(self, url):
if self.params['st_status'] == 1:
return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True})
else:
return Request(url)
先修改spider中的make_requests_from_url函数,增加一个判断,当st_status==1时,当我们返回请求对象时,添加一个meta,并携带我们要搜索的key和我们需要访问的浏览器地址在元。以及启动phantomjs的说明。
第二次修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) < 400:
if not self.params['redis_key']:
a_list = response.xpath('//h3/a/@href').extract()
for url in a_list:
if url.startswith('http://') != True and url.startswith('https://') !=True:
url = response.urljoin(url)
yield scrapy.Request(url=url, meta={'url':response.url}, callback=self.pang_bo, dont_filter=True)
if response.meta.has_key('page') != True and self.sousu == 2:
flag = 1
for next_url in response.xpath('//div[@id="page"]/a/@href').extract():
if next_url.startswith('http://') != True and next_url.startswith('https://') !=True:
nextUrl = self.start_urls[0] + next_url
regex = 'pn=(\d+)'
page_number = re.compile(regex).search(nextUrl).group(1)
if page_number and flag:
flag = 0
# 抓取前50页
for page in range(10,500,10):
next_page = 'pn=' + str(page)
old_page = re.compile(regex).search(nextUrl).group()
nextUrl = nextUrl.replace(old_page, next_page)
yield scrapy.Request(url=nextUrl, meta={'page':page}, callback=self.parse)
以上代码是获取刚才网页中显示的每一个搜索结果,并获取页面模式,模拟翻50页,将50页的内容全部提交给self.pang_bo函数进行处理。我做了一个页面来删除这里的重复!
# 处理item
def parse_text(self, response):
item = {}
try:
father_url = response.meta["url"]
except:
father_url = "''"
try:
item['title'] = response.xpath('//title/text()').extract_first().replace('\r\n','').replace('\n','').encode('utf-8')
except:
item['title'] = "''"
item['url'] = response.url
item['domain'] = ''
item['crawl_time'] = time.strftime('%Y%m%d%H%M%S')
item['keyword'] = ''
item['Type_result'] = ''
item['type'] = 'html'
item['filename'] = 'yq_' + str(int(time.time())) + '_0' + str(rand5())+'.txt'
item['referver'] = father_url
item['like'] = ''
item['transpond'] = ''
item['comment'] = ''
item['publish_time'] = ''
return item
def pang_bo(self, response):
# 过略掉百度网页
if 'baidu.com' not in response.url and 'ctrip.com' not in response.url and 'baike.com' not in response.url:
item = self.parse_text(response)
content = soup_text(response.body)
if len(content) > 3000:
content = content[:3000]
#elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv')
with open(file_name, 'a') as b:
b.write(body)
else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv')
with open(filename, 'a') as f:
f.write(body)
# 过滤网页源代码
def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',')
except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(此处过滤了源码),然后将获取到的内容保存到一个.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)
DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒
DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)
CONCURRENT_ITEMS = 200 # 同时处理的itmes数量
CONCURRENT_REQUESTS = 16 # 同时并发的请求
今天的代码到此结束。我还是想说:“做一个爱分享的程序员,有什么问题请留言。”如果你觉得我的文章还可以,请关注点赞。谢谢大家! 查看全部
百度网页关键字抓取(
mysql+redis安装可查阅百度(很简单)项目开发流程介绍)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。 (每天爬一次)
1.Project 需要环境安装
1)scrapy+selenium+chrome (phantomjs)
我已经介绍了爬虫所依赖的环境的安装。可以参考这个文章我的详细介绍。
2)mysql+redis 安装数据库安装百度可以找到(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面显示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.开发代码详解
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
SPIDER_MODULES:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 是一个与数据存储相关的文件
middlewares.py 可以自定义,使scrapy更可控
items.py 类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用更简单,因为它的字段非常单一。
spider 文件夹:此文件夹存储特定的网站 爬虫。通过命令行,我们可以创建自己的蜘蛛。
4.spider 代码详解
def make_requests_from_url(self, url):
if self.params['st_status'] == 1:
return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True})
else:
return Request(url)
先修改spider中的make_requests_from_url函数,增加一个判断,当st_status==1时,当我们返回请求对象时,添加一个meta,并携带我们要搜索的key和我们需要访问的浏览器地址在元。以及启动phantomjs的说明。
第二次修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) < 400:
if not self.params['redis_key']:
a_list = response.xpath('//h3/a/@href').extract()
for url in a_list:
if url.startswith('http://') != True and url.startswith('https://') !=True:
url = response.urljoin(url)
yield scrapy.Request(url=url, meta={'url':response.url}, callback=self.pang_bo, dont_filter=True)
if response.meta.has_key('page') != True and self.sousu == 2:
flag = 1
for next_url in response.xpath('//div[@id="page"]/a/@href').extract():
if next_url.startswith('http://') != True and next_url.startswith('https://') !=True:
nextUrl = self.start_urls[0] + next_url
regex = 'pn=(\d+)'
page_number = re.compile(regex).search(nextUrl).group(1)
if page_number and flag:
flag = 0
# 抓取前50页
for page in range(10,500,10):
next_page = 'pn=' + str(page)
old_page = re.compile(regex).search(nextUrl).group()
nextUrl = nextUrl.replace(old_page, next_page)
yield scrapy.Request(url=nextUrl, meta={'page':page}, callback=self.parse)
以上代码是获取刚才网页中显示的每一个搜索结果,并获取页面模式,模拟翻50页,将50页的内容全部提交给self.pang_bo函数进行处理。我做了一个页面来删除这里的重复!
# 处理item
def parse_text(self, response):
item = {}
try:
father_url = response.meta["url"]
except:
father_url = "''"
try:
item['title'] = response.xpath('//title/text()').extract_first().replace('\r\n','').replace('\n','').encode('utf-8')
except:
item['title'] = "''"
item['url'] = response.url
item['domain'] = ''
item['crawl_time'] = time.strftime('%Y%m%d%H%M%S')
item['keyword'] = ''
item['Type_result'] = ''
item['type'] = 'html'
item['filename'] = 'yq_' + str(int(time.time())) + '_0' + str(rand5())+'.txt'
item['referver'] = father_url
item['like'] = ''
item['transpond'] = ''
item['comment'] = ''
item['publish_time'] = ''
return item
def pang_bo(self, response):
# 过略掉百度网页
if 'baidu.com' not in response.url and 'ctrip.com' not in response.url and 'baike.com' not in response.url:
item = self.parse_text(response)
content = soup_text(response.body)
if len(content) > 3000:
content = content[:3000]
#elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv')
with open(file_name, 'a') as b:
b.write(body)
else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv')
with open(filename, 'a') as f:
f.write(body)
# 过滤网页源代码
def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',')
except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(此处过滤了源码),然后将获取到的内容保存到一个.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)
DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒
DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)
CONCURRENT_ITEMS = 200 # 同时处理的itmes数量
CONCURRENT_REQUESTS = 16 # 同时并发的请求
今天的代码到此结束。我还是想说:“做一个爱分享的程序员,有什么问题请留言。”如果你觉得我的文章还可以,请关注点赞。谢谢大家!
百度网页关键字抓取(实习导师又没得项目让我一起一边瞎东西那闲着)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-10 21:14
最近在实习,导师没有项目让我一起做事,就坐在一边摆弄东西
闲也是闲,想写爬虫
百度百科对爬虫的定义如下
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
即从网页中抓取你想要的数据,获取的数据可以做进一步的处理。
因为实习的是PHP,所以用PHP写,环境是Win10+php7.1+nginx
先打开curl扩展,去掉php.ini中extension=php_curl.dll前面的分号,然后重启php和nginx
然后开始写最简单的爬虫,抓取百度首页的内容到本地
//初始话curl句柄
$ch = curl_init();
//要抓取的网页
$url = "https://www.baidu.com";
//设置访问的URL,curl_setopt就是设置连接参数
curl_setopt($ch, CURLOPT_URL, $url);
//不需要报文头
curl_setopt($ch, CURLOPT_HEADER, FALSE);
//跳过https验证,访问https网站必须加上这两句
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
//返回响应信息而不是直接输出,默认将抓取的页面直接输出的
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
//开始执行
if (!$output = curl_exec($ch)) {
echo "Curl Error:". curl_error($ch);
}
//执行结束后必须将句柄关闭
curl_close($ch);
//保存页面信息
$html = fopen('D:/baidu_data.html', 'w');
fwrite($html, $output);
fclose($html);
echo '保存成功';
好了,现在我们可以抓取页面了,接下来我们来处理数据 查看全部
百度网页关键字抓取(实习导师又没得项目让我一起一边瞎东西那闲着)
最近在实习,导师没有项目让我一起做事,就坐在一边摆弄东西
闲也是闲,想写爬虫
百度百科对爬虫的定义如下
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
即从网页中抓取你想要的数据,获取的数据可以做进一步的处理。
因为实习的是PHP,所以用PHP写,环境是Win10+php7.1+nginx
先打开curl扩展,去掉php.ini中extension=php_curl.dll前面的分号,然后重启php和nginx
然后开始写最简单的爬虫,抓取百度首页的内容到本地
//初始话curl句柄
$ch = curl_init();
//要抓取的网页
$url = "https://www.baidu.com";
//设置访问的URL,curl_setopt就是设置连接参数
curl_setopt($ch, CURLOPT_URL, $url);
//不需要报文头
curl_setopt($ch, CURLOPT_HEADER, FALSE);
//跳过https验证,访问https网站必须加上这两句
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
//返回响应信息而不是直接输出,默认将抓取的页面直接输出的
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
//开始执行
if (!$output = curl_exec($ch)) {
echo "Curl Error:". curl_error($ch);
}
//执行结束后必须将句柄关闭
curl_close($ch);
//保存页面信息
$html = fopen('D:/baidu_data.html', 'w');
fwrite($html, $output);
fclose($html);
echo '保存成功';
好了,现在我们可以抓取页面了,接下来我们来处理数据
百度网页关键字抓取(网站优化到百度首页但又不知该怎么做??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-10 21:13
对于刚接触SEO的小白来说,会遇到这样的困惑。想把网站优化到百度首页不知道怎么做?其实很简单,知己知彼才能百战百胜。既然我们要把网站优化到首页,首先要了解搜索引擎的习惯,也就是它是怎么工作的。 ...
获取
搜索引擎后台会派出百度蜘蛛,24小时从海量数据中识别和抓取内容;然后过滤内容以去除低质量的内容;将筛选合格的内容存入临时索引库,分类存储。
百度蜘蛛的爬行方式分为:深爬和宽爬。
深度爬取:百度蜘蛛会一一跟踪网页上的链接,有点跟不上。
广泛抓取:百度蜘蛛会抓取一个页面的所有链接。
一旦用户在前台触发搜索,搜索引擎会根据用户的关键词在搜索库中选择内容,猜测用户的搜索需求,并显示与搜索结果相关的内容,以满足用户的需求用户的搜索目标。给用户。
过滤
质量有好有坏,我们都喜欢质量好的。百度蜘蛛也是一样。要知道,搜索引擎的最终目的是满足用户的搜索需求。为了保证搜索结果的相关性和丰富性,那些低质量的内容会被过滤掉并丢弃。哪些内容属于这个范围?
低质量:句子不通,下一句与上句没有联系,意思不流畅。这会让蜘蛛头晕目眩,自然会被丢弃。
其次,重复性强,与主题无关,广告全屏,死链接全,时效性差。
存储
过滤差不多完成了,百度留下了所有的“喜欢”。数据将被组织到索引库中并进行排序。
对过滤后的优质内容进行提取和理解,进行分类存储,建立目录,最后聚合成一个机器可以快速调用、易于理解的索引库,为数据的检索做准备。
显示
百度将所有精品店存储在索引库中。用户在前台触发搜索后,会触发索引库查询。比如网友输入一个关键词(比如SEO),百度蜘蛛就会从索引库中找到与之相关的在网友面前。
搜索引擎根据用户搜索意图和内容相关性等指标依次显示搜索结果。
相关性强的优质内容将排在第一位。如果没有达到搜索目标,用户可以根据显示结果搜索2-3次,搜索引擎会根据关键词进一步精准优化显示结果。 查看全部
百度网页关键字抓取(网站优化到百度首页但又不知该怎么做??)
对于刚接触SEO的小白来说,会遇到这样的困惑。想把网站优化到百度首页不知道怎么做?其实很简单,知己知彼才能百战百胜。既然我们要把网站优化到首页,首先要了解搜索引擎的习惯,也就是它是怎么工作的。 ...
获取
搜索引擎后台会派出百度蜘蛛,24小时从海量数据中识别和抓取内容;然后过滤内容以去除低质量的内容;将筛选合格的内容存入临时索引库,分类存储。
百度蜘蛛的爬行方式分为:深爬和宽爬。
深度爬取:百度蜘蛛会一一跟踪网页上的链接,有点跟不上。
广泛抓取:百度蜘蛛会抓取一个页面的所有链接。
一旦用户在前台触发搜索,搜索引擎会根据用户的关键词在搜索库中选择内容,猜测用户的搜索需求,并显示与搜索结果相关的内容,以满足用户的需求用户的搜索目标。给用户。
过滤
质量有好有坏,我们都喜欢质量好的。百度蜘蛛也是一样。要知道,搜索引擎的最终目的是满足用户的搜索需求。为了保证搜索结果的相关性和丰富性,那些低质量的内容会被过滤掉并丢弃。哪些内容属于这个范围?
低质量:句子不通,下一句与上句没有联系,意思不流畅。这会让蜘蛛头晕目眩,自然会被丢弃。
其次,重复性强,与主题无关,广告全屏,死链接全,时效性差。
存储
过滤差不多完成了,百度留下了所有的“喜欢”。数据将被组织到索引库中并进行排序。
对过滤后的优质内容进行提取和理解,进行分类存储,建立目录,最后聚合成一个机器可以快速调用、易于理解的索引库,为数据的检索做准备。
显示
百度将所有精品店存储在索引库中。用户在前台触发搜索后,会触发索引库查询。比如网友输入一个关键词(比如SEO),百度蜘蛛就会从索引库中找到与之相关的在网友面前。
搜索引擎根据用户搜索意图和内容相关性等指标依次显示搜索结果。
相关性强的优质内容将排在第一位。如果没有达到搜索目标,用户可以根据显示结果搜索2-3次,搜索引擎会根据关键词进一步精准优化显示结果。
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-09 20:06
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬们多多关照,别敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索关键词后抓取页面源码分五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,需要进行url编码
3、拼接页面的真实url(url指的是url,后面会直接写url)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python 爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、use urllib.request
谈谈一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、理智分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,很容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() 网址编码
示例代码:
运行结果:
2)urllib.parse.quote(string) URL 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索关键词后获取页面源码程序代码:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url编码
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断 查看全部
百度网页关键字抓取(Python爬虫下载器.request.urlopen(url))
[直奔主题]
最近整理了一下之前做过的项目,学到了很多东西,乱七八糟的。打算写一些关于Python爬虫的东西,新人,希望大佬们多多关照,别敲我歪了。
前面先磨一些基础的东西,对新爬虫更友好一些,总代码在最后,直接Ctrl+C就行了。
工具:
我们需要两个工具,这两件事:PyCharm 和 Google 浏览器
PyCharm
谷歌浏览器
我使用的版本是 PyCharm 5.0.3 和 Python 3.6.6
教学开始!
第一步,打开PyCharm
第二步,打开谷歌浏览器
第三步,开始分析
...
百度搜索关键词后抓取页面源码分五步:
1、获取你想抓取的信息
2、如果要获取的信息是中文的,需要进行url编码
3、拼接页面的真实url(url指的是url,后面会直接写url)
4、通过下载模块抓取网页信息
5、将获取的网页源代码保存为html文件并保存在本地
一、Python 爬虫下载器
分为urllib.request和request两种类型
urllib.request-python2版本的升级版
requests-python3 中的新版本
这里可以直接用import语句导入,简单方便,省事
二、use urllib.request
谈谈一些比较常用的小工具:
1)urllib.request.urlopen(url):向网页发起请求并得到响应
示例代码:
2)urllib.request.Request(url,headers) 创建请求对象
示例代码:
三、理智分析
我们试着用百度搜索一下,比如:
让我们复制它,你会看到它
哔哩哔哩:
%25E7%25AF%25AE%25E7%2590%2583&rsv_pq = 83f19419001be70a&rsv_t = 4115%2F8nYNTS0ycM92Jyo7EyG93G5SsWNuSPyrV5xFkZ2RPcEpqYZWJVokzM&rqlang = CN&rsv_enter = 1&rsv_dl = TB&rsv_sug3 = 11&rsv_sug1 = 8&rsv_sug7 = 100& rsv_sug2 = 0 & inputT = 7505 & rsv_sug4 = 7789
B站:
%E7%AB%99&OQ = Bilibili&rsv_pq = a2665be400255edc&rsv_t = 5c8aBmClupFcVXiNpBa79qMXk3UM6qIj614z6VmEmtJHhkeIvp7hddX9oio&rqlang = CN&rsv_enter = 1&rsv_dl = TB&inputT = 7100&rsv_sug3 = 22&rsv_sug1 = 17&rsv_sug7 = 100& rsv_sug2 = 0 & rsv_sug4 = 7455
让我们仔细看看...
这只特别的猫有什么意义?
和
是的,它对‘Station’这个词进行了url编码,很容易处理
四、url 编码模块 urllib.parse
我们用这个东西来杀死它。说一下常用的东西
1)urllib.parse.urlencode() 网址编码
示例代码:
运行结果:
2)urllib.parse.quote(string) URL 编码
示例代码:
运行结果:
3)urllib.parse.unquote(url encoding)反向编码url编码
示例代码:
运行结果:
五、最后一步
看到这里,相信大部分人都明白了,问题就解决了。我们要搜索“B站”,无非就是站。同样,它是 %E7%AB%99
百度搜索关键词后获取页面源码程序代码:
import urllib.request
import urllib.parse
key=input("请输入您要查询的内容:") # 获取想要搜索的信息
key={"wd":key}
data=urllib.parse.urlencode(key) # 对关键字进行url编码
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
总结:
我们将这个项目分为五个步骤:
一、获取你想抓取的信息
key=input("请输入您要查询的内容:")
二、如果要获取的信息是中文的,需要进行url编码
key={"wd":key}
data=urllib.parse.urlencode(key)
三、拼接页面的真实url
base_url="https://www.baidu.com/s?" #搜索网页的默认url
url=base_url+data #拼接得到真实的url
四、通过下载模块抓取网页信息
headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"}
req=urllib.request.Request(url,headers=headers) #创建请求对象
res=urllib.request.urlopen(req) #对网页发起请求并获取响应
五、将获取的网页源代码保存为html文件并保存在本地
html=res.read().decode("utf-8")
with open("百度.html","w",encoding="utf-8") as f:
f.write(html)
新人报到,互相咨询,玩得开心,精彩不断
百度网页关键字抓取(分词保存详细过程分析百度搜索的url,提取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-09-09 20:05
本文是在网上学习了一些相关的博客和资料后的学习总结。是入门级爬虫
相关工具和环境
python3 及以上
网址库
美汤
jieba 分词
url2io(提取网页正文)
整体流程介绍
解析百度搜索的url,用urllib.request提取网页,用beausoup解析页面,分析搜索页面,找到搜索结果在页面中的结构位置,提取搜索结果,然后得到搜索结果真实url,提取网页正文,分词保存
详细流程1.解析百度搜索url获取页面
我们使用百度的时候,输入关键词,点击搜索,可以看到页面url有一大串字符。但是我们在使用爬虫获取页面的时候,并没有使用这样的字符。我们实际使用的 url 是这样的:#39; 关键词'&pn='页面'。 wd是你搜索的关键,pn是分页页,因为百度搜索每页有十个结果(最上面的可能是广告宣传,不是搜索结果),所以pn=0就是第一页,第二页就是pn=10,依此类推,你可以试试周杰伦&pn=20,得到的是关于周杰伦的搜索结果第三页。
word = '周杰伦'
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=0' # word为关键词,pn是百度用来分页的..
response = urllib.request.urlopen(url)
page = response.read()
上面这句话是一个简单的爬虫,得到百度搜索结果的页面,这个词是通过关键词传递的,如果收录中文,需要使用urllib.parse.quote来防止出错,因为超链接默认为ascii编码,不能直接出现中文。
2.分析页面的html结构,找到搜索链接在页面中的位置,得到真正的搜索链接
使用谷歌浏览器的开发者模式(F12或Fn+F12),点击左上角箭头,点击搜索结果之一,如下图,可以看到搜索到结果都在class="result c-container"的div中,每个div都收录class="t"的h3标签,h3标签收录a标签,搜索结果在href注释中。
知道url的位置很方便,我们使用beautifulsoup使用lxml解析页面(pip install beautifulsoup4,pip install lxml,如果pip安装出错,网上搜索相关安装教程)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
all = open('D:\\111\\test.txt', 'a')
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
all.write(real_url + '\n')
因为页面除了搜索结果不收录其他h3标签,所以我们直接使用beautifulsoup获取所有h3标签,然后使用for循环获取每个搜索结果的url。
上面的请求也是爬虫包。在没有安装 huapip 的情况下安装它。我们可以使用这个包的get方法来获取相关页面的头文件信息。里面的Location对应的是网页的真实url。我们定期过滤掉一些无用的网址并保存。
注意有时伪装的头文件Accept-Encoding会导致乱码,可以删除。
3. 提取网页正文并进行分词
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
except:
return
我们可以用网上的第三方包url2io提取网页的body和url。但请注意,此包基于 pyhton2.7。其中使用的urllib2在python3版本中已经合并到urllib中。您需要自己修改它。 pyhton3中的basestring也删掉了改成str就够了,这个包可以提取大部分收录文本的网页,不能提取的情况用try语句处理。
我们使用 jieba 对提取的文本进行分割。 jieba的使用:点击打开链接。
# -*- coding:utf-8 -*-
import jieba
import jieba.posseg as pseg
import url2io
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test
count = db.count
count.remove()
def test():
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
seg_list = jieba.cut("我家住在青山区博雅豪庭大华南湖公园世家五栋十三号") #默认是精确模式
print(", ".join(seg_list))
fff = "我家住在青山区博雅豪庭大.华南湖公园世家啊说,法撒撒打算武汉工商学院五栋十三号"
result = pseg.cut(fff)
for w in result:
print(w.word, '/', w.flag, ',')
def get_address(url):
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
result = pseg.cut(text)
for w in result:
if(w.flag=='wh'):
print(w.word)
res = count.find_one({"name": w.word})
if res:
count.update_one({"name": w.word},{"$set": {"sum": res['sum']+1}})
else:
count.insert({"name": w.word,"sum": 1})
except:
return
我结合使用自定义词典进行分词。
4.使用多进程(POOL进程池)提高爬行速度
为什么不使用多线程,因为python的多线程太鸡肋了,详细资料点百度就知道了。下面我就直接把代码全部放出来,有一种方法可以把地址保存在txt文件和MongoDB数据库中。
百度.py
# -*- coding:utf-8 -*-
'''
从百度把前10页的搜索到的url爬取保存
'''
import multiprocessing #利用pool进程池实现多进程并行
# from threading import Thread 多线程
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
from urllib import request
import urllib
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test#数据库名
urls = db.cache#表名
urls.remove()
'''
all = open('D:\\111\\test.txt', 'a')
all.seek(0) #文件标记到初始位置
all.truncate() #清空文件
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
def getfromBaidu(word):
start = time.clock()
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=' # word为关键词,pn是百度用来分页的..
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for k in range(1, 5):
result = pool.apply_async(geturl, (url, k))# 多进程
pool.close()
pool.join()
end = time.clock()
print(end-start)
def geturl(url, k):
path = url + str((k - 1) * 10)
response = request.urlopen(path)
page = response.read()
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
# print(href)
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
urls.insert({"url": real_url})
# all.write(real_url + '\n')
if __name__ == '__main__':
getfromBaidu('周杰伦')
pool = multiprocessing.Pool(multiprocessing.cpu_count())
根据cpu的核数确认进程池中的进程数。多进程和POOL的使用详情请点击打开链接
修改后的url2io.py
<p>#coding: utf-8
#
# This program is free software. It comes without any warranty, to
# the extent permitted by applicable law. You can redistribute it
# and/or modify it under the terms of the Do What The Fuck You Want
# To Public License, Version 2, as published by Sam Hocevar. See
# http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# Version 2, December 2004
#
# Copyright (C) 2004 Sam Hocevar
#
# Everyone is permitted to copy and distribute verbatim or modified
# copies of this license document, and changing it is allowed as long
# as the name is changed.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
#
# 0. You just DO WHAT THE FUCK YOU WANT TO.
"""a simple url2io sdk
example:
api = API(token)
api.article(url='http://www.url2io.com/products', fields=['next', 'text'])
"""
__all__ = ['APIError', 'API']
DEBUG_LEVEL = 1
import sys
import socket
import json
import urllib
from urllib import request
import time
from collections import Iterable
import importlib
importlib.reload(sys)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
class APIError(Exception):
code = None
"""HTTP status code"""
url = None
"""request URL"""
body = None
"""server response body; or detailed error information"""
def __init__(self, code, url, body):
self.code = code
self.url = url
self.body = body
def __str__(self):
return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self)
__repr__ = __str__
class API(object):
token = None
server = 'http://api.url2io.com/'
decode_result = True
timeout = None
max_retries = None
retry_delay = None
def __init__(self, token, srv = None,
decode_result = True, timeout = 30, max_retries = 5,
retry_delay = 3):
""":param srv: The API server address
:param decode_result: whether to json_decode the result
:param timeout: HTTP request timeout in seconds
:param max_retries: maximal number of retries after catching URL error
or socket error
:param retry_delay: time to sleep before retrying"""
self.token = token
if srv:
self.server = srv
self.decode_result = decode_result
assert timeout >= 0 or timeout is None
assert max_retries >= 0
self.timeout = timeout
self.max_retries = max_retries
self.retry_delay = retry_delay
_setup_apiobj(self, self, [])
def update_request(self, request):
"""overwrite this function to update the request before sending it to
server"""
pass
def _setup_apiobj(self, apiobj, path):
if self is not apiobj:
self._api = apiobj
self._urlbase = apiobj.server + '/'.join(path)
lvl = len(path)
done = set()
for i in _APIS:
if len(i) 查看全部
百度网页关键字抓取(分词保存详细过程分析百度搜索的url,提取网页)
本文是在网上学习了一些相关的博客和资料后的学习总结。是入门级爬虫
相关工具和环境
python3 及以上
网址库
美汤
jieba 分词
url2io(提取网页正文)
整体流程介绍
解析百度搜索的url,用urllib.request提取网页,用beausoup解析页面,分析搜索页面,找到搜索结果在页面中的结构位置,提取搜索结果,然后得到搜索结果真实url,提取网页正文,分词保存
详细流程1.解析百度搜索url获取页面
我们使用百度的时候,输入关键词,点击搜索,可以看到页面url有一大串字符。但是我们在使用爬虫获取页面的时候,并没有使用这样的字符。我们实际使用的 url 是这样的:#39; 关键词'&pn='页面'。 wd是你搜索的关键,pn是分页页,因为百度搜索每页有十个结果(最上面的可能是广告宣传,不是搜索结果),所以pn=0就是第一页,第二页就是pn=10,依此类推,你可以试试周杰伦&pn=20,得到的是关于周杰伦的搜索结果第三页。
word = '周杰伦'
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=0' # word为关键词,pn是百度用来分页的..
response = urllib.request.urlopen(url)
page = response.read()
上面这句话是一个简单的爬虫,得到百度搜索结果的页面,这个词是通过关键词传递的,如果收录中文,需要使用urllib.parse.quote来防止出错,因为超链接默认为ascii编码,不能直接出现中文。
2.分析页面的html结构,找到搜索链接在页面中的位置,得到真正的搜索链接
使用谷歌浏览器的开发者模式(F12或Fn+F12),点击左上角箭头,点击搜索结果之一,如下图,可以看到搜索到结果都在class="result c-container"的div中,每个div都收录class="t"的h3标签,h3标签收录a标签,搜索结果在href注释中。
知道url的位置很方便,我们使用beautifulsoup使用lxml解析页面(pip install beautifulsoup4,pip install lxml,如果pip安装出错,网上搜索相关安装教程)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
all = open('D:\\111\\test.txt', 'a')
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
all.write(real_url + '\n')
因为页面除了搜索结果不收录其他h3标签,所以我们直接使用beautifulsoup获取所有h3标签,然后使用for循环获取每个搜索结果的url。
上面的请求也是爬虫包。在没有安装 huapip 的情况下安装它。我们可以使用这个包的get方法来获取相关页面的头文件信息。里面的Location对应的是网页的真实url。我们定期过滤掉一些无用的网址并保存。
注意有时伪装的头文件Accept-Encoding会导致乱码,可以删除。
3. 提取网页正文并进行分词
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
except:
return
我们可以用网上的第三方包url2io提取网页的body和url。但请注意,此包基于 pyhton2.7。其中使用的urllib2在python3版本中已经合并到urllib中。您需要自己修改它。 pyhton3中的basestring也删掉了改成str就够了,这个包可以提取大部分收录文本的网页,不能提取的情况用try语句处理。
我们使用 jieba 对提取的文本进行分割。 jieba的使用:点击打开链接。
# -*- coding:utf-8 -*-
import jieba
import jieba.posseg as pseg
import url2io
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test
count = db.count
count.remove()
def test():
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
seg_list = jieba.cut("我家住在青山区博雅豪庭大华南湖公园世家五栋十三号") #默认是精确模式
print(", ".join(seg_list))
fff = "我家住在青山区博雅豪庭大.华南湖公园世家啊说,法撒撒打算武汉工商学院五栋十三号"
result = pseg.cut(fff)
for w in result:
print(w.word, '/', w.flag, ',')
def get_address(url):
api = url2io.API('bjb4w0WATrG7Lt6PVx_TrQ')
try:
ret = api.article(url=url,fields=['text', 'next'])
text = ret['text']
filename = 'C:\\xxx\\include.txt'
jieba.load_userdict(filename)
result = pseg.cut(text)
for w in result:
if(w.flag=='wh'):
print(w.word)
res = count.find_one({"name": w.word})
if res:
count.update_one({"name": w.word},{"$set": {"sum": res['sum']+1}})
else:
count.insert({"name": w.word,"sum": 1})
except:
return
我结合使用自定义词典进行分词。
4.使用多进程(POOL进程池)提高爬行速度
为什么不使用多线程,因为python的多线程太鸡肋了,详细资料点百度就知道了。下面我就直接把代码全部放出来,有一种方法可以把地址保存在txt文件和MongoDB数据库中。
百度.py
# -*- coding:utf-8 -*-
'''
从百度把前10页的搜索到的url爬取保存
'''
import multiprocessing #利用pool进程池实现多进程并行
# from threading import Thread 多线程
import time
from bs4 import BeautifulSoup #处理抓到的页面
import sys
import requests
import importlib
importlib.reload(sys)#编码转换,python3默认utf-8,一般不用加
from urllib import request
import urllib
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
db = conn.test#数据库名
urls = db.cache#表名
urls.remove()
'''
all = open('D:\\111\\test.txt', 'a')
all.seek(0) #文件标记到初始位置
all.truncate() #清空文件
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
def getfromBaidu(word):
start = time.clock()
url = 'http://www.baidu.com.cn/s?wd=' + urllib.parse.quote(word) + '&pn=' # word为关键词,pn是百度用来分页的..
pool = multiprocessing.Pool(multiprocessing.cpu_count())
for k in range(1, 5):
result = pool.apply_async(geturl, (url, k))# 多进程
pool.close()
pool.join()
end = time.clock()
print(end-start)
def geturl(url, k):
path = url + str((k - 1) * 10)
response = request.urlopen(path)
page = response.read()
soup = BeautifulSoup(page, 'lxml')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
# print(href)
baidu_url = requests.get(url=href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] #得到网页原始地址
if real_url.startswith('http'):
urls.insert({"url": real_url})
# all.write(real_url + '\n')
if __name__ == '__main__':
getfromBaidu('周杰伦')
pool = multiprocessing.Pool(multiprocessing.cpu_count())
根据cpu的核数确认进程池中的进程数。多进程和POOL的使用详情请点击打开链接
修改后的url2io.py
<p>#coding: utf-8
#
# This program is free software. It comes without any warranty, to
# the extent permitted by applicable law. You can redistribute it
# and/or modify it under the terms of the Do What The Fuck You Want
# To Public License, Version 2, as published by Sam Hocevar. See
# http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# Version 2, December 2004
#
# Copyright (C) 2004 Sam Hocevar
#
# Everyone is permitted to copy and distribute verbatim or modified
# copies of this license document, and changing it is allowed as long
# as the name is changed.
#
# DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
# TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
#
# 0. You just DO WHAT THE FUCK YOU WANT TO.
"""a simple url2io sdk
example:
api = API(token)
api.article(url='http://www.url2io.com/products', fields=['next', 'text'])
"""
__all__ = ['APIError', 'API']
DEBUG_LEVEL = 1
import sys
import socket
import json
import urllib
from urllib import request
import time
from collections import Iterable
import importlib
importlib.reload(sys)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
} #定义头文件,伪装成浏览器
class APIError(Exception):
code = None
"""HTTP status code"""
url = None
"""request URL"""
body = None
"""server response body; or detailed error information"""
def __init__(self, code, url, body):
self.code = code
self.url = url
self.body = body
def __str__(self):
return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self)
__repr__ = __str__
class API(object):
token = None
server = 'http://api.url2io.com/'
decode_result = True
timeout = None
max_retries = None
retry_delay = None
def __init__(self, token, srv = None,
decode_result = True, timeout = 30, max_retries = 5,
retry_delay = 3):
""":param srv: The API server address
:param decode_result: whether to json_decode the result
:param timeout: HTTP request timeout in seconds
:param max_retries: maximal number of retries after catching URL error
or socket error
:param retry_delay: time to sleep before retrying"""
self.token = token
if srv:
self.server = srv
self.decode_result = decode_result
assert timeout >= 0 or timeout is None
assert max_retries >= 0
self.timeout = timeout
self.max_retries = max_retries
self.retry_delay = retry_delay
_setup_apiobj(self, self, [])
def update_request(self, request):
"""overwrite this function to update the request before sending it to
server"""
pass
def _setup_apiobj(self, apiobj, path):
if self is not apiobj:
self._api = apiobj
self._urlbase = apiobj.server + '/'.join(path)
lvl = len(path)
done = set()
for i in _APIS:
if len(i)

