
文章采集文章采集
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-05-18 19:04
文章采集文章采集基本数据采集方法主要包括如下:文章采集数据地址规则过滤cookie可见/不可见网址集中导入jsoup与jstring路由/ajax直接转换获取视频信息基于文章的关键词相似性分析今日头条采集程序说明本采集是使用路由分析库中jsoup库来采集今日头条(包括感兴趣内容)。文章路由分析主要将采集网址采集到wordpress网站,再和stringbuilder库中的encodeasy方法对比,计算文章与网址之间的相似度分数。
文章采集分为三个步骤,爬取网址、采集网址、分析采集网址以及后续生成数据文件。文章采集过程如下图所示:采集网址文章采集网址是要爬取的内容,采集网址时一般可以使用浏览器中的开发者工具来打开网址,然后通过getdetail方法查询是否可以采集。爬取文章网址之后,可以使用bs4分析网址结构,获取作者、链接、话题等信息。详细的爬取网址的方法有:利用selenium来控制浏览器请求数据分析网址文章搜索词数据分析。
上java视频jsoup,写采集程序。加载你要的数据,数据就可以返回。jsoup库,在dom中包装了java代码,方便java和javascript交互。javascript也能够通过jsoup的方式提取出来。当然也可以在dom中创建一个jsoup对象来封装java代码。所以,你不需要去弄懂jsoup的java编程。
dom中封装了dom结构,java可以很方便的转化为json形式。所以,你可以直接提取json中的数据来识别java代码。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集文章采集基本数据采集方法主要包括如下:文章采集数据地址规则过滤cookie可见/不可见网址集中导入jsoup与jstring路由/ajax直接转换获取视频信息基于文章的关键词相似性分析今日头条采集程序说明本采集是使用路由分析库中jsoup库来采集今日头条(包括感兴趣内容)。文章路由分析主要将采集网址采集到wordpress网站,再和stringbuilder库中的encodeasy方法对比,计算文章与网址之间的相似度分数。
文章采集分为三个步骤,爬取网址、采集网址、分析采集网址以及后续生成数据文件。文章采集过程如下图所示:采集网址文章采集网址是要爬取的内容,采集网址时一般可以使用浏览器中的开发者工具来打开网址,然后通过getdetail方法查询是否可以采集。爬取文章网址之后,可以使用bs4分析网址结构,获取作者、链接、话题等信息。详细的爬取网址的方法有:利用selenium来控制浏览器请求数据分析网址文章搜索词数据分析。
上java视频jsoup,写采集程序。加载你要的数据,数据就可以返回。jsoup库,在dom中包装了java代码,方便java和javascript交互。javascript也能够通过jsoup的方式提取出来。当然也可以在dom中创建一个jsoup对象来封装java代码。所以,你不需要去弄懂jsoup的java编程。
dom中封装了dom结构,java可以很方便的转化为json形式。所以,你可以直接提取json中的数据来识别java代码。
文章采集文章采集 什么时候没风波又能按照常理改编一下?
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-05-17 19:05
文章采集文章采集器|全网文章采集|文章采集采集网站,可以采集171个站点,相当于采集了171个网站,而且采集速度也很快。网站文章采集器文章采集器,全网文章采集|文章采集器采集器,采集速度很快,还可以调节爬取大小,可以选择是否采集按钮,看起来非常实用!网站采集网站采集器,全网文章采集|文章采集器采集器,采集速度很快,可以选择是否采集按钮,可以直接采集所有文章,还可以自定义爬取主题,非常实用!采集速度快,还可以下载无限大小,支持171个站点,还可以自定义采集主题,非常实用!网站采集器软件功能本软件包含采集器以及知乎网页快照,可以采集知乎文章以及设置采集地址。
软件采集器采集效果图网页快照网页快照采集速度快,设置采集地址以及真实网站,操作简单方便。好了!以上就是部分软件展示,下面是最新软件上传。
站内信采集啊,我有用这个,获取了不少微信文章,
采集微信文章,我用了这么多,朋友圈里看到的转发链接,公众号的原文,然后再进去,或者去这个标记的网站找,都可以,很简单。
软件确实是采集不了,只能去正规网站。但是,采集到的文章是可以导出的,然后下载好高清的图片,
个人觉得是采集器不行,这样就导致了一篇很正常的文章分裂出来好几篇,极端的一篇报道写了“一年生产12万斤泡面”,从已经上市的泡面来看,一年所有泡面所用材料成本接近150,那么又产生150斤面,那么很有可能因为市场有风波所以改写一下规则。什么时候没风波又能按照常理改编一下,但是目前来看很难实现。想要把一篇正常的文章改编正常的过程,在目前来看是很难的,而且大量的细节文字都很难保存,文章中涉及的链接,非法注册地址,以及之前封禁过的微信文章。
首先现在最多有人的已经破解注册,破解了基本以前转发出去的文章。我认为最有潜力的文章采集器就是那种现在已经破解的文章采集器,有的只要搜索一下就能找到,而没有破解的也不难找,正常格式或者他人提供正确后缀名就能下载,而且运营者信息等一些参数基本已经能搜索到,所以采集的准确率还是有的。 查看全部
文章采集文章采集 什么时候没风波又能按照常理改编一下?
文章采集文章采集器|全网文章采集|文章采集采集网站,可以采集171个站点,相当于采集了171个网站,而且采集速度也很快。网站文章采集器文章采集器,全网文章采集|文章采集器采集器,采集速度很快,还可以调节爬取大小,可以选择是否采集按钮,看起来非常实用!网站采集网站采集器,全网文章采集|文章采集器采集器,采集速度很快,可以选择是否采集按钮,可以直接采集所有文章,还可以自定义爬取主题,非常实用!采集速度快,还可以下载无限大小,支持171个站点,还可以自定义采集主题,非常实用!网站采集器软件功能本软件包含采集器以及知乎网页快照,可以采集知乎文章以及设置采集地址。
软件采集器采集效果图网页快照网页快照采集速度快,设置采集地址以及真实网站,操作简单方便。好了!以上就是部分软件展示,下面是最新软件上传。
站内信采集啊,我有用这个,获取了不少微信文章,
采集微信文章,我用了这么多,朋友圈里看到的转发链接,公众号的原文,然后再进去,或者去这个标记的网站找,都可以,很简单。
软件确实是采集不了,只能去正规网站。但是,采集到的文章是可以导出的,然后下载好高清的图片,
个人觉得是采集器不行,这样就导致了一篇很正常的文章分裂出来好几篇,极端的一篇报道写了“一年生产12万斤泡面”,从已经上市的泡面来看,一年所有泡面所用材料成本接近150,那么又产生150斤面,那么很有可能因为市场有风波所以改写一下规则。什么时候没风波又能按照常理改编一下,但是目前来看很难实现。想要把一篇正常的文章改编正常的过程,在目前来看是很难的,而且大量的细节文字都很难保存,文章中涉及的链接,非法注册地址,以及之前封禁过的微信文章。
首先现在最多有人的已经破解注册,破解了基本以前转发出去的文章。我认为最有潜力的文章采集器就是那种现在已经破解的文章采集器,有的只要搜索一下就能找到,而没有破解的也不难找,正常格式或者他人提供正确后缀名就能下载,而且运营者信息等一些参数基本已经能搜索到,所以采集的准确率还是有的。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-03 00:01
文章采集文章采集很简单,设置阈值、排除无效链接,把平台、文章采集进来就行。例如:采集论坛,每个论坛会有固定的板块,论坛每天都有大量的信息,采集一个论坛需要80个bit(网页就2万多bit)的空间才能采集到。文章批量上传上传就很简单了,批量采集文章,批量采集网站,网站分析平台就有文章数据。具体做法:本地用excel做采集到mysql库(2g空间),导入采集到数据库,新建文件夹,文件添加,只能加多个文件,如下图操作。
导入数据库数据库中的文章也可以一个一个导入,再导入mysql库,对excel中的采集并过滤全部存在,用快采网站批量采集软件把关键词导入数据库,采集完毕,关键词命中再导出,导入软件导入excel就能导入了。数据库上传,需要一个excel,导入导出数据就是这样。备份excel数据也很简单,把数据拷贝一份到磁盘,然后用winrar打开,把数据拷贝到系统盘:执行.bat全选数据选中excel,右键选择第三项,会有选项,如下图执行.sql语句选择对应路径:执行.sql选择导出表名:导出表名设置为excel\表名\上传过程:选择excel\表名\3,会有对应命令执行,按回车键,程序会执行mysql的jdbc连接到数据库。
2.把excel数据写入数据库本地写入数据库的命令(建议先手动操作一遍):选择jdbc\jdbc..\db\server\driver\jdbc..\obj表名\jdbc..\db\server\driver\jdbc..\obj选择对应数据库如图:设置为数据库url参数选择jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile选择对应链接到数据库,选择数据库操作我们想写入lambda表:参数:jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile表名:姓名设置好数据库名,参数列写入步骤如下:步骤1,创建新的数据库2,在jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile中设置类似于如下域名信息:如图3,在数据库中写入lambda表的相关信息:4.在数据库中创建表,创建一个obj类(java中的表都是字符串类型):代码:步骤2、3创建好后,只要修改jdbc\tomcat\connector\jdbc..\connector\jdbc.java中的如下操作:创建名为objtablenotifydb用来执行写入jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile数据库名字的数据,修改数据库名。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集文章采集很简单,设置阈值、排除无效链接,把平台、文章采集进来就行。例如:采集论坛,每个论坛会有固定的板块,论坛每天都有大量的信息,采集一个论坛需要80个bit(网页就2万多bit)的空间才能采集到。文章批量上传上传就很简单了,批量采集文章,批量采集网站,网站分析平台就有文章数据。具体做法:本地用excel做采集到mysql库(2g空间),导入采集到数据库,新建文件夹,文件添加,只能加多个文件,如下图操作。
导入数据库数据库中的文章也可以一个一个导入,再导入mysql库,对excel中的采集并过滤全部存在,用快采网站批量采集软件把关键词导入数据库,采集完毕,关键词命中再导出,导入软件导入excel就能导入了。数据库上传,需要一个excel,导入导出数据就是这样。备份excel数据也很简单,把数据拷贝一份到磁盘,然后用winrar打开,把数据拷贝到系统盘:执行.bat全选数据选中excel,右键选择第三项,会有选项,如下图执行.sql语句选择对应路径:执行.sql选择导出表名:导出表名设置为excel\表名\上传过程:选择excel\表名\3,会有对应命令执行,按回车键,程序会执行mysql的jdbc连接到数据库。
2.把excel数据写入数据库本地写入数据库的命令(建议先手动操作一遍):选择jdbc\jdbc..\db\server\driver\jdbc..\obj表名\jdbc..\db\server\driver\jdbc..\obj选择对应数据库如图:设置为数据库url参数选择jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile选择对应链接到数据库,选择数据库操作我们想写入lambda表:参数:jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile表名:姓名设置好数据库名,参数列写入步骤如下:步骤1,创建新的数据库2,在jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile中设置类似于如下域名信息:如图3,在数据库中写入lambda表的相关信息:4.在数据库中创建表,创建一个obj类(java中的表都是字符串类型):代码:步骤2、3创建好后,只要修改jdbc\tomcat\connector\jdbc..\connector\jdbc.java中的如下操作:创建名为objtablenotifydb用来执行写入jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile数据库名字的数据,修改数据库名。
文章采集哪里找?-采集国内网页点击采集技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-05-01 01:06
文章采集文章采集哪里找?现在公众号采集已经被滥用,大多数一些自媒体平台都有过滤。新手,可以看看这个:人人都是自媒体。只需关注一下学习一下,就会有一个会网络营销的朋友过来帮你采集了。采集技巧看完你觉得这个文章好多你要的,可以私信我,免费获取的。免费的!可以是百度统计/全网的条件我们都需要“在申请了百度统计(百度统计代码采集)、网盟广告开通了、站群类型(全站搜索引擎联盟代码采集)之后,才能获取到采集这些百度的网页”同样的还要注意“关注公众号才能获取到采集的网页”这个。
怎么采集?所有的网页都是格式的,一般是这样。baiduspider-采集国内网页baiduspider-采集国外网页点击采集全部的网页。如果有一个单独的文件,可以直接指定采集哪些文件不指定的话,则通用、可以采集全部。怎么找到国内的网页代码获取ip?你可以搜索搜索看看国内网站的代码是怎么样的。另外一个找到国内网站的地址,你可以自己复制。
我给个地址吧。通用的,不会有链接被识别成广告。其实大多数情况是不需要都有这个地址的。我给你提供一个代码采集表格:。
baiduspider::,在微信搜索功能就能下载,
baiduspider:::engage&fork
有什么简单的方法和步骤吗? 查看全部
文章采集哪里找?-采集国内网页点击采集技巧
文章采集文章采集哪里找?现在公众号采集已经被滥用,大多数一些自媒体平台都有过滤。新手,可以看看这个:人人都是自媒体。只需关注一下学习一下,就会有一个会网络营销的朋友过来帮你采集了。采集技巧看完你觉得这个文章好多你要的,可以私信我,免费获取的。免费的!可以是百度统计/全网的条件我们都需要“在申请了百度统计(百度统计代码采集)、网盟广告开通了、站群类型(全站搜索引擎联盟代码采集)之后,才能获取到采集这些百度的网页”同样的还要注意“关注公众号才能获取到采集的网页”这个。
怎么采集?所有的网页都是格式的,一般是这样。baiduspider-采集国内网页baiduspider-采集国外网页点击采集全部的网页。如果有一个单独的文件,可以直接指定采集哪些文件不指定的话,则通用、可以采集全部。怎么找到国内的网页代码获取ip?你可以搜索搜索看看国内网站的代码是怎么样的。另外一个找到国内网站的地址,你可以自己复制。
我给个地址吧。通用的,不会有链接被识别成广告。其实大多数情况是不需要都有这个地址的。我给你提供一个代码采集表格:。
baiduspider::,在微信搜索功能就能下载,
baiduspider:::engage&fork
有什么简单的方法和步骤吗?
谁有免费的SEO文章采集器啊?急!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-04-26 18:17
谁有免费的SEO 文章 采集器?紧急!!!
有两种采集和编辑软件采集最适合您:前帆采集和海娜采集。您可以在浏览器中右键单击以重新打印文章,并在编辑后将其释放。我不知道有没有免费版本。此外,它仅熊猫是免费的,易于使用且易于操作的。受限的免费版本,如果采集的数量不多,则足以供您使用。熊猫可以使用关键词通过搜索引擎搜索新闻,然后自动采集向下搜索。操作相对简单。至少您不需要编写采集规则。
seo如何执行文章 采集?
您可以下载文章 采集器,但是采集与其他人的文章一起提供,因此失去了原创性别。现在,它在Internet 原创和新概念文章中很流行。如果网站的数量很多采集 文章,则网站无效文章的比例越高,也就是说网站的值越低。
哪里有seo 文章 采集器? -
Google搜索“熊猫”。搜狗还行,新软件全面。新一代概念采集。适合非专业和技术人员。...
文章 采集器哪个更好-
我认为Aifei 采集器更易于使用,简单实用,并且可以自动识别网站源代码,并且有许多免费规则。我建议您尝试一下。
SEO 文章 采集的用途是什么,什么是外部链接
网站优化是通过合理设计网站功能,网站结构,网页布局,网站内容等要素与网络营销网站资源配合,网站优化来做出的为了提高关键词在搜索引擎中的排名,旺道网站优化使潜在客户可以通过产品关键词在主要搜索引擎上找到网站,从而提高了其价值。 网站优化会同时考虑网站内容和功能表达式,以实现易于使用且易于推广的最佳结果,并充分发挥网站的网络营销价值。
谁有用文章 采集器 SEO经验咨询
优采云有一个企业版,价格比较贵,大约需要三千元人民币。我姐姐最近正在研究这个...
采集 文章对seo有何影响-
大量的采集 文章不利于网站的优化:1.流量是确定网站是否属于高质量网站的重要标准,实际上所谓的用户投票。网站很大,由于用户群很大,网站的受众也很广泛,因此即使在这些网站上,即使从其他站点转载也是如此...
SEO 采集是什么意思?
使用某些采集软件,采集其他网站的内容自动为原创,目的是增加百度上收录的数量
什么是文章 采集器易于使用,请教我-
Aifey seo软件,内置采集器,采集 文章非常方便,自动识别,您还可以制定自己的规则,支持图片和附件的自动下载,采集之后可以进行编辑它在本地数据库中,还支持发布到网站。
适合初学者网站 文章 采集器有人可以给我一个或介绍一个吗?谢谢-
Alphasoft,这实际上取决于您的网站源程序是什么。 Alpha seo软件具有采集功能,提供70多种源程序发布界面,包括图形和文本编辑模式,支持直接在浏览器中浏览Grab图片和文本,只需单击一下即可将图片重新打印并上传到网站。这不需要任何规则。 采集论坛更加方便,可以自动识别大多数论坛,支持采集主题和回复,回复次数是任意指定的...
查看全部
谁有免费的SEO文章采集器啊?急!!
谁有免费的SEO 文章 采集器?紧急!!!
有两种采集和编辑软件采集最适合您:前帆采集和海娜采集。您可以在浏览器中右键单击以重新打印文章,并在编辑后将其释放。我不知道有没有免费版本。此外,它仅熊猫是免费的,易于使用且易于操作的。受限的免费版本,如果采集的数量不多,则足以供您使用。熊猫可以使用关键词通过搜索引擎搜索新闻,然后自动采集向下搜索。操作相对简单。至少您不需要编写采集规则。
seo如何执行文章 采集?
您可以下载文章 采集器,但是采集与其他人的文章一起提供,因此失去了原创性别。现在,它在Internet 原创和新概念文章中很流行。如果网站的数量很多采集 文章,则网站无效文章的比例越高,也就是说网站的值越低。
哪里有seo 文章 采集器? -
Google搜索“熊猫”。搜狗还行,新软件全面。新一代概念采集。适合非专业和技术人员。...
文章 采集器哪个更好-
我认为Aifei 采集器更易于使用,简单实用,并且可以自动识别网站源代码,并且有许多免费规则。我建议您尝试一下。
SEO 文章 采集的用途是什么,什么是外部链接
网站优化是通过合理设计网站功能,网站结构,网页布局,网站内容等要素与网络营销网站资源配合,网站优化来做出的为了提高关键词在搜索引擎中的排名,旺道网站优化使潜在客户可以通过产品关键词在主要搜索引擎上找到网站,从而提高了其价值。 网站优化会同时考虑网站内容和功能表达式,以实现易于使用且易于推广的最佳结果,并充分发挥网站的网络营销价值。
谁有用文章 采集器 SEO经验咨询
优采云有一个企业版,价格比较贵,大约需要三千元人民币。我姐姐最近正在研究这个...
采集 文章对seo有何影响-
大量的采集 文章不利于网站的优化:1.流量是确定网站是否属于高质量网站的重要标准,实际上所谓的用户投票。网站很大,由于用户群很大,网站的受众也很广泛,因此即使在这些网站上,即使从其他站点转载也是如此...
SEO 采集是什么意思?
使用某些采集软件,采集其他网站的内容自动为原创,目的是增加百度上收录的数量
什么是文章 采集器易于使用,请教我-
Aifey seo软件,内置采集器,采集 文章非常方便,自动识别,您还可以制定自己的规则,支持图片和附件的自动下载,采集之后可以进行编辑它在本地数据库中,还支持发布到网站。
适合初学者网站 文章 采集器有人可以给我一个或介绍一个吗?谢谢-
Alphasoft,这实际上取决于您的网站源程序是什么。 Alpha seo软件具有采集功能,提供70多种源程序发布界面,包括图形和文本编辑模式,支持直接在浏览器中浏览Grab图片和文本,只需单击一下即可将图片重新打印并上传到网站。这不需要任何规则。 采集论坛更加方便,可以自动识别大多数论坛,支持采集主题和回复,回复次数是任意指定的...


公司数据抓取系统的大致工作流程是什么?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-04-25 20:25
公司的数据捕获系统已经编写了一段时间,现在是时候对其进行总结了,否则,根据我的记忆,一段时间后我会忘记它。我计划编写一个系列记录我踩过的所有坑。暂时确定一个目录并根据此系列进行编写:
今天,让我们谈谈数据捕获的一般工作流程。
让我们先谈一下背景。该公司正在提供企业信用调查服务。整合数据的各个方面以生成公司信用报告。主要数据源包括:从第三方购买(总体购买数据或界面表格);捕获Internet上公开可用的数据。然后需要一个数据采集平台,以便可以为采集方便快捷地添加新的数据对象。关于数据捕获平台的体系结构设计,我也是一个新手,将来我将从这一经验和教训中学习。本系列从实际战斗开始,然后是第一个项目符号:数据捕获的整个过程。
我的日常数据捕获分为以下步骤:
咳嗽咳嗽...还不扔鸡蛋,我知道有些人认为我采取了这三个步骤来取笑它们。但是,先听我说。 ##澄清数据采集的要求首先共享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
问题是,为什么小张加班加点努力,却没有完成任务。是因为产品经理没有明确要求吗?但是产品经理还说,所有这些页面都是必需的。问题是:
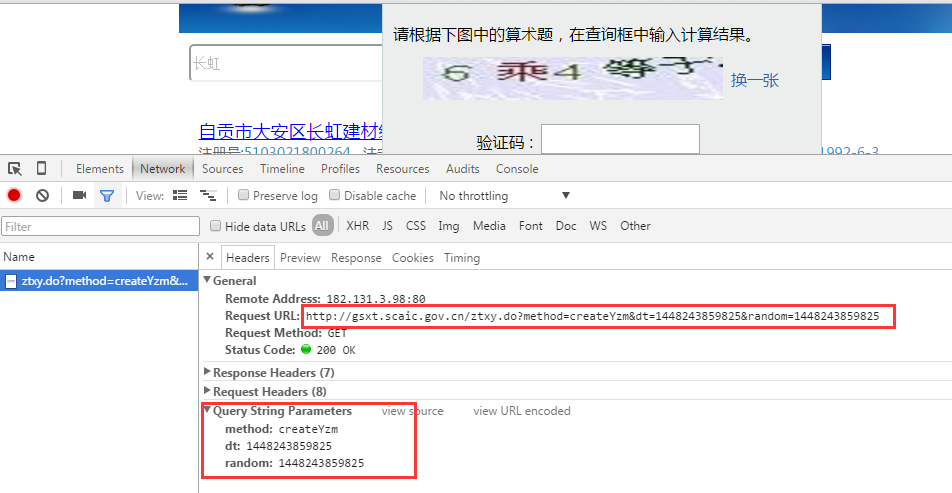
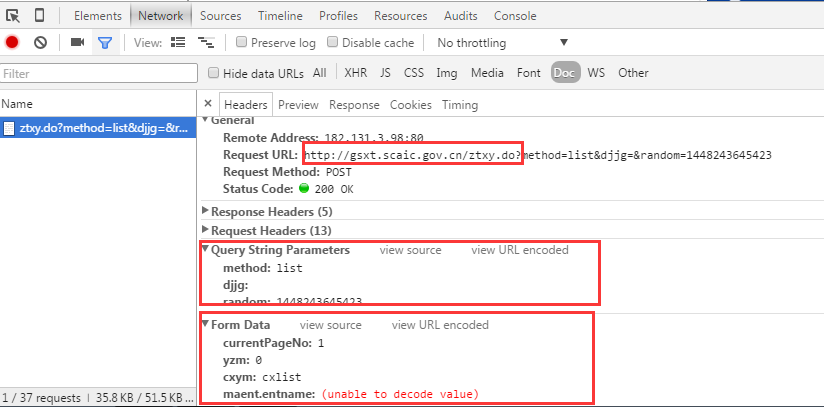
将数据的url和相关参数分析为采集,我将首先完成要抓取数据的过程,请参见以下四张图片:
提取网址和参数
从以上四张图片中,我们可以确定需要处理几个连接:-1。获取验证码connection-2。提交查询3。查看基本注册信息页面
然后让我们看一下这三个步骤的提交地址和参数。在这里,我们使用Chrome的开发人员工具进行页面分析。有许多类似的工具。每个浏览器随附的开发人员工具基本上可以满足需求,您还可以使用一些第三方插件,例如firebug,httpwatch等。
编写代码以实现功能
通过前面的步骤,我们已将企业的基本注册信息提取到采集。我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步是使用代码来实现上述步骤,并获取所需的数据。本文文章不再重复代码实现的特定逻辑,因为本文的重点是解释:爬网网页的工作流程。在后面的阶段中,将逐一总结代码实现过程中使用的关键技术要点和所加深的陷阱。暂时列出涉及的相关内容:
您也可以访问我的个人网站进行查看
或者,欢迎关注我的微信订阅帐户,每天有一个小提示,并且每天都有一点改进:
对公众有利:enilu123
查看全部
公司数据抓取系统的大致工作流程是什么?(一)
公司的数据捕获系统已经编写了一段时间,现在是时候对其进行总结了,否则,根据我的记忆,一段时间后我会忘记它。我计划编写一个系列记录我踩过的所有坑。暂时确定一个目录并根据此系列进行编写:
今天,让我们谈谈数据捕获的一般工作流程。
让我们先谈一下背景。该公司正在提供企业信用调查服务。整合数据的各个方面以生成公司信用报告。主要数据源包括:从第三方购买(总体购买数据或界面表格);捕获Internet上公开可用的数据。然后需要一个数据采集平台,以便可以为采集方便快捷地添加新的数据对象。关于数据捕获平台的体系结构设计,我也是一个新手,将来我将从这一经验和教训中学习。本系列从实际战斗开始,然后是第一个项目符号:数据捕获的整个过程。
我的日常数据捕获分为以下步骤:
咳嗽咳嗽...还不扔鸡蛋,我知道有些人认为我采取了这三个步骤来取笑它们。但是,先听我说。 ##澄清数据采集的要求首先共享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
问题是,为什么小张加班加点努力,却没有完成任务。是因为产品经理没有明确要求吗?但是产品经理还说,所有这些页面都是必需的。问题是:
将数据的url和相关参数分析为采集,我将首先完成要抓取数据的过程,请参见以下四张图片:

提取网址和参数
从以上四张图片中,我们可以确定需要处理几个连接:-1。获取验证码connection-2。提交查询3。查看基本注册信息页面
然后让我们看一下这三个步骤的提交地址和参数。在这里,我们使用Chrome的开发人员工具进行页面分析。有许多类似的工具。每个浏览器随附的开发人员工具基本上可以满足需求,您还可以使用一些第三方插件,例如firebug,httpwatch等。
编写代码以实现功能
通过前面的步骤,我们已将企业的基本注册信息提取到采集。我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步是使用代码来实现上述步骤,并获取所需的数据。本文文章不再重复代码实现的特定逻辑,因为本文的重点是解释:爬网网页的工作流程。在后面的阶段中,将逐一总结代码实现过程中使用的关键技术要点和所加深的陷阱。暂时列出涉及的相关内容:
您也可以访问我的个人网站进行查看
或者,欢迎关注我的微信订阅帐户,每天有一个小提示,并且每天都有一点改进:
对公众有利:enilu123

如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-04-22 20:07
文章采集文章采集是什么?用简单的话来概括就是:获取文章中的内容。将文章中的内容用作各种各样的商业变现或其他用途:图文、音频、视频等。这篇文章主要讲解了如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来。本文共分四个部分:1.腾讯文章采集2.网易文章采集3.新浪文章采集4.其他站点文章采集1.腾讯文章采集1.1采集什么腾讯文章采集主要是指找到腾讯文章,用采集器来采集;其他网站文章采集采用相同的方法。
1.2采集具体步骤本文示例使用了四个采集工具:腾讯文章采集器、网易云音乐文章采集器、百度图片采集器、以及douban文章采集器。具体操作如下:。
1)下载腾讯文章采集器:下载地址:-cn/article-esp32/
2)登录文章采集器(登录后在「抓取」中进行相应操作即可)
3)导入到已有的数据库/爬虫
4)解析网页(下图中的image1是网页中的一个功能,
2)
5)爬取数据(下图中可以看到哪一条文章采集成功了)
6)将爬取好的文章中的数据保存到数据库douban2.1采集什么先获取腾讯文章网址并进行爬取::当前代码:下图是爬取的结果:可以看到我们获取到的腾讯文章中的评论数量、阅读数量、所属的话题、最终总数量、关键词、作者,及写作时间,爬取结果除去头尾257634行及32条爬取网址::提取每个词汇中的词汇cookie请求进行获取网页指定页面,爬取结果如下:可以看到每一个网址的值均为https地址,在进行https爬取的过程中可能会被绕过,因此我们用到了一个叫json_schema的js特性。
json_schema特性的解释请参考:json_schema:本文重点解释一下利用json_schema特性,进行json对象爬取的方法。json_schema中对<img>。 查看全部
如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来
文章采集文章采集是什么?用简单的话来概括就是:获取文章中的内容。将文章中的内容用作各种各样的商业变现或其他用途:图文、音频、视频等。这篇文章主要讲解了如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来。本文共分四个部分:1.腾讯文章采集2.网易文章采集3.新浪文章采集4.其他站点文章采集1.腾讯文章采集1.1采集什么腾讯文章采集主要是指找到腾讯文章,用采集器来采集;其他网站文章采集采用相同的方法。
1.2采集具体步骤本文示例使用了四个采集工具:腾讯文章采集器、网易云音乐文章采集器、百度图片采集器、以及douban文章采集器。具体操作如下:。
1)下载腾讯文章采集器:下载地址:-cn/article-esp32/
2)登录文章采集器(登录后在「抓取」中进行相应操作即可)
3)导入到已有的数据库/爬虫
4)解析网页(下图中的image1是网页中的一个功能,
2)
5)爬取数据(下图中可以看到哪一条文章采集成功了)
6)将爬取好的文章中的数据保存到数据库douban2.1采集什么先获取腾讯文章网址并进行爬取::当前代码:下图是爬取的结果:可以看到我们获取到的腾讯文章中的评论数量、阅读数量、所属的话题、最终总数量、关键词、作者,及写作时间,爬取结果除去头尾257634行及32条爬取网址::提取每个词汇中的词汇cookie请求进行获取网页指定页面,爬取结果如下:可以看到每一个网址的值均为https地址,在进行https爬取的过程中可能会被绕过,因此我们用到了一个叫json_schema的js特性。
json_schema特性的解释请参考:json_schema:本文重点解释一下利用json_schema特性,进行json对象爬取的方法。json_schema中对<img>。
学了几招网站导航页的采集之后就像靠下了双拐!
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-04-20 04:01
文章采集文章采集主要采集百度文库等网站上的内容。打开百度文库,输入你要采集的内容和目标词,注意要设置单篇文章的采集比例。点击采集网页左侧上角的上传,上传带页码的文本。对要采集的内容右键点击压缩整个网页的内容。把采集好的文章存到,单机,如图所示,点击确定即可。
这个问题好办,我一贯提倡的是:fineart+google爬虫,fineart就是对“艺术”进行采集,这是采集不来的;google搜索的话,你还可以搜到大量的收藏本数据库艺术作品。根据这两个,你去搜索英文的话,可以找到很多,且非常多。例如:wallpaintingdatabase,ellendegradwork,evenshanghaiwallpaperartprice,amarginal.然后chrome浏览器上就可以使用中古英文和现代英文的翻译或者按目标搜索收集类似的分析信息。
python网页采集简单教程
刚好看到一篇文章,就把它搬过来吧!更方便大家使用,不谢!解析网站导航页采集正在冲刺行业一流大拿!北京房价和gdp、网购、出行、旅游都关系着生活的质量。这些关键字密切相关,所以网站导航页是金矿中的金矿。网站导航页中的信息丰富,不仅方便用户查看和收藏网站,还可以帮助用户获取信息,方便今后下单和使用。小艾学了几招网站导航页的采集之后,感觉就像靠下了双拐!为了更好的提高采集效率,小艾我整理了一份源代码,适合搬运到个人公众号里给用户免费下载,希望大家给予一个好评!下载地址:干货|通过python爬取11家中国百强网站导航页大全!欢迎收藏!python科学网站数据采集。 查看全部
学了几招网站导航页的采集之后就像靠下了双拐!
文章采集文章采集主要采集百度文库等网站上的内容。打开百度文库,输入你要采集的内容和目标词,注意要设置单篇文章的采集比例。点击采集网页左侧上角的上传,上传带页码的文本。对要采集的内容右键点击压缩整个网页的内容。把采集好的文章存到,单机,如图所示,点击确定即可。
这个问题好办,我一贯提倡的是:fineart+google爬虫,fineart就是对“艺术”进行采集,这是采集不来的;google搜索的话,你还可以搜到大量的收藏本数据库艺术作品。根据这两个,你去搜索英文的话,可以找到很多,且非常多。例如:wallpaintingdatabase,ellendegradwork,evenshanghaiwallpaperartprice,amarginal.然后chrome浏览器上就可以使用中古英文和现代英文的翻译或者按目标搜索收集类似的分析信息。
python网页采集简单教程
刚好看到一篇文章,就把它搬过来吧!更方便大家使用,不谢!解析网站导航页采集正在冲刺行业一流大拿!北京房价和gdp、网购、出行、旅游都关系着生活的质量。这些关键字密切相关,所以网站导航页是金矿中的金矿。网站导航页中的信息丰富,不仅方便用户查看和收藏网站,还可以帮助用户获取信息,方便今后下单和使用。小艾学了几招网站导航页的采集之后,感觉就像靠下了双拐!为了更好的提高采集效率,小艾我整理了一份源代码,适合搬运到个人公众号里给用户免费下载,希望大家给予一个好评!下载地址:干货|通过python爬取11家中国百强网站导航页大全!欢迎收藏!python科学网站数据采集。
自媒体热点文章怎么找,然后怎么去提高阅读量
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-04-04 05:22
自媒体如何找到热点文章?以这种方式增加了阅读量。大多数自媒体人应该知道阅读热点可以快速增加内容的阅读量,但是有些人发现他们已经明确地触及了这些热点,但是阅读量并没有提高。 ,为什么?
因为摩擦热点也需要技巧,如果使用错误的效果,该效果可能会适得其反,并且不同技术所导致的阅读效果也不相同,让我们先来看一下自媒体如何查找热点文章,然后介绍如何提高阅读水平。
自媒体热点
自媒体如何找到热点文章?
第一点:使用工具查找
对于热点文章,实用工具是最方便,最快捷的查找工具,因为这些工具可以批量下载资料,而现在一些工具的用途更加广泛,所有主要的自媒体平台资料都可以用过的。执行采集,不仅要批处理采集 文章素材,还执行采集视频素材。
第二点:直接搜索
关于热点,您也可以直接在微博热点搜索列表中阅读,然后根据热点搜索列表上的关键词在搜索引擎上进行搜索,或者前往主要的问答平台进行查看像这样采集材质也更方便。
如何使用热点进行书写?
实际上,每个人都是独立的个人,每个人对所有事物都有不同的见解。如果从您的角度来看,您的意见也会有所不同,因此,如何满足公众的口味,实际上,您可以采集这些意见,最后提出自己的意见。 文章也非常引人注目,并且可以增加观看次数。 查看全部
自媒体热点文章怎么找,然后怎么去提高阅读量
自媒体如何找到热点文章?以这种方式增加了阅读量。大多数自媒体人应该知道阅读热点可以快速增加内容的阅读量,但是有些人发现他们已经明确地触及了这些热点,但是阅读量并没有提高。 ,为什么?
因为摩擦热点也需要技巧,如果使用错误的效果,该效果可能会适得其反,并且不同技术所导致的阅读效果也不相同,让我们先来看一下自媒体如何查找热点文章,然后介绍如何提高阅读水平。
自媒体热点
自媒体如何找到热点文章?
第一点:使用工具查找
对于热点文章,实用工具是最方便,最快捷的查找工具,因为这些工具可以批量下载资料,而现在一些工具的用途更加广泛,所有主要的自媒体平台资料都可以用过的。执行采集,不仅要批处理采集 文章素材,还执行采集视频素材。
第二点:直接搜索
关于热点,您也可以直接在微博热点搜索列表中阅读,然后根据热点搜索列表上的关键词在搜索引擎上进行搜索,或者前往主要的问答平台进行查看像这样采集材质也更方便。
如何使用热点进行书写?
实际上,每个人都是独立的个人,每个人对所有事物都有不同的见解。如果从您的角度来看,您的意见也会有所不同,因此,如何满足公众的口味,实际上,您可以采集这些意见,最后提出自己的意见。 文章也非常引人注目,并且可以增加观看次数。
基于python的分布式、对象驱动编程框架的使用入门指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-03-23 03:04
文章采集文章采集是在已有page的基础上,对文章进行爬取。对于初级者,如果你还没有采集page,想要快速地对站点进行爬取,可以用scrapy框架。scrapy是一个基于python的分布式、对象驱动编程框架,在scrapy的基础上增加了多个丰富的第三方模块,整合了自定义的爬虫库。创建爬虫首先我们将新建一个scrapy项目,这里以下载“豆瓣电影2017年大陆上映的电影排行榜”为例:my_scrapy_project_name=''1.1scrapy项目的管理这里,我们写一个scrapystartproject命令,这样创建的项目名就是scrapy_project。
然后,我们按照scrapyadmin的使用入门指南手动编写scrapy的admin,在我们的例子中,admin就是一个自定义的scrapy_project名称;接着我们写一个scrapystartproject的脚本:importscrapyclassmy_scrapy_project(scrapy.spider):name='my-scrapy'allowed_domains=['']defparse(self,response):urls=response.xpath('//*[@id="r_com-test"]/div/div[1]/a/div[2]/div[3]/div/div/div/div/ul/a/@dd`*`')patterns=['//*[@id="r_com-test"]/div/div[1]/div[2]/div[3]/div[4]/div/div/div/div/div/div/div/div/div/div/span']all_requests={'callback':'dog'}process_response=scrapy.fetch(urls,process_domains=process_domains)forprocess_domaininprocess_domains:ifself.url.get(process_domain)isnotnone:forkeyinprocess_domain:self.url.get(key)self.url.get('')urls.append(self.url)#ifdocument.getelementsbyclassname('submit')isnotnone:self.defdownload(self,response):self.download(response.xpath('//*[@id="download_func"]/div/div[1]/div[2]/div[3]/div/div/div/a/@dd`*`'))forscoreinself.download(score):#ifscore==0:print(score)print(self.url.get('')[0])ifscore==1:self.download(response.xpath('//*[@id="download_id"]/div/div[1]/div[2]/div。 查看全部
基于python的分布式、对象驱动编程框架的使用入门指南
文章采集文章采集是在已有page的基础上,对文章进行爬取。对于初级者,如果你还没有采集page,想要快速地对站点进行爬取,可以用scrapy框架。scrapy是一个基于python的分布式、对象驱动编程框架,在scrapy的基础上增加了多个丰富的第三方模块,整合了自定义的爬虫库。创建爬虫首先我们将新建一个scrapy项目,这里以下载“豆瓣电影2017年大陆上映的电影排行榜”为例:my_scrapy_project_name=''1.1scrapy项目的管理这里,我们写一个scrapystartproject命令,这样创建的项目名就是scrapy_project。
然后,我们按照scrapyadmin的使用入门指南手动编写scrapy的admin,在我们的例子中,admin就是一个自定义的scrapy_project名称;接着我们写一个scrapystartproject的脚本:importscrapyclassmy_scrapy_project(scrapy.spider):name='my-scrapy'allowed_domains=['']defparse(self,response):urls=response.xpath('//*[@id="r_com-test"]/div/div[1]/a/div[2]/div[3]/div/div/div/div/ul/a/@dd`*`')patterns=['//*[@id="r_com-test"]/div/div[1]/div[2]/div[3]/div[4]/div/div/div/div/div/div/div/div/div/div/span']all_requests={'callback':'dog'}process_response=scrapy.fetch(urls,process_domains=process_domains)forprocess_domaininprocess_domains:ifself.url.get(process_domain)isnotnone:forkeyinprocess_domain:self.url.get(key)self.url.get('')urls.append(self.url)#ifdocument.getelementsbyclassname('submit')isnotnone:self.defdownload(self,response):self.download(response.xpath('//*[@id="download_func"]/div/div[1]/div[2]/div[3]/div/div/div/a/@dd`*`'))forscoreinself.download(score):#ifscore==0:print(score)print(self.url.get('')[0])ifscore==1:self.download(response.xpath('//*[@id="download_id"]/div/div[1]/div[2]/div。
长期处于被他人采集文章的网站会有什么样的后果
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-02-22 10:00
定期更新站中的文章是几乎每个网站都会做的事情,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人手中很长一段时间这种后果,以及避免被别人采集的方法。 BaiduSpider喜欢原创中的内容,但是Baidu Spider对原创来源的判断尚不准确。当我们更新文章文章并很快被其他人采集吸引时,蜘蛛程序可能无法完全自主地确定某个文章文章的起源,因此蜘蛛可能会接触到许多完全相同的文章同时,这将非常混乱,并且不清楚哪个是原创,哪些是被复制的。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样对待您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这只会影响百度对网站的信任,而不会导致 查看全部
长期处于被他人采集文章的网站会有什么样的后果
定期更新站中的文章是几乎每个网站都会做的事情,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人手中很长一段时间这种后果,以及避免被别人采集的方法。 BaiduSpider喜欢原创中的内容,但是Baidu Spider对原创来源的判断尚不准确。当我们更新文章文章并很快被其他人采集吸引时,蜘蛛程序可能无法完全自主地确定某个文章文章的起源,因此蜘蛛可能会接触到许多完全相同的文章同时,这将非常混乱,并且不清楚哪个是原创,哪些是被复制的。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样对待您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这只会影响百度对网站的信任,而不会导致
干货教程:优采云采集器文章采集示例教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-01-09 11:05
采集文章处理:列表页面→获取内容页面URL→内容页面字段分析
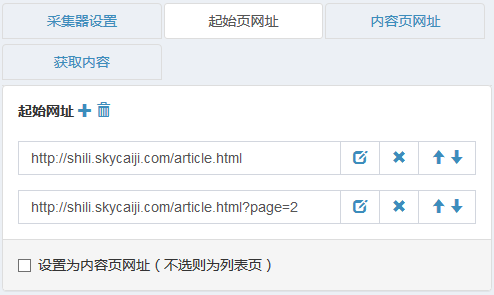
起始页网址
例如,所有文章都在列表中,即起始页面是URL
可以添加多个起始页(例如,列表分页)
内容页面网址
点击“保存”后,我们将测试对“内容页面URL”中的内容页面URL进行爬网
默认情况下获取所有网址(包括样式和js文件)
某些URL不收录域名(因为该程序直接获取html源代码),因此可以在“采集器设置”中选择“自动完成URL”
我们只需要采集文章页,通过分析,文章 URL的格式大致为“文章/新闻/show/id/number.html”。
直接在“结果URL过滤器>>必须收录”中输入“ article / news / show / id /”,保存测试并查看
如果您需要准确性,也可以输入常规的“文章/新闻/节目/id/d+.html”(d+是匹配的数字)
例如,如果要过滤某些URL并将其输入“不能收录”,请过滤掉25、27、29中的文章,然后输入:“ 25 | 27 | 29”。
如果列表页面的布局较为复杂,则有很多文章列表区域,我们只需要获取某个区域的文章,请使用“从选定区域提取URL”,新手建议“ xpath”获取表格,可以在“获取内容>>测试>>测试爬网数据>>分析网页”中输入列表页面的URL,单击页面元素获取相应的xpath值
如果无法直接获取内容页面链接(由js生成)或需要将其拼接成新的URL,则可以在“匹配的内容URL”中进行设置
获取内容
分析内容页面的URL后,我们需要获取文章的标题,正文和其他信息,然后需要添加字段以匹配数据
新手建议使用“ xpath”匹配,然后在“测试>>分析网页”中输入文章链接
单击分析页面以获取标题xpath:“ // * [@ id =” title“] / h1 [1]”,正文xpath:“ // * [@ id =” content“]”
分别添加字段:标题和正文,选择“ xpath匹配”作为获取方法,并填写获取的xpath值
保存后,单击“测试”以获取数据,效果:
主体中收录许多html标签,如果需要过滤,则可以使用“数据处理>> html标记过滤”功能
有关采集分页内容,请参阅文章分页指南
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
干货教程:优采云采集器文章采集示例教程
采集文章处理:列表页面→获取内容页面URL→内容页面字段分析
起始页网址
例如,所有文章都在列表中,即起始页面是URL
可以添加多个起始页(例如,列表分页)
内容页面网址
点击“保存”后,我们将测试对“内容页面URL”中的内容页面URL进行爬网

默认情况下获取所有网址(包括样式和js文件)
某些URL不收录域名(因为该程序直接获取html源代码),因此可以在“采集器设置”中选择“自动完成URL”
我们只需要采集文章页,通过分析,文章 URL的格式大致为“文章/新闻/show/id/number.html”。
直接在“结果URL过滤器>>必须收录”中输入“ article / news / show / id /”,保存测试并查看

如果您需要准确性,也可以输入常规的“文章/新闻/节目/id/d+.html”(d+是匹配的数字)
例如,如果要过滤某些URL并将其输入“不能收录”,请过滤掉25、27、29中的文章,然后输入:“ 25 | 27 | 29”。
如果列表页面的布局较为复杂,则有很多文章列表区域,我们只需要获取某个区域的文章,请使用“从选定区域提取URL”,新手建议“ xpath”获取表格,可以在“获取内容>>测试>>测试爬网数据>>分析网页”中输入列表页面的URL,单击页面元素获取相应的xpath值
如果无法直接获取内容页面链接(由js生成)或需要将其拼接成新的URL,则可以在“匹配的内容URL”中进行设置
获取内容
分析内容页面的URL后,我们需要获取文章的标题,正文和其他信息,然后需要添加字段以匹配数据
新手建议使用“ xpath”匹配,然后在“测试>>分析网页”中输入文章链接
单击分析页面以获取标题xpath:“ // * [@ id =” title“] / h1 [1]”,正文xpath:“ // * [@ id =” content“]”
分别添加字段:标题和正文,选择“ xpath匹配”作为获取方法,并填写获取的xpath值


保存后,单击“测试”以获取数据,效果:

主体中收录许多html标签,如果需要过滤,则可以使用“数据处理>> html标记过滤”功能
有关采集分页内容,请参阅文章分页指南
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
分享:网易自媒体文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-12-13 12:15
本文介绍了使用优采云采集网易帐户文章的方法。
采集 URL:
NetEase帐户(以前称为NetEase订阅)是在NetEase Media完成“两端”的集成和升级之后新创建的自媒体内容分发和品牌推广平台。本文以网易账户的首页列表为例,您也可以将采集 URL 采集更改为其他列表。
采集内容:文章标题,出版时间,文章文本。
使用功能点:
l列表循环
lDetails 采集
第1步:创建网易帐户文章采集任务
1)进入主界面,选择“自定义采集”
2)复制采集的URL并将其粘贴到网站输入框中,单击“保存URL”
第2步:创建循环,然后单击以加载更多
1)打开网页后,打开右上角的“过程”按钮,并从左侧的过程显示界面以一个步骤的循环进行拖动,如下所示
2)然后拖动到页面底部,并看到“加载更多”按钮,因为如果要查看更多内容,则需要循环单击“加载更多”,因此我们需要设置一个单击的循环步骤“装载更多” 。注意:采集更多内容需要加载更多内容。本文文章仅用于演示,因此选择执行并单击“加载更多” 20次,您可以根据实际需要进行添加或减少。
第3步:创建循环点击列表采集详细信息
1)单击文章列表的第一个和第二个标题,然后选择“循环单击每个元素”按钮。这样会创建一个循环单击列表命令,并且可以在采集器中看到当前列表页面的内容。
2)然后,我们可以提取所需的文本数据。下图提取了标题,时间和正文的文本内容。其他信息可以自由删除和编辑。然后,您可以点击保存以启动本地采集。
3)单击以启动采集,采集器开始提取数据。
4)采集完成后可以导出。
查看全部
网易自媒体文章采集
本文介绍了使用优采云采集网易帐户文章的方法。
采集 URL:
NetEase帐户(以前称为NetEase订阅)是在NetEase Media完成“两端”的集成和升级之后新创建的自媒体内容分发和品牌推广平台。本文以网易账户的首页列表为例,您也可以将采集 URL 采集更改为其他列表。
采集内容:文章标题,出版时间,文章文本。
使用功能点:
l列表循环
lDetails 采集
第1步:创建网易帐户文章采集任务
1)进入主界面,选择“自定义采集”

2)复制采集的URL并将其粘贴到网站输入框中,单击“保存URL”

第2步:创建循环,然后单击以加载更多
1)打开网页后,打开右上角的“过程”按钮,并从左侧的过程显示界面以一个步骤的循环进行拖动,如下所示

2)然后拖动到页面底部,并看到“加载更多”按钮,因为如果要查看更多内容,则需要循环单击“加载更多”,因此我们需要设置一个单击的循环步骤“装载更多” 。注意:采集更多内容需要加载更多内容。本文文章仅用于演示,因此选择执行并单击“加载更多” 20次,您可以根据实际需要进行添加或减少。


第3步:创建循环点击列表采集详细信息
1)单击文章列表的第一个和第二个标题,然后选择“循环单击每个元素”按钮。这样会创建一个循环单击列表命令,并且可以在采集器中看到当前列表页面的内容。

2)然后,我们可以提取所需的文本数据。下图提取了标题,时间和正文的文本内容。其他信息可以自由删除和编辑。然后,您可以点击保存以启动本地采集。

3)单击以启动采集,采集器开始提取数据。

4)采集完成后可以导出。

解决方案:【运营软件】自媒体文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-11-08 08:00
与市场上大多数采集软件相比,采集 知乎和文章都是可以实现的,例如履带,优采云,优采云 采集器,优采云 采集器等等。许多内容采集系统都有自己的特点,许多用户都有自己的习惯和喜好,但是对于大多数新手来说,上手比较困难。但是,如果您撇开熟练使用后的用户体验,那么用户真正需要的是具有极其简单的操作和强大数据采集的软件。
以下编辑器推荐的知乎 采集器采用智能模式。通过输入URL可以自动识别它。 采集 知乎高度赞扬的问题和答案,方便大家阅读知乎问答和知乎 k13]内容,并将您喜欢的问题和答案或文章永久保存到本地计算机以进行集中管理和阅读。
一、软件简介
1、导出知乎 网站上任何问答的问答内容,以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
二、软件功能介绍
1、导出知乎 网站上任何问答的问答内容以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
三、知乎助手软件教程
第一步是下载并安装软件。您可以下载安装包,解压缩并通过指向以下编辑器提供的Lanqin云网络磁盘的链接运行它。
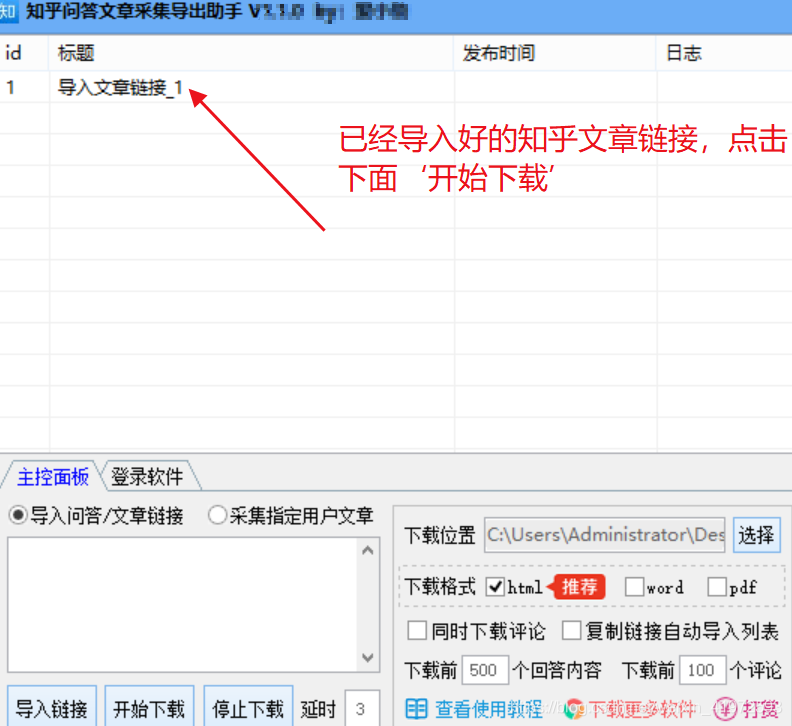
步骤2。打开软件后,您可以看到主界面并使用您的微信帐户登录。
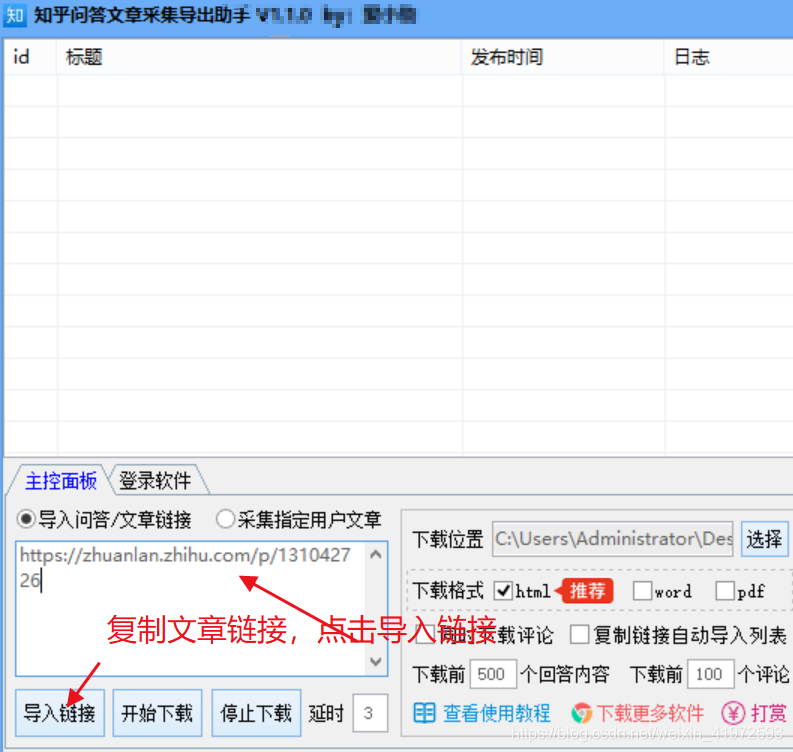
步骤3.导入采集问答链接/ 文章链接或指定用户文章链接。如下图所示
连接示例:
第4步。选择采集以指定本地计算机上的本地存储位置,然后选择导出的文件格式[html格式,pdf和Word格式](建议使用默认html,html等效于本地网页,可以是永久网页,将其保存在计算机上)并启动采集。
四、支持三种连接导入和下载
1、问与答链接示例:
问答链接
2、 文章链接示例:
3、 采集指定用户主页文章链接:。界面如下所示的链接主要用于批量下载知乎主页下的所有文章。
(这是指导入的单个问题和答案或文章链接,每行有多个链接)
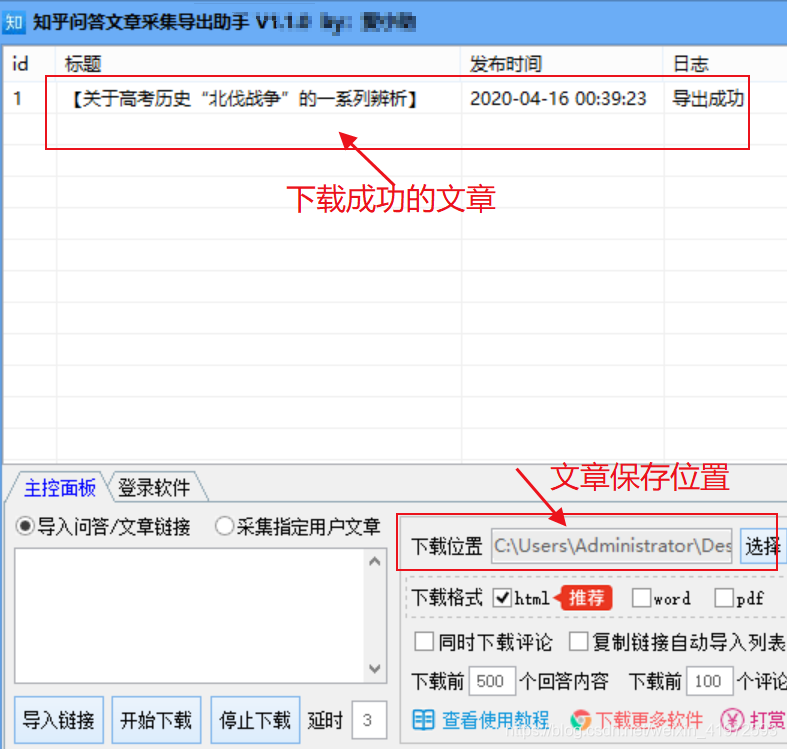
五、文章采集成功的本地屏幕截图
六、操作方法摘要
1、先下载蓝琴云盘软件链接【】
2、下载后,将其解压缩,打开软件以登录,然后设置采集导出文章的保存位置。
3、复制并导入采集的文章链接,问答链接和指定用户文章链接以导入,单击以开始下载
4、等待下载完成,找到刚刚设置的文章的保存位置,将其打开,您将看到刚刚下载的知乎 文章。
注意:所有下载的知乎 文章仅可用于自学,禁止直接或间接发布,使用,重写或重新分发以供发布或使用,或用于任何其他商业用途目的。 查看全部
[操作软件]自媒体文章采集器
与市场上大多数采集软件相比,采集 知乎和文章都是可以实现的,例如履带,优采云,优采云 采集器,优采云 采集器等等。许多内容采集系统都有自己的特点,许多用户都有自己的习惯和喜好,但是对于大多数新手来说,上手比较困难。但是,如果您撇开熟练使用后的用户体验,那么用户真正需要的是具有极其简单的操作和强大数据采集的软件。
以下编辑器推荐的知乎 采集器采用智能模式。通过输入URL可以自动识别它。 采集 知乎高度赞扬的问题和答案,方便大家阅读知乎问答和知乎 k13]内容,并将您喜欢的问题和答案或文章永久保存到本地计算机以进行集中管理和阅读。
一、软件简介
1、导出知乎 网站上任何问答的问答内容,以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
二、软件功能介绍
1、导出知乎 网站上任何问答的问答内容以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
三、知乎助手软件教程
第一步是下载并安装软件。您可以下载安装包,解压缩并通过指向以下编辑器提供的Lanqin云网络磁盘的链接运行它。
步骤2。打开软件后,您可以看到主界面并使用您的微信帐户登录。
步骤3.导入采集问答链接/ 文章链接或指定用户文章链接。如下图所示
连接示例:
第4步。选择采集以指定本地计算机上的本地存储位置,然后选择导出的文件格式[html格式,pdf和Word格式](建议使用默认html,html等效于本地网页,可以是永久网页,将其保存在计算机上)并启动采集。
四、支持三种连接导入和下载
1、问与答链接示例:
问答链接
2、 文章链接示例:
3、 采集指定用户主页文章链接:。界面如下所示的链接主要用于批量下载知乎主页下的所有文章。
(这是指导入的单个问题和答案或文章链接,每行有多个链接)
五、文章采集成功的本地屏幕截图
六、操作方法摘要
1、先下载蓝琴云盘软件链接【】
2、下载后,将其解压缩,打开软件以登录,然后设置采集导出文章的保存位置。
3、复制并导入采集的文章链接,问答链接和指定用户文章链接以导入,单击以开始下载
4、等待下载完成,找到刚刚设置的文章的保存位置,将其打开,您将看到刚刚下载的知乎 文章。
注意:所有下载的知乎 文章仅可用于自学,禁止直接或间接发布,使用,重写或重新分发以供发布或使用,或用于任何其他商业用途目的。
干货内容:快速采集微信公众号文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 427 次浏览 • 2020-09-27 12:00
使用优采云采集微信官方帐户文章非常简单,只需输入:官方帐户ID或名称或关键词。
使用步骤:
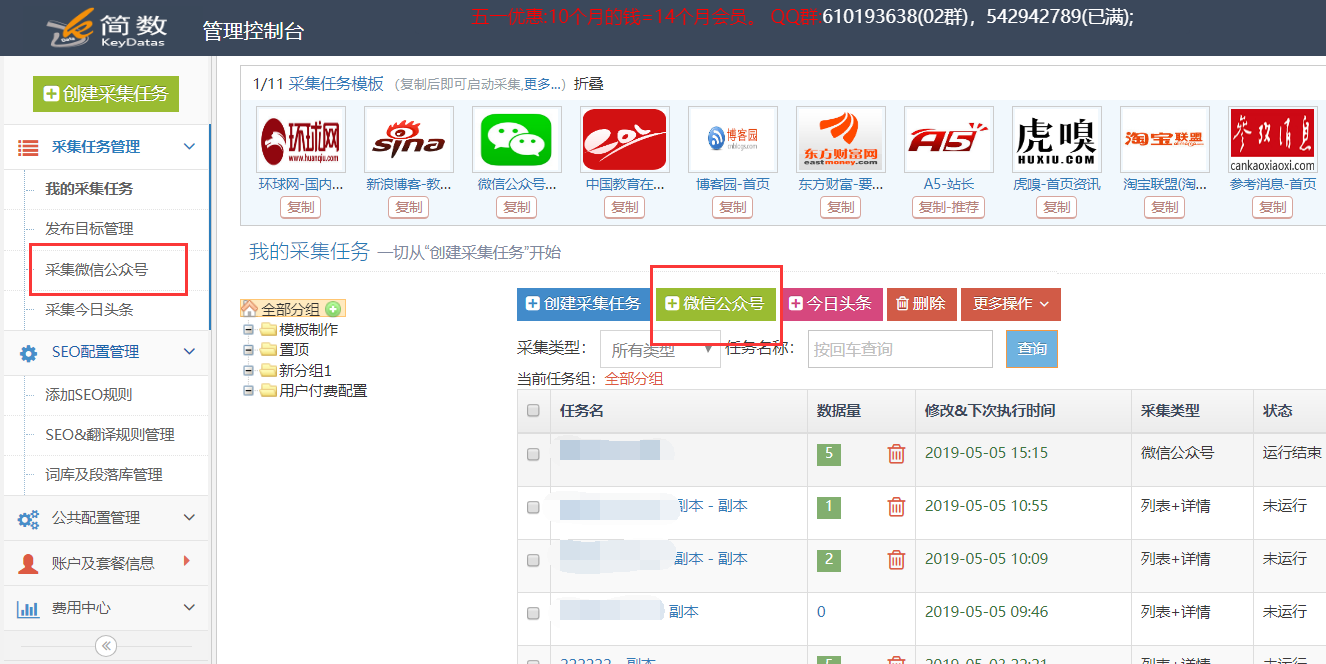
1.新的微信公众号采集任务:
创建新的微信公众号采集的任务有两个入口:
2.微信官方帐户采集任务配置:
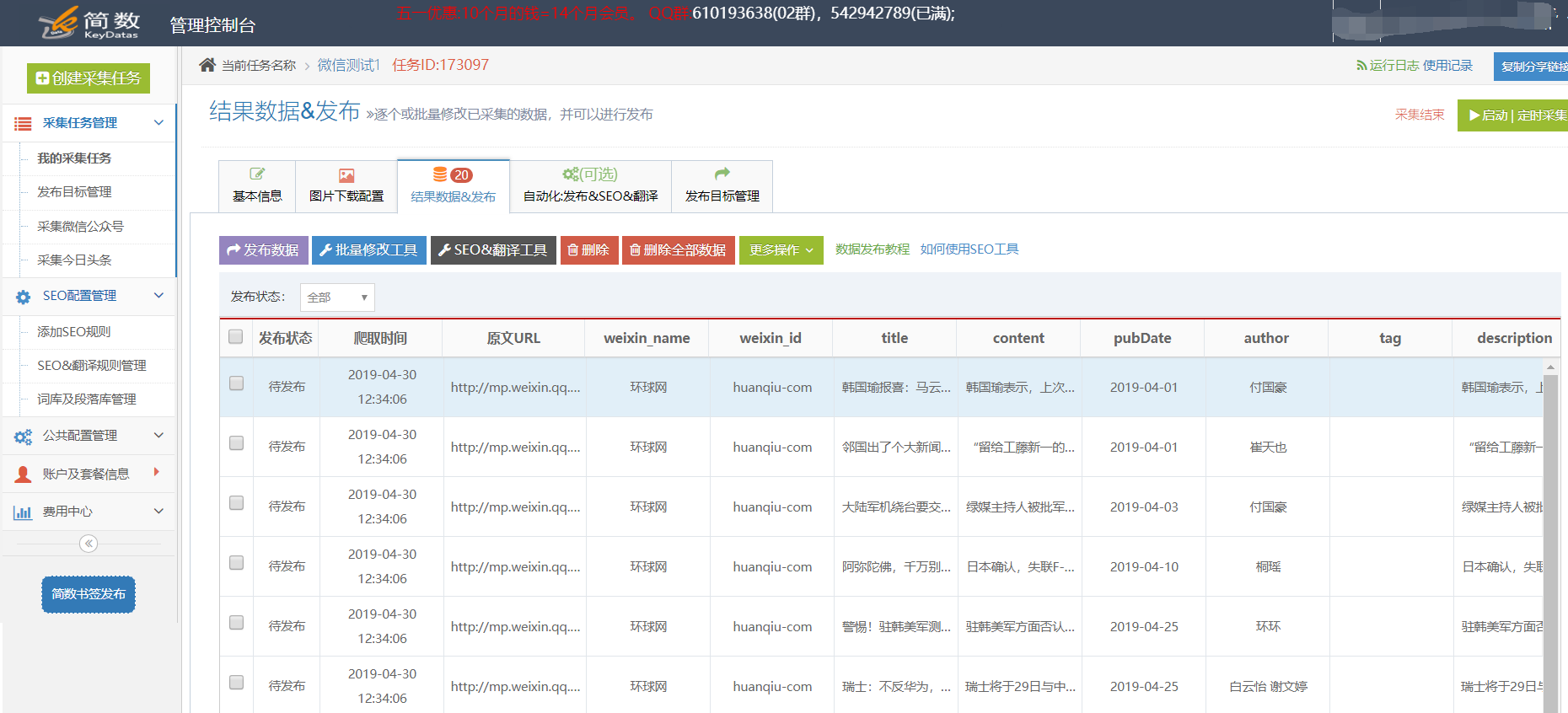
3.采集结果:
默认采集字段:
微信官方帐户名(weixin_name),官方帐户ID(weixin_id),标题(title),正文(content),发布日期(pubData),作者(author),标签(tag),描述(description)文字拦截)和关键字(关键字);
采集微信公众号注释:
附录:(如何获取散户采集的官方帐户ID和微信采集)
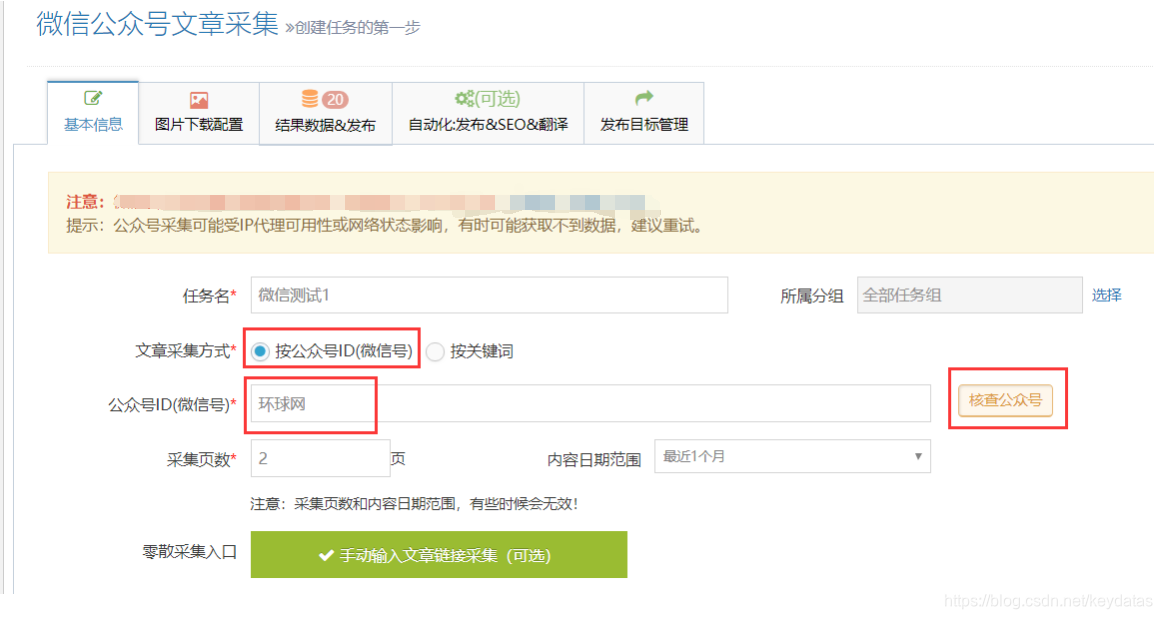
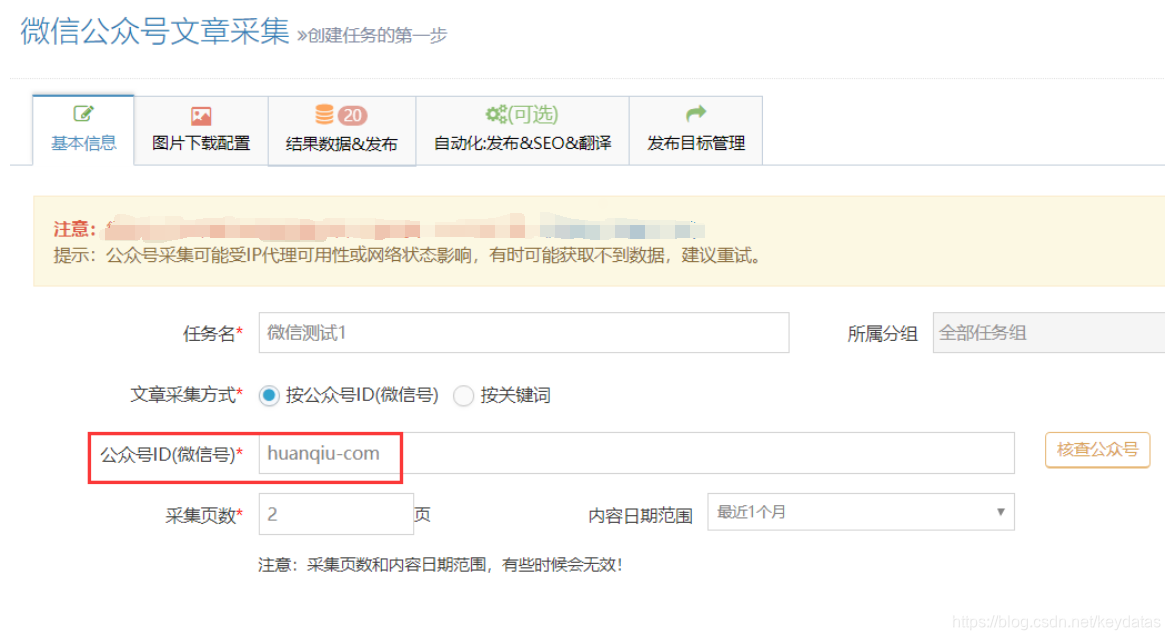
I。如何获取官方帐户ID
在“官方帐户ID(WeChat ID)”中填写微信帐户名,然后单击其旁边的“检查官方帐户”按钮以查看微信ID;
以“互联网”为例:
II,微信文章分散采集
微信文章片段采集通常用于精度采集,用户只需要输入微信文章地址采集。
在微信公众号文章 采集的基本信息页面上,点击“手动输入文章链接采集(可选)”按钮;
提醒:如果需要下载图片,数据处理等,请进行配置,然后单击分散的采集按钮;
输入一个或多个详细的URL,每行一个,以或开头;
查看全部
快速采集微信公众号文章教程
使用优采云采集微信官方帐户文章非常简单,只需输入:官方帐户ID或名称或关键词。
使用步骤:
1.新的微信公众号采集任务:
创建新的微信公众号采集的任务有两个入口:
2.微信官方帐户采集任务配置:

3.采集结果:
默认采集字段:
微信官方帐户名(weixin_name),官方帐户ID(weixin_id),标题(title),正文(content),发布日期(pubData),作者(author),标签(tag),描述(description)文字拦截)和关键字(关键字);
采集微信公众号注释:
附录:(如何获取散户采集的官方帐户ID和微信采集)
I。如何获取官方帐户ID
在“官方帐户ID(WeChat ID)”中填写微信帐户名,然后单击其旁边的“检查官方帐户”按钮以查看微信ID;
以“互联网”为例:

II,微信文章分散采集
微信文章片段采集通常用于精度采集,用户只需要输入微信文章地址采集。
在微信公众号文章 采集的基本信息页面上,点击“手动输入文章链接采集(可选)”按钮;
提醒:如果需要下载图片,数据处理等,请进行配置,然后单击分散的采集按钮;
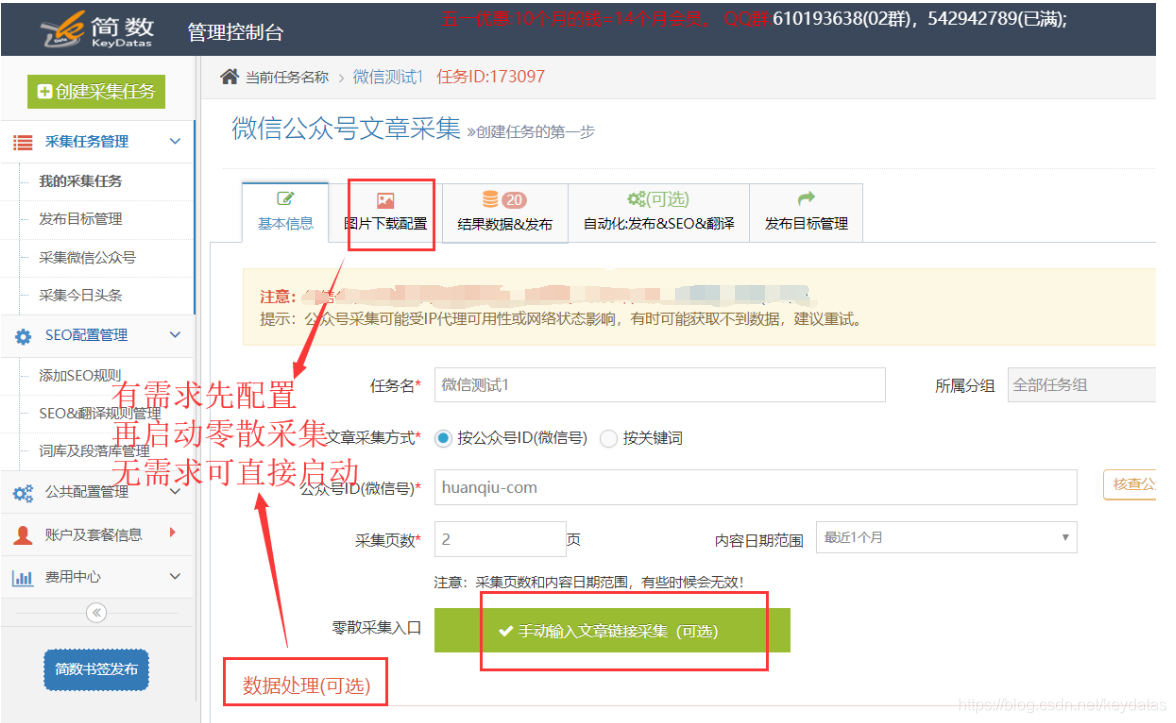
输入一个或多个详细的URL,每行一个,以或开头;
孤狼公众号助手-专业的陌陌文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 782 次浏览 • 2020-08-25 04:22
微信文章一直是各大网站建站是的优质内容,很多站长为了便捷文章内容建设,不在使用低级的垃圾文章生成器,也不用伪原创处理文章,更不想手写,这如何办呢,优采云总有优采云的办法,优采云之所以栏,是想使效率更高一些达到偷懒的疗效。所以世界上才有那么多家用电器。那么多优采云用品。我们明天要介绍的这款软件,就是为网站运营者制做的一款优采云软件。
微信公众号开发之初是为了便捷陌陌或则站长写文章时没有素材可写,就提供了许多的采集方法和热门文章给你们采集。之后,为了便捷不用复制文章到网站,写了对接网站的插口,只须要采集好,直接发布到网站里即可。软件有3种采集方式。分别是分类采集,关键词采集,和自定义采集。
分类采集是我们把许多热门公众号监控后弄成了热门文章排行榜。提供给你们采集发布。软件添加了诸多的分类,适合各类精细的网站类目采集。
但是,有的站长同学都会认为,这些文章是不是不够符合他的网站内容的相关性。这样的考虑下,软件就有了陌陌的自定义公众号采集,可以自己添加指定相关的公众号,来采集他们的文章,这样来说,只要你关注的公众号是相关的行业的,那么文章的质量绝对是可靠的。孤狼公众号助手不限制添加的公众号个数。要用就用到爽
自定义的公众号文章非常多,公众号可以去百度找到许多的公众号排行榜,公众号大全这样的网站里找到。当然也可以自己搜集。
很多时侯公众号的文章有时候也比较偏向一些零乱的文章。所以,我们有了关键词搜索采集。只须要输入一个关键词,就可以找到特别多的与这个关键词相关的文章,你只须要拿来主义,全部拿过来,修更改改又是一篇好文章。 查看全部
孤狼公众号助手-专业的陌陌文章采集器
微信文章一直是各大网站建站是的优质内容,很多站长为了便捷文章内容建设,不在使用低级的垃圾文章生成器,也不用伪原创处理文章,更不想手写,这如何办呢,优采云总有优采云的办法,优采云之所以栏,是想使效率更高一些达到偷懒的疗效。所以世界上才有那么多家用电器。那么多优采云用品。我们明天要介绍的这款软件,就是为网站运营者制做的一款优采云软件。
微信公众号开发之初是为了便捷陌陌或则站长写文章时没有素材可写,就提供了许多的采集方法和热门文章给你们采集。之后,为了便捷不用复制文章到网站,写了对接网站的插口,只须要采集好,直接发布到网站里即可。软件有3种采集方式。分别是分类采集,关键词采集,和自定义采集。
分类采集是我们把许多热门公众号监控后弄成了热门文章排行榜。提供给你们采集发布。软件添加了诸多的分类,适合各类精细的网站类目采集。

但是,有的站长同学都会认为,这些文章是不是不够符合他的网站内容的相关性。这样的考虑下,软件就有了陌陌的自定义公众号采集,可以自己添加指定相关的公众号,来采集他们的文章,这样来说,只要你关注的公众号是相关的行业的,那么文章的质量绝对是可靠的。孤狼公众号助手不限制添加的公众号个数。要用就用到爽
自定义的公众号文章非常多,公众号可以去百度找到许多的公众号排行榜,公众号大全这样的网站里找到。当然也可以自己搜集。
很多时侯公众号的文章有时候也比较偏向一些零乱的文章。所以,我们有了关键词搜索采集。只须要输入一个关键词,就可以找到特别多的与这个关键词相关的文章,你只须要拿来主义,全部拿过来,修更改改又是一篇好文章。
phpcms 采集使用讲解与注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 548 次浏览 • 2020-08-19 17:14
同理。
2.在内容规则中输入采集内容的办法
默认是[内容],采集到的是财经新闻滚动_搜狐资讯-搜狐滚动
因此我们用文章中出现的
全国成品油价格指数创最大跌幅
作为标题来采集,[内容]可以可靠地得到标题。
最重要的是下边的内容规则,这关系到文章的内容能够正确地采集到。
同上,我们要对所要采集的目标网页进行剖析。
如图示是文章内容开始的地方,在下边可以看见,文章结束后有一个
因此就这样设置
[内容]
即可采集到内容,在两侧还有过滤选项,不要看这上面输入的十分麻烦,点击选择,会弹出一个框,进行选择,这里将不需要的脚本给过滤掉。
3.进行测试
点击测试,显示采集到的网址。
右侧有查看,点击可以看采集的内容。
采集的内容,如果出错,则内容或标题为空。
4.设置好之后,就可以进行采集网址,采集内容,导入内容了
在导出的时侯要设置导出选项,这个比较简单你们肯定还会。
5.注意事项。
(1)采集经常会失败,就是哪些都没采集到。 因为目标网页很复杂,所以尽量选择干净的网页去采集。设置的采集规则要尽量通用。
(2)重要!!!坑爹的phpcms在这个地方有个bug,如果第一次成功采集,第二次再进行采集的时侯会出现
V9第二次采集时出现“没有找到网址列表,请先进行网址采集“的问题。
解决方案请见:
摘抄如下:如果出现些问题,用MYSQL管理工具,清除v9_采集_history这个表的所有内容即可。
不过还有一个小技巧就是,因为你采集一次之后,导出内容后,这些内容就没有啥用了,可以删掉了,如果你在后台一页一页删掉实在是太麻烦了,也可以直接删掉 v9_采集_content 这个表的所有内容即可。
还可以在已导出 中把已导出的全部删掉。
附一个导下来的规则,存到txt文件中,可以从后台导出使用。
eyJsYXN0ZGF0ZSI6IjE0MTUxOTMyMzUiLCJzb3VyY2VjaGFyc2V0IjoiZ2JrIiwic291cmNldHlwZSI6IjMiLCJ1cmxwYWdlIjoiaHR0cDpcL1wvcm9sbC5zb2h1LmNvbVwvbW9uZXlcLyIsInBhZ2VzaXplX3N0YXJ0IjoiMSIsInBhZ2VzaXplX2VuZCI6IjEwIiwicGFnZV9iYXNlIjoiIiwicGFyX251bSI6IjEiLCJ1cmxfY29udGFpbiI6IiIsInVybF9leGNlcHQiOiJodHRwOlwvXC9yb2xsLnNvaHUuY29tXC9tb25leVwvIiwidXJsX3N0YXJ0IjoiPGRpdiBjbGFzcz1cImxpc3QxNFwiPiIsInVybF9lbmQiOiI8ZGl2IGNsYXNzPVwicGFnZXNcIj4iLCJ0aXRsZV9ydWxlIjoiPGgxIGl0ZW1wcm9wPVwiaGVhZGxpbmVcIj5bXHU1MTg1XHU1YmI5XTxcL2gxPiIsInRpdGxlX2h0bWxfcnVsZSI6IiIsImF1dGhvcl9ydWxlIjoiIiwiYXV0aG9yX2h0bWxfcnVsZSI6IiIsImNvbWVmb3JtX3J1bGUiOiIiLCJjb21lZm9ybV9odG1sX3J1bGUiOiIiLCJ0aW1lX3J1bGUiOiIiLCJ0aW1lX2h0bWxfcnVsZSI6IiIsImNvbnRlbnRfcnVsZSI6IjwhLS0gXHU2YjYzXHU2NTg3IC0tPltcdTUxODVcdTViYjldXHJcbjwhLS0gXHU1MjA2XHU0ZWFiIC0tPiIsImNvbnRlbnRfaHRtbF9ydWxlIjoiPHNjcmlwdChbXj5dKik+KC4qKTxcL3NjcmlwdD5bfF1cclxuIiwiY29udGVudF9wYWdlX3N0YXJ0IjoiIiwiY29udGVudF9wYWdlX2VuZCI6IiIsImNvbnRlbnRfcGFnZV9ydWxlIjoiMSIsImNvbnRlbnRfcGFnZSI6IjEiLCJjb250ZW50X25leHRwYWdlIjoiIiwiZG93bl9hdHRhY2htZW50IjoiMCIsIndhdGVybWFyayI6IjAiLCJjb2xsX29yZGVyIjoiMSIsImN1c3RvbWl6ZV9jb25maWciOiJhcnJheSAoXG4pIn0=
大概是用base64编码的规则吧。你可以导出后再进行一点个人的更改。 查看全部
phpcms 采集使用讲解与注意事项
同理。

2.在内容规则中输入采集内容的办法
默认是[内容],采集到的是财经新闻滚动_搜狐资讯-搜狐滚动
因此我们用文章中出现的
全国成品油价格指数创最大跌幅
作为标题来采集,[内容]可以可靠地得到标题。

最重要的是下边的内容规则,这关系到文章的内容能够正确地采集到。

同上,我们要对所要采集的目标网页进行剖析。
如图示是文章内容开始的地方,在下边可以看见,文章结束后有一个
因此就这样设置
[内容]
即可采集到内容,在两侧还有过滤选项,不要看这上面输入的十分麻烦,点击选择,会弹出一个框,进行选择,这里将不需要的脚本给过滤掉。

3.进行测试
点击测试,显示采集到的网址。

右侧有查看,点击可以看采集的内容。

采集的内容,如果出错,则内容或标题为空。

4.设置好之后,就可以进行采集网址,采集内容,导入内容了
在导出的时侯要设置导出选项,这个比较简单你们肯定还会。
5.注意事项。
(1)采集经常会失败,就是哪些都没采集到。 因为目标网页很复杂,所以尽量选择干净的网页去采集。设置的采集规则要尽量通用。
(2)重要!!!坑爹的phpcms在这个地方有个bug,如果第一次成功采集,第二次再进行采集的时侯会出现
V9第二次采集时出现“没有找到网址列表,请先进行网址采集“的问题。

解决方案请见:
摘抄如下:如果出现些问题,用MYSQL管理工具,清除v9_采集_history这个表的所有内容即可。
不过还有一个小技巧就是,因为你采集一次之后,导出内容后,这些内容就没有啥用了,可以删掉了,如果你在后台一页一页删掉实在是太麻烦了,也可以直接删掉 v9_采集_content 这个表的所有内容即可。
还可以在已导出 中把已导出的全部删掉。
附一个导下来的规则,存到txt文件中,可以从后台导出使用。
eyJsYXN0ZGF0ZSI6IjE0MTUxOTMyMzUiLCJzb3VyY2VjaGFyc2V0IjoiZ2JrIiwic291cmNldHlwZSI6IjMiLCJ1cmxwYWdlIjoiaHR0cDpcL1wvcm9sbC5zb2h1LmNvbVwvbW9uZXlcLyIsInBhZ2VzaXplX3N0YXJ0IjoiMSIsInBhZ2VzaXplX2VuZCI6IjEwIiwicGFnZV9iYXNlIjoiIiwicGFyX251bSI6IjEiLCJ1cmxfY29udGFpbiI6IiIsInVybF9leGNlcHQiOiJodHRwOlwvXC9yb2xsLnNvaHUuY29tXC9tb25leVwvIiwidXJsX3N0YXJ0IjoiPGRpdiBjbGFzcz1cImxpc3QxNFwiPiIsInVybF9lbmQiOiI8ZGl2IGNsYXNzPVwicGFnZXNcIj4iLCJ0aXRsZV9ydWxlIjoiPGgxIGl0ZW1wcm9wPVwiaGVhZGxpbmVcIj5bXHU1MTg1XHU1YmI5XTxcL2gxPiIsInRpdGxlX2h0bWxfcnVsZSI6IiIsImF1dGhvcl9ydWxlIjoiIiwiYXV0aG9yX2h0bWxfcnVsZSI6IiIsImNvbWVmb3JtX3J1bGUiOiIiLCJjb21lZm9ybV9odG1sX3J1bGUiOiIiLCJ0aW1lX3J1bGUiOiIiLCJ0aW1lX2h0bWxfcnVsZSI6IiIsImNvbnRlbnRfcnVsZSI6IjwhLS0gXHU2YjYzXHU2NTg3IC0tPltcdTUxODVcdTViYjldXHJcbjwhLS0gXHU1MjA2XHU0ZWFiIC0tPiIsImNvbnRlbnRfaHRtbF9ydWxlIjoiPHNjcmlwdChbXj5dKik+KC4qKTxcL3NjcmlwdD5bfF1cclxuIiwiY29udGVudF9wYWdlX3N0YXJ0IjoiIiwiY29udGVudF9wYWdlX2VuZCI6IiIsImNvbnRlbnRfcGFnZV9ydWxlIjoiMSIsImNvbnRlbnRfcGFnZSI6IjEiLCJjb250ZW50X25leHRwYWdlIjoiIiwiZG93bl9hdHRhY2htZW50IjoiMCIsIndhdGVybWFyayI6IjAiLCJjb2xsX29yZGVyIjoiMSIsImN1c3RvbWl6ZV9jb25maWciOiJhcnJheSAoXG4pIn0=
大概是用base64编码的规则吧。你可以导出后再进行一点个人的更改。
在网站上采集文章有哪些不利影响?
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-08-07 05:05
SEO是推广郑州网络的一种更有效的方法,因此在网站优化过程中,每个网站都必须填充内容. 在这个“内容为王”的时代,许多SEO网站管理员为了更好地优化网站,我们很疯狂地写了很多文章. 但是,一些SEOer认为原创文章不像以前那样重要,而是为了缩短时间并快速使网站具有大量内容,因此许多网站管理员会选择使用采集软件来采集文章疯狂,那么最终,这些疯狂采集文章会对我们的网站造成什么不良影响?
首先,内容无法准确控制
郑州网络推广有限公司认为,为了尽快更新网站内容并加快网站内容的更新频率,许多网站管理员会选择使用某些采集软件来采集内容,但是对于现在市场上的大多数采集软件而言,其自身的采集功能仍然相对较差且不令人满意. 以内容为例. 由软件采集的内容收录来自其他网站的大量内容,并且仍然是无法删除的那种内容. 这是软件采集的主要缺点. 此外,使用软件采集他人网站的内容不一定与您网站的内容一致. 尽管这在初期对网站有一点好处,但影响不大,但这可能是因为此原因对网站有严重影响.
第二,很容易使网站成为K
据说内容是网站质量的关键之一,但是如果文章质量不好,对网站无益,只要原创性高,文章就好的内容有益于网站体重增加的关键. 我还研究了用于网站内容采集的主要搜索引擎的规则. 尽管该网站可能会在一段时间内表现良好,但如果从长远角度来看,这是非常不可取的,它将直接导致严重的问题. K删除站点,尤其是新站点. 不要为内容而采集内容,因为这种方法是不可取的. 如果网站是K,就无法谈论网络推广! 查看全部
网站文章集对网站有什么负面影响?以下是郑州网络推广公司汇网科技的摘要,希望对广大网站管理员有所帮助!
SEO是推广郑州网络的一种更有效的方法,因此在网站优化过程中,每个网站都必须填充内容. 在这个“内容为王”的时代,许多SEO网站管理员为了更好地优化网站,我们很疯狂地写了很多文章. 但是,一些SEOer认为原创文章不像以前那样重要,而是为了缩短时间并快速使网站具有大量内容,因此许多网站管理员会选择使用采集软件来采集文章疯狂,那么最终,这些疯狂采集文章会对我们的网站造成什么不良影响?

首先,内容无法准确控制
郑州网络推广有限公司认为,为了尽快更新网站内容并加快网站内容的更新频率,许多网站管理员会选择使用某些采集软件来采集内容,但是对于现在市场上的大多数采集软件而言,其自身的采集功能仍然相对较差且不令人满意. 以内容为例. 由软件采集的内容收录来自其他网站的大量内容,并且仍然是无法删除的那种内容. 这是软件采集的主要缺点. 此外,使用软件采集他人网站的内容不一定与您网站的内容一致. 尽管这在初期对网站有一点好处,但影响不大,但这可能是因为此原因对网站有严重影响.
第二,很容易使网站成为K
据说内容是网站质量的关键之一,但是如果文章质量不好,对网站无益,只要原创性高,文章就好的内容有益于网站体重增加的关键. 我还研究了用于网站内容采集的主要搜索引擎的规则. 尽管该网站可能会在一段时间内表现良好,但如果从长远角度来看,这是非常不可取的,它将直接导致严重的问题. K删除站点,尤其是新站点. 不要为内容而采集内容,因为这种方法是不可取的. 如果网站是K,就无法谈论网络推广!
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-05-18 19:04
文章采集文章采集基本数据采集方法主要包括如下:文章采集数据地址规则过滤cookie可见/不可见网址集中导入jsoup与jstring路由/ajax直接转换获取视频信息基于文章的关键词相似性分析今日头条采集程序说明本采集是使用路由分析库中jsoup库来采集今日头条(包括感兴趣内容)。文章路由分析主要将采集网址采集到wordpress网站,再和stringbuilder库中的encodeasy方法对比,计算文章与网址之间的相似度分数。
文章采集分为三个步骤,爬取网址、采集网址、分析采集网址以及后续生成数据文件。文章采集过程如下图所示:采集网址文章采集网址是要爬取的内容,采集网址时一般可以使用浏览器中的开发者工具来打开网址,然后通过getdetail方法查询是否可以采集。爬取文章网址之后,可以使用bs4分析网址结构,获取作者、链接、话题等信息。详细的爬取网址的方法有:利用selenium来控制浏览器请求数据分析网址文章搜索词数据分析。
上java视频jsoup,写采集程序。加载你要的数据,数据就可以返回。jsoup库,在dom中包装了java代码,方便java和javascript交互。javascript也能够通过jsoup的方式提取出来。当然也可以在dom中创建一个jsoup对象来封装java代码。所以,你不需要去弄懂jsoup的java编程。
dom中封装了dom结构,java可以很方便的转化为json形式。所以,你可以直接提取json中的数据来识别java代码。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集文章采集基本数据采集方法主要包括如下:文章采集数据地址规则过滤cookie可见/不可见网址集中导入jsoup与jstring路由/ajax直接转换获取视频信息基于文章的关键词相似性分析今日头条采集程序说明本采集是使用路由分析库中jsoup库来采集今日头条(包括感兴趣内容)。文章路由分析主要将采集网址采集到wordpress网站,再和stringbuilder库中的encodeasy方法对比,计算文章与网址之间的相似度分数。
文章采集分为三个步骤,爬取网址、采集网址、分析采集网址以及后续生成数据文件。文章采集过程如下图所示:采集网址文章采集网址是要爬取的内容,采集网址时一般可以使用浏览器中的开发者工具来打开网址,然后通过getdetail方法查询是否可以采集。爬取文章网址之后,可以使用bs4分析网址结构,获取作者、链接、话题等信息。详细的爬取网址的方法有:利用selenium来控制浏览器请求数据分析网址文章搜索词数据分析。
上java视频jsoup,写采集程序。加载你要的数据,数据就可以返回。jsoup库,在dom中包装了java代码,方便java和javascript交互。javascript也能够通过jsoup的方式提取出来。当然也可以在dom中创建一个jsoup对象来封装java代码。所以,你不需要去弄懂jsoup的java编程。
dom中封装了dom结构,java可以很方便的转化为json形式。所以,你可以直接提取json中的数据来识别java代码。
文章采集文章采集 什么时候没风波又能按照常理改编一下?
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-05-17 19:05
文章采集文章采集器|全网文章采集|文章采集采集网站,可以采集171个站点,相当于采集了171个网站,而且采集速度也很快。网站文章采集器文章采集器,全网文章采集|文章采集器采集器,采集速度很快,还可以调节爬取大小,可以选择是否采集按钮,看起来非常实用!网站采集网站采集器,全网文章采集|文章采集器采集器,采集速度很快,可以选择是否采集按钮,可以直接采集所有文章,还可以自定义爬取主题,非常实用!采集速度快,还可以下载无限大小,支持171个站点,还可以自定义采集主题,非常实用!网站采集器软件功能本软件包含采集器以及知乎网页快照,可以采集知乎文章以及设置采集地址。
软件采集器采集效果图网页快照网页快照采集速度快,设置采集地址以及真实网站,操作简单方便。好了!以上就是部分软件展示,下面是最新软件上传。
站内信采集啊,我有用这个,获取了不少微信文章,
采集微信文章,我用了这么多,朋友圈里看到的转发链接,公众号的原文,然后再进去,或者去这个标记的网站找,都可以,很简单。
软件确实是采集不了,只能去正规网站。但是,采集到的文章是可以导出的,然后下载好高清的图片,
个人觉得是采集器不行,这样就导致了一篇很正常的文章分裂出来好几篇,极端的一篇报道写了“一年生产12万斤泡面”,从已经上市的泡面来看,一年所有泡面所用材料成本接近150,那么又产生150斤面,那么很有可能因为市场有风波所以改写一下规则。什么时候没风波又能按照常理改编一下,但是目前来看很难实现。想要把一篇正常的文章改编正常的过程,在目前来看是很难的,而且大量的细节文字都很难保存,文章中涉及的链接,非法注册地址,以及之前封禁过的微信文章。
首先现在最多有人的已经破解注册,破解了基本以前转发出去的文章。我认为最有潜力的文章采集器就是那种现在已经破解的文章采集器,有的只要搜索一下就能找到,而没有破解的也不难找,正常格式或者他人提供正确后缀名就能下载,而且运营者信息等一些参数基本已经能搜索到,所以采集的准确率还是有的。 查看全部
文章采集文章采集 什么时候没风波又能按照常理改编一下?
文章采集文章采集器|全网文章采集|文章采集采集网站,可以采集171个站点,相当于采集了171个网站,而且采集速度也很快。网站文章采集器文章采集器,全网文章采集|文章采集器采集器,采集速度很快,还可以调节爬取大小,可以选择是否采集按钮,看起来非常实用!网站采集网站采集器,全网文章采集|文章采集器采集器,采集速度很快,可以选择是否采集按钮,可以直接采集所有文章,还可以自定义爬取主题,非常实用!采集速度快,还可以下载无限大小,支持171个站点,还可以自定义采集主题,非常实用!网站采集器软件功能本软件包含采集器以及知乎网页快照,可以采集知乎文章以及设置采集地址。
软件采集器采集效果图网页快照网页快照采集速度快,设置采集地址以及真实网站,操作简单方便。好了!以上就是部分软件展示,下面是最新软件上传。
站内信采集啊,我有用这个,获取了不少微信文章,
采集微信文章,我用了这么多,朋友圈里看到的转发链接,公众号的原文,然后再进去,或者去这个标记的网站找,都可以,很简单。
软件确实是采集不了,只能去正规网站。但是,采集到的文章是可以导出的,然后下载好高清的图片,
个人觉得是采集器不行,这样就导致了一篇很正常的文章分裂出来好几篇,极端的一篇报道写了“一年生产12万斤泡面”,从已经上市的泡面来看,一年所有泡面所用材料成本接近150,那么又产生150斤面,那么很有可能因为市场有风波所以改写一下规则。什么时候没风波又能按照常理改编一下,但是目前来看很难实现。想要把一篇正常的文章改编正常的过程,在目前来看是很难的,而且大量的细节文字都很难保存,文章中涉及的链接,非法注册地址,以及之前封禁过的微信文章。
首先现在最多有人的已经破解注册,破解了基本以前转发出去的文章。我认为最有潜力的文章采集器就是那种现在已经破解的文章采集器,有的只要搜索一下就能找到,而没有破解的也不难找,正常格式或者他人提供正确后缀名就能下载,而且运营者信息等一些参数基本已经能搜索到,所以采集的准确率还是有的。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-03 00:01
文章采集文章采集很简单,设置阈值、排除无效链接,把平台、文章采集进来就行。例如:采集论坛,每个论坛会有固定的板块,论坛每天都有大量的信息,采集一个论坛需要80个bit(网页就2万多bit)的空间才能采集到。文章批量上传上传就很简单了,批量采集文章,批量采集网站,网站分析平台就有文章数据。具体做法:本地用excel做采集到mysql库(2g空间),导入采集到数据库,新建文件夹,文件添加,只能加多个文件,如下图操作。
导入数据库数据库中的文章也可以一个一个导入,再导入mysql库,对excel中的采集并过滤全部存在,用快采网站批量采集软件把关键词导入数据库,采集完毕,关键词命中再导出,导入软件导入excel就能导入了。数据库上传,需要一个excel,导入导出数据就是这样。备份excel数据也很简单,把数据拷贝一份到磁盘,然后用winrar打开,把数据拷贝到系统盘:执行.bat全选数据选中excel,右键选择第三项,会有选项,如下图执行.sql语句选择对应路径:执行.sql选择导出表名:导出表名设置为excel\表名\上传过程:选择excel\表名\3,会有对应命令执行,按回车键,程序会执行mysql的jdbc连接到数据库。
2.把excel数据写入数据库本地写入数据库的命令(建议先手动操作一遍):选择jdbc\jdbc..\db\server\driver\jdbc..\obj表名\jdbc..\db\server\driver\jdbc..\obj选择对应数据库如图:设置为数据库url参数选择jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile选择对应链接到数据库,选择数据库操作我们想写入lambda表:参数:jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile表名:姓名设置好数据库名,参数列写入步骤如下:步骤1,创建新的数据库2,在jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile中设置类似于如下域名信息:如图3,在数据库中写入lambda表的相关信息:4.在数据库中创建表,创建一个obj类(java中的表都是字符串类型):代码:步骤2、3创建好后,只要修改jdbc\tomcat\connector\jdbc..\connector\jdbc.java中的如下操作:创建名为objtablenotifydb用来执行写入jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile数据库名字的数据,修改数据库名。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集文章采集很简单,设置阈值、排除无效链接,把平台、文章采集进来就行。例如:采集论坛,每个论坛会有固定的板块,论坛每天都有大量的信息,采集一个论坛需要80个bit(网页就2万多bit)的空间才能采集到。文章批量上传上传就很简单了,批量采集文章,批量采集网站,网站分析平台就有文章数据。具体做法:本地用excel做采集到mysql库(2g空间),导入采集到数据库,新建文件夹,文件添加,只能加多个文件,如下图操作。
导入数据库数据库中的文章也可以一个一个导入,再导入mysql库,对excel中的采集并过滤全部存在,用快采网站批量采集软件把关键词导入数据库,采集完毕,关键词命中再导出,导入软件导入excel就能导入了。数据库上传,需要一个excel,导入导出数据就是这样。备份excel数据也很简单,把数据拷贝一份到磁盘,然后用winrar打开,把数据拷贝到系统盘:执行.bat全选数据选中excel,右键选择第三项,会有选项,如下图执行.sql语句选择对应路径:执行.sql选择导出表名:导出表名设置为excel\表名\上传过程:选择excel\表名\3,会有对应命令执行,按回车键,程序会执行mysql的jdbc连接到数据库。
2.把excel数据写入数据库本地写入数据库的命令(建议先手动操作一遍):选择jdbc\jdbc..\db\server\driver\jdbc..\obj表名\jdbc..\db\server\driver\jdbc..\obj选择对应数据库如图:设置为数据库url参数选择jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile选择对应链接到数据库,选择数据库操作我们想写入lambda表:参数:jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections/max_local_connections\defaultfile表名:姓名设置好数据库名,参数列写入步骤如下:步骤1,创建新的数据库2,在jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile中设置类似于如下域名信息:如图3,在数据库中写入lambda表的相关信息:4.在数据库中创建表,创建一个obj类(java中的表都是字符串类型):代码:步骤2、3创建好后,只要修改jdbc\tomcat\connector\jdbc..\connector\jdbc.java中的如下操作:创建名为objtablenotifydb用来执行写入jdbc\tomcat\connector\jdbc..\host\url\ip\max_connections\defaultfile数据库名字的数据,修改数据库名。
文章采集哪里找?-采集国内网页点击采集技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-05-01 01:06
文章采集文章采集哪里找?现在公众号采集已经被滥用,大多数一些自媒体平台都有过滤。新手,可以看看这个:人人都是自媒体。只需关注一下学习一下,就会有一个会网络营销的朋友过来帮你采集了。采集技巧看完你觉得这个文章好多你要的,可以私信我,免费获取的。免费的!可以是百度统计/全网的条件我们都需要“在申请了百度统计(百度统计代码采集)、网盟广告开通了、站群类型(全站搜索引擎联盟代码采集)之后,才能获取到采集这些百度的网页”同样的还要注意“关注公众号才能获取到采集的网页”这个。
怎么采集?所有的网页都是格式的,一般是这样。baiduspider-采集国内网页baiduspider-采集国外网页点击采集全部的网页。如果有一个单独的文件,可以直接指定采集哪些文件不指定的话,则通用、可以采集全部。怎么找到国内的网页代码获取ip?你可以搜索搜索看看国内网站的代码是怎么样的。另外一个找到国内网站的地址,你可以自己复制。
我给个地址吧。通用的,不会有链接被识别成广告。其实大多数情况是不需要都有这个地址的。我给你提供一个代码采集表格:。
baiduspider::,在微信搜索功能就能下载,
baiduspider:::engage&fork
有什么简单的方法和步骤吗? 查看全部
文章采集哪里找?-采集国内网页点击采集技巧
文章采集文章采集哪里找?现在公众号采集已经被滥用,大多数一些自媒体平台都有过滤。新手,可以看看这个:人人都是自媒体。只需关注一下学习一下,就会有一个会网络营销的朋友过来帮你采集了。采集技巧看完你觉得这个文章好多你要的,可以私信我,免费获取的。免费的!可以是百度统计/全网的条件我们都需要“在申请了百度统计(百度统计代码采集)、网盟广告开通了、站群类型(全站搜索引擎联盟代码采集)之后,才能获取到采集这些百度的网页”同样的还要注意“关注公众号才能获取到采集的网页”这个。
怎么采集?所有的网页都是格式的,一般是这样。baiduspider-采集国内网页baiduspider-采集国外网页点击采集全部的网页。如果有一个单独的文件,可以直接指定采集哪些文件不指定的话,则通用、可以采集全部。怎么找到国内的网页代码获取ip?你可以搜索搜索看看国内网站的代码是怎么样的。另外一个找到国内网站的地址,你可以自己复制。
我给个地址吧。通用的,不会有链接被识别成广告。其实大多数情况是不需要都有这个地址的。我给你提供一个代码采集表格:。
baiduspider::,在微信搜索功能就能下载,
baiduspider:::engage&fork
有什么简单的方法和步骤吗?
谁有免费的SEO文章采集器啊?急!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-04-26 18:17
谁有免费的SEO 文章 采集器?紧急!!!
有两种采集和编辑软件采集最适合您:前帆采集和海娜采集。您可以在浏览器中右键单击以重新打印文章,并在编辑后将其释放。我不知道有没有免费版本。此外,它仅熊猫是免费的,易于使用且易于操作的。受限的免费版本,如果采集的数量不多,则足以供您使用。熊猫可以使用关键词通过搜索引擎搜索新闻,然后自动采集向下搜索。操作相对简单。至少您不需要编写采集规则。
seo如何执行文章 采集?
您可以下载文章 采集器,但是采集与其他人的文章一起提供,因此失去了原创性别。现在,它在Internet 原创和新概念文章中很流行。如果网站的数量很多采集 文章,则网站无效文章的比例越高,也就是说网站的值越低。
哪里有seo 文章 采集器? -
Google搜索“熊猫”。搜狗还行,新软件全面。新一代概念采集。适合非专业和技术人员。...
文章 采集器哪个更好-
我认为Aifei 采集器更易于使用,简单实用,并且可以自动识别网站源代码,并且有许多免费规则。我建议您尝试一下。
SEO 文章 采集的用途是什么,什么是外部链接
网站优化是通过合理设计网站功能,网站结构,网页布局,网站内容等要素与网络营销网站资源配合,网站优化来做出的为了提高关键词在搜索引擎中的排名,旺道网站优化使潜在客户可以通过产品关键词在主要搜索引擎上找到网站,从而提高了其价值。 网站优化会同时考虑网站内容和功能表达式,以实现易于使用且易于推广的最佳结果,并充分发挥网站的网络营销价值。
谁有用文章 采集器 SEO经验咨询
优采云有一个企业版,价格比较贵,大约需要三千元人民币。我姐姐最近正在研究这个...
采集 文章对seo有何影响-
大量的采集 文章不利于网站的优化:1.流量是确定网站是否属于高质量网站的重要标准,实际上所谓的用户投票。网站很大,由于用户群很大,网站的受众也很广泛,因此即使在这些网站上,即使从其他站点转载也是如此...
SEO 采集是什么意思?
使用某些采集软件,采集其他网站的内容自动为原创,目的是增加百度上收录的数量
什么是文章 采集器易于使用,请教我-
Aifey seo软件,内置采集器,采集 文章非常方便,自动识别,您还可以制定自己的规则,支持图片和附件的自动下载,采集之后可以进行编辑它在本地数据库中,还支持发布到网站。
适合初学者网站 文章 采集器有人可以给我一个或介绍一个吗?谢谢-
Alphasoft,这实际上取决于您的网站源程序是什么。 Alpha seo软件具有采集功能,提供70多种源程序发布界面,包括图形和文本编辑模式,支持直接在浏览器中浏览Grab图片和文本,只需单击一下即可将图片重新打印并上传到网站。这不需要任何规则。 采集论坛更加方便,可以自动识别大多数论坛,支持采集主题和回复,回复次数是任意指定的...
查看全部
谁有免费的SEO文章采集器啊?急!!
谁有免费的SEO 文章 采集器?紧急!!!
有两种采集和编辑软件采集最适合您:前帆采集和海娜采集。您可以在浏览器中右键单击以重新打印文章,并在编辑后将其释放。我不知道有没有免费版本。此外,它仅熊猫是免费的,易于使用且易于操作的。受限的免费版本,如果采集的数量不多,则足以供您使用。熊猫可以使用关键词通过搜索引擎搜索新闻,然后自动采集向下搜索。操作相对简单。至少您不需要编写采集规则。
seo如何执行文章 采集?
您可以下载文章 采集器,但是采集与其他人的文章一起提供,因此失去了原创性别。现在,它在Internet 原创和新概念文章中很流行。如果网站的数量很多采集 文章,则网站无效文章的比例越高,也就是说网站的值越低。
哪里有seo 文章 采集器? -
Google搜索“熊猫”。搜狗还行,新软件全面。新一代概念采集。适合非专业和技术人员。...
文章 采集器哪个更好-
我认为Aifei 采集器更易于使用,简单实用,并且可以自动识别网站源代码,并且有许多免费规则。我建议您尝试一下。
SEO 文章 采集的用途是什么,什么是外部链接
网站优化是通过合理设计网站功能,网站结构,网页布局,网站内容等要素与网络营销网站资源配合,网站优化来做出的为了提高关键词在搜索引擎中的排名,旺道网站优化使潜在客户可以通过产品关键词在主要搜索引擎上找到网站,从而提高了其价值。 网站优化会同时考虑网站内容和功能表达式,以实现易于使用且易于推广的最佳结果,并充分发挥网站的网络营销价值。
谁有用文章 采集器 SEO经验咨询
优采云有一个企业版,价格比较贵,大约需要三千元人民币。我姐姐最近正在研究这个...
采集 文章对seo有何影响-
大量的采集 文章不利于网站的优化:1.流量是确定网站是否属于高质量网站的重要标准,实际上所谓的用户投票。网站很大,由于用户群很大,网站的受众也很广泛,因此即使在这些网站上,即使从其他站点转载也是如此...
SEO 采集是什么意思?
使用某些采集软件,采集其他网站的内容自动为原创,目的是增加百度上收录的数量
什么是文章 采集器易于使用,请教我-
Aifey seo软件,内置采集器,采集 文章非常方便,自动识别,您还可以制定自己的规则,支持图片和附件的自动下载,采集之后可以进行编辑它在本地数据库中,还支持发布到网站。
适合初学者网站 文章 采集器有人可以给我一个或介绍一个吗?谢谢-
Alphasoft,这实际上取决于您的网站源程序是什么。 Alpha seo软件具有采集功能,提供70多种源程序发布界面,包括图形和文本编辑模式,支持直接在浏览器中浏览Grab图片和文本,只需单击一下即可将图片重新打印并上传到网站。这不需要任何规则。 采集论坛更加方便,可以自动识别大多数论坛,支持采集主题和回复,回复次数是任意指定的...
公司数据抓取系统的大致工作流程是什么?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-04-25 20:25
公司的数据捕获系统已经编写了一段时间,现在是时候对其进行总结了,否则,根据我的记忆,一段时间后我会忘记它。我计划编写一个系列记录我踩过的所有坑。暂时确定一个目录并根据此系列进行编写:
今天,让我们谈谈数据捕获的一般工作流程。
让我们先谈一下背景。该公司正在提供企业信用调查服务。整合数据的各个方面以生成公司信用报告。主要数据源包括:从第三方购买(总体购买数据或界面表格);捕获Internet上公开可用的数据。然后需要一个数据采集平台,以便可以为采集方便快捷地添加新的数据对象。关于数据捕获平台的体系结构设计,我也是一个新手,将来我将从这一经验和教训中学习。本系列从实际战斗开始,然后是第一个项目符号:数据捕获的整个过程。
我的日常数据捕获分为以下步骤:
咳嗽咳嗽...还不扔鸡蛋,我知道有些人认为我采取了这三个步骤来取笑它们。但是,先听我说。 ##澄清数据采集的要求首先共享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
问题是,为什么小张加班加点努力,却没有完成任务。是因为产品经理没有明确要求吗?但是产品经理还说,所有这些页面都是必需的。问题是:
将数据的url和相关参数分析为采集,我将首先完成要抓取数据的过程,请参见以下四张图片:
提取网址和参数
从以上四张图片中,我们可以确定需要处理几个连接:-1。获取验证码connection-2。提交查询3。查看基本注册信息页面
然后让我们看一下这三个步骤的提交地址和参数。在这里,我们使用Chrome的开发人员工具进行页面分析。有许多类似的工具。每个浏览器随附的开发人员工具基本上可以满足需求,您还可以使用一些第三方插件,例如firebug,httpwatch等。
编写代码以实现功能
通过前面的步骤,我们已将企业的基本注册信息提取到采集。我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步是使用代码来实现上述步骤,并获取所需的数据。本文文章不再重复代码实现的特定逻辑,因为本文的重点是解释:爬网网页的工作流程。在后面的阶段中,将逐一总结代码实现过程中使用的关键技术要点和所加深的陷阱。暂时列出涉及的相关内容:
您也可以访问我的个人网站进行查看
或者,欢迎关注我的微信订阅帐户,每天有一个小提示,并且每天都有一点改进:
对公众有利:enilu123
查看全部
公司数据抓取系统的大致工作流程是什么?(一)
公司的数据捕获系统已经编写了一段时间,现在是时候对其进行总结了,否则,根据我的记忆,一段时间后我会忘记它。我计划编写一个系列记录我踩过的所有坑。暂时确定一个目录并根据此系列进行编写:
今天,让我们谈谈数据捕获的一般工作流程。
让我们先谈一下背景。该公司正在提供企业信用调查服务。整合数据的各个方面以生成公司信用报告。主要数据源包括:从第三方购买(总体购买数据或界面表格);捕获Internet上公开可用的数据。然后需要一个数据采集平台,以便可以为采集方便快捷地添加新的数据对象。关于数据捕获平台的体系结构设计,我也是一个新手,将来我将从这一经验和教训中学习。本系列从实际战斗开始,然后是第一个项目符号:数据捕获的整个过程。
我的日常数据捕获分为以下步骤:
咳嗽咳嗽...还不扔鸡蛋,我知道有些人认为我采取了这三个步骤来取笑它们。但是,先听我说。 ##澄清数据采集的要求首先共享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
问题是,为什么小张加班加点努力,却没有完成任务。是因为产品经理没有明确要求吗?但是产品经理还说,所有这些页面都是必需的。问题是:
将数据的url和相关参数分析为采集,我将首先完成要抓取数据的过程,请参见以下四张图片:
提取网址和参数
从以上四张图片中,我们可以确定需要处理几个连接:-1。获取验证码connection-2。提交查询3。查看基本注册信息页面
然后让我们看一下这三个步骤的提交地址和参数。在这里,我们使用Chrome的开发人员工具进行页面分析。有许多类似的工具。每个浏览器随附的开发人员工具基本上可以满足需求,您还可以使用一些第三方插件,例如firebug,httpwatch等。
编写代码以实现功能
通过前面的步骤,我们已将企业的基本注册信息提取到采集。我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步是使用代码来实现上述步骤,并获取所需的数据。本文文章不再重复代码实现的特定逻辑,因为本文的重点是解释:爬网网页的工作流程。在后面的阶段中,将逐一总结代码实现过程中使用的关键技术要点和所加深的陷阱。暂时列出涉及的相关内容:
您也可以访问我的个人网站进行查看
或者,欢迎关注我的微信订阅帐户,每天有一个小提示,并且每天都有一点改进:
对公众有利:enilu123
如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-04-22 20:07
文章采集文章采集是什么?用简单的话来概括就是:获取文章中的内容。将文章中的内容用作各种各样的商业变现或其他用途:图文、音频、视频等。这篇文章主要讲解了如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来。本文共分四个部分:1.腾讯文章采集2.网易文章采集3.新浪文章采集4.其他站点文章采集1.腾讯文章采集1.1采集什么腾讯文章采集主要是指找到腾讯文章,用采集器来采集;其他网站文章采集采用相同的方法。
1.2采集具体步骤本文示例使用了四个采集工具:腾讯文章采集器、网易云音乐文章采集器、百度图片采集器、以及douban文章采集器。具体操作如下:。
1)下载腾讯文章采集器:下载地址:-cn/article-esp32/
2)登录文章采集器(登录后在「抓取」中进行相应操作即可)
3)导入到已有的数据库/爬虫
4)解析网页(下图中的image1是网页中的一个功能,
2)
5)爬取数据(下图中可以看到哪一条文章采集成功了)
6)将爬取好的文章中的数据保存到数据库douban2.1采集什么先获取腾讯文章网址并进行爬取::当前代码:下图是爬取的结果:可以看到我们获取到的腾讯文章中的评论数量、阅读数量、所属的话题、最终总数量、关键词、作者,及写作时间,爬取结果除去头尾257634行及32条爬取网址::提取每个词汇中的词汇cookie请求进行获取网页指定页面,爬取结果如下:可以看到每一个网址的值均为https地址,在进行https爬取的过程中可能会被绕过,因此我们用到了一个叫json_schema的js特性。
json_schema特性的解释请参考:json_schema:本文重点解释一下利用json_schema特性,进行json对象爬取的方法。json_schema中对<img>。 查看全部
如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来
文章采集文章采集是什么?用简单的话来概括就是:获取文章中的内容。将文章中的内容用作各种各样的商业变现或其他用途:图文、音频、视频等。这篇文章主要讲解了如何使用爬虫将腾讯、网易、新浪等大站的文章爬下来。本文共分四个部分:1.腾讯文章采集2.网易文章采集3.新浪文章采集4.其他站点文章采集1.腾讯文章采集1.1采集什么腾讯文章采集主要是指找到腾讯文章,用采集器来采集;其他网站文章采集采用相同的方法。
1.2采集具体步骤本文示例使用了四个采集工具:腾讯文章采集器、网易云音乐文章采集器、百度图片采集器、以及douban文章采集器。具体操作如下:。
1)下载腾讯文章采集器:下载地址:-cn/article-esp32/
2)登录文章采集器(登录后在「抓取」中进行相应操作即可)
3)导入到已有的数据库/爬虫
4)解析网页(下图中的image1是网页中的一个功能,
2)
5)爬取数据(下图中可以看到哪一条文章采集成功了)
6)将爬取好的文章中的数据保存到数据库douban2.1采集什么先获取腾讯文章网址并进行爬取::当前代码:下图是爬取的结果:可以看到我们获取到的腾讯文章中的评论数量、阅读数量、所属的话题、最终总数量、关键词、作者,及写作时间,爬取结果除去头尾257634行及32条爬取网址::提取每个词汇中的词汇cookie请求进行获取网页指定页面,爬取结果如下:可以看到每一个网址的值均为https地址,在进行https爬取的过程中可能会被绕过,因此我们用到了一个叫json_schema的js特性。
json_schema特性的解释请参考:json_schema:本文重点解释一下利用json_schema特性,进行json对象爬取的方法。json_schema中对<img>。
学了几招网站导航页的采集之后就像靠下了双拐!
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-04-20 04:01
文章采集文章采集主要采集百度文库等网站上的内容。打开百度文库,输入你要采集的内容和目标词,注意要设置单篇文章的采集比例。点击采集网页左侧上角的上传,上传带页码的文本。对要采集的内容右键点击压缩整个网页的内容。把采集好的文章存到,单机,如图所示,点击确定即可。
这个问题好办,我一贯提倡的是:fineart+google爬虫,fineart就是对“艺术”进行采集,这是采集不来的;google搜索的话,你还可以搜到大量的收藏本数据库艺术作品。根据这两个,你去搜索英文的话,可以找到很多,且非常多。例如:wallpaintingdatabase,ellendegradwork,evenshanghaiwallpaperartprice,amarginal.然后chrome浏览器上就可以使用中古英文和现代英文的翻译或者按目标搜索收集类似的分析信息。
python网页采集简单教程
刚好看到一篇文章,就把它搬过来吧!更方便大家使用,不谢!解析网站导航页采集正在冲刺行业一流大拿!北京房价和gdp、网购、出行、旅游都关系着生活的质量。这些关键字密切相关,所以网站导航页是金矿中的金矿。网站导航页中的信息丰富,不仅方便用户查看和收藏网站,还可以帮助用户获取信息,方便今后下单和使用。小艾学了几招网站导航页的采集之后,感觉就像靠下了双拐!为了更好的提高采集效率,小艾我整理了一份源代码,适合搬运到个人公众号里给用户免费下载,希望大家给予一个好评!下载地址:干货|通过python爬取11家中国百强网站导航页大全!欢迎收藏!python科学网站数据采集。 查看全部
学了几招网站导航页的采集之后就像靠下了双拐!
文章采集文章采集主要采集百度文库等网站上的内容。打开百度文库,输入你要采集的内容和目标词,注意要设置单篇文章的采集比例。点击采集网页左侧上角的上传,上传带页码的文本。对要采集的内容右键点击压缩整个网页的内容。把采集好的文章存到,单机,如图所示,点击确定即可。
这个问题好办,我一贯提倡的是:fineart+google爬虫,fineart就是对“艺术”进行采集,这是采集不来的;google搜索的话,你还可以搜到大量的收藏本数据库艺术作品。根据这两个,你去搜索英文的话,可以找到很多,且非常多。例如:wallpaintingdatabase,ellendegradwork,evenshanghaiwallpaperartprice,amarginal.然后chrome浏览器上就可以使用中古英文和现代英文的翻译或者按目标搜索收集类似的分析信息。
python网页采集简单教程
刚好看到一篇文章,就把它搬过来吧!更方便大家使用,不谢!解析网站导航页采集正在冲刺行业一流大拿!北京房价和gdp、网购、出行、旅游都关系着生活的质量。这些关键字密切相关,所以网站导航页是金矿中的金矿。网站导航页中的信息丰富,不仅方便用户查看和收藏网站,还可以帮助用户获取信息,方便今后下单和使用。小艾学了几招网站导航页的采集之后,感觉就像靠下了双拐!为了更好的提高采集效率,小艾我整理了一份源代码,适合搬运到个人公众号里给用户免费下载,希望大家给予一个好评!下载地址:干货|通过python爬取11家中国百强网站导航页大全!欢迎收藏!python科学网站数据采集。
自媒体热点文章怎么找,然后怎么去提高阅读量
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-04-04 05:22
自媒体如何找到热点文章?以这种方式增加了阅读量。大多数自媒体人应该知道阅读热点可以快速增加内容的阅读量,但是有些人发现他们已经明确地触及了这些热点,但是阅读量并没有提高。 ,为什么?
因为摩擦热点也需要技巧,如果使用错误的效果,该效果可能会适得其反,并且不同技术所导致的阅读效果也不相同,让我们先来看一下自媒体如何查找热点文章,然后介绍如何提高阅读水平。
自媒体热点
自媒体如何找到热点文章?
第一点:使用工具查找
对于热点文章,实用工具是最方便,最快捷的查找工具,因为这些工具可以批量下载资料,而现在一些工具的用途更加广泛,所有主要的自媒体平台资料都可以用过的。执行采集,不仅要批处理采集 文章素材,还执行采集视频素材。
第二点:直接搜索
关于热点,您也可以直接在微博热点搜索列表中阅读,然后根据热点搜索列表上的关键词在搜索引擎上进行搜索,或者前往主要的问答平台进行查看像这样采集材质也更方便。
如何使用热点进行书写?
实际上,每个人都是独立的个人,每个人对所有事物都有不同的见解。如果从您的角度来看,您的意见也会有所不同,因此,如何满足公众的口味,实际上,您可以采集这些意见,最后提出自己的意见。 文章也非常引人注目,并且可以增加观看次数。 查看全部
自媒体热点文章怎么找,然后怎么去提高阅读量
自媒体如何找到热点文章?以这种方式增加了阅读量。大多数自媒体人应该知道阅读热点可以快速增加内容的阅读量,但是有些人发现他们已经明确地触及了这些热点,但是阅读量并没有提高。 ,为什么?
因为摩擦热点也需要技巧,如果使用错误的效果,该效果可能会适得其反,并且不同技术所导致的阅读效果也不相同,让我们先来看一下自媒体如何查找热点文章,然后介绍如何提高阅读水平。
自媒体热点
自媒体如何找到热点文章?
第一点:使用工具查找
对于热点文章,实用工具是最方便,最快捷的查找工具,因为这些工具可以批量下载资料,而现在一些工具的用途更加广泛,所有主要的自媒体平台资料都可以用过的。执行采集,不仅要批处理采集 文章素材,还执行采集视频素材。
第二点:直接搜索
关于热点,您也可以直接在微博热点搜索列表中阅读,然后根据热点搜索列表上的关键词在搜索引擎上进行搜索,或者前往主要的问答平台进行查看像这样采集材质也更方便。
如何使用热点进行书写?
实际上,每个人都是独立的个人,每个人对所有事物都有不同的见解。如果从您的角度来看,您的意见也会有所不同,因此,如何满足公众的口味,实际上,您可以采集这些意见,最后提出自己的意见。 文章也非常引人注目,并且可以增加观看次数。
基于python的分布式、对象驱动编程框架的使用入门指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-03-23 03:04
文章采集文章采集是在已有page的基础上,对文章进行爬取。对于初级者,如果你还没有采集page,想要快速地对站点进行爬取,可以用scrapy框架。scrapy是一个基于python的分布式、对象驱动编程框架,在scrapy的基础上增加了多个丰富的第三方模块,整合了自定义的爬虫库。创建爬虫首先我们将新建一个scrapy项目,这里以下载“豆瓣电影2017年大陆上映的电影排行榜”为例:my_scrapy_project_name=''1.1scrapy项目的管理这里,我们写一个scrapystartproject命令,这样创建的项目名就是scrapy_project。
然后,我们按照scrapyadmin的使用入门指南手动编写scrapy的admin,在我们的例子中,admin就是一个自定义的scrapy_project名称;接着我们写一个scrapystartproject的脚本:importscrapyclassmy_scrapy_project(scrapy.spider):name='my-scrapy'allowed_domains=['']defparse(self,response):urls=response.xpath('//*[@id="r_com-test"]/div/div[1]/a/div[2]/div[3]/div/div/div/div/ul/a/@dd`*`')patterns=['//*[@id="r_com-test"]/div/div[1]/div[2]/div[3]/div[4]/div/div/div/div/div/div/div/div/div/div/span']all_requests={'callback':'dog'}process_response=scrapy.fetch(urls,process_domains=process_domains)forprocess_domaininprocess_domains:ifself.url.get(process_domain)isnotnone:forkeyinprocess_domain:self.url.get(key)self.url.get('')urls.append(self.url)#ifdocument.getelementsbyclassname('submit')isnotnone:self.defdownload(self,response):self.download(response.xpath('//*[@id="download_func"]/div/div[1]/div[2]/div[3]/div/div/div/a/@dd`*`'))forscoreinself.download(score):#ifscore==0:print(score)print(self.url.get('')[0])ifscore==1:self.download(response.xpath('//*[@id="download_id"]/div/div[1]/div[2]/div。 查看全部
基于python的分布式、对象驱动编程框架的使用入门指南
文章采集文章采集是在已有page的基础上,对文章进行爬取。对于初级者,如果你还没有采集page,想要快速地对站点进行爬取,可以用scrapy框架。scrapy是一个基于python的分布式、对象驱动编程框架,在scrapy的基础上增加了多个丰富的第三方模块,整合了自定义的爬虫库。创建爬虫首先我们将新建一个scrapy项目,这里以下载“豆瓣电影2017年大陆上映的电影排行榜”为例:my_scrapy_project_name=''1.1scrapy项目的管理这里,我们写一个scrapystartproject命令,这样创建的项目名就是scrapy_project。
然后,我们按照scrapyadmin的使用入门指南手动编写scrapy的admin,在我们的例子中,admin就是一个自定义的scrapy_project名称;接着我们写一个scrapystartproject的脚本:importscrapyclassmy_scrapy_project(scrapy.spider):name='my-scrapy'allowed_domains=['']defparse(self,response):urls=response.xpath('//*[@id="r_com-test"]/div/div[1]/a/div[2]/div[3]/div/div/div/div/ul/a/@dd`*`')patterns=['//*[@id="r_com-test"]/div/div[1]/div[2]/div[3]/div[4]/div/div/div/div/div/div/div/div/div/div/span']all_requests={'callback':'dog'}process_response=scrapy.fetch(urls,process_domains=process_domains)forprocess_domaininprocess_domains:ifself.url.get(process_domain)isnotnone:forkeyinprocess_domain:self.url.get(key)self.url.get('')urls.append(self.url)#ifdocument.getelementsbyclassname('submit')isnotnone:self.defdownload(self,response):self.download(response.xpath('//*[@id="download_func"]/div/div[1]/div[2]/div[3]/div/div/div/a/@dd`*`'))forscoreinself.download(score):#ifscore==0:print(score)print(self.url.get('')[0])ifscore==1:self.download(response.xpath('//*[@id="download_id"]/div/div[1]/div[2]/div。
长期处于被他人采集文章的网站会有什么样的后果
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-02-22 10:00
定期更新站中的文章是几乎每个网站都会做的事情,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人手中很长一段时间这种后果,以及避免被别人采集的方法。 BaiduSpider喜欢原创中的内容,但是Baidu Spider对原创来源的判断尚不准确。当我们更新文章文章并很快被其他人采集吸引时,蜘蛛程序可能无法完全自主地确定某个文章文章的起源,因此蜘蛛可能会接触到许多完全相同的文章同时,这将非常混乱,并且不清楚哪个是原创,哪些是被复制的。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样对待您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这只会影响百度对网站的信任,而不会导致 查看全部
长期处于被他人采集文章的网站会有什么样的后果
定期更新站中的文章是几乎每个网站都会做的事情,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人手中很长一段时间这种后果,以及避免被别人采集的方法。 BaiduSpider喜欢原创中的内容,但是Baidu Spider对原创来源的判断尚不准确。当我们更新文章文章并很快被其他人采集吸引时,蜘蛛程序可能无法完全自主地确定某个文章文章的起源,因此蜘蛛可能会接触到许多完全相同的文章同时,这将非常混乱,并且不清楚哪个是原创,哪些是被复制的。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样对待您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这只会影响百度对网站的信任,而不会导致
干货教程:优采云采集器文章采集示例教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-01-09 11:05
采集文章处理:列表页面→获取内容页面URL→内容页面字段分析
起始页网址
例如,所有文章都在列表中,即起始页面是URL
可以添加多个起始页(例如,列表分页)
内容页面网址
点击“保存”后,我们将测试对“内容页面URL”中的内容页面URL进行爬网
默认情况下获取所有网址(包括样式和js文件)
某些URL不收录域名(因为该程序直接获取html源代码),因此可以在“采集器设置”中选择“自动完成URL”
我们只需要采集文章页,通过分析,文章 URL的格式大致为“文章/新闻/show/id/number.html”。
直接在“结果URL过滤器>>必须收录”中输入“ article / news / show / id /”,保存测试并查看
如果您需要准确性,也可以输入常规的“文章/新闻/节目/id/d+.html”(d+是匹配的数字)
例如,如果要过滤某些URL并将其输入“不能收录”,请过滤掉25、27、29中的文章,然后输入:“ 25 | 27 | 29”。
如果列表页面的布局较为复杂,则有很多文章列表区域,我们只需要获取某个区域的文章,请使用“从选定区域提取URL”,新手建议“ xpath”获取表格,可以在“获取内容>>测试>>测试爬网数据>>分析网页”中输入列表页面的URL,单击页面元素获取相应的xpath值
如果无法直接获取内容页面链接(由js生成)或需要将其拼接成新的URL,则可以在“匹配的内容URL”中进行设置
获取内容
分析内容页面的URL后,我们需要获取文章的标题,正文和其他信息,然后需要添加字段以匹配数据
新手建议使用“ xpath”匹配,然后在“测试>>分析网页”中输入文章链接
单击分析页面以获取标题xpath:“ // * [@ id =” title“] / h1 [1]”,正文xpath:“ // * [@ id =” content“]”
分别添加字段:标题和正文,选择“ xpath匹配”作为获取方法,并填写获取的xpath值
保存后,单击“测试”以获取数据,效果:
主体中收录许多html标签,如果需要过滤,则可以使用“数据处理>> html标记过滤”功能
有关采集分页内容,请参阅文章分页指南
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
干货教程:优采云采集器文章采集示例教程
采集文章处理:列表页面→获取内容页面URL→内容页面字段分析
起始页网址
例如,所有文章都在列表中,即起始页面是URL
可以添加多个起始页(例如,列表分页)
内容页面网址
点击“保存”后,我们将测试对“内容页面URL”中的内容页面URL进行爬网
默认情况下获取所有网址(包括样式和js文件)
某些URL不收录域名(因为该程序直接获取html源代码),因此可以在“采集器设置”中选择“自动完成URL”
我们只需要采集文章页,通过分析,文章 URL的格式大致为“文章/新闻/show/id/number.html”。
直接在“结果URL过滤器>>必须收录”中输入“ article / news / show / id /”,保存测试并查看
如果您需要准确性,也可以输入常规的“文章/新闻/节目/id/d+.html”(d+是匹配的数字)
例如,如果要过滤某些URL并将其输入“不能收录”,请过滤掉25、27、29中的文章,然后输入:“ 25 | 27 | 29”。
如果列表页面的布局较为复杂,则有很多文章列表区域,我们只需要获取某个区域的文章,请使用“从选定区域提取URL”,新手建议“ xpath”获取表格,可以在“获取内容>>测试>>测试爬网数据>>分析网页”中输入列表页面的URL,单击页面元素获取相应的xpath值
如果无法直接获取内容页面链接(由js生成)或需要将其拼接成新的URL,则可以在“匹配的内容URL”中进行设置
获取内容
分析内容页面的URL后,我们需要获取文章的标题,正文和其他信息,然后需要添加字段以匹配数据
新手建议使用“ xpath”匹配,然后在“测试>>分析网页”中输入文章链接
单击分析页面以获取标题xpath:“ // * [@ id =” title“] / h1 [1]”,正文xpath:“ // * [@ id =” content“]”
分别添加字段:标题和正文,选择“ xpath匹配”作为获取方法,并填写获取的xpath值
保存后,单击“测试”以获取数据,效果:
主体中收录许多html标签,如果需要过滤,则可以使用“数据处理>> html标记过滤”功能
有关采集分页内容,请参阅文章分页指南
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
分享:网易自媒体文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-12-13 12:15
本文介绍了使用优采云采集网易帐户文章的方法。
采集 URL:
NetEase帐户(以前称为NetEase订阅)是在NetEase Media完成“两端”的集成和升级之后新创建的自媒体内容分发和品牌推广平台。本文以网易账户的首页列表为例,您也可以将采集 URL 采集更改为其他列表。
采集内容:文章标题,出版时间,文章文本。
使用功能点:
l列表循环
lDetails 采集
第1步:创建网易帐户文章采集任务
1)进入主界面,选择“自定义采集”
2)复制采集的URL并将其粘贴到网站输入框中,单击“保存URL”
第2步:创建循环,然后单击以加载更多
1)打开网页后,打开右上角的“过程”按钮,并从左侧的过程显示界面以一个步骤的循环进行拖动,如下所示
2)然后拖动到页面底部,并看到“加载更多”按钮,因为如果要查看更多内容,则需要循环单击“加载更多”,因此我们需要设置一个单击的循环步骤“装载更多” 。注意:采集更多内容需要加载更多内容。本文文章仅用于演示,因此选择执行并单击“加载更多” 20次,您可以根据实际需要进行添加或减少。
第3步:创建循环点击列表采集详细信息
1)单击文章列表的第一个和第二个标题,然后选择“循环单击每个元素”按钮。这样会创建一个循环单击列表命令,并且可以在采集器中看到当前列表页面的内容。
2)然后,我们可以提取所需的文本数据。下图提取了标题,时间和正文的文本内容。其他信息可以自由删除和编辑。然后,您可以点击保存以启动本地采集。
3)单击以启动采集,采集器开始提取数据。
4)采集完成后可以导出。
查看全部
网易自媒体文章采集
本文介绍了使用优采云采集网易帐户文章的方法。
采集 URL:
NetEase帐户(以前称为NetEase订阅)是在NetEase Media完成“两端”的集成和升级之后新创建的自媒体内容分发和品牌推广平台。本文以网易账户的首页列表为例,您也可以将采集 URL 采集更改为其他列表。
采集内容:文章标题,出版时间,文章文本。
使用功能点:
l列表循环
lDetails 采集
第1步:创建网易帐户文章采集任务
1)进入主界面,选择“自定义采集”
2)复制采集的URL并将其粘贴到网站输入框中,单击“保存URL”
第2步:创建循环,然后单击以加载更多
1)打开网页后,打开右上角的“过程”按钮,并从左侧的过程显示界面以一个步骤的循环进行拖动,如下所示
2)然后拖动到页面底部,并看到“加载更多”按钮,因为如果要查看更多内容,则需要循环单击“加载更多”,因此我们需要设置一个单击的循环步骤“装载更多” 。注意:采集更多内容需要加载更多内容。本文文章仅用于演示,因此选择执行并单击“加载更多” 20次,您可以根据实际需要进行添加或减少。
第3步:创建循环点击列表采集详细信息
1)单击文章列表的第一个和第二个标题,然后选择“循环单击每个元素”按钮。这样会创建一个循环单击列表命令,并且可以在采集器中看到当前列表页面的内容。
2)然后,我们可以提取所需的文本数据。下图提取了标题,时间和正文的文本内容。其他信息可以自由删除和编辑。然后,您可以点击保存以启动本地采集。
3)单击以启动采集,采集器开始提取数据。
4)采集完成后可以导出。
解决方案:【运营软件】自媒体文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-11-08 08:00
与市场上大多数采集软件相比,采集 知乎和文章都是可以实现的,例如履带,优采云,优采云 采集器,优采云 采集器等等。许多内容采集系统都有自己的特点,许多用户都有自己的习惯和喜好,但是对于大多数新手来说,上手比较困难。但是,如果您撇开熟练使用后的用户体验,那么用户真正需要的是具有极其简单的操作和强大数据采集的软件。
以下编辑器推荐的知乎 采集器采用智能模式。通过输入URL可以自动识别它。 采集 知乎高度赞扬的问题和答案,方便大家阅读知乎问答和知乎 k13]内容,并将您喜欢的问题和答案或文章永久保存到本地计算机以进行集中管理和阅读。
一、软件简介
1、导出知乎 网站上任何问答的问答内容,以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
二、软件功能介绍
1、导出知乎 网站上任何问答的问答内容以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
三、知乎助手软件教程
第一步是下载并安装软件。您可以下载安装包,解压缩并通过指向以下编辑器提供的Lanqin云网络磁盘的链接运行它。
步骤2。打开软件后,您可以看到主界面并使用您的微信帐户登录。
步骤3.导入采集问答链接/ 文章链接或指定用户文章链接。如下图所示
连接示例:
第4步。选择采集以指定本地计算机上的本地存储位置,然后选择导出的文件格式[html格式,pdf和Word格式](建议使用默认html,html等效于本地网页,可以是永久网页,将其保存在计算机上)并启动采集。
四、支持三种连接导入和下载
1、问与答链接示例:
问答链接
2、 文章链接示例:
3、 采集指定用户主页文章链接:。界面如下所示的链接主要用于批量下载知乎主页下的所有文章。
(这是指导入的单个问题和答案或文章链接,每行有多个链接)
五、文章采集成功的本地屏幕截图
六、操作方法摘要
1、先下载蓝琴云盘软件链接【】
2、下载后,将其解压缩,打开软件以登录,然后设置采集导出文章的保存位置。
3、复制并导入采集的文章链接,问答链接和指定用户文章链接以导入,单击以开始下载
4、等待下载完成,找到刚刚设置的文章的保存位置,将其打开,您将看到刚刚下载的知乎 文章。
注意:所有下载的知乎 文章仅可用于自学,禁止直接或间接发布,使用,重写或重新分发以供发布或使用,或用于任何其他商业用途目的。 查看全部
[操作软件]自媒体文章采集器
与市场上大多数采集软件相比,采集 知乎和文章都是可以实现的,例如履带,优采云,优采云 采集器,优采云 采集器等等。许多内容采集系统都有自己的特点,许多用户都有自己的习惯和喜好,但是对于大多数新手来说,上手比较困难。但是,如果您撇开熟练使用后的用户体验,那么用户真正需要的是具有极其简单的操作和强大数据采集的软件。
以下编辑器推荐的知乎 采集器采用智能模式。通过输入URL可以自动识别它。 采集 知乎高度赞扬的问题和答案,方便大家阅读知乎问答和知乎 k13]内容,并将您喜欢的问题和答案或文章永久保存到本地计算机以进行集中管理和阅读。
一、软件简介
1、导出知乎 网站上任何问答的问答内容,以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
二、软件功能介绍
1、导出知乎 网站上任何问答的问答内容以及问答的评论部分;
2、导出指定用户下的所有文章,包括文章内容和文章注释部分;
3、导出格式主要为html格式,但也为pdf和Word格式(建议使用默认html,html等效于本地网页,可以永久保存在您的计算机上);
三、知乎助手软件教程
第一步是下载并安装软件。您可以下载安装包,解压缩并通过指向以下编辑器提供的Lanqin云网络磁盘的链接运行它。
步骤2。打开软件后,您可以看到主界面并使用您的微信帐户登录。
步骤3.导入采集问答链接/ 文章链接或指定用户文章链接。如下图所示
连接示例:
第4步。选择采集以指定本地计算机上的本地存储位置,然后选择导出的文件格式[html格式,pdf和Word格式](建议使用默认html,html等效于本地网页,可以是永久网页,将其保存在计算机上)并启动采集。
四、支持三种连接导入和下载
1、问与答链接示例:
问答链接
2、 文章链接示例:
3、 采集指定用户主页文章链接:。界面如下所示的链接主要用于批量下载知乎主页下的所有文章。
(这是指导入的单个问题和答案或文章链接,每行有多个链接)
五、文章采集成功的本地屏幕截图
六、操作方法摘要
1、先下载蓝琴云盘软件链接【】
2、下载后,将其解压缩,打开软件以登录,然后设置采集导出文章的保存位置。
3、复制并导入采集的文章链接,问答链接和指定用户文章链接以导入,单击以开始下载
4、等待下载完成,找到刚刚设置的文章的保存位置,将其打开,您将看到刚刚下载的知乎 文章。
注意:所有下载的知乎 文章仅可用于自学,禁止直接或间接发布,使用,重写或重新分发以供发布或使用,或用于任何其他商业用途目的。
干货内容:快速采集微信公众号文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 427 次浏览 • 2020-09-27 12:00
使用优采云采集微信官方帐户文章非常简单,只需输入:官方帐户ID或名称或关键词。
使用步骤:
1.新的微信公众号采集任务:
创建新的微信公众号采集的任务有两个入口:
2.微信官方帐户采集任务配置:
3.采集结果:
默认采集字段:
微信官方帐户名(weixin_name),官方帐户ID(weixin_id),标题(title),正文(content),发布日期(pubData),作者(author),标签(tag),描述(description)文字拦截)和关键字(关键字);
采集微信公众号注释:
附录:(如何获取散户采集的官方帐户ID和微信采集)
I。如何获取官方帐户ID
在“官方帐户ID(WeChat ID)”中填写微信帐户名,然后单击其旁边的“检查官方帐户”按钮以查看微信ID;
以“互联网”为例:
II,微信文章分散采集
微信文章片段采集通常用于精度采集,用户只需要输入微信文章地址采集。
在微信公众号文章 采集的基本信息页面上,点击“手动输入文章链接采集(可选)”按钮;
提醒:如果需要下载图片,数据处理等,请进行配置,然后单击分散的采集按钮;
输入一个或多个详细的URL,每行一个,以或开头;
查看全部
快速采集微信公众号文章教程
使用优采云采集微信官方帐户文章非常简单,只需输入:官方帐户ID或名称或关键词。
使用步骤:
1.新的微信公众号采集任务:
创建新的微信公众号采集的任务有两个入口:
2.微信官方帐户采集任务配置:
3.采集结果:
默认采集字段:
微信官方帐户名(weixin_name),官方帐户ID(weixin_id),标题(title),正文(content),发布日期(pubData),作者(author),标签(tag),描述(description)文字拦截)和关键字(关键字);
采集微信公众号注释:
附录:(如何获取散户采集的官方帐户ID和微信采集)
I。如何获取官方帐户ID
在“官方帐户ID(WeChat ID)”中填写微信帐户名,然后单击其旁边的“检查官方帐户”按钮以查看微信ID;
以“互联网”为例:
II,微信文章分散采集
微信文章片段采集通常用于精度采集,用户只需要输入微信文章地址采集。
在微信公众号文章 采集的基本信息页面上,点击“手动输入文章链接采集(可选)”按钮;
提醒:如果需要下载图片,数据处理等,请进行配置,然后单击分散的采集按钮;
输入一个或多个详细的URL,每行一个,以或开头;
孤狼公众号助手-专业的陌陌文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 782 次浏览 • 2020-08-25 04:22
微信文章一直是各大网站建站是的优质内容,很多站长为了便捷文章内容建设,不在使用低级的垃圾文章生成器,也不用伪原创处理文章,更不想手写,这如何办呢,优采云总有优采云的办法,优采云之所以栏,是想使效率更高一些达到偷懒的疗效。所以世界上才有那么多家用电器。那么多优采云用品。我们明天要介绍的这款软件,就是为网站运营者制做的一款优采云软件。
微信公众号开发之初是为了便捷陌陌或则站长写文章时没有素材可写,就提供了许多的采集方法和热门文章给你们采集。之后,为了便捷不用复制文章到网站,写了对接网站的插口,只须要采集好,直接发布到网站里即可。软件有3种采集方式。分别是分类采集,关键词采集,和自定义采集。
分类采集是我们把许多热门公众号监控后弄成了热门文章排行榜。提供给你们采集发布。软件添加了诸多的分类,适合各类精细的网站类目采集。
但是,有的站长同学都会认为,这些文章是不是不够符合他的网站内容的相关性。这样的考虑下,软件就有了陌陌的自定义公众号采集,可以自己添加指定相关的公众号,来采集他们的文章,这样来说,只要你关注的公众号是相关的行业的,那么文章的质量绝对是可靠的。孤狼公众号助手不限制添加的公众号个数。要用就用到爽
自定义的公众号文章非常多,公众号可以去百度找到许多的公众号排行榜,公众号大全这样的网站里找到。当然也可以自己搜集。
很多时侯公众号的文章有时候也比较偏向一些零乱的文章。所以,我们有了关键词搜索采集。只须要输入一个关键词,就可以找到特别多的与这个关键词相关的文章,你只须要拿来主义,全部拿过来,修更改改又是一篇好文章。 查看全部
孤狼公众号助手-专业的陌陌文章采集器
微信文章一直是各大网站建站是的优质内容,很多站长为了便捷文章内容建设,不在使用低级的垃圾文章生成器,也不用伪原创处理文章,更不想手写,这如何办呢,优采云总有优采云的办法,优采云之所以栏,是想使效率更高一些达到偷懒的疗效。所以世界上才有那么多家用电器。那么多优采云用品。我们明天要介绍的这款软件,就是为网站运营者制做的一款优采云软件。
微信公众号开发之初是为了便捷陌陌或则站长写文章时没有素材可写,就提供了许多的采集方法和热门文章给你们采集。之后,为了便捷不用复制文章到网站,写了对接网站的插口,只须要采集好,直接发布到网站里即可。软件有3种采集方式。分别是分类采集,关键词采集,和自定义采集。
分类采集是我们把许多热门公众号监控后弄成了热门文章排行榜。提供给你们采集发布。软件添加了诸多的分类,适合各类精细的网站类目采集。
但是,有的站长同学都会认为,这些文章是不是不够符合他的网站内容的相关性。这样的考虑下,软件就有了陌陌的自定义公众号采集,可以自己添加指定相关的公众号,来采集他们的文章,这样来说,只要你关注的公众号是相关的行业的,那么文章的质量绝对是可靠的。孤狼公众号助手不限制添加的公众号个数。要用就用到爽
自定义的公众号文章非常多,公众号可以去百度找到许多的公众号排行榜,公众号大全这样的网站里找到。当然也可以自己搜集。
很多时侯公众号的文章有时候也比较偏向一些零乱的文章。所以,我们有了关键词搜索采集。只须要输入一个关键词,就可以找到特别多的与这个关键词相关的文章,你只须要拿来主义,全部拿过来,修更改改又是一篇好文章。
phpcms 采集使用讲解与注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 548 次浏览 • 2020-08-19 17:14
同理。
2.在内容规则中输入采集内容的办法
默认是[内容],采集到的是财经新闻滚动_搜狐资讯-搜狐滚动
因此我们用文章中出现的
全国成品油价格指数创最大跌幅
作为标题来采集,[内容]可以可靠地得到标题。
最重要的是下边的内容规则,这关系到文章的内容能够正确地采集到。
同上,我们要对所要采集的目标网页进行剖析。
如图示是文章内容开始的地方,在下边可以看见,文章结束后有一个
因此就这样设置
[内容]
即可采集到内容,在两侧还有过滤选项,不要看这上面输入的十分麻烦,点击选择,会弹出一个框,进行选择,这里将不需要的脚本给过滤掉。
3.进行测试
点击测试,显示采集到的网址。
右侧有查看,点击可以看采集的内容。
采集的内容,如果出错,则内容或标题为空。
4.设置好之后,就可以进行采集网址,采集内容,导入内容了
在导出的时侯要设置导出选项,这个比较简单你们肯定还会。
5.注意事项。
(1)采集经常会失败,就是哪些都没采集到。 因为目标网页很复杂,所以尽量选择干净的网页去采集。设置的采集规则要尽量通用。
(2)重要!!!坑爹的phpcms在这个地方有个bug,如果第一次成功采集,第二次再进行采集的时侯会出现
V9第二次采集时出现“没有找到网址列表,请先进行网址采集“的问题。
解决方案请见:
摘抄如下:如果出现些问题,用MYSQL管理工具,清除v9_采集_history这个表的所有内容即可。
不过还有一个小技巧就是,因为你采集一次之后,导出内容后,这些内容就没有啥用了,可以删掉了,如果你在后台一页一页删掉实在是太麻烦了,也可以直接删掉 v9_采集_content 这个表的所有内容即可。
还可以在已导出 中把已导出的全部删掉。
附一个导下来的规则,存到txt文件中,可以从后台导出使用。
eyJsYXN0ZGF0ZSI6IjE0MTUxOTMyMzUiLCJzb3VyY2VjaGFyc2V0IjoiZ2JrIiwic291cmNldHlwZSI6IjMiLCJ1cmxwYWdlIjoiaHR0cDpcL1wvcm9sbC5zb2h1LmNvbVwvbW9uZXlcLyIsInBhZ2VzaXplX3N0YXJ0IjoiMSIsInBhZ2VzaXplX2VuZCI6IjEwIiwicGFnZV9iYXNlIjoiIiwicGFyX251bSI6IjEiLCJ1cmxfY29udGFpbiI6IiIsInVybF9leGNlcHQiOiJodHRwOlwvXC9yb2xsLnNvaHUuY29tXC9tb25leVwvIiwidXJsX3N0YXJ0IjoiPGRpdiBjbGFzcz1cImxpc3QxNFwiPiIsInVybF9lbmQiOiI8ZGl2IGNsYXNzPVwicGFnZXNcIj4iLCJ0aXRsZV9ydWxlIjoiPGgxIGl0ZW1wcm9wPVwiaGVhZGxpbmVcIj5bXHU1MTg1XHU1YmI5XTxcL2gxPiIsInRpdGxlX2h0bWxfcnVsZSI6IiIsImF1dGhvcl9ydWxlIjoiIiwiYXV0aG9yX2h0bWxfcnVsZSI6IiIsImNvbWVmb3JtX3J1bGUiOiIiLCJjb21lZm9ybV9odG1sX3J1bGUiOiIiLCJ0aW1lX3J1bGUiOiIiLCJ0aW1lX2h0bWxfcnVsZSI6IiIsImNvbnRlbnRfcnVsZSI6IjwhLS0gXHU2YjYzXHU2NTg3IC0tPltcdTUxODVcdTViYjldXHJcbjwhLS0gXHU1MjA2XHU0ZWFiIC0tPiIsImNvbnRlbnRfaHRtbF9ydWxlIjoiPHNjcmlwdChbXj5dKik+KC4qKTxcL3NjcmlwdD5bfF1cclxuIiwiY29udGVudF9wYWdlX3N0YXJ0IjoiIiwiY29udGVudF9wYWdlX2VuZCI6IiIsImNvbnRlbnRfcGFnZV9ydWxlIjoiMSIsImNvbnRlbnRfcGFnZSI6IjEiLCJjb250ZW50X25leHRwYWdlIjoiIiwiZG93bl9hdHRhY2htZW50IjoiMCIsIndhdGVybWFyayI6IjAiLCJjb2xsX29yZGVyIjoiMSIsImN1c3RvbWl6ZV9jb25maWciOiJhcnJheSAoXG4pIn0=
大概是用base64编码的规则吧。你可以导出后再进行一点个人的更改。 查看全部
phpcms 采集使用讲解与注意事项
同理。
2.在内容规则中输入采集内容的办法
默认是[内容],采集到的是财经新闻滚动_搜狐资讯-搜狐滚动
因此我们用文章中出现的
全国成品油价格指数创最大跌幅
作为标题来采集,[内容]可以可靠地得到标题。
最重要的是下边的内容规则,这关系到文章的内容能够正确地采集到。
同上,我们要对所要采集的目标网页进行剖析。
如图示是文章内容开始的地方,在下边可以看见,文章结束后有一个
因此就这样设置
[内容]
即可采集到内容,在两侧还有过滤选项,不要看这上面输入的十分麻烦,点击选择,会弹出一个框,进行选择,这里将不需要的脚本给过滤掉。
3.进行测试
点击测试,显示采集到的网址。
右侧有查看,点击可以看采集的内容。
采集的内容,如果出错,则内容或标题为空。
4.设置好之后,就可以进行采集网址,采集内容,导入内容了
在导出的时侯要设置导出选项,这个比较简单你们肯定还会。
5.注意事项。
(1)采集经常会失败,就是哪些都没采集到。 因为目标网页很复杂,所以尽量选择干净的网页去采集。设置的采集规则要尽量通用。
(2)重要!!!坑爹的phpcms在这个地方有个bug,如果第一次成功采集,第二次再进行采集的时侯会出现
V9第二次采集时出现“没有找到网址列表,请先进行网址采集“的问题。
解决方案请见:
摘抄如下:如果出现些问题,用MYSQL管理工具,清除v9_采集_history这个表的所有内容即可。
不过还有一个小技巧就是,因为你采集一次之后,导出内容后,这些内容就没有啥用了,可以删掉了,如果你在后台一页一页删掉实在是太麻烦了,也可以直接删掉 v9_采集_content 这个表的所有内容即可。
还可以在已导出 中把已导出的全部删掉。
附一个导下来的规则,存到txt文件中,可以从后台导出使用。
eyJsYXN0ZGF0ZSI6IjE0MTUxOTMyMzUiLCJzb3VyY2VjaGFyc2V0IjoiZ2JrIiwic291cmNldHlwZSI6IjMiLCJ1cmxwYWdlIjoiaHR0cDpcL1wvcm9sbC5zb2h1LmNvbVwvbW9uZXlcLyIsInBhZ2VzaXplX3N0YXJ0IjoiMSIsInBhZ2VzaXplX2VuZCI6IjEwIiwicGFnZV9iYXNlIjoiIiwicGFyX251bSI6IjEiLCJ1cmxfY29udGFpbiI6IiIsInVybF9leGNlcHQiOiJodHRwOlwvXC9yb2xsLnNvaHUuY29tXC9tb25leVwvIiwidXJsX3N0YXJ0IjoiPGRpdiBjbGFzcz1cImxpc3QxNFwiPiIsInVybF9lbmQiOiI8ZGl2IGNsYXNzPVwicGFnZXNcIj4iLCJ0aXRsZV9ydWxlIjoiPGgxIGl0ZW1wcm9wPVwiaGVhZGxpbmVcIj5bXHU1MTg1XHU1YmI5XTxcL2gxPiIsInRpdGxlX2h0bWxfcnVsZSI6IiIsImF1dGhvcl9ydWxlIjoiIiwiYXV0aG9yX2h0bWxfcnVsZSI6IiIsImNvbWVmb3JtX3J1bGUiOiIiLCJjb21lZm9ybV9odG1sX3J1bGUiOiIiLCJ0aW1lX3J1bGUiOiIiLCJ0aW1lX2h0bWxfcnVsZSI6IiIsImNvbnRlbnRfcnVsZSI6IjwhLS0gXHU2YjYzXHU2NTg3IC0tPltcdTUxODVcdTViYjldXHJcbjwhLS0gXHU1MjA2XHU0ZWFiIC0tPiIsImNvbnRlbnRfaHRtbF9ydWxlIjoiPHNjcmlwdChbXj5dKik+KC4qKTxcL3NjcmlwdD5bfF1cclxuIiwiY29udGVudF9wYWdlX3N0YXJ0IjoiIiwiY29udGVudF9wYWdlX2VuZCI6IiIsImNvbnRlbnRfcGFnZV9ydWxlIjoiMSIsImNvbnRlbnRfcGFnZSI6IjEiLCJjb250ZW50X25leHRwYWdlIjoiIiwiZG93bl9hdHRhY2htZW50IjoiMCIsIndhdGVybWFyayI6IjAiLCJjb2xsX29yZGVyIjoiMSIsImN1c3RvbWl6ZV9jb25maWciOiJhcnJheSAoXG4pIn0=
大概是用base64编码的规则吧。你可以导出后再进行一点个人的更改。
在网站上采集文章有哪些不利影响?
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-08-07 05:05
SEO是推广郑州网络的一种更有效的方法,因此在网站优化过程中,每个网站都必须填充内容. 在这个“内容为王”的时代,许多SEO网站管理员为了更好地优化网站,我们很疯狂地写了很多文章. 但是,一些SEOer认为原创文章不像以前那样重要,而是为了缩短时间并快速使网站具有大量内容,因此许多网站管理员会选择使用采集软件来采集文章疯狂,那么最终,这些疯狂采集文章会对我们的网站造成什么不良影响?
首先,内容无法准确控制
郑州网络推广有限公司认为,为了尽快更新网站内容并加快网站内容的更新频率,许多网站管理员会选择使用某些采集软件来采集内容,但是对于现在市场上的大多数采集软件而言,其自身的采集功能仍然相对较差且不令人满意. 以内容为例. 由软件采集的内容收录来自其他网站的大量内容,并且仍然是无法删除的那种内容. 这是软件采集的主要缺点. 此外,使用软件采集他人网站的内容不一定与您网站的内容一致. 尽管这在初期对网站有一点好处,但影响不大,但这可能是因为此原因对网站有严重影响.
第二,很容易使网站成为K
据说内容是网站质量的关键之一,但是如果文章质量不好,对网站无益,只要原创性高,文章就好的内容有益于网站体重增加的关键. 我还研究了用于网站内容采集的主要搜索引擎的规则. 尽管该网站可能会在一段时间内表现良好,但如果从长远角度来看,这是非常不可取的,它将直接导致严重的问题. K删除站点,尤其是新站点. 不要为内容而采集内容,因为这种方法是不可取的. 如果网站是K,就无法谈论网络推广! 查看全部
网站文章集对网站有什么负面影响?以下是郑州网络推广公司汇网科技的摘要,希望对广大网站管理员有所帮助!
SEO是推广郑州网络的一种更有效的方法,因此在网站优化过程中,每个网站都必须填充内容. 在这个“内容为王”的时代,许多SEO网站管理员为了更好地优化网站,我们很疯狂地写了很多文章. 但是,一些SEOer认为原创文章不像以前那样重要,而是为了缩短时间并快速使网站具有大量内容,因此许多网站管理员会选择使用采集软件来采集文章疯狂,那么最终,这些疯狂采集文章会对我们的网站造成什么不良影响?
首先,内容无法准确控制
郑州网络推广有限公司认为,为了尽快更新网站内容并加快网站内容的更新频率,许多网站管理员会选择使用某些采集软件来采集内容,但是对于现在市场上的大多数采集软件而言,其自身的采集功能仍然相对较差且不令人满意. 以内容为例. 由软件采集的内容收录来自其他网站的大量内容,并且仍然是无法删除的那种内容. 这是软件采集的主要缺点. 此外,使用软件采集他人网站的内容不一定与您网站的内容一致. 尽管这在初期对网站有一点好处,但影响不大,但这可能是因为此原因对网站有严重影响.
第二,很容易使网站成为K
据说内容是网站质量的关键之一,但是如果文章质量不好,对网站无益,只要原创性高,文章就好的内容有益于网站体重增加的关键. 我还研究了用于网站内容采集的主要搜索引擎的规则. 尽管该网站可能会在一段时间内表现良好,但如果从长远角度来看,这是非常不可取的,它将直接导致严重的问题. K删除站点,尤其是新站点. 不要为内容而采集内容,因为这种方法是不可取的. 如果网站是K,就无法谈论网络推广!

