
抓取ajax动态网页java
抓取ajax动态网页java(:现代社会互联网技术日新月异,论文摘要(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-28 16:15
ADissertationSubmittedinPartialFulfillmentoftheDegree ofMasterofEngineeringResearchandImplementofDistributedCrawlerSystemSupportingAJAXCandidate:通信&信息系统Supervisor:AssociateProfessorTanYunmengHuazhong科技大学 据我所知,本文不收录
任何个人或其他已发表的文本或研究成果。对本文的研究有贡献的个人和集体已在文章中明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期:年、月、日、
本人授权华中科技大学将本论文的全部或部分内容编入相关数据库进行检索,并通过影印、缩小或扫描等复印方式保存和编辑本论文。保密□,本授权书将在________解密后生效。本文不保密。(请在上框打“√”) 论文作者签名: 导师签名: 日期:年、月、日:年、月、日,华中科技大学 层出不穷,AJAX技术越来越受到开发者的青睐。该技术对传统的网络爬虫不友好,使用传统的网络爬虫方式获取内容是不完整的。所以,研究支持AJAX的网络爬虫系统具有重要的现实意义。本文首先调查了异步加载网页获取方式的国内外研究现状,阐述了其收录困难的原因,分析了目前爬取方案的优缺点,提出了一种调用浏览器界面进行请求和获取的方案。获取网页。其次,为了提高网络爬虫的效率,协调AJAX爬虫和静态网络爬虫的资源分配,本文提出了一种网络属性分类器的解决方案。该解决方案可以通过网页处理模块的主体来提取反馈并纠正分类结果。根据分类结果,使用不同的方法捕获不同的网页。
本文研究实现的支持AJAX的分布式爬虫系统可以采集异步加载的网页和普通静态页面,实现爬取任务的高效分配,为异步加载网页的爬取提供了一种新思路。系统测试结果表明,可以实现预期的功能,取得了良好的性能指标。关键词:分布式爬虫;阿贾克斯;动态加载;技术、产品已经出现。其中AJAX技术越来越受到软件开发者的青睐。但是,该技术对传统网络爬虫不友好,传统网络爬虫抓取的网页内容也很不完美。因此,研究支持AJAX的爬虫系统具有很大的实用意义。 查看全部
抓取ajax动态网页java(:现代社会互联网技术日新月异,论文摘要(组图))
ADissertationSubmittedinPartialFulfillmentoftheDegree ofMasterofEngineeringResearchandImplementofDistributedCrawlerSystemSupportingAJAXCandidate:通信&信息系统Supervisor:AssociateProfessorTanYunmengHuazhong科技大学 据我所知,本文不收录
任何个人或其他已发表的文本或研究成果。对本文的研究有贡献的个人和集体已在文章中明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期:年、月、日、
本人授权华中科技大学将本论文的全部或部分内容编入相关数据库进行检索,并通过影印、缩小或扫描等复印方式保存和编辑本论文。保密□,本授权书将在________解密后生效。本文不保密。(请在上框打“√”) 论文作者签名: 导师签名: 日期:年、月、日:年、月、日,华中科技大学 层出不穷,AJAX技术越来越受到开发者的青睐。该技术对传统的网络爬虫不友好,使用传统的网络爬虫方式获取内容是不完整的。所以,研究支持AJAX的网络爬虫系统具有重要的现实意义。本文首先调查了异步加载网页获取方式的国内外研究现状,阐述了其收录困难的原因,分析了目前爬取方案的优缺点,提出了一种调用浏览器界面进行请求和获取的方案。获取网页。其次,为了提高网络爬虫的效率,协调AJAX爬虫和静态网络爬虫的资源分配,本文提出了一种网络属性分类器的解决方案。该解决方案可以通过网页处理模块的主体来提取反馈并纠正分类结果。根据分类结果,使用不同的方法捕获不同的网页。
本文研究实现的支持AJAX的分布式爬虫系统可以采集异步加载的网页和普通静态页面,实现爬取任务的高效分配,为异步加载网页的爬取提供了一种新思路。系统测试结果表明,可以实现预期的功能,取得了良好的性能指标。关键词:分布式爬虫;阿贾克斯;动态加载;技术、产品已经出现。其中AJAX技术越来越受到软件开发者的青睐。但是,该技术对传统网络爬虫不友好,传统网络爬虫抓取的网页内容也很不完美。因此,研究支持AJAX的爬虫系统具有很大的实用意义。
抓取ajax动态网页java(详细说明Explain网站建设的重要程度显现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-28 16:15
详细解释
因为大家都知道搜索引擎会爬
网站建设的重要性日益凸显
网站建设不是盲目的,而是有条不紊的,一点一点的。针对用户体验,人性化的网站建设是网站质量非常重要的一步,所以找一家有实力、有创新的公司。沉阳网站制作公司很重要
网站建设不仅要从技术上做,更要从理念上做。人性化非常重要。
第一点是网站建设的整个导航需要人性化,要符合优化后的导航菜单。导航需要一目了然,一目了然,让客户可以自由点击返回。导航结构没有固定的样式,你可以自己设计。它简洁、清晰、大方。
第二点是网站首页不能有太多的图片或flash动画。当然,考虑到用户体验,一些必须加的地方也必须加,即双方比例相近,美感和优化同时进行。因为大家都知道,搜索引擎在抓取网站的时候,一般抓取的网站中的文字内容、图片或者动画,还是很难抓取到的。
第三点是整个网站的网页必须是静态页面。静态页面以htm,html域名结尾,有利于搜索引擎的抓取和优化。
在网站建设中,网站建设有一些技巧和技巧:
一、静态
以百度为首的搜索引擎不断更新算法和规则,他们要找的是静态网址链接。静态页面更有利于引擎的抓取和收录。站长也知道这个标题。动态链接位置不幸因为搜索引擎友好,容易陷入死循环,用户体验效果也很差。同时,动态链接位置给引擎一种不清楚的感觉,而静态位置清晰,所以网站页面只是静态的。
二、无效链接
网站由很多页面组成,每个页面都有对应的链接位置,每个网站的链接都是一样的。如果网站内容中有两个或两个以上不同的链接,沉阳建站百度只会点击其中一个链接。来评价一下,因为不同的链接是相同的内容,会对网站产生负面影响。这样会分散页面的权重,排名结果也不好,影响整个网站的权重。
三、空页
网站的空页是偶尔出现的页面,搜索引擎会认为网站内部优化不到位。同时,沉阳网站建设会被搜索引擎删除大量重复的空页,影响相应的页面排名。对大量空页进行灌注的站长应该实时处理,否则对网站的成长来说是不走运的。
丹东网站建设丹东网站制作 查看全部
抓取ajax动态网页java(详细说明Explain网站建设的重要程度显现(图))
详细解释
因为大家都知道搜索引擎会爬
网站建设的重要性日益凸显
网站建设不是盲目的,而是有条不紊的,一点一点的。针对用户体验,人性化的网站建设是网站质量非常重要的一步,所以找一家有实力、有创新的公司。沉阳网站制作公司很重要
网站建设不仅要从技术上做,更要从理念上做。人性化非常重要。
第一点是网站建设的整个导航需要人性化,要符合优化后的导航菜单。导航需要一目了然,一目了然,让客户可以自由点击返回。导航结构没有固定的样式,你可以自己设计。它简洁、清晰、大方。
第二点是网站首页不能有太多的图片或flash动画。当然,考虑到用户体验,一些必须加的地方也必须加,即双方比例相近,美感和优化同时进行。因为大家都知道,搜索引擎在抓取网站的时候,一般抓取的网站中的文字内容、图片或者动画,还是很难抓取到的。
第三点是整个网站的网页必须是静态页面。静态页面以htm,html域名结尾,有利于搜索引擎的抓取和优化。
在网站建设中,网站建设有一些技巧和技巧:
一、静态
以百度为首的搜索引擎不断更新算法和规则,他们要找的是静态网址链接。静态页面更有利于引擎的抓取和收录。站长也知道这个标题。动态链接位置不幸因为搜索引擎友好,容易陷入死循环,用户体验效果也很差。同时,动态链接位置给引擎一种不清楚的感觉,而静态位置清晰,所以网站页面只是静态的。
二、无效链接
网站由很多页面组成,每个页面都有对应的链接位置,每个网站的链接都是一样的。如果网站内容中有两个或两个以上不同的链接,沉阳建站百度只会点击其中一个链接。来评价一下,因为不同的链接是相同的内容,会对网站产生负面影响。这样会分散页面的权重,排名结果也不好,影响整个网站的权重。
三、空页
网站的空页是偶尔出现的页面,搜索引擎会认为网站内部优化不到位。同时,沉阳网站建设会被搜索引擎删除大量重复的空页,影响相应的页面排名。对大量空页进行灌注的站长应该实时处理,否则对网站的成长来说是不走运的。
丹东网站建设丹东网站制作
抓取ajax动态网页java(谷歌搜索建议(GoogleSuggest)使用AJAX创造出动态性极强的web界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 04:27
AJAX 简介
AJAX 是一种无需重新加载整个网页即可更新网页的一部分的技术。
什么是 AJAX?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
AJAX在后台与服务器交换少量数据,从而实现网页的异步更新。这意味着可以在不重新加载整个页面的情况下更新网页的某些部分。
如果需要更新传统网页的内容(不使用 AJAX),则必须重新加载整个页面。
有许多使用 AJAX 的应用程序示例:Google Maps、Gmail、Youtube 和 Facebook。
AJAX 的工作原理
AJAX 基于 Internet 标准
AJAX 基于 Internet 标准并使用以下技术组合:
AJAX 应用与浏览器和平台无关!
谷歌建议
随着 2005 年 Google 的搜索建议功能的发布,AJAX 开始流行。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中键入时,JavaScript 会将字符发送到服务器,服务器将返回建议列表。
立即开始使用 AJAX
在我们的 PHP 教程中,我们将演示 AJAX 如何在不重新加载整个页面的情况下更新网页的某些部分。服务器脚本将用 PHP 编写。
如果您想了解有关 AJAX 的更多信息,请访问我们的 AJAX 教程。 查看全部
抓取ajax动态网页java(谷歌搜索建议(GoogleSuggest)使用AJAX创造出动态性极强的web界面)
AJAX 简介
AJAX 是一种无需重新加载整个网页即可更新网页的一部分的技术。
什么是 AJAX?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
AJAX在后台与服务器交换少量数据,从而实现网页的异步更新。这意味着可以在不重新加载整个页面的情况下更新网页的某些部分。
如果需要更新传统网页的内容(不使用 AJAX),则必须重新加载整个页面。
有许多使用 AJAX 的应用程序示例:Google Maps、Gmail、Youtube 和 Facebook。
AJAX 的工作原理

AJAX 基于 Internet 标准
AJAX 基于 Internet 标准并使用以下技术组合:

AJAX 应用与浏览器和平台无关!
谷歌建议
随着 2005 年 Google 的搜索建议功能的发布,AJAX 开始流行。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中键入时,JavaScript 会将字符发送到服务器,服务器将返回建议列表。
立即开始使用 AJAX
在我们的 PHP 教程中,我们将演示 AJAX 如何在不重新加载整个页面的情况下更新网页的某些部分。服务器脚本将用 PHP 编写。
如果您想了解有关 AJAX 的更多信息,请访问我们的 AJAX 教程。
抓取ajax动态网页java( 抓取结果如下:静态分析对动态分析的缺点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-20 21:22
抓取结果如下:静态分析对动态分析的缺点及解决办法)
<p style="text-align:center">
0x01 简介
随着Web 2.0的发展,页面中的AJAX也越来越多。由于传统爬虫依靠静态分析,不能准确的抓取到页面中的AJAX请求以及动态更新的内容,已经越来越不能满足需求。基于动态解析的Web 2.0爬虫应运而生,通过浏览器内核解析页面源码,模拟用户操作,能有效解决上述问题。本文将详细分析利用PhantomJS + Python 编写爬虫并进行去重的思路。
0x02 PhantomJS
PhantomJS 是无界面的 Webkit 解析器,提供了 JavaScript API 。由于去除了可视化界面,速度比一般 Webkit 浏览器要快很多。同时提供了很多监控和事件接口,可以方便的操作 DOM 节点,模拟用户操作等。
接下来我们通过一个简单的例子,来展示下动态爬虫和传统爬虫的区别。目标:加载一个页面,并且获取其中所有的 <a> 标签。 // example.js var page = require('webpage').create(); page.onAlert = function (message) { console.log(message); return true; }; page.onCallback = function() { page.evaluate(function(){ atags = document.getElementsByTagName("a"); for(var i=0;i 查看全部
抓取ajax动态网页java(
抓取结果如下:静态分析对动态分析的缺点及解决办法)
<p style="text-align:center">

0x01 简介
随着Web 2.0的发展,页面中的AJAX也越来越多。由于传统爬虫依靠静态分析,不能准确的抓取到页面中的AJAX请求以及动态更新的内容,已经越来越不能满足需求。基于动态解析的Web 2.0爬虫应运而生,通过浏览器内核解析页面源码,模拟用户操作,能有效解决上述问题。本文将详细分析利用PhantomJS + Python 编写爬虫并进行去重的思路。
0x02 PhantomJS
PhantomJS 是无界面的 Webkit 解析器,提供了 JavaScript API 。由于去除了可视化界面,速度比一般 Webkit 浏览器要快很多。同时提供了很多监控和事件接口,可以方便的操作 DOM 节点,模拟用户操作等。
接下来我们通过一个简单的例子,来展示下动态爬虫和传统爬虫的区别。目标:加载一个页面,并且获取其中所有的 <a> 标签。 // example.js var page = require('webpage').create(); page.onAlert = function (message) { console.log(message); return true; }; page.onCallback = function() { page.evaluate(function(){ atags = document.getElementsByTagName("a"); for(var i=0;i
抓取ajax动态网页java(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 03:22
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们的抓取和收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在Google爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、动态插入元数据和页面元素
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
等等
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释 网站 使用 AngularJS 框架和 HTML5 History API (pushState) 构建,可以渲染和 收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。例如,在加载到 DOM 后将获取图像并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想要测试 Google 如何响应出现在源代码和 DOM 之间的链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加了 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果将href="nofollow"的a元素插入到DOM中,nofollow和链接是同时插入的,所以会被跟踪。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是元标记,例如 rel 规范注释,无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(记住要允许 Google 爬虫获取那些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
抓取ajax动态网页java(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。

长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们的抓取和收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。

JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在Google爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、动态插入元数据和页面元素
5、rel = "nofollow" 的一个重要例子

示例:用于测试 Google 爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。

示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
等等
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释 网站 使用 AngularJS 框架和 HTML5 History API (pushState) 构建,可以渲染和 收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。例如,在加载到 DOM 后将获取图像并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想要测试 Google 如何响应出现在源代码和 DOM 之间的链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。

对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加了 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果将href="nofollow"的a元素插入到DOM中,nofollow和链接是同时插入的,所以会被跟踪。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是元标记,例如 rel 规范注释,无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(记住要允许 Google 爬虫获取那些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
抓取ajax动态网页java(说句大实话,请为我这么爱学习的新手点赞!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-19 03:07
老实说,以下都是百度的,请给我这样一个爱学习的新手点个赞!23333333
C语言是一种通用的计算机程序设计语言。虽然它的应用范围很广,但它接近底层,很难掌握操作符和操作顺序。不适合新手。
HTML 超文本标记语言:超文本是指可以收录图片、链接、音乐甚至程序等非文本元素的页面。结构主要包括网页(head)信息和网页具体内容(body),结合其他网页技术,如脚本语言、组件等,创建一个功能齐全的网页。既然是显示网页,自然要结合浏览器,但是对于不同的浏览器,同一个标签可能有不同的解释,所以显示效果也可能不同。
CSS,Cascading Style Sheet,是一种用于表达HTML或XML等文档样式的计算机语言,可以实现网页性能与内容的分离。与传统的 HTML 相比,CSS 可以更准确地控制网页中对象的位置和布局,并具有编辑网页对象和模型样式的能力。当然,还有其他功能。可以说是目前最优秀的基于文本显示的性能设计语言。具有很强的易读性。
JavaScript 是一种网络脚本语言,广泛用于 Web 应用程序开发。它在程序运行期间被解释和解释。比如我们经常看到的网页上的各种动态功能,都是用JS实现的。一般情况下,JavaScript 脚本通过嵌入 HTML 来实现其功能。
AJAX 是一种用于创建快速动态网页的技术。核心是JavaScript对象XMLHttpRequest,可以实现网页的异步更新。
C++是在C语言的基础上发展起来的面向对象的编程语言,在很多方面与C语言兼容。当然,这同样困难。
Java是一种面向对象的编程语言,看起来很像C++,但Java取其精华,去其糟粕。它功能强大且易于使用。(后端语言)
楼上的都建议新手考虑Python。其实这里也推荐学习Python,因为我也是新手。
我看到了一张照片,然后发了过来。
为了说得好不吵闹,PHP是世界上最好的语言。主题由你决定。 查看全部
抓取ajax动态网页java(说句大实话,请为我这么爱学习的新手点赞!)
老实说,以下都是百度的,请给我这样一个爱学习的新手点个赞!23333333
C语言是一种通用的计算机程序设计语言。虽然它的应用范围很广,但它接近底层,很难掌握操作符和操作顺序。不适合新手。
HTML 超文本标记语言:超文本是指可以收录图片、链接、音乐甚至程序等非文本元素的页面。结构主要包括网页(head)信息和网页具体内容(body),结合其他网页技术,如脚本语言、组件等,创建一个功能齐全的网页。既然是显示网页,自然要结合浏览器,但是对于不同的浏览器,同一个标签可能有不同的解释,所以显示效果也可能不同。
CSS,Cascading Style Sheet,是一种用于表达HTML或XML等文档样式的计算机语言,可以实现网页性能与内容的分离。与传统的 HTML 相比,CSS 可以更准确地控制网页中对象的位置和布局,并具有编辑网页对象和模型样式的能力。当然,还有其他功能。可以说是目前最优秀的基于文本显示的性能设计语言。具有很强的易读性。
JavaScript 是一种网络脚本语言,广泛用于 Web 应用程序开发。它在程序运行期间被解释和解释。比如我们经常看到的网页上的各种动态功能,都是用JS实现的。一般情况下,JavaScript 脚本通过嵌入 HTML 来实现其功能。
AJAX 是一种用于创建快速动态网页的技术。核心是JavaScript对象XMLHttpRequest,可以实现网页的异步更新。
C++是在C语言的基础上发展起来的面向对象的编程语言,在很多方面与C语言兼容。当然,这同样困难。
Java是一种面向对象的编程语言,看起来很像C++,但Java取其精华,去其糟粕。它功能强大且易于使用。(后端语言)
楼上的都建议新手考虑Python。其实这里也推荐学习Python,因为我也是新手。
我看到了一张照片,然后发了过来。

为了说得好不吵闹,PHP是世界上最好的语言。主题由你决定。
抓取ajax动态网页java(NutchNutchX版本实现请访问:基于ApacheNutch1.8和Htmlunit组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 07:04
-------------------------------------------------- -------------------------------------------------- ------提醒:项目当前版本不会更新。最新的Apache Nutch 2.X 版本实现请访问:---------------------- ----------- ------------------------------- ----------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 通过必要的动态 AJAX 请求来获取整个页面的内容。它是用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或重构源代码作为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已全部获取。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,在保留本项目源码信息,保证项目不会被非法出售的前提下,可以任何方式自由使用:开源、非开源、商业和非商业。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目: 查看全部
抓取ajax动态网页java(NutchNutchX版本实现请访问:基于ApacheNutch1.8和Htmlunit组件)
-------------------------------------------------- -------------------------------------------------- ------提醒:项目当前版本不会更新。最新的Apache Nutch 2.X 版本实现请访问:---------------------- ----------- ------------------------------- ----------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 通过必要的动态 AJAX 请求来获取整个页面的内容。它是用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或重构源代码作为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已全部获取。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,在保留本项目源码信息,保证项目不会被非法出售的前提下,可以任何方式自由使用:开源、非开源、商业和非商业。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目:
抓取ajax动态网页java(1.初识JavaScript1.1历史1.2JavaScript导读 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-04 07:01
)
JavaScript 的第一次介绍1.JavaScript 的介绍1.1 JavaScript 的历史1.2 JavaScript 是什么
JavaScript 是世界上最流行的语言之一。它是一种运行在客户端的脚本语言(Script 表示脚本)
脚本语言:无需编译,js解释器(js引擎)运行时会逐行解释执行
1.3 JavaScript 的作用
1.表单动态验证(密码强度检测)(JS生成的初衷)
2.网页特效
3.服务端开发(Node.js)
4.桌面程序(电子)
5.App(Cordova)
6.控制插件——物联网(Ruff)
7.游戏开发(cocos2d-js)
1.4 HTML/CSS/JS 关系
HTML/CSS 标记语言-描述语言
HTML决定网页的结构和内容(决定看什么),相当于人体
CSS决定了网页给用户的外观(决定好看与否),相当于给人们穿衣打扮
JS 脚本语言-编程语言
实现业务逻辑和页面控制(决策功能),相当于各种人工操作
1.4 浏览器执行JS介绍
浏览器分为渲染引擎和JS引擎两部分
渲染引擎:用于解析HTML和CSS,俗称内核,比如chrome浏览器的blink和老版本的wekit
JS引擎:又称JS解释器,用于读取网页中的JavaScript代码,处理后运行,如chrome浏览器的V8
浏览器本身并不执行JS代码,而是通过内置的JavaScript引擎(解释器)来执行JS代码。 JS引擎通过逐行解释每个源代码(转换成机器语言)来执行代码,然后有计算机去执行,所以JavaScript语言被归类为脚本语言,会被逐行解释执行.
1.5 JS的组成
JavaScript:
ECMAScript(JavaScript 语法),
DOM(页面文档对象模型),
BOM(浏览器对象模型)
1.ECMAScript
是 ECMA International(前身为欧洲计算机制造商协会)标准化的一种编程语言。这种语言在万维网上被广泛使用。它通常被称为 JavaScript 或 JScript,但实际上后两者是 ECMAScript 语言的实现和扩展
ECMAScript:JavaScript (Netscape)、Jscript (Microsoft)
ECMAScript:ECMAScript规定了JS的编程语法和基础核心知识,是所有浏览器厂商都遵守的一套JS语法行业标准
2.DOM——文档对象模型
文档对象模型(简称DOM)是W3C组织推荐的处理可扩展标记语言的标准编程接口。通过DOM提供的界面,可以操作页面上的各种元素(大小、位置、颜色等)。
3.BOM——浏览器对象模型
BOM(Browser Object Model,简称BOM)指的是浏览器对象模型。它提供了一个独立于内容并且可以与浏览器窗口交互的对象结构。可以通过BOM操作的浏览器窗口,如弹窗、控制浏览器跳转、获取分辨率等
1.6 JS初体验
JS 有 3 个书写位置,分别是 inline、inline 和 external
1.内联JS
可以在HTML标签的event属性(以on开头的属性)中写一行或少量的JS代码,如:onclick;
注意单双引号的使用:HTML中推荐使用双引号,JS中推荐使用单引号;
可读性差。 Abin在html中写了很多js代码,不方便阅读;
引号容易出错,多级嵌套和匹配引号时很容易混淆;
特殊情况下使用;
2.嵌入式JS
可以写多行JS代码
嵌入式JS是一种常见的学习方式
3.外部JS文件
有利于HTML页面代码的结构化,将大段JS代码从HTML页面中分离出来,既美观又方便文件级复用
引用外部JS文件的script标签不能写代码
适用于JS代码量比较大的情况
2.JS 评论
// 单行注释:ctrl + /
/*
1.多行注释 HBuilder X 默认快捷键 shift + ctrl + /
2.多行注释 VScode中修改多行注释的快捷键:ctrl + shift + /
*/
3.JavaScript 输入输出语句
为了方便信息的输入输出,JS提供了一些输入输出语句:
**alert(msg)*浏览器弹出警告框;属于浏览器
**console.log(msg)*浏览器控制台打印输出信息;属于浏览器
**prompt(info)*浏览器弹出输入框,用户可以输入;属于浏览器
代码示例:
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序测试用的
console.log('我是程序员能看到的');
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序员测试用的
console.log('我是程序员能看到的'); 查看全部
抓取ajax动态网页java(1.初识JavaScript1.1历史1.2JavaScript导读
)
JavaScript 的第一次介绍1.JavaScript 的介绍1.1 JavaScript 的历史1.2 JavaScript 是什么
JavaScript 是世界上最流行的语言之一。它是一种运行在客户端的脚本语言(Script 表示脚本)
脚本语言:无需编译,js解释器(js引擎)运行时会逐行解释执行
1.3 JavaScript 的作用
1.表单动态验证(密码强度检测)(JS生成的初衷)
2.网页特效
3.服务端开发(Node.js)
4.桌面程序(电子)
5.App(Cordova)
6.控制插件——物联网(Ruff)
7.游戏开发(cocos2d-js)
1.4 HTML/CSS/JS 关系
HTML/CSS 标记语言-描述语言
HTML决定网页的结构和内容(决定看什么),相当于人体
CSS决定了网页给用户的外观(决定好看与否),相当于给人们穿衣打扮
JS 脚本语言-编程语言
实现业务逻辑和页面控制(决策功能),相当于各种人工操作
1.4 浏览器执行JS介绍
浏览器分为渲染引擎和JS引擎两部分
渲染引擎:用于解析HTML和CSS,俗称内核,比如chrome浏览器的blink和老版本的wekit
JS引擎:又称JS解释器,用于读取网页中的JavaScript代码,处理后运行,如chrome浏览器的V8
浏览器本身并不执行JS代码,而是通过内置的JavaScript引擎(解释器)来执行JS代码。 JS引擎通过逐行解释每个源代码(转换成机器语言)来执行代码,然后有计算机去执行,所以JavaScript语言被归类为脚本语言,会被逐行解释执行.
1.5 JS的组成
JavaScript:
ECMAScript(JavaScript 语法),
DOM(页面文档对象模型),
BOM(浏览器对象模型)
1.ECMAScript
是 ECMA International(前身为欧洲计算机制造商协会)标准化的一种编程语言。这种语言在万维网上被广泛使用。它通常被称为 JavaScript 或 JScript,但实际上后两者是 ECMAScript 语言的实现和扩展
ECMAScript:JavaScript (Netscape)、Jscript (Microsoft)
ECMAScript:ECMAScript规定了JS的编程语法和基础核心知识,是所有浏览器厂商都遵守的一套JS语法行业标准
2.DOM——文档对象模型
文档对象模型(简称DOM)是W3C组织推荐的处理可扩展标记语言的标准编程接口。通过DOM提供的界面,可以操作页面上的各种元素(大小、位置、颜色等)。
3.BOM——浏览器对象模型
BOM(Browser Object Model,简称BOM)指的是浏览器对象模型。它提供了一个独立于内容并且可以与浏览器窗口交互的对象结构。可以通过BOM操作的浏览器窗口,如弹窗、控制浏览器跳转、获取分辨率等
1.6 JS初体验
JS 有 3 个书写位置,分别是 inline、inline 和 external
1.内联JS
可以在HTML标签的event属性(以on开头的属性)中写一行或少量的JS代码,如:onclick;
注意单双引号的使用:HTML中推荐使用双引号,JS中推荐使用单引号;
可读性差。 Abin在html中写了很多js代码,不方便阅读;
引号容易出错,多级嵌套和匹配引号时很容易混淆;
特殊情况下使用;
2.嵌入式JS
可以写多行JS代码
嵌入式JS是一种常见的学习方式
3.外部JS文件
有利于HTML页面代码的结构化,将大段JS代码从HTML页面中分离出来,既美观又方便文件级复用
引用外部JS文件的script标签不能写代码
适用于JS代码量比较大的情况
2.JS 评论
// 单行注释:ctrl + /
/*
1.多行注释 HBuilder X 默认快捷键 shift + ctrl + /
2.多行注释 VScode中修改多行注释的快捷键:ctrl + shift + /
*/
3.JavaScript 输入输出语句
为了方便信息的输入输出,JS提供了一些输入输出语句:
**alert(msg)*浏览器弹出警告框;属于浏览器
**console.log(msg)*浏览器控制台打印输出信息;属于浏览器
**prompt(info)*浏览器弹出输入框,用户可以输入;属于浏览器
代码示例:
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序测试用的
console.log('我是程序员能看到的');
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序员测试用的
console.log('我是程序员能看到的');
抓取ajax动态网页java(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-28 12:42
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在,越来越多的网页使用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
抓取ajax动态网页java(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在,越来越多的网页使用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
抓取ajax动态网页java(,ajax动态加载的网页并提取网页信息(需进行) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-25 03:10
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$ 查看全部
抓取ajax动态网页java(,ajax动态加载的网页并提取网页信息(需进行)
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$
抓取ajax动态网页java(实现成果实现思路我主要是借鉴了博客的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 23:22
取得成果
实现思路
我主要借鉴了这个博客的想法
让我简要描述一下他的想法。他的前端使用ajax异步请求。一种用于获取冗长的数据。比如我要在后台运行一千个统计,这需要很长时间。另一种是周期性的ajax。每隔一段时间去后台访问一下数据。后台巧妙的部分是打开一个全局变量来存储程序的运行状态。伪代码如下
全局变量s
主函数(前端请求这个链接需要比较长的时间才能返回数据):
s=0
''''
后台处理数据
''''
s=10
''''
后台处理数据
''''
如此重复
最后返回数据的时候s=100
辅助函数:
返回s的值
这是他的实现思路,就是通过全局变量来检测主函数,告知辅助函数主函数跑了哪一步。
两个ajxa用的很巧妙,很简单的实现方式
他山的石头可以用来做玉
他想法的问题是没有考虑并发,同一个全局变量s不能在多个用户下使用。
我的想法之一
众所周知,每个用户都有一个独立的会话,那么把这个全局变量保存在会话中就可以了,互不干扰。
思路肯定没问题,但是被ajax机制坑了。ajax异步请求的时候,不执行后台函数的情况下是无法更新session的。这导致辅助功能无法访问尚未完成主功能的会话。
我的第二个想法
然后会话不起作用。我只是将全局变量更改为地图。前端的两个ajax在访问后台的时候,带了一个过去的随机数,作为map的key,全局变量作为map的value,这样随机数之间的冲突就很小了。可以,后台执行进度可以并发访问
前端伪代码
ajax1:
异步访问主函数
传递一个随机数seed
等待数据返回并显示
杀死定时器
定时器:
ajax2:
异步访问辅助函数
传递一个随机数seed
拿到后台map中的全局变量
更改进度条显示为全局遍历的值
使用flask框架踩到的一些坑
一、开启flask的多线程
第二阶段是单线程,前端异步访问,后端在处理main函数的时候没时间考虑辅助函数。
app.run(debug=True, threaded=True)
对于前端表单,JavaScript处理完后返回false,否则JavaScript会一次提交到后端,html表单再次提交。. .
在前端表单表单中设置pattern值后,先由JavaScript处理click事件,然后再处理pattern。因此,JavaScript 也必须正则匹配。如果成功,它将返回false。如果失败,它将返回true。图案被处理。输入标签自带前端提示 查看全部
抓取ajax动态网页java(实现成果实现思路我主要是借鉴了博客的思路)
取得成果

实现思路
我主要借鉴了这个博客的想法
让我简要描述一下他的想法。他的前端使用ajax异步请求。一种用于获取冗长的数据。比如我要在后台运行一千个统计,这需要很长时间。另一种是周期性的ajax。每隔一段时间去后台访问一下数据。后台巧妙的部分是打开一个全局变量来存储程序的运行状态。伪代码如下
全局变量s
主函数(前端请求这个链接需要比较长的时间才能返回数据):
s=0
''''
后台处理数据
''''
s=10
''''
后台处理数据
''''
如此重复
最后返回数据的时候s=100
辅助函数:
返回s的值
这是他的实现思路,就是通过全局变量来检测主函数,告知辅助函数主函数跑了哪一步。
两个ajxa用的很巧妙,很简单的实现方式
他山的石头可以用来做玉
他想法的问题是没有考虑并发,同一个全局变量s不能在多个用户下使用。
我的想法之一
众所周知,每个用户都有一个独立的会话,那么把这个全局变量保存在会话中就可以了,互不干扰。
思路肯定没问题,但是被ajax机制坑了。ajax异步请求的时候,不执行后台函数的情况下是无法更新session的。这导致辅助功能无法访问尚未完成主功能的会话。
我的第二个想法
然后会话不起作用。我只是将全局变量更改为地图。前端的两个ajax在访问后台的时候,带了一个过去的随机数,作为map的key,全局变量作为map的value,这样随机数之间的冲突就很小了。可以,后台执行进度可以并发访问
前端伪代码
ajax1:
异步访问主函数
传递一个随机数seed
等待数据返回并显示
杀死定时器
定时器:
ajax2:
异步访问辅助函数
传递一个随机数seed
拿到后台map中的全局变量
更改进度条显示为全局遍历的值
使用flask框架踩到的一些坑
一、开启flask的多线程
第二阶段是单线程,前端异步访问,后端在处理main函数的时候没时间考虑辅助函数。
app.run(debug=True, threaded=True)
对于前端表单,JavaScript处理完后返回false,否则JavaScript会一次提交到后端,html表单再次提交。. .
在前端表单表单中设置pattern值后,先由JavaScript处理click事件,然后再处理pattern。因此,JavaScript 也必须正则匹配。如果成功,它将返回false。如果失败,它将返回true。图案被处理。输入标签自带前端提示
抓取ajax动态网页java(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-23 16:12
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面中找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了,把你写的js代码解析一下,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后的驱动的状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对这一点有很深的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取收录动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。需要说明一点:phantomjs端的js代码一定不能有语法错误,否则java端等待js代码编译不一样,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么要说的,欢迎大家讨论,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
抓取ajax动态网页java(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面中找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。

以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了,把你写的js代码解析一下,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后的驱动的状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对这一点有很深的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取收录动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码

在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。需要说明一点:phantomjs端的js代码一定不能有语法错误,否则java端等待js代码编译不一样,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么要说的,欢迎大家讨论,因为我确实没有找到稳定爬虫结果的相关资料。
抓取ajax动态网页java(使用RSelenium包和Rwebdriver包都包的前期准备步骤及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-22 02:16
在pm2.5地图数据展示文章的R实现中,使用rvest包实现静态页面的数据抓取,但是rvest只能抓取静态网页,比如异步ajax加载动态网页结构无能为力。在R语言中,可以使用RSelenium包和Rwebdriver包来爬取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包直接从CRAN下载安装,Rwebdriver包需要从github下载。下载过程参考install_github无法安装Rwebdriver包的解决方法
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、 JDK 下载
本文档下载最新版本的jdk-11.0.1_windows-x64_bin.zip
2、JDK 安装
由于下载的是不需要安装的版本,直接解压文件放在D:\Program Files\java目录下。
3、环境变量设置(参考Java环境变量设置)
需要设置JAVA_HOME、CLASS_PATH、PATH三个环境变量
JAVA_HOME
D:\Program Files\java\jdk-11.0.1
类路径
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
路径
%JAVA_HOME%\bin
设置三个环境变量后,打开cmd,输入javac。如果没有报错,则安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
下载最新版本,也可以去下载以前的版本。
2、下载浏览器驱动
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
本环境下下载的是最新版v2.44
3、打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以输入java -Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.141.59.罐子
如果出现下图所示的界面,则启动成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、到此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例
<p>library(RSelenium)
remDr 查看全部
抓取ajax动态网页java(使用RSelenium包和Rwebdriver包都包的前期准备步骤及步骤)
在pm2.5地图数据展示文章的R实现中,使用rvest包实现静态页面的数据抓取,但是rvest只能抓取静态网页,比如异步ajax加载动态网页结构无能为力。在R语言中,可以使用RSelenium包和Rwebdriver包来爬取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包直接从CRAN下载安装,Rwebdriver包需要从github下载。下载过程参考install_github无法安装Rwebdriver包的解决方法
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、 JDK 下载
本文档下载最新版本的jdk-11.0.1_windows-x64_bin.zip
2、JDK 安装
由于下载的是不需要安装的版本,直接解压文件放在D:\Program Files\java目录下。
3、环境变量设置(参考Java环境变量设置)
需要设置JAVA_HOME、CLASS_PATH、PATH三个环境变量
JAVA_HOME
D:\Program Files\java\jdk-11.0.1
类路径
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
路径
%JAVA_HOME%\bin
设置三个环境变量后,打开cmd,输入javac。如果没有报错,则安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
下载最新版本,也可以去下载以前的版本。
2、下载浏览器驱动
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
本环境下下载的是最新版v2.44
3、打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以输入java -Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.141.59.罐子

如果出现下图所示的界面,则启动成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。

四、到此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例
<p>library(RSelenium)
remDr
抓取ajax动态网页java(北京大学介绍如何解决ajax动态加载页面的问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-15 05:12
1、遇到的问题描述
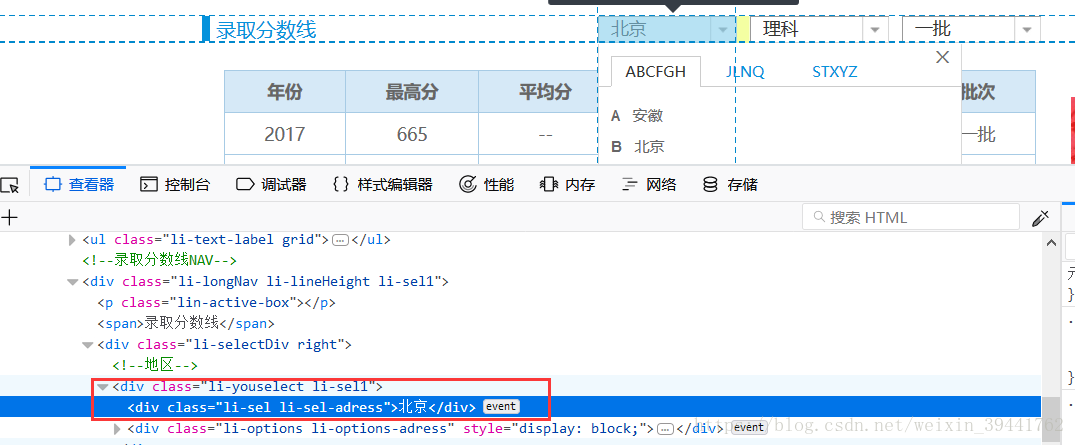
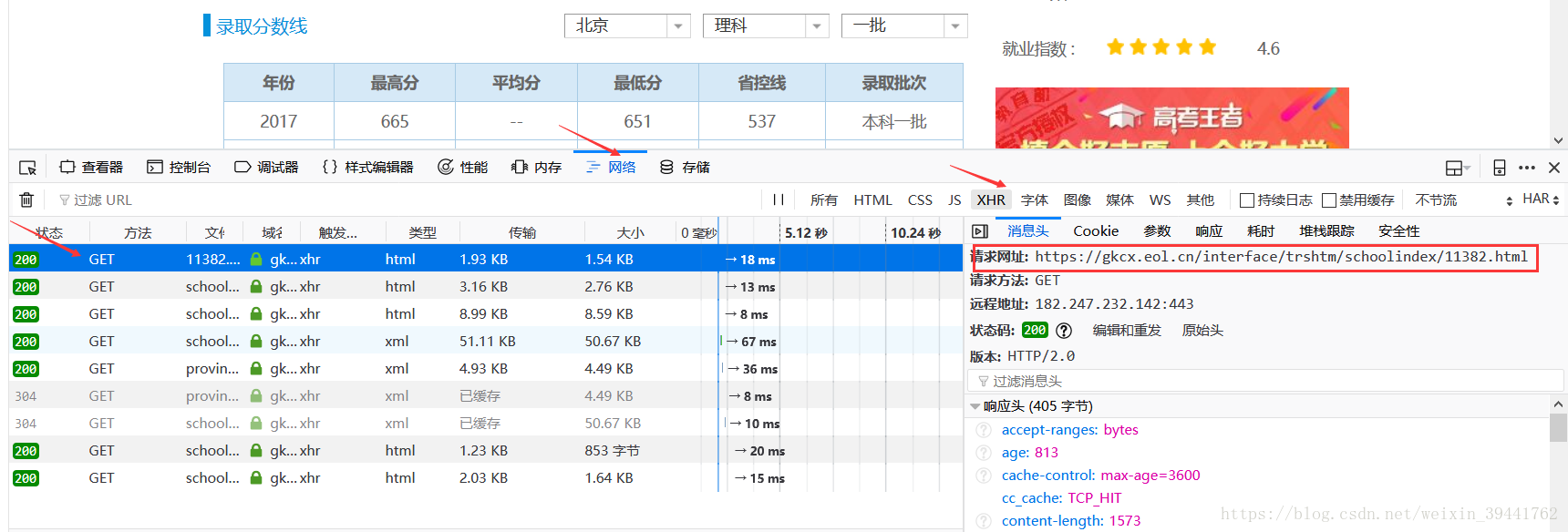
最近需要爬取网站中的一个内容。网页中的内容有下拉选项,如图:
笔者一直以为这是一个下拉框选项,打开网页的“视图元素”,如下图:
作者搜索的下拉框中没有选项。我很困惑。在我意识到这是一个Ajax动态加载页面之前,我向其他人描述了这个问题。于是我去搜集资料解决问题。
2、问题解决
搜了一篇《通过Ajax动态加载页面(实时监控华尔街新闻和新闻)(url:)》的文章,介绍了ajax动态加载页面。用户每次发送请求时,页面都会不时发生变化,但其 URL 不会发生变化。接下来我自己来抓一把:在中国教育在线,以北大不同学科、不同批次的各省录取分数线为例,介绍如何解决ajax动态加载页面的问题。
打开网页--->'查看元素'--->'网络'--->刷新页面:
在这张图片中,点击左栏可以找到你需要的信息。在右栏中,您可以获取相应的网页源 URL 和响应头信息。可以从请求 URL 中获取作者需要的内容:
图中的网站,北京大学,向该网站查询了北京一批理科录取分数线。发现网站上的数字是有规律的,于是修改了网站上的数字,得到了外省的录取分数线。
3、 根据规则抓取网页
剩下的部分是静态页面获取和提取需要的信息。当然,除了发现 URL 规则和修改规则之外,还有一种发送请求响应的方式。这部分笔者不做解释,有兴趣的读者自行查找资料。 查看全部
抓取ajax动态网页java(北京大学介绍如何解决ajax动态加载页面的问题(图))
1、遇到的问题描述
最近需要爬取网站中的一个内容。网页中的内容有下拉选项,如图:
笔者一直以为这是一个下拉框选项,打开网页的“视图元素”,如下图:
作者搜索的下拉框中没有选项。我很困惑。在我意识到这是一个Ajax动态加载页面之前,我向其他人描述了这个问题。于是我去搜集资料解决问题。
2、问题解决
搜了一篇《通过Ajax动态加载页面(实时监控华尔街新闻和新闻)(url:)》的文章,介绍了ajax动态加载页面。用户每次发送请求时,页面都会不时发生变化,但其 URL 不会发生变化。接下来我自己来抓一把:在中国教育在线,以北大不同学科、不同批次的各省录取分数线为例,介绍如何解决ajax动态加载页面的问题。
打开网页--->'查看元素'--->'网络'--->刷新页面:
在这张图片中,点击左栏可以找到你需要的信息。在右栏中,您可以获取相应的网页源 URL 和响应头信息。可以从请求 URL 中获取作者需要的内容:

图中的网站,北京大学,向该网站查询了北京一批理科录取分数线。发现网站上的数字是有规律的,于是修改了网站上的数字,得到了外省的录取分数线。
3、 根据规则抓取网页
剩下的部分是静态页面获取和提取需要的信息。当然,除了发现 URL 规则和修改规则之外,还有一种发送请求响应的方式。这部分笔者不做解释,有兴趣的读者自行查找资料。
抓取ajax动态网页java(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 04:01
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种会更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能会提前在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望做的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=> 构建链接=> 下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取ajax动态网页java(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种会更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以为js渲染。

在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……

对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能会提前在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望做的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=> 构建链接=> 下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取ajax动态网页java(完善转盘抽奖,实现从后台jsp页面生成随机数,以随机抽奖 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 04:01
)
【今日任务一】:
改进转盘抽奖,实现从后台jsp页面生成随机数,然后使用ajax获取随机数实现随机抽奖。
之前学过一点ajax,只是在看书,把原生代码和jQuery代码都看了,还做了笔记,但是今天想完成这个任务的时候,却无从下手!!!感觉宝宝好苦。于是查了资料,又看了书,又查了N个网页,一上午都不知道怎么弄的。后来,是主人吩咐的,这才恍然大悟。其实代码和原理都很简单。接下来说说我自己的学习过程和理解。
在这里,我仍然使用 jQuery 库,明天我将使用原生 JavaScript 代码编译 ajax() 函数。
前端的HTML代码如下:
幸运大转盘-转盘转动-用CSS3实现
使用ajax的地方是“body-转盘”。我需要得到一个随机数来控制转盘的旋转角度。转盘的旋转是通过CSS3动画实现的。设置了6个奖项,使用了6个。关键帧控制旋转角度,具体CSS代码不再赘述。
接下来是js代码
function luck(){
var index = "";
$.ajax({
type:"GET",
url: "/luck.jsp",
dataType:"json",
success:function(data){
index = data.value;
}
});
var zhuanpan = document.getElementById("body-zhuanpan");
switch(index){
case "1":
zhuanpan.style.animation = "2s one forwards";
setTimeout(function(){alert("1等奖");},2000);
break;
case "2":
zhuanpan.style.animation = "2s two forwards";
setTimeout(function(){alert("2等奖");},2000);
break;
case "3":
zhuanpan.style.animation = "2s three forwards";
setTimeout(function(){alert("3等奖");},2000);
break;
case "4":
zhuanpan.style.animation = "2s four forwards";
setTimeout(function(){alert("4等奖");},2000);
break;
case "5":
zhuanpan.style.animation = "2s five forwards";
setTimeout(function(){alert("5等奖");},2000);
break;
default:
zhuanpan.style.animation = "2s zero forwards";
setTimeout(function(){alert("谢谢参与");},2000);
}
}
var btn = document.getElementById("button");
btn.addEventListener("click",function(){
luck();
},false);
我用的是jQuery的ajax()函数,后台请求页面是luck.jsp
运气.jsp如下:
{
"value": (int)(Math.random()*10)
}
使用json存储数据,调用random()生成随机数。
我不太明白之前发生了什么。现在让我们谈谈整个逻辑。当我点击“btn”按钮时,会调用luck()函数,这个函数中有ajax请求。这时候我会访问url指向的后台页面luck.jsp。请求成功后,会以json格式返回luck.jsp里面的数据,即success函数的参数数据。data.value 是后台页面生成的随机数。我将此随机数分配给索引以使转盘随机旋转。
【任务二】:使用ajax将数据从前端表单传输到后端jsp,然后将数据保存到数据库中。
任务1其实挺简单的,只要明白前后的逻辑,就很容易理解了。但是听到任务二的时候,宝宝又晕了过去。我只是觉得我掌握了 Ajax,但我突然觉得它是什么!!后来查了一些网页,在师父的指导下,终于弄明白了。
前端有这样一个div,里面有两个文本框。当我点击按钮时,需要将文本框的内容通过ajax传递给后台jsp页面db.jsp。
我的js代码如下:
$("#submit-button").click(function(){
$.ajax({
type:"get",
url:"/lucky/db.jsp",
dataType:"json",
data:{
qq:$("#qq").val(),
phone:$("#phone").val()
},
success:function(obj){
console.log(obj)
}
});
});
在ajax()方法中,有一个json格式的数据,用于获取页面文本框中输入的内容。后台页面db.jsp可以通过访问这个json中的值来获取你想要的参数。
db.jsp 如下:
这样,qqNum中存放的就是页面文本框中数据的内容。
通过ajax数据获取页面表单的数据,然后通过ajax将数据传递给url指向的后台页面,在后台页面中可以获取到相应的参数。
其实我之前没有用ajax的时候,jsp页面也是可以获取到表单数据的。当时我用的是表单的动作。与ajax的区别在于:
如果为表单指定了一个动作,点击提交按钮后,页面会跳转到该动作指向的页面,当前页面不存在,ajax会停留在当前页面不跳转。但是数据也已经转移到后台jsp了,可以继续数据库操作了。
今天出现的错误:
1、 把switch函数放在ajax请求之外,这样每次索引都为空,因为ajax是异步请求,需要时间,所以如果代码顺序执行,索引不会得到值,它永远是空的。.
更正:把switch函数放在成功回调函数中,这样索引就可以拿到值了
2、写luck.jsp时,没有包引入,包引入方法:
3、ajax() 中的 url 错误。 查看全部
抓取ajax动态网页java(完善转盘抽奖,实现从后台jsp页面生成随机数,以随机抽奖
)
【今日任务一】:
改进转盘抽奖,实现从后台jsp页面生成随机数,然后使用ajax获取随机数实现随机抽奖。
之前学过一点ajax,只是在看书,把原生代码和jQuery代码都看了,还做了笔记,但是今天想完成这个任务的时候,却无从下手!!!感觉宝宝好苦。于是查了资料,又看了书,又查了N个网页,一上午都不知道怎么弄的。后来,是主人吩咐的,这才恍然大悟。其实代码和原理都很简单。接下来说说我自己的学习过程和理解。
在这里,我仍然使用 jQuery 库,明天我将使用原生 JavaScript 代码编译 ajax() 函数。
前端的HTML代码如下:
幸运大转盘-转盘转动-用CSS3实现
使用ajax的地方是“body-转盘”。我需要得到一个随机数来控制转盘的旋转角度。转盘的旋转是通过CSS3动画实现的。设置了6个奖项,使用了6个。关键帧控制旋转角度,具体CSS代码不再赘述。
接下来是js代码
function luck(){
var index = "";
$.ajax({
type:"GET",
url: "/luck.jsp",
dataType:"json",
success:function(data){
index = data.value;
}
});
var zhuanpan = document.getElementById("body-zhuanpan");
switch(index){
case "1":
zhuanpan.style.animation = "2s one forwards";
setTimeout(function(){alert("1等奖");},2000);
break;
case "2":
zhuanpan.style.animation = "2s two forwards";
setTimeout(function(){alert("2等奖");},2000);
break;
case "3":
zhuanpan.style.animation = "2s three forwards";
setTimeout(function(){alert("3等奖");},2000);
break;
case "4":
zhuanpan.style.animation = "2s four forwards";
setTimeout(function(){alert("4等奖");},2000);
break;
case "5":
zhuanpan.style.animation = "2s five forwards";
setTimeout(function(){alert("5等奖");},2000);
break;
default:
zhuanpan.style.animation = "2s zero forwards";
setTimeout(function(){alert("谢谢参与");},2000);
}
}
var btn = document.getElementById("button");
btn.addEventListener("click",function(){
luck();
},false);
我用的是jQuery的ajax()函数,后台请求页面是luck.jsp
运气.jsp如下:
{
"value": (int)(Math.random()*10)
}
使用json存储数据,调用random()生成随机数。
我不太明白之前发生了什么。现在让我们谈谈整个逻辑。当我点击“btn”按钮时,会调用luck()函数,这个函数中有ajax请求。这时候我会访问url指向的后台页面luck.jsp。请求成功后,会以json格式返回luck.jsp里面的数据,即success函数的参数数据。data.value 是后台页面生成的随机数。我将此随机数分配给索引以使转盘随机旋转。
【任务二】:使用ajax将数据从前端表单传输到后端jsp,然后将数据保存到数据库中。
任务1其实挺简单的,只要明白前后的逻辑,就很容易理解了。但是听到任务二的时候,宝宝又晕了过去。我只是觉得我掌握了 Ajax,但我突然觉得它是什么!!后来查了一些网页,在师父的指导下,终于弄明白了。
前端有这样一个div,里面有两个文本框。当我点击按钮时,需要将文本框的内容通过ajax传递给后台jsp页面db.jsp。
我的js代码如下:
$("#submit-button").click(function(){
$.ajax({
type:"get",
url:"/lucky/db.jsp",
dataType:"json",
data:{
qq:$("#qq").val(),
phone:$("#phone").val()
},
success:function(obj){
console.log(obj)
}
});
});
在ajax()方法中,有一个json格式的数据,用于获取页面文本框中输入的内容。后台页面db.jsp可以通过访问这个json中的值来获取你想要的参数。
db.jsp 如下:
这样,qqNum中存放的就是页面文本框中数据的内容。
通过ajax数据获取页面表单的数据,然后通过ajax将数据传递给url指向的后台页面,在后台页面中可以获取到相应的参数。
其实我之前没有用ajax的时候,jsp页面也是可以获取到表单数据的。当时我用的是表单的动作。与ajax的区别在于:
如果为表单指定了一个动作,点击提交按钮后,页面会跳转到该动作指向的页面,当前页面不存在,ajax会停留在当前页面不跳转。但是数据也已经转移到后台jsp了,可以继续数据库操作了。
今天出现的错误:
1、 把switch函数放在ajax请求之外,这样每次索引都为空,因为ajax是异步请求,需要时间,所以如果代码顺序执行,索引不会得到值,它永远是空的。.
更正:把switch函数放在成功回调函数中,这样索引就可以拿到值了
2、写luck.jsp时,没有包引入,包引入方法:
3、ajax() 中的 url 错误。
抓取ajax动态网页java(AjaxtooltipJS是一个简单好用的javascript程序实例的截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-12 18:04
Ajax tooltip JS是一个简单易用的javascript程序,当鼠标移动到连接上时,可以从后台动态获取相关提示信息;在一些需要通过链接文本提供更详细信息,甚至包括统计信息的应用中,从后台动态获取相关数据可能会更加高效,同时也能给用户带来更好的可用性。而且Ajax tooltip JS的提示框也做得非常简洁优雅。(请看文末它的项目网站demo 示例截图)
使用说明:
1. 到 下载 ajax-tooltip.zip 文件。
2. 解压zip文件,将arrow.gif放入你的web目录下的images等文件夹中;将ajax-tooltip.js脚本文件和ajax-添加到要动态显示内容的页面的标签中tooltip.css样式文件;类似于以下内容:
<br /><br /><br />
3. 调用连接文本中的ajaz-tooltip函数:
<br />查看提示<br />
这里的“viewDynamicTip.html”请求可以从后台动态获取相关信息,然后以文本形式返回给浏览器,通过ajax-tooltip提供的功能展示给用户。 查看全部
抓取ajax动态网页java(AjaxtooltipJS是一个简单好用的javascript程序实例的截图)
Ajax tooltip JS是一个简单易用的javascript程序,当鼠标移动到连接上时,可以从后台动态获取相关提示信息;在一些需要通过链接文本提供更详细信息,甚至包括统计信息的应用中,从后台动态获取相关数据可能会更加高效,同时也能给用户带来更好的可用性。而且Ajax tooltip JS的提示框也做得非常简洁优雅。(请看文末它的项目网站demo 示例截图)
使用说明:
1. 到 下载 ajax-tooltip.zip 文件。
2. 解压zip文件,将arrow.gif放入你的web目录下的images等文件夹中;将ajax-tooltip.js脚本文件和ajax-添加到要动态显示内容的页面的标签中tooltip.css样式文件;类似于以下内容:
<br /><br /><br />
3. 调用连接文本中的ajaz-tooltip函数:
<br />查看提示<br />
这里的“viewDynamicTip.html”请求可以从后台动态获取相关信息,然后以文本形式返回给浏览器,通过ajax-tooltip提供的功能展示给用户。
抓取ajax动态网页java(看一个和动态网页的相关概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-12 16:27
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等。网页界面可以收录文本、图像、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式且快速的动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当您滚动鼠标滚轮时,网页将自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文本,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。 查看全部
抓取ajax动态网页java(看一个和动态网页的相关概念(一)_)
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等。网页界面可以收录文本、图像、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式且快速的动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当您滚动鼠标滚轮时,网页将自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:

除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文本,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:

或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。
抓取ajax动态网页java( Python即时网络爬虫GitHub源7,文档修改历史(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 22:02
Python即时网络爬虫GitHub源7,文档修改历史(组图))
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。我们将在未来添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1、Python即时网络爬虫:API说明
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-24: V1.0 查看全部
抓取ajax动态网页java(
Python即时网络爬虫GitHub源7,文档修改历史(组图))

1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:

3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下

4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。我们将在未来添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1、Python即时网络爬虫:API说明
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-24: V1.0
抓取ajax动态网页java(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-09 10:06
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压不会显示。上面的动态图片中也有演示。下载地址可以在 SeimiAgent 主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。 查看全部
抓取ajax动态网页java(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示

SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压不会显示。上面的动态图片中也有演示。下载地址可以在 SeimiAgent 主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
抓取ajax动态网页java(:现代社会互联网技术日新月异,论文摘要(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-28 16:15
ADissertationSubmittedinPartialFulfillmentoftheDegree ofMasterofEngineeringResearchandImplementofDistributedCrawlerSystemSupportingAJAXCandidate:通信&信息系统Supervisor:AssociateProfessorTanYunmengHuazhong科技大学 据我所知,本文不收录
任何个人或其他已发表的文本或研究成果。对本文的研究有贡献的个人和集体已在文章中明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期:年、月、日、
本人授权华中科技大学将本论文的全部或部分内容编入相关数据库进行检索,并通过影印、缩小或扫描等复印方式保存和编辑本论文。保密□,本授权书将在________解密后生效。本文不保密。(请在上框打“√”) 论文作者签名: 导师签名: 日期:年、月、日:年、月、日,华中科技大学 层出不穷,AJAX技术越来越受到开发者的青睐。该技术对传统的网络爬虫不友好,使用传统的网络爬虫方式获取内容是不完整的。所以,研究支持AJAX的网络爬虫系统具有重要的现实意义。本文首先调查了异步加载网页获取方式的国内外研究现状,阐述了其收录困难的原因,分析了目前爬取方案的优缺点,提出了一种调用浏览器界面进行请求和获取的方案。获取网页。其次,为了提高网络爬虫的效率,协调AJAX爬虫和静态网络爬虫的资源分配,本文提出了一种网络属性分类器的解决方案。该解决方案可以通过网页处理模块的主体来提取反馈并纠正分类结果。根据分类结果,使用不同的方法捕获不同的网页。
本文研究实现的支持AJAX的分布式爬虫系统可以采集异步加载的网页和普通静态页面,实现爬取任务的高效分配,为异步加载网页的爬取提供了一种新思路。系统测试结果表明,可以实现预期的功能,取得了良好的性能指标。关键词:分布式爬虫;阿贾克斯;动态加载;技术、产品已经出现。其中AJAX技术越来越受到软件开发者的青睐。但是,该技术对传统网络爬虫不友好,传统网络爬虫抓取的网页内容也很不完美。因此,研究支持AJAX的爬虫系统具有很大的实用意义。 查看全部
抓取ajax动态网页java(:现代社会互联网技术日新月异,论文摘要(组图))
ADissertationSubmittedinPartialFulfillmentoftheDegree ofMasterofEngineeringResearchandImplementofDistributedCrawlerSystemSupportingAJAXCandidate:通信&信息系统Supervisor:AssociateProfessorTanYunmengHuazhong科技大学 据我所知,本文不收录
任何个人或其他已发表的文本或研究成果。对本文的研究有贡献的个人和集体已在文章中明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期:年、月、日、
本人授权华中科技大学将本论文的全部或部分内容编入相关数据库进行检索,并通过影印、缩小或扫描等复印方式保存和编辑本论文。保密□,本授权书将在________解密后生效。本文不保密。(请在上框打“√”) 论文作者签名: 导师签名: 日期:年、月、日:年、月、日,华中科技大学 层出不穷,AJAX技术越来越受到开发者的青睐。该技术对传统的网络爬虫不友好,使用传统的网络爬虫方式获取内容是不完整的。所以,研究支持AJAX的网络爬虫系统具有重要的现实意义。本文首先调查了异步加载网页获取方式的国内外研究现状,阐述了其收录困难的原因,分析了目前爬取方案的优缺点,提出了一种调用浏览器界面进行请求和获取的方案。获取网页。其次,为了提高网络爬虫的效率,协调AJAX爬虫和静态网络爬虫的资源分配,本文提出了一种网络属性分类器的解决方案。该解决方案可以通过网页处理模块的主体来提取反馈并纠正分类结果。根据分类结果,使用不同的方法捕获不同的网页。
本文研究实现的支持AJAX的分布式爬虫系统可以采集异步加载的网页和普通静态页面,实现爬取任务的高效分配,为异步加载网页的爬取提供了一种新思路。系统测试结果表明,可以实现预期的功能,取得了良好的性能指标。关键词:分布式爬虫;阿贾克斯;动态加载;技术、产品已经出现。其中AJAX技术越来越受到软件开发者的青睐。但是,该技术对传统网络爬虫不友好,传统网络爬虫抓取的网页内容也很不完美。因此,研究支持AJAX的爬虫系统具有很大的实用意义。
抓取ajax动态网页java(详细说明Explain网站建设的重要程度显现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-28 16:15
详细解释
因为大家都知道搜索引擎会爬
网站建设的重要性日益凸显
网站建设不是盲目的,而是有条不紊的,一点一点的。针对用户体验,人性化的网站建设是网站质量非常重要的一步,所以找一家有实力、有创新的公司。沉阳网站制作公司很重要
网站建设不仅要从技术上做,更要从理念上做。人性化非常重要。
第一点是网站建设的整个导航需要人性化,要符合优化后的导航菜单。导航需要一目了然,一目了然,让客户可以自由点击返回。导航结构没有固定的样式,你可以自己设计。它简洁、清晰、大方。
第二点是网站首页不能有太多的图片或flash动画。当然,考虑到用户体验,一些必须加的地方也必须加,即双方比例相近,美感和优化同时进行。因为大家都知道,搜索引擎在抓取网站的时候,一般抓取的网站中的文字内容、图片或者动画,还是很难抓取到的。
第三点是整个网站的网页必须是静态页面。静态页面以htm,html域名结尾,有利于搜索引擎的抓取和优化。
在网站建设中,网站建设有一些技巧和技巧:
一、静态
以百度为首的搜索引擎不断更新算法和规则,他们要找的是静态网址链接。静态页面更有利于引擎的抓取和收录。站长也知道这个标题。动态链接位置不幸因为搜索引擎友好,容易陷入死循环,用户体验效果也很差。同时,动态链接位置给引擎一种不清楚的感觉,而静态位置清晰,所以网站页面只是静态的。
二、无效链接
网站由很多页面组成,每个页面都有对应的链接位置,每个网站的链接都是一样的。如果网站内容中有两个或两个以上不同的链接,沉阳建站百度只会点击其中一个链接。来评价一下,因为不同的链接是相同的内容,会对网站产生负面影响。这样会分散页面的权重,排名结果也不好,影响整个网站的权重。
三、空页
网站的空页是偶尔出现的页面,搜索引擎会认为网站内部优化不到位。同时,沉阳网站建设会被搜索引擎删除大量重复的空页,影响相应的页面排名。对大量空页进行灌注的站长应该实时处理,否则对网站的成长来说是不走运的。
丹东网站建设丹东网站制作 查看全部
抓取ajax动态网页java(详细说明Explain网站建设的重要程度显现(图))
详细解释
因为大家都知道搜索引擎会爬
网站建设的重要性日益凸显
网站建设不是盲目的,而是有条不紊的,一点一点的。针对用户体验,人性化的网站建设是网站质量非常重要的一步,所以找一家有实力、有创新的公司。沉阳网站制作公司很重要
网站建设不仅要从技术上做,更要从理念上做。人性化非常重要。
第一点是网站建设的整个导航需要人性化,要符合优化后的导航菜单。导航需要一目了然,一目了然,让客户可以自由点击返回。导航结构没有固定的样式,你可以自己设计。它简洁、清晰、大方。
第二点是网站首页不能有太多的图片或flash动画。当然,考虑到用户体验,一些必须加的地方也必须加,即双方比例相近,美感和优化同时进行。因为大家都知道,搜索引擎在抓取网站的时候,一般抓取的网站中的文字内容、图片或者动画,还是很难抓取到的。
第三点是整个网站的网页必须是静态页面。静态页面以htm,html域名结尾,有利于搜索引擎的抓取和优化。
在网站建设中,网站建设有一些技巧和技巧:
一、静态
以百度为首的搜索引擎不断更新算法和规则,他们要找的是静态网址链接。静态页面更有利于引擎的抓取和收录。站长也知道这个标题。动态链接位置不幸因为搜索引擎友好,容易陷入死循环,用户体验效果也很差。同时,动态链接位置给引擎一种不清楚的感觉,而静态位置清晰,所以网站页面只是静态的。
二、无效链接
网站由很多页面组成,每个页面都有对应的链接位置,每个网站的链接都是一样的。如果网站内容中有两个或两个以上不同的链接,沉阳建站百度只会点击其中一个链接。来评价一下,因为不同的链接是相同的内容,会对网站产生负面影响。这样会分散页面的权重,排名结果也不好,影响整个网站的权重。
三、空页
网站的空页是偶尔出现的页面,搜索引擎会认为网站内部优化不到位。同时,沉阳网站建设会被搜索引擎删除大量重复的空页,影响相应的页面排名。对大量空页进行灌注的站长应该实时处理,否则对网站的成长来说是不走运的。
丹东网站建设丹东网站制作
抓取ajax动态网页java(谷歌搜索建议(GoogleSuggest)使用AJAX创造出动态性极强的web界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 04:27
AJAX 简介
AJAX 是一种无需重新加载整个网页即可更新网页的一部分的技术。
什么是 AJAX?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
AJAX在后台与服务器交换少量数据,从而实现网页的异步更新。这意味着可以在不重新加载整个页面的情况下更新网页的某些部分。
如果需要更新传统网页的内容(不使用 AJAX),则必须重新加载整个页面。
有许多使用 AJAX 的应用程序示例:Google Maps、Gmail、Youtube 和 Facebook。
AJAX 的工作原理
AJAX 基于 Internet 标准
AJAX 基于 Internet 标准并使用以下技术组合:
AJAX 应用与浏览器和平台无关!
谷歌建议
随着 2005 年 Google 的搜索建议功能的发布,AJAX 开始流行。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中键入时,JavaScript 会将字符发送到服务器,服务器将返回建议列表。
立即开始使用 AJAX
在我们的 PHP 教程中,我们将演示 AJAX 如何在不重新加载整个页面的情况下更新网页的某些部分。服务器脚本将用 PHP 编写。
如果您想了解有关 AJAX 的更多信息,请访问我们的 AJAX 教程。 查看全部
抓取ajax动态网页java(谷歌搜索建议(GoogleSuggest)使用AJAX创造出动态性极强的web界面)
AJAX 简介
AJAX 是一种无需重新加载整个网页即可更新网页的一部分的技术。
什么是 AJAX?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
AJAX在后台与服务器交换少量数据,从而实现网页的异步更新。这意味着可以在不重新加载整个页面的情况下更新网页的某些部分。
如果需要更新传统网页的内容(不使用 AJAX),则必须重新加载整个页面。
有许多使用 AJAX 的应用程序示例:Google Maps、Gmail、Youtube 和 Facebook。
AJAX 的工作原理
AJAX 基于 Internet 标准
AJAX 基于 Internet 标准并使用以下技术组合:
AJAX 应用与浏览器和平台无关!
谷歌建议
随着 2005 年 Google 的搜索建议功能的发布,AJAX 开始流行。
Google Suggest 使用 AJAX 创建高度动态的 Web 界面:当您在 Google 搜索框中键入时,JavaScript 会将字符发送到服务器,服务器将返回建议列表。
立即开始使用 AJAX
在我们的 PHP 教程中,我们将演示 AJAX 如何在不重新加载整个页面的情况下更新网页的某些部分。服务器脚本将用 PHP 编写。
如果您想了解有关 AJAX 的更多信息,请访问我们的 AJAX 教程。
抓取ajax动态网页java( 抓取结果如下:静态分析对动态分析的缺点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-20 21:22
抓取结果如下:静态分析对动态分析的缺点及解决办法)
<p style="text-align:center">
0x01 简介
随着Web 2.0的发展,页面中的AJAX也越来越多。由于传统爬虫依靠静态分析,不能准确的抓取到页面中的AJAX请求以及动态更新的内容,已经越来越不能满足需求。基于动态解析的Web 2.0爬虫应运而生,通过浏览器内核解析页面源码,模拟用户操作,能有效解决上述问题。本文将详细分析利用PhantomJS + Python 编写爬虫并进行去重的思路。
0x02 PhantomJS
PhantomJS 是无界面的 Webkit 解析器,提供了 JavaScript API 。由于去除了可视化界面,速度比一般 Webkit 浏览器要快很多。同时提供了很多监控和事件接口,可以方便的操作 DOM 节点,模拟用户操作等。
接下来我们通过一个简单的例子,来展示下动态爬虫和传统爬虫的区别。目标:加载一个页面,并且获取其中所有的 <a> 标签。 // example.js var page = require('webpage').create(); page.onAlert = function (message) { console.log(message); return true; }; page.onCallback = function() { page.evaluate(function(){ atags = document.getElementsByTagName("a"); for(var i=0;i 查看全部
抓取ajax动态网页java(
抓取结果如下:静态分析对动态分析的缺点及解决办法)
<p style="text-align:center">
0x01 简介
随着Web 2.0的发展,页面中的AJAX也越来越多。由于传统爬虫依靠静态分析,不能准确的抓取到页面中的AJAX请求以及动态更新的内容,已经越来越不能满足需求。基于动态解析的Web 2.0爬虫应运而生,通过浏览器内核解析页面源码,模拟用户操作,能有效解决上述问题。本文将详细分析利用PhantomJS + Python 编写爬虫并进行去重的思路。
0x02 PhantomJS
PhantomJS 是无界面的 Webkit 解析器,提供了 JavaScript API 。由于去除了可视化界面,速度比一般 Webkit 浏览器要快很多。同时提供了很多监控和事件接口,可以方便的操作 DOM 节点,模拟用户操作等。
接下来我们通过一个简单的例子,来展示下动态爬虫和传统爬虫的区别。目标:加载一个页面,并且获取其中所有的 <a> 标签。 // example.js var page = require('webpage').create(); page.onAlert = function (message) { console.log(message); return true; }; page.onCallback = function() { page.evaluate(function(){ atags = document.getElementsByTagName("a"); for(var i=0;i
抓取ajax动态网页java(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 03:22
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们的抓取和收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在Google爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、动态插入元数据和页面元素
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
等等
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释 网站 使用 AngularJS 框架和 HTML5 History API (pushState) 构建,可以渲染和 收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。例如,在加载到 DOM 后将获取图像并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想要测试 Google 如何响应出现在源代码和 DOM 之间的链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加了 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果将href="nofollow"的a元素插入到DOM中,nofollow和链接是同时插入的,所以会被跟踪。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是元标记,例如 rel 规范注释,无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(记住要允许 Google 爬虫获取那些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
抓取ajax动态网页java(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,谷歌显然不仅可以制定他们的抓取和收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在Google爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、动态插入元数据和页面元素
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您没有访问您的 网站 服务器的权限,您可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
等等
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释 网站 使用 AngularJS 框架和 HTML5 History API (pushState) 构建,可以渲染和 收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。例如,在加载到 DOM 后将获取图像并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想要测试 Google 如何响应出现在源代码和 DOM 之间的链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加了 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果将href="nofollow"的a元素插入到DOM中,nofollow和链接是同时插入的,所以会被跟踪。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是元标记,例如 rel 规范注释,无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。不可思议!(记住要允许 Google 爬虫获取那些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
抓取ajax动态网页java(说句大实话,请为我这么爱学习的新手点赞!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-19 03:07
老实说,以下都是百度的,请给我这样一个爱学习的新手点个赞!23333333
C语言是一种通用的计算机程序设计语言。虽然它的应用范围很广,但它接近底层,很难掌握操作符和操作顺序。不适合新手。
HTML 超文本标记语言:超文本是指可以收录图片、链接、音乐甚至程序等非文本元素的页面。结构主要包括网页(head)信息和网页具体内容(body),结合其他网页技术,如脚本语言、组件等,创建一个功能齐全的网页。既然是显示网页,自然要结合浏览器,但是对于不同的浏览器,同一个标签可能有不同的解释,所以显示效果也可能不同。
CSS,Cascading Style Sheet,是一种用于表达HTML或XML等文档样式的计算机语言,可以实现网页性能与内容的分离。与传统的 HTML 相比,CSS 可以更准确地控制网页中对象的位置和布局,并具有编辑网页对象和模型样式的能力。当然,还有其他功能。可以说是目前最优秀的基于文本显示的性能设计语言。具有很强的易读性。
JavaScript 是一种网络脚本语言,广泛用于 Web 应用程序开发。它在程序运行期间被解释和解释。比如我们经常看到的网页上的各种动态功能,都是用JS实现的。一般情况下,JavaScript 脚本通过嵌入 HTML 来实现其功能。
AJAX 是一种用于创建快速动态网页的技术。核心是JavaScript对象XMLHttpRequest,可以实现网页的异步更新。
C++是在C语言的基础上发展起来的面向对象的编程语言,在很多方面与C语言兼容。当然,这同样困难。
Java是一种面向对象的编程语言,看起来很像C++,但Java取其精华,去其糟粕。它功能强大且易于使用。(后端语言)
楼上的都建议新手考虑Python。其实这里也推荐学习Python,因为我也是新手。
我看到了一张照片,然后发了过来。
为了说得好不吵闹,PHP是世界上最好的语言。主题由你决定。 查看全部
抓取ajax动态网页java(说句大实话,请为我这么爱学习的新手点赞!)
老实说,以下都是百度的,请给我这样一个爱学习的新手点个赞!23333333
C语言是一种通用的计算机程序设计语言。虽然它的应用范围很广,但它接近底层,很难掌握操作符和操作顺序。不适合新手。
HTML 超文本标记语言:超文本是指可以收录图片、链接、音乐甚至程序等非文本元素的页面。结构主要包括网页(head)信息和网页具体内容(body),结合其他网页技术,如脚本语言、组件等,创建一个功能齐全的网页。既然是显示网页,自然要结合浏览器,但是对于不同的浏览器,同一个标签可能有不同的解释,所以显示效果也可能不同。
CSS,Cascading Style Sheet,是一种用于表达HTML或XML等文档样式的计算机语言,可以实现网页性能与内容的分离。与传统的 HTML 相比,CSS 可以更准确地控制网页中对象的位置和布局,并具有编辑网页对象和模型样式的能力。当然,还有其他功能。可以说是目前最优秀的基于文本显示的性能设计语言。具有很强的易读性。
JavaScript 是一种网络脚本语言,广泛用于 Web 应用程序开发。它在程序运行期间被解释和解释。比如我们经常看到的网页上的各种动态功能,都是用JS实现的。一般情况下,JavaScript 脚本通过嵌入 HTML 来实现其功能。
AJAX 是一种用于创建快速动态网页的技术。核心是JavaScript对象XMLHttpRequest,可以实现网页的异步更新。
C++是在C语言的基础上发展起来的面向对象的编程语言,在很多方面与C语言兼容。当然,这同样困难。
Java是一种面向对象的编程语言,看起来很像C++,但Java取其精华,去其糟粕。它功能强大且易于使用。(后端语言)
楼上的都建议新手考虑Python。其实这里也推荐学习Python,因为我也是新手。
我看到了一张照片,然后发了过来。
为了说得好不吵闹,PHP是世界上最好的语言。主题由你决定。
抓取ajax动态网页java(NutchNutchX版本实现请访问:基于ApacheNutch1.8和Htmlunit组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-04 07:04
-------------------------------------------------- -------------------------------------------------- ------提醒:项目当前版本不会更新。最新的Apache Nutch 2.X 版本实现请访问:---------------------- ----------- ------------------------------- ----------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 通过必要的动态 AJAX 请求来获取整个页面的内容。它是用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或重构源代码作为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已全部获取。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,在保留本项目源码信息,保证项目不会被非法出售的前提下,可以任何方式自由使用:开源、非开源、商业和非商业。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目: 查看全部
抓取ajax动态网页java(NutchNutchX版本实现请访问:基于ApacheNutch1.8和Htmlunit组件)
-------------------------------------------------- -------------------------------------------------- ------提醒:项目当前版本不会更新。最新的Apache Nutch 2.X 版本实现请访问:---------------------- ----------- ------------------------------- ----------- -----------------------Nutch Htmlunit Plugin项目介绍
基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容爬取分析。
根据Apache Nutch 1.8 的实现,我们无法从收录AJAX 请求的fetch 页面中获取动态HTML 信息,因为它会忽略所有AJAX 请求。
这个插件将使用 Htmlunit 通过必要的动态 AJAX 请求来获取整个页面的内容。它是用 Apache Nutch 1.8 开发和测试的,您可以在其他 Nutch 版本上试用它或重构源代码作为您的设计。
主要特点 跑步体验
由于Nutch基于Unix/Linux环境运行,请自行准备Unix/Linux系统或Cygwin运行环境。
git clone 整个项目代码后,进入到本地的git下载目录:
cd nutch-htmlunit/运行时/本地
bin/crawl urls crawl false 1
//urls参数为爬虫存放url文件目录;crawl 是爬虫输出目录;false应该是solr索引url参数,这里设置为false不做solr索引处理;1是爬虫执行次数
操作结束后,可以看到天猫商品页面的价格/描述/滚动加载图片等信息已全部获取。
运行日志输入示例参考:
扩展插件说明源码项目说明
整个项目基于Apache Nutch 1.8 源代码项目扩展插件实现。插件的定义和配置与官方插件处理方式一致。详情请参考Apache Nutch 1.8 官方文档。具体实现原理和代码请导入Eclipse项目查看。
开源许可说明
本项目所有代码完整开源,在保留本项目源码信息,保证项目不会被非法出售的前提下,可以任何方式自由使用:开源、非开源、商业和非商业。
如果您想提供基于Apache Nutch/Solr/Lucene等系列技术的定制化扩展实现/技术咨询服务/毕业设计指导/二次开发项目指导,可联系E-Mail:或(加Q请注明:nutch/ solr/lucene) 议价服务。【以上联系方式不直接提供免费技术咨询查询。如果您对项目有任何技术问题或issue反馈,请直接提交到项目站点提问或在Git平台上Issue]
参考
欢迎关注作者的其他项目:
抓取ajax动态网页java(1.初识JavaScript1.1历史1.2JavaScript导读 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-04 07:01
)
JavaScript 的第一次介绍1.JavaScript 的介绍1.1 JavaScript 的历史1.2 JavaScript 是什么
JavaScript 是世界上最流行的语言之一。它是一种运行在客户端的脚本语言(Script 表示脚本)
脚本语言:无需编译,js解释器(js引擎)运行时会逐行解释执行
1.3 JavaScript 的作用
1.表单动态验证(密码强度检测)(JS生成的初衷)
2.网页特效
3.服务端开发(Node.js)
4.桌面程序(电子)
5.App(Cordova)
6.控制插件——物联网(Ruff)
7.游戏开发(cocos2d-js)
1.4 HTML/CSS/JS 关系
HTML/CSS 标记语言-描述语言
HTML决定网页的结构和内容(决定看什么),相当于人体
CSS决定了网页给用户的外观(决定好看与否),相当于给人们穿衣打扮
JS 脚本语言-编程语言
实现业务逻辑和页面控制(决策功能),相当于各种人工操作
1.4 浏览器执行JS介绍
浏览器分为渲染引擎和JS引擎两部分
渲染引擎:用于解析HTML和CSS,俗称内核,比如chrome浏览器的blink和老版本的wekit
JS引擎:又称JS解释器,用于读取网页中的JavaScript代码,处理后运行,如chrome浏览器的V8
浏览器本身并不执行JS代码,而是通过内置的JavaScript引擎(解释器)来执行JS代码。 JS引擎通过逐行解释每个源代码(转换成机器语言)来执行代码,然后有计算机去执行,所以JavaScript语言被归类为脚本语言,会被逐行解释执行.
1.5 JS的组成
JavaScript:
ECMAScript(JavaScript 语法),
DOM(页面文档对象模型),
BOM(浏览器对象模型)
1.ECMAScript
是 ECMA International(前身为欧洲计算机制造商协会)标准化的一种编程语言。这种语言在万维网上被广泛使用。它通常被称为 JavaScript 或 JScript,但实际上后两者是 ECMAScript 语言的实现和扩展
ECMAScript:JavaScript (Netscape)、Jscript (Microsoft)
ECMAScript:ECMAScript规定了JS的编程语法和基础核心知识,是所有浏览器厂商都遵守的一套JS语法行业标准
2.DOM——文档对象模型
文档对象模型(简称DOM)是W3C组织推荐的处理可扩展标记语言的标准编程接口。通过DOM提供的界面,可以操作页面上的各种元素(大小、位置、颜色等)。
3.BOM——浏览器对象模型
BOM(Browser Object Model,简称BOM)指的是浏览器对象模型。它提供了一个独立于内容并且可以与浏览器窗口交互的对象结构。可以通过BOM操作的浏览器窗口,如弹窗、控制浏览器跳转、获取分辨率等
1.6 JS初体验
JS 有 3 个书写位置,分别是 inline、inline 和 external
1.内联JS
可以在HTML标签的event属性(以on开头的属性)中写一行或少量的JS代码,如:onclick;
注意单双引号的使用:HTML中推荐使用双引号,JS中推荐使用单引号;
可读性差。 Abin在html中写了很多js代码,不方便阅读;
引号容易出错,多级嵌套和匹配引号时很容易混淆;
特殊情况下使用;
2.嵌入式JS
可以写多行JS代码
嵌入式JS是一种常见的学习方式
3.外部JS文件
有利于HTML页面代码的结构化,将大段JS代码从HTML页面中分离出来,既美观又方便文件级复用
引用外部JS文件的script标签不能写代码
适用于JS代码量比较大的情况
2.JS 评论
// 单行注释:ctrl + /
/*
1.多行注释 HBuilder X 默认快捷键 shift + ctrl + /
2.多行注释 VScode中修改多行注释的快捷键:ctrl + shift + /
*/
3.JavaScript 输入输出语句
为了方便信息的输入输出,JS提供了一些输入输出语句:
**alert(msg)*浏览器弹出警告框;属于浏览器
**console.log(msg)*浏览器控制台打印输出信息;属于浏览器
**prompt(info)*浏览器弹出输入框,用户可以输入;属于浏览器
代码示例:
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序测试用的
console.log('我是程序员能看到的');
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序员测试用的
console.log('我是程序员能看到的'); 查看全部
抓取ajax动态网页java(1.初识JavaScript1.1历史1.2JavaScript导读
)
JavaScript 的第一次介绍1.JavaScript 的介绍1.1 JavaScript 的历史1.2 JavaScript 是什么
JavaScript 是世界上最流行的语言之一。它是一种运行在客户端的脚本语言(Script 表示脚本)
脚本语言:无需编译,js解释器(js引擎)运行时会逐行解释执行
1.3 JavaScript 的作用
1.表单动态验证(密码强度检测)(JS生成的初衷)
2.网页特效
3.服务端开发(Node.js)
4.桌面程序(电子)
5.App(Cordova)
6.控制插件——物联网(Ruff)
7.游戏开发(cocos2d-js)
1.4 HTML/CSS/JS 关系
HTML/CSS 标记语言-描述语言
HTML决定网页的结构和内容(决定看什么),相当于人体
CSS决定了网页给用户的外观(决定好看与否),相当于给人们穿衣打扮
JS 脚本语言-编程语言
实现业务逻辑和页面控制(决策功能),相当于各种人工操作
1.4 浏览器执行JS介绍
浏览器分为渲染引擎和JS引擎两部分
渲染引擎:用于解析HTML和CSS,俗称内核,比如chrome浏览器的blink和老版本的wekit
JS引擎:又称JS解释器,用于读取网页中的JavaScript代码,处理后运行,如chrome浏览器的V8
浏览器本身并不执行JS代码,而是通过内置的JavaScript引擎(解释器)来执行JS代码。 JS引擎通过逐行解释每个源代码(转换成机器语言)来执行代码,然后有计算机去执行,所以JavaScript语言被归类为脚本语言,会被逐行解释执行.
1.5 JS的组成
JavaScript:
ECMAScript(JavaScript 语法),
DOM(页面文档对象模型),
BOM(浏览器对象模型)
1.ECMAScript
是 ECMA International(前身为欧洲计算机制造商协会)标准化的一种编程语言。这种语言在万维网上被广泛使用。它通常被称为 JavaScript 或 JScript,但实际上后两者是 ECMAScript 语言的实现和扩展
ECMAScript:JavaScript (Netscape)、Jscript (Microsoft)
ECMAScript:ECMAScript规定了JS的编程语法和基础核心知识,是所有浏览器厂商都遵守的一套JS语法行业标准
2.DOM——文档对象模型
文档对象模型(简称DOM)是W3C组织推荐的处理可扩展标记语言的标准编程接口。通过DOM提供的界面,可以操作页面上的各种元素(大小、位置、颜色等)。
3.BOM——浏览器对象模型
BOM(Browser Object Model,简称BOM)指的是浏览器对象模型。它提供了一个独立于内容并且可以与浏览器窗口交互的对象结构。可以通过BOM操作的浏览器窗口,如弹窗、控制浏览器跳转、获取分辨率等
1.6 JS初体验
JS 有 3 个书写位置,分别是 inline、inline 和 external
1.内联JS
可以在HTML标签的event属性(以on开头的属性)中写一行或少量的JS代码,如:onclick;
注意单双引号的使用:HTML中推荐使用双引号,JS中推荐使用单引号;
可读性差。 Abin在html中写了很多js代码,不方便阅读;
引号容易出错,多级嵌套和匹配引号时很容易混淆;
特殊情况下使用;
2.嵌入式JS
可以写多行JS代码
嵌入式JS是一种常见的学习方式
3.外部JS文件
有利于HTML页面代码的结构化,将大段JS代码从HTML页面中分离出来,既美观又方便文件级复用
引用外部JS文件的script标签不能写代码
适用于JS代码量比较大的情况
2.JS 评论
// 单行注释:ctrl + /
/*
1.多行注释 HBuilder X 默认快捷键 shift + ctrl + /
2.多行注释 VScode中修改多行注释的快捷键:ctrl + shift + /
*/
3.JavaScript 输入输出语句
为了方便信息的输入输出,JS提供了一些输入输出语句:
**alert(msg)*浏览器弹出警告框;属于浏览器
**console.log(msg)*浏览器控制台打印输出信息;属于浏览器
**prompt(info)*浏览器弹出输入框,用户可以输入;属于浏览器
代码示例:
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序测试用的
console.log('我是程序员能看到的');
// 这是一个输入框
prompt('请你输入你的年龄');
// alert弹出警示框,输出的,展示给用户的
alert('计算的结果是');
// console控制台输出,给程序员测试用的
console.log('我是程序员能看到的');
抓取ajax动态网页java(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-28 12:42
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在,越来越多的网页使用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
抓取ajax动态网页java(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在,越来越多的网页使用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
抓取ajax动态网页java(,ajax动态加载的网页并提取网页信息(需进行) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-25 03:10
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$ 查看全部
抓取ajax动态网页java(,ajax动态加载的网页并提取网页信息(需进行)
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$
抓取ajax动态网页java(实现成果实现思路我主要是借鉴了博客的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 23:22
取得成果
实现思路
我主要借鉴了这个博客的想法
让我简要描述一下他的想法。他的前端使用ajax异步请求。一种用于获取冗长的数据。比如我要在后台运行一千个统计,这需要很长时间。另一种是周期性的ajax。每隔一段时间去后台访问一下数据。后台巧妙的部分是打开一个全局变量来存储程序的运行状态。伪代码如下
全局变量s
主函数(前端请求这个链接需要比较长的时间才能返回数据):
s=0
''''
后台处理数据
''''
s=10
''''
后台处理数据
''''
如此重复
最后返回数据的时候s=100
辅助函数:
返回s的值
这是他的实现思路,就是通过全局变量来检测主函数,告知辅助函数主函数跑了哪一步。
两个ajxa用的很巧妙,很简单的实现方式
他山的石头可以用来做玉
他想法的问题是没有考虑并发,同一个全局变量s不能在多个用户下使用。
我的想法之一
众所周知,每个用户都有一个独立的会话,那么把这个全局变量保存在会话中就可以了,互不干扰。
思路肯定没问题,但是被ajax机制坑了。ajax异步请求的时候,不执行后台函数的情况下是无法更新session的。这导致辅助功能无法访问尚未完成主功能的会话。
我的第二个想法
然后会话不起作用。我只是将全局变量更改为地图。前端的两个ajax在访问后台的时候,带了一个过去的随机数,作为map的key,全局变量作为map的value,这样随机数之间的冲突就很小了。可以,后台执行进度可以并发访问
前端伪代码
ajax1:
异步访问主函数
传递一个随机数seed
等待数据返回并显示
杀死定时器
定时器:
ajax2:
异步访问辅助函数
传递一个随机数seed
拿到后台map中的全局变量
更改进度条显示为全局遍历的值
使用flask框架踩到的一些坑
一、开启flask的多线程
第二阶段是单线程,前端异步访问,后端在处理main函数的时候没时间考虑辅助函数。
app.run(debug=True, threaded=True)
对于前端表单,JavaScript处理完后返回false,否则JavaScript会一次提交到后端,html表单再次提交。. .
在前端表单表单中设置pattern值后,先由JavaScript处理click事件,然后再处理pattern。因此,JavaScript 也必须正则匹配。如果成功,它将返回false。如果失败,它将返回true。图案被处理。输入标签自带前端提示 查看全部
抓取ajax动态网页java(实现成果实现思路我主要是借鉴了博客的思路)
取得成果
实现思路
我主要借鉴了这个博客的想法
让我简要描述一下他的想法。他的前端使用ajax异步请求。一种用于获取冗长的数据。比如我要在后台运行一千个统计,这需要很长时间。另一种是周期性的ajax。每隔一段时间去后台访问一下数据。后台巧妙的部分是打开一个全局变量来存储程序的运行状态。伪代码如下
全局变量s
主函数(前端请求这个链接需要比较长的时间才能返回数据):
s=0
''''
后台处理数据
''''
s=10
''''
后台处理数据
''''
如此重复
最后返回数据的时候s=100
辅助函数:
返回s的值
这是他的实现思路,就是通过全局变量来检测主函数,告知辅助函数主函数跑了哪一步。
两个ajxa用的很巧妙,很简单的实现方式
他山的石头可以用来做玉
他想法的问题是没有考虑并发,同一个全局变量s不能在多个用户下使用。
我的想法之一
众所周知,每个用户都有一个独立的会话,那么把这个全局变量保存在会话中就可以了,互不干扰。
思路肯定没问题,但是被ajax机制坑了。ajax异步请求的时候,不执行后台函数的情况下是无法更新session的。这导致辅助功能无法访问尚未完成主功能的会话。
我的第二个想法
然后会话不起作用。我只是将全局变量更改为地图。前端的两个ajax在访问后台的时候,带了一个过去的随机数,作为map的key,全局变量作为map的value,这样随机数之间的冲突就很小了。可以,后台执行进度可以并发访问
前端伪代码
ajax1:
异步访问主函数
传递一个随机数seed
等待数据返回并显示
杀死定时器
定时器:
ajax2:
异步访问辅助函数
传递一个随机数seed
拿到后台map中的全局变量
更改进度条显示为全局遍历的值
使用flask框架踩到的一些坑
一、开启flask的多线程
第二阶段是单线程,前端异步访问,后端在处理main函数的时候没时间考虑辅助函数。
app.run(debug=True, threaded=True)
对于前端表单,JavaScript处理完后返回false,否则JavaScript会一次提交到后端,html表单再次提交。. .
在前端表单表单中设置pattern值后,先由JavaScript处理click事件,然后再处理pattern。因此,JavaScript 也必须正则匹配。如果成功,它将返回false。如果失败,它将返回true。图案被处理。输入标签自带前端提示
抓取ajax动态网页java(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-23 16:12
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面中找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了,把你写的js代码解析一下,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后的驱动的状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对这一点有很深的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取收录动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。需要说明一点:phantomjs端的js代码一定不能有语法错误,否则java端等待js代码编译不一样,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么要说的,欢迎大家讨论,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
抓取ajax动态网页java(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,后来就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面中找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了,把你写的js代码解析一下,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个带界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后的驱动的状态,所以不需要使用Thread.sleep(2000)这样的不确定代码,可惜我找不到它。它真的让我感到难过。领域。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对这一点有很深的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取收录动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。需要说明一点:phantomjs端的js代码一定不能有语法错误,否则java端等待js代码编译不一样,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以结合使用Nutch和WebDirver,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么要说的,欢迎大家讨论,因为我确实没有找到稳定爬虫结果的相关资料。
抓取ajax动态网页java(使用RSelenium包和Rwebdriver包都包的前期准备步骤及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-22 02:16
在pm2.5地图数据展示文章的R实现中,使用rvest包实现静态页面的数据抓取,但是rvest只能抓取静态网页,比如异步ajax加载动态网页结构无能为力。在R语言中,可以使用RSelenium包和Rwebdriver包来爬取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包直接从CRAN下载安装,Rwebdriver包需要从github下载。下载过程参考install_github无法安装Rwebdriver包的解决方法
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、 JDK 下载
本文档下载最新版本的jdk-11.0.1_windows-x64_bin.zip
2、JDK 安装
由于下载的是不需要安装的版本,直接解压文件放在D:\Program Files\java目录下。
3、环境变量设置(参考Java环境变量设置)
需要设置JAVA_HOME、CLASS_PATH、PATH三个环境变量
JAVA_HOME
D:\Program Files\java\jdk-11.0.1
类路径
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
路径
%JAVA_HOME%\bin
设置三个环境变量后,打开cmd,输入javac。如果没有报错,则安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
下载最新版本,也可以去下载以前的版本。
2、下载浏览器驱动
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
本环境下下载的是最新版v2.44
3、打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以输入java -Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.141.59.罐子
如果出现下图所示的界面,则启动成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、到此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例
<p>library(RSelenium)
remDr 查看全部
抓取ajax动态网页java(使用RSelenium包和Rwebdriver包都包的前期准备步骤及步骤)
在pm2.5地图数据展示文章的R实现中,使用rvest包实现静态页面的数据抓取,但是rvest只能抓取静态网页,比如异步ajax加载动态网页结构无能为力。在R语言中,可以使用RSelenium包和Rwebdriver包来爬取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包直接从CRAN下载安装,Rwebdriver包需要从github下载。下载过程参考install_github无法安装Rwebdriver包的解决方法
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、 JDK 下载
本文档下载最新版本的jdk-11.0.1_windows-x64_bin.zip
2、JDK 安装
由于下载的是不需要安装的版本,直接解压文件放在D:\Program Files\java目录下。
3、环境变量设置(参考Java环境变量设置)
需要设置JAVA_HOME、CLASS_PATH、PATH三个环境变量
JAVA_HOME
D:\Program Files\java\jdk-11.0.1
类路径
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
路径
%JAVA_HOME%\bin
设置三个环境变量后,打开cmd,输入javac。如果没有报错,则安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
下载最新版本,也可以去下载以前的版本。
2、下载浏览器驱动
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
本环境下下载的是最新版v2.44
3、打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以输入java -Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.141.59.罐子
如果出现下图所示的界面,则启动成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、到此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例
<p>library(RSelenium)
remDr
抓取ajax动态网页java(北京大学介绍如何解决ajax动态加载页面的问题(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-15 05:12
1、遇到的问题描述
最近需要爬取网站中的一个内容。网页中的内容有下拉选项,如图:
笔者一直以为这是一个下拉框选项,打开网页的“视图元素”,如下图:
作者搜索的下拉框中没有选项。我很困惑。在我意识到这是一个Ajax动态加载页面之前,我向其他人描述了这个问题。于是我去搜集资料解决问题。
2、问题解决
搜了一篇《通过Ajax动态加载页面(实时监控华尔街新闻和新闻)(url:)》的文章,介绍了ajax动态加载页面。用户每次发送请求时,页面都会不时发生变化,但其 URL 不会发生变化。接下来我自己来抓一把:在中国教育在线,以北大不同学科、不同批次的各省录取分数线为例,介绍如何解决ajax动态加载页面的问题。
打开网页--->'查看元素'--->'网络'--->刷新页面:
在这张图片中,点击左栏可以找到你需要的信息。在右栏中,您可以获取相应的网页源 URL 和响应头信息。可以从请求 URL 中获取作者需要的内容:
图中的网站,北京大学,向该网站查询了北京一批理科录取分数线。发现网站上的数字是有规律的,于是修改了网站上的数字,得到了外省的录取分数线。
3、 根据规则抓取网页
剩下的部分是静态页面获取和提取需要的信息。当然,除了发现 URL 规则和修改规则之外,还有一种发送请求响应的方式。这部分笔者不做解释,有兴趣的读者自行查找资料。 查看全部
抓取ajax动态网页java(北京大学介绍如何解决ajax动态加载页面的问题(图))
1、遇到的问题描述
最近需要爬取网站中的一个内容。网页中的内容有下拉选项,如图:
笔者一直以为这是一个下拉框选项,打开网页的“视图元素”,如下图:
作者搜索的下拉框中没有选项。我很困惑。在我意识到这是一个Ajax动态加载页面之前,我向其他人描述了这个问题。于是我去搜集资料解决问题。
2、问题解决
搜了一篇《通过Ajax动态加载页面(实时监控华尔街新闻和新闻)(url:)》的文章,介绍了ajax动态加载页面。用户每次发送请求时,页面都会不时发生变化,但其 URL 不会发生变化。接下来我自己来抓一把:在中国教育在线,以北大不同学科、不同批次的各省录取分数线为例,介绍如何解决ajax动态加载页面的问题。
打开网页--->'查看元素'--->'网络'--->刷新页面:
在这张图片中,点击左栏可以找到你需要的信息。在右栏中,您可以获取相应的网页源 URL 和响应头信息。可以从请求 URL 中获取作者需要的内容:
图中的网站,北京大学,向该网站查询了北京一批理科录取分数线。发现网站上的数字是有规律的,于是修改了网站上的数字,得到了外省的录取分数线。
3、 根据规则抓取网页
剩下的部分是静态页面获取和提取需要的信息。当然,除了发现 URL 规则和修改规则之外,还有一种发送请求响应的方式。这部分笔者不做解释,有兴趣的读者自行查找资料。
抓取ajax动态网页java(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 04:01
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种会更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能会提前在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望做的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=> 构建链接=> 下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取ajax动态网页java(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种会更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能会提前在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望做的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=> 构建链接=> 下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取ajax动态网页java(完善转盘抽奖,实现从后台jsp页面生成随机数,以随机抽奖 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 04:01
)
【今日任务一】:
改进转盘抽奖,实现从后台jsp页面生成随机数,然后使用ajax获取随机数实现随机抽奖。
之前学过一点ajax,只是在看书,把原生代码和jQuery代码都看了,还做了笔记,但是今天想完成这个任务的时候,却无从下手!!!感觉宝宝好苦。于是查了资料,又看了书,又查了N个网页,一上午都不知道怎么弄的。后来,是主人吩咐的,这才恍然大悟。其实代码和原理都很简单。接下来说说我自己的学习过程和理解。
在这里,我仍然使用 jQuery 库,明天我将使用原生 JavaScript 代码编译 ajax() 函数。
前端的HTML代码如下:
幸运大转盘-转盘转动-用CSS3实现
使用ajax的地方是“body-转盘”。我需要得到一个随机数来控制转盘的旋转角度。转盘的旋转是通过CSS3动画实现的。设置了6个奖项,使用了6个。关键帧控制旋转角度,具体CSS代码不再赘述。
接下来是js代码
function luck(){
var index = "";
$.ajax({
type:"GET",
url: "/luck.jsp",
dataType:"json",
success:function(data){
index = data.value;
}
});
var zhuanpan = document.getElementById("body-zhuanpan");
switch(index){
case "1":
zhuanpan.style.animation = "2s one forwards";
setTimeout(function(){alert("1等奖");},2000);
break;
case "2":
zhuanpan.style.animation = "2s two forwards";
setTimeout(function(){alert("2等奖");},2000);
break;
case "3":
zhuanpan.style.animation = "2s three forwards";
setTimeout(function(){alert("3等奖");},2000);
break;
case "4":
zhuanpan.style.animation = "2s four forwards";
setTimeout(function(){alert("4等奖");},2000);
break;
case "5":
zhuanpan.style.animation = "2s five forwards";
setTimeout(function(){alert("5等奖");},2000);
break;
default:
zhuanpan.style.animation = "2s zero forwards";
setTimeout(function(){alert("谢谢参与");},2000);
}
}
var btn = document.getElementById("button");
btn.addEventListener("click",function(){
luck();
},false);
我用的是jQuery的ajax()函数,后台请求页面是luck.jsp
运气.jsp如下:
{
"value": (int)(Math.random()*10)
}
使用json存储数据,调用random()生成随机数。
我不太明白之前发生了什么。现在让我们谈谈整个逻辑。当我点击“btn”按钮时,会调用luck()函数,这个函数中有ajax请求。这时候我会访问url指向的后台页面luck.jsp。请求成功后,会以json格式返回luck.jsp里面的数据,即success函数的参数数据。data.value 是后台页面生成的随机数。我将此随机数分配给索引以使转盘随机旋转。
【任务二】:使用ajax将数据从前端表单传输到后端jsp,然后将数据保存到数据库中。
任务1其实挺简单的,只要明白前后的逻辑,就很容易理解了。但是听到任务二的时候,宝宝又晕了过去。我只是觉得我掌握了 Ajax,但我突然觉得它是什么!!后来查了一些网页,在师父的指导下,终于弄明白了。
前端有这样一个div,里面有两个文本框。当我点击按钮时,需要将文本框的内容通过ajax传递给后台jsp页面db.jsp。
我的js代码如下:
$("#submit-button").click(function(){
$.ajax({
type:"get",
url:"/lucky/db.jsp",
dataType:"json",
data:{
qq:$("#qq").val(),
phone:$("#phone").val()
},
success:function(obj){
console.log(obj)
}
});
});
在ajax()方法中,有一个json格式的数据,用于获取页面文本框中输入的内容。后台页面db.jsp可以通过访问这个json中的值来获取你想要的参数。
db.jsp 如下:
这样,qqNum中存放的就是页面文本框中数据的内容。
通过ajax数据获取页面表单的数据,然后通过ajax将数据传递给url指向的后台页面,在后台页面中可以获取到相应的参数。
其实我之前没有用ajax的时候,jsp页面也是可以获取到表单数据的。当时我用的是表单的动作。与ajax的区别在于:
如果为表单指定了一个动作,点击提交按钮后,页面会跳转到该动作指向的页面,当前页面不存在,ajax会停留在当前页面不跳转。但是数据也已经转移到后台jsp了,可以继续数据库操作了。
今天出现的错误:
1、 把switch函数放在ajax请求之外,这样每次索引都为空,因为ajax是异步请求,需要时间,所以如果代码顺序执行,索引不会得到值,它永远是空的。.
更正:把switch函数放在成功回调函数中,这样索引就可以拿到值了
2、写luck.jsp时,没有包引入,包引入方法:
3、ajax() 中的 url 错误。 查看全部
抓取ajax动态网页java(完善转盘抽奖,实现从后台jsp页面生成随机数,以随机抽奖
)
【今日任务一】:
改进转盘抽奖,实现从后台jsp页面生成随机数,然后使用ajax获取随机数实现随机抽奖。
之前学过一点ajax,只是在看书,把原生代码和jQuery代码都看了,还做了笔记,但是今天想完成这个任务的时候,却无从下手!!!感觉宝宝好苦。于是查了资料,又看了书,又查了N个网页,一上午都不知道怎么弄的。后来,是主人吩咐的,这才恍然大悟。其实代码和原理都很简单。接下来说说我自己的学习过程和理解。
在这里,我仍然使用 jQuery 库,明天我将使用原生 JavaScript 代码编译 ajax() 函数。
前端的HTML代码如下:
幸运大转盘-转盘转动-用CSS3实现
使用ajax的地方是“body-转盘”。我需要得到一个随机数来控制转盘的旋转角度。转盘的旋转是通过CSS3动画实现的。设置了6个奖项,使用了6个。关键帧控制旋转角度,具体CSS代码不再赘述。
接下来是js代码
function luck(){
var index = "";
$.ajax({
type:"GET",
url: "/luck.jsp",
dataType:"json",
success:function(data){
index = data.value;
}
});
var zhuanpan = document.getElementById("body-zhuanpan");
switch(index){
case "1":
zhuanpan.style.animation = "2s one forwards";
setTimeout(function(){alert("1等奖");},2000);
break;
case "2":
zhuanpan.style.animation = "2s two forwards";
setTimeout(function(){alert("2等奖");},2000);
break;
case "3":
zhuanpan.style.animation = "2s three forwards";
setTimeout(function(){alert("3等奖");},2000);
break;
case "4":
zhuanpan.style.animation = "2s four forwards";
setTimeout(function(){alert("4等奖");},2000);
break;
case "5":
zhuanpan.style.animation = "2s five forwards";
setTimeout(function(){alert("5等奖");},2000);
break;
default:
zhuanpan.style.animation = "2s zero forwards";
setTimeout(function(){alert("谢谢参与");},2000);
}
}
var btn = document.getElementById("button");
btn.addEventListener("click",function(){
luck();
},false);
我用的是jQuery的ajax()函数,后台请求页面是luck.jsp
运气.jsp如下:
{
"value": (int)(Math.random()*10)
}
使用json存储数据,调用random()生成随机数。
我不太明白之前发生了什么。现在让我们谈谈整个逻辑。当我点击“btn”按钮时,会调用luck()函数,这个函数中有ajax请求。这时候我会访问url指向的后台页面luck.jsp。请求成功后,会以json格式返回luck.jsp里面的数据,即success函数的参数数据。data.value 是后台页面生成的随机数。我将此随机数分配给索引以使转盘随机旋转。
【任务二】:使用ajax将数据从前端表单传输到后端jsp,然后将数据保存到数据库中。
任务1其实挺简单的,只要明白前后的逻辑,就很容易理解了。但是听到任务二的时候,宝宝又晕了过去。我只是觉得我掌握了 Ajax,但我突然觉得它是什么!!后来查了一些网页,在师父的指导下,终于弄明白了。
前端有这样一个div,里面有两个文本框。当我点击按钮时,需要将文本框的内容通过ajax传递给后台jsp页面db.jsp。
我的js代码如下:
$("#submit-button").click(function(){
$.ajax({
type:"get",
url:"/lucky/db.jsp",
dataType:"json",
data:{
qq:$("#qq").val(),
phone:$("#phone").val()
},
success:function(obj){
console.log(obj)
}
});
});
在ajax()方法中,有一个json格式的数据,用于获取页面文本框中输入的内容。后台页面db.jsp可以通过访问这个json中的值来获取你想要的参数。
db.jsp 如下:
这样,qqNum中存放的就是页面文本框中数据的内容。
通过ajax数据获取页面表单的数据,然后通过ajax将数据传递给url指向的后台页面,在后台页面中可以获取到相应的参数。
其实我之前没有用ajax的时候,jsp页面也是可以获取到表单数据的。当时我用的是表单的动作。与ajax的区别在于:
如果为表单指定了一个动作,点击提交按钮后,页面会跳转到该动作指向的页面,当前页面不存在,ajax会停留在当前页面不跳转。但是数据也已经转移到后台jsp了,可以继续数据库操作了。
今天出现的错误:
1、 把switch函数放在ajax请求之外,这样每次索引都为空,因为ajax是异步请求,需要时间,所以如果代码顺序执行,索引不会得到值,它永远是空的。.
更正:把switch函数放在成功回调函数中,这样索引就可以拿到值了
2、写luck.jsp时,没有包引入,包引入方法:
3、ajax() 中的 url 错误。
抓取ajax动态网页java(AjaxtooltipJS是一个简单好用的javascript程序实例的截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-12 18:04
Ajax tooltip JS是一个简单易用的javascript程序,当鼠标移动到连接上时,可以从后台动态获取相关提示信息;在一些需要通过链接文本提供更详细信息,甚至包括统计信息的应用中,从后台动态获取相关数据可能会更加高效,同时也能给用户带来更好的可用性。而且Ajax tooltip JS的提示框也做得非常简洁优雅。(请看文末它的项目网站demo 示例截图)
使用说明:
1. 到 下载 ajax-tooltip.zip 文件。
2. 解压zip文件,将arrow.gif放入你的web目录下的images等文件夹中;将ajax-tooltip.js脚本文件和ajax-添加到要动态显示内容的页面的标签中tooltip.css样式文件;类似于以下内容:
<br /><br /><br />
3. 调用连接文本中的ajaz-tooltip函数:
<br />查看提示<br />
这里的“viewDynamicTip.html”请求可以从后台动态获取相关信息,然后以文本形式返回给浏览器,通过ajax-tooltip提供的功能展示给用户。 查看全部
抓取ajax动态网页java(AjaxtooltipJS是一个简单好用的javascript程序实例的截图)
Ajax tooltip JS是一个简单易用的javascript程序,当鼠标移动到连接上时,可以从后台动态获取相关提示信息;在一些需要通过链接文本提供更详细信息,甚至包括统计信息的应用中,从后台动态获取相关数据可能会更加高效,同时也能给用户带来更好的可用性。而且Ajax tooltip JS的提示框也做得非常简洁优雅。(请看文末它的项目网站demo 示例截图)
使用说明:
1. 到 下载 ajax-tooltip.zip 文件。
2. 解压zip文件,将arrow.gif放入你的web目录下的images等文件夹中;将ajax-tooltip.js脚本文件和ajax-添加到要动态显示内容的页面的标签中tooltip.css样式文件;类似于以下内容:
<br /><br /><br />
3. 调用连接文本中的ajaz-tooltip函数:
<br />查看提示<br />
这里的“viewDynamicTip.html”请求可以从后台动态获取相关信息,然后以文本形式返回给浏览器,通过ajax-tooltip提供的功能展示给用户。
抓取ajax动态网页java(看一个和动态网页的相关概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-12 16:27
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等。网页界面可以收录文本、图像、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式且快速的动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当您滚动鼠标滚轮时,网页将自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文本,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。 查看全部
抓取ajax动态网页java(看一个和动态网页的相关概念(一)_)
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等。网页界面可以收录文本、图像、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式且快速的动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当您滚动鼠标滚轮时,网页将自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文本,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。
抓取ajax动态网页java( Python即时网络爬虫GitHub源7,文档修改历史(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 22:02
Python即时网络爬虫GitHub源7,文档修改历史(组图))
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。我们将在未来添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1、Python即时网络爬虫:API说明
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-24: V1.0 查看全部
抓取ajax动态网页java(
Python即时网络爬虫GitHub源7,文档修改历史(组图))
1 简介
本文介绍了如何使用 Java 和 JavaScript 中的 GooSeeker API 接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么要使用这种方法?源自Python即时网络爬虫开源项目:通过生成内容提取器,大大节省了程序员的时间。详情请参考“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前的编程语言发展来看,Java实现网页内容提取并不合适。除了语言不够灵活方便,整个生态不够活跃,可选库增长缓慢。另外,从JavaScript动态网页中提取内容,Java也很不方便,需要JavaScript引擎。使用 JavaScript 下载内容提取器可以直接跳转到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非站点网页的内容。因此,运行在有特权的 JavaScript 引擎上,例如浏览器扩展、自研浏览器以及自己程序中的 JavaScript 引擎。
为方便实验,本示例仍在网页上运行。为了避免跨域问题,目标网页被保存和修改,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他方法。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4. 展望
您也可以使用 Python 来获取指定网页的内容。感觉Python的语法更简洁。我们将在未来添加 Python 语言的示例。有兴趣的朋友可以加入一起学习。
五、相关文件
1、Python即时网络爬虫:API说明
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
1, 2016-06-24: V1.0
抓取ajax动态网页java(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-09 10:06
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压不会显示。上面的动态图片中也有演示。下载地址可以在 SeimiAgent 主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。 查看全部
抓取ajax动态网页java(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特点和 Spring 的特点,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压不会显示。上面的动态图片中也有演示。下载地址可以在 SeimiAgent 主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。

