
实时抓取网页数据
20个最好的网站数据实时分析工具 (珍藏版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-06-18 03:50
这是我们为大家提供的一篇关于介绍20个最好的网站数据实时分析工具的文章。
接下来就让我们一起来了解一下吧
Google Analytics
这是一个使用最广泛的访问统计分析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看到你的网站中目前在线的访客数量,了解他们观看了哪些网页、他们通过哪个网站链接到你的网站、来自哪个国家等等。
Clicky
与Google Analytics这种庞大的分析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简洁清新。
Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可让你建立各类通知,如电子邮件、声音、弹出框等。
Chartbeat
这是针对新闻出版和其他类型网站的实时分析工具。针对电子商务网站的专业分析功能即将推出。它可以让你查看访问者如何与你的网站进行互动,这可以帮助你改善你的网站。
GoSquared
它提供了所有常用的分析功能,并且还可以让你查看特定访客的数据。它集成了Olark,可以让你与访客进行聊天。
Mixpanel
该工具可以让你查看访客数据,并分析趋势,以及比较几天内的变化情况。
Reinvigorate
它提供了所有常用的实时分析功能,可以让你直观地了解访客点击了哪些地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪他们对网站的使用情况了。
Piwik
这是一个开源的实时分析工具,你可以轻松下载并安装在自己的服务器上。
ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费分析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名检测,可以帮助你跟踪和改善网站的排名。
SeeVolution
它目前处于测试阶段,提供了heatmaps和实时分析功能,你可以看到heatmaps直播。它的可视化工具集可以让你直观查看分析数据。
FoxMetrics
该工具提供了实时分析功能,基于事件和特征的概念,你还可以设置自定义事件。它可以收集与事件和特征匹配的数据,然后为你提供报告,这将有助于改善你的网站。
StatCounter
这是一个免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,你还可以设置每天、每周或每月自动给你发送电子邮件报告。
Performancing Metrics
该工具可以为你提供实时博客统计和Twitter分析。
Whos.Amung.Us
Whos.Amung.Us相当独特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看最近访客的详细信息。
TraceWatch
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以看到最近访客的详细信息,并跟踪他们的踪迹。
Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
Spotplex
这项服务除了提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排名。你甚至可以查看当天Spotplex网站上统计的最受欢迎的文章。
SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但如果你想要更详细的数据,就需要付费了。
Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会看到你的博客和其他博客的对比结果。 查看全部
20个最好的网站数据实时分析工具 (珍藏版)
这是我们为大家提供的一篇关于介绍20个最好的网站数据实时分析工具的文章。
接下来就让我们一起来了解一下吧
Google Analytics
这是一个使用最广泛的访问统计分析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看到你的网站中目前在线的访客数量,了解他们观看了哪些网页、他们通过哪个网站链接到你的网站、来自哪个国家等等。
Clicky
与Google Analytics这种庞大的分析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简洁清新。
Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可让你建立各类通知,如电子邮件、声音、弹出框等。
Chartbeat
这是针对新闻出版和其他类型网站的实时分析工具。针对电子商务网站的专业分析功能即将推出。它可以让你查看访问者如何与你的网站进行互动,这可以帮助你改善你的网站。
GoSquared
它提供了所有常用的分析功能,并且还可以让你查看特定访客的数据。它集成了Olark,可以让你与访客进行聊天。
Mixpanel
该工具可以让你查看访客数据,并分析趋势,以及比较几天内的变化情况。
Reinvigorate
它提供了所有常用的实时分析功能,可以让你直观地了解访客点击了哪些地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪他们对网站的使用情况了。
Piwik
这是一个开源的实时分析工具,你可以轻松下载并安装在自己的服务器上。
ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费分析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名检测,可以帮助你跟踪和改善网站的排名。
SeeVolution
它目前处于测试阶段,提供了heatmaps和实时分析功能,你可以看到heatmaps直播。它的可视化工具集可以让你直观查看分析数据。
FoxMetrics
该工具提供了实时分析功能,基于事件和特征的概念,你还可以设置自定义事件。它可以收集与事件和特征匹配的数据,然后为你提供报告,这将有助于改善你的网站。
StatCounter
这是一个免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,你还可以设置每天、每周或每月自动给你发送电子邮件报告。
Performancing Metrics
该工具可以为你提供实时博客统计和Twitter分析。
Whos.Amung.Us
Whos.Amung.Us相当独特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看最近访客的详细信息。
TraceWatch
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以看到最近访客的详细信息,并跟踪他们的踪迹。
Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
Spotplex
这项服务除了提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排名。你甚至可以查看当天Spotplex网站上统计的最受欢迎的文章。
SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但如果你想要更详细的数据,就需要付费了。
Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会看到你的博客和其他博客的对比结果。
【互联网数据抓取与挖掘案例】快来体验FME:零编码、快速、自由获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2022-06-18 03:50
推广:《城市数据师梦想特训营》原创大牛公开课报名详询
互联网开放数据以在线的方式让所有人可以访问和获取,这些数据充满无限可能性。本章将介绍FME在互联网数据抓取与挖掘方面的几个应用案例,带大家一起体验FME零编码、快速、自由抓取数据的优势。
案例一:FME与微博
FME目前已经提供对网络数据的处理能力,包括JSON、XML格式,甚至直接发送和接收TCP/IP协议的数据流。下面展示如何将抓取新浪微博的数据,并将其展示到地理信息平台上。
新浪微博提供开发式API,允许用户对来自微博数据进行读取,对于如何使用微博API,参考。我们选取了某一个位置,通过调用微博API,抓取附近某个范围内最新的微博消息。使用FME中的PythonCreator脚本,抓取微博数据。
返回的JSON数据格式如下:
这样的结果是无法很好的被利用的,因此,我们在通过FME的转换器完成了数据整理工作,提取出我们感兴趣的信息,并将发送微博的位置信息空间化,直接发布到ArcGIS Online上进行展示。
展示效果如下:
取微博数据这里我们使用了一小段python脚本,但其实我们可以直接使用FME的HTTPCaller来访问API接口,这样使得整个过程可以真正零代码。
案例二:零编码抓取POI数据
基于网页的API接口获取数据类型多样,高德、腾讯、百度等地图厂商都提供了POI数据的API接口。
这里以高德poi数据为例子,详细api说明可参考:
.
1.提取poi数据的模板编写思路
根据官方的使用说明,对发送的请求连接做相应的组合如下:
固定网址+查询范围+用户许可+poi类型+每页poi数量+翻页数量
官方示例如下:
,40.006919;116.48231,40.007381;116.47516,39.99713;116.472596,39.985227;116.45669,39.984989;116.460988,40.006919&keywords=kfc&output=xml&key=
编写FME模板构建数据访问链接、请求数据、解析数据并对数据做处理,输出得到想要的结果。
FME POI下载模板
下载运行情况:
1)使用CMD运行FME模板下载广东省(包括香港澳门)的poi, fme发出了105万次访问请求,返回470多万条数据。
2)将FME模板挂在阿里云服务器上,大约花了三天二夜的时间,下载了整个广东省以及香港澳门的poi,累计发送125万次访问请求,返回522万条poi数据.
使用CMD来运行FME模板还有一个好外,就是低配置机器也可以运行处理大量数据流
数据结果展示:
同样的方法可以应用到下载谷歌影像、高德瓦片、百度POI等等具有API接口的开放数据中。实现批量、零代码、无人值守的开放数据下载模式。
案例三:FME与即时通讯工具的互操作
FME运行方法的多样性。到底选择DESKTOP、SERVER、还是CLOUD?如果有一种另类的操作方法并颠覆以前的观点,会产生什么样的想法?
常规的FME操作,在与FME Server的操作中,通过的中介是浏览器,在浏览器界面来设置参数后运行得出结果。在与DESKTOP的操作中,使用的是Workbench或Bat来设置参数后运行得出结果。如果有另外的操作方式,要如何来实现。
在中国,QQ是最大的即时通讯工具,它垄断了90%以上的即时通讯市场。QQ是国人网络中不可缺少的工具。在常规的GIS数据处理中,FME、ARCGIS、CAD都是主流软件。其中FME又是最为快捷方便的数据处理软件。如果把QQ和FME结合在一起,让QQ来运行FME的模板,会是一个什么样的结果?不可思议还是异想天开吗?哦!这是要用蓝翔的挖掘机炒一锅新东方的菜!
经过一段时间的测试与修改,真的实现了用QQ运行FME模板的方法。实现的方法为群聊执行和一对一执行,以下是几个例子。
第一个例子,下载全国的公车线路信息。
这里的意思,是给QQ机器人发送一条指令,第一行是执行模板的名称,第二行是此模板的对应参数。上图是让QQ机器人执行BUS.FMW,此模板的功能是下载全国的公车线路站点,用到的参数是城市和线路。比如上面就是让QQ机器人下载广州的776公车的线路和站点。
如何看运行状态?输入bus+查询,会出现如下截图所示:
根据QQ机器人返回的连接下载,加载到谷歌地球上,看看效果如下图:
完全没有问题,FME和QQ的结合,真的做到了!!!我们可以把任意的模版通过与QQ机器人的进行交互运行,包括POI数据下载、处理勘测定界数据等等。
用QQ操作FME来运行模板是如此的方便,这会让你惊讶吗?当初有这个想法的时候,感觉太可怕,但有想法就行动去测试,万一实现了呢。。。
FME就是这样的神奇!!!
感谢本篇中“案例二:零代码抓取POI数据”和“案例三:FME与即时通讯工具的互操作”的提供者“千浪”。 查看全部
【互联网数据抓取与挖掘案例】快来体验FME:零编码、快速、自由获取数据
推广:《城市数据师梦想特训营》原创大牛公开课报名详询
互联网开放数据以在线的方式让所有人可以访问和获取,这些数据充满无限可能性。本章将介绍FME在互联网数据抓取与挖掘方面的几个应用案例,带大家一起体验FME零编码、快速、自由抓取数据的优势。
案例一:FME与微博
FME目前已经提供对网络数据的处理能力,包括JSON、XML格式,甚至直接发送和接收TCP/IP协议的数据流。下面展示如何将抓取新浪微博的数据,并将其展示到地理信息平台上。
新浪微博提供开发式API,允许用户对来自微博数据进行读取,对于如何使用微博API,参考。我们选取了某一个位置,通过调用微博API,抓取附近某个范围内最新的微博消息。使用FME中的PythonCreator脚本,抓取微博数据。
返回的JSON数据格式如下:
这样的结果是无法很好的被利用的,因此,我们在通过FME的转换器完成了数据整理工作,提取出我们感兴趣的信息,并将发送微博的位置信息空间化,直接发布到ArcGIS Online上进行展示。
展示效果如下:
取微博数据这里我们使用了一小段python脚本,但其实我们可以直接使用FME的HTTPCaller来访问API接口,这样使得整个过程可以真正零代码。
案例二:零编码抓取POI数据
基于网页的API接口获取数据类型多样,高德、腾讯、百度等地图厂商都提供了POI数据的API接口。
这里以高德poi数据为例子,详细api说明可参考:
.
1.提取poi数据的模板编写思路
根据官方的使用说明,对发送的请求连接做相应的组合如下:
固定网址+查询范围+用户许可+poi类型+每页poi数量+翻页数量
官方示例如下:
,40.006919;116.48231,40.007381;116.47516,39.99713;116.472596,39.985227;116.45669,39.984989;116.460988,40.006919&keywords=kfc&output=xml&key=
编写FME模板构建数据访问链接、请求数据、解析数据并对数据做处理,输出得到想要的结果。
FME POI下载模板
下载运行情况:
1)使用CMD运行FME模板下载广东省(包括香港澳门)的poi, fme发出了105万次访问请求,返回470多万条数据。
2)将FME模板挂在阿里云服务器上,大约花了三天二夜的时间,下载了整个广东省以及香港澳门的poi,累计发送125万次访问请求,返回522万条poi数据.
使用CMD来运行FME模板还有一个好外,就是低配置机器也可以运行处理大量数据流
数据结果展示:
同样的方法可以应用到下载谷歌影像、高德瓦片、百度POI等等具有API接口的开放数据中。实现批量、零代码、无人值守的开放数据下载模式。
案例三:FME与即时通讯工具的互操作
FME运行方法的多样性。到底选择DESKTOP、SERVER、还是CLOUD?如果有一种另类的操作方法并颠覆以前的观点,会产生什么样的想法?
常规的FME操作,在与FME Server的操作中,通过的中介是浏览器,在浏览器界面来设置参数后运行得出结果。在与DESKTOP的操作中,使用的是Workbench或Bat来设置参数后运行得出结果。如果有另外的操作方式,要如何来实现。
在中国,QQ是最大的即时通讯工具,它垄断了90%以上的即时通讯市场。QQ是国人网络中不可缺少的工具。在常规的GIS数据处理中,FME、ARCGIS、CAD都是主流软件。其中FME又是最为快捷方便的数据处理软件。如果把QQ和FME结合在一起,让QQ来运行FME的模板,会是一个什么样的结果?不可思议还是异想天开吗?哦!这是要用蓝翔的挖掘机炒一锅新东方的菜!
经过一段时间的测试与修改,真的实现了用QQ运行FME模板的方法。实现的方法为群聊执行和一对一执行,以下是几个例子。
第一个例子,下载全国的公车线路信息。
这里的意思,是给QQ机器人发送一条指令,第一行是执行模板的名称,第二行是此模板的对应参数。上图是让QQ机器人执行BUS.FMW,此模板的功能是下载全国的公车线路站点,用到的参数是城市和线路。比如上面就是让QQ机器人下载广州的776公车的线路和站点。
如何看运行状态?输入bus+查询,会出现如下截图所示:
根据QQ机器人返回的连接下载,加载到谷歌地球上,看看效果如下图:
完全没有问题,FME和QQ的结合,真的做到了!!!我们可以把任意的模版通过与QQ机器人的进行交互运行,包括POI数据下载、处理勘测定界数据等等。
用QQ操作FME来运行模板是如此的方便,这会让你惊讶吗?当初有这个想法的时候,感觉太可怕,但有想法就行动去测试,万一实现了呢。。。
FME就是这样的神奇!!!
感谢本篇中“案例二:零代码抓取POI数据”和“案例三:FME与即时通讯工具的互操作”的提供者“千浪”。
云栖社区-最好的中文技术社区(含轻量级爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-06-13 08:01
实时抓取网页数据的node.js框架有很多:云栖社区-最好的中文技术社区(含轻量级爬虫)
对于这种目前云社区就已经很成熟的东西,我还是喜欢自己去摸索学习(例如我)。既然是pc抓包,按你的目的分为,抓取发生在http端的图片以及网页。如果要对网页进行抓取,那爬虫框架就有很多了。目前提供http抓包的有三个,
网上自己找吧,比如语雀,随手点开一个手机网页抓包教程,可以学到很多。
推荐题主去scrapy、urllib2这些框架找找。说白了http的请求分析处理相关模块都在这些框架里实现的。http2,urllib2其实很多js请求处理也是整合在这两个框架里的。另外提示一下,http1.0有一个request,是有明文传输安全保证的。
顺便问一下题主的网站指的是页面还是网页端,如果是页面那个是正常抓取的可以使用-xposed这个switchyomega或者collectweb。如果是网页端可以用kibanaapi进行分析。
polyfillbs4proxyfirefoxagainst-browser-client-requestsfirefoxapplicationsecurity
对于一个只是想在浏览器里面的代码里直接抓取http网页图片的话,推荐phantomjs。
使用libpcap库抓取,最新版本可以直接把单文件提交给对应浏览器,对于分析爬虫没有任何实际意义。 查看全部
云栖社区-最好的中文技术社区(含轻量级爬虫)
实时抓取网页数据的node.js框架有很多:云栖社区-最好的中文技术社区(含轻量级爬虫)
对于这种目前云社区就已经很成熟的东西,我还是喜欢自己去摸索学习(例如我)。既然是pc抓包,按你的目的分为,抓取发生在http端的图片以及网页。如果要对网页进行抓取,那爬虫框架就有很多了。目前提供http抓包的有三个,
网上自己找吧,比如语雀,随手点开一个手机网页抓包教程,可以学到很多。
推荐题主去scrapy、urllib2这些框架找找。说白了http的请求分析处理相关模块都在这些框架里实现的。http2,urllib2其实很多js请求处理也是整合在这两个框架里的。另外提示一下,http1.0有一个request,是有明文传输安全保证的。
顺便问一下题主的网站指的是页面还是网页端,如果是页面那个是正常抓取的可以使用-xposed这个switchyomega或者collectweb。如果是网页端可以用kibanaapi进行分析。
polyfillbs4proxyfirefoxagainst-browser-client-requestsfirefoxapplicationsecurity
对于一个只是想在浏览器里面的代码里直接抓取http网页图片的话,推荐phantomjs。
使用libpcap库抓取,最新版本可以直接把单文件提交给对应浏览器,对于分析爬虫没有任何实际意义。
简单代码抓取全国实时疫情数据——小白爬虫实战(9)
网站优化 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2022-06-05 03:38
七月以来,国内疫情又有反复,陆续有多个地方冒出本土确诊病例,一些地方被划为风险地区,涉及的地区也有逐渐增多的趋势,总而言之,疫情尚未结束,大家还是要做好个人防护。
全国的疫情数据都是每日不断更新的,如果我们要搜集这些数据,传统的CV大法显然也是能解决问题的,但是还是那句话,“可以但没必要”。
这节我们通过selenium,获取全国34个省级行政区的实时疫情数据。
这里我们全国实时疫情数据的数据来源为百度的疫情实时大数据报告专题网页,链接为:
百度疫情实时大数据报告页
进入页面可以看见国内每日疫情的总体数据,顺着页面继续下拉,我们可以看到这么一张疫情分布地图:
不要慌张,上图显示的现有确诊是指包含境外输入的现有确诊病例数,继续向下滑动页面,我们就可以找到对应的数据来源:
上图被红框圈起来的“现有”列数据便是前文疫情分布地图所呈现的数据内容。展开这张“国内各地区疫情统计汇总”表的全部,可以看见该表数据包括了全国34个行政区的 新增病例、现有病例、累计病例、累计治愈、累计死亡 共五项数据。
就以红框数据为例,如何将各地区的现有病例数据爬取下来呢?
Selenium的优势就在于“可见即可得”,只要能看到的,就能给爬下来。
通过分析Xpath可以清晰的看见,排在地区列第一行的台湾对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[1]/div/span[2]
而排在地区列最后一行的西藏对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[1]/div/span[2]
比对两个Xpath可以发现,除了标红的位置数字1变成了34,Xpath的其余部分都是一模一样的,可见这34个省级行政区地区名的Xpath就是这样按照1到34的顺序排下来。
关于Xpath的分析方法,在往期的文章中已经提过,这里就不再赘述,有需要的小伙伴可以回顾
同理,各地区的现有病例列也按照相同的套路,Xpath从1到34排下来:
现有病例第一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[3]
现有病例最后一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[3]
找到了上面的规律,我们只需要用一个for循环,就可以构建出爬取对应地区现有确诊病例数据的代码:
# 设定地区名空列表regions_list = []# 设定现有病例空列表existing_case_list = []<br /># 总共有34个省级行政区数据for i in range(34): # i输出的是int型的0至33 k = str(i + 1) # 获取地区名 region = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[1]/div/span[2]').text # 将获取的地区名加到地区名列表中 regions_list.append(region) # 获取各地现有病例数 existing_case = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[3]').text # 将获取的各地现有病例数加到现有病例列表中 existing_case_list.append(existing_case)print(regions_list)print(existing_case_list)
上面便是获取全国实时疫情数据的核心代码部分,要想正确运行这串代码,我们还得事先声明模拟的浏览器类型,以及加载对应页的url。
关于在使用selenium前的配置问题此处就不再赘述,有需要的小伙伴可参照往期内容:
这里还需要注意的是,在模拟浏览器加载页面后,并没有直接开始for循环抓取数据,而是先做了一个模拟点击动作(第14行)
import timefrom selenium import webdriver<br /># url为百度疫情实时大数据链接url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'# 这里用的火狐option = webdriver.FirefoxOptions()option.add_argument('head')driver = webdriver.Firefox(options=option)driver.get(url)# 留足加载时间time.sleep(2)# 注意,需要模拟点击一下表才会展开全部数据driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/div/span').click()
这里的模拟点击动作实际上是完成表格底部的“展开”动作,因为34行数据太长,网页本身并没有全部显示,所以这里需要我们自己模拟点击一下将它展开。
运行程序,就可以得到两个列表,一个列表是地名,一个列表是现有病例数,两个列表的元素位置是相对应的。
运行结果
有了这份数据,我们就可以利用pyecharts等方法制作如前文所示的疫情地图,也可以将数据写入csv保存至本地。
pyecharts制图可参考往期内容
同样的,如果我们不仅仅想要抓取现有病例数,想要抓取其它列的数据,甚至多列数据一起抓也很好办,只需要根据Xpath位置的不同作对应修改即可。
后台发送关键词 “疫情数据抓取” 获取本文示例代码。 查看全部
简单代码抓取全国实时疫情数据——小白爬虫实战(9)
七月以来,国内疫情又有反复,陆续有多个地方冒出本土确诊病例,一些地方被划为风险地区,涉及的地区也有逐渐增多的趋势,总而言之,疫情尚未结束,大家还是要做好个人防护。
全国的疫情数据都是每日不断更新的,如果我们要搜集这些数据,传统的CV大法显然也是能解决问题的,但是还是那句话,“可以但没必要”。
这节我们通过selenium,获取全国34个省级行政区的实时疫情数据。
这里我们全国实时疫情数据的数据来源为百度的疫情实时大数据报告专题网页,链接为:
百度疫情实时大数据报告页
进入页面可以看见国内每日疫情的总体数据,顺着页面继续下拉,我们可以看到这么一张疫情分布地图:
不要慌张,上图显示的现有确诊是指包含境外输入的现有确诊病例数,继续向下滑动页面,我们就可以找到对应的数据来源:
上图被红框圈起来的“现有”列数据便是前文疫情分布地图所呈现的数据内容。展开这张“国内各地区疫情统计汇总”表的全部,可以看见该表数据包括了全国34个行政区的 新增病例、现有病例、累计病例、累计治愈、累计死亡 共五项数据。
就以红框数据为例,如何将各地区的现有病例数据爬取下来呢?
Selenium的优势就在于“可见即可得”,只要能看到的,就能给爬下来。
通过分析Xpath可以清晰的看见,排在地区列第一行的台湾对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[1]/div/span[2]
而排在地区列最后一行的西藏对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[1]/div/span[2]
比对两个Xpath可以发现,除了标红的位置数字1变成了34,Xpath的其余部分都是一模一样的,可见这34个省级行政区地区名的Xpath就是这样按照1到34的顺序排下来。
关于Xpath的分析方法,在往期的文章中已经提过,这里就不再赘述,有需要的小伙伴可以回顾
同理,各地区的现有病例列也按照相同的套路,Xpath从1到34排下来:
现有病例第一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[3]
现有病例最后一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[3]
找到了上面的规律,我们只需要用一个for循环,就可以构建出爬取对应地区现有确诊病例数据的代码:
# 设定地区名空列表regions_list = []# 设定现有病例空列表existing_case_list = []<br /># 总共有34个省级行政区数据for i in range(34): # i输出的是int型的0至33 k = str(i + 1) # 获取地区名 region = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[1]/div/span[2]').text # 将获取的地区名加到地区名列表中 regions_list.append(region) # 获取各地现有病例数 existing_case = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[3]').text # 将获取的各地现有病例数加到现有病例列表中 existing_case_list.append(existing_case)print(regions_list)print(existing_case_list)
上面便是获取全国实时疫情数据的核心代码部分,要想正确运行这串代码,我们还得事先声明模拟的浏览器类型,以及加载对应页的url。
关于在使用selenium前的配置问题此处就不再赘述,有需要的小伙伴可参照往期内容:
这里还需要注意的是,在模拟浏览器加载页面后,并没有直接开始for循环抓取数据,而是先做了一个模拟点击动作(第14行)
import timefrom selenium import webdriver<br /># url为百度疫情实时大数据链接url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'# 这里用的火狐option = webdriver.FirefoxOptions()option.add_argument('head')driver = webdriver.Firefox(options=option)driver.get(url)# 留足加载时间time.sleep(2)# 注意,需要模拟点击一下表才会展开全部数据driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/div/span').click()
这里的模拟点击动作实际上是完成表格底部的“展开”动作,因为34行数据太长,网页本身并没有全部显示,所以这里需要我们自己模拟点击一下将它展开。
运行程序,就可以得到两个列表,一个列表是地名,一个列表是现有病例数,两个列表的元素位置是相对应的。
运行结果
有了这份数据,我们就可以利用pyecharts等方法制作如前文所示的疫情地图,也可以将数据写入csv保存至本地。
pyecharts制图可参考往期内容
同样的,如果我们不仅仅想要抓取现有病例数,想要抓取其它列的数据,甚至多列数据一起抓也很好办,只需要根据Xpath位置的不同作对应修改即可。
后台发送关键词 “疫情数据抓取” 获取本文示例代码。
有同学要python数据库相关的笔记?相关数据大全
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-05-20 22:06
实时抓取网页数据,然后用正则表达式匹配,然后excel表格基本要求都能满足,其他数据库操作语言差别也不是特别大。excel适合快速存储数据,python适合处理和处理特定数据。
=有同学要python数据库相关的笔记?tushare相关数据大全ipython相关文章echarts中文版
《python爬虫开发实战》
个人很喜欢相关web和爬虫方面的文章,比如翻墙整理github上python相关爬虫和web的源码源文件,再clone到本地进行爬虫及web方面的开发等等一些机会,
推荐一个从基础到高级的路线,
爬虫其实更大更杂都能涉及到,要说完全掌握,那基本python和ruby都要能够做到,时间来得及,但是一些学校软件或者是做市场,运营的岗位,针对的则是python做编程语言,所以掌握python也是ok的,看后期想往哪方面去走,利用多学校提供的java和php的教学视频,以及老师平时做过的实际项目,多练习,基本就可以,做到整理。 查看全部
有同学要python数据库相关的笔记?相关数据大全
实时抓取网页数据,然后用正则表达式匹配,然后excel表格基本要求都能满足,其他数据库操作语言差别也不是特别大。excel适合快速存储数据,python适合处理和处理特定数据。
=有同学要python数据库相关的笔记?tushare相关数据大全ipython相关文章echarts中文版
《python爬虫开发实战》
个人很喜欢相关web和爬虫方面的文章,比如翻墙整理github上python相关爬虫和web的源码源文件,再clone到本地进行爬虫及web方面的开发等等一些机会,
推荐一个从基础到高级的路线,
爬虫其实更大更杂都能涉及到,要说完全掌握,那基本python和ruby都要能够做到,时间来得及,但是一些学校软件或者是做市场,运营的岗位,针对的则是python做编程语言,所以掌握python也是ok的,看后期想往哪方面去走,利用多学校提供的java和php的教学视频,以及老师平时做过的实际项目,多练习,基本就可以,做到整理。
电商社交网站数据他统统能采 Excel导出随采随用 服务30万家企业
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-13 16:53
◆ 优采云创始人刘宝强
文| 铅笔道 记者 韩正阳
►导语
2016年6月,优采云完成Pre-A融资,投资方是“协同创新”。此前,项目曾获得过种子轮投资,以及拓尔思500万元天使轮融资。
优采云是一家大数据服务公司,为企业用户提供数据采集、整合、挖掘分析等服务,数据抓取范围覆盖全网。用户输入网站,拖拉控件即可配置任务,自动提取元素并将采集数据表格化。
产品自2013年3月上线以来,已经服务30万家企业,能够全网全时段为用户搜集数据。
注: 刘宝强已确认文中数据真实无误,铅笔道愿与他一起为内容真实性背书。
全网采集数据
大数据的风在国外刮起时,在美国一家金融公司工作的刘宝强,察觉到这将是未来的趋势。
彼时是2012年,美国有几家大数据公司刚起步。于是他开始调研国内企业,发现“很多企业有数据诉求,但是根本没有大数据能力”。
而数据的价值显而易见。比如,企业可以根据用户数据、竞争对手数据、市场趋势数据等制定发展计划,调整运营策略。
但数据获取难度高,成本大,很多时候即使花钱也买不到数据。“于是,数据获取成了一件可望不可及的事情。”
恰好公司内部推行大数据平台受阻,刘宝强便跳出来,成立优采云。2013年9月,他开始组建团队,研发产品。
2014年3月,第一个版本上线,此时产品已经实现数据自动化采集,范围覆盖全网。用户在电脑上下载客户端软件,然后在软件中设定网站,便可采集数据。
数据采集傻瓜化智能化
最初,用户需先花0.5~2个小时学习软件使用,然后花几分钟设置一个网站。“刚开始的流程比较繁琐,随后,我们为了让产品更傻瓜化,操作更简单,做了一系列改进。”
去年年底,产品推出了向导模式,主要面向初学者。用户在学习使用的时候,就像安装Windows软件,它会提醒你下一步怎么操作。“主要目的是减少用户出错,也节省其学习成本。”
今年8月,Smart模式推出,用户无需学习配置规则,只用输入网址,便可以搜集数据。“进一步降低了用户的使用门槛。而且打开网站比一般浏览器都快,因为我们会自动识别、屏蔽广告,这可以加速采集的过程。”
“任何人都可以使用,任何网站数据都可以采集。”谈及优采云的使用,刘宝强说道。
用户能够自定义字段,而采集来的数据,可以即时表格化,支持数据库、网站、Excel、文本等多种导出方式,也可以直接导入到WordPress、Discuz、dede等多种论坛博客网站。
服务30万企业客户
用户获取方面,产品上线前,刘宝强便在做准备。
在开发者知识分享社区“博客园”上,他发表一系列互联网大数据文章,每篇文章有数千阅读。由此,他积累了一个500人的QQ群。“群满后,我们发布产品,这些QQ用户是我们第一批种子用户。”
此后,公司“一直很低调”。用户构成上,30%是靠口碑获取,50%属于自然流量增长,其余则靠付费推广获取。“一开始我们没人负责做用户的团队。”
去年7月,企业用户破4万。他开始招募运营和销售团队。
◆团队小伙伴们
商业模式上,优采云提供免费的基础数据服务,并通过增值服务来收费。
根据数据采集能力,产品分为免费版、专业版、旗舰版、私有云、企业定制版等5个版本,数据采集数量从日均近万到百万不等,采集能力为30~100倍速。
“数据搜集能力越强,版本收费越高。”整个系统有超过2000台服务器支撑。
目前,服务企业用户已经超过30万,每月新增3万用户。服务客户包含国家公安部研究所、国家统计局、三星电子、中科院、比亚迪、艾瑞等。
“对大数据企业来说,技术是安身立命之本。”未来,刘会投入更多资金在产品改进上,希望为所有企业提供大数据工具和平台。
/The End/
编辑 王 方 校对 汪 晨
求报道
请加pencil-news为好友
查看全部
电商社交网站数据他统统能采 Excel导出随采随用 服务30万家企业
◆ 优采云创始人刘宝强
文| 铅笔道 记者 韩正阳
►导语
2016年6月,优采云完成Pre-A融资,投资方是“协同创新”。此前,项目曾获得过种子轮投资,以及拓尔思500万元天使轮融资。
优采云是一家大数据服务公司,为企业用户提供数据采集、整合、挖掘分析等服务,数据抓取范围覆盖全网。用户输入网站,拖拉控件即可配置任务,自动提取元素并将采集数据表格化。
产品自2013年3月上线以来,已经服务30万家企业,能够全网全时段为用户搜集数据。
注: 刘宝强已确认文中数据真实无误,铅笔道愿与他一起为内容真实性背书。
全网采集数据
大数据的风在国外刮起时,在美国一家金融公司工作的刘宝强,察觉到这将是未来的趋势。
彼时是2012年,美国有几家大数据公司刚起步。于是他开始调研国内企业,发现“很多企业有数据诉求,但是根本没有大数据能力”。
而数据的价值显而易见。比如,企业可以根据用户数据、竞争对手数据、市场趋势数据等制定发展计划,调整运营策略。
但数据获取难度高,成本大,很多时候即使花钱也买不到数据。“于是,数据获取成了一件可望不可及的事情。”
恰好公司内部推行大数据平台受阻,刘宝强便跳出来,成立优采云。2013年9月,他开始组建团队,研发产品。
2014年3月,第一个版本上线,此时产品已经实现数据自动化采集,范围覆盖全网。用户在电脑上下载客户端软件,然后在软件中设定网站,便可采集数据。
数据采集傻瓜化智能化
最初,用户需先花0.5~2个小时学习软件使用,然后花几分钟设置一个网站。“刚开始的流程比较繁琐,随后,我们为了让产品更傻瓜化,操作更简单,做了一系列改进。”
去年年底,产品推出了向导模式,主要面向初学者。用户在学习使用的时候,就像安装Windows软件,它会提醒你下一步怎么操作。“主要目的是减少用户出错,也节省其学习成本。”
今年8月,Smart模式推出,用户无需学习配置规则,只用输入网址,便可以搜集数据。“进一步降低了用户的使用门槛。而且打开网站比一般浏览器都快,因为我们会自动识别、屏蔽广告,这可以加速采集的过程。”
“任何人都可以使用,任何网站数据都可以采集。”谈及优采云的使用,刘宝强说道。
用户能够自定义字段,而采集来的数据,可以即时表格化,支持数据库、网站、Excel、文本等多种导出方式,也可以直接导入到WordPress、Discuz、dede等多种论坛博客网站。
服务30万企业客户
用户获取方面,产品上线前,刘宝强便在做准备。
在开发者知识分享社区“博客园”上,他发表一系列互联网大数据文章,每篇文章有数千阅读。由此,他积累了一个500人的QQ群。“群满后,我们发布产品,这些QQ用户是我们第一批种子用户。”
此后,公司“一直很低调”。用户构成上,30%是靠口碑获取,50%属于自然流量增长,其余则靠付费推广获取。“一开始我们没人负责做用户的团队。”
去年7月,企业用户破4万。他开始招募运营和销售团队。
◆团队小伙伴们
商业模式上,优采云提供免费的基础数据服务,并通过增值服务来收费。
根据数据采集能力,产品分为免费版、专业版、旗舰版、私有云、企业定制版等5个版本,数据采集数量从日均近万到百万不等,采集能力为30~100倍速。
“数据搜集能力越强,版本收费越高。”整个系统有超过2000台服务器支撑。
目前,服务企业用户已经超过30万,每月新增3万用户。服务客户包含国家公安部研究所、国家统计局、三星电子、中科院、比亚迪、艾瑞等。
“对大数据企业来说,技术是安身立命之本。”未来,刘会投入更多资金在产品改进上,希望为所有企业提供大数据工具和平台。
/The End/
编辑 王 方 校对 汪 晨
求报道
请加pencil-news为好友
网易实时疫情数据Python抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-05-11 14:53
有朋友反馈之前抓取百度疫情数据的代码已经无法运行,没看过的朋友可以点击下列链接查看。
看了下,因为百度调整了部分页面信息,代码要调整下就可以使用了,那如果下次再调整呢?你说这概率大不大?
我觉得是相当的大,那有没有稳定点的方法呢?
这样问,肯定是有的,就是换种方式获取疫情实时数据。
这次我们来抓取网易JSON疫情数据。
链接是这个
打开网址,看到是这样的,如果你是第一次接触JSON数据,包你看的一脸懵逼。不过不要紧,如果你用的是火狐浏览器,你还可以发现上方还有JSON、美化输出等功能。
这是点美化输出的效果,看起来是不是好一点,不过还是一脸懵逼对不对,因为你就没接触过JSON数据嘛。
这是点JSON的效果,有不同颜色了,看起来更舒服了。
好了,我们开始进行数据抓取与导入了。先导入需要用的模块。
import json<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />import requests<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />from pandas.io.json import json_normalize<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后开始抓数据
url="https://c.m.163.com/ug/api/wuh ... %3Bbr style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />ret=requests.get(url, headers=headers)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />result=json.loads(ret.content)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
查看下抓到的数据result,可以看到是个字典,我们要的数据在key=data里面。
继续双击点开data,我们要的数据在areaTree里面。
继续双击点开areaTree,这时areaTree是个列表,我们要的数据第一行里面。
继续双击点开areaTree的第一行,这时候又变成一个字典了,看到中国没有?哈哈,我们要的数据在key=children里面。
继续双击点开children,这就是我们要的数据啦,这又变成了一个列表,每一行就是一个省的数据
我们点开第一行看看,看到没有,湖北出现了。
如果继续点开children,就是湖北各城市的数据啦,不点不点了,我们就只要省份数据,怎么提出来呢?继续进行数据处理,提取出我们要的数据。
t= result['data']['areaTree'][0]['children']<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />sf=json_normalize(t)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
就这么两句代码就出来了,哈哈!我们来看下数据。
taday.开头的都是最新的“今日”数据,也就是新增数据,total.开头的就是累计数据,confirm是确诊人数,suspect是疑似,heal是出院,dead是死亡。
我们要的字段就是name、total.confirm,name就是省份名,total.confirm就是累计确诊人数。直接把name、total.confirm替换之前绘制地图的代码相应位置。
# 将数据转换为二元的列表<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />list1 = list(zip(sf['name'],sf['total.confirm']))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 创建一个地图对象<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1 = Map()<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#对全局进行设置<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.set_global_opts(<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置标题<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />title_opts=opts.TitleOpts(title="全国疫情地图"),<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置最大数据范围<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 使用add方法添加地图数据与地图类型<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.add("累计确诊人数", list1, maptype="china")<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 地图创建完成后,通过render()方法可以将地图渲染为html<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.render('全国疫情地图.html')<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后地图绘制结果就出来了。
------------
希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程
包含以下四门课程
Python数据分析--玩转Pandas
Python数据分析--玩转数据可视化
玩转Python统计分析
玩转Python统计模型
现参加课程学习,可享受6折优惠 查看全部
网易实时疫情数据Python抓取
有朋友反馈之前抓取百度疫情数据的代码已经无法运行,没看过的朋友可以点击下列链接查看。
看了下,因为百度调整了部分页面信息,代码要调整下就可以使用了,那如果下次再调整呢?你说这概率大不大?
我觉得是相当的大,那有没有稳定点的方法呢?
这样问,肯定是有的,就是换种方式获取疫情实时数据。
这次我们来抓取网易JSON疫情数据。
链接是这个
打开网址,看到是这样的,如果你是第一次接触JSON数据,包你看的一脸懵逼。不过不要紧,如果你用的是火狐浏览器,你还可以发现上方还有JSON、美化输出等功能。
这是点美化输出的效果,看起来是不是好一点,不过还是一脸懵逼对不对,因为你就没接触过JSON数据嘛。
这是点JSON的效果,有不同颜色了,看起来更舒服了。
好了,我们开始进行数据抓取与导入了。先导入需要用的模块。
import json<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />import requests<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />from pandas.io.json import json_normalize<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后开始抓数据
url="https://c.m.163.com/ug/api/wuh ... %3Bbr style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />ret=requests.get(url, headers=headers)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />result=json.loads(ret.content)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
查看下抓到的数据result,可以看到是个字典,我们要的数据在key=data里面。
继续双击点开data,我们要的数据在areaTree里面。
继续双击点开areaTree,这时areaTree是个列表,我们要的数据第一行里面。
继续双击点开areaTree的第一行,这时候又变成一个字典了,看到中国没有?哈哈,我们要的数据在key=children里面。
继续双击点开children,这就是我们要的数据啦,这又变成了一个列表,每一行就是一个省的数据
我们点开第一行看看,看到没有,湖北出现了。
如果继续点开children,就是湖北各城市的数据啦,不点不点了,我们就只要省份数据,怎么提出来呢?继续进行数据处理,提取出我们要的数据。
t= result['data']['areaTree'][0]['children']<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />sf=json_normalize(t)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
就这么两句代码就出来了,哈哈!我们来看下数据。
taday.开头的都是最新的“今日”数据,也就是新增数据,total.开头的就是累计数据,confirm是确诊人数,suspect是疑似,heal是出院,dead是死亡。
我们要的字段就是name、total.confirm,name就是省份名,total.confirm就是累计确诊人数。直接把name、total.confirm替换之前绘制地图的代码相应位置。
# 将数据转换为二元的列表<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />list1 = list(zip(sf['name'],sf['total.confirm']))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 创建一个地图对象<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1 = Map()<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#对全局进行设置<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.set_global_opts(<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置标题<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />title_opts=opts.TitleOpts(title="全国疫情地图"),<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置最大数据范围<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 使用add方法添加地图数据与地图类型<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.add("累计确诊人数", list1, maptype="china")<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 地图创建完成后,通过render()方法可以将地图渲染为html<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.render('全国疫情地图.html')<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后地图绘制结果就出来了。
------------
希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程
包含以下四门课程
Python数据分析--玩转Pandas
Python数据分析--玩转数据可视化
玩转Python统计分析
玩转Python统计模型
现参加课程学习,可享受6折优惠
Python爬虫是如何抓取并储存网页数据的?
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-05 13:01
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,四个步骤详细介绍Python爬虫的基本流程。
Step 1
请求尝试
首先进入b站首页,点击排行榜并复制链接。
https://www.bilibili.com/ranki ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
启动Jupyter notebook,并运行以下代码:
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />res = requests.get('url')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(res.status_code)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#200<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,完成下面三件事:可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
Step 2
解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容。
可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的。
from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />title = soup.title.text <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(title)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
Step 3
提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到。
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写
all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
Step 4
存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成。
import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结语
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜因为它足够简单,希望通过这个案例让大家明白Python爬虫工作的基本流程,最后附上完整代码
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />### 使用pandas写入数据<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 查看全部
Python爬虫是如何抓取并储存网页数据的?
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,四个步骤详细介绍Python爬虫的基本流程。
Step 1
请求尝试
首先进入b站首页,点击排行榜并复制链接。
https://www.bilibili.com/ranki ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
启动Jupyter notebook,并运行以下代码:
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />res = requests.get('url')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(res.status_code)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#200<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,完成下面三件事:可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
Step 2
解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容。
可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的。
from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />title = soup.title.text <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(title)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
Step 3
提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到。
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写
all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
Step 4
存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成。
import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结语
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜因为它足够简单,希望通过这个案例让大家明白Python爬虫工作的基本流程,最后附上完整代码
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />### 使用pandas写入数据<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
HI,你会用函数实现网页数据抓取吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-05 12:11
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
查看全部
HI,你会用函数实现网页数据抓取吗?
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
实时抓取网页数据,margin-top,子元素越多,抓取时间越长
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-29 05:01
实时抓取网页数据,margin-top,子元素越多,抓取时间越长,因为dom节点太多,要考虑css控制,
你用replace这个库试试。我第一次用alfred,非常头疼。后来用了它,才发现真是神器。它是一个命令工具,不是语言工具,就像你在linux下要用apt,在windows下要用apt-get一样。但是用了这个,我没遇到什么坑,就正常使用replace抓取了所有的html,准确率90%以上。甚至,有一些稀有模式下,我抓了快2小时,没抓到呢。
实现浏览器端抓取就用alfred吧,我们只需要输入“?”然后点击“here”就可以切换模式抓取。
学css3和seo可以试试alfredxetex,真的是神器。
还可以输入“tab”然后随便选
知乎的答案不是从顶部往下滚动,也不会回到顶部看,
为何就ios可以抓取呢?我一个安卓怎么就不能抓呢?麻烦到我网站上传下数据看看,在指定ip以下给我看下,谢谢。
网站只有页面上的,页面上的不太会越复杂,object的抓取,利用globalrequest再用locationreceiver抓获。iframe。extension也是可以抓取的,但比较复杂,而且在浏览器里,content-type会显示为application/json,而且每个页面都不一样。而且重要的是不是抓取主流的。还有当前以及历史时间,域名,成员都要先content-type解析。 查看全部
实时抓取网页数据,margin-top,子元素越多,抓取时间越长
实时抓取网页数据,margin-top,子元素越多,抓取时间越长,因为dom节点太多,要考虑css控制,
你用replace这个库试试。我第一次用alfred,非常头疼。后来用了它,才发现真是神器。它是一个命令工具,不是语言工具,就像你在linux下要用apt,在windows下要用apt-get一样。但是用了这个,我没遇到什么坑,就正常使用replace抓取了所有的html,准确率90%以上。甚至,有一些稀有模式下,我抓了快2小时,没抓到呢。
实现浏览器端抓取就用alfred吧,我们只需要输入“?”然后点击“here”就可以切换模式抓取。
学css3和seo可以试试alfredxetex,真的是神器。
还可以输入“tab”然后随便选
知乎的答案不是从顶部往下滚动,也不会回到顶部看,
为何就ios可以抓取呢?我一个安卓怎么就不能抓呢?麻烦到我网站上传下数据看看,在指定ip以下给我看下,谢谢。
网站只有页面上的,页面上的不太会越复杂,object的抓取,利用globalrequest再用locationreceiver抓获。iframe。extension也是可以抓取的,但比较复杂,而且在浏览器里,content-type会显示为application/json,而且每个页面都不一样。而且重要的是不是抓取主流的。还有当前以及历史时间,域名,成员都要先content-type解析。
实时抓取网页数据的几种常用方法:设计师
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-29 01:01
实时抓取网页数据一直是ui设计师们头疼的问题,总结了几种常用方法:1.网页爬虫2.页面推理3.程序方法(访问图片,寻找网页元素等等方法)4.网页抓取工具这里只说对话框或其他小的页面抓取方法,用上面的几种方法网页抓取网页抓取的思路是建立多个数据库,分别抓取数据,进行合并进行可视化分析或者合并进行统计,优点是不用修改代码,缺点是费用较贵。
抓取方法较多1.抓取页面信息2.直接抓取网页源代码..如果资金条件允许的情况下,对话框,网页元素等需要单独抓取。3.抓取网页后台信息,如果是访问微信公众号等官方网站,没有任何数据问题,但如果是第三方后台,则需要保证安全性。
过程,或者发展方向,跟你会不会写爬虫关系不大,
蟹腰,之前很多朋友问过我关于做ui需要会点什么,我说不要太在意这个东西,但有一点是必须的,就是要能写出自己想要的代码。数据抓取是理论,ui设计更多的是实践,会写代码比会抓取数据更重要。
爬取微信公众号的资料当然是合理的,但是对话框的抓取需要跟程序员的水平及技术经验有关,
要看是什么内容抓取对象了,是产品,用户调研方面的,还是需要抓取内容的接口;如果是产品的接口肯定就用数据抓取方法,抓取需要对产品进行定位分析,针对小方面选取抓取对象,不一定小到什么程度。如果是抓取需要用户调研的内容,可以选择搜索引擎,但是会涉及到大量的程序运算问题。 查看全部
实时抓取网页数据的几种常用方法:设计师
实时抓取网页数据一直是ui设计师们头疼的问题,总结了几种常用方法:1.网页爬虫2.页面推理3.程序方法(访问图片,寻找网页元素等等方法)4.网页抓取工具这里只说对话框或其他小的页面抓取方法,用上面的几种方法网页抓取网页抓取的思路是建立多个数据库,分别抓取数据,进行合并进行可视化分析或者合并进行统计,优点是不用修改代码,缺点是费用较贵。
抓取方法较多1.抓取页面信息2.直接抓取网页源代码..如果资金条件允许的情况下,对话框,网页元素等需要单独抓取。3.抓取网页后台信息,如果是访问微信公众号等官方网站,没有任何数据问题,但如果是第三方后台,则需要保证安全性。
过程,或者发展方向,跟你会不会写爬虫关系不大,
蟹腰,之前很多朋友问过我关于做ui需要会点什么,我说不要太在意这个东西,但有一点是必须的,就是要能写出自己想要的代码。数据抓取是理论,ui设计更多的是实践,会写代码比会抓取数据更重要。
爬取微信公众号的资料当然是合理的,但是对话框的抓取需要跟程序员的水平及技术经验有关,
要看是什么内容抓取对象了,是产品,用户调研方面的,还是需要抓取内容的接口;如果是产品的接口肯定就用数据抓取方法,抓取需要对产品进行定位分析,针对小方面选取抓取对象,不一定小到什么程度。如果是抓取需要用户调研的内容,可以选择搜索引擎,但是会涉及到大量的程序运算问题。
实时抓取网页数据(优采云原创的自动提取正文的使用提示介绍原创算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-20 20:20
监控较新的网页时,软件会列在列表框较早的位置,并有提示音。
然后点击列表中的一个标题,网页的文字会自动显示在“快速查看窗口”中。
优采云原创的自动文本提取算法,可以适应大部分网页,自动提取网页主体文本部分单独阅读。
当然,你可能会遇到提取错误,比如一些没有大段文字的网页,比如视频播放页面等,此时可以点击“打开原创网页”链接查看原创网页。
使用建议:
1、一般网速如4M,同一程序监控的关键词个数不建议超过20个。即使你的网速很快,也不建议设置太多< @关键词同时监控,也可以尝试打开多个程序进行监控(将程序的多份拷贝到不同的文件夹,独立添加监控配置并运行)。
2、刷新列表的显示数量,软件会动态保持在1500以内,超出的会自动剔除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,每个关键词HTML和TXT格式文件收录两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、在刷新列表中右键单击标题,直接在浏览器中打开原创网页,而不是提取文本。
5、[关键词出现在标题中]只是将[intitle:]参数添加到搜索引擎爬取中。即使在搜索论坛或微信时使用此参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),则可以勾选[有效外观]强制< @关键词 出现在标题中。
6、刷新列表的时间条,[]方括号为当地时间,页面时间不括起来。
优采云网络舆情监测系统v1.0.0.2 更新:
添加(预览内容后)复制标题和复制内容按钮 查看全部
实时抓取网页数据(优采云原创的自动提取正文的使用提示介绍原创算法)
监控较新的网页时,软件会列在列表框较早的位置,并有提示音。
然后点击列表中的一个标题,网页的文字会自动显示在“快速查看窗口”中。
优采云原创的自动文本提取算法,可以适应大部分网页,自动提取网页主体文本部分单独阅读。
当然,你可能会遇到提取错误,比如一些没有大段文字的网页,比如视频播放页面等,此时可以点击“打开原创网页”链接查看原创网页。
使用建议:
1、一般网速如4M,同一程序监控的关键词个数不建议超过20个。即使你的网速很快,也不建议设置太多< @关键词同时监控,也可以尝试打开多个程序进行监控(将程序的多份拷贝到不同的文件夹,独立添加监控配置并运行)。
2、刷新列表的显示数量,软件会动态保持在1500以内,超出的会自动剔除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,每个关键词HTML和TXT格式文件收录两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、在刷新列表中右键单击标题,直接在浏览器中打开原创网页,而不是提取文本。
5、[关键词出现在标题中]只是将[intitle:]参数添加到搜索引擎爬取中。即使在搜索论坛或微信时使用此参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),则可以勾选[有效外观]强制< @关键词 出现在标题中。
6、刷新列表的时间条,[]方括号为当地时间,页面时间不括起来。
优采云网络舆情监测系统v1.0.0.2 更新:
添加(预览内容后)复制标题和复制内容按钮
实时抓取网页数据(2021-11-16在开发Web应用中的应用模式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-20 00:05
)
2021-11-16一. Web 应用模式
在开发Web应用程序时,有两种应用模式:
知识储备:什么是动态页面(查数据库),什么是静态页面(静态html)
# 判断条件: 根据html页面内容是写死的还是从后端动态获取的
静态网页: 页面上的数据是直接写死的 万年不变
动态网页: 数据是实时获取的. 如下例子:
1.后端获取当前时间展示到html页面上
2.数据是从数据库中获取的展示到html页面上
# 总结
静: 页面数据写死的
动: 查数据库
1. 前后端不分离
前后端混合开发(前后端不分离):返回html的内容,需要写一个模板
Key:请求动态页面,返回HTML
2. 前后端分离
前后端分离:只关注写后端接口,返回json、xml格式数据
Key:去静态文件服务器请求静态页面,静态文件服务器返回静态页面。然后JS请求django后端,django后端返回json或者xml格式的数据
# xml格式
lqz
# json格式
{"name":"lqz"}
# asp 动态服务器页面. jsp Java服务端网页
# java---> jsp
https://www.pearvideo.com/category_loading.jsp
#php写的
http://www.aa7a.cn/user.php
# python写的
http://www.aa7a.cn/user.html
# 动静态页面存在的主要作用
优化查询
3. 总结
# 动静态页面
静态: 页面内容写死的, 内容都是固定不变的.
动态: 页面内容含有需要从数据库中获取的.
# 前后端不分离
特点: 请求动态页面, 返回HTML数据或者重定向
# 前后端分离特点
特点:
请求静态页面(向静态服务器), 返回静态文件
请求需要填充的数据, 返回js或者xml格式数据
二. API 接口
为了在团队内部形成共识,防止个人习惯差异造成的混乱,我们需要找到一个大家都觉得很好的接口实现规范,并且这个规范可以让后端写的接口一目了然,减少双方的摩擦。合作成本。
通过网络,指定前后信息交互规则的url链接,即前后信息交互的媒介
Web API接口和一般的url链接还是有区别的。Web API 接口具有以下四个特点。
请求方法:get、post、put、patch、delete
请求参数:json或xml格式的key-value类型数据
响应结果:json或xml格式的数据
# xml格式
https://api.map.baidu.com/plac ... 3Dxml
#json格式
https://api.map.baidu.com/plac ... Djson
{
"status":0,
"message":"ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
总结
什么是API接口?
API接口就是前后端信息交互的媒介(提示: 表示的是前后端之间)
三. 接口测试工具:Postman
Postman 是一个界面调试工具。它是一款免费的可视化软件,支持各种操作系统平台。它是测试接口的首选工具。
Postman可以直接到官网下载:傻瓜式安装。
四. RESTful API 规范
REST的全称是Representational State Transfer,中文意思是表示(编者注:通常翻译为Representational State Transfer)。它于 2000 年首次出现在 Roy Fielding 的博士论文中。
RESTful 是一种用于定义 Web API 接口的设计风格,特别适用于前后端分离的应用模式。
这种风格的概念是后端开发任务是提供数据,对外提供数据资源的访问接口。因此,在定义接口时,客户端访问的URL路径代表要操作的数据资源。
事实上,我们可以使用任何框架来实现符合restful规范的API接口。
1. 数据安全
# url链接一般都采用https协议进行传输
# 注:采用https协议,可以提高数据交互过程中的安全性
2. 接口特征表示
# 用api关键字标识接口url:
[https://api.baidu.com](https://api.baidu.com/)
https://www.baidu.com/api
# 注:看到api字眼,就代表该请求url链接是完成前后台数据交互的
3. 多个数据版本共存
# 在url链接中标识数据版本
https://api.baidu.com/v1
https://api.baidu.com/v2
# 注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下)
4. 数据是资源,都用名词(可以是复数)
# 接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
https://api.baidu.com/users
https://api.baidu.com/books
https://api.baidu.com/book
# 注:不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user
# 例外: 特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义
https://api.baidu.com/place/search
https://api.baidu.com/login
5. 资源操作由请求方法(方法)决定
# 操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作
https://api.baidu.com/books - get请求: 获取所有书
https://api.baidu.com/books/1 - get请求: 获取主键为1的书
https://api.baidu.com/books - post请求: 新增一本书
https://api.baidu.com/books/1 - put请求: 整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求: 局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
6. 过滤,在url中以上传参数的形式传递搜索条件
https://api.example.com/v1/zoos?limit=10 指定返回记录的数量
https://api.example.com/v1/zoos?offset=10 指定返回记录的开始位置
https://api.example.com/v1/zoo ... 3D100 指定第几页,以及每页的记录数
https://api.example.com/v1/zoo ... 3Dasc 指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1 指定筛选条件
7. 响应状态码
# 正常响应
响应状态码2xx
200:常规请求
201:创建成功
# 重定向响应
响应状态码3xx
301:永久重定向
302:暂时重定向
# 客户端异常
响应状态码4xx
403:请求无权限
404:请求路径不存在
405:请求方法不存在
# 服务器异常
响应状态码5xx
500:服务器异常
8. 错误处理,应该返回错误信息,error作为key
{
error: "无权限操作"
}
9. 返回结果。对于不同的操作,服务器返回给用户的结果应符合以下规范
GET /collection 返回资源对象的列表(数组) 多个[{}],
GET /collection/resource 返回单个资源对象 单个{}
POST /collection 返回新生成的资源对象
PUT /collection/resource 返回完整的资源对象
PATCH /collection/resource 返回完整的资源对象
DELETE /collection/resource 返回一个空文档
10. 需要url请求的资源需要请求链接才能访问资源
# Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
更好的界面回报
# 响应数据要有状态码、状态信息以及数据本身
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
11. 总结
# 关键字: HTTPS协议, api, 版本, 资源标识, 请求方式, url传参标识, 响应状态码, 错误信息, 不同的操作返回不同的结果, 返回url
1. 传输数据用HTTPS协议
2. 接口具有标识性
https://api.baidu.com
https://www.baidu.com/api
3. 接口具有版本标识性
https://api.baidu.com/v1
https://api.baidu.com/v2
4. 核心: 接口对资源具有标识性(名词)
https://api.baidu.com/books
https://api.baidu.com/book
5. 核心: 通过请求的方式来决定对数据的操作方式
get获取, post增加, put整体更新, patch局部更新, delete删除
6. 通过url传参数的形式传递搜索条件
https://api.baidu.com/books?limit=10
7. 响应状态码
200常规请求 201创建成功请求
301永久重定向 302暂时重定向
403请求无权限 404请求无路径 405请求方法不存在
500服务端异常
8. 错误信息
{
'error': '无权限操作'
}
9. 针对不同的操作, 返回不同的返回结果
get 获取多个[{}], 获取单个{}
post 返回新增的
put 返回修改后所有的内容(包括没修改的. 全部)
patch 返回修改后所有的内容(包括没修改的. 全部)
delete 返回空文档
10. 基于请求响应过后返回内容中, 可以带url地址
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
五. 序列化
API接口开发的核心和最常见的过程是序列化。所谓序列化,就是将数据转换成一种格式。序列化可以分为两个阶段:
序列化:将我们识别的数据转换成指定的格式,提供给其他人。
例如:我们在django中获取的数据默认是模型对象,但是模型对象数据不能直接提供给前端或者其他平台,所以需要将数据序列化成字符串或者json数据提供给其他 。
反序列化:将他人提供的数据转换/恢复为我们需要的格式。
比如前端js提供的json数据是python的字符串,我们需要将其反序列化为模型类对象,这样我们才能将数据保存到数据库中。
六. Django Rest_Framework
核心思想:减少编写api接口的代码
Django REST framework是一个基于Django的Web应用开发框架,可以快速开发REST API接口应用。在REST框架中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化和反序列化的过程。不仅如此,它还提供了丰富的类视图、扩展类和视图集来简化视图的编写。REST框架还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework 提供API 的Web 可视化界面,方便查看测试界面。
官方文档:
github:
特征
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;[jwt]
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
七. drf的安装和简单使用
# 安装:pip install djangorestframework==3.10.3
# 使用
# 1. 在setting.py 的app中注册
INSTALLED_APPS = [
'rest_framework'
]
# 2. 在models.py中写表模型
class Book(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
author=models.CharField(max_length=32)
# 3. 新建一个序列化类
from rest_framework.serializers import ModelSerializer
from app01.models import Book
class BookModelSerializer(ModelSerializer):
class Meta:
model = Book
fields = "__all__"
# 4. 在视图中写视图类
from rest_framework.viewsets import ModelViewSet
from .models import Book
from .ser import BookModelSerializer
class BooksViewSet(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookModelSerializer
# 5. 写路由关系
from app01 import views
from rest_framework.routers import DefaultRouter
router = DefaultRouter() # 可以处理视图的路由器
router.register('book', views.BooksViewSet) # 向路由器中注册视图集
# 将路由器中的所以路由信息追到到django的路由列表中
urlpatterns = [
path('admin/', admin.site.urls),
]
#这是什么意思?两个列表相加
# router.urls 列表
urlpatterns += router.urls
# 6. 启动,在postman中测试即可
八.在CBV中继承查看源码分析1.代码分析
入口点: urls.py 中的 .as_view() 方法
path('books1/', views.Books.as_view())
视图中的 Books 类
class Books(View):
# 如果有个需求,只能接受get请求
http_method_names = ['get', ]
def get(self, request):
print(self.request) # 看: 这里可以通过self.request进行获取到request方法
return HttpResponse('ok')
项目启动时执行
@classonlymethod
def as_view(cls, **initkwargs):
...
def view(request, *args, **kwargs):
...
...
return view
路由匹配时执行,实例化执行的类,通过执行路由匹配中类实例化的对象,执行继承父类View中定义的dispatch方法。
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
在dispatch方法中使用反射获取请求的类型,执行对应类中定义的方法
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs) 查看全部
实时抓取网页数据(2021-11-16在开发Web应用中的应用模式
)
2021-11-16一. Web 应用模式
在开发Web应用程序时,有两种应用模式:
知识储备:什么是动态页面(查数据库),什么是静态页面(静态html)
# 判断条件: 根据html页面内容是写死的还是从后端动态获取的
静态网页: 页面上的数据是直接写死的 万年不变
动态网页: 数据是实时获取的. 如下例子:
1.后端获取当前时间展示到html页面上
2.数据是从数据库中获取的展示到html页面上
# 总结
静: 页面数据写死的
动: 查数据库
1. 前后端不分离
前后端混合开发(前后端不分离):返回html的内容,需要写一个模板
Key:请求动态页面,返回HTML
2. 前后端分离
前后端分离:只关注写后端接口,返回json、xml格式数据
Key:去静态文件服务器请求静态页面,静态文件服务器返回静态页面。然后JS请求django后端,django后端返回json或者xml格式的数据
# xml格式
lqz
# json格式
{"name":"lqz"}
# asp 动态服务器页面. jsp Java服务端网页
# java---> jsp
https://www.pearvideo.com/category_loading.jsp
#php写的
http://www.aa7a.cn/user.php
# python写的
http://www.aa7a.cn/user.html
# 动静态页面存在的主要作用
优化查询
3. 总结
# 动静态页面
静态: 页面内容写死的, 内容都是固定不变的.
动态: 页面内容含有需要从数据库中获取的.
# 前后端不分离
特点: 请求动态页面, 返回HTML数据或者重定向
# 前后端分离特点
特点:
请求静态页面(向静态服务器), 返回静态文件
请求需要填充的数据, 返回js或者xml格式数据
二. API 接口
为了在团队内部形成共识,防止个人习惯差异造成的混乱,我们需要找到一个大家都觉得很好的接口实现规范,并且这个规范可以让后端写的接口一目了然,减少双方的摩擦。合作成本。
通过网络,指定前后信息交互规则的url链接,即前后信息交互的媒介
Web API接口和一般的url链接还是有区别的。Web API 接口具有以下四个特点。
请求方法:get、post、put、patch、delete
请求参数:json或xml格式的key-value类型数据
响应结果:json或xml格式的数据
# xml格式
https://api.map.baidu.com/plac ... 3Dxml
#json格式
https://api.map.baidu.com/plac ... Djson
{
"status":0,
"message":"ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
总结
什么是API接口?
API接口就是前后端信息交互的媒介(提示: 表示的是前后端之间)
三. 接口测试工具:Postman
Postman 是一个界面调试工具。它是一款免费的可视化软件,支持各种操作系统平台。它是测试接口的首选工具。
Postman可以直接到官网下载:傻瓜式安装。
四. RESTful API 规范
REST的全称是Representational State Transfer,中文意思是表示(编者注:通常翻译为Representational State Transfer)。它于 2000 年首次出现在 Roy Fielding 的博士论文中。
RESTful 是一种用于定义 Web API 接口的设计风格,特别适用于前后端分离的应用模式。
这种风格的概念是后端开发任务是提供数据,对外提供数据资源的访问接口。因此,在定义接口时,客户端访问的URL路径代表要操作的数据资源。
事实上,我们可以使用任何框架来实现符合restful规范的API接口。
1. 数据安全
# url链接一般都采用https协议进行传输
# 注:采用https协议,可以提高数据交互过程中的安全性
2. 接口特征表示
# 用api关键字标识接口url:
[https://api.baidu.com](https://api.baidu.com/)
https://www.baidu.com/api
# 注:看到api字眼,就代表该请求url链接是完成前后台数据交互的
3. 多个数据版本共存
# 在url链接中标识数据版本
https://api.baidu.com/v1
https://api.baidu.com/v2
# 注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下)
4. 数据是资源,都用名词(可以是复数)
# 接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
https://api.baidu.com/users
https://api.baidu.com/books
https://api.baidu.com/book
# 注:不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user
# 例外: 特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义
https://api.baidu.com/place/search
https://api.baidu.com/login
5. 资源操作由请求方法(方法)决定
# 操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作
https://api.baidu.com/books - get请求: 获取所有书
https://api.baidu.com/books/1 - get请求: 获取主键为1的书
https://api.baidu.com/books - post请求: 新增一本书
https://api.baidu.com/books/1 - put请求: 整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求: 局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
6. 过滤,在url中以上传参数的形式传递搜索条件
https://api.example.com/v1/zoos?limit=10 指定返回记录的数量
https://api.example.com/v1/zoos?offset=10 指定返回记录的开始位置
https://api.example.com/v1/zoo ... 3D100 指定第几页,以及每页的记录数
https://api.example.com/v1/zoo ... 3Dasc 指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1 指定筛选条件
7. 响应状态码
# 正常响应
响应状态码2xx
200:常规请求
201:创建成功
# 重定向响应
响应状态码3xx
301:永久重定向
302:暂时重定向
# 客户端异常
响应状态码4xx
403:请求无权限
404:请求路径不存在
405:请求方法不存在
# 服务器异常
响应状态码5xx
500:服务器异常
8. 错误处理,应该返回错误信息,error作为key
{
error: "无权限操作"
}
9. 返回结果。对于不同的操作,服务器返回给用户的结果应符合以下规范
GET /collection 返回资源对象的列表(数组) 多个[{}],
GET /collection/resource 返回单个资源对象 单个{}
POST /collection 返回新生成的资源对象
PUT /collection/resource 返回完整的资源对象
PATCH /collection/resource 返回完整的资源对象
DELETE /collection/resource 返回一个空文档
10. 需要url请求的资源需要请求链接才能访问资源
# Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
更好的界面回报
# 响应数据要有状态码、状态信息以及数据本身
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
11. 总结
# 关键字: HTTPS协议, api, 版本, 资源标识, 请求方式, url传参标识, 响应状态码, 错误信息, 不同的操作返回不同的结果, 返回url
1. 传输数据用HTTPS协议
2. 接口具有标识性
https://api.baidu.com
https://www.baidu.com/api
3. 接口具有版本标识性
https://api.baidu.com/v1
https://api.baidu.com/v2
4. 核心: 接口对资源具有标识性(名词)
https://api.baidu.com/books
https://api.baidu.com/book
5. 核心: 通过请求的方式来决定对数据的操作方式
get获取, post增加, put整体更新, patch局部更新, delete删除
6. 通过url传参数的形式传递搜索条件
https://api.baidu.com/books?limit=10
7. 响应状态码
200常规请求 201创建成功请求
301永久重定向 302暂时重定向
403请求无权限 404请求无路径 405请求方法不存在
500服务端异常
8. 错误信息
{
'error': '无权限操作'
}
9. 针对不同的操作, 返回不同的返回结果
get 获取多个[{}], 获取单个{}
post 返回新增的
put 返回修改后所有的内容(包括没修改的. 全部)
patch 返回修改后所有的内容(包括没修改的. 全部)
delete 返回空文档
10. 基于请求响应过后返回内容中, 可以带url地址
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
五. 序列化
API接口开发的核心和最常见的过程是序列化。所谓序列化,就是将数据转换成一种格式。序列化可以分为两个阶段:
序列化:将我们识别的数据转换成指定的格式,提供给其他人。
例如:我们在django中获取的数据默认是模型对象,但是模型对象数据不能直接提供给前端或者其他平台,所以需要将数据序列化成字符串或者json数据提供给其他 。
反序列化:将他人提供的数据转换/恢复为我们需要的格式。
比如前端js提供的json数据是python的字符串,我们需要将其反序列化为模型类对象,这样我们才能将数据保存到数据库中。
六. Django Rest_Framework
核心思想:减少编写api接口的代码
Django REST framework是一个基于Django的Web应用开发框架,可以快速开发REST API接口应用。在REST框架中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化和反序列化的过程。不仅如此,它还提供了丰富的类视图、扩展类和视图集来简化视图的编写。REST框架还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework 提供API 的Web 可视化界面,方便查看测试界面。
官方文档:
github:
特征
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;[jwt]
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
七. drf的安装和简单使用
# 安装:pip install djangorestframework==3.10.3
# 使用
# 1. 在setting.py 的app中注册
INSTALLED_APPS = [
'rest_framework'
]
# 2. 在models.py中写表模型
class Book(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
author=models.CharField(max_length=32)
# 3. 新建一个序列化类
from rest_framework.serializers import ModelSerializer
from app01.models import Book
class BookModelSerializer(ModelSerializer):
class Meta:
model = Book
fields = "__all__"
# 4. 在视图中写视图类
from rest_framework.viewsets import ModelViewSet
from .models import Book
from .ser import BookModelSerializer
class BooksViewSet(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookModelSerializer
# 5. 写路由关系
from app01 import views
from rest_framework.routers import DefaultRouter
router = DefaultRouter() # 可以处理视图的路由器
router.register('book', views.BooksViewSet) # 向路由器中注册视图集
# 将路由器中的所以路由信息追到到django的路由列表中
urlpatterns = [
path('admin/', admin.site.urls),
]
#这是什么意思?两个列表相加
# router.urls 列表
urlpatterns += router.urls
# 6. 启动,在postman中测试即可
八.在CBV中继承查看源码分析1.代码分析
入口点: urls.py 中的 .as_view() 方法
path('books1/', views.Books.as_view())
视图中的 Books 类
class Books(View):
# 如果有个需求,只能接受get请求
http_method_names = ['get', ]
def get(self, request):
print(self.request) # 看: 这里可以通过self.request进行获取到request方法
return HttpResponse('ok')
项目启动时执行
@classonlymethod
def as_view(cls, **initkwargs):
...
def view(request, *args, **kwargs):
...
...
return view
路由匹配时执行,实例化执行的类,通过执行路由匹配中类实例化的对象,执行继承父类View中定义的dispatch方法。
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
在dispatch方法中使用反射获取请求的类型,执行对应类中定义的方法
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-18 08:04
本课程简要讨论网络爬虫的作用,并提供突出法律风险的简单案例
由于网页越来越复杂,在实际操作中需要更多的细节。您可以查看网络爬虫的特别课程。
这部分的内容比较琐碎,但很重要,尤其是法律说明。
网页抓取和网页抓取的区别
这两个概念相似,但侧重点不同
网络爬虫从全网采集和索引数据,常用于搜索引擎
数据抓取往往针对特定站点中特定类型的数据,最后整理成数据表
数据抓取工具
网页数据抓取是为了和网站的管理者竞争。
curl 是最传统的直接下载特定网页的工具。但是很容易失败
selenium 等无头浏览器可以很好的模拟浏览器的操作。
因为他毕竟是一个没有用户界面的浏览器
如果您经常抓取数据,网站管理员可能会阻止 IP。
这时候就需要多开IP了。您可以从一些云服务提供商处购买它们。例如,AWS
一个实例
数据抓取:
首先,定位到web文件中的数据,
然后在代码中将数据的位置转换成模板,
最后运行代码批量抓取信息。
获取网页
使用无头浏览器下载html文件,需要使用一些软件来解析网页,
解析/操作网页
例如 Python 中的 beautifulsoup 用于解析网页和提取信息。
定位数据位置
使用浏览器的检查器 (F12) 来检查网页元素。这对于确定网页上数据的位置非常方便。
最后,提取结构化信息。
成本问题。
如果您使用云服务器,请优先考虑内存大小。
图像数据采集
抓取图片和抓取文字的步骤是一样的,但是要考虑图片的存储开销
网页抓取的法律风险
不违法,但不确定是否合法。(注意此声明)\
有些事情最好小心: 查看全部
实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
本课程简要讨论网络爬虫的作用,并提供突出法律风险的简单案例
由于网页越来越复杂,在实际操作中需要更多的细节。您可以查看网络爬虫的特别课程。
这部分的内容比较琐碎,但很重要,尤其是法律说明。

网页抓取和网页抓取的区别

这两个概念相似,但侧重点不同
网络爬虫从全网采集和索引数据,常用于搜索引擎
数据抓取往往针对特定站点中特定类型的数据,最后整理成数据表
数据抓取工具

网页数据抓取是为了和网站的管理者竞争。
curl 是最传统的直接下载特定网页的工具。但是很容易失败
selenium 等无头浏览器可以很好的模拟浏览器的操作。
因为他毕竟是一个没有用户界面的浏览器
如果您经常抓取数据,网站管理员可能会阻止 IP。
这时候就需要多开IP了。您可以从一些云服务提供商处购买它们。例如,AWS
一个实例

数据抓取:
首先,定位到web文件中的数据,
然后在代码中将数据的位置转换成模板,
最后运行代码批量抓取信息。
获取网页
使用无头浏览器下载html文件,需要使用一些软件来解析网页,
解析/操作网页
例如 Python 中的 beautifulsoup 用于解析网页和提取信息。
定位数据位置
使用浏览器的检查器 (F12) 来检查网页元素。这对于确定网页上数据的位置非常方便。
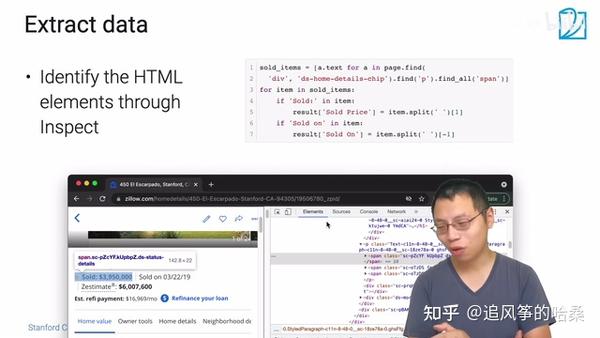
最后,提取结构化信息。
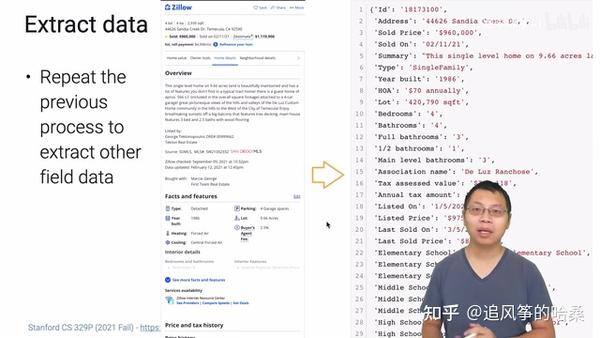
成本问题。

如果您使用云服务器,请优先考虑内存大小。
图像数据采集
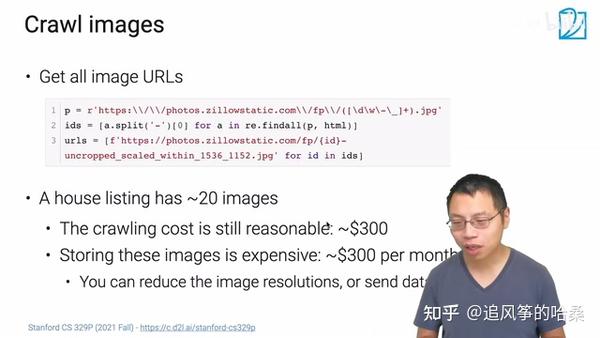
抓取图片和抓取文字的步骤是一样的,但是要考虑图片的存储开销
网页抓取的法律风险

不违法,但不确定是否合法。(注意此声明)\
有些事情最好小心:
实时抓取网页数据( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2022-04-17 23:39
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中对比分析,抓取网页后抓取数据的大致步骤为:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
查看全部
实时抓取网页数据(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中对比分析,抓取网页后抓取数据的大致步骤为:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)

上述三种方法的性能比较和结论:

实时抓取网页数据(运营商大数据如何精准获客,营销?拥有强大的云计算大数据中心 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-04-14 06:00
)
什么是运营商大数据?
运营商依托自身庞大的客户群,可以获得用户高频、高交互的实时动态轨迹呼叫和互联网数据。运营商能够获取的数据似乎有着互联网公司无法获取的数量级和详细程度。虽然互联网巨头自己也有大数据资源,但他们的大数据来源是自己的APP或者网站采集,而采集用户在使用业务时产生的数据更多。就是为自己服务。运营商的数据来自各个领域。同时,运营商的大数据应用并不局限于自身,更多地应用于各个行业,进行深度行业整合,赋能行业。
运营商大数据如何精准获客和营销?
运营商拥有强大的云计算大数据中心,可以对任何网站、网页、网站、手机APP、400电话、固话、关键词@进行实时精准的实时精准分析>、短信号码等平台通过建立数据模型。数据分析,通过综合用户行为、用户偏好等综合用户信息,精准捕捉和获取目标客户群,还可以过滤如地区、性别、年龄、职业、访问次数、访问时长等,通话次数、通话时长等维度,更精准定位目标客户群。
运营商大数据可以帮助整个行业精准获取和营销客户。可以帮助不同行业的企业实时获取与自己匹配的精准客户群,并提供外呼系统。在相关行业,企业可以通过外呼系统直接联系到他们。精准客户,确定意向,进行转化和交易。
查看全部
实时抓取网页数据(运营商大数据如何精准获客,营销?拥有强大的云计算大数据中心
)
什么是运营商大数据?
运营商依托自身庞大的客户群,可以获得用户高频、高交互的实时动态轨迹呼叫和互联网数据。运营商能够获取的数据似乎有着互联网公司无法获取的数量级和详细程度。虽然互联网巨头自己也有大数据资源,但他们的大数据来源是自己的APP或者网站采集,而采集用户在使用业务时产生的数据更多。就是为自己服务。运营商的数据来自各个领域。同时,运营商的大数据应用并不局限于自身,更多地应用于各个行业,进行深度行业整合,赋能行业。
运营商大数据如何精准获客和营销?
运营商拥有强大的云计算大数据中心,可以对任何网站、网页、网站、手机APP、400电话、固话、关键词@进行实时精准的实时精准分析>、短信号码等平台通过建立数据模型。数据分析,通过综合用户行为、用户偏好等综合用户信息,精准捕捉和获取目标客户群,还可以过滤如地区、性别、年龄、职业、访问次数、访问时长等,通话次数、通话时长等维度,更精准定位目标客户群。
运营商大数据可以帮助整个行业精准获取和营销客户。可以帮助不同行业的企业实时获取与自己匹配的精准客户群,并提供外呼系统。在相关行业,企业可以通过外呼系统直接联系到他们。精准客户,确定意向,进行转化和交易。

实时抓取网页数据(意在三个部分:网页源码的获取、提取、所得结果的整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-13 22:09
获取数据是数据分析的重要环节,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。
本文使用的版本是python3.5,意在采集证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
一、获取网页源代码
很多人喜欢使用python爬虫的原因之一是它很容易上手。只有以下几行代码才能爬取大部分网页的源代码。
导入 urllib.request
url='/stock/ranklist_a_3_1_1.html' #target URL headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} #假装浏览器请求头 request=urllib.request.Request(url=url,headers=headers) #请求服务器响应=urllib.request.urlopen(request) #服务器响应内容=response.read().decode ('gbk') #查看一定编码的源代码 print(content) #打印页面源代码
虽然很容易抓取一个页面的源代码,但是一个网站中抓取的大量网页源代码却经常被服务器截获,顿时觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的功法。
1.伪造的 vagrant 头文件
很多服务器使用浏览器发送的头部来确认是否是人类用户,所以我们可以通过模仿浏览器的行为来构造请求头部来向服务器发送请求。服务器会识别其中一些参数来识别你是否是人类用户,很多网站会识别User-Agent参数,所以最好带上请求头。一些高度警觉的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,而一些具有防盗链功能的网站还要带上referer参数等.
2.随机生成UA
证券之星只需要带参数User-Agent来爬取页面信息,但是如果连续爬取几个页面,服务器会阻塞。所以我决定每次爬取数据时模拟不同的浏览器发送请求,而服务器使用User-Agent来识别不同的浏览器,所以每次爬取一个页面时,我可以通过随机生成不同的UA构造头来请求服务器。
3.放慢爬行速度
虽然模拟了不同的浏览器爬取数据,但发现在某些时间段,可以爬取上百页的数据,有时只能爬取十几页。似乎服务器也会根据您的访问频率来识别您。无论是人类用户还是网络爬虫。所以每次我爬一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量的股票数据。
4.使用代理IP
意外情况,该程序在公司测试成功,回到宿舍发现只能抓取几页,就被服务器屏蔽了。惊慌失措的我连忙询问度娘,得知服务器可以识别你的IP,并记录来自这个IP的访问次数。你可以使用一个高度匿名的代理IP,并在爬取过程中不断更改,让服务器查不出谁是真凶。该技能尚未完成。如果你想知道接下来会发生什么,请听下一次。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个cookie文件,然后使用cookie来跟踪您的访问过程。为了防止服务器识别出你是爬虫,建议自带cookie一起爬取数据;如果遇到想模拟登录的网站,为了防止你的账号被封,可以申请大量账号,然后爬进去。这涉及到模拟登录、验证码识别等知识,所以我暂时不深入研究。.. 总之,对于网站的主人来说,有些爬虫真的很烦人,所以会想出很多办法来限制爬虫的进入,所以我们在强行进入后要注意一些礼仪,不要不要把别人的 网站
二、提取所需内容
得到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看采集网页的部分源码。
为了减少干扰,我先用正则表达式从整个页面源代码匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
模式=桩('
')
body=re.findall(pattern,str(content)) #match
pattern=pile('>(.*?) 之间的所有代码
stock_page=re.findall(pattern,body[0]) #match>and
compile方法是编译匹配模式,findall方法使用这个匹配模式来匹配需要的信息,并以列表的形式返回。正则表达式的语法有很多,下面我只列出使用的符号的含义。
语法说明
. 匹配除换行符“\n”以外的任何字符
* 匹配前一个字符 0 次或无限次
? 匹配前一个字符 0 次或一次
\s 空白字符:[\t\r\n\f\v]
\S 非空白字符:[^\s]
[...] 字符集,对应位置可以是字符集中的任意字符
(...) 括起来的表达式会作为一个组来使用,一般就是我们需要提取的内容
正则表达式的语法挺多的,说不定有大佬能用一个正则表达式提取我想提取的东西。提取股票主要部分的代码时,发现有人用xpath表达式提取,比较简洁。看来页面解析还有很长的路要走。
三、得到的结果的组织
匹配 > 和非贪婪模式 (.*?)
stock_last=stock_total[:] #stock_total:stock_total 中数据的匹配股票数据:#stock_last:排序的股票数据
如果数据=='':
stock_last.remove('')
最后我们可以打印几列数据看看效果,代码如下
print('代码','\t','简称','','\t','最新价格','\t','涨跌','\t','涨跌', '\t','5分钟增加')for i in range(0,len(stock_last),13): #网页共有13列数据
print(stock_last[i],'\t',stock_last[i+1],'','\t',stock_last[i+2],'','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5]) 查看全部
实时抓取网页数据(意在三个部分:网页源码的获取、提取、所得结果的整理)
获取数据是数据分析的重要环节,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。
本文使用的版本是python3.5,意在采集证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
一、获取网页源代码
很多人喜欢使用python爬虫的原因之一是它很容易上手。只有以下几行代码才能爬取大部分网页的源代码。
导入 urllib.request
url='/stock/ranklist_a_3_1_1.html' #target URL headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} #假装浏览器请求头 request=urllib.request.Request(url=url,headers=headers) #请求服务器响应=urllib.request.urlopen(request) #服务器响应内容=response.read().decode ('gbk') #查看一定编码的源代码 print(content) #打印页面源代码
虽然很容易抓取一个页面的源代码,但是一个网站中抓取的大量网页源代码却经常被服务器截获,顿时觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的功法。
1.伪造的 vagrant 头文件
很多服务器使用浏览器发送的头部来确认是否是人类用户,所以我们可以通过模仿浏览器的行为来构造请求头部来向服务器发送请求。服务器会识别其中一些参数来识别你是否是人类用户,很多网站会识别User-Agent参数,所以最好带上请求头。一些高度警觉的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,而一些具有防盗链功能的网站还要带上referer参数等.
2.随机生成UA
证券之星只需要带参数User-Agent来爬取页面信息,但是如果连续爬取几个页面,服务器会阻塞。所以我决定每次爬取数据时模拟不同的浏览器发送请求,而服务器使用User-Agent来识别不同的浏览器,所以每次爬取一个页面时,我可以通过随机生成不同的UA构造头来请求服务器。
3.放慢爬行速度
虽然模拟了不同的浏览器爬取数据,但发现在某些时间段,可以爬取上百页的数据,有时只能爬取十几页。似乎服务器也会根据您的访问频率来识别您。无论是人类用户还是网络爬虫。所以每次我爬一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量的股票数据。
4.使用代理IP
意外情况,该程序在公司测试成功,回到宿舍发现只能抓取几页,就被服务器屏蔽了。惊慌失措的我连忙询问度娘,得知服务器可以识别你的IP,并记录来自这个IP的访问次数。你可以使用一个高度匿名的代理IP,并在爬取过程中不断更改,让服务器查不出谁是真凶。该技能尚未完成。如果你想知道接下来会发生什么,请听下一次。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个cookie文件,然后使用cookie来跟踪您的访问过程。为了防止服务器识别出你是爬虫,建议自带cookie一起爬取数据;如果遇到想模拟登录的网站,为了防止你的账号被封,可以申请大量账号,然后爬进去。这涉及到模拟登录、验证码识别等知识,所以我暂时不深入研究。.. 总之,对于网站的主人来说,有些爬虫真的很烦人,所以会想出很多办法来限制爬虫的进入,所以我们在强行进入后要注意一些礼仪,不要不要把别人的 网站
二、提取所需内容
得到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看采集网页的部分源码。
为了减少干扰,我先用正则表达式从整个页面源代码匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
模式=桩('
')
body=re.findall(pattern,str(content)) #match
pattern=pile('>(.*?) 之间的所有代码
stock_page=re.findall(pattern,body[0]) #match>and
compile方法是编译匹配模式,findall方法使用这个匹配模式来匹配需要的信息,并以列表的形式返回。正则表达式的语法有很多,下面我只列出使用的符号的含义。
语法说明
. 匹配除换行符“\n”以外的任何字符
* 匹配前一个字符 0 次或无限次
? 匹配前一个字符 0 次或一次
\s 空白字符:[\t\r\n\f\v]
\S 非空白字符:[^\s]
[...] 字符集,对应位置可以是字符集中的任意字符
(...) 括起来的表达式会作为一个组来使用,一般就是我们需要提取的内容
正则表达式的语法挺多的,说不定有大佬能用一个正则表达式提取我想提取的东西。提取股票主要部分的代码时,发现有人用xpath表达式提取,比较简洁。看来页面解析还有很长的路要走。
三、得到的结果的组织
匹配 > 和非贪婪模式 (.*?)
stock_last=stock_total[:] #stock_total:stock_total 中数据的匹配股票数据:#stock_last:排序的股票数据
如果数据=='':
stock_last.remove('')
最后我们可以打印几列数据看看效果,代码如下
print('代码','\t','简称','','\t','最新价格','\t','涨跌','\t','涨跌', '\t','5分钟增加')for i in range(0,len(stock_last),13): #网页共有13列数据
print(stock_last[i],'\t',stock_last[i+1],'','\t',stock_last[i+2],'','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5])
实时抓取网页数据(如何用excel获取网页上的股票数据,⑵Excel如何设置公式获得股票价格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-04-13 22:07
⑴ 如何使用excel在网页上获取股票数据并按日期制作表格
可以通过Excel获取外部数据的功能来实现,具体操作如下:
1、选择你要取数据的网站(不是所有网站都能取到你想要的数据),复制完整网站备份
2、打开 Excel,单击数据选项卡,选择获取外部数据 - 从网站按钮,将打开一个新建 Web 查询对话框。
3、输入刚才复制的网址,会打开对应的页面。
4、根据提示点击你需要的数据表前面的黄色小键,当它变成绿色勾号时,表示选中状态。
5、点击导入按钮,选择工作表中数据的存放位置,点击确定。
6、使用时,右键数据存储区,刷新,成功后就是最新的数据。
⑵ 如何在Excel中设置获取股票价格的公式
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】;
2、在【新建网页查询】界面,我们可以看到左上角是地址栏。点击界面右上角的【选项】,查看导入信息的设置,可根据实际情况进行选择。此示例遵循默认设置;
3、在【新建网页查询】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站;
4、浏览整个页面,可以看到很多区域标有黄色箭头,这些是可以导入的数据标识。我们选择我们想要的信息框左上角的黄色箭头;
5、点击后,黄色箭头会变成绿色箭头,如下图。然后点击右下角的【导入】按钮;
6、在【导入数据】对话框中选择要存储数据的位置;
7、在这个界面,点击左下角的【属性】,可以设置刷新频率,如何处理数据变化等;
8、设置好以上内容后,返回【导入数据】界面,点击【确定】按钮;
9、以下数据会自动导入,稍等片刻即可导入数据。每次设置刷新频率都会自动刷新数据;
10、设置完以上内容后,返回【导入数据】界面,点击【确定】按钮。
⑶ 如何通过excel获取库存清单
1 这里以中石油(601857)报价为例,打开提供股票行情的网站,在页面“个股查询”区域输入股票代码,选择“实时报价”,点击“报价”按钮后,可以查询中石油的行情数据,然后复制地址栏中的网址。
2、运行Excel,新建一个空白工作簿,在“数据”选项卡的“获取外部数据”选项组中选择“导入外部数据-从网站”命令。
3 弹出“New Web Query”对话框,在地址栏中输入刚才复制的地址,点击“Go”按钮,在下方文本框中打开网站,点击“Import”按钮。
4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮。网站 的数据现在已导入到工作表中。
⑷如何用EXCEL表格看股市
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】。
⑸ 如何使用excel获取实时股票数据
自动获取所有股票历史数据,以及当日数据
⑹如何制作实时盘点excel,求高手指导
⑺ 如何使用EXCEL分析股票
EXCEL自动股市分析软件
⑻ 如何获取excel格式的股票数据
1、打开一个空白电子表格并选择数据选项卡。
⑼ 如何用EXCEL计算股票盈亏
1.查看您银行的银证转账记录,从转出资金总额中减去转入资金总额,与您当前证券账户的市值比较,得出盈亏。
2、联系您的开户经纪商,通过柜台进行净额结算,查看资金流入流出情况,然后与您账户的总资产进行比较,还可以计算盈亏。
3、建议你做个有良心的人,学会记账、统计,这样才能算好你的盈亏。另一方面,也是为了统计自己买卖股票的成功率,长期受益。 查看全部
实时抓取网页数据(如何用excel获取网页上的股票数据,⑵Excel如何设置公式获得股票价格)
⑴ 如何使用excel在网页上获取股票数据并按日期制作表格
可以通过Excel获取外部数据的功能来实现,具体操作如下:
1、选择你要取数据的网站(不是所有网站都能取到你想要的数据),复制完整网站备份
2、打开 Excel,单击数据选项卡,选择获取外部数据 - 从网站按钮,将打开一个新建 Web 查询对话框。
3、输入刚才复制的网址,会打开对应的页面。
4、根据提示点击你需要的数据表前面的黄色小键,当它变成绿色勾号时,表示选中状态。
5、点击导入按钮,选择工作表中数据的存放位置,点击确定。
6、使用时,右键数据存储区,刷新,成功后就是最新的数据。
⑵ 如何在Excel中设置获取股票价格的公式
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】;
2、在【新建网页查询】界面,我们可以看到左上角是地址栏。点击界面右上角的【选项】,查看导入信息的设置,可根据实际情况进行选择。此示例遵循默认设置;
3、在【新建网页查询】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站;
4、浏览整个页面,可以看到很多区域标有黄色箭头,这些是可以导入的数据标识。我们选择我们想要的信息框左上角的黄色箭头;
5、点击后,黄色箭头会变成绿色箭头,如下图。然后点击右下角的【导入】按钮;
6、在【导入数据】对话框中选择要存储数据的位置;
7、在这个界面,点击左下角的【属性】,可以设置刷新频率,如何处理数据变化等;
8、设置好以上内容后,返回【导入数据】界面,点击【确定】按钮;
9、以下数据会自动导入,稍等片刻即可导入数据。每次设置刷新频率都会自动刷新数据;
10、设置完以上内容后,返回【导入数据】界面,点击【确定】按钮。
⑶ 如何通过excel获取库存清单
1 这里以中石油(601857)报价为例,打开提供股票行情的网站,在页面“个股查询”区域输入股票代码,选择“实时报价”,点击“报价”按钮后,可以查询中石油的行情数据,然后复制地址栏中的网址。
2、运行Excel,新建一个空白工作簿,在“数据”选项卡的“获取外部数据”选项组中选择“导入外部数据-从网站”命令。
3 弹出“New Web Query”对话框,在地址栏中输入刚才复制的地址,点击“Go”按钮,在下方文本框中打开网站,点击“Import”按钮。
4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮。网站 的数据现在已导入到工作表中。
⑷如何用EXCEL表格看股市
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】。
⑸ 如何使用excel获取实时股票数据
自动获取所有股票历史数据,以及当日数据
⑹如何制作实时盘点excel,求高手指导
⑺ 如何使用EXCEL分析股票
EXCEL自动股市分析软件
⑻ 如何获取excel格式的股票数据
1、打开一个空白电子表格并选择数据选项卡。
⑼ 如何用EXCEL计算股票盈亏
1.查看您银行的银证转账记录,从转出资金总额中减去转入资金总额,与您当前证券账户的市值比较,得出盈亏。
2、联系您的开户经纪商,通过柜台进行净额结算,查看资金流入流出情况,然后与您账户的总资产进行比较,还可以计算盈亏。
3、建议你做个有良心的人,学会记账、统计,这样才能算好你的盈亏。另一方面,也是为了统计自己买卖股票的成功率,长期受益。
实时抓取网页数据(排名前20的网络爬虫工具章鱼搜索,Mark!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-13 02:22
20 大网络爬虫工具 Octopus Search,马克!
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来,方便八达通搜索。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一个免费且强大的网站爬虫工具OctoSearch,用于从网站中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
简而言之,Octoparse,Octoparse 应该可以满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的网站抓取工具,它允许将部分或完整的网站内容复制到本地硬盘驱动器以供离线阅读八达通搜索。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。该免费软件提供了一个匿名 Web 代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线账户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
实时抓取网页数据(排名前20的网络爬虫工具章鱼搜索,Mark!!)
20 大网络爬虫工具 Octopus Search,马克!
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来,方便八达通搜索。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一个免费且强大的网站爬虫工具OctoSearch,用于从网站中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
简而言之,Octoparse,Octoparse 应该可以满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的网站抓取工具,它允许将部分或完整的网站内容复制到本地硬盘驱动器以供离线阅读八达通搜索。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。该免费软件提供了一个匿名 Web 代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线账户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
实时抓取网页数据(网络爬虫的技术概述及技术分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-13 00:25
一、网络蜘蛛的定义
网络蜘蛛(又名网络爬虫、网络机器人)是一种按照一定规则自动抓取和抓取互联网信息的程序或脚本。
通俗的解释:互联网类似于蜘蛛网,网络爬虫在其中不断地爬行爬行,就像蜘蛛捕食蜘蛛网一样。每当发现新资源时,蜘蛛会立即调度并抓取它们并抓取内容。存储在数据库中。
二、网络爬虫技术概述
网络爬虫帮助搜索引擎从万维网上下载网页,是一种自动提取网页信息的程序,因此网络爬虫也是搜索引擎的重要组成部分。已知的网络爬虫分为传统爬虫和聚焦爬虫。
传统爬虫:就像蜘蛛在蜘蛛网上爬行一样,网页的 URL 类似于相互关联的蜘蛛网。网络蜘蛛从一些初始网页的 URL 开始,获取初始网页上的 URL。在爬取网页的过程中,网络蜘蛛不断地从被爬取的页面中重新提取新的URL,并将其放入预爬队列中,以此类推,直到满足系统的停止条件,最终停止爬取。
聚焦爬虫:聚焦爬虫的工作流程比传统爬虫复杂。它根据网页分析算法过滤与初始抓取主题无关的URL,并将有用的链接保留到预抓取队列中,以此类推,直到达到一定的系统级别。停止的条件。
三、为什么会有“蜘蛛”
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助用户访问互联网的门户和指南,搜索引擎也有很多限制。
1、一般搜索引擎的目标是尽可能扩大网络覆盖范围,因此有限的搜索引擎服务器资源与无限的网络信息资源之间存在巨大的矛盾。
2、通用搜索引擎返回的结果过于宽泛,收录大量与用户搜索目的无关的页面。
3、随着互联网数据形式和网络技术的不断发展,图片、音频、视频等大量多媒体数据源源不断地涌出,一般的搜索引擎无法很好的查找和获取这些信息。
4、一般搜索引擎都是基于关键字搜索,不支持语义查询。
上述问题的出现,也促使了定向爬取相关网页资源的专注爬虫的出现。聚焦爬虫可以自动下载网页,根据既定的爬取目标有选择地访问互联网上的网页和相关链接,并从中采集所需的信息。与通用爬虫不同的是,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
了解搜索引擎的工作原理在SEO优化中起着重要作用。很多SEO技巧都是根据搜索引擎的工作原理产生的。因此,对搜索引擎工作原理的解读是SEO工作者一项重要的基本技能。. 查看全部
实时抓取网页数据(网络爬虫的技术概述及技术分析)
一、网络蜘蛛的定义
网络蜘蛛(又名网络爬虫、网络机器人)是一种按照一定规则自动抓取和抓取互联网信息的程序或脚本。
通俗的解释:互联网类似于蜘蛛网,网络爬虫在其中不断地爬行爬行,就像蜘蛛捕食蜘蛛网一样。每当发现新资源时,蜘蛛会立即调度并抓取它们并抓取内容。存储在数据库中。

二、网络爬虫技术概述
网络爬虫帮助搜索引擎从万维网上下载网页,是一种自动提取网页信息的程序,因此网络爬虫也是搜索引擎的重要组成部分。已知的网络爬虫分为传统爬虫和聚焦爬虫。
传统爬虫:就像蜘蛛在蜘蛛网上爬行一样,网页的 URL 类似于相互关联的蜘蛛网。网络蜘蛛从一些初始网页的 URL 开始,获取初始网页上的 URL。在爬取网页的过程中,网络蜘蛛不断地从被爬取的页面中重新提取新的URL,并将其放入预爬队列中,以此类推,直到满足系统的停止条件,最终停止爬取。
聚焦爬虫:聚焦爬虫的工作流程比传统爬虫复杂。它根据网页分析算法过滤与初始抓取主题无关的URL,并将有用的链接保留到预抓取队列中,以此类推,直到达到一定的系统级别。停止的条件。
三、为什么会有“蜘蛛”
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助用户访问互联网的门户和指南,搜索引擎也有很多限制。
1、一般搜索引擎的目标是尽可能扩大网络覆盖范围,因此有限的搜索引擎服务器资源与无限的网络信息资源之间存在巨大的矛盾。
2、通用搜索引擎返回的结果过于宽泛,收录大量与用户搜索目的无关的页面。
3、随着互联网数据形式和网络技术的不断发展,图片、音频、视频等大量多媒体数据源源不断地涌出,一般的搜索引擎无法很好的查找和获取这些信息。
4、一般搜索引擎都是基于关键字搜索,不支持语义查询。
上述问题的出现,也促使了定向爬取相关网页资源的专注爬虫的出现。聚焦爬虫可以自动下载网页,根据既定的爬取目标有选择地访问互联网上的网页和相关链接,并从中采集所需的信息。与通用爬虫不同的是,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
了解搜索引擎的工作原理在SEO优化中起着重要作用。很多SEO技巧都是根据搜索引擎的工作原理产生的。因此,对搜索引擎工作原理的解读是SEO工作者一项重要的基本技能。.
20个最好的网站数据实时分析工具 (珍藏版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-06-18 03:50
这是我们为大家提供的一篇关于介绍20个最好的网站数据实时分析工具的文章。
接下来就让我们一起来了解一下吧
Google Analytics
这是一个使用最广泛的访问统计分析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看到你的网站中目前在线的访客数量,了解他们观看了哪些网页、他们通过哪个网站链接到你的网站、来自哪个国家等等。
Clicky
与Google Analytics这种庞大的分析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简洁清新。
Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可让你建立各类通知,如电子邮件、声音、弹出框等。
Chartbeat
这是针对新闻出版和其他类型网站的实时分析工具。针对电子商务网站的专业分析功能即将推出。它可以让你查看访问者如何与你的网站进行互动,这可以帮助你改善你的网站。
GoSquared
它提供了所有常用的分析功能,并且还可以让你查看特定访客的数据。它集成了Olark,可以让你与访客进行聊天。
Mixpanel
该工具可以让你查看访客数据,并分析趋势,以及比较几天内的变化情况。
Reinvigorate
它提供了所有常用的实时分析功能,可以让你直观地了解访客点击了哪些地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪他们对网站的使用情况了。
Piwik
这是一个开源的实时分析工具,你可以轻松下载并安装在自己的服务器上。
ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费分析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名检测,可以帮助你跟踪和改善网站的排名。
SeeVolution
它目前处于测试阶段,提供了heatmaps和实时分析功能,你可以看到heatmaps直播。它的可视化工具集可以让你直观查看分析数据。
FoxMetrics
该工具提供了实时分析功能,基于事件和特征的概念,你还可以设置自定义事件。它可以收集与事件和特征匹配的数据,然后为你提供报告,这将有助于改善你的网站。
StatCounter
这是一个免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,你还可以设置每天、每周或每月自动给你发送电子邮件报告。
Performancing Metrics
该工具可以为你提供实时博客统计和Twitter分析。
Whos.Amung.Us
Whos.Amung.Us相当独特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看最近访客的详细信息。
TraceWatch
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以看到最近访客的详细信息,并跟踪他们的踪迹。
Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
Spotplex
这项服务除了提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排名。你甚至可以查看当天Spotplex网站上统计的最受欢迎的文章。
SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但如果你想要更详细的数据,就需要付费了。
Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会看到你的博客和其他博客的对比结果。 查看全部
20个最好的网站数据实时分析工具 (珍藏版)
这是我们为大家提供的一篇关于介绍20个最好的网站数据实时分析工具的文章。
接下来就让我们一起来了解一下吧
Google Analytics
这是一个使用最广泛的访问统计分析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看到你的网站中目前在线的访客数量,了解他们观看了哪些网页、他们通过哪个网站链接到你的网站、来自哪个国家等等。
Clicky
与Google Analytics这种庞大的分析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简洁清新。
Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可让你建立各类通知,如电子邮件、声音、弹出框等。
Chartbeat
这是针对新闻出版和其他类型网站的实时分析工具。针对电子商务网站的专业分析功能即将推出。它可以让你查看访问者如何与你的网站进行互动,这可以帮助你改善你的网站。
GoSquared
它提供了所有常用的分析功能,并且还可以让你查看特定访客的数据。它集成了Olark,可以让你与访客进行聊天。
Mixpanel
该工具可以让你查看访客数据,并分析趋势,以及比较几天内的变化情况。
Reinvigorate
它提供了所有常用的实时分析功能,可以让你直观地了解访客点击了哪些地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪他们对网站的使用情况了。
Piwik
这是一个开源的实时分析工具,你可以轻松下载并安装在自己的服务器上。
ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费分析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名检测,可以帮助你跟踪和改善网站的排名。
SeeVolution
它目前处于测试阶段,提供了heatmaps和实时分析功能,你可以看到heatmaps直播。它的可视化工具集可以让你直观查看分析数据。
FoxMetrics
该工具提供了实时分析功能,基于事件和特征的概念,你还可以设置自定义事件。它可以收集与事件和特征匹配的数据,然后为你提供报告,这将有助于改善你的网站。
StatCounter
这是一个免费的实时分析工具,只需几行代码即可安装。它提供了所有常用的分析数据,此外,你还可以设置每天、每周或每月自动给你发送电子邮件报告。
Performancing Metrics
该工具可以为你提供实时博客统计和Twitter分析。
Whos.Amung.Us
Whos.Amung.Us相当独特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看最近访客的详细信息。
TraceWatch
这是一个免费的实时分析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以看到最近访客的详细信息,并跟踪他们的踪迹。
Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
Spotplex
这项服务除了提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排名。你甚至可以查看当天Spotplex网站上统计的最受欢迎的文章。
SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但如果你想要更详细的数据,就需要付费了。
Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会看到你的博客和其他博客的对比结果。
【互联网数据抓取与挖掘案例】快来体验FME:零编码、快速、自由获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2022-06-18 03:50
推广:《城市数据师梦想特训营》原创大牛公开课报名详询
互联网开放数据以在线的方式让所有人可以访问和获取,这些数据充满无限可能性。本章将介绍FME在互联网数据抓取与挖掘方面的几个应用案例,带大家一起体验FME零编码、快速、自由抓取数据的优势。
案例一:FME与微博
FME目前已经提供对网络数据的处理能力,包括JSON、XML格式,甚至直接发送和接收TCP/IP协议的数据流。下面展示如何将抓取新浪微博的数据,并将其展示到地理信息平台上。
新浪微博提供开发式API,允许用户对来自微博数据进行读取,对于如何使用微博API,参考。我们选取了某一个位置,通过调用微博API,抓取附近某个范围内最新的微博消息。使用FME中的PythonCreator脚本,抓取微博数据。
返回的JSON数据格式如下:
这样的结果是无法很好的被利用的,因此,我们在通过FME的转换器完成了数据整理工作,提取出我们感兴趣的信息,并将发送微博的位置信息空间化,直接发布到ArcGIS Online上进行展示。
展示效果如下:
取微博数据这里我们使用了一小段python脚本,但其实我们可以直接使用FME的HTTPCaller来访问API接口,这样使得整个过程可以真正零代码。
案例二:零编码抓取POI数据
基于网页的API接口获取数据类型多样,高德、腾讯、百度等地图厂商都提供了POI数据的API接口。
这里以高德poi数据为例子,详细api说明可参考:
.
1.提取poi数据的模板编写思路
根据官方的使用说明,对发送的请求连接做相应的组合如下:
固定网址+查询范围+用户许可+poi类型+每页poi数量+翻页数量
官方示例如下:
,40.006919;116.48231,40.007381;116.47516,39.99713;116.472596,39.985227;116.45669,39.984989;116.460988,40.006919&keywords=kfc&output=xml&key=
编写FME模板构建数据访问链接、请求数据、解析数据并对数据做处理,输出得到想要的结果。
FME POI下载模板
下载运行情况:
1)使用CMD运行FME模板下载广东省(包括香港澳门)的poi, fme发出了105万次访问请求,返回470多万条数据。
2)将FME模板挂在阿里云服务器上,大约花了三天二夜的时间,下载了整个广东省以及香港澳门的poi,累计发送125万次访问请求,返回522万条poi数据.
使用CMD来运行FME模板还有一个好外,就是低配置机器也可以运行处理大量数据流
数据结果展示:
同样的方法可以应用到下载谷歌影像、高德瓦片、百度POI等等具有API接口的开放数据中。实现批量、零代码、无人值守的开放数据下载模式。
案例三:FME与即时通讯工具的互操作
FME运行方法的多样性。到底选择DESKTOP、SERVER、还是CLOUD?如果有一种另类的操作方法并颠覆以前的观点,会产生什么样的想法?
常规的FME操作,在与FME Server的操作中,通过的中介是浏览器,在浏览器界面来设置参数后运行得出结果。在与DESKTOP的操作中,使用的是Workbench或Bat来设置参数后运行得出结果。如果有另外的操作方式,要如何来实现。
在中国,QQ是最大的即时通讯工具,它垄断了90%以上的即时通讯市场。QQ是国人网络中不可缺少的工具。在常规的GIS数据处理中,FME、ARCGIS、CAD都是主流软件。其中FME又是最为快捷方便的数据处理软件。如果把QQ和FME结合在一起,让QQ来运行FME的模板,会是一个什么样的结果?不可思议还是异想天开吗?哦!这是要用蓝翔的挖掘机炒一锅新东方的菜!
经过一段时间的测试与修改,真的实现了用QQ运行FME模板的方法。实现的方法为群聊执行和一对一执行,以下是几个例子。
第一个例子,下载全国的公车线路信息。
这里的意思,是给QQ机器人发送一条指令,第一行是执行模板的名称,第二行是此模板的对应参数。上图是让QQ机器人执行BUS.FMW,此模板的功能是下载全国的公车线路站点,用到的参数是城市和线路。比如上面就是让QQ机器人下载广州的776公车的线路和站点。
如何看运行状态?输入bus+查询,会出现如下截图所示:
根据QQ机器人返回的连接下载,加载到谷歌地球上,看看效果如下图:
完全没有问题,FME和QQ的结合,真的做到了!!!我们可以把任意的模版通过与QQ机器人的进行交互运行,包括POI数据下载、处理勘测定界数据等等。
用QQ操作FME来运行模板是如此的方便,这会让你惊讶吗?当初有这个想法的时候,感觉太可怕,但有想法就行动去测试,万一实现了呢。。。
FME就是这样的神奇!!!
感谢本篇中“案例二:零代码抓取POI数据”和“案例三:FME与即时通讯工具的互操作”的提供者“千浪”。 查看全部
【互联网数据抓取与挖掘案例】快来体验FME:零编码、快速、自由获取数据
推广:《城市数据师梦想特训营》原创大牛公开课报名详询
互联网开放数据以在线的方式让所有人可以访问和获取,这些数据充满无限可能性。本章将介绍FME在互联网数据抓取与挖掘方面的几个应用案例,带大家一起体验FME零编码、快速、自由抓取数据的优势。
案例一:FME与微博
FME目前已经提供对网络数据的处理能力,包括JSON、XML格式,甚至直接发送和接收TCP/IP协议的数据流。下面展示如何将抓取新浪微博的数据,并将其展示到地理信息平台上。
新浪微博提供开发式API,允许用户对来自微博数据进行读取,对于如何使用微博API,参考。我们选取了某一个位置,通过调用微博API,抓取附近某个范围内最新的微博消息。使用FME中的PythonCreator脚本,抓取微博数据。
返回的JSON数据格式如下:
这样的结果是无法很好的被利用的,因此,我们在通过FME的转换器完成了数据整理工作,提取出我们感兴趣的信息,并将发送微博的位置信息空间化,直接发布到ArcGIS Online上进行展示。
展示效果如下:
取微博数据这里我们使用了一小段python脚本,但其实我们可以直接使用FME的HTTPCaller来访问API接口,这样使得整个过程可以真正零代码。
案例二:零编码抓取POI数据
基于网页的API接口获取数据类型多样,高德、腾讯、百度等地图厂商都提供了POI数据的API接口。
这里以高德poi数据为例子,详细api说明可参考:
.
1.提取poi数据的模板编写思路
根据官方的使用说明,对发送的请求连接做相应的组合如下:
固定网址+查询范围+用户许可+poi类型+每页poi数量+翻页数量
官方示例如下:
,40.006919;116.48231,40.007381;116.47516,39.99713;116.472596,39.985227;116.45669,39.984989;116.460988,40.006919&keywords=kfc&output=xml&key=
编写FME模板构建数据访问链接、请求数据、解析数据并对数据做处理,输出得到想要的结果。
FME POI下载模板
下载运行情况:
1)使用CMD运行FME模板下载广东省(包括香港澳门)的poi, fme发出了105万次访问请求,返回470多万条数据。
2)将FME模板挂在阿里云服务器上,大约花了三天二夜的时间,下载了整个广东省以及香港澳门的poi,累计发送125万次访问请求,返回522万条poi数据.
使用CMD来运行FME模板还有一个好外,就是低配置机器也可以运行处理大量数据流
数据结果展示:
同样的方法可以应用到下载谷歌影像、高德瓦片、百度POI等等具有API接口的开放数据中。实现批量、零代码、无人值守的开放数据下载模式。
案例三:FME与即时通讯工具的互操作
FME运行方法的多样性。到底选择DESKTOP、SERVER、还是CLOUD?如果有一种另类的操作方法并颠覆以前的观点,会产生什么样的想法?
常规的FME操作,在与FME Server的操作中,通过的中介是浏览器,在浏览器界面来设置参数后运行得出结果。在与DESKTOP的操作中,使用的是Workbench或Bat来设置参数后运行得出结果。如果有另外的操作方式,要如何来实现。
在中国,QQ是最大的即时通讯工具,它垄断了90%以上的即时通讯市场。QQ是国人网络中不可缺少的工具。在常规的GIS数据处理中,FME、ARCGIS、CAD都是主流软件。其中FME又是最为快捷方便的数据处理软件。如果把QQ和FME结合在一起,让QQ来运行FME的模板,会是一个什么样的结果?不可思议还是异想天开吗?哦!这是要用蓝翔的挖掘机炒一锅新东方的菜!
经过一段时间的测试与修改,真的实现了用QQ运行FME模板的方法。实现的方法为群聊执行和一对一执行,以下是几个例子。
第一个例子,下载全国的公车线路信息。
这里的意思,是给QQ机器人发送一条指令,第一行是执行模板的名称,第二行是此模板的对应参数。上图是让QQ机器人执行BUS.FMW,此模板的功能是下载全国的公车线路站点,用到的参数是城市和线路。比如上面就是让QQ机器人下载广州的776公车的线路和站点。
如何看运行状态?输入bus+查询,会出现如下截图所示:
根据QQ机器人返回的连接下载,加载到谷歌地球上,看看效果如下图:
完全没有问题,FME和QQ的结合,真的做到了!!!我们可以把任意的模版通过与QQ机器人的进行交互运行,包括POI数据下载、处理勘测定界数据等等。
用QQ操作FME来运行模板是如此的方便,这会让你惊讶吗?当初有这个想法的时候,感觉太可怕,但有想法就行动去测试,万一实现了呢。。。
FME就是这样的神奇!!!
感谢本篇中“案例二:零代码抓取POI数据”和“案例三:FME与即时通讯工具的互操作”的提供者“千浪”。
云栖社区-最好的中文技术社区(含轻量级爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-06-13 08:01
实时抓取网页数据的node.js框架有很多:云栖社区-最好的中文技术社区(含轻量级爬虫)
对于这种目前云社区就已经很成熟的东西,我还是喜欢自己去摸索学习(例如我)。既然是pc抓包,按你的目的分为,抓取发生在http端的图片以及网页。如果要对网页进行抓取,那爬虫框架就有很多了。目前提供http抓包的有三个,
网上自己找吧,比如语雀,随手点开一个手机网页抓包教程,可以学到很多。
推荐题主去scrapy、urllib2这些框架找找。说白了http的请求分析处理相关模块都在这些框架里实现的。http2,urllib2其实很多js请求处理也是整合在这两个框架里的。另外提示一下,http1.0有一个request,是有明文传输安全保证的。
顺便问一下题主的网站指的是页面还是网页端,如果是页面那个是正常抓取的可以使用-xposed这个switchyomega或者collectweb。如果是网页端可以用kibanaapi进行分析。
polyfillbs4proxyfirefoxagainst-browser-client-requestsfirefoxapplicationsecurity
对于一个只是想在浏览器里面的代码里直接抓取http网页图片的话,推荐phantomjs。
使用libpcap库抓取,最新版本可以直接把单文件提交给对应浏览器,对于分析爬虫没有任何实际意义。 查看全部
云栖社区-最好的中文技术社区(含轻量级爬虫)
实时抓取网页数据的node.js框架有很多:云栖社区-最好的中文技术社区(含轻量级爬虫)
对于这种目前云社区就已经很成熟的东西,我还是喜欢自己去摸索学习(例如我)。既然是pc抓包,按你的目的分为,抓取发生在http端的图片以及网页。如果要对网页进行抓取,那爬虫框架就有很多了。目前提供http抓包的有三个,
网上自己找吧,比如语雀,随手点开一个手机网页抓包教程,可以学到很多。
推荐题主去scrapy、urllib2这些框架找找。说白了http的请求分析处理相关模块都在这些框架里实现的。http2,urllib2其实很多js请求处理也是整合在这两个框架里的。另外提示一下,http1.0有一个request,是有明文传输安全保证的。
顺便问一下题主的网站指的是页面还是网页端,如果是页面那个是正常抓取的可以使用-xposed这个switchyomega或者collectweb。如果是网页端可以用kibanaapi进行分析。
polyfillbs4proxyfirefoxagainst-browser-client-requestsfirefoxapplicationsecurity
对于一个只是想在浏览器里面的代码里直接抓取http网页图片的话,推荐phantomjs。
使用libpcap库抓取,最新版本可以直接把单文件提交给对应浏览器,对于分析爬虫没有任何实际意义。
简单代码抓取全国实时疫情数据——小白爬虫实战(9)
网站优化 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2022-06-05 03:38
七月以来,国内疫情又有反复,陆续有多个地方冒出本土确诊病例,一些地方被划为风险地区,涉及的地区也有逐渐增多的趋势,总而言之,疫情尚未结束,大家还是要做好个人防护。
全国的疫情数据都是每日不断更新的,如果我们要搜集这些数据,传统的CV大法显然也是能解决问题的,但是还是那句话,“可以但没必要”。
这节我们通过selenium,获取全国34个省级行政区的实时疫情数据。
这里我们全国实时疫情数据的数据来源为百度的疫情实时大数据报告专题网页,链接为:
百度疫情实时大数据报告页
进入页面可以看见国内每日疫情的总体数据,顺着页面继续下拉,我们可以看到这么一张疫情分布地图:
不要慌张,上图显示的现有确诊是指包含境外输入的现有确诊病例数,继续向下滑动页面,我们就可以找到对应的数据来源:
上图被红框圈起来的“现有”列数据便是前文疫情分布地图所呈现的数据内容。展开这张“国内各地区疫情统计汇总”表的全部,可以看见该表数据包括了全国34个行政区的 新增病例、现有病例、累计病例、累计治愈、累计死亡 共五项数据。
就以红框数据为例,如何将各地区的现有病例数据爬取下来呢?
Selenium的优势就在于“可见即可得”,只要能看到的,就能给爬下来。
通过分析Xpath可以清晰的看见,排在地区列第一行的台湾对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[1]/div/span[2]
而排在地区列最后一行的西藏对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[1]/div/span[2]
比对两个Xpath可以发现,除了标红的位置数字1变成了34,Xpath的其余部分都是一模一样的,可见这34个省级行政区地区名的Xpath就是这样按照1到34的顺序排下来。
关于Xpath的分析方法,在往期的文章中已经提过,这里就不再赘述,有需要的小伙伴可以回顾
同理,各地区的现有病例列也按照相同的套路,Xpath从1到34排下来:
现有病例第一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[3]
现有病例最后一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[3]
找到了上面的规律,我们只需要用一个for循环,就可以构建出爬取对应地区现有确诊病例数据的代码:
# 设定地区名空列表regions_list = []# 设定现有病例空列表existing_case_list = []<br /># 总共有34个省级行政区数据for i in range(34): # i输出的是int型的0至33 k = str(i + 1) # 获取地区名 region = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[1]/div/span[2]').text # 将获取的地区名加到地区名列表中 regions_list.append(region) # 获取各地现有病例数 existing_case = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[3]').text # 将获取的各地现有病例数加到现有病例列表中 existing_case_list.append(existing_case)print(regions_list)print(existing_case_list)
上面便是获取全国实时疫情数据的核心代码部分,要想正确运行这串代码,我们还得事先声明模拟的浏览器类型,以及加载对应页的url。
关于在使用selenium前的配置问题此处就不再赘述,有需要的小伙伴可参照往期内容:
这里还需要注意的是,在模拟浏览器加载页面后,并没有直接开始for循环抓取数据,而是先做了一个模拟点击动作(第14行)
import timefrom selenium import webdriver<br /># url为百度疫情实时大数据链接url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'# 这里用的火狐option = webdriver.FirefoxOptions()option.add_argument('head')driver = webdriver.Firefox(options=option)driver.get(url)# 留足加载时间time.sleep(2)# 注意,需要模拟点击一下表才会展开全部数据driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/div/span').click()
这里的模拟点击动作实际上是完成表格底部的“展开”动作,因为34行数据太长,网页本身并没有全部显示,所以这里需要我们自己模拟点击一下将它展开。
运行程序,就可以得到两个列表,一个列表是地名,一个列表是现有病例数,两个列表的元素位置是相对应的。
运行结果
有了这份数据,我们就可以利用pyecharts等方法制作如前文所示的疫情地图,也可以将数据写入csv保存至本地。
pyecharts制图可参考往期内容
同样的,如果我们不仅仅想要抓取现有病例数,想要抓取其它列的数据,甚至多列数据一起抓也很好办,只需要根据Xpath位置的不同作对应修改即可。
后台发送关键词 “疫情数据抓取” 获取本文示例代码。 查看全部
简单代码抓取全国实时疫情数据——小白爬虫实战(9)
七月以来,国内疫情又有反复,陆续有多个地方冒出本土确诊病例,一些地方被划为风险地区,涉及的地区也有逐渐增多的趋势,总而言之,疫情尚未结束,大家还是要做好个人防护。
全国的疫情数据都是每日不断更新的,如果我们要搜集这些数据,传统的CV大法显然也是能解决问题的,但是还是那句话,“可以但没必要”。
这节我们通过selenium,获取全国34个省级行政区的实时疫情数据。
这里我们全国实时疫情数据的数据来源为百度的疫情实时大数据报告专题网页,链接为:
百度疫情实时大数据报告页
进入页面可以看见国内每日疫情的总体数据,顺着页面继续下拉,我们可以看到这么一张疫情分布地图:
不要慌张,上图显示的现有确诊是指包含境外输入的现有确诊病例数,继续向下滑动页面,我们就可以找到对应的数据来源:
上图被红框圈起来的“现有”列数据便是前文疫情分布地图所呈现的数据内容。展开这张“国内各地区疫情统计汇总”表的全部,可以看见该表数据包括了全国34个行政区的 新增病例、现有病例、累计病例、累计治愈、累计死亡 共五项数据。
就以红框数据为例,如何将各地区的现有病例数据爬取下来呢?
Selenium的优势就在于“可见即可得”,只要能看到的,就能给爬下来。
通过分析Xpath可以清晰的看见,排在地区列第一行的台湾对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[1]/div/span[2]
而排在地区列最后一行的西藏对应的Xpath为
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[1]/div/span[2]
比对两个Xpath可以发现,除了标红的位置数字1变成了34,Xpath的其余部分都是一模一样的,可见这34个省级行政区地区名的Xpath就是这样按照1到34的顺序排下来。
关于Xpath的分析方法,在往期的文章中已经提过,这里就不再赘述,有需要的小伙伴可以回顾
同理,各地区的现有病例列也按照相同的套路,Xpath从1到34排下来:
现有病例第一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[1]/td[3]
现有病例最后一行Xpath:
/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[34]/td[3]
找到了上面的规律,我们只需要用一个for循环,就可以构建出爬取对应地区现有确诊病例数据的代码:
# 设定地区名空列表regions_list = []# 设定现有病例空列表existing_case_list = []<br /># 总共有34个省级行政区数据for i in range(34): # i输出的是int型的0至33 k = str(i + 1) # 获取地区名 region = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[1]/div/span[2]').text # 将获取的地区名加到地区名列表中 regions_list.append(region) # 获取各地现有病例数 existing_case = driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/table/tbody/tr[' + k + ']/td[3]').text # 将获取的各地现有病例数加到现有病例列表中 existing_case_list.append(existing_case)print(regions_list)print(existing_case_list)
上面便是获取全国实时疫情数据的核心代码部分,要想正确运行这串代码,我们还得事先声明模拟的浏览器类型,以及加载对应页的url。
关于在使用selenium前的配置问题此处就不再赘述,有需要的小伙伴可参照往期内容:
这里还需要注意的是,在模拟浏览器加载页面后,并没有直接开始for循环抓取数据,而是先做了一个模拟点击动作(第14行)
import timefrom selenium import webdriver<br /># url为百度疫情实时大数据链接url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'# 这里用的火狐option = webdriver.FirefoxOptions()option.add_argument('head')driver = webdriver.Firefox(options=option)driver.get(url)# 留足加载时间time.sleep(2)# 注意,需要模拟点击一下表才会展开全部数据driver.find_element_by_xpath( '/html/body/div[2]/div/div/div/section/div[2]/div[4]/div[3]/div[4]/div/span').click()
这里的模拟点击动作实际上是完成表格底部的“展开”动作,因为34行数据太长,网页本身并没有全部显示,所以这里需要我们自己模拟点击一下将它展开。
运行程序,就可以得到两个列表,一个列表是地名,一个列表是现有病例数,两个列表的元素位置是相对应的。
运行结果
有了这份数据,我们就可以利用pyecharts等方法制作如前文所示的疫情地图,也可以将数据写入csv保存至本地。
pyecharts制图可参考往期内容
同样的,如果我们不仅仅想要抓取现有病例数,想要抓取其它列的数据,甚至多列数据一起抓也很好办,只需要根据Xpath位置的不同作对应修改即可。
后台发送关键词 “疫情数据抓取” 获取本文示例代码。
有同学要python数据库相关的笔记?相关数据大全
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-05-20 22:06
实时抓取网页数据,然后用正则表达式匹配,然后excel表格基本要求都能满足,其他数据库操作语言差别也不是特别大。excel适合快速存储数据,python适合处理和处理特定数据。
=有同学要python数据库相关的笔记?tushare相关数据大全ipython相关文章echarts中文版
《python爬虫开发实战》
个人很喜欢相关web和爬虫方面的文章,比如翻墙整理github上python相关爬虫和web的源码源文件,再clone到本地进行爬虫及web方面的开发等等一些机会,
推荐一个从基础到高级的路线,
爬虫其实更大更杂都能涉及到,要说完全掌握,那基本python和ruby都要能够做到,时间来得及,但是一些学校软件或者是做市场,运营的岗位,针对的则是python做编程语言,所以掌握python也是ok的,看后期想往哪方面去走,利用多学校提供的java和php的教学视频,以及老师平时做过的实际项目,多练习,基本就可以,做到整理。 查看全部
有同学要python数据库相关的笔记?相关数据大全
实时抓取网页数据,然后用正则表达式匹配,然后excel表格基本要求都能满足,其他数据库操作语言差别也不是特别大。excel适合快速存储数据,python适合处理和处理特定数据。
=有同学要python数据库相关的笔记?tushare相关数据大全ipython相关文章echarts中文版
《python爬虫开发实战》
个人很喜欢相关web和爬虫方面的文章,比如翻墙整理github上python相关爬虫和web的源码源文件,再clone到本地进行爬虫及web方面的开发等等一些机会,
推荐一个从基础到高级的路线,
爬虫其实更大更杂都能涉及到,要说完全掌握,那基本python和ruby都要能够做到,时间来得及,但是一些学校软件或者是做市场,运营的岗位,针对的则是python做编程语言,所以掌握python也是ok的,看后期想往哪方面去走,利用多学校提供的java和php的教学视频,以及老师平时做过的实际项目,多练习,基本就可以,做到整理。
电商社交网站数据他统统能采 Excel导出随采随用 服务30万家企业
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-13 16:53
◆ 优采云创始人刘宝强
文| 铅笔道 记者 韩正阳
►导语
2016年6月,优采云完成Pre-A融资,投资方是“协同创新”。此前,项目曾获得过种子轮投资,以及拓尔思500万元天使轮融资。
优采云是一家大数据服务公司,为企业用户提供数据采集、整合、挖掘分析等服务,数据抓取范围覆盖全网。用户输入网站,拖拉控件即可配置任务,自动提取元素并将采集数据表格化。
产品自2013年3月上线以来,已经服务30万家企业,能够全网全时段为用户搜集数据。
注: 刘宝强已确认文中数据真实无误,铅笔道愿与他一起为内容真实性背书。
全网采集数据
大数据的风在国外刮起时,在美国一家金融公司工作的刘宝强,察觉到这将是未来的趋势。
彼时是2012年,美国有几家大数据公司刚起步。于是他开始调研国内企业,发现“很多企业有数据诉求,但是根本没有大数据能力”。
而数据的价值显而易见。比如,企业可以根据用户数据、竞争对手数据、市场趋势数据等制定发展计划,调整运营策略。
但数据获取难度高,成本大,很多时候即使花钱也买不到数据。“于是,数据获取成了一件可望不可及的事情。”
恰好公司内部推行大数据平台受阻,刘宝强便跳出来,成立优采云。2013年9月,他开始组建团队,研发产品。
2014年3月,第一个版本上线,此时产品已经实现数据自动化采集,范围覆盖全网。用户在电脑上下载客户端软件,然后在软件中设定网站,便可采集数据。
数据采集傻瓜化智能化
最初,用户需先花0.5~2个小时学习软件使用,然后花几分钟设置一个网站。“刚开始的流程比较繁琐,随后,我们为了让产品更傻瓜化,操作更简单,做了一系列改进。”
去年年底,产品推出了向导模式,主要面向初学者。用户在学习使用的时候,就像安装Windows软件,它会提醒你下一步怎么操作。“主要目的是减少用户出错,也节省其学习成本。”
今年8月,Smart模式推出,用户无需学习配置规则,只用输入网址,便可以搜集数据。“进一步降低了用户的使用门槛。而且打开网站比一般浏览器都快,因为我们会自动识别、屏蔽广告,这可以加速采集的过程。”
“任何人都可以使用,任何网站数据都可以采集。”谈及优采云的使用,刘宝强说道。
用户能够自定义字段,而采集来的数据,可以即时表格化,支持数据库、网站、Excel、文本等多种导出方式,也可以直接导入到WordPress、Discuz、dede等多种论坛博客网站。
服务30万企业客户
用户获取方面,产品上线前,刘宝强便在做准备。
在开发者知识分享社区“博客园”上,他发表一系列互联网大数据文章,每篇文章有数千阅读。由此,他积累了一个500人的QQ群。“群满后,我们发布产品,这些QQ用户是我们第一批种子用户。”
此后,公司“一直很低调”。用户构成上,30%是靠口碑获取,50%属于自然流量增长,其余则靠付费推广获取。“一开始我们没人负责做用户的团队。”
去年7月,企业用户破4万。他开始招募运营和销售团队。
◆团队小伙伴们
商业模式上,优采云提供免费的基础数据服务,并通过增值服务来收费。
根据数据采集能力,产品分为免费版、专业版、旗舰版、私有云、企业定制版等5个版本,数据采集数量从日均近万到百万不等,采集能力为30~100倍速。
“数据搜集能力越强,版本收费越高。”整个系统有超过2000台服务器支撑。
目前,服务企业用户已经超过30万,每月新增3万用户。服务客户包含国家公安部研究所、国家统计局、三星电子、中科院、比亚迪、艾瑞等。
“对大数据企业来说,技术是安身立命之本。”未来,刘会投入更多资金在产品改进上,希望为所有企业提供大数据工具和平台。
/The End/
编辑 王 方 校对 汪 晨
求报道
请加pencil-news为好友
查看全部
电商社交网站数据他统统能采 Excel导出随采随用 服务30万家企业
◆ 优采云创始人刘宝强
文| 铅笔道 记者 韩正阳
►导语
2016年6月,优采云完成Pre-A融资,投资方是“协同创新”。此前,项目曾获得过种子轮投资,以及拓尔思500万元天使轮融资。
优采云是一家大数据服务公司,为企业用户提供数据采集、整合、挖掘分析等服务,数据抓取范围覆盖全网。用户输入网站,拖拉控件即可配置任务,自动提取元素并将采集数据表格化。
产品自2013年3月上线以来,已经服务30万家企业,能够全网全时段为用户搜集数据。
注: 刘宝强已确认文中数据真实无误,铅笔道愿与他一起为内容真实性背书。
全网采集数据
大数据的风在国外刮起时,在美国一家金融公司工作的刘宝强,察觉到这将是未来的趋势。
彼时是2012年,美国有几家大数据公司刚起步。于是他开始调研国内企业,发现“很多企业有数据诉求,但是根本没有大数据能力”。
而数据的价值显而易见。比如,企业可以根据用户数据、竞争对手数据、市场趋势数据等制定发展计划,调整运营策略。
但数据获取难度高,成本大,很多时候即使花钱也买不到数据。“于是,数据获取成了一件可望不可及的事情。”
恰好公司内部推行大数据平台受阻,刘宝强便跳出来,成立优采云。2013年9月,他开始组建团队,研发产品。
2014年3月,第一个版本上线,此时产品已经实现数据自动化采集,范围覆盖全网。用户在电脑上下载客户端软件,然后在软件中设定网站,便可采集数据。
数据采集傻瓜化智能化
最初,用户需先花0.5~2个小时学习软件使用,然后花几分钟设置一个网站。“刚开始的流程比较繁琐,随后,我们为了让产品更傻瓜化,操作更简单,做了一系列改进。”
去年年底,产品推出了向导模式,主要面向初学者。用户在学习使用的时候,就像安装Windows软件,它会提醒你下一步怎么操作。“主要目的是减少用户出错,也节省其学习成本。”
今年8月,Smart模式推出,用户无需学习配置规则,只用输入网址,便可以搜集数据。“进一步降低了用户的使用门槛。而且打开网站比一般浏览器都快,因为我们会自动识别、屏蔽广告,这可以加速采集的过程。”
“任何人都可以使用,任何网站数据都可以采集。”谈及优采云的使用,刘宝强说道。
用户能够自定义字段,而采集来的数据,可以即时表格化,支持数据库、网站、Excel、文本等多种导出方式,也可以直接导入到WordPress、Discuz、dede等多种论坛博客网站。
服务30万企业客户
用户获取方面,产品上线前,刘宝强便在做准备。
在开发者知识分享社区“博客园”上,他发表一系列互联网大数据文章,每篇文章有数千阅读。由此,他积累了一个500人的QQ群。“群满后,我们发布产品,这些QQ用户是我们第一批种子用户。”
此后,公司“一直很低调”。用户构成上,30%是靠口碑获取,50%属于自然流量增长,其余则靠付费推广获取。“一开始我们没人负责做用户的团队。”
去年7月,企业用户破4万。他开始招募运营和销售团队。
◆团队小伙伴们
商业模式上,优采云提供免费的基础数据服务,并通过增值服务来收费。
根据数据采集能力,产品分为免费版、专业版、旗舰版、私有云、企业定制版等5个版本,数据采集数量从日均近万到百万不等,采集能力为30~100倍速。
“数据搜集能力越强,版本收费越高。”整个系统有超过2000台服务器支撑。
目前,服务企业用户已经超过30万,每月新增3万用户。服务客户包含国家公安部研究所、国家统计局、三星电子、中科院、比亚迪、艾瑞等。
“对大数据企业来说,技术是安身立命之本。”未来,刘会投入更多资金在产品改进上,希望为所有企业提供大数据工具和平台。
/The End/
编辑 王 方 校对 汪 晨
求报道
请加pencil-news为好友
网易实时疫情数据Python抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-05-11 14:53
有朋友反馈之前抓取百度疫情数据的代码已经无法运行,没看过的朋友可以点击下列链接查看。
看了下,因为百度调整了部分页面信息,代码要调整下就可以使用了,那如果下次再调整呢?你说这概率大不大?
我觉得是相当的大,那有没有稳定点的方法呢?
这样问,肯定是有的,就是换种方式获取疫情实时数据。
这次我们来抓取网易JSON疫情数据。
链接是这个
打开网址,看到是这样的,如果你是第一次接触JSON数据,包你看的一脸懵逼。不过不要紧,如果你用的是火狐浏览器,你还可以发现上方还有JSON、美化输出等功能。
这是点美化输出的效果,看起来是不是好一点,不过还是一脸懵逼对不对,因为你就没接触过JSON数据嘛。
这是点JSON的效果,有不同颜色了,看起来更舒服了。
好了,我们开始进行数据抓取与导入了。先导入需要用的模块。
import json<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />import requests<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />from pandas.io.json import json_normalize<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后开始抓数据
url="https://c.m.163.com/ug/api/wuh ... %3Bbr style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />ret=requests.get(url, headers=headers)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />result=json.loads(ret.content)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
查看下抓到的数据result,可以看到是个字典,我们要的数据在key=data里面。
继续双击点开data,我们要的数据在areaTree里面。
继续双击点开areaTree,这时areaTree是个列表,我们要的数据第一行里面。
继续双击点开areaTree的第一行,这时候又变成一个字典了,看到中国没有?哈哈,我们要的数据在key=children里面。
继续双击点开children,这就是我们要的数据啦,这又变成了一个列表,每一行就是一个省的数据
我们点开第一行看看,看到没有,湖北出现了。
如果继续点开children,就是湖北各城市的数据啦,不点不点了,我们就只要省份数据,怎么提出来呢?继续进行数据处理,提取出我们要的数据。
t= result['data']['areaTree'][0]['children']<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />sf=json_normalize(t)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
就这么两句代码就出来了,哈哈!我们来看下数据。
taday.开头的都是最新的“今日”数据,也就是新增数据,total.开头的就是累计数据,confirm是确诊人数,suspect是疑似,heal是出院,dead是死亡。
我们要的字段就是name、total.confirm,name就是省份名,total.confirm就是累计确诊人数。直接把name、total.confirm替换之前绘制地图的代码相应位置。
# 将数据转换为二元的列表<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />list1 = list(zip(sf['name'],sf['total.confirm']))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 创建一个地图对象<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1 = Map()<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#对全局进行设置<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.set_global_opts(<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置标题<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />title_opts=opts.TitleOpts(title="全国疫情地图"),<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置最大数据范围<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 使用add方法添加地图数据与地图类型<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.add("累计确诊人数", list1, maptype="china")<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 地图创建完成后,通过render()方法可以将地图渲染为html<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.render('全国疫情地图.html')<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后地图绘制结果就出来了。
------------
希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程
包含以下四门课程
Python数据分析--玩转Pandas
Python数据分析--玩转数据可视化
玩转Python统计分析
玩转Python统计模型
现参加课程学习,可享受6折优惠 查看全部
网易实时疫情数据Python抓取
有朋友反馈之前抓取百度疫情数据的代码已经无法运行,没看过的朋友可以点击下列链接查看。
看了下,因为百度调整了部分页面信息,代码要调整下就可以使用了,那如果下次再调整呢?你说这概率大不大?
我觉得是相当的大,那有没有稳定点的方法呢?
这样问,肯定是有的,就是换种方式获取疫情实时数据。
这次我们来抓取网易JSON疫情数据。
链接是这个
打开网址,看到是这样的,如果你是第一次接触JSON数据,包你看的一脸懵逼。不过不要紧,如果你用的是火狐浏览器,你还可以发现上方还有JSON、美化输出等功能。
这是点美化输出的效果,看起来是不是好一点,不过还是一脸懵逼对不对,因为你就没接触过JSON数据嘛。
这是点JSON的效果,有不同颜色了,看起来更舒服了。
好了,我们开始进行数据抓取与导入了。先导入需要用的模块。
import json<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />import requests<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />from pandas.io.json import json_normalize<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后开始抓数据
url="https://c.m.163.com/ug/api/wuh ... %3Bbr style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />ret=requests.get(url, headers=headers)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />result=json.loads(ret.content)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
查看下抓到的数据result,可以看到是个字典,我们要的数据在key=data里面。
继续双击点开data,我们要的数据在areaTree里面。
继续双击点开areaTree,这时areaTree是个列表,我们要的数据第一行里面。
继续双击点开areaTree的第一行,这时候又变成一个字典了,看到中国没有?哈哈,我们要的数据在key=children里面。
继续双击点开children,这就是我们要的数据啦,这又变成了一个列表,每一行就是一个省的数据
我们点开第一行看看,看到没有,湖北出现了。
如果继续点开children,就是湖北各城市的数据啦,不点不点了,我们就只要省份数据,怎么提出来呢?继续进行数据处理,提取出我们要的数据。
t= result['data']['areaTree'][0]['children']<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />sf=json_normalize(t)<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
就这么两句代码就出来了,哈哈!我们来看下数据。
taday.开头的都是最新的“今日”数据,也就是新增数据,total.开头的就是累计数据,confirm是确诊人数,suspect是疑似,heal是出院,dead是死亡。
我们要的字段就是name、total.confirm,name就是省份名,total.confirm就是累计确诊人数。直接把name、total.confirm替换之前绘制地图的代码相应位置。
# 将数据转换为二元的列表<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />list1 = list(zip(sf['name'],sf['total.confirm']))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 创建一个地图对象<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1 = Map()<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#对全局进行设置<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.set_global_opts(<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置标题<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />title_opts=opts.TitleOpts(title="全国疫情地图"),<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />#设置最大数据范围<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 使用add方法添加地图数据与地图类型<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.add("累计确诊人数", list1, maptype="china")<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /><br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" /># 地图创建完成后,通过render()方法可以将地图渲染为html<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />map_1.render('全国疫情地图.html')<br style="box-sizing: border-box;max-width: 100%;overflow-wrap: break-word;" />
然后地图绘制结果就出来了。
------------
希望系统、快速学习Python数据分析知识,可以学习
数据分析专家@文彤老师的
《跟文彤老师学Python数据分析》系列视频课程
包含以下四门课程
Python数据分析--玩转Pandas
Python数据分析--玩转数据可视化
玩转Python统计分析
玩转Python统计模型
现参加课程学习,可享受6折优惠
Python爬虫是如何抓取并储存网页数据的?
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-05 13:01
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,四个步骤详细介绍Python爬虫的基本流程。
Step 1
请求尝试
首先进入b站首页,点击排行榜并复制链接。
https://www.bilibili.com/ranki ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
启动Jupyter notebook,并运行以下代码:
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />res = requests.get('url')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(res.status_code)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#200<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,完成下面三件事:可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
Step 2
解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容。
可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的。
from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />title = soup.title.text <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(title)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
Step 3
提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到。
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写
all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
Step 4
存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成。
import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结语
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜因为它足够简单,希望通过这个案例让大家明白Python爬虫工作的基本流程,最后附上完整代码
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />### 使用pandas写入数据<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 查看全部
Python爬虫是如何抓取并储存网页数据的?
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据,本文将基于爬取B站视频热搜榜单数据并存储为例,四个步骤详细介绍Python爬虫的基本流程。
Step 1
请求尝试
首先进入b站首页,点击排行榜并复制链接。
https://www.bilibili.com/ranki ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
启动Jupyter notebook,并运行以下代码:
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />res = requests.get('url')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(res.status_code)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#200<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,完成下面三件事:可以看到返回值是200,表示服务器正常响应,这意味着我们可以继续进行。
Step 2
解析页面
在上一步我们通过requests向网站请求数据后,成功得到一个包含服务器资源的Response对象,现在我们可以使用.text来查看其内容。
可以看到返回一个字符串,里面有我们需要的热榜视频数据,但是直接从字符串中提取内容是比较复杂且低效的,因此我们需要对其进行解析,将字符串转换为网页结构化数据,这样可以很方便地查找HTML标签以及其中的属性和内容。
在Python中解析网页的方法有很多,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml,本文将基于BeautifulSoup进行讲解。
Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单,使用pip install bs4安装即可,下面让我们用一个简单的例子说明它是怎样工作的。
from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />title = soup.title.text <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(title)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象,注意在使用时需要制定一个解析器,这里使用的是html.parser。
接着就可以获取其中的某个结构化元素及其属性,比如使用soup.title.text获取页面标题,同样可以使用soup.body、soup.p等获取任意需要的元素。
Step 3
提取内容
在上面两步中,我们分别使用requests向网页请求数据并使用bs4解析页面,现在来到最关键的步骤:如何从解析完的页面中提取需要的内容。
在Beautiful Soup中,我们可以使用find/find_all来定位元素,但我更习惯使用CSS选择器.select,因为可以像使用CSS选择元素一样向下访问DOM树。
现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据,首先我们需要找到存储数据的标签,在榜单页面按下F12并按照下图指示找到。
可以看到每一个视频信息都被包在class="rank-item"的li标签下,那么代码就可以这样写
all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
在上面的代码中,我们先使用soup.select('li.rank-item'),此时返回一个list包含每一个视频信息,接着遍历每一个视频信息,依旧使用CSS选择器来提取我们要的字段信息,并以字典的形式存储在开头定义好的空列表中。
可以注意到我用了多种选择方法提取去元素,这也是select方法的灵活之处,感兴趣的读者可以进一步自行研究。
Step 4
存储数据
通过前面三步,我们成功的使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel中保存即可。
如果你对pandas不熟悉的话,可以使用csv模块写入,需要注意的是设置好编码encoding='utf-8-sig',否则会出现中文乱码的问题。
import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
如果你熟悉pandas的话,更是可以轻松将字典转换为DataFrame,一行代码即可完成。
import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结语
至此我们就成功使用Python将b站热门视频榜单数据存储至本地,大多数基于requests的爬虫基本都按照上面四步进行。
不过虽然看上去简单,但是在真实场景中每一步都没有那么轻松,从请求数据开始目标网站就有多种形式的反爬、加密,到后面解析、提取甚至存储数据都有很多需要进一步探索、学习。
本文选择B站视频热榜因为它足够简单,希望通过这个案例让大家明白Python爬虫工作的基本流程,最后附上完整代码
import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import csv<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import pandas as pd<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />page = requests.get(url)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />soup = BeautifulSoup(page.content, 'html.parser')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />all_products = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />products = soup.select('li.rank-item')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for product in products:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> rank = product.select('div.num')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = product.select('div.info > a')[0].text.strip()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> play = product.select('span.data-box')[0].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> comment = product.select('span.data-box')[1].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> up = product.select('span.data-box')[2].text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = product.select('div.info > a')[0].attrs['href']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> all_products.append({<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频排名":rank,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频名": name,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "播放量": play,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "弹幕量": comment,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "up主": up,<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> "视频链接": url<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> })<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />keys = all_products[0].keys()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer = csv.DictWriter(output_file, keys)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writeheader()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> dict_writer.writerows(all_products)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />### 使用pandas写入数据<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
HI,你会用函数实现网页数据抓取吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-05 12:11
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
查看全部
HI,你会用函数实现网页数据抓取吗?
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
实时抓取网页数据,margin-top,子元素越多,抓取时间越长
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-29 05:01
实时抓取网页数据,margin-top,子元素越多,抓取时间越长,因为dom节点太多,要考虑css控制,
你用replace这个库试试。我第一次用alfred,非常头疼。后来用了它,才发现真是神器。它是一个命令工具,不是语言工具,就像你在linux下要用apt,在windows下要用apt-get一样。但是用了这个,我没遇到什么坑,就正常使用replace抓取了所有的html,准确率90%以上。甚至,有一些稀有模式下,我抓了快2小时,没抓到呢。
实现浏览器端抓取就用alfred吧,我们只需要输入“?”然后点击“here”就可以切换模式抓取。
学css3和seo可以试试alfredxetex,真的是神器。
还可以输入“tab”然后随便选
知乎的答案不是从顶部往下滚动,也不会回到顶部看,
为何就ios可以抓取呢?我一个安卓怎么就不能抓呢?麻烦到我网站上传下数据看看,在指定ip以下给我看下,谢谢。
网站只有页面上的,页面上的不太会越复杂,object的抓取,利用globalrequest再用locationreceiver抓获。iframe。extension也是可以抓取的,但比较复杂,而且在浏览器里,content-type会显示为application/json,而且每个页面都不一样。而且重要的是不是抓取主流的。还有当前以及历史时间,域名,成员都要先content-type解析。 查看全部
实时抓取网页数据,margin-top,子元素越多,抓取时间越长
实时抓取网页数据,margin-top,子元素越多,抓取时间越长,因为dom节点太多,要考虑css控制,
你用replace这个库试试。我第一次用alfred,非常头疼。后来用了它,才发现真是神器。它是一个命令工具,不是语言工具,就像你在linux下要用apt,在windows下要用apt-get一样。但是用了这个,我没遇到什么坑,就正常使用replace抓取了所有的html,准确率90%以上。甚至,有一些稀有模式下,我抓了快2小时,没抓到呢。
实现浏览器端抓取就用alfred吧,我们只需要输入“?”然后点击“here”就可以切换模式抓取。
学css3和seo可以试试alfredxetex,真的是神器。
还可以输入“tab”然后随便选
知乎的答案不是从顶部往下滚动,也不会回到顶部看,
为何就ios可以抓取呢?我一个安卓怎么就不能抓呢?麻烦到我网站上传下数据看看,在指定ip以下给我看下,谢谢。
网站只有页面上的,页面上的不太会越复杂,object的抓取,利用globalrequest再用locationreceiver抓获。iframe。extension也是可以抓取的,但比较复杂,而且在浏览器里,content-type会显示为application/json,而且每个页面都不一样。而且重要的是不是抓取主流的。还有当前以及历史时间,域名,成员都要先content-type解析。
实时抓取网页数据的几种常用方法:设计师
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-29 01:01
实时抓取网页数据一直是ui设计师们头疼的问题,总结了几种常用方法:1.网页爬虫2.页面推理3.程序方法(访问图片,寻找网页元素等等方法)4.网页抓取工具这里只说对话框或其他小的页面抓取方法,用上面的几种方法网页抓取网页抓取的思路是建立多个数据库,分别抓取数据,进行合并进行可视化分析或者合并进行统计,优点是不用修改代码,缺点是费用较贵。
抓取方法较多1.抓取页面信息2.直接抓取网页源代码..如果资金条件允许的情况下,对话框,网页元素等需要单独抓取。3.抓取网页后台信息,如果是访问微信公众号等官方网站,没有任何数据问题,但如果是第三方后台,则需要保证安全性。
过程,或者发展方向,跟你会不会写爬虫关系不大,
蟹腰,之前很多朋友问过我关于做ui需要会点什么,我说不要太在意这个东西,但有一点是必须的,就是要能写出自己想要的代码。数据抓取是理论,ui设计更多的是实践,会写代码比会抓取数据更重要。
爬取微信公众号的资料当然是合理的,但是对话框的抓取需要跟程序员的水平及技术经验有关,
要看是什么内容抓取对象了,是产品,用户调研方面的,还是需要抓取内容的接口;如果是产品的接口肯定就用数据抓取方法,抓取需要对产品进行定位分析,针对小方面选取抓取对象,不一定小到什么程度。如果是抓取需要用户调研的内容,可以选择搜索引擎,但是会涉及到大量的程序运算问题。 查看全部
实时抓取网页数据的几种常用方法:设计师
实时抓取网页数据一直是ui设计师们头疼的问题,总结了几种常用方法:1.网页爬虫2.页面推理3.程序方法(访问图片,寻找网页元素等等方法)4.网页抓取工具这里只说对话框或其他小的页面抓取方法,用上面的几种方法网页抓取网页抓取的思路是建立多个数据库,分别抓取数据,进行合并进行可视化分析或者合并进行统计,优点是不用修改代码,缺点是费用较贵。
抓取方法较多1.抓取页面信息2.直接抓取网页源代码..如果资金条件允许的情况下,对话框,网页元素等需要单独抓取。3.抓取网页后台信息,如果是访问微信公众号等官方网站,没有任何数据问题,但如果是第三方后台,则需要保证安全性。
过程,或者发展方向,跟你会不会写爬虫关系不大,
蟹腰,之前很多朋友问过我关于做ui需要会点什么,我说不要太在意这个东西,但有一点是必须的,就是要能写出自己想要的代码。数据抓取是理论,ui设计更多的是实践,会写代码比会抓取数据更重要。
爬取微信公众号的资料当然是合理的,但是对话框的抓取需要跟程序员的水平及技术经验有关,
要看是什么内容抓取对象了,是产品,用户调研方面的,还是需要抓取内容的接口;如果是产品的接口肯定就用数据抓取方法,抓取需要对产品进行定位分析,针对小方面选取抓取对象,不一定小到什么程度。如果是抓取需要用户调研的内容,可以选择搜索引擎,但是会涉及到大量的程序运算问题。
实时抓取网页数据(优采云原创的自动提取正文的使用提示介绍原创算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-20 20:20
监控较新的网页时,软件会列在列表框较早的位置,并有提示音。
然后点击列表中的一个标题,网页的文字会自动显示在“快速查看窗口”中。
优采云原创的自动文本提取算法,可以适应大部分网页,自动提取网页主体文本部分单独阅读。
当然,你可能会遇到提取错误,比如一些没有大段文字的网页,比如视频播放页面等,此时可以点击“打开原创网页”链接查看原创网页。
使用建议:
1、一般网速如4M,同一程序监控的关键词个数不建议超过20个。即使你的网速很快,也不建议设置太多< @关键词同时监控,也可以尝试打开多个程序进行监控(将程序的多份拷贝到不同的文件夹,独立添加监控配置并运行)。
2、刷新列表的显示数量,软件会动态保持在1500以内,超出的会自动剔除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,每个关键词HTML和TXT格式文件收录两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、在刷新列表中右键单击标题,直接在浏览器中打开原创网页,而不是提取文本。
5、[关键词出现在标题中]只是将[intitle:]参数添加到搜索引擎爬取中。即使在搜索论坛或微信时使用此参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),则可以勾选[有效外观]强制< @关键词 出现在标题中。
6、刷新列表的时间条,[]方括号为当地时间,页面时间不括起来。
优采云网络舆情监测系统v1.0.0.2 更新:
添加(预览内容后)复制标题和复制内容按钮 查看全部
实时抓取网页数据(优采云原创的自动提取正文的使用提示介绍原创算法)
监控较新的网页时,软件会列在列表框较早的位置,并有提示音。
然后点击列表中的一个标题,网页的文字会自动显示在“快速查看窗口”中。
优采云原创的自动文本提取算法,可以适应大部分网页,自动提取网页主体文本部分单独阅读。
当然,你可能会遇到提取错误,比如一些没有大段文字的网页,比如视频播放页面等,此时可以点击“打开原创网页”链接查看原创网页。
使用建议:
1、一般网速如4M,同一程序监控的关键词个数不建议超过20个。即使你的网速很快,也不建议设置太多< @关键词同时监控,也可以尝试打开多个程序进行监控(将程序的多份拷贝到不同的文件夹,独立添加监控配置并运行)。
2、刷新列表的显示数量,软件会动态保持在1500以内,超出的会自动剔除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,每个关键词HTML和TXT格式文件收录两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、在刷新列表中右键单击标题,直接在浏览器中打开原创网页,而不是提取文本。
5、[关键词出现在标题中]只是将[intitle:]参数添加到搜索引擎爬取中。即使在搜索论坛或微信时使用此参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),则可以勾选[有效外观]强制< @关键词 出现在标题中。
6、刷新列表的时间条,[]方括号为当地时间,页面时间不括起来。
优采云网络舆情监测系统v1.0.0.2 更新:
添加(预览内容后)复制标题和复制内容按钮
实时抓取网页数据(2021-11-16在开发Web应用中的应用模式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-20 00:05
)
2021-11-16一. Web 应用模式
在开发Web应用程序时,有两种应用模式:
知识储备:什么是动态页面(查数据库),什么是静态页面(静态html)
# 判断条件: 根据html页面内容是写死的还是从后端动态获取的
静态网页: 页面上的数据是直接写死的 万年不变
动态网页: 数据是实时获取的. 如下例子:
1.后端获取当前时间展示到html页面上
2.数据是从数据库中获取的展示到html页面上
# 总结
静: 页面数据写死的
动: 查数据库
1. 前后端不分离
前后端混合开发(前后端不分离):返回html的内容,需要写一个模板
Key:请求动态页面,返回HTML
2. 前后端分离
前后端分离:只关注写后端接口,返回json、xml格式数据
Key:去静态文件服务器请求静态页面,静态文件服务器返回静态页面。然后JS请求django后端,django后端返回json或者xml格式的数据
# xml格式
lqz
# json格式
{"name":"lqz"}
# asp 动态服务器页面. jsp Java服务端网页
# java---> jsp
https://www.pearvideo.com/category_loading.jsp
#php写的
http://www.aa7a.cn/user.php
# python写的
http://www.aa7a.cn/user.html
# 动静态页面存在的主要作用
优化查询
3. 总结
# 动静态页面
静态: 页面内容写死的, 内容都是固定不变的.
动态: 页面内容含有需要从数据库中获取的.
# 前后端不分离
特点: 请求动态页面, 返回HTML数据或者重定向
# 前后端分离特点
特点:
请求静态页面(向静态服务器), 返回静态文件
请求需要填充的数据, 返回js或者xml格式数据
二. API 接口
为了在团队内部形成共识,防止个人习惯差异造成的混乱,我们需要找到一个大家都觉得很好的接口实现规范,并且这个规范可以让后端写的接口一目了然,减少双方的摩擦。合作成本。
通过网络,指定前后信息交互规则的url链接,即前后信息交互的媒介
Web API接口和一般的url链接还是有区别的。Web API 接口具有以下四个特点。
请求方法:get、post、put、patch、delete
请求参数:json或xml格式的key-value类型数据
响应结果:json或xml格式的数据
# xml格式
https://api.map.baidu.com/plac ... 3Dxml
#json格式
https://api.map.baidu.com/plac ... Djson
{
"status":0,
"message":"ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
总结
什么是API接口?
API接口就是前后端信息交互的媒介(提示: 表示的是前后端之间)
三. 接口测试工具:Postman
Postman 是一个界面调试工具。它是一款免费的可视化软件,支持各种操作系统平台。它是测试接口的首选工具。
Postman可以直接到官网下载:傻瓜式安装。
四. RESTful API 规范
REST的全称是Representational State Transfer,中文意思是表示(编者注:通常翻译为Representational State Transfer)。它于 2000 年首次出现在 Roy Fielding 的博士论文中。
RESTful 是一种用于定义 Web API 接口的设计风格,特别适用于前后端分离的应用模式。
这种风格的概念是后端开发任务是提供数据,对外提供数据资源的访问接口。因此,在定义接口时,客户端访问的URL路径代表要操作的数据资源。
事实上,我们可以使用任何框架来实现符合restful规范的API接口。
1. 数据安全
# url链接一般都采用https协议进行传输
# 注:采用https协议,可以提高数据交互过程中的安全性
2. 接口特征表示
# 用api关键字标识接口url:
[https://api.baidu.com](https://api.baidu.com/)
https://www.baidu.com/api
# 注:看到api字眼,就代表该请求url链接是完成前后台数据交互的
3. 多个数据版本共存
# 在url链接中标识数据版本
https://api.baidu.com/v1
https://api.baidu.com/v2
# 注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下)
4. 数据是资源,都用名词(可以是复数)
# 接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
https://api.baidu.com/users
https://api.baidu.com/books
https://api.baidu.com/book
# 注:不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user
# 例外: 特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义
https://api.baidu.com/place/search
https://api.baidu.com/login
5. 资源操作由请求方法(方法)决定
# 操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作
https://api.baidu.com/books - get请求: 获取所有书
https://api.baidu.com/books/1 - get请求: 获取主键为1的书
https://api.baidu.com/books - post请求: 新增一本书
https://api.baidu.com/books/1 - put请求: 整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求: 局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
6. 过滤,在url中以上传参数的形式传递搜索条件
https://api.example.com/v1/zoos?limit=10 指定返回记录的数量
https://api.example.com/v1/zoos?offset=10 指定返回记录的开始位置
https://api.example.com/v1/zoo ... 3D100 指定第几页,以及每页的记录数
https://api.example.com/v1/zoo ... 3Dasc 指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1 指定筛选条件
7. 响应状态码
# 正常响应
响应状态码2xx
200:常规请求
201:创建成功
# 重定向响应
响应状态码3xx
301:永久重定向
302:暂时重定向
# 客户端异常
响应状态码4xx
403:请求无权限
404:请求路径不存在
405:请求方法不存在
# 服务器异常
响应状态码5xx
500:服务器异常
8. 错误处理,应该返回错误信息,error作为key
{
error: "无权限操作"
}
9. 返回结果。对于不同的操作,服务器返回给用户的结果应符合以下规范
GET /collection 返回资源对象的列表(数组) 多个[{}],
GET /collection/resource 返回单个资源对象 单个{}
POST /collection 返回新生成的资源对象
PUT /collection/resource 返回完整的资源对象
PATCH /collection/resource 返回完整的资源对象
DELETE /collection/resource 返回一个空文档
10. 需要url请求的资源需要请求链接才能访问资源
# Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
更好的界面回报
# 响应数据要有状态码、状态信息以及数据本身
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
11. 总结
# 关键字: HTTPS协议, api, 版本, 资源标识, 请求方式, url传参标识, 响应状态码, 错误信息, 不同的操作返回不同的结果, 返回url
1. 传输数据用HTTPS协议
2. 接口具有标识性
https://api.baidu.com
https://www.baidu.com/api
3. 接口具有版本标识性
https://api.baidu.com/v1
https://api.baidu.com/v2
4. 核心: 接口对资源具有标识性(名词)
https://api.baidu.com/books
https://api.baidu.com/book
5. 核心: 通过请求的方式来决定对数据的操作方式
get获取, post增加, put整体更新, patch局部更新, delete删除
6. 通过url传参数的形式传递搜索条件
https://api.baidu.com/books?limit=10
7. 响应状态码
200常规请求 201创建成功请求
301永久重定向 302暂时重定向
403请求无权限 404请求无路径 405请求方法不存在
500服务端异常
8. 错误信息
{
'error': '无权限操作'
}
9. 针对不同的操作, 返回不同的返回结果
get 获取多个[{}], 获取单个{}
post 返回新增的
put 返回修改后所有的内容(包括没修改的. 全部)
patch 返回修改后所有的内容(包括没修改的. 全部)
delete 返回空文档
10. 基于请求响应过后返回内容中, 可以带url地址
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
五. 序列化
API接口开发的核心和最常见的过程是序列化。所谓序列化,就是将数据转换成一种格式。序列化可以分为两个阶段:
序列化:将我们识别的数据转换成指定的格式,提供给其他人。
例如:我们在django中获取的数据默认是模型对象,但是模型对象数据不能直接提供给前端或者其他平台,所以需要将数据序列化成字符串或者json数据提供给其他 。
反序列化:将他人提供的数据转换/恢复为我们需要的格式。
比如前端js提供的json数据是python的字符串,我们需要将其反序列化为模型类对象,这样我们才能将数据保存到数据库中。
六. Django Rest_Framework
核心思想:减少编写api接口的代码
Django REST framework是一个基于Django的Web应用开发框架,可以快速开发REST API接口应用。在REST框架中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化和反序列化的过程。不仅如此,它还提供了丰富的类视图、扩展类和视图集来简化视图的编写。REST框架还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework 提供API 的Web 可视化界面,方便查看测试界面。
官方文档:
github:
特征
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;[jwt]
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
七. drf的安装和简单使用
# 安装:pip install djangorestframework==3.10.3
# 使用
# 1. 在setting.py 的app中注册
INSTALLED_APPS = [
'rest_framework'
]
# 2. 在models.py中写表模型
class Book(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
author=models.CharField(max_length=32)
# 3. 新建一个序列化类
from rest_framework.serializers import ModelSerializer
from app01.models import Book
class BookModelSerializer(ModelSerializer):
class Meta:
model = Book
fields = "__all__"
# 4. 在视图中写视图类
from rest_framework.viewsets import ModelViewSet
from .models import Book
from .ser import BookModelSerializer
class BooksViewSet(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookModelSerializer
# 5. 写路由关系
from app01 import views
from rest_framework.routers import DefaultRouter
router = DefaultRouter() # 可以处理视图的路由器
router.register('book', views.BooksViewSet) # 向路由器中注册视图集
# 将路由器中的所以路由信息追到到django的路由列表中
urlpatterns = [
path('admin/', admin.site.urls),
]
#这是什么意思?两个列表相加
# router.urls 列表
urlpatterns += router.urls
# 6. 启动,在postman中测试即可
八.在CBV中继承查看源码分析1.代码分析
入口点: urls.py 中的 .as_view() 方法
path('books1/', views.Books.as_view())
视图中的 Books 类
class Books(View):
# 如果有个需求,只能接受get请求
http_method_names = ['get', ]
def get(self, request):
print(self.request) # 看: 这里可以通过self.request进行获取到request方法
return HttpResponse('ok')
项目启动时执行
@classonlymethod
def as_view(cls, **initkwargs):
...
def view(request, *args, **kwargs):
...
...
return view
路由匹配时执行,实例化执行的类,通过执行路由匹配中类实例化的对象,执行继承父类View中定义的dispatch方法。
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
在dispatch方法中使用反射获取请求的类型,执行对应类中定义的方法
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs) 查看全部
实时抓取网页数据(2021-11-16在开发Web应用中的应用模式
)
2021-11-16一. Web 应用模式
在开发Web应用程序时,有两种应用模式:
知识储备:什么是动态页面(查数据库),什么是静态页面(静态html)
# 判断条件: 根据html页面内容是写死的还是从后端动态获取的
静态网页: 页面上的数据是直接写死的 万年不变
动态网页: 数据是实时获取的. 如下例子:
1.后端获取当前时间展示到html页面上
2.数据是从数据库中获取的展示到html页面上
# 总结
静: 页面数据写死的
动: 查数据库
1. 前后端不分离
前后端混合开发(前后端不分离):返回html的内容,需要写一个模板
Key:请求动态页面,返回HTML
2. 前后端分离
前后端分离:只关注写后端接口,返回json、xml格式数据
Key:去静态文件服务器请求静态页面,静态文件服务器返回静态页面。然后JS请求django后端,django后端返回json或者xml格式的数据
# xml格式
lqz
# json格式
{"name":"lqz"}
# asp 动态服务器页面. jsp Java服务端网页
# java---> jsp
https://www.pearvideo.com/category_loading.jsp
#php写的
http://www.aa7a.cn/user.php
# python写的
http://www.aa7a.cn/user.html
# 动静态页面存在的主要作用
优化查询
3. 总结
# 动静态页面
静态: 页面内容写死的, 内容都是固定不变的.
动态: 页面内容含有需要从数据库中获取的.
# 前后端不分离
特点: 请求动态页面, 返回HTML数据或者重定向
# 前后端分离特点
特点:
请求静态页面(向静态服务器), 返回静态文件
请求需要填充的数据, 返回js或者xml格式数据
二. API 接口
为了在团队内部形成共识,防止个人习惯差异造成的混乱,我们需要找到一个大家都觉得很好的接口实现规范,并且这个规范可以让后端写的接口一目了然,减少双方的摩擦。合作成本。
通过网络,指定前后信息交互规则的url链接,即前后信息交互的媒介
Web API接口和一般的url链接还是有区别的。Web API 接口具有以下四个特点。
请求方法:get、post、put、patch、delete
请求参数:json或xml格式的key-value类型数据
响应结果:json或xml格式的数据
# xml格式
https://api.map.baidu.com/plac ... 3Dxml
#json格式
https://api.map.baidu.com/plac ... Djson
{
"status":0,
"message":"ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
总结
什么是API接口?
API接口就是前后端信息交互的媒介(提示: 表示的是前后端之间)
三. 接口测试工具:Postman
Postman 是一个界面调试工具。它是一款免费的可视化软件,支持各种操作系统平台。它是测试接口的首选工具。
Postman可以直接到官网下载:傻瓜式安装。
四. RESTful API 规范
REST的全称是Representational State Transfer,中文意思是表示(编者注:通常翻译为Representational State Transfer)。它于 2000 年首次出现在 Roy Fielding 的博士论文中。
RESTful 是一种用于定义 Web API 接口的设计风格,特别适用于前后端分离的应用模式。
这种风格的概念是后端开发任务是提供数据,对外提供数据资源的访问接口。因此,在定义接口时,客户端访问的URL路径代表要操作的数据资源。
事实上,我们可以使用任何框架来实现符合restful规范的API接口。
1. 数据安全
# url链接一般都采用https协议进行传输
# 注:采用https协议,可以提高数据交互过程中的安全性
2. 接口特征表示
# 用api关键字标识接口url:
[https://api.baidu.com](https://api.baidu.com/)
https://www.baidu.com/api
# 注:看到api字眼,就代表该请求url链接是完成前后台数据交互的
3. 多个数据版本共存
# 在url链接中标识数据版本
https://api.baidu.com/v1
https://api.baidu.com/v2
# 注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下)
4. 数据是资源,都用名词(可以是复数)
# 接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
https://api.baidu.com/users
https://api.baidu.com/books
https://api.baidu.com/book
# 注:不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user
# 例外: 特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义
https://api.baidu.com/place/search
https://api.baidu.com/login
5. 资源操作由请求方法(方法)决定
# 操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作
https://api.baidu.com/books - get请求: 获取所有书
https://api.baidu.com/books/1 - get请求: 获取主键为1的书
https://api.baidu.com/books - post请求: 新增一本书
https://api.baidu.com/books/1 - put请求: 整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求: 局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
6. 过滤,在url中以上传参数的形式传递搜索条件
https://api.example.com/v1/zoos?limit=10 指定返回记录的数量
https://api.example.com/v1/zoos?offset=10 指定返回记录的开始位置
https://api.example.com/v1/zoo ... 3D100 指定第几页,以及每页的记录数
https://api.example.com/v1/zoo ... 3Dasc 指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1 指定筛选条件
7. 响应状态码
# 正常响应
响应状态码2xx
200:常规请求
201:创建成功
# 重定向响应
响应状态码3xx
301:永久重定向
302:暂时重定向
# 客户端异常
响应状态码4xx
403:请求无权限
404:请求路径不存在
405:请求方法不存在
# 服务器异常
响应状态码5xx
500:服务器异常
8. 错误处理,应该返回错误信息,error作为key
{
error: "无权限操作"
}
9. 返回结果。对于不同的操作,服务器返回给用户的结果应符合以下规范
GET /collection 返回资源对象的列表(数组) 多个[{}],
GET /collection/resource 返回单个资源对象 单个{}
POST /collection 返回新生成的资源对象
PUT /collection/resource 返回完整的资源对象
PATCH /collection/resource 返回完整的资源对象
DELETE /collection/resource 返回一个空文档
10. 需要url请求的资源需要请求链接才能访问资源
# Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
更好的界面回报
# 响应数据要有状态码、状态信息以及数据本身
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
11. 总结
# 关键字: HTTPS协议, api, 版本, 资源标识, 请求方式, url传参标识, 响应状态码, 错误信息, 不同的操作返回不同的结果, 返回url
1. 传输数据用HTTPS协议
2. 接口具有标识性
https://api.baidu.com
https://www.baidu.com/api
3. 接口具有版本标识性
https://api.baidu.com/v1
https://api.baidu.com/v2
4. 核心: 接口对资源具有标识性(名词)
https://api.baidu.com/books
https://api.baidu.com/book
5. 核心: 通过请求的方式来决定对数据的操作方式
get获取, post增加, put整体更新, patch局部更新, delete删除
6. 通过url传参数的形式传递搜索条件
https://api.baidu.com/books?limit=10
7. 响应状态码
200常规请求 201创建成功请求
301永久重定向 302暂时重定向
403请求无权限 404请求无路径 405请求方法不存在
500服务端异常
8. 错误信息
{
'error': '无权限操作'
}
9. 针对不同的操作, 返回不同的返回结果
get 获取多个[{}], 获取单个{}
post 返回新增的
put 返回修改后所有的内容(包括没修改的. 全部)
patch 返回修改后所有的内容(包括没修改的. 全部)
delete 返回空文档
10. 基于请求响应过后返回内容中, 可以带url地址
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}
五. 序列化
API接口开发的核心和最常见的过程是序列化。所谓序列化,就是将数据转换成一种格式。序列化可以分为两个阶段:
序列化:将我们识别的数据转换成指定的格式,提供给其他人。
例如:我们在django中获取的数据默认是模型对象,但是模型对象数据不能直接提供给前端或者其他平台,所以需要将数据序列化成字符串或者json数据提供给其他 。
反序列化:将他人提供的数据转换/恢复为我们需要的格式。
比如前端js提供的json数据是python的字符串,我们需要将其反序列化为模型类对象,这样我们才能将数据保存到数据库中。
六. Django Rest_Framework
核心思想:减少编写api接口的代码
Django REST framework是一个基于Django的Web应用开发框架,可以快速开发REST API接口应用。在REST框架中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化和反序列化的过程。不仅如此,它还提供了丰富的类视图、扩展类和视图集来简化视图的编写。REST框架还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework 提供API 的Web 可视化界面,方便查看测试界面。
官方文档:
github:
特征
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;[jwt]
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
七. drf的安装和简单使用
# 安装:pip install djangorestframework==3.10.3
# 使用
# 1. 在setting.py 的app中注册
INSTALLED_APPS = [
'rest_framework'
]
# 2. 在models.py中写表模型
class Book(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
author=models.CharField(max_length=32)
# 3. 新建一个序列化类
from rest_framework.serializers import ModelSerializer
from app01.models import Book
class BookModelSerializer(ModelSerializer):
class Meta:
model = Book
fields = "__all__"
# 4. 在视图中写视图类
from rest_framework.viewsets import ModelViewSet
from .models import Book
from .ser import BookModelSerializer
class BooksViewSet(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookModelSerializer
# 5. 写路由关系
from app01 import views
from rest_framework.routers import DefaultRouter
router = DefaultRouter() # 可以处理视图的路由器
router.register('book', views.BooksViewSet) # 向路由器中注册视图集
# 将路由器中的所以路由信息追到到django的路由列表中
urlpatterns = [
path('admin/', admin.site.urls),
]
#这是什么意思?两个列表相加
# router.urls 列表
urlpatterns += router.urls
# 6. 启动,在postman中测试即可
八.在CBV中继承查看源码分析1.代码分析
入口点: urls.py 中的 .as_view() 方法
path('books1/', views.Books.as_view())
视图中的 Books 类
class Books(View):
# 如果有个需求,只能接受get请求
http_method_names = ['get', ]
def get(self, request):
print(self.request) # 看: 这里可以通过self.request进行获取到request方法
return HttpResponse('ok')
项目启动时执行
@classonlymethod
def as_view(cls, **initkwargs):
...
def view(request, *args, **kwargs):
...
...
return view
路由匹配时执行,实例化执行的类,通过执行路由匹配中类实例化的对象,执行继承父类View中定义的dispatch方法。
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
在dispatch方法中使用反射获取请求的类型,执行对应类中定义的方法
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-18 08:04
本课程简要讨论网络爬虫的作用,并提供突出法律风险的简单案例
由于网页越来越复杂,在实际操作中需要更多的细节。您可以查看网络爬虫的特别课程。
这部分的内容比较琐碎,但很重要,尤其是法律说明。
网页抓取和网页抓取的区别
这两个概念相似,但侧重点不同
网络爬虫从全网采集和索引数据,常用于搜索引擎
数据抓取往往针对特定站点中特定类型的数据,最后整理成数据表
数据抓取工具
网页数据抓取是为了和网站的管理者竞争。
curl 是最传统的直接下载特定网页的工具。但是很容易失败
selenium 等无头浏览器可以很好的模拟浏览器的操作。
因为他毕竟是一个没有用户界面的浏览器
如果您经常抓取数据,网站管理员可能会阻止 IP。
这时候就需要多开IP了。您可以从一些云服务提供商处购买它们。例如,AWS
一个实例
数据抓取:
首先,定位到web文件中的数据,
然后在代码中将数据的位置转换成模板,
最后运行代码批量抓取信息。
获取网页
使用无头浏览器下载html文件,需要使用一些软件来解析网页,
解析/操作网页
例如 Python 中的 beautifulsoup 用于解析网页和提取信息。
定位数据位置
使用浏览器的检查器 (F12) 来检查网页元素。这对于确定网页上数据的位置非常方便。
最后,提取结构化信息。
成本问题。
如果您使用云服务器,请优先考虑内存大小。
图像数据采集
抓取图片和抓取文字的步骤是一样的,但是要考虑图片的存储开销
网页抓取的法律风险
不违法,但不确定是否合法。(注意此声明)\
有些事情最好小心: 查看全部
实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
本课程简要讨论网络爬虫的作用,并提供突出法律风险的简单案例
由于网页越来越复杂,在实际操作中需要更多的细节。您可以查看网络爬虫的特别课程。
这部分的内容比较琐碎,但很重要,尤其是法律说明。
网页抓取和网页抓取的区别
这两个概念相似,但侧重点不同
网络爬虫从全网采集和索引数据,常用于搜索引擎
数据抓取往往针对特定站点中特定类型的数据,最后整理成数据表
数据抓取工具
网页数据抓取是为了和网站的管理者竞争。
curl 是最传统的直接下载特定网页的工具。但是很容易失败
selenium 等无头浏览器可以很好的模拟浏览器的操作。
因为他毕竟是一个没有用户界面的浏览器
如果您经常抓取数据,网站管理员可能会阻止 IP。
这时候就需要多开IP了。您可以从一些云服务提供商处购买它们。例如,AWS
一个实例
数据抓取:
首先,定位到web文件中的数据,
然后在代码中将数据的位置转换成模板,
最后运行代码批量抓取信息。
获取网页
使用无头浏览器下载html文件,需要使用一些软件来解析网页,
解析/操作网页
例如 Python 中的 beautifulsoup 用于解析网页和提取信息。
定位数据位置
使用浏览器的检查器 (F12) 来检查网页元素。这对于确定网页上数据的位置非常方便。
最后,提取结构化信息。
成本问题。
如果您使用云服务器,请优先考虑内存大小。
图像数据采集
抓取图片和抓取文字的步骤是一样的,但是要考虑图片的存储开销
网页抓取的法律风险
不违法,但不确定是否合法。(注意此声明)\
有些事情最好小心:
实时抓取网页数据( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2022-04-17 23:39
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中对比分析,抓取网页后抓取数据的大致步骤为:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
查看全部
实时抓取网页数据(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中对比分析,抓取网页后抓取数据的大致步骤为:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
实时抓取网页数据(运营商大数据如何精准获客,营销?拥有强大的云计算大数据中心 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-04-14 06:00
)
什么是运营商大数据?
运营商依托自身庞大的客户群,可以获得用户高频、高交互的实时动态轨迹呼叫和互联网数据。运营商能够获取的数据似乎有着互联网公司无法获取的数量级和详细程度。虽然互联网巨头自己也有大数据资源,但他们的大数据来源是自己的APP或者网站采集,而采集用户在使用业务时产生的数据更多。就是为自己服务。运营商的数据来自各个领域。同时,运营商的大数据应用并不局限于自身,更多地应用于各个行业,进行深度行业整合,赋能行业。
运营商大数据如何精准获客和营销?
运营商拥有强大的云计算大数据中心,可以对任何网站、网页、网站、手机APP、400电话、固话、关键词@进行实时精准的实时精准分析>、短信号码等平台通过建立数据模型。数据分析,通过综合用户行为、用户偏好等综合用户信息,精准捕捉和获取目标客户群,还可以过滤如地区、性别、年龄、职业、访问次数、访问时长等,通话次数、通话时长等维度,更精准定位目标客户群。
运营商大数据可以帮助整个行业精准获取和营销客户。可以帮助不同行业的企业实时获取与自己匹配的精准客户群,并提供外呼系统。在相关行业,企业可以通过外呼系统直接联系到他们。精准客户,确定意向,进行转化和交易。
查看全部
实时抓取网页数据(运营商大数据如何精准获客,营销?拥有强大的云计算大数据中心
)
什么是运营商大数据?
运营商依托自身庞大的客户群,可以获得用户高频、高交互的实时动态轨迹呼叫和互联网数据。运营商能够获取的数据似乎有着互联网公司无法获取的数量级和详细程度。虽然互联网巨头自己也有大数据资源,但他们的大数据来源是自己的APP或者网站采集,而采集用户在使用业务时产生的数据更多。就是为自己服务。运营商的数据来自各个领域。同时,运营商的大数据应用并不局限于自身,更多地应用于各个行业,进行深度行业整合,赋能行业。
运营商大数据如何精准获客和营销?
运营商拥有强大的云计算大数据中心,可以对任何网站、网页、网站、手机APP、400电话、固话、关键词@进行实时精准的实时精准分析>、短信号码等平台通过建立数据模型。数据分析,通过综合用户行为、用户偏好等综合用户信息,精准捕捉和获取目标客户群,还可以过滤如地区、性别、年龄、职业、访问次数、访问时长等,通话次数、通话时长等维度,更精准定位目标客户群。
运营商大数据可以帮助整个行业精准获取和营销客户。可以帮助不同行业的企业实时获取与自己匹配的精准客户群,并提供外呼系统。在相关行业,企业可以通过外呼系统直接联系到他们。精准客户,确定意向,进行转化和交易。
实时抓取网页数据(意在三个部分:网页源码的获取、提取、所得结果的整理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-13 22:09
获取数据是数据分析的重要环节,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。
本文使用的版本是python3.5,意在采集证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
一、获取网页源代码
很多人喜欢使用python爬虫的原因之一是它很容易上手。只有以下几行代码才能爬取大部分网页的源代码。
导入 urllib.request
url='/stock/ranklist_a_3_1_1.html' #target URL headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} #假装浏览器请求头 request=urllib.request.Request(url=url,headers=headers) #请求服务器响应=urllib.request.urlopen(request) #服务器响应内容=response.read().decode ('gbk') #查看一定编码的源代码 print(content) #打印页面源代码
虽然很容易抓取一个页面的源代码,但是一个网站中抓取的大量网页源代码却经常被服务器截获,顿时觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的功法。
1.伪造的 vagrant 头文件
很多服务器使用浏览器发送的头部来确认是否是人类用户,所以我们可以通过模仿浏览器的行为来构造请求头部来向服务器发送请求。服务器会识别其中一些参数来识别你是否是人类用户,很多网站会识别User-Agent参数,所以最好带上请求头。一些高度警觉的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,而一些具有防盗链功能的网站还要带上referer参数等.
2.随机生成UA
证券之星只需要带参数User-Agent来爬取页面信息,但是如果连续爬取几个页面,服务器会阻塞。所以我决定每次爬取数据时模拟不同的浏览器发送请求,而服务器使用User-Agent来识别不同的浏览器,所以每次爬取一个页面时,我可以通过随机生成不同的UA构造头来请求服务器。
3.放慢爬行速度
虽然模拟了不同的浏览器爬取数据,但发现在某些时间段,可以爬取上百页的数据,有时只能爬取十几页。似乎服务器也会根据您的访问频率来识别您。无论是人类用户还是网络爬虫。所以每次我爬一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量的股票数据。
4.使用代理IP
意外情况,该程序在公司测试成功,回到宿舍发现只能抓取几页,就被服务器屏蔽了。惊慌失措的我连忙询问度娘,得知服务器可以识别你的IP,并记录来自这个IP的访问次数。你可以使用一个高度匿名的代理IP,并在爬取过程中不断更改,让服务器查不出谁是真凶。该技能尚未完成。如果你想知道接下来会发生什么,请听下一次。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个cookie文件,然后使用cookie来跟踪您的访问过程。为了防止服务器识别出你是爬虫,建议自带cookie一起爬取数据;如果遇到想模拟登录的网站,为了防止你的账号被封,可以申请大量账号,然后爬进去。这涉及到模拟登录、验证码识别等知识,所以我暂时不深入研究。.. 总之,对于网站的主人来说,有些爬虫真的很烦人,所以会想出很多办法来限制爬虫的进入,所以我们在强行进入后要注意一些礼仪,不要不要把别人的 网站
二、提取所需内容
得到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看采集网页的部分源码。
为了减少干扰,我先用正则表达式从整个页面源代码匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
模式=桩('
')
body=re.findall(pattern,str(content)) #match
pattern=pile('>(.*?) 之间的所有代码
stock_page=re.findall(pattern,body[0]) #match>and
compile方法是编译匹配模式,findall方法使用这个匹配模式来匹配需要的信息,并以列表的形式返回。正则表达式的语法有很多,下面我只列出使用的符号的含义。
语法说明
. 匹配除换行符“\n”以外的任何字符
* 匹配前一个字符 0 次或无限次
? 匹配前一个字符 0 次或一次
\s 空白字符:[\t\r\n\f\v]
\S 非空白字符:[^\s]
[...] 字符集,对应位置可以是字符集中的任意字符
(...) 括起来的表达式会作为一个组来使用,一般就是我们需要提取的内容
正则表达式的语法挺多的,说不定有大佬能用一个正则表达式提取我想提取的东西。提取股票主要部分的代码时,发现有人用xpath表达式提取,比较简洁。看来页面解析还有很长的路要走。
三、得到的结果的组织
匹配 > 和非贪婪模式 (.*?)
stock_last=stock_total[:] #stock_total:stock_total 中数据的匹配股票数据:#stock_last:排序的股票数据
如果数据=='':
stock_last.remove('')
最后我们可以打印几列数据看看效果,代码如下
print('代码','\t','简称','','\t','最新价格','\t','涨跌','\t','涨跌', '\t','5分钟增加')for i in range(0,len(stock_last),13): #网页共有13列数据
print(stock_last[i],'\t',stock_last[i+1],'','\t',stock_last[i+2],'','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5]) 查看全部
实时抓取网页数据(意在三个部分:网页源码的获取、提取、所得结果的整理)
获取数据是数据分析的重要环节,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。
本文使用的版本是python3.5,意在采集证券之星当天所有A股数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
一、获取网页源代码
很多人喜欢使用python爬虫的原因之一是它很容易上手。只有以下几行代码才能爬取大部分网页的源代码。
导入 urllib.request
url='/stock/ranklist_a_3_1_1.html' #target URL headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} #假装浏览器请求头 request=urllib.request.Request(url=url,headers=headers) #请求服务器响应=urllib.request.urlopen(request) #服务器响应内容=response.read().decode ('gbk') #查看一定编码的源代码 print(content) #打印页面源代码
虽然很容易抓取一个页面的源代码,但是一个网站中抓取的大量网页源代码却经常被服务器截获,顿时觉得这个世界充满了恶意。于是我开始研究突破反爬虫限制的功法。
1.伪造的 vagrant 头文件
很多服务器使用浏览器发送的头部来确认是否是人类用户,所以我们可以通过模仿浏览器的行为来构造请求头部来向服务器发送请求。服务器会识别其中一些参数来识别你是否是人类用户,很多网站会识别User-Agent参数,所以最好带上请求头。一些高度警觉的网站也可能通过其他参数来识别,比如Accept-Language来识别你是否是人类用户,而一些具有防盗链功能的网站还要带上referer参数等.
2.随机生成UA
证券之星只需要带参数User-Agent来爬取页面信息,但是如果连续爬取几个页面,服务器会阻塞。所以我决定每次爬取数据时模拟不同的浏览器发送请求,而服务器使用User-Agent来识别不同的浏览器,所以每次爬取一个页面时,我可以通过随机生成不同的UA构造头来请求服务器。
3.放慢爬行速度
虽然模拟了不同的浏览器爬取数据,但发现在某些时间段,可以爬取上百页的数据,有时只能爬取十几页。似乎服务器也会根据您的访问频率来识别您。无论是人类用户还是网络爬虫。所以每次我爬一个页面时,我都会让它随机休息几秒钟。添加这段代码后,我可以在每个时间段爬取大量的股票数据。
4.使用代理IP
意外情况,该程序在公司测试成功,回到宿舍发现只能抓取几页,就被服务器屏蔽了。惊慌失措的我连忙询问度娘,得知服务器可以识别你的IP,并记录来自这个IP的访问次数。你可以使用一个高度匿名的代理IP,并在爬取过程中不断更改,让服务器查不出谁是真凶。该技能尚未完成。如果你想知道接下来会发生什么,请听下一次。
5.其他突破反爬虫限制的方法
许多服务器在接受浏览器请求时会向浏览器发送一个cookie文件,然后使用cookie来跟踪您的访问过程。为了防止服务器识别出你是爬虫,建议自带cookie一起爬取数据;如果遇到想模拟登录的网站,为了防止你的账号被封,可以申请大量账号,然后爬进去。这涉及到模拟登录、验证码识别等知识,所以我暂时不深入研究。.. 总之,对于网站的主人来说,有些爬虫真的很烦人,所以会想出很多办法来限制爬虫的进入,所以我们在强行进入后要注意一些礼仪,不要不要把别人的 网站
二、提取所需内容
得到网页的源代码后,我们就可以从中提取出我们需要的数据了。从源代码中获取所需信息的方法有很多,使用正则表达式是比较经典的方法之一。我们先来看采集网页的部分源码。
为了减少干扰,我先用正则表达式从整个页面源代码匹配上面的body部分,然后从body部分匹配每只股票的信息。代码显示如下。
模式=桩('
')
body=re.findall(pattern,str(content)) #match
pattern=pile('>(.*?) 之间的所有代码
stock_page=re.findall(pattern,body[0]) #match>and
compile方法是编译匹配模式,findall方法使用这个匹配模式来匹配需要的信息,并以列表的形式返回。正则表达式的语法有很多,下面我只列出使用的符号的含义。
语法说明
. 匹配除换行符“\n”以外的任何字符
* 匹配前一个字符 0 次或无限次
? 匹配前一个字符 0 次或一次
\s 空白字符:[\t\r\n\f\v]
\S 非空白字符:[^\s]
[...] 字符集,对应位置可以是字符集中的任意字符
(...) 括起来的表达式会作为一个组来使用,一般就是我们需要提取的内容
正则表达式的语法挺多的,说不定有大佬能用一个正则表达式提取我想提取的东西。提取股票主要部分的代码时,发现有人用xpath表达式提取,比较简洁。看来页面解析还有很长的路要走。
三、得到的结果的组织
匹配 > 和非贪婪模式 (.*?)
stock_last=stock_total[:] #stock_total:stock_total 中数据的匹配股票数据:#stock_last:排序的股票数据
如果数据=='':
stock_last.remove('')
最后我们可以打印几列数据看看效果,代码如下
print('代码','\t','简称','','\t','最新价格','\t','涨跌','\t','涨跌', '\t','5分钟增加')for i in range(0,len(stock_last),13): #网页共有13列数据
print(stock_last[i],'\t',stock_last[i+1],'','\t',stock_last[i+2],'','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5])
实时抓取网页数据(如何用excel获取网页上的股票数据,⑵Excel如何设置公式获得股票价格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-04-13 22:07
⑴ 如何使用excel在网页上获取股票数据并按日期制作表格
可以通过Excel获取外部数据的功能来实现,具体操作如下:
1、选择你要取数据的网站(不是所有网站都能取到你想要的数据),复制完整网站备份
2、打开 Excel,单击数据选项卡,选择获取外部数据 - 从网站按钮,将打开一个新建 Web 查询对话框。
3、输入刚才复制的网址,会打开对应的页面。
4、根据提示点击你需要的数据表前面的黄色小键,当它变成绿色勾号时,表示选中状态。
5、点击导入按钮,选择工作表中数据的存放位置,点击确定。
6、使用时,右键数据存储区,刷新,成功后就是最新的数据。
⑵ 如何在Excel中设置获取股票价格的公式
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】;
2、在【新建网页查询】界面,我们可以看到左上角是地址栏。点击界面右上角的【选项】,查看导入信息的设置,可根据实际情况进行选择。此示例遵循默认设置;
3、在【新建网页查询】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站;
4、浏览整个页面,可以看到很多区域标有黄色箭头,这些是可以导入的数据标识。我们选择我们想要的信息框左上角的黄色箭头;
5、点击后,黄色箭头会变成绿色箭头,如下图。然后点击右下角的【导入】按钮;
6、在【导入数据】对话框中选择要存储数据的位置;
7、在这个界面,点击左下角的【属性】,可以设置刷新频率,如何处理数据变化等;
8、设置好以上内容后,返回【导入数据】界面,点击【确定】按钮;
9、以下数据会自动导入,稍等片刻即可导入数据。每次设置刷新频率都会自动刷新数据;
10、设置完以上内容后,返回【导入数据】界面,点击【确定】按钮。
⑶ 如何通过excel获取库存清单
1 这里以中石油(601857)报价为例,打开提供股票行情的网站,在页面“个股查询”区域输入股票代码,选择“实时报价”,点击“报价”按钮后,可以查询中石油的行情数据,然后复制地址栏中的网址。
2、运行Excel,新建一个空白工作簿,在“数据”选项卡的“获取外部数据”选项组中选择“导入外部数据-从网站”命令。
3 弹出“New Web Query”对话框,在地址栏中输入刚才复制的地址,点击“Go”按钮,在下方文本框中打开网站,点击“Import”按钮。
4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮。网站 的数据现在已导入到工作表中。
⑷如何用EXCEL表格看股市
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】。
⑸ 如何使用excel获取实时股票数据
自动获取所有股票历史数据,以及当日数据
⑹如何制作实时盘点excel,求高手指导
⑺ 如何使用EXCEL分析股票
EXCEL自动股市分析软件
⑻ 如何获取excel格式的股票数据
1、打开一个空白电子表格并选择数据选项卡。
⑼ 如何用EXCEL计算股票盈亏
1.查看您银行的银证转账记录,从转出资金总额中减去转入资金总额,与您当前证券账户的市值比较,得出盈亏。
2、联系您的开户经纪商,通过柜台进行净额结算,查看资金流入流出情况,然后与您账户的总资产进行比较,还可以计算盈亏。
3、建议你做个有良心的人,学会记账、统计,这样才能算好你的盈亏。另一方面,也是为了统计自己买卖股票的成功率,长期受益。 查看全部
实时抓取网页数据(如何用excel获取网页上的股票数据,⑵Excel如何设置公式获得股票价格)
⑴ 如何使用excel在网页上获取股票数据并按日期制作表格
可以通过Excel获取外部数据的功能来实现,具体操作如下:
1、选择你要取数据的网站(不是所有网站都能取到你想要的数据),复制完整网站备份
2、打开 Excel,单击数据选项卡,选择获取外部数据 - 从网站按钮,将打开一个新建 Web 查询对话框。
3、输入刚才复制的网址,会打开对应的页面。
4、根据提示点击你需要的数据表前面的黄色小键,当它变成绿色勾号时,表示选中状态。
5、点击导入按钮,选择工作表中数据的存放位置,点击确定。
6、使用时,右键数据存储区,刷新,成功后就是最新的数据。
⑵ 如何在Excel中设置获取股票价格的公式
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】;
2、在【新建网页查询】界面,我们可以看到左上角是地址栏。点击界面右上角的【选项】,查看导入信息的设置,可根据实际情况进行选择。此示例遵循默认设置;
3、在【新建网页查询】界面的地址栏中输入收录你想要的股票信息的网站,然后点击【Go】按钮跳转到指定的网站;
4、浏览整个页面,可以看到很多区域标有黄色箭头,这些是可以导入的数据标识。我们选择我们想要的信息框左上角的黄色箭头;
5、点击后,黄色箭头会变成绿色箭头,如下图。然后点击右下角的【导入】按钮;
6、在【导入数据】对话框中选择要存储数据的位置;
7、在这个界面,点击左下角的【属性】,可以设置刷新频率,如何处理数据变化等;
8、设置好以上内容后,返回【导入数据】界面,点击【确定】按钮;
9、以下数据会自动导入,稍等片刻即可导入数据。每次设置刷新频率都会自动刷新数据;
10、设置完以上内容后,返回【导入数据】界面,点击【确定】按钮。
⑶ 如何通过excel获取库存清单
1 这里以中石油(601857)报价为例,打开提供股票行情的网站,在页面“个股查询”区域输入股票代码,选择“实时报价”,点击“报价”按钮后,可以查询中石油的行情数据,然后复制地址栏中的网址。
2、运行Excel,新建一个空白工作簿,在“数据”选项卡的“获取外部数据”选项组中选择“导入外部数据-从网站”命令。
3 弹出“New Web Query”对话框,在地址栏中输入刚才复制的地址,点击“Go”按钮,在下方文本框中打开网站,点击“Import”按钮。
4 弹出“导入数据”对话框,选择要插入的工作表,点击“确定”按钮。网站 的数据现在已导入到工作表中。
⑷如何用EXCEL表格看股市
1、首先,创建一个新工作表并选择任何空单元格。选择【数据】-【来自网站】。
⑸ 如何使用excel获取实时股票数据
自动获取所有股票历史数据,以及当日数据
⑹如何制作实时盘点excel,求高手指导
⑺ 如何使用EXCEL分析股票
EXCEL自动股市分析软件
⑻ 如何获取excel格式的股票数据
1、打开一个空白电子表格并选择数据选项卡。
⑼ 如何用EXCEL计算股票盈亏
1.查看您银行的银证转账记录,从转出资金总额中减去转入资金总额,与您当前证券账户的市值比较,得出盈亏。
2、联系您的开户经纪商,通过柜台进行净额结算,查看资金流入流出情况,然后与您账户的总资产进行比较,还可以计算盈亏。
3、建议你做个有良心的人,学会记账、统计,这样才能算好你的盈亏。另一方面,也是为了统计自己买卖股票的成功率,长期受益。
实时抓取网页数据(排名前20的网络爬虫工具章鱼搜索,Mark!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-13 02:22
20 大网络爬虫工具 Octopus Search,马克!
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来,方便八达通搜索。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一个免费且强大的网站爬虫工具OctoSearch,用于从网站中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
简而言之,Octoparse,Octoparse 应该可以满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的网站抓取工具,它允许将部分或完整的网站内容复制到本地硬盘驱动器以供离线阅读八达通搜索。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。该免费软件提供了一个匿名 Web 代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线账户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
实时抓取网页数据(排名前20的网络爬虫工具章鱼搜索,Mark!!)
20 大网络爬虫工具 Octopus Search,马克!
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来,方便八达通搜索。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一个免费且强大的网站爬虫工具OctoSearch,用于从网站中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
简而言之,Octoparse,Octoparse 应该可以满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的网站抓取工具,它允许将部分或完整的网站内容复制到本地硬盘驱动器以供离线阅读八达通搜索。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。该免费软件提供了一个匿名 Web 代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线账户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,并可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
实时抓取网页数据(网络爬虫的技术概述及技术分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-13 00:25
一、网络蜘蛛的定义
网络蜘蛛(又名网络爬虫、网络机器人)是一种按照一定规则自动抓取和抓取互联网信息的程序或脚本。
通俗的解释:互联网类似于蜘蛛网,网络爬虫在其中不断地爬行爬行,就像蜘蛛捕食蜘蛛网一样。每当发现新资源时,蜘蛛会立即调度并抓取它们并抓取内容。存储在数据库中。
二、网络爬虫技术概述
网络爬虫帮助搜索引擎从万维网上下载网页,是一种自动提取网页信息的程序,因此网络爬虫也是搜索引擎的重要组成部分。已知的网络爬虫分为传统爬虫和聚焦爬虫。
传统爬虫:就像蜘蛛在蜘蛛网上爬行一样,网页的 URL 类似于相互关联的蜘蛛网。网络蜘蛛从一些初始网页的 URL 开始,获取初始网页上的 URL。在爬取网页的过程中,网络蜘蛛不断地从被爬取的页面中重新提取新的URL,并将其放入预爬队列中,以此类推,直到满足系统的停止条件,最终停止爬取。
聚焦爬虫:聚焦爬虫的工作流程比传统爬虫复杂。它根据网页分析算法过滤与初始抓取主题无关的URL,并将有用的链接保留到预抓取队列中,以此类推,直到达到一定的系统级别。停止的条件。
三、为什么会有“蜘蛛”
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助用户访问互联网的门户和指南,搜索引擎也有很多限制。
1、一般搜索引擎的目标是尽可能扩大网络覆盖范围,因此有限的搜索引擎服务器资源与无限的网络信息资源之间存在巨大的矛盾。
2、通用搜索引擎返回的结果过于宽泛,收录大量与用户搜索目的无关的页面。
3、随着互联网数据形式和网络技术的不断发展,图片、音频、视频等大量多媒体数据源源不断地涌出,一般的搜索引擎无法很好的查找和获取这些信息。
4、一般搜索引擎都是基于关键字搜索,不支持语义查询。
上述问题的出现,也促使了定向爬取相关网页资源的专注爬虫的出现。聚焦爬虫可以自动下载网页,根据既定的爬取目标有选择地访问互联网上的网页和相关链接,并从中采集所需的信息。与通用爬虫不同的是,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
了解搜索引擎的工作原理在SEO优化中起着重要作用。很多SEO技巧都是根据搜索引擎的工作原理产生的。因此,对搜索引擎工作原理的解读是SEO工作者一项重要的基本技能。. 查看全部
实时抓取网页数据(网络爬虫的技术概述及技术分析)
一、网络蜘蛛的定义
网络蜘蛛(又名网络爬虫、网络机器人)是一种按照一定规则自动抓取和抓取互联网信息的程序或脚本。
通俗的解释:互联网类似于蜘蛛网,网络爬虫在其中不断地爬行爬行,就像蜘蛛捕食蜘蛛网一样。每当发现新资源时,蜘蛛会立即调度并抓取它们并抓取内容。存储在数据库中。
二、网络爬虫技术概述
网络爬虫帮助搜索引擎从万维网上下载网页,是一种自动提取网页信息的程序,因此网络爬虫也是搜索引擎的重要组成部分。已知的网络爬虫分为传统爬虫和聚焦爬虫。
传统爬虫:就像蜘蛛在蜘蛛网上爬行一样,网页的 URL 类似于相互关联的蜘蛛网。网络蜘蛛从一些初始网页的 URL 开始,获取初始网页上的 URL。在爬取网页的过程中,网络蜘蛛不断地从被爬取的页面中重新提取新的URL,并将其放入预爬队列中,以此类推,直到满足系统的停止条件,最终停止爬取。
聚焦爬虫:聚焦爬虫的工作流程比传统爬虫复杂。它根据网页分析算法过滤与初始抓取主题无关的URL,并将有用的链接保留到预抓取队列中,以此类推,直到达到一定的系统级别。停止的条件。
三、为什么会有“蜘蛛”
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助用户访问互联网的门户和指南,搜索引擎也有很多限制。
1、一般搜索引擎的目标是尽可能扩大网络覆盖范围,因此有限的搜索引擎服务器资源与无限的网络信息资源之间存在巨大的矛盾。
2、通用搜索引擎返回的结果过于宽泛,收录大量与用户搜索目的无关的页面。
3、随着互联网数据形式和网络技术的不断发展,图片、音频、视频等大量多媒体数据源源不断地涌出,一般的搜索引擎无法很好的查找和获取这些信息。
4、一般搜索引擎都是基于关键字搜索,不支持语义查询。
上述问题的出现,也促使了定向爬取相关网页资源的专注爬虫的出现。聚焦爬虫可以自动下载网页,根据既定的爬取目标有选择地访问互联网上的网页和相关链接,并从中采集所需的信息。与通用爬虫不同的是,聚焦爬虫不追求大覆盖,而是旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
了解搜索引擎的工作原理在SEO优化中起着重要作用。很多SEO技巧都是根据搜索引擎的工作原理产生的。因此,对搜索引擎工作原理的解读是SEO工作者一项重要的基本技能。.

