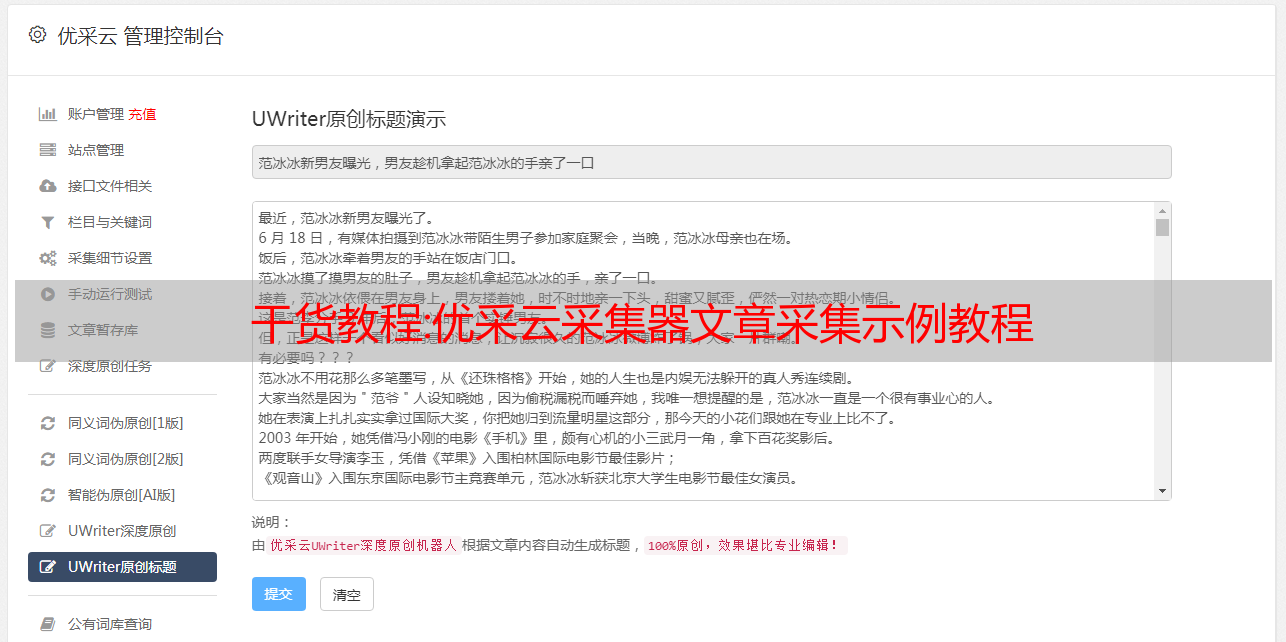
干货教程:优采云采集器文章采集示例教程
优采云 发布时间: 2021-01-09 11:05采集文章处理:列表页面→获取内容页面URL→内容页面字段分析
起始页网址
例如,所有文章都在列表中,即起始页面是URL
可以添加多个起始页(例如,列表分页)
内容页面网址
点击“保存”后,我们将测试对“内容页面URL”中的内容页面URL进行爬网
默认情况下获取所有网址(包括样式和js文件)
某些URL不收录域名(因为该程序直接获取html源代码),因此可以在“采集器设置”中选择“自动完成URL”
我们只需要采集文章页,通过分析,文章 URL的格式大致为“文章/新闻/show/id/number.html”。
直接在“结果URL过滤器>>必须收录”中输入“ article / news / show / id /”,保存测试并查看
如果您需要准确性,也可以输入常规的“文章/新闻/节目/id/d+.html”(d+是匹配的数字)
例如,如果要过滤某些URL并将其输入“不能收录”,请过滤掉25、27、29中的文章,然后输入:“ 25 | 27 | 29”。
如果列表页面的布局较为复杂,则有很多文章列表区域,我们只需要获取某个区域的文章,请使用“从选定区域提取URL”,新手建议“ xpath”获取表格,可以在“获取内容>>测试>>测试爬网数据>>分析网页”中输入列表页面的URL,单击页面元素获取相应的xpath值
如果无法直接获取内容页面链接(由js生成)或需要将其拼接成新的URL,则可以在“匹配的内容URL”中进行设置
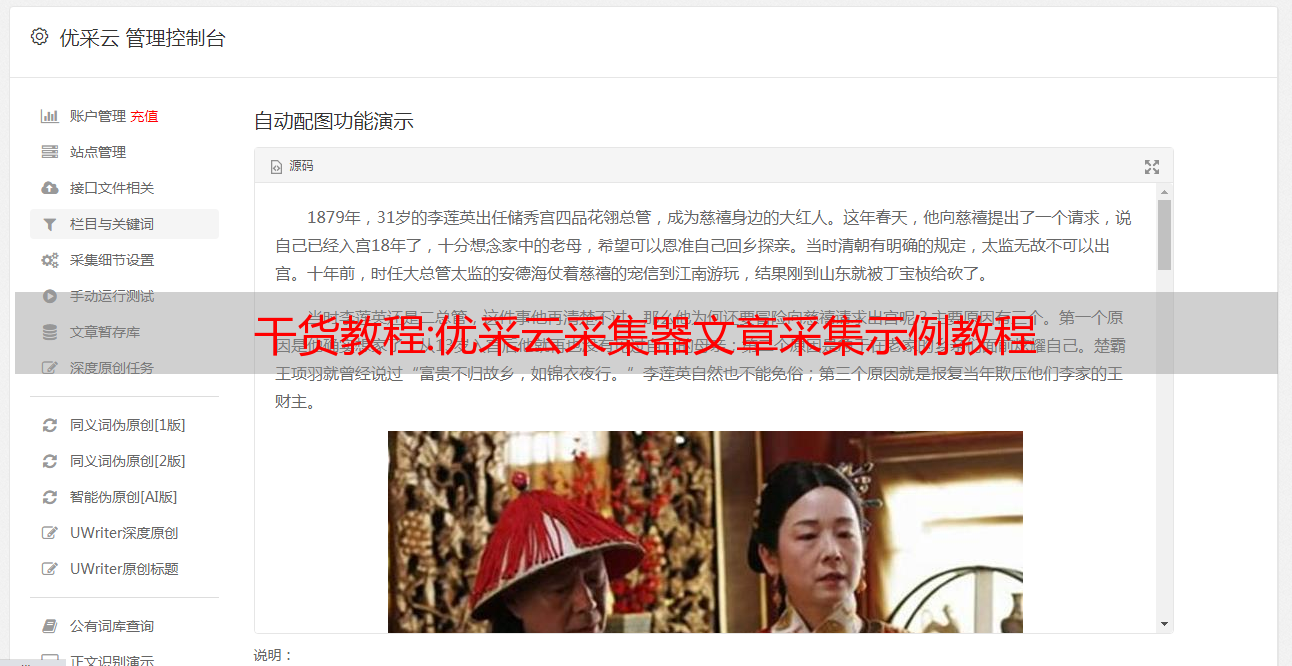
获取内容
分析内容页面的URL后,我们需要获取文章的标题,正文和其他信息,然后需要添加字段以匹配数据
新手建议使用“ xpath”匹配,然后在“测试>>分析网页”中输入文章链接
单击分析页面以获取标题xpath:“ // * [@ id =” title“] / h1 [1]”,正文xpath:“ // * [@ id =” content“]”
分别添加字段:标题和正文,选择“ xpath匹配”作为获取方法,并填写获取的xpath值
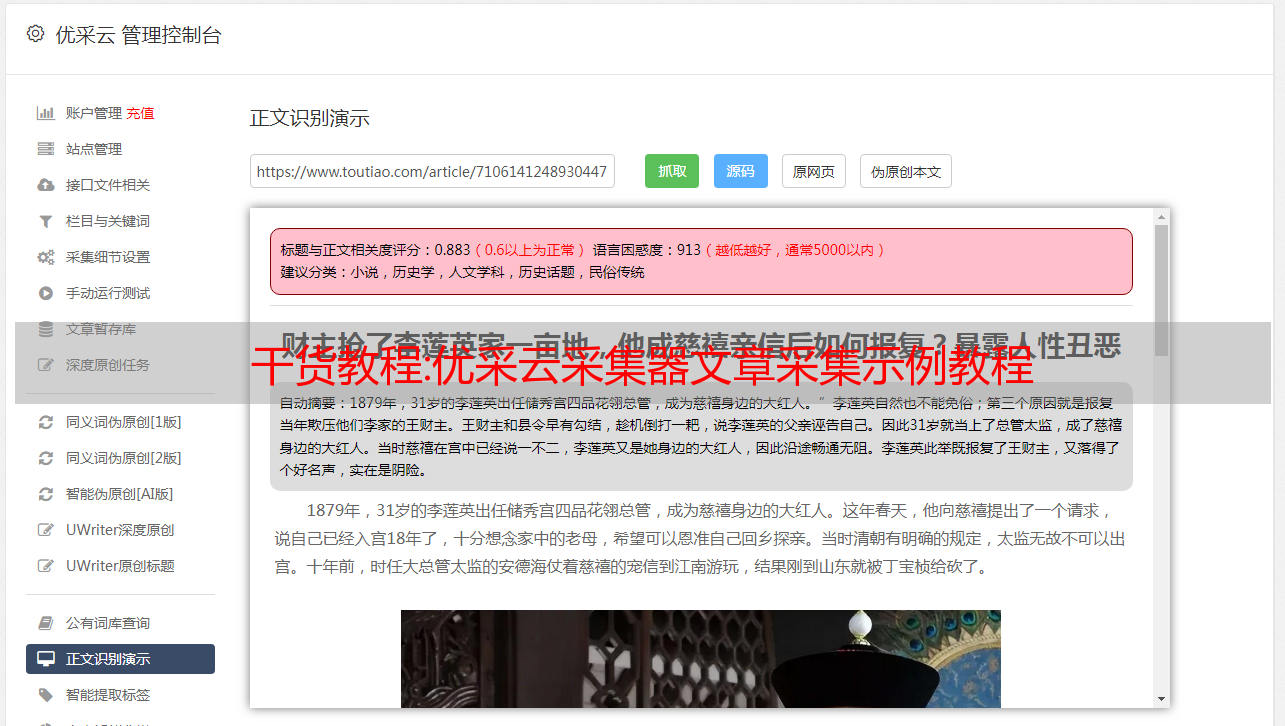
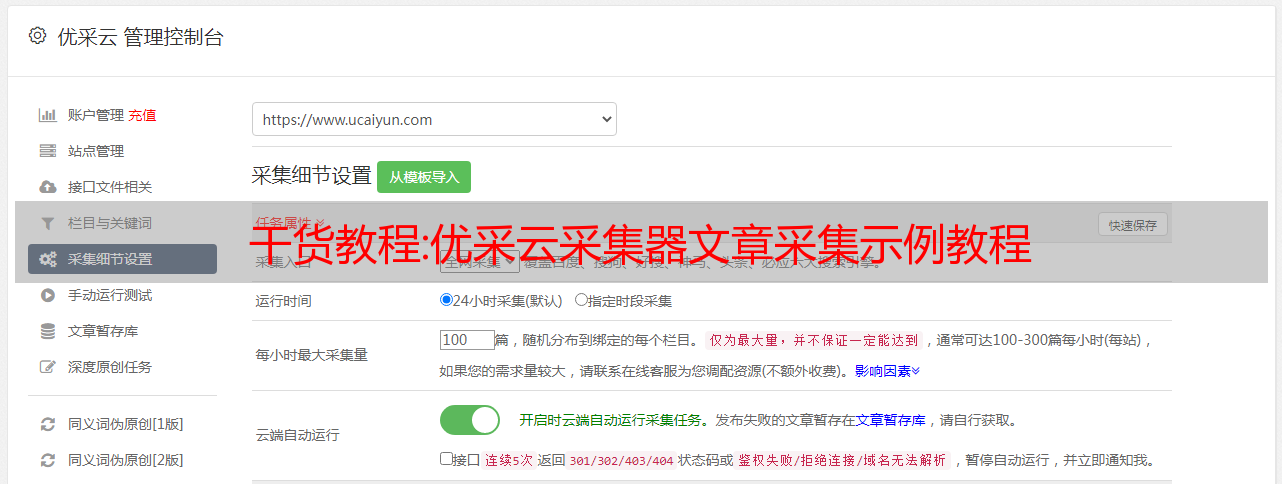
保存后,单击“测试”以获取数据,效果:
主体中收录许多html标签,如果需要过滤,则可以使用“数据处理>> html标记过滤”功能
有关采集分页内容,请参阅文章分页指南
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...

