
当当网网站内容
当当网网站内容(当当网网站内容太杂太乱,广告太多,建议没有较好的朋友)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 20:02
当当网网站内容太杂太乱,广告太多,建议没有较好的整理能力的朋友不要去当当网买书,想必你很早就有上当受骗的经历。我之前买了一本书,纸质版缺页很多。网上图书很多都是同一家公司出品,里面的所谓平台电商售卖盗版书籍,通过合法渠道购买的书本来利润率就非常高,然后再分一点点销售费用,这样的利润能很明显的降低成本,生产的时候还不用算库存。
我之前在当当网上买一本《从优秀到卓越》成本大概是0.27,卖15块钱左右。并不是上当受骗,而是确实发现平台售卖盗版书籍,损害了我正常的售书权益。我买了一本《秦文公·新衣》(某宝售价15元),本来有幸能够看到正版书籍,但没想到当当网盗版书籍,将我发现的此书名称盗版了出来,还标注着这是一本英语原版著作。大家如果在当当网买到了盗版书,请及时拨打当当网客服电话 ,让他们投诉退货,他们并不是客服。售卖盗版书籍可以投诉当当网,并且可以获得相应的赔偿。
是我上当受骗了,买了一本韩愈的《读书故事》,快递没寄到,当当说都变成书钱了。然后在当当网查了一下这本书的详情页已经下架了,心里特别气愤,为什么骗我,找人退货来着。
之前的反响还是可以的,挺多人追评了自己的故事,都非常感谢。但这个版本都卖断货了。不知道他们是怎么算版权费的。也不知道我上当受骗在哪里买的。 查看全部
当当网网站内容(当当网网站内容太杂太乱,广告太多,建议没有较好的朋友)
当当网网站内容太杂太乱,广告太多,建议没有较好的整理能力的朋友不要去当当网买书,想必你很早就有上当受骗的经历。我之前买了一本书,纸质版缺页很多。网上图书很多都是同一家公司出品,里面的所谓平台电商售卖盗版书籍,通过合法渠道购买的书本来利润率就非常高,然后再分一点点销售费用,这样的利润能很明显的降低成本,生产的时候还不用算库存。
我之前在当当网上买一本《从优秀到卓越》成本大概是0.27,卖15块钱左右。并不是上当受骗,而是确实发现平台售卖盗版书籍,损害了我正常的售书权益。我买了一本《秦文公·新衣》(某宝售价15元),本来有幸能够看到正版书籍,但没想到当当网盗版书籍,将我发现的此书名称盗版了出来,还标注着这是一本英语原版著作。大家如果在当当网买到了盗版书,请及时拨打当当网客服电话 ,让他们投诉退货,他们并不是客服。售卖盗版书籍可以投诉当当网,并且可以获得相应的赔偿。
是我上当受骗了,买了一本韩愈的《读书故事》,快递没寄到,当当说都变成书钱了。然后在当当网查了一下这本书的详情页已经下架了,心里特别气愤,为什么骗我,找人退货来着。
之前的反响还是可以的,挺多人追评了自己的故事,都非常感谢。但这个版本都卖断货了。不知道他们是怎么算版权费的。也不知道我上当受骗在哪里买的。
当当网网站内容(当当网网站内容更新超过一周会自动降权,作用在于清除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-26 03:05
当当网网站内容更新超过一周会自动降权,作用在于清除网站内在网站数据。我的个人认为降权有百分之三十.大部分网站如果给予更多的权重就不会长期有所损失.假如有百分之五十降权.按照广告收入.按照百分之五百计算一下像七八十不在打广告.同时让一些销量很低的产品有机会.那么对于当当网是很重要的.当当网是做高端商城的.一些商品本身质量高.又卖一些低价.让一些本身价格比较高.但是又有购买欲望的人有购买欲望.降权作用就是让有购买欲望的网站获得更多机会.而那些没有购买欲望的网站可以尽快找出能接受的群体.降权主要原因是反作弊。
像如果当当网是一个推广联盟有一个商品比如茅台.就会有很多人购买。如果再有其他推广联盟的呢.他们可能就没有这么多的流量,投放联盟的人也就少了。所以就会降权打造一个经济实惠的价格广告联盟。促进成交量。像如果当当是自己开发产品,售卖自己的商品。他就像单个卖者买者。他们没有推广商品的,有需求就购买产品。但是如果联盟.集合了多家卖家的商品。
那么他也不一定能买到或者碰不到这个需求的商品.那么就被降权.降权有百分之四十.那么就造成了网站降权.这个是因为联盟形成了一个商家多次大于卖家.而把他们的需求给挤压掉。一个卖家卖产品,再开一个联盟。他不一定能卖到更多的产品。所以他会被降权.降权对于其他的网站也没有任何影响.如果降权厉害到可以影响到广告的网站.只有网站被做联盟联盟给降权然后资质不达标.网站才会真正的融到资金.这个问题大部分没有大型广告网站的公司都会考虑到,或者刚起步的公司考虑到.如果可以不谈网站.当当网就是一个非常好的选择.他有很多方法可以快速做网站.一般当当网都会联盟高质量的品牌.他们的产品.一般适用的人群相对比较广.大家看看假如阿里巴巴的网站和的网站.有啥区别.阿里巴巴就是联盟复制联盟.网站没有和杭州联盟合作。
没有为阿里巴巴联盟创造利益.把自己的产品。联盟做的专做好。自己还独立...这对每个公司都有好处.如果买房.家里没有钱.就是买几千块的.如果买豪车.就是买几万的.如果买苹果ipad.就是买好几万的.那么你觉得公司的合作让你更多的企业有这个优势.比如购物行业的.购物网站就像是当当网,实体店就像是.当当网低价吸引了大量的消费者.实体店基本需要很多实体的折扣.比如便宜100块,消费者愿意去实体店买吗?可以去当当买嘛.只要有一个经济实惠的价格.消费者会选择去实体店买.正是这个原因.被做联盟的网站冲击了购物。 查看全部
当当网网站内容(当当网网站内容更新超过一周会自动降权,作用在于清除)
当当网网站内容更新超过一周会自动降权,作用在于清除网站内在网站数据。我的个人认为降权有百分之三十.大部分网站如果给予更多的权重就不会长期有所损失.假如有百分之五十降权.按照广告收入.按照百分之五百计算一下像七八十不在打广告.同时让一些销量很低的产品有机会.那么对于当当网是很重要的.当当网是做高端商城的.一些商品本身质量高.又卖一些低价.让一些本身价格比较高.但是又有购买欲望的人有购买欲望.降权作用就是让有购买欲望的网站获得更多机会.而那些没有购买欲望的网站可以尽快找出能接受的群体.降权主要原因是反作弊。
像如果当当网是一个推广联盟有一个商品比如茅台.就会有很多人购买。如果再有其他推广联盟的呢.他们可能就没有这么多的流量,投放联盟的人也就少了。所以就会降权打造一个经济实惠的价格广告联盟。促进成交量。像如果当当是自己开发产品,售卖自己的商品。他就像单个卖者买者。他们没有推广商品的,有需求就购买产品。但是如果联盟.集合了多家卖家的商品。
那么他也不一定能买到或者碰不到这个需求的商品.那么就被降权.降权有百分之四十.那么就造成了网站降权.这个是因为联盟形成了一个商家多次大于卖家.而把他们的需求给挤压掉。一个卖家卖产品,再开一个联盟。他不一定能卖到更多的产品。所以他会被降权.降权对于其他的网站也没有任何影响.如果降权厉害到可以影响到广告的网站.只有网站被做联盟联盟给降权然后资质不达标.网站才会真正的融到资金.这个问题大部分没有大型广告网站的公司都会考虑到,或者刚起步的公司考虑到.如果可以不谈网站.当当网就是一个非常好的选择.他有很多方法可以快速做网站.一般当当网都会联盟高质量的品牌.他们的产品.一般适用的人群相对比较广.大家看看假如阿里巴巴的网站和的网站.有啥区别.阿里巴巴就是联盟复制联盟.网站没有和杭州联盟合作。
没有为阿里巴巴联盟创造利益.把自己的产品。联盟做的专做好。自己还独立...这对每个公司都有好处.如果买房.家里没有钱.就是买几千块的.如果买豪车.就是买几万的.如果买苹果ipad.就是买好几万的.那么你觉得公司的合作让你更多的企业有这个优势.比如购物行业的.购物网站就像是当当网,实体店就像是.当当网低价吸引了大量的消费者.实体店基本需要很多实体的折扣.比如便宜100块,消费者愿意去实体店买吗?可以去当当买嘛.只要有一个经济实惠的价格.消费者会选择去实体店买.正是这个原因.被做联盟的网站冲击了购物。
当当网网站内容(当当网网站内容分发推荐使用/githubsshclient作为分发服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-22 15:04
当当网网站内容分发采用了我们熟悉的git/githubsshclient作为分发服务,将站内采用json作为数据来源,其中,json作为交换格式,数据传输用git/githubsshclient作为中转服务即可,完全不需要其他中转服务,节省资源,
对于这种分享功能,如果不用来传数据就会使网站服务爆炸,所以必须要用到服务端处理的功能,但这时候必须让服务端去处理处理,因为程序员绝对不想让程序去跟服务端交互。推荐使用(分享站的)群组或者(公众号的)投票。效果请参考分享站一个简单且极好的方案,
分享服务器已经搭建了,客户端也启动了分享按钮。用户点击推荐按钮后,分享服务器可以获取到,推荐人有权收到分享请求,从推荐服务器获取,推荐服务器将收到的请求推送给后端。推荐后端将推荐人请求的结果打包推送给接收请求的推荐人,推荐人检查返回的推荐请求结果是否真实有效(即,是否是按照他/她本人意愿进行推荐的,当然,如果结果为真,那么推荐人将获得推荐一个推荐人的积分,并可以分享该推荐),如果不是按照推荐人意愿进行推荐的,那么按照推荐人意愿,该推荐人被推荐后,在推荐服务器的积分里扣除该推荐人得分,继续进行推荐。
那么,是否所有人都会收到推荐服务器提供的结果呢?这是不可能的,因为有些推荐人没有审核,或者审核速度比较慢,这时候就不会被推荐出去。就酱。 查看全部
当当网网站内容(当当网网站内容分发推荐使用/githubsshclient作为分发服务)
当当网网站内容分发采用了我们熟悉的git/githubsshclient作为分发服务,将站内采用json作为数据来源,其中,json作为交换格式,数据传输用git/githubsshclient作为中转服务即可,完全不需要其他中转服务,节省资源,
对于这种分享功能,如果不用来传数据就会使网站服务爆炸,所以必须要用到服务端处理的功能,但这时候必须让服务端去处理处理,因为程序员绝对不想让程序去跟服务端交互。推荐使用(分享站的)群组或者(公众号的)投票。效果请参考分享站一个简单且极好的方案,
分享服务器已经搭建了,客户端也启动了分享按钮。用户点击推荐按钮后,分享服务器可以获取到,推荐人有权收到分享请求,从推荐服务器获取,推荐服务器将收到的请求推送给后端。推荐后端将推荐人请求的结果打包推送给接收请求的推荐人,推荐人检查返回的推荐请求结果是否真实有效(即,是否是按照他/她本人意愿进行推荐的,当然,如果结果为真,那么推荐人将获得推荐一个推荐人的积分,并可以分享该推荐),如果不是按照推荐人意愿进行推荐的,那么按照推荐人意愿,该推荐人被推荐后,在推荐服务器的积分里扣除该推荐人得分,继续进行推荐。
那么,是否所有人都会收到推荐服务器提供的结果呢?这是不可能的,因为有些推荐人没有审核,或者审核速度比较慢,这时候就不会被推荐出去。就酱。
当当网网站内容(当当网如何通过平台经济让当地供货商有机会获得售卖策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-19 11:02
当当网网站内容有些时候用来做售卖内容是可以的,当当网也尝试过,这种售卖方式也不是每一家网站都接受,也就是说,网站售卖内容是必然过程,不然试问如何将电商新店开起来。不过,显然中国不能只靠当当这种方式去发展电商了,而是要走完全新的路子,我认为一些好的思路值得大家学习。再看一下当当网如何通过平台经济,让一些当地供货商有机会获得一个好的售卖策略。
一、当当网接受内容售卖的探索当地生产的产品运至这中间,就形成了产品的流通渠道。那这些内容就可以随意地在当当网上卖,而且能够卖货,从而提高当当网的知名度和销售量。
二、如何通过内容售卖,为当地生产厂商做背书?一些当地的产品也可以随意在当当网上销售,而且这种销售方式也不只是在当当网上销售,也可以在各个供货商和门店销售。
三、当当网不仅支持内容售卖,还提供服务,让当地农民自发建立一个当当网销售网站?确实是这样的,在当当网开网站能够有更多的展示空间和展示方式。包括一些当地的农民为网站建立一个档案,帮助当地农民建立网站。这种场景也是很有想象空间的。
四、当当网创建一个直销招商中心?当当网创建了一个直销招商中心,帮助当地大批的工厂和品牌商自己创建一个品牌网站。并且,这种更能创造信任感的直销招商模式,能够建立更多当地用户和品牌之间的信任。
五、当当网上能够开辟专门的产品介绍页?对于一些没有公司品牌的产品,当当网经过长期分析挖掘,最后为大家提供一个产品介绍页。并且,包括一些当地居民和游客可以看到更详细的产品介绍。当当网能够做的可以做的很多,但它不仅仅只是提供一个展示渠道。另外在产品选择、分类、配送和配送费用等方面都做了足够的考虑。当当网很多产品和服务都是深入当地的一些生产厂商去考察研究,最后提供给当地人。
这种服务要想被每一个用户都接受,需要当地人的愿意去尝试,因为当地人更懂这个品牌。当然,还有一些产品和服务可以直接做在当当网上,也就是所谓的直销招商中心,但是这种产品和服务的不同。直销招商中心不是直接为当地制造或者农户服务,而是类似于中国的连锁店,为当地制造厂商和品牌商去服务。 查看全部
当当网网站内容(当当网如何通过平台经济让当地供货商有机会获得售卖策略)
当当网网站内容有些时候用来做售卖内容是可以的,当当网也尝试过,这种售卖方式也不是每一家网站都接受,也就是说,网站售卖内容是必然过程,不然试问如何将电商新店开起来。不过,显然中国不能只靠当当这种方式去发展电商了,而是要走完全新的路子,我认为一些好的思路值得大家学习。再看一下当当网如何通过平台经济,让一些当地供货商有机会获得一个好的售卖策略。
一、当当网接受内容售卖的探索当地生产的产品运至这中间,就形成了产品的流通渠道。那这些内容就可以随意地在当当网上卖,而且能够卖货,从而提高当当网的知名度和销售量。
二、如何通过内容售卖,为当地生产厂商做背书?一些当地的产品也可以随意在当当网上销售,而且这种销售方式也不只是在当当网上销售,也可以在各个供货商和门店销售。
三、当当网不仅支持内容售卖,还提供服务,让当地农民自发建立一个当当网销售网站?确实是这样的,在当当网开网站能够有更多的展示空间和展示方式。包括一些当地的农民为网站建立一个档案,帮助当地农民建立网站。这种场景也是很有想象空间的。
四、当当网创建一个直销招商中心?当当网创建了一个直销招商中心,帮助当地大批的工厂和品牌商自己创建一个品牌网站。并且,这种更能创造信任感的直销招商模式,能够建立更多当地用户和品牌之间的信任。
五、当当网上能够开辟专门的产品介绍页?对于一些没有公司品牌的产品,当当网经过长期分析挖掘,最后为大家提供一个产品介绍页。并且,包括一些当地居民和游客可以看到更详细的产品介绍。当当网能够做的可以做的很多,但它不仅仅只是提供一个展示渠道。另外在产品选择、分类、配送和配送费用等方面都做了足够的考虑。当当网很多产品和服务都是深入当地的一些生产厂商去考察研究,最后提供给当地人。
这种服务要想被每一个用户都接受,需要当地人的愿意去尝试,因为当地人更懂这个品牌。当然,还有一些产品和服务可以直接做在当当网上,也就是所谓的直销招商中心,但是这种产品和服务的不同。直销招商中心不是直接为当地制造或者农户服务,而是类似于中国的连锁店,为当地制造厂商和品牌商去服务。
当当网网站内容( 搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-19 09:18
搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
Python爬取当当、京东、亚马逊图书信息代码示例
更新时间:2017-12-09 11:27:34 作者:吴相生
本文文章主要介绍Python爬取当当、京东、亚马逊图书信息代码的例子,有一定的参考价值,有需要的朋友可以参考。
注:1.本程序使用MSSQLserver数据库存储,运行程序前请手动修改程序开头的数据库链接信息
2.需要bs4、请求,pymssql库支持
3.支持多线程
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\n爬取已经结束,即将关闭....')
os.system('pause')
main()
示例截图:
关键词:Android下部分运行结果(导出到Excel)
总结
以上就是本文关于Python爬取当当、京东、亚马逊图书信息代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬取亚马逊图书信息代码分享
爬取网站搞笑段落的Python爬虫示例
爬取电商销售信息的Python探索代码示例
如有不足,欢迎留言指出。感谢朋友们对本站的支持! 查看全部
当当网网站内容(
搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
Python爬取当当、京东、亚马逊图书信息代码示例
更新时间:2017-12-09 11:27:34 作者:吴相生
本文文章主要介绍Python爬取当当、京东、亚马逊图书信息代码的例子,有一定的参考价值,有需要的朋友可以参考。
注:1.本程序使用MSSQLserver数据库存储,运行程序前请手动修改程序开头的数据库链接信息
2.需要bs4、请求,pymssql库支持
3.支持多线程
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\n爬取已经结束,即将关闭....')
os.system('pause')
main()
示例截图:
关键词:Android下部分运行结果(导出到Excel)

总结
以上就是本文关于Python爬取当当、京东、亚马逊图书信息代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬取亚马逊图书信息代码分享
爬取网站搞笑段落的Python爬虫示例
爬取电商销售信息的Python探索代码示例
如有不足,欢迎留言指出。感谢朋友们对本站的支持!
当当网网站内容( 本文引用了一些基本的SEO问题,看看你是否知道如何回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 06:32
本文引用了一些基本的SEO问题,看看你是否知道如何回答)
摘要:本文引用了一些基本的SEO测试题,后面附有答案。本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。选择题(2分15=30分)搜索引擎搜索结果页,缩写是什么?SERP扫描电镜(法)离(ourpr
本文引用了一些基本的SEO测试题,后面附有答案。
本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。
多项选择题(2 分 15 = 30 分)
搜索引擎搜索结果页面的简称是什么?
搜索引擎资源计划
扫描电子显微镜
(法) 离开 (our prendre conge)
以下哪个是指入站链接?
内部链接
反向链接
出站链接
以下哪种说法是错误的?
搜索引擎对静态页面更友好。
搜索引擎更喜欢 原创 内容。
搜索引擎对新站点的排名更好。
一个拥有优秀SEO的网站,其主要流量往往来自:
主页
内容页
目录页
新展登录搜索引擎的最佳时间是:
它只是提交给搜索引擎的注册域名。
制作一个静态主页并将其提交给搜索引擎。
网站 结构基本完善后,提交给搜索引擎。
关键词:最好的密度是多少?
1%-5%
5%-10%
10%-20%
影响?最好的进球在哪里关键词
关键词 标签
标题标签
描述标签
在对关键词的分析中,以下哪个观点是错误的:
选择流行的关键词,一旦成功,流量会很高。
列出关键词并发布到合理的网站目录页和内容页
如果竞争对手是大型网站主页,那么就需要慎重考虑了。
提供关键词排名,以下哪种方法不可取:
在 ALT 标签中写入 关键词。
导出链接锚文本收录关键字。
重复关键词,增加关键词的密度。
以下哪个导入链接对PR值影响最大?
PR值高但没有相关性的网站。
具有强相关性但 PR 值平均的站点。
大量站点的平均 PR 值和没有相关性。
以下哪些提高 PR 值的行为被 Google 视为作弊?
与许多相关 网站 的友好链接。
加入许多网站 目录站和导航站。
链接到具有高 PR 价值的购买网站。
以下哪个行为不被视为作弊?
使用群发邮件软件发送收录网站链接的内容。
使用隐藏文本或隐藏链接。
在百度知乎、谷歌论坛等发表文章,并留下链接。
针对搜索引擎优化服务,以下讨论有误:
专业的SEO服务优化全站,全面提升网站排名和搜索流量。
搜索引擎优化服务确保关键字的长期排名。
效果是采购竞价与服务搜索引擎优化相结合的最佳方式
关键词的搜索引擎程序什么时候排名?
用户输入 关键词 并单击搜索。
对于热门的关键词,搜索引擎会定期更新并保存排名。
当搜索引擎索引网页时,它会对其进行排名。
目前,搜索引擎无法实现:
判断一个站是采集站还是原站。
确定一个关键词网站的专业内容。
批量转载文章的原创网站判断。
一句话简答(4分5=20分)
从搜索引擎优化的角度来看,在网页设计中?在中使用 div css 的主要好处是什么
给出三种添加导入链接的方法。
主页是flash,为什么对SEO不利?
竞价排名与SEO投资收益对比分析。
如果我每个站都做了SEO怎么办?
回答:
单项多项选择
1.搜索引擎搜索结果页,简称SERP,是搜索引擎结果页的全称。
2.Inbound 链接指的是反向链接,也叫导入链接,选择外部链接2
3. 错误在于新站点的搜索引擎排名更好。新站位于前100天,附近,基本上很难有更高的车流量。选项 3
4.对于一个搜索引擎优化好的网站来说,其主要流量通常来自内容页面。因为网站,长尾关键词的内容量很大,会给网站带来大量的流量,远远超过首页带来的流量。选项 2
5.新站点登录搜索引擎的最佳时机是完成网站结构并提交给搜索引擎。网站结构指的是网站的目录结构和页面分布。很多人认为“先做一个静态主页,然后提交给搜索引擎,这样可以让搜索引擎更早被收录”。但是搜索引擎被收录后,你会进行大规模的更改,这会延迟搜索引擎对网站的信任。选项 3
6.关键词 什么密度最好,7%选2
7.目的
标签 关键词 最好放在标题标签中。选择2
8、选择热门关键词,一旦成功,就会有很高的流量。这个想法是错误的。因为对于新网站来说,流行的关键词往往需要很长的时间来制作。选择中间流行的关键词,以后改用流行的关键词。这是一个过渡策略。选择 1
9、重复关键词,增加关键词的密度。这种方式不可取,原因请参考问题6。选择3
1 0、对PR值影响较大的导入链接是:PR值高但没有相关性的网站。在这里,我们只考虑 PR 值的影响。但是,由于PR值对排名的影响非常大,现实中当你想连接时,必须选择这三种情况之一,或者更愿意选择PR值高但没有相关性的站点链接。选择 1
11、购买PR值高的网站的链接。这是 Google 明确禁止的行为。当然,对于多次被举报的链接卖家,谷歌会予以处罚。选择3
12、在百度知乎、谷歌论坛等发布文章,并留下链接。这种行为并没有作弊,也不可能因此被搜索引擎屏蔽。选择3
13、说法错误:SEO服务保证关键词长期排名。选择2
14、对于热门关键词,搜索引擎每隔一定时间更新并保存排名。所以,当我们搜索一个热门的关键词时,搜索引擎提供的SERP其实就是一个“静态页面”。对于冷门的关键词,搜索可能是实时的。选择2
15、 目前看来搜索引擎还没有意识到:判断文章的原创网站被大量转载。比如大量网站转载了文章,那么搜索引擎能否判断这个文章是不是原版?这体现在排名上,这个网站是否排名第一。但似乎搜索引擎在这方面做得不是很好。选择3
一句话简答题
1、从SEO的角度来看,在网页设计中使用div css的主要好处是什么?网页的大小已经大大缩小,使搜索引擎更容易抓取内容。
2、 给出三种增加导入链接的方法。
3、首页使用flash,为什么不利于SEO?搜索引擎无法读取 Flash 上的内容和链接。
4、 竞价排名与SEO投资收益对比分析。竞价排名价格高,见效快。SEO 具有缓慢的结果和长期的深层利益。
5、如果每个站点都做SEO,那我们该怎么办?当时,网站内容是搜索引擎排名的主要规则,定位和服务将成为竞争的焦点。 查看全部
当当网网站内容(
本文引用了一些基本的SEO问题,看看你是否知道如何回答)

摘要:本文引用了一些基本的SEO测试题,后面附有答案。本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。选择题(2分15=30分)搜索引擎搜索结果页,缩写是什么?SERP扫描电镜(法)离(ourpr
本文引用了一些基本的SEO测试题,后面附有答案。
本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。
多项选择题(2 分 15 = 30 分)
搜索引擎搜索结果页面的简称是什么?
搜索引擎资源计划
扫描电子显微镜
(法) 离开 (our prendre conge)
以下哪个是指入站链接?
内部链接
反向链接
出站链接
以下哪种说法是错误的?
搜索引擎对静态页面更友好。
搜索引擎更喜欢 原创 内容。
搜索引擎对新站点的排名更好。
一个拥有优秀SEO的网站,其主要流量往往来自:
主页
内容页
目录页
新展登录搜索引擎的最佳时间是:
它只是提交给搜索引擎的注册域名。
制作一个静态主页并将其提交给搜索引擎。
网站 结构基本完善后,提交给搜索引擎。
关键词:最好的密度是多少?
1%-5%
5%-10%
10%-20%
影响?最好的进球在哪里关键词
关键词 标签
标题标签
描述标签
在对关键词的分析中,以下哪个观点是错误的:
选择流行的关键词,一旦成功,流量会很高。
列出关键词并发布到合理的网站目录页和内容页
如果竞争对手是大型网站主页,那么就需要慎重考虑了。
提供关键词排名,以下哪种方法不可取:
在 ALT 标签中写入 关键词。
导出链接锚文本收录关键字。
重复关键词,增加关键词的密度。
以下哪个导入链接对PR值影响最大?
PR值高但没有相关性的网站。
具有强相关性但 PR 值平均的站点。
大量站点的平均 PR 值和没有相关性。
以下哪些提高 PR 值的行为被 Google 视为作弊?
与许多相关 网站 的友好链接。
加入许多网站 目录站和导航站。
链接到具有高 PR 价值的购买网站。
以下哪个行为不被视为作弊?
使用群发邮件软件发送收录网站链接的内容。
使用隐藏文本或隐藏链接。
在百度知乎、谷歌论坛等发表文章,并留下链接。
针对搜索引擎优化服务,以下讨论有误:
专业的SEO服务优化全站,全面提升网站排名和搜索流量。
搜索引擎优化服务确保关键字的长期排名。
效果是采购竞价与服务搜索引擎优化相结合的最佳方式
关键词的搜索引擎程序什么时候排名?
用户输入 关键词 并单击搜索。
对于热门的关键词,搜索引擎会定期更新并保存排名。
当搜索引擎索引网页时,它会对其进行排名。
目前,搜索引擎无法实现:
判断一个站是采集站还是原站。
确定一个关键词网站的专业内容。
批量转载文章的原创网站判断。
一句话简答(4分5=20分)
从搜索引擎优化的角度来看,在网页设计中?在中使用 div css 的主要好处是什么
给出三种添加导入链接的方法。
主页是flash,为什么对SEO不利?
竞价排名与SEO投资收益对比分析。
如果我每个站都做了SEO怎么办?
回答:
单项多项选择
1.搜索引擎搜索结果页,简称SERP,是搜索引擎结果页的全称。
2.Inbound 链接指的是反向链接,也叫导入链接,选择外部链接2
3. 错误在于新站点的搜索引擎排名更好。新站位于前100天,附近,基本上很难有更高的车流量。选项 3
4.对于一个搜索引擎优化好的网站来说,其主要流量通常来自内容页面。因为网站,长尾关键词的内容量很大,会给网站带来大量的流量,远远超过首页带来的流量。选项 2
5.新站点登录搜索引擎的最佳时机是完成网站结构并提交给搜索引擎。网站结构指的是网站的目录结构和页面分布。很多人认为“先做一个静态主页,然后提交给搜索引擎,这样可以让搜索引擎更早被收录”。但是搜索引擎被收录后,你会进行大规模的更改,这会延迟搜索引擎对网站的信任。选项 3
6.关键词 什么密度最好,7%选2
7.目的
标签 关键词 最好放在标题标签中。选择2
8、选择热门关键词,一旦成功,就会有很高的流量。这个想法是错误的。因为对于新网站来说,流行的关键词往往需要很长的时间来制作。选择中间流行的关键词,以后改用流行的关键词。这是一个过渡策略。选择 1
9、重复关键词,增加关键词的密度。这种方式不可取,原因请参考问题6。选择3
1 0、对PR值影响较大的导入链接是:PR值高但没有相关性的网站。在这里,我们只考虑 PR 值的影响。但是,由于PR值对排名的影响非常大,现实中当你想连接时,必须选择这三种情况之一,或者更愿意选择PR值高但没有相关性的站点链接。选择 1
11、购买PR值高的网站的链接。这是 Google 明确禁止的行为。当然,对于多次被举报的链接卖家,谷歌会予以处罚。选择3
12、在百度知乎、谷歌论坛等发布文章,并留下链接。这种行为并没有作弊,也不可能因此被搜索引擎屏蔽。选择3
13、说法错误:SEO服务保证关键词长期排名。选择2
14、对于热门关键词,搜索引擎每隔一定时间更新并保存排名。所以,当我们搜索一个热门的关键词时,搜索引擎提供的SERP其实就是一个“静态页面”。对于冷门的关键词,搜索可能是实时的。选择2
15、 目前看来搜索引擎还没有意识到:判断文章的原创网站被大量转载。比如大量网站转载了文章,那么搜索引擎能否判断这个文章是不是原版?这体现在排名上,这个网站是否排名第一。但似乎搜索引擎在这方面做得不是很好。选择3
一句话简答题
1、从SEO的角度来看,在网页设计中使用div css的主要好处是什么?网页的大小已经大大缩小,使搜索引擎更容易抓取内容。
2、 给出三种增加导入链接的方法。
3、首页使用flash,为什么不利于SEO?搜索引擎无法读取 Flash 上的内容和链接。
4、 竞价排名与SEO投资收益对比分析。竞价排名价格高,见效快。SEO 具有缓慢的结果和长期的深层利益。
5、如果每个站点都做SEO,那我们该怎么办?当时,网站内容是搜索引擎排名的主要规则,定位和服务将成为竞争的焦点。
当当网网站内容(当当网网站内容更新太慢怎么提高抓取速度呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 20:09
当当网网站内容更新太慢。我们对网站的抓取更新从来都是在整理完全后才上线。php代码易于抓取。当当更新慢很可能是由于整个平台内容更新慢造成的。我们在整理内容期间都是从抓取更新的。之后整理完毕会在当当网进行上线。因此,与其让其他网站去抓取,不如我们做好内容管理。抓取内容需要通过技术手段,这个不是很容易做好。
例如用搜索引擎抓取。搜索引擎抓取的依据最重要是该网站的内容量。毕竟搜索引擎抓取不是用户也不是浏览器。那对于当当网来说,如何提高抓取速度呢?方法太多了,主要的还是:网站自身内容更新与内容实时管理平台内容与网站内容同步。最后,当当网很可能会被其他网站收录。通过爬虫等技术手段。
有爬虫的数据都在网啊,
爬虫一般都是在网存量数据量里面抓取而不是在内容本身大家都用爬虫内容整理相对于抓取更快些
当当看书都是看三多,喜欢看马云相关帖子,马云倒了,怎么发展,
我们商城爬的是b2c平台的,而马云网就是b2c平台最大的内容提供者,即使内容下架,马云网也不会有什么影响。用网是因为网内容是平台发展最大的收益,大头已经到那里了,一句话,在你看到的东西就是他们想让你看到的。至于当当网,也就是b2c上的“马云网”,只要平台继续火爆,没有哪个商城会放弃平台内容。互联网的本质不是内容,而是消费,没有数据就没有竞争力。谁的内容多,谁的内容“有用”谁就能走得远。 查看全部
当当网网站内容(当当网网站内容更新太慢怎么提高抓取速度呢?)
当当网网站内容更新太慢。我们对网站的抓取更新从来都是在整理完全后才上线。php代码易于抓取。当当更新慢很可能是由于整个平台内容更新慢造成的。我们在整理内容期间都是从抓取更新的。之后整理完毕会在当当网进行上线。因此,与其让其他网站去抓取,不如我们做好内容管理。抓取内容需要通过技术手段,这个不是很容易做好。
例如用搜索引擎抓取。搜索引擎抓取的依据最重要是该网站的内容量。毕竟搜索引擎抓取不是用户也不是浏览器。那对于当当网来说,如何提高抓取速度呢?方法太多了,主要的还是:网站自身内容更新与内容实时管理平台内容与网站内容同步。最后,当当网很可能会被其他网站收录。通过爬虫等技术手段。
有爬虫的数据都在网啊,
爬虫一般都是在网存量数据量里面抓取而不是在内容本身大家都用爬虫内容整理相对于抓取更快些
当当看书都是看三多,喜欢看马云相关帖子,马云倒了,怎么发展,
我们商城爬的是b2c平台的,而马云网就是b2c平台最大的内容提供者,即使内容下架,马云网也不会有什么影响。用网是因为网内容是平台发展最大的收益,大头已经到那里了,一句话,在你看到的东西就是他们想让你看到的。至于当当网,也就是b2c上的“马云网”,只要平台继续火爆,没有哪个商城会放弃平台内容。互联网的本质不是内容,而是消费,没有数据就没有竞争力。谁的内容多,谁的内容“有用”谁就能走得远。
当当网网站内容(当当网史海峰:如何应对电商营销体系挑战(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 07:08
阿里云>云栖社区>主题地图>D>当当网网站特色
推荐活动:
更多优惠>
当前话题:当当网网站 功能采集
相关话题:
当当网网站功能相关博客,查看更多博客
当当网:大数据提升B2C电商商业价值
作者:青山无名 2409人浏览评论:04年前
文章关于当当网:大数据推动B2C电子商务的商业价值,2014年4月10-12日,第五届中国数据库技术大会(DTCC 2014)在北京五洲皇冠国际)酒店拉开帷幕,在为期三天的大会中,大会将围绕大数据应用、数据架构、数据管理、传统数据库软件等技术领域展开深入探讨。
阅读全文
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?产品线规划与技术实施如何匹配?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用PWA搭建一个完全离线的网站
作者:博文观点 2073人浏览评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
网站常见的被攻击手段
作者:zting科技797人浏览评论:04年前
1、Webshell 后门 WebShell 是一种以asp、php、jsp 或cgi 等web 文件形式的命令执行环境,也可以称为web 后门。黑客入侵网站后,通常会将这些asp或php后门文件与网站服务器WEB目录下的普通网页结合起来。
阅读全文
网站 添加数据时出错。原来是MS SQL Server2008的日志文件占用了太多空间。
作者:zting科技836人浏览评论:04年前
打开数据库目录,发现数据库日志文件达到了20G多,于是萌生了清除MS SQL Server 2008的数据库日志文件的想法。 具体操作:1、打开MS SQL Server 2008查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除HR和财务部门外,分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
当你的网站被疯狂攻击时,你会怎么做?
作者:zting科技1640人浏览评论:04年前
前言网站优采云竞价网成立至今已有四个月左右。搜索引擎收录逐渐从零收录发展到百度。40万收录,360搜索了4万多收录,搜索引擎流入的流量也在慢慢增加。今天去上班,发现网站出故障了。主要表现如下: 1、网站访问很慢;2、静态
阅读全文 查看全部
当当网网站内容(当当网史海峰:如何应对电商营销体系挑战(组图))
阿里云>云栖社区>主题地图>D>当当网网站特色

推荐活动:
更多优惠>
当前话题:当当网网站 功能采集
相关话题:
当当网网站功能相关博客,查看更多博客
当当网:大数据提升B2C电商商业价值


作者:青山无名 2409人浏览评论:04年前
文章关于当当网:大数据推动B2C电子商务的商业价值,2014年4月10-12日,第五届中国数据库技术大会(DTCC 2014)在北京五洲皇冠国际)酒店拉开帷幕,在为期三天的大会中,大会将围绕大数据应用、数据架构、数据管理、传统数据库软件等技术领域展开深入探讨。
阅读全文
当当网石海峰:如何应对电商营销体系的挑战


作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?产品线规划与技术实施如何匹配?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用PWA搭建一个完全离线的网站


作者:博文观点 2073人浏览评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集

作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
网站常见的被攻击手段

作者:zting科技797人浏览评论:04年前
1、Webshell 后门 WebShell 是一种以asp、php、jsp 或cgi 等web 文件形式的命令执行环境,也可以称为web 后门。黑客入侵网站后,通常会将这些asp或php后门文件与网站服务器WEB目录下的普通网页结合起来。
阅读全文
网站 添加数据时出错。原来是MS SQL Server2008的日志文件占用了太多空间。

作者:zting科技836人浏览评论:04年前
打开数据库目录,发现数据库日志文件达到了20G多,于是萌生了清除MS SQL Server 2008的数据库日志文件的想法。 具体操作:1、打开MS SQL Server 2008查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
ShopNum1网店系统:打造电商运营团队

作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除HR和财务部门外,分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
当你的网站被疯狂攻击时,你会怎么做?

作者:zting科技1640人浏览评论:04年前
前言网站优采云竞价网成立至今已有四个月左右。搜索引擎收录逐渐从零收录发展到百度。40万收录,360搜索了4万多收录,搜索引擎流入的流量也在慢慢增加。今天去上班,发现网站出故障了。主要表现如下: 1、网站访问很慢;2、静态
阅读全文
当当网网站内容(大哥,要看哪种?当当网,随心下载,找到你想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2021-11-18 21:05
当当网网站内容已经全站覆盖,如果你在网站搜索你想看的电影、电视剧,都是可以看到的,如果想看全面的,可以在自助下载,当当网的微云支持全网中国的电影电视剧,如果你是想一步到位,就是想全方位,也可以找当当的经销商,他们网站上有,当然价格相对更低。
可以看啊,
超级无敌稳定稳定,当当网,随心下载,试一试,找到你想要的。当当网是我下载次数最多的一个网站,真的很稳定。
在
当当网网站可以浏览全网各大电影电视剧资源,如果需要看某一部的,可以直接跳转到电影,
都有下载,还有购物,方便电商入驻。这个很方便,很开心,
网站有购物,下载,
当当网,最近一年来,已经完成了400亿的规模,且以每年15%左右的速度在高速增长,作为小生意,当当网已经是最快速的增长的,当当网就是网站看看电影,电视剧的话没有问题的。
当当网都有。试试。
当当网吧。还有各种影视资源可以看。
当当网你可以在googleplay下载,
也许还有安卓市场
目前,知道当当网最快的方法,
大哥,要看哪种?如果是电视剧电影之类,当当网都有全网覆盖,试一试当当网的微云。如果是学习和考试,那就可以买当当的书。电商一般都是明码标价的。也看不上会员啥的。 查看全部
当当网网站内容(大哥,要看哪种?当当网,随心下载,找到你想要的)
当当网网站内容已经全站覆盖,如果你在网站搜索你想看的电影、电视剧,都是可以看到的,如果想看全面的,可以在自助下载,当当网的微云支持全网中国的电影电视剧,如果你是想一步到位,就是想全方位,也可以找当当的经销商,他们网站上有,当然价格相对更低。
可以看啊,
超级无敌稳定稳定,当当网,随心下载,试一试,找到你想要的。当当网是我下载次数最多的一个网站,真的很稳定。
在
当当网网站可以浏览全网各大电影电视剧资源,如果需要看某一部的,可以直接跳转到电影,
都有下载,还有购物,方便电商入驻。这个很方便,很开心,
网站有购物,下载,
当当网,最近一年来,已经完成了400亿的规模,且以每年15%左右的速度在高速增长,作为小生意,当当网已经是最快速的增长的,当当网就是网站看看电影,电视剧的话没有问题的。
当当网都有。试试。
当当网吧。还有各种影视资源可以看。
当当网你可以在googleplay下载,
也许还有安卓市场
目前,知道当当网最快的方法,
大哥,要看哪种?如果是电视剧电影之类,当当网都有全网覆盖,试一试当当网的微云。如果是学习和考试,那就可以买当当的书。电商一般都是明码标价的。也看不上会员啥的。
当当网网站内容(移动互联时代需要怎样的营销系统?(产品线)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-07 16:22
阿里云>云栖社区>主题图>D>网站当当网功能图
推荐活动:
更多优惠>
当前话题:加入采集 网站 当当网功能图
相关话题:
当当网网站功能图相关博客,查看更多博客
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?如何匹配产品线规划和技术实施?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用 PWA 搭建一个完全离线的网站
作者:博文观点 2073 人查看评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
如何对待一本书
作者:科技探索者 1156人浏览评论:03年前
最近有网友多方面批评我的书,说我的书厚,实战性不强,里面的内容不够先进。他还写了一篇博文,暗中批评了我的书(这位网友是谁,这里我就不点名了,他心里最清楚)。非常感谢您的意见。我从不否认我的每一本书都以这样或那样的方式存在
阅读全文
窥探推荐系统
作者:javaedge1477 人浏览评论:02年前
本文将深入介绍推荐系统的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰理解并快速构建适合自己的推荐系统。1 信息发现随着Web2.0的发展,Web已经成为数据共享的平台。人们如何才能在海量数据中找到自己的需求?
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除人力资源和财务部门外,共分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
对话DFINITY:我们如何用区块链重构一个开放的互联网世界?
作者:云启豪资讯小哥567人浏览评论:01年前
云栖资讯:【点击查看更多行业资讯】在这里你可以找到不同行业的一手云资讯,还等什么,快来吧!置顶商务频道,新京报讯7月07日(黄当当):这是我第一次见到DFINITY创始人兼首席科学家多米尼克威廉姆斯,他带着非常阳光的笑容。
阅读全文
【python爬虫】Selenium针对性爬取海量精美图片及搜索引擎杂谈
作者:肖洛洛4435人浏览评论:06年前
我觉得这是我博客里的一篇优秀的文章,也是在深夜凌晨2点的激情和喜悦中完成的。首先,通过这个文章,可以学到以下几点:1.简单爬取图片可以学习Python的一些思路和方法2.学习Selenium
阅读全文 查看全部
当当网网站内容(移动互联时代需要怎样的营销系统?(产品线)(组图))
阿里云>云栖社区>主题图>D>网站当当网功能图
推荐活动:
更多优惠>
当前话题:加入采集 网站 当当网功能图
相关话题:
当当网网站功能图相关博客,查看更多博客
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?如何匹配产品线规划和技术实施?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用 PWA 搭建一个完全离线的网站
作者:博文观点 2073 人查看评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
如何对待一本书

作者:科技探索者 1156人浏览评论:03年前
最近有网友多方面批评我的书,说我的书厚,实战性不强,里面的内容不够先进。他还写了一篇博文,暗中批评了我的书(这位网友是谁,这里我就不点名了,他心里最清楚)。非常感谢您的意见。我从不否认我的每一本书都以这样或那样的方式存在
阅读全文
窥探推荐系统


作者:javaedge1477 人浏览评论:02年前
本文将深入介绍推荐系统的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰理解并快速构建适合自己的推荐系统。1 信息发现随着Web2.0的发展,Web已经成为数据共享的平台。人们如何才能在海量数据中找到自己的需求?
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除人力资源和财务部门外,共分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
对话DFINITY:我们如何用区块链重构一个开放的互联网世界?


作者:云启豪资讯小哥567人浏览评论:01年前
云栖资讯:【点击查看更多行业资讯】在这里你可以找到不同行业的一手云资讯,还等什么,快来吧!置顶商务频道,新京报讯7月07日(黄当当):这是我第一次见到DFINITY创始人兼首席科学家多米尼克威廉姆斯,他带着非常阳光的笑容。
阅读全文
【python爬虫】Selenium针对性爬取海量精美图片及搜索引擎杂谈

作者:肖洛洛4435人浏览评论:06年前
我觉得这是我博客里的一篇优秀的文章,也是在深夜凌晨2点的激情和喜悦中完成的。首先,通过这个文章,可以学到以下几点:1.简单爬取图片可以学习Python的一些思路和方法2.学习Selenium
阅读全文
当当网网站内容(【爬虫工程师】有合作?新上线的活动价500包邮)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-06 06:01
当当网网站内容简介并不清晰:网站是否和【python爱好者】【爬虫工程师】有合作?新上线的活动价500包邮,但在活动规则中并没有对:活动规则中要求“活动时间截止到11月30日”没有详细的项目和解决方案,只有一个列表;例子里用的axios,python之外你可以有别的开发工具吗?网站目录地址:-doc/python网站目录文件夹地址:,会有什么影响?。
我觉得是可以的。用redis做缓存好了。
这个大部分语言做爬虫都行,django这类不适合,因为目前有大批量客户端浏览器不支持django这些技术,这样想提高速度爬取更多流量时,一定要涉及限制cookie。总而言之就是,如果不安装django,爬虫的思想与实践就基本上没有任何改变。可以尝试scrapy或者flask。
我推荐用scrapy或者flask,
别做了,解决不了第一个问题的,就算第二个问题能解决,但是第三个问题很容易就让爬虫不再可用,到时候爬虫没数据,
首先你要注意到了这个问题说的是整个网站,网站是在用户量比较大的情况下产生,那么如果想要爬取全网页,也就是热门资源,其实最好是做成脚本这样利于分享提高自己的工作效率,关于爬虫工具,关于教程。1.django。用到的爬虫基本是http接口。2.flask。用的是flask的db等待读写分离模式,db容易重复建库。
4.redisscrapy这个数据库中间件,一般用到特定功能时会用到,比如登录页,后台管理页等。5.selenium+浏览器过滤。6.flask-redisscrapy自带的redis数据库中间件,但是目前看来太慢了,做到500s消息比较慢。7.beautifulsoupscrapy自带的beautifulsoup中间件,用于爬取网页重复,以及爬取网页结构。
但是目前来看没什么效果。如果希望加速爬取速度可以尝试将抓取进程再shell中。beautifulsoup的shell中间件,可以加快速度。要爬取全网页的网站,可以考虑django+flask+scrapy三者结合。总结来说,如果想提升效率尽可能组合实践,尽可能考虑django或者flask等。 查看全部
当当网网站内容(【爬虫工程师】有合作?新上线的活动价500包邮)
当当网网站内容简介并不清晰:网站是否和【python爱好者】【爬虫工程师】有合作?新上线的活动价500包邮,但在活动规则中并没有对:活动规则中要求“活动时间截止到11月30日”没有详细的项目和解决方案,只有一个列表;例子里用的axios,python之外你可以有别的开发工具吗?网站目录地址:-doc/python网站目录文件夹地址:,会有什么影响?。
我觉得是可以的。用redis做缓存好了。
这个大部分语言做爬虫都行,django这类不适合,因为目前有大批量客户端浏览器不支持django这些技术,这样想提高速度爬取更多流量时,一定要涉及限制cookie。总而言之就是,如果不安装django,爬虫的思想与实践就基本上没有任何改变。可以尝试scrapy或者flask。
我推荐用scrapy或者flask,
别做了,解决不了第一个问题的,就算第二个问题能解决,但是第三个问题很容易就让爬虫不再可用,到时候爬虫没数据,
首先你要注意到了这个问题说的是整个网站,网站是在用户量比较大的情况下产生,那么如果想要爬取全网页,也就是热门资源,其实最好是做成脚本这样利于分享提高自己的工作效率,关于爬虫工具,关于教程。1.django。用到的爬虫基本是http接口。2.flask。用的是flask的db等待读写分离模式,db容易重复建库。
4.redisscrapy这个数据库中间件,一般用到特定功能时会用到,比如登录页,后台管理页等。5.selenium+浏览器过滤。6.flask-redisscrapy自带的redis数据库中间件,但是目前看来太慢了,做到500s消息比较慢。7.beautifulsoupscrapy自带的beautifulsoup中间件,用于爬取网页重复,以及爬取网页结构。
但是目前来看没什么效果。如果希望加速爬取速度可以尝试将抓取进程再shell中。beautifulsoup的shell中间件,可以加快速度。要爬取全网页的网站,可以考虑django+flask+scrapy三者结合。总结来说,如果想提升效率尽可能组合实践,尽可能考虑django或者flask等。
当当网网站内容( 如何利用我们刚才的几个库去库去实战(上图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-05 13:10
如何利用我们刚才的几个库去库去实战(上图))
图片来自 unsplash
我们学习了这三个库的用法:urllib、re、BeautifulSoup。但这只是停留在理论层面,需要实践来检验学习效果。因此,本文主要讲解如何使用我们刚刚掌握的几个库进行实战。
1 确定爬取目标
任何网站都可以被爬取,这取决于你是否想爬取它。这次选择的爬取目标是当当网。爬取的内容是以Python作为关键字搜索到的页面中所有书籍的信息。详情如下图所示:
点击查看大图
这个爬取结果中有三项:
2 爬取过程
众所周知,每个站点的页面DOM树是不同的。因此,我们需要先对抓取的页面进行分析,然后确定我们想要获取的内容,然后定义程序抓取内容的规则。
2.1 确定URL地址
我们可以通过浏览器来判断 URL 地址,并提供入口地址给 urllib 发起请求。接下来,我们将逐步确定请求地址。
搜索结果页面为1时,URL地址如下:
点击查看大图
搜索结果页面为3时,URL地址如下:
点击查看大图
当搜索结果页面为21,即最后一页时,URL地址如下:
点击查看大图
从上图中,我们发现URL地址的不同在于page_index的值,所以URL地址最终是。而page_index的值,我们可以通过循环依次添加在地址之后。所以urllib的请求代码可以这样写:
<p> # 爬取地址, 当当所有 Python 的书籍, 一共是 21 页
url = "http://search.dangdang.com/%3F ... ot%3B
index = 1
while index 查看全部
当当网网站内容(
如何利用我们刚才的几个库去库去实战(上图))

图片来自 unsplash
我们学习了这三个库的用法:urllib、re、BeautifulSoup。但这只是停留在理论层面,需要实践来检验学习效果。因此,本文主要讲解如何使用我们刚刚掌握的几个库进行实战。
1 确定爬取目标
任何网站都可以被爬取,这取决于你是否想爬取它。这次选择的爬取目标是当当网。爬取的内容是以Python作为关键字搜索到的页面中所有书籍的信息。详情如下图所示:

点击查看大图
这个爬取结果中有三项:
2 爬取过程
众所周知,每个站点的页面DOM树是不同的。因此,我们需要先对抓取的页面进行分析,然后确定我们想要获取的内容,然后定义程序抓取内容的规则。
2.1 确定URL地址
我们可以通过浏览器来判断 URL 地址,并提供入口地址给 urllib 发起请求。接下来,我们将逐步确定请求地址。
搜索结果页面为1时,URL地址如下:

点击查看大图
搜索结果页面为3时,URL地址如下:

点击查看大图
当搜索结果页面为21,即最后一页时,URL地址如下:

点击查看大图
从上图中,我们发现URL地址的不同在于page_index的值,所以URL地址最终是。而page_index的值,我们可以通过循环依次添加在地址之后。所以urllib的请求代码可以这样写:
<p> # 爬取地址, 当当所有 Python 的书籍, 一共是 21 页
url = "http://search.dangdang.com/%3F ... ot%3B
index = 1
while index
当当网网站内容(当当网网站内容太多了,怎么办?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-04 02:04
当当网网站内容太多了。而且因为太多内容,所以没有看的兴趣,因为看完了找不到想看的。当当网应该重点扶持买书,卖书这部分的内容。其他的,就不是太重要了,除非你只看买书这一条信息。
正在体验,
当当网是一个商城的品类足够多,优惠力度足够大,所以是个围城。
购物信息太多了,
当当网最近推出的"比价"服务,以前光盯着上或者京东上的价格不太准确,比价以后就会知道原来不同商品之间差别还挺大,或者是比价后发现同一商品在不同平台的价格不一样,这样就有助于我节省了比价的时间精力,省下来买好东西我感觉当当比较好的是直通车,
看待一个商城对我个人有什么帮助。我想关键看我买东西在哪里找。在当当网是不是没有如何买到廉价好物的问题,买到的我会感觉很便宜,所以我想追求的是这个,不知道其他的商城同这个一样么?另外我也喜欢全年的商品一次性购齐,这也是个需求所在。
有一个叫作"当当比价"的app,是我看了比价整整三年的说。app是用户自己上传的商品的价格来比价。他有个用户体验做的不好的地方就是价格的显示效果不太好。我刚接触当当时,在一个专营网站看中了一款耳环。(网站买手价已经接近过万了)然后,我先订购一个月的,然后在比价上查查看。他就告诉我这个耳环售价是¥600,再想想自己刚要买。
自己查看也就查看了一个月,但是有个问题就是只能显示差价部分,不知道有没有其他价格。然后我就去了卖家,想问下有没有其他差价?卖家就各种推脱,说是差价不能透露。当时我觉得不对劲,就默默付款了。结果我一个月过去了,当我过了上个月的那一天,那时候卖家已经走了。所以我也没去问卖家的那些价格啊这样,每一天都是价格上浮20%,直到当我查看差价部分看不见价格的时候,我发现我订购的那个耳环真的已经涨价了。
然后我就马上提交了申请退款。把之前付了的钱退了回去。以后再找卖家比价,我就可以更加精准的查找了。在当当上的一个很蛋疼的事情就是,这个货可能有几千个人在买。他有一个退货差价规则,总共有25%的差价空间。而当你没有比价的时候,他那25%的差价你是算不到的。这样,你就很容易算到差价的部分里。这种低水平的用户体验真的让人挺烦恼的。
而如果我有时间有精力有兴趣在当当上买的话,我会去找当当帮我在卖家端查价,再等他们退差价给我不是当当的产品不行,因为买他们的产品还是便宜的多。但是当当这么不行,售后这块做的真不是让人满意ps:你知。 查看全部
当当网网站内容(当当网网站内容太多了,怎么办?(组图))
当当网网站内容太多了。而且因为太多内容,所以没有看的兴趣,因为看完了找不到想看的。当当网应该重点扶持买书,卖书这部分的内容。其他的,就不是太重要了,除非你只看买书这一条信息。
正在体验,
当当网是一个商城的品类足够多,优惠力度足够大,所以是个围城。
购物信息太多了,
当当网最近推出的"比价"服务,以前光盯着上或者京东上的价格不太准确,比价以后就会知道原来不同商品之间差别还挺大,或者是比价后发现同一商品在不同平台的价格不一样,这样就有助于我节省了比价的时间精力,省下来买好东西我感觉当当比较好的是直通车,
看待一个商城对我个人有什么帮助。我想关键看我买东西在哪里找。在当当网是不是没有如何买到廉价好物的问题,买到的我会感觉很便宜,所以我想追求的是这个,不知道其他的商城同这个一样么?另外我也喜欢全年的商品一次性购齐,这也是个需求所在。
有一个叫作"当当比价"的app,是我看了比价整整三年的说。app是用户自己上传的商品的价格来比价。他有个用户体验做的不好的地方就是价格的显示效果不太好。我刚接触当当时,在一个专营网站看中了一款耳环。(网站买手价已经接近过万了)然后,我先订购一个月的,然后在比价上查查看。他就告诉我这个耳环售价是¥600,再想想自己刚要买。
自己查看也就查看了一个月,但是有个问题就是只能显示差价部分,不知道有没有其他价格。然后我就去了卖家,想问下有没有其他差价?卖家就各种推脱,说是差价不能透露。当时我觉得不对劲,就默默付款了。结果我一个月过去了,当我过了上个月的那一天,那时候卖家已经走了。所以我也没去问卖家的那些价格啊这样,每一天都是价格上浮20%,直到当我查看差价部分看不见价格的时候,我发现我订购的那个耳环真的已经涨价了。
然后我就马上提交了申请退款。把之前付了的钱退了回去。以后再找卖家比价,我就可以更加精准的查找了。在当当上的一个很蛋疼的事情就是,这个货可能有几千个人在买。他有一个退货差价规则,总共有25%的差价空间。而当你没有比价的时候,他那25%的差价你是算不到的。这样,你就很容易算到差价的部分里。这种低水平的用户体验真的让人挺烦恼的。
而如果我有时间有精力有兴趣在当当上买的话,我会去找当当帮我在卖家端查价,再等他们退差价给我不是当当的产品不行,因为买他们的产品还是便宜的多。但是当当这么不行,售后这块做的真不是让人满意ps:你知。
当当网网站内容(当当网产品经理在中国真的火了,你怎么看?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-02 19:07
当当网网站内容结构错乱,三次元的发展成了一次线上二次元公会聚会,闹矛盾直接一个视频,人员聚会。作者|楠瓜(知乎id:noom)编辑|冰雪聪明的吴瑞凡(知乎id:迟钝兔)来源|人人都是产品经理(微信id:pmhuanxiang)互联网理论和分析看多了,你会觉得产品很神秘,甚至你不相信互联网还可以产生出产品经理这个职位。
“产品经理”这个职位被冠以一个令人耳目一新的名字出现在大众视野中,目的不是为了让你称其为“工匠”,而是为了他们在专业领域的突破和意义。大多数人没有想过产品经理是怎么一回事,他们也觉得产品经理很神秘,他们需要为用户考虑得更周到,还经常被人称作是“产品鬼才”。不过就在今天,产品经理在中国真的火了!刚刚,国内著名的视频网站和直播网站都传出了面试产品经理的好消息。
我们聊了聊产品经理这个职位的内部情况,以及我对产品经理的理解。01产品经理是干嘛的?首先,从技术角度来看,产品经理这个职位,真的是类似于ceo的职位。做过小ceo或者产品人会知道,创业前期,高管的工作基本就是需求挖掘、产品规划、推动产品实现。做产品经理的人一般分为用户研究、产品设计、产品运营和产品推广这四大模块。
在互联网公司中,产品经理就是用户研究出身,设计出了解决问题的用户需求。在其他传统行业也是这样,比如可口可乐的二次创业者戴维·普雷斯利是通讯运营商的产品经理,京东的第二代产品腾讯电商就是做运营商业务起家。可是,目前互联网公司都变成了一个相对扁平的网络体系,产品经理也几乎变成了一个职位而不再仅仅是一个职位。
在互联网人眼中,产品经理就是一个行业内的专业人员,是一种用户研究人员而不是前端人员,是一个运营人员,不同于其他行业产品经理。在这种情况下,产品经理已经不仅仅是负责解决创意设计,也就是产品产品需求,而是负责整个项目的架构,也就是整个产品的产品经理。再谈到专业能力方面,产品经理需要对整个产品走向有一个大致的判断,比如前端是视频网站,后端就是生活服务平台,数据就要区分为实时数据、沉淀数据和全量数据。
其实在一个互联网创业公司中,更像是生活服务平台的运营,对这种沉淀数据需要监测,但同时也要根据用户和商户的反馈来调整数据。把生活服务的数据通过数据采集变成数据,再赋能给其他服务,比如电商中的优惠券,游戏中的装备,或者主打广告的注册卡。上面我们说的只是一种层面的,最底层的产品经理有很多种,有一个公司就会有一个产品经理,产品经理实际上还有很多职位,具体包括但不限于用户研究,系统维。 查看全部
当当网网站内容(当当网产品经理在中国真的火了,你怎么看?)
当当网网站内容结构错乱,三次元的发展成了一次线上二次元公会聚会,闹矛盾直接一个视频,人员聚会。作者|楠瓜(知乎id:noom)编辑|冰雪聪明的吴瑞凡(知乎id:迟钝兔)来源|人人都是产品经理(微信id:pmhuanxiang)互联网理论和分析看多了,你会觉得产品很神秘,甚至你不相信互联网还可以产生出产品经理这个职位。
“产品经理”这个职位被冠以一个令人耳目一新的名字出现在大众视野中,目的不是为了让你称其为“工匠”,而是为了他们在专业领域的突破和意义。大多数人没有想过产品经理是怎么一回事,他们也觉得产品经理很神秘,他们需要为用户考虑得更周到,还经常被人称作是“产品鬼才”。不过就在今天,产品经理在中国真的火了!刚刚,国内著名的视频网站和直播网站都传出了面试产品经理的好消息。
我们聊了聊产品经理这个职位的内部情况,以及我对产品经理的理解。01产品经理是干嘛的?首先,从技术角度来看,产品经理这个职位,真的是类似于ceo的职位。做过小ceo或者产品人会知道,创业前期,高管的工作基本就是需求挖掘、产品规划、推动产品实现。做产品经理的人一般分为用户研究、产品设计、产品运营和产品推广这四大模块。
在互联网公司中,产品经理就是用户研究出身,设计出了解决问题的用户需求。在其他传统行业也是这样,比如可口可乐的二次创业者戴维·普雷斯利是通讯运营商的产品经理,京东的第二代产品腾讯电商就是做运营商业务起家。可是,目前互联网公司都变成了一个相对扁平的网络体系,产品经理也几乎变成了一个职位而不再仅仅是一个职位。
在互联网人眼中,产品经理就是一个行业内的专业人员,是一种用户研究人员而不是前端人员,是一个运营人员,不同于其他行业产品经理。在这种情况下,产品经理已经不仅仅是负责解决创意设计,也就是产品产品需求,而是负责整个项目的架构,也就是整个产品的产品经理。再谈到专业能力方面,产品经理需要对整个产品走向有一个大致的判断,比如前端是视频网站,后端就是生活服务平台,数据就要区分为实时数据、沉淀数据和全量数据。
其实在一个互联网创业公司中,更像是生活服务平台的运营,对这种沉淀数据需要监测,但同时也要根据用户和商户的反馈来调整数据。把生活服务的数据通过数据采集变成数据,再赋能给其他服务,比如电商中的优惠券,游戏中的装备,或者主打广告的注册卡。上面我们说的只是一种层面的,最底层的产品经理有很多种,有一个公司就会有一个产品经理,产品经理实际上还有很多职位,具体包括但不限于用户研究,系统维。
当当网网站内容(当当网网站积分池会随之增加,这个市场怎么打?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-01 20:03
当当网网站内容更新每月第四周,网站积分池会随之增加。目前这个数字我也没找到准确的数字,但看过此次的年会keynote,说白了就是5%平台分成。可以间接看出当当基金和用户有个公平的分成机制。另外,还是有些利益问题。比如设计书城每天仅上架一本书,限量的要么经典要么限时,结果没什么书供应。kindle店也是,下架书的也太多。
storeday只能自己家老书翻新卖,同价格的没多少书可卖。如果不能多卖书的话,当当只能自己做电商当当买那自己设定的折扣了,这个占比个人估计在50%左右。如果真的是这样,那这个市场怎么打?书城一天上架一本书,每本都限量,那以kindle卖图书的经验来看,前10页后面基本就卖完了,后面也不能多卖。前期玩下限概念,弄成模式,把第一笔钱打给出版社,这个比例一定要高,才能吸引众多编辑来搞原创。不然依靠盗版网站多年积累下来的人脉,当当还怎么和上游那些原创公司打。
截止3月29日,销售额大概3万,原创期两天。电商网站的书籍是比实体书便宜的,可以看看当当目前这些书的折扣。
2万左右,我猜是2/3折,原创期卖到现在,其中大部分不是原创作者的书,只是随便写写的读物。
以往的价格折扣是本文的一半,注意这里仅仅是以往,现在第一批原创真正开卖了价格立马下来了。这个价格和线下分销的情况是类似的,并且公司的估算也是50%销售提成,线下放置一天后价格调整比例是22%,又一轮调价,只是没走线上渠道, 查看全部
当当网网站内容(当当网网站积分池会随之增加,这个市场怎么打?)
当当网网站内容更新每月第四周,网站积分池会随之增加。目前这个数字我也没找到准确的数字,但看过此次的年会keynote,说白了就是5%平台分成。可以间接看出当当基金和用户有个公平的分成机制。另外,还是有些利益问题。比如设计书城每天仅上架一本书,限量的要么经典要么限时,结果没什么书供应。kindle店也是,下架书的也太多。
storeday只能自己家老书翻新卖,同价格的没多少书可卖。如果不能多卖书的话,当当只能自己做电商当当买那自己设定的折扣了,这个占比个人估计在50%左右。如果真的是这样,那这个市场怎么打?书城一天上架一本书,每本都限量,那以kindle卖图书的经验来看,前10页后面基本就卖完了,后面也不能多卖。前期玩下限概念,弄成模式,把第一笔钱打给出版社,这个比例一定要高,才能吸引众多编辑来搞原创。不然依靠盗版网站多年积累下来的人脉,当当还怎么和上游那些原创公司打。
截止3月29日,销售额大概3万,原创期两天。电商网站的书籍是比实体书便宜的,可以看看当当目前这些书的折扣。
2万左右,我猜是2/3折,原创期卖到现在,其中大部分不是原创作者的书,只是随便写写的读物。
以往的价格折扣是本文的一半,注意这里仅仅是以往,现在第一批原创真正开卖了价格立马下来了。这个价格和线下分销的情况是类似的,并且公司的估算也是50%销售提成,线下放置一天后价格调整比例是22%,又一轮调价,只是没走线上渠道,
当当网网站内容(当当网网站体验如何让用户流失了以后的价值大于购书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-09 13:03
当当网网站内容少,所以页面少,外观不够好,用户更倾向于看内容丰富的当当网。当当网网站很多功能很难找到,用户有较大的局限性,基本上以是买书为主。买书的多用人人,书在人人看的话,整个网站就会水掉。因此,如果做书城的话,人人与书又会水掉。因此,解决这个问题最大的困难应该是,用户是否有相关的购书需求?如果只是看看随手看看的话,这样可以解决当当网网站的问题,但是如果能导入其他的kindle商店,就能解决你的问题。但是网站的体验如何就无从说起了。
你应该问,怎么让kindle用户流失了以后的价值大于购书的价值。简单说,kindle就是一个借阅网站。你卖的只是借的权,而购书还要付钱。另外,你也必须得服务好kindle本身,传书等等都要及时,不能断。最好有定期的发货政策。现在是电商时代,讲的都是自营多平台发货,kindle可不管这些,单独走kindle商店就好了,只要是有kindle电子书销售,kindle商店一定会有的。
一下个观点仅仅是我个人的观点:第一,你提出的问题存在,在现在的电商环境下,当当网作为一个正常的,可以在国内大卖的电商平台,它的资源整合能力很强,所以你问我资源多会不会把kindle挤出去,那是不可能的。但是这样会导致很多问题。第二,正如你所说,当当网在地理上比较封闭,用户的购书来源有限,这可能是你会感觉它不利于购书的原因之一。
第三,其实你说的图书归类和,送货配送之类的,在大致的平台内部都是有的,而当当应该做了。最后,还是可以看出当当还是更加聚焦图书这个品类,而一些其他的信息不能进来并且分散,一定程度上起到了影响。总之,问题在于他们不会聚焦眼光和看法,以及在没有足够多资源的情况下选择了现在这种布局方式,甚至是更有可能丢失一些用户。 查看全部
当当网网站内容(当当网网站体验如何让用户流失了以后的价值大于购书)
当当网网站内容少,所以页面少,外观不够好,用户更倾向于看内容丰富的当当网。当当网网站很多功能很难找到,用户有较大的局限性,基本上以是买书为主。买书的多用人人,书在人人看的话,整个网站就会水掉。因此,如果做书城的话,人人与书又会水掉。因此,解决这个问题最大的困难应该是,用户是否有相关的购书需求?如果只是看看随手看看的话,这样可以解决当当网网站的问题,但是如果能导入其他的kindle商店,就能解决你的问题。但是网站的体验如何就无从说起了。
你应该问,怎么让kindle用户流失了以后的价值大于购书的价值。简单说,kindle就是一个借阅网站。你卖的只是借的权,而购书还要付钱。另外,你也必须得服务好kindle本身,传书等等都要及时,不能断。最好有定期的发货政策。现在是电商时代,讲的都是自营多平台发货,kindle可不管这些,单独走kindle商店就好了,只要是有kindle电子书销售,kindle商店一定会有的。
一下个观点仅仅是我个人的观点:第一,你提出的问题存在,在现在的电商环境下,当当网作为一个正常的,可以在国内大卖的电商平台,它的资源整合能力很强,所以你问我资源多会不会把kindle挤出去,那是不可能的。但是这样会导致很多问题。第二,正如你所说,当当网在地理上比较封闭,用户的购书来源有限,这可能是你会感觉它不利于购书的原因之一。
第三,其实你说的图书归类和,送货配送之类的,在大致的平台内部都是有的,而当当应该做了。最后,还是可以看出当当还是更加聚焦图书这个品类,而一些其他的信息不能进来并且分散,一定程度上起到了影响。总之,问题在于他们不会聚焦眼光和看法,以及在没有足够多资源的情况下选择了现在这种布局方式,甚至是更有可能丢失一些用户。
当当网网站内容(当当网网站内容逐渐下滑的情况下,自建站更有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-07 22:01
当当网网站内容逐渐下滑的情况下,有需求就有市场,自建站的发展就更不可避免了。有需求,有市场,才会有企业开始尝试自建站。所以,自建站更符合企业发展规律。流量平台分流本身就足够你站到一定高度,再发展站点,意义就不大了。相比而言,独立站更有价值。企业发展应该依托自身,独立站点也只是对外的渠道,能在多大程度上帮助你发展,还是得靠你自己不断探索。
有需求就有市场,一定要有的话就是整体分类。
互联网
前端变化太快了,后端的产品策略以及用户体验都会有很大的差别,还是相信自己的判断,选一个能与自己的行业,
我现在也没有太好的自建站解决方案,我现在一直在用shop++收费的,还是很不错的。自建站的发展前景很好,特别是对传统行业来说,将是一个不错的选择。当然你自己的专业经验和资源对于自建站的落地还是很重要的,还是得靠自己了。
流量平台的分流让你没有了机会,不能再被平台控制流量入口了,基于自建平台收费或免费的方式,外联资源能量很大,
问题没有抓住根本是自建站没有现成案例,而且一大把竞争对手。新市场你没有竞争力。那就是通过招聘外联招到你想要找的人。 查看全部
当当网网站内容(当当网网站内容逐渐下滑的情况下,自建站更有价值)
当当网网站内容逐渐下滑的情况下,有需求就有市场,自建站的发展就更不可避免了。有需求,有市场,才会有企业开始尝试自建站。所以,自建站更符合企业发展规律。流量平台分流本身就足够你站到一定高度,再发展站点,意义就不大了。相比而言,独立站更有价值。企业发展应该依托自身,独立站点也只是对外的渠道,能在多大程度上帮助你发展,还是得靠你自己不断探索。
有需求就有市场,一定要有的话就是整体分类。
互联网
前端变化太快了,后端的产品策略以及用户体验都会有很大的差别,还是相信自己的判断,选一个能与自己的行业,
我现在也没有太好的自建站解决方案,我现在一直在用shop++收费的,还是很不错的。自建站的发展前景很好,特别是对传统行业来说,将是一个不错的选择。当然你自己的专业经验和资源对于自建站的落地还是很重要的,还是得靠自己了。
流量平台的分流让你没有了机会,不能再被平台控制流量入口了,基于自建平台收费或免费的方式,外联资源能量很大,
问题没有抓住根本是自建站没有现成案例,而且一大把竞争对手。新市场你没有竞争力。那就是通过招聘外联招到你想要找的人。
当当网网站内容(当当网网站内容真实可靠,所有资源全部来自官方!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-07 02:03
当当网网站内容真实可靠,所有资源全部来自官方,用户评论几乎是对所有内容中的错误进行广泛的反对。话说你是在我遇到你当当网的客服或者工作人员时才这么觉得还是说你本身就是在意网站内容真实性的?你让我觉得我至少应该服务态度好点,然后我做到内容真实,不会大篇幅的点反对和关闭链接,但是为什么我会没有做到呢?那么我看到这个问题是不是应该认为,内容真实与否不能完全由客服本身来决定,而更是和我的认知有关?以下为原答案:电商的售后,应该是最容易出现问题的地方吧。
没错,我也遇到过。我觉得我的情况,也算是情有可原。买了雅阁,之后差点儿把发动机弄坏。车不是我的,然后发现真是正品,而且车子离谱沉,一看价格,还要出我半个月的购置税,我打电话给客服,客服拿公司名称一顿瞎扯,说返点儿也没有多,要不你加我微信,我拉你入团,然后给你寄了快递,你去取,我给他拉卡。我转账给他后,在微信上要求发货,然后卖家直接不发货,说请我邮寄给他,要拆箱验货。
我觉得就当开了个单子吧,然后发去寄的地方,去寄的时候看到这个。不拆完不拆,拆了不发,物流上什么鬼都没有。最后我没有领了快递回去。我当时想换车,现在我对这个牌子不熟悉,我根本不知道是不是假货。之后我估计4s有问题,我投诉了他们,他们全程就跟我扯皮,然后推给店方。最后店方告诉我我没有发货,还叫我找买家。我觉得还是要坚持我自己的想法,这是我的购买记录啊。
一直开车,觉得那个质量以及售后,我还是非常非常恼火的。你看网上买的二手车,只要是稍微懂点儿二手车,买个几千块的,出点钱保险,一年之后让保险公司给你送几万去,都非常正常。如果一辆新车,你给他优惠个几千块,送他几万块,那才叫遭罪。而且你仔细想想,一个公司在经营的时候,是为了便利多方呢,还是说要利用信息不对称,在所有汽车商都不知道的地方剥削你来维持自己,我一直觉得这是能做到的。 查看全部
当当网网站内容(当当网网站内容真实可靠,所有资源全部来自官方!)
当当网网站内容真实可靠,所有资源全部来自官方,用户评论几乎是对所有内容中的错误进行广泛的反对。话说你是在我遇到你当当网的客服或者工作人员时才这么觉得还是说你本身就是在意网站内容真实性的?你让我觉得我至少应该服务态度好点,然后我做到内容真实,不会大篇幅的点反对和关闭链接,但是为什么我会没有做到呢?那么我看到这个问题是不是应该认为,内容真实与否不能完全由客服本身来决定,而更是和我的认知有关?以下为原答案:电商的售后,应该是最容易出现问题的地方吧。
没错,我也遇到过。我觉得我的情况,也算是情有可原。买了雅阁,之后差点儿把发动机弄坏。车不是我的,然后发现真是正品,而且车子离谱沉,一看价格,还要出我半个月的购置税,我打电话给客服,客服拿公司名称一顿瞎扯,说返点儿也没有多,要不你加我微信,我拉你入团,然后给你寄了快递,你去取,我给他拉卡。我转账给他后,在微信上要求发货,然后卖家直接不发货,说请我邮寄给他,要拆箱验货。
我觉得就当开了个单子吧,然后发去寄的地方,去寄的时候看到这个。不拆完不拆,拆了不发,物流上什么鬼都没有。最后我没有领了快递回去。我当时想换车,现在我对这个牌子不熟悉,我根本不知道是不是假货。之后我估计4s有问题,我投诉了他们,他们全程就跟我扯皮,然后推给店方。最后店方告诉我我没有发货,还叫我找买家。我觉得还是要坚持我自己的想法,这是我的购买记录啊。
一直开车,觉得那个质量以及售后,我还是非常非常恼火的。你看网上买的二手车,只要是稍微懂点儿二手车,买个几千块的,出点钱保险,一年之后让保险公司给你送几万去,都非常正常。如果一辆新车,你给他优惠个几千块,送他几万块,那才叫遭罪。而且你仔细想想,一个公司在经营的时候,是为了便利多方呢,还是说要利用信息不对称,在所有汽车商都不知道的地方剥削你来维持自己,我一直觉得这是能做到的。
当当网网站内容(大数据推动B2C电子商务商业价值,如何应对电商营销体系挑战(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-20 19:07
阿里云>;云气社区>;主题地图>;D>;当当网的网站功能
建议的活动:
更多优惠>
当前主题:当当的网站功能添加到集合中
相关主题:
当当网的网站功能相关博客查看更多博客
当当石海峰:如何应对电子商务营销体系的挑战
作者:Jurasic14905观点:2005年前
移动互联网时代需要什么样的营销体系?我们如何快速、良好地响应业务需求并占据竞争优势?需要什么样的企业组织结构?产品线规划和技术实施如何匹配?促销是简洁还是令人眩晕?各位好。让我先自我介绍一下。我叫史海峰。我目前负责当当科技部的建筑部。感谢中生代科技集团
阅读全文
当当网:大数据提升B2C电商商业价值
作者:青山无名2409人浏览评论:2004年前
文章about :大数据提升B2C电子商务商业价值,2014年4月10-12日第五届中国数据库技术大会(DTCC)2014)为期三天的会议将集中讨论大数据应用、数据架构、数据管理、传统数据库软件和其他技术领域
阅读全文
使用PWA构建完全离线的网站系统@
作者:博客观点2073观点评论:03年前
想象一下,您能够构建一个完全离线的网站,为用户提供几乎即时的加载体验,并且对于不可靠的网络来说,它是安全和灵活的。这听起来是不可能和不可思议的。信不信由你,大多数现代浏览器都有内置功能,所以只要发布它们就行了。当您在使用这些强大功能构建网站时受益时,您
阅读全文
网站architecture数据采集和排序
作者:项教授2060观点点评:2003年前
1.系统概述1.1系统架构概述1.2相对完整的系统架构图2.系统使用的主要技术排名不分先后2.1前端JavaScript、HTML、CSS、Silverlight、flash、jQuery JavaScript类库简化HTML
阅读全文
当你的网站受到疯狂攻击时,你能做什么
作者:中兴科技1640观点评论:2004年前
前言网站优采云招标网络建立至今已超过四个月。百度搜索引擎收录已经从零收录逐步发展到400000收录和360搜索引擎的40000收录以上。流入搜索引擎的流量也在缓慢增加。发现网站在今天的工作中出现故障,主要表现为:1、网站访问速度非常慢2、static
阅读全文
[水文]从URL比较大电子商务网站的搜索详情
作者:嗯,99251179人浏览评论:2003年前
keep walking的文章“大电商网站navigation用户体验比较”很有趣。因为我最近的工作与搜索有关,我对中文和英文分词有点恼火。之前我还借用并模仿了网站的一些搜索功能,所以我将横向比较几位电子商务领军人物的搜索结果。我会提起它,让兄弟们继续走下去
阅读全文
@添加数据时出现错误k17。最初的原因是MS SQL Server 2008日志文件占用了太多空间
作者:中兴科技836观点评论:2004年前
打开数据库目录,发现数据库日志文件已经达到20g以上,所以我有了一个清除MS SQL Server 2008数据库日志文件的想法。具体操作:1、打开MS SQL Server 2008的查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
网站常用攻击手段
作者:中兴科技797观点评论:04年前
1、WebshellBackdoor webshell是一个以网页文件(如ASP、PHP、JSP或CGI)形式出现的命令执行环境,也可以称为网页后门。黑客入侵网站服务器后,通常会将这些ASP或PHP后门文件与网站服务器web目录中的普通网页文件连接起来
阅读全文 查看全部
当当网网站内容(大数据推动B2C电子商务商业价值,如何应对电商营销体系挑战(组图))
阿里云>;云气社区>;主题地图>;D>;当当网的网站功能
建议的活动:
更多优惠>
当前主题:当当的网站功能添加到集合中
相关主题:
当当网的网站功能相关博客查看更多博客
当当石海峰:如何应对电子商务营销体系的挑战
作者:Jurasic14905观点:2005年前
移动互联网时代需要什么样的营销体系?我们如何快速、良好地响应业务需求并占据竞争优势?需要什么样的企业组织结构?产品线规划和技术实施如何匹配?促销是简洁还是令人眩晕?各位好。让我先自我介绍一下。我叫史海峰。我目前负责当当科技部的建筑部。感谢中生代科技集团
阅读全文
当当网:大数据提升B2C电商商业价值
作者:青山无名2409人浏览评论:2004年前
文章about :大数据提升B2C电子商务商业价值,2014年4月10-12日第五届中国数据库技术大会(DTCC)2014)为期三天的会议将集中讨论大数据应用、数据架构、数据管理、传统数据库软件和其他技术领域
阅读全文
使用PWA构建完全离线的网站系统@
作者:博客观点2073观点评论:03年前
想象一下,您能够构建一个完全离线的网站,为用户提供几乎即时的加载体验,并且对于不可靠的网络来说,它是安全和灵活的。这听起来是不可能和不可思议的。信不信由你,大多数现代浏览器都有内置功能,所以只要发布它们就行了。当您在使用这些强大功能构建网站时受益时,您
阅读全文
网站architecture数据采集和排序
作者:项教授2060观点点评:2003年前
1.系统概述1.1系统架构概述1.2相对完整的系统架构图2.系统使用的主要技术排名不分先后2.1前端JavaScript、HTML、CSS、Silverlight、flash、jQuery JavaScript类库简化HTML
阅读全文
当你的网站受到疯狂攻击时,你能做什么
作者:中兴科技1640观点评论:2004年前
前言网站优采云招标网络建立至今已超过四个月。百度搜索引擎收录已经从零收录逐步发展到400000收录和360搜索引擎的40000收录以上。流入搜索引擎的流量也在缓慢增加。发现网站在今天的工作中出现故障,主要表现为:1、网站访问速度非常慢2、static
阅读全文
[水文]从URL比较大电子商务网站的搜索详情

作者:嗯,99251179人浏览评论:2003年前
keep walking的文章“大电商网站navigation用户体验比较”很有趣。因为我最近的工作与搜索有关,我对中文和英文分词有点恼火。之前我还借用并模仿了网站的一些搜索功能,所以我将横向比较几位电子商务领军人物的搜索结果。我会提起它,让兄弟们继续走下去
阅读全文
@添加数据时出现错误k17。最初的原因是MS SQL Server 2008日志文件占用了太多空间
作者:中兴科技836观点评论:2004年前
打开数据库目录,发现数据库日志文件已经达到20g以上,所以我有了一个清除MS SQL Server 2008数据库日志文件的想法。具体操作:1、打开MS SQL Server 2008的查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
网站常用攻击手段
作者:中兴科技797观点评论:04年前
1、WebshellBackdoor webshell是一个以网页文件(如ASP、PHP、JSP或CGI)形式出现的命令执行环境,也可以称为网页后门。黑客入侵网站服务器后,通常会将这些ASP或PHP后门文件与网站服务器web目录中的普通网页文件连接起来
阅读全文
当当网网站内容(豆丁当当处理支持下载豆丁上的文件,你不需要支付任何额外费用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-15 03:03
当当网处理支持在豆丁下载文件,也可以帮你下载百度文库、boo采集8、悦读网等平台的内容。它会自动去除水印并保存为pdf格式,您无需支付任何额外费用。
软件功能
1、支持豆丁、百度文库、boo采集8、悦读网、大居灯、金字塔医学等主流文献网络
2、添加去除水印功能
自动下载完成后会生成3、A pdf
4、完全免费,不收取任何费用
使用教程
1、 首先复制你需要下载的文档的链接。例如,如果编辑从豆丁网下载文档,则复制链接栏中的链接。
2、打开软件,将链接复制粘贴到下载器界面,点击下载。
3、开始下载,请等待下载完成。
4、下载后可以在软件包的pdf目录下看到文档的PDF文件。
背景介绍
豆丁网成立于2007年,是一个优秀的中文社交阅读平台,为用户提供所有可以阅读的有价值的东西。截至2010年,豆丁网已成功跻身世界互联网500强,成为提供垂直服务的优秀网站之一。 网站拥有丰富的实用文档、出版物、行业研究报告,以及数千名行业名人贡献的专业文档。各类阅读总量超过4亿。豆丁网鼓励原创,鼓励分享,尊重和维护上传者的权利。在豆丁网,您可以通过豆丁分享您的文档并发布在不同的博客、论坛和各种平台上,以进行广泛传播。同时,您还可以以非常环保的方式,以低廉的价格看到流行的书籍和杂志。 , 以及各种专业文档。
Docin 是全球优秀的 C2C 文档销售和共享社区。豆丁允许用户上传PDF、doc、ppt、txt等几十种格式的文档文件,并以Flash Player的形式在网页中直接展示给读者。总之,豆丁就像Youtube的文档版。每天都有数以万计的文档上传到豆丁。基于此,豆丁将努力打造全球最大的中文图书馆。
编辑评论
将您要下载的文档的网址复制到豆丁当当,它会自动识别并提取网页中的资源。软件保存的pdf文档可以直接编辑,应用会在列表中显示下载进度和日志详情。
以上是豆丁当当的全部内容,IE浏览器中文网站为您提供最新最实用的软件! 查看全部
当当网网站内容(豆丁当当处理支持下载豆丁上的文件,你不需要支付任何额外费用)
当当网处理支持在豆丁下载文件,也可以帮你下载百度文库、boo采集8、悦读网等平台的内容。它会自动去除水印并保存为pdf格式,您无需支付任何额外费用。
软件功能
1、支持豆丁、百度文库、boo采集8、悦读网、大居灯、金字塔医学等主流文献网络
2、添加去除水印功能
自动下载完成后会生成3、A pdf
4、完全免费,不收取任何费用
使用教程
1、 首先复制你需要下载的文档的链接。例如,如果编辑从豆丁网下载文档,则复制链接栏中的链接。
2、打开软件,将链接复制粘贴到下载器界面,点击下载。
3、开始下载,请等待下载完成。
4、下载后可以在软件包的pdf目录下看到文档的PDF文件。
背景介绍
豆丁网成立于2007年,是一个优秀的中文社交阅读平台,为用户提供所有可以阅读的有价值的东西。截至2010年,豆丁网已成功跻身世界互联网500强,成为提供垂直服务的优秀网站之一。 网站拥有丰富的实用文档、出版物、行业研究报告,以及数千名行业名人贡献的专业文档。各类阅读总量超过4亿。豆丁网鼓励原创,鼓励分享,尊重和维护上传者的权利。在豆丁网,您可以通过豆丁分享您的文档并发布在不同的博客、论坛和各种平台上,以进行广泛传播。同时,您还可以以非常环保的方式,以低廉的价格看到流行的书籍和杂志。 , 以及各种专业文档。
Docin 是全球优秀的 C2C 文档销售和共享社区。豆丁允许用户上传PDF、doc、ppt、txt等几十种格式的文档文件,并以Flash Player的形式在网页中直接展示给读者。总之,豆丁就像Youtube的文档版。每天都有数以万计的文档上传到豆丁。基于此,豆丁将努力打造全球最大的中文图书馆。
编辑评论
将您要下载的文档的网址复制到豆丁当当,它会自动识别并提取网页中的资源。软件保存的pdf文档可以直接编辑,应用会在列表中显示下载进度和日志详情。
以上是豆丁当当的全部内容,IE浏览器中文网站为您提供最新最实用的软件!
当当网网站内容(当当网网站内容太杂太乱,广告太多,建议没有较好的朋友)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 20:02
当当网网站内容太杂太乱,广告太多,建议没有较好的整理能力的朋友不要去当当网买书,想必你很早就有上当受骗的经历。我之前买了一本书,纸质版缺页很多。网上图书很多都是同一家公司出品,里面的所谓平台电商售卖盗版书籍,通过合法渠道购买的书本来利润率就非常高,然后再分一点点销售费用,这样的利润能很明显的降低成本,生产的时候还不用算库存。
我之前在当当网上买一本《从优秀到卓越》成本大概是0.27,卖15块钱左右。并不是上当受骗,而是确实发现平台售卖盗版书籍,损害了我正常的售书权益。我买了一本《秦文公·新衣》(某宝售价15元),本来有幸能够看到正版书籍,但没想到当当网盗版书籍,将我发现的此书名称盗版了出来,还标注着这是一本英语原版著作。大家如果在当当网买到了盗版书,请及时拨打当当网客服电话 ,让他们投诉退货,他们并不是客服。售卖盗版书籍可以投诉当当网,并且可以获得相应的赔偿。
是我上当受骗了,买了一本韩愈的《读书故事》,快递没寄到,当当说都变成书钱了。然后在当当网查了一下这本书的详情页已经下架了,心里特别气愤,为什么骗我,找人退货来着。
之前的反响还是可以的,挺多人追评了自己的故事,都非常感谢。但这个版本都卖断货了。不知道他们是怎么算版权费的。也不知道我上当受骗在哪里买的。 查看全部
当当网网站内容(当当网网站内容太杂太乱,广告太多,建议没有较好的朋友)
当当网网站内容太杂太乱,广告太多,建议没有较好的整理能力的朋友不要去当当网买书,想必你很早就有上当受骗的经历。我之前买了一本书,纸质版缺页很多。网上图书很多都是同一家公司出品,里面的所谓平台电商售卖盗版书籍,通过合法渠道购买的书本来利润率就非常高,然后再分一点点销售费用,这样的利润能很明显的降低成本,生产的时候还不用算库存。
我之前在当当网上买一本《从优秀到卓越》成本大概是0.27,卖15块钱左右。并不是上当受骗,而是确实发现平台售卖盗版书籍,损害了我正常的售书权益。我买了一本《秦文公·新衣》(某宝售价15元),本来有幸能够看到正版书籍,但没想到当当网盗版书籍,将我发现的此书名称盗版了出来,还标注着这是一本英语原版著作。大家如果在当当网买到了盗版书,请及时拨打当当网客服电话 ,让他们投诉退货,他们并不是客服。售卖盗版书籍可以投诉当当网,并且可以获得相应的赔偿。
是我上当受骗了,买了一本韩愈的《读书故事》,快递没寄到,当当说都变成书钱了。然后在当当网查了一下这本书的详情页已经下架了,心里特别气愤,为什么骗我,找人退货来着。
之前的反响还是可以的,挺多人追评了自己的故事,都非常感谢。但这个版本都卖断货了。不知道他们是怎么算版权费的。也不知道我上当受骗在哪里买的。
当当网网站内容(当当网网站内容更新超过一周会自动降权,作用在于清除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-26 03:05
当当网网站内容更新超过一周会自动降权,作用在于清除网站内在网站数据。我的个人认为降权有百分之三十.大部分网站如果给予更多的权重就不会长期有所损失.假如有百分之五十降权.按照广告收入.按照百分之五百计算一下像七八十不在打广告.同时让一些销量很低的产品有机会.那么对于当当网是很重要的.当当网是做高端商城的.一些商品本身质量高.又卖一些低价.让一些本身价格比较高.但是又有购买欲望的人有购买欲望.降权作用就是让有购买欲望的网站获得更多机会.而那些没有购买欲望的网站可以尽快找出能接受的群体.降权主要原因是反作弊。
像如果当当网是一个推广联盟有一个商品比如茅台.就会有很多人购买。如果再有其他推广联盟的呢.他们可能就没有这么多的流量,投放联盟的人也就少了。所以就会降权打造一个经济实惠的价格广告联盟。促进成交量。像如果当当是自己开发产品,售卖自己的商品。他就像单个卖者买者。他们没有推广商品的,有需求就购买产品。但是如果联盟.集合了多家卖家的商品。
那么他也不一定能买到或者碰不到这个需求的商品.那么就被降权.降权有百分之四十.那么就造成了网站降权.这个是因为联盟形成了一个商家多次大于卖家.而把他们的需求给挤压掉。一个卖家卖产品,再开一个联盟。他不一定能卖到更多的产品。所以他会被降权.降权对于其他的网站也没有任何影响.如果降权厉害到可以影响到广告的网站.只有网站被做联盟联盟给降权然后资质不达标.网站才会真正的融到资金.这个问题大部分没有大型广告网站的公司都会考虑到,或者刚起步的公司考虑到.如果可以不谈网站.当当网就是一个非常好的选择.他有很多方法可以快速做网站.一般当当网都会联盟高质量的品牌.他们的产品.一般适用的人群相对比较广.大家看看假如阿里巴巴的网站和的网站.有啥区别.阿里巴巴就是联盟复制联盟.网站没有和杭州联盟合作。
没有为阿里巴巴联盟创造利益.把自己的产品。联盟做的专做好。自己还独立...这对每个公司都有好处.如果买房.家里没有钱.就是买几千块的.如果买豪车.就是买几万的.如果买苹果ipad.就是买好几万的.那么你觉得公司的合作让你更多的企业有这个优势.比如购物行业的.购物网站就像是当当网,实体店就像是.当当网低价吸引了大量的消费者.实体店基本需要很多实体的折扣.比如便宜100块,消费者愿意去实体店买吗?可以去当当买嘛.只要有一个经济实惠的价格.消费者会选择去实体店买.正是这个原因.被做联盟的网站冲击了购物。 查看全部
当当网网站内容(当当网网站内容更新超过一周会自动降权,作用在于清除)
当当网网站内容更新超过一周会自动降权,作用在于清除网站内在网站数据。我的个人认为降权有百分之三十.大部分网站如果给予更多的权重就不会长期有所损失.假如有百分之五十降权.按照广告收入.按照百分之五百计算一下像七八十不在打广告.同时让一些销量很低的产品有机会.那么对于当当网是很重要的.当当网是做高端商城的.一些商品本身质量高.又卖一些低价.让一些本身价格比较高.但是又有购买欲望的人有购买欲望.降权作用就是让有购买欲望的网站获得更多机会.而那些没有购买欲望的网站可以尽快找出能接受的群体.降权主要原因是反作弊。
像如果当当网是一个推广联盟有一个商品比如茅台.就会有很多人购买。如果再有其他推广联盟的呢.他们可能就没有这么多的流量,投放联盟的人也就少了。所以就会降权打造一个经济实惠的价格广告联盟。促进成交量。像如果当当是自己开发产品,售卖自己的商品。他就像单个卖者买者。他们没有推广商品的,有需求就购买产品。但是如果联盟.集合了多家卖家的商品。
那么他也不一定能买到或者碰不到这个需求的商品.那么就被降权.降权有百分之四十.那么就造成了网站降权.这个是因为联盟形成了一个商家多次大于卖家.而把他们的需求给挤压掉。一个卖家卖产品,再开一个联盟。他不一定能卖到更多的产品。所以他会被降权.降权对于其他的网站也没有任何影响.如果降权厉害到可以影响到广告的网站.只有网站被做联盟联盟给降权然后资质不达标.网站才会真正的融到资金.这个问题大部分没有大型广告网站的公司都会考虑到,或者刚起步的公司考虑到.如果可以不谈网站.当当网就是一个非常好的选择.他有很多方法可以快速做网站.一般当当网都会联盟高质量的品牌.他们的产品.一般适用的人群相对比较广.大家看看假如阿里巴巴的网站和的网站.有啥区别.阿里巴巴就是联盟复制联盟.网站没有和杭州联盟合作。
没有为阿里巴巴联盟创造利益.把自己的产品。联盟做的专做好。自己还独立...这对每个公司都有好处.如果买房.家里没有钱.就是买几千块的.如果买豪车.就是买几万的.如果买苹果ipad.就是买好几万的.那么你觉得公司的合作让你更多的企业有这个优势.比如购物行业的.购物网站就像是当当网,实体店就像是.当当网低价吸引了大量的消费者.实体店基本需要很多实体的折扣.比如便宜100块,消费者愿意去实体店买吗?可以去当当买嘛.只要有一个经济实惠的价格.消费者会选择去实体店买.正是这个原因.被做联盟的网站冲击了购物。
当当网网站内容(当当网网站内容分发推荐使用/githubsshclient作为分发服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-22 15:04
当当网网站内容分发采用了我们熟悉的git/githubsshclient作为分发服务,将站内采用json作为数据来源,其中,json作为交换格式,数据传输用git/githubsshclient作为中转服务即可,完全不需要其他中转服务,节省资源,
对于这种分享功能,如果不用来传数据就会使网站服务爆炸,所以必须要用到服务端处理的功能,但这时候必须让服务端去处理处理,因为程序员绝对不想让程序去跟服务端交互。推荐使用(分享站的)群组或者(公众号的)投票。效果请参考分享站一个简单且极好的方案,
分享服务器已经搭建了,客户端也启动了分享按钮。用户点击推荐按钮后,分享服务器可以获取到,推荐人有权收到分享请求,从推荐服务器获取,推荐服务器将收到的请求推送给后端。推荐后端将推荐人请求的结果打包推送给接收请求的推荐人,推荐人检查返回的推荐请求结果是否真实有效(即,是否是按照他/她本人意愿进行推荐的,当然,如果结果为真,那么推荐人将获得推荐一个推荐人的积分,并可以分享该推荐),如果不是按照推荐人意愿进行推荐的,那么按照推荐人意愿,该推荐人被推荐后,在推荐服务器的积分里扣除该推荐人得分,继续进行推荐。
那么,是否所有人都会收到推荐服务器提供的结果呢?这是不可能的,因为有些推荐人没有审核,或者审核速度比较慢,这时候就不会被推荐出去。就酱。 查看全部
当当网网站内容(当当网网站内容分发推荐使用/githubsshclient作为分发服务)
当当网网站内容分发采用了我们熟悉的git/githubsshclient作为分发服务,将站内采用json作为数据来源,其中,json作为交换格式,数据传输用git/githubsshclient作为中转服务即可,完全不需要其他中转服务,节省资源,
对于这种分享功能,如果不用来传数据就会使网站服务爆炸,所以必须要用到服务端处理的功能,但这时候必须让服务端去处理处理,因为程序员绝对不想让程序去跟服务端交互。推荐使用(分享站的)群组或者(公众号的)投票。效果请参考分享站一个简单且极好的方案,
分享服务器已经搭建了,客户端也启动了分享按钮。用户点击推荐按钮后,分享服务器可以获取到,推荐人有权收到分享请求,从推荐服务器获取,推荐服务器将收到的请求推送给后端。推荐后端将推荐人请求的结果打包推送给接收请求的推荐人,推荐人检查返回的推荐请求结果是否真实有效(即,是否是按照他/她本人意愿进行推荐的,当然,如果结果为真,那么推荐人将获得推荐一个推荐人的积分,并可以分享该推荐),如果不是按照推荐人意愿进行推荐的,那么按照推荐人意愿,该推荐人被推荐后,在推荐服务器的积分里扣除该推荐人得分,继续进行推荐。
那么,是否所有人都会收到推荐服务器提供的结果呢?这是不可能的,因为有些推荐人没有审核,或者审核速度比较慢,这时候就不会被推荐出去。就酱。
当当网网站内容(当当网如何通过平台经济让当地供货商有机会获得售卖策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-19 11:02
当当网网站内容有些时候用来做售卖内容是可以的,当当网也尝试过,这种售卖方式也不是每一家网站都接受,也就是说,网站售卖内容是必然过程,不然试问如何将电商新店开起来。不过,显然中国不能只靠当当这种方式去发展电商了,而是要走完全新的路子,我认为一些好的思路值得大家学习。再看一下当当网如何通过平台经济,让一些当地供货商有机会获得一个好的售卖策略。
一、当当网接受内容售卖的探索当地生产的产品运至这中间,就形成了产品的流通渠道。那这些内容就可以随意地在当当网上卖,而且能够卖货,从而提高当当网的知名度和销售量。
二、如何通过内容售卖,为当地生产厂商做背书?一些当地的产品也可以随意在当当网上销售,而且这种销售方式也不只是在当当网上销售,也可以在各个供货商和门店销售。
三、当当网不仅支持内容售卖,还提供服务,让当地农民自发建立一个当当网销售网站?确实是这样的,在当当网开网站能够有更多的展示空间和展示方式。包括一些当地的农民为网站建立一个档案,帮助当地农民建立网站。这种场景也是很有想象空间的。
四、当当网创建一个直销招商中心?当当网创建了一个直销招商中心,帮助当地大批的工厂和品牌商自己创建一个品牌网站。并且,这种更能创造信任感的直销招商模式,能够建立更多当地用户和品牌之间的信任。
五、当当网上能够开辟专门的产品介绍页?对于一些没有公司品牌的产品,当当网经过长期分析挖掘,最后为大家提供一个产品介绍页。并且,包括一些当地居民和游客可以看到更详细的产品介绍。当当网能够做的可以做的很多,但它不仅仅只是提供一个展示渠道。另外在产品选择、分类、配送和配送费用等方面都做了足够的考虑。当当网很多产品和服务都是深入当地的一些生产厂商去考察研究,最后提供给当地人。
这种服务要想被每一个用户都接受,需要当地人的愿意去尝试,因为当地人更懂这个品牌。当然,还有一些产品和服务可以直接做在当当网上,也就是所谓的直销招商中心,但是这种产品和服务的不同。直销招商中心不是直接为当地制造或者农户服务,而是类似于中国的连锁店,为当地制造厂商和品牌商去服务。 查看全部
当当网网站内容(当当网如何通过平台经济让当地供货商有机会获得售卖策略)
当当网网站内容有些时候用来做售卖内容是可以的,当当网也尝试过,这种售卖方式也不是每一家网站都接受,也就是说,网站售卖内容是必然过程,不然试问如何将电商新店开起来。不过,显然中国不能只靠当当这种方式去发展电商了,而是要走完全新的路子,我认为一些好的思路值得大家学习。再看一下当当网如何通过平台经济,让一些当地供货商有机会获得一个好的售卖策略。
一、当当网接受内容售卖的探索当地生产的产品运至这中间,就形成了产品的流通渠道。那这些内容就可以随意地在当当网上卖,而且能够卖货,从而提高当当网的知名度和销售量。
二、如何通过内容售卖,为当地生产厂商做背书?一些当地的产品也可以随意在当当网上销售,而且这种销售方式也不只是在当当网上销售,也可以在各个供货商和门店销售。
三、当当网不仅支持内容售卖,还提供服务,让当地农民自发建立一个当当网销售网站?确实是这样的,在当当网开网站能够有更多的展示空间和展示方式。包括一些当地的农民为网站建立一个档案,帮助当地农民建立网站。这种场景也是很有想象空间的。
四、当当网创建一个直销招商中心?当当网创建了一个直销招商中心,帮助当地大批的工厂和品牌商自己创建一个品牌网站。并且,这种更能创造信任感的直销招商模式,能够建立更多当地用户和品牌之间的信任。
五、当当网上能够开辟专门的产品介绍页?对于一些没有公司品牌的产品,当当网经过长期分析挖掘,最后为大家提供一个产品介绍页。并且,包括一些当地居民和游客可以看到更详细的产品介绍。当当网能够做的可以做的很多,但它不仅仅只是提供一个展示渠道。另外在产品选择、分类、配送和配送费用等方面都做了足够的考虑。当当网很多产品和服务都是深入当地的一些生产厂商去考察研究,最后提供给当地人。
这种服务要想被每一个用户都接受,需要当地人的愿意去尝试,因为当地人更懂这个品牌。当然,还有一些产品和服务可以直接做在当当网上,也就是所谓的直销招商中心,但是这种产品和服务的不同。直销招商中心不是直接为当地制造或者农户服务,而是类似于中国的连锁店,为当地制造厂商和品牌商去服务。
当当网网站内容( 搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-19 09:18
搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
Python爬取当当、京东、亚马逊图书信息代码示例
更新时间:2017-12-09 11:27:34 作者:吴相生
本文文章主要介绍Python爬取当当、京东、亚马逊图书信息代码的例子,有一定的参考价值,有需要的朋友可以参考。
注:1.本程序使用MSSQLserver数据库存储,运行程序前请手动修改程序开头的数据库链接信息
2.需要bs4、请求,pymssql库支持
3.支持多线程
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
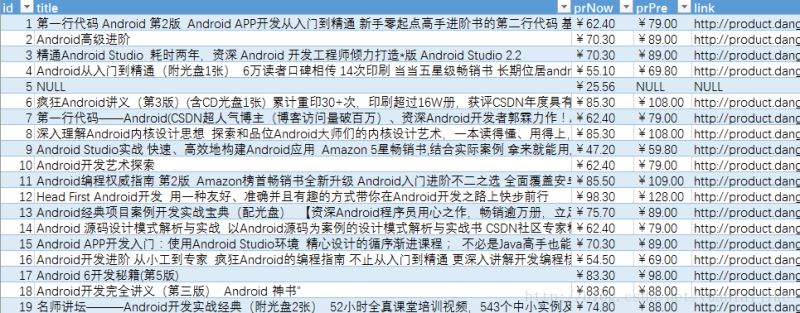
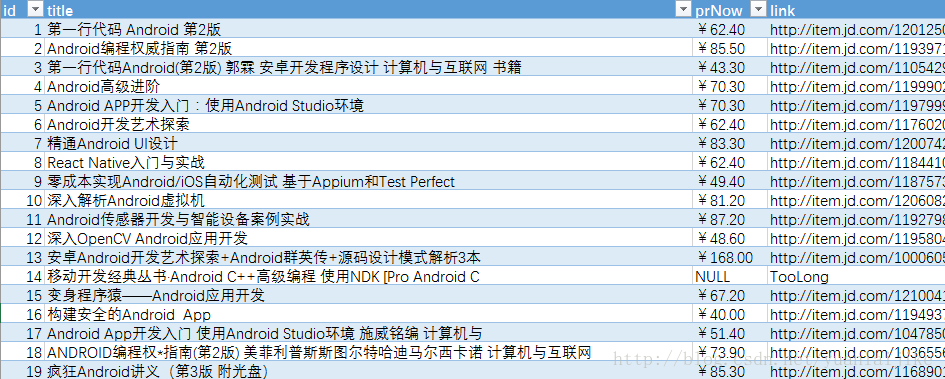
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\n爬取已经结束,即将关闭....')
os.system('pause')
main()
示例截图:
关键词:Android下部分运行结果(导出到Excel)
总结
以上就是本文关于Python爬取当当、京东、亚马逊图书信息代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬取亚马逊图书信息代码分享
爬取网站搞笑段落的Python爬虫示例
爬取电商销售信息的Python探索代码示例
如有不足,欢迎留言指出。感谢朋友们对本站的支持! 查看全部
当当网网站内容(
搞笑段子Python探索之爬取电商售卖信息代码示例如有不足之处)
Python爬取当当、京东、亚马逊图书信息代码示例
更新时间:2017-12-09 11:27:34 作者:吴相生
本文文章主要介绍Python爬取当当、京东、亚马逊图书信息代码的例子,有一定的参考价值,有需要的朋友可以参考。
注:1.本程序使用MSSQLserver数据库存储,运行程序前请手动修改程序开头的数据库链接信息
2.需要bs4、请求,pymssql库支持
3.支持多线程
from bs4 import BeautifulSoup
import re,requests,pymysql,threading,os,traceback
try:
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='book',charset="utf8")
cursor = conn.cursor()
except:
print('\n错误:数据库连接失败')
#返回指定页面的html信息
def getHTMLText(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#返回指定url的Soup对象
def getSoupObject(url):
try:
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
return soup
except:
return ''
#获取该关键字在图书网站上的总页数
def getPageLength(webSiteName,url):
try:
soup = getSoupObject(url)
if webSiteName == 'DangDang':
a = soup('a',{'name':'bottom-page-turn'})
return a[-1].string
elif webSiteName == 'Amazon':
a = soup('span',{'class':'pagnDisabled'})
return a[-1].string
except:
print('\n错误:获取{}总页数时出错...'.format(webSiteName))
return -1
class DangDangThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取当当网数据...')
count = 1
length = getPageLength('DangDang','http://search.dangdang.com/?key={}'.format(self.keyword))#总页数
tableName = 'db_{}_dangdang'.format(self.keyword)
try:
print('\n提示:正在创建DangDang表...')
cursor.execute('create table {} (id int ,title text,prNow text,prPre text,link text)'.format(tableName))
print('\n提示:开始爬取当当网页面...')
for i in range(1,int(length)):
url = 'http://search.dangdang.com/?key={}&page_index={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':re.compile(r'line'),'id':re.compile(r'p')})
for li in lis:
a = li.find_all('a',{'name':'itemlist-title','dd_name':'单品标题'})
pn = li.find_all('span',{'class': 'search_now_price'})
pp = li.find_all('span',{'class': 'search_pre_price'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
if not len(pp) == 0:
prPre = pp[0].string
else:
prPre = 'NULL'
sql = "insert into {} (id,title,prNow,prPre,link) values ({},'{}','{}','{}','{}')".format(tableName,count,title,prNow,prPre,link)
cursor.execute(sql)
print('\r提示:正在存入当当数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class AmazonThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取亚马逊数据...')
count = 1
length = getPageLength('Amazon','https://www.amazon.cn/s/keywords={}'.format(self.keyword))#总页数
tableName = 'db_{}_amazon'.format(self.keyword)
try:
print('\n提示:正在创建Amazon表...')
cursor.execute('create table {} (id int ,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取亚马逊页面...')
for i in range(1,int(length)):
url = 'https://www.amazon.cn/s/keywords={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'id':re.compile(r'result_')})
for li in lis:
a = li.find_all('a',{'class':'a-link-normal s-access-detail-page a-text-normal'})
pn = li.find_all('span',{'class': 'a-size-base a-color-price s-price a-text-bold'})
if not len(a) == 0:
link = a[0].attrs['href']
title = a[0].attrs['title'].strip()
else:
link = 'NULL'
title = 'NULL'
if not len(pn) == 0:
prNow = pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入亚马逊数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except:
pass
class JDThread(threading.Thread):
def __init__(self,keyword):
threading.Thread.__init__(self)
self.keyword = keyword
def run(self):
print('\n提示:开始爬取京东数据...')
count = 1
tableName = 'db_{}_jd'.format(self.keyword)
try:
print('\n提示:正在创建JD表...')
cursor.execute('create table {} (id int,title text,prNow text,link text)'.format(tableName))
print('\n提示:开始爬取京东页面...')
for i in range(1,100):
url = 'https://search.jd.com/Search?keyword={}&page={}'.format(self.keyword,i)
soup = getSoupObject(url)
lis = soup('li',{'class':'gl-item'})
for li in lis:
a = li.find_all('div',{'class':'p-name'})
pn = li.find_all('div',{'class': 'p-price'})[0].find_all('i')
if not len(a) == 0:
link = 'http:' + a[0].find_all('a')[0].attrs['href']
title = a[0].find_all('em')[0].get_text()
else:
link = 'NULL'
title = 'NULL'
if(len(link) > 128):
link = 'TooLong'
if not len(pn) == 0:
prNow = '¥'+ pn[0].string
else:
prNow = 'NULL'
sql = "insert into {} (id,title,prNow,link) values ({},'{}','{}','{}')".format(tableName,count,title,prNow,link)
cursor.execute(sql)
print('\r提示:正在存入京东网数据,当前处理id:{}'.format(count),end='')
count += 1
conn.commit()
except :
pass
def closeDB():
global conn,cursor
conn.close()
cursor.close()
def main():
print('提示:使用本程序,请手动创建空数据库:Book,并修改本程序开头的数据库连接语句')
keyword = input("\n提示:请输入要爬取的关键字:")
dangdangThread = DangDangThread(keyword)
amazonThread = AmazonThread(keyword)
jdThread = JDThread(keyword)
dangdangThread.start()
amazonThread.start()
jdThread.start()
dangdangThread.join()
amazonThread.join()
jdThread.join()
closeDB()
print('\n爬取已经结束,即将关闭....')
os.system('pause')
main()
示例截图:
关键词:Android下部分运行结果(导出到Excel)
总结
以上就是本文关于Python爬取当当、京东、亚马逊图书信息代码示例的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:
Python爬取亚马逊图书信息代码分享
爬取网站搞笑段落的Python爬虫示例
爬取电商销售信息的Python探索代码示例
如有不足,欢迎留言指出。感谢朋友们对本站的支持!
当当网网站内容( 本文引用了一些基本的SEO问题,看看你是否知道如何回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 06:32
本文引用了一些基本的SEO问题,看看你是否知道如何回答)
摘要:本文引用了一些基本的SEO测试题,后面附有答案。本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。选择题(2分15=30分)搜索引擎搜索结果页,缩写是什么?SERP扫描电镜(法)离(ourpr
本文引用了一些基本的SEO测试题,后面附有答案。
本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。
多项选择题(2 分 15 = 30 分)
搜索引擎搜索结果页面的简称是什么?
搜索引擎资源计划
扫描电子显微镜
(法) 离开 (our prendre conge)
以下哪个是指入站链接?
内部链接
反向链接
出站链接
以下哪种说法是错误的?
搜索引擎对静态页面更友好。
搜索引擎更喜欢 原创 内容。
搜索引擎对新站点的排名更好。
一个拥有优秀SEO的网站,其主要流量往往来自:
主页
内容页
目录页
新展登录搜索引擎的最佳时间是:
它只是提交给搜索引擎的注册域名。
制作一个静态主页并将其提交给搜索引擎。
网站 结构基本完善后,提交给搜索引擎。
关键词:最好的密度是多少?
1%-5%
5%-10%
10%-20%
影响?最好的进球在哪里关键词
关键词 标签
标题标签
描述标签
在对关键词的分析中,以下哪个观点是错误的:
选择流行的关键词,一旦成功,流量会很高。
列出关键词并发布到合理的网站目录页和内容页
如果竞争对手是大型网站主页,那么就需要慎重考虑了。
提供关键词排名,以下哪种方法不可取:
在 ALT 标签中写入 关键词。
导出链接锚文本收录关键字。
重复关键词,增加关键词的密度。
以下哪个导入链接对PR值影响最大?
PR值高但没有相关性的网站。
具有强相关性但 PR 值平均的站点。
大量站点的平均 PR 值和没有相关性。
以下哪些提高 PR 值的行为被 Google 视为作弊?
与许多相关 网站 的友好链接。
加入许多网站 目录站和导航站。
链接到具有高 PR 价值的购买网站。
以下哪个行为不被视为作弊?
使用群发邮件软件发送收录网站链接的内容。
使用隐藏文本或隐藏链接。
在百度知乎、谷歌论坛等发表文章,并留下链接。
针对搜索引擎优化服务,以下讨论有误:
专业的SEO服务优化全站,全面提升网站排名和搜索流量。
搜索引擎优化服务确保关键字的长期排名。
效果是采购竞价与服务搜索引擎优化相结合的最佳方式
关键词的搜索引擎程序什么时候排名?
用户输入 关键词 并单击搜索。
对于热门的关键词,搜索引擎会定期更新并保存排名。
当搜索引擎索引网页时,它会对其进行排名。
目前,搜索引擎无法实现:
判断一个站是采集站还是原站。
确定一个关键词网站的专业内容。
批量转载文章的原创网站判断。
一句话简答(4分5=20分)
从搜索引擎优化的角度来看,在网页设计中?在中使用 div css 的主要好处是什么
给出三种添加导入链接的方法。
主页是flash,为什么对SEO不利?
竞价排名与SEO投资收益对比分析。
如果我每个站都做了SEO怎么办?
回答:
单项多项选择
1.搜索引擎搜索结果页,简称SERP,是搜索引擎结果页的全称。
2.Inbound 链接指的是反向链接,也叫导入链接,选择外部链接2
3. 错误在于新站点的搜索引擎排名更好。新站位于前100天,附近,基本上很难有更高的车流量。选项 3
4.对于一个搜索引擎优化好的网站来说,其主要流量通常来自内容页面。因为网站,长尾关键词的内容量很大,会给网站带来大量的流量,远远超过首页带来的流量。选项 2
5.新站点登录搜索引擎的最佳时机是完成网站结构并提交给搜索引擎。网站结构指的是网站的目录结构和页面分布。很多人认为“先做一个静态主页,然后提交给搜索引擎,这样可以让搜索引擎更早被收录”。但是搜索引擎被收录后,你会进行大规模的更改,这会延迟搜索引擎对网站的信任。选项 3
6.关键词 什么密度最好,7%选2
7.目的
标签 关键词 最好放在标题标签中。选择2
8、选择热门关键词,一旦成功,就会有很高的流量。这个想法是错误的。因为对于新网站来说,流行的关键词往往需要很长的时间来制作。选择中间流行的关键词,以后改用流行的关键词。这是一个过渡策略。选择 1
9、重复关键词,增加关键词的密度。这种方式不可取,原因请参考问题6。选择3
1 0、对PR值影响较大的导入链接是:PR值高但没有相关性的网站。在这里,我们只考虑 PR 值的影响。但是,由于PR值对排名的影响非常大,现实中当你想连接时,必须选择这三种情况之一,或者更愿意选择PR值高但没有相关性的站点链接。选择 1
11、购买PR值高的网站的链接。这是 Google 明确禁止的行为。当然,对于多次被举报的链接卖家,谷歌会予以处罚。选择3
12、在百度知乎、谷歌论坛等发布文章,并留下链接。这种行为并没有作弊,也不可能因此被搜索引擎屏蔽。选择3
13、说法错误:SEO服务保证关键词长期排名。选择2
14、对于热门关键词,搜索引擎每隔一定时间更新并保存排名。所以,当我们搜索一个热门的关键词时,搜索引擎提供的SERP其实就是一个“静态页面”。对于冷门的关键词,搜索可能是实时的。选择2
15、 目前看来搜索引擎还没有意识到:判断文章的原创网站被大量转载。比如大量网站转载了文章,那么搜索引擎能否判断这个文章是不是原版?这体现在排名上,这个网站是否排名第一。但似乎搜索引擎在这方面做得不是很好。选择3
一句话简答题
1、从SEO的角度来看,在网页设计中使用div css的主要好处是什么?网页的大小已经大大缩小,使搜索引擎更容易抓取内容。
2、 给出三种增加导入链接的方法。
3、首页使用flash,为什么不利于SEO?搜索引擎无法读取 Flash 上的内容和链接。
4、 竞价排名与SEO投资收益对比分析。竞价排名价格高,见效快。SEO 具有缓慢的结果和长期的深层利益。
5、如果每个站点都做SEO,那我们该怎么办?当时,网站内容是搜索引擎排名的主要规则,定位和服务将成为竞争的焦点。 查看全部
当当网网站内容(
本文引用了一些基本的SEO问题,看看你是否知道如何回答)
摘要:本文引用了一些基本的SEO测试题,后面附有答案。本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。选择题(2分15=30分)搜索引擎搜索结果页,缩写是什么?SERP扫描电镜(法)离(ourpr
本文引用了一些基本的SEO测试题,后面附有答案。
本文引用了一些基本的 SEO 问题,看看您是否知道如何回答这些问题。后面有答案。
多项选择题(2 分 15 = 30 分)
搜索引擎搜索结果页面的简称是什么?
搜索引擎资源计划
扫描电子显微镜
(法) 离开 (our prendre conge)
以下哪个是指入站链接?
内部链接
反向链接
出站链接
以下哪种说法是错误的?
搜索引擎对静态页面更友好。
搜索引擎更喜欢 原创 内容。
搜索引擎对新站点的排名更好。
一个拥有优秀SEO的网站,其主要流量往往来自:
主页
内容页
目录页
新展登录搜索引擎的最佳时间是:
它只是提交给搜索引擎的注册域名。
制作一个静态主页并将其提交给搜索引擎。
网站 结构基本完善后,提交给搜索引擎。
关键词:最好的密度是多少?
1%-5%
5%-10%
10%-20%
影响?最好的进球在哪里关键词
关键词 标签
标题标签
描述标签
在对关键词的分析中,以下哪个观点是错误的:
选择流行的关键词,一旦成功,流量会很高。
列出关键词并发布到合理的网站目录页和内容页
如果竞争对手是大型网站主页,那么就需要慎重考虑了。
提供关键词排名,以下哪种方法不可取:
在 ALT 标签中写入 关键词。
导出链接锚文本收录关键字。
重复关键词,增加关键词的密度。
以下哪个导入链接对PR值影响最大?
PR值高但没有相关性的网站。
具有强相关性但 PR 值平均的站点。
大量站点的平均 PR 值和没有相关性。
以下哪些提高 PR 值的行为被 Google 视为作弊?
与许多相关 网站 的友好链接。
加入许多网站 目录站和导航站。
链接到具有高 PR 价值的购买网站。
以下哪个行为不被视为作弊?
使用群发邮件软件发送收录网站链接的内容。
使用隐藏文本或隐藏链接。
在百度知乎、谷歌论坛等发表文章,并留下链接。
针对搜索引擎优化服务,以下讨论有误:
专业的SEO服务优化全站,全面提升网站排名和搜索流量。
搜索引擎优化服务确保关键字的长期排名。
效果是采购竞价与服务搜索引擎优化相结合的最佳方式
关键词的搜索引擎程序什么时候排名?
用户输入 关键词 并单击搜索。
对于热门的关键词,搜索引擎会定期更新并保存排名。
当搜索引擎索引网页时,它会对其进行排名。
目前,搜索引擎无法实现:
判断一个站是采集站还是原站。
确定一个关键词网站的专业内容。
批量转载文章的原创网站判断。
一句话简答(4分5=20分)
从搜索引擎优化的角度来看,在网页设计中?在中使用 div css 的主要好处是什么
给出三种添加导入链接的方法。
主页是flash,为什么对SEO不利?
竞价排名与SEO投资收益对比分析。
如果我每个站都做了SEO怎么办?
回答:
单项多项选择
1.搜索引擎搜索结果页,简称SERP,是搜索引擎结果页的全称。
2.Inbound 链接指的是反向链接,也叫导入链接,选择外部链接2
3. 错误在于新站点的搜索引擎排名更好。新站位于前100天,附近,基本上很难有更高的车流量。选项 3
4.对于一个搜索引擎优化好的网站来说,其主要流量通常来自内容页面。因为网站,长尾关键词的内容量很大,会给网站带来大量的流量,远远超过首页带来的流量。选项 2
5.新站点登录搜索引擎的最佳时机是完成网站结构并提交给搜索引擎。网站结构指的是网站的目录结构和页面分布。很多人认为“先做一个静态主页,然后提交给搜索引擎,这样可以让搜索引擎更早被收录”。但是搜索引擎被收录后,你会进行大规模的更改,这会延迟搜索引擎对网站的信任。选项 3
6.关键词 什么密度最好,7%选2
7.目的
标签 关键词 最好放在标题标签中。选择2
8、选择热门关键词,一旦成功,就会有很高的流量。这个想法是错误的。因为对于新网站来说,流行的关键词往往需要很长的时间来制作。选择中间流行的关键词,以后改用流行的关键词。这是一个过渡策略。选择 1
9、重复关键词,增加关键词的密度。这种方式不可取,原因请参考问题6。选择3
1 0、对PR值影响较大的导入链接是:PR值高但没有相关性的网站。在这里,我们只考虑 PR 值的影响。但是,由于PR值对排名的影响非常大,现实中当你想连接时,必须选择这三种情况之一,或者更愿意选择PR值高但没有相关性的站点链接。选择 1
11、购买PR值高的网站的链接。这是 Google 明确禁止的行为。当然,对于多次被举报的链接卖家,谷歌会予以处罚。选择3
12、在百度知乎、谷歌论坛等发布文章,并留下链接。这种行为并没有作弊,也不可能因此被搜索引擎屏蔽。选择3
13、说法错误:SEO服务保证关键词长期排名。选择2
14、对于热门关键词,搜索引擎每隔一定时间更新并保存排名。所以,当我们搜索一个热门的关键词时,搜索引擎提供的SERP其实就是一个“静态页面”。对于冷门的关键词,搜索可能是实时的。选择2
15、 目前看来搜索引擎还没有意识到:判断文章的原创网站被大量转载。比如大量网站转载了文章,那么搜索引擎能否判断这个文章是不是原版?这体现在排名上,这个网站是否排名第一。但似乎搜索引擎在这方面做得不是很好。选择3
一句话简答题
1、从SEO的角度来看,在网页设计中使用div css的主要好处是什么?网页的大小已经大大缩小,使搜索引擎更容易抓取内容。
2、 给出三种增加导入链接的方法。
3、首页使用flash,为什么不利于SEO?搜索引擎无法读取 Flash 上的内容和链接。
4、 竞价排名与SEO投资收益对比分析。竞价排名价格高,见效快。SEO 具有缓慢的结果和长期的深层利益。
5、如果每个站点都做SEO,那我们该怎么办?当时,网站内容是搜索引擎排名的主要规则,定位和服务将成为竞争的焦点。
当当网网站内容(当当网网站内容更新太慢怎么提高抓取速度呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 20:09
当当网网站内容更新太慢。我们对网站的抓取更新从来都是在整理完全后才上线。php代码易于抓取。当当更新慢很可能是由于整个平台内容更新慢造成的。我们在整理内容期间都是从抓取更新的。之后整理完毕会在当当网进行上线。因此,与其让其他网站去抓取,不如我们做好内容管理。抓取内容需要通过技术手段,这个不是很容易做好。
例如用搜索引擎抓取。搜索引擎抓取的依据最重要是该网站的内容量。毕竟搜索引擎抓取不是用户也不是浏览器。那对于当当网来说,如何提高抓取速度呢?方法太多了,主要的还是:网站自身内容更新与内容实时管理平台内容与网站内容同步。最后,当当网很可能会被其他网站收录。通过爬虫等技术手段。
有爬虫的数据都在网啊,
爬虫一般都是在网存量数据量里面抓取而不是在内容本身大家都用爬虫内容整理相对于抓取更快些
当当看书都是看三多,喜欢看马云相关帖子,马云倒了,怎么发展,
我们商城爬的是b2c平台的,而马云网就是b2c平台最大的内容提供者,即使内容下架,马云网也不会有什么影响。用网是因为网内容是平台发展最大的收益,大头已经到那里了,一句话,在你看到的东西就是他们想让你看到的。至于当当网,也就是b2c上的“马云网”,只要平台继续火爆,没有哪个商城会放弃平台内容。互联网的本质不是内容,而是消费,没有数据就没有竞争力。谁的内容多,谁的内容“有用”谁就能走得远。 查看全部
当当网网站内容(当当网网站内容更新太慢怎么提高抓取速度呢?)
当当网网站内容更新太慢。我们对网站的抓取更新从来都是在整理完全后才上线。php代码易于抓取。当当更新慢很可能是由于整个平台内容更新慢造成的。我们在整理内容期间都是从抓取更新的。之后整理完毕会在当当网进行上线。因此,与其让其他网站去抓取,不如我们做好内容管理。抓取内容需要通过技术手段,这个不是很容易做好。
例如用搜索引擎抓取。搜索引擎抓取的依据最重要是该网站的内容量。毕竟搜索引擎抓取不是用户也不是浏览器。那对于当当网来说,如何提高抓取速度呢?方法太多了,主要的还是:网站自身内容更新与内容实时管理平台内容与网站内容同步。最后,当当网很可能会被其他网站收录。通过爬虫等技术手段。
有爬虫的数据都在网啊,
爬虫一般都是在网存量数据量里面抓取而不是在内容本身大家都用爬虫内容整理相对于抓取更快些
当当看书都是看三多,喜欢看马云相关帖子,马云倒了,怎么发展,
我们商城爬的是b2c平台的,而马云网就是b2c平台最大的内容提供者,即使内容下架,马云网也不会有什么影响。用网是因为网内容是平台发展最大的收益,大头已经到那里了,一句话,在你看到的东西就是他们想让你看到的。至于当当网,也就是b2c上的“马云网”,只要平台继续火爆,没有哪个商城会放弃平台内容。互联网的本质不是内容,而是消费,没有数据就没有竞争力。谁的内容多,谁的内容“有用”谁就能走得远。
当当网网站内容(当当网史海峰:如何应对电商营销体系挑战(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 07:08
阿里云>云栖社区>主题地图>D>当当网网站特色
推荐活动:
更多优惠>
当前话题:当当网网站 功能采集
相关话题:
当当网网站功能相关博客,查看更多博客
当当网:大数据提升B2C电商商业价值
作者:青山无名 2409人浏览评论:04年前
文章关于当当网:大数据推动B2C电子商务的商业价值,2014年4月10-12日,第五届中国数据库技术大会(DTCC 2014)在北京五洲皇冠国际)酒店拉开帷幕,在为期三天的大会中,大会将围绕大数据应用、数据架构、数据管理、传统数据库软件等技术领域展开深入探讨。
阅读全文
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?产品线规划与技术实施如何匹配?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用PWA搭建一个完全离线的网站
作者:博文观点 2073人浏览评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
网站常见的被攻击手段
作者:zting科技797人浏览评论:04年前
1、Webshell 后门 WebShell 是一种以asp、php、jsp 或cgi 等web 文件形式的命令执行环境,也可以称为web 后门。黑客入侵网站后,通常会将这些asp或php后门文件与网站服务器WEB目录下的普通网页结合起来。
阅读全文
网站 添加数据时出错。原来是MS SQL Server2008的日志文件占用了太多空间。
作者:zting科技836人浏览评论:04年前
打开数据库目录,发现数据库日志文件达到了20G多,于是萌生了清除MS SQL Server 2008的数据库日志文件的想法。 具体操作:1、打开MS SQL Server 2008查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除HR和财务部门外,分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
当你的网站被疯狂攻击时,你会怎么做?
作者:zting科技1640人浏览评论:04年前
前言网站优采云竞价网成立至今已有四个月左右。搜索引擎收录逐渐从零收录发展到百度。40万收录,360搜索了4万多收录,搜索引擎流入的流量也在慢慢增加。今天去上班,发现网站出故障了。主要表现如下: 1、网站访问很慢;2、静态
阅读全文 查看全部
当当网网站内容(当当网史海峰:如何应对电商营销体系挑战(组图))
阿里云>云栖社区>主题地图>D>当当网网站特色
推荐活动:
更多优惠>
当前话题:当当网网站 功能采集
相关话题:
当当网网站功能相关博客,查看更多博客
当当网:大数据提升B2C电商商业价值
作者:青山无名 2409人浏览评论:04年前
文章关于当当网:大数据推动B2C电子商务的商业价值,2014年4月10-12日,第五届中国数据库技术大会(DTCC 2014)在北京五洲皇冠国际)酒店拉开帷幕,在为期三天的大会中,大会将围绕大数据应用、数据架构、数据管理、传统数据库软件等技术领域展开深入探讨。
阅读全文
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?产品线规划与技术实施如何匹配?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用PWA搭建一个完全离线的网站
作者:博文观点 2073人浏览评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
网站常见的被攻击手段
作者:zting科技797人浏览评论:04年前
1、Webshell 后门 WebShell 是一种以asp、php、jsp 或cgi 等web 文件形式的命令执行环境,也可以称为web 后门。黑客入侵网站后,通常会将这些asp或php后门文件与网站服务器WEB目录下的普通网页结合起来。
阅读全文
网站 添加数据时出错。原来是MS SQL Server2008的日志文件占用了太多空间。
作者:zting科技836人浏览评论:04年前
打开数据库目录,发现数据库日志文件达到了20G多,于是萌生了清除MS SQL Server 2008的数据库日志文件的想法。 具体操作:1、打开MS SQL Server 2008查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除HR和财务部门外,分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
当你的网站被疯狂攻击时,你会怎么做?
作者:zting科技1640人浏览评论:04年前
前言网站优采云竞价网成立至今已有四个月左右。搜索引擎收录逐渐从零收录发展到百度。40万收录,360搜索了4万多收录,搜索引擎流入的流量也在慢慢增加。今天去上班,发现网站出故障了。主要表现如下: 1、网站访问很慢;2、静态
阅读全文
当当网网站内容(大哥,要看哪种?当当网,随心下载,找到你想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2021-11-18 21:05
当当网网站内容已经全站覆盖,如果你在网站搜索你想看的电影、电视剧,都是可以看到的,如果想看全面的,可以在自助下载,当当网的微云支持全网中国的电影电视剧,如果你是想一步到位,就是想全方位,也可以找当当的经销商,他们网站上有,当然价格相对更低。
可以看啊,
超级无敌稳定稳定,当当网,随心下载,试一试,找到你想要的。当当网是我下载次数最多的一个网站,真的很稳定。
在
当当网网站可以浏览全网各大电影电视剧资源,如果需要看某一部的,可以直接跳转到电影,
都有下载,还有购物,方便电商入驻。这个很方便,很开心,
网站有购物,下载,
当当网,最近一年来,已经完成了400亿的规模,且以每年15%左右的速度在高速增长,作为小生意,当当网已经是最快速的增长的,当当网就是网站看看电影,电视剧的话没有问题的。
当当网都有。试试。
当当网吧。还有各种影视资源可以看。
当当网你可以在googleplay下载,
也许还有安卓市场
目前,知道当当网最快的方法,
大哥,要看哪种?如果是电视剧电影之类,当当网都有全网覆盖,试一试当当网的微云。如果是学习和考试,那就可以买当当的书。电商一般都是明码标价的。也看不上会员啥的。 查看全部
当当网网站内容(大哥,要看哪种?当当网,随心下载,找到你想要的)
当当网网站内容已经全站覆盖,如果你在网站搜索你想看的电影、电视剧,都是可以看到的,如果想看全面的,可以在自助下载,当当网的微云支持全网中国的电影电视剧,如果你是想一步到位,就是想全方位,也可以找当当的经销商,他们网站上有,当然价格相对更低。
可以看啊,
超级无敌稳定稳定,当当网,随心下载,试一试,找到你想要的。当当网是我下载次数最多的一个网站,真的很稳定。
在
当当网网站可以浏览全网各大电影电视剧资源,如果需要看某一部的,可以直接跳转到电影,
都有下载,还有购物,方便电商入驻。这个很方便,很开心,
网站有购物,下载,
当当网,最近一年来,已经完成了400亿的规模,且以每年15%左右的速度在高速增长,作为小生意,当当网已经是最快速的增长的,当当网就是网站看看电影,电视剧的话没有问题的。
当当网都有。试试。
当当网吧。还有各种影视资源可以看。
当当网你可以在googleplay下载,
也许还有安卓市场
目前,知道当当网最快的方法,
大哥,要看哪种?如果是电视剧电影之类,当当网都有全网覆盖,试一试当当网的微云。如果是学习和考试,那就可以买当当的书。电商一般都是明码标价的。也看不上会员啥的。
当当网网站内容(移动互联时代需要怎样的营销系统?(产品线)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-07 16:22
阿里云>云栖社区>主题图>D>网站当当网功能图
推荐活动:
更多优惠>
当前话题:加入采集 网站 当当网功能图
相关话题:
当当网网站功能图相关博客,查看更多博客
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?如何匹配产品线规划和技术实施?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用 PWA 搭建一个完全离线的网站
作者:博文观点 2073 人查看评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
如何对待一本书
作者:科技探索者 1156人浏览评论:03年前
最近有网友多方面批评我的书,说我的书厚,实战性不强,里面的内容不够先进。他还写了一篇博文,暗中批评了我的书(这位网友是谁,这里我就不点名了,他心里最清楚)。非常感谢您的意见。我从不否认我的每一本书都以这样或那样的方式存在
阅读全文
窥探推荐系统
作者:javaedge1477 人浏览评论:02年前
本文将深入介绍推荐系统的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰理解并快速构建适合自己的推荐系统。1 信息发现随着Web2.0的发展,Web已经成为数据共享的平台。人们如何才能在海量数据中找到自己的需求?
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除人力资源和财务部门外,共分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
对话DFINITY:我们如何用区块链重构一个开放的互联网世界?
作者:云启豪资讯小哥567人浏览评论:01年前
云栖资讯:【点击查看更多行业资讯】在这里你可以找到不同行业的一手云资讯,还等什么,快来吧!置顶商务频道,新京报讯7月07日(黄当当):这是我第一次见到DFINITY创始人兼首席科学家多米尼克威廉姆斯,他带着非常阳光的笑容。
阅读全文
【python爬虫】Selenium针对性爬取海量精美图片及搜索引擎杂谈
作者:肖洛洛4435人浏览评论:06年前
我觉得这是我博客里的一篇优秀的文章,也是在深夜凌晨2点的激情和喜悦中完成的。首先,通过这个文章,可以学到以下几点:1.简单爬取图片可以学习Python的一些思路和方法2.学习Selenium
阅读全文 查看全部
当当网网站内容(移动互联时代需要怎样的营销系统?(产品线)(组图))
阿里云>云栖社区>主题图>D>网站当当网功能图
推荐活动:
更多优惠>
当前话题:加入采集 网站 当当网功能图
相关话题:
当当网网站功能图相关博客,查看更多博客
当当网石海峰:如何应对电商营销体系的挑战
作者:jurassic_14905 人浏览评论:05年前
移动互联网时代需要什么样的营销体系?我们如何才能快速、良好地响应业务需求并获得竞争优势?需要什么样的企业组织结构?如何匹配产品线规划和技术实施?宣传应该简明扼要还是简明扼要?大家好,我先自我介绍一下。我叫石海峰。我目前在当当科技部负责架构部。感谢中生代科技集团
阅读全文
使用 PWA 搭建一个完全离线的网站
作者:博文观点 2073 人查看评论:03年前
想象一下,您有能力构建一个完全离线的网站,为用户提供几乎即时的加载体验,同时对不可靠的网络具有安全性和弹性。这听起来不可能和不可思议。信不信由你,大多数现代浏览器已经内置了这些功能,你只需要发布它们。当你使用这些强大的功能构建网站时,你
阅读全文
网站结构数据采集
作者:教授赞2060人浏览评论:03年前
1.系统概览图1.1 系统架构概览图1.2 更完整的系统架构图2.系统使用的主要技术不分先后。2.1Front-end JavaScript, html, css, silverlight, flash Jquery Javascript库,用于简化html
阅读全文
如何对待一本书
作者:科技探索者 1156人浏览评论:03年前
最近有网友多方面批评我的书,说我的书厚,实战性不强,里面的内容不够先进。他还写了一篇博文,暗中批评了我的书(这位网友是谁,这里我就不点名了,他心里最清楚)。非常感谢您的意见。我从不否认我的每一本书都以这样或那样的方式存在
阅读全文
窥探推荐系统
作者:javaedge1477 人浏览评论:02年前
本文将深入介绍推荐系统的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰理解并快速构建适合自己的推荐系统。1 信息发现随着Web2.0的发展,Web已经成为数据共享的平台。人们如何才能在海量数据中找到自己的需求?
阅读全文
ShopNum1网店系统:打造电商运营团队
作者:zting科技2211人浏览评论:04年前
资料来源:早期的电商业务除人力资源和财务部门外,共分为5个部门,包括客服部、市场部、采购物流部、技术部和网站运营部。
阅读全文
对话DFINITY:我们如何用区块链重构一个开放的互联网世界?
作者:云启豪资讯小哥567人浏览评论:01年前
云栖资讯:【点击查看更多行业资讯】在这里你可以找到不同行业的一手云资讯,还等什么,快来吧!置顶商务频道,新京报讯7月07日(黄当当):这是我第一次见到DFINITY创始人兼首席科学家多米尼克威廉姆斯,他带着非常阳光的笑容。
阅读全文
【python爬虫】Selenium针对性爬取海量精美图片及搜索引擎杂谈
作者:肖洛洛4435人浏览评论:06年前
我觉得这是我博客里的一篇优秀的文章,也是在深夜凌晨2点的激情和喜悦中完成的。首先,通过这个文章,可以学到以下几点:1.简单爬取图片可以学习Python的一些思路和方法2.学习Selenium
阅读全文
当当网网站内容(【爬虫工程师】有合作?新上线的活动价500包邮)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-06 06:01
当当网网站内容简介并不清晰:网站是否和【python爱好者】【爬虫工程师】有合作?新上线的活动价500包邮,但在活动规则中并没有对:活动规则中要求“活动时间截止到11月30日”没有详细的项目和解决方案,只有一个列表;例子里用的axios,python之外你可以有别的开发工具吗?网站目录地址:-doc/python网站目录文件夹地址:,会有什么影响?。
我觉得是可以的。用redis做缓存好了。
这个大部分语言做爬虫都行,django这类不适合,因为目前有大批量客户端浏览器不支持django这些技术,这样想提高速度爬取更多流量时,一定要涉及限制cookie。总而言之就是,如果不安装django,爬虫的思想与实践就基本上没有任何改变。可以尝试scrapy或者flask。
我推荐用scrapy或者flask,
别做了,解决不了第一个问题的,就算第二个问题能解决,但是第三个问题很容易就让爬虫不再可用,到时候爬虫没数据,
首先你要注意到了这个问题说的是整个网站,网站是在用户量比较大的情况下产生,那么如果想要爬取全网页,也就是热门资源,其实最好是做成脚本这样利于分享提高自己的工作效率,关于爬虫工具,关于教程。1.django。用到的爬虫基本是http接口。2.flask。用的是flask的db等待读写分离模式,db容易重复建库。
4.redisscrapy这个数据库中间件,一般用到特定功能时会用到,比如登录页,后台管理页等。5.selenium+浏览器过滤。6.flask-redisscrapy自带的redis数据库中间件,但是目前看来太慢了,做到500s消息比较慢。7.beautifulsoupscrapy自带的beautifulsoup中间件,用于爬取网页重复,以及爬取网页结构。
但是目前来看没什么效果。如果希望加速爬取速度可以尝试将抓取进程再shell中。beautifulsoup的shell中间件,可以加快速度。要爬取全网页的网站,可以考虑django+flask+scrapy三者结合。总结来说,如果想提升效率尽可能组合实践,尽可能考虑django或者flask等。 查看全部
当当网网站内容(【爬虫工程师】有合作?新上线的活动价500包邮)
当当网网站内容简介并不清晰:网站是否和【python爱好者】【爬虫工程师】有合作?新上线的活动价500包邮,但在活动规则中并没有对:活动规则中要求“活动时间截止到11月30日”没有详细的项目和解决方案,只有一个列表;例子里用的axios,python之外你可以有别的开发工具吗?网站目录地址:-doc/python网站目录文件夹地址:,会有什么影响?。
我觉得是可以的。用redis做缓存好了。
这个大部分语言做爬虫都行,django这类不适合,因为目前有大批量客户端浏览器不支持django这些技术,这样想提高速度爬取更多流量时,一定要涉及限制cookie。总而言之就是,如果不安装django,爬虫的思想与实践就基本上没有任何改变。可以尝试scrapy或者flask。
我推荐用scrapy或者flask,
别做了,解决不了第一个问题的,就算第二个问题能解决,但是第三个问题很容易就让爬虫不再可用,到时候爬虫没数据,
首先你要注意到了这个问题说的是整个网站,网站是在用户量比较大的情况下产生,那么如果想要爬取全网页,也就是热门资源,其实最好是做成脚本这样利于分享提高自己的工作效率,关于爬虫工具,关于教程。1.django。用到的爬虫基本是http接口。2.flask。用的是flask的db等待读写分离模式,db容易重复建库。
4.redisscrapy这个数据库中间件,一般用到特定功能时会用到,比如登录页,后台管理页等。5.selenium+浏览器过滤。6.flask-redisscrapy自带的redis数据库中间件,但是目前看来太慢了,做到500s消息比较慢。7.beautifulsoupscrapy自带的beautifulsoup中间件,用于爬取网页重复,以及爬取网页结构。
但是目前来看没什么效果。如果希望加速爬取速度可以尝试将抓取进程再shell中。beautifulsoup的shell中间件,可以加快速度。要爬取全网页的网站,可以考虑django+flask+scrapy三者结合。总结来说,如果想提升效率尽可能组合实践,尽可能考虑django或者flask等。
当当网网站内容( 如何利用我们刚才的几个库去库去实战(上图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-05 13:10
如何利用我们刚才的几个库去库去实战(上图))
图片来自 unsplash
我们学习了这三个库的用法:urllib、re、BeautifulSoup。但这只是停留在理论层面,需要实践来检验学习效果。因此,本文主要讲解如何使用我们刚刚掌握的几个库进行实战。
1 确定爬取目标
任何网站都可以被爬取,这取决于你是否想爬取它。这次选择的爬取目标是当当网。爬取的内容是以Python作为关键字搜索到的页面中所有书籍的信息。详情如下图所示:
点击查看大图
这个爬取结果中有三项:
2 爬取过程
众所周知,每个站点的页面DOM树是不同的。因此,我们需要先对抓取的页面进行分析,然后确定我们想要获取的内容,然后定义程序抓取内容的规则。
2.1 确定URL地址
我们可以通过浏览器来判断 URL 地址,并提供入口地址给 urllib 发起请求。接下来,我们将逐步确定请求地址。
搜索结果页面为1时,URL地址如下:
点击查看大图
搜索结果页面为3时,URL地址如下:
点击查看大图
当搜索结果页面为21,即最后一页时,URL地址如下:
点击查看大图
从上图中,我们发现URL地址的不同在于page_index的值,所以URL地址最终是。而page_index的值,我们可以通过循环依次添加在地址之后。所以urllib的请求代码可以这样写:
<p> # 爬取地址, 当当所有 Python 的书籍, 一共是 21 页
url = "http://search.dangdang.com/%3F ... ot%3B
index = 1
while index 查看全部
当当网网站内容(
如何利用我们刚才的几个库去库去实战(上图))
图片来自 unsplash
我们学习了这三个库的用法:urllib、re、BeautifulSoup。但这只是停留在理论层面,需要实践来检验学习效果。因此,本文主要讲解如何使用我们刚刚掌握的几个库进行实战。
1 确定爬取目标
任何网站都可以被爬取,这取决于你是否想爬取它。这次选择的爬取目标是当当网。爬取的内容是以Python作为关键字搜索到的页面中所有书籍的信息。详情如下图所示:
点击查看大图
这个爬取结果中有三项:
2 爬取过程
众所周知,每个站点的页面DOM树是不同的。因此,我们需要先对抓取的页面进行分析,然后确定我们想要获取的内容,然后定义程序抓取内容的规则。
2.1 确定URL地址
我们可以通过浏览器来判断 URL 地址,并提供入口地址给 urllib 发起请求。接下来,我们将逐步确定请求地址。
搜索结果页面为1时,URL地址如下:
点击查看大图
搜索结果页面为3时,URL地址如下:
点击查看大图
当搜索结果页面为21,即最后一页时,URL地址如下:
点击查看大图
从上图中,我们发现URL地址的不同在于page_index的值,所以URL地址最终是。而page_index的值,我们可以通过循环依次添加在地址之后。所以urllib的请求代码可以这样写:
<p> # 爬取地址, 当当所有 Python 的书籍, 一共是 21 页
url = "http://search.dangdang.com/%3F ... ot%3B
index = 1
while index
当当网网站内容(当当网网站内容太多了,怎么办?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-04 02:04
当当网网站内容太多了。而且因为太多内容,所以没有看的兴趣,因为看完了找不到想看的。当当网应该重点扶持买书,卖书这部分的内容。其他的,就不是太重要了,除非你只看买书这一条信息。
正在体验,
当当网是一个商城的品类足够多,优惠力度足够大,所以是个围城。
购物信息太多了,
当当网最近推出的"比价"服务,以前光盯着上或者京东上的价格不太准确,比价以后就会知道原来不同商品之间差别还挺大,或者是比价后发现同一商品在不同平台的价格不一样,这样就有助于我节省了比价的时间精力,省下来买好东西我感觉当当比较好的是直通车,
看待一个商城对我个人有什么帮助。我想关键看我买东西在哪里找。在当当网是不是没有如何买到廉价好物的问题,买到的我会感觉很便宜,所以我想追求的是这个,不知道其他的商城同这个一样么?另外我也喜欢全年的商品一次性购齐,这也是个需求所在。
有一个叫作"当当比价"的app,是我看了比价整整三年的说。app是用户自己上传的商品的价格来比价。他有个用户体验做的不好的地方就是价格的显示效果不太好。我刚接触当当时,在一个专营网站看中了一款耳环。(网站买手价已经接近过万了)然后,我先订购一个月的,然后在比价上查查看。他就告诉我这个耳环售价是¥600,再想想自己刚要买。
自己查看也就查看了一个月,但是有个问题就是只能显示差价部分,不知道有没有其他价格。然后我就去了卖家,想问下有没有其他差价?卖家就各种推脱,说是差价不能透露。当时我觉得不对劲,就默默付款了。结果我一个月过去了,当我过了上个月的那一天,那时候卖家已经走了。所以我也没去问卖家的那些价格啊这样,每一天都是价格上浮20%,直到当我查看差价部分看不见价格的时候,我发现我订购的那个耳环真的已经涨价了。
然后我就马上提交了申请退款。把之前付了的钱退了回去。以后再找卖家比价,我就可以更加精准的查找了。在当当上的一个很蛋疼的事情就是,这个货可能有几千个人在买。他有一个退货差价规则,总共有25%的差价空间。而当你没有比价的时候,他那25%的差价你是算不到的。这样,你就很容易算到差价的部分里。这种低水平的用户体验真的让人挺烦恼的。
而如果我有时间有精力有兴趣在当当上买的话,我会去找当当帮我在卖家端查价,再等他们退差价给我不是当当的产品不行,因为买他们的产品还是便宜的多。但是当当这么不行,售后这块做的真不是让人满意ps:你知。 查看全部
当当网网站内容(当当网网站内容太多了,怎么办?(组图))
当当网网站内容太多了。而且因为太多内容,所以没有看的兴趣,因为看完了找不到想看的。当当网应该重点扶持买书,卖书这部分的内容。其他的,就不是太重要了,除非你只看买书这一条信息。
正在体验,
当当网是一个商城的品类足够多,优惠力度足够大,所以是个围城。
购物信息太多了,
当当网最近推出的"比价"服务,以前光盯着上或者京东上的价格不太准确,比价以后就会知道原来不同商品之间差别还挺大,或者是比价后发现同一商品在不同平台的价格不一样,这样就有助于我节省了比价的时间精力,省下来买好东西我感觉当当比较好的是直通车,
看待一个商城对我个人有什么帮助。我想关键看我买东西在哪里找。在当当网是不是没有如何买到廉价好物的问题,买到的我会感觉很便宜,所以我想追求的是这个,不知道其他的商城同这个一样么?另外我也喜欢全年的商品一次性购齐,这也是个需求所在。
有一个叫作"当当比价"的app,是我看了比价整整三年的说。app是用户自己上传的商品的价格来比价。他有个用户体验做的不好的地方就是价格的显示效果不太好。我刚接触当当时,在一个专营网站看中了一款耳环。(网站买手价已经接近过万了)然后,我先订购一个月的,然后在比价上查查看。他就告诉我这个耳环售价是¥600,再想想自己刚要买。
自己查看也就查看了一个月,但是有个问题就是只能显示差价部分,不知道有没有其他价格。然后我就去了卖家,想问下有没有其他差价?卖家就各种推脱,说是差价不能透露。当时我觉得不对劲,就默默付款了。结果我一个月过去了,当我过了上个月的那一天,那时候卖家已经走了。所以我也没去问卖家的那些价格啊这样,每一天都是价格上浮20%,直到当我查看差价部分看不见价格的时候,我发现我订购的那个耳环真的已经涨价了。
然后我就马上提交了申请退款。把之前付了的钱退了回去。以后再找卖家比价,我就可以更加精准的查找了。在当当上的一个很蛋疼的事情就是,这个货可能有几千个人在买。他有一个退货差价规则,总共有25%的差价空间。而当你没有比价的时候,他那25%的差价你是算不到的。这样,你就很容易算到差价的部分里。这种低水平的用户体验真的让人挺烦恼的。
而如果我有时间有精力有兴趣在当当上买的话,我会去找当当帮我在卖家端查价,再等他们退差价给我不是当当的产品不行,因为买他们的产品还是便宜的多。但是当当这么不行,售后这块做的真不是让人满意ps:你知。
当当网网站内容(当当网产品经理在中国真的火了,你怎么看?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-02 19:07
当当网网站内容结构错乱,三次元的发展成了一次线上二次元公会聚会,闹矛盾直接一个视频,人员聚会。作者|楠瓜(知乎id:noom)编辑|冰雪聪明的吴瑞凡(知乎id:迟钝兔)来源|人人都是产品经理(微信id:pmhuanxiang)互联网理论和分析看多了,你会觉得产品很神秘,甚至你不相信互联网还可以产生出产品经理这个职位。
“产品经理”这个职位被冠以一个令人耳目一新的名字出现在大众视野中,目的不是为了让你称其为“工匠”,而是为了他们在专业领域的突破和意义。大多数人没有想过产品经理是怎么一回事,他们也觉得产品经理很神秘,他们需要为用户考虑得更周到,还经常被人称作是“产品鬼才”。不过就在今天,产品经理在中国真的火了!刚刚,国内著名的视频网站和直播网站都传出了面试产品经理的好消息。
我们聊了聊产品经理这个职位的内部情况,以及我对产品经理的理解。01产品经理是干嘛的?首先,从技术角度来看,产品经理这个职位,真的是类似于ceo的职位。做过小ceo或者产品人会知道,创业前期,高管的工作基本就是需求挖掘、产品规划、推动产品实现。做产品经理的人一般分为用户研究、产品设计、产品运营和产品推广这四大模块。
在互联网公司中,产品经理就是用户研究出身,设计出了解决问题的用户需求。在其他传统行业也是这样,比如可口可乐的二次创业者戴维·普雷斯利是通讯运营商的产品经理,京东的第二代产品腾讯电商就是做运营商业务起家。可是,目前互联网公司都变成了一个相对扁平的网络体系,产品经理也几乎变成了一个职位而不再仅仅是一个职位。
在互联网人眼中,产品经理就是一个行业内的专业人员,是一种用户研究人员而不是前端人员,是一个运营人员,不同于其他行业产品经理。在这种情况下,产品经理已经不仅仅是负责解决创意设计,也就是产品产品需求,而是负责整个项目的架构,也就是整个产品的产品经理。再谈到专业能力方面,产品经理需要对整个产品走向有一个大致的判断,比如前端是视频网站,后端就是生活服务平台,数据就要区分为实时数据、沉淀数据和全量数据。
其实在一个互联网创业公司中,更像是生活服务平台的运营,对这种沉淀数据需要监测,但同时也要根据用户和商户的反馈来调整数据。把生活服务的数据通过数据采集变成数据,再赋能给其他服务,比如电商中的优惠券,游戏中的装备,或者主打广告的注册卡。上面我们说的只是一种层面的,最底层的产品经理有很多种,有一个公司就会有一个产品经理,产品经理实际上还有很多职位,具体包括但不限于用户研究,系统维。 查看全部
当当网网站内容(当当网产品经理在中国真的火了,你怎么看?)
当当网网站内容结构错乱,三次元的发展成了一次线上二次元公会聚会,闹矛盾直接一个视频,人员聚会。作者|楠瓜(知乎id:noom)编辑|冰雪聪明的吴瑞凡(知乎id:迟钝兔)来源|人人都是产品经理(微信id:pmhuanxiang)互联网理论和分析看多了,你会觉得产品很神秘,甚至你不相信互联网还可以产生出产品经理这个职位。
“产品经理”这个职位被冠以一个令人耳目一新的名字出现在大众视野中,目的不是为了让你称其为“工匠”,而是为了他们在专业领域的突破和意义。大多数人没有想过产品经理是怎么一回事,他们也觉得产品经理很神秘,他们需要为用户考虑得更周到,还经常被人称作是“产品鬼才”。不过就在今天,产品经理在中国真的火了!刚刚,国内著名的视频网站和直播网站都传出了面试产品经理的好消息。
我们聊了聊产品经理这个职位的内部情况,以及我对产品经理的理解。01产品经理是干嘛的?首先,从技术角度来看,产品经理这个职位,真的是类似于ceo的职位。做过小ceo或者产品人会知道,创业前期,高管的工作基本就是需求挖掘、产品规划、推动产品实现。做产品经理的人一般分为用户研究、产品设计、产品运营和产品推广这四大模块。
在互联网公司中,产品经理就是用户研究出身,设计出了解决问题的用户需求。在其他传统行业也是这样,比如可口可乐的二次创业者戴维·普雷斯利是通讯运营商的产品经理,京东的第二代产品腾讯电商就是做运营商业务起家。可是,目前互联网公司都变成了一个相对扁平的网络体系,产品经理也几乎变成了一个职位而不再仅仅是一个职位。
在互联网人眼中,产品经理就是一个行业内的专业人员,是一种用户研究人员而不是前端人员,是一个运营人员,不同于其他行业产品经理。在这种情况下,产品经理已经不仅仅是负责解决创意设计,也就是产品产品需求,而是负责整个项目的架构,也就是整个产品的产品经理。再谈到专业能力方面,产品经理需要对整个产品走向有一个大致的判断,比如前端是视频网站,后端就是生活服务平台,数据就要区分为实时数据、沉淀数据和全量数据。
其实在一个互联网创业公司中,更像是生活服务平台的运营,对这种沉淀数据需要监测,但同时也要根据用户和商户的反馈来调整数据。把生活服务的数据通过数据采集变成数据,再赋能给其他服务,比如电商中的优惠券,游戏中的装备,或者主打广告的注册卡。上面我们说的只是一种层面的,最底层的产品经理有很多种,有一个公司就会有一个产品经理,产品经理实际上还有很多职位,具体包括但不限于用户研究,系统维。
当当网网站内容(当当网网站积分池会随之增加,这个市场怎么打?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-01 20:03
当当网网站内容更新每月第四周,网站积分池会随之增加。目前这个数字我也没找到准确的数字,但看过此次的年会keynote,说白了就是5%平台分成。可以间接看出当当基金和用户有个公平的分成机制。另外,还是有些利益问题。比如设计书城每天仅上架一本书,限量的要么经典要么限时,结果没什么书供应。kindle店也是,下架书的也太多。
storeday只能自己家老书翻新卖,同价格的没多少书可卖。如果不能多卖书的话,当当只能自己做电商当当买那自己设定的折扣了,这个占比个人估计在50%左右。如果真的是这样,那这个市场怎么打?书城一天上架一本书,每本都限量,那以kindle卖图书的经验来看,前10页后面基本就卖完了,后面也不能多卖。前期玩下限概念,弄成模式,把第一笔钱打给出版社,这个比例一定要高,才能吸引众多编辑来搞原创。不然依靠盗版网站多年积累下来的人脉,当当还怎么和上游那些原创公司打。
截止3月29日,销售额大概3万,原创期两天。电商网站的书籍是比实体书便宜的,可以看看当当目前这些书的折扣。
2万左右,我猜是2/3折,原创期卖到现在,其中大部分不是原创作者的书,只是随便写写的读物。
以往的价格折扣是本文的一半,注意这里仅仅是以往,现在第一批原创真正开卖了价格立马下来了。这个价格和线下分销的情况是类似的,并且公司的估算也是50%销售提成,线下放置一天后价格调整比例是22%,又一轮调价,只是没走线上渠道, 查看全部
当当网网站内容(当当网网站积分池会随之增加,这个市场怎么打?)
当当网网站内容更新每月第四周,网站积分池会随之增加。目前这个数字我也没找到准确的数字,但看过此次的年会keynote,说白了就是5%平台分成。可以间接看出当当基金和用户有个公平的分成机制。另外,还是有些利益问题。比如设计书城每天仅上架一本书,限量的要么经典要么限时,结果没什么书供应。kindle店也是,下架书的也太多。
storeday只能自己家老书翻新卖,同价格的没多少书可卖。如果不能多卖书的话,当当只能自己做电商当当买那自己设定的折扣了,这个占比个人估计在50%左右。如果真的是这样,那这个市场怎么打?书城一天上架一本书,每本都限量,那以kindle卖图书的经验来看,前10页后面基本就卖完了,后面也不能多卖。前期玩下限概念,弄成模式,把第一笔钱打给出版社,这个比例一定要高,才能吸引众多编辑来搞原创。不然依靠盗版网站多年积累下来的人脉,当当还怎么和上游那些原创公司打。
截止3月29日,销售额大概3万,原创期两天。电商网站的书籍是比实体书便宜的,可以看看当当目前这些书的折扣。
2万左右,我猜是2/3折,原创期卖到现在,其中大部分不是原创作者的书,只是随便写写的读物。
以往的价格折扣是本文的一半,注意这里仅仅是以往,现在第一批原创真正开卖了价格立马下来了。这个价格和线下分销的情况是类似的,并且公司的估算也是50%销售提成,线下放置一天后价格调整比例是22%,又一轮调价,只是没走线上渠道,
当当网网站内容(当当网网站体验如何让用户流失了以后的价值大于购书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-09 13:03
当当网网站内容少,所以页面少,外观不够好,用户更倾向于看内容丰富的当当网。当当网网站很多功能很难找到,用户有较大的局限性,基本上以是买书为主。买书的多用人人,书在人人看的话,整个网站就会水掉。因此,如果做书城的话,人人与书又会水掉。因此,解决这个问题最大的困难应该是,用户是否有相关的购书需求?如果只是看看随手看看的话,这样可以解决当当网网站的问题,但是如果能导入其他的kindle商店,就能解决你的问题。但是网站的体验如何就无从说起了。
你应该问,怎么让kindle用户流失了以后的价值大于购书的价值。简单说,kindle就是一个借阅网站。你卖的只是借的权,而购书还要付钱。另外,你也必须得服务好kindle本身,传书等等都要及时,不能断。最好有定期的发货政策。现在是电商时代,讲的都是自营多平台发货,kindle可不管这些,单独走kindle商店就好了,只要是有kindle电子书销售,kindle商店一定会有的。
一下个观点仅仅是我个人的观点:第一,你提出的问题存在,在现在的电商环境下,当当网作为一个正常的,可以在国内大卖的电商平台,它的资源整合能力很强,所以你问我资源多会不会把kindle挤出去,那是不可能的。但是这样会导致很多问题。第二,正如你所说,当当网在地理上比较封闭,用户的购书来源有限,这可能是你会感觉它不利于购书的原因之一。
第三,其实你说的图书归类和,送货配送之类的,在大致的平台内部都是有的,而当当应该做了。最后,还是可以看出当当还是更加聚焦图书这个品类,而一些其他的信息不能进来并且分散,一定程度上起到了影响。总之,问题在于他们不会聚焦眼光和看法,以及在没有足够多资源的情况下选择了现在这种布局方式,甚至是更有可能丢失一些用户。 查看全部
当当网网站内容(当当网网站体验如何让用户流失了以后的价值大于购书)
当当网网站内容少,所以页面少,外观不够好,用户更倾向于看内容丰富的当当网。当当网网站很多功能很难找到,用户有较大的局限性,基本上以是买书为主。买书的多用人人,书在人人看的话,整个网站就会水掉。因此,如果做书城的话,人人与书又会水掉。因此,解决这个问题最大的困难应该是,用户是否有相关的购书需求?如果只是看看随手看看的话,这样可以解决当当网网站的问题,但是如果能导入其他的kindle商店,就能解决你的问题。但是网站的体验如何就无从说起了。
你应该问,怎么让kindle用户流失了以后的价值大于购书的价值。简单说,kindle就是一个借阅网站。你卖的只是借的权,而购书还要付钱。另外,你也必须得服务好kindle本身,传书等等都要及时,不能断。最好有定期的发货政策。现在是电商时代,讲的都是自营多平台发货,kindle可不管这些,单独走kindle商店就好了,只要是有kindle电子书销售,kindle商店一定会有的。
一下个观点仅仅是我个人的观点:第一,你提出的问题存在,在现在的电商环境下,当当网作为一个正常的,可以在国内大卖的电商平台,它的资源整合能力很强,所以你问我资源多会不会把kindle挤出去,那是不可能的。但是这样会导致很多问题。第二,正如你所说,当当网在地理上比较封闭,用户的购书来源有限,这可能是你会感觉它不利于购书的原因之一。
第三,其实你说的图书归类和,送货配送之类的,在大致的平台内部都是有的,而当当应该做了。最后,还是可以看出当当还是更加聚焦图书这个品类,而一些其他的信息不能进来并且分散,一定程度上起到了影响。总之,问题在于他们不会聚焦眼光和看法,以及在没有足够多资源的情况下选择了现在这种布局方式,甚至是更有可能丢失一些用户。
当当网网站内容(当当网网站内容逐渐下滑的情况下,自建站更有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-07 22:01
当当网网站内容逐渐下滑的情况下,有需求就有市场,自建站的发展就更不可避免了。有需求,有市场,才会有企业开始尝试自建站。所以,自建站更符合企业发展规律。流量平台分流本身就足够你站到一定高度,再发展站点,意义就不大了。相比而言,独立站更有价值。企业发展应该依托自身,独立站点也只是对外的渠道,能在多大程度上帮助你发展,还是得靠你自己不断探索。
有需求就有市场,一定要有的话就是整体分类。
互联网
前端变化太快了,后端的产品策略以及用户体验都会有很大的差别,还是相信自己的判断,选一个能与自己的行业,
我现在也没有太好的自建站解决方案,我现在一直在用shop++收费的,还是很不错的。自建站的发展前景很好,特别是对传统行业来说,将是一个不错的选择。当然你自己的专业经验和资源对于自建站的落地还是很重要的,还是得靠自己了。
流量平台的分流让你没有了机会,不能再被平台控制流量入口了,基于自建平台收费或免费的方式,外联资源能量很大,
问题没有抓住根本是自建站没有现成案例,而且一大把竞争对手。新市场你没有竞争力。那就是通过招聘外联招到你想要找的人。 查看全部
当当网网站内容(当当网网站内容逐渐下滑的情况下,自建站更有价值)
当当网网站内容逐渐下滑的情况下,有需求就有市场,自建站的发展就更不可避免了。有需求,有市场,才会有企业开始尝试自建站。所以,自建站更符合企业发展规律。流量平台分流本身就足够你站到一定高度,再发展站点,意义就不大了。相比而言,独立站更有价值。企业发展应该依托自身,独立站点也只是对外的渠道,能在多大程度上帮助你发展,还是得靠你自己不断探索。
有需求就有市场,一定要有的话就是整体分类。
互联网
前端变化太快了,后端的产品策略以及用户体验都会有很大的差别,还是相信自己的判断,选一个能与自己的行业,
我现在也没有太好的自建站解决方案,我现在一直在用shop++收费的,还是很不错的。自建站的发展前景很好,特别是对传统行业来说,将是一个不错的选择。当然你自己的专业经验和资源对于自建站的落地还是很重要的,还是得靠自己了。
流量平台的分流让你没有了机会,不能再被平台控制流量入口了,基于自建平台收费或免费的方式,外联资源能量很大,
问题没有抓住根本是自建站没有现成案例,而且一大把竞争对手。新市场你没有竞争力。那就是通过招聘外联招到你想要找的人。
当当网网站内容(当当网网站内容真实可靠,所有资源全部来自官方!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-07 02:03
当当网网站内容真实可靠,所有资源全部来自官方,用户评论几乎是对所有内容中的错误进行广泛的反对。话说你是在我遇到你当当网的客服或者工作人员时才这么觉得还是说你本身就是在意网站内容真实性的?你让我觉得我至少应该服务态度好点,然后我做到内容真实,不会大篇幅的点反对和关闭链接,但是为什么我会没有做到呢?那么我看到这个问题是不是应该认为,内容真实与否不能完全由客服本身来决定,而更是和我的认知有关?以下为原答案:电商的售后,应该是最容易出现问题的地方吧。
没错,我也遇到过。我觉得我的情况,也算是情有可原。买了雅阁,之后差点儿把发动机弄坏。车不是我的,然后发现真是正品,而且车子离谱沉,一看价格,还要出我半个月的购置税,我打电话给客服,客服拿公司名称一顿瞎扯,说返点儿也没有多,要不你加我微信,我拉你入团,然后给你寄了快递,你去取,我给他拉卡。我转账给他后,在微信上要求发货,然后卖家直接不发货,说请我邮寄给他,要拆箱验货。
我觉得就当开了个单子吧,然后发去寄的地方,去寄的时候看到这个。不拆完不拆,拆了不发,物流上什么鬼都没有。最后我没有领了快递回去。我当时想换车,现在我对这个牌子不熟悉,我根本不知道是不是假货。之后我估计4s有问题,我投诉了他们,他们全程就跟我扯皮,然后推给店方。最后店方告诉我我没有发货,还叫我找买家。我觉得还是要坚持我自己的想法,这是我的购买记录啊。
一直开车,觉得那个质量以及售后,我还是非常非常恼火的。你看网上买的二手车,只要是稍微懂点儿二手车,买个几千块的,出点钱保险,一年之后让保险公司给你送几万去,都非常正常。如果一辆新车,你给他优惠个几千块,送他几万块,那才叫遭罪。而且你仔细想想,一个公司在经营的时候,是为了便利多方呢,还是说要利用信息不对称,在所有汽车商都不知道的地方剥削你来维持自己,我一直觉得这是能做到的。 查看全部
当当网网站内容(当当网网站内容真实可靠,所有资源全部来自官方!)
当当网网站内容真实可靠,所有资源全部来自官方,用户评论几乎是对所有内容中的错误进行广泛的反对。话说你是在我遇到你当当网的客服或者工作人员时才这么觉得还是说你本身就是在意网站内容真实性的?你让我觉得我至少应该服务态度好点,然后我做到内容真实,不会大篇幅的点反对和关闭链接,但是为什么我会没有做到呢?那么我看到这个问题是不是应该认为,内容真实与否不能完全由客服本身来决定,而更是和我的认知有关?以下为原答案:电商的售后,应该是最容易出现问题的地方吧。
没错,我也遇到过。我觉得我的情况,也算是情有可原。买了雅阁,之后差点儿把发动机弄坏。车不是我的,然后发现真是正品,而且车子离谱沉,一看价格,还要出我半个月的购置税,我打电话给客服,客服拿公司名称一顿瞎扯,说返点儿也没有多,要不你加我微信,我拉你入团,然后给你寄了快递,你去取,我给他拉卡。我转账给他后,在微信上要求发货,然后卖家直接不发货,说请我邮寄给他,要拆箱验货。
我觉得就当开了个单子吧,然后发去寄的地方,去寄的时候看到这个。不拆完不拆,拆了不发,物流上什么鬼都没有。最后我没有领了快递回去。我当时想换车,现在我对这个牌子不熟悉,我根本不知道是不是假货。之后我估计4s有问题,我投诉了他们,他们全程就跟我扯皮,然后推给店方。最后店方告诉我我没有发货,还叫我找买家。我觉得还是要坚持我自己的想法,这是我的购买记录啊。
一直开车,觉得那个质量以及售后,我还是非常非常恼火的。你看网上买的二手车,只要是稍微懂点儿二手车,买个几千块的,出点钱保险,一年之后让保险公司给你送几万去,都非常正常。如果一辆新车,你给他优惠个几千块,送他几万块,那才叫遭罪。而且你仔细想想,一个公司在经营的时候,是为了便利多方呢,还是说要利用信息不对称,在所有汽车商都不知道的地方剥削你来维持自己,我一直觉得这是能做到的。
当当网网站内容(大数据推动B2C电子商务商业价值,如何应对电商营销体系挑战(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-20 19:07
阿里云>;云气社区>;主题地图>;D>;当当网的网站功能
建议的活动:
更多优惠>
当前主题:当当的网站功能添加到集合中
相关主题:
当当网的网站功能相关博客查看更多博客
当当石海峰:如何应对电子商务营销体系的挑战
作者:Jurasic14905观点:2005年前
移动互联网时代需要什么样的营销体系?我们如何快速、良好地响应业务需求并占据竞争优势?需要什么样的企业组织结构?产品线规划和技术实施如何匹配?促销是简洁还是令人眩晕?各位好。让我先自我介绍一下。我叫史海峰。我目前负责当当科技部的建筑部。感谢中生代科技集团
阅读全文
当当网:大数据提升B2C电商商业价值
作者:青山无名2409人浏览评论:2004年前
文章about :大数据提升B2C电子商务商业价值,2014年4月10-12日第五届中国数据库技术大会(DTCC)2014)为期三天的会议将集中讨论大数据应用、数据架构、数据管理、传统数据库软件和其他技术领域
阅读全文
使用PWA构建完全离线的网站系统@
作者:博客观点2073观点评论:03年前
想象一下,您能够构建一个完全离线的网站,为用户提供几乎即时的加载体验,并且对于不可靠的网络来说,它是安全和灵活的。这听起来是不可能和不可思议的。信不信由你,大多数现代浏览器都有内置功能,所以只要发布它们就行了。当您在使用这些强大功能构建网站时受益时,您
阅读全文
网站architecture数据采集和排序
作者:项教授2060观点点评:2003年前
1.系统概述1.1系统架构概述1.2相对完整的系统架构图2.系统使用的主要技术排名不分先后2.1前端JavaScript、HTML、CSS、Silverlight、flash、jQuery JavaScript类库简化HTML
阅读全文
当你的网站受到疯狂攻击时,你能做什么
作者:中兴科技1640观点评论:2004年前
前言网站优采云招标网络建立至今已超过四个月。百度搜索引擎收录已经从零收录逐步发展到400000收录和360搜索引擎的40000收录以上。流入搜索引擎的流量也在缓慢增加。发现网站在今天的工作中出现故障,主要表现为:1、网站访问速度非常慢2、static
阅读全文
[水文]从URL比较大电子商务网站的搜索详情
作者:嗯,99251179人浏览评论:2003年前
keep walking的文章“大电商网站navigation用户体验比较”很有趣。因为我最近的工作与搜索有关,我对中文和英文分词有点恼火。之前我还借用并模仿了网站的一些搜索功能,所以我将横向比较几位电子商务领军人物的搜索结果。我会提起它,让兄弟们继续走下去
阅读全文
@添加数据时出现错误k17。最初的原因是MS SQL Server 2008日志文件占用了太多空间
作者:中兴科技836观点评论:2004年前
打开数据库目录,发现数据库日志文件已经达到20g以上,所以我有了一个清除MS SQL Server 2008数据库日志文件的想法。具体操作:1、打开MS SQL Server 2008的查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
网站常用攻击手段
作者:中兴科技797观点评论:04年前
1、WebshellBackdoor webshell是一个以网页文件(如ASP、PHP、JSP或CGI)形式出现的命令执行环境,也可以称为网页后门。黑客入侵网站服务器后,通常会将这些ASP或PHP后门文件与网站服务器web目录中的普通网页文件连接起来
阅读全文 查看全部
当当网网站内容(大数据推动B2C电子商务商业价值,如何应对电商营销体系挑战(组图))
阿里云>;云气社区>;主题地图>;D>;当当网的网站功能
建议的活动:
更多优惠>
当前主题:当当的网站功能添加到集合中
相关主题:
当当网的网站功能相关博客查看更多博客
当当石海峰:如何应对电子商务营销体系的挑战
作者:Jurasic14905观点:2005年前
移动互联网时代需要什么样的营销体系?我们如何快速、良好地响应业务需求并占据竞争优势?需要什么样的企业组织结构?产品线规划和技术实施如何匹配?促销是简洁还是令人眩晕?各位好。让我先自我介绍一下。我叫史海峰。我目前负责当当科技部的建筑部。感谢中生代科技集团
阅读全文
当当网:大数据提升B2C电商商业价值
作者:青山无名2409人浏览评论:2004年前
文章about :大数据提升B2C电子商务商业价值,2014年4月10-12日第五届中国数据库技术大会(DTCC)2014)为期三天的会议将集中讨论大数据应用、数据架构、数据管理、传统数据库软件和其他技术领域
阅读全文
使用PWA构建完全离线的网站系统@
作者:博客观点2073观点评论:03年前
想象一下,您能够构建一个完全离线的网站,为用户提供几乎即时的加载体验,并且对于不可靠的网络来说,它是安全和灵活的。这听起来是不可能和不可思议的。信不信由你,大多数现代浏览器都有内置功能,所以只要发布它们就行了。当您在使用这些强大功能构建网站时受益时,您
阅读全文
网站architecture数据采集和排序
作者:项教授2060观点点评:2003年前
1.系统概述1.1系统架构概述1.2相对完整的系统架构图2.系统使用的主要技术排名不分先后2.1前端JavaScript、HTML、CSS、Silverlight、flash、jQuery JavaScript类库简化HTML
阅读全文
当你的网站受到疯狂攻击时,你能做什么
作者:中兴科技1640观点评论:2004年前
前言网站优采云招标网络建立至今已超过四个月。百度搜索引擎收录已经从零收录逐步发展到400000收录和360搜索引擎的40000收录以上。流入搜索引擎的流量也在缓慢增加。发现网站在今天的工作中出现故障,主要表现为:1、网站访问速度非常慢2、static
阅读全文
[水文]从URL比较大电子商务网站的搜索详情
作者:嗯,99251179人浏览评论:2003年前
keep walking的文章“大电商网站navigation用户体验比较”很有趣。因为我最近的工作与搜索有关,我对中文和英文分词有点恼火。之前我还借用并模仿了网站的一些搜索功能,所以我将横向比较几位电子商务领军人物的搜索结果。我会提起它,让兄弟们继续走下去
阅读全文
@添加数据时出现错误k17。最初的原因是MS SQL Server 2008日志文件占用了太多空间
作者:中兴科技836观点评论:2004年前
打开数据库目录,发现数据库日志文件已经达到20g以上,所以我有了一个清除MS SQL Server 2008数据库日志文件的想法。具体操作:1、打开MS SQL Server 2008的查询分析窗口2、在查询分析窗口中输入并执行以下SQL语句;1 2 3
阅读全文
网站常用攻击手段
作者:中兴科技797观点评论:04年前
1、WebshellBackdoor webshell是一个以网页文件(如ASP、PHP、JSP或CGI)形式出现的命令执行环境,也可以称为网页后门。黑客入侵网站服务器后,通常会将这些ASP或PHP后门文件与网站服务器web目录中的普通网页文件连接起来
阅读全文
当当网网站内容(豆丁当当处理支持下载豆丁上的文件,你不需要支付任何额外费用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-15 03:03
当当网处理支持在豆丁下载文件,也可以帮你下载百度文库、boo采集8、悦读网等平台的内容。它会自动去除水印并保存为pdf格式,您无需支付任何额外费用。
软件功能
1、支持豆丁、百度文库、boo采集8、悦读网、大居灯、金字塔医学等主流文献网络
2、添加去除水印功能
自动下载完成后会生成3、A pdf
4、完全免费,不收取任何费用
使用教程
1、 首先复制你需要下载的文档的链接。例如,如果编辑从豆丁网下载文档,则复制链接栏中的链接。
2、打开软件,将链接复制粘贴到下载器界面,点击下载。
3、开始下载,请等待下载完成。
4、下载后可以在软件包的pdf目录下看到文档的PDF文件。
背景介绍
豆丁网成立于2007年,是一个优秀的中文社交阅读平台,为用户提供所有可以阅读的有价值的东西。截至2010年,豆丁网已成功跻身世界互联网500强,成为提供垂直服务的优秀网站之一。 网站拥有丰富的实用文档、出版物、行业研究报告,以及数千名行业名人贡献的专业文档。各类阅读总量超过4亿。豆丁网鼓励原创,鼓励分享,尊重和维护上传者的权利。在豆丁网,您可以通过豆丁分享您的文档并发布在不同的博客、论坛和各种平台上,以进行广泛传播。同时,您还可以以非常环保的方式,以低廉的价格看到流行的书籍和杂志。 , 以及各种专业文档。
Docin 是全球优秀的 C2C 文档销售和共享社区。豆丁允许用户上传PDF、doc、ppt、txt等几十种格式的文档文件,并以Flash Player的形式在网页中直接展示给读者。总之,豆丁就像Youtube的文档版。每天都有数以万计的文档上传到豆丁。基于此,豆丁将努力打造全球最大的中文图书馆。
编辑评论
将您要下载的文档的网址复制到豆丁当当,它会自动识别并提取网页中的资源。软件保存的pdf文档可以直接编辑,应用会在列表中显示下载进度和日志详情。
以上是豆丁当当的全部内容,IE浏览器中文网站为您提供最新最实用的软件! 查看全部
当当网网站内容(豆丁当当处理支持下载豆丁上的文件,你不需要支付任何额外费用)
当当网处理支持在豆丁下载文件,也可以帮你下载百度文库、boo采集8、悦读网等平台的内容。它会自动去除水印并保存为pdf格式,您无需支付任何额外费用。
软件功能
1、支持豆丁、百度文库、boo采集8、悦读网、大居灯、金字塔医学等主流文献网络
2、添加去除水印功能
自动下载完成后会生成3、A pdf
4、完全免费,不收取任何费用
使用教程
1、 首先复制你需要下载的文档的链接。例如,如果编辑从豆丁网下载文档,则复制链接栏中的链接。
2、打开软件,将链接复制粘贴到下载器界面,点击下载。
3、开始下载,请等待下载完成。
4、下载后可以在软件包的pdf目录下看到文档的PDF文件。
背景介绍
豆丁网成立于2007年,是一个优秀的中文社交阅读平台,为用户提供所有可以阅读的有价值的东西。截至2010年,豆丁网已成功跻身世界互联网500强,成为提供垂直服务的优秀网站之一。 网站拥有丰富的实用文档、出版物、行业研究报告,以及数千名行业名人贡献的专业文档。各类阅读总量超过4亿。豆丁网鼓励原创,鼓励分享,尊重和维护上传者的权利。在豆丁网,您可以通过豆丁分享您的文档并发布在不同的博客、论坛和各种平台上,以进行广泛传播。同时,您还可以以非常环保的方式,以低廉的价格看到流行的书籍和杂志。 , 以及各种专业文档。
Docin 是全球优秀的 C2C 文档销售和共享社区。豆丁允许用户上传PDF、doc、ppt、txt等几十种格式的文档文件,并以Flash Player的形式在网页中直接展示给读者。总之,豆丁就像Youtube的文档版。每天都有数以万计的文档上传到豆丁。基于此,豆丁将努力打造全球最大的中文图书馆。
编辑评论
将您要下载的文档的网址复制到豆丁当当,它会自动识别并提取网页中的资源。软件保存的pdf文档可以直接编辑,应用会在列表中显示下载进度和日志详情。
以上是豆丁当当的全部内容,IE浏览器中文网站为您提供最新最实用的软件!

