
抓取ajax动态网页java
抓取ajax动态网页java(什么是静态页面?HTML+PHP+JavaScript(早期的动态网页技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-05 15:16
内容
一. 什么是静态页面?
1. 一个静态页面只有一个固定的URL,网页上的内容也是固定的,不会随着不同浏览器的访问而改变。
2. 一旦网页内容发布到网站 服务器,无论是否有用户访问,每个静态网页的内容都会保存在网站 服务器上。这样就可以理解为静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件。
3. 静态网页通常以.html、.hml、.xml、.shtml等常用形式后缀,不带“?”。
4. 静态页面无法连接数据库;
5. 静态页面开发技术:HTML;
优势:
1.静态网页内容比较稳定,网站格式友好,容易被搜索引擎检索;
2. 静态页面访问速度最快,不需要从数据库中提取数据;
3. 网站更安全,HTML页面不会受到Asp相关漏洞的影响;并且可以减少攻击和防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
缺点:
1. 内容固定,交互性差,功能有限,内容更新维护复杂;
2. 没有自动化工具,维护大量静态页面文件是不现实的;
3. 不能充分支持用户需求。
二. 什么是动态页面?
1. 当浏览器向服务器请求某个页面时,服务器根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,然后发送给浏览器。显然,动态网页中的“动态”是指服务器端页面的动态生成;只有当用户请求时,服务器才返回一个完整的网页。相反,“静态”是指实际的、单独的文件。
2. 动态页面开发技术:
HTML+JavaScript (Node.js)
HTML+PHP
HTML+ASP.NET(或 ASP)
HTML+JSP
HTML+CGI(早期动态网络技术)
3. 使用动态网页技术可以实现很多功能,例如:用户注册、登录、用户管理、在线调查/研究、订单管理、用户评论等。
4. “?” 在动态网页中的 URL 对搜索引擎不是很友好。通常,搜索引擎不会访问 网站 数据库中的所有内容,或者出于技术原因。搜索引擎不会抓取“?”之后的内容。在网址中。因此,需要进行一些技术处理以适应搜索引擎的要求。
5. 动态页面常用后缀:.asp、.jsp、.php、.perl、.cgi;
优势:
1.动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
2. 可以实现用户的各种需求;
3. 查询信息方便,可存储大量数据,需要时可立即查询。
缺点:
1.动态网站不利于搜索引擎检索或收录;
2.动态网站制作成本较高;
3.动态网页也调用数据库中的数据,对数据库的安全保密要求很高,需要专业技术人员维护网站的安全。
三. 什么是伪静态页面?
1. 伪静态相对于纯静态。“假”静态页面本质上是动态页面。
2. 通常,为了增加搜索引擎的友好度,静态页面是由动态页面生成的。
3. 并非所有以 html 为后缀的页面都是静态页面。动态页面也可以通过服务器端技术使用静态页面的后缀。比较常见的是Apache和Nginx的Rewrite技术,也就是通常所说的伪静态页面。实际上,它们仍然是动态页面,但它们是静态的。
优势:
1. 与静态页面相比,伪静态页面在速度上并没有明显的提升。毕竟是“假”的静态页面,本质上是动态页面翻译成静态页面。从SEO优化的角度来看,最明显的优势就是让搜索引擎把伪静态页面当作静态页面。
2. 提高用户对网页的信任度。
缺点:
使用伪静态会占用一定的CPU,大量的伪静态页面会导致CPU过载。
四. 总结
1. 静态页面意味着 网站 上的所有内容都已设置、完成,然后放在上面。无论用户何时看到内容,内容都是相同的。
2. 动态页面的内容是由数据库中的程序生成的。当不同的用户在不同的时间访问该页面时,显示的内容可能会有所不同。网页内容会根据程序设置自动更改。
3. 伪静态页面就是让动态页面静态化。
4. 静态网页是构建网站的基础,静态网页和动态网页并不矛盾。技术还可以将 Web 内容转换为静态网页以供发布。
5. 静态页面和动态页面各有特点。网站 是使用静态页面还是动态页面,主要取决于网站 的功能需求和网站 的内容。如果网站的功能比较简单,网站的更新量不大,使用纯静态网页会比较简单。否则,通常使用动态网络技术。
6.动态网站也可以采用动静结合的原则,动态网页适合动态网页的使用。如果需要使用静态网页,可以考虑使用静态网页。在 网站 上,动态和静态 Web 内容共存也很常见。
7. 静态页面访问速度最快;维修比较麻烦。
8. 动态页面占用空间小,易于维护;访问速度慢,如果访问的人多,会对数据库造成压力。
9. 使用纯静态和伪静态进行SEO优化没有本质区别。
10. 使用伪静态会占用一定的CPU使用率,使用过多会导致CPU过载。 查看全部
抓取ajax动态网页java(什么是静态页面?HTML+PHP+JavaScript(早期的动态网页技术))
内容
一. 什么是静态页面?
1. 一个静态页面只有一个固定的URL,网页上的内容也是固定的,不会随着不同浏览器的访问而改变。
2. 一旦网页内容发布到网站 服务器,无论是否有用户访问,每个静态网页的内容都会保存在网站 服务器上。这样就可以理解为静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件。
3. 静态网页通常以.html、.hml、.xml、.shtml等常用形式后缀,不带“?”。
4. 静态页面无法连接数据库;
5. 静态页面开发技术:HTML;
优势:
1.静态网页内容比较稳定,网站格式友好,容易被搜索引擎检索;
2. 静态页面访问速度最快,不需要从数据库中提取数据;
3. 网站更安全,HTML页面不会受到Asp相关漏洞的影响;并且可以减少攻击和防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
缺点:
1. 内容固定,交互性差,功能有限,内容更新维护复杂;
2. 没有自动化工具,维护大量静态页面文件是不现实的;
3. 不能充分支持用户需求。
二. 什么是动态页面?
1. 当浏览器向服务器请求某个页面时,服务器根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,然后发送给浏览器。显然,动态网页中的“动态”是指服务器端页面的动态生成;只有当用户请求时,服务器才返回一个完整的网页。相反,“静态”是指实际的、单独的文件。
2. 动态页面开发技术:
HTML+JavaScript (Node.js)
HTML+PHP
HTML+ASP.NET(或 ASP)
HTML+JSP
HTML+CGI(早期动态网络技术)
3. 使用动态网页技术可以实现很多功能,例如:用户注册、登录、用户管理、在线调查/研究、订单管理、用户评论等。
4. “?” 在动态网页中的 URL 对搜索引擎不是很友好。通常,搜索引擎不会访问 网站 数据库中的所有内容,或者出于技术原因。搜索引擎不会抓取“?”之后的内容。在网址中。因此,需要进行一些技术处理以适应搜索引擎的要求。
5. 动态页面常用后缀:.asp、.jsp、.php、.perl、.cgi;
优势:
1.动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
2. 可以实现用户的各种需求;
3. 查询信息方便,可存储大量数据,需要时可立即查询。
缺点:
1.动态网站不利于搜索引擎检索或收录;
2.动态网站制作成本较高;
3.动态网页也调用数据库中的数据,对数据库的安全保密要求很高,需要专业技术人员维护网站的安全。
三. 什么是伪静态页面?
1. 伪静态相对于纯静态。“假”静态页面本质上是动态页面。
2. 通常,为了增加搜索引擎的友好度,静态页面是由动态页面生成的。
3. 并非所有以 html 为后缀的页面都是静态页面。动态页面也可以通过服务器端技术使用静态页面的后缀。比较常见的是Apache和Nginx的Rewrite技术,也就是通常所说的伪静态页面。实际上,它们仍然是动态页面,但它们是静态的。
优势:
1. 与静态页面相比,伪静态页面在速度上并没有明显的提升。毕竟是“假”的静态页面,本质上是动态页面翻译成静态页面。从SEO优化的角度来看,最明显的优势就是让搜索引擎把伪静态页面当作静态页面。
2. 提高用户对网页的信任度。
缺点:
使用伪静态会占用一定的CPU,大量的伪静态页面会导致CPU过载。
四. 总结
1. 静态页面意味着 网站 上的所有内容都已设置、完成,然后放在上面。无论用户何时看到内容,内容都是相同的。
2. 动态页面的内容是由数据库中的程序生成的。当不同的用户在不同的时间访问该页面时,显示的内容可能会有所不同。网页内容会根据程序设置自动更改。
3. 伪静态页面就是让动态页面静态化。
4. 静态网页是构建网站的基础,静态网页和动态网页并不矛盾。技术还可以将 Web 内容转换为静态网页以供发布。
5. 静态页面和动态页面各有特点。网站 是使用静态页面还是动态页面,主要取决于网站 的功能需求和网站 的内容。如果网站的功能比较简单,网站的更新量不大,使用纯静态网页会比较简单。否则,通常使用动态网络技术。
6.动态网站也可以采用动静结合的原则,动态网页适合动态网页的使用。如果需要使用静态网页,可以考虑使用静态网页。在 网站 上,动态和静态 Web 内容共存也很常见。
7. 静态页面访问速度最快;维修比较麻烦。
8. 动态页面占用空间小,易于维护;访问速度慢,如果访问的人多,会对数据库造成压力。
9. 使用纯静态和伪静态进行SEO优化没有本质区别。
10. 使用伪静态会占用一定的CPU使用率,使用过多会导致CPU过载。
抓取ajax动态网页java(谷歌爬虫是如何抓取和收录什么类型的抓取JavaScript?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 01:06
身体的一部分
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
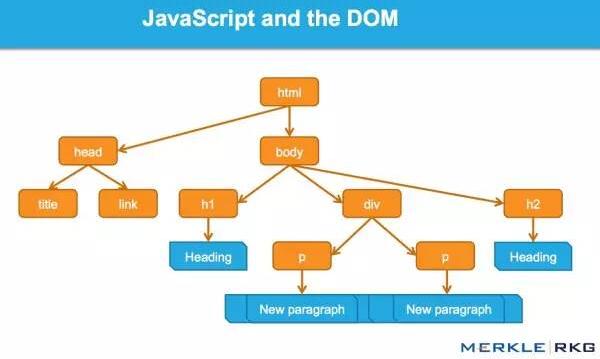
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
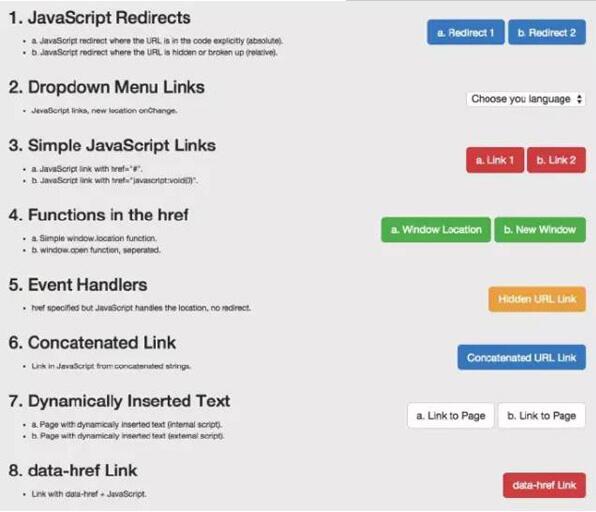
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
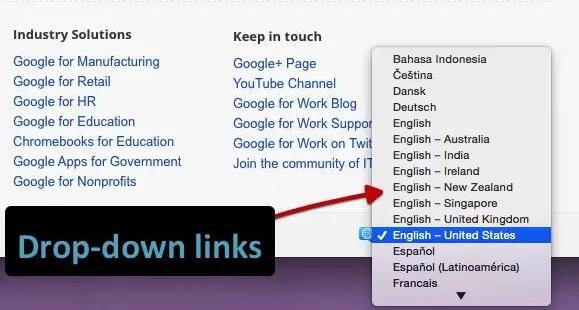
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
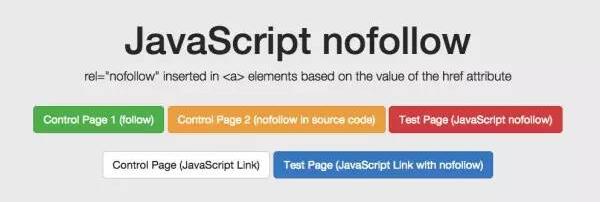
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
抓取ajax动态网页java(谷歌爬虫是如何抓取和收录什么类型的抓取JavaScript?)
身体的一部分
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
抓取ajax动态网页java(如何抓取网页特定数据的爬虫,我是怎么做到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-05 01:04
最近有朋友让我帮我设计一个爬虫,可以爬取网页上的特定数据。我以为这种程序实现起来很简单,只要通过对应的url获取html页面代码,然后解析html得到需要的数据。
但在实践中,我发现我想的太简单了。页面上有很多数据不能简单的从html源码中抓取,因为页面上显示的很多数据其实是在js代码运行时通过ajax从远程服务器获取的。正在加载页面,因此仅仅通过阅读html源代码无法获得所需的数据。
举个例子,我们打开京东首页,在搜索框输入关键词“乌鸡白凤丸”,返回页面显示60个商品,如下图:
打开js控制台,选择element,然后点击左上角的箭头,然后将箭头移到item item,我们可以在html中看到它对应的元素:
我们可以看到页面显示的item对应了id为“gl-i-wrap”的div控件,也就是说如果我们要从html中抓取页面显示的信息,就必须从给定的id中获取html代码div组件然后分析里面的内容,问题是如果你用右键调出他页面的源代码,然后查找字符串“gl-i-wrap”,你会发现它只收录30个,但页面上显示的产品数量是计算出来的。60,也就是30个产品信息不能直接通过html代码获取。
额外的30条信息实际上是在一定条件下触发一段js代码后通过ajax从服务端获取然后添加到DOM中的,所以我们不能简单的从页面对应的html中获取。我通过网上搜索发现对应的解决方法是分析是哪一段js代码负责获取这些数据,然后通过类似于逆向工程的方法研究它是如何构造http请求的,然后模拟发送这些请求获取数据.
我认为这种方法存在一系列问题。首先,要分析很多难读的js代码,工作量和难度可想而知。其次,如果以后这种方式发生变化网站数据采集方式,那么就得再次逆向工程,所以这种方式不经济。
我们怎样才能轻松便捷地获取动态加载的数据呢?
只要在页面上展示商品信息,就可以通过DOM获取,所以如果我们有办法获取浏览器内部的DOM模型,就可以读取动态加载的数据,因为冗余数据触发后页面被下拉。js代码是通过ajax动态获取的,所以如果我们可以通过代码控制浏览器加载网页,然后让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以获取到动态加载的数据。
经过一番调查,我们发现一个叫selenium的控件可以通过代码来动态控制浏览器,比如让浏览器加载一个特定的页面,让浏览器下拉页面,然后在浏览器,所以我们可以用它来方便的抓取动态页面数据。
首先通过命令pip install selenium下载控件,如果我们要使用它来控制chrome浏览器,我们还需要下载chromedriver控件,首先确定你使用的chrome版本,chromedriver必须和chrome完全一样您当前使用的版本,请从以下链接下载:
请记住选择与您的 chrome 浏览器相同的版本进行下载。完成后,我们可以通过以下代码启动浏览器并使用给定的 URL 加载网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('#x27;)
运行上述代码后,可以启动浏览器,看到他打开了京东首页。这时候我想在搜索框中自动输入关键词。因此,我们可以使用下面的代码,通过模拟人工输入,在搜索框中输入关键词,然后模拟点击回车键,实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(字)
search_box.send_keys(Keys.ENTER)
超时 = 10
尝试:
print("等待页面...")
WebDriverWait(驱动程序,超时)
除了超时异常:
print("等待页面加载超时")
最后:
.
.
.
.
由于浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们需要模拟一个人拉下页面。行动:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("返回 document.body.scrollHeight")
while True: #将页面滑到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("返回 document.body.scrollHeight")
如果 new_height == last_height:
休息
last_height = new_height
上面的代码执行完后,你会发现浏览器页面自动下拉到了底部,所以js会向服务器发送ajax请求获取另外30项的数据,然后我们得到对应的html源码通过执行一段js代码到body组件,然后获取到id为gl-i-wrap的div对象,你会看到它返回了60个对应的组件,也就是说可以获取到页面上的所有商品数据:
page_source = driver.execute_script("返回 document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里的输出是60
这样我们就可以读取所有页面显示的商品价格信息。这种方法比解析js代码然后逆向构造http请求获取页面上动态加载的数据要简单、方便、省事得多。更详细的讲解和调试演示请点击“阅读原文”观看视频 查看全部
抓取ajax动态网页java(如何抓取网页特定数据的爬虫,我是怎么做到的)
最近有朋友让我帮我设计一个爬虫,可以爬取网页上的特定数据。我以为这种程序实现起来很简单,只要通过对应的url获取html页面代码,然后解析html得到需要的数据。
但在实践中,我发现我想的太简单了。页面上有很多数据不能简单的从html源码中抓取,因为页面上显示的很多数据其实是在js代码运行时通过ajax从远程服务器获取的。正在加载页面,因此仅仅通过阅读html源代码无法获得所需的数据。
举个例子,我们打开京东首页,在搜索框输入关键词“乌鸡白凤丸”,返回页面显示60个商品,如下图:

打开js控制台,选择element,然后点击左上角的箭头,然后将箭头移到item item,我们可以在html中看到它对应的元素:

我们可以看到页面显示的item对应了id为“gl-i-wrap”的div控件,也就是说如果我们要从html中抓取页面显示的信息,就必须从给定的id中获取html代码div组件然后分析里面的内容,问题是如果你用右键调出他页面的源代码,然后查找字符串“gl-i-wrap”,你会发现它只收录30个,但页面上显示的产品数量是计算出来的。60,也就是30个产品信息不能直接通过html代码获取。
额外的30条信息实际上是在一定条件下触发一段js代码后通过ajax从服务端获取然后添加到DOM中的,所以我们不能简单的从页面对应的html中获取。我通过网上搜索发现对应的解决方法是分析是哪一段js代码负责获取这些数据,然后通过类似于逆向工程的方法研究它是如何构造http请求的,然后模拟发送这些请求获取数据.
我认为这种方法存在一系列问题。首先,要分析很多难读的js代码,工作量和难度可想而知。其次,如果以后这种方式发生变化网站数据采集方式,那么就得再次逆向工程,所以这种方式不经济。
我们怎样才能轻松便捷地获取动态加载的数据呢?
只要在页面上展示商品信息,就可以通过DOM获取,所以如果我们有办法获取浏览器内部的DOM模型,就可以读取动态加载的数据,因为冗余数据触发后页面被下拉。js代码是通过ajax动态获取的,所以如果我们可以通过代码控制浏览器加载网页,然后让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以获取到动态加载的数据。
经过一番调查,我们发现一个叫selenium的控件可以通过代码来动态控制浏览器,比如让浏览器加载一个特定的页面,让浏览器下拉页面,然后在浏览器,所以我们可以用它来方便的抓取动态页面数据。
首先通过命令pip install selenium下载控件,如果我们要使用它来控制chrome浏览器,我们还需要下载chromedriver控件,首先确定你使用的chrome版本,chromedriver必须和chrome完全一样您当前使用的版本,请从以下链接下载:
请记住选择与您的 chrome 浏览器相同的版本进行下载。完成后,我们可以通过以下代码启动浏览器并使用给定的 URL 加载网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('#x27;)
运行上述代码后,可以启动浏览器,看到他打开了京东首页。这时候我想在搜索框中自动输入关键词。因此,我们可以使用下面的代码,通过模拟人工输入,在搜索框中输入关键词,然后模拟点击回车键,实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(字)
search_box.send_keys(Keys.ENTER)
超时 = 10
尝试:
print("等待页面...")
WebDriverWait(驱动程序,超时)
除了超时异常:
print("等待页面加载超时")
最后:
.
.
.
.
由于浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们需要模拟一个人拉下页面。行动:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("返回 document.body.scrollHeight")
while True: #将页面滑到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("返回 document.body.scrollHeight")
如果 new_height == last_height:
休息
last_height = new_height
上面的代码执行完后,你会发现浏览器页面自动下拉到了底部,所以js会向服务器发送ajax请求获取另外30项的数据,然后我们得到对应的html源码通过执行一段js代码到body组件,然后获取到id为gl-i-wrap的div对象,你会看到它返回了60个对应的组件,也就是说可以获取到页面上的所有商品数据:
page_source = driver.execute_script("返回 document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里的输出是60
这样我们就可以读取所有页面显示的商品价格信息。这种方法比解析js代码然后逆向构造http请求获取页面上动态加载的数据要简单、方便、省事得多。更详细的讲解和调试演示请点击“阅读原文”观看视频
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-02 13:16
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,页面表单暴力**等等。在自动化渗透方面也会起到很大的作用,而且以后也会用到。会提这个。 查看全部
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,页面表单暴力**等等。在自动化渗透方面也会起到很大的作用,而且以后也会用到。会提这个。
抓取ajax动态网页java(2020-07-31181次浏览原文:幽沉窥唐虞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 20:01
2020-07-31 原创 API 示例的 181 次查看:使用 Java/JavaScript 下载内容提取器
关键词:
默默的谢天谢地,低头窥视着唐羽。本文章主要介绍API示例:Java/JavaScript下载内容提取器相关知识,希望对您有所帮助。
1 简介
本文介绍了如何在 java 中下载内容提取器并使用 GooSeeker API 接口,这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 python 即时网络爬虫开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,Java并不适合提取网页内容。再加上语言不够灵活方便,整个生态系统不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613961050143x.shtml"; // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
[object Object]
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
一、Python即时网络爬虫:API说明
6.Jisouke GooSeeker开源代码下载源
1、GooSeeker开源Python网络爬虫GitHub源码
7.文档修改历史
1、2016-06-27:V1.0
本文来自“富勒华的博客”博客,请勿转载!
至此,这篇关于 API 示例的文章:使用 Java/JavaScript 下载内容提取器已经完成了内容。如果没有解决你的问题,请参考下面的文章:
相关文章
366API!完美解决微信h5页面点击文件下载链接无响应的问题
微信被禁网页如何处理?366API将被屏蔽的网页从微信恢复正常访问的解决方案
图像识别快速入门:使用 TensorFlow API 进行图像分类的示例
VBA绘制Excel图表
cesium1.65api版贴纸模型绘图工具效果(附源码下载)
吐槽贴:百度地图api包实用功能【源码下载】
cesium1.63.1api版贴纸模型测量工具效果(附源码下载)
使用百度地图API分析交通大数据 查看全部
抓取ajax动态网页java(2020-07-31181次浏览原文:幽沉窥唐虞)
2020-07-31 原创 API 示例的 181 次查看:使用 Java/JavaScript 下载内容提取器
关键词:
默默的谢天谢地,低头窥视着唐羽。本文章主要介绍API示例:Java/JavaScript下载内容提取器相关知识,希望对您有所帮助。
1 简介
本文介绍了如何在 java 中下载内容提取器并使用 GooSeeker API 接口,这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 python 即时网络爬虫开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,Java并不适合提取网页内容。再加上语言不够灵活方便,整个生态系统不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613961050143x.shtml"; // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
[object Object]
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下

4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
一、Python即时网络爬虫:API说明
6.Jisouke GooSeeker开源代码下载源
1、GooSeeker开源Python网络爬虫GitHub源码
7.文档修改历史
1、2016-06-27:V1.0
本文来自“富勒华的博客”博客,请勿转载!
至此,这篇关于 API 示例的文章:使用 Java/JavaScript 下载内容提取器已经完成了内容。如果没有解决你的问题,请参考下面的文章:
相关文章
366API!完美解决微信h5页面点击文件下载链接无响应的问题
微信被禁网页如何处理?366API将被屏蔽的网页从微信恢复正常访问的解决方案
图像识别快速入门:使用 TensorFlow API 进行图像分类的示例
VBA绘制Excel图表
cesium1.65api版贴纸模型绘图工具效果(附源码下载)
吐槽贴:百度地图api包实用功能【源码下载】
cesium1.63.1api版贴纸模型测量工具效果(附源码下载)
使用百度地图API分析交通大数据
抓取ajax动态网页java(7开发语言:Myeclipse微博爬虫:Tomcat情感分析算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-20 19:23
#WeiboEmotionAnalyzer###系统介绍在本系统中,视图层使用JSP+CSS+JavaScript设计前端界面,包括数据校验、用户交互、图表展示等功能,其中JSON文本格式用于与背景的互动;control 层由servlet实现。servlet根据前端发来的用户的具体请求,选择合适的视图进行展示,对请求进行解释,并以JSON格式返回数据给客户端;本系统模型层的功能是分析微博数据。进行情感分析,并为servlet提供一个使用分析结果的接口,经过一定的处理后发回给客户端。###主要内容1.微博爬虫1. 1 使用 JSOUP 抓取和解析在线微博。2.情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。
###开发环境开发工具:Myeclipse 服务器:Tomcat 7 开发语言:Java、jsp、css、JavaScript(jQuery)js脚本调试:Firebug插件(火狐浏览器)###Deploy复制项目的所有内容tomcat_bin文件夹放入tomcat的bin目录下的###TODO: - 重构代码,尽量消除重复,让代码更具表现力。- 提升微博爬虫性能,增加多进程。- 添加一个数据库来存储爬取的微博数据,而不是静态文件。- 改进情感分析算法,尝试基于机器学习的算法。(待定)——添加新的功能需求,尽可能接近实际需求 查看全部
抓取ajax动态网页java(7开发语言:Myeclipse微博爬虫:Tomcat情感分析算法)
#WeiboEmotionAnalyzer###系统介绍在本系统中,视图层使用JSP+CSS+JavaScript设计前端界面,包括数据校验、用户交互、图表展示等功能,其中JSON文本格式用于与背景的互动;control 层由servlet实现。servlet根据前端发来的用户的具体请求,选择合适的视图进行展示,对请求进行解释,并以JSON格式返回数据给客户端;本系统模型层的功能是分析微博数据。进行情感分析,并为servlet提供一个使用分析结果的接口,经过一定的处理后发回给客户端。###主要内容1.微博爬虫1. 1 使用 JSOUP 抓取和解析在线微博。2.情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。
###开发环境开发工具:Myeclipse 服务器:Tomcat 7 开发语言:Java、jsp、css、JavaScript(jQuery)js脚本调试:Firebug插件(火狐浏览器)###Deploy复制项目的所有内容tomcat_bin文件夹放入tomcat的bin目录下的###TODO: - 重构代码,尽量消除重复,让代码更具表现力。- 提升微博爬虫性能,增加多进程。- 添加一个数据库来存储爬取的微博数据,而不是静态文件。- 改进情感分析算法,尝试基于机器学习的算法。(待定)——添加新的功能需求,尽可能接近实际需求
抓取ajax动态网页java( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-20 10:29
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取ajax动态网页java(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
抓取ajax动态网页java(一下JSP的思想就好了,现在已经没有用了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-18 00:25
)
上节课讲了JSP,大家应该掌握思路。至于更多的JSP知识,现在其实也没什么用了,因为没有人会直接用JSP来做web开发。这是古老的编程知识。
关于服务端的知识,我们暂停一下,从http协议的角度学习一个前端知识。在前端技术中,有一个非常重要的技术叫做ajax。我们先展示一个ajax的例子,然后看看这个技术的本质。
AJAX 用例
在许多应用程序中,我们实际上并不想刷新整个网页。例如,一个网页上有很多产品的图片列表。当我们将鼠标向上移动时,我们想在网页上弹出一个小框,显示产品的详细信息。. 在这种情况下,我们实际上并不需要刷新整个页面。但是如何向服务器发送请求以获取产品的详细信息?
这时,有一种技术叫做Ajax。AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。AJAX 是一种与服务器交换数据并更新网页的一部分的技术,允许与服务器进行数据交互而无需重新加载整个页面。
我们仍然在 jetty 的根目录下新建一个名为 ajax.html 的文件:
function loadXMLDoc() {
var xmlhttp;
xmlhttp=new XMLHttpRequest();
// 当数据返回以后才会调用这个匿名方法,把从服务端得到的内容设置到myDiv这个标签里
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","ajax_info.txt",true);
xmlhttp.send();
}
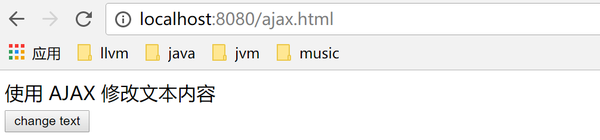
使用 AJAX 修改文本内容
change text
注意新建文件的时候一定要保证文件的编码是UTF-8
让我们分析一下这个页面上的javascript代码是什么意思。此网页上有一个按钮,当单击该按钮时,将调用 loadXMLDoc。在这个方法中创建了一个XMLHttpRequest,通过这个对象的open方法访问服务器的ajax_info.txt。返回数据时,会调用一个匿名函数来设置网页的内容。看看上面代码中的注释。
所以我们在服务器端再创建一个名为ajax_info.txt的文件,文件内容随便填写即可。
点击后可以看到:
查看全部
抓取ajax动态网页java(一下JSP的思想就好了,现在已经没有用了
)
上节课讲了JSP,大家应该掌握思路。至于更多的JSP知识,现在其实也没什么用了,因为没有人会直接用JSP来做web开发。这是古老的编程知识。
关于服务端的知识,我们暂停一下,从http协议的角度学习一个前端知识。在前端技术中,有一个非常重要的技术叫做ajax。我们先展示一个ajax的例子,然后看看这个技术的本质。
AJAX 用例
在许多应用程序中,我们实际上并不想刷新整个网页。例如,一个网页上有很多产品的图片列表。当我们将鼠标向上移动时,我们想在网页上弹出一个小框,显示产品的详细信息。. 在这种情况下,我们实际上并不需要刷新整个页面。但是如何向服务器发送请求以获取产品的详细信息?
这时,有一种技术叫做Ajax。AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。AJAX 是一种与服务器交换数据并更新网页的一部分的技术,允许与服务器进行数据交互而无需重新加载整个页面。
我们仍然在 jetty 的根目录下新建一个名为 ajax.html 的文件:
function loadXMLDoc() {
var xmlhttp;
xmlhttp=new XMLHttpRequest();
// 当数据返回以后才会调用这个匿名方法,把从服务端得到的内容设置到myDiv这个标签里
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","ajax_info.txt",true);
xmlhttp.send();
}
使用 AJAX 修改文本内容
change text
注意新建文件的时候一定要保证文件的编码是UTF-8
让我们分析一下这个页面上的javascript代码是什么意思。此网页上有一个按钮,当单击该按钮时,将调用 loadXMLDoc。在这个方法中创建了一个XMLHttpRequest,通过这个对象的open方法访问服务器的ajax_info.txt。返回数据时,会调用一个匿名函数来设置网页的内容。看看上面代码中的注释。
所以我们在服务器端再创建一个名为ajax_info.txt的文件,文件内容随便填写即可。
点击后可以看到:

抓取ajax动态网页java( HTML2019-04-28编程之家收集整理的篇文章介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-16 13:21
HTML2019-04-28编程之家收集整理的篇文章介绍)
Web scraper - scrapy 中的动态 start_urls
HTML 2019-04-28
编程之家采集的这篇文章文章主要介绍了网页抓取工具——scrapy中的动态start_urls。编程之家的小编觉得挺不错的。 .
我正在使用 scrapy 在 网站 上抓取多个页面。
变量start_urls用于定义要爬取的页面。
我最初从第一页开始,因此在文件 example_spider.py 中定义 start_urls = [first page]
一旦我从第 1 页获得更多信息,我会找出要抓取的下一页是什么,然后相应地分配 start_urls。所以我要start_urls = [page 1, page 2, ..., Changes to page K]覆盖example_spider.py,然后再执行scrapy。
这是最好的方法还是有更好的方法来使用scrapy API动态分配start_urls而不必覆盖example_splider.py?
谢谢。
解决方案
start_urls 类属性收录起始 URL - 仅此而已。如果你提取要删除的其他页面的URL-从[another]回调的解析回调中获取对应的请求:
class Spider(BaseSpider):
name = 'my_spider'
start_urls = [
'http://www.domain.com/'
]
allowed_domains = ['domain.com']
def parse(self,response):
'''Parse main page and extract categories links.'''
hxs = HtmlXPathSelector(response)
urls = hxs.select("//*[@id='tSubmenuContent']/a[position()>1]/@href").extract()
for url in urls:
url = urlparse.urljoin(response.url,url)
self.log('Found category url: %s' % url)
yield Request(url,callback = self.parseCategory)
def parseCategory(self,response):
'''Parse category page and extract links of the items.'''
hxs = HtmlXPathSelector(response)
links = hxs.select("//*[@id='_list']//td[@class='tListDesc']/a/@href").extract()
for link in links:
itemLink = urlparse.urljoin(response.url,link)
self.log('Found item link: %s' % itemLink,log.DEBUG)
yield Request(itemLink,callback = self.parseItem)
def parseItem(self,response):
...
如果你还想自定义启动请求创建,请重写方法
总结
以上是编程之家为你采集的网页抓取工具——scrapy全部内容中的动态start_urls,希望文章可以帮助你解决scrapy程序开发中遇到的网页抓取工具——动态start_urls问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
抓取ajax动态网页java(
HTML2019-04-28编程之家收集整理的篇文章介绍)
Web scraper - scrapy 中的动态 start_urls
HTML 2019-04-28
编程之家采集的这篇文章文章主要介绍了网页抓取工具——scrapy中的动态start_urls。编程之家的小编觉得挺不错的。 .
我正在使用 scrapy 在 网站 上抓取多个页面。
变量start_urls用于定义要爬取的页面。
我最初从第一页开始,因此在文件 example_spider.py 中定义 start_urls = [first page]
一旦我从第 1 页获得更多信息,我会找出要抓取的下一页是什么,然后相应地分配 start_urls。所以我要start_urls = [page 1, page 2, ..., Changes to page K]覆盖example_spider.py,然后再执行scrapy。
这是最好的方法还是有更好的方法来使用scrapy API动态分配start_urls而不必覆盖example_splider.py?
谢谢。
解决方案
start_urls 类属性收录起始 URL - 仅此而已。如果你提取要删除的其他页面的URL-从[another]回调的解析回调中获取对应的请求:
class Spider(BaseSpider):
name = 'my_spider'
start_urls = [
'http://www.domain.com/'
]
allowed_domains = ['domain.com']
def parse(self,response):
'''Parse main page and extract categories links.'''
hxs = HtmlXPathSelector(response)
urls = hxs.select("//*[@id='tSubmenuContent']/a[position()>1]/@href").extract()
for url in urls:
url = urlparse.urljoin(response.url,url)
self.log('Found category url: %s' % url)
yield Request(url,callback = self.parseCategory)
def parseCategory(self,response):
'''Parse category page and extract links of the items.'''
hxs = HtmlXPathSelector(response)
links = hxs.select("//*[@id='_list']//td[@class='tListDesc']/a/@href").extract()
for link in links:
itemLink = urlparse.urljoin(response.url,link)
self.log('Found item link: %s' % itemLink,log.DEBUG)
yield Request(itemLink,callback = self.parseItem)
def parseItem(self,response):
...
如果你还想自定义启动请求创建,请重写方法
总结
以上是编程之家为你采集的网页抓取工具——scrapy全部内容中的动态start_urls,希望文章可以帮助你解决scrapy程序开发中遇到的网页抓取工具——动态start_urls问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
抓取ajax动态网页java(SEO的基本就是要语义化,方便搜索引擎,但有作用吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-13 05:18
我们知道SEO的基础是语义化、易于搜索引擎爬取,但这是否意味着单页应用中的传统多页应用没有经过改造对SEO有影响?
先看一下搜索引擎的原理
# URL 搜索引擎会是 收录 吗?
1、什么是哈希值?
在阮一峰的博客里,有一篇文章文章可以很好的解释哈希值。# 值不是 http 请求,而是浏览器操作。使用#,您可以快速定位网页中的特定位置。比如 id="comment-121" 或者这个位置很快就定位到了。
2、搜索引擎会抓取带有#(哈希值)的网址吗
答案一般不是。搜索引擎抓取页面首先要遵循http协议,但#不是协议的内容。事实上,情况也是如此。我们从来没有在搜索引擎的搜索结果中看到过可以快速定位到网页中某个位置的记录。因此,希望搜索引擎通过在网站内外添加#锚链接来快速定位第一次访问是不现实的。当然,为了模拟真实用户,搜索引擎蜘蛛在输入网站后会使用一些技术来模拟鼠标点击。此时页面的锚链接仍然有效,但是当搜索结果中有任何链接时,将没有#。
#! 是什么意思?在3、URL 里做什么?
这是违反 2 的特殊情况,Google 抓取带有 #! 的 URL。. Google 规定,如果想让 Ajax 生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中(这种 URL 一般对普通页面没有定位作用),Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。例如 /#!/username 等价于 /?escaped_fragment=/username,并且 URL 带有 ? 将被抓取,所以 #! 网址将被 Google 搜索 收录。
4、搜索引擎是否会抓取带有#(哈希值)的URL给我们
一、不要试图用 robots.txt 屏蔽 # 个 URL。我之前翻过一个错误,就是在的robots.txt中加入disallow:/*#规则,试图阻止这些带#的URL被抓取。但实际上,这种做法是错误的。首先,#是robots.txt中的注释符号,后面的内容会被注释掉,所以这条规则变成了disallow:/,也就是阻止了本站所有收录站点。页面,幸好今天早上找到并立即修改。其次,搜索引擎不会抓取带有#的URL,所以不需要添加这样的规则。
二、你可以使用#和ajax的组合来隐藏你不想被抓取的内容。在我们的一些网页中,可能有一些我们不想直接告诉搜索引擎的内容,或者一些我们不想被抓取的隐私,所以我们可以使用#来控制这些信息的显示。例如,我们添加一个按钮,当 URL 中收录#show-info-123 时显示 123 的个人信息,但不收录时不显示。对于搜索引擎,带有#的URL会被自动忽略,因此123的个人信息不会被抓取。
也就是说,哈希模式的语义对SEO影响不大。当然,我们的语义不仅仅适用于 SEO。 查看全部
抓取ajax动态网页java(SEO的基本就是要语义化,方便搜索引擎,但有作用吗)
我们知道SEO的基础是语义化、易于搜索引擎爬取,但这是否意味着单页应用中的传统多页应用没有经过改造对SEO有影响?
先看一下搜索引擎的原理
# URL 搜索引擎会是 收录 吗?
1、什么是哈希值?
在阮一峰的博客里,有一篇文章文章可以很好的解释哈希值。# 值不是 http 请求,而是浏览器操作。使用#,您可以快速定位网页中的特定位置。比如 id="comment-121" 或者这个位置很快就定位到了。
2、搜索引擎会抓取带有#(哈希值)的网址吗
答案一般不是。搜索引擎抓取页面首先要遵循http协议,但#不是协议的内容。事实上,情况也是如此。我们从来没有在搜索引擎的搜索结果中看到过可以快速定位到网页中某个位置的记录。因此,希望搜索引擎通过在网站内外添加#锚链接来快速定位第一次访问是不现实的。当然,为了模拟真实用户,搜索引擎蜘蛛在输入网站后会使用一些技术来模拟鼠标点击。此时页面的锚链接仍然有效,但是当搜索结果中有任何链接时,将没有#。
#! 是什么意思?在3、URL 里做什么?
这是违反 2 的特殊情况,Google 抓取带有 #! 的 URL。. Google 规定,如果想让 Ajax 生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中(这种 URL 一般对普通页面没有定位作用),Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。例如 /#!/username 等价于 /?escaped_fragment=/username,并且 URL 带有 ? 将被抓取,所以 #! 网址将被 Google 搜索 收录。
4、搜索引擎是否会抓取带有#(哈希值)的URL给我们
一、不要试图用 robots.txt 屏蔽 # 个 URL。我之前翻过一个错误,就是在的robots.txt中加入disallow:/*#规则,试图阻止这些带#的URL被抓取。但实际上,这种做法是错误的。首先,#是robots.txt中的注释符号,后面的内容会被注释掉,所以这条规则变成了disallow:/,也就是阻止了本站所有收录站点。页面,幸好今天早上找到并立即修改。其次,搜索引擎不会抓取带有#的URL,所以不需要添加这样的规则。
二、你可以使用#和ajax的组合来隐藏你不想被抓取的内容。在我们的一些网页中,可能有一些我们不想直接告诉搜索引擎的内容,或者一些我们不想被抓取的隐私,所以我们可以使用#来控制这些信息的显示。例如,我们添加一个按钮,当 URL 中收录#show-info-123 时显示 123 的个人信息,但不收录时不显示。对于搜索引擎,带有#的URL会被自动忽略,因此123的个人信息不会被抓取。
也就是说,哈希模式的语义对SEO影响不大。当然,我们的语义不仅仅适用于 SEO。
抓取ajax动态网页java(JavaWeb应用设计及实战目录上一章下一章加载新闻源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-10 13:26
JavaWeb应用设计及实用目录
上一章 下一章
上一个任务/上一节 下一个任务/下一节
加载新闻来源。
内容
(2)
(6)
系统首页新闻中心部分采用Ajax技术,按主题动态展示新闻功能,按条件加载
一个话题下的所有话题或新闻,并使用Ajax技术实现分页显示。使用 Ajax 技术加载
添加主题页面,实现Ajax方式添加主题功能,利用Ajax技术实现主题修改
并删除。
8.2.1 Ajax模式下根据主题动态加载新闻1.需求介绍
访问系统首页,以Ajax方式加载页面“新闻中心”部分的新闻列表,默认加载所有新闻
主题下的新闻按创建时间降序排列,并实现分页,如图8.1。
当点击某个主题的超链接时,该主题下的新闻以Ajax方式加载,按创建时间降序排列,
并实现分页。
2.实现思路(1)实现数据层访问
需求中有两个分页查询要求:对所有主题下的新闻进行分页查询,对某一个进行分页查询
主题下的新闻可以分页搜索。事实上,这两个查询的区别仅在于 SQL 语句的一个主要方面。
查询问题 ID。事实上,对于SQL语句来说,这两个查询只是主题id的一个查询条件不同,
因此,考虑整合这两个查询。
图8.1 分页显示所有类别的新闻
修改NewsDao接口中分页查询相关方法的设计,增加topic id参数。
public interface NewsDao {
……// 省略其他方法
//获得新闻总数
public int getTotalCount(Integer id) throws SQLException;
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException;
}
在其实现类NewsDaoImpl中,根据传入参数tid是否有效,动态组装SQL语句并查询
查询条件。
public class NewsDaoImpl extends BaseDao implements NewsDao{
public NewsDaoImpl(Connection conn){
super(conn);
}
……//省略其他方法
//获得新闻的数量
public int getTotalCount(Integer tid) throws SQLEception{
ResultSet rs = null:
List params = new ArrayList ();
String sql = "SELECT COUNT('nid') FROM 'news'";
if(tid!= null){
sql += "WHERE 'ntid' = ?";
params.add(tid);
}
int count = -1;
try {
rs = this.executeQuery(sql,params.toArrary()) ;
rs.next();
count = rs.getInt(1);
}……省略异常处理和资源释放代码
return count;
}
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException{
List list = new ArrayList ();
ResultSet rs = null;
List params = new ArrayList ();
String sql = "SELECT'nid','ntid','ntitle','nauthor',"
+"'ncreateDate','nsummary','tname' FROM 'NEWS',"
+"'TOPIC''WHERE''NEWS'.'NTID' = 'TOPIC'.'tid'";
if{tid! = null){
sql +="AND 'NEWS'.'ntid' = ?";
params.add(tid);
}
sql += " ORDER BY 'ncreateDate' DESC LIMIT ?,?";
params.add((pageNo - 1)* pageSize);
params.add(pageSize);
try{
rs = this.executeQuery(sql,params.toArray());
……// 省略封装数据过程
}……//省略异常处理和资源释放代码
return list;
}
}
(2) 实现业务层
业务层接口NewsService及其实现类NewsServiceImpl也作了相应的调整和设计。
也是添加传入参数主题ID的方法。
修改NewsService接口中分页相关方法的设计,增加主题id参数。
public interface NewsService{
……//省略其他方法
//分页获取新闻
public void findPageNews(Integer tid,Page pageObj)
throws SQLException;
}
在其实现类NewsServiceImpl中调用Dao相关方法时传入tid即可。
public class NewsServiceImpl implements NewsService{
……//省略部分方法
//分页获取新闻
public void findPageNews(Inter tid,Page pageObj)
throws SQLException{
Connection conn = null;
try{
conn = DatebaseUtil.getConnection();
NewsDao newsDao = new NewsDaoImpl(conn);
……//省略部分代码
List newsList = newsDao.getPageNewsList(tid,
pageObj.getCurrPageNo(),
pageObj.getPageSize());
……//省略部分代码
}……// 省略异常处理和资源释放
}
}
}
(3)写Servlet
将原来的首页初始化公告拆解成两部分:按照传统初始化方式初始化最新消息和话题列表(如
图8.2)并使用Ajax方法加载新闻列表(如图8.1)。
图8.2 初始化最新消息和话题列表
以传统方式初始化最新消息和主题列表的关键代码如下。
……//省略其他功能
else if("topicLatest".equals(opr)){//初始化首页侧边栏和主题列表
Maptopics = new HashMap();
topics.put(1,5);
topics.put(2,5);
topics.Put(5,5);
List latests = newsService
.findLatestNewsByTid(topics); //查询最新消息
List list = topicService.findAllTopics(); //查询所有主题
request.setAttribute("list1",latests.get(0)); // 左侧国内新闻
request.setAttribute("list2",latests.get(1)); //左侧国际新闻
request.setAttribute("list3",latests.get(2)); // 左侧国际新闻
request.setAttribute("list",list); //所有的主题
request.getRequestDispatcher("/index.jsp").forward(request,response);
}……//省略其他功能
处理分页加载新闻列表的Ajax请求的关键代码如下。
else if("topicNews".equals(opr)){ //分页查询新闻
//获得主题id 和当前页数
String tid = request.getParameter("tid");
String pageIndex = request.getParameter("pageIndex");
……//省略部分代码
Page pageObj = new page();
……//省略部分代码
//调用业务方法查询
if(tid ==null||(tid = tid.trim()).length() ==0)
newsService.findPageNews(null,pageObj);
else
newsService.findPageNews(Integer.valueOf(tid),pageObj);
//使用 FastJSON 将 Page 对象序列化成 JSON 字符串
String newsJSON = JSON.toJSONStringWithDataFormat(pageObj,
"yyyy-MM-dd HH:mm:ss",
SerializerFeature.WriteMapNullValue);
//向客户端返回响应数据
out.print("[{\"tid\":\""+tid+"\"},"+newsJSON +"]");
}……//省略其他功能
注意
为了保证客户端分页条件的完整性,响应数据是一个JSON数组,包括主题id
和查询结果。
(4) 调整 index.jsp 页面
删除与获取和输出新闻列表相关的原创代码,只保留列表的容器。
……//省略其他页面内容
……//省略其他页面内容
为了适应拆分servlet功能和实际Ajax分页的需求,主题列表的超链接在
输出也需要相应调整。
<a href = "javascript:;" id = "${topic.tid}">
${topic.tname}</a>
点击主题超链接查询相关新闻的功能将在 JavaScript 脚本中使用 Ajax 方法实现。
添加了 id 属性,用于在点击事件中获取主题 id 作为查询参数。
(5) 编写 JavaScript 脚本
分别在以下代码块中编写相关的 JavaScript 脚本。
jQuery.noConflict();//让渡 "$" 的使用权,其他脚本库可以使用 "$"
(function($){
$(document).ready(function(){
//其他脚本编写于此处
});
})(jQuery);
1. 编写发送Ajax分页请求的getpagi()方法,在首页加载时调用它进行初始化
新闻列表。
function getPagi(tid,pageIndex){ //发送 Ajax 请求实现分页
var data = "opr = topicNews"; //准备请求参数
if(tid)
data += "&tid=" +tid;
if(pageIndex && pageIndex>0)
data += "&pageIndex="+pageIndex;
$.getJSON("util/news",data,pagi); //发送 Ajax 请求
};
getPage();//首页加载时,初始化加载新闻列表
2.编写回调方法pagi()处理响应,主要完成两件事:在这个页面显示数据和生成分页操作链接。
<p>//获取显示新闻列表的首页中心区域
var $centerNewsList = $("#container.main.content.classlist");
function pagi(data){ //分页查询的回调函数
var tid = datas[0].tid == "null"?"";datas[0].tid;
var data = datas[1]; //获取分页相关数据
//1.展示本页新闻数据
$centerNewsList.html("");
if(data.newsList == null)
$centerNewsList.html(
"出现错误,请稍后再试或与管理员联系1){
var $first = $("<a href=\"javascrit:;\">首页</a>").click(
function(){getPagi(tid,1);});
var $prev = $("<a href = \"javascript:;\">上一页</a>).click(
function(){getPagi(tid,(data.currPageNo-1));});
$operArea.append($first).append(" ").append($prev);
}
if(data.currPageNo 查看全部
抓取ajax动态网页java(JavaWeb应用设计及实战目录上一章下一章加载新闻源码)
JavaWeb应用设计及实用目录
上一章 下一章
上一个任务/上一节 下一个任务/下一节
加载新闻来源。
内容
(2)
(6)
系统首页新闻中心部分采用Ajax技术,按主题动态展示新闻功能,按条件加载
一个话题下的所有话题或新闻,并使用Ajax技术实现分页显示。使用 Ajax 技术加载
添加主题页面,实现Ajax方式添加主题功能,利用Ajax技术实现主题修改
并删除。
8.2.1 Ajax模式下根据主题动态加载新闻1.需求介绍
访问系统首页,以Ajax方式加载页面“新闻中心”部分的新闻列表,默认加载所有新闻
主题下的新闻按创建时间降序排列,并实现分页,如图8.1。
当点击某个主题的超链接时,该主题下的新闻以Ajax方式加载,按创建时间降序排列,
并实现分页。
2.实现思路(1)实现数据层访问
需求中有两个分页查询要求:对所有主题下的新闻进行分页查询,对某一个进行分页查询
主题下的新闻可以分页搜索。事实上,这两个查询的区别仅在于 SQL 语句的一个主要方面。
查询问题 ID。事实上,对于SQL语句来说,这两个查询只是主题id的一个查询条件不同,
因此,考虑整合这两个查询。
图8.1 分页显示所有类别的新闻
修改NewsDao接口中分页查询相关方法的设计,增加topic id参数。
public interface NewsDao {
……// 省略其他方法
//获得新闻总数
public int getTotalCount(Integer id) throws SQLException;
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException;
}
在其实现类NewsDaoImpl中,根据传入参数tid是否有效,动态组装SQL语句并查询
查询条件。
public class NewsDaoImpl extends BaseDao implements NewsDao{
public NewsDaoImpl(Connection conn){
super(conn);
}
……//省略其他方法
//获得新闻的数量
public int getTotalCount(Integer tid) throws SQLEception{
ResultSet rs = null:
List params = new ArrayList ();
String sql = "SELECT COUNT('nid') FROM 'news'";
if(tid!= null){
sql += "WHERE 'ntid' = ?";
params.add(tid);
}
int count = -1;
try {
rs = this.executeQuery(sql,params.toArrary()) ;
rs.next();
count = rs.getInt(1);
}……省略异常处理和资源释放代码
return count;
}
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException{
List list = new ArrayList ();
ResultSet rs = null;
List params = new ArrayList ();
String sql = "SELECT'nid','ntid','ntitle','nauthor',"
+"'ncreateDate','nsummary','tname' FROM 'NEWS',"
+"'TOPIC''WHERE''NEWS'.'NTID' = 'TOPIC'.'tid'";
if{tid! = null){
sql +="AND 'NEWS'.'ntid' = ?";
params.add(tid);
}
sql += " ORDER BY 'ncreateDate' DESC LIMIT ?,?";
params.add((pageNo - 1)* pageSize);
params.add(pageSize);
try{
rs = this.executeQuery(sql,params.toArray());
……// 省略封装数据过程
}……//省略异常处理和资源释放代码
return list;
}
}
(2) 实现业务层
业务层接口NewsService及其实现类NewsServiceImpl也作了相应的调整和设计。
也是添加传入参数主题ID的方法。
修改NewsService接口中分页相关方法的设计,增加主题id参数。
public interface NewsService{
……//省略其他方法
//分页获取新闻
public void findPageNews(Integer tid,Page pageObj)
throws SQLException;
}
在其实现类NewsServiceImpl中调用Dao相关方法时传入tid即可。
public class NewsServiceImpl implements NewsService{
……//省略部分方法
//分页获取新闻
public void findPageNews(Inter tid,Page pageObj)
throws SQLException{
Connection conn = null;
try{
conn = DatebaseUtil.getConnection();
NewsDao newsDao = new NewsDaoImpl(conn);
……//省略部分代码
List newsList = newsDao.getPageNewsList(tid,
pageObj.getCurrPageNo(),
pageObj.getPageSize());
……//省略部分代码
}……// 省略异常处理和资源释放
}
}
}
(3)写Servlet
将原来的首页初始化公告拆解成两部分:按照传统初始化方式初始化最新消息和话题列表(如
图8.2)并使用Ajax方法加载新闻列表(如图8.1)。
图8.2 初始化最新消息和话题列表
以传统方式初始化最新消息和主题列表的关键代码如下。
……//省略其他功能
else if("topicLatest".equals(opr)){//初始化首页侧边栏和主题列表
Maptopics = new HashMap();
topics.put(1,5);
topics.put(2,5);
topics.Put(5,5);
List latests = newsService
.findLatestNewsByTid(topics); //查询最新消息
List list = topicService.findAllTopics(); //查询所有主题
request.setAttribute("list1",latests.get(0)); // 左侧国内新闻
request.setAttribute("list2",latests.get(1)); //左侧国际新闻
request.setAttribute("list3",latests.get(2)); // 左侧国际新闻
request.setAttribute("list",list); //所有的主题
request.getRequestDispatcher("/index.jsp").forward(request,response);
}……//省略其他功能
处理分页加载新闻列表的Ajax请求的关键代码如下。
else if("topicNews".equals(opr)){ //分页查询新闻
//获得主题id 和当前页数
String tid = request.getParameter("tid");
String pageIndex = request.getParameter("pageIndex");
……//省略部分代码
Page pageObj = new page();
……//省略部分代码
//调用业务方法查询
if(tid ==null||(tid = tid.trim()).length() ==0)
newsService.findPageNews(null,pageObj);
else
newsService.findPageNews(Integer.valueOf(tid),pageObj);
//使用 FastJSON 将 Page 对象序列化成 JSON 字符串
String newsJSON = JSON.toJSONStringWithDataFormat(pageObj,
"yyyy-MM-dd HH:mm:ss",
SerializerFeature.WriteMapNullValue);
//向客户端返回响应数据
out.print("[{\"tid\":\""+tid+"\"},"+newsJSON +"]");
}……//省略其他功能
注意
为了保证客户端分页条件的完整性,响应数据是一个JSON数组,包括主题id
和查询结果。
(4) 调整 index.jsp 页面
删除与获取和输出新闻列表相关的原创代码,只保留列表的容器。
……//省略其他页面内容
……//省略其他页面内容
为了适应拆分servlet功能和实际Ajax分页的需求,主题列表的超链接在
输出也需要相应调整。
<a href = "javascript:;" id = "${topic.tid}">
${topic.tname}</a>
点击主题超链接查询相关新闻的功能将在 JavaScript 脚本中使用 Ajax 方法实现。
添加了 id 属性,用于在点击事件中获取主题 id 作为查询参数。
(5) 编写 JavaScript 脚本
分别在以下代码块中编写相关的 JavaScript 脚本。
jQuery.noConflict();//让渡 "$" 的使用权,其他脚本库可以使用 "$"
(function($){
$(document).ready(function(){
//其他脚本编写于此处
});
})(jQuery);
1. 编写发送Ajax分页请求的getpagi()方法,在首页加载时调用它进行初始化
新闻列表。
function getPagi(tid,pageIndex){ //发送 Ajax 请求实现分页
var data = "opr = topicNews"; //准备请求参数
if(tid)
data += "&tid=" +tid;
if(pageIndex && pageIndex>0)
data += "&pageIndex="+pageIndex;
$.getJSON("util/news",data,pagi); //发送 Ajax 请求
};
getPage();//首页加载时,初始化加载新闻列表
2.编写回调方法pagi()处理响应,主要完成两件事:在这个页面显示数据和生成分页操作链接。
<p>//获取显示新闻列表的首页中心区域
var $centerNewsList = $("#container.main.content.classlist");
function pagi(data){ //分页查询的回调函数
var tid = datas[0].tid == "null"?"";datas[0].tid;
var data = datas[1]; //获取分页相关数据
//1.展示本页新闻数据
$centerNewsList.html("");
if(data.newsList == null)
$centerNewsList.html(
"出现错误,请稍后再试或与管理员联系1){
var $first = $("<a href=\"javascrit:;\">首页</a>").click(
function(){getPagi(tid,1);});
var $prev = $("<a href = \"javascript:;\">上一页</a>).click(
function(){getPagi(tid,(data.currPageNo-1));});
$operArea.append($first).append(" ").append($prev);
}
if(data.currPageNo
抓取ajax动态网页java(开发工具IDEA2019开发环境JDK1.8+MySQL5.6+Tomcat8.0主要技术JSP+Servlet源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-09 20:01
前言
这是我在疫情期间和尚硅谷视频一起做的一个书店项目。昨天整理SSM文件的时候,发现还在草稿箱里。写完了(笑),因为当时没有想过给大家看,主要是想自己看看,但是项目实现的功能还是写在文档里,虽然写的不是完成了,但是有了视频,我还是能看懂的。今天看到有小伙伴想要源码,所以先把源码分享一下,后面再补充。
开发工具
IDEA2019
开发环境
JDK1.8+MySQL5.6+Tomcat8.0
主要技术
JSP+Servlet
源代码
先补个网盘链接: 解压码:qqfu
数据库文件根目录下有个book.sql
对于Github,等我以后学习,然后上传到那里。主要原因是这个项目还存在一些问题。虽然我在做的时候修复了一些,但还是希望能上传到Github,让大家一起完善。
无关
如果您觉得本项目文档对您有帮助,请扫描二维码获取优惠券,这对我来说真的很重要,操作步骤如下!
项目功能用户页面JSP动态
注册登录失败后在页面中提取相同的内容,在页面上保存一些数据并合并注册和登录的servlet创建BaseServlet
数据封装及使用BeanUtils抽取
BeanUtils 工具类,可以一次性将所有请求的参数注入JavaBean。
BeanUtils工具类常用于将Map中的值注入JavaBeans,或者复制对象属性的值。
BeanUtils 不是 Jdk 类。但是第三方工具。所以需要引导包。
1、导入需要的jar包:
2、编写WebUtils工具类使用
使用EL表达式修改表单以呼应图书列表
添加书籍
添加工具方法将int类型转换为WebUtils工具类删除书籍
编辑本书
分页
分页模型Page实现在首页、上一页、下一页、最后一页分页模块中跳转到指定页数的功能。点击页码跳转后,自定义显示页码,修改页面、添加、删除、修改图书信息。回显页面
以修改一本书为例: 查看全部
抓取ajax动态网页java(开发工具IDEA2019开发环境JDK1.8+MySQL5.6+Tomcat8.0主要技术JSP+Servlet源码)
前言
这是我在疫情期间和尚硅谷视频一起做的一个书店项目。昨天整理SSM文件的时候,发现还在草稿箱里。写完了(笑),因为当时没有想过给大家看,主要是想自己看看,但是项目实现的功能还是写在文档里,虽然写的不是完成了,但是有了视频,我还是能看懂的。今天看到有小伙伴想要源码,所以先把源码分享一下,后面再补充。
开发工具
IDEA2019
开发环境
JDK1.8+MySQL5.6+Tomcat8.0
主要技术
JSP+Servlet
源代码
先补个网盘链接: 解压码:qqfu
数据库文件根目录下有个book.sql
对于Github,等我以后学习,然后上传到那里。主要原因是这个项目还存在一些问题。虽然我在做的时候修复了一些,但还是希望能上传到Github,让大家一起完善。
无关

如果您觉得本项目文档对您有帮助,请扫描二维码获取优惠券,这对我来说真的很重要,操作步骤如下!




项目功能用户页面JSP动态

注册登录失败后在页面中提取相同的内容,在页面上保存一些数据并合并注册和登录的servlet创建BaseServlet

数据封装及使用BeanUtils抽取
BeanUtils 工具类,可以一次性将所有请求的参数注入JavaBean。
BeanUtils工具类常用于将Map中的值注入JavaBeans,或者复制对象属性的值。
BeanUtils 不是 Jdk 类。但是第三方工具。所以需要引导包。
1、导入需要的jar包:
2、编写WebUtils工具类使用
使用EL表达式修改表单以呼应图书列表

添加书籍

添加工具方法将int类型转换为WebUtils工具类删除书籍

编辑本书

分页

分页模型Page实现在首页、上一页、下一页、最后一页分页模块中跳转到指定页数的功能。点击页码跳转后,自定义显示页码,修改页面、添加、删除、修改图书信息。回显页面
以修改一本书为例:
抓取ajax动态网页java(大数据行业数据价值不言而喻的技术总结及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-08 11:13
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理 查看全部
抓取ajax动态网页java(大数据行业数据价值不言而喻的技术总结及解决办法!)
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
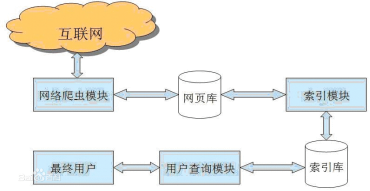
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
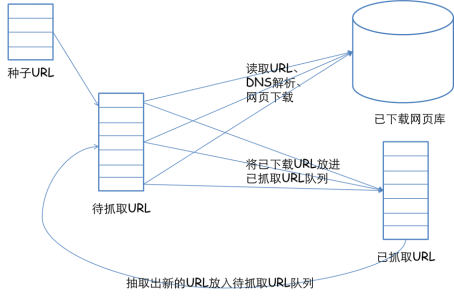
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
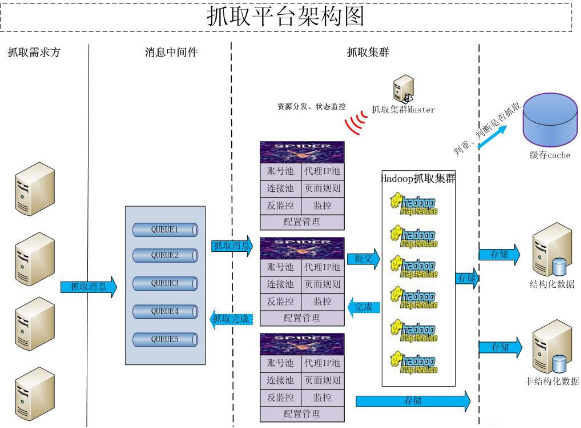
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理
抓取ajax动态网页java(目前为止只有网文快捕可以实现该功能下载网址文章的采集对吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-06 13:11
到目前为止,只有网页快拍可以实现这个功能
下载网址
是 文章 的 采集 对吧?用优采云看百度。
您可以使用绘图。如果不会画,那就用最简单的QQ截图。
可能会。
可以同时按下三个键ALT+CTRL+A,看看你的指针会变色,然后在你要剪切的地方左上角点住鼠标左键,然后把指针拖到那个地方你要剪切,然后松开鼠标左键,然后双击左键,会打开一个QQ对话框,在里面点击鼠标右键,看到粘贴,点击它,剪切出来的图片就出来了显示。否则,您也可以从 Internet 下载快照软件。
给你一个想法
1、从上到下、从左到右在全图中搜索红色,得到第一个点A0
2、从0度逆时针搜索A0周围8个点,得到第一个红点A1
3.从A0逆时针搜索A1周围8个点,得到A2
4,以此类推,直到回到 A0
5.得到的A0到An就是Y的包络线,取这些点的最大和最小坐标切出Y
6.在原图中,将原Y占据的位置用蓝色填充
7.重复以上步骤,直到图片中没有红色
如何爬取网页中的动态数据》》》首先要明确我的意思是动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即没有网页源文件,是在页面中加载到浏览器后动态生成的。让我们进入主题。很简单的抓取一个静态页面,通过Java获取html源代码,然后分析...
python如何抓取动态页面内容?- 》》》 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑网站/流程及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具你提到的Firefox的firebug可以也可以用,不过我用过,觉得还是不如IE9的F12好用。3. 已经分析出来了,具体是哪个url生成了你需要的数据,然后在python中实现对应的代码。
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面……
如何使用Python抓取动态页面信息——""" selenium webdriverFirefox()implicitly_wait(3)查看网页请求获取数据时,一般会请求其他地址,也获取信息。你的问题太笼统了,只能如此回答
如何在网页中捕获动态数据-》》》网页是网站的基本元素,也是承载各种网站应用程序的平台。通俗的说,你的网站是由你的网站组成的。网页是一个收录HTML标签的纯文本文件,可以存储在世界的某个角落的电脑上,是万维网上的一个“页面”,它是一种超文本标记语言格式(标准的应用通用标记语言,文件扩展名为 .html 或 .htm)。网页通常用作图像文件。图纸。网页将通过网络浏览器阅读。
如何使用Python抓取动态页面信息——“””这个要先研究动态页面不变的部分,然后通过字符串处理提取出需要的信息
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此...
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果你想捕获的动态页面没有这些限制,那么你可以使用和静态页面一样的方法,例如: import urllib2 url = "xxxxxx" print urllib2.urlopen(url).read ()
如何使用Python抓取动态页面信息——“”” 1、使用模拟浏览器 2、找到对应的ajax url,提交ajax请求,如果是js动态加载的,可以使用pyV8第三方包解析js
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果要捕获的动态页面没有这些限制,那么可以使用和静态页面一样的方法,比如: import urllib2url = "xxxxxx" print urllib2.urlopen(url).read( ) 查看全部
抓取ajax动态网页java(目前为止只有网文快捕可以实现该功能下载网址文章的采集对吗)
到目前为止,只有网页快拍可以实现这个功能
下载网址
是 文章 的 采集 对吧?用优采云看百度。
您可以使用绘图。如果不会画,那就用最简单的QQ截图。
可能会。
可以同时按下三个键ALT+CTRL+A,看看你的指针会变色,然后在你要剪切的地方左上角点住鼠标左键,然后把指针拖到那个地方你要剪切,然后松开鼠标左键,然后双击左键,会打开一个QQ对话框,在里面点击鼠标右键,看到粘贴,点击它,剪切出来的图片就出来了显示。否则,您也可以从 Internet 下载快照软件。
给你一个想法
1、从上到下、从左到右在全图中搜索红色,得到第一个点A0
2、从0度逆时针搜索A0周围8个点,得到第一个红点A1
3.从A0逆时针搜索A1周围8个点,得到A2
4,以此类推,直到回到 A0
5.得到的A0到An就是Y的包络线,取这些点的最大和最小坐标切出Y
6.在原图中,将原Y占据的位置用蓝色填充
7.重复以上步骤,直到图片中没有红色
如何爬取网页中的动态数据》》》首先要明确我的意思是动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即没有网页源文件,是在页面中加载到浏览器后动态生成的。让我们进入主题。很简单的抓取一个静态页面,通过Java获取html源代码,然后分析...
python如何抓取动态页面内容?- 》》》 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑网站/流程及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具你提到的Firefox的firebug可以也可以用,不过我用过,觉得还是不如IE9的F12好用。3. 已经分析出来了,具体是哪个url生成了你需要的数据,然后在python中实现对应的代码。
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面……
如何使用Python抓取动态页面信息——""" selenium webdriverFirefox()implicitly_wait(3)查看网页请求获取数据时,一般会请求其他地址,也获取信息。你的问题太笼统了,只能如此回答
如何在网页中捕获动态数据-》》》网页是网站的基本元素,也是承载各种网站应用程序的平台。通俗的说,你的网站是由你的网站组成的。网页是一个收录HTML标签的纯文本文件,可以存储在世界的某个角落的电脑上,是万维网上的一个“页面”,它是一种超文本标记语言格式(标准的应用通用标记语言,文件扩展名为 .html 或 .htm)。网页通常用作图像文件。图纸。网页将通过网络浏览器阅读。
如何使用Python抓取动态页面信息——“””这个要先研究动态页面不变的部分,然后通过字符串处理提取出需要的信息
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此...
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果你想捕获的动态页面没有这些限制,那么你可以使用和静态页面一样的方法,例如: import urllib2 url = "xxxxxx" print urllib2.urlopen(url).read ()
如何使用Python抓取动态页面信息——“”” 1、使用模拟浏览器 2、找到对应的ajax url,提交ajax请求,如果是js动态加载的,可以使用pyV8第三方包解析js
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果要捕获的动态页面没有这些限制,那么可以使用和静态页面一样的方法,比如: import urllib2url = "xxxxxx" print urllib2.urlopen(url).read( )
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-04 10:03
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载) 查看全部
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载)
抓取ajax动态网页java((二)如何掌握最低的最低可行知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-03 01:11
如果您的工作涉及某种程度的 SEO,您可能会越来越多地听到 Java 及其对爬网和索引的影响。坦率地说,百度蜘蛛在为此苦苦挣扎,许多 网站 使用现代 Java 来加载关键内容。正因为如此,我们需要具备这个话题才能有效地讨论它。分享此 文章 的目的是为您提供必要的最低可行知识。
(一)相关域是否依赖客户端 Java 来加载/更改页面内容或链接?
诊断涉及 Java 的任何问题的第一步是检查域是否使用它来加载可能影响 SEO(页面内容或链接)的关键内容。理想情况下,每当您获得新客户(在初始技术审查期间),或者每当您的客户重新设计/推出新功能 网站 时,都会发生这种情况。
我们该如何做呢?
询问客户
问你应该接受!尽管如此,作为顾问,您可以做的最快/最简单的事情之一就是联系您的 POC(或帐户开发人员)并询问他们。毕竟,这些都是日复一日在 网站 工作的人!
手动检查
即使在拥有数百万页面的大型电子商务网站上,也往往只有几个重要的页面模板。以我的经验,手动检查最多只需要一个小时。您可以使用插件,从那里禁用 Java,并手动检查 网站 是否有重要模板(主页、类别页面、产品页面、博客文章 等)
换句话说,本页第一个问题的答案是“是的,Java 用于加载 网站 的关键部分”。
(二)如果是,百度蜘蛛能否正确查看Java加载的内容?
如果您的客户在其 网站 的某些部分中依赖 Java(在我们的例子中是这样),那么我们的工作就是尝试复制百度实际查看页面的方式。我们想回答这个问题:“百度是否以我们想要的方式看到了页面/网站?”
为了更准确地描述百度蜘蛛看到的内容,我们需要尝试模仿百度蜘蛛爬网的方式。
(三)如果我们确定百度蜘蛛没有正确看到我们的内容怎么办?
既然我们知道域使用 Java 加载关键内容,并且我们知道百度蜘蛛很可能没有看到该内容,那么最后一步就是向客户端推荐理想的解决方案。关键词:推荐,未实施。我们的工作是向我们的客户提出问题,解释为什么它很重要(以及可能的影响),并强调理想的解决方案。尝试为具有独特堆栈/资源/等的开发人员找出理想的解决方案根本不是我们的工作。
概括
冒着严重过度简化的风险,为了在 2018 年开始使用 Java 和 SEO,您需要做以下事情:
找出客户端的域名何时/何地使用客户端 Java 加载页面内容或链接。询问开发商。关闭 Java 并通过页面模板进行一些手动测试。使用 Java 爬虫进行爬取。检查百度蜘蛛是否按照我们预期的方式查看内容。百度的手机友谊检查器。执行 网站:在网络上搜索可见内容。使用 Java 爬虫进行爬取。给客户一个理想的建议。服务器端渲染。混合解决方案(同构)。不是 AJAX 爬取。 查看全部
抓取ajax动态网页java((二)如何掌握最低的最低可行知识)
如果您的工作涉及某种程度的 SEO,您可能会越来越多地听到 Java 及其对爬网和索引的影响。坦率地说,百度蜘蛛在为此苦苦挣扎,许多 网站 使用现代 Java 来加载关键内容。正因为如此,我们需要具备这个话题才能有效地讨论它。分享此 文章 的目的是为您提供必要的最低可行知识。
(一)相关域是否依赖客户端 Java 来加载/更改页面内容或链接?
诊断涉及 Java 的任何问题的第一步是检查域是否使用它来加载可能影响 SEO(页面内容或链接)的关键内容。理想情况下,每当您获得新客户(在初始技术审查期间),或者每当您的客户重新设计/推出新功能 网站 时,都会发生这种情况。
我们该如何做呢?
询问客户
问你应该接受!尽管如此,作为顾问,您可以做的最快/最简单的事情之一就是联系您的 POC(或帐户开发人员)并询问他们。毕竟,这些都是日复一日在 网站 工作的人!
手动检查
即使在拥有数百万页面的大型电子商务网站上,也往往只有几个重要的页面模板。以我的经验,手动检查最多只需要一个小时。您可以使用插件,从那里禁用 Java,并手动检查 网站 是否有重要模板(主页、类别页面、产品页面、博客文章 等)
换句话说,本页第一个问题的答案是“是的,Java 用于加载 网站 的关键部分”。
(二)如果是,百度蜘蛛能否正确查看Java加载的内容?
如果您的客户在其 网站 的某些部分中依赖 Java(在我们的例子中是这样),那么我们的工作就是尝试复制百度实际查看页面的方式。我们想回答这个问题:“百度是否以我们想要的方式看到了页面/网站?”
为了更准确地描述百度蜘蛛看到的内容,我们需要尝试模仿百度蜘蛛爬网的方式。
(三)如果我们确定百度蜘蛛没有正确看到我们的内容怎么办?
既然我们知道域使用 Java 加载关键内容,并且我们知道百度蜘蛛很可能没有看到该内容,那么最后一步就是向客户端推荐理想的解决方案。关键词:推荐,未实施。我们的工作是向我们的客户提出问题,解释为什么它很重要(以及可能的影响),并强调理想的解决方案。尝试为具有独特堆栈/资源/等的开发人员找出理想的解决方案根本不是我们的工作。
概括
冒着严重过度简化的风险,为了在 2018 年开始使用 Java 和 SEO,您需要做以下事情:
找出客户端的域名何时/何地使用客户端 Java 加载页面内容或链接。询问开发商。关闭 Java 并通过页面模板进行一些手动测试。使用 Java 爬虫进行爬取。检查百度蜘蛛是否按照我们预期的方式查看内容。百度的手机友谊检查器。执行 网站:在网络上搜索可见内容。使用 Java 爬虫进行爬取。给客户一个理想的建议。服务器端渲染。混合解决方案(同构)。不是 AJAX 爬取。
抓取ajax动态网页java( 小哥带你看剧2019-07-26简介值得强调的是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-02 19:09
小哥带你看剧2019-07-26简介值得强调的是)
网站动态页面
小哥带你看剧2019-07-26
介绍
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何通过网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
从网站查看者的角度来看,无论是动态网页还是静态网页,都可以展示基本的文字和图片信息,但是从网站开发、管理、维护的角度来看,却是非常很难有大的区别。
对应静态网页,可以与后台数据库交互,传输数据。也就是说,网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页制作格式,而是. cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visualstudio2008等实现。
特征
简要总结如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,一般搜索引擎不可能从一个网站数据库中访问所有网页,或者出于技术考虑, search URL中“?”后面的内容是不被抓取的,所以使用动态网页的网站在推广搜索引擎时需要做一定的技术处理,以满足搜索引擎的要求。
客户
客户端脚本更改特定网页上的界面和行为,以响应鼠标或键盘操作,或在指定时间事件。在这种情况下,动态行为正在发生。客户端生成的内容驻留在用户的本地计算机系统上。
这些页面使用的表示技术称为富界面页面。客户端脚本语言如JavaScript(Java Script)或ActionScript(Action Script)、动态HTML(DHTML)和Flash技术的使用经常被用来对媒体类型(声音、动画、修改过的文本等)的呈现进行编程.)。该脚本还允许使用远程脚本,这是一种允许 DHTML 页面使用隐藏框架、XMLHttpRequest 或 Web (web) 服务从服务器请求附加信息的技术。
缺点
1、首先,动态网页在访问速度上并不占优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到该指令对应的数据,然后传输给服务器。用户看到网页。问题就出来了。每次访问网页时,都必须经过这样一个过程。这个过程至少需要几秒钟。当访问者数量较多时,页面的加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的 网站。
静态网页很简单。静态网页实际上是存在的,没有经过服务器编译,直接加载到客户端的浏览器中显示。
可以看出,动态网页在访问速度上并不占优势。
2、在搜索引擎中不占优势收录
上面我是从服务器和用户体验的角度讲的,下面从搜索引擎的角度讲收录。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会爬现成的,不会自己打字,网站在搜索引擎收录中没有优势。搜索引擎仍然更喜欢静态页面。
但是,搜索引擎正在不断改进。到目前为止,绝大多数搜索引擎都支持动态页面的爬取。 查看全部
抓取ajax动态网页java(
小哥带你看剧2019-07-26简介值得强调的是)
网站动态页面
小哥带你看剧2019-07-26
介绍
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何通过网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
从网站查看者的角度来看,无论是动态网页还是静态网页,都可以展示基本的文字和图片信息,但是从网站开发、管理、维护的角度来看,却是非常很难有大的区别。
对应静态网页,可以与后台数据库交互,传输数据。也就是说,网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页制作格式,而是. cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visualstudio2008等实现。
特征
简要总结如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,一般搜索引擎不可能从一个网站数据库中访问所有网页,或者出于技术考虑, search URL中“?”后面的内容是不被抓取的,所以使用动态网页的网站在推广搜索引擎时需要做一定的技术处理,以满足搜索引擎的要求。
客户
客户端脚本更改特定网页上的界面和行为,以响应鼠标或键盘操作,或在指定时间事件。在这种情况下,动态行为正在发生。客户端生成的内容驻留在用户的本地计算机系统上。
这些页面使用的表示技术称为富界面页面。客户端脚本语言如JavaScript(Java Script)或ActionScript(Action Script)、动态HTML(DHTML)和Flash技术的使用经常被用来对媒体类型(声音、动画、修改过的文本等)的呈现进行编程.)。该脚本还允许使用远程脚本,这是一种允许 DHTML 页面使用隐藏框架、XMLHttpRequest 或 Web (web) 服务从服务器请求附加信息的技术。
缺点
1、首先,动态网页在访问速度上并不占优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到该指令对应的数据,然后传输给服务器。用户看到网页。问题就出来了。每次访问网页时,都必须经过这样一个过程。这个过程至少需要几秒钟。当访问者数量较多时,页面的加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的 网站。
静态网页很简单。静态网页实际上是存在的,没有经过服务器编译,直接加载到客户端的浏览器中显示。
可以看出,动态网页在访问速度上并不占优势。
2、在搜索引擎中不占优势收录
上面我是从服务器和用户体验的角度讲的,下面从搜索引擎的角度讲收录。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会爬现成的,不会自己打字,网站在搜索引擎收录中没有优势。搜索引擎仍然更喜欢静态页面。
但是,搜索引擎正在不断改进。到目前为止,绝大多数搜索引擎都支持动态页面的爬取。
抓取ajax动态网页java(HTML5的pushState+Ajax(pjax)提供HTML5接口的使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 19:08
)
如果您玩过 Google+ 并看到过 YouTube 的新界面,那么您就已经体验过这项新的 HTML5 功能。使用pushState + Ajax(pjax),可以实现网页的ajax加载,同时可以完成URL的改变,没有网页跳转和刷新的迹象,就像改变网页的hash(#)一样.
旧解决方案
据说SEO和ajax是天敌。自 Twitter 以来,调用内容的 Ajax+hash 方法一直很流行。谷歌给出的解决方案是自动将“#!~string”转换为“?_excaped_fragment_=~string”来捕获动态内容。但这无疑会很麻烦:首先需要在网站上配置“?_excaped_fragment_=~string”的处理,如果用户直接复制分享URL“#!/~string”,表示网页还必须监听 hashchange。不过你这么想也没关系#!看起来不错。
新解决方案:pushState
不过,HTML5 的新接口 pushState/replaceState 可以完美解决这个问题。避免了改变hash的问题,也避免了不懂URL形式的用户的困惑。同时还有 onpopstate 提供监控和良好的响应来回前进。而且它不需要 URL 实际存在。
HTML5 pushState+Ajax
HTML5提供了历史接口,以状态的形式添加或替换浏览器的URL。它的实现函数是pushState和replaceState。
pushState 示例
pushState()的基本参数是:
window.history.pushState(state, title, url);
state和title都可以为空,但建议不要为空。应该创建一个状态来配合 popstate 监控。
例如,我们现在可以通过 pushState 更改 URL 而无需刷新页面。
var state = ( {
url: ~href, title: ~title, ~additionalKEY: ~additionalVALUE
} );
window.history.pushState(state, ~title, ~href);
带有“~”符号的内容是自定义内容。您可以将此 ~href (URL) 推送到浏览器的历史记录中。如果你想改变页面的标题,你应该:
document.title= ~newTitle;
注意,只是 pushState 不能改变页面标题。
replaceState 也一样
window.history.replaceState( state, ~title, ~href);
pushState和replaceState的区别
pushState()可以创建历史,可以配合popstate事件,而replaceState()替换当前URL,不生成历史。
限制因素
只能替换为同域的 URL,即不能替换为。并且 state 对象并不像 DOM 那样存储不可序列化的对象。
Ajax 与 pushState 示例
Ajax + pushState 现在用于提供一种新的 ajax 调用样式。以 jQuery 为例,为了 SEO 的需要,应该在 a 标签的 onclick 中添加一个方法。
$("~target a").click(function(evt){
evt.preventDefault(); // 阻止默认的跳转操作
var uri=$(this).attr('href');
var newTitle=ajax_Load(uri); // 你自定义的Ajax加载函数,例如它会返回newTitle
document.title=newTitle; // 分配新的页面标题
if(history.pushState){
var state=({
url: uri, title: newTitle
});
window.history.pushState(state, newTitle, uri);
}else{ window.location.href="#!"+~fakeURI; } // 如果不支持,使用旧的解决方案
return false;
});
function ajax_Load(uri){ ... return newTitle; } // 你自定义的ajax函数,例如它会返回newTitle
pushState 已完成。新标题newTitle的获取是另一个问题。比如你可以把data-newtitle=~title属性赋给a标签并在那个时候读取它,或者如果你使用$.ajax()函数,你可以使用$(result)。 filter("title").text() 来获取。
另外,如果需要使用这个ajax来连接新加载的页面,需要重新部署新内容的a标签,例如
$("~newContentTarget a").click(function(evt){ ... });
pushState配合popstate监控
如果你想很好地支持浏览器的历史向前和向后操作,你应该部署popstate监听器:
window.addEventListener('popstate', function(evt){
var state = evt.state;
var newTitle = ajax_Load(state.url); //你自定义的ajax加载函数,例如它会返回newTitle
document.title=newTitle;
}, false);
提醒,您可以使用 setRequestHeader() 让服务器输出带有您的 ajax 请求的特殊内容。
流程图
本例的大致流程如下图所示
jQuery + PJAX 插件
已在github上发布。有人把PJAX做成了一个jQuery插件,调用方便,省了很多代码:
if ($.support.pjax) {
$(document).on('click', 'a[data-pjax]', function(event) {
var container = $(this).closest('[data-pjax-container]')
$.pjax.click(event, {container: container})
});}
感谢观看,如有错误请指出。
下载:jquery-pjax-master
原文: 查看全部
抓取ajax动态网页java(HTML5的pushState+Ajax(pjax)提供HTML5接口的使用
)
如果您玩过 Google+ 并看到过 YouTube 的新界面,那么您就已经体验过这项新的 HTML5 功能。使用pushState + Ajax(pjax),可以实现网页的ajax加载,同时可以完成URL的改变,没有网页跳转和刷新的迹象,就像改变网页的hash(#)一样.
旧解决方案
据说SEO和ajax是天敌。自 Twitter 以来,调用内容的 Ajax+hash 方法一直很流行。谷歌给出的解决方案是自动将“#!~string”转换为“?_excaped_fragment_=~string”来捕获动态内容。但这无疑会很麻烦:首先需要在网站上配置“?_excaped_fragment_=~string”的处理,如果用户直接复制分享URL“#!/~string”,表示网页还必须监听 hashchange。不过你这么想也没关系#!看起来不错。

新解决方案:pushState
不过,HTML5 的新接口 pushState/replaceState 可以完美解决这个问题。避免了改变hash的问题,也避免了不懂URL形式的用户的困惑。同时还有 onpopstate 提供监控和良好的响应来回前进。而且它不需要 URL 实际存在。
HTML5 pushState+Ajax
HTML5提供了历史接口,以状态的形式添加或替换浏览器的URL。它的实现函数是pushState和replaceState。
pushState 示例
pushState()的基本参数是:
window.history.pushState(state, title, url);
state和title都可以为空,但建议不要为空。应该创建一个状态来配合 popstate 监控。
例如,我们现在可以通过 pushState 更改 URL 而无需刷新页面。
var state = ( {
url: ~href, title: ~title, ~additionalKEY: ~additionalVALUE
} );
window.history.pushState(state, ~title, ~href);
带有“~”符号的内容是自定义内容。您可以将此 ~href (URL) 推送到浏览器的历史记录中。如果你想改变页面的标题,你应该:
document.title= ~newTitle;
注意,只是 pushState 不能改变页面标题。
replaceState 也一样
window.history.replaceState( state, ~title, ~href);
pushState和replaceState的区别
pushState()可以创建历史,可以配合popstate事件,而replaceState()替换当前URL,不生成历史。
限制因素
只能替换为同域的 URL,即不能替换为。并且 state 对象并不像 DOM 那样存储不可序列化的对象。
Ajax 与 pushState 示例
Ajax + pushState 现在用于提供一种新的 ajax 调用样式。以 jQuery 为例,为了 SEO 的需要,应该在 a 标签的 onclick 中添加一个方法。
$("~target a").click(function(evt){
evt.preventDefault(); // 阻止默认的跳转操作
var uri=$(this).attr('href');
var newTitle=ajax_Load(uri); // 你自定义的Ajax加载函数,例如它会返回newTitle
document.title=newTitle; // 分配新的页面标题
if(history.pushState){
var state=({
url: uri, title: newTitle
});
window.history.pushState(state, newTitle, uri);
}else{ window.location.href="#!"+~fakeURI; } // 如果不支持,使用旧的解决方案
return false;
});
function ajax_Load(uri){ ... return newTitle; } // 你自定义的ajax函数,例如它会返回newTitle
pushState 已完成。新标题newTitle的获取是另一个问题。比如你可以把data-newtitle=~title属性赋给a标签并在那个时候读取它,或者如果你使用$.ajax()函数,你可以使用$(result)。 filter("title").text() 来获取。
另外,如果需要使用这个ajax来连接新加载的页面,需要重新部署新内容的a标签,例如
$("~newContentTarget a").click(function(evt){ ... });
pushState配合popstate监控
如果你想很好地支持浏览器的历史向前和向后操作,你应该部署popstate监听器:
window.addEventListener('popstate', function(evt){
var state = evt.state;
var newTitle = ajax_Load(state.url); //你自定义的ajax加载函数,例如它会返回newTitle
document.title=newTitle;
}, false);
提醒,您可以使用 setRequestHeader() 让服务器输出带有您的 ajax 请求的特殊内容。
流程图
本例的大致流程如下图所示

jQuery + PJAX 插件
已在github上发布。有人把PJAX做成了一个jQuery插件,调用方便,省了很多代码:
if ($.support.pjax) {
$(document).on('click', 'a[data-pjax]', function(event) {
var container = $(this).closest('[data-pjax-container]')
$.pjax.click(event, {container: container})
});}
感谢观看,如有错误请指出。
下载:jquery-pjax-master
原文:
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-29 00:03
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以爬取重复数据,爬虫可以爬取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。当遇到这样的网站时,我们不能使用上面的方法。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等等。在自动化渗透中会很有用,会在未来。提到这个。
转载于: 查看全部
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。

2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。


2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。

分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以爬取重复数据,爬虫可以爬取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。当遇到这样的网站时,我们不能使用上面的方法。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等等。在自动化渗透中会很有用,会在未来。提到这个。
转载于:
抓取ajax动态网页java( 视频地址相关文件语言入门()介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 09:04
视频地址相关文件语言入门()介绍)
JavaWeb
视频地址
相关文件
day1 HTML&&CSS 1、B/S软件结构2、前端开发流程3、网页组件4、html介绍
副题 2
5、创建html6、html编写规范7、Heml标签介绍8、常用标签介绍文档9、css技术day2 JavaScript语言介绍1、@ >JavaScript介绍JS2、JavaScript与html代码的结合4、变量5、比较(关系)运算,逻辑运算7、数组8、函数9、自定义对象
对象定义:
var variable name = new Object();//对象实例(空对象)
VariableName.PropertyName = Value;//定义一个属性
变量名。 Function name = function(){}//定义一个函数
访问对象:
变量名.属性/函数名();
10、js中的事件11、DOM模型
了解 Document 对象:
1、Document 他管理着所有的HTML文档内容
2、document是具有层次关系的树状结构文档
3、他要求我们将所有标签客观化
4、我们可以通过document访问所有的tag对象
Document对象中的方法介绍
document.getElementById(elementId) 通过标签的id属性找到标签dom对象,elementId是标签的id属性的值
身份证
名字
标签名
页面加载完成后必须执行对应的三个方法,才能查询到标签对象
第三天 jQuery jQuery = JavaScript + 查询
核心理念:少写,多做(少写,多做)
2、使用jQuery绑定一个按钮点击事件
1]要使用jQuery,必须导入jQuery库
2] $是jQuery中的一个函数
3] 为按钮添加点击响应功能
1、使用jQuery查询标签对象
2、使用标签object.click(function(){}):
3、jQuery核心函数4、jQuery对象和dom对象5、jQuery选择器6、jQuery元素过滤day4 jQuery 1、jQuery属性操作
val 同时选择多个表单状态
全选、取消全选、反转
4、DOM 的增删改查
内部插入
a.append(b)
a.prepend(b)
外部插入
a.insertAfter(b)ba
a.insertBefore(b) ab
替换
a.replaceWith(b) 用 b 替换 a
a.replaceAll(b) 将所有 b 替换为 a
删除
a.remove()
a.empty();
表记录的动态增删
6、CSS 样式操作
添加删除获取
7、jQuery 动画
隐藏、显示、隐藏()、显示()、切换()
淡入淡出
8、jQuery 事件操作
$(function(){});与window.οnlοad=function(){}的区别
触发时间
浏览器内核解析页面的标签并在创建DOM对象后立即执行
原生jsye表面加载完成后,等待浏览器内核解析并创建DOM对象,等待标签显示所需的内容加载完毕。
触发序列
页面加载后执行jQuery
原生js页面加载后
执行次数
jQuery页面加载完成后,封装成函数function,依次执行
原生js页面加载后,只会执行最后一个赋值函数
day5 Tomcat&&xml Tomcat
网络资源的分类:
静态资源html css js txt mp4 jpg
动态资源jsp页面Servlet程序
常用的网络服务器
Tomcat:提供对jsp和servlet的支持,是一个轻量级的javaWeb容器,是目前应用最广泛的JavaWeb服务器
老板
玻璃鱼
树脂
网络逻辑
xml day6 Servlet Serlet是javaEE规范之一,规范就是接口
Servlet是JavaWeb的三大组件之一,三大组件分别是Servlet程序、Filter过滤器、Listener监听器
Servlet是一个运行在服务端的java小程序,可以接受客户端发出的请求,并将相应的数据发送给客户端
Get 和 Post 请求的分发处理
HTTP协议07 day8 jsp jsp中的一些其他请求响应:java server pages Java server pages,本质上是一个servlet程序
作用:代替servlet程序,返回html页面的数据
jsp的三种语法:
jsp头部中的page指令
jsp中的常用脚本
jsp中的三种注释
9个jsp Listener内置对象day9 EL表达式&& JSTL标签库1、EL表达式:
Expression Language 表达语言,非常简洁
格式:${表达式}
功能:
替换jsp页面中的表达式脚本,输出jsp页面中的数据
运算:关系运算、逻辑运算、算术运算、三元运算
day14 Cookie和Session Cookie:服务端通知客户端保存键值对的技术
客户端有cookie后,每个请求都发给服务器
每个cookie的大小不能超过4kb
一个创造
b 服务器获取
c Cookie 值修改
d 浏览器查看 cookie
e Cookie 生命控制(创建和销毁)
f Cookie有效路径Path设置(过滤掉哪些cookie可以发送到服务器,哪些不发送)
由服务器(Tomcat)创建并通知客户端(浏览器)
服务器只需要一行代码即可获取cookie req.getCookies():Cookie[]
Session session:Session是一个接口(HttpSession)
一种用于维护客户端和服务器之间关联的技术
每个客户端都有自己的会话
Session session,常用于用户登录后保存信息
day15 Filter Filter 过滤器是JavaWeb的三个组件之一(Servlet Listener Filter)
作用:拦截请求、过滤响应(权限检查、日志操作、事务管理)
如何使用Filter过滤器:
1、写一个类来实现Filter接口
2、实现过滤方法doFilter()
3、去web.xml配置Filter的拦截路径
子主题2 子主题3 day16 JSON, AJAX, i18n JSON: JavaScript Object Notation 一种轻量级(与xml相比)数据交换(客户端和服务器之间业务数据的传输格式)格式
json 定义:由键值对组成,本身就是一个对象,
json以两种形式存在,json对象,json字符串,
一般来说,当你想对json中的数据进行操作时,需要json对象JSON.parse()的格式来将字符串转化为对象
一般在客户端和服务端交换数据时,使用json字符串JSON.stringify()对象将其转为字符串
java中JSON的使用
AJAX 请求:指一种用于创建交互式 Web 应用程序的 Web 开发技术
ajax是浏览器通过js异步发起请求,部分更新页面(部分更新不会丢弃原页面内容)页面的技术
i18国际书店项目04第一阶段:表单验证08第二阶段:用户注册和登录
要求2:用户登录
要求如下:
1)访问登陆页面
2)填写用户名和密码并提交
3)服务器判断用户是否存在
4)如果登录失败——>>>>返回用户名或密码错误信息
5)如果登录成功-->>>>返回登录
- JavaEE项目的三层架构
Web层/视图表示层:获取请求参数,封装成Bean对象,调用Service层处理服务,响应数据给客户端请求转发和重定向
服务业务层:处理业务逻辑,调用持久层保存到数据库
Dao持久层:只负责与数据库交互
分层的目的是解耦,降低代码的耦合度,方便后期项目的维护和升级
-
- 1、创建书城需要的数据库和表
2、编写数据库表对应的JavaBean对象
3、编写工具类JdbcUtils
4、写BaseDao
5、写一个 UserDao 测试
6、编写 UserService 和测试
7、编写web层实现用户注册功能
Debug调试的使用
10 第三阶段:
从页面中提取相同的内容
登录、注册错误提示和表单回显
BaseServlet的提取:用户模块的UserServlet程序和图书模块的BookServlet程序中相同的部分都是从父类BaseServlet中抽象出来的,然后分别继承
使用EL表达式修改表单回显
11 阶段 5 书籍模块
2、图书标签
副题 4
14的第六阶段
注销用户
表单重复提交-验证码
15 第八阶段 16 第九阶段 查看全部
抓取ajax动态网页java(
视频地址相关文件语言入门()介绍)
JavaWeb
视频地址
相关文件
day1 HTML&&CSS 1、B/S软件结构2、前端开发流程3、网页组件4、html介绍
副题 2
5、创建html6、html编写规范7、Heml标签介绍8、常用标签介绍文档9、css技术day2 JavaScript语言介绍1、@ >JavaScript介绍JS2、JavaScript与html代码的结合4、变量5、比较(关系)运算,逻辑运算7、数组8、函数9、自定义对象
对象定义:
var variable name = new Object();//对象实例(空对象)
VariableName.PropertyName = Value;//定义一个属性
变量名。 Function name = function(){}//定义一个函数
访问对象:
变量名.属性/函数名();
10、js中的事件11、DOM模型
了解 Document 对象:
1、Document 他管理着所有的HTML文档内容
2、document是具有层次关系的树状结构文档
3、他要求我们将所有标签客观化
4、我们可以通过document访问所有的tag对象
Document对象中的方法介绍
document.getElementById(elementId) 通过标签的id属性找到标签dom对象,elementId是标签的id属性的值
身份证
名字
标签名
页面加载完成后必须执行对应的三个方法,才能查询到标签对象
第三天 jQuery jQuery = JavaScript + 查询
核心理念:少写,多做(少写,多做)
2、使用jQuery绑定一个按钮点击事件
1]要使用jQuery,必须导入jQuery库
2] $是jQuery中的一个函数
3] 为按钮添加点击响应功能
1、使用jQuery查询标签对象
2、使用标签object.click(function(){}):
3、jQuery核心函数4、jQuery对象和dom对象5、jQuery选择器6、jQuery元素过滤day4 jQuery 1、jQuery属性操作
val 同时选择多个表单状态
全选、取消全选、反转
4、DOM 的增删改查
内部插入
a.append(b)
a.prepend(b)
外部插入
a.insertAfter(b)ba
a.insertBefore(b) ab
替换
a.replaceWith(b) 用 b 替换 a
a.replaceAll(b) 将所有 b 替换为 a
删除
a.remove()
a.empty();
表记录的动态增删
6、CSS 样式操作
添加删除获取
7、jQuery 动画
隐藏、显示、隐藏()、显示()、切换()
淡入淡出
8、jQuery 事件操作
$(function(){});与window.οnlοad=function(){}的区别
触发时间
浏览器内核解析页面的标签并在创建DOM对象后立即执行
原生jsye表面加载完成后,等待浏览器内核解析并创建DOM对象,等待标签显示所需的内容加载完毕。
触发序列
页面加载后执行jQuery
原生js页面加载后
执行次数
jQuery页面加载完成后,封装成函数function,依次执行
原生js页面加载后,只会执行最后一个赋值函数
day5 Tomcat&&xml Tomcat
网络资源的分类:
静态资源html css js txt mp4 jpg
动态资源jsp页面Servlet程序
常用的网络服务器
Tomcat:提供对jsp和servlet的支持,是一个轻量级的javaWeb容器,是目前应用最广泛的JavaWeb服务器
老板
玻璃鱼
树脂
网络逻辑
xml day6 Servlet Serlet是javaEE规范之一,规范就是接口
Servlet是JavaWeb的三大组件之一,三大组件分别是Servlet程序、Filter过滤器、Listener监听器
Servlet是一个运行在服务端的java小程序,可以接受客户端发出的请求,并将相应的数据发送给客户端
Get 和 Post 请求的分发处理
HTTP协议07 day8 jsp jsp中的一些其他请求响应:java server pages Java server pages,本质上是一个servlet程序
作用:代替servlet程序,返回html页面的数据
jsp的三种语法:
jsp头部中的page指令
jsp中的常用脚本
jsp中的三种注释
9个jsp Listener内置对象day9 EL表达式&& JSTL标签库1、EL表达式:
Expression Language 表达语言,非常简洁
格式:${表达式}
功能:
替换jsp页面中的表达式脚本,输出jsp页面中的数据
运算:关系运算、逻辑运算、算术运算、三元运算
day14 Cookie和Session Cookie:服务端通知客户端保存键值对的技术
客户端有cookie后,每个请求都发给服务器
每个cookie的大小不能超过4kb
一个创造
b 服务器获取
c Cookie 值修改
d 浏览器查看 cookie
e Cookie 生命控制(创建和销毁)
f Cookie有效路径Path设置(过滤掉哪些cookie可以发送到服务器,哪些不发送)
由服务器(Tomcat)创建并通知客户端(浏览器)
服务器只需要一行代码即可获取cookie req.getCookies():Cookie[]
Session session:Session是一个接口(HttpSession)
一种用于维护客户端和服务器之间关联的技术
每个客户端都有自己的会话
Session session,常用于用户登录后保存信息
day15 Filter Filter 过滤器是JavaWeb的三个组件之一(Servlet Listener Filter)
作用:拦截请求、过滤响应(权限检查、日志操作、事务管理)
如何使用Filter过滤器:
1、写一个类来实现Filter接口
2、实现过滤方法doFilter()
3、去web.xml配置Filter的拦截路径
子主题2 子主题3 day16 JSON, AJAX, i18n JSON: JavaScript Object Notation 一种轻量级(与xml相比)数据交换(客户端和服务器之间业务数据的传输格式)格式
json 定义:由键值对组成,本身就是一个对象,
json以两种形式存在,json对象,json字符串,
一般来说,当你想对json中的数据进行操作时,需要json对象JSON.parse()的格式来将字符串转化为对象
一般在客户端和服务端交换数据时,使用json字符串JSON.stringify()对象将其转为字符串
java中JSON的使用
AJAX 请求:指一种用于创建交互式 Web 应用程序的 Web 开发技术
ajax是浏览器通过js异步发起请求,部分更新页面(部分更新不会丢弃原页面内容)页面的技术
i18国际书店项目04第一阶段:表单验证08第二阶段:用户注册和登录
要求2:用户登录
要求如下:
1)访问登陆页面
2)填写用户名和密码并提交
3)服务器判断用户是否存在
4)如果登录失败——>>>>返回用户名或密码错误信息
5)如果登录成功-->>>>返回登录
- JavaEE项目的三层架构
Web层/视图表示层:获取请求参数,封装成Bean对象,调用Service层处理服务,响应数据给客户端请求转发和重定向
服务业务层:处理业务逻辑,调用持久层保存到数据库
Dao持久层:只负责与数据库交互
分层的目的是解耦,降低代码的耦合度,方便后期项目的维护和升级
-
- 1、创建书城需要的数据库和表
2、编写数据库表对应的JavaBean对象
3、编写工具类JdbcUtils
4、写BaseDao
5、写一个 UserDao 测试
6、编写 UserService 和测试
7、编写web层实现用户注册功能
Debug调试的使用
10 第三阶段:
从页面中提取相同的内容
登录、注册错误提示和表单回显
BaseServlet的提取:用户模块的UserServlet程序和图书模块的BookServlet程序中相同的部分都是从父类BaseServlet中抽象出来的,然后分别继承
使用EL表达式修改表单回显
11 阶段 5 书籍模块
2、图书标签
副题 4
14的第六阶段
注销用户
表单重复提交-验证码
15 第八阶段 16 第九阶段
抓取ajax动态网页java(什么是静态页面?HTML+PHP+JavaScript(早期的动态网页技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-05 15:16
内容
一. 什么是静态页面?
1. 一个静态页面只有一个固定的URL,网页上的内容也是固定的,不会随着不同浏览器的访问而改变。
2. 一旦网页内容发布到网站 服务器,无论是否有用户访问,每个静态网页的内容都会保存在网站 服务器上。这样就可以理解为静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件。
3. 静态网页通常以.html、.hml、.xml、.shtml等常用形式后缀,不带“?”。
4. 静态页面无法连接数据库;
5. 静态页面开发技术:HTML;
优势:
1.静态网页内容比较稳定,网站格式友好,容易被搜索引擎检索;
2. 静态页面访问速度最快,不需要从数据库中提取数据;
3. 网站更安全,HTML页面不会受到Asp相关漏洞的影响;并且可以减少攻击和防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
缺点:
1. 内容固定,交互性差,功能有限,内容更新维护复杂;
2. 没有自动化工具,维护大量静态页面文件是不现实的;
3. 不能充分支持用户需求。
二. 什么是动态页面?
1. 当浏览器向服务器请求某个页面时,服务器根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,然后发送给浏览器。显然,动态网页中的“动态”是指服务器端页面的动态生成;只有当用户请求时,服务器才返回一个完整的网页。相反,“静态”是指实际的、单独的文件。
2. 动态页面开发技术:
HTML+JavaScript (Node.js)
HTML+PHP
HTML+ASP.NET(或 ASP)
HTML+JSP
HTML+CGI(早期动态网络技术)
3. 使用动态网页技术可以实现很多功能,例如:用户注册、登录、用户管理、在线调查/研究、订单管理、用户评论等。
4. “?” 在动态网页中的 URL 对搜索引擎不是很友好。通常,搜索引擎不会访问 网站 数据库中的所有内容,或者出于技术原因。搜索引擎不会抓取“?”之后的内容。在网址中。因此,需要进行一些技术处理以适应搜索引擎的要求。
5. 动态页面常用后缀:.asp、.jsp、.php、.perl、.cgi;
优势:
1.动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
2. 可以实现用户的各种需求;
3. 查询信息方便,可存储大量数据,需要时可立即查询。
缺点:
1.动态网站不利于搜索引擎检索或收录;
2.动态网站制作成本较高;
3.动态网页也调用数据库中的数据,对数据库的安全保密要求很高,需要专业技术人员维护网站的安全。
三. 什么是伪静态页面?
1. 伪静态相对于纯静态。“假”静态页面本质上是动态页面。
2. 通常,为了增加搜索引擎的友好度,静态页面是由动态页面生成的。
3. 并非所有以 html 为后缀的页面都是静态页面。动态页面也可以通过服务器端技术使用静态页面的后缀。比较常见的是Apache和Nginx的Rewrite技术,也就是通常所说的伪静态页面。实际上,它们仍然是动态页面,但它们是静态的。
优势:
1. 与静态页面相比,伪静态页面在速度上并没有明显的提升。毕竟是“假”的静态页面,本质上是动态页面翻译成静态页面。从SEO优化的角度来看,最明显的优势就是让搜索引擎把伪静态页面当作静态页面。
2. 提高用户对网页的信任度。
缺点:
使用伪静态会占用一定的CPU,大量的伪静态页面会导致CPU过载。
四. 总结
1. 静态页面意味着 网站 上的所有内容都已设置、完成,然后放在上面。无论用户何时看到内容,内容都是相同的。
2. 动态页面的内容是由数据库中的程序生成的。当不同的用户在不同的时间访问该页面时,显示的内容可能会有所不同。网页内容会根据程序设置自动更改。
3. 伪静态页面就是让动态页面静态化。
4. 静态网页是构建网站的基础,静态网页和动态网页并不矛盾。技术还可以将 Web 内容转换为静态网页以供发布。
5. 静态页面和动态页面各有特点。网站 是使用静态页面还是动态页面,主要取决于网站 的功能需求和网站 的内容。如果网站的功能比较简单,网站的更新量不大,使用纯静态网页会比较简单。否则,通常使用动态网络技术。
6.动态网站也可以采用动静结合的原则,动态网页适合动态网页的使用。如果需要使用静态网页,可以考虑使用静态网页。在 网站 上,动态和静态 Web 内容共存也很常见。
7. 静态页面访问速度最快;维修比较麻烦。
8. 动态页面占用空间小,易于维护;访问速度慢,如果访问的人多,会对数据库造成压力。
9. 使用纯静态和伪静态进行SEO优化没有本质区别。
10. 使用伪静态会占用一定的CPU使用率,使用过多会导致CPU过载。 查看全部
抓取ajax动态网页java(什么是静态页面?HTML+PHP+JavaScript(早期的动态网页技术))
内容
一. 什么是静态页面?
1. 一个静态页面只有一个固定的URL,网页上的内容也是固定的,不会随着不同浏览器的访问而改变。
2. 一旦网页内容发布到网站 服务器,无论是否有用户访问,每个静态网页的内容都会保存在网站 服务器上。这样就可以理解为静态网页是实际保存在服务器上的文件,每个网页都是一个独立的文件。
3. 静态网页通常以.html、.hml、.xml、.shtml等常用形式后缀,不带“?”。
4. 静态页面无法连接数据库;
5. 静态页面开发技术:HTML;
优势:
1.静态网页内容比较稳定,网站格式友好,容易被搜索引擎检索;
2. 静态页面访问速度最快,不需要从数据库中提取数据;
3. 网站更安全,HTML页面不会受到Asp相关漏洞的影响;并且可以减少攻击和防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
缺点:
1. 内容固定,交互性差,功能有限,内容更新维护复杂;
2. 没有自动化工具,维护大量静态页面文件是不现实的;
3. 不能充分支持用户需求。
二. 什么是动态页面?
1. 当浏览器向服务器请求某个页面时,服务器根据当前时间、环境参数、数据库操作等动态生成一个HTML页面,然后发送给浏览器。显然,动态网页中的“动态”是指服务器端页面的动态生成;只有当用户请求时,服务器才返回一个完整的网页。相反,“静态”是指实际的、单独的文件。
2. 动态页面开发技术:
HTML+JavaScript (Node.js)
HTML+PHP
HTML+ASP.NET(或 ASP)
HTML+JSP
HTML+CGI(早期动态网络技术)
3. 使用动态网页技术可以实现很多功能,例如:用户注册、登录、用户管理、在线调查/研究、订单管理、用户评论等。
4. “?” 在动态网页中的 URL 对搜索引擎不是很友好。通常,搜索引擎不会访问 网站 数据库中的所有内容,或者出于技术原因。搜索引擎不会抓取“?”之后的内容。在网址中。因此,需要进行一些技术处理以适应搜索引擎的要求。
5. 动态页面常用后缀:.asp、.jsp、.php、.perl、.cgi;
优势:
1.动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
2. 可以实现用户的各种需求;
3. 查询信息方便,可存储大量数据,需要时可立即查询。
缺点:
1.动态网站不利于搜索引擎检索或收录;
2.动态网站制作成本较高;
3.动态网页也调用数据库中的数据,对数据库的安全保密要求很高,需要专业技术人员维护网站的安全。
三. 什么是伪静态页面?
1. 伪静态相对于纯静态。“假”静态页面本质上是动态页面。
2. 通常,为了增加搜索引擎的友好度,静态页面是由动态页面生成的。
3. 并非所有以 html 为后缀的页面都是静态页面。动态页面也可以通过服务器端技术使用静态页面的后缀。比较常见的是Apache和Nginx的Rewrite技术,也就是通常所说的伪静态页面。实际上,它们仍然是动态页面,但它们是静态的。
优势:
1. 与静态页面相比,伪静态页面在速度上并没有明显的提升。毕竟是“假”的静态页面,本质上是动态页面翻译成静态页面。从SEO优化的角度来看,最明显的优势就是让搜索引擎把伪静态页面当作静态页面。
2. 提高用户对网页的信任度。
缺点:
使用伪静态会占用一定的CPU,大量的伪静态页面会导致CPU过载。
四. 总结
1. 静态页面意味着 网站 上的所有内容都已设置、完成,然后放在上面。无论用户何时看到内容,内容都是相同的。
2. 动态页面的内容是由数据库中的程序生成的。当不同的用户在不同的时间访问该页面时,显示的内容可能会有所不同。网页内容会根据程序设置自动更改。
3. 伪静态页面就是让动态页面静态化。
4. 静态网页是构建网站的基础,静态网页和动态网页并不矛盾。技术还可以将 Web 内容转换为静态网页以供发布。
5. 静态页面和动态页面各有特点。网站 是使用静态页面还是动态页面,主要取决于网站 的功能需求和网站 的内容。如果网站的功能比较简单,网站的更新量不大,使用纯静态网页会比较简单。否则,通常使用动态网络技术。
6.动态网站也可以采用动静结合的原则,动态网页适合动态网页的使用。如果需要使用静态网页,可以考虑使用静态网页。在 网站 上,动态和静态 Web 内容共存也很常见。
7. 静态页面访问速度最快;维修比较麻烦。
8. 动态页面占用空间小,易于维护;访问速度慢,如果访问的人多,会对数据库造成压力。
9. 使用纯静态和伪静态进行SEO优化没有本质区别。
10. 使用伪静态会占用一定的CPU使用率,使用过多会导致CPU过载。
抓取ajax动态网页java(谷歌爬虫是如何抓取和收录什么类型的抓取JavaScript?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-05 01:06
身体的一部分
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
抓取ajax动态网页java(谷歌爬虫是如何抓取和收录什么类型的抓取JavaScript?)
身体的一部分
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
抓取ajax动态网页java(如何抓取网页特定数据的爬虫,我是怎么做到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-05 01:04
最近有朋友让我帮我设计一个爬虫,可以爬取网页上的特定数据。我以为这种程序实现起来很简单,只要通过对应的url获取html页面代码,然后解析html得到需要的数据。
但在实践中,我发现我想的太简单了。页面上有很多数据不能简单的从html源码中抓取,因为页面上显示的很多数据其实是在js代码运行时通过ajax从远程服务器获取的。正在加载页面,因此仅仅通过阅读html源代码无法获得所需的数据。
举个例子,我们打开京东首页,在搜索框输入关键词“乌鸡白凤丸”,返回页面显示60个商品,如下图:
打开js控制台,选择element,然后点击左上角的箭头,然后将箭头移到item item,我们可以在html中看到它对应的元素:
我们可以看到页面显示的item对应了id为“gl-i-wrap”的div控件,也就是说如果我们要从html中抓取页面显示的信息,就必须从给定的id中获取html代码div组件然后分析里面的内容,问题是如果你用右键调出他页面的源代码,然后查找字符串“gl-i-wrap”,你会发现它只收录30个,但页面上显示的产品数量是计算出来的。60,也就是30个产品信息不能直接通过html代码获取。
额外的30条信息实际上是在一定条件下触发一段js代码后通过ajax从服务端获取然后添加到DOM中的,所以我们不能简单的从页面对应的html中获取。我通过网上搜索发现对应的解决方法是分析是哪一段js代码负责获取这些数据,然后通过类似于逆向工程的方法研究它是如何构造http请求的,然后模拟发送这些请求获取数据.
我认为这种方法存在一系列问题。首先,要分析很多难读的js代码,工作量和难度可想而知。其次,如果以后这种方式发生变化网站数据采集方式,那么就得再次逆向工程,所以这种方式不经济。
我们怎样才能轻松便捷地获取动态加载的数据呢?
只要在页面上展示商品信息,就可以通过DOM获取,所以如果我们有办法获取浏览器内部的DOM模型,就可以读取动态加载的数据,因为冗余数据触发后页面被下拉。js代码是通过ajax动态获取的,所以如果我们可以通过代码控制浏览器加载网页,然后让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以获取到动态加载的数据。
经过一番调查,我们发现一个叫selenium的控件可以通过代码来动态控制浏览器,比如让浏览器加载一个特定的页面,让浏览器下拉页面,然后在浏览器,所以我们可以用它来方便的抓取动态页面数据。
首先通过命令pip install selenium下载控件,如果我们要使用它来控制chrome浏览器,我们还需要下载chromedriver控件,首先确定你使用的chrome版本,chromedriver必须和chrome完全一样您当前使用的版本,请从以下链接下载:
请记住选择与您的 chrome 浏览器相同的版本进行下载。完成后,我们可以通过以下代码启动浏览器并使用给定的 URL 加载网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('#x27;)
运行上述代码后,可以启动浏览器,看到他打开了京东首页。这时候我想在搜索框中自动输入关键词。因此,我们可以使用下面的代码,通过模拟人工输入,在搜索框中输入关键词,然后模拟点击回车键,实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(字)
search_box.send_keys(Keys.ENTER)
超时 = 10
尝试:
print("等待页面...")
WebDriverWait(驱动程序,超时)
除了超时异常:
print("等待页面加载超时")
最后:
.
.
.
.
由于浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们需要模拟一个人拉下页面。行动:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("返回 document.body.scrollHeight")
while True: #将页面滑到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("返回 document.body.scrollHeight")
如果 new_height == last_height:
休息
last_height = new_height
上面的代码执行完后,你会发现浏览器页面自动下拉到了底部,所以js会向服务器发送ajax请求获取另外30项的数据,然后我们得到对应的html源码通过执行一段js代码到body组件,然后获取到id为gl-i-wrap的div对象,你会看到它返回了60个对应的组件,也就是说可以获取到页面上的所有商品数据:
page_source = driver.execute_script("返回 document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里的输出是60
这样我们就可以读取所有页面显示的商品价格信息。这种方法比解析js代码然后逆向构造http请求获取页面上动态加载的数据要简单、方便、省事得多。更详细的讲解和调试演示请点击“阅读原文”观看视频 查看全部
抓取ajax动态网页java(如何抓取网页特定数据的爬虫,我是怎么做到的)
最近有朋友让我帮我设计一个爬虫,可以爬取网页上的特定数据。我以为这种程序实现起来很简单,只要通过对应的url获取html页面代码,然后解析html得到需要的数据。
但在实践中,我发现我想的太简单了。页面上有很多数据不能简单的从html源码中抓取,因为页面上显示的很多数据其实是在js代码运行时通过ajax从远程服务器获取的。正在加载页面,因此仅仅通过阅读html源代码无法获得所需的数据。
举个例子,我们打开京东首页,在搜索框输入关键词“乌鸡白凤丸”,返回页面显示60个商品,如下图:
打开js控制台,选择element,然后点击左上角的箭头,然后将箭头移到item item,我们可以在html中看到它对应的元素:
我们可以看到页面显示的item对应了id为“gl-i-wrap”的div控件,也就是说如果我们要从html中抓取页面显示的信息,就必须从给定的id中获取html代码div组件然后分析里面的内容,问题是如果你用右键调出他页面的源代码,然后查找字符串“gl-i-wrap”,你会发现它只收录30个,但页面上显示的产品数量是计算出来的。60,也就是30个产品信息不能直接通过html代码获取。
额外的30条信息实际上是在一定条件下触发一段js代码后通过ajax从服务端获取然后添加到DOM中的,所以我们不能简单的从页面对应的html中获取。我通过网上搜索发现对应的解决方法是分析是哪一段js代码负责获取这些数据,然后通过类似于逆向工程的方法研究它是如何构造http请求的,然后模拟发送这些请求获取数据.
我认为这种方法存在一系列问题。首先,要分析很多难读的js代码,工作量和难度可想而知。其次,如果以后这种方式发生变化网站数据采集方式,那么就得再次逆向工程,所以这种方式不经济。
我们怎样才能轻松便捷地获取动态加载的数据呢?
只要在页面上展示商品信息,就可以通过DOM获取,所以如果我们有办法获取浏览器内部的DOM模型,就可以读取动态加载的数据,因为冗余数据触发后页面被下拉。js代码是通过ajax动态获取的,所以如果我们可以通过代码控制浏览器加载网页,然后让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以获取到动态加载的数据。
经过一番调查,我们发现一个叫selenium的控件可以通过代码来动态控制浏览器,比如让浏览器加载一个特定的页面,让浏览器下拉页面,然后在浏览器,所以我们可以用它来方便的抓取动态页面数据。
首先通过命令pip install selenium下载控件,如果我们要使用它来控制chrome浏览器,我们还需要下载chromedriver控件,首先确定你使用的chrome版本,chromedriver必须和chrome完全一样您当前使用的版本,请从以下链接下载:
请记住选择与您的 chrome 浏览器相同的版本进行下载。完成后,我们可以通过以下代码启动浏览器并使用给定的 URL 加载网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('#x27;)
运行上述代码后,可以启动浏览器,看到他打开了京东首页。这时候我想在搜索框中自动输入关键词。因此,我们可以使用下面的代码,通过模拟人工输入,在搜索框中输入关键词,然后模拟点击回车键,实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(字)
search_box.send_keys(Keys.ENTER)
超时 = 10
尝试:
print("等待页面...")
WebDriverWait(驱动程序,超时)
除了超时异常:
print("等待页面加载超时")
最后:
.
.
.
.
由于浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们需要模拟一个人拉下页面。行动:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("返回 document.body.scrollHeight")
while True: #将页面滑到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("返回 document.body.scrollHeight")
如果 new_height == last_height:
休息
last_height = new_height
上面的代码执行完后,你会发现浏览器页面自动下拉到了底部,所以js会向服务器发送ajax请求获取另外30项的数据,然后我们得到对应的html源码通过执行一段js代码到body组件,然后获取到id为gl-i-wrap的div对象,你会看到它返回了60个对应的组件,也就是说可以获取到页面上的所有商品数据:
page_source = driver.execute_script("返回 document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里的输出是60
这样我们就可以读取所有页面显示的商品价格信息。这种方法比解析js代码然后逆向构造http请求获取页面上动态加载的数据要简单、方便、省事得多。更详细的讲解和调试演示请点击“阅读原文”观看视频
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-02 13:16
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,页面表单暴力**等等。在自动化渗透方面也会起到很大的作用,而且以后也会用到。会提这个。 查看全部
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,页面表单暴力**等等。在自动化渗透方面也会起到很大的作用,而且以后也会用到。会提这个。
抓取ajax动态网页java(2020-07-31181次浏览原文:幽沉窥唐虞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 20:01
2020-07-31 原创 API 示例的 181 次查看:使用 Java/JavaScript 下载内容提取器
关键词:
默默的谢天谢地,低头窥视着唐羽。本文章主要介绍API示例:Java/JavaScript下载内容提取器相关知识,希望对您有所帮助。
1 简介
本文介绍了如何在 java 中下载内容提取器并使用 GooSeeker API 接口,这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 python 即时网络爬虫开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,Java并不适合提取网页内容。再加上语言不够灵活方便,整个生态系统不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613961050143x.shtml"; // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
[object Object]
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
一、Python即时网络爬虫:API说明
6.Jisouke GooSeeker开源代码下载源
1、GooSeeker开源Python网络爬虫GitHub源码
7.文档修改历史
1、2016-06-27:V1.0
本文来自“富勒华的博客”博客,请勿转载!
至此,这篇关于 API 示例的文章:使用 Java/JavaScript 下载内容提取器已经完成了内容。如果没有解决你的问题,请参考下面的文章:
相关文章
366API!完美解决微信h5页面点击文件下载链接无响应的问题
微信被禁网页如何处理?366API将被屏蔽的网页从微信恢复正常访问的解决方案
图像识别快速入门:使用 TensorFlow API 进行图像分类的示例
VBA绘制Excel图表
cesium1.65api版贴纸模型绘图工具效果(附源码下载)
吐槽贴:百度地图api包实用功能【源码下载】
cesium1.63.1api版贴纸模型测量工具效果(附源码下载)
使用百度地图API分析交通大数据 查看全部
抓取ajax动态网页java(2020-07-31181次浏览原文:幽沉窥唐虞)
2020-07-31 原创 API 示例的 181 次查看:使用 Java/JavaScript 下载内容提取器
关键词:
默默的谢天谢地,低头窥视着唐羽。本文章主要介绍API示例:Java/JavaScript下载内容提取器相关知识,希望对您有所帮助。
1 简介
本文介绍了如何在 java 中下载内容提取器并使用 GooSeeker API 接口,这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 python 即时网络爬虫开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,Java并不适合提取网页内容。再加上语言不够灵活方便,整个生态系统不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613961050143x.shtml"; // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
[object Object]
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
一、Python即时网络爬虫:API说明
6.Jisouke GooSeeker开源代码下载源
1、GooSeeker开源Python网络爬虫GitHub源码
7.文档修改历史
1、2016-06-27:V1.0
本文来自“富勒华的博客”博客,请勿转载!
至此,这篇关于 API 示例的文章:使用 Java/JavaScript 下载内容提取器已经完成了内容。如果没有解决你的问题,请参考下面的文章:
相关文章
366API!完美解决微信h5页面点击文件下载链接无响应的问题
微信被禁网页如何处理?366API将被屏蔽的网页从微信恢复正常访问的解决方案
图像识别快速入门:使用 TensorFlow API 进行图像分类的示例
VBA绘制Excel图表
cesium1.65api版贴纸模型绘图工具效果(附源码下载)
吐槽贴:百度地图api包实用功能【源码下载】
cesium1.63.1api版贴纸模型测量工具效果(附源码下载)
使用百度地图API分析交通大数据
抓取ajax动态网页java(7开发语言:Myeclipse微博爬虫:Tomcat情感分析算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-20 19:23
#WeiboEmotionAnalyzer###系统介绍在本系统中,视图层使用JSP+CSS+JavaScript设计前端界面,包括数据校验、用户交互、图表展示等功能,其中JSON文本格式用于与背景的互动;control 层由servlet实现。servlet根据前端发来的用户的具体请求,选择合适的视图进行展示,对请求进行解释,并以JSON格式返回数据给客户端;本系统模型层的功能是分析微博数据。进行情感分析,并为servlet提供一个使用分析结果的接口,经过一定的处理后发回给客户端。###主要内容1.微博爬虫1. 1 使用 JSOUP 抓取和解析在线微博。2.情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。
###开发环境开发工具:Myeclipse 服务器:Tomcat 7 开发语言:Java、jsp、css、JavaScript(jQuery)js脚本调试:Firebug插件(火狐浏览器)###Deploy复制项目的所有内容tomcat_bin文件夹放入tomcat的bin目录下的###TODO: - 重构代码,尽量消除重复,让代码更具表现力。- 提升微博爬虫性能,增加多进程。- 添加一个数据库来存储爬取的微博数据,而不是静态文件。- 改进情感分析算法,尝试基于机器学习的算法。(待定)——添加新的功能需求,尽可能接近实际需求 查看全部
抓取ajax动态网页java(7开发语言:Myeclipse微博爬虫:Tomcat情感分析算法)
#WeiboEmotionAnalyzer###系统介绍在本系统中,视图层使用JSP+CSS+JavaScript设计前端界面,包括数据校验、用户交互、图表展示等功能,其中JSON文本格式用于与背景的互动;control 层由servlet实现。servlet根据前端发来的用户的具体请求,选择合适的视图进行展示,对请求进行解释,并以JSON格式返回数据给客户端;本系统模型层的功能是分析微博数据。进行情感分析,并为servlet提供一个使用分析结果的接口,经过一定的处理后发回给客户端。###主要内容1.微博爬虫1. 1 使用 JSOUP 抓取和解析在线微博。2.情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。情感分析算法2.1 中文分词,使用中文自然语言处理(NLPIR)对微博文本进行分词。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用中文自然语言处理 (NLPIR) 来分割微博文本。2.2 情感分析,使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。使用基于情感字典的方法(包括七种情感的概率值)进行情感分析,该算法综合表情符号、程度副词和否定副词计算微博的情感值。3.图文展示3.1 数据处理,对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。对微博文本情感分析结果进行一定的分析和统计。3.2 图表展示,使用highcharts插件绘制曲线图、饼图、折线图、柱状图等统计图表,直观展示情感分析结果。
###开发环境开发工具:Myeclipse 服务器:Tomcat 7 开发语言:Java、jsp、css、JavaScript(jQuery)js脚本调试:Firebug插件(火狐浏览器)###Deploy复制项目的所有内容tomcat_bin文件夹放入tomcat的bin目录下的###TODO: - 重构代码,尽量消除重复,让代码更具表现力。- 提升微博爬虫性能,增加多进程。- 添加一个数据库来存储爬取的微博数据,而不是静态文件。- 改进情感分析算法,尝试基于机器学习的算法。(待定)——添加新的功能需求,尽可能接近实际需求
抓取ajax动态网页java( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-20 10:29
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取ajax动态网页java(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
抓取ajax动态网页java(一下JSP的思想就好了,现在已经没有用了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-18 00:25
)
上节课讲了JSP,大家应该掌握思路。至于更多的JSP知识,现在其实也没什么用了,因为没有人会直接用JSP来做web开发。这是古老的编程知识。
关于服务端的知识,我们暂停一下,从http协议的角度学习一个前端知识。在前端技术中,有一个非常重要的技术叫做ajax。我们先展示一个ajax的例子,然后看看这个技术的本质。
AJAX 用例
在许多应用程序中,我们实际上并不想刷新整个网页。例如,一个网页上有很多产品的图片列表。当我们将鼠标向上移动时,我们想在网页上弹出一个小框,显示产品的详细信息。. 在这种情况下,我们实际上并不需要刷新整个页面。但是如何向服务器发送请求以获取产品的详细信息?
这时,有一种技术叫做Ajax。AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。AJAX 是一种与服务器交换数据并更新网页的一部分的技术,允许与服务器进行数据交互而无需重新加载整个页面。
我们仍然在 jetty 的根目录下新建一个名为 ajax.html 的文件:
function loadXMLDoc() {
var xmlhttp;
xmlhttp=new XMLHttpRequest();
// 当数据返回以后才会调用这个匿名方法,把从服务端得到的内容设置到myDiv这个标签里
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","ajax_info.txt",true);
xmlhttp.send();
}
使用 AJAX 修改文本内容
change text
注意新建文件的时候一定要保证文件的编码是UTF-8
让我们分析一下这个页面上的javascript代码是什么意思。此网页上有一个按钮,当单击该按钮时,将调用 loadXMLDoc。在这个方法中创建了一个XMLHttpRequest,通过这个对象的open方法访问服务器的ajax_info.txt。返回数据时,会调用一个匿名函数来设置网页的内容。看看上面代码中的注释。
所以我们在服务器端再创建一个名为ajax_info.txt的文件,文件内容随便填写即可。
点击后可以看到:
查看全部
抓取ajax动态网页java(一下JSP的思想就好了,现在已经没有用了
)
上节课讲了JSP,大家应该掌握思路。至于更多的JSP知识,现在其实也没什么用了,因为没有人会直接用JSP来做web开发。这是古老的编程知识。
关于服务端的知识,我们暂停一下,从http协议的角度学习一个前端知识。在前端技术中,有一个非常重要的技术叫做ajax。我们先展示一个ajax的例子,然后看看这个技术的本质。
AJAX 用例
在许多应用程序中,我们实际上并不想刷新整个网页。例如,一个网页上有很多产品的图片列表。当我们将鼠标向上移动时,我们想在网页上弹出一个小框,显示产品的详细信息。. 在这种情况下,我们实际上并不需要刷新整个页面。但是如何向服务器发送请求以获取产品的详细信息?
这时,有一种技术叫做Ajax。AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。AJAX 是一种与服务器交换数据并更新网页的一部分的技术,允许与服务器进行数据交互而无需重新加载整个页面。
我们仍然在 jetty 的根目录下新建一个名为 ajax.html 的文件:
function loadXMLDoc() {
var xmlhttp;
xmlhttp=new XMLHttpRequest();
// 当数据返回以后才会调用这个匿名方法,把从服务端得到的内容设置到myDiv这个标签里
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","ajax_info.txt",true);
xmlhttp.send();
}
使用 AJAX 修改文本内容
change text
注意新建文件的时候一定要保证文件的编码是UTF-8
让我们分析一下这个页面上的javascript代码是什么意思。此网页上有一个按钮,当单击该按钮时,将调用 loadXMLDoc。在这个方法中创建了一个XMLHttpRequest,通过这个对象的open方法访问服务器的ajax_info.txt。返回数据时,会调用一个匿名函数来设置网页的内容。看看上面代码中的注释。
所以我们在服务器端再创建一个名为ajax_info.txt的文件,文件内容随便填写即可。
点击后可以看到:
抓取ajax动态网页java( HTML2019-04-28编程之家收集整理的篇文章介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-16 13:21
HTML2019-04-28编程之家收集整理的篇文章介绍)
Web scraper - scrapy 中的动态 start_urls
HTML 2019-04-28
编程之家采集的这篇文章文章主要介绍了网页抓取工具——scrapy中的动态start_urls。编程之家的小编觉得挺不错的。 .
我正在使用 scrapy 在 网站 上抓取多个页面。
变量start_urls用于定义要爬取的页面。
我最初从第一页开始,因此在文件 example_spider.py 中定义 start_urls = [first page]
一旦我从第 1 页获得更多信息,我会找出要抓取的下一页是什么,然后相应地分配 start_urls。所以我要start_urls = [page 1, page 2, ..., Changes to page K]覆盖example_spider.py,然后再执行scrapy。
这是最好的方法还是有更好的方法来使用scrapy API动态分配start_urls而不必覆盖example_splider.py?
谢谢。
解决方案
start_urls 类属性收录起始 URL - 仅此而已。如果你提取要删除的其他页面的URL-从[another]回调的解析回调中获取对应的请求:
class Spider(BaseSpider):
name = 'my_spider'
start_urls = [
'http://www.domain.com/'
]
allowed_domains = ['domain.com']
def parse(self,response):
'''Parse main page and extract categories links.'''
hxs = HtmlXPathSelector(response)
urls = hxs.select("//*[@id='tSubmenuContent']/a[position()>1]/@href").extract()
for url in urls:
url = urlparse.urljoin(response.url,url)
self.log('Found category url: %s' % url)
yield Request(url,callback = self.parseCategory)
def parseCategory(self,response):
'''Parse category page and extract links of the items.'''
hxs = HtmlXPathSelector(response)
links = hxs.select("//*[@id='_list']//td[@class='tListDesc']/a/@href").extract()
for link in links:
itemLink = urlparse.urljoin(response.url,link)
self.log('Found item link: %s' % itemLink,log.DEBUG)
yield Request(itemLink,callback = self.parseItem)
def parseItem(self,response):
...
如果你还想自定义启动请求创建,请重写方法
总结
以上是编程之家为你采集的网页抓取工具——scrapy全部内容中的动态start_urls,希望文章可以帮助你解决scrapy程序开发中遇到的网页抓取工具——动态start_urls问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
抓取ajax动态网页java(
HTML2019-04-28编程之家收集整理的篇文章介绍)
Web scraper - scrapy 中的动态 start_urls
HTML 2019-04-28
编程之家采集的这篇文章文章主要介绍了网页抓取工具——scrapy中的动态start_urls。编程之家的小编觉得挺不错的。 .
我正在使用 scrapy 在 网站 上抓取多个页面。
变量start_urls用于定义要爬取的页面。
我最初从第一页开始,因此在文件 example_spider.py 中定义 start_urls = [first page]
一旦我从第 1 页获得更多信息,我会找出要抓取的下一页是什么,然后相应地分配 start_urls。所以我要start_urls = [page 1, page 2, ..., Changes to page K]覆盖example_spider.py,然后再执行scrapy。
这是最好的方法还是有更好的方法来使用scrapy API动态分配start_urls而不必覆盖example_splider.py?
谢谢。
解决方案
start_urls 类属性收录起始 URL - 仅此而已。如果你提取要删除的其他页面的URL-从[another]回调的解析回调中获取对应的请求:
class Spider(BaseSpider):
name = 'my_spider'
start_urls = [
'http://www.domain.com/'
]
allowed_domains = ['domain.com']
def parse(self,response):
'''Parse main page and extract categories links.'''
hxs = HtmlXPathSelector(response)
urls = hxs.select("//*[@id='tSubmenuContent']/a[position()>1]/@href").extract()
for url in urls:
url = urlparse.urljoin(response.url,url)
self.log('Found category url: %s' % url)
yield Request(url,callback = self.parseCategory)
def parseCategory(self,response):
'''Parse category page and extract links of the items.'''
hxs = HtmlXPathSelector(response)
links = hxs.select("//*[@id='_list']//td[@class='tListDesc']/a/@href").extract()
for link in links:
itemLink = urlparse.urljoin(response.url,link)
self.log('Found item link: %s' % itemLink,log.DEBUG)
yield Request(itemLink,callback = self.parseItem)
def parseItem(self,response):
...
如果你还想自定义启动请求创建,请重写方法
总结
以上是编程之家为你采集的网页抓取工具——scrapy全部内容中的动态start_urls,希望文章可以帮助你解决scrapy程序开发中遇到的网页抓取工具——动态start_urls问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
抓取ajax动态网页java(SEO的基本就是要语义化,方便搜索引擎,但有作用吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-13 05:18
我们知道SEO的基础是语义化、易于搜索引擎爬取,但这是否意味着单页应用中的传统多页应用没有经过改造对SEO有影响?
先看一下搜索引擎的原理
# URL 搜索引擎会是 收录 吗?
1、什么是哈希值?
在阮一峰的博客里,有一篇文章文章可以很好的解释哈希值。# 值不是 http 请求,而是浏览器操作。使用#,您可以快速定位网页中的特定位置。比如 id="comment-121" 或者这个位置很快就定位到了。
2、搜索引擎会抓取带有#(哈希值)的网址吗
答案一般不是。搜索引擎抓取页面首先要遵循http协议,但#不是协议的内容。事实上,情况也是如此。我们从来没有在搜索引擎的搜索结果中看到过可以快速定位到网页中某个位置的记录。因此,希望搜索引擎通过在网站内外添加#锚链接来快速定位第一次访问是不现实的。当然,为了模拟真实用户,搜索引擎蜘蛛在输入网站后会使用一些技术来模拟鼠标点击。此时页面的锚链接仍然有效,但是当搜索结果中有任何链接时,将没有#。
#! 是什么意思?在3、URL 里做什么?
这是违反 2 的特殊情况,Google 抓取带有 #! 的 URL。. Google 规定,如果想让 Ajax 生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中(这种 URL 一般对普通页面没有定位作用),Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。例如 /#!/username 等价于 /?escaped_fragment=/username,并且 URL 带有 ? 将被抓取,所以 #! 网址将被 Google 搜索 收录。
4、搜索引擎是否会抓取带有#(哈希值)的URL给我们
一、不要试图用 robots.txt 屏蔽 # 个 URL。我之前翻过一个错误,就是在的robots.txt中加入disallow:/*#规则,试图阻止这些带#的URL被抓取。但实际上,这种做法是错误的。首先,#是robots.txt中的注释符号,后面的内容会被注释掉,所以这条规则变成了disallow:/,也就是阻止了本站所有收录站点。页面,幸好今天早上找到并立即修改。其次,搜索引擎不会抓取带有#的URL,所以不需要添加这样的规则。
二、你可以使用#和ajax的组合来隐藏你不想被抓取的内容。在我们的一些网页中,可能有一些我们不想直接告诉搜索引擎的内容,或者一些我们不想被抓取的隐私,所以我们可以使用#来控制这些信息的显示。例如,我们添加一个按钮,当 URL 中收录#show-info-123 时显示 123 的个人信息,但不收录时不显示。对于搜索引擎,带有#的URL会被自动忽略,因此123的个人信息不会被抓取。
也就是说,哈希模式的语义对SEO影响不大。当然,我们的语义不仅仅适用于 SEO。 查看全部
抓取ajax动态网页java(SEO的基本就是要语义化,方便搜索引擎,但有作用吗)
我们知道SEO的基础是语义化、易于搜索引擎爬取,但这是否意味着单页应用中的传统多页应用没有经过改造对SEO有影响?
先看一下搜索引擎的原理
# URL 搜索引擎会是 收录 吗?
1、什么是哈希值?
在阮一峰的博客里,有一篇文章文章可以很好的解释哈希值。# 值不是 http 请求,而是浏览器操作。使用#,您可以快速定位网页中的特定位置。比如 id="comment-121" 或者这个位置很快就定位到了。
2、搜索引擎会抓取带有#(哈希值)的网址吗
答案一般不是。搜索引擎抓取页面首先要遵循http协议,但#不是协议的内容。事实上,情况也是如此。我们从来没有在搜索引擎的搜索结果中看到过可以快速定位到网页中某个位置的记录。因此,希望搜索引擎通过在网站内外添加#锚链接来快速定位第一次访问是不现实的。当然,为了模拟真实用户,搜索引擎蜘蛛在输入网站后会使用一些技术来模拟鼠标点击。此时页面的锚链接仍然有效,但是当搜索结果中有任何链接时,将没有#。
#! 是什么意思?在3、URL 里做什么?
这是违反 2 的特殊情况,Google 抓取带有 #! 的 URL。. Google 规定,如果想让 Ajax 生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中(这种 URL 一般对普通页面没有定位作用),Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。例如 /#!/username 等价于 /?escaped_fragment=/username,并且 URL 带有 ? 将被抓取,所以 #! 网址将被 Google 搜索 收录。
4、搜索引擎是否会抓取带有#(哈希值)的URL给我们
一、不要试图用 robots.txt 屏蔽 # 个 URL。我之前翻过一个错误,就是在的robots.txt中加入disallow:/*#规则,试图阻止这些带#的URL被抓取。但实际上,这种做法是错误的。首先,#是robots.txt中的注释符号,后面的内容会被注释掉,所以这条规则变成了disallow:/,也就是阻止了本站所有收录站点。页面,幸好今天早上找到并立即修改。其次,搜索引擎不会抓取带有#的URL,所以不需要添加这样的规则。
二、你可以使用#和ajax的组合来隐藏你不想被抓取的内容。在我们的一些网页中,可能有一些我们不想直接告诉搜索引擎的内容,或者一些我们不想被抓取的隐私,所以我们可以使用#来控制这些信息的显示。例如,我们添加一个按钮,当 URL 中收录#show-info-123 时显示 123 的个人信息,但不收录时不显示。对于搜索引擎,带有#的URL会被自动忽略,因此123的个人信息不会被抓取。
也就是说,哈希模式的语义对SEO影响不大。当然,我们的语义不仅仅适用于 SEO。
抓取ajax动态网页java(JavaWeb应用设计及实战目录上一章下一章加载新闻源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-10 13:26
JavaWeb应用设计及实用目录
上一章 下一章
上一个任务/上一节 下一个任务/下一节
加载新闻来源。
内容
(2)
(6)
系统首页新闻中心部分采用Ajax技术,按主题动态展示新闻功能,按条件加载
一个话题下的所有话题或新闻,并使用Ajax技术实现分页显示。使用 Ajax 技术加载
添加主题页面,实现Ajax方式添加主题功能,利用Ajax技术实现主题修改
并删除。
8.2.1 Ajax模式下根据主题动态加载新闻1.需求介绍
访问系统首页,以Ajax方式加载页面“新闻中心”部分的新闻列表,默认加载所有新闻
主题下的新闻按创建时间降序排列,并实现分页,如图8.1。
当点击某个主题的超链接时,该主题下的新闻以Ajax方式加载,按创建时间降序排列,
并实现分页。
2.实现思路(1)实现数据层访问
需求中有两个分页查询要求:对所有主题下的新闻进行分页查询,对某一个进行分页查询
主题下的新闻可以分页搜索。事实上,这两个查询的区别仅在于 SQL 语句的一个主要方面。
查询问题 ID。事实上,对于SQL语句来说,这两个查询只是主题id的一个查询条件不同,
因此,考虑整合这两个查询。
图8.1 分页显示所有类别的新闻
修改NewsDao接口中分页查询相关方法的设计,增加topic id参数。
public interface NewsDao {
……// 省略其他方法
//获得新闻总数
public int getTotalCount(Integer id) throws SQLException;
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException;
}
在其实现类NewsDaoImpl中,根据传入参数tid是否有效,动态组装SQL语句并查询
查询条件。
public class NewsDaoImpl extends BaseDao implements NewsDao{
public NewsDaoImpl(Connection conn){
super(conn);
}
……//省略其他方法
//获得新闻的数量
public int getTotalCount(Integer tid) throws SQLEception{
ResultSet rs = null:
List params = new ArrayList ();
String sql = "SELECT COUNT('nid') FROM 'news'";
if(tid!= null){
sql += "WHERE 'ntid' = ?";
params.add(tid);
}
int count = -1;
try {
rs = this.executeQuery(sql,params.toArrary()) ;
rs.next();
count = rs.getInt(1);
}……省略异常处理和资源释放代码
return count;
}
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException{
List list = new ArrayList ();
ResultSet rs = null;
List params = new ArrayList ();
String sql = "SELECT'nid','ntid','ntitle','nauthor',"
+"'ncreateDate','nsummary','tname' FROM 'NEWS',"
+"'TOPIC''WHERE''NEWS'.'NTID' = 'TOPIC'.'tid'";
if{tid! = null){
sql +="AND 'NEWS'.'ntid' = ?";
params.add(tid);
}
sql += " ORDER BY 'ncreateDate' DESC LIMIT ?,?";
params.add((pageNo - 1)* pageSize);
params.add(pageSize);
try{
rs = this.executeQuery(sql,params.toArray());
……// 省略封装数据过程
}……//省略异常处理和资源释放代码
return list;
}
}
(2) 实现业务层
业务层接口NewsService及其实现类NewsServiceImpl也作了相应的调整和设计。
也是添加传入参数主题ID的方法。
修改NewsService接口中分页相关方法的设计,增加主题id参数。
public interface NewsService{
……//省略其他方法
//分页获取新闻
public void findPageNews(Integer tid,Page pageObj)
throws SQLException;
}
在其实现类NewsServiceImpl中调用Dao相关方法时传入tid即可。
public class NewsServiceImpl implements NewsService{
……//省略部分方法
//分页获取新闻
public void findPageNews(Inter tid,Page pageObj)
throws SQLException{
Connection conn = null;
try{
conn = DatebaseUtil.getConnection();
NewsDao newsDao = new NewsDaoImpl(conn);
……//省略部分代码
List newsList = newsDao.getPageNewsList(tid,
pageObj.getCurrPageNo(),
pageObj.getPageSize());
……//省略部分代码
}……// 省略异常处理和资源释放
}
}
}
(3)写Servlet
将原来的首页初始化公告拆解成两部分:按照传统初始化方式初始化最新消息和话题列表(如
图8.2)并使用Ajax方法加载新闻列表(如图8.1)。
图8.2 初始化最新消息和话题列表
以传统方式初始化最新消息和主题列表的关键代码如下。
……//省略其他功能
else if("topicLatest".equals(opr)){//初始化首页侧边栏和主题列表
Maptopics = new HashMap();
topics.put(1,5);
topics.put(2,5);
topics.Put(5,5);
List latests = newsService
.findLatestNewsByTid(topics); //查询最新消息
List list = topicService.findAllTopics(); //查询所有主题
request.setAttribute("list1",latests.get(0)); // 左侧国内新闻
request.setAttribute("list2",latests.get(1)); //左侧国际新闻
request.setAttribute("list3",latests.get(2)); // 左侧国际新闻
request.setAttribute("list",list); //所有的主题
request.getRequestDispatcher("/index.jsp").forward(request,response);
}……//省略其他功能
处理分页加载新闻列表的Ajax请求的关键代码如下。
else if("topicNews".equals(opr)){ //分页查询新闻
//获得主题id 和当前页数
String tid = request.getParameter("tid");
String pageIndex = request.getParameter("pageIndex");
……//省略部分代码
Page pageObj = new page();
……//省略部分代码
//调用业务方法查询
if(tid ==null||(tid = tid.trim()).length() ==0)
newsService.findPageNews(null,pageObj);
else
newsService.findPageNews(Integer.valueOf(tid),pageObj);
//使用 FastJSON 将 Page 对象序列化成 JSON 字符串
String newsJSON = JSON.toJSONStringWithDataFormat(pageObj,
"yyyy-MM-dd HH:mm:ss",
SerializerFeature.WriteMapNullValue);
//向客户端返回响应数据
out.print("[{\"tid\":\""+tid+"\"},"+newsJSON +"]");
}……//省略其他功能
注意
为了保证客户端分页条件的完整性,响应数据是一个JSON数组,包括主题id
和查询结果。
(4) 调整 index.jsp 页面
删除与获取和输出新闻列表相关的原创代码,只保留列表的容器。
……//省略其他页面内容
……//省略其他页面内容
为了适应拆分servlet功能和实际Ajax分页的需求,主题列表的超链接在
输出也需要相应调整。
<a href = "javascript:;" id = "${topic.tid}">
${topic.tname}</a>
点击主题超链接查询相关新闻的功能将在 JavaScript 脚本中使用 Ajax 方法实现。
添加了 id 属性,用于在点击事件中获取主题 id 作为查询参数。
(5) 编写 JavaScript 脚本
分别在以下代码块中编写相关的 JavaScript 脚本。
jQuery.noConflict();//让渡 "$" 的使用权,其他脚本库可以使用 "$"
(function($){
$(document).ready(function(){
//其他脚本编写于此处
});
})(jQuery);
1. 编写发送Ajax分页请求的getpagi()方法,在首页加载时调用它进行初始化
新闻列表。
function getPagi(tid,pageIndex){ //发送 Ajax 请求实现分页
var data = "opr = topicNews"; //准备请求参数
if(tid)
data += "&tid=" +tid;
if(pageIndex && pageIndex>0)
data += "&pageIndex="+pageIndex;
$.getJSON("util/news",data,pagi); //发送 Ajax 请求
};
getPage();//首页加载时,初始化加载新闻列表
2.编写回调方法pagi()处理响应,主要完成两件事:在这个页面显示数据和生成分页操作链接。
<p>//获取显示新闻列表的首页中心区域
var $centerNewsList = $("#container.main.content.classlist");
function pagi(data){ //分页查询的回调函数
var tid = datas[0].tid == "null"?"";datas[0].tid;
var data = datas[1]; //获取分页相关数据
//1.展示本页新闻数据
$centerNewsList.html("");
if(data.newsList == null)
$centerNewsList.html(
"出现错误,请稍后再试或与管理员联系1){
var $first = $("<a href=\"javascrit:;\">首页</a>").click(
function(){getPagi(tid,1);});
var $prev = $("<a href = \"javascript:;\">上一页</a>).click(
function(){getPagi(tid,(data.currPageNo-1));});
$operArea.append($first).append(" ").append($prev);
}
if(data.currPageNo 查看全部
抓取ajax动态网页java(JavaWeb应用设计及实战目录上一章下一章加载新闻源码)
JavaWeb应用设计及实用目录
上一章 下一章
上一个任务/上一节 下一个任务/下一节
加载新闻来源。
内容
(2)
(6)
系统首页新闻中心部分采用Ajax技术,按主题动态展示新闻功能,按条件加载
一个话题下的所有话题或新闻,并使用Ajax技术实现分页显示。使用 Ajax 技术加载
添加主题页面,实现Ajax方式添加主题功能,利用Ajax技术实现主题修改
并删除。
8.2.1 Ajax模式下根据主题动态加载新闻1.需求介绍
访问系统首页,以Ajax方式加载页面“新闻中心”部分的新闻列表,默认加载所有新闻
主题下的新闻按创建时间降序排列,并实现分页,如图8.1。
当点击某个主题的超链接时,该主题下的新闻以Ajax方式加载,按创建时间降序排列,
并实现分页。
2.实现思路(1)实现数据层访问
需求中有两个分页查询要求:对所有主题下的新闻进行分页查询,对某一个进行分页查询
主题下的新闻可以分页搜索。事实上,这两个查询的区别仅在于 SQL 语句的一个主要方面。
查询问题 ID。事实上,对于SQL语句来说,这两个查询只是主题id的一个查询条件不同,
因此,考虑整合这两个查询。
图8.1 分页显示所有类别的新闻
修改NewsDao接口中分页查询相关方法的设计,增加topic id参数。
public interface NewsDao {
……// 省略其他方法
//获得新闻总数
public int getTotalCount(Integer id) throws SQLException;
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException;
}
在其实现类NewsDaoImpl中,根据传入参数tid是否有效,动态组装SQL语句并查询
查询条件。
public class NewsDaoImpl extends BaseDao implements NewsDao{
public NewsDaoImpl(Connection conn){
super(conn);
}
……//省略其他方法
//获得新闻的数量
public int getTotalCount(Integer tid) throws SQLEception{
ResultSet rs = null:
List params = new ArrayList ();
String sql = "SELECT COUNT('nid') FROM 'news'";
if(tid!= null){
sql += "WHERE 'ntid' = ?";
params.add(tid);
}
int count = -1;
try {
rs = this.executeQuery(sql,params.toArrary()) ;
rs.next();
count = rs.getInt(1);
}……省略异常处理和资源释放代码
return count;
}
//分页获得新闻
public List getPageNewsList(Integer tid,
int pageNo,int pageSize) throws SQLException{
List list = new ArrayList ();
ResultSet rs = null;
List params = new ArrayList ();
String sql = "SELECT'nid','ntid','ntitle','nauthor',"
+"'ncreateDate','nsummary','tname' FROM 'NEWS',"
+"'TOPIC''WHERE''NEWS'.'NTID' = 'TOPIC'.'tid'";
if{tid! = null){
sql +="AND 'NEWS'.'ntid' = ?";
params.add(tid);
}
sql += " ORDER BY 'ncreateDate' DESC LIMIT ?,?";
params.add((pageNo - 1)* pageSize);
params.add(pageSize);
try{
rs = this.executeQuery(sql,params.toArray());
……// 省略封装数据过程
}……//省略异常处理和资源释放代码
return list;
}
}
(2) 实现业务层
业务层接口NewsService及其实现类NewsServiceImpl也作了相应的调整和设计。
也是添加传入参数主题ID的方法。
修改NewsService接口中分页相关方法的设计,增加主题id参数。
public interface NewsService{
……//省略其他方法
//分页获取新闻
public void findPageNews(Integer tid,Page pageObj)
throws SQLException;
}
在其实现类NewsServiceImpl中调用Dao相关方法时传入tid即可。
public class NewsServiceImpl implements NewsService{
……//省略部分方法
//分页获取新闻
public void findPageNews(Inter tid,Page pageObj)
throws SQLException{
Connection conn = null;
try{
conn = DatebaseUtil.getConnection();
NewsDao newsDao = new NewsDaoImpl(conn);
……//省略部分代码
List newsList = newsDao.getPageNewsList(tid,
pageObj.getCurrPageNo(),
pageObj.getPageSize());
……//省略部分代码
}……// 省略异常处理和资源释放
}
}
}
(3)写Servlet
将原来的首页初始化公告拆解成两部分:按照传统初始化方式初始化最新消息和话题列表(如
图8.2)并使用Ajax方法加载新闻列表(如图8.1)。
图8.2 初始化最新消息和话题列表
以传统方式初始化最新消息和主题列表的关键代码如下。
……//省略其他功能
else if("topicLatest".equals(opr)){//初始化首页侧边栏和主题列表
Maptopics = new HashMap();
topics.put(1,5);
topics.put(2,5);
topics.Put(5,5);
List latests = newsService
.findLatestNewsByTid(topics); //查询最新消息
List list = topicService.findAllTopics(); //查询所有主题
request.setAttribute("list1",latests.get(0)); // 左侧国内新闻
request.setAttribute("list2",latests.get(1)); //左侧国际新闻
request.setAttribute("list3",latests.get(2)); // 左侧国际新闻
request.setAttribute("list",list); //所有的主题
request.getRequestDispatcher("/index.jsp").forward(request,response);
}……//省略其他功能
处理分页加载新闻列表的Ajax请求的关键代码如下。
else if("topicNews".equals(opr)){ //分页查询新闻
//获得主题id 和当前页数
String tid = request.getParameter("tid");
String pageIndex = request.getParameter("pageIndex");
……//省略部分代码
Page pageObj = new page();
……//省略部分代码
//调用业务方法查询
if(tid ==null||(tid = tid.trim()).length() ==0)
newsService.findPageNews(null,pageObj);
else
newsService.findPageNews(Integer.valueOf(tid),pageObj);
//使用 FastJSON 将 Page 对象序列化成 JSON 字符串
String newsJSON = JSON.toJSONStringWithDataFormat(pageObj,
"yyyy-MM-dd HH:mm:ss",
SerializerFeature.WriteMapNullValue);
//向客户端返回响应数据
out.print("[{\"tid\":\""+tid+"\"},"+newsJSON +"]");
}……//省略其他功能
注意
为了保证客户端分页条件的完整性,响应数据是一个JSON数组,包括主题id
和查询结果。
(4) 调整 index.jsp 页面
删除与获取和输出新闻列表相关的原创代码,只保留列表的容器。
……//省略其他页面内容
……//省略其他页面内容
为了适应拆分servlet功能和实际Ajax分页的需求,主题列表的超链接在
输出也需要相应调整。
<a href = "javascript:;" id = "${topic.tid}">
${topic.tname}</a>
点击主题超链接查询相关新闻的功能将在 JavaScript 脚本中使用 Ajax 方法实现。
添加了 id 属性,用于在点击事件中获取主题 id 作为查询参数。
(5) 编写 JavaScript 脚本
分别在以下代码块中编写相关的 JavaScript 脚本。
jQuery.noConflict();//让渡 "$" 的使用权,其他脚本库可以使用 "$"
(function($){
$(document).ready(function(){
//其他脚本编写于此处
});
})(jQuery);
1. 编写发送Ajax分页请求的getpagi()方法,在首页加载时调用它进行初始化
新闻列表。
function getPagi(tid,pageIndex){ //发送 Ajax 请求实现分页
var data = "opr = topicNews"; //准备请求参数
if(tid)
data += "&tid=" +tid;
if(pageIndex && pageIndex>0)
data += "&pageIndex="+pageIndex;
$.getJSON("util/news",data,pagi); //发送 Ajax 请求
};
getPage();//首页加载时,初始化加载新闻列表
2.编写回调方法pagi()处理响应,主要完成两件事:在这个页面显示数据和生成分页操作链接。
<p>//获取显示新闻列表的首页中心区域
var $centerNewsList = $("#container.main.content.classlist");
function pagi(data){ //分页查询的回调函数
var tid = datas[0].tid == "null"?"";datas[0].tid;
var data = datas[1]; //获取分页相关数据
//1.展示本页新闻数据
$centerNewsList.html("");
if(data.newsList == null)
$centerNewsList.html(
"出现错误,请稍后再试或与管理员联系1){
var $first = $("<a href=\"javascrit:;\">首页</a>").click(
function(){getPagi(tid,1);});
var $prev = $("<a href = \"javascript:;\">上一页</a>).click(
function(){getPagi(tid,(data.currPageNo-1));});
$operArea.append($first).append(" ").append($prev);
}
if(data.currPageNo
抓取ajax动态网页java(开发工具IDEA2019开发环境JDK1.8+MySQL5.6+Tomcat8.0主要技术JSP+Servlet源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-09 20:01
前言
这是我在疫情期间和尚硅谷视频一起做的一个书店项目。昨天整理SSM文件的时候,发现还在草稿箱里。写完了(笑),因为当时没有想过给大家看,主要是想自己看看,但是项目实现的功能还是写在文档里,虽然写的不是完成了,但是有了视频,我还是能看懂的。今天看到有小伙伴想要源码,所以先把源码分享一下,后面再补充。
开发工具
IDEA2019
开发环境
JDK1.8+MySQL5.6+Tomcat8.0
主要技术
JSP+Servlet
源代码
先补个网盘链接: 解压码:qqfu
数据库文件根目录下有个book.sql
对于Github,等我以后学习,然后上传到那里。主要原因是这个项目还存在一些问题。虽然我在做的时候修复了一些,但还是希望能上传到Github,让大家一起完善。
无关
如果您觉得本项目文档对您有帮助,请扫描二维码获取优惠券,这对我来说真的很重要,操作步骤如下!
项目功能用户页面JSP动态
注册登录失败后在页面中提取相同的内容,在页面上保存一些数据并合并注册和登录的servlet创建BaseServlet
数据封装及使用BeanUtils抽取
BeanUtils 工具类,可以一次性将所有请求的参数注入JavaBean。
BeanUtils工具类常用于将Map中的值注入JavaBeans,或者复制对象属性的值。
BeanUtils 不是 Jdk 类。但是第三方工具。所以需要引导包。
1、导入需要的jar包:
2、编写WebUtils工具类使用
使用EL表达式修改表单以呼应图书列表
添加书籍
添加工具方法将int类型转换为WebUtils工具类删除书籍
编辑本书
分页
分页模型Page实现在首页、上一页、下一页、最后一页分页模块中跳转到指定页数的功能。点击页码跳转后,自定义显示页码,修改页面、添加、删除、修改图书信息。回显页面
以修改一本书为例: 查看全部
抓取ajax动态网页java(开发工具IDEA2019开发环境JDK1.8+MySQL5.6+Tomcat8.0主要技术JSP+Servlet源码)
前言
这是我在疫情期间和尚硅谷视频一起做的一个书店项目。昨天整理SSM文件的时候,发现还在草稿箱里。写完了(笑),因为当时没有想过给大家看,主要是想自己看看,但是项目实现的功能还是写在文档里,虽然写的不是完成了,但是有了视频,我还是能看懂的。今天看到有小伙伴想要源码,所以先把源码分享一下,后面再补充。
开发工具
IDEA2019
开发环境
JDK1.8+MySQL5.6+Tomcat8.0
主要技术
JSP+Servlet
源代码
先补个网盘链接: 解压码:qqfu
数据库文件根目录下有个book.sql
对于Github,等我以后学习,然后上传到那里。主要原因是这个项目还存在一些问题。虽然我在做的时候修复了一些,但还是希望能上传到Github,让大家一起完善。
无关
如果您觉得本项目文档对您有帮助,请扫描二维码获取优惠券,这对我来说真的很重要,操作步骤如下!
项目功能用户页面JSP动态
注册登录失败后在页面中提取相同的内容,在页面上保存一些数据并合并注册和登录的servlet创建BaseServlet
数据封装及使用BeanUtils抽取
BeanUtils 工具类,可以一次性将所有请求的参数注入JavaBean。
BeanUtils工具类常用于将Map中的值注入JavaBeans,或者复制对象属性的值。
BeanUtils 不是 Jdk 类。但是第三方工具。所以需要引导包。
1、导入需要的jar包:
2、编写WebUtils工具类使用
使用EL表达式修改表单以呼应图书列表
添加书籍
添加工具方法将int类型转换为WebUtils工具类删除书籍
编辑本书
分页
分页模型Page实现在首页、上一页、下一页、最后一页分页模块中跳转到指定页数的功能。点击页码跳转后,自定义显示页码,修改页面、添加、删除、修改图书信息。回显页面
以修改一本书为例:
抓取ajax动态网页java(大数据行业数据价值不言而喻的技术总结及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-08 11:13
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理 查看全部
抓取ajax动态网页java(大数据行业数据价值不言而喻的技术总结及解决办法!)
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个的链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理
抓取ajax动态网页java(目前为止只有网文快捕可以实现该功能下载网址文章的采集对吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-06 13:11
到目前为止,只有网页快拍可以实现这个功能
下载网址
是 文章 的 采集 对吧?用优采云看百度。
您可以使用绘图。如果不会画,那就用最简单的QQ截图。
可能会。
可以同时按下三个键ALT+CTRL+A,看看你的指针会变色,然后在你要剪切的地方左上角点住鼠标左键,然后把指针拖到那个地方你要剪切,然后松开鼠标左键,然后双击左键,会打开一个QQ对话框,在里面点击鼠标右键,看到粘贴,点击它,剪切出来的图片就出来了显示。否则,您也可以从 Internet 下载快照软件。
给你一个想法
1、从上到下、从左到右在全图中搜索红色,得到第一个点A0
2、从0度逆时针搜索A0周围8个点,得到第一个红点A1
3.从A0逆时针搜索A1周围8个点,得到A2
4,以此类推,直到回到 A0
5.得到的A0到An就是Y的包络线,取这些点的最大和最小坐标切出Y
6.在原图中,将原Y占据的位置用蓝色填充
7.重复以上步骤,直到图片中没有红色
如何爬取网页中的动态数据》》》首先要明确我的意思是动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即没有网页源文件,是在页面中加载到浏览器后动态生成的。让我们进入主题。很简单的抓取一个静态页面,通过Java获取html源代码,然后分析...
python如何抓取动态页面内容?- 》》》 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑网站/流程及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具你提到的Firefox的firebug可以也可以用,不过我用过,觉得还是不如IE9的F12好用。3. 已经分析出来了,具体是哪个url生成了你需要的数据,然后在python中实现对应的代码。
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面……
如何使用Python抓取动态页面信息——""" selenium webdriverFirefox()implicitly_wait(3)查看网页请求获取数据时,一般会请求其他地址,也获取信息。你的问题太笼统了,只能如此回答
如何在网页中捕获动态数据-》》》网页是网站的基本元素,也是承载各种网站应用程序的平台。通俗的说,你的网站是由你的网站组成的。网页是一个收录HTML标签的纯文本文件,可以存储在世界的某个角落的电脑上,是万维网上的一个“页面”,它是一种超文本标记语言格式(标准的应用通用标记语言,文件扩展名为 .html 或 .htm)。网页通常用作图像文件。图纸。网页将通过网络浏览器阅读。
如何使用Python抓取动态页面信息——“””这个要先研究动态页面不变的部分,然后通过字符串处理提取出需要的信息
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此...
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果你想捕获的动态页面没有这些限制,那么你可以使用和静态页面一样的方法,例如: import urllib2 url = "xxxxxx" print urllib2.urlopen(url).read ()
如何使用Python抓取动态页面信息——“”” 1、使用模拟浏览器 2、找到对应的ajax url,提交ajax请求,如果是js动态加载的,可以使用pyV8第三方包解析js
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果要捕获的动态页面没有这些限制,那么可以使用和静态页面一样的方法,比如: import urllib2url = "xxxxxx" print urllib2.urlopen(url).read( ) 查看全部
抓取ajax动态网页java(目前为止只有网文快捕可以实现该功能下载网址文章的采集对吗)
到目前为止,只有网页快拍可以实现这个功能
下载网址
是 文章 的 采集 对吧?用优采云看百度。
您可以使用绘图。如果不会画,那就用最简单的QQ截图。
可能会。
可以同时按下三个键ALT+CTRL+A,看看你的指针会变色,然后在你要剪切的地方左上角点住鼠标左键,然后把指针拖到那个地方你要剪切,然后松开鼠标左键,然后双击左键,会打开一个QQ对话框,在里面点击鼠标右键,看到粘贴,点击它,剪切出来的图片就出来了显示。否则,您也可以从 Internet 下载快照软件。
给你一个想法
1、从上到下、从左到右在全图中搜索红色,得到第一个点A0
2、从0度逆时针搜索A0周围8个点,得到第一个红点A1
3.从A0逆时针搜索A1周围8个点,得到A2
4,以此类推,直到回到 A0
5.得到的A0到An就是Y的包络线,取这些点的最大和最小坐标切出Y
6.在原图中,将原Y占据的位置用蓝色填充
7.重复以上步骤,直到图片中没有红色
如何爬取网页中的动态数据》》》首先要明确我的意思是动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即没有网页源文件,是在页面中加载到浏览器后动态生成的。让我们进入主题。很简单的抓取一个静态页面,通过Java获取html源代码,然后分析...
python如何抓取动态页面内容?- 》》》 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑网站/流程及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具你提到的Firefox的firebug可以也可以用,不过我用过,觉得还是不如IE9的F12好用。3. 已经分析出来了,具体是哪个url生成了你需要的数据,然后在python中实现对应的代码。
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面……
如何使用Python抓取动态页面信息——""" selenium webdriverFirefox()implicitly_wait(3)查看网页请求获取数据时,一般会请求其他地址,也获取信息。你的问题太笼统了,只能如此回答
如何在网页中捕获动态数据-》》》网页是网站的基本元素,也是承载各种网站应用程序的平台。通俗的说,你的网站是由你的网站组成的。网页是一个收录HTML标签的纯文本文件,可以存储在世界的某个角落的电脑上,是万维网上的一个“页面”,它是一种超文本标记语言格式(标准的应用通用标记语言,文件扩展名为 .html 或 .htm)。网页通常用作图像文件。图纸。网页将通过网络浏览器阅读。
如何使用Python抓取动态页面信息——“””这个要先研究动态页面不变的部分,然后通过字符串处理提取出需要的信息
如何使用Python抓取动态页面信息——“”” 很久以前,在学习Python web编程的时候,涉及到一个Python urllib,可以使用urllib.urlopen(“url”).read()轻松读取页面不过随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此...
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果你想捕获的动态页面没有这些限制,那么你可以使用和静态页面一样的方法,例如: import urllib2 url = "xxxxxx" print urllib2.urlopen(url).read ()
如何使用Python抓取动态页面信息——“”” 1、使用模拟浏览器 2、找到对应的ajax url,提交ajax请求,如果是js动态加载的,可以使用pyV8第三方包解析js
如何使用Python爬取动态页面信息》》》Python爬取动态和静态页面基本相同。不同的是,一些动态页面对请求头有限制(如cookie\user agent)或ip限制。如果要捕获的动态页面没有这些限制,那么可以使用和静态页面一样的方法,比如: import urllib2url = "xxxxxx" print urllib2.urlopen(url).read( )
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-04 10:03
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载) 查看全部
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载)
抓取ajax动态网页java((二)如何掌握最低的最低可行知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-03 01:11
如果您的工作涉及某种程度的 SEO,您可能会越来越多地听到 Java 及其对爬网和索引的影响。坦率地说,百度蜘蛛在为此苦苦挣扎,许多 网站 使用现代 Java 来加载关键内容。正因为如此,我们需要具备这个话题才能有效地讨论它。分享此 文章 的目的是为您提供必要的最低可行知识。
(一)相关域是否依赖客户端 Java 来加载/更改页面内容或链接?
诊断涉及 Java 的任何问题的第一步是检查域是否使用它来加载可能影响 SEO(页面内容或链接)的关键内容。理想情况下,每当您获得新客户(在初始技术审查期间),或者每当您的客户重新设计/推出新功能 网站 时,都会发生这种情况。
我们该如何做呢?
询问客户
问你应该接受!尽管如此,作为顾问,您可以做的最快/最简单的事情之一就是联系您的 POC(或帐户开发人员)并询问他们。毕竟,这些都是日复一日在 网站 工作的人!
手动检查
即使在拥有数百万页面的大型电子商务网站上,也往往只有几个重要的页面模板。以我的经验,手动检查最多只需要一个小时。您可以使用插件,从那里禁用 Java,并手动检查 网站 是否有重要模板(主页、类别页面、产品页面、博客文章 等)
换句话说,本页第一个问题的答案是“是的,Java 用于加载 网站 的关键部分”。
(二)如果是,百度蜘蛛能否正确查看Java加载的内容?
如果您的客户在其 网站 的某些部分中依赖 Java(在我们的例子中是这样),那么我们的工作就是尝试复制百度实际查看页面的方式。我们想回答这个问题:“百度是否以我们想要的方式看到了页面/网站?”
为了更准确地描述百度蜘蛛看到的内容,我们需要尝试模仿百度蜘蛛爬网的方式。
(三)如果我们确定百度蜘蛛没有正确看到我们的内容怎么办?
既然我们知道域使用 Java 加载关键内容,并且我们知道百度蜘蛛很可能没有看到该内容,那么最后一步就是向客户端推荐理想的解决方案。关键词:推荐,未实施。我们的工作是向我们的客户提出问题,解释为什么它很重要(以及可能的影响),并强调理想的解决方案。尝试为具有独特堆栈/资源/等的开发人员找出理想的解决方案根本不是我们的工作。
概括
冒着严重过度简化的风险,为了在 2018 年开始使用 Java 和 SEO,您需要做以下事情:
找出客户端的域名何时/何地使用客户端 Java 加载页面内容或链接。询问开发商。关闭 Java 并通过页面模板进行一些手动测试。使用 Java 爬虫进行爬取。检查百度蜘蛛是否按照我们预期的方式查看内容。百度的手机友谊检查器。执行 网站:在网络上搜索可见内容。使用 Java 爬虫进行爬取。给客户一个理想的建议。服务器端渲染。混合解决方案(同构)。不是 AJAX 爬取。 查看全部
抓取ajax动态网页java((二)如何掌握最低的最低可行知识)
如果您的工作涉及某种程度的 SEO,您可能会越来越多地听到 Java 及其对爬网和索引的影响。坦率地说,百度蜘蛛在为此苦苦挣扎,许多 网站 使用现代 Java 来加载关键内容。正因为如此,我们需要具备这个话题才能有效地讨论它。分享此 文章 的目的是为您提供必要的最低可行知识。
(一)相关域是否依赖客户端 Java 来加载/更改页面内容或链接?
诊断涉及 Java 的任何问题的第一步是检查域是否使用它来加载可能影响 SEO(页面内容或链接)的关键内容。理想情况下,每当您获得新客户(在初始技术审查期间),或者每当您的客户重新设计/推出新功能 网站 时,都会发生这种情况。
我们该如何做呢?
询问客户
问你应该接受!尽管如此,作为顾问,您可以做的最快/最简单的事情之一就是联系您的 POC(或帐户开发人员)并询问他们。毕竟,这些都是日复一日在 网站 工作的人!
手动检查
即使在拥有数百万页面的大型电子商务网站上,也往往只有几个重要的页面模板。以我的经验,手动检查最多只需要一个小时。您可以使用插件,从那里禁用 Java,并手动检查 网站 是否有重要模板(主页、类别页面、产品页面、博客文章 等)
换句话说,本页第一个问题的答案是“是的,Java 用于加载 网站 的关键部分”。
(二)如果是,百度蜘蛛能否正确查看Java加载的内容?
如果您的客户在其 网站 的某些部分中依赖 Java(在我们的例子中是这样),那么我们的工作就是尝试复制百度实际查看页面的方式。我们想回答这个问题:“百度是否以我们想要的方式看到了页面/网站?”
为了更准确地描述百度蜘蛛看到的内容,我们需要尝试模仿百度蜘蛛爬网的方式。
(三)如果我们确定百度蜘蛛没有正确看到我们的内容怎么办?
既然我们知道域使用 Java 加载关键内容,并且我们知道百度蜘蛛很可能没有看到该内容,那么最后一步就是向客户端推荐理想的解决方案。关键词:推荐,未实施。我们的工作是向我们的客户提出问题,解释为什么它很重要(以及可能的影响),并强调理想的解决方案。尝试为具有独特堆栈/资源/等的开发人员找出理想的解决方案根本不是我们的工作。
概括
冒着严重过度简化的风险,为了在 2018 年开始使用 Java 和 SEO,您需要做以下事情:
找出客户端的域名何时/何地使用客户端 Java 加载页面内容或链接。询问开发商。关闭 Java 并通过页面模板进行一些手动测试。使用 Java 爬虫进行爬取。检查百度蜘蛛是否按照我们预期的方式查看内容。百度的手机友谊检查器。执行 网站:在网络上搜索可见内容。使用 Java 爬虫进行爬取。给客户一个理想的建议。服务器端渲染。混合解决方案(同构)。不是 AJAX 爬取。
抓取ajax动态网页java( 小哥带你看剧2019-07-26简介值得强调的是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-02 19:09
小哥带你看剧2019-07-26简介值得强调的是)
网站动态页面
小哥带你看剧2019-07-26
介绍
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何通过网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
从网站查看者的角度来看,无论是动态网页还是静态网页,都可以展示基本的文字和图片信息,但是从网站开发、管理、维护的角度来看,却是非常很难有大的区别。
对应静态网页,可以与后台数据库交互,传输数据。也就是说,网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页制作格式,而是. cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visualstudio2008等实现。
特征
简要总结如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,一般搜索引擎不可能从一个网站数据库中访问所有网页,或者出于技术考虑, search URL中“?”后面的内容是不被抓取的,所以使用动态网页的网站在推广搜索引擎时需要做一定的技术处理,以满足搜索引擎的要求。
客户
客户端脚本更改特定网页上的界面和行为,以响应鼠标或键盘操作,或在指定时间事件。在这种情况下,动态行为正在发生。客户端生成的内容驻留在用户的本地计算机系统上。
这些页面使用的表示技术称为富界面页面。客户端脚本语言如JavaScript(Java Script)或ActionScript(Action Script)、动态HTML(DHTML)和Flash技术的使用经常被用来对媒体类型(声音、动画、修改过的文本等)的呈现进行编程.)。该脚本还允许使用远程脚本,这是一种允许 DHTML 页面使用隐藏框架、XMLHttpRequest 或 Web (web) 服务从服务器请求附加信息的技术。
缺点
1、首先,动态网页在访问速度上并不占优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到该指令对应的数据,然后传输给服务器。用户看到网页。问题就出来了。每次访问网页时,都必须经过这样一个过程。这个过程至少需要几秒钟。当访问者数量较多时,页面的加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的 网站。
静态网页很简单。静态网页实际上是存在的,没有经过服务器编译,直接加载到客户端的浏览器中显示。
可以看出,动态网页在访问速度上并不占优势。
2、在搜索引擎中不占优势收录
上面我是从服务器和用户体验的角度讲的,下面从搜索引擎的角度讲收录。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会爬现成的,不会自己打字,网站在搜索引擎收录中没有优势。搜索引擎仍然更喜欢静态页面。
但是,搜索引擎正在不断改进。到目前为止,绝大多数搜索引擎都支持动态页面的爬取。 查看全部
抓取ajax动态网页java(
小哥带你看剧2019-07-26简介值得强调的是)
网站动态页面
小哥带你看剧2019-07-26
介绍
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何通过网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
从网站查看者的角度来看,无论是动态网页还是静态网页,都可以展示基本的文字和图片信息,但是从网站开发、管理、维护的角度来看,却是非常很难有大的区别。
对应静态网页,可以与后台数据库交互,传输数据。也就是说,网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页制作格式,而是. cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visualstudio2008等实现。
特征
简要总结如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,一般搜索引擎不可能从一个网站数据库中访问所有网页,或者出于技术考虑, search URL中“?”后面的内容是不被抓取的,所以使用动态网页的网站在推广搜索引擎时需要做一定的技术处理,以满足搜索引擎的要求。
客户
客户端脚本更改特定网页上的界面和行为,以响应鼠标或键盘操作,或在指定时间事件。在这种情况下,动态行为正在发生。客户端生成的内容驻留在用户的本地计算机系统上。
这些页面使用的表示技术称为富界面页面。客户端脚本语言如JavaScript(Java Script)或ActionScript(Action Script)、动态HTML(DHTML)和Flash技术的使用经常被用来对媒体类型(声音、动画、修改过的文本等)的呈现进行编程.)。该脚本还允许使用远程脚本,这是一种允许 DHTML 页面使用隐藏框架、XMLHttpRequest 或 Web (web) 服务从服务器请求附加信息的技术。
缺点
1、首先,动态网页在访问速度上并不占优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到该指令对应的数据,然后传输给服务器。用户看到网页。问题就出来了。每次访问网页时,都必须经过这样一个过程。这个过程至少需要几秒钟。当访问者数量较多时,页面的加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的 网站。
静态网页很简单。静态网页实际上是存在的,没有经过服务器编译,直接加载到客户端的浏览器中显示。
可以看出,动态网页在访问速度上并不占优势。
2、在搜索引擎中不占优势收录
上面我是从服务器和用户体验的角度讲的,下面从搜索引擎的角度讲收录。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会爬现成的,不会自己打字,网站在搜索引擎收录中没有优势。搜索引擎仍然更喜欢静态页面。
但是,搜索引擎正在不断改进。到目前为止,绝大多数搜索引擎都支持动态页面的爬取。
抓取ajax动态网页java(HTML5的pushState+Ajax(pjax)提供HTML5接口的使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 19:08
)
如果您玩过 Google+ 并看到过 YouTube 的新界面,那么您就已经体验过这项新的 HTML5 功能。使用pushState + Ajax(pjax),可以实现网页的ajax加载,同时可以完成URL的改变,没有网页跳转和刷新的迹象,就像改变网页的hash(#)一样.
旧解决方案
据说SEO和ajax是天敌。自 Twitter 以来,调用内容的 Ajax+hash 方法一直很流行。谷歌给出的解决方案是自动将“#!~string”转换为“?_excaped_fragment_=~string”来捕获动态内容。但这无疑会很麻烦:首先需要在网站上配置“?_excaped_fragment_=~string”的处理,如果用户直接复制分享URL“#!/~string”,表示网页还必须监听 hashchange。不过你这么想也没关系#!看起来不错。
新解决方案:pushState
不过,HTML5 的新接口 pushState/replaceState 可以完美解决这个问题。避免了改变hash的问题,也避免了不懂URL形式的用户的困惑。同时还有 onpopstate 提供监控和良好的响应来回前进。而且它不需要 URL 实际存在。
HTML5 pushState+Ajax
HTML5提供了历史接口,以状态的形式添加或替换浏览器的URL。它的实现函数是pushState和replaceState。
pushState 示例
pushState()的基本参数是:
window.history.pushState(state, title, url);
state和title都可以为空,但建议不要为空。应该创建一个状态来配合 popstate 监控。
例如,我们现在可以通过 pushState 更改 URL 而无需刷新页面。
var state = ( {
url: ~href, title: ~title, ~additionalKEY: ~additionalVALUE
} );
window.history.pushState(state, ~title, ~href);
带有“~”符号的内容是自定义内容。您可以将此 ~href (URL) 推送到浏览器的历史记录中。如果你想改变页面的标题,你应该:
document.title= ~newTitle;
注意,只是 pushState 不能改变页面标题。
replaceState 也一样
window.history.replaceState( state, ~title, ~href);
pushState和replaceState的区别
pushState()可以创建历史,可以配合popstate事件,而replaceState()替换当前URL,不生成历史。
限制因素
只能替换为同域的 URL,即不能替换为。并且 state 对象并不像 DOM 那样存储不可序列化的对象。
Ajax 与 pushState 示例
Ajax + pushState 现在用于提供一种新的 ajax 调用样式。以 jQuery 为例,为了 SEO 的需要,应该在 a 标签的 onclick 中添加一个方法。
$("~target a").click(function(evt){
evt.preventDefault(); // 阻止默认的跳转操作
var uri=$(this).attr('href');
var newTitle=ajax_Load(uri); // 你自定义的Ajax加载函数,例如它会返回newTitle
document.title=newTitle; // 分配新的页面标题
if(history.pushState){
var state=({
url: uri, title: newTitle
});
window.history.pushState(state, newTitle, uri);
}else{ window.location.href="#!"+~fakeURI; } // 如果不支持,使用旧的解决方案
return false;
});
function ajax_Load(uri){ ... return newTitle; } // 你自定义的ajax函数,例如它会返回newTitle
pushState 已完成。新标题newTitle的获取是另一个问题。比如你可以把data-newtitle=~title属性赋给a标签并在那个时候读取它,或者如果你使用$.ajax()函数,你可以使用$(result)。 filter("title").text() 来获取。
另外,如果需要使用这个ajax来连接新加载的页面,需要重新部署新内容的a标签,例如
$("~newContentTarget a").click(function(evt){ ... });
pushState配合popstate监控
如果你想很好地支持浏览器的历史向前和向后操作,你应该部署popstate监听器:
window.addEventListener('popstate', function(evt){
var state = evt.state;
var newTitle = ajax_Load(state.url); //你自定义的ajax加载函数,例如它会返回newTitle
document.title=newTitle;
}, false);
提醒,您可以使用 setRequestHeader() 让服务器输出带有您的 ajax 请求的特殊内容。
流程图
本例的大致流程如下图所示
jQuery + PJAX 插件
已在github上发布。有人把PJAX做成了一个jQuery插件,调用方便,省了很多代码:
if ($.support.pjax) {
$(document).on('click', 'a[data-pjax]', function(event) {
var container = $(this).closest('[data-pjax-container]')
$.pjax.click(event, {container: container})
});}
感谢观看,如有错误请指出。
下载:jquery-pjax-master
原文: 查看全部
抓取ajax动态网页java(HTML5的pushState+Ajax(pjax)提供HTML5接口的使用
)
如果您玩过 Google+ 并看到过 YouTube 的新界面,那么您就已经体验过这项新的 HTML5 功能。使用pushState + Ajax(pjax),可以实现网页的ajax加载,同时可以完成URL的改变,没有网页跳转和刷新的迹象,就像改变网页的hash(#)一样.
旧解决方案
据说SEO和ajax是天敌。自 Twitter 以来,调用内容的 Ajax+hash 方法一直很流行。谷歌给出的解决方案是自动将“#!~string”转换为“?_excaped_fragment_=~string”来捕获动态内容。但这无疑会很麻烦:首先需要在网站上配置“?_excaped_fragment_=~string”的处理,如果用户直接复制分享URL“#!/~string”,表示网页还必须监听 hashchange。不过你这么想也没关系#!看起来不错。
新解决方案:pushState
不过,HTML5 的新接口 pushState/replaceState 可以完美解决这个问题。避免了改变hash的问题,也避免了不懂URL形式的用户的困惑。同时还有 onpopstate 提供监控和良好的响应来回前进。而且它不需要 URL 实际存在。
HTML5 pushState+Ajax
HTML5提供了历史接口,以状态的形式添加或替换浏览器的URL。它的实现函数是pushState和replaceState。
pushState 示例
pushState()的基本参数是:
window.history.pushState(state, title, url);
state和title都可以为空,但建议不要为空。应该创建一个状态来配合 popstate 监控。
例如,我们现在可以通过 pushState 更改 URL 而无需刷新页面。
var state = ( {
url: ~href, title: ~title, ~additionalKEY: ~additionalVALUE
} );
window.history.pushState(state, ~title, ~href);
带有“~”符号的内容是自定义内容。您可以将此 ~href (URL) 推送到浏览器的历史记录中。如果你想改变页面的标题,你应该:
document.title= ~newTitle;
注意,只是 pushState 不能改变页面标题。
replaceState 也一样
window.history.replaceState( state, ~title, ~href);
pushState和replaceState的区别
pushState()可以创建历史,可以配合popstate事件,而replaceState()替换当前URL,不生成历史。
限制因素
只能替换为同域的 URL,即不能替换为。并且 state 对象并不像 DOM 那样存储不可序列化的对象。
Ajax 与 pushState 示例
Ajax + pushState 现在用于提供一种新的 ajax 调用样式。以 jQuery 为例,为了 SEO 的需要,应该在 a 标签的 onclick 中添加一个方法。
$("~target a").click(function(evt){
evt.preventDefault(); // 阻止默认的跳转操作
var uri=$(this).attr('href');
var newTitle=ajax_Load(uri); // 你自定义的Ajax加载函数,例如它会返回newTitle
document.title=newTitle; // 分配新的页面标题
if(history.pushState){
var state=({
url: uri, title: newTitle
});
window.history.pushState(state, newTitle, uri);
}else{ window.location.href="#!"+~fakeURI; } // 如果不支持,使用旧的解决方案
return false;
});
function ajax_Load(uri){ ... return newTitle; } // 你自定义的ajax函数,例如它会返回newTitle
pushState 已完成。新标题newTitle的获取是另一个问题。比如你可以把data-newtitle=~title属性赋给a标签并在那个时候读取它,或者如果你使用$.ajax()函数,你可以使用$(result)。 filter("title").text() 来获取。
另外,如果需要使用这个ajax来连接新加载的页面,需要重新部署新内容的a标签,例如
$("~newContentTarget a").click(function(evt){ ... });
pushState配合popstate监控
如果你想很好地支持浏览器的历史向前和向后操作,你应该部署popstate监听器:
window.addEventListener('popstate', function(evt){
var state = evt.state;
var newTitle = ajax_Load(state.url); //你自定义的ajax加载函数,例如它会返回newTitle
document.title=newTitle;
}, false);
提醒,您可以使用 setRequestHeader() 让服务器输出带有您的 ajax 请求的特殊内容。
流程图
本例的大致流程如下图所示
jQuery + PJAX 插件
已在github上发布。有人把PJAX做成了一个jQuery插件,调用方便,省了很多代码:
if ($.support.pjax) {
$(document).on('click', 'a[data-pjax]', function(event) {
var container = $(this).closest('[data-pjax-container]')
$.pjax.click(event, {container: container})
});}
感谢观看,如有错误请指出。
下载:jquery-pjax-master
原文:
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-29 00:03
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以爬取重复数据,爬虫可以爬取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。当遇到这样的网站时,我们不能使用上面的方法。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等等。在自动化渗透中会很有用,会在未来。提到这个。
转载于: 查看全部
抓取ajax动态网页java(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以爬取重复数据,爬虫可以爬取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。当遇到这样的网站时,我们不能使用上面的方法。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等等。在自动化渗透中会很有用,会在未来。提到这个。
转载于:
抓取ajax动态网页java( 视频地址相关文件语言入门()介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 09:04
视频地址相关文件语言入门()介绍)
JavaWeb
视频地址
相关文件
day1 HTML&&CSS 1、B/S软件结构2、前端开发流程3、网页组件4、html介绍
副题 2
5、创建html6、html编写规范7、Heml标签介绍8、常用标签介绍文档9、css技术day2 JavaScript语言介绍1、@ >JavaScript介绍JS2、JavaScript与html代码的结合4、变量5、比较(关系)运算,逻辑运算7、数组8、函数9、自定义对象
对象定义:
var variable name = new Object();//对象实例(空对象)
VariableName.PropertyName = Value;//定义一个属性
变量名。 Function name = function(){}//定义一个函数
访问对象:
变量名.属性/函数名();
10、js中的事件11、DOM模型
了解 Document 对象:
1、Document 他管理着所有的HTML文档内容
2、document是具有层次关系的树状结构文档
3、他要求我们将所有标签客观化
4、我们可以通过document访问所有的tag对象
Document对象中的方法介绍
document.getElementById(elementId) 通过标签的id属性找到标签dom对象,elementId是标签的id属性的值
身份证
名字
标签名
页面加载完成后必须执行对应的三个方法,才能查询到标签对象
第三天 jQuery jQuery = JavaScript + 查询
核心理念:少写,多做(少写,多做)
2、使用jQuery绑定一个按钮点击事件
1]要使用jQuery,必须导入jQuery库
2] $是jQuery中的一个函数
3] 为按钮添加点击响应功能
1、使用jQuery查询标签对象
2、使用标签object.click(function(){}):
3、jQuery核心函数4、jQuery对象和dom对象5、jQuery选择器6、jQuery元素过滤day4 jQuery 1、jQuery属性操作
val 同时选择多个表单状态
全选、取消全选、反转
4、DOM 的增删改查
内部插入
a.append(b)
a.prepend(b)
外部插入
a.insertAfter(b)ba
a.insertBefore(b) ab
替换
a.replaceWith(b) 用 b 替换 a
a.replaceAll(b) 将所有 b 替换为 a
删除
a.remove()
a.empty();
表记录的动态增删
6、CSS 样式操作
添加删除获取
7、jQuery 动画
隐藏、显示、隐藏()、显示()、切换()
淡入淡出
8、jQuery 事件操作
$(function(){});与window.οnlοad=function(){}的区别
触发时间
浏览器内核解析页面的标签并在创建DOM对象后立即执行
原生jsye表面加载完成后,等待浏览器内核解析并创建DOM对象,等待标签显示所需的内容加载完毕。
触发序列
页面加载后执行jQuery
原生js页面加载后
执行次数
jQuery页面加载完成后,封装成函数function,依次执行
原生js页面加载后,只会执行最后一个赋值函数
day5 Tomcat&&xml Tomcat
网络资源的分类:
静态资源html css js txt mp4 jpg
动态资源jsp页面Servlet程序
常用的网络服务器
Tomcat:提供对jsp和servlet的支持,是一个轻量级的javaWeb容器,是目前应用最广泛的JavaWeb服务器
老板
玻璃鱼
树脂
网络逻辑
xml day6 Servlet Serlet是javaEE规范之一,规范就是接口
Servlet是JavaWeb的三大组件之一,三大组件分别是Servlet程序、Filter过滤器、Listener监听器
Servlet是一个运行在服务端的java小程序,可以接受客户端发出的请求,并将相应的数据发送给客户端
Get 和 Post 请求的分发处理
HTTP协议07 day8 jsp jsp中的一些其他请求响应:java server pages Java server pages,本质上是一个servlet程序
作用:代替servlet程序,返回html页面的数据
jsp的三种语法:
jsp头部中的page指令
jsp中的常用脚本
jsp中的三种注释
9个jsp Listener内置对象day9 EL表达式&& JSTL标签库1、EL表达式:
Expression Language 表达语言,非常简洁
格式:${表达式}
功能:
替换jsp页面中的表达式脚本,输出jsp页面中的数据
运算:关系运算、逻辑运算、算术运算、三元运算
day14 Cookie和Session Cookie:服务端通知客户端保存键值对的技术
客户端有cookie后,每个请求都发给服务器
每个cookie的大小不能超过4kb
一个创造
b 服务器获取
c Cookie 值修改
d 浏览器查看 cookie
e Cookie 生命控制(创建和销毁)
f Cookie有效路径Path设置(过滤掉哪些cookie可以发送到服务器,哪些不发送)
由服务器(Tomcat)创建并通知客户端(浏览器)
服务器只需要一行代码即可获取cookie req.getCookies():Cookie[]
Session session:Session是一个接口(HttpSession)
一种用于维护客户端和服务器之间关联的技术
每个客户端都有自己的会话
Session session,常用于用户登录后保存信息
day15 Filter Filter 过滤器是JavaWeb的三个组件之一(Servlet Listener Filter)
作用:拦截请求、过滤响应(权限检查、日志操作、事务管理)
如何使用Filter过滤器:
1、写一个类来实现Filter接口
2、实现过滤方法doFilter()
3、去web.xml配置Filter的拦截路径
子主题2 子主题3 day16 JSON, AJAX, i18n JSON: JavaScript Object Notation 一种轻量级(与xml相比)数据交换(客户端和服务器之间业务数据的传输格式)格式
json 定义:由键值对组成,本身就是一个对象,
json以两种形式存在,json对象,json字符串,
一般来说,当你想对json中的数据进行操作时,需要json对象JSON.parse()的格式来将字符串转化为对象
一般在客户端和服务端交换数据时,使用json字符串JSON.stringify()对象将其转为字符串
java中JSON的使用
AJAX 请求:指一种用于创建交互式 Web 应用程序的 Web 开发技术
ajax是浏览器通过js异步发起请求,部分更新页面(部分更新不会丢弃原页面内容)页面的技术
i18国际书店项目04第一阶段:表单验证08第二阶段:用户注册和登录
要求2:用户登录
要求如下:
1)访问登陆页面
2)填写用户名和密码并提交
3)服务器判断用户是否存在
4)如果登录失败——>>>>返回用户名或密码错误信息
5)如果登录成功-->>>>返回登录
- JavaEE项目的三层架构
Web层/视图表示层:获取请求参数,封装成Bean对象,调用Service层处理服务,响应数据给客户端请求转发和重定向
服务业务层:处理业务逻辑,调用持久层保存到数据库
Dao持久层:只负责与数据库交互
分层的目的是解耦,降低代码的耦合度,方便后期项目的维护和升级
-
- 1、创建书城需要的数据库和表
2、编写数据库表对应的JavaBean对象
3、编写工具类JdbcUtils
4、写BaseDao
5、写一个 UserDao 测试
6、编写 UserService 和测试
7、编写web层实现用户注册功能
Debug调试的使用
10 第三阶段:
从页面中提取相同的内容
登录、注册错误提示和表单回显
BaseServlet的提取:用户模块的UserServlet程序和图书模块的BookServlet程序中相同的部分都是从父类BaseServlet中抽象出来的,然后分别继承
使用EL表达式修改表单回显
11 阶段 5 书籍模块
2、图书标签
副题 4
14的第六阶段
注销用户
表单重复提交-验证码
15 第八阶段 16 第九阶段 查看全部
抓取ajax动态网页java(
视频地址相关文件语言入门()介绍)
JavaWeb
视频地址
相关文件
day1 HTML&&CSS 1、B/S软件结构2、前端开发流程3、网页组件4、html介绍
副题 2
5、创建html6、html编写规范7、Heml标签介绍8、常用标签介绍文档9、css技术day2 JavaScript语言介绍1、@ >JavaScript介绍JS2、JavaScript与html代码的结合4、变量5、比较(关系)运算,逻辑运算7、数组8、函数9、自定义对象
对象定义:
var variable name = new Object();//对象实例(空对象)
VariableName.PropertyName = Value;//定义一个属性
变量名。 Function name = function(){}//定义一个函数
访问对象:
变量名.属性/函数名();
10、js中的事件11、DOM模型
了解 Document 对象:
1、Document 他管理着所有的HTML文档内容
2、document是具有层次关系的树状结构文档
3、他要求我们将所有标签客观化
4、我们可以通过document访问所有的tag对象
Document对象中的方法介绍
document.getElementById(elementId) 通过标签的id属性找到标签dom对象,elementId是标签的id属性的值
身份证
名字
标签名
页面加载完成后必须执行对应的三个方法,才能查询到标签对象
第三天 jQuery jQuery = JavaScript + 查询
核心理念:少写,多做(少写,多做)
2、使用jQuery绑定一个按钮点击事件
1]要使用jQuery,必须导入jQuery库
2] $是jQuery中的一个函数
3] 为按钮添加点击响应功能
1、使用jQuery查询标签对象
2、使用标签object.click(function(){}):
3、jQuery核心函数4、jQuery对象和dom对象5、jQuery选择器6、jQuery元素过滤day4 jQuery 1、jQuery属性操作
val 同时选择多个表单状态
全选、取消全选、反转
4、DOM 的增删改查
内部插入
a.append(b)
a.prepend(b)
外部插入
a.insertAfter(b)ba
a.insertBefore(b) ab
替换
a.replaceWith(b) 用 b 替换 a
a.replaceAll(b) 将所有 b 替换为 a
删除
a.remove()
a.empty();
表记录的动态增删
6、CSS 样式操作
添加删除获取
7、jQuery 动画
隐藏、显示、隐藏()、显示()、切换()
淡入淡出
8、jQuery 事件操作
$(function(){});与window.οnlοad=function(){}的区别
触发时间
浏览器内核解析页面的标签并在创建DOM对象后立即执行
原生jsye表面加载完成后,等待浏览器内核解析并创建DOM对象,等待标签显示所需的内容加载完毕。
触发序列
页面加载后执行jQuery
原生js页面加载后
执行次数
jQuery页面加载完成后,封装成函数function,依次执行
原生js页面加载后,只会执行最后一个赋值函数
day5 Tomcat&&xml Tomcat
网络资源的分类:
静态资源html css js txt mp4 jpg
动态资源jsp页面Servlet程序
常用的网络服务器
Tomcat:提供对jsp和servlet的支持,是一个轻量级的javaWeb容器,是目前应用最广泛的JavaWeb服务器
老板
玻璃鱼
树脂
网络逻辑
xml day6 Servlet Serlet是javaEE规范之一,规范就是接口
Servlet是JavaWeb的三大组件之一,三大组件分别是Servlet程序、Filter过滤器、Listener监听器
Servlet是一个运行在服务端的java小程序,可以接受客户端发出的请求,并将相应的数据发送给客户端
Get 和 Post 请求的分发处理
HTTP协议07 day8 jsp jsp中的一些其他请求响应:java server pages Java server pages,本质上是一个servlet程序
作用:代替servlet程序,返回html页面的数据
jsp的三种语法:
jsp头部中的page指令
jsp中的常用脚本
jsp中的三种注释
9个jsp Listener内置对象day9 EL表达式&& JSTL标签库1、EL表达式:
Expression Language 表达语言,非常简洁
格式:${表达式}
功能:
替换jsp页面中的表达式脚本,输出jsp页面中的数据
运算:关系运算、逻辑运算、算术运算、三元运算
day14 Cookie和Session Cookie:服务端通知客户端保存键值对的技术
客户端有cookie后,每个请求都发给服务器
每个cookie的大小不能超过4kb
一个创造
b 服务器获取
c Cookie 值修改
d 浏览器查看 cookie
e Cookie 生命控制(创建和销毁)
f Cookie有效路径Path设置(过滤掉哪些cookie可以发送到服务器,哪些不发送)
由服务器(Tomcat)创建并通知客户端(浏览器)
服务器只需要一行代码即可获取cookie req.getCookies():Cookie[]
Session session:Session是一个接口(HttpSession)
一种用于维护客户端和服务器之间关联的技术
每个客户端都有自己的会话
Session session,常用于用户登录后保存信息
day15 Filter Filter 过滤器是JavaWeb的三个组件之一(Servlet Listener Filter)
作用:拦截请求、过滤响应(权限检查、日志操作、事务管理)
如何使用Filter过滤器:
1、写一个类来实现Filter接口
2、实现过滤方法doFilter()
3、去web.xml配置Filter的拦截路径
子主题2 子主题3 day16 JSON, AJAX, i18n JSON: JavaScript Object Notation 一种轻量级(与xml相比)数据交换(客户端和服务器之间业务数据的传输格式)格式
json 定义:由键值对组成,本身就是一个对象,
json以两种形式存在,json对象,json字符串,
一般来说,当你想对json中的数据进行操作时,需要json对象JSON.parse()的格式来将字符串转化为对象
一般在客户端和服务端交换数据时,使用json字符串JSON.stringify()对象将其转为字符串
java中JSON的使用
AJAX 请求:指一种用于创建交互式 Web 应用程序的 Web 开发技术
ajax是浏览器通过js异步发起请求,部分更新页面(部分更新不会丢弃原页面内容)页面的技术
i18国际书店项目04第一阶段:表单验证08第二阶段:用户注册和登录
要求2:用户登录
要求如下:
1)访问登陆页面
2)填写用户名和密码并提交
3)服务器判断用户是否存在
4)如果登录失败——>>>>返回用户名或密码错误信息
5)如果登录成功-->>>>返回登录
- JavaEE项目的三层架构
Web层/视图表示层:获取请求参数,封装成Bean对象,调用Service层处理服务,响应数据给客户端请求转发和重定向
服务业务层:处理业务逻辑,调用持久层保存到数据库
Dao持久层:只负责与数据库交互
分层的目的是解耦,降低代码的耦合度,方便后期项目的维护和升级
-
- 1、创建书城需要的数据库和表
2、编写数据库表对应的JavaBean对象
3、编写工具类JdbcUtils
4、写BaseDao
5、写一个 UserDao 测试
6、编写 UserService 和测试
7、编写web层实现用户注册功能
Debug调试的使用
10 第三阶段:
从页面中提取相同的内容
登录、注册错误提示和表单回显
BaseServlet的提取:用户模块的UserServlet程序和图书模块的BookServlet程序中相同的部分都是从父类BaseServlet中抽象出来的,然后分别继承
使用EL表达式修改表单回显
11 阶段 5 书籍模块
2、图书标签
副题 4
14的第六阶段
注销用户
表单重复提交-验证码
15 第八阶段 16 第九阶段

