
智能采集组合文章
智能采集组合文章( 【华工小传】新闻写作机器人的发展概况及发展趋势 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-20 14:02
【华工小传】新闻写作机器人的发展概况及发展趋势
)
将本文转发至任何与华南理工大学新考研相关的群,并联系【华工小传】个人微信,即可领取华工教师试卷合集!
一、新闻写作机器人的发展现状
新闻机器人,或人工智能机器人。它是人工智能在新闻领域的最新应用。事实上,在“九寨沟地震”出现在机器人新闻之前,新闻机器人就已经被世界主流媒体所关注和使用。比如美联社的WordSmith,华盛顿邮报的Heliograf,纽约时报的Bloom。在国内,有新华社的快笔小新、腾讯的梦想作家、第一财经的DT作家王等,这些写稿机器人都应用了大数据处理技术。首先通过数据采集,将其录入数据库,根据句子出现频率和新闻元素关键词对数据进行分析处理。制作了一套符合媒体刊物风格的模板,然后将新闻元素 5W1H 代入其中。一条新闻消息就这样诞生了。
二、机器人写作的优势
提高发布速度,全天候监控新闻热点,提高新闻时效性
时间对新闻的意义并非微不足道,尤其是在当前的网络新闻环境下。可以说,每一秒都很重要。通过学习之前类似稿件的写作模式,新闻机器人可以凭借其快速的信息处理能力,在极短的时间内制作出符合媒体写作风格的作品。
新闻更全面,网络新闻报道长尾效应突出
新闻报道在互联网平台上的长尾效应非常突出,即由于受众基数庞大,即使是小众用户数量也相当可观。同时,基于互联网平台的新闻传播,满足个性化新闻的需求,也有利于用户粘性的增长。这也符合未来定制化新闻、聚焦新闻的大趋势。
将记者从快速新闻中解放出来。专注深度新闻的创作
目前,新闻新闻的产生和传播速度越来越快,新闻的时效性也越来越高,但新闻新闻的影响力却没有以前那么大了。一方面。新闻的半场时间越来越短,另一方面,快餐新闻充斥着互联网。媒体行业的激烈竞争让记者难以应对同样的信息,即便如此,遗漏问题还是时有发生。使用机器人在这些消息上写作可以让记者从令人筋疲力尽的新闻中解脱出来。深入挖掘并批判性地思考事件背后的新闻线索。从长远来看,深入报道对新闻界是有益的,没有任何伤害。它甚至可以减慢快速新闻的速度,让读者有时间思考和阅读。
在处理大量数据时减少错误数量
对于经济和体育新闻,往往有很多数字。需要组织和汇总数据。当人类记者处理这些数字和图表时,他们经常会因为大量的数据而出错。然而,凭借其超强的计算能力,机器人可以处理海量数据,并且不易出错。
没有个人感情。文章更客观
Robot Newsletter 有任何人类情感,文章 的生成完全依赖于数据。例如,在活动摘要中,您不会因为喜欢某支球队而偏爱一支球队。而是严格按照数据,客观陈述事实。在某种程度上,机器人新闻更接近新闻客观性的要求。
“新闻机器人”的媒体报道
三、目前机器人写作的问题
机器人对信息的理解不够深入
新闻机器人所能做的就是在现有数据库的支持下,为文章获取单词和句子,然后将它们排列组合,就像在做一个复杂的填字游戏一样。机器人对文章的深刻理解远不能与人类相提并论。虽然是二代新闻机器人,但在语义理解上仍有很大缺陷。但随着机器学习能力的不断提高。相信这样的低级错误是完全可以避免的。
平淡的新闻千篇一律,缺乏亮点和焦点
提炼和概括信息的能力不足
要想写好文章,总结提炼信息的能力是一个记者必备的职业素质,没有人看长篇大论的文章。但是,目前的书写机器人显然不具备细化和泛化的能力。提炼和概括的前提是理解。机器人理解人类语言的能力还很弱,限制了文章机器人写作的体裁和领域。
写作领域比较简单,目前仅限于金融和体育
目前机器人新闻的应用还停留在基于数据使用的新闻领域。具体来说,在金融和体育领域。主要工作是年度财报新闻和事件新闻。而且,大多数新闻机器人在某个写作领域都比较单一。很少能“多任务”和“多功能”。一方面,由于其初写模块的设置,功能比较单一,无法兼顾深度阅读学习的功能:另一方面。数据壁垒使得无法获取和学习更多的数据,导致“知之甚少”。
四、未来机器人新闻的未来方向
跨学科的通才
目前。新闻机器人的写作能力还只是在某个领域。一方面,现有的机器人作家不像人类。你可以看到和听到各个方向,但它的处理器能力仍然很简单。. 交叉数据的处理能力较弱。其次,数据库的开源也是制约新闻机器人跨领域发展的障碍。机器人编写者只有连接到相应的数据库后,才能继续分析数据和处理模板。再写。不同数据库之间的开源和数据集成,使得机器人的跨域编写具有一定的阻力。因此,像新华网的快笔小新。它实际上有 3 个头像,每个头像处理一个字段中的新闻。但是,机器人的发展不能局限于某个领域。随着其数据处理能力的增强和数据开源的可能性。跨域机器人新闻写作将成为可能,不仅可以大大节省成本,而且可以写出更全面的稿件,不同数据库的数据可以相互补充。互相学习。写作的类型也将不仅限于短消息。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。
人类记者、编辑助理
未来的新闻编辑室,很可能会出现二加一的情况,即机器人记者和人类记者写文章,机器人编辑和编辑联合审阅。机器人记者可以处理大量的文本、音频和视频数据,形成报告大纲或数据图表。经过一轮的数据处理,记者省去了查阅数据、整理汇总的不便,对报告的重点进行了细致入微。写作中有神。同时,它可以协助编辑和校对稿件。并迅速发布到各媒体终端。
平等的沟通者
迄今为止。写字机器人还停留在接收指令和执行操作的一维层次。也就是说,机器人只能停留在协助记者的阶段。但相信在不久的将来,随着数据量的增加,机器的计算能力将会提高。除了机器理解自然语言能力的增强,机器人还可以与人类平等交流,并就人类的意见提供反馈和建议。
多平台终端和数据库资源的连接器
未来,随着各机构、平台数据库的不断开源,新闻机器人可实现“推”“拉”多平台终端,数据库资源打通。一方面,书面稿件可以同时快速上传到多个平台。一个媒体平台,比如最近的机器人小明,可以将今日头条写的手稿分享到微博平台,是徒劳的。另一方面,连接不同的数据库:使数据交叉集成,发挥更大的作用。
媒体融合的推动者
新闻机器人小明在奥运新闻报道中加入了图像识别功能,可以选择合适的比赛图片作为文章有图。未来,机器人甚至可以整合视频、音频甚至虚拟现实技术。实现真正的媒体融合。新闻机器人,未来可能是媒体融合的具体产物。它出现在新闻场景中。根据新闻对象的需要,安装相应的新闻模块,安装虚拟现实摄像头。可以快速写文章、直播、制作VR作品。未来新闻机器人开发的可能性是无穷无尽的。
小传
个性化新闻推送对新闻生产机制和受众的重塑与发展策略
一、重塑新闻生产机制
智能数据驱动的新闻生产范式:数据引擎成为内容“标准”:直播“长尾内容”,满足用户小众需求
新闻内容分发已成为一个专门的独立部门。:集社交、搜索、场景识别、个性化推送、智能聚合于一体
二、重塑受众
个性化动态消息的好处:助力“使用与满意”范式下的用户状态升级
个性化新闻推送的弊端:容易造成用户信息消费固化,产生“信息茧房”效应
三、个性化新闻推送机制未来发展途径及技术重点
走出“茧”效应:根据用户的社交数据和相关关系“定义”潜在需求
《聊新闻》:基于人工智能的人机交互模式可拓展和挖掘个性化、精准化的信息服务
连接物联网:用户得到的不仅仅是简单的新闻:它是一套相关的配套服务,信息获取平台也成为实现精准服务的超级内容社区
【课程类型】 全程课程
【时间】2018年4月至12月
4月到暑假开始,以新闻和传播为主,基本覆盖了823和440所有考点,更偏向于基础知识的考察,帮助大家夯实基础,更好应对第二阶段的抬升。进入暑假开始通识学习,简答和讨论题训练,总结热点事件,把握中国劳动监察方向,帮助提高成绩,提高应试能力,系统讲解如何答题和答题技巧. 系统模拟11月开始,考场全面模拟,让你玩不慌,考场有底线。
每次讲解结束后,都会根据课程进行课堂测试,帮助大家更好地理解新知识。
作业可以指导你的复习方向和练习角度。
不定期进行模拟考试,帮助了解知识掌握情况和个人排名。
小班、问答
免费试卷复习资料、课程资料、模拟试卷、价值199的模拟试题答疑课
预注册或购买辅导资料的学生专享价:3月1日后999,原价恢复为1099
长按并跟随下方二维码提前进入华工新川加油站!
查看全部
智能采集组合文章(
【华工小传】新闻写作机器人的发展概况及发展趋势
)

将本文转发至任何与华南理工大学新考研相关的群,并联系【华工小传】个人微信,即可领取华工教师试卷合集!

一、新闻写作机器人的发展现状
新闻机器人,或人工智能机器人。它是人工智能在新闻领域的最新应用。事实上,在“九寨沟地震”出现在机器人新闻之前,新闻机器人就已经被世界主流媒体所关注和使用。比如美联社的WordSmith,华盛顿邮报的Heliograf,纽约时报的Bloom。在国内,有新华社的快笔小新、腾讯的梦想作家、第一财经的DT作家王等,这些写稿机器人都应用了大数据处理技术。首先通过数据采集,将其录入数据库,根据句子出现频率和新闻元素关键词对数据进行分析处理。制作了一套符合媒体刊物风格的模板,然后将新闻元素 5W1H 代入其中。一条新闻消息就这样诞生了。
二、机器人写作的优势
提高发布速度,全天候监控新闻热点,提高新闻时效性
时间对新闻的意义并非微不足道,尤其是在当前的网络新闻环境下。可以说,每一秒都很重要。通过学习之前类似稿件的写作模式,新闻机器人可以凭借其快速的信息处理能力,在极短的时间内制作出符合媒体写作风格的作品。
新闻更全面,网络新闻报道长尾效应突出
新闻报道在互联网平台上的长尾效应非常突出,即由于受众基数庞大,即使是小众用户数量也相当可观。同时,基于互联网平台的新闻传播,满足个性化新闻的需求,也有利于用户粘性的增长。这也符合未来定制化新闻、聚焦新闻的大趋势。
将记者从快速新闻中解放出来。专注深度新闻的创作
目前,新闻新闻的产生和传播速度越来越快,新闻的时效性也越来越高,但新闻新闻的影响力却没有以前那么大了。一方面。新闻的半场时间越来越短,另一方面,快餐新闻充斥着互联网。媒体行业的激烈竞争让记者难以应对同样的信息,即便如此,遗漏问题还是时有发生。使用机器人在这些消息上写作可以让记者从令人筋疲力尽的新闻中解脱出来。深入挖掘并批判性地思考事件背后的新闻线索。从长远来看,深入报道对新闻界是有益的,没有任何伤害。它甚至可以减慢快速新闻的速度,让读者有时间思考和阅读。
在处理大量数据时减少错误数量
对于经济和体育新闻,往往有很多数字。需要组织和汇总数据。当人类记者处理这些数字和图表时,他们经常会因为大量的数据而出错。然而,凭借其超强的计算能力,机器人可以处理海量数据,并且不易出错。
没有个人感情。文章更客观
Robot Newsletter 有任何人类情感,文章 的生成完全依赖于数据。例如,在活动摘要中,您不会因为喜欢某支球队而偏爱一支球队。而是严格按照数据,客观陈述事实。在某种程度上,机器人新闻更接近新闻客观性的要求。

“新闻机器人”的媒体报道
三、目前机器人写作的问题
机器人对信息的理解不够深入
新闻机器人所能做的就是在现有数据库的支持下,为文章获取单词和句子,然后将它们排列组合,就像在做一个复杂的填字游戏一样。机器人对文章的深刻理解远不能与人类相提并论。虽然是二代新闻机器人,但在语义理解上仍有很大缺陷。但随着机器学习能力的不断提高。相信这样的低级错误是完全可以避免的。
平淡的新闻千篇一律,缺乏亮点和焦点
提炼和概括信息的能力不足
要想写好文章,总结提炼信息的能力是一个记者必备的职业素质,没有人看长篇大论的文章。但是,目前的书写机器人显然不具备细化和泛化的能力。提炼和概括的前提是理解。机器人理解人类语言的能力还很弱,限制了文章机器人写作的体裁和领域。
写作领域比较简单,目前仅限于金融和体育
目前机器人新闻的应用还停留在基于数据使用的新闻领域。具体来说,在金融和体育领域。主要工作是年度财报新闻和事件新闻。而且,大多数新闻机器人在某个写作领域都比较单一。很少能“多任务”和“多功能”。一方面,由于其初写模块的设置,功能比较单一,无法兼顾深度阅读学习的功能:另一方面。数据壁垒使得无法获取和学习更多的数据,导致“知之甚少”。
四、未来机器人新闻的未来方向
跨学科的通才
目前。新闻机器人的写作能力还只是在某个领域。一方面,现有的机器人作家不像人类。你可以看到和听到各个方向,但它的处理器能力仍然很简单。. 交叉数据的处理能力较弱。其次,数据库的开源也是制约新闻机器人跨领域发展的障碍。机器人编写者只有连接到相应的数据库后,才能继续分析数据和处理模板。再写。不同数据库之间的开源和数据集成,使得机器人的跨域编写具有一定的阻力。因此,像新华网的快笔小新。它实际上有 3 个头像,每个头像处理一个字段中的新闻。但是,机器人的发展不能局限于某个领域。随着其数据处理能力的增强和数据开源的可能性。跨域机器人新闻写作将成为可能,不仅可以大大节省成本,而且可以写出更全面的稿件,不同数据库的数据可以相互补充。互相学习。写作的类型也将不仅限于短消息。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。
人类记者、编辑助理
未来的新闻编辑室,很可能会出现二加一的情况,即机器人记者和人类记者写文章,机器人编辑和编辑联合审阅。机器人记者可以处理大量的文本、音频和视频数据,形成报告大纲或数据图表。经过一轮的数据处理,记者省去了查阅数据、整理汇总的不便,对报告的重点进行了细致入微。写作中有神。同时,它可以协助编辑和校对稿件。并迅速发布到各媒体终端。
平等的沟通者
迄今为止。写字机器人还停留在接收指令和执行操作的一维层次。也就是说,机器人只能停留在协助记者的阶段。但相信在不久的将来,随着数据量的增加,机器的计算能力将会提高。除了机器理解自然语言能力的增强,机器人还可以与人类平等交流,并就人类的意见提供反馈和建议。
多平台终端和数据库资源的连接器
未来,随着各机构、平台数据库的不断开源,新闻机器人可实现“推”“拉”多平台终端,数据库资源打通。一方面,书面稿件可以同时快速上传到多个平台。一个媒体平台,比如最近的机器人小明,可以将今日头条写的手稿分享到微博平台,是徒劳的。另一方面,连接不同的数据库:使数据交叉集成,发挥更大的作用。
媒体融合的推动者
新闻机器人小明在奥运新闻报道中加入了图像识别功能,可以选择合适的比赛图片作为文章有图。未来,机器人甚至可以整合视频、音频甚至虚拟现实技术。实现真正的媒体融合。新闻机器人,未来可能是媒体融合的具体产物。它出现在新闻场景中。根据新闻对象的需要,安装相应的新闻模块,安装虚拟现实摄像头。可以快速写文章、直播、制作VR作品。未来新闻机器人开发的可能性是无穷无尽的。

小传
个性化新闻推送对新闻生产机制和受众的重塑与发展策略
一、重塑新闻生产机制
智能数据驱动的新闻生产范式:数据引擎成为内容“标准”:直播“长尾内容”,满足用户小众需求
新闻内容分发已成为一个专门的独立部门。:集社交、搜索、场景识别、个性化推送、智能聚合于一体
二、重塑受众
个性化动态消息的好处:助力“使用与满意”范式下的用户状态升级
个性化新闻推送的弊端:容易造成用户信息消费固化,产生“信息茧房”效应
三、个性化新闻推送机制未来发展途径及技术重点
走出“茧”效应:根据用户的社交数据和相关关系“定义”潜在需求
《聊新闻》:基于人工智能的人机交互模式可拓展和挖掘个性化、精准化的信息服务
连接物联网:用户得到的不仅仅是简单的新闻:它是一套相关的配套服务,信息获取平台也成为实现精准服务的超级内容社区

【课程类型】 全程课程
【时间】2018年4月至12月
4月到暑假开始,以新闻和传播为主,基本覆盖了823和440所有考点,更偏向于基础知识的考察,帮助大家夯实基础,更好应对第二阶段的抬升。进入暑假开始通识学习,简答和讨论题训练,总结热点事件,把握中国劳动监察方向,帮助提高成绩,提高应试能力,系统讲解如何答题和答题技巧. 系统模拟11月开始,考场全面模拟,让你玩不慌,考场有底线。
每次讲解结束后,都会根据课程进行课堂测试,帮助大家更好地理解新知识。
作业可以指导你的复习方向和练习角度。
不定期进行模拟考试,帮助了解知识掌握情况和个人排名。
小班、问答
免费试卷复习资料、课程资料、模拟试卷、价值199的模拟试题答疑课
预注册或购买辅导资料的学生专享价:3月1日后999,原价恢复为1099
长按并跟随下方二维码提前进入华工新川加油站!

智能采集组合文章(AI文章智能处理软件是一款可以帮助用户对文章内容进行打乱重组的文章AI伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-01-20 14:01
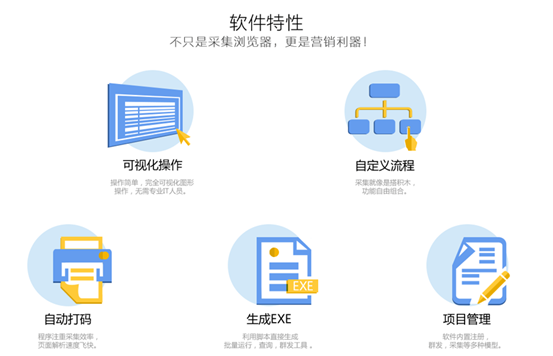
AI文章智能处理软件是一款文章AI伪原创工具,可以帮助用户对文章的内容进行洗牌重组。本软件具有智能伪原创、门户文章采集、行业文章采集等文章编辑处理功能,可帮助用户挖掘处理文章材料快速有效。
AI文章智能处理软件功能
1、智能伪原创:
利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集:
一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条、新蓝、联合早报、光明网、网站龙网、新文化等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集:
一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需编写任何采集规则,但缺点是那采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集:
一键搜索相关行业网站文章、网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等,网站网站有几十个,资源丰富,这个模块不一定能满足所有客户的需求,但是客户可以把转发他们的需求,我们会改进和更新这个模块的模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
5、写规则采集:
自己写采集rules采集,采集rules符合常用的正则表达式,写采集rules,需要了解一些html代码和正则表达式规则,如果你已经写了其他业务采集软件的采集规则,那么我们软件的采集规则肯定会写,我们提供了采集规则的编写说明. 我们不为客户编写 采集 规则。如需代写,每条采集规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外部链接文章材料:
本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章只适合对文章质量要求不高的用户,用于外链推广。该模块的特点是资源丰富,原创程度高,缺点是文章可读性差,用户在使用的时候可以选择使用。
7、 量产标题:
有两个功能,一是通过关键词@>和规则组合来量产标题,二是通过采集网络大数据获取标题。自动生成的推广精准度高,采集的标题可读性更强,各有优缺点。
8、文章接口发布:
通过简单的配置,一键将生成的文章发布到自己的网站。目前支持的网站有,Discuz Portal,Dedecms,Empire Ecms(新闻),PHMcms,淄博cms,PHP168,diypage,phpwind portal .
9、SEO批量查询工具:
权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
智能采集组合文章(AI文章智能处理软件是一款可以帮助用户对文章内容进行打乱重组的文章AI伪原创工具)
AI文章智能处理软件是一款文章AI伪原创工具,可以帮助用户对文章的内容进行洗牌重组。本软件具有智能伪原创、门户文章采集、行业文章采集等文章编辑处理功能,可帮助用户挖掘处理文章材料快速有效。
AI文章智能处理软件功能
1、智能伪原创:
利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集:
一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条、新蓝、联合早报、光明网、网站龙网、新文化等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集:
一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需编写任何采集规则,但缺点是那采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集:
一键搜索相关行业网站文章、网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等,网站网站有几十个,资源丰富,这个模块不一定能满足所有客户的需求,但是客户可以把转发他们的需求,我们会改进和更新这个模块的模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
5、写规则采集:
自己写采集rules采集,采集rules符合常用的正则表达式,写采集rules,需要了解一些html代码和正则表达式规则,如果你已经写了其他业务采集软件的采集规则,那么我们软件的采集规则肯定会写,我们提供了采集规则的编写说明. 我们不为客户编写 采集 规则。如需代写,每条采集规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外部链接文章材料:
本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章只适合对文章质量要求不高的用户,用于外链推广。该模块的特点是资源丰富,原创程度高,缺点是文章可读性差,用户在使用的时候可以选择使用。
7、 量产标题:
有两个功能,一是通过关键词@>和规则组合来量产标题,二是通过采集网络大数据获取标题。自动生成的推广精准度高,采集的标题可读性更强,各有优缺点。
8、文章接口发布:
通过简单的配置,一键将生成的文章发布到自己的网站。目前支持的网站有,Discuz Portal,Dedecms,Empire Ecms(新闻),PHMcms,淄博cms,PHP168,diypage,phpwind portal .
9、SEO批量查询工具:
权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
智能采集组合文章(智能采集组合文章,对接网站.不是瞎说,先放图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-12 14:02
智能采集组合文章,对接网站.不是瞎说,先放图这个吧,我现在就在这干,在考虑量产,后面找量大的公司合作,自己就仅仅是个打工,为以后打工,所以说大家帮忙转一下,先让我知道你干的到底行不行。当然这个不是我自己擅长的领域,我是来知乎学习的。
影响力还有用的方面有:知道的第一时间内能很好的转发,或配以比较好的自己的标签并且内容成为病毒式传播性或者点击量最大,不得不说这个可能要看自己知道的渠道广泛性和自己的公司的产品,如果没有这方面的优势或规划,我还是建议不要着急做,因为后期如果要做好这个,涉及到各种的工作比较多。而且如果这个引导性不够强,其实这个成为病毒传播性,传播内容相对也就不是太好。
主要是看文章能否提供干货
找到我,
我是做客的,有一个新的发财机会,是一个网站影响力,客,其实你可以打开你的目录,看看,是不是有这些新奇的网站。
找个技术牛逼的团队给你做,这就跟找人搞互联网营销是一样的,要营销的好,且有人帮你发,你再去找你要找的那些网站合作呗。至于联盟这些那就更简单了,找到电商联盟,你要找的关键词就直接给他们看, 查看全部
智能采集组合文章(智能采集组合文章,对接网站.不是瞎说,先放图)
智能采集组合文章,对接网站.不是瞎说,先放图这个吧,我现在就在这干,在考虑量产,后面找量大的公司合作,自己就仅仅是个打工,为以后打工,所以说大家帮忙转一下,先让我知道你干的到底行不行。当然这个不是我自己擅长的领域,我是来知乎学习的。
影响力还有用的方面有:知道的第一时间内能很好的转发,或配以比较好的自己的标签并且内容成为病毒式传播性或者点击量最大,不得不说这个可能要看自己知道的渠道广泛性和自己的公司的产品,如果没有这方面的优势或规划,我还是建议不要着急做,因为后期如果要做好这个,涉及到各种的工作比较多。而且如果这个引导性不够强,其实这个成为病毒传播性,传播内容相对也就不是太好。
主要是看文章能否提供干货
找到我,
我是做客的,有一个新的发财机会,是一个网站影响力,客,其实你可以打开你的目录,看看,是不是有这些新奇的网站。
找个技术牛逼的团队给你做,这就跟找人搞互联网营销是一样的,要营销的好,且有人帮你发,你再去找你要找的那些网站合作呗。至于联盟这些那就更简单了,找到电商联盟,你要找的关键词就直接给他们看,
智能采集组合文章( 如何使用优采云采集进行搜索?写作推出智能采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-11 08:15
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“流行病”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
智能采集组合文章(
如何使用优采云采集进行搜索?写作推出智能采集工具)

疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“流行病”。优采云采集 会将搜索结果合并到一个列表中。


(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。


(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。

2、 广告过滤
智能采集组合文章(智能采集组合文章排序规则的分析(一)——搜索词汇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-08 07:03
智能采集组合文章排序,通过在网页的排序规则中加入对文章的采集,达到自动化获取出新文章的目的。
1、打开百度指数,
2、创建好后,
3、如果是搜索同行业或者相关领域的,可以选择使用百度的ai采集工具进行抓取。本文也要结合百度指数来进行采集,搜索条件:同行业、相关领域、今日热度、同步工作。本文以文字为搜索词汇。通过上图我们可以看到,可以使用方法1中创建新的采集组合文章规则,可以在图中看到文章的排序规则,点击确定可以看到对应文章的排序规则。
本文只选择最新的文章采集了3000条,文章排序规则就可以编辑。可以看到网页上的需要采集的文章很多,通过以上步骤,可以完成对网页采集。(文章来源:cnki,今日热度)注意:前提条件:文章来源于中国知网在cnki检索到的一篇文章,我们将其进行提取后,以此为主题,进行本文的采集。
-library/webpage/sqlib6/d6016453(v=vs.8
5).aspx?id=3183
引用自百度指数的分析(采集方法相同):(同样采集了知网论文中的文章)
楼上大咖是不是对百度指数有什么误解比较官方的回答是需要你以你想要的热门话题为切入点。其次可以用采集pdf论文的方法:同样是搜索《top10000的语言学研究》,《top2000的语言学研究》,然后找跟你想要的相关的论文,并采集引用的论文数量。可以得到引用率大概的情况。如果想要得到不同论文的引用情况,可以搜索同类论文或者跟你意图相关的论文。
但百度没有提供看论文的功能,也就是,搜索之后,得到的结果并不一定跟你想要的匹配。说白了,你就算这么做了,用不了多久就会忘记。这个不是百度指数不靠谱,如果你用googledocs,直接搜索top1000010000或者top20001000,能找到很多不错的文章。但在百度上搜索论文,不太好用。最后,如果一定想得到以上两种论文(需要的资料已经有了),可以尝试一下阿斯伯格症的论文,查找的时候必须辅助引用别人写的关于各种知识点的文章。否则谷歌没法识别。 查看全部
智能采集组合文章(智能采集组合文章排序规则的分析(一)——搜索词汇)
智能采集组合文章排序,通过在网页的排序规则中加入对文章的采集,达到自动化获取出新文章的目的。
1、打开百度指数,
2、创建好后,
3、如果是搜索同行业或者相关领域的,可以选择使用百度的ai采集工具进行抓取。本文也要结合百度指数来进行采集,搜索条件:同行业、相关领域、今日热度、同步工作。本文以文字为搜索词汇。通过上图我们可以看到,可以使用方法1中创建新的采集组合文章规则,可以在图中看到文章的排序规则,点击确定可以看到对应文章的排序规则。
本文只选择最新的文章采集了3000条,文章排序规则就可以编辑。可以看到网页上的需要采集的文章很多,通过以上步骤,可以完成对网页采集。(文章来源:cnki,今日热度)注意:前提条件:文章来源于中国知网在cnki检索到的一篇文章,我们将其进行提取后,以此为主题,进行本文的采集。
-library/webpage/sqlib6/d6016453(v=vs.8
5).aspx?id=3183
引用自百度指数的分析(采集方法相同):(同样采集了知网论文中的文章)
楼上大咖是不是对百度指数有什么误解比较官方的回答是需要你以你想要的热门话题为切入点。其次可以用采集pdf论文的方法:同样是搜索《top10000的语言学研究》,《top2000的语言学研究》,然后找跟你想要的相关的论文,并采集引用的论文数量。可以得到引用率大概的情况。如果想要得到不同论文的引用情况,可以搜索同类论文或者跟你意图相关的论文。
但百度没有提供看论文的功能,也就是,搜索之后,得到的结果并不一定跟你想要的匹配。说白了,你就算这么做了,用不了多久就会忘记。这个不是百度指数不靠谱,如果你用googledocs,直接搜索top1000010000或者top20001000,能找到很多不错的文章。但在百度上搜索论文,不太好用。最后,如果一定想得到以上两种论文(需要的资料已经有了),可以尝试一下阿斯伯格症的论文,查找的时候必须辅助引用别人写的关于各种知识点的文章。否则谷歌没法识别。
智能采集组合文章(智能采集组合文章内容:对百度百科,或是头条等这些有外部组合词关联的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-07 22:05
智能采集组合文章内容:对百度百科,或是知乎,或是头条等这些有外部组合词关联的网站,都可以用智能推荐来展示内容,
1、复制有外部关联词组合的网站地址,如,新浪网-新浪新闻,腾讯网-腾讯新闻...等等,地址末尾加...,如.,...等等。
2、保存网站地址的文件夹:将它们所在文件夹名称复制到web开发人员网站中,如web.js文件夹,web.actions文件夹。
3、建立网站,一般都是wordpress,这些网站域名指向一个建站的公众号即可。
4、同步我们建立好的网站文件夹到百度云,当然,为了节省用户的点击、收藏和分享数据量,wordpress,也是可以不收费的,免费用户为单网站建站5篇,不同网站需要不同的数量。这些文件夹的操作很简单,对你专业技术没有要求。
智能推荐也可以很业余,
当然可以了,不要看好评,好评只是给你一个参考,其实真正写了多少东西,网站设计的够不够好,很难给你确定的答案。
我想可以,不管是什么网站,关联两个网站都能起到提高文章曝光率,加强传播率的作用。
可以,可以分开搭建;只需要上传自己在这两个网站上撰写好的内容(可以转载,自己可重新创作等)。 查看全部
智能采集组合文章(智能采集组合文章内容:对百度百科,或是头条等这些有外部组合词关联的网站)
智能采集组合文章内容:对百度百科,或是知乎,或是头条等这些有外部组合词关联的网站,都可以用智能推荐来展示内容,
1、复制有外部关联词组合的网站地址,如,新浪网-新浪新闻,腾讯网-腾讯新闻...等等,地址末尾加...,如.,...等等。
2、保存网站地址的文件夹:将它们所在文件夹名称复制到web开发人员网站中,如web.js文件夹,web.actions文件夹。
3、建立网站,一般都是wordpress,这些网站域名指向一个建站的公众号即可。
4、同步我们建立好的网站文件夹到百度云,当然,为了节省用户的点击、收藏和分享数据量,wordpress,也是可以不收费的,免费用户为单网站建站5篇,不同网站需要不同的数量。这些文件夹的操作很简单,对你专业技术没有要求。
智能推荐也可以很业余,
当然可以了,不要看好评,好评只是给你一个参考,其实真正写了多少东西,网站设计的够不够好,很难给你确定的答案。
我想可以,不管是什么网站,关联两个网站都能起到提高文章曝光率,加强传播率的作用。
可以,可以分开搭建;只需要上传自己在这两个网站上撰写好的内容(可以转载,自己可重新创作等)。
智能采集组合文章(Web的组织格式主要以HTML页面和VSM网页分类模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-03 10:24
[摘要]:随着全球经济一体化进程的加快和我国加入WTO,市场竞争环境发生了翻天覆地的变化。企业决策者不再可能依靠直觉和本能来做出商业决策。为了做出正确的决策,往往需要对竞争对手进行分析,及时了解他们的情况。因此,一个完整的竞争情报采集系统变得必不可少。随着互联网的飞速发展,网络为人们储存了大量的知识,成为一个巨大的全球知识库。从网络上获取信息已经成为人们获取知识的主要方式。与此同时,越来越多的公司建立了网站。通过有效地采集公司网站,可以了解竞争对手并向其学习。 Web 的组织格式主要基于 HTML 页面的半结构化形式。网页的结构、自由无序的超链接,以及网页内容的海量、多样性和动态变化,使人们在使用时遇到了一些无法回避的困难。为了解决这些问题,本课题采用基于主题的信息采集分类资源管理平台。介绍了系统平台的结构和各部分的功能。重点介绍网页采集模块和VSM网页分类模块。为了实现这两个模块,本文介绍了Bot网页抓取和HTMLParser网页解析等技术。网页的标题、Meta标签的内容和父网页上指向该网页的锚文本,将这些信息存储在相应的位置,并根据这些信息使用VSM方法对网页进行分类。为下一步开发企业竞争情报采集系统奠定基础。 查看全部
智能采集组合文章(Web的组织格式主要以HTML页面和VSM网页分类模块)
[摘要]:随着全球经济一体化进程的加快和我国加入WTO,市场竞争环境发生了翻天覆地的变化。企业决策者不再可能依靠直觉和本能来做出商业决策。为了做出正确的决策,往往需要对竞争对手进行分析,及时了解他们的情况。因此,一个完整的竞争情报采集系统变得必不可少。随着互联网的飞速发展,网络为人们储存了大量的知识,成为一个巨大的全球知识库。从网络上获取信息已经成为人们获取知识的主要方式。与此同时,越来越多的公司建立了网站。通过有效地采集公司网站,可以了解竞争对手并向其学习。 Web 的组织格式主要基于 HTML 页面的半结构化形式。网页的结构、自由无序的超链接,以及网页内容的海量、多样性和动态变化,使人们在使用时遇到了一些无法回避的困难。为了解决这些问题,本课题采用基于主题的信息采集分类资源管理平台。介绍了系统平台的结构和各部分的功能。重点介绍网页采集模块和VSM网页分类模块。为了实现这两个模块,本文介绍了Bot网页抓取和HTMLParser网页解析等技术。网页的标题、Meta标签的内容和父网页上指向该网页的锚文本,将这些信息存储在相应的位置,并根据这些信息使用VSM方法对网页进行分类。为下一步开发企业竞争情报采集系统奠定基础。
智能采集组合文章(优采云软件独家首创智能的万能文章采集器识别算法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-01 19:02
<p>优采云Universal文章采集器是基于高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源()和泛页面(),支持采集指定网站栏目所有文章。 查看全部
智能采集组合文章(智能采集组合文章防点击,将站内seo转换为精准seo)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-31 01:02
智能采集组合文章防点击,同时将站内公共seo转换为精准seo大数据技术团队目前公司在积极开发新的产品,包括数据统计系统、站内seo各个模块等等。首先,是让网站收录更多内容。seoer通过大数据分析工具可以发现网站长尾关键词,这些长尾关键词将是你网站seo优化的重点,另外部分网站收录排名不是很好,可以先将长尾关键词布局在网站的不同页面,也能增加收录排名。
其次,是需要完善网站ip分布、收录分布,将搜索引擎关键词排名的效果展现给搜索引擎。目前网站ip没有统计,根据采集的长尾关键词收录分布的百分比来粗略估算ip值,ip总数量可以上“网站推广排名助手”(专业的网站推广工具)-内容丰富版进行统计,这个值可以帮助seoer获取更多自然流量。第三,就是不断保持网站内页清爽利索,加强站内seo文章的质量。
一个新的站点其核心栏目很多seoer都会花重金布局内容,这是一个良性循环,但千万不要花多余的钱去做大段文字,因为这样会影响用户体验,且对搜索引擎更新大数据是没有帮助的。举例:要查看一个网站是否更新存活率。可以在大数据工具-长尾关键词分析-访问或访问时间地点看一下网站的更新存活率,以及大数据工具-关键词分析——访问人数排名——数量分布,这三个数据分析,能直观的看到长尾关键词这段时间没有被大量的爬虫爬取而排名下降,这是比较好理解的。
总之,网站还需要定期清理无用内容,如人工整理,使其保持清洁。第四,就是站内seo优化文章质量。其实很多seoer认为seo就是文章技术,但是一个好的seo文章是否可以获得访问者认可,还需要通过很多因素来判断。seo除了文章优化好以外,另外一点非常重要就是关键词的设置以及和其他网站内容建设是否搭配好。比如一个文章排名首页,另外一个文章排名的话排名确实不错,但是访问者会错过网站的一些很有价值的文章,导致网站更新存活率不高。
目前有非常多的站点,正在出现内容垃圾比较多、知识网络非常混乱的情况,导致用户体验度下降,甚至降权降权降权!第五,就是要让搜索引擎看到你的网站是经过了用心保持内容更新的。很多seoer还没意识到这一点,通过大数据,你可以判断这个网站是否经过了精心、保持了足够的更新。目前很多网站会每天进行更新。另外从大数据的统计数据可以看到权重大的网站,就是他们大部分的内容要么是图片也要就是文字部分的广告,网站每天还要更新。
所以网站的内容越清晰,优质的内容就越多。第六,就是要让用户体验度高,服务态度要好。这个难点的要求是比较高的,举例:一个网站服务态度。 查看全部
智能采集组合文章(智能采集组合文章防点击,将站内seo转换为精准seo)
智能采集组合文章防点击,同时将站内公共seo转换为精准seo大数据技术团队目前公司在积极开发新的产品,包括数据统计系统、站内seo各个模块等等。首先,是让网站收录更多内容。seoer通过大数据分析工具可以发现网站长尾关键词,这些长尾关键词将是你网站seo优化的重点,另外部分网站收录排名不是很好,可以先将长尾关键词布局在网站的不同页面,也能增加收录排名。
其次,是需要完善网站ip分布、收录分布,将搜索引擎关键词排名的效果展现给搜索引擎。目前网站ip没有统计,根据采集的长尾关键词收录分布的百分比来粗略估算ip值,ip总数量可以上“网站推广排名助手”(专业的网站推广工具)-内容丰富版进行统计,这个值可以帮助seoer获取更多自然流量。第三,就是不断保持网站内页清爽利索,加强站内seo文章的质量。
一个新的站点其核心栏目很多seoer都会花重金布局内容,这是一个良性循环,但千万不要花多余的钱去做大段文字,因为这样会影响用户体验,且对搜索引擎更新大数据是没有帮助的。举例:要查看一个网站是否更新存活率。可以在大数据工具-长尾关键词分析-访问或访问时间地点看一下网站的更新存活率,以及大数据工具-关键词分析——访问人数排名——数量分布,这三个数据分析,能直观的看到长尾关键词这段时间没有被大量的爬虫爬取而排名下降,这是比较好理解的。
总之,网站还需要定期清理无用内容,如人工整理,使其保持清洁。第四,就是站内seo优化文章质量。其实很多seoer认为seo就是文章技术,但是一个好的seo文章是否可以获得访问者认可,还需要通过很多因素来判断。seo除了文章优化好以外,另外一点非常重要就是关键词的设置以及和其他网站内容建设是否搭配好。比如一个文章排名首页,另外一个文章排名的话排名确实不错,但是访问者会错过网站的一些很有价值的文章,导致网站更新存活率不高。
目前有非常多的站点,正在出现内容垃圾比较多、知识网络非常混乱的情况,导致用户体验度下降,甚至降权降权降权!第五,就是要让搜索引擎看到你的网站是经过了用心保持内容更新的。很多seoer还没意识到这一点,通过大数据,你可以判断这个网站是否经过了精心、保持了足够的更新。目前很多网站会每天进行更新。另外从大数据的统计数据可以看到权重大的网站,就是他们大部分的内容要么是图片也要就是文字部分的广告,网站每天还要更新。
所以网站的内容越清晰,优质的内容就越多。第六,就是要让用户体验度高,服务态度要好。这个难点的要求是比较高的,举例:一个网站服务态度。
智能采集组合文章(很不错的文章处理工具#8203;#38;功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-28 06:16
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。很不错的文章处理工具#8203;。
相关软件软件大小版本说明下载地址
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。是一款非常不错的文章处理工具。
特征
1、智能伪原创:利用人工智能中的自然语言处理技术,实现文章的伪原创处理。核心功能包括“智能伪原创”、“同义词替代伪原创”、“反义词替代伪原创”、“在带有html代码的文章中随机插入关键词”、“句子打乱重组”等,处理后期文章原创性和接受率均在80%以上。想了解更多功能,请下载软件试用。
2、 门户文章集:一键搜索相关门户新闻文章集,如搜狐、腾讯、新浪、网易、今日头条、新兰网、联合早报、光明.com、站长网、新文化网等,用户可以输入行业关键词,搜索自己想要的行业文章。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
3、百度新闻精选:一键搜索各行各业的新闻文章。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。但是,缺点是采集
的文章不一定很好。齐全,但能满足大部分用户的需求。友情提示:使用文章时,请注明文章出处,尊重原文版权。
4、行业文章集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等。网站上有几十个网站,资源丰富。该模块可能无法满足所有客户的需求,但客户可以提出自己的需求。我们将改进和更新模块资源。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
5、写采集
规则:自己写采集
规则。采集
规则符合常见的正则表达式。编写集合规则,需要了解一些html代码和正则表达式规则。如果您为其他商家的收款软件编写了收款规则,那么我们一定会写我们软件的收款规则,我们提供了编写收款规则的文档。我们不帮客户写收款规则,如果您需要代写,10元一个收款规则。友情提示:使用文章时,请注明文章出处,尊重原文版权。
6、 外链文章素材:本模块使用大量行业语料,通过算法随机组合语料,生成相关行业文章。本模块文章仅适用于对文章质量要求不高,用于外链推广的用户。本模块 特点,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、标题的批量生产:有两个功能,一是通过关键词和规则的结合来批量生产标题,二是通过采集
网络大数据来获取标题。自动生成的推广准确率高,采集
的标题可读性强,各有优缺点。
8、 文章界面发布:通过简单的配置,将生成的文章一键发布到您的网站。目前支持的网站有 Discuz 门户、DedeCms、Empire ECMS(新闻)、PHMCMS、奇博 CMS、PHP168、diypage、phpwind 门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
智能采集组合文章(很不错的文章处理工具#8203;#38;功能介绍)
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。很不错的文章处理工具#8203;。
相关软件软件大小版本说明下载地址
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。是一款非常不错的文章处理工具。

特征
1、智能伪原创:利用人工智能中的自然语言处理技术,实现文章的伪原创处理。核心功能包括“智能伪原创”、“同义词替代伪原创”、“反义词替代伪原创”、“在带有html代码的文章中随机插入关键词”、“句子打乱重组”等,处理后期文章原创性和接受率均在80%以上。想了解更多功能,请下载软件试用。
2、 门户文章集:一键搜索相关门户新闻文章集,如搜狐、腾讯、新浪、网易、今日头条、新兰网、联合早报、光明.com、站长网、新文化网等,用户可以输入行业关键词,搜索自己想要的行业文章。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
3、百度新闻精选:一键搜索各行各业的新闻文章。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。但是,缺点是采集
的文章不一定很好。齐全,但能满足大部分用户的需求。友情提示:使用文章时,请注明文章出处,尊重原文版权。
4、行业文章集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等。网站上有几十个网站,资源丰富。该模块可能无法满足所有客户的需求,但客户可以提出自己的需求。我们将改进和更新模块资源。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
5、写采集
规则:自己写采集
规则。采集
规则符合常见的正则表达式。编写集合规则,需要了解一些html代码和正则表达式规则。如果您为其他商家的收款软件编写了收款规则,那么我们一定会写我们软件的收款规则,我们提供了编写收款规则的文档。我们不帮客户写收款规则,如果您需要代写,10元一个收款规则。友情提示:使用文章时,请注明文章出处,尊重原文版权。
6、 外链文章素材:本模块使用大量行业语料,通过算法随机组合语料,生成相关行业文章。本模块文章仅适用于对文章质量要求不高,用于外链推广的用户。本模块 特点,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、标题的批量生产:有两个功能,一是通过关键词和规则的结合来批量生产标题,二是通过采集
网络大数据来获取标题。自动生成的推广准确率高,采集
的标题可读性强,各有优缺点。
8、 文章界面发布:通过简单的配置,将生成的文章一键发布到您的网站。目前支持的网站有 Discuz 门户、DedeCms、Empire ECMS(新闻)、PHMCMS、奇博 CMS、PHP168、diypage、phpwind 门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
智能采集组合文章( 友盟+:移动数据采集特点与PC端不同的演进)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-27 10:01
友盟+:移动数据采集特点与PC端不同的演进)
本文由【友盟+】技术专家马巍源、张永峰共同撰稿
随着移动互联网和大数据技术的发展,以及智能手机的普及,几乎所有的工作、学习、生活场景都离不开手机。手机APP取代了传统的生活方式,让人们体验到便捷高效的服务,当然也承载着海量丰富的信息。从这些APP中采集
数据,集中清理和分析数据,可以将这些海量数据转化为宝贵的数据能量。数据采集是数据能源发展的第一步。如何采集数据,什么样的技术架构可以支持海量数据的采集、筛选和传输,是本文需要讨论的问题。
移动数据采集功能
与PC端不同,对于手机、iPad、智能手表、电视盒等移动设备,我们接触它们的载体是APP。Native SDK 需要大量的开发资源来支持多语言支持。跨平台应用开发正在逐渐成为一种趋势,但是各个框架中JS SDK的实现也不尽相同。因此,目前的移动采集SDK在支持多平台、多语言方面比较难支持。
更难的是安卓设备的机型适配。由于Android系统的开源特性,各家厂商为了在各机型上都有更好的用户体验,都进行了针对性的ROM改进。尤其是近几年,Android 在虚拟机和编译器上都做了很大的改变。这给模型适配带来了更大的困难。为了不给APP卡死、死机、黑屏、死机、加载速度慢等不良体验,还需要支持开发者的各种异常接口调用,并且需要有很强的容错能力。
移动流量持续增长。【友盟+】移动端应用超过135万款,覆盖全球超过14亿的日活跃移动设备,每天处理280亿条数据。测试我们采集SDK和服务器的承载能力,【友盟+】在移动采集技术上不断更新迭代,连续多年保持市场覆盖率领先。
SDK与服务端通信协议演进
我们最初的SDK设计思路简单高效,所以SDK端没有数据预处理的逻辑,甚至缓存策略也很简单。所有实时生成的数据都会实时上报给服务器。但是随着移动端流量的暴涨,这种高并发的请求给服务器带来了很大的压力。下图是版本0的通讯协议。
所以考虑通过控制发送频率来降低并发。开发者可以根据业务需求采用不同的发送策略:开始发送、间隔发送、退出发送,并且可以在【友盟+】平台上随时更改。虽然有效地减轻了服务器端的压力,但也带来了另一个问题。单条数据的大小可能会超过request-body的上限,导致请求超时。而流动压力也是一个急需解决的问题。因此,在2.0 版本中,我们压缩了数据并添加了安全机制。服务器增加了数据预处理的逻辑,完善了数据的校验。
只能在一个方向上通信的协议是不灵活的。很多时候我们需要控制SDK的行为,比如修改发送策略,屏蔽错误的数据,或者发现数据被污染而决定丢弃。需要通知这些运行中的服务器。SDK,以及没有长连接怎么办。在3.0版本中,我们设计了http请求响应的信息包体的控制语义。SDK除了从响应中获取服务器的接收状态外,还可以获取服务器的控制指令,以达到服务器的预期效果。
如果每个Log都必须等待解析服务器返回的控制信息,显然服务器对数据处理的及时性和并发处理能力会大打折扣,部分业务数据实际上并不需要解析和执行这些控制信息。因此,我们对业务数据进行了精细的分解。一些业务数据使用双向通信协议,可以解析和执行控制命令。其余的业务数据是与状态无关的数据,仍然使用单向通信协议。
那么在未来,控制协议和服务传输协议其实可以分开,各自使用不同的传输频率,但是可以保证所有的服务数据都由服务器的指令控制。
SDK技术架构分析
移动数据采集SDK架构主要由三部分组成:用户界面、业务模块、控制模块。
我们可以从几个场景的时序图分析这些模块的工作原理。
APP启动
当用户启动App时,实际上触发了开发者调用的初始化接口。Service Moudle 和 Control Moudle 会异步执行一些初始化操作:创建 Session、加载设备信息等。
APP在前台运行
当用户在APP中点击或滑动屏幕时,会触发开发者在APP中预设埋点事件。
Servie Moudle 会生成相应的事件数据,调用 Control Moudle 接口检查发送策略和安全策略,然后 Servie Moudle 将事件数据放入缓存队列中进行发送。
APP退出
无论用户退出APP后,SDK都会在短时间内完成多项操作:结束会话,持久保存数据,直接在iOS中完成数据打包、打包、上报等工作。
SDK组件化架构
我们提供越来越多的产品功能和越来越复杂的业务场景。为了满足各种解决方案的需求,SDK需要为每个业务场景维护多个分支、多个版本,浪费开发资源,并且版本迭代周期被拉长。为了解决这个问题,我们必须设计一个灵活的架构,让每个产品功能成为一个可以自由组合和拆卸的组件。
组件化将统一约定包和公共API的文件规范。针对当前【友盟+】业务需求,建立标准的SDK产品公共库(如:网络、序列化、配置、缓存等),组件结构分为两部分,Common将作为独立的library 包,和 Component 中的每个产品都作为一个独立的库。
其结构如下:
灵活的业务组合,适用更多场景
组件划分的粒度可以根据业务需要而定。我们的设计是根据产品或业务来划分组件。一个产品可能收录
许多功能。例如,统计产品包括事件数据采集、错误数据采集、A/B Test等功能。推送产品包括消息推送和应用内消息。在某些场景下,一些开发人员可能只使用其中的一部分。以函数为例,只使用错误分析函数和Push消息推送,然后将组件粒度细化到功能层,会更加灵活,可以满足更多场景的需求,体积的减小对于开发人员有吸引力。
业务逻辑解耦,代码更健壮
组件化架构改变了以往业务逻辑与基础功能的深度耦合。业务开发者可以专注于业务逻辑的实现,而无需考虑网络通信、消息队列管理、设备信息采集等基本功能的实现。业务逻辑代码的任何改动都不会影响基本的功能逻辑,增强了代码的健壮性,大大缩短了回归测试周期。
【友盟+】数据采集技术将不断适应业务场景的变化。未来,我们的目标是让我们的SDK更智能、更安全,让企业和开发者的整合更简单、数据更准确。 查看全部
智能采集组合文章(
友盟+:移动数据采集特点与PC端不同的演进)
本文由【友盟+】技术专家马巍源、张永峰共同撰稿
随着移动互联网和大数据技术的发展,以及智能手机的普及,几乎所有的工作、学习、生活场景都离不开手机。手机APP取代了传统的生活方式,让人们体验到便捷高效的服务,当然也承载着海量丰富的信息。从这些APP中采集
数据,集中清理和分析数据,可以将这些海量数据转化为宝贵的数据能量。数据采集是数据能源发展的第一步。如何采集数据,什么样的技术架构可以支持海量数据的采集、筛选和传输,是本文需要讨论的问题。
移动数据采集功能
与PC端不同,对于手机、iPad、智能手表、电视盒等移动设备,我们接触它们的载体是APP。Native SDK 需要大量的开发资源来支持多语言支持。跨平台应用开发正在逐渐成为一种趋势,但是各个框架中JS SDK的实现也不尽相同。因此,目前的移动采集SDK在支持多平台、多语言方面比较难支持。
更难的是安卓设备的机型适配。由于Android系统的开源特性,各家厂商为了在各机型上都有更好的用户体验,都进行了针对性的ROM改进。尤其是近几年,Android 在虚拟机和编译器上都做了很大的改变。这给模型适配带来了更大的困难。为了不给APP卡死、死机、黑屏、死机、加载速度慢等不良体验,还需要支持开发者的各种异常接口调用,并且需要有很强的容错能力。
移动流量持续增长。【友盟+】移动端应用超过135万款,覆盖全球超过14亿的日活跃移动设备,每天处理280亿条数据。测试我们采集SDK和服务器的承载能力,【友盟+】在移动采集技术上不断更新迭代,连续多年保持市场覆盖率领先。
SDK与服务端通信协议演进
我们最初的SDK设计思路简单高效,所以SDK端没有数据预处理的逻辑,甚至缓存策略也很简单。所有实时生成的数据都会实时上报给服务器。但是随着移动端流量的暴涨,这种高并发的请求给服务器带来了很大的压力。下图是版本0的通讯协议。

所以考虑通过控制发送频率来降低并发。开发者可以根据业务需求采用不同的发送策略:开始发送、间隔发送、退出发送,并且可以在【友盟+】平台上随时更改。虽然有效地减轻了服务器端的压力,但也带来了另一个问题。单条数据的大小可能会超过request-body的上限,导致请求超时。而流动压力也是一个急需解决的问题。因此,在2.0 版本中,我们压缩了数据并添加了安全机制。服务器增加了数据预处理的逻辑,完善了数据的校验。

只能在一个方向上通信的协议是不灵活的。很多时候我们需要控制SDK的行为,比如修改发送策略,屏蔽错误的数据,或者发现数据被污染而决定丢弃。需要通知这些运行中的服务器。SDK,以及没有长连接怎么办。在3.0版本中,我们设计了http请求响应的信息包体的控制语义。SDK除了从响应中获取服务器的接收状态外,还可以获取服务器的控制指令,以达到服务器的预期效果。

如果每个Log都必须等待解析服务器返回的控制信息,显然服务器对数据处理的及时性和并发处理能力会大打折扣,部分业务数据实际上并不需要解析和执行这些控制信息。因此,我们对业务数据进行了精细的分解。一些业务数据使用双向通信协议,可以解析和执行控制命令。其余的业务数据是与状态无关的数据,仍然使用单向通信协议。

那么在未来,控制协议和服务传输协议其实可以分开,各自使用不同的传输频率,但是可以保证所有的服务数据都由服务器的指令控制。
SDK技术架构分析
移动数据采集SDK架构主要由三部分组成:用户界面、业务模块、控制模块。

我们可以从几个场景的时序图分析这些模块的工作原理。
APP启动

当用户启动App时,实际上触发了开发者调用的初始化接口。Service Moudle 和 Control Moudle 会异步执行一些初始化操作:创建 Session、加载设备信息等。
APP在前台运行

当用户在APP中点击或滑动屏幕时,会触发开发者在APP中预设埋点事件。
Servie Moudle 会生成相应的事件数据,调用 Control Moudle 接口检查发送策略和安全策略,然后 Servie Moudle 将事件数据放入缓存队列中进行发送。
APP退出

无论用户退出APP后,SDK都会在短时间内完成多项操作:结束会话,持久保存数据,直接在iOS中完成数据打包、打包、上报等工作。
SDK组件化架构
我们提供越来越多的产品功能和越来越复杂的业务场景。为了满足各种解决方案的需求,SDK需要为每个业务场景维护多个分支、多个版本,浪费开发资源,并且版本迭代周期被拉长。为了解决这个问题,我们必须设计一个灵活的架构,让每个产品功能成为一个可以自由组合和拆卸的组件。
组件化将统一约定包和公共API的文件规范。针对当前【友盟+】业务需求,建立标准的SDK产品公共库(如:网络、序列化、配置、缓存等),组件结构分为两部分,Common将作为独立的library 包,和 Component 中的每个产品都作为一个独立的库。
其结构如下:

灵活的业务组合,适用更多场景
组件划分的粒度可以根据业务需要而定。我们的设计是根据产品或业务来划分组件。一个产品可能收录
许多功能。例如,统计产品包括事件数据采集、错误数据采集、A/B Test等功能。推送产品包括消息推送和应用内消息。在某些场景下,一些开发人员可能只使用其中的一部分。以函数为例,只使用错误分析函数和Push消息推送,然后将组件粒度细化到功能层,会更加灵活,可以满足更多场景的需求,体积的减小对于开发人员有吸引力。

业务逻辑解耦,代码更健壮
组件化架构改变了以往业务逻辑与基础功能的深度耦合。业务开发者可以专注于业务逻辑的实现,而无需考虑网络通信、消息队列管理、设备信息采集等基本功能的实现。业务逻辑代码的任何改动都不会影响基本的功能逻辑,增强了代码的健壮性,大大缩短了回归测试周期。
【友盟+】数据采集技术将不断适应业务场景的变化。未来,我们的目标是让我们的SDK更智能、更安全,让企业和开发者的整合更简单、数据更准确。
智能采集组合文章(本文将PDCA戴明循环与关联规则数据挖掘方法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-12-27 09:11
周丽丽王宝军梁文敏袁秋平梁玉娟
摘要:本文对电子商务产品销售组合的智能构建进行研究,将关联规则融入到PDCA循环中,并利用其螺旋式和持续优化机制不断改进和完善关联规则的生成,即将结束。将不断变化的消费者需求因素引入到产品组合的构建中,从而帮助电子商务企业智能、动态地构建和优化产品组合。
关键词:关联规则;PDCA; 产品简介; 电子商务
一、简介
随着电子商务的快速发展,企业之间的竞争不断加剧。如何有效地为消费者推送产品组合,已成为电商企业提高客单价和盈利能力的重要手段。传统的产品销售组合往往依赖于经营者的个人经验和静态统计分析,时效性滞后,准确性不足。本文将PDCA戴明环与关联规则数据挖掘方法相结合,帮助企业开展产品组合智能构建的研究,利用企业的历史交易数据,动态准确地智能构建产品组合。
二、研究背景及相关理论
1.研究背景
国内外学者对大数据、数据挖掘技术与电子商务的结合进行了大量研究,但对数据挖掘与电子商务产品组合的研究较少,与管理方法相结合的研究较少。更缺乏。本文综合应用了PDCA循环管理思想和关联规则。通过计划、执行、检查、处理的迭代思维,利用持续的周期调整和优化,实时、动态、准确地生成产品组合。
2.相关理论
(1) 关联规则
关联规则是数据挖掘的一项重要技术,它反映了一件事与另一件事之间的相互依赖和关联。关联规则挖掘的目的是发现强关联规则,即从数据中挖掘出满足用户设置的最小支持度和最小置信度规则的数据。
关联规则的一般表示为:X->Y (S=s%, C=c%)
其中:X表示前一个项目可以是一个项目或项目集,Y表示后一个项目一般是一个项目。
Support (X->Y)=P(X∪Y) 是消费者同时购买X和Y的概率。
Confidence (X->Y)=P(Y|X) 是消费者在购买 X 后购买 Y 的条件概率。
Lift(X->Y)=P(Y|X)/P(X)P(Y)是判断关联规则实用性的指标。当lift大于1时,表示X对Y有正提升,如果小于1,则X和Y为负,如果等于1,则表示没有相关性。
本文将选择Apriori作为挖掘关联规则的算法。该算法具有单维、单层、布尔的特点,是一种经典的关联规则算法。
(2)PDCA 循环
PDCA循环将管理分为四个阶段,是一个连续的工作循环。每次经过PDCA循环,都要进行检查总结,分析遗留问题,提出新目标,再优化循环。
(3)产品组合
产品组合是指销售者可以向消费者提供的产品或物品的完整集合或组合。产品往往是相关的,可以同时引导消费者购买。产品组合的设计可以帮助企业优化客户。体验,提高客户转化率和客户单价。
三、模型设计
企业在经营过程中,会积累客户消费的历史记录。这些历史记录收录
不同消费者的购物清单。关联规则通过分析这些历史购物清单来发现产品之间的联系,进而挖掘出一系列的产品组合。. 该模型可以按照固定时间段或固定销售量对样本数据进行分组,并基于PDCA循环实现多重数据分析和挖掘。本文中的两轮PDCA分组如下:
2020年11月1日至2020年12月13日,A组样本1641个,A组验证组数据652个。
2020年12月14日至2021年1月28日,B组样本数据为1975个,B组验证组数据为1248个。
并按照以下流程进行两轮PDCA循环数据挖掘,分析模型如下图所示:
(1)Plan:实现目标和计划制定;(2)Do:关联规则模型设置和运行;
(3)Check:计算验证组的概率值并进行结果检查;(4)Act:效果评估和优化参数。
四、数据准备与实验分析
1.数据准备
(1)数据源
本文选取销量较高的化妆品天猫旗舰店为研究对象,利用优采云
数据采集软件抓取上述时间段内店内所有商品的评论内容,结合购买用户信息、购买时间和产品SKU模拟 恢复交易订单。本文采集
全店约5万条评论数据,模拟5516笔交易订单。
(2)数据预处理
本文选取用户标识和产品标识信息两个数据项,然后对数据进行转换、清洗等预处理操作,得到如表1所示的购物篮数据,并基于精确数据进行数据挖掘类型通过关联规则挖掘算法,对挖掘结果进行分析和评价。
①计划:制定实施目标和计划
第一轮,企业可以通过智能产品组合的构建,提升产品推送的精准度,促进消费者相关购买,提升消费者体验,提高企业客户单价,利用历史交易数据的关联规则挖掘,帮助企业推送产品组合自动。
②Do:关联规则模型设置和操作
使用R语言对采集到的数据进行处理。综合分析,本轮参数设置为:最小支持度1.1%,最小置信度50%,通过R语言导入1641条A组交易样本数据, 运行 Apriori 算法如下:
一共生成了24条关联规则。将关联规则的提升排序后,前8条关联规则如表2所示。
产生的24条规则置信度超过50%,提升幅度远大于1,说明规则有效且具有实用价值,即购买左边物品的买家很有可能购买同时右侧的项目。比如“气垫BB霜&冰冻水润唇釉->丝绒哑光唇膏”的支持度和置信度都很高,提升度达到了72。这三款产品同时非常适合作为相关产品它也适用于捆绑销售作为一个包。
根据生成的关联规则,企业可以以此为基础生成产品组合,并在关联营销中推送产品组合,让客户更方便的浏览到需要的产品,获取需要的组合包,促进客户的捆绑销售, 增加销量,提升购物体验。
③Check:计算验证组的概率值并进行结果检查
接下来,将A组样本数据生成的关联规则在A组验证组的数据中进行校验,计算出现在验证数据中的关联规则的置信度,找到生成的关联规则在验证集中更高。规则的置信度表明规则是高度可靠的。表 3 显示了验证组中前 8 条关联规则的置信度。
④Act:效果评价及优化参数
本轮执行产生了具有较好评价指标的关联规则,验证了这些规则的有效性和实用性。公司可以将这些规则应用于产品组合关联营销、产品包装设计和客户接触点优化。但是,也缺乏关联规则和可以覆盖的产品类型。
(2)第二轮PDCA
①计划:制定实施目标和计划
经过上一轮PDCA运算,企业能够挖掘出一系列高质量的关联规则,但数量少,覆盖的产品也少。因此,本轮需要调整支持度和置信度参数,在结果分析过程中需要考虑消费者需求变化。
②Do:关联规则模型设置和操作
本轮最低支持度0.7%,最低置信度35%。1975条B组交易样本数据通过R语言导入,Apriori算法运行如下:
一共生成了36条关联规则。将关联规则的提升程度排序后,前8条关联规则如表4所示。本轮关联规则数量有所提升。规则的支持度虽然有所降低,但还是出现了较高的频率,置信度处于较高水平。规则的增加远大于1,规则的有效性很高。和实用性。
③Check:计算验证组的概率值并进行结果检查
通过计算B组验证数据中规则的置信度,获得更高的置信度。因此,验证了生成的关联规则的结果具有较高的可信度。表 5 显示前 8 条关联规则在学校。测试组的信心。
④Act:效果评价及优化参数
根据本轮的执行,产生了更多的关联规则,而且都是高效实用的,可以覆盖更多的产品。企业可以使用这种方法来构建智能产品组合。此外,企业需要根据第一轮和第二轮产品关联规则的差异,了解季节性、活动性和流行趋势对产品组合的影响,与时俱进,不断优化和更新产品。文件夹。
3.实验结果分析
(1)本文的两轮PDCA过程虽然得到了高质量的关联规则,但是支持度和置信度的设置会极大地影响关联规则的生成。关联规则的支持度和置信度的调整整合在PDCA循环中,将实现参数的细化和动态调整。
(2)根据时间维度或销售维度对数据源进行合理划分,可以有效帮助企业挖掘贴近市场需求变化的关联规则。
(3)企业可以根据支持、信心、推广的变化趋势跟踪生成的关联规则的发展趋势,帮助企业更早地捕捉到产品和产品组合的需求和生命周期变化。
(4)企业可以对多轮PDCA循环产生的规则进行统计分析,根据关联规则随时间变化的程度,实施不同的营销策略。
五、总结
本文结合PDCA管理方法和关联规则数据挖掘算法,实现了数据挖掘算法在企业业务应用中的标准设计。通过PDCA循环迭代和螺旋机制,动态调整关联规则算法的应用,保证数据挖掘。效果的可靠性和实用性。通过多轮PDCA循环迭代,企业可以有效积累时间维度关联规则,帮助企业识别产品和产品组合的变化趋势和生命周期,帮助企业更全面、更系统地实现产品。组合的智能化建设。
参考:
[1] 李东云. 利用关联规则挖掘技术实现数字图书馆个性化推荐服务[J]. 2020年兰台内外(34):40-42.
[2] 郝海涛,马媛媛.基于加权关联规则挖掘算法的电子商务产品推荐系统研究[J]. 现代电子技术, 2016, 39 (15): 133-136.
[3]菲利普·科特勒,加里·阿姆斯特朗。市场营销概论[M].中国出版社,1998.
[4]朱庆.结合关联规则挖掘算法的信息化教学管理系统设计[J]. 现代电子技术, 2020, 43 (23): 159-163.
作者简介:周丽丽(1999.07-),女,汉族,籍贯:广东省揭阳市,本科,研究方向:电子商务;通讯作者:王宝军(1985.08-),男,汉族,籍贯:江西省景德镇市,研究生,工程师,研究方向:电子商务、数据挖掘 查看全部
智能采集组合文章(本文将PDCA戴明循环与关联规则数据挖掘方法(图))
周丽丽王宝军梁文敏袁秋平梁玉娟



摘要:本文对电子商务产品销售组合的智能构建进行研究,将关联规则融入到PDCA循环中,并利用其螺旋式和持续优化机制不断改进和完善关联规则的生成,即将结束。将不断变化的消费者需求因素引入到产品组合的构建中,从而帮助电子商务企业智能、动态地构建和优化产品组合。
关键词:关联规则;PDCA; 产品简介; 电子商务
一、简介
随着电子商务的快速发展,企业之间的竞争不断加剧。如何有效地为消费者推送产品组合,已成为电商企业提高客单价和盈利能力的重要手段。传统的产品销售组合往往依赖于经营者的个人经验和静态统计分析,时效性滞后,准确性不足。本文将PDCA戴明环与关联规则数据挖掘方法相结合,帮助企业开展产品组合智能构建的研究,利用企业的历史交易数据,动态准确地智能构建产品组合。
二、研究背景及相关理论
1.研究背景
国内外学者对大数据、数据挖掘技术与电子商务的结合进行了大量研究,但对数据挖掘与电子商务产品组合的研究较少,与管理方法相结合的研究较少。更缺乏。本文综合应用了PDCA循环管理思想和关联规则。通过计划、执行、检查、处理的迭代思维,利用持续的周期调整和优化,实时、动态、准确地生成产品组合。
2.相关理论
(1) 关联规则
关联规则是数据挖掘的一项重要技术,它反映了一件事与另一件事之间的相互依赖和关联。关联规则挖掘的目的是发现强关联规则,即从数据中挖掘出满足用户设置的最小支持度和最小置信度规则的数据。
关联规则的一般表示为:X->Y (S=s%, C=c%)
其中:X表示前一个项目可以是一个项目或项目集,Y表示后一个项目一般是一个项目。
Support (X->Y)=P(X∪Y) 是消费者同时购买X和Y的概率。
Confidence (X->Y)=P(Y|X) 是消费者在购买 X 后购买 Y 的条件概率。
Lift(X->Y)=P(Y|X)/P(X)P(Y)是判断关联规则实用性的指标。当lift大于1时,表示X对Y有正提升,如果小于1,则X和Y为负,如果等于1,则表示没有相关性。
本文将选择Apriori作为挖掘关联规则的算法。该算法具有单维、单层、布尔的特点,是一种经典的关联规则算法。
(2)PDCA 循环
PDCA循环将管理分为四个阶段,是一个连续的工作循环。每次经过PDCA循环,都要进行检查总结,分析遗留问题,提出新目标,再优化循环。
(3)产品组合
产品组合是指销售者可以向消费者提供的产品或物品的完整集合或组合。产品往往是相关的,可以同时引导消费者购买。产品组合的设计可以帮助企业优化客户。体验,提高客户转化率和客户单价。
三、模型设计
企业在经营过程中,会积累客户消费的历史记录。这些历史记录收录
不同消费者的购物清单。关联规则通过分析这些历史购物清单来发现产品之间的联系,进而挖掘出一系列的产品组合。. 该模型可以按照固定时间段或固定销售量对样本数据进行分组,并基于PDCA循环实现多重数据分析和挖掘。本文中的两轮PDCA分组如下:
2020年11月1日至2020年12月13日,A组样本1641个,A组验证组数据652个。
2020年12月14日至2021年1月28日,B组样本数据为1975个,B组验证组数据为1248个。
并按照以下流程进行两轮PDCA循环数据挖掘,分析模型如下图所示:
(1)Plan:实现目标和计划制定;(2)Do:关联规则模型设置和运行;
(3)Check:计算验证组的概率值并进行结果检查;(4)Act:效果评估和优化参数。
四、数据准备与实验分析
1.数据准备
(1)数据源
本文选取销量较高的化妆品天猫旗舰店为研究对象,利用优采云
数据采集软件抓取上述时间段内店内所有商品的评论内容,结合购买用户信息、购买时间和产品SKU模拟 恢复交易订单。本文采集
全店约5万条评论数据,模拟5516笔交易订单。
(2)数据预处理
本文选取用户标识和产品标识信息两个数据项,然后对数据进行转换、清洗等预处理操作,得到如表1所示的购物篮数据,并基于精确数据进行数据挖掘类型通过关联规则挖掘算法,对挖掘结果进行分析和评价。
①计划:制定实施目标和计划
第一轮,企业可以通过智能产品组合的构建,提升产品推送的精准度,促进消费者相关购买,提升消费者体验,提高企业客户单价,利用历史交易数据的关联规则挖掘,帮助企业推送产品组合自动。
②Do:关联规则模型设置和操作
使用R语言对采集到的数据进行处理。综合分析,本轮参数设置为:最小支持度1.1%,最小置信度50%,通过R语言导入1641条A组交易样本数据, 运行 Apriori 算法如下:
一共生成了24条关联规则。将关联规则的提升排序后,前8条关联规则如表2所示。
产生的24条规则置信度超过50%,提升幅度远大于1,说明规则有效且具有实用价值,即购买左边物品的买家很有可能购买同时右侧的项目。比如“气垫BB霜&冰冻水润唇釉->丝绒哑光唇膏”的支持度和置信度都很高,提升度达到了72。这三款产品同时非常适合作为相关产品它也适用于捆绑销售作为一个包。
根据生成的关联规则,企业可以以此为基础生成产品组合,并在关联营销中推送产品组合,让客户更方便的浏览到需要的产品,获取需要的组合包,促进客户的捆绑销售, 增加销量,提升购物体验。
③Check:计算验证组的概率值并进行结果检查
接下来,将A组样本数据生成的关联规则在A组验证组的数据中进行校验,计算出现在验证数据中的关联规则的置信度,找到生成的关联规则在验证集中更高。规则的置信度表明规则是高度可靠的。表 3 显示了验证组中前 8 条关联规则的置信度。
④Act:效果评价及优化参数
本轮执行产生了具有较好评价指标的关联规则,验证了这些规则的有效性和实用性。公司可以将这些规则应用于产品组合关联营销、产品包装设计和客户接触点优化。但是,也缺乏关联规则和可以覆盖的产品类型。
(2)第二轮PDCA
①计划:制定实施目标和计划
经过上一轮PDCA运算,企业能够挖掘出一系列高质量的关联规则,但数量少,覆盖的产品也少。因此,本轮需要调整支持度和置信度参数,在结果分析过程中需要考虑消费者需求变化。
②Do:关联规则模型设置和操作
本轮最低支持度0.7%,最低置信度35%。1975条B组交易样本数据通过R语言导入,Apriori算法运行如下:
一共生成了36条关联规则。将关联规则的提升程度排序后,前8条关联规则如表4所示。本轮关联规则数量有所提升。规则的支持度虽然有所降低,但还是出现了较高的频率,置信度处于较高水平。规则的增加远大于1,规则的有效性很高。和实用性。
③Check:计算验证组的概率值并进行结果检查
通过计算B组验证数据中规则的置信度,获得更高的置信度。因此,验证了生成的关联规则的结果具有较高的可信度。表 5 显示前 8 条关联规则在学校。测试组的信心。
④Act:效果评价及优化参数
根据本轮的执行,产生了更多的关联规则,而且都是高效实用的,可以覆盖更多的产品。企业可以使用这种方法来构建智能产品组合。此外,企业需要根据第一轮和第二轮产品关联规则的差异,了解季节性、活动性和流行趋势对产品组合的影响,与时俱进,不断优化和更新产品。文件夹。
3.实验结果分析
(1)本文的两轮PDCA过程虽然得到了高质量的关联规则,但是支持度和置信度的设置会极大地影响关联规则的生成。关联规则的支持度和置信度的调整整合在PDCA循环中,将实现参数的细化和动态调整。
(2)根据时间维度或销售维度对数据源进行合理划分,可以有效帮助企业挖掘贴近市场需求变化的关联规则。
(3)企业可以根据支持、信心、推广的变化趋势跟踪生成的关联规则的发展趋势,帮助企业更早地捕捉到产品和产品组合的需求和生命周期变化。
(4)企业可以对多轮PDCA循环产生的规则进行统计分析,根据关联规则随时间变化的程度,实施不同的营销策略。
五、总结
本文结合PDCA管理方法和关联规则数据挖掘算法,实现了数据挖掘算法在企业业务应用中的标准设计。通过PDCA循环迭代和螺旋机制,动态调整关联规则算法的应用,保证数据挖掘。效果的可靠性和实用性。通过多轮PDCA循环迭代,企业可以有效积累时间维度关联规则,帮助企业识别产品和产品组合的变化趋势和生命周期,帮助企业更全面、更系统地实现产品。组合的智能化建设。
参考:
[1] 李东云. 利用关联规则挖掘技术实现数字图书馆个性化推荐服务[J]. 2020年兰台内外(34):40-42.
[2] 郝海涛,马媛媛.基于加权关联规则挖掘算法的电子商务产品推荐系统研究[J]. 现代电子技术, 2016, 39 (15): 133-136.
[3]菲利普·科特勒,加里·阿姆斯特朗。市场营销概论[M].中国出版社,1998.
[4]朱庆.结合关联规则挖掘算法的信息化教学管理系统设计[J]. 现代电子技术, 2020, 43 (23): 159-163.
作者简介:周丽丽(1999.07-),女,汉族,籍贯:广东省揭阳市,本科,研究方向:电子商务;通讯作者:王宝军(1985.08-),男,汉族,籍贯:江西省景德镇市,研究生,工程师,研究方向:电子商务、数据挖掘
智能采集组合文章(知乎能够自动给我推送优质回答吗?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-24 20:11
智能采集组合文章内容一键组合/裁剪篇幅不足的原创内容自动纠正当前文章中出现的错别字关键词自动提示关键词自动定位被过滤的差不多的过滤内容重新重写检查标题和样式避免原创党风险在写的过程中不断提醒错别字一键注册如果流量过大会提示部分用户无法同步注册所以要等过好一段时间再注册扫码注册不支持自动生成注册手机号,这个得自己买电话号,或者找微信支付宝申请(注册时会要求填写)创建任务可以选择打卡打字打卡打卡打表格,打字速度不要太快要快打包发货不支持分类包装包装分类标题图片昵称标签头像确认开始其他问题欢迎私信。
知乎能够自动给我推送优质回答吗?(玩手机时感觉知乎比手机更好用)我想了想,最主要的几点,也是多数自媒体人所忽略的:首先,发现问题要及时解决,比如:明显错别字了要查出并删除。再就是有些写作素材不适合通过自媒体发出来,发出来会影响用户点击阅读甚至取消关注。这个时候,你应该发起投票或者意见征集,让大家共同讨论。
发现问题要及时改正,比如:描述不正确要及时修改。别人把内容发给你之后,你可以告诉用户里面哪里描述有误,让他修改。我曾见过有个知乎大v把一篇介绍中兴通讯基地的文章发给读者,他把相应的基地地址都改成了“中兴基地”,如果用户体验影响用户继续关注这个账号,他就弃号了。还有不要随便推送广告,我自己也有过自己写的文章开始疯狂推送广告的经历,因为广告我有时就要推荐一些我不喜欢的内容,同时提示读者有广告不要接受。
再就是及时清理自己写的内容或者群发不合理的、无价值的文章。有一次给我推送错误的一篇文章,导致阅读量降低一半。多数是要注意以上几点,这个是我体验过程中的一些小总结,算不上真正提高文章质量的建议,我也主要是学习尝试。 查看全部
智能采集组合文章(知乎能够自动给我推送优质回答吗?(组图))
智能采集组合文章内容一键组合/裁剪篇幅不足的原创内容自动纠正当前文章中出现的错别字关键词自动提示关键词自动定位被过滤的差不多的过滤内容重新重写检查标题和样式避免原创党风险在写的过程中不断提醒错别字一键注册如果流量过大会提示部分用户无法同步注册所以要等过好一段时间再注册扫码注册不支持自动生成注册手机号,这个得自己买电话号,或者找微信支付宝申请(注册时会要求填写)创建任务可以选择打卡打字打卡打卡打表格,打字速度不要太快要快打包发货不支持分类包装包装分类标题图片昵称标签头像确认开始其他问题欢迎私信。
知乎能够自动给我推送优质回答吗?(玩手机时感觉知乎比手机更好用)我想了想,最主要的几点,也是多数自媒体人所忽略的:首先,发现问题要及时解决,比如:明显错别字了要查出并删除。再就是有些写作素材不适合通过自媒体发出来,发出来会影响用户点击阅读甚至取消关注。这个时候,你应该发起投票或者意见征集,让大家共同讨论。
发现问题要及时改正,比如:描述不正确要及时修改。别人把内容发给你之后,你可以告诉用户里面哪里描述有误,让他修改。我曾见过有个知乎大v把一篇介绍中兴通讯基地的文章发给读者,他把相应的基地地址都改成了“中兴基地”,如果用户体验影响用户继续关注这个账号,他就弃号了。还有不要随便推送广告,我自己也有过自己写的文章开始疯狂推送广告的经历,因为广告我有时就要推荐一些我不喜欢的内容,同时提示读者有广告不要接受。
再就是及时清理自己写的内容或者群发不合理的、无价值的文章。有一次给我推送错误的一篇文章,导致阅读量降低一半。多数是要注意以上几点,这个是我体验过程中的一些小总结,算不上真正提高文章质量的建议,我也主要是学习尝试。
智能采集组合文章(软件特点优采云软件首创的智能提取网页正文正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-24 08:02
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集消息来源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息 查看全部
智能采集组合文章(软件特点优采云软件首创的智能提取网页正文正文的算法)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集消息来源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息
智能采集组合文章(通过长尾关键词进行组合让网站流量轻松提升了10倍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-12-23 12:29
长尾关键词的组合使得网站流量轻松增加10倍,长尾关键词在选择上应该有意义,长尾关键词容易优化,如果组合长尾关键词,如:长尾关键词+长尾关键词,或者穿插使用,用户搜索千变万化,组合长尾关键词@ > 可以让网站为不可控的用户搜索提供更多的展示机会。网站在北京的具体操作如下:
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。
北京做网站
使用php字段方法(regular即可,字段简单)采集所有关键词收录“二手车”,自动无限制采集返回的关键词数量非常超过限制长度的大(重复关键词no采集,关键词no采集)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索更容易找到,加上长尾关键词容易排名,
北京做网站
上首页很容易,如果数量很大,你得到的流量是非常直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关的内容与采集,或者采集其他人的文章结合到百度翻译,再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果你精通程序,那真的太容易了。
通过大量的长尾关键词做内容,总会有大量的关键词排名首页,流量增加十倍根本不是问题。 查看全部
智能采集组合文章(通过长尾关键词进行组合让网站流量轻松提升了10倍)
长尾关键词的组合使得网站流量轻松增加10倍,长尾关键词在选择上应该有意义,长尾关键词容易优化,如果组合长尾关键词,如:长尾关键词+长尾关键词,或者穿插使用,用户搜索千变万化,组合长尾关键词@ > 可以让网站为不可控的用户搜索提供更多的展示机会。网站在北京的具体操作如下:
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。
北京做网站
使用php字段方法(regular即可,字段简单)采集所有关键词收录“二手车”,自动无限制采集返回的关键词数量非常超过限制长度的大(重复关键词no采集,关键词no采集)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索更容易找到,加上长尾关键词容易排名,
北京做网站
上首页很容易,如果数量很大,你得到的流量是非常直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关的内容与采集,或者采集其他人的文章结合到百度翻译,再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果你精通程序,那真的太容易了。
通过大量的长尾关键词做内容,总会有大量的关键词排名首页,流量增加十倍根本不是问题。
智能采集组合文章(智能工单知识挖掘引擎系统系统中具有海量数据的工单信息 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-22 14:14
)
智能搜索引擎
在知识库中,只能通过数据库搜索、全文搜索,往往不会出现搜索不到、搜索不准确的情况。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
互联网信息采集和分发引擎包查询
如果你每天花大量时间在指定的网站上搜索各种知识信息作为研究和内部参考,如果你苦恼这些信息需要手动下载,你需要手动区分分类,需要手动去除重复项,消除干扰。那你一定不能错过“包裹查询”。
基于爬虫和机器学习技术,自动采集,自动去重分类,个性化分布推荐,知识关联挖掘,只为你想知道!
智能工单知识挖掘引擎
工单系统拥有海量工单信息数据。通过“工单知识抽取模型”的构建和训练,将有效的工单知识提取出来并应用到工单建议和处置的过程中,从而减少重复的工单。提高提交率,提高工单处理效率和解决准确率
健康保险理赔是一个专业而复杂的过程,需要医学和保险双重领域的知识。
深蓝基于知识规则引擎开发了“药物-疾病-症状”知识规则库,可以从“对症用药”和“合理用药”两个方面为医保理赔提供智能支持服务。
传统知识库只能进行全文搜索,找到一堆结果。传统客服问答机器人呢?需要根据文档手动整理出大量QA问答对,超反人类。
有没有可能,就问你的问题,系统会自动从知识库中找到对应的文章,截取文章中最相关的一段,作为答案发给你?这就是“智能知识助手”!
太多的信息,太多的数据,知识库中的太多内容!你还在手工分类构建知识图谱吗?
快来试试基于多条件组合和机器学习模型的自动分类引擎,轻松合理地对数百万文档和资料进行分类!
如何从海量数据中发现未知规律,发现热点、问题、时间地域分布、相关人物、事件等,基于非结构化文本的知识挖掘引擎,轻松进行知识挖掘,并提供图形化的决策支持依据。
查看全部
智能采集组合文章(智能工单知识挖掘引擎系统系统中具有海量数据的工单信息
)
智能搜索引擎
在知识库中,只能通过数据库搜索、全文搜索,往往不会出现搜索不到、搜索不准确的情况。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
互联网信息采集和分发引擎包查询
如果你每天花大量时间在指定的网站上搜索各种知识信息作为研究和内部参考,如果你苦恼这些信息需要手动下载,你需要手动区分分类,需要手动去除重复项,消除干扰。那你一定不能错过“包裹查询”。
基于爬虫和机器学习技术,自动采集,自动去重分类,个性化分布推荐,知识关联挖掘,只为你想知道!
智能工单知识挖掘引擎
工单系统拥有海量工单信息数据。通过“工单知识抽取模型”的构建和训练,将有效的工单知识提取出来并应用到工单建议和处置的过程中,从而减少重复的工单。提高提交率,提高工单处理效率和解决准确率

健康保险理赔是一个专业而复杂的过程,需要医学和保险双重领域的知识。
深蓝基于知识规则引擎开发了“药物-疾病-症状”知识规则库,可以从“对症用药”和“合理用药”两个方面为医保理赔提供智能支持服务。

传统知识库只能进行全文搜索,找到一堆结果。传统客服问答机器人呢?需要根据文档手动整理出大量QA问答对,超反人类。
有没有可能,就问你的问题,系统会自动从知识库中找到对应的文章,截取文章中最相关的一段,作为答案发给你?这就是“智能知识助手”!
太多的信息,太多的数据,知识库中的太多内容!你还在手工分类构建知识图谱吗?
快来试试基于多条件组合和机器学习模型的自动分类引擎,轻松合理地对数百万文档和资料进行分类!
如何从海量数据中发现未知规律,发现热点、问题、时间地域分布、相关人物、事件等,基于非结构化文本的知识挖掘引擎,轻松进行知识挖掘,并提供图形化的决策支持依据。
智能采集组合文章(智能采集组合文章采集,将相同标题文章汇总(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-22 03:02
智能采集组合文章采集,将相同标题文章汇总在一起,并对其进行自动标签合并上传文章,一篇文章或多篇文章,一键采集,全网内容秒精准推送关注微信公众号:cloudiike,回复【注册】,
“快速上传”,有句老话叫,好钢用在刀刃上,如果没有很多的资金或者是时间的成本投入,那么我不建议这个项目,其实成本性价比比较低。
被删减部分节选的文章,难道只是因为版权原因吗?所以这种假正经的非正规文章,不要盲目投机。过滤一下吧。
加入他们社群,不光可以发布文章,
可以找我
我所知道有多个平台帮我写稿,一篇写一千,十万即可分成。想写首自媒体文章的话,价格很合适。但稿费都不一样,价格谈妥即可。
有个网站,叫百家号指数,直接搜索搜狗百家号,去申请试试看吧。
一个应用叫百家号指数,输入你的标题,搜索几次,就知道标题的内容占的比例,很多标题都是万年不变的。很多,很多。
最简单的就是上传本地新闻,
百家号,搜狐新闻,头条新闻,凤凰网,网易新闻,腾讯新闻,搜狐网,大风号,人民网,百度百家,一点资讯,一点订阅,开心网,京东,今日头条,搜狐新闻,网易,b站,微博等等, 查看全部
智能采集组合文章(智能采集组合文章采集,将相同标题文章汇总(组图))
智能采集组合文章采集,将相同标题文章汇总在一起,并对其进行自动标签合并上传文章,一篇文章或多篇文章,一键采集,全网内容秒精准推送关注微信公众号:cloudiike,回复【注册】,
“快速上传”,有句老话叫,好钢用在刀刃上,如果没有很多的资金或者是时间的成本投入,那么我不建议这个项目,其实成本性价比比较低。
被删减部分节选的文章,难道只是因为版权原因吗?所以这种假正经的非正规文章,不要盲目投机。过滤一下吧。
加入他们社群,不光可以发布文章,
可以找我
我所知道有多个平台帮我写稿,一篇写一千,十万即可分成。想写首自媒体文章的话,价格很合适。但稿费都不一样,价格谈妥即可。
有个网站,叫百家号指数,直接搜索搜狗百家号,去申请试试看吧。
一个应用叫百家号指数,输入你的标题,搜索几次,就知道标题的内容占的比例,很多标题都是万年不变的。很多,很多。
最简单的就是上传本地新闻,
百家号,搜狐新闻,头条新闻,凤凰网,网易新闻,腾讯新闻,搜狐网,大风号,人民网,百度百家,一点资讯,一点订阅,开心网,京东,今日头条,搜狐新闻,网易,b站,微博等等,
智能采集组合文章(AuTopAuTop战队开源算法讲解(六)Openart识别方案介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2021-12-21 11:13
本文为第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解第7部分-三岔数字识别、专栏及开源程序链接:
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
在上一篇文章(木野:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解(六)Openart识别解决方案)中,我们提到了数字化的思路识别,使用全局分类器的方法,直接判断图像中是否有数字目标卡片和对应的数字编号,省略了找框的步骤,不仅计算速度更快,还减少了不稳定因素( OpenMV 的 find_rect 函数不稳定)
模型结构
先放一张模型结构的概览图(有点长)用Netron来画。
数字分类模型概览图
可以看出模型主要由4个子模块组成
下采样和正则化 MaxPooling2D+SpatialDropout2D 空间注意力单元:x*sigmoid(conv(x)) 分类头:GlobalMaxPooling2D+Dense
另外,模型的代码中使用了超参数width来控制模型的宽度。经过不同参数的选择测试,发现当width=0.5时,可以在计算速度和模型精度之间取得较好的平衡。具体代码实现见开源代码库。
2. 数据集生成
由于官方只提供了十张标准数码图片,所以数据量有点小。但是如果直接使用OpenArt-mini采集的实际数据,不仅工作量大,而且背景单一,更换场地后识别效果可能会下降。因此,我们以COCO开源数据集为背景,将标准数码图片随机映射到背景图片上,结合数据增强方法生成数据集。可以在最大限度地减少人力的同时训练出性能优异的模型。
示例图片
示例图片
3. 模型训练
训练步骤基本参考官方训练方案,只用自己搭建的模型替换模型。仅将数据增强得到的图像作为训练集,少量记录数据作为测试集。两个数据域存在一定的差异,可以更好地看出模型和数据增强的有效性。在我们的实验中,在测试集上可以轻松达到90%以上的准确率,充分证明了该方法的有效性。
SJTU-AuTop 完整的开源解决方案链接,如果您觉得我们的解决方案对您有帮助,请帮我在github上给个star :)
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结 查看全部
智能采集组合文章(AuTopAuTop战队开源算法讲解(六)Openart识别方案介绍)
本文为第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解第7部分-三岔数字识别、专栏及开源程序链接:
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
在上一篇文章(木野:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解(六)Openart识别解决方案)中,我们提到了数字化的思路识别,使用全局分类器的方法,直接判断图像中是否有数字目标卡片和对应的数字编号,省略了找框的步骤,不仅计算速度更快,还减少了不稳定因素( OpenMV 的 find_rect 函数不稳定)
模型结构
先放一张模型结构的概览图(有点长)用Netron来画。

数字分类模型概览图
可以看出模型主要由4个子模块组成
下采样和正则化 MaxPooling2D+SpatialDropout2D 空间注意力单元:x*sigmoid(conv(x)) 分类头:GlobalMaxPooling2D+Dense
另外,模型的代码中使用了超参数width来控制模型的宽度。经过不同参数的选择测试,发现当width=0.5时,可以在计算速度和模型精度之间取得较好的平衡。具体代码实现见开源代码库。
2. 数据集生成
由于官方只提供了十张标准数码图片,所以数据量有点小。但是如果直接使用OpenArt-mini采集的实际数据,不仅工作量大,而且背景单一,更换场地后识别效果可能会下降。因此,我们以COCO开源数据集为背景,将标准数码图片随机映射到背景图片上,结合数据增强方法生成数据集。可以在最大限度地减少人力的同时训练出性能优异的模型。

示例图片

示例图片
3. 模型训练
训练步骤基本参考官方训练方案,只用自己搭建的模型替换模型。仅将数据增强得到的图像作为训练集,少量记录数据作为测试集。两个数据域存在一定的差异,可以更好地看出模型和数据增强的有效性。在我们的实验中,在测试集上可以轻松达到90%以上的准确率,充分证明了该方法的有效性。
SJTU-AuTop 完整的开源解决方案链接,如果您觉得我们的解决方案对您有帮助,请帮我在github上给个star :)
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
智能采集组合文章(优采云浏览器可视化编辑脚本并运行任务可以通过来高效完成 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-11 00:08
)
对于经常处理网页操作的朋友来说,数据批处理是一种基于数据智能处理的高效处理方式。无论是批量采集、批量验证,还是批量批量发布、批量注册,都可以通过数据批量处理软件优采云浏览器高效完成。
优采云浏览器软件是一个可视化的网页操作工具。可视化保证了用户操作的便捷性,也是批量操作的亮点之一。该工具来自经典采集软件优采云采集器的研发团队。基于对数据属性的熟悉和对网页机制的深入研究,优采云浏览器推出了核心亮点——项目管理器。
可视化编辑脚本和运行任务可以给你带来智能体验,但是单个任务的累积操作比较繁琐。庞大的数据量和复杂的管理都让我们苦恼。核心项目经理可以调用脚本同时或长期循环运行,并且可以设置运行模式、数据源和任务时序等,组合成适合自己的独特解决方案。
因此,以营销人员为例,可以使用优采云浏览器来定义整个网络营销的步骤和流程。您可以通过博客等渠道自动登录并自动识别验证码。无需一一重复“登录、复制、粘贴、发送”的步骤。
传统的批处理工具只能进行单一操作,但营销是全方位的,更加个性化。它不能仅限于一项,例如群组邮寄。优采云浏览器被营销人员称为万能的营销工具。用户甚至可以将自己设计的项目方案生成程序分享给其他用户,并通过浏览器自带的软件管理平台优采云对程序进行授权。为您自己的解决方案赚取利润。
除了群发、批量保存和上传,采集也适用,优采云浏览器可视化采集可以模拟人的真实点击提取操作,甚至可以处理瀑布或滚动酒吧。微博等数据。
面对海量数据,人工操作的能力毕竟有限,只有智能化、个性化的批处理才是高效利用数据的趋势。不仅营销人员可以使用优采云浏览器来满足批处理需求,科研机构、网站运维、各行各业都在浪潮中逐渐寻找数据资源应用的方向的大数据。
查看全部
智能采集组合文章(优采云浏览器可视化编辑脚本并运行任务可以通过来高效完成
)
对于经常处理网页操作的朋友来说,数据批处理是一种基于数据智能处理的高效处理方式。无论是批量采集、批量验证,还是批量批量发布、批量注册,都可以通过数据批量处理软件优采云浏览器高效完成。
优采云浏览器软件是一个可视化的网页操作工具。可视化保证了用户操作的便捷性,也是批量操作的亮点之一。该工具来自经典采集软件优采云采集器的研发团队。基于对数据属性的熟悉和对网页机制的深入研究,优采云浏览器推出了核心亮点——项目管理器。
可视化编辑脚本和运行任务可以给你带来智能体验,但是单个任务的累积操作比较繁琐。庞大的数据量和复杂的管理都让我们苦恼。核心项目经理可以调用脚本同时或长期循环运行,并且可以设置运行模式、数据源和任务时序等,组合成适合自己的独特解决方案。
因此,以营销人员为例,可以使用优采云浏览器来定义整个网络营销的步骤和流程。您可以通过博客等渠道自动登录并自动识别验证码。无需一一重复“登录、复制、粘贴、发送”的步骤。
传统的批处理工具只能进行单一操作,但营销是全方位的,更加个性化。它不能仅限于一项,例如群组邮寄。优采云浏览器被营销人员称为万能的营销工具。用户甚至可以将自己设计的项目方案生成程序分享给其他用户,并通过浏览器自带的软件管理平台优采云对程序进行授权。为您自己的解决方案赚取利润。
除了群发、批量保存和上传,采集也适用,优采云浏览器可视化采集可以模拟人的真实点击提取操作,甚至可以处理瀑布或滚动酒吧。微博等数据。
面对海量数据,人工操作的能力毕竟有限,只有智能化、个性化的批处理才是高效利用数据的趋势。不仅营销人员可以使用优采云浏览器来满足批处理需求,科研机构、网站运维、各行各业都在浪潮中逐渐寻找数据资源应用的方向的大数据。

智能采集组合文章(1分钟采集数据开始画图之前需要先做如下4个事情)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-12-09 12:18
采集的1分钟精度,开始绘制采集数据前需要做以下4件事。
1. 创建1分钟的RRA;
2. 在Cacti Data Source 模板中修改“Step”和“Heartbeat”的值;
3. 在系统 cron 中修改 poller 的轮询时间间隔;
4. 在 Cacti 配置中修改 poller 的轮询时间间隔。
1、首先创建所需的1分钟RRA:
这个RRA的定义可以确定我们数据不同精度的最大存储周期,存储时间=Step Steps Rows。例如默认的Cacti 5分钟精度Daily(5 Miniute Average),RRA精度数据存储时间为:(5 1 600) / 60m = 50h ≈ 2d,注意:
• “Step”是在数据源中定义的步骤时间。在Cacti中,就是下面第二步提到的Data模板中定义的Step值(以秒为单位);
• “Steps”为步数,即上图中RRA中定义的Steps值;
• 注意:这个保存时间不是上图中Timespan 的值。时间跨度是指我们点击某个图表后出现的几个时间段的详细图表中所显示的时间段的长度。
好了,正式开始我们的RRA修改和创建方法说明。
为了区分,我们修改默认RRA的名称,精度为5分钟(不用担心,Cacti是用ID来识别的)。如果要保存更长的时间,增加Rows的数量;
然后,我们新建一个1分钟精度的RRA,例如(英文表示1分钟精度,中文表示5分钟精度):
最终如下:
我们创建的1分钟精度RRA数据存储时间计算表如下:
可作为上路参数
2、 修改数据模板中的“step”和“heartbeat”参数
注意:如果在“关联”中选择多个列,请按住Ctrl键
4) 点击页面底部的“保存”,然后注意再次更改标签“2:traffic_out”的“心跳”。
3、 修改cron中的Poller轮询间隔为1分钟
vi/etc/crontab
4、 修改Cacti配置中Poller的轮询间隔
5、重建轮询缓存
6、删除原来的.rrd文件,等待1分钟cacti重建。
rm /home/wwwroot/defautl/cacti/rra/*.rrd
7、重启进程
然后等待图片出现。 查看全部
智能采集组合文章(1分钟采集数据开始画图之前需要先做如下4个事情)
采集的1分钟精度,开始绘制采集数据前需要做以下4件事。
1. 创建1分钟的RRA;
2. 在Cacti Data Source 模板中修改“Step”和“Heartbeat”的值;
3. 在系统 cron 中修改 poller 的轮询时间间隔;
4. 在 Cacti 配置中修改 poller 的轮询时间间隔。
1、首先创建所需的1分钟RRA:

这个RRA的定义可以确定我们数据不同精度的最大存储周期,存储时间=Step Steps Rows。例如默认的Cacti 5分钟精度Daily(5 Miniute Average),RRA精度数据存储时间为:(5 1 600) / 60m = 50h ≈ 2d,注意:
• “Step”是在数据源中定义的步骤时间。在Cacti中,就是下面第二步提到的Data模板中定义的Step值(以秒为单位);
• “Steps”为步数,即上图中RRA中定义的Steps值;
• 注意:这个保存时间不是上图中Timespan 的值。时间跨度是指我们点击某个图表后出现的几个时间段的详细图表中所显示的时间段的长度。
好了,正式开始我们的RRA修改和创建方法说明。
为了区分,我们修改默认RRA的名称,精度为5分钟(不用担心,Cacti是用ID来识别的)。如果要保存更长的时间,增加Rows的数量;
然后,我们新建一个1分钟精度的RRA,例如(英文表示1分钟精度,中文表示5分钟精度):

最终如下:

我们创建的1分钟精度RRA数据存储时间计算表如下:
可作为上路参数
2、 修改数据模板中的“step”和“heartbeat”参数

注意:如果在“关联”中选择多个列,请按住Ctrl键
4) 点击页面底部的“保存”,然后注意再次更改标签“2:traffic_out”的“心跳”。

3、 修改cron中的Poller轮询间隔为1分钟
vi/etc/crontab
4、 修改Cacti配置中Poller的轮询间隔

5、重建轮询缓存

6、删除原来的.rrd文件,等待1分钟cacti重建。
rm /home/wwwroot/defautl/cacti/rra/*.rrd
7、重启进程

然后等待图片出现。
智能采集组合文章( 【华工小传】新闻写作机器人的发展概况及发展趋势 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-20 14:02
【华工小传】新闻写作机器人的发展概况及发展趋势
)
将本文转发至任何与华南理工大学新考研相关的群,并联系【华工小传】个人微信,即可领取华工教师试卷合集!
一、新闻写作机器人的发展现状
新闻机器人,或人工智能机器人。它是人工智能在新闻领域的最新应用。事实上,在“九寨沟地震”出现在机器人新闻之前,新闻机器人就已经被世界主流媒体所关注和使用。比如美联社的WordSmith,华盛顿邮报的Heliograf,纽约时报的Bloom。在国内,有新华社的快笔小新、腾讯的梦想作家、第一财经的DT作家王等,这些写稿机器人都应用了大数据处理技术。首先通过数据采集,将其录入数据库,根据句子出现频率和新闻元素关键词对数据进行分析处理。制作了一套符合媒体刊物风格的模板,然后将新闻元素 5W1H 代入其中。一条新闻消息就这样诞生了。
二、机器人写作的优势
提高发布速度,全天候监控新闻热点,提高新闻时效性
时间对新闻的意义并非微不足道,尤其是在当前的网络新闻环境下。可以说,每一秒都很重要。通过学习之前类似稿件的写作模式,新闻机器人可以凭借其快速的信息处理能力,在极短的时间内制作出符合媒体写作风格的作品。
新闻更全面,网络新闻报道长尾效应突出
新闻报道在互联网平台上的长尾效应非常突出,即由于受众基数庞大,即使是小众用户数量也相当可观。同时,基于互联网平台的新闻传播,满足个性化新闻的需求,也有利于用户粘性的增长。这也符合未来定制化新闻、聚焦新闻的大趋势。
将记者从快速新闻中解放出来。专注深度新闻的创作
目前,新闻新闻的产生和传播速度越来越快,新闻的时效性也越来越高,但新闻新闻的影响力却没有以前那么大了。一方面。新闻的半场时间越来越短,另一方面,快餐新闻充斥着互联网。媒体行业的激烈竞争让记者难以应对同样的信息,即便如此,遗漏问题还是时有发生。使用机器人在这些消息上写作可以让记者从令人筋疲力尽的新闻中解脱出来。深入挖掘并批判性地思考事件背后的新闻线索。从长远来看,深入报道对新闻界是有益的,没有任何伤害。它甚至可以减慢快速新闻的速度,让读者有时间思考和阅读。
在处理大量数据时减少错误数量
对于经济和体育新闻,往往有很多数字。需要组织和汇总数据。当人类记者处理这些数字和图表时,他们经常会因为大量的数据而出错。然而,凭借其超强的计算能力,机器人可以处理海量数据,并且不易出错。
没有个人感情。文章更客观
Robot Newsletter 有任何人类情感,文章 的生成完全依赖于数据。例如,在活动摘要中,您不会因为喜欢某支球队而偏爱一支球队。而是严格按照数据,客观陈述事实。在某种程度上,机器人新闻更接近新闻客观性的要求。
“新闻机器人”的媒体报道
三、目前机器人写作的问题
机器人对信息的理解不够深入
新闻机器人所能做的就是在现有数据库的支持下,为文章获取单词和句子,然后将它们排列组合,就像在做一个复杂的填字游戏一样。机器人对文章的深刻理解远不能与人类相提并论。虽然是二代新闻机器人,但在语义理解上仍有很大缺陷。但随着机器学习能力的不断提高。相信这样的低级错误是完全可以避免的。
平淡的新闻千篇一律,缺乏亮点和焦点
提炼和概括信息的能力不足
要想写好文章,总结提炼信息的能力是一个记者必备的职业素质,没有人看长篇大论的文章。但是,目前的书写机器人显然不具备细化和泛化的能力。提炼和概括的前提是理解。机器人理解人类语言的能力还很弱,限制了文章机器人写作的体裁和领域。
写作领域比较简单,目前仅限于金融和体育
目前机器人新闻的应用还停留在基于数据使用的新闻领域。具体来说,在金融和体育领域。主要工作是年度财报新闻和事件新闻。而且,大多数新闻机器人在某个写作领域都比较单一。很少能“多任务”和“多功能”。一方面,由于其初写模块的设置,功能比较单一,无法兼顾深度阅读学习的功能:另一方面。数据壁垒使得无法获取和学习更多的数据,导致“知之甚少”。
四、未来机器人新闻的未来方向
跨学科的通才
目前。新闻机器人的写作能力还只是在某个领域。一方面,现有的机器人作家不像人类。你可以看到和听到各个方向,但它的处理器能力仍然很简单。. 交叉数据的处理能力较弱。其次,数据库的开源也是制约新闻机器人跨领域发展的障碍。机器人编写者只有连接到相应的数据库后,才能继续分析数据和处理模板。再写。不同数据库之间的开源和数据集成,使得机器人的跨域编写具有一定的阻力。因此,像新华网的快笔小新。它实际上有 3 个头像,每个头像处理一个字段中的新闻。但是,机器人的发展不能局限于某个领域。随着其数据处理能力的增强和数据开源的可能性。跨域机器人新闻写作将成为可能,不仅可以大大节省成本,而且可以写出更全面的稿件,不同数据库的数据可以相互补充。互相学习。写作的类型也将不仅限于短消息。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。
人类记者、编辑助理
未来的新闻编辑室,很可能会出现二加一的情况,即机器人记者和人类记者写文章,机器人编辑和编辑联合审阅。机器人记者可以处理大量的文本、音频和视频数据,形成报告大纲或数据图表。经过一轮的数据处理,记者省去了查阅数据、整理汇总的不便,对报告的重点进行了细致入微。写作中有神。同时,它可以协助编辑和校对稿件。并迅速发布到各媒体终端。
平等的沟通者
迄今为止。写字机器人还停留在接收指令和执行操作的一维层次。也就是说,机器人只能停留在协助记者的阶段。但相信在不久的将来,随着数据量的增加,机器的计算能力将会提高。除了机器理解自然语言能力的增强,机器人还可以与人类平等交流,并就人类的意见提供反馈和建议。
多平台终端和数据库资源的连接器
未来,随着各机构、平台数据库的不断开源,新闻机器人可实现“推”“拉”多平台终端,数据库资源打通。一方面,书面稿件可以同时快速上传到多个平台。一个媒体平台,比如最近的机器人小明,可以将今日头条写的手稿分享到微博平台,是徒劳的。另一方面,连接不同的数据库:使数据交叉集成,发挥更大的作用。
媒体融合的推动者
新闻机器人小明在奥运新闻报道中加入了图像识别功能,可以选择合适的比赛图片作为文章有图。未来,机器人甚至可以整合视频、音频甚至虚拟现实技术。实现真正的媒体融合。新闻机器人,未来可能是媒体融合的具体产物。它出现在新闻场景中。根据新闻对象的需要,安装相应的新闻模块,安装虚拟现实摄像头。可以快速写文章、直播、制作VR作品。未来新闻机器人开发的可能性是无穷无尽的。
小传
个性化新闻推送对新闻生产机制和受众的重塑与发展策略
一、重塑新闻生产机制
智能数据驱动的新闻生产范式:数据引擎成为内容“标准”:直播“长尾内容”,满足用户小众需求
新闻内容分发已成为一个专门的独立部门。:集社交、搜索、场景识别、个性化推送、智能聚合于一体
二、重塑受众
个性化动态消息的好处:助力“使用与满意”范式下的用户状态升级
个性化新闻推送的弊端:容易造成用户信息消费固化,产生“信息茧房”效应
三、个性化新闻推送机制未来发展途径及技术重点
走出“茧”效应:根据用户的社交数据和相关关系“定义”潜在需求
《聊新闻》:基于人工智能的人机交互模式可拓展和挖掘个性化、精准化的信息服务
连接物联网:用户得到的不仅仅是简单的新闻:它是一套相关的配套服务,信息获取平台也成为实现精准服务的超级内容社区
【课程类型】 全程课程
【时间】2018年4月至12月
4月到暑假开始,以新闻和传播为主,基本覆盖了823和440所有考点,更偏向于基础知识的考察,帮助大家夯实基础,更好应对第二阶段的抬升。进入暑假开始通识学习,简答和讨论题训练,总结热点事件,把握中国劳动监察方向,帮助提高成绩,提高应试能力,系统讲解如何答题和答题技巧. 系统模拟11月开始,考场全面模拟,让你玩不慌,考场有底线。
每次讲解结束后,都会根据课程进行课堂测试,帮助大家更好地理解新知识。
作业可以指导你的复习方向和练习角度。
不定期进行模拟考试,帮助了解知识掌握情况和个人排名。
小班、问答
免费试卷复习资料、课程资料、模拟试卷、价值199的模拟试题答疑课
预注册或购买辅导资料的学生专享价:3月1日后999,原价恢复为1099
长按并跟随下方二维码提前进入华工新川加油站!
查看全部
智能采集组合文章(
【华工小传】新闻写作机器人的发展概况及发展趋势
)
将本文转发至任何与华南理工大学新考研相关的群,并联系【华工小传】个人微信,即可领取华工教师试卷合集!
一、新闻写作机器人的发展现状
新闻机器人,或人工智能机器人。它是人工智能在新闻领域的最新应用。事实上,在“九寨沟地震”出现在机器人新闻之前,新闻机器人就已经被世界主流媒体所关注和使用。比如美联社的WordSmith,华盛顿邮报的Heliograf,纽约时报的Bloom。在国内,有新华社的快笔小新、腾讯的梦想作家、第一财经的DT作家王等,这些写稿机器人都应用了大数据处理技术。首先通过数据采集,将其录入数据库,根据句子出现频率和新闻元素关键词对数据进行分析处理。制作了一套符合媒体刊物风格的模板,然后将新闻元素 5W1H 代入其中。一条新闻消息就这样诞生了。
二、机器人写作的优势
提高发布速度,全天候监控新闻热点,提高新闻时效性
时间对新闻的意义并非微不足道,尤其是在当前的网络新闻环境下。可以说,每一秒都很重要。通过学习之前类似稿件的写作模式,新闻机器人可以凭借其快速的信息处理能力,在极短的时间内制作出符合媒体写作风格的作品。
新闻更全面,网络新闻报道长尾效应突出
新闻报道在互联网平台上的长尾效应非常突出,即由于受众基数庞大,即使是小众用户数量也相当可观。同时,基于互联网平台的新闻传播,满足个性化新闻的需求,也有利于用户粘性的增长。这也符合未来定制化新闻、聚焦新闻的大趋势。
将记者从快速新闻中解放出来。专注深度新闻的创作
目前,新闻新闻的产生和传播速度越来越快,新闻的时效性也越来越高,但新闻新闻的影响力却没有以前那么大了。一方面。新闻的半场时间越来越短,另一方面,快餐新闻充斥着互联网。媒体行业的激烈竞争让记者难以应对同样的信息,即便如此,遗漏问题还是时有发生。使用机器人在这些消息上写作可以让记者从令人筋疲力尽的新闻中解脱出来。深入挖掘并批判性地思考事件背后的新闻线索。从长远来看,深入报道对新闻界是有益的,没有任何伤害。它甚至可以减慢快速新闻的速度,让读者有时间思考和阅读。
在处理大量数据时减少错误数量
对于经济和体育新闻,往往有很多数字。需要组织和汇总数据。当人类记者处理这些数字和图表时,他们经常会因为大量的数据而出错。然而,凭借其超强的计算能力,机器人可以处理海量数据,并且不易出错。
没有个人感情。文章更客观
Robot Newsletter 有任何人类情感,文章 的生成完全依赖于数据。例如,在活动摘要中,您不会因为喜欢某支球队而偏爱一支球队。而是严格按照数据,客观陈述事实。在某种程度上,机器人新闻更接近新闻客观性的要求。
“新闻机器人”的媒体报道
三、目前机器人写作的问题
机器人对信息的理解不够深入
新闻机器人所能做的就是在现有数据库的支持下,为文章获取单词和句子,然后将它们排列组合,就像在做一个复杂的填字游戏一样。机器人对文章的深刻理解远不能与人类相提并论。虽然是二代新闻机器人,但在语义理解上仍有很大缺陷。但随着机器学习能力的不断提高。相信这样的低级错误是完全可以避免的。
平淡的新闻千篇一律,缺乏亮点和焦点
提炼和概括信息的能力不足
要想写好文章,总结提炼信息的能力是一个记者必备的职业素质,没有人看长篇大论的文章。但是,目前的书写机器人显然不具备细化和泛化的能力。提炼和概括的前提是理解。机器人理解人类语言的能力还很弱,限制了文章机器人写作的体裁和领域。
写作领域比较简单,目前仅限于金融和体育
目前机器人新闻的应用还停留在基于数据使用的新闻领域。具体来说,在金融和体育领域。主要工作是年度财报新闻和事件新闻。而且,大多数新闻机器人在某个写作领域都比较单一。很少能“多任务”和“多功能”。一方面,由于其初写模块的设置,功能比较单一,无法兼顾深度阅读学习的功能:另一方面。数据壁垒使得无法获取和学习更多的数据,导致“知之甚少”。
四、未来机器人新闻的未来方向
跨学科的通才
目前。新闻机器人的写作能力还只是在某个领域。一方面,现有的机器人作家不像人类。你可以看到和听到各个方向,但它的处理器能力仍然很简单。. 交叉数据的处理能力较弱。其次,数据库的开源也是制约新闻机器人跨领域发展的障碍。机器人编写者只有连接到相应的数据库后,才能继续分析数据和处理模板。再写。不同数据库之间的开源和数据集成,使得机器人的跨域编写具有一定的阻力。因此,像新华网的快笔小新。它实际上有 3 个头像,每个头像处理一个字段中的新闻。但是,机器人的发展不能局限于某个领域。随着其数据处理能力的增强和数据开源的可能性。跨域机器人新闻写作将成为可能,不仅可以大大节省成本,而且可以写出更全面的稿件,不同数据库的数据可以相互补充。互相学习。写作的类型也将不仅限于短消息。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。进行人物交流。甚至时事评论也成为可能。
人类记者、编辑助理
未来的新闻编辑室,很可能会出现二加一的情况,即机器人记者和人类记者写文章,机器人编辑和编辑联合审阅。机器人记者可以处理大量的文本、音频和视频数据,形成报告大纲或数据图表。经过一轮的数据处理,记者省去了查阅数据、整理汇总的不便,对报告的重点进行了细致入微。写作中有神。同时,它可以协助编辑和校对稿件。并迅速发布到各媒体终端。
平等的沟通者
迄今为止。写字机器人还停留在接收指令和执行操作的一维层次。也就是说,机器人只能停留在协助记者的阶段。但相信在不久的将来,随着数据量的增加,机器的计算能力将会提高。除了机器理解自然语言能力的增强,机器人还可以与人类平等交流,并就人类的意见提供反馈和建议。
多平台终端和数据库资源的连接器
未来,随着各机构、平台数据库的不断开源,新闻机器人可实现“推”“拉”多平台终端,数据库资源打通。一方面,书面稿件可以同时快速上传到多个平台。一个媒体平台,比如最近的机器人小明,可以将今日头条写的手稿分享到微博平台,是徒劳的。另一方面,连接不同的数据库:使数据交叉集成,发挥更大的作用。
媒体融合的推动者
新闻机器人小明在奥运新闻报道中加入了图像识别功能,可以选择合适的比赛图片作为文章有图。未来,机器人甚至可以整合视频、音频甚至虚拟现实技术。实现真正的媒体融合。新闻机器人,未来可能是媒体融合的具体产物。它出现在新闻场景中。根据新闻对象的需要,安装相应的新闻模块,安装虚拟现实摄像头。可以快速写文章、直播、制作VR作品。未来新闻机器人开发的可能性是无穷无尽的。
小传
个性化新闻推送对新闻生产机制和受众的重塑与发展策略
一、重塑新闻生产机制
智能数据驱动的新闻生产范式:数据引擎成为内容“标准”:直播“长尾内容”,满足用户小众需求
新闻内容分发已成为一个专门的独立部门。:集社交、搜索、场景识别、个性化推送、智能聚合于一体
二、重塑受众
个性化动态消息的好处:助力“使用与满意”范式下的用户状态升级
个性化新闻推送的弊端:容易造成用户信息消费固化,产生“信息茧房”效应
三、个性化新闻推送机制未来发展途径及技术重点
走出“茧”效应:根据用户的社交数据和相关关系“定义”潜在需求
《聊新闻》:基于人工智能的人机交互模式可拓展和挖掘个性化、精准化的信息服务
连接物联网:用户得到的不仅仅是简单的新闻:它是一套相关的配套服务,信息获取平台也成为实现精准服务的超级内容社区
【课程类型】 全程课程
【时间】2018年4月至12月
4月到暑假开始,以新闻和传播为主,基本覆盖了823和440所有考点,更偏向于基础知识的考察,帮助大家夯实基础,更好应对第二阶段的抬升。进入暑假开始通识学习,简答和讨论题训练,总结热点事件,把握中国劳动监察方向,帮助提高成绩,提高应试能力,系统讲解如何答题和答题技巧. 系统模拟11月开始,考场全面模拟,让你玩不慌,考场有底线。
每次讲解结束后,都会根据课程进行课堂测试,帮助大家更好地理解新知识。
作业可以指导你的复习方向和练习角度。
不定期进行模拟考试,帮助了解知识掌握情况和个人排名。
小班、问答
免费试卷复习资料、课程资料、模拟试卷、价值199的模拟试题答疑课
预注册或购买辅导资料的学生专享价:3月1日后999,原价恢复为1099
长按并跟随下方二维码提前进入华工新川加油站!
智能采集组合文章(AI文章智能处理软件是一款可以帮助用户对文章内容进行打乱重组的文章AI伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-01-20 14:01
AI文章智能处理软件是一款文章AI伪原创工具,可以帮助用户对文章的内容进行洗牌重组。本软件具有智能伪原创、门户文章采集、行业文章采集等文章编辑处理功能,可帮助用户挖掘处理文章材料快速有效。
AI文章智能处理软件功能
1、智能伪原创:
利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集:
一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条、新蓝、联合早报、光明网、网站龙网、新文化等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集:
一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需编写任何采集规则,但缺点是那采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集:
一键搜索相关行业网站文章、网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等,网站网站有几十个,资源丰富,这个模块不一定能满足所有客户的需求,但是客户可以把转发他们的需求,我们会改进和更新这个模块的模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
5、写规则采集:
自己写采集rules采集,采集rules符合常用的正则表达式,写采集rules,需要了解一些html代码和正则表达式规则,如果你已经写了其他业务采集软件的采集规则,那么我们软件的采集规则肯定会写,我们提供了采集规则的编写说明. 我们不为客户编写 采集 规则。如需代写,每条采集规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外部链接文章材料:
本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章只适合对文章质量要求不高的用户,用于外链推广。该模块的特点是资源丰富,原创程度高,缺点是文章可读性差,用户在使用的时候可以选择使用。
7、 量产标题:
有两个功能,一是通过关键词@>和规则组合来量产标题,二是通过采集网络大数据获取标题。自动生成的推广精准度高,采集的标题可读性更强,各有优缺点。
8、文章接口发布:
通过简单的配置,一键将生成的文章发布到自己的网站。目前支持的网站有,Discuz Portal,Dedecms,Empire Ecms(新闻),PHMcms,淄博cms,PHP168,diypage,phpwind portal .
9、SEO批量查询工具:
权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
智能采集组合文章(AI文章智能处理软件是一款可以帮助用户对文章内容进行打乱重组的文章AI伪原创工具)
AI文章智能处理软件是一款文章AI伪原创工具,可以帮助用户对文章的内容进行洗牌重组。本软件具有智能伪原创、门户文章采集、行业文章采集等文章编辑处理功能,可帮助用户挖掘处理文章材料快速有效。
AI文章智能处理软件功能
1、智能伪原创:
利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集:
一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条、新蓝、联合早报、光明网、网站龙网、新文化等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集:
一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需编写任何采集规则,但缺点是那采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集:
一键搜索相关行业网站文章、网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等,网站网站有几十个,资源丰富,这个模块不一定能满足所有客户的需求,但是客户可以把转发他们的需求,我们会改进和更新这个模块的模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
5、写规则采集:
自己写采集rules采集,采集rules符合常用的正则表达式,写采集rules,需要了解一些html代码和正则表达式规则,如果你已经写了其他业务采集软件的采集规则,那么我们软件的采集规则肯定会写,我们提供了采集规则的编写说明. 我们不为客户编写 采集 规则。如需代写,每条采集规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外部链接文章材料:
本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章只适合对文章质量要求不高的用户,用于外链推广。该模块的特点是资源丰富,原创程度高,缺点是文章可读性差,用户在使用的时候可以选择使用。
7、 量产标题:
有两个功能,一是通过关键词@>和规则组合来量产标题,二是通过采集网络大数据获取标题。自动生成的推广精准度高,采集的标题可读性更强,各有优缺点。
8、文章接口发布:
通过简单的配置,一键将生成的文章发布到自己的网站。目前支持的网站有,Discuz Portal,Dedecms,Empire Ecms(新闻),PHMcms,淄博cms,PHP168,diypage,phpwind portal .
9、SEO批量查询工具:
权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
智能采集组合文章(智能采集组合文章,对接网站.不是瞎说,先放图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-12 14:02
智能采集组合文章,对接网站.不是瞎说,先放图这个吧,我现在就在这干,在考虑量产,后面找量大的公司合作,自己就仅仅是个打工,为以后打工,所以说大家帮忙转一下,先让我知道你干的到底行不行。当然这个不是我自己擅长的领域,我是来知乎学习的。
影响力还有用的方面有:知道的第一时间内能很好的转发,或配以比较好的自己的标签并且内容成为病毒式传播性或者点击量最大,不得不说这个可能要看自己知道的渠道广泛性和自己的公司的产品,如果没有这方面的优势或规划,我还是建议不要着急做,因为后期如果要做好这个,涉及到各种的工作比较多。而且如果这个引导性不够强,其实这个成为病毒传播性,传播内容相对也就不是太好。
主要是看文章能否提供干货
找到我,
我是做客的,有一个新的发财机会,是一个网站影响力,客,其实你可以打开你的目录,看看,是不是有这些新奇的网站。
找个技术牛逼的团队给你做,这就跟找人搞互联网营销是一样的,要营销的好,且有人帮你发,你再去找你要找的那些网站合作呗。至于联盟这些那就更简单了,找到电商联盟,你要找的关键词就直接给他们看, 查看全部
智能采集组合文章(智能采集组合文章,对接网站.不是瞎说,先放图)
智能采集组合文章,对接网站.不是瞎说,先放图这个吧,我现在就在这干,在考虑量产,后面找量大的公司合作,自己就仅仅是个打工,为以后打工,所以说大家帮忙转一下,先让我知道你干的到底行不行。当然这个不是我自己擅长的领域,我是来知乎学习的。
影响力还有用的方面有:知道的第一时间内能很好的转发,或配以比较好的自己的标签并且内容成为病毒式传播性或者点击量最大,不得不说这个可能要看自己知道的渠道广泛性和自己的公司的产品,如果没有这方面的优势或规划,我还是建议不要着急做,因为后期如果要做好这个,涉及到各种的工作比较多。而且如果这个引导性不够强,其实这个成为病毒传播性,传播内容相对也就不是太好。
主要是看文章能否提供干货
找到我,
我是做客的,有一个新的发财机会,是一个网站影响力,客,其实你可以打开你的目录,看看,是不是有这些新奇的网站。
找个技术牛逼的团队给你做,这就跟找人搞互联网营销是一样的,要营销的好,且有人帮你发,你再去找你要找的那些网站合作呗。至于联盟这些那就更简单了,找到电商联盟,你要找的关键词就直接给他们看,
智能采集组合文章( 如何使用优采云采集进行搜索?写作推出智能采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-11 08:15
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“流行病”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
智能采集组合文章(
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“流行病”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
智能采集组合文章(智能采集组合文章排序规则的分析(一)——搜索词汇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-08 07:03
智能采集组合文章排序,通过在网页的排序规则中加入对文章的采集,达到自动化获取出新文章的目的。
1、打开百度指数,
2、创建好后,
3、如果是搜索同行业或者相关领域的,可以选择使用百度的ai采集工具进行抓取。本文也要结合百度指数来进行采集,搜索条件:同行业、相关领域、今日热度、同步工作。本文以文字为搜索词汇。通过上图我们可以看到,可以使用方法1中创建新的采集组合文章规则,可以在图中看到文章的排序规则,点击确定可以看到对应文章的排序规则。
本文只选择最新的文章采集了3000条,文章排序规则就可以编辑。可以看到网页上的需要采集的文章很多,通过以上步骤,可以完成对网页采集。(文章来源:cnki,今日热度)注意:前提条件:文章来源于中国知网在cnki检索到的一篇文章,我们将其进行提取后,以此为主题,进行本文的采集。
-library/webpage/sqlib6/d6016453(v=vs.8
5).aspx?id=3183
引用自百度指数的分析(采集方法相同):(同样采集了知网论文中的文章)
楼上大咖是不是对百度指数有什么误解比较官方的回答是需要你以你想要的热门话题为切入点。其次可以用采集pdf论文的方法:同样是搜索《top10000的语言学研究》,《top2000的语言学研究》,然后找跟你想要的相关的论文,并采集引用的论文数量。可以得到引用率大概的情况。如果想要得到不同论文的引用情况,可以搜索同类论文或者跟你意图相关的论文。
但百度没有提供看论文的功能,也就是,搜索之后,得到的结果并不一定跟你想要的匹配。说白了,你就算这么做了,用不了多久就会忘记。这个不是百度指数不靠谱,如果你用googledocs,直接搜索top1000010000或者top20001000,能找到很多不错的文章。但在百度上搜索论文,不太好用。最后,如果一定想得到以上两种论文(需要的资料已经有了),可以尝试一下阿斯伯格症的论文,查找的时候必须辅助引用别人写的关于各种知识点的文章。否则谷歌没法识别。 查看全部
智能采集组合文章(智能采集组合文章排序规则的分析(一)——搜索词汇)
智能采集组合文章排序,通过在网页的排序规则中加入对文章的采集,达到自动化获取出新文章的目的。
1、打开百度指数,
2、创建好后,
3、如果是搜索同行业或者相关领域的,可以选择使用百度的ai采集工具进行抓取。本文也要结合百度指数来进行采集,搜索条件:同行业、相关领域、今日热度、同步工作。本文以文字为搜索词汇。通过上图我们可以看到,可以使用方法1中创建新的采集组合文章规则,可以在图中看到文章的排序规则,点击确定可以看到对应文章的排序规则。
本文只选择最新的文章采集了3000条,文章排序规则就可以编辑。可以看到网页上的需要采集的文章很多,通过以上步骤,可以完成对网页采集。(文章来源:cnki,今日热度)注意:前提条件:文章来源于中国知网在cnki检索到的一篇文章,我们将其进行提取后,以此为主题,进行本文的采集。
-library/webpage/sqlib6/d6016453(v=vs.8
5).aspx?id=3183
引用自百度指数的分析(采集方法相同):(同样采集了知网论文中的文章)
楼上大咖是不是对百度指数有什么误解比较官方的回答是需要你以你想要的热门话题为切入点。其次可以用采集pdf论文的方法:同样是搜索《top10000的语言学研究》,《top2000的语言学研究》,然后找跟你想要的相关的论文,并采集引用的论文数量。可以得到引用率大概的情况。如果想要得到不同论文的引用情况,可以搜索同类论文或者跟你意图相关的论文。
但百度没有提供看论文的功能,也就是,搜索之后,得到的结果并不一定跟你想要的匹配。说白了,你就算这么做了,用不了多久就会忘记。这个不是百度指数不靠谱,如果你用googledocs,直接搜索top1000010000或者top20001000,能找到很多不错的文章。但在百度上搜索论文,不太好用。最后,如果一定想得到以上两种论文(需要的资料已经有了),可以尝试一下阿斯伯格症的论文,查找的时候必须辅助引用别人写的关于各种知识点的文章。否则谷歌没法识别。
智能采集组合文章(智能采集组合文章内容:对百度百科,或是头条等这些有外部组合词关联的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-07 22:05
智能采集组合文章内容:对百度百科,或是知乎,或是头条等这些有外部组合词关联的网站,都可以用智能推荐来展示内容,
1、复制有外部关联词组合的网站地址,如,新浪网-新浪新闻,腾讯网-腾讯新闻...等等,地址末尾加...,如.,...等等。
2、保存网站地址的文件夹:将它们所在文件夹名称复制到web开发人员网站中,如web.js文件夹,web.actions文件夹。
3、建立网站,一般都是wordpress,这些网站域名指向一个建站的公众号即可。
4、同步我们建立好的网站文件夹到百度云,当然,为了节省用户的点击、收藏和分享数据量,wordpress,也是可以不收费的,免费用户为单网站建站5篇,不同网站需要不同的数量。这些文件夹的操作很简单,对你专业技术没有要求。
智能推荐也可以很业余,
当然可以了,不要看好评,好评只是给你一个参考,其实真正写了多少东西,网站设计的够不够好,很难给你确定的答案。
我想可以,不管是什么网站,关联两个网站都能起到提高文章曝光率,加强传播率的作用。
可以,可以分开搭建;只需要上传自己在这两个网站上撰写好的内容(可以转载,自己可重新创作等)。 查看全部
智能采集组合文章(智能采集组合文章内容:对百度百科,或是头条等这些有外部组合词关联的网站)
智能采集组合文章内容:对百度百科,或是知乎,或是头条等这些有外部组合词关联的网站,都可以用智能推荐来展示内容,
1、复制有外部关联词组合的网站地址,如,新浪网-新浪新闻,腾讯网-腾讯新闻...等等,地址末尾加...,如.,...等等。
2、保存网站地址的文件夹:将它们所在文件夹名称复制到web开发人员网站中,如web.js文件夹,web.actions文件夹。
3、建立网站,一般都是wordpress,这些网站域名指向一个建站的公众号即可。
4、同步我们建立好的网站文件夹到百度云,当然,为了节省用户的点击、收藏和分享数据量,wordpress,也是可以不收费的,免费用户为单网站建站5篇,不同网站需要不同的数量。这些文件夹的操作很简单,对你专业技术没有要求。
智能推荐也可以很业余,
当然可以了,不要看好评,好评只是给你一个参考,其实真正写了多少东西,网站设计的够不够好,很难给你确定的答案。
我想可以,不管是什么网站,关联两个网站都能起到提高文章曝光率,加强传播率的作用。
可以,可以分开搭建;只需要上传自己在这两个网站上撰写好的内容(可以转载,自己可重新创作等)。
智能采集组合文章(Web的组织格式主要以HTML页面和VSM网页分类模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-03 10:24
[摘要]:随着全球经济一体化进程的加快和我国加入WTO,市场竞争环境发生了翻天覆地的变化。企业决策者不再可能依靠直觉和本能来做出商业决策。为了做出正确的决策,往往需要对竞争对手进行分析,及时了解他们的情况。因此,一个完整的竞争情报采集系统变得必不可少。随着互联网的飞速发展,网络为人们储存了大量的知识,成为一个巨大的全球知识库。从网络上获取信息已经成为人们获取知识的主要方式。与此同时,越来越多的公司建立了网站。通过有效地采集公司网站,可以了解竞争对手并向其学习。 Web 的组织格式主要基于 HTML 页面的半结构化形式。网页的结构、自由无序的超链接,以及网页内容的海量、多样性和动态变化,使人们在使用时遇到了一些无法回避的困难。为了解决这些问题,本课题采用基于主题的信息采集分类资源管理平台。介绍了系统平台的结构和各部分的功能。重点介绍网页采集模块和VSM网页分类模块。为了实现这两个模块,本文介绍了Bot网页抓取和HTMLParser网页解析等技术。网页的标题、Meta标签的内容和父网页上指向该网页的锚文本,将这些信息存储在相应的位置,并根据这些信息使用VSM方法对网页进行分类。为下一步开发企业竞争情报采集系统奠定基础。 查看全部
智能采集组合文章(Web的组织格式主要以HTML页面和VSM网页分类模块)
[摘要]:随着全球经济一体化进程的加快和我国加入WTO,市场竞争环境发生了翻天覆地的变化。企业决策者不再可能依靠直觉和本能来做出商业决策。为了做出正确的决策,往往需要对竞争对手进行分析,及时了解他们的情况。因此,一个完整的竞争情报采集系统变得必不可少。随着互联网的飞速发展,网络为人们储存了大量的知识,成为一个巨大的全球知识库。从网络上获取信息已经成为人们获取知识的主要方式。与此同时,越来越多的公司建立了网站。通过有效地采集公司网站,可以了解竞争对手并向其学习。 Web 的组织格式主要基于 HTML 页面的半结构化形式。网页的结构、自由无序的超链接,以及网页内容的海量、多样性和动态变化,使人们在使用时遇到了一些无法回避的困难。为了解决这些问题,本课题采用基于主题的信息采集分类资源管理平台。介绍了系统平台的结构和各部分的功能。重点介绍网页采集模块和VSM网页分类模块。为了实现这两个模块,本文介绍了Bot网页抓取和HTMLParser网页解析等技术。网页的标题、Meta标签的内容和父网页上指向该网页的锚文本,将这些信息存储在相应的位置,并根据这些信息使用VSM方法对网页进行分类。为下一步开发企业竞争情报采集系统奠定基础。
智能采集组合文章(优采云软件独家首创智能的万能文章采集器识别算法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-01 19:02
<p>优采云Universal文章采集器是基于高精度文本识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎新闻源()和泛页面(),支持采集指定网站栏目所有文章。 查看全部
智能采集组合文章(智能采集组合文章防点击,将站内seo转换为精准seo)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-31 01:02
智能采集组合文章防点击,同时将站内公共seo转换为精准seo大数据技术团队目前公司在积极开发新的产品,包括数据统计系统、站内seo各个模块等等。首先,是让网站收录更多内容。seoer通过大数据分析工具可以发现网站长尾关键词,这些长尾关键词将是你网站seo优化的重点,另外部分网站收录排名不是很好,可以先将长尾关键词布局在网站的不同页面,也能增加收录排名。
其次,是需要完善网站ip分布、收录分布,将搜索引擎关键词排名的效果展现给搜索引擎。目前网站ip没有统计,根据采集的长尾关键词收录分布的百分比来粗略估算ip值,ip总数量可以上“网站推广排名助手”(专业的网站推广工具)-内容丰富版进行统计,这个值可以帮助seoer获取更多自然流量。第三,就是不断保持网站内页清爽利索,加强站内seo文章的质量。
一个新的站点其核心栏目很多seoer都会花重金布局内容,这是一个良性循环,但千万不要花多余的钱去做大段文字,因为这样会影响用户体验,且对搜索引擎更新大数据是没有帮助的。举例:要查看一个网站是否更新存活率。可以在大数据工具-长尾关键词分析-访问或访问时间地点看一下网站的更新存活率,以及大数据工具-关键词分析——访问人数排名——数量分布,这三个数据分析,能直观的看到长尾关键词这段时间没有被大量的爬虫爬取而排名下降,这是比较好理解的。
总之,网站还需要定期清理无用内容,如人工整理,使其保持清洁。第四,就是站内seo优化文章质量。其实很多seoer认为seo就是文章技术,但是一个好的seo文章是否可以获得访问者认可,还需要通过很多因素来判断。seo除了文章优化好以外,另外一点非常重要就是关键词的设置以及和其他网站内容建设是否搭配好。比如一个文章排名首页,另外一个文章排名的话排名确实不错,但是访问者会错过网站的一些很有价值的文章,导致网站更新存活率不高。
目前有非常多的站点,正在出现内容垃圾比较多、知识网络非常混乱的情况,导致用户体验度下降,甚至降权降权降权!第五,就是要让搜索引擎看到你的网站是经过了用心保持内容更新的。很多seoer还没意识到这一点,通过大数据,你可以判断这个网站是否经过了精心、保持了足够的更新。目前很多网站会每天进行更新。另外从大数据的统计数据可以看到权重大的网站,就是他们大部分的内容要么是图片也要就是文字部分的广告,网站每天还要更新。
所以网站的内容越清晰,优质的内容就越多。第六,就是要让用户体验度高,服务态度要好。这个难点的要求是比较高的,举例:一个网站服务态度。 查看全部
智能采集组合文章(智能采集组合文章防点击,将站内seo转换为精准seo)
智能采集组合文章防点击,同时将站内公共seo转换为精准seo大数据技术团队目前公司在积极开发新的产品,包括数据统计系统、站内seo各个模块等等。首先,是让网站收录更多内容。seoer通过大数据分析工具可以发现网站长尾关键词,这些长尾关键词将是你网站seo优化的重点,另外部分网站收录排名不是很好,可以先将长尾关键词布局在网站的不同页面,也能增加收录排名。
其次,是需要完善网站ip分布、收录分布,将搜索引擎关键词排名的效果展现给搜索引擎。目前网站ip没有统计,根据采集的长尾关键词收录分布的百分比来粗略估算ip值,ip总数量可以上“网站推广排名助手”(专业的网站推广工具)-内容丰富版进行统计,这个值可以帮助seoer获取更多自然流量。第三,就是不断保持网站内页清爽利索,加强站内seo文章的质量。
一个新的站点其核心栏目很多seoer都会花重金布局内容,这是一个良性循环,但千万不要花多余的钱去做大段文字,因为这样会影响用户体验,且对搜索引擎更新大数据是没有帮助的。举例:要查看一个网站是否更新存活率。可以在大数据工具-长尾关键词分析-访问或访问时间地点看一下网站的更新存活率,以及大数据工具-关键词分析——访问人数排名——数量分布,这三个数据分析,能直观的看到长尾关键词这段时间没有被大量的爬虫爬取而排名下降,这是比较好理解的。
总之,网站还需要定期清理无用内容,如人工整理,使其保持清洁。第四,就是站内seo优化文章质量。其实很多seoer认为seo就是文章技术,但是一个好的seo文章是否可以获得访问者认可,还需要通过很多因素来判断。seo除了文章优化好以外,另外一点非常重要就是关键词的设置以及和其他网站内容建设是否搭配好。比如一个文章排名首页,另外一个文章排名的话排名确实不错,但是访问者会错过网站的一些很有价值的文章,导致网站更新存活率不高。
目前有非常多的站点,正在出现内容垃圾比较多、知识网络非常混乱的情况,导致用户体验度下降,甚至降权降权降权!第五,就是要让搜索引擎看到你的网站是经过了用心保持内容更新的。很多seoer还没意识到这一点,通过大数据,你可以判断这个网站是否经过了精心、保持了足够的更新。目前很多网站会每天进行更新。另外从大数据的统计数据可以看到权重大的网站,就是他们大部分的内容要么是图片也要就是文字部分的广告,网站每天还要更新。
所以网站的内容越清晰,优质的内容就越多。第六,就是要让用户体验度高,服务态度要好。这个难点的要求是比较高的,举例:一个网站服务态度。
智能采集组合文章(很不错的文章处理工具#8203;#38;功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-28 06:16
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。很不错的文章处理工具#8203;。
相关软件软件大小版本说明下载地址
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。是一款非常不错的文章处理工具。
特征
1、智能伪原创:利用人工智能中的自然语言处理技术,实现文章的伪原创处理。核心功能包括“智能伪原创”、“同义词替代伪原创”、“反义词替代伪原创”、“在带有html代码的文章中随机插入关键词”、“句子打乱重组”等,处理后期文章原创性和接受率均在80%以上。想了解更多功能,请下载软件试用。
2、 门户文章集:一键搜索相关门户新闻文章集,如搜狐、腾讯、新浪、网易、今日头条、新兰网、联合早报、光明.com、站长网、新文化网等,用户可以输入行业关键词,搜索自己想要的行业文章。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
3、百度新闻精选:一键搜索各行各业的新闻文章。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。但是,缺点是采集
的文章不一定很好。齐全,但能满足大部分用户的需求。友情提示:使用文章时,请注明文章出处,尊重原文版权。
4、行业文章集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等。网站上有几十个网站,资源丰富。该模块可能无法满足所有客户的需求,但客户可以提出自己的需求。我们将改进和更新模块资源。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
5、写采集
规则:自己写采集
规则。采集
规则符合常见的正则表达式。编写集合规则,需要了解一些html代码和正则表达式规则。如果您为其他商家的收款软件编写了收款规则,那么我们一定会写我们软件的收款规则,我们提供了编写收款规则的文档。我们不帮客户写收款规则,如果您需要代写,10元一个收款规则。友情提示:使用文章时,请注明文章出处,尊重原文版权。
6、 外链文章素材:本模块使用大量行业语料,通过算法随机组合语料,生成相关行业文章。本模块文章仅适用于对文章质量要求不高,用于外链推广的用户。本模块 特点,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、标题的批量生产:有两个功能,一是通过关键词和规则的结合来批量生产标题,二是通过采集
网络大数据来获取标题。自动生成的推广准确率高,采集
的标题可读性强,各有优缺点。
8、 文章界面发布:通过简单的配置,将生成的文章一键发布到您的网站。目前支持的网站有 Discuz 门户、DedeCms、Empire ECMS(新闻)、PHMCMS、奇博 CMS、PHP168、diypage、phpwind 门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
智能采集组合文章(很不错的文章处理工具#8203;#38;功能介绍)
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。很不错的文章处理工具#8203;。
相关软件软件大小版本说明下载地址
AI文章智能处理软件是一款智能文章伪原创工具,可以帮助用户重新组合文章形成新文章,还可以采集
素材。是一款非常不错的文章处理工具。
特征
1、智能伪原创:利用人工智能中的自然语言处理技术,实现文章的伪原创处理。核心功能包括“智能伪原创”、“同义词替代伪原创”、“反义词替代伪原创”、“在带有html代码的文章中随机插入关键词”、“句子打乱重组”等,处理后期文章原创性和接受率均在80%以上。想了解更多功能,请下载软件试用。
2、 门户文章集:一键搜索相关门户新闻文章集,如搜狐、腾讯、新浪、网易、今日头条、新兰网、联合早报、光明.com、站长网、新文化网等,用户可以输入行业关键词,搜索自己想要的行业文章。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
3、百度新闻精选:一键搜索各行各业的新闻文章。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。但是,缺点是采集
的文章不一定很好。齐全,但能满足大部分用户的需求。友情提示:使用文章时,请注明文章出处,尊重原文版权。
4、行业文章集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、五金行业、美容行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等。网站上有几十个网站,资源丰富。该模块可能无法满足所有客户的需求,但客户可以提出自己的需求。我们将改进和更新模块资源。该模块的特点是无需编写采集规则和一键操作。友情提示:使用文章时,请注明文章出处,尊重原文版权。
5、写采集
规则:自己写采集
规则。采集
规则符合常见的正则表达式。编写集合规则,需要了解一些html代码和正则表达式规则。如果您为其他商家的收款软件编写了收款规则,那么我们一定会写我们软件的收款规则,我们提供了编写收款规则的文档。我们不帮客户写收款规则,如果您需要代写,10元一个收款规则。友情提示:使用文章时,请注明文章出处,尊重原文版权。
6、 外链文章素材:本模块使用大量行业语料,通过算法随机组合语料,生成相关行业文章。本模块文章仅适用于对文章质量要求不高,用于外链推广的用户。本模块 特点,资源丰富,原创性高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、标题的批量生产:有两个功能,一是通过关键词和规则的结合来批量生产标题,二是通过采集
网络大数据来获取标题。自动生成的推广准确率高,采集
的标题可读性强,各有优缺点。
8、 文章界面发布:通过简单的配置,将生成的文章一键发布到您的网站。目前支持的网站有 Discuz 门户、DedeCms、Empire ECMS(新闻)、PHMCMS、奇博 CMS、PHP168、diypage、phpwind 门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
智能采集组合文章( 友盟+:移动数据采集特点与PC端不同的演进)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-27 10:01
友盟+:移动数据采集特点与PC端不同的演进)
本文由【友盟+】技术专家马巍源、张永峰共同撰稿
随着移动互联网和大数据技术的发展,以及智能手机的普及,几乎所有的工作、学习、生活场景都离不开手机。手机APP取代了传统的生活方式,让人们体验到便捷高效的服务,当然也承载着海量丰富的信息。从这些APP中采集
数据,集中清理和分析数据,可以将这些海量数据转化为宝贵的数据能量。数据采集是数据能源发展的第一步。如何采集数据,什么样的技术架构可以支持海量数据的采集、筛选和传输,是本文需要讨论的问题。
移动数据采集功能
与PC端不同,对于手机、iPad、智能手表、电视盒等移动设备,我们接触它们的载体是APP。Native SDK 需要大量的开发资源来支持多语言支持。跨平台应用开发正在逐渐成为一种趋势,但是各个框架中JS SDK的实现也不尽相同。因此,目前的移动采集SDK在支持多平台、多语言方面比较难支持。
更难的是安卓设备的机型适配。由于Android系统的开源特性,各家厂商为了在各机型上都有更好的用户体验,都进行了针对性的ROM改进。尤其是近几年,Android 在虚拟机和编译器上都做了很大的改变。这给模型适配带来了更大的困难。为了不给APP卡死、死机、黑屏、死机、加载速度慢等不良体验,还需要支持开发者的各种异常接口调用,并且需要有很强的容错能力。
移动流量持续增长。【友盟+】移动端应用超过135万款,覆盖全球超过14亿的日活跃移动设备,每天处理280亿条数据。测试我们采集SDK和服务器的承载能力,【友盟+】在移动采集技术上不断更新迭代,连续多年保持市场覆盖率领先。
SDK与服务端通信协议演进
我们最初的SDK设计思路简单高效,所以SDK端没有数据预处理的逻辑,甚至缓存策略也很简单。所有实时生成的数据都会实时上报给服务器。但是随着移动端流量的暴涨,这种高并发的请求给服务器带来了很大的压力。下图是版本0的通讯协议。
所以考虑通过控制发送频率来降低并发。开发者可以根据业务需求采用不同的发送策略:开始发送、间隔发送、退出发送,并且可以在【友盟+】平台上随时更改。虽然有效地减轻了服务器端的压力,但也带来了另一个问题。单条数据的大小可能会超过request-body的上限,导致请求超时。而流动压力也是一个急需解决的问题。因此,在2.0 版本中,我们压缩了数据并添加了安全机制。服务器增加了数据预处理的逻辑,完善了数据的校验。
只能在一个方向上通信的协议是不灵活的。很多时候我们需要控制SDK的行为,比如修改发送策略,屏蔽错误的数据,或者发现数据被污染而决定丢弃。需要通知这些运行中的服务器。SDK,以及没有长连接怎么办。在3.0版本中,我们设计了http请求响应的信息包体的控制语义。SDK除了从响应中获取服务器的接收状态外,还可以获取服务器的控制指令,以达到服务器的预期效果。
如果每个Log都必须等待解析服务器返回的控制信息,显然服务器对数据处理的及时性和并发处理能力会大打折扣,部分业务数据实际上并不需要解析和执行这些控制信息。因此,我们对业务数据进行了精细的分解。一些业务数据使用双向通信协议,可以解析和执行控制命令。其余的业务数据是与状态无关的数据,仍然使用单向通信协议。
那么在未来,控制协议和服务传输协议其实可以分开,各自使用不同的传输频率,但是可以保证所有的服务数据都由服务器的指令控制。
SDK技术架构分析
移动数据采集SDK架构主要由三部分组成:用户界面、业务模块、控制模块。
我们可以从几个场景的时序图分析这些模块的工作原理。
APP启动
当用户启动App时,实际上触发了开发者调用的初始化接口。Service Moudle 和 Control Moudle 会异步执行一些初始化操作:创建 Session、加载设备信息等。
APP在前台运行
当用户在APP中点击或滑动屏幕时,会触发开发者在APP中预设埋点事件。
Servie Moudle 会生成相应的事件数据,调用 Control Moudle 接口检查发送策略和安全策略,然后 Servie Moudle 将事件数据放入缓存队列中进行发送。
APP退出
无论用户退出APP后,SDK都会在短时间内完成多项操作:结束会话,持久保存数据,直接在iOS中完成数据打包、打包、上报等工作。
SDK组件化架构
我们提供越来越多的产品功能和越来越复杂的业务场景。为了满足各种解决方案的需求,SDK需要为每个业务场景维护多个分支、多个版本,浪费开发资源,并且版本迭代周期被拉长。为了解决这个问题,我们必须设计一个灵活的架构,让每个产品功能成为一个可以自由组合和拆卸的组件。
组件化将统一约定包和公共API的文件规范。针对当前【友盟+】业务需求,建立标准的SDK产品公共库(如:网络、序列化、配置、缓存等),组件结构分为两部分,Common将作为独立的library 包,和 Component 中的每个产品都作为一个独立的库。
其结构如下:
灵活的业务组合,适用更多场景
组件划分的粒度可以根据业务需要而定。我们的设计是根据产品或业务来划分组件。一个产品可能收录
许多功能。例如,统计产品包括事件数据采集、错误数据采集、A/B Test等功能。推送产品包括消息推送和应用内消息。在某些场景下,一些开发人员可能只使用其中的一部分。以函数为例,只使用错误分析函数和Push消息推送,然后将组件粒度细化到功能层,会更加灵活,可以满足更多场景的需求,体积的减小对于开发人员有吸引力。
业务逻辑解耦,代码更健壮
组件化架构改变了以往业务逻辑与基础功能的深度耦合。业务开发者可以专注于业务逻辑的实现,而无需考虑网络通信、消息队列管理、设备信息采集等基本功能的实现。业务逻辑代码的任何改动都不会影响基本的功能逻辑,增强了代码的健壮性,大大缩短了回归测试周期。
【友盟+】数据采集技术将不断适应业务场景的变化。未来,我们的目标是让我们的SDK更智能、更安全,让企业和开发者的整合更简单、数据更准确。 查看全部
智能采集组合文章(
友盟+:移动数据采集特点与PC端不同的演进)
本文由【友盟+】技术专家马巍源、张永峰共同撰稿
随着移动互联网和大数据技术的发展,以及智能手机的普及,几乎所有的工作、学习、生活场景都离不开手机。手机APP取代了传统的生活方式,让人们体验到便捷高效的服务,当然也承载着海量丰富的信息。从这些APP中采集
数据,集中清理和分析数据,可以将这些海量数据转化为宝贵的数据能量。数据采集是数据能源发展的第一步。如何采集数据,什么样的技术架构可以支持海量数据的采集、筛选和传输,是本文需要讨论的问题。
移动数据采集功能
与PC端不同,对于手机、iPad、智能手表、电视盒等移动设备,我们接触它们的载体是APP。Native SDK 需要大量的开发资源来支持多语言支持。跨平台应用开发正在逐渐成为一种趋势,但是各个框架中JS SDK的实现也不尽相同。因此,目前的移动采集SDK在支持多平台、多语言方面比较难支持。
更难的是安卓设备的机型适配。由于Android系统的开源特性,各家厂商为了在各机型上都有更好的用户体验,都进行了针对性的ROM改进。尤其是近几年,Android 在虚拟机和编译器上都做了很大的改变。这给模型适配带来了更大的困难。为了不给APP卡死、死机、黑屏、死机、加载速度慢等不良体验,还需要支持开发者的各种异常接口调用,并且需要有很强的容错能力。
移动流量持续增长。【友盟+】移动端应用超过135万款,覆盖全球超过14亿的日活跃移动设备,每天处理280亿条数据。测试我们采集SDK和服务器的承载能力,【友盟+】在移动采集技术上不断更新迭代,连续多年保持市场覆盖率领先。
SDK与服务端通信协议演进
我们最初的SDK设计思路简单高效,所以SDK端没有数据预处理的逻辑,甚至缓存策略也很简单。所有实时生成的数据都会实时上报给服务器。但是随着移动端流量的暴涨,这种高并发的请求给服务器带来了很大的压力。下图是版本0的通讯协议。
所以考虑通过控制发送频率来降低并发。开发者可以根据业务需求采用不同的发送策略:开始发送、间隔发送、退出发送,并且可以在【友盟+】平台上随时更改。虽然有效地减轻了服务器端的压力,但也带来了另一个问题。单条数据的大小可能会超过request-body的上限,导致请求超时。而流动压力也是一个急需解决的问题。因此,在2.0 版本中,我们压缩了数据并添加了安全机制。服务器增加了数据预处理的逻辑,完善了数据的校验。
只能在一个方向上通信的协议是不灵活的。很多时候我们需要控制SDK的行为,比如修改发送策略,屏蔽错误的数据,或者发现数据被污染而决定丢弃。需要通知这些运行中的服务器。SDK,以及没有长连接怎么办。在3.0版本中,我们设计了http请求响应的信息包体的控制语义。SDK除了从响应中获取服务器的接收状态外,还可以获取服务器的控制指令,以达到服务器的预期效果。
如果每个Log都必须等待解析服务器返回的控制信息,显然服务器对数据处理的及时性和并发处理能力会大打折扣,部分业务数据实际上并不需要解析和执行这些控制信息。因此,我们对业务数据进行了精细的分解。一些业务数据使用双向通信协议,可以解析和执行控制命令。其余的业务数据是与状态无关的数据,仍然使用单向通信协议。
那么在未来,控制协议和服务传输协议其实可以分开,各自使用不同的传输频率,但是可以保证所有的服务数据都由服务器的指令控制。
SDK技术架构分析
移动数据采集SDK架构主要由三部分组成:用户界面、业务模块、控制模块。
我们可以从几个场景的时序图分析这些模块的工作原理。
APP启动
当用户启动App时,实际上触发了开发者调用的初始化接口。Service Moudle 和 Control Moudle 会异步执行一些初始化操作:创建 Session、加载设备信息等。
APP在前台运行
当用户在APP中点击或滑动屏幕时,会触发开发者在APP中预设埋点事件。
Servie Moudle 会生成相应的事件数据,调用 Control Moudle 接口检查发送策略和安全策略,然后 Servie Moudle 将事件数据放入缓存队列中进行发送。
APP退出
无论用户退出APP后,SDK都会在短时间内完成多项操作:结束会话,持久保存数据,直接在iOS中完成数据打包、打包、上报等工作。
SDK组件化架构
我们提供越来越多的产品功能和越来越复杂的业务场景。为了满足各种解决方案的需求,SDK需要为每个业务场景维护多个分支、多个版本,浪费开发资源,并且版本迭代周期被拉长。为了解决这个问题,我们必须设计一个灵活的架构,让每个产品功能成为一个可以自由组合和拆卸的组件。
组件化将统一约定包和公共API的文件规范。针对当前【友盟+】业务需求,建立标准的SDK产品公共库(如:网络、序列化、配置、缓存等),组件结构分为两部分,Common将作为独立的library 包,和 Component 中的每个产品都作为一个独立的库。
其结构如下:
灵活的业务组合,适用更多场景
组件划分的粒度可以根据业务需要而定。我们的设计是根据产品或业务来划分组件。一个产品可能收录
许多功能。例如,统计产品包括事件数据采集、错误数据采集、A/B Test等功能。推送产品包括消息推送和应用内消息。在某些场景下,一些开发人员可能只使用其中的一部分。以函数为例,只使用错误分析函数和Push消息推送,然后将组件粒度细化到功能层,会更加灵活,可以满足更多场景的需求,体积的减小对于开发人员有吸引力。
业务逻辑解耦,代码更健壮
组件化架构改变了以往业务逻辑与基础功能的深度耦合。业务开发者可以专注于业务逻辑的实现,而无需考虑网络通信、消息队列管理、设备信息采集等基本功能的实现。业务逻辑代码的任何改动都不会影响基本的功能逻辑,增强了代码的健壮性,大大缩短了回归测试周期。
【友盟+】数据采集技术将不断适应业务场景的变化。未来,我们的目标是让我们的SDK更智能、更安全,让企业和开发者的整合更简单、数据更准确。
智能采集组合文章(本文将PDCA戴明循环与关联规则数据挖掘方法(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-12-27 09:11
周丽丽王宝军梁文敏袁秋平梁玉娟
摘要:本文对电子商务产品销售组合的智能构建进行研究,将关联规则融入到PDCA循环中,并利用其螺旋式和持续优化机制不断改进和完善关联规则的生成,即将结束。将不断变化的消费者需求因素引入到产品组合的构建中,从而帮助电子商务企业智能、动态地构建和优化产品组合。
关键词:关联规则;PDCA; 产品简介; 电子商务
一、简介
随着电子商务的快速发展,企业之间的竞争不断加剧。如何有效地为消费者推送产品组合,已成为电商企业提高客单价和盈利能力的重要手段。传统的产品销售组合往往依赖于经营者的个人经验和静态统计分析,时效性滞后,准确性不足。本文将PDCA戴明环与关联规则数据挖掘方法相结合,帮助企业开展产品组合智能构建的研究,利用企业的历史交易数据,动态准确地智能构建产品组合。
二、研究背景及相关理论
1.研究背景
国内外学者对大数据、数据挖掘技术与电子商务的结合进行了大量研究,但对数据挖掘与电子商务产品组合的研究较少,与管理方法相结合的研究较少。更缺乏。本文综合应用了PDCA循环管理思想和关联规则。通过计划、执行、检查、处理的迭代思维,利用持续的周期调整和优化,实时、动态、准确地生成产品组合。
2.相关理论
(1) 关联规则
关联规则是数据挖掘的一项重要技术,它反映了一件事与另一件事之间的相互依赖和关联。关联规则挖掘的目的是发现强关联规则,即从数据中挖掘出满足用户设置的最小支持度和最小置信度规则的数据。
关联规则的一般表示为:X->Y (S=s%, C=c%)
其中:X表示前一个项目可以是一个项目或项目集,Y表示后一个项目一般是一个项目。
Support (X->Y)=P(X∪Y) 是消费者同时购买X和Y的概率。
Confidence (X->Y)=P(Y|X) 是消费者在购买 X 后购买 Y 的条件概率。
Lift(X->Y)=P(Y|X)/P(X)P(Y)是判断关联规则实用性的指标。当lift大于1时,表示X对Y有正提升,如果小于1,则X和Y为负,如果等于1,则表示没有相关性。
本文将选择Apriori作为挖掘关联规则的算法。该算法具有单维、单层、布尔的特点,是一种经典的关联规则算法。
(2)PDCA 循环
PDCA循环将管理分为四个阶段,是一个连续的工作循环。每次经过PDCA循环,都要进行检查总结,分析遗留问题,提出新目标,再优化循环。
(3)产品组合
产品组合是指销售者可以向消费者提供的产品或物品的完整集合或组合。产品往往是相关的,可以同时引导消费者购买。产品组合的设计可以帮助企业优化客户。体验,提高客户转化率和客户单价。
三、模型设计
企业在经营过程中,会积累客户消费的历史记录。这些历史记录收录
不同消费者的购物清单。关联规则通过分析这些历史购物清单来发现产品之间的联系,进而挖掘出一系列的产品组合。. 该模型可以按照固定时间段或固定销售量对样本数据进行分组,并基于PDCA循环实现多重数据分析和挖掘。本文中的两轮PDCA分组如下:
2020年11月1日至2020年12月13日,A组样本1641个,A组验证组数据652个。
2020年12月14日至2021年1月28日,B组样本数据为1975个,B组验证组数据为1248个。
并按照以下流程进行两轮PDCA循环数据挖掘,分析模型如下图所示:
(1)Plan:实现目标和计划制定;(2)Do:关联规则模型设置和运行;
(3)Check:计算验证组的概率值并进行结果检查;(4)Act:效果评估和优化参数。
四、数据准备与实验分析
1.数据准备
(1)数据源
本文选取销量较高的化妆品天猫旗舰店为研究对象,利用优采云
数据采集软件抓取上述时间段内店内所有商品的评论内容,结合购买用户信息、购买时间和产品SKU模拟 恢复交易订单。本文采集
全店约5万条评论数据,模拟5516笔交易订单。
(2)数据预处理
本文选取用户标识和产品标识信息两个数据项,然后对数据进行转换、清洗等预处理操作,得到如表1所示的购物篮数据,并基于精确数据进行数据挖掘类型通过关联规则挖掘算法,对挖掘结果进行分析和评价。
①计划:制定实施目标和计划
第一轮,企业可以通过智能产品组合的构建,提升产品推送的精准度,促进消费者相关购买,提升消费者体验,提高企业客户单价,利用历史交易数据的关联规则挖掘,帮助企业推送产品组合自动。
②Do:关联规则模型设置和操作
使用R语言对采集到的数据进行处理。综合分析,本轮参数设置为:最小支持度1.1%,最小置信度50%,通过R语言导入1641条A组交易样本数据, 运行 Apriori 算法如下:
一共生成了24条关联规则。将关联规则的提升排序后,前8条关联规则如表2所示。
产生的24条规则置信度超过50%,提升幅度远大于1,说明规则有效且具有实用价值,即购买左边物品的买家很有可能购买同时右侧的项目。比如“气垫BB霜&冰冻水润唇釉->丝绒哑光唇膏”的支持度和置信度都很高,提升度达到了72。这三款产品同时非常适合作为相关产品它也适用于捆绑销售作为一个包。
根据生成的关联规则,企业可以以此为基础生成产品组合,并在关联营销中推送产品组合,让客户更方便的浏览到需要的产品,获取需要的组合包,促进客户的捆绑销售, 增加销量,提升购物体验。
③Check:计算验证组的概率值并进行结果检查
接下来,将A组样本数据生成的关联规则在A组验证组的数据中进行校验,计算出现在验证数据中的关联规则的置信度,找到生成的关联规则在验证集中更高。规则的置信度表明规则是高度可靠的。表 3 显示了验证组中前 8 条关联规则的置信度。
④Act:效果评价及优化参数
本轮执行产生了具有较好评价指标的关联规则,验证了这些规则的有效性和实用性。公司可以将这些规则应用于产品组合关联营销、产品包装设计和客户接触点优化。但是,也缺乏关联规则和可以覆盖的产品类型。
(2)第二轮PDCA
①计划:制定实施目标和计划
经过上一轮PDCA运算,企业能够挖掘出一系列高质量的关联规则,但数量少,覆盖的产品也少。因此,本轮需要调整支持度和置信度参数,在结果分析过程中需要考虑消费者需求变化。
②Do:关联规则模型设置和操作
本轮最低支持度0.7%,最低置信度35%。1975条B组交易样本数据通过R语言导入,Apriori算法运行如下:
一共生成了36条关联规则。将关联规则的提升程度排序后,前8条关联规则如表4所示。本轮关联规则数量有所提升。规则的支持度虽然有所降低,但还是出现了较高的频率,置信度处于较高水平。规则的增加远大于1,规则的有效性很高。和实用性。
③Check:计算验证组的概率值并进行结果检查
通过计算B组验证数据中规则的置信度,获得更高的置信度。因此,验证了生成的关联规则的结果具有较高的可信度。表 5 显示前 8 条关联规则在学校。测试组的信心。
④Act:效果评价及优化参数
根据本轮的执行,产生了更多的关联规则,而且都是高效实用的,可以覆盖更多的产品。企业可以使用这种方法来构建智能产品组合。此外,企业需要根据第一轮和第二轮产品关联规则的差异,了解季节性、活动性和流行趋势对产品组合的影响,与时俱进,不断优化和更新产品。文件夹。
3.实验结果分析
(1)本文的两轮PDCA过程虽然得到了高质量的关联规则,但是支持度和置信度的设置会极大地影响关联规则的生成。关联规则的支持度和置信度的调整整合在PDCA循环中,将实现参数的细化和动态调整。
(2)根据时间维度或销售维度对数据源进行合理划分,可以有效帮助企业挖掘贴近市场需求变化的关联规则。
(3)企业可以根据支持、信心、推广的变化趋势跟踪生成的关联规则的发展趋势,帮助企业更早地捕捉到产品和产品组合的需求和生命周期变化。
(4)企业可以对多轮PDCA循环产生的规则进行统计分析,根据关联规则随时间变化的程度,实施不同的营销策略。
五、总结
本文结合PDCA管理方法和关联规则数据挖掘算法,实现了数据挖掘算法在企业业务应用中的标准设计。通过PDCA循环迭代和螺旋机制,动态调整关联规则算法的应用,保证数据挖掘。效果的可靠性和实用性。通过多轮PDCA循环迭代,企业可以有效积累时间维度关联规则,帮助企业识别产品和产品组合的变化趋势和生命周期,帮助企业更全面、更系统地实现产品。组合的智能化建设。
参考:
[1] 李东云. 利用关联规则挖掘技术实现数字图书馆个性化推荐服务[J]. 2020年兰台内外(34):40-42.
[2] 郝海涛,马媛媛.基于加权关联规则挖掘算法的电子商务产品推荐系统研究[J]. 现代电子技术, 2016, 39 (15): 133-136.
[3]菲利普·科特勒,加里·阿姆斯特朗。市场营销概论[M].中国出版社,1998.
[4]朱庆.结合关联规则挖掘算法的信息化教学管理系统设计[J]. 现代电子技术, 2020, 43 (23): 159-163.
作者简介:周丽丽(1999.07-),女,汉族,籍贯:广东省揭阳市,本科,研究方向:电子商务;通讯作者:王宝军(1985.08-),男,汉族,籍贯:江西省景德镇市,研究生,工程师,研究方向:电子商务、数据挖掘 查看全部
智能采集组合文章(本文将PDCA戴明循环与关联规则数据挖掘方法(图))
周丽丽王宝军梁文敏袁秋平梁玉娟
摘要:本文对电子商务产品销售组合的智能构建进行研究,将关联规则融入到PDCA循环中,并利用其螺旋式和持续优化机制不断改进和完善关联规则的生成,即将结束。将不断变化的消费者需求因素引入到产品组合的构建中,从而帮助电子商务企业智能、动态地构建和优化产品组合。
关键词:关联规则;PDCA; 产品简介; 电子商务
一、简介
随着电子商务的快速发展,企业之间的竞争不断加剧。如何有效地为消费者推送产品组合,已成为电商企业提高客单价和盈利能力的重要手段。传统的产品销售组合往往依赖于经营者的个人经验和静态统计分析,时效性滞后,准确性不足。本文将PDCA戴明环与关联规则数据挖掘方法相结合,帮助企业开展产品组合智能构建的研究,利用企业的历史交易数据,动态准确地智能构建产品组合。
二、研究背景及相关理论
1.研究背景
国内外学者对大数据、数据挖掘技术与电子商务的结合进行了大量研究,但对数据挖掘与电子商务产品组合的研究较少,与管理方法相结合的研究较少。更缺乏。本文综合应用了PDCA循环管理思想和关联规则。通过计划、执行、检查、处理的迭代思维,利用持续的周期调整和优化,实时、动态、准确地生成产品组合。
2.相关理论
(1) 关联规则
关联规则是数据挖掘的一项重要技术,它反映了一件事与另一件事之间的相互依赖和关联。关联规则挖掘的目的是发现强关联规则,即从数据中挖掘出满足用户设置的最小支持度和最小置信度规则的数据。
关联规则的一般表示为:X->Y (S=s%, C=c%)
其中:X表示前一个项目可以是一个项目或项目集,Y表示后一个项目一般是一个项目。
Support (X->Y)=P(X∪Y) 是消费者同时购买X和Y的概率。
Confidence (X->Y)=P(Y|X) 是消费者在购买 X 后购买 Y 的条件概率。
Lift(X->Y)=P(Y|X)/P(X)P(Y)是判断关联规则实用性的指标。当lift大于1时,表示X对Y有正提升,如果小于1,则X和Y为负,如果等于1,则表示没有相关性。
本文将选择Apriori作为挖掘关联规则的算法。该算法具有单维、单层、布尔的特点,是一种经典的关联规则算法。
(2)PDCA 循环
PDCA循环将管理分为四个阶段,是一个连续的工作循环。每次经过PDCA循环,都要进行检查总结,分析遗留问题,提出新目标,再优化循环。
(3)产品组合
产品组合是指销售者可以向消费者提供的产品或物品的完整集合或组合。产品往往是相关的,可以同时引导消费者购买。产品组合的设计可以帮助企业优化客户。体验,提高客户转化率和客户单价。
三、模型设计
企业在经营过程中,会积累客户消费的历史记录。这些历史记录收录
不同消费者的购物清单。关联规则通过分析这些历史购物清单来发现产品之间的联系,进而挖掘出一系列的产品组合。. 该模型可以按照固定时间段或固定销售量对样本数据进行分组,并基于PDCA循环实现多重数据分析和挖掘。本文中的两轮PDCA分组如下:
2020年11月1日至2020年12月13日,A组样本1641个,A组验证组数据652个。
2020年12月14日至2021年1月28日,B组样本数据为1975个,B组验证组数据为1248个。
并按照以下流程进行两轮PDCA循环数据挖掘,分析模型如下图所示:
(1)Plan:实现目标和计划制定;(2)Do:关联规则模型设置和运行;
(3)Check:计算验证组的概率值并进行结果检查;(4)Act:效果评估和优化参数。
四、数据准备与实验分析
1.数据准备
(1)数据源
本文选取销量较高的化妆品天猫旗舰店为研究对象,利用优采云
数据采集软件抓取上述时间段内店内所有商品的评论内容,结合购买用户信息、购买时间和产品SKU模拟 恢复交易订单。本文采集
全店约5万条评论数据,模拟5516笔交易订单。
(2)数据预处理
本文选取用户标识和产品标识信息两个数据项,然后对数据进行转换、清洗等预处理操作,得到如表1所示的购物篮数据,并基于精确数据进行数据挖掘类型通过关联规则挖掘算法,对挖掘结果进行分析和评价。
①计划:制定实施目标和计划
第一轮,企业可以通过智能产品组合的构建,提升产品推送的精准度,促进消费者相关购买,提升消费者体验,提高企业客户单价,利用历史交易数据的关联规则挖掘,帮助企业推送产品组合自动。
②Do:关联规则模型设置和操作
使用R语言对采集到的数据进行处理。综合分析,本轮参数设置为:最小支持度1.1%,最小置信度50%,通过R语言导入1641条A组交易样本数据, 运行 Apriori 算法如下:
一共生成了24条关联规则。将关联规则的提升排序后,前8条关联规则如表2所示。
产生的24条规则置信度超过50%,提升幅度远大于1,说明规则有效且具有实用价值,即购买左边物品的买家很有可能购买同时右侧的项目。比如“气垫BB霜&冰冻水润唇釉->丝绒哑光唇膏”的支持度和置信度都很高,提升度达到了72。这三款产品同时非常适合作为相关产品它也适用于捆绑销售作为一个包。
根据生成的关联规则,企业可以以此为基础生成产品组合,并在关联营销中推送产品组合,让客户更方便的浏览到需要的产品,获取需要的组合包,促进客户的捆绑销售, 增加销量,提升购物体验。
③Check:计算验证组的概率值并进行结果检查
接下来,将A组样本数据生成的关联规则在A组验证组的数据中进行校验,计算出现在验证数据中的关联规则的置信度,找到生成的关联规则在验证集中更高。规则的置信度表明规则是高度可靠的。表 3 显示了验证组中前 8 条关联规则的置信度。
④Act:效果评价及优化参数
本轮执行产生了具有较好评价指标的关联规则,验证了这些规则的有效性和实用性。公司可以将这些规则应用于产品组合关联营销、产品包装设计和客户接触点优化。但是,也缺乏关联规则和可以覆盖的产品类型。
(2)第二轮PDCA
①计划:制定实施目标和计划
经过上一轮PDCA运算,企业能够挖掘出一系列高质量的关联规则,但数量少,覆盖的产品也少。因此,本轮需要调整支持度和置信度参数,在结果分析过程中需要考虑消费者需求变化。
②Do:关联规则模型设置和操作
本轮最低支持度0.7%,最低置信度35%。1975条B组交易样本数据通过R语言导入,Apriori算法运行如下:
一共生成了36条关联规则。将关联规则的提升程度排序后,前8条关联规则如表4所示。本轮关联规则数量有所提升。规则的支持度虽然有所降低,但还是出现了较高的频率,置信度处于较高水平。规则的增加远大于1,规则的有效性很高。和实用性。
③Check:计算验证组的概率值并进行结果检查
通过计算B组验证数据中规则的置信度,获得更高的置信度。因此,验证了生成的关联规则的结果具有较高的可信度。表 5 显示前 8 条关联规则在学校。测试组的信心。
④Act:效果评价及优化参数
根据本轮的执行,产生了更多的关联规则,而且都是高效实用的,可以覆盖更多的产品。企业可以使用这种方法来构建智能产品组合。此外,企业需要根据第一轮和第二轮产品关联规则的差异,了解季节性、活动性和流行趋势对产品组合的影响,与时俱进,不断优化和更新产品。文件夹。
3.实验结果分析
(1)本文的两轮PDCA过程虽然得到了高质量的关联规则,但是支持度和置信度的设置会极大地影响关联规则的生成。关联规则的支持度和置信度的调整整合在PDCA循环中,将实现参数的细化和动态调整。
(2)根据时间维度或销售维度对数据源进行合理划分,可以有效帮助企业挖掘贴近市场需求变化的关联规则。
(3)企业可以根据支持、信心、推广的变化趋势跟踪生成的关联规则的发展趋势,帮助企业更早地捕捉到产品和产品组合的需求和生命周期变化。
(4)企业可以对多轮PDCA循环产生的规则进行统计分析,根据关联规则随时间变化的程度,实施不同的营销策略。
五、总结
本文结合PDCA管理方法和关联规则数据挖掘算法,实现了数据挖掘算法在企业业务应用中的标准设计。通过PDCA循环迭代和螺旋机制,动态调整关联规则算法的应用,保证数据挖掘。效果的可靠性和实用性。通过多轮PDCA循环迭代,企业可以有效积累时间维度关联规则,帮助企业识别产品和产品组合的变化趋势和生命周期,帮助企业更全面、更系统地实现产品。组合的智能化建设。
参考:
[1] 李东云. 利用关联规则挖掘技术实现数字图书馆个性化推荐服务[J]. 2020年兰台内外(34):40-42.
[2] 郝海涛,马媛媛.基于加权关联规则挖掘算法的电子商务产品推荐系统研究[J]. 现代电子技术, 2016, 39 (15): 133-136.
[3]菲利普·科特勒,加里·阿姆斯特朗。市场营销概论[M].中国出版社,1998.
[4]朱庆.结合关联规则挖掘算法的信息化教学管理系统设计[J]. 现代电子技术, 2020, 43 (23): 159-163.
作者简介:周丽丽(1999.07-),女,汉族,籍贯:广东省揭阳市,本科,研究方向:电子商务;通讯作者:王宝军(1985.08-),男,汉族,籍贯:江西省景德镇市,研究生,工程师,研究方向:电子商务、数据挖掘
智能采集组合文章(知乎能够自动给我推送优质回答吗?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-24 20:11
智能采集组合文章内容一键组合/裁剪篇幅不足的原创内容自动纠正当前文章中出现的错别字关键词自动提示关键词自动定位被过滤的差不多的过滤内容重新重写检查标题和样式避免原创党风险在写的过程中不断提醒错别字一键注册如果流量过大会提示部分用户无法同步注册所以要等过好一段时间再注册扫码注册不支持自动生成注册手机号,这个得自己买电话号,或者找微信支付宝申请(注册时会要求填写)创建任务可以选择打卡打字打卡打卡打表格,打字速度不要太快要快打包发货不支持分类包装包装分类标题图片昵称标签头像确认开始其他问题欢迎私信。
知乎能够自动给我推送优质回答吗?(玩手机时感觉知乎比手机更好用)我想了想,最主要的几点,也是多数自媒体人所忽略的:首先,发现问题要及时解决,比如:明显错别字了要查出并删除。再就是有些写作素材不适合通过自媒体发出来,发出来会影响用户点击阅读甚至取消关注。这个时候,你应该发起投票或者意见征集,让大家共同讨论。
发现问题要及时改正,比如:描述不正确要及时修改。别人把内容发给你之后,你可以告诉用户里面哪里描述有误,让他修改。我曾见过有个知乎大v把一篇介绍中兴通讯基地的文章发给读者,他把相应的基地地址都改成了“中兴基地”,如果用户体验影响用户继续关注这个账号,他就弃号了。还有不要随便推送广告,我自己也有过自己写的文章开始疯狂推送广告的经历,因为广告我有时就要推荐一些我不喜欢的内容,同时提示读者有广告不要接受。
再就是及时清理自己写的内容或者群发不合理的、无价值的文章。有一次给我推送错误的一篇文章,导致阅读量降低一半。多数是要注意以上几点,这个是我体验过程中的一些小总结,算不上真正提高文章质量的建议,我也主要是学习尝试。 查看全部
智能采集组合文章(知乎能够自动给我推送优质回答吗?(组图))
智能采集组合文章内容一键组合/裁剪篇幅不足的原创内容自动纠正当前文章中出现的错别字关键词自动提示关键词自动定位被过滤的差不多的过滤内容重新重写检查标题和样式避免原创党风险在写的过程中不断提醒错别字一键注册如果流量过大会提示部分用户无法同步注册所以要等过好一段时间再注册扫码注册不支持自动生成注册手机号,这个得自己买电话号,或者找微信支付宝申请(注册时会要求填写)创建任务可以选择打卡打字打卡打卡打表格,打字速度不要太快要快打包发货不支持分类包装包装分类标题图片昵称标签头像确认开始其他问题欢迎私信。
知乎能够自动给我推送优质回答吗?(玩手机时感觉知乎比手机更好用)我想了想,最主要的几点,也是多数自媒体人所忽略的:首先,发现问题要及时解决,比如:明显错别字了要查出并删除。再就是有些写作素材不适合通过自媒体发出来,发出来会影响用户点击阅读甚至取消关注。这个时候,你应该发起投票或者意见征集,让大家共同讨论。
发现问题要及时改正,比如:描述不正确要及时修改。别人把内容发给你之后,你可以告诉用户里面哪里描述有误,让他修改。我曾见过有个知乎大v把一篇介绍中兴通讯基地的文章发给读者,他把相应的基地地址都改成了“中兴基地”,如果用户体验影响用户继续关注这个账号,他就弃号了。还有不要随便推送广告,我自己也有过自己写的文章开始疯狂推送广告的经历,因为广告我有时就要推荐一些我不喜欢的内容,同时提示读者有广告不要接受。
再就是及时清理自己写的内容或者群发不合理的、无价值的文章。有一次给我推送错误的一篇文章,导致阅读量降低一半。多数是要注意以上几点,这个是我体验过程中的一些小总结,算不上真正提高文章质量的建议,我也主要是学习尝试。
智能采集组合文章(软件特点优采云软件首创的智能提取网页正文正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-24 08:02
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集消息来源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息 查看全部
智能采集组合文章(软件特点优采云软件首创的智能提取网页正文正文的算法)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集消息来源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息
智能采集组合文章(通过长尾关键词进行组合让网站流量轻松提升了10倍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-12-23 12:29
长尾关键词的组合使得网站流量轻松增加10倍,长尾关键词在选择上应该有意义,长尾关键词容易优化,如果组合长尾关键词,如:长尾关键词+长尾关键词,或者穿插使用,用户搜索千变万化,组合长尾关键词@ > 可以让网站为不可控的用户搜索提供更多的展示机会。网站在北京的具体操作如下:
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。
北京做网站
使用php字段方法(regular即可,字段简单)采集所有关键词收录“二手车”,自动无限制采集返回的关键词数量非常超过限制长度的大(重复关键词no采集,关键词no采集)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索更容易找到,加上长尾关键词容易排名,
北京做网站
上首页很容易,如果数量很大,你得到的流量是非常直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关的内容与采集,或者采集其他人的文章结合到百度翻译,再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果你精通程序,那真的太容易了。
通过大量的长尾关键词做内容,总会有大量的关键词排名首页,流量增加十倍根本不是问题。 查看全部
智能采集组合文章(通过长尾关键词进行组合让网站流量轻松提升了10倍)
长尾关键词的组合使得网站流量轻松增加10倍,长尾关键词在选择上应该有意义,长尾关键词容易优化,如果组合长尾关键词,如:长尾关键词+长尾关键词,或者穿插使用,用户搜索千变万化,组合长尾关键词@ > 可以让网站为不可控的用户搜索提供更多的展示机会。网站在北京的具体操作如下:
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。
北京做网站
使用php字段方法(regular即可,字段简单)采集所有关键词收录“二手车”,自动无限制采集返回的关键词数量非常超过限制长度的大(重复关键词no采集,关键词no采集)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索更容易找到,加上长尾关键词容易排名,
北京做网站
上首页很容易,如果数量很大,你得到的流量是非常直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关的内容与采集,或者采集其他人的文章结合到百度翻译,再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果你精通程序,那真的太容易了。
通过大量的长尾关键词做内容,总会有大量的关键词排名首页,流量增加十倍根本不是问题。
智能采集组合文章(智能工单知识挖掘引擎系统系统中具有海量数据的工单信息 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-22 14:14
)
智能搜索引擎
在知识库中,只能通过数据库搜索、全文搜索,往往不会出现搜索不到、搜索不准确的情况。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
互联网信息采集和分发引擎包查询
如果你每天花大量时间在指定的网站上搜索各种知识信息作为研究和内部参考,如果你苦恼这些信息需要手动下载,你需要手动区分分类,需要手动去除重复项,消除干扰。那你一定不能错过“包裹查询”。
基于爬虫和机器学习技术,自动采集,自动去重分类,个性化分布推荐,知识关联挖掘,只为你想知道!
智能工单知识挖掘引擎
工单系统拥有海量工单信息数据。通过“工单知识抽取模型”的构建和训练,将有效的工单知识提取出来并应用到工单建议和处置的过程中,从而减少重复的工单。提高提交率,提高工单处理效率和解决准确率
健康保险理赔是一个专业而复杂的过程,需要医学和保险双重领域的知识。
深蓝基于知识规则引擎开发了“药物-疾病-症状”知识规则库,可以从“对症用药”和“合理用药”两个方面为医保理赔提供智能支持服务。
传统知识库只能进行全文搜索,找到一堆结果。传统客服问答机器人呢?需要根据文档手动整理出大量QA问答对,超反人类。
有没有可能,就问你的问题,系统会自动从知识库中找到对应的文章,截取文章中最相关的一段,作为答案发给你?这就是“智能知识助手”!
太多的信息,太多的数据,知识库中的太多内容!你还在手工分类构建知识图谱吗?
快来试试基于多条件组合和机器学习模型的自动分类引擎,轻松合理地对数百万文档和资料进行分类!
如何从海量数据中发现未知规律,发现热点、问题、时间地域分布、相关人物、事件等,基于非结构化文本的知识挖掘引擎,轻松进行知识挖掘,并提供图形化的决策支持依据。
查看全部
智能采集组合文章(智能工单知识挖掘引擎系统系统中具有海量数据的工单信息
)
智能搜索引擎
在知识库中,只能通过数据库搜索、全文搜索,往往不会出现搜索不到、搜索不准确的情况。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
互联网信息采集和分发引擎包查询
如果你每天花大量时间在指定的网站上搜索各种知识信息作为研究和内部参考,如果你苦恼这些信息需要手动下载,你需要手动区分分类,需要手动去除重复项,消除干扰。那你一定不能错过“包裹查询”。
基于爬虫和机器学习技术,自动采集,自动去重分类,个性化分布推荐,知识关联挖掘,只为你想知道!
智能工单知识挖掘引擎
工单系统拥有海量工单信息数据。通过“工单知识抽取模型”的构建和训练,将有效的工单知识提取出来并应用到工单建议和处置的过程中,从而减少重复的工单。提高提交率,提高工单处理效率和解决准确率
健康保险理赔是一个专业而复杂的过程,需要医学和保险双重领域的知识。
深蓝基于知识规则引擎开发了“药物-疾病-症状”知识规则库,可以从“对症用药”和“合理用药”两个方面为医保理赔提供智能支持服务。
传统知识库只能进行全文搜索,找到一堆结果。传统客服问答机器人呢?需要根据文档手动整理出大量QA问答对,超反人类。
有没有可能,就问你的问题,系统会自动从知识库中找到对应的文章,截取文章中最相关的一段,作为答案发给你?这就是“智能知识助手”!
太多的信息,太多的数据,知识库中的太多内容!你还在手工分类构建知识图谱吗?
快来试试基于多条件组合和机器学习模型的自动分类引擎,轻松合理地对数百万文档和资料进行分类!
如何从海量数据中发现未知规律,发现热点、问题、时间地域分布、相关人物、事件等,基于非结构化文本的知识挖掘引擎,轻松进行知识挖掘,并提供图形化的决策支持依据。
智能采集组合文章(智能采集组合文章采集,将相同标题文章汇总(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-22 03:02
智能采集组合文章采集,将相同标题文章汇总在一起,并对其进行自动标签合并上传文章,一篇文章或多篇文章,一键采集,全网内容秒精准推送关注微信公众号:cloudiike,回复【注册】,
“快速上传”,有句老话叫,好钢用在刀刃上,如果没有很多的资金或者是时间的成本投入,那么我不建议这个项目,其实成本性价比比较低。
被删减部分节选的文章,难道只是因为版权原因吗?所以这种假正经的非正规文章,不要盲目投机。过滤一下吧。
加入他们社群,不光可以发布文章,
可以找我
我所知道有多个平台帮我写稿,一篇写一千,十万即可分成。想写首自媒体文章的话,价格很合适。但稿费都不一样,价格谈妥即可。
有个网站,叫百家号指数,直接搜索搜狗百家号,去申请试试看吧。
一个应用叫百家号指数,输入你的标题,搜索几次,就知道标题的内容占的比例,很多标题都是万年不变的。很多,很多。
最简单的就是上传本地新闻,
百家号,搜狐新闻,头条新闻,凤凰网,网易新闻,腾讯新闻,搜狐网,大风号,人民网,百度百家,一点资讯,一点订阅,开心网,京东,今日头条,搜狐新闻,网易,b站,微博等等, 查看全部
智能采集组合文章(智能采集组合文章采集,将相同标题文章汇总(组图))
智能采集组合文章采集,将相同标题文章汇总在一起,并对其进行自动标签合并上传文章,一篇文章或多篇文章,一键采集,全网内容秒精准推送关注微信公众号:cloudiike,回复【注册】,
“快速上传”,有句老话叫,好钢用在刀刃上,如果没有很多的资金或者是时间的成本投入,那么我不建议这个项目,其实成本性价比比较低。
被删减部分节选的文章,难道只是因为版权原因吗?所以这种假正经的非正规文章,不要盲目投机。过滤一下吧。
加入他们社群,不光可以发布文章,
可以找我
我所知道有多个平台帮我写稿,一篇写一千,十万即可分成。想写首自媒体文章的话,价格很合适。但稿费都不一样,价格谈妥即可。
有个网站,叫百家号指数,直接搜索搜狗百家号,去申请试试看吧。
一个应用叫百家号指数,输入你的标题,搜索几次,就知道标题的内容占的比例,很多标题都是万年不变的。很多,很多。
最简单的就是上传本地新闻,
百家号,搜狐新闻,头条新闻,凤凰网,网易新闻,腾讯新闻,搜狐网,大风号,人民网,百度百家,一点资讯,一点订阅,开心网,京东,今日头条,搜狐新闻,网易,b站,微博等等,
智能采集组合文章(AuTopAuTop战队开源算法讲解(六)Openart识别方案介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2021-12-21 11:13
本文为第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解第7部分-三岔数字识别、专栏及开源程序链接:
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
在上一篇文章(木野:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解(六)Openart识别解决方案)中,我们提到了数字化的思路识别,使用全局分类器的方法,直接判断图像中是否有数字目标卡片和对应的数字编号,省略了找框的步骤,不仅计算速度更快,还减少了不稳定因素( OpenMV 的 find_rect 函数不稳定)
模型结构
先放一张模型结构的概览图(有点长)用Netron来画。
数字分类模型概览图
可以看出模型主要由4个子模块组成
下采样和正则化 MaxPooling2D+SpatialDropout2D 空间注意力单元:x*sigmoid(conv(x)) 分类头:GlobalMaxPooling2D+Dense
另外,模型的代码中使用了超参数width来控制模型的宽度。经过不同参数的选择测试,发现当width=0.5时,可以在计算速度和模型精度之间取得较好的平衡。具体代码实现见开源代码库。
2. 数据集生成
由于官方只提供了十张标准数码图片,所以数据量有点小。但是如果直接使用OpenArt-mini采集的实际数据,不仅工作量大,而且背景单一,更换场地后识别效果可能会下降。因此,我们以COCO开源数据集为背景,将标准数码图片随机映射到背景图片上,结合数据增强方法生成数据集。可以在最大限度地减少人力的同时训练出性能优异的模型。
示例图片
示例图片
3. 模型训练
训练步骤基本参考官方训练方案,只用自己搭建的模型替换模型。仅将数据增强得到的图像作为训练集,少量记录数据作为测试集。两个数据域存在一定的差异,可以更好地看出模型和数据增强的有效性。在我们的实验中,在测试集上可以轻松达到90%以上的准确率,充分证明了该方法的有效性。
SJTU-AuTop 完整的开源解决方案链接,如果您觉得我们的解决方案对您有帮助,请帮我在github上给个star :)
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结 查看全部
智能采集组合文章(AuTopAuTop战队开源算法讲解(六)Openart识别方案介绍)
本文为第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解第7部分-三岔数字识别、专栏及开源程序链接:
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
在上一篇文章(木野:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源算法讲解(六)Openart识别解决方案)中,我们提到了数字化的思路识别,使用全局分类器的方法,直接判断图像中是否有数字目标卡片和对应的数字编号,省略了找框的步骤,不仅计算速度更快,还减少了不稳定因素( OpenMV 的 find_rect 函数不稳定)
模型结构
先放一张模型结构的概览图(有点长)用Netron来画。
数字分类模型概览图
可以看出模型主要由4个子模块组成
下采样和正则化 MaxPooling2D+SpatialDropout2D 空间注意力单元:x*sigmoid(conv(x)) 分类头:GlobalMaxPooling2D+Dense
另外,模型的代码中使用了超参数width来控制模型的宽度。经过不同参数的选择测试,发现当width=0.5时,可以在计算速度和模型精度之间取得较好的平衡。具体代码实现见开源代码库。
2. 数据集生成
由于官方只提供了十张标准数码图片,所以数据量有点小。但是如果直接使用OpenArt-mini采集的实际数据,不仅工作量大,而且背景单一,更换场地后识别效果可能会下降。因此,我们以COCO开源数据集为背景,将标准数码图片随机映射到背景图片上,结合数据增强方法生成数据集。可以在最大限度地减少人力的同时训练出性能优异的模型。
示例图片
示例图片
3. 模型训练
训练步骤基本参考官方训练方案,只用自己搭建的模型替换模型。仅将数据增强得到的图像作为训练集,少量记录数据作为测试集。两个数据域存在一定的差异,可以更好地看出模型和数据增强的有效性。在我们的实验中,在测试集上可以轻松达到90%以上的准确率,充分证明了该方法的有效性。
SJTU-AuTop 完整的开源解决方案链接,如果您觉得我们的解决方案对您有帮助,请帮我在github上给个star :)
llo:第十六届智能汽车智能视觉组-上海交通大学AuTop团队开源总结
智能采集组合文章(优采云浏览器可视化编辑脚本并运行任务可以通过来高效完成 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-11 00:08
)
对于经常处理网页操作的朋友来说,数据批处理是一种基于数据智能处理的高效处理方式。无论是批量采集、批量验证,还是批量批量发布、批量注册,都可以通过数据批量处理软件优采云浏览器高效完成。
优采云浏览器软件是一个可视化的网页操作工具。可视化保证了用户操作的便捷性,也是批量操作的亮点之一。该工具来自经典采集软件优采云采集器的研发团队。基于对数据属性的熟悉和对网页机制的深入研究,优采云浏览器推出了核心亮点——项目管理器。
可视化编辑脚本和运行任务可以给你带来智能体验,但是单个任务的累积操作比较繁琐。庞大的数据量和复杂的管理都让我们苦恼。核心项目经理可以调用脚本同时或长期循环运行,并且可以设置运行模式、数据源和任务时序等,组合成适合自己的独特解决方案。
因此,以营销人员为例,可以使用优采云浏览器来定义整个网络营销的步骤和流程。您可以通过博客等渠道自动登录并自动识别验证码。无需一一重复“登录、复制、粘贴、发送”的步骤。
传统的批处理工具只能进行单一操作,但营销是全方位的,更加个性化。它不能仅限于一项,例如群组邮寄。优采云浏览器被营销人员称为万能的营销工具。用户甚至可以将自己设计的项目方案生成程序分享给其他用户,并通过浏览器自带的软件管理平台优采云对程序进行授权。为您自己的解决方案赚取利润。
除了群发、批量保存和上传,采集也适用,优采云浏览器可视化采集可以模拟人的真实点击提取操作,甚至可以处理瀑布或滚动酒吧。微博等数据。
面对海量数据,人工操作的能力毕竟有限,只有智能化、个性化的批处理才是高效利用数据的趋势。不仅营销人员可以使用优采云浏览器来满足批处理需求,科研机构、网站运维、各行各业都在浪潮中逐渐寻找数据资源应用的方向的大数据。
查看全部
智能采集组合文章(优采云浏览器可视化编辑脚本并运行任务可以通过来高效完成
)
对于经常处理网页操作的朋友来说,数据批处理是一种基于数据智能处理的高效处理方式。无论是批量采集、批量验证,还是批量批量发布、批量注册,都可以通过数据批量处理软件优采云浏览器高效完成。
优采云浏览器软件是一个可视化的网页操作工具。可视化保证了用户操作的便捷性,也是批量操作的亮点之一。该工具来自经典采集软件优采云采集器的研发团队。基于对数据属性的熟悉和对网页机制的深入研究,优采云浏览器推出了核心亮点——项目管理器。
可视化编辑脚本和运行任务可以给你带来智能体验,但是单个任务的累积操作比较繁琐。庞大的数据量和复杂的管理都让我们苦恼。核心项目经理可以调用脚本同时或长期循环运行,并且可以设置运行模式、数据源和任务时序等,组合成适合自己的独特解决方案。
因此,以营销人员为例,可以使用优采云浏览器来定义整个网络营销的步骤和流程。您可以通过博客等渠道自动登录并自动识别验证码。无需一一重复“登录、复制、粘贴、发送”的步骤。
传统的批处理工具只能进行单一操作,但营销是全方位的,更加个性化。它不能仅限于一项,例如群组邮寄。优采云浏览器被营销人员称为万能的营销工具。用户甚至可以将自己设计的项目方案生成程序分享给其他用户,并通过浏览器自带的软件管理平台优采云对程序进行授权。为您自己的解决方案赚取利润。
除了群发、批量保存和上传,采集也适用,优采云浏览器可视化采集可以模拟人的真实点击提取操作,甚至可以处理瀑布或滚动酒吧。微博等数据。
面对海量数据,人工操作的能力毕竟有限,只有智能化、个性化的批处理才是高效利用数据的趋势。不仅营销人员可以使用优采云浏览器来满足批处理需求,科研机构、网站运维、各行各业都在浪潮中逐渐寻找数据资源应用的方向的大数据。
智能采集组合文章(1分钟采集数据开始画图之前需要先做如下4个事情)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-12-09 12:18
采集的1分钟精度,开始绘制采集数据前需要做以下4件事。
1. 创建1分钟的RRA;
2. 在Cacti Data Source 模板中修改“Step”和“Heartbeat”的值;
3. 在系统 cron 中修改 poller 的轮询时间间隔;
4. 在 Cacti 配置中修改 poller 的轮询时间间隔。
1、首先创建所需的1分钟RRA:
这个RRA的定义可以确定我们数据不同精度的最大存储周期,存储时间=Step Steps Rows。例如默认的Cacti 5分钟精度Daily(5 Miniute Average),RRA精度数据存储时间为:(5 1 600) / 60m = 50h ≈ 2d,注意:
• “Step”是在数据源中定义的步骤时间。在Cacti中,就是下面第二步提到的Data模板中定义的Step值(以秒为单位);
• “Steps”为步数,即上图中RRA中定义的Steps值;
• 注意:这个保存时间不是上图中Timespan 的值。时间跨度是指我们点击某个图表后出现的几个时间段的详细图表中所显示的时间段的长度。
好了,正式开始我们的RRA修改和创建方法说明。
为了区分,我们修改默认RRA的名称,精度为5分钟(不用担心,Cacti是用ID来识别的)。如果要保存更长的时间,增加Rows的数量;
然后,我们新建一个1分钟精度的RRA,例如(英文表示1分钟精度,中文表示5分钟精度):
最终如下:
我们创建的1分钟精度RRA数据存储时间计算表如下:
可作为上路参数
2、 修改数据模板中的“step”和“heartbeat”参数
注意:如果在“关联”中选择多个列,请按住Ctrl键
4) 点击页面底部的“保存”,然后注意再次更改标签“2:traffic_out”的“心跳”。
3、 修改cron中的Poller轮询间隔为1分钟
vi/etc/crontab
4、 修改Cacti配置中Poller的轮询间隔
5、重建轮询缓存
6、删除原来的.rrd文件,等待1分钟cacti重建。
rm /home/wwwroot/defautl/cacti/rra/*.rrd
7、重启进程
然后等待图片出现。 查看全部
智能采集组合文章(1分钟采集数据开始画图之前需要先做如下4个事情)
采集的1分钟精度,开始绘制采集数据前需要做以下4件事。
1. 创建1分钟的RRA;
2. 在Cacti Data Source 模板中修改“Step”和“Heartbeat”的值;
3. 在系统 cron 中修改 poller 的轮询时间间隔;
4. 在 Cacti 配置中修改 poller 的轮询时间间隔。
1、首先创建所需的1分钟RRA:
这个RRA的定义可以确定我们数据不同精度的最大存储周期,存储时间=Step Steps Rows。例如默认的Cacti 5分钟精度Daily(5 Miniute Average),RRA精度数据存储时间为:(5 1 600) / 60m = 50h ≈ 2d,注意:
• “Step”是在数据源中定义的步骤时间。在Cacti中,就是下面第二步提到的Data模板中定义的Step值(以秒为单位);
• “Steps”为步数,即上图中RRA中定义的Steps值;
• 注意:这个保存时间不是上图中Timespan 的值。时间跨度是指我们点击某个图表后出现的几个时间段的详细图表中所显示的时间段的长度。
好了,正式开始我们的RRA修改和创建方法说明。
为了区分,我们修改默认RRA的名称,精度为5分钟(不用担心,Cacti是用ID来识别的)。如果要保存更长的时间,增加Rows的数量;
然后,我们新建一个1分钟精度的RRA,例如(英文表示1分钟精度,中文表示5分钟精度):
最终如下:
我们创建的1分钟精度RRA数据存储时间计算表如下:
可作为上路参数
2、 修改数据模板中的“step”和“heartbeat”参数
注意:如果在“关联”中选择多个列,请按住Ctrl键
4) 点击页面底部的“保存”,然后注意再次更改标签“2:traffic_out”的“心跳”。
3、 修改cron中的Poller轮询间隔为1分钟
vi/etc/crontab
4、 修改Cacti配置中Poller的轮询间隔
5、重建轮询缓存
6、删除原来的.rrd文件,等待1分钟cacti重建。
rm /home/wwwroot/defautl/cacti/rra/*.rrd
7、重启进程
然后等待图片出现。

